- 投稿日:2020-07-25T23:44:45+09:00
PythonでJPG/PNG→PDF変換
お題
オタ活に勤しんでいる娘がダウンロードした推しの画像をローソン等でプリントしてポスターやらウチワやら缶バ1やら作るのにいちいち変換してくれるサイト2でPDFに変換しているようです。そんな面倒なことをせずとも前回のように自分のPCだけで完結するやんという話をしましてまた別のコンバータを作ることになりました。
今回はJPG/PNG→PDF変換になります。
尤もわざわざPDFに変換したものをマルチコピー機でPDFプリントしなくても自宅PCからネットワークプリントで先にアップロードだけしておけばいいようなものですが、PDFプリントのA3カラーは80円でネットワークプリントのA3カラーは100円なのです。また、ネットワークプリントではJPGとPDFは印刷可能ですがPNGはダメなようです。開発環境
- OS:Windows10Home(1903)
- Editor:Visual Studio Code
- Python:3.8.3
調べてみた
「python jpg pdf」でググるとどうやらimg2pdfというライブラリを使えば変換できるらしいので早速導入。
> pip install img2pdfまた、画像を扱うためPIL(Python Imaging Library)も必要なので調達。
> pip install pillowなぜpillow(枕)なのかは不明。
コード
Image2PDF.pyimport sys import os import img2pdf from PIL import Image def RemoveAlpha(src): dstPath = os.path.dirname(src) dstName = os.path.basename(src) dstPNG = os.path.join(dstPath, "_" + dstName) img = Image.open(src) img = img.convert("RGB") img.save(dstPNG) return dstPNG if __name__ == "__main__": srcOrgImage = sys.argv[1] print(f"IN:{srcOrgImage}") srcExt = os.path.splitext(os.path.basename(srcOrgImage))[1] dstPath = os.path.dirname(srcOrgImage) dstName = os.path.splitext(os.path.basename(srcOrgImage))[0] dstPdf = os.path.join(dstPath, f"{dstName}.pdf") print(f"OUT:{dstPdf}") if srcExt.upper() == ".PNG": srcImage = RemoveAlpha(srcOrgImage) else: srcImage = srcOrgImage with open(dstPdf, 'wb') as f: f.write(img2pdf.convert(srcImage)) if srcOrgImage != srcImage: os.remove(srcImage)構想としては前回と同じようにデスクトップ上のショートカットに変換したいファイルをD&Dすると同じフォルダに.pdfを生成するものです。今回もパス周りの処理が延々とあってヤボったいですが。
いくつかの画像ファイルの変換を試していると.jpgでは問題ありませんでしたが.pngファイルの場合にアルファチャンネルを含んでいるPNGはPDFに変換できないとエラーになったのでRemoveAlpha()でRGBA→RGBとして一時ファイルに保存、それを入力ファイルとしてPDF変換させています。運用
で、今回も起動用のバッチファイルを用意してめでたし。
Image2PDF.bat@echo off py Image2PDF.py %1だがしかし・・・
前回の続きになりますがフォルダ名・ファイル名に全角スペースが含まれている場合にD&Dで正しいフルパスが取得できない問題。調べてみると全角スペース以外にもアウト判定な文字があるようです。例えばちょっと細工して
argvTest.bat@echo off py argvTest.py %1 %2 %3 %4 %5 %6 %7 %8 %9argvTest.pyimport sys if __name__ == "__main__": len = len(sys.argv) print(f"len={len}") for i in range(len): print(sys.argv[i])これに「C:\Tmp\aaa bbb ccc.txt」(全角スペース入り)を喰わせると
len=3 argvTest.py C:\Tmp\aaa bbb ccc.txtとなるのでぶった切られた文字が全角スペースとわかっているのであればargv[1]以降を最後まで全角スペースを挟んでjoinしてやればなんとかできそうですが、ぶった切られる文字の候補が複数あってしかもその情報はもう失われているので復元は無理かなと。
でもこれが今回のようにバッチファイル経由で動かすPythonではなく.exeのショートカットに対してD&Dすると特にぶった切られることなく一つの文字列として取得できます3。
つまりWindowsのコマンドプロンプト4がイケてない?ですかね。
- 投稿日:2020-07-25T23:20:24+09:00
「データサイエンス100本ノック(構造化データ加工編)」 Python-013 解説
Youtube
動画解説もしています。
問題
P-013: 顧客データフレーム(df_customer)から、ステータスコード(status_cd)の先頭がアルファベットのA〜Fで始まるデータを全項目抽出し、10件だけ表示せよ。
解答
コードdf_customer.query("status_cd.str.contains('^A|^B|^C|^D|^E|^F')", engine='python').head(10)出力customer_id customer_name gender_cd gender birth_day age postal_cd address application_store_cd application_date status_cd 2 CS031415000172 宇多田 貴美子 1 女性 1976-10-04 42 151-0053 東京都渋谷区代々木********** S13031 20150529 D-20100325-C 6 CS015414000103 奥野 陽子 1 女性 1977-08-09 41 136-0073 東京都江東区北砂********** S13015 20150722 B-20100609-B 12 CS011215000048 芦田 沙耶 1 女性 1992-02-01 27 223-0062 神奈川県横浜市港北区日吉本町********** S14011 20150228 C-20100421-9 15 CS029415000023 梅田 里穂 1 女性 1976-01-17 43 279-0043 千葉県浦安市富士見********** S12029 20150610 D-20100918-E 21 CS035415000029 寺沢 真希 9 不明 1977-09-27 41 158-0096 東京都世田谷区玉川台********** S13035 20141220 F-20101029-F 32 CS031415000106 宇野 由美子 1 女性 1970-02-26 49 151-0053 東京都渋谷区代々木********** S13031 20150201 F-20100511-E 33 CS029215000025 石倉 美帆 1 女性 1993-09-28 25 279-0022 千葉県浦安市今川********** S12029 20150708 B-20100820-C 40 CS033605000005 猪股 雄太 0 男性 1955-12-05 63 246-0031 神奈川県横浜市瀬谷区瀬谷********** S14033 20150425 F-20100917-E 44 CS033415000229 板垣 菜々美 1 女性 1977-11-07 41 246-0021 神奈川県横浜市瀬谷区二ツ橋町********** S14033 20150712 F-20100326-E 53 CS008415000145 黒谷 麻緒 1 女性 1977-06-27 41 157-0067 東京都世田谷区喜多見********** S13008 20150829 F-20100622-F解説
・PandasのDataFrame/Seriesにて、条件に当てはまる先頭データを確認する方法です。
・条件に当てはまる情報を確認したい時に使用します。
・'contains(<文字列>)'は、指定した文字列が含まれているどうかを判定する関数であり、含まれる場合はTrue、含まれない場合はFalseを返します。
・ただし、'.query('---.str.contains(<文字列>))'は、指定した文字列が含まれることを条件として指定します。
・今回の場合、status_cd を文字列に置換するために'status_cd.str'とし、'.contains('^A|^B|^C|^D|^E|^F')'を続けることで、「A or B or C or D or E or F」が先頭にある status_cd を指定しています。('^'は先頭文字であることを表す正規表現です。正規表現とは、「複数の文字列を1つの記号で表す方法」のことを指します。)
・'engine = 'python''について、query の引数である engine には'python'か、'numexpr'かを選択することができますが、strを用いる場合は、'python'を指定してあげないとエラーが発生してしまいます。※正解を見ると、以下のような表現になっています。確かに'^[A-F]'については、先頭を表す正規表現'^'と、範囲を表す'[A-F]'で表した方が、より簡単に表現することができます。
※'regex=True'は、正規表現を扱う際に必要とされていました。以下の解答例では'^''-'が正規表現として扱われています。現在は、書かなくても正規表現として扱われるようになっているので、なくても問題ないですコードdf_customer.query("status_cd.str.contains('^[A-F]', regex=True)", engine='python').head(10)※先頭文字なんだから'str.startswith'を使うんじゃないか、と思われた方もいるかもしれませんが、以下のコードを実行しても何も抽出できません。なぜなら、'str.startswith'は正規表現を処理することができず、'|'を読み取ることができないためです。
コードdf_customer.query("status_cd.str.startswith('A|B|C|D|E|F')", engine='python').head(10)※正規表現については、こちらの記事が参考になります。
https://qiita.com/hiroyuki_mrp/items/29e87bf5fe46de62983c
- 投稿日:2020-07-25T23:03:23+09:00
PythonでM-SOLUTIONS プロコンオープン 2020のCを解く
はじめに
おひさしぶりです。今回はA,Cの二完でした。
今回はC問題の解説を書きます。C - Marks
考えたこと
最初はふつうに評点を計算していましたが、さすがに数が大きくなりすぎてTLEしました。
ですので少し頭を使います。この問題で聞かれているのは各学期間の大小だけです。また、学期ごとの評点の計算方法は直近$K$回の積なので、i学期の成績は$a_{(i-k)}*a_{(i-k+1)},\cdots,a_{i-1}$と書けます($i\geq k$)。ここで、$i+1$学期の評点は$i$学期の評点を$a_{(i-k)}$で割って$a_i$を掛けた値です。つまり、各学期間の大小を比べるだけなら、全ての積を計算しなくても各学期の最初と最後の大小関係を比べればよいことになります
n, k = map(int,input().split()) a = list(map(int,input().split())) f = 0 for _ in range(n-k): if a[f] < a[f+k]: print('Yes') else: print('No') f += 1まとめ
自分の力不足を感じました。もっと精進しなければ。ではまた、おやすみなさい。
- 投稿日:2020-07-25T22:53:08+09:00
AtCoder M-SOLUTIONS プロコンオープン 2020 参戦記
AtCoder M-SOLUTIONS プロコンオープン 2020 参戦記
m-solutions2020A - Kyu in AtCoder
4分で突破. 書くだけ……だったが、4分もかかってしまっていると、さすがに素直に200で割って処理すべきだったと反省.
X = int(input()) if 400 <= X <= 599: print(8) elif 600 <= X <= 799: print(7) elif 800 <= X <= 999: print(6) elif 1000 <= X <= 1199: print(5) elif 1200 <= X <= 1399: print(4) elif 1400 <= X <= 1599: print(3) elif 1600 <= X <= 1799: print(2) elif X >= 1800: print(1)m-solutions2020B - Magic 2
3分で突破. 2倍なら素直にループを回しても大丈夫だろうと、素直に書き下ろした.
A, B, C = map(int, input().split()) K = int(input()) while A >= B: K -= 1 B *= 2 while B >= C: K -= 1 C *= 2 if K >= 0: print('Yes') else: print('No')m-solutions2020C - Marks
13分半で突破. TLE1. 固定窓だと思った私がアホでした. なまじ TLE になるものの計算は出来てしまうのが裏目になってしまう Python だった.
N, K = map(int, input().split()) A = list(map(int, input().split())) result = [] for i in range(K, N): if A[i] > A[i - K]: result.append('Yes') else: result.append('No') print(*result, sep='\n')m-solutions2020D - Road to Millionaire
18分半で突破. DP だろうけど、どう DP 回せばいいんだろうなとそこそこ悩んだ.
N = int(input()) A = list(map(int, input().split())) t = [-1] * (N + 1) t[0] = 1000 for i in range(N): t[i + 1] = max(t[i + 1], t[i]) k = t[i] // A[i] y = t[i] % A[i] for j in range(i + 1, N): t[j + 1] = max(t[j + 1], k * A[j] + y) print(t[N])m-solutions2020E - M's Solution
突破できず. 順位表を見て F の方が簡単なことに途中で気づいたが手遅れ. 正しい答えが出るナイーブなコードは書けたが、そこから計算量を減らせず.
- 投稿日:2020-07-25T22:45:02+09:00
VSCodeでプロジェクトのディレクトリをPYTHONPATHに追加する。
VSCodeでPythonを書いていて
- ./hoge/__init__.py
- ./fuga/script.py
みたいなディレクトリ構造があった時に、script.py から
import hogeしようとすると怒られます。プロジェクトのディレクトリ直下に .env ファイルを作って中身にPYTHONPATH=.:$PYTHONPATHと記述するとプロジェクトのディレクトリがPYTHONPATHに追加されて快適になります。便利なんですけどこれでいいんですかね?あんまりPythonで開発しないのでGood Practiceがあったら教えていただきたいです。
- 投稿日:2020-07-25T21:57:51+09:00
ゼロから作るDeep Learning❷で素人がつまずいたことメモ:3章
はじめに
ふと思い立って勉強を始めた「ゼロから作るDeep Learning❷ーー自然言語処理編」の3章で私がつまずいたことのメモです。
実行環境はmacOS Catalina + Anaconda 2019.10、Pythonのバージョンは3.7.4です。詳細はこのメモの1章をご参照ください。
3章 word2vec
この章では、シンプルなword2vecを実装します。
3.1 推論ベースの手法とニューラルネットワーク
単語の意味を理解させる手法として、2章でシソーラスを使うものとカウントベースの2つを学びましたが、3番目としてニューラルネットワークを使った推論ベースの手法を学びます。
3.2 シンプルなword2vec
シンプルなword2vecとして、2つのモデルのうちのCBOWモデルを実装します。
3.3 学習データの準備
学習データの準備については、特につまずく点はありませんでした。
3.4 CBOWモデルの実装
CBOWモデル自体はシンプルなので大きくつまずく点はなかったのですが、コードの理解は少し大変でした。今回作る3つのMatMulレイヤーのうちの2つは同じ重み$ W_{in} $を共有しており、重みを束ねているリストの中でも共有された要素がでてきます。そのため、各オブジェクトがどのように共有されているのかの理解が必要です。
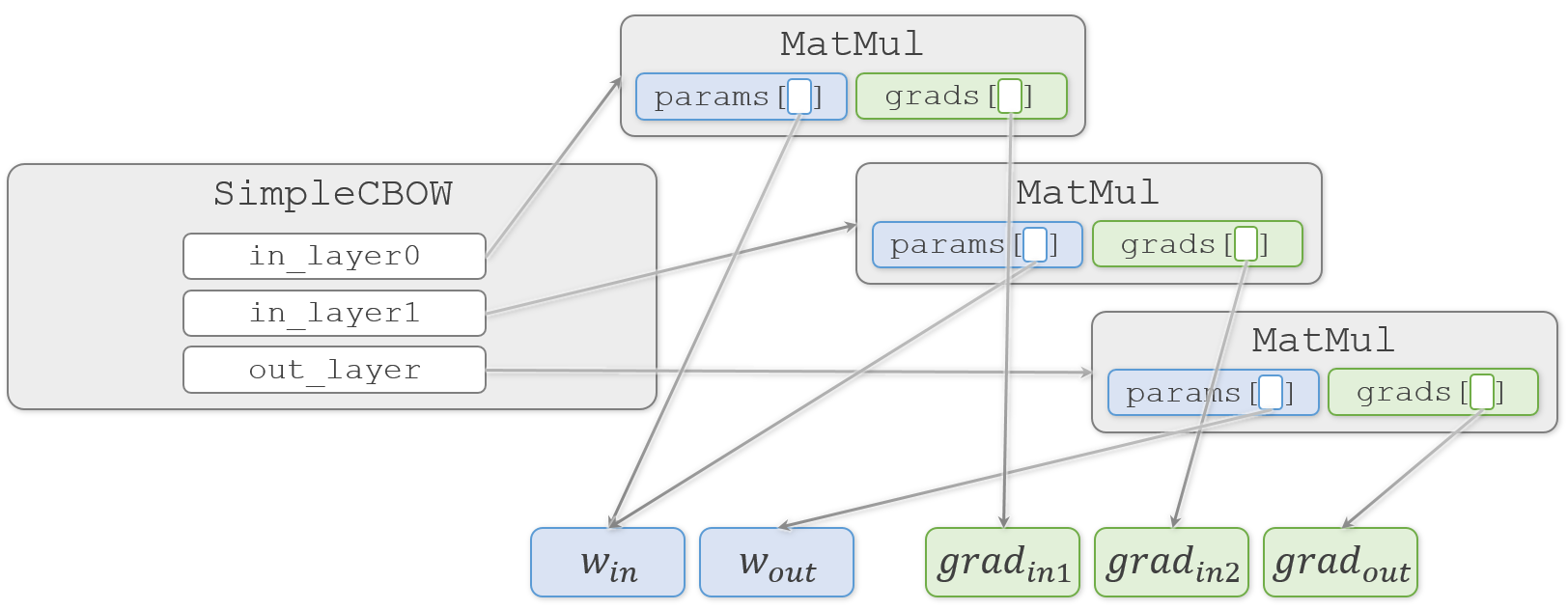
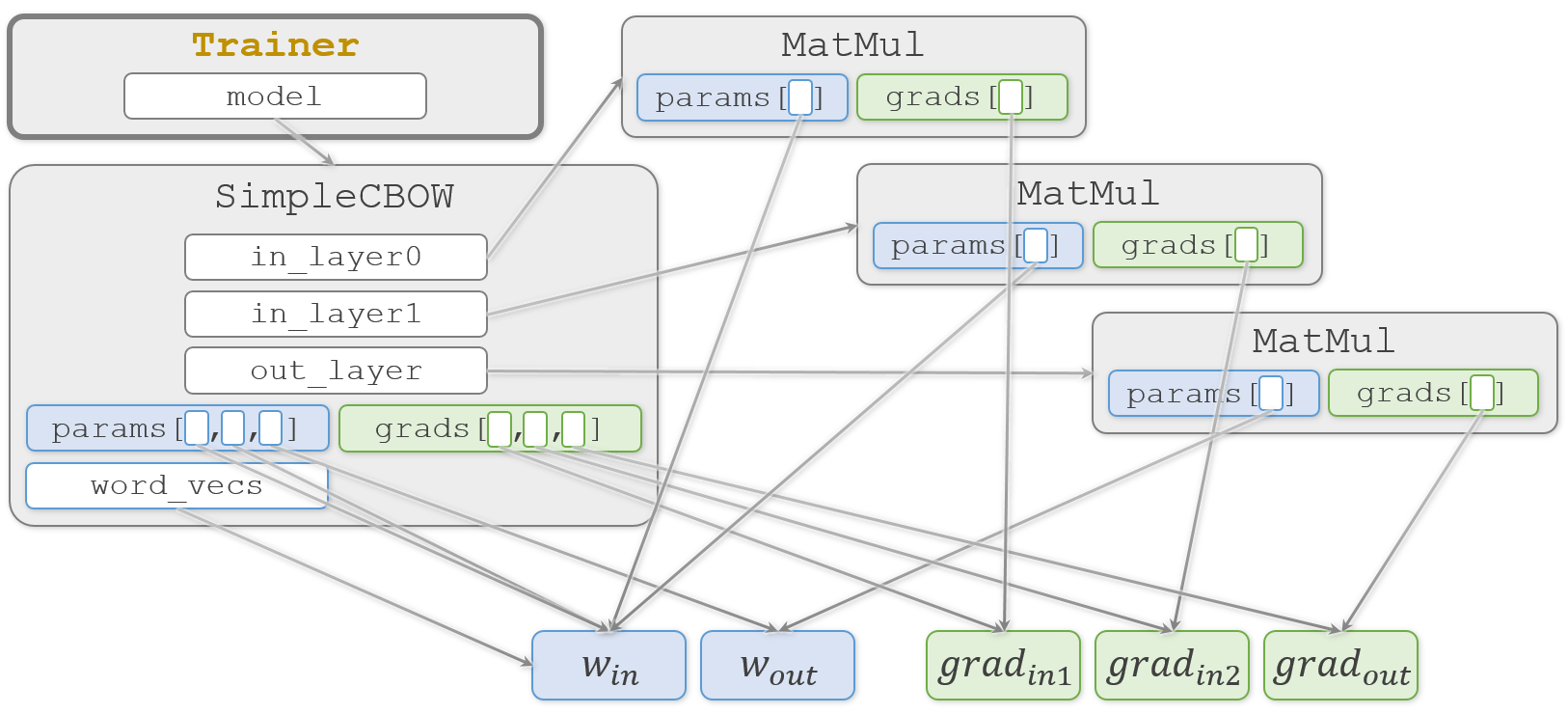
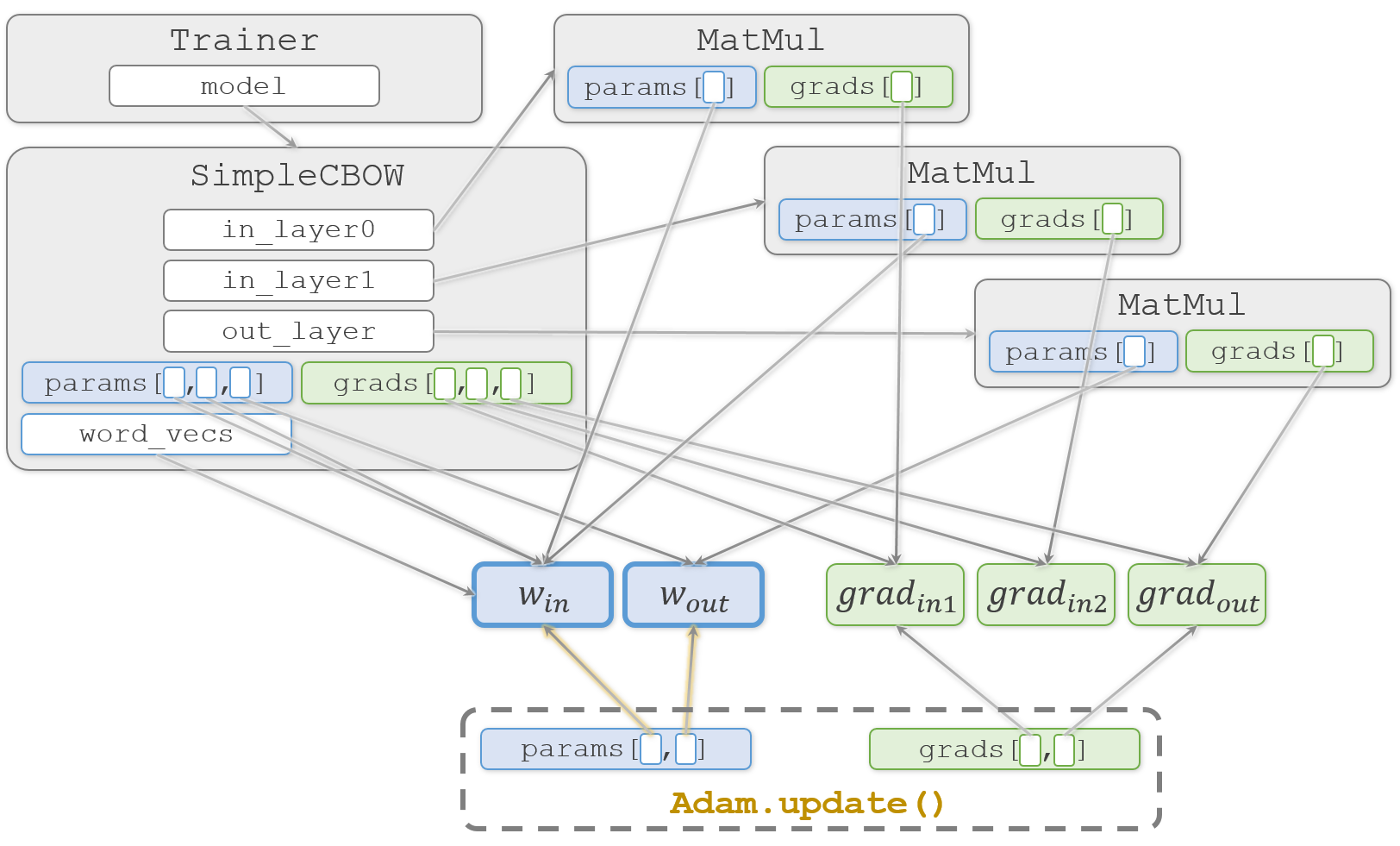
整理のために、登場する2つの重み( $W_{in}$、$W_{out}$ )と3つの勾配(ここでは $ grad_{in1}$、$grad_{in2}$、$grad_{out}$ とします)に注目して、本のコードを追ってみます。
まず、
SimpleCBOW.__init__()で $W_{in}$ と $W_{out}$ を生成します。ch03/simple_cbow.pyclass SimpleCBOW: def __init__(self, vocab_size, hidden_size): # (中略) # 重みの初期化 W_in = 0.01 * np.random.randn(V, H).astype('f') W_out = 0.01 * np.random.randn(H, V).astype('f')そして、MatMulオブジェクトを3つ生成し、それぞれ
SimpleCBOW.in_layer0、SimpleCBOW.in_layer1、SimpleCBOW.out_layerに代入します。ch03/simple_cbow.py# レイヤの生成 self.in_layer0 = MatMul(W_in) self.in_layer1 = MatMul(W_in) self.out_layer = MatMul(W_out)重みを受け取った
MatMul.__init__()側では、それをMatMul.paramsに代入します。また、3つのMatMulオブジェクトの中でそれぞれの勾配( $ grad_{in1}$、$grad_{in2}$、$grad_{out}$ )を生成しMatMul.gradsに代入します。common/layers.pyclass MatMul: def __init__(self, W): self.params = [W] self.grads = [np.zeros_like(W)]この時、2つの重み( $W_{in}$、$W_{out}$ )と3つの勾配( $ grad_{in1}$、$grad_{in2}$、$grad_{out}$ )と各オブジェクトの関係は、こんな感じになっています。
塗りつぶしていない四角はそこに実体がなく、矢印の先の実体を指しています(実際には
MatMul.paramsやMatMul.gradsなどのリストもMatMulオブジェクトの中に実体がある訳ではないのですが、今注目したいのは重みと勾配なので、それ以外については簡略化してオブジェクトの中に書いています)。
SimpleCBOW.__init__()に戻ります。
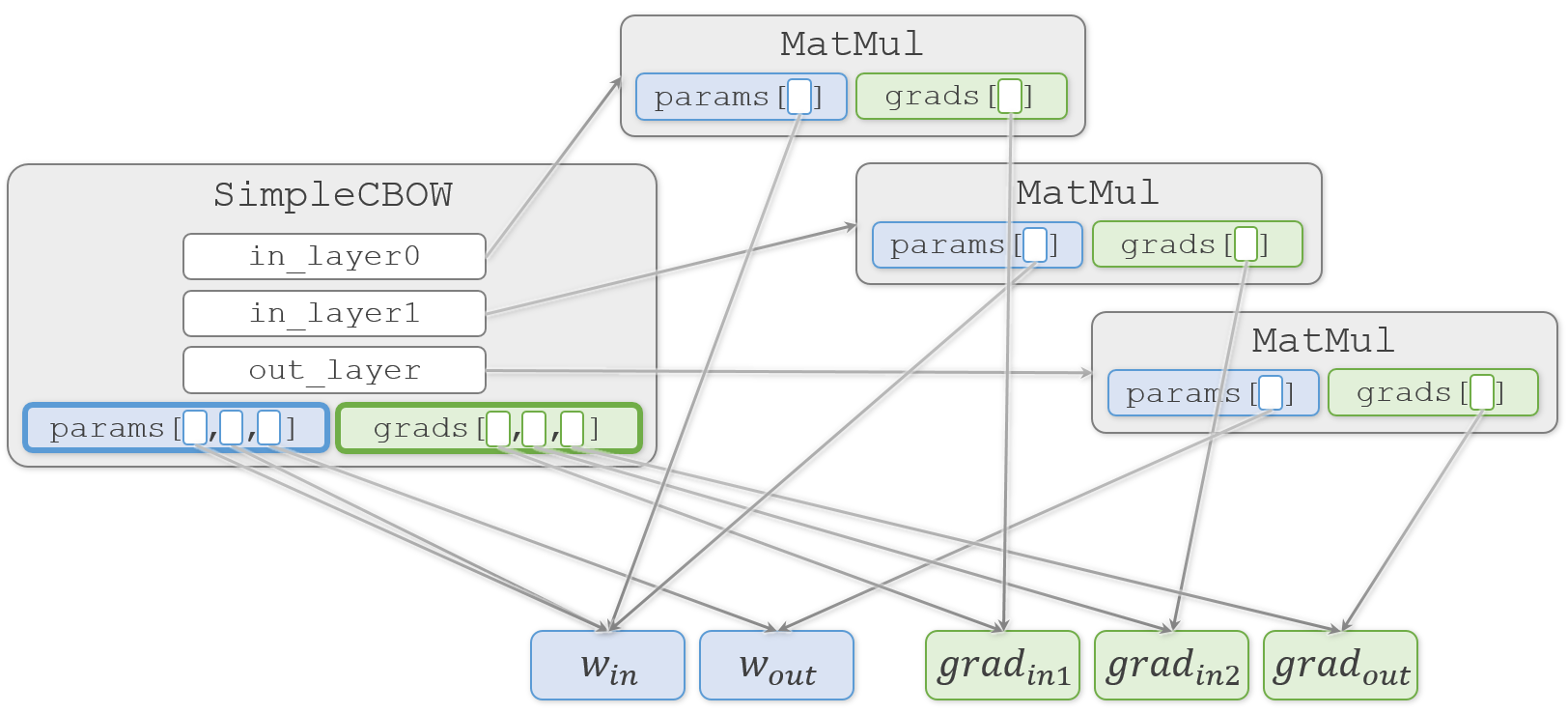
生成した3つのMatMulオブジェクトから重みを取り出してSimpleCBOW.paramsリストへ代入し、同様に勾配を取り出してSimpleCBOW.gradsリストへ代入します。ch03/simple_cbow.pyclass SimpleCBOW: def __init__(self, vocab_size, hidden_size): # (中略) # すべての重みと勾配をリストにまとめる layers = [self.in_layer0, self.in_layer1, self.out_layer] self.params, self.grads = [], [] for layer in layers: self.params += layer.params self.grads += layer.gradsここまでの重みや勾配の代入はすべて浅いコピー(shallow copy)です。そのため、重みや勾配の複製は行われず、実体(塗りつぶした四角)は1つのままです。
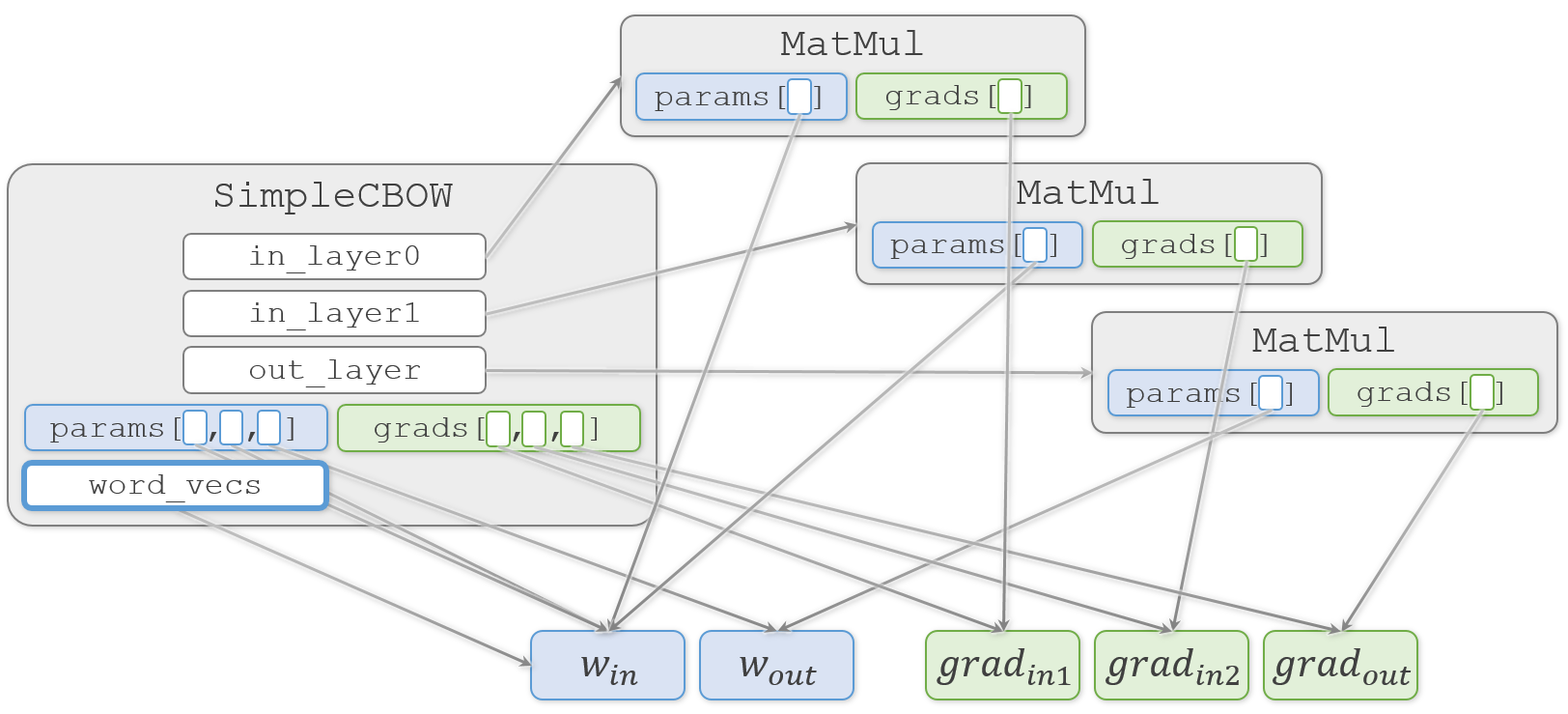
そして、結果になる
SimpleCBOW.word_vecsへ重みを代入します。ch03/simple_cbow.py# メンバ変数に単語の分散表現を設定 self.word_vecs = W_in
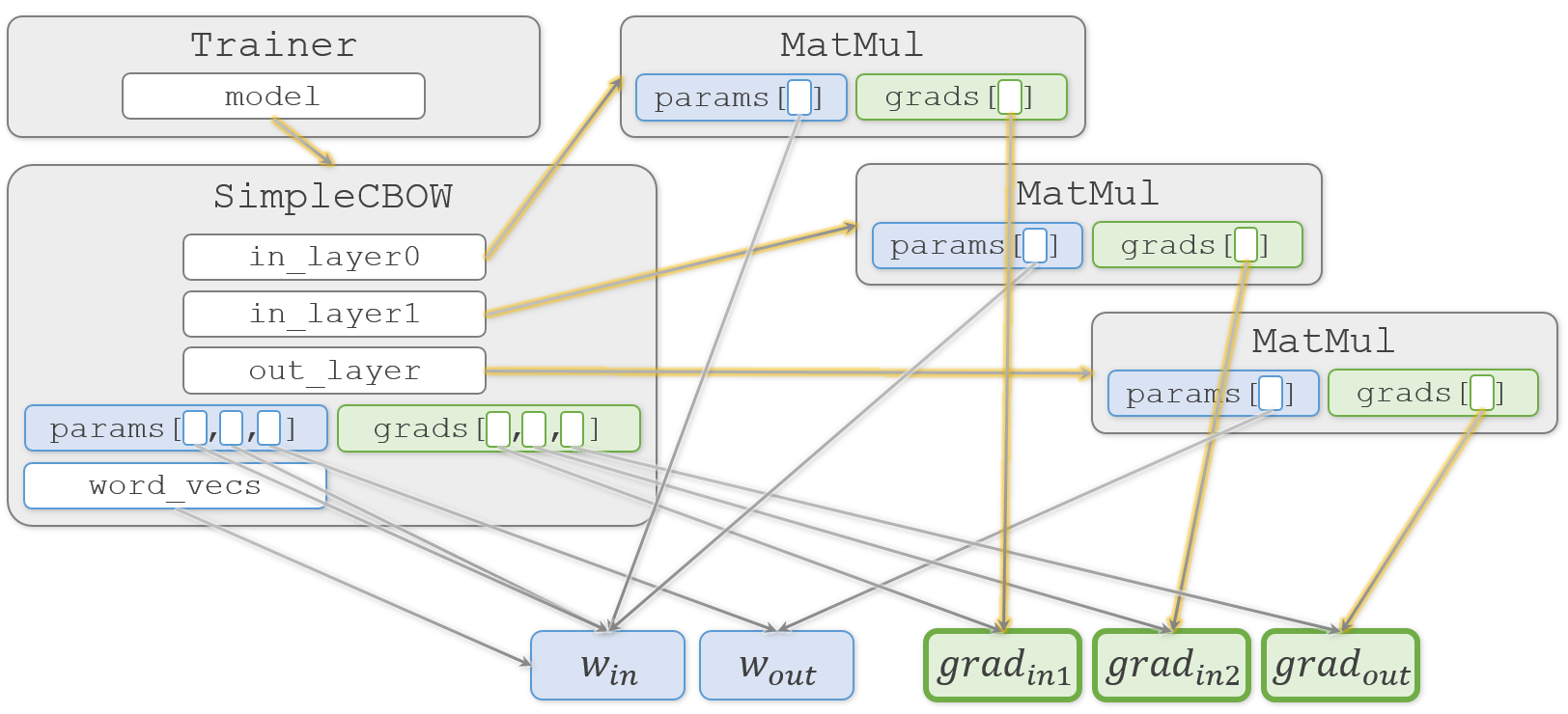
わかりやすく説明しようとして描き始めた図が、矢印だらけでわかりにくくなってきました
おさらいですが、この図では矢印の先のオブジェクトを矢印の元で共有していることを示しています。そのため、矢印の先のオブジェクトをどこかで更新すると、それを見ている矢印の元でも更新されていることになります。
続いて、メインのコードである
train.pyに移ります。
まずSimpleCBOWオブジェクトとAdamオブジェクトを生成し、作ったオブジェクトをTrainerオブジェクトの生成時に渡します。ch03/train.pymodel = SimpleCBOW(vocab_size, hidden_size) optimizer = Adam() trainer = Trainer(model, optimizer)受け取った
Trainer.__init__()側では、それをTrainer.modelとTrainer.optimizerに代入します。common/trainer.pyclass Trainer: def __init__(self, model, optimizer): self.model = model self.optimizer = optimizer
図をシンプルにするため、今回あまり関係しない
Adamオブジェクトは図から省いています。ここまでで学習に必要なオブジェクトが完成しました。続いて学習です。学習の実装は
Trainer.fit()です。ch03/train.pytrainer.fit(contexts, target, max_epoch, batch_size)
Trainer.fit()の中ではTrainer.model.forward()で順伝播し、Trainer.model.backward()で逆伝播します。common/trainer.pyclass Trainer: def fit(self, x, t, max_epoch=10, batch_size=32, max_grad=None, eval_interval=20): #(中略) model, optimizer = self.model, self.optimizer #(中略) for epoch in range(max_epoch): #(中略) for iters in range(max_iters): #(中略) # 勾配を求め、パラメータを更新 loss = model.forward(batch_x, batch_t) model.backward()逆伝播の
Trainer.model.backward()の実装はSimpleCBOW.backward()です。この中では各レイヤーの逆伝播であるSimpleCBOW.out_layer.backward()、SimpleCBOW.in_layer1.backward()、SimpleCBOW.in_layer0.backward()を呼び出します。ch03/simple_cbow.pyclass SimpleCBOW: def backward(self, dout=1): ds = self.loss_layer.backward(dout) da = self.out_layer.backward(ds) da *= 0.5 self.in_layer1.backward(da) self.in_layer0.backward(da) return Noneいずれのレイヤーも実行される関数は
MatMul.backward()です。common/layers.pyclass MatMul: def backward(self, dout): W, = self.params dx = np.dot(dout, W.T) dW = np.dot(self.x.T, dout) self.grads[0][...] = dW return dxここで
MatMul.grads[0]を更新するので、結果として各レイヤーに対応する3つの勾配( $ grad_{in1}$、$grad_{in2}$、$grad_{out}$ )を更新することになります。
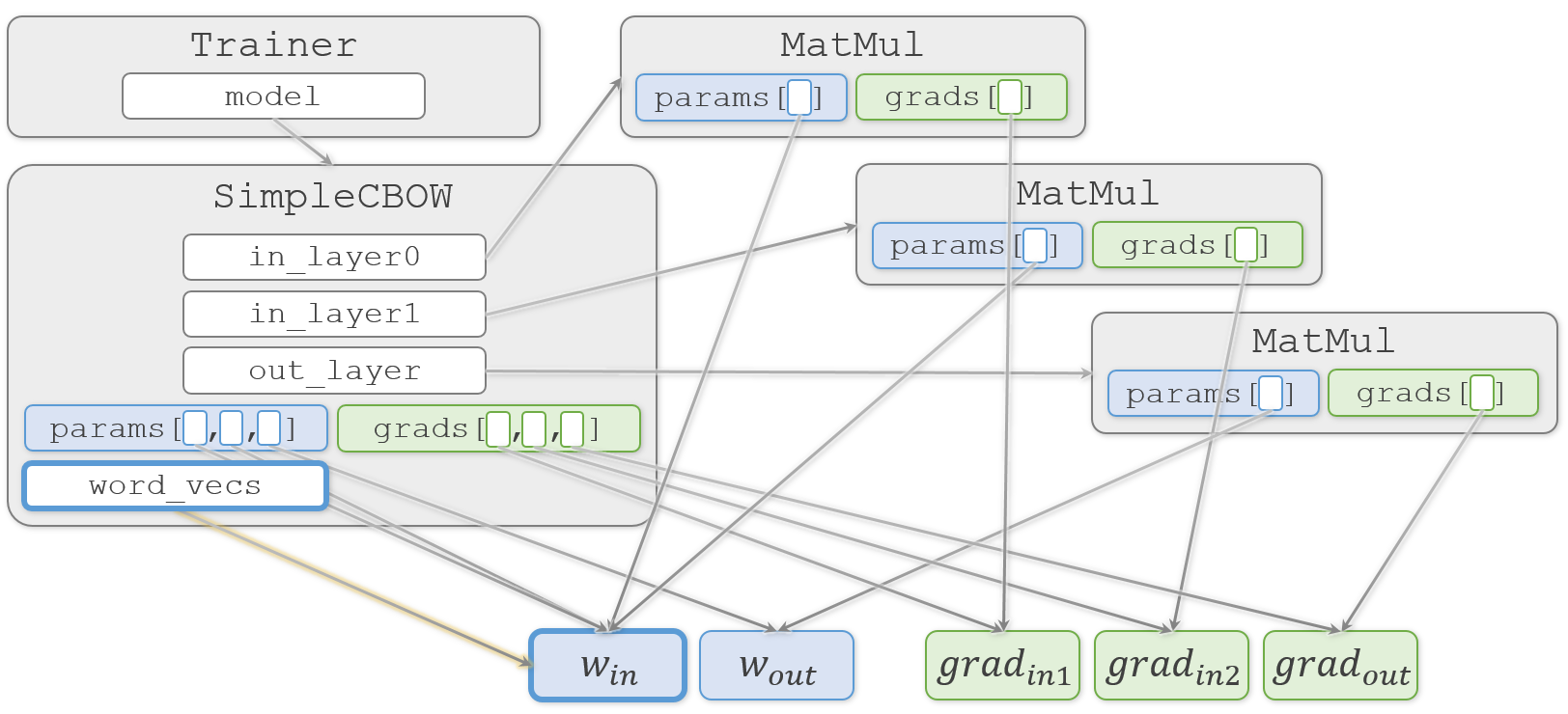
ここまでの学習の流れを図の中で黄色にしてみました。
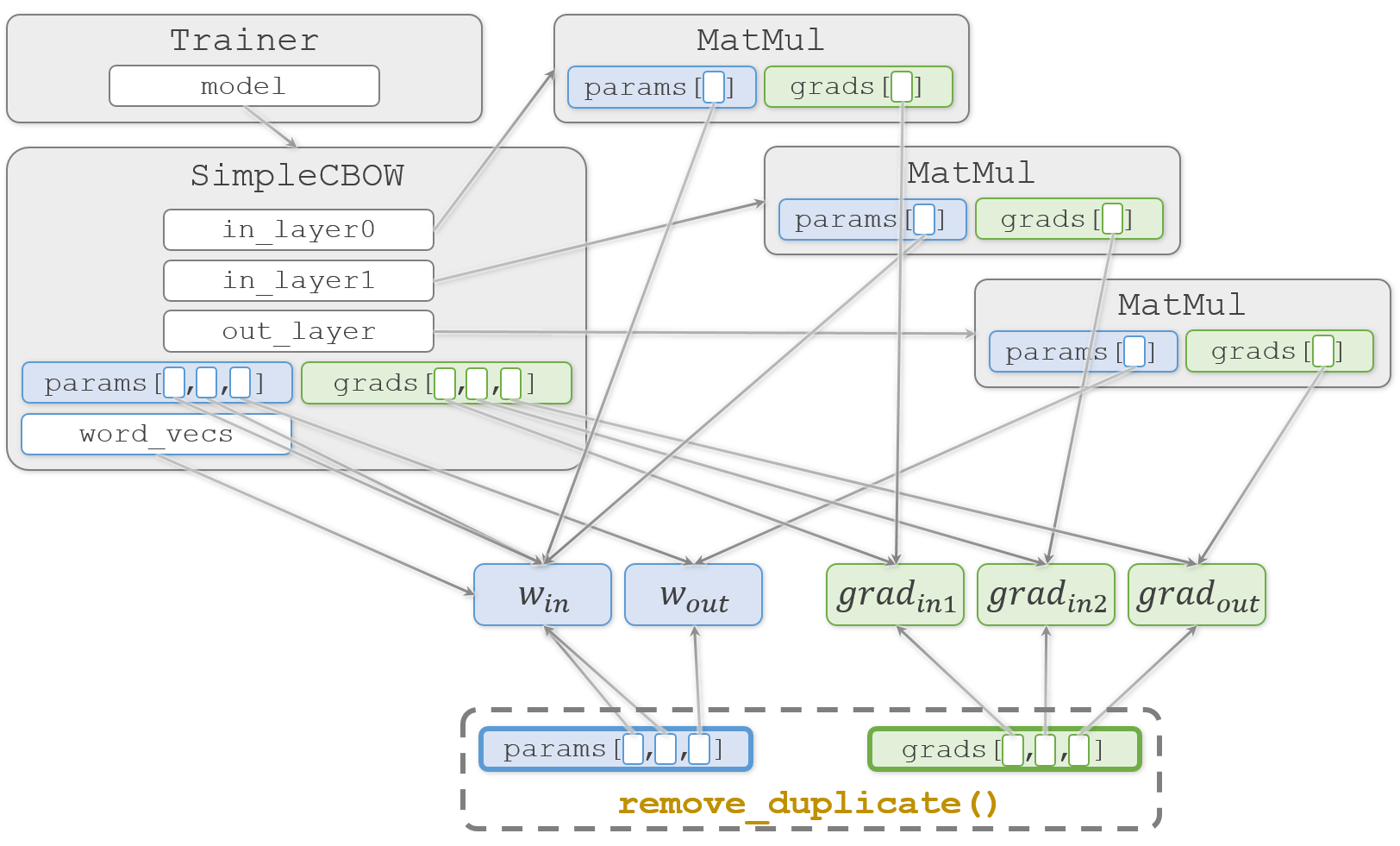
Trainer.fit()の続きに戻ります。
ここまでの処理で勾配情報のTrainer.model.gradsリストが更新されたので、これを使って重み情報のTrainer.model.paramsリストを更新します。ただし、このリストには中身の重複があるので、特殊な処理が入っています。common/trainer.pyparams, grads = remove_duplicate(model.params, model.grads) # 共有された重みを1つに集約本では
remove_duplicate()の解説が省略されていますが、中を覗いてみます。common/trainer.pydef remove_duplicate(params, grads): ''' パラメータ配列中の重複する重みをひとつに集約し、 その重みに対応する勾配を加算する ''' params, grads = params[:], grads[:] # copy listまず渡された重みと勾配のリストを複製します。この複製により
SimpleCBOW.paramsとSimpleCBOW.gradsとは別のリストオブジェクトparamsとgradsが生成されます。ただし、その中身は複製されません。図の下の部分になります。
続いて、重複している重みを総当たりで探します。
common/trainer.pywhile True: find_flg = False L = len(params) for i in range(0, L - 1): for j in range(i + 1, L): # 重みを共有する場合 if params[i] is params[j]: grads[i] += grads[j] # 勾配の加算 find_flg = True params.pop(j) grads.pop(j) # (中略) if find_flg: break if find_flg: break if not find_flg: break return params, grads
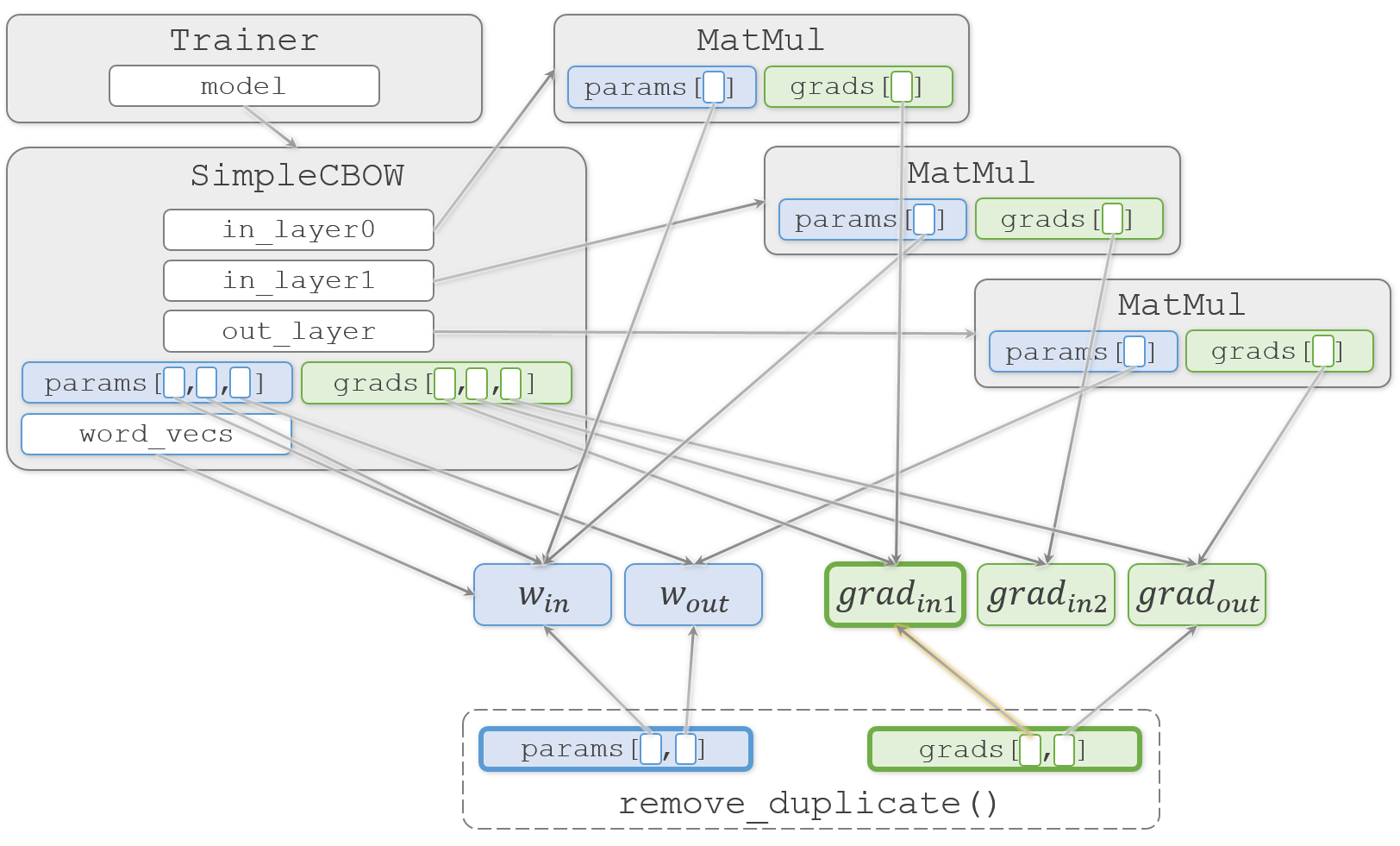
if params[i] is params[j]:で、オブジェクトが同じものかどうかをチェックします。ここで、iが0、jが1の時に、どちらも同じ $W_{in}$ を指していることがわかり、中の処理に進みます。common/trainer.py# 重みを共有する場合 if params[i] is params[j]: grads[i] += grads[j] # 勾配の加算 find_flg = True params.pop(j) grads.pop(j)ここで $W_{in}$ に対応する2つの勾配 $ grad_{in1}$ と $grad_{in2}$ を加算して $ grad_{in1}$ を更新します。そして、
paramsとgradsの両方のリストから2番目の要素を削除することで、更新対象の重みを2つにします。
重みの重複を除く理由は、除かないと1回のイテレーションで $W_{in}$ を2回更新してしまうからです。2回更新してしまうと困るのは、更新時のAdamの挙動が変わってしまうためです。
AdamはMomentumとRMSPropを掛け合わせたようなアルゴリズムで、Momentumは勾配の移動平均を使うことで振動を抑え、RMSPropは振動時の学習率を抑えることで振動を抑えます。どちらも以前の勾配情報を蓄積しながら調整するのですが、 $W_{in}$ を入力レイヤー#0用と#1用とで2回に分けて更新してしまうと、それぞれ独立して以前の勾配情報を蓄え振動を抑えようとするために、入力レイヤー#0用と#1用を交互で更新することによる振動が考慮できません。そのため、両方の勾配を足し合わせて1度で更新する必要があります。
なお、Adamについては @omiita さんの 【2020決定版】スーパーわかりやすい最適化アルゴリズム -損失関数からAdamとニュートン法- がスーパーわかりやすいです。
1つ気になるのは、2レイヤー分を1回で更新するために $ grad_{in1}$ へ $ grad_{in2}$ の勾配を足しこんでしまうので、
SimpleCBOW.in_layer0のMauMulオブジェクトから見ると、勾配情報が勝手に破壊されてしまう点です。ただ、破壊前の勾配は次回のイテレーションまでもう使われることはなく、次回の逆伝播で正しい値で上書きされるので気にしないで大丈夫です。この辺りの実装方法が少し気持ち悪く感じる方もいるかとは思いますが、無駄な複製を防ぐ措置だと思います。
remove_duplicate()の続きに戻ります。
重複を除いた際にfind_flgを立てているので、後続の2つのbreakが実行されて、再び総当たりのチェックをやり直します。今回は他に重みの重複はないので、結果として要素数が2のparamsとgradsが返ります。そして、
Trainer.fit()の続きに戻ります。common/trainer.pyoptimizer.update(params, grads)
optimizerはAdamオブジェクトです。要素数が2つになったparamsとgradsをAdam.update()に渡して実行し、$W_{in}$ と $W_{out}$ を更新する形になります。
これを繰り返して学習を進めます。これで
Trainer.fit()の処理が終わります。最後に完成した単語の分散表現を
SimpleCBOW.word_vecsから取り出して完了です。word_vecs = model.word_vecs for word_id, word in id_to_word.items(): print(word, word_vecs[word_id])
実行結果you [ 0.93458694 1.6282444 0.94795746 -0.92400223 0.8647629 ] say [-1.2477087 0.24887817 -1.199617 0.8608295 -1.2035855 ] goodbye [ 0.92808425 0.01414002 0.9206358 -1.155395 1.0054088 ] and [-0.72053814 1.7237687 -0.74599844 1.3244902 -0.7532529 ] i [ 0.91120744 0.01902297 0.92178065 -1.1321857 1.0154353 ] hello [ 0.9499151 1.6287371 0.96806735 -0.9076484 0.87147075] . [-1.3032959 -1.5691308 -1.2686406 -1.2225806 -1.2338196]おつかれさまでした。
Pythonは普通にコードを書くとオブジェクトが共有されまくるので、いつの間にか値が書き変えられていた!という事故が起きてしまいがちです。共有して良いのか複製が必要なのかは、常に気にしておかないといけません。なお共有と複製については、Pythonのcopy関数とdeepcopy関数の違いと使い方の解説がわかりやすかったです。
3.5 word2vecに関する補足
word2vecのもう1つのモデルであるskip-gramが紹介されています。また、カウントベースと推論ベースの論争(?)についても紹介されています。
3.6 まとめ
この章でCBOWの実装は終わりましたが、まだまだシンプルな形で大きなコーパスには耐えられず、前章のように青空文庫で遊ぶことができません。次の章で高速化が終わったら試してみたいですね。
この章は以上です。誤りなどありましたら、ご指摘いただけますとうれしいです。
- 投稿日:2020-07-25T21:04:23+09:00
Cloud ArmorへIP自動登録削除
概要
CLoud Armorを使って送信元IPでGCPへのアクセス制限している環境があり、
外部アクセスからのIP以外にも、内部通信用としてGCEやGKEノードのグローバルIPも登録をしてますが、
GKEノードはマネージドなので、障害等で自動的にノードの入れ替えが行われます。
そこでIPの登録を自動化したいというのが目的です。構成
- Operations loggingでgkeノードのinsert/deleteのログが出力されるので、そのフィルターをかけたログのsink先をpub/subに向ける。
- pub/subからcloud functionを起動してcloud armorへ登録/削除を行う。
Operations logging(sink)=>cloud pub/sub=>cloud function=>cloud armor※ stack driver loggingから Operations loggingに名前が変わった様です。
※ sinkとはエクスポートのことで、syncではなくsinkで、sink先はgcsと、pub/subと、big queryです。Operations logging
ログのフィルターの掛け方とsinkのやり方
Operations logging => Logs Router => CCREATE SINK
ログのフィルターを以下のようにかけると、GKE Nodeのinset/deleteのみに絞れました。resource.type="gce_instance" protoPayload.requestMetadata.callerSuppliedUserAgent="GCE Managed Instance Group for GKE" AND (protoPayload.methodName="v1.compute.instances.insert" OR protoPayload.methodName="v1.compute.instances.delete")sinkするpub/subを指定する。
※事前にcloud pub/subの topicの作成が必要です(2クリックで作成可能)
cloud function
cloud pub/subとの連携部分
cloud function設定のtrigger部分で、pub/subを選択するだけです。
cloud puc/subからログ情報をもらうところ
https://cloud.google.com/functions/docs/calling/logging?hl=ja
ここの公式にサンプルがありますが、今回必要な情報、リソース名、メソッド名(insert or delete)、zoneを以下で取得します。def process_log_entry(data, context): data_buffer = base64.b64decode(data['data']) log_entry = json.loads(data_buffer)['protoPayload'] print(f"# resourceName is: {log_entry['resourceName']}") print(f"# method is: {log_entry['methodName']}") print(f"# zone is: {log_entry['resourceLocation']['currentLocations']}")結果
google-api-python-client
gcpのpython用ライブラリは、以下のオフィシャルを使うのが良さそうです。
https://cloud.google.com/compute/docs/tutorials/python-guide?hl=ja
https://github.com/googleapis/google-api-python-client先ずはローカルで使いたいと思うので、その場合必要な準備は以下です。
※cloud functionで使うだけであれば必要ないです。
- Cloud SDKのインストール
gcloud auth application-default loginで認証- ライブラリのインストール
$ pip install --upgrade google-api-python-client
- api 初期化
import googleapiclient.discovery compute = googleapiclient.discovery.build('compute', 'v1')後はリファレンスを見て好きな様に操作するだけです。
Library reference documentation by API.
https://github.com/googleapis/google-api-python-client/blob/master/docs/dyn/index.md#computecompute v1のapiリファレンス
http://googleapis.github.io/google-api-python-client/docs/dyn/compute_v1.htmlinstanceの情報取得
policy登録に必要なグローバルIPの取得します。
resourceNameはpub/sub経由のログから取得したinstance名を使用します。※ どこかに書いてありましたが、関数の実行にはお尻に
.execute()を付けないと実行されません。project = "test-project" zone = "asia-northeast1-a" compute = googleapiclient.discovery.build('compute', 'v1') getinstance = compute.instances().get(project=project, zone=zone, instance=resourceName).execute() print(f"natIP is: {getinstance['networkInterfaces'][0]['accessConfigs'][0]['natIP']}")結果
natIP is: xx.xx.xx.xxcloud armorへの登録削除
既存のpolicy内容を取得
project = "test-project" securityPolicy = "test-policy" compute = googleapiclient.discovery.build('compute', 'v1') getpolicy = compute.securityPolicies().get( project=project, securityPolicy=securityPolicy).execute() for i in getpolicy["rules"]: print(f"rules: {i}")結果
rules: {'description': '', 'priority': 1, 'match': {'versionedExpr': 'SRC_IPS_V1', 'config': {'srcIpRanges': ['xxx.xxx.xxx.xxx']}}, 'action': 'allow', 'preview': False, 'kind': 'compute#securityPolicyRule'} rules: {'description': 'Default rule, higher priority overrides it', 'priority': 2147483647, 'match': {'versionedExpr': 'SRC_IPS_V1', 'config': {'srcIpRanges': ['*']}}, 'action': 'deny(403)', 'preview': False, 'kind': 'compute#securityPolicyRule'}ruleの登録
resourceNameはpub/sub経由のログから取得したinstance名を使用します。
set_priorityの指定に少し工夫が必要です。
priority は 1 ~ 2147483647まで指定可能で、どの範囲を使うか事前に決める必要があるのと、
連番で付与していく場合、空きをどうするかなど。
今回は1,000,000,000(10億)~ 2,147,483,646までを使用可能として、既存の最大値に1インクリメントするようにしました。
(仮に1日100台入れ替わったとしても、上限達するには30,000年かかるので問題ないと思います。多分)
※ 以下はサンプルなので、そのロジックは省いています。project = "test-project" securityPolicy = "test-policy" set_ip = getinstance['networkInterfaces'][0]['accessConfigs'][0]['natIP'] body = {"description": resourceName, "priority": str(set_priority), "match": {"versionedExpr": "SRC_IPS_V1", "config": {"srcIpRanges": [set_ip]}}, "action": "allow", "preview": "False", "kind": "compute#securityPolicyRule"} addResult = compute.securityPolicies().addRule( project=project, securityPolicy=securityPolicy, body=body).execute() print(f"addResult is: {addResult}")結果
ruleの削除
instance名をdescriptionに登録しているので、マッチしたpriorityを消す様にしてます。
project = "test-project" securityPolicy = "test-policy" getpolicy = compute.securityPolicies().get( project=project, securityPolicy=securityPolicy).execute() for i in getpolicy["rules"]: if i["description"] == resourceName: delResult = compute.securityPolicies().removeRule( project=project, securityPolicy=securityPolicy, priority=i['priority']).execute()




- 投稿日:2020-07-25T20:48:31+09:00
Fusion 360 を Pythonで動かそう その9 スケッチの交差
はじめに
Fusion360 のAPIの理解を深めるために公式ドキュメント内のサンプルコード Sketch Intersect API Sample (スケッチの交差 APIサンプル) の内容からドキュメントを読み込んでみたメモ書きです
指定されたエンティティをスケッチ平面と交差させ、その交差を表すスケッチ ジオメトリを作成します。スクリプトの内容を確認する
最初と最後のおまじないから途中まで
最初と最後のお決まりのパターンについては その5で、スプライン曲線の作成は その7で、長方形の作成はその4で触れたので説明を省略します。
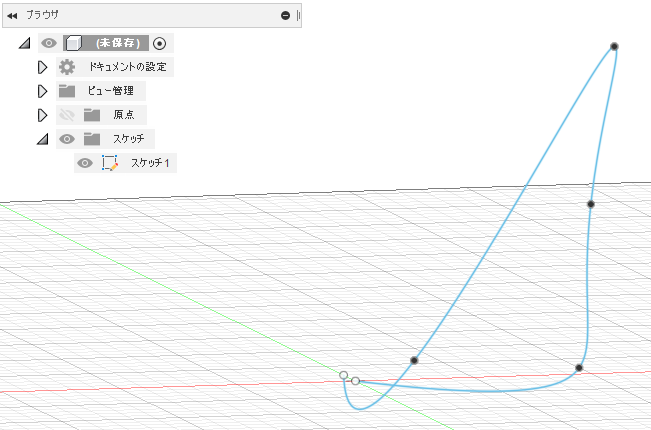
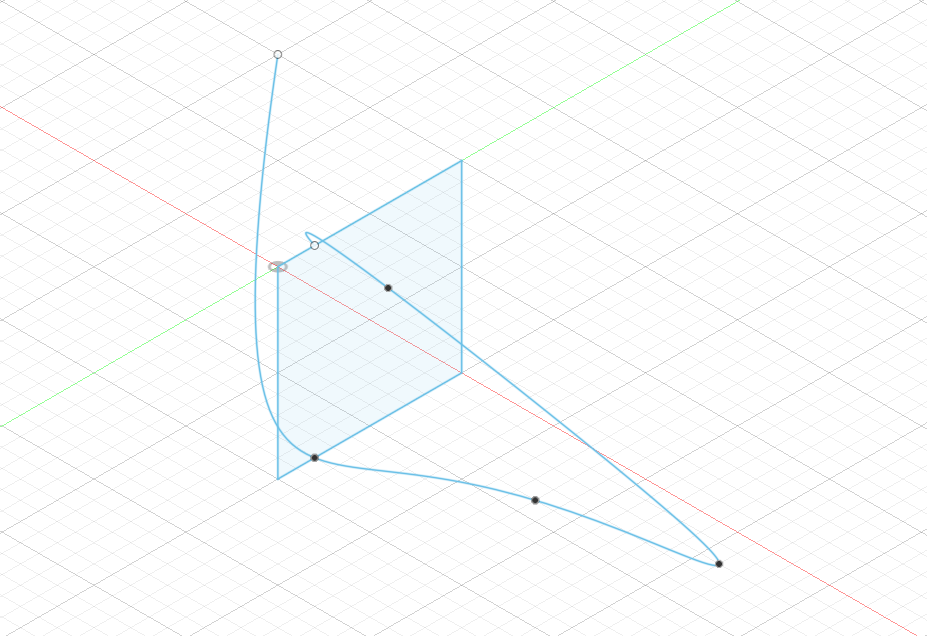
import adsk.core, adsk.fusion, traceback def run(context): ui = None try: app = adsk.core.Application.get() ui = app.userInterface # Create a document. doc = app.documents.add(adsk.core.DocumentTypes.FusionDesignDocumentType) product = app.activeProduct design = adsk.fusion.Design.cast(product) # Get the root component of the active design rootComp = design.rootComponent # Create a sketch sketches = rootComp.sketches sketch1 = sketches.add(rootComp.yZConstructionPlane) # Create an object collection for the points. points = adsk.core.ObjectCollection.create() # Define the points the spline with fit through. points.add(adsk.core.Point3D.create(-5, 0, 0)) points.add(adsk.core.Point3D.create(5, 1, 0)) points.add(adsk.core.Point3D.create(6, 4, 3)) points.add(adsk.core.Point3D.create(7, 6, 6)) points.add(adsk.core.Point3D.create(2, 3, 0)) points.add(adsk.core.Point3D.create(0, 1, 0)) # Create the spline. spline = sketch1.sketchCurves.sketchFittedSplines.add(points) # Get sketch lines sketchLines = sketch1.sketchCurves.sketchLines # Create sketch rectangle startPoint = adsk.core.Point3D.create(0, 0, 0) endPoint = adsk.core.Point3D.create(5.0, 5.0, 0) sketchLines.addTwoPointRectangle(startPoint, endPoint) # # ここにコードを追加していく # except: if ui: ui.messageBox('Failed:\n{}'.format(traceback.format_exc()))ここまでの内容でこのようなスプライン曲線と長方形ができます
このサンプルではスケッチの基準平面がYZ平面になっているのですが、Point3DのXYZ座標値とスケッチ内の座標系とグローバル座標系との関係がよくわからない・・・
Point3D の X 座標値がグローバル座標の -Z に Point3D の Y 座標値 が グローバル座標の Y になっている???スケッチから line を取得して変数に代入
# Get two sketch lines sketchLineOne = sketchLines.item(0) sketchLineTwo = sketchLines.item(1)SketchLines.item メソッドでインデックス 0 と 1 のラインを取得して変数に代入する
スケッチからプロファイルを取得して変数に代入
# Get the profile prof = sketch1.profiles.item(0)
sketch1の Sketch.profiles プロパティで Profiles オブジェクトを取得し、Profiles.item メソッドで Profile オブジェクトを取得してprofに代入する押し出しの準備
# Create an extrusion input extrudes = rootComp.features.extrudeFeatures extInput = extrudes.createInput(prof, adsk.fusion.FeatureOperations.NewBodyFeatureOperation)Component オブジェクトの features プロパティで Features オブジェクトを取得して、
Features オブジェクトの extrudeFeatures プロパティで ExtrudeFeatures オブジェクトを取得し、extrudesに代入
ExtrudeFeatures オブジェクトの createInput メソッドで ExtrudeFeatureInput オブジェクトを作成し、extInputに代入押し出し距離の設定
# Define that the extent is a distance extent of 5 cm distance = adsk.core.ValueInput.createByReal(5.0)押し出し距離を設定するためにはValueInput オブジェクトを作らなきゃいけないらしい。ValueInput.createByReal メソッドで実数値 (5.0) を指定している。
ExtrudeFeatureInput の設定(setDistanceExtent プロパティ)
# Set the distance extent extInput.setDistanceExtent(False, distance)ExtrudeFeatureInput オブジェクトの setDistanceExtent メソッドがリファレンスマニュアルに見当たらなかったのでVSCODEで確認
一つ目の引数は対称にするかどうかを指定しているExtrudeFeatureInput の設定(isSolid プロパティ)
# Set the extrude type to be solid extInput.isSolid = TrueisSolid プロパティを
Trueに設定している。デフォルトが True なので省略してもよい押し出し
# Create the extrusion ext = extrudes.add(extInput)ExtrudeFeatures.add メソッドで
extという名前の ExtrudeFeature オブジェクトを作成。
押し出しを作成するのに結構な手数がかかるのね・・・
ボディから情報を取得して変数に代入
# Get the body with the extrude body = ext.bodies.item(0) # Get a vertex of the body vertex = body.vertices.item(5) # Get a face of the vertex face = vertex.faces.item(0)ExtrudeFeature オブジェクトの bodies プロパティで BRepBodies オブジェクトを取得し、item メソッドで インデックス 0 の BRepBody オブジェクトを取得して
bodyに代入
BRepBody.vertices プロパティ で BRepBody.vertices オブジェクトを取得し、item メソッドでインデックス 5 のBRepVertex オブジェクトを取得し、vertexに代入
BRepVertex オブジェクトの faces プロパティで BRepFaces オブジェクトを取得し、item メソッドでインデックス 0 の BRepFace オブジェクトを取得し、faceに代入垂直軸の作成
# Create perpendicular construction axis axes = rootComp.constructionAxes axisInput = axes.createInput() axisInput.setByPerpendicularAtPoint(face, vertex) axis = axes.add(axisInput)ルートコンポーネントのconstructionAxes プロパティで ConstructionAxes オブジェクトを取得して
axesに代入
ConstructionAxes.createInput メソッドでConstructionAxisInput オブジェクトを作成してaxisInputに代入
setByPerpendicularAtPoint メソッドで指定された点で面に対して法線となる軸を作成する
axesに add メソッドで追加しaxisに代入
axisInput をかませた手順がややこしい・・・コンストラクションポイントの作成
# Create construction point points = rootComp.constructionPoints pointInput = points.createInput() pointInput.setByTwoEdges(sketchLineOne, sketchLineTwo) point = points.add(pointInput)軸の作成と同じような手順
constructionPoints オブジェクトの createInput メソッドで ConstructionPointInput オブジェクトを作成
setByTwoEdges メソッドで 2つの直線的なエッジまたはスケッチラインの交点に施工点を作成する
pointsに add メソッドで追加しpointに代入するコンストラクションプレーンの作成
# Create construction plane planes = rootComp.constructionPlanes planeInput = planes.createInput() offsetValue = adsk.core.ValueInput.createByReal(3.0) planeInput.setByOffset(prof, offsetValue) plane = planes.add(planeInput)こちらも軸の作成と同じような手順。Input用のオブジェクトをかませる手順の理解を深めたい
新しいスケッチの作成
# Create another sketch sketch2 = sketches.add(rootComp.xZConstructionPlane)entitiesというリストを作り色々とappend
entities = [] entities.append(body) # body entities.append(face) # face entities.append(sketchLineOne) # edge entities.append(vertex) # vertex entities.append(spline) # sketch curve entities.append(axis) # construction axis entities.append(point) # construction point entities.append(plane) # construction plane新しいスケッチの作成
sketchEntities = sketch2.intersectWithSketchPlane(entities)Sketch.intersectWithSketchPlane メソッドで指定されたエンティティをスケッチ平面と交差させ、その交差を表すスケッチ・ジオメトリを作成し、
sketchEntitiesに代入します
まとめ
Intersect に関するサンプルだったはずだけど Extrude や構築平面・軸・点に関する内容がややこしかった。もっと整理しながら進めないと理解が難しそう
前の記事 Fusion 360 を Pythonで動かそう その8 スケッチのフィレットとオフセット
参考


- 投稿日:2020-07-25T20:38:54+09:00
Pythonで0からディシジョンツリーを作って理解する (6. ツリー生成編)
Pythonで0からディシジョンツリーを作って理解する
1.概要編 - 2. Pythonプログラム基礎編 - 3. データ分析ライブラリPandas編 - 4.データ構造編 - 5.情報エントロピー編 - 6.ツリー生成編AI(機械学習)やデータマイニングの学習のために、Pythonで0からディシジョンツリーを作成することによって理解していきます。
6.1 ツリー生成のアルゴリズム
6.1.1 ツリー生成のアルゴリズムとは
ツリー構造を、例えば親子関係のデータをつなぎ合わせて作り出すアルゴリズムのことを、ツリー生成のアルゴリズムとここでは呼んでいます。
6.1.2 親ノードから子ノードを捜してつなぐ
ツリーのデータ構造としては、親ノードが子ノード一覧を保持する方法と、子ノードが親を保持する方法の2種類が考えられます。ただ、ツリー構造のデータを生成する方法としては、基本的には、親から子を捜すことになります。その理由は、ツリー構造は、親から複数の子ノードがあるため、子から親に遡るだけだとツリー構造に含まれない子ノードが現れてしまうからです。ただもちろん、親ノードから子ノードを捜す過程の中で、作成するツリー構造は、子ノードが親ノードを記録するという構造にすることは出来ます。
6.1.3 アルゴリズムの例
ツリー構造の元になる、あるデータがありそこから子ノード一覧を取得し続けるアルゴリズムです。
- ツリーの最上部の根になるデータを、これから調査対象となるopen配列に入れる。
- open配列が空になるまで3~5を繰り返す。
- openの先頭を取り出す。これをnとする。
- nの子ノード一覧を調査し、それらをmとする。
- nの子ノード一覧と、open配列にそれぞれmを追加する。
「4. nの子ノード一覧を調査し、それらをmとする。」の調査の部分を具体化することによって、以下に示す家系図の作成や、本記事の主テーマであるディシジョンツリーの作成に使用することができます。
6.1.4 ツリー生成を途中でやめる(一部だけを作る)場合の2つの戦略、幅優先(横型)、深さ優先(縦型)
すべての親子関係をツリー構造にする場合には、関係のない話です。ここでは、例えばメモリ容量の関係で、膨大な親子関係のデータから一部分だけをツリー構造にする場合について、その2つの戦略について説明します。
ツリーの一部分だけを作成する場合、ツリーの全体像が分からないので、データを探索してツリーを生成しながら、ある程度ツリー構造が大きくなった時点でツリー生成を止める、ということになります。
そのツリー生成の戦略には、幅優先(横型)と、深さ優先(縦型)の探索方法があります。この2つは、6.1.2 アルゴリズムで紹介した「5. nの子ノード一覧と、open配列にそれぞれmを追加する。」のopenへの追加の仕方によって変わってきます。
「3. openの先頭を取り出す。これをnとする。」でopenの先頭から次に調べるノードを取り出しているので、openに新たな調査対象の子ノードを追加するときに、openの最後に追加すると先に見つかっているノードから順番に調査され、openの先頭に追加すると新しく見つかったノードを優先して調査するようになります。前者が幅優先で、後者が深さ優先です。感覚的には、openの最後に子ノードを追加する幅優先は、調査を待っているノードがちゃんと順番待ちしている、openの先頭に追加する深さ優先は、新しいノードが割り込んで待ち行列に入ってくる、という感じです。
結果的に、幅優先の戦略だと、生成されるツリーは、アルゴリズムがスタートする最初の祖先のノードから見てほぼ同じだけ下の段に下がったツリーが作られます。一方、深さ優先は、ある1か所だけ深堀されて、縦に長いツリーとなります。
どちらの戦略が良いかは、一概には言えません。ただ実装の仕方として、6.1.2のアルゴリズムは、どちらでも対応できますが、深さ優先の場合には6.1.2のアルゴリズムではなく、再帰関数を用いた実装もできます。その実装のし易さから深さ優先が選ばれることもあります。
6.2 徳川将軍家の家系図のツリー構造化
次のような徳川将軍家の家系図を、ツリー構造としてデータ化する例を示します。
(参照: wikipedia)6.2.1 親子関係のデータからツリーを作る
ツリー構造を作るための元データは、次のような、["親","子"]といった親子関係を配列のセットとします。
# 親子関係を配列で表したデータ parent_childs = [ ["家康","信康"],["家康","秀康"],["家康","秀忠"],["家康","忠輝"],["家康","義直"], ["秀忠","家光"],["秀忠","忠長"],["秀忠","和子"],["秀忠","正之"],["家光","家綱"], ["家光","綱重"],["家光","綱吉"],["綱重","家宣"],["家宣","家継"],["家康","頼信"], ["頼信","光貞"],["光貞","吉宗"],["吉宗","家重"],["家重","家治"],["家重","重好"], ["吉宗","宗武"],["宗武","定信"],["吉宗","宗尹"],["宗尹","治済"],["治済","家斉"], ["治済","斉敦"],["治済","斉匡"],["家斉","家慶"],["家慶","家定"],["家斉","斉順"], ["斉順","家茂"],["斉匡","慶頼"],["慶頼","家達"],["家康","頼房"],["頼房","頼重"], ["頼重","頼侯"],["頼侯","頼豊"],["頼豊","宗堯"],["宗堯","宗翰"],["宗翰","治保"], ["治保","治紀"],["治紀","斉昭"],["斉昭","慶喜"], ]6.2.2 ツリー生成アルゴリズムの実装例
根元になるノードを指定して、そこから下の子ノードをすべてツリー構造データ化する関数を示します。関数の引数には、親ノードと、親子関係のデータを指定します。戻り値は、生成されたツリー構造です。また、引数として指定した親ノードに追加する形でツリー構造を作成するので、引数の親ノードの値は改変されます。
# 祖を指定して、ツリー構造を作成する。 def tree_generator(tree,rdata): # こから調査する対象のノード一覧 open = [tree] # openが空になるまで繰り返す。 while(len(open)!=0): # open の先頭を取り出す。 node1 = open.pop(0) # 親子関係のデータをすべてループする。 for pc in rdata: # 親データと調査対象データが一致する場合 if pc[0]==node1[0]: # ツリーデータを作成して、調査対象のツリーの子ノードとして追加する。 tree2 = [pc[1],[]] node1[1].append(tree2) # さらに発見された子ノードを、これから調査をする対象としてopenに登録する。 open.append(tree2) pass pass pass return tree6.2.3 ツリーの表示
4.データ構造編で示した。ツリー構造を文字化する関数です。
# ツリー構造の文字化関数 def tstr(node,indent=""): s = indent+str(node[0])+"\n" for c in node[1]: # 子ノードでループ s += tstr(c,indent+"+-") pass return s6.2.4 ついでに何代の将軍かを表示
ツリー構造とは関係が無いのですけど、せっかくなので、徳川宗家の誰が何代将軍なのかを名前の横に数値を記すことによって表したいと思います。
まず、将軍配列(shogun)を作成し、そのインデックス+1が何代かを表すので、それを取得するラムダ式を作っておきます。将軍ではない名前が指定されると空欄が返されます。
これを、先ほどのツリー構造の文字化関数(tstr)の文字生成部分に追加します。
# 歴代将軍の配列 shogun = ["家康","秀忠","家光","家綱","綱吉","家宣","家継", "吉宗","家重","家治","家斉","家慶","家定","家茂","慶喜"] # 名前から何代将軍かを求める。将軍ではない場合は、空文字が返る。 sno = lambda name: "" if name not in shogun else " "+str(shogun.index(name)+1) # tstr関数の文字生成部分に、sno(node[0])を追加する。 s = indent+str(node[0])+sno(node[0])+"\n"6.2.5 実行例
家康を祖とした全家系図を表示する場合です。
# 家康を祖とした家系図を作成する。 tree = ["家康",[]] tree_generator(tree,parent_childs) print(tstr(tree)) #出力 #家康 1 #+-信康 #+-秀康 #+-秀忠 2 #+-+-家光 3 #+-+-+-家綱 4 #+-+-+-綱重 #+-+-+-+-家宣 6 #+-+-+-+-+-家継 7 #+-+-+-綱吉 5 #+-+-忠長 #+-+-和子 #+-+-正之 #+-忠輝 #+-義直 #+-頼信 #+-+-光貞 #+-+-+-吉宗 8 #+-+-+-+-家重 9 #+-+-+-+-+-家治 10 #+-+-+-+-+-重好 #+-+-+-+-宗武 #+-+-+-+-+-定信 #+-+-+-+-宗尹 #+-+-+-+-+-治済 #+-+-+-+-+-+-家斉 11 #+-+-+-+-+-+-+-家慶 12 #+-+-+-+-+-+-+-+-家定 13 #+-+-+-+-+-+-+-斉順 #+-+-+-+-+-+-+-+-家茂 14 #+-+-+-+-+-+-斉敦 #+-+-+-+-+-+-斉匡 #+-+-+-+-+-+-+-慶頼 #+-+-+-+-+-+-+-+-家達 #+-頼房 #+-+-頼重 #+-+-+-頼侯 #+-+-+-+-頼豊 #+-+-+-+-+-宗堯 #+-+-+-+-+-+-宗翰 #+-+-+-+-+-+-+-治保 #+-+-+-+-+-+-+-+-治紀 #+-+-+-+-+-+-+-+-+-斉昭 #+-+-+-+-+-+-+-+-+-+-慶喜 15また、例えば、吉宗を祖とするツリーについても作ることができます。
# 吉宗を祖とした家系図(家康の家系図の一部)を作成する。 tree = ["吉宗",[]] tree_generator(tree,parent_childs) print(tstr(tree)) #出力 #吉宗 8 #+-家重 9 #+-+-家治 10 #+-+-重好 #+-宗武 #+-+-定信 #+-宗尹 #+-+-治済 #+-+-+-家斉 11 #+-+-+-+-家慶 12 #+-+-+-+-+-家定 13 #+-+-+-+-斉順 #+-+-+-+-+-家茂 14 #+-+-+-斉敦 #+-+-+-斉匡 #+-+-+-+-慶頼 #+-+-+-+-+-家達6.2.6 完成版のプログラム
上のプログラムをすべて入れた、完成版のプログラムを示します。
# 親子関係を配列で表したデータ parent_childs = [ ["家康","信康"],["家康","秀康"],["家康","秀忠"],["家康","忠輝"],["家康","義直"], ["秀忠","家光"],["秀忠","忠長"],["秀忠","和子"],["秀忠","正之"],["家光","家綱"], ["家光","綱重"],["家光","綱吉"],["綱重","家宣"],["家宣","家継"],["家康","頼信"], ["頼信","光貞"],["光貞","吉宗"],["吉宗","家重"],["家重","家治"],["家重","重好"], ["吉宗","宗武"],["宗武","定信"],["吉宗","宗尹"],["宗尹","治済"],["治済","家斉"], ["治済","斉敦"],["治済","斉匡"],["家斉","家慶"],["家慶","家定"],["家斉","斉順"], ["斉順","家茂"],["斉匡","慶頼"],["慶頼","家達"],["家康","頼房"],["頼房","頼重"], ["頼重","頼侯"],["頼侯","頼豊"],["頼豊","宗堯"],["宗堯","宗翰"],["宗翰","治保"], ["治保","治紀"],["治紀","斉昭"],["斉昭","慶喜"], ] # 歴代将軍の配列 shogun = ["家康","秀忠","家光","家綱","綱吉","家宣","家継", "吉宗","家重","家治","家斉","家慶","家定","家茂","慶喜"] # 名前から何代将軍かを求める。将軍ではない場合は、空文字が返る。 sno = lambda name: "" if name not in shogun else " "+str(shogun.index(name)+1) # 祖を指定して、ツリー構造を作成する。 def tree_generator(tree,rdata): # こから調査する対象のノード一覧 open = [tree] # openが空になるまで繰り返す。 while(len(open)!=0): # open の先頭を取り出す。 node1 = open.pop(0) # 親子関係のデータをすべてループする。 for pc in rdata: # 親データと調査対象データが一致する場合 if pc[0]==node1[0]: # ツリーデータを作成して、調査対象のツリーの子ノードとして追加する。 tree2 = [pc[1],[]] node1[1].append(tree2) # さらに発見された子ノードを、これから調査をする対象としてopenに登録する。 open.append(tree2) pass pass pass return tree # ツリー構造の表示関数 def tstr(node,indent=""): s = indent+str(node[0])+sno(node[0])+"\n" for c in node[1]: # 子ノードでループ s += tstr(c,indent+"+-") pass return s # 家康を祖とした家系図を作成する。 tree = ["家康",[]] tree_generator(tree,parent_childs) print(tstr(tree)) #出力 #家康 1 # ...(略)... # 吉宗を祖とした家系図(家康の家系図の一部)を作成する。 tree = ["吉宗",[]] tree_generator(tree,parent_childs) print(tstr(tree)) #出力 #吉宗 8 # ...(略)...6.3 ディシジョンツリーの生成
6.3.1 子ノード一覧の調査は、エントロピーを最も下げる属性を捜すこと
6.1.2 アルゴリズムの「4. nの子ノード一覧を調査し、それらをmとする。」を、データのエントロピーを最も下げる属性を捜すことを調査とすることにより、ディシジョンツリーを生成することができます。
以下のプログラムは、1.概要編のディシジョンツリーを作るプログラムの一部です。親ノード n、親ノードに関連付けられたデータ df_nとなっています。
最初のif文は、親ノードのエントロピーが0のときには、子ノードの追加は行わない、です。
# このノードのエントロピーが0の場合、これ以上エッジを展開できないので、 # このノードからの枝分かれはしない。 if 0==entropy(df_n.iloc[:,-1]): continue # 分岐可能性の属性値一覧を保存する変数を作成しておく。 attrs = {} # クラス属性の最後の列以外の属性をすべて調査する。 for attr in df_n.columns[:-1]: # この属性で分岐する場合のエントロピーと、 # 分岐後のデータと分岐する属性値を保存する変数を作成する。 attrs[attr] = {"entropy":0,"dfs":[],"values":[]} # この属性の取りうる値をすべて調査する。またsortedは、属性値の重複除去された配列を、 # 実行のたびに順番が入れ替わらないようにするためである。 for value in sorted(set(df_n[attr])): # 属性値でデータをフィルタリングする。 df_m = df_n.query(attr+"=='"+value+"'") # エントロピーを計算し、関連するデータ、値をそれぞれ保存しておく。 attrs[attr]["entropy"] += entropy(df_m.iloc[:,-1])*df_m.shape[0]/df_n.shape[0] attrs[attr]["dfs"] += [df_m] attrs[attr]["values"] += [value] pass pass # クラス値を分離可能な属性が1つも無い場合は、このノードの調査を終了する。 if len(attrs)==0: continue # エントロピーが最小になる属性を取得する。 attr = min(attrs,key=lambda x:attrs[x]["entropy"]) # 分岐する属性のそれぞれの値、分岐後のデータを、ツリーとopenにそれぞれ追加する。 for d,v in zip(attrs[attr]["dfs"],attrs[attr]["values"]): m = {"name":attr+"="+v,"edges":[],"df":d.drop(columns=attr)} n["edges"].append(m) open.append(m)以上で、Pythonで0からディシジョンツリーを作って理解する、の全編を終了いたします。

- 投稿日:2020-07-25T19:38:11+09:00
Google翻訳とPythonを使ってPDF論文を一気に翻訳する
概要
Google翻訳APIをPythonで実行するでは、四苦八苦しながらも、Google翻訳APIにより、テキストファイルに書かれた英文を日本語に翻訳するPythonスクリプトを書いた。
元々の動機は論文の翻訳する際に、ちまちまGoogle翻訳にコピペするのが面倒くさいということであった。
そこで今回は、Pythonスクリプトを拡張し、PDFの論文を一気に翻訳するようにしたので共有したい。そもそもなんで日本語に翻訳して論文を読むの?
もちろん、細かい内容は原文を精読する必要がある。そりゃそうだ。
日本語で読む理由はなんといっても、論文の内容を俯瞰的に把握できるということに尽きる。俯瞰的に把握できることで、以下のメリットがある。
- 俯瞰的に把握した上で原文を読むことになるため、より早く理解することができる。
- 俯瞰的に把握できるため、原文を読む前に、自分にとって読む必要がある論文かどうかかが判断できる。
- 英文のみを読んでいるだけでは、気づかなかった情報が得られる。
英語が苦手な人間にとってはいいことづくめである。
もちろん、このメリットは昨今のAI技術による翻訳精度の向上によるところが大きいのだが(感謝)。作ったもの
- pdfを引数に与えると、pdfと同じフォルダに "translate.txt"とう名前のテキストファイルに翻訳文を生成。
- pdfからテキストを抽出する処理はpdfminer.sixを利用。PDFから全テキストを抽出する方法をそのまま利用させていただいた。
- 英語を日本語に翻訳するために、前回書いたようにGoogle Apps Scriptというシロモノを使ってGoogle翻訳を呼び出すAPIを作成し、Pythonから叩いている。
ソース
取り急ぎソースを載せる。解説は後程。
translate.pyimport argparse import requests from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter from pdfminer.converter import TextConverter from pdfminer.layout import LAParams from pdfminer.pdfpage import PDFPage from io import StringIO import re import os def is_float(n): try: float(n) except ValueError: return False else: return True def get_text_from_pdf(pdfname, limit=1000): # PDFファイル名が未指定の場合は、空文字列を返して終了 if (pdfname == ''): return '' else: # 処理するPDFファイルを開く/開けなければ try: fp = open(pdfname, 'rb') except: return '' # PDFからテキストの抽出 rsrcmgr = PDFResourceManager() out_fp = StringIO() la_params = LAParams() la_params.detect_vertical = True device = TextConverter(rsrcmgr, out_fp, codec='utf-8', laparams=la_params) interpreter = PDFPageInterpreter(rsrcmgr, device) for page in PDFPage.get_pages(fp, pagenos=None, maxpages=0, password=None, caching=True, check_extractable=True): interpreter.process_page(page) text = out_fp.getvalue() fp.close() device.close() out_fp.close() # 改行で分割する lines = text.splitlines() outputs = [] output = "" replace_strs = [b'\x00'] is_blank_line = False for line in lines: # byte文字列に変換 line_utf8 = line.encode('utf-8') # 余分な文字を除去する for replace_str in replace_strs: line_utf8 = line_utf8.replace(replace_str, b'') # strに戻す line = line_utf8.decode() # 連続する空白を一つにする line = re.sub("[ ]+", " ", line) # 前後の空白を除く line = line.strip() #print("aft:[" + line + "]") # 空行は無視 if len(line) == 0: is_blank_line = True continue # 数字だけの行は無視 if is_float(line): continue # 1単語しかなく、末尾がピリオドで終わらないものは無視 if line.split(" ").count == 1 and not line.endswith("."): continue # 文章の切れ目の場合 if is_blank_line or output.endswith("."): # 文字数がlimitを超えていたらここで一旦区切る if(len(output) > limit): outputs.append(output) output = "" else: output += "\r\n" #前の行からの続きの場合 elif not is_blank_line and output.endswith("-"): output = output[:-1] #それ以外の場合は、単語の切れ目として半角空白を入れる else: output += " " #print("[" + str(line) + "]") output += str(line) is_blank_line = False outputs.append(output) return outputs def translate(input): api_url = "https://script.google.com/macros/s/AKfycbwxgoXYt7bOio6QRWmnBEwEQEyi5Fz2-UaEZGxP2s0FmxoLVT4/exec" params = { 'text': "\"" + input + "\"", 'source': 'en', 'target': 'ja' } #print(params) r_post = requests.post(api_url, data=params) return r_post.json()["text"] def main(): parser = argparse.ArgumentParser() parser.add_argument("-input", type=str, required=True) parser.add_argument("-limit", type=int, default=1000) args = parser.parse_args() path = os.path.dirname(args.input) base_name = os.path.splitext(os.path.basename(args.input))[0] # pdfをテキストに変換 inputs = get_text_from_pdf(args.input, limit=args.limit) with open(path + os.sep + "text.txt", "w", encoding="utf-8") as f_text: with open(path + os.sep + "translate.txt", "w", encoding="utf-8") as f_trans: for i, input in enumerate(inputs): print("{0}/{1} is proccessing".format((i+1), len(inputs))) f_text.write(input) f_trans.write(translate(input)) if __name__ == "__main__": main()解説
PDFからテキストの抽出処理
まず、
get_text_from_pdfがPDFからテキストの抽出処理である。
抽出したテキストをそのままGoogle翻訳にかけると、変な文字が入っていたり、切れ目が悪くGoogle翻訳の精度が下がるので、改行で区切って1行ずつ、次の工夫をしながら文章を再構築した。翻訳の精度を上げる工夫
- 英文の場合、ハイフンの後に改行がはいると、単語の途中の改行と考えられるので、その場合前の行のハイフンを除去して次の行をつなげるようにした。逆にハイフンなしの場合は、単語の切れ目と考えられるので、前後の行に空白を挟むようにした。
- 抽出されたテキストの中に、ただの空白文字ではなく、"\x00"というNULLのutf8文字が入ってくることがある。数式等に含まれることが多いが、翻訳にはノイズとなるため、バイト文字列に変換した上で除去している。
- 空行や数字だけの行は、翻訳の妨げになるので削除している。
- 1単語しかなく、末尾がピリオドで終わらない行も、数式や図表の一部の可能性が高いため無視している。(見出しの可能性があるなぁ)
- 前の行がピリオドで終わっていたり、空行の場合は、文の切れ目と考えられるので、改行を明示的に入れている。
- 構築した文字列が一定数を超えた場合、Googleが正しく翻訳できない可能性がるため、一旦その文字列をリストに入れて、別の文字列を構築するようにしている。この一定数はlimitオプションとしてコマンドラインの引数で指定することもできる(デフォルトは1000文字とした)
テキストの翻訳処理
得られた文字列のリスト毎に
translate(input)を実行し、その結果をファイルに出力している。使い方
$ python translate.py --h usage: translate.py [-h] -input INPUT [-limit LIMIT] optional arguments: -h, --help show this help message and exit -input input pdf file -limit max string length per request (default 1000)実行するとpdfと同じファイルに translate.txt (翻訳文)とtext.txt (PDFからの抽出テキスト)が生成される。
ためしに2本ほど論文を一気に翻訳してみてみたが、十分が概要をつかむことができた。
今後の展望
数字だけの行を除いてはいるが、それだけでは除けない不要な情報がある。ページ番号、ジャーナルの情報、数式の断片などである。うまく改行処理が機能しているため、翻訳がおかしくなっているわけではないが、これらをテキスト抽出後、翻訳にかける前に除外できるような、対話的なGUIを作成してみたい。
- 投稿日:2020-07-25T19:38:11+09:00
Google翻訳とPythonを使ってPDF論文を一発で翻訳する
概要
Google翻訳APIをPythonで実行するでは、四苦八苦しながらも、Google翻訳APIにより、テキストファイルに書かれた英文を日本語に翻訳するPythonスクリプトを書いた。
元々の動機は論文の翻訳する際に、ちまちまGoogle翻訳にコピペするのが面倒くさいということであった。
そこで今回は、Pythonスクリプトを拡張し、PDFの論文を一気に翻訳するようにしたので共有したい。そもそもなんで日本語に翻訳して論文を読むの?
もちろん、細かい内容は原文を精読する必要がある。そりゃそうだ。
日本語で読む理由はなんといっても、論文の内容を俯瞰的に把握できるということに尽きる。俯瞰的に把握できることで、以下のメリットがある。
- 俯瞰的に把握した上で原文を読むことになるため、より早く理解することができる。
- 俯瞰的に把握できるため、原文を読む前に、自分にとって読む必要がある論文かどうかかが判断できる。
- 英文のみを読んでいるだけでは、気づかなかった情報が得られる。
英語が苦手な人間にとってはいいことづくめである。
もちろん、このメリットは昨今のAI技術による翻訳精度の向上によるところが大きいのだが(感謝)。作ったもの
- pdfを引数に与えて実行すると、pdfと同じフォルダに "translate.txt"という名前のテキストファイルに翻訳文を生成するコマンドを作成。
- pdfからテキストを抽出する処理はpdfminer.sixを利用。PDFから全テキストを抽出する方法をそのまま利用させていただいた。
- 英語を日本語に翻訳するために、前回書いたようにGoogle Apps Scriptというシロモノを使ってGoogle翻訳を呼び出すAPIを作成し、Pythonから叩いている。
ソース
取り急ぎソースを載せる。解説は後程。
translate.pyimport argparse import requests from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter from pdfminer.converter import TextConverter from pdfminer.layout import LAParams from pdfminer.pdfpage import PDFPage from io import StringIO import re import os def is_float(n): try: float(n) except ValueError: return False else: return True def get_text_from_pdf(pdfname, limit=1000): # PDFファイル名が未指定の場合は、空文字列を返して終了 if (pdfname == ''): return '' else: # 処理するPDFファイルを開く/開けなければ try: fp = open(pdfname, 'rb') except: return '' # PDFからテキストの抽出 rsrcmgr = PDFResourceManager() out_fp = StringIO() la_params = LAParams() la_params.detect_vertical = True device = TextConverter(rsrcmgr, out_fp, codec='utf-8', laparams=la_params) interpreter = PDFPageInterpreter(rsrcmgr, device) for page in PDFPage.get_pages(fp, pagenos=None, maxpages=0, password=None, caching=True, check_extractable=True): interpreter.process_page(page) text = out_fp.getvalue() fp.close() device.close() out_fp.close() # 改行で分割する lines = text.splitlines() outputs = [] output = "" # 除去するutf8文字 replace_strs = [b'\x00'] is_blank_line = False # 分割した行でループ for line in lines: # byte文字列に変換 line_utf8 = line.encode('utf-8') # 余分な文字を除去する for replace_str in replace_strs: line_utf8 = line_utf8.replace(replace_str, b'') # strに戻す line = line_utf8.decode() # 連続する空白を一つにする line = re.sub("[ ]+", " ", line) # 前後の空白を除く line = line.strip() #print("aft:[" + line + "]") # 空行は無視 if len(line) == 0: is_blank_line = True continue # 数字だけの行は無視 if is_float(line): continue # 1単語しかなく、末尾がピリオドで終わらないものは無視 if line.split(" ").count == 1 and not line.endswith("."): continue # 文章の切れ目の場合 if is_blank_line or output.endswith("."): # 文字数がlimitを超えていたらここで一旦区切る if(len(output) > limit): outputs.append(output) output = "" else: output += "\r\n" #前の行からの続きの場合 elif not is_blank_line and output.endswith("-"): output = output[:-1] #それ以外の場合は、単語の切れ目として半角空白を入れる else: output += " " #print("[" + str(line) + "]") output += str(line) is_blank_line = False outputs.append(output) return outputs def translate(input): api_url = "https://script.google.com/macros/s/*******************/exec" params = { 'text': "\"" + input + "\"", 'source': 'en', 'target': 'ja' } #print(params) r_post = requests.post(api_url, data=params) return r_post.json()["text"] def main(): parser = argparse.ArgumentParser() parser.add_argument("-input", type=str, required=True) parser.add_argument("-limit", type=int, default=1000) args = parser.parse_args() path = os.path.dirname(args.input) base_name = os.path.splitext(os.path.basename(args.input))[0] # pdfをテキストに変換 inputs = get_text_from_pdf(args.input, limit=args.limit) with open(path + os.sep + "text.txt", "w", encoding="utf-8") as f_text: with open(path + os.sep + "translate.txt", "w", encoding="utf-8") as f_trans: # 一定文字列で分割した文章毎にAPIを叩く for i, input in enumerate(inputs): print("{0}/{1} is proccessing".format((i+1), len(inputs))) # 結果をファイルに出力 f_text.write(input) f_trans.write(translate(input)) if __name__ == "__main__": main()解説
PDFからテキストの抽出処理
まず、
get_text_from_pdfがPDFからテキストの抽出処理である。
抽出したテキストをそのままGoogle翻訳にかけると、変な文字が入っていたり、切れ目が悪くGoogle翻訳の精度が下がるので、改行で区切って1行ずつ、次の工夫をしながら文章を再構築した。翻訳の精度を上げる工夫
- 英文の場合、ハイフンの後に改行がはいると、単語の途中の改行と考えられるので、その場合前の行のハイフンを除去して次の行をつなげるようにした。逆にハイフンなしの場合は、単語の切れ目と考えられるので、前後の行に空白を挟むようにした。
- 抽出されたテキストの中に、ただの空白文字ではなく、"\x00"というNULLのutf8文字が入ってくることがある。数式等に含まれることが多いが、翻訳にはノイズとなるため、バイト文字列に変換した上で除去している。
- 空行や数字だけの行は、翻訳の妨げになるので削除している。
- 1単語しかなく、末尾がピリオドで終わらない行も、数式や図表の一部の可能性が高いため無視している。(見出しの可能性があるなぁ)
- 前の行がピリオドで終わっていたり、空行の場合は、文の切れ目と考えられるので、改行を明示的に入れている。
- 構築した文字列が一定数を超えた場合、Googleが正しく翻訳できない可能性がるため、一旦その文字列をリストに入れて、別の文字列を構築するようにしている。この一定数はlimitオプションとしてコマンドラインの引数で指定することもできる(デフォルトは1000文字とした)
テキストの翻訳処理
得られた文字列のリスト毎に
translate(input)を実行し、その結果をファイルに出力している。
APIのURLは念のためアスタリスクでマスクした。使い方
$ python translate.py --h usage: translate.py [-h] -input INPUT [-limit LIMIT] optional arguments: -h, --help show this help message and exit -input input pdf file -limit max string length per request (default 1000)実行するとpdfと同じフォルダに translate.txt (翻訳文)とtext.txt (PDFからの抽出テキスト)が生成される。
ためしに2本ほど論文を一気に翻訳してみてみたが、十分に概要をつかむことができた。もちろん、翻訳APIのおかげなのだが。
今後の展望
数字だけの行を除いてはいるが、それ以外にも不要な情報がある。ページ番号、ジャーナルの情報、数式の断片などである。うまく改行処理が機能しているため、翻訳がおかしくなっているわけではないが、これらをテキスト抽出後、翻訳にかける前に除外できるような、対話的なGUIを作成してみたい。
- 投稿日:2020-07-25T18:39:46+09:00
【Python】特定のハッシュタグが付いたツイートを自動的にTrelloのカードに追加
はじめに
背景
初めまして、桃熊猫(@momopanda_jp )です。
私はTwitterでやりたいことを結構書くのですが、TLで流れて忘れてしまうので、
ツイートしたら自動的にTrelloのカードに追加できたら便利そうだなと思い、
コーディングすることにしました。今回はTwitterのデータの操作に便利なライブラリ「tweepy」を使ってみようと思います。
詳しくはこちら→tweepy対象
・Twitter API未取得の方
・Trello API未取得の方
・Google Cloud Platform(GCP)未登録の方
・やりたいことなどをリスト化したい方
・ツイートはするけど、Trelloに一々追加するのが面倒な方環境
Windows10 Home
Python3.7
VSCode
Chrome目次
1.Twitter API・Trello APIの取得
1-1. Twitter API取得
1-2. Trello API取得2.ツイートの取得
3.Trelloへのカード追加
3-1. Trelloのボード・リストのIDを取得
3-2.カードの名前をツイート内容にして追加
3-3. 同じ内容のツイートは追加しないようにする4.GCPの登録・自動化
1.Twitter API・Trello APIの取得
1-1. Twitter API取得
Twitter API 登録 (アカウント申請方法) から承認されるまでの手順まとめ ※2019年8月時点の情報を
参考に取得しました。1-2.Trello API取得
PythonでTrelloのタスクを取得するの「【準備】TrelloのAPIトークンとシークレットを取得する」を参考に、
キー・トークンを取得しました。2.ツイートの取得
2-1.tweepyのインストール
コマンドpip install tweepy2-2. ツイートの取得・整形
Pythonimport tweepy #Twitter API #各キーを取得 consumer_key = 'xxxxxxxxxxxxxxxxx' consumer_secret = 'xxxxxxxxxxxxxxxxxxx' access_token = 'xxxxxxxxx-xxxxxxxxxxxxxx' access_token_secret = 'xxxxxxxxxxxxxxxxxx' #認証情報を設定 auth = tweepy.OAuthHandler(consumer_key, consumer_secret) auth.set_access_token(access_token, access_token_secret) #APIインスタンスの作成 api = tweepy.API(auth) #自分のハッシュタグが付いた最新のツイートの内容を一つずつ出力 #qは出力したいワード(今回はハッシュタグ)を指定 #screen_nameは出力したいアカウントのID #result_type='recent'で最新のツイートを指定 #itemsの引数で一回で出力できるツイート数を指定できる for tweet in tweepy.Cursor(api.search, q = '#○○○○', screen_name = 'xxxxxxxxxx', result_type = 'recent').items(1): wish = tweet.text.replace('\\n', '').replace('RT @xxxxxxxxxx: ', '').replace('#○○○○', '').replace('\n','')参考:Pythonで特定のキーワードが付与されたツイート収集する方法
tweepyレファレンス3.Trelloへのカード追加
3-1. Trelloのボード・リストのIDを取得
Trelloの情報がJSON形式なので、見やすいようにjqをインストールして、PATHを通します。
PATHの通し方はWindows で環境変数 PATH をいじる方法のまとめを参考にさせてもらいました。
curlしたいURLはTrello(Get Boards that Member belongs to)の例を参考にしてください。追加したいボードのIDを以下のように取得します。
コマンドcurl "https://trello.com/1/members/{userID}/boards?key={Key}&token={token}&fields=name" | jq出力結果はこのように表示されます。
コマンド(結果)% Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 117 100 117 0 0 117 0 0:00:01 --:--:-- 0:00:01 207 [ { "name": "To do list", "id": "xxxxxxxxxxxxxxxxxxxxxxxx" }, { "name": "やりたいこと", "id": "xxxxxxxxxxxxxxxxxxxxxxxx" } ]追加したいリストのIDも以下で取得できます。
コマンドcurl "https://trello.com/1/boards/{BoardID}/lists?key={key}&token={token}&fields=name" | jqコマンド(結果)% Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 319 100 319 0 0 319 0 0:00:01 --:--:-- 0:00:01 600 [ { "id": "xxxxxxxxxxxxxxxxxxxxxxxx", "name": "未着手" }, { "id": "xxxxxxxxxxxxxxxxxxxxxxxx", "name": "勉強すること" }, { "id": "xxxxxxxxxxxxxxxxxxxxxxxx", "name": "作業中" }, { "id": "xxxxxxxxxxxxxxxxxxxxxxxx", "name": "完了" }, { "id": "xxxxxxxxxxxxxxxxxxxxxxxx", "name": "合格" }, { "id": "xxxxxxxxxxxxxxxxxxxxxxxx", "name": "中止" } ]3-2. カードの名前をツイート内容にして追加
Pythonimport tweepy from trello import TrelloApi # Trello API # Key Token #trello = TrelloApi('キー', 'トークン') key = 'xxxxxxxxxxxxxx' token = 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx' trello = TrelloApi(key, token) # List ID ボードIDから調べたリストID listid = 'xxxxxxxxxxxxxxxxxxxxxx' #自分のハッシュタグが付いたツイートを一つずつ出力 for tweet in tweepy.Cursor(api.search, q = '#○○○○', screen_name = 'xxxxxxxxxx', result_type = 'recent').items(1): wish = tweet.text.replace('\\n', '').replace('RT @xxxxxxxxxx: ', '').replace('#○○○○', '').replace('\n','') # Card Name cardname = wish #特定のハッシュタグ付きのツイート内容 # Card Description #desc = '新しいタスクの内容です。1行目n新しいタスクの内容です。2行目n新しいタスクの内容です。3行目n' desc = '' card = trello.cards.new(cardname, listid, desc)3-3.同じ内容のツイートは追加しないようにする
Pythonimport tweepy import json from trello import TrelloApi import requests # Trello API # Key Token #trello = TrelloApi('キー', 'トークン') key = 'xxxxxxxxxxxxxxxxxxxx' token = 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx' trello = TrelloApi(key, token) # List ID ボードIDから調べたリストID listid = 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx' #既にあるカードの確認 url = "https://trello.com/1/lists/" + listid + "/cards" query = {'key': key, 'token': token, 'fields': 'name'} r = requests.get(url, params = query) data = r.json() name_list = [] for x in range(len(data)): name = data[x]['name'].replace('\n','') name_list.append(name) #自分のハッシュタグが付いたツイートを一つずつ出力 for tweet in tweepy.Cursor(api.search, q = '#○○○○', screen_name = 'xxxxxxxxxxx', result_type = 'recent').items(1): wish = tweet.text.replace('\\n', '').replace('RT @xxxxxxxxxxx: ', '').replace('#○○○○', '').replace('\n','') #カードが重複しないように設定 if wish not in name_list: # Card Name cardname = wish #カードの名前を特定のハッシュタグ付きのツイート内容にする # Card Description #desc = '新しいタスクの内容です。1行目n新しいタスクの内容です。2行目n新しいタスクの内容です。3行目n' desc = '' card = trello.cards.new(cardname, listid, desc) else: break参考:【30分で動かすシリーズ】TrelloにAPIを使ってカードの起票や取得をしてみる
Trello(Create a new card)4.GCPの登録・自動化
まずGoogle Cloud Platformを登録しましょう。
サーバーレス + Pythonで定期的にスクレイピングを行う方法を参考に、登録から作ったジョブの実行まで進めていきます。
順番は以下の通りです。
・GCP登録
・GCPでプロジェクト作成
・Cloud Functionsの作成
・関数の作成
・ソースコードの作成
・関数のテスト
・Cloud Schedulerの作成
・ジョブの実行関数の作成時に、私はランタイムをPython3.7にして、
ソースコードの入力時にmain.py、requirement.txtは以下のように書きました。
mainの引数のevent、contextは関数に含まれていなくても、書いておかないと実行できないので注意しましょう。main.pyimport tweepy import json from trello import TrelloApi import requests def main(event, context): #Twitter API #各キーを取得 consumer_key = 'xxxxxxxxxxxx' consumer_secret = 'xxxxxxxxxxxxxxx' access_token = 'xxxxxxxxxxxxxx-xxxxxxxxxxxxxxxxxxxxxxx' access_token_secret = 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx' #認証情報を設定 auth = tweepy.OAuthHandler(consumer_key, consumer_secret) auth.set_access_token(access_token, access_token_secret) #APIインスタンスの作成 api = tweepy.API(auth) # Trello API # Key Token #trello = TrelloApi('キー', 'トークン') key = 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx' token = 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx' trello = TrelloApi(key, token) # List ID 上記で調べたボードIDから調べたリストID listid = 'xxxxxxxxxxxxxxxxxx' #既にあるカードの確認 url = "https://trello.com/1/lists/" + listid + "/cards" query = {'key': key, 'token': token, 'fields': 'name'} r = requests.get(url, params = query) data = r.json() name_list = [] for x in range(len(data)): name = data[x]['name'].replace('\n','') name_list.append(name) #自分のハッシュタグが付いたツイートを一つずつ出力 for tweet in tweepy.Cursor(api.search, q = '#○○○○', screen_name = 'xxxxxxxxxxx', result_type = 'recent').items(1): wish = tweet.text.replace('\\n', '').replace('RT @xxxxxxxxxxx: ', '').replace('#○○○○', '').replace('\n','') #カードが重複しないように設定 if wish not in name_list: # Card Name cardname = wish #特定のハッシュタグ付きのツイート内容 # Card Description #desc = '新しいタスクの内容です。1行目n新しいタスクの内容です。2行目n新しいタスクの内容です。3行目n' desc = '' card = trello.cards.new(cardname, listid, desc) else: breakrequirement.txt# Function dependencies, for example: # package>=version tweepy>=3.8.0 trello>=0.9.4 requests>=2.23.0今回、Cloud Schedulerでは、1分ごとに関数が実行されるように設定しました。
ツイートを沢山する方は、出力するツイート数を増やしたりして調整してください。参考:Cloud Function
Cloud Scheduler以上になります。閲覧ありがとうございました!
- 投稿日:2020-07-25T18:26:31+09:00
pandasでcsv読み込み matplotlibでグラフ
メモです。
サンプルコード
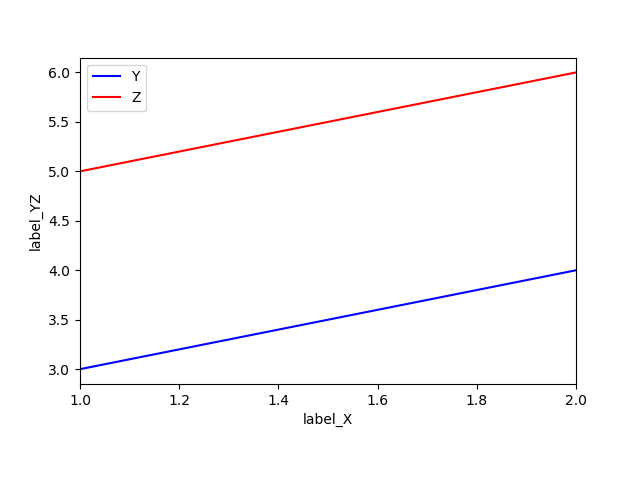
pandas_matplotlib.pyimport pandas as pd #csv読み込みなどもできる import matplotlib.pyplot as plt#グラフ描写 file_name = "test.csv" """ test.csv の中身↓ 1, 3, 5 2, 4, 6 """ #ヘッダーがcsvにないので読み込み時に追加 name_ = ["X", "Y", "Z"] df = pd.read_csv(file_name, names=name_, encoding='cp932') print(df) # fig = plt.figure() # ax = fig.add_subplot(1,1,1) #グラフ(X, Y) とグラフ(X, Z)の重ね合わせ ax = df.plot(x="X",y="Y", color="b", label="Y") df.plot(x="X",y="Z", color="r", label="Z", ax=ax) ax.set_xlabel("label_X") ax.set_ylabel("label_YZ") plt.show() fig = ax.get_figure() fig.subplots_adjust(bottom=0.2)#はみ出し阻止 fig.savefig("pandas_matplotlib.png")結果
X Y Z 0 1 3 5 1 2 4 6
- 投稿日:2020-07-25T18:26:01+09:00
【AWS・Python】SlackのEventAPIを利用してファイルの送受信してみる
1. はじめに
本記事では、Slackへのファイルアップロードをトリガーとして、
ファイルの受け取りと何かしらの処理をしてSlackへ送り返す処理についてまとめます。環境はAWSのLambdaとPythonを利用します。
2. 実装
2.1 できるもの
以下のように、ファイルをアップロードすると、
アップロードしたユーザにメンションして、何かしらの処理を加えたファイルを返します。
2.2 処理のイメージ図
Slack → AWS → Slackへのデータの流れです。
- Slack上でファイルがuploadされると、API Gatewayに設定したエンドポイントが呼ばれる
- API GatewayがLambdaを起動
- 処理用のLambdaをさらに起動し、
- 最初のLambdaは、処理を返す
- 最後に呼ばれたLambdaがファイルを処理してメッセージとともにSlackへアップロード
3にて別のLambdaを起動するのは、Slackへのレスポンスを3秒以内に返す必要があるためです参考2.3 slack上での準備
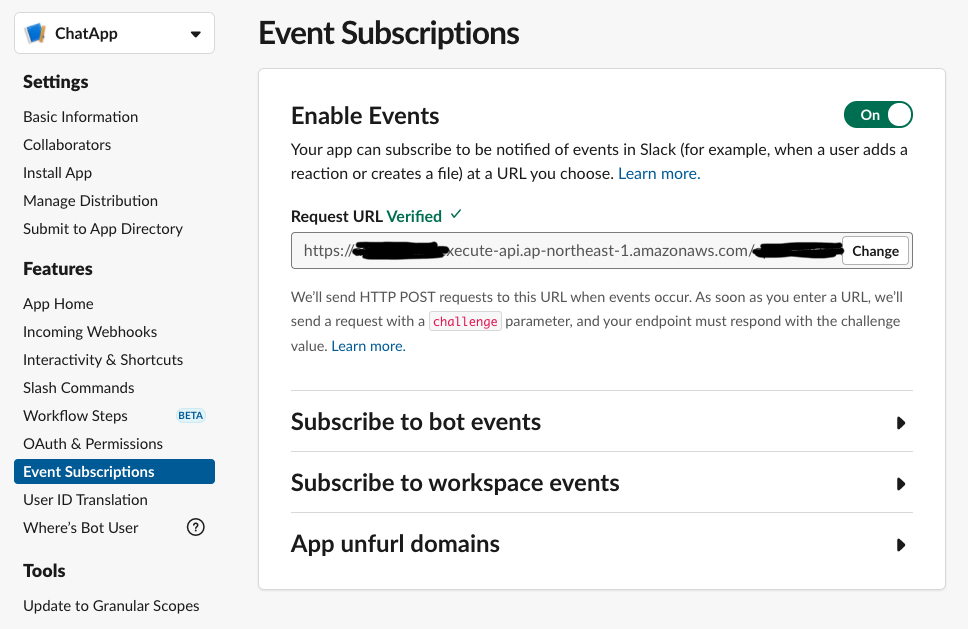
SlackのAppを管理しているページの
Event Subscriptionの項目を有効にしておきましょう。
加えて、
Incoming Webhooksの項目も有効にしておいてください。2.4 Chaliceでの実装
Chaliceとは、AWS Lambdaやそれに付随するサービスを簡単に構築してくれるAWS公式のライブラリです。2.4.1 SlackからのEventを受け取るLambda(API Gateway + Lambda)の実装
まずは、SlackからのEventを受け取るLambdaを実装します。
処理の内容は
- Slackからの
payloadを受け取る- BOTからの送信でなければ、ファイルを処理するLambdaを起動
- 最後に、Slackから受け取った
payloadを返す
3をしている理由としては、Slackから送信されたpayloadに含まれるchallengeパラメータを返す必要があるためです。
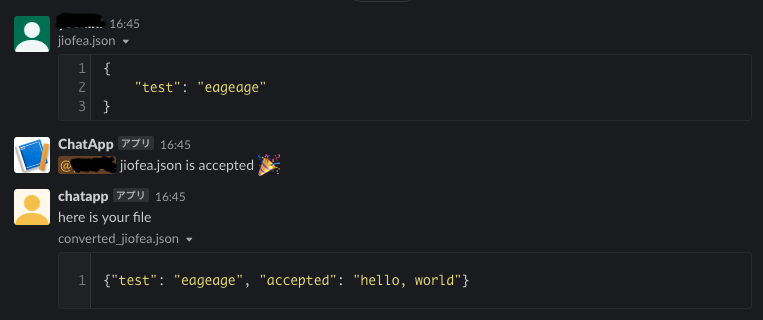
これをしていない場合は、2.3項で設定したURLがVerifiedになりません。app.pyimport io import json import logging import os import requests from slack import WebClient from slack.errors import SlackApiError import boto3 app = Chalice(app_name='<your chalice-app name>') logger = logging.getLogger() logger.setLevel(logging.INFO) # lambda client to invoke lambda_client = boto3.client("lambda") BOT_USER_ID = "<appのuser_id>" @app.route('/your/root', methods=['POST']) def event_subscription(): request = app.current_request if request.raw_body is None: # 予期しない呼び出し。400 Bad Requestを返す return {'statusCode': 400} payload = request.json_body logger.info(f"payload:= {payload}") user_id = payload['event']['user_id'] # BOTからファイルを上た場合は、Lambdaでの処理をしないようにする # ループを避けるため if user_id == BOT_USER_ID: return payload event_handler_lambda = "<この次に実装するLambdaのARN>" lambda_client.invoke( FunctionName=event_handler_lambda, InvocationType='Event', Payload=json.dumps(payload) ) return payload2.4.2 API ファイルを処理するLambdaの実装
次は、アップロードされたファイルに対して処理をするLambdaを実装します。
Slackへファイルがアップロードされると、file_idが発行されます。
そのfile_idからファイルを取得し、処理を行っていきます。また、その
file_idにはファイルがアップロードされたchennel_idが付与されているので
これを利用してファイルをアップロードするチャンネルを指定します。ユーザへのメンションは
<@{user_id}>で行えます。
user_idは、ファイルがアップロードされたイベントに付与されているのでそれを取得して行います。ファイルの処理は、今は適当に行っているので、いい感じに変更してください。
client.files_upload()の関数へ渡せる引数としてfileとcontentの2種類があります。
違いは以下の通りです。
- file: ファイル名を指定して、アップロードする。例:
file="test.csv"- content: bytesオブジェクトをアップロードする。例:
content=json.dumps({"aaa": "bbb"}).encode('utf-8')どちらでも行けると思うので、便利な方を利用したらいいと思います。
ちなみに、Lambdaだと/tmp以下の領域は500MBくらいまで自由に読み書きができるはずなので、そこを利用したら良いかと思います。app.py# =============================== # # ここには2.4.1項で実装した内容がある想定 # # =============================== # @app.lambda_function() def event_handler(event, _): # globalで読み込むとslackへのレスポンスに3秒以上かかるため、ここでpandasを読み込む import pandas as pd # tokenとslack_clientの生成 slack_oauth_token = os.environ['OAuthAccessToken'] slack_bot_token = os.environ['BotUserOAuthAccessToken'] oauth_client = WebClient(token=slack_oauth_token) bot_client = WebClient(token=slack_bot_token) # call file info to get url file_id = event['event']['file_id'] logger.info(f"file_id:= {file_id}") response = oauth_client.files_info(file=file_id) file_name = response.data["file"]["name"] file_url = response.data["file"]["url_private"] # slack上でファイル共有をした場合は1つのchannel_idしか入らないため file_upload_channel_id = response.data['file']['channels'][0] user_id = event['event']['user_id'] logger.info(f"file from {user_id}") print("Downloaded " + file_name) # download file file_data = _get_slack_file_bytes(slack_token=slack_oauth_token, file_url=file_url) converted_data = b'' if file_name.endswith(".json"): sent_data = json.loads(file_data) sent_data['accepted'] = "hello, world" converted_data = json.dumps(sent_data).encode('utf-8') elif file_name.endswith(".csv"): df = pd.read_csv(io.BytesIO(file_data)) df['accepted'] = "world" converted_data = df.to_csv(index=False).encode('utf-8') # response try: chat_response = bot_client.chat_postMessage( channel=file_upload_channel_id, text=f"<@{user_id}> {file_name} is accepted :tada:" ) logger.info(f"chat_response:= {chat_response}") upload_response = bot_client.files_upload( content=converted_data, title=f"converted_{file_name}", filename=f"converted_{file_name}", initial_comment="here is your file", channels=file_upload_channel_id ) logger.info(f"upload_response:= {upload_response}") except SlackApiError as e: # You will get a SlackApiError if "ok" is False assert e.response["error"] print(e) print(e.__str__()) return {"ok": True} def _get_slack_file_bytes(slack_token: str, file_url) -> bytes: r = requests.get(file_url, headers={'Authorization': f'Bearer {slack_token}'}) # get binary content return r.content2.5 LambdaのdeployとSlackへのURL設定
ここまできたら、chaliceのコマンドでAWSに実装して、発行されるURLを取得します。
$ chalice deploy Creating deployment package. Updating policy for IAM role: <chalice_project_name>-dev Updating lambda function: <chalice_project_name>-dev-event_handler Updating lambda function: <chalice_project_name>-dev Updating rest API Resources deployed: - Lambda ARN: arn:aws:lambda:<region>-<account_number>:function:<chalice_project_name>-dev-event_handler - Lambda ARN: arn:aws:lambda:<region>-<account_number>:function:<chalice_project_name>-dev - Rest API URL: https://<chalice_generated_chars>.execute-api.<region>.amazonaws.com/api/API GatewayのURLを取得したら、2.3項での
Event SubscriptionのRequest URLに設定します。
この時、プログラムの@app.route(/your/root, ...)に設定した/your/rootを追記します。
例で、/your/rootとしましたが、/slack/eventなどが良いと思います。https://<chalice_generated_chars>.execute-api.<region>.amazonaws.com/api/your/root2.6 実行時の注意
2.6.1 Slack Bot Userの実行権限付与
おそらく、初めて
Event SubscriptionやIncoming Webhooksの項目を利用していると、
Botの権限が足りずに関数の実行が失敗する場合があります。その場合は、Slack Appの以下のページから必要そうな権限を追加していってください。
関数の実行に必要な権限は実行時に失敗したら、エラーメッセージに含まれています。
2.6.2 LambdaがLambdaを実行する権限を付与
LambdaからLambdaを呼ぶ権限もIAMに付与する必要があります。
AWSコンソールから、Lambdaに付与されているロールを選び、「ポリシーをアタッチします」ボタンから
AWSLambdaFullAccessを付与してください(権限が強すぎるので本当はよくないのですが)。
2.6.3 Slackでファイルを実際にルームに共有される前にLambdaが実行されてしまう。
fileに関するSlackの
Event Subscriptionのうち、file_uploadを選択してしまうと、
ルームに共有しようとしているファイルがSlack上のサーバーへアップロードが完了した時点で、Eventが発火します。処理そのものに影響はないのですが、挙動としてちょっと気持ち悪いので
file_publicのEventが発火した場合に
Lambdaなどの処理を行った方が良いです。3. おわりに
今回は、Slackを利用してファイルの送受信を行えるようにしてみました。
ファイル以外にもSlackのEvent Subscriptionには、スタンプが押されたらとかメンションがあったらとか
いろいろあるのでぜひ遊んでみてください。
Event Subscriptionでは、イベントのタイプを{..., 'event': {'type': 'file_public', 'file_id': '', ...}}と言う
dictの'type'で受け取れるので、以前書いたChainOfRespontibilityでゴニョゴニョとかも利用できると思います。Slackが提供している公式ライブラリのSlackClientが
かなり使いやすく、自分で独自の関数を組む必要がないので便利でした。また、
Event Subscriptionの設定方法などは【Slackにファイルをアップロードする】が参考になるかもです。参考

- 投稿日:2020-07-25T18:06:37+09:00
Pythonチュートリアルをざっと見る
「6 モジュール」まで。
個人的に知らなかったことや覚えておきたいことに絞り書き留めました。
Pythonはある程度知っているが、公式のチュートリアルをざっと見ておきたいと思ったのが動機。はじめに
- このチュートリアルは、Pythonのすべてを包括的に記しているわけではないが、中心的・特徴的な機能を十分にまとめている。
- 読み終えれば、Pythonのモジュールやプログラムを読み書きできるようになっているはずである。また、標準ライブラリのさまざまなライブラリモジュールについて詳しく調べられる力がつく。
1. やる気を高めよう
- Pythonは簡単な言語であるが多くの機構があり、大きなプログラムの開発にも適している。高級な型を組み込みで持つ"超"高級言語である。
- インタプリタ言語であり、コンパイルやリンクの必要がないので、開発の際かなりの時間を節約できる。実験的にプログラムを動かしたり、便利な電卓にもなりうる。
- CやJavaなどと比べ、とてもコンパクトで読みやすいプログラムを書ける。理由は、高レベルのデータ型や、宣言が省略できる点など様々。
- プログラミングを習得する最良の方法は、使ってみることだ。早速、次の項目からPythonインタプリタを使ってみよう。
2. Pythonインタプリタを使う
Python インタプリタは、それが使えるマシン上では通常 /usr/local/bin/python3.8 としてインストールされています; Unix シェルの検索パスに /usr/local/bin を入れることによって、次のコマンドをタイプしてインタプリタを開始することができます:
Python3.8
- インタプリタは、Unixシェルと同じように使える。端末が標準入力なら、コマンドを対話的に読み込んで実行する。ファイルからスクリプトを読み込んで実行することももちろん可能。
- Pythonを起動する際のコマンドについては、こちらを参照。
- インタプリタが命令待ちをしているとき、対話モードで動作していると言う。コマンド入力を促す際、一次プロンプト(>>>)を表示し、複合文の継続行を入力する際は二次プロンプト(...)を表示します。
- 対話モードの詳細はこちら。
- デフォルトの文字コードはUTF-8である。
3. 形式ばらないPythonの紹介
- Pythonを電卓として使おう。
- 文字列は、単引用符('...')もしくは二重引用符("...")で囲って使う。
- 三連引用符を用いて複数行にわたる文字列を書くとき、改行文字が自動的に含まれるが、行末に¥をつけることで改行を含めないようにできる:
kaigyou.pyprint("""¥ Usage: thingy [OPTIONS] -h Display this usage message -H hostname Hostname to connect to """)
- スライスのイメージは、次のようになる:
+---+---+---+---+---+---+ | P | y | t | h | o | n | +---+---+---+---+---+---+ 0 1 2 3 4 5 6 -6 -5 -4 -3 -2 -1
- 最も汎用性の高いコンテナはリストで、コンマ区切りの値(要素)を角カッコに囲んだものとして書き表される。異なるデータ型の要素を1つのリストに含むこともできるが、通常は統一される。
list.py>>> squares = [1, 4, 9, 16, 25] >>> squares [1, 4, 9, 16, 25]
- リストは可変なので、要素を自由に入れ替えられる。
- 入れ子のリストを作ることもできる:
ireko.py>> a = ['a', 'b', 'c'] >>> n = [1, 2, 3] >>> x = [a, n] # 入れ子のリスト >>> x [['a', 'b', 'c'], [1, 2, 3]] >>> x[0] ['a', 'b', 'c'] >>> x[0][1] 'b'
- 複雑な課題にも、もちろんPythonは使える。例えば、フィボナッチ数列の先頭の部分列を計算しよう:
fibonacci.py>>> # Fibonacci series: ... # the sum of two elements defines the next ... a, b = 0, 1 >>> while a < 10: ... print(a) ... a, b = b, a+b ... 0 1 1 2 3 5 8
- 変数a, bを、複数同時代入している。
インデントはPythonにおいて、実行分をグループにまとめるのに用いる。複合文を対話的に入力するときは、入力完了を示すために空行をEnterする。これにより、最後の行を判断できるようになる。
キーワード引数 end を使うと、出力の末尾に改行文字を出力しないようにしたり、別の文字列を末尾に出力したりできる:
end.py>>> a, b = 0, 1 >>> while a < 1000: ... print(a, end=',') ... a, b = b, a+b ... 0,1,1,2,3,5,8,13,21,34,55,89,144,233,377,610,987,4. その他の制御フローツール
- if文 ...if elif elseのキーワード
- for文 ...C言語やPascal等の言語で慣れ親しんでいるものとは少し違う。Pythonのfor文は、任意のシーケンス型(反復可能なデータ型(リスト、文字列))にわたって反復を行う。
- 反復の順番は、要素を先頭から見る。
for.py>>> # Measure some strings: ... words = ['cat', 'window', 'defenestrate'] >>> for w in words: ... print(w, len(w)) ... cat 3 window 6 defenestrate 12
- 通常のC言語などの数列にわたる反復を行いたい場合は、組み込み関数range()が便利。次のように使おう:
range.py >>> for i in range(5): ... print(i) ... 0 1 2 3 4- こんな使い方もできる:
range(5, 10) 5, 6, 7, 8, 9 range(0, 10, 3) 0, 3, 6, 9 range(-10, -100, -30) -10, -40, -70
- range()は、イテラブルを返す。rangeからリストを作りたいなら、こうする。
range2list.py>>> list(range(4)) [0, 1, 2, 3]
- ループ文は、else節をもつことができる。これは、イテラブルを使い切ってループが終了したときに実行されるのだが、breakでループを抜け出した際には、実行されない。
for_else.py# 素数を探すプログラム >>> for n in range(2, 10): ... for x in range(2, n): ... if n % x == 0: ... print(n, 'equals', x, '*', n//x) ... break ... else: ... # loop fell through without finding a factor ... print(n, 'is a prime number') ... 2 is a prime number 3 is a prime number 4 equals 2 * 2 5 is a prime number 6 equals 2 * 3 7 is a prime number 8 equals 2 * 4 9 equals 3 * 3
- pass文は、何もしない。最小のクラスを定義するときなどによく使われる。関数や条件文の「仮置き」としても使える。
empty_class.py>>> class MyEmptyClass: ... pass ...
- Pythonの関数定義は、fibキーワードを使う。例えば、次の例のようにする。
fib.py>>> def fib(n): ... """nまでのフィボナッチ数列""" ... a, b = 0, 1 ... while a < n: ... print(a, end=' ') ... a, b = b, a+b ... print() ... >>> # 関数呼び出し ... fib(2000) 0 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987 1597
- returnがない関数は、実際にはNone値を返している。returnを使えば、関数から値を1つだけ受け取れる。
- メソッドは、オブジェクトに"属している"関数である。
- 関数について。デフォルトの引数値を
default=4のように与えられる。キーワード引数と呼ばれるものがある。(関数引数を今は詳しくやらない。必要なとき、またまとめる)- ラムダ式(キーワードlambda)を使うと、名前のない小さな関数を作れる。
- ドキュメンテーション文字列の例と、その表示:
>>> def my_function(): ... """Do nothing, but document it. ... ... No, really, it doesn't do anything. ... """ ... pass ... >>> print(my_function.__doc__) Do nothing, but document it. No, really, it doesn't do anything.
- 他人にとって読み易いコードを書くことはよいことだ。Pythonのコーディングスタイルとして、ほとんどのプロジェクトが守っているスタイルガイドでPEP 8がある。
- その内容は、「インデントはタブを使わず、空白4つにすべきである」「演算子の前後とコンマの後には空白を入れ、括弧類のすぐ内側には空白を入れないこと:
a = f(1, 2) + g(3, 4)。」「クラスや関数名に一貫性のある名前をつけること」などがある。- すべてのPython開発者はある時点でこれを読むべきである。
5. データ構造
- リストのほぼすべてのメソッドを使った例を次に示す:
>>> fruits = ['orange', 'apple', 'pear', 'banana', 'kiwi', 'apple', 'banana'] >>> fruits.count('apple') 2 >>> fruits.count('tangerine') 0 >>> fruits.index('banana') 3 >>> fruits.index('banana', 4) # Find next banana starting a position 4 6 >>> fruits.reverse() >>> fruits ['banana', 'apple', 'kiwi', 'banana', 'pear', 'apple', 'orange'] >>> fruits.append('grape') >>> fruits ['banana', 'apple', 'kiwi', 'banana', 'pear', 'apple', 'orange', 'grape'] >>> fruits.sort() >>> fruits ['apple', 'apple', 'banana', 'banana', 'grape', 'kiwi', 'orange', 'pear'] >>> fruits.pop() 'pear'
- リストをスタックとしてすぐに使える。プッシュはappend()、ポップはpop()を引数なしでリストに呼び出せば、実現できる。
- キューの実装には、 collections.deque クラスを使うとよい。
- リスト内包表記は、括弧の中の 式、 for 句、そして0個以上の for か if 句で構成される。例えば、次のように書く。
>>> [(x, y) for x in [1,2,3] for y in [3,1,4] if x != y] [(1, 3), (1, 4), (2, 3), (2, 1), (2, 4), (3, 1), (3, 4)]
- これは、次のコードと等価であるが、その簡潔さ、短さに差がみられる。
>>> for x in [1,2,3]: ... for y in [3,1,4]: ... if x != y: ... combs.append((x, y)) ... >>> combs [(1, 3), (1, 4), (2, 3), (2, 1), (2, 4), (3, 1), (3, 4)]リスト内包表記の式には、複雑な式や関数呼び出しのネストができます:
>>> from math import pi >>> [str(round(pi, i)) for i in range(1, 6)] ['3.1', '3.14', '3.142', '3.1416', '3.14159']コードが短く、分かりやすくかけるので積極的に使おう。
- del文を使えば、リストのインデックスを指定して値を削除できる。pop()と違い、値を返さない。スライスを除去することも可能である。
>>> a = [1, 66.25, 333, 333, 1234.5] >>> del a[2:4] >>> a [1, 66.25, 1234.5]変数全体を削除したければ、
del aと書く。
- リストや文字列の他に、代表的なシーケンス(sequence)型としてタプルがある。()丸カッコを使い、コンマで値を区切る。
>>> t = 12345, 54321, 'hello!' >>> t[0] 12345 >>> t (12345, 54321, 'hello!')
- タプルは不変(イミュータブル)であり、リストと異なる。
- 要素が0、もしくは1つのタプルを作成したいときは、次のようにする:
empty = () singetion = 'hello', # string型と区別(,を置く)
- タプルのパックは
t = 12345, 54321, 'hello!'、アンパックはx, y, z = t(右辺のシーケンスの長さは3)のように行う。- Pythonでは集合(set)を扱える。和や積などの集合演算も行える。中カッコ{}、もしくはset()でsetオブジェクトを作成する。
>>> basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'} >>> print(basket) # show that duplicates have been removed {'orange', 'banana', 'pear', 'apple'}
- 辞書型は、「キー」(文字列や数値など)でインデクス化している。
- 辞書は キー(key): 値(value) のペアの集合であり、キーが (辞書の中で)一意でなければならない。
>>> tel = {'jack': 4098, 'sape': 4139} >>> tel['guido'] = 4127 >>> tel {'jack': 4098, 'sape': 4139, 'guido': 4127} >>> tel['jack'] 4098 >>> del tel['sape'] >>> tel['irv'] = 4127 >>> tel {'jack': 4098, 'guido': 4127, 'irv': 4127} >>> list(tel) # キーの列挙 ['jack', 'guido', 'irv'] >>> sorted(tel) # キーのソート ['guido', 'irv', 'jack'] >>> 'guido' in tel True >>> 'jack' not in tel False
- 各データ型に関するループのテクニックがまとめられている。
- Pythonでは、Cとは異なり、式の中での代入は セイウチ演算子
:=を使用して明示的に行う必要があることに注意しよう。6.モジュール
- 長いプログラムを書きたければ、テキストエディタ等を使ってインタプリタへの入力をファイルで用意しておき、そのファイルを入力して動作させるとよい。Pythonの定義や文が入ったファイルのことをモジュールと呼び、
.py拡張子がついたファイルになる。- 例えば、次のようなファイルをテキストエディタで作ってみよう:
fibo.py# Fibonacci numbers module def fib(n): # write Fibonacci series up to n a, b = 0, 1 while a < n: print(a, end=' ') a, b = b, a+b print() def fib2(n): # return Fibonacci series up to n result = [] a, b = 0, 1 while a < n: result.append(a) a, b = b, a+b return resultPythonインタプリタで、このモジュールをインポートすれば、関数を使用できる。
# インタプリタ上 >>> import fibo >>> fibo.fib(1000) 0 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987次のように、特定の関数だけをインポートすることもできる:
# fromキーワード >>> from fibo import fib, fib2 >>> fib(500) 0 1 1 2 3 5 8 13 21 34 55 89 144 233 377
- モジュールをスクリプトとして実行したければ、
python fibo.py <引数名>と書けばよい。
- パッケージについて詳しく書かれているが、飛ばす。
おわりに
まだ残っているが、残りは必要を感じた時に調べる。
チュートリアルにどんなことが書かれているか大体分かったのでよかった。
「標準ライブラリミニツアー」は、見て理解しておくと役に立ちそう。
- 投稿日:2020-07-25T18:06:37+09:00
公式のPython チュートリアルをざっと見る
「6 モジュール」まで。
個人的に知らなかったことや覚えておきたいことに絞り書き留めました。
Pythonはある程度知っているが、公式のチュートリアルをざっと見ておきたいと思ったのが動機。はじめに
- このチュートリアルは、Pythonのすべてを包括的に記しているわけではないが、中心的・特徴的な機能を十分にまとめている。
- 読み終えれば、Pythonのモジュールやプログラムを読み書きできるようになっているはずである。また、標準ライブラリのさまざまなライブラリモジュールについて詳しく調べられる力がつく。
1. やる気を高めよう
- Pythonは簡単な言語であるが多くの機構があり、大きなプログラムの開発にも適している。高級な型を組み込みで持つ"超"高級言語である。
- インタプリタ言語であり、コンパイルやリンクの必要がないので、開発の際かなりの時間を節約できる。実験的にプログラムを動かしたり、便利な電卓にもなりうる。
- CやJavaなどと比べ、とてもコンパクトで読みやすいプログラムを書ける。理由は、高レベルのデータ型や、宣言が省略できる点など様々。
- プログラミングを習得する最良の方法は、使ってみることだ。早速、次の項目からPythonインタプリタを使ってみよう。
2. Pythonインタプリタを使う
Python インタプリタは、それが使えるマシン上では通常 /usr/local/bin/python3.8 としてインストールされています; Unix シェルの検索パスに /usr/local/bin を入れることによって、次のコマンドをタイプしてインタプリタを開始することができます:
Python3.8
- インタプリタは、Unixシェルと同じように使える。端末が標準入力なら、コマンドを対話的に読み込んで実行する。ファイルからスクリプトを読み込んで実行することももちろん可能。
- Pythonを起動する際のコマンドについては、こちらを参照。
- インタプリタが命令待ちをしているとき、対話モードで動作していると言う。コマンド入力を促す際、一次プロンプト(>>>)を表示し、複合文の継続行を入力する際は二次プロンプト(...)を表示します。
- 対話モードの詳細はこちら。
- デフォルトの文字コードはUTF-8である。
3. 形式ばらないPythonの紹介
- Pythonを電卓として使おう。
- 文字列は、単引用符('...')もしくは二重引用符("...")で囲って使う。
- 三連引用符を用いて複数行にわたる文字列を書くとき、改行文字が自動的に含まれるが、行末に¥をつけることで改行を含めないようにできる:
print("""¥ Usage: thingy [OPTIONS] -h Display this usage message -H hostname Hostname to connect to """)
- スライスのイメージは、次のようになる:
+---+---+---+---+---+---+ | P | y | t | h | o | n | +---+---+---+---+---+---+ 0 1 2 3 4 5 6 -6 -5 -4 -3 -2 -1
- 最も汎用性の高いコンテナはリストで、コンマ区切りの値(要素)を角カッコに囲んだものとして書き表される。異なるデータ型の要素を1つのリストに含むこともできるが、通常は統一される。
>>> squares = [1, 4, 9, 16, 25] >>> squares [1, 4, 9, 16, 25]
- リストは可変なので、要素を自由に入れ替えられる。
- 入れ子のリストを作ることもできる:
>> a = ['a', 'b', 'c'] >>> n = [1, 2, 3] >>> x = [a, n] # 入れ子のリスト >>> x [['a', 'b', 'c'], [1, 2, 3]] >>> x[0] ['a', 'b', 'c'] >>> x[0][1] 'b'
- 複雑な課題にも、もちろんPythonは使える。例えば、フィボナッチ数列の先頭の部分列を計算しよう:
>>> # Fibonacci series: ... # the sum of two elements defines the next ... a, b = 0, 1 >>> while a < 10: ... print(a) ... a, b = b, a+b ... 0 1 1 2 3 5 8
- 変数a, bを、複数同時代入している。
インデントはPythonにおいて、実行分をグループにまとめるのに用いる。複合文を対話的に入力するときは、入力完了を示すために空行をEnterする。これにより、最後の行を判断できるようになる。
キーワード引数 end を使うと、出力の末尾に改行文字を出力しないようにしたり、別の文字列を末尾に出力したりできる:
>>> a, b = 0, 1 >>> while a < 1000: ... print(a, end=',') ... a, b = b, a+b ... 0,1,1,2,3,5,8,13,21,34,55,89,144,233,377,610,987,4. その他の制御フローツール
- if文 ...if elif elseのキーワード
- for文 ...C言語やPascal等の言語で慣れ親しんでいるものとは少し違う。Pythonのfor文は、任意のシーケンス型(反復可能なデータ型(リスト、文字列))にわたって反復を行う。
- 反復の順番は、要素を先頭から見る。
>>> # Measure some strings: ... words = ['cat', 'window', 'defenestrate'] >>> for w in words: ... print(w, len(w)) ... cat 3 window 6 defenestrate 12
- 通常のC言語などの数列にわたる反復を行いたい場合は、組み込み関数range()が便利。次のように使おう:
python >>> for i in range(5): ... print(i) ... 0 1 2 3 4- こんな使い方もできる:
range(5, 10) 5, 6, 7, 8, 9 range(0, 10, 3) 0, 3, 6, 9 range(-10, -100, -30) -10, -40, -70
- range()は、イテラブルを返す。rangeからリストを作りたいなら、こうする。
>>> list(range(4)) [0, 1, 2, 3]
- ループ文は、else節をもつことができる。これは、イテラブルを使い切ってループが終了したときに実行されるのだが、breakでループを抜け出した際には、実行されない。
# 素数を探すプログラム >>> for n in range(2, 10): ... for x in range(2, n): ... if n % x == 0: ... print(n, 'equals', x, '*', n//x) ... break ... else: ... # loop fell through without finding a factor ... print(n, 'is a prime number') ... 2 is a prime number 3 is a prime number 4 equals 2 * 2 5 is a prime number 6 equals 2 * 3 7 is a prime number 8 equals 2 * 4 9 equals 3 * 3
- pass文は、何もしない。最小のクラスを定義するときなどによく使われる。関数や条件文の「仮置き」としても使える。
>>> class MyEmptyClass: ... pass ...
- Pythonの関数定義は、fibキーワードを使う。例えば、次の例のようにする。
>>> def fib(n): ... """nまでのフィボナッチ数列""" ... a, b = 0, 1 ... while a < n: ... print(a, end=' ') ... a, b = b, a+b ... print() ... >>> # 関数呼び出し ... fib(2000) 0 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987 1597
- returnがない関数は、実際にはNone値を返している。returnを使えば、関数から値を1つだけ受け取れる。
- メソッドは、オブジェクトに"属している"関数である。
- 関数について。デフォルトの引数値を
default=4のように与えられる。キーワード引数と呼ばれるものがある。(関数引数を今は詳しくやらない。必要なとき、またまとめる)- ラムダ式(キーワードlambda)を使うと、名前のない小さな関数を作れる。
- ドキュメンテーション文字列の例と、その表示:
>>> def my_function(): ... """Do nothing, but document it. ... ... No, really, it doesn't do anything. ... """ ... pass ... >>> print(my_function.__doc__) Do nothing, but document it. No, really, it doesn't do anything.
- 他人にとって読み易いコードを書くことはよいことだ。Pythonのコーディングスタイルとして、ほとんどのプロジェクトが守っているスタイルガイドでPEP 8がある。
- その内容は、「インデントはタブを使わず、空白4つにすべきである」「演算子の前後とコンマの後には空白を入れ、括弧類のすぐ内側には空白を入れないこと:
a = f(1, 2) + g(3, 4)。」「クラスや関数名に一貫性のある名前をつけること」などがある。- すべてのPython開発者はある時点でこれを読むべきである。
5. データ構造
- リストのほぼすべてのメソッドを使った例を次に示す:
>>> fruits = ['orange', 'apple', 'pear', 'banana', 'kiwi', 'apple', 'banana'] >>> fruits.count('apple') 2 >>> fruits.count('tangerine') 0 >>> fruits.index('banana') 3 >>> fruits.index('banana', 4) # Find next banana starting a position 4 6 >>> fruits.reverse() >>> fruits ['banana', 'apple', 'kiwi', 'banana', 'pear', 'apple', 'orange'] >>> fruits.append('grape') >>> fruits ['banana', 'apple', 'kiwi', 'banana', 'pear', 'apple', 'orange', 'grape'] >>> fruits.sort() >>> fruits ['apple', 'apple', 'banana', 'banana', 'grape', 'kiwi', 'orange', 'pear'] >>> fruits.pop() 'pear'
- リストをスタックとしてすぐに使える。プッシュはappend()、ポップはpop()を引数なしでリストに呼び出せば、実現できる。
- キューの実装には、 collections.deque クラスを使うとよい。
- リスト内包表記は、括弧の中の 式、 for 句、そして0個以上の for か if 句で構成される。例えば、次のように書く。
>>> [(x, y) for x in [1,2,3] for y in [3,1,4] if x != y] [(1, 3), (1, 4), (2, 3), (2, 1), (2, 4), (3, 1), (3, 4)]
- これは、次のコードと等価であるが、その簡潔さ、短さに差がみられる。
>>> for x in [1,2,3]: ... for y in [3,1,4]: ... if x != y: ... combs.append((x, y)) ... >>> combs [(1, 3), (1, 4), (2, 3), (2, 1), (2, 4), (3, 1), (3, 4)]リスト内包表記の式には、複雑な式や関数呼び出しのネストができます:
>>> from math import pi >>> [str(round(pi, i)) for i in range(1, 6)] ['3.1', '3.14', '3.142', '3.1416', '3.14159']コードが短く、分かりやすくかけるので積極的に使おう。
- del文を使えば、リストのインデックスを指定して値を削除できる。pop()と違い、値を返さない。スライスを除去することも可能である。
>>> a = [1, 66.25, 333, 333, 1234.5] >>> del a[2:4] >>> a [1, 66.25, 1234.5]変数全体を削除したければ、
del aと書く。
- リストや文字列の他に、代表的なシーケンス(sequence)型としてタプルがある。()丸カッコを使い、コンマで値を区切る。
>>> t = 12345, 54321, 'hello!' >>> t[0] 12345 >>> t (12345, 54321, 'hello!')
- タプルは不変(イミュータブル)であり、リストと異なる。
- 要素が0、もしくは1つのタプルを作成したいときは、次のようにする:
empty = () singetion = 'hello', # string型と区別(,を置く)
- タプルのパックは
t = 12345, 54321, 'hello!'、アンパックはx, y, z = t(右辺のシーケンスの長さは3)のように行う。- Pythonでは集合(set)を扱える。和や積などの集合演算も行える。中カッコ{}、もしくはset()でsetオブジェクトを作成する。
>>> basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'} >>> print(basket) # show that duplicates have been removed {'orange', 'banana', 'pear', 'apple'}
- 辞書型は、「キー」(文字列や数値など)でインデクス化している。
- 辞書は キー(key): 値(value) のペアの集合であり、キーが (辞書の中で)一意でなければならない。
>>> tel = {'jack': 4098, 'sape': 4139} >>> tel['guido'] = 4127 >>> tel {'jack': 4098, 'sape': 4139, 'guido': 4127} >>> tel['jack'] 4098 >>> del tel['sape'] >>> tel['irv'] = 4127 >>> tel {'jack': 4098, 'guido': 4127, 'irv': 4127} >>> list(tel) # キーの列挙 ['jack', 'guido', 'irv'] >>> sorted(tel) # キーのソート ['guido', 'irv', 'jack'] >>> 'guido' in tel True >>> 'jack' not in tel False
- 各データ型に関するループのテクニックがまとめられている。
- Pythonでは、Cとは異なり、式の中での代入は セイウチ演算子
:=を使用して明示的に行う必要があることに注意しよう。6.モジュール
- 長いプログラムを書きたければ、テキストエディタ等を使ってインタプリタへの入力をファイルで用意しておき、そのファイルを入力して動作させるとよい。Pythonの定義や文が入ったファイルのことをモジュールと呼び、
.py拡張子がついたファイルになる。- 例えば、次のようなファイルをテキストエディタで作ってみよう:
fibo.py# Fibonacci numbers module def fib(n): # write Fibonacci series up to n a, b = 0, 1 while a < n: print(a, end=' ') a, b = b, a+b print() def fib2(n): # return Fibonacci series up to n result = [] a, b = 0, 1 while a < n: result.append(a) a, b = b, a+b return resultPythonインタプリタで、このモジュールをインポートすれば、関数を使用できる。
# インタプリタ上 >>> import fibo >>> fibo.fib(1000) 0 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987次のように、特定の関数だけをインポートすることもできる:
# fromキーワード >>> from fibo import fib, fib2 >>> fib(500) 0 1 1 2 3 5 8 13 21 34 55 89 144 233 377
- モジュールをスクリプトとして実行したければ、
python fibo.py <引数名>と書けばよい。
- パッケージについて詳しく書かれているが、飛ばす。
おわりに
まだ残っているが、残りは必要を感じた時に調べる。
チュートリアルにどんなことが書かれているか大体分かったのでよかった。
「標準ライブラリミニツアー」は、見て理解しておくと役に立ちそう。
- 投稿日:2020-07-25T17:29:03+09:00
Python勉強用 用語まとめ
この記事の目的
調べものするたびに何だったっけ?ってなる用語の意味や参考リンクをまとめます。用語検索の効率化用。
インタプリタ方式とコンパイル方式
インタプリタ方式
命令を一つずつ実行する方式。Pythonはこっち。実行結果がすぐに出力されるのでお手軽かつわかりやすい。また、実行環境にあったインタプリタを使うことで、OSやCPUなどが異なる実行環境に対応できる。デメリットは速度。特にfor文などで繰り返しの処理を行うときに遅くなる。
コンパイル方式
ソースプログラムから実行ファイルを生成する方式。C言語など。インタプリタ方式に比べて速い。コンパイルしないと実行できないので人手間かかることと、実行ファイルが環境に依存することがデメリットとして挙げられる。
スクリプト言語
比較的簡単に使えるプログラミング言語のこと。Pythonもこのカテゴリに入る。他にはJavascriptやRubyが挙げられる。
その多くがインタプリタ方式の言語なので、用語として混同されることが多いが、スクリプト言語=インタプリタ方式という定義はない。静的型付けと動的型付け
静的型付け
変数や引数、返り値に対してどの型かを宣言しておく方式。型の整合性チェックを実行時には行わないので実行速度にメリットあり。逆に言うとプログラムを書くときに型の整合性を理解しておく必要がある。C言語やJavaなど。
動的型付け
実行時に自動的に型を判別する方式。Pythonはこっち。インタプリタ方式の言語に採用されている。実行ごとに型の整合性をとるので速度は遅くなる。プログラムを書くときには型をあまり意識しなくて良いので、学習コストが低く、記述量も減らせる。
リテラル
- 投稿日:2020-07-25T17:11:40+09:00
状態とふるまいを持つモデルを実装する (2)
前回 (状態とふるまいを持つモデルを実装する)では、状態とふるまいを持つプリミティブなモデル
Switchを実装した。今回はSwitchに状態を追加して拡張を試みる。
ストップウォッチのような、三つの状態、待機状態WAIT, 計測状態MEASURE, 停止状態PAUSEがあるモデルを考える。ストップウォッチには、二つのボタンstart_stop(),reset()があり、以下のような状態とふるまいを想定する1。
- 待機状態
WAITでボタンstart_stop()が押下されると、計測状態MEASUREになる。- 計測状態
MEASUREでボタンstart_stop()が押下されると、停止状態PAUSEになる。- 停止状態
PAUSEでボタンstart_stop()が押下されると再び、計測状態MEASUREになる。- また、停止状態
PAUSEでボタンreset()が押下されると、待機状態WAITになる。このモデルは以下のように状態遷移する。
watch = StopWatch() assert watch.state == StopWatch.WAIT watch.start_stop() assert watch.state == StopWatch.MEASURE watch.start_stop() assert watch.state == StopWatch.PAUSE watch.start_stop() assert watch.state == StopWatch.MEASURE watch.reset() # nothing to happen assert watch.state == StopWatch.MEASURE watch.start_stop() assert watch.state == StopWatch.PAUSE watch.reset() assert watch.state == StopWatch.WAITまずは、ふるまいが状態に応じて変わるように実装する。
from enum import auto class StopWatch: WAIT, PAUSE, MEASURE = auto(), auto(), auto() def __init__(self): self._state = StopWatch.WAIT @property def state(self): return self._state def start_stop(self): if self.state == StopWatch.WAIT: self._state = StopWatch.MEASURE # process that counts up the time... elif self.state == StopWatch.MEASURE: self._state = StopWatch.PAUSE # do something elif self.state == StopWatch.PAUSE: self._state = StopWatch.MEASURE # do something else: raise ValueError(self.__class__.__name__ + " has an unexpected state: {}".format(self.state)) def reset(self): if self.state == StopWatch.PAUSE: self._state = StopWatch.WAIT # do something前回は状態を列挙する
Enumを作成したが、今回はもう少し簡便な実装にしている。
なお、今はふるまいの状態遷移に興味があるので、時間をカウントする、時間を表示するといったストップウォッチとしての処理については割愛している。今度はふるまいの違いによって状態を表すように実装する。さらに、状態遷移表
self._TRANSITを利用する2 ことで、状態遷移全体の見通しをよくする。from enum import auto class StopWatch: WAIT, PAUSE, MEASURE = auto(), auto(), auto() def __init__(self): self._TRANSIT = {StopWatch.WAIT: (self.start, lambda *args: None), StopWatch.PAUSE: (self.start, self.reset_time), StopWatch.MEASURE: (self.pause, lambda *args: None)} self._TRANSIT_REVERSED = {v: k for k, v in self._TRANSIT.items()} self.start_stop, self.reset = self._TRANSIT[StopWatch.WAIT] @property def state(self): return self._TRANSIT_REVERSED[self.start_stop, self.reset] def start(self): self.start_stop, self.reset = self._TRANSIT[StopWatch.MEASURE] def pause(self): self.start_stop, self.reset = self._TRANSIT[StopWatch.PAUSE] def reset_time(self): self.start_stop, self.reset = self._TRANSIT[StopWatch.WAIT]
第4回 「状態遷移図」と「状態遷移表」で見えるもの:上流工程で効く,「テストの考え方」|gihyo.jp … 技術評論社 ↩
前回の投稿 (状態とふるまいを持つモデルを実装する)に対していただいたコメントのアイデアを拝借いたしました。 ↩
- 投稿日:2020-07-25T17:02:31+09:00
単にテキストを出力して差分を見るというテスト手法
この記事ではどこでも使えて強力なテスト手法を紹介します
- テストフレームワークを使いません。
- テキストが出力できれば、どの言語でも使えます。
手順
- プログラムを Git 管理する
- 結果をテキストでファイル出力するプログラム書く(出力結果は
.gitignoreしない)- 出力ディレクトリについて
git diffを表示する以上
実践
テスト対象のコードとして、コサインの近似値の計算を Python で書きました。
my_math.pyimport math def cos(t): t %= math.pi * 2 if (t < math.pi * 0.25): return _cos(t) elif (t < math.pi * 0.75): return _sin(t - math.pi * 0.5) elif (t < math.pi * 1.25): return -_cos(t - math.pi) elif (t < math.pi * 1.75): return _sin(t - math.pi * 1.5) else: return _cos(t - math.pi * 2) def _sin(t): result = current = t; # テイラー展開 for i in range(2, 10, 2): current *= - t * t / (i * (i + 1)) result += current return result def _cos(t): result = current = 1; # テイラー展開 for i in range(1, 11, 2): current *= - t * t / (i * (i + 1)) result += current return result1. Git 管理する
サンプルの Git レポジトリは
https://github.com/shohei909/diff_test
に用意しました2. テキストを標準出力する
これに対して以下のようなテストコードを書きます。単に
-3 * PIから3 * PIまでのmy_math.cos()の計算結果を標準出力していますtest/code/my_cos_test.pyimport sys import math import os sys.path.append(os.path.dirname(__file__) + '/../../') import my_math print("ver:0.0") # このテストのバージョン print("my_math.cos()の戻り値に対するテスト") # このテストの説明文 resolution = 8 for i in range(-3 * resolution, 3 * resolution): t = i / resolution print("cos({:<6} * PI): {}".format(t, my_math.cos(math.pi * t)))3. 結果をファイルにリダイレクトして、
git diffを見るテストコードの実行結果をファイルに保存していくスクリプトを書きます。具体的には以下の内容です
test/code以下のすべてのコードを実行する- その標準出力を
test/out下のファイルにリダイレクトtest/run.pyimport glob import subprocess import os import sys test_dir = os.path.dirname(__file__) out_files = set() # code 以下の *.py ファイルを検索 for file in glob.glob(test_dir + "/code/**/*.py", recursive=True): relpath = os.path.relpath(file, test_dir + "/code") file_name = os.path.splitext(relpath)[0] extension = ".txt" out_file_path = test_dir + "/out/" + file_name + extension os.makedirs(os.path.dirname(out_file_path), exist_ok=True) # 出力フォルダが無ければ作成 out_file = open(out_file_path, "w") # `python *.py` のプロセスを実行 subprocess.run([sys.executable, file], stdout=out_file) # 出力したファイルを記録 out_files.add(os.path.abspath(out_file_path)) # 削除ずみのテストの出力を削除 for file in glob.glob(test_dir + "/out/**/*", recursive=True): if os.path.isfile(file): if not os.path.abspath(file) in out_files: # 出力ファイルに含まれてないファイルを削除 os.remove(file)次に、出力結果の
git diffを出すスクリプトですtest/diff.pyimport subprocess import os # Git で差分を表示 test_dir = os.path.dirname(__file__) subprocess.run(["git", "add", "-N", test_dir + "/out"]) subprocess.run(["git", "--no-pager", "diff", "--relative=test/out", "--ignore-space-change"])上記2つを合わせて実行します
test/test.pyimport importlib importlib.import_module('run') importlib.import_module('diff')以上の3つのスクリプトのうち
run.pyを少し改変すればテスト対象が Python でない場合でも使用できます。実行結果は以下のようになります
diff --git a/my_cos_test.txt b/my_cos_test.txt new file mode 100644 index 0000000..0f305ad --- /dev/null +++ b/my_cos_test.txt @@ -0,0 +1,50 @@ +ver:0.0 +my_math.cos()の戻り値に対するテスト +cos(-3.0 * PI): -1.0 +cos(-2.875 * PI): -0.9238795325112585 +cos(-2.75 * PI): -0.7071067829368665 +cos(-2.625 * PI): -0.3826834323659474 +cos(-2.5 * PI): 0.0 +cos(-2.375 * PI): 0.3826834323659474 +cos(-2.25 * PI): 0.7071067810719247 +cos(-2.125 * PI): 0.9238795325112585 +cos(-2.0 * PI): 1.0 +cos(-1.875 * PI): 0.9238795325112585 +cos(-1.75 * PI): 0.7071067829368671 +cos(-1.625 * PI): 0.3826834323659474 +cos(-1.5 * PI): -0.0 +cos(-1.375 * PI): -0.3826834323659474 +cos(-1.25 * PI): -0.7071067810719247 +cos(-1.125 * PI): -0.9238795325112586 +cos(-1.0 * PI): -1.0 +cos(-0.875 * PI): -0.9238795325112586 +cos(-0.75 * PI): -0.7071067829368671 +cos(-0.625 * PI): -0.3826834323659474 +cos(-0.5 * PI): 0.0 +cos(-0.375 * PI): 0.3826834323659474 +cos(-0.25 * PI): 0.7071067810719247 +cos(-0.125 * PI): 0.9238795325112585 +cos(0.0 * PI): 1.0 +cos(0.125 * PI): 0.9238795325112586 +cos(0.25 * PI): 0.7071067829368671 +cos(0.375 * PI): 0.38268343236594693 +cos(0.5 * PI): -0.0 +cos(0.625 * PI): -0.38268343236594693 +cos(0.75 * PI): -0.7071067810719247 +cos(0.875 * PI): -0.9238795325112586 +cos(1.0 * PI): -1.0 +cos(1.125 * PI): -0.9238795325112586 +cos(1.25 * PI): -0.7071067829368671 +cos(1.375 * PI): -0.3826834323659474 +cos(1.5 * PI): 0.0 +cos(1.625 * PI): 0.3826834323659474 +cos(1.75 * PI): 0.7071067810719247 +cos(1.875 * PI): 0.9238795325112585 +cos(2.0 * PI): 1.0 +cos(2.125 * PI): 0.9238795325112585 +cos(2.25 * PI): 0.7071067829368671 +cos(2.375 * PI): 0.3826834323659474 +cos(2.5 * PI): -0.0 +cos(2.625 * PI): -0.3826834323659474 +cos(2.75 * PI): -0.7071067829368665 +cos(2.875 * PI): -0.9238795325112585出てきた差分が意図通りならOKです。
達成できたこと
これだけではテストとして、不十分に見えますか?
しかし、少なくともテストに求められる重要なことのいくつかは達成できています
- プログラムの挙動の可視化
- プログラムが最後まで動くことのチェック
- デグレード(退化)を起こしていないことのチェック
特に重要なのが3つ目です。Git 差分の表示で変更行がないことを確認すれば挙動が変わってないことのチェックができます。
また、不安に思う部分には assert も書いていけば、いわゆるテストファースト的な手法を複合できます。
テストを書く際のポイント
よく「テストはドキュメント」といった言い回しを耳にしますが、この手法の場合は出力もドキュメントです。
ですから、以下のことを意識して書くといいです
- テストのファイル名に、より良く内容を表現した名前を付ける
- 出力ファイルの冒頭にテスト内容の説明文を書く
- テストのプログラムから出力される各行にはそれが何かわかるようなラベルを書く
CIを行う
CI(継続的インテグレーション)を行うとより快適に開発できるでしょう。
具体的には、プルリクエストをトリガーとして、自動で以下の2つを行うといいです
test/run.pyを実行して差分をコミットする- 出力に意図しない差分があったら failure させる
test/run.pyを実行して差分をコミットするこれを行うことで、テストを実行し忘れた状態でマージされることを防げます。
さらに
- 終了コードが
0であること- 標準エラー出力がされていないこと
を見てテストが正常に終了したかを判定するといいです。
出力に意図しない差分があったら failure させる
プルリクエスト内容の差分を見るだけであれば以下のコマンドを実行すればいいです
git diff --no-pager マージ先ブランチ(base)...リクエストしてるブランチ(head) --relative=test/out(
--ignore-space-changeをつけるべきかは、ソフトウェアの性質に応じて要検討)ただ、これだけでは変更が意図的かどうかの区別ができません。
変更が意図的なものかどうかを区別するためにつけてるのが、出力ファイルの先頭の
ver:0.0のバージョン情報です。このバージョン番号は以下のルールに従って書き換えをします
- 出力ファイルの変更が、行の追加のみであることを意図しているなら、マイナーバージョンを上げる。(
0.0->0.1)- 出力ファイルの変更が、行の削除を含むことを意図しているなら、メジャーバージョンを上げる。(
0.1->1.0)diff を読んで上記のルールを満たしているか判定するプログラムを書けば、マージの可否を判定する CI を組むことができます。
この判定を行うプログラムは以下に公開しています
https://github.com/shohei909/diff_test/blob/master/test/check.py
テスト対象を広げる
実践例で紹介したのは、いわゆる単体テスト的なものですが、より結合テスト的なものに対しても効果的です。
例えば、以下のようなものです
- JSON返すWebサーバーなら、実際にアクセスしたレスポンスを記録する (JSONは
jq . -sort-keysなどで内容のソートをしておくといい)- コマンドラインツールなら、実際にそのツールを実行した結果を記録する
- Webサイトなら、 Headless Chrome でそのページにアクセスした結果のスクリーンショット画像などを記録する
差分を見るテストのメリット
デグレードに対する耐性が高い
この手法はデグレードを発見する力高いです。この点については、あらかじめ期待される結果を手で書く手法と比べても強力です。
というのも、期待される結果を手で書く場合、「手で書ける程度の個数」のケースしか用意できません。網羅的にデグレードをチェックできるほどのケースを書いて用意するのは時間がかかります。
しかし、単に結果を出力しておくのであれば、「目を通せる程度の個数」にまで広がります。
プロトタイピングや仕様変更の速度を落とさない
テストを書く大きなメリットは、リファクタリングが容易になることです。リファクタリング時のデグレードのリスクが抑えられます。
逆に、テストを大量に書くデメリットもあります
- ソフトウェアのプロトタイプが実際に動くまでに時間がかかる
- 仕様変更が発生したときのテストの書き直しが大変になる
単にテキストを出力しておく手法はテストコードは比較的小さく、これらのデメリットが小さいです。
仕様の変更内容によっては、テストコードに対する変更は単に
ver:*.*を書き換えるだけで済みます。それでいて、プログラムの挙動がどう変わったかは出力の差分を見れば明確です。このテスト手法は、すばやくプロトタイプを作って、その挙動や反省を踏まえてリファクタリングや仕様の改善を繰り返していくような開発フローとの相性がいいです。
挙動が可視化される & 挙動の履歴をたどれるようになる
この手法でテストを書くということは、サンプルコードとその実行結果を残しておくということそのものです。これらがあれば、レビュアーも、新規メンバーも、実装者自身もコードがどういう動きをするのか理解しやすくなります。
また、 Git 上に挙動ベースでの変更履歴が残ることにもメリットがあります。この履歴は、例えば、後からバグが発見された場合に、その原因になった挙動がいつから発生していたか、どの修正によって発生かを調べる手助けになります。
テストフレームワークにロックインされない
テストコードはコード量が多くなりがちな部分なので、例えばテストフレームワークが言語のアップデートに追随してないといった事態には対処が大変です。
この手法では、テストフレームワークのへの依存が無いのでそのリスクがありません。
発展:SVGを出力して差分を見る
テキストの出力はより挙動をわかりやすく表現する形で行うのが理想です。より視覚的に表現する方法として SVG を出力するというのがあります。
先ほどの
my_math.cos()でそれをやってみたのが以下です。https://github.com/shohei909/diff_test/pull/1/files#diff-859f44ef4608ed7f4557a2bfcb2ce991
ちゃんとコサインの近似ができていることが視覚的にわかります。
SVG はテキストと画像の両面の性質があるので、両面のメリット受けられます。例えば、値が変わったかを厳密に見たければテキストで見ればいいですし、目視でわかる変化があったかを見たければ画像としてみればいいです。
試しに、
my_math.cos()の精度を落とす変更を加えてみます
誤差が目視ではわからないレベルであることが確認できました。

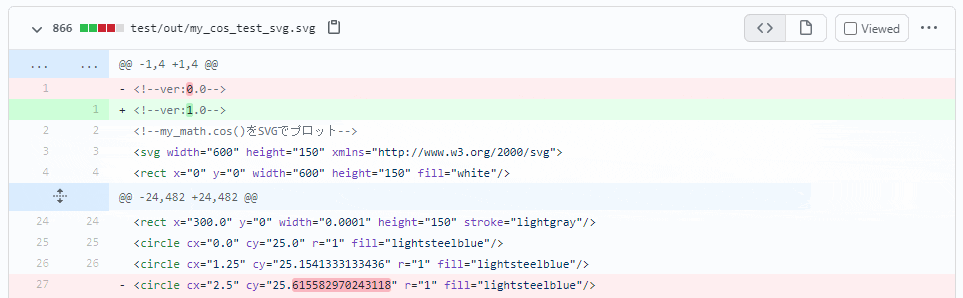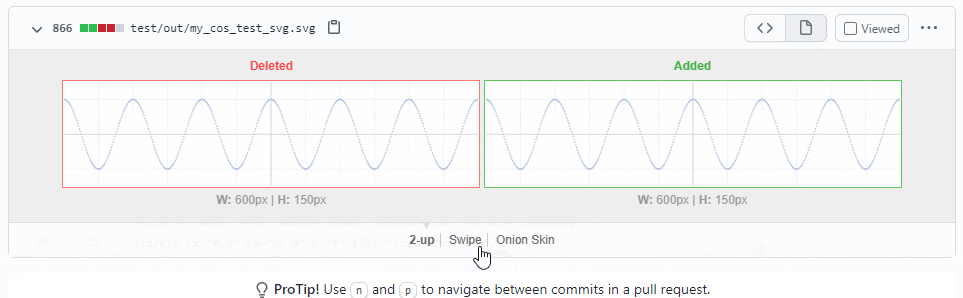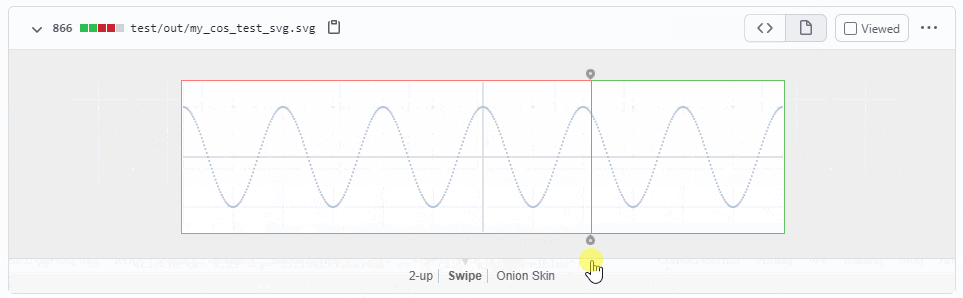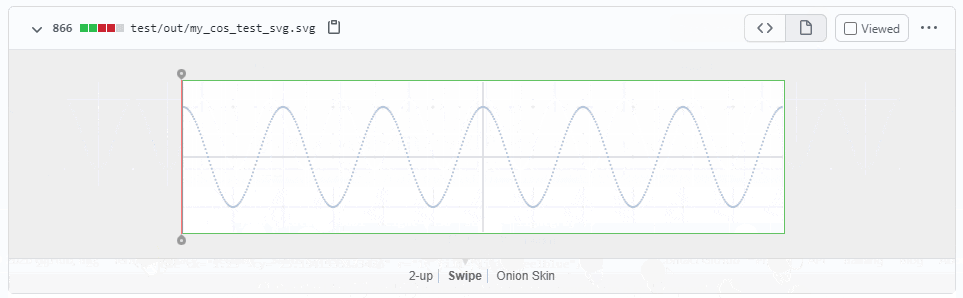
- 投稿日:2020-07-25T17:02:31+09:00
単にテキストを出力して差分を見るというテスト手法のススメ
この記事ではどこでも使えて強力なテスト手法を紹介します
- テストフレームワークを使いません。
- テキストが出力できれば、どの言語でも使えます。
手順
- プログラムを Git 管理する
- 結果をテキストでファイル出力するプログラム書く(出力結果は
.gitignoreしない)- 出力ディレクトリについて
git diffを表示する以上
実践
テスト対象のコードとして、コサインの近似値の計算を Python で書きました。
my_math.pyimport math def cos(t): t %= math.pi * 2 if (t < math.pi * 0.25): return _cos(t) elif (t < math.pi * 0.75): return _sin(t - math.pi * 0.5) elif (t < math.pi * 1.25): return -_cos(t - math.pi) elif (t < math.pi * 1.75): return _sin(t - math.pi * 1.5) else: return _cos(t - math.pi * 2) def _sin(t): result = current = t; # テイラー展開 for i in range(2, 10, 2): current *= - t * t / (i * (i + 1)) result += current return result def _cos(t): result = current = 1; # テイラー展開 for i in range(1, 11, 2): current *= - t * t / (i * (i + 1)) result += current return result1. Git 管理する
サンプルの Git レポジトリは
https://github.com/shohei909/diff_test
に用意しました2. テキストを標準出力する
これに対して以下のようなテストコードを書きます。単に
-3 * PIから3 * PIまでのmy_math.cos()の計算結果を標準出力していますtest/code/my_cos_test.pyimport sys import math import os sys.path.append(os.path.dirname(__file__) + '/../../') import my_math print("ver:0.0") # このテストのバージョン print("my_math.cos()の戻り値に対するテスト") # このテストの説明文 resolution = 8 for i in range(-3 * resolution, 3 * resolution): t = i / resolution print("cos({:<6} * PI): {}".format(t, my_math.cos(math.pi * t)))3. 結果をファイルにリダイレクトして、
git diffを見るテストコードの実行結果をファイルに保存していくスクリプトを書きます。具体的には以下の内容です
test/code以下のすべてのコードを実行する- その標準出力を
test/out下のファイルにリダイレクトtest/run.pyimport glob import subprocess import os import sys test_dir = os.path.dirname(__file__) out_files = set() # code 以下の *.py ファイルを検索 for file in glob.glob(test_dir + "/code/**/*.py", recursive=True): relpath = os.path.relpath(file, test_dir + "/code") file_name = os.path.splitext(relpath)[0] extension = ".txt" out_file_path = test_dir + "/out/" + file_name + extension os.makedirs(os.path.dirname(out_file_path), exist_ok=True) # 出力フォルダが無ければ作成 out_file = open(out_file_path, "w") # `python *.py` のプロセスを実行 subprocess.run([sys.executable, file], stdout=out_file) # 出力したファイルを記録 out_files.add(os.path.abspath(out_file_path)) # 削除ずみのテストの出力を削除 for file in glob.glob(test_dir + "/out/**/*", recursive=True): if os.path.isfile(file): if not os.path.abspath(file) in out_files: # 出力ファイルに含まれてないファイルを削除 os.remove(file)次に、出力結果の
git diffを出すスクリプトですtest/diff.pyimport subprocess import os # Git で差分を表示 test_dir = os.path.dirname(__file__) subprocess.run(["git", "add", "-N", test_dir + "/out"]) subprocess.run(["git", "--no-pager", "diff", "--relative=test/out", "--ignore-space-change"])上記2つを合わせて実行します
test/test.pyimport importlib importlib.import_module('run') importlib.import_module('diff')以上の3つのスクリプトのうち
run.pyを少し改変すればテスト対象が Python でない場合でも使用できます。実行結果は以下のようになります
diff --git a/my_cos_test.txt b/my_cos_test.txt new file mode 100644 index 0000000..0f305ad --- /dev/null +++ b/my_cos_test.txt @@ -0,0 +1,50 @@ +ver:0.0 +my_math.cos()の戻り値に対するテスト +cos(-3.0 * PI): -1.0 +cos(-2.875 * PI): -0.9238795325112585 +cos(-2.75 * PI): -0.7071067829368665 +cos(-2.625 * PI): -0.3826834323659474 +cos(-2.5 * PI): 0.0 +cos(-2.375 * PI): 0.3826834323659474 +cos(-2.25 * PI): 0.7071067810719247 +cos(-2.125 * PI): 0.9238795325112585 +cos(-2.0 * PI): 1.0 +cos(-1.875 * PI): 0.9238795325112585 +cos(-1.75 * PI): 0.7071067829368671 +cos(-1.625 * PI): 0.3826834323659474 +cos(-1.5 * PI): -0.0 +cos(-1.375 * PI): -0.3826834323659474 +cos(-1.25 * PI): -0.7071067810719247 +cos(-1.125 * PI): -0.9238795325112586 +cos(-1.0 * PI): -1.0 +cos(-0.875 * PI): -0.9238795325112586 +cos(-0.75 * PI): -0.7071067829368671 +cos(-0.625 * PI): -0.3826834323659474 +cos(-0.5 * PI): 0.0 +cos(-0.375 * PI): 0.3826834323659474 +cos(-0.25 * PI): 0.7071067810719247 +cos(-0.125 * PI): 0.9238795325112585 +cos(0.0 * PI): 1.0 +cos(0.125 * PI): 0.9238795325112586 +cos(0.25 * PI): 0.7071067829368671 +cos(0.375 * PI): 0.38268343236594693 +cos(0.5 * PI): -0.0 +cos(0.625 * PI): -0.38268343236594693 +cos(0.75 * PI): -0.7071067810719247 +cos(0.875 * PI): -0.9238795325112586 +cos(1.0 * PI): -1.0 +cos(1.125 * PI): -0.9238795325112586 +cos(1.25 * PI): -0.7071067829368671 +cos(1.375 * PI): -0.3826834323659474 +cos(1.5 * PI): 0.0 +cos(1.625 * PI): 0.3826834323659474 +cos(1.75 * PI): 0.7071067810719247 +cos(1.875 * PI): 0.9238795325112585 +cos(2.0 * PI): 1.0 +cos(2.125 * PI): 0.9238795325112585 +cos(2.25 * PI): 0.7071067829368671 +cos(2.375 * PI): 0.3826834323659474 +cos(2.5 * PI): -0.0 +cos(2.625 * PI): -0.3826834323659474 +cos(2.75 * PI): -0.7071067829368665 +cos(2.875 * PI): -0.9238795325112585出てきた差分が意図通りならOKです。
達成できたこと
これだけではテストとして、不十分に見えますか?
しかし、少なくともテストに求められる重要なことのいくつかは達成できています
- プログラムの挙動の可視化
- プログラムが最後まで動くことのチェック
- デグレード(退化)を起こしていないことのチェック
特に重要なのが3つ目です。Git 差分の表示で変更行がないことを確認すれば挙動が変わってないことのチェックができます。
また、不安に思う部分には assert も書いていけば、いわゆるテストファースト的な手法を複合できます。
テストを書く際のポイント
よく「テストはドキュメント」といった言い回しを耳にしますが、この手法の場合は出力もドキュメントです。
ですから、以下のことを意識して書くといいです
- テストのファイル名に、より良く内容を表現した名前を付ける
- 出力ファイルの冒頭にテスト内容の説明文を書く
- テストのプログラムから出力される各行にはそれが何かわかるようなラベルを書く
CIを行う
CI(継続的インテグレーション)を行うとより快適に開発できるでしょう。
具体的には、プルリクエストをトリガーとして、自動で以下の2つを行うといいです
test/run.pyを実行して差分をコミットする- 出力に意図しない差分があったら failure させる
test/run.pyを実行して差分をコミットするこれを行うことで、テストを実行し忘れた状態でマージされることを防げます。
さらに
- 終了コードが
0であること- 標準エラー出力がされていないこと
を見てテストが正常に終了したかを判定するといいです。
出力に意図しない差分があったら failure させる
プルリクエスト内容の差分を見るだけであれば以下のコマンドを実行すればいいです
git diff --no-pager マージ先ブランチ(base)...リクエストしてるブランチ(head) --relative=test/out(
--ignore-space-changeをつけるべきかは、ソフトウェアの性質に応じて要検討)ただ、これだけでは変更が意図的かどうかの区別ができません。
変更が意図的なものかどうかを区別するためにつけてるのが、出力ファイルの先頭の
ver:0.0のバージョン情報です。このバージョン番号は以下のルールに従って書き換えをします
- 出力ファイルの変更が、行の追加のみであることを意図しているなら、マイナーバージョンを上げる。(
0.0->0.1)- 出力ファイルの変更が、行の削除を含むことを意図しているなら、メジャーバージョンを上げる。(
0.1->1.0)diff を読んで上記のルールを満たしているか判定するプログラムを書けば、マージの可否を判定する CI を組むことができます。
この判定を行うプログラムは以下に公開しています
https://github.com/shohei909/diff_test/blob/master/test/check.py
テスト対象を広げる
実践例で紹介したのは、いわゆる単体テスト的なものですが、より結合テスト的なものに対しても効果的です。
例えば、以下のようなものです
- JSON返すWebサーバーなら、実際にアクセスしたレスポンスを記録する (JSONは
jq . -sort-keysなどで内容のソートをしておくといい)- コマンドラインツールなら、実際にそのツールを実行した結果を記録する
- Webサイトなら、 Headless Chrome でそのページにアクセスした結果のスクリーンショット画像などを記録する
差分を見るテストのメリット
デグレードに対する耐性が高い
この手法はデグレードを発見する力高いです。この点については、あらかじめ期待される結果を手で書く手法と比べても強力です。
というのも、期待される結果を手で書く場合、「手で書ける程度の個数」のケースしか用意できません。網羅的にデグレードをチェックできるほどのケースを書いて用意するのは時間がかかります。
しかし、単に結果を出力しておくのであれば、「目を通せる程度の個数」にまで広がります。
プロトタイピングや仕様変更の速度を落とさない
テストを書く大きなメリットは、リファクタリングが容易になることです。リファクタリング時のデグレードのリスクが抑えられます。
逆に、テストを大量に書くデメリットもあります
- ソフトウェアのプロトタイプが実際に動くまでに時間がかかる
- 仕様変更が発生したときのテストの書き直しが大変になる
単にテキストを出力しておく手法はテストコードは比較的小さく、これらのデメリットが小さいです。
仕様の変更内容によっては、テストコードに対する変更は単に
ver:*.*を書き換えるだけで済みます。それでいて、プログラムの挙動がどう変わったかは出力の差分を見れば明確です。このテスト手法は、すばやくプロトタイプを作って、その挙動や反省を踏まえてリファクタリングや仕様の改善を繰り返していくような開発フローとの相性がいいです。
挙動が可視化される & 挙動の履歴をたどれるようになる
この手法でテストを書くということは、サンプルコードとその実行結果を残しておくということそのものです。これらがあれば、レビュアーも、新規メンバーも、実装者自身もコードがどういう動きをするのか理解しやすくなります。
また、 Git 上に挙動ベースでの変更履歴が残ることにもメリットがあります。この履歴は、例えば、後からバグが発見された場合に、その原因になった挙動がいつから発生していたか、どの修正によって発生かを調べる手助けになります。
テストフレームワークにロックインされない
テストコードはコード量が多くなりがちな部分なので、例えばテストフレームワークが言語のアップデートに追随してないといった事態には対処が大変です。
この手法では、テストフレームワークのへの依存が無いのでそのリスクがありません。
発展:SVGを出力して差分を見る
テキストの出力はより挙動をわかりやすく表現する形で行うのが理想です。より視覚的に表現する方法として SVG を出力するというのがあります。
先ほどの
my_math.cos()でそれをやってみたのが以下です。https://github.com/shohei909/diff_test/pull/1/files#diff-859f44ef4608ed7f4557a2bfcb2ce991
ちゃんとコサインの近似ができていることが視覚的にわかります。
SVG はテキストと画像の両面の性質があるので、両面のメリット受けられます。例えば、値が変わったかを厳密に見たければテキストで見ればいいですし、目視でわかる変化があったかを見たければ画像としてみればいいです。
試しに、
my_math.cos()の精度を落とす変更を加えてみます
誤差が目視ではわからないレベルであることが確認できました。
- 投稿日:2020-07-25T16:59:03+09:00
[cx_Oracle入門](第14回) コネクションプールを使用した接続(サーバーサイド)
連載目次
検証環境
- Oracle Cloud利用
- Oracle Linux 7.7 (VM.Standard2.1)
- Python 3.6
- cx_Oracle 8.0
- Oracle Database 19.6 (DBCS HP, 2OCPU)
- Oracle Instant Client 18.5
概要
前回はcx_Oracle自身の持つクライアントサイドのコネクションプール(セッションプール)について解説しましたが、今回はサーバーサイドのコネクションプール機能であるDRCP(Database Resident Connection Pool、データベース常駐接続プーリング)を使用した接続を採り上げます。サーバーサイドと言いつつ、オプションを指定するだけとはいえ、cx_Oracle側でもコーディングが必要です。なお、DRCPとクライアントサイドのコネクションプールは併用が可能です。
準備:Oracle Database側
DRCPの操作はDBMS_CONNECTION_POOLというPL/SQLユーティリティ・パッケージを使用します。以下SQL*Plusでの利用例です。マルチテナント構成の場合は、コンテナ・データベースに接続して実施する必要があります。
■DRCPの設定
execute dbms_connection_pool.configure_pool(minsize=>5, maxsize=>5)■DRCPの起動
execute dbms_connection_pool.start_pool■DRCPの起動
execute dbms_connection_pool.stop_pool■DRCPの定義内容の確認
ディクショナリDBA_CPOOL_INFOを検索してください。■DRCPの稼働状況の確認
動的パフォーマンスビューV\$CPOOL_STATSを検索してください。他にもV\$CPOOL_CC_STATS、V\$CPOOL_CONN_INFOといったビューが存在します。(参考)Oracle Database の DRCP(データベース常駐接続プーリング)の MINSIZE と MAXSIZE を 1 に設定して、複数セッションから接続してみる。
準備:Oracle Client側
EZCONNECTを利用する場合は事前の準備は不要です。tnsnames.oraを使用する方は、事前に、DRCPを利用する形の設定を指定する必要があります。既存の接続定義への設定追加でも、新規の接続設定追加でも、どちらでも構いません。追加すべき設定は、以下のサンプルの「(SERVER=POOLED)」の部分が該当します。既に「SERVER=DEDICATED」や「SERVER=SHARED」の設定が記述されている場合は置き換える必要があります。
tnsnames.oraPDB1 = (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = 10.0.1.2)(PORT = 1521)) (CONNECT_DATA = (SERVICE_NAME = pdb1.sub04070214581.vcn0.oraclevcn.com) (SERVER=POOLED) ) )PythonアプリケーションのDRCP接続
まずはサンプルを見てみましょう。
sample14a.pyimport cx_Oracle import time USERID = "test" PASSWORD = "FooBar" DESTINATION = "10.0.1.2/pdb1.sub04070214581.vcn0.oraclevcn.com:pooled" # 1. # DRCPのみ利用 t1 = time.time() connection = cx_Oracle.connect(USERID, PASSWORD, DESTINATION, cclass="MYCLASS", purity=cx_Oracle.ATTR_PURITY_SELF) # 2. t2 = time.time() connection.close() print(f"DRCP利用時接続時間 : {t2 - t1}秒") # DRCPとクライアントサイドのコネクションプールを併用 pool = cx_Oracle.SessionPool(USERID, PASSWORD, DESTINATION, min=2, max=2) t1 = time.time() connection = pool.acquire(cclass="MYCLASS", purity=cx_Oracle.ATTR_PURITY_SELF) # 3. t2 = time.time() pool.release(connection) print(f"両コネクションプール併用時接続時間 : {t2 - t1}秒")本サンプルではまだ解説していないEZCONNECTを使用しています。EZCONNECT利用時にDRCP接続を行うには、コメント1.の部分のように、最後に「:pooled」の設定を追加する必要があります。tnsnames.ora利用時は、SERVER=POOLEDを設定している接続子を指定してください。しかし、cx_Oracleでは、SQL*Plusなどとは異なり、接続設定でDRCPを利用する指定を行っただけでは実際にはDRCPは利用されず、通常接続となります。
cx_OracleでDRCPを利用するためには、コメント2.の部分のように、接続コマンド実施の際にcclass引数とpurity引数の設定が必要となります。
cclass引数は接続クラス名を指定します。接続クラスとは接続に付与する論理名のようなものです。1024バイトまでの文字列が指定可能です。複数の接続で接続クラスを分けると、異なる接続クラスとは該当のコネクションプールが共有されないことが保証されます。一例としては、異なるDBユーザー、異なるアプリケーションなどで異なる接続クラスを指定することで、セッションのより効率的な共有が可能になります。
purity引数はセッションの再利用に関する動きを指定します。以下の値から選択して指定します。
値 説明 cx_Oracle.ATTR_PURITY_NEW クライアントサイドのコネクションプールを利用していない場合のデフォルト値。接続要求の都度新しい接続を利用する cx_Oracle.ATTR_PURITY_SELF クライアントサイドのコネクションプールを利用している場合のデフォルト値。古い空き接続があれば再利用する cx_Oracle.ATTR_PURITY_DEFAULT 引数無指定時のデフォルト。上記条件により、cx_Oracle.ATTR_PURITY_NEWもしくはcx_Oracle.ATTR_PURITY_SELFのいずれかになる 最後に、両サイドのコネクションプールを併用する場合、cclass引数とpurity引数は、コメント3.の部分のように、cx_Oracle.SessionPool()ではなく、Connection.acquire()にて指定する必要があります。
- 投稿日:2020-07-25T16:29:38+09:00
【感染症モデル入門】感染数と重症化の関係を対数グラフで見る♬
世の中は、「感染数は多いけど、重症者は少ないので大丈夫」というご意見が多い。
まあ、実際感染者は若者中心で高齢者の感染は少ないようだ。
とはいえ、重症化は感染から遅れてやってくるのでどのように増えてくるのかをグラフを描いて確認してみようと思う。
方法は、このところやっているのとほぼ同様な方法で以下のとおりです。
①厚労省からデータ入手
②重症数をデータ化(5月7日までは未公表)
③感染数と重症数を同じグラフ上にプロット
結果は、以下のとおり得られました。全国
以下のとおり、対数プロットで見ると、
①現存感染数(赤いプロット)と現存重症数(黒いプロット)は約18日遅れで、しかも800:30程度の比で同じようなグラフである
②新規感染数(青のバーグラフ)と現存感染数は同じような推移で、比は約1000:6000である
①から、重症化率=約4%
②から、入院日数=約6日程度(実際の入院日数とは異なります)
また、本来は第一波の余波の影響を無視した分析なので、正しくやろうとすれば第一波分のデータを差し引くなどの処理が必要ですが、今回は無視することとします。
東京
東京のデータも赤いプロット、黒いプロット、そして青いバーグラフが類似しています。ただし、重症数が6月24日辺りから大幅減(直線の傾きが変わったので退院基準などの変更だと思います)となり、7月10日辺りから急激に増加しているのが分かります。東京の場合は、傾きが現存感染数や新規感染数の傾きより大きいので、重症化率が増加しているように見えます。
また、東京アラート解除が6月11日なので、6月24日の約二週間前になります。
ということはありますが、ここでも重症化は18日程度遅れでほぼ似たような曲線を描くことが分かります。重症化率=1-2%程度です。
入院日数=約7日程度です。
東京以外
このデータでは、重症数の立ち上がりはだらだらしていて、傾きが現存感染数の直線より小さいです。つまり、第一波の余波が大きく、そのため傾きが小さくなっているか、実際に重症化率が下がっているかまだ不明です。これから立ち上がって平行な直線に乗ってくると思われます。
大阪(厚労省データは荒れているが)
このデータは誤差が大きそうです。しかし、それでも上記の3つのグラフと比較すると、以下の議論に記載したような一定の傾向が見えます。
議論
ここでは、医療崩壊について、考察しておこうと思います。
主にグラフの傾きがこれからの傾向を示してくれます。
東京は、現在現存感染数は2000人で、重症数21人です。
傾きから、30日程度で10倍に増加すると懸念されます。つまり、20000人、特に重症数200人です。ECMOなどの設備と人の準備状況はどうなんだろうと心配になります。何の対策もしなければ、60日後は200000人、2000人です。なんの対策もしていなければ、医療崩壊してしまいそうです。一方、大阪のグラフの特徴は傾きが大きいというところにあります。
上記の大阪以外のグラフでは、10倍/30日でしたが、ここでは10倍/20日程度の傾きを持っています。医療崩壊を起こさないために、あと20日後に今の10倍になるということを考えて早めの施策が必要です。現存感染数と重症数を重ねて表示する
一応、ずれを示したので、以下グラフを平行移動して重ねてみた。
重症数データのプロットを縦軸10倍とデータそのものを2倍し、横軸を19日ずらしてみると以下のように重なった。
つまり、今後全国は以下のように赤いプロットに乗って、重症数が増加しそうである。
東京は以下のとおり、重ならないが、これは重症数が大きく減少し、徐々に増加しているためであり、今後赤い線に乗ってきそうである。
東京以外は以下のとおり、だいたい乗っているが、少し大きめであり、第一波が影響していそうであるし、東京の寄与と合わせて全国として乗っているのでその程度の誤差なのであろう。
同じスケールで大阪も見ると以下のとおりであまり一致しませんが、データが荒れているので様子を見ようと思います。
こうしてみると、重症数は、たぶん定義もまちまちであり、統一的な数値を求めるのは難しそうである。
それでも、全体として重症化率は一定値となるか、弱毒化の指標として減少するかを見ていくことは有意義であると思う。
今、このスケールでグラフが重なったことから、上述の目の子換算と異なりますが、グラフから求められる(現存感染数当たりの)重症化率は以下のとおりです。
重症化率=1/20=約5%
程度であると推定できる。上記は、データを2倍して一桁ずらしたが、単に重ねるには、以下のように縦軸の表示範囲をずらしても重なるので、示しておく。
※生データを2倍するとはなにごとだと怒られそうなので。。。
まとめ
・感染数と重症化の関係を対数グラフを描いて見た
・重症化率は、約5%であった
・重症数は現存感染数グラフの変化と相関して、現存感染数の19日遅れのグラフに(重症化率倍すると)乗る事が分かった
・全国と東京、東京以外、そして大阪と重症数の変化の特徴が異なる部分もあり、医療崩壊の状況を見極めるためにも、今後もウォッチする必要があると考える・国内のデータは、発生も少なく、全体に日々データの精度がいまいちであり、他国の例も含めて検証したいと思う
おまけ(コード)
import numpy as np import matplotlib.pyplot as plt import pandas as pd data = pd.read_csv('data/covid19/test_confirmed.csv',encoding="cp932") data_r = pd.read_csv('data/covid19/test_recovered.csv',encoding="cp932") data_d = pd.read_csv('data/covid19/test_deaths.csv',encoding="cp932") data_s = pd.read_csv('data/covid19/test_serious.csv',encoding="cp932") confirmed = [0] * (len(data.columns) - 1) day_confirmed = [0] * (len(data.columns) - 1) confirmed_r = [0] * (len(data_r.columns) - 1) day_confirmed_r = [0] * (len(data.columns) - 1) confirmed_d = [0] * (len(data_d.columns) - 1) diff_confirmed = [0] * (len(data.columns) - 1) confirmed_s = [0] * (len(data.columns) - 1) days_from_1_Jun_20 = np.arange(0, len(data.columns) - 1, 1) beta_ = [0] * (len(data_r.columns) - 1) gamma_ = [0] * (len(data_d.columns) - 1) daystamp = "531" city,city0 = "東京以外","extokyo" skd=1 #2 #1 #4 #3 #2 #slopes average factor #データを加工する t_cases = 0 t_recover = 0 t_deaths = 0 for i in range(0, len(data_r), 1): if (data_r.iloc[i][0] == city): #for country/region print(str(data_r.iloc[i][0])) for day in range(1, len(data.columns), 1): confirmed_r[day - 1] += data_r.iloc[i][day] if day < 1+skd: day_confirmed_r[day-1] += data_r.iloc[i][day] else: day_confirmed_r[day-1] += (data_r.iloc[i][day] - data_r.iloc[i][day-skd])/(skd) t_recover += data_r.iloc[i][day] for i in range(0, len(data_d), 1): if (data_d.iloc[i][0] == city): #for country/region print(str(data_d.iloc[i][0]) ) for day in range(1, len(data.columns), 1): confirmed_d[day - 1] += float(data_d.iloc[i][day]) #fro drawings t_deaths += float(data_d.iloc[i][day]) for i in range(0, len(data), 1): if (data.iloc[i][0] == city): #for country/region print(str(data.iloc[i][0])) for day in range(1, len(data.columns), 1): confirmed[day - 1] += data.iloc[i][day] - confirmed_r[day - 1] -confirmed_d[day-1] if day == 1: day_confirmed[day-1] += data.iloc[i][day] else: day_confirmed[day-1] += data.iloc[i][day] - data.iloc[i][day-1] for i in range(0, len(data_d), 1): if (data_d.iloc[i][0] == city): #for country/region print(str(data_d.iloc[i][0]) ) for day in range(1, len(data.columns), 1): confirmed_s[day - 1] += float(data_s.iloc[i][day])*2 #ここで重症数を2倍している def EMA(x, n): a= 2/(n+1) return pd.Series(x).ewm(alpha=a).mean() day_confirmed[0]=0 df_c = pd.DataFrame(day_confirmed) df_c.to_csv('data/day_comfirmed_{}.csv'.format(city0)) m=15 dc_m = EMA(day_confirmed,m) #EMA(day_confirmed,m) #df_c.rolling(m).mean() dc_m.to_csv('data/day_comfirmed_EMAmean{}_{}.csv'.format(m,city0)) dc_m_l=dc_m.values.tolist() tl_confirmed = 0 for i in range(skd, len(confirmed), 1): if confirmed[i] > 0: gamma_[i]=float(day_confirmed_r[i])/float(confirmed[i]) else: continue tl_confirmed = confirmed[len(confirmed)-1] + confirmed_r[len(confirmed)-1] + confirmed_d[len(confirmed)-1] t_cases = tl_confirmed #matplotlib描画 fig, ax1 = plt.subplots(1,1,figsize=(1.6180 * 4, 4*1)) ax3 = ax1.twinx() lns1=ax3.plot(days_from_1_Jun_20[1:], confirmed[1:], "o-", color="red",label = "cases") lns4=ax1.plot(days_from_1_Jun_20[1:35], confirmed_s[20:55], "o-", color="black",label = "serious") #ここで横軸を19日ずらしている lns_ax1 = lns4 labs_ax1 = [l.get_label() for l in lns_ax1] ax1.legend(lns_ax1, labs_ax1, loc=2) ax3.legend(loc=1) ax1.set_title(city0 +" ; {} cases, {} recovered, {} deaths".format(t_cases,t_recover,t_deaths)) ax1.set_xlabel("days from 1, Jun, 2020") ax1.set_ylabel("serious, day_cases ") ax3.set_ylabel("cases") ax3.set_xlim(0,60) ax1.set_xlim(0,60) ax3.set_ylim(10,1000) ax1.set_ylim(1,100) #1500 ax3.set_yscale('log') ax1.set_yscale('log') ax1.grid() plt.pause(1) plt.savefig('./fig/original_data_{}_{}_new.png'.format(city,daystamp)) plt.close()
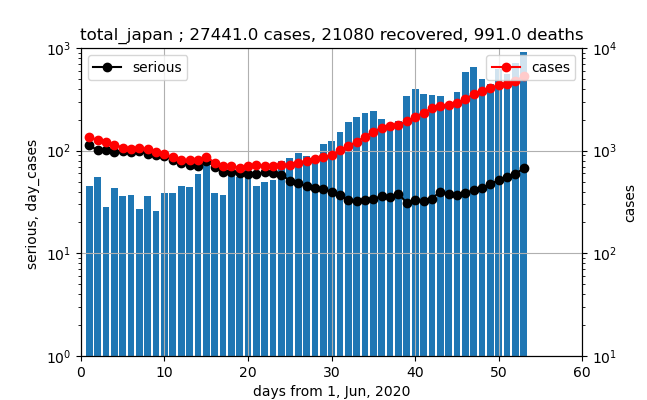
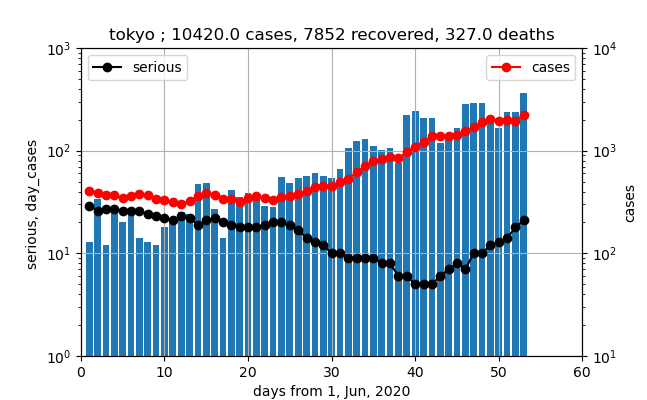
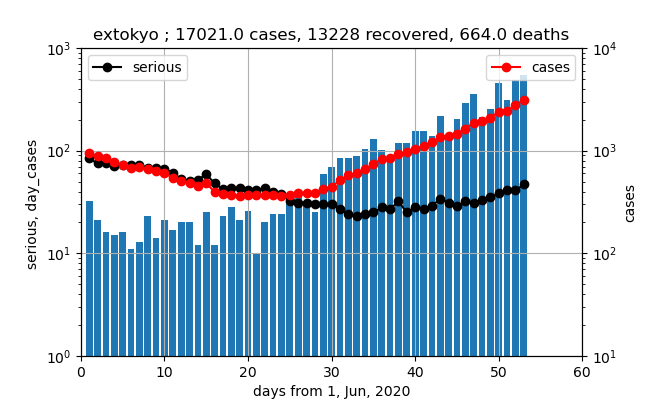

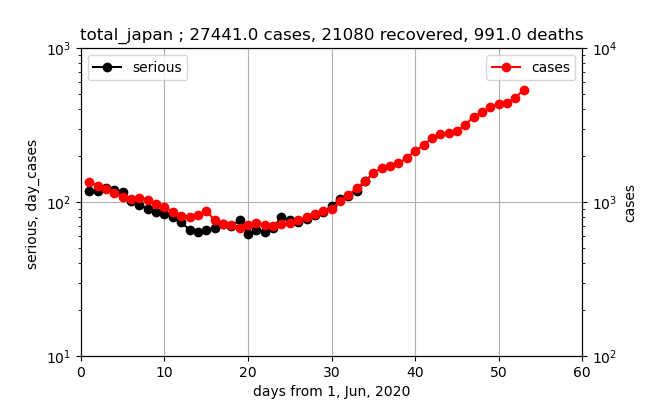
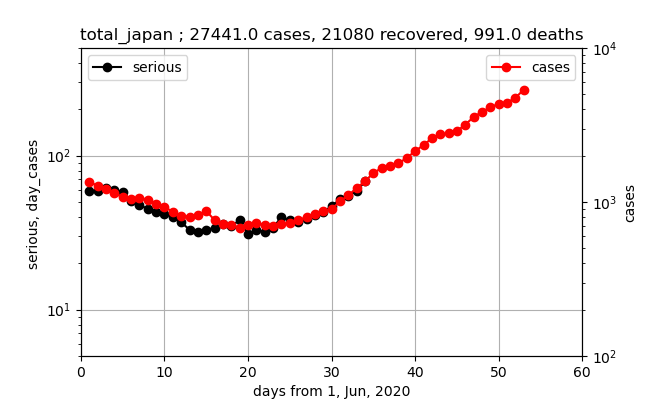
- 投稿日:2020-07-25T15:44:09+09:00
競馬予想AIの回収率を86%→91%に上げた意外な方法とは?
目的
機械学習で競馬予想して回収率100%を目指す
今回やること
今回の記事は以下の記事の続きになります。
・pandasのread_htmlを用いてレース結果データをスクレイピングする
・BeautifulSoupを用いてレース詳細情報をスクレイピングする
・LightGBMで3着以内に入る馬を予想する
・馬の過去成績データを特徴量に加える
・回収率をシミュレーションする具体的な方法今回は、
・血統データを特徴量に追加する
・普通の機械学習ではあまりやらない「あること」をして回収率を86%→91%に改善する
の2つをやります。詳しい解説
ここには簡単にソースコードだけを載せ、動画で詳しい解説をしています↓
競馬予想で始めるデータ分析・機械学習
血統データを入れる
まずは、netkeiba.comから血統データをスクレイピングします。
import time from tqdm.notebook import tqdm import pandas as pd def scrape_peds(horse_id_list, pre_peds={}): peds = pre_peds for horse_id in tqdm(horse_id_list): if horse_id in peds.keys(): continue try: url = "https://db.netkeiba.com/horse/ped/" + horse_id df = pd.read_html(url)[0] generations = {} for i in reversed(range(5)): generations[i] = df[i] df.drop([i], axis=1, inplace=True) df = df.drop_duplicates() ped = pd.concat([generations[i] for i in range(5)]).rename(horse_id) peds[horse_id] = ped.reset_index(drop=True) time.sleep(1) except IndexError: continue except Exception as e: print(e) break return pedsこれで下のようなデータができます。
LightGBMには、カテゴリ変数を自動で扱ってくれるcategorical_featureという機能があるのですが、ドキュメントを見るとやり方が2つあり、
- パラメータでcategorical_feature=[列名]or[列番号のリスト]のように指定する。
- 列をpandasのcategory型に変換して入れる
1をやると謎のwarningが出てくるし、LightGBMは日本語の列名に対応してないので、2でいこうと思うのですが、ドキュメントを見ると注意点があり、
Note: only supports categorical with int type
(整数のcategory型を入れてください。)
Note: using large values could be memory consuming. Tree decision rule works best when categorical features are presented by consecutive integers starting from zero
(大きい値を使うとメモリを食いますよ。精度を上げるには0から始まる連続した整数にしてください。)
Note: all negative values will be treated as missing values
(負の値は欠損値として扱いますね。)と書いてあります。なので、まずはLabelEncodingによって0から始まる整数値にしてから、pandasのcategory型に変換します。
def process_categorical(df, target_columns): df2 = df.copy() for column in target_columns: df2[column] = LabelEncoder().fit_transform(df2[column].fillna('Na')) #target_columns以外にカテゴリ変数があれば、ダミー変数にする df2 = pd.get_dummies(df2) for column in target_columns: df2[column] = df2[column].astype('category') return df2前回の記事と同じ手順で実際に回収率をシミュレーションしてみます。
class Return: def __init__(self, return_tables): self.return_tables = return_tables @property def fukusho(self): fukusho = self.return_tables[self.return_tables[0]=='複勝'][[1,2]] wins = fukusho[1].str.split('br', expand=True).drop([3], axis=1) wins.columns = ['win_0', 'win_1', 'win_2'] returns = fukusho[2].str.split('br', expand=True).drop([3], axis=1) returns.columns = ['return_0', 'return_1', 'return_2'] df = pd.concat([wins, returns], axis=1) for column in df.columns: df[column] = df[column].str.replace(',', '') return df.fillna(0).astype(int) @property def tansho(self): tansho = self.return_tables[self.return_tables[0]=='単勝'][[1,2]] tansho.columns = ['win', 'return'] for column in tansho.columns: tansho[column] = pd.to_numeric(tansho[column], errors='coerce') return tansho class ModelEvaluator: def __init__(self, model, return_tables): self.model = model self.fukusho = Return(return_tables).fukusho self.tansho = Return(return_tables).tansho def predict_proba(self, X): return self.model.predict_proba(X)[:, 1] def predict(self, X, threshold=0.5): y_pred = self.predict_proba(X) return [0 if p<threshold else 1 for p in y_pred] def score(self, y_true, X): return roc_auc_score(y_true, self.predict_proba(X)) def feature_importance(self, X, n_display=20): importances = pd.DataFrame({"features": X.columns, "importance": self.model.feature_importances_}) return importances.sort_values("importance", ascending=False)[:n_display] def pred_table(self, X, threshold=0.5, bet_only=True): pred_table = X.copy()[['馬番']] pred_table['pred'] = self.predict(X, threshold) if bet_only: return pred_table[pred_table['pred']==1]['馬番'] else: return pred_table def fukusho_return(self, X, threshold=0.5): pred_table = self.pred_table(X, threshold) n_bets = len(pred_table) money = -100 * n_bets df = self.fukusho.copy() df = df.merge(pred_table, left_index=True, right_index=True, how='right') for i in range(3): money += df[df['win_{}'.format(i)]==df['馬番']]['return_{}'.format(i)].sum() return n_bets, money def tansho_return(self, X, threshold=0.5): pred_table = self.pred_table(X, threshold) n_bets = len(pred_table) money = -100 * n_bets df = self.tansho.copy() df = df.merge(pred_table, left_index=True, right_index=True, how='right') money += df[df['win']==df['馬番']]['return'].sum() return n_bets, money def gain(return_func, X, n_samples=100, lower=50, min_threshold=0.5): gain = {} for i in tqdm(range(n_samples)): threshold = 1 * i / n_samples + min_threshold * (1-(i/n_samples)) n_bets, money = return_func(X, threshold) if n_bets > lower: gain[n_bets] = (n_bets*100 + money) / (n_bets*100) return pd.Series(gain) me = ModelEvaluator(lgb_clf, return_tables) gain_1 = gain(me.fukusho_return, X_test) gain_1.plot()
横軸が買った馬券の枚数、縦軸が回収率です。90%という値が出ていますが、左の方は買った枚数が少なく分散が大きいことを考えると、実際は1600枚あたりに出ている86%というところでしょうか。
これをbaselineとして、次に単勝でもやってみます。gain_tansho = gain(me.tansho_return, X_test) gain_1.rename('baseline').plot(legend=True) gain_tansho.rename('tansho').plot(legend=True)
下がってしまいました・・・オッズと人気のデータを使わない
feature_importanceを見てみると、折角血統データなどを追加しているのに、ほぼ単勝オッズのデータしか反映していないモデルになっていることがわかります。
ただ精度を求める機械学習なら良いのですが、今回の場合オッズのデータに頼ることは、払い戻しの少ない馬券を買うことなので好ましくないです。そこで、思い切って単勝オッズのデータを削除してみます。X_train.drop(['単勝', '人気'], axis=1, inplace=True) X_test.drop(['単勝', '人気'], axis=1, inplace=True)結果
回収率を約91%に上げることができました!動画で詳しい解説をしています↓
競馬予想で始めるデータ分析・機械学習


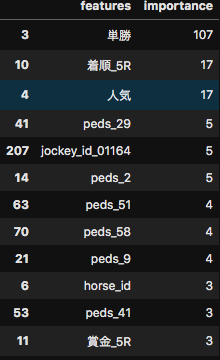
- 投稿日:2020-07-25T15:34:46+09:00
Classがわからない人のために
1.はじめに
身内向けに書きます。そして自分のためにも。超テキトウです。
2.オブジェクト指向
オブジェクト指向とは「指向」つまり「考え方」「概念」です。オブジェクト指向は「プログラミングのソースコードをオブジェクトとして扱おう」という考え方なのです。こういったオブジェクト指向を採用している言語は数多くあります。また、オブジェクト指向の反対は「手続き指向」です。
3.classとは
classとはオブジェクト指向を取り込む際に「このclassってのを一つの塊(オブジェクト)にしようぜ」って決めた単位です。名前に価値はありません。また、後述しますが、classは「オブジェクトそのものではなくオブジェクトの設計図」を表します。4.手続き指向
オブジェクト指向を見る前に今まで(オブジェクト指向が考え出されるまえ)のソースコードを見てみましょう。
ソースコードを模式的に表した図です。手続き型言語は一般的に自然落下、つまり上から下に順番にソースコードを実行しています。ただ、その流れを無理やり変えることもできます。例えば条件分岐
if (a > 10): # 処理A else: # 処理Bpythonは手続き型言語ではないですがあくまで例として。
aが10より大きくない場合、処理Aは飛ばされますよね?これが流れを変えるということです。手続き型言語ではその流れを変える方法が少ない、というか基本的に流れを変えません。
流れを変えられるのはif、for、goto、サブルーチン等のみです。原則は自然落下になります。5.classは設計図
それではPythonの話に戻します。Pythonも特に何もしなければ手続き型言語と同じです。ただ、
classというものを定義するその瞬間、オブジェクト指向になります。これを弱いオブジェクト指向とでもいいましょうか。(Javaなどはすべてがオブジェクト指向で動いている強いオブジェクト指向です)このclass name: # 処理
classに囲まれた部分は「設計図」となります。設計図なので実際になにか作ってるわけではありません。頭のいい皆さんならお気づきだとおもいますが、この設計図を実際に部品や製品として製造しなければ使うことはできません。この製造のことを「インスタンス化」といいます。また、出てきた部品、製品を「インスタンス」といいます。インスタンスの名前 = classの名前(コンストラクタに入れる値)こう書くとclassをインスタンス化して「インスタンスの名前」を付けます。
なぜ、インスタンスの名前を付けないといけないかというと複数インスタンスを生成できるからです。
例えばhouseというクラスを設計してインスタンス化してみます。class house: # 省略 houseA = house() houseB = house()
6.で?だからなに
まぁ、ここまでだったらコピペみたいなものです。インスタンスの名前しか違いません。今度は高度なことをやってみましょう。
class house: def __init__(self, toti, bairitu): self.toti = toti self.bairitu = bairitu def get_price(self) return self.toti * self.bairituこんなクラスを作ってみました。順を追って解説しましょう。
__init__はクラスがインスタンス化された時に行う処理です。defで囲まれた部分を関数というのは習ったと思いますが、__init__という名前は特殊でそうゆう意味になります。また、クラスの中のdefは必ず()のなかにselfをいれてください。これは自分という意味で外部から与えられなくても勝手に受け取ります。self.toti = totiでは自分にtotiという変数を作ってそとから持ってきたtotiを代入しています。外からもらったtotiだとすぐに消えてしまいますが、self.totiだと製造された部品の中に永遠に値が残ります。同じようにbairituも受け取ります。こうするとインスタンス化のときにこう書かなければなりません。house A = house(30000, 3.4) house B = house(40000, 2.5)ご覧の通り、selfにはなにも渡していません。渡さないのが正解です。
この状態だと
houseAの土地の値段は30000、倍率は3.4で同様にhouseBの土地の値段は40000、倍率は2.5になりました。さっきまで同じだったインスタンスですが「家」という構造は変わらないまま(外見は違うかも)土地の値段と倍率が異なるインスタンスを生成できました。ではこの2つの家、どちらが高いのでしょうか。今回は土地×倍率を値段とします。このために
get_price()を用意したのです。おわかりのとおり、自分の土地と倍率かけ合わせた数を返してくれます。ではさっそくじっこうなのですが、ここでhouse.get_price()は誤りです。houseはただの設計図なので何にも実態はありません。値段を聞くならインスタンスに聞きましょう。でも、インスタンスは2つあるのでどっちに聞くかも教える必要がありそうです。
houseA_price = houseA.get_price() houseB_price = houseB.get_price() houseA_price > houseB_price
get_price()にはselfを渡さないといけませんがクラスのなかの関数ですので勝手に渡してくれます。7. ソースコードの流れ
さて、Classがまぁまぁわかったと思いますけど、じゃあ手続き型言語とは何が違うのということです。最後にオブジェクト指向型言語の処理の流れを見て終わりたいと思います。
かなりぐちゃぐちゃしてる感じもありますが、それぞれのクラスで役割分担をすることが最大の理由です。カメラ一つにしても起動するところ写真をとくところ、印刷するところといろんな関数が混在するのは面倒です。そこで、cameraっていうクラスを用意してカメラに関する処理をすべて集めてしまえば、カメラを起動しているときに別の処理を行うこともできますし、何よりすっきりします。手続き型言語ではそれができず、カメラについての機能とマイクについて、指紋認証について...etcの機能がすべて混在していました。8. さいごに
オブジェクト指向は人間の考え方に素直な考え方、プログラミング言語の在り方だと思います。それぞれのクラスに適材適所の機能を載せることでプログラミング言語はさらなる進歩を繰り返してきました。初心者にとっては難しいものですが、クラスのつくり方、関数のつくり方さえ分かっていれば割と簡単だと思います。
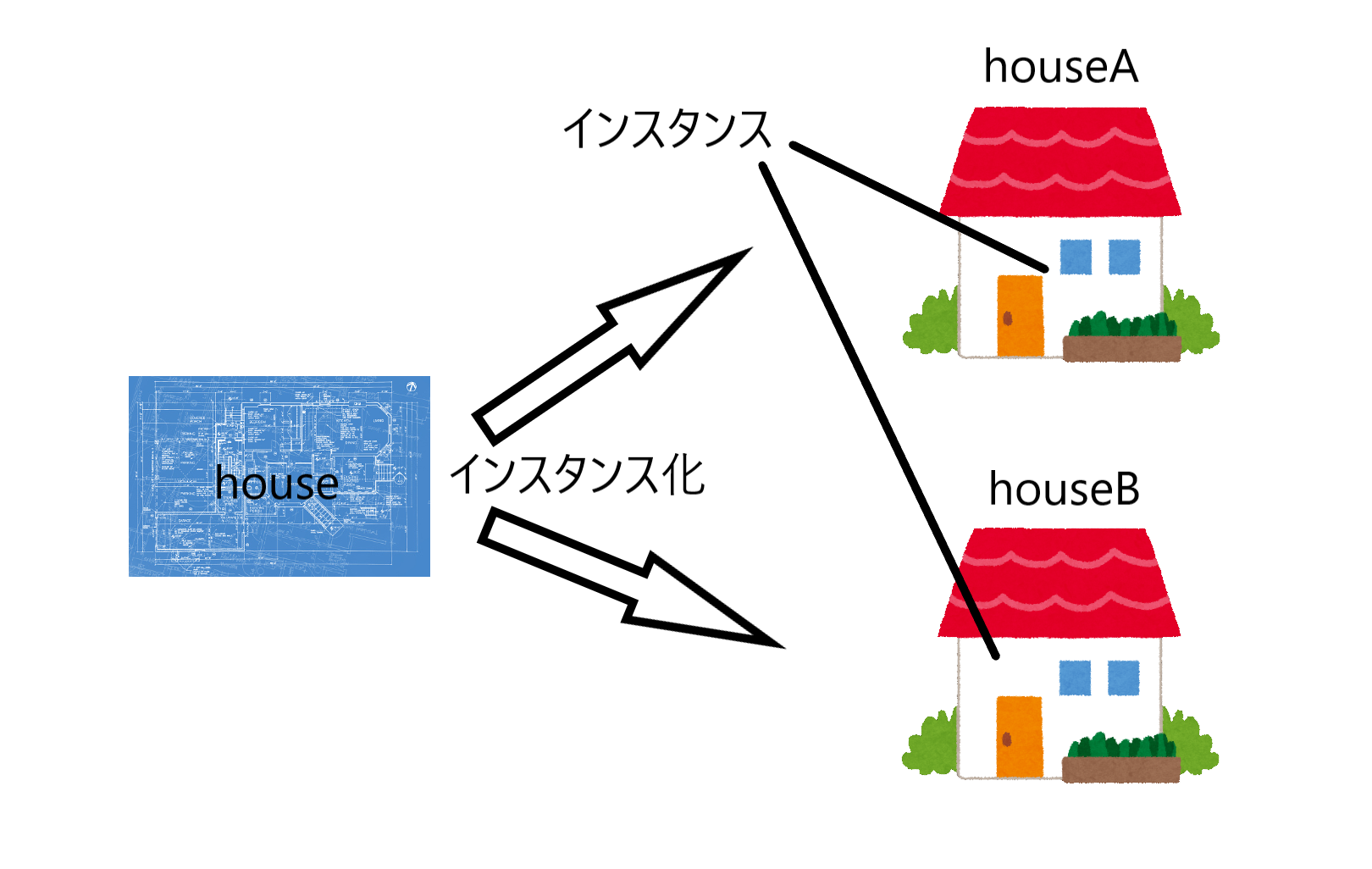
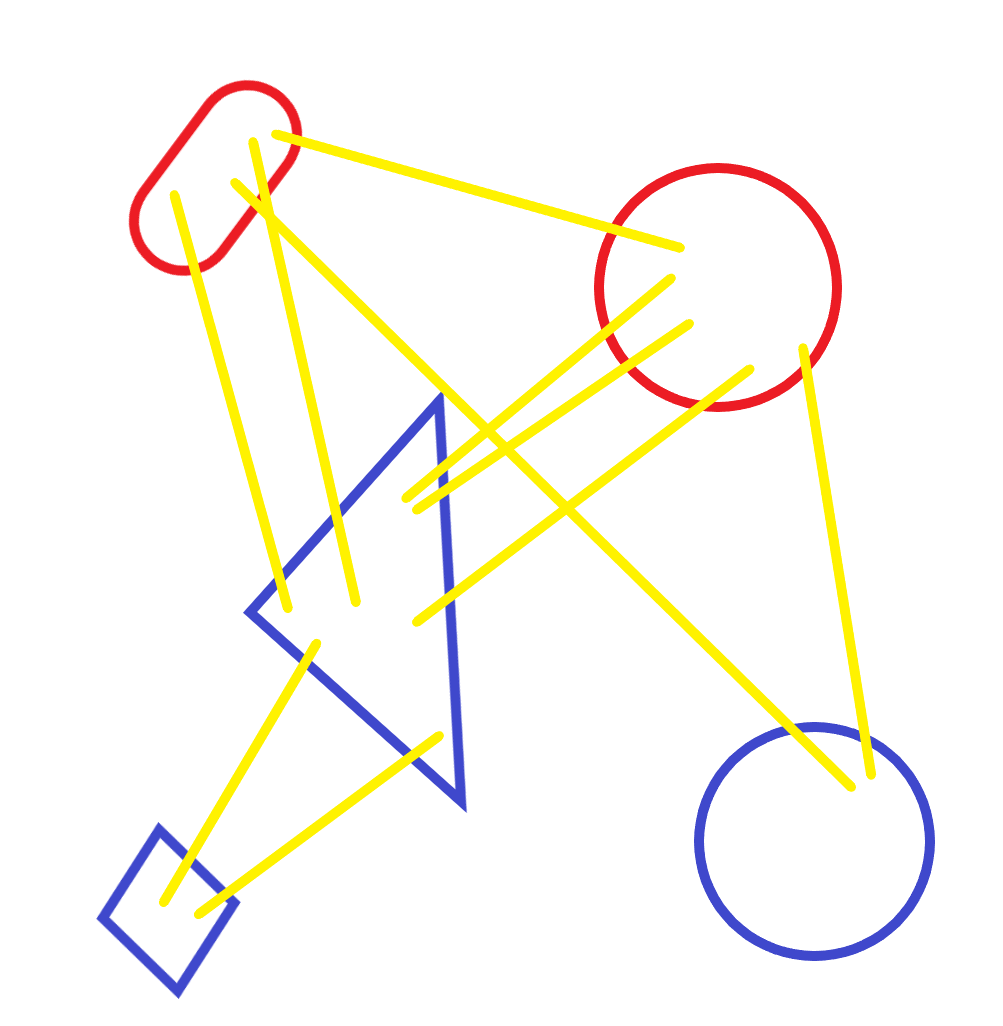
- 投稿日:2020-07-25T14:52:46+09:00
ファイルをごそっと移動するPython3スクリプト
はじめに
- 必要に迫られ、
/hoge/fuga/moto配下にあるファイル群を/hoge/fugaに移動するPythonスクリプトを作成- 移動前、後の証跡をCSV形式で残す
- CSVファイルは、BOM付きのUTF-8
- ↑ エクセルで開いても文字化けしない対策
スクリプトの引数説明
-hでヘルプ表示-s-dは必須オプション- 実行ログ(拡張子
.csv)は、カレントディレクトに出力。# /hoge/fuga/moto->/hoge/fugaに移動する場合 $ python3 mv-python3.py -s /hoge/fuga/moto -d /hoge/fuga # -h でヘルプ表示 $ python3 mv-python3.py -h usage: mv2.py [-h] -s SRCDIR -d DSTDIR 移動元ディレクトリ内のファイルを移動先ディレクトリに移動する。移動後、移動元ディレクトリを削除する。 optional arguments: -h, --help show this help message and exit -s SRCDIR, --srcdir SRCDIR 移動元ディレクトリ -d DSTDIR, --dstdir DSTDIR 移動先ディレクトリ # 必須オプションを指定しないとファイル移動しない $ python3 mv-python3.py usage: mv-python3.py [-h] -s SRCDIR -d DSTDIR mv-python3.py: error: the following arguments are required: -s/--srcdir, -d/--dstdirスクリプト
作成したスクリプト
mv-python3.pyimport glob import os import datetime import time import argparse import sys import shutil parser = argparse.ArgumentParser(description='移動元ディレクトリ内のファイルを移動先ディレクトリに移動する。移動後、移動元ディレクトリを削除する。') parser.add_argument('-s','--srcdir', required=True, type=str, help='移動元ディレクトリ') parser.add_argument('-d','--dstdir', required=True, type=str, help='移動先ディレクトリ') args = parser.parse_args() srcdir = args.srcdir dstdir = args.dstdir # 最後の文字列が / (スラッシュ) なら削除 srcdir = srcdir.rstrip('/') dstdir = dstdir.rstrip('/') # ログファイル名を設定 dt_now = datetime.datetime.now() logFileName = "./log-" + dt_now.strftime('%Y%m%d-%H%M%S') + ".csv" # ファイルを一覧表示 def resouceList( tgtTitle, curPath ): curPath += "/*" resouces = glob.glob(curPath) resType = "" for resouce in resouces : if os.path.isfile(resouce) : resType = "[FILE]" resSize=os.path.getsize(resouce) resMtime=datetime.datetime.fromtimestamp(os.path.getmtime(resouce)) log_list=[tgtTitle, resType, resouce, str(resSize), str(resMtime)] setlog( log_list, "PF" ) else: resType = "[DIRECTORY]" nxtPath = resouce log_list=[tgtTitle, resType, resouce] setlog( log_list, "PF" ) resouceList( tgtTitle , nxtPath ) # ファイル/ディレクトリを削除。ただし、移動元ディレクトリは削除しない def resouceDelete(tgtTitle, exPath, curPath): curPath += "/*" resouces = glob.glob(curPath) resType = "" skpFlg = 0 for resouce in resouces : print("src:{0}\ndst:{1}".format(exPath, resouce) ) if exPath == resouce : skpFlg = 1 if skpFlg == 0 : if os.path.isfile(resouce) : resType = "[FILE]" os.remove(resouce) # DELETE FILE else: resType = "[DIRECTORY]" shutil.rmtree(resouce) # DELETE DIRECTORY else : resType = "[NOT-DELETE]" skpFlg = 0 log_list = [tgtTitle, resType, resouce] setlog( log_list, "PF" ) # 標準出力、ログ出力 def setlog(log_list, logFlg): log_dt = datetime.datetime.now().strftime('%Y%m%d-%H%M%S') log_list.insert(0, log_dt) log_str=','.join(log_list) if "P" in logFlg : print(log_str) if "F" in logFlg : f.writelines("{0}\n".format(log_str) ) # ファイル/ディレクトリを移動 def moveResource( tgtTitle, src_dir , dst_dir ): for p in os.listdir(src_dir): shutil.move(os.path.join(src_dir, p), dst_dir) log_list = [tgtTitle, os.path.join(src_dir, p), dst_dir] setlog( log_list, "PF" ) # 移動元ディレクトリを削除 def sourceDelete( tgtTitle, srcPath) : shutil.rmtree(srcPath) # DELETE DIRECTORY log_list = [tgtTitle, srcPath] setlog( log_list, "PF" ) ##------------------------------## ## ROOT FLOW ##------------------------------## with open( logFileName , 'w' , encoding="utf_8_sig") as f: resouceList ( "[Step01/08-BEFORE|SOURCE]" , srcdir) # (現状確認)移動元ディレクトリのファイル一覧を表示 resouceList ( "[Step02/08-BEFORE|DISTINATION]" , dstdir) # (現状確認)移動先ディレクトリのファイル一覧を表示 resouceDelete( "[Step03/08-DELETE|DISTINATION]" , srcdir, dstdir) # 移動先ディレクトリ配下のファイルを削除する resouceList ( "[Step04/08-DELETE-AFTER|DISTINATION]" , dstdir) # (削除確認)移動先ディレクトリのファイル一覧を表示 moveResource ( "[Step05/08-MOVE|DISTINATION]" , srcdir , dstdir ) # 移動元ディレクトリ配下のファイルを移動先ディレクトリに移動 resouceList ( "[Step06/08-AFTER|SOURCE]" , srcdir) # (移動確認)移動元ディレクトリのファイル一覧を表示 resouceList ( "[Step07/08-AFTER|DISTINATION]" , dstdir) # (移動確認)移動先ディレクトリのファイル一覧を表示 sourceDelete ( "[Step08/08-DELETE|SOURCE]" , srcdir) # 移動元ディレクトリを削除 setlog( ["SCRIPT-DONE"], "PF" ) # スクリプト終了をログに記録 f.close() print("\n|--- DONE ---|\n")実行例
以下の状態で、
…/hoge/fuga->…/hogeに移動してみる~/data/python/temp/hoge $ tree . ├── fileA.txt ├── fileB.txt ├── fileC.txt └── fuga ├── fileA.txt └── fileB.txt 1 directory, 5 filesスクリプト実行
$ python3 mv-python3.py -s '/home/pi/data/python/temp/hoge/fuga' -d '/home/pi/data/python/temp/hoge' 20200725-144112,[Step01/08-BEFORE|SOURCE],[FILE],/home/pi/data/python/temp/hoge/fuga/fileB.txt,8,2020-07-24 09:29:09.405717 20200725-144112,[Step01/08-BEFORE|SOURCE],[FILE],/home/pi/data/python/temp/hoge/fuga/fileA.txt,8,2020-07-24 <省略>スクリプト実行後の状態
~/data/python/temp/hoge $ tree . ├── fileA.txt └── fileB.txt 0 directories, 2 filesログファイル
log-20200725-144112.csv20200725-144112,[Step01/08-BEFORE|SOURCE],[FILE],/home/pi/data/python/temp/hoge/fuga/fileB.txt,8,2020-07-24 09:29:09.405717 20200725-144112,[Step01/08-BEFORE|SOURCE],[FILE],/home/pi/data/python/temp/hoge/fuga/fileA.txt,8,2020-07-24 09:29:09.405717 20200725-144112,[Step02/08-BEFORE|DISTINATION],[FILE],/home/pi/data/python/temp/hoge/fileB.txt,8,2020-07-24 09:29:09.405717 20200725-144112,[Step02/08-BEFORE|DISTINATION],[FILE],/home/pi/data/python/temp/hoge/fileC.txt,8,2020-07-24 09:29:09.405717 20200725-144112,[Step02/08-BEFORE|DISTINATION],[FILE],/home/pi/data/python/temp/hoge/fileA.txt,8,2020-07-24 09:29:09.405717 20200725-144112,[Step02/08-BEFORE|DISTINATION],[DIRECTORY],/home/pi/data/python/temp/hoge/fuga 20200725-144112,[Step02/08-BEFORE|DISTINATION],[FILE],/home/pi/data/python/temp/hoge/fuga/fileB.txt,8,2020-07-24 09:29:09.405717 20200725-144112,[Step02/08-BEFORE|DISTINATION],[FILE],/home/pi/data/python/temp/hoge/fuga/fileA.txt,8,2020-07-24 09:29:09.405717 20200725-144112,[Step03/08-DELETE|DISTINATION],[FILE],/home/pi/data/python/temp/hoge/fileB.txt 20200725-144112,[Step03/08-DELETE|DISTINATION],[FILE],/home/pi/data/python/temp/hoge/fileC.txt 20200725-144112,[Step03/08-DELETE|DISTINATION],[FILE],/home/pi/data/python/temp/hoge/fileA.txt 20200725-144112,[Step03/08-DELETE|DISTINATION],[NOT-DELETE],/home/pi/data/python/temp/hoge/fuga 20200725-144112,[Step04/08-DELETE-AFTER|DISTINATION],[DIRECTORY],/home/pi/data/python/temp/hoge/fuga 20200725-144112,[Step04/08-DELETE-AFTER|DISTINATION],[FILE],/home/pi/data/python/temp/hoge/fuga/fileB.txt,8,2020-07-24 09:29:09.405717 20200725-144112,[Step04/08-DELETE-AFTER|DISTINATION],[FILE],/home/pi/data/python/temp/hoge/fuga/fileA.txt,8,2020-07-24 09:29:09.405717 20200725-144112,[Step05/08-MOVE|DISTINATION],/home/pi/data/python/temp/hoge/fuga/fileB.txt,/home/pi/data/python/temp/hoge 20200725-144112,[Step05/08-MOVE|DISTINATION],/home/pi/data/python/temp/hoge/fuga/fileA.txt,/home/pi/data/python/temp/hoge 20200725-144112,[Step07/08-AFTER|DISTINATION],[FILE],/home/pi/data/python/temp/hoge/fileB.txt,8,2020-07-24 09:29:09.405717 20200725-144112,[Step07/08-AFTER|DISTINATION],[FILE],/home/pi/data/python/temp/hoge/fileA.txt,8,2020-07-24 09:29:09.405717 20200725-144112,[Step07/08-AFTER|DISTINATION],[DIRECTORY],/home/pi/data/python/temp/hoge/fuga 20200725-144112,[Step08/08-DELETE|SOURCE],/home/pi/data/python/temp/hoge/fuga 20200725-144112,SCRIPT-DONE
久しぶりにスクリプト書いて楽しかった。

- 投稿日:2020-07-25T14:13:20+09:00
JuliaならDataFrameでforループしても十分速い
うわっ…私のpandas、遅すぎ…?って時にやるべきこと(先人の知恵より)
こちらに書かれている通り、pandasはたしかに遅い、特に使い方によっては極端に遅い。かといってforループを回避するためにあれこれ読みにくいコードを書きたくない。……だったらJuliaにしたらいいよ! という記事です。
pandasはどのくらい遅いか?
元記事のデータは非公開のコードで加工されたもののようなので、ここでは他の公共データセットのデータを使わせてもらいます。Scikit-learnに入っているCalifornia Housingを使いましょう。約2万件しかデータがないのはちょっと物足りないので10回連結して約20万件に水増しします。
import sklearn from sklearn.datasets import fetch_california_housing import pandas as pd cal_housing = fetch_california_housing(as_frame=True)["data"] cal_housing.to_csv("california_housing.csv", index=False) # save it for Julia cal_housing.shape # (20640, 8) cal_housing_long = pd.concat([cal_housing for i in range(10)]) cal_housing_long.shape # (206400, 8)このデータでは(Kaggleにあるものと違って)合計のHousehold数のカラムがありません。PopulationとAverage Occupancyから計算してみることにしましょう(こんなものはわざわざforループを使うまでもない? おっしゃる通りです。その点も含めて比較します。ただ、実際のユースケースでは複雑な処理を行うこともあり、素直にロジックを書き下していけるforループは便利かと思います。)。
Forループで計算
まずは安直にforループで。
def calc_numhouses_iter(df: pd.DataFrame) -> pd.DataFrame: for i, row in df.iterrows(): df.at[i, "NumHouses"] = row["Population"] / row["AveOccup"] return df %time calc_numhouses_iter(cal_housing_long)CPU times: user 1min, sys: 708 ms, total: 1min 1s
Wall time: 1min 5s一分以上! ずいぶんかかってしまいました。もっとも、forループが遅いのは既知の話ですが。
Applyは速いか?
こういう場合の定石はapplyを使うことです。続いて試してみましょう。
def calc_numhouses_apply(row: pd.Series) -> float: return row["Population"] / row["AveOccup"] %time cal_housing_long.apply(calc_numhouses_apply, axis=1)CPU times: user 4.75 s, sys: 42.4 ms, total: 4.79 s
Wall time: 5.2 s大幅に速くなりました。これならあまり問題ないかもしれません。でももっと大きなデータだったらどうなるでしょう? データ量に対してどんなオーダーで所要時間が延びるのでしょう? さらに10倍に増やしてみましょう。
cal_housing_long_long = pd.concat([cal_housing_long for i in range(10)]) cal_housing_long_long.shape # (2064000, 8) %time cal_housing_long_long.apply(calc_numhouses_apply, axis=1)CPU times: user 47.6 s, sys: 438 ms, total: 48.1 s
Wall time: 50.3 s実行時間も10倍になりました。自然な結果ですが、200万件、200MB程度のCSVでこれだけかかるのはちょと厳しい用途もあるかもしれません。
列を減らしてみる
列が多すぎるのがpandasが遅くなる要因ということなので、減らして実験してみます。
cal_housing_long_long_fewcol = cal_housing_long_long.loc[:, ["Population", "AveOccup"]] %time cal_housing_long_long_fewcol.apply(calc_numhouses_apply, axis=1)CPU times: user 47.7 s, sys: 368 ms, total: 48 s
Wall time: 49.9 s差が見られません。今回のデータではもともと8列しかないこと、またすべての列が浮動小数点型なので行方向にpd.Seriesを作ったときの型がfloatのままでいけるという事情が効いているかもしれません。
その他?
元記事で挙げられているmapを使う方法はいったん一つの列に統合する必要があります。文字列結合ならすでに高速なメソッドが用意されているので簡単ですが、数値の場合はたとえばtupleにまとめるにしても、けっきょく一度applyを使う必要があり、素直に速くすることは難しそうです。できたとしても見通しがいいコードにはなりそうにありません。ほかにもdask、vaex、swifterなどあれこれ使う方法もありますが、そこまでするならもうPythonでなくてもいいような気がしてきませんか?
Julia
続いてJuliaでやってみましょう。同様に下準備、こちらはパッケージのインストールから書いています。データは先ほどScikit-learnから保存したCSVを読み込みます。
import Pkg Pkg.add("DataFrames") Pkg.add("DataFramesMeta") Pkg.add("CSV") Pkg.add("BenchmarkTools") using DataFrames using DataFramesMeta using CSV using BenchmarkTools cal_housing = DataFrame!(CSV.File("california_housing.csv")); cal_housing_long = vcat([cal_housing for i in 1:10]...); # list expansion by ... cal_housing_long_long = vcat([cal_housing_long for i in 1:10]...);Forループで十分速い
function calc_numhouses_iter(df::DataFrame)::DataFrame len = size(df, 1) df[!, :NumHouses] .= 0.0 for i in 1:len df[i, :NumHouses] = df[i, :Population] / df[i, :AveOccup] end return df end @benchmark calc_numhouses_iter(cal_housing_long_long)BenchmarkTools.Trial:
memory estimate: 330.66 MiB
allocs estimate: 20637969
minimum time: 470.266 ms (4.60% GC)
median time: 475.537 ms (6.13% GC)
mean time: 477.809 ms (6.20% GC)
maximum time: 491.495 ms (5.62% GC)
samples: 11
evals/sample: 1こちらも極めて安直なforループです。Juliaを知らなくてもまったく支障なく読めるかと思います。そしていきなりオリジナルの100倍サイズでやっていますが、十分に高速です。ざっとPythonの100倍速い。これがこんなシンプルで可読性の高いコードでできるのはさすがJuliaですね。
単に四則演算する
実際は今回の問題はただの四則演算なので、もっと簡単にできてしまいます。
function calc_justcalc(df::DataFrame)::DataFrame df[!,:NumHouses] = df[!,:Population] ./ df[!,:AveOccup] return df end @benchmark calc_justcalc(cal_housing_long_long)BenchmarkTools.Trial:
memory estimate: 15.75 MiB
allocs estimate: 5
minimum time: 2.293 ms (0.00% GC)
median time: 8.054 ms (0.00% GC)
mean time: 8.260 ms (21.57% GC)
maximum time: 95.126 ms (90.65% GC)
samples: 609
evals/sample: 1予想通り、こちらの方が大幅に速いですね。ちなみに、記述が前後しますが同様に単にベクトルの四則演算でPythonで計算すると以下の通りで、これでもまだJuliaのほうが速いという結果になりました。
CPU times: user 16.6 ms, sys: 14.9 ms, total: 31.5 ms
Wall time: 38.4 ms自作の関数を適用
ループの一回一回に依存関係がなければ、自分で作った関数を簡単にベクトル化して適用することもできます。試してみましょう。
function calc_eachrow(x1::Float64, x2::Float64)::Float64 x1 / x2 end function wrapper(df::DataFrame)::DataFrame df[!, :NumHouses] = calc_eachrow.(df[!, :Population], df[!, :AveOccup]) df end @benchmark wrapper(cal_housing_long_long)BenchmarkTools.Trial:
memory estimate: 15.75 MiB
allocs estimate: 5
minimum time: 2.489 ms (0.00% GC)
median time: 9.123 ms (0.00% GC)
mean time: 10.485 ms (22.33% GC)
maximum time: 182.663 ms (86.56% GC)
samples: 478
evals/sample: 1こちらも極めて速い結果、単に四則演算をベクトルに適用したのと同じ速さになりました。Pythonでnumpyの関数を使う場合は用意された機能以外のことをしたくなった途端には遅くなってしまいますが、このJuliaの関数なら自由に拡張し放題です。ここで、いちいち
returnを書かずに省略しているところがあります。Juliaでは最後に評価したexpressionの値が返されるので、returnがあるものと思って読んでください。(おまけ)LINQで処理してみる
Forループはなんでもできるけどちょっと遅い、一方であれこれ複数の種類の処理を重ねる必要があることもあるかもしれない、ということで特にデータのフィルタ、集計などの処理をあれこれするのに便利なLINQ的な表記を試してみましょう。DataFramesMeta.jlを使います。
function calc_numhouses_linq(df::DataFrame)::DataFrame df = @linq df |> transform(NumHouses = :Population ./ :AveOccup) return df end @benchmark calc_numhouses_linq(cal_housing_long_long)BenchmarkTools.Trial:
memory estimate: 157.47 MiB
allocs estimate: 48
minimum time: 25.448 ms (0.00% GC)
median time: 40.034 ms (22.30% GC)
mean time: 43.995 ms (24.52% GC)
maximum time: 123.423 ms (68.54% GC)
samples: 114
evals/sample: 1このシンプルさ! ループを書かなくていいし、この先あれこれ他の処理をつなげていくとしてもきわめて直感的な表現ができます。実は先ほども登場していますが、一点だけ見慣れないのは
./でしょう。これはJuliaによくあるパターンで、.を頭につけると演算子を含め関数をベクトル化して適用してくれます。 そして先ほどのforループの場合よりもさらに高速になりました。ここまで来るとJITコンパイルのオーバーヘッドのため初回実行が遅いのが足を引っ張りますが、いずれにせよこれだけ速ければ問題ないはずです。とはいえ、これだけ簡単に処理できるのは単なる四則演算だからで、あれこれ難しい処理をするとなるとこうはいきません。上述のForループならあれこれのロジックも簡単に書けるし、前後の行の間での相互関係にも対応できる柔軟性があるので、適宜使い分けになるでしょう。並列化
JuliaならforループをOpenMPのようにマルチスレッドで処理するのも極めて簡単です。PythonだとGILがあるのでマルチプロセスにせざるを得えないし、そうするとメモリ周りが煩雑になることを考えると手軽にマルチスレッドにできるJuliaは強いです。
まずシェルで搭載コア数に応じて環境変数を設定してやります。私のマシンは2コアだったので劇的な差は期待できませんが、ともかく2に設定します。
export JULIA_NUM_THREADS=2反映されたことを確認します。Jupyterで作業している場合はカーネル再起動ではなく、Jupyterごと再起動する必要があることに注意します。
Threads.nthreads() # 2関数自体はループの頭に
Threads.@threadsを付け加えるだけです。function calc_numhouses_iter_p(df::DataFrame)::DataFrame len = size(df, 1) df[!, :NumHouses] .= 0.0 Threads.@threads for i in 1:len df[i, :NumHouses] = df[i, :Population] / df[i, :AveOccup] end return df end @benchmark calc_numhouses_iter_p(cal_housing_long_long)BenchmarkTools.Trial:
memory estimate: 330.66 MiB
allocs estimate: 20637984
minimum time: 263.896 ms (0.00% GC)
median time: 329.071 ms (0.00% GC)
mean time: 370.615 ms (13.02% GC)
maximum time: 637.808 ms (41.56% GC)
samples: 14
evals/sample: 1Forループ以外の処理もあるので必然的に2倍には届かないものの、それでも速くなりました。ガベージコレクションで遅くなってしまっているのは気になりますが、大勢には影響なさそうです。このマルチスレッド化はループの一回一回に依存関係がなければこのようにごくごく簡単に使え、もちろんDataFrameの処理以外にも使えるので便利です。
おわりに
ということで、Juliaを使ったらテーブルデータを簡単かつ高速に処理できるよというお話でした。Juliaの最適化として不十分な部分もあるかと思いますし、おそらくPythonでももっとよい方法があると思うので、気づいたことがあったらどうぞご指摘ください。ただ、「難しいこと考えたりトリッキーなコードを書かなくても素直に簡単に速くなる」という意味でもやはりJuliaは使いやすいように感じます。当然のことではありますが、今回の結果はあくまで一例であり、ベンチマークは用いるデータや実行する計算によって大幅に変化します。みなさまのユースケースでもぜひベンチマークして結果を共有していただければ幸いです。
- 投稿日:2020-07-25T13:58:40+09:00
Fusion 360 を Pythonで動かそう その8 スケッチのフィレットとオフセット
はじめに
Fusion360 のAPIの理解を深めるために公式ドキュメント内のサンプルコード Sketch fillet and offset API Sample (スケッチのフィレットとオフセット APIサンプル) の内容からドキュメントを読み込んでみたメモ書きです
スケッチでのフィレットを作成し、その結果を元にオフセットします。スクリプトの内容を確認する
最初と最後のおまじないとスケッチの作成まで
最初と最後のこの辺りはFusion360 APIのお決まりのパターンです。その5で触れたので説明を省略します。
import adsk.core, adsk.fusion, traceback def run(context): ui = None try: app = adsk.core.Application.get() ui = app.userInterface doc = app.documents.add(adsk.core.DocumentTypes.FusionDesignDocumentType) design = app.activeProduct # Get the root component of the active design. rootComp = design.rootComponent # Create a new sketch on the xy plane. sketches = rootComp.sketches xyPlane = rootComp.xYConstructionPlane sketch = sketches.add(xyPlane) # # ここにコードを追加していく # except: if ui: ui.messageBox('Failed:\n{}'.format(traceback.format_exc()))二つのつながった線を描く
# Draw two connected lines. lines = sketch.sketchCurves.sketchLines line1 = lines.addByTwoPoints(adsk.core.Point3D.create(0, 0, 0), adsk.core.Point3D.create(3, 1, 0)) line2 = lines.addByTwoPoints(line1.endSketchPoint, adsk.core.Point3D.create(1, 4, 0))ここはその4にも出てきた内容なので説明は省略
SketchArcs.addFillet メソッドでフィレットを作成
# Add a fillet. arc = sketch.sketchCurves.sketchArcs.addFillet( line1, line1.endSketchPoint.geometry, line2, line2.startSketchPoint.geometry, 1)SketchArcs.addFillet メソッドで
arcという名前の SketchArc オブジェクトを作成。
パラメーターにはline1とline1の終点、line2とLine2の終点、フィレットの半径を指定している
line1につながっている曲線を見つける
# Add the geometry to a collection. This uses a utility function that # automatically finds the connected curves and returns a collection. curves = sketch.findConnectedCurves(line1)Sketch.findConnectedCurves メソッドで line1 につながっている曲線を見つける。結果は ObjectCollection オブジェクトが得られるのでそれを
curvesに代入するオフセットカーブを描く
# Create the offset. dirPoint = adsk.core.Point3D.create(0, .5, 0) offsetCurves = sketch.offset(curves, dirPoint, 0.25)Sketch.offset メソッドでオフセットカーブを作成。
パラメータは3つ
curves:端部がつながった曲線のセットをObjectCollectionで指定する
directionPoint:入力曲線のどちら側でオフセットを作成するかPoint3Dで指定する
offset:曲線をオフセットする距離を cm 単位で指定する
まとめ
直線一本だけをオフセットしようと思い line1 を Sketch.offset メソッドに入れてみたがエラーが出た。ちゃんと ObjectCollection にしないといけないってことかな?
前の記事 Fusion 360 を Pythonで動かそう その7 点を通過するスプライン作成
参考
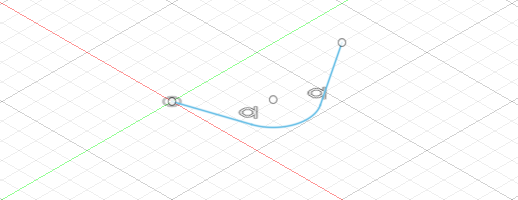
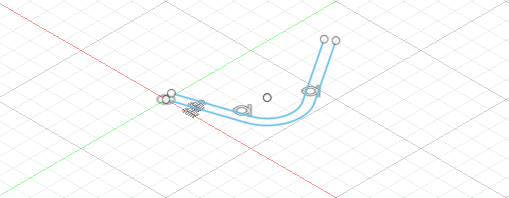
- 投稿日:2020-07-25T13:40:22+09:00
1. Appiumインストール for Android App on Mac
Mac上でJavaとPythonを使ってAppiumのプログラムを書いてみます。
Install
コマンドラインとGUIの両方があるみたいです、まあ多量のAppiumのテストコードを書くことを想定して、コマンドラインでのインストトール
> brew install node # get node.js > npm install -g appium # get appium > npm install wd # get appium client > appium & # start appium > node your-appium-test.js参考
https://www.capa.co.jp/archives/27328
このプロジェクトでやりたいこと
- 単体テストの自動化
- Circle CIで単体テストの自動実行()
- 機能テストの自動化
- 投稿日:2020-07-25T13:15:56+09:00
直観でわかる、Pandas → Scikit-learnへの渡し方
何があったか
手元に Pandas の DataFrame がある条件で、ひさしぶりに Scikit-learn を使おうとしたら、どういう形で渡すんだっけ?と少し迷いました。同じ境遇のとき、直観的に思い出せるように書き出します。
前提
手元にDataFrame がある前提です( 今回はダミーデータで DataFrame を自作します )。
直観的理解を目指して、サンプルでは説明変数3つ ( X1, X2, X3 ) だけの、超簡易なものを使います。
目的変数 ( Y ) はバイナリラベル ( 1, 0 ) とします。import pandas as pd data = [[1,1,0,0], [0,0,0,1], [0,0,1,1]] index = ["a", "b", "c"] columns = ["Y","X1","X2","X3"] df = pd.DataFrame(data, index=index, columns=columns)
Y X1 X2 X3 a 1 1 0 0 b 0 0 0 1 c 0 0 1 1 この DataFrame から、学習データ ( X_train ) とラベルデータ ( y_train ) を Numpy Array として作成し、sklearnに渡して学習させます。
モデルはここでは、決定木分類にしておきましょう。
ちなみに、決定木やランダムフォレストは、そのアルゴリズム性質上、データを正規化しなくてよいので、とりあえずモデルを作ってみるというような時にはおすすめです。from sklearn.tree import DecisionTreeClassifier y_train = df["Y"].values X_train = df.drop("Y", axis=1).values model = DecisionTreeClassifier().fit(X_train, y_train)ちゃんと学習できたのか、以下の新しいデータをテストデータとして、モデルに予測させてみます ( 予測というか暗記ですが… )。3つのインスタンスの Y を予測しますが、仮に d, e, f とすると、d=0, e=1, f=0になると想像できます。
new_data = [[0,0,1], [1,0,0], [0,1,1]] model.predict(new_data) # 出力は array([0, 1, 0], dtype=int64)ちゃんと学習できているようです。
- 投稿日:2020-07-25T12:55:34+09:00
Fusion 360 を Pythonで動かそう その7 点を通過するスプライン作成
はじめに
Fusion360 のAPIの理解を深めるために公式ドキュメント内のサンプルコード Sketch spline through points creation API Sample (点を通過するスプライン作成 APIサンプル) の内容からドキュメントを読み込んでみたメモ書きです
新しいスケッチを作成し、スケッチ内にスプライン曲線を作成します。スクリプトの内容を確認する
最初と最後のおまじないとスケッチの作成まで
最初と最後のこの辺りはFusion360 APIのお決まりのパターンです。その5で触れたので説明を省略します。
import adsk.core, adsk.fusion, traceback def run(context): ui = None try: app = adsk.core.Application.get() ui = app.userInterface doc = app.documents.add(adsk.core.DocumentTypes.FusionDesignDocumentType) design = app.activeProduct # Get the root component of the active design. rootComp = design.rootComponent # Create a new sketch on the xy plane. sketch = rootComp.sketches.add(rootComp.xYConstructionPlane) # # ここにコードを追加していく # except: if ui: ui.messageBox('Failed:\n{}'.format(traceback.format_exc()))ObjectCollection オブジェクトを作成
# Create an object collection for the points. points = adsk.core.ObjectCollection.create()ObjectCollection.create メソッドで
pointsという名前の ObjectCollection オブジェクトを作成。
ObjectCollection オブジェクト :任意のオブジェクト型のリストを扱うために使用される汎用コレクションです。ObjectCollection オブジェクトに Point3D オブジェクトを追加
# Define the points the spline with fit through. points.add(adsk.core.Point3D.create(0, 0, 0)) points.add(adsk.core.Point3D.create(5, 1, 0)) points.add(adsk.core.Point3D.create(6, 4, 3)) points.add(adsk.core.Point3D.create(7, 6, 6)) points.add(adsk.core.Point3D.create(2, 3, 0)) points.add(adsk.core.Point3D.create(0, 1, 0))ObjectCollection.add Method メソッドで6個のPoint3D オブジェクトを追加
スケッチにスプラインを追加
# Create the spline. sketch.sketchCurves.sketchFittedSplines.add(points)SketchFittedSplines.add メソッドで点を通過するスプラインを作成。
まとめ
複数のポイントをリストとして扱うために ObjectCollection オブジェクトが初登場しました。こいつの使いこなしをうまくできるようにならないといけなさそう
前の記事 Fusion 360 を Pythonで動かそう その6 スケッチポイントを描く
次の記事 Fusion 360 を Pythonで動かそう その8 スケッチのフィレットとオフセット参考