- 投稿日:2020-05-31T23:59:26+09:00
ゼロから始めるLeetCode Day42「2. Add Two Numbers」
概要
海外ではエンジニアの面接においてコーディングテストというものが行われるらしく、多くの場合、特定の関数やクラスをお題に沿って実装するという物がメインである。
その対策としてLeetCodeなるサイトで対策を行うようだ。
早い話が本場でも行われているようなコーディングテストに耐えうるようなアルゴリズム力を鍛えるサイト。
せっかくだし人並みのアルゴリズム力くらいは持っておいた方がいいだろうということで不定期に問題を解いてその時に考えたやり方をメモ的に書いていこうかと思います。
前回
ゼロから始めるLeetCode Day41「394. Decode String」今はTop 100 Liked QuestionsのMediumを解いています。
Easyは全て解いたので気になる方は目次の方へどうぞ。Twitterやってます。
問題
難易度はMedium。
Top 100 Liked Questionsからの抜粋です。空ではない連結リストを与えられるので与えられた数字をそれぞれ桁ごとに足していき、反転させて返すようなアルゴリズムを設計してください、というものです。
Input: (2 -> 4 -> 3) + (5 -> 6 -> 4)
Output: 7 -> 0 -> 8
Explanation: 342 + 465 = 807.解法
# Definition for singly-linked list. # class ListNode: # def __init__(self, val=0, next=None): # self.val = val # self.next = next class Solution: def addTwoNumbers(self, l1: ListNode, l2: ListNode) -> ListNode: tempsum = 0 root = cur = ListNode(0) while l1 or l2 or tempsum: if l1: tempsum += l1.val; l1 = l1.next if l2: tempsum += l2.val; l2 = l2.next cur.next = cur = ListNode(tempsum % 10) tempsum //= 10 return root.next # Runtime: 64 ms, faster than 95.04% of Python3 online submissions for Add Two Numbers. # Memory Usage: 13.9 MB, less than 5.67% of Python3 online submissions for Add Two Numbers.シンプルなものにはなりましたが、良さげですね。
問題番号でも最初の方のものは良問揃いな気がしますね。
今回のようにしっかりとした数学的な知識というよりは頭を使ってしっかりとフローチャートを考えれば解けるような問題が多い気がします。今回はこの辺で。お疲れ様でした。
- 投稿日:2020-05-31T23:57:50+09:00
【python selenium】Google検索結果をスクレイピング後 タイトルとURLをcsv出力
環境
macOS Catalina 10.15.3
Python 3.6.5概要
任意のワードでGoogle検索し、その検索結果の一覧を任意のページ数まで取得
タイトルとurlをcsv出力する方法(コピペOK)
※コピペOKですがコード内のディレクトリや検索ワードは任意で書き換えてください
# !python3 # google検索結果のタイトルとURLを取得してcsv出力 import time, chromedriver_binary, os, csv from selenium import webdriver output_path = "/最終的なcsv出力ディレクトリ os.chdir(putput_path) driver = webdriver.Chrome() # Chromeを準備 #htmlを開く driver.get("https://www.google.com/") # Googleを開く search = driver.find_element_by_name("q") # 検索ボックス"q"を指定する search.send_keys(“xxx yyy zzz“) # 検索ワードを送信 search.submit() # 検索を実行 time.sleep(3) # 3秒待機 def ranking(driver): i = 1 # 1で固定 i_max = 10 # 何ページ目まで検索するか? title_list = [] link_list = [] #現在のページが指定した最大分析ページを超えるまでループする(i_max) while i <= i_max: # タイトルとリンクはclass="r"に入っている class_group = driver.find_elements_by_class_name("r") # class="r" からタイトルとリンクを抽出し,リストに追加するforループ for elem in class_group: title_list.append(elem.find_element_by_class_name('LC20lb').text) # タイトル(class="LC20lb") link_list.append(elem.find_element_by_tag_name('a').get_attribute('href')) # リンク(aタグのhref) #「次へ」のボタンはひとつしかないがあえてelementsで複数検索. 空のリストであれば最終ページという意味. if driver.find_elements_by_id("pnnext") == []: i = i_max + 1 # 次のページがなければ,最大ページ数を強制的に越してループ終了 else: # 次ページのURLはid="pnnext"のhref属性 next_page = driver.find_element_by_id("pnnext").get_attribute("href") driver.get(next_page) i = i + 1 # ページを進む time.sleep(3) # 3秒休憩, これを指定の最大ページ数まで繰り返す return title_list, link_list # 上記で定義したranking関数を実行してタイトルとURLリストを取得する title, link = ranking(driver) # csvで吐き出すために[[a,1],[b,2]]みたいなリストを作成 result = [list(row) for row in zip(title, link)] # resultを使ってcsv出力 with open("result.csv", mode="w", encoding="utf-8") as f: writer = csv.writer(f, lineterminator="\n") writer.writerows(result) # ブラウザを閉じる driver.quit()
- 投稿日:2020-05-31T23:14:46+09:00
AtCoder Beginner Contest 169 参戦記
AtCoder Beginner Contest 169 参戦記
ABC169A - Multiplication 1
1分半で突破. 書くだけ. コードテストがなかなか実行されなかったせいで無駄に時間がかかってしまった.
A, B = map(int, input().split()) print(A * B)ABC169B - Multiplication 2
3分で突破. 64bit 整数でもオーバーフローする問題だけど、Python だと何も考えなくていいので楽ですねー. 0を先頭にするためにソートするのを忘れなければ OK!
N = int(input()) A = list(map(int, input().split())) limit = 10 ** 18 A.sort() result = A[0] for a in A[1:]: result *= a if result > limit: print(-1) exit() print(result)ABC169C - Multiplication 3
3分で突破. Ai≤1018 を見た瞬間に double だとヤバいと理解したので、decimal に逃げた.
from decimal import Decimal A, B = map(Decimal, input().split()) print(int(A * B))ABC169D - Div Game
22分半で突破、WA1. とりあえずエラトステネスの篩を貼り付けようと思ったが、N≤1012 なので貼れず、sqrt(N) までの処理に直すところからスタート. その後に pe を列挙して、ガンガン順に割っていって残った値を処理するところで失敗して WA を貰ったけど、もしかしてこのコードも嘘解法かもしれない. (ちゃんと残ったのが素数かどうかチェックしないと駄目なような?)
from math import sqrt N = int(input()) rn = int(sqrt(N)) sieve = [0] * (rn + 1) sieve[0] = -1 sieve[1] = -1 t = [0] * (rn + 1) for i in range(2, rn + 1): if sieve[i] != 0: continue sieve[i] = i j = i while j < rn + 1: t[j] = 1 j *= i for j in range(i * i, rn + 1, i): if sieve[j] == 0: sieve[j] = i result = 0 last = -1 for i in range(2, rn + 1): if t[i] == 0: continue if N % i == 0: result += 1 N //= i last = i if N != 1 and N > rn: result += 1 print(result)ABC169E - Count Median
突破できず. 1時間以上考えてたわけだが、考えれば考えるほど難しい.
- 投稿日:2020-05-31T23:13:18+09:00
Google ドライブのファイルを Python でダウンロードする
Google ドライブからファイルをダウンロードするのを試してみました。これがうまくいけば、ファイルを置くだけで処理できるシステムを作ろうと思っています。
今回の記事より簡単なものが公式にあります。
公式クイックスタート(Java, Node, Python)
https://developers.google.com/drive/api/v3/quickstart/pythonソース
以下の Python を実行します。初回実行時には client_secret.json が必要です。成功すると token.pickle が作成されます。実行すると Google ドライブの AAA というフォルダ直下の jpg,png をダウンロードします。
main.py# -*- coding: utf-8 -*- from __future__ import print_function import pickle import os.path import io import sys # pip install --upgrade google-api-python-client google-auth-httplib2 google-auth-oauthlib from googleapiclient.discovery import build from google_auth_oauthlib.flow import InstalledAppFlow from google.auth.transport.requests import Request from googleapiclient.http import MediaIoBaseDownload SCOPES = ['https://www.googleapis.com/auth/drive'] FOLDER_NAME = 'AAA' def main(): # OAuth drive = None creds = None if os.path.exists('token.pickle'): with open('token.pickle', 'rb') as token: creds = pickle.load(token) if not creds or not creds.valid: if creds and creds.expired and creds.refresh_token: creds.refresh(Request()) elif os.path.exists('client_secret.json'): flow = InstalledAppFlow.from_client_secrets_file( 'client_secret.json', SCOPES) creds = flow.run_local_server(port=0) with open('token.pickle', 'wb') as token: pickle.dump(creds, token) if creds and creds.valid: drive = build('drive', 'v3', credentials=creds) if not drive: print('Drive auth failed.') # Folfer list folders = None if drive: results = drive.files().list( pageSize=100, fields='nextPageToken, files(id, name)', q='name="' + FOLDER_NAME + '" and mimeType="application/vnd.google-apps.folder"' ).execute() folders = results.get('files', []) if not folders: print('No folders found.') # File list files = None if folders: query = '' for folder in folders: if query != '' : query += ' or ' query += '"' + folder['id'] + '" in parents' query = '(' + query + ')' query += ' and (name contains ".jpg" or name contains ".png")' results = drive.files().list( pageSize=100, fields='nextPageToken, files(id, name)', q=query ).execute() files = results.get('files', []) if not files: print('No files found.') # Download if files: for file in files: request = drive.files().get_media(fileId=file['id']) fh = io.FileIO(file['name'], mode='wb') downloader = MediaIoBaseDownload(fh, request) done = False while not done: _, done = downloader.next_chunk() if __name__ == '__main__': main()準備から実行まで
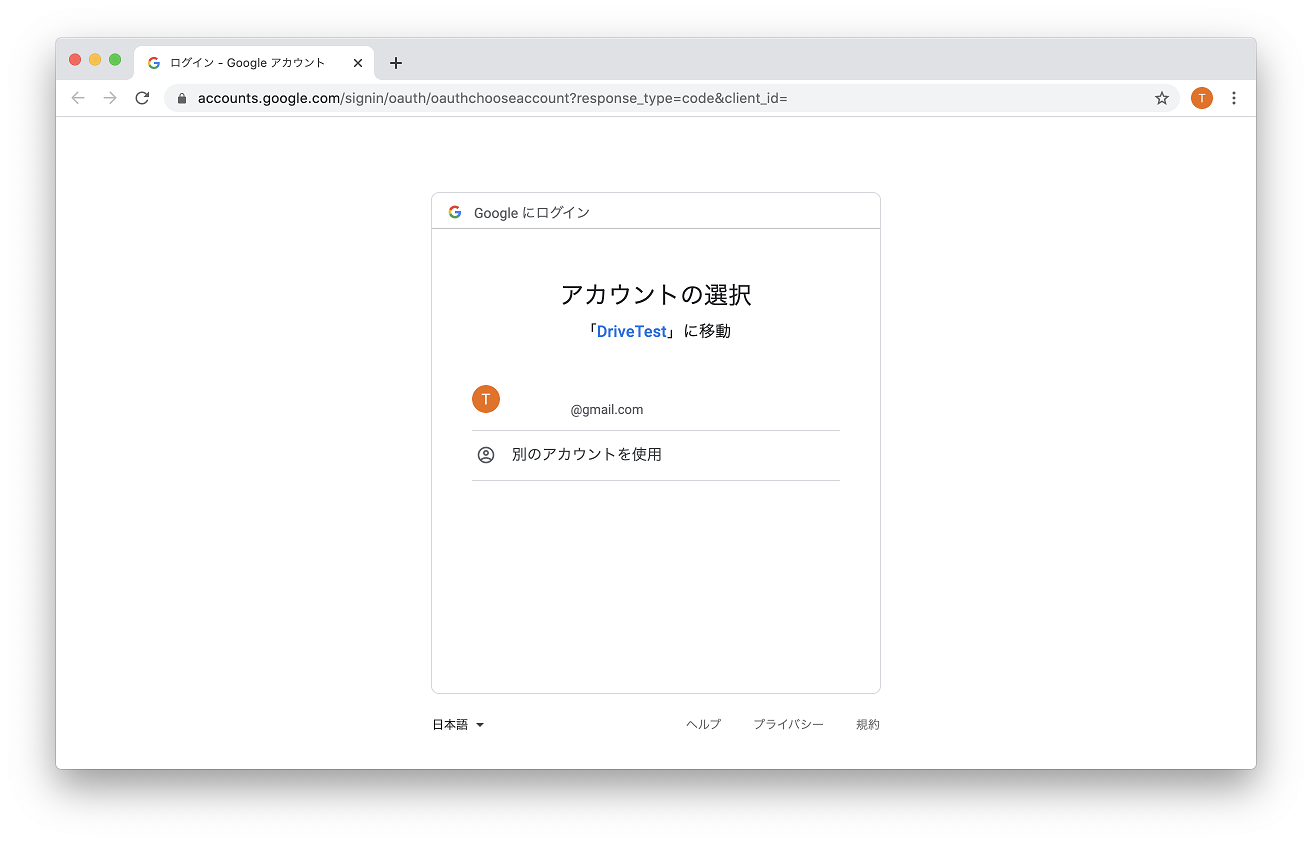
1. Google APIs にアクセス
https://console.developers.google.com/apis/credentials
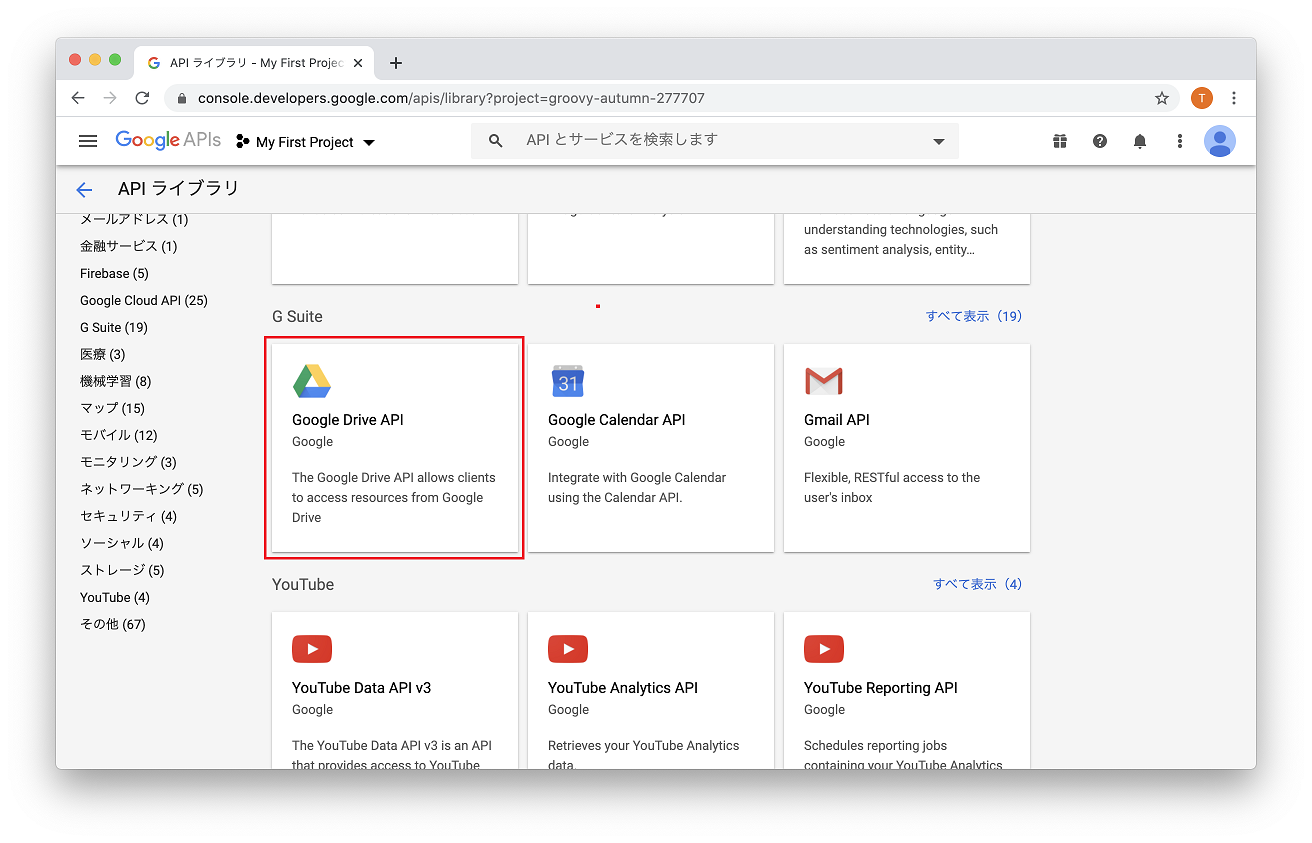
Google アカウントでログインします。初回はプロジェクト作成が呼ばれるので、My Project など付けてください。2. Google Drive API を有効
ライブラリから GoogleDriveAPI を選び、API を有効にします。
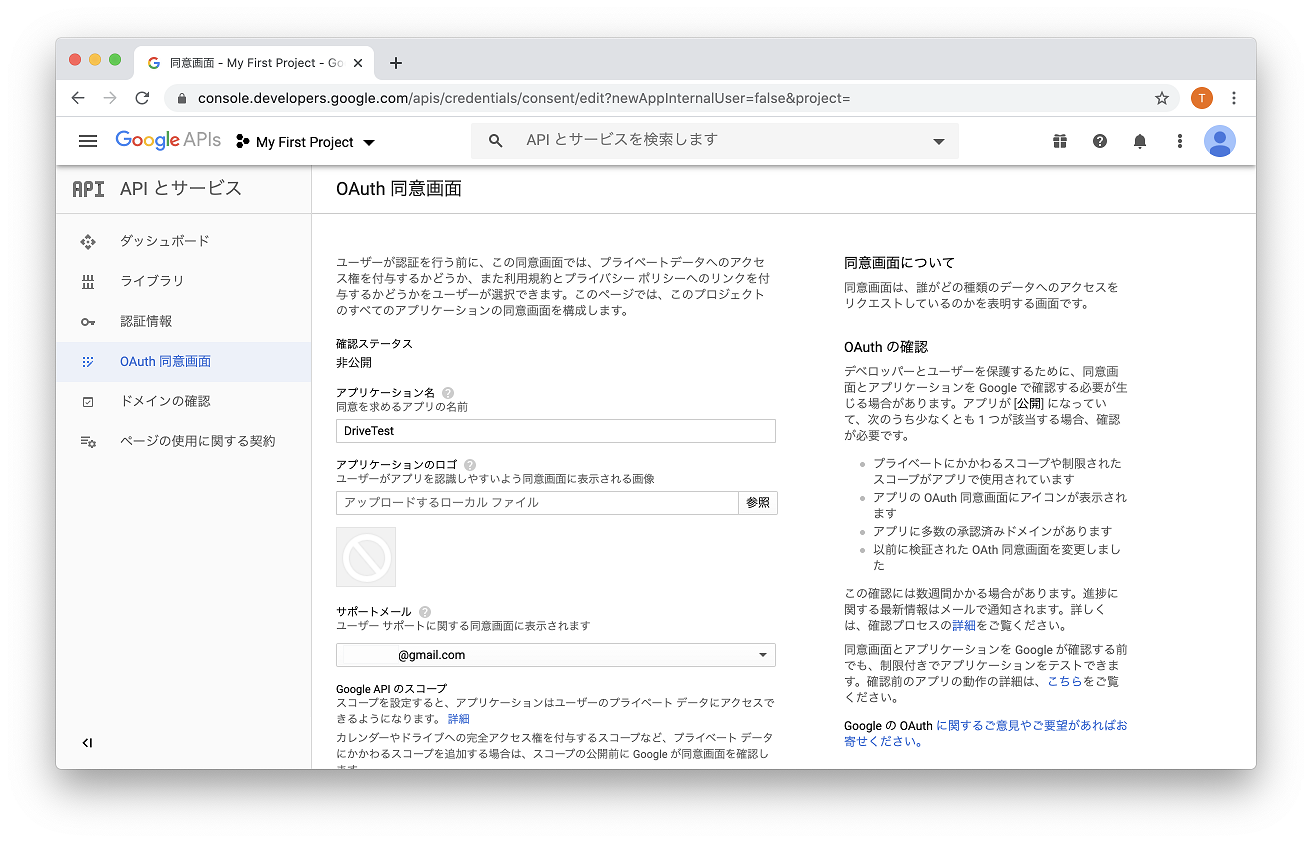
3. OAuth 同意画面の作成
同意画面の作成を行います。
UserType = 外部
アプリケーション名 = 適当な名前(後で変更可能)
他は空白でOKです。ここで付けた名前は認証画面で表示されます。
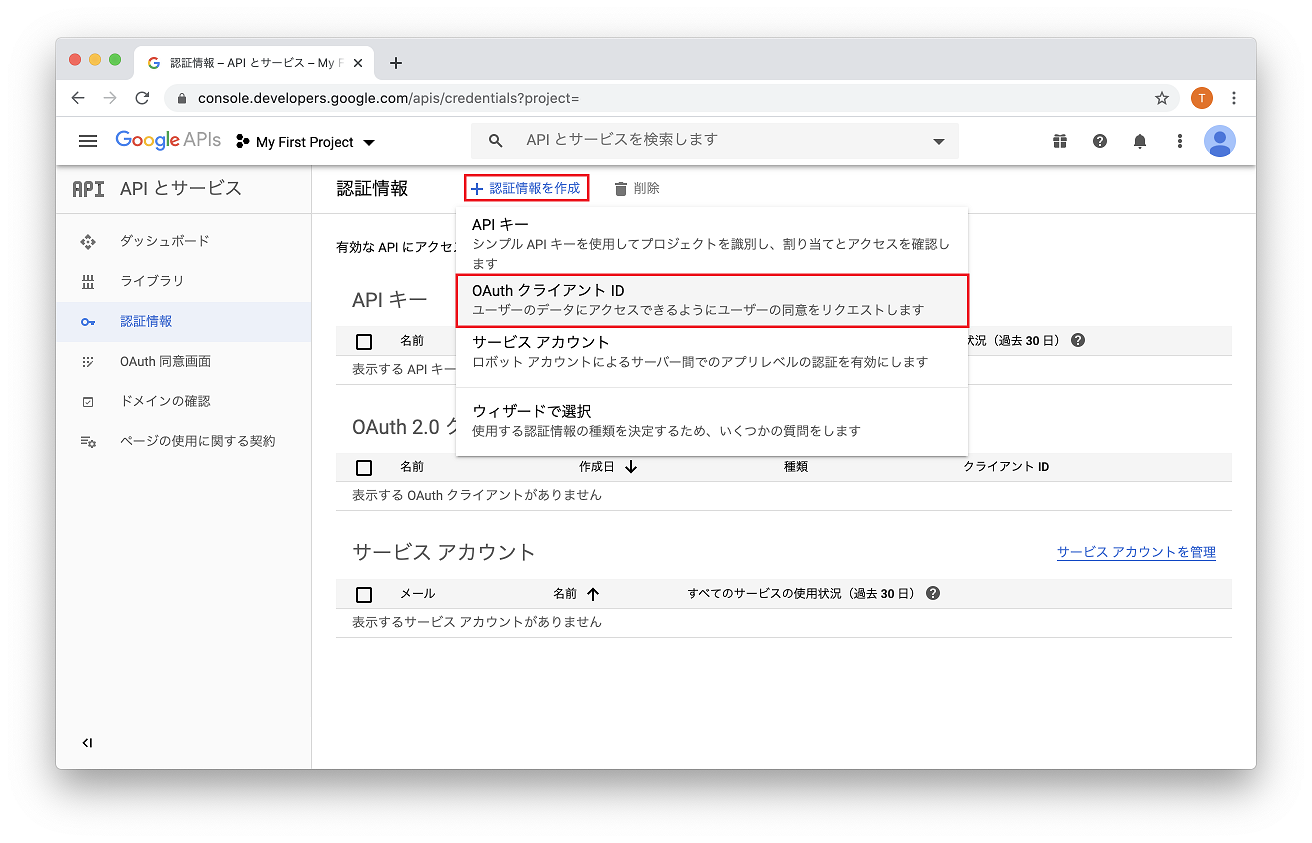
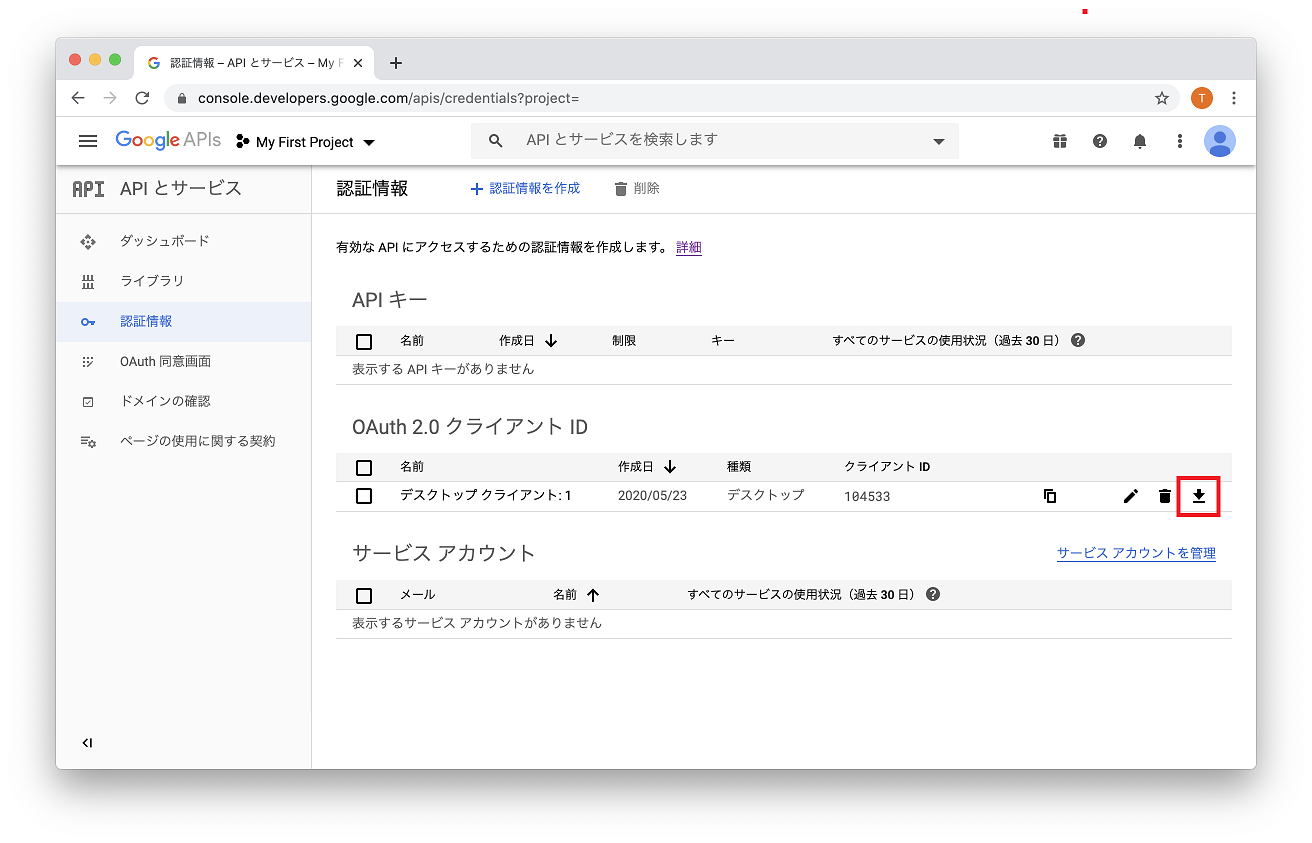
4. client_secret.json をダウンロード
OAuth クライアントIDを作成します。認証情報を作成から OAuthクライアントID を選び、アプリケーションの種類 = デスクトップアプリ で作成します。作成されたら、クライアントIDのダウンロードボタンを押すと、client_secret-xxx.json がダウンロードされます。
5. アプリを実行
上記の python コードを実行します。
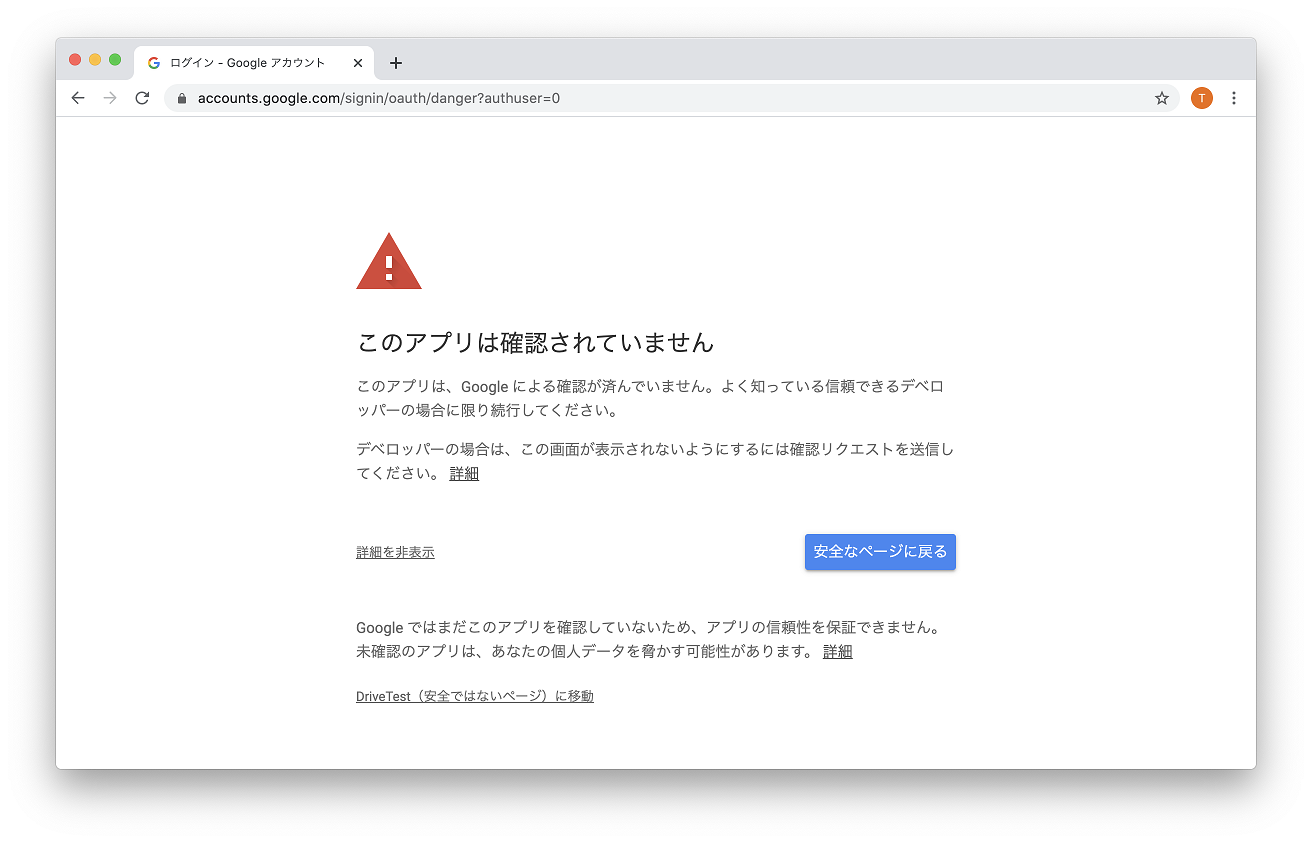
pip install --upgrade google-api-python-client google-auth-httplib2 google-auth-oauthlib python main.pyブラウザが立ち上がるので Google アカウントでログインします。「このアプリは確認されていません」で「詳細を表示」「安全でないページに移動」を選びます。認証に成功すると token.pickle が作成されます。Google ドライブの AAA フォルダ直下の jpg,png ファイルがダウンロードされると成功です。
実行結果
Google ドライブに次のようにファイルを置いてみました。AAA という名前のフォルダの直下をダウンロードします。Google ドライブは同じフォルダー名、同じファイル名を作成できることに注意です。
フォルダ ファイル 結果 AAA img1.jpg OK AAA img1.jpg OK AAA/AAA img2.jpg OK AAA/BBB img3.jpg NG AAA img4.jpg OK BBB img5.jpg NG BBB/AAA img6.jpg OK / img7.jpg NG 解説
OAuth 認証
SCOPES = ['https://www.googleapis.com/auth/drive'] # 既に token があるとき creds = None if os.path.exists('token.pickle'): with open('token.pickle', 'rb') as token: creds = pickle.load(token) if not creds or not creds.valid: if creds and creds.expired and creds.refresh_token: creds.refresh(Request()) elif os.path.exists('client_secret.json'): # 認証URLが発行されるのでログインして許可します flow = InstalledAppFlow.from_client_secrets_file( 'client_secret.json', SCOPES) creds = flow.run_local_server(port=0) # ピクルで保存 with open('token.pickle', 'wb') as token: pickle.dump(creds, token)SCOPES = ['https://www.googleapis.com/auth/drive'] にはすべての権限があるので、実際には範囲を絞った方がいいと思います。
初めは Node で作りました。そのときは、URL → ログインして許可 → コードが表示されるのでアプリにコピペ → トークンゲットです。python の方が楽です。
今回初めて pickle(ピクル、漬物)というものを使いました。オブジェクト(実体のあるクラスなど)を丸ごとバイナリー保存できるみたいです。 他の言語でいうシリアライズでしょうか。便利そうです。Google ドライブからリストを取得
results = drive.files().list( # 上限数 pageSize=100, # 取得したいパラメーター fields='nextPageToken, files(id, name, parents)', # クエリー(指定しなければ全部取得) q='name contains ".jpg" or name contains ".png"' ).execute() files = results.get('files', []) for file in files: print(file['name'] +' '+ file['parents'][0])parents は親フォルダーのIDです。ここではフォルダーの名前は分からないので、別途IDを調べる必要があります。上記の main.py コードでは、フォルダー名からIDを取得して、ファイルを検索しています。
上記の例は .jpg .png で検索しています。検索しないと余計なファイルなどで json が大きくなってしまいます。他にも mimeType="application/vnd.google-apps.folder" と書けばフォルダーのみの検索もできます。
今回はやってないですが、pageSize=100 を超えた場合は、nextPageToken を使って再取得する処理が必要です。
fields files() のパラメータ一覧
コードで fields='files(id, name, parents)' と書くと parents が取得できます。初め何を指定してよいのか分からず悩んでいました。結果的には fields='files' で実行するとすべて取得できます。すべて取得するとJsonが長くなるので指定した方がよいです。取得した結果を載せておきます。
{"kind":"drive#file", "id":"1PTrhGA14N-xxxx", "name":"img1.jpg", "mimeType":"image/jpeg", "starred":false, "trashed":false, "explicitlyTrashed":false, "parents":["1Jigt87nbz-xxxx"], "spaces":["drive"], "version":"1", "webContentLink":"https://drive.google.com/xxxx", "webViewLink":"https://drive.google.com/file/xxxx", "iconLink":"https://drive-thirdparty.xxxx", "hasThumbnail":true, "thumbnailVersion":"1", "viewedByMe":true, "viewedByMeTime":"2020-05-23T19:13:29.882Z", "createdTime":"2020-05-23T19:13:29.882Z", "modifiedTime":"2013-08-13T23:05:18.000Z", "modifiedByMeTime":"2013-08-13T23:05:18.000Z", "modifiedByMe":true, "owners":[{xxxx}], "lastModifyingUser":{xxxx}, "shared":false, "ownedByMe":true, "capabilities":{xx,xx,xx}, "viewersCanCopyContent":true, "copyRequiresWriterPermission":false, "writersCanShare":true, "permissions":[{xxxx}], "permissionIds":["1485xxxx"], "originalFilename":"img1.jpg", "fullFileExtension":"jpg", "fileExtension":"jpg", "md5Checksum":"95c10exxxx", "size":"492642", "quotaBytesUsed":"492642", "headRevisionId":"0BzjG8APx-xxxx", "imageMediaMetadata":{"width":1920, "height":1200, xx}, "isAppAuthorized":false}まとめ
Google ドライブからファイルのダウンロードを試してみました。実際にやってみて色々気付かされました。
AWS S3 同様、Googleドライブもクラウドであること。ローカルファイルの検索のようにはいかず、ひと癖あります。AWSの場合はこちらで用意したモノをお客様に提供しているのですが、Googleドライブの場合はお客様側のモノを想定しています。なのでもう少し手間が必要になりそうです。
AWS Lambda を使えば個人的にもなんかできそう。

- 投稿日:2020-05-31T23:12:32+09:00
Atcoder ABC169 A-DをPythonで解く
4完。Eは20分ほど考えてまったくわからず。FはTLEでした。
A Multiplication 1
コメント:特になし
# ABC169 A Multiplication 1 a, b = map(int, input().split()) print(a*b)B Multiplication 2
コメント:はじめは、全て計算していたが、
TLEになったため、途中でbreakさせる方法に変更。# ABC169 B Multiplication 2 from collections import deque n = int(input()) a_list = [int(x) for x in input().split()] if min(a_list) == 0: print("0") else: a_dq = deque(a_list) ans = 1 for i in range(n): ans *= a_dq.popleft() if ans > 10**18: break if ans > 10**18: print("-1") else: print(ans)C Multiplication 3
コメント:予想通りだったが、
floatでそのまま計算すると、WAになったのでいったん整数で計算する方法に変更。# ABC169 C Multiplication 3 a, b = map(lambda x: int(x.replace(".","")), input().split()) print(a*b//100)D Div Game
コメント:素因数分解するだけ。
# ABC169 D Div Game n = int(input()) def factorization(n): arr = [] if n == 1: return arr temp = n for i in range(2, int(-(-n**0.5//1))+1): if temp%i==0: cnt=0 while temp%i==0: cnt+=1 temp //= i arr.append([i, cnt]) if temp!=1: arr.append([temp, 1]) if arr==[]: arr.append([n, 1]) return arr f_list = factorization(n) ans = 0 for i in range(len(f_list)): _tmp = f_list[i][1] j = 1 while _tmp >= 0: _tmp -= j j += 1 ans += j-2 print(ans)F Knapsack for All Subsets(TLE)
コメント:$S$を構成する要素数とパターン数を保持したかったので、
dict型を使ったがTLEになった。# ABC169 F Knapsack for All Subsets from collections import deque from collections import Counter def merge_dict_add_values(d1, d2): return dict(Counter(d1) + Counter(d2)) n, s = map(int, input().split()) a_dq = deque([int(x) for x in input().split()]) dp = [[{0:0}] * (s+1) for _ in range(n+1)] dp[0][0] = {0:1} for i in range(n): _tmp = a_dq.popleft() for j in range(s+1): if j-_tmp < 0: dp[i+1][j] = dp[i][j] else: _tmp_d = dp[i][j-_tmp] _dict = dict() for k in _tmp_d.keys(): _dict[k+1] = _tmp_d[k] dp[i+1][j] = merge_dict_add_values(dp[i][j],_dict) # print(dp[n][s]) ans = 0 for k in dp[n][s].keys(): v = dp[n][s][k] ans += (2**(n-k)) * v print(ans%998244353)
- 投稿日:2020-05-31T23:08:47+09:00
チュートリアルでlibrosaを学ぼう 1
はじめに
この記事はlibrosaを使ってみたいけど何から始めたらいいのかわからないという人向けです。
かく言う僕もその一人です(笑)ここではlibrosaのチュートリアルをベースにして、チュートリアルで何をしているのかを自分なりに解釈して理解したことを共有できたらと思います。
具体的には元のチュートリアルを日本語でコメントしつつ、変数の中身や図を示すことで挙動を補足するという形式で説明していきます。
ですが僕自身が初心者であるため、あまり難しいことは書いていません。初記事となりますのでどうか温かい目で見ていただけたらと思います。
もし誤り等ありましたら、お気軽に指摘いただけると幸いです!今回のポイント
- サンプル音源のロード
- ビートの情報を取得
librosaのインストールの方法はこちらで!
今回はlibrosaのチュートリアルのQuickstartです。
まずは基本からという感じですね。
少しずつlibrosaに慣れていきたいですね!サンプル音源のロード
まずはサンプル音源のパス(場所)を取得しましょう。
# librosaをインポート import librosa # サンプルoggファイルのパスを取得 filename = librosa.util.example_audio_file() print(filename) # C:~\Python\Python36\site-packages\librosa\util\example_data\Kevin_MacLeod_-_Vibe_Ace.oggここではサンプル音源としてKevin_MacLeod_-_Vibe_Ace.oggファイルをロードしています。
このfilenameを変えることで任意の音源をロードできます。
ちなみにこの曲はファイル名の通り、Kevin MacleodのVibe Aceです。
GoogleのPlay Musicによると、曲の長さは1:05と短めで、ジャンルはJazzらしいです。またoggファイルとはWikipediaによると、
Oggはコンテナであり、1つないし複数のコーデックを内容物として格納する。Oggの最も代表的なコーデックは音声コーデックのVorbisである。Vorbisを格納したOggはOgg Vorbisと呼ばれる(他のコーデックも同様)。Ogg Vorbisを単にOggと呼ぶことがあるが、Oggはコンテナの名称であってコーデックではないことに注意すべきである。
(中略)
当初Xiph.Org FoundationはOgg共通の拡張子を.oggと定めていたが、2007年に共通の拡張子を.ogx、動画の拡張子を.ogv、音声の拡張子を.ogaに改めた。元々の共通の拡張子であった.oggはOgg Vorbis音声ファイルにのみ互換目的で使われる。らしいので、その中身はVorbisと呼ばれるファイルフォーマットのようです。
では早速ロードしてみましょう。
#先ほどのパスを使用してロード # y:波形 # sr:サンプリングレート y, sr = librosa.load(filename) print(type(y)) # <class 'numpy.ndarray'> print(y.shape) # (1355168,) print(type(sr), sr) # <class 'int'> 22050
librosa.load
- 入力:音声ファイルのパス
filename- 出力:音声波形
y, サンプリングレートsrこれは音声ファイルの読みこみに使用するメソッドであり、
wavやflac, aiffなどほとんどの音声ファイル形式に対応しているようです。この出力
yとsrはそれぞれnumpy配列とintで表現されています。
print(y.shape)よりyには1355168個の数値が入っていることが分かります。
またsrはデフォルトだと22050Hzで、これは22050個の数値が1秒に相当することを示しています。ビート情報の取得
続いてビート情報の取得です。
ここで重要となるのが、波形のいくつか(
hop_lengthで定義される個数)の数値をまとめたフレームです。
デフォルトではhop_length=512となっているため、512の数値→1フレームとなります。
今回はビート(打点)となっているフレームを取得します。# tempo:BPM # beat_frames:ビートのタイミングのフレーム # 1フレームは512サンプル(hop_length=512) tempo, beat_frames = librosa.beat.beat_track(y=y, sr=sr) print('Estimated tempo: {:.2f} beats per minute'.format(tempo)) # Estimated tempo: 129.20 beats per minute print(beat_frames) # [ 5 24 43 63 83 103 122 142 162 182 202 222 242 262 # 281 301 321 341 361 382 401 421 441 461 480 500 520 540 # 560 580 600 620 639 658 678 698 718 737 758 777 798 817 # 837 857 877 896 917 936 957 976 996 1016 1036 1055 1075 1095 # 1116 1135 1155 1175 1195 1214 1234 1254 1275 1295 1315 1334 1354 1373 # 1394 1414 1434 1453 1473 1493 1513 1532 1553 1573 1593 1612 1632 1652 # 1672 1691 1712 1732 1752 1771 1791 1811 1831 1850 1871 1890 1911 1931 # 1951 1971 1990 2010 2030 2050 2070 2090 2110 2130 2150 2170 2190 2209 # 2229 2249 2269 2289 2309 2328 2348 2368 2388 2408 2428 2448 2468 2488 # 2508 2527 2547]
librosa.beat.beat_track
- 入力:波形
y, サンプリングレートsr- 出力:BPM
tempo, ビートとなっているフレームのインデックスをまとめたリストbeat_framesこのメソッドより音楽のBPMを取得できます。
今回だと、BPM=129.20なので1分間に129.2個のビートがあることを示します。
またprint(beat_frames)より、5フレーム目、24フレーム目、...にビートが来ることがわかります。約20フレームごとにビートが来るようですね。次はビートのタイミングを時刻で見ていきましょう。
# beat_frames->beat_times # ビートのタイミングを時間で知りたい場合使用する beat_times = librosa.frames_to_time(beat_frames, sr=sr) # 計算式は以下の通り # beat_times[i] = beat_frames[i] * hop_length / sr print(beat_times) # [ 0.11609977 0.55727891 0.99845805 1.46285714 1.92725624 2.39165533 # 2.83283447 3.29723356 3.76163265 4.22603175 4.69043084 5.15482993 # 5.61922902 6.08362812 6.52480726 6.98920635 7.45360544 7.91800454 # 8.38240363 8.87002268 9.31120181 9.77560091 10.24 10.70439909 # 11.14557823 11.60997732 12.07437642 12.53877551 13.0031746 13.4675737 # 13.93197279 14.39637188 14.83755102 15.27873016 15.74312925 16.20752834 # 16.67192744 17.11310658 17.60072562 18.04190476 18.52952381 18.97070295 # 19.43510204 19.89950113 20.36390023 20.80507937 21.29269841 21.73387755 # 22.2214966 22.66267574 23.12707483 23.59147392 24.05587302 24.49705215 # 24.96145125 25.42585034 25.91346939 26.35464853 26.81904762 27.28344671 # 27.7478458 28.18902494 28.65342404 29.11782313 29.60544218 30.06984127 # 30.53424036 30.9754195 31.43981859 31.88099773 32.36861678 32.83301587 # 33.29741497 33.7385941 34.2029932 34.66739229 35.13179138 35.57297052 # 36.06058957 36.52498866 36.98938776 37.43056689 37.89496599 38.35936508 # 38.82376417 39.26494331 39.75256236 40.21696145 40.68136054 41.12253968 # 41.58693878 42.05133787 42.51573696 42.9569161 43.44453515 43.88571429 # 44.37333333 44.83773243 45.30213152 45.76653061 46.20770975 46.67210884 # 47.13650794 47.60090703 48.06530612 48.52970522 48.99410431 49.4585034 # 49.92290249 50.38730159 50.85170068 51.29287982 51.75727891 52.221678 # 52.6860771 53.15047619 53.61487528 54.05605442 54.52045351 54.98485261 # 55.4492517 55.91365079 56.37804989 56.84244898 57.30684807 57.77124717 # 58.23564626 58.6768254 59.14122449]
librosa.frames_to_time
- 入力:ビートとなっているフレームのインデックスをまとめたリスト
beat_frames, サンプリングレートsr- 出力:ビートのタイミング(秒)をまとめたリスト
beat_timesここでは以下のような計算が行われます。
\mathrm{beat\_times[i]=beat\_frames[i] \times hop\_length / sr}\\例えば、$\mathrm{i=0}$の場合
\begin{align} \mathrm{beat\_times}[0]&=\mathrm{beat\_frames[0]} \times \mathrm{hop\_length} / \mathrm{sr}\\ &=5 \times 512 / 22050\\ &=0.1160997732...\\ &\simeq0.11609977 \end{align}これより
beat_framesとsrからbeat_timesを計算できることが分かりました。おわりに
初回はチュートリアルのQuickstartでしたがどうでしたか?
内容だけでなく、記事に関するコメントもいただけると幸いです。次回はチュートリアルのAdvanced usage、その後はAdvanced examplesに行けたらと思っています。
- 投稿日:2020-05-31T23:02:20+09:00
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (8) 確率的最急降下法を自作
前回
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (7) 最急降下法を自作
https://github.com/legacyworld/sklearn-basic課題 4.3 最急降下法と確率的最急降下法
解説は第5回(1) 24分30秒あたり
前回は再急降下法しか出来なかったので、今回は確率的再急降下法を実装してみる。
プログラム自体はそこまで大きくは変わらない。
数学的には以下のような感じ。\lambda = 正則化パラメータ, \beta = \begin{pmatrix} \beta_0 \\ \beta_1\\ \vdots \\ \beta_m \end{pmatrix}, y = \begin{pmatrix} y_1 \\ y_2 \\ \vdots \\ y_N \end{pmatrix}, X = \begin{pmatrix} 1&x_{11}&x_{12}&\cdots&x_{1m}\\ 1&x_{21}&x_{22}&\cdots&x_{2m}\\ \vdots\\ 1&x_{N1}&x_{N2}&\cdots&x_{Nm} \end{pmatrix}\\ \\ \beta^{t+1} = \beta^{t}(1-2\lambda\eta) - \eta\frac{1}{N}x_i^T(x_i\beta^t-y_i)これまで勾配の計算に全てのデータを利用していたのをランダムに選んだ$x_i,y_i$のみで計算を行う。
ちょっとひっかかったのが、NumpyのTransposeの仕様。
1次元ベクトルの場合transpose(.T)を使うとそのまま返ってきてしまうため、.reshape(-1,1)を使う必要がある。
こちらを参照。
https://note.nkmk.me/python-numpy-transpose/a_1d = np.arange(3) print(a_1d) # [0 1 2] print(a_1d.T) # [0 1 2] a_col = a_1d.reshape(-1, 1) print(a_col) # [[0] # [1] # [2]]ソースコードはこちら。
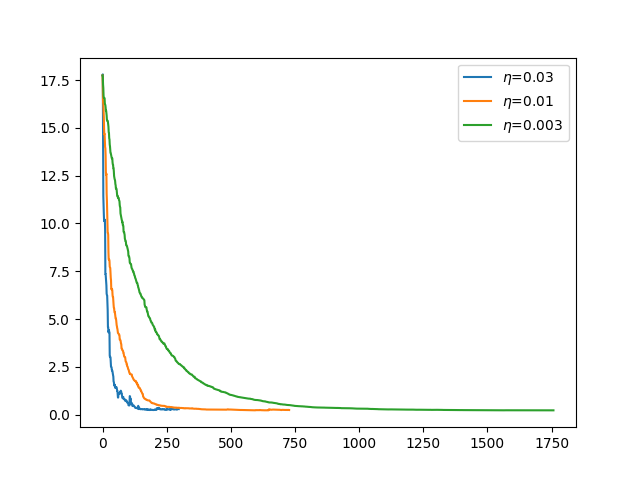
Homework_4.3SGD.pyimport pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn import preprocessing from sklearn.base import BaseEstimator from sklearn.model_selection import cross_validate import statsmodels.api as sm class MyEstimator(BaseEstimator): def __init__(self,ep,eta,l): self.ep = ep self.eta = eta self.l = l self.loss = [] # fit()を実装 def fit(self, X, y): self.coef_ = self.stochastic_grad_desc(X,y) # fit は self を返す return self # predict()を実装 def predict(self, X): return np.dot(X, self.coef_) def shuffle(self,X,y): r = np.random.permutation(len(y)) return X[r],y[r] def stochastic_grad_desc(self,X,y): m = len(y) loss = [] # 特徴量の種類 dim = X.shape[1] # betaの初期値 beta = np.ones(dim).reshape(-1,1) eta = self.eta l = self.l X_shuffle, y_shuffle = self.shuffle(X,y) # T回改善されなければ終了 T = 100 # 改善されない回数 not_improve = 0 # 目的関数最小値初期値 min = 10 ** 9 while True: for Xi,yi in zip(X_shuffle,y_shuffle): loss.append((1/(2*m))*np.sum(np.square(np.dot(X,beta)-y))) beta = beta*(1-2*l*eta) - eta*Xi.reshape(-1,1)*(np.dot(Xi,beta)-yi) if loss[len(loss)-1] < min: min = loss[len(loss)-1] min_beta = beta not_improve = 0 else: # 目的関数の最小値が更新されない場合 not_improve += 1 if not_improve >= T: break # 全サンプル終わったがT回以内に最小値が変わっている場合再度ループ if not_improve >= T: self.loss = loss break return min_beta #scikit-leanよりワインのデータをインポートする df= pd.read_csv('winequality-red.csv',sep=';') # 目標値であるqualityが入っているので落としたdataframeを作る df1 = df.drop(columns='quality') y = df['quality'].values.reshape(-1,1) X = df1.values scaler = preprocessing.StandardScaler() X_fit = scaler.fit_transform(X) X_fit = sm.add_constant(X_fit) #最初の列に1を加える epsilon = 10 ** (-7) eta_list = [0.03,0.01,0.003] loss = [] coef = [] for eta in eta_list: l = 10**(-5) test_min = 10**(9) while l <= 1/(2*eta): myest = MyEstimator(epsilon,eta,l) myest.fit(X_fit,y) scores = cross_validate(myest,X_fit,y,scoring="neg_mean_squared_error",cv=10) if abs(scores['test_score'].mean()) < test_min: test_min = abs(scores['test_score'].mean()) loss = myest.loss l_min = l coef = myest.coef_ l = l * 10**(0.5) plt.plot(loss,label=f"$\eta$={eta}") print(f"eta = {eta} : iter = {len(loss)}, loss = {loss[-1]}, lambda = {l_min}, TestErr = {test_min}") # 係数の出力 一番最初に切片が入っているので2つ目から取り出して、最後に切片を出力 i = 1 for column in df1.columns: print(column,coef[i][0]) i+=1 print('intercept',coef[0][0]) plt.legend() plt.savefig("sgd.png")解説の中で「100回連続で改善が無ければ停止」という条件が書いてあったので、それにあわせてある。
$\eta$が小さいパターンでは1599個すべて使ってもこの条件に当てはまらないため2周目に入ることもある。
結果はこんな感じ。
$\eta = 0.03$では最後の方で少し誤差が増えたりしているのがよくわかる。
最後に求められた係数等。eta = 0.03 : iter = 298, loss = 0.29072324272824085, lambda = 0.0031622776601683803, TestErr = 0.47051639691326796 fixed acidity 0.1904239451124434 volatile acidity -0.11242984344193296 citric acid -0.00703125780915424 residual sugar 0.2092352618792849 chlorides -0.044795495356479025 free sulfur dioxide -0.018863685196341816 total sulfur dioxide 0.07447982325062003 density -0.17305138620126106 pH 0.05808006453308803 sulphates 0.13876262568557934 alcohol 0.2947134691111974 intercept 5.6501294014064145 eta = 0.01 : iter = 728, loss = 0.24203354045966255, lambda = 0.00010000000000000002, TestErr = 0.45525344581852156 fixed acidity 0.25152952212309976 volatile acidity -0.03876889927769888 citric acid 0.14059421863669852 residual sugar 0.06793602828251821 chlorides -0.0607861479963043 free sulfur dioxide 0.08441853171277111 total sulfur dioxide -0.09642176480191654 density -0.2345690991118163 pH 0.1396740265674562 sulphates 0.1449843342292861 alcohol 0.19737851967044345 intercept 5.657998427200384 eta = 0.003 : iter = 1758, loss = 0.22475918775097103, lambda = 0.00010000000000000002, TestErr = 0.44693442950748147 fixed acidity 0.2953542653448508 volatile acidity -0.12934364893075953 citric acid 0.04629080083382285 residual sugar 0.013753852832452122 chlorides -0.03688613363045954 free sulfur dioxide 0.045541235818534614 total sulfur dioxide -0.049594638329345575 density -0.17427360277645224 pH 0.13897225246491407 sulphates 0.15425590075925466 alcohol 0.26518804857692096 intercept 5.597149258230254ランダムにシャッフルされているので、実行するごとに結果が変わっている。
過去の投稿
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (1)
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (2)
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (3)
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (4)
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (5)
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (6)
https://github.com/legacyworld/sklearn-basic
- 投稿日:2020-05-31T22:55:33+09:00
【python】pandas で to_csvするときのフォーマット
何度も同じことをググって使っているので、自分なりにメモします。pandas にデータを格納してto_csv としてファイルに保存するときに使います。公開するようのきれいな形式にしたい場合、桁数をそろえたいときに使います。
float のフォーマットを整える
- float 全体に指定するには、to_csv の引数に
float_format="%10.4f"のように設定できるround()を使えます。
- Series に対して整数を引数にし、小数点や整数の桁数(百の位なら-2)で丸めることができる。
- DataFrame に
roundを用いる場合は、引数に辞書をとることで、複数の列に対して独立した設定をできる。- 各列ごとに形式を指定するには、map(lambda x: '{形式}'.format(x)) で指定できる。週数点以下1桁なら
{0:.1f}、指数表記にしたければ{:.6e}のようにできる。import pandas as pd df = pd.read_csv("latlon.csv") df['val'] = df['val'].map(lambda x: '{0:.1f}'.format(x)) df.to_csv("out.csv", index=False, header=True, float_format='%11.6f')で、out.csv は
year,month,day,lat,lon,val 2012,6,16,80.862745,-39.834254,0.0 2012,6,16,80.862745,-39.502762,0.1のように出力されます。同内容は
roundを用いて、df = df.round({"lat":7, "lon":7, "val":1})
- 投稿日:2020-05-31T22:53:07+09:00
RaspberryPi センサーサンプルプロジェクト URLまとめ
RaspberryPi センサーサンプルプロジェクト URLまとめ
センサーのサンプルプロジェクトファイルをWeb上で配布している会社のまとめです。
基本どの会社のセットもCDの中にサンプルを収録しセットに付いてきます。OSOYOO
OSOYOO(オソヨー) Raspberry Pi 学ぶ電子工作キット 初心者演習用パーツセット ラズパイ11実例 回路配線図とサンプルスケッチ有り プログラミング ラズベリー パイ 超入門 スターター学習キット LED制御 スイッチ I2C LCD 温湿度センサー マイクロサーボ 人体感知センサー A/Dコンバータ ブザー 大気圧センサー リレーモジュール制御 赤外線リモコン等IoTを実践する電子部品セット (Pi 3 DIY Kit 22in1)
Project FileELEGOO
ELEGOO Arduino用のMega2560スタータキット最終版 初心者向け、チュートリアル付、MEGA 2560ボード, LCD1602
Project FileKuman
Kuman 44個キット センサー キット Raspberry Pi用 センサーモジュール スターター キット iot学習キット 電子工作 Raspberry Pi 4 B 3 2 Model B B+ A A+に適用 ラズベリーパイ K47
Project Filesunfounder
SunFounder Raspberry pi スターター電子工作キット,ラズベリーパイ初心者向けプログラミング,詳細な教本と豊富な学習用レッスン付き,Raspberry pi 4B/3B+/3B/3A+/2B/1B+/1A+/Zero W/Zeroに対応、C/Pythonコードをサポート
Project FileKeeYees
KeeYees 電子工作キット 初心者向け スターターキット 電子部品 基本部品56種類 エレクトロニクス入門キット Electronics Fun Kit Arduino用 Raspberry Pi用 チュートリアルあり
Project FileFreenove
Freenove Raspberry Pi 4 B 3 BのためのRFIDスターターキット +、423ページ詳細ガイド、Python C Java、204アイテム、53プロジェクト、エレクトロニクスとプログラミングを学ぶ、ソルダーレスブレッドボード
Project FileKEYESTUDIO
KEYESTUDIO ラズベリーパイ 拡張ボード スターターキット for Raspberry Pi 3 4 4B 電子工作 電子部品 キット 実験キット LED, 超音波 センサー, RFID モジュール,ブレッドボード セット
Project FileWayinTop
WayinTop Raspberry Pi用センサーキット 電子工作キット ラズベリー パイ 超入門 初心者向け 中級者向け 学習キット 電子部品セット プログラミング JAVA C++ Python 日本語チュートリアル
Web上未確認 CD教材UNIROI
Miuzei
Miuzei 初心者スターターキット mega2560 r3 nanoと互換できる(日本語マニュアル付き)
Web上未確認 CD教材









- 投稿日:2020-05-31T22:53:07+09:00
RaspberryPi センサーサンプルファイル配布 URLまとめ
RaspberryPi センサーサンプルファイル配布 URLまとめ
センサーをまとめ売りしている業者はサンプルファイルをCDに収録しセット売りしているのですが、Web上にもファイルを公開している会社をまとめてみました。
OSOYOO
OSOYOO(オソヨー) Raspberry Pi 学ぶ電子工作キット 初心者演習用パーツセット ラズパイ11実例 回路配線図とサンプルスケッチ有り プログラミング ラズベリー パイ 超入門 スターター学習キット LED制御 スイッチ I2C LCD 温湿度センサー マイクロサーボ 人体感知センサー A/Dコンバータ ブザー 大気圧センサー リレーモジュール制御 赤外線リモコン等IoTを実践する電子部品セット (Pi 3 DIY Kit 22in1)
Project FileELEGOO
ELEGOO Arduino用のMega2560スタータキット最終版 初心者向け、チュートリアル付、MEGA 2560ボード, LCD1602
Project FileKuman
Kuman 44個キット センサー キット Raspberry Pi用 センサーモジュール スターター キット iot学習キット 電子工作 Raspberry Pi 4 B 3 2 Model B B+ A A+に適用 ラズベリーパイ K47
Project Filesunfounder
SunFounder Raspberry pi スターター電子工作キット,ラズベリーパイ初心者向けプログラミング,詳細な教本と豊富な学習用レッスン付き,Raspberry pi 4B/3B+/3B/3A+/2B/1B+/1A+/Zero W/Zeroに対応、C/Pythonコードをサポート
Project FileKeeYees
KeeYees 電子工作キット 初心者向け スターターキット 電子部品 基本部品56種類 エレクトロニクス入門キット Electronics Fun Kit Arduino用 Raspberry Pi用 チュートリアルあり
Project FileFreenove
Freenove Raspberry Pi 4 B 3 BのためのRFIDスターターキット +、423ページ詳細ガイド、Python C Java、204アイテム、53プロジェクト、エレクトロニクスとプログラミングを学ぶ、ソルダーレスブレッドボード
Project FileKEYESTUDIO
KEYESTUDIO ラズベリーパイ 拡張ボード スターターキット for Raspberry Pi 3 4 4B 電子工作 電子部品 キット 実験キット LED, 超音波 センサー, RFID モジュール,ブレッドボード セット
Project FileWayinTop
WayinTop Raspberry Pi用センサーキット 電子工作キット ラズベリー パイ 超入門 初心者向け 中級者向け 学習キット 電子部品セット プログラミング JAVA C++ Python 日本語チュートリアル
Web上未確認 CD教材UNIROI
Miuzei
Miuzei 初心者スターターキット mega2560 r3 nanoと互換できる(日本語マニュアル付き)
Web上未確認 CD教材
- 投稿日:2020-05-31T22:51:59+09:00
PythonでABC169を解く
はじめに
A~Dの四完でした。
A問題
考えたこと
やるだけa, b = map(int,input().split()) print(a*b)B問題
考えたこと
0が入ってると積は0なのでsortで小さい順に並べてやる。n = int(input()) a = list(map(int,input().split())) a.sort() ans = 1 for i in range(n): ans *= a[i] if ans > 10**18: print(-1) quit() print(ans)C問題
考えたこと
はい。こいつのせいでパフォが落ちました。くそ。
精度が不安だったのでdecimal使いました。「decimalの切り捨てはquantize使おうな! 約束だぞ!!!!」from decimal import * a, b = input().split() a = Decimal(a) b = Decimal(b) ans = a * b ans = ans.quantize(Decimal(0),rounding=ROUND_FLOOR) print(ans)D問題
考えたこと
とりあえず$N$を素因数分解します。
サンプルケース1の場合を考えます。
24を素因数分解すると$2^3*3^1$となります。このとき行える操作の最大数は$2^1,2^2,3^1$です。$2^3$はNの約数ではないので、できません。$3^2$も同様です。
このことから、$N$の素因数の指数部分を超えないように足していけばいいことが分かります。(例:24だと、2の数は3個なので1+2まで、3の数は1個なので1)。あとは、それぞれの素因数ごとに何回使えるかを計算するだけ。n = int(input()) def factorization(n): arr = [] temp = n for i in range(2, int(-(-n**0.5//1))+1): if temp%i==0: cnt=0 while temp%i==0: cnt+=1 temp //= i arr.append([i, cnt]) if temp!=1: arr.append([temp, 1]) if arr==[]: arr.append([n, 1]) return arr if n == 1: print(0) quit() f = factorization(n) ans = 0 c = len(f) for i in range(c): s = 0 g = f[i][1] if g == 2: ans += 1 else: for j in range(g): s += j + 1 f[i][1] -= j+1 if s > g: break ans += 1 print(ans)まとめ
最近のCに嫌われているtax_free。こういう精度問題が出たときに、脳死で提出しまくる癖を直したい。
ではまた、おやすみなさい。
- 投稿日:2020-05-31T22:50:20+09:00
Cloud Composerで定期的にYoutube APIを叩きBigqueryに格納してみる
はじめに
こんにちは。AIベンチャーでデータサイエンティストをしているたむたむです。
最近Youtuberの東海オンエアにどハマりしているのですが、ふと彼らが最近どのくらいの勢いで総再生回数や登録者数を伸ばしているのか気になり、Cloud ComposerでYoutube APIを定期的に叩き、Bigqueryに日々の数値を格納するコードを書いてみました。ちなみに以下のサイトとかから過去1ヶ月分の再生回数の推移とか見れるのですが、もっと長期間データを溜めて分析したいなと思ったため、今回こんなことをしています。
【簡単】YouTubeチャンネル登録者数の推移を確認する3つの方法Youtube APIの初期設定
Youtube APIを叩けるように初期設定を行います。基本はGCPのServices項目の中からYouTube Data APIを探し、有効化すれば扱えるようになります。その後、Youtube API keyの保存をしておきます。
ここら辺は、公式サイトを見ればわかると思います。GCPサービスの初期設定
以下のサイトを参考に諸々設定すれば問題ないです。ただ、私はUIを使って設定する方が楽なのでUIを使用してComposerとBigqueryの設定を行っています。
GCP Cloud ComposerでBigQueryのテーブルを操作するワークフローを作る手順Cloud Composer
以下の部分だけ設定し、あとは何も設定せずで「作成」を押します。composerの作成にはかなり時間かかります。
ライブラリのインストール
composerの作成が完了したら以下の作業に進みます。
ここでは、composerにyoutube-APIをインストールしないと、後々composer上からYoutubeAPIが叩けるようにならないので、予めcomposerにYoutubeAPIをインストールします。
まずは、以下のような中身のファイルを作成しておきます。requirement.txtyoutube-data-apiこちらのファイルをCloud Shellにアップロードします。アップロードは公式サイトを参考にすればできます。
そして以下のコードをCloud Shell上で実行します。gcloud config set core/project プロジェクト名 gcloud composer environments update composer名(toukai-onair-composer) --update-pypi-packages-from-file requirements.txt --location ロケーション名(asia-northeast1)Bigquery
以下のサイトに記載されている通りに、テーブルを作成します。
- テーブルの作成と使用ComposerのDAG定義を作成
環境設定は大体終わったので、YoutubeAPIを叩いて、Bigqueryに格納するコードを書いていきます。
Youtube APIを叩くコード
以下は、channel_idとapi_keyを与えると、特定のチャンネルの総再生回数とチャンネル登録者数を返すコードです。
youtubelib.pyfrom apiclient.discovery import build class Youtubeapi: def __init__(self, channel_id, api_key): self.channel_id = channel_id if not channel_id: raise Exception("need channel_id") self.api_key = api_key if not api_key: raise Exception("need api_key") def get_statistics_data(self): youtube = build('youtube', 'v3', developerKey=self.api_key) search_response = youtube.channels().list( part='statistics', id=self.channel_id, ).execute() return search_response['items'][0]['statistics']Bigqueryへ格納するDAG定義
以下は、Youtubeapiクラスを利用してYoutubeAPIを叩き、Bigqueryにデータを格納するDAGのコードです。
dag.pyfrom airflow import DAG from airflow.operators.dummy_operator import DummyOperator from airflow.operators.python_operator import PythonOperator from datetime import datetime from google.cloud import bigquery from lib import youtubelib start = DummyOperator(task_id='start') GCP_PROJECT = プロジェクト名 BQ_YOUTUBE_DATASET = データセット名.テーブル名 YOUTUBE_CHANNEL_ID = 東海オンエアのチャンネルID('UCutJqz56653xV2wwSvut_hQ') YOUTUBE_API_KEY = YoutubeのAPIKey # see https://cloud-textbook.com/69/#_start_dateschedule_intervalcatchup default_args = { 'owner': 'airflow', 'start_date': datetime(2020, 5, 18), 'retries': 0, 'max_active_runs': 1, } schedule_interval = '0 17 * * *' # define dag dag = DAG('toukai_trends', default_args=default_args, schedule_interval=schedule_interval, catchup=False) youtubeapi = youtubelib.Youtubeapi(channel_id=YOUTUBE_CHANNEL_ID, api_key=YOUTUBE_API_KEY) def pull_youtube_statistics_api(ds, **kwargs): statistics = youtubeapi.get_statistics_data() dt = datetime.now().strftime("%Y-%m-%d %H:%M:%S") print('dt', dt) viewcount = statistics['viewCount'] print('viewCount', viewcount) subscribercount = statistics['subscriberCount'] print('subscriberCount', subscribercount) videocount = statistics['videoCount'] print('videoCount', videocount) bigquery_client = bigquery.Client() query = ''' INSERT `{0}.{1}` SELECT CAST("{2}" AS timestamp) AS datetime, CAST("{3}" AS INT64) AS viewcount, CAST("{4}" AS INT64) as subscribercount, CAST("{5}" AS INT64) as videocount '''.format(GCP_PROJECT, BQ_YOUTUBE_DATASET, str(dt), str(viewcount), str(subscribercount), str(videocount)) rows = bigquery_client.query(query).result() return 'ok' job_transactiondetail_puller = PythonOperator( task_id='pull_youtube_statistics_api', provide_context=True, python_callable=pull_youtube_statistics_api, dag=dag, )composerの定期実行に関しては色々ややこしい部分があるのでクラウドサービス徹底比較・徹底解説 (2020年版)を確認してみてください。
DAGの定義をCloud Composerにアップロード
dag.pyをCloud Shellにアップロードし、Shell上で以下を行います。
gcloud composer environments storage dags import --environment=toukai-onair-composer --location=asia-northeast1 --source=./dag.py実行するとGCS上にファイルができており、そこにyoutubelib.pyも置いておきます。
動作確認
GCP Cloud ComposerでBigQueryのテーブルを操作するワークフローを作る手順の
Cloud ComposerのDAGの実行状況確認と同じように確認すれば問題ありません。
view logsから実行結果のログも確認できます。価格感
実行してみて実感したのですが、やっぱり高いです。
僕のお小遣いだと痛いレベルだったので、長期間実行はやめました、、、
(これならYoutube Premiumに登録したQOL高い、、、)
値段感はクラウドサービス徹底比較・徹底解説 (2020年版)の料金編をみてみてください。まとめ
作ってみたものの、値段が高すぎて個人で使うのは難しそうでした、、、
次はCloud Finctionの定期実行とかで行ってみることで安くできたりするのかなと思っているので、作成してみようかなと思っています。
それでは、良いYoutubeライフを!!
- 投稿日:2020-05-31T22:50:20+09:00
Cloud Composerを用いて定期的にYoutube APIを叩きBigqueryに結果を格納してみる
はじめに
こんにちは。AIベンチャーでデータサイエンティストをしているたむたむです。
最近Youtuberの東海オンエアにどハマりしているのですが、ふと彼らが最近どのくらいの勢いで総再生回数や登録者数を伸ばしているのか気になり、Cloud ComposerでYoutube APIを定期的に叩き、Bigqueryに日々の数値を格納するコードを書いてみました。ちなみに以下のサイトとかから過去1ヶ月分の再生回数の推移とか見れるのですが、もっと長期間データを溜めて分析したいなと思ったため、今回こんなことをしています。
【簡単】YouTubeチャンネル登録者数の推移を確認する3つの方法Youtube APIの初期設定
Youtube APIを叩けるように初期設定を行います。基本はGCPのServices項目の中からYouTube Data APIを探し、有効化すれば扱えるようになります。その後、Youtube API keyの保存をしておきます。
ここら辺は、公式サイトを見ればわかると思います。GCPサービスの初期設定
以下のサイトを参考に諸々設定すれば問題ないです。ただ、私はUIを使って設定する方が楽なのでUIを使用してComposerとBigqueryの設定を行っています。
GCP Cloud ComposerでBigQueryのテーブルを操作するワークフローを作る手順Cloud Composer
以下の部分だけ設定し、あとは何も設定せずで「作成」を押します。composerの作成にはかなり時間かかります。
ライブラリのインストール
composerの作成が完了したら以下の作業に進みます。
ここでは、composerにyoutube-APIをインストールしないと、後々composer上からYoutubeAPIが叩けるようにならないので、予めcomposerにYoutubeAPIをインストールします。
まずは、以下のような中身のファイルを作成しておきます。requirement.txtyoutube-data-apiこちらのファイルをCloud Shellにアップロードします。アップロードは公式サイトを参考にすればできます。
そして以下のコードをCloud Shell上で実行します。gcloud config set core/project プロジェクト名 gcloud composer environments update composer名(toukai-onair-composer) --update-pypi-packages-from-file requirements.txt --location ロケーション名(asia-northeast1)Bigquery
以下のサイトに記載されている通りに、テーブルを作成します。
- テーブルの作成と使用ComposerのDAG定義を作成
環境設定は大体終わったので、YoutubeAPIを叩いて、Bigqueryに格納するコードを書いていきます。
Youtube APIを叩くコード
以下は、channel_idとapi_keyを与えると、特定のチャンネルの総再生回数とチャンネル登録者数を返すコードです。
youtubelib.pyfrom apiclient.discovery import build class Youtubeapi: def __init__(self, channel_id, api_key): self.channel_id = channel_id if not channel_id: raise Exception("need channel_id") self.api_key = api_key if not api_key: raise Exception("need api_key") def get_statistics_data(self): youtube = build('youtube', 'v3', developerKey=self.api_key) search_response = youtube.channels().list( part='statistics', id=self.channel_id, ).execute() return search_response['items'][0]['statistics']Bigqueryへ格納するDAG定義
以下は、Youtubeapiクラスを利用してYoutubeAPIを叩き、Bigqueryにデータを格納するDAGのコードです。
dag.pyfrom airflow import DAG from airflow.operators.dummy_operator import DummyOperator from airflow.operators.python_operator import PythonOperator from datetime import datetime from google.cloud import bigquery from lib import youtubelib start = DummyOperator(task_id='start') GCP_PROJECT = プロジェクト名 BQ_YOUTUBE_DATASET = データセット名.テーブル名 YOUTUBE_CHANNEL_ID = 東海オンエアのチャンネルID('UCutJqz56653xV2wwSvut_hQ') YOUTUBE_API_KEY = YoutubeのAPIKey # see https://cloud-textbook.com/69/#_start_dateschedule_intervalcatchup default_args = { 'owner': 'airflow', 'start_date': datetime(2020, 5, 18), 'retries': 0, 'max_active_runs': 1, } schedule_interval = '0 17 * * *' # define dag dag = DAG('toukai_trends', default_args=default_args, schedule_interval=schedule_interval, catchup=False) youtubeapi = youtubelib.Youtubeapi(channel_id=YOUTUBE_CHANNEL_ID, api_key=YOUTUBE_API_KEY) def pull_youtube_statistics_api(ds, **kwargs): statistics = youtubeapi.get_statistics_data() dt = datetime.now().strftime("%Y-%m-%d %H:%M:%S") print('dt', dt) viewcount = statistics['viewCount'] print('viewCount', viewcount) subscribercount = statistics['subscriberCount'] print('subscriberCount', subscribercount) videocount = statistics['videoCount'] print('videoCount', videocount) bigquery_client = bigquery.Client() query = ''' INSERT `{0}.{1}` SELECT CAST("{2}" AS timestamp) AS datetime, CAST("{3}" AS INT64) AS viewcount, CAST("{4}" AS INT64) as subscribercount, CAST("{5}" AS INT64) as videocount '''.format(GCP_PROJECT, BQ_YOUTUBE_DATASET, str(dt), str(viewcount), str(subscribercount), str(videocount)) rows = bigquery_client.query(query).result() return 'ok' job_transactiondetail_puller = PythonOperator( task_id='pull_youtube_statistics_api', provide_context=True, python_callable=pull_youtube_statistics_api, dag=dag, )composerの定期実行に関しては色々ややこしい部分があるのでクラウドサービス徹底比較・徹底解説 (2020年版)を確認してみてください。
DAGの定義をCloud Composerにアップロード
dag.pyをCloud Shellにアップロードし、Shell上で以下を行います。
gcloud composer environments storage dags import --environment=toukai-onair-composer --location=asia-northeast1 --source=./dag.py実行するとGCS上にファイルができており、そこにyoutubelib.pyも置いておきます。
動作確認
GCP Cloud ComposerでBigQueryのテーブルを操作するワークフローを作る手順の
Cloud ComposerのDAGの実行状況確認と同じように確認すれば問題ありません。
view logsから実行結果のログも確認できます。価格感
実行してみて実感したのですが、やっぱり高いです。
僕のお小遣いだと痛いレベルだったので、長期間実行はやめました、、、
(これならYoutube Premiumに登録したQOL高い、、、)
値段感はクラウドサービス徹底比較・徹底解説 (2020年版)の料金編をみてみてください。まとめ
作ってみたものの、値段が高すぎて個人で使うのは難しそうでした、、、
次はCloud Finctionの定期実行とかで行ってみることで安くできたりするのかなと思っているので、作成してみようかなと思っています。
それでは、良いYoutubeライフを!!
- 投稿日:2020-05-31T22:49:00+09:00
Python--Pygalの第一歩
Pygal
機能概要
グラフなどでデータを可視化する際、このライブラリを使用して、ベクター画像(SVG)ファイルを生成することにより、すべてのデバイス上に自動的に調整し、きれい表示することができる。
インストール
pip install pygal参考
- オフィシャルサイト: http://www.pygal.org
- 投稿日:2020-05-31T22:47:30+09:00
[Python]04章-07 いろいろなデータ構造(ディクショナリの操作)
[Python]04章-07 ディクショナリの操作
ディクショナリは、キーについてはイミュータブルのため操作ができないことは説明しましたが、値についてはミュータブルのため、操作が可能です。
今回はディクショナリの操作について説明していきたいと思います。ディクショナリの要素の追加
まずは、要素の追加について説明します。
Python Consoleから以下のコードを入力してください。>>> foodD = {'a' : 'apple', 'b' : 'banana', 'c': 'cake'} >>> foodD {'a': 'apple', 'b': 'banana', 'c': 'cake'}ここまでは前回説明した通り、ディクショナリの作成となります。
では、ディクショナリの変数foodDに要素を追加してみますが、追加方法には2つあります。1つの要素の追加方法について
まずは1つの要素を追加する方法を説明します。
Python Consoleに以下のコードを入力してください。一度変数foodDの内容を表示してから実行します。>>> foodD {'a': 'apple', 'b': 'banana', 'c': 'cake'} >>> foodD['d'] = 'dragon fruits' >>> foodD {'a': 'apple', 'b': 'banana', 'c': 'cake', 'd': 'dragon fruits'}ディクショナリに要素を追加する際には、変数名[キー] = 値という形で要素を新たに追加していきます。
では、すでにキーがあった際にはどうなるでしょうか?
Python Consoleに以下のコードを入力してください。一度変数foodDの内容を表示してから実行します。>>> foodD {'a': 'apple', 'b': 'banana', 'c': 'cake', 'd': 'dragon fruits'} >>> foodD['c'] = 'carrot' >>> foodD {'a': 'apple', 'b': 'banana', 'c': 'carrot', 'd': 'dragon fruits'}'c'の個所が上書きされていることを確認できます。実は1つのディクショナリについて、重複したキーは指定できません。重複していた場合は、別の値を上書きすることになります。
複数の要素の追加方法について
ディクショナリに複数の要素を追加するには、updateメソッドを利用します。
Python Consoleに以下のコードを入力してください。一度変数foodDの内容を表示してから実行します。>>> foodD {'a': 'apple', 'b': 'banana', 'c': 'carrot', 'd': 'dragon fruits'} >>> foodD.update({'e' : 'egg', 'f' : 'fried potato'}) >>> foodD {'a': 'apple', 'b': 'banana', 'c': 'carrot', 'd': 'dragon fruits', 'e': 'egg', 'f': 'fried potato'}別の辞書をマージしている形式となります。foodDを確認すると、'e'と'f'が追記されていることを確認できます。
ディクショナリの要素の削除
ディクショナリの要素もキーを指定して削除することができます。実はリストと同じく、del文を使用して削除ができます。
Python consoleに以下のコードを入力してください。一度変数foodDの内容を表示してから実行します。>>> foodD {'a': 'apple', 'b': 'banana', 'c': 'carrot', 'd': 'dragon fruits', 'e': 'egg', 'f': 'fried potato'} >>> del foodD['b'] >>> foodD {'a': 'apple', 'c': 'carrot', 'd': 'dragon fruits', 'e': 'egg', 'f': 'fried potato'}'b'が削除されているのが確認できました。
また、ディクショナリの全要素を削除するには、リストと同じくclearメソッドを使用します。
>>> foodD {'a': 'apple', 'c': 'carrot', 'd': 'dragon fruits', 'e': 'egg', 'f': 'fried potato'} >>> foodD.clear() >>> foodD {}ディクショナリの全要素が削除されて、{ }が出力され、空であることを確認できます。
ディクショナリの要素の探索
ディクショナリでも要素の探索は可能です。今回もキーを指定して探索していきます。
前節では変数名[キー]を指定して探索しましたが、もし該当するキーがないとエラーが出力されます。
今回はキーがない場合でもエラーが出力されない方法を説明します。Python consoleに以下のコードを入力してください。まずはDにディクショナリを代入していきます。
>>> D = {'NRT' : '成田空港', 'CTS' : '新千歳空港', 'HIJ' : '広島空港'} >>> D {'NRT': '成田空港', 'CTS': '新千歳空港', 'HIJ': '広島空港'}キーがない場合でもエラーが出力されない方法として、getメソッドを使用します。
>>> D {'NRT': '成田空港', 'CTS': '新千歳空港', 'HIJ': '広島空港'} >>> D.get('NRT') '成田空港' >>> D.get('MYJ')まず、'NRT'はDに存在するので、'成田空港'が返ってきます。'MYJ'についてはDに存在しないため、何も返ってきません。
ちなみに、print関数を用いて存在しないキーを指定すると、Noneと返ってきます。
>>> print(D.get('MYJ')) None他にも、リストの時に説明した、in演算子を使うことでも存在を確認できます。リストとは異なり、キーを指定して確認します。
>>>'NRT' in D True >>>'MYJ' in D False最後に
ディクショナリについて一通り見てきましたが、基本的にはリストとほぼ同じ操作であることは確認できたかと思います。違いとしては要素の番号を指定するリストに対して、ディクショナリはキーを指定するという点です。今後もよく出てくるデータ構造ですので押さえておきましょう。
【目次リンク】へ戻る
- 投稿日:2020-05-31T22:46:53+09:00
2次元熱拡散シミュレーション結果をPython VTKで出力する
はじめに
熱拡散シミュレーションで得たndarray形式の2次元格子の温度データを、VTKデータで出力する方法を記載します。
方法
Python VTKライブラリを利用して、StructuredGrid形式で出力します。
環境
- Windows 10 home(FEniCSの計算ではWSLを利用)
- Anaconda(python 3.7.6)
- FEniCS 2018
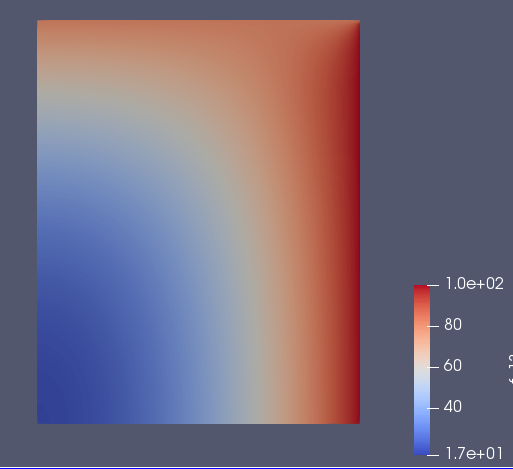
シミュレーション結果
温度拡散シミュレーションは、次の熱拡散方程式をPythonインターフェースのFEniCSを利用して、有限要素法で計算しました。
$$
\frac{\partial}{\partial t} u = \alpha\nabla ^2 u
$$
$u$:温度スカラー $\alpha$:熱拡散係数です。計算結果は、次の図のようになります。
図:計算結果FEniCSは、以下の記事を参考にしてください。
https://qiita.com/matsxxx/items/b696d2fe730be1683d8d
今回利用したシミュレーション結果を作るコードは、以下になります。import fenics as fe import numpy as np tol = 1e-14 # Lx = 80 #x方向長さ Ly = 100 #y方向長さ Nx = 80 #x軸セル数 Ny = 100 #y軸セル数 T = 10.0 #計算する時間 num_steps = 10 #時間ステップ dt = T/num_steps #時間刻み alpha = 100.#熱拡散係数 #メッシュ作成 mesh = fe.RectangleMesh(fe.Point(0, 0), fe.Point(Lx, Ly), Nx, Ny) V = fe.FunctionSpace(mesh, "P", 1)#有限要素空間 #fenicsの配列を並べ替えるのに利用する。 vertex_to_dof_map = fe.vertex_to_dof_map(V) #境界条件の位置設定 def boundary_right(x, on_boundary): #x[0]:x座標、x[1]:y座標 return on_boundary and fe.near(x[0], Lx, tol) def boundary_top(x, on_boundary): #x[0]:x座標、x[1]:y座標 return on_boundary and fe.near(x[1], Ly, tol) #第一種境界条件の設定 bc_right = fe.DirichletBC(V, fe.Constant(100), boundary_right)#Lx側を100℃ bc_top = fe.DirichletBC(V, fe.Constant(80), boundary_top)#Ly側を80℃ #試行/試験関数の設定 u = fe.TrialFunction(V) #解きたい変数 v = fe.TestFunction(V) #重み関数 #初期条件 u_0 = fe.Expression('0',degree=2)#初期温度0 u_n = fe.interpolate(u_0, V) #変分法の熱拡散方程式 F= u * v * fe.dx + alpha * dt * fe.dot(fe.grad(u), fe.grad(v)) * fe.dx - (u_n) * v * fe.dx a, L = fe.lhs(F), fe.rhs(F) #変数 u = fe.Function(V) t = 0#時間 #非定常計算の実行 for n in range(num_steps): #時間更新 t += dt #方程式を解く fe.solve(a == L, u, [bc_right, bc_top]) #解を更新 u_n.assign(u) #最終結果をndarrayで取り出す。 u_np_temp = u.vector().get_local() #fenics内の変数の並びからT[0,0], T[0,1]・・・T[Nx-1,Ny-2],T[Nx-1,Ny-1]の並びに変換 u_np = np.zeros_like(u_np_temp) for i,v in enumerate(vertex_to_dof_map): u_np[i] = u_np_temp[v] #npyで保存 np.save("solution", u_np) #fenicsにはVTKデータで出力することが可能なので、通常はこちらを使う。 #vtk = fe.File("output.pvd") #vtk << uVTKライブラリを用いた出力
ndarray形式のシミュレーション結果を、VTKライブラリのStructuredGrid形式で出力します。
import numpy as np import vtk Nx = 80 Ny = 100 #シミュレーション結果読み込み u = np.load("solution.npy") #点データの作成 points = vtk.vtkPoints() for iy in range(Ny+1): for ix in range(Nx+1): x = ix y = iy points.InsertNextPoint(x,y,0)#2次元なので、z座標は0にする #点データをstructuredGridにセットする structured_mesh = vtk.vtkStructuredGrid() structured_mesh.SetExtent(0, Nx, 0, Ny, 0, 0) structured_mesh.SetPoints(points) #温度データをvtk arrayに入力する temp_value = vtk.vtkDoubleArray() temp_value.SetName("Temperature") for t in u: temp_value.InsertNextValue(t) #StructuredGridのPointDataに温度データを追加 structured_mesh.GetPointData().AddArray(temp_value) #データ出力 writer = vtk.vtkXMLDataObjectWriter() writer.SetFileName("temperature.vts") writer.SetInputData(structured_mesh) writer.Update()おまけ:PyEVTKを利用して出力
VTKデータで出力するだけなら、PyEVTKを利用したほうが簡単です。
import numpy as np import evtk Nx = 80 Ny = 100 u = np.load("solution.npy") u = u.reshape(Ny+1, -1)#x,yの並び注意 u = u[:,:,np.newaxis] #meshgridで座標作成 x = np.arange(0, Nx+1) y = np.arange(0, Ny+1) X, Y = np.meshgrid(x,y) X = X[:,:,np.newaxis] Y = Y[:,:,np.newaxis] Z = np.zeros_like(X)#2次元のため、Z座標は0 evtk.hl.gridToVTK("temperature_evtk", X, Y, Z, pointData={"temperature":u})
- 投稿日:2020-05-31T22:45:45+09:00
Google Colaboratory で Python を勉強する
機械学習といえば Python
少し前から、AIや機械学習に注目が集まっています。エンジニアとしてたしなみ程度でも勉強しておく必要があると思い、これから基礎的なことを勉強しようと思いました。
まずは、勉強するにあたって、以下のページを参考にしました。
やはり機械学習といえばPythonというのが一般的みたいなので、まずはPythonから勉強しようと思います。
Pythonを学ぶための準備
Pythonの学習、ひいてはその先の機械学習をを学ぶために、環境構築に手間取ると学習のモチベーションが下がってしまう可能性があります。あくまで学習のためなので、手早く構築したいと考えていたところ、Googleが提供しているColaboratory(略称: Colab)を使用するとWebブラウザを介してPythonを実行できるようです。さらに、機械学習のための構成が組まれていてGPUも無料で利用できるみたいです。
Google Colaboratory の使用法
Googleアカウントの作成・ログイン
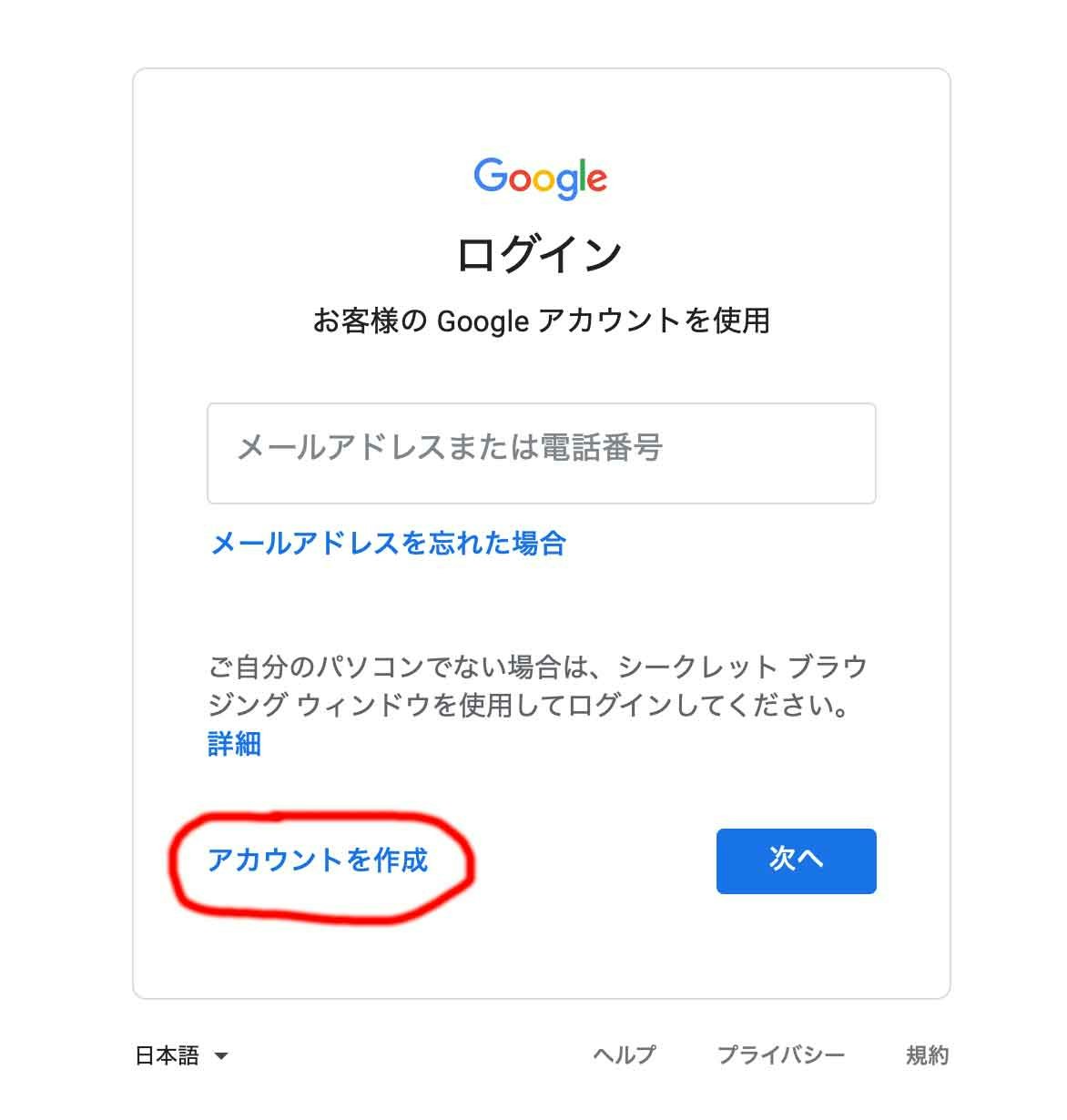
まずは Google にアカウントを作ります。
Googleのサイトにアクセスして、右上の「ログイン」を押します。
ログイン画面が出るので、左下の「アカウントを作成」を押します。その後、必要な情報を登録してアカウントを作成します。
その後、登録したアカウントでGoogleのサイトにログインします。
Googleドライブにフォルダを作成
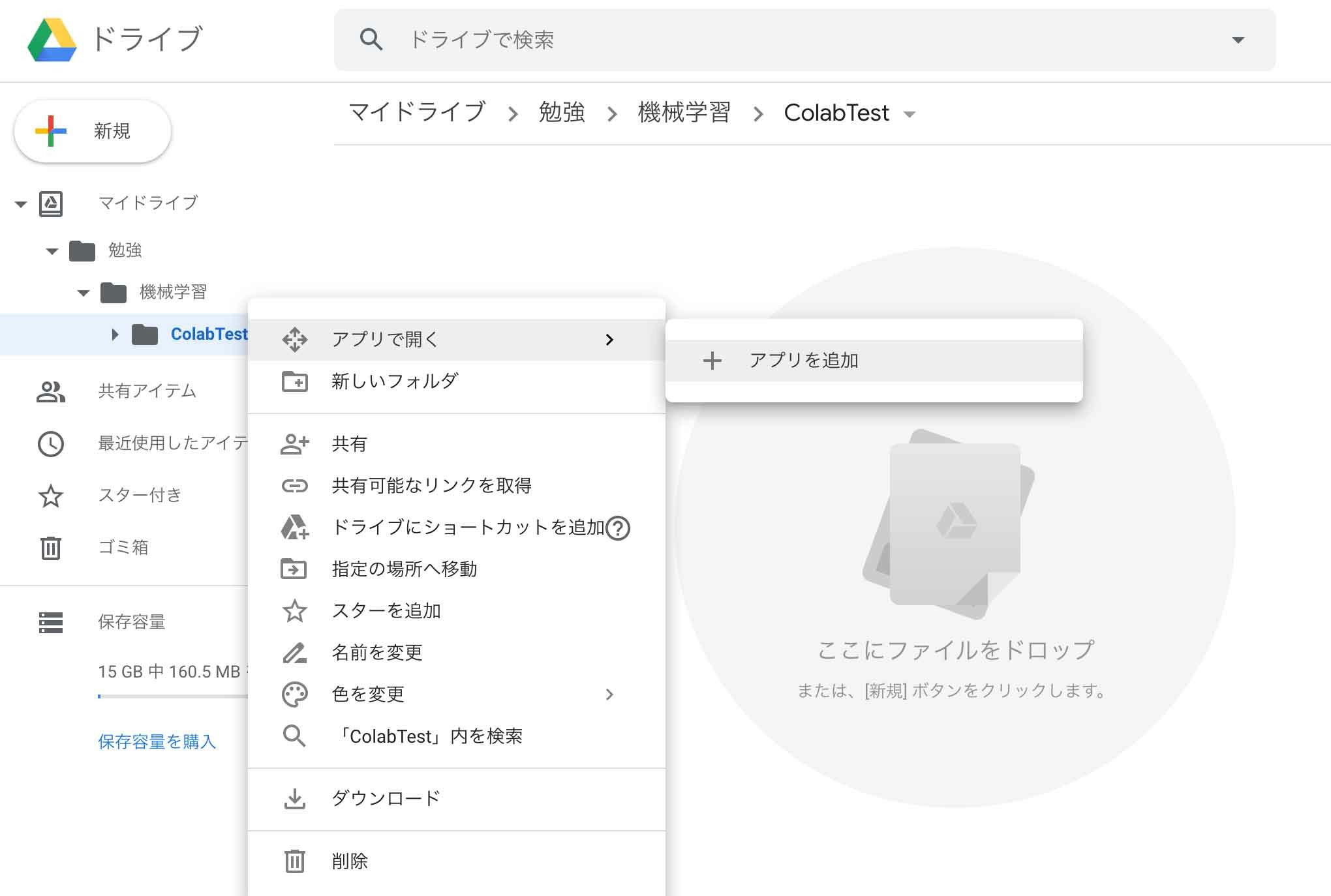
Google Colaboratory用にGoogleドライブにフォルダを作成します。
Googleドライブのフォルダ上にColaboratoryアプリを追加
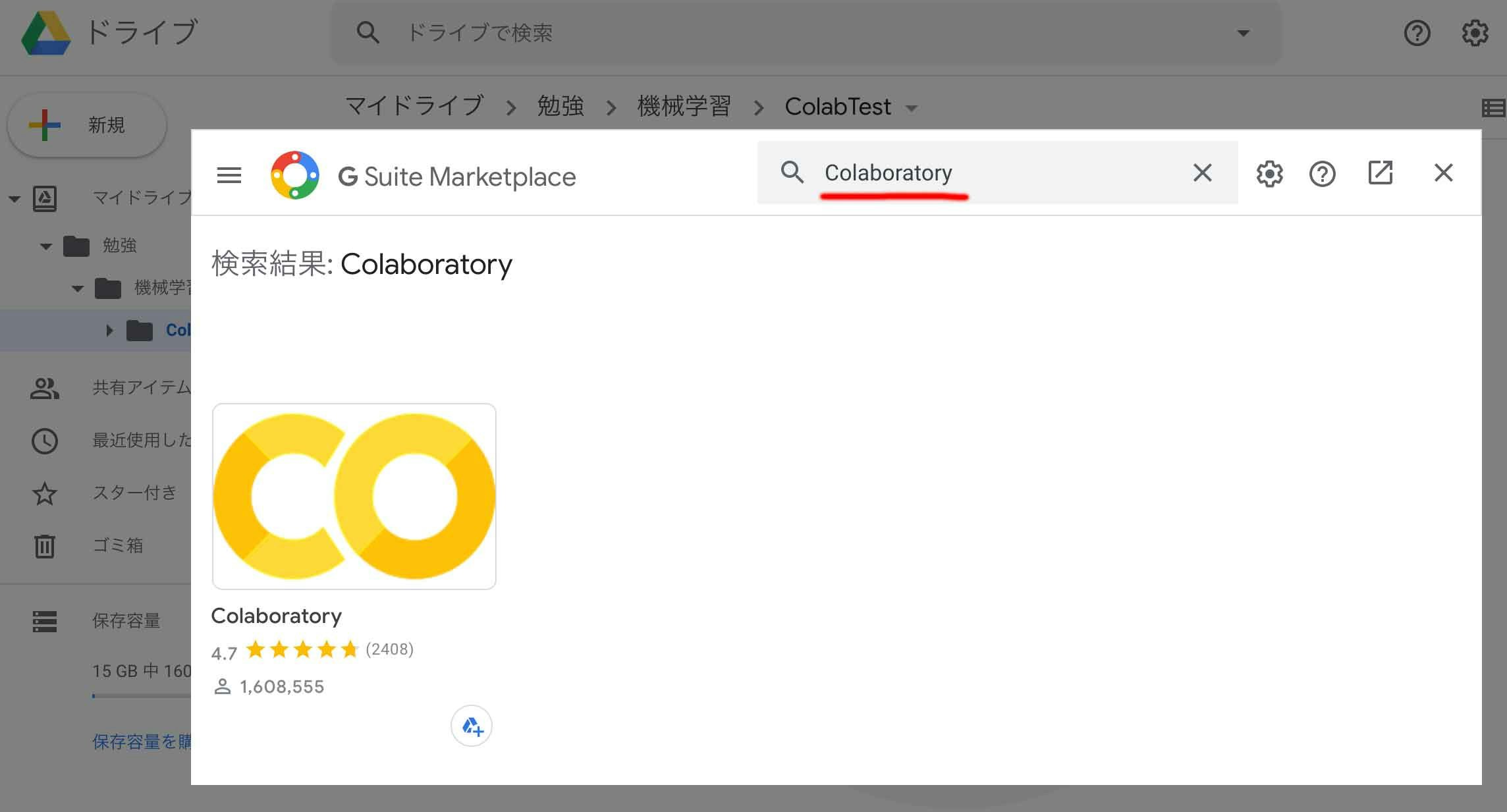
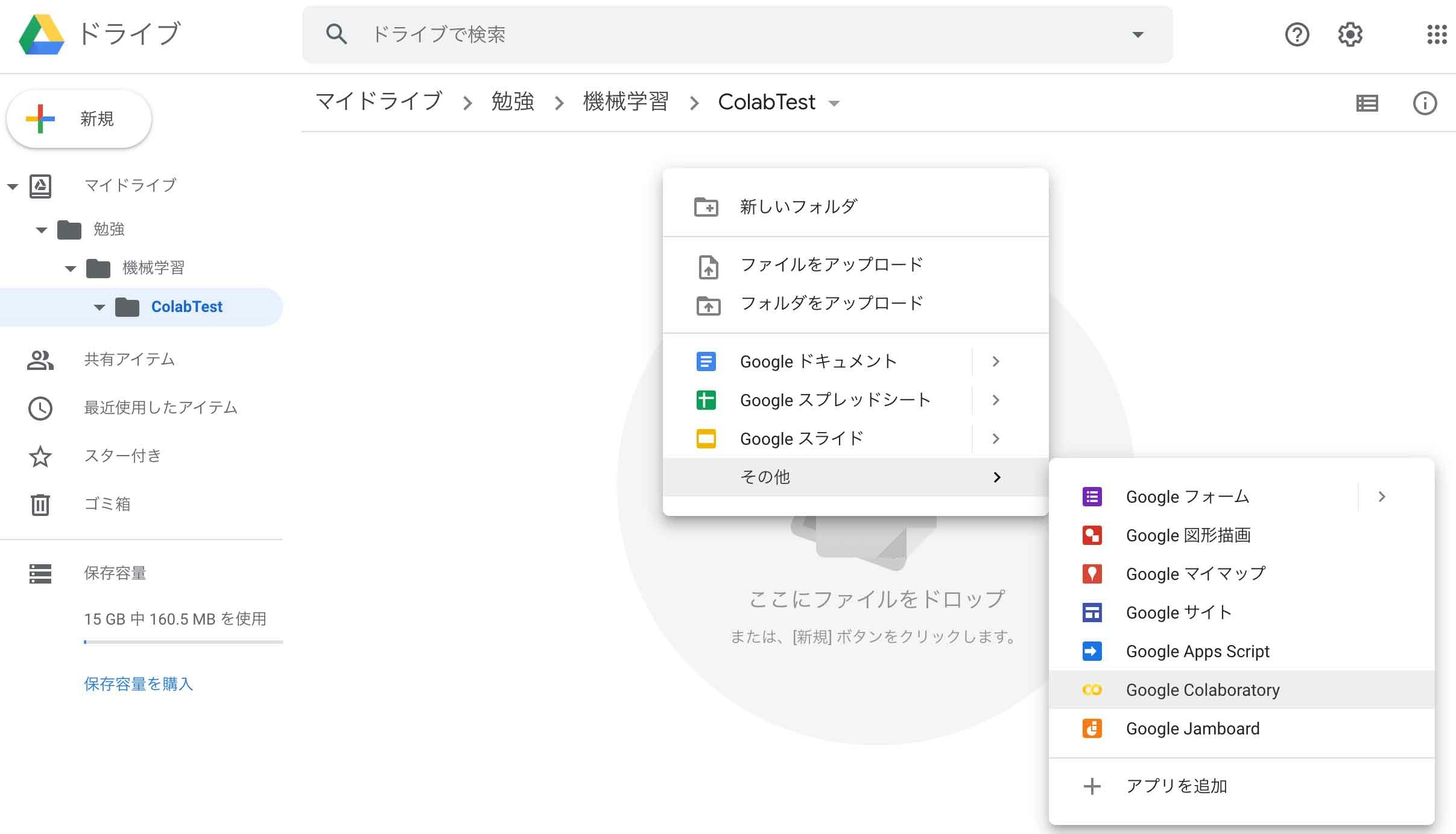
作成したフォルダを右クリックして「アプリで開く」-「アプリを追加」を選択します。
ダイアログが出てきて様々なアプリを追加できますが、ダイアログ上部の検索テキストフィールドに「Colaboratory」と入力し、出てきたアプリ「Colaboratory」を選択します。
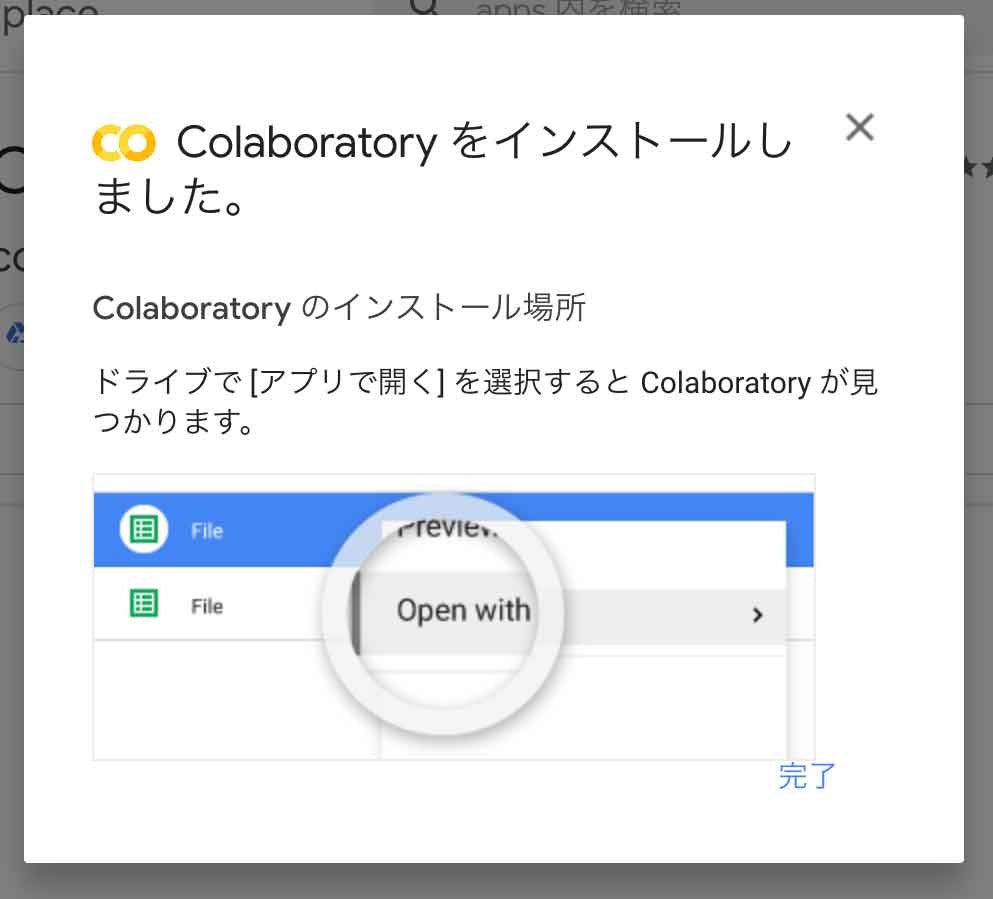
そして、インストールボタンを押してインストールします。
利用規約やプライバシーポリシーを同意し「続行」ボタンを押します。
すると、すとインストールが完了します。
Pythonの実行
先ほど作成したGoogleドライブ上のフォルダを右クリックして「その他」-「Google Corablratory」を選択します。
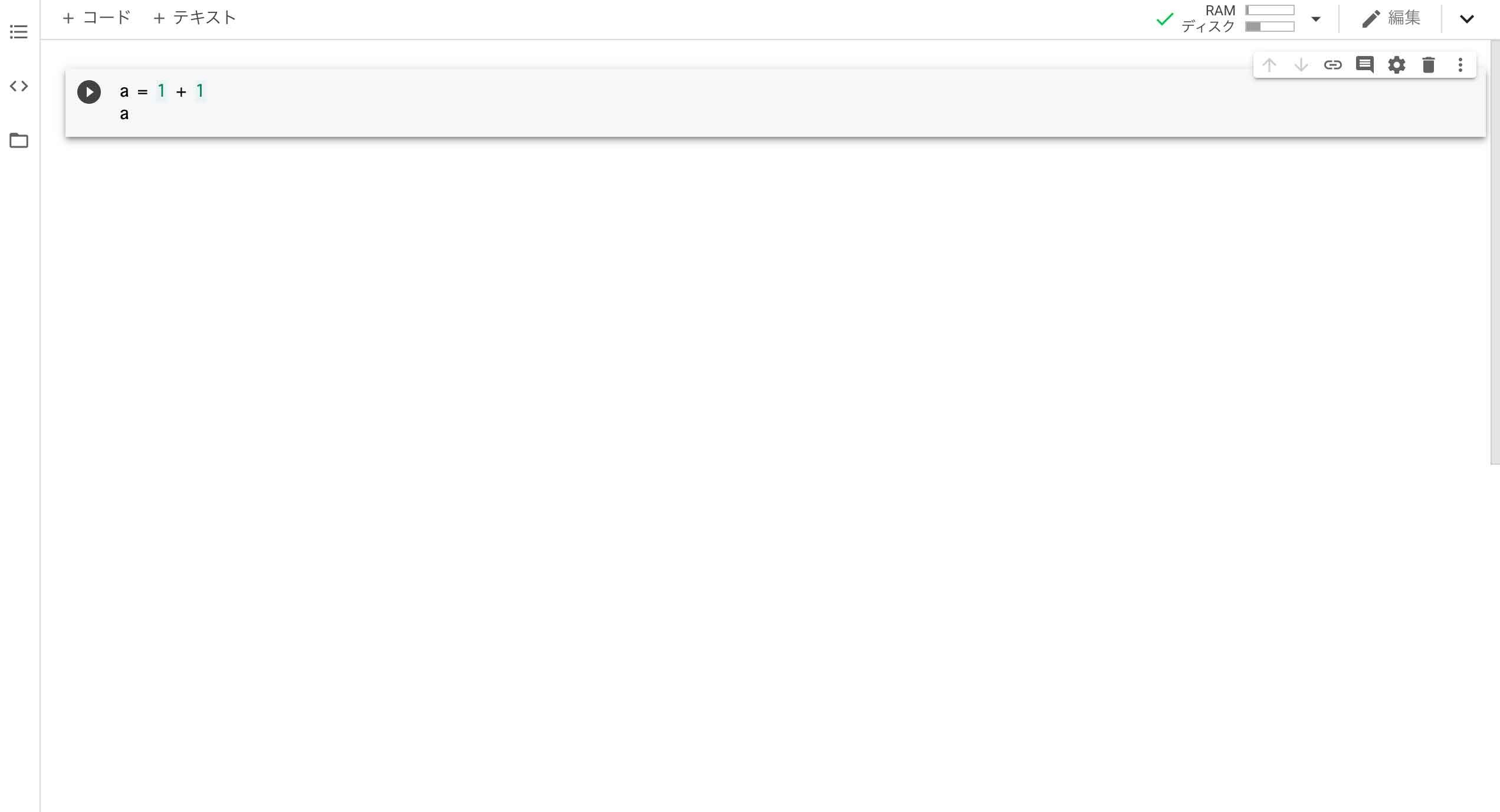
Pythonのコードを入力する画面が出ます。
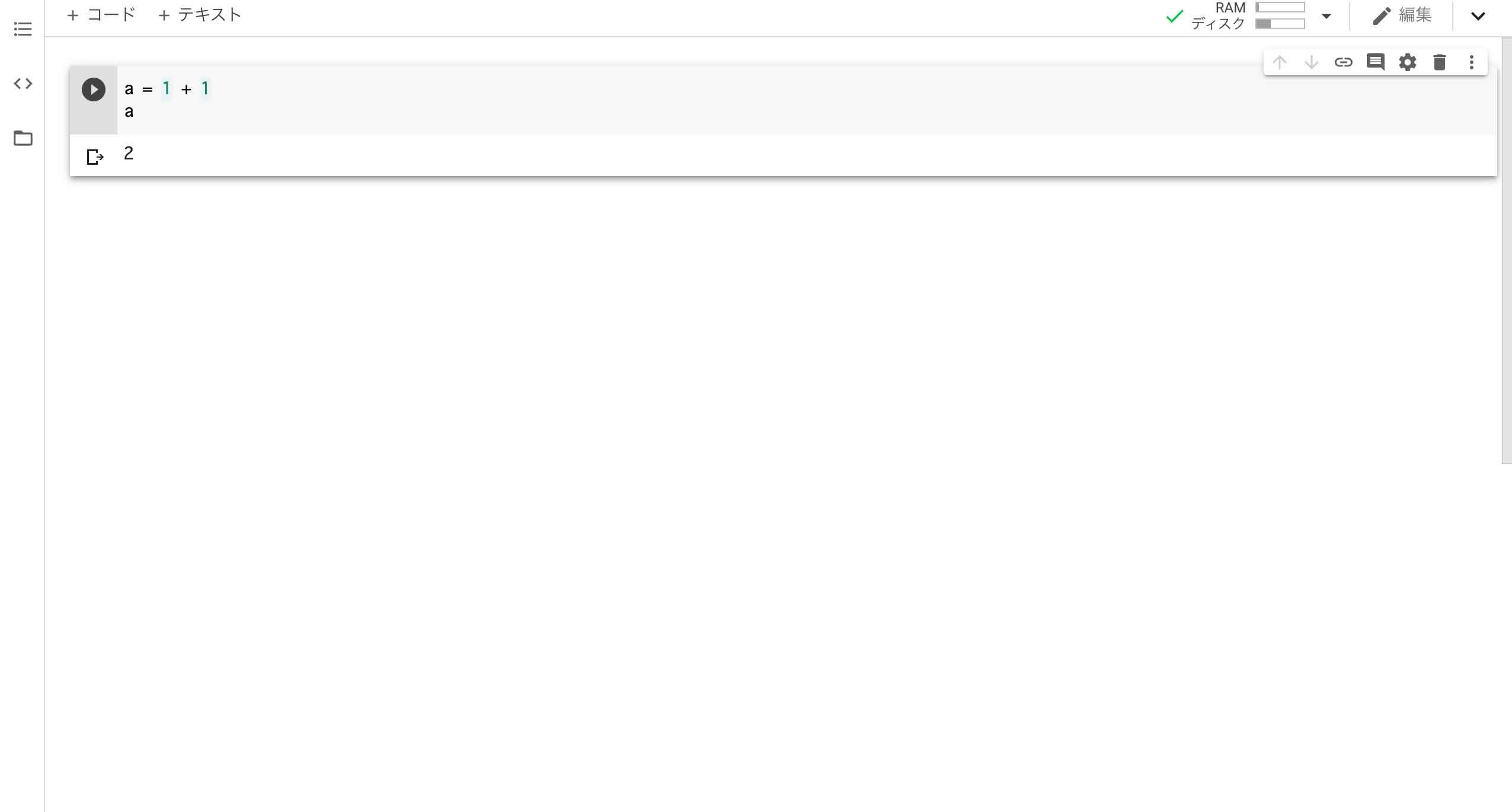
テキストフィールドにPythonのコードを入力して、左側にある再生ボタン「▶︎」を押すと入力したPythonのコードが実行されます。
これでPythonの実行環境を手に入れることができました。今後は、Pythonのコードを実行しながら勉強して行きたいと思います。
最後まで読んでいただいた方、有難うございました。



- 投稿日:2020-05-31T22:32:27+09:00
Bitbucketのリポジトリをバックアップする
Bitbucket の API でリポジトリの情報集めてバックアップします。
主な目的は Mercurial 廃止に伴うリポジトリ削除への対応ですが、Git リポジトリにも対応しています。
※ 当初、Mercurial 廃止は2020年5月31日が期限でしたが、情勢を鑑みて1カ月延期されました。
この記事ではリポジトリ移行の話題は扱いません。以下の記事などを参考にしてください。
API
Bitbucket のリポジトリなどの情報は API で取得できます。
以下の記事を参考にしました。
スクリプト
Python で情報収集用のスクリプトを書きました。
プライベートリポジトリの情報を取得するためユーザー名とパスワードを書き換えてください。
3行目authinfo = "USER:PASS"スクリプトを実行すると API でリポジトリとスニペットの情報を集めます。複数ページに分割された情報を 1 ファイルにまとめます。(整形済)
- repositories.json
- snippets.json
issues や pullrequests などの情報は、リポジトリごとにディレクトリを作って保存します。(未整形)
- 例: repositories/xxx/issues.json
リポジトリやスニペットのクローンは自動では行いません。出力されたクローン用のシェルスクリプトを実行してください。
- repositories-clone.sh
- snippets-clone.sh
仕様
アクセスにはウェイトを入れています。
19行目time.sleep(1)保存した JSON は cache ディレクトリに入れて、再度実行した時はそちらを参照します。再取得したいときは削除してください。
cache 内の JSON は送られたままの形で保存します。改行が入っていないため、読むときは整形すると良いでしょう。
整形の例python -m json.tool cache/repositories-1.jsonlinks に記載された情報のうち、API を参照しているものを取得します。
"links": { "watchers": { (略) }, "branches": { (略) }, "tags": { (略) }, "commits": { (略) }, (略) },
- 投稿日:2020-05-31T22:14:58+09:00
初心者なりの、kaggleの始め方ベストプラクティス~画像処理編~
今回は僕が、kaggleコンペに初めて本腰を入れて取り組んだ中で考えた,初心者なりのkaggle画像コンペの取り組み方のベストプラクティスをご紹介いたします。
タイトル通り、この記事は画像処理(DeepLearning)が対象であり、タイタニックの様な分析系のコンペを対象にはしておりません。
これからkaggleに挑む(挑んでいる)人の助けになれば幸いです。
執筆の励みになりますので、よろしければLGTMくださいm(__)mこの記事の対象者
kaggleコンペに初めて取り組んでいる方、もしくは取り組みたい方
DeepLearningをコンペで使いたい方初心者なりのkaggle(画像処理コンペ)への取り組みベストプラクティス
基礎を固めよう
何事も最初が肝心です。
コンペを始める前に基礎を固めることによって、kaggleに取り組んでいる間の勉強(作業)効率が全く違ってきます。例えば、画像を推論(predict)する際には、一枚一枚for文で回して予測結果を出力することもできますが、バッチ処理をして推論する方が、処理時間が大幅に異なります。
DeepLearningを勉強する上で、おすすめは以下の本です。
初心者としては、一度これをしっかり手を動かしてやることで基礎が身につきます。
テーブルデータのコンペはまだ参加したことがないので、おいおい追記します。
実際にコンペに取り組んでみる(codeの共有が許可されているもの)
基礎が身についたら、さっそく実践してみましょう。
kaggleを初心者が学ぶ上で活用すべき機能はnotebookとdiscussionです。notebookはコンペティションごとに公開されているjupyter notebook形式の記事です。
↑のように様々な人が、どのようにコードを書いているのかが見れるので、とても勉強になります。
また、公開されているnotebookをForkする(自分のnotebookとしてコピーして使うこと)こともできます。notebook形式ですので、もちろん自分で動かして結果を試すこともできます。discussionはコンペごとに設けられる掲示板のようなものです。
「このような分析をするとこんな感じの結果が出たよ!」とか「このエラーが解決できない」といったいろんな情報や質問をkaggle参加者の間で議論します。
中にはとても有用な情報が飛び交っていたりします。ですので、コンペ期間中には、積極的に活用してスコアを上げていきましょう。
またコンペが終結した後には、「第~位を取った手法」のように、自分たちの分析手法を公開してくれている参加者もいます。
上に挙げたnotebookとdiscussionはどちらも英語で書かれたものがほとんどです(たまにちらほら中国語も)。最近はchromeやedgeの翻訳機能も素晴らしいです。
英語だからって構える必要はありません。
どんどん翻訳していきましょう。さて、実際のコンペに取り組む際には、いくつか注意しておいた方がいいことがあります。
A. 既に終わっているコンペを選ぶこと
B. ある程度データセットの大きさが小さいものを選ぶこと(10GB以内)
C. コードのシェアが許可されているコンペを選ぶことAに関しては、すでに終わっているコンペだと、様々な議論や有益なnotebookが多数公開されているからです。
この段階での目標は
- 公開されているnotebookを実際に動かしてみて、submissionまでやってみる
- discussionなどでどのような情報が共有されているかを確認するの2つです。
ですので、いきなり開催中のコンペに参加するよりも、終わっているコンペの方が、短期間で実力を伸ばすことができます。Bに関しては、自分で試行錯誤するときに、あまりにデータセットの数が多いと苦労するからです。kaggleのnotebookで計算を行う分には問題がないのですが、kaggleのnotebookはGPUが30時間しか使えなかったり、動作が不安定であるなどの問題があるため、あまりお勧めできません。
google colaboratoryか自前のパソコンでやるにしても、10GBを超えるデータセットはメモリ的にもディスク容量的にも、扱いが大変です。
Cに関しては後述しますが、質問などをする際に、シェアが禁止されているコンペだとコードや情報をシェアできないという制約がついてしまいます。
教えてもらえる環境を整える
(質問などで自分の書いたコードやコンペの情報を他人に共有する場合は、コンペの規約に違反していないかを十分に確認してください。)
やっぱり初心者なので、経験者から教えてもらえると、伸びが全然違います。でも、身の回りにkaggleの経験者がいる人なんてほとんどいないですよね?
僕もそうでした。
ですが、心配いりません。世の中には素晴らしいサービスや団体があるのです。まずご紹介したいのが、日本人kagglerのslackワークスペース
こちらの記事でも紹介されていますが、beginners-helpというチャンネルで質問することで、高確率で経験者からの回答を得ることができます。僕も何度もこのslackワークスペースにお世話になりました。(何としても、もっと実力をつけて恩返ししたい所存です?)
続いて紹介したいのが、(TechTrain)[https://techbowl.co.jp/techtrain]
というサービスです。こちらのサービスですが、30歳以下という制限はありますが、なんと無料で30分間も現役エンジニアの人と面談ができ質問をすることができる激熱なサービスです。
(なんか宣伝みたいになってしまったのですが、本当に素晴らしいサービスだと思うので気にしません)僕も、コンペの中でうまくいかないことがたくさんあり、5回ぐらいお世話になりましたが、的確に質問に答えてくださりました。
他にも、実際の仕事内容やインターンについても相談に乗っていただけたので、とてもお勧めです。
開催中のコンペに参加してみる
さて、いよいよあなたのkaggleライフの始まりです!
開催中のコンペの中から、開始からある程度時間がたっており、活発なコンペを選んで参加してみましょう。参加した後にやることは以下の通りです。
1. とにかく早くベースラインを構築する
2. (必要があれば) 計算環境を準備する
3. 検証環境を用意する
4. notebookやdiscussionの中から有用そうな手法をまねる
5. 最終手段:アンサンブル1.とにかく早くベースラインを構築する
一番大事なことです。コンペに参加したら、ある程度voteが多いnotebookを写経(notコピペ)してsubmissionまで行って、ベースライン(基礎となるスコア)を出しましょう。
初心者が1からコードを書いてsubmitまでもっていくのは本当に大変な労力です。
pandasやnumpyに結構習熟している必要があるためです。
ですので、最初は丸パクリでも大丈夫なので、経験豊富なkagglerの手法を学びましょう。2.(必要であれば)計算環境を構築する
ベースラインを作った後は、ハイパーパラメーターの調整や特徴量エンジニアリングなど、様々な試行錯誤をする必要があります。
しかし、先ほども説明したように、手持ちのコンピューターの計算能力低いと、試行錯誤するにしてもとても時間がかかってしまいます。ですので、GPUやTPUが使える、kaggleのnotebookやgoogle colabの使用が検討されますが、両者ともGPUやTPUの使用には制限があり、多数の検証をするには苦しいのが現状です。
そこで、僕がおすすめしたいのはgoogle colaboratoryのpro版です。
これは最近でたサービスなのですが、google colaboratoryの制限がかなり緩和されます。月額約1000円の課金で、GPU環境が手に入るのですから、ちょっとした投資と思って課金することをお勧めします。使い始めて1か月半ほどですが、印象としては、ほぼ無制限にGPUが使えるという感じです(使用方法によっては制限がかかるらしいですが。)
3. 検証環境を用意する
さて、ベースラインもできたし、いろんなパラメーターや手法を試してどんどんスコアを上げていきたいのですが、1つだけ注意点があります。
それは、kaggleのsubmission回数には制限があるということです。
僕の参加したコンペでは1日の最大提出回数が5回となっていました。
つまり、自分の試した手法が正しいかを判断する機会が1日にたったの5回しか無いということなのです。これでは十分な試行錯誤をすることができません。
そこで、検証環境を用意します。scikit-learnの
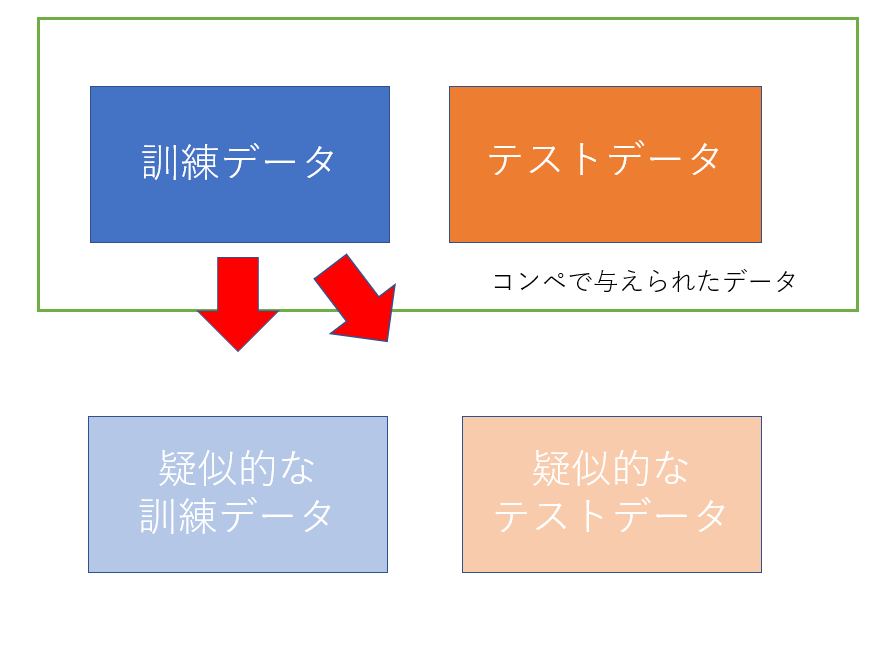
train_test_splitとconfusion_matrixを使用します。まず最初に
train_test_splitを使い、訓練データを疑似的な訓練データとテストデータに分けます。
そして、訓練では疑似的な訓練データのみを使ってモデルを訓練します。
訓練が終わった後に、疑似的なテストデータを使ってモデルの正答率を検証します。
こうすることで、submitしなくても、自分が作ったモデルの性能がわかります。
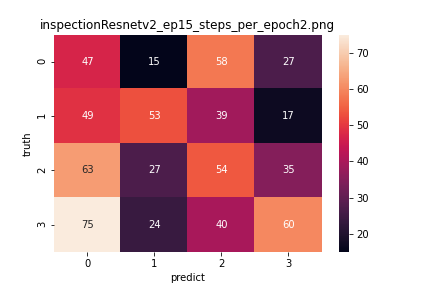
続いて、
confusion_matrixを用いて、混合行列を作成します。
混合行列についてはこちらの記事がわかりやすいです。詳しい説明は省きますが、混合行列を作成することで、モデルがどのクラスとどれを間違えているのかを知ることができます。
↑は僕が実際にやってみた例です。
0番にまちがえて推論してしまった例や、0番と推論すべきところを2番に間違えているのだな。ということがわかります。間違いの種類が分かれば、データとにらめっこしたり、1枚1枚推論することで、どのような特徴量をとらえられていないのかがわかるので、画像の前処理やパラメーター変更などの助けになります。
4. notebookやdiscussionの中から有用そうな手法をまねる
実際にnotebookやdiscussionを漁り、様々な方法をトライしていきます。
以下では、僕がdiscussionやnotebookで「?」となった用語をまとめてみます。
俗称 意味 fold K(Kは数字) k分割交差検証法 lr 学習率(learning rate)のこと。均一な学習率ではなく、epochごとに学習率をチューニングしてあげることで、モデルの精度が結構変わります。 EDA Exploratory Data Analysisの略。どんなデータがあるのかを実際に見たり、各種統計量などを整理することです。 fine tune ファインチューニング,学習済みモデルの一部の層を学習させず(frozen)、少ないデータで学習させること ~~net たいていの場合は学習済みモデルのこと data augmentation(水増し) モデルに入力する画像を加工して、枚数を増やすテクニック。少ない訓練画像でもモデルの精度を上げるために必須です。このページが参考になります。 (随時更新していこうと思います。)
こうして試行錯誤していくのはいいのですが、注意すべきことが2つあります。
1つ目は、乱数のseedは固定すること
2つ目は、試行錯誤の証をちゃんと記録を残しておくこと1つ目に関しては、乱数のseedを固定することで、同じ手法で同じパラメーターを使えば全く同じ結果を得ることができます。
終盤はスコアが0.001上がるか下がるかで、順位に差がつくこともあります。ちゃんとした評価をするためにも乱数のseedは固定するようにしましょう。2つ目に関しては、試したい手法やパラメーターはたくさんありますが、使える時間や計算資源は有限なので、ムダなことをしないためです。
特にいろいろ手法を試していくと、どの手法でどれぐらいの結果が出たのかがごっちゃになってきます。
僕はnotionというアプリで記録してましたが、単純にスプレッドシートとかでもいいかもしれませんね。
5. 最終手段 アンサンブル
最後の手段として、アンサンブルという手法があります。
これは、様々なモデルで学習した結果を加重平均して、結果を出すことです。大体の場合、アンサンブルを行うことでスコアはよくなります。
しかし、この方法には最初はなるべく頼るべきではありません。
なぜなら、アンサンブルによってスコアが60から80に上がるといった劇的な変化はまず、見られないからです。一つのモデル単体で頑張って、最後の最後に、奥の手としてアンサンブルを使うようにしましょう。
終わりに
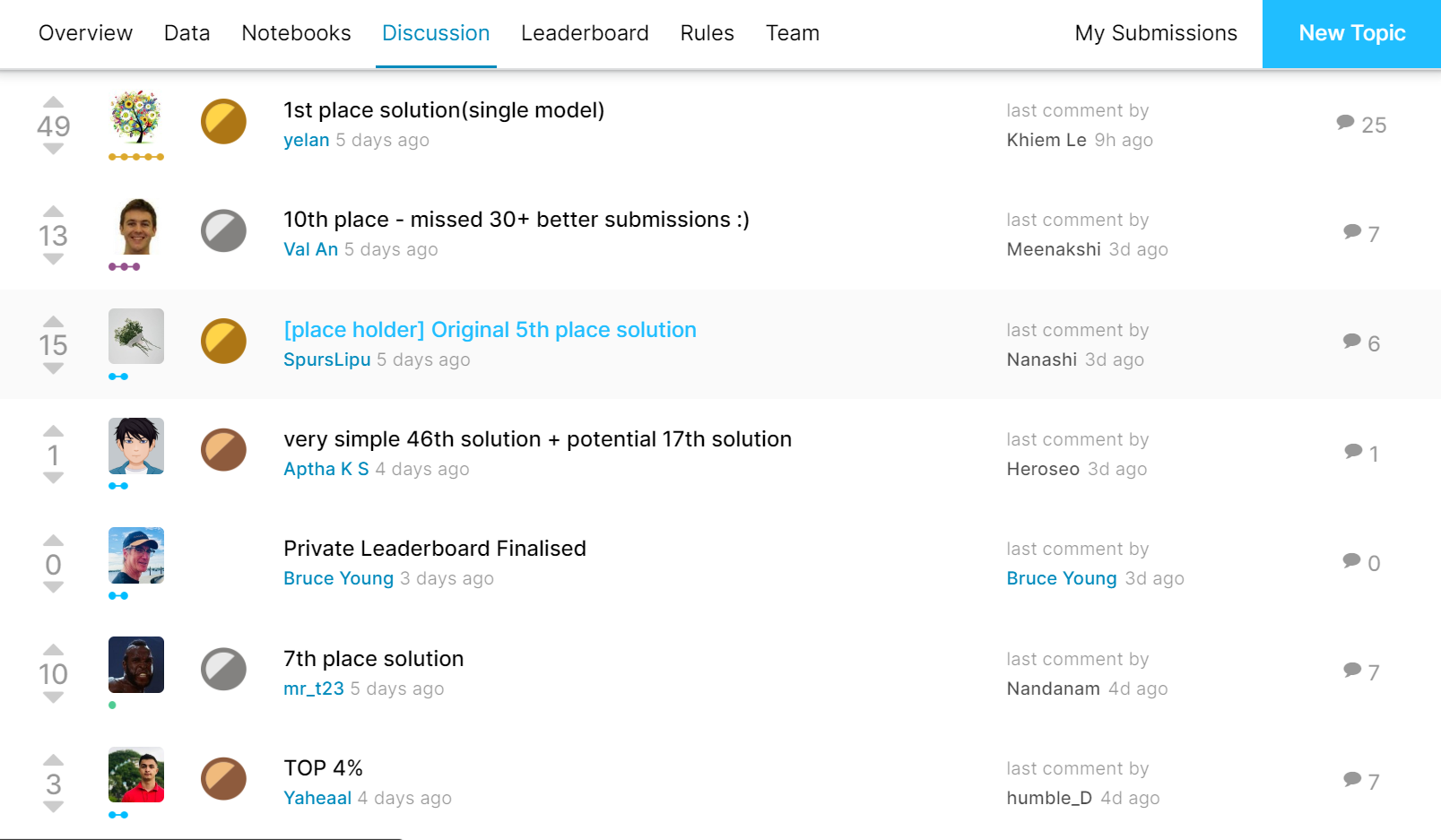
今回参加したコンペは植物の葉っぱを4分類するというコンペでした→リンク
今回のコンペでは、大学の課題などであまり時間が取れず、1317エントリー中442位という不甲斐ない結果に終わってしまいました。しかし、この記事に書いたように多くのことを学ぶことができました。
質問に答えてくださった、slackワークスペースkaggler-jaの皆様や、tech-trainのメンターの方々に本当に感謝です。次回はさらに実力をつけてメダル獲得を目指していきたいと思います。
記事内に間違いや改善点などございましたら、コメントにてご指摘いただけると嬉しいです。


- 投稿日:2020-05-31T22:14:58+09:00
初心者のkaggleの始め方ベストプラクティス~画像処理編~
今回は僕が、kaggleコンペに初めて本腰を入れて取り組んだ中で考えた,初心者なりのkaggle画像コンペの取り組み方のベストプラクティスをご紹介いたします。
タイトル通り、この記事は画像処理(DeepLearning)が対象であり、タイタニックの様な分析系のコンペを対象にはしておりません。
これからkaggleに挑む(挑んでいる)人の助けになれば幸いです。
執筆の励みになりますので、よろしければLGTMくださいm(__)mこの記事の対象者
kaggleコンペに初めて取り組んでいる方、もしくは取り組みたい方
DeepLearningをコンペで使いたい方初心者なりのkaggle(画像処理コンペ)への取り組みベストプラクティス
基礎を固めよう
何事も最初が肝心です。
コンペを始める前に基礎を固めることによって、kaggleに取り組んでいる間の勉強(作業)効率が全く違ってきます。例えば、画像を推論(predict)する際には、一枚一枚for文で回して予測結果を出力することもできますが、バッチ処理をして推論する方が、処理時間が大幅に異なります。
DeepLearningを勉強する上で、おすすめは以下の本です。
初心者としては、一度これをしっかり手を動かしてやることで基礎が身につきます。
テーブルデータのコンペはまだ参加したことがないので、おいおい追記します。
実際にコンペに取り組んでみる(codeの共有が許可されているもの)
基礎が身についたら、さっそく実践してみましょう。
kaggleを初心者が学ぶ上で活用すべき機能はnotebookとdiscussionです。notebookはコンペティションごとに公開されているjupyter notebook形式の記事です。
↑のように様々な人が、どのようにコードを書いているのかが見れるので、とても勉強になります。
また、公開されているnotebookをForkする(自分のnotebookとしてコピーして使うこと)こともできます。notebook形式ですので、もちろん自分で動かして結果を試すこともできます。discussionはコンペごとに設けられる掲示板のようなものです。
「このような分析をするとこんな感じの結果が出たよ!」とか「このエラーが解決できない」といったいろんな情報や質問をkaggle参加者の間で議論します。
中にはとても有用な情報が飛び交っていたりします。ですので、コンペ期間中には、積極的に活用してスコアを上げていきましょう。
またコンペが終結した後には、「第~位を取った手法」のように、自分たちの分析手法を公開してくれている参加者もいます。
上に挙げたnotebookとdiscussionはどちらも英語で書かれたものがほとんどです(たまにちらほら中国語も)。最近はchromeやedgeの翻訳機能も素晴らしいです。
英語だからって構える必要はありません。
どんどん翻訳していきましょう。さて、実際のコンペに取り組む際には、いくつか注意しておいた方がいいことがあります。
A. 既に終わっているコンペを選ぶこと
B. ある程度データセットの大きさが小さいものを選ぶこと(10GB以内)
C. コードのシェアが許可されているコンペを選ぶことAに関しては、すでに終わっているコンペだと、様々な議論や有益なnotebookが多数公開されているからです。
この段階での目標は
- 公開されているnotebookを実際に動かしてみて、submissionまでやってみる
- discussionなどでどのような情報が共有されているかを確認するの2つです。
ですので、いきなり開催中のコンペに参加するよりも、終わっているコンペの方が、短期間で実力を伸ばすことができます。Bに関しては、自分で試行錯誤するときに、あまりにデータセットの数が多いと苦労するからです。kaggleのnotebookで計算を行う分には問題がないのですが、kaggleのnotebookはGPUが30時間しか使えなかったり、動作が不安定であるなどの問題があるため、あまりお勧めできません。
google colaboratoryか自前のパソコンでやるにしても、10GBを超えるデータセットはメモリ的にもディスク容量的にも、扱いが大変です。
Cに関しては後述しますが、質問などをする際に、シェアが禁止されているコンペだとコードや情報をシェアできないという制約がついてしまいます。
教えてもらえる環境を整える
(質問などで自分の書いたコードやコンペの情報を他人に共有する場合は、コンペの規約に違反していないかを十分に確認してください。)
やっぱり初心者なので、経験者から教えてもらえると、伸びが全然違います。でも、身の回りにkaggleの経験者がいる人なんてほとんどいないですよね?
僕もそうでした。
ですが、心配いりません。世の中には素晴らしいサービスや団体があるのです。まずご紹介したいのが、日本人kagglerのslackワークスペース
こちらの記事でも紹介されていますが、beginners-helpというチャンネルで質問することで、高確率で経験者からの回答を得ることができます。僕も何度もこのslackワークスペースにお世話になりました。(何としても、もっと実力をつけて恩返ししたい所存です?)
続いて紹介したいのが、(TechTrain)[https://techbowl.co.jp/techtrain]
というサービスです。こちらのサービスですが、30歳以下という制限はありますが、なんと無料で30分間も現役エンジニアの人と面談ができ質問をすることができる激熱なサービスです。
(なんか宣伝みたいになってしまったのですが、本当に素晴らしいサービスだと思うので気にしません)僕も、コンペの中でうまくいかないことがたくさんあり、5回ぐらいお世話になりましたが、的確に質問に答えてくださりました。
他にも、実際の仕事内容やインターンについても相談に乗っていただけたので、とてもお勧めです。
開催中のコンペに参加してみる
さて、いよいよあなたのkaggleライフの始まりです!
開催中のコンペの中から、開始からある程度時間がたっており、活発なコンペを選んで参加してみましょう。参加した後にやることは以下の通りです。
1. とにかく早くベースラインを構築する
2. (必要があれば) 計算環境を準備する
3. 検証環境を用意する
4. notebookやdiscussionの中から有用そうな手法をまねる
5. 最終手段:アンサンブル1.とにかく早くベースラインを構築する
一番大事なことです。コンペに参加したら、ある程度voteが多いnotebookを写経(notコピペ)してsubmissionまで行って、ベースライン(基礎となるスコア)を出しましょう。
初心者が1からコードを書いてsubmitまでもっていくのは本当に大変な労力です。
pandasやnumpyに結構習熟している必要があるためです。
ですので、最初は丸パクリでも大丈夫なので、経験豊富なkagglerの手法を学びましょう。2.(必要であれば)計算環境を構築する
ベースラインを作った後は、ハイパーパラメーターの調整や特徴量エンジニアリングなど、様々な試行錯誤をする必要があります。
しかし、先ほども説明したように、手持ちのコンピューターの計算能力低いと、試行錯誤するにしてもとても時間がかかってしまいます。ですので、GPUやTPUが使える、kaggleのnotebookやgoogle colabの使用が検討されますが、両者ともGPUやTPUの使用には制限があり、多数の検証をするには苦しいのが現状です。
そこで、僕がおすすめしたいのはgoogle colaboratoryのpro版です。
これは最近でたサービスなのですが、google colaboratoryの制限がかなり緩和されます。月額約1000円の課金で、GPU環境が手に入るのですから、ちょっとした投資と思って課金することをお勧めします。使い始めて1か月半ほどですが、印象としては、ほぼ無制限にGPUが使えるという感じです(使用方法によっては制限がかかるらしいですが。)
3. 検証環境を用意する
さて、ベースラインもできたし、いろんなパラメーターや手法を試してどんどんスコアを上げていきたいのですが、1つだけ注意点があります。
それは、kaggleのsubmission回数には制限があるということです。
僕の参加したコンペでは1日の最大提出回数が5回となっていました。
つまり、自分の試した手法が正しいかを判断する機会が1日にたったの5回しか無いということなのです。これでは十分な試行錯誤をすることができません。
そこで、検証環境を用意します。scikit-learnの
train_test_splitとconfusion_matrixを使用します。まず最初に
train_test_splitを使い、訓練データを疑似的な訓練データとテストデータに分けます。
そして、訓練では疑似的な訓練データのみを使ってモデルを訓練します。
訓練が終わった後に、疑似的なテストデータを使ってモデルの正答率を検証します。
こうすることで、submitしなくても、自分が作ったモデルの性能がわかります。
続いて、
confusion_matrixを用いて、混合行列を作成します。
混合行列についてはこちらの記事がわかりやすいです。詳しい説明は省きますが、混合行列を作成することで、モデルがどのクラスとどれを間違えているのかを知ることができます。
↑は僕が実際にやってみた例です。
0番にまちがえて推論してしまった例や、0番と推論すべきところを2番に間違えているのだな。ということがわかります。間違いの種類が分かれば、データとにらめっこしたり、1枚1枚推論することで、どのような特徴量をとらえられていないのかがわかるので、画像の前処理やパラメーター変更などの助けになります。
4. notebookやdiscussionの中から有用そうな手法をまねる
実際にnotebookやdiscussionを漁り、様々な方法をトライしていきます。
以下では、僕がdiscussionやnotebookで「?」となった用語をまとめてみます。
俗称 意味 fold K(Kは数字) k分割交差検証法 lr 学習率(learning rate)のこと。均一な学習率ではなく、epochごとに学習率をチューニングしてあげることで、モデルの精度が結構変わります。 EDA Exploratory Data Analysisの略。どんなデータがあるのかを実際に見たり、各種統計量などを整理することです。 fine tune ファインチューニング,学習済みモデルの一部の層を学習させず(frozen)、少ないデータで学習させること ~~net たいていの場合は学習済みモデルのこと data augmentation(水増し) モデルに入力する画像を加工して、枚数を増やすテクニック。少ない訓練画像でもモデルの精度を上げるために必須です。このページが参考になります。 (随時更新していこうと思います。)
こうして試行錯誤していくのはいいのですが、注意すべきことが2つあります。
1つ目は、乱数のseedは固定すること
2つ目は、試行錯誤の証をちゃんと記録を残しておくこと1つ目に関しては、乱数のseedを固定することで、同じ手法で同じパラメーターを使えば全く同じ結果を得ることができます。
終盤はスコアが0.001上がるか下がるかで、順位に差がつくこともあります。ちゃんとした評価をするためにも乱数のseedは固定するようにしましょう。2つ目に関しては、試したい手法やパラメーターはたくさんありますが、使える時間や計算資源は有限なので、ムダなことをしないためです。
特にいろいろ手法を試していくと、どの手法でどれぐらいの結果が出たのかがごっちゃになってきます。
僕はnotionというアプリで記録してましたが、単純にスプレッドシートとかでもいいかもしれませんね。
5. 最終手段 アンサンブル
最後の手段として、アンサンブルという手法があります。
これは、様々なモデルで学習した結果を加重平均して、結果を出すことです。大体の場合、アンサンブルを行うことでスコアはよくなります。
しかし、この方法には最初はなるべく頼るべきではありません。
なぜなら、アンサンブルによってスコアが60から80に上がるといった劇的な変化はまず、見られないからです。一つのモデル単体で頑張って、最後の最後に、奥の手としてアンサンブルを使うようにしましょう。
終わりに
今回参加したコンペは植物の葉っぱを4分類するというコンペでした→リンク
今回のコンペでは、大学の課題などであまり時間が取れず、1317エントリー中442位という不甲斐ない結果に終わってしまいました。しかし、この記事に書いたように多くのことを学ぶことができました。
質問に答えてくださった、slackワークスペースkaggler-jaの皆様や、tech-trainのメンターの方々に本当に感謝です。次回はさらに実力をつけてメダル獲得を目指していきたいと思います。
記事内に間違いや改善点などございましたら、コメントにてご指摘いただけると嬉しいです。
- 投稿日:2020-05-31T21:35:49+09:00
anyenvでNodeやRubyやPythonのバージョン管理
概要
- github:https://github.com/anyenv/anyenv
- anyenvはnodenv, rbenv, pyenvなど*env系を管理するライブラリ
- nodenv, rbenv, pyenvは、Node, Ruby, Pythonのバージョンを管理してくれる。
anyevnでnodenvをインストールしてnodenvでほしいバージョンのNodeをインストールして管理しておくという感じ
anyenv インストール
$ git clone https://github.com/riywo/anyenv ~/.anyenv $ echo 'export PATH="~/.anyenv/bin:$PATH"' >> ~/.bash_profile $ echo 'eval "$(anyenv init -)"' >> ~/.bash_profile $ exec $SHELL -l # 確認 $ anyenv -v anyenv 1.1.1 # 初期化しておく $ anyenv install --initnodenvインストール
$ anyenv install nodenv $ echo 'export PATH="$HOME/.nodenv/bin:$PATH"' >> ~/.bash_profile $ exec $SHELL -l # 確認 $ nodenv -v nodenv 1.3.1+5.dd4534eNodejsインストール
$ touch $(nodenv root)/default-packages # インストールできるバージョンチェック $ nodenv install --list # インストール $ nodenv install 14.3.0 # 確認 $ node -v v14.3.0 # npmの同時にインストールされる $ npm -v v6.14.5 # globalに設定 # globalに設定するとnodeコマンドは常にそのバージョンで実行される $ nodenv global 12.13.0 # インストールされたバージョンをリストで確認 $ nodenv versions # 別バージョンをローカルに設定する場合 # ディレクトリごとにローカルに設定するバージョンを設定できる。 # 特定のプロジェクトのディレクトリでlocal設定しておくとそのバージョンで実行される $ nodenv local 12.12.0rbenvインストール
$ anyenv install rbenv $ echo 'export PATH="$HOME/.rbenv/bin:$PATH"' >> ~/.bash_profile $ exec $SHELL -l # 確認 $ rbenv -v rbenv 1.1.2-30-gc879cb0Rubyインストール
# インストールするバージョンチェック $ rbenv install --list # ほしいバージョンインストール $ rbenv install 2.7.1 # globalに設定 # globalに設定するとnodeコマンドは常にそのバージョンで実行される $ rbenv global 2.7.1 # 確認 $ rbenv versions # 別バージョンをローカルに設定する場合 # ディレクトリごとにローカルに設定するバージョンを設定できる。 # 特定のプロジェクトのディレクトリでlocal設定しておくとそのバージョンで実行される $ rbenv local 2.6.0BUILD FAILEDエラー
下記のようなエラーが出た場合の対処
$ rbenv install 2.7.1 Downloading ruby-2.7.1.tar.bz2... -> https://cache.ruby-lang.org/pub/ruby/2.7/ruby-2.7.1.tar.bz2 Installing ruby-2.7.1... BUILD FAILED (Ubuntu 20.04 using ruby-build 20200520) Inspect or clean up the working tree at /tmp/ruby-build.20200529010032.1915.2716Kv Results logged to /tmp/ruby-build.20200529010032.1915.log Last 10 log lines: checking for ruby... false checking build system type... x86_64-pc-linux-gnu checking host system type... x86_64-pc-linux-gnu checking target system type... x86_64-pc-linux-gnu checking for gcc... no checking for cc... no checking for cl.exe... no configure: error: in `/tmp/ruby-build.20200529010032.1915.2716Kv/ruby-2.7.1': configure: error: no acceptable C compiler found in $PATH See `config.log' for more detailsエラー出た人はここら辺実行すれば大体解決するかも
$ sudo apt-get update $ sudo apt-get install -y build-essential checkinstall $ sudo apt-get install libreadline-gplv2-dev libncursesw5-dev libssl-dev libsqlite3-dev tk-dev libgdbm-dev libc6-dev libbz2-devpyenvインストール
上記と同様
やってないけど多分下記の感じでいけるかも$ anyenv install pyenv $ echo 'export PATH="$HOME/.pyenv/bin:$PATH"' >> ~/.bash_profile $ exec $SHELL -l # 確認 $ pyenv -vPythonインストール
# インストールするバージョンチェック $ pyenv install --list # ほしいバージョンインストール $ pyenv install [version] # globalに設定 # globalに設定するとnodeコマンドは常にそのバージョンで実行される $ pyenv global [version] # 確認 $ pyenv versions # 別バージョンをローカルに設定する場合 # ディレクトリごとにローカルに設定するバージョンを設定できる。 # 特定のプロジェクトのディレクトリでlocal設定しておくとそのバージョンで実行される $ pyenv local [version]
- 投稿日:2020-05-31T21:16:33+09:00
flaskの基本的な使い方
flaskで作成したAPIにfetch APIを使ってpostとgetリクエストを送る。
/app.pyfrom flask import Flask,request,jsonify,render_template app = Flask(__name__) app.config['TEMPLATES_AUTO_RELOAD'] = True @app.route('/') def index_html(): return render_template('index.html') @app.route('/get',methods=['get']) def get(): return jsonify({'message':'Hello world!'}) @app.route('/post',methods=['POST']) def post(): #送られてきたjsonをそのまま返す。 req = request.json return jsonify(req) if __name__ == '__main__': app.run(port=5000)/templates/index.html<html> <head> <body> <button onclick='get();'>get</button> <button onclick='post();'>post</button> <script> function get(){ fetch('/get').then( response => response.json() ).then( json => console.log(json) ).catch( e => console.log(e) ); } function post(){ fetch('/post', { method: "POST", headers: { "Content-Type": "application/json"}, body: JSON.stringify({"message": "Hello World!"}) }).then( response => response.json() ).then( json => console.log(json) ).catch( e => console.log(e) ); } </script> </body> </html>
- 投稿日:2020-05-31T20:45:18+09:00
VGG16を使ったフルーツの画像認識
1.背景
興味本位でKerasを使った画像認識を実装してみたところ、思いの外簡単だったので、より高精度なモデルを実装したく友人のススメでVGG16を使ってみることにした。
初学者なので、詳しいことは調べながらやってみる。
今回はりんごの王林の画像を使用して、品種まで当てられるのか評価を行う。
あくまでもメモ。2.そもそもVGG16ってなに?

VGG16というのは,「ImageNet」と呼ばれる大規模画像データセットで学習された,16層からなるCNNモデルのことです.2014年に発表されました.様々な研究で利用されている,有名な学習済みモデルの1つです.ImageNetで学習されたモデルには他にAlexNet,GoogLeNet,ResNetがあります.
https://www.y-shinno.com/keras-vgg16/ここででているAlexNet,GoogLeNet,ResNetとの比較は以下が参考になる。
(引用元:http://thunders1028.hatenablog.com/entry/2017/11/01/035609)
2014年のILSVRCで2位になった、オックスフォード大学のVGGチームのネットワーク。AlexNetをより深くした、畳み込み層とプーリング層から成るどノーマルなCNNで、重みがある層(畳み込み層や全結合層)を16層、もしくは19層重ねたもの。それぞれVGG16やVGG19と呼ばれる。
小さいフィルターを持つ畳み込み層を2〜4つ連続して重ね、それをプーリング層でサイズを半分にするというのを繰り返し行う構造が特徴。大きいフィルターで画像を一気に畳み込むよりも小さいフィルターを何個も畳み込む(=層を深くする)方が特徴をより良く抽出できるらしい。(理由はよくわかってないが、活性化関数を通る回数が増えるため、表現力が増す?)[2]
GoogleNetのほうが強そうではあるが、わかりやすさ重視でVGGをやってみる。(難しそうなものは次回以降)
3.VGG16の導入(GoogleColab使用)
早速コードを書いていく。
まずはKerasのimportvgg16_fluits.py!pip install keras次に必要なライブラリをインポートしていく。
VGG16はKerasの中に含まれている。
以下の3行目で重みを指定している。#モデルをimportしてサマリー表示してみる import numpy as np from keras.applications.vgg16 import VGG16, preprocess_input, decode_predictions model = VGG16(include_top=True, weights='imagenet', input_tensor=None, input_shape=None) model.summary()
model.summary()結果
Model: "vgg16"
Layer (type) Output Shape Param #
input_3 (InputLayer) (None, 224, 224, 3) 0
block1_conv1 (Conv2D) (None, 224, 224, 64) 1792
block1_conv2 (Conv2D) (None, 224, 224, 64) 36928
block1_pool (MaxPooling2D) (None, 112, 112, 64) 0
block2_conv1 (Conv2D) (None, 112, 112, 128) 73856
block2_conv2 (Conv2D) (None, 112, 112, 128) 147584
block2_pool (MaxPooling2D) (None, 56, 56, 128) 0
block3_conv1 (Conv2D) (None, 56, 56, 256) 295168
block3_conv2 (Conv2D) (None, 56, 56, 256) 590080
block3_conv3 (Conv2D) (None, 56, 56, 256) 590080
block3_pool (MaxPooling2D) (None, 28, 28, 256) 0
block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160
block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808
block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808
block4_pool (MaxPooling2D) (None, 14, 14, 512) 0
block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808
block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808
block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
flatten (Flatten) (None, 25088) 0
fc1 (Dense) (None, 4096) 102764544
fc2 (Dense) (None, 4096) 16781312
predictions (Dense) (None, 1000) 4097000
Total params: 138,357,544
Trainable params: 138,357,544
Non-trainable params: 0
今回使用する画像はりんご(王林)を評価する。
#画像の読み取り from PIL import Image #import glob url = '/content/drive/My Drive/Colab Notebooks/img' files=url+"/apple_orin.jpg" image =Image.open(files) image=image.convert('RGB') image=image.resize((224,224)) # 読み込んだPIL形式の画像をarrayに変換 data = np.asarray(image)#評価 from keras.preprocessing import image #サンプル数の次元を1つ増やし四次元テンソルに data = np.expand_dims(data, axis=0) #上位5を出力 preds = model.predict(preprocess_input(data)) results = decode_predictions(preds, top=5)[0] for result in results: print(result)('n07742313', 'Granny_Smith', 0.9861995)
('n02948072', 'candle', 0.0040857443)
('n07747607', 'orange', 0.001778649)
('n03887697', 'paper_towel', 0.0016588464)
('n07693725', 'bagel', 0.0012920648)となった。
4.結果
1位の「Granny_Smith」ってなに?
ラニースミス (英語:Granny Smith) はリンゴの栽培品種である。1868年にオーストラリアで、名前の由来ともなったマリア・アン・スミスにより、偶発実生で開発された
と、いうことで、画像自体はかなり近いので精度は高いとみてもよさそう。ImageNetに王林のデータがないのだろう。
ImageNetの1000クラス分の順番とラベル、クラス名の情報は以下のJSONファイルにまとめられている。
以下にGranny_Smithあり。https://storage.googleapis.com/download.tensorflow.org/data/imagenet_class_index.json
品種まで判定する画像認識を行うには別途学習させる必要があるため、次回以降にやる。
今回はあくまでも使ってみることが目的だったのでOK。
次回以降は品種まで当てられるモデルを作成する。
5.考察
VGG16のモデルを使用するにあたって、キーとなるのは以下の箇所。
model = VGG16(include_top=True, weights='imagenet', input_tensor=None, input_shape=None)詳細
引数 説明 include_top 1000クラスに分類するフル結合層を含むかどうか. True:含む(元の1000分類に使う場合はこちら) False:含まない(カスタマイズする場合はこちら) weights 重みの種類 imagenet:ImageNetを使って学習した重み None:ランダム input_tensor モデル画像を入力する場合に使用 任意の画像データ:それを使用 None:使用しない input_shape 入力画像の形状を指定 任意の形状:それを使用 None:(224, 224, 3)が使用される include_topをFalseにしてVGG16を特徴量抽出に使用してファインチューニングする。(次回)
参考(にしようとしているもの)
http://aidiary.hatenablog.com/entry/20170131/1485864665


- 投稿日:2020-05-31T20:23:18+09:00
機械学習・分類関係テクニック
ロジスティック回帰
from sklearn.datasets import load_breast_cancer data = load_breast_cancer() X = data.data y = 1 - data.target # ラベルの0と1を反転 X = X[:, :10] from sklearn.linear_model import LogisticRegression model_lor = LogisticRegression(max_iter=1000) model_lor.fit(X, y) y_pred = model_lor.predict(X)混合行列
・2行×2列の行列が表示
・実データと予測データの行列が作成される
・左上が(0, 0)、右下が(1, 1)from sklearn.metrics import confusion_matrix cm = confusion_matrix(y, y_pred) print(cm)正解率
・予測結果全体に対し、正しく予測できたものの割合
from sklearn.metrics import accuracy_score accuracy_score(y, y_pred)適合率
・ポジティブと予測したものに対し、正しくポジティブと予測できたものの割合
(右列側)from sklearn.metrics import precision_score precision_score(y, y_pred)再現率
・実際にポジティブのものに対し、正しくポジティブと予測できたものの割合
(下行側)from sklearn.metrics import f1_score f1_score(y, y_pred)F値
・再現率と適合率の調和平均
・適合率と再現率はトレードオフの関係from sklearn.metrics import f1_score f1_score(y, y_pred)予測確率
・0に分類されるか、1に分類されるかを0-1の連続値で表す手法(足したら1に等しくなる)
・scilit-learnはデフォルトで0.5が閾値に設定されている#model_lor.predict_proba(X) import numpy as np y_pred2 = (model_lor.predict_proba(X)[:, 1]>0.1).astype(np.int) print(confusion_matrix(y, y_pred2)) print(accuracy_score(y, y_pred2)) print(recall_score(y, y_pred2))ROC曲線・AUC(要勉強)
・AUC:Area Under the Curve
・ROC:Recceiver Operating Characteristic
・AUCはROC曲線の下側面積
・ROC曲線・・・
横軸:偽陽性率(False Positive Rate)、FP
縦軸:真陽性率(True Positive Rate)、TPfrom sklearn.metrics import roc_curve probas = model_lor.predict_proba(X) fpr, tpr, thresholds = roc_curve(y, probas[:, 1]) %matplotlib inline import matplotlib.pyplot as plt plt.style.use('fivethirtyeight') fig, ax = plt.subplots() fig.set_size_inches(4.8, 5) ax.step(fpr, tpr, 'gray') ax.fill_between(fpr, tpr, 0, color='skyblue', alpha=0.8) ax.set_xlabel('False Positive Rate') ax.set_ylabel('True Positive Rate') ax.set_facecolor('xkcd:white') plt.show() from sklearn.metrics import roc_auc_score roc_auc_score(y, probas[:, 1])
- 投稿日:2020-05-31T20:07:23+09:00
スーパーカミオカンデのイベントディスプレイを作ってみよう
東京大学宇宙線研究所の神岡宇宙素粒子研究施設より、スーパーカミオカンデ実験のシミュレーションデータが公開されました。Python の描画スクリプト付きなので、遊んでみたいと思います。
スーパーカミオカンデのイベントディスプレイ作成用データの公開を始めました。ニュートリノや陽子崩壊のシミュレーションデータを元に、あなた独自のイベントディスプレイを作ってみませんか?データには光電子増倍管の位置座標と光の量や時間の情報が含まれています。https://t.co/YTqHhOTHAP pic.twitter.com/PZVXqA0rLJ
— 神岡宇宙素粒子研究施設 (@Kamiokaobs_pr) May 29, 2020スーパーカミオカンデとは
スーパーカミオカンデとは、岐阜県飛騨市の神岡鉱山内にある、ニュートリノや陽子崩壊の検出を目的とした装置、および実験の名前です。検出器は直径および高さが約 40 m の水タンクと、約10000本の光センサーからなっています。
詳しくは、builderscon 2019 において中の人である宇宙線研究所の早戸さんがエンジニア向けに話されている動画があるので、以下を参照してください。公開されたデータについて
配布されている zip ファイルを展開すると以下のようになっており、CSV と PDF がそれぞれ8ファイル、Python スクリプトが1つ含まれています。CSV については配布ページ に説明があります。 PDF については説明がないですが、おそらくそれぞれの CSV を図示したものと思われます。
1ring-e.0000.000002.csv 1ring-e.0001.000018.csv 1ring-mu.0000.000021.csv 1ring-mu.0001.000031.csv 2rings-pi0.0000.000065.csv 2rings-pi0.0001.000529.csv multirings.0000.000014.csv multirings.0001.000015.csv run999999_001_000002.pdf run999999_001_000014.pdf run999999_001_000015.pdf run999999_001_000018.pdf run999999_001_000021.pdf run999999_001_000031.pdf run999999_001_000065.pdf run999999_001_000529.pdf skdata_sample.pyCSV はファイル名から4種類に分かれていることが分かりますが、名前から類推するに、
1ring-eは電子ニュートリノの事象、1ring-muはミューニュートリノの事象と思われます。2rings-pi0は、こちらの粒子IDなどを参照して CSV を解読すると、ミューニュートリノが入ってきて中性のパイオンが生成され、パイオンが2つの光子に崩壊する事象と思われます。multiringsについては、ニュートリノが入ってきて複数の荷電粒子が生成された事象のようでした。配布ページには「大気ニュートリノや陽子崩壊のシミュレーションデータを公開します」とあるのですが、陽子崩壊で3つのチェレンコフリングができる事象は含まれていないように見えます。今後に期待しましょう。(間違っていたらすみません)図示してみる
先行例
2020/05/31 時点で以下の3つの先行例を観測しました。
付属している Python スクリプトを動かして図示する例は、すでに以下の記事でひだ宇宙科学館 カミオカラボの高知尾さんがやられているので、参照してください。
また以下の記事では、名古屋大学の奥村さんが LEGO 風に描画されています。
KEK の高橋さんは2次元でプロットする方法を紹介されています。
アニメーションを作る
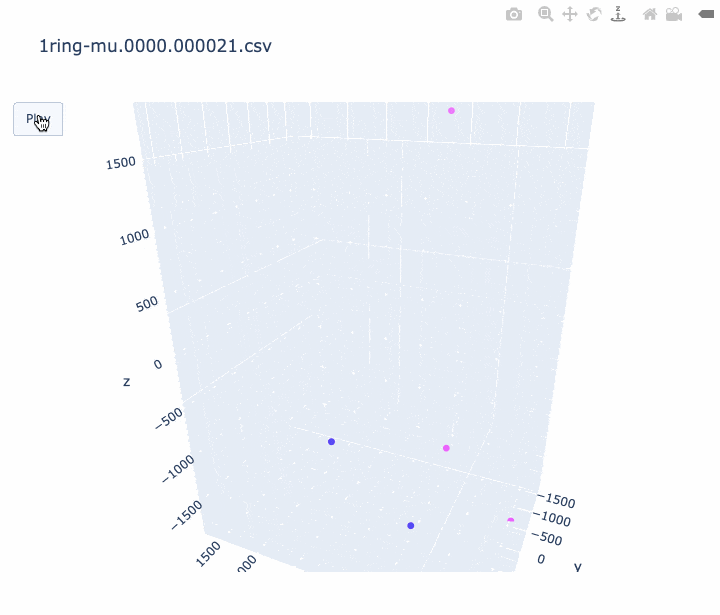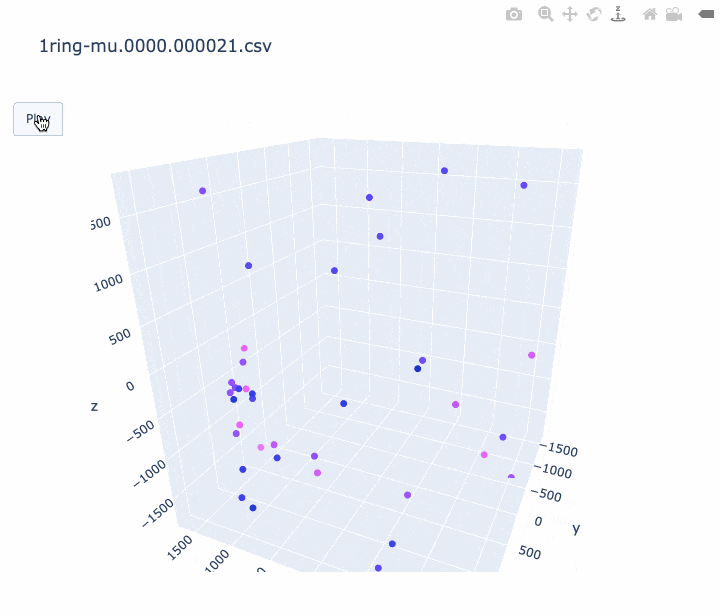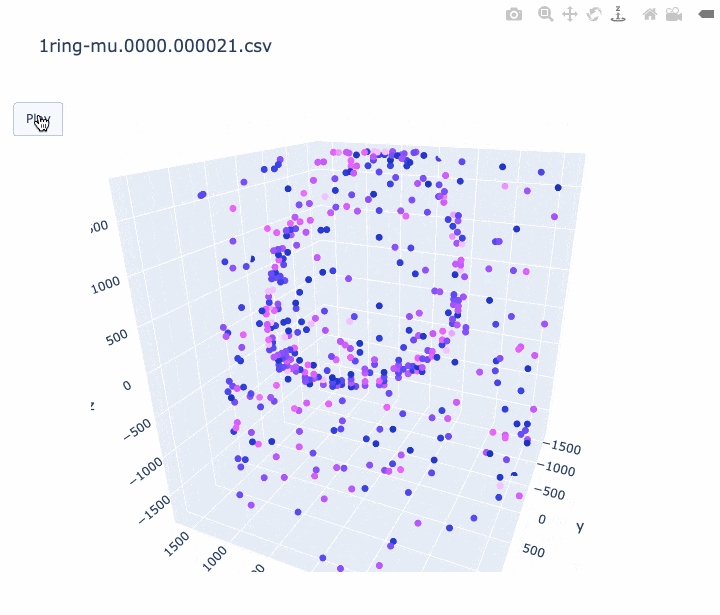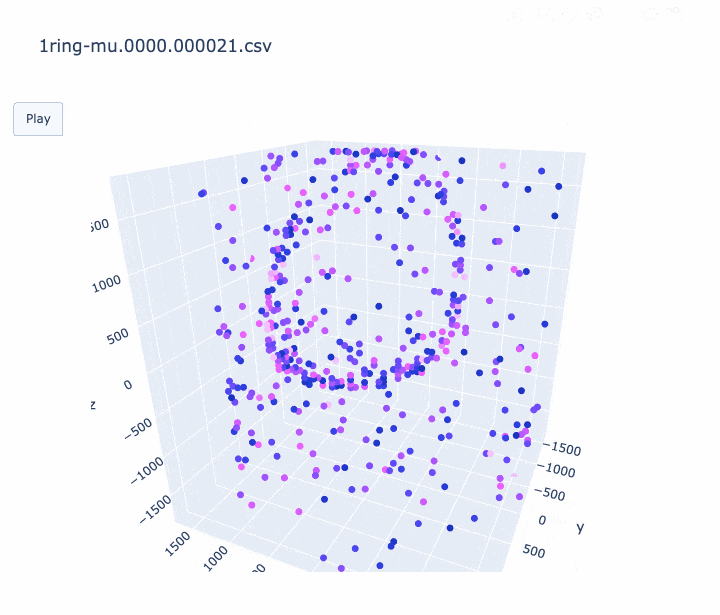
本記事では、 CSV に記録されている時間情報を使って、アニメーションを作ってみたいと思います。Plotly の Python 版を使用して描いてみました。Plotly には Plotly Express という簡単な API がありますが、そちらでは求めるアニメーションが作れなそうだったので、plotly.graph_objects.Scatter3d を使いました。以下、コードです。
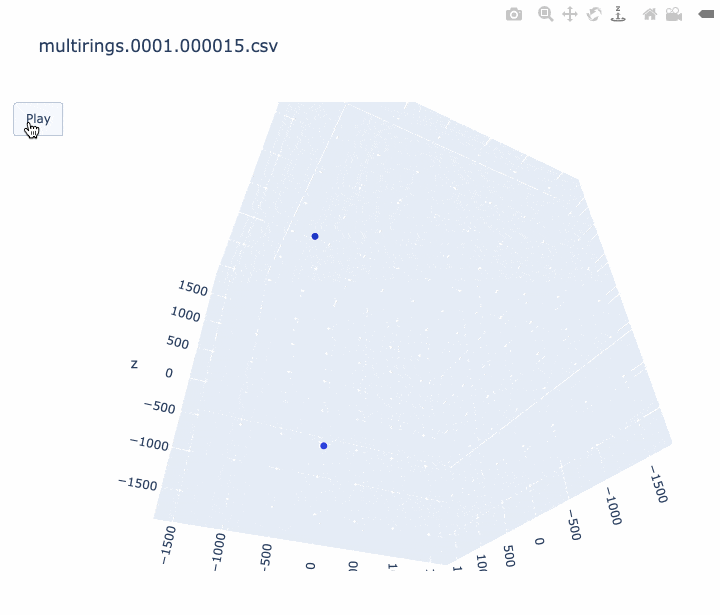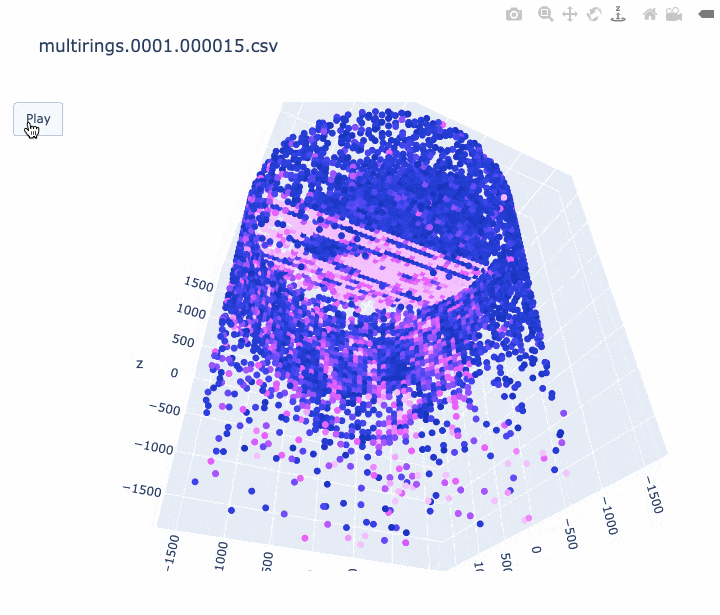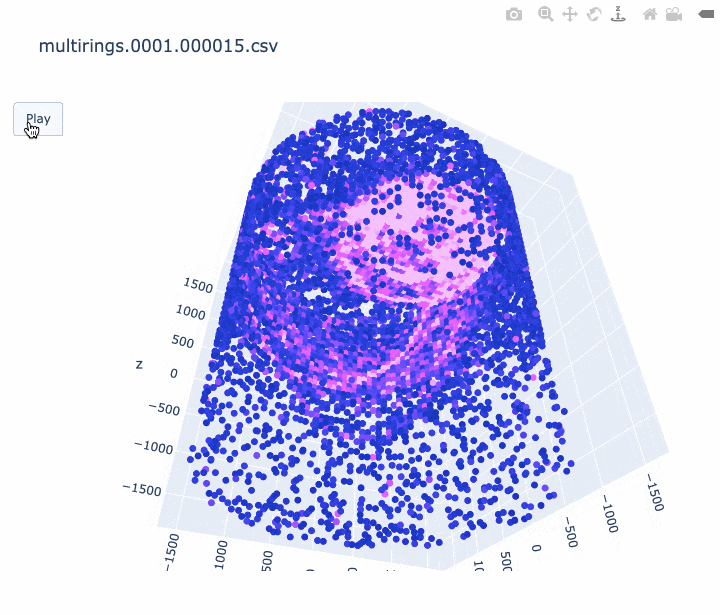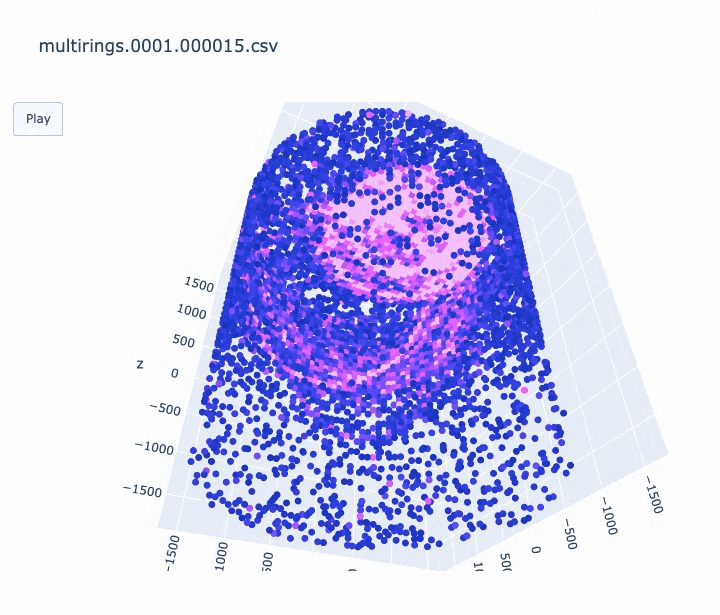
import pandas as pd import sys import plotly.graph_objects as go print('input file :', sys.argv[1]) df = pd.read_csv(sys.argv[1], comment='#') #df.columns = ['cable', 'Charge(p.e.)', 'time(ns)', 'x', 'y', 'z'] df.columns = ['cable', 'q', 't', 'x', 'y', 'z'] # 元のスクリプトと同じ規格化を行う q_avg = df['q'].mean() df['q_disp'] = [q_avg * 3 if q_val > q_avg * 3 else q_val for q_val in df['q']] frame_interval = 50 # フレーム間を何 ns 空けるか。小さくすると重くなります。 frames = [] for i in range(int(min(df['t'])), int(max(df['t'])), frame_interval): # フレームの作成する。 # i より前の時間のヒットは図に残しておく。 df_slice = df[df["t"] < i] frames.append( go.Frame(data=go.Scatter3d( x=df_slice['x'], y=df_slice['y'], z=df_slice['z']))) # アニメーションを作成する。 fig = go.Figure( data=[ go.Scatter3d( x=df['x'], y=df['y'], z=df['z'], mode='markers', marker=dict( size=4, color=df['q_disp'], colorscale='Plotly3', # カラースケールはお好みで #colorscale='Plasma', #colorscale='Bluered', opacity=1.0)) ], layout=go.Layout( scene=dict(xaxis=dict(range=[min(df['x']), max(df['x'])], autorange=False), yaxis=dict(range=[min(df['y']), max(df['y'])], autorange=False), zaxis=dict(range=[min(df['z']), max(df['z'])], autorange=False)), # autosize=True, title=sys.argv[1], updatemenus=[ dict(type="buttons", buttons=[dict(label="Play", method="animate", args=[None])]) ]), frames=frames) fig.write_html(sys.argv[1] + '.html', auto_open=False) #アニメーションを HTML に書き込む。 # fig.show() # すぐに見たいときはコメントアウト出来上がったアニメーションの例は以下です。
- ミューオンの事象 (1枚目) はリングがきれいに見えました。
- 軸のスケールがフレームごとに変わってしまうのは
go.Layout(scene=dict(xaxis= ...の部分で指定しているはずなのですがうまくいきませんでした。Other References

- 投稿日:2020-05-31T19:25:42+09:00
韻を扱いたいpart7(BOW)
内容
これまでとはちょっと違ったことをしてみる。テキストの分割方法に頭を悩ましていたが、母音「aiueo」の一致を見るのであれば、母音を様々に並べ、その母音が文章中に出てきたかどうかを示すことで、文章同士を比べられるのでは?という考えのもとやってみる。つまり、「出現頻度を気にせず、各単語が出現したかどうかのみに着目する」バイナリ表現という方法の各単語を母音の様々な並びにする。
様々な母音の並びを単語に見立てたword_listの作成
from pykakasi import kakasi import re import numpy as np import pandas as pd with open("./gennama.txt","r", encoding="utf-8") as f: data = f.read() vowel_list = ["a","i","u","e","o"] #単語リスト。母音のみ使ってできる2文字から4文字の単語。775種類 word_list = [] for i in vowel_list: for j in vowel_list: for k in vowel_list: for l in vowel_list: word_list.append(i+j) word_list.append(i+j+k) word_list.append(i+j+k+l) text_data = re.split("\u3000|\n", data) kakasi = kakasi() kakasi.setMode('J', 'a') kakasi.setMode('H', 'a') kakasi.setMode('K', 'a') conv = kakasi.getConverter() vowel_text_list = [conv.do(d) for d in text_data] vowel_text_list = [re.sub(r"[^aeiou]+","",text) for text in vowel_text_list]以外にあっさりしたものである。単語の種類も755とそこまで多くない。これまでの経験則で、5文字以上の母音の一致はごく稀であるため、4文字までとした。今までは様々な辞書を作成していたが、DataFrameにまとめてみる。
DataFrame作成
df = pd.DataFrame({"文章": text_data, "母音": vowel_text_list}) #カラム名"aa"等で、文章中に出現したら1、しなければ0 binaly_dic = {} temp = [] for word in word_list: for vowel in vowel_text_list: if word in vowel: temp.append(1) else: temp.append(0) binaly_dic[word] = temp temp = [] for k, v in binaly_dic.items(): df[k] = v df.to_csv("df_test.csv")カラムは「文章、母音、単語…」とし、「文章」には元のテキストデータを分割した文章、「母音」にはそれを母音のみに変換したもの、「単語…」にはその単語が文章中に入っていれば1、入っていなければ0をそれぞれ与えた。
活用例
#コサイン類似度 def cosine_similarity(v1, v2): cos_sim = np.dot(v1, v2) / (np.linalg.norm(v1) * np.linalg.norm(v2)) return cos_sim print(cosine_similarity(df.iloc[0, 2:].values, df.iloc[3, 2:].values))例えばこのようにして、文章0と文章3の類似度を表示させる。他にも
sumを使って、どの単語が一番共通して使われているか、等もすぐに分かる。まとめ
母音のみに着目しているので、2~4文字で全ての組み合わせを考えても単語数755に抑えられた。これまで文章を分割して取り扱おうとしていたが、そのままでも出来ることがあった。自分の中で大きな出来事なので、内容が薄いが記事にした。今後は文章の類似度からさらに何か処理をしたり出来ないか等、作ったDataFrameを元にやっていこうと思う。
- 投稿日:2020-05-31T19:14:55+09:00
100日後にエンジニアになるキミ - 72日目 - プログラミング - スクレイピングについて3
昨日までのはこちら
100日後にエンジニアになるキミ - 70日目 - プログラミング - スクレイピングについて
100日後にエンジニアになるキミ - 66日目 - プログラミング - 自然言語処理について
100日後にエンジニアになるキミ - 63日目 - プログラミング - 確率について1
100日後にエンジニアになるキミ - 59日目 - プログラミング - アルゴリズムについて
100日後にエンジニアになるキミ - 53日目 - Git - Gitについて
100日後にエンジニアになるキミ - 42日目 - クラウド - クラウドサービスについて
100日後にエンジニアになるキミ - 36日目 - データベース - データベースについて
100日後にエンジニアになるキミ - 24日目 - Python - Python言語の基礎1
100日後にエンジニアになるキミ - 18日目 - Javascript - JavaScriptの基礎1
100日後にエンジニアになるキミ - 14日目 - CSS - CSSの基礎1
100日後にエンジニアになるキミ - 6日目 - HTML - HTMLの基礎1
今回もスクレイピングの続きです。
前回はリクエストを行い情報取得をするところまで行いました。
今回からは通信後のデータの解析方法をやっていきます。HTMLを解析する方法
レスポンスボディは基本テキスト型(文字列)構造であるため
そのままでは必要な情報を取り出すのに都合が悪いです。HTMLの構文を解析するにはPython言語では
BeautifulSoupライブラリを用います
BeautifulSoupライブラリを用いて、文字列型のデータを
BeautifulSoup型に変換します。from bs4 import BeautifulSoup 変数名 = BeautifulSoup(レスポンスオブジェクト名.content , "HTMLパーサー名")これで
BeautifulSoup型にデータ変換できます。試しに生のHTMLを変換してみましょう。
from bs4 import BeautifulSoup html=''' <HTML> <head><title>タイトルだよ</title></head> <body> <h1>h1だよ</h1> <h2>h2だよ</h2> <div class='c1'> <a class='a1' href='http://sample.com'><p>sampleへのリンク</p></a> </div> <div id='id1'> <p><a href='http://sample.com'>aaa</a></p> </div> </body> </HTML> ''' # html.parserを用いてレスポンスをBeautifulSoupに変換 soup = BeautifulSoup(html , "html.parser") print(type(soup))データ型は
bs4.BeautifulSoupです。
変数をそのままprintして中身をみると文字列型と同じように見ることができます。これ以降は
BeautifulSoup型のメソッドなどがつかえるようになり
それを使ってHTMLの構文にしたがって処理をすることが出来ます。HTMLパーサー
パースとは一定の規則で記述されたテキストを解析し、プログラムで扱いやすいようなデータに変換する処理のことです。パーサーはHTMLを
パースする際のプログラムです。Python言語で指定できる
HTMLパーサーは主に次の3つがあります。
パーサー名 内容 html.parser デフォルトのパーサー lxml C言語の高速実装な解析器,複雑な構造や動的な物に少し弱い html5lib html5の規則に対応したパーサー
BeautifulSoupでの変換時には何かしらのパーサーを指定します。HTMLについて
HTMLは木構造(入子構造)のマークアップ言語で、ハイパーリンクや画像等のマルチメディアを埋め込むハイパーテキストとしての機能、見出しや段落といったドキュメントの抽象構造フォントや文字色の指定などの見た目の指定、などといった機能があります。
タグとは、<で始まり、>で終わっている部分(マークアップ)のみを指し
要素(エレメント)は開始タグ~終了タグに囲まれた全体を指す概念です。要素(エレメント)
<開始タグ>コンテンツ</終了タグ>HTMLには様々な
タグが存在し、構文解析はタグの構造を読み解いてゆく方法で行います。BeautifulSoupでの構文解析
さて構文解析をするサンプルを用意して構文解析してみましょう。
from bs4 import BeautifulSoup html=''' <HTML> <head><title>タイトルだよ</title></head> <body> <h1>h1だよ</h1> <h2>h2だよ</h2> <div class='c1'> <a class='a1' href='http://sample.com'><p>sampleへのリンク</p></a> </div> <div id='id1'> <p><a href='http://sample.com'>aaa</a></p> </div> </body> </HTML> ''' soup = BeautifulSoup(html , "html.parser")任意のタグを指定して要素の取得
以下、BeautifulSoup型の変数を
soupとします。
soup.タグ#任意の部分を個別抽出 h1 = soup.html.body.h1 p1 = soup.html.body.p a1 = soup.html.body.a z1 = soup.html.body.z print(h1) print(p1) print(a1) print(z1) print(type(a1)) ------------------------------------------- <h1>h1だよ</h1> <p>sampleへのリンク</p> <a class="a1" href="http://sample.com"><p>sampleへのリンク</p></a> None <class 'bs4.element.Tag'>タグが複数ある場合は最初に見つかったものが返り、見つからない場合はNoneが返ります。
任意のidやクラスで要素を探す
soup.find(id="id名")
soup.find(class_="クラス名")
soup.find(text="テキスト")任意で検索したものが複数有った場合は最初に見つかった要素(HTMLタグ)が取得できます。この場合も取得できない場合は
Noneとなります。div = soup.find('div',id='id1') p = div.find('p') a = p.find('a') print(div.a) ------------------------------------ <a href="http://sample.com">aaa</a>title = soup.find(id="id1") body = soup.find(class_="c1") text = soup.find(text="aaa") print(title) print(body) print(text) ------------------------------------ <div id="id1"> <p><a href="http://sample.com">aaa</a></p> </div> <div class="c1"> <a href="http://sample.com"><p>sampleへのリンク</p></a> </div> aaa複数の条件で任意のidやクラスで要素を探す
soup.find('タグ名',attrs={'要素名':'値','要素名':'値'})# attrs = の後に辞書型で指定する a_tag = soup.find("a", attrs={"class": "a1", "href": "http://sample.com"}) print(a_tag) ------------------------------------ <a class="a1" href="http://sample.com"><p>sampleへのリンク</p></a>任意のidやクラスで複数の要素を取得する
find_all('タグ名')
soup.find_all(id="id名")
soup.find_all(class_="クラス名")
soup.find_all(text="テキスト")
soup.find_all('タグ名' , attrs={'要素名':'値' , '要素名':'値'})links = soup.find_all("a") print(links) ---------------------------- [<a class="a1" href="http://sample.com"><p>sampleへのリンク</p></a>, <a href="http://sample.com">aaa</a>]
find_allを用いると条件に該当するHTMLタグの情報全てが取得され
結果はリスト型になります。
何も取得できない場合は要素なしの空のリスト型になります。タグはリスト型で複数指定が出来ます
links = soup.find_all(["a", "h1"]) for link in links[0:5]: print(link) ---------------------------- <h1>h1だよ</h1> <a class="a1" href="http://sample.com"><p>sampleへのリンク</p></a> <a href="http://sample.com">aaa</a>正規表現を用いる方法
タグやid,クラス名での検索方法では完全一致で検索されます。
部分一致で検索したい場合は
reライブラリを用いて探すことが出来ます。
re.compile('検索文字列')この条件で指定した要素は部分一致で検索されます。
import re soup.find_all("タグ名", text=re.compile("検索文字列"))import re # re.compile でテキストに「aa」が含まれるものを抽出 links = soup.find_all("a", text=re.compile("リ")) for link in links[0:5]: print(link) ---------------------------- <a class="a1" href="http://sample.com"><p>sampleへのリンク</p></a>cssセレクタを使ったタグの取得
CSSセレクタとは、どの要素がそのスタイル規則によって影響されるかを指定するものでスクレイピングでは指定方法を工夫することで、特定の部分の要素を抽出することができます。なおBeautifulSoupを使ったスクレイピングで
CSSセレクタはHTMLパーサーにも依存します。CSSセレクタで要素を一つだけ取り出す
soup.select_one(セレクタ)CSSセレクタで複数要素を取り出す
soup.select(セレクタ)# select 結果はリスト型 links = soup.select('a[href^="http://s"]') for link in links[0:5]: print(link) --------------------------- <a class="a1" href="http://sample.com"><p>sampleへのリンク</p></a> <a href="http://sample.com">aaa</a>CSSセレクタの種類
下記のようなセレクタの指定ができます。
セレクタ 例 例の説明 .class .intro class="intro" を持った全要素を選択する #id #firstname id="firstname" を持った要素を選択する * * 全要素を選択する element p 全ての p 要素を選択する element,element div, p 全ての div 要素と、全ての p 要素を選択する element element div p div 要素内の、全ての p 要素を選択する element>element div > p 親要素が div 要素である、全ての p 要素を選択する element+element div + p div 要素の直後に配置された全ての p 要素を選択する element1~element2 p ~ ul p 要素が先行しているすべての ul 要素を選択する [attribute] [target] target 属性を持った全ての要素を選択する [attribute=value] [target=_blank] target="_blank" を持った全ての要素を選択する [attribute~=value] [title~=flower] 単語 "flower" を含む title 属性を持った全ての要素を選択する [attribute^=value] a[href^="https"] href 属性値が "https" で始まるすべての a 要素を選択する [attribute*=value] a[href*="w3schools"] href 属性値が部分文字列 "w3schools" を含んでいるすべての a 要素を選択する 属性の取得
上記で取得したものはタグ(要素)になります。
要素の中から属性を取り出すには下記のように行います。
タグ.get("属性名")例:
aタグのhref属性
aタグ.get('href')テキストの取得
開始 - 終了タグで囲まれた部分がテキストになります。
テキストはタグ.textで抽出できますが、タグが取得できていない場合は
抽出はできないので注意が必要です。print(soup.a) print(soup.a.text) ---------------------------- <a class="a1" href="http://sample.com"><p>sampleへのリンク</p></a> sampleへのリンクまとめ
HTMLからBeautifulSoupへの変換方法
BeautifulSoupからタグの取得の仕方
タグから属性やテキストの取得の仕方をやりました。これで情報のほとんどを取得できたはずです。
様々なやり方があるので、試しながら少しづつ覚えましょう。君がエンジニアになるまであと28日
作者の情報
乙pyのHP:
http://www.otupy.net/Youtube:
https://www.youtube.com/channel/UCaT7xpeq8n1G_HcJKKSOXMwTwitter:
https://twitter.com/otupython
- 投稿日:2020-05-31T19:08:33+09:00
Python3.9の新機能(2) - Pythonで有向非巡回グラフのソートをする
はじめに
2020年10月にリリースが予定されているPython3.9で新たに加わる変更をPython3.9の新機能 (まとめ)という記事でまとめています。少し分量のありそうな話題を別記事にしていますが、これはその第二弾で、有向非巡回グラフのソートについてです。
有向非巡回グラフとトポロジカルソート
まず、ここでいうグラフは折れ線グラフとか棒グラフとかデータを視覚的に表す図表のことではなく、グラフ理論のグラフです。グラフはデータ構造の一種で、ノード(頂点)とそれらを繋ぐエッジ(枝)で構成されています。ノードやエッジに何かしらの意味をもたせることによって、関連性を持つ情報を表すことができます。
グラフにもいくつか種類があり、その最初の分かれ道がエッジに方向があるかないか。方向があるものを有向グラフ(左側)、無いものを無向グラフ(右側)といいます。
エッジはノードを繋ぐものですが、繋がれたノードの間に何かしらの主従関係的なものがあれば有向グラフを、そうではなく対等な関係であれば無向グラフを使うことができます。
そして、巡回グラフであるかどうかもポイントになります。エッジをたどっていくことで自分に戻ってくるノードがある場合は巡回グラフ、そうではないものを非巡回グラフと言います。有向でかつ非巡回の2つの特徴を持ち合わせたのが、有向非巡回グラフ (Directed Acyclic Graph: DAG)で、これが今回取り扱うグラフになります。
この有向非巡回グラフ(DAG)は色々な情報を表現するのに用いることができます。変わった例だと暗号資産のIOTAがDAGを使っています。通常の暗号資産はブロックチェーンを使っていて、一本道のDAGということができると思いますが、IOTAはそれを複数のエッジを持つDAGで繋げていく。面白いですね。
もう少し普通の応用だと依存関係のあるタスクのスケジュール問題があります。一つ一つのタスクがノードで、タスクの依存関係がエッジで表現され、例えば A → BとなっていたらAが終わるまでBは始められないという風に表していく。込み入った依存関係をもつタスクのリストがあったとしてもタスクとタスクの関係に分解していけばDAGで表現できることがわかると思います。
例えば BとCはAが終わるまで始められない。そしてDはBとCが終わるまで始められない、そういう依存関係は以下のように表されます。
より複雑な例だと、例えばこの様になります。
話が少し脱線してしまいますが、DAGを視覚化するためのツールに Graphvizというものがあります。これは、DAGをdot形式という独自のフォーマットで記述し、それを描画してPNGなどの画像形式に変換してくれるものです。面白いのは、描画のアルゴリズムがいくつか用意されていて同じ入力でもぜんぜん違う出力が得られます。
例えば上の2つ目の例をdot形式で記述するとこうなります。
digraph example { graph [ labeljust = "c" ]; 7, 5, 3, 11, 8, 2, 9, 10; 7 -> 11; 7 -> 8; 5 -> 11; 3 -> 8; 3 -> 10; 11 -> 2; 11 -> 9; 11 -> 10; 8 -> 9; }これをGraphvizの描画ツールで出力してみるとこれだけバリエーションができます。
面白いですね。とても同じDAGには見えませんが、全て同じdotファイルから描画されたものです。
さて、DAGで表現されたタスクの間には順序関係があるので、どの順番で片付けていけば良いのかを知りたくなります。それがスケジュール問題ですね。そのためには、依存関係が満たしながら一次元上に並べるという操作が必要で、それをトポロジカルソートと呼びます。
前置きが長くなりましたが、Python3.9では
functoolsモジュールにTopologicalSorterという機能が追加されていて、このトポロジカルソートを標準機能で行えるようになります。TopologicalSorterを使ってみる
一番最初に示した、A,B,C,Dのノードを持つ例で試してみましょう。
>>> from functools import TopologicalSorter >>> ts = TopologicalSorter() >>> ts.add('B', 'A') >>> ts.add('C', 'A') >>> ts.add('D', 'B', 'C') >>> tuple(ts.static_order()) ('A', 'B', 'C', 'D')空のソーターを
TopologySorter()で作った後にノードを一つずつ追加しています。TopologySorter.add()は第一引数に登録するノード、それ以降の引数に依存関係のあるノードを羅列します。依存するノードのないノード(この場合はA)は登録を省略することができます(他のノードの登録時に依存するものとして出てくるので)。そして、TopologySorter.static_order()でソートされた結果をgeneratorで返してきます。そのままだと見にくいのでタプルに変換して表示しています。グラフが最初から決まっている場合はコンストラクターにそれを与えて一気に作ることもできます。
>>> from functools import TopologicalSorter >>> graph = {'B': {'A'}, 'C': {'A'}, 'D': {'B', 'C'}} >>> ts = TopologicalSorter(graph) >>> tuple(ts.static_order()) ('A', 'B', 'C', 'D')ここで、コンストラクターに与えるのは辞書型のデータで、キーがノード、値が依存するノード(の集合)になっています。複数指定するときにはここではset型を使っていますが、タプルでもリストでも良いようです。
ソートするだけならこれだけで良いのですが、もう少し細かく制御したい時のメソッドもいくつか用意されています。まずは「今現時点で実行可能なもの」。依存関係が満たされているタスクのリストになりますが、これには
get_ready()を用います。例として先ほどの少し複雑な例を使います。
>>> from functools import TopologicalSorter >>> graph = { ... 2: {11}, ... 8: {7, 3}, ... 9: {11, 8}, ... 10: {11, 3}, ... 11: {7, 5}, ... } >>> ts = TopologicalSorter(graph) >>> ts.prepare() >>> ts.get_ready() (3, 7, 5)コンストラクターでグラフの依存関係データを与えてTopologySorterを作った後に、まずは
prepare()します。これはこの後の処理を行う上での前処理を行うメソッドです。ここで登録したグラフが巡回になっていないかのチェックも行っていて、巡回になっている場合にはCycleErrorがでます。上の例ではこのprepare()を呼んでいませんでしたが、static_order()の中で自動で呼ばれています(実際にはgeneratorの最初の値を取り出すときに呼ばれる)。その後に
get_ready()を呼び出すと(3, 7, 5)が返ってきます。これは、グラフに含まれるノードの中で依存関係の無いものが「実行可能」としてリストアップされています。もう一度prepare()を呼んでみると今度は()が返ってきます。「(今の所)これ以外には無いよ」ということですね。先ほどのグラフに色を付けて行きます。薄緑色はそのノードが実行可能であることを示します。
では、実行可能なタスクのうち
5と7が終わったとしたらどうなるか?それをソーターに教えるのがdone()メソッドです。終わったタスクを引数に並べて呼び出すと内部の状態が変わります。それで再度get_ready()を実行すると今度は(11,)が返ってきます。>>> ts.done(5,7) >>> ts.get_ready() (11,)図の方は
5と7が完了したことを示すために濃い色に変更します。そして11は依存していたタスクが全て完了したので実行可能になります。上記のts.get_ready()の結果と一致しますね。
これを繰り返していくわけですが、
11→3→8の順で完了にしていきましょう。>>> ts.done(11) >>> ts.get_ready() (2,) >>> ts.done(3) >>> ts.get_ready() (8, 10) >>> ts.done(8) >>> ts.get_ready() (9,)
なおグラフの中に未実行のタスクがあるかどうかは、
is_active()で調べることができます。上の状態だとまだ2,9,10が未実行なので、それらをdone()にする前後でis_active()の返り値が変わることがわかります。>>> ts.is_active() True >>> ts.done(2, 9 ,10) >>> ts.is_active() Falseまとめ
Python 3.9の
functoolsモジュールに新たに追加されるToplogicalSorterの機能を調べて使ってみました。依存関係のあるバッチ処理とかの順番を決めたりするのに使えるかもしれないなと思いました。

- 投稿日:2020-05-31T18:39:06+09:00
Pythonでローグライクゲーム作ってみた
概要
pythonの言語勉強としてローグライクのサンプルゲームを作成しました。
GitHubにプロジェクトを公開していますので、その紹介記事となります。こちらは、廣瀬 豪さん著「Pythonでつくるゲーム開発 入門講座」の題材となっている、本格RPGのサンプルゲームをベースとして、ゲーム内容の調整やオブジェクト指向の取り入れ等を行った物となります。
なのでコードを確認する前に一旦こちらの入門書を終わらせておくと、内容が理解しやすいかも知れません。
プロジェクトの詳細な説明については、GitHubの
readmeを参照ください。https://github.com/becky3/python_dungeon_game_sample
プレイ動画
プレイ動画です。
https://youtu.be/MsCe81pIWYY
環境
- OS:Windows 10
- Python:3.7.4
利用ライブラリ
pygame 1.9.6
pythonで2Dゲーム制作を行う際に便利なライブラリ
https://github.com/pygame/pygame/numpy 1.18.4
配列の利用にちょっと参照した程度。 単に使ってみたかったので入れました。
オリジナルからの主な変更点
オリジナルのRPGは戦闘シーンがドラクエ風対面式バトルとなってましたが、マップ上でシームレスにバトルができる仕組みへと変更してます。
また、GitHubへ公開するに当たり、リソース類をすべて自作のものに差し替えています。以下、主な変更点です。
- オブジェクト指向で制作
- クラス単位でファイル分割
- バトル方式を対面式からシームレスタイプに
- ゲームの進行にシーンとタスクの手続き導入
- 移動のアニメーションをスムーズに
- 画像描画手続きをカメラを用いた構造に変更
- リソース類の置き換え
利用したツール
MusicStudio (作曲)
https://apps.apple.com/jp/app/music-studio/id328608539
iPadで作曲ができるDAWアプリです。 Winで気軽に使えるDAWになかなか巡り会えず、5年前くらいに買ってほぼ放置していたアプリを引っ張り出してきました。
Serverモードという、ブラウザからアクセスしてファイルを直でダウンロードできる機能がなかなか良い。KanaWave (効果音)
https://www.vector.co.jp/soft/win95/art/se232653.html
ひらがなで効果音が作成できるフリーウェアのツールです。 ちょっとした効果音をサクッと作りたいときにすごく重宝してます。
Audacity (効果音調整)
https://forest.watch.impress.co.jp/library/software/audacity/
音声波形編集ツールで、こちらもフリーウェア。 音声ファイルの音量調整や、wav → ogg 変換等に利用しました。
Aseprite (ドット絵)
https://store.steampowered.com/app/431730/Aseprite/?l=japanese
ドット作成ツールです。 STEAMのストアで購入しました。 アニメーションの確認ツールなども含まれており、かなり本格的なツールですが、ちょっとしたドットを書きたい時でも、ストレスなく簡単に使えて良いです。
参考書籍
今回の題材としたこちらの書籍ですが、
とにかく実践的な内容で、細かい言語仕様の解説よりまずは手を動かしてものを作っていくスタイルとなっていました。
最終的には今回参照した本格RPGに、落ちものパズル等、結構ガッツリしたゲームの作成解説があり、プログラミング楽しみながら覚える入門書として、すごく優れている本だと思います。
逆に、Pythonの言語仕様については解説が少なめなので、この本でコードを書くという事になれたら、別の入門書で保管する流れが良さそうです。■ Pythonでつくるゲーム開発 入門講座
https://amzn.to/2ZNCgps
GitHub
https://github.com/becky3/python_dungeon_game_sample
感想
Pythonの勉強のために、軽くリファクタリングをしながら、2~3日で終わらせるつもりが、ゲームエンジン部の作り込みにハマってしまい、いつの間にか2週間規模の作業となってしまいました。
IDEはVSCodeを使ったのですが、デバッグ実行等もでき、軽くならリネームも効いて、かなり開発が行いやすかったです。
また、lintライブラリとして、pylintとflake8を使ったのですが、これらのおかげでpythonの一般的なコーディングルールが学べました。
新しい言語を勉強する際はとりあえずlintを入れるというのはかなり有効ですね。ある程度汎用的に利用できる直前くらいまでは作り込めたと思うので、今回の学習を活かして、今後スマホで同様のアプリを作ってみるなり何らかの展開が見せていければ良いなと思っています。

- 投稿日:2020-05-31T18:26:12+09:00
Pythonを使ってGmailの未読メールを取得するLine Botを作った!
目的
Line BotでGmailからメールを取得し、未読のメッセージをの送信主、題名をLineに送る。
開発環境
- Flask==1.1.1
- line-bot-sdk==1.14.0
- oauth2client==4.1.3
- httplib2==0.14.0
- google-api-python-client==1.7.11
- google-auth==1.6.3
- google-auth-httplib2==0.0.3
- google-auth-oauthlib==0.4.1
参考
PythonでGmailのメールを確認しよう
-- GoogleのAPIを有効にするのに参考にさせていただきました。
Pythonを使ってGmail APIからメールを取得する
-- Gmail APIの使い方を参考にさせていただきました。ソースコード
main.pyfrom flask import Flask, request, abort from linebot import ( LineBotApi, WebhookHandler ) from linebot.exceptions import ( InvalidSignatureError ) from linebot.models import ( MessageEvent, TextMessage, TextSendMessage, LocationMessage, VideoMessage, FollowEvent, UnfollowEvent, PostbackEvent, TemplateSendMessage, ButtonsTemplate, CarouselTemplate, CarouselColumn, PostbackTemplateAction ) from linebot.exceptions import LineBotApiError import os import json import sys import re import Gmail app = Flask(__name__) YOUR_CHANNEL_ACCESS_TOKEN = os.environ["YOUR_CHANNEL_ACCESS_TOKEN"] YOUR_CHANNEL_SECRET = os.environ["YOUR_CHANNEL_SECRET"] line_bot_api = LineBotApi(YOUR_CHANNEL_ACCESS_TOKEN) handler = WebhookHandler(YOUR_CHANNEL_SECRET) @app.route("/callback", methods=['POST']) def callback(): signature = request.headers['X-Line-Signature'] body = request.get_data(as_text=True) app.logger.info("Request body: " + body) try: handler.handle(body, signature) except InvalidSignatureError: abort(400) return 'OK' @handler.add(MessageEvent, message=TextMessage) def handle_message(event): text = event.message.text user_id = event.source.user_id if 'メール' in text: mail = Gmail.GmailAPI() # get the reply message messages = mail.process_message() # reply line_bot_api.reply_message( event.reply_token, TextSendMessage(text=str(messages)) ) if __name__ == "__main__": port = int(os.getenv("PORT", 5000)) app.run(host="0.0.0.0", port=port)「メール」という文字列が入ったメッセージをBotが受け取ると、Gmailから未読のメッセージを取得し、返信するようにしています。
Gmail.pyfrom googleapiclient.discovery import build from httplib2 import Http from oauth2client import file, client, tools class GmailAPI: def __init__(self): # If modifying these scopes, delete the file token.json. self._SCOPES = 'https://www.googleapis.com/auth/gmail.readonly' def ConnectGmail(self): store = file.Storage('token.json') creds = store.get() if not creds or creds.invalid: flow = client.flow_from_clientsecrets('credentials.json', self._SCOPES) creds = tools.run_flow(flow, store) service = build('gmail', 'v1', http=creds.authorize(Http())) return service def GetMessageList(self): # connect to API service = self.ConnectGmail() MessageList = [] query = 'is:unread' # get all the messages (maximum=20) messageIDlist = service.users().messages().list(userId='me',maxResults=20,q=query).execute() # if no messages, stop return error if messageIDlist['resultSizeEstimate'] == 0: return 'error' # Get information about the mails for message in messageIDlist['messages']: row = {} MessageDetail = service.users().messages().get(userId='me',id=message['id']).execute() for header in MessageDetail['payload']['headers']: # get the senders of the messages if header['name'] == 'From': row['from'] = header['value'] # get the subject of the messages elif header['name'] == 'Subject': row['subject'] = header['value'] MessageList.append(row) return MessageList def process_message(self): messagelist = self.GetMessageList() # If there is no messages new, reply 'No message' if messagelist == 'error': reply = 'No message' return reply # make reply message reply = '' for mlist in messagelist: from_name = mlist['from'].split('<')[0] + ':' sub = '「' + mlist['subject'] + '」' message = '{}\n{}'.format(from_name, sub) reply += message reply += '\n\n' return replyGmail APIを使用し、GetMessageListでは未読メールの送信主、題名を取得し、process_messageではそれらを返信する際の文字列に変換して返すようにしています。
結果
送信主の名前は消していますが、名前、題名を取得し、返信することができました!今後について
今後以下の2つを実装していきたいです。
- プッシュ機能を使って自動で未読メールを取得し、送るようにする。
- 「メール」と打つのではなく、ボタンを設置して、そのボタンで未読メールを取得できるようにする。