- 投稿日:2020-05-31T23:21:14+09:00
Db2を利用したJavaアプリケーションでERRORCODE=-4471が発生する。
環境
本記事を書くにあたって利用した主なソフトウェアのバージョンは次の通りです。
- javac 11.0.4
- openjdk version "11.0.4" 2019-07-16
- IBM DB2 Developer-C Edition 11.5 (Docker/wsl2)
- IBM Data Server Driver for JDBC and SQLJ 4.26.14
事象
以下のコードは
EMPというテーブルからすべてのEMPNOを取得し、標準出力に出力するというものです。import java.sql.Connection; import java.sql.DriverManager; import java.sql.PreparedStatement; import java.sql.ResultSet; import java.sql.SQLException; public class Main { public static void main(String[] args) { String url = "jdbc:db2://<hostname>:<port>/<dbname>"; String user = "<user>"; String password = "<password>"; try (Connection con = DriverManager.getConnection(url, user, password)) { con.setAutoCommit(false); PreparedStatement ps = con.prepareStatement("SELECT * FROM EMP"); ResultSet rs = ps.executeQuery(); while (rs.next()) { System.out.println(rs.getString("EMPNO")); } } catch (SQLException e) { e.printStackTrace(); } } }このソースコードをコンパイルし、実行すると、標準出力にすべての
EMPNOを出力したあと、次のような例外が発生します。com.ibm.db2.jcc.am.SqlException: [jcc][t4][10251][10308][4.26.14] 接続でのトランザクション進行中に java.sql.Connection.close() が要求されました。 トランザクションはアクティブのままとなり、接続はクローズできません。 ERRORCODE=-4471, SQLSTATE=null at com.ibm.db2.jcc.am.b7.a(b7.java:794) at com.ibm.db2.jcc.am.b7.a(b7.java:66) at com.ibm.db2.jcc.am.b7.a(b7.java:133) at com.ibm.db2.jcc.am.Connection.checkForTransactionInProgress(Connection.java:1484) at com.ibm.db2.jcc.t4.b.checkForTransactionInProgress(b.java:7581) at com.ibm.db2.jcc.am.Connection.closeResourcesX(Connection.java:1507) at com.ibm.db2.jcc.am.Connection.closeX(Connection.java:1493) at com.ibm.db2.jcc.am.Connection.close(Connection.java:1470) at Main.main(Main.java:22)
java.sql.Connection.close()はtry-catch-with-resourceが勝手に呼び出してくれているから理解できるとして、そもそも「トランザクションはアクティブのままとなり、接続はクローズできません」ってなんのこっちゃ??? となるわけです。原因
Db2ではDBコネクションをクローズする前に、
COMMITやROLLBACKによってトランザクションを確定させる必要があります。COMMITやROLLBACKをするのは、INSERTやDELETEなど、DBのデータに変更を加えたときだけで、データを参照するだけのSELECTではCOMMITやROLLBACKに注意が回らない--という人も多いかと思いますが、少なくともDb2ではSELECTの場合でもトランザクションを意識する必要があります。前述のソースコードでは、自動コミットがオフの状態になっていました(
con.setAutoCommit(false))。自動コミット=trueの場合、Connection::closeを呼び出すと、jdbcドライバが自動でコミットしてくれるのですが、自動コミット=falseだと、プログラマが明示的にConnection::commitやConnection::rollbackを呼び出さないと、トランザクションが確定しません。つまり、前述のソースコードでは自動コミットをオフにしたために、トランザクションが確定しないまま、コネクションをクローズしようとし、その結果ERRORCODE=-4471が発生してしまったわけです。対策
Connection::commitもしくはConnection::rollbackを呼び出して、トランザクションを明示的に完了させる- 自動コミット=trueにして、トランザクションの完了をJDBC Driverに丸投げする。
対策はこんなもんでしょうか(´・ω・`)
- 投稿日:2020-05-31T22:35:57+09:00
Javaアプリケーションの状態を監視ツールを入れずに確認してみる
概要
jstackはJDKに付属するコマンドです。javaを起動してるマシンであれば特別監視ツールなんかを入れなくても簡単にプロセスの状態を取得することができます。
このツールは、コマンドラインコンソールにスレッドダンプを表示します。JavaのPIDさえわかれば使用することができる。性能が出ない時やデッドロックのような現象が発生した際はこのツールを使ってスレッドの状態を取得し調査に使うことができる。
Usage
$ jstack -l <pid>出力結果はthread単位のスタックトレースを確認することができる。
"Thread-0" #12 prio=5 os_prio=0 cpu=0.00ms elapsed=496.25s tid=0x00007f6a741f1800 nid=0x1a5 waiting on condition [0x00007f6a17a9f000] java.lang.Thread.State: TIMED_WAITING (sleeping) at java.lang.Thread.sleep(java.base@11.0.4/Native Method) at Server.sleepForever(Server.java:20) at Server.lambda$0(Server.java:9) at Server$$Lambda$1/0x0000000840060840.run(Unknown Source) at java.lang.Thread.run(java.base@11.0.4/Thread.java:834) "Thread-1" #13 prio=5 os_prio=0 cpu=0.00ms elapsed=496.25s tid=0x00007f6a741f3800 nid=0x1a6 waiting on condition [0x00007f6a1798f000] java.lang.Thread.State: TIMED_WAITING (sleeping) at java.lang.Thread.sleep(java.base@11.0.4/Native Method) at Server.sleepForever(Server.java:20) at Server.lambda$0(Server.java:9) at Server$$Lambda$1/0x0000000840060840.run(Unknown Source) at java.lang.Thread.run(java.base@11.0.4/Thread.java:834) "Thread-2" #14 prio=5 os_prio=0 cpu=0.00ms elapsed=496.25s tid=0x00007f6a741f5000 nid=0x1a7 waiting on condition [0x00007f6a1787f000] java.lang.Thread.State: TIMED_WAITING (sleeping) at java.lang.Thread.sleep(java.base@11.0.4/Native Method) at Server.sleepForever(Server.java:20) at Server.lambda$0(Server.java:9) at Server$$Lambda$1/0x0000000840060840.run(Unknown Source) at java.lang.Thread.run(java.base@11.0.4/Thread.java:834)例えばjavaがマルチスレッドで動いてるケースでどこかのスレッドが特にCPU使用率やメモリをたくさん食ってるといった現象が起きた際は以下のように特定することができる。
① プロセスからリソースを食ってるプロセスを特定する。
$ top -H -b -n 1 -p ${javaのpid}上記のコマンドからリソースを食ってるPIDを取得する
② PIDを16進数へ変換し、jstackの結果からgrep
③ nid と 16進数が一致するトレースがリソースを食ってる処理なのでそこから追っていくといった流れで調査することが可能。
- 投稿日:2020-05-31T21:50:37+09:00
多段階選抜 (Java/Groovy/Scala)
Swiftで書けるならJVM系でも問題なく書けますよね…
Java
tyama_hena24_enum.java//usr/bin/env java $0 $@;exit # pseudo-shebang for Java 11+ // http://qiita.com/Nabetani/items/1c83005a854d2c6cbb69 // http://nabetani.sakura.ne.jp/hena/ord24eliseq/ import java.util.Map; import java.util.HashMap; import java.util.Scanner; import java.util.Iterator; import java.util.function.Function; import java.util.function.BiFunction; class Hena24{ static int isqrt(int n){ if(n<=0)return 0; if(n<4)return 1; int x=0,y=n; for(;x!=y&&x+1!=y;){x=y;y=(n/y+y)/2;} return x; } static int icbrt(int n){ if(n<0)return icbrt(-n); if(n==0)return 0; if(n<8)return 1; int x=0,y=n; for(;x!=y&&x+1!=y;){x=y;y=(n/y/y+y*2)/3;} return x; } class generate implements Iterator<Integer>{ int i=0; public boolean hasNext(){return true;} public Integer next(){ i+=1; return i; } } class drop_prev implements Iterator<Integer>{ Iterator<Integer> prev; Function<Integer,Boolean> check; int a=0; int b=0; drop_prev(Function<Integer,Boolean> check_, Iterator<Integer> prev_){ check = check_; prev = prev_; b = prev.next(); } public boolean hasNext(){return true;} public Integer next(){ for(;;){ a = b; b = prev.next(); if(!check.apply(b)){ return a; } } } } class drop_next implements Iterator<Integer>{ Iterator<Integer> prev; Function<Integer,Boolean> check; boolean first = true; int a=0; int b=0; drop_next(Function<Integer,Boolean> check_, Iterator<Integer> prev_){ check = check_; prev = prev_; } public boolean hasNext(){return true;} public Integer next(){ for(;;){ a = b; b = prev.next(); if(first||!check.apply(a)){ first = false; return b; } } } } class drop_n implements Iterator<Integer>{ Iterator<Integer> prev; BiFunction<Integer,Integer,Boolean> check; int n=0; int i=0; drop_n(BiFunction<Integer,Integer,Boolean> check_, int n_, Iterator<Integer> prev_){ check = check_; prev = prev_; n = n_; } public boolean hasNext(){return true;} public Integer next(){ for(;;){ i++; int a = prev.next(); if(!check.apply(i,n)){ return a; } } } } static boolean is_sq(int n){ int x=isqrt(n); return x*x==n; } static boolean is_cb(int n){ int x=icbrt(n); return x*x*x==n; } static boolean is_multiple(int i,int n){return i%n==0;} static boolean is_le(int i,int n){return i<=n;} public void Run(){ Map<Character,Function<Iterator<Integer>,Iterator<Integer>>> f=new HashMap<Character,Function<Iterator<Integer>,Iterator<Integer>>>(){ { put('S',(e)->new drop_next(Hena24::is_sq,e)); put('s',(e)->new drop_prev(Hena24::is_sq,e)); put('C',(e)->new drop_next(Hena24::is_cb,e)); put('c',(e)->new drop_prev(Hena24::is_cb,e)); put('h',(e)->new drop_n(Hena24::is_le,100,e)); } }; for(int i=2;i<=9;i++){ int j=i; f.put(String.valueOf(i).charAt(0),(e)->new drop_n(Hena24::is_multiple,j,e)); } Scanner cin = new Scanner(System.in); for(;cin.hasNext();){ String line = cin.nextLine(); boolean first=true; Iterator<Integer> z=new generate(); for(char e:line.toCharArray())z=f.get(e).apply(z); for(int i=0;i<10;i++){ int n=z.next(); if(!first)System.out.print(','); first=false; System.out.print(n); } System.out.print('\n'); System.out.flush(); } } public static void main(String[]z){new Hena24().Run();} }Groovy
(Javaとほとんど同じですが、HashMapの宣言及びクロージャの呼び方が異なっています)
(動くことは確認しましたが、HashMapの型があっているかはわかりません…)tyama_hena24_enum.groovy#!/usr/bin/env groovy // http://qiita.com/Nabetani/items/1c83005a854d2c6cbb69 // http://nabetani.sakura.ne.jp/hena/ord24eliseq/ import java.util.Map; import java.util.HashMap; import java.util.Scanner; import java.util.Iterator; import java.util.function.Function; import java.util.function.BiFunction; class Hena24{ static int isqrt(int n){ if(n<=0)return 0; if(n<4)return 1; int x=0,y=n; for(;x!=y&&x+1!=y;){x=y;y=(n/y+y)/2;} return x; } static int icbrt(int n){ if(n<0)return icbrt(-n); if(n==0)return 0; if(n<8)return 1; int x=0,y=n; for(;x!=y&&x+1!=y;){x=y;y=(n/y/y+y*2)/3;} return x; } class generate implements Iterator<Integer>{ int i=0; public boolean hasNext(){return true;} public Integer next(){ i+=1; return i; } } class drop_prev implements Iterator<Integer>{ Iterator<Integer> prev; Function<Integer,Boolean> check; int a=0; int b=0; drop_prev(Function<Integer,Boolean> check_, Iterator<Integer> prev_){ check = check_; prev = prev_; b = prev.next(); } public boolean hasNext(){return true;} public Integer next(){ for(;;){ a = b; b = prev.next(); if(!check.apply(b)){ return a; } } } } class drop_next implements Iterator<Integer>{ Iterator<Integer> prev; Function<Integer,Boolean> check; boolean first = true; int a=0; int b=0; drop_next(Function<Integer,Boolean> check_, Iterator<Integer> prev_){ check = check_; prev = prev_; } public boolean hasNext(){return true;} public Integer next(){ for(;;){ a = b; b = prev.next(); if(first||!check.apply(a)){ first = false; return b; } } } } class drop_n implements Iterator<Integer>{ Iterator<Integer> prev; BiFunction<Integer,Integer,Boolean> check; int n=0; int i=0; drop_n(BiFunction<Integer,Integer,Boolean> check_, int n_, Iterator<Integer> prev_){ check = check_; prev = prev_; n = n_; } public boolean hasNext(){return true;} public Integer next(){ for(;;){ i++; int a = prev.next(); if(!check.apply(i,n)){ return a; } } } } static boolean is_sq(int n){ int x=isqrt(n); return x*x==n; } static boolean is_cb(int n){ int x=icbrt(n); return x*x*x==n; } static boolean is_multiple(int i,int n){return i%n==0;} static boolean is_le(int i,int n){return i<=n;} public void Run(){ Map<Character,Function<Iterator<Integer>,Iterator<Integer>>> f=[ ('S' as char):(e)->new drop_next(Hena24::is_sq,e), ('s' as char):(e)->new drop_prev(Hena24::is_sq,e), ('C' as char):(e)->new drop_next(Hena24::is_cb,e), ('c' as char):(e)->new drop_prev(Hena24::is_cb,e), ('h' as char):(e)->new drop_n(Hena24::is_le,100,e), ] as HashMap for(int i=2;i<=9;i++){ int j=i; f.put(String.valueOf(i).charAt(0),(e)->new drop_n(Hena24::is_multiple,j,e)); } Scanner cin = new Scanner(System.in); for(;cin.hasNext();){ String line = cin.nextLine(); boolean first=true; Iterator<Integer> z=new generate(); for(char e:line.toCharArray()){z=f.get(e)(z);} for(int i=0;i<10;i++){ int n=z.next(); if(!first)System.out.print(','); first=false; System.out.print(n); } System.out.print('\n'); System.out.flush(); } } public static void main(String[]z){new Hena24().Run();} }Scala
tyama_hena24_enum.scala//usr/bin/env scala $0 $@;exit // http://qiita.com/Nabetani/items/1c83005a854d2c6cbb69 // http://nabetani.sakura.ne.jp/hena/ord24eliseq/ import java.util.Map; import java.util.HashMap import java.util.Scanner import java.util.Iterator import java.util.function.Function import java.util.function.BiFunction object Hena24{ def isqrt(n:Int):Int = { if(n<=0)return 0 if(n<4)return 1 var x=0 var y=n while(x!=y&&x+1!=y){x=y;y=(n/y+y)/2} return x } def icbrt(n:Int):Int = { if(n<0)return icbrt(-n) if(n==0)return 0 if(n<8)return 1 var x=0 var y=n while(x!=y&&x+1!=y){x=y;y=(n/y/y+y*2)/3} return x } class generate extends Iterator[Int]{ var i=0 def hasNext():Boolean = {return true} def next():Int = { i+=1 return i } } class drop_prev(check:Function[Int,Boolean], prev:Iterator[Int]) extends Iterator[Int]{ var a=0 var b=prev.next() def hasNext():Boolean = {return true} def next():Int = { while(true){ a = b b = prev.next() if(!check.apply(b)){ return a } } assert(false); return -1 } } class drop_next(check:Function[Int,Boolean], prev:Iterator[Int]) extends Iterator[Int]{ var first = true var a=0 var b=0 def hasNext():Boolean = {return true} def next():Int = { while(true){ a = b b = prev.next() if(first || !check.apply(a)){ first = false return b } } assert(false); return -1 } } class drop_n(check:BiFunction[Int,Int,Boolean], n:Int, prev:Iterator[Int]) extends Iterator[Int]{ var i=0 def hasNext():Boolean = {return true} def next():Int = { while(true){ i+=1 val a = prev.next() if(!check.apply(i,n)){ return a } } assert(false); return -1 } } def is_sq(n:Int):Boolean = { val x=isqrt(n) return x*x==n } def is_cb(n:Int):Boolean = { val x=icbrt(n) return x*x*x==n } def is_multiple(i:Int,n:Int):Boolean = {return i%n==0} def is_le(i:Int,n:Int):Boolean = {return i<=n} def main(z:Array[String]):Unit = { var f:Map[Character,Function[Iterator[Int],Iterator[Int]]] = new HashMap[Character,Function[Iterator[Int],Iterator[Int]]](){ { put('S',(e:Iterator[Int])=>new drop_next(is_sq _,e)) put('s',(e:Iterator[Int])=>new drop_prev(is_sq _,e)) put('C',(e:Iterator[Int])=>new drop_next(is_cb _,e)) put('c',(e:Iterator[Int])=>new drop_prev(is_cb _,e)) put('h',(e:Iterator[Int])=>new drop_n(is_le _,100,e)) } } for(i<-2 to 9){ val j=i f.put(String.valueOf(i).charAt(0),(e:Iterator[Int])=>new drop_n(is_multiple _,j,e)) } val cin = new Scanner(System.in) while(cin.hasNext()){ val line = cin.nextLine() var first=true var z:Iterator[Int] = new generate() for(e<-line.toCharArray())z=f.get(e).apply(z) for(i<-1 to 10){ var n=z.next() if(!first)System.out.print(',') first=false System.out.print(n) } System.out.print('\n') System.out.flush() } } }
- 投稿日:2020-05-31T18:45:31+09:00
覗き見可能なイテレータを作ってみる
前書き
イテレータのラッパークラスを作る際、hasNextの実装に困ることが多い。
ただラップするだけなら内部のイテレータに委譲すれば良いが、都合上そのような戦略を取れない場合だ。次の要素を覗き見れれば便利なのに... というわけで、作ってみる。
本題
次のような動作をするクラス、PeekableIteratorを作ってみた。
var src = java.util.List.of(3, 1, 4); var peekIt = new PeekableIterator<>(src); while(peekIt.hasNext()) { System.out.printf("次の要素は %d です。\n", peekIt.peek()); System.out.printf("もう一度言います。 %d です。\n", peekIt.peek()); System.out.printf("ほら、本当に %d だったでしょ?\n", peekIt.next()); System.out.println(); } System.out.println("おしまい");実行結果
次の要素は 3 です。 もう一度言います。 3 です。 ほら、本当に 3 だったでしょ? 次の要素は 1 です。 もう一度言います。 1 です。 ほら、本当に 1 だったでしょ? 次の要素は 4 です。 もう一度言います。 4 です。 ほら、本当に 4 だったでしょ? おしまい実装
メソッドの構成
コンストラクタと本命のメソッドpeek()だけを加えたシンプルな構成である。
hasNext()が偽のとき、peek()は例外NoSuch~を投げる。これはIterator#next()の仕様をなぞったものである。PeekableIterator.javaimport java.util.Iterator; import java.util.NoSuchElementException; public class PeekableIterator<T> implements Iterator<T> { public PeekableIterator(Iterable<T> iterable) { ... } public PeekableIterator(Iterator<T> it) { ... } public T peek() throws NoSuchElementException { ... } @Override public T next() throws NoSuchElementException { ... } @Override public boolean hasNext() { ... } }フィールドの構成
構成は次のとおりである。
it.next()がnullを返す可能性も考慮し、nextElemとhasNextをセットで取り扱っている。private final Iterator<T> it; // 大元のイテレータ private T nextElem; // 次の要素 private boolean hasNext = false; // 次の要素が存在するか?メソッドの実装
コンストラクタではさっそく覗き見をし、次の要素をフィールドに保持している。
PeekableIterator#newpublic PeekableIterator(Iterable<T> iterable) { this(iterable.iterator()); } public PeekableIterator(Iterator<T> it) { this.it = it; if(it.hasNext()) { nextElem = it.next(); hasNext = true; } }メソッドhasNext()は、結局ただのゲッターである。
next()はnextElemを返すだけだが、次の要素を覗き見する処理が必要だ。PeekableIterator#hasNext,#next@Override public boolean hasNext() { return hasNext; } @Override public T next() throws NoSuchElementException { if(!hasNext()) { throw new NoSuchElementException(); } final T ret = nextElem; if(it.hasNext()) { nextElem = it.next(); } else { hasNext = false; } return ret; }本命peek()の実装も簡単だ。ただしnextElemが無効であるかチェックしなければならない。
PeekableIteratorpublic T peek() throws NoSuchElementException { if(!hasNext()) { throw new NoSuchElementException(); } return nextElem; }
全体のコード
Peekable.javaimport java.util.Iterator; import java.util.NoSuchElementException; public class PeekableIterator<T> implements Iterator<T> { // private final Iterator<T> it; private T nextElem; private boolean hasNext = false; public PeekableIterator(Iterable<T> iterable) { this(iterable.iterator()); } public PeekableIterator(Iterator<T> it) { this.it = it; if (it.hasNext()) { nextElem = it.next(); hasNext = true; } } // public T peek() throws NoSuchElementException { if (!hasNext()) { throw new NoSuchElementException(); } return nextElem; } // @Override public boolean hasNext() { return hasNext; } @Override public T next() throws NoSuchElementException { if (!hasNext()) { throw new NoSuchElementException(); } final T ret = nextElem; if (it.hasNext()) { nextElem = it.next(); } else { hasNext = false; } return ret; } }利用上の問題
イテレータを独占していないことに起因する問題
コンストラクタでイテレータを受け取ったとき、特に複製などはしていない。
そのため、呼び出し元でイテレータを直接操作してしまうと要素がスキップされたように見えてしまう。var it = java.util.List.of(3, 1, 4).iterator(); var peekIt = new itertools.PeekableIterator<>(it); it.next(); while(peekIt.hasNext()) { System.out.printf("次の要素は %d です。\n", peekIt.peek()); System.out.printf("もう一度言います。 %d です。\n", peekIt.peek()); System.out.printf("ほら、本当に %d だったでしょ?\n", peekIt.next()); System.out.println(); } System.out.println("おしまい");実行結果
次の要素は 3 です。 もう一度言います。 3 です。 ほら、本当に 3 だったでしょ? 次の要素は 4 です。 もう一度言います。 4 です。 ほら、本当に 4 だったでしょ? おしまいしかしイテレータを完全に独立させるのは、どうやら不可能そうである。
- イテレータはいわば『状態』であり、それがそのまま複製できるかどうかは提供側に依存する。
- 全要素を読み出せば幾らでもイテレータが作れるが、要素の取得を遅延できるメリットが消える。
- そもそも全要素を読み出した時点で、元のイテレータが枯れる。
- そもそも無限に要素を返すイテレータはどうするのだ。
イテレータに『利用不可』属性を付与できるような仕組みがあると良いのだが...
端点でpeek()した際に例外が発生する問題
仕様どおりではあるけれど。
var src = java.util.List.of(3, 1); var peekIt = new PeekableIterator<>(src); while(peekIt.hasNext()) { System.out.printf("今の要素は %d です。\n", peekIt.next()); System.out.printf("次の要素は %d です。お楽しみに。\n", peekIt.peek()); System.out.println(); } System.out.println("おしまい");実行結果
今の要素は 3 です。 次の要素は 1 です。お楽しみに。 今の要素は 1 です。 Exception in thread "main" java.util.NoSuchElementException at ...既存のライブラリ
本プログラムのインターフェースを決定する際には、Pythonのmore_itertools.peekableを参考にした。
しかし改めて調べてみると、Javaでも同様のクラスが提供されているらしい。
端点をどのように処理しているのか着目しながら、実際に使ってみることとする。Apache Commons: Class PeekingIterator<E>
peekingIterator() でもインスタンスを得られるが、コンストラクタとの違いは不明。1
目的に応じてelement()とpeek()を使い分けられる。地味に便利。var src = java.util.List.of(3, 1); var peekIt = new PeekingIterator<>(src.iterator()); while(peekIt.hasNext()) { System.out.printf("今の要素は %d です。\n", peekIt.next()); System.out.printf("次の要素は %d です。お楽しみに。(peek)\n", peekIt.peek()); System.out.printf("次の要素は %d です。お楽しみに。(element)\n", peekIt.element()); System.out.println(); } System.out.println("おしまい");実行結果
今の要素は 3 です。 次の要素は 1 です。お楽しみに。(peek) 次の要素は 1 です。お楽しみに。(element) 今の要素は 1 です。 次の要素は null です。お楽しみに。(peek) Exception in thread "main" java.util.NoSuchElementException at ...Guava: Interface PeekingIterator<E>
Iterators.peekingIteratorを介してインスタンスを受け取ることになる。
こちらにはelement()メソッドは無く、終端のpeek()は例外を吐いて終わるようだ。var src = java.util.List.of(3, 1); var peekIt = Iterators.peekingIterator(src.iterator()); while(peekIt.hasNext()) { System.out.printf("今の要素は %d です。\n", peekIt.next()); System.out.printf("次の要素は %d です。お楽しみに。\n", peekIt.peek()); System.out.println(); } System.out.println("おしまい");今の要素は 3 です。 次の要素は 1 です。お楽しみに。 今の要素は 1 です。 Exception in thread "main" java.util.NoSuchElementException at ...後書き
おしまい。
そんなに真面目に調べていないので、案外ググったらすぐ出るかも。 ↩
- 投稿日:2020-05-31T18:30:40+09:00
Apache Camel Spring Boot starters でDB上のデータをバッチ処理するサンプル
「Apache Camel Spring Boot starters を使った単純なcamelアプリの作成手順」の続きで、MySQLにためたタスクを処理するバッチを実装する。
本当は複数マシンで並行処理させる際の排他制御を実験するという目的があるのだが、SQLもcamelもJavaも中途半端な理解なのでまだそこまでできない。今回のアプリはそこへ繋がりそうなサンプルという位置付け。
前回の分は説明しないが、必要なファイルは全てこちらの記事に書くので見返さなくても動かせる。
ファイル一覧path/to/app/ ├── src/main/ │ ├── java/org/example/mycamelapp/ │ │ ├── db/ │ │ │ ├── TaskSql.java │ │ │ └── TaskTable.java │ │ ├── processors/ │ │ │ └── PseudoWorkProcessor.java │ │ ├── routes/ │ │ │ └── TaskExecutionRoute.java │ │ └── MyCamelApplication.java │ └── resources/ │ └── application.yml └── pom.xml環境
DBを追加した以外は前回と同じ。
- Java: 1.8.0_191
- Maven: 3.6.3
- Camel: 3.2.0
- Spring: 5.2.5.RELEASE
- Spring Boot: 2.2.6.RELEASE
- MySQL: 5.7.30
DBテーブル定義
taskテーブルを作る。「タスク処理」をイメージしたカラムは以下の2つ。
status: タスクの処理段階を表す。各バッチ(今回は1つだけ)は自分の担当する段階のタスクを抜き出して、完了したらステータスを進める。executor: タスクを処理する/したホストを記録する。アプリを複数のマシンで並列実行する際に排他制御に使うかもしれない。いずれ実験したい排他制御の想定は、異なるタスクは順序を気にせず並行して処理してもいいが、同じタスクを二重に実行してはいけないというもの。
CREATE DATABASE IF NOT EXISTS my_camel_app; CREATE TABLE IF NOT EXISTS my_camel_app.task ( task_id int(11) NOT NULL AUTO_INCREMENT, status int(11) NOT NULL DEFAULT 0, executor varchar(255) DEFAULT NULL, created_at datetime NOT NULL DEFAULT CURRENT_TIMESTAMP, updated_at datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (task_id) );レコードの追加は
INSERT INTO my_camel_app.task () VALUES ();という感じで行える。前回のtimerを使って自動で増やしてもいいかもしれない。pom.xml
全文(クリックして展開)
pom.xml (mycamelapp)<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>org.example</groupId> <artifactId>mycamelapp</artifactId> <version>1.0-SNAPSHOT</version> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.2.6.RELEASE</version> </parent> <!-- https://camel.apache.org/camel-spring-boot/latest/index.html --> <dependencyManagement> <dependencies> <!-- Camel BOM --> <dependency> <groupId>org.apache.camel.springboot</groupId> <artifactId>camel-spring-boot-dependencies</artifactId> <version>3.2.0</version> <type>pom</type> <scope>import</scope> </dependency> <!-- ... other BOMs or dependencies ... --> </dependencies> </dependencyManagement> <dependencies> <!-- Camel Starter --> <dependency> <groupId>org.apache.camel.springboot</groupId> <artifactId>camel-spring-boot-starter</artifactId> </dependency> <dependency> <groupId>org.apache.camel.springboot</groupId> <artifactId>camel-sql-starter</artifactId> </dependency> <!-- ... other dependencies ... --> <!-- JDBC --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-jdbc</artifactId> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> </dependency> <!-- Utils --> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <scope>provided</scope> </dependency> </dependencies> </project>変更点:
- 親プロジェクトに spring-boot-starter-parent を指定
- dependencyManagementに spring-boot-dependencies を追加した場合は、pluginsは継承されず明示しなければならないため
2.2.6.RELEASEはcamelバージョンに合わせたもの- dependenciesへの追加
- camel-sql-starter
- spring-boot-starter-jdbc
- mysql-connector-java
- lombok (getterなどの自動生成用、コンパイル時に利用)
- その他
- buildは丸ごと削除(pluginsは spring-boot-dependencies の設定を利用するため)
dependencyManagement(親プロジェクトを含む)の中で書かれているものは改めてバージョンを書く必要が無いのが便利。 mysql-connector-java や lombok もあった。
タスク処理の実装
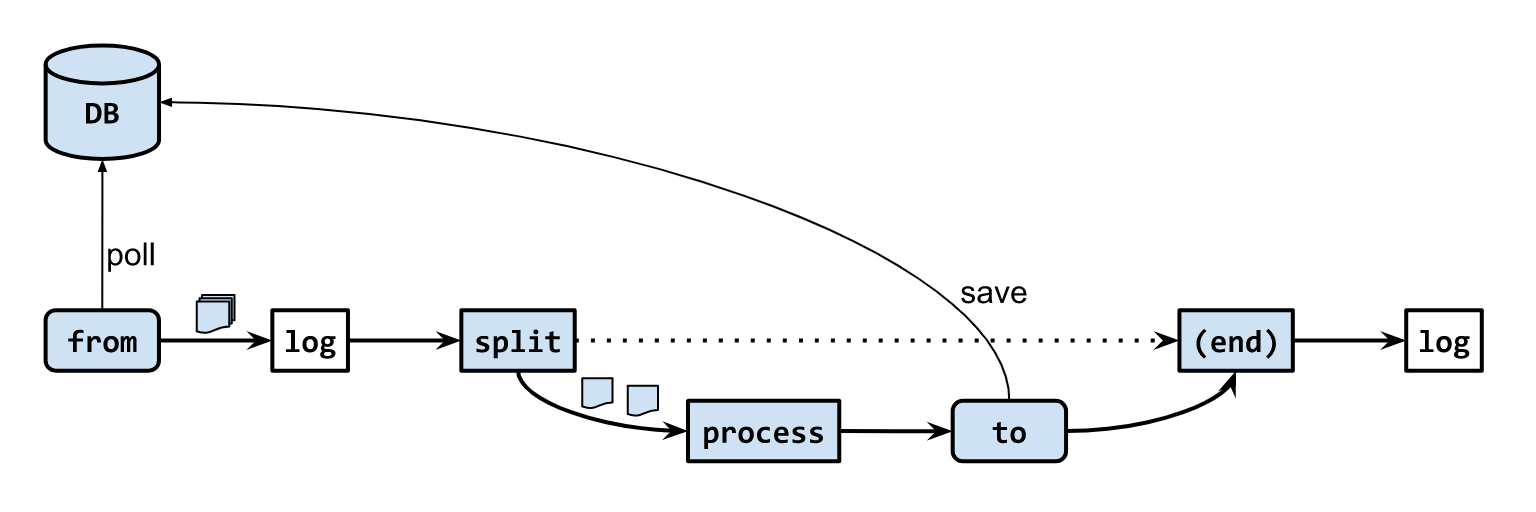
「DBからタスクを一度に複数取得し、並列で処理してDBを更新する」というrouteを作ってみる。
処理するタスクのステータスは
UNEXECUTED→SUCCEEDED。(各ステータスには後で適当に数字を割り当てる)Route
細かい設定や処理は別で定義することにして、まずは絵の通りに構造だけ作成する。(コードをコピペする場合は、他のクラスをimportする必要があるので最後がいい)
src/main/java/org/example/mycamelapp/routes/TaskExecutionRoute.java@Component public class TaskExecutionRoute extends RouteBuilder { // dummy hostname static public final String HOSTNAME = "host-" + Integer.toHexString(new SecureRandom().nextInt()); @Override public void configure() throws Exception { from(TaskSql.selectTasks(TaskTable.Status.UNEXECUTED, 5)) // exchange.getIn().getBody() is List<Map<String, Object>> of records .log("${body.size} rows selected.") .split(body()).parallelProcessing() // exchange.getIn().getBody() is Map<String, Object> of a record .process(new PseudoWorkProcessor()) .to(TaskSql.updateTask(TaskTable.Status.SUCCEEDED, HOSTNAME)) .end() .log("all tasks finished.") ; } }
from()にデータを受け取る設定をURI文字列で書く。- camelでは文字列の中に
${expr}という形で式展開を書けることが多い。split()でデータを分割してそれぞれ処理する。
- 分割されたデータは新しいexchangeに詰められる。
- 今回は順序を気にしないので
parallelProcessing()を指定して並行処理させる。- メソッドチェーンでもexchangeを色々操作できるが、今回は
process()で自作クラスによってexchangeを編集する。to()にデータを渡す設定をURI文字列で書く。end()で入れ子構造の終わりを示す。JavaのDSLだと
end()を入れ忘れても滅多に構文エラーにならず、想像と異なるroute構造になってしまう危険性がある。なお、
RouteBuilderやconfigure()という名前が示す通り、このメソッドはデータが来る度に呼ばれるのではなくアプリ起動時に一度だけ呼ばれる。そのためブレークポイントを置いてもデータ処理のデバッグはできない。テーブルとクエリ
src/main/java/org/example/mycamelapp/db/TaskTable.javapublic interface TaskTable { String TABLE_NAME = "task"; String TASK_ID = "task_id"; String STATUS = "status"; String EXECUTOR = "executor"; String CREATED_AT = "created_at"; String UPDATED_AT = "updated_at"; @AllArgsConstructor @Getter enum Status { UNEXECUTED(0), SUCCEEDED(10), FAILED(-1), ; private final int code; } }src/main/java/org/example/mycamelapp/db/TaskSql.javapublic class TaskSql implements TaskTable { public static String insertTask() { return "sql:INSERT INTO " + TABLE_NAME + " () VALUES ()"; } public static String selectTasks(Status status, int limit) { return "sql:SELECT * FROM " + TABLE_NAME + " WHERE " + STATUS + " = " + status.getCode() + " LIMIT " + limit + "?useIterator=false" // List<Map<String, Object>> ; } public static String updateTask(Status nextStatus, String hostname) { return "sql:UPDATE " + TABLE_NAME + " SET " + STATUS + " = " + nextStatus.getCode() + ", " + EXECUTOR + " = " + quote(hostname) + " WHERE " + TASK_ID + " = " + ref(TASK_ID) ; } private static String quote(String value) { if (value == null) return "NULL"; return "'" + value + "'"; } private static String ref(String key) { return ":#" + key; } }
from()やto()に指定する文字列はURIであり、?以降にオプションを指定できる。今回使っているのはuseIterator=falseで、DBから取得したデータをrouteへ1行ずつMap<>で流すのではなくList<Map<>>で1個に纏めて流す。クエリの中に
:#task_id(←ref(TASK_ID))という文字列が登場する。これはcamelがexchange内のbodyまたはheaderからキーに対応する値を取り出して埋め込む。Process
「時間のかかる処理をしている」という想定で、ランダムに1〜3秒のスリープを入れる。
src/main/java/org/example/mycamelapp/processors/PseudoWorkProcessor.java@Slf4j public class PseudoWorkProcessor implements Processor { @Override public void process(Exchange exchange) throws Exception { Map<String, Object> task = exchange.getIn().getBody(Map.class); int processingTime = ThreadLocalRandom.current().nextInt(1000, 3000); String infoMsg = "task_id = " + task.get(TaskTable.TASK_ID) + ", time = " + processingTime + "[ms]"; log.info("start working :: " + infoMsg); Thread.sleep(processingTime); log.info("finish working :: " + infoMsg); } }こちらはデータが来るたびに呼ばれるので、ブレークポイントを置いてデバッグできる。
起動
設定
MySQLへの接続設定を追加する。ここではyamlに書いているが、環境変数や
-Dオプションで与えてもいい(SpringBootで優先順位が決まっている)。長く書くのが面倒だったので、URLにユーザー名やパスワードも入れた。src/main/resources/application.yml# to keep the JVM running camel: springboot: main-run-controller: true spring: data-source: url: jdbc:mysql://user:password@localhost:3306/my_camel_appアプリの開始地点は前回と同じ。
src/main/java/org/example/mycamelapp/MyCamelApplication.java@SpringBootApplication public class MyCamelApplication { public static void main(String[] args) { SpringApplication.run(MyCamelApplication.class, args); } }実行
terminalcd path/to/app mvn spring-boot:run参考
- 投稿日:2020-05-31T14:54:51+09:00
十数年前のJava使いが、今更ながらJava8 の機能を勉強してみた( ラムダ式編 )
はじめに
最近お仕事の都合で、Java を使う機会に恵まれたので
太古のJava( 1.3 )知識をアップデートしてみました。ラムダ式 とは
関数的インターフェイスを簡単に実装するための機能です。
これだけでは何のことかさっぱりなので、例を出しつつ説明したいと思います。
ラムダ式の違いをコードで比較
ラムダ式を使わないコード
public static void main(String[] args) { class Sample implements Runnable { public void run() { System.out.println("I Love Pengin!"); } } Runnable runner = new Sample(); times( 10, runner ); } public static void times( int count, Runnable runner ) { for( int i = 0; i < count; i++ ) { runner.run(); } }ラムダ式を使ったコード
public static void main(String[] args) { funcCall( 10, () -> System.out.println("I Love Pengin!") ); } public static void times( int count, Runnable runner ) { for( int i = 0; i < count; i++ ) { runner.run(); } }使うと何が良いの?
指定の処理を複数回繰り返す
times関数への処理を例にしました。
見比べてみると、ラムダ式を使うと随分と完結に処理がかけていることが見比べていただけると思います。処理の一部を他のオブジェクトに代替させる手法を委譲と呼ぶのですが、
ラムダ式を使うことで、この委譲が随分と書きやすくなることがメリットに上がると思います。ラムダ式の書き方
書式
ラムダ式を使う場合の書式を見ていきましょう
() -> System.out.println("I Love Pengin!")
- 最初の
()はメソッドの引数を表します。今回は引数を使用してませんが引数を使用することも可能です。->が実際の処理内容を記載しています。 処理内容が複数にまたがる場合は、-> { ここに処理 }と記載します。※引数や、戻り値を利用する場合、呼び出される側( 今回ならtimes関数 )の実装が少し異なります。
引数を使用したラムダ式
使うとき
ラムダ式の引数を指定することで、処理中に引数が利用できます。
java
(i) -> System.out.println("I Love Pengin!" + i)
作るとき
利用する引数、戻り値の種類に応じて、関数インターフェイスを使い分ける必要があります。
引数1つ、戻り値なしの場合は、以下のようになります。public static void times( int count, Consumer<Integer> runner ) { for( int i = 0; i < count; i++ ) { runner.accept(new Integer(i)); } }使い分けるインターフェイスは以下の様になります。
種類 関数インターフェイス メソッド 値を返さない 引数0個 Runnable run 値を返さない 引数1個 Consumer accept 値を返さない 引数2個 BiConsumer accept 値を返す 引数0個 Supplier get 値を返す 引数1個 Function apply 値を返す 引数2個 BiFunction apply 真偽値を返す 引数1個 Predicate test 真偽値を返す 引数2個 BiPredicate test 演算結果を返す 引数1個 UnaryOperator test 演算結果を返す 引数2個 BinaryOperator test
- 投稿日:2020-05-31T14:54:32+09:00
十数年前のJava使いが、今更ながらJava8 の機能を勉強してみた( Generics編 )
はじめに
最近お仕事の都合で、Java を使う機会に恵まれたので
太古のJava( 1.3 )知識をアップデートしてみました。Generics とは
利用する型の処理を実装時に確定する機能です。
これだけでは何のことかさっぱりなので、例を出しつつ説明したいと思います。
Generics 有無をコードで比較
Java1.3の頃のコード
List list = new ArrayList(); // list に値を格納 // String -> Object への変換なので暗黙的に格納出来る list.add("1"); list.add("2"); list.add("3"); for (Iterator it = list.iterator(); it.hasNext(); ) { // list の値を取得して表示 // 取得時は Object -> String は明示的なキャストが必要 String str = (String) it.next(); System.out.println(str); }Java8のコード
// String 型を利用するArrayList を準備 List<String> list = new ArrayList<String>(); // List<String> list = new ArrayList<>(); // 変数宣言時に型が確定しているので、インスタンス作成時は <> と省略可能 // list に値を格納 // String をそのまま格納出来る list.add("1"); list.add("2"); list.add("3"); for (Iterator<String> it = list.iterator(); it.hasNext(); ) { // list の値を取得して表示 // String で取得できるのでキャスト不要 String str = it.next(); System.out.println(str); }使うと何が良いの?
Java1.3 では、コレクションを使う場合
Object 型で格納する必要がありました。
当然、取り出すときもObject 型なので、使う型に合わせてキャストする必要がありました。この取り出し時にキャストするというのが曲者で
格納する型を間違えると、ClassCastException が発生してしまいます。
当然ながらException なので実行してみないと間違いに気が付かないのです。一方で Generics を使うと、実装時に型の確定が出来るので
格納する型を間違える=コンパイルエラーが発生
と、イージーミスの削減にも役立つ機能です。
- 投稿日:2020-05-31T12:11:41+09:00
JavaのStringクラスのメソッドいろいろ
文字列調査に関するメソッド
メソッド 操作 引数型 戻り値型 equals 内容が等しいかどうか調べる String boolean equalsIgnoreCase 大文字、小文字の区別を無視して内容が等しいかどうか調べる String boolean length 文字列の長さを調べる String int isEmpty 空文字かどうか調べる String int 文字列検索に関するメソッド
メソッド 操作 引数型 戻り値型 contains 文字列が含まれるかどうか調べる String boolean startsWith 指定された文字列で始まるかどうか調べる String boolean endsWith 指定された文字列で終わるかどうか調べる String boolean indexOf 指定された文字または文字列が最初に登場する位置を調べる String int lastIndexOf 指定された文字または文字列が後ろから検索して最初に登場する位置を調べる String int 文字列切り出しに関するメソッド
メソッド 操作 引数型 戻り値型 charAt 指定位置の1文字を切り出す int String startsWith 指定された文字列で始まるかどうか調べる String boolean endsWith 指定された文字列で終わるかどうか調べる String boolean indexOf 指定された文字または文字列が最初に登場する位置を調べる String int lastIndexOf 指定された文字または文字列が後ろから検索して最初に登場する位置を調べる String int 文字列変換に関するメソッド
メソッド 操作 引数型 戻り値型 toLowerCase 大文字を小文字に変換 String String toUpperCase 大文字を小文字に変換 String trim 前後の空白を除去 String replace 指定された文字列に置き換える String,String String reverse 指定された文字列を反転 String 参考文献
スッキリわかるJava入門実践編
- 投稿日:2020-05-31T01:56:57+09:00
OpenJAVA で Spring Boot
はじめに
Spring Boot って便利ですよね!
Javaで少し規模が大きなWebアプリケーションを開発しようと思ったら、アプリケーションフレームワークが必要になると思いますが、EJBにしてもStrutsにしてもSpring Frameworkにしても、Javaのフレームワークはなかなか手ごわい。
そこへ行くと、Spring Tool Suiteの使いやすさもあって手軽に本格的なアプリケーションを構築できるSpring Bootは本当に便利だと思います。ところが、Spring BootのデフォルトJDKってOracle Java SE 8だったりします。
OracleのJDKはライセンス条項が変更されて、開発や個人の学習用途では無償利用できるけど会社の業務として利用する場合は注意が必要ですね。
そんなわけでOpenJDKで使えないものかと考えました。いきなり結論から
まず、できたのかできないのかが気になるところなので結論から。
できます。全然問題ありません。少なくとも私が作成した程度のWebアプリでは
今のところ問題は出ていません。
というわけで、私の環境を以下に紹介していきます。Oracle JDKのアンインストールとOpenJDKのインストール
これまで、なんだかんだで必要だったOracle Java SE Developer kitをインストールしてありましたが、思い切ってアンインストールしました。
OpenJDKのダウンロードは、Oracle Java SEのダウンロードページに案内のある通り以下のサイトからダウンロードします。
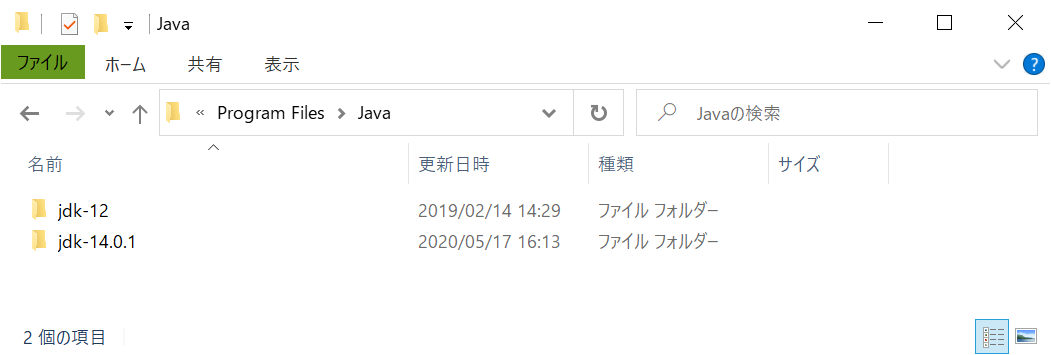
Windows/64 の zipをダウンロードして展開し、Program Files¥Java の下にコピーします。
見ての通り、Program Filesの中にはOpenJDKしか入っていません。12も入ってますが、気にしないでください。^^;
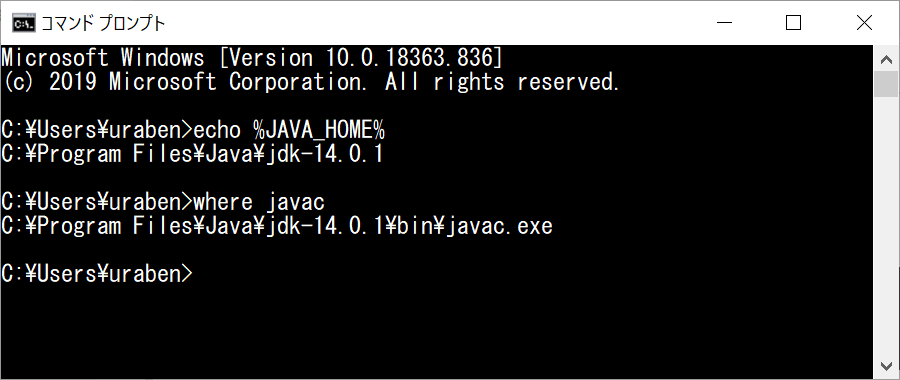
環境変数JAVA_HOMEにはOpenJDK-14のフォルダを、PATHにはOpenJDK-14のbinフォルダを指定しています。
Spring Tool Suiteの設定
Spring Tool Suiteの方は、インストール時にJava 8がデフォルトJDKとして選択されているので、OpenJDK 14を使用するように変更します。
- [Window]->[Preferences]を開きます。
- 左のペインから[Java]->[Installed JREs]を選択します。
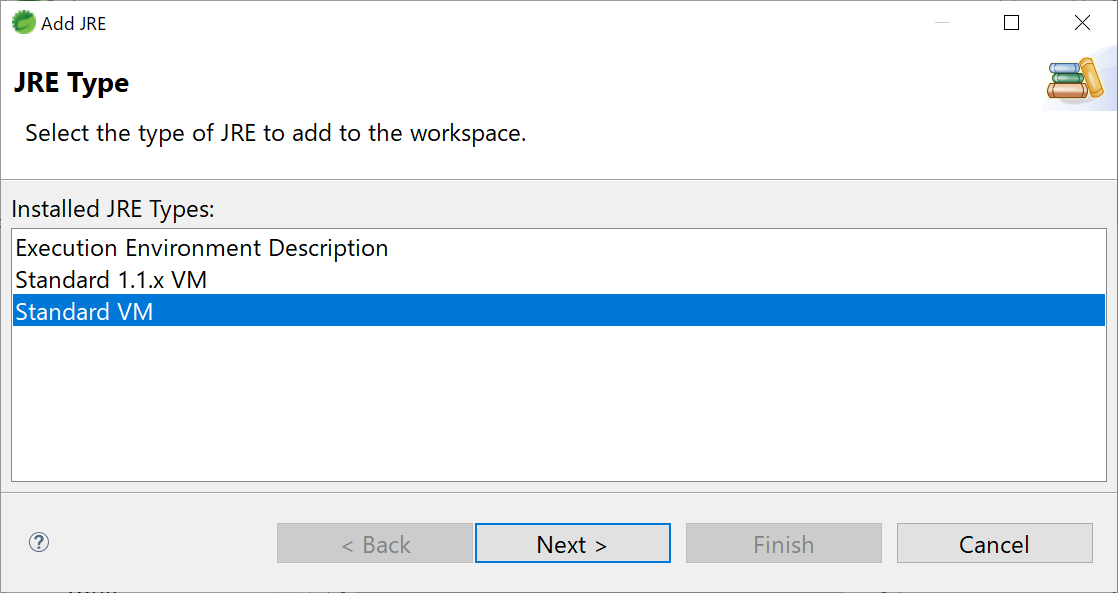
- [Add]ボタンをクリックします。
- Standard VMを選択します。
- JRE Definitionダイアログの一番上にあるJRE home: の[Directory...]をクリックします。
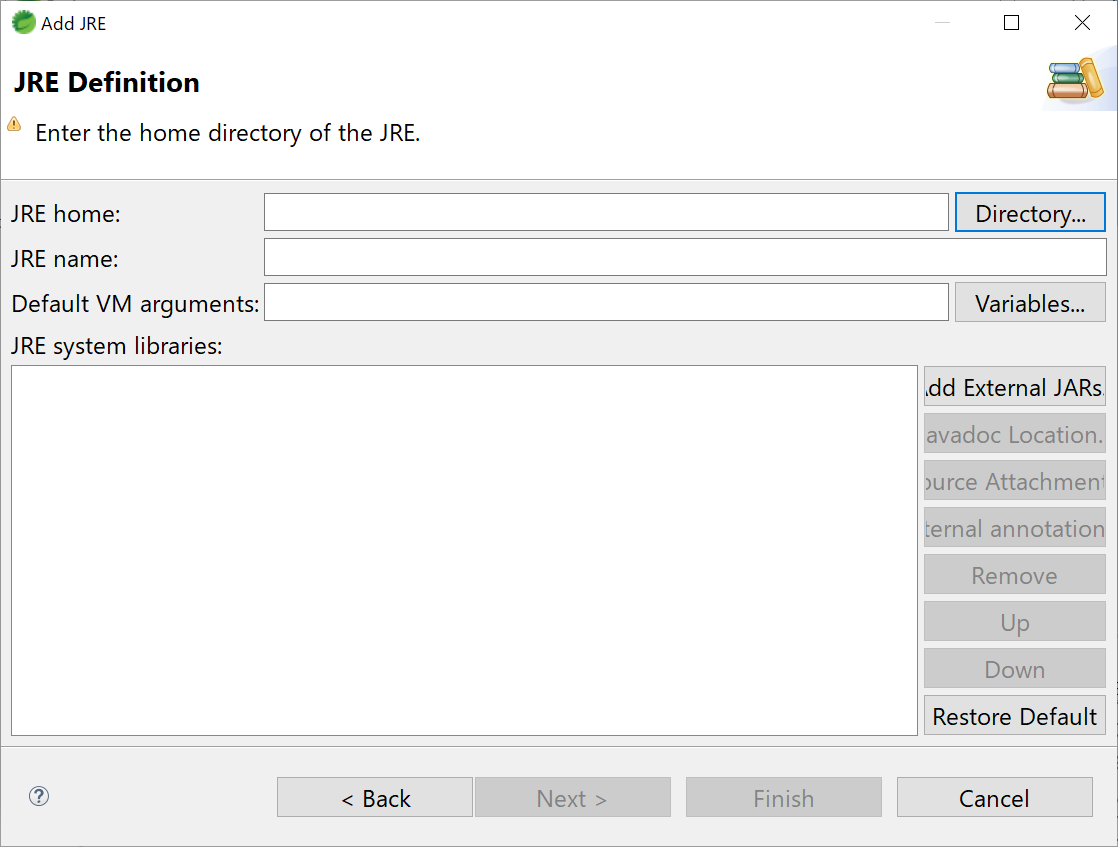
- C:¥Program Files¥Java¥jdk-14.0.1フォルダを選択します。
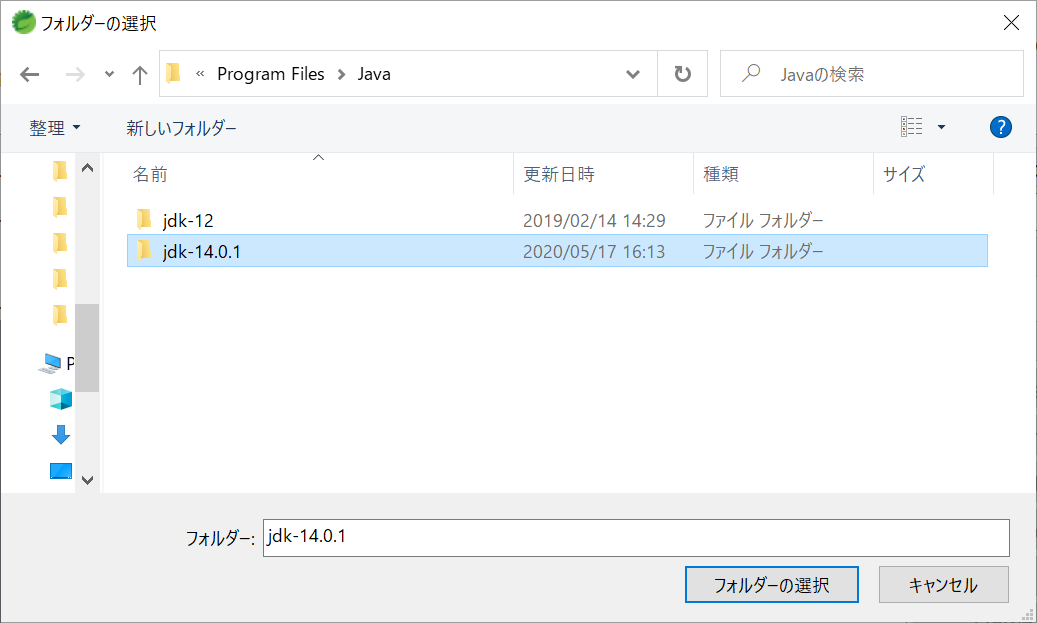
- jdk-14.0.1が追加されますので、[finish]をクリックします。
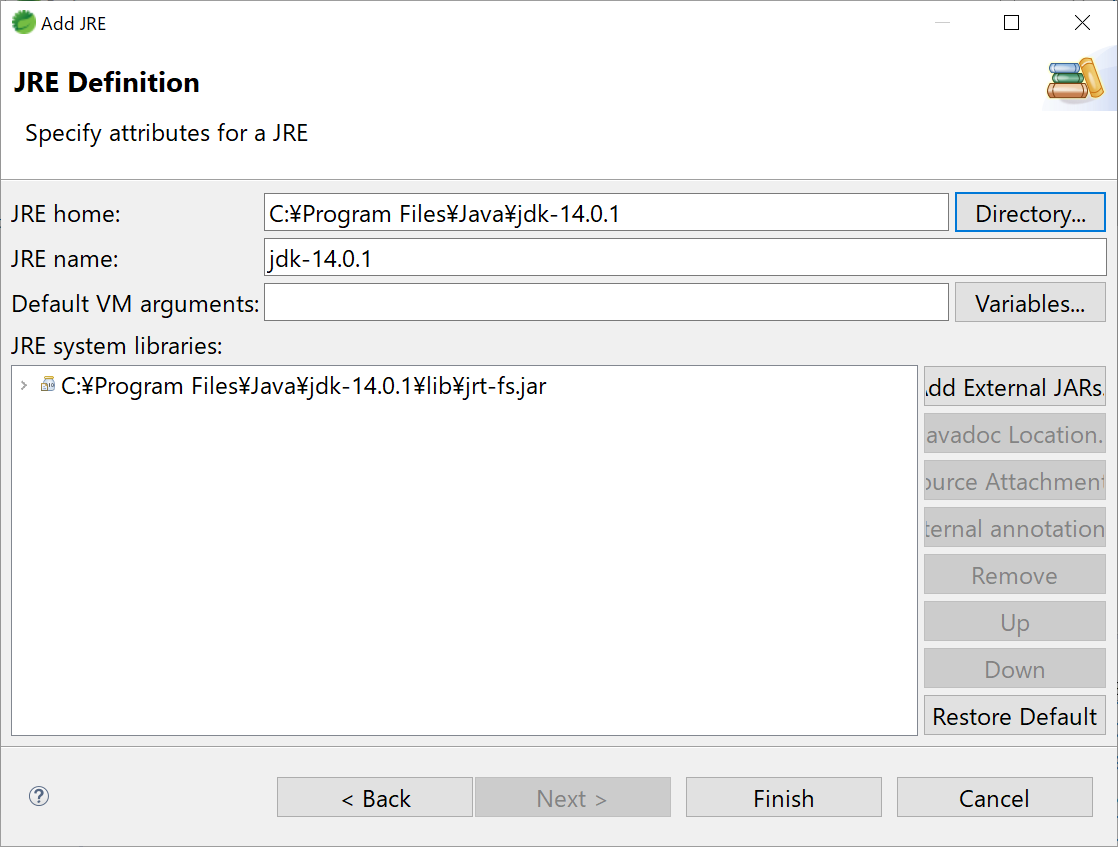
- Installed JREsにjdk-14.0.1が追加されます。もしチェックが入っていなかったら、チェックを入れてApplyをクリックしてください。
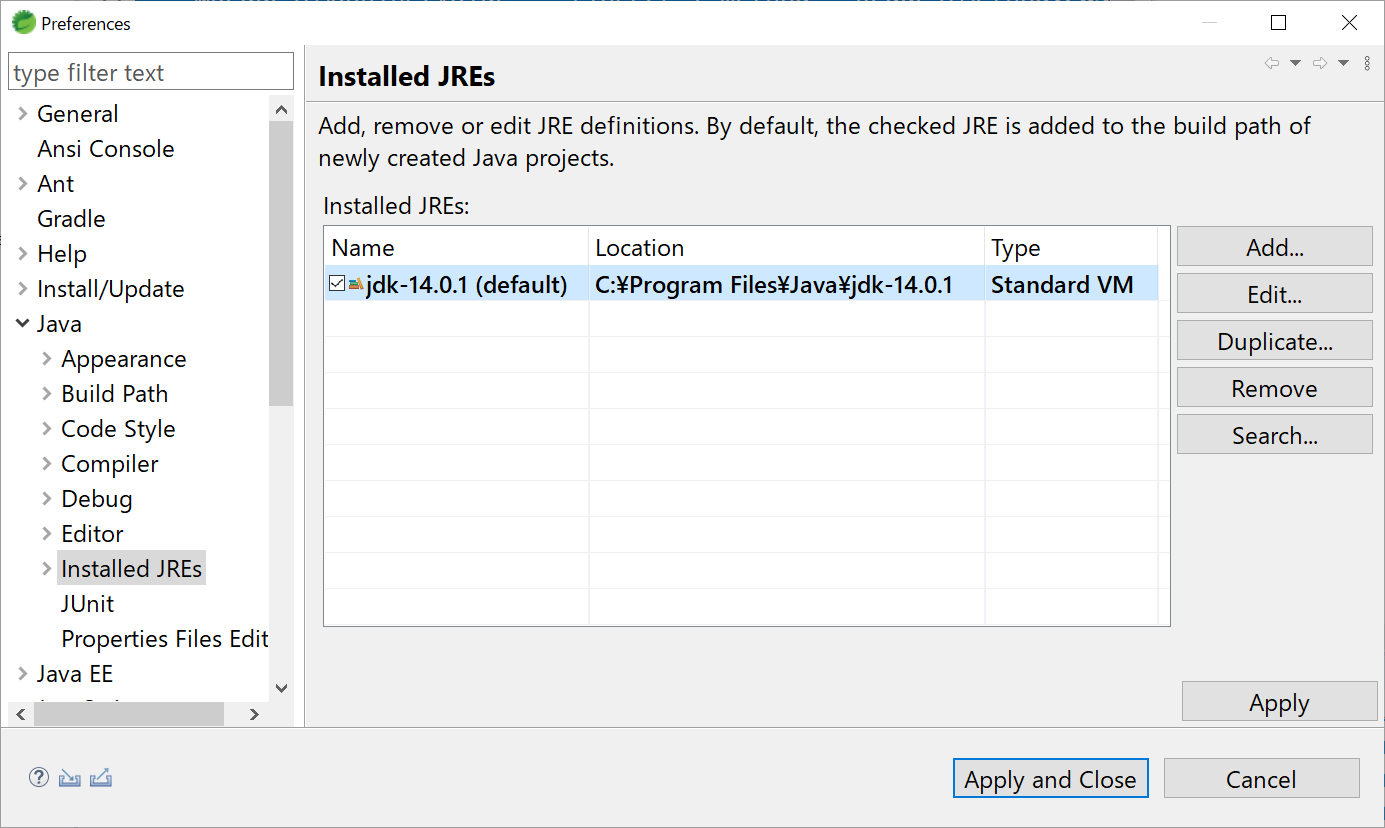
これでだいたい大丈夫だと思いますが、プロジェクトのライブラリ参照や実行環境を編集する必要がある場合があるみたいなので、以下に手順を記述します。
ライブラリパスの追加
- [Project]->[Preferences]を開く。
- 左のペインから[Java Build Path]を開く。
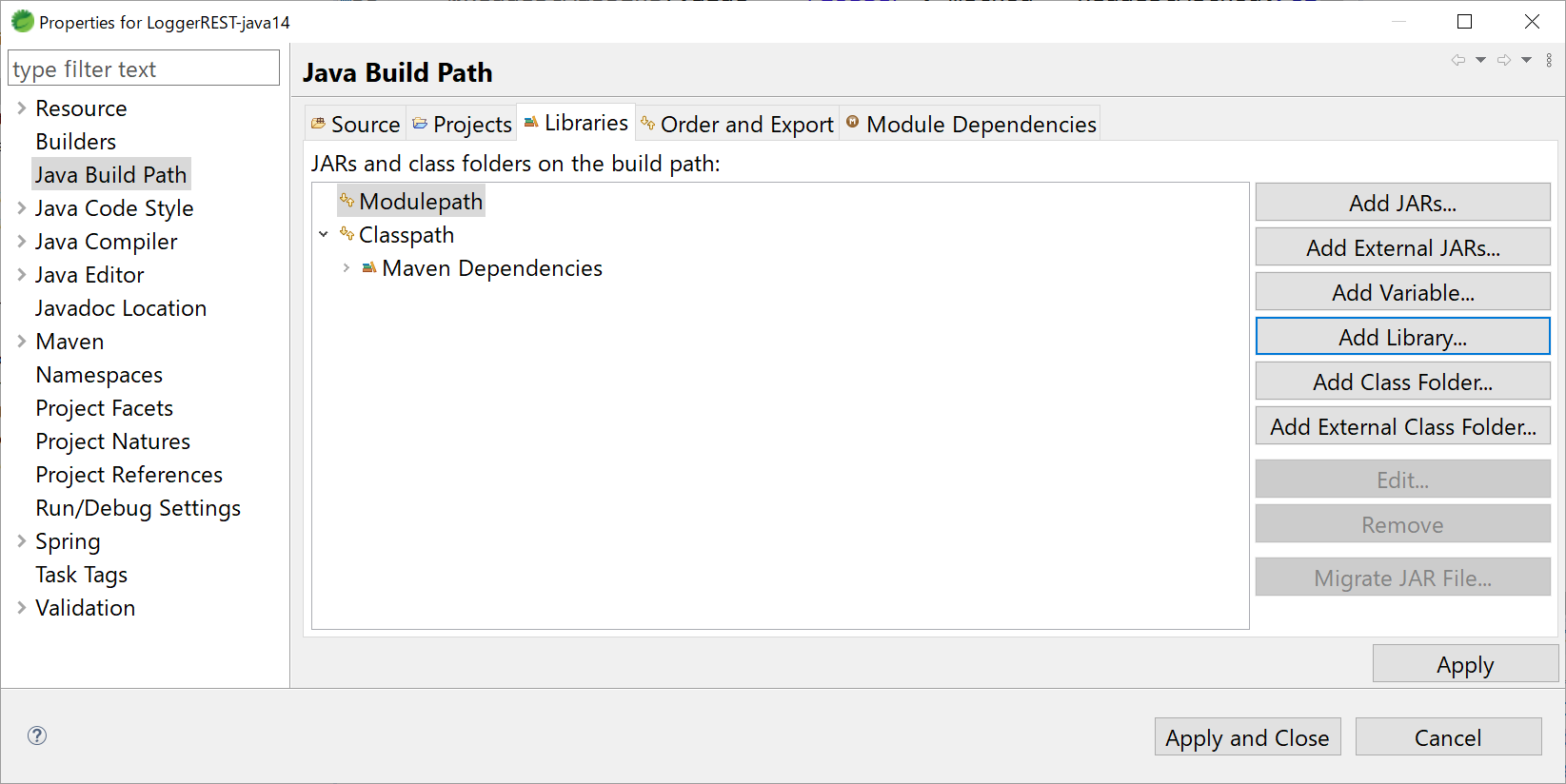
- Java Build Pathのタブのうち、[Libraries]を開く。
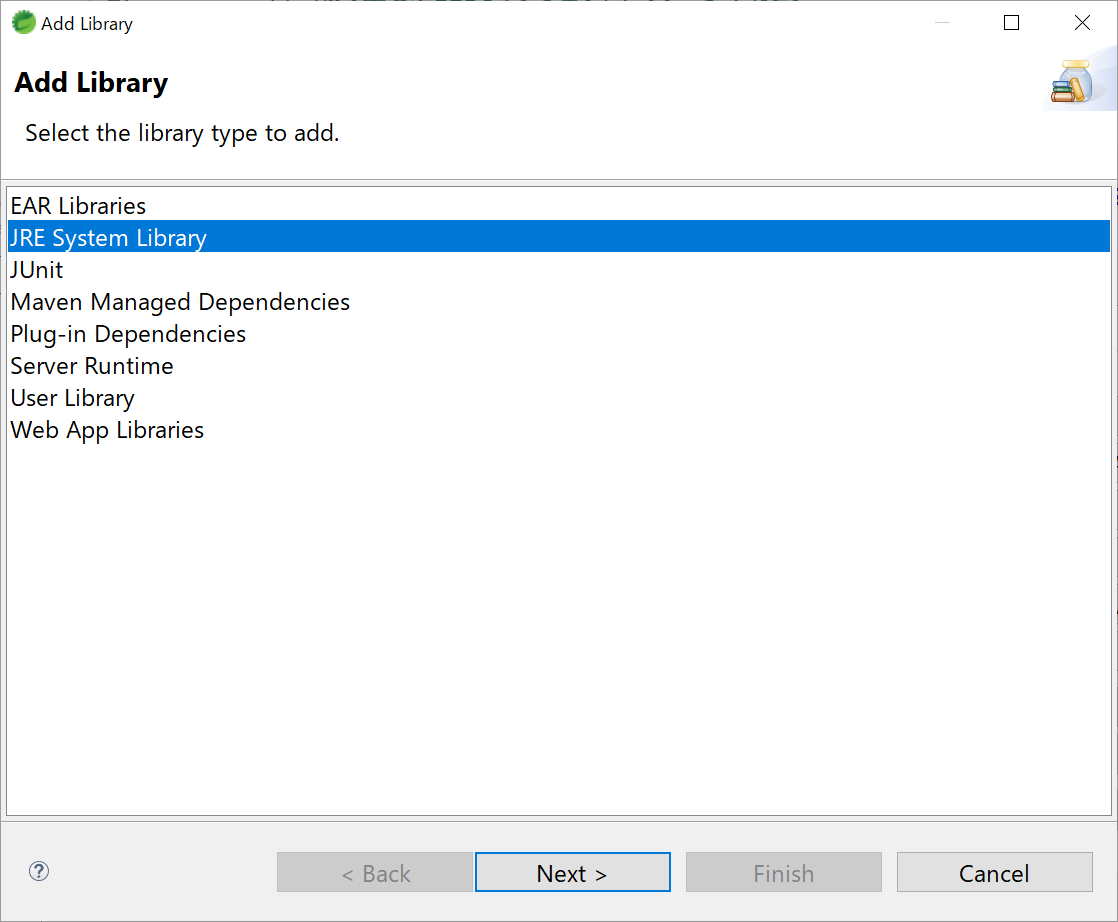
- ここで、Modulepathにjdk-14.0.1が選択されていれば問題なし。もし違う場合は、いったんRemoveして、[Add Library]をクリックする。
- JRE System Libraryを選択して[Next]をクリックする。
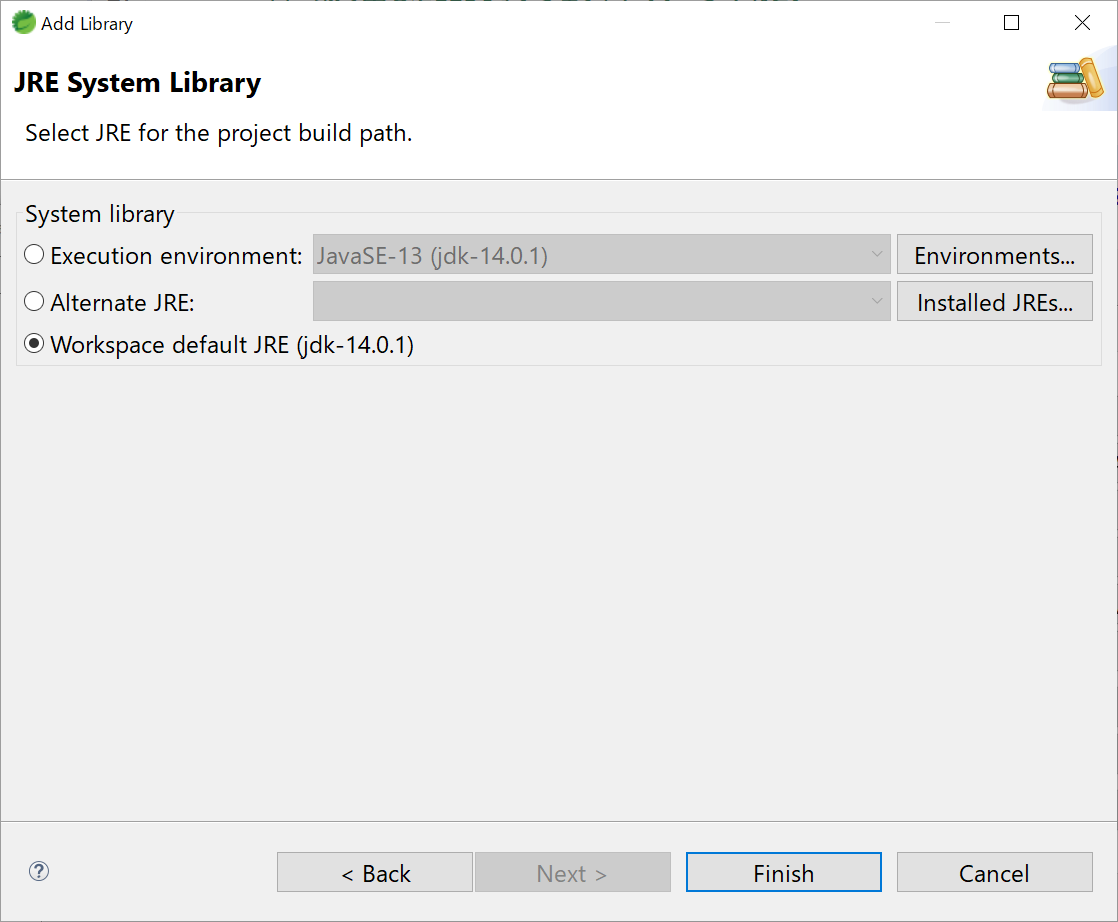
- Workspace default JRE(jdk-14.0.1)を選択する。
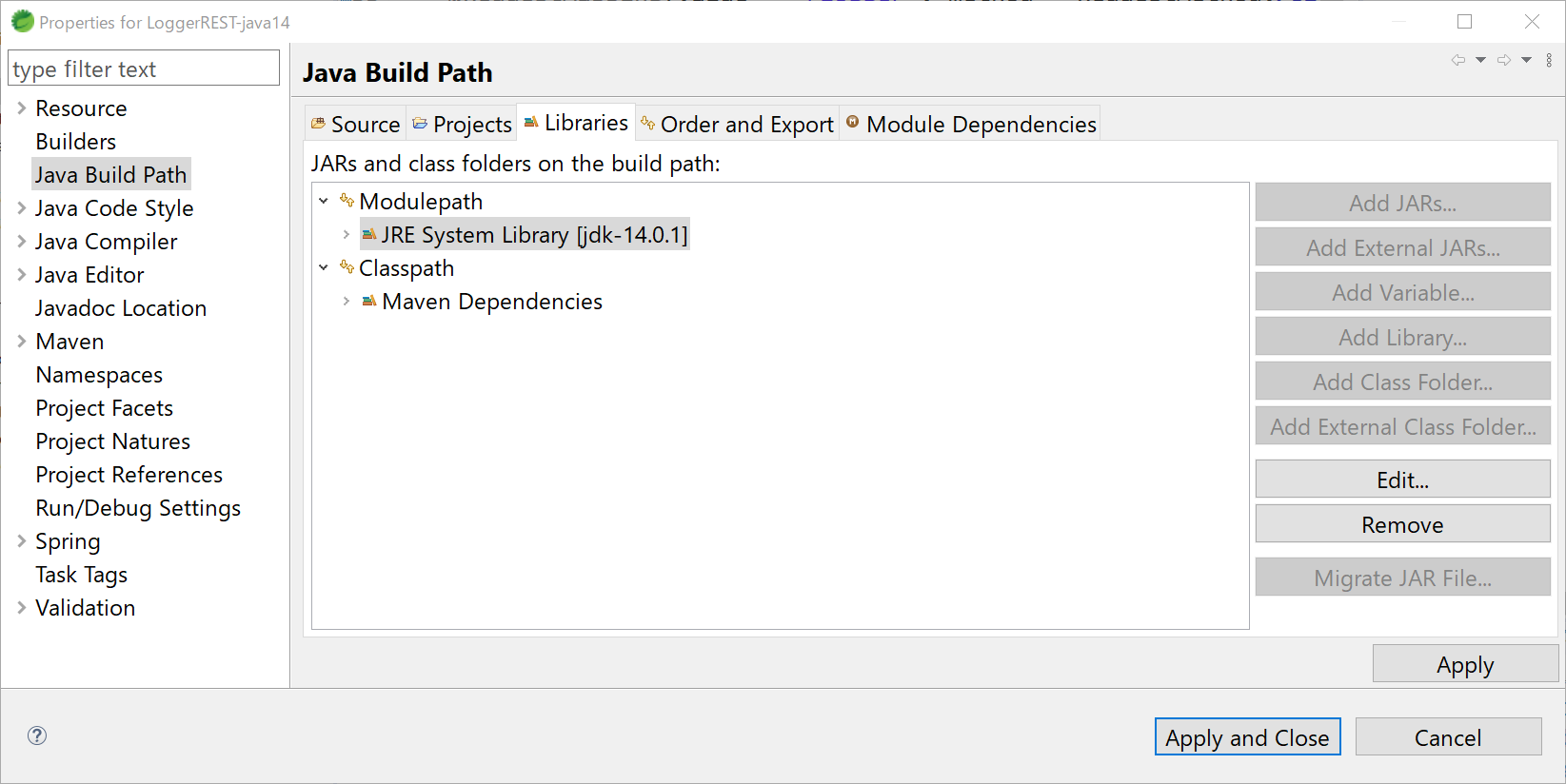
- ModulepathにJRE System Library[jdk-14.0.1]が追加されればOKなので、[Apply]をクリックする。
実行環境の設定
Spring Tool Suiteで「Run as」により実行する場合のJREを設定します。
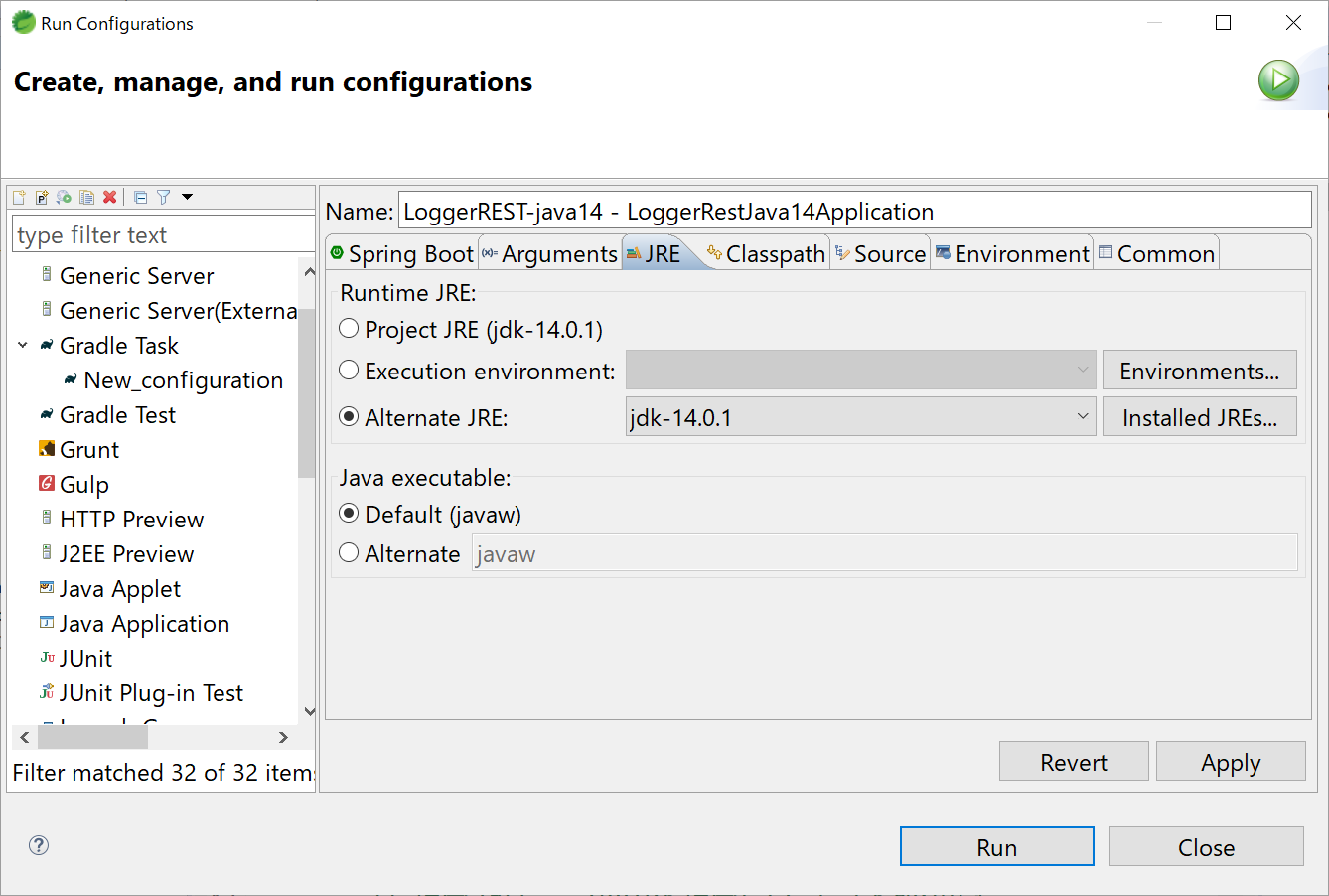
- Package Explorerでプロジェクトフォルダを右クリック->[Run As]->[Run Configuration]を選択する。
- [JRE]タブを選択する。
- ここで、jdk-14.0.1が選択されていれば問題なし。もし、違うJREが選択されている場合は、[ALternate JRE]を選択して、ドロップダウンからjdk-14.0.1を選択する。
Mavenの設定
Mavenの依存環境設定(pom.xml)にも、Javaのバージョンを記載する場所があるのでここを14にしておきます。なお、Spring Starterプロジェクトを作成する際にJava 14を選んでおくと、最初から14が設定されています。
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.3.0.RELEASE</version> <relativePath/> <!-- lookup parent from repository --> </parent> <groupId>com.example</groupId> <artifactId>LoggerREST-java14</artifactId> <version>0.0.1-SNAPSHOT</version> <name>LoggerREST-java14</name> <description>Database Interface for Android</description> <properties> <java.version>14</java.version> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-jpa</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <scope>runtime</scope> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> <exclusions> <exclusion> <groupId>org.junit.vintage</groupId> <artifactId>junit-vintage-engine</artifactId> </exclusion> </exclusions> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> </plugin> </plugins> </build> </project>Spring Boot の実行
さて、設定は終わりました。実行してみましょう。
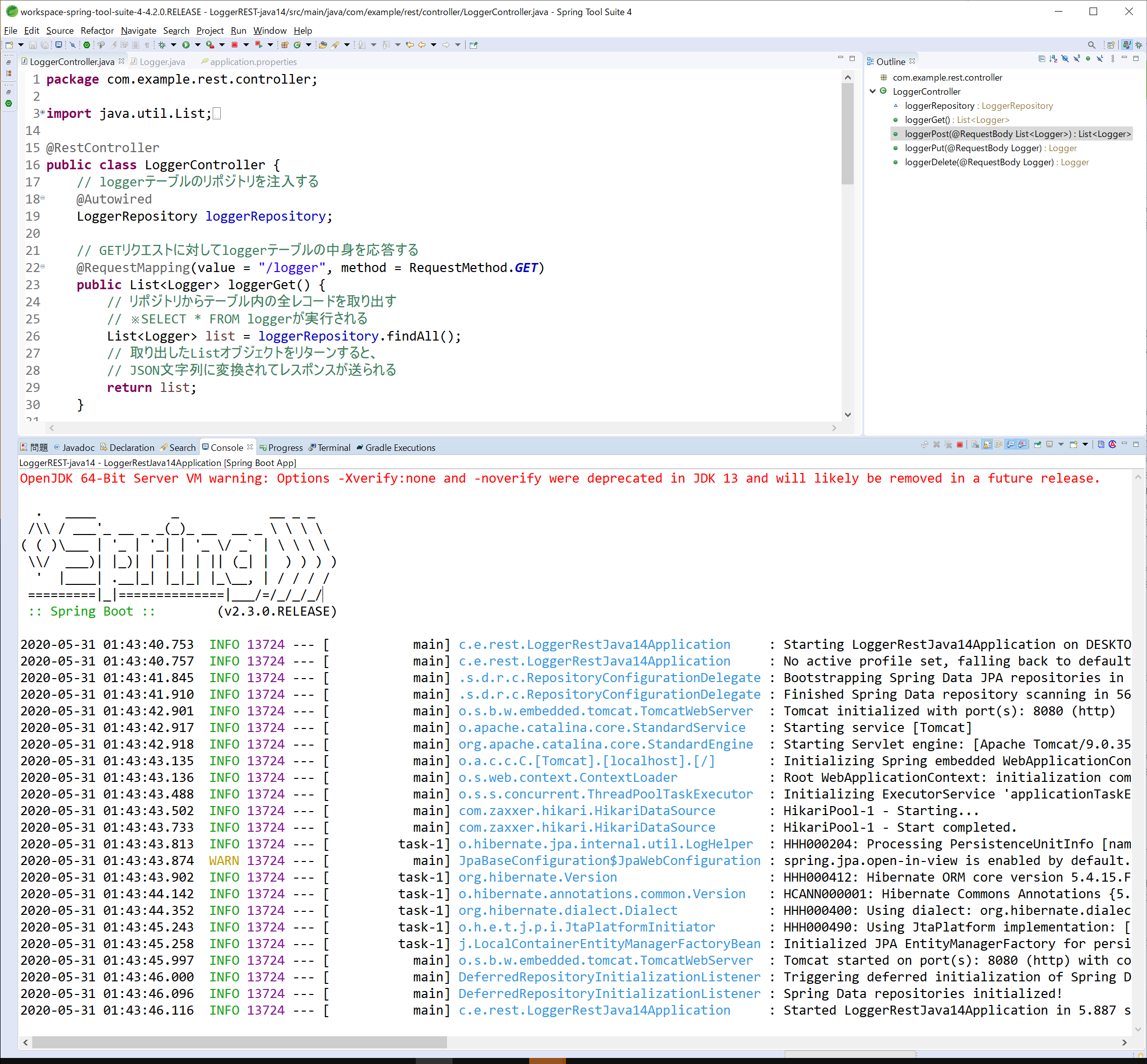
Package Explorerでプロジェクトを右クリック->[Run as]->[Spring Boot App]を選択します。
すると先頭に、OpenJDKのWarningメッセージが出ますが、「-Xverify:noneと-noverifyはdeprecatedですよ~」とのこと。Spring Tool Suiteでjavaコマンドを実行する際に、このオプションが指定されているんだと思いますが、探しても見つからなかった。とりあえず無視しても大丈夫でしょう。^^;
実際、Qiitaにアップしているプロジェクトはこの環境で動かしています。
まとめ
結果として、OpenJDK 14でSpring Bootは普通に動くことが判りました。
デフォルトがOracle Java8になっているのはなぜかわかりませんが、開発/実行環境はOracleの正式版を使う事で、パッケージを制作して販売する場合は相応のライセンスを購入するのが正しいという事なんでしょうね。
考えてみれば、エンタープライズ用途のLinuxは当然のようにRHELを使用して、ライセンスも購入するのが日本のITゼネコンのやり方なので。。。もっとも、ここ数年はそういった開発からは遠ざかっているので現在の状況はどうなんでしょうか。。今回使用した環境
- Windows 10 Pro 1909
- OpenJDK 14.0.1
- Spring Tool Suite 4 Version 4.6.2.RELEASE
- Spring Boot v2.3.0.RELEASE