- 投稿日:2020-05-31T16:37:15+09:00
TPUを使った写真の美しさスコア付けモデルの学習
概要
TPUの勉強のため、1から10の10段階で写真の美しさをスコア付けするDeep Learningモデルを学習させました。
写真の美しさのスコア付け
入力された写真を1から10の10段階でスコア付けをします。類似の研究事例としてはGoogleのNIMA[1]などがあります。学習用データセットとしてAVA dataset[2]を使用しました。AVA datasetは約25万枚の写真に対し、複数のアノテータが10段階のスコア付けを行ったデータセットになります。加重平均を取ることで、その写真に対する美しさのスコアを得ることができます。
ソースコード
ソースはこちらに格納しました。
https://github.com/myzkyuki/aesthetic_imageTPUの利用
Google Colabにおいて無料で利用でき、高速な学習が可能なTPUを使用しました。TPUの利用にあたっては以下のサイトを参考にさせていただきました。
- TensorFlow2.0 with KerasでいろいろなMNIST(TPU対応)
- Tensorflow 2.0 と Colab TPU, GCS を使った楽しいfine-tuning
- Google Cloud Colabノートブック
- Custom training with tf.distribute.Strategy
- Distributed training with TensorFlow
- tensorflow/modelsのコード
学習時の工夫点
学習では色々ハマりどころがあり、以下の点を工夫しました。
Cloud Storageの使用
TPUではローカルファイルシステムを使用できないため、TPUを使った学習を行う場合Cloud Storageを使用する必要があります。この際、学習時間を短くするため、作成するバケットは
us-central1に作成します。当初、asia-northeast1に作成したところ、TPUを使っているのに学習が非常に遅くなってしまいました。詳細はコチラをご参照ください。データ拡張
一般的に画像の学習ではデータ拡張として、回転・平行移動・明るさ変更・切り抜きなどを行います。しかし、それらを行ってしまうと写真の美しさに影響すると考えられるため、今回のデータ拡張は左右反転のみ適用しました。
画像サイズの正規化
CNNの入力に対しては縦横を同じ長さに揃えてリサイズする必要にあり、3種類の方法があります。いずれも写真の美しさスコアへの影響が考えられますが、一番影響が少なそうな
1. アスペクト比を変更してリサイズを行いました。
# リサイズ方法 スコアへの影響の懸念点 1 アスペクト比を変更してリサイズ 画像中のオブジェクトの形が歪む。 2 アスペクト比を維持してパディング 余白に挿入された黒帯がスコアに影響する。微妙な写真でも評価が高い写真と似たアスペクト比だとスコアが高くなりそう。 3 アスペクト比を維持して切り抜く 美しさの評価に影響するオブジェクトが取り除かれ、構図が崩れる。 モデル
モデルには軽めのSoTAモデルであるEfficientNet-B0を使用しました。
ロス関数
2つのロス関数を試しましたが、Multi Lossの方が精度が高くなりました。
- 蒸留のようにアノテータによるスコア付けの分布を学習させるためKLDivergence
- CategoricalCrossentropyとMSEの和をとったMulti Loss[3]
最適化関数
当初EfficientNetで使用されている、ExponentialDecayを用いたRMSpropを試したのですが、勾配爆発してしまったため、Adamにしたところうまく進みました。
結果
15エポックほどの学習により、以下の結果が得られました。
Train lossとValidation Loss
Golabの時間制限により何回かチェックポイントから始めたため、Train Lossは余計な線が入ってしまっていますが、学習がちゃんと進んでいることがわかるかと思います。
正解スコアと予測スコアの分布
Validationデータにおける正解スコア(true)と予測スコア(pred)の分布は以下のようになりました。まだ、バラツキがありますが、緩やかな相関関係はあるかと思います。
予測サンプル
AVA datasetに対する予測とと正解のサンプルです。予測スコアとしては差がありますが、スコア順に並べると大体近い順序になるのではないかと思います。
Landscape写真
Animals写真
まとめ
TPUを使ってAVA datasetを用いた写真の美しさスコア付けを行うモデルの学習を行いました。精度は改善の余地がありそうですが、それなりに納得性のあるスコア付けをできているのかと思います。こういった、人によってアノテーション結果が分かれるデータの学習は評価が難しいと思いました。画像によっては予測スコアの方が正解スコアよりも納得感がある画像もあったりします。
参考
以下の文献を参考にさせていただきました。
[1] NIMA: Neural Image Assessment
[2] AVA: A Large-Scale Database for Aesthetic Visual Analysis
[3] Fine-Grained Head Pose Estimation Without Keypoints





- 投稿日:2020-05-31T13:36:27+09:00
VAEでMNISTデータをAugmentationして分類機を学習する
この記事について
VAE(Variational Autoencoder)を勉強しているとData augmentationに利用したらどうなる?と疑問に思ったが,調べてもあまりでてこなかったので実際にやってみた.
・・・という記事です.勉強がてらやったものとして気軽に御覧ください.ご指摘などあればぜひお願いします!
コード(ipynbファイル)はここを参照.
環境
GPU持ってないのでGoogle Colabにて.(時々インスタンス切られつつ)なんとか動作.
つぎからColabでめんどい時はGCP使おうと決意,,,,はじめに
VAE(変分オートエンコーダー)とオートエンコーダー
詳細は
割あ下記などにて・・・
【超初心者向け】VAEの分かりやすい説明とPyTorchの実装オートエンコーダー
inputとoutputが同じ.
中間層で次元削減し特徴量抽出 -> 教師なし学習として用いられる
VAE
inputとoutputが同じなのは共通.
異なるのは潜在変数を直接学習するのではなく,潜在変数空間として学習(具体的には平均と分散)する.
潜在変数空間からサンプリングされたベクトルを用いてoutputを「生成」する.要は生成モデル.
もと論文は"Semi-Supervised Learning with Deep Generative Models"
方法
分類器
VGG16 likeなものにBatchNormalization層を追加
コードは下記(冗長ですみませんCNNmodel.py#! /usr/bin/env python # -*- coding: utf-8 -*- import keras from keras import layers def base_layer(output_dim): '''CNN block for function(baseConvModel)''' initializer = keras.initializers.he_normal() def f(input_tensor): x = layers.Conv2D(output_dim, (3, 3), padding='same', kernel_initializer=initializer)(input_tensor) x = layers.BatchNormalization()(x) x = layers.Activation('relu')(x) x = layers.Conv2D(output_dim, (3, 3), padding='same', kernel_initializer=initializer)(x) x = layers.BatchNormalization()(x) x = layers.Activation('relu')(x) out = layers.MaxPooling2D((2,2),strides=(2,2),padding='same')(x) return out return f def baseConvModel(lr=0.0002,clipvalue=1.0,beta_1=0.9,beta_2=0.99): ''' light VGG-like CNN model for MNIST. (28,28,1) - > (14, 14, 16) -> (7, 7, 64) -> (3136, ) -> (512, ) -> (10, ) #######CAUTION###### Return -> COMPILED model #################### Args: lr: learning rate of adam-optimizer beta_1, beta_2, clip_value : for adam_optimizer Returns : COMPILED model ''' initializer = keras.initializers.he_normal() inputs = layers.Input(shape=(28,28,1)) '''small VGG-like network''' x = base_layer(16)(inputs) x = base_layer(64)(x) '''FL''' x = layers.Flatten()(x)# 7x7x64 = 3136 x = layers.core.Dropout(0.3)(x) x = layers.Dense(512,activation='relu',kernel_initializer=initializer)(x) x = layers.core.Dropout(0.5)(x) predict = layers.Dense(10,activation='softmax',kernel_initializer=keras.initializers.glorot_normal())(x) model = keras.models.Model(inputs=inputs,outputs=predict) '''Compilie''' adam = keras.optimizers.Adam(lr=lr,beta_1=beta_1,beta_2=beta_2,decay=1e-8,clipvalue=clipvalue) model.compile(optimizer=adam,loss='categorical_crossentropy',metrics=['accuracy']) #model.summary() return modelデータ拡張
VAEを用いて,
・ことなるオリジナル画像数で(100,200,400,800)
・異なる学習具合(lossで表現)
・ことなる増幅数(x10, x50, x250)
で画像を増幅.コードは下記参照.
↓VAE
vae.py#! /usr/bin/env python # -*- coding: utf-8 -*- import keras from keras import layers from keras import backend as K import numpy as np class CustomVariationalLayer(keras.layers.Layer): '''Custom loss functiond(dummy layer) return: image_loss + KL divergense''' def vae_loss(self, x, z_decoded,z_mean,z_log_var): input_dim = np.prod(K.int_shape(x)[1:]) x = K.flatten(x) z_decoded = K.flatten(z_decoded) reconst_loss = input_dim * keras.metrics.binary_crossentropy(x, z_decoded) kl_loss = -0.5 * K.sum(1 + z_log_var - K.square(z_mean) - K.exp(z_log_var), axis=-1) return K.mean(reconst_loss + kl_loss) def call(self, inputs): x, z_decoded, z_mean, z_log_var = inputs loss = self.vae_loss(*inputs) self.add_loss(loss, inputs=inputs) return x def sampling(arg): ''' Samping z from encoded values for decoder(For VAE training) ''' z_mean, z_log_var = arg ep = K.random_normal(shape=(K.int_shape(z_mean)[1], ),# K.int_shape(z_mean)[0], mean = 0,stddev = 1) return z_mean + ep * K.exp(0.5 * z_log_var) def base_layers_enc(output_dim, strides=(1,1)): initializer = keras.initializers.he_normal() def f(input_tensor): x = layers.Conv2D(output_dim, (3, 3), padding='same',strides=strides, kernel_initializer=initializer)(input_tensor) x = layers.BatchNormalization()(x) out = layers.LeakyReLU(0.2)(x) return out return f def set_vae(img_shape=(28,28,1),latent_dim=20): ''' Define VAE, VAE-encoder, VAE-decoder (28, 28, 1) -> (28, 28, 32) -> (14, 14, 64) -> (14, 14, 64)[decoder] - >(12544, ) -> (32, ) -> (latent_dim) ''' #for Encoder########################################### input_img_vae = keras.Input(shape=img_shape) initializer = keras.initializers.he_normal() out_dims = [[32, (1,1)], [64, (2,2)], [64, (1,1)]] x = input_img_vae for _d, _st in out_dims: x = base_layers_enc(_d, _st)(x) x = layers.Conv2D(64,(3,3),padding='same',kernel_initializer=initializer)(x) cache_shape = K.int_shape(x)# for decoder_dim x = layers.BatchNormalization()(x) x = layers.LeakyReLU(0.2)(x) x = layers.Flatten()(x) #x = layers.Dropout(0.3)(x) x = layers.Dense(32,kernel_initializer=initializer)(x) x = layers.BatchNormalization()(x) x = layers.LeakyReLU(0.2)(x) z_mean = layers.Dense(latent_dim)(x) z_log_var = layers.Dense(latent_dim)(x) VaeEnc = keras.models.Model(input_img_vae, [z_mean, z_log_var]) #VaeEnc.summary() # samping z = layers.Lambda(sampling, output_shape = (latent_dim, ))([z_mean, z_log_var]) # for decoder################################################ ''' (laten_dim) -> (12544, ) -> (14, 14, 64) -> (28, 28, 32) -> (28, 28, 1) ''' decoder_input_vae = keras.Input(shape=(latent_dim,)) fl_dim = np.prod(cache_shape[1:]) x = layers.Dense(fl_dim,kernel_initializer=initializer)(decoder_input_vae) x = layers.BatchNormalization()(x) x = layers.LeakyReLU(0.2)(x) x = layers.Reshape(cache_shape[1:])(x) x = layers.Conv2DTranspose(32,(3,3),strides=(2,2),padding='same',kernel_initializer=initializer)(x) x = layers.BatchNormalization()(x) x = layers.LeakyReLU(0.2)(x) x = layers.Conv2D(1,(3,3),padding='same',kernel_initializer=keras.initializers.glorot_normal())(x) x = layers.BatchNormalization()(x) x = layers.Activation('sigmoid')(x) VaeDec = keras.models.Model(decoder_input_vae,x) #VaeDec.summary() # define encoder-to-decoder z_decoded = VaeDec(z) # define loss-layer y = CustomVariationalLayer()([input_img_vae, z_decoded,z_mean,z_log_var]) Vae = keras.models.Model(input_img_vae,y) Vae.compile(optimizer='rmsprop', loss=None) #Vae.summary() return VaeEnc, VaeDec, Vae def dec_sampling(arg,n): '''Sampling z from encoded values(For decoder test)''' z_mean, z_log_var = arg ep = np.random.normal(size=(n,z_mean.shape[-1]),loc=0,scale=1) return z_mean + ep * np.exp(0.5 * z_log_var)cnn = baseConvModel() VaeEnc,VaeDec,Vae = set_vae()でモデル(Compile済)を定義しています.
ここからはソースファイルを参照ください.
1.VAE学習->一定の間隔で止める, データ増幅・保存
を繰り返したのち
2.CNNで学習,プロットを保存
を繰り返しています.(Colabでやるのは刻まないといけないので大変だった)結果
まず,100個のデータのみを用いた時の学習結果を下に示します.
validationに対しては80%弱の予測となっており,トレーニングデータが不足していると考えられます.オリジナルデータのみ(100枚用いた場合)
下に示すのがVAEで増幅した画像で学習したときの結果です.データは
プラトーに達した段階でのvalidation-accuracyをプロットに用いました.
※
n_train: オリジナルの画像数
aug: 増幅画像数
破線:オリジナル画像のみを用いた時のAccuracyVAE増幅->学習結果
どうやら,特にオリジナル画像が少ない際は分類器にいい影響を与えそうです.
VAE-Lossが小さくなりすぎないほうが元画像から若干離れた画像を生成できていることのなるので学習に良い影響を与えるかもしれないと考えていましたが,VAE-Lossは低ければ低いほうが(≒オリジナルにより似た画像を生成できている方が)よいようです.これが他のAugmentation手段と同時に用いることでさらにいい結果を期待できるか,他のデータセットでも同様の結果が得られるか,などはやっていないので,また時間ができたら試しにやってみようかななどと思っています.
結論
VAEはMNISTデータセットの増幅には有効らしい.




- 投稿日:2020-05-31T12:50:43+09:00
TensorflowでYOLOv2を動かす
はじめに
先行研究(DeepStyle: Multimodal Search Engine for Fashion and Interior Design)の環境を再現するために物体検出モデルであるYOLOv2を動かしてみました.
darkflowではYOLOv3を対応していないみたいなので,darkflowユーザーの方に見ていただけると幸いです.実行環境
- Ubuntu:16.04
- GPU:Quadro P5000
- CUDA:8.0
- cuDNN:6.0
- Tensorflow-gpu:1.4.0
- Python:3.6
tensorflow-gpuはCUDA, cuDNNと互換性があるので,以下のサイトで自分の環境にあったバージョンをインストールしてください.
https://www.tensorflow.org/install/source#common_installation_problemsdarkflowインストール手順
githubからdarkflowをクローンする.
binディレクトリを作成し,binディレクトリにyoloのweightをダウンロードする.
wget https://pjreddie.com/media/files/yolov2.weightsdarkflowをインストールする.
darkflowディレクトリで実行↓
python3 setup.py build_ext --inplace
pip3 install -e .
pip3 install .サンプルプログラム実行
READMEの”Using darkflow from another python application”に書かれているプログラムを動かしてみます.
thresholdはコード
[test.py] from darkflow.net.build import TFNet import cv2 options = {"model": "cfg/yolo.cfg", "load": "bin/yolov2.weights", "threshold": 0.4, "gpu": 0.3} tfnet = TFNet(options) imgcv = cv2.imread("./sample_img/sample_dog.jpg") result = tfnet.return_predict(imgcv) print(result)実行
python3 test.py結果
sample_img/out/配下に検出結果が保存される.
パラメータ
test.pyのパラメータ(options部分)について説明します.
- load:ダウンロードしていたweightsファイルを指定
- threshold:検出結果の閾値.高くすると評価の高い物体のみが出力される.
- gpu:gpuの使用率まとめ
darkflowを用いてYOLOv2を動かしてみました!
KerasでYOLOv3を動かすのが主流となっているので,需要があるのかわかりませんが,
先行研究の環境再現などの際に参考にしていただけると嬉しいです!
次は矩形内の物体画像切り抜きについて記事を書きたいと思います!

- 投稿日:2020-05-31T10:44:11+09:00
Jetson NanoにJetPack 4.4を入れてTensorFlow・物体検出・姿勢推定・ROS2(Realsense)・ROS1動かしてみた
Jetson Nanoに満を持してJetPack 4.4を入れてみました
からあげといいます。半年ほど前に「Jetson Nano超入門」という本を共著で書きました。詳しくは以下ブログ記事参照ください。
共著で書いた本「Jetson Nano超入門」が12/21に発売されます
ただ、この手の本の宿命として、書いたタイミングと発売するタイミングで基本ソフト(JetPack)のバージョンが異なり、本の通りにやってもうまく動かないということがありました。一応本やサポートサイトでは、古いバージョンのソフトでの動作を推奨しているのですが、気づかない人も多いし、最新のソフトで動かしたいのが人情というものですよね。
というわけで、ずっと先延ばしにしていたJetPack 4.4を入れて、本に書いてあることを色々試してみました。書籍のサポートという位置付けで記事を書きたいと思います。
以下のまとめ記事の方も、JetPack 4.4に関して追記していますが、この記事ではJetPack 4.4に特化して情報をまとめています。
Jetson Nano関係のTIPSまとめJetPack4.4で変わったこと
JetPackはバージョンごとで、変更が結構あります。、今までJetPack 4.2以前しか使っていなかったのですが、4.2以降の変更として、以下が影響大きそうです。
- TensorFlow 1.x -> 2.x
- OpenCV3.x -> 4.x
TensorFlowは 1.x系をインストールする方法があるのですが、今回は漢らしく2.xにしました(嘘です、間違えてうっかり2.xをインストールしてしまいました)。
その他、いつのバージョンからの変更か分からないハマりどころも色々ありました。まとめて紹介します。なお、最初に書いておくと現状以下の2点の理由でJetPack4.4はオススメできません。JetPack4.3か4.2を入れる方が良いと思います。
- TensorFlow2.xの問題が多い(フォーラムでも議論されている)
カメラが遅れる(現状原因不明)
JetPack 4.4でやったこと
以下を実施しました。順に説明していきます。
TensorFlowセットアップ
物体検出
姿勢推定
ROS2(+Realsense)セットアップ
使用している画像は、古いJetPackを使用したものもありますが、全部JetPack4.4で動作確認をしています。
TensorFlowのインストール
色々変わっていたので、JetPack 4.4用のセットアップスクリプトを作成しました。以下を実行すればセットアップできます。
$ git clone https://github.com/karaage0703/jetson-nano-tools $ cd jetson-nano-tools $ ./install-tensorflow-v44.sh参考にしたのは以下の公式情報です。
Jetson NanoへのTensorFlowセットアップ方法(公式)
追記:JetPackでのTensorFlow2.x系ですが、本記事のコメントにもあります通り、正直挙動が相当怪しいです。JetPack4.4では、当面ver1.x系を使用した方が無難かもしれません。ver1.x系のセットアップ方法に関しては、上記の公式情報を参照ください。私自身は、JetPackでTensorFlow1.x系に関しては動作未確認となります。すみません。
物体検出
TensorFlowのObject Detection APIというソフトを使いやすくする、拙作のソフト「Object Detection Tools」を使用します。以下コマンド実行すれば、物体検出がうごきます。
$ cd && git clone https://github.com/karaage0703/object_detection_tools $ cd ~/object_detection_tools/models $ ./get_ssdlite_mobilenet_v2_coco_model.sh $ cd ~/object_detection_tools $ python3 scripts/object_detection.py -l='models/coco-labels-paper.txt' -m='models/ssdlite_mobilenet_v2_coco_2018_05_09/frozen_inference_graph.pb' -d='jetson_nano_raspi_cam'実行結果のイメージ画像です。写真の人物は私ではなく、友人のロンスタさん(変デジ研究所)です。
Object Detection Toolsに関して詳しく知りたい方は、以下ブログ記事やQiita記事も参照ください。
TensorFlowの物体検出用ライブラリ「Object Detection API」を手軽に使えるソフト「Object Detection Tools」を作ってみた
姿勢推定
以下でセットアップします(
./install-tensorflow-v44.shは実行済みでしたら実行不要です)。$ git clone https://github.com/karaage0703/jetson-nano-tools $ cd jetson-nano-tools $ ./install-tensorflow-v44.sh $ ./install-pose-estimation-v44.sh姿勢推定のソフト「tf-pose-estimation」がTensorFlow2.xでそのまま動かなかったので、色々ソフト修正しています。基本的にはコメントアウトしまくっただけです。推論だけなら不要なコードが多いので動いています(学習はできなくなっていると思います)。
ラズパイカメラモジュールを使用する場合は、以下実行してください。
$ cd ~/tf-pose-estimation $ python3 run_jetson_nano.py --model=mobilenet_v2_small --resize=320x176普通のWebカメラの場合は、以下実行してください。
$ python3 run_webcam.py --model=mobilenet_v2_small --resize=320x176ラズパイカメラモジュールが接続されている状態でWebカメラを使用する場合は、以下となります。
$ python3 run_webcam.py --model=mobilenet_v2_small --resize=320x176 --camera=1実行した結果のイメージ図は以下です。
姿勢推定(骨格検出)に関して、詳細は以下記事参照ください(JetPack4.4に関しても追記してあります)。
Jetson Nanoに骨格検出を実現するソフト「tf-pose-estimation」をセットアップする方法
ROS2のインストールとRealSense D435のセットアップ
過去ROS1を使っていたので、今回は初めてROS2をセットアップしてみました。セットアップスクリプトは以下です。
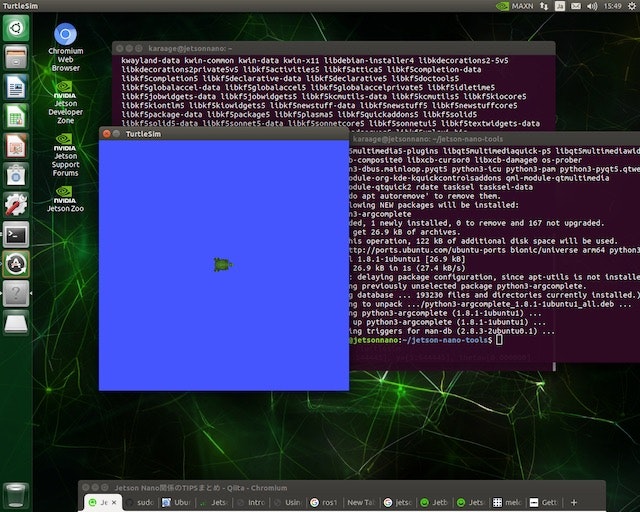
$ git clone $ cd jetson-nano-tools $ ./install-ros2-dashing.shあとは亀のシミュレータを動かします。以下でインストールして起動します。
$ sudo apt install ros-dashing-turtlesim $ source /opt/ros/dashing/setup.bash $ ros2 run turtlesim turtlesim_node
亀出ました続いて、3DカメラモジュールのRealSense D435を動かしてみます。RealSense D435のROS2ラッパーをインストールします。
Intelの公式リポジトリのREADME通りでセットアップできました。intel/ros2_intel_realsense
以下はREADMEからの抜粋した、実行したコマンドです。最新のセットアップ方法に関しては、公式のREADMEを確認するようにしましょう。
$ sudo apt-get install ros-dashing-cv-bridge ros-dashing-librealsense2 ros-dashing-message-filters ros-dashing-image-transport $ sudo apt-get install -y libssl-dev libusb-1.0-0-dev pkg-config libgtk-3-dev $ sudo apt-get install -y libglfw3-dev libgl1-mesa-dev libglu1-mesa-dev $ sudo apt-get install ros-dashing-realsense-camera-msgs ros-dashing-realsense-ros2-cameraあとは、Rvizの設定ファイルもダウンロードしておきます。
$ wget https://raw.githubusercontent.com/intel/ros2_intel_realsense/master/realsense_ros2_camera/rviz/ros2.rviz起動は、以下実行すればOKです。
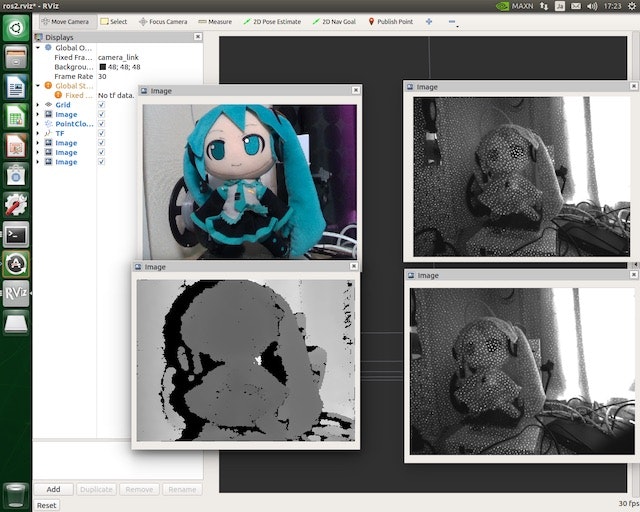
$ source /opt/ros/dashing/setup.bash $ ros2 run realsense_ros2_camera realsense_ros2_cameraRvizというソフトで可視化してみましょう。別のウィンドウを開いて、以下コマンドでダウンロードした設定ファイルを読み込んでRvizを起動します。
$ source /opt/ros/dashing/setup.bash $ ros2 run rviz2 rviz2 -d ros2.rvizババーンと、カラーカメラ情報、デプス情報、赤外線画像が表示されます。赤外線画像は、奥行き推定のために照射している赤外線のランダムドットパターンが見えますね。
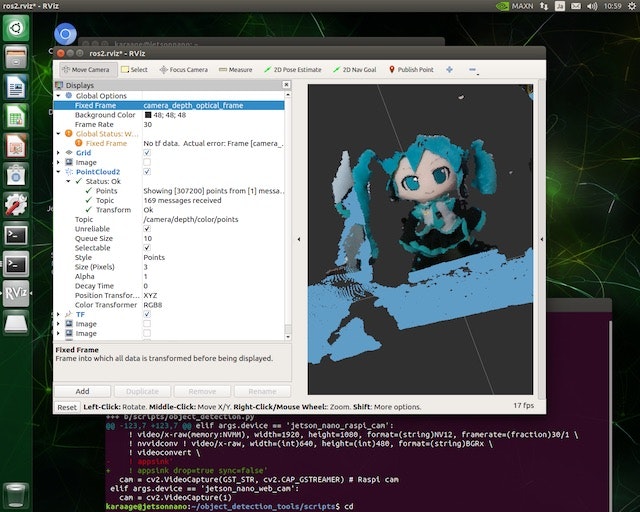
PCL(Point Cloud)をみるときは、少し注意が必要です。何故か、 ROS1では繋がっていた
camera_depth_optical_frameとcamera_linkのフレームが繋がっていないので、Fixed Frameにcamera_depth_optical_frameを指定して、/camera/depth/color/pointsを指定する必要があります。設定と表示した様子は以下となります。
単純に、リアルセンス単体の動作を確認する場合は、以下のコマンドでもOKです。
$ rs-captureまた、ファームウェアのバージョンアップに必要なrealsense-viewerが含まれているlirealsenseは、ダウンロードしておいた方がよいでしょう。以下記事も参考にしてみてください。
Jetson NanoでIntel Realsense D435を使う方法(ROS対応)
Jetson NanoでRealsenseのPythonラッパーPyRealsenseを使用する方法
ちなみにJetPack4.4でROS1が動くかや、ROS2と共存できるかはまだ確認していません。
今回のセットアップに参考にしたのは、以下のサイトです。
ROS1のインストール
JetPack 4.4でROS1もRealsenseも動きました。特に問題なくROS2とも共存できるようです。
セットアップ記事は以下参照ください。
Jetson NanoでIntel Realsense D435を使う方法(ROS対応)
JetPack4.4でのハマりどころ
JetPack4.4でのハマりどころのまとめです。TensorFlow2.xになったことでのハマりどころもたくさんありますが、それはJetPackの問題ではないので割愛しています(エラーメッセージでググりましょう)。
tf.__version__でエラーが発生するJetPack4.4で発生しました。Twitterで教えてもらいましたが、
tf.version.VERSIONでバージョンが確認できるようです。何故…Twitter情報だと JetPack4.3では発生しないとのこと。何故…やっぱりそうなんですね。
— nb.o (@Nextremer_nb_o) May 30, 2020
jetpack 4.4のtensorflow2.xの挙動がよくわかりません...
わかったのは、
tf .__ version__ => NG
tf.version.VERSION => OK
でした。https://t.co/6jwSRl3Yzl pic.twitter.com/e6DqcEp3hgとりあえず使いたいソフトに
tf.__version__がある場合は、コメントアウトするなりしましょう。自分のソフトに関しては、tryで囲んでます。ラズパイカメラモジュール(RaspiCamV2)が動かない
いつからかは不明ですが、解像度設定 3280 x 2464ではラズパイカメラが動かなくなっていました。解像度を 1920 x 1080 に落とすことで解決しました。自分で作成したソフトは、解像度1920x1080に修正しています。
ディープラーニングで推論するとカメラが遅れる
カメラが数秒遅れます。Twitterで対策をフォロワーさんに教えてもらいました。
私自身は試せていませんが、参考情報として教えてもらった対策方法を紹介いたします。試しました。両方とも効果ありです!手っ取り早くは、キャプチャのreadを何度か空打ちすれば良いようです。Gstreamerのバッファがたまってしまっているのが問題ではないかとのことです。
while(cap.isOpened()): # ret, frame = cap.read() for i in range(5): ret, frame = cap.read() if ret == False: print('VideoCapture read return false.') breakちょっくんにhttps://t.co/18fE7Hx4Mf()を数回空打ちしてあげると、遅れないようになったのでやっぱりバッファに溜まっているのですね...
— nb.o (@Nextremer_nb_o) May 31, 2020
うーん... 過去のJetPackはどうだったでしょうかね?思い出せないです。https://t.co/aJ6bWPrxshもしくは、gstreamerのオプション変更でも対応できるそうです。こっちのほうがスマートそうですね。
(昨日の夜読むと言いながら、子供の寝かしつけでそのままおねんねしていました?)
— nb.o (@Nextremer_nb_o) June 1, 2020
リンクにあるgstreamerの文字列に”drop=true sync=false”を追加したところ遅延がなくなりました。
こちらのほうがすっきりします。https://t.co/xPpJjOzI4xまとめ
Jetson NanoをJetPack4.4に対応してみました。バージョンアップするだけで、ソフトがそのままでは色々動かなくなるのはOSSの宿命とはいえ、なかなか辛いものがありますね。ただ、最新の技術に触れる良い機会でもありますね、色々発見もありました(不毛な時間も多いですが)。そこまで理由がなければ、JetPack4.2か4.3を使用した方が良いかなというのが自分の感想です。
最後に「Jetson Nano超入門」はJetson Nanoの入門書としては有用な数少ない書籍と思いますので、もしよろしければ合わせてご購入検討ください。書籍の紹介や、サポートサイトへのリンクは以下参照ください。
共著で書いた本「Jetson Nano超入門」が12/21に発売されます
まあ、本を買わなくても今回の記事の内容は、記事読めば全部できちゃうんですけどね、HAHA!
関連記事
変更履歴
- 2020/06/05 ROS1のインストールに関して追記
- 2020/06/02 カメラが遅れる問題に関して実機確認結果を追記 / ROS2のPCL表示に関して追記
- 2020/06/01 ディープラーニング使用時にカメラが遅れる問題に対する対策追記


- 投稿日:2020-05-31T10:44:11+09:00
Jetson NanoにJetPack 4.4を入れてTensorFlow・物体検出・姿勢推定・ROS2(Realsense)動かしてみた
Jetson Nanoに満を持してJetPack 4.4を入れてみました
からあげといいます。半年ほど前に「Jetson Nano超入門」という本を共著で書きました。詳しくは以下ブログ記事参照ください。
共著で書いた本「Jetson Nano超入門」が12/21に発売されます
ただ、この手の本の宿命として、書いたタイミングと発売するタイミングで基本ソフト(JetPack)のバージョンが異なり、本の通りにやってもうまく動かないということがありました。一応本やサポートサイトでは、古いバージョンのソフトでの動作を推奨しているのですが、気づかない人も多いし、最新のソフトで動かしたいのが人情というものですよね。
というわけで、ずっと先延ばしにしていたJetPack 4.4を入れて、本に書いてあることを色々試してみました。書籍のサポートという位置付けで記事を書きたいと思います。
以下のまとめ記事の方も、JetPack 4.4に関して追記していますが、この記事ではJetPack 4.4に特化して情報をまとめています。
Jetson Nano関係のTIPSまとめJetPack4.4で変わったこと
JetPackはバージョンごとで、変更が結構あります。、今までJetPack 4.2以前しか使っていなかったのですが、4.2以降の変更として、以下が影響大きそうです。
- TensorFlow 1.x -> 2.x
- OpenCV3.x -> 4.x
TensorFlowは 1.x系をインストールする方法があるのですが、今回は漢らしく2.xにしました(嘘です、間違えてうっかり2.xをインストールしてしまいました)。
その他、いつのバージョンからの変更か分からないハマりどころも色々ありました。まとめて紹介します。なお、最初に書いておくと現状以下の2点の理由でJetPack4.4はオススメできません。JetPack4.3か4.2を入れる方が良いと思います。
- TensorFlow2.xの問題が多い(フォーラムでも議論されている)
カメラが遅れる(現状原因不明)
JetPack 4.4でやったこと
以下を実施しました。順に説明していきます。
TensorFlowセットアップ
物体検出
姿勢推定
ROS2(+Realsense)セットアップ
使用している画像は、古いJetPackを使用したものもありますが、全部JetPack4.4で動作確認をしています。
TensorFlowのインストール
色々変わっていたので、JetPack 4.4用のセットアップスクリプトを作成しました。以下を実行すればセットアップできます。
$ git clone https://github.com/karaage0703/jetson-nano-tools $ cd jetson-nano-tools $ ./install-tensorflow-v44.sh参考にしたのは以下の公式情報です。
Jetson NanoへのTensorFlowセットアップ方法(公式)
追記:JetPackでのTensorFlow2.x系ですが、本記事のコメントにもあります通り、正直挙動が相当怪しいです。JetPack4.4では、当面ver1.x系を使用した方が無難かもしれません。ver1.x系のセットアップ方法に関しては、上記の公式情報を参照ください。私自身は、JetPackでTensorFlow1.x系に関しては動作未確認となります。すみません。
物体検出
TensorFlowのObject Detection APIというソフトを使いやすくする、拙作のソフト「Object Detection Tools」を使用します。以下コマンド実行すれば、物体検出がうごきます。
$ cd && git clone https://github.com/karaage0703/object_detection_tools $ cd ~/object_detection_tools/models $ ./get_ssdlite_mobilenet_v2_coco_model.sh $ cd ~/object_detection_tools $ python3 scripts/object_detection.py -l='models/coco-labels-paper.txt' -m='models/ssdlite_mobilenet_v2_coco_2018_05_09/frozen_inference_graph.pb' -d='jetson_nano_raspi_cam'実行結果のイメージ画像です。写真の人物は私ではなく、友人のロンスタさん(変デジ研究所)です。
Object Detection Toolsに関して詳しく知りたい方は、以下ブログ記事やQiita記事も参照ください。
TensorFlowの物体検出用ライブラリ「Object Detection API」を手軽に使えるソフト「Object Detection Tools」を作ってみた
姿勢推定
以下でセットアップします(
./install-tensorflow-v44.shは実行済みでしたら実行不要です)。$ git clone https://github.com/karaage0703/jetson-nano-tools $ cd jetson-nano-tools $ ./install-tensorflow-v44.sh $ ./install-pose-estimation-v44.sh姿勢推定のソフト「tf-pose-estimation」がTensorFlow2.xでそのまま動かなかったので、色々ソフト修正しています。基本的にはコメントアウトしまくっただけです。推論だけなら不要なコードが多いので動いています(学習はできなくなっていると思います)。
ラズパイカメラモジュールを使用する場合は、以下実行してください。
$ cd ~/tf-pose-estimation $ python3 run_jetson_nano.py --model=mobilenet_v2_small --resize=320x176普通のWebカメラの場合は、以下実行してください。
$ python3 run_webcam.py --model=mobilenet_v2_small --resize=320x176ラズパイカメラモジュールが接続されている状態でWebカメラを使用する場合は、以下となります。
$ python3 run_webcam.py --model=mobilenet_v2_small --resize=320x176 --camera=1実行した結果のイメージ図は以下です。
姿勢推定(骨格検出)に関して、詳細は以下記事参照ください(JetPack4.4に関しても追記してあります)。
Jetson Nanoに骨格検出を実現するソフト「tf-pose-estimation」をセットアップする方法
ROS2のインストールとRealSense D435のセットアップ
過去ROS1を使っていたので、今回は初めてROS2をセットアップしてみました。セットアップスクリプトは以下です。
$ git clone $ cd jetson-nano-tools $ ./install-ros2-dashing.shあとは亀のシミュレータを動かします。以下でインストールして起動します。
$ sudo apt install ros-dashing-turtlesim $ source /opt/ros/dashing/setup.bash $ ros2 run turtlesim turtlesim_node
亀出ました続いて、3DカメラモジュールのRealSense D435を動かしてみます。RealSense D435のROS2ラッパーをインストールします。
Intelの公式リポジトリのREADME通りでセットアップできました。intel/ros2_intel_realsense
以下はREADMEからの抜粋した、実行したコマンドです。最新のセットアップ方法に関しては、公式のREADMEを確認するようにしましょう。
$ sudo apt-get install ros-dashing-cv-bridge ros-dashing-librealsense2 ros-dashing-message-filters ros-dashing-image-transport $ sudo apt-get install -y libssl-dev libusb-1.0-0-dev pkg-config libgtk-3-dev $ sudo apt-get install -y libglfw3-dev libgl1-mesa-dev libglu1-mesa-dev $ sudo apt-get install ros-dashing-realsense-camera-msgs ros-dashing-realsense-ros2-cameraあとは、Rvizの設定ファイルもダウンロードしておきます。
$ wget https://raw.githubusercontent.com/intel/ros2_intel_realsense/master/realsense_ros2_camera/rviz/ros2.rviz起動は、以下実行すればOKです。
$ source /opt/ros/dashing/setup.bash $ ros2 run realsense_ros2_camera realsense_ros2_cameraRvizというソフトで可視化してみましょう。別のウィンドウを開いて、以下コマンドでダウンロードした設定ファイルを読み込んでRvizを起動します。
$ source /opt/ros/dashing/setup.bash $ ros2 run rviz2 rviz2 -d ros2.rvizババーンと、カラーカメラ情報、デプス情報、赤外線画像が表示されます。赤外線画像は、奥行き推定のために照射している赤外線のランダムドットパターンが見えますね。
PCL(Point Cloud)をみるときは、少し注意が必要です。何故か、 ROS1では繋がっていた
camera_depth_optical_frameとcamera_linkのフレームが繋がっていないので、Fixed Frameにcamera_depth_optical_frameを指定して、/camera/depth/color/pointsを指定する必要があります。設定と表示した様子は以下となります。
単純に、リアルセンス単体の動作を確認する場合は、以下のコマンドでもOKです。
$ rs-captureまた、ファームウェアのバージョンアップに必要なrealsense-viewerが含まれているlirealsenseは、ダウンロードしておいた方がよいでしょう。以下記事も参考にしてみてください。
Jetson NanoでIntel Realsense D435を使う方法(ROS対応)
Jetson NanoでRealsenseのPythonラッパーPyRealsenseを使用する方法
ちなみにJetPack4.4でROS1が動くかや、ROS2と共存できるかはまだ確認していません。
今回のセットアップに参考にしたのは、以下のサイトです。
Jetson Nano+ROS2上でのIntel RealSenseの動作と注意点
Installing ROS 2 via Debian Packages¶JetPack4.4でのハマりどころ
JetPack4.4でのハマりどころのまとめです。TensorFlow2.xになったことでのハマりどころもたくさんありますが、それはJetPackの問題ではないので割愛しています(エラーメッセージでググりましょう)。
tf.__version__でエラーが発生するJetPack4.4で発生しました。Twitterで教えてもらいましたが、
tf.version.VERSIONでバージョンが確認できるようです。何故…Twitter情報だと JetPack4.3では発生しないとのこと。何故…やっぱりそうなんですね。
— nb.o (@Nextremer_nb_o) May 30, 2020
jetpack 4.4のtensorflow2.xの挙動がよくわかりません...
わかったのは、
tf .__ version__ => NG
tf.version.VERSION => OK
でした。https://t.co/6jwSRl3Yzl pic.twitter.com/e6DqcEp3hgとりあえず使いたいソフトに
tf.__version__がある場合は、コメントアウトするなりしましょう。自分のソフトに関しては、tryで囲んでます。ラズパイカメラモジュール(RaspiCamV2)が動かない
いつからかは不明ですが、解像度設定 3280 x 2464ではラズパイカメラが動かなくなっていました。解像度を 1920 x 1080 に落とすことで解決しました。自分で作成したソフトは、解像度1920x1080に修正しています。
ディープラーニングで推論するとカメラが遅れる
カメラが数秒遅れます。Twitterで対策をフォロワーさんに教えてもらいました。
私自身は試せていませんが、参考情報として教えてもらった対策方法を紹介いたします。試しました。両方とも効果ありです!手っ取り早くは、キャプチャのreadを何度か空打ちすれば良いようです。Gstreamerのバッファがたまってしまっているのが問題ではないかとのことです。
while(cap.isOpened()): # ret, frame = cap.read() for i in range(5): ret, frame = cap.read() if ret == False: print('VideoCapture read return false.') breakちょっくんにhttps://t.co/18fE7Hx4Mf()を数回空打ちしてあげると、遅れないようになったのでやっぱりバッファに溜まっているのですね...
— nb.o (@Nextremer_nb_o) May 31, 2020
うーん... 過去のJetPackはどうだったでしょうかね?思い出せないです。https://t.co/aJ6bWPrxshもしくは、gstreamerのオプション変更でも対応できるそうです。こっちのほうがスマートそうですね。
(昨日の夜読むと言いながら、子供の寝かしつけでそのままおねんねしていました?)
— nb.o (@Nextremer_nb_o) June 1, 2020
リンクにあるgstreamerの文字列に”drop=true sync=false”を追加したところ遅延がなくなりました。
こちらのほうがすっきりします。https://t.co/xPpJjOzI4xまとめ
Jetson NanoをJetPack4.4に対応してみました。バージョンアップするだけで、ソフトがそのままでは色々動かなくなるのはOSSの宿命とはいえ、なかなか辛いものがありますね。ただ、最新の技術に触れる良い機会でもありますね、色々発見もありました(不毛な時間も多いですが)。そこまで理由がなければ、JetPack4.2か4.3を使用した方が良いかなというのが自分の感想です。
最後に「Jetson Nano超入門」はJetson Nanoの入門書としては有用な数少ない書籍と思いますので、もしよろしければ合わせてご購入検討ください。書籍の紹介や、サポートサイトへのリンクは以下参照ください。
共著で書いた本「Jetson Nano超入門」が12/21に発売されます
まあ、本を買わなくても今回の記事の内容は、記事読めば全部できちゃうんですけどね、HAHA!
関連記事
変更履歴
- 2020/06/02 カメラが遅れる問題に関して実機確認結果を追記 / ROS2のPCL表示に関して追記
- 2020/06/01 ディープラーニング使用時にカメラが遅れる問題に対する対策追記