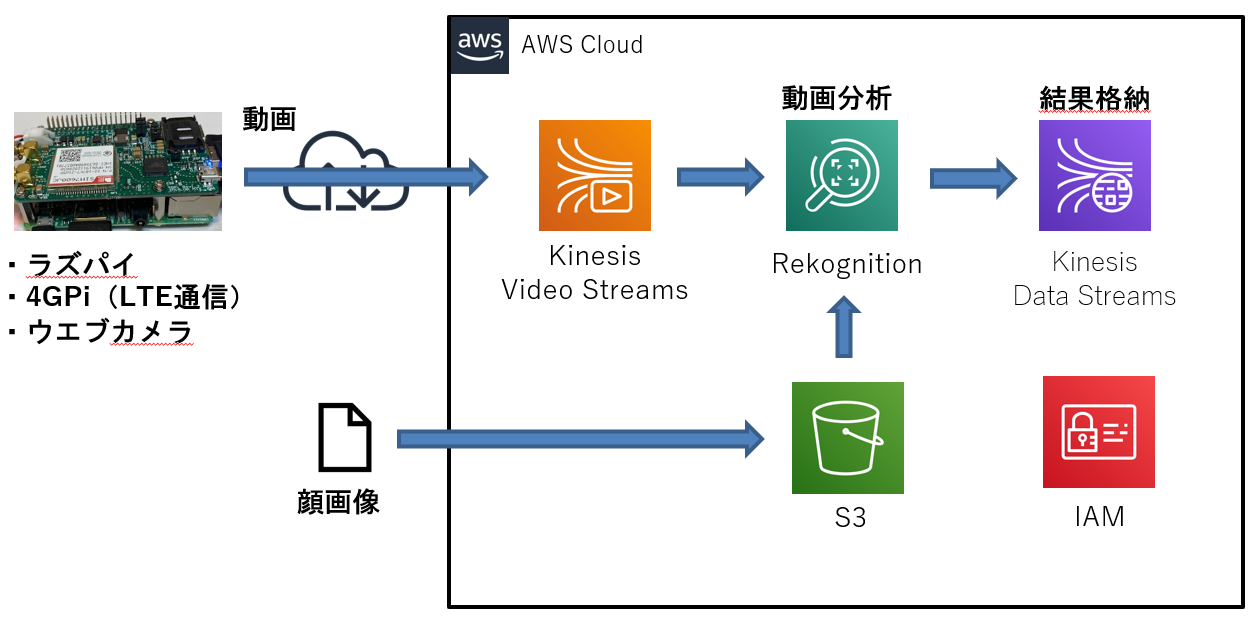
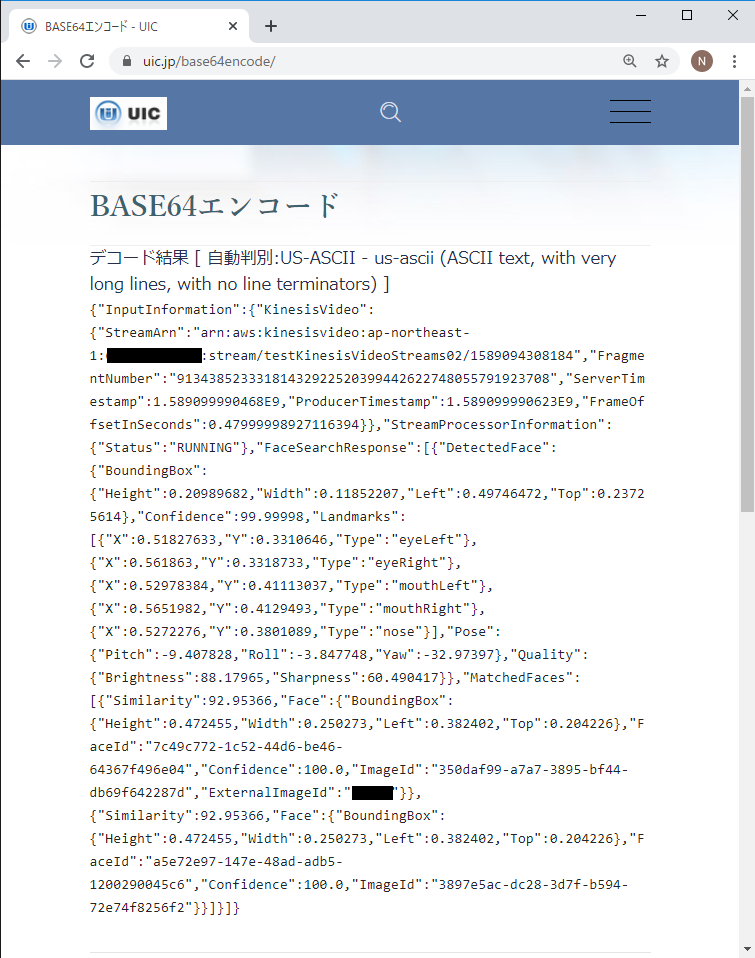
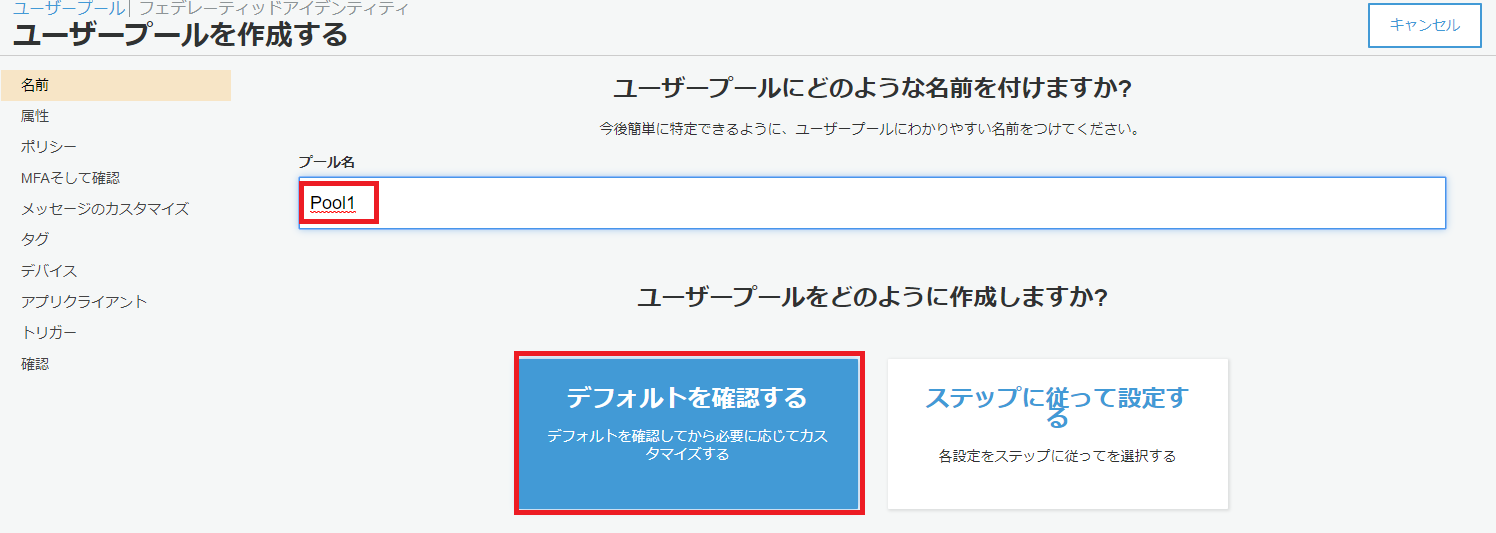
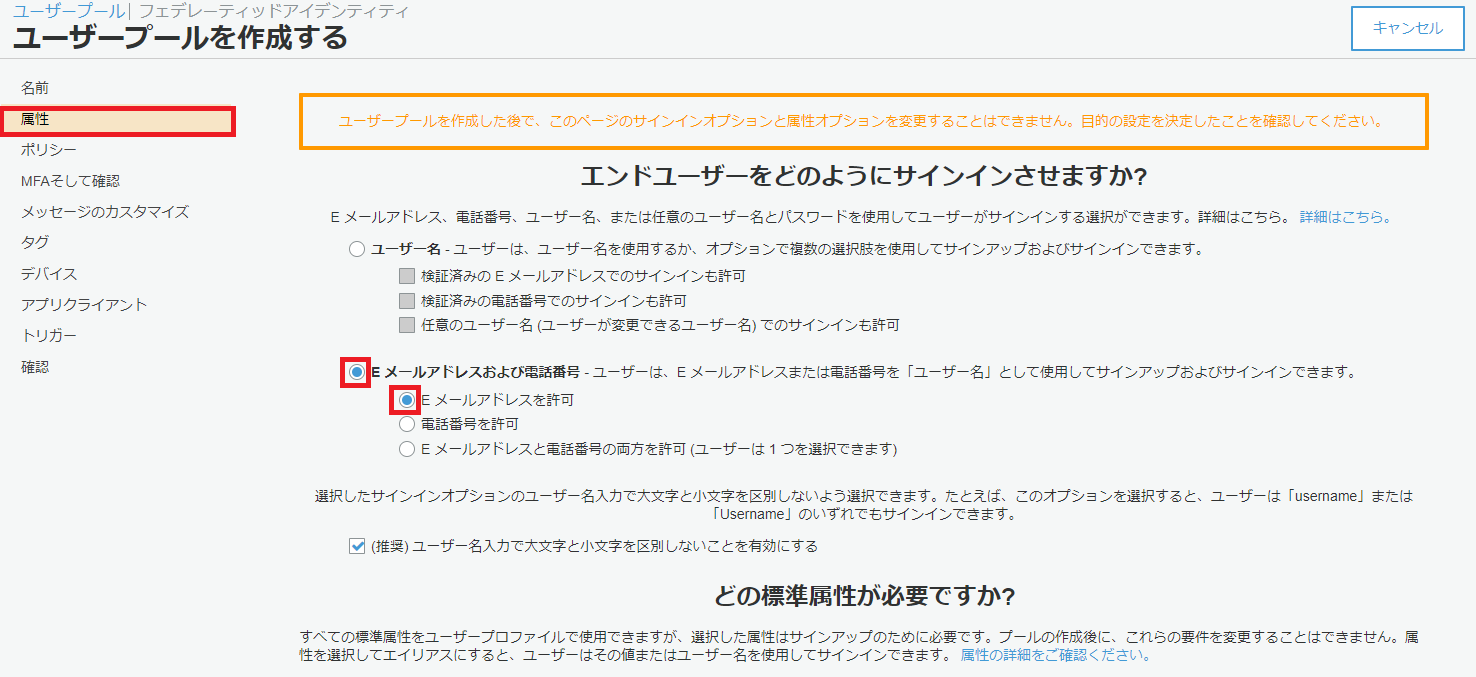
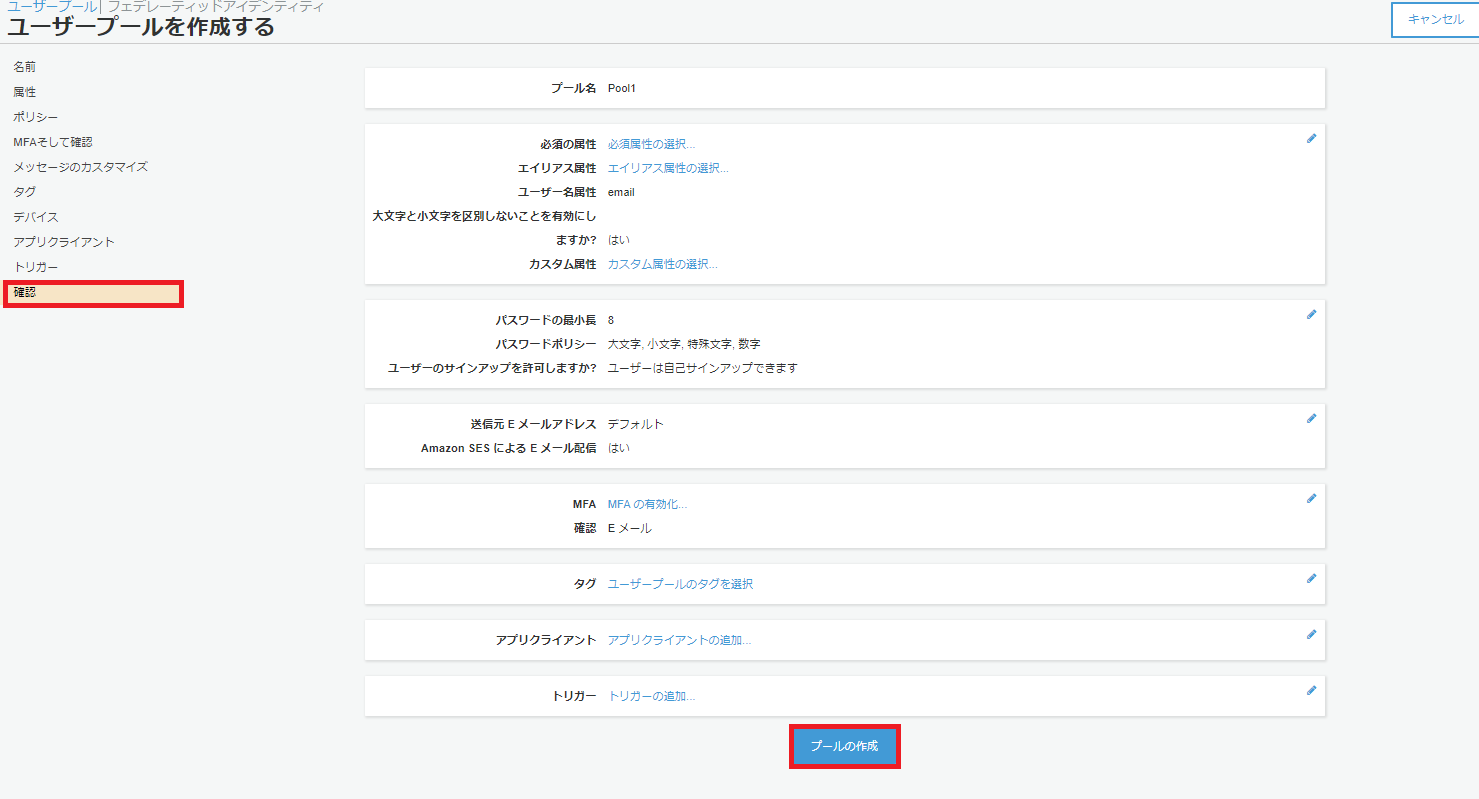
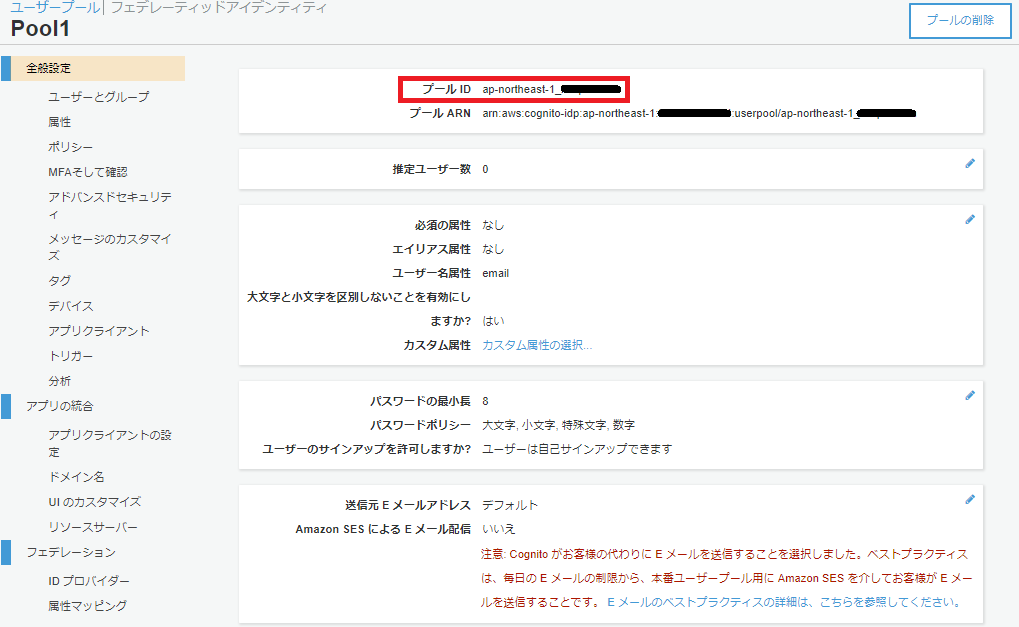
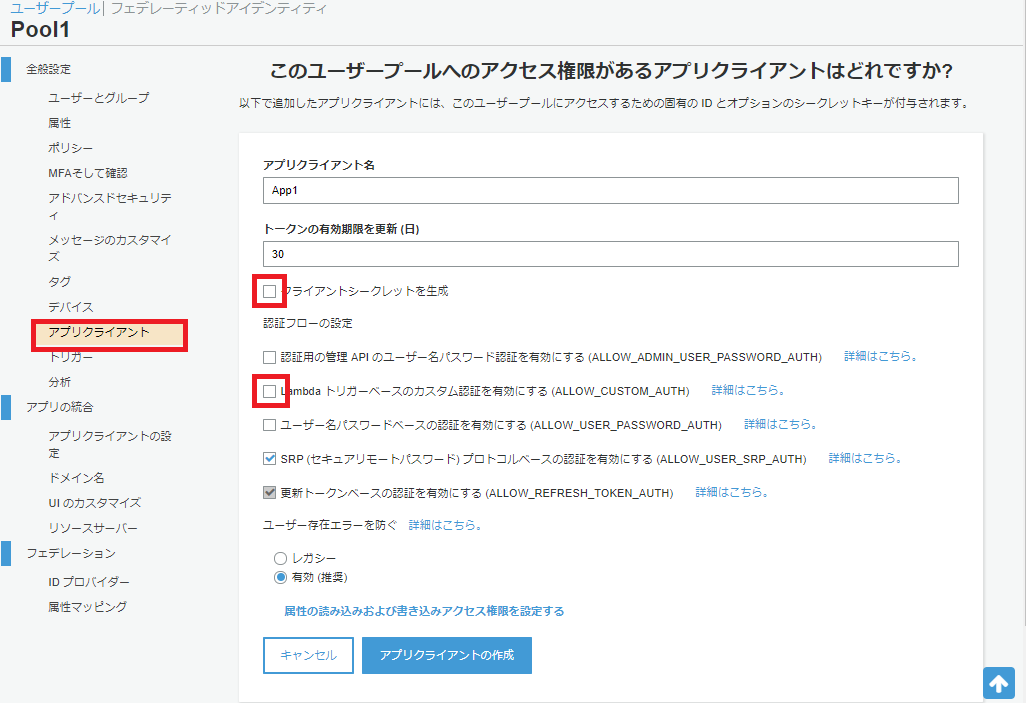
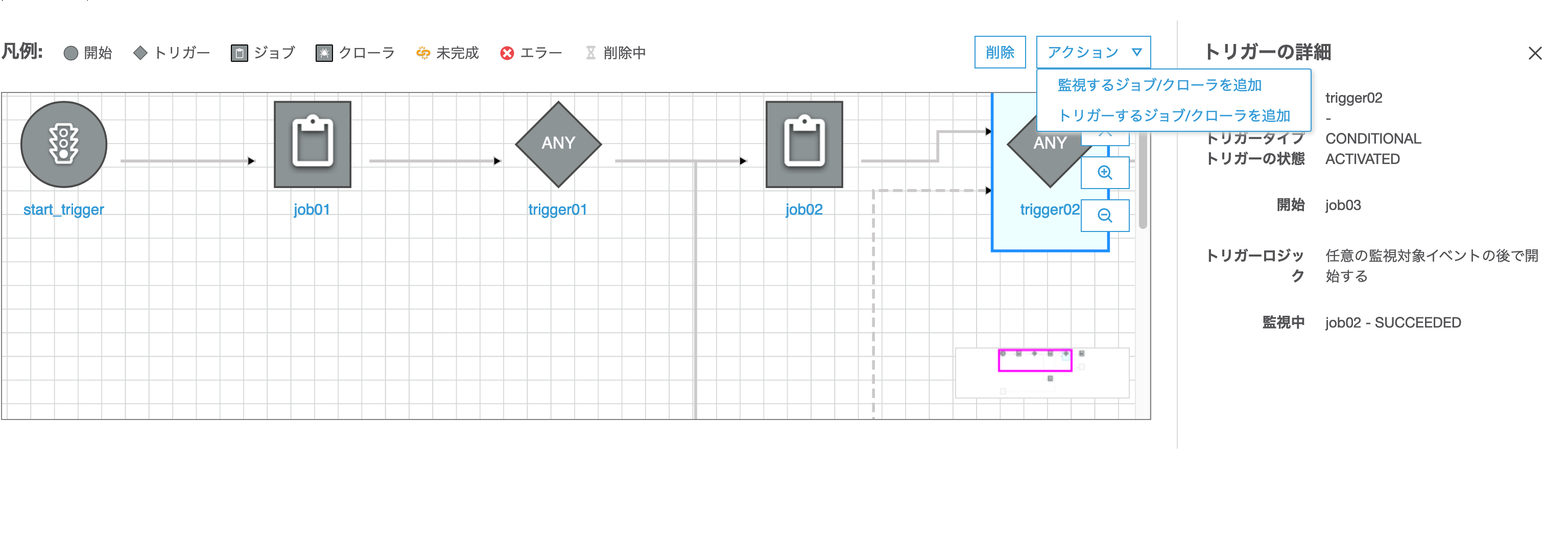
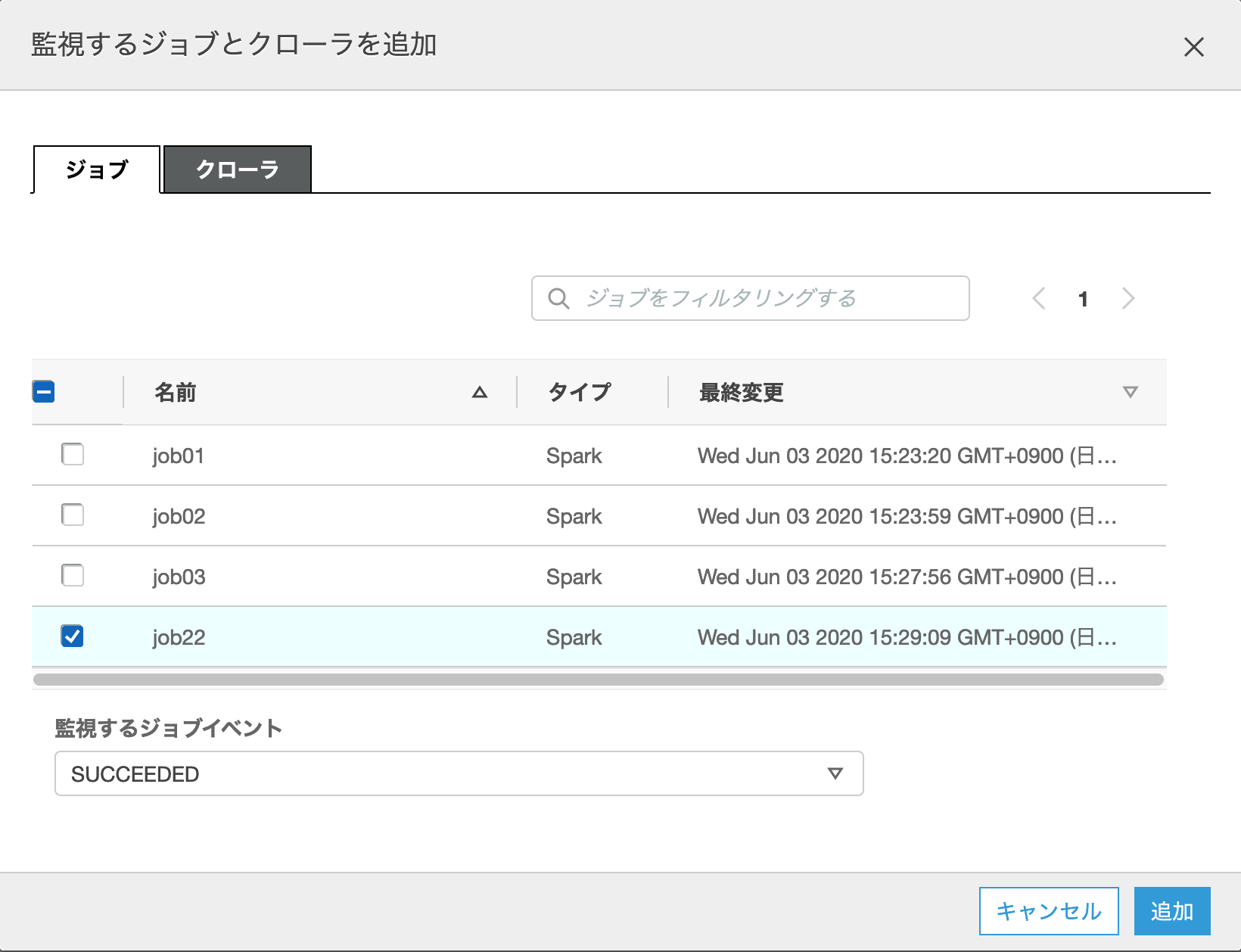
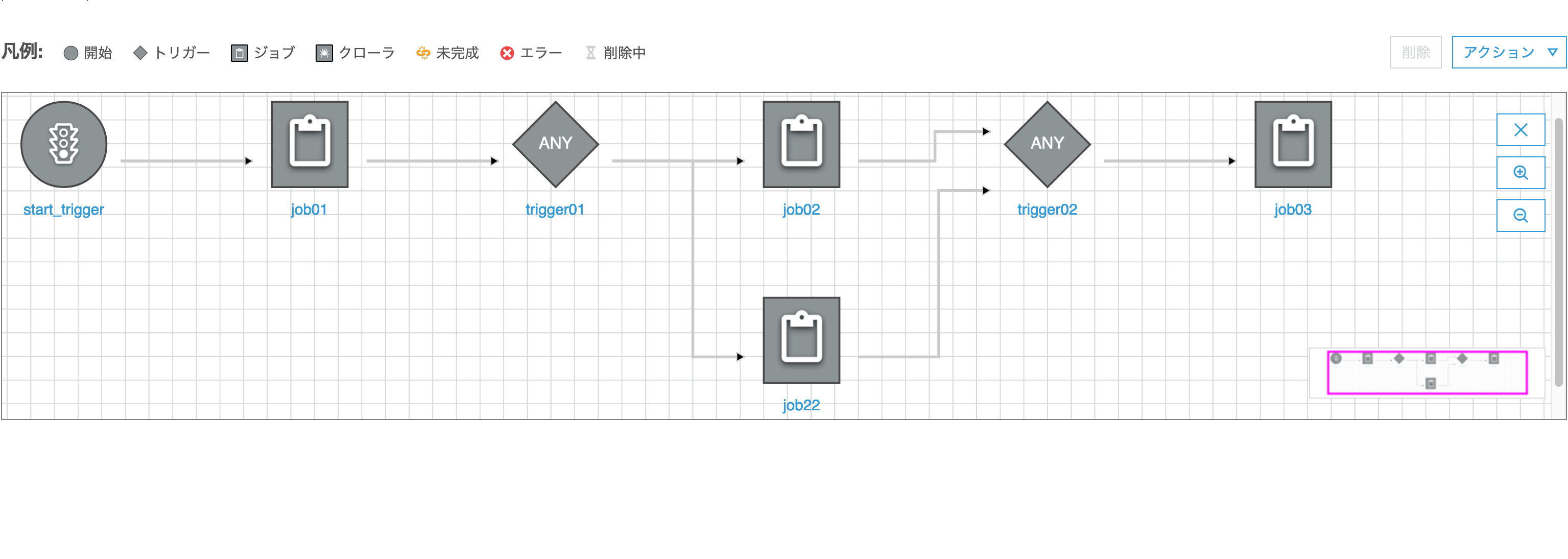
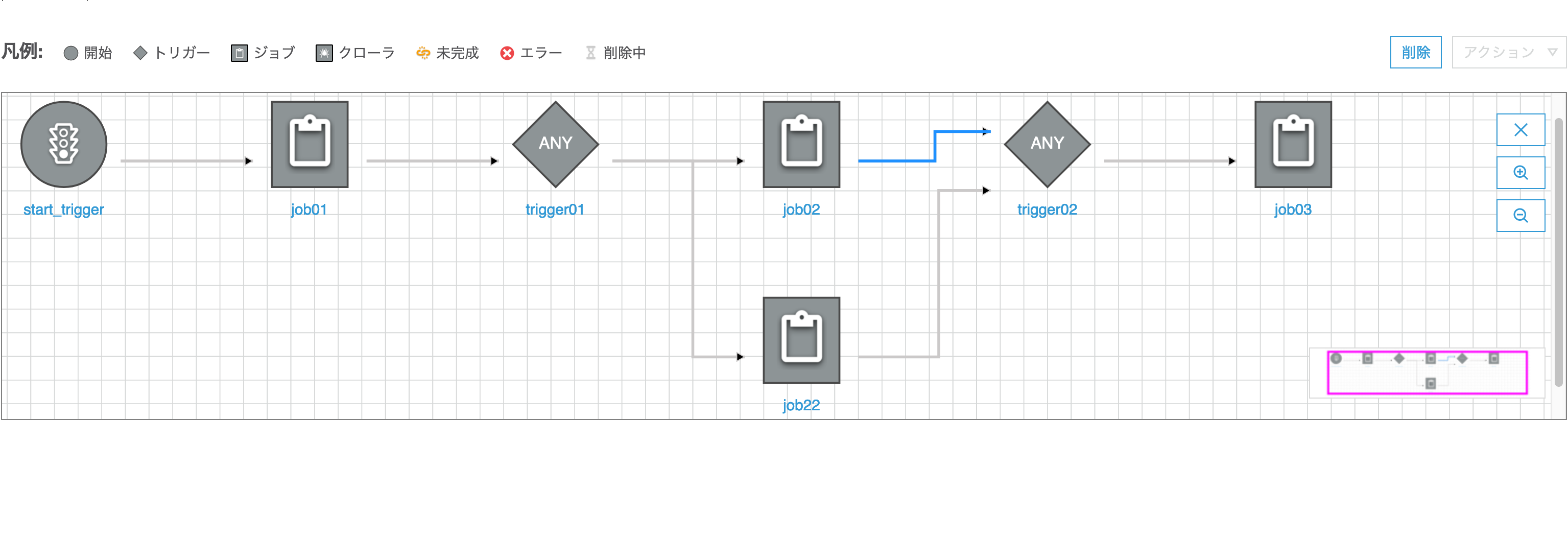
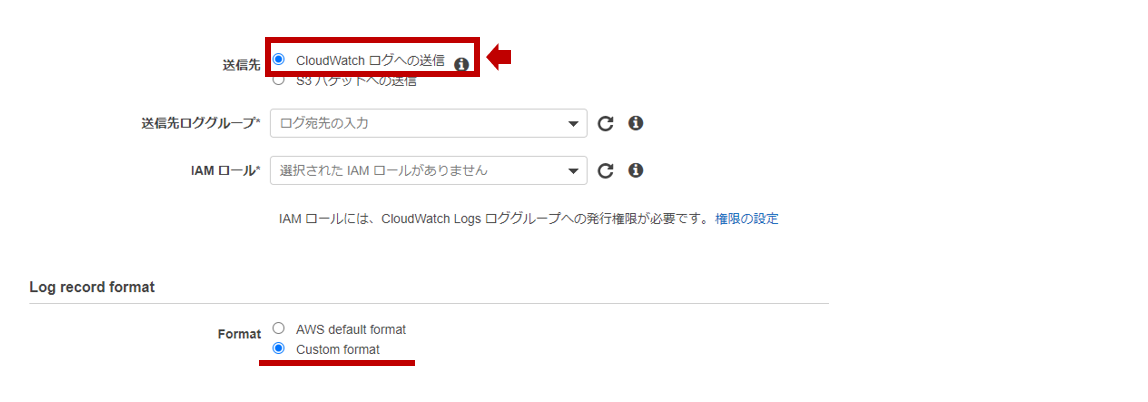
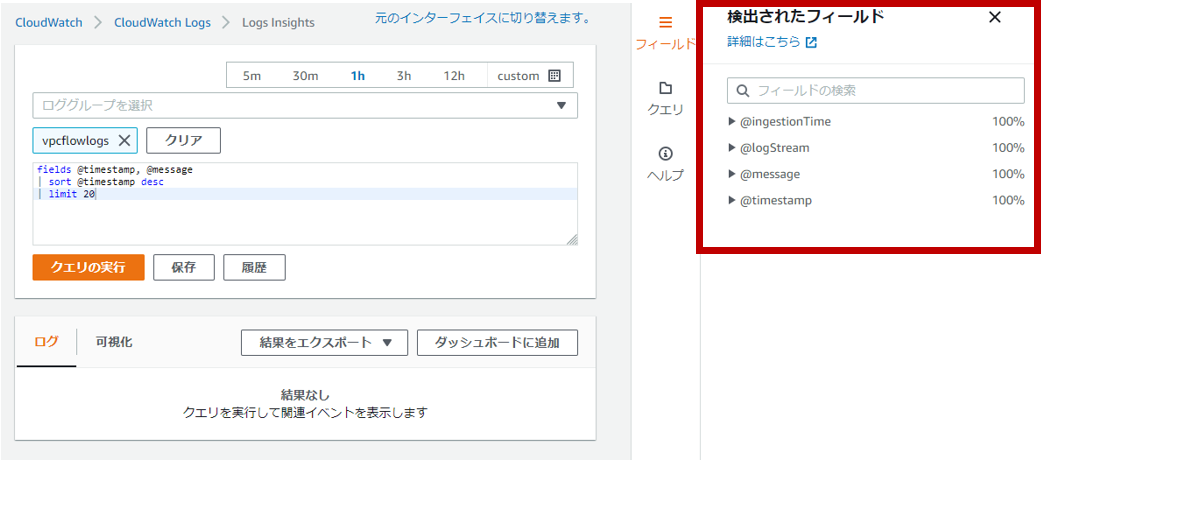
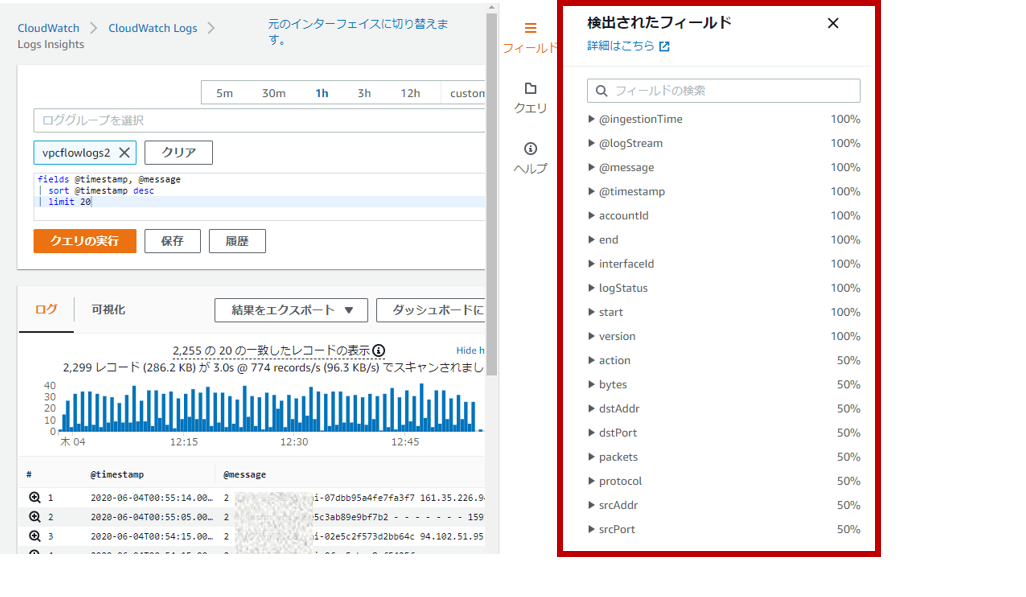
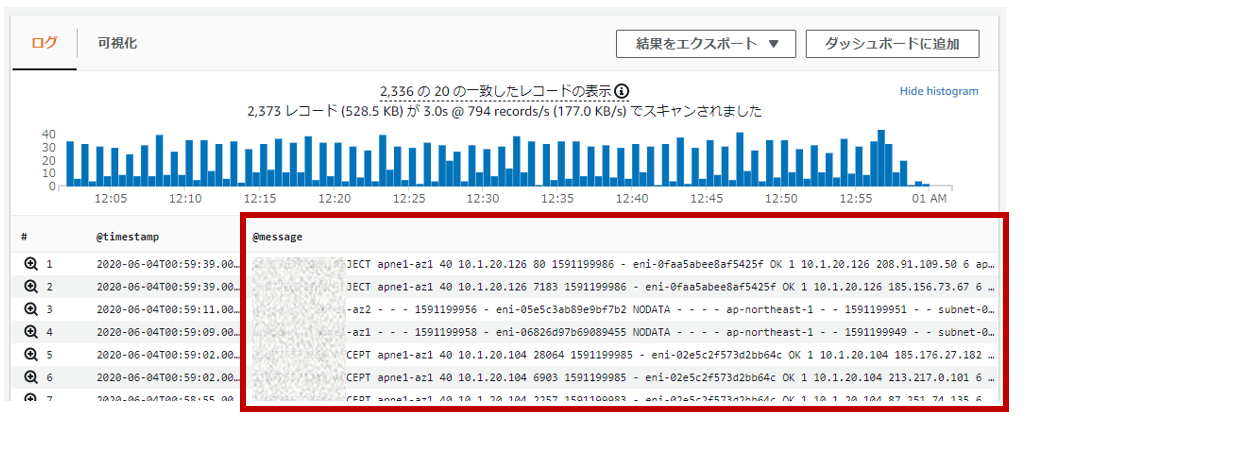
まず、Amazon Cognito Identity SDK for Dartをプロジェクトに組み込みます。pubspec.yamlファイルのdependenciesセクションに以下のようにパッケージを追記します。Visual Studio Codeのpliuginにて自動でパッケージの取得処理が実行されます。
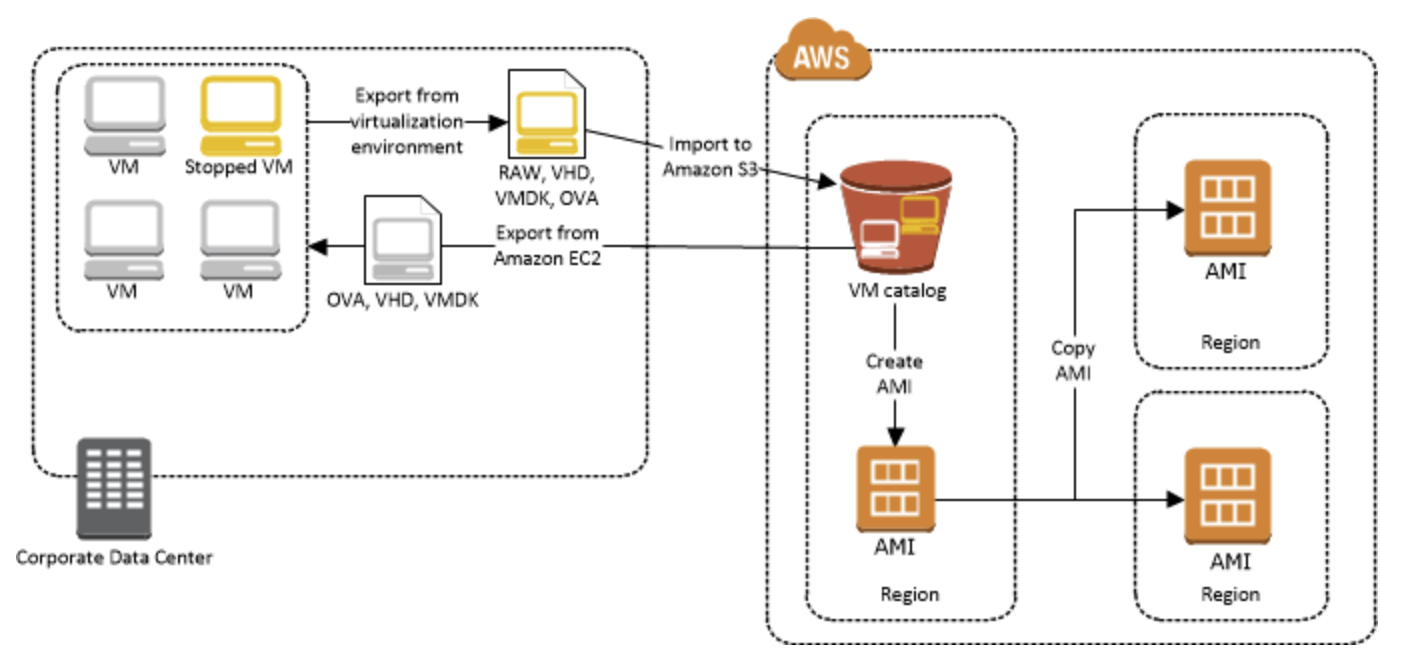
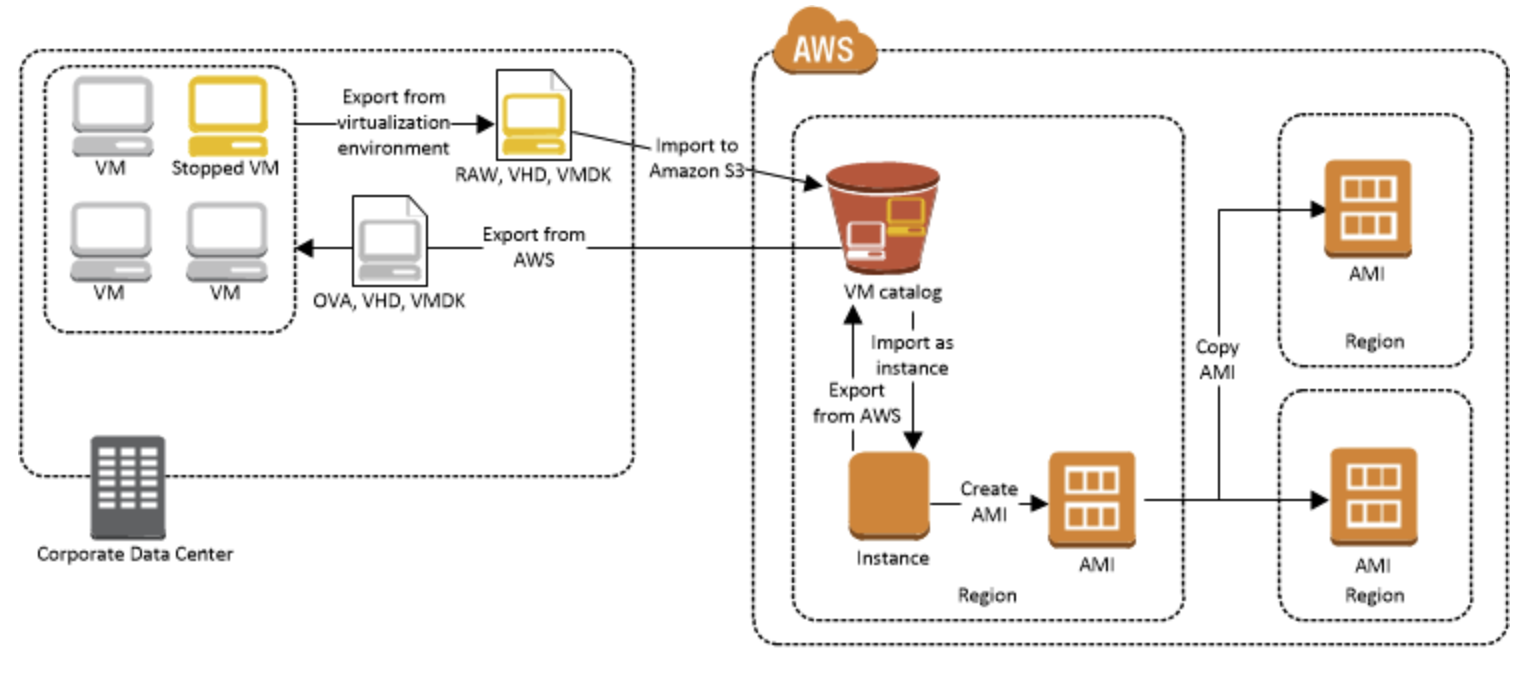
VM Import/Export を使用すると、仮想マシン (VM) イメージを既存の仮想化環境から Amazon EC2 にインポートし、それを元の環境にエクスポートすることができます。この方法を使うと、アプリケーションおよびワークロードを Amazon EC2 へ移行したり、VM イメージカタログを Amazon EC2 にコピーしたり、バックアップと災害対策のために VM イメージのリポジトリを作成することができます。
ほとんどの VM Import ニーズには、AWS Server Migration Service の使用をお勧めします。AWS SMS はインポートプロセスを自動化し (大きな VM インフラストラクチャの移行ワークロードを軽減)、変化する VM の増分更新のサポートを追加して、インポートされた VM をすぐに使用できる Amazon マシンイメージ (AMI) に変換します。
AWS Service Catalog では、AWS での使用が承認された IT サービスのカタログを作成および管理できます。この IT サービスには、仮想マシンイメージ、サーバー、ソフトウェア、データベースから包括的な多層アプリケーションアーキテクチャまで、あらゆるものが含まれます。AWS Service Catalog により、組織は一般的にデプロイされる IT サービスを集中管理でき、一貫性のあるガバナンスを達成し、コンプライアンス要件を満たすうえで役立ちます。エンドユーザーは、組織によって設定された制約に従って、必要な承認済みの IT サービスのみをすばやくデプロイできます。
ユーザー
カタログ管理者 (管理者)
製品 (アプリケーションおよびサービス) のカタログを管理し、ポートフォリオに整理してエンドユーザーにアクセス権限を付与します。カタログ管理者は、AWS CloudFormation テンプレートの準備や制約の設定を行い、製品に割り当てられた IAM ロールを管理して、高度なリソース管理を提供
エンドユーザー
IT 部門またはマネージャーから AWS 認証情報を受け取り、AWS マネジメントコンソールを使用して、アクセス権限を付与されている製品を起動します。単純にユーザーと呼ばれることもあるエンドユーザーには、操作要件によって異なるアクセス許可を付与できます。たとえば、ユーザーに (使用する製品によって求められるすべてのリソースを起動および管理できるように) 最大限のアクセス許可レベルを付与することも、特定のサービス機能の使用に対するアクセス許可のみを付与することもできます。
ポートフォリオとは、製品の集合で、設定情報も組み込まれています。ポートフォリオは、特定の製品を使用できるユーザー、そのユーザーに許可される製品の使用方法の管理に役立ちます。AWS Service Catalog では、組織のユーザータイプごとにカスタマイズしたポートフォリオを作成し、適切なポートフォリオへのアクセス権を選択的に付与できます。製品の新しいバージョンをポートフォリオに追加すると、そのバージョンは、現在のすべてのユーザーに対して自動的に利用可能になります。また、自分のポートフォリオを他の AWS アカウントと共有して、そのアカウントの管理者がそのポートフォリオに制約 (ユーザーが作成できる EC2 インスタンスの制限など) を加えて配布できるようにすることができます。ポートフォリオ、アクセス権限、共有、制約を使用することで、組織のニーズおよび標準に合わせて適切に設定された製品をユーザーが起動するよう制御できます。
バージョニング
AWS Service Catalog では、カタログで複数のバージョンの製品を管理できます。これにより、ソフトウェアの更新または設定の変更に基づいて新しいバージョンのテンプレートと関連するリソースを追加できます。新しいバージョンの製品を作成すると、その製品にアクセスできるすべてのユーザーに更新が自動的に配信されるので、ユーザーは使用する製品のバージョンを選択できます。ユーザーは、製品の実行中のインスタンスを新しいバージョンにすばやく簡単に更新できます。
アクセス許可
ポートフォリオへのアクセス権をユーザーに付与すると、ユーザーはポートフォリオを閲覧して、それに含まれる製品を起動できます。AWS Identity and Access Management (IAM) アクセス許可を適用して、カタログを表示および変更できるユーザーを制御できます。IAM アクセス許可は IAM ユーザー、グループ、およびロールに割り当てることができます。ユーザーが IAM ロールが割り当てられている製品を起動すると、AWS Service Catalog では、そのロールで、AWS CloudFormation を使用して製品のクラウドリソースを起動します。IAM ロールを各製品に割り当てると、承認されていない操作を実行できるアクセス権限がユーザーに割り当てられないようにすることができます。また、ユーザーは、カタログを使用してリソースをプロビジョニングできます。
制約
制約によって、特定の AWS リソースを製品に対してデプロイできる方法を制御します。制約を使用して、製品に制限を適用し、ガバナンスまたはコスト管理を実現できます。AWS Service Catalog の制約にはさまざまなタイプがあります。起動の制約、通知の制約、テンプレートの制約です。