はじめに アクセス数がすごい環境は大抵高負荷環境でもあるので対策としてApacheの設定やサーバ構成のセオリーをすぐ見つけられて実際試しても目に見えて良くなります。 アクセス数の多さで起こる問題は実際に負荷をかけてみないと表面化しません。 問題が分かったら設定やパラメータを調整して現状がましになるようにするだけです。 ですが限りあるリソースの中でTCPセッションを十分にコントロールしようとするとすぐ手詰まりです。 WEBサーバがしているやりとりの基礎が足りていないそんな気がしていたのでTCPに目を向けてみました。 行き着いた結果は 待ち受け側とリクエスト側ではボトルネックが違う リクエスト時はTCPのエフェメラルポートが上限 待ち受け時はTCPよりもファイルディスクリプタが上限 になりやすい という良く見かける設定を見直すということになりましたが、どうやってそうなっているのかが今回の成果だと思います。 TCPセッションはどうやって区別されるか? 1つのサーバでのTCPセッションは複数のクライアントと複数のセッションを組むことができてそれぞれを識別しています。 それをどう区別つけているのかというと 以下の5つの組み合わせで行われるとのこと プロトコル 送信側IP 送信側ポート 受信側IP 受信側ポート そしてこの組み合わせの数がTCPセッションでの限界となります。 WEBサーバが直接待ち受ける場合netstatで状況を見ると例えばこうなります。 {ServerIPaddress}:80 {ClientIPaddress}:60233 TIME_WAIT 192.168.11.1:80 10.0.0.1:60234 TIME_WAIT 192.168.11.1:80 10.0.0.2:60233 TIME_WAIT 待ち受け側は一定のポートで待ち受けてリクエストを送信してきたクライアント側ではエフェメラルポートでセッションを組みます。 なのでとの時の組み合わせの数は 1 IP * 1 Port * {Global IP Address} * エフェメラルポート数 プロトコルはTCPで一定なのでグローバルIPとエフェメラルポート数の組み合わせで有限ではあるけれど他の性能で受けきれないくらいはありますね。 L4LB下でもWEBサーバ側から見ると同じようになるのですがこちらはIPアドレスやポートを書き換えているのでそこはLBの仕様が上限になりうるのかなと思います。 TCPセッションと一緒に増えるのはファイルディスクリプタ ということで待ち受け側ではTCPセッションではさほど問題にならないのですが、TCPセッションを受け取るとそれがファイルのストリームを開けたことと同じ扱いになります。 Linuxではファイルをオープンできる数がプロセス毎に制限されています。 それがファイルディスクリプタです。 systemdではserviceのパラメータで増やすことができるので [Service] LimitNOFILE=65536 と加えて制限を広げるあの設定です。 受けるセッション と セッション毎に実際にオープンするファイル数が消費されていきます。 それが1プロセスにつき最大65536個までになります nginxだとすぐファイルディスクリプタの制限がきて Apacheのpreforkでは問題にならなかったりするのはプロセスをたくさん作っておくpreforkのやり方の違いそのものだったんですね。 TCPポートの枯渇 『TCPポートは枯渇する』 といきなり言われても良くわからない。 Linuxにはエフェメラルポートというのが設定されていてネットワーク接続の度に消費される。その空きがなくなると接続できなくなる。 エフェメラルポートはデフォルトで32768-60999で数は28232ポート だからサーバ1台で拡げないと大体28kが上限 でも監視しているWEBサーバのTCPステータスの統計では全部で50kとかいったりするのでなんか違う。 しかし実際エフェメラルポートは枯渇するしただの怖い話ではなかったのです。 クライアント側のエフェメラルポート ReverseProxy(L7LB)とWEBサーバ間の場合で クライアント側になるReverseProxyでnetstatを見ると {ReverseProxy IPaddress}:60100 {WEB Server IPaddress}:80 TIME_WAIT 192.168.11.1::60100 192.168.20.1:80 TIME_WAIT 192.168.11.1::50100 192.168.20.1:80 TIME_WAIT となるのでReverseProxyが送信する際相手WEBサーバが複数台あっても自分のIPアドレスは一つでポートは開放されるまで割当られません。 リクエストするIPアドレスでのセッションはエフェメラルポート数分までなのです。 良くありがちなことにこれがTIME_WAITで埋め尽くされてしまうと新たなセッションを作れないことになります。 しかしReverseProxyではよくbackend側の接続にはHTTPのKeepAliveを有効にするという設定があります。接続相手先もReverseProxyに対するWEBサーバということで特定の台数に限定されるのでTCPの再利用の機会が多くなります。そのおかげで大量のHTTPリクエストを渡せるようになるのです。 keepalive_timeout 60 AWS ALBのドキュメントのベストプラティクスではKeepalive timeout 60くらいを推奨していますがそれはALBがなるべく同じReverseProxyから送るようにしているおかげで分散型のシステムなのにTCPセッションの再利用を高められるのです。 リクエスト(問合せ)と言えばDBですが WEBサーバでは静的ファイルをレスポンスしているだけではなく大抵CGIなどのプログラムからDBへ問合せしてその結果をレスポンスしています。 そのDBへの問合せもTCPを使用していればエフェメラルポート数を消費しています。 アクセス数が多いサイトでは大抵Memcached や Redisも使っていたりするのでそちらへのリクエストも発生します。 そうなるとレスポンスに至る過程でファイルディスクリプタも消費しそうな場面でありますが わりとWEBサーバではエフェメラルポートの需要が高いので気をつけなければいけない。 これが『TCPポートが枯渇する』という話で大事な部分でした。 大量の新規TCP接続はコストが積み重なっていく 大量のコネクションが発生する箇所で都度接続してすぐ廃棄しているとTIME_WAITですぐ埋まりCPUもそれなりに使うようになります。 そこで予め数本接続しておき再利用できるように管理しておけば手続きも省略され多くのリクエストが可能になるでしょう。需要に応じて接続を増減してくれれば便利です。 これを『コネクションプーリング』と呼ぶのですがこの言葉がJava界隈以外ではまずあやふやになっていてこの機能を謳っていても実装がどうなっているか気にする必要があるようです。 最近ではMySQLProxyのマネージドサービスがAWSで登場するなどしていてコネクションプーリングとそれ以外の目的もあると思いますがDBでもProxy需要が高まっていそうですね。 そんなDBProxyを利用してTCPセッションを再利用しつつ他の問合せとエフェメラルポートを共有していく方法は選択肢に入れておいて良いのかもしれません。 参考にさせていただきました Webサーバにおけるソケット周りの知識
アクセス数がすごい環境は大抵高負荷環境でもあるので対策としてApacheの設定やサーバ構成のセオリーをすぐ見つけられて実際試しても目に見えて良くなります。 アクセス数の多さで起こる問題は実際に負荷をかけてみないと表面化しません。 問題が分かったら設定やパラメータを調整して現状がましになるようにするだけです。 ですが限りあるリソースの中でTCPセッションを十分にコントロールしようとするとすぐ手詰まりです。 WEBサーバがしているやりとりの基礎が足りていないそんな気がしていたのでTCPに目を向けてみました。
待ち受け側とリクエスト側ではボトルネックが違う
リクエスト時はTCPのエフェメラルポートが上限 待ち受け時はTCPよりもファイルディスクリプタが上限 になりやすい
という良く見かける設定を見直すということになりましたが、どうやってそうなっているのかが今回の成果だと思います。
1つのサーバでのTCPセッションは複数のクライアントと複数のセッションを組むことができてそれぞれを識別しています。 それをどう区別つけているのかというと 以下の5つの組み合わせで行われるとのこと
そしてこの組み合わせの数がTCPセッションでの限界となります。 WEBサーバが直接待ち受ける場合netstatで状況を見ると例えばこうなります。
{ServerIPaddress}:80 {ClientIPaddress}:60233 TIME_WAIT 192.168.11.1:80 10.0.0.1:60234 TIME_WAIT 192.168.11.1:80 10.0.0.2:60233 TIME_WAIT
待ち受け側は一定のポートで待ち受けてリクエストを送信してきたクライアント側ではエフェメラルポートでセッションを組みます。 なのでとの時の組み合わせの数は
1 IP * 1 Port * {Global IP Address} * エフェメラルポート数
プロトコルはTCPで一定なのでグローバルIPとエフェメラルポート数の組み合わせで有限ではあるけれど他の性能で受けきれないくらいはありますね。
L4LB下でもWEBサーバ側から見ると同じようになるのですがこちらはIPアドレスやポートを書き換えているのでそこはLBの仕様が上限になりうるのかなと思います。
ということで待ち受け側ではTCPセッションではさほど問題にならないのですが、TCPセッションを受け取るとそれがファイルのストリームを開けたことと同じ扱いになります。 Linuxではファイルをオープンできる数がプロセス毎に制限されています。 それがファイルディスクリプタです。 systemdではserviceのパラメータで増やすことができるので
[Service] LimitNOFILE=65536
と加えて制限を広げるあの設定です。 受けるセッション と セッション毎に実際にオープンするファイル数が消費されていきます。 それが1プロセスにつき最大65536個までになります
nginxだとすぐファイルディスクリプタの制限がきて Apacheのpreforkでは問題にならなかったりするのはプロセスをたくさん作っておくpreforkのやり方の違いそのものだったんですね。
『TCPポートは枯渇する』 といきなり言われても良くわからない。 Linuxにはエフェメラルポートというのが設定されていてネットワーク接続の度に消費される。その空きがなくなると接続できなくなる。
エフェメラルポートはデフォルトで32768-60999で数は28232ポート
だからサーバ1台で拡げないと大体28kが上限 でも監視しているWEBサーバのTCPステータスの統計では全部で50kとかいったりするのでなんか違う。
しかし実際エフェメラルポートは枯渇するしただの怖い話ではなかったのです。
ReverseProxy(L7LB)とWEBサーバ間の場合で クライアント側になるReverseProxyでnetstatを見ると
{ReverseProxy IPaddress}:60100 {WEB Server IPaddress}:80 TIME_WAIT 192.168.11.1::60100 192.168.20.1:80 TIME_WAIT 192.168.11.1::50100 192.168.20.1:80 TIME_WAIT
となるのでReverseProxyが送信する際相手WEBサーバが複数台あっても自分のIPアドレスは一つでポートは開放されるまで割当られません。 リクエストするIPアドレスでのセッションはエフェメラルポート数分までなのです。 良くありがちなことにこれがTIME_WAITで埋め尽くされてしまうと新たなセッションを作れないことになります。
しかしReverseProxyではよくbackend側の接続にはHTTPのKeepAliveを有効にするという設定があります。接続相手先もReverseProxyに対するWEBサーバということで特定の台数に限定されるのでTCPの再利用の機会が多くなります。そのおかげで大量のHTTPリクエストを渡せるようになるのです。
AWS ALBのドキュメントのベストプラティクスではKeepalive timeout 60くらいを推奨していますがそれはALBがなるべく同じReverseProxyから送るようにしているおかげで分散型のシステムなのにTCPセッションの再利用を高められるのです。
Keepalive timeout 60
WEBサーバでは静的ファイルをレスポンスしているだけではなく大抵CGIなどのプログラムからDBへ問合せしてその結果をレスポンスしています。 そのDBへの問合せもTCPを使用していればエフェメラルポート数を消費しています。 アクセス数が多いサイトでは大抵Memcached や Redisも使っていたりするのでそちらへのリクエストも発生します。 そうなるとレスポンスに至る過程でファイルディスクリプタも消費しそうな場面でありますが
わりとWEBサーバではエフェメラルポートの需要が高いので気をつけなければいけない。 これが『TCPポートが枯渇する』という話で大事な部分でした。
大量のコネクションが発生する箇所で都度接続してすぐ廃棄しているとTIME_WAITですぐ埋まりCPUもそれなりに使うようになります。 そこで予め数本接続しておき再利用できるように管理しておけば手続きも省略され多くのリクエストが可能になるでしょう。需要に応じて接続を増減してくれれば便利です。 これを『コネクションプーリング』と呼ぶのですがこの言葉がJava界隈以外ではまずあやふやになっていてこの機能を謳っていても実装がどうなっているか気にする必要があるようです。
最近ではMySQLProxyのマネージドサービスがAWSで登場するなどしていてコネクションプーリングとそれ以外の目的もあると思いますがDBでもProxy需要が高まっていそうですね。 そんなDBProxyを利用してTCPセッションを再利用しつつ他の問合せとエフェメラルポートを共有していく方法は選択肢に入れておいて良いのかもしれません。
Webサーバにおけるソケット周りの知識
Railsでアプリケーションを久しぶりに作ろうとした際にMySQLに関連したエラーが出たので、一度MySQL(MySQL Community Server 8.0.15)を再インストールする事にしました。 しかし、アンインストール後に再度インストールしようとするとインストーラーが途中で止まってしまう問題が発生した為、下記の通り色々な試みを行いなんとかインストールに成功したのでメモしておきます。 したこと。 ・MySQLアンインストール後に残っていたゴミファイルの削除(Program Files、ProgramData内のファイルを消したり、環境変数のPATHにある欄を消す等) → 解決せず ・様々なバージョンのMySQLを試す → 解決せず ・Visual C++ 再頒布可能パッケージを全て削除し、2013年版、2015年版、2015年版~2019年版を改めてインストール → 解決しました 本来Visual C++ 再頒布可能パッケージが欠けている場合はインストーラーからさらに先に進んでランチャー起動時に警告されるのが普通のようですが、どういうわけか今回はインストーラー起動時に発生してしまい解決までに数時間掛かってしまいました。 またインストーラーで停止する問題はいくら検索しても全くヒットしなかったのでかなり特殊な環境でないと起こらないのではないかと思います。 こういう時が一番やっかいですね…。 恐らくアンインストールに不備があったのだろうと思います。
Railsでアプリケーションを久しぶりに作ろうとした際にMySQLに関連したエラーが出たので、一度MySQL(MySQL Community Server 8.0.15)を再インストールする事にしました。
しかし、アンインストール後に再度インストールしようとするとインストーラーが途中で止まってしまう問題が発生した為、下記の通り色々な試みを行いなんとかインストールに成功したのでメモしておきます。
したこと。 ・MySQLアンインストール後に残っていたゴミファイルの削除(Program Files、ProgramData内のファイルを消したり、環境変数のPATHにある欄を消す等) → 解決せず
・様々なバージョンのMySQLを試す → 解決せず
・Visual C++ 再頒布可能パッケージを全て削除し、2013年版、2015年版、2015年版~2019年版を改めてインストール → 解決しました
本来Visual C++ 再頒布可能パッケージが欠けている場合はインストーラーからさらに先に進んでランチャー起動時に警告されるのが普通のようですが、どういうわけか今回はインストーラー起動時に発生してしまい解決までに数時間掛かってしまいました。 またインストーラーで停止する問題はいくら検索しても全くヒットしなかったのでかなり特殊な環境でないと起こらないのではないかと思います。 こういう時が一番やっかいですね…。 恐らくアンインストールに不備があったのだろうと思います。
何かを簡単に作って、ちょっとした勉強になる。そんなシリーズになる予定のものの第3回です。 今回は、シンプルなAPIサーバーをCircleCIで自動テストをします。テストは前回にしてあるものを使います。 完成品はこちら -> sequelize-todo-api-server JS1日クッキング まとめページ - Qiita 材料 ユニットテストをした前回のサーバー CircleCI jest-junit 作り方 1. テストメタデータの設定 テストの結果をテストメタデータとしてファイルへ保存できるようにします。CircleCIでテストした後、テストメタデータをCircleCIへアップロードすると、テスト結果がCircleCIのダッシュボードで確認できるようになります。 Jestのテストメタデータを作成するために、jest-junitをインストールします。 npm install -D jest-junit jest.config.js というファイルを作り、設定を書いていきます。 jest.config.js module.exports = { reporters: ["default", ["jest-junit", { outputDirectory: "reports/jest" }]], }; ここまでできたら、npm run testでテストを実行すると、reports/jestディレクトリ内にjunit.xmlが生成されるようになります。この中にテストメタデータが入っています。 2. CircleCIの設定ファイルの用意 npm-scriptに "test:ci": "export NODE_ENV=test && npx jest --ci --runInBand" を加えます。--ciと--runInBandがCIでJestを使うときに必要になります。 CircleCIで使用する設定ファイルを用意します。設定ファイルは、.circleciディレクトリ内のconfig.ymlに書きます。 .circleci/config.yml version: 2.1 jobs: build: docker: - image: circleci/node:lts - image: circleci/mysql:8-ram environment: MYSQL_USER: sequelize MYSQL_PASSWORD: sequepass MYSQL_DATABASE: database_test steps: - checkout - restore_cache: name: キャッシュの読み込み key: dependency-cache-{{ checksum "package-lock.json" }} - run: name: パッケージをインストール command: npm install - save_cache: name: キャッシュを保存 key: dependency-cache-{{ checksum "package-lock.json" }} paths: - node_modules - run: name: db を待機 command: dockerize -wait tcp://localhost:3306 -timeout 1m - run: name: JUnit をレポーターとしてテストを実行 command: npm run test:ci - store_test_results: name: テスト結果を保存 path: reports jobsのbuild内に、使うコンテナと作業を記述していきます。 dockerキーに使用するコンテナを指定します。最初に使うイメージがコマンドを実行するコンテナになります。なので、Node.jsのコンテナを最初に書き、続いてDBのイメージを書きます。DBの設定は環境変数を使用して設定します。circleci/mysqlの環境変数は、MySQLの公式イメージと同じです。 mysql - Docker Hub ここでは、sequelizeで設定したユーザー名とパスワードだけでなく、使用するデータベースも設定します。使用するデータベースを設定しないとアクセスが拒否されます。 stepsキーに処理を順番に書いていきます。主に、 checkoutでリポジトリからデータをダウンロード npm installでライブラリのインストール dockerize -wait tcp://localhost:3306 -timeout 1mでDBが準備できるまで待つ npm run test:ciでCI用のテストを実行 store_test_resultsでテストメタデータをCircleCIへアップロード ということをしています。 3. CircleCIへリポジトリの登録 CircleCIで自動テストができるようにします。CircleCIに登録をした後、「Projects」のページに移動します。 「Set Up Project」をクリックします。 「Start Building」をクリックします。 新しいブランチ作って、そこにデフォルトの設定ファイルを加えるか尋ねられますが、今回は自分で用意したものを使うので、「Add Manually」をクリックします。 「Start Building」をクリックします。これで、CircleCIで使用するリポジトリの設定ができました。 4. 自動テストをする では、実際に自動テストをしましょう。Githubにプッシュすると、自動的にCircleCIが処理を始めます。 「Piplines」で、CircleCIの処理中の様子や結果をみることができます。 処理が終わった後、「build」をクリックすると、以下のように処理結果をみることができます。 「TESTS」をクリックすると、テストメタデータからテスト結果を表示してくれます。 テストが失敗しているときは、以下のようにテストメッセージが表示されます。 5. ステータスバッヂの表示 CircleCIのステータスバッヂをGithubに表示することができます。CircleCIのステータスバッヂは、以下のようなものです。 これは、 []([画像のリンク先(大抵はGithubのブランチ)]) の中の[]を全部埋めると、MDファイルにステータスバッヂを表示できます。例えば、今回使ったブランチだと、 [](https://circleci.com/gh/kei-lb6/sequelize-todo-api-server/tree/ci-test) のようになります。これをREADME.mdに含めて、Githubでステータスバッヂを表示しています。 詳しくは下のページを参考にしてください。 Adding Status Badges - CircleCI おわりに CircleCIで自動テストをしました。workflowを使ってテスト成功後にデプロイをすることもできるので、使いこなせれば楽ができそうです。Netlifyもそうですけど、設定すればGithubにプッシュすれば自動に何かやってくれます系のサービスはとても便利ですね。 コード -> sequelize-todo-api-server
何かを簡単に作って、ちょっとした勉強になる。そんなシリーズになる予定のものの第3回です。
今回は、シンプルなAPIサーバーをCircleCIで自動テストをします。テストは前回にしてあるものを使います。
完成品はこちら -> sequelize-todo-api-server
JS1日クッキング まとめページ - Qiita
テストの結果をテストメタデータとしてファイルへ保存できるようにします。CircleCIでテストした後、テストメタデータをCircleCIへアップロードすると、テスト結果がCircleCIのダッシュボードで確認できるようになります。
Jestのテストメタデータを作成するために、jest-junitをインストールします。
npm install -D jest-junit
jest.config.js というファイルを作り、設定を書いていきます。
module.exports = { reporters: ["default", ["jest-junit", { outputDirectory: "reports/jest" }]], };
ここまでできたら、npm run testでテストを実行すると、reports/jestディレクトリ内にjunit.xmlが生成されるようになります。この中にテストメタデータが入っています。
npm run test
npm-scriptに
"test:ci": "export NODE_ENV=test && npx jest --ci --runInBand"
を加えます。--ciと--runInBandがCIでJestを使うときに必要になります。
--ci
--runInBand
CircleCIで使用する設定ファイルを用意します。設定ファイルは、.circleciディレクトリ内のconfig.ymlに書きます。
version: 2.1 jobs: build: docker: - image: circleci/node:lts - image: circleci/mysql:8-ram environment: MYSQL_USER: sequelize MYSQL_PASSWORD: sequepass MYSQL_DATABASE: database_test steps: - checkout - restore_cache: name: キャッシュの読み込み key: dependency-cache-{{ checksum "package-lock.json" }} - run: name: パッケージをインストール command: npm install - save_cache: name: キャッシュを保存 key: dependency-cache-{{ checksum "package-lock.json" }} paths: - node_modules - run: name: db を待機 command: dockerize -wait tcp://localhost:3306 -timeout 1m - run: name: JUnit をレポーターとしてテストを実行 command: npm run test:ci - store_test_results: name: テスト結果を保存 path: reports
jobsのbuild内に、使うコンテナと作業を記述していきます。
dockerキーに使用するコンテナを指定します。最初に使うイメージがコマンドを実行するコンテナになります。なので、Node.jsのコンテナを最初に書き、続いてDBのイメージを書きます。DBの設定は環境変数を使用して設定します。circleci/mysqlの環境変数は、MySQLの公式イメージと同じです。
mysql - Docker Hub
ここでは、sequelizeで設定したユーザー名とパスワードだけでなく、使用するデータベースも設定します。使用するデータベースを設定しないとアクセスが拒否されます。
stepsキーに処理を順番に書いていきます。主に、
npm install
dockerize -wait tcp://localhost:3306 -timeout 1m
npm run test:ci
ということをしています。
CircleCIで自動テストができるようにします。CircleCIに登録をした後、「Projects」のページに移動します。
「Set Up Project」をクリックします。
「Start Building」をクリックします。
新しいブランチ作って、そこにデフォルトの設定ファイルを加えるか尋ねられますが、今回は自分で用意したものを使うので、「Add Manually」をクリックします。
「Start Building」をクリックします。これで、CircleCIで使用するリポジトリの設定ができました。
では、実際に自動テストをしましょう。Githubにプッシュすると、自動的にCircleCIが処理を始めます。
「Piplines」で、CircleCIの処理中の様子や結果をみることができます。
処理が終わった後、「build」をクリックすると、以下のように処理結果をみることができます。
「TESTS」をクリックすると、テストメタデータからテスト結果を表示してくれます。
テストが失敗しているときは、以下のようにテストメッセージが表示されます。
CircleCIのステータスバッヂをGithubに表示することができます。CircleCIのステータスバッヂは、以下のようなものです。
これは、
[]([画像のリンク先(大抵はGithubのブランチ)])
の中の[]を全部埋めると、MDファイルにステータスバッヂを表示できます。例えば、今回使ったブランチだと、
[](https://circleci.com/gh/kei-lb6/sequelize-todo-api-server/tree/ci-test)
のようになります。これをREADME.mdに含めて、Githubでステータスバッヂを表示しています。
詳しくは下のページを参考にしてください。
Adding Status Badges - CircleCI
CircleCIで自動テストをしました。workflowを使ってテスト成功後にデプロイをすることもできるので、使いこなせれば楽ができそうです。Netlifyもそうですけど、設定すればGithubにプッシュすれば自動に何かやってくれます系のサービスはとても便利ですね。
コード -> sequelize-todo-api-server
解決したい問題 mysqldumpを使ってDBをダンプするときにLOCK TABLEを無効にしたい 通常なら以下で解決するらしい mysqldump --skip-lock-tables -h$HOST -P$PORT -u$USER $DB -p$PW $TABLE > dump.sql 自分の環境ではこれが上手くいかずLOCKが残ってしまいました。 解決法 --skip-add-locksを使う mysqldump --skip-add-locks -h$HOST -P$PORT -u$USER $DB -p$PW $TABLE > dump.sql 参考文献 調べたところデフォルトでいくつかのオプションが有効になっていてそれを打ち消すには--をつけると良いらしい。LOCK TABLEに関するオプションが2つあったので試してみたところ上手くいきました。 参考
mysqldumpを使ってDBをダンプするときにLOCK TABLEを無効にしたい 通常なら以下で解決するらしい
LOCK TABLE
mysqldump --skip-lock-tables -h$HOST -P$PORT -u$USER $DB -p$PW $TABLE > dump.sql
自分の環境ではこれが上手くいかずLOCKが残ってしまいました。
--skip-add-locksを使う
--skip-add-locks
mysqldump --skip-add-locks -h$HOST -P$PORT -u$USER $DB -p$PW $TABLE > dump.sql
調べたところデフォルトでいくつかのオプションが有効になっていてそれを打ち消すには--をつけると良いらしい。LOCK TABLEに関するオプションが2つあったので試してみたところ上手くいきました。 参考
--
何をした? operationsテーブルから"第三工種"というカラムで重複するレコードに付随しているデータの塊を作りたいと考えました。 具体的には"第三工種"に"土工"というレコードが複数ある場合、それ以降の”第四工種”以降が"埋め戻し"のものや”掘削"のものなどに分岐します。 それを”第三工種に土工を持つもの全て"で一括りの配列にして、呼び出したいと考えました。 (参考)ER図 失敗した方法 ひとことで言うと、クエリによる処理でなく配列処理で対応しようとしたらドツボにはまりました。 ※詳細(分かりにくいので、お急ぎの方は読まなくて大丈夫です) まずテーブルから全レコードを呼び出し、distinct()で重複を絞った後、その"id"を持つ"第三工種"を抜き出します。その"第三工種"のレコードを持つものをforeachとarray_keys()により、distinct()してないものと比較することで新しい1次配列を作り、そこからviewに呼び出そうとしました。 →array_key()はオブジェクトに対して使えないというエラーで挫折しました。 コレクションを使えばいけるかもしれなかったですが、1次配列にしてしまうと呼び出しも厄介なので中断しました。 →代案で"id"を抽出した後、全て入ったデータからarray_column()でそれぞれのカラムを抜き出して、呼び出しの時に該当のidを使って呼び出すことを考えましたが、array_column()もオブジェクトに対して使えないというエラーが出たので中断しました。 解決方法 下記のsqlをコントローラで書き出して、”第三工種”が同じものだけの配列にまとめることで対応しました。 sequelproのクエリで実行した記述 SELECT operations.id, operations.third_operation_class FROM -- サブクエリで件数を取得 ( SELECT third_operation_class, COUNT(third_operation_class) AS CNT FROM operations GROUP BY third_operation_class ) AS third_operation_class_CNT -- 自己結合 INNER JOIN operations ON third_operation_class_CNT.third_operation_class = operations.third_operation_class AND third_operation_class_CNT.CNT > 0; #上記の結果 id third_operation_class 8 お試し3 9 河川土工 16 土工 17 土工 18 土工 19 土工 20 土工 21 土工 22 土工 その後 この記述で他のカラムも呼び出して、"third_operation_class"が同じものだけでまとめることで、欲しい値だけの配列ができるので、そこにforeachでインデックス番号をふって、そのインデックス番号でページを分けて表示しました。 参考 https://johobase.com/extracts-duplicate-records-sql/
operationsテーブルから"第三工種"というカラムで重複するレコードに付随しているデータの塊を作りたいと考えました。
具体的には"第三工種"に"土工"というレコードが複数ある場合、それ以降の”第四工種”以降が"埋め戻し"のものや”掘削"のものなどに分岐します。 それを”第三工種に土工を持つもの全て"で一括りの配列にして、呼び出したいと考えました。
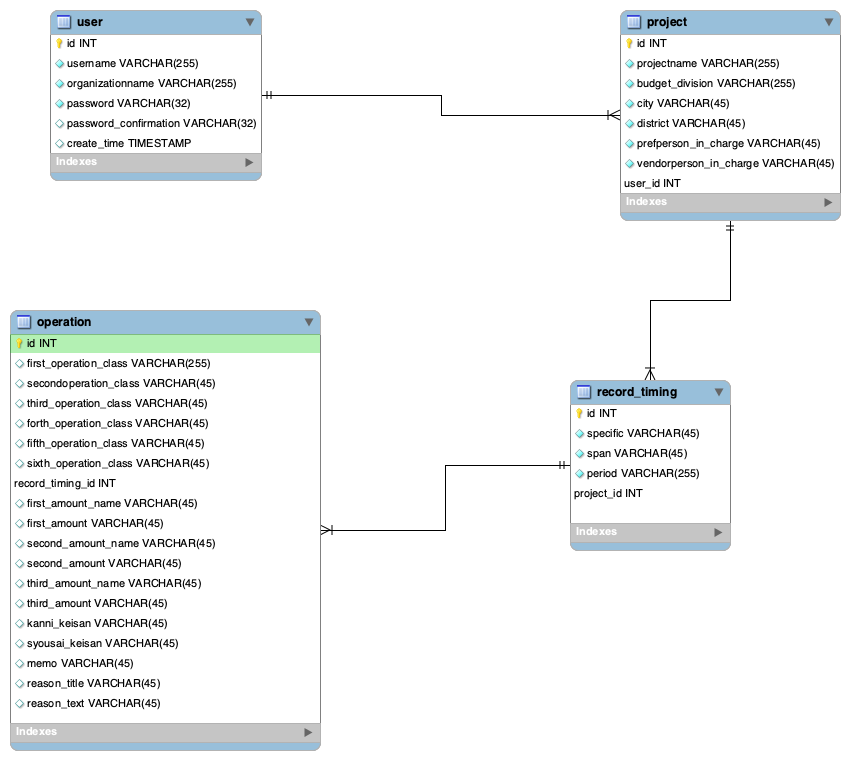
(参考)ER図
ひとことで言うと、クエリによる処理でなく配列処理で対応しようとしたらドツボにはまりました。
まずテーブルから全レコードを呼び出し、distinct()で重複を絞った後、その"id"を持つ"第三工種"を抜き出します。その"第三工種"のレコードを持つものをforeachとarray_keys()により、distinct()してないものと比較することで新しい1次配列を作り、そこからviewに呼び出そうとしました。
distinct()
foreach
array_keys()
→array_key()はオブジェクトに対して使えないというエラーで挫折しました。 コレクションを使えばいけるかもしれなかったですが、1次配列にしてしまうと呼び出しも厄介なので中断しました。
array_key()
→代案で"id"を抽出した後、全て入ったデータからarray_column()でそれぞれのカラムを抜き出して、呼び出しの時に該当のidを使って呼び出すことを考えましたが、array_column()もオブジェクトに対して使えないというエラーが出たので中断しました。
array_column()
下記のsqlをコントローラで書き出して、”第三工種”が同じものだけの配列にまとめることで対応しました。
SELECT operations.id, operations.third_operation_class FROM -- サブクエリで件数を取得 ( SELECT third_operation_class, COUNT(third_operation_class) AS CNT FROM operations GROUP BY third_operation_class ) AS third_operation_class_CNT -- 自己結合 INNER JOIN operations ON third_operation_class_CNT.third_operation_class = operations.third_operation_class AND third_operation_class_CNT.CNT > 0;
#上記の結果 id third_operation_class 8 お試し3 9 河川土工 16 土工 17 土工 18 土工 19 土工 20 土工 21 土工 22 土工
この記述で他のカラムも呼び出して、"third_operation_class"が同じものだけでまとめることで、欲しい値だけの配列ができるので、そこにforeachでインデックス番号をふって、そのインデックス番号でページを分けて表示しました。
https://johobase.com/extracts-duplicate-records-sql/
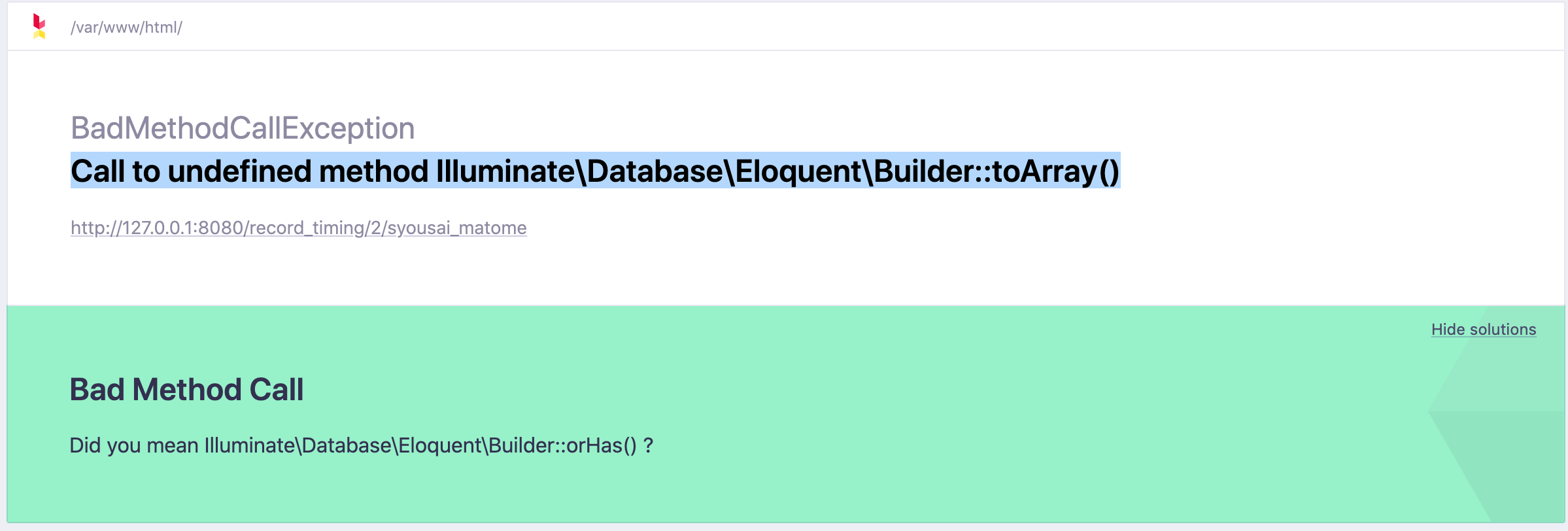
エラー文の様子 どんなエラー? app/Http/Controllers/RecordTimingController public function syousai_matome($id) { $third_operation_class_id = Operation::query()->where('record_timing_id',$id)->distinct()->select('third_operation_class'); return $third_operation_class_id->toArray(); } 上記のように、コントローラで構文的に問題なくデータベースから情報を取得しようとしたら出てきたものです。 原因 データベースの情報をクエリ(今回は抽出)した状態で止まっており、その抽出したものをコントローラに呼び出していなかったため起きました。 ※クエリとは:データベース上で特定の条件に合致したデータを検索したり、置換や削除などを行ったりすること。 解決策 下記のように、クエリ(今回は抽出)した状態のものを->get()で取得すればエラーが解消されました。 app/Http/Controllers/RecordTimingController public function syousai_matome($id) { $third_operation_class_id = Operation::query()->where('record_timing_id',$id)->distinct()->select('third_operation_class')->get(); return $third_operation_class_id->toArray(); }
public function syousai_matome($id) { $third_operation_class_id = Operation::query()->where('record_timing_id',$id)->distinct()->select('third_operation_class'); return $third_operation_class_id->toArray(); }
上記のように、コントローラで構文的に問題なくデータベースから情報を取得しようとしたら出てきたものです。
データベースの情報をクエリ(今回は抽出)した状態で止まっており、その抽出したものをコントローラに呼び出していなかったため起きました。
※クエリとは:データベース上で特定の条件に合致したデータを検索したり、置換や削除などを行ったりすること。
下記のように、クエリ(今回は抽出)した状態のものを->get()で取得すればエラーが解消されました。
->get()
public function syousai_matome($id) { $third_operation_class_id = Operation::query()->where('record_timing_id',$id)->distinct()->select('third_operation_class')->get(); return $third_operation_class_id->toArray(); }
はじめに 外部制約キーを設定しているデータは、通常テーブルから削除する事ができない。 ただ、DBのテーブルからデータを削除には論理削除と物理削除の2種類ある。 先ほど挙げた通常の削除とは物理削除の事を指します。 では、物理削除の場合はどうなるのか、検証していくぅ! マイグレーション作成 外部制約キーを使用するために、まずテーブルを2つ用意しましょう。 親テーブルには論理削除の為に、deleted_atカラムを用意しましょう。 CreateSchoolsTable /** * Run the migrations. * * @return void */ public function up() { Schema::create('schools', function (Blueprint $table) { $table->id(); $table->timestamps(); $table->softDeletes('deleted_at', 0); }); } /** * Reverse the migrations. * * @return void */ public function down() { Schema::dropIfExists('parent'); } 子テーブルにはForeignKeyを指定しましょう。 CreateStudentsTable /** * Run the migrations. * * @return void */ public function up() { Schema::create('students', function (Blueprint $table) { $table->id(); $table->foreignId('school_id')->constrained(); $table->timestamps(); }); } /** * Reverse the migrations. * * @return void */ public function down() { Schema::dropIfExists('child'); } はいこれでおけい。 Model作成 はい次ぃー、Modelの作成をしていきましょう。 親テーブルのモデルは論理削除を行いたいので、SoftDeleteを使用します。 School use Illuminate\Database\Eloquent\SoftDeletes; class School extends Model { use SoftDeletes; } 次に子テーブルのモデルのカラムは親のテーブルのIDだけですので、これだけ。 Student class Student extends Model { protected $fillable = [ 'school_id' ]; } 削除してみる まずは、外部制約キーが動いているか確認する為に物理削除してみる。 まずはSchoolモデルのSoftDeleteをコメントアウトして、削除してみた。 英語で何て書いてあるかよく分かりませんが、外部制約キーの関係で削除できませんと書いてあるのでしょう。 次にSchoolモデルのSoftDeleteをコメントアウトを解錠して論理削除して見ましょう。 School { "id":1, "created_at":null, "updated_at":"2020-06-03T14:59:17.000000Z", "deleted_at":"2020-06-03T14:59:17.000000Z" } deleted_atに論理削除された時刻が挿入されています、論理削除成功ですね。 ちなみに、Schoolのidが1のデータはDB上には残っていますが、取得をしようとするとnullで返ってきます。 しっかりしていますね。 結果 DBからデータが無くなっている訳ではないんだから論理削除できて当たり前だよね。 また気になることがあれば検証していきますぅ! ではまた。
外部制約キーを設定しているデータは、通常テーブルから削除する事ができない。 ただ、DBのテーブルからデータを削除には論理削除と物理削除の2種類ある。 先ほど挙げた通常の削除とは物理削除の事を指します。 では、物理削除の場合はどうなるのか、検証していくぅ!
外部制約キーを使用するために、まずテーブルを2つ用意しましょう。 親テーブルには論理削除の為に、deleted_atカラムを用意しましょう。
/** * Run the migrations. * * @return void */ public function up() { Schema::create('schools', function (Blueprint $table) { $table->id(); $table->timestamps(); $table->softDeletes('deleted_at', 0); }); } /** * Reverse the migrations. * * @return void */ public function down() { Schema::dropIfExists('parent'); }
子テーブルにはForeignKeyを指定しましょう。
/** * Run the migrations. * * @return void */ public function up() { Schema::create('students', function (Blueprint $table) { $table->id(); $table->foreignId('school_id')->constrained(); $table->timestamps(); }); } /** * Reverse the migrations. * * @return void */ public function down() { Schema::dropIfExists('child'); }
はいこれでおけい。
はい次ぃー、Modelの作成をしていきましょう。 親テーブルのモデルは論理削除を行いたいので、SoftDeleteを使用します。
use Illuminate\Database\Eloquent\SoftDeletes; class School extends Model { use SoftDeletes; }
次に子テーブルのモデルのカラムは親のテーブルのIDだけですので、これだけ。
class Student extends Model { protected $fillable = [ 'school_id' ]; }
まずは、外部制約キーが動いているか確認する為に物理削除してみる。 まずはSchoolモデルのSoftDeleteをコメントアウトして、削除してみた。 英語で何て書いてあるかよく分かりませんが、外部制約キーの関係で削除できませんと書いてあるのでしょう。
次にSchoolモデルのSoftDeleteをコメントアウトを解錠して論理削除して見ましょう。
{ "id":1, "created_at":null, "updated_at":"2020-06-03T14:59:17.000000Z", "deleted_at":"2020-06-03T14:59:17.000000Z" }
deleted_atに論理削除された時刻が挿入されています、論理削除成功ですね。 ちなみに、Schoolのidが1のデータはDB上には残っていますが、取得をしようとするとnullで返ってきます。 しっかりしていますね。
DBからデータが無くなっている訳ではないんだから論理削除できて当たり前だよね。 また気になることがあれば検証していきますぅ! ではまた。