- 投稿日:2020-07-25T23:35:57+09:00
【AWS】MFA多要素認証 - セキュリティの追加
アカウント使用の流れ
- 開始前知っておくべきポイント
- アカウント申請
- ログイン
- IAM設定
- MFA多要素認証
- アカウント削除
参考資料
AWS公式のビデオがないため、ビデオでの操作手順については、「Youtube」の「Android and Tech Solutions」を参照
https://www.youtube.com/watch?v=FUXy2t28oqcMFA多要素認証
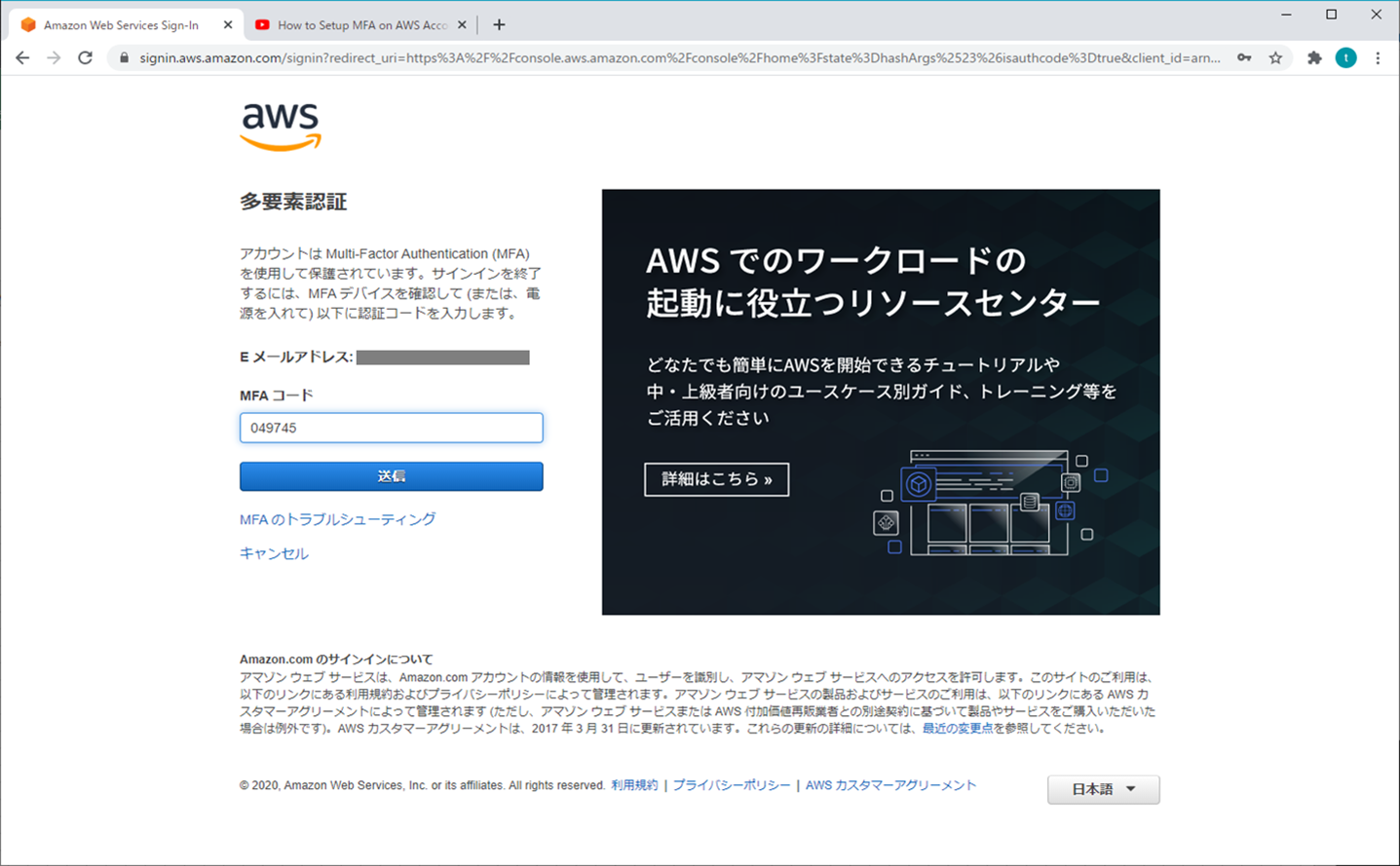
セキュリティを向上させるには、多要素認証(MFA)を設定して AWS リソースを保護することを推奨します。IAM ユーザーまたは AWS アカウントのルートユーザー に対して MFA を有効にすることができます。ルートユーザー の MFA を有効にすると、ルートユーザー 認証情報のみが影響を受けます。アカウントの IAM ユーザーは固有の認証情報を持つ独立した ID であり、各 ID には固有の MFA 設定があります。
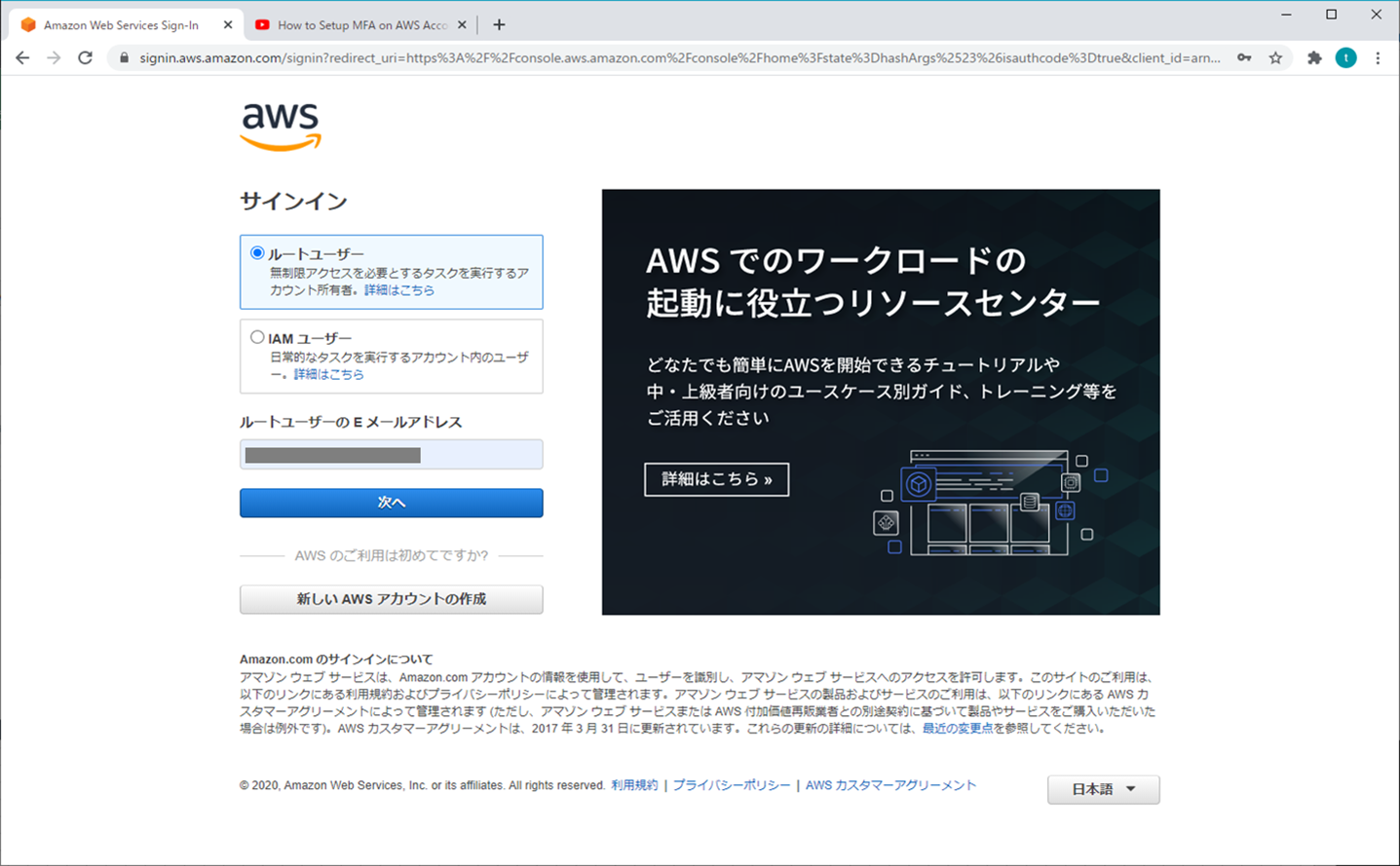
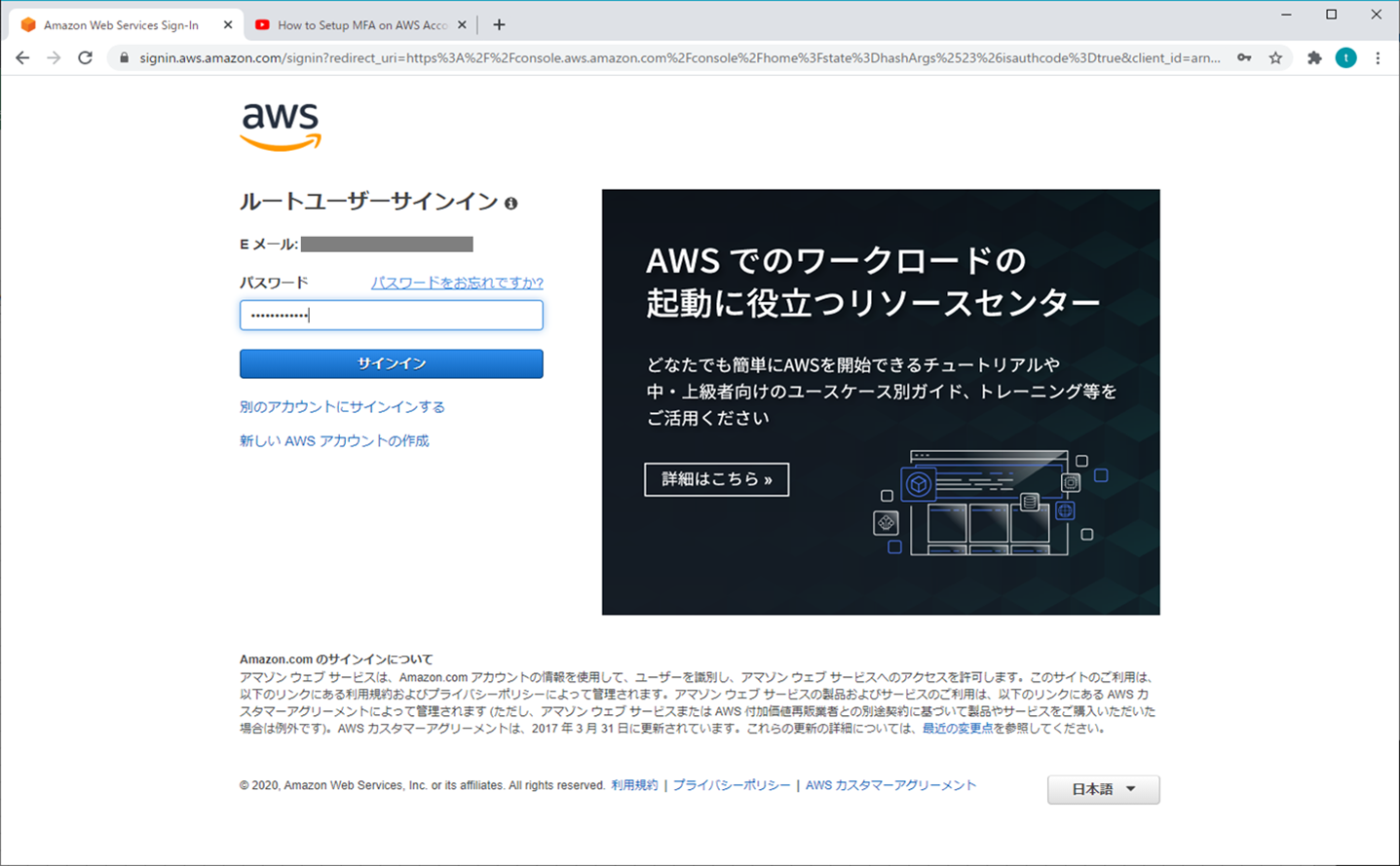
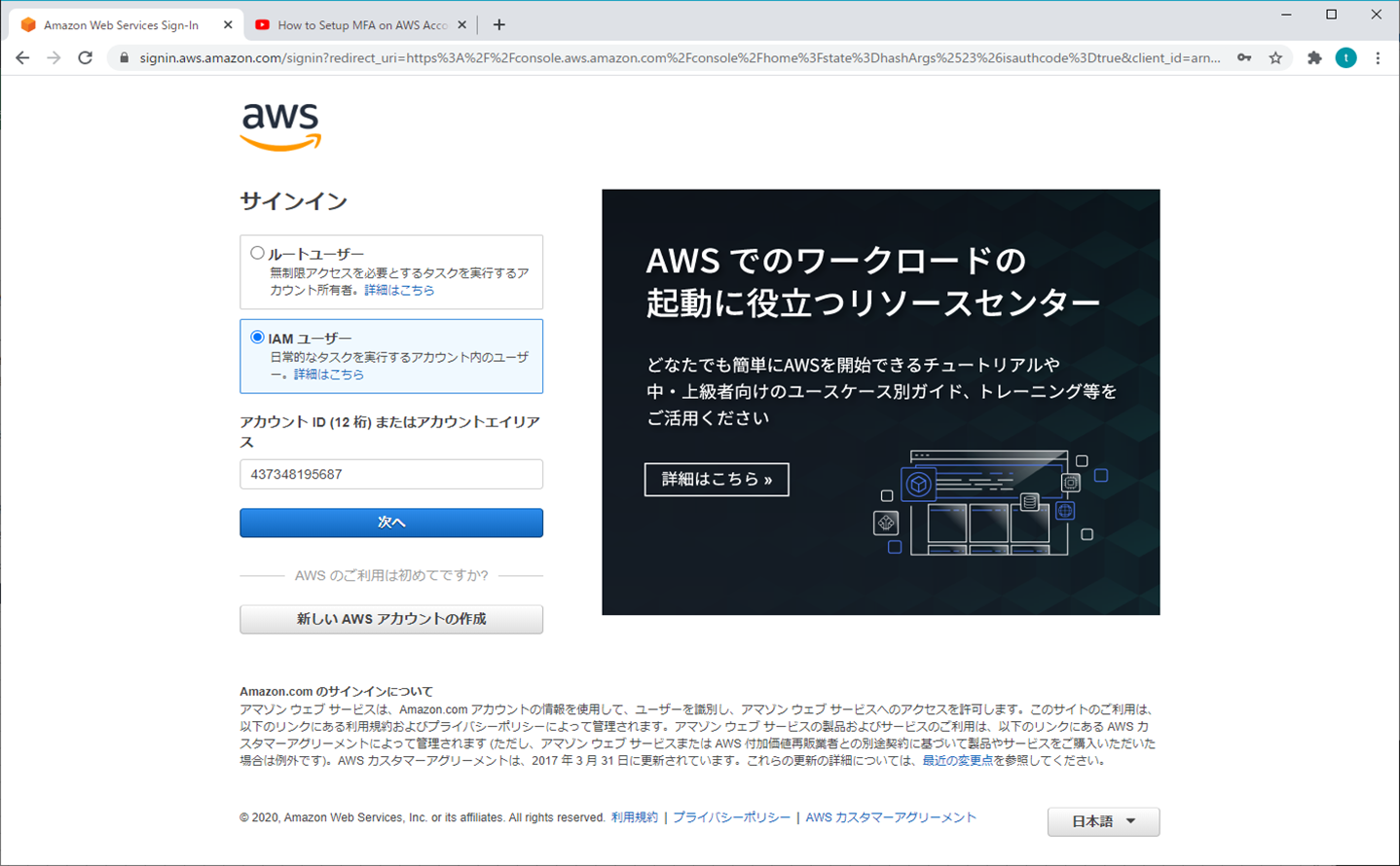
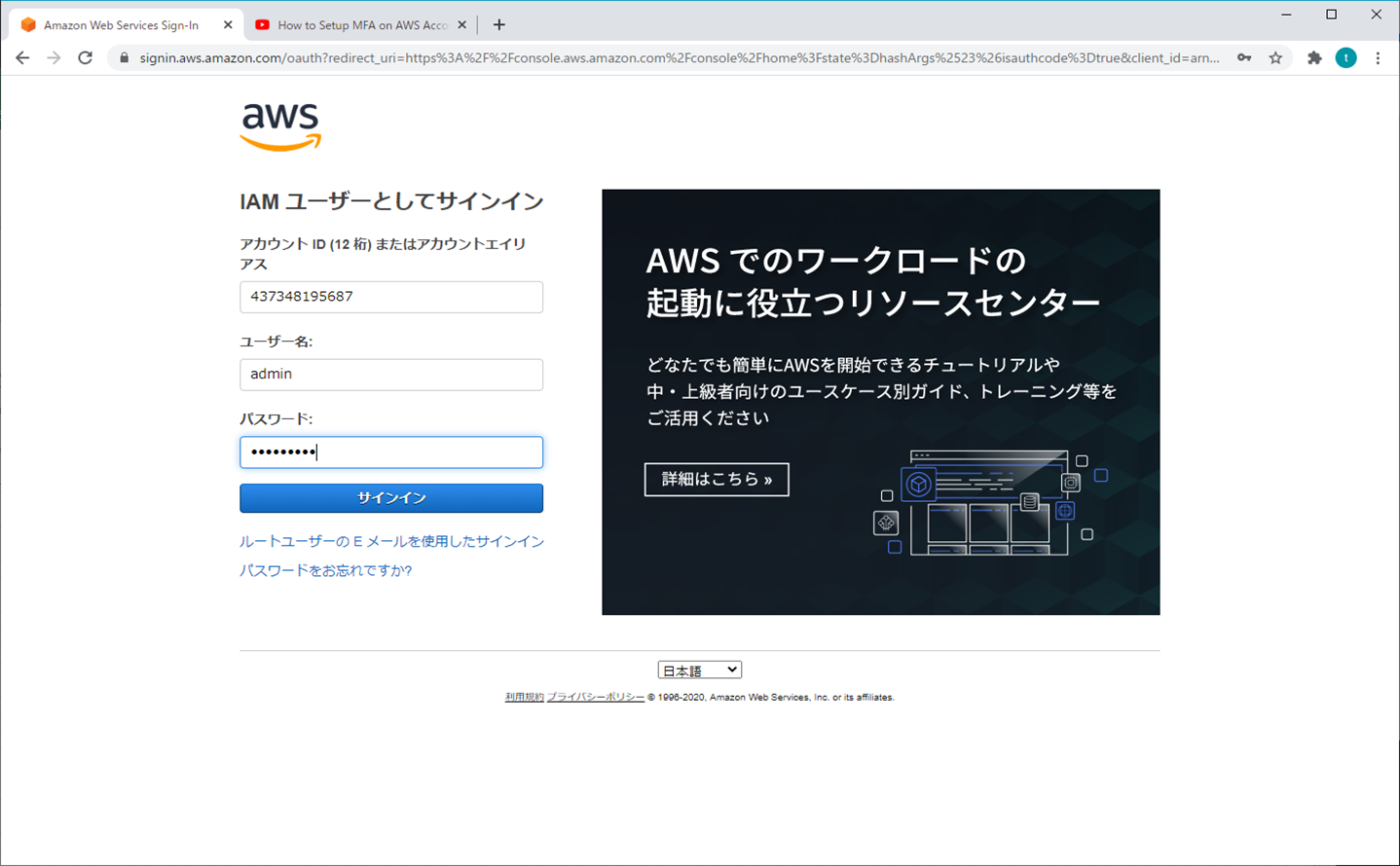
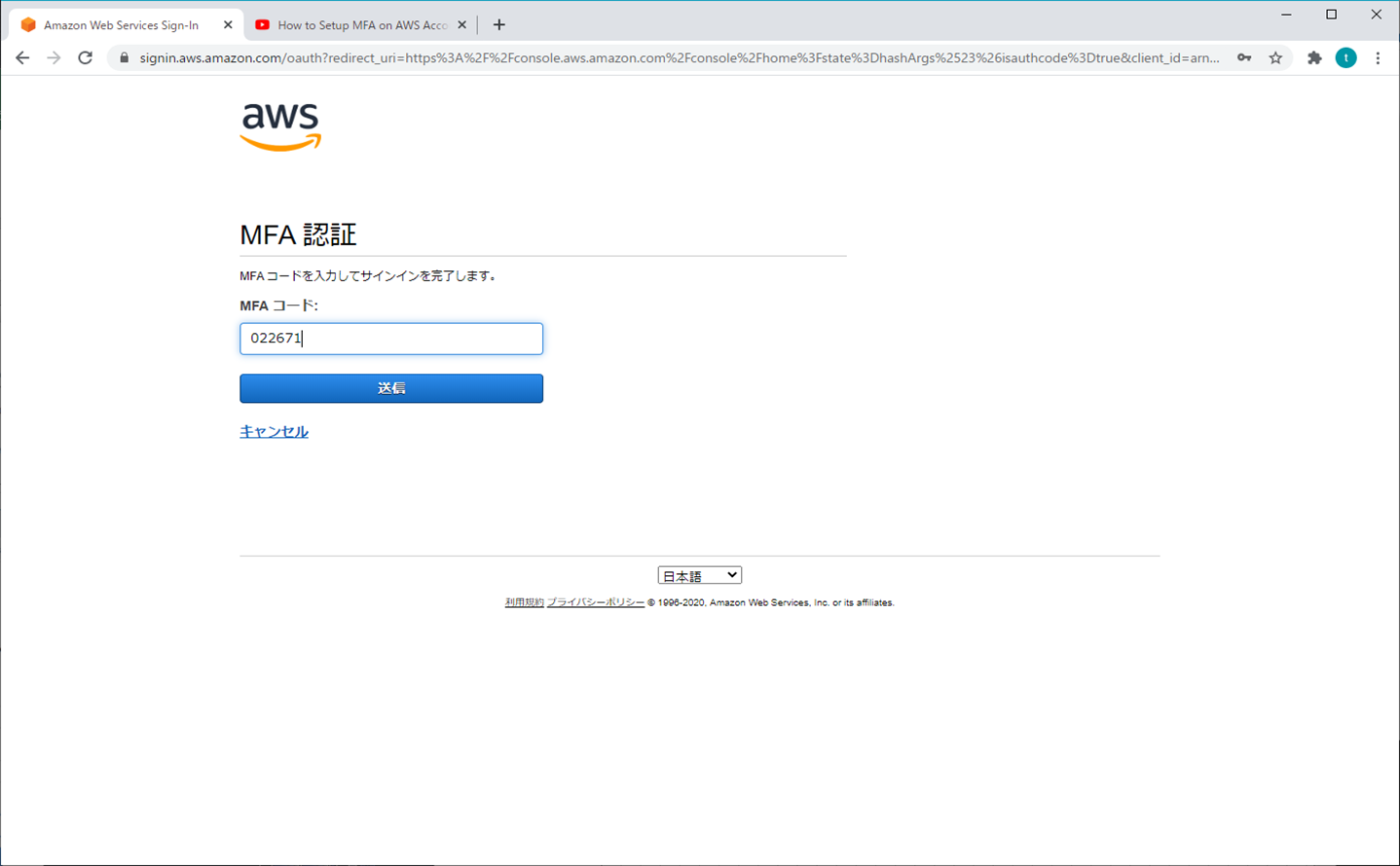
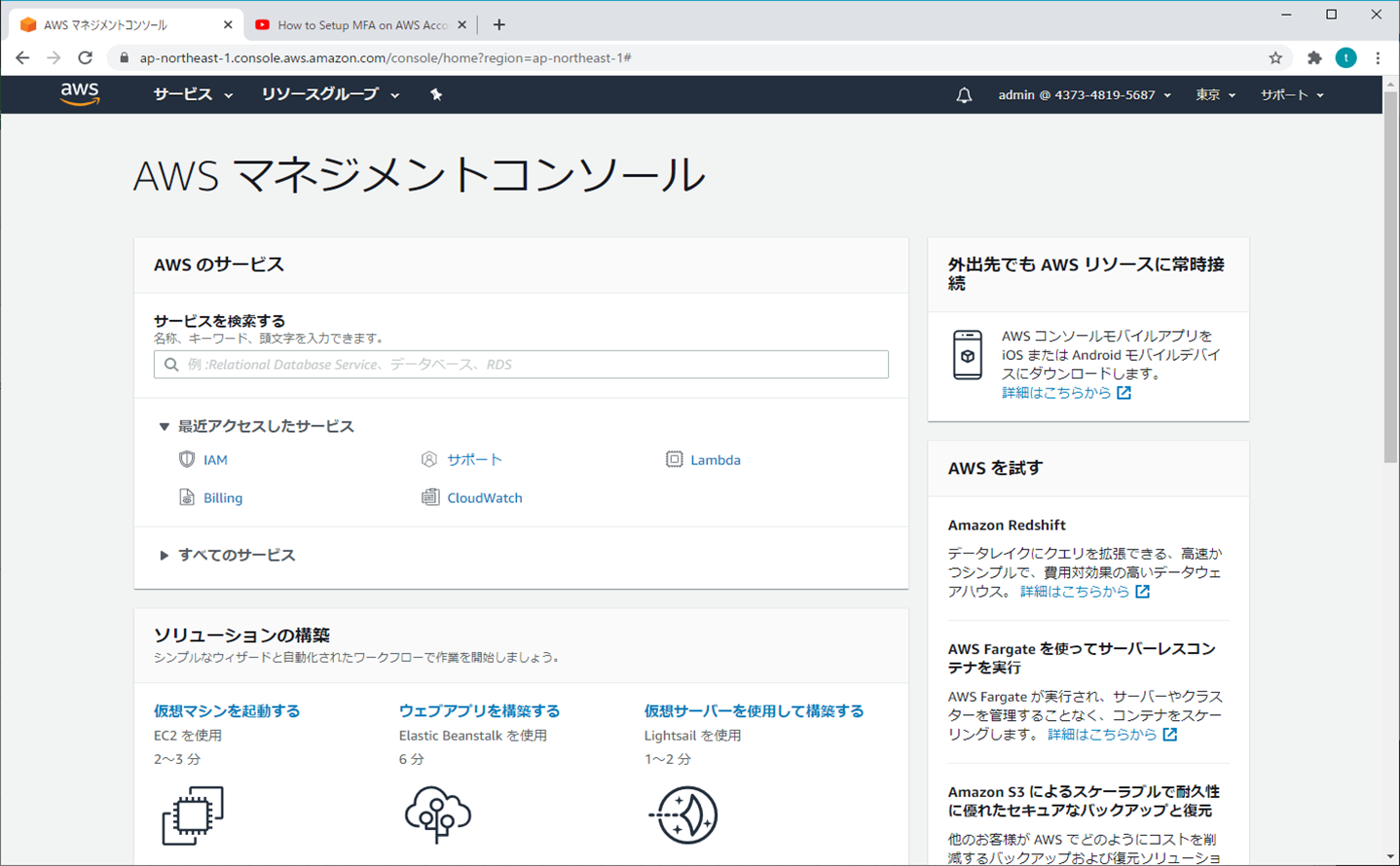
1.ルートユーザー
① AWSマネジメントコンソール
② マイセキュリティ資格情報
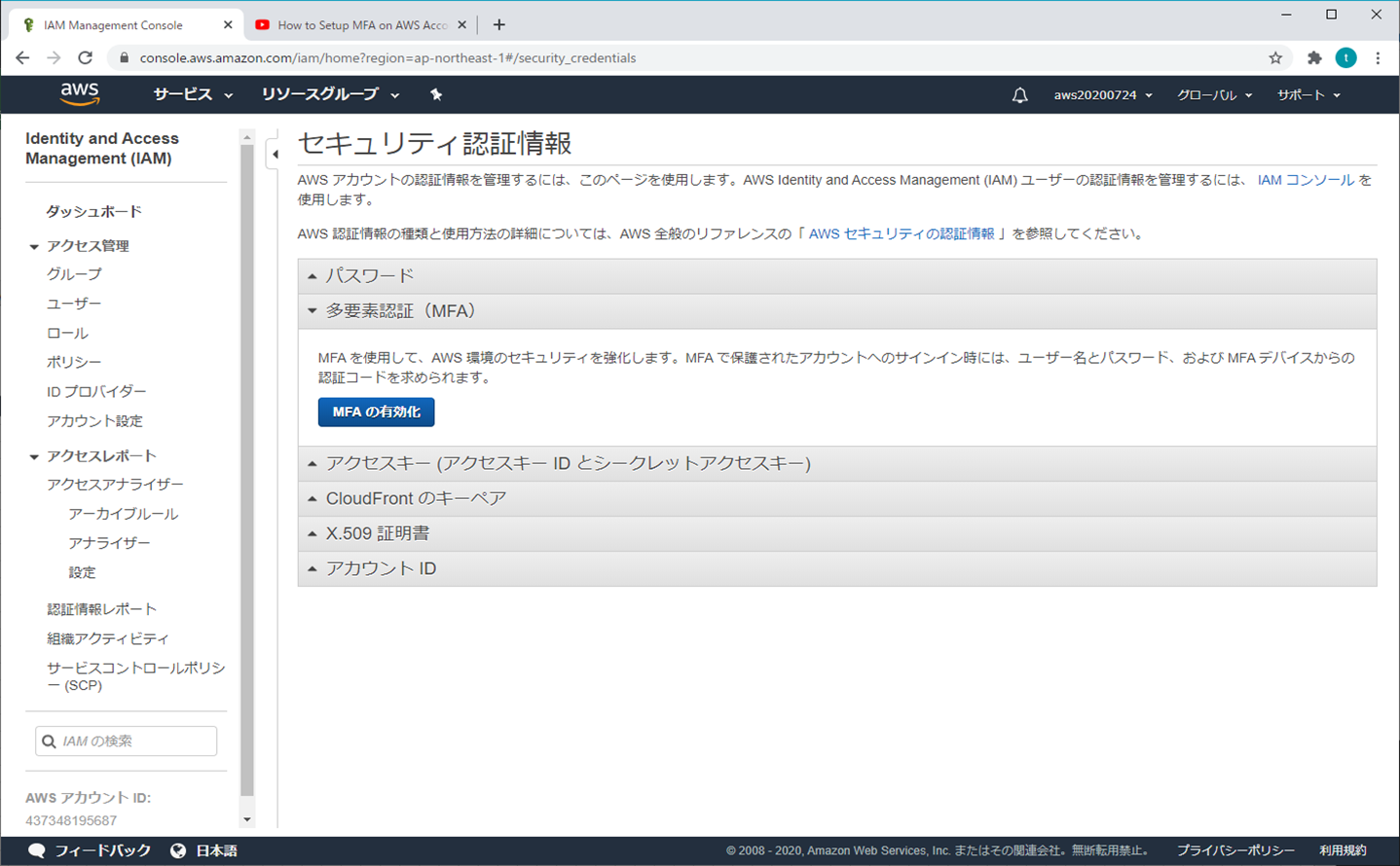
③ MFAの有効化
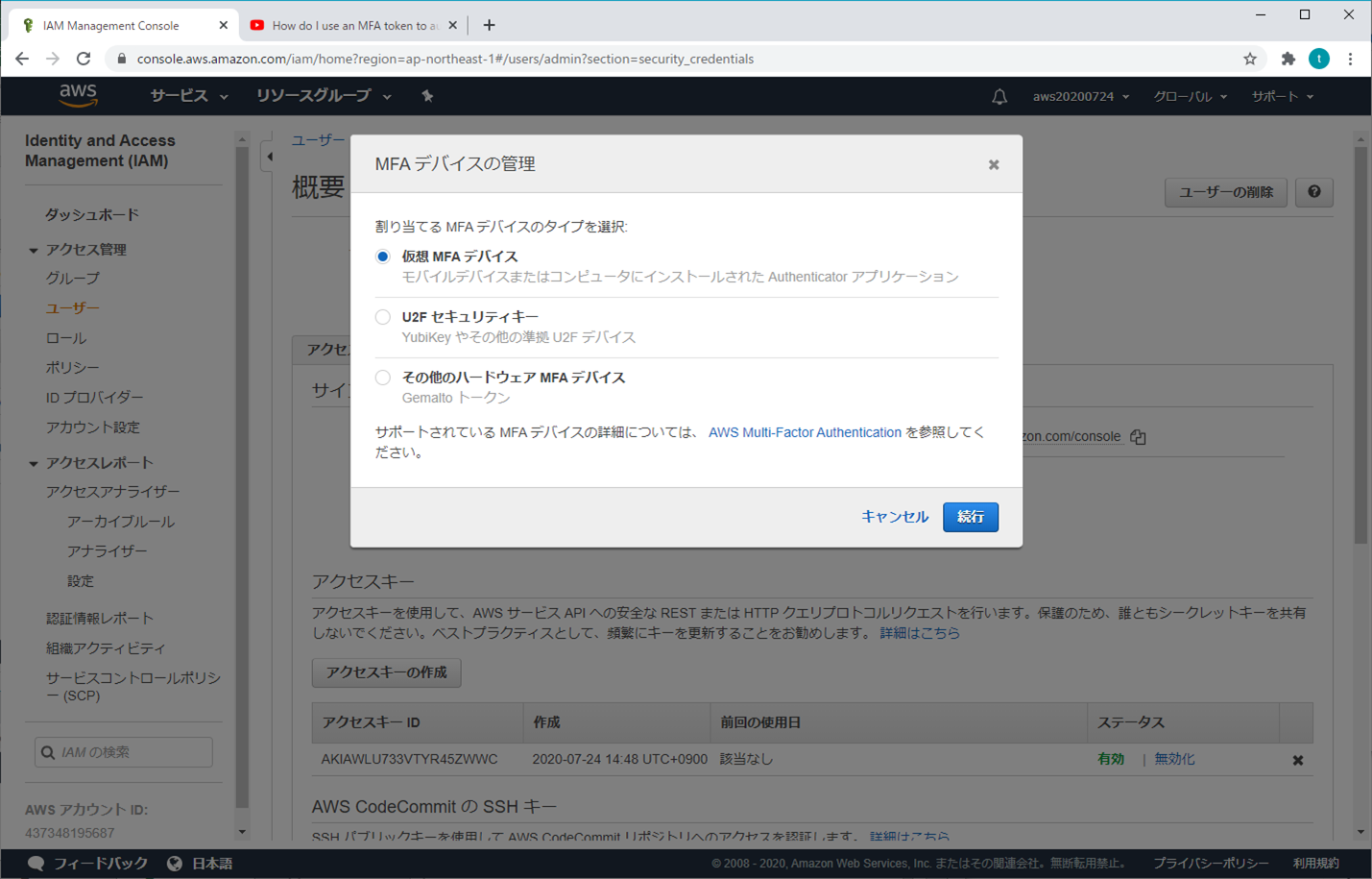
④ MFAデバイスの管理
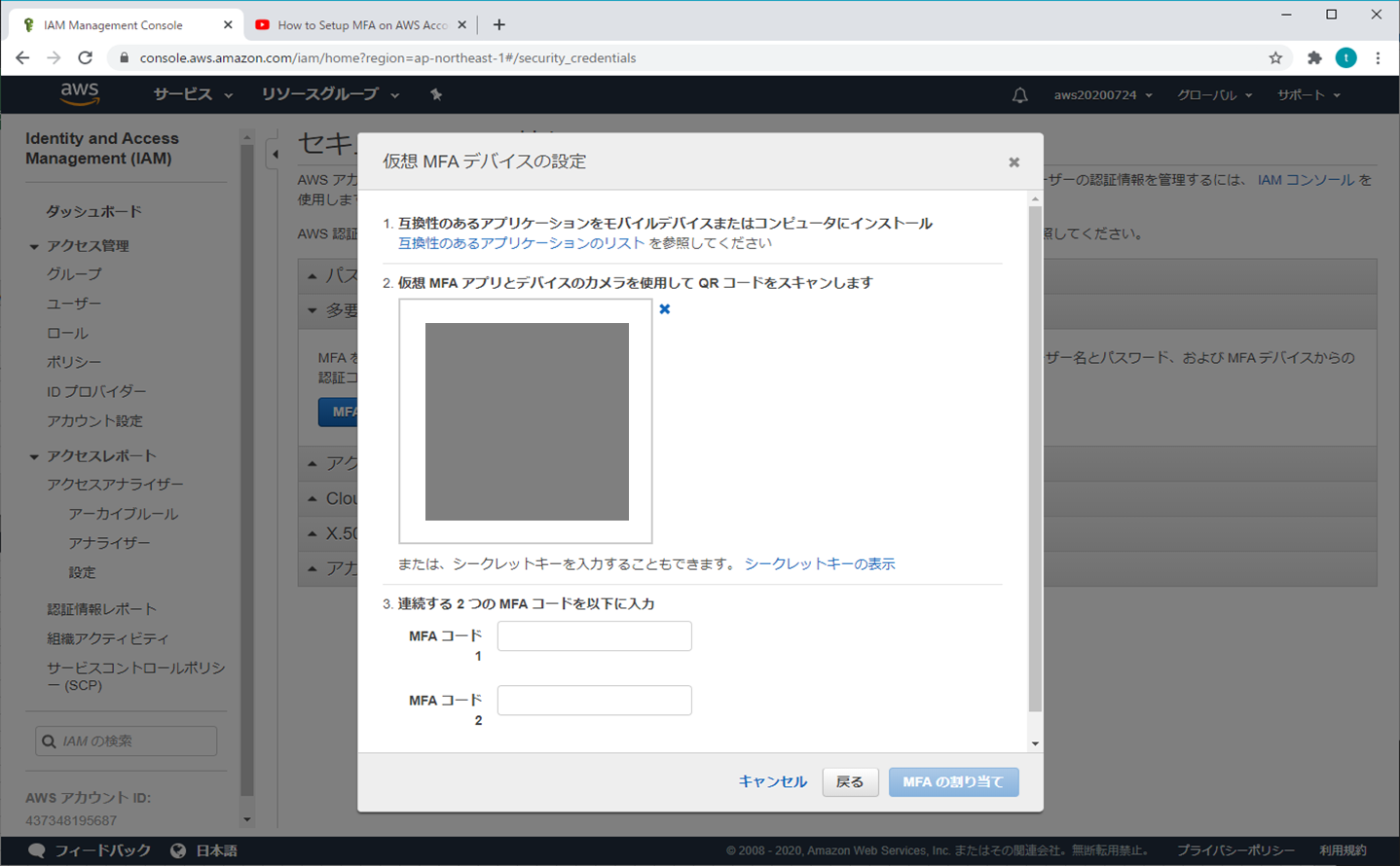
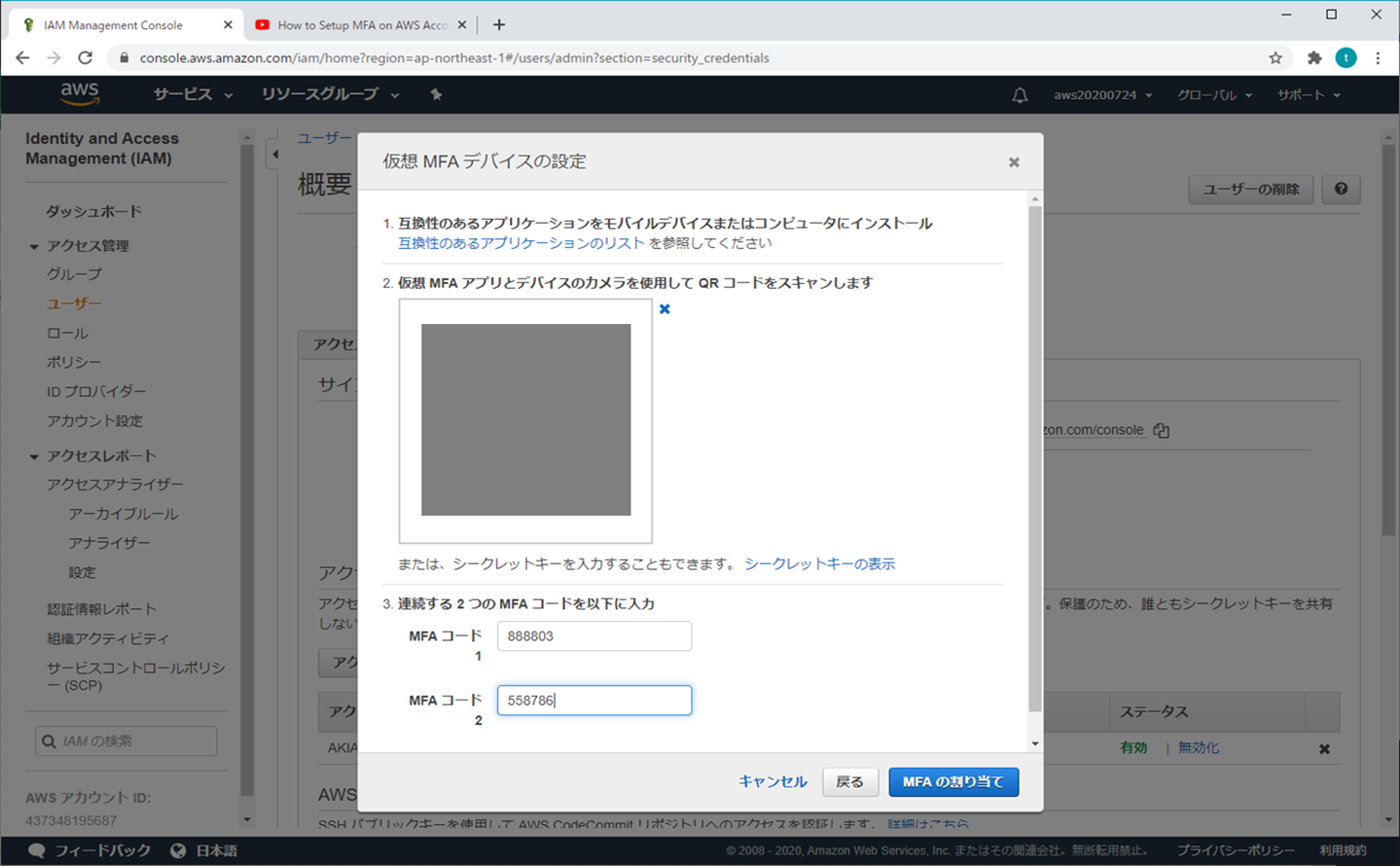
⑤ 仮想MFAデバイスの設定
⑥ スマホの操作
スマホでQRコードをスキャン(ご自身の好みで選択)
⑦ MFAコードを入力する
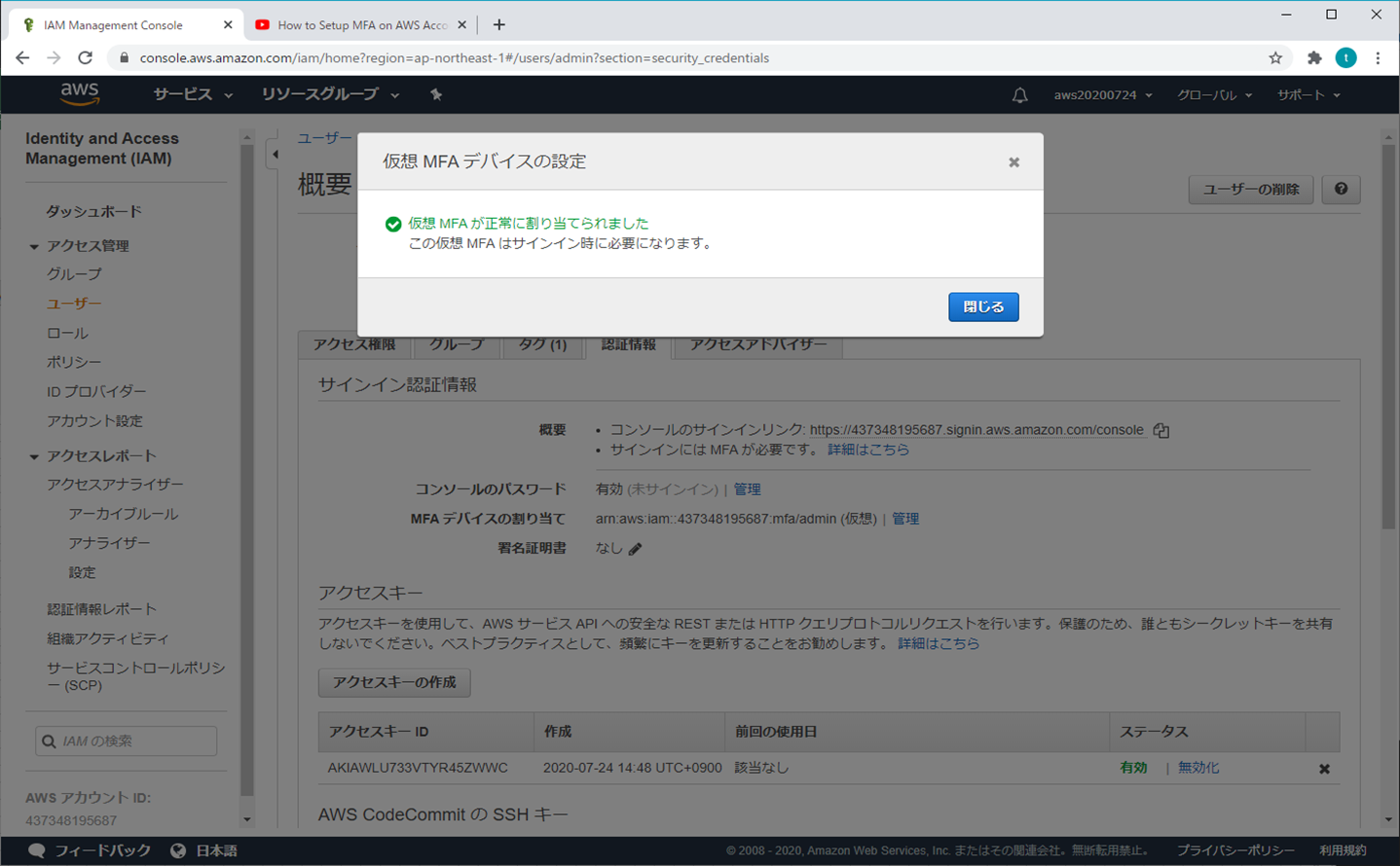
⑧ 設定終了
⑨ 再ログイン
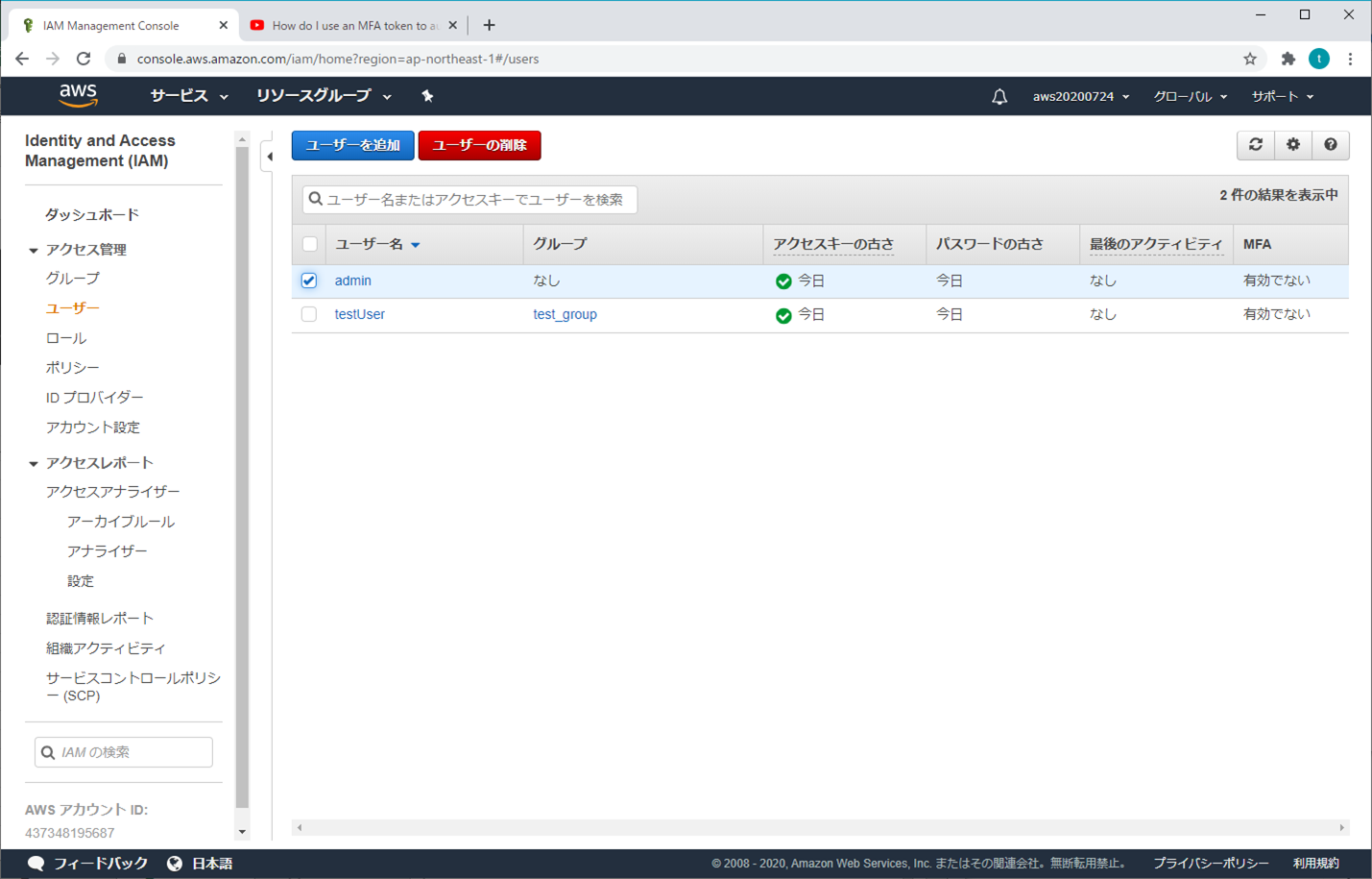
2.IAMユーザー
① AWSマネジメントコンソール
② ユーザーを追加
③ MFAデバイスの管理
④ スマホの操作
⑤ MFAコードを入力する
⑥ 設定終了
⑦ 再ログイン











- 投稿日:2020-07-25T23:27:00+09:00
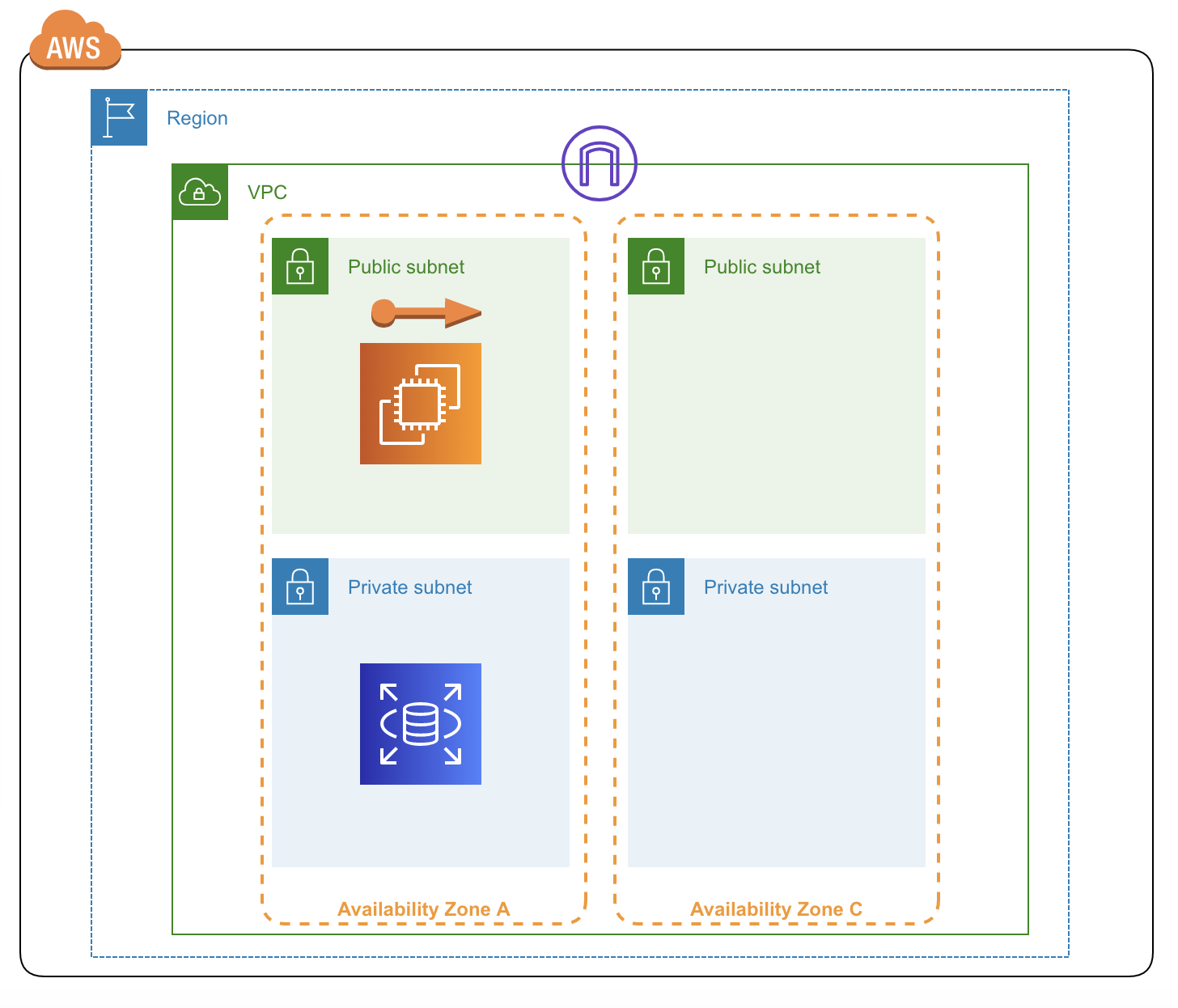
AWS Client VPN の構築・設定(AWS公式VPNアプリ利用)
AWS Client VPNの構築・設定
今回はテレワークの促進で注目のAWSサービスの1つのであるAWS Clinet VPNをお試し構築してみます。
この手の記事は大量にありますが意外と記事の手順通りにやっても上手くいかないものです...(´・ω・`)
そこで初心者向けに自分が躓いたところを何が必要で、実際にどう設定したか、備忘録もかねて記事にしました。皆さんのお役に立てれば幸いです。AWS Client VPNとは
AWS VPN は、AWS サイト間 VPN と AWS Client VPN で構成されています。これらを組み合わせることで、ネットワークトラフィックを保護する、高可用性かつ柔軟なマネージドクラウド VPN ソリューションを提供します。
AWS サイト間 VPN は、ネットワークと Amazon Virtual Private Cloud または AWS Transit Gateway の間に暗号化されたトンネルを作成します。リモートアクセスを管理するために、AWS Client VPN は無料 VPN ソフトウェアクライアントを使用して、ユーザーを AWS またはオンプレミスのリソースに接続します。
ざっくりと何ができるかというとAWS VPCにVPN接続できるようになり、インスタンスなどにプライベートIPアドレスで接続できるようになります。Cisco Anyconnect のAWS版のようなイメージです。
今回のゴール
AWS 公式のクライアントツール(VPNアプリ)を使って、VPN接続を確立し、PCからプライベートIPアドレスでVPC内のEC2インスタンスにRDPできる。
イメージ図
注意事項
AWS Clinet VPN はエンドポイントにサブネットを関連付けしたタイミングで課金が発生します
前提条件
- AWS Client VPNアプリをインストールできるPCの準備する
- 各種証明書発行を行うEC2(Amazon Linux)とVPN接続後にRDP接続するEC2(WindowsOS)を用意する
- VPNの認証には「相互認証(証明書認証)」を利用
- VPN接続元のPCのセグメントと接続先EC2のセグメントを別セグメントにしておく
- 基本的に無料もしくは最低限のスペックで構築する
構築手順
- 証明書発行を行うEC2(Amazon Linux)をデプロイし、SSH接続できるようにセキュリティグループを設定する
- 上記EC2で各種証明書発行を行う
- EC2から発行したサーバ証明書と秘密鍵をACMへアップロードする
- EC2から発行したクライアント証明書をS3にアップロードする
- S3のコンソール画面からPCにクライアント証明書をダウンロードする
- クライアントVPNエンドポイントを作成し、有効化する
- PCにAWS Client VPNアプリをインストールし、プロファイルを設定する
- VPC内にRDP接続試験を行うEC2(WindowsOS) をデプロイする
実際にやってみた
1. は各所に詳しい記事があるので割愛して、2.より始めます。
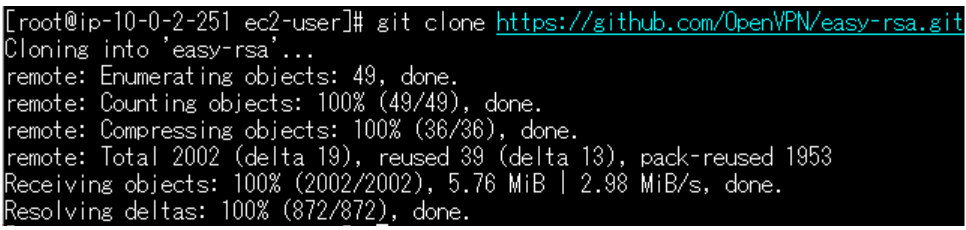
#EC2にSSH接続して、rootに切替 sudo su root #git コマンドが使えるようにインストール yum -y install git #git からEASY-RSA をインストール git clone https://github.com/OpenVPN/easy-rsa.gitコマンド実行とする以下画面のようになります。
#Eeasyrsa3 のディレクトに移動 cd easy-rsa/easyrsa3 #pkiを初期化します ./easyrsa init-pkiコマンド実行すると以下画面のようになります。
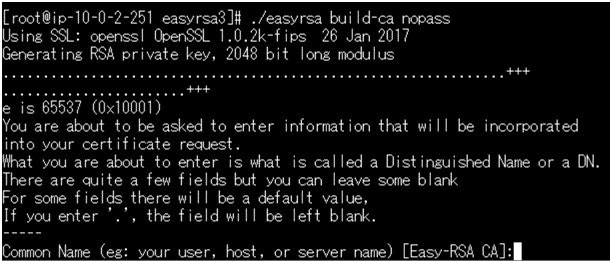
#CA作成 ./easyrsa build-ca nopass Common Name (eg: your user, host, or server name) [Easy-RSA CA]:sample "Sample"の部分は任意の名前に変えてもらってOKですコマンド実行すると以下画面のようになります。
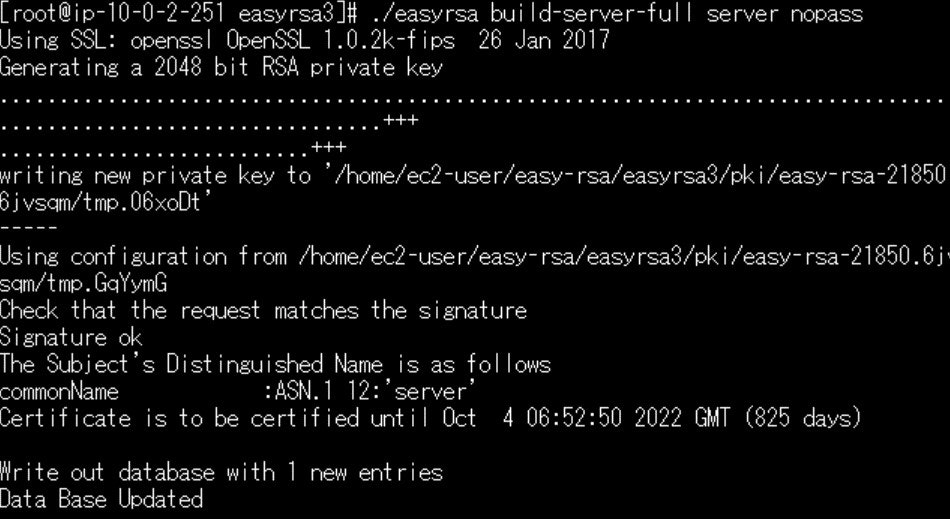
#サーバ証明書作成 ./easyrsa build-server-full server nopass「server」という名前のサーバ証明書が出来上がります。
コマンド実行すると以下画面のようになります。
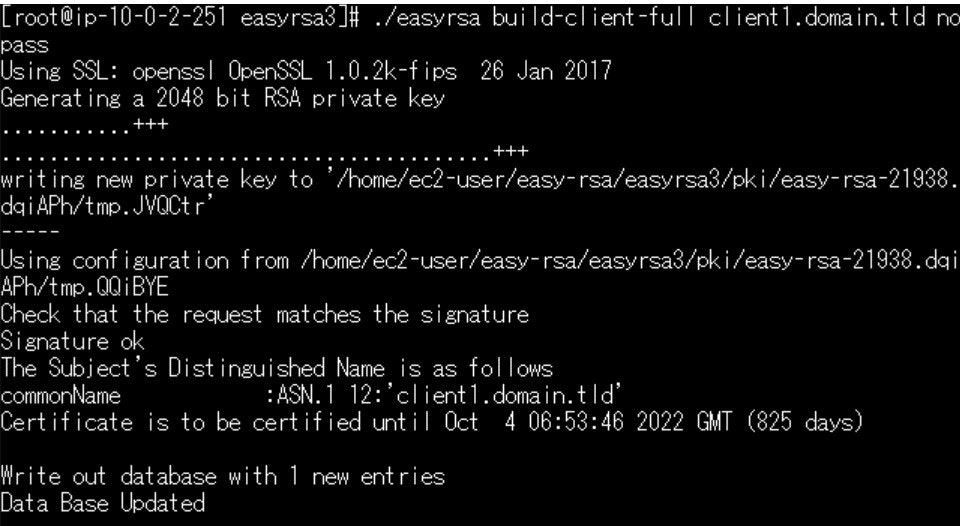
#クライアント証明書作成 ./easyrsa build-client-full client1.domain.tld nopassコモンネームが「client1.domain.tld」というクライアント証明書が出来上がります。
コマンド実行すると以下画面のようになります。
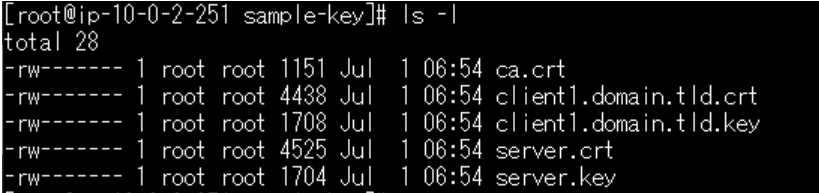
#作成したサーバ証明書、クライアント証明書、キーを「tmp/sample-key」というディレクトリを作り、そこに集約 pwd mkdir /tmp/sample-key/ cp pki/ca.crt /tmp/sample-key/ cp pki/issued/server.crt /tmp/sample-key/ cp pki/private/server.key /tmp/sample-key/ cp pki/issued/client1.domain.tld.crt /tmp/sample-key/ cp pki/private/client1.domain.tld.key /tmp/sample-key/ # /tmp/sample-keyへディレクトリ移動 cd /tmp/sample-key/ # コピーされているか確認 ls- lコマンド実行して、以下画面のような表示であればOKです。
これで各種証明書の発行は完了しました。
続いて発行した証明書をACMへアップロードします。
今回はAWS CLIを使ってEC2から直接ACMへアップロードしていきます。EC2からACMにアップロードするにはEC2にACMへのアクセス権限(IAMロール)をアタッチする必要があります。
IMAロールを作成は他に詳しい記事がたくさんありますので、本記事では割愛します。とりあえず「信頼されたエンティティ」はEC2で、ロールにアタッチするポリシーは「AWSCertificateManagerFullAccess」がついていればOKです。
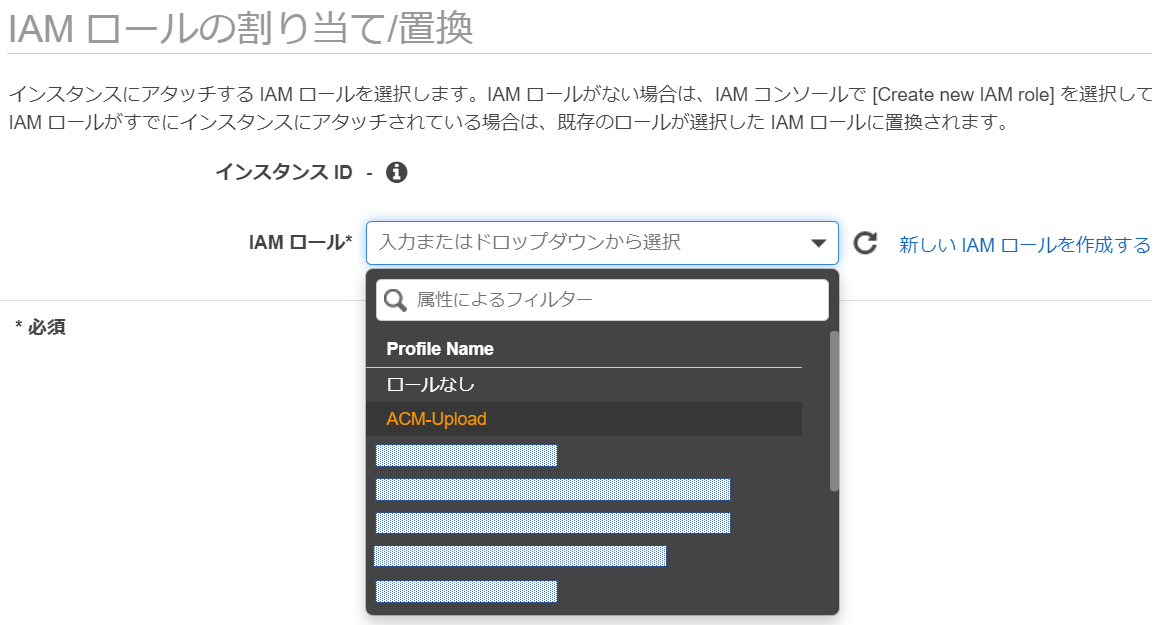
IAMロールの作成が完了したら、作成したIAMロールをEC2へアタッチします。
EC2のコンソール画面から、対象のEC2インスタンスを選択して、「インスタンスの設定」-「IAMロールの割当て/置換」を選択します。
今回は「ACM-Upload」というロールを作成しましたので、それをアタッチします。
これでEC2からACMへ証明書をアップロードできる環境が整いしましたので、アップロードしていきます。
#サーバ証明書をACMへ登録 aws acm import-certificate --certificate file://server.crt --private-key file://server.key --certificate-chain file://ca.crt --region ap-northeast-1 #秘密鍵をACMへ登録 aws acm import-certificate --certificate file://client1.domain.tld.crt --private-key file://client1.domain.tld.key --certificate-chain file://ca.crt --region ap-northeast-1これで必要な証明書のACM登録はOKです。
ACMのコンソール画面で登録されているか確認してみましょう。
以下の画面のようになっていればOKです。
VPN接続の認証のために作成したクライアント証明書とキーファイルをPCに入れておく必要があります。
それにはPCからアクセスできる場所に各種ファイルをエクスポートしておく必要がありますので、今回はS3へエクスポートします。まずEC2からS3へデータをアップロードするにあたり、ACMと同じくIAMロールをアタッチする必要があります。EC2からS3へのデータアップロードは以前に記事にしましたので、以下を参考に進めてください。
参考記事:Amazon EC2(Amazon linux)から直接S3へのファイルコピーPCにダウンロードする必要があるのは「client1.domain.tld.crt」と「client1.domain.tld.key」の2つのため、この2つをS3へアップロードして、PCへダウンロードできるようにしておきます。
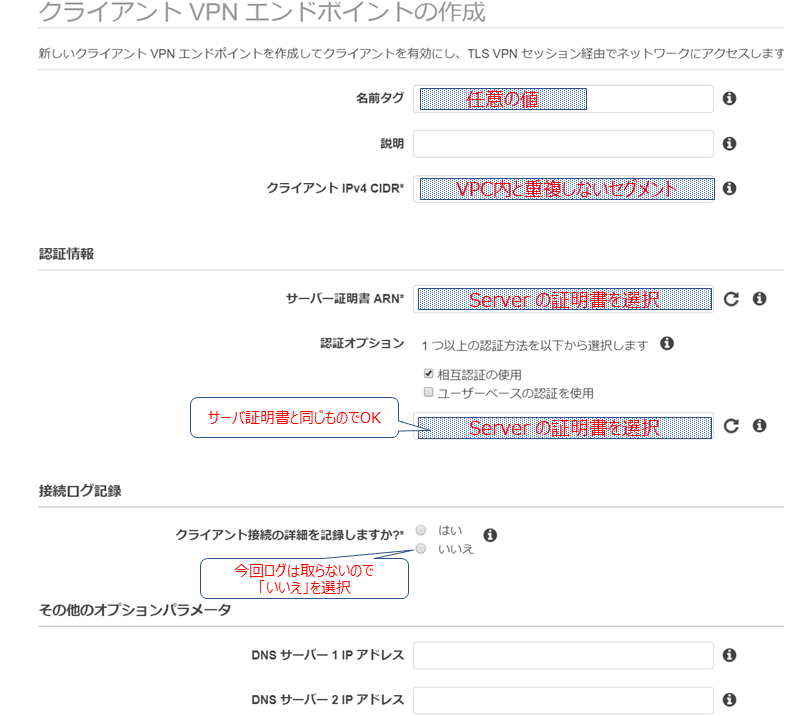
次にVPCに接続できるようにClient VPN エンドポイントを設定していきます。
VPCのコンソール画面の「クライアントVPN エンドポイント」を選択
設定は以下の画面の通りに行います。
設定が完了したら、ステータスが「使用可能」になるのを待って
「関連付」でVPN接続で接続可能にするサブネットを設定していきます。
★サブネットを関連付けしたタイミングで課金が発生するので注意してください★
必要なくなったら、関連付けを解除するか、エンドポイントごと削除しましょう!セキュリティグループで、VPN接続元のCIDRからのRDPを許可しておきましょう。
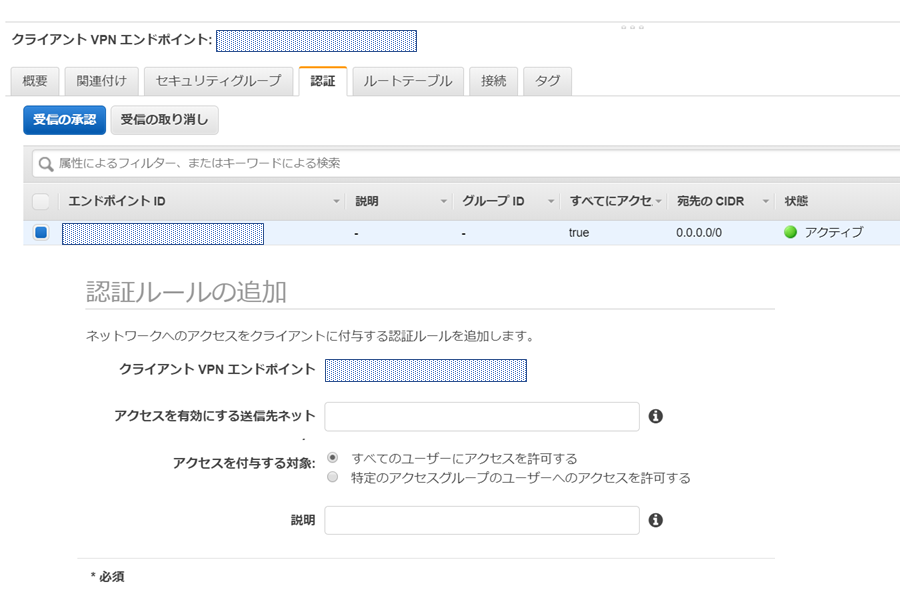
そして「認証」でVPNでアクセスを有効にするサブネットを設定します。
「受信の承認」をクリックすると15分ほどでステータスが「アクティブ」になります。
これでACMとクライアントVPNエンドポイントの設定は完了です。
最後にVPN接続を行うPCへの設定を行っていきます。
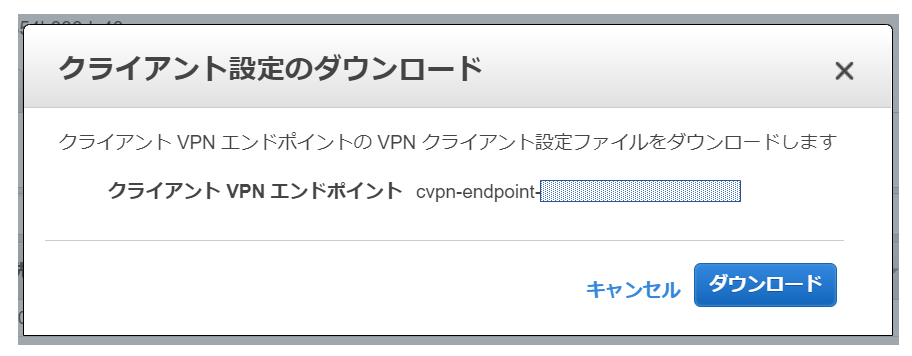
まず当該PCへAWS Clinet VPNアプリをダウンロードします。
DLページ:AWS Client VPN download次にPCからクライアントVPNエンドポイントのコンソール画面にアクセスして、画面上に表示されている「クライアント設定のダウンロード」をクリックし、プロファイルをダウンロードします。
「downloaded-client-config.ovpn」というファイルがダウンロードされます。
次にEC2からS3へアップデートした証明書と秘密鍵をPCにダウンロードします。downloaded-client-config.ovpn をテキストファイルで開くと以下のようになってます。
client dev tun proto udp remote cvpn-endpoint-xxxxxxxxxx.prod.clientvpn.ap-northeast-1.amazonaws.com 443 remote-random-hostname resolv-retry infinite nobind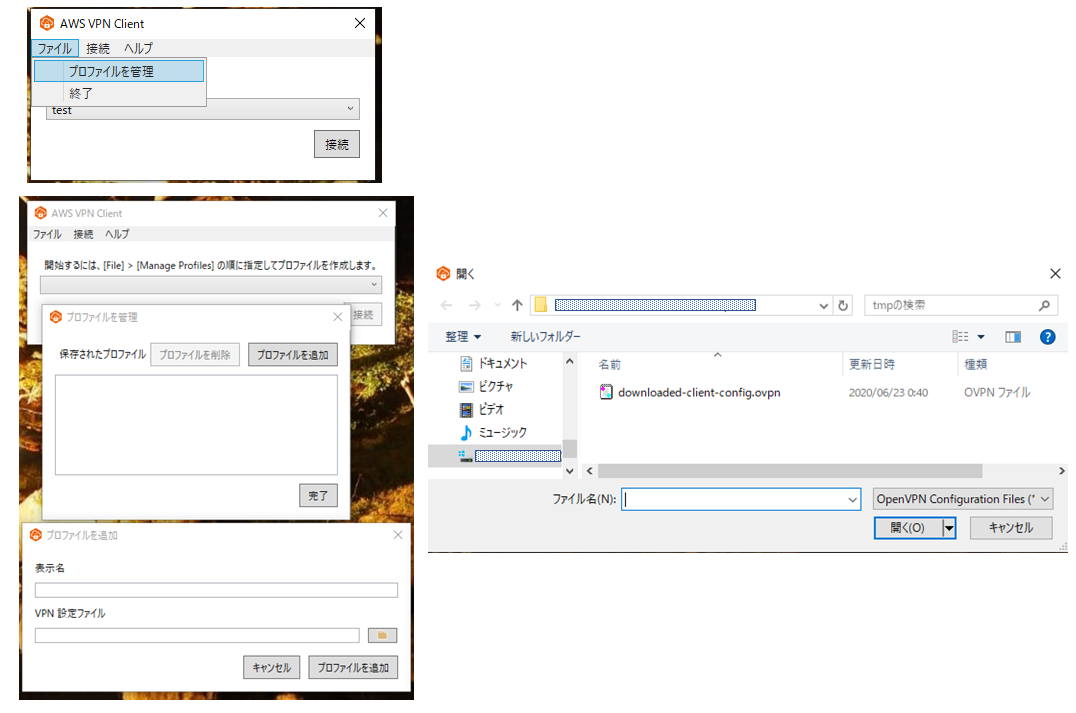 persist-key persist-tun remote-cert-tls server cipher AES-256-GCM verb 3 <ca> -----BEGIN CERTIFICATE----- XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX -----END CERTIFICATE----- </ca> reneg-sec 0上記の最後に以下を追記します。
cert /"ファイルを格納しているフォルダ"/client1.domain.tld.crt key /"ファイルを格納しているフォルダ"/client1.domain.tld.key上記2つへのファイルパスはdownloaded-client-config.ovpn からの相対パスで記述します。
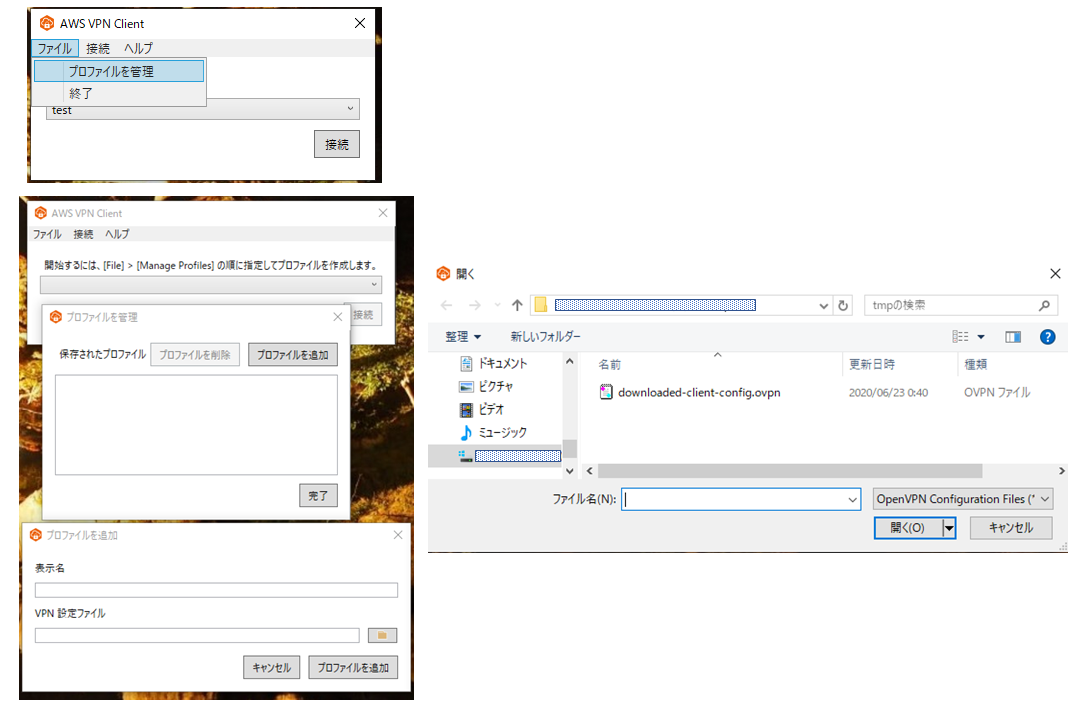
PCにダウンロードしたアプリを起動し、プロファイル設定をします。
★プロファイルを追加しようとして、エラーが出る場合、パスの記述を確認してください。★
"¥"が含まれていたり、パスが間違っていないか確認してください。
downloaded-client-config.ovpn とclient1.domain.tld.crtおよびclient1.domain.tld.keyは同じフォルダに格納しておいた方が分かりやすくて良いと思います。
ただ格納するフォルダにアクセス制限が設定されているとエラーになったりしますので注意しましょう!プロファイルを設定して接続できるようになれば実際にVPN接続してみましょう。
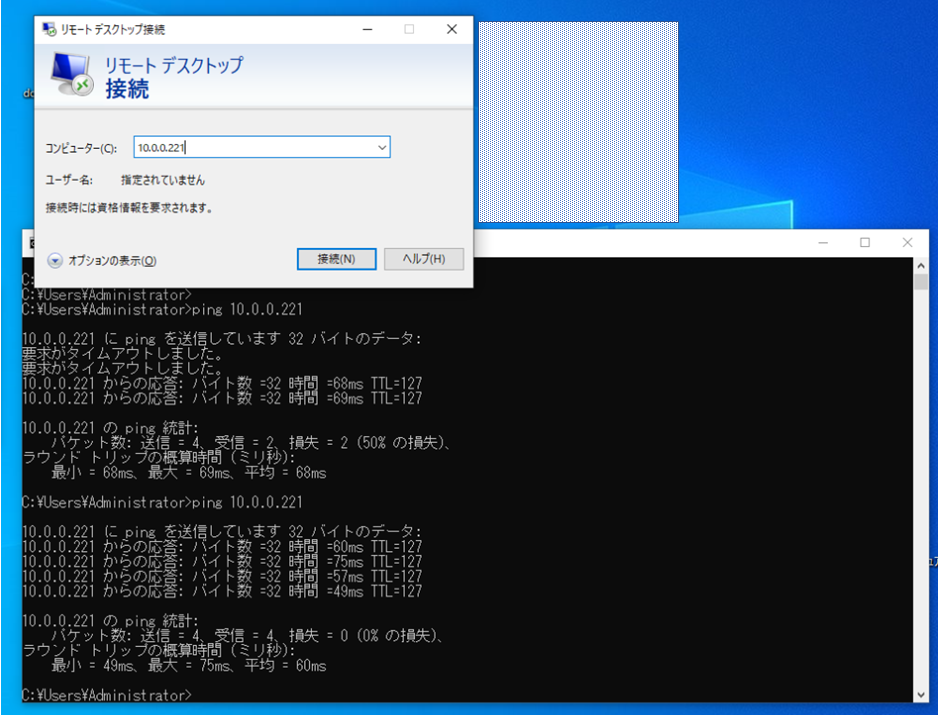
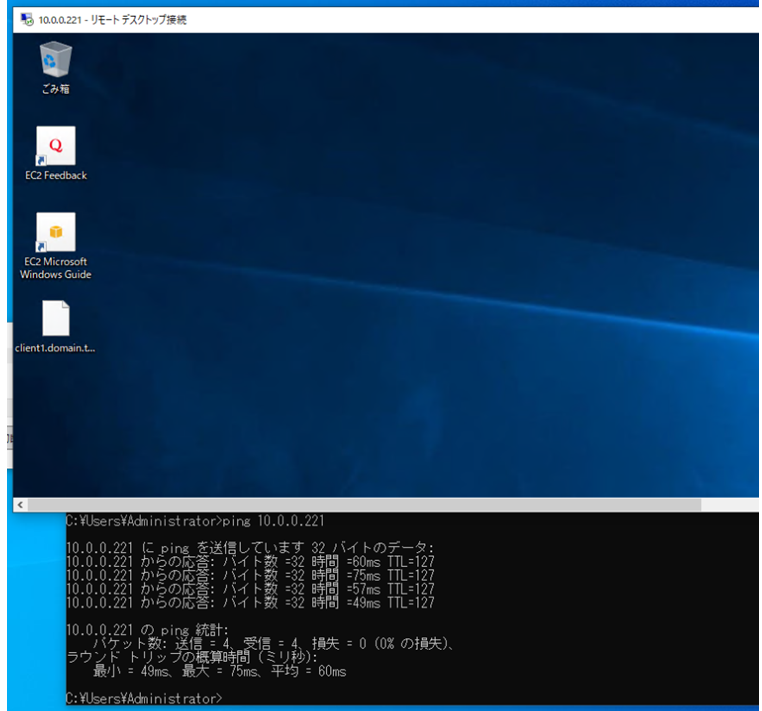
プライベートIPでEC2インスタンスへRDPしてみます。
RDPできましたね!
長くなりましたがこれで設定完了です。参考にしたページ
[AWS Client VPN] VPC を経由して固定のIPでインターネットへアクセスする
AWS Client VPN 設定メモAWS Client VPN の使いどころ
クライアント数に制限なく、、AWS環境へどのPCからでもVPN接続できるようになるのは便利だと思いますが、ランニング費用がVPN Connectと比べてかかるため、利用するシーンを選ぶ必要のあるサービスになります。
例えば会社支給の持ち出し用PCで使うとかですかね。
テレワークの一環として、BYODでの活用できなくはないですが、セキュリティの観点からWorkSpacesの方がいいような気がします...







- 投稿日:2020-07-25T23:15:28+09:00
Terraform で構築した AWS AppSync で GraphQL を触る
概要
- Serverless 界隈でよく使われる GraphQL を触ってみた
- Backend を用意するのが面倒なので AWS AppSync を採用
- 簡単に構築できるように Terraform で書いた
サンプルコード
以下リポジトリを clone するとすぐに terraform で環境構築できます。
https://github.com/tsubasaogawa/terraform-appsync-graphql-testTerraform v0.12.24 で動作確認
おさらい
GraphQL
- API によく使われる言語
- REST API と比べ
- リクエストの回数を減らしやすい (一度に複数の機能を呼び出せる)
- レスポンスされる項目を自由に指定できる
- スキーマ第一主義
- フロントエンドとバックエンドの認識齟齬を防ぐ
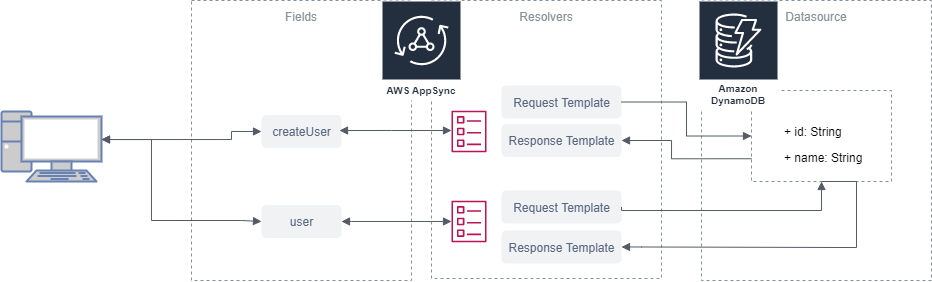
AppSync
- GraphQL の API サーバーをマネージドで提供してくれるサービス
- REST における API Gateway の GraphQL 版のようなもの
- データソース (API のデータ読み取り先) として AWS の各サービス (Dynamo/Elasticsearch/Lambda etc.) や HTTP が選択できる
- ノンプログラミングで DB からデータを読み書きする API が作れる
作るもの
- AppSync (GraphQL API)
- Query (SQL の SELECT に相当)
- user: ユーザー情報を DB から取得
- Mutation (SQL の UPDATE/INSERT/DELETE に相当)
- createUser: ユーザー情報を DB に書き込み
- DynamoDB
- user の保存先
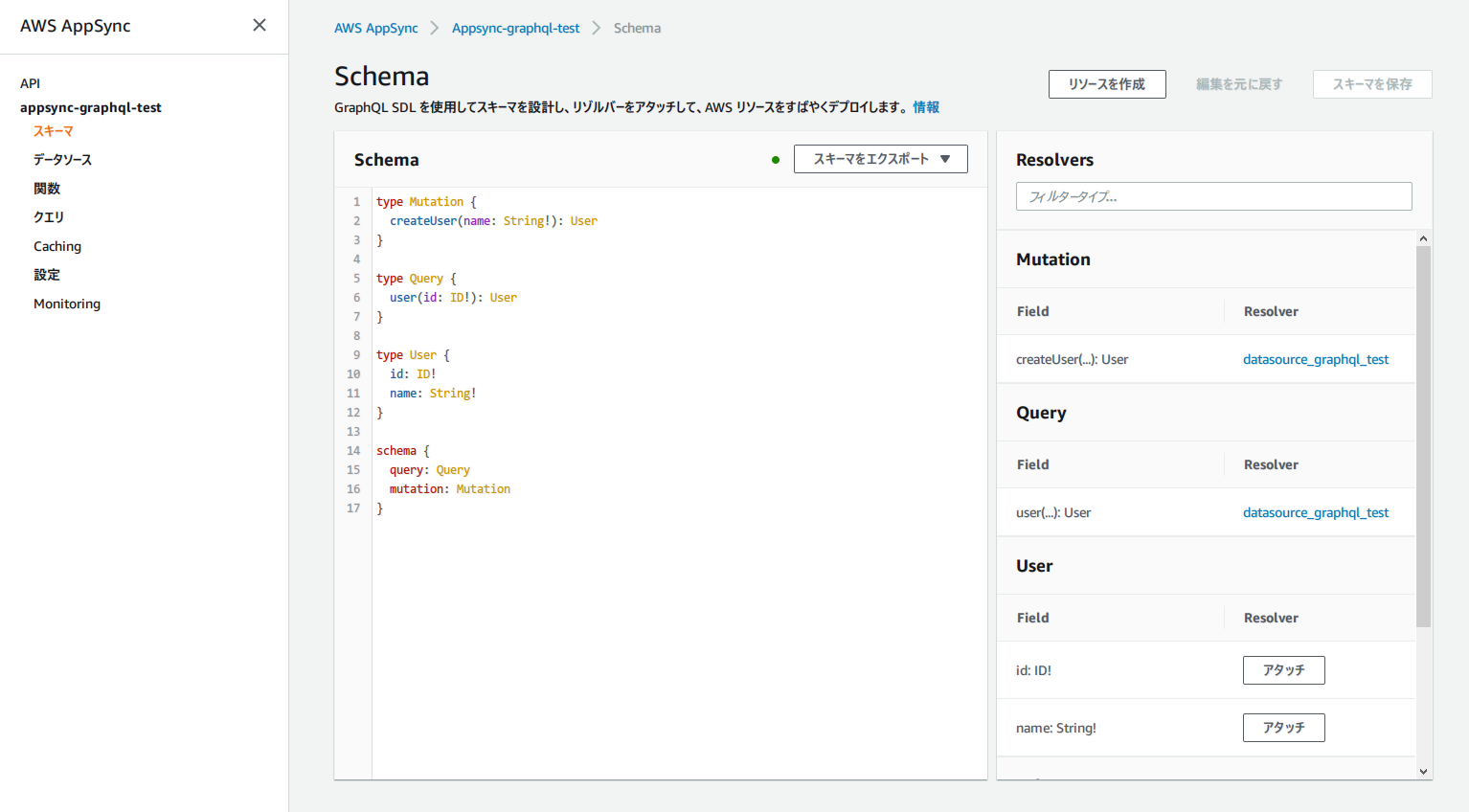
コード抜粋
ここでは AppSync の tf ファイルを掲載。variables は別ファイルで定義されている。
必要となる resource は以下の 4 つ。
- aws_appsync_graphql_api
- aws_appsync_api_key
- aws_appsync_datasource
- aws_appsync_resolver
modules/appsync/main.tf# schema は別ファイルで定義しておく data "local_file" "graphql_schema" { filename = "modules/appsync/resources/schema.graphql" } resource "aws_appsync_graphql_api" "this" { name = var.name authentication_type = "API_KEY" schema = data.local_file.graphql_schema.content } resource "aws_appsync_api_key" "this" { api_id = aws_appsync_graphql_api.this.id } resource "aws_appsync_datasource" "this" { api_id = aws_appsync_graphql_api.this.id name = var.datasource_name[ # IAM Role も別ファイルで定義 service_role_arn = aws_iam_role.this.arn type = "AMAZON_DYNAMODB" dynamodb_config { table_name = var.dynamo_table_name } } # field の数だけ resolver を定義できるように map 型の resolvers 変数を使う # https://github.com/tsubasaogawa/terraform-appsync-graphql-test/blob/c112fbd649ef80aeae2648a1fab21ff0bf64af6d/locals.tf#L13-L24 data "local_file" "resolver_requests" { for_each = var.resolvers filename = "modules/appsync/resources/resolver_templates/${each.key}/request.template" } data "local_file" "resolver_responses" { for_each = var.resolvers filename = "modules/appsync/resources/resolver_templates/${each.key}/response.template" } resource "aws_appsync_resolver" "this" { for_each = var.resolvers api_id = aws_appsync_graphql_api.this.id field = lookup(each.value, "field") type = lookup(each.value, "type") data_source = lookup(each.value, "data_source") request_template = lookup(data.local_file.resolver_requests, each.key).content response_template = lookup(data.local_file.resolver_responses, each.key).content }実行
環境構築
# Setup cd terraform-appsync-graphql-test terraform init terraform apply成功すると AppSync のマネジメントコンソールで API が作成されていることが確認できる。
API テスト
下準備
ここでは作成された GraphQL API を curl で叩いてみる。
curl するために必要な API KEY とホスト名を terraform の output から取得する。# Set environment variables from tfstate API_KEY=$(cat terraform.tfstate | jq -r '.outputs.appsync_api_key.value') HOST=$(cat terraform.tfstate | jq -r '.outputs.appsync_api_uris.value.GRAPHQL' | grep -oP '[^/]+\.amazonaws.com')createUser でユーザーを作成
requestcurl \ -H 'Content-Type: application/json' \ -H "x-api-key: $API_KEY" \ -H "Host: $HOST" \ -X POST -d ' { "query": "mutation { createUser(name: \"yoshida\") { id name } }" }' \ https://$HOST/graphqlresponse{"data":{"createUser":{"id":"2e591d0b-c4cd-41bd-b66a-ad637e506f5f","name":"yoshida"}}}
yoshidaというユーザーが2e591...という ID で作成されたことがわかる。user でユーザー情報を取得
先程作成した yoshida さんの情報を DB から取得する。ここでは name 属性のみを取得する。
requestcurl \ -H 'Content-Type: application/json' \ -H "x-api-key: $API_KEY" \ -H "Host: $HOST" \ -X POST -d ' { "query": "query { user(id: \"2e591d0b-c4cd-41bd-b66a-ad637e506f5f\") { name } }" }' \ https://$HOST/graphqlresponse{"data":{"user":{"name":"yoshida"}}}必要な項目を API の利用者側が選択できるため、データのやり取りが軽量で済む。
備考/所感
AppSync の Resolver
AWS AppSync 特有の機能が Resolver であり、GraphQL の Field (本頁における
user/createUser) のロジックを表現する。Request と Response を別々の mapping template ファイルとして定義する。
例えばuserの Resolver は以下のように定義されている。
- Request: DynamoDB に GetItem を発行する。
- Response: 得られた結果を JSON で返す。
Mapping template のリファレンスは以下にまとめられている。
https://docs.aws.amazon.com/ja_jp/appsync/latest/devguide/resolver-mapping-template-reference.html学習コスト
上記の通り Resolver の考え方が若干複雑なのと、GraphQL の Schema における記法がこれまた独特であることから、REST API と比べると若干の取っ付きにくさ・学習コストの高さを感じる。ちょっとした API であれば素直に API Gateway を使うのが手っ取り早い。
※ なお、API Gateway であっても Service Proxy を用いることで Lambda レスで DynamoDB などの AWS リソースを扱うことができる。
https://dev.classmethod.jp/articles/api-gateway-aws-service-proxy-dynamodb/一方、比較的大きい (育ちそうな) API であれば GraphQL のメリットをしっかり享受できるため、利用を検討してもいいかもしれない。
- 投稿日:2020-07-25T23:13:33+09:00
TerraformでAmazon API Gatewayを構築する(ゲートウェイのレスポンス&ステージ詳細編)
はじめに
以前の記事で、TerraformでAPI Gatewayを構築することを書いてみたが、基本的な部分過ぎて実用的ではなかったので今回はゲートウェイのレスポンスと、ステージの詳細設定をするためのIaCをまとめる。
例によって、Terraformの公式ドキュメントは書き味が薄くて困るので、内容の薄い部分について、AWSの開発者ガイドやCLIのリファレンス等を組み合わせながらまとめる。
文中の画面キャプチャや画面文言は2020年7月25日時点のものなので、今後文言が変わったり、項目の増減があるかもしれないことをご了承いただきたい。
前提条件
- 以前のTerraform+Amazon API Gatewayの記事の中身がなんとなく理解できる
- Terraformについてはある程度書き方を理解していて、自力でリファレンスを見ながら書くことができる程度の知識量を期待する
ゲートウェイのレスポンスを設定する
以下の画面のことを指す。
Terraformのリソースとしては、api_gateway_gateway_responseとなる。
これを見ると、
response_type- (Required) The response type of the associated GatewayResponse.
と書かれていて、いきなり心が折れることになる。
一体画面の項目が何のタイプにマッピングされるのよ……ということで、TerraformはバックエンドではCLIを動かしていると思われるので、該当のCLIのリファレンスを見てみる。
The response type of the associated GatewayResponse . Valid values are
- ACCESS_DENIED (以下略)
とある。よしよし、これならいけそうだ。
というわけで、画面の日本語とマッピングしていってみる。
マネコン画面の日本語 CLIのパラメータ(Terraformでも使える) アクセスが拒否されました ACCESS_DENIED API 設定エラー API_CONFIGURATION_ERROR オーソライザー設定エラー AUTHORIZER_CONFIGURATION_ERROR オーソライザーエラー AUTHORIZER_FAILURE リクエスト本文が不正です BAD_REQUEST_BODY リクエストパラメータが不正です BAD_REQUEST_PARAMETERS DEFAULT 4XX DEFAULT_4XX DEFAULT 5XX DEFAULT_5XX 期限切れのトークン EXPIRED_TOKEN 統合の失敗 INTEGRATION_FAILURE 統合のタイムアウト INTEGRATION_TIMEOUT 無効な API キー INVALID_API_KEY 無効な署名 INVALID_SIGNATURE 認証トークンが見つかりません MISSING_AUTHENTICATION_TOKEN クォータを超過しました QUOTA_EXCEEDED リクエストが大きすぎます REQUEST_TOO_LARGE リソースは存在しません RESOURCE_NOT_FOUND スロットル済み THROTTLED 権限がありません UNAUTHORIZED(たぶん) サポートされていないメディアタイプ UNSUPPORTED_MEDIA_TYPE WAF フィルター WAF_FILTERED ちなみに、CLIのリファレンスやmanには
WAFフィルター該当するCLI項目がない。
開発者ガイドを見ると、どうやらWAF_FILTEREDらしい。いや、これ日本語おかしいだろ。WAFにフィルターされたとかにしないと分かりにくい……。
※ちなみに、リファレンスやmanには載っていないが、WAF_FILTEREDで設定変更できたので、パラメータとしては有効なようだ。それでは、よくcurlで間違ったURIとかメソッドを狙って返される
{"message":"Missing Authentication Token"}を変更してみよう。
response_typeはMISSING_AUTHENTICATION_TOKENで、デフォルトのHTTPレスポンスコードは403なので、レスポンスコードも変えてみよう(存在しないパスが403 Forbiddenになるのはある意味正しいので、本来はコードまでは変更する必要がないかもしれないが、今回はおためしということで)。resource "aws_api_gateway_gateway_response" "missing_authentication_token" { rest_api_id = aws_api_gateway_rest_api.my_api.id response_type = "MISSING_AUTHENTICATION_TOKEN" status_code = "404" response_templates = { "application/json" = "{'message':'Resource Not Found'}" } response_parameters = { "gatewayresponse.header.test-header" : "'test'" } }
response_parametersでは、統合レスポンスを使用している場合に、その値をAPIのレスポンスにマッピングすることができる。詳細はAmazon API Gateway API リクエストおよびレスポンスデータマッピングのリファレンスを見ると良い。
今回のケースでは、このレスポンスのパターンになった場合、test-header: testを返す。では、これを
terraform applyした後にアクセスしてみよう。curl -i https://xxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/prod/user?id=11111\&name=Taro HTTP/2 404 date: Sat, 25 Jul 2020 08:57:45 GMT content-type: application/json content-length: 32 x-amzn-requestid: xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx test-header: test x-amzn-errortype: MissingAuthenticationTokenException x-amz-apigw-id: xxxxxxxxxxxxxxxx {'message':'Resource Not Found'}といった具合で、設定した通りのレスポンスが返却されるようになった。
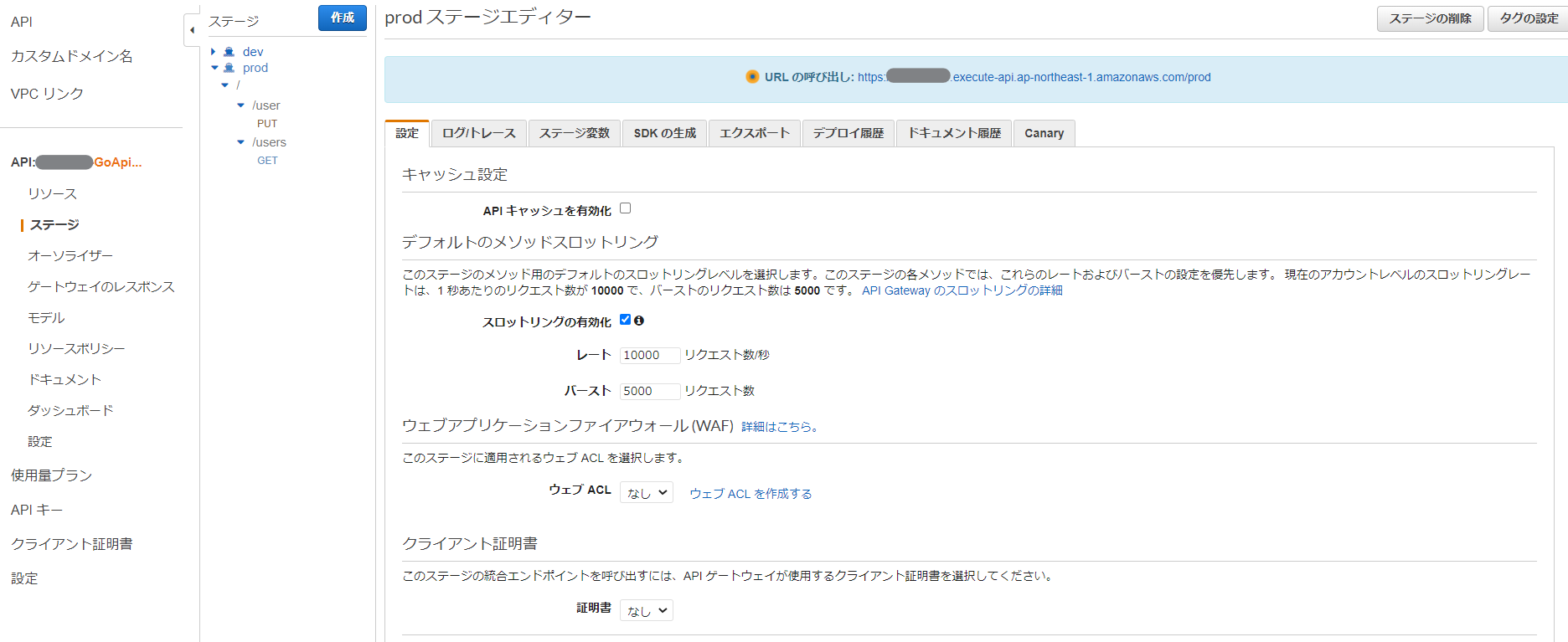
ステージの詳細設定
次に以下の画面について。
主なTerraformのリソースとしてはaws_api_gateway_stageだ。
ここも、マネコン画面に表示されている日本語とTerraformの引数の内容をマッピングしてみる。
設定タブ
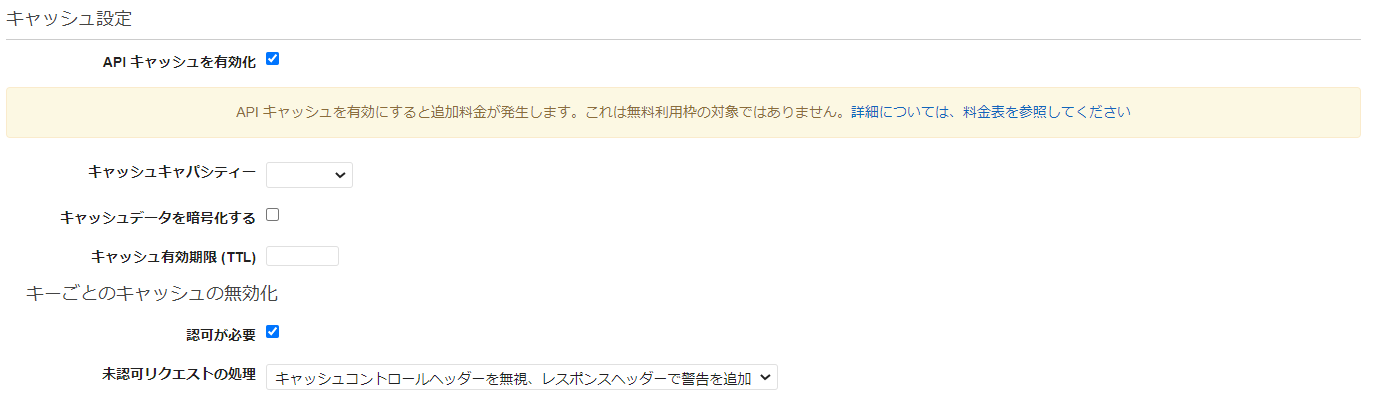
キャッシュ設定
マネコン画面の日本語 Terraformの引数 キャッシュ設定 cache_cluster_enabled ※true/falseのboolean なお、キャッシュ設定は、マネコン画面上ではチェックボックスをONにすると、
な画面が表示されるが、これを詳細設定するリソースは、aws_api_gateway_method_settingsになる。
aws_api_gateway_stageで設定できるのは、「キャッシュキャパシティー(cache_cluster_size)」までだ。aws_api_gateway_method_settingsでは、以下のようにマッピングされる。
マネコン画面の日本語 Terraformの引数 キャッシュデータを暗号化する cache_data_encrypted ※true/falseのboolean キャッシュ有効期限 (TTL) cache_ttl_in_seconds 認可が必要 require_authorization_for_cache_control ※true/falseのboolean 未認可リクエストの処理 unauthorized_cache_control_header_strategy デフォルトのメソッドスロットリング
これも、
aws_api_gateway_stageではなくてaws_api_gateway_method_settingsで定義する。
マネコン画面の日本語 Terraformの引数 デフォルトのメソッドスロットリング throttling_rate_limit か throttling_burst_limit のいずれかが-1だとチェックOFFになる レート throttling_rate_limit バースト throttling_burst_limit ウェブアプリケーションファイアウォール (WAF)
これはイマイチよく分からなかった……。
aws_wafregional_web_acl_associationのリソースにAPI Gateway Association Example
という項があるので、おそらくこのことだろうか。
クライアント証明書
実験できていないので、多分この引数で合っていると思うが、詳細は不明。
マネコン画面の日本語 Terraformの引数 証明書 client_certificate_id ログ/トレースタブ
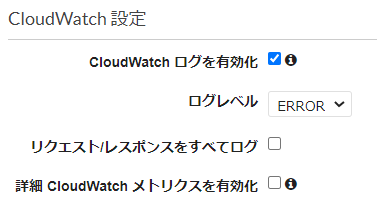
CloudWatch 設定
この項目は、
aws_api_gateway_stageではなくてaws_api_gateway_method_settingsで定義する。
マネコン画面の日本語 Terraformの引数 CloudWatch ログを有効化 logging_level(OFFで未チェック、ERRORまたはINFOでチェック済み) 詳細 CloudWatch メトリクスを有効化 metrics_enabled なお、CloudWatch ログを有効化をチェックすると、画面上では以下の項目が表示される。
マネコン画面の日本語 Terraformの引数 ログレベル logging_level リクエスト/レスポンスをすべてログ data_trace_enabled ※true/falseのboolean 詳細CloudWatch メトリクスを有効化 metrics_enabled ※true/falseのboolean また、CloudWatch ログを有効化するためには、以下の「設定」で、CloudWatchLogsの書き込み権を持ったIAMロールを設定する必要がある。
このため、今回は以下のようにIAMロールを定義する。CloudWatchLogsの書き込みポリシについては、
AmazonAPIGatewayPushToCloudWatchLogsを使えとAWSのブログに書いてあった。################################################################################ # IAM Role for API Gateway Put CloudWatch Logs # ################################################################################ resource "aws_iam_role" "apigateway_putlog" { name = local.rest_api_putlog_role_name assume_role_policy = <<EOF { "Version": "2012-10-17", "Statement": [ { "Action": "sts:AssumeRole", "Principal": { "Service": "apigateway.amazonaws.com" }, "Effect": "Allow", "Sid": "" } ] } EOF } resource "aws_iam_role_policy_attachment" "apigateway_putlog" { role = "${aws_iam_role.apigateway_putlog.name}" policy_arn = "arn:aws:iam::aws:policy/service-role/AmazonAPIGatewayPushToCloudWatchLogs" }これを、以下のように
aws_api_gateway_accountで設定すれば良い。resource "aws_api_gateway_account" "my_api" { cloudwatch_role_arn = aws_iam_role.apigateway_putlog.arn }で、ここで油断してはならないのは、
aws_api_gateway_accountはそのままだとaws_api_gateway_method_settingsとの依存関係がないため、順序性が保証されず、ログ設定がエラーになってしまう。そのため、以下のように依存関係を定義しておく。resource "aws_api_gateway_method_settings" "all" { depends_on = [ aws_api_gateway_account.my_api, ] rest_api_id = "${aws_api_gateway_rest_api.my_api.id}" stage_name = "${aws_api_gateway_stage.prod.stage_name}" method_path = "*/*" settings { logging_level = "ERROR" } }カスタムアクセスのログ設定
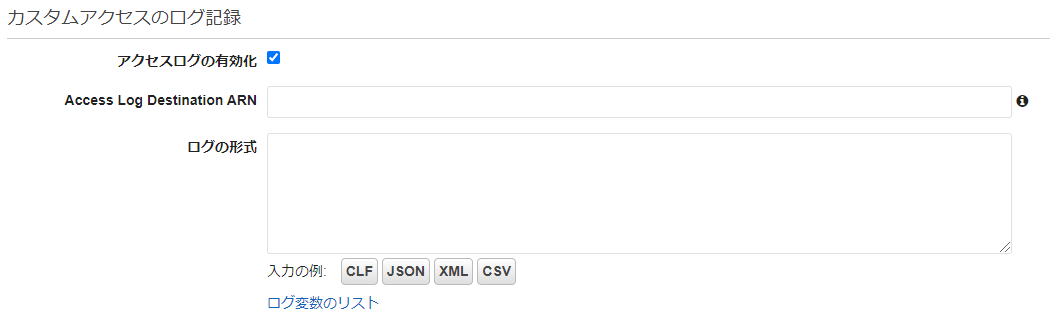
この項目はなんか日本語が変な気が…。「の」は要らないような。
マネコン画面の日本語 Terraformの引数 アクセスログの有効化 access_log_settings ※ブロックに以下の項目を記載する なお、アクセスログの有効化をチェックすると、画面上では以下の項目が表示される。
これは、
aws_api_gateway_stageのリソースのaccess_log_settingsのブロックで定義する。
マネコン画面の日本語 Terraformの引数 Access Log Destination ARN destination_arn ログの形式 format ログの形式の出力例は、画面のボタンをポチっと押すか、AWSの開発者ガイドを参照。
この項目を有効にするためには、まずはCloudWatch Logsのリソースを作らなければいけないので、以下のように作成する。
resource "aws_cloudwatch_log_group" "apigateway_accesslog" { name = local.rest_api_accesslog_loggroup_name }次に、
aws_api_gateway_stageに以下のように定義したアクセスログを設定すれば良い。resource "aws_api_gateway_stage" "prod" { stage_name = "prod" rest_api_id = aws_api_gateway_rest_api.my_api.id deployment_id = aws_api_gateway_deployment.dev.id access_log_settings { destination_arn = aws_cloudwatch_log_group.apigateway_accesslog.arn format = "$context.identity.sourceIp $context.identity.caller $context.identity.user [$context.requestTime] \"$context.httpMethod $context.resourcePath $context.protocol\" $context.status $context.responseLength $context.requestId" } }X-Ray トレース
これはシンプルに設定可能。
マネコン画面の日本語 Terraformの引数 X-Ray トレースの有効化 xray_tracing_enabled ステージ変数タブ
これは
variablesの引数で渡すことができる。
Terraformのドキュメントでは、(Optional) A map that defines the stage variables
と書かれているので、渡し方に注意が必要。
SDKの生成/エクスポート/デプロイ履歴/ドキュメント履歴タブ
この辺は設定項目ではなく参照系であるため、特にTerraformに紐づく項目は無い。
Canaryタブ
うーん、これはTerraform未実装な気がする。
CLIのドキュメントには
--canary-settingsオプションが存在するが、Terraformでは難しいということだろうか(いずれにしろ、CodeDeployのような便利なCanaryリリースではないので、あまり使えないのだが)。デプロイについて
API Gatewayのリソースについては、以下のようにデプロイを定義する。
triggersは、「このリソースが変更されたら再デプロイする」という機能らしい。
詳細は、公式のNotesを参照。
lifecycleは、スキマを作らないようにするための施策だ。resource "aws_api_gateway_deployment" "dev" { rest_api_id = aws_api_gateway_rest_api.my_api.id stage_name = "dev" triggers = { redeployment = sha1(join(",", list( jsonencode(module.get_user), jsonencode(module.put_user), jsonencode(aws_api_gateway_gateway_response.missing_authentication_token), ))) } lifecycle { create_before_destroy = true } }ただ、これだけだと、devにデプロイした機能がprodまで伝播してくれない。
うーむ、prod側にも設定を入れるべきなのだろうか。それとも、そこは別契機でデプロイするということか。


- 投稿日:2020-07-25T23:13:33+09:00
TerraformでAmazon API Gatewayを詳細設定する
はじめに
TerraformでAmazon API Gatewayを作ろうとすると、公式ドキュメントの書き味が薄くて困ることがあるのでまとめる。
前提条件
- 以前のTerraform+Amazon API Gatewayの記事の中身がなんとなく理解できる
- Terraformについてはある程度書き方を理解していて、自力でリファレンスを見ながら書くことができる程度の知識量を期待する
ゲートウェイのレスポンスを設定する
以下の画面のことを指す(2020年7月25日時点)。
Terraformのリソースとしては、api_gateway_gateway_responseとなる。
これを見ると、
response_type- (Required) The response type of the associated GatewayResponse.
と書かれていて、いきなり心が折れることになる。
一体画面の項目が何のタイプにマッピングされるのよ……ということで、TerraformはバックエンドではCLIを動かしていると思われるので、該当のCLIのリファレンスを見てみる。
The response type of the associated GatewayResponse . Valid values are
- ACCESS_DENIED (以下略)
とある。よしよし、これならいけそうだ。
というわけで、画面の日本語とマッピングしていってみる。
マネコン画面の日本語 CLIのパラメータ(Terraformでも使える) アクセスが拒否されました ACCESS_DENIED API 設定エラー API_CONFIGURATION_ERROR オーソライザー設定エラー AUTHORIZER_CONFIGURATION_ERROR オーソライザーエラー AUTHORIZER_FAILURE リクエスト本文が不正です BAD_REQUEST_BODY リクエストパラメータが不正です BAD_REQUEST_PARAMETERS DEFAULT 4XX DEFAULT_4XX DEFAULT 5XX DEFAULT_5XX 期限切れのトークン EXPIRED_TOKEN 統合の失敗 INTEGRATION_FAILURE 統合のタイムアウト INTEGRATION_TIMEOUT 無効な API キー INVALID_API_KEY 無効な署名 INVALID_SIGNATURE 認証トークンが見つかりません MISSING_AUTHENTICATION_TOKEN クォータを超過しました QUOTA_EXCEEDED リクエストが大きすぎます REQUEST_TOO_LARGE リソースは存在しません RESOURCE_NOT_FOUND スロットル済み THROTTLED 権限がありません UNAUTHORIZED(たぶん) サポートされていないメディアタイプ UNSUPPORTED_MEDIA_TYPE WAF フィルター WAF_FILTERED ちなみに、CLIのリファレンスやmanには
WAFフィルター該当するCLI項目がない。
開発者ガイドを見ると、どうやらWAF_FILTEREDらしい。いや、これ日本語おかしいだろ。WAFにフィルターされたとかにしないと分かりにくい……。
※ちなみに、リファレンスやmanには載っていないが、WAF_FILTEREDで設定変更できたので、パラメータとしては有効なようだ。それでは、よくcurlで間違ったURIとかメソッドを狙って返される
{"message":"Missing Authentication Token"}を変更してみよう。
response_typeはMISSING_AUTHENTICATION_TOKENで、デフォルトのHTTPレスポンスコードは403なので、レスポンスコードも変えてみよう。resource "aws_api_gateway_gateway_response" "missing_authentication_token" { rest_api_id = aws_api_gateway_rest_api.my_api.id response_type = "MISSING_AUTHENTICATION_TOKEN" status_code = "404" response_templates = { "application/json" = "{'message':'Resource Not Found'}" } response_parameters = { "gatewayresponse.header.test-header" : "'test'" } }
response_parametersでは、統合レスポンスを使用している場合に、その値をAPIのレスポンスにマッピングすることができる。詳細はAmazon API Gateway API リクエストおよびレスポンスデータマッピングのリファレンスを見ると良い。
今回のケースでは、このレスポンスのパターンになった場合、test-header: testを返す。では、これを
terraform applyした後にアクセスしてみよう。curl -i https://xxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/prod/user?id=11111\&name=Taro HTTP/2 404 date: Sat, 25 Jul 2020 08:57:45 GMT content-type: application/json content-length: 32 x-amzn-requestid: xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx test-header: test x-amzn-errortype: MissingAuthenticationTokenException x-amz-apigw-id: xxxxxxxxxxxxxxxx {'message':'Resource Not Found'}といった具合で、設定した通りのレスポンスが返却されるようになった。
ステージの詳細設定
次に以下の画面について。
主なTerraformのリソースとしては
aws_api_gateway_stageだ。ここも、マネコン画面に表示されている日本語とTerraformの引数の内容をマッピングしてみる。
設定タブ
キャッシュ設定
マネコン画面の日本語 Terraformの引数 キャッシュ設定 cache_cluster_enabled ※true/falseのboolean なお、キャッシュ設定は、マネコン画面上ではチェックボックスをONにすると、
な画面が表示されるが、これを詳細設定するリソースは、
aws_api_gateway_method_settingsになる。
aws_api_gateway_stageで設定できるのは、「キャッシュキャパシティー(cache_cluster_size)」までだ。aws_api_gateway_method_settingsでは、以下のようにマッピングされる。
マネコン画面の日本語 Terraformの引数 キャッシュデータを暗号化する cache_data_encrypted ※true/falseのboolean キャッシュ有効期限 (TTL) cache_ttl_in_seconds 認可が必要 require_authorization_for_cache_control ※true/falseのboolean 未認可リクエストの処理 unauthorized_cache_control_header_strategy デフォルトのメソッドスロットリング
これも、
aws_api_gateway_stageではなくてaws_api_gateway_method_settingsで定義する。
マネコン画面の日本語 Terraformの引数 デフォルトのメソッドスロットリング throttling_rate_limit か throttling_burst_limit のいずれかが-1だとチェックOFFになる レート throttling_rate_limit バースト throttling_burst_limit ウェブアプリケーションファイアウォール (WAF)
これはイマイチよく分からなかった……。
aws_wafregional_web_acl_associationのリソースにAPI Gateway Association Example
という項があるので、おそらくこのことだろうか。
クライアント証明書
実験できていないので、多分この引数で合っていると思うが、詳細は不明。
マネコン画面の日本語 Terraformの引数 証明書 client_certificate_id ログ/トレースタブ
CloudWatch 設定
この項目は、
aws_api_gateway_stageではなくてaws_api_gateway_method_settingsで定義する。
マネコン画面の日本語 Terraformの引数 CloudWatch ログを有効化 logging_level(OFFで未チェック、ERRORまたはINFOでチェック済み) 詳細 CloudWatch メトリクスを有効化 metrics_enabled なお、CloudWatch ログを有効化をチェックすると、画面上では以下の項目が表示される。
マネコン画面の日本語 Terraformの引数 ログレベル logging_level リクエスト/レスポンスをすべてログ data_trace_enabled ※true/falseのboolean 詳細CloudWatch メトリクスを有効化 metrics_enabled ※true/falseのboolean また、CloudWatch ログを有効化するためには、以下の「設定」で、CloudWatchLogsの書き込み権を持ったIAMロールを設定する必要がある。
このため、今回は以下のようにIAMロールを定義する。CloudWatchLogsの書き込みポリシについては、
AmazonAPIGatewayPushToCloudWatchLogsを使えとAWSのブログに書いてあった。################################################################################ # IAM Role for API Gateway Put CloudWatch Logs # ################################################################################ resource "aws_iam_role" "apigateway_putlog" { name = local.rest_api_putlog_role_name assume_role_policy = <<EOF { "Version": "2012-10-17", "Statement": [ { "Action": "sts:AssumeRole", "Principal": { "Service": "apigateway.amazonaws.com" }, "Effect": "Allow", "Sid": "" } ] } EOF } resource "aws_iam_role_policy_attachment" "apigateway_putlog" { role = "${aws_iam_role.apigateway_putlog.name}" policy_arn = "arn:aws:iam::aws:policy/service-role/AmazonAPIGatewayPushToCloudWatchLogs" }これを、以下のように
aws_api_gateway_accountで設定すれば良い。resource "aws_api_gateway_account" "my_api" { cloudwatch_role_arn = aws_iam_role.apigateway_putlog.arn }で、ここで油断してはならないのは、
aws_api_gateway_accountはそのままだとaws_api_gateway_method_settingsとの依存関係がないため、順序性が保証されず、ログ設定がエラーになってしまう。そのため、以下のように依存関係を定義しておく。resource "aws_api_gateway_method_settings" "all" { depends_on = [ aws_api_gateway_account.my_api, ] rest_api_id = "${aws_api_gateway_rest_api.my_api.id}" stage_name = "${aws_api_gateway_stage.prod.stage_name}" method_path = "*/*" settings { logging_level = "ERROR" } }カスタムアクセスのログ設定
この項目はなんか日本語が変な気が…。「の」は要らないような。
マネコン画面の日本語 Terraformの引数 アクセスログの有効化 access_log_settings ※ブロックに以下の項目を記載する なお、アクセスログの有効化をチェックすると、画面上では以下の項目が表示される。
これは、
aws_api_gateway_stageのリソースのaccess_log_settingsのブロックで定義する。
マネコン画面の日本語 Terraformの引数 Access Log Destination ARN destination_arn ログの形式 format ログの形式の出力例は、画面のボタンをポチっと押すか、AWSの開発者ガイドを参照。
この項目を有効にするためには、まずはCloudWatch Logsのリソースを作らなければいけないので、以下のように作成する。
resource "aws_cloudwatch_log_group" "apigateway_accesslog" { name = local.rest_api_accesslog_loggroup_name }次に、
aws_api_gateway_stageに以下のように定義したアクセスログを設定すれば良い。resource "aws_api_gateway_stage" "prod" { stage_name = "prod" rest_api_id = aws_api_gateway_rest_api.my_api.id deployment_id = aws_api_gateway_deployment.dev.id access_log_settings { destination_arn = aws_cloudwatch_log_group.apigateway_accesslog.arn format = "$context.identity.sourceIp $context.identity.caller $context.identity.user [$context.requestTime] \"$context.httpMethod $context.resourcePath $context.protocol\" $context.status $context.responseLength $context.requestId" } }X-Ray トレース
これはシンプルに設定可能。
マネコン画面の日本語 Terraformの引数 X-Ray トレースの有効化 xray_tracing_enabled ステージ変数タブ
これは
variablesの引数で渡すことができる。
Terraformのドキュメントでは、(Optional) A map that defines the stage variables
と書かれているので、渡し方に注意が必要。
SDKの生成/エクスポート/デプロイ履歴/ドキュメント履歴タブ
この辺は設定項目ではなく参照系であるため、特にTerraformに紐づく項目は無い。
Canaryタブ
うーん、これはTerraform未実装な気がする。
CLIのドキュメントには
--canary-settingsオプションが存在するが、Terraformでは難しいということだろうか(いずれにしろ、CodeDeployのような便利なCanaryリリースではないので、あまり使えないのだが)。デプロイについて
API Gatewayのリソースについては、以下のようにデプロイを定義する。
triggersは、「このリソースが変更されたら再デプロイする」という機能らしい。
詳細は、公式のNotesを参照。
lifecycleは、スキマを作らないようにするための施策だ。resource "aws_api_gateway_deployment" "dev" { rest_api_id = aws_api_gateway_rest_api.my_api.id stage_name = "dev" triggers = { redeployment = sha1(join(",", list( jsonencode(module.get_user), jsonencode(module.put_user), jsonencode(aws_api_gateway_gateway_response.missing_authentication_token), ))) } lifecycle { create_before_destroy = true } }ただ、これだけだと、devにデプロイした機能がprodまで伝播してくれない。
うーむ、prod側にも設定を入れるべきなのだろうか。それとも、そこは別契機でデプロイするということか。
- 投稿日:2020-07-25T22:23:33+09:00
【AWS】IAM設定
アカウント使用の流れ
- 開始前知っておくべきポイント
- アカウント申請
- ログイン
- IAM設定
- MFA多要素認証
- アカウント削除
参考資料
操作の詳細は、「Youtube」の「Amazon Web Services Japan 公式」を参照
https://www.youtube.com/watch?v=Z1I4dsN7dhAIAM設定
普段の操作は、ルートユーザーの使用を避けるため、適切な権限を持つのユーザーを追加する
1.アドミニストレーター
基本的に全てのアクセス権限を持っているが、使えない機能がある(請求書、支払い情報などは見えない)
① AWS マネジメントコンソール
② Identity and Access Management (IAM)
「ユーザー」をクリックする
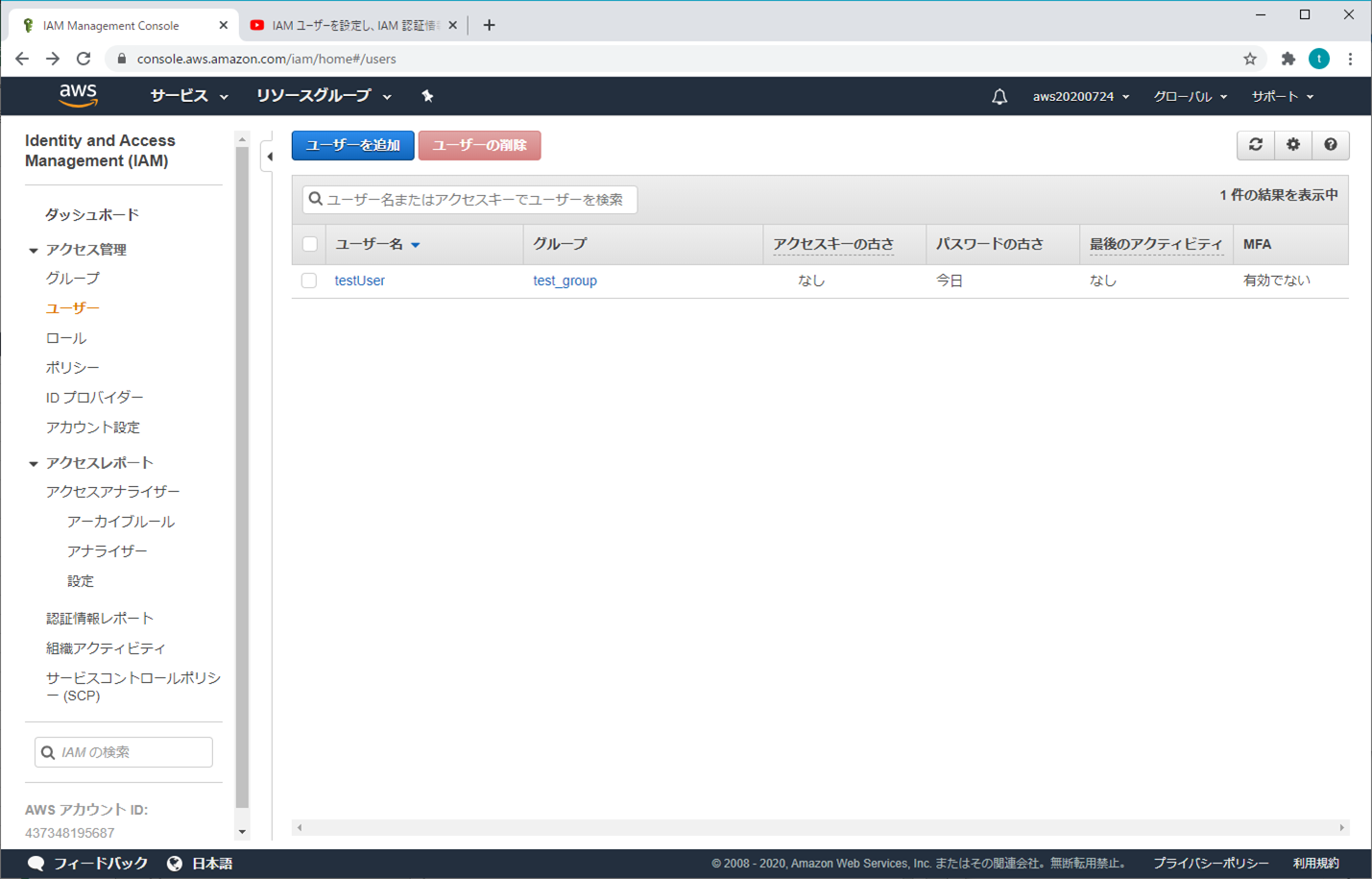
「ユーザーを追加」をクリックする
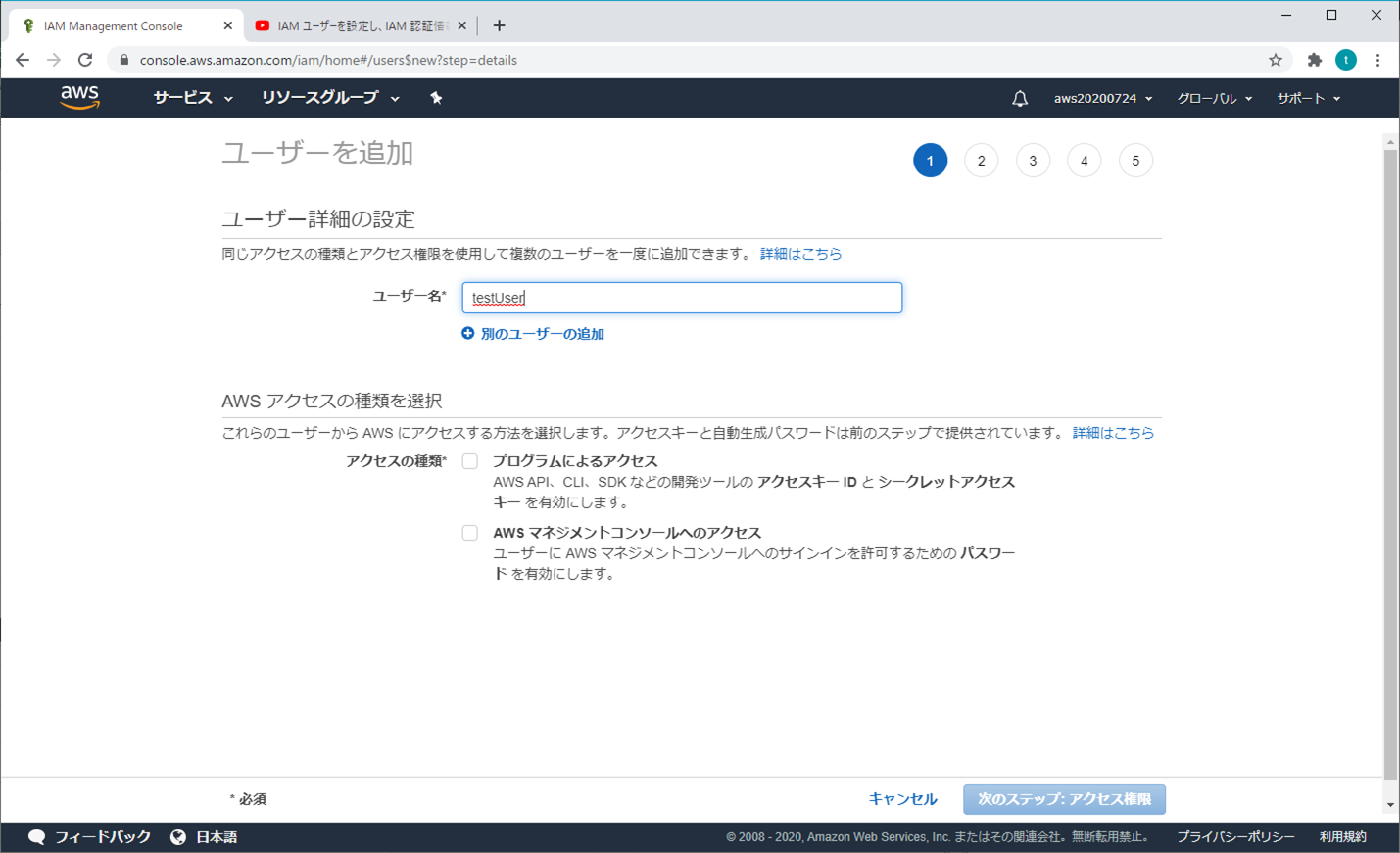
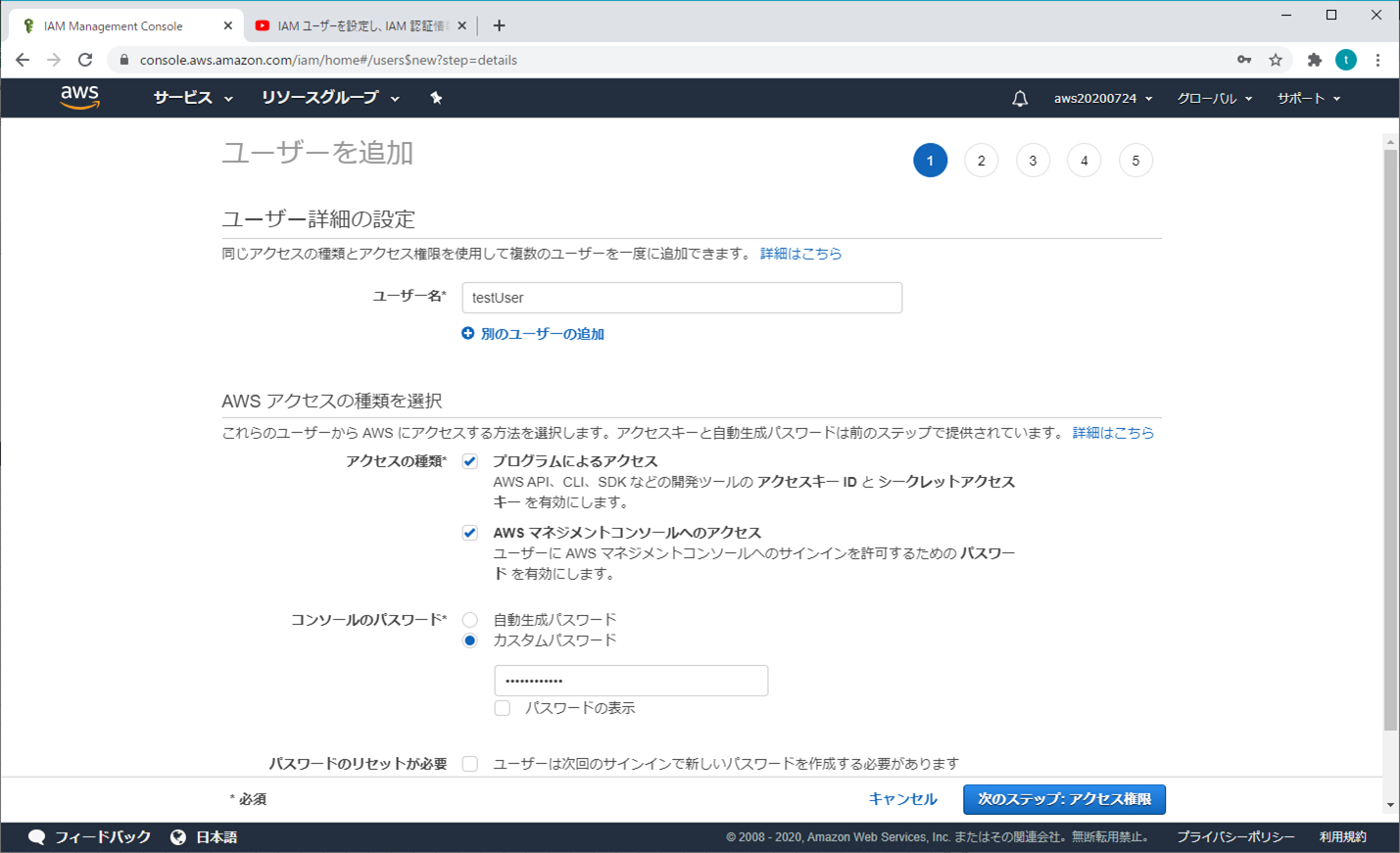
③ ユーザーを追加 - ユーザー詳細の設定
ユーザー名を入力する。
アクセスの種類とカスタマイズパスワードを選択し、パスワードを入力し、「次のステップ:アクセス権限」をクリックする
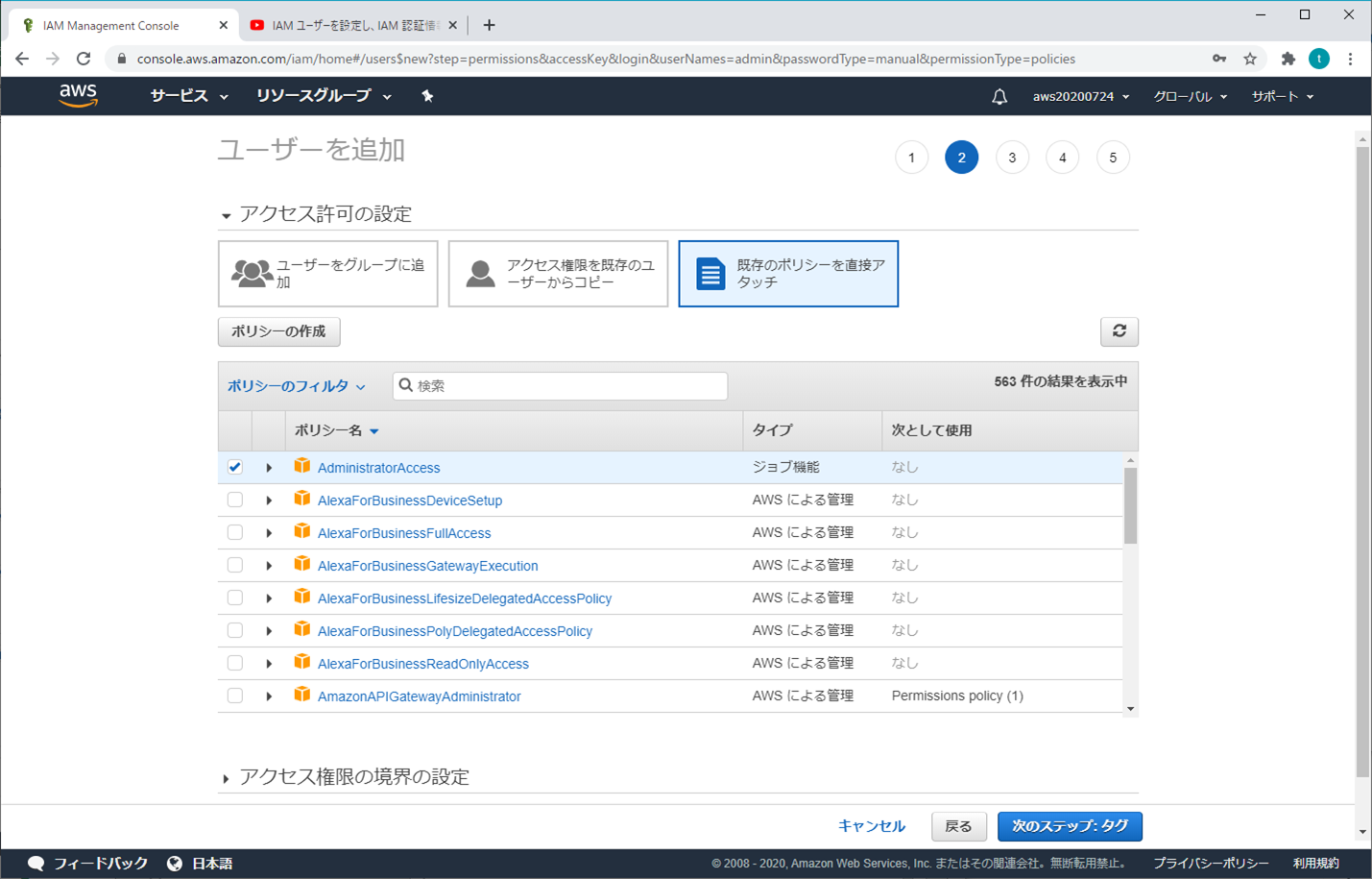
④ ユーザーを追加 - アクセス許可の設定
既存のポリシーを直接アタッチから「AdministratorAccess」を選択して、「次のステップ:タブ」をクリックする
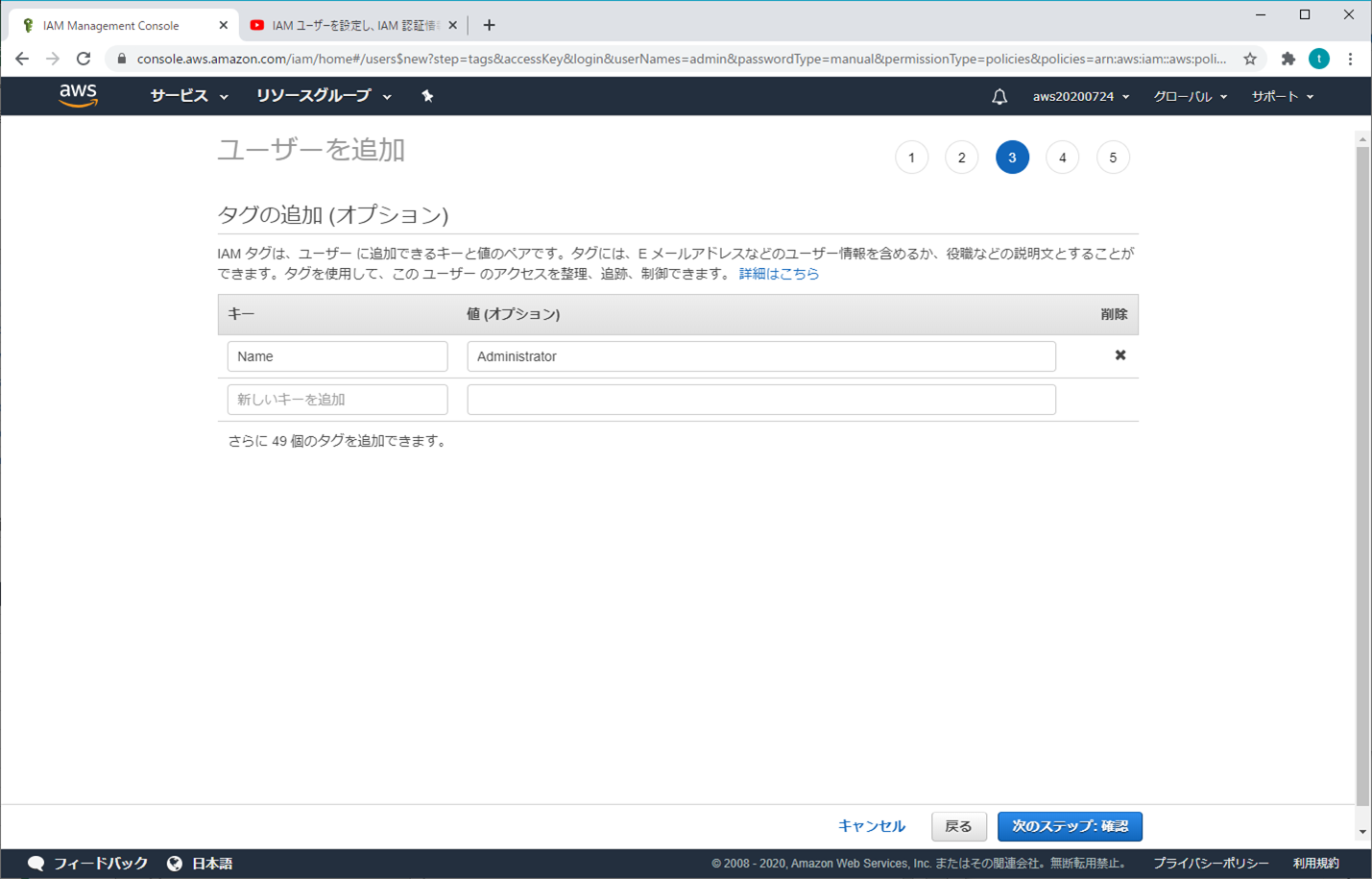
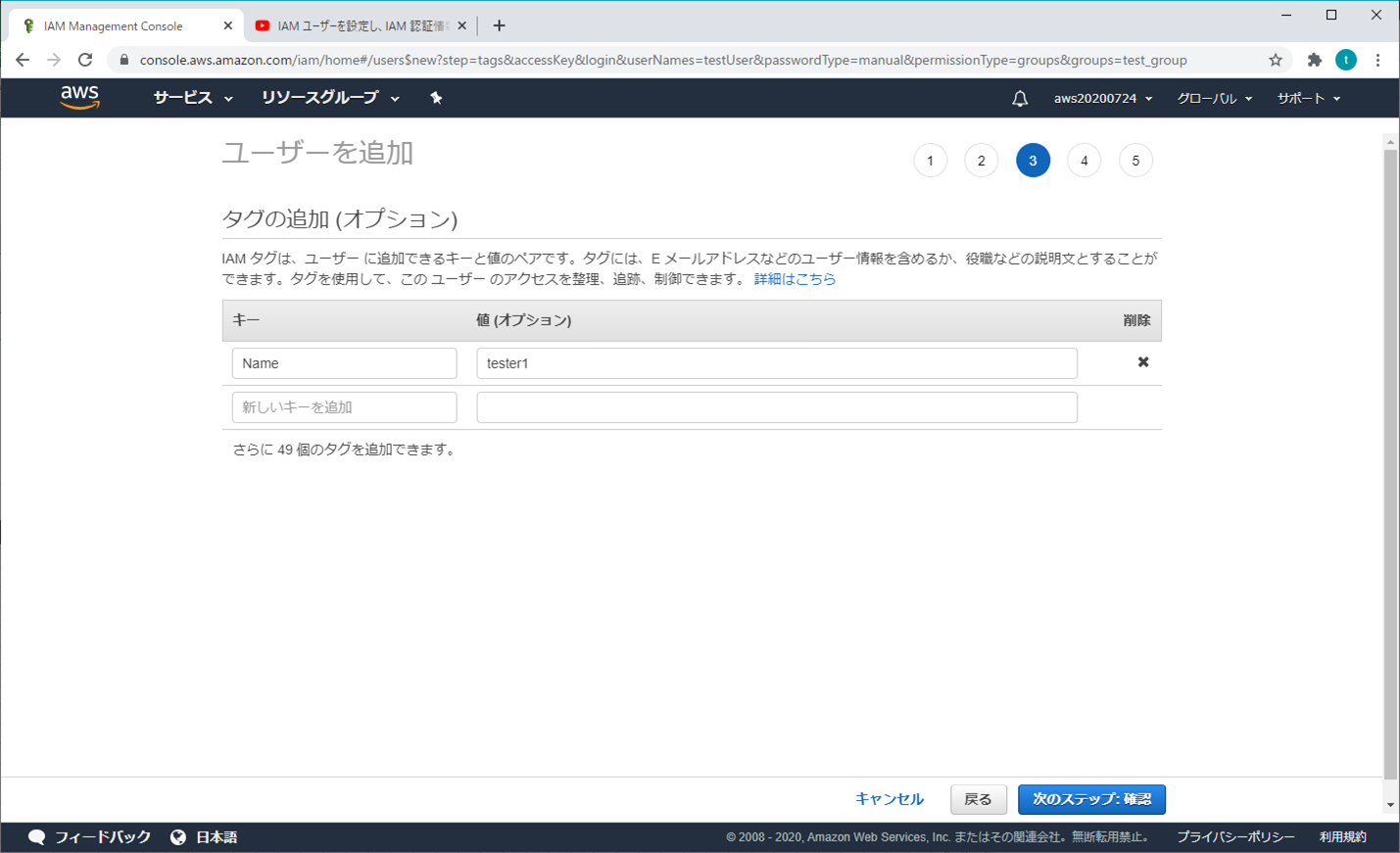
⑤ ユーザーを追加 - タブの追加(オプション)
キーと値を入力し、「次のステップ:確認」をクリックする
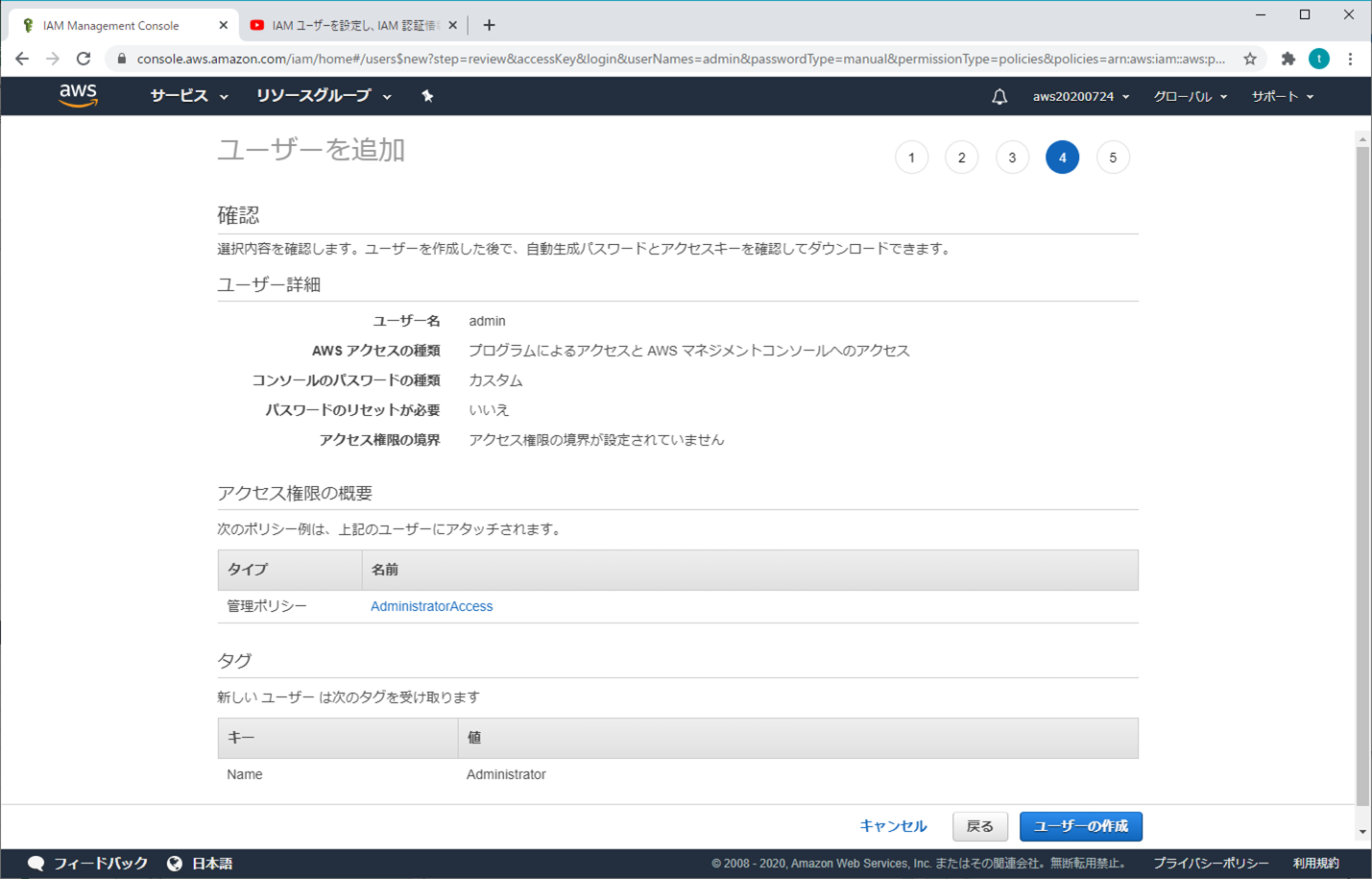
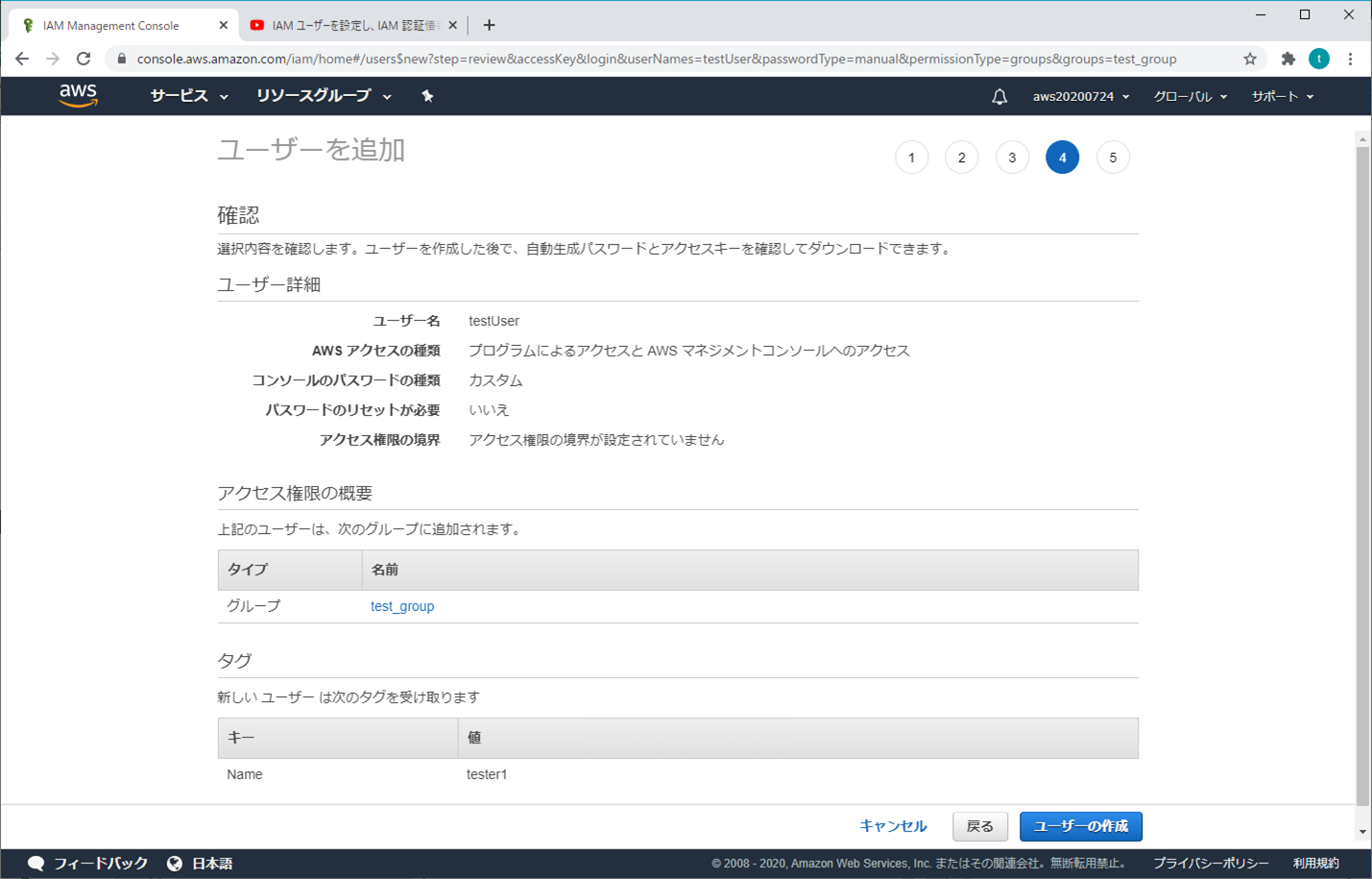
⑥ ユーザーを追加 - 確認
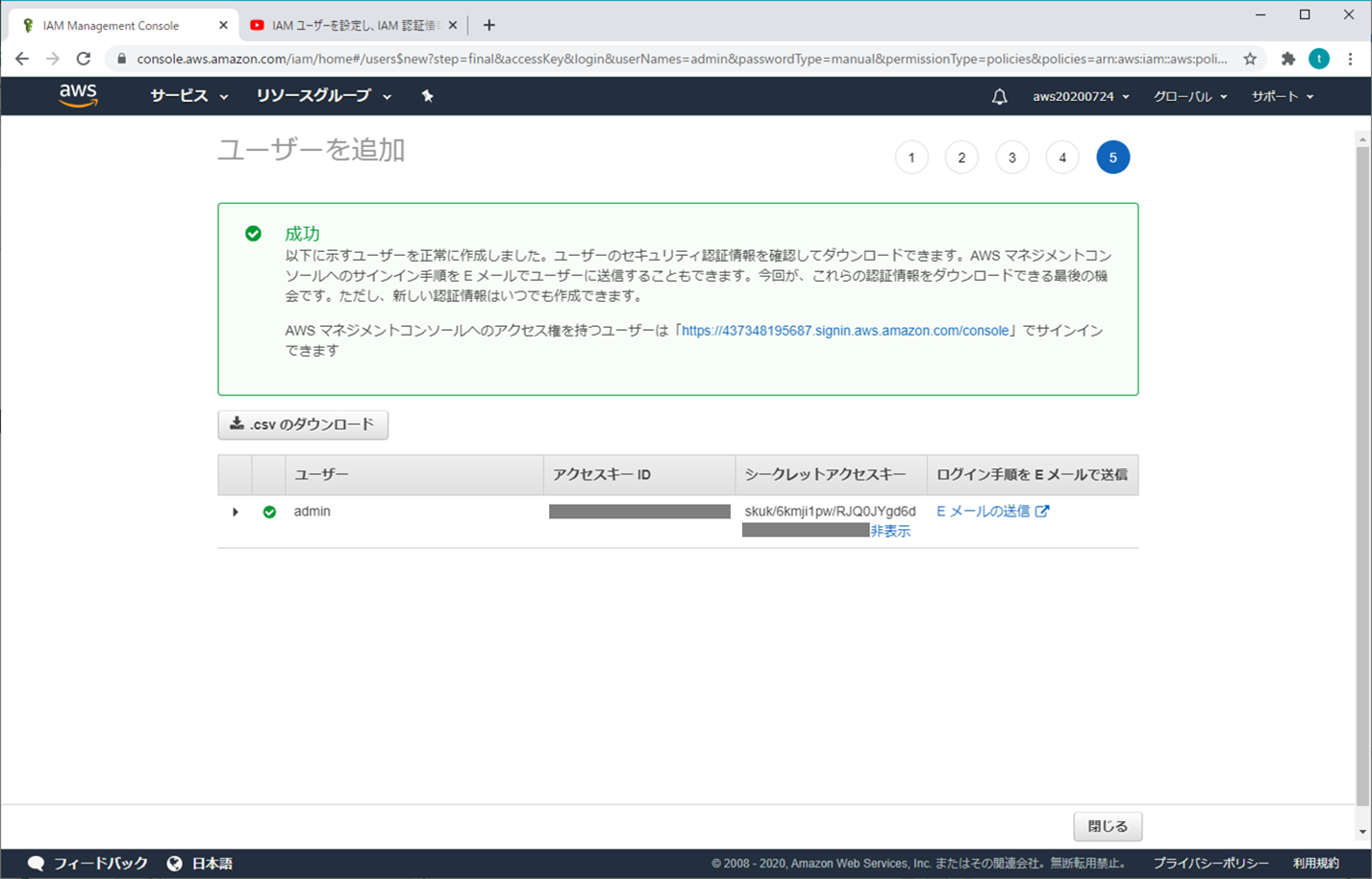
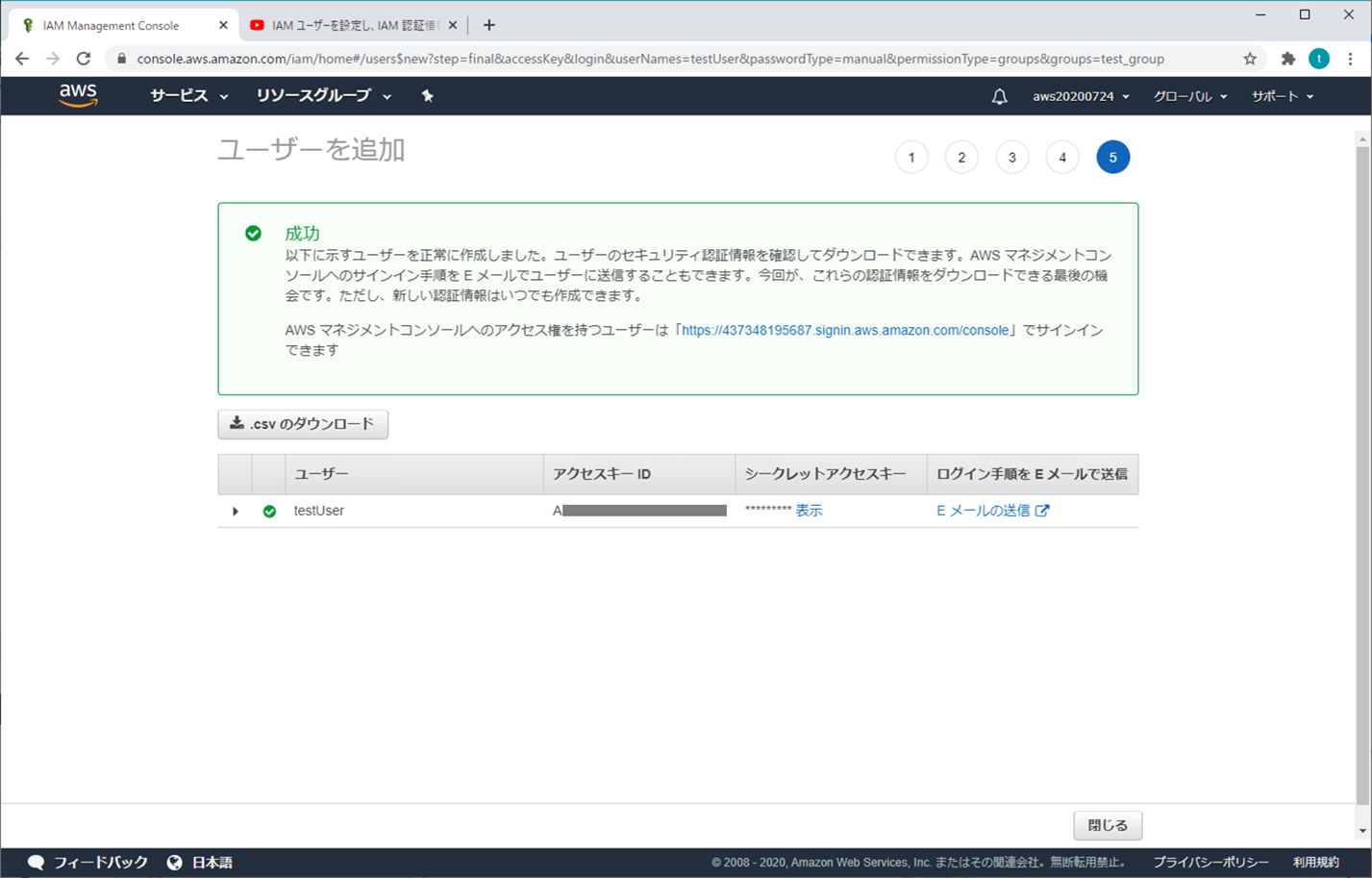
⑦ 成功
「アクセスキー」と「シークレットアクセスキー」をメモしておく(「.csvのダウンロード」クリックしてもOK)
→ アカウントとパスワードがなくても、この2つでAWSにアクセスができるから、大事に保管しないといけない
2.普通のユーザー(開発、テストなど)
① AWS マネジメントコンソール
② Identity and Access Management (IAM)
「ユーザー」をクリックする
「ユーザーを追加」をクリックする
③ ユーザーを追加 - ユーザー詳細の設定
ユーザー名を入力する
アクセスの種類とカスタマイズパスワードを選択し、パスワードを入力し、「次のステップ:アクセス権限」をクリックする
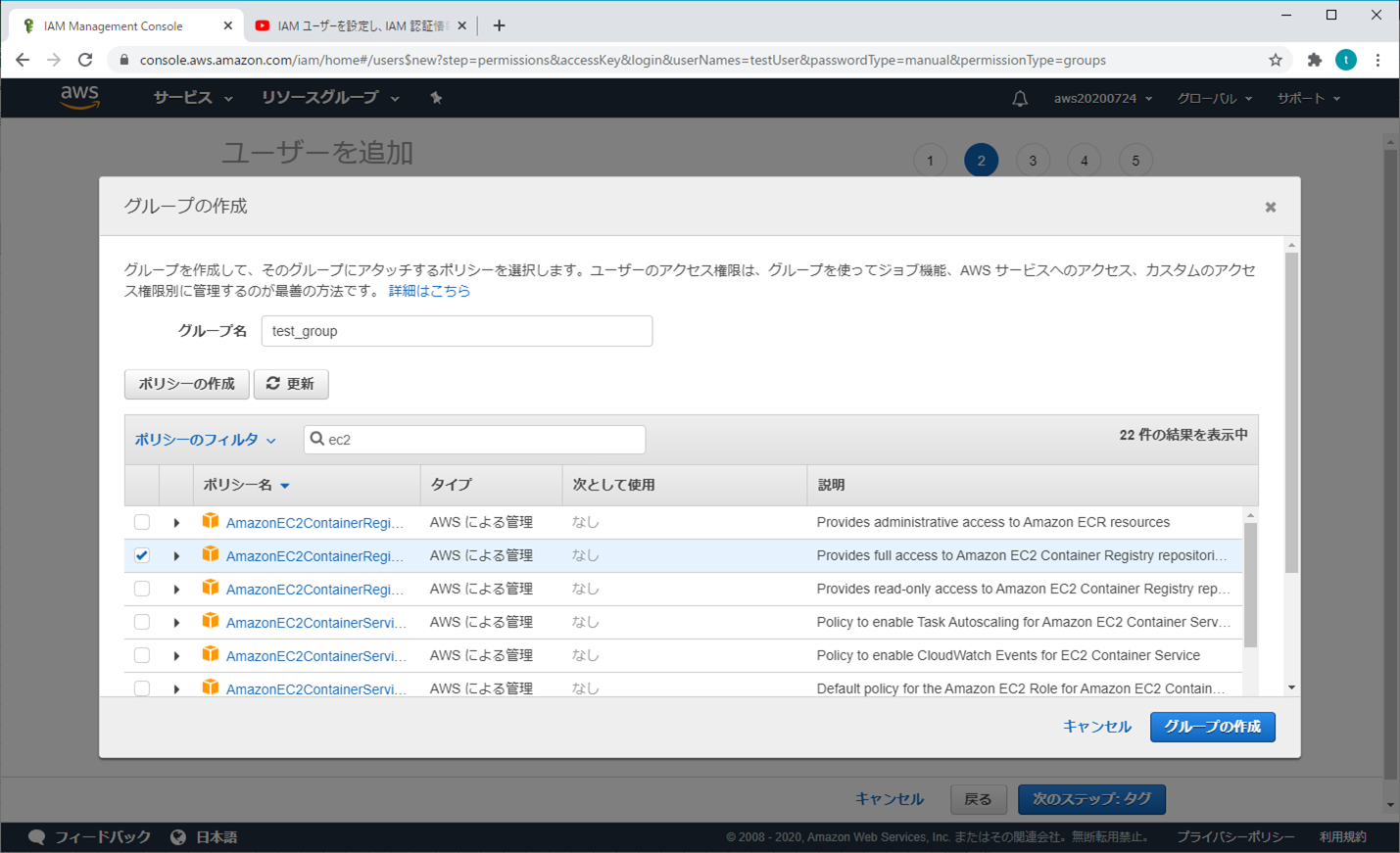
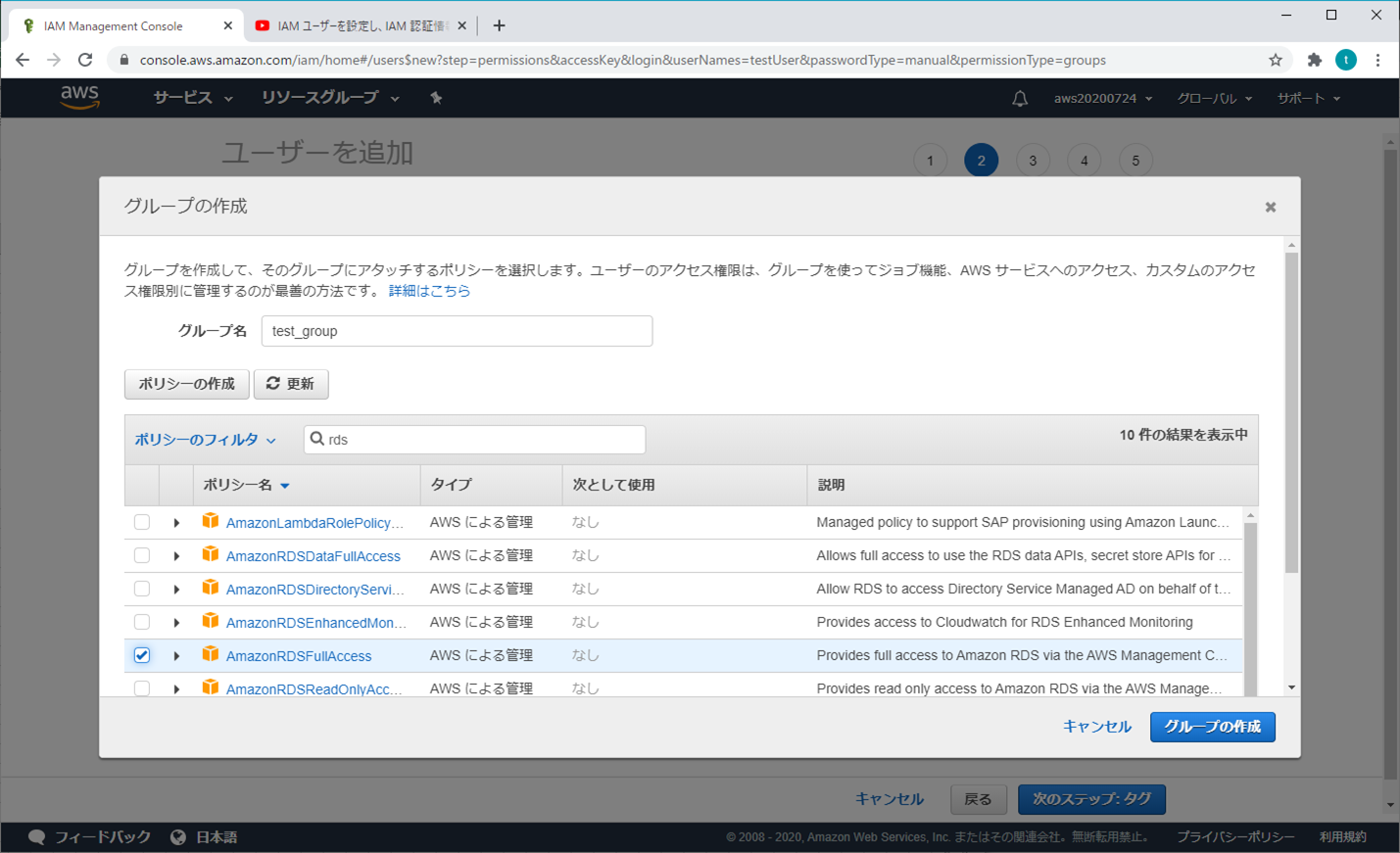
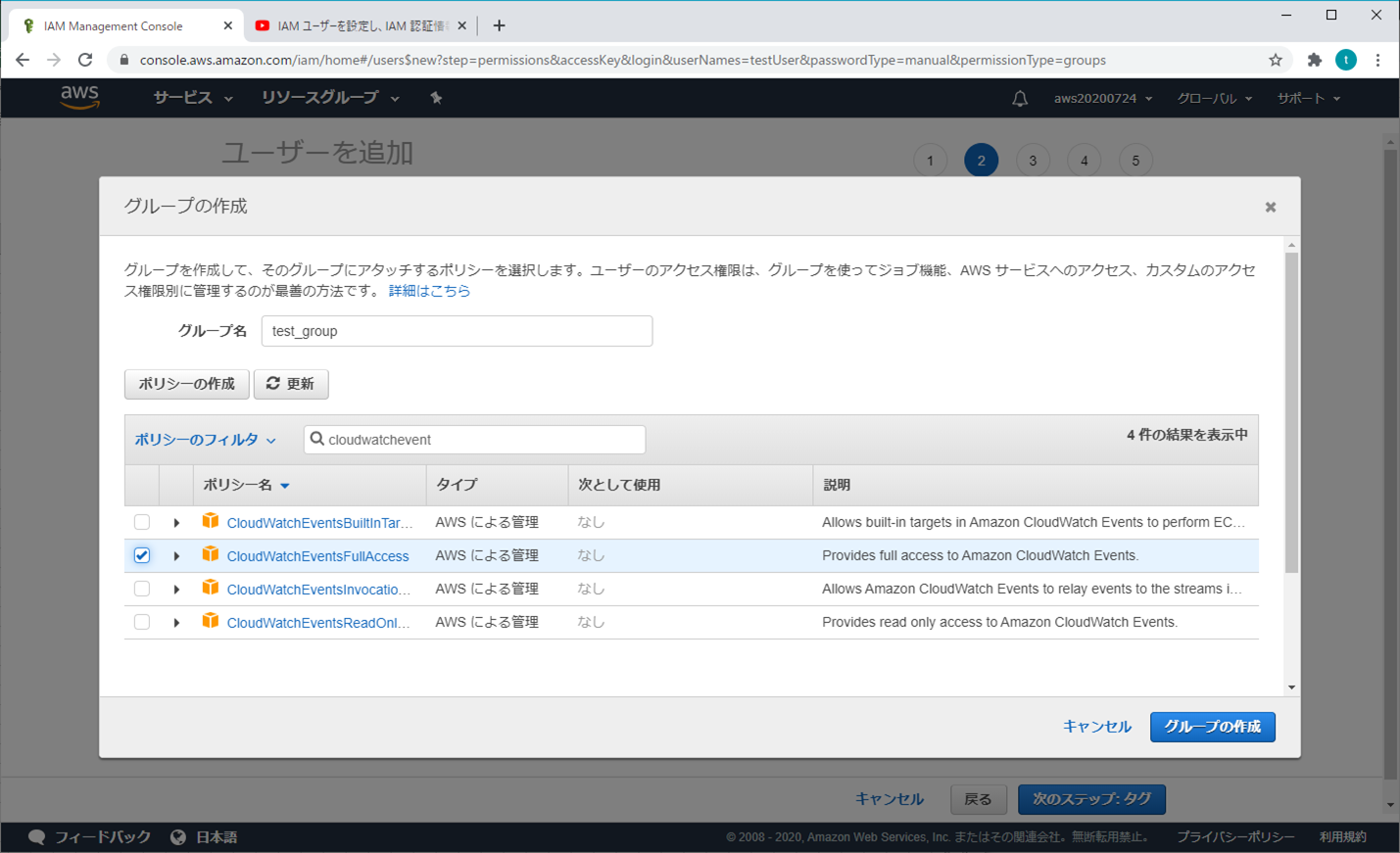
④ ユーザーを追加 - アクセス許可の設定
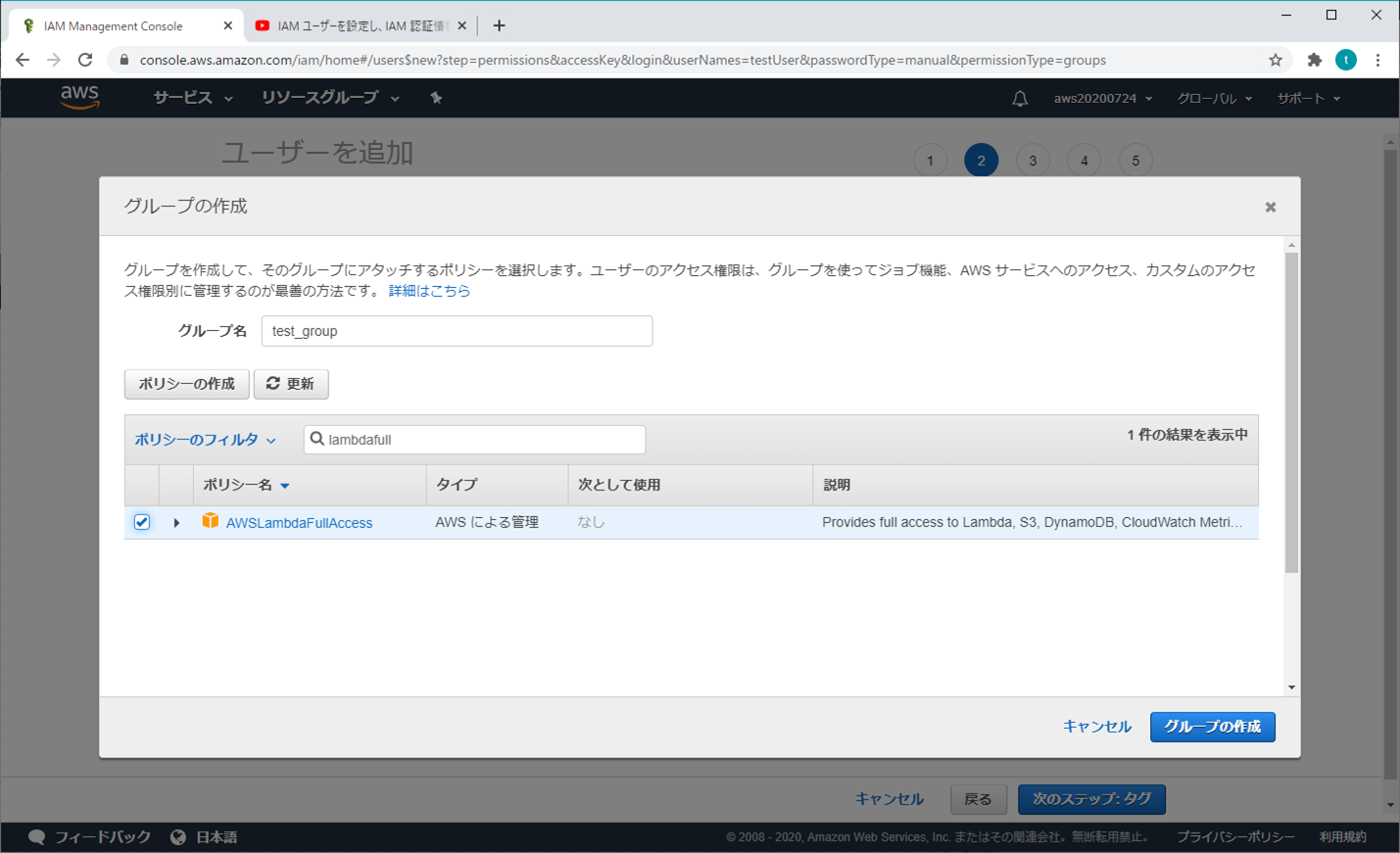
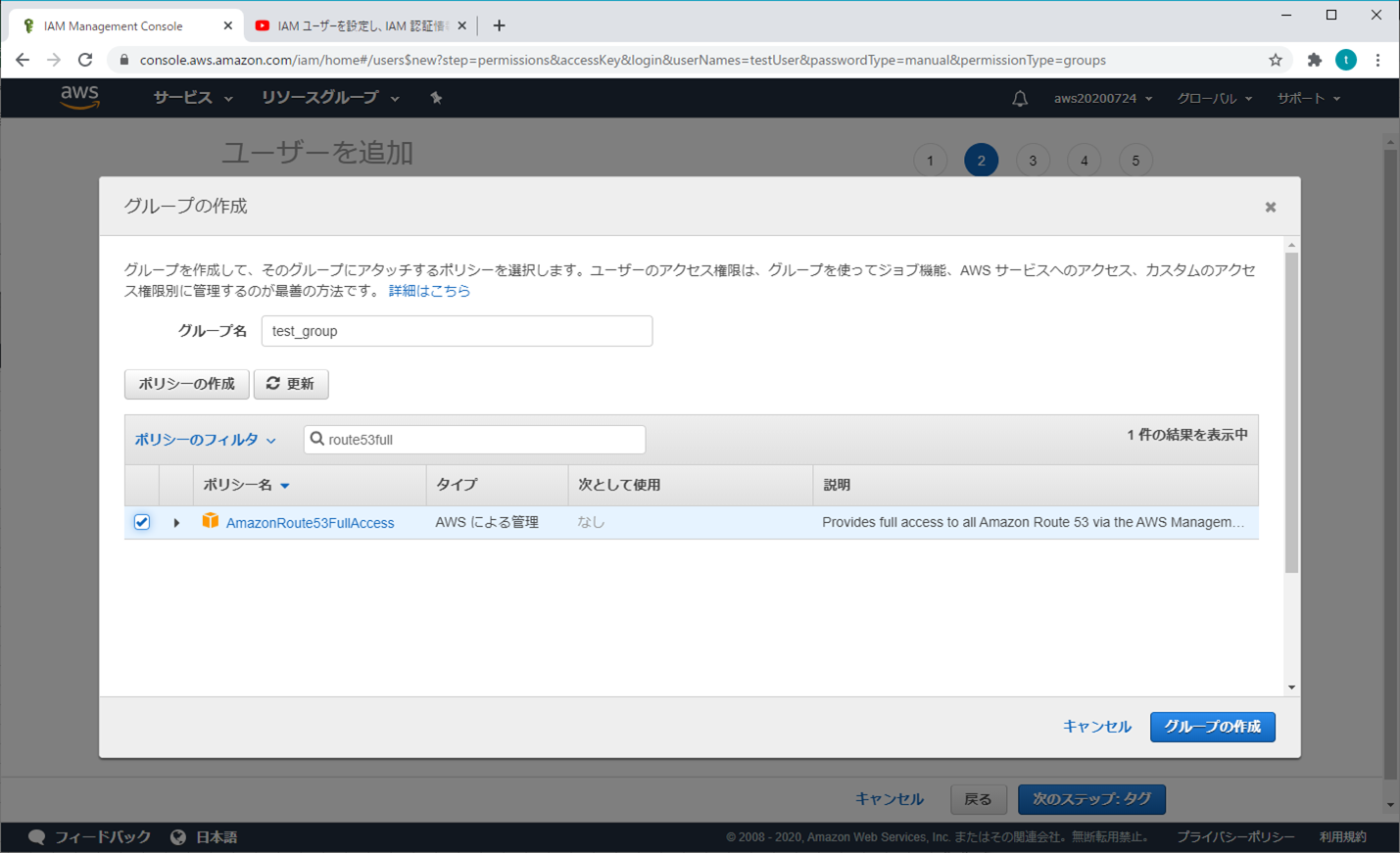
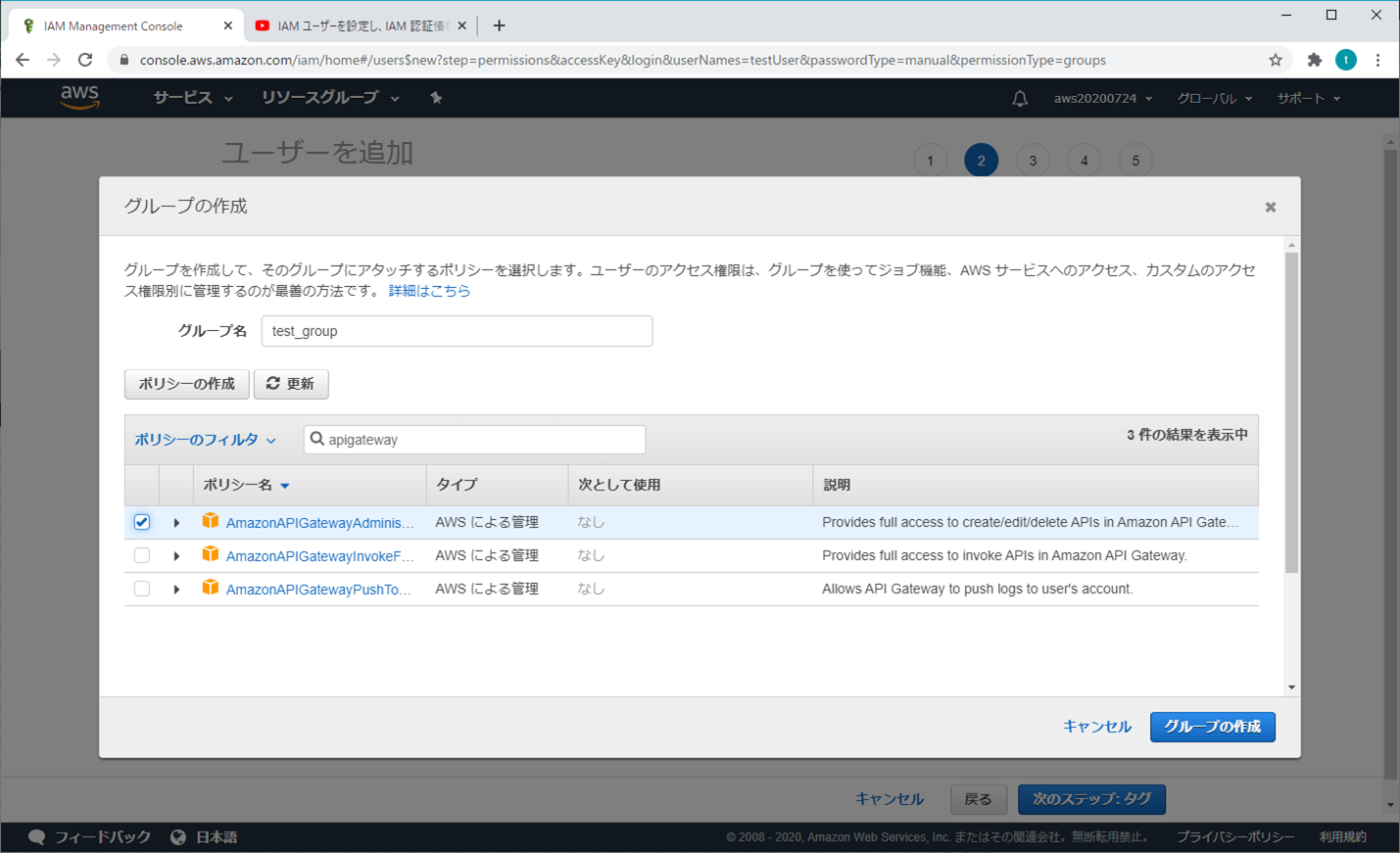
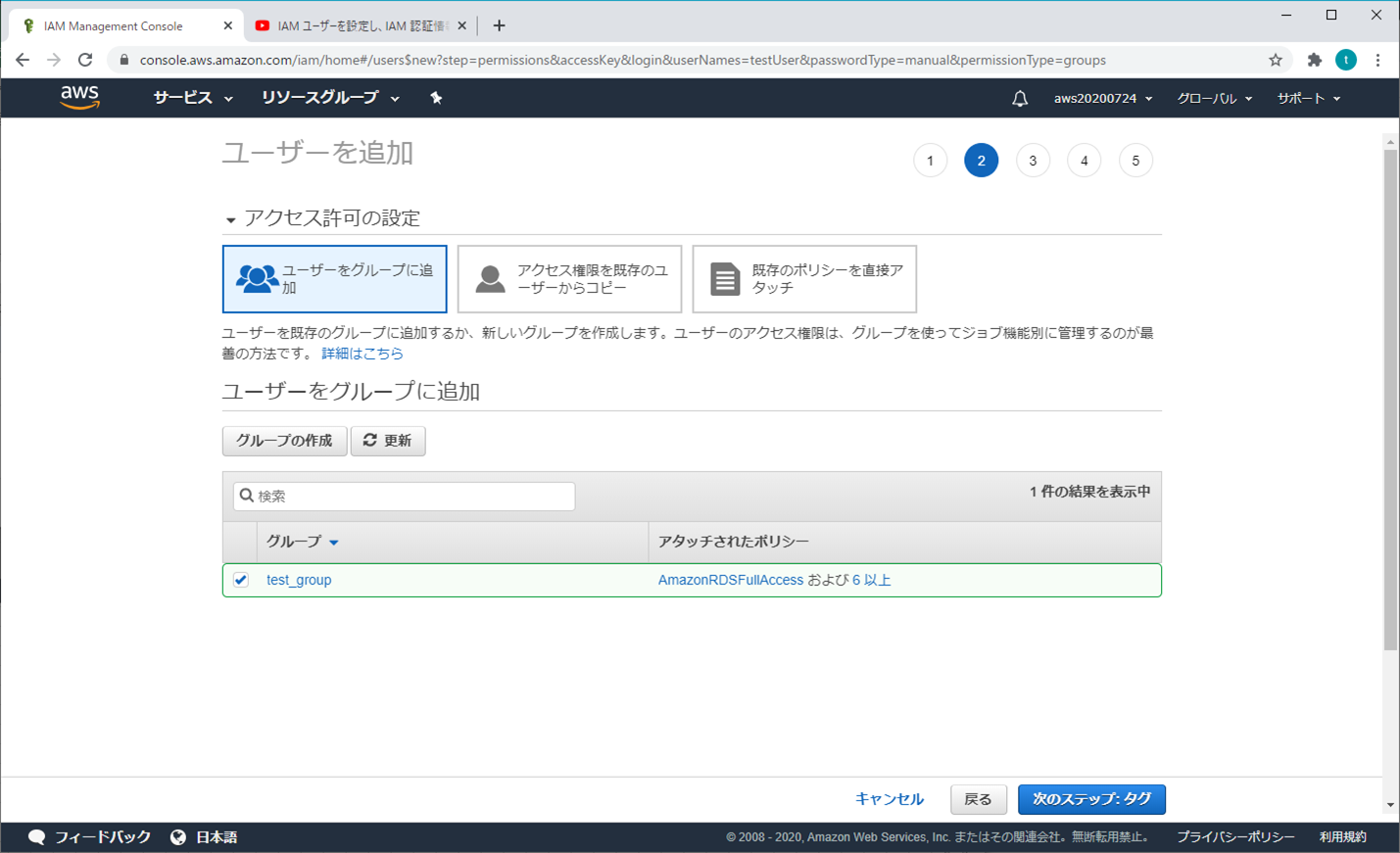
「グループの作成」をクリックする(個人的な推奨)
必要な項目(オプション)を選択し、「グループの作成」をクリックする
「次のステップ:タブ」をクリックする
⑤ ユーザーを追加 - タブの追加(オプション)
キーとアタッチされたポリシーを入力し、「次のステップ:確認」をクリックする
⑥ ユーザーを追加 - 確認
問題がなければ、「ユーザーの作成」をクリックする
⑦ 成功
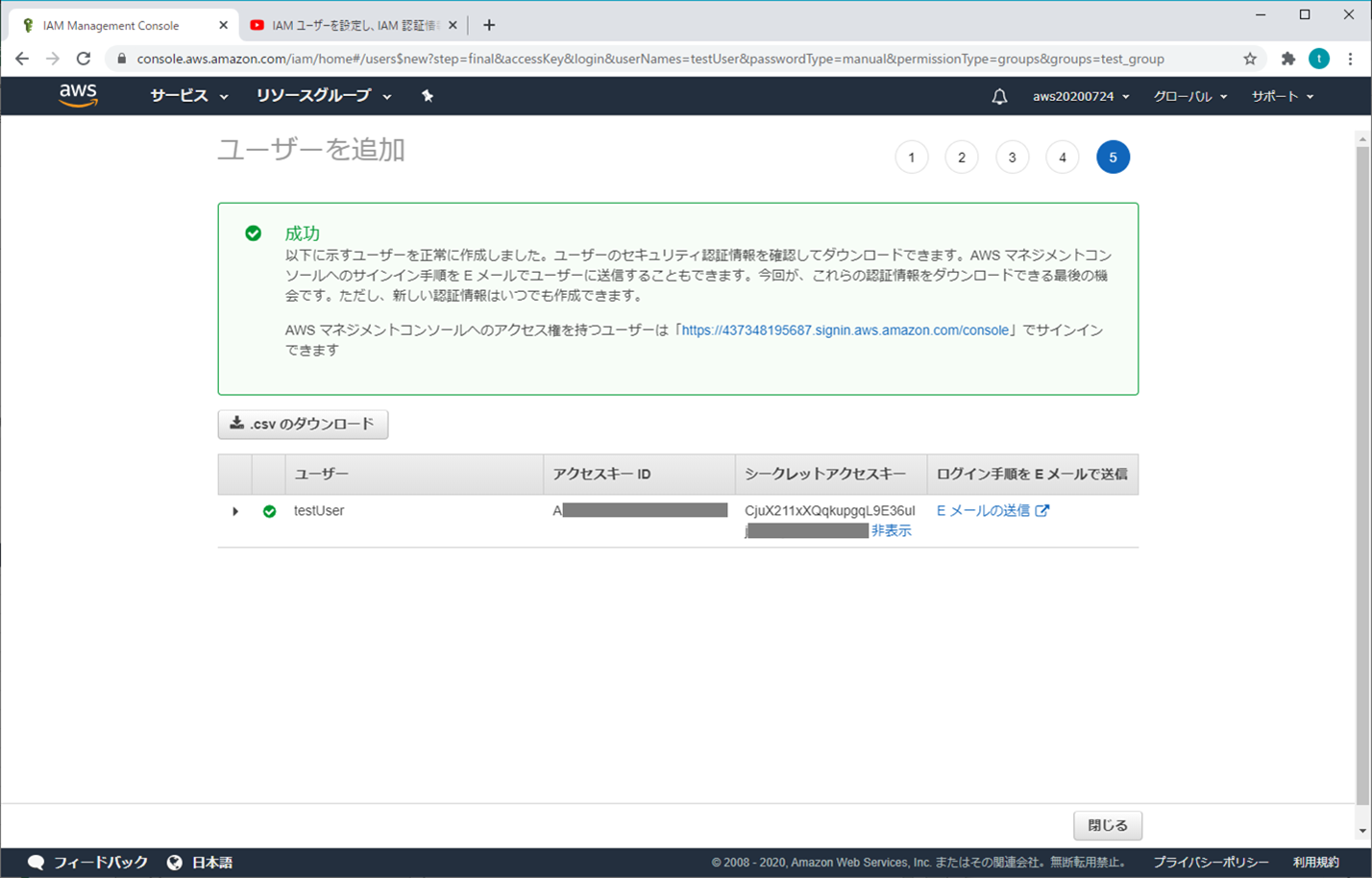
シークレットアクセスキーにて、「表示」をクリックして展開させる
「アクセスキー」と「シークレットアクセスキー」をメモしておく(「.csvのダウンロード」クリックしてもOK)
⑧ ユーザーの追加が終了







- 投稿日:2020-07-25T22:23:33+09:00
【AWS】IAM設定 - ユーザーやグループを管理と作成
アカウント使用の流れ
- 開始前知っておくべきポイント
- アカウント申請
- ログイン
- IAM設定
- MFA多要素認証
- アカウント削除
参考資料
操作の詳細は、「Youtube」の「Amazon Web Services Japan 公式」を参照
https://www.youtube.com/watch?v=Z1I4dsN7dhAIAM設定
普段の操作は、ルートユーザーの使用を避けるため、適切な権限を持つのユーザーを追加する
1.アドミニストレーター
基本的に全てのアクセス権限を持っているが、使えない機能がある(請求書、支払い情報などは見えない)
① AWS マネジメントコンソール
② Identity and Access Management (IAM)
「ユーザー」をクリックする
「ユーザーを追加」をクリックする
③ ユーザーを追加 - ユーザー詳細の設定
ユーザー名を入力する。
アクセスの種類とカスタマイズパスワードを選択し、パスワードを入力し、「次のステップ:アクセス権限」をクリックする
④ ユーザーを追加 - アクセス許可の設定
既存のポリシーを直接アタッチから「AdministratorAccess」を選択して、「次のステップ:タブ」をクリックする
⑤ ユーザーを追加 - タブの追加(オプション)
キーと値を入力し、「次のステップ:確認」をクリックする
⑥ ユーザーを追加 - 確認
⑦ 成功
「アクセスキー」と「シークレットアクセスキー」をメモしておく(「.csvのダウンロード」クリックしてもOK)
→ アカウントとパスワードがなくても、この2つでAWSにアクセスができるから、大事に保管しないといけない
2.普通のユーザー(開発、テストなど)
① AWS マネジメントコンソール
② Identity and Access Management (IAM)
「ユーザー」をクリックする
「ユーザーを追加」をクリックする
③ ユーザーを追加 - ユーザー詳細の設定
ユーザー名を入力する
アクセスの種類とカスタマイズパスワードを選択し、パスワードを入力し、「次のステップ:アクセス権限」をクリックする
④ ユーザーを追加 - アクセス許可の設定
「グループの作成」をクリックする(個人的な推奨)
必要な項目(オプション)を選択し、「グループの作成」をクリックする
「次のステップ:タブ」をクリックする
⑤ ユーザーを追加 - タブの追加(オプション)
キーとアタッチされたポリシーを入力し、「次のステップ:確認」をクリックする
⑥ ユーザーを追加 - 確認
問題がなければ、「ユーザーの作成」をクリックする
⑦ 成功
シークレットアクセスキーにて、「表示」をクリックして展開させる
「アクセスキー」と「シークレットアクセスキー」をメモしておく(「.csvのダウンロード」クリックしてもOK)
⑧ ユーザーの追加が終了
- 投稿日:2020-07-25T22:09:09+09:00
SageMakerで利用できるDeepChemのためDockerfile
SageMakerで利用できるDeepChemのためDockerfile
TL;DR
SageMakerでトレーニングのために使用できるDeepChem用のDockerfileです。
バージョン依存にするため、取り急ぎ以下のバージョン専用です。
- deepchem-2.3.0
- python-3.6
- tensorflow-1.14.0
Dockerfileにより独自コンテナでSageMaker上でトレーニングする方法はSageMakerで独自コンテナでトレーニングする方法を参照してください。
Dockerfile
FROM nvidia/cuda:10.0-cudnn7-devel ENV PATH /opt/conda/bin:$PATH ENV PYTHON_VERSION 3.6 ENV PATH /usr/local/cuda-10.1/bin:$PATH ENV LD_LIBRARY_PATH /usr/local/cuda-10.0/lib64:$LD_LIBRARY_PATH ENV LD_LIBRARY_PATH /usr/local/cuda10.0/targets/x86_64linux:$LD_LIBRARY_PATH RUN apt-get update --fix-missing && apt-get install -y wget bzip2 ca-certificates \ libglib2.0-0 libxext6 libsm6 libxrender1 \ git mercurial subversion RUN wget --quiet https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda.sh && \ /bin/bash ~/miniconda.sh -b -p /opt/conda && \ rm ~/miniconda.sh && \ ln -s /opt/conda/etc/profile.d/conda.sh /etc/profile.d/conda.sh && \ echo ". /opt/conda/etc/profile.d/conda.sh" >> ~/.bashrc && \ echo "conda activate base" >> ~/.bashrc # deepchemはscikit-learnが0.20.1以外だと動作しないため注意が必要です。 RUN conda install scikit-learn==0.20.1 RUN conda install -c deepchem -c rdkit -c conda-forge -c omnia deepchem-gpu=2.3.0 python=3.6 --yes RUN pip install sagemaker-containers # deepchemの後にtensorflow-gpuを入れ直します。そうしないとGPUが利用されません。 RUN pip uninstall tensorflow --yes RUN pip install tensorflow-gpu==1.14.0 # Copies the training code inside the container COPY code/train.py /opt/ml/code/train.py # Defines train.py as script entrypoint ENV SAGEMAKER_PROGRAM train.pySageMakerが利用するCUDAのバージョンは固定されている
実際に実行すると
10.0とマイナーバージョンまで指定してライブラリを検索している様です。
このため、10.1や10.2など必要なライブラリの一部が見つからないとエラーになります。scikit-learnは最新だとdeepchemが必要なモジュールを見つけられない
最新のscikit-learnを利用するとdeepchemがscikit-learnに含まれると想定している
joblibを見つけられずにエラーになります。
また、あまりバージョンを下げすぎるとjaccard_similarity_scoreの名前が変わっていて見つけられません。
このため、0.20.1を指定しています。tensorflow-gpuはdeepchemのインストール後に明示的に再インストールする
deepchemの前に
tensorflow-gpuをインストールしてもtensorflowがインストールされていました。
このため、deepchemのインストール後にtensorflowをアンインストールして明示的にtensorflow-gpuをインストールします。GPUを利用していることを確認する方法
from tensorflow.python.client import device_lib print(device_lib.list_local_devices()) print(f'Use gpu: {tf.test.is_gpu_available()}')

- 投稿日:2020-07-25T21:55:43+09:00
samで構築したBFFのCORSエラーが解消できなくて困った話
はじめに
こんにちは
みなさん、AWS sam使っているでしょうか。
API gateway + Lambdaを利用したアプリケーションの構築や更新頻度の多いアプリケーションではよく利用されるsamですが、今回iOS系でCORSエラーが解消できなくて3、4ヶ月ほど困っていたので備忘録がてら書き残しておこうと思います。
※弊社コンプライアンス的なところが怖いので必要ない部分は特に記載してないです。TL;DR
- Api gatewayのCORSの設定は明示的に記載する
構成図
プラットフォームはiOS/Androidで以下のような構成図をとっています。
API GatewayとLambdaはAWS samで構築されており、CI/CDパイプラインを通してsam templateからデプロイを行います。
template.ymlはこんな感じでした。
開発メインのメンバーが初期に記載した部分で、これまでこの部分の書き換え等はほぼ行われていませんでした。
CORSの設定が全てワイルドカードになっていますね。AWSTemplateFormatVersion: '2010-09-09' Transform: AWS::Serverless-2016-10-31 Description: Googlesensei # Global Settings Api: Cors: AllowOrigin: "'*'" AllowHeaders: "'*'" AllowMethods: "'*'" Resources: // このあとも続いてるよ事象
iOS12系以下の端末でAPにリクエストを送ると CORSエラーとなり、403で弾かれていました。
iOS13系、AndroidではCORSエラーが発生することがなく、エラーなくアプリを利用することができていました。iOS13系はいけるのに、12系以下はエラーを返す理由は明確に調査は行っていませんが。おそらくバージョン間でSafariのCORS設定に差分があり、たまたま13系は突破できたのではないかと推測しています。
調査
samと手動で構築した際にAPI gatewayに差分がありました。
手動で構築したAPI gatewayはマネジメントコンソールが裏側でAPIのレスポンスのモデルを作成し、自動的にモデルをセットしてくれていましたが、samで構築したAPIにはモデルが存在せずメソッドレスポンスが指定されていない状態になっていました。
そしてこれに対しマネジメントコンソールから手動で構築した場合と同じ設定にしてやることで、iOS12系がCORSエラーを取得することなくアプリを利用することができるようになりました。
しかし、 API gatewayのメソッドレスポンスの設定はあくまでも API gateway側でレスポンスの整形を行う ことであり、今回のケースのようにLambda Proxyを利用している場合はLambda内で正しいレスポンスの形式で返却することができているなら不要なのです。
これで以下の2点が整理できました。
- 正しく設定が行われていればiOS12系でもアプリ利用が可能
- API gatewayの設定かLambdaのレスポンスに問題が発生している。Lambdaのレスポンス
Lambda Proxy統合を利用している場合、Lambdaのレスポンスは以下の形式にする必要があります。
{ "isBase64Encoded": true|false, "statusCode": httpStatusCode, "headers": { "headerName": "headerValue", ... }, "multiValueHeaders": { "headerName": ["headerValue", "headerValue2", ...], ... }, "body": "..." }Lambdaの資源を見直すとこの形式になっていたのでLambdaに問題がないことがわかりました。
API gatewayの設定
以下になっていました。見た感じ特別な設定は見当たりませんね。
modelsの設定なども試しましたが、AWS samではメソッドレスポンスを設定するプロパティが無く、Cloudformation記法で書くためにはtemplateの大幅改造が必要だったのでやりたくない、別の視点から調査をすることにしました。Api: Type: AWS::Serverless::Api TracingEnabled: X-Rayの利用 Properties: Name: Api gatewayの名前 StageName: Api gatewayのステージ名 Auth: // 認可の設定 AccessLogSetting: // アクセスログの設定CORS設定の見直し
iOS12系以下で表示されているエラーの内容を改めて確認してみました。
Request header field Authorization is not allowed by Access-Control-Allow-Headers.AuthorizationがHeaderで渡ってないみたいですね。
Access-Control-Allow-Headersで調べてみると、こんな記載がみつかりました。※markdownの仕様上消えちゃうので大文字で。* (ワイルドカード)
"*" の値は、資格情報のないリクエスト (HTTP Cookie や HTTP の認証情報のないリクエスト) の特殊なワイルドカード値です。認証情報付きのリクエストでは、特別な意味のない "*" というヘッダー名として扱われます。なお、 Authorization ヘッダーはワイルドカードで表すことができず、常に明示的に列挙する必要があります。IAMを使っているのでワイルドカードをやめて、Authorizationも含めて明示的に記述をしてみます。
細かく言うと、以下の3つのリソースを修正しました。
- API gateway
- Cloudfront
- S3
API gateway
Api: Cors: AllowOrigin: "'*'" AllowHeaders: "'Origin, Authorization, Accept, X-Requested-With, Content-Type, x-amz-date, X-Amz-Security-Token'" AllowMethods: "'POST, GET, OPTIONS, DELETE, PATCH, PUT'" AllowCredentials: "'true'"AllowOriginについては、ローカルからのアクセスもあるのでワイルドカードを残しました。検証したところ問題なく動作したのでここはワイルドカードでも良さそうです。
まだ自分でも精査できていないのですが、この記事を書いている最中にMDN Web Docsから Headersの一部は常に許可されているので記述する必要がない という記載もみつけたので、もう少し記述を減らせそうですね。
Cloudfront
CloudfrontのWhitelistにAuthorizationを追加。
S3
S3のCORSの設定も明示的に記述します。
<?xml version="1.0" encoding="UTF-8"?> <CORSConfiguration xmlns="http://s3.amazonaws.com/doc/2006-03-01/"> <CORSRule> <AllowedOrigin>https://*</AllowedOrigin> <AllowedOrigin>http://*</AllowedOrigin> <AllowedMethod>GET</AllowedMethod> <AllowedMethod>HEAD</AllowedMethod> <AllowedMethod>POST</AllowedMethod> <AllowedMethod>PUT</AllowedMethod> <AllowedMethod>DELETE</AllowedMethod> <MaxAgeSeconds>3000</MaxAgeSeconds> <AllowedHeader>Origin</AllowedHeader> <AllowedHeader>X-Requested-With</AllowedHeader> <AllowedHeader>Content-Type</AllowedHeader> <AllowedHeader>Accept</AllowedHeader> <AllowedHeader>Authorization</AllowedHeader> <AllowedHeader>x-amz-*</AllowedHeader> </CORSRule> </CORSConfiguration>少し荒削りなところもありますが、以上でiOS12系以下でのCORSエラーを解消することができ、APIを利用することができるようになりました。
最後に
CORSのエラーは開発者からすると悩みの種の一つのように感じますが、今回なんとか解決することができて良かったと思います。ワイルドカードは便利に思われがちですが、こう言った場面で足元をすくわれることもあるんだなという良い経験になったように感じます。
状態的にはとりあえず動く、といったところなので動作検証しつつ精査をしようと思います。
でも検証のために毎回プッシュしてデプロイしなきゃいけないので、コミットが少し汚れ気味……。ではまた。
参照
MDN Web Docs(Access-Control-Allow-Headers)
プロキシ統合用の Lambda 関数の出力形式


- 投稿日:2020-07-25T21:30:04+09:00
FireLensを使ってFargateコンテナのファイルログを転送してみた
はじめに
通常はTwelve-Factor Appに「ログをイベントストリームとして扱う」とあるように、コンテナアプリケーションのログは標準出力を集約先とするのが設計原則です。しかし、もともと仮想マシンで動かしていたサーバをコンテナ化しようとする時など、
「まずはアプリケーションコンテナを極力改修せず(ログ出力先を、ファイルから標準出力に変更)になんとかならないか。。。」
というニーズもあるかと思います。ここでは、ファイル出力されたアプリケーションコンテナのログをFireLens(Fluentbit)を使ってCloudWatchへ転送する方法を紹介します。尚、FireLensを使わずとも、サイドカー(Fluentd)を自前で準備する方法として「Fargateで起動するコンテナのログをFluentd経由でS3に保存してみた」というのもあり、ご一緒に確認されると良いかと思います。
検証の流れ
検証は、次の手順で進めています。
1. Fluentbitコンテナ作成 :設定ファイルの取込みと、ECRへイメージpush
2. アプリケーションコンテナ作成 : tomcat上にsample.warをデプロイと、ECRへイメージpush
3. Task定義作成 : CloudFormationのテンプレートを準備したので、それを使ってスタック作成
4. Fargateクラスタ&サービス作成: AWSマネジメントコンソールから操作
5. アプリケーションへアクセス : ブラウザから
6. ログの確認(Cloud Watch Logs)システム構成は、こんな感じになります。
また、コンテナをビルドしたりするために使用したファイル(プロジェクト)はこちらです。
$ tree . ├── my-fluentbit │ ├── Dockerfile │ └── extra.conf //Fluentbit用設定ファイル ├── my-tomcat | └── Dockerfile ├── task-def.yaml //Cloud Formationにこのテンプレートファイルを指定して、スタック作成コンテナイメージ作成
Fluentbitコンテナ
Fluentbitの設定ファイル(extra.conf)を作成します。
./my-fluentbit/extra.conf[INPUT] Name tail Path /usr/local/tomcat/logs/localhost_access_log.*.txt Tag file-app-logs [OUTPUT] Name cloudwatch Match fargate-fluentbit-app* region ap-northeast-1 log_group_name fluentbit-cloudwatch-stdout log_stream_prefix fluentbit-stdout- auto_create_group true [OUTPUT] Name cloudwatch Match file-app-logs* region ap-northeast-1 log_group_name fluentbit-cloudwatch-file log_stream_prefix fluentbit-file- auto_create_group true[補足]tailプラグインではpos_fileで、どのファイルのどの部分まで読込み済みかチェックするための指定ができたりしますが、今回は省略しています。
次に、AWS公式イメージ(fluentbit)元に、上記設定ファイルを取り込むためのDockerfileを作成。
./my-fluentbit/DockerfileFROM amazon/aws-for-fluent-bit COPY extra.conf /fluent-bit/etc/extra.conf最後に、ECRへ登録します。
$ aws ecr get-login-password --region ap-northeast-1 | docker login --username AWS --password-stdin <AWSアカウントID>.dkr.ecr.ap-northeast-1.amazonaws.com $ docker build -t my-fluentbit . $ docker tag my-fluentbit:latest <AWSアカウントID>.dkr.ecr.ap-northeast-1.amazonaws.com/my-fluentbit:latest $ docker push <AWSアカウントID>.dkr.ecr.ap-northeast-1.amazonaws.com/my-fluentbit:latestTomcatコンテナ
今回はtomcat:9.0をベースイメージにしました。tomcatだけだとブラウザでアクセス確認できないので、sampleアプリケーションをデプロイ(単にtomcatのwebappにコピーしているだけですが)します。
./my-tomcat/DockerfileFROM tomcat:9.0 ENV CATALINA_HOME /usr/local/tomcat ENV PATH $CATALINA_HOME/bin:$PATH WORKDIR $CATALINA_HOME RUN set -ex; \ cd webapps && \ wget https://tomcat.apache.org/tomcat-9.0-doc/appdev/sample/sample.war先ほど同様、次のコマンドでこちらもECRに登録します。
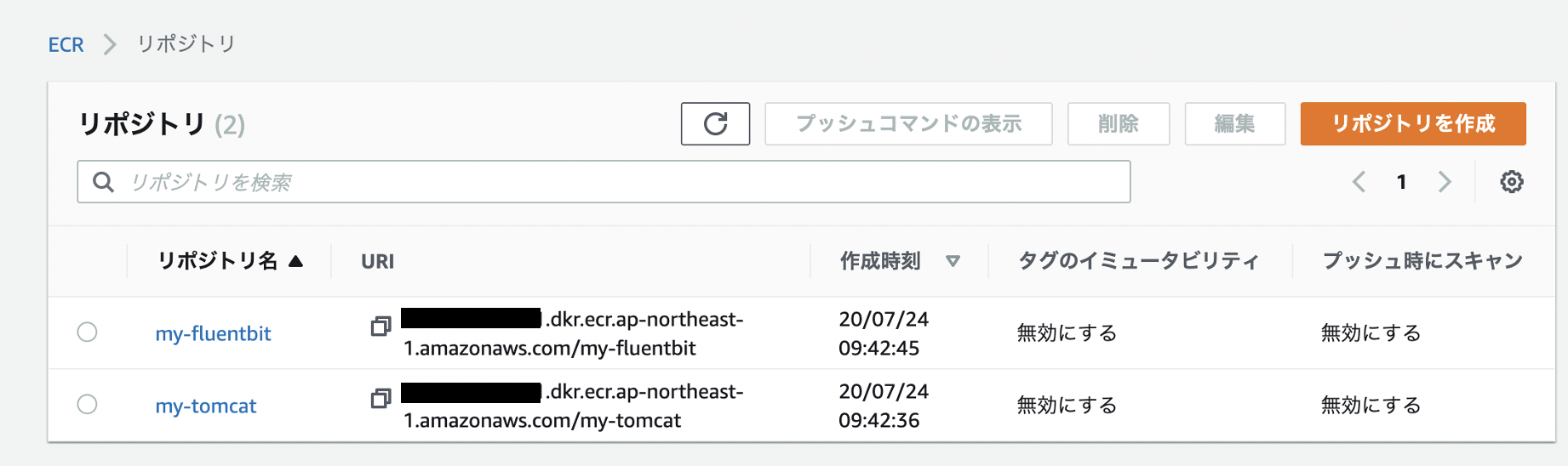
$ aws ecr get-login-password --region ap-northeast-1 | docker login --username AWS --password-stdin <AWSアカウントID>.dkr.ecr.ap-northeast-1.amazonaws.com $ docker build -t my-tomcat . $ docker tag my-tomcat:latest <AWSアカウントID>.dkr.ecr.ap-northeast-1.amazonaws.com/my-tomcat:latest $ docker push <AWSアカウントID>.dkr.ecr.ap-northeast-1.amazonaws.com/my-tomcat:latestAWSのマネジメントコンソールから、ECRサービス画面で、2つのコンテナが無事登録できているか確認します。
Task定義作成
Fargate用のタスクは、下記のCloud Formation用テンプレートで作成します。
./ecs-task-def.yamlAWSTemplateFormatVersion: '2010-09-09' Description: ecs task definition Parameters: projectName: Type: String Default: 'fargate-fluentbit' Resources: ecsTaskExecutionRole: Type: AWS::IAM::Role Properties: AssumeRolePolicyDocument: Version: "2012-10-17" Statement: - Effect: "Allow" Principal: Service: - "ecs-tasks.amazonaws.com" Action: - "sts:AssumeRole" ManagedPolicyArns: - arn:aws:iam::aws:policy/service-role/AmazonECSTaskExecutionRolePolicy - arn:aws:iam::aws:policy/AmazonS3FullAccess - arn:aws:iam::aws:policy/CloudWatchFullAccess RoleName: !Sub ${projectName}-ecsTaskExecutionRole Taskdefinition: Type: AWS::ECS::TaskDefinition DependsOn: ecsTaskExecutionRole Properties: Family: !Sub ${projectName}-task RequiresCompatibilities: - FARGATE Cpu: 1024 Memory: 2048 NetworkMode: awsvpc ExecutionRoleArn: !GetAtt ecsTaskExecutionRole.Arn TaskRoleArn: !GetAtt ecsTaskExecutionRole.Arn ContainerDefinitions: - Name: !Sub ${projectName}-fluentbit Image: !Sub ${AWS::AccountId}.dkr.ecr.ap-northeast-1.amazonaws.com/my-fluentbit:latest Cpu: 512 MemoryReservation: 1024 MountPoints: - SourceVolume: "volume-for-file-logs" ContainerPath: "/usr/local/tomcat/logs/" FirelensConfiguration: Type: fluentbit Options: config-file-type: file config-file-value: "/fluent-bit/etc/extra.conf" LogConfiguration: LogDriver: awslogs Options: awslogs-region: !Ref AWS::Region awslogs-group: "firelens-container" awslogs-stream-prefix: !Sub ${projectName}-fluentbit awslogs-create-group: true Essential: true - Name: !Sub ${projectName}-app Image: !Sub ${AWS::AccountId}.dkr.ecr.ap-northeast-1.amazonaws.com/my-tomcat:latest Cpu: 512 MemoryReservation: 1024 MountPoints: - SourceVolume: "volume-for-file-logs" ContainerPath: "/usr/local/tomcat/logs/" PortMappings: - ContainerPort: 8080 LogConfiguration: LogDriver: awsfirelens Essential: true Volumes: - Name: "volume-for-file-logs" Outputs: ecsTaskExecutionRole: Value: !Ref ecsTaskExecutionRole Export: Name: ecsTaskExecutionRole ecsTaskExecutionRoleArn: Value: !GetAtt ecsTaskExecutionRole.Arn Export: Name: ecsTaskExecutionRoleArn taskdefinition: Value: !Ref Taskdefinition Export: Name: my-task-definition検証
Fargateクラスタ構成
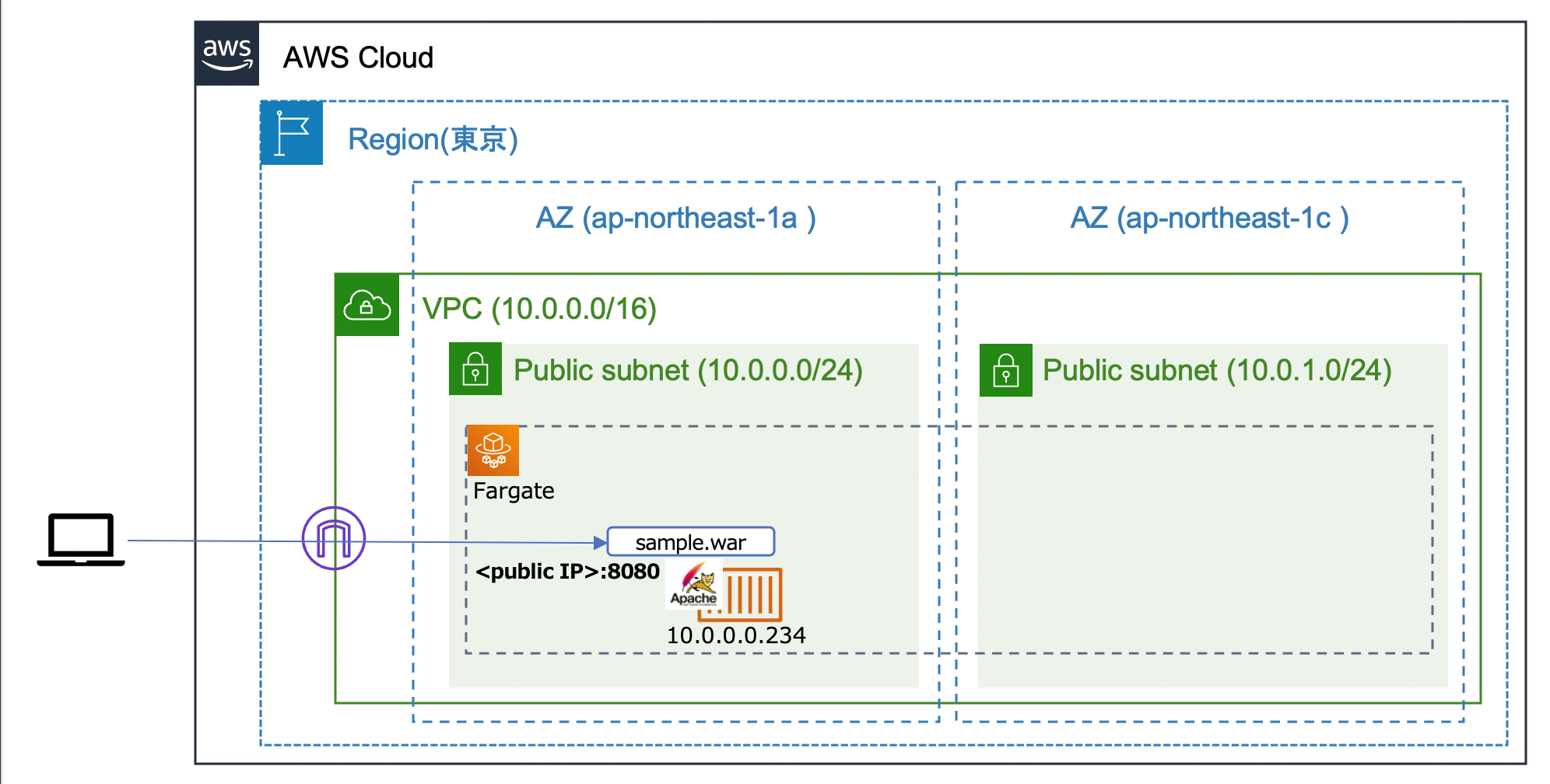
なにはともあれ、検証にはFargateクラスタが必要です。今回は下記のようなクラスタ構成を使いました。 例) VPC(10.0.0.0/16)内の2つの(パブリック)サブネット(10.0.0.0/24と10.0.1.0/24)上にFargateクラスタ構成。
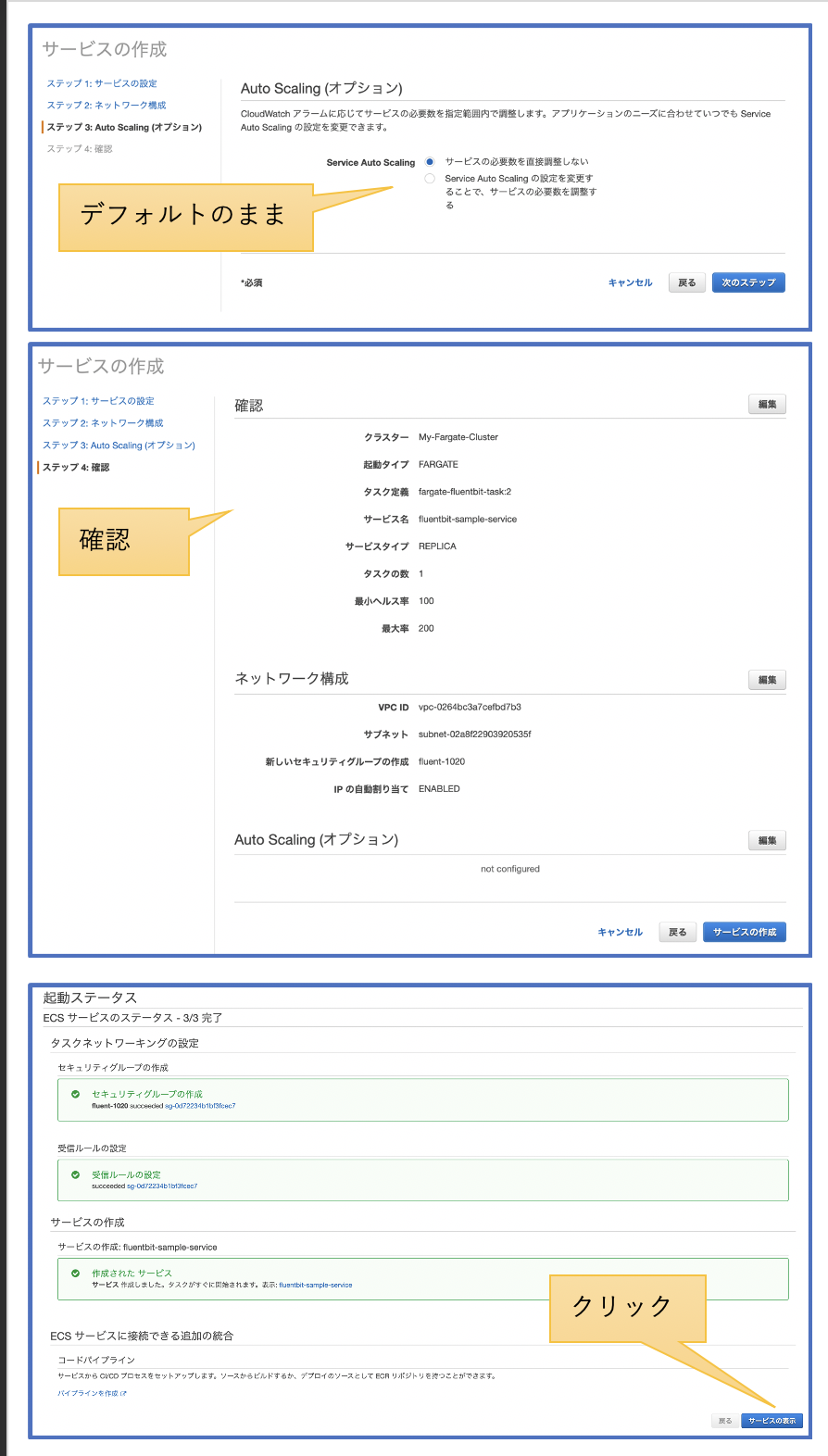
サービスからTask起動
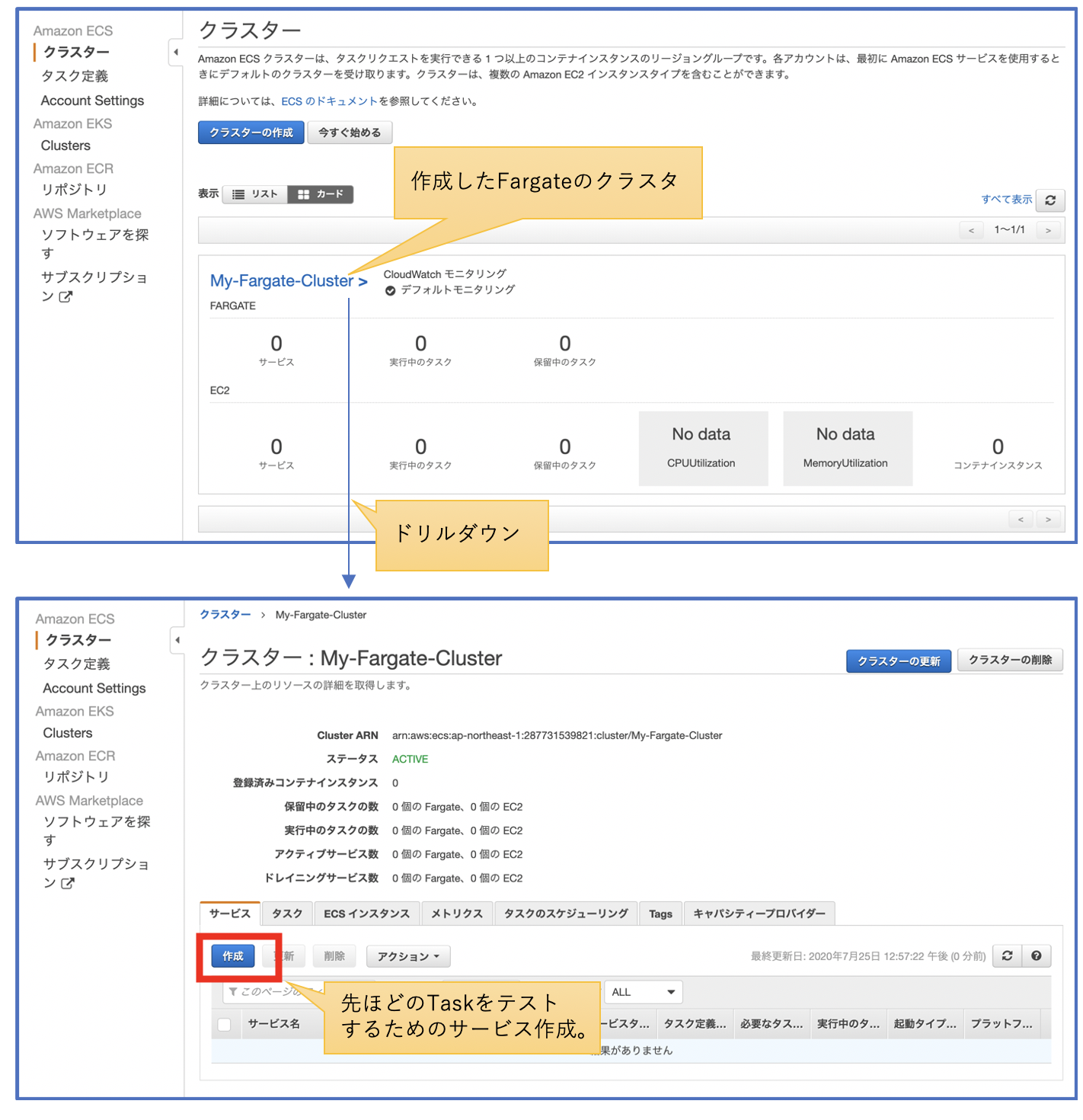
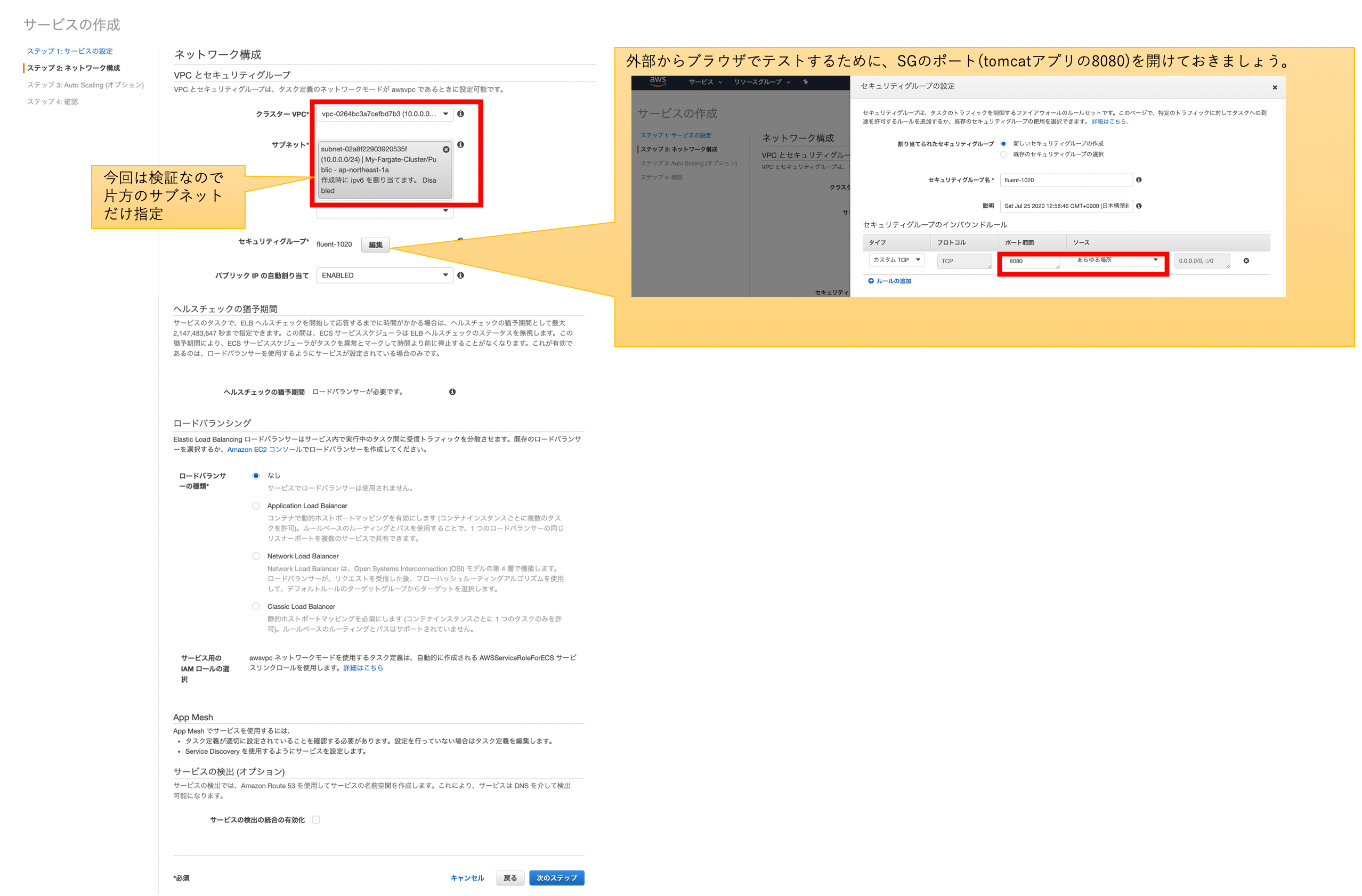
※Task定義同様、CloudFormation用のテンプレートを作れば良かったのですが、今回は手を抜いてマネジメントコンソールから作成しました。。。
クラスタから、新規にサービスを作成します。特に特別な設定はないと思います。気を付けるとしtら、先ほど作成したTask定義を指定する事と、アプリケーションにアクセスするためのSGの設定をする事くらいです。
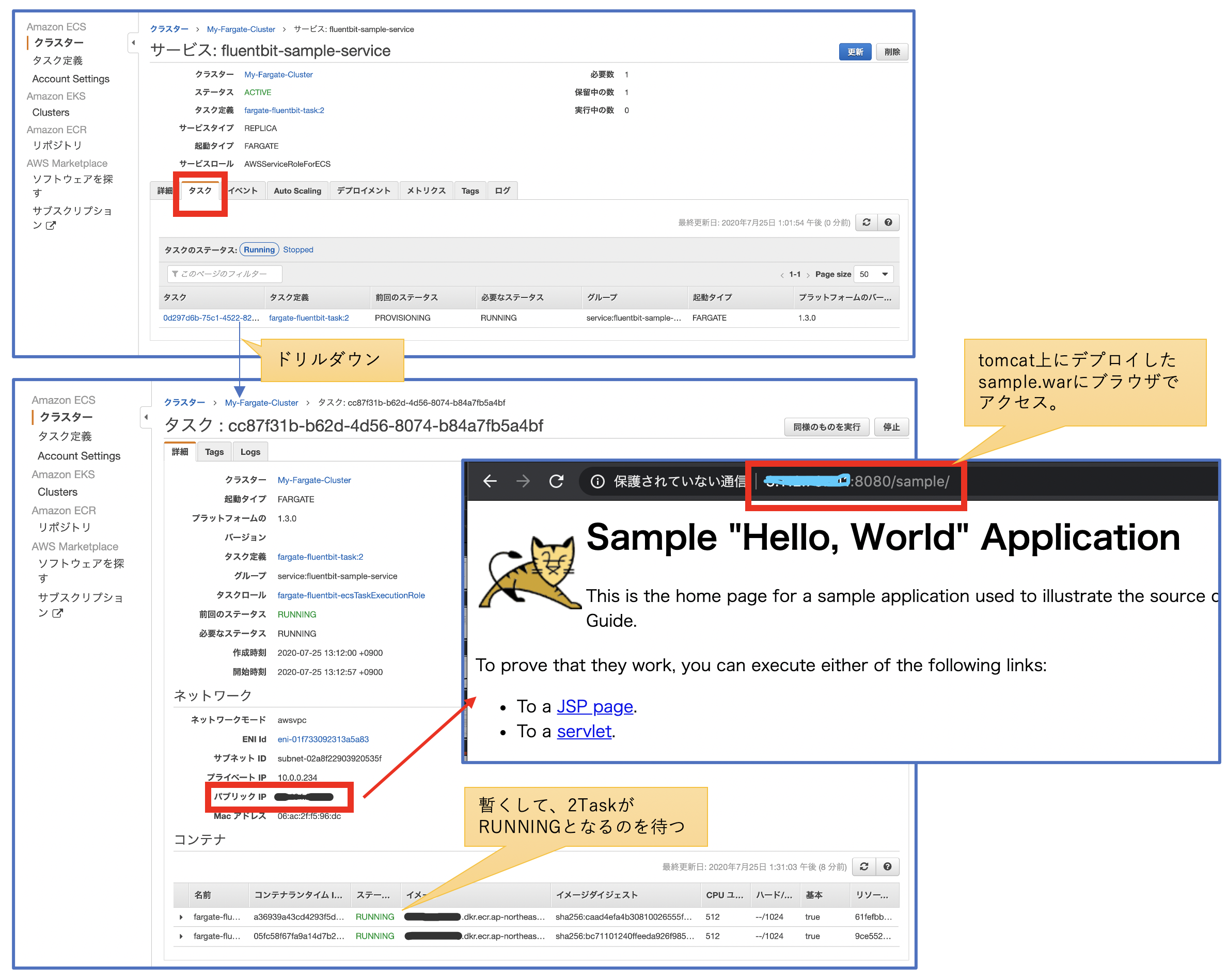
ブラウザからアプリにアクセスしてみよう
サービスを設定し、暫くするとTaskが起動します。Task内のコンテナが「RUNNING」 であることを確認し、アプリケーションにブラウザでアクセスしてみましょう。問題なければ、tomcatのsampleアプリがブラウザに表示されます。
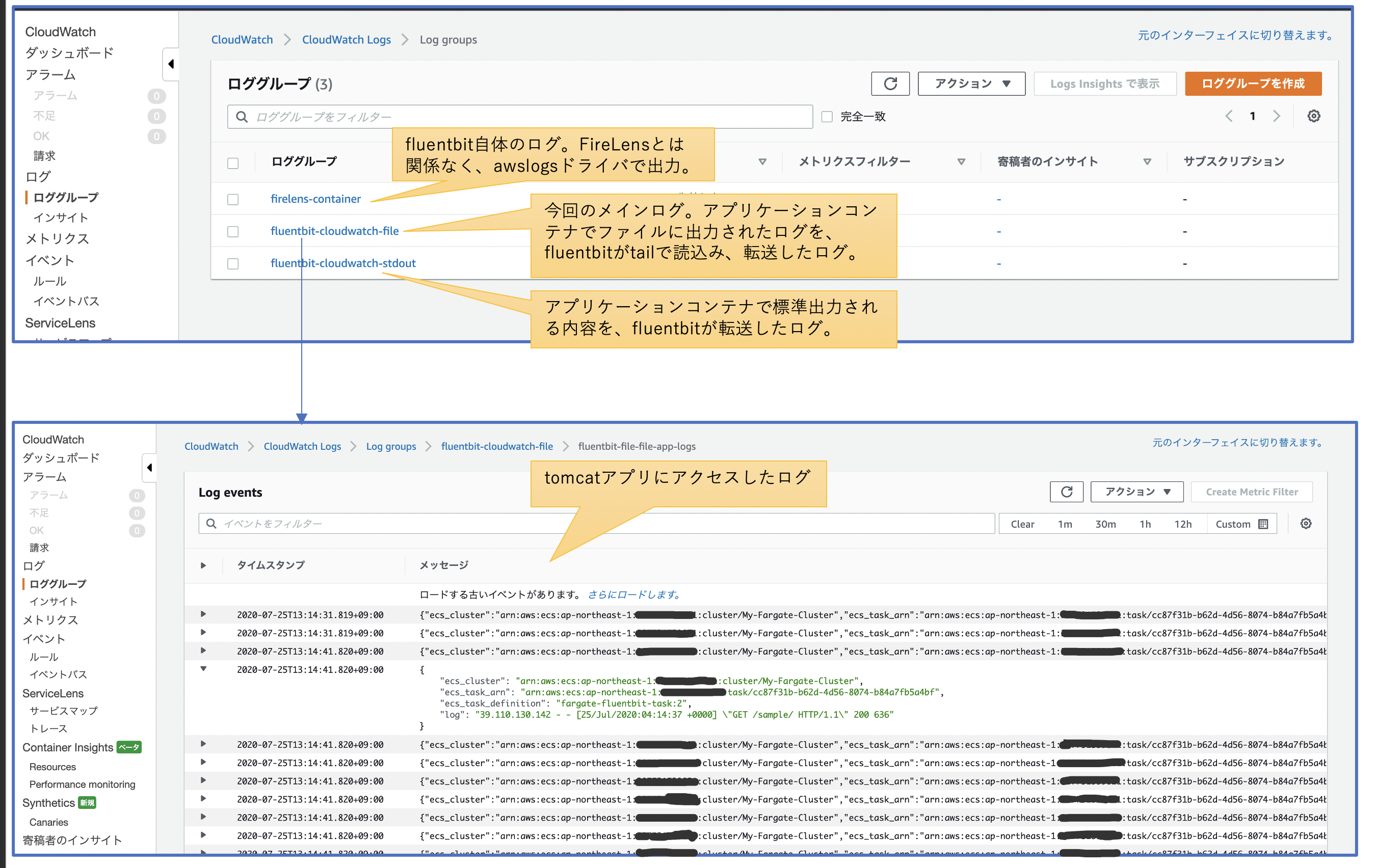
ログの確認
Cloud Watch Logsの画面で、ログが出力されていることを確認します。
まとめ
FireLensのFluentbitを使って、アプリケーションコンテナが出力するログファイルを転送してみました。
本番環境で使う場合は、予期しないコンテナ再起動などによる必要なログの抜漏れ対策に最新の注意が必要になると思います。冒頭でも述べましたが、アプリログはコンテナ内部に出力するのでなく、標準出力経由で集約できないかの検討も考慮いただければと思います。
参考
[付録1] FireLensを使うメリット?
自前でサイドカーとしてFluentコンテナを準備する事もできる中、あえてFireLensを使うと嬉しい点につきましては、こちらの記事Under the hood: FireLens for Amazon ECS Tasksの中で、Wesley氏は次の2点だと述べています:
Why not simply recommend Fluentd and Fluent Bit? Why FireLens?
1. Those who want a simple way to send logs anywhere, powered by Fluentd and Fluent Bit.
2. Those who want the full power of Fluentd and Fluent Bit, with AWS managing the undifferentiated labor that’s needed to pipe a Task’s logs to these log routers.1点目について、こちらにある豊富なExampleが使えます。
2点目について、Fluentd/Fluentbitの設定ファイルを自由にカスタマイズでき、S3に設定ファイルを置く事ができます。ただ、2020.7時点では、AWSによるドキュメントによると、Fargateでは残念ながらS3に設定ファイルを置く事ができないようですorz。(ですので、今回は設定ファイルをコンテナ内に取込みました)。今後のアップデートに期待ですね!
[付録2] Tomcatコンテナの中身確認
tomcatコンテナに、どのようなログが出力されているかの確認。
$ docker container run --rm -p 8080:8080 --name tomcat my-tomcat $ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 7350e84b95b9 my-tomcat "catalina.sh run" 9 seconds ago Up 8 seconds 0.0.0.0:8080->8080/tcp tomcat $ docker container exec -it tomcat /bin/bash root@7350e84b95b9:/usr/local/tomcat# cd logs/ root@7350e84b95b9:/usr/local/tomcat/logs# pwd /usr/local/tomcat/logs root@7350e84b95b9:/usr/local/tomcat/logs# ls -l total 8 -rw-r----- 1 root root 5131 Jul 26 00:36 catalina.2020-07-26.log -rw-r----- 1 root root 0 Jul 26 00:36 host-manager.2020-07-26.log -rw-r----- 1 root root 0 Jul 26 00:36 localhost.2020-07-26.log -rw-r----- 1 root root 0 Jul 26 00:36 localhost_access_log.2020-07-26.txt -rw-r----- 1 root root 0 Jul 26 00:36 manager.2020-07-26.log root@7350e84b95b9:/usr/local/tomcat/logs#



- 投稿日:2020-07-25T20:14:35+09:00
EC2、SSHポート番号を変更するための手順。
はじめに
EC2インスタンスにSSHで接続する際ですが、ポート番号をデフォルトの22番ではなく、その他の番号にすることで、少しでもハッキングの危険から逃れたりと、セキュリティ向上に寄与出来るのではないかと思われます。
ということで、今回は題名の通り、SSHポート番号を変更する手順について書きます。手順
一時的にセキュリティーグループのインバウンドで22番を認めます。
公開鍵を使用して、EC2インスタンスにssh接続をします。
EC2インスタンス内で
sshd_configファイルの記述を変更します。具体的には下記コマンドを打ってください。
cd /etc/sshsudo vi sshd_config(viエディターでファイルを開いています。)- #port22 のコメントアウトを外す
port2222に書き換える。(今回は例でポート番号を2222にしていますが、ここを自分の変更したいポート番号に設定してください。)sudo service sshd restartセキュリティグループのインバウンドで、カスタムTCPルール(今回の場合、TCP2222)を開放してください。
一時的に認めていた22番はインバウンドルールから外しましょう。
ssh接続のコマンドで、末尾に -p 2222を付けて接続します。具体的には以下のようなコマンドになります。
ssh -i .ssh/秘密鍵ファイル ec2-user@パブリックIP -p 2222まとめ
簡単に手順だけをまとめましたが、これで以上になります。
間違っている点などがありましたら、コメントで教えて頂けますと、幸いです。
ありがとうございました。
- 投稿日:2020-07-25T20:07:22+09:00
serverlessを使ってLambdaにmultipart/form-dataでバイナリデータをアップロードする
serverlessを使ってLambdaをデプロイする際、Lambda統合の時にバイナリデータをどうやって送るのか地味にハマったのでメモとして残しておきます。
(たぶんうちの若い子達がココ見るはず..)serverless便利ですね。コマンド一発でデプロイから各種AWSリソースをいい感じにセットアップしてくれます。いらなくなったら同じくコマンド一発でまるっと削除してくれます。これを使わない手はないですね。
TL;DR
- serverless.ymlのcustomキー配下にapiBinaryでバイナリメディアタイプを指定する
- serverless.ymlのpluginsキー配下にserverless-apigw-binaryを追加する
- Lambdaに送られてくるリクエストはbase64エンコードされたmultipart/form-dataなのでデコードしてaws-lambda-multipart-parserでマルチパートデータをバイナリにする
serverless.ymlcustom: ...省略 apigwBinary: types: - multipart/form-data ...省略 plugins: - serverless-apigw-binaryserverless.yml
serverless.ymlの記載内容をまとめると以下のようになるかと思います。
- S3バケットの設定
- Lambdaの設定
- APIGatewayの設定
serverless.ymlservice: name: FileUploadTest custom: webpack: webpackConfig: ./webpack.config.js includeModules: true apigwBinary: types: - multipart/form-data # ← バイナリメディアタイプの指定 webSiteName: jp.co.onewedge.test.fileuploadtest s3Sync: - bucketName: ${self:custom.webSiteName} localDir: static # ← プロジェクトのstaticフォルダ配下のファイルをS3にアップロード # Add the serverless-webpack plugin plugins: - serverless-webpack - serverless-apigw-binary # ← APIGatewayのバイナリメディアタイプでアップロードするために必要 - serverless-s3-sync # ← S3に静的ファイルをアップロードするために必要 provider: name: aws runtime: nodejs12.x region: us-east-1 endpointType: REGIONAL apiGateway: minimumCompressionSize: 1024 environment: AWS_NODEJS_CONNECTION_REUSE_ENABLED: 1 functions: fileUpload: handler: index.handler events: - http: method: post path: doUpload cors: false resources: Resources: # ←S3バケットでHTMLを配信するための設定 StaticSite: Type: AWS::S3::Bucket Properties: BucketName: ${self:custom.webSiteName} AccessControl: PublicRead WebsiteConfiguration: IndexDocument: index.html ErrorDocument: error.html StaticSiteS3BucketPolicy: Type: AWS::S3::BucketPolicy Properties: Bucket: Ref: StaticSite PolicyDocument: Statement: - Sid: PublicReadGetObject Effect: Allow Principal: "*" Action: - s3:GetObject Resource: Fn::Join: ["", ["arn:aws:s3:::",{"Ref": "StaticSite"},"/*"]]multipart/form-dataでバイナリデータをアップロードする場合、キモとなるのはAWSコンソールのバイナリメディアタイプとなります。serverlessを利用する場合はserverless-apigw-binaryプラグインの導入と、customキー配下apigwBinaryキーの指定となります。このtypesで指定した値がバイナリメディアタイプとなります。
serverless.ymlcustom: ...省略 apigwBinary: types: - multipart/form-data ...省略 plugins: - serverless-apigw-binary
Lambda実装
Labmda側は、通常のLambda統合のリクエストでデータを取得できます。
この際、event.bodyにはbase64エンコードされたmultipart/form-dataが格納されています。
つまり、そのままでは利用できないので受け取ったevent.bodyはデコードしたあとmultipartの処理を行います。index.ts'use strict'; import { APIGatewayProxyHandler, APIGatewayProxyEvent, Context} from 'aws-lambda'; import multipart from 'aws-lambda-multipart-parser'; import { S3 } from 'aws-sdk'; import 'source-map-support/register'; export const handler: APIGatewayProxyHandler = async (event:APIGatewayProxyEvent, _context:Context) => { // 受け取ったevent.bodyがbase64エンコードされているのでデコード const event2:APIGatewayProxyEvent = event; event2.body = Buffer.from(event.body, 'base64').toString('binary'); // multipart/form-dataをパースする const multipartBuffer = multipart.parse(event2, true); // クライアント側で特に指定なき場合、アップロードされたファイルはfile.contentとして取り出せる // ここではアップロードされたファイルをS3に保管します const s3 = new S3(); const params:S3.Types.PutObjectRequest = { Bucket:'jp.co.onewedge.test.fileuploadtest', Key: '保存ファイル名', Body: multipartBuffer.file.content }; await s3.putObject(params).promise(); // ... 省略 }デプロイ
ここまでできたらコマンドラインからいったんデプロイしましょう。
デプロイするとAPIGatewayのエンドポイントがコンソールに表示されたログの中のendpoints欄に表示されるので、メモっておきます。$ sls deploy ...省略 Service Information service: FileUploadTest stage: dev region: us-east-1 stack: FileUploadTest-dev resources: xx api keys: None endpoints: POST - https://xxxx.execute-api.us-east-1.amazonaws.com/dev/doUpload # ←これです functions: fileUpload: fileUpload-dev-doUpload layers: None ...省略HTML作成
HTMLを作成し、先ほどメモったAPIのエンドポイントに向けてファイルをPostするようにしてください。今回はVue.jsとAxiosで作りました。
index.html<html> <head> <script src="https://cdn.jsdelivr.net/npm/vue/dist/vue.js"></script> <script src="https://cdn.jsdelivr.net/npm/axios/dist/axios.min.js"></script> </head> <body> <div id="app"> <form > <input type="file" id="file" ref="file" @change="handledUploadFile" /> <button type="button" @click="onClickUpload">アップロード</button> </form> </div> <script type="text/javascript"> const v = new Vue({ el: '#app', data: function(){ return { file:'' } }, methods:{ handledUploadFile: function(){ this.file = this.$refs.file.files[0]; }, onClickUpload: function(){ const formData = new FormData(); formData.append('file', this.file); axios.post('メモったエンドポイントURL', formData, { headers: { 'Content-Type': 'multipart/form-data' } } ).then(function(data){ console.log(`SUCCESS!!:${data}`); }).catch(function(err){ console.log(`FAILURE!!${err}`); }); } } }) </script> </body> </html>作成したHTMLはstaticディレクトリに配置します。
配置したら再度デプロイしましょう。今度は作成したHTMLがS3にアップロードされるはずです$ sls deployだいぶ端折りましたがこんな感じで動くかと思います。
仲間募集!
株式会社ONE WEDGEでは元気なエンジニア募集中です!一緒に「おもしろい」を作りましょう!

- 投稿日:2020-07-25T19:04:36+09:00
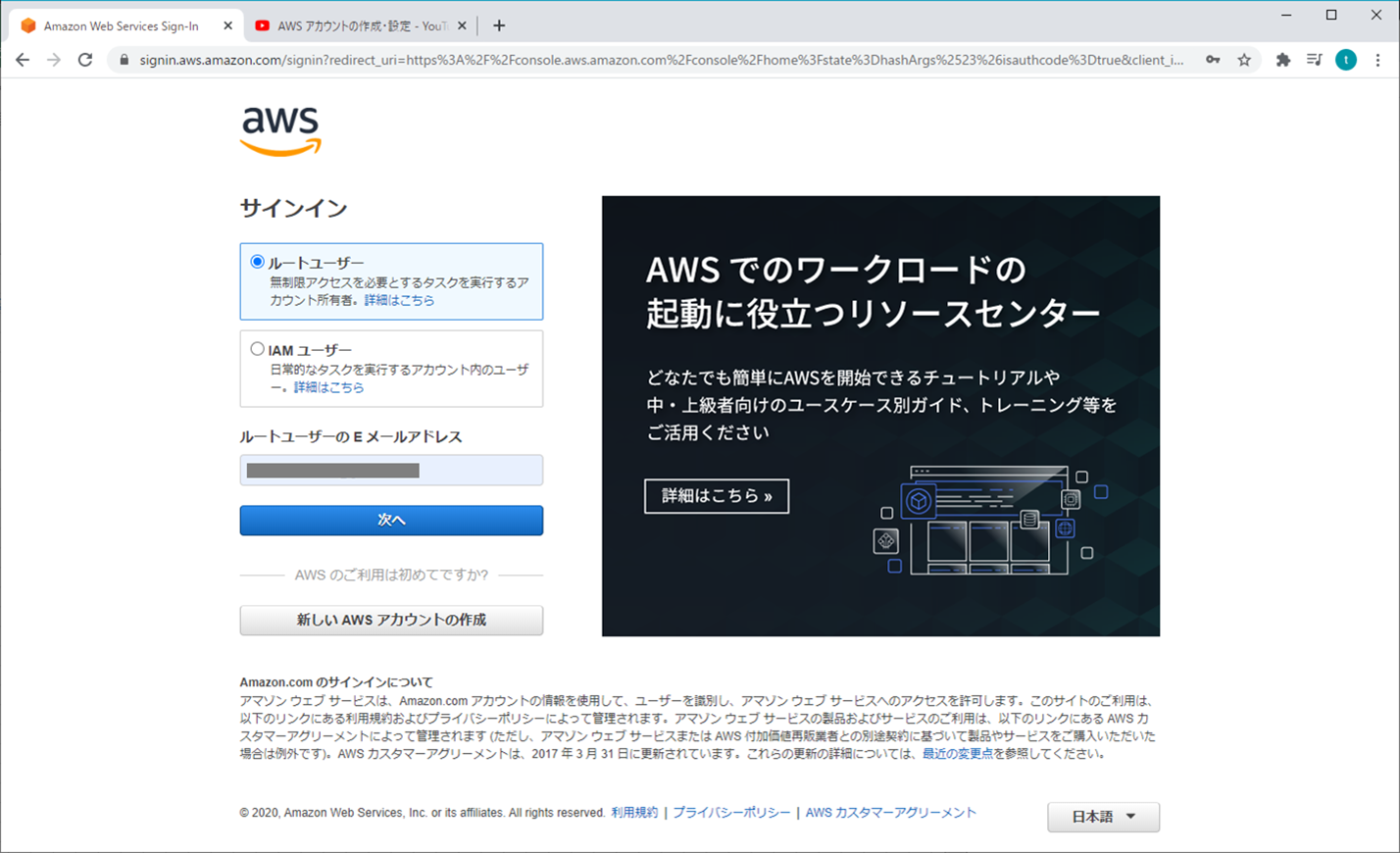
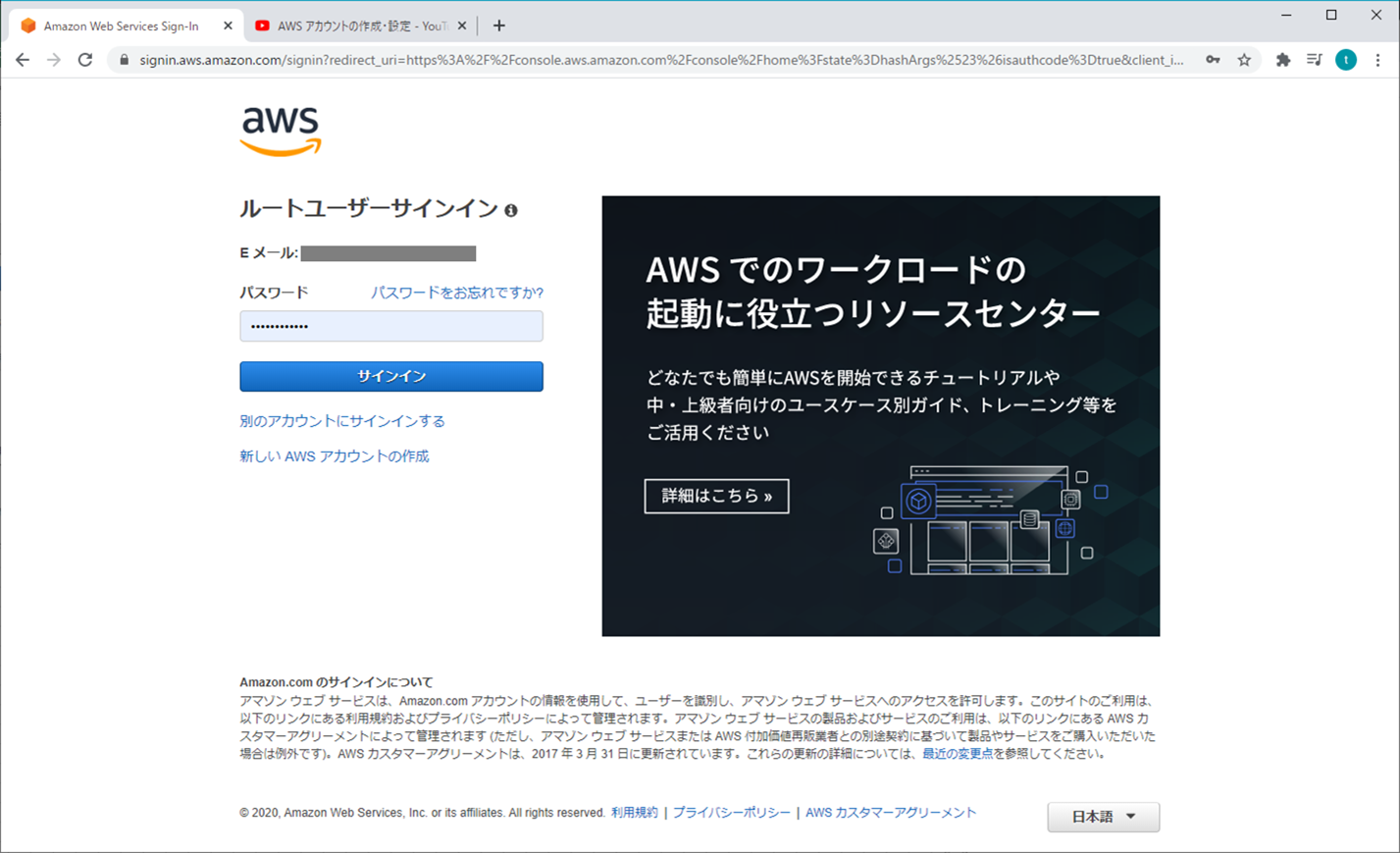
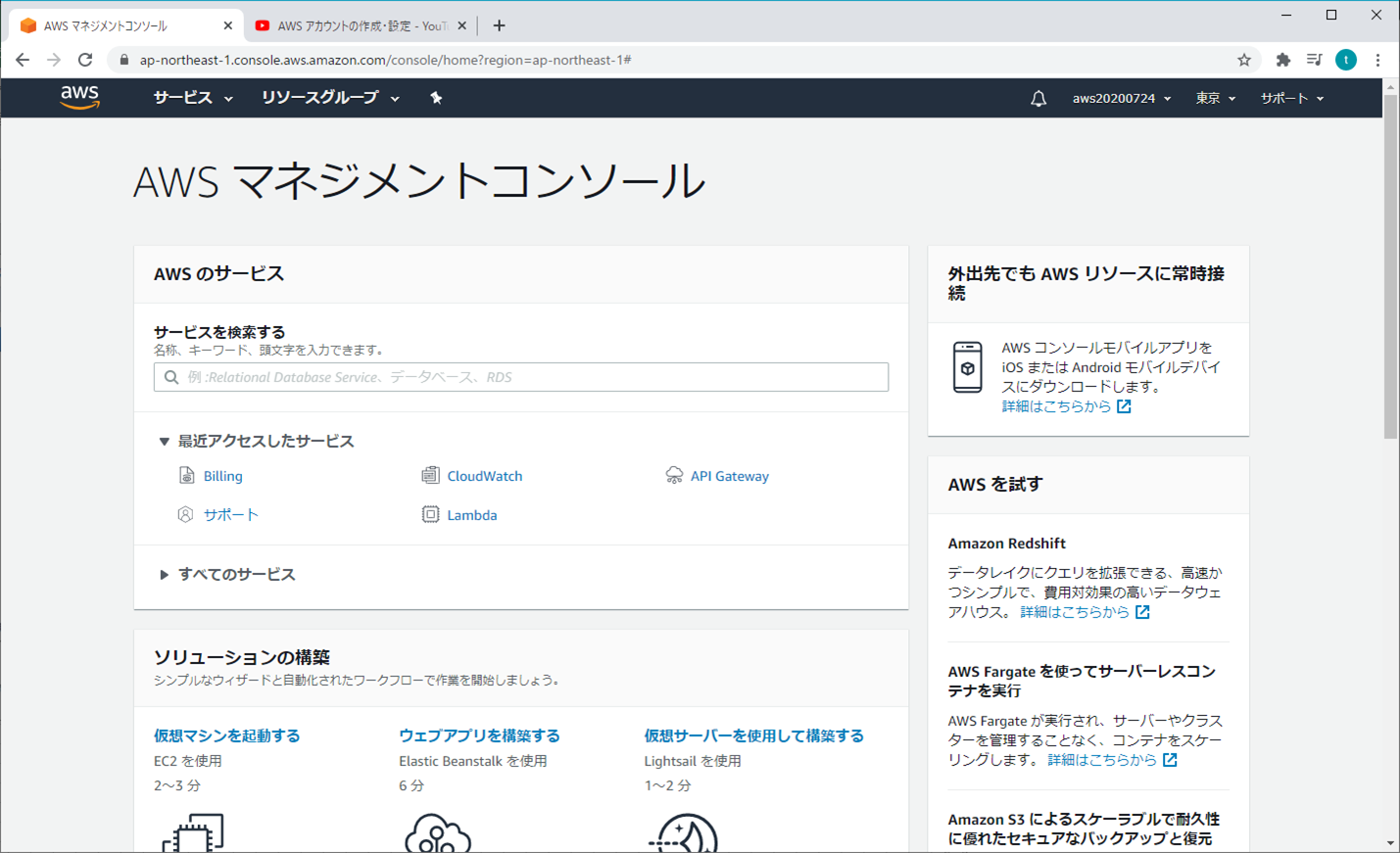
【AWS】ログイン - ルートユーザーサインイン
- 投稿日:2020-07-25T18:26:01+09:00
【AWS・Python】SlackのEventAPIを利用してファイルの送受信してみる
1. はじめに
本記事では、Slackへのファイルアップロードをトリガーとして、
ファイルの受け取りと何かしらの処理をしてSlackへ送り返す処理についてまとめます。環境はAWSのLambdaとPythonを利用します。
2. 実装
2.1 できるもの
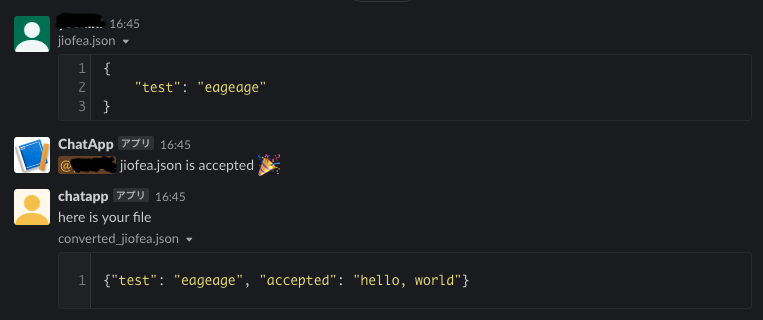
以下のように、ファイルをアップロードすると、
アップロードしたユーザにメンションして、何かしらの処理を加えたファイルを返します。
2.2 処理のイメージ図
Slack → AWS → Slackへのデータの流れです。
- Slack上でファイルがuploadされると、API Gatewayに設定したエンドポイントが呼ばれる
- API GatewayがLambdaを起動
- 処理用のLambdaをさらに起動し、
- 最初のLambdaは、処理を返す
- 最後に呼ばれたLambdaがファイルを処理してメッセージとともにSlackへアップロード
3にて別のLambdaを起動するのは、Slackへのレスポンスを3秒以内に返す必要があるためです参考2.3 slack上での準備
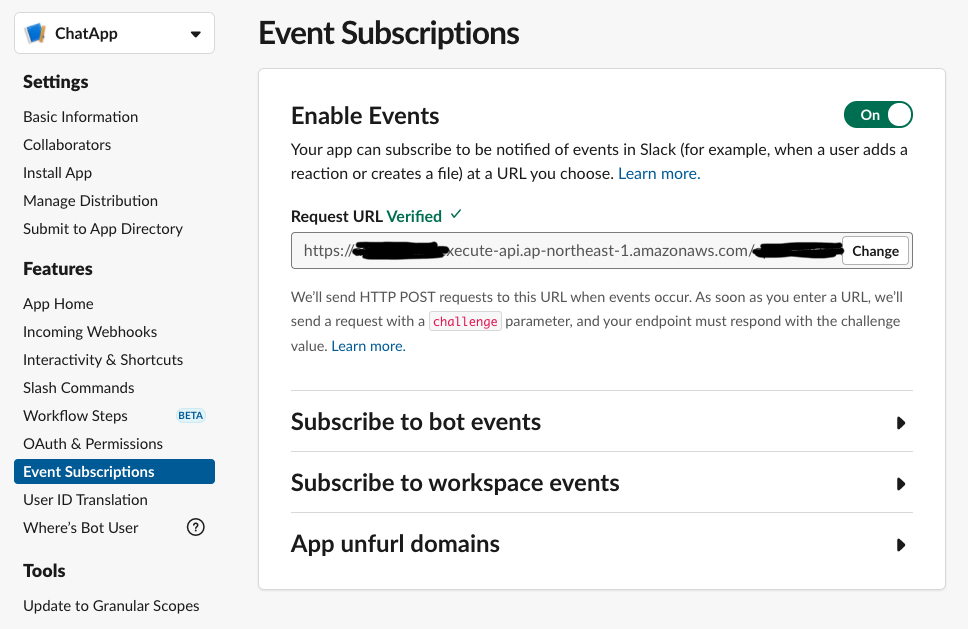
SlackのAppを管理しているページの
Event Subscriptionの項目を有効にしておきましょう。
加えて、
Incoming Webhooksの項目も有効にしておいてください。2.4 Chaliceでの実装
Chaliceとは、AWS Lambdaやそれに付随するサービスを簡単に構築してくれるAWS公式のライブラリです。2.4.1 SlackからのEventを受け取るLambda(API Gateway + Lambda)の実装
まずは、SlackからのEventを受け取るLambdaを実装します。
処理の内容は
- Slackからの
payloadを受け取る- BOTからの送信でなければ、ファイルを処理するLambdaを起動
- 最後に、Slackから受け取った
payloadを返す
3をしている理由としては、Slackから送信されたpayloadに含まれるchallengeパラメータを返す必要があるためです。
これをしていない場合は、2.3項で設定したURLがVerifiedになりません。app.pyimport io import json import logging import os import requests from slack import WebClient from slack.errors import SlackApiError import boto3 app = Chalice(app_name='<your chalice-app name>') logger = logging.getLogger() logger.setLevel(logging.INFO) # lambda client to invoke lambda_client = boto3.client("lambda") BOT_USER_ID = "<appのuser_id>" @app.route('/your/root', methods=['POST']) def event_subscription(): request = app.current_request if request.raw_body is None: # 予期しない呼び出し。400 Bad Requestを返す return {'statusCode': 400} payload = request.json_body logger.info(f"payload:= {payload}") user_id = payload['event']['user_id'] # BOTからファイルを上た場合は、Lambdaでの処理をしないようにする # ループを避けるため if user_id == BOT_USER_ID: return payload event_handler_lambda = "<この次に実装するLambdaのARN>" lambda_client.invoke( FunctionName=event_handler_lambda, InvocationType='Event', Payload=json.dumps(payload) ) return payload2.4.2 API ファイルを処理するLambdaの実装
次は、アップロードされたファイルに対して処理をするLambdaを実装します。
Slackへファイルがアップロードされると、file_idが発行されます。
そのfile_idからファイルを取得し、処理を行っていきます。また、その
file_idにはファイルがアップロードされたchennel_idが付与されているので
これを利用してファイルをアップロードするチャンネルを指定します。ユーザへのメンションは
<@{user_id}>で行えます。
user_idは、ファイルがアップロードされたイベントに付与されているのでそれを取得して行います。ファイルの処理は、今は適当に行っているので、いい感じに変更してください。
client.files_upload()の関数へ渡せる引数としてfileとcontentの2種類があります。
違いは以下の通りです。
- file: ファイル名を指定して、アップロードする。例:
file="test.csv"- content: bytesオブジェクトをアップロードする。例:
content=json.dumps({"aaa": "bbb"}).encode('utf-8')どちらでも行けると思うので、便利な方を利用したらいいと思います。
ちなみに、Lambdaだと/tmp以下の領域は500MBくらいまで自由に読み書きができるはずなので、そこを利用したら良いかと思います。app.py# =============================== # # ここには2.4.1項で実装した内容がある想定 # # =============================== # @app.lambda_function() def event_handler(event, _): # globalで読み込むとslackへのレスポンスに3秒以上かかるため、ここでpandasを読み込む import pandas as pd # tokenとslack_clientの生成 slack_oauth_token = os.environ['OAuthAccessToken'] slack_bot_token = os.environ['BotUserOAuthAccessToken'] oauth_client = WebClient(token=slack_oauth_token) bot_client = WebClient(token=slack_bot_token) # call file info to get url file_id = event['event']['file_id'] logger.info(f"file_id:= {file_id}") response = oauth_client.files_info(file=file_id) file_name = response.data["file"]["name"] file_url = response.data["file"]["url_private"] # slack上でファイル共有をした場合は1つのchannel_idしか入らないため file_upload_channel_id = response.data['file']['channels'][0] user_id = event['event']['user_id'] logger.info(f"file from {user_id}") print("Downloaded " + file_name) # download file file_data = _get_slack_file_bytes(slack_token=slack_oauth_token, file_url=file_url) converted_data = b'' if file_name.endswith(".json"): sent_data = json.loads(file_data) sent_data['accepted'] = "hello, world" converted_data = json.dumps(sent_data).encode('utf-8') elif file_name.endswith(".csv"): df = pd.read_csv(io.BytesIO(file_data)) df['accepted'] = "world" converted_data = df.to_csv(index=False).encode('utf-8') # response try: chat_response = bot_client.chat_postMessage( channel=file_upload_channel_id, text=f"<@{user_id}> {file_name} is accepted :tada:" ) logger.info(f"chat_response:= {chat_response}") upload_response = bot_client.files_upload( content=converted_data, title=f"converted_{file_name}", filename=f"converted_{file_name}", initial_comment="here is your file", channels=file_upload_channel_id ) logger.info(f"upload_response:= {upload_response}") except SlackApiError as e: # You will get a SlackApiError if "ok" is False assert e.response["error"] print(e) print(e.__str__()) return {"ok": True} def _get_slack_file_bytes(slack_token: str, file_url) -> bytes: r = requests.get(file_url, headers={'Authorization': f'Bearer {slack_token}'}) # get binary content return r.content2.5 LambdaのdeployとSlackへのURL設定
ここまできたら、chaliceのコマンドでAWSに実装して、発行されるURLを取得します。
$ chalice deploy Creating deployment package. Updating policy for IAM role: <chalice_project_name>-dev Updating lambda function: <chalice_project_name>-dev-event_handler Updating lambda function: <chalice_project_name>-dev Updating rest API Resources deployed: - Lambda ARN: arn:aws:lambda:<region>-<account_number>:function:<chalice_project_name>-dev-event_handler - Lambda ARN: arn:aws:lambda:<region>-<account_number>:function:<chalice_project_name>-dev - Rest API URL: https://<chalice_generated_chars>.execute-api.<region>.amazonaws.com/api/API GatewayのURLを取得したら、2.3項での
Event SubscriptionのRequest URLに設定します。
この時、プログラムの@app.route(/your/root, ...)に設定した/your/rootを追記します。
例で、/your/rootとしましたが、/slack/eventなどが良いと思います。https://<chalice_generated_chars>.execute-api.<region>.amazonaws.com/api/your/root2.6 実行時の注意
2.6.1 Slack Bot Userの実行権限付与
おそらく、初めて
Event SubscriptionやIncoming Webhooksの項目を利用していると、
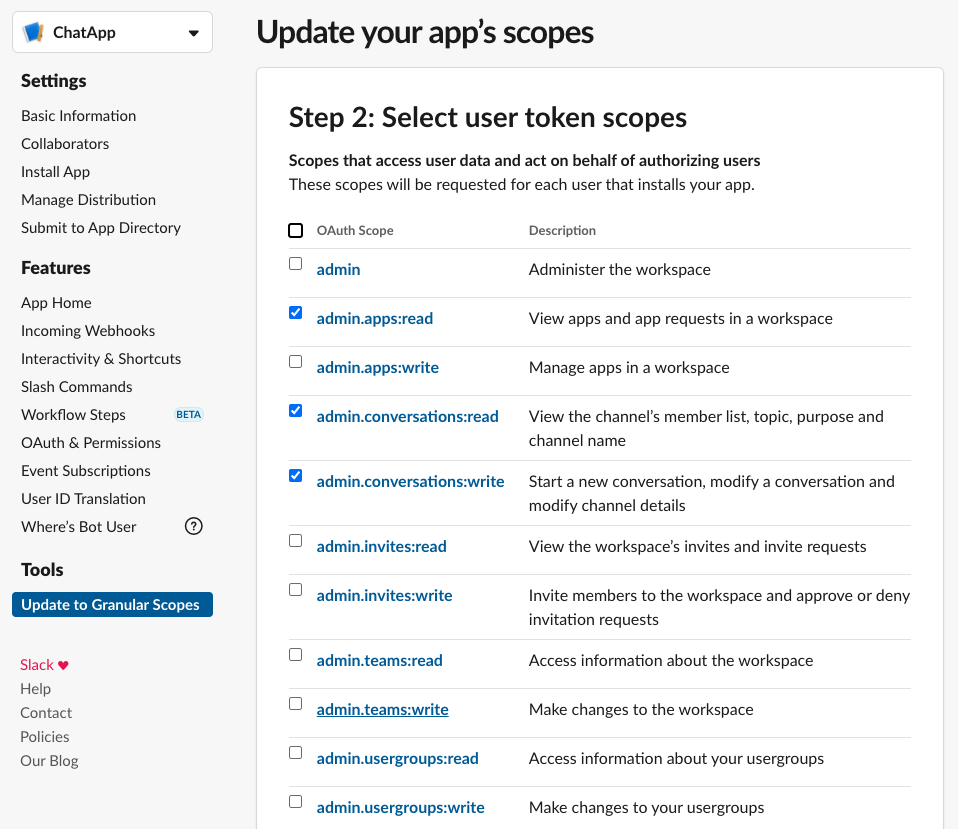
Botの権限が足りずに関数の実行が失敗する場合があります。その場合は、Slack Appの以下のページから必要そうな権限を追加していってください。
関数の実行に必要な権限は実行時に失敗したら、エラーメッセージに含まれています。
2.6.2 LambdaがLambdaを実行する権限を付与
LambdaからLambdaを呼ぶ権限もIAMに付与する必要があります。
AWSコンソールから、Lambdaに付与されているロールを選び、「ポリシーをアタッチします」ボタンから
AWSLambdaFullAccessを付与してください(権限が強すぎるので本当はよくないのですが)。
2.6.3 Slackでファイルを実際にルームに共有される前にLambdaが実行されてしまう。
fileに関するSlackの
Event Subscriptionのうち、file_uploadを選択してしまうと、
ルームに共有しようとしているファイルがSlack上のサーバーへアップロードが完了した時点で、Eventが発火します。処理そのものに影響はないのですが、挙動としてちょっと気持ち悪いので
file_publicのEventが発火した場合に
Lambdaなどの処理を行った方が良いです。3. おわりに
今回は、Slackを利用してファイルの送受信を行えるようにしてみました。
ファイル以外にもSlackのEvent Subscriptionには、スタンプが押されたらとかメンションがあったらとか
いろいろあるのでぜひ遊んでみてください。
Event Subscriptionでは、イベントのタイプを{..., 'event': {'type': 'file_public', 'file_id': '', ...}}と言う
dictの'type'で受け取れるので、以前書いたChainOfRespontibilityでゴニョゴニョとかも利用できると思います。Slackが提供している公式ライブラリのSlackClientが
かなり使いやすく、自分で独自の関数を組む必要がないので便利でした。また、
Event Subscriptionの設定方法などは【Slackにファイルをアップロードする】が参考になるかもです。参考

- 投稿日:2020-07-25T18:13:48+09:00
【AWS】アカウント申請(無料ベーシックプラン)
アカウント使用の流れ
- 開始前知っておくべきポイント
- アカウント申請
- ログイン
- IAM設定
- MFA多要素認証
- アカウント削除
参照資料
操作の詳細は、「Youtube」の「Amazon Web Services Japan 公式」を参照
https://www.youtube.com/watch?v=1VCIFN8B72oアカウント申請
1. 基本情報
2. 連絡先情報
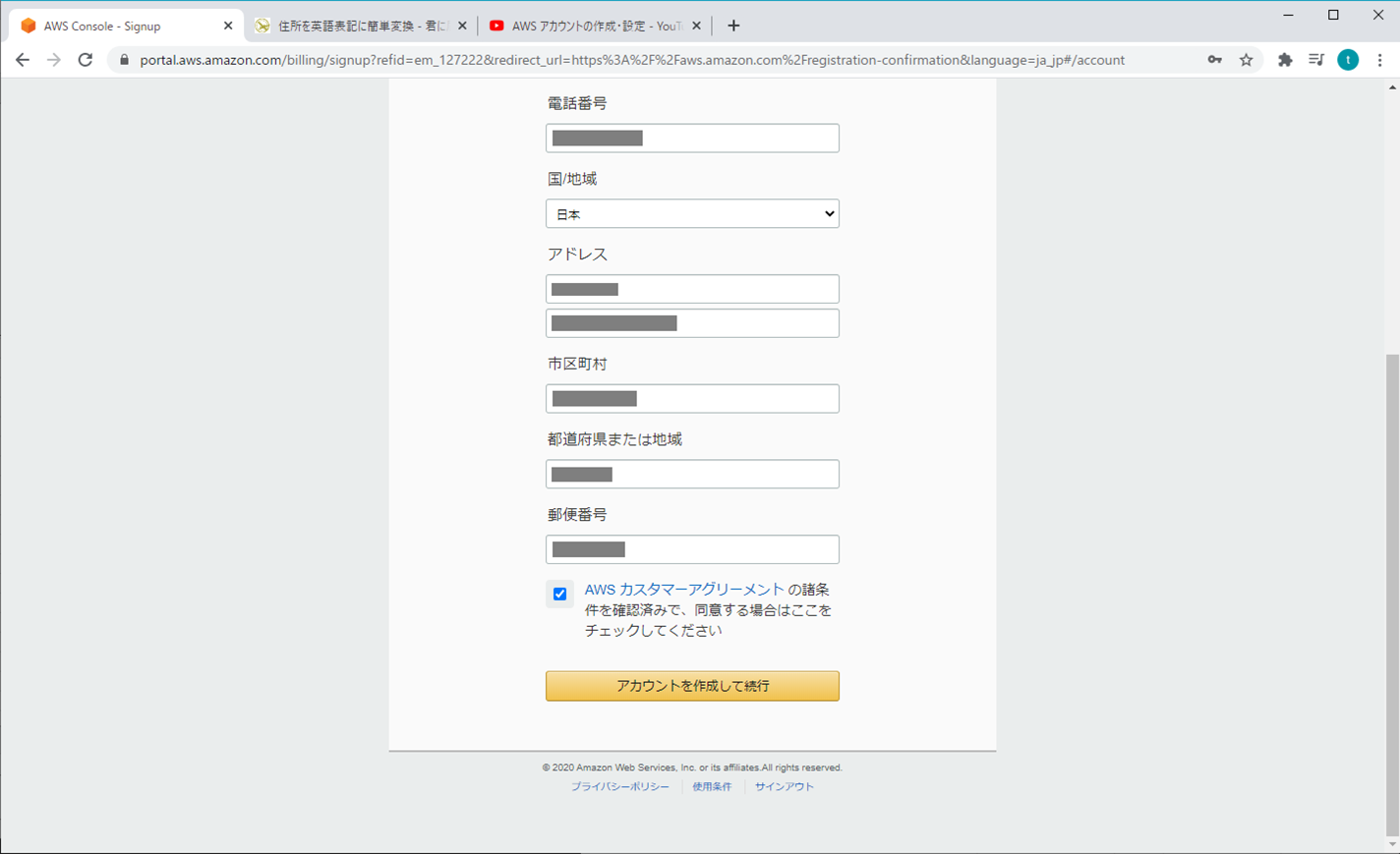
連絡先情報は、半角英数字で入力する必要があるから、住所を英字に変換する
- Ju Dress http://judress.tsukuenoue.com/
- 君に届け https://kimini.jp/
- Google Map(英語) https://www.google.com/maps/@36.087542,136.321622,15z?hl=en
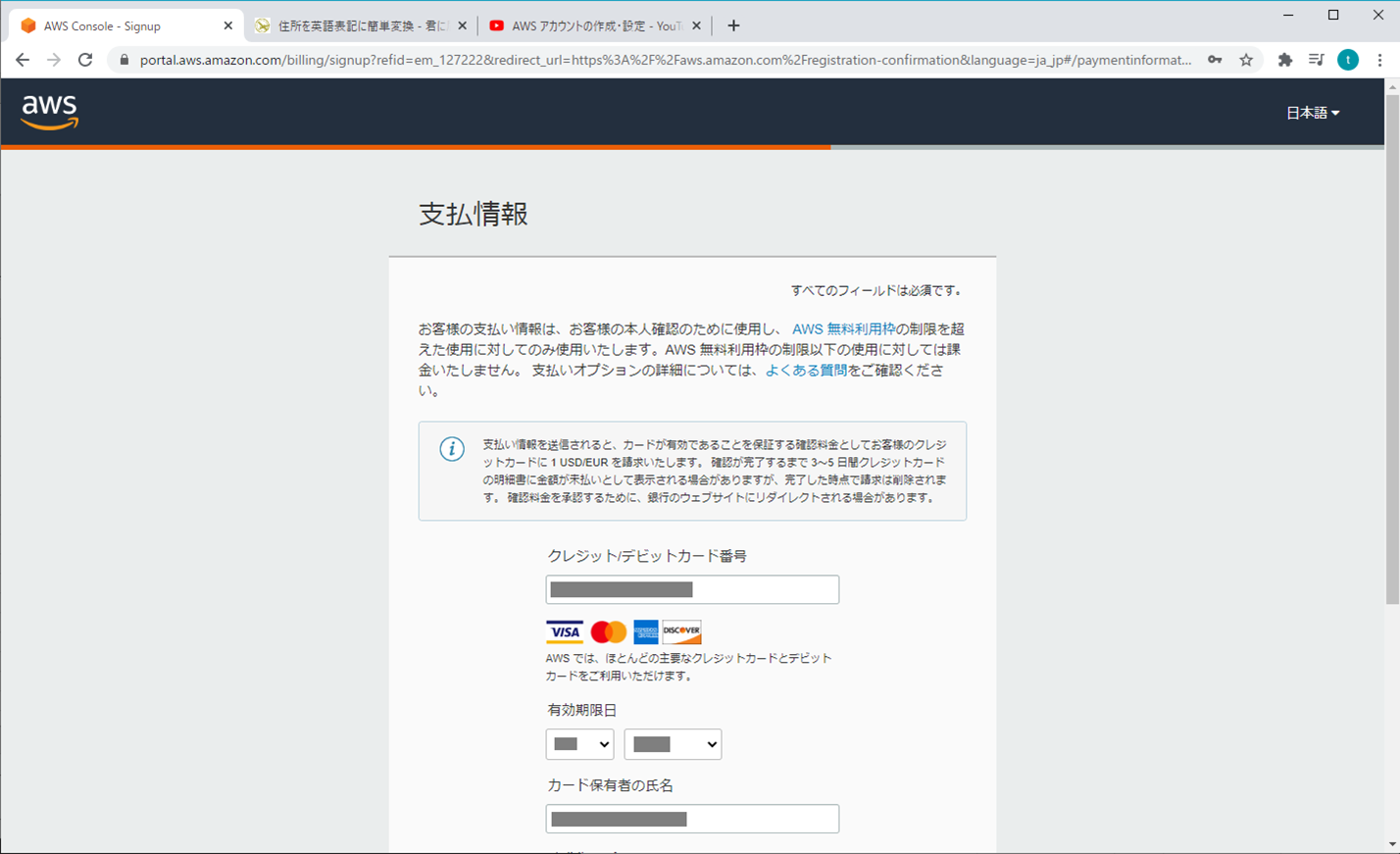
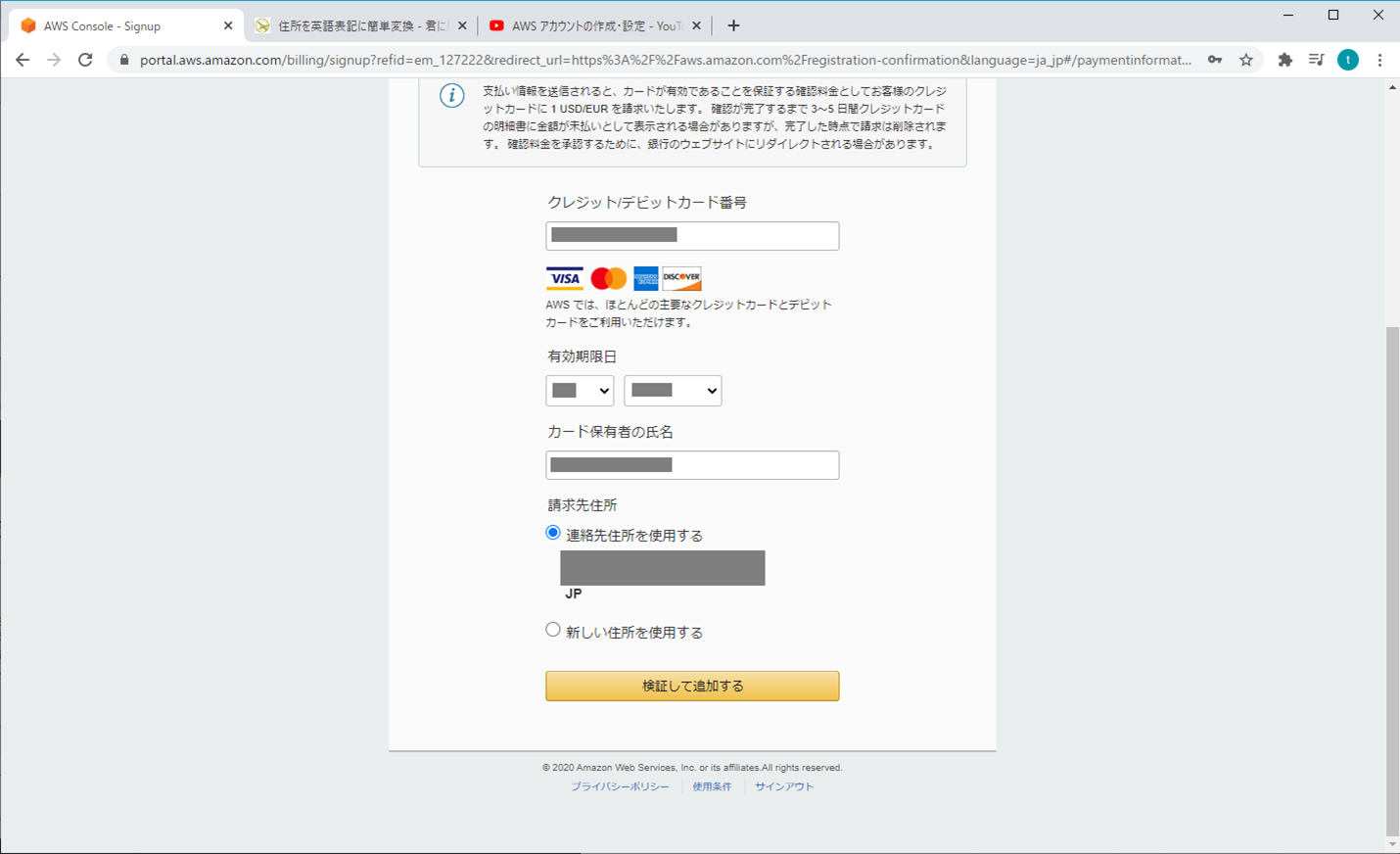
3. 支払情報
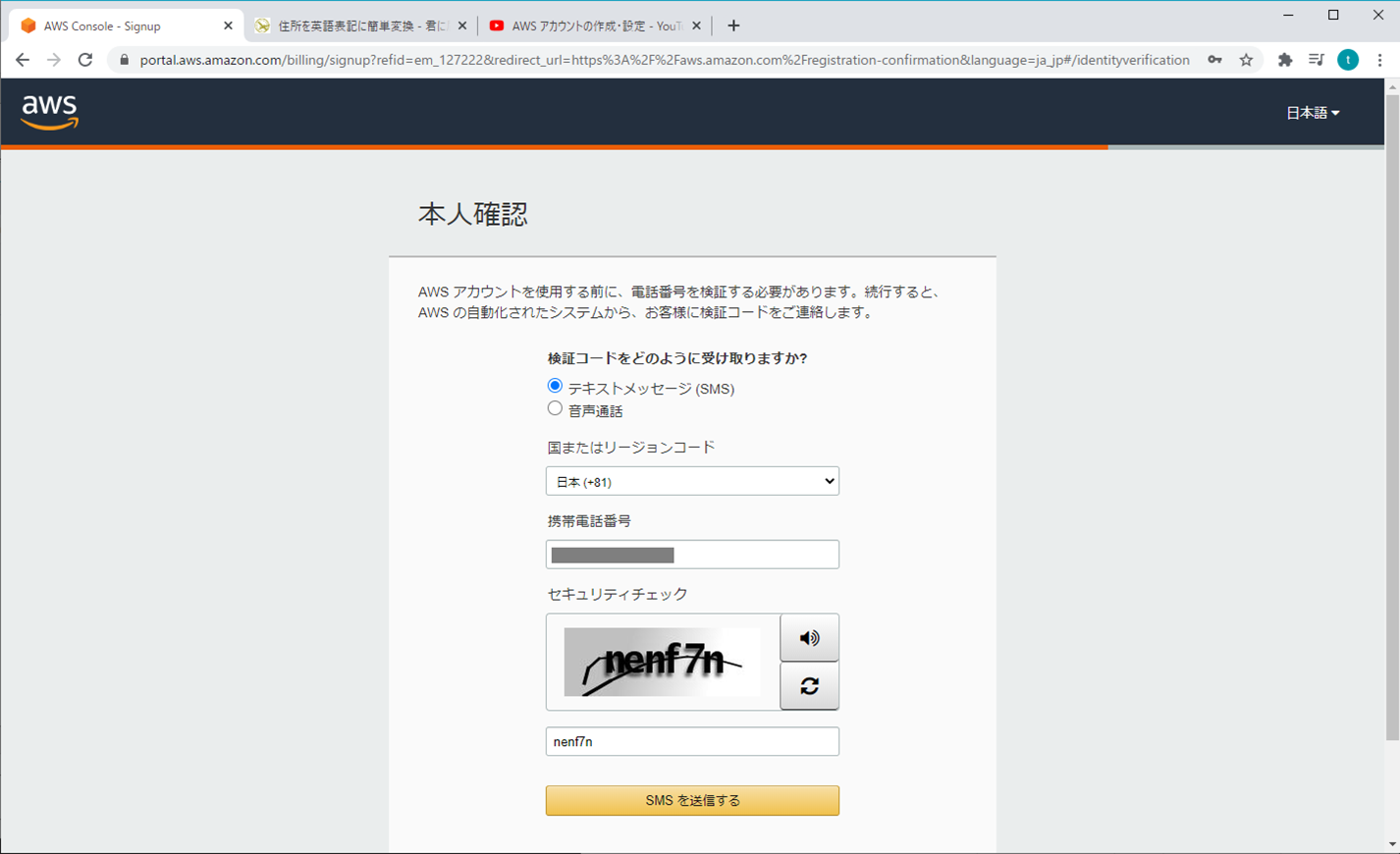
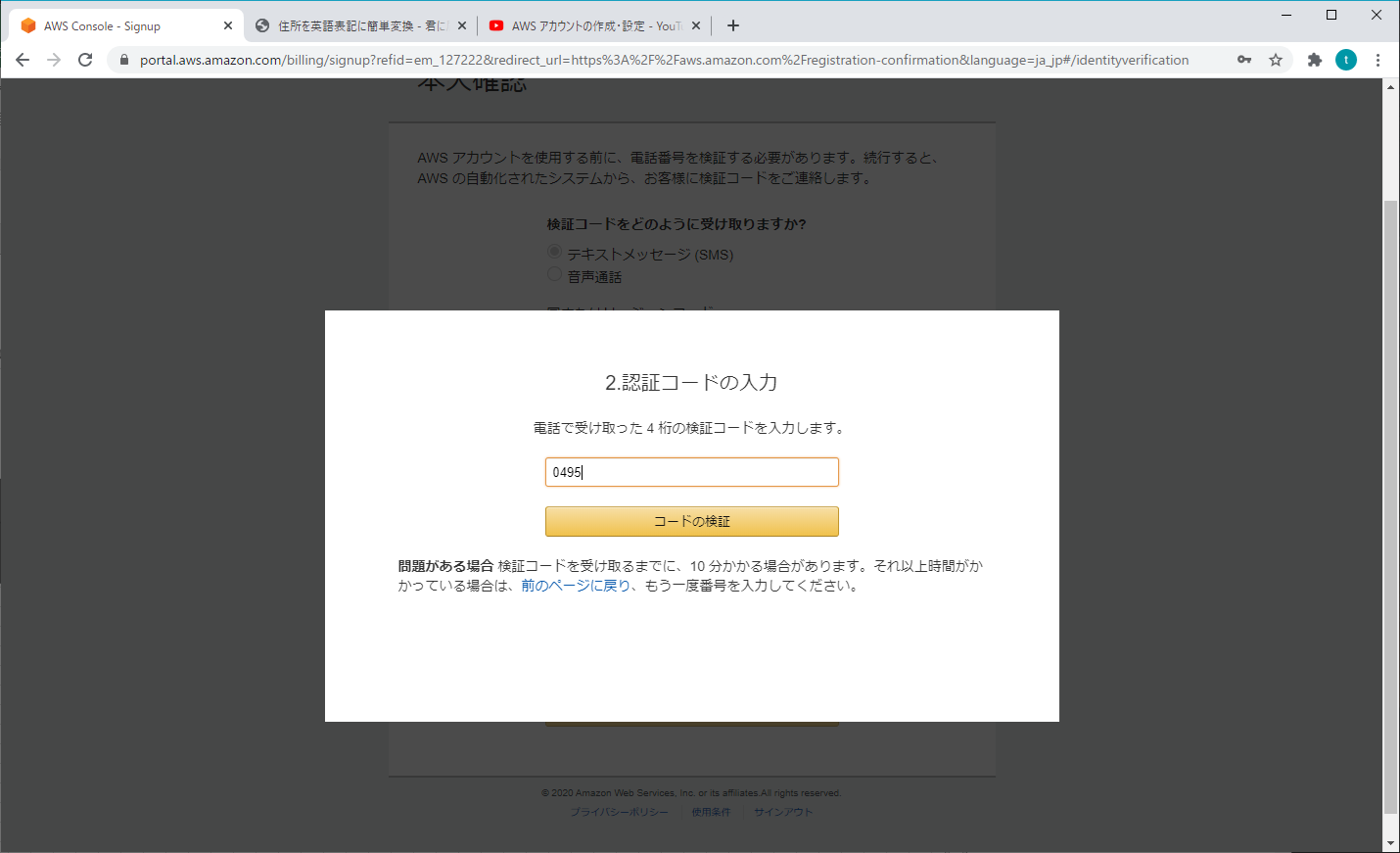
4. 本人確認
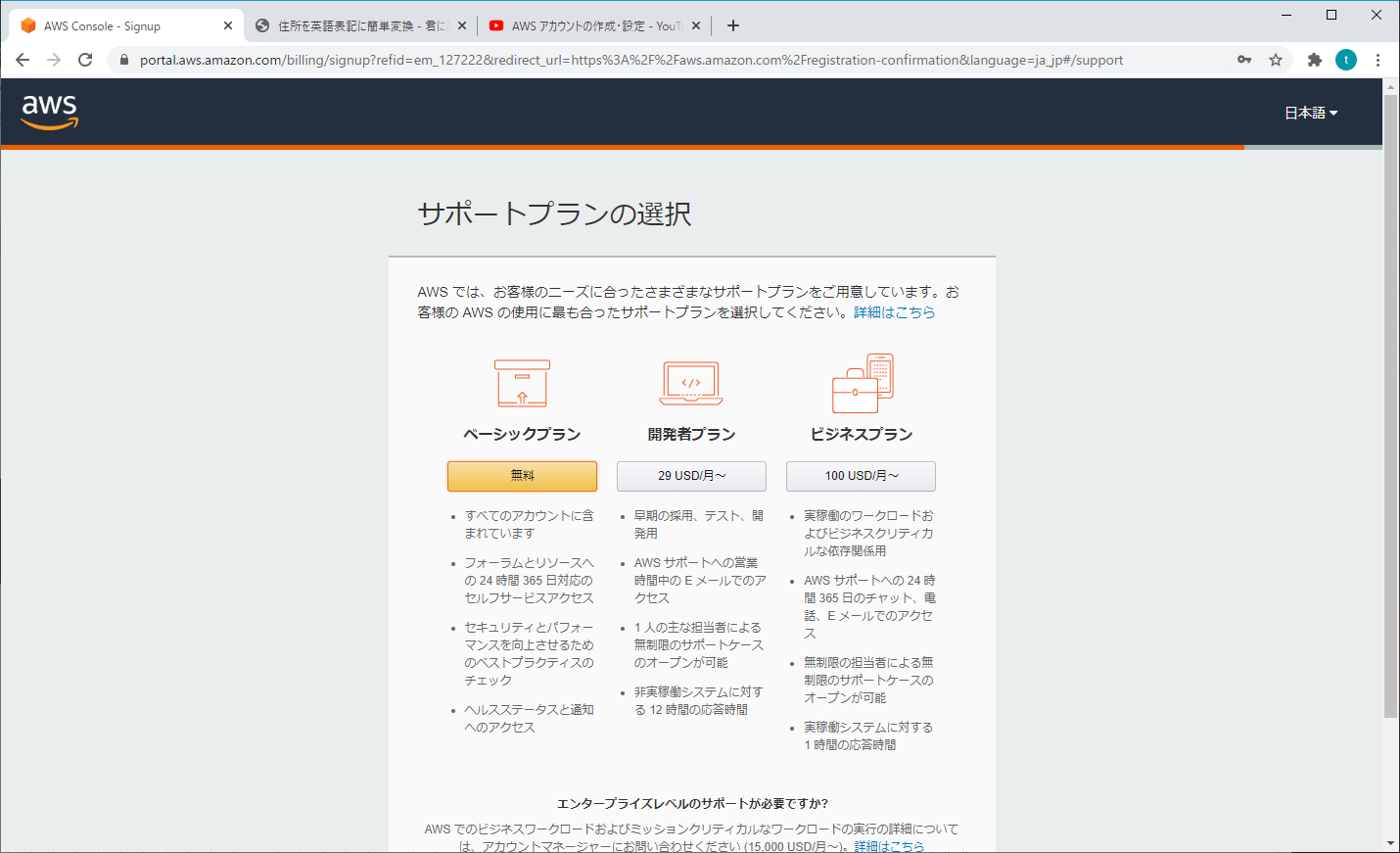
5. サポートプランの選択
6. 案内(オプション)



- 投稿日:2020-07-25T18:13:48+09:00
【AWS】アカウント申請 - 無料ベーシックプラン
アカウント使用の流れ
- 開始前知っておくべきポイント
- アカウント申請
- ログイン
- IAM設定
- MFA多要素認証
- アカウント削除
参照資料
操作の詳細は、「Youtube」の「Amazon Web Services Japan 公式」を参照
https://www.youtube.com/watch?v=1VCIFN8B72oアカウント申請
1. 基本情報
2. 連絡先情報
連絡先情報は、半角英数字で入力する必要があるから、住所を英字に変換する
- Ju Dress http://judress.tsukuenoue.com/
- 君に届け https://kimini.jp/
- Google Map(英語) https://www.google.com/maps/@36.087542,136.321622,15z?hl=en
3. 支払情報
4. 本人確認
5. サポートプランの選択
6. 案内(オプション)
- 投稿日:2020-07-25T15:31:55+09:00
【AWS】開始前知っておくべきポイント - 無料利用枠
アカウント使用の流れ
参考資料
「Youtube」の「Amazon Web Services Japan 公式」を参照
https://www.youtube.com/watch?v=nPEp0L3MIfc開始前知っておくべきポイント
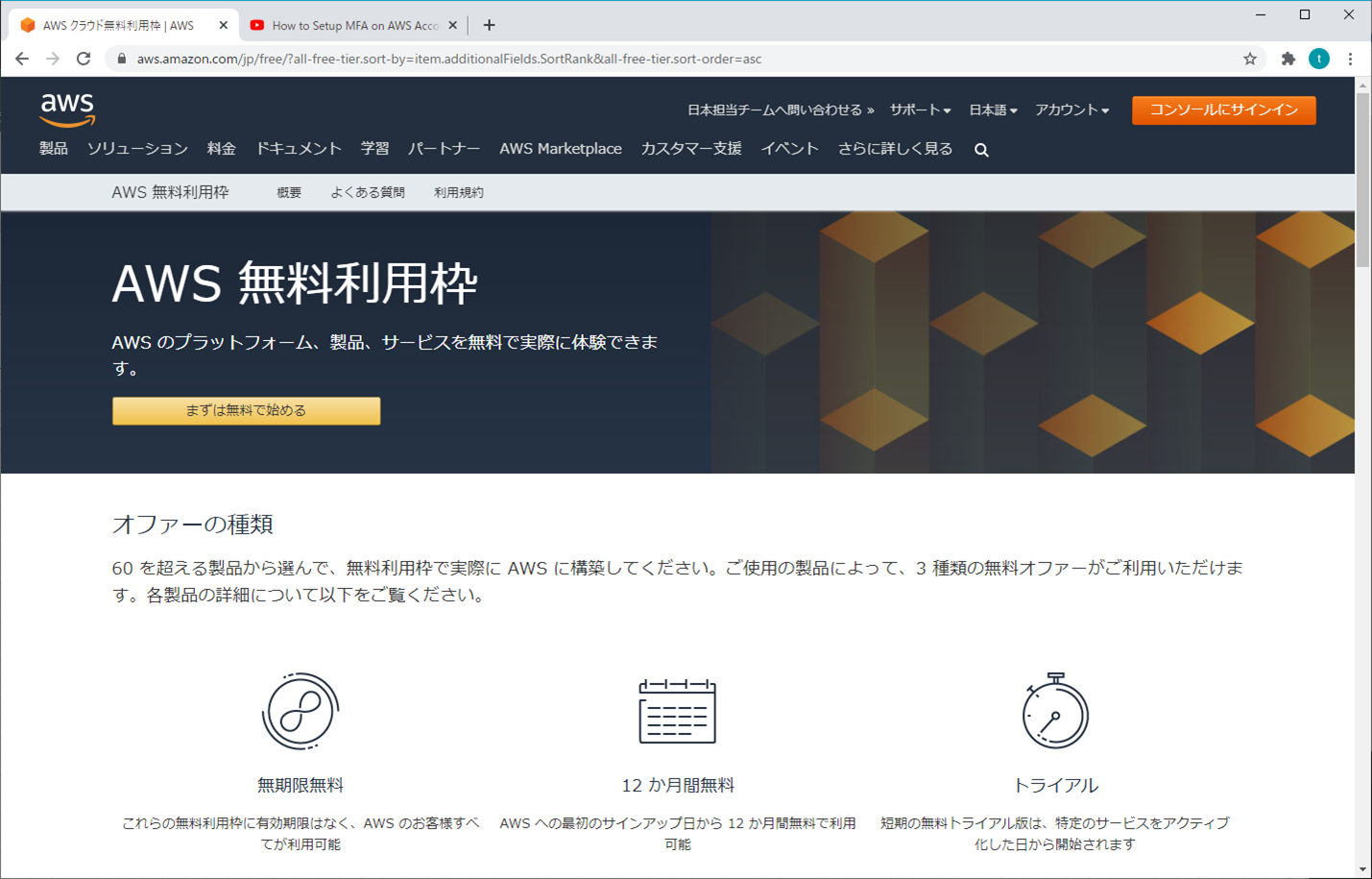
AWS 無料利用枠
AWSの無料利用枠については、3種類のタイプがありますが、よく使うのは「新規登録ができてから12カ月間無料の枠」と「無期限無料の枠」です。それぞれの使用条件を気を付けないと、知らずに利用料金を請求されるかもしれません。
詳細は、「AWS」の公式サイトを参照
- https://aws.amazon.com/jp/free
1. 12カ月間無料
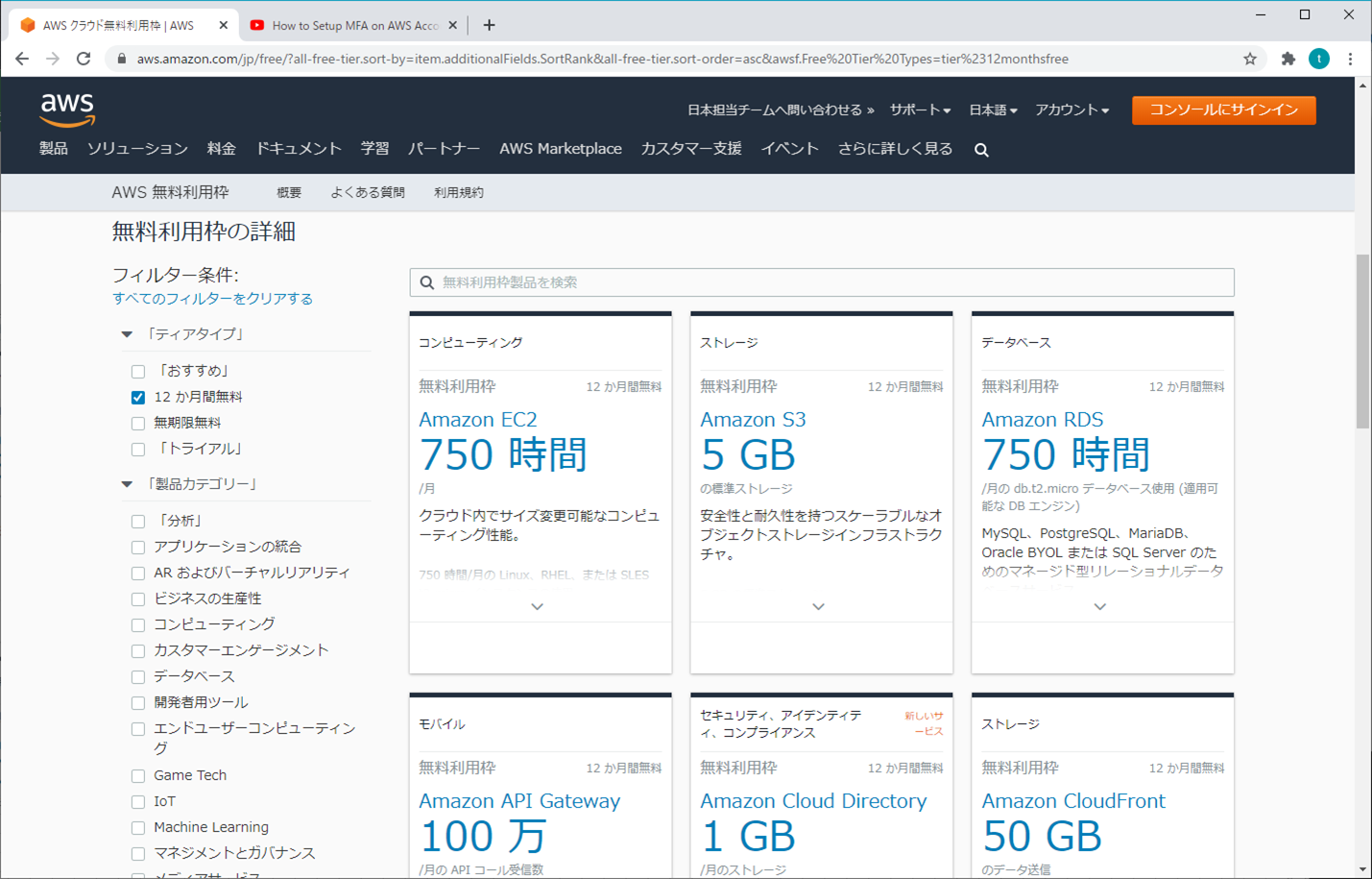
AWS の新規のお客様のみが対象であり、AWS にサインアップした日から 12 か月間ご利用いただけます。12 か月間の無料利用の有効期限が切れた場合、またはアプリケーション使用量が無料利用枠を超えた場合は、標準の料金、つまり従量課金制でお支払いください (価格の詳細については、各サービスのページをご覧ください)。ご利用にあたっての条件が適用されます。詳細については、提供規約をご覧ください。
- EC2、RDSなど
2. 無期限無料
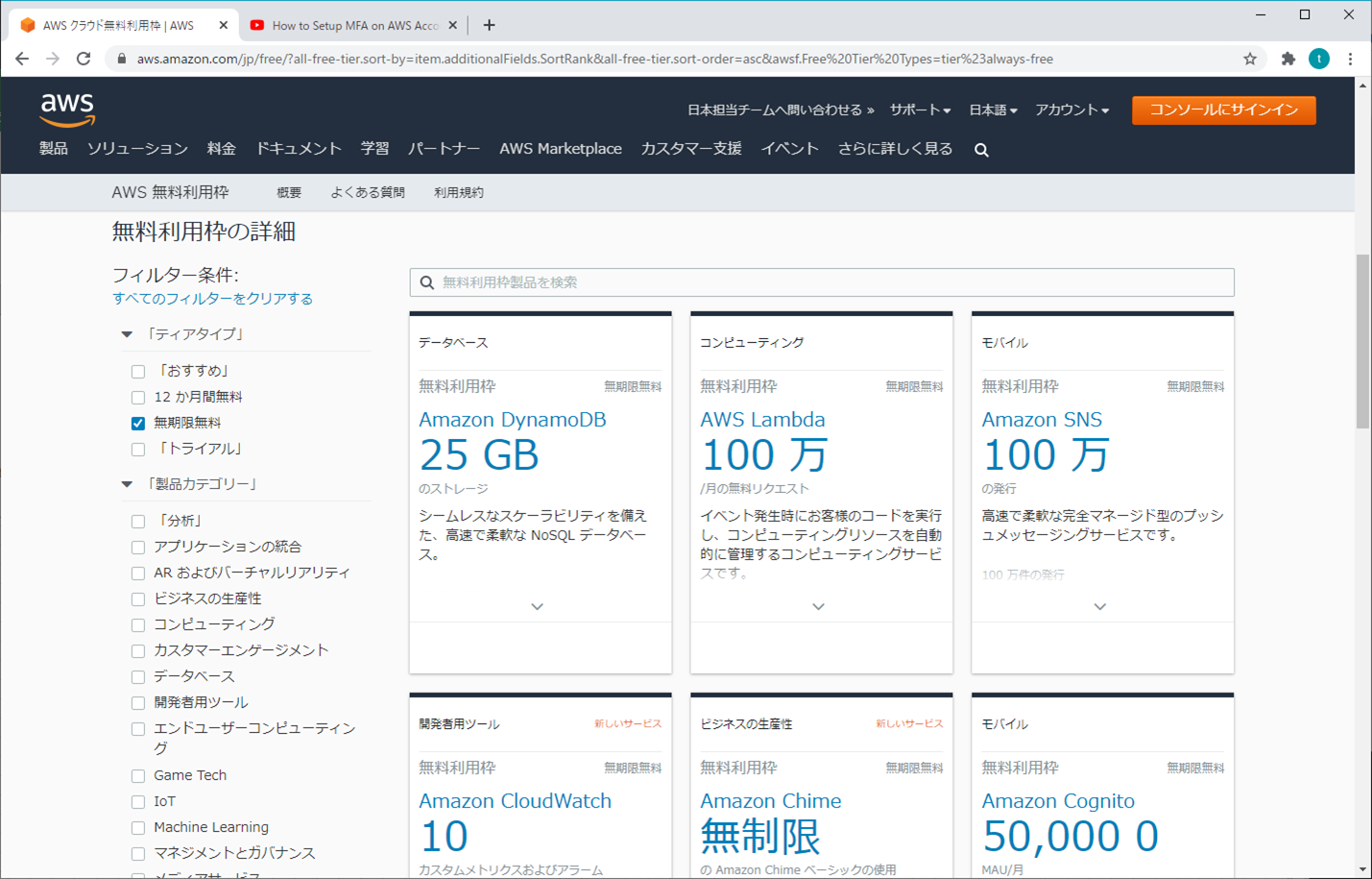
これらの無料利用枠は、12 か月間の AWS 無料利用枠の期間が終了しても自動的に期限切れにはなりません。既存および新規の AWS のお客様のいずれも、無期限にご利用いただけます。
- DynamoDB、Lambdaなど
- 投稿日:2020-07-25T14:45:13+09:00
チャットアプリ制作
個人の学習の知見を広げるため、チャットアプリを制作しました。
アプリの概要
・ユーザーの登録ができる
・ユーザーがグループを作成できる
・グループを指定して、メッセージを送ることができる使用技術
・Ruby
・Ruby on Rails
・JavaScript
・MySQL
・AWS
・nginx
・unicorn
・Capistrano本番環境のリンク
githubのリンク
https://github.com/mitsugu3/ChatSpace
感想
アプリ制作の流れを掴むことができた。
AWSで、本番環境にあげるのが
シークレットキーなどの知識が必要だったので難しく感じたが、
検索記事を参考に自走することができた。
- 投稿日:2020-07-25T12:42:10+09:00
AWS CodeDeployとCodePipelineを触ってみた
きっかけ
前回記事でAWS Copilotを触ってみて色々便利だったので、Copilot Pipelineにも手を出してみようと思いました。
が、そもそもCodePipelineを触ったことがなかったので、まずこちらを触ってみることにしました。目標構成
ローカルで編集したindex.htmlファイルをGitHubにプッシュするだけで、自動でEC2内のindex.htmlファイルを更新し即座に公開内容に反映したい。
準備
EC2インスタンスの作成
CodeDeployで使うEC2インスタンスを作成しておきます。以下のものが必要になります。
以下の条件のVPC
- インターネットゲートウェイがアタッチされている
送信先:0.0.0.0/0、ターゲット:上記のインターネットゲートウェイのルートがルートテーブルに設定されている以下の条件のロール
- 一般的なユースケース EC2に、
AWSCodeDeployRoleポリシーとAmazonS3FullAccessポリシーが付与されたロール- ユースケースが
CodeDeployのロール以下の条件のEC2インスタンス
- 作成したVPCとサブネットの付与
- 作成した
AWSCodeDeployRoleポリシーとAmazonS3FullAccessポリシーが紐づいているEC2ロールの付与- キーがNameのタグの付与(値は任意)
- セキュリティーグループに
タイプ:HTTP(ソースは初期値の0.0.0.0/0, ::/0のまま)の追加CodeDeployエージェントをEC2インスタンスにインストール
作成したEC2インスタンスにCodeDeployエージェントをインストールします。
$ ssh -i 『EC2作成時に指定したpemファイル』 ec2-user@『EC2のIPv4パブリックIP』 # 作成したEC2インスタンスにSSH接続 $ sudo yum update $ sudo yum install ruby $ sudo yum install wget # すでにインストール済みの可能性あり $ cd /home/ec2-user $ wget https://aws-codedeploy-ap-northeast-1.s3.ap-northeast-1.amazonaws.com/latest/install # 下記コメント参照 $ chmod +x ./install $ sudo ./install auto上記のインストールの詳細はAmazon Linux 用または RHEL 用の CodeDeploy エージェントをインストールします。 - AWS CodeDeployを確認してください。
6行目の
$ wget https://〜の行はリージョンによってURLが変わってきます。
変更する必要がある箇所は以下の赤文字の箇所です。
$ wget https://bucket-name.s3.region-identifier.amazonaws.com/latest/install
リージョン毎の入れるべき値はCodeDeploy リソースキットのリファレンス - AWS CodeDeployを確認してください。必要なファイルをGitHubに上げる
AWSの公式サンプルファイルがGitHubに上がっているので今回はこれを利用します。
サンプルは以下のような構成になっています。. ├── LICENSE.txt ├── appspec.yml # CodeDeployに必須のファイルで、デプロイ時に実行する内容が書かれている ├── index.html # 今回の更新対象のファイル └── scripts # デプロイ時に呼び出されるスクリプトが格納されている ├── install_dependencies ├── start_server └── stop_serverappspec.ymlの中身は以下のような形で、どのタイミングで何を実行するか指示するファイルです。
appspec.ymlには以下のルールがあります。
- CodeDeployに必須のファイル
- appspec.ymlのファイル名は固定
- appspec.ymlを格納する場所は同期させるフォルダのルート
詳しくは以下のサイトを確認してください。
- CodeDeploy AppSpec File リファレンス - AWS CodeDeploy
- AppSpec の「hooks」セクション - AWS CodeDeploy
- AWS CodeDeploy の AppSpec を読み解く | Developers.IO
version: 0.0 os: linux files: - source: /index.html # 同期させる元 destination: /var/www/html/ # 同期させる先(今回はEC2インスタンスの中身) hooks: BeforeInstall: # 上記のファイルセクションで指定した場所にファイルをコピーする前 - location: scripts/install_dependencies # 必須項目。実行したいスクリプトの場所を指定 timeout: 300 # オプション。スクリプト実行時のタイムアウトを秒で指定 runas: root # オプション。スクリプトの実行ユーザーを指定 - location: scripts/start_server timeout: 300 runas: root ApplicationStop: # アプリケーションのリビジョンが開始する直前 - location: scripts/stop_server timeout: 300 runas: rootスクリプトファイルはシンプルにこのような形です。(3ファイルまとめて)
### install_dependencies ### #!/bin/bash yum install -y httpd ### start_server ### #!/bin/bash service httpd start ### stop_server ### #!/bin/bash isExistApp=`pgrep httpd` if [[ -n $isExistApp ]]; then service httpd stop fiAWS CodeDeployの設定
AWSマネジメントコンソールからCodeDeployの設定を行います。
- AWS マネジメントコンソールからCodeDeployに飛ぶ
- 左のメニューから
アプリケーションをクリックし、アプリケーション画面右上のアプリケーションの作成をクリックするアプリケーションの作成画面で、以下を入力・選択し
アプリケーションの作成をクリックする
- アプリケーション名:任意の名前を入力
- コンピューティングプラットフォーム:
EC2/オンプレミスを選択アプリケーションを作成して遷移した画面下部のデプロイグループエリア右上の
デプロイグループの作成をクリックするデプロイグループの作成画面で、以下を入力・選択し
デプロイグループの作成をクリックする
- デプロイグループ名:任意の名前を入力
- サービスロール:本記事の始めに作成した、ユースケースがCodeDeployのロールを指定
- 環境設定:
Amazon EC2 インスタンスにチェックを入れ、EC2に設定したタグを指定- Load balancer:
ロードバランシングを有効にするのチェックを外すCodeDeployの動作確認
CodeDeployの設定が終わったら動作確認をしてみます。
- デプロイグループが作成できたら、その画面の右上の
デプロイの作成をクリックする- Create deployment画面で、以下を選択・入力し
デプロイの作成をクリックする
- デプロイグループ:作成したデプロイグループを指定(自動で指定されているはず)
- リビジョンタイプ:
アプリケーションは GitHub に格納されていますを選択- GitHub トークン名:検索入力欄にアカウントのエイリアスを入力し
GitHubに接続をクリックする(未接続の場合のみ)- リポジトリ名:GitHubの『アカウント名』/『リポジトリ名』を入力(「/」前後にスペースは入れない)
- コミットID:GitHubのCodeタブのコミット数リンク→最新コミット右のコピーボタンでコピーした値
デプロイの作成を行うとデプロイが開始され、デプロイのステータスが表示されます。
デプロイ処理中は進行中ステータスで、終わるまで時間がかかるのでステータスが成功になるまで少し待ちます。
表示されている画面一番下のデプロイのライフサイクルイベントの一覧のイベント列のView eventsをクリックするとappspec.ymlのhooksで出てきたイベントの実行結果が確認できます。EC2のファイルの確認
デプロイが成功したので、EC2の
/var/www/html/(appspec.ymlのdestinationで指定した場所)を確認するとindex.htmlが格納されています。$ ssh -i 『EC2作成時に指定したpemファイル』 ec2-user@『EC2のIPv4パブリックIP』 $ cd /var/www/html/ $ ls index.html # ファイルが格納されている!ブラウザでの確認
EC2の
IPv4パブリック IPの値をブラウザに貼り付けてアクセスすることで、index.htmlの内容を確認出来ます。これでCodeDeployは動かせるようになりました
ただ毎回コミットIDを調べてデプロイを作成するのは手間なので、GitHubにプッシュしたらEC2インスタンスにアップされるまでを自動で行えるようCodePipelineで設定します。AWS CodePipelineの設定
AWSマネジメントコンソールからCodePipelineの設定を行います。
- AWS マネジメントコンソールからCodePipelineに飛ぶ
- パイプラインの一覧画面の右上の
パイプラインを作成するをクリックする- パイプラインの設定を選択する画面で、以下を入力し
次へをクリックする
- パイプライン名:任意の名前を入力
ソースステージを追加する画面で、以下を選択・入力し
次へをクリックする
- ソースプロバイダー:GitHub
GitHubに接続するをクリック- リポジトリ名:GitHubの『アカウント名』/『リポジトリ名』を入力(「/」前後にスペースは入れない)
- ブランチ:対象のブランチを選択
ビルドステージを追加する画面で、AWS CodeBuildを指定できます。
が、今回は使わないのでビルドステージをスキップをクリックするデプロイステージを追加する画面で、以下を選択して
次へをクリックする
- デプロイプロバイダー:
AWS CodeDeployを選択- アプリケーション名:CodeDeployで作成したものを選択
- デプロイグループ :CodeDeployで作成したものを選択
- レビュー画面で、内容を確認して
パイプラインを作成するをクリックするCodePipelineの設定が終わると、自動でGitHubからファイルを取得してデプロイが行われます。
ローカルのindex.htmlファイルを適当に編集してGitHubにプッシュし、ブラウザで確認してみましょう。
ばっちりローカルでの変更がブラウザで反映されている!...はず。
まとめ
サービス名の頭のAWSとAmazonはどう違うのだろう..
We're hiring!
AIチャットボットを開発しています。
ご興味ある方は Wantedlyページ からお気軽にご連絡ください!参考
Amazon Linux 用または RHEL 用の CodeDeploy エージェントをインストールします。 - AWS CodeDeploy
CodeDeploy リソースキットのリファレンス - AWS CodeDeploy
CodeDeploy AppSpec File リファレンス - AWS CodeDeploy
AppSpec の「hooks」セクション - AWS CodeDeploy
aws-samples / aws-codedeploy-samples - GitHub
AWS CodeDeploy の AppSpec を読み解く | Developers.IO
【はじめてのCI/CD】AWSでやってみるDevOps最初の一歩、CodeDeploy、CodePipelineを使った自動デプロイのハンズオン - Youtube
- 投稿日:2020-07-25T11:50:04+09:00
ドメイン駆動設計の戦略的デザインとA2AD戦略を組み合わせた多層防御システムの考案
領域支配戦略に基づくドメイン駆動設計の戦略的デザインの考案
サイバー空間はクラッカーによるDoS攻撃やハッキングによる遠隔操作など行われる攻撃手法が年々進化しているが、攻撃に対する有効な防衛手法が確立されていない。
これは、防衛方法に統一された理論が存在せず、各々がファイヤーウォールやDMZなど様々な手段で対抗しているのが原因だと思われる。
今回の記事では、エリックエヴァンスが考案した戦略的デザインのアイディアに領域支配戦略であるA2AD戦略の思想を取り入れ、サイバー空間に統一した防衛理論を提案する。A2AD戦略とは
A2AD(接近阻止・領域拒否)戦略とは、空母や戦闘機による支配領域への侵入を拒否するために考案された領域支配戦略のことである。
A2AD戦略は接近阻止(A2)戦略と領域拒否(AD)作戦によって構成される。
A2AD戦略は領域に侵入する対象の手段に対抗する非対称的なアプローチを用いる。
空母や戦闘機は電子機器の塊であるため、電磁波領域からのジャミングなどに脆弱である。
戦略レベルによって実行されミサイル防衛システムによる接近阻止(A2)戦略と電磁波領域からの戦闘機や空母へのジャミング、ハッキングなどによる領域拒否(AD)作戦を組み合わせる。
A2AD戦略は領域に侵入する対象の脆弱性に焦点を当て、安価で容易な非対称的な対抗手段を組み合わせることによって、領域侵入を阻止する多層防御システムを構築する。ドメイン駆動設計における戦略的デザインとは
ドメイン駆動設計における戦略的デザインとは、以下の概念を包括した設計手法である。
境界付けられたコンテキスト
コンテキストマップ
組織パターン
戦略的設計戦略的デザインについては以下のURLを参照
https://qiita.com/aLtrh3IpQEnXKN7/items/c66739ce872e440c1a7dマイクロサービス
マイクロサービスとは1つのアプリケーションを、ビジネス機能に沿った複数の小さいサービスの疎に結合された集合体として構成するサービス指向アーキテクチャ(service-oriented architecture; SOA)の1種。
A2AD戦略は、マイクロサービスの設計手法が実現可能なクラウドシステム上で実現される。
核となるマイクロサービスを多層防御するサーバをクラスウドシステム上に多数配置し、侵入するクラッカーを自動検知、自動防御を実施する反射的自動防衛システムを構築する。多層防御システムを構築するためのプロセス
領域へ侵入する手段をターゲッティング
核となるマイクロサービスへ侵入する手法のターゲッティングを行う。
侵入する方法として以下のシナリオが想定される。
・正式なユーザーとしてシステムにログイン
・独自のプラットフォームを利用して、違法的にシステム内に侵入
・管理者などのPCやアカウントを乗っ取り、システム内に侵入対抗手段
・正式なユーザーとしてシステムにログイン・・・この手法を利用して侵入してくるクラッカーなどは、システムの破壊やデータの抜き取りではなく、システムを利用した社会的扇動や違法行為としてツールの活用を目的としている。
正式なルートで侵入してくるため、システムの運用方法にビジネスルールを設け、違法なアカウントなどを自動調査する自動検知システムなどを導入して対抗する。・独自のプラットフォームを利用して、違法的にシステム内に侵入・・・違法ソフトなどを活用してシステム内に窓を設け、侵入を行う。
この手法に対抗する方法として、侵入手段に利用するプラットフォームの調査を実施し、プラットフォームの脆弱性を突き止める。脆弱性を活用し、プラットフォームとクラッカー間のコントロールを切断することによって、システム内への侵入を阻止する。・管理者などのPCやアカウントを乗っ取り、システム内に侵入・・・正式なログイン権限を保持しているユーザーのPCやアカウントを乗っ取ることによって、システム内に侵入を行う。この手法は、システムが容易にアクセスできる入り口を提供していることに問題がある。アクセスの入り口を迷路上にすることによるログインルートの複雑化、ワインタイムパスワードを配布する媒体をPCやアカウント以外に設けるといった手法が考えられる。
多層防御システムを実現するための具体的手段の検討
多層防御システムを実現するための手段として、以下の方法が存在している
・ハード防御・・・PCの規格情報、NATの物理アドレス、ポート番号の設定、アクセスを行うプロトコルの設定など、ハードウェアに依存した情報に基づくセキュリティ防御
・ミドル防御・・・DMZの緩衝地帯設置、ファイヤーウォールによる領域防御などのハード防御とソフト防御の中間領域に存在する領域に基づくセキュリティ防御
・ソフト防御・・・ウィルス検知ソフト、ワンタイムパスワードなどルールや運用に基づくセキュリティ防御。
多層防御システムを実現する上で、ミドル防御の方法を最初に検討する。
ミドル防御は領域に基づくセキュリティ防御方法ため、システムを防衛する範囲と防衛外の境界線を区切ることができる。
次にハード防御の手法について検討を行う。ハード防御はシステムにアクセスする機器や手段について明確な定義を行う。
ハード防御が検討されることによって、クラウド上で動作するシステムの運用方法などが具体化される。
最後にソフト防御について検討を行う。ソフト防御はミドル防御やハード防御によって防ぐことができない、侵入手段に対抗する方法として検討を行う。
ソフト防御は特定の概念や手段に依存しない包括的なアプローチとして検討する。多層防御システムを設置するネットワークレイヤー層について
多層防御システムを設置する場所を検討する上で、下記のネットワークレイヤー層に基づいてシステムの配置を決定する。
1) 物理層・・・「端末」と「端末」とをつないで電気信号を送るために必要な物理的取り決め
2) データリンク層・・・ネットワーク間をつなぐハブの間の通信領域
3) ネットワーク層・・・ネットワーク間のパケットの経路に関する取り決めが行われている。「IPアドレス」によって管理され、ルーターによってトラフィックの管理がまとめられている。
4) トランスポート層・・・アプリケーションからデータを受け取り、パケットに分割してネットワーク層に送られる流れを受け持っている。
5) アプリケーション層・・・ネットワーク間の通信するプロトコルの設定、アクセスするパート番号の設定などを行う
1) 物理層、5) アプリケーション層はハード防御が担当し、2) データリンク層、3) ネットワーク層、4) トランスポート層はミドル防御が担当する。抑止環境の構築
抑止とは、罪や罰則を明確化することによって対象者に心理的圧迫を加え、攻撃の実行の中止、戦闘力の低下、攻撃方法を変化させることを目的としている。
抑止を効率よく機能させるためには以下の条件が必要である。
1.罪に対する罰則に基づく物理的手段が確実に実行されると認知されていること
2.攻撃に対するリターンよりも罪に対する罰則が上回っていること
3.多層防御システムが有効に機能し、攻撃者の身分などが特定できること
4.グローバルな国際機関内で情報交換が行われ、攻撃者に対する情報共有が行われていること抑止を効率よく機能させる条件が整った後、動画やメディアを利用した情報ツールを活用して情報を拡散することによって、攻撃者の心理に介入する環境を整える。
抑止環境を構築することによって、攻撃を行わせない環境を作成することが重要である。まとめ
サイバー攻撃の犯罪などが増加しているなか、有効なセキュリティシステムを構築できない原因は防衛方法が守勢であることが原因である。
防御方法が守勢であることが判明すれば、攻撃者は安心して攻撃に取り組むことができるため、攻撃方法の学習と反省から新しい戦術を開発し攻撃力の増加を招く。
真の防御は積極的攻勢にある。積極的攻勢によって攻撃者に心理的圧迫を加え、安易なサイバー攻撃が身の破滅に繋がることを攻撃者に自覚させることによって、サイバー犯罪の防止と抑止につながる。
- 投稿日:2020-07-25T11:32:52+09:00
図解で、AWS新サービスでローコード・アプリ開発を理解する。Honeycode
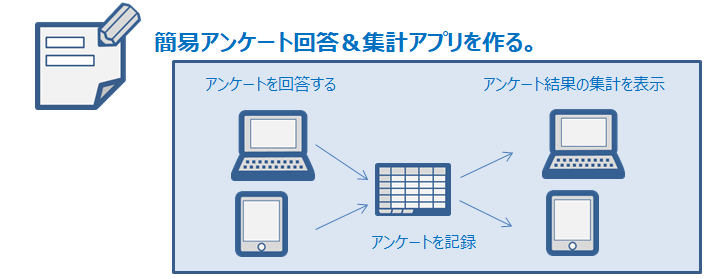
図解で、AWS新サービスでのアプリ開発を理解する(簡易アンケート回答&集計アプリ)AWS Honeycode
パソコンもしくはスマホでアンケートに回答し、AWS Workbook(表データ)を経由して、アンケート結果を集計して表示するアプリのテンプレートが提供しているので、日本語版へと改造しながらアプリ制作過程を理解しようと思う。
AWSが提供するテンプレート
AWS Honeycode で新しいアプリを作るときは、最初に[Create workbook]を実行し、(1) CSVファイルから作成する、(2) テンプレートから作成する、(3) イチから自分で作成する、の3つから開発方法を選ぶ。ここではテンプレート[Simple Survey]から作成してみた。
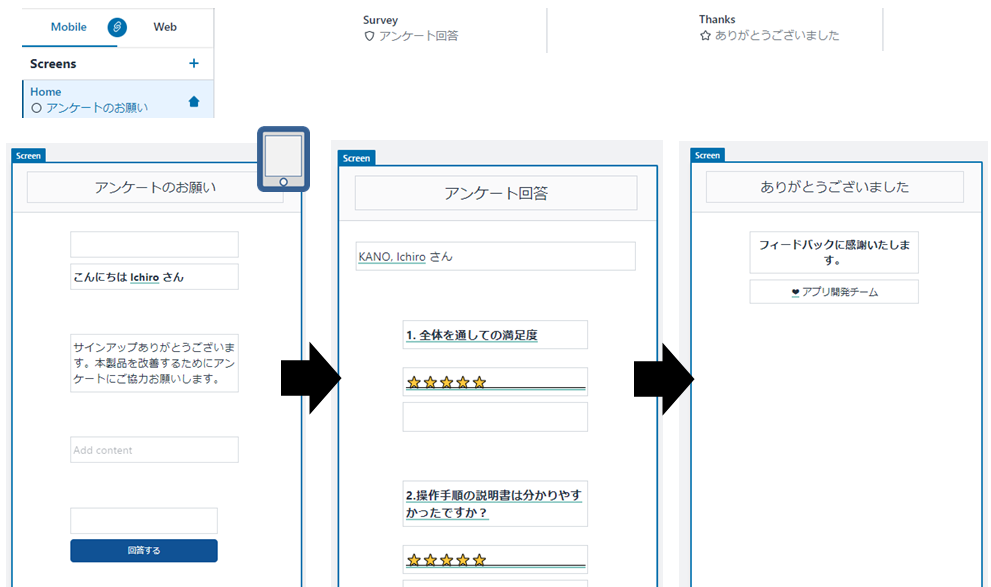
画面レイアウトの設計(モバイル用)を日本語版に改造したもの
画面(Screen)が3つ用意されている。プログラム上での画面の名前は [Home] [Survey] [Thanks] としている。
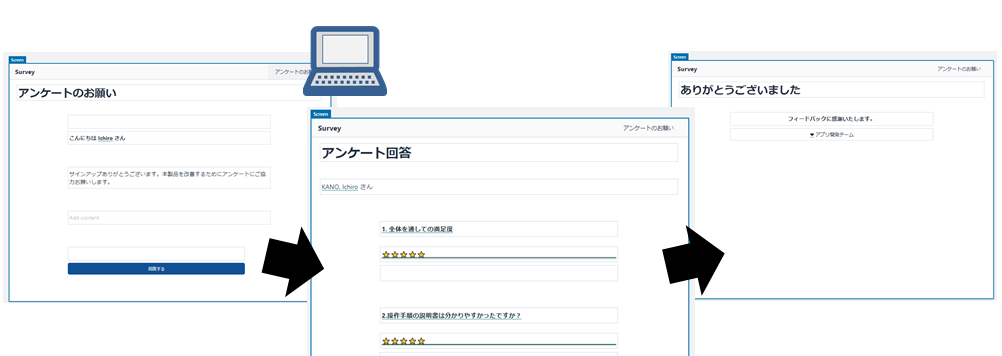
画面レイアウトの設計(パソコン用)を日本語版に改造したもの
レイアウトが横に間延びするものの、モバイル用を作るとパソコン用も同時に作成される(というか兼ねている)。
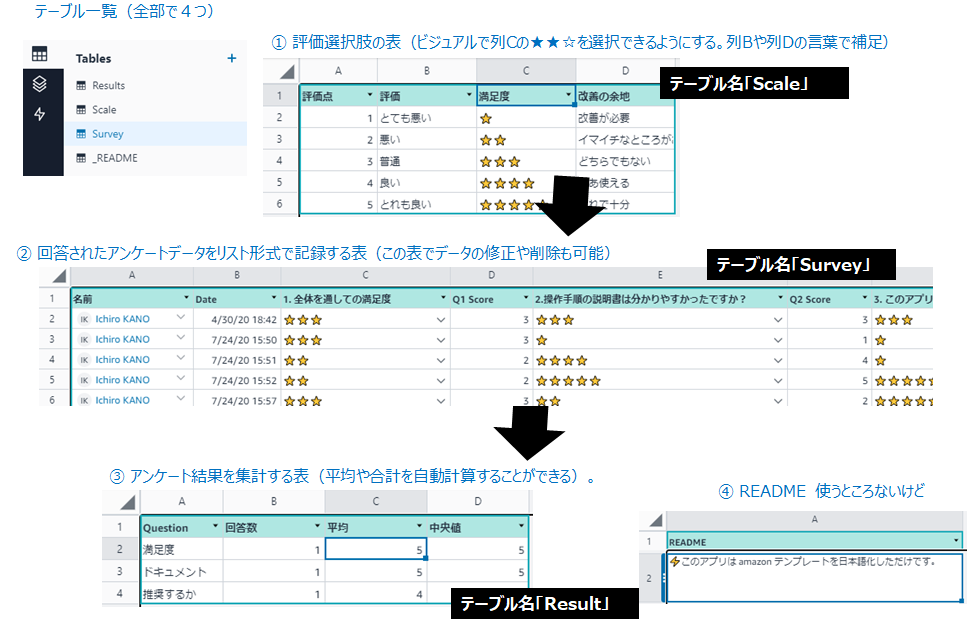
データベースとなるワークシート(workbook)の確認
テーブルは全部で4個用意されていた。下図の通り (1) アンケート選択肢の表 (2) 回答されたアンケートの一覧 (3) アンケート結果を集計する計算表 (4) 使ってないけどREADME の4つ。
ワークシートのテーブルとテーブルのリレーショナル設定
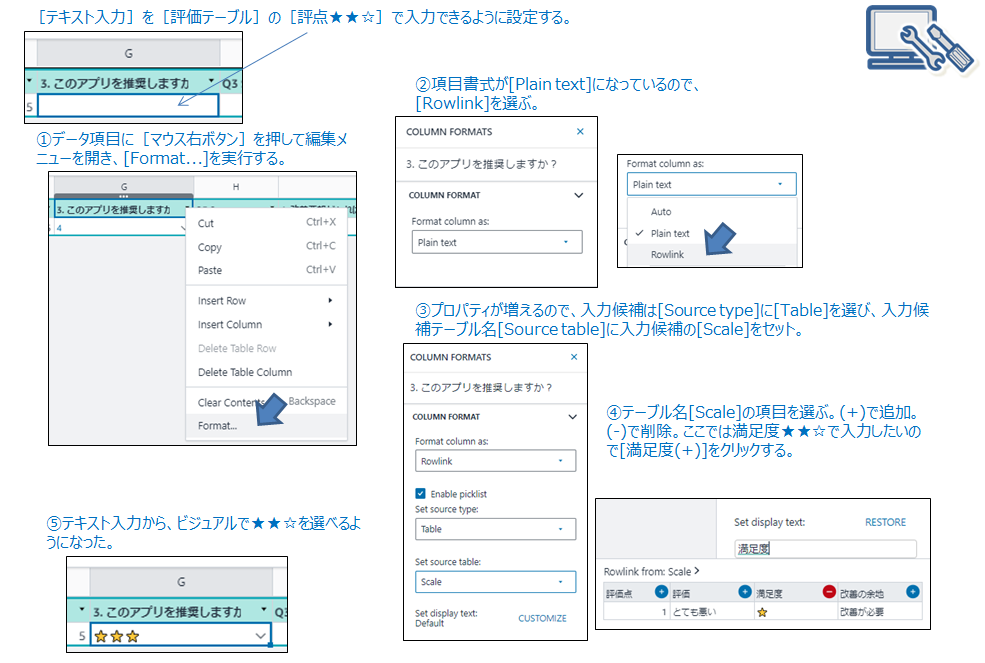
Excelでいうところの「セルに入力する選択肢をリストで表示する」設定。アンケートの質問「アプリを推奨しますか?」に対して「★」「★★」「★★★」から選べるようにする。画面のプロパティで設定するので下図に手順を記載する。
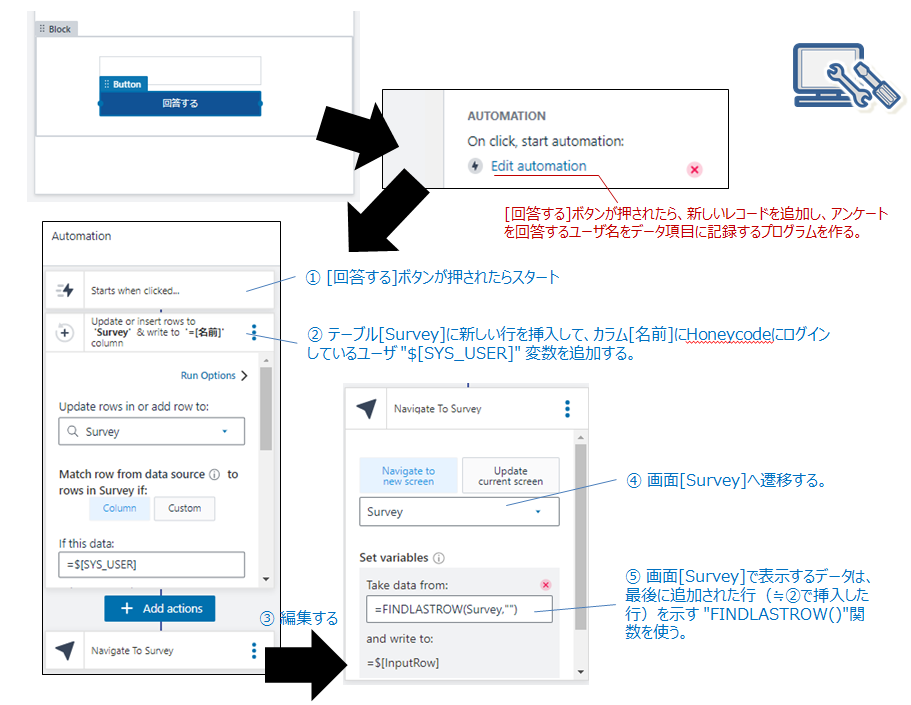
画面に表示される部品を使ってプログラミング(automation)その1
[回答する]ボタンが押されたときの自動処理を追加する。ワークシートに新しいレコードを追加して、アンケート回答する人の名前をカラム名「名前」にセットし、アンケート入力画面に遷移する。
編集画面を設定する(Screenのレイアウト)
レイアウト
アンケート入力画面で表示される質問と回答欄を設定する。Screenには大きく3つのブロックがある [Header] [List] [Global Navigation] 。[Header]部分がアプリ名称や現在の操作タイトル(見出し)などに使えて、[Global Navigation] がアプリ内で操作できる(遷移できる)メニューに便利、[List]部分がワークシートのデータを操作する場所になる。
ワークシートとのデータ連動
データ入力フィールド[Input field]などの入力UIコントロールにあるプロパティを操作して、その入力フィールドがワークシートのどこに連動するのかを設定する。
画面に表示される部品を使ってプログラミング(automation)その2
アンケート入力が終わったら[アンケートを提出する]ボタンの自動処理を追加する。現在、編集しているレコードの日付カラムに最新の日付時刻を登録して、次の[Thanks]画面へ遷移する。
まとめ
完成したアプリの動作確認。モバイル(iPhone)でアンケートを回答できる。アンケート集計結果を表示できる。AWS Honeycode は2020年7月時点でプレビュー提供(オレゴンリージョンのみ)されています。AWS Honeycode コミュニティではSSOによるログインなど積極的に意見収集しており、今後、UIパーツや自動処理Automationによる接続先コネクタなどがどんどん発表されていき、やがて MS PowerApps や Google App Maker のような強力なサービスに育っていくものと予想されています。




- 投稿日:2020-07-25T10:09:25+09:00
AWS ソリューションアーキテクト アソシエイト合格体験記(SAA-C02) おすすめ教材や難しく感じた点
はじめに
2020年7月24日、AWSソリューションアーキテクト アソシエイト試験(以下、SAA)に、2度目の受験で合格しました。
1度不合格を経験していることもあり、合格結果をみた時は声が出るぐらい嬉しかったです!SAAを受験してみて、難しいと感じたところやおすすめ教材を書いていきたいと思います。
これから受験を予定されている方やリベンジに燃えている方は、参考にして頂けると幸いです。私の経歴
- SIer勤務5年目。これまでは主に検証作業をしており、最近やっと開発プロジェクトに参画できた
- 勉強をはじめるまでAWSの経験はなし。インフラ知識もほとんどなく、DNSとかの単語を多少知っている程度
合格までの道のり
日付 内容 2019年9月 AWS案件にアサインされたことを機に勉強開始 ~ 仕事に忙殺されながらudemy(後述)で勉強 2020年5月 受験を決意してテストセンターに赴くも、あえなく不合格。コロナ禍だったこともあり死ぬほどテンションが下がる ~ 下がりきったテンションのままひたすら模擬試験(後述)を解く 2020年7月24 なんとか合格 勉強期間は1年たらずという結果になりました。SAAの対象者が「1 年以上の実務経験者」であることを考えると、妥当な期間かなと思います。
ちなみに、AWS案件にアサインされたものの、業務ではコーディング一辺倒で、インフラ構築をする機会には恵まれませんでした。個人的に難しいと感じた点
難しさを感じる点は個々人それぞれかと思いますが、個人的には以下3つに苦しめられました。
VPCとIAMは基本にして鬼門
VPCとIAMはそれぞれAWSのネットワークと権限まわりの根幹をなすサービスですが、ここを理解することが合格の第一関門だと思います。
特にVPCは、これを理解しないとことには合格はないといっても良いくらい重要です。
私は初回に受験したとき、VPCがよくわからないままだったため、そもそも問題文の意味がほとんど理解できませんでした。
幸い業務でVPCでネットワーク構築する機会があったため、2回目の受験では問題がありませんでしたが、AWSの利用経験がない方は、ハンズオンなどを通して理解を深めていくと良いと思います。それぞれのデータベースの違いの理解
SAAでは、主に以下の5つのデータベースに関する問題が出題されます。
- RDS
- Aurora
- Elasticache
- Dynamo DB
- Redshift
RDSとAuroraの違いや、それ以外の3つのデータベースのユースケースに関する問題がよく出題されます。
ですので、これらのデータベースの特性やユースケースを理解していくことが重要になります。私はRDSとElasticacheは業務で使用したことがあったのでイメージがつきやすかったのですが、Dynamo DBとRedshiftはいまいち理解が進みませんでした。
正直、合格した今でもこの2つはよくわからないままです。問題の日本語がわかりづらい
SAAの問題文は英語を日本語訳したもののため、問題文の意味を理解しにくいことがあります。
私は2回目の受験時、緊張してるわ昨日寝れなかったわで、試験開始から30分くらいは何を書いているのか全く頭に入ってきませんでした。
さすがに解読不能な文章は出てこないので、落ち着いて問題文を読み解いていけば大丈夫です。
試験では英語で問題の原文も読めますので、英語が読める方は活用するとよいでしょう。おすすめ教材
これだけでOK! AWS 認定ソリューションアーキテクト – アソシエイト試験突破講座
勉強をはじめたばかりの頃はこの教材をやっていました。
講義形式でSAAの試験範囲となるサービスのハンズオンができます。
定価だと2万円ちかいですが、セールの時に買う2,000円くらいで買えます。※講義中に使用したサービスは講義終了時に削除するようにしましょう。余計なお金が(しかも結構)かかるリスクがあります。(講義内でも指示があります)
AWS認定資格試験テキスト AWS認定 ソリューションアーキテクト-アソシエイト
一度目の受験に失敗したタイミングで購入。
試験範囲のサービスについて綺麗にまとまっており、テキストでは断トツでこれがおすすめです。
特に第13章「AWSのアーキテクチャ設計」が素晴らしい。試験前日にこの章を読んだことが、合格にかなり寄与しました。付属の模擬試験はかなり優しめなので、次に紹介する模擬問題集をやっておいた方がよいです。
【SAA-C02版】AWS 認定ソリューションアーキテクト アソシエイト模擬試験問題集(6回分390問)
模擬試験が6つもついています。SAC-02にも対応しているので、この模擬試験で合格できていれば本番でも問題はないでしょう。
6つある模擬試験のうち4つは「高難易度の模擬試験」と銘打たれていますが、本番では高難易度試験と同等レベルの問題が平気で出てきます。マイナーサービスだと思っていたAWS snowballに関する問題も、本番で3題ほど出題されました。問題解説はそれほど親切ではないので、公式ドキュメントやネットの記事を読んで知識を補強していく必要があります。
以上
お読みいただきありがとうございました。
誤字や情報に不足等あればご指摘いただければ幸いです。
- 投稿日:2020-07-25T10:09:25+09:00
AWS ソリューションアーキテクト アソシエイト試験 合格体験記(SAA-C02) おすすめ教材や難しく感じた点
はじめに
2020年7月24日、AWSソリューションアーキテクト アソシエイト試験(以下、SAA)に、2度目の受験で合格しました。
1度不合格を経験していることもあり、合格結果をみた時は声が出るぐらい嬉しかったです!SAAを受験してみて、難しいと感じたところやおすすめ教材を書いていきたいと思います。
これから受験を予定されている方やリベンジに燃えている方は、参考にして頂けると幸いです。私の経歴
- SIer勤務5年目。これまでは主に検証作業をしており、最近やっと開発プロジェクトに参画できた
- 勉強をはじめるまでAWSの経験はなし。インフラ知識もほとんどなく、DNSとかの単語を多少知っている程度
合格までの道のり
日付 内容 2019年9月 AWS案件にアサインされたことを機に勉強開始 ~ 仕事に忙殺されながらudemy(後述)で勉強 2020年5月 受験を決意してテストセンターに赴くも、あえなく不合格。コロナ禍だったこともあり死ぬほどテンションが下がる ~ 下がりきったテンションのままひたすら模擬試験(後述)を解く 2020年7月24 なんとか合格 勉強期間は1年たらずという結果になりました。SAAの対象者が「1 年以上の実務経験者」であることを考えると、妥当な期間かなと思います。
ちなみに、AWS案件にアサインされたものの、業務ではコーディング一辺倒で、インフラ構築をする機会には恵まれませんでした。個人的に難しいと感じた点
難しさを感じる点は個々人それぞれかと思いますが、個人的には以下3つに苦しめられました。
VPCとIAMは基本にして鬼門
VPCとIAMはそれぞれAWSのネットワークと権限まわりの根幹をなすサービスですが、ここを理解することが合格の第一関門だと思います。
特にVPCは、これを理解しないとことには合格はないといっても良いくらい重要です。
私は初回に受験したとき、VPCがよくわからないままだったため、そもそも問題文の意味がほとんど理解できませんでした。
幸い業務でVPCでネットワーク構築する機会があったため、2回目の受験では問題がありませんでしたが、AWSの利用経験がない方は、ハンズオンなどを通して理解を深めていくと良いと思います。それぞれのデータベースの違いの理解
SAAでは、主に以下の5つのデータベースに関する問題が出題されます。
- RDS
- Aurora
- Elasticache
- Dynamo DB
- Redshift
RDSとAuroraの違いや、それ以外の3つのデータベースのユースケースに関する問題がよく出題されます。
ですので、これらのデータベースの特性やユースケースを理解していくことが重要になります。私はRDSとElasticacheは業務で使用したことがあったのでイメージがつきやすかったのですが、Dynamo DBとRedshiftはいまいち理解が進みませんでした。
正直、合格した今でもこの2つはよくわからないままです。問題の日本語がわかりづらい
SAAの問題文は英語を日本語訳したもののため、問題文の意味を理解しにくいことがあります。
私は2回目の受験時、緊張してるわ昨日寝れなかったわで、試験開始から30分くらいは何を書いているのか全く頭に入ってきませんでした。
さすがに解読不能な文章は出てこないので、落ち着いて問題文を読み解いていけば大丈夫です。
試験では英語で問題の原文も読めますので、英語が読める方は活用するとよいでしょう。おすすめ教材
これだけでOK! AWS 認定ソリューションアーキテクト – アソシエイト試験突破講座
勉強をはじめたばかりの頃はこの教材をやっていました。
講義形式でSAAの試験範囲となるサービスのハンズオンができます。
定価だと2万円ちかいですが、セールの時に買う2,000円くらいで買えます。※講義中に使用したサービスは講義終了時に削除するようにしましょう。余計なお金が(しかも結構)かかるリスクがあります。(講義内でも指示があります)
AWS認定資格試験テキスト AWS認定 ソリューションアーキテクト-アソシエイト
一度目の受験に失敗したタイミングで購入。
試験範囲のサービスについて綺麗にまとまっており、テキストでは断トツでこれがおすすめです。
特に第13章「AWSのアーキテクチャ設計」が素晴らしい。試験前日にこの章を読んだことが、合格にかなり寄与しました。付属の模擬試験はかなり優しめなので、次に紹介する模擬問題集をやっておいた方がよいです。
【SAA-C02版】AWS 認定ソリューションアーキテクト アソシエイト模擬試験問題集(6回分390問)
模擬試験が6つもついています。SAC-02にも対応しているので、この模擬試験で合格できていれば本番でも問題はないでしょう。
6つある模擬試験のうち4つは「高難易度の模擬試験」と銘打たれていますが、本番では高難易度試験と同等レベルの問題が平気で出てきます。マイナーサービスだと思っていたAWS snowballに関する問題も、本番で3題ほど出題されました。問題解説はそれほど親切ではないので、公式ドキュメントやネットの記事を読んで知識を補強していく必要があります。
以上
お読みいただきありがとうございました。
誤字等あればご指摘よろしくお願いいたします。
- 投稿日:2020-07-25T01:11:19+09:00
AWS EC2 (Ubuntu) で DNS のスタブリゾルバ 127.0.0.53 と Amazon Provided DNS の関連を確認する
はじめに
AWS で VPC を構築した時、VPC 内のインスタンスが参照する DNS サーバ ( Amazon Provided DNS ) のアドレスは 「 VPC のネットワークアドレス + 2 」です。
例えば VPC のネットワークアドレスが 10.0.0.0 であれば、DNS サーバのアドレスは 10.0.0.2 です。
公式ドキュメントに書いてあるので、間違いありません。しかし、EC2 インスタンスの OS を Ubuntu とした場合、参照先の DNS サーバはデフォルトで 127.0.0.53 となっているように見えます。
本記事では、この 127.0.0.53 について深堀りし、Amazon Provided DNS との関連を確認した結果を備忘録としてまとめます。想定される参照先 DNS サーバのアドレス
検証用のクライアント (EC2) のプライベート IP アドレスは、以下で示されるように 172.31.43.50 で、VPC のネットワークアドレスは 172.31.0.0 です。
この時、通常は参照先の DNS サーバのアドレスが 172.31.0.2 であるはずです。$ ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: ens5: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001 qdisc mq state UP group default qlen 1000 link/ether 06:72:1e:15:cd:f4 brd ff:ff:ff:ff:ff:ff inet 172.31.43.50/20 brd 172.31.47.255 scope global dynamic ens5 valid_lft 1986sec preferred_lft 1986sec inet6 fe80::472:1eff:fe15:cdf4/64 scope link valid_lft forever preferred_lft foreverまずは nslookup で検証
Ubuntu OS の設定上、どこの DNS サーバを参照しているかは、適当に
nslookupすると分かります。
以下の通り、nslookup を打った時に参照しているアドレスは 127.0.0.53 で、Amazon Provided DNS の IP アドレスではありません。
この 127.0.0.53 は、ローカルアドレスに見えますが、一体何者なのでしょうか。$ nslookup amazonaws.com Server: 127.0.0.53 Address: 127.0.0.53#53 Non-authoritative answer: Name: amazonaws.com Address: 72.21.206.80 Name: amazonaws.com Address: 207.171.166.22 Name: amazonaws.com Address: 72.21.210.29/etc/resolv.conf を見る
DNSと言えば /etc/resolv.conf であり、ここを見れば 127.0.0.53 の正体も分かるだろうと思い、覗いてみました。
ひとまず
lsしてみるのですが、ここで resolv.conf がシンボリックリンクになっていることが判明します。$ ls -l /etc/resolv.conf lrwxrwxrwx 1 root root 39 9月 13 2018 /etc/resolv.conf -> ../run/systemd/resolve/stub-resolv.confさて、肝心の resolv.conf を読むと 127.0.0.53 と書いてあるだけです。
$ cat /etc/resolv.conf # This file is managed by man:systemd-resolved(8). Do not edit. # # This is a dynamic resolv.conf file for connecting local clients to the # internal DNS stub resolver of systemd-resolved. This file lists all # configured search domains. # # Run "systemd-resolve --status" to see details about the uplink DNS servers # currently in use. # # Third party programs must not access this file directly, but only through the # symlink at /etc/resolv.conf. To manage man:resolv.conf(5) in a different way, # replace this symlink by a static file or a different symlink. # # See man:systemd-resolved.service(8) for details about the supported modes of # operation for /etc/resolv.conf. nameserver 127.0.0.53 options edns0 search ap-northeast-1.compute.internalしかし、この設定ファイルのコメントをよく読むと、手がかりが見えてきました。
コメントには次のように書かれています。This is a dynamic resolv.conf file for connecting local clients to the internal DNS stub resolver of systemd-resolved. This file lists all configured search domains. Run "systemd-resolve --status" to see details about the uplink DNS servers currently in use.コメントには resolv.conf の設定が内部の DNS スタブリゾルバである systemd-resolved に接続するためのものと書かれています。
おそらく systemd-resolved が IP アドレス 127.0.0.53 を持っていそうです。
またsystemd-resolve --statusを実行すると、systemd-resolved が現在参照している DNS サーバの詳細が分かりそうです。lsof してみる
system-resolved が本当に 53 番ポート ( DNS ) で待ち受けているのかどうかは
lsofすれば分かります。
実行すると、以下の通り systemd-resolve が炙り出されました。$ sudo lsof -i:53 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME systemd-r 786 systemd-resolve 12u IPv4 16116 0t0 UDP localhost:domain systemd-r 786 systemd-resolve 13u IPv4 16117 0t0 TCP localhost:domain (LISTEN)systemd-resolve --status してみる
先程のコメントの通り
systemd-resolve --statusを実行します。
すると DNS Servers: 172.31.0.2 の文字列が発見されました。
この IP アドレスは VPC の Amazon Provided DNS の IP アドレスと一致します。どうやら /etc/resolv.conf ではなく、最終的に問い合わせる systemd-resolved の設定に Amazon Provided DNS のアドレスが書かれているようです。
$ systemd-resolve --status Global DNSSEC NTA: 10.in-addr.arpa 16.172.in-addr.arpa 168.192.in-addr.arpa 17.172.in-addr.arpa 18.172.in-addr.arpa 19.172.in-addr.arpa 20.172.in-addr.arpa 21.172.in-addr.arpa 22.172.in-addr.arpa 23.172.in-addr.arpa 24.172.in-addr.arpa 25.172.in-addr.arpa 26.172.in-addr.arpa 27.172.in-addr.arpa 28.172.in-addr.arpa 29.172.in-addr.arpa 30.172.in-addr.arpa 31.172.in-addr.arpa corp d.f.ip6.arpa home internal intranet lan local private test Link 2 (ens5) Current Scopes: DNS LLMNR setting: yes MulticastDNS setting: no DNSSEC setting: no DNSSEC supported: no DNS Servers: 172.31.0.2 DNS Domain: ap-northeast-1.compute.internalDHCP オプションセットの効き目
DNS Servers に 172.31.0.2 が書かれている 「ens5」 そのものの設定を確認します。
/etc/network/interfaces の下には何もなく、/etc/netplan/ の下に .yaml が置かれていますので、確認します。$ cat /etc/netplan/50-cloud-init.yaml # This file is generated from information provided by the datasource. Changes # to it will not persist across an instance reboot. To disable cloud-init's # network configuration capabilities, write a file # /etc/cloud/cloud.cfg.d/99-disable-network-config.cfg with the following: # network: {config: disabled} network: version: 2 ethernets: ens5: dhcp4: true match: macaddress: 06:72:1e:15:cd:f4 set-name: ens5ens5 で DHCP が有効になっていることが確認できましたが、これは AWS の VPC なので当然と言えば当然の結果となります。
AWS VPC では、デフォルトの DHCP オプションセットで Amazon Provided DNS が指定されており、Amazon Provided DNS のアドレスは、今回の場合、冒頭で述べた 172.31.0.2 です。
172.31.0.2 は、AWS VPC の DHCP で OS 側に通知されています。まとめ
- VPC の DHCP オプションセットの設定がデフォルトで、NIC が DHCP 設定であれば、 Amazon Provided DNS のプライベート IP アドレスが、参照先 DNS サーバの IP アドレスとして通知されます。
- しかし Ubuntu OS では、nslookup すると、デフォルト設定により、まずは DNS のスタブリゾルバである systemd-resolved ( 127.0.0.53 ) に問い合わせされます。
- その後 systemd-resolved が、Amazon Provided DNS のプライベート IP アドレスに問い合わせます。
参考文献
- ubuntu18.04のネットワーク周り設定
- Ubuntu 18.04 の systemd-resolved で local DNS stub listener の利用をやめる
- Ubuntu 18.04: ネットワークを設定する (From Narrow Escape)
- VPC とサブネット (From AWS公式)
- DHCP オプションセット (From AWS公式)
- 投稿日:2020-07-25T00:48:39+09:00
PulumiでAWSにWEBアプリの最小構成を構築する
はじめに
Pulumiはプログラミング言語(現在サポートされているのは、JavaScript、TypeScript、python、go、C#)によりインフラをコード管理するためのツールです。
Pulumiを使ってpythonでAWSにWEBアプリを動かすための基本的な構成を構築してみて気づいたことなどを書いてみます。
pulumi環境構築事などについては下記のチュートリアルを参考にしてください
https://www.pulumi.com/docs/get-started/aws/実行環境
python: 3.7.7
pulumi: 2.7.1
aws-cli: 1.18.102構成について
構成図
今回作成したリソース
- VPC
- Subnet(public、private)
- InternetGateway
- RouteTable
- RouteTableAssociation
- SecurityGroup(EC2用、RDS用)
- KeyPair(ec2 ssh用)
- EC2
- EIP
- RDS SubnetGroup
- RDS
実際のコード
VPC
vpc = aws.ec2.Vpc( "pulumi-vpc", cidr_block="10.0.0.0/16", tags={ "Name": "pulumi-vpc", })vpcについては、最低限、resource_nameとcidr_blockが設定されていれば良い
Subnet
#public subnetの作成 public_subnet_a = aws.ec2.Subnet( "pulumi-public-subnet-a", cidr_block="10.0.1.0/24", availability_zone="ap-northeast-1a", tags={ "Name": "pulumi-public-subnet-a", }, vpc_id=vpc.id) public_subnet_c = aws.ec2.Subnet( "pulumi-public-subnet-c", cidr_block="10.0.2.0/24", availability_zone="ap-northeast-1c", tags={ "Name": "pulumi-public-subnet-c", }, vpc_id=vpc.id) #private subnetの作成 private_subnet_a = aws.ec2.Subnet( "pulumi-private-subnet-a", cidr_block="10.0.3.0/24", availability_zone="ap-northeast-1a", tags={ "Name": "pulumi-private-subnet-a", }, vpc_id=vpc.id) private_subnet_c = aws.ec2.Subnet( "pulumi-private-subnet-c", cidr_block="10.0.4.0/24", availability_zone="ap-northeast-1c", tags={ "Name": "pulumi-private-subnet-c", }, vpc_id=vpc.id)
vpc_idには上記で作成したvpcのid(vpc.id)を入れています
pulumi側で依存関係を解決してくれて、vpc->subnetという順番でawsにリソースを作成してくれます(依存関係がないリソースは並列で作成してくれる)
また、リソースの依存関係についてはpulumiのコンソールから確認することも可能です
InternetGateway
igw = aws.ec2.InternetGateway( "pulumi-igw", tags={ "Name": "pulumi-igw", }, vpc_id=vpc.id)RouteTable、RouteTableAssociation
# RouteTableの作成 public_route_table_a = aws.ec2.RouteTable( "pulumi-public-route-table-a", routes=[ { "cidr_block": "0.0.0.0/0", "gateway_id": igw.id, }, ], tags={ "Name": "pulumi-public-route-table-a", }, vpc_id=vpc.id) public_route_table_c = aws.ec2.RouteTable( "pulumi-public-route-table-c", routes=[ { "cidr_block": "0.0.0.0/0", "gateway_id": igw.id, }, ], tags={ "Name": "pulumi-public-route-table-c", }, vpc_id=vpc.id) # RouteTableAssociationの作成 route_table_association_public_a = aws.ec2.RouteTableAssociation( "pulumi-route-table-association-public-a", subnet_id=public_subnet_a.id, route_table_id=public_route_table_a.id) route_table_association_public_c = aws.ec2.RouteTableAssociation( "pulumi-route-table-association-public-c", subnet_id=public_subnet_c.id, route_table_id=public_route_table_c.id)RouteTableのrouteについてcider_blockと宛先のdic型(pulumi docではRouteTableRoute)で設定し、routesにリスト形式で設定します
今回はinternet gateway向けのルートしかないので宛先をgateway_idのkeyを使用していますが、他にも下記のようなkeyも設定可能です
keyに設定する値 宛先 gateway_id Internet Gateway instance_id ec2インスタンス nat_gateway_id NAT Gateway vpc_peering_connection_id VPC Peeringの接続先VPC SecurityGroup
# SecurityGroupの作成 ec2_sg = aws.ec2.SecurityGroup( "pulumi-ec2-sg", ingress=[ { "from_port": 80, "protocol": "TCP", "to_port": 80, "cidr_blocks": ["0.0.0.0/0"] }, { "from_port": 22, "protocol": "TCP", "to_port": 22, "cidr_blocks": ["0.0.0.0/0"] }, ], egress=[ { "from_port": 0, "protocol": "TCP", "to_port": 65535, "cidr_blocks": ["0.0.0.0/0"] }, ], tags={ "Name": "pulumi-ec2-sg", }, vpc_id=vpc.id) rds_sg = aws.ec2.SecurityGroup( "pulumi-rds-sg", ingress=[ { "from_port": 3306, "protocol": "TCP", "to_port": 3306, "security_groups": [ec2_sg.id] }, ], egress=[ { "from_port": 0, "protocol": "TCP", "to_port": 65535, "cidr_blocks": ["0.0.0.0/0"] }, ], tags={ "Name": "pulumi-rds-sg", }, vpc_id=vpc.id)ingressとegressを指定する際に、dic型(SecurityGroupEgress、SecurityGroupEgress)のリストで設定します
protocolはHTTPやSSHなどのレイヤーのプロトコルを指定できるわけではなく、TCP、UDPなどを指定するパラメータとなります。
HTTPやSSHなどのプロトコルを直接設定したい場合でもコードのようにfrom_port、to_portにポート番号で直接設定する必要があるようでした。
ポート番号で指定しても、作成したリソースをAWSコンソール上で確認するとHTTPやSSHと解釈してくれています。
KeyPair
key_pair = aws.ec2.KeyPair( "pulumi-keypair", public_key="ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQD3F6tyPEFEzV0LX3X8BsXdMsQz1x2cEikKDEY0aIj41qgxMCP/iteneqXSIFZBp5vizPvaoIR3Um9xK7PGoW8giupGn+EPuxIA4cDM4vzOqOkiMPhz5XK0whEjkVzTo4+S0puvDZuwIsdiW9mxhJc7tgBNL0cYlWSYVkz4G/fslNfRPW5mYAM49f4fhtxPb5ok4Q2Lg9dPKVHO/Bgeu5woMc7RY0p1ej6D4CKFE6lymSDJpW0YHX/wqE9+cfEauh7xZcG0q9t2ta6F6fmX0agvpFyZo8aFbXeUBr7osSCJNgvavWbM/06niWrOvYX2xwWdhXmXSrbX8ZbabVohBK41 email@example.com", tags={ "Name": "pulumi-keypair", })EC2
ec2 = aws.ec2.Instance( "pulumi-ec2", ami="ami-0ee1410f0644c1cac", instance_type="t2.micro", subnet_id=public_subnet_a.id, tags={ "Name": "pulumi-ec2", }, associate_public_ip_address=True, key_name=key_pair.key_name, user_data="#!/bin/bash \n\n yum install -y mysql", vpc_security_group_ids=[ec2_sg.id])
amiはamiのidを直接指定していますが、pulumiにはgetのapiも用意されているのでそれを利用して、既存のリソースからidを取得しても良いと思います。
user_dataについては、String型での指定となります。
今回は、直接ユーザデータをStringとしてベタ書きしていますが、別ファイルに切り出してファイル読み込みする方が良いと思います
また、user_data_base64というパラメータもあり、ユーザデータをbase64でエンコードしたものでも設定できるようでしたEC2インスタンスに紐付けるsecurity_groupの設定ですが、
security_groupsというパラメータがDeprecatedとなっていたためvpc_security_group_idsで指定していますEIP
ec2_eip = aws.ec2.Eip( "pulumi-eip-ec2", instance=ec2.id, tags={ "Name": "pulumi-eip-ec2", }, vpc=True)今回はeip作成時にeipを紐付けるec2インスタンスまで指定していますが、下記のように作成と紐付けを別々にコード化することも可能です
ec2_eip = aws.ec2.Eip( "pulumi-eip-ec2", tags={ "Name": "pulumi-eip-ec2", }, vpc=True) eip_assoc = aws.ec2.EipAssociation("eipAssoc", allocation_id=ec2_eip.id, instance_id=ec2.id)RDS SubnetGroup
rds_subnet = aws.rds.SubnetGroup( "pulumi-rds-subnet", subnet_ids=[ private_subnet_a.id, private_subnet_c.id, ], tags={ "Name": "pulumi-rds-subnet", })RDS
rds = aws.rds.Instance( "pulumi-rds", allocated_storage=20, db_subnet_group_name=rds_subnet.name, engine="mysql", engine_version="5.7", identifier="pulumi-rds", instance_class="db.t2.micro", name="pulumi", parameter_group_name="default.mysql5.7", password="password", skip_final_snapshot=True, storage_type="gp2", tags={ "Name": "pulumi-rds", }, username="admin", vpc_security_group_ids=[rds_sg.id])RDSを作成する際に注意が必要なのが
skip_final_snapshotのパラメータです。
このパラメータはDefaultではFalseが設定されているのですが、そのままではRDSを削除する際に、snap shotを残そうとしてます。
この場合pulumi destroyで削除しようとした際に下記のようなエラーが出てしまいます。DB Instance FinalSnapshotIdentifier is required when a final snapshot is requiredpulumiからRDSを削除できるようにしておくには
skip_final_snapshotはTrueに設定しておく必要があります。コード全体
import pulumi import pulumi_aws as aws # VPCの作成 vpc = aws.ec2.Vpc( "pulumi-vpc", cidr_block="10.0.0.0/16", tags={ "Name": "pulumi-vpc", }) # Subnetの作成 public_subnet_a = aws.ec2.Subnet( "pulumi-public-subnet-a", cidr_block="10.0.1.0/24", availability_zone="ap-northeast-1a", tags={ "Name": "pulumi-public-subnet-a", }, vpc_id=vpc.id) public_subnet_c = aws.ec2.Subnet( "pulumi-public-subnet-c", cidr_block="10.0.2.0/24", availability_zone="ap-northeast-1c", tags={ "Name": "pulumi-public-subnet-c", }, vpc_id=vpc.id) private_subnet_a = aws.ec2.Subnet( "pulumi-private-subnet-a", cidr_block="10.0.3.0/24", availability_zone="ap-northeast-1a", tags={ "Name": "pulumi-private-subnet-a", }, vpc_id=vpc.id) private_subnet_c = aws.ec2.Subnet( "pulumi-private-subnet-c", cidr_block="10.0.4.0/24", availability_zone="ap-northeast-1c", tags={ "Name": "pulumi-private-subnet-c", }, vpc_id=vpc.id) # InternetGatewayの作成 igw = aws.ec2.InternetGateway( "pulumi-igw", tags={ "Name": "pulumi-igw", }, vpc_id=vpc.id) # RouteTableの作成 public_route_table_a = aws.ec2.RouteTable( "pulumi-public-route-table-a", routes=[ { "cidr_block": "0.0.0.0/0", "gateway_id": igw.id, }, ], tags={ "Name": "pulumi-public-route-table-a", }, vpc_id=vpc.id) public_route_table_c = aws.ec2.RouteTable( "pulumi-public-route-table-c", routes=[ { "cidr_block": "0.0.0.0/0", "gateway_id": igw.id, }, ], tags={ "Name": "pulumi-public-route-table-c", }, vpc_id=vpc.id) # RouteTableAssociationの作成 route_table_association_public_a = aws.ec2.RouteTableAssociation( "pulumi-route-table-association-public-a", subnet_id=public_subnet_a.id, route_table_id=public_route_table_a.id) route_table_association_public_c = aws.ec2.RouteTableAssociation( "pulumi-route-table-association-public-c", subnet_id=public_subnet_c.id, route_table_id=public_route_table_c.id) # SecurityGroupの作成 ec2_sg = aws.ec2.SecurityGroup( "pulumi-ec2-sg", ingress=[ { "from_port": 80, "protocol": "TCP", "to_port": 80, "cidr_blocks": ["0.0.0.0/0"] }, { "from_port": 22, "protocol": "TCP", "to_port": 22, "cidr_blocks": ["0.0.0.0/0"] }, ], egress=[ { "from_port": 0, "protocol": "TCP", "to_port": 65535, "cidr_blocks": ["0.0.0.0/0"] }, ], tags={ "Name": "pulumi-ec2-sg", }, vpc_id=vpc.id) rds_sg = aws.ec2.SecurityGroup( "pulumi-rds-sg", ingress=[ { "from_port": 3306, "protocol": "TCP", "to_port": 3306, "security_groups": [ec2_sg.id] }, ], egress=[ { "from_port": 0, "protocol": "TCP", "to_port": 65535, "cidr_blocks": ["0.0.0.0/0"] }, ], tags={ "Name": "pulumi-rds-sg", }, vpc_id=vpc.id) # KeyPairの作成 key_pair = aws.ec2.KeyPair( "pulumi-keypair", public_key="ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDDoh/IrdxamyghEb22+wUAFqz1Hd/dxAQaaUO050WaZgKzFTl/gpiJokNNGY9lA1PmilHW9ZGYW8aTrbGyiOIF4l6hsGVFWXMjwZdY0b4rM1uHkLUnf8X26uDn/BUzTZLCgeoThp4IAuHWCKoJJucVuN09Kpdsd75vSjRyDBl3/q0ex0rQIrCmpqA7OrYr7PaJlgoFk1dpaQvxrQZyVR5oh7+IvMLdm+NP4uUSAlPpHUv3XoPKZ74bsnd/G+oNIWlo4ZW/uJX4oM1g7sSKxRmkF5VQK3afEt28Su1mpdrJczQPBm0Dq0sfYg+sS432KLanc7cGPbKf6tjLE6ouxZYN fukusako@yutanoMacBook-puro-3.local", tags={ "Name": "pulumi-keypair", }) # EC2インスタンスの作成 ec2 = aws.ec2.Instance( "pulumi-ec2", ami="ami-0ee1410f0644c1cac", instance_type="t2.micro", subnet_id=public_subnet_a.id, tags={ "Name": "pulumi-ec2", }, associate_public_ip_address=True, key_name=key_pair.key_name, user_data="#!/bin/bash \n\n yum install -y mysql", vpc_security_group_ids=[ec2_sg.id]) # EIPの作成 ec2_eip = aws.ec2.Eip( "pulumi-eip-ec2", instance=ec2.id, tags={ "Name": "pulumi-eip-ec2", }, vpc=True) # RDS SubnetGroupの作成 rds_subnet = aws.rds.SubnetGroup( "pulumi-rds-subnet", subnet_ids=[ private_subnet_a.id, private_subnet_c.id, ], tags={ "Name": "pulumi-rds-subnet", }) #RDSインスタンスの作成 rds = aws.rds.Instance( "pulumi-rds", allocated_storage=20, db_subnet_group_name=rds_subnet.name, engine="mysql", engine_version="5.7", identifier="pulumi-rds", instance_class="db.t2.micro", name="pulumi", parameter_group_name="default.mysql5.7", password="password", skip_final_snapshot=True, storage_type="gp2", tags={ "Name": "pulumi-rds", }, username="admin", vpc_security_group_ids=[rds_sg.id])まとめ
普段、terraformを用いてaws環境のリソースをコード管理しているのですが、pulumiはterraformと違いpythonなど馴染みのある言語で記述できるので、個人的には直感的にわかりやすくコード化できた気がします。
また、state管理を専用のコンソールで管理できるため、terraformの用にtfstateファイルを管理する必要もないですし、pulumi up/destroy時の依存関係も勝手に解決してくれるので、コード化できる言語云々よりもステート管理がterraformよりもpulumiの方が長けているのではと感じました。
ただし、pulumiはterraformよりもplan、apply時の差分がlogとして分かりづらい(変更されるパラメータ名しか表示されない)のが残念でした。コンソールから差分の詳細を確認できました
また、チームなど複数メンバーで使用するとなると料金がかかってしまうので、それがterraformと比べて導入するハードルになっているのかなと思います。今後はALB+EC2(auto scaling)のような基本的なwebアプリ構成やAPIGW+Lambdaのようなサーバレスの構築もpulumiで構築してみたいと思います。
おまけ
pulumiを触っていてハマったことなど
pulumi up/destroyで任意のリソースだけを更新したい場合
# -t オプションで任意のリソースを指定できる > pulumi up -t リソースのURN > pulumi destroy -t リソースのURN #リソースのURNは、恐らくpulumiがリソースを管理するためのIDでstackオプションで確認できる > pulumi stack -u Current stack resources (16): TYPE NAME pulumi:pulumi:Stack aws-ec2-public-aws-ec2 │ URN: urn:pulumi:aws-ec2::aws-ec2-public::pulumi:pulumi:Stack::aws-ec2-public-aws-ec2 ├─ aws:ec2/vpc:Vpc pulumi-vpc │ URN: urn:pulumi:aws-ec2::aws-ec2-public::aws:ec2/vpc:Vpc::pulumi-vpc ├─ aws:ec2/subnet:Subnet pulumi-public-subnet-a │ URN: urn:pulumi:aws-ec2::aws-ec2-public::aws:ec2/subnet:Subnet::pulumi-public-subnet-a ├─ aws:ec2/subnet:Subnet pulumi-public-subnet-c │ URN: urn:pulumi:aws-ec2::aws-ec2-public::aws:ec2/subnet:Subnet::pulumi-public-subnet-c ├─ aws:ec2/subnet:Subnet pulumi-private-subnet-a │ URN: urn:pulumi:aws-ec2::aws-ec2-public::aws:ec2/subnet:Subnet::pulumi-private-subnet-a ├─ aws:ec2/subnet:Subnet pulumi-private-subnet-c │ URN: urn:pulumi:aws-ec2::aws-ec2-public::aws:ec2/subnet:Subnet::pulumi-private-subnet-c ├─ aws:ec2/internetGateway:InternetGateway pulumi-igw │ URN: urn:pulumi:aws-ec2::aws-ec2-public::aws:ec2/internetGateway:InternetGateway::pulumi-igw ├─ aws:ec2/securityGroup:SecurityGroup pulumi-ec2-sg │ URN: urn:pulumi:aws-ec2::aws-ec2-public::aws:ec2/securityGroup:SecurityGroup::pulumi-ec2-sg ├─ aws:rds/subnetGroup:SubnetGroup pulumi-rds-subnet │ URN: urn:pulumi:aws-ec2::aws-ec2-public::aws:rds/subnetGroup:SubnetGroup::pulumi-rds-subnet ├─ aws:ec2/routeTable:RouteTable pulumi-public-route-table-a │ URN: urn:pulumi:aws-ec2::aws-ec2-public::aws:ec2/routeTable:RouteTable::pulumi-public-route-table-a ├─ aws:ec2/routeTable:RouteTable pulumi-public-route-table-c │ URN: urn:pulumi:aws-ec2::aws-ec2-public::aws:ec2/routeTable:RouteTable::pulumi-public-route-table-c ├─ aws:ec2/securityGroup:SecurityGroup pulumi-rds-sg │ URN: urn:pulumi:aws-ec2::aws-ec2-public::aws:ec2/securityGroup:SecurityGroup::pulumi-rds-sg ├─ aws:ec2/keyPair:KeyPair pulumi-keypair │ URN: urn:pulumi:aws-ec2::aws-ec2-public::aws:ec2/keyPair:KeyPair::pulumi-keypair ├─ aws:rds/instance:Instance pulumi-rds │ URN: urn:pulumi:aws-ec2::aws-ec2-public::aws:rds/instance:Instance::pulumi-rds ├─ aws:ec2/instance:Instance pulumi-ec2 │ URN: urn:pulumi:aws-ec2::aws-ec2-public::aws:ec2/instance:Instance::pulumi-ec2 └─ pulumi:providers:aws default_2_13_1 URN: urn:pulumi:aws-ec2::aws-ec2-public::pulumi:providers:aws::default_2_13_1AWSのコンソールからリソースを更新した場合
state管理されているリソースをAWSコンソールから直接更新した場合、stateファイルと実際の環境で差分が出てしまい、この状態でコードから改めて更新(pulumi upなど)しようとするとうまく動作しないことがあります(当たり前ですが)。
このような場合refreshオプションを使用するとstate管理されているリソースについて現行のAWSリソースの情報を元にstate情報をアップデートしてくれます。> pulumi refreshterraform planのようなdryrun機能
#差分だけ確認する > pulumi preview #apply > pulumi up -y
pulumi upだけでも差分を確認した後に適用するか、yes、noで確認されてnoを選択すれば差分を確認だけできる。
ただし、CIサーバーなどからのdeployを想定する場合コンソールからyes、noを選択するやり方はやりにくいので、dryrunはpulumi preview、実際の適用はpulumi up -yを利用するのが良い参考
https://www.pulumi.com/docs/
https://qiita.com/KsntsTt/items/6fb71af2d265939184c3