- 投稿日:2020-05-31T23:46:33+09:00
waidayoを使って手軽にUnityやUE4でフェイシャルキャプチャ(表情取得)しよう
はじめに
こんなツールを作りました。
Oredayo4V (おれだよ for VTuber)です。#Oredayo4V がどれだけ多機能かというと、DiscordとOredayo4V (とWaidayo)だけで、こんなビデオ通話が実現できます。
— Segmentation Fault (@Seg_Faul) May 31, 2020
仮想Webカメラ機能、PostProcessing機能、背景画像機能のあわせ技です。https://t.co/oXtb2JiE7N pic.twitter.com/aeAFr7I1g2私は、iOSのアバターフェイシャルキャプチャアプリ「waidayo」の作者ではありません。
赤の他人です。データや通信仕様の解析や問い合わせをしたわけでもありません。
- ではなぜ、こういうものが作れたのか?
- どういう仕組で連携できているのか?
- 同様のものを作るにはどうすればいいのか?
について本記事では解説いたします。
VMCProtocol
突然ですが、皆さんはVirtual Motion Capture Protocol (VMCProtocol)はご存知でしょうか?
https://sh-akira.github.io/VirtualMotionCaptureProtocol/バーチャルモーションキャプチャープロトコルの名前の通り、バーチャルモーションキャプチャーと通信するためのプロトコルです。
通信して何をするのかというと、キャプチャしたモーション情報を送受信します。もともとはバーチャルモーションキャプチャーからUnityにモーションを送信するために作られたものでしたが、元より仕様は公開されており、誰でも利用することができます。
サンプルや、リファレンスとなる実装も公開されており、現在15以上のアプリケーションが対応しています。
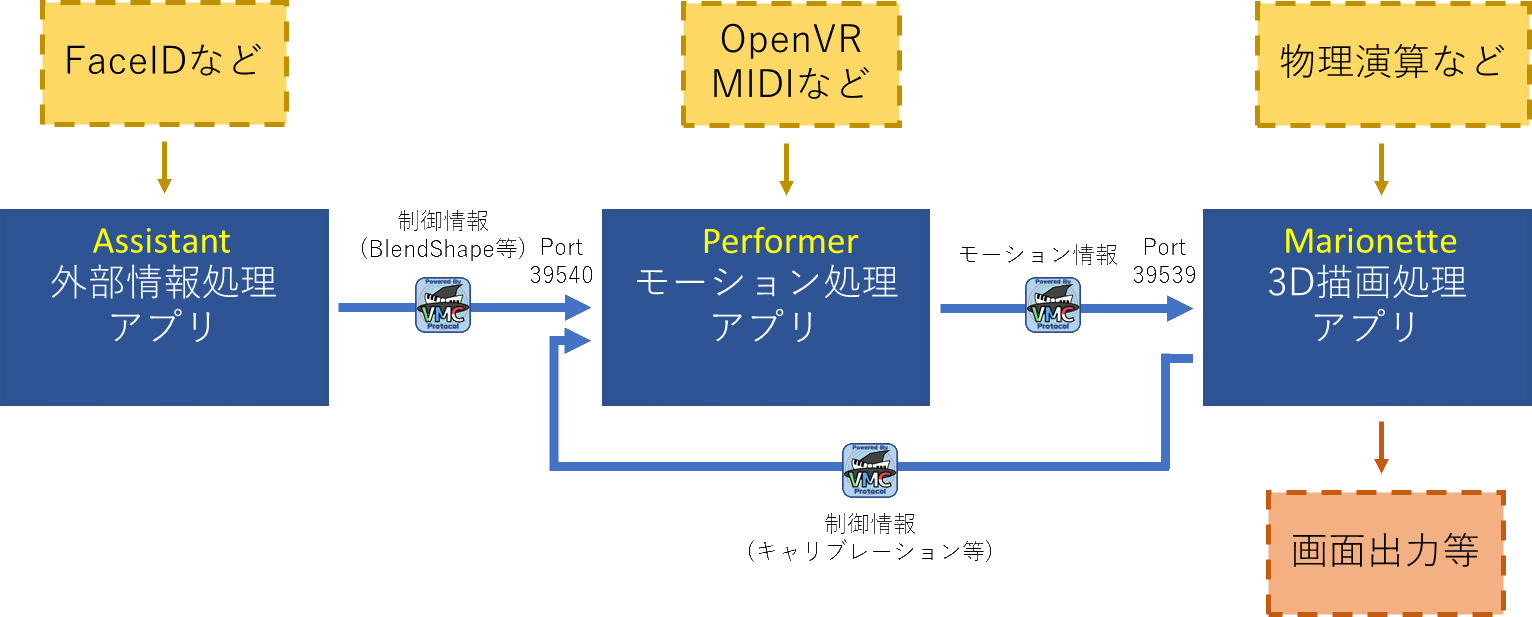
これにより、アバターの姿勢や表情などのトラッキングと、描画、センシングをそれぞれ別々のアプリケーションで行うことができるようになります。
そう、ここでFace IDの表記がある通り、nmちゃん氏のwaidayoもこのVMCProtocolに対応したアプリケーションです。
具体的な実装
Oredayo4VはUnityで実装されています。
VMCProcolには代表的な2つのライブラリ実装があります。(どちらもMITライセンスです)今回は、先に述べたとおり、Unityで実装したため、EVMC4Uを使いました。
EVMC4Uには、ボーン情報、表情その他の受信状機能があらかじめ備わっており、UnityPackageをインポートするだけでもう動きます。あとはVRMを読み込み、waidayoの送信先をEVMC4Uのポートに設定するだけです。
概ねの実装はこれだけで、あとはカメラの移動やその他を制御する仕組み、UIを延々載せていっただけです。WPFとの通信は、sh-akira氏のUnityMemoryMappedFile
ウィンドウ制御はsh-akira氏のVMCUnityWindowExtensions
仮想Webカメラはschellingb氏のUnityCaptureなど、
ひたすらライブラリを組み合わせていった結果です。VMC4UEを使えば、UnrealEngine4版も簡単に作れることと思いますし、既存のゲームなどのプロジェクトにこれらライブラリを導入すれば、簡単に背景付きの撮影環境を構築することができます。
もちろん、ゲーム自体に組み込んでしまうこともできます。
(VR飛行ゲームPilotXrossという例があります)ボーンの受信
EVMC4Uには様々な支援機能や最適化が含まれていますが、やっていることは単純です。
以下がVMCProtocol公式ページに記載のボーン・表情受信サンプルです。waidayoから受信すればフェイシャルキャプチャになりますし、バーチャルモーションキャプチャーから受信すればフルボディトラッキングになります。単純ですね。
/* * SampleBonesReceive * gpsnmeajp * https://sh-akira.github.io/VirtualMotionCaptureProtocol/ * * These codes are licensed under CC0. * http://creativecommons.org/publicdomain/zero/1.0/deed.ja */ using System; using System.Collections; using System.Collections.Generic; using UnityEngine; using VRM; [RequireComponent(typeof(uOSC.uOscServer))] public class SampleBonesReceive : MonoBehaviour { public GameObject Model; private GameObject OldModel = null; Animator animator = null; VRMBlendShapeProxy blendShapeProxy = null; uOSC.uOscServer server; void Start() { server = GetComponent<uOSC.uOscServer>(); server.onDataReceived.AddListener(OnDataReceived); } void Update() { if (blendShapeProxy == null) { blendShapeProxy = Model.GetComponent<VRMBlendShapeProxy>(); } } void OnDataReceived(uOSC.Message message) { if (message.address == "/VMC/Ext/Root/Pos") { Vector3 pos = new Vector3((float)message.values[1], (float)message.values[2], (float)message.values[3]); Quaternion rot = new Quaternion((float)message.values[4], (float)message.values[5], (float)message.values[6], (float)message.values[7]); Model.transform.localPosition = pos; Model.transform.localRotation = rot; } else if (message.address == "/VMC/Ext/Bone/Pos") { //モデルが更新されたときのみ読み込み if (Model != null && OldModel != Model) { animator = Model.GetComponent<Animator>(); blendShapeProxy = Model.GetComponent<VRMBlendShapeProxy>(); OldModel = Model; } HumanBodyBones bone; if (Enum.TryParse<HumanBodyBones>((string)message.values[0], out bone)) { if ((animator != null) && (bone != HumanBodyBones.LastBone)) { Vector3 pos = new Vector3((float)message.values[1], (float)message.values[2], (float)message.values[3]); Quaternion rot = new Quaternion((float)message.values[4], (float)message.values[5], (float)message.values[6], (float)message.values[7]); var t = animator.GetBoneTransform(bone); if (t != null) { t.localPosition = pos; t.localRotation = rot; } } } } else if (message.address == "/VMC/Ext/Blend/Val") { string BlendName = (string)message.values[0]; float BlendValue = (float)message.values[1]; blendShapeProxy.AccumulateValue(BlendName, BlendValue); } else if (message.address == "/VMC/Ext/Blend/Apply") { blendShapeProxy.Apply(); } } }おわりに
VMCProtocolを使用すると、非常に安価に、かつ様々な資産を活用してソフトウェアや撮影環境を構築できます。
ぜひお試しください。

- 投稿日:2020-05-31T20:26:29+09:00
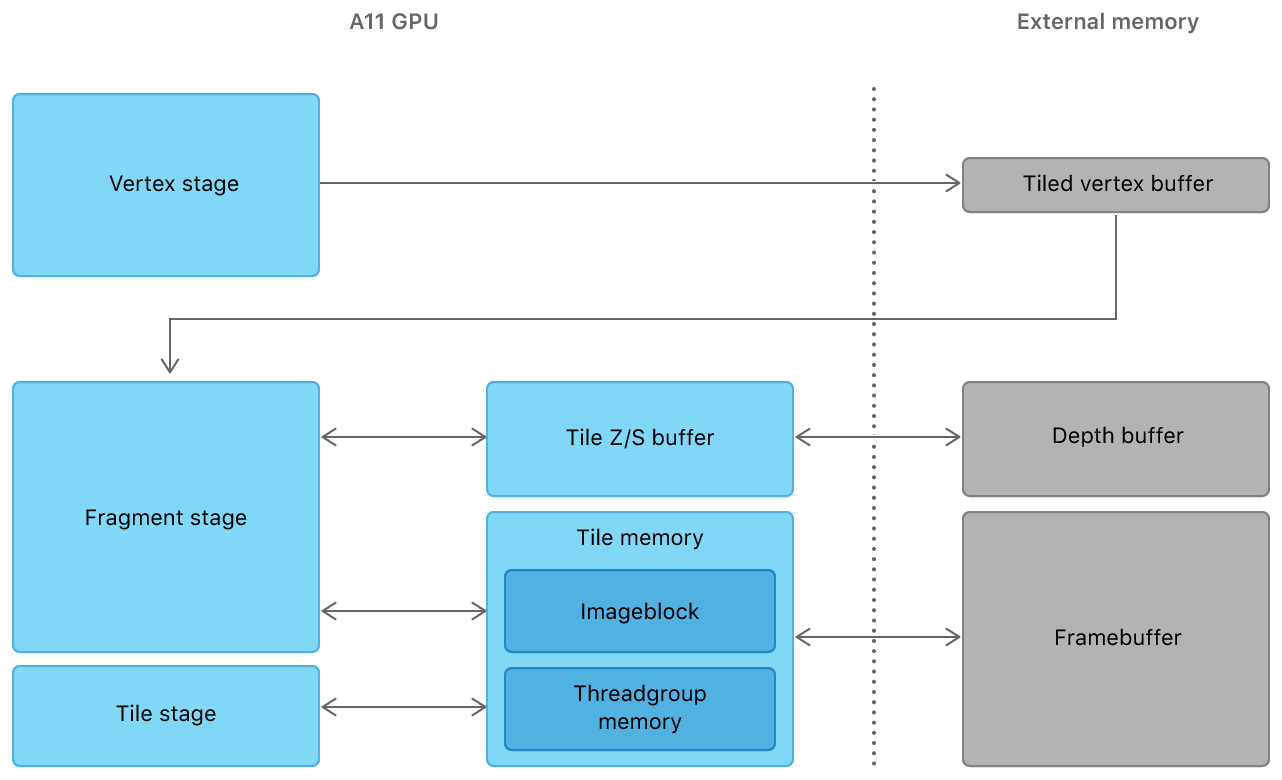
[iOS] Metalで効率的にループ計算する機能 "Raster Order Group" について
Apple製のGPUシェーダー言語Metalにて、ループ計算を効率的に行うことができる仕組み「Raster Order Group」について実験してみたのでまとめてみたいと思います。
はじめに
この記事では以下について紹介します。
- Raster Order Groupとは?
- Raster Order Groupの処理の流れ
- 実装における注意点
以下では、Appleが公開しているサンプルコード (リンク) をベースに、コードの中身の簡単な解説と実装時の注意点について説明します。
Raster Order Groupとは?
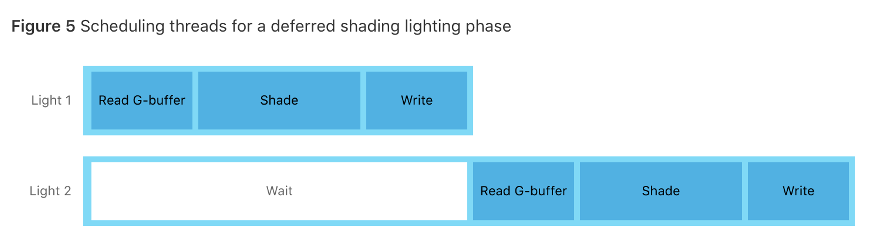
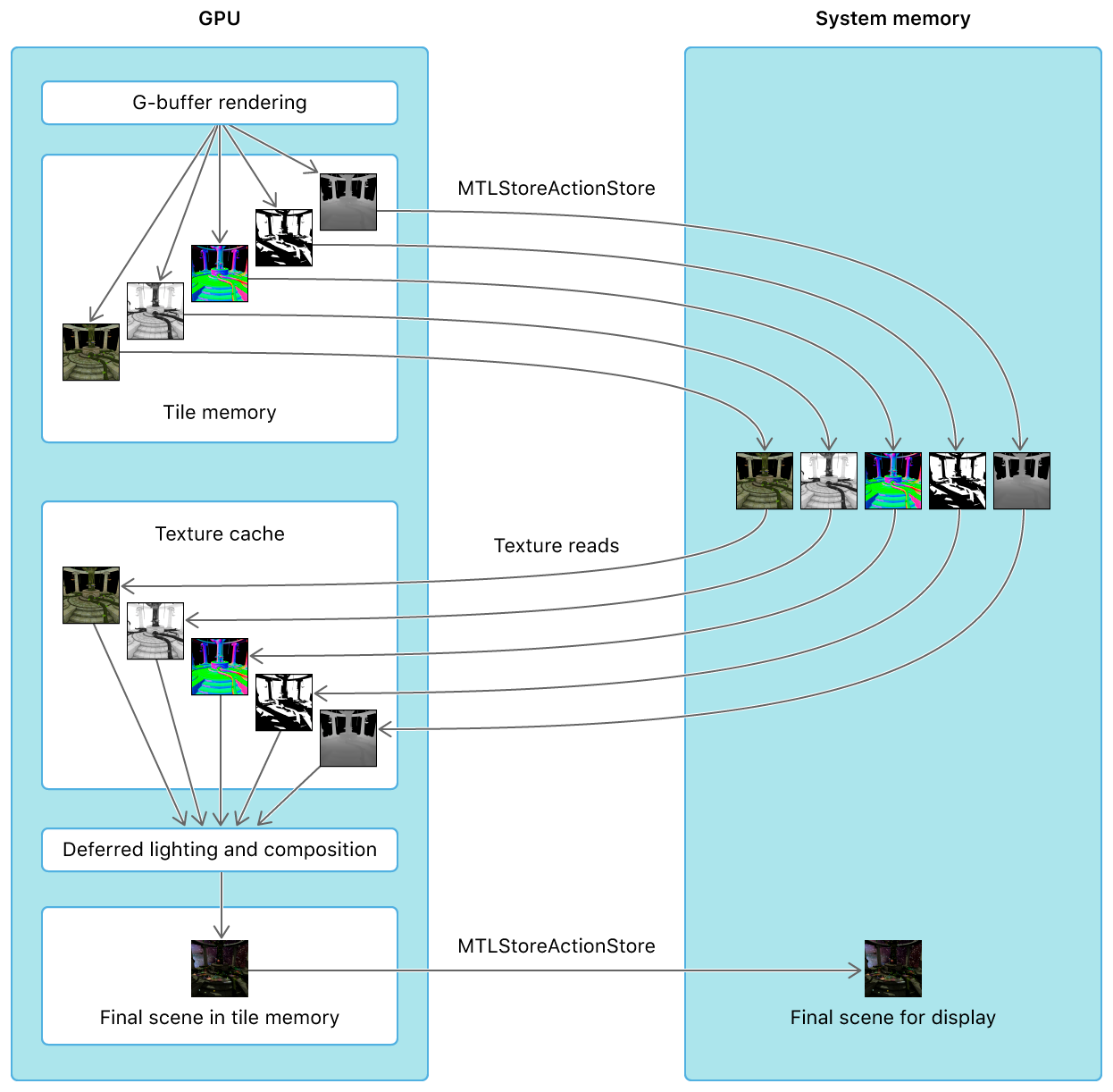
例えば以下例のように、一番めのテクスチャに対してカーネル計算を行い、その結果を使って次のテクスチャを描画するような場合、従来の方法だとTexture1のカーネル計算の結果を受け取るためには一度結果のデータをGPUからCPUへ転送し、改めてCPUからGPUへ転送するような手順を踏まなければ、計算結果を反映下処理ができませんでした。
*Apple開発者ページより (リンク) より.このような手順を踏むと、上図のように余計な待ち時間が発生することは素より、この実装におけるより大きな問題はCPU-GPU間のデータ転送に小さくないコストが掛かる事にあります。(下図)
*Apple開発者ページより (同上ページ)
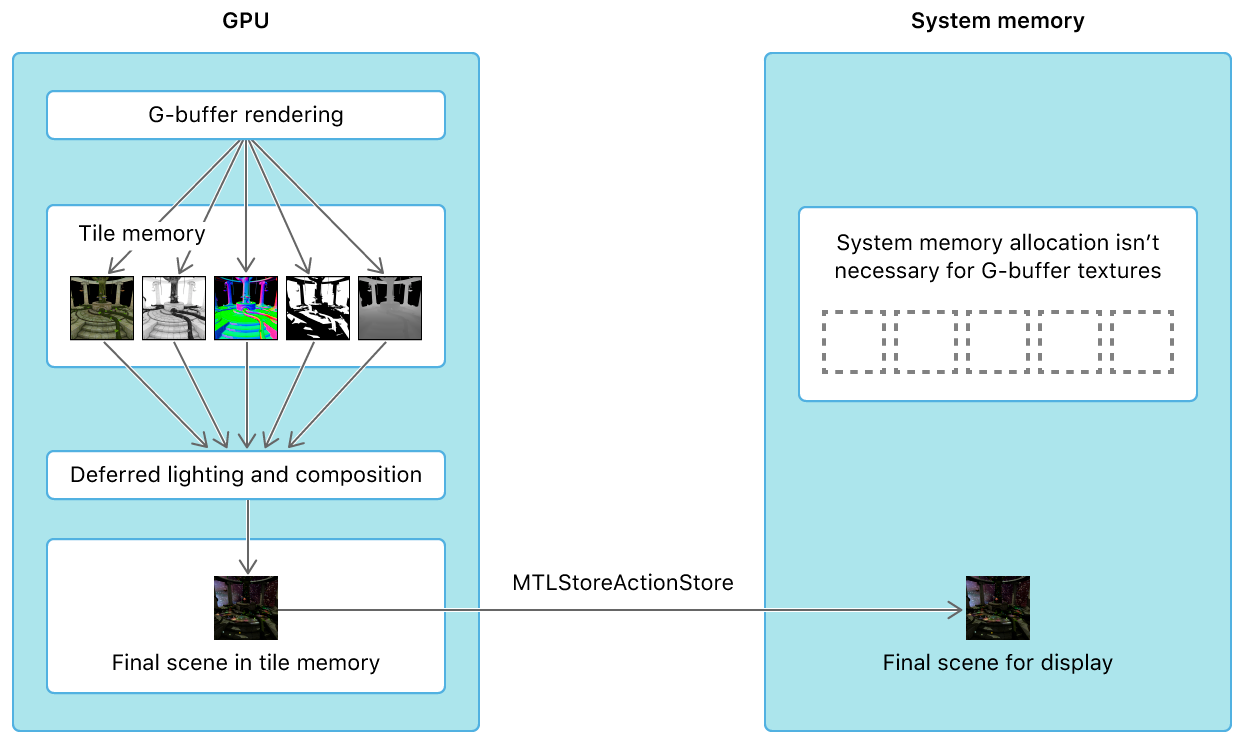
CPUへの無駄なデータ転送を抑制する
そこでこのような計算を実施するための自然な方法として、GPU内部のメモリに一時的に中間状態のbufferを保持しておき、CPU-GPU間のデータ転送に係るオーバーヘッドを極力減らす手法 "Raster Order Group" がMetal2で公開されました。
*Apple開発者ページ (同上ページ)これと同様の機能は、例えば Unity (HLSL) では GrabPass{} が相当します. 一般的にはマルチパスレンダリングと呼ばれる機能になります.
Raster Order Groupの処理の流れ
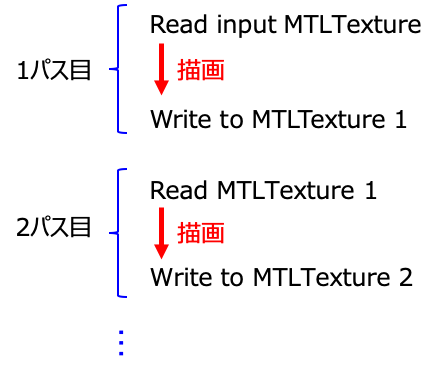
基本的に下図のように、MTLTextureオブジェクトを用意してループ計算結果をRead/Writeしながら描画を進めることになります.
textureの設定の仕方は筆者の把握する限り、2通りのやり方があると思います.
-renderEncoder.setFragmentTexture()でループ描画用の MTLTexture オブジェクトを設置して描画する方法.
- 1つはrenderPassDescriptor.colorAttachmentに設置する MTLTexture オブジェクトに描画する方法.これらに共通する点は、入力に加えて描画のループ回数分だけCPU側で MTLTexture オブジェクトを用意し、ループ計算の度に結果を texture に write するという点です. この texture の Read/Write においては注意点があります.
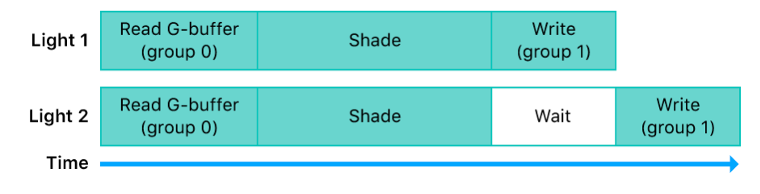
- 1つのrenderPassDescriptorに対しcolorAttachmentは8つまで. つまり8ループが限界である.
- これはどうやら renderEncoder.setFragmentTexture() を使う場合でも同じで、1度に8ループまでが限度になっているようである.
- 同じtextureに2度書き込むことはできない. よって必ず描画回数分のtextureを用意する必要がある.
- (textureのReadに関する重要な注意点は次節で述べます.)
具体的な実装
1. colorAttachmentを使う方法
ここではApple開発者ページのコードを引用します.
struct GBufferData { half4 lighting [[color(AAPLRenderTargetLighting), raster_order_group(AAPLLightingROG)]]; half4 albedo_specular [[color(AAPLRenderTargetAlbedo), raster_order_group(AAPLGBufferROG)]]; half4 normal_shadow [[color(AAPLRenderTargetNormal), raster_order_group(AAPLGBufferROG)]]; float depth [[color(AAPLRenderTargetDepth), raster_order_group(AAPLGBufferROG)]]; };lightingやalbedo_specularはtexture名で、それぞれに紐づくtextureオブジェクトはrenderPassDescriptorで設定するcolorAttachmentに渡されています.
そして上記のcolor(n)はcolorAttachmentのインデックスを、raster_order_group(n)は本稿の主題であるループ計算のグループを示すインデックスを、それぞれ設定している修飾子です.raster_order_groupのインデックス値が同じtexture同士は同じタイミング (同じループ) で描画されます.
ちなみにraster_order_groupのインデックスの数値はループ計算の順番とは関係ありません. しかし可読性のため、ループ計算の順番とインデックスの数値を揃えておいた方が無難かもしれません.以下は入力されたMTLTextureをreadしてraster_order_group指定されたcolorAttachmentへwriteする部分の抜粋です.
fragment GBufferData gbuffer_fragment(ColorInOut in [[ stage_in ]], constant AAPLUniforms &uniforms [[ buffer(AAPLBufferIndexUniforms) ]], texture2d<half> baseColorMap [[ texture(AAPLTextureIndexBaseColor) ]], texture2d<half> normalMap [[ texture(AAPLTextureIndexNormal) ]], texture2d<half> specularMap [[ texture(AAPLTextureIndexSpecular) ]], depth2d<float> shadowMap [[ texture(AAPLTextureIndexShadow) ]]) { (略) half4 base_color_sample = baseColorMap.sample(linearSampler, in.tex_coord.xy); half4 normal_sample = normalMap.sample(linearSampler, in.tex_coord.xy); half specular_contrib = specularMap.sample(linearSampler, in.tex_coord.xy).r; // Fill in on-chip geometry buffer data GBufferData gBuffer; (略) // Store shadow with albedo in unused fourth channel gBuffer.albedo_specular = half4(base_color_sample.xyz, specular_contrib); // Store the specular contribution with the normal in unused fourth channel. gBuffer.normal_shadow = half4(eye_normal.xyz, shadow_sample); gBuffer.depth = in.eye_position.z; (略) return gBuffer;colorAttachmentへの書き込みはreturnによって行われます. 複数のcolorAttachment (MTLTexture) へwriteするためには上記のように構造体を用います.
texture2dオブジェクトのbaseColorMapなどはrenderEncoderのsetFragmentTexture()で渡される入力textureです. これを所定の描画を行い、raster_order_groupを指定したGBufferDataの要素に渡します. これをreturnすれば描画順を考慮して出力してくれます.
fragment AccumLightBuffer deferred_directional_lighting_fragment(QuadInOut in [[ stage_in ]], constant AAPLUniforms & uniforms [[ buffer(AAPLBufferIndexUniforms) ]], GBufferData GBuffer) { AccumLightBuffer output; output.lighting = deferred_directional_lighting_fragment_common(in, uniforms, GBuffer.depth, GBuffer.normal_shadow, GBuffer.albedo_specular); return output; }次ループで先ほど書き込まれたtextureをreadするのは簡単で、fragment関数の入力にGBufferDataを指定して要素にアクセスするだけです.
なおraster_order_group指定されたtextureの描画順ですが、これはrenderEncoderのdraw関数のコール順となります.
_viewRenderPassDescriptor.colorAttachments[AAPLRenderTargetLighting].texture = drawableTexture; _viewRenderPassDescriptor.depthAttachment.texture = self.view.depthStencilTexture; _viewRenderPassDescriptor.stencilAttachment.texture = self.view.depthStencilTexture; id <MTLRenderCommandEncoder> renderEncoder = [commandBuffer renderCommandEncoderWithDescriptor:_viewRenderPassDescriptor]; renderEncoder.label = @"Combined GBuffer & Lighting Pass"; [super drawGBuffer:renderEncoder]; [self drawDirectionalLight:renderEncoder]; [super drawPointLightMask:renderEncoder]; [self drawPointLights:renderEncoder]; [super drawSky:renderEncoder]; [super drawFairies:renderEncoder]; [renderEncoder endEncoding];コードの詳細は割愛しますが下記のdrawGBuffer等の関数中でrenderEncoder.draw---が呼ばれ描画されています. renderEncoderが生成されてからrenderEncoder.endEncoding()が呼ばれるまでの間にfragment関数を呼ぶ順でループ順が考慮されてraster_order_groupが機能する仕組みです.
2. setFragmentTextureを使う方法
renderEncoder.setFragmentTexture()に渡すtextureへのread/writeでも、shader側の修飾子による指定でraster_order_groupを利用することができます. こちらのApple開発者ページよりコードを引用します.
fragment void blend(texture2d<float, access::read_write> out[[texture(0), raster_order_group(0)]]) { float4 newColor = 0.5f; // the GPU now waits on first access to raster ordered memory float4 oldColor = out.read(position); float4 blended = someCustomBlendingFunction(newColor, oldColor); out.write(blended, position); }なおtextureの修飾子にはwriteが必要になりますが、読み込み時に用いることができる
.sample()に相当するピクセル間をサブサンプリングしてくれるようなfunctionは、書き込みにおいては(多分)ありません. したがって座標値を正しく指定してwriteする必要がありそうです.実装における注意点
CPU側の設定
colorAttachmentの設定
_viewRenderPassDescriptor = [MTLRenderPassDescriptor new]; _viewRenderPassDescriptor.colorAttachments[AAPLRenderTargetAlbedo].loadAction = MTLLoadActionDontCare; _viewRenderPassDescriptor.colorAttachments[AAPLRenderTargetAlbedo].storeAction = MTLStoreActionDontCare; _viewRenderPassDescriptor.colorAttachments[AAPLRenderTargetNormal].loadAction = MTLLoadActionDontCare; _viewRenderPassDescriptor.colorAttachments[AAPLRenderTargetNormal].storeAction = MTLStoreActionDontCare; _viewRenderPassDescriptor.colorAttachments[AAPLRenderTargetDepth].loadAction = MTLLoadActionDontCare; _viewRenderPassDescriptor.colorAttachments[AAPLRenderTargetDepth].storeAction = MTLStoreActionDontCare;colorAttachmentのパラメータとして、storeActionには
MTLStoreActionDontCareを指定します. loadActionにも同じものを指定しており、これはraster_order_groupを使用してもしなくても変わりません.MTLTextureの設定
MTLTextureDescriptor *GBufferTextureDesc = [MTLTextureDescriptor texture2DDescriptorWithPixelFormat:MTLPixelFormatRGBA8Unorm_sRGB width:size.width height:size.height mipmapped:NO]; GBufferTextureDesc.textureType = MTLTextureType2D; GBufferTextureDesc.usage |= MTLTextureUsageRenderTarget; GBufferTextureDesc.storageMode = storageMode; // !ここは MTLStorageModeMemoryless を指定!Raster Order Groupの書き込み用MTLTextureの生成において、textureDescriptorには
.memorylessを指定する必要があるようです. memorylessはCPU側のメモリを使わないという意味らしい.ループ途中のtexture読み込み時の注意
Raster Order Groupを使用する際の最大の注意点と言っても良いかもしれません. 実はRaster Order Groupは非常に使いにくい一面があります. ループ途中のtextureはkernel計算等で必要な周囲の画素を読み込むことが (`20/May時点で) できません.
これはraster_order_groupループ途中のtextureはGPUの "Tile Memory" という仕組みを活用する一時メモリ領域に格納されるからです. Tile Memoryは、画素を一定サイズのブロックに分けてGPU描画を効率化する仕組みであり、どのメーカーのGPUでもよく使われる類の工夫のようです.
各タイルの描画は非同期であり、早く計算が完了したら随時次のタイルの計算に移行します. すなわちraster_order_groupのループ計算はタイル単位で非同期であることに気を付けねばなりません. この非同期計算を所謂awaitするような機能は、筆者がざっと探したところありませんでした.
(ただしMetalにはNeural Networkを効率化する機能が多数実装されており、kernel計算をループで同期的に処理する手段も用意されているはずです. これについてはいずれ調べてみたいと思います.)
おわりに
いかがでしたでしょうか?
ご参考になれば幸いです!
改善方法やご意見などあれば、どしどしコメント下さい!

- 投稿日:2020-05-31T20:14:10+09:00
iOSでお気に入りの写真以外を一括削除する
こんにちは。
今回はiOSのカメラロールで、お気に入りの写真以外を一括削除するショートカットを作ったので紹介します。
ちなみにちょっといじると選択したフォルダ以外の写真を一括削除することもできます。目次
- 完成形
- 必要なアプリ
- ざっくりな流れと説明
- できあがり
- あとがき
1.完成形
お気に入りの写真以外を一括削除
ちなみに、実行すると本当に削除して良いか最初に尋ねられます。(なんか怖いから)
これは仕様なのですが、前述とは別に削除を実行する際も再度尋ねられます。
まぁボタン一つ押したら全部消えちゃうのも怖いですし確認はあった方がいいかなと個人的に思ってます。ショートカットが開けない時は、
iPhoneの設定→ショートカット→信頼されていないショートカットを許可
にチェックを入れると開けるようになります。(※自己責任でお願いします)また、そのチェックさえ入れられない時は、一度ショートカットアプリでなんらかのショートカットを実行するとチェックを入れられるようになります。
2.必要なアプリ
3. ざっくりな流れと説明
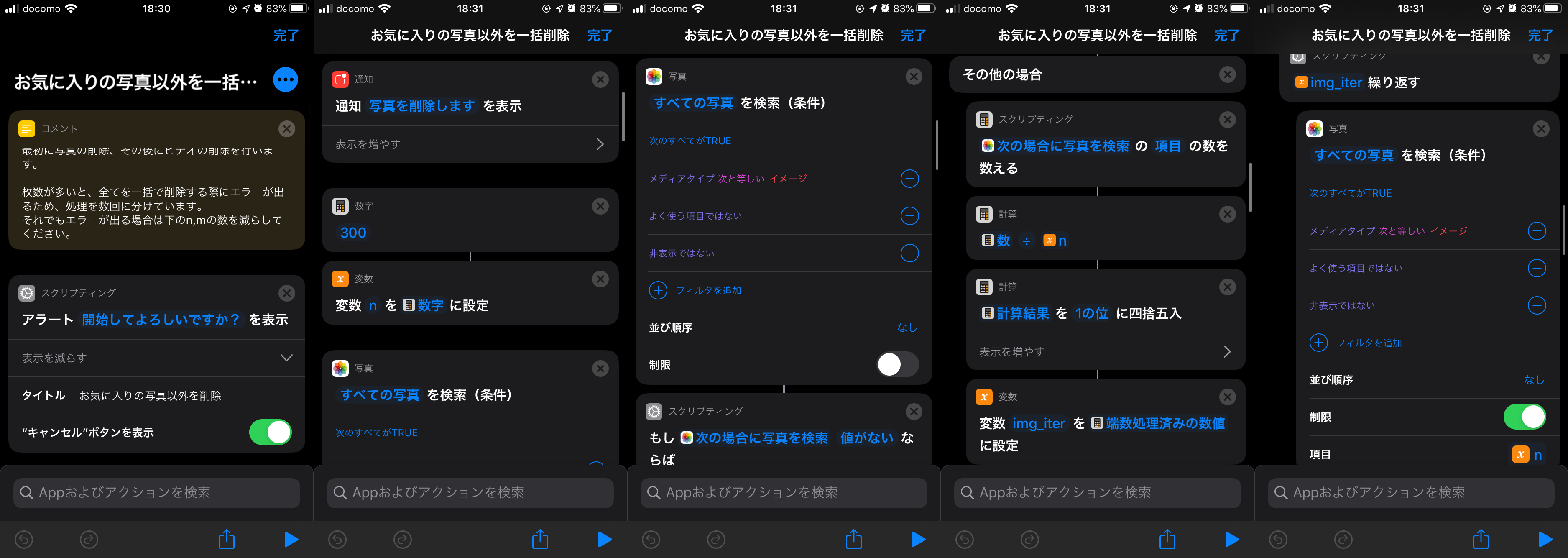
細かいところまで説明するとめちゃくちゃ長くなりそうなのでとりあえずスクショを貼っておきます。
最初は写真と動画をまとめて消したかったんですが、いい方法が思いつかなかったので写真と動画は別々に削除するようにしています。
また、タイトルでは「一括削除」と書いていますが、厳密には300件ずつ自動で削除する感じになっています。
また、先ほど「300件ずつ自動で削除」と書いていますが、厳密には300件ずつ手動で削除か否かを選択していきます。(苦ではない)
- 変数nに300を設定しているのは、後で写真を削除する時に本当に一括で選択して削除しようとすると、仕様でエラーが出るからです。(たぶんメモリエラー的な。)
- 「すべての写真を検索(条件)」で以下に当てはまるアイテムを指定しています。
- 写真・動画のうち写真のみ
- よく使う項目ではない(=お気に入りではない)
- 非表示ではない
ちなみにここで写真を指定した理由は、ただ単にアイテムの数を取得したいからであり、ここで指定した写真をそのまま削除するわけではありません。- 「次の場合に写真を検索 の 項目 の数を数える」らへんでは、後に繰り返し処理を行う際のループ数を決定しています。
- 繰り返しの中の 「すべての写真 を検索(条件)」では、(最新のものから)写真を300件選んで、次のアクションでそれを削除しています。
上記の繰り返し処理をして、すべてのお気に入り以外の写真を分割で削除します。- お次は動画です。
しかしやることはほとんど変わりないので説明は省きます。 ちなみに変数mが50なのは、ファイルサイズが写真よりも大きいと考え、エラーにならないようにしています。- 終わり!
なんかエラー出るんだけど
n,mも300件,50件と設定していますが、一つ当たりのファイルサイズが大きいとこれでもエラーが出る場合があります。その時はn,mの値を減らしてみましょう。
最初の確認は必要ない
最初のアラートを消してください。
間違えて実行して写真消しちゃった
カメラロールには「最近削除した項目」という項目があるのでそこから復元してください。
4. できあがり
完成したら、ホーム画面からでもウィジェットからでも実行できるようになるはずです。(たぶん)(そんなに実行の頻度高くないだろうからいらなさそう)
5. あとがき
ショートカットアプリが楽しくていろいろ試してみてます。
JavaScriptを活かしてできることもあるみたいですが、JSはあまり詳しくなくて歯痒さがあります。無駄なところは多々ありますがご愛嬌と言うことで・・・
重大なミスやさすがにこうした方がいいとかがあればぜひ教えてください。ではまた!

- 投稿日:2020-05-31T02:22:09+09:00
Swiftでセマフォ(semaphore)にさわってみよう
はじめに
最近セマフォ(semaphore)について振り返る機会があり、Swiftでの動作を確認する意味もあってSwiftでセマフォのサンプルソースコードを作成しました。
そのソースコードを用いて、「セマフォって聞いたことはあるけど??」と思っているエンジニアのために本記事を書いてみました。
セマフォ(semaphore)とは
下記はwikipediaからの引用です
セマフォ(英: semaphore)とは、計算機科学において、並列プログラミング環境での複数の実行単位(主にプロセス)が共有する資源にアクセスするのを制御する際の、単純だが便利な抽象化を提供する変数または抽象データ型である。
セマフォを理解するキーワードは、「並列」と「資源」だと思います。
「並列」な動作を行う複数のスレッドやプロセスが、共有する「資源」を正しく利用できる(アクセス制御する)仕組みがセマフォです。
まずは、セマフォがない場合に何が起こるか、の例をSwiftのソースコード 1で以下に提示します。
セマフォ(semaphore)がない場合
このソースコード内では、resourceが「資源」で、スレッド1、スレッド2が「並列」に動作します。
スレッドは何度も繰り返すタスクをもっていて、それを完了すればスレッドも終了します。
それぞれのタスクは、resourceがゼロ以上の場合は、自分のカウンターを1加算してresourceを1減算します。resourceがゼロになれば処理を終了します。また
DispatchQueue.global(qos: .background).async( リファレンス?) がそれぞれ使われており、qosが同じレベルのため、ほぼ均等のタイミングで実行状態が切り替わります。func testHandleResourceWithoutSemaphoreQiita() throws { var resource: Int = 100 var task1_counter: Int = 0 var task2_counter: Int = 0 // resourceがゼロ以上の場合は、自分のカウンターを1加算してresourceを1減算する func task1() -> Bool { var value = resource guard value > 0 else { return false } task1_counter += 1 value -= 1 resource = value return true } // resourceがゼロ以上の場合は、自分のカウンターを1加算してresourceを1減算する func task2() -> Bool { var value = resource guard value > 0 else { return false } task2_counter += 1 value -= 1 resource = value return true } // スレッド 1 DispatchQueue.global(qos: .background).async { var executing = true while executing { executing = task1() } } // スレッド 2 DispatchQueue.global(qos: .background).async { var executing = true while executing { executing = task2() } } // 2つのスレッドが完了するまで待つ print("task1_counter = \(task1_counter)") print("task2_counter = \(task2_counter)") }結果は、
task1_counter = 88
task2_counter = 102だったり
task1_counter = 100
task2_counter = 0だったり
task1_counter = 13
task2_counter = 101します。
resourceがゼロ以上の場合は、自分のカウンターを1加算してresourceを1減算します。resourceがゼロになれば処理を終了します。
であればtask1_counterとtask2_counterの合計は100になりそうなものですが、そうはなりません(なることもあります)
これはなぜかというと、
var value = resource guard value > 0 else { break } task2_counter += 1 value -= 1 resource = valueこの処理を行っている間に、別の処理が割り込んできて、resourceの値を書き換えてしまうからです。
つまり、変数resourceはアクセス制御されていません。スレッドセーフではない、という言い方がよくされます。セマフォ(semaphore)を使ってみる
関数の先頭で
let semaphore = DispatchSemaphore(value: 1)を宣言します。
DispatchSemaphore(value: 1)で、アクセス制御するリソースは1つだけだと宣言しています。リソースとは、var resource: Int = 100のことです。
この変数をアクセス制御できれば、おかしな現象は起こりません。続いて、先ほどの割り込みされるtask1(), task2()の先頭でそれぞれ
defer { semaphore.signal() } semaphore.wait()を追加します。
これで、関数に入った時点でsemaphore.wait()が実行され、関数を抜けるタイミングで必ずsemaphore.signal()が実行されます。
wait()ではDispatchSemaphoreで指定したカウンタを1減算し、signal()で1増加させます。カウンタがゼロの状態でwait()を呼び出したスレッドは、後述のようにBlocking状態となり処理は停止します。このスレッドは、signal()によってリソースが解放されるまでOSによってブロックされます。 2このような仕組みを導入することで、task1_counterとtask2_counterの合計は必ず100になることが保証されます。
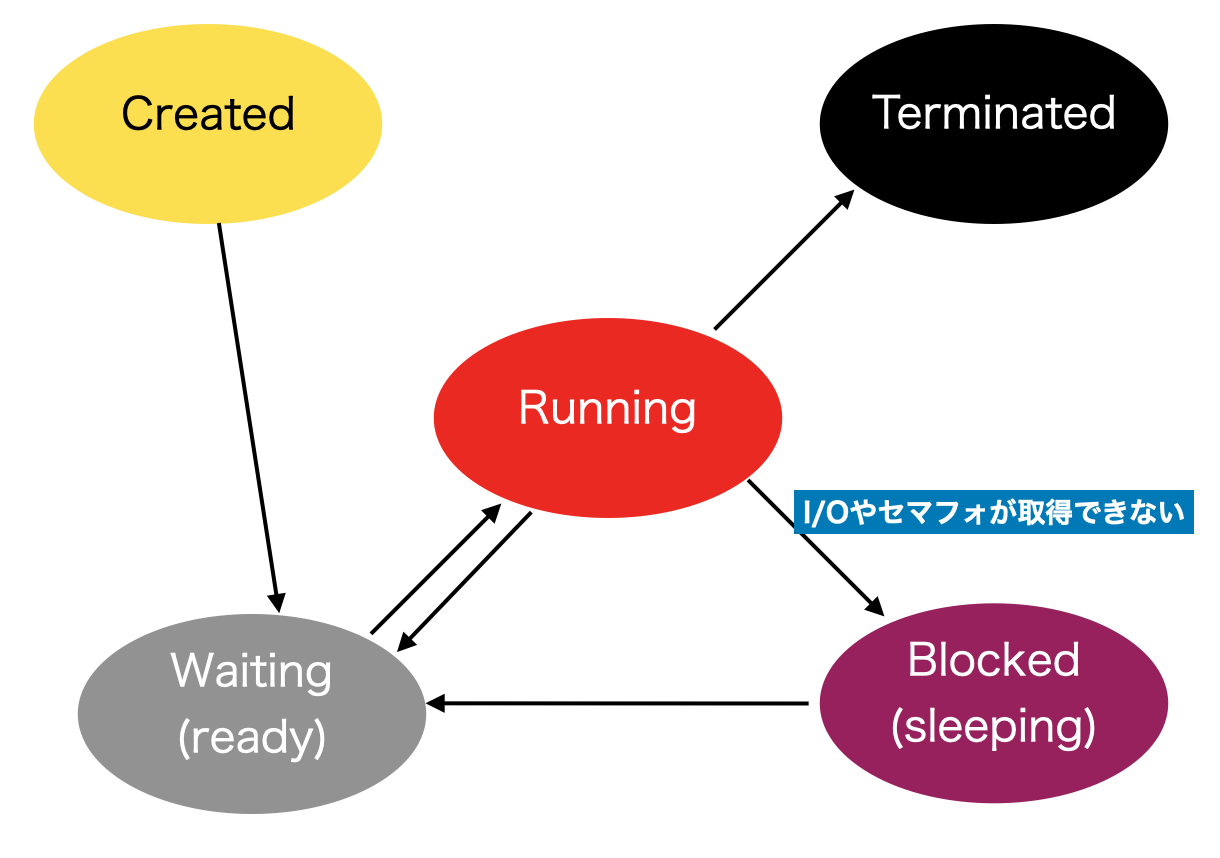
スレッド/プロセスの状態遷移
Running(実行中)状態で、wait()を呼び出して運悪く誰かがリソースを使用していた場合は、Blocked状態になります。その後利用していたスレッドがsignal()を発行してリソースを解放すると、うまくOSスケジューラに拾ってもらえれば、Waiting状態に遷移し、無事Runningに復帰し、リソースにアクセスする権限を得られます。
上記の状態遷移図はiOSのものとは若干異なるのかもしれませんが、おおよそ同じような動きになるはずです。(正式な情報をお持ちでしたらお教えください)
セマフォがない場合のコンテキストスイッチ
アクセス制御がなされていない最初のコードでは、下記のようにスレッドが強制的にWaiting状態にスイッチされる(プリエンプションされてコンテキストスイッチが発生する)ことでtaskが中断しています。この中断の間に別のスレッドで、変数resourceが操作されるのが問題です。
繰り返しになりますが、ここで重要なのはセマフォがアクセス制御しているのは、リソースである変数resourceです。当該のリソースが何なのかを意識しないで漠然とセマフォを利用すると痛い目に遭います。要注意です。
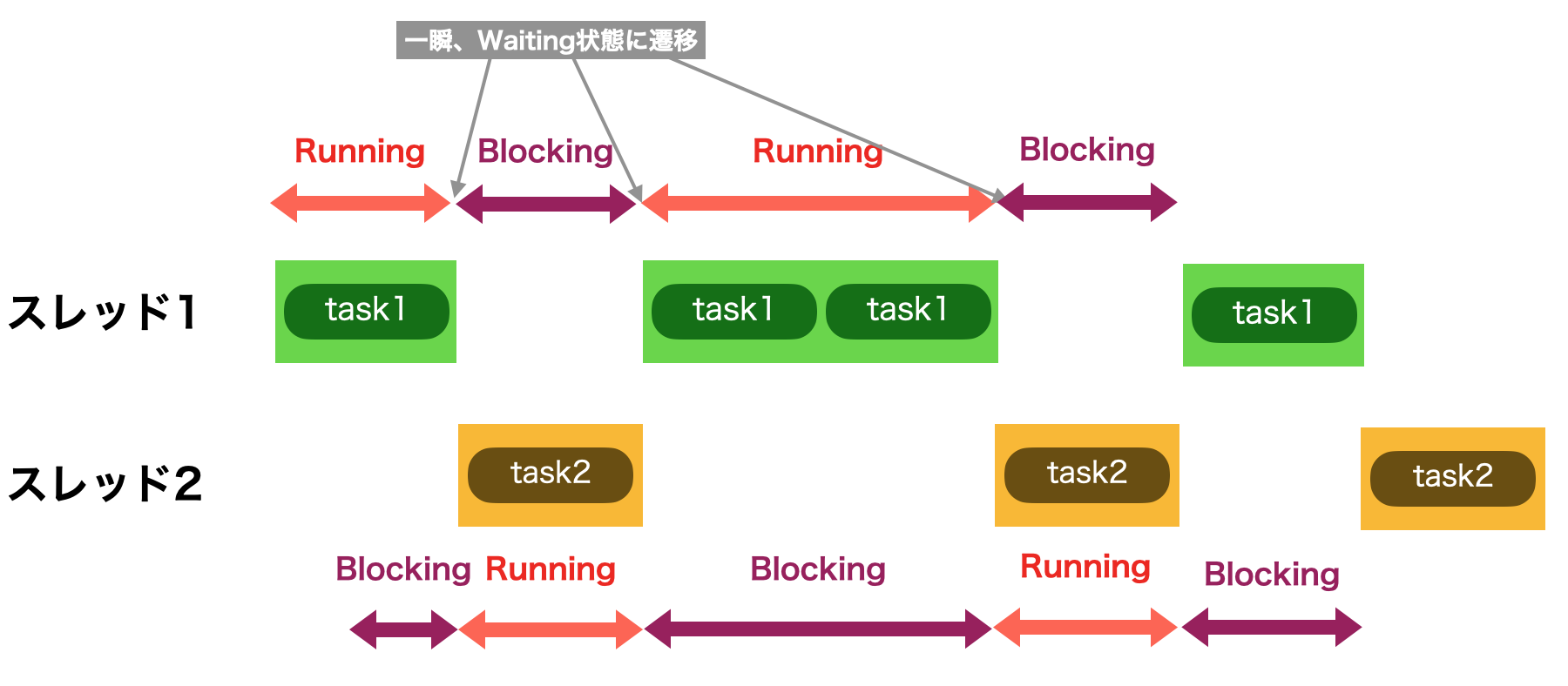
セマフォがある場合のコンテキストスイッチ
セマフォを用いた状態遷移は下図のようになります。task1がセマフォを取得するとtask2はwait()を読んだ時点でBlocking状態に遷移します。のちにOSによって実行許可が出た場合は、Waitingを介してRunning状態に遷移し、wait()関数を抜けることになります。
セマフォが解放されたタイミングで次にどちらのスレッドが割り当てられるかは、OSのスケジューリングに寄ります。これを制御しようと思うのならば、
DispatchQueue.global(qos: .background).asyncのQoS(リファレンス?)を変更することである程度は可能です。QoSとはquality of serviceの略で、優先制御と呼ばれることが多いです。例えばインターネットで動画を途切れなく見るためにはQoSが有効なネットワークを利用することが必要だったりします。この場合は優先制御の他にも帯域制御が行われたりします。(参考記事?)
ここでは、iOSのスレッドスケジューリングの優先制御に影響を与えるパラメータと言うことができるでしょう。DispatchQueue.globalでは下記のようなオプションが用意されています。(リファレンス?)
定義値 説明 補足 userInteractive The quality-of-service class for user-interactive tasks, such as animations, event handling, or updating your app's user interface. アニメーションやUIの更新などはモバイルアプリにとっては重要です。そこでiOSではuserInteractive には最も高い優先順位が与えられています3 userInitiated The quality-of-service class for tasks that prevent the user from actively using your app. ユーザが開始したアクション、またそれに付随する動作、結果に対して高い優先順位を与えるオプションです defaultThe default quality-of-service class. 標準優先順位 utility The quality-of-service class for tasks that the user does not track actively. すぐに実行する必要がない処理に対して指定する background The quality-of-service class for maintenance or cleanup tasks that you create. バックグラウンドでCPUリソースなどに余裕がある時に実行される優先順位 unspecified The absence of a quality-of-service class. (?参考記事)
カウンティングセマフォ(Counting Semaphore)
let semaphore = DispatchSemaphore(value: 1)ではリソースが1つのために初期値として
1を与えています。リソースが1つだけのセマフォをバイナリーセマフォ(Binary Semaphore)と呼びます。厳密には違う(参考時事?)のですが、ミューテックス(Mutex)と呼ばれることもあります。
リソースが2以上のセマフォはカウンティングセマフォ(計数セマフォ)と呼ばれ、アクセス制御に使うことはできません。
実は筆者も使ったことはありません?実際に2にしたらどうなるでしょうか。
サンプルソースコードの中でも実験していますが、興味がある方は試してみてください。?♂️?♂️?♂️?♂️
イベントフラグ(Event Flag)
イベントフラグにも触れておきたいと思います。
イベントフラグとは、主に組み込みプログラミングなどで利用されるμITRONで使われる用語です。実はPOSIXなどにもこの機能は明示されておらず、良い名称が無いのでイベントフラグという名称を使いたいと思います。イベントフラグについてはこちらの記事ITRON入門 イベントフラグで学ぶタスク間同期・通信機能を参照してください。
サンプルソースコードに記載されているソースコードを紹介します。
このサンプルでは、
DispatchSemaphore(value: 0)で初期値をゼロとしています。バイナリーセマフォがスレッドをBlockすることを利用して、別のスレッドにイベントフラグとしてをsignalを送信し、Blockを解除します。func testSingleEventFlag() throws { let semaphore = DispatchSemaphore(value: 0) // ⚠️ イベントフラグの初期化 let expectation1 = XCTestExpectation(description: "expectation1") let expectation2 = XCTestExpectation(description: "expectation2") semLog.format("✳️ Start") DispatchQueue.global(qos: .background).async { usleep(1000_000) semaphore.signal() // ⚠️ イベントフラグを送信 semLog.format("✳️ Sent EventFlag") expectation1.fulfill() } semaphore.wait() // ⚠️ イベントフラグを受信 semLog.format("✴️ Recieved EventFlag") expectation2.fulfill() wait(for: [expectation1, expectation2], timeout: 10.0) }こちらの実行結果は、下記のようになります(semLog.format()は自作のログ出力ツールです。サンプルソースコードの中にあります)
テストを開始してから約1秒後にbackgroundのスレッドからイベントフラグの送信が起こり、待ち受けていたメインスレッドがBlockingからRunningに状態遷移して続きの処理が実行された様子が分かります。
/* ✳️ Start [18:37:25.837] [main] ✳️ Sent EventFlag [18:37:26.847] [com.apple.root.background-qos] ✴️ Recieved EventFlag [18:37:26.847] [main] */リソースのアクセス制御という観点から見ると、最初に説明した手法が
変数などを守るためにあるのに対して、こちらはスレッドそれ自身を対象にしています。そのためスレッドが、いつ生成されて、いつ消滅するのかを考慮して設計、実装しなければなりません。上記のようなシンプルなものであれば良いのですが、大規模なマルチスレッドのシステムに動的に適用しようとすると、
イベントフラグの初期化と送受信のタイミングが問題になることもあります。デッドロック(Deadlock)/ リソーススタベーション(Resource Starvation)
最後に、バイナリセマフォ、ミューテックスで必ず取り上げられるデッドロックについても紹介いたします。
下記は、二つのスレッドが、互いの管理するリソースを参照して動作しようとしてデッドロックします。
大きな問題は、wait() → signal()の間に、外部の(しかも相互参照している)オブジェクトを呼び出していることです。
外部のオブジェクトが実は、自分のリソースを操作する関数を呼び出していると知らなければ、容易にデッドロックが発生します。func testDeadlockBySemaphore() throws { var expectations: [XCTestExpectation] = [XCTestExpectation]() class SemThread { let semaphore = DispatchSemaphore(value: 1) var resource: Int = 0 var other: SemThread? let expectation: XCTestExpectation let name: String // 生成時にセマフォを取得し、外部からのインクリメントをブロックする init(name: String) { self.name = name expectation = XCTestExpectation(description: name) } // otherに対してカウントアップ要求を出す。その後、外部からのインクリメントを許可 func run() { DispatchQueue.global(qos: .background).async { self.increment() self.expectation.fulfill() semLog.format("⭐️\(self.name) completed") } } func increment() { semLog.format("⭐️\(self.name) will wait") semaphore.wait() usleep(100) semLog.format("⭐️\(self.name) make other increment") // 自セマフォを取得中に、相互参照している外部オブジェクトを利用する self.other?.increment() resource += 1 semaphore.signal() } } let thread1 = SemThread(name: "thread1") let thread2 = SemThread(name: "thread2") expectations.append(thread1.expectation) expectations.append(thread2.expectation) // クロス参照する thread1.other = thread2 thread2.other = thread1 // スレッド開始 thread1.run() thread2.run() // 2つのスレッドが完了するまで待つ(が、必ず失敗) wait(for: expectations, timeout: 5.0) }iOSではあまりセマフォを使う機会はないのですが、安易に導入すると、このようなデッドロックを引き起こす可能性があります。セマフォが本当に必要なのか、対象となるリソースは何なのか、相互参照はあるのか、wait() → signal()区間でreturnしていないか、などを十分に吟味して利用することが必要です。
iOSの場合、このようなプリミティブな操作を使うことなく、マルチスレッドを使いこなすために、DispatchQueueが用意されています。
セマフォの説明を延々した後でなんですが、まずDispatchQueueを使うことを検討した方が良いかもしれません。(自戒?)DispatchQueueとマルチスレッド操作については、別途記事を書いてみたいと思います。