- 投稿日:2020-06-04T23:55:25+09:00
機械学習の統計量を特徴量として加える際のスマートな書き方
数値データの行方向の統計量を特徴量として生成するコードの書き方です。
ありがちな特徴量生成
まずは良く見る書き方
# 一個一個付け加えていくやり方 df["sum"] = df.sum(axis=1) df["max"] = df.max(axis=1) df["min"] = df.min(axis=1) df["mean"] = df.mean(axis=1) df["median"] = df.median(axis=1) df["mad"] = df.mad(axis=1) df["var"] = df.var(axis=1) df["std"] = df.std(axis=1) df["skew"] = df.skew(axis=1) df["kurt"] = df.kurt(axis=1) df.head()これでも良いが、拡張性やメンテナンスを考えるとちょっと気持ち悪い。
スマートな特徴量生成
func_list =["sum", "max", "min", "mean", "median", "mad", "var", "std", "skew", "kurt"] for func in func_list: df[func] = df.apply(func, axis=1)Lambda関数も使える
f_diff = lambda x: df["xxx"]-df["yyy"] func_list =["sum", "max", "min", "mean", "median", "mad", "var", "std", "skew", "kurt", f_diff] for func in func_list: df[func] = df.apply(func, axis=1)
機械学習ではその場限りの実験が多いので”書き捨て”のコードが量産されがち。
※実際、Kaggleのカーネルなどを見ると結構汚いコードが多い気がする。なるべくスッキリしたコードを書くと、再利用しやすいし拡張性も高まる。
- 投稿日:2020-06-04T23:12:13+09:00
PythonもQGISプラグイン開発も素人が8日間没頭してQGISプラグインを作ってみた
開発のきっかけ
業務でQGIS+ogr2ogrを使った手作業が面倒だなと思っていた。
PythonにもQGISのプラグイン開発にも興味があった。
コロナ休業+ゴールデンウィークで長期の休み発生!。
「プラグイン作ってみるしかないっしょっ!」
ということで、
PythonもQGISプラグイン開発も素人だけどQGISプラグインを作ってみた。
をまとめます。まず自分のスペック
位置情報関係の開発業務経験有、C++でのWindowsアプリ開発経験有、ESRI社のArcObjectsでのアプリ開発経験有、GUIフレームワークは一通り経験有(MFC、wxWidget、Qt etc)。
しかし、pythonはググりながら読めばなんとなく理解できる程度。pyqtもpyqgisも触ったことは無い。
ということで、pythonもpyqtもpyqgis初心者レベル。つくるもの
- ソースDB(群)の表示設定されているQGISプロジェクトファイルを読み込んで
- Clippingしたいエリアを指定して
- 出力するDBファイル名(GeoPackageのみ)
- 出力するQGISプロジェクトファイル名を指定して実行すると
- 指定エリアでソースDB(群)をクリッピングして
- 指定されたDBに出力して
- 元のQGISプロジェクトファイルで設定されているスタイルが適用されている
- 指定されたQGISプロジェクトを作成する
というQGISのプラグインを開発する。
開発環境準備
Windows10での開発環境構築方法です。
QGISのダウンロードとインストール
QGISビギナーズマニュアル(3系)を参照しLTR版(長期リリース版) QGISスタンドアロンインストーラバージョン版(64bit)をダウンロードし、インストールする。
念のためPATH環境変数に以下が設定されていない場合は設定しておく。
確認方法はこちらを参照。%QGIS%\bin %QGIS%\apps\qgis-ltr\binVisual Studio 2019(コミュニティ版)
Pythonのデバッグ環境としてVisual Studio 2019(コミュニティ版)を選択しました。
VSCodeという選択肢もありましたが、今回の開発は初物づくしのため次回以降に使ってみることにしました。
Visual StudioのインストールとPython環境の設定はこちらを参照して行います。QGISプラグイン開発準備
Plugin Builderを動かしてみる
以下のサイトを参考にしてダミーのプラグインのGUIを作成。
https://gis-oer.github.io/gitbook/book/materials/python/10/10.html
https://blog.goo.ne.jp/yoossh/e/925867ada61a401daa7602d8bcc3270dpyrcc5の実行
以下の手順で実行し、プラグインの動作確認を行います。
- Osgeo4W Shellを開く
- ダミーのプラグインを保存したディレクトリに移動
- pyrcc5 -o resources.py resources.qrc を実行
- 動作確認
- QGISを起動して「プラグインの管理とインストール」メニューから作成したダミーのプラグインをインストールし動作確認しエラーが出なければOK
環境変数 QGIS_PLUGINPATH の設定
QGISがプラグインを検索するデフォルトは
ユーザーのホームディレクトリ/AppData\Roaming\QGIS\QGIS3\profiles\default\python\plugins
と奥深い場所になることと、開発の過程でソース管理する場合Gitを使いたいこともあるでしょうから、環境変数でQGIS_PLUGINPATH を設定することを強くお勧めします。スタンドアロンスクリプトでクリッピング処理を試す
ここでは、処理の骨格となる以下の機能を勉強も兼ねてスタンドアロンスクリプトと実装してみます。
- 指定エリアでソースDB(群)をクリッピングして
- 指定されたDBに出力して
- 元のQGISプロジェクトファイルで設定されているスタイルが適用されている
- 指定されたQGISプロジェクトを作成する
クリッピング処理の検討
結果的に試してみたのは以下の4パターン。
Processingプラグイン(clipvectorbyextent)で解決するのは今となっては自明でしたが、取り組み当初は暗中模索で、取り敢えず以下の順番で試しました。
- ogr2ogrをpythonから呼び出すパターン
- QgsVectorFileWriter.writeAsVectorFormatV2()を利用するパターン
- Processingプラグイン(clipvectorbyextent)を利用するパターン
- Processingプラグイン(nativeclip)を利用するパターン
ogr2ogrをpythonから呼び出すパターン
よくよく調べてみると、Processing(clipvectorbyextent)ではogr2ogrを実行していることを発見。
しかし、ogr2ogrの引数を作るためのpythonの文字列処理の勉強することになったので良かった。QgsVectorFileWriter.writeAsVectorFormatV2()を利用するパターン
得られる結果がClippingではなくIntersectであったためボツ。
しかし、QgsVectorFileWriterの使い方などいろいろ勉強になりました。processing(clipvectorbyextent)
Processingプラグインの下図の機能をプログラム的に実行してみます。
今回は敢えて、クリッピングする領域のポリゴンをQgsVectorlayerのメモリ上に作成し、その後GeoPackageに保存して、QGISプロジェクトに追加しています。
processing.run()をデバッガーでステップインしていくことで、前述のコマンドプロンプト表示を回避している箇所(%QGIS%\apps\qgis-ltr\python\plugins\processing\algs\gdal\GdalUtils.pyの100行目あたりのsubprocess.Popen())の発見や、processingプラグインの作り方も何となく理解できました。ハマりポイント(EXTENT指定)
params = { 'INPUT' : layer, 'EXTENT' : cliplayer, # QgsRectangle指定はエラーとなる 敢えてQgsVectorLayer指定 'OPTIONS': option, 'OUTPUT' : outputlayer } res = processing.run('gdal:clipvectorbyextent', params)下記を実行し得られるヘルプではEXTENTにQgsRectangleを指定可能ですが、実際はエラーとなりました。
import os import processing from processing.core.Processing import Processing,GdalAlgorithmProvider Processing.initialize() print(processing.algorithmHelp("gdal:clipvectorbyextent"))processing(nativeclip)
Processingプラグインの下図の機能をプログラム的に実行してみます。
ループ2回目以降は出力DBが上書きされてしまい、テーブルが追加されません。
QGISのC++ソースを見てみましたが、結果的にOUTPUTパラメータで出力DBにテーブルを追加する方法がわからず、QGIS自体をコンパイルしてデバッグしてみようかとも思いましたがそれだけで新たな記事を書けそうなボリュームになりそうなので深堀はしませんでした。おそらく仕様なのではないかなと推察。これまでのまとめ
これまでの取り組みによって、クリッピング処理はclipvectorbyextentを利用することで決まり。
やりたいことの骨格はできあがりました。(取り消し線は確認済)
残りは、GUIを通してユーザに入力してもらう部分となります。
- ソースDB(群)の表示設定されているQGISプロジェクトファイルを読み込んで
- Clippingしたいエリアを指定して
- 出力するDBファイル名(GeoPackageのみ)
- 出力するQGISプロジェクトファイル名を指定して実行すると
指定エリアでソースDB(群)をクリッピングして指定されたDBに出力して元のQGISプロジェクトファイルで設定されているスタイルが適用されている指定されたQGISプロジェクトを作成する次はプラグインとして実装ですが、スクラッチから作るのはしんどいので、様々なプラグインを触っだりソースを見たりしてphoto2shapeが、画面イメージや処理フローが考えていたものに近かったためこれを参考にして開発を進めます。
QGISプラグイン実装開始
既に各種設定はできているので、取り組みの順番としては
- Plugin Builderでプラグインを新規作成する
- Qt Designerで画面を作成
- photo2shapeを参考に、スタンドアロンスクリプトとして書いたコードをプラグイン用に修正
といったところになります。
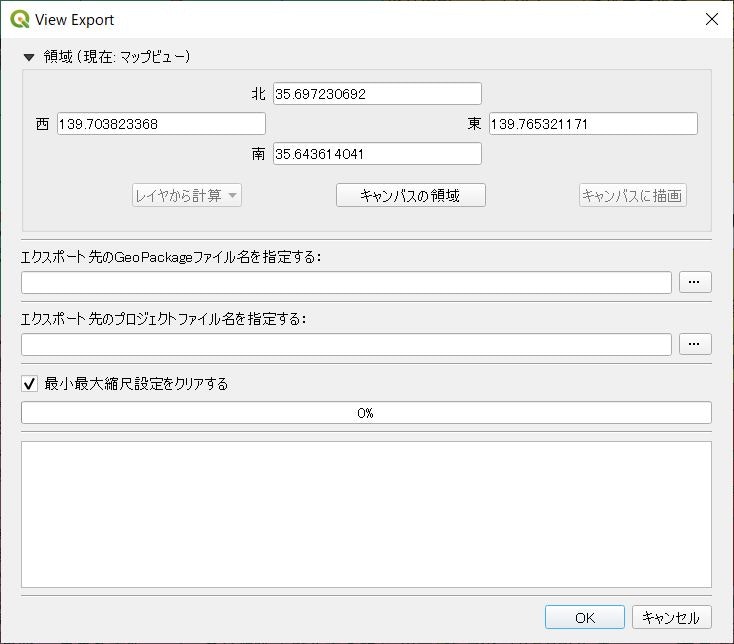
Qt Designerで画面を作成
Plugin Builderでプラグインの作成してpyrcc5を実行したら、Qt Designerで画面を作成します。(Qt Designerの使い方こちら)
Qt Designerは使ったことがあるので画面作成は時間をかけずにこんな感じの仕上がりにしました。
領域(現在:マップビュー)
現在のキャンバスの四隅座標が表示されています。
モードレスダイアログのため、GIS本体で拡大縮小やスクロールすると自動的に四隅座標が更新されるようにシグナル・スロットを設定します。
また、「レイヤから計算」「キャンバスに描画」ボタンは今回利用しないため常にDisableとなるように設定しました。最小最大縮尺設定をクリアする
読み込んだプロジェクトをリネームして設定済のスタイルそのままでデータソースのみ書換を行いますが、その際縮尺設定をクリアするかどうかを選択できるようにします。
クリッピングするということはある程度の狭い領域ということを想定し、その場合縮尺設定されていると表示されなくなって焦ったりして使い勝手が悪いだろうとの想定です。その他
処理の進捗を示すプログレスバーとログを表示するテキストエリアを用意しました。
スレッドを使ってクリッピング処理中にブロックされない工夫が必要です。そして完成へ
photo2shapeという参考になるコードがあったので、ダイアログボックスへのアクセス・スレッドの扱いなどさほど苦労せず取り敢えず動くものが完成。
まとめ
タイトルどおりの素人が8日間(実質50時間ぐらい)で作ったものなので、pythonの言語仕様やしきたりを知らずに書いている部分も多分にあり、また、PyQGISの使い方も見よう見真似で作っているのでもっとエレガントな書き方があるのだと思います。
今後も引き続き勉強しながら更新していきたいと考えています。


- 投稿日:2020-06-04T23:04:37+09:00
[Python]05章-02 制御構文(条件の組み合わせ)
[Python]05章-02 条件の組み合わせ
前節では、1つの条件を用いて、if文による分岐について触れました。例えば以下のものです。
>>> 5 == 5 True >>> 5 != 5 False >>> 5 != 4 True >>> 5 > 4 True >>> 5 >= 5 True >>> 5 > 5 Falseしかし、条件についてはもっと複雑なものもあります。例えば「aとbが等しく、かつcとdも等しいとき」といったものです。
こういった条件の組み合わせについて触れていきます。AND演算
条件Aと条件Bがあったときに、両方満たす場合(つまり両方ともTrue)に、Trueとなります。
Python Consoleに以下のコードを入力してください。
>>> a = 1 >>> b = -1 >>> a > 0 True >>> b > 0 False >>> a > 0 and b > 0 False上記で、a > 0は条件を満たしていますが、b > 0は条件を満たしていません。
したがって、両方満たしていないため、a > 0 and b > 0はFalseとなります。今、2つの条件しか記載していませんが、これが3つの条件についてand演算をした場合でも、3つの条件を満たした場合にはTrueとなります。
AND演算について表でまとめると以下の通りになります。
条件A 条件B 条件A and 条件B True True True True False False False True False False False False OR演算
条件Aと条件Bがあったときに、どちらかを満たす場合(つまりどちらかがTrue)に、Trueとなります。
Python Consoleに以下のコードを入力してください。
>>> a = 1 >>> b = -1 >>> a > 0 True >>> b > 0 False >>> a > 0 or b > 0 True上記で、a > 0は条件を満たしていますが、b > 0は条件を満たしていません。
しかし、OR演算の場合、どちらかを満たしていればよいためため、a > 0 or b > 0はTrueとなります。OR演算について表でまとめると以下の通りになります。
条件A 条件B 条件A and 条件B True True True True False True False True True False False False NOT演算
条件Aがあったときに、それを否定する場合に使用します。
Python Consoleに以下のコードを入力してください。
>>> a = 1 >>> a > 0 True >>> not a > 0 Falseまず、a > 0は1 > 0なので、Trueとなります。しかし、NOT演算の場合は否定するため、それが逆となり、Falseという結果になります。
条件A not 条件A True False False True 条件の組み合わせを用いたプログラムの作成
では実際に、条件を組み合わせたif文のプログラムを作成してみましょう。
今回の内容のプログラムは以下のものです。
1から12まで、何月かを入力して、3~5月であれば「春です」、6~8月であれば「夏です」、9~11月であれば「秋です」、12月~2月であれば「冬です」と表示するプログラムを作成します。
また、1から12まで以外の数値が入力されたら「その月は存在しません」と表示するようにしてください。
実際にプログラムを作成してみましょう。chap05フォルダ内に05-02-01.pyというファイルを作成し、以下のコードを入力してください。
05-02-01.pymonth = int(input('何月かを入力してください(1~12):')) if month >= 3 and month <= 5: print('春です') elif month >= 6 and month <= 8: print('夏です') elif month >= 9 and month <= 11: print('秋です') elif month == 12 or month <= 2: print('冬です') else: print('その月は存在しません。')<05-02-01.py実行結果>
【実行結果】
何月かを入力してください(1~12):7
夏です解説していきましょう。
まず、最初に何月かを入力して、そのあと各条件いずれかにあてはまる箇所のif文内の処理が実行されます。
今回、7と入力したため、month >= 6 and month <= 8の個所にあてはまるのでそこのif文内の処理が実行され「夏です」と表示されます。なお、month >= 6 and month <= 8の条件の個所について、6 <= month <= 8という形に変更できないのでしょうか?そのような表記も実際可能です。
05-02-01.pyのプログラムを以下のように改良して実行してみましょう。05-02-01.pymonth = int(input('何月かを入力してください(1~12):')) if 3 <= month <= 5: print('春です') elif 6 <= month <= 8: print('夏です') elif 9 <= month <= 11: print('秋です') elif month == 12 or 1 <= month <= 2: print('冬です') else: print('その月は存在しません。')<05-02-01.py実行結果>
【実行結果】
何月かを入力してください(1~12):1
冬ですどちらかと言えば、こちらの範囲で書く形式の条件のほうが見やすいかと思います。
ただし、現在範囲で記載する条件はPythonのみとなっています。ほかの言語のC言語やJava言語などは範囲で書く形式は使用できないので注意してください。演習問題
演習問題を用意しました。ぜひ解いてみてください。なお、ファイル名は[ ]内に指定したものを使用して、chap05内に作成ください。使用する変数名は好きな変数名を指定してかまいません。
[05-02-p1.py]
【1】身長(cm)と体重(kg)を入力し、BMIを求めるプログラムを作成してください。
また、BMIの結果から、以下の条件に基づいて画面に表示するようにしてください。
BMI値 出力内容 18.5未満 「やせすぎです」と出力 18.5以上25.0未満 「普通体重です」と出力 25.0以上 「肥満です」と出力 ※本来は肥満にもさらに区分けされるのですが、簡素化のため上記としています。
BMIの求め方は以下の式で求められます。
BMI =体重(kg)÷(身長(m))2
(ヒント:まず身長(cm)を身長(m)に変更しましょう)
また、今まで文字列を数値に変える際にint関数で変換していましたが、体重や身長は整数でなく小数の可能性もありますので、そういう場合の変換は以下のようにfloat関数で変換します。
weight = float(input('体重(kg)を入力してください:'))
<05-02-p1.py実行結果>
【実行結果】
身長(cm)を入力してください:184
体重(kg)を入力してください:77.9
標準体重です最後に
今回は、条件を組み合わせた制御構文について見ていきました。ただし、あまり長い条件を書いてしまうと、後でプログラムをメンテナンスする際に読みづらくなるというデメリットもありますので、必要最低限にとどめておきましょう。
このAND、OR、NOT演算は「4章-09」のセットのところに出てきた集合の演算の話に近い内容となっています。ぜひ確認してみてください。
【目次リンク】へ戻る
- 投稿日:2020-06-04T23:03:09+09:00
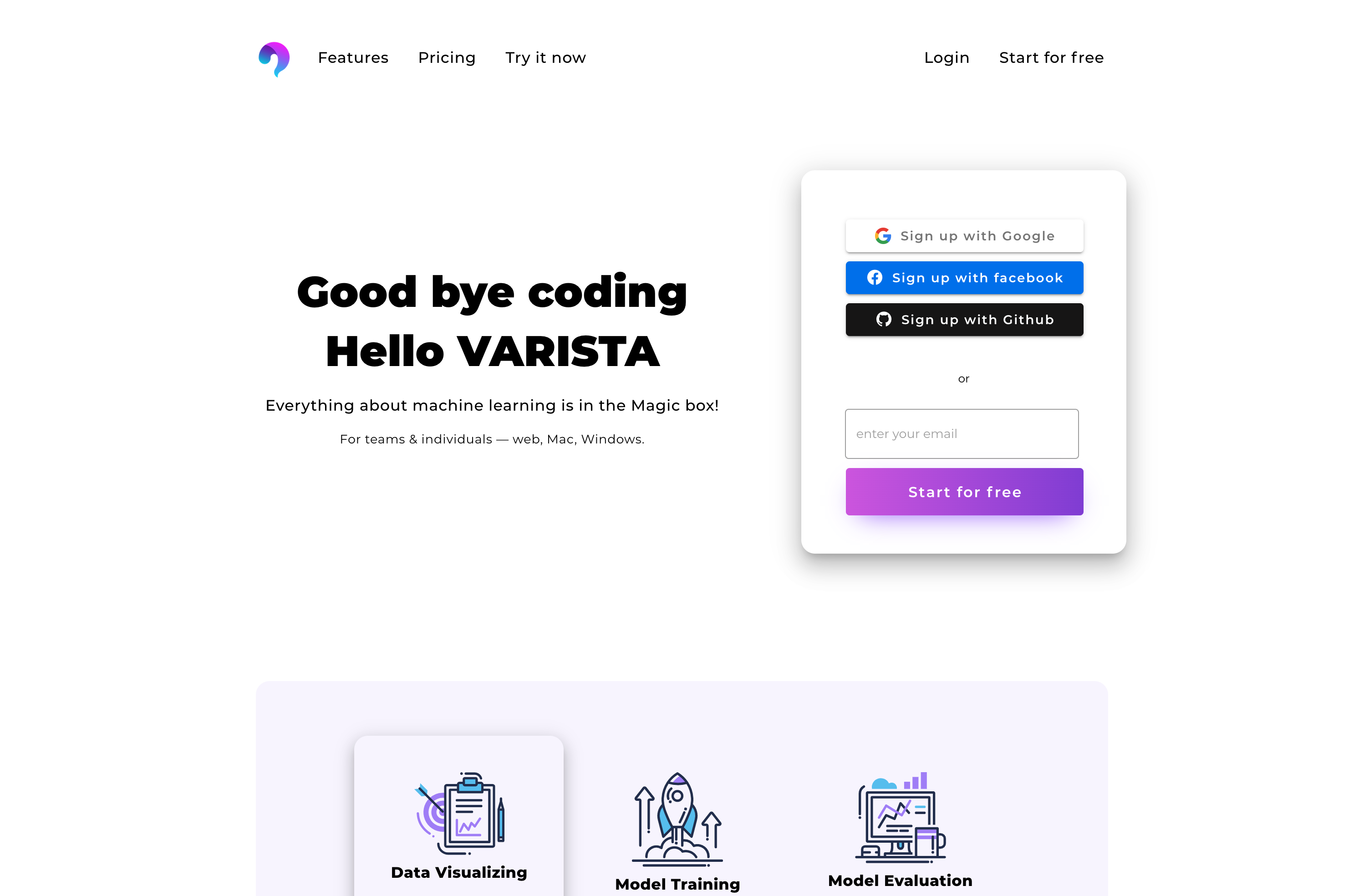
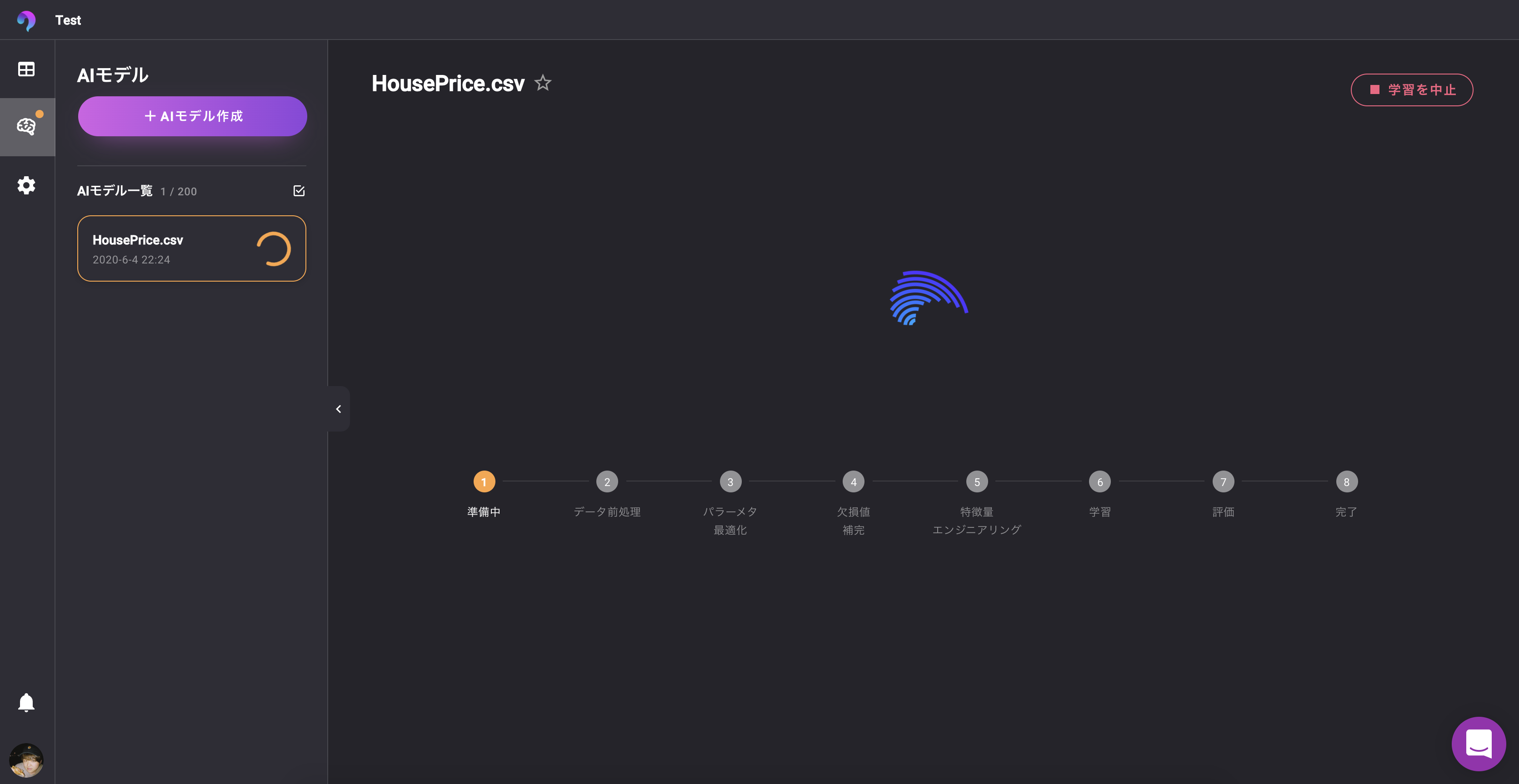
【王者DataRobot・最新ツールRealityEngines・無料のVARISTA 】AutoMLツールを比較してみた。【機械学習】
はじめに⚡️
私が実際に触って、体感したことのある3つのAutoMLツールに関する記事です。
あくまで、UI/UX、サービス視点での比較になります。
生成されたモデルの精度の比較ではございませんのでご注意ください。
なぜ、精度の比較をしないのか??
それは、現在私が利用できないツールが含まれているからです。
DataRobotやRealityEnginesに関しましては、私がアーリーアクセスで一時的に利用していたため
現在推論を行うことができませんでした。各リンク?
DataRobot ? https://www.datarobot.com/
RealityEngines ? https://realityengines.ai/
VARISTA ? https://www.varista.ai/王者DataRobot
? https://www.datarobot.com/
AutoMLの先駆者であり、王者と言えばDataRobotですね。
世界のグランドマスターを牛耳っていると言っても過言ではありません。
それにともなって、モデルの精度や機能の多さは群を抜いています。
しかし、その分コストも高く、利用料金は1ユーザー1ヶ月○百万円だとか...
導入してる会社で働いて、ガッツリ使い込んでみたいものです。最新ツールRealityEngines
? https://realityengines.ai/
まだ知らない方も多いのでは?
知る人ぞ知る、RealityEngines.AI
こちらのサービス、現在はまだサービスインしていなく(2020年6月現在)、つい最近アーリーアクセスを行っていたため応募して触ってみました。
テーブルデータだけでなく、自然言語や画像などのディープラーニングにも対応しているみたいです。(触ってない)無料のVARISTA
? https://www.varista.ai/
こちらも、新しめのツールVARISTA.AI
上の二つと一番違うのは、すぐに無料で使い始められることです。
UIもシンプルで機械学習がわからない人でも、とりあえずモデル生成できるよう設計されています。さっそく比較?
各ツールにグッドなところを?でまとめていきます。
データまわりのUI/UX
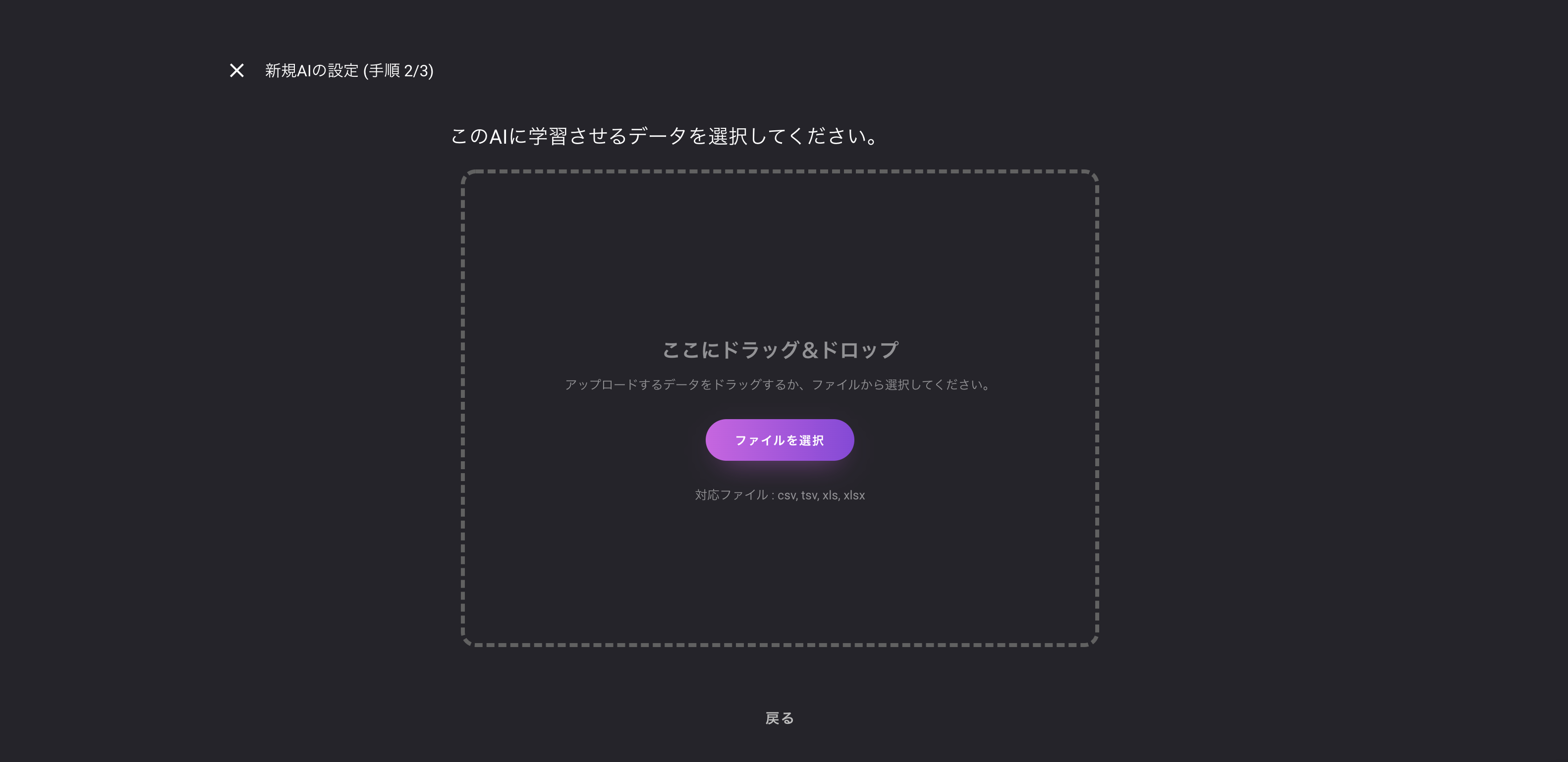
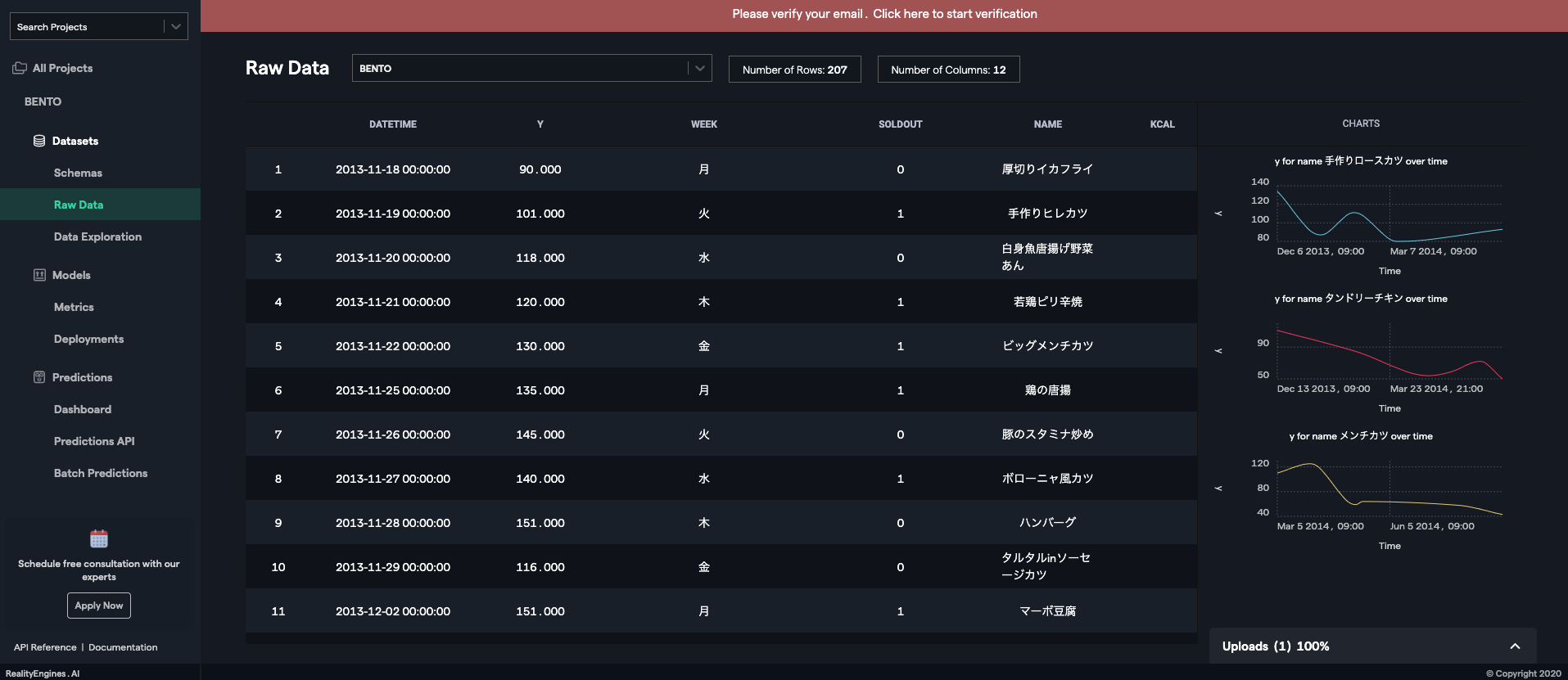
データのアップロード
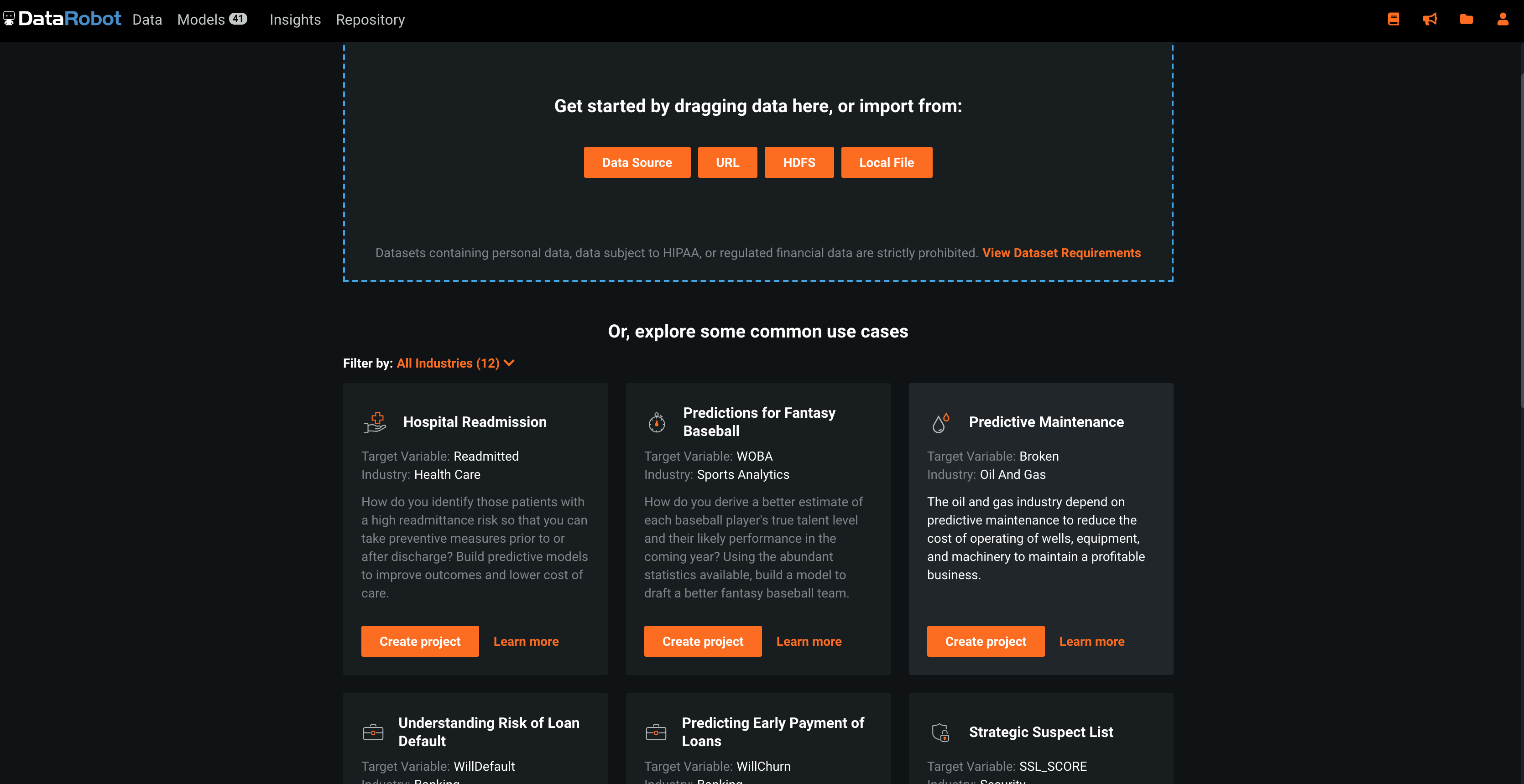
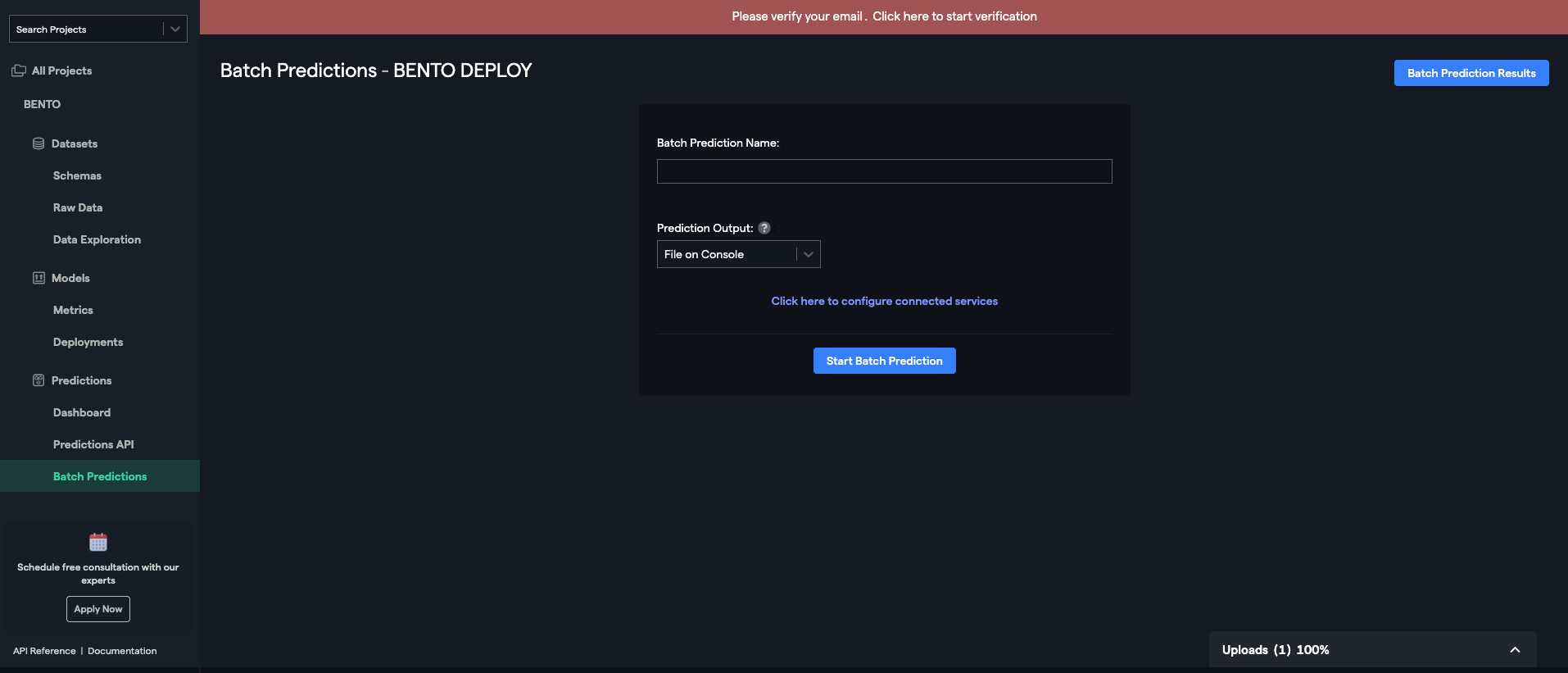
DataRobot
? エリア内にファイルをドラッグアンドドロップするほか「DataSource」、「URL」、「HDFS」に対応しています。
? サンプルファイルが下のリストから選択できるのはとてもいい機能。
データに関する知識がそこまでない、これから機械学習を初めて行く方には、これらのサンプルデータ内から、自分たちにあったものを探して、実際に触ってみることができるのは大きいです。RealityEngines
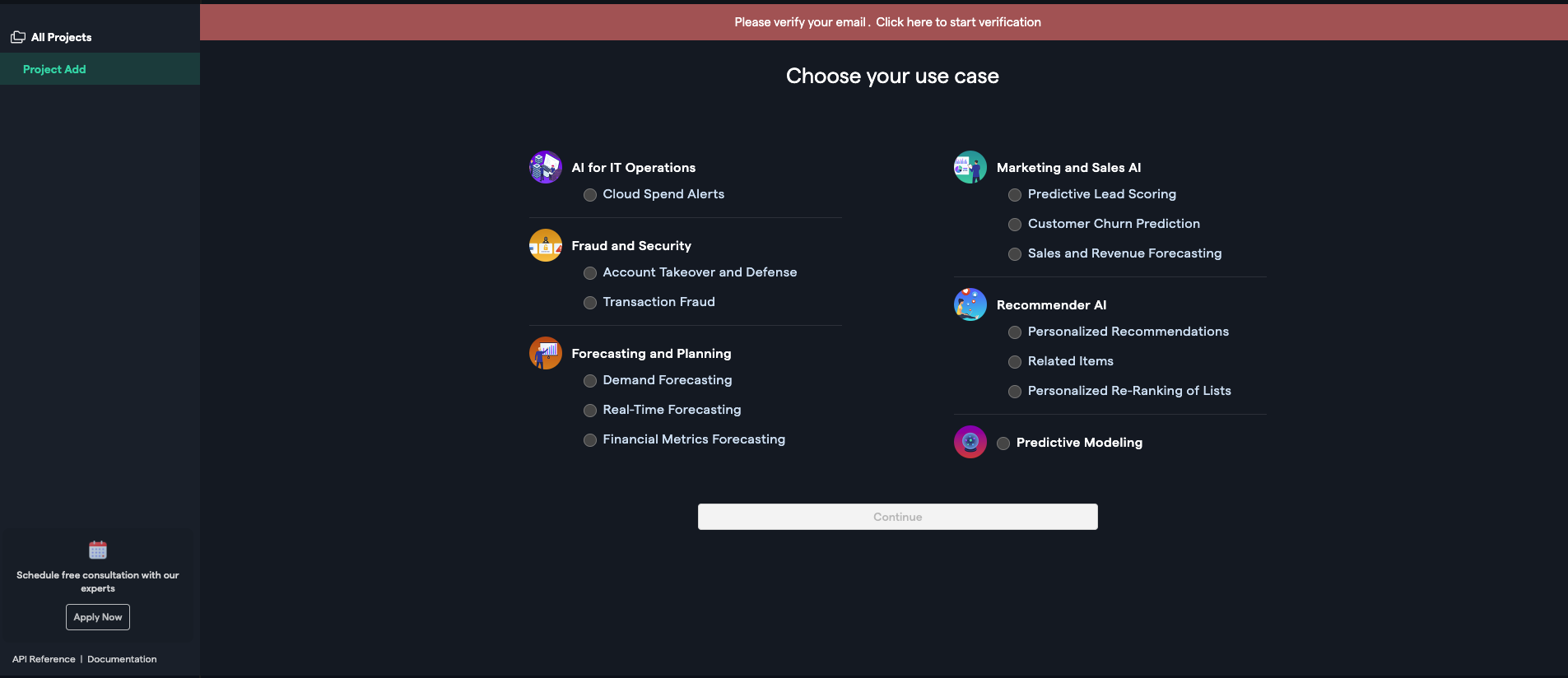
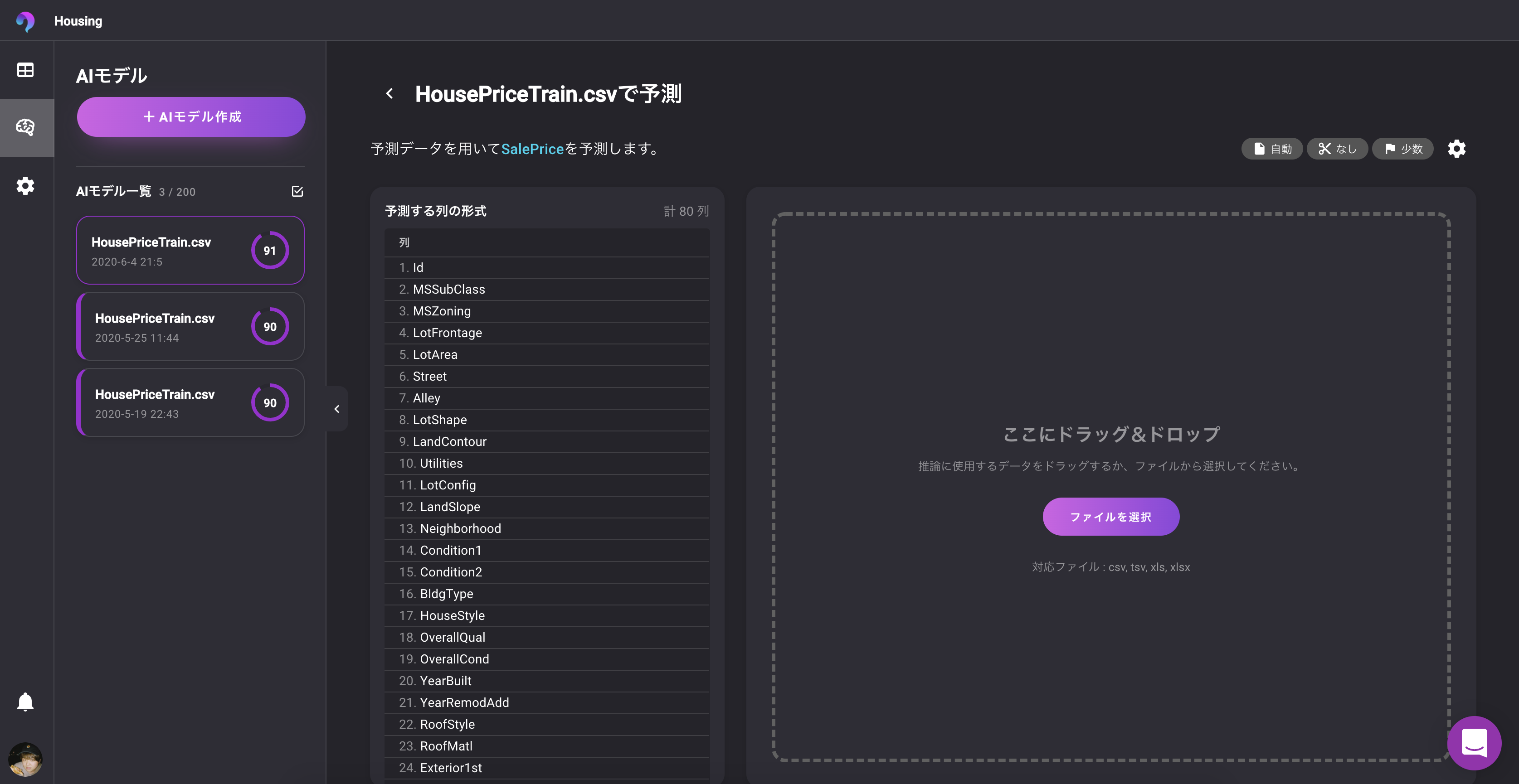
? ユースケースを選んでプロジェクトを作れる。
ビジネスユーザにはとてもわかりやすい機能ですね。
ユースケースを選んでプロジェクト名を設定するとデータアップロード画面になります。
? 必要なデータを教えてくれる
売り上げ予測にはこんなデータを用意してくださいっていうのを教えてくれます!神機能
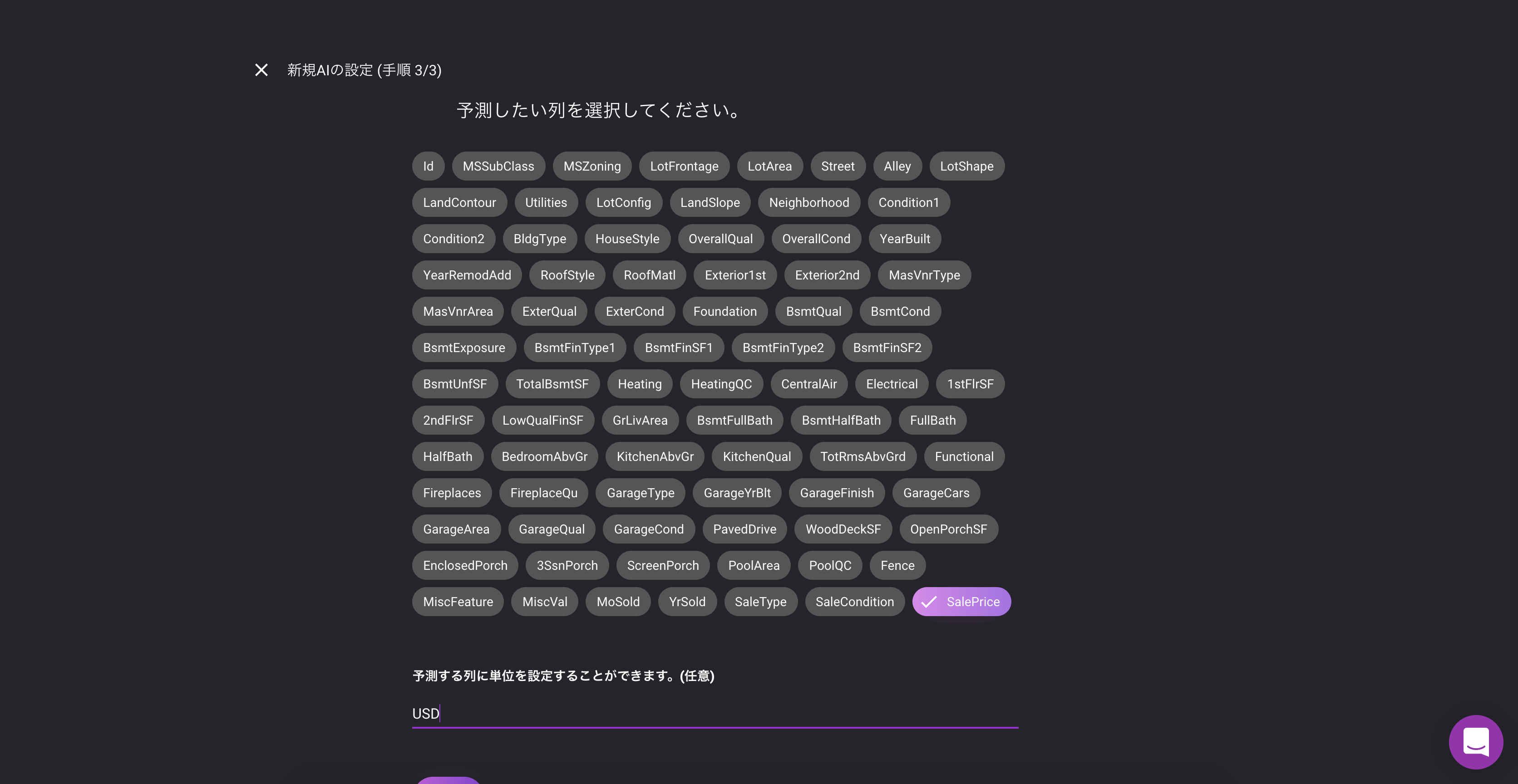
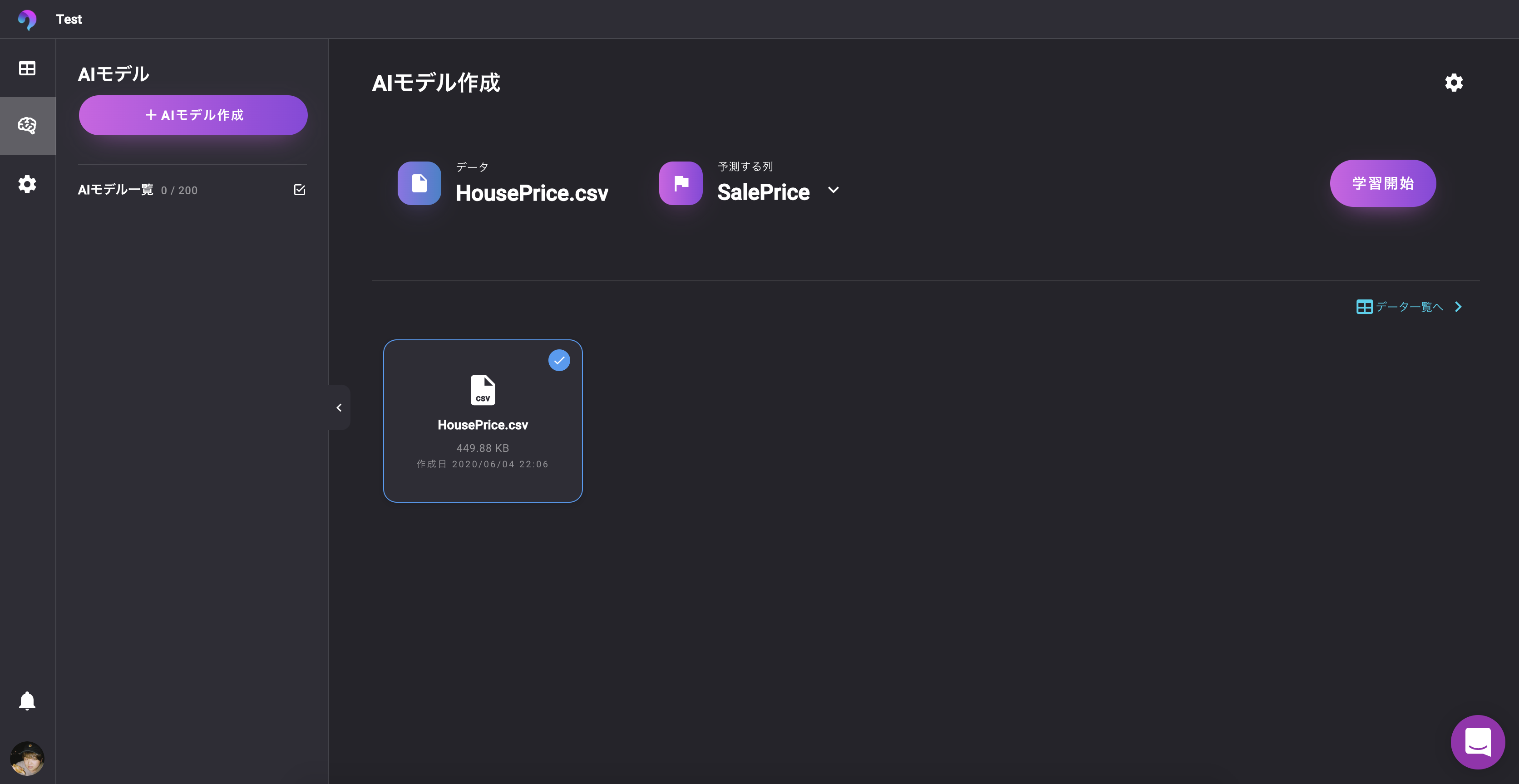
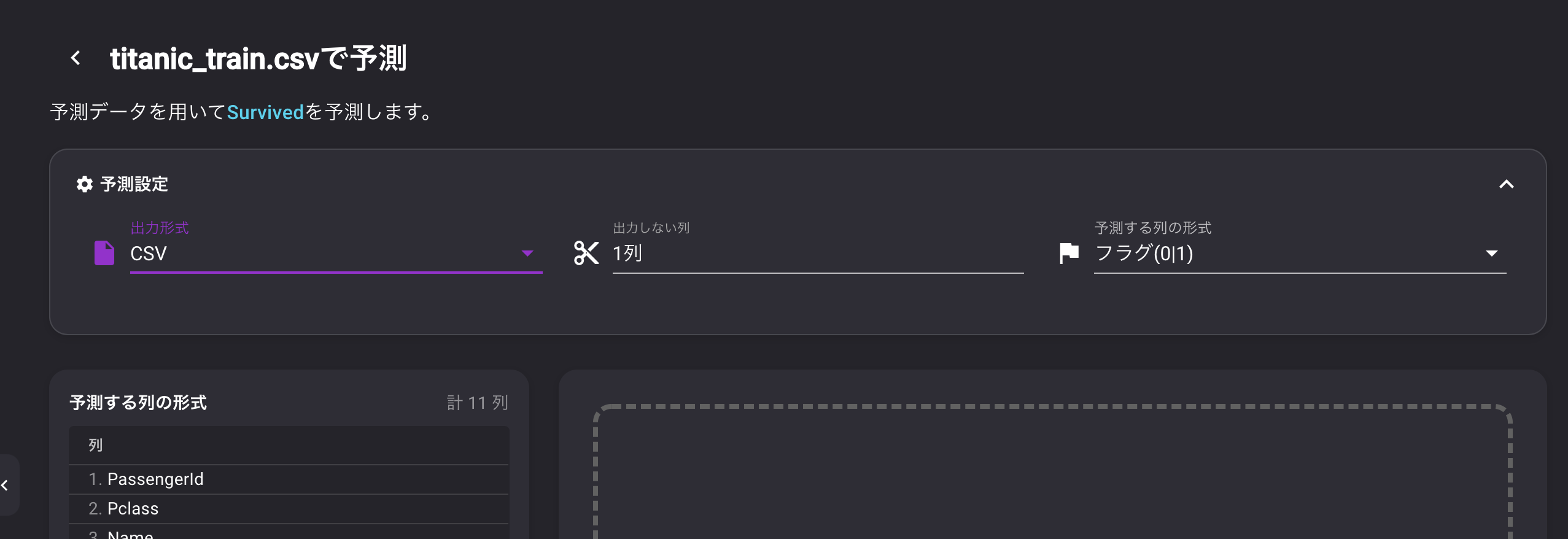
データの各列とアイテムID、ターゲット列などをマッピングします。VARISTA
? UIをみていただければ分かる通り、とてもシンプル
予測したい列を選択して、単位を設定すると完了データの確認、分析
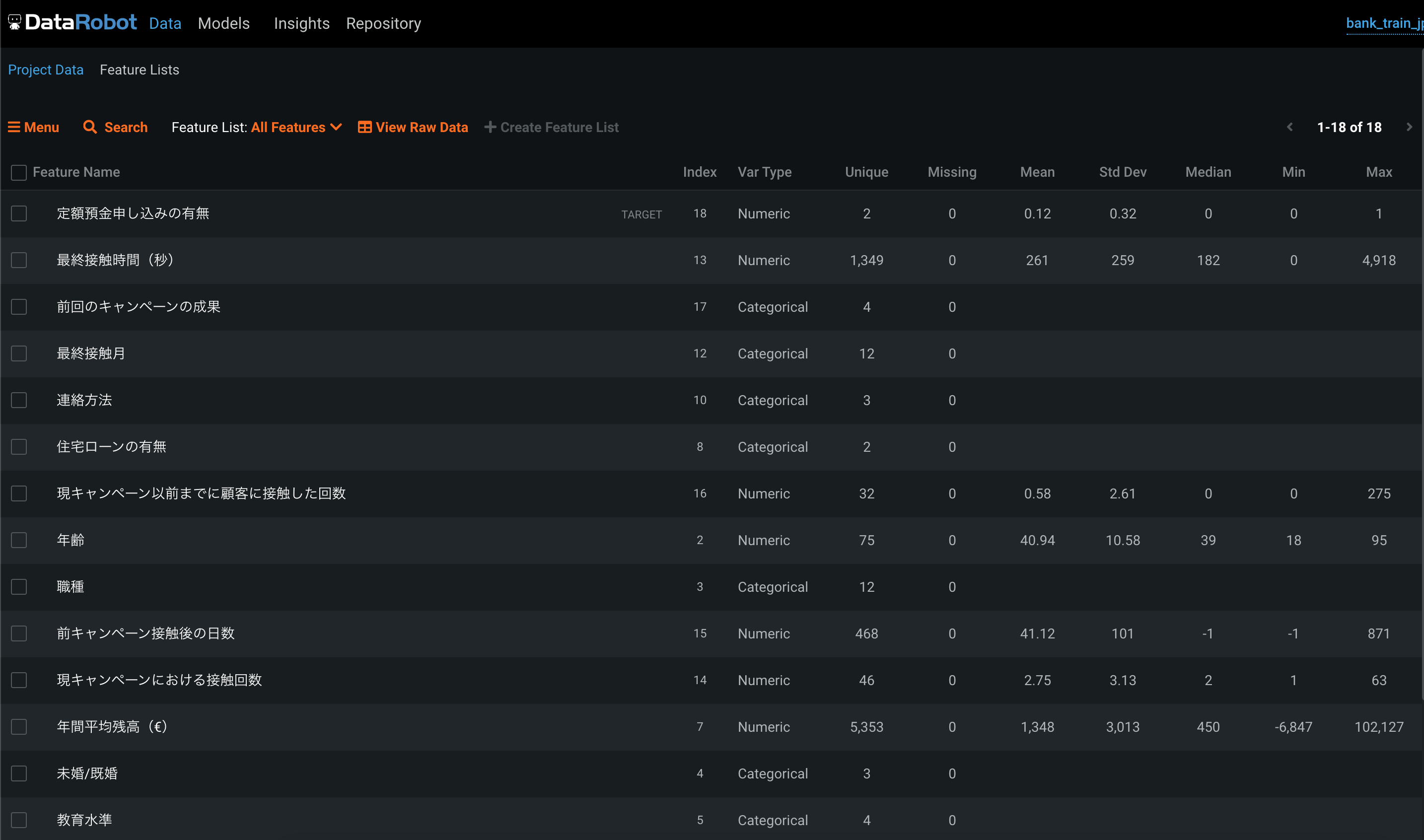
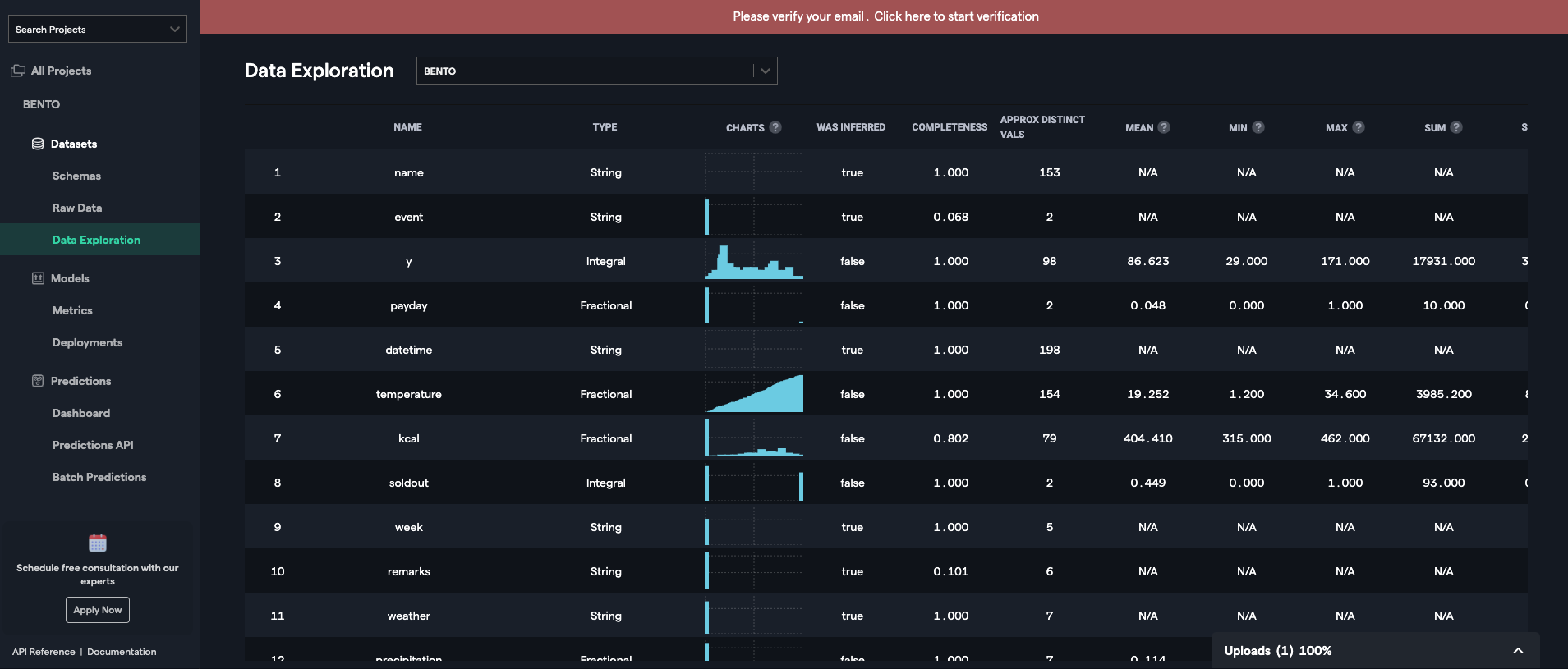
DataRobot
アップロードしたデータは、このようなリストで確認できます。
必要そうな情報はだいたいありますね。
? 学習を始めると、FeatureImportanceもここに表示されます。RealityEngines
? 時系列だと、アイテムごとの需要の変化が可視化されています。
ヒストグラム各種情報は同じように確認できます。VARISTA
列の一覧が確認できます。
? 学習に利用するかどうか、欠損値の量が一眼でわかります。
集計情報から同じように情報を確認できます。学習・モデル生成
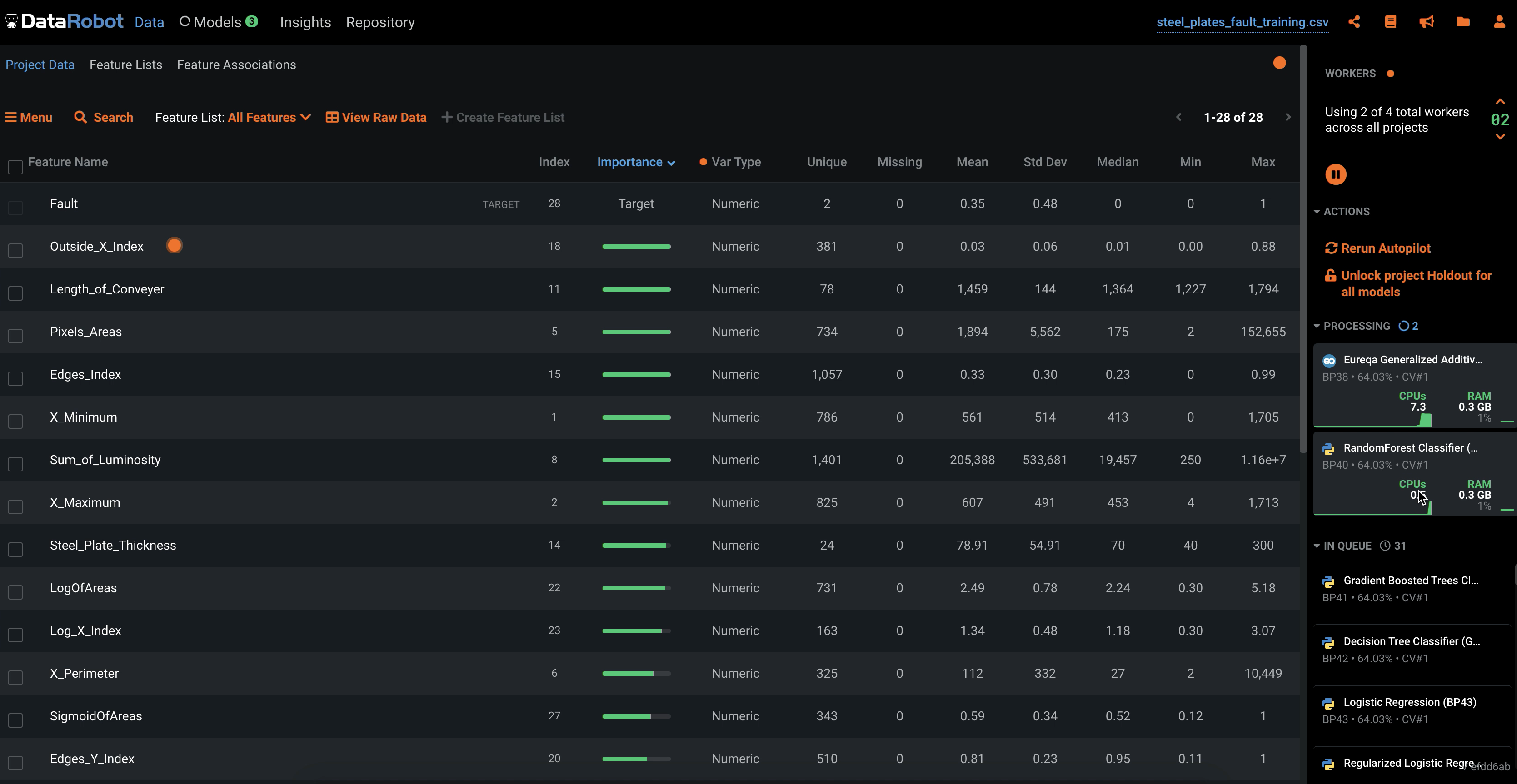
DataRobot
Startボタンを押すと学習開始
学習完了したモデルからどんどん結果が表示されていきます。
? アンサンブルモデルを含め、膨大な量のアルゴリズムをランキング付してくれるため、安心感があります。RealityEngines
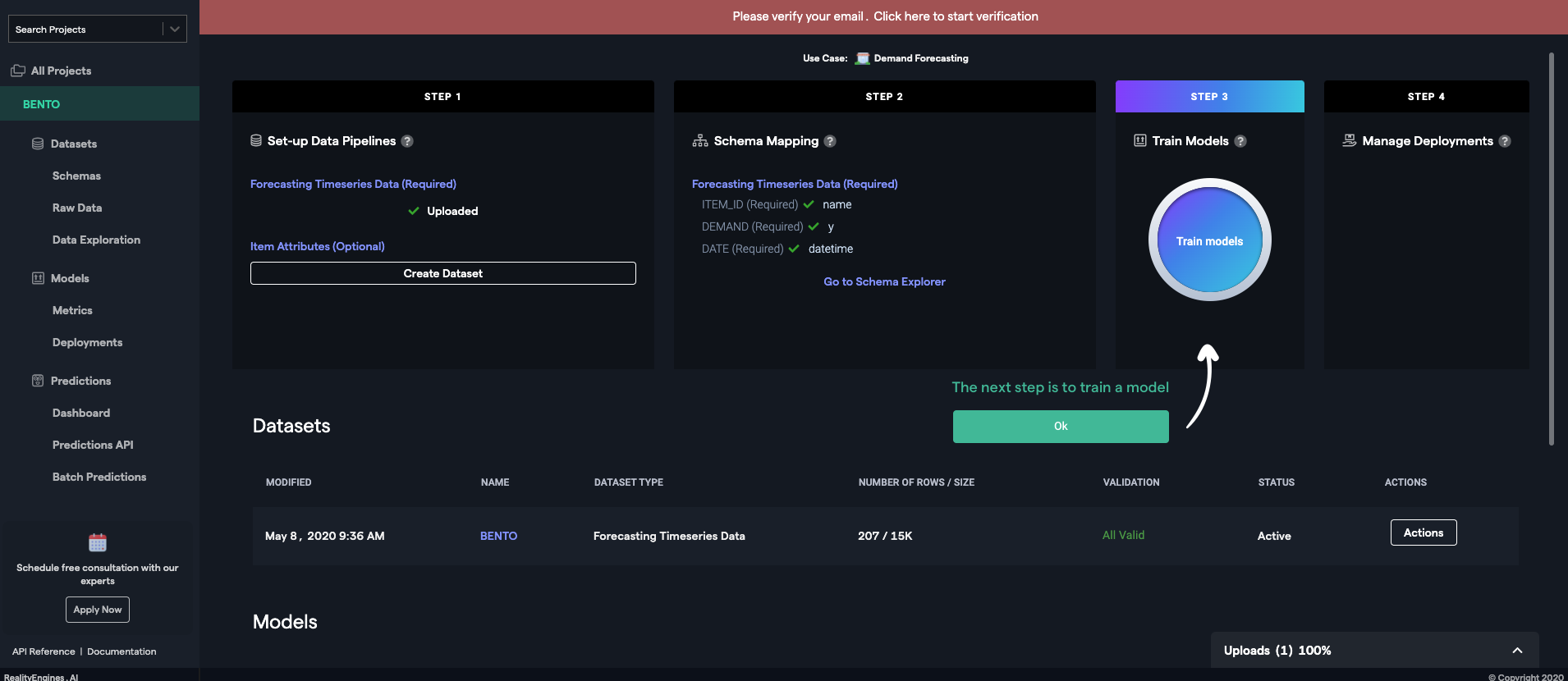
Train modelボタンを押すと、学習が開始されます。
学習が始まるとダイアログが表示されます。
? あとは完了するまで待つだけ。VARISTA
学習開始ボタンを押すと学習が開始されます。
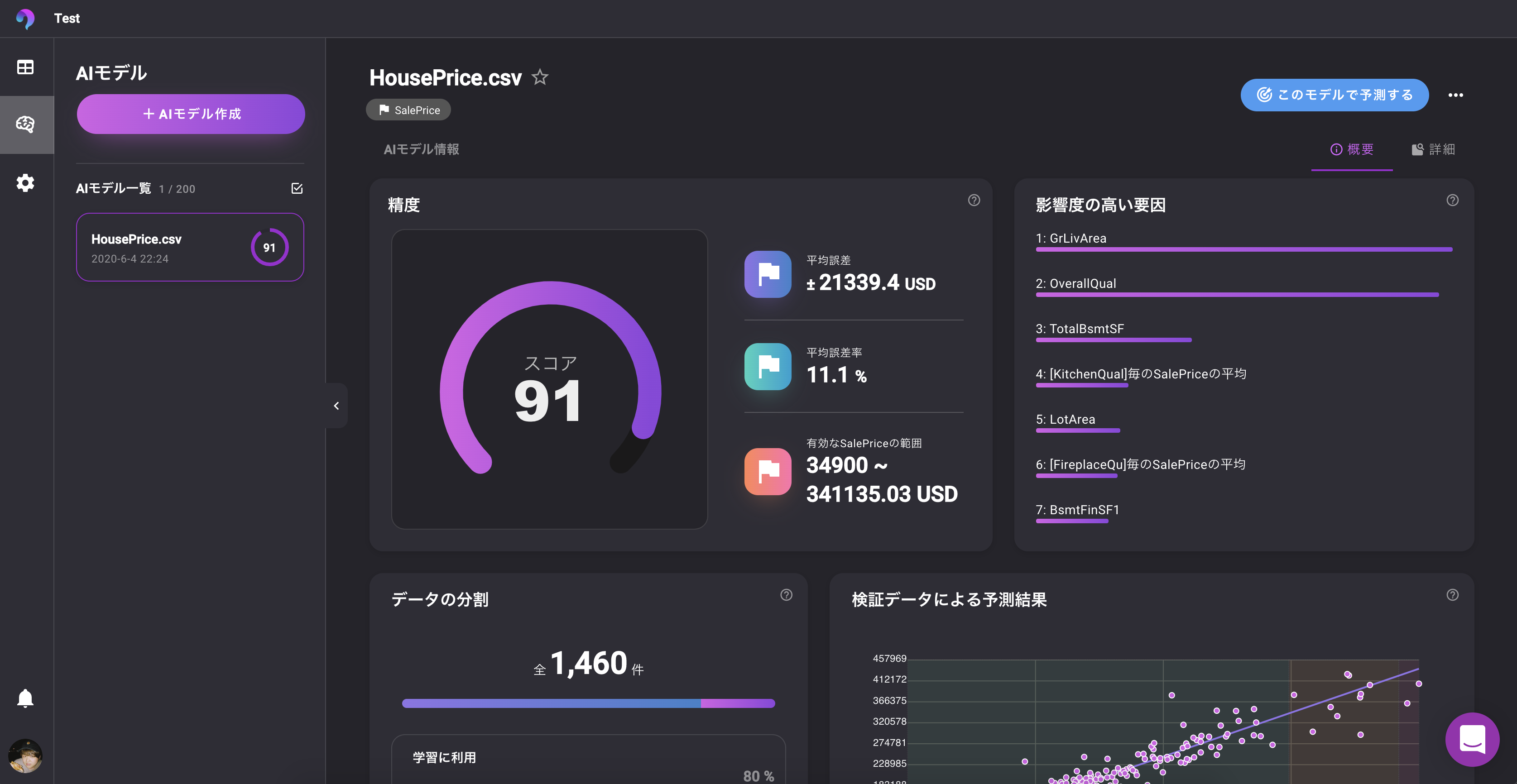
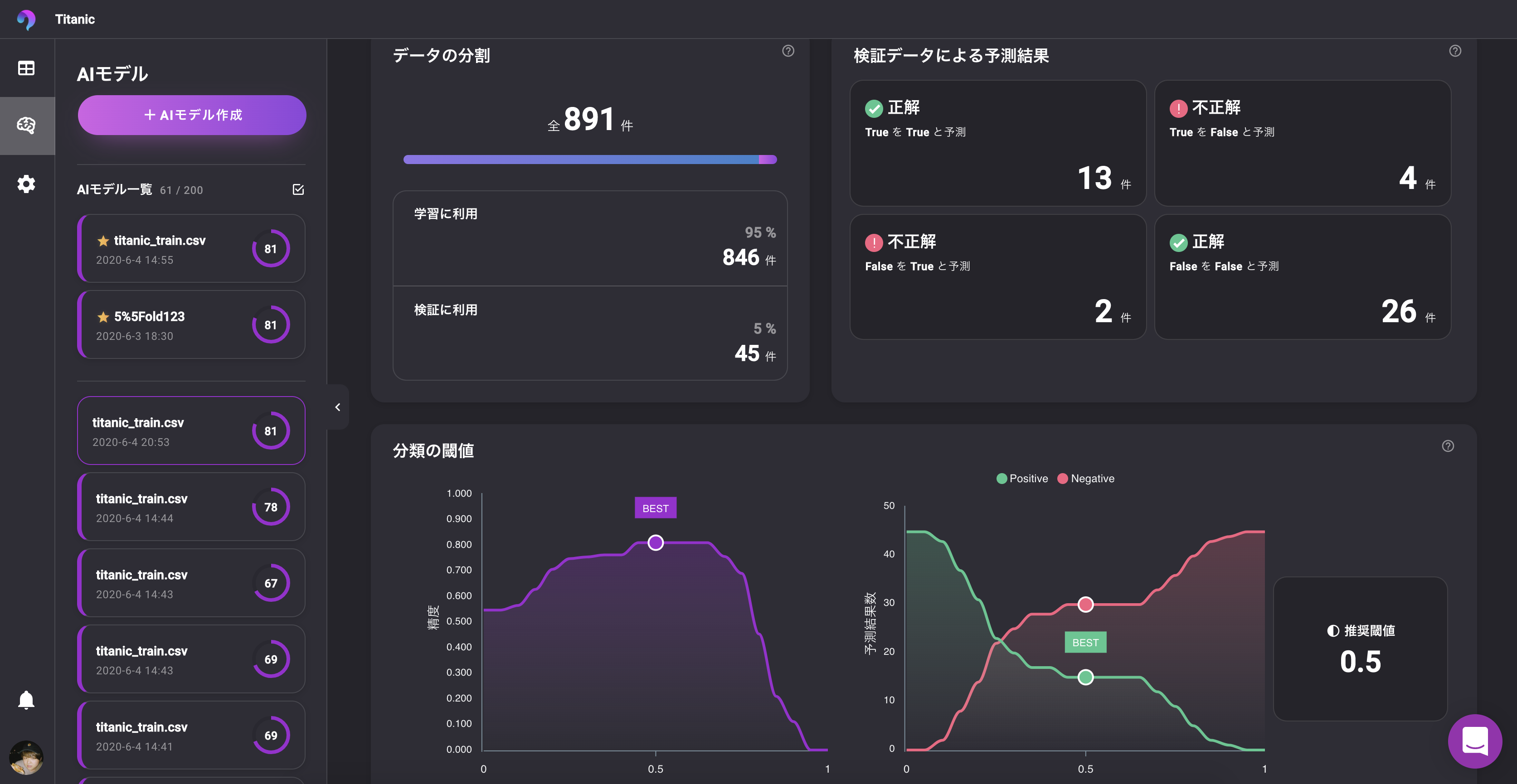
? モデルが追加され、学習プロセスがチェックできます。終わるまで待ちましょう。モデル評価
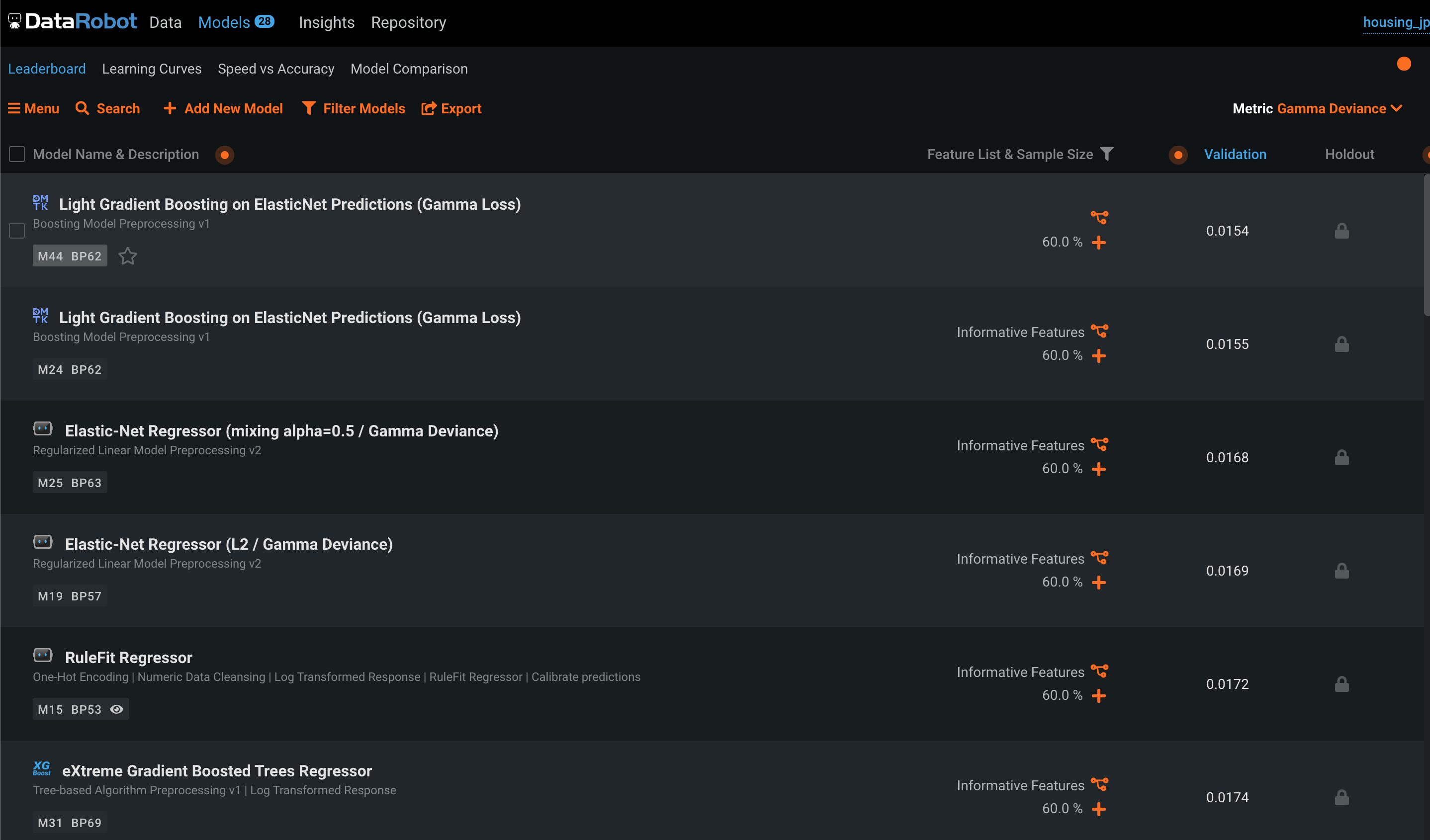
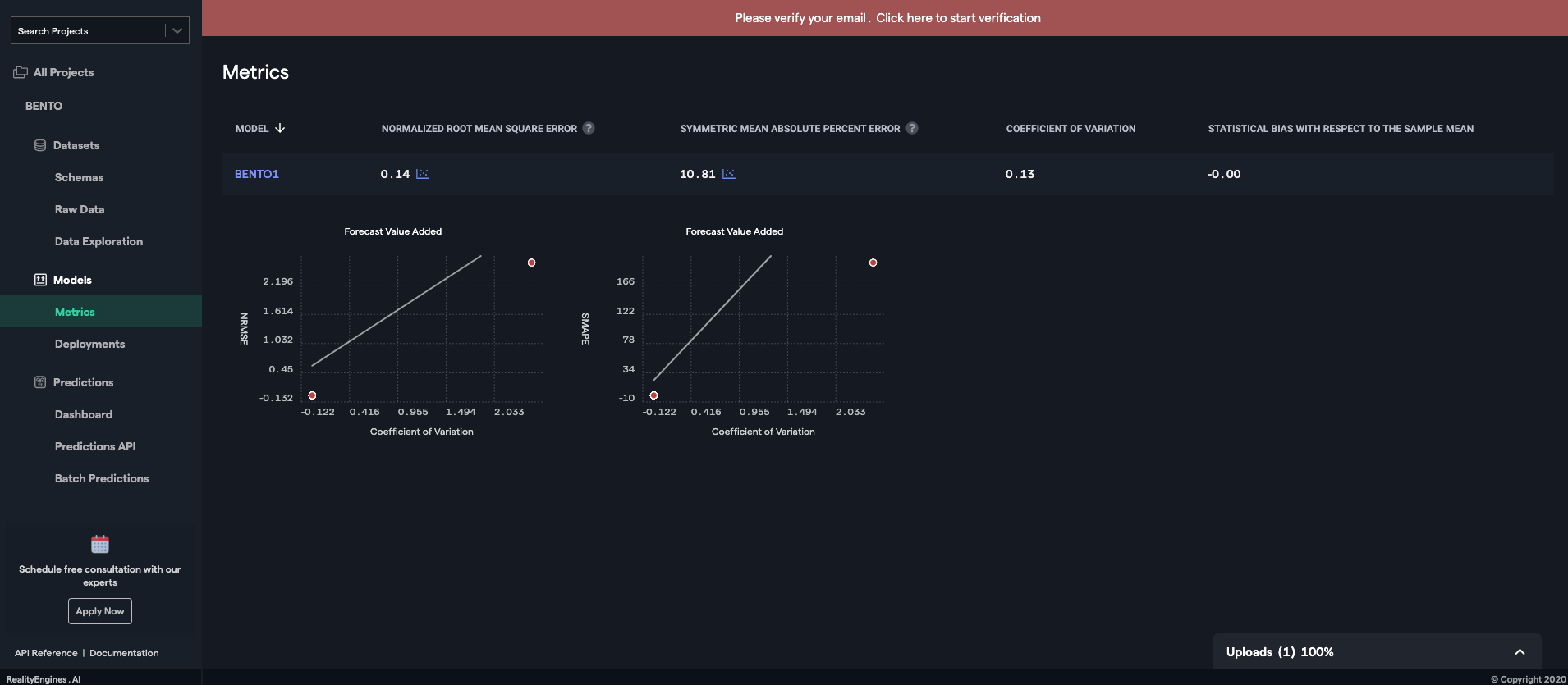
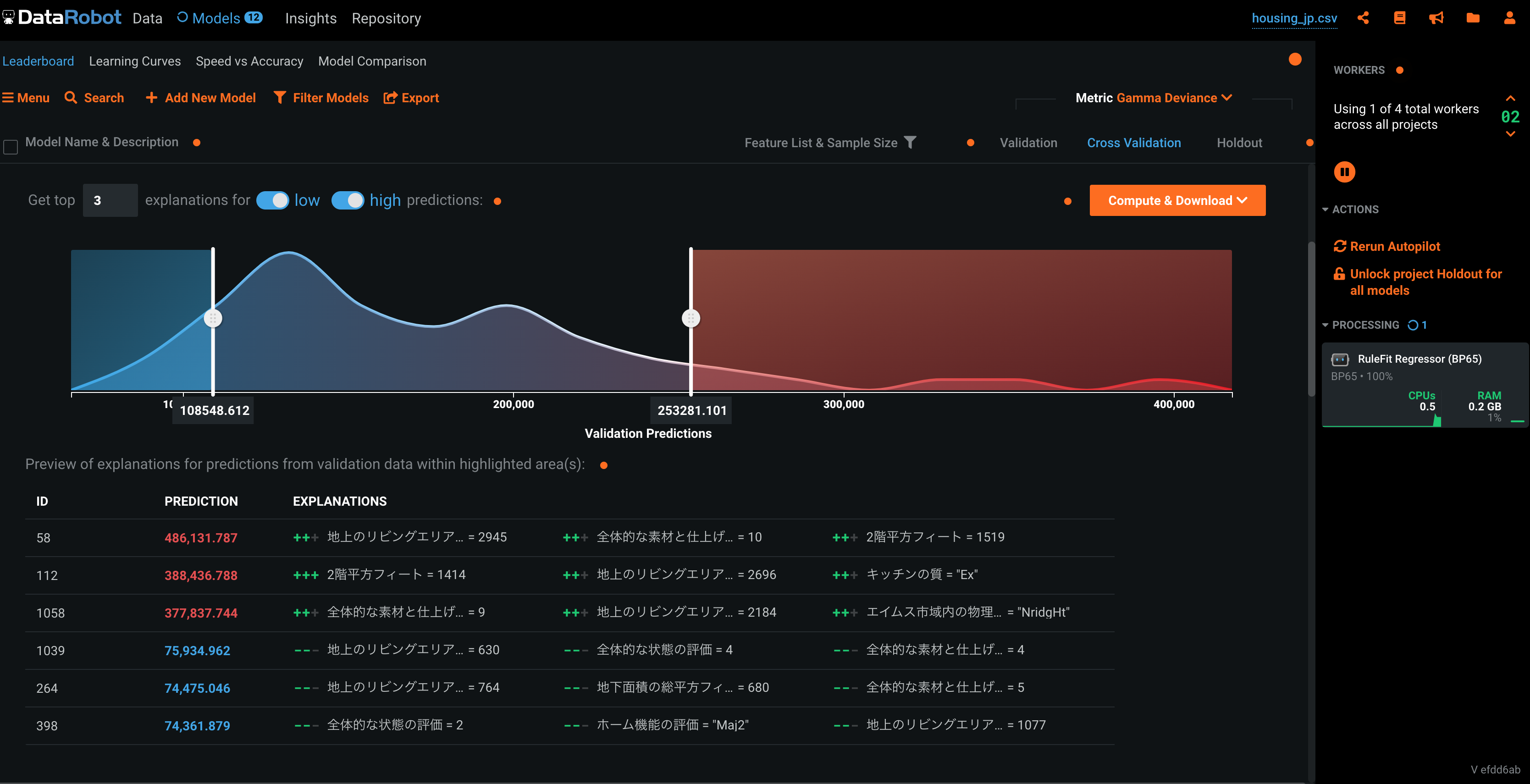
DataRobot
DataRobotのとても強いところです。
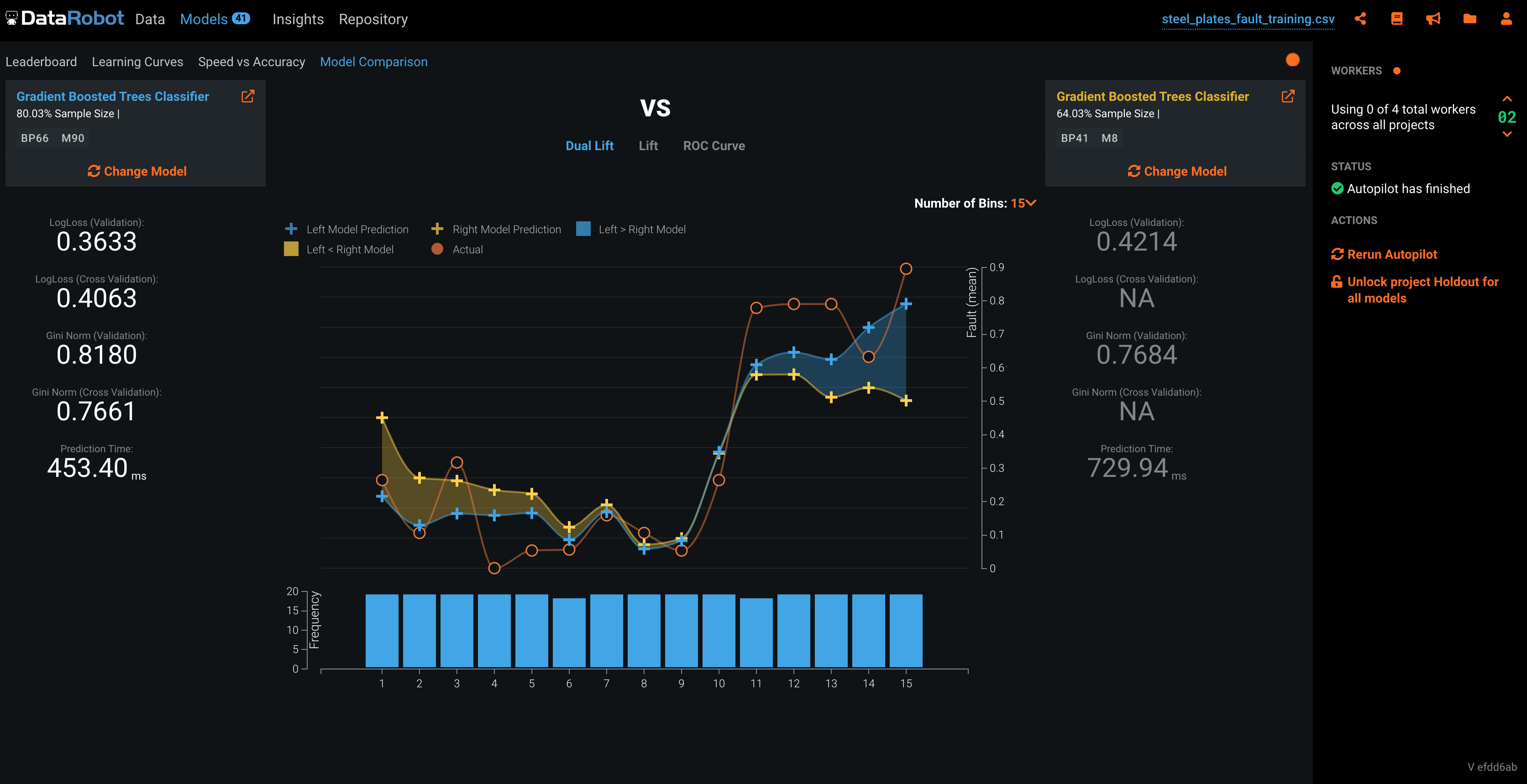
画面は二値分類の結果画面です。
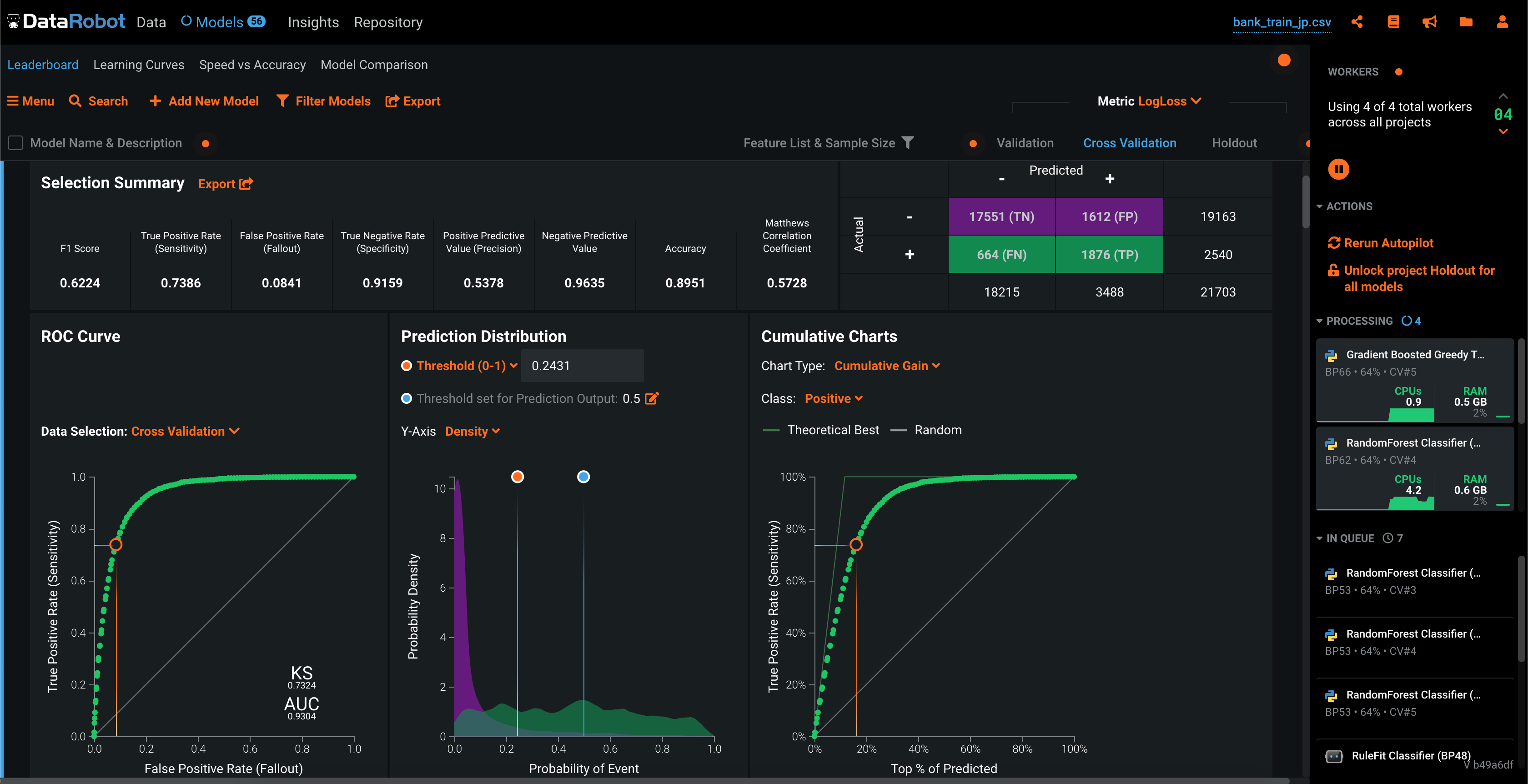
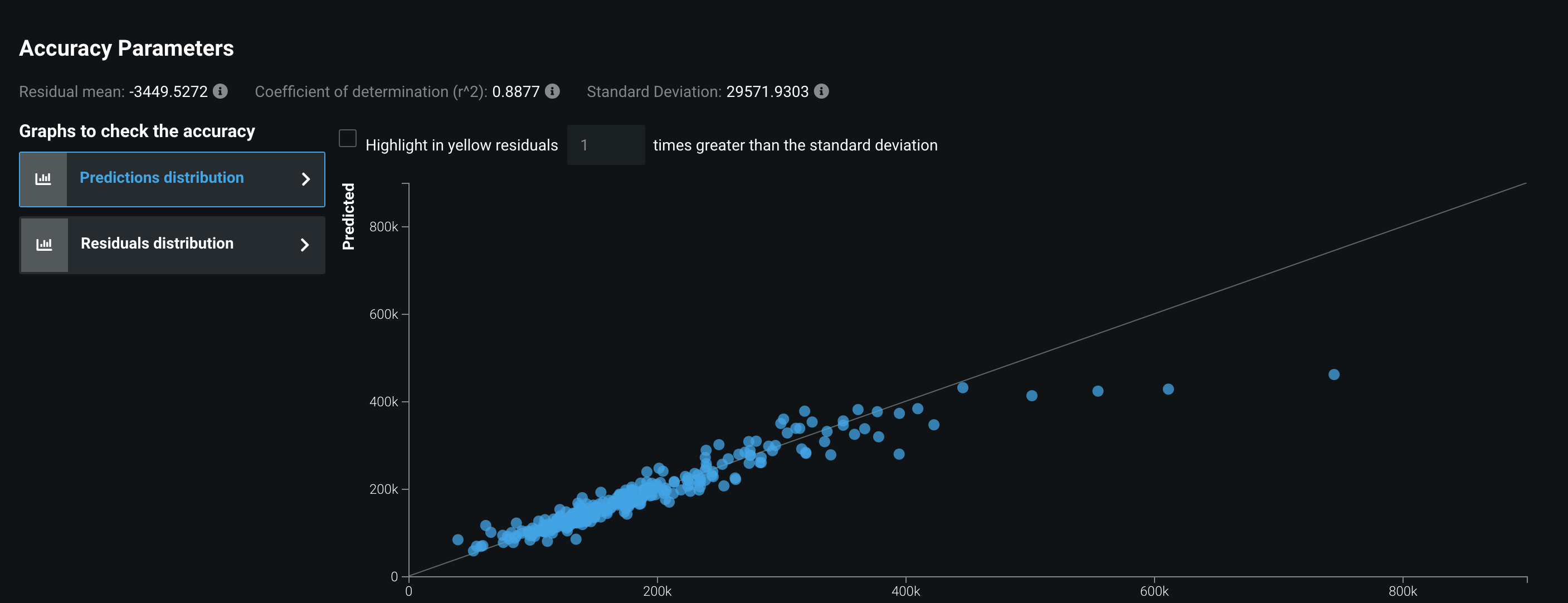
? 各種スコアから、Confusion Matrix, ROC Curve, Thresholdなど、必要な情報はすべてあります。
? 回帰問題では予測値のプロットも確認できます。
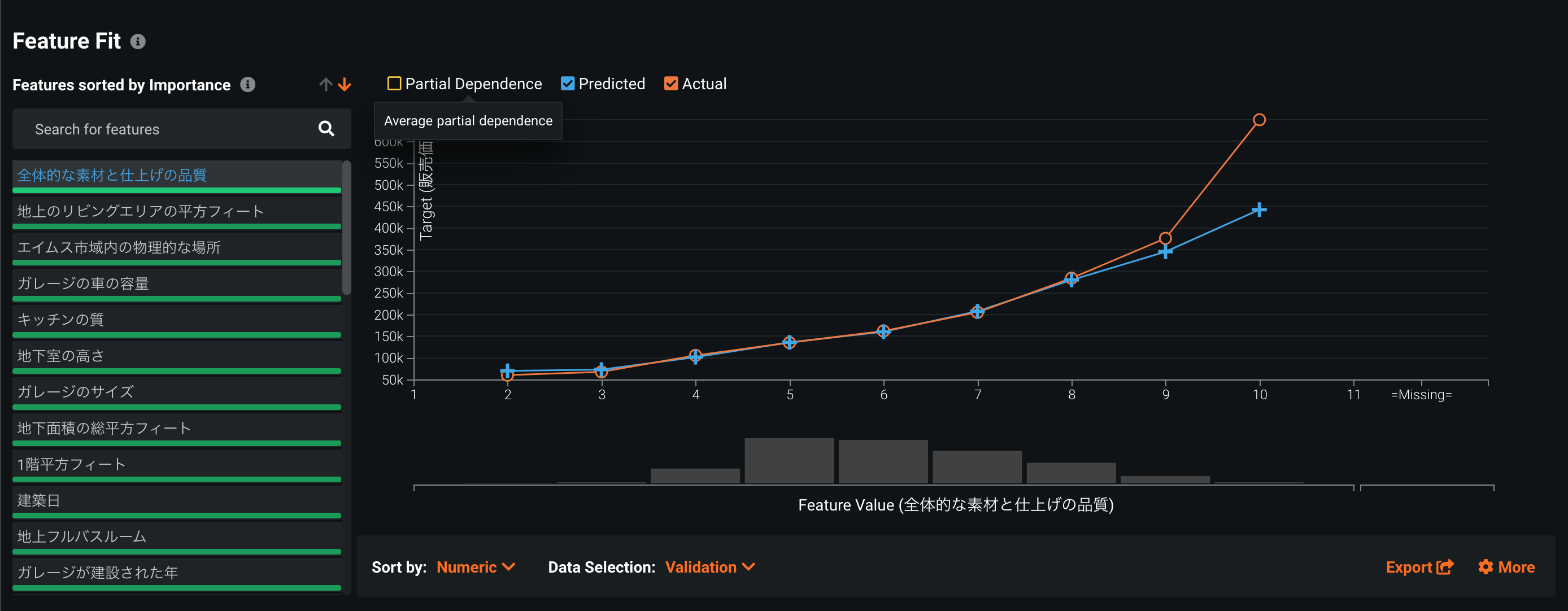
**? 部分依存により、どの特徴のどの値が推論に影響を与えているかも確認できます。RealityEngines
? とにかくシンプルです。
他に情報がないのか、目を疑いました。
? ターゲットとなるユーザーが機械学習エンジニアではなくビジネスユーザーのためか、細かいところはすべてツールに任せろと言わんばかりです。VARISTA
みやすさ、情報量のバランスが◎
? スコアという概念でモデルの性能が一目瞭然
単位がついているので誤差が理解しやすいのもいいですね。
? FeatureImportanceや予測のプロットも確認できます。
分類問題ではわかりやすく表示された混同行列的なものも確認できます。
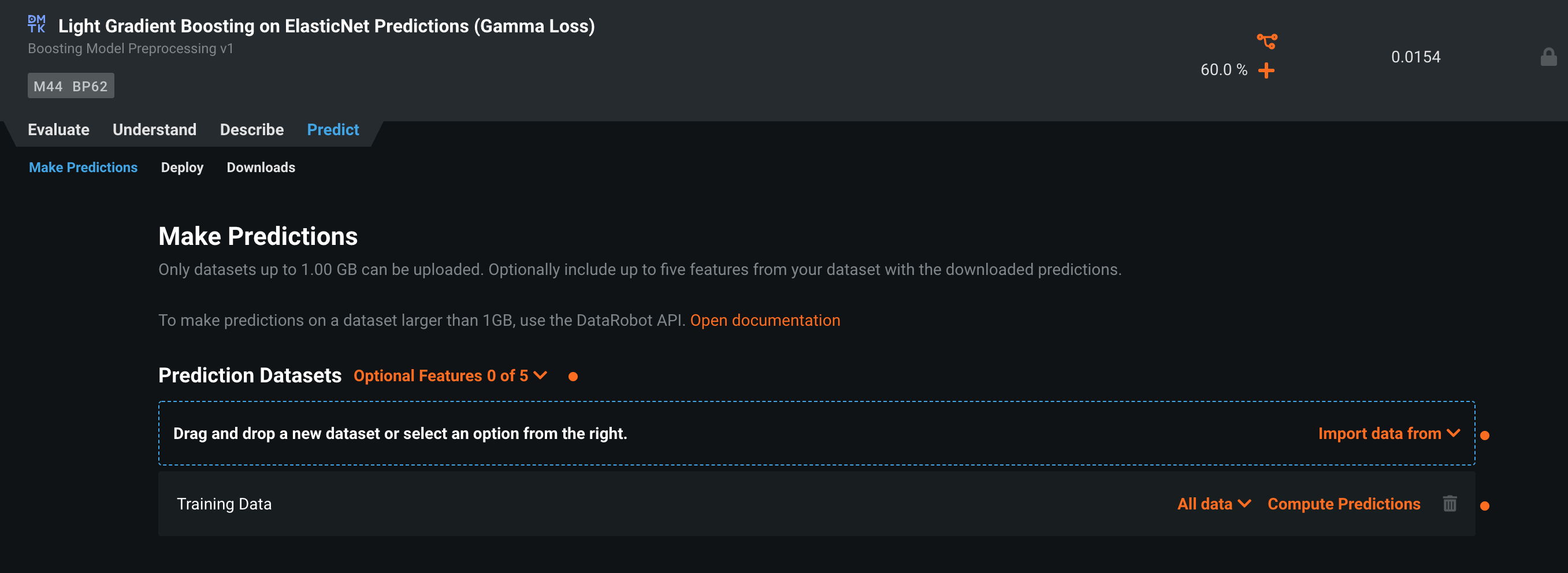
? 閾値の探索も自動でやってくれます。推論
DataRobot
利用するモデルをリストから選択し、Predictionを選びます。
次に推論データをアップロードします。
? 推論が実行されるので、完了したら結果をダウンロードすれば完了。RealityEngines
ファイルを選択し、予測値を推論することができます。
? シンプルでわかりやすいVARISTA
推論に利用するモデルを指定して、予測を行います。
? 推論データに必要な列が表示されています。
? 予測時のフォーマットを設定できるのはkaggleなどにSubmitするときなどに重宝するかもしれませんその他 それぞれ注目の機能?
DataRobot
Validation Predictions
? 見た目もかっこいいが、それだけじゃない。検証データの予測値とその結論に至った理由が明記されています。
いわゆる決定木の通ったルートをカッコよく表示してくれる機能です。
なんでこの予測値になったのかが確認できるのは、ビジネス面でも非常に重要ですね。モデル比較
生成したモデル同士を比較することができます。
? どんな点が優れているのか、どのモデルを利用するべきなのかを把握するのに使いましょうRealityEngines
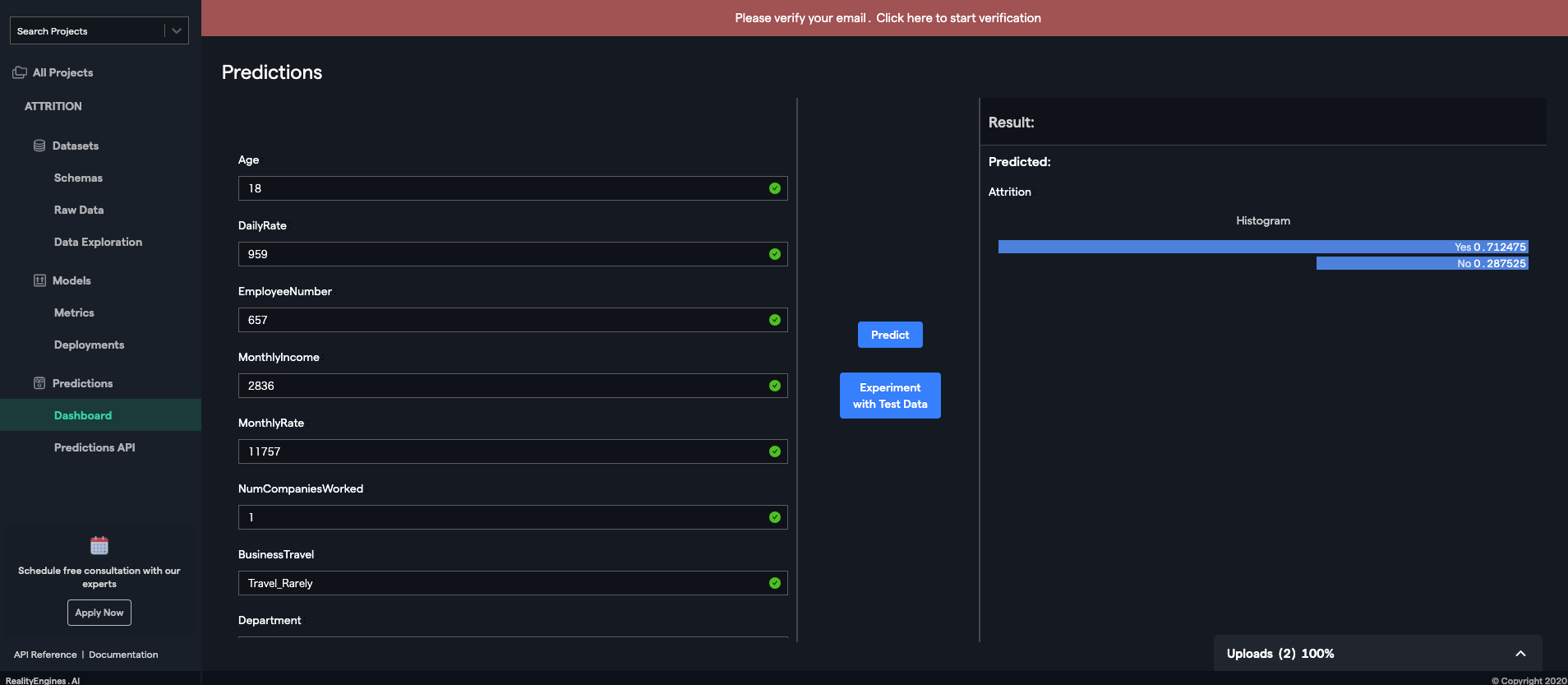
フォーム入力による推論
? データからではなく、その場で値を入力し、予測値を確認できます
どんな感じのモデルになったかすぐに確認できるので便利VARISTA
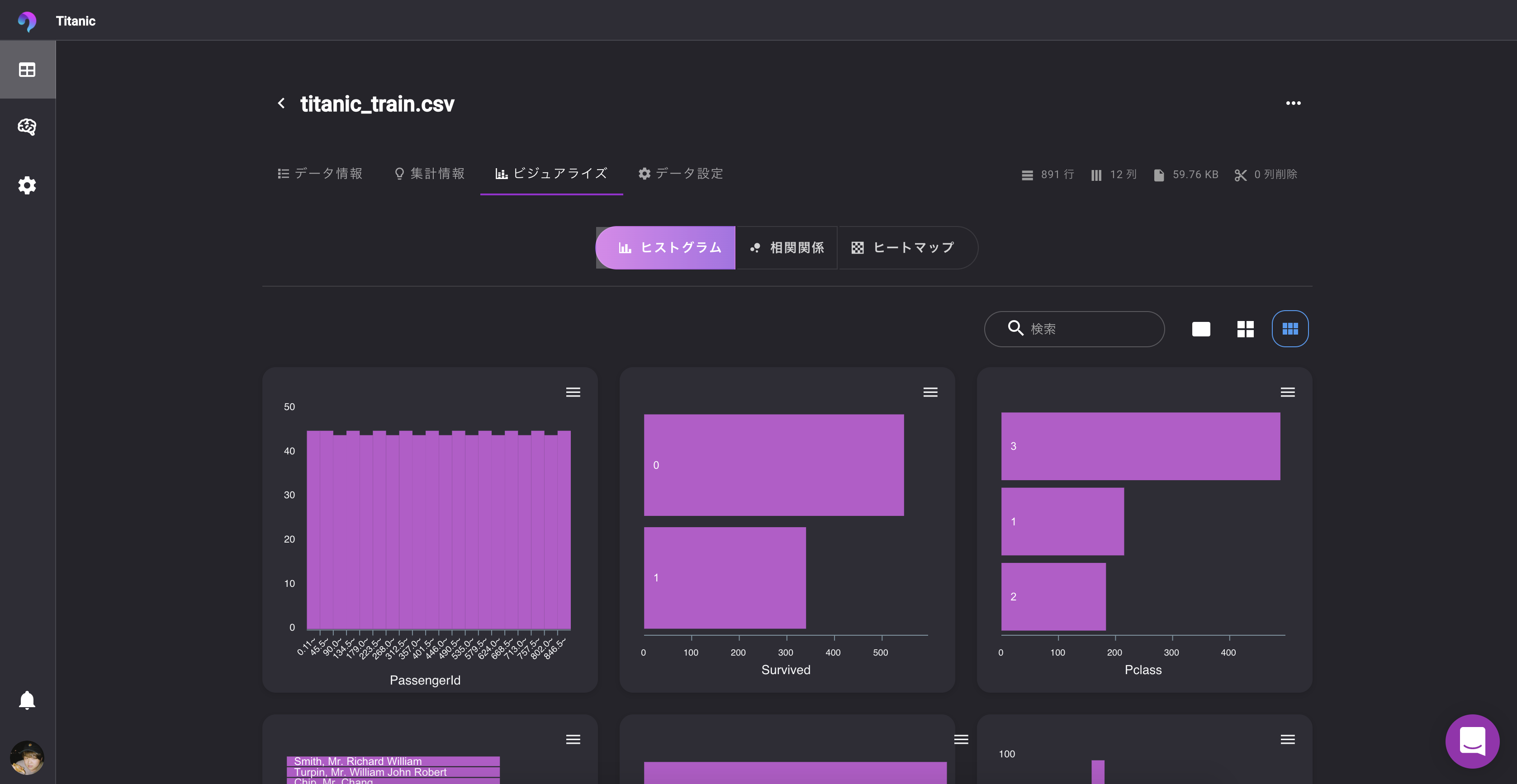
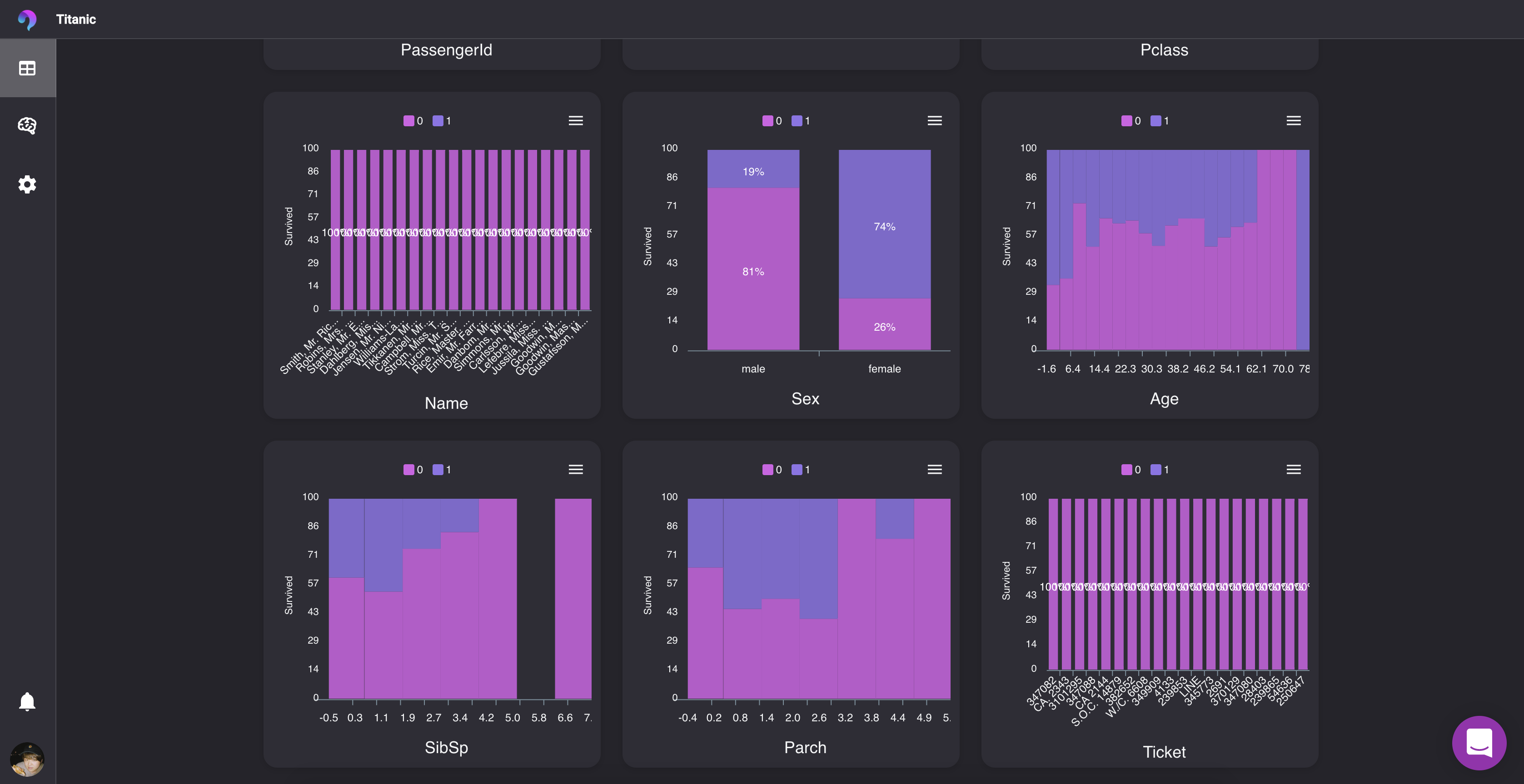
クイックビジュアライズ
? データをアップするだけで、ヒストグラム、相関関係、ヒートマップを可視化してくれます。
文字通り何もしなくていいです。さらに、jpgやpngに書き出すことも可能。データリーク・過学習検知
過学習や、データリークによって精度が異常に高くなってしまうことありますよね。
? データに詳しくない人でも、何が原因でどうすればいいのか指示が出るのがすごいおわり?
以上、3つツールを比較してみました。
それぞれとても優秀なツールでしたね。これからどんどん新しい機能が入っていくのもSaaS型ツールのいいところですね。
AutoML自体の進化にも目が離せません。
それでは良いAutoMLライフを✨


- 投稿日:2020-06-04T23:01:20+09:00
Jupyter上で認証付きProxyの設定を簡単に変更できるようにしてみた
利点
- OSの環境変数にProxyの設定を行う事で、Selenium,Requestsなど複数のパッケージに対して、個々にProxy設定せずに済むようになります。
- 下記実装にすることで、環境変数への設定はこのコードを実行しているブックのみで有効になるので、他への影響が少ない
- ID/パスワードをコードに固定で設定せず毎回入力するため、ソースが漏れてもセキュリティ上の影響が少ない
ソースコード
import os import getpass class PROXY: # プロキシー一覧 proxies = { "office":{社内で利用するプロキシーサーバーのアドレス:ポート}, "mobile":{社外で利用するプロキシーサーバーのアドレス:ポート}, } def __init__(self,prxy=None): self.conf(prxy=prxy) def conf(self,prxy=""): if prxy not in [None,"office","mobile"]: prxy = input("Proxy(office|mobile|none)") if prxy in ["office","mobile"]: name = input("ID:") password = getpass.getpass("Password") self.set_proxy(name,password,prxy=prxy) else: prxy = None self.set_proxy(prxy=prxy) #プロキシのID,パスワードと接続元から環境変数にProxyを設定 def set_proxy(self,uid=None,pwd=None,prxy=None): #プロキシを削除 if prxy == None: os.environ.pop('HTTP_PROXY', None) os.environ.pop('HTTPS_PROXY', None) print("clear Proxy") #プロキシを設定 elif prxy in self.proxies.keys(): prx = self.proxies[prxy] os.environ['HTTP_PROXY']="http://{}:{}@{}".format(uid,pwd,prx) os.environ['HTTPS_PROXY']="http://{}:{}@{}".format(uid,pwd,prx) print("Set {} as Proxy".format(prx)) #プロキシを削除 else: os.environ.pop('HTTP_PROXY', None) os.environ.pop('HTTPS_PROXY', None) print("clear Proxy") #プロキシのID,パスワードと接続元から環境変数にProxyを設定 def check_proxy(self): print('HTTP_PROXY:{}'.format(os.environ.get('HTTP_PROXY', None))) print('HTTPS_PROXY:{}'.format(os.environ.get('HTTPS_PROXY', None)))利用方法
下記を記載する事で、prxy=None以外はID,パスワードの入力を求められる。
正しいID,パスワードを入力する事で、当該ブックにのみ有効なプロキシ設定が環境変数に設定される。#OfficeのProxy利用時 _ = PROXY(prxy="office") #mobileのProxy利用時 _ = PROXY(prxy="mobile") #Proxyを使わないとき _ = PROXY(prxy=None)
- 投稿日:2020-06-04T22:44:51+09:00
Google Colab環境でWebスクレイピングを行うためのメモ。スクレイピングした情報をGoogle Driveに書き込むまでの流れ
pip installを行わなくとも、Google Colabには最初からrequestsとBeautiful Soupは入っている
GoogleのColabでWebスクレイピングを行う際の導入を書いていこうと思います。
ちなみにハードウェアアクセラレータなどの設定は初期状態のnoneで行っています。
(別のものに変えた場合、これから書く内容に変化が起きるのかは、まだ自分自身がColabに慣れていないのでわかりません。)ちなみに
Google Colabでは現在3.6.9のPythonが使えるようです。!python --version # => Python 3.6.9最初
!pip installを使ってrequestsとbeautifulsoup4をインストールするのかと思っていましたが、どうやら!pip feezeコマンドで調べてみると、最初からこれらのライブラリはインストールされているようでした。!pip freeze | grep request # => requests==2.23.0 # => requests-oauthlib==1.3.0 !pip freeze | grep beautiful # => beautifulsoup4==4.6.3そのため、わざわざ
pip installを行わなくとも、webスクレイピング自体は実行できそうです。なお、わざわざここで書くまでもないかもしれませんが、webスクレイピングはマナーを守って正しく行っていきましょう?
Google Colab上でrequestsを使ってみる
requestsは最初から入っていることが分かったので、早速試しに実行してみます。requestsのgithubリポジトリ 内のREADMEの記述を参照して試してみます。
import requests r = requests.get('https://api.github.com/repos/psf/requests') r.json()["description"] # => 'A simple, yet elegant HTTP library.'簡単にできますね!気軽にこうやって簡単に試せるのもGoogle Colabのいいところかと思います。
Google Colab上でBeautiful Soupを試してみる
こちらもBeautiful Soupのドキュメントに書かれているgetting started的な内容を試して見ようと思います。
html_doc = """ <html><head><title>The Dormouse's story</title></head> <body> <p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """ from bs4 import BeautifulSoup soup = BeautifulSoup(html_doc, 'html.parser') print(soup.prettify())すると下記のように整形されたHTMLが出力されます。
<html> <head> <title> The Dormouse's story </title> </head> <body> <p class="title"> <b> The Dormouse's story </b> </p> <p class="story"> Once upon a time there were three little sisters; and their names were <a class="sister" href="http://example.com/elsie" id="link1"> Elsie </a> , <a class="sister" href="http://example.com/lacie" id="link2"> Lacie </a> and <a class="sister" href="http://example.com/tillie" id="link3"> Tillie </a> ; and they lived at the bottom of a well. </p> <p class="story"> ... </p> </body> </html>他にもこんな感じで使えます。
print(soup.title) print(soup.find_all('a')) print(soup.find(id="link3")) # => <title>The Dormouse's story</title> # => [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>] # => <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>Google Colab上でWebスクレイピングを試してみる
試しに自分のサイトにアクセスして情報を取得できるか試してみようと思います。
from bs4 import BeautifulSoup import requests url = "https://safa-dayo.com/" r = requests.get(url) soup = BeautifulSoup(r.text, "lxml") print(soup.title)これは対象のwebサイトにアクセスして、ページのタイトルを取得するためだけのコードです。
実行すると、<title>サファはYoutuber</title>と表示されます。また下記のように実行すると、
from bs4 import BeautifulSoup import requests url = "https://safa-dayo.com/" r = requests.get(url) soup = BeautifulSoup(r.text, "lxml") h4_list = soup.find_all('h4') for h4 in h4_list: print(h4.text)このような実行結果が返ってきます。
ワオン るさお ゴマちゃん むらさきいろのきりんさん(将来的にページのサイトが変わる可能性もあるため、数年後も同様の結果が返ってくるとは限りませんので試される方はご注意ください...?)
以上のようにして、Colab上で問題なく
requestsとBeautiful Soupが使えることが分かりました。Webスクレイピングで取得したデータをGoogle Driveに格納する
ここからGoogle Colabならではの内容になるかと思います。
Colab上ではGoogle Driveをマウントして読み書きが可能です。
スクレイピングで取得したデータをCSVに保存してGoogle Drive上に保存したいケースも出てくるかと思います。
こちらのドキュメント(外部データ: ローカル ファイル、ドライブ、スプレッドシート、Cloud Storage)を参照して、実際にGoogle Drive内のファイルに書き込んでみました。with open("/content/drive/My Drive/test/test.txt", mode="w") as f: f.write("これはテストだよ!")これは
Google Drive内のtestディレクトリ内にtest.txtファイルを新規作成し、そこにこれはテストだよ!と書き込む内容となっています。
実際に実行すると、test.txtが作成されます。Google Drive上からも参照できますし、Colab内のUI上からファイルのダウンロードも可能です。では、さきほど試してみたスクレイピングコードを改良し、取得したデータをGoogle Drive内にcsvとして保存していくコードを書いてみます。
csvファイルに書き込むため、import csvをしています。from bs4 import BeautifulSoup import requests import csv url = "https://safa-dayo.com/" r = requests.get(url) soup = BeautifulSoup(r.text, "lxml") list_item = soup.find_all("li") with open("/content/drive/My Drive/test/test.csv", mode="w") as f: writer = csv.DictWriter(f, ['name', 'description']) writer.writeheader() for item in list_item: if item.find("h4") is not None: d = {} d["name"] = item.find("h4").text d["description"] = item.find("p").text.strip() writer.writerow(d)実行すると下記のようにCSVファイルがGoogle Drive上に保存されているのが確認できます。
Google ColabではPC環境に左右されずに、一通りファイル入出力も含め、様々なことがPythonを使って行えるのでとても便利ですね!
- 投稿日:2020-06-04T22:39:21+09:00
Postfixメールサーバーを構築し、メール受信をトリガーにPythonコードを起動し、メールをSlackに投稿する(ローカル環境編)
記事の内容
Postfixでメールサーバーを構築し、メールが受信される度にサーバー側で自作プログラムを動かします。
自作プログラムは受信メールをインプットデータにして何らかの処理を行います。これはどの言語で実装しても良いのですが、本記事ではPythonを使ってSlackへの投稿を実装します。
メールサーバーは今回はローカル環境で最低限動くように構築し、メールの送受信はローカル環境内でのみ行います。セキュリティ等、詳細な設定は行いません。環境
CentOS 8とUbuntu 20.04の両方の手順を示します。
BIND9、Postfix、Dovecot は Linuxパッケージからインストールします。
メールサーバーを構築するサーバーの環境は以下の通りです。
- ドメイン名:localdomain
- ホスト名:localhost
- Linuxの一般ユーザー名とパスワード:usrname、secret
CentOS の Python バージョン
$ python3 -V Python 3.6.8Ubuntu の Python バージョン
$ python3 -V Python 3.8.2CentOS の ifconfig 結果
ens160: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.79.128 netmask 255.255.255.0 broadcast 192.168.79.255 inet6 fe80::59ac:7015:10c9:543c prefixlen 64 scopeid 0x20<link> ether 00:0c:29:93:f6:a7 txqueuelen 1000 (Ethernet) RX packets 914 bytes 156651 (152.9 KiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 284 bytes 25365 (24.7 KiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536 inet 127.0.0.1 netmask 255.0.0.0 inet6 ::1 prefixlen 128 scopeid 0x10<host> loop txqueuelen 1000 (Local Loopback) RX packets 0 bytes 0 (0.0 B) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 0 bytes 0 (0.0 B) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 virbr0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500 inet 192.168.122.1 netmask 255.255.255.0 broadcast 192.168.122.255 ether 52:54:00:be:03:9b txqueuelen 1000 (Ethernet) RX packets 0 bytes 0 (0.0 B) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 0 bytes 0 (0.0 B) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0Ubuntu の ifconfig 結果
docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500 inet 172.17.0.1 netmask 255.255.0.0 broadcast 172.17.255.255 ether 02:42:cd:65:85:ad txqueuelen 0 (イーサネット) RX packets 0 bytes 0 (0.0 B) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 0 bytes 0 (0.0 B) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.79.130 netmask 255.255.255.0 broadcast 192.168.79.255 inet6 fe80::f8e9:90fd:cfc4:280e prefixlen 64 scopeid 0x20<link> ether 00:0c:29:cc:76:18 txqueuelen 1000 (イーサネット) RX packets 159457 bytes 233626546 (233.6 MB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 10206 bytes 690515 (690.5 KB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536 inet 127.0.0.1 netmask 255.0.0.0 inet6 ::1 prefixlen 128 scopeid 0x10<host> loop txqueuelen 1000 (ローカルループバック) RX packets 514 bytes 48478 (48.4 KB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 514 bytes 48478 (48.4 KB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0Postfixメールサーバーを構築する
以下の2冊の書籍を見ながら、Postfix メールサーバーを構築します。
これらの書籍には、構築手順と解説が書かれていますので、本記事ではローカル環境構築に必要な手順のみ示します。
両書籍ともにCentOS 5.4を使用していますが、本記事では CentOS 8 と Ubuntu 20.04 用にコマンドを書き換えます。
- 書名:BIND9によるDNSサーバ構築(改定新版)
- 著者:伊藤宏通/著 川原龍人/著 野津新/著
- 出版者:技術評論社
- 出版年月:2010-07
- ISBN:9784774142753
- https://www.amazon.co.jp/dp/4774142751/
- 書名:Postfix実践入門
- 著者:清水正人/著
- 出版者:技術評論社
- 出版年月:2010-10
- ISBN:9784774143750
- https://www.amazon.co.jp/dp/4774143758/
DNSの設定
書籍「BIND9によるDNSサーバ構築」p.84~p.86
rootユーザーで、BIND9 をインストールします。
CentOSでは書籍に従って chroot を使用します。
Ubuntuでは今回は chroot を使用しません。CentOS
yum install bind bind-chroot cd /var/named/chroot/etc mv /etc/named.conf . ln -s /var/named/chroot/etc/named.conf /etc/Ubuntu
apt install bind9 bind9utils書籍「BIND9によるDNSサーバ構築」p.86、p.96
rootユーザーで、/etc/resolv.conf を編集します。
editor /etc/resolv.confCentOS
/etc/resolv.conf# Generated by NetworkManager search localdomain -nameserver 192.168.79.2 +nameserver 127.0.0.1Ubuntu
/etc/resolv.conf-nameserver 127.0.0.53 +nameserver 127.0.0.1 options edns0 search localdomain書籍「BIND9によるDNSサーバ構築」p.87
rootユーザーで、named.conf を編集します。
CentOS
editor /etc/named.conf/etc/named.conf(前略) options { - listen-on port 53 { 127.0.0.1; }; + //listen-on port 53 { 127.0.0.1; }; - listen-on-v6 port 53 { ::1; }; + //listen-on-v6 port 53 { ::1; }; directory "/var/named"; dump-file "/var/named/data/cache_dump.db"; statistics-file "/var/named/data/named_stats.txt"; memstatistics-file "/var/named/data/named_mem_stats.txt"; secroots-file "/var/named/data/named.secroots"; recursing-file "/var/named/data/named.recursing"; - allow-query { localhost; }; + //allow-query { localhost; }; (中略) include "/etc/named.rfc1912.zones"; include "/etc/named.root.key"; + +zone "localdomain" IN { + type master; + file "localdomain.zone"; + allow-update { none; }; +};Ubuntu
editor /etc/bind/named.conf.local/etc/bind/named.conf.local// // Do any local configuration here // // Consider adding the 1918 zones here, if they are not used in your // organization //include "/etc/bind/zones.rfc1918"; +zone "localdomain" IN { + type master; + file "localdomain.zone"; + allow-update { none; }; +};書籍「BIND9によるDNSサーバ構築」p.89
rootユーザーで、named.conf の構文チェックを行います。
CentOS
/usr/sbin/named-checkconf /etc/named.confUbuntu
/usr/sbin/named-checkconf /etc/bind/named.conf書籍「BIND9によるDNSサーバ構築」p.89
rootユーザーで、localdomain.zone を新規作成します。
CentOS
editor /var/named/chroot/var/named/localdomain.zone/var/named/chroot/var/named/localdomain.zone$TTL 10800 localdomain. 1D IN SOA ns.localdomain. root.localdomain. ( 2020052601 ; serial 43200 ; refresh 5400 ; retry 3600000 ; expiry 3600 ) ; minimum localdomain. 1D IN NS ns.localdomain. localdomain. 1D IN MX 10 mail01.localdomain. ns.localdomain. 1D IN A 192.168.79.128 mail01.localdomain. 1D IN A 192.168.79.128Ubuntu
editor /var/cache/bind/localdomain.zone/var/cache/bind/localdomain.zone$TTL 10800 localdomain. 1D IN SOA ns.localdomain. root.localdomain. ( 2020052601 ; serial 43200 ; refresh 5400 ; retry 3600000 ; expiry 3600 ) ; minimum localdomain. 1D IN NS ns.localdomain. localdomain. 1D IN MX 10 mail01.localdomain. ns.localdomain. 1D IN A 192.168.79.130 mail01.localdomain. 1D IN A 192.168.79.130書籍「BIND9によるDNSサーバ構築」p.91
rootユーザーで、ゾーンファイルのパーミッション設定を行います。
CentOS
chmod 640 /var/named/chroot/var/named/localdomain.zone chown root:named /var/named/chroot/var/named/localdomain.zone ln -s /var/named/chroot/var/named/localdomain.zone /var/named/Ubuntu
chmod 640 /var/cache/bind/localdomain.zone chown root:bind /var/cache/bind/localdomain.zone書籍「BIND9によるDNSサーバ構築」p.93
rootユーザーで、ゾーンファイルの構文チェックを行います。
CentOS
/usr/sbin/named-checkzone localdomain /var/named/chroot/var/named/localdomain.zoneUbuntu
/usr/sbin/named-checkzone localdomain /var/cache/bind/localdomain.zone書籍「BIND9によるDNSサーバ構築」p.94
rootユーザーで、BIND を起動します。
CentOS、Ubuntu共通
# 現在の状態を調べたい時 systemctl status named.service # 停止してから起動したい時 systemctl stop named.service systemctl start named.service # OSブート時に自動起動したい時 systemctl enable named.service書籍「BIND9によるDNSサーバ構築」p.100
rootユーザーで、ゾーン転送をテストします。
CentOS
dig @192.168.79.128 localdomain AXFRCentOS 結果
; <<>> DiG 9.11.4-P2-RedHat-9.11.4-26.P2.el8 <<>> @192.168.79.128 localdomain AXFR ; (1 server found) ;; global options: +cmd localdomain. 86400 IN SOA ns.localdomain. root.localdomain. 2020052601 43200 5400 3600000 3600 localdomain. 86400 IN NS ns.localdomain. localdomain. 86400 IN MX 10 mail01.localdomain. mail01.localdomain. 86400 IN A 192.168.79.128 ns.localdomain. 86400 IN A 192.168.79.128 localdomain. 86400 IN SOA ns.localdomain. root.localdomain. 2020052601 43200 5400 3600000 3600 ;; Query time: 1 msec ;; SERVER: 192.168.79.128#53(192.168.79.128) ;; WHEN: 木 6月 04 15:35:22 JST 2020 ;; XFR size: 6 records (messages 1, bytes 217)Ubuntu
dig @192.168.79.130 localdomain AXFRUbuntu 結果
; <<>> DiG 9.16.1-Ubuntu <<>> @192.168.79.130 localdomain AXFR ; (1 server found) ;; global options: +cmd localdomain. 86400 IN SOA ns.localdomain. root.localdomain. 2020052601 43200 5400 3600000 3600 localdomain. 86400 IN NS ns.localdomain. localdomain. 86400 IN MX 10 mail01.localdomain. mail01.localdomain. 86400 IN A 192.168.79.130 ns.localdomain. 86400 IN A 192.168.79.130 localdomain. 86400 IN SOA ns.localdomain. root.localdomain. 2020052601 43200 5400 3600000 3600 ;; Query time: 3 msec ;; SERVER: 192.168.79.130#53(192.168.79.130) ;; WHEN: 木 6月 04 15:36:11 JST 2020 ;; XFR size: 6 records (messages 1, bytes 217)Postfixの設定
書籍「Postfix実践入門」p.89
rootユーザーで、sendmail が動作していたら停止します。
CentOS、Ubuntu 共通
ps ax | grep sendmail当記事の環境では sendmail は動作していなかったので、何もしませんでした。
書籍「Postfix実践入門」p.104
rootユーザーで、Postfixをインストールします。
CentOS
yum install postfixUbuntu
apt install postfix書籍「Postfix実践入門」p.105(CentOS のみ)
rootユーザーで、alternatives コマンドで Postfix を選択します。
CentOS
alternatives --config mta当記事の環境では、選択肢は Postfix のみでしたので、何もしませんでした。
書籍「Postfix実践入門」p.121
rootユーザーで、main.cf を編集します。
CentOS、Ubuntu 共通
cd /etc/postfix cp main.cf main.cf.org editor main.cfCentOS
/etc/postfix/main.cf(前略) #myhostname = host.domain.tld #myhostname = virtual.domain.tld +myhostname = mail01.localdomain (中略) #mydomain = domain.tld +mydomain = localdomain (中略) -#myorigin = $mydomain +myorigin = $mydomain (中略) -mydestination = $myhostname, localhost.$mydomain, localhost -#mydestination = $myhostname, localhost.$mydomain, localhost, $mydomain +#mydestination = $myhostname, localhost.$mydomain, localhost +mydestination = $myhostname, localhost.$mydomain, localhost, $mydomain (以下をファイル末尾に追加) +# Allowed to run :include: method in /etc/aliases +alias_maps = hash:/etc/aliases +alias_database = hash:/etc/aliases +allow_mail_to_commands = alias,forward,include +allow_mail_to_files = alias,forward,includeUbuntu
/etc/postfix/main.cf# See /usr/share/postfix/main.cf.dist for a commented, more complete version # Debian specific: Specifying a file name will cause the first # line of that file to be used as the name. The Debian default # is /etc/mailname. #myorigin = /etc/mailname smtpd_banner = $myhostname ESMTP $mail_name (Ubuntu) biff = no # appending .domain is the MUA's job. append_dot_mydomain = no # Uncomment the next line to generate "delayed mail" warnings #delay_warning_time = 4h readme_directory = no # See http://www.postfix.org/COMPATIBILITY_README.html -- default to 2 on # fresh installs. compatibility_level = 2 # TLS parameters smtpd_tls_cert_file=/etc/ssl/certs/ssl-cert-snakeoil.pem smtpd_tls_key_file=/etc/ssl/private/ssl-cert-snakeoil.key smtpd_tls_security_level=may smtp_tls_CApath=/etc/ssl/certs smtp_tls_security_level=may smtp_tls_session_cache_database = btree:${data_directory}/smtp_scache smtpd_relay_restrictions = permit_mynetworks permit_sasl_authenticated defer_unauth_destination -#myhostname = sample.localdomain +myhostname = mail01.localdomain alias_maps = hash:/etc/aliases alias_database = hash:/etc/aliases myorigin = /etc/mailname -mydestination = mail01.localhost.localdomain, $myhostname, sample, localhost.localdomain, localhost +mydestination = mail01.localhost.localdomain, $myhostname, mail01, localhost.localdomain, localhost localdomain relayhost = mynetworks = 127.0.0.0/8 [::ffff:127.0.0.0]/104 [::1]/128 mailbox_size_limit = 0 recipient_delimiter = + inet_interfaces = loopback-only default_transport = error relay_transport = error inet_protocols = all +allow_mail_to_commands = alias,forward,include +allow_mail_to_files = alias,forward,include書籍「Postfix実践入門」p.130
rootユーザーで、Postfixを起動します。
CentOS、Ubuntu 共通
# 設定をチェックしたい時 postfix check # 現在の状態を調べたい時 postfix status # 停止してから起動したい時 postfix stop postfix start # リロードしたい時 postfix reload書籍「Postfix実践入門」p.134
一般ユーザーで、telnet で SMTP 接続して Postfix の動作確認を行います。
CentOS、Ubuntu 共通
telnet localhost 25 EHLO localdomain MAIL FROM:<usrname@localdomain> RCPT TO:<usrname@localdomain> DATA This is test1 This is test2 This is test3 . NOOP QUIT途中で以下のエラーが出た場合は、
RCPT TO:<usrname@localdomain> 451 4.3.0 <usrname@localdomain>: Temporary lookup failurerootユーザーで以下を実行し(書籍「Postfix実践入門」p.142)、一般ユーザーに戻って telnet から再実行します。
postalias /etc/aliases postfix reload実行した時の画面イメージは以下の通り。
CentOS
[usrname@localhost ~]$ telnet localhost 25 Trying ::1... Connected to localhost. Escape character is '^]'. 220 mail01.localdomain ESMTP Postfix EHLO localdomain 250-mail01.localdomain 250-PIPELINING 250-SIZE 10240000 250-VRFY 250-ETRN 250-STARTTLS 250-ENHANCEDSTATUSCODES 250-8BITMIME 250-DSN 250 SMTPUTF8 MAIL FROM:<usrname@localdomain> 250 2.1.0 Ok RCPT TO:<usrname@localdomain> 250 2.1.5 Ok DATA 354 End data with <CR><LF>.<CR><LF> This is test1 This is test2 This is test3 . 250 2.0.0 Ok: queued as 39B219AF86 NOOP 250 2.0.0 Ok QUIT 221 2.0.0 Bye Connection closed by foreign host.Ubuntu
usrname@localhost:~$ telnet localhost 25 Trying 127.0.0.1... Connected to localhost. Escape character is '^]'. 220 mail01.localdomain ESMTP Postfix (Ubuntu) EHLO localdomain 250-mail01.localdomain 250-PIPELINING 250-SIZE 10240000 250-VRFY 250-ETRN 250-STARTTLS 250-ENHANCEDSTATUSCODES 250-8BITMIME 250-DSN 250-SMTPUTF8 250 CHUNKING MAIL FROM:<usrname@localdomain> 250 2.1.0 Ok RCPT TO:<usrname@localdomain> 250 2.1.5 Ok DATA 354 End data with <CR><LF>.<CR><LF> This is test1 This is test2 This is test3 . 250 2.0.0 Ok: queued as 49F8B2F816F8 NOOP 250 2.0.0 Ok QUIT 221 2.0.0 Bye Connection closed by foreign host.書籍「Postfix実践入門」p.141
rootユーザーで、エイリアスファイルを設定します。
書籍の手順に加えて、メール受信時に起動させるコマンドもここで指定しておきます。当記事では、メール受信の度に「/home/usrname/email_hook/hook」を起動することにします。このhookという名前のファイルは後に作成します。CentOS、Ubuntu 共通
editor /etc/aliasesCentOS
(ファイル末尾) # Person who should get root's mail #root: marc +root: usrname + +# hook +usrname: usrname, :include:/home/usrname/email_hook/hookUbuntu
# See man 5 aliases for format postmaster: root # Person who should get root's mail root: usrname + +# hook +usrname: usrname, :include:/home/usrname/email_hook/hook書籍「Postfix実践入門」p.142
rootユーザーで、aliases.db を更新して Postfix をリロードします。
CentOS、Ubuntu 共通
postalias /etc/aliases postfix reloadDovecotの設定
書籍「Postfix実践入門」p.215
rootユーザーで、Dovecot をインストールします。
CentOS
yum install dovecotUbuntu
apt install dovecot-core dovecot-imapd dovecot-pop3d書籍「Postfix実践入門」p.222
rootユーザーで、dovecot-openssl.cnf を各々の状況に合わせて編集します。
CentOS
editor /etc/pki/dovecot/dovecot-openssl.cnfCentOS は私の場合は以下の通り。
/etc/pki/dovecot/dovecot-openssl.cnf[ req ] default_bits = 3072 encrypt_key = yes distinguished_name = req_dn x509_extensions = cert_type prompt = no [ req_dn ] # country (2 letter code) #C=FI +C=JP # State or Province Name (full name) #ST= +ST=TOKYO # Locality Name (eg. city) #L=Helsinki +L=Chofu # Organization (eg. company) #O=Dovecot +O=Kanedaq Office # Organizational Unit Name (eg. section) OU=IMAP server # Common Name (*.example.com is also possible) -CN=imap.example.com +CN=mail01.localdomain # E-mail contact -emailAddress=postmaster@example.com +emailAddress=postmaster@localdomain [ cert_type ] nsCertType = serverUbuntu
editor /usr/share/dovecot/dovecot-openssl.cnfUbuntu は今回は内容を変更しませんでした。
/usr/share/dovecot/dovecot-openssl.cnf# # SSLeay configuration file for Dovecot. # RANDFILE = /dev/urandom [ req ] default_bits = 2048 default_keyfile = privkey.pem distinguished_name = req_distinguished_name prompt = no policy = policy_anything req_extensions = v3_req x509_extensions = v3_req [ req_distinguished_name ] organizationName = Dovecot mail server organizationalUnitName = @commonName@ commonName = @commonName@ emailAddress = @emailAddress@ [ v3_req ] basicConstraints = CA:FALSE書籍「Postfix実践入門」p.223
rootユーザーで、証明書を再作成します。
CentOS
sh /usr/share/doc/dovecot/mkcert.shUbuntu は、実行するなら以下のコマンドですが、今回は実行しませんでした。
sh /usr/share/dovecot/mkcert.sh書籍「Postfix実践入門」p.227
rootユーザーで、dovecot.conf を編集します。
CentOS、Ubuntu 共通
editor /etc/dovecot/dovecot.confCentOS
/etc/dovecot/dovecot.conf(前略) # Protocols we want to be serving. #protocols = imap pop3 lmtp +protocols = pop3 (以下をファイル末尾に追加) +log_path = /var/log/dovecot.log +disable_plaintext_auth = no # とりあえず平文パスワードを許可(安全でない)Ubuntu
/etc/dovecot/dovecot.conf(前略) # Enable installed protocols -!include_try /usr/share/dovecot/protocols.d/*.protocol +!include_try /usr/share/dovecot/protocols.d/pop3d.protocol (以下をファイル末尾に追加) +log_path = /var/log/dovecot.log +disable_plaintext_auth = no # とりあえず平文パスワードを許可(安全でない)書籍「Postfix実践入門」p.228
rootユーザーで、メールボックスの位置を編集します。
CentOS、Ubuntu 共通
editor /etc/dovecot/conf.d/10-mail.confCentOS
/etc/dovecot/conf.d/10-mail.conf(前略) #mail_location = +mail_location = mbox:~/mail:INBOX=/var/mail/%u (後略)Ubuntu は、以下のように既に意図通りに設定されていたので、変更しませんでした。
/etc/dovecot/conf.d/10-mail.conf(前略) mail_location = mbox:~/mail:INBOX=/var/mail/%u (後略)書籍「Postfix実践入門」p.229
rootユーザーで、Dovecot を起動します。
CentOS、Ubuntu 共通
# 現在の状態を調べたい時 systemctl status dovecot.service # 停止してから起動したい時 systemctl stop dovecot.service systemctl start dovecot.service # OSブート時に自動起動したい時 systemctl enable dovecot.service書籍「Postfix実践入門」p.230
rootユーザーで、Dovecotの起動設定を確認します。
CentOS、Ubuntu 共通
systemctl list-unit-files -t service | grep dovecot書籍「Postfix実践入門」p.231
rootユーザーで、開いているポートを確認します。
CentOS、Ubuntu 共通
netstat -ln | grep tcpCentOS 結果
tcp 0 0 0.0.0.0:5355 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:110 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:111 0.0.0.0:* LISTEN tcp 0 0 192.168.79.128:53 0.0.0.0:* LISTEN tcp 0 0 127.0.0.1:53 0.0.0.0:* LISTEN tcp 0 0 192.168.122.1:53 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN tcp 0 0 127.0.0.1:631 0.0.0.0:* LISTEN tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN tcp 0 0 127.0.0.1:953 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:995 0.0.0.0:* LISTEN tcp6 0 0 :::5355 :::* LISTEN tcp6 0 0 :::110 :::* LISTEN tcp6 0 0 :::111 :::* LISTEN tcp6 0 0 :::53 :::* LISTEN tcp6 0 0 :::22 :::* LISTEN tcp6 0 0 ::1:631 :::* LISTEN tcp6 0 0 ::1:25 :::* LISTEN tcp6 0 0 ::1:953 :::* LISTEN tcp6 0 0 :::995 :::* LISTENUbuntu 結果
tcp 0 0 172.17.0.1:53 0.0.0.0:* LISTEN tcp 0 0 192.168.79.130:53 0.0.0.0:* LISTEN tcp 0 0 127.0.0.1:53 0.0.0.0:* LISTEN tcp 0 0 127.0.0.53:53 0.0.0.0:* LISTEN tcp 0 0 127.0.0.1:631 0.0.0.0:* LISTEN tcp 0 0 127.0.0.1:953 0.0.0.0:* LISTEN tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:995 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:110 0.0.0.0:* LISTEN tcp6 0 0 fe80::f8e9:90fd:cfc4:53 :::* LISTEN tcp6 0 0 ::1:53 :::* LISTEN tcp6 0 0 ::1:631 :::* LISTEN tcp6 0 0 ::1:25 :::* LISTEN tcp6 0 0 ::1:953 :::* LISTEN tcp6 0 0 :::995 :::* LISTEN tcp6 0 0 :::110 :::* LISTEN書籍「Postfix実践入門」p.232
一般ユーザーで、telnet で POP サーバーの動作確認を行います。
その前に、CentOS では root ユーザーで以下の処理が必要でした。CentOS
chmod 0600 /var/mail/* chmod 0600 /var/spool/mail/*それでは telnet を起動します。
CentOS、Ubuntu 共通
telnet localhost 110 USER usrname PASS secret LIST RETR 1 QUIT実行した時の画面イメージは以下の通り。
CentOS
[usrname@localhost ~]$ telnet localhost 110 Trying ::1... Connected to localhost. Escape character is '^]'. +OK Dovecot ready. USER usrname +OK PASS secret +OK Logged in. LIST +OK 1 messages: 1 463 . RETR 1 +OK 463 octets Return-Path: <usrname@localdomain> X-Original-To: usrname@localdomain Delivered-To: usrname@localdomain Received: from localdomain (localhost [IPv6:::1]) by mail01.localdomain (Postfix) with ESMTP id 39B219AF86 for <usrname@localdomain>; Thu, 4 Jun 2020 17:52:38 +0900 (JST) Message-Id: <20200604085241.39B219AF86@mail01.localdomain> Date: Thu, 4 Jun 2020 17:52:38 +0900 (JST) From: usrname@localdomain This is test1 This is test2 This is test3 . QUIT +OK Logging out. Connection closed by foreign host.Ubuntu
usrname@localhost:~$ telnet localhost 110 Trying 127.0.0.1... Connected to localhost. Escape character is '^]'. +OK Dovecot (Ubuntu) ready. USER usrname +OK PASS secret +OK Logged in. LIST +OK 1 messages: 1 468 . RETR 1 +OK 468 octets Return-Path: <usrname@localdomain> X-Original-To: usrname@localdomain Delivered-To: usrname@localdomain Received: from localdomain (localhost [127.0.0.1]) by mail01.localdomain (Postfix) with ESMTP id 49F8B2F816F8 for <usrname@localdomain>; Thu, 4 Jun 2020 17:08:33 +0900 (JST) Message-Id: <20200604080837.49F8B2F816F8@mail01.localdomain> Date: Thu, 4 Jun 2020 17:08:33 +0900 (JST) From: usrname@localdomain This is test1 This is test2 This is test3 . QUIT +OK Logging out. Connection closed by foreign host.以上で Postfix メールサーバーの構築は完了です。
メール受信時に起動されるコードの実装
以降の作業は一般ユーザーで行います。
CentOS と Ubuntu で、作業に違いはありません。ホームディレクトリ( /home/usrname )の下にサブディレクトリ( email_hook )を作成し、ここに全てのファイルを置くことにします。
cd mkdir email_hook cd email_hook以降の作業は /home/usrname/email_hook の下で行います。
メール受信時に起動されるコマンドの新規作成
hookという名前で(名前は何でも良いですが)、ファイルを新規作成し、そこにコマンドを記述します。
editor hookコマンドの内容は、Postfix が受信したメールを、パイプラインを通して hook_slack.pyという Python コード(後で実装します)に渡します。
"|LC_CTYPE='C.UTF-8' /usr/bin/python3 /home/usrname/email_hook/hook_slack.py || true"メール受信時に起動されるPythonコードの新規作成
hook_slack.py というファイル名(名前は何でも良いです)で新規作成します。
editor hook_slack.py内容は以下の通りです。
コードの行儀があまり良くないのはお許しを。
Slack Incoming Webhooks の URL は適切なものを設定してください。/home/usrname/email_hook/hook_slack.pyimport logging import os import sys import time import datetime import json import email.parser import urllib.request import urllib.parse from pathlib import Path def make_logfile_path(file): directory = Path("/home/usrname/email_hook/log") # ディレクトリがなければ作成 directory.mkdir(parents=True, exist_ok=True) # フルパスのログファイル名を返す return directory / os.path.basename(os.path.splitext(file)[0] + datetime.datetime.today().strftime("_%Y%m%d_%H%M%S.log")) def get_logger(name, filepath): LOG_LEVEL_FILE = logging.DEBUG LOG_LEVEL_CONSOLE = logging.INFO _detail_formatting = "\n%(asctime)s %(levelname)-8s [%(module)s#%(funcName)s %(lineno)d]\n%(message)s" logging.basicConfig( level=LOG_LEVEL_FILE, format=_detail_formatting, filename=filepath ) # ログをコンソールに送るハンドラconsoleを作成 console = logging.StreamHandler() console.setLevel(LOG_LEVEL_CONSOLE) console_formatter = logging.Formatter(_detail_formatting) console.setFormatter(console_formatter) # ロガーを取得し、consoleハンドラを追加する logger = logging.getLogger(name) logger.addHandler(console) return console, logger # ロガー console, logger = get_logger(__name__, make_logfile_path(__file__)) def main(): start = time.time() logger.info(f"hook started : {time.strftime('%d %b %X', time.localtime(start))}") # Postfixが受信したメールを標準入力から受け取る mime_str = sys.stdin.read() logger.debug(f"mime_str={mime_str}") message = email.parser.Parser().parsestr(mime_str) logger.debug(f"message={message}") ## Slack Incoming Webhooks の URL url = "内緒" payload = {} logger.debug(f'message.get("Subject")={message.get("Subject")}') logger.debug(f"message.get_payload()={message.get_payload()}") payload["text"] = message.get("Subject") + "\n" + message.get_payload(0).get_payload() logger.debug(f"payload={payload}") data = json.dumps(payload).encode("utf-8") logger.debug(f"data={data}") request = urllib.request.Request(url, data) urllib.request.urlopen(request) stop = time.time() delta = stop - start logger.info(f"hook started : {time.strftime('%d %b %X', time.localtime(start))}") logger.info(f"hook finished : {time.strftime('%d %b %X', time.localtime(stop))}") logger.info("hook duration : {:0.3} seconds".format(delta)) if __name__ == "__main__": try: main() except Exception as ee: logger.exception(ee)hook_slack.py.pyのSlack投稿テスト用データを用意しました。
editor hook_test_stdin.txt/home/usrname/email_hook/hook_test_stdin.txtFrom usrname@localdomain Wed Jun 3 21:41:32 2020 Return-Path: <usrname@localdomain> X-Original-To: usrname@localdomain Delivered-To: usrname@localdomain Received: from localhost.localdomain (localhost [127.0.0.1]) by mail01.localdomain (Postfix) with ESMTPS id 9630E40D18C9 for <usrname@localdomain>; Wed, 3 Jun 2020 21:41:32 +0900 (JST) Content-Type: multipart/mixed; boundary="===============8887878637416477407==" MIME-Version: 1.0 Subject: Slack投稿テストsubject From: usrname@localdomain To: usrname@localdomain Date: Wed, 03 Jun 2020 12:41:32 -0000 Message-Id: <20200603124132.9630E40D18C9@mail01.localdomain> --===============8887878637416477407== Content-Type: text/plain; charset="us-ascii" MIME-Version: 1.0 Content-Transfer-Encoding: 7bit Slack投稿テストbody --===============8887878637416477407==--hook_slack.py を動かして、Slackに投稿されるかテストしてみます。
cat hook_test_stdin.txt | LC_CTYPE='C.UTF-8' /usr/bin/python3 ./hook_slack.py || truelogサブディレクトリの下にログファイルが出力され、Slackには以下のように投稿されました。
テストメールを送信するPythonコードの新規作成
send_testmail.py というファイル名(名前は何でも良いです)で新規作成します。
editor send_testmail.py内容は以下の通りです。
/home/usrname/email_hook/send_testmail.pyimport smtplib from email.mime.text import MIMEText from email.utils import formatdate from email.mime.multipart import MIMEMultipart def create_message(from_addr, to_addr, subject, body): # ヘッダー msg = MIMEMultipart() msg['Subject'] = subject msg['From'] = from_addr msg['To'] = to_addr msg['Date'] = formatdate() # 本文 msg.attach(MIMEText(body)) return msg def send_mail(from_addr, to_addr, body_msg): smtpobj = smtplib.SMTP("localhost", 25) smtpobj.ehlo() smtpobj.starttls() smtpobj.ehlo() smtpobj.sendmail(from_addr, to_addr, body_msg.as_string()) smtpobj.close() MAIL_ADDRESS = "usrname@localdomain" from_addr = MAIL_ADDRESS to_addr = MAIL_ADDRESS subject = "test mail" body = "We'll send you a test email." msg = create_message(from_addr, to_addr, subject, body) send_mail(from_addr, to_addr, msg)このプログラムを動かしてメールを送信し、hookが起動するかテストします。
python3 ./send_testmail.pySlackには以下のように投稿されました。
今後やってみたいことリスト
- IMAP IDLEを使ってプッシュメール
- VPSにメールサーバーを立てて、セキュリティ等しっかり設定する
- MetaTraderのインジケーターやEAには、メール送信機能がついているものが多いらしいので、EAにローカルサーバー宛にメールを送信してもらって、hookプログラムで何らかの処理を行いたい。
以上です。

- 投稿日:2020-06-04T22:23:09+09:00
コードテストで力を付ける⑤
はじめに
毎日コードテストをしてより言語に精通したと思った。初学者みたいな人が書いています。
ほぼ覚書殴り書き次回への教訓を書いています。結果
スコア:100
問題の特性
C 7 9
ある特定の状態になっているかを確認する。
考え方毎回値を取得する。
取得した値が格納してある何かにあればパス 無ければ追加をしていく
値を格納していって目標の状態とほぼ同じ状態になればクリア そうでなければループの終わりで終了というような感じであった。
振り返り Pythonの値を格納できるもの達
- リスト 重複可 値に対して色々処理できる
最初リストに指定された値を追加してリストと同じ状態になるか確認したが、順番も同一でないとダメでした。
- 辞書 キーと値 値単体でもいけた 今回はこれを使用
- set 値の重複無し これを使えばいいのかなっと思ったけど値の追加が分からなかった。
- タプル 要素の変更できないリストみたいなもの反省点
値を保存してそれをもとに処理を行うというタスクに対して何を使えばいいか という選択が浅はかだった。
コード
import sys input_line = input().split() count, lens = input_line #print(count, lens) sets = {} for i in range(int(lens)): sets.setdefault(i+1) #sets = { i+1 for i in range(int(lens))}#intの種類番号を設定 #print(sets) count_card = {} for i in range(int(count)):#引いた回数分ループする。 out_card = input()#出たカード #print(out_card) if int(out_card) not in count_card: count_card.setdefault(int(out_card)) #print("追加しました", count_card) if count_card == sets: print(i+1) sys.exit() elif i+1 == int(count): print("unlucky") elif i+1 == int(count): print("unlucky")
- 投稿日:2020-06-04T22:20:46+09:00
Pythonでスクリーンショットを作成する
pythonで,デスクトップ画像の一部を別のプログラムに渡す用事ができたので作成.
環境
Windows10
動き
- デスクトップの画像を保存して表示
- ドラッグ&ドロップで範囲選択
- 選択範囲した部分を切り抜いて保存
コード
python_screenshot.pywimport datetime import os from ctypes import windll from PIL import Image, ImageGrab import tkinter as tk class CropScreenShot(tk.Frame): def __init__(self, master=None): super().__init__(master) self.master = master self.flag = False current_dir = os.path.split(os.path.abspath(__file__))[0] self.ss_folder = os.path.join(current_dir,'crop_screen_shot_temp') os.makedirs(self.ss_folder, exist_ok=True) self.make_ss() root.minsize(self.screen_width, self.screen_height) self.image = tk.PhotoImage(file=self.ss_file_path) self.draw_ss(self.image,self.screen_width, self.screen_height) def make_ss(self): self.screen_width = windll.user32.GetSystemMetrics(0) self.screen_height = windll.user32.GetSystemMetrics(1) dt_now = datetime.datetime.now() ss_name = 'ss_{}.png'.format(dt_now.strftime('%Y%m%d_%H%M%S')) self.ss_file_path = os.path.join(self.ss_folder, ss_name) screen_shot = ImageGrab.grab().resize((self.screen_width, self.screen_height)) screen_shot.save(self.ss_file_path) def draw_ss(self,image,width,height): self.canvas = tk.Canvas(bg='black', width=width, height=height) self.canvas.place(x=0, y=0) self.canvas.create_image(0, 0, image=image, anchor=tk.NW) self.left_x = tk.IntVar(value=0) self.upper_y = tk.IntVar(value=0) self.right_x = tk.IntVar(value=width+1) self.lower_y = tk.IntVar(value=height+1) self.canvas.bind('<ButtonPress-1>',self.light_click_down) self.canvas.bind('<B1-Motion>',self.light_click_drag) self.canvas.bind('<ButtonRelease-1>',self.light_click_up) def crop_ss(self,left_x,upper_y,right_x,lower_y): pil_image = Image.open(self.ss_file_path) dt_now = datetime.datetime.now() crop_ss_name = 'crop_{}.png'.format(dt_now.strftime('%Y%m%d_%H%M%S')) crop_file_path = os.path.join(self.ss_folder, crop_ss_name) trim_image = pil_image.crop((left_x,upper_y,right_x,lower_y)) new_width = right_x - left_x new_height = lower_y - upper_y new_image = Image.new(trim_image.mode, (new_width, new_height),'white') new_image.paste(trim_image, (0,0)) new_image.save(crop_file_path) def delete_rectangle(self,tag): objs = self.canvas.find_withtag(tag) for obj in objs: self.canvas.delete(obj) def draw_rectangle(self,left_x,upper_y,right_x,lower_y): self.canvas.create_rectangle( left_x, upper_y, right_x, lower_y, outline='blue', width=2, tag='crop_area' ) def light_click_down(self,event): if self.flag == False: self.delete_rectangle(tag='crop_area') self.left_x.set(event.x) self.upper_y.set(event.y) self.right_x.set(event.x) self.lower_y.set(event.y) self.draw_rectangle( self.left_x.get(), self.upper_y.get(), self.right_x.get(), self.lower_y.get() ) def light_click_drag(self,event): if self.flag == False: self.delete_rectangle(tag='crop_area') self.right_x.set(event.x) self.lower_y.set(event.y) if self.left_x.get() > self.right_x.get(): if self.upper_y.get() > self.lower_y.get(): self.draw_rectangle( self.right_x.get(), self.lower_y.get(), self.left_x.get(), self.upper_y.get(), ) else: self.draw_rectangle( self.right_x.get(), self.upper_y.get(), self.left_x.get(), self.lower_y.get(), ) else: if self.upper_y.get() > self.lower_y.get(): self.draw_rectangle( self.left_x.get(), self.lower_y.get(), self.right_x.get(), self.upper_y.get(), ) else: self.draw_rectangle( self.left_x.get(), self.upper_y.get(), self.right_x.get(), self.lower_y.get(), ) def light_click_up(self,event): if self.flag == False: self.flag = True self.delete_rectangle(tag='crop_area') self.right_x.set(event.x) self.lower_y.set(event.y) if self.left_x.get() > self.right_x.get(): if self.upper_y.get() > self.lower_y.get(): self.draw_rectangle( self.right_x.get(), self.lower_y.get(), self.left_x.get(), self.upper_y.get(), ) self.crop_ss( self.right_x.get(), self.lower_y.get(), self.left_x.get(), self.upper_y.get(), ) else: self.draw_rectangle( self.right_x.get(), self.upper_y.get(), self.left_x.get(), self.lower_y.get(), ) self.crop_ss( self.right_x.get(), self.upper_y.get(), self.left_x.get(), self.lower_y.get(), ) else: if self.upper_y.get() > self.lower_y.get(): self.draw_rectangle( self.left_x.get(), self.lower_y.get(), self.right_x.get(), self.upper_y.get(), ) self.crop_ss( self.left_x.get(), self.lower_y.get(), self.right_x.get(), self.upper_y.get(), ) else: self.draw_rectangle( self.left_x.get(), self.upper_y.get(), self.right_x.get(), self.lower_y.get(), ) self.crop_ss( self.left_x.get(), self.upper_y.get(), self.right_x.get(), self.lower_y.get(), ) root.destroy() root = tk.Tk() app = CropScreenShot(master=root) app.mainloop()参考
先人の方々,感謝です.記憶の限り記載.
https://qiita.com/koara-local/items/6a98298d793f22cf2e36
https://note.nkmk.me/python-pillow-image-crop-trimming/
https://daeudaeu.com/programming/python/tkinter/trimming_appli/
https://betashort-lab.com/%E3%83%97%E3%83%AD%E3%82%B0%E3%83%A9%E3%83%9F%E3%83%B3%E3%82%B0/python/tkinter%E3%81%A7%E7%94%BB%E5%83%8F%E3%82%92%E8%A1%A8%E7%A4%BA%E3%81%95%E3%81%9B%E3%82%8B%E6%96%B9%E6%B3%95/
- 投稿日:2020-06-04T22:00:19+09:00
Python 3 varsの応用
Python 3.xの組み込み関数
varsの応用的なコード集です。辞書内包記法でコピーする
varsの戻り値は辞書なのでitems()と辞書内包記法でコピーできます。items()の要素(ここではitem)はキーと値のタプルです。import sys from pprint import pp dict1 = {item[0]: item[1] for item in vars(sys).items()} pp(dict1)出力{'__name__': 'sys', '__doc__': 'This module provides access to some objects ..., ...注意:
vars組み込み関数の戻り値は辞書型(<class 'dict'>)です。要素(キーと値のタプル)を列挙するにはvars(sys).items()とする必要があります。for item in vars(sys)とした場合はvars(sys).keys()として扱われ、キーの1文字目をキー、2文字目を値とした辞書が作成されます。キーと値の型の辞書を作成する
import sys from pprint import pp dict1 = {item[0]: type(item[1]) for item in vars(sys).items()} pp(dict1)出力{'__name__': <class 'str'>, '__doc__': <class 'str'>, '__package__': <class 'str'>, '__loader__': <class 'type'>, ...値の型を列挙する
import sys from pprint import pp set1 = {type(value).__name__ for value in vars(sys).values()} pp(set1)出力{'ModuleSpec', 'NoneType', 'SimpleNamespace', 'TextIOWrapper', 'bool', 'builtin_function_or_method', 'dict', 'flags', 'float_info', 'function', 'hash_info', 'int', 'int_info', 'list', 'str', 'thread_info', 'tuple', 'type', 'version_info'}
- 型の名前は
type(...).__name__で取得できます。{e for e in v}は集合内包記法です。値の型の出現回数を数える
import sys from collections import Counter from pprint import pp counter = Counter((type(value).__name__ for value in vars(sys).values())) pp(counter)出力Counter({'builtin_function_or_method': 42, 'str': 16, 'TextIOWrapper': 6, 'int': 5, 'list': 5, 'dict': 3, 'tuple': 2, 'NoneType': 2, 'type': 1, 'ModuleSpec': 1, 'float_info': 1, 'int_info': 1, 'hash_info': 1, 'version_info': 1, 'SimpleNamespace': 1, 'flags': 1, 'thread_info': 1, 'bool': 1, 'function': 1})組み込み関数・メソッドのみ取得する
import sys import types from pprint import pp dict1 = {item[0]: item[1] for item in vars(sys).items() if isinstance(item[1], types.BuiltinFunctionType)} pp(dict1)出力{'addaudithook': <built-in function addaudithook>, 'audit': <built-in function audit>, 'breakpointhook': <built-in function breakpointhook>, 'callstats': <built-in function callstats>, '_clear_type_cache': <built-in function _clear_type_cache>, ...組み込み関数・メソッド以外を取得する
import sys import types from pprint import pp dict1 = {item[0]: item[1] for item in vars(sys).items() if not isinstance(item[1], types.BuiltinFunctionType)} pp(dict1)出力{'__name__': 'sys', '__doc__': 'This module provides ...', '__package__': '', '__loader__': <class '_frozen_importlib.BuiltinImporter'>, '__spec__': ModuleSpec(name='sys', loader=<class '_frozen_importlib.BuiltinImporter'>), ...適当な長さに切り詰める
import sys import types from pprint import pp from typing import Optional def str_truncate_singleline(s, width: int, linesep: Optional[str]): s = str(s) if not isinstance(width, int): raise TypeError() addsEllipsis: bool = False if linesep is not None: i: int = s.find(linesep) if i != -1: s = s[0:i] addsEllipsis = True if len(s) + len("...") > width: return s[0:width-len("...")] + "..." return s + "..." if addsEllipsis else s dict1 = {item[0]: str_truncate_singleline(item[1], 50, "\n") for item in vars(sys).items() if not isinstance(item[1], types.BuiltinFunctionType)} pp(dict1)
- 投稿日:2020-06-04T21:56:13+09:00
【自動化】PythonでOutlookメールを送信する
最近のコミュニケーションツールはLINEなどチャットベースのものが主流になってきていますね。
ですが、日本ビジネスメール協会の『ビジネスメール実態調査2020』によると、仕事で使っている主なコミュニケーション手段の第1位は「メール」(99.1%)なのだそうです。
メールって面倒…
私の会社は『メール文化』なので、あらゆる情報をメールでやり取りしています。
中でも面倒なのが、
【ソフトウェアのバグのステイタスを毎日夕方にチームメンバーにメールする】
というものです。定期的に同じような情報を同じようなメンバーにメールするという事務作業はどこの会社でも少なからずあるのではないでしょうか?
このような機械的な業務こそ、最も自動化の効果が大きいのです。
早速、具体的な方法を見ていきます。
PythonでOutlookメールを送信
先ほどの『ビジネスメール実態調査2020』によると、仕事で使用しているメールソフトは「Outlook」(50.52%)と「Gmail」(38.40%)が二強だそうです。
そこで、本記事ではOutlookでのメール作成の方法をご紹介します。
outlookを操作するためにはwin32com.clientをimportする必要があります。
私はAnacondaを使っていますが、特に追加でインストールしなくてもimportできました。pythonimport win32com.client次にOutlookのオブジェクトを作成します。
pythonoutlook = win32com.client.Dispatch("Outlook.Application")そして次にメールオブジェクトを作ります。
pythonmail = outlook.CreateItem(0)
CreateItem(n)のnの部分を変えることにより、Outlookのメールや予定表など様々なアイテムを作ることができます。0にするとメールのオブジェクトを作成できます。このmailオブジェクトに属性をセットしていくことで、メールを作成していきます。
属性 意味 mail.to 宛先 mail.cc CC mail.bcc BCC mail.subject 件名 mail.bodyFormat メール書式
1:テキスト
2:HTML
3:リッチテキストmail.body 本文 pythonmail.to = 'hazuki@mahodo.com; aiko@mahodo.com' mail.cc = 'onpu@mahodo.com' mail.bcc = 'momoko@mahodo.com' mail.subject = '1級試験の件' mail.bodyFormat = 1 mail.body = '''お疲れ様です。どれみです。 なんか今年の試験はコロナの影響でリモート面接になったらしいです。 さっきマジョリカから聞きました。 びっくりしたので取り急ぎご連絡です。 よろしくお願いいたします。 '''ここまでで作成したメールをいきなり送信する前に確認することをオススメします。
確認するには、mail.display(True)とします。pythonmail.display(True)このようにメールが開きますので、確認してOKなら送信してください。
皆様が面倒なメール送信業務から解放されることを願っています。
最後にコードをまとめて載せておきます。pythonimport win32com.client outlook = win32com.client.Dispatch("Outlook.Application") mail = outlook.CreateItem(0) mail.to = 'hazuki@mahodo.com; aiko@mahodo.com' mail.cc = 'onpu@mahodo.com' mail.bcc = 'momoko@mahodo.com' mail.subject = '1級試験の件' mail.bodyFormat = 1 mail.body = '''お疲れ様です。どれみです。 なんか今年の試験はコロナの影響でリモート面接になったらしいです。 さっきマジョリカから聞きました。 びっくりしたので取り急ぎご連絡です。 よろしくお願いいたします。 ''' mail.display(True)Outlookのメールを読み込むには?
今回はOutlookのメール送信の自動化をご紹介しましたが、OutlookのメールをPythonで読み込む方法についてはこちらの記事をご覧ください。
https://qiita.com/konitech913/items/fa0cf66aad27d16258c0
- 投稿日:2020-06-04T21:44:46+09:00
「いちばんやさしいpython入門教室」7章
作成
キャンバスを作り円を描画する
- canvasメソッドでキャンバスを作りここに色々表示さる
- bgは背景色
- create_oval で円を表示できる
- (左上の座標 ,右下の座標)の長方形に内接する円もしくは楕円が描画される
import tkinter as tk root = tk.Tk() root.geometry("600x400") canvas = tk.Canvas(root, width=600, height=400, bg="white") canvas.place(x=0, y=0) canvas.create_oval(300-20, 200-20, 300+20, 200+20)
クリックした場所に円を表示する
bindメソッドでクリックした時に関数を呼び出すようにする
- 関数には自動的に色々な情報が引数として渡される
- <Button-1> はクリックの種類などを決めている
- かなり色々あるのでP190参照
円を消すのは、円の場所に白色の円を上書きすることで消している
import tkinter as tk x, y = 300, 200 #とりあえず宣言 def click(event): global x, y canvas.create_oval(x-20, y-20, x + 20, y + 20, fill="white", width=0)#白色の円を上書き x, y = event.x, event.y canvas.create_oval(x-20, y-20, x + 20, y+20, fill="red", width=0) root = tk.Tk() root.geometry("600x400") canvas = tk.Canvas(root, width=600, height=400, bg="white") canvas.place(x=0, y=0) canvas.bind("<Button-1>", click) root.mainloop()
円を移動させる
- afterメソッドを使って特定時間後に関数を実行
- 円を消しながら微妙に位置をずらしていくことで、動いているように見せている
- 画面端に到達したときにif で動く向きを変えている
import tkinter as tk x, y = 300, 200 dx, dy = 1, 1 def move(): global x, y, dx, dy canvas.create_oval(x-20, y-20, x + 20, y + 20, fill="white", width=0) x += dx y += dy canvas.create_oval(x-20, y-20, x + 20, y + 20, fill="red", width=0) # 横方向 if x >= canvas.winfo_width(): dx = -1 if x <= 0: dx = 1 # 縦方向 if y >= canvas.winfo_height(): dy = -1 if y <= 0: dy = 1 root.after(10, move) root = tk.Tk() root.geometry("600x400") canvas = tk.Canvas(root, width=600, height=400, bg="white") canvas.place(x=0, y=0) root.after(10, move) root.mainloop()
classにする
- __init__でオブジェクトが呼び出された際の処理を書く
- move()で動くようにする
- erase()で消し、draw()で表示するようにする
import tkinter as tk class Ball: def __init__(self, x, y, dx, dy, color): self.x = x self.y = y self.dx = dx self.dy = dy self.color = color def move(self, canvas): self.erase(canvas) self.x += self.dx self.y += self.dy self.draw(canvas) # 横方向 if self.x >= canvas.winfo_width(): self.dx = -1 if self.x <= 0: self.dx = 1 # 縦方向 if self.y >= canvas.winfo_height(): self.dy = -1 if self.y <= 0: self.dy = 1 def erase(self, canvas): canvas.create_oval(self.x-20, self.y-20, self.x + 20, self.y + 20, fill="white", width=0) def draw(self, canvas): canvas.create_oval(self.x-20, self.y-20, self.x + 20, self.y + 20, fill=self.color, width=0) b = Ball(400, 300, 1, 1, "red") def loop(): b.move(canvas) root.after(10, loop) root = tk.Tk() root.geometry("600x400") canvas = tk.Canvas(root, width=600, height=400, bg="white") canvas.place(x=0, y=0) root.after(10, loop) root.mainloop()
class の継承
- 子class(親class)とすることでクラスを継承することができる
- 今回は三角形と四角形を移動させるのは継承することで使える
- 消すのと表示するのは別に作らなければならない
- 三角形はめちゃくちゃ引数が他のに比べて多い
class Rectangle(Ball): def erase(self, canvas): canvas.create_rectangle(self.x-20, self.y-20, self.x + 20, self.y + 20, fill="white", width=0) def draw(self, canvas): canvas.create_rectangle(self.x-20, self.y-20, self.x + 20, self.y + 20, fill=self.color, width=0) class Triangle(Ball): def erase(self, canvas): canvas.create_polygon(self.x, self.y-20, self.x+20, self.y+20, self.x - 20, self.y + 20, fill="white", width=0) def draw(self, canvas): canvas.create_polygon(self.x, self.y-20, self.x+20, self.y+20, self.x - 20, self.y + 20, fill=self.color, width=0)
完成!
# cording:utf-8 import tkinter as tk class Ball: def __init__(self, x, y, dx, dy, color): self.x = x self.y = y self.dx = dx self.dy = dy self.color = color def move(self, canvas): self.erase(canvas) self.x += self.dx self.y += self.dy self.draw(canvas) # 横方向 if self.x >= canvas.winfo_width(): self.dx = -1 if self.x <= 0: self.dx = 1 # 縦方向 if self.y >= canvas.winfo_height(): self.dy = -1 if self.y <= 0: self.dy = 1 def erase(self, canvas): canvas.create_oval(self.x-20, self.y-20, self.x + 20, self.y + 20, fill="white", width=0) def draw(self, canvas): canvas.create_oval(self.x-20, self.y-20, self.x + 20, self.y + 20, fill=self.color, width=0) class Rectangle(Ball): def erase(self, canvas): canvas.create_rectangle(self.x-20, self.y-20, self.x + 20, self.y + 20, fill="white", width=0) def draw(self, canvas): canvas.create_rectangle(self.x-20, self.y-20, self.x + 20, self.y + 20, fill=self.color, width=0) class Triangle(Ball): def erase(self, canvas): canvas.create_polygon(self.x, self.y-20, self.x+20, self.y+20, self.x - 20, self.y + 20, fill="white", width=0) def draw(self, canvas): canvas.create_polygon(self.x, self.y-20, self.x+20, self.y+20, self.x - 20, self.y + 20, fill=self.color, width=0) balls = [Triangle(100, 200, 1, -1, "blue"), Rectangle(400, 200, 1, -1, "blue"), Ball(300, 400, 1, -1, "blue")] def loop(): for b in balls: b.move(canvas) root.after(10, loop) root = tk.Tk() root.geometry("600x400") canvas = tk.Canvas(root, width=600, height=400, bg="#fff") canvas.place(x=0, y=0) root.after(10, loop) root.mainloop()
感想(授業以前)
- classは存在を知っている程度で使ったことがなかったので新鮮だった。
- プログラムがめちゃくちゃ重たくて実用的ではないと感じた
- しばらく動かすとカクカクした
- 表示が一部欠けたりしていた
リメイク
- 授業で重たい理由が分かったので作り変える
- erase()が重たくなる原因なので削除
- メモリを食ってしまう
- 代わりにdelete()を使う
- drawを少し変更して、self.figureに代入する
- delete()で消せるようになった
- ただ、事前に宣言しておかないと怒られるので、__init__の中でNoneで宣言している
- canvasの位置も変えないといけない
- 先生の見本ではスピード変更できるようになっていたのでスピード変更できるようにした
- speedを変えることで倍率を変えられるようにした
remake.py# cording:utf-8 import tkinter as tk speed = 30 class Ball: global speed def __init__(self, x, y, dx, dy, color): self.x = x self.y = y self.dx = dx self.dy = dy self.color = color self.figure = None def move(self, canvas): canvas.delete(self.figure) self.draw(canvas) self.x += self.dx*speed self.y += self.dy*speed # 横方向 if self.x >= canvas.winfo_width(): self.dx = -1 if self.x <= 0: self.dx = 1 # 縦方向 if self.y >= canvas.winfo_height(): self.dy = -1 if self.y <= 0: self.dy = 1 def draw(self, canvas): self.figure = canvas.create_oval( self.x - 20, self.y - 20, self.x + 20, self.y + 20, fill=self.color, width=0) class Rectangle(Ball): def draw(self, canvas): self.figure = canvas.create_rectangle( self.x-20, self.y-20, self.x + 20, self.y + 20, fill=self.color, width=0) class Triangle(Ball): def draw(self, canvas): self.figure = canvas.create_polygon(self.x, self.y-20, self.x+20, self.y+20, self.x - 20, self.y + 20, fill=self.color, width=0) root = tk.Tk() root.geometry("600x400") canvas = tk.Canvas(root, width=600, height=400, bg="#fff") canvas.place(x=0, y=0) balls = [Triangle(100, 200, 1, -1, "blue"), Rectangle(400, 200, 1, -1, "blue"), Ball(300, 400, 1, -1, "blue")] def loop(): for b in balls: b.move(canvas) root.after(10, loop) root.after(10, loop) root.mainloop()実行結果
感想
- カクつきがなくなってよかった
- 表示が欠けるのは健在なのでなんだかなあといったところ
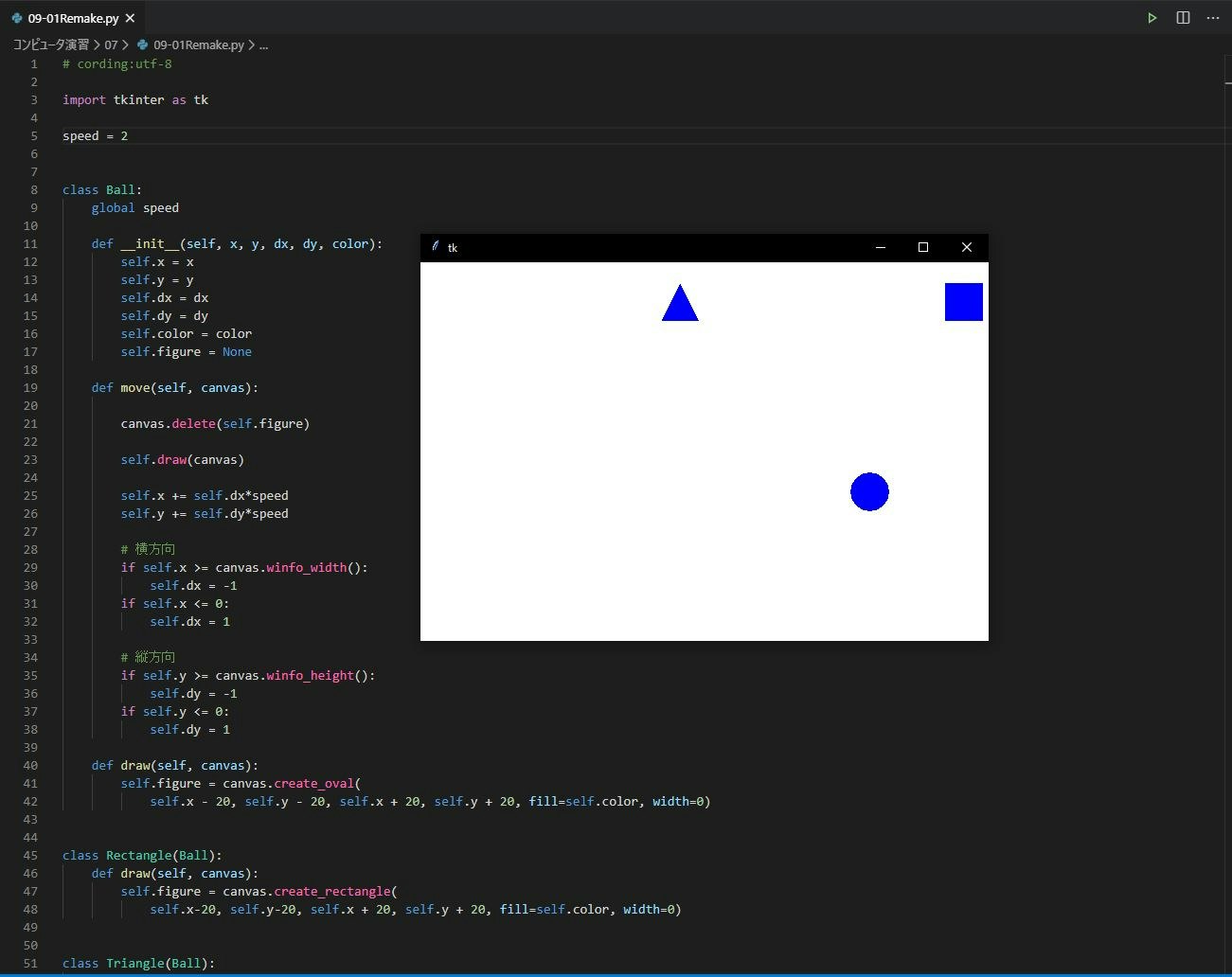
- 投稿日:2020-06-04T21:43:55+09:00
UbuntuでBeep音を鳴らす
pythonでBeep音を鳴らす(Ubuntu16.04)
pythonプログラムを起動してから何秒後かに
Beep音が欲しかったけど、なかなか鳴らせなかったのでメモします。環境
ubuntu 16.04
python 3.6プログラム
import os import time duration = 1 # seconds freq = 440 # Hz bool1 = True elapsed_time = 0 while bool1: start = time.time() elapsed_time += time.time() - start if elapsed_time >= 2.5:#各自調整 os.system('play -nq -t alsa synth {} sine {}'.format(duration, freq)) bool1 = False
メモ程度です。。。もっと最適な方法があったら教えてください。
- 投稿日:2020-06-04T21:43:55+09:00
PythonでBeep音を鳴らす(Ubuntu)
pythonでBeep音を鳴らす(Ubuntu16.04)
pythonプログラムを起動してから何秒後かに
Beep音が欲しかったけど、なかなか鳴らせなかったのでメモします。環境
ubuntu 16.04
python 3.6プログラム
import os import time duration = 1 # seconds freq = 440 # Hz bool1 = True elapsed_time = 0 while bool1: start = time.time() elapsed_time += time.time() - start if elapsed_time >= 2.5:#各自調整 os.system('play -nq -t alsa synth {} sine {}'.format(duration, freq)) bool1 = False
メモ程度です。。。もっと最適な方法があったら教えてください。
- 投稿日:2020-06-04T21:31:09+09:00
ゼロから始めるLeetCode Day46「406. Queue Reconstruction by Height」
概要
海外ではエンジニアの面接においてコーディングテストというものが行われるらしく、多くの場合、特定の関数やクラスをお題に沿って実装するという物がメインである。
その対策としてLeetCodeなるサイトで対策を行うようだ。
早い話が本場でも行われているようなコーディングテストに耐えうるようなアルゴリズム力を鍛えるサイト。
せっかくだし人並みのアルゴリズム力くらいは持っておいた方がいいだろうということで不定期に問題を解いてその時に考えたやり方をメモ的に書いていこうかと思います。
前回
ゼロから始めるLeetCode Day45 「1379. Find a Corresponding Node of a Binary Tree in a Clone of That Tree」今はTop 100 Liked QuestionsのMediumを解いています。
Easyは全て解いたので気になる方は目次の方へどうぞ。Twitterやってます。
問題
406. Queue Reconstruction by Height
難易度はMedium。
Top 100 Liked Questionsからの抜粋です。待ち行列に立っている人のランダムなリストがあるとします。
それぞれの人は整数のペア、(h,k)で構成されており、hは人の高さ、kはその人の前にいてh以上の高さを持つ人の人数を指します。この問題では与えられた待ち行列を再構成するようなアルゴリズムを設計します。
Input:
[[7,0], [4,4], [7,1], [5,0], [6,1], [5,2]]Output:
[[5,0], [7,0], [5,2], [6,1], [4,4], [7,1]]解法
二つの整数についてしっかりと整理し、的確にアルゴリズムを組むことが求められる良い問題です。
こういった問題の場合はやはり問題を細かく分割し、それぞれの処理を独立させて考えた方が分かりやすくなると思います。
class Solution: def reconstructQueue(self, people: List[List[int]]) -> List[List[int]]: if not people: return [] dic, height, res = {}, [], [] for i in range(len(people)): p = people[i] if p[0] in dic: dic[p[0]] += (p[1], i), else: dic[p[0]] = [(p[1], i)] height += p[0], height.sort() for h in height[::-1]: dic[h].sort() for p in dic[h]: res.insert(p[0], people[p[1]]) return res # Runtime: 88 ms, faster than 99.14% of Python3 online submissions for Queue Reconstruction by Height. # Memory Usage: 14.3 MB, less than 5.88% of Python3 online submissions for Queue Reconstruction by Height.めちゃ速い!
よくよくdiscuss調べてみたらこれとほとんど一緒でびっくりしました。今回はここまでです。お疲れ様でした。
- 投稿日:2020-06-04T21:26:52+09:00
【Python】エネルギーデータをなんちゃってCalenderHeatmap【Plotly】メモ
概要
- エネルギーデータのカレンダー状のヒートマップを作りたかった。
- calmapがあるけど、pandas1.0以上に対応していないっぽい。(ixつかってる?)
- せっかくだからplotlyで作ってみた。(hovertextとかおしゃれだし・・・)
実装
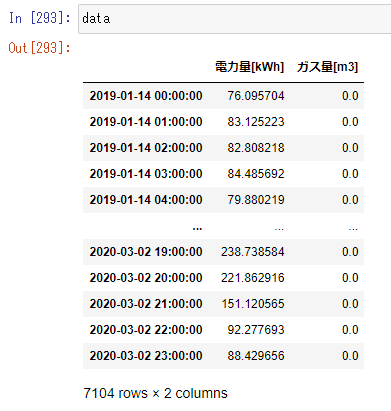
使用データ
ソースコード
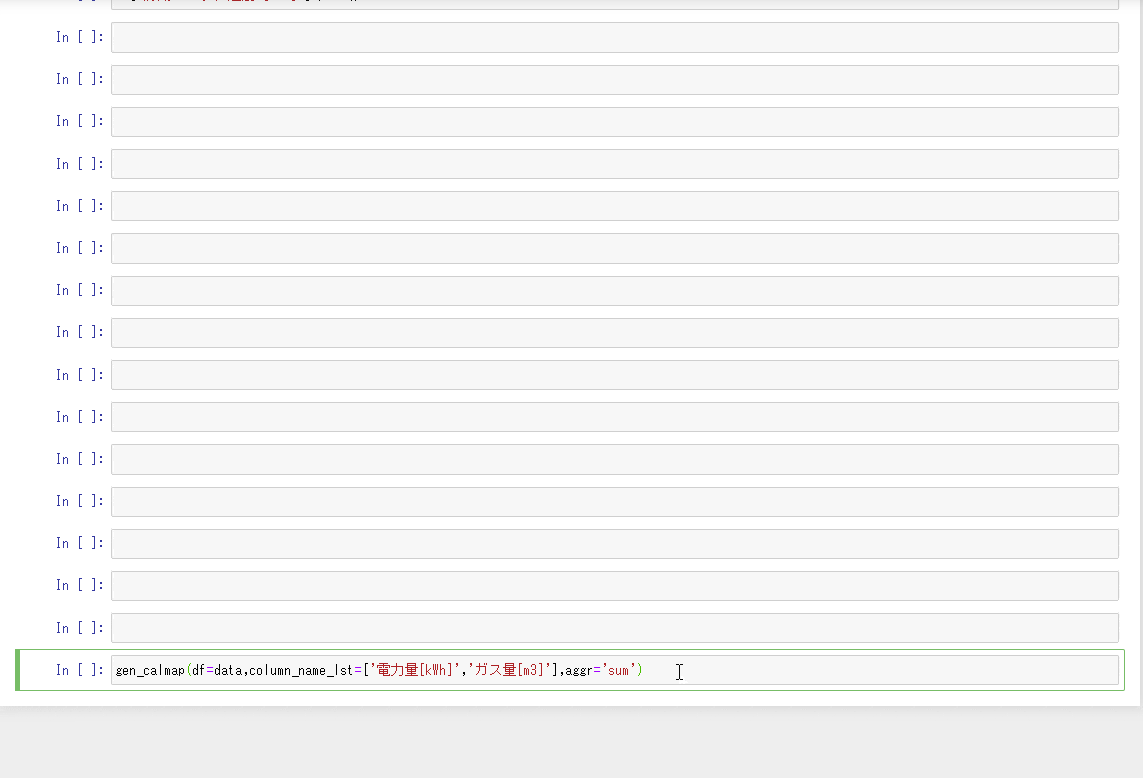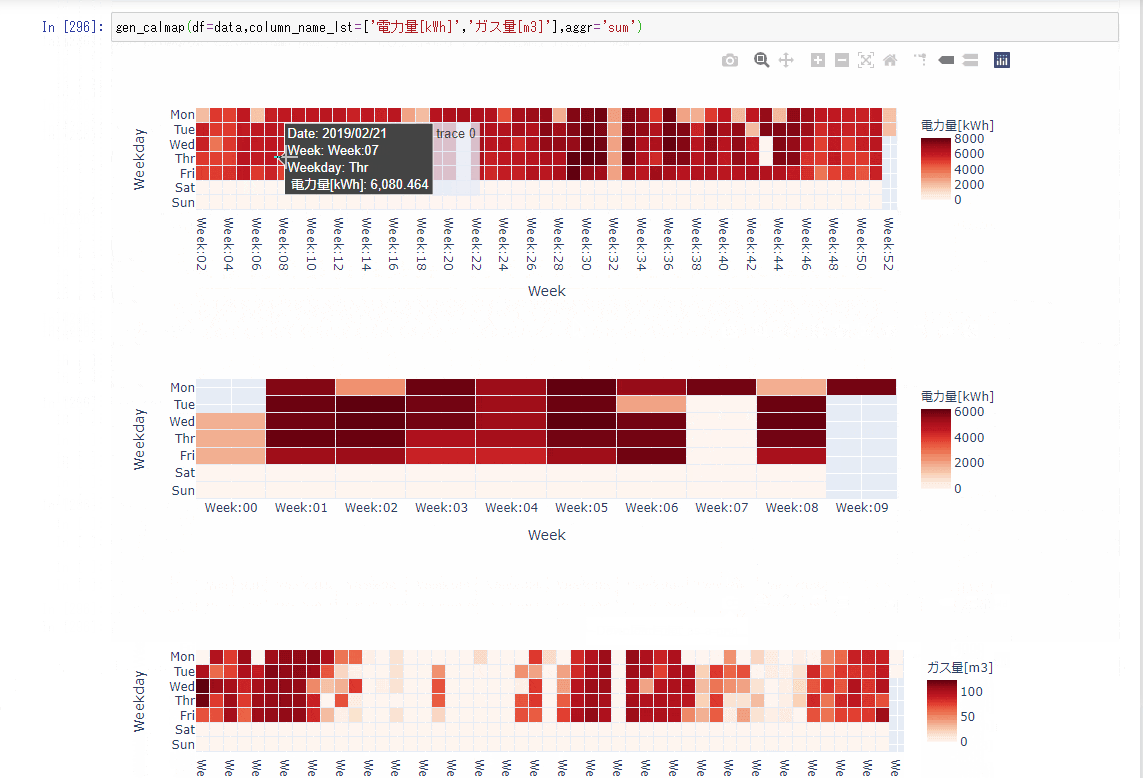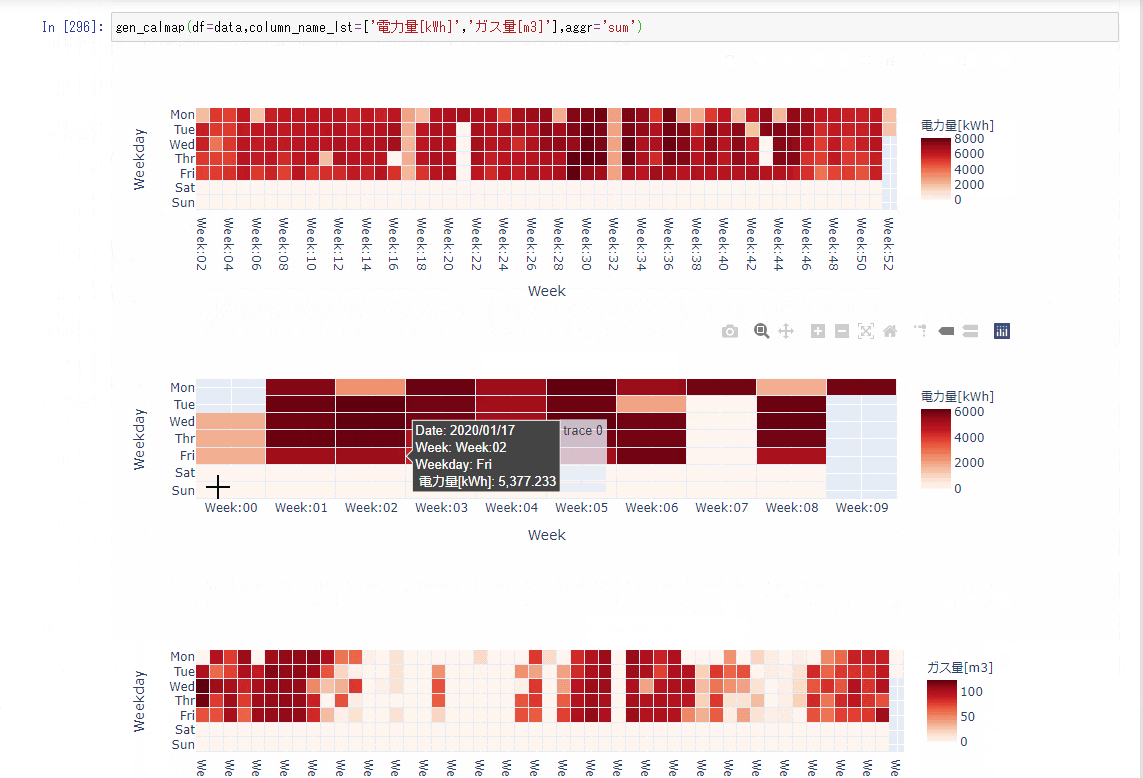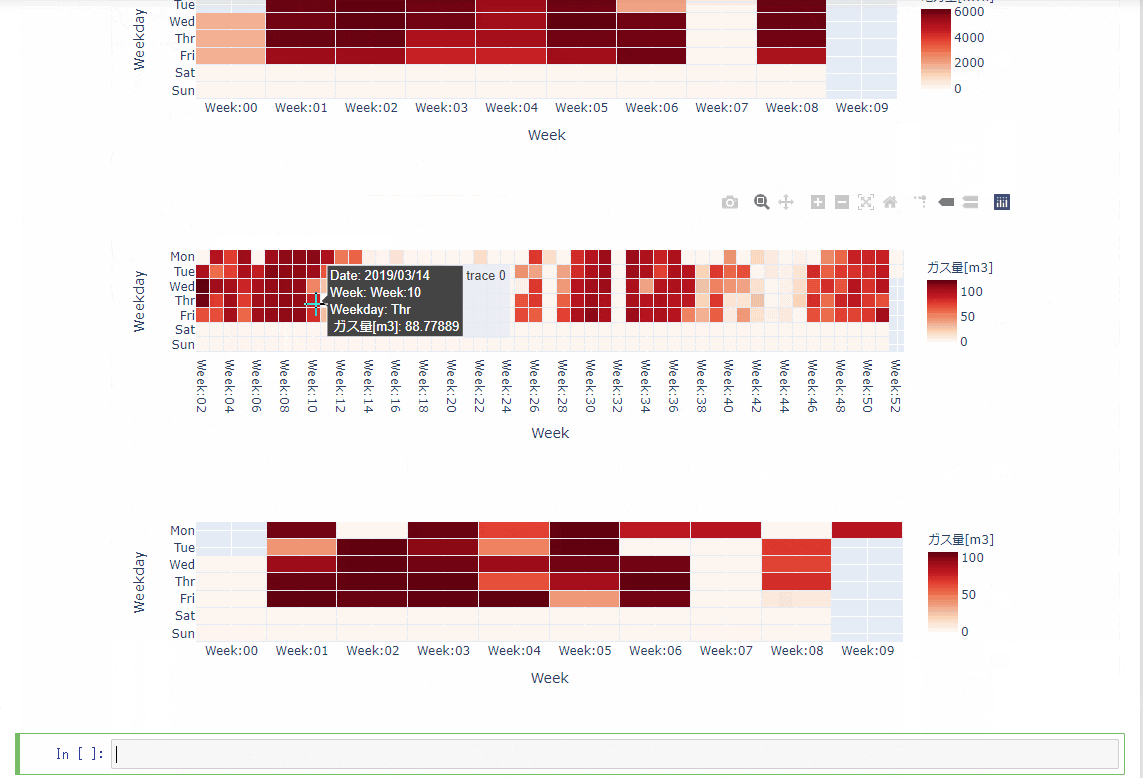
gen_calmapdef gen_calmap(df,column_name_lst,aggr='sum',height= 260,width = 900): try: for column_name in column_name_lst: # heatmap_df_lst生成 heatmap_df_lst = _calender_heatmap_df(df,column_name,aggr) for heatmap_df in heatmap_df_lst: fig = px.imshow(heatmap_df[0], x=heatmap_df[0].columns.unique(), y=heatmap_df[0].index.unique(), labels={'y':'Weekday','x':'Week','color':column_name}, width=width, height=height, aspect='auto', ) # セル間に隙間を入れる fig.data[0]['ygap']=1 fig.data[0]['xgap']=1 fig.update_traces( text = heatmap_df[1], hovertemplate="Date: %{text} <br>Week: %{x} <br>Weekday: %{y} <br> "+ column_name +": %{z}" ) fig.show() except: print('calmapの生成に失敗しました。') def _calender_heatmap_df(df,column_name,aggr='sum'): heatmap_df_lst =[] # DataFrame再生成 data = pd.DataFrame(eval("df[column_name].resample('D').{}()".format(aggr))) data.index = pd.to_datetime(data.index) ## add data data['week'] = pd.to_datetime(data.index).strftime('Week:%W') data['weekday'] = pd.to_datetime(data.index).weekday data['date'] = pd.to_datetime(data.index).strftime('%Y/%m/%d') weekday_dic = {0:'Mon',1:'Tue',2:'Wed',3:'Thr',4:'Fri',5:'Sat',6:'Sun'} # データの展開 for year in data.index.year.unique(): # heatmap生成 heatmap_df = data.loc[data.index.year == year,:].pivot_table(index='weekday',columns='week',values=column_name) # 曜日を月曜日→日曜日の順番に並べ替える heatmap_df = heatmap_df.rename(index=weekday_dic) # 日付dfを生成 date_df = data.loc[data.index.year == year,:].pivot(index='weekday',columns='week',values='date') date_df = date_df.rename(index=weekday_dic) # dfをリストに加える heatmap_df_lst.append([heatmap_df,np.array(date_df)]) return heatmap_df_lst実行gen_calmap(df=data,column_name_lst=['電力量[kWh]','ガス量[m3]'],aggr='sum')結果
- 割といい感じにできた。
まとめ
- 特にエラーのことは考えていない。
- Githubっぽくできた。
- 投稿日:2020-06-04T20:57:20+09:00
DataFrameでmulti columnsをsingle columnに戻す関数
関数の機能
このようなmulti columnsのデータフレームを
single columnsのデータフレームに変換します。
役に立つシーン
- pythonのmulti columnsをsingle columnになおす。
- mergeするときにmulti columnsはちょっと不便。
- df.groupby("hoge").agg("A":{"sum","mean"]}) で集計した値がmulti columnsになってしまうので、結合するときに使用しました。
- 既存の関数がありそうな気がしたが探しても見つからなかった...有識者の方教えて下さい。
マルチカラムの参考
- pandasのMultiIndexから任意の行・列を選択、抽出: https://note.nkmk.me/python-pandas-multiindex-indexing/
- pandasのマルチカラムをいい感じに処理するtips: https://qiita.com/tenajima/items/55bb8b5843690d464225
実際のコード
#dfの1行目、2行目の列名を連結した列名に変換する関数 def rename_multicol(df): df_col=df.columns #列名をコピー df = df.T.reset_index(drop=False).T #一回列名をリセット for i in range(df.shape[1]): #列名を新たに定義 rename_col = {i:"".join(df_col[i])} df = df.rename(columns = rename_col) df = df.drop(["level_0","level_1"],axis=0) return df実際にこの関数を使った例がこちら。
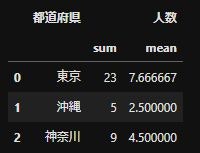
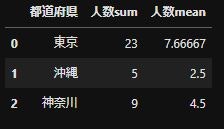
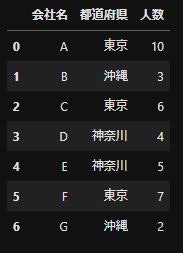
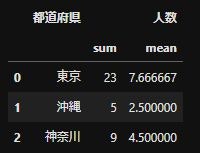
company_list =["A","B","C","D","E","F","G"] pref_list = ["東京","沖縄", "東京", "神奈川", "神奈川", "東京", "沖縄"] num_list = [10,3,6,4,5,7,2] df = pd.DataFrame({"会社名":company_list, "都道府県":pref_list, "人数":num_list}) #人数の合計と平均を計算 number_df = df.groupby("都道府県",as_index=False).agg({"人数":["sum","mean"]}) #シングルカラムに変換する number_df_rename = rename_multicol(number_df)dfから都道府県ごとの人数の合計と平均を集計したいとします。
'df.groupby("都道府県",as_index=False).agg({"人数":["sum","mean"]})'で同時に集計かのうです。
集計後のnumber_df。人数とsum,meanがmulti columnsになっている。
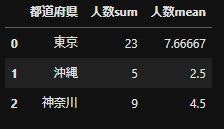
rename_multicolの関数をつかってsingle columnsに変換したnumber_df_rename。
これで都道府県をkeyとして別のdataframeと結合できます。
終わりに
そもそもmulticolumnsっていうのも知らずに「複数列 解除」とかで検索してました...。
テーブル単体でいうと便利ですけど結合を考えると取りあつかいずらかったです。
- 投稿日:2020-06-04T19:53:05+09:00
data structure Python push pop
#データがの一番上に値を入れる:push(n) #nは入れる値 #データの一番上から値を取り除く+表示する :pop() push(5) push(6) pop() >>6 #emptyからpop()しようとすると、'stuck underflow'エラーとなり、 上限以上にpush(n)しようとすると、'stuck overflow'エラーとなる。 push(7) pop() pop() >>stuck underflow #peekを使うと、削除せずに一番上から値を表示できる。 push(5) peek() >>5
- 投稿日:2020-06-04T19:52:05+09:00
Pythonで寿司打を自動化する
※筆者はqiitaを使うのが初めてです。至らない点があると思いますが、ご了承ください。
コードもめちゃくちゃ変で、汚いですが、気が向いたら直します()こんにちは。
突然ですが皆さん
寿司打
してますか?
タイピング練習をしたことがある人なら、ほとんどの人がこのゲームをプレイしたことがあるはずです。
寿司打はブラウザゲームです。
なので、PythonでHTMLを取得すればかんたんに自動化できるのではないかと思い、作ることにしました。私はHTMLを取得しようとしていたのですが、
実は寿司打はOpenGLという技術が使われていて、
文字を画像として表示しているようです。
そこで、方針変更です。
画像認識しましょう。まず、スタートボタン、おすすめボタンを押します。
import pyautogui import time x,y=pyautogui.locateCenterOnScreen("susida.png") print(x) print(y) pyautogui.click(x, y+100) print("スタートボタンを押しました。") time.sleep(1) pyautogui.click(x, y+100) print("おすすめを押しました。") time.sleep(1) pyautogui.typewrite(" ") print("開始します。") time.sleep(2)絶対座標で指定してしまうと、ウィンドウサイズなどで変わってしまうので、
susida.pngからの相対座標を使うことにしました。
←susida.png
そして、その座標をpyautoguiでクリックします。
pyautoguiのインストールは、
pip install pyautogui
です。次に、画像認識部分です。
import pyocr import pyocr.builders from PIL import Image import sys import cv2 i=1 result=0 tools=pyocr.get_available_tools() if len(tools) == 0: print("OCRツールが見つかりませんでした。") sys.exit(1) tool=tools[0] while(i<201): sc=pyautogui.screenshot(region=(x-110, y+85, 210, 25)) sc.save("original.png") original=cv2.imread("original.png",0) threshold=100 ret, img_thresh = cv2.threshold(original, threshold, 255, cv2.THRESH_BINARY) cv2.imwrite("gray.png", img_thresh) hanten = cv2.imread("gray.png") hanten2=cv2.bitwise_not(hanten) cv2.imwrite("sushida_sc.png", hanten2) img_org=Image.open("sushida_sc.png") builder = pyocr.builders.TextBuilder() tmp=result result=tool.image_to_string(img_org, lang="eng", builder=builder) if(tmp != result): print(i,"皿目:",result) pyautogui.typewrite(result) i=i+1 time.sleep(0.3)画像認識には、pyocrを使っています。
導入方法はこちらをご覧ください↓
https://gammasoft.jp/blog/ocr-by-python/
まず、普通にローマ字のところをスクショします。
しかし、これでは背景が透けていて、認識精度が低くなります。
なので、2値化します。
さらにそれを色反転させて、文字を黒にします。
認識したものをpyautoguiで打ち込めば、寿司打の自動化完了です。
200で止めているのは、寿司打は食べすぎるとエラーが出るからです。
以下に全文を載せます。import pyautogui import time import pyocr import pyocr.builders from PIL import Image import sys import cv2 i=1 result=0 tools=pyocr.get_available_tools() if len(tools) == 0: print("OCRツールが見つかりませんでした。") sys.exit(1) tool=tools[0] x,y=pyautogui.locateCenterOnScreen("susida.png") print(x) print(y) pyautogui.click(x, y+100) print("スタートボタンを押しました。") time.sleep(1) pyautogui.click(x, y+100) print("おすすめを押しました。") time.sleep(1) pyautogui.typewrite(" ") print("開始します。") time.sleep(2) while(i<201): sc=pyautogui.screenshot(region=(x-110, y+85, 210, 25)) sc.save("original.png") original=cv2.imread("original.png",0) threshold=100 ret, img_thresh = cv2.threshold(original, threshold, 255, cv2.THRESH_BINARY) cv2.imwrite("gray.png", img_thresh) hanten = cv2.imread("gray.png") hanten2=cv2.bitwise_not(hanten) cv2.imwrite("sushida_sc.png", hanten2) img_org=Image.open("sushida_sc.png") builder = pyocr.builders.TextBuilder() tmp=result result=tool.image_to_string(img_org, lang="eng", builder=builder) if(tmp != result): print(i,"皿目:",result) pyautogui.typewrite(result) i=i+1 time.sleep(0.3)
- 投稿日:2020-06-04T19:40:30+09:00
【Python】matplotlib3.2の日本語フォント設定方法【公式遵守】
はじめに
matplotlib(https://matplotlib.org/) はPythonでグラフなどを描画するための有名なライブラリです- ただし、グラフ内のラベルなどで日本語を使いたい場合、デフォルトだと文字化け(◻︎◻︎◻︎◻︎◻︎となるので豆腐と呼ばれているよう)が発生してしまいます
- 自分が
matplotlib 日本語で調べた時に出てきた記事が結構力技の方法(インストールしたmatplotlibの中身を直接書き換えるようなやつ等)ばかりで困ったので、公式で紹介されている方法を書いておきます
日本語化ライブラリは使わないの?
japanize-matplotlib(https://github.com/uehara1414/japanize-matplotlib) というmatpotlibの日本語化ライブラリを作ってくれている親切な方がいます- これを使うこともできるのですが、このライブラリで使われている
font_manager.createFontListというメソッドがmatpotlibの3.2.0より非推奨になりましたfont_manager.createFontList is deprecated. font_manager.FontManager.addfont is now available to register a font at a given path.
- よって、matpotlibを3.2.0以上で使用している場合、次のような警告が表示されるようになりました
MatplotlibDeprecationWarning: The createFontList function was deprecated in Matplotlib 3.2 and will be removed two minor releases later. Use FontManager.addfont instead.
japanize-matplotlibのソースコードを読めば分かるように複雑なことはしていないので、今回は自前で同等の実装をFontManager.addfontに置き換えて行います
FontManager.addfont で日本語フォントを追加する
- 日本語フォント(今回はIPAexゴシック)をダウンロード&解凍する
- IPAexフォント: https://ipafont.ipa.go.jp/node193
- 使用するリポジトリにダウンロードした
.ttfファイルを置く
- 例えばfontsディレクトリを作って
/fonts/ipag.ttfのように置く- fontManager.addfont で読み込むだけ
自分はclassmethodだと思い込んで時間を無駄にした...from matplotlib import font_manager font_manager.fontManager.addfont("/fonts/ipag.ttf") matplotlib.rc('font', family="IPAGothic")
- フォントが複数がある場合は次のようにすればOK
from matplotlib import font_manager font_files = font_manager.findSystemFonts(fontpaths=["/fonts"]) for font_file in font_files: font_manager.fontManager.addfont(font_file) matplotlib.rc('font', family="IPAGothic")
おまけ
- ちなみにバージョンが3.2未満の場合は次のように対応できます
japanize-matplotlibでやってることとほぼ同じfrom matplotlib import font_manager font_files = font_manager.findSystemFonts(fontpaths=["/fonts"]) font_list = font_manager.createFontList(font_files) # 3.2以上の場合は警告が出る font_manager.fontManager.ttflist.extend(font_list) matplotlib.rc('font', family="IPAGothic")
- なにも大したことはしてないのですが他の人が調べた時に惑わされないように書き残します
- 投稿日:2020-06-04T19:34:50+09:00
【python】#で階段を作るプログラム
【python】#で階段を作るプログラム
hackerrankの自分用メモです。
与えられた整数の段を持つ#の階段を作る。
n=6の場合# ## ### #### ##### ######▼my answer
def staircase(n): for i in range(n): i += 1 a = " "*(n-i)+"#"*i print(a) if __name__ == '__main__': n = int(input()) staircase(n)
・文字列*数値
数値分文字列を繰り返す"#"*6 #出力 '######'"abc"*6 #出力 'abcabcabcabcabcabc'
・指定した数だけ、1から整数を取り出す。
range(n):0からの数字になる。
→ nに1を足す。n=3 for i in range(n): i += 1 print(i) #出力 1 2 3
- 投稿日:2020-06-04T19:34:45+09:00
zappa経由でデプロイした AWS Lambda 関数に CloudWatch Events を設定する
やりたいこと
zappa経由でAWSLambdaにデプロイしたWebAPIに、定期的に動く(タイムスケジュールの)イベントをトリガーしたい。
用途としては、AWS上にあるなんらかのファイルを時間で自動更新するような感じです。※WebAPIをzappa経由でAWSLambdaにデプロイする方法は、以下を参考にしてください。
AWSを利用したサーバーレスWebAPI開発環境の構築成功条件
以下を同時にクリアすること。
- URIを呼びだしたときに、HTMLやJSONデータが返ってくる
- 設定したタイムスケジュールに従って、イベントハンドラが呼び出される
- ファイルを更新する
テストファイル
test2/sever.pyfrom flask import Flask, jsonify, request app = Flask(__name__) app.config["JSON_AS_ASCII"] = False @app.route("/") def index(): return jsonify({"language": "パイソン"}) if __name__ == "__main__": app.run(debug=True)test2/lambda_function.pyimport time, datetime import os def lambda_handler_1(event, context): today = datetime.datetime.fromtimestamp(time.time()) t = today.strftime('%Y/%m/%d %H:%M:%S') msg = t + ':' + 'hello lambda_handler_1' return msg def lambda_handler_2(event, context): today = datetime.datetime.fromtimestamp(time.time()) t = today.strftime('%Y/%m/%d %H:%M:%S') msg = t + ':' + 'hello lambda_handler_2' return msg def lambda_handler_write(event, context): today = datetime.datetime.fromtimestamp(time.time()) t = today.strftime('%Y/%m/%d %H:%M:%S') msg = t + ':' + 'hello lambda_handler_write' # file_path = os.path.join('tmp', 'test_write.txt') file_path = '/tmp/' + 'test_write.txt' with open(file_path, 'a', encoding='utf-16') as f: f.write(msg + '\n') rmsg = '' with open(file_path, 'r', encoding='utf-16') as f: rmsg = f.read() print(rmsg) return rmsgリクエスト/レスポンスの確認
WebAPIをzappa経由でAWSLambdaにデプロイした後に、発行されたURIを参照します。
問題なく、エンドポイントで指定したJSONデータが返ってくることを確認します。
※URIは、AWSコンソールの以下で確認できます。(ステージ名はd1にしています。デフォルトではdev)
CloudWatch Events の設定
[Lamda]→[関数]でデプロイした関数名を選択すると以下の画面が表示されます。
[+トリガーを追加]を選択して、以下のように設定します。
ここで、一番重要な設定がルール名です。以下のように設定します。
test2-d1-<スクリプトファイル名>.<関数名>
test2-d1-lambda_function.lambda_handler_1
スケジュール式は、
rate(1 minute)が正解です。(画像は誤り)
1分以上を選択する場合は画像のように入力します。rate(5 minutes)など。[追加]を押してイベントの登録が完了します。
Designer画面で、[CloudWatch Events/EventBridge]を選択すると、追加したイベントが確認できます。
test2-d1-zappa-keep-warm-handler.keep_warm_callbackは、zappa経由でデプロイをしたときにデフォルトで追加されるトリガーです。
Lambda関数のインスタンスを保持しておくためのトリガーで、rate(4 minutes)となっているので、「前回のアクセスから4分間インスタンスを保持する」ということだと思います。これがないと、起動するたびにインスタンスを生成する分、WebAPIの呼び出しが遅くなります。(may be...)
ルールの設定の変更や詳細な設定は、
上の画面でイベント名をクリックするか、[CloudWatch]→[ルール]から作成したルール名を選択し、その後、[アクション]から編集を選択します。ログの確認
設定したトリガーが動作しているか確認します。
ルールの設定の変更と同様に、上の画面でイベント名をクリックするか、AWSコンソールメインから[CloudWatch]を選択し、左のツリーから[ロググループ]を選択します。
ログストリームを選択して、ログを確認します。(ログストリームはインスタンスが生成するたびに追加されるようです)
ログで、1分ごとに
2020/06/04 09:05:09:hello lambda_handler_1と表示されていることを確認します。
内容は、lambda_function.py - lambda_handler_1 の return です。
(時間はおそらくUSとかになっているんだと思います。デプロイしたサーバーがUS?)ファイルの更新
AWSLambda関数(デプロイしたWebAPI)上でファイルを更新する場合、以下のようにファイルパスを設定する必要があります。
aws lambda file書き込む時のエラーS3バケットを使用する場合も同様のようです。
Python Read-only file system Error With S3 and Lambda when opening a file for reading
'/tmp/' + filename # テストファイルだと以下のように設定してます file_path = '/tmp/' + 'test_write.txt'テストファイルの
lambda_handler_writeをトリガーに設定して、ログを確認したらちゃんと動作していました。ちなみに
/tmp/を指定しなかった場合、ログで以下のようなエラーがでます。IOError: [Errno 30] Read-only file system: 'test_write.txt'はまったポイント
トリガーの設定で、自分で作成したイベントハンドラーをどうやって指定していいのかがわかりませんでした。
どこかしらで指定するんだろうとは思っていましたが、指定する場所が見当たらないんです。最初は、以下で設定するのかなーって思ってたけど、ここをいじるとURIが正常に呼び出せなくなりました。
5時間くらい調べて、以下の記事を見た時にようやく理解できました。
Zappaのスケジューリング機能を試してみるこれ・・・
デプロイされたLambda Functionの中身を覗いてみると、zappa_settings.jsonで指定した関数の名前を、CloudWatch Eventのリソース名から特定して実行していることがわかります。
handler.pyclass LambdaHandler(object): ... def handler(self, event, context): if event.get('detail-type') == u'Scheduled Event': whole_function = event['resources'][0].split('/')[-1].split('-')[-1] # This is a scheduled function. if '.' in whole_function: app_function = self.import_module_and_get_function(whole_function) # Execute the function! return self.run_function(app_function, event, context) # Else, let this execute as it were. ...・・・つまり、リソース名(ルール名)でイベントハンドラを識別してるのかー!って・・・
-でsplitしてるから、先ほど設定した以下のルール名は、<スクリプトファイル名>.<関数名>だけでもいい気がします。
test2-d1-<スクリプトファイル名>.<関数名>
test2-d1-lambda_function.lambda_handler_1ちなみにzappa経由でデプロイするとアップロードファイルの容量がでかくなって、Lambda Functionの中身を覗けない...
余談(zappa_settings.json でイベントの設定)
先ほどの記事で紹介されていた通り、デプロイする前に、zappa_settings.json からもトリガーを設定できます。
デフォルトで作成されたファイルに、eventsとkeep_warmを追加しています。
"keep_warm": falseにすることで、test2-d1-zappa-keep-warm-handler.keep_warm_callbackトリガーが生成されなくなります。デフォルトではtrueとなっています。(個人的にはtureでいいと思います)zappa_settings.json{ "d1": { "app_function": "server.app", "profile_name": "zappa-exec-user", "project_name": "test2", "runtime": "python3.7", "s3_bucket": "zappa-*******", "events": [{ "function": "lambda_function.lambda_handler_1", "expression": "rate(1 minute)" } ], "keep_warm": false } }ただし、こちらで設定したトリガーは、AWSコンソール上からは無効にできませんでした。
自動で生成された、test2-d1-zappa-keep-warm-handler.keep_warm_callbackも無効にできませんでした。参考

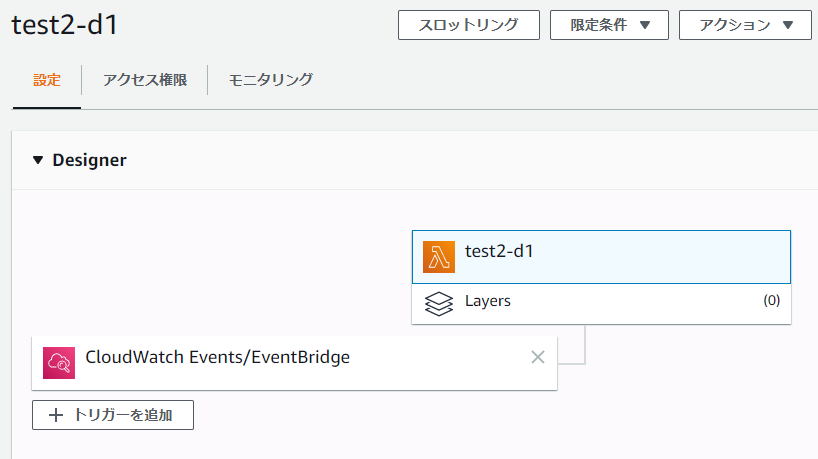
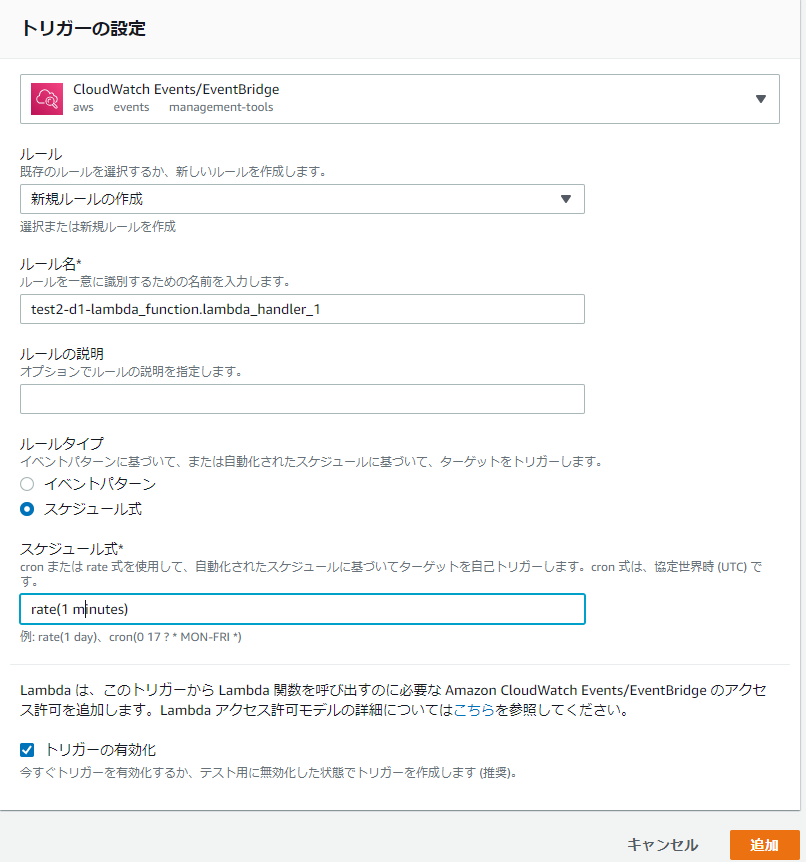
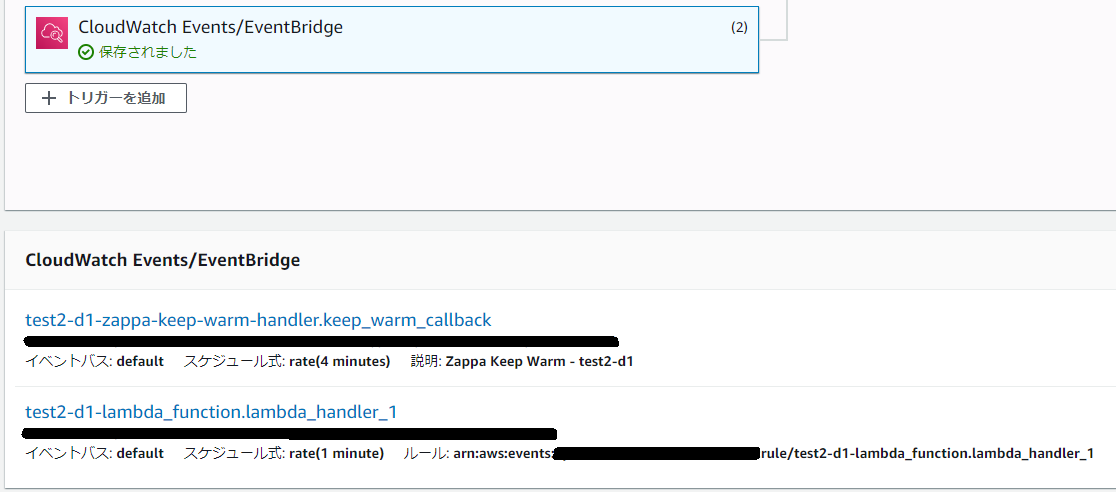
- 投稿日:2020-06-04T19:34:45+09:00
zappa経由でデプロイしたAWSLambda関数(WebAPI)にCloudWatch Eventsを設定する
やりたいこと
zappa経由でAWSLambdaにデプロイしたWebAPIに、定期的に動く(タイムスケジュールの)イベントをトリガーしたい。
用途としては、AWS上にあるなんらかのファイルを時間で自動更新するような感じです。※WebAPIをzappa経由でAWSLambdaにデプロイする方法は、以下を参考にしてください。
AWSを利用したサーバーレスWebAPI開発環境の構築成功条件
以下を同時にクリアすること。
- URIを呼びだしたときに、HTMLやJSONデータが返ってくる
- 設定したタイムスケジュールに従って、イベントハンドラが呼び出される
- ファイルを更新する
テストファイル
test2/sever.pyfrom flask import Flask, jsonify, request app = Flask(__name__) app.config["JSON_AS_ASCII"] = False @app.route("/") def index(): return jsonify({"language": "パイソン"}) if __name__ == "__main__": app.run(debug=True)test2/lambda_function.pyimport time, datetime import os def lambda_handler_1(event, context): today = datetime.datetime.fromtimestamp(time.time()) t = today.strftime('%Y/%m/%d %H:%M:%S') msg = t + ':' + 'hello lambda_handler_1' print(msg) def lambda_handler_2(event, context): today = datetime.datetime.fromtimestamp(time.time()) t = today.strftime('%Y/%m/%d %H:%M:%S') msg = t + ':' + 'hello lambda_handler_2' print(msg) def lambda_handler_write(event, context): today = datetime.datetime.fromtimestamp(time.time()) t = today.strftime('%Y/%m/%d %H:%M:%S') msg = t + ':' + 'hello lambda_handler_write' # file_path = os.path.join('tmp', 'test_write.txt') file_path = '/tmp/' + 'test_write.txt' with open(file_path, 'a', encoding='utf-16') as f: f.write(msg + '\n') rmsg = '' with open(file_path, 'r', encoding='utf-16') as f: rmsg = f.read() print(rmsg)リクエスト/レスポンスの確認
WebAPIをzappa経由でAWSLambdaにデプロイした後に、発行されたURIを参照します。
問題なく、エンドポイントで指定したJSONデータが返ってくることを確認します。
※URIは、AWSコンソールの以下で確認できます。(ステージ名はd1にしています。デフォルトではdev)
CloudWatch Events の設定
[Lamda]→[関数]でデプロイした関数名を選択すると以下の画面が表示されます。
[+トリガーを追加]を選択して、以下のように設定します。
ここで、一番重要な設定がルール名です。以下のように設定します。
test2-d1-<スクリプトファイル名>.<関数名>
test2-d1-lambda_function.lambda_handler_1
スケジュール式は、
rate(1 minute)が正解です。(画像は誤り)
1分以上を選択する場合は画像のように入力します。rate(5 minutes)など。[追加]を押してイベントの登録が完了します。
Designer画面で、[CloudWatch Events/EventBridge]を選択すると、追加したイベントが確認できます。
test2-d1-zappa-keep-warm-handler.keep_warm_callbackは、zappa経由でデプロイをしたときにデフォルトで追加されるトリガーです。
Lambda関数のインスタンスを保持しておくためのトリガーで、rate(4 minutes)となっているので、「前回のアクセスから4分間インスタンスを保持する」ということだと思います。これがないと、起動するたびにインスタンスを生成する分、WebAPIの呼び出しが遅くなります。(may be...ルールの設定の変更や詳細な設定は、
上の画面でイベント名をクリックするか、[CloudWatch]→[ルール]から作成したルール名を選択し、その後、[アクション]から編集を選択します。ログの確認
設定したトリガーが動作しているか確認します。
ルールの設定の変更と同様に、上の画面でイベント名をクリックするか、AWSコンソールメインから[CloudWatch]を選択し、左のツリーから[ロググループ]を選択します。
ログストリームを選択して、ログを確認します。(ログストリームはインスタンスが生成するたびに追加されるようです)
ログで、1分ごとに
2020/06/04 09:05:09:hello lambda_handler_1と表示されていることを確認します。
lambda_function.py - lambda_handler_1 の
(時間はおそらくUSとかになっているんだと思います。デプロイしたサーバーがUS?)ファイルの更新
AWSLambda関数(デプロイしたWebAPI)上でファイルを更新する場合、以下のようにファイルパスを設定する必要があります。
aws lambda file書き込む時のエラーS3バケットを使用する場合も同様のようです。
Python Read-only file system Error With S3 and Lambda when opening a file for reading
'/tmp/' + filename # テストファイルだと以下のように設定してます file_path = '/tmp/' + 'test_write.txt'テストファイルの
lambda_handler_writeをトリガーに設定して、ログを確認したらちゃんと動作していました。ちなみに
/tmp/を指定しなかった場合、ログで以下のようなエラーがでます。IOError: [Errno 30] Read-only file system: 'test_write.txt'はまったポイント
トリガーの設定で、自分で作成したイベントハンドラーをどうやって指定していいのかがわかりませんでした。
どこかしらで指定するんだろうとは思っていましたが、指定する場所が見当たらないんです。最初は、以下で設定するのかなーって思ってたけど、ここをいじるとURIが正常に呼び出せなくなりました。
5時間くらい調べて、以下の記事を見た時にようやく理解できました。
Zappaのスケジューリング機能を試してみるこれ・・・
デプロイされたLambda Functionの中身を覗いてみると、zappa_settings.jsonで指定した関数の名前を、CloudWatch Eventのリソース名から特定して実行していることがわかります。
handler.pyclass LambdaHandler(object): ... def handler(self, event, context): if event.get('detail-type') == u'Scheduled Event': whole_function = event['resources'][0].split('/')[-1].split('-')[-1] # This is a scheduled function. if '.' in whole_function: app_function = self.import_module_and_get_function(whole_function) # Execute the function! return self.run_function(app_function, event, context) # Else, let this execute as it were. ...・・・つまり、リソース名(ルール名)でイベントハンドラを識別してるのかー!って・・・
-でsplitしてるから、先ほど設定した以下のルール名は、<スクリプトファイル名>.<関数名>だけでもいいです。
test2-d1-<スクリプトファイル名>.<関数名>
test2-d1-lambda_function.lambda_handler_1(lambda_function.lambda_handler_1 でもいい)ちなみにzappa経由でデプロイするとアップロードファイルの容量がでかくなって、Lambda Functionの中身を覗けない...
余談(zappa_settings.json でイベントの設定)
先ほどの記事で紹介されていた通り、デプロイする前に、zappa_settings.json からもトリガーを設定できます。
デフォルトで作成されたファイルに、eventsとkeep_warmを追加しています。
"keep_warm": falseにすることで、test2-d1-zappa-keep-warm-handler.keep_warm_callbackトリガーが生成されなくなります。デフォルトではtrueとなっています。(個人的にはtureでいいと思います)zappa_settings.json{ "d1": { "app_function": "server.app", "profile_name": "zappa-exec-user", "project_name": "test2", "runtime": "python3.7", "s3_bucket": "zappa-*******", "events": [{ "function": "lambda_function.lambda_handler_1", "expression": "rate(1 minute)" } ], "keep_warm": false } }ただし、こちらで設定したトリガーは、AWSコンソール上からは無効にできませんでした。
自動で生成された、test2-d1-zappa-keep-warm-handler.keep_warm_callbackも無効にできませんでした。参考
- 投稿日:2020-06-04T19:34:23+09:00
実装で学ぶ深層学習~異常検知編(教師なし学習)~
はじめに
この記事はAuto Encoderを実装、チューニング、考察する記事である。
Target となる読者
1.異常検知を教師なしでするモデルを作りたい人
2.基礎的なニューラルネットワークを自身で読んで改良できる。上記に当てはまる人に対しておすすめのモデルを提案する。
異常検知の流れの説明
問題設定
まず教師なしの異常検知とはなにかについて例を用いて説明する。
製品をつくるとどうしても不良品というものができてしまう。
その不良品の画像をとるとシワが目視できるような場合それを人が分離するのは非常に大変なのでニューラルネットワークで自動で検知してしまおうというものである。
しかしシワのついた画像が異常か正常かを2値分類するには足りない時に正常な画像のみを訓練に使って画像の異常値をもとめることができないかというものである。ベーシックなアプローチ
正常画像を入力として正常画像を返す関数:$f(x)=x$となる$f$をニューラルネットワークで学ぶ($x$は正常画像)。
異常値を$|x-f(x)|$によって定義すると$x$が正常画像なら0になるように訓練されているので小さくなるが、$x$が異常画像の場合ニューラルネットワークにとって初見のものなので$|x-f(x)|$は大きくなり,成立するというものだ。
このようなモデルをAuto Encoderと呼び,モデルの内部構造としては畳み込み層で小さくしてUp Sampling で画像を大きくして返すようなものが多い。(砂時計型)
ここでU-netなどの賢いモデルを使うと異常画像などに対しても予測がうまくいってしまいやすいので異常値をうまく取れないことに注意する。デノイズを行うアプローチ
上に書いたモデルだとある程度アホなモデルにして正常だとうまく予想するけど異常だと失敗するようなモデルを作る必要がある。
そこでモデルは最大限賢くして入力にノイズを加えたものを元に戻す(デノイズ),つまり$x=f(x+z)$($z$はノイズ)を学習するというものがそれなりによく動くようである。筆者のおすすめ
画像の予測を難しくする上でデノイズではなく超解像を用いるとうまく動くのではないかと当たりをつけて行ったところシワや傷を検知する問題においてかなり良いパフォーマンスになった。
ここまでに紹介した3つのアプローチを比較してどの程度差が出るかを示す。具体的実装
問題設定
実際の製品の画像を使って結果を考察するのは権利の関係から行うことができないので問題がかなり簡単になってしまうが,mnistの手書き数字のうち1を正常画像、1以外の数字を異常画像として上記3つのアプローチを比較する。
データの整理
コードの部分を全てコピーすれば動く形で紹介する。
kerasで実装を行う。
まずもろもろimportしてデータダウンロードする。import numpy as np import seaborn as sns import matplotlib.pyplot as plt from tensorflow.keras.datasets import mnist from keras import layers from keras import models from keras import optimizers (train_images, train_labels), (test_images, test_labels) = mnist.load_data()データを扱いやすい形式に変換する
train_true = train_images[train_labels==1].reshape(6742,28,28,1)/255#訓練画像(1)は6742枚 test_true = test_images[test_labels==1].reshape(1135,28,28,1)/255#検証の正常画像(1)は1135枚 test_false = test_images[test_labels!=1].reshape(8865,28,28,1)/255#検証の異常画像(1以外)は1032枚mnistのデータセットは0~9まで枚数が均一だと思っていたがバラバラのようだ。
画像は[0,1]の範囲に正規化した。モデルの定義
model1をただのエンコーダデコーダmodel1を定義
ffc = 8#first filter count model1 = models.Sequential() model1.add(layers.Conv2D(ffc,(3,3),padding="same",activation="relu",input_shape = (28,28,1))) model1.add(layers.BatchNormalization()) model1.add(layers.MaxPooling2D((2,2))) model1.add(layers.Conv2D(ffc,(3,3),padding="same",activation="relu")) model1.add(layers.BatchNormalization()) model1.add(layers.MaxPooling2D((2,2))) model1.add(layers.Conv2D(ffc,(3,3),padding="same",activation="relu")) model1.add(layers.BatchNormalization()) model1.add(layers.UpSampling2D()) model1.add(layers.Conv2D(ffc,(3,3),padding="same",activation="relu")) model1.add(layers.BatchNormalization()) model1.add(layers.UpSampling2D()) model1.add(layers.Conv2D(ffc,(3,3),padding="same",activation="relu")) model1.add(layers.BatchNormalization()) model1.add(layers.Conv2D(1,(3,3),padding="same",activation="sigmoid")) model1.compile(loss = "mae",optimizer="adam") model1.summary()ここで畳み込みと畳み込みの間にバッチ正則化をほどこした。
出力層の活性化はsigmoidである。([0,1]に写像するため)
損失関数はMAEで二乗誤差でなく絶対値を使った方が画像生成ではボケづらいなどの利点がある。
同様にmodel2を定義していった。ffc = 8#first filter count model2 = models.Sequential() model2.add(layers.MaxPooling2D((4,4),input_shape = (28,28,1))) model2.add(layers.UpSampling2D()) model2.add(layers.Conv2D(ffc,(3,3),padding="same",activation="relu")) model2.add(layers.BatchNormalization()) model2.add(layers.Conv2D(ffc,(3,3),padding="same",activation="relu")) model2.add(layers.BatchNormalization()) model2.add(layers.UpSampling2D()) model2.add(layers.Conv2D(ffc,(3,3),padding="same",activation="relu")) model2.add(layers.BatchNormalization()) model2.add(layers.Conv2D(ffc,(3,3),padding="same",activation="relu")) model2.add(layers.BatchNormalization()) model2.add(layers.Conv2D(1,(3,3),padding="same",activation="sigmoid")) model2.compile(loss = "mae",optimizer="adam") model2.summary()maxpooling のみを行ってエンコードすることでデコードに計算材料をさいている。
訓練と結果
それでは実際に訓練してみよう。
通常のエンコーダデコーダ
t_acc = np.zeros(50) f_acc = np.zeros(50) for i in range(50): hist = model1.fit(train_true,train_true,steps_per_epoch=10,epochs = 1,verbose=0) true_d = ((test_true - model1.predict(test_true))**2).reshape(1135,28*28).mean(axis=-1) false_d = ((test_false- model1.predict(test_false))**2).reshape(8865,28*28).mean(axis=-1) t_acc[i] = (true_d<=true_d.mean()+3*true_d.std()).sum()/len(true_d) f_acc[i] = (false_d>true_d.mean()+3*true_d.std()).sum()/len(false_d) print("{}週目の学習正常画像の正答率は{:.2f}%で、異常画像の正答率は{:.2f}%です".format(i+1,t_acc[i]*100,f_acc[i]*100)) plt.plot(t_acc) plt.plot(f_acc) plt.show()異常値の導出は損失関数と違い二乗誤差をもちいた。
これを行うとmodel1つまり普通のエンコーダデコーダが訓練する中で正常画像と異常画像をそれぞれどの程度正しく判断できたかの確率の推移を表したグラフが出力される。
閾値を正常画像の$\mu(平均)+3\sigma(標準偏差)$とおいた。以下出力例
青は正常画像を正常と判断する確率の推移でオレンジが異常画像を異常画像と判断するの確率の推移である。
正常画像の平均から上に標準偏差3つ分のところに常に閾値があるので正常画像を正常画像と判断する確率は常に98%程度である。
50epoch程度で十分学習できたようだ。
(最終値は正常画像の正答率が98.68%で、異常画像の正答率は97.13)ノイズ付きエンコーダデコーダ
モデルはmodel1を用いて入力に0中心でscale0.1で学習するサイズと同じサイズのノイズを加えて学習を行う。具体的なコードは以下の通りである。
t_acc = np.zeros(50) f_acc = np.zeros(50) for i in range(50): hist = model1.fit(train_true,train_true+0.1*np.random.normal(size=train_true.shape),steps_per_epoch=10,epochs = 1,verbose=0) true_d = ((test_true - model1.predict(test_true))**2).reshape(1135,28*28).mean(axis=-1) false_d = ((test_false- model1.predict(test_false))**2).reshape(8865,28*28).mean(axis=-1) t_acc[i] = (true_d<=true_d.mean()+3*true_d.std()).sum()/len(true_d) f_acc[i] = (false_d>true_d.mean()+3*true_d.std()).sum()/len(false_d) print("{}週目の学習正常画像の正答率は{:.2f}%で、異常画像の正答率は{:.2f}%です".format(i+1,t_acc[i]*100,f_acc[i]*100)) plt.plot(t_acc) plt.plot(f_acc) plt.show()これを実行すると以下のようなグラフが得られる。
収束がある程度早くなったようだ。
最終値は正常画像の正答率が98.68%で、異常画像の正答率は97.59%であった。超解像的アプローチ
それではmodel2を訓練して結果を見てみよう。
t_acc = np.zeros(50) f_acc = np.zeros(50) for i in range(50): hist = model2.fit(train_true,train_true,steps_per_epoch=10,epochs = 1,verbose=0) true_d = ((test_true - model2.predict(test_true))**2).reshape(1135,28*28).mean(axis=-1) false_d = ((test_false- model2.predict(test_false))**2).reshape(8865,28*28).mean(axis=-1) t_acc[i] = (true_d<=true_d.mean()+3*true_d.std()).sum()/len(true_d) f_acc[i] = (false_d>true_d.mean()+3*true_d.std()).sum()/len(false_d) print("{}週目の学習正常画像の正答率は{:.2f}%で、異常画像の正答率は{:.2f}%です".format(i+1,t_acc[i]*100,f_acc[i]*100)) plt.plot(t_acc) plt.plot(f_acc) plt.show()結果グラフ
想像以上にだめなモデルであった。
最終値も収束していなさそうだが正常正答率が98.59%で、異常画像の正答率は84.85%であった。結論
手書き文字の1を見て1とそれ以外を区別していったがこの問題の場合ノイズを加えるのが効果的であることがわかった。それはこのノイズを加えるという操作で1は7に見えたり9に見えたりするのでそれを1に戻すのに慣れたモデルが精度向上をするのはかなり目に見えている。
つまり異常の種類がわかっていればその種類の異常を付け足すような変換をしてそれを戻すという訓練を入れるとAuto Encoder の性能は非常に高くなると考えられる。今回のデータセットでおすすめした超解像的アプローチがあまり効果を得なかったが、実際の工業製品のシワや傷を検知する場合解像度を落としてシワや傷を一度見えなくしてから復元するというアプローチが効果的なケースもあるので、対象となる問題を見ながら使うモデルを変えていくといいだろう。
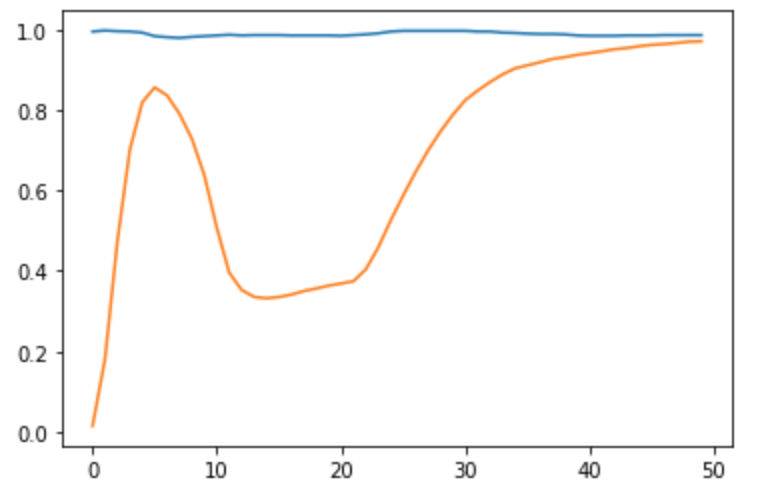
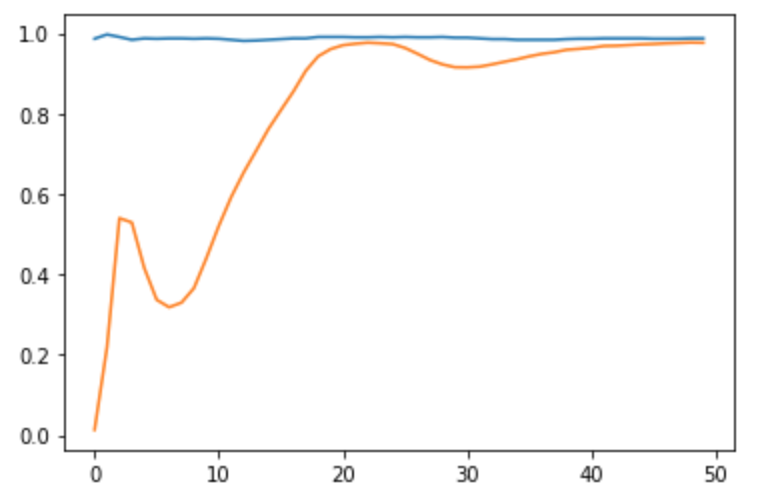
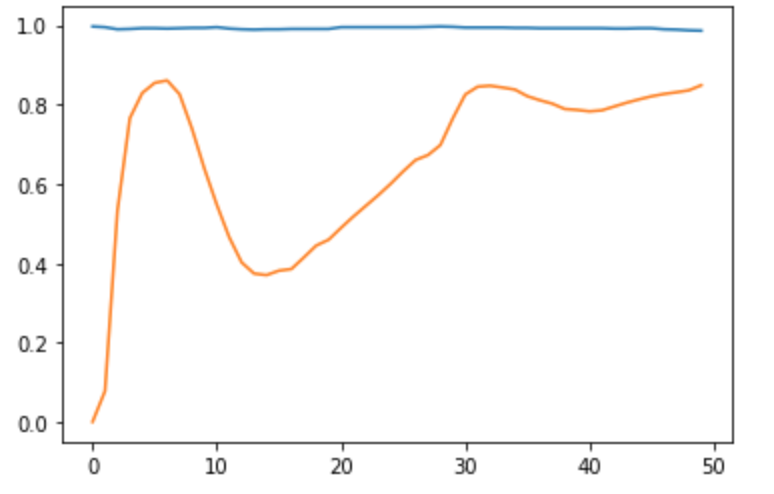
- 投稿日:2020-06-04T19:33:17+09:00
Python基礎:Socket、Dnspython
はじめに
nslookup、ドメインからIP取得、IPからドメイン取得などの処理がしたい場合があります。
socket、dnspythonを使って処理できます。
socket
doc:https://docs.python.org/ja/3/library/socket.html
ドメインからIPを取得
import socket print(socket.gethostbyname("google.com"))172.217.161.78
ドメインからIPアドレス情報を取得
import socket print(socket.getaddrinfo("yahoo.co.jp", 443))[(, 0, 0, '', ('182.22.59.229', 443)), (, 0, 0, '', ('183.79.135.206', 443))]
IPからFQDNを取得
import socket print(socket.getfqdn("182.22.59.229"))f1.top.vip.ssk.yahoo.co.jp
などなど。
dnspython
doc: http://www.dnspython.org/docs/1.16.0/
インストール
pip install dnspythonnslookup
nslookupコマンド
nslookup yahoo.co.jp名前: yahoo.co.jp
Addresses: 182.22.59.229
183.79.135.206dnspythonでnslookupコマンドと同じ結果を取る
import dns.resolver print(dns.resolver.query("yahoo.co.jp", "A").response.answer[0])yahoo.co.jp. 0 IN A 182.22.59.229
yahoo.co.jp. 0 IN A 183.79.135.206など。
以上
- 投稿日:2020-06-04T19:24:02+09:00
linked list
linked listは、access timeはO(n)でよくないが、
insertion timeがO(1)で優れている。linked listのnodeには、データと次のリンクを指すnextが格納されている。nextにはnullが格納されている。
Node1.data = "G" Node1.next = Node2 Node2.data = "R" Node2.next = Node3 Node3.data = "O" Node3.next = Node4 Node4.data = "W" Node4.next = null #Node1.next.nextは、Node3を意味する。また、bi-directionalと呼ばれる双方型のlinked listも存在する。
Node2.data = "5" Node1.next = Node2 Node2.previous = Node1 #1から2と、2から1の両方が定義されている。
- 投稿日:2020-06-04T19:10:34+09:00
Discordで登録した画像を絵文字のように呼び出せるBOTを作る
最初に(?)
LINEのスタンプと同じようにすぐ画像をだせるようなのは便利そうだなー
と思ったから作る完成品
1 まず画像を登録する
2 登録する時に使った名前を!で囲んで送信するメッセージにいれる。
そしたら画像が送信される。
登録した画像を削除する時はs!del [名前]とやればいい
プログラム
#coding=utf-8 import discord import re import os import glob client = discord.Client() @client.event async def on_ready(): print('接続しました') @client.event async def on_message(message): if message.author.bot: return word = re.compile("s!add (.+)").search(message.content) if word: wo = word.group(1) await message.channel.send("設定中...") picu = message.attachments[0].url file = str(message.guild.id) + "/" + wo + ".txt" try: os.mkdir(f"./{str(message.guild.id)}") except FileExistsError: pass with open(file, mode='w') as f: f.write(str(picu)) await message.channel.send("スタンプを追加しました。") f.close() return wordd = re.compile("s!del (.+)").search(message.content) if wordd: woo = wordd.group(1) file = str(message.guild.id) + "/" + woo + ".txt" if (os.path.exists(file)): await message.channel.send("削除中...") os.remove(file) await message.channel.send("スタンプを削除しました。") else: await message.channel.send("そのスタンプが見つかりませんでした。") return pe = re.compile('s!list (.+)').search(message.content) if pe: casfo = glob.glob(str(message.guild.id) + "/*") nopas = str(message.guild.id) lis = [] for file in casfo: # ファイル一覧 prii = file.lstrip(nopas) pri = prii.rstrip(".txt") pr = pri.rstrip("/") p = pr.lstrip("\\") lis.append(p) pa = int(pe.group(1)) no = len(lis) embed = discord.Embed(title="スタンプ一覧", description=f"{str(pa)}ページ目\nスタンプの数:{len(lis)}", color=0x4682b4) c = 0 cc = 0 if pa > 1: ccc = pa*10 c = ccc - 10 while True: try: naiy = lis[c] except: if pa == 1: await message.channel.send("まだスタンプがありません。") return await message.channel.send(f"{str(pa)}ページ目はまだありません") return c = c + 1 embed.add_field(name=str(c), value=naiy) if c == pa * 10: await message.channel.send(embed=embed) return if c == len(lis): break await message.channel.send(embed=embed) return s = message.content if s.count("!") == 2: x = s.find("!") y = s.find("!", x+2) sta = s[x + 1 : y] if sta == None: return pas = str(message.guild.id) + "/" + sta + ".txt" if os.path.exists(pas) == False: return with open(pas) as f: url = f.read() f.close() await message.channel.send(url) return print('接続中...') #test用のTOKENだから流出してもいい client.run("NzA2MzQwNTMwMDE5MjM3OTQ0.Xq405w.pwRREjj-8N4MKph3QcV9NGb5EIM")コードの語彙力(?)がないからすごい長い。
仕組み
画像を登録するときはサーバーIDのフォルダを作り、
その中に画像の名前で画像のURLを書いたテキストファイルを作るだけ。
スタンプを送る時の動作は
!が二つあったらその二つある!の間にある文章を調べる。
そしたらそのサーバーIDのフォルダにある!の間の文章の名前のテキストファイルを読み込む。
その中にある画像のURLを送る。
完成このプログラムで一番重要なこ↑こ↓の解説
二つある!の間にある文章を調べるやつs = message.content # 長いからsに入れる if s.count("!") == 2: x = s.find("!") y = s.find("!", x+2) sta = s[x + 1 : y] if sta == None: return pas = str(message.guild.id) + "/" + sta + ".txt" if os.path.exists(pas) == False: return with open(pas) as f: url = f.read() f.close() await message.channel.send(url) returnメッセージに!二つとそれに囲まれた名前を調べる部分。
仕組み:
1
最初に if s.count("!") == 2: で!が二つあるか調べる。
2
x = s.find("1") と y = s.find("!", x+2)で一個目の!と二個目の!の場所の数を調べる。
3
sta = s[x + 1 : y] のとこで!で囲まれている部分にある文字を調べる
4
if sta == None:で空じゃないことを確認
5
pas = str(message.guild.id) + "/" + sta + ".txt"
は登録した画像のURLが記録されてるテキストファイルのパス
6
if os.path.exists(pas) == False:
で5のパスのファイルが存在するか確認
7
with open(pas) as f:
のとこで5のパスのテキストファイルの中身を読み込みそれを送る終わりに
思いつかないから
終わり


- 投稿日:2020-06-04T18:56:57+09:00
100日後にエンジニアになるキミ - 76日目 - プログラミング - 機械学習について
昨日までのはこちら
100日後にエンジニアになるキミ - 70日目 - プログラミング - スクレイピングについて
100日後にエンジニアになるキミ - 66日目 - プログラミング - 自然言語処理について
100日後にエンジニアになるキミ - 63日目 - プログラミング - 確率について1
100日後にエンジニアになるキミ - 59日目 - プログラミング - アルゴリズムについて
100日後にエンジニアになるキミ - 53日目 - Git - Gitについて
100日後にエンジニアになるキミ - 42日目 - クラウド - クラウドサービスについて
100日後にエンジニアになるキミ - 36日目 - データベース - データベースについて
100日後にエンジニアになるキミ - 24日目 - Python - Python言語の基礎1
100日後にエンジニアになるキミ - 18日目 - Javascript - JavaScriptの基礎1
100日後にエンジニアになるキミ - 14日目 - CSS - CSSの基礎1
100日後にエンジニアになるキミ - 6日目 - HTML - HTMLの基礎1
今回は機械学習についてのお話です。
機械学習について
昨今色々な事情で休校になったり、出勤できなかったりしてたりするので
この機会にお勉強はいかがでしょうか?機械学習について数式なんかを用いずに
小学生でも分かるような内容で説明してみたいと思います。解説動画はこちら
機械学習って何?
まずはじめに、機械学習って何?っていうところからです。
機械学習はコンピューターにデータを学習させて
未知データに対して予測をする試みを行うことです。大量のデータに潜むパターンを覚えさせることを学習
未知のデータを判断するルールのことをモデルと言い
このモデル作りが機械学習のポイントになります。機械学習とAI
次に昨今の人口知能などとの言葉の関係についてです。
人工知能のことを英語ではAIと言っています。
AIの多くは機械学習を元に作られているものがほとんどです。
そして機械学習のことを英語ではマシンラーニングと呼んでいます。
深層学習は機械学習の手法の一つで、英語ではディープラーニングと呼んでいます。言葉の関係性は図のような感じです。
機械学習はどこで使われているの?
機械学習がどんな場面で用いられているかと言うと現在では様々な分野で幅広く用いられています。
自動運転のために行われる画像の判別や物体検知、人物や動物の分類、手書き文字の判別などが主な分野です。
人の行動に関わるデータについても多く用いられています。
ショッピングサイトでは、入会するかどうか、退会してしまうかどうか
この人のオススメの商品は何か、と言った判断に機械学習が多く用いられています。学習させたものから、様々なものの生成を行うこともできます。
画像のスタイルを学習させて、それっぽい画風の画像を作ったり、
それっぽい曲を作る、英語の文章を日本語に翻訳するのも機械学習で行われています。機械学習でできること
機械学習でできることは主に3つ
回帰
分類
クラスタリング
です。それぞれ
回帰:数値を予測する
分類:カテゴリを予測する
クラスタリング:いい感じに分ける
と言うことができます。学習の方法
学習方法も大きく分けて3つ
教師あり学習
教師なし学習
強化学習
です。
教師あり学習は答えがあって、その答えに沿って学習させる学習方法です。
教師なし学習は答えが分からないものに対して行う学習方法です。
強化学習はゲームの勝利など、何かしらの価値観に基づき、その価値を最大化させるような学習方法のことを言います。実際のデータ
データは縦横のある
表形式のデータを用いて行います。
通常はデータの種類(列)は1つではありません。複数存在することがほとんどです。この列方向のデータの種類のことを機械学習では
変数とも呼んでいます。教師あり学習
教師あり学習について
部屋の広さから、価格を当てに行くことを考えてみましょう。
まずはデータ(部屋の広さと価格)を用意しておきます。データに当てはまるような、いい感じの線を引くことを考えてみてください。
右側の図のような線が引けるんじゃないでしょうか?
この線のようなことを
学習モデル(判別のルール)と呼んでいます。
できた
予測モデルを用いて、データから予測を行ってみましょう。部屋の広さのデータから、それに当てはまる線の部分を見ていくと
価格の方が出てきます。これが予測した値になります。予測はあくまでも答えに近い値を出すだけで、ぴったり当てる事はなかなか難しいです。
またデータは一つだけではないので、いろいろなデータをみながら
いい感じの線を引く方法を考えてあげる必要があります。今回は数値を当てにいくことを例にしましたが、これは
回帰と言う方になります。
男性,女性などの数値でないものを当てに行くものは判別と言っています。教師なし学習
続いて教師なし学習です。
教師なし学習は
クラスタリングのようにいい感じに分ける学習方法のことを言います。答えはないので、予測された結果が正しいかどうかは人間の判断に委ねられることになります。
深層学習について
深層学習についてです。
ニューラルネットという学習モデルを用いた学習方法です。
人の脳の構造を真似した学習モデルで入力層、隠れ層、出力層の3つの層を設定できます。そのうち、隠れ層が2つ以上のものを
ディープニューラルネットワーク(DNN)とも呼んでいます。
そのDNNを用いた学習方法がディープラーニングです。
めちゃくちゃざっくりですが
ディープラーニングの何が凄いのかというと
機械が人間の精度を超えたということです。特に世界的に行われている
画像認識のコンテストでは
人間の精度を超えるモデルが出来上がっています。ということで、人間の代わりにより精度の高い判別をしてくれるようになってきたため
英語の文章を日本語に翻訳するなど、様々な分野で活躍するようになってきています。機械学習に必要なもの
機械学習を初めてみたい方にはまずはPCを用意しましょう。
次にPythonというプログラム言語をインストールしましょう。
最後に機械学習に使う表形式のデータを用意すれば良いです。
さて、機械学習をしてみたいけど
プログラミングとか分からないなーという方が居たら
当方で講座を用意していますのでそちらを参考にしてみてください!!!参考:
Pythonプログラミング講座まとめ
ハイパーざっくりですが機械学習についての説明です。
機械学習自体は、このご時世、どこの企業でも取り入れられており
サービスには欠かすことのできないツールになってしまいました。そのため、知らないよでは済まされなくなってきています。
概念だけであればあまり難しくはありません。
細かく追求しようとするとキリがありません。まずはざっくりとした知識として身につけておき
業務などでやるようになったらどうやって実現すれば良いのかを
学べば良いと思います。君がエンジニアになるまであと24日
作者の情報
乙pyのHP:
http://www.otupy.net/Youtube:
https://www.youtube.com/channel/UCaT7xpeq8n1G_HcJKKSOXMwTwitter:
https://twitter.com/otupython













- 投稿日:2020-06-04T17:43:48+09:00
DiscordのURLを短縮バージョンにしてくれるBOTを作る
タイトル通り
URLが長い時、YouTubeのURLの時にプレビューが表示される時スマホを使ってる人は、上のメッセージが見えなくなる。
それが不便だなーと思ってこのBOTを作った。
Python製完成品
↑このようにメッセージにURLが入ってる時、下の鎖のリアクションが押されたら短縮にするというBOT結果↓
全体のプログラム
import discord import re import asyncio from urllib.parse import urlparse # このTOKENテスト用のだから別に使っていいよ TOKEN = "NzA2MzQwNTMwMDE5MjM3OTQ0.Xq405w.pwRREjj-8N4MKph3QcV9NGb5EIM" client = discord.Client() @client.event async def on_ready(): print("準備完了") @client.event async def on_message(message): if message.author.bot: return pattern = "https?://[\w/:%#\$&\?\(\)~\.=\+\-]+" url_list = re.findall(pattern, message.content) if url_list != []: await message.add_reaction("⛓") return @client.event async def on_reaction_add(reaction, user): channel = client.get_channel(reaction.message.channel.id) if reaction.count >= 2 and reaction.emoji == "⛓": if reaction.count >= 3: pass else: s = reaction.message.content pattern = "https?://[\w/:%#\$&\?\(\)~\.=\+\-]+" url_list = re.findall(pattern, s) url_list[0] mes = s.strip(url_list[0]) parsed_url = urlparse(url_list[0]) site = '{uri.scheme}://{uri.netloc}/'.format(uri=urlparse(url_list[0])) embed = discord.Embed(title=f"{mes}", description=f"[短縮URL]({url_list[0]})", color=0x87cefa) embed.set_author(name=reaction.message.author.display_name, icon_url=reaction.message.author.avatar_url_as(format="png")) embed.set_footer(text=f"{site}") await channel.send(embed=embed) return client.run(TOKEN)(がんばって書いた)解説
まず一つ目
@client.event async def on_message(message): if message.author.bot: return # こ↑こ↓ pattern = "https?://[\w/:%#\$&\?\(\)~\.=\+\-]+" url_list = re.findall(pattern, message.content) if url_list != []: # リストが空かどうか await message.add_reaction("⛓") returnここはメッセージが来たときに呼び出される場所で、こ↑こ↓からが本命。
こ↑こ↓からのプログラムはメッセージに含まれるURLをリストに入れるとこ。
リストが空だったらリアクションをつけます。
URLのやつは
http://trelab.info/python/python-%E6%AD%A3%E8%A6%8F%E8%A1%A8%E7%8F%BE%E3%81%A7url%E3%81%AE%E4%B8%80%E8%87%B4%E3%83%81%E3%82%A7%E3%83%83%E3%82%AF%E3%80%81%E6%8A%BD%E5%87%BA%E3%82%92%E8%A1%8C%E3%81%86/
を参考...いやマルパクリしました。二つ目
@client.event async def on_reaction_add(reaction, user): channel = client.get_channel(reaction.message.channel.id) if reaction.count >= 2 and reaction.emoji == "⛓": if reaction.count >= 3: pass else: s = reaction.message.content #こ↑こ↓ pattern = "https?://[\w/:%#\$&\?\(\)~\.=\+\-]+" url_list = re.findall(pattern, s) url_list[0] mes = s.strip(url_list[0]) parsed_url = urlparse(url_list[0]) site = '{uri.scheme}://{uri.netloc}/'.format(uri=urlparse(url_list[0])) embed = discord.Embed(title=f"{mes}", description=f"[短縮URL]({url_list[0]})", color=0x87cefa) embed.set_author(name=reaction.message.author.display_name, icon_url=reaction.message.author.avatar_url_as(format="png")) embed.set_footer(text=f"{site}") await channel.send(embed=embed) returnURLを短縮にして送るプログラムがある場所。
リアクションがつけられた時に呼び出されます。
こ↑こ↓と書いてあるところからが本命
その前はリアクションが鎖か判別したりするやつ
こ↑こ↓以降のpattern = "https?://[\w/:%#\$&\?\(\)~\.=\+\-]+" url_list = re.findall(pattern, s) url_list[0] #こ↑こ↓ mes = s.strip(url_list[0])#メッセージからURLをとる parsed_url = urlparse(url_list[0])#URLから余計なのを取り除く site = '{uri.scheme}://{uri.netloc}/'.format(uri=urlparse(url_list[0]))は まず一つ目 でやったやつとほぼいっしょ
こ↑こ↓以降はメッセージからURLを取るのと、URLから余計なのを取り除くやつ。
URLから余計なのを取り除くやつは
https://www.python.ambitious-engineer.com/archives/35
を参考...マルパクリしました。embed = discord.Embed(title=f"{mes}", description=f"[短縮URL]({url_list[0]})", color=0x87cefa) embed.set_author(name=reaction.message.author.display_name, icon_url=reaction.message.author.avatar_url_as(format="png")) embed.set_footer(text=f"{site}") await channel.send(embed=embed)これはembedで短縮したやつとかを送るやつ
これで完成
最後に
うーん
思いつかない終わり
- 投稿日:2020-06-04T17:17:02+09:00
Pybind11でC++関数をPythonから実行する環境を構築する(Windows & Visual Studio Codeな人向け)
Pybind11を使ってC++の関数をPythonから呼び出せるようにする環境を構築する方法を説明します。WindowsかつVisual Studio Codeを使っている人向けの記事があまりなかったので、いろいろ調べたことをまとめておきます。ただ、エディターはVisual Studio Codeでなくても大丈夫です。
0. 環境
以下の環境で確認しています。CMake以下のインストール方法はこの記事で説明します。
- OS: Windows 10
- エディター: Visual Studio Code
- Python: 3.7 (Anaconda 3 2019.7)
- この記事でインストールするもの
- CMake: 3.17.2
- Mingw-w64: x86_64-8.1.0-posix-seh-rt_v6-rev0
- pybind11: 2.5.0
1. 環境構築
1.1. CMakeのインストール
CMakeとは、C++等をビルドする際の設定を様々なコンパイラーで利用できるようにするツールです。が、私自身よく分かっていないので、詳しくはこちらをみてください。
ダウンロード ページからWindows win64-x64 Installerをダウンロードし、インストールします。
1.2. Mingw-w64のインストール
Mingw-w64とは、フリーのC++コンパイラg++のWindwos 64bit版です。これも私自身よく分かっていないので、グーグル先生に聞いてみてください。
ダウンロードページからインストーラー等をダウンロードします。オンライン環境であれば、インストーラー
MinGW-W64-install.exeでインストールします。オフライン環境であれば、7z形式のファイルをインストールして展開します。以下、この記事では
g++.exeの配置が次のようになっているとします:D:\UserProgram\mingw-w64\x86_64-8.1.0-posix-seh-rt_v6-rev0\mingw64\bin\g++.exe次に、上記フォルダーを環境変数Pathに追加します。Powershellで追加するには、
ユーザー単位> $envPath = [System.Environment]::GetEnvironmentVariable("Path", "User") > $envPath += ";D:\UserProgram\mingw-w64\x86_64-8.1.0-posix-seh-rt_v6-rev0\mingw64\bin" #←g++.exeが含まれているパス > [System.Environment]::SetEnvironmentVariable("Path", $envPath, "User")端末単位で設定するには1行目と3行目の
"User"を"Macine"に置き換えます。この場合、管理者権限が必要になります。端末単位(要管理者権限)> $envPath = [System.Environment]::GetEnvironmentVariable("Path", "Machine") > $envPath += ";D:\UserProgram\mingw-w64\x86_64-8.1.0-posix-seh-rt_v6-rev0\mingw64\bin" #←g++.exeが含まれているパス > [System.Environment]::SetEnvironmentVariable("Path", $envPath, "Machine")1.3. Pybind11のインストール
オンライン環境なら、
pipでインストールします。Powershell> pip install pybind11オフライン環境の場合は、
PyPIのダウンロード ページからpybind11-x.y.z-py2.py3-none-any.wh(x, y, zは数字)をダウンロードしてから、pipでインストールします。Powershell> pip install ダウンロード先/pybind11-2.5.0-py2.py3-none-any.whl #2.5.0部分は適宜読み替え後で使うので、公式のサンプルもダウンロードします。オンライン環境(かつGitをインストール済み)なら、Powershell上でダウンロードしたい場所まで移動し、
Powershellgit clone --recursive https://github.com/pybind/cmake_example.gitとしてダウンロードします。オフライン環境の場合は、公式のサンプルの
Clone or downloadボタンを押します。また、pybind11フォルダーも同様にダウンロードします。【重要】
cmake_example/pybind11/include/pybind11以下のファイルを、C:\ProgramData\Anaconda3\include\pybind11以下のファイルで置き換えます。置き換える前のファイルは古いみたいで、コンパイルは通りますが、warning: 'void PyThread_delete_key_value(int)' is deprecated [-Wdeprecated-declarations]というワーニングが大量に出ます。2. やってみるさ( ■ 一 ■)
先ほどダウンロードした
cmake_exmpleフォルダーから、pybind11、src、CMakeLists.txtを適当なフォルダー(以下、project_rootとします)にコピーします。フォルダー構成project_root ├ pybind11 │ ├ docs │ ├ include │ │ └pybind11 #このフォルダーの中身を │ │ └・・・ # C:\ProgramData\Anaconda3\include\pybind11の中身で置き換えておく │ └・・・ ├ src │ └main.cpp └ CMakeLists.txtproject_root/src/main.cpp#include <pybind11/pybind11.h> int add(int i, int j) { return i + j; } namespace py = pybind11; PYBIND11_MODULE(cmake_example, m) { (略) m.def("add", &add, R"pbdoc( Add two numbers Some other explanation about the add function. )pbdoc"); (略) }project_root/CMakeLists.txtcmake_minimum_required(VERSION 2.8.12) project(cmake_example) add_subdirectory(pybind11) pybind11_add_module(cmake_example src/main.cpp)
project_rootをVisual Studio Codeで開き、Ctrl+@でターミナルに移動し、以下を実行します。Powershell> mkdir build # ビルド先のフォルダーを作成 > cd build # ビルド先に移動 > cmake -G "MinGW Makefiles" .. # ConfigureとGenarate > cmake --build .. # ビルド成功すれば、
buildフォルダーにcmake_example.cp37-win_amd64.pydが作成されます。先ほどのターミナルで試してみましょう。Powershell> python # Pythonを起動 >>> from cmake_example import add >>> add(1,2) 3 >>> exit() # Powershellに戻る
add関数を呼び出せていれば成功です。3. おわりに
最後まで読んでいただき、ありがとうございます。
この記事では公式のサンプルを使っただけでしたが、他の人の記事を参考に、main.cppやCMakeLists.txtを修正してみてください。
C++に疎いため、たったこれだけの事が出来るようになるまでに時間がかかりました。これからC++デビューしたいと思います。あと、VSCodeの拡張機能CMake Toolsの使い方もそのうち調べて記事にしたいです。参考
以下の記事を参考にさせていただきました。
Mingw-w64のインストール方法
CMakeの解説
Pybind11の使い方