- 投稿日:2020-05-31T21:50:43+09:00
Azure上のRHELでファイルシステムの拡張が必要になったらどうする?
はじめに
Azureの大きなメリットとして「スモールスタートが可能」が歌われています。ストレージの観点で言うと、Azure上の既存インスタンスにブロックストレージを追加したり既存ブロックストレージを拡張したりするのは簡単です。したがって、スモールスタートして、ビジネスの拡大に応じてディスク容量を拡張していくのは容易に思えます。ただし、本当に必要なのは、ブロックストレージの容量を増やすことではなく、ファイルシステムの容量を増やす事であり、且つ拡張作業をビジネスへの影響を最小限にとどめながら行う事です。特に、クラスタリングされているようなシステムの場合、いかにしてサービスの停止時間をゼロもしくは少なくしながらファイルシステムの拡張が行えるかが重要です。
前述したように、Azure上のインスタンスのストレージ容量を増やす手法は、以下の2種類があります。
1.既存ブロックストレージの拡張
2.ブロックストレージの新規追加ベリタスのInfoScaleを使用すると、上記の2種類の手法を、以下の4種類の構成で実現できます。全てのパターンを網羅ホワイトペーパーがベリタスから公開されています。是非こちらをご覧ください。
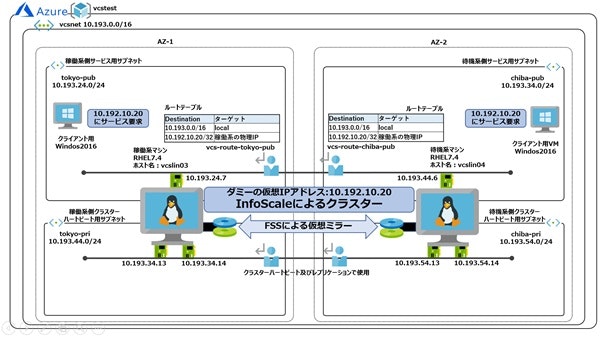
・非クラスター構成
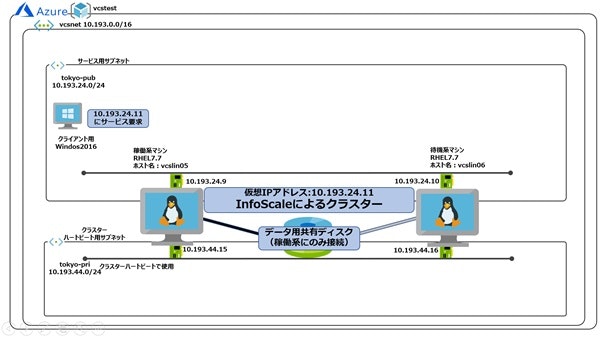
・共有ディスク型クラスター構成(もっとも一般的なクラスター要件に対応)
上記クラスター構成の詳しい実装方法については、ベリタスよりホワイトペーパーが公開されています。是非こちらをご覧ください・FSSを用いた仮想ミラー型クラスター構成(AZを跨ぐ必要があるクラスター要件に対応)
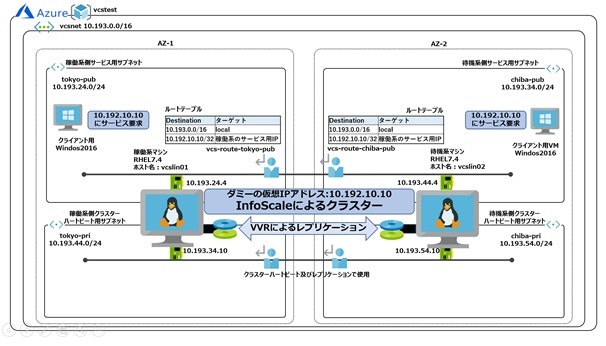
上記クラスター構成の詳しい実装方法については、ベリタスよりホワイトペーパーが公開されています。是非こちらをご覧ください・VVRを用いたレプリケーション型クラスター構成(リージョンを跨ぐ必要があるクラスター要件に対応)
上記クラスター構成の詳しい実装方法については、ベリタスよりホワイトペーパーが公開されています。是非こちらをご覧ください。既存のインスタンスのブロックストレージを増やす手法毎の特徴
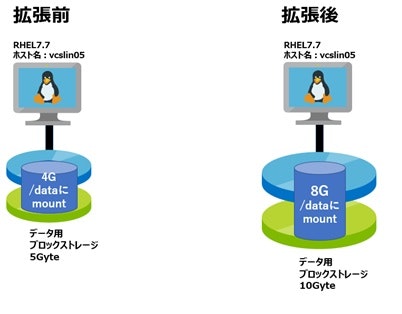
既存ブロックストレージの拡張
Azureでは、RHELインスタンスに関連付けられたブロックストレージを拡張する事ができます。この手法のメリットは、RHELインスタンスに新たなデバイスを追加する必要が無いので構成変更を最小限に抑えられる事です。デメリットは、ブロックストレージの拡張の限界が32Tbyteである事です。
拡張後に必要なブロックストレージの容量が32Tbyte以内で、且つシステム構成への変更を最小限にとどめたい場合は、この方法を用いてください。詳しい作業方法については、ベリタスよりホワイトペーパーが公開されています。是非こちらをご覧ください。
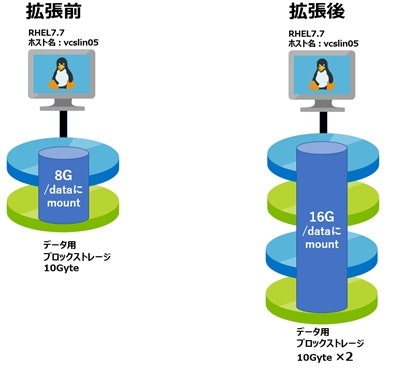
ブロックストレージの新規追加
Azureでは、RHELインスタンスに新たなブロックストレージを追加する事ができます。この手法のメリットは、32Tbyteを超える容量を提供できる事です。デメリットは、新たなブロックストレージが追加されるのでシステムの構成が大きく変更される事と、ブロックストレージの追加の限界(BasicレベルのVMでは約66、StandardレベルのVMでは約40)がある事です。
拡張後にインスタンスに接続されるブロックストレージの数が制限内で容量が32Tbyteを超える場合、この方法を用いてください。詳しい実装方法については、ベリタスよりホワイトペーパーが公開されています。是非こちらをご覧ください。
おわりに
如何でしたでしょうか? 今回の記事と記事中に紹介したホワイトペーパーによって、Azure上のRHEL上でファイルシステムの拡張が必要になった場合の対処が明確になり、スモールスタートを検討する際のハードルはかなり下がったのではないでしょうか? 今回の内容は、ストレージ管理に関する様々な顧客要件を満たすInfoScaleのほんの一部をご紹介にしたにすぎません。次回は、Windows環境で、クラスタリングした後でファイルシステムの拡張が必要になった場合の対応策をお送りします!
商談のご相談はこちら
本稿からのお問合せをご記入の際には「お問合せ内容」に#GWCのタグを必ずご記入ください。ご記入いただきました内容はベリタスのプライバシーポリシーに従って管理されます。
その他のリンク
【まとめ記事】ベリタステクノロジーズ 全記事へのリンク集もよろしくお願いいたします。

- 投稿日:2020-05-31T17:29:05+09:00
Splunk Cloudにサーバーからログデータを送信する
はじめに
Splunk Cloud を使用する機会ががありました。
そこで、Linuxサーバーから各種ログを転送する方法を備忘録として残しておきますこの記事はGet *nix data into Splunk Cloud に基づいています
事前準備
- Splunk Cloud に登録しておく
- 無料トライアルで大丈夫です
- Linuxのインスタンスを用意する
- GCPのMarketplaceにあるWordpress で動作確認をしています
手順
- サーバーにUniversal Forwarderをインストールする
- Universal Forwarder のクレデンシャルをダウンロードしインストールする
- Universal Forwarder にLinux用のAdd-onをインストールする
- 3.でインストールしたAdd-onをパースするためのAppをインストールする
- データが受信できることを確認する
1. サーバーにUniversal Forwarderをインストールする
splunk.com にログインしたあと、ここ からUniversal Forwarder をダウンロードします。
お好きなパッケージのDownload Nowをクリックします。
規約に同意したあと、Download via Command Line(wget)を押すことでインスタンス内から実行できるコマンドを取得することができます$ cd /tmp $ wget ... #先程取得したコマンド # 環境に合ったパッケージを取得してください $ sudo rpm -i splunkforwarder-<…>-linux-2.6-x86_64.rpm $ sudo dpkg -i splunkforwarder-<…>-linux-2.6-x86_64.deb # インストール後、splunkユーザが追加されます $ sudo su - spulnk $ cd /opt/splunkforwarder/bin $ ./splunk start # ユーザー名とパスワードの入力が求められます。 # splunkforwarderで使用するものなのでsplunk.com とは違うもので大丈夫です # 下記のように表示されたら終了 All installed files intact. Done All preliminary checks passed. Starting splunk server daemon (splunkd)... Done2. Universal Forwarder のクレデンシャルをダウンロードしインストールする
https://<自分のインスタンス>.splunkcloud.com/ja-JP/app/splunkclouduf/setupufにアクセス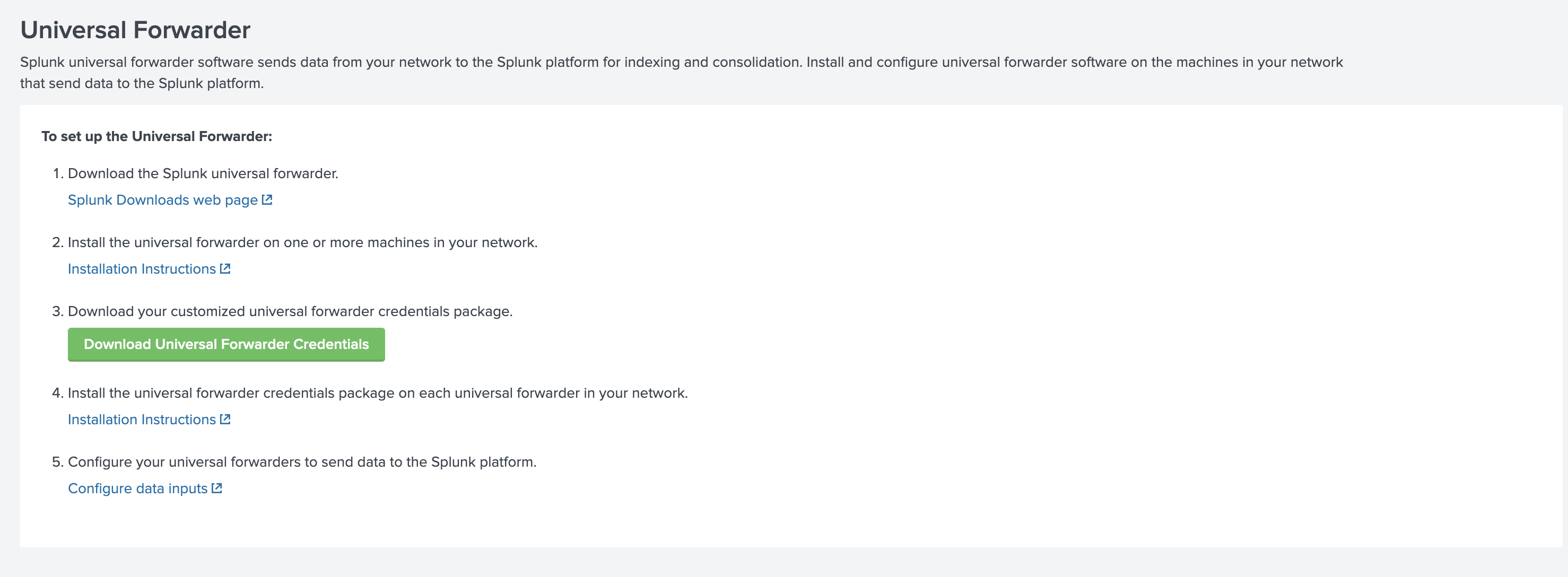
3. Download your customized universal forwarder credentials package.からクレデンシャルをダウンロードします- ダウンロードしたクレデンシャルをインスタンスに
sftpなどで転送します$ pwd <PATH-TO-FILE> $ ls splunkclouduf.spl $ sudo su - splunk $ /opt/splunkforwarder/bin/splunk install app <PATH-TO-FILE>/splunkclouduf.spl # ユーザー名とパスワードの入力を求められた場合、先程のものを入力します # 下記のメッセージが表示されたらインストールは終了です App '<PATH-TO-FILE>/splunkclouduf.spl' installed # universal forwarder を再起動します $ ./splunk restart3. Universal Forwarder にLinux用のAdd-onをインストールする
SplunkbaseからAdd-onをダウンロードし、フォワーダーにインストールすること機能の拡張を行うことができます。
今回はSplunk Add-on for Unix and Linuxを導入します。
このAdd-onを導入することでLinux環境における各種ログの転送の設定を行ってくれます。
- Splunk Add-on for Unix and Linuxをダウンロードします。
以下ターミナルで作業
# /Downloads/splunk-add-on-for-unix-and-linux_602.tgz にAdd-onがダウンロードされたとします # scpなどを使ってインスタンスにダウンロードしたtarファイルをコピーします。 $ scp splunk@<LINUX_INSTANCE_IP_ADDR>:/tmp/ /Downloads/splunk-add-on-for-unix-and-linux_602.tgz # Linuxインスタンスにログインします。これより下はLinuxインスタンスで作業します。 $ ssh splunk@<LINUX_INSTANCE_IP_ADDR> $ cd /tmp $ tar xvfz splunk-add-on-for-unix-and-linux_602.tgz # Splunk_TA_nix というディレクトリができていることを確認 $ ls # splunkforwarder/etc/appsに移動させる $ mv Splunk_TA_nix/ /opt/splunkforwarder/etc/apps $ cd /opt/splunkforwarder/etc/apps/Splunk_TA_nix # 設定ファイルをコピーします $ mkdir local $ cp default/inputs.conf local # 設定ファイル $ cat local/inputs.conf | head -n 6 # Copyright (C) 2020 Splunk Inc. All Rights Reserved. [script://./bin/vmstat.sh] interval = 60 sourcetype = vmstat source = vmstat disabled = 1 # disabled = 0 にすることでデータの転送ができます $ sed -e 's/disabled = 0/disabled = 1/g' local/inputs.conf > local/inputs.conf $ sed -e 's/disabled = true/disabled = false/g' local/inputs.conf > local/inputs.conf # 変更できたあと、再起動します $ cd /opt/splunkforwarder/bin $ ./splunk restart4. 3.でインストールしたAdd-onをパースするためのAppをインストールする
上記の設定を済ませた段階で、すでにLinuxからのデータが送られてきています。
しかし、一部のデータのパースができていないためそのままでは使いづらいデータになっています。
そのため、Splunk CloudにSplunk Add-on for Unix and Linuxを導入します。
このAdd-onを導入することでデータのパースを行うことができます。
- Splunk Cloudの左上から、
他のAppのサーチを選択します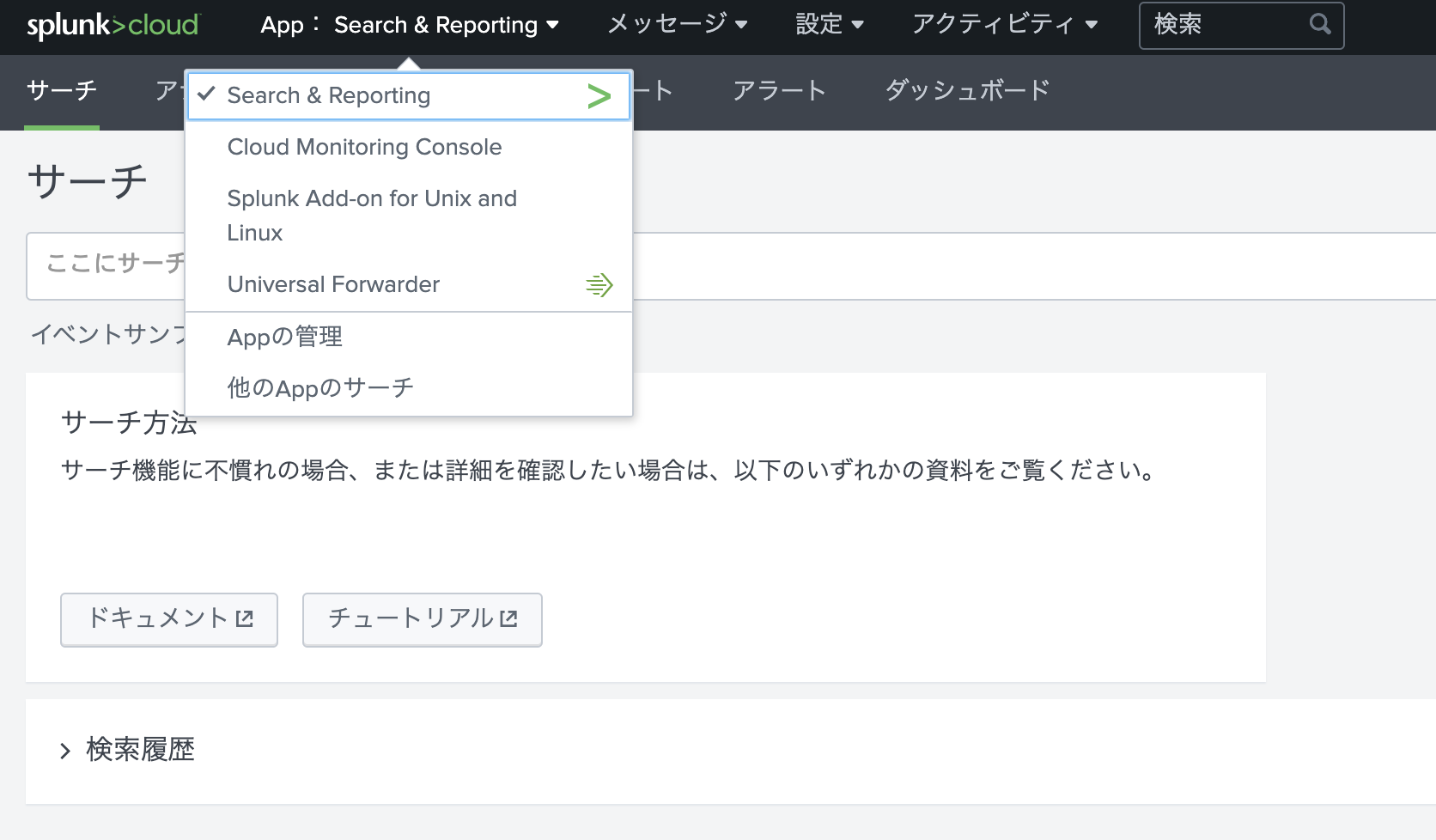
Splunk Add-on for Unix and Linuxを検索して、インストールします。5. データが受信できることを確認する
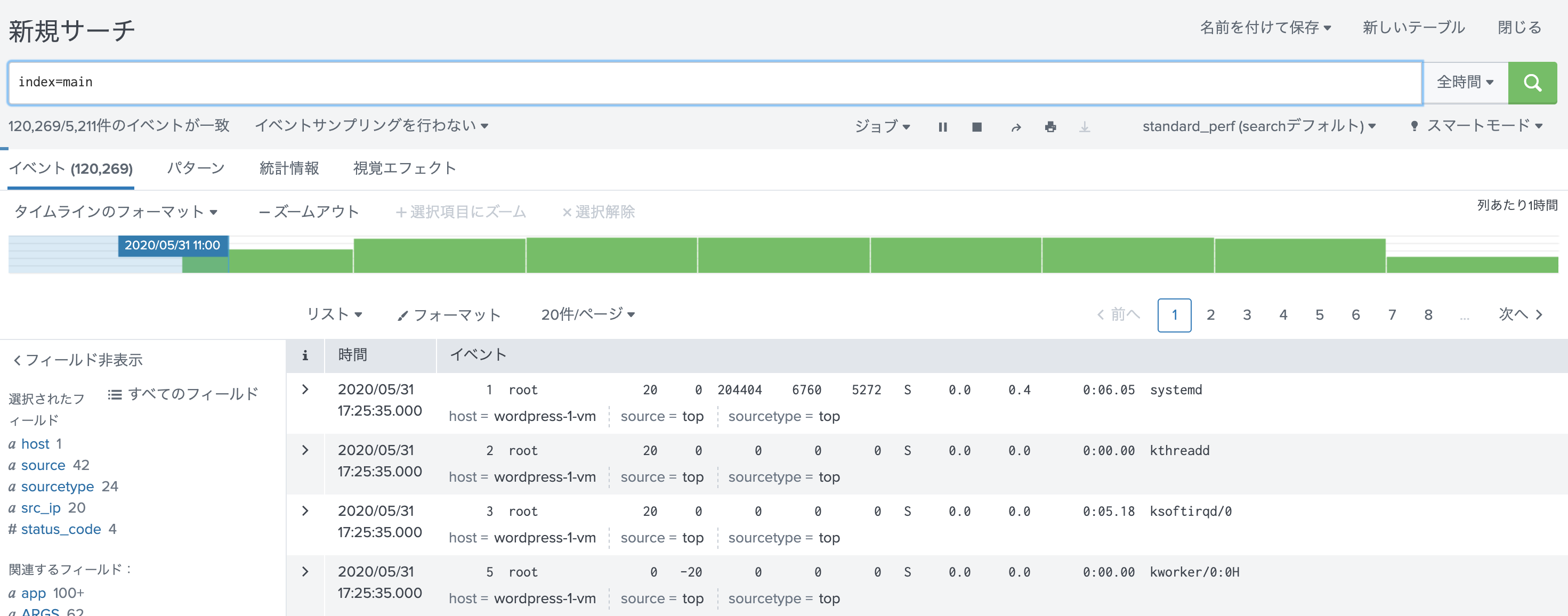
設定が正しく出来ていれば、topの結果がこのようにパースされて表示されます。参考リンク
- 投稿日:2020-05-31T17:17:01+09:00
Ubuntu (Kali Linux) で、AutoHotkey っぽいことを AutoKey で実現したい
はじめに
わたしのメインマシンは Windows です。カーソルキーやファンクションキーを押す際に手がホームポジションから離れてしまうのがイヤなので、AutoHotkey を使って極力ホームポジションから離れなくても済むよう設定しています。
関連記事:
- AutoHotKeyで日本語キーボードのホームポジションに引きこもりたい
- Autohotkey で、いつでもどこでもGoogle検索最近、Kali Linux を使う機会が増えたのですが、Linux には AutoHotkey が無いのでキーボード操作が面倒でした。しかし、AutoKey というソフトを使うことで、ホームポジションから手を離さずにカーソル移動ができたり、マウス操作ゼロで Google 検索ができたりなど、AutoHotkey に近いことが実現できました。
需要がないことは分かっていますが、キーボードの変態設定大好き人間なのでここに記しておきます。
Kali Linux のバージョンは、2020.2 です。要件定義
- 「変換」と h, j, k, l キー(のいずれか)の同時押しで、カーソルの上下左右移動したい(←達成)
- 「変換」と b, n, m キー(のいずれか)の同時押しで、1行削除, BackSpace, Delete したい(←達成)
- 「無変換」と h, j, k, l(のいずれか)の同時押しで、全角かな変換, 全角カナ変換, 半角カナ変換, 半角英数字変換したい(日本語入力時の F7 ~ F10 変換と同じ)(←達成)
- Alt + 1,2(のいずれか)で、Chrome のタブ移動をしたい(←達成)
- 「無変換」だけで、日本語入力と直接入力を切り替えたい(←未達成)
方針
AutoKeyは、Ctrl, Alt, Shift, Super, Hyper, Meta の6種類の修飾キーと他のキーの組み合わせでショートカットキーを作成します。
Super とは Windows キーのことです。Linux の世界では Super と呼ぶらしいです。Hyper, Meta は、昔の特殊なキーボードにあった修飾キーで、現在の一般的なキーボードにはありません。また、Autokey は日本語キーボードには対応していないので、「変換」「無変換」などの特殊なキーには対応していません。
Hyper, Meta は使われていないこと、「変換」「無変換」は使えないということならば、Hyper に「変換」を、Meta に「無変換」を割り当ててしまえば、やりたいことができるはずです。xkb 設定
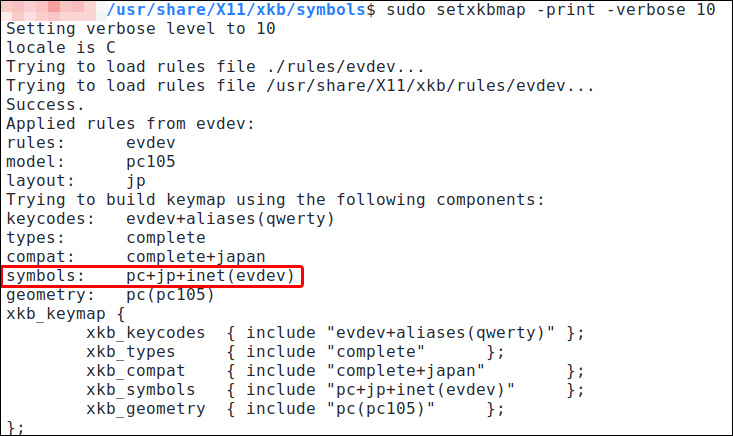
このキー割り当ての変更に xkb(X Keyboard Extension)を使用します。まずは、「setxkbmap -print」で、現在の xkb の挙動(設定ファイルの読込対象)を確認します。
$ sudo setxkbmap -print -verbose 10「/usr/share/X11/xkb/symbols」フォルダの、「pc」「jp」「inet」の3ファイルを読み込んでいるようです。
3つのファイルを読み込んでいますが、今回編集するのは、「inet」だけです。バックアップの後、編集します。
$ sudo cp /usr/share/X11/xkb/symbols/inet /usr/share/X11/xkb/symbols/inet_bak $ sudo vi /usr/share/X11/xkb/symbols/inet編集する箇所は、 の2箇所です。
<HENK> の 「Henkan」を「Hyper_L」に、<MUHE> の「Muhenkan」を「Meta_L」に修正します。
保存して終了したら、xkb のキャッシュをクリアします。
$ sudo rm -rf /var/lib/xkb/*その後、Kali Linux を再起動します。
Autokey 設定
いよいよ AutoKey の作業です。なにはなくとも、まずはインストールしましょう。
$ sudo apt install autokey-gtk画面構成
- 保存した設定一覧
- 処理内容(Pythonコード)
- 実行条件設定
- ホットキー

設定方法
左上の「新規」からフォルダを切ります(後ででもできます)。
わたしは「MySettings」というフォルダの下に、「browser」「cursor」「input_conversion」という3つのサブフォルダを作りました。
今回は、「変換」と「h」を同時に押した際、カーソルを左に動かす設定を作ります。「新規」から「Script」を選択し、名前を入力します。
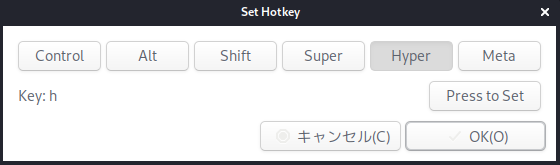
「Hotkey」の行の「Set」ボタンを押します。
「Press to Set」ボタンを押し、「h」キーを押し、「Hyper」ボタンを押します。
設定されました。
画面右上のスクリプト入力欄に以下のように入力します。
「Save」ボタンを押すと、入力内容が保存されます。
これで、「変換」と「h」を同時に押すとカーソルを左に動くようになります。同じ手順で、上下左右、Delete、BackSpace などを作ります。ホットキーはお好みで設定してください。
カーソルキーや制御キーなど、特殊キーの名称はこちらを参考にしてください。
autokey - SpecialKeys.wikiOS のショートカットの無効化
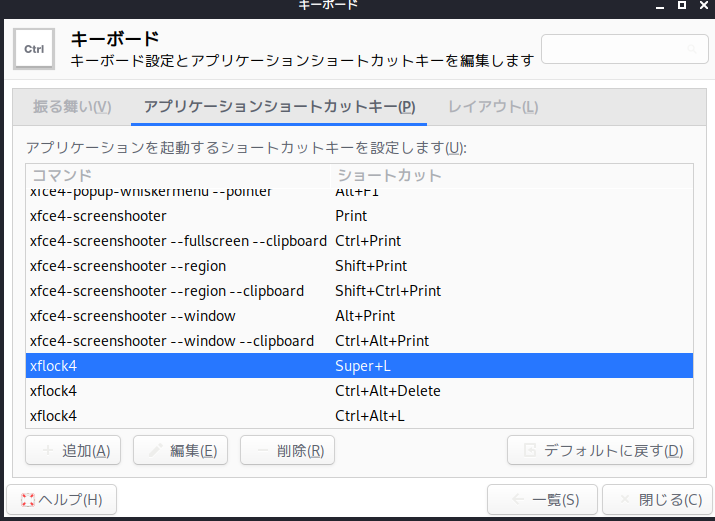
h, j, k, l を上下左右移動に設定すると、「Hyper」+「l」が 、OSで設定されている「ログオフ」とバッティングしてしまうので、これを削除します。
「設定」→「キーボード」→「アプリケーションショートカットキー」タブを選択します。この行を削除します。
以上で設定は終了です。
設定一覧
cursor
カーソル左移動 Hyper+h left.pykeyboard.send_keys("<left>")カーソル右移動 Hyper+l right.pykeyboard.send_keys("<right>")カーソル上移動 Hyper+k up.pykeyboard.send_keys("<up>")カーソル下移動 Hyper+j down.pykeyboard.send_keys("<down>")delete.py Hyper+nkeyboard.send_keys("<delete>")backspace.py Hyper+mkeyboard.send_keys("<backspace>")1行削除 Hyper+b line_delete.pykeyboard.send_keys("<home>") keyboard.send_keys("<shift>+<end>") keyboard.send_keys("<delete>")変換(日本語モードで入力時に押下)
ひらがな Meta+h hiragana_zen.pykeyboard.send_keys("<f6>")カタカナ全角 Meta+j katakana_zen.pykeyboard.send_keys("<f7>")カタカナ半角 Meta+k katakana_han.pykeyboard.send_keys("<f8>")アルファベット Meta+l alphabet.pykeyboard.send_keys("<f10>")Chrome タブ操作
左タブ移動 ctrl+1 chrome_lefttab.pykeyboard.send_keys("<ctrl>+<page_up>")右タブ移動 ctrl+2 chrome_righttab.pykeyboard.send_keys("<ctrl>+<page_down>")Google検索 meta+g chrome_search.py(アドレスバーにフォーカスする。Chromeが起動している必要アリ)window.activate("Chrome") keyboard.send_keys("<ctrl>+l")余談
- その1
本当は、「無変換」だけで日本語入力/直接入力を切り替えたかったのですが、「無変換」を Meta に設定してしまったのでできなくなりました。ctrl + space などで代用しようかと思います。
その2
Meta を「無変換」に割り当てたことで、「無変換」でウインドウがつかめるようになりました。地味に便利かも。
その3
処理のコードは Python らしいので、Python が書ける人はもっと高度なことができると思います。参考サイト
AutoKey : Linux Utility for Text Substitution , Hotkeys and Desktop Automation
サンプルのスクリプトやチュートリアルが飼いてあってわかりやすいです(英語だけど機械翻訳でもなんとかなります)Ubuntu:無変換・変換キーをMeta・Hyperキー化してAutoKeyでカスタマイズ可能な修飾キーにする方法
かなりお世話になりました。ありがとうございます。autokey - SpecialKeys.wiki
カーソルキーや制御キーなど、特殊キーの名称






- 投稿日:2020-05-31T14:44:02+09:00
そのファイル、消せますか?
サーバー上の不要ファイルを消す必要が出たときに、「どういうパーミッションが付いていればそのファイルを消せるか?」という問いをすると、間違える人が割と居る。
その問いへの正しい答えと、どうしてそうなるかを見てみよう。
ファイルを消すとは?
ファイルを消すという操作について、
- ファイルの内容を消す
- ファイルパスを消す
の二つのパターンを考えてみよう。「ファイルを消す」と言った場合、通常は後者を指すと思うが、その条件を問いかけたときに、後者の条件を答えてしまう間違いがよくある。
まず、それぞれの操作によって得られる状態の期待値を明確化しておこう。
ファイルの内容を消した場合には、ファイルの内容が空になっていることが期待値である:
$ ls -s path/to/file 0 path/to/file $ wc -c path/to/file 0 path/to/file $ file path/to/file path/to/file: empty一方、ファイルパスを消した場合には、存在していたパスでファイルにアクセスできなくなっていることが期待値である:
$ ls path/to/file ls: cannot access 'path/to/file': No such file or directory $ cat path/to/file cat: path/to/file: No such file or directoryそれぞれを達成するための具体的な操作例を示す:
- ファイルの内容を消す: echo -n > path/to/file
- ファイルパスを消す: rm path/to/file
パーミッションとこれらの操作が可能かどうかの関係を見ていこう。
ファイルの内容を消せるか?
ファイルの内容を消すには、ファイルの write パーミッションが必要。write パーミッションを外すと
$ cat path/to/file hello $ ls -li path/to/file 161504 -rw-r--r-- 1 yoichinakayama yoichinakayama 6 May 31 11:55 path/to/file $ chmod -w path/to/file $ ls -li path/to/file 161504 -r--r--r-- 1 yoichinakayama yoichinakayama 6 May 31 11:55 path/to/file $ echo -n > path/to/file -bash: path/to/file: Permission deniedとなって、ファイルの内容を消すことができない。write パーミッションを付けると
$ chmod +w path/to/file $ ls -li path/to/file 161504 -rw-r--r-- 1 yoichinakayama yoichinakayama 6 May 31 11:55 path/to/file $ echo -n > path/to/file $ ls -li path/to/file 161504 -rw-r--r-- 1 yoichinakayama yoichinakayama 0 May 31 11:56 path/to/file $ wc -c path/to/file 0 path/to/file $ file path/to/file path/to/file: emptyとファイルの内容を消すことができる。ファイルの内容を編集するので、そのファイルの write パーミッションが必要というわけだ。
ファイルパスを消せるか?
ファイルパスを消すには親ディレクトリの write パーミッションが必要。write パーミッションを外すと
$ ls -l path/to/file -rw-r--r-- 1 yoichinakayama yoichinakayama 0 May 31 12:00 path/to/file yoichinakayama@penguin:~$ ls -ld path/to drwxr-xr-x 1 yoichinakayama yoichinakayama 8 May 31 11:55 path/to yoichinakayama@penguin:~$ chmod -w path/to yoichinakayama@penguin:~$ ls -ld path/to dr-xr-xr-x 1 yoichinakayama yoichinakayama 8 May 31 11:55 path/to yoichinakayama@penguin:~$ rm path/to/file rm: cannot remove 'path/to/file': Permission deniedとなって、ファイルパスを消すことができない。write パーミッションを付けると
$ chmod +w path/to $ ls -ld path/to drwxr-xr-x 1 yoichinakayama yoichinakayama 8 May 31 11:55 path/to $ rm path/to/file $ ls path/to/file ls: cannot access 'path/to/file': No such file or directoryとファイルパスを消すことができる。
ディレクトリの中身を見る
ファイルを消すのに何故ディレクトリの write パーミッションが必要だったかを知るには、ディレクトリにどんな情報が格納されているのかを見ると良い。以下のC言語のプログラムで、引数にディレクトリのパスを与えると、そのディレクトリの内容を出力してくれるのでそれを使おう。
$ cat sample.c #include <sys/types.h> #include <dirent.h> #include <stdio.h> int main(int argc, char *argv[]) { DIR *dir = opendir(argv[1]); struct dirent *ent; if (dir == NULL) { return 1; } while ((ent = readdir(dir)) != NULL) { printf("d_ino=%d, d_name=%s\n", ent->d_ino, ent->d_name); } closedir(dir); return 0; } $ gcc sample.cまず、ディレクトリにファイルがある状態で実行してみる。
$ touch path/to/file $ ./a.out path/to d_ino=161394, d_name=. d_ino=161393, d_name=.. d_ino=161598, d_name=file $ ls -li path/to/file 161598 -rw-r--r-- 1 yoichinakayama yoichinakayama 0 May 31 12:14 path/to/file対象ファイルのinode番号と、ファイル名 "file" がディレクトリに格納されていることがわかる。
次にファイルパスを消すとどうなるか見てみよう。
$ rm path/to/file $ ./a.out path/to d_ino=161394, d_name=. d_ino=161393, d_name=..ディレクトリに格納されていた dirent 構造体が一つ減っている。つまり、ディレクトリが変更されている。この例だと、path/to/file というファイルパスを消すという操作は、ディレクトリ(inode番号161394)の内容を変更するという操作である。したがってそのディレクトリの write パーミッションが必要になる。
まとめ
その操作で何を編集しているのか?何の情報がどこに保持されているのかを意識すると、ファイルの内容を消すとき、ファイルパスを消すときに必要なパーミッションが何かということが理解できると思う。
確認環境
Chromebook のターミナル上で確認した。
$ uname -a Linux penguin 4.19.113-08528-g5803a1c7e9f9 #1 SMP PREEMPT Thu Apr 2 15:16:47 PDT 2020 aarch64 GNU/Linux $ gcc --version gcc (Debian 6.3.0-18+deb9u1) 6.3.0 20170516 Copyright (C) 2016 Free Software Foundation, Inc. This is free software; see the source for copying conditions. There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
- 投稿日:2020-05-31T13:31:52+09:00
Linux基礎14 -シェルスクリプトを書こう-
はじめに
ここからしばらくは、シェルスクリプトについての記事になります。シェルスクリプトの知識を身につけておくと、作業を効率的にこなすことができるようになります。また、Linuxを使いこなす上では、シェルスクリプトの知識は必須です。
今回は、シェルスクリプトの基礎知識とその実行方法について紹介します。シェルスクリプトとは
実行したい一連のコマンドを予めファイルに書いておき、そのファイルをシェルに読み込ませることでコマンドを実行することができます。
シェルのコマンドを予め記述しておくファイルのことをシェルスクリプトと呼びます。シェルスクリプトは単にコマンドを並べられるだけではなく、条件分岐や繰り返しを利用した制御構造も記述できることから、一種のプログラミング言語であるとも言えるかもしれません。シェルスクリプトの利用により、作業を自動化できることのメリットには次のようなものがあります。
シェルスクリプトのメリット- 一度シェルスクリプトを作れば、あとで同じ処理が必要になったときにそのシェルスクリプトを再利用することができる - 自分だけでなく、他人にもシェルスクリプトを配布して使ってもらうことができる - コマンドを打ち間違えることによる作業ミスをなくすことができるシェルの選択
シェルスクリプトを書き始める前にどのシェル向けのシェルスクリプトを書くかを決めなければいけません。今回は、
bashでシェルスクリプトを記述します。理由は以下の2点です。bashを使用するメリット- bashで書かれたシェルスクリプトの互換性・移植性はとても高い - bashにはシェルスクリプトを書く上で便利な機能が多く用意されている過去の記事で少し触れましたが、現在シェルスクリプトが書かれる対象のシェルとしては、shかbashが一般的です。過去のシェルスクリプトがsh向けに書かれていることや、全てのLinuxには必ずshが存在することからも、shを選んでも良いのですが、shには問題点も多く、最近ではbashでシェルスクリプトを書く方が好ましいという意見も強くなっていることから、今回はbashを使うことにしました。気になる方は詳細を調べてみてください。
シェルスクリプトを作成する
シェルスクリプトは実行したいコマンドを記述したテキストファイルですので、Vimなどのテキストエディタを利用して作成できます。まずは例として、ホームディレクトリのファイルの使用量を表示する簡単な物を作ってみましょう。
duコマンドはディレクトリ内のファイルの使用量を表示するコマンドです。duコマンドは全てのサブディレクトリを対象としますが、ここではホームディレクトリ全体の使用量がわかれば良いので、tailコマンドの -nオプションを使用して、最後の1行だけを表示しています。シェルスクリプトのファイル名はなんでも構いませんが、今回は
homesize.shとしておきます。ファイルの拡張子を.shとするのは、シェルスクリプトの慣習です。.shはつけずに、homesizeでも構いませんが、ファイルをみただけでシェルスクリプトとわかるように拡張子をつけておくのが好ましいでしょう。Vimでテキストファイルを作成します。
ここで、1行目の#!で始まる行はshebang(シェバン)と呼ばれる行です。この意味については、後ほど述べます。
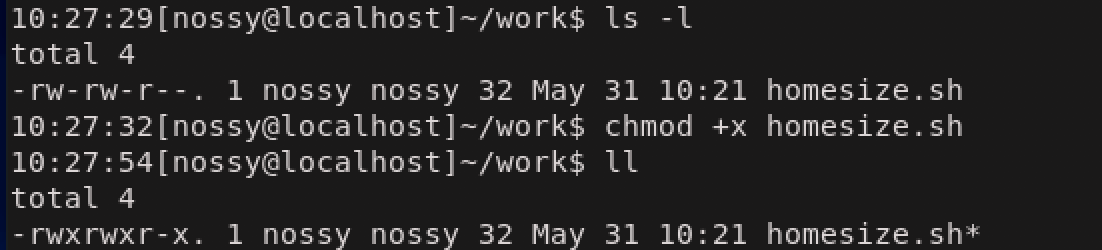
2行目がコマンドラインを記述した行です。実行したいコマンドをそのまま記述するだけでシェルスクリプトは完成します。ファイルを保存したら。シェルスクリプトは
実行されるファイルですので。chmodコマンドを使用して実行権限をつけておく必要があります。
これでシェルスクリプトが実行できるようになりましたので、実行してみましょう。
このとき、ファイル名の前に./をつけることに注意してください。ここではカレントディレクトリにおけるhomesize.shを実行しています。シェルスクリプトの実行形式
先ほど登場した
#!の記号で表されるshebang(シェバン)について詳しく述べます。shebang(シェバン)
Linuxではファイルを実行する際は、シェルから実行したいファイル名を指定します。シェルから実行命令を受けたLinuxカーネルは、まず対象ファイルの先頭を確認し、
#!があった場合には、その後ろに書かれたコマンドを実行するという動作をします。
つまり、#!/bin/bashという行は、このシェルスクリプトは/bin/bashで動かしますという宣言をしていることになります。これがshebang(シェバン)の役割です。また普段使用しているシェルがzshなどの場合でも、ユーザは自分のシェルからbashスクリプトを直接実行することができます。
なお、シェルは#を書くと、その行の終わりまで、コマンと行として無視するため、シェバンはシェルから無視されます。shebang(シェバン)の解釈$ ./homesize.sh ↓ シェルから実行を指示 $ /bin/bash ./homesize.sh #Linuxカーネルがシェバンを解釈し、実質的にはこのようなコマンドラインとして実行されるsourceコマンド -ファイルからコマンドを読み込んで実行する-
ファイル名のみを指定してシェルスクリプトを実行する以外にも
sourceコマンドを使用して、シェルスクリプトを実行する方法があります。sourceコマンドによる実行は、ファイル名を指定して実行した場合と動作が異なります。ここでは例として、シェバンのないスクリプトを準備して実行していきます。
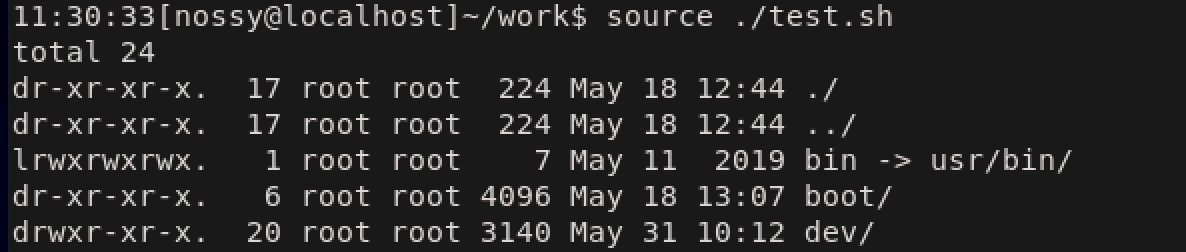
sourceコマンド用いて、上記のシェルスクリプトを実行します。
sourceコマンドは、指定したファイルの内容をそのままコマンドラインに入力したときと同じように実行します。
この場合、実行するシェルはカレントシェルなので、シェルスクリプト自体にシェバンは不要です。また、sourceコマンドは対象ファイルを直接実行するわけではないため、ファイルに実行権限は不要です。
なお、sourceコマンドと同じ意味を持つ.(ドット)コマンドがあります。
実行方法による違い
ここまででシェルスクリプトには3つの実行方法があることがわかりました。以下の3つです。
シェルスクリプトの実行方法① ファイル名のみ指定して実行する ./homesize.sh ② シェルの引数として実行する bash homesize-noshebang.sh ③ sourceコマンドを使用して実行する source ./homesize-noshebang.shこのうち、
①②については、シェバンが必要かどうかを除いて、ほぼ同じ動作となります。一方で③は注意が必要です。
③のsourceコマンドを用いた方法では、カレントシェルの中で、シェルスクリプトに書かれた内容を実行するため、現在設定されているシェル環境の影響を受けます。例えば、シェル環境でエイリアスを設定していた場合は、シェルスクリプトの中でもエイリアスが有効になります。例を示します。次のようなエイリアスを実行するシェルスクリプトを用意しました。
次にカレントシェルにエイリアスの設定をします。
シェルスクリプトをsourceコマンドで実行します。
ファイル名を指定して実行します。
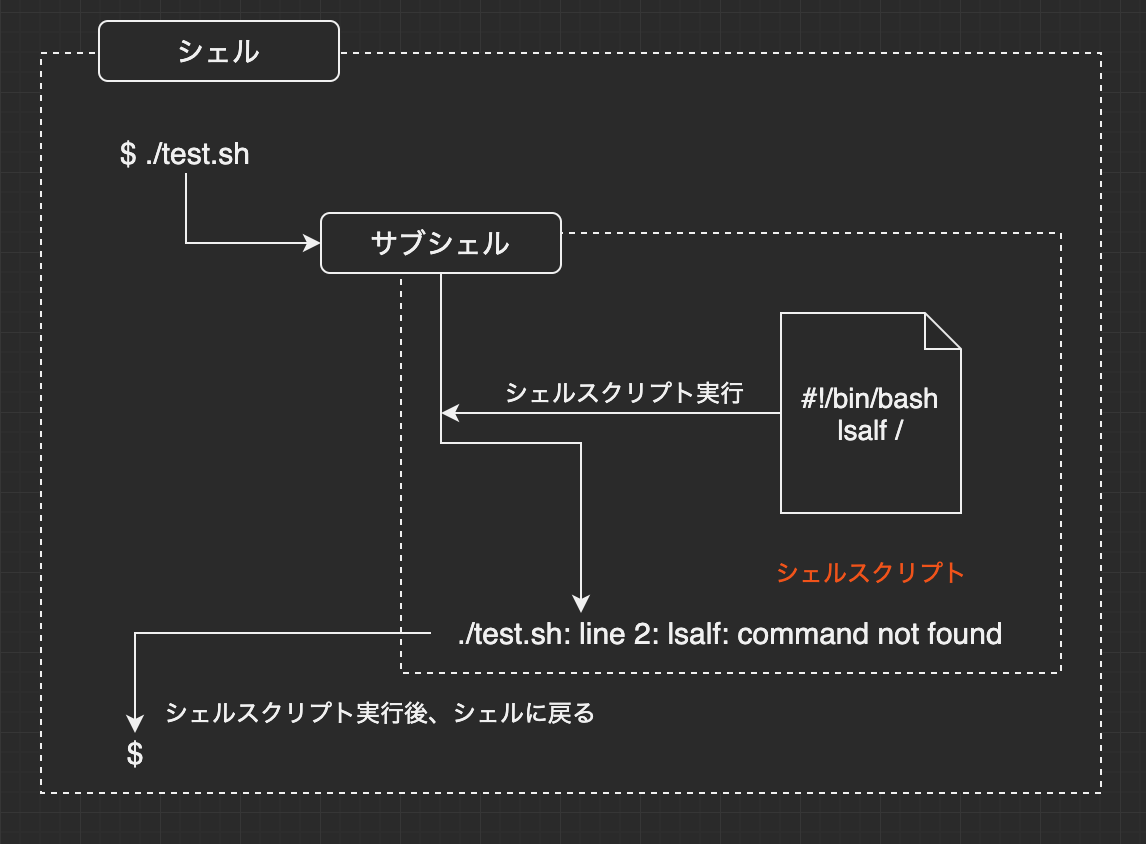
ファイル名を指定して実行した方は、コマンドがないとエラーが表示されていますね。これはsourceコマンドではカレントシェルでスクリプトが実行されるため、現在の設定が引き継がれるのに対して、ファイル名で実行した場合にはサブシェルでシェルスクリプトが実行されるためです。サブシェルとは、現在のシェルから新しく起動される子プロセスのシェルのことです。
サブシェルは下のシェルとは別物であるため、環境変数は引き継がれますが、エイリアスなどの設定は引継ぎません。このために、コマンドがないというエラーが発生しています。
また、sourceコマンドはカレントシェルでシェルスクリプトを実行するため、実行後は元のシェルにも影響を及ぼすことに注意が必要です。sourceコマンドによるカレントシェルへの影響例
次のようなエイリアスを設定するシェルスクリプトを用意しましょう。
まずは現在のシェルにエイリアスが設定されていないことを確認します。
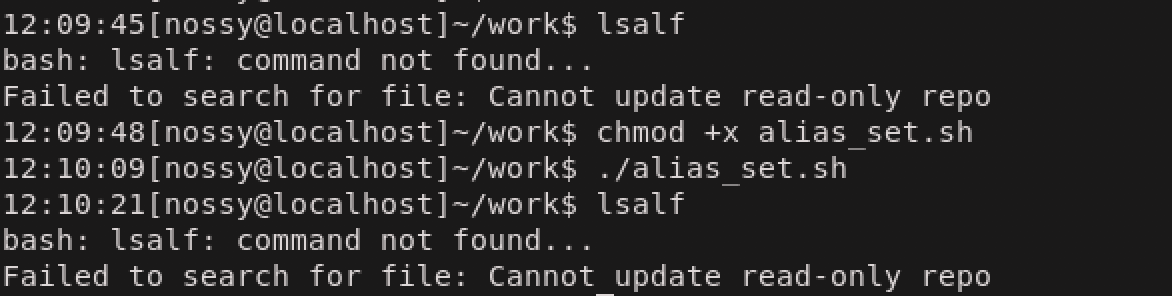
次にsourceコマンドを用いて、シェルスクリプトを実行してみます。そのあとで、エイリアスコマンドを実行します。
エイリアスコマンドが実行されていますね。これは./alias_set.shがカレントシェルで実行されたためです。同様のシェルスクリプトを
ファイル名を指定して実行するとエイリアスコマンドは設定されません。
このように、シェルスクリプトは実行方法によって、動作が変わるため、どの方法でシェルスクリプトを実行するかを意識する必要があります。sourceコマンドの利用例
一般的に多くのシェルスクリプトは
ファイル名を指定する形で実行されます。これには次のような理由があります。シェバンによるシェル指定を使う理由- シェバンによりシェルを指定することで、ユーザが使用しているシェルに依存せずに正常に動作させることができる - sourceコマンドによる実行で、カレントシェルの状態を引き継ぐと、設定の違いによってシェルスクリプト作成時には想定しない動作をすることがある - sourceコマンドによる実行で、終了後も元のシェルに影響をおよぼす一方で、
sourceコマンドの設定を引き継ぐという特徴を活かした使い方もあります。わかりやすい例は、bashの設定ファイルの~/.bashrcです。~/.bashrcは~/.bash_profileから次のようにsourceコマンドで読み込まれています。シェル設定のカスタマイズをカレントシェルに反映させたいので、sourceコマンドで記述されています。sourceコマンドによるシェルへの設定反映if [ -f ~/.bashrc ]; then source ~/.bashrc fiシェルスクリプトを配置する
これまでの説明の中で、ファイル名の先頭に
./を付けていました。これを付けずに実行するとどうなるのでしょうか。
コマンドが見つからないエラーが発生しました。これは正確には、サーチパスからhomesize.shという名前のコマンドを探したが、見つからなかったというエラーです。サーチパスはシェルからコマンドを実行する際に、コマンドの実体ファイルを探すディレクトリのことです。サーチパスは環境変数$PATHに設定されています。通常、
サーチパスにはカレントディレクトリが登録されていないため、シェルスクリプトのファイル名を指定するだけでは実行できません。サーチパスの確認$ echo $PATH自分のシェルスクリプト置き場を作る
独自のコマンドの置き場には
~/binというディレクトリがよく使用されます。~/binを作成し、homesize.shを移動しましょう。そのあとで、サーチパスに~/binを追加しましょう。Vimで~/.bash_profileに追記します。
設定を反省させるために、sourceコマンドで~/.bash_profileを読み込みます。
これで、~/binに置いたシェルスクリプトが、カレントディレクトリに関係なく実行できるようになりました。sourceコマンドとパス
sourceコマンドは指定されたファイルを実行しますが、パスを指定せずファイル名だけを指定すると、
bashはサーチパスの中からもファイルを探します。そのため先ほど~/binに格納したシェルスクリプトは、sourceコマンドからもパスを指定せずそのまま実行できます。
この機能は便利ですが、予期せぬファイルをsourceコマンドで読み込んでしまう危険がありますので、sourceコマンドを実行する際は、ファイル名だけを書くことは避けた方が無難です。なお、sourceコマンドでファイルをサーチパスから探さないようにするには、shoptコマンドをつかってsourcepathオプションをオフにします。
参考資料


















- 投稿日:2020-05-31T12:03:50+09:00
ファイルの「穴」の話
ファイルの「穴」の話
$ dd if=/dev/zero of=testfile1 bs=1 seek=104857599 count=1 ; ls -ls testfile1 1+0 records in 1+0 records out 1 bytes transferred in 0.000114 secs (8775 bytes/sec) 8 -rw-r--r-- 1 user staff 104857600 5 25 13:24 testfile $ファイルサイズは100MBだけど、消費しているブロック数は8ブロックだけ、というファイルができる。Linux (coreutils) のコマンドtruncateや、qemuの管理コマンドqemu-imgコマンドを使っても、似たようなことができる。
$ truncate -s 100M testfile2 $ qemu-img create -f raw testfile3 100M $ddはlseek(2)、write(2)という2つのシステムコールを使い、truncateとqemu-imgはftruncate(2)というシステムコールを使っているが、結果はほぼ同じである1。
これらのファイルを読むと、「0」で埋まったデータが読み出され、また書き込むとその時点でディスクブロックがアロケートされて書いた情報が保存される。この、ディスクブロックがアロケートされていない部分を「穴」「hole」といい、そのような部分を持つファイルのことを「穴あきファイル」「sparse file」と呼ぶ。古くから、DBファイルのように文字通り疎な (情報量と比較してファイルサイズが大きい) ファイルは穴あきであることもよくあったし、最近ではQemu/KVM仮想マシンの仮想ディスクイメージが穴あきであることがある。
穴の検出と穴あけ
このファイルの穴は、ファイルシステム内部でどのようにディスクスペースを利用するかという話であって、伝統的にはAPIには現れてきてこなかった。通常のPOSIX APIの外で、DMAPIというものもあったが、あまり流行らなかったようだ。
古くからLinuxでは、ファイルを開いてioctl(2)を発行する方法でファイルの穴を検出することができた。FIBMAPというioctlは、ファイルデータの格納されているディスクブロックの番号を返す。穴の部分はディスクブロック番号として0を返すので、それで検出できる。問題は、このioctlを実行するためにはrootの特権が必要であることと、1ブロック調べるのに1回のioctl(2)発行が必要である点だ。
Linuxにはもう一つ、FS_IOC_FIEMAPというioctl(2)もある。これは、FIBMAPの強化版ともいえるもので、ファイルの指定範囲の情報を一気に取得することができる上に、root特権は要らない。FIEMAPは、2008年10月、2.6.28の開発途上で導入された。
FIBMAP、FS_IOC_FIEMAPともに、ファイルデータが格納されている具体的なディスク上の位置を知る方法で、その副作用として穴がわかるものであった。穴を検出する専用のAPIとして、lseek(2)システムコールにSEEK_HOLE、SEEK_DATAというオプションがある。これは当初Solarisで実装され、のちにFreeBSDやLinuxにも実装されているため、標準ではないけれどもある程度の移植性があると考えて良さそうだ。
SEEK_HOLEは、指定されたオフセット以降の最初の穴に移動する。SEEK_DATAは、指定されたオフセット以降の最初の穴ではない部分に移動する。適切に組み合わせれば、ファイル全体の穴を正しく列挙することができる。
一方で、穴を開ける方はどうか。最初に述べたlseek(2)+write(2)や、ftruncate(2)による方法は、ファイルの末尾に穴を追加することしかできない。つまり、既にデータブロックがアロケートされた部分を穴にするようなことはできない。
ここでもやはりSolarisが先行し、fcntl(2)にF_FREESPというコマンドが追加されている。ファイルの指定された領域に穴を開けることができる。このAPIは他のOSが追従することはなく2、Linuxではfallocate(2)というシステムコールにFALLOC_FL_PUNCH_HOLEというフラグが追加されており、やはり指定した領域に穴を開けることができる。どちらの実装でも、指定された領域に記録されていたデータは失われる (読み出すと0で埋められたデータが返る)。
穴を保存してコピーする
穴を検出するのに (root特権なく) 利用できるAPIが追加される以前から、coreutilsのcpコマンドや、GNU tarなどでは穴あきファイルを検出して効率的にコピーやアーカイブが可能であった。これはどうやって検出していたのだろうか。
coreutilsの更新履歴によると、FS_IOC_FIEMAPによる穴検出が実装されたのは、2010年5月のcommitである。これ以前のコードを見てみればよい。
ざっくり追いかけると、通常ファイルのコピーはcopy_reg()でやっている。707行目あたりのwhileループでコピーが実行されている。
注目は746行目あたりで、0の数を数えてそれだけ分シークしている。つまり、コピー元のデータが0ならコピー先に0を書くのではなく、単にシークしているので、もしかすると穴になってくれるかもしれない、という感じだ。
なお、最新のcoreutilsでも、FIEMAPが使えないときにはこの方法で穴を処理している。
ファイルの穴とTRIM (UNMAP) コマンド
話は変わるが、SSDが普及してきた数年前に、TRIMコマンドという言葉が話題になった。TRIMは、SSDの記憶媒体であるNANDフラッシュメモリが、書き換えに先立って消去という操作を必要とするために、データの書き込みが比較的遅いという問題を解消するためのものだ。OS (ファイルシステム) からSSDに向けて未使用ないし解放済みのブロックを知らせてやることで、SSDはあらかじめ消去を済ませておくことができる。このほか、書き込み回数に上限のあるNANDフラッシュのブロックごとの書き込み頻度を平準化するウェアレベリングにおいても有利となる。
TRIMはSATAのコマンドであるが、SCSIにおいてもUNMAPという似たようなコマンドがある。SCSI接続のSSDも存在するが、SANなどでシンプロビジョニングを行う場合にも有効である。ファイル削除時などに、アロケート済みの領域をストレージに返却できるので、従来のように利用領域が単調増加するばかりではなくなる。
シンプロビジョニングといえば、仮想マシン用の仮想ディスクはシンプロビジョニングで提供されることがある。たとえば、QemuのQcow2ファイルは、ファイルフォーマット自体がシンプロビジョニング可能な形式であるし、rawイメージでも穴あきファイルとして作成すると、シンプロビジョニングとなる。ということで、穴に戻ってきた。
QemuとTRIM/UNMAPコマンド
QemuのエミュレートするSATAディスクやSCSIディスクは、TRIM (UNMAP) コマンドを理解して、バックエンドのディスクイメージを適切に操作する (オプションによる)。
まず、SATAは、2011年5月のcommitでTRIMを解釈するようになった。SCSIディスクの方は、2012年8月である。VirtIOブロックデバイスの場合はずっと新しくて2019年2月だ。それぞれ、Qemuのバージョンで言えば、0.15、1.2.0、4.0のリリースサイクルにあたる。
いっぽう、バックエンドの仮想イメージファイルのドライバのうち、Qcow2は2011年1月に、TRIM (UNMAP) された部分を解放するようになった。ただし、ファイルサイズが縮小されることはなく、開放された領域はfallocateにより穴を開けられる。また、raw形式では2013年1月にfallocate()によりTRIM (UNMAP) された領域を開放するようになった。それ以前からXFSではioctl()による解放を行なっていたようだ。
さて、実際にUbuntu 20.04 LTS (focal、Linux-5.4系、Qemu-4.2系) の環境で仮想マシンを作成すると、仮想ディスク (いずれもVirtIO SCSIの例) は「シンプロビジョニング可能」なディスクとしてゲストOSから見えるようになっている。たとえば、Linuxゲストを起動すると、以下のようにsysfsのディスクのエントリにthin_provisioning、provisioning_modeというファイルができるが、これが以下のようになっている。
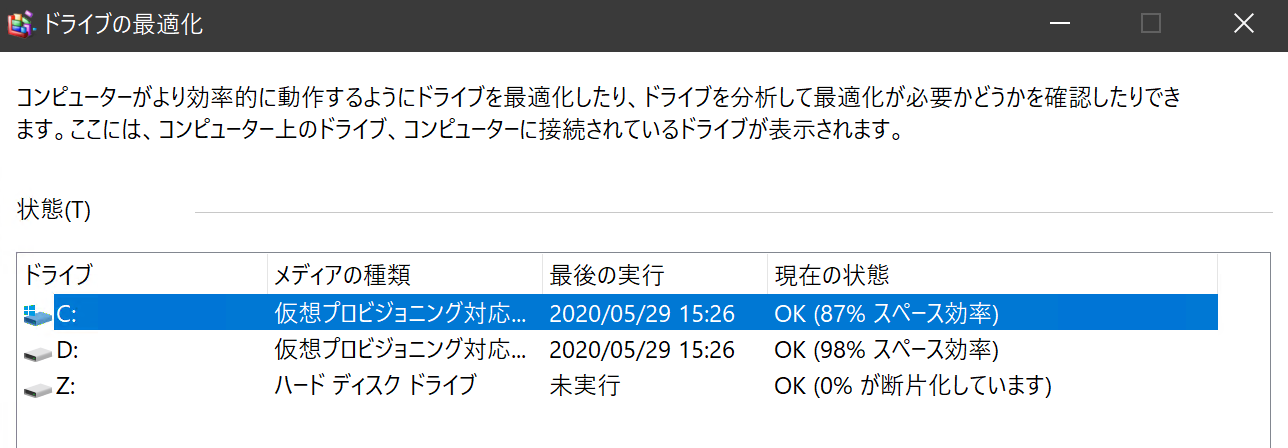
$ cat /sys/bus/scsi/devices/0\:0\:0\:0/scsi_disk/0\:0\:0\:0/thin_provisioning 1 $ cat /sys/bus/scsi/devices/0\:0\:0\:0/scsi_disk/0\:0\:0\:0/provisioning_mode unmap $Windowsゲストの場合、「ドライブのデフラグと最適化」ツール (スタート→Windows 管理ツール配下) で見ると、「メディアの種類」項が「仮想プロビジョニング対応ドライブ」になっており、「最適化」を選ぶとTRIMが実行される (図中のZ:はiSCSIディスク)。
通常のディスクを繋いでいるホスト側で、Linuxゲストで見たのと同じファイルを見ると、
$ cat /sys/bus/scsi/devices/0\:0\:0\:0/scsi_disk/0\:0\:0\:0/thin_provisioning 0 $ cat /sys/bus/scsi/devices/0\:0\:0\:0/scsi_disk/0\:0\:0\:0/provisioning_mode full $のようになっており、シンプロビジョニングではない (thick provisioning) とわかる。
実際に、ゲストがUNMAPコマンド (SCSIなので) を発行すると、そのブロックデバイスにdiscardオプションがついていれば、fallocate(2)で領域が開放される。Ubuntu 20.04など、Linux 4.9以降のカーネルを利用していれば、仮想ディスクがファイルの時だけではなく、ホストデバイスである時 (LVMのボリュームなど) にもfallocate(2)が働き、TRIM (UNMAP) がpaththroughされる。
実際にrawイメージで実験してみた。
host# qemu-img create -f raw vol.img 20G Formatting 'vol.img', fmt=raw size=21474836480 host# qemu-img info vol.img ; ls -lsh vol.img image: vol.img file format: raw virtual size: 20 GiB (21474836480 bytes) disk size: 4 KiB 4.0K -rw-r--r-- 1 libvirt-qemu kvm 20G May 30 13:42 vol.img host#このディスクをゲストのsdbにアタッチする。discardオプションをつけるため、libvirtなら
<driver name='qemu' type='raw'/>のようになっているところを、
<driver name='qemu' type='raw' discard='unmap'/>のようにする。ゲストを起動し、対象のディスクを特定したら、これをフォーマットする。ここではXFSにした。
guest:~# mkfs.xfs /dev/sdb meta-data=/dev/sdb isize=512 agcount=4, agsize=1310720 blks = sectsz=512 attr=2, projid32bit=1 = crc=1 finobt=1, sparse=0, rmapbt=0, reflink=0 data = bsize=4096 blocks=5242880, imaxpct=25 = sunit=0 swidth=0 blks naming =version 2 bsize=4096 ascii-ci=0 ftype=1 log =internal log bsize=4096 blocks=2560, version=2 = sectsz=512 sunit=0 blks, lazy-count=1 realtime =none extsz=4096 blocks=0, rtextents=0 guest:~#ホスト側でイメージを調べてみると、メタデータ分大きくなっていることがわかる。
host# qemu-img info vol.img ; ls -lsh vol.img image: vol.img file format: raw virtual size: 20 GiB (21474836480 bytes) disk size: 10.3 MiB 11M -rw-r--r-- 1 libvirt-qemu kvm 20G May 30 13:51 vol.img host#これをmountし、512MBのファイルを作る。
guest:~# mount /dev/sdb /mnt guest:~# dd if=/dev/urandom of=/mnt/randomfile bs=1M count=512 512+0 records in 512+0 records out 536870912 bytes (537 MB, 512 MiB) copied, 2.95154 s, 182 MB/s guest:~#ホスト側でイメージを調べると、512MBほど大きくなっていることがわかる。
host# qemu-img info vol.img ; ls -lsh vol.img image: vol.img file format: raw virtual size: 20 GiB (21474836480 bytes) disk size: 522 MiB 523M -rw-r--r-- 1 libvirt-qemu kvm 20G May 30 13:52 vol.img host#次に、このファイルを削除してみる。TRIMが発行されるのは、mountオプションにdiscardをつけたときか、fstrim(8)を実行したときであるので、fstrimを実行する (-vはverbose)。
guest:~# rm /mnt/randomfile guest:~# fstrim -v /mnt /mnt: 20 GiB (21464170496 bytes) trimmed guest:~#イメージを調べると、mkfs直後とだいたい同じ大きさに戻っているのがわかる。
host# qemu-img info vol.img ; ls -lsh vol.img image: vol.img file format: raw virtual size: 20 GiB (21474836480 bytes) disk size: 10.1 MiB 11M -rw-r--r-- 1 libvirt-qemu kvm 20G May 30 13:53 vol.img host#最近のDebianやubuntuにはzerofreeというコマンドがあり、ext3やext4の空き領域をゼロフィルしてくれるようだ。これと、qemuのdetect-zeros=unmapオプションを組み合わせると、ディスクイメージのアロケート済みの領域を縮小することができるかもしれない。
- 投稿日:2020-05-31T10:00:26+09:00
risc-v linux kernelでcrypt/xor.c実装の効率化を考える(考察のみ
crypt/xor.c は小さいし調査しやすい
cryptの中の実装で、一番小さいのは多分、xorだと思う。
ということで、この部分についてもう少しバイナリベースで調査を進めてみた。TL;DR
- risc-v用のxor.hがないので、genericな実装を参照しているよ
- だけど、ものすごいsimpleな実装だから
遅いよ!コンパイラ次第で遅くなるよ!gcc9ならそこそこ早いかも!- RISC-VだとSIMDじゃなくてVECTORがあるから、要検討かもね!
- でも、RISC-Vボードがないから、誰も検討できない…
実験方法
$ riscv32-unknown-linux-gnu-gcc --version riscv32-unknown-linux-gnu-gcc (GCC) 9.2.0 Copyright (C) 2019 Free Software Foundation, Inc. This is free software; see the source for copying conditions. There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. $ make ARCH=riscv CROSS_COMPILE=riscv32-unknown-linux-gnu- menuconfig
CONFIG_BTRFS_FS=yすると、いもづるでCONFIG_XOR_BLOCKS=yになる。xor.h がないけど何とかなる
xor.cのコードを見るとxor.hへのincludeがある。でも、arch/riscv 以下にはないぞ?と焦りました。crypt/xor.c#include <linux/module.h> #include <linux/gfp.h> #include <linux/raid/xor.h> #include <linux/jiffies.h> #include <linux/preempt.h> #include <asm/xor.h>他アーキテクチャ含めてみると…うん、確かにRISC-V用が存在しないことが確認できる。まさか、ここでおしまいかなーと思ったのですが、そうは問屋が卸さない。
コンパイル前$find arch -name "xor.h" arch/alpha/include/asm/xor.h arch/arm/include/asm/xor.h arch/arm64/include/asm/xor.h arch/ia64/include/asm/xor.h arch/powerpc/include/asm/xor.h arch/s390/include/asm/xor.h arch/sparc/include/asm/xor.h arch/um/include/asm/xor.h arch/x86/include/asm/xor.hこれではコンパイルができないの…?と思ったら、コンパイル時に自動生成されたヘッダで、汎用の
xor.hに繋げることで、問題なく動かします。コンパイル後$ find arch -name "xor.h" arch/alpha/include/asm/xor.h arch/arm/include/asm/xor.h arch/arm64/include/asm/xor.h arch/ia64/include/asm/xor.h arch/powerpc/include/asm/xor.h arch/riscv/include/generated/asm/xor.h arch/s390/include/asm/xor.h arch/sparc/include/asm/xor.h arch/um/include/asm/xor.h arch/x86/include/asm/xor.h $ cat arch/riscv/include/generated/asm/xor.h #include <asm-generic/xor.h> $ find include -name "xor.h" include/asm-generic/xor.h先にxor.hのコードを確認しておく。
ソースコード{
include/asm-genetic/xor.h) を見ると、うーん、実にシンプルな感じですね…基本に忠実です、確実に。include/asm-generic/xor.hstatic void xor_8regs_2(unsigned long bytes, unsigned long *p1, unsigned long *p2) { long lines = bytes / (sizeof (long)) / 8; do { p1[0] ^= p2[0]; p1[1] ^= p2[1]; p1[2] ^= p2[2]; p1[3] ^= p2[3]; p1[4] ^= p2[4]; p1[5] ^= p2[5]; p1[6] ^= p2[6]; p1[7] ^= p2[7]; p1 += 8; p2 += 8; } while (--lines > 0); }楽しいdisassemble time
よし、それではさっそく xor.o を disassmbleして、どんなのができているのかを見てみよう!!
まずsymbolを確認する。
シンボルとして何が定義されているのかを確認すると以下を観察できる。
- xorは、8regs と、32regs がある。
- 8 regs = 8 bit = unsigned char (先の例)
- 32 regs = 32 bit = unsigned int
- xorは、2,3,4.5をまとめて処理する系がある。
xor.oのシンボル$ riscv32-unknown-linux-gnu-objdump -t xor.o xor.o: file format elf64-littleriscv SYMBOL TABLE: 0000000000000000 l df *ABS* 0000000000000000 xor.c 0000000000000000 l d .text 0000000000000000 .text 0000000000000000 l d .data 0000000000000000 .data 0000000000000000 l d .bss 0000000000000000 .bss 0000000000000000 l d __ksymtab_strings 0000000000000000 __ksymtab_strings 0000000000000000 l __ksymtab_strings 0000000000000000 __kstrtab_xor_blocks 000000000000000b l __ksymtab_strings 0000000000000000 __kstrtabns_xor_blocks 0000000000000000 l F .text 0000000000000082 xor_8regs_2 0000000000000082 l F .text 00000000000000bc xor_8regs_3 000000000000013e l F .text 0000000000000104 xor_8regs_4 0000000000000242 l F .text 0000000000000168 xor_8regs_5 00000000000003aa l F .text 000000000000008c xor_32regs_2 0000000000000436 l F .text 00000000000000c0 xor_32regs_3 00000000000004f6 l F .text 0000000000000112 xor_32regs_4 0000000000000608 l F .text 0000000000000160 xor_32regs_5 0000000000000000 l O .sbss 0000000000000008 active_template 0000000000000000 l d .exit.text 0000000000000000 .exit.text 0000000000000000 l F .exit.text 000000000000000c xor_exit 0000000000000000 l d .rodata.str1.8 0000000000000000 .rodata.str1.8 0000000000000000 l d .init.text 0000000000000000 .init.text 0000000000000000 l F .init.text 00000000000000c6 do_xor_speed 00000000000000c6 l F .init.text 00000000000000f6 calibrate_xor_blocks 00000000000007d8 l F .text 000000000000015e xor_32regs_p_5 0000000000000936 l F .text 0000000000000112 xor_32regs_p_4 0000000000000a48 l F .text 00000000000000c4 xor_32regs_p_3 0000000000000b0c l F .text 0000000000000092 xor_32regs_p_2 0000000000000b9e l F .text 0000000000000150 xor_8regs_p_5 0000000000000cee l F .text 0000000000000108 xor_8regs_p_4 0000000000000df6 l F .text 00000000000000c0 xor_8regs_p_3 0000000000000eb6 l F .text 0000000000000088 xor_8regs_p_2 0000000000000000 l .data 0000000000000000 .LANCHOR1 0000000000000000 l O .data 0000000000000038 xor_block_8regs 0000000000000038 l O .data 0000000000000038 xor_block_8regs_p 0000000000000070 l O .data 0000000000000038 xor_block_32regs 00000000000000a8 l O .data 0000000000000038 xor_block_32regs_p 0000000000000000 l d .exitcall.exit 0000000000000000 .exitcall.exit 0000000000000000 l O .exitcall.exit 0000000000000008 __exitcall_xor_exit 0000000000000000 l d .init.data 0000000000000000 .init.data <略>バイナリを確認する
バイナリの中身を確認すると8byte単位で、xorして保持していますね。
それにしてもうん、非常に人間の可読性はきつい(読めないことはない)。unrollingしたりなんだりした結果ですね…memoa0 = bytes a1 = *p1 a2 = *p2xor.oのasm$ riscv32-unknown-linux-gnu-objdump -d xor.o xor.o: file format elf64-littleriscv Disassembly of section .text: 0000000000000000 <xor_8regs_2>: 0: 1141 addi sp,sp,-16 % Stack確保 2: e422 sd s0,8(sp) % 4: 0800 addi s0,sp,16 % 6: 8119 srli a0,a0,0x6 % a0 = bytes >> 8 0000000000000008 <.L2>: 8: 00063803 ld a6,0(a2) % a6 = p2[0] c: 6194 ld a3,0(a1) % a3 = p1[0] e: 6598 ld a4,8(a1) % a4 = p1[8] 10: 699c ld a5,16(a1) % a5 = p1[16] 12: 0106c6b3 xor a3,a3,a6 % a3 = a3 ^ a6 16: e194 sd a3,0(a1) % p1[0] = a3 18: 6614 ld a3,8(a2) % a3 = p1[8] 1a: 0185b883 ld a7,24(a1) % a7 = p1[24] 1e: 0205b803 ld a6,32(a1) % a6 = p1[32] 22: 8f35 xor a4,a4,a3 % a4 = a4 ^ a3 24: e598 sd a4,8(a1) % p1[8] = a4 26: 01063303 ld t1,16(a2) % t1 = p2[16] 2a: 7594 ld a3,40(a1) % a3 = a1[40] 2c: 7998 ld a4,48(a1) % a4 = a1[48] 2e: 0067c7b3 xor a5,a5,t1 % a5 = a5 ^ t1 32: e99c sd a5,16(a1) % p1[16] = a5 34: 01863303 ld t1,24(a2) % t1 = p2[24] 38: 7d9c ld a5,56(a1) % a5 = p1[56] 3a: 04058593 addi a1,a1,64 % <a1 = a1 + 64> 3e: 0068c8b3 xor a7,a7,t1 % a7 = a7 ^ t1 42: fd15bc23 sd a7,-40(a1) % p1[-40] = a7 (実質24) 46: 02063883 ld a7,32(a2) % a7 = p2[32] 4a: 04060613 addi a2,a2,64 % <a2 = a2 + 64> 4e: 157d addi a0,a0,-1 % <a0 = a0 - 1> 50: 01184833 xor a6,a6,a7 % a6 = a6 ^ a7 54: ff05b023 sd a6,-32(a1) % p1[-32] = a6(実質32) 58: fe863803 ld a6,-24(a2) % a6 = p2[-24](実質40) 5c: 0106c6b3 xor a3,a3,a6 % a3 = a3 ^ a6 60: fed5b423 sd a3,-24(a1) % p1[-24] = a3(実質40) 64: ff063683 ld a3,-16(a2) % a3 = a2[-16](実質48) 68: 8f35 xor a4,a4,a3 % a4 = a4 ^ a3 6a: fee5b823 sd a4,-16(a1) % a1[-16] = a4(実質48) 6e: ff863703 ld a4,-8(a2) % a4 = a2[-8](実質56) 72: 8fb9 xor a5,a5,a4 % a5 = a5 ^ a4 74: fef5bc23 sd a5,-8(a1) % p1[-8] = a5 (実質56) 78: f8a048e3 bgtz a0,8 <.L2> % if(a0 > 0) goto L2 7c: 6422 ld s0,8(sp) % 7e: 0141 addi sp,sp,16 % Stack復元 80: 8082 retこれは(常に)最適解ではない!(という妄想)
RISC-Vには、Vector Extensionがある。SIMDではない。繰り返すが、SIMDではない。
一番良いのは、こちらの fixstars様の記事をよく読むことなのですが……。
https://proc-cpuinfo.fixstars.com/2019/10/riscv-v 簡単にいうと「何をどれだけ並列で処理するのかは、コンパイル時ではなく実行時に任せる」こともできる、という感じ。
妄想だけで記載するとこんな感じ。
これで、64x8 でも、32x8 でも、32x4 でも、それなりに動くはず……loop: vlsetvli t0, a0, e128,m8 % 128bit単位で8要素ずつa0回。今回の回数はt0に入る。 vle.v v1, (a1), vm % v1 = *a1 vle.v v2, (a2), vm % v2 = *a2 vor.vv v1, v1, v2, vm % v1 = v1 ^ v2 vse.v v1, (a1) % p1 = v1 addi a1, t0 % a1 = a1 - t0 addi a2, t0 % a2 = a2 - t0 sub a0, a0, t0 % a0 = a0 - t0 bnez a0, loop % 繰り返し以上です。
- 投稿日:2020-05-31T09:46:04+09:00
早見表: Linux ディスク関連コマンド集
時々、ど忘れしちゃうので。自分用にまとめたコマンド集。
ディスク容量
ディスクドライブの容量を確認
$ df -h
- -h オプションで、バイトではなく、MB やGB 表示
ディレクトリの容量を確認
$ du -d 1 -h
- -d + 階層、で現在の位置からのディレクトリのディスク容量
- -h オプションで、バイトではなく、MB やGB 表示
設定
ディスク & パーティション情報
ディスク & パーティション情報を表示
lsblkSWAP ファイルを作る
別の記事にまとめました
https://qiita.com/katzueno/items/0a63b46c69602ecdeae5ディスクを増量する
AWS EC2 の EBS などでディスク容量後に設定する方法 (Amazon Linux & Amazon Linux 2)
https://qiita.com/katzueno/items/4ceb93cc14bbab4e3064
- 投稿日:2020-05-31T09:40:11+09:00
さくらVPSでLAMP + Wordpress環境を構築する方法まとめ
さくらVPSでLAMP + Wordpress環境を構築する方法まとめ
学習用にさくらVPSでLAMP環境を構築したので、手順をまとめます.
目次
動作環境
OS : macOS Mojave 10.14.6
VPS OS : centOS手順
さくらVPSの申し込み
さくらのwebサイト>VPS>2週間無料でお試しにアクセス
サーバをカートに入れ申し込み.メールに記載されているIDとパスワードでログインし,VPSコントロールパネルにログイン
各種設定>OSインストール
*OSをインストールする際にVPSにログインするためのパスワードを入力するので忘れずにメモします.
これでさくらVPSの申し込みからOSのインストールまでが完了です.
ssh接続
つぎにローカルPCからインターネット上のVPSに接続するためのSSH接続の設定手順をまとめます.
1. Terminal起動とroot権限でログイン
手元のMACでTerminalを起動します.
そして以下のsshコマンドで接続します.
パスワードはOSをインストールした際に入力したものです.$ ssh root@VPSのIPアドレス2. ソフトウエアのupdate
$ yum update3. 一般ユーザの作成
$ adduser jun1 #user追加 $ passwd jun1 #password設定sudoが使えるように設定
$ visudowheel ALL=(ALL) ALL #コメントアウトを外すjun1ユーザをwheelグループに追加
$ usermod -aG wheel jun1 $ groups jun1 jun1 : jun1 wheeljun1でログインできるか確認
$ ssh jun1@VPSのIPアドレス $ パスワード入力4. ssh鍵認証の設定
ローカルのPCのターミナルを起動して実行
MAC$ ssh-keygen -t rsa -v MAC$ ls ~/.ssh config id_rsa id_rsa.pub known_hostssshでVPSに接続
VPS$ mkdir .ssh VPS$ chmod 700 .sshローカルPCからVPSへ公開鍵を転送
ローカルPCMAC$ scp ~/.ssh/id_rsa.pub jun1@VPSのIPアドレス:~/.ssh/authorized_keys MAC$ VPSのパスワード入力鍵を利用してサーバにログイン
ローカルPCMAC$ ssh -i ~/.ssh/id_rsa jun1@VPSのIPアドレスssh接続のセキュリティ設定
1.ポート番号の設定
VPS$ sudo cp /etc/ssh/sshd_config /etc/ssh/sshd_config.ort #設定ファイルのバックアップ $ sudo vim /etc/ssh/sshd_configPortを検索し、#を消して, 22 -> 56789(任意の番号で可)
2.パスワード認証の無効化
PasswordAuthenticationを検索し、
noに変更3.rootログインの無効化
PermitRootLoginで検索し,noに変更
4.設定ファイルの確認
VPS$ sudo sshd -t #設定ファイルに構文ミスがないか確認.何も出なければOK $ sudo systemctl restart sshd #sshdの再起動5.ファイアウォールの設定
VPS$ sudo cp /usr/lib/firewalld/services/ssh.xml /etc/firewalld/services/ssh-56789.xml $ sudo vim /etc/firewalld/services/ssh-56789.xmlport番号を22 -> 56789に変更
VPS$ sudo firewall-cmd --reload >success $ sudo firewall-cmd --permanent --add-service=ssh-56789 >success $ sudo firewall-cmd --reload >success $ sudo firewall-cmd --list-all >ssh-567896.SSH動作確認
上記で開いていたターミナルを閉じずに別タブを開く
MAC$ ssh -p 56789 -i ~/.ssh/id_rsa jun1@VPSのIPアドレス7. sshをファイアウォールから削除
VPS$ sudo firewall-cmd --permanent --remove-service=ssh $ sudo firewall-cmd --reload最後に念の為、ssh接続できるか確認
MAC$ ssh -p 56789 -i ~/.ssh/id_rsa jun1@VPSのIPアドレスapacheのインストール
VPS$ sudo yum install httpdApacheを起動
VPS$ sudo systemctl start httpd $ systemctl status httpd #Activeと表示されているか確認Firewallの設定
VPS$ sudo firewall-cmd --add-service=http --zone=public --permanent $ sudo firewall-cmd --add-service=https --zone=public --permanent $ sudo systemctl restart firewalldさくらVPSのパケットフィルタの設定
さくらVPSのコントロールパネル>設定>パケットフィルタ>WEBを許可
ブラウザからApacheの動作確認
ブラウザにVPSのIPアドレスを入力し,以下のテストページが表示されればOK
Apacheの自動起動の設定
VPS$sudo systemctl enable httpd権限の設定
ドキュメントルートの所有権をapacheに変更します.
VPS$sudo groupadd web #グループの作成 $sudo usermod -aG web jun1 #グループにユーザの追加VPS$sudo chown apache:web /va/www/html/ $sudo chmod -R 775 /var/www/html/htmlファイルを作成しApacheの動作確認
VPS$ vim /var/www/html/index.html #適当に編集して保存ブラウザから開いて確認
ドメインの設定
ドメイン取得サイトから購入
今回はバリュードメインに会員登録し、購入します。
DNS設定
バリュードメインにログインし、DNSを設定
詳細は各ドメインサイトから確認します.バリュードメインの設定画面a VPSのIPアドレスブラウザにドメインを入力し、表示されるか確認
*DNSの反映には1日かかることもあります.リポジトリの設定
2つのリポジトリをインストールします.
epelリポジトリ(Linuxのリポジトリ)
remiリポジトリ(PHPのリポジトリ)epelリポジトリ
VPS$sudo yum repolist #epelリポジトリがない場合は以下実行 $sudo yum install epelremiリポジトリ
ブラウザからremiリポジトリのURLをコピー
VPS$sudo yum localinstall remiのurlphpのインストール
インストールできるバージョンを確認
VPS$ yum list available | grep php-php71-common.x86_64を確認
VPS$ sudo yum --enablerepo=remi-php71 install php php-devel php-mysql php-gd php-mbstringApaceh再起動
VPS$ sudo systemctl restart httpdPHPの設定
VPS$ sudo cp /etc/php.ini /etc/php.ini.org #設定ファイルのバックアップ $ sudo vim /etc/php.iniファイルのアップロード上限を変更
php.inipost_max_size = 128M #8M -> 128M upload_max_filesize = 128M #2M -> 128MApaceh再起動
VPS$ sudo systemctl restart httpdPHPの動作確認
/var/www/html/index.php<?php echo 'Hello World';ブラウザにドメイン名を入力し,index.phpを確認する
mysqlのインストール
MariaDBの削除
VPS$ sudo yum remove mariadb-libs $ sudo rm -rf /var/lib/mysqlMySQLインストール
MySQL 5.7をインストールする
VPS$ sudo yum localinstall https://dev.mysql.com/get/mysql57-community-release-el7-11.noarch.rpm $ sudo yum install mysql-community-serverMySQLの設定
VPS$ sudo systemctl start mysqld $ sudo cat /var/log/mysqld.log | grep 'temporary password' #初期接続パスワードを確認VPS$ mysql_secure_installation #以下、指示どおり設定していくVPS$ mysql -u root -p #ログインできるか確認文字コードをUTFに変更
VPS$ sudo vim /etc/my.confmy.confcharacter-set-server=utf8VPS$ sudo systemctl restart mysqld自動起動の設定
VPS$ sudo systemctl enable mysqldsslの設定
certbotを利用するためバーチャルホストを設定
VPS$ sudo vim /etc/httpd/conf.d/ドメイン名.confドメイン名.conf<VirtualHost *:80> DocumentRoot /var/www/html ServerName ドメイン名 </VirtualHost>certbotをインストール
certbotのwebサイトからソフトウエアとOSを選択
VPS$ sudo vim install certbot-apache証明書を取得
VPS$ sudo certbot --apache動作確認
ブラウザにドメイン名を入力し、httpsになっているか確認
wordpressのインストール
DBの準備
VPS$ mysql -u root -p mysql> create database myblog; mysql> create user 'myblog_user'@'localhost' identified with mysql_native_password by '任意のpassword' mysql> grant all privileges on myblog.* to 'myblog_user'@'localhost'; mysql> flush privileges;wordpressのダウンロード
VPS$ wget https://ja.wordpress.org/latest-ja.tar.gz $ sudo tart -zxvf latest-ja.tar.gz -C /var/www/ #圧縮ファイルを展開 $sudo chown -R apache:web wordpress/ $sudo vim /etc/httpd/conf/httpd.confhttpd.confDocumentRoot "/var/www/wordpress" <Directory "/var/www/wordpress">ドメイン名.confDocumentRoot /var/www/wordpressドメイン名-le-ssl.confDocumentRoot /var/www/wordpresswordpressの確認
ドメインにアクセスして以下のページが表示されるか確認
終わりに
今回はさくらVPSにLAMP環境を構築する学習の内容をまとめました。
Linuxコマンドの勉強になりました。