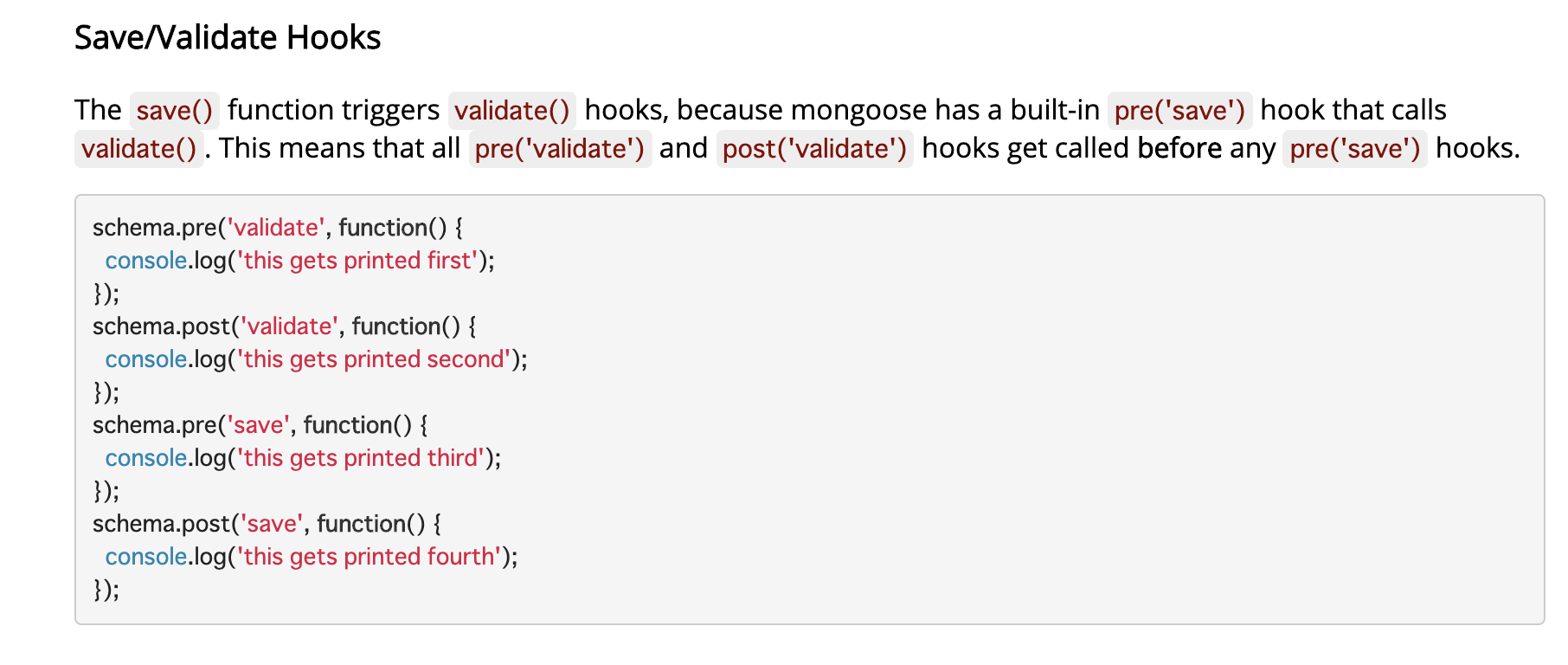
constmongoose=require('mongoose')constbcrypt=require('bcryptjs')constuserSchema=newmongoose.Schema({name:{type:String,//データ型の設定required:true,trim:true},password:{type:String,required:true,}})//middlewareを記述。saveする前にプレーンテキストをハッシュするuserSchema.pre('save',asyncfunction(next){//アローファンクションは使わない。このbindingは大事な役割を果たすものだからconstuser=thisconsole.log('Middleware is working')//ミドルウェアが動いているか確認するためのテストコードif(user.isModified('password')){//ハッシュ化されていないパスワードがある時user.password=awaitbcrypt.hash(user.password,8)}//ここで値がハッシュされるnext()})
varkuromoji=require("kuromoji");kuromoji.builder({dicPath:"node_modules/kuromoji/dict"}).build(function(err,tokenizer){// tokenizer is readyvarpath=tokenizer.tokenize("すもももももももものうち");console.log(path);});
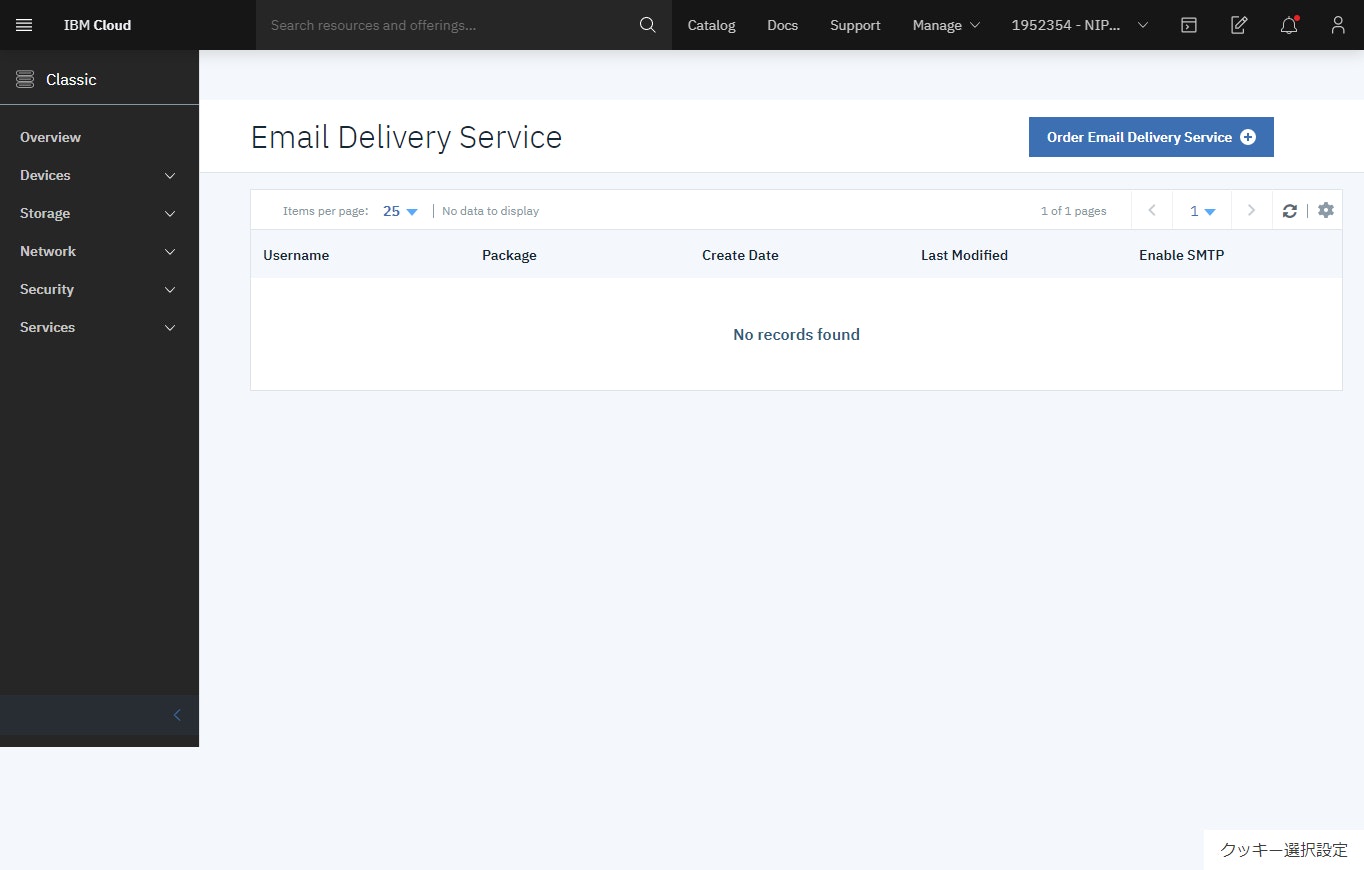
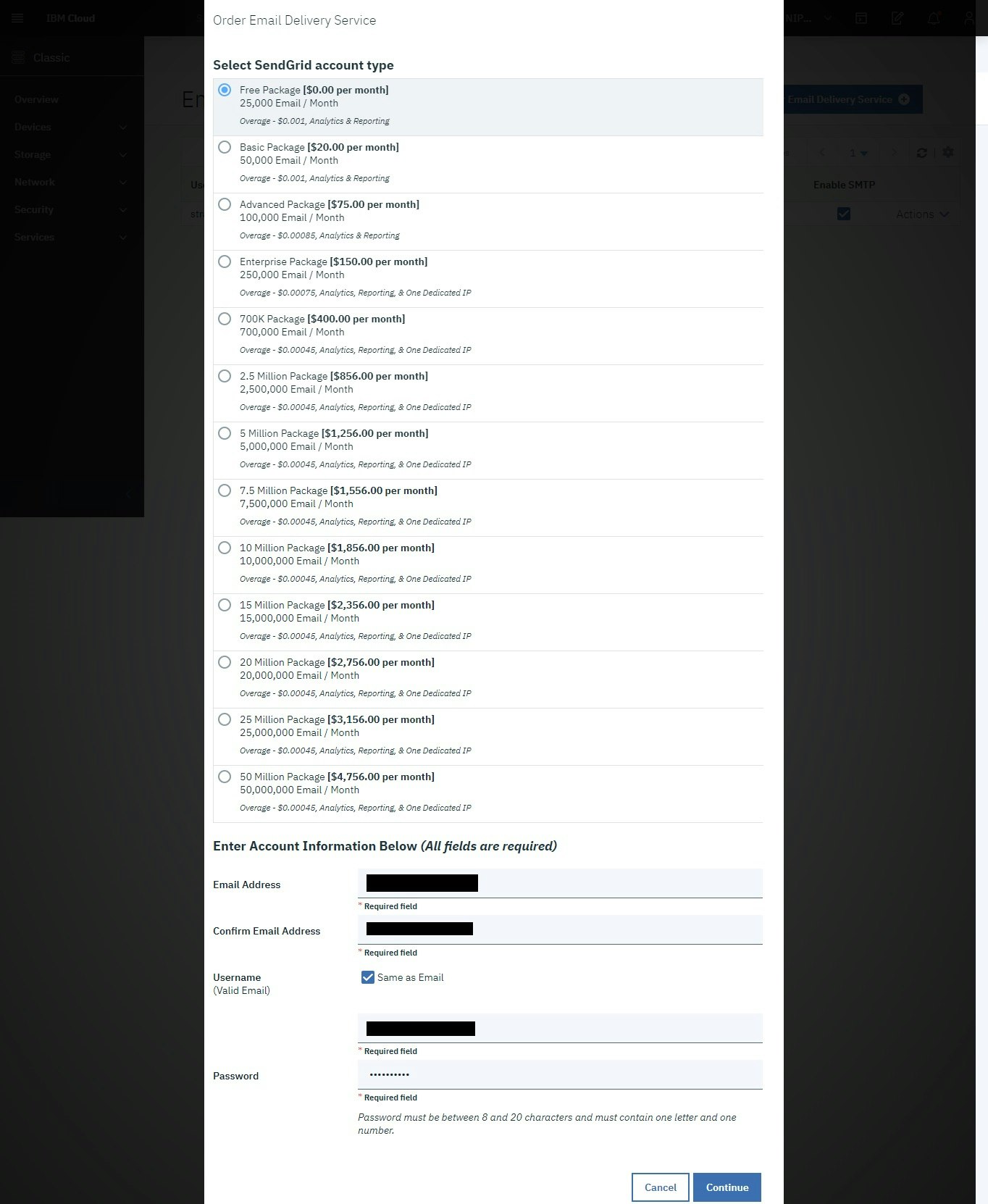
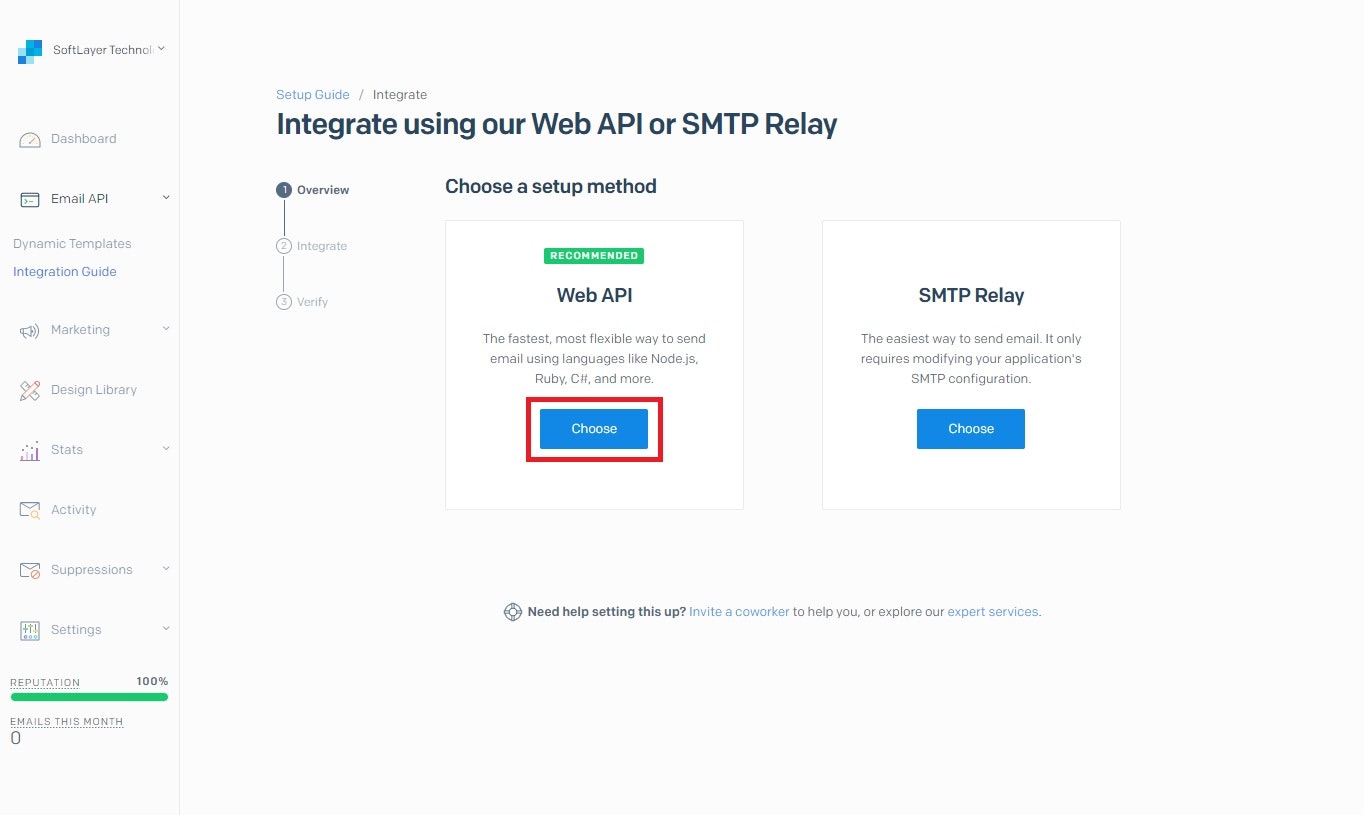
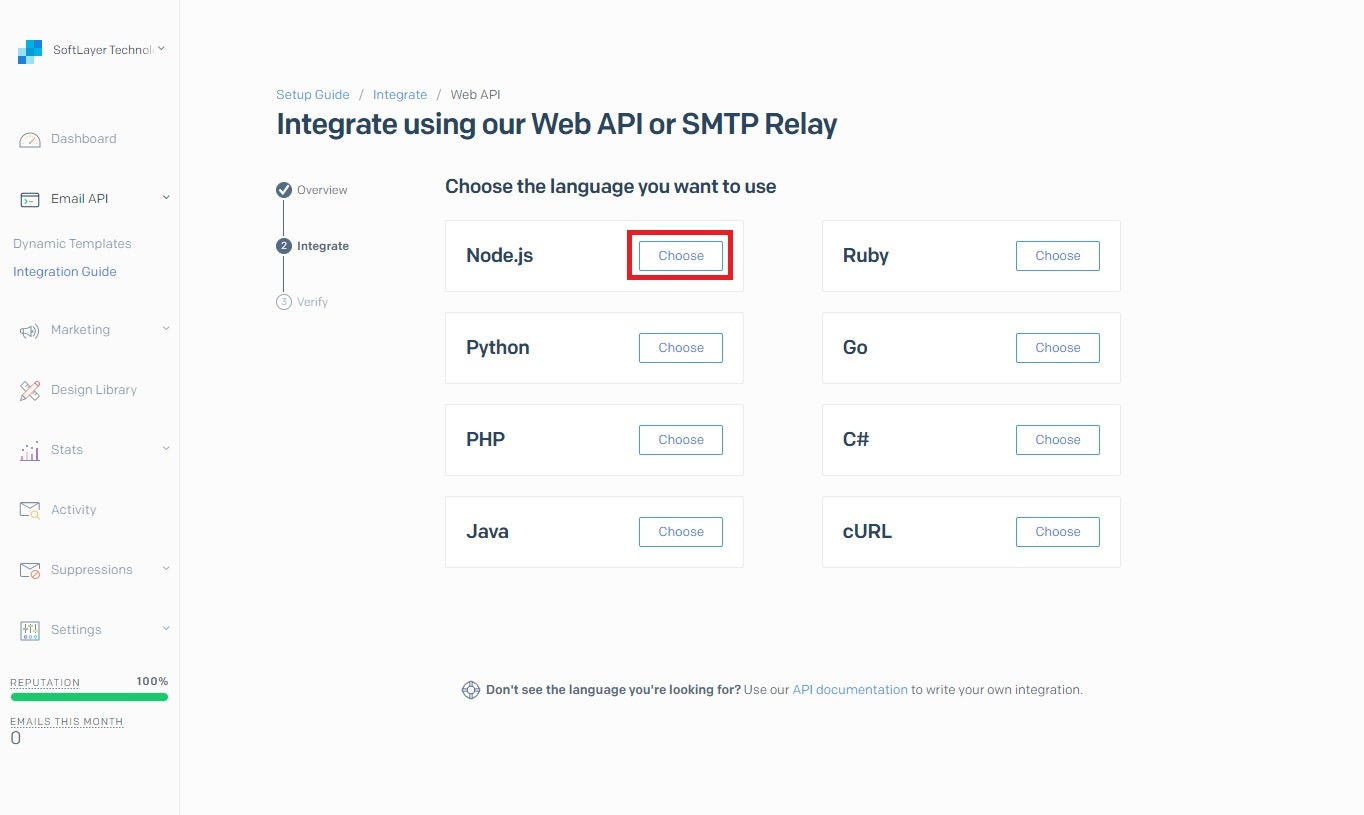
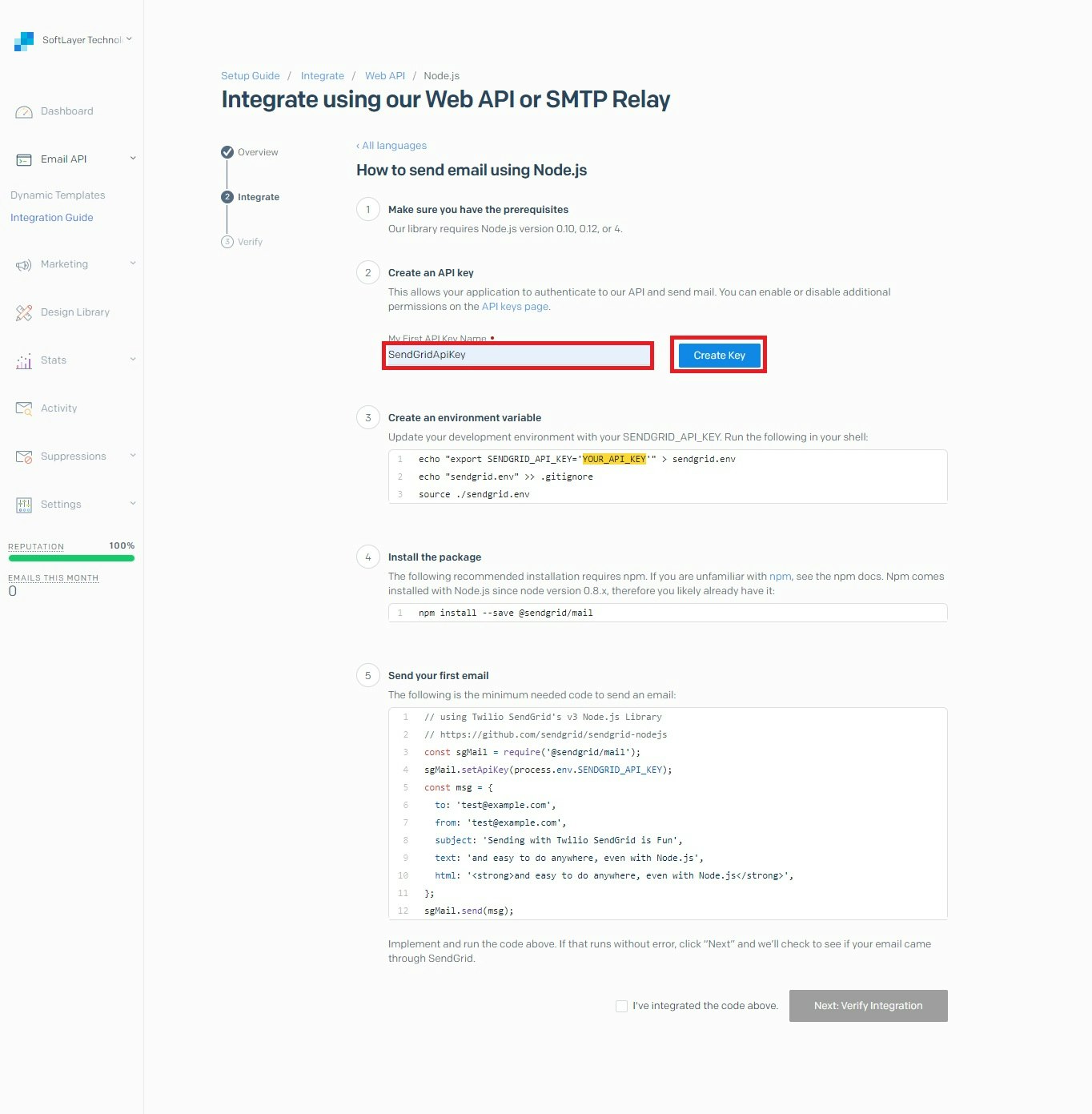
E メール配信について
SendGrid の IBM Cloud E メール配信サービスは、メール・リレー・サービスです。このサービスにより、スマート・ホストを使用してアウトバウンド・メール・サービスのリレーが可能になります。スマート・ホストは、SMTP サーバー、メール・クライアント、または SMTP を処理可能な任意のサービスまたはプログラム言語からの SMTP トラフィックをリレーします。 また、このサービスでは、メトリックの生成、E メール・リストの追跡、E メール・アクティビティー (E メールのバウンス、クリック、ドロップ、オープンなど) の追跡も行います。 このサービスには、ニュースレター支援や認証などの他の機能も用意されています。