- 投稿日:2020-05-31T23:53:21+09:00
AWS CloudFormationでの試行錯誤を回避するためのメモ
CloudFormationは、ネットの解説記事を読むよりも、実際に自分でテンプレートを書いてみて試行錯誤を重ねたほうが理解が早い気がします(解説記事で完成形のテンプレートを見せられて心が折れた人は、僕も含めて少なくないのではないでしょうか)。
ただ、テンプレートの記述に敷居の高さを感じている人は多いと思いますので、本記事では「はじめてCloudFormationを触る人がつまづきやすい点」をピンポイントに解説したいと思います。
なお、本記事ではテンプレートの記述にはYAML形式を採用しています。
CloudFormationへの慣れ方
これからCloudFormationに入門しようという時に、いきなりテンプレートの完成形を読んで理解するのは心理的なハードルが高いかと思います。
そこで最初は「VPCを作ること」を目標にして、VPCができたら次はサブネット、次はインターネットゲートウェイ、次はルートテーブルやセキュリティグループ…というように、ミニマムな目標からはじめてインクリメンタルに目標ラインを上げていくことで挫折を避けられるのではないかと勝手に思っています。
目安となるように、目標を三段階に設定してみました。
- VPCだけ定義してみる。
- サブネットの定義を追加してみる。組込み関数
!Refを使ってみる。- インターネットゲートウェイ、ルートテーブル、セキュリティグループ等を追加し、EC2インスタンスの足場を構築する。
ステップ3まで辿り着けば、あとは公式リファレンスを見ながら自走できるんじゃないかと思ってます。
…と偉そうに書いてますが、僕も今日はじめてCloudFormationを触って、1日かけてなんとかステップ3まで辿り着いた人間です(2020年5月31日記)。
インデントについて
YAML形式ではタブインデントは使用できません。スペースインデントのみです。VS Codeなどタブ入力をスペースに変換してくれるエディタで記述するのが賢明かもしれません。
ミニマムなサンプル
はじめてテンプレートファイルを触る人のために、ミニマムなテンプレートのサンプルを載せておきます。
見ての通り、VPCだけ定義したサンプルです。YAML形式の読み方は、JSON形式と見比べればなんとなく理解できるかと思います。
VPCのリソース定義(YAML形式)AWSTemplateFormatVersion: '2010-09-09' Resources: MyVpc: Type: AWS::EC2::VPC Properties: CidrBlock: 10.1.0.0/16 Tags: - Key: Name Value: MyVpcVPCのリソース定義(JSON形式){ "AWSTemplateFormatVersion": "2010-09-09", "Resources": { "MyVpc": { "Type": "AWS::EC2::VPC", "Properties": { "CidrBlock": "10.1.0.0/16", "Tags": [ { "Key": "Name", "Value": "MyVpc" } ] } } } }リソース定義の記述パターン
リソースの定義は、以下のパターンで記述します。
Resourcesセクション内に、リソースを列挙して記述します。
「リソースの論理名」など、日本語の部分はプレースホルダです。ResourcesResources: リソースの論理名: Type: リソースタイプ Properties: リソースプロパティ名: 値 リソースプロパティ名: 値 リソースの論理名: Type: リソースタイプ Properties: リソースプロパティ名: 値 リソースプロパティ名: 値 # (以下、繰り返し)
- 「リソースの論理名」とはリソースの識別子です(例「
MyVpc」)。- 「リソースタイプ」とはリソースの型のようなものです(例「
AWS::S3::EC2」)。- 「リソースプロパティ」とは、例えばVPCのCIDRブロックなどです。
組込み関数「!Ref」について
公式ドキュメントの解説にはこう書いてあります。
組み込み関数 Ref は、指定したパラメータまたはリソースの値を返します。
・パラメータの論理名を指定すると、それはパラメータの値を返します。
・リソースの論理名を指定すると、それはそのリソースを参照するために通常使用できる値を返します (物理 ID)。箇条書きのうち前者はともかく、後者が何を言っているか。
・リソースの論理名を指定すると、それはそのリソースを参照するために通常使用できる値を返します (物理 ID)。
これは例えば
!Refの引数にリソースの論理名を指定すると、!Ref リソースの論理名の部分が物理IDに展開される、ということを言っています。Ref(展開前)VpcId: !Ref MyVpcRef(展開後のイメージ)VpcId: vpc-053ffba26196d40c0
- 「リソースの論理名」とは、先述のサンプルでいうと
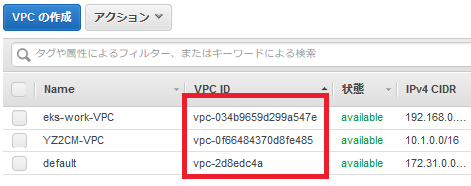
MyVpcにあたるものです。- 「物理ID」が何を指すかはコンテキストに依存しますが、リソースがVPCの場合は
VPC ID(マネージメントコンソールでいうと以下の赤枠の値)に展開されます。つまり、vpc-053ffba26196d40c0のようなIDに展開されます。
物理IDはリソースを構築するまでどんなIDが採番されるか分からないですし、既存の物理IDをハードコードするのはあり得ないので、こういう組込み関数が存在するのですね。
セキュリティグループのインバウンド・アウトバウンドに該当するプロパティは?
- インバウンド …
SecurityGroupIngress- アウトバウンド …
SecurityGroupEgressです。あまり聞きなれない用語ですね。
セキュリティグループのルールで「すべてのトラフィック」を定義するには?
SecurityGroupMySecurityGroup1: Type: AWS::EC2::SecurityGroup Properties: SecurityGroupEgress: - CidrIp: 0.0.0.0/0 IpProtocol: -1と記述してリソースを作成すると、マネージメントコンソール上のエントリの内容は以下になります。
ソース or 送信先にセキュリティグループを指定するには?
SecurityGroupMySecurityGroup2: Type: AWS::EC2::SecurityGroup Properties: SecurityGroupIngress: - SourceSecurityGroupId: !Ref MySecurityGroup1 IpProtocol: -1マネージメントコンソール上のエントリの内容は以下になります。
FromPort、ToPortって?
SecurityGroupEgress、SecurityGroupIngressのFromPort、ToPortはポート番号を範囲指定するプロパティです。
ソースポートやデスティネーションポートの指定ではありません。例えば「TCPの80番ポート」を指定する場合、以下のように
FromPortとToPortに同じポート番号(80)を指定します。SecurityGroupMySecurityGroup1: Type: AWS::EC2::SecurityGroup Properties: SecurityGroupIngress: - CidrIp: 0.0.0.0/0 IpProtocol: tcp FromPort: 80 ToPort: 80マネージメントコンソール上のエントリの内容は以下になります。
自動生成されるDHCPオプションセットのリソース定義
VPC作成時に自動生成されるDHCPオプションセットですが、そのリソース定義は以下です。
DomainNameの値はリージョン.compute.internalになります。自動生成されるけど使用しない、でもNameタグだけはつけておきたい...という時に使えるサンプルです。DHCPOptionsMyDhcpOptions: Type: AWS::EC2::DHCPOptions Properties: DomainName: ap-northeast-1.compute.internal DomainNameServers: - AmazonProvidedDNS MyVPCDHCPOptionsAssociation: Type: AWS::EC2::VPCDHCPOptionsAssociation Properties: DhcpOptionsId: !Ref MyDhcpOptions VpcId: !Ref MyVpcこの先は?
本記事は育っていく記事なので、また気づきがあれば随時追加していきます。
参考ドキュメント
- AWS CloudFormation テンプレートリファレンス
- AWS リソースおよびプロパティタイプのリファレンス … テンプレートでリソースを定義する際は、このリファレンスからサンプルをコピペしてカスタマイズする、というのが常套ですかね。ドキュメントを読むついでに各プロパティにも目を通しておくと、AWS認定試験の勉強にもなりそうです。



- 投稿日:2020-05-31T23:37:38+09:00
Amazon Linux 2 に AWS CloudFormation ヘルパースクリプトがプレインストールされていなかった話
事の起こり
AWS上にWordPressサーバを建てていたときに、CloudFormationのサンプル1をもとにyamlを書いていた。
PHPのバージョン引き上げるのにamazon-linux-extrasを使いたかったこともあり、Amazon LinuxからAmazon Linux 2に変更したところCloudFormationが通らなくなった。問題のコード
AutoScalingのインスタンス起動時にこけていることはわかっていたので、コードを消したり戻したりを繰り返した結果以下のコードが原因と判明。
yum update -y aws-cfn-bootstrap
aws-cfn-bootstrapが何者かよくわからずに使っていたので公式のドキュメント2を改めてよく読むと以下の記述があった。Amazon Linux AMI イメージ
AWS CloudFormation ヘルパースクリプトは Amazon Linux AMI イメージにプレインストールされています。
Amazon Linux AMI の最新バージョンでは、スクリプトは /opt/aws/bin にプレインストールされています。
以前の Amazon Linux AMI バージョンでは、スクリプトを含む aws-cfn-bootstrap パッケージは、Yum リポジトリにあります。その他のプラットフォーム用パッケージのダウンロード
Amazon Linux AMI イメージと Microsoft Windows (2008 以降) を除く Linux/Unix ディストリビューション用に、aws-cfn-bootstrap パッケージをダウンロードできます。Amazon LinuxにプレインストールされているならAmazon Linux 2にもあると勝手に思っていたけど、そんなことどこにも書いてないんですね。
updateをinstallに変えたら無事通りました。結論
いい加減WordPressやめてAmplifyでReactとかVue.jsを使ったページ作れって話なんですが、そこまでの気力がなかったので妥協した結果がこれでした。
いろいろ勉強にはなったんですがやっぱり楽するための苦労は妥協すべきではないですね。
- 投稿日:2020-05-31T23:14:39+09:00
AWS日記⑩ (Transcribe)
はじめに
今回は Amazon Transcribeの文字起こしを試すページを作成します。
準備
Lambda , API Gatewayの準備をします。
S3の準備をします。[Amazon Transcribeの資料]
音声を文字起こしする
Amazon Transcribe 日本語版で遊んでみた
Amazon Transcribeで音声の文字起こしを行う。WEBページ・API作成
GO言語のAWS Lambda関数ハンドラー aws-lambda-go を使用してHTMLやJSONを返す処理を作成します。
また、Transcribe を使用するため aws-sdk-go を利用します。[参考資料]
AWS SDK for Go API Reference全体の処理の流れ
- 音声ファイルをS3にアップロード
- 文字起こしの処理を開始
- 処理の進捗を確認
- 処理完了(S3に結果ファイルが配置される)
- 結果ファイルをS3からダウンロード
文字起こし処理を開始するには StartTranscriptionJob を使う。
main.gofunc startTranscription(filedata string)(string, error) { t := time.Now() b64data := filedata[strings.IndexByte(filedata, ',')+1:] data, err := base64.StdEncoding.DecodeString(b64data) if err != nil { return "", err } sess, err := session.NewSession(&aws.Config{ Region: aws.String(bucketRegion)}, ) if err != nil { return "", err } contentType := "audio/mp3" filename := t.Format(layout2) + ".mp3" uploader := s3manager.NewUploader(sess) _, err = uploader.Upload(&s3manager.UploadInput{ ACL: aws.String("public-read"), Bucket: aws.String(bucketName), Key: aws.String(S3MediaPath + "/" + filename), Body: bytes.NewReader(data), ContentType: aws.String(contentType), }) if err != nil { return "", err } url := "s3://" + bucketName + "/" + S3MediaPath + "/" + filename svc := transcribeservice.New(session.New(), &aws.Config{ Region: aws.String("ap-northeast-1"), }) input := &transcribeservice.StartTranscriptionJobInput{ TranscriptionJobName: aws.String(filename), LanguageCode: aws.String(languageCode), OutputBucketName: aws.String(bucketName), MediaFormat: aws.String(mediaFormat), Media: &transcribeservice.Media{ MediaFileUri: aws.String(url), }, } _, err = svc.StartTranscriptionJob(input) if err != nil { return "", err } return filename, nil }文字起こし処理の進捗を確認するには ListTranscriptionJobs を使う。
main.gofunc checkProgress(jobName string)(string, error) { svc := transcribeservice.New(session.New(), &aws.Config{ Region: aws.String("ap-northeast-1"), }) input := &transcribeservice.ListTranscriptionJobsInput{ JobNameContains: aws.String(jobName), } res, err := svc.ListTranscriptionJobs(input) if err != nil { return "", err } return aws.StringValue(res.TranscriptionJobSummaries[0].TranscriptionJobStatus), nil }文字起こし処理の結果を確認するには GetTranscriptionJob を使う。
main.gofunc getTranscriptionJob(jobName string)(string, error) { svc := transcribeservice.New(session.New(), &aws.Config{ Region: aws.String("ap-northeast-1"), }) input := &transcribeservice.GetTranscriptionJobInput{ TranscriptionJobName: aws.String(jobName), } res, err := svc.GetTranscriptionJob(input) if err != nil { return "", err } url := aws.StringValue(res.TranscriptionJob.Transcript.TranscriptFileUri) rep := regexp.MustCompile(`\s*/\s*`) tmp := rep.Split(url, -1) svc_ := s3.New(session.New(), &aws.Config{ Region: aws.String("ap-northeast-1"), }) obj, err2 := svc_.GetObject(&s3.GetObjectInput{ Bucket: aws.String(bucketName), Key: aws.String(tmp[len(tmp) - 1]), }) if err2 != nil { return "", err2 } defer obj.Body.Close() buf := new(bytes.Buffer) buf.ReadFrom(obj.Body) res_ := buf.String() jsonBytes := ([]byte)(res_) var data interface{} if err3 := json.Unmarshal(jsonBytes, &data); err3 != nil { return "", err3 } results := data.(map[string]interface{})["results"] results_, err4 := json.Marshal(results) if err4 != nil { return "", err4 } return string(results_), nil }今回は、ページ表示とAPIの API Gatewayを別々に作成し、APIのメソッドはPOSTに設定しました。
また、結果ファイルから内容を文字列として返し、Webページ上に表示する方法をとりました。
今回作成したAmazon Transcribe の機能を試すページ終わりに
今回はAmazon Transcribeの文字起こし機能を試しました。
Rekognition、Comprehend、Pollyに比べて処理時間が長い印象がありました。
- 投稿日:2020-05-31T22:39:06+09:00
Amazon APIGatewayのIaC運用はどうするべきかを考える(結論出ず)
はじめに
Amazon APIGatewayは複数のLambda関数や別のALB配下のアプリケーションとかを簡単に統合できて便利。
でも、色々なデプロイ方法が競合して死ぬことってないの?SAMとCloudFormation両方で更新したらどうなってしまうの?というのがよく分からないので、実験してどのように運用すれば良いのかを考えてみる。SAM上で
AWS::DynamoDB::Tableを定義するという方法もあるが、基本/共通リソースとサービスリソースを分割した方が良かろうということで、先にDynamoDBテーブルを作成する構成にしている。あと、Lambda関数中でDynamoDBを扱うので、サービスロールにはDynamoDBを触れるようなIAMポリシをアタッチしておく。
DynamoDBの準備
何でも良いが、↓こんな感じで用意しておく。
01_createDynamlDB.yml
01_createDynamlDB.ymlAWSTemplateFormatVersion: "2010-09-09" Description: Create DynamoDB template for ApigwTest2 Parameters: Prefix: Description: "Project name prefix" Type: "String" Default: "ApigwTest2" TableNameSuffix: Description: "Lambda function name suffix" Type: "String" Default: "-Table" Metadata: AWS::CloudFormation::Interface: ParameterGroups: - Label: default: "Project name prefix" Parameters: - Prefix - Label: default: "DynamlDB configuration" Parameters: - TableNameSuffix Resources: # ------------------------------------------------------------# # DynamoDB # ------------------------------------------------------------# DynamoDBTable: Type: AWS::DynamoDB::Table Properties: TableName: !Sub ${Prefix}${TableNameSuffix} KeySchema: - AttributeName: id KeyType: HASH AttributeDefinitions: - AttributeName: id AttributeType: S ProvisionedThroughput: ReadCapacityUnits: 1 WriteCapacityUnits: 1 Tags: - Key: Name Value: !Sub ${Prefix}イベントソースで対応する
SAMテンプレート中の
AWS::Serverless::Functionの中でEvents指定するのが一番お手軽なので試してみる。
SetName.yml
SetName.ymlAWSTemplateFormatVersion: 2010-09-09 Transform: AWS::Serverless-2016-10-31 Description: Create Pipeline Lambda for Branch Make Parameters: Prefix: Description: "Project name prefix" Type: "String" Default: "ApigwTest2-SetName" LambdaFunctionNameSuffix: Description: "Lambda function name suffix" Type: "String" Default: "-LambdaFunction" Metadata: AWS::CloudFormation::Interface: ParameterGroups: - Label: default: "Project name prefix" Parameters: - Prefix - Label: default: "Lambda Configuration" Parameters: - LambdaFunctionNameSuffix Globals: Function: Timeout: 60 Resources: LambdaFunction: Type: AWS::Serverless::Function Properties: FunctionName: !Sub ${Prefix}${LambdaFunctionNameSuffix} Handler: index.lambda_handler Runtime: python3.7 MemorySize: 128 Role: !Sub arn:aws:iam::${AWS::AccountId}:role/lambda-test Events: ApigwTest2: Type: Api Properties: Method: put Path: /name InlineCode: | import json import pprint import boto3 from botocore.exceptions import ClientError def lambda_handler(event, context): dynamodb = boto3.resource('dynamodb') table = dynamodb.Table('ApigwTest2-Table') try: response = table.put_item(Item={'id': event['queryStringParameters']['id'], 'name': event['queryStringParameters']['name']}) except ClientError as e: if e.response['Error']['Message'] == 'The provided key element does not match the schema': response_statuscode = 404 else: pprint.pprint(e.response['Error']['Message']) response_statuscode = 500 else: response_statuscode = 200 return { 'statusCode': response_statuscode, 'isBase64Encoded': 'false' }ポイントは以下の部分。
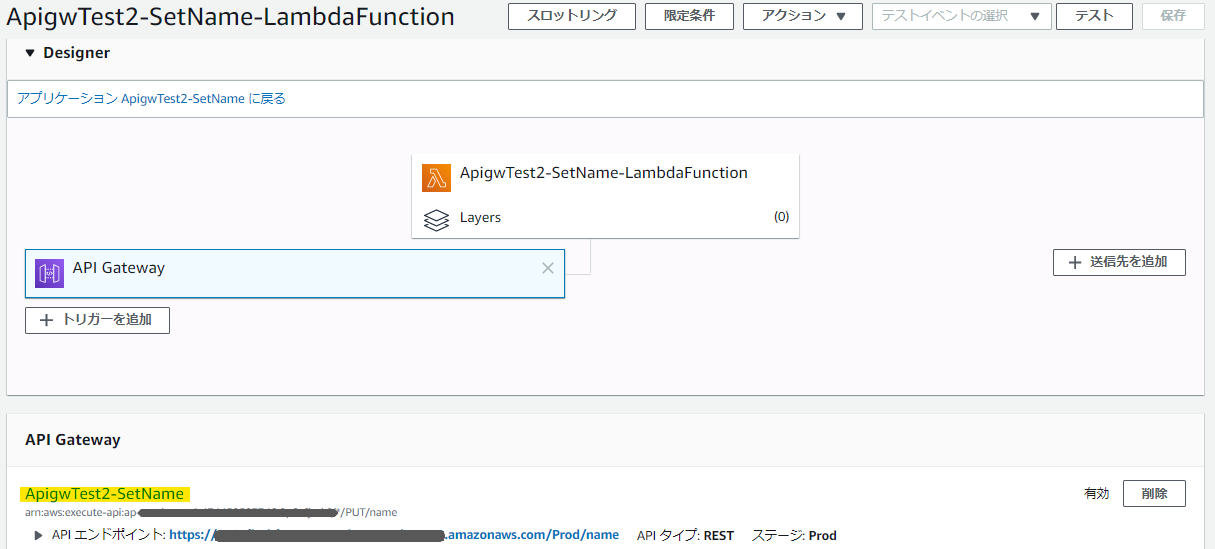
Events: ApigwTest2: Type: Api Properties: Method: put Path: /nameこれでAPIGatewayをイベントソースとして、以下の様に取り込むことができる。
だがしかし、この方法だと、APIGatewayの名前が勝手に決まってしまう。
※しかも、割と良い感じの名前になっているが、どうやって抽出しているのだろうか……
これでは、複数のLambdaを1つのAPIGatewayに統合できないので、別の手段が必要だ。もう少し細かい話は以下のサイトに書いてある。
結局、公式に「変更はできない」と書いてある。ついでに、ステージはProdが適用されるからね!とも書いてあるように見える。
CloudFormation Resources Generated By SAMたしかに、このSAMテンプレートをCloudFormationに流し込むと、見覚えのないリソースを勝手に作っていた。なるほどこういう仕組みだったのか。
ちゃんとRESTAPIのリソースを定義する
自動作成されるリソースなんぞには任せていられん!
ということで、以下の様にSAMテンプレートを修正する。リソースを手動作成する場合、作ったAPIGatewayに対するLambdaのパーミッションを設定しなければいけない。
あとは、API GatewayとLambdaの紐付けをSwaggerで定義してあげないといけないようだ。
うーむ、なかなか面倒だ……。
SwaggerはAWS拡張形式で書く必要があるx-amazon-apigateway-integrationについては、ちゃんと公式のドキュメントを読もう。PUTだとかGETを扱うからといって、プロキシのメソッドまで変えてしまうと動かなくなる。
SetName.yml
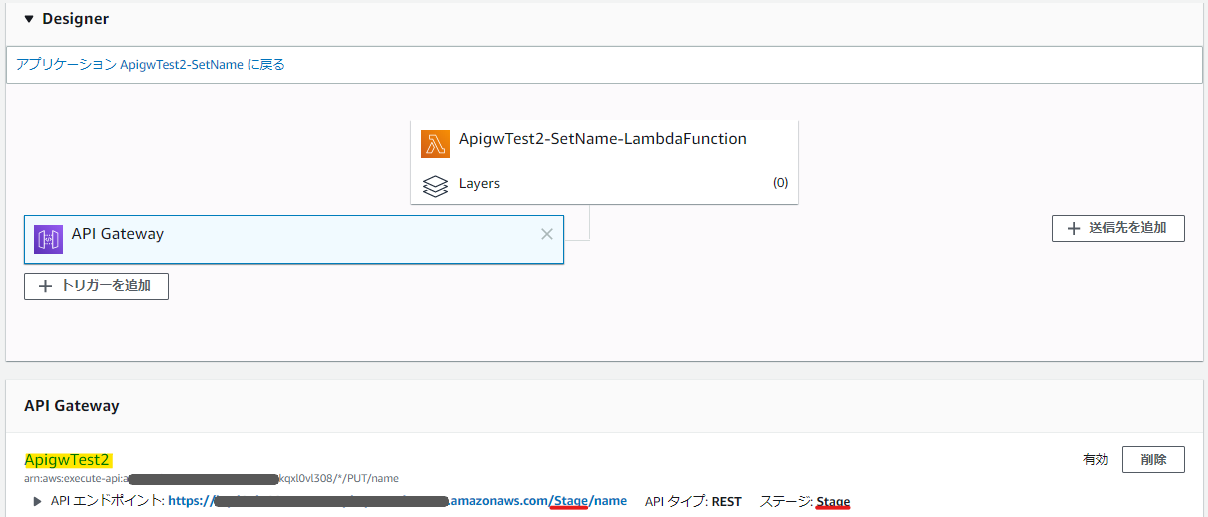
SetName.ymlAWSTemplateFormatVersion: 2010-09-09 Transform: AWS::Serverless-2016-10-31 Description: API Gateway and Lambda Test Parameters: Prefix: Description: "Project name prefix" Type: "String" Default: "ApigwTest2-GetName" LambdaFunctionNameSuffix: Description: "Lambda function name suffix" Type: "String" Default: "-LambdaFunction" APIGatewayName: Description: "Lambda function name suffix" Type: "String" Default: "ApigwTest2" APIGatewayStageName: Description: "Lambda function name suffix" Type: "String" Default: "default" Metadata: AWS::CloudFormation::Interface: ParameterGroups: - Label: default: "Project name prefix" Parameters: - Prefix - Label: default: "Lambda Configuration" Parameters: - LambdaFunctionNameSuffix - Label: default: "API Gateway Configuration" Parameters: - APIGatewayName - APIGatewayStageName Globals: Function: Timeout: 60 Resources: # ------------------------------------------------------------# # API Gateway # ------------------------------------------------------------# APIGateway: Type: AWS::Serverless::Api Properties: Name: !Sub ${APIGatewayName} StageName: !Sub ${APIGatewayStageName} DefinitionBody: swagger: "2.0" info: description: "Created by SAM template" version: "1.0.0" title: "ApiGatewayTest2" basePath: "/default" schemes: - "https" paths: /names: get: produces: - "application/json" responses: "200": description: "200 response" schema: $ref: "#/definitions/Empty" x-amazon-apigateway-integration: uri: !Sub arn:aws:apigateway:${AWS::Region}:lambda:path/2015-03-31/functions/${LambdaFunction.Arn}/invocations passthroughBehavior: when_no_templates httpMethod: POST type: aws_proxy definitions: Empty: type: "object" title: "Empty Schema" Tags: Key: Name Value: !Sub ${APIGatewayName} # ------------------------------------------------------------# # Lambda Function # ------------------------------------------------------------# LambdaFunction: Type: AWS::Serverless::Function Properties: FunctionName: !Sub ${Prefix}${LambdaFunctionNameSuffix} Handler: index.lambda_handler Runtime: python3.7 MemorySize: 128 Role: !Sub arn:aws:iam::${AWS::AccountId}:role/lambda-test Events: ApigwTest2: Type: Api Properties: Path: /names Method: get RestApiId: !Ref APIGateway InlineCode: | import json import pprint import boto3 from botocore.exceptions import ClientError def lambda_handler(event, context): dynamodb = boto3.resource('dynamodb') table = dynamodb.Table('ApigwTest2-Table') try: response = table.get_item(Key={'id': event['queryStringParameters']['id']}) except ClientError as e: response_statuscode = 500 pprint.pprint(e.response['Error']['Message']) else: if 'Item' not in response: response_statuscode = 404 response_body = json.dumps({'name': 'null'}) else: response_statuscode = 200 response_body =json.dumps({'name': response['Item']['name']}) return { 'statusCode': response_statuscode, 'body': response_body, 'isBase64Encoded': 'false' } LambdaInvokePermission: Type: AWS::Lambda::Permission Properties: FunctionName: !Ref LambdaFunction Action: 'lambda:InvokeFunction' Principal: apigateway.amazonaws.comだが、これで任意の名前でAPI Gatewayを作成することができるようになった。
でも、なぜかこれ、指定したステージ名じゃなくて勝手にStageとかいうのまで作ってしまうんだよなぁ……バグなのか??
で、ここからが本題。
別のLambda関数のSAMテンプレートから、上手くこのAPI Gatewayを更新することができるだろうか。これまで作ってきたDynamoDBにレコードを挿入するAPIに対して、同じAPI Gatewayにレコードを参照するAPIをぶら下げてみよう。
GetName.yml
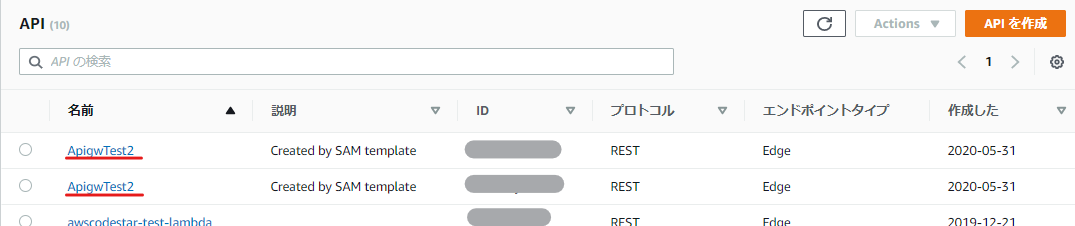
GetName.ymlAWSTemplateFormatVersion: 2010-09-09 Transform: AWS::Serverless-2016-10-31 Description: API Gateway and Lambda Test Parameters: Prefix: Description: "Project name prefix" Type: "String" Default: "ApigwTest2-GetName" LambdaFunctionNameSuffix: Description: "Lambda function name suffix" Type: "String" Default: "-LambdaFunction" APIGatewayName: Description: "Lambda function name suffix" Type: "String" Default: "ApigwTest2" APIGatewayStageName: Description: "Lambda function name suffix" Type: "String" Default: "default" Metadata: AWS::CloudFormation::Interface: ParameterGroups: - Label: default: "Project name prefix" Parameters: - Prefix - Label: default: "Lambda Configuration" Parameters: - LambdaFunctionNameSuffix - Label: default: "API Gateway Configuration" Parameters: - APIGatewayName - APIGatewayStageName Globals: Function: Timeout: 60 Resources: # ------------------------------------------------------------# # API Gateway # ------------------------------------------------------------# APIGateway: Type: AWS::Serverless::Api Properties: Name: !Sub ${APIGatewayName} StageName: !Sub ${APIGatewayStageName} DefinitionBody: swagger: "2.0" info: description: "Created by SAM template" version: "1.0.0" title: "ApiGatewayTest2" basePath: "/default" schemes: - "https" paths: /names: get: produces: - "application/json" responses: "200": description: "200 response" schema: $ref: "#/definitions/Empty" x-amazon-apigateway-integration: uri: !Sub arn:aws:apigateway:${AWS::Region}:lambda:path/2015-03-31/functions/${LambdaFunction.Arn}/invocations passthroughBehavior: when_no_templates httpMethod: POST type: aws_proxy definitions: Empty: type: "object" title: "Empty Schema" Tags: Key: Name Value: !Sub ${APIGatewayName} # ------------------------------------------------------------# # Lambda Function # ------------------------------------------------------------# LambdaFunction: Type: AWS::Serverless::Function Properties: FunctionName: !Sub ${Prefix}${LambdaFunctionNameSuffix} Handler: index.lambda_handler Runtime: python3.7 MemorySize: 128 Role: !Sub arn:aws:iam::${AWS::AccountId}:role/lambda-test Events: ApigwTest2: Type: Api Properties: Path: /names Method: get RestApiId: !Ref APIGateway InlineCode: | import json import pprint import boto3 from botocore.exceptions import ClientError def lambda_handler(event, context): dynamodb = boto3.resource('dynamodb') table = dynamodb.Table('ApigwTest2-Table') try: response = table.get_item(Key={'id': event['queryStringParameters']['id']}) except ClientError as e: response_statuscode = 500 pprint.pprint(e.response['Error']['Message']) else: if 'Item' not in response: response_statuscode = 404 response_body = json.dumps({'name': 'null'}) else: response_statuscode = 200 response_body =json.dumps({'name': response['Item']['name']}) return { 'statusCode': response_statuscode, 'body': response_body, 'isBase64Encoded': 'false' } LambdaInvokePermission: Type: AWS::Lambda::Permission Properties: FunctionName: !Ref LambdaFunction Action: 'lambda:InvokeFunction' Principal: apigateway.amazonaws.comさて、これでCloudFormationを実行してみると、
残念なことに、同じAPI名が二つ作られてしまった。ガーン……。
ではどうするか
2つのLambda関数を1つのSAMテンプレートに書いてしまえば狙った動作をさせられる気がする。
ただ、これはCI/CDとの親和性が悪い(というか、うまく動かない)気がする。
CodePipelineに渡すためのアーティファクトで、どっちの関数を更新されたかがハンドリングできない気がするからだ。
※この記事だと、設定はできそうに見える。試してみないと分からない。もう一つの案は、API Gatewayのリソースを分離することか。
これもCI/CDパイプラインで本当に正しく実現できるかが分からないので、試してみるしかない。別の記事でまた色々と試してみることにしよう。
- 投稿日:2020-05-31T22:31:28+09:00
AWS日記⑨ (Polly)
はじめに
今回は Amazon Pollyの音声合成を試すページを作成します。
準備
Lambda , API Gatewayの準備をします。
S3の準備をします。[Amazon Pollyの資料]
Amazon Polly を使用した日本語テキスト読み上げの最適化
Amazon Pollyを触ってみたよ by PHPWEBページ・API作成
GO言語のAWS Lambda関数ハンドラー aws-lambda-go を使用してHTMLやJSONを返す処理を作成します。
また、Polly を使用するため aws-sdk-go を利用します。[参考資料]
AWS SDK for Go API Reference音声合成を利用するには SynthesizeSpeech を使う。
main.gofunc synthesizeSpeech(message string)(string, error) { t := time.Now() svc := polly.New(session.New(), &aws.Config{ Region: aws.String("ap-northeast-1"), }) voiceId := "Takumi" input := &polly.SynthesizeSpeechInput{ Text: aws.String(message), TextType: aws.String("text"), VoiceId: aws.String(voiceId), LanguageCode: aws.String(languageCode), OutputFormat: aws.String(outputFormat), } res, err := svc.SynthesizeSpeech(input) if err != nil { return "", err } buf := new(bytes.Buffer) io.Copy(buf, res.AudioStream) data := buf.Bytes() contentType := "audio/mp3" filename := t.Format(layout2) + ".mp3" sess, _ := session.NewSession(&aws.Config{ Region: aws.String(bucketRegion)}, ) uploader := s3manager.NewUploader(sess) _, err = uploader.Upload(&s3manager.UploadInput{ ACL: aws.String("public-read"), Bucket: aws.String(bucketName), Key: aws.String(filename), Body: bytes.NewReader(data), ContentType: aws.String(contentType), }) if err != nil { return "", err } url := "https://" + bucketName + ".s3-" + bucketRegion + ".amazonaws.com/" + filename return url, nil }今回は、ページ表示とAPIの API Gatewayを別々に作成し、APIのメソッドはPOSTに設定しました。
また、作成された音声ファイルをS3にアップロードし、そのURLを指定することでWebページ上で再生する方法をとりました。
今回作成したAmazon Polly の機能を試すページ終わりに
今回はAmazon Pollyの音声合成機能を試しました。
他の機能として、発話スタイルを指定した音声を合成ができます。現在は米国英語限定です。
- 投稿日:2020-05-31T21:59:52+09:00
AWS日記⑧ (Comprehend)
はじめに
今回は Amazon Comprehend の「感情分析」を試すページを作成します。
準備
[Amazon Comprehendの資料]
Amazon Comprehend が日本語に対応しました
Amazon Comprehendが日本語対応したのでAlexaスキルで感情分析してみた
【初心者でも使える】AWSが提供する文書解析サービス「Amazon Comprehend」が日本語対応したので触ってみた!WEBページ・API作成
GO言語のAWS Lambda関数ハンドラー aws-lambda-go を使用してHTMLやJSONを返す処理を作成します。
また、Comprehend を使用するため aws-sdk-go を利用します。[参考資料]
AWS SDK for Go API Reference感情分析するには DetectSentiment を使う。
main.gofunc detectSentiment(message string)(string, error) { svc := comprehend.New(session.New(), &aws.Config{ Region: aws.String("ap-northeast-1"), }) input := &comprehend.DetectSentimentInput{ LanguageCode: aws.String(languageCode), Text: aws.String(message), } res, err := svc.DetectSentiment(input) if err != nil { return "", err } return aws.StringValue(res.Sentiment), nil }今回は、ページ表示とAPIの API Gatewayを別々に作成し、APIのメソッドはPOSTに設定しました。
今回作成したAmazon Comprehend の機能を試すページ終わりに
今回はAmazon Comprehendの 感情分析の機能を試しました。
他にもComprehendの機能が利用できるため、今後試していきたいと思います。
- 投稿日:2020-05-31T20:59:46+09:00
AWS日記⑦ (Rekognition)
はじめに
今回は Amazon Rekognition の「イメージ内の安全でないコンテンツを検出する機能」を試すページを作成します。
準備
[Amazon Rekognitionの資料]
Amazon Rekognition 開発者ガイド 安全でないイメージの検出
Amazon Rekognitionの概要
AWSでサーバレスな動画解析(Amazon Rekognition)
Amazon Rekognition
めちゃくちゃ簡単 Amazon RekognitionWEBページ・API作成
GO言語のAWS Lambda関数ハンドラー aws-lambda-go を使用してHTMLやJSONを返す処理を作成します。
また、Rekognition を使用するため aws-sdk-go を利用します。[参考資料]
AWS SDK for Go API Referenceイメージ内の安全でないコンテンツを検出するには DetectModerationLabels を使う。
main.gofunc detectModeration(img string)(string, error) { b64data := img[strings.IndexByte(img, ',')+1:] data, err := base64.StdEncoding.DecodeString(b64data) if err != nil { log.Print(err) return "", err } svc := rekognition.New(session.New(), &aws.Config{ Region: aws.String("ap-northeast-1"), }) input := &rekognition.DetectModerationLabelsInput{ Image: &rekognition.Image{ Bytes: data, }, } res, err2 := svc.DetectModerationLabels(input) if err2 != nil { return "", err2 } if len(res.ModerationLabels) < 1 { return "No ModerationLabel", nil } results, err3 := json.Marshal(res.ModerationLabels) if err3 != nil { return "", err3 } return string(results), nil }今回は、ページ表示とAPIの API Gatewayを別々に作成し、APIのメソッドはPOSTに設定しました。
今回作成したAmazon Rekognition の機能を試すページ終わりに
今回はAmazon Rekognitionの イメージ内の安全でないコンテンツを検出する機能を試しました。
他にもRekognitionの機能が利用できるため、今後試していきたいと思います。
- 投稿日:2020-05-31T20:22:49+09:00
ESP32をAWS IoTにつなぐ3つの方法
ESP32をAWS IoTにつなぐ方法です。
自分用のメモです。Arduino+外部ライブラリー(MQTT+ArduinoJson)
簡単度:★★★★★
一般的なArduinoのライブラリー(MQTTとArduinoJson)を使って実現します。
参考
https://github.com/aws-samples/aws-iot-esp32-arduino-examples
https://aws.amazon.com/jp/blogs/compute/building-an-aws-iot-core-device-using-aws-serverless-and-an-esp32/Arduino+AWS製ライブラリー
期待度:★★★★★
aws-samplesのリポジトリ内で開発されています。Amazon iot C-SDKに存在しないGreengrass部分を開発しているようです。
名前がGreengrassとなっていますが、AWS IoTと直接やり取りすることもできます。参考
https://github.com/aws-samples/arduino-aws-greengrass-iotFreeRTOS
本気度:★★★★★
お手軽ではありませんが、AWS謹製でございます。おそらく新機能も一番早いでしょう
- 投稿日:2020-05-31T19:50:23+09:00
aws-sdk-goを通してlocal-kmsを使う
この記事を書いた経緯
aws-sdk-goを用いた案件ソース中にkmsを用いた暗号・復号化の実装があり
kmsという概念すらわからなかった私が、ローカル環境での検証に四苦八苦した時の覚書を認めたものですコマンドだけ知りたい人へ
local-kmsコンテナを立ち上げる
そのままdev環境・本番環境のKMSに作られている鍵を使おうとしても、IAMの認証をかけられてしまうので
権限のないローカル環境では暗号化・復号操作を行うことができません。ローカル環境においてkmsを用いた処理をデバッグしたい場合、local-kmsというdocker imageを用いて実現することが可能です。
他コンテナとポートが重複する場合は、環境変数PORTを用いることで競合を回避できます$ docker run -p 8080:8081 -e PORT=8081 nsmithuk/local-kmsaws configureの作成
local-kmsを使用する際も通常のインスタンスを用いる場合と同様にクレデンシャル情報が参照されますが
適当なダミーデータで問題ありません
すでに何かしらのconfigureがローカルに作成されていればスルーで問題ないと思います$ aws configure AWS Access Key ID [None]: dummy AWS Secret Access Key [None]: dummy Default region name [None]: ap-northeast-1 Default output format [None]:create-key コマンドによりCMKを作成する
暗号・復号化に必要な、いわゆるCMK(Customer Master Key)と呼ばれるものを作成します。
この時出力されるAccountID・KeyIDなどは適当なダミー値になります$ aws kms create-key --endpoint-url http://localhost:8080 { "KeyMetadata": { "AWSAccountId": "111122223333", "KeyId": "23aeebbd-cb83-43a3-8870-a6f9ee5a4ace", "Arn": "arn:aws:kms:eu-west-2:111122223333:key/23aeebbd-cb83-43a3-8870-a6f9ee5a4ace", "CreationDate": 1590853469, "Enabled": true, "KeyUsage": "ENCRYPT_DECRYPT", "KeyState": "Enabled", "Origin": "AWS_KMS", "KeyManager": "CUSTOMER", "CustomerMasterKeySpec": "SYMMETRIC_DEFAULT", "EncryptionAlgorithms": [ "SYMMETRIC_DEFAULT" ] } }ここで出力された
KeyIDを用いて、kms encryptを実行しますaws-sdk-goからlocal-kmsを介してkms encryptとdecryptを使う
aws-sdk-goのこちらのドキュメントに記載されているサンプルソースを拝借し、若干加筆しました。
WithEndPoint()へlocal-kmsのコンテナのアドレスを持たせ、WithDisableSSL(true)を使ってhttpへのアクセスを前提とさせたものを
aws.NewConfig()へメソッドチェーンさせることで、local-kmsを用いた暗号・復号化を可能としますlocalkms.gopackage main import ( "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/session" "github.com/aws/aws-sdk-go/service/kms" "fmt" "os" ) func main() { sess, err := session.NewSession() if err != nil { fmt.Println("aws newsession error: ", err) os.Exit(1) } svc := kms.New(sess, aws.NewConfig().WithRegion("ap-northeast-1").WithEndpoint("localhost:8080").WithDisableSSL(true)) keyId := "arn:aws:kms:eu-west-2:111122223333:key/23aeebbd-cb83-43a3-8870-a6f9ee5a4ace" text := "1234567890" //kms encrypt encResult, err := svc.Encrypt(&kms.EncryptInput{ KeyId: aws.String(keyId), Plaintext: []byte(text), }) if err != nil { fmt.Println("got error encrypting data: ", err) os.Exit(1) } //kms decrypt decResult, err := svc.Decrypt(&kms.DecryptInput{ CiphertextBlob: encResult.CiphertextBlob, }) if err != nil { fmt.Println("got error decrypting data: ", err) os.Exit(1) } fmt.Println("decoded Plaintext:") fmt.Println(string(decResult.Plaintext)) }ソースのビルド
$ go build localkms.goソースの実行
$ go run localkms.go decoded Plaintext: 1234567890Dockerfileでgoのソースをビルドしたい場合
このような階層の簡素なプロジェクトがあることを想定します
tree -L 3 localkms/ localkms/ ├── Dockerfile └── src ├── go.mod ├── go.sum ├── localkms ├── localkms.go └── vendor ├── github.com └── modules.txtDockerFile
マルチステージビルドの書き方が望ましいですが、とりあえず簡素に作ってみます
DockerfileFROM golang:1.13.0 ADD ./src /go/src/local-kms WORKDIR /go/src/local-kms RUN cd /go/src/local-kms ENV AWS_ACCESS_KEY_ID=dummy ENV AWS_SECRET_ACCESS_KEY=dummy RUN go build -mod=vendor localkms.go ENTRYPOINT ["./localkms"]go.mod
ファイルを作成後、go mod vendorを実行し、srcディレクトリの下にvendorディレクトリを作成します
go.modmodule src/localkms go 1.13 require github.com/aws/aws-sdk-go v1.25.14-0.20200528180948-645efefb5bceソースの修正
コンテナの中からは
localhostでlocal-kmsを参照できなくなるので
WithEndPointの記述を下記のように変更します(コンテナ名を記載することでそのコンテナのIPアドレスにリクエストが飛ぶようになります)19行目- svc := kms.New(sess, aws.NewConfig().WithRegion("ap-northeast-1").WithEndpoint("localhost:8080").WithDisableSSL(true)) + svc := kms.New(sess, aws.NewConfig().WithRegion("ap-northeast-1").WithEndpoint("local-kms:8081").WithDisableSSL(true))ソースのビルド
$ docker build ./ -t go-containerソースの実行
local-kmsコンテナと連携するため
--linkオプションを利用します$ docker run --link local-kms:local-kms go-container decoded Plaintext: 1234567890
ここから参考文献など
aws cliのインストール
aws kms コマンドの実行にはaws cliのインストールが必要となります
AWS CLI バージョン 1 のインストールkmsとは?
データの暗号化に利用されるCMK(Customer Master Key)の作成と管理を容易にするマネージド型サービスです。
kms encryot
CMKのKeyIDを用いて平文を暗号化します
encryptコマンドリファレンス暗号化されたテキストは、
EncryptionAlgorithmでのエンクリプションを行った結果ががさらに
base64エンコードされて出力されます。local-kmsを使ったencryptの一例$ aws kms encrypt --key-id arn:aws:kms:eu-west-2:111122223333:key/23aeebbd-cb83-43a3-8870-a6f9ee5a4ace --plaintext "hoge" --endpoint-url http://localhost:8080 { "CiphertextBlob": "S2Fybjphd3M6a21zOmV1LXdlc3QtMjoxMTExMjIyMjMzMzM6a2V5LzIzYWVlYmJkLWNiODMtNDNhMy04ODcwLWE2ZjllZTVhNGFjZQAAAADmlRx1OQCCTk5LQoIkNseoCofCRhLXo3iPpQ2lwx8E5A==", "KeyId": "arn:aws:kms:eu-west-2:111122223333:key/23aeebbd-cb83-43a3-8870-a6f9ee5a4ace", "EncryptionAlgorithm": "SYMMETRIC_DEFAULT" }kms decrypt
CMKにより暗号化されたCiphertextを復号します。
encryptコマンドと異なり、この時keyIDを指定する必要はありません
(ciphertextblobに含まれているメタデータからこの情報を取り込むため、明示的に指定する必要がありません)また、この時の復号結果の出力である
Plaintextはbase64エンコードされて出てくるため
本来の平文を得るためにはbase64デコードする必要がありますlocal-kmsを使ったdecryptの一例$ aws kms decrypt --ciphertext-blob fileb://<(echo 'S2Fybjphd3M6a21zOmV1LXdlc3QtMjoxMTExMjIyMjMzMzM6a2V5LzIzYWVlYmJkLWNiODMtNDNhMy04ODcwLWE2ZjllZTVhNGFjZQAAAADmlRx1OQCCTk5LQoIkNseoCofCRhLXo3iPpQ2lwx8E5A==' | base64 --decode) --endpoint-url http://localhost:8080 | jq .Plaintext --raw-output | base64 --decode hoge
- 投稿日:2020-05-31T19:47:11+09:00
AWSの各サービスの説明が15文字程度シンプルすぎて妙にわかりやすかった件
(備忘録)
サービスが増えすぎてAWSやAzure全体像が分かりにくくなってきている今、
各サービスに対し極めてシンプルな説明が喜ばれる時代になってきている気がした。【日本語】
https://gigazine.net/news/20200528-aws-one-line-explanation/【英語 / English Simple Explanation of AWS Services】
https://adayinthelifeof.nl/2020/05/20/aws.html【Azureとの対比日本語】
https://docs.microsoft.com/ja-jp/azure/architecture/aws-professional/services【Azureとの対比英語 AWS vs. Azure Comparison】
https://docs.microsoft.com/en-us/azure/architecture/aws-professional/services
- 投稿日:2020-05-31T19:34:12+09:00
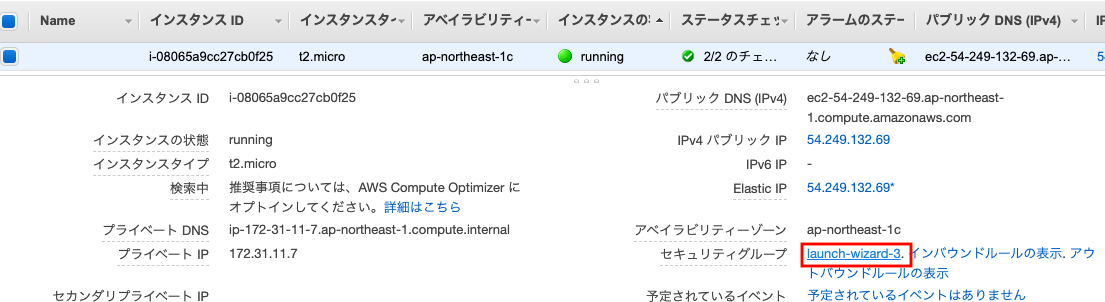
【AWS】EC2のSSHログイン時に環境を知るためのアスキーアートを表示する
やったこと
EC2にログインした時に、ステージング環境、本番環境のどちらにログインしたかを表示させたかったので、アスキーアートを表示させるようにしました。
以下のような表示になります。
やり方
以下のコマンドで、EC2へログインした時の表示メッセージが管理されているディレクトリへ行きます。
$ cd /etc/update-motd.d/ここがEC2へSSHした時に表示させるメッセージを追加する場所になります。
このディレクトリ内にはいくつかファイルがあり、SSHした時にはファイル名先頭の数字の昇順に表示されていくことになります。
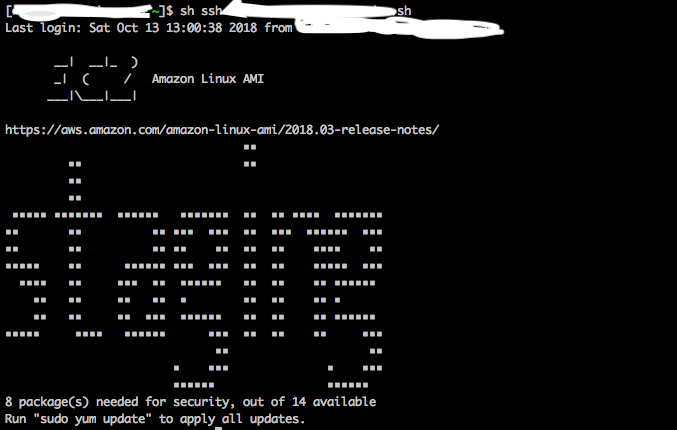
$ ls 30-banner 70-available-updates 75-system-update30-bannerの中身を覗くと、よく見るあの表示が出てきますね。
$ cat 30-banner #!/bin/sh version=$(rpm -q --qf '%{version}' system-release) cat << EOF __| __|_ ) _| ( / Amazon Linux AMI ___|\___|___| https://aws.amazon.com/amazon-linux-ami/$version-release-notes/ EOFメッセージを追加する
それでは、メッセージを追加しましょう。
アスキーアートをフリーで作成できるサイトはググって見つけます。今回は30-bannerの次に表示させたいため、40-environmentというファイルを作ります。
$ sudo vi 40-environment以下を記述。
#!/bin/sh cat << 'EOF' ■■ ■■ ■■ ■■ ■■ ■■■■■ ■■■■■■■ ■■■■■■ ■■■■■■■ ■■ ■■ ■■■■ ■■■■■■■ ■■ ■■ ■■ ■■■ ■■■ ■■ ■■■ ■■■■■■ ■■■ ■■ ■■ ■■ ■■ ■■ ■■ ■■ ■■■■ ■■ ■■■■■ ■■ ■■■■■■ ■■■ ■■■ ■■ ■■ ■■■■■ ■■■ ■■■■ ■■ ■■■ ■■ ■■■■■■ ■■ ■■ ■■ ■■■■■■ ■■ ■■ ■■ ■■ ■ ■■ ■■ ■■ ■ ■■ ■■ ■■ ■■■ ■■■■■■ ■■ ■■ ■■ ■■■■■■ ■■■■■ ■■■■ ■■■■■■ ■■■ ■■ ■■ ■■ ■■■ ■■ ■■ ■ ■■■ ■ ■■■ ■■■■■■ ■■■■■■ EOF以下コマンドで権限を変更し、メッセージを更新します。
$ sudo chmod 755 40-environment $ sudo update-motd再度SSH
無事に表示されました!
これで意図していない環境で作業してしまうのも防ぎやすくなりますね。参考サイト
- 投稿日:2020-05-31T19:08:55+09:00
AWS Step Functionsでバッチ処理を行う手段を考える
はじめに
JP1を代表するジョブ管理ツールをAWSで実現するにはどうするか、について検討したことをまとめておきます。
単一のバッチ処理では無くて、依存関係があるものを考えるのでStep Functionsを前提に考えました。
依存関係があるというのは、
- JobAが毎日午前7時に実行される
- JobBはJobAが完了したら実行される
- JobBが完了したらJobCとJobDが同時に呼ばれる
のような構造のことをイメージしています。
Step Functionsとの組み合わせ案
Step Functionsから呼び出せるものの中でバッチに使えるものは大きく分けると以下の3つです。
- AWS Lambda
- AWS Batch
- AWS Fargate
それぞれの比較はこちらの記事が大変参考になりました。
順番に特徴を見ていきます。
Lambda
- シンプルで運用しやすい
- 実行時間15分以内という制限がある
- 同時実行数を管理すればスケールすることが可能
- コードの反映が簡単(ZipをUpすればOK)
- サーバレスなのでミドル層の柔軟な管理はできない
- CloudWatch Eventsによる定期実行が可能
Batch
- 実行時間の制限は無い
- 内部的にはキュー(おそらくSQSと同じ機構)+ECSが起動している
- ミドルウェアの設定も可能(EC2レベルで設定が可能)
- ECRにイメージをプッシュしておく必要がある
- コードの更新の際は、再ビルドしてプッシュするまでを自動化しておくと便利
- キューのたまりをみていい感じにスケールしてくれる
- Batchの中でも依存関係の管理ができる
- 起動までに時間がかかることが多い。(キュー→コンテナインスタンスUP→ECS Task実行)
Fargate
- 実行時間の制限は無い
- EC2のファミリーも選べる
- クラスター、サービス、タスク定義などを準備しておく必要がある
- すでにECSクラスターが存在しているなら追加が簡単
- ECRにイメージをプッシュしておく必要がある
- 複数タスクの同時実行によってスケールできる
- オートスケーリングの機構は無いので自分で作る必要がある
- CloudWatch Eventsによる定期実行が可能
補足
念の為断っておきますが、依存関係の無いバッチ処理であればStep Functionsは不要です。
その場合、基本の選び方は以下になると思います。
- 15分以内で完了する処理→Lambda
- すでにECSを運用している or EC2の管理はしたくない→Fargate
- EC2の微調整をしつつパフォーマンスをだしたい→Batch
アーキテクチャ案
以上の特徴を踏まえつつ、Step Functionsとの組み合わせを検討していきます。
ここでは呼ばれたジョブがAuroraとやり取りをするという前提で図を書いています。
案①SQS+EC2
SQSでキューを管理しつつ、EC2でポーリングをする案です。
この場合、CloudWatchを使用し、EC2の稼働状況に応じてオートスケーリングを組むことも出来ます。
しかしこれではEC2の管理が大変なのであまり採用することは無いかなと思います。
案②SQS+Lambda
非常にシンプルです。LambdaはSQSからの呼び出しを設定していると、自動でポーリングしてくれます。キューのたまり具合に応じて同時実行数が変化し、並列実行してくれるのでスケール管理も不要です。
実行時間が15分以内で済むのであれば、この案がファーストチョイスになりうるのではないでしょうか。
案③SQS+Fargate
Lambda部分がFargateに置き換わったバージョンです。これによって15分以上の処理が可能になりますが、オートスケーリングは自分で用意しなければなりません。
例えば、キューのたまりを監視し、ある一定の水準を超えたら(下回ったら)Fargateのタスク数を増やす(減らす)というLambdaを書き、StepFunctionsの中に組み込む。といったやり方が考えられます。
すでに実装している方がいらっしゃるようです。
https://dev.classmethod.jp/articles/afargate-fast-autoscaler/オートスケーリングがそこまで必要ないけど15分以上のタスクを動かしたい場合はこちらでしょうか。
案④AWS Batch
Batchはオートスケーリングもいい感じにやってくれますし、実行時間の制限もありません。
ただここでネックになるのがやはり、最初のEC2の設定・調整・管理が面倒ということでしょう。せっかくStep Functionsでサーバレスに構築できているのですから、できればLambdaやFargateのようなサーバーレスのサービスを使いたいと思ってしまうかたもいるのではないでしょうか。
その点が気にならず、逆にEC2の細かい設定をしてパフォーマンスを出したい場合はBatchを使用すると良いでしょう。
補足
SQSは最低一回呼ばれることのみ保証しているので同じメッセージが二回実行されることもありえます。冪等性を担保するか、重複実行を管理する処理をワーカーに実装する必要があるので注意です。
ちなみにですが、今回のようなケースではAWS Batchのみでバッチ処理の運用をすることは無いです。以下の資料で言うところの、Aの使い方を検討しているからです。
引用元:https://aws.amazon.com/jp/blogs/news/webinar-bb-aws-batch-2019/
まとめ
- Lambda
- 基本的に15分以内で終わる簡単な処理はStep Functions+LambdaでOK。
- 並行処理して欲しいものはSQS+Lambda。SQSあるとメッセージ量に応じてLambdaがスケールする。
- Fargate
- 15分以上かかる処理やミドル・ランタイム・ライブラリの自由さが求められるものはStep Functions+Fargate。
- Batchよりも設定が簡単。EC2インスタンスを気にしなくてよい。
- Batch
- 高機能。EC2インスタンスレベルでカスタマイズ・チューニングしたい、動的なリソースのプロビジョニング、カスタムAMI使用、パイプライン処理(依存関係)など、リッチなことを期待するならこれ。
- その代わり設定が大変、コンテナインスタンスの起動・削除にオーバーヘッドあり。
といった感じで、それぞれにメリット・デメリットがあるので使用用途に合わせて適用していくことが大事です。





- 投稿日:2020-05-31T18:26:03+09:00
AWS Certified Database - Specialty合格記
AWS Certified Database - Specialtyを受けてきました。
取得を考えている方の参考になれば幸いです。試験概要
https://aws.amazon.com/jp/certification/certified-database-specialty/
- 時間:180分
- 問題数:65問1
事前準備
- 関連しそうなAWSのドキュメントを読む
- RDS
- Aurora
- Neptune
- DynamoDB
- DocumentDB
- 他
- 模擬試験を受ける
結果
合格 (スコアは後日ダウンロードできるようになってから)
受験者のスペック
参考になるかわかりませんが。。。
- AWS歴:6年
- クラウド関連の保有資格
- AWS: アソシエイト×3+プロフェッショナル×2+スペシャルティ×5+プラクティショナー
- GCP: クラウドアーキテクト+データエンジニア+デベロッパー+ネットワーク+セキュリティ
- Azure: ソリューションアーキテクトエキスパート
- 外観:メガネぼーず
難易度等
時間は1周目で半分余りました。慌てなくても十分時間はあると思います。
難易度はAWSソリューションアーキテクトプロフェッショナルと同じか、ちょっと難しい位だと思います。
ゴリゴリRDSさわっている方でも、結構歯応えを感じるのではないでしょうか。
今更データベースぅ?とか言わず、是非チャレンジしてみてください。感想
これでとりあえずAWSの認定はコンプしたけどIoTやメディアあたりとか、また認定増えたりするのかなぁ。
何か認定の更新と新規取得で1年が終わる感じがする。
試験ガイドに記載が無いので、問題数は変わるかもしれません ↩
- 投稿日:2020-05-31T17:56:34+09:00
Cloud 9 + lambdaでbot作成 ーpart4
はじめに
これまでの投稿で、
・Twitter APIを使用開始し(part1)
・Cloud9でLambda Functionをデプロイし(part2)
・Lambda FunctionからS3オブジェクトへの読み書き(part3)
を実装してきました。
本投稿は下記のパート4として、計算するための関数を実装していきます。
・S3オブジェクトへの書き込み内容を30日分とし、それ以前を削除する
・仮想通貨の前日比較を計算する過去のこちら
・part1 : https://qiita.com/htanaka/items/a13fe6da23c3fcdc172a ・part2 : https://qiita.com/htanaka/items/2e6bdc3f54bdfdf542a9 ・part3 : https://qiita.com/htanaka/items/2438b2cb876d4a33c436S3オブジェクトには1か月分のデータを保持する
S3オブジェクトに毎日書き込みを行うと、
ファイルサイズが大きくなる心配があります。
過去にさかのぼるとしても1か月分あればとりあえず十分なので
それ以前のデータを削除するようなプログラムにします。「# write S3 Object (on this month)」にあたる部分がそれです。
一か月前の日付を取得し、one_month_ago = datetime.datetime(today.year, today.month-1, today.day)一か月以内のデータのみ書き込むようにしています。
if(line_date >= one_month_ago): line = line + '\r\n' writelines.append(line)・Lambda Functionすべて(lambda_function.py)
import json import requests import datetime import boto3 def lambda_handler(event, context): # difinition bucket_name = 'bottest-200423' s3_prefix = 'dailyRate' fileName = 'dailyRate.csv' s3 = boto3.client('s3') s3_resource = boto3.resource('s3') key=s3_prefix+"/"+fileName # get S3 Object response = s3.get_object(Bucket=bucket_name, Key=key) body = response['Body'].read() bodystr = body.decode('utf-8') lines = bodystr.split('\r\n') # today rate url_items = 'https://bitflyer.com/api/echo/price' r_get = requests.get(url_items).json() lines[-1]=datetime.date.today().strftime('%Y-%m-%d')+","+str(r_get['mid']) # write S3 Object (on this month) writelines = [] today= datetime.datetime.today() one_month_ago = datetime.datetime(today.year, today.month-1, today.day) for line in lines: if(line[0:1]=="2") : line_date = datetime.datetime.strptime(line[0:10], '%Y-%m-%d') if(line_date >= one_month_ago): line = line + '\r\n' writelines.append(line) else : line = line + '\r\n' writelines.append(line) writebody = "".join(writelines) writebody = writebody.encode('utf-8') bucket = s3_resource.Object(bucket_name,key) bucket.put(Body=writebody)仮想通貨の前日比較を計算する
前日の仮想通貨価格と当日の仮想通貨価格を比較し、
上昇率に応じて発するメッセージを変えるようにします。※ 「# today rate」に追記しています。
※ 現在はprintにしていますが、この後ツイートできるように変更します。・Lambda Functionすべて(lambda_function.py)
import json import requests import datetime import boto3 import math def lambda_handler(event, context): # difinition bucket_name = 'bottest-200423' s3_prefix = 'dailyRate' fileName = 'dailyRate.csv' s3 = boto3.client('s3') s3_resource = boto3.resource('s3') key=s3_prefix+"/"+fileName # get S3 Object response = s3.get_object(Bucket=bucket_name, Key=key) body = response['Body'].read() bodystr = body.decode('utf-8') lines = bodystr.split('\r\n') # today rate url_items = 'https://bitflyer.com/api/echo/price' r_get = requests.get(url_items).json() first_2_digits = math.floor(r_get['mid']/10000) lines[-1]=datetime.date.today().strftime('%Y-%m-%d')+","+str(r_get['mid']) if(lines[-2][0:1]=="2"): day_before_ratio = (float(lines[-1][11:])/float(lines[-2][11:])-1)*100 if(day_before_ratio > 10): print("BitCoin:"+str(first_2_digits)+"万"+str(math.floor(r_get['mid']-first_2_digits*10000))+"円\r" +"前日上昇率:"+str(round(day_before_ratio, 2))+"%\r" +"今日は焼肉にしよう") elif(10 >= day_before_ratio > 2): print("BitCoin:"+str(first_2_digits)+"万"+str(math.floor(r_get['mid']-first_2_digits*10000))+"円\r" +"前日上昇率:"+str(round(day_before_ratio, 2))+"%\r" +"今日は外食しよう") elif(2 >= day_before_ratio > -2): print("BitCoin:"+str(first_2_digits)+"万"+str(math.floor(r_get['mid']-first_2_digits*10000))+"円\r" +"前日上昇率:"+str(round(day_before_ratio, 2))+"%\r" +"今日は自炊しよう") elif(-2 >= day_before_ratio > -10): print("BitCoin:"+str(first_2_digits)+"万"+str(math.floor(r_get['mid']-first_2_digits*10000))+"円\r" +"前日上昇率:"+str(round(day_before_ratio, 2))+"%\r" +"今日は冷凍チャーハンにしよう") else : print("BitCoin:"+str(first_2_digits)+"万"+str(math.floor(r_get['mid']-first_2_digits*10000))+"円\r" +"前日上昇率:"+str(round(day_before_ratio, 2))+"%\r" +"今日はモヤシ炒めにしよう") # write S3 Object (on this month) writelines = [] today= datetime.datetime.today() one_month_ago = datetime.datetime(today.year, today.month-1, today.day) for line in lines: if(line[0:1]=="2") : line_date = datetime.datetime.strptime(line[0:10], '%Y-%m-%d') if(line_date >= one_month_ago): line = line + '\r\n' writelines.append(line) else : line = line + '\r\n' writelines.append(line) writebody = "".join(writelines) writebody = writebody.encode('utf-8') bucket = s3_resource.Object(bucket_name,key) bucket.put(Body=writebody)おわりに
いかがでしょうか。
プログラムとして残すはツイートするのみとなりました。
次回はツイートできるようにプログラムを追加します。シリーズ
part1: https://qiita.com/htanaka/items/a13fe6da23c3fcdc172a
part2: https://qiita.com/htanaka/items/2e6bdc3f54bdfdf542a9
part3: https://qiita.com/htanaka/items/2438b2cb876d4a33c436
part4: https://qiita.com/htanaka/items/578d6005adca400f4424本投稿のBotはこちらでツイートしています。
ぜひ一度見てみてください。
アカウント名:@YsI6HEMQ0EEwfN8
アカウントURL:https://twitter.com/YsI6HEMQ0EEwfN8
- 投稿日:2020-05-31T17:51:17+09:00
AWS 上の ALB の HealthChecker に 200 を返す方法
AWS 上の ALB のターゲットの Moodle で HealthChecker に認識させることはできないのは、config.php が読み込んでいる lib/setuplib.php でリダイレクトしているからで、ターゲットでは 303 になりうまくいきません。
config.php の最上部で、以下のように記述すれば、200 を返す事ができます。
コツは、lib/setuplib.php を読み込む前に処理を入れることです。$http_user_agent = $_SERVER['HTTP_USER_AGENT']; if (strstr($http_user_agent, "ELB-HealthChecker")) { echo "ok"; die; }
- 投稿日:2020-05-31T17:24:25+09:00
Terraform の aws_route_table が何もしてないのに壊れた
Terraform の aws_route_table が何もしてないのに壊れた
月イチ連載になるのか?「何もしてないのに壊れた」シリーズ
2019-12にterraformしたAWS上の開発環境を、サブセットにしてもう一丁建立というタスクが発生したのです。
- tf コード一式をコピー
- 不要なところを削除
tags.Nameとかsubnet.cidr_blockとかの環境固有部分を置換terraform initterraform planterraform applyserverspecで疎通テスト毎日とか毎週の頻度じゃないけど、いつもの段取りでやれる作業のはずだったのです。
未知のエラーとの遭遇
typoがないか、環境固有値の設定漏れがないか code差分チェックして、いよいよ
terraform planするとこれまで見たことのないエラーが出ました。$ terraform plan ... Error: expected "route.0.ipv6_cidr_block" to be a valid IPv4 Value, got : invalid CIDR address: on route.tf line 17, in resource "aws_route_table" "private-rt": 17: resource "aws_route_table" "private-rt" {なぜ? ipv6 のところに IPv4 Value なの? まあ、言われたとおりにしてみます。
ipv6_cidr_block = "0.0.0.0/0"たしかに terraform plan は通るようになるのですが、
terraform applyするとEnter a value: yes aws_route_table.private-rt: Modifying... [id=rtb-xxxxxxxxxxxxxxxx] Error: Error creating route: InvalidParameterCombination: The parameter destinationCidrBlock cannot be used with the parameter destinationIpv6CidrBlock status code: 400, request id: xxxx on route.tf line 17, in resource "aws_route_table" "private-rt": 17: resource "aws_route_table" "private-rt" {そりゃそうだろうと。空文字列が気にいらなかったのかな、
ipv6_cidr_block = "::/0"Enter a value: yes aws_route_table.private-rt: Modifying... [id=rtb-xxxxxxxxxxxxxxxx] Error: Error creating route: InvalidParameterCombination: The parameter destinationCidrBlock cannot be used with the parameter destinationIpv6CidrBlock
terraform planは通ってもterraform applyはできない。terraform import
コピペ元の
aws_route_tableの resource文resource "aws_route_table" "private-rt" { route = [ { cidr_block = "0.0.0.0/0" egress_only_gateway_id = "" gateway_id = "" instance_id = "" ipv6_cidr_block = "" nat_gateway_id = aws_nat_gateway.ngw.id network_interface_id = "" transit_gateway_id = "" vpc_peering_connection_id = "" }, ] tags = { "Name" = "private-rt" } vpc_id = data.aws_vpc.vpc.id }このresource文の出所は、既存 route_table を
terraform importしてterraform state showした結果だったはず。既存環境の route table の 現時点で state show した結果もこの形式になっています。
$ terraform state show aws_route_table."private-rt" # aws_route_table.private-rt: resource "aws_route_table" "private-rt" { id = "rtb-xxxxxxxxxxxxxxxx" owner_id = "xxxxxxxx" propagating_vgws = [] route = [ { cidr_block = "0.0.0.0/0" egress_only_gateway_id = "" gateway_id = "" instance_id = "" ipv6_cidr_block = "" nat_gateway_id = "nat-xxxxxxxxxxxxxxxxf" network_interface_id = "" transit_gateway_id = "" vpc_peering_connection_id = "" }, ] tags = { "Name" = "private-rt" } vpc_id = "vpc-xxxxxxxx" }「何もしてないのに壊れた」
コード修正
https://www.terraform.io/docs/providers/aws/r/route_table.html
aws_route_table の公式構文は state show結果と随分と違うみたい。
こちらに合わせて下記で通った。resource "aws_route_table" "private-rt" { route { cidr_block = "0.0.0.0/0" nat_gateway_id = aws_nat_gateway.ngw.id } tags = { "Name" = "private-rt" } vpc_id = data.aws_vpc.vpc.id }実行環境
- Amazon Linux 2
- Terraform v0.12.26
- aws-cli/1.16.102 Python/2.7.16 Linux/4.14.138-114.102.amzn2.x86_64 botocore/1.12.92
- 投稿日:2020-05-31T17:09:20+09:00
AWSへのRailsアプリのデプロイ その1
はじめに
チームで開発したアプリを自分で建てたEC2に移行させたため記事に残しておきます。
EC2インスタンスを作る
まず、アプリの移行先のインスタンスを作りましょう。
ここは各個人で違うと思いますが、今回は「Amazon Linux AMI」を選択。
EC2インスタンスを起動させるとキーペアの作成画面が表示されます。
ここでは新しいキーペアの作成を選択し、キーペア名を入力した後、キーペアのダウンロードをしておきましょう。(キーは厳重に保管してください)
Elastic IPの紐付け
インスタンスにElastic IPを紐付けます。
「AmazonのIPv4アドレスプール」を選択肢て「割り当て」を押下。
これでElastic IPが割り当てられます。
続いて、IPアドレスとEC2インスタンスを関連づけます。
EC2のインスタンスIDが分からないと関連付けできないので、確認しておきましょう
Elastic IPの関連付けを選択します。
インスタンスに、先ほど確認したインスタンスIDを入力して「関連付ける」を押下します。
ポートを開く
現状のままだと、HTTPでの通信ができないため、ポートを開きます。
下記の画像の赤枠の部分をクリックしてください。
インバウンドルールの編集を行います。
HTTPのルールを追加して保存します。
ターミナルからEC2インスタンスへログインする。
先ほどダウンロードした秘密鍵を~/.sshフォルダに移動させます。
mv 秘密鍵のパス ~/.ssh秘密鍵のパーミッションをいじってルートユーザーのみ読み書き可能にします。
chmod 600 ダウンロードした鍵の名前.pemssh -i 秘密鍵のパス ec2-user@EC2インスタンスと紐付けたElastic IP成功したらターミナルにデカデカとEC2と表示されます。
__| __|_ ) _| ( / Amazon Linux AMI ___|\___|___|EC2の設定
EC2上で以下のコマンドを実行して、パッケージをアップデートしましょう。
sudo yum -y update続いて、必要なパッケージをインストールします。
sudo yum -y install git make gcc-c++ patch libyaml-devel libffi-devel libicu-devel zlib-devel readline-devel libxml2-devel libxslt-devel ImageMagick ImageMagick-devel openssl-devel libcurl libcurl-devel curl上記のパッケージをインストールしたらNode.jsをインストールしましょう。
sudo curl -sL https://rpm.nodesource.com/setup_14.x | sudo bash -sudo yum -y install nodejsこれでnode.jsのインストール完了です。ですが、まだまだインストールするものがあります。
続いてRuby関係のインストールです。まずコマンドでgitからrbenvをクローンしましょう。git clone https://github.com/sstephenson/rbenv.git ~/.rbenv以下の2つのコマンドでパスを通します。パスを通すことで、どのディレクトリにいてもアプリを呼び出せます。
echo 'export PATH="$HOME/.rbenv/bin:$PATH"' >> ~/.bash_profileecho 'eval "$(rbenv init -)"' >> ~/.bash_profile~/.bash_profileの編集内容はログインし直さないと反映されないので、sourceコマンドで即時反映させます。
source .bash_profilegitからruby-buildをクローンします。
git clone https://github.com/sstephenson/ruby-build.git ~/.rbenv/plugins/ruby-buildrehashでgemのコマンドを使えるようにします。
rbenv rehashここからはRubyのインストールです。
使用しているRubyのバージョンを確認し、コマンドを各々で読み替えてください。rbenv install x.x.x(バージョン)EC2インスタンス内で使用するRubyのバージョンを決めます
rbenv global x.x.x(バージョン)rehashしてRubyのインストールは終了です。
rbenv rehash今回はここまで
長くなったので今回はここまでです。次の記事で完成予定。



- 投稿日:2020-05-31T16:44:13+09:00
地方プログラマでもAWS認定ソリューションアーキテクチャアソシエイトを取得したい
概要
2020年3月19日に939点でAWS SAAに合格することができました。
AWS並びにクラウドがより広まってくれるように、勉強の流れや地方ならではの悩みなどを記載していこうと思います。
S3にPython、PHPなどのバックグラウンドからアクセスする方法は知っていても、VPCやセキュリティグループなどは全くわからないプログラマがAWS SAAを取得するまでの話です。
試験勉強の流れ
試験勉強の期間は年末から初めて約3ヶ月です。
その間に行った勉強方法について簡単に解説していければと思います。AWS認定資格試験テキスト AWS認定 ソリューションアーキテクト-アソシエイ
www.amazon.co.jp/dp/479739739X
試験問題の解き方については詳しく解説されていますが、AWSの概要についてをテキストで学ぶのは難しかったです。
時間はかかりますが、初めての方はハンズオンから行ったほうが良いかと思います。
いきなりテキストを手に取ると挫折するかもしれません。
ある程度AWSについて理解が深まったら利用するのが良いと思います。Udemy
これだけでOK! AWS 認定ソリューションアーキテクト – アソシエイト試験突破講座(SAA-C02試験対応版)
https://www.udemy.com/course/aws-associate/ハンズオンを交えながら試験対策を行うことができるので、AWSの基本的な知識をかなり身に付けることができました。
しかし試験問題を解く力を得ることはできないかもしれません。AWS WEB問題集で学習しよう
AWSの模擬問題はとても少なく、どのような問題がでるかもイメージが付きにくいです。
このサイトを活用することで大量の模擬問題を解くことができました。
多少お金はかかりますが、有料会員ですと問題数が大きく増えますのでゴールドプランをおすすめします。
本番試験に近い問題も多くあるため、模擬問題を解くことによって試験合格への大きな近道になると思いました。BlackBelt
https://aws.amazon.com/jp/aws-jp-introduction/aws-jp-webinar-service-cut/
あまり活用しませんでしたが、AWS公式なだけあってかなり詳しい説明が書いてあります。
問題を解いていて、この答えになる理由がわからないときに積極的に活用していきました。AWSの公式模擬問題
https://aws.amazon.com/jp/certification/certification-prep/
1,500円でAWS公式が提供する模擬問題を受けることができます。
試験当日に慌てないためにも受けておくと良いと思います。おすすめの勉強の流れ
- Udemyを使ってハンズオン
- Web問題集をひたすら解く(可能なら全問を2,3回繰り返す)
- 不明なところをBlackBeltやテキスト理解できるまでで調べる
- 仕上げとして本番試験形式の問題を解く
合格したあとに私がこうすればよかったかなと思った勉強の流れになります。
これから勉強される方の参考になればと思います。地方で受験する際の注意点
ここからは地方で受験する方の注意点となります。
AWS認定試験の受験会場はPSIもしくはピアソンVUEテストセンターの2パターン用意されています。
調べてみるとピアソンVUEテストセンターはほぼ全国にあるようなので油断していました。ある程度、合格に自信も付いてきたので、とりあえず受験の申し込みをしようと思いました。
私の住んでいる市内にもテストセンターがあったので、そちらで受験しようと思ったのですが、
そこではAWS認定試験を行っていませんでした。実施されている近隣のテスト会場は車で1時間ぐらいのところになり、しかも土日は試験を行っていませんでした。
東京まで行くことも考えたのですが、コロナの影響もあったので、そちらは自粛して平日に有給を使い受験しました。試験当日にわかったのですが、受験時間は午後からで人数も最大4人でした。
しかも他の試験を受験してる方と同じ枠でしたので、空いていたらすぐに予約しない受験することもできないと思います。都市圏に住んでいる方は気にしなくても良いと思いますが、もし地方在中でAWS認定試験を受験したいという方は、先に受験方法を確立しておくことをおすすめします。
この件を機に、東京への転職を考え始めました。

- 投稿日:2020-05-31T16:21:37+09:00
SORACOM Kryptonを使ってDynamoDBのテーブルをScanする
はじめに
IoTデバイスとAWS間で通信を行う場合は、デバイスにIAMのアクセスキーとシークレットキーを埋め込み、利用するのが一般的かと思います。
その場合、デバイスに不正アクセスされた場合や、盗難されると、認証情報を不正に利用される可能性があります
その影響として、当てている権限にもよりますが、データを盗まれたり、EC2立てられてマイニングに使用されたりするかもしれません。そのため、認証情報を盗まれるのは避ける必要がありますが、かと言って認証情報を使わないわけにもいきません。
そこで登場するのが SORACOM Krypton です
SORACOM Krypton
SORACOM Krypton(以下 Krypton)は、ざっくり説明すると、
クラウドサービスを使いたいときに、認証情報を取得する機能です。kryptonを利用することによって、セキュリティ性が向上します。
なぜなら、デバイスに認証情報を持たせなくてもよくなるからです。説明は一度、公式の「セルラー回線を使用したプロビジョニング」に記載がある図を見ていただいたほうがわかりやすいと思います
流れとしては、認証が必要な処理をクラウドに対して行いたい場合、まずkyrptonに対してリクエストを送ります。
kryptonは、あらかじめ登録されている情報を元に、クラウドから認証情報等を取得し、レスポンスとして返します。そうすることによって、デバイス側は、認証情報を持つ必要はなくなります。
kryptonいいですね!DynamoDBのデータを取得
kryptonでは、何パターンか認証情報を取得する方法がありますが、今回は
Cognitoから期限付き認証情報を取得して、DynamoDBのデータ取得を行います。基本的には以下の手順に近いです。
https://dev.soracom.io/jp/start/krypton_cognito/ステップ3までは同じなので、公式を参照してください。
ステップ4以降はnode.jsでしかサンプルが用意されていません。
nodeがよければ、そのまま公式の手順で進めてください。(S3からファイルをダウンロードする内容ですが...)今回はpythonを使用したいのでサンプルがないのと、公式と同じことをしても面白くないので、DynamoDBのデータを取得するようにしています。
以下はKryptonが提供しているAPIのリファレンスです
https://dev.soracom.io/jp/krypton/api/最初に説明したようにCognitoから期限付きの権限を取得してDynamoDBへのアクセスを行うので、使うAPIとしては
/v1/provisioning/aws/cognito/open_id_tokens
となります。
また、エンドポイントについては
Krypton プロビジョニング API("/v1/provisioning/*") のエンドポイントはプロビジョニングのための認証方法によって異なります。
SORACOM Air のセルラー回線を使用した認証の場合
https://krypton.soracom.io:8036
SORACOM Endorse による SIM 認証
https://g.api.soracom.ioと記載があり、今回はSORACOM Air のセルラー回線を使用した認証を行うので、
https://krypton.soracom.io:8036
となります。2点あわせると今回実装するURLができます
https://krypton.soracom.io:8036/v1/provisioning/aws/cognito/open_id_tokensここまで準備が整ったら、あとは以下のソースコードを実行するだけです。
ソースコード
# -*- coding:utf-8 -*- # モジュール import json import boto3 from boto3.session import Session import subprocess import logging import traceback LOG_DIR = "/var/log/" LOG_FILE = LOG_DIR + "get_dynamo_data.log" LOG_FORMAT = "[%(asctime)s %(levelname)s] %(message)s" logging.basicConfig(filename=LOG_FILE, level=logging.INFO, format=LOG_FORMAT) logger = logging.getLogger("logger") cognito = boto3.client("cognito-identity", region_name="ap-northeast-1") cmd = "curl -X POST -H content-type: application/json https://krypton.soracom.io:8036/v1/provisioning/aws/cognito/open_id_tokens" # kryptonからtokenを取得する def getToken(): token = subprocess.Popen( cmd, stdout=subprocess.PIPE, shell=True ).stdout.readlines()[0] token_str = token.decode("UTF-8") return json.loads(token_str) # tokenを使用してcognitoから期限付きのcredentialを取得し、DynamoDBからデータを取得する def getDynamoData(tokens): resp = cognito.get_credentials_for_identity( IdentityId=tokens["identityId"], Logins={"cognito-identity.amazonaws.com": tokens["token"]}, ) secretKey = resp["Credentials"]["SecretKey"] accessKey = resp["Credentials"]["AccessKeyId"] token = resp["Credentials"]["SessionToken"] session = Session( aws_access_key_id=accessKey, aws_secret_access_key=secretKey, aws_session_token=token, region_name="ap-northeast-1", ) dynamo = session.resource("dynamodb") table = dynamo.Table("test_table") response = table.scan() return response["Items"] if __name__ == "__main__": try: logger.info("start dynamo data ...") tokens = getToken() dynamo_data = getDynamoData(tokens) logger.info(dynamo_data) except Exception as e: logger.error("exception") logger.error(traceback.format_exc())まとめ
IAMユーザーの権限を適切に設定すれば、認証情報が漏れたとしても、極力被害を抑えられるとは思いますが、
不正なデータをあげられたり、データを盗まれたりする可能性はあります。
めんどくさいからadminでいいやって声は聞こえなかったことにします。今回紹介したKryptonを使用すれば、万が一の際にも、キーペアは漏れず、不正利用されることは少なくなるでしょう。
最悪なケースでは、プログラムを改変されて、一時トークンを使われることはあるかもしれませんが、できてそこまでです。
Kryptonを使ったほうが確実にセキュアです。また、上記の明確な利点がありますが、それとは別に精神的な安心を得られるのは、大きなメリットかと思います。
月額の料金は高くないと思っているので、安心を買うために、導入を検討してみてはいかがでしょうか
お客さんがいる場合は、こんなセキュリテイ対策をやってるんだよと、説明できるのもいいですね。
より安全にIoTライフを楽しみましょう!
- 投稿日:2020-05-31T15:47:12+09:00
AWS ubuntu wordpress構築
sudo yum install httpd -y sudo systemctl start httpd sudo systemctl enable httpd.service udo usermod -a -G apache ec2-user /var/www とそのコンテンツのグループ所有権を apache グループに変更します。 sudo chown -R ec2-user:apache /var/www グループの書き込み許可を追加します。 sudo chmod 2775 /var/www && find /var/www -type d -exec sudo chmod 2775 {} \; find /var/www -type f -exec sudo chmod 0664 {} \; sudo amazon-linux-extras enable php7.3 では、実際に PHP と関連するパッケージをインストールしていきます。 sudo yum install php php-gd php-mysqlnd php-xmlrpc -y Complete! と出たらインストール成功です。 ■MariaDB をインストールする sudo yum install mariadb mariadb-server -y Complete! と出たらインストール成功です。 では早速起動します。 sudo systemctl start mariadb Apache と同じように、MariaDB も自動起動するようにしておきましょう。 sudo systemctl enable mariadb 次に、mysql_secure_installation を実行します。 sudo mysql_secure_installation 上記の後は全部YESでもいいです。 sudo yum install php-mbstring php-fpm -y Apache を再起動します。 sudo systemctl restart httpd /var/www/html で Apache ドキュメントルート (Web サイトとして公開するトップページのディレクトリ) に移動します。 ここで使っている cd というコマンドはディレクトリを移動するよ、change directory するよ、という意味です。 cd /var/www/html Web フラウザから http://[パブリックDNS]/phpMyAdmin にアクセスしてみましょう。 ログイン画面が表示されたら、Username に "root"、Password にさきほど mysql_secure_installation で設定したパスワードを入力して "Go" ボタンをクリックします。 wget https://wordpress.org/latest.tar.gz tar -xzvf latest.tar.gz mysql -u root -p ログイン成功しました。 mysql -u root -p MariaDB [(none)]> CREATE USER によって、データベースのユーザーとパスワードを作成します。 your_strong_password の部分はご自身で考えた独自のパスワードに置き換えます。 CREATE USER 'wordpress-user'@'localhost' IDENTIFIED BY 'your_strong_password'; ちなみに、ここで作成したユーザーは mysql_secure_installation で作成した root ユーザーとは別です。 もし紛らわしい場合等は詳しく調べるもしくは、RDSごとパスワードを同じにする等の方法を用いてもいいかもしれません。 CREATE DATABASE によって、データベースを作成します。 CREATE DATABASE `データベース名`; GRANT によって、データベースに対して、さきほど作成した wordpress-user ユーザーの権限を追加します。 GRANT ALL PRIVILEGES ON `データベース名`.* TO "user名"@"localhost"; すべての変更を有効にするため、データベース権限をフラッシュします。 FLUSH PRIVILEGES; mysql クライアントを終了します。 exit
- 投稿日:2020-05-31T15:36:30+09:00
【備忘録】AWS ECS Blue / Green Deploy で 複数コンテナを含んだ ECS サービス / タスク を更新する
はじめに
以前、CodePipelineを利用した「ECS Blue / Green Deploy」を実現したのですが、その後 タスク定義の構成を変更(1タスク定義内に1コンテナを配置→2コンテナを配置)するにあたって必要だった設定について備忘録のために投稿させていただきます。
以前の投稿
【備忘録】AWS ECS Blue / Green Deploy 実現のために学んだこと - Qiita
本投稿で説明しないこと
本投稿では、実現したいことのために必要なCodeBuild/Deploy設定の追加・変更・差分についてのみ記載させていただきます。
「ECS Blue / Green Deploy」の基本的な構築方法については、以前の投稿に記載しているため、省略させていただきます。
- CodePipeline の設定方法
- CodeBuild の設定方法
- CodeDeploy の設定方法
- appspec.yaml の記述方法
- taskdef.json の記述方法
- buildspec.yml の記述方法 など
実現したいこと
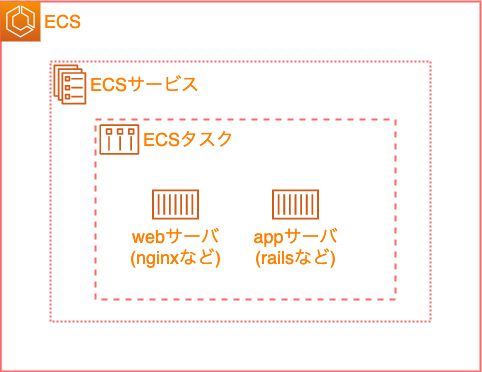
1つのタスク定義内に複数コンテナ(webサーバとappサーバ)が含まれている構成のECSサービス/タスクに対して、「ECS Blue / Green Deploy」を実現したい。
ECSの構成
ECSの構成イメージは以下になります。
- 1つのタスク定義内に複数コンテナ(webサーバとappサーバ)が含まれている
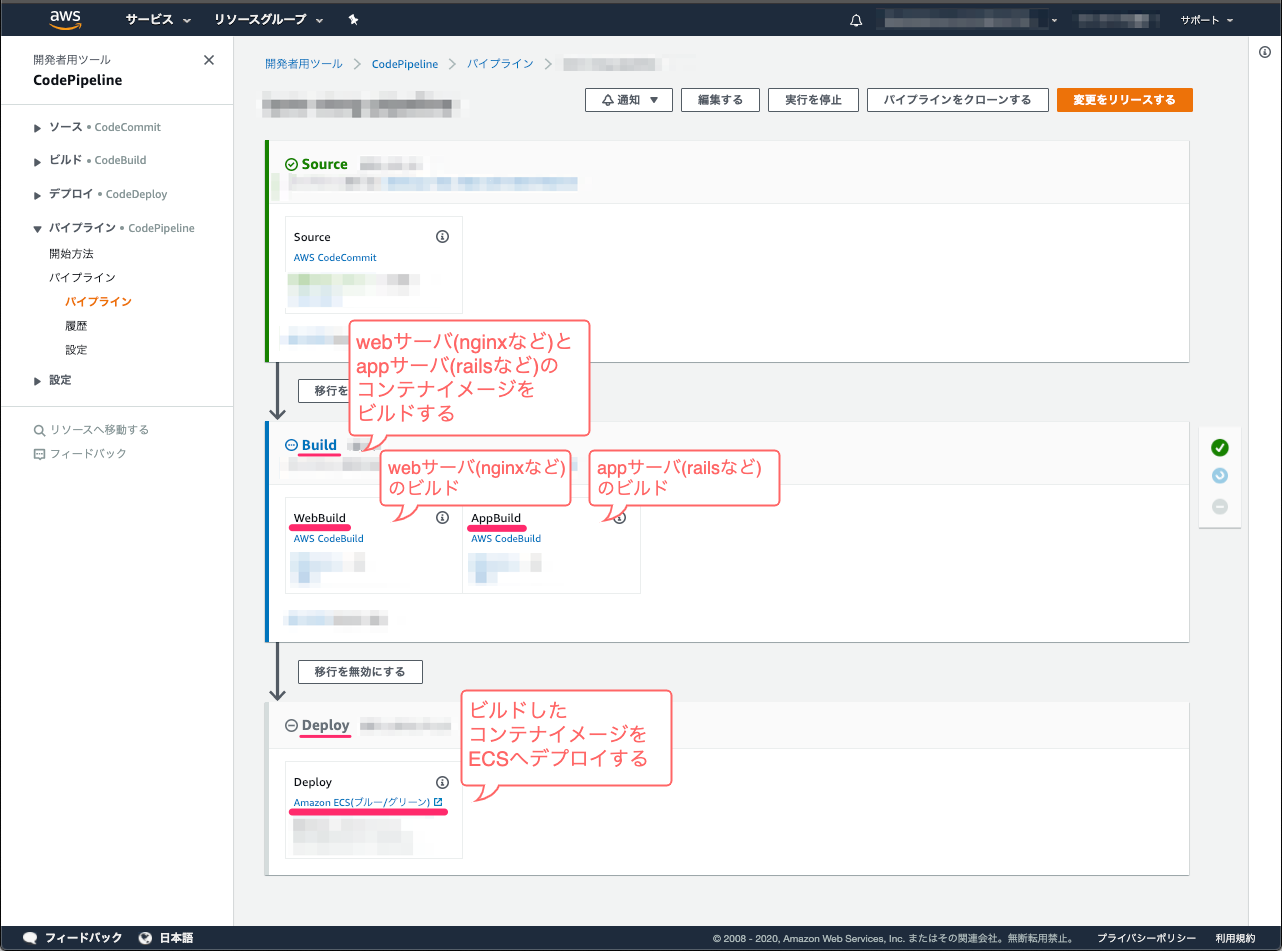
CodePipelineの構成
CodePipelineの構成イメージは以下になります。
- Buildステージでは、webサーバとappサーバのコンテナイメージをビルドする
- Deployステージでは、ビルドしたコンテナイメージをECSへデプロイする
実現するための設定方法
もくじ
- CodeBuildで、各ステップに適切な出力アーティファクト名を付ける
- CodeDeployで、入力アーティファクトに、CodeBuildの出力アーティファクトを指定する
- CodeDeployで、入力アーティファクト毎に、プレースホルダー文字を設定する
- taskdef.jsonで、プレースホルダー文字を指定する
1. CodeBuildで、各ステップに適切な出力アーティファクト名を付ける
各コンテナをビルドするステップの出力アーティファクトに適切な名前をつけておきます
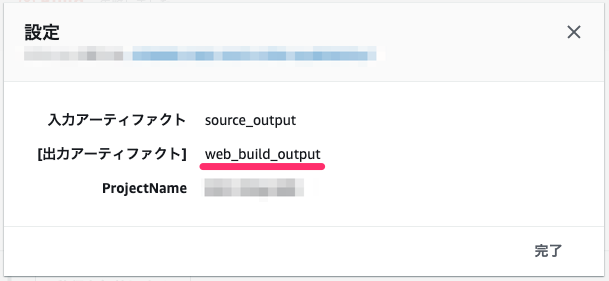
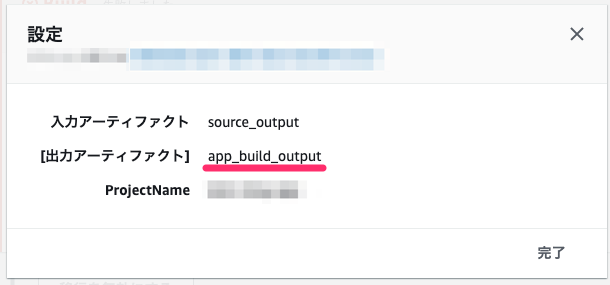
- 1-1. webサーバのビルドステップの出力アーティファクトにアーティファクト名(例:web_build_output)を設定する
- 1-2. appサーバのビルドステップの出力アーティファクトにアーティファクト名(例:app_build_output)を設定する
2. CodeDeployで、入力アーティファクトに、CodeBuildの出力アーティファクトを指定する
ビルドステップの出力アーティファクト名を入力アーティファクトとして利用するように指定します。
入力アーティファクト
- 2-1. webサーバの出力アーティファクト(例:web_build_output)を指定する
- 2-2. appサーバの出力アーティファクト(例:app_build_output)を指定する
3. CodeDeployで、入力アーティファクト毎に、プレースホルダー文字を設定する
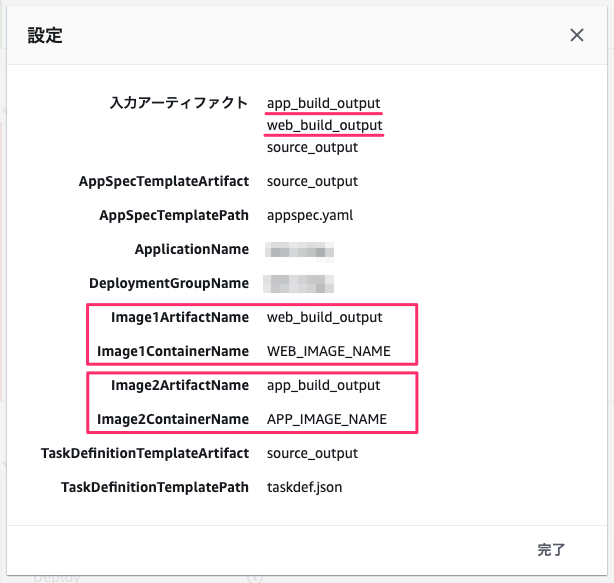
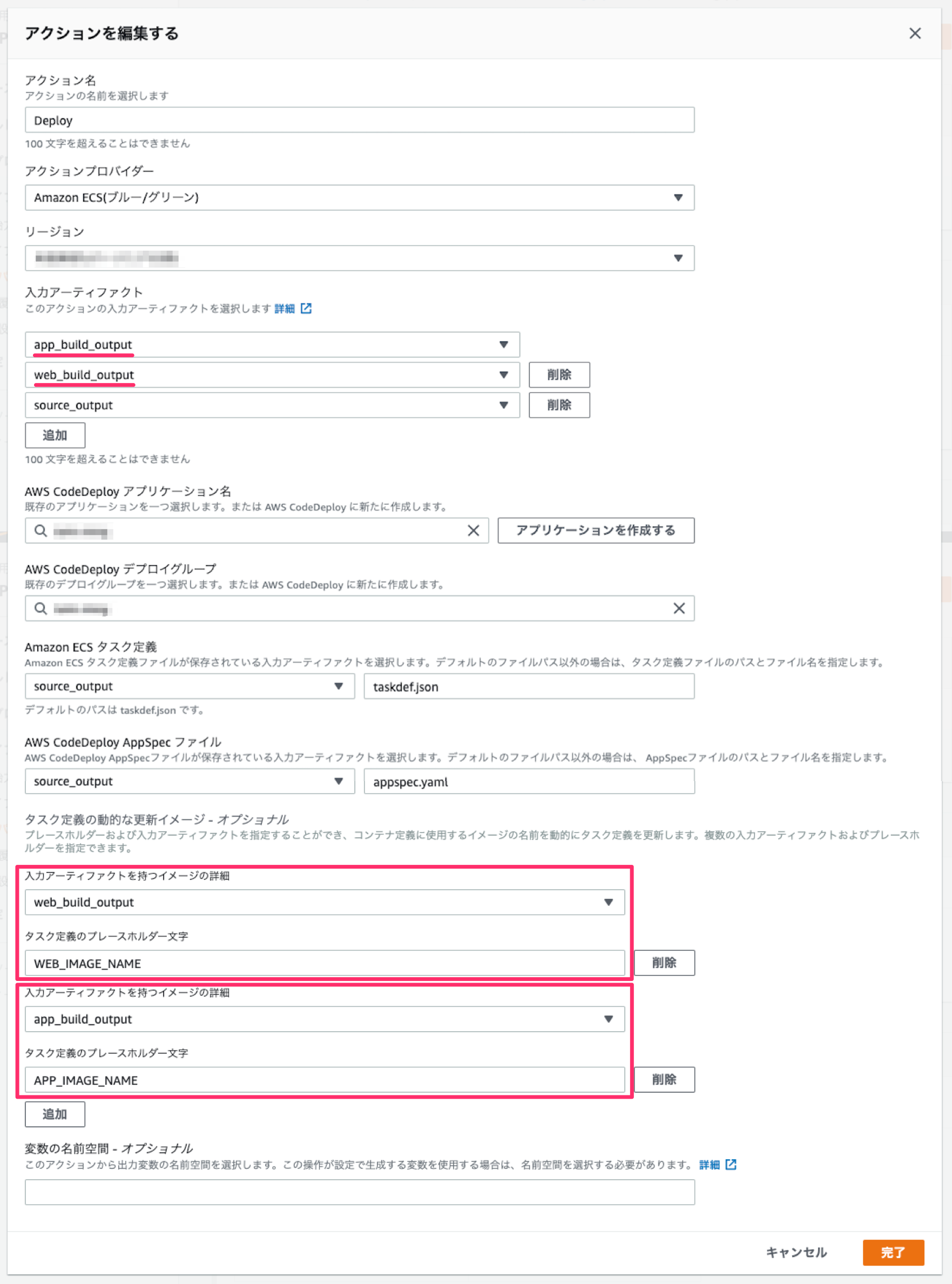
タスク定義の動的な更新イメージ
また、タスク定義の動的な更新イメージで、各ビルドステップの出力アーティファクトとプレースホルダ文字を指定します。
- 3-1. 入力アーティファクトを持つイメージの詳細に、webサーバの出力アーティファクト(例:web_build_output)を指定する
3-2. タスク定義のプレースホルダー文字に、プレースホルダ(例:WEB_IMAGE_NAME)を設定する
3-3. 入力アーティファクトを持つイメージの詳細に、appサーバの出力アーティファクト(例:app_build_output)を指定する
3-4. タスク定義のプレースホルダー文字に、プレースホルダ(例:APP_IMAGE_NAME)を設定する
4. taskdef.jsonで、プレースホルダー文字を指定する
taskdef.jsonで、イメージ名を指定する項目にCodeDeployで設定した、プレースホルダ(例:WEB_IMAGE_NAME、APP_IMAGE_NAME)を指定します。こうすることで、DeployステージでECSタスクを更新する際に、Buildステージでビルドされたコンテナイメージが利用されるようになります。
- 4-1. taskdef.jsonで、webサーバのイメージ名にプレースホルダー文字(例:<WEB_IMAGE_NAME>)を指定する
- 4-2. taskdef.jsonで、appサーバのイメージ名にプレースホルダー文字(例:<APP_IMAGE_NAME>)を指定する
taskdef.json... (省略) "containerDefinitions": [ ... (省略) { "name" : "web" "image": "<WEB_IMAGE_NAME>", ... (省略) }, { "name" : "app" "image": "<APP_IMAGE_NAME>", ... (省略) } ... (省略) ] ... (省略)注意事項
すごく基本的なことなのですが、構築中に「アーティファクト名」や「プレースホルダー文字」をコピペミスしたことで、うまくデプロイされずハマってしまったことがありました orz
着手する前に簡単に設定する名称を整理しておいたほうが、ささいなミスを減らせるかもしれません orz
以下は本投稿で用いた名称です。webサーバ
役割 名前 ビルドステップ名 WebBuild ビルドステップの出力アーティファクト名 web_build_output 出力アーティファクトに対してつけたプレースホルダー文字 WEB_IMAGE_NAME appサーバ
役割 名前 ビルドステップ名 AppBuild ビルドステップの出力アーティファクト名 app_build_output 出力アーティファクトに対してつけたプレースホルダー文字 APP_IMAGE_NAME
- 投稿日:2020-05-31T15:36:30+09:00
【備忘録】AWS ECS Blue / Green Deploy 実現のために学んだこと(複数コンテナ編)
はじめに
以前、CodePipelineを利用した「ECS Blue / Green Deploy」を実現したのですが、その後 タスク定義の構成を変更(1タスク定義内に1コンテナを配置→2コンテナを配置)するにあたって必要だった設定について備忘録のために投稿させていただきます。
以前の投稿
【備忘録】AWS ECS Blue / Green Deploy 実現のために学んだこと - Qiita
本投稿で説明しないこと
本投稿では、実現したいことのために必要なCodeBuild/Deploy設定の追加・変更・差分についてのみ記載させていただきます。
「ECS Blue / Green Deploy」の基本的な構築方法については、以前の投稿に記載しているため、省略させていただきます。
- CodePipeline の設定方法
- CodeBuild の設定方法
- CodeDeploy の設定方法
- appspec.yaml の記述方法
- taskdef.json の記述方法
- buildspec.yml の記述方法 など
実現したいこと
1つのタスク定義内に複数コンテナ(webサーバとappサーバ)が含まれている構成のECSサービス/タスクに対して、「ECS Blue / Green Deploy」を実現したい。
ECSの構成
ECSの構成イメージは以下になります。
- 1つのタスク定義内に複数コンテナ(webサーバとappサーバ)が含まれている
CodePipelineの構成
CodePipelineの構成イメージは以下になります。
- Buildステージでは、webサーバとappサーバのコンテナイメージをビルドする
- Deployステージでは、ビルドしたコンテナイメージをECSへデプロイする
実現するための設定方法
もくじ
- CodeBuildで、各ステップに適切な出力アーティファクト名を付ける
- CodeDeployで、入力アーティファクトに、CodeBuildの出力アーティファクトを指定する
- CodeDeployで、入力アーティファクト毎に、プレースホルダー文字を設定する
- taskdef.jsonで、プレースホルダー文字を指定する
1. CodeBuildで、各ステップに適切な出力アーティファクト名を付ける
各コンテナをビルドするステップの出力アーティファクトに適切な名前をつけておきます
- 1-1. webサーバのビルドステップの出力アーティファクトにアーティファクト名(例:web_build_output)を設定する
- 1-2. appサーバのビルドステップの出力アーティファクトにアーティファクト名(例:app_build_output)を設定する
2. CodeDeployで、入力アーティファクトに、CodeBuildの出力アーティファクトを指定する
ビルドステップの出力アーティファクト名を入力アーティファクトとして利用するように指定します。
入力アーティファクト
- 2-1. webサーバの出力アーティファクト(例:web_build_output)を指定する
- 2-2. appサーバの出力アーティファクト(例:app_build_output)を指定する
3. CodeDeployで、入力アーティファクト毎に、プレースホルダー文字を設定する
タスク定義の動的な更新イメージ
また、タスク定義の動的な更新イメージで、各ビルドステップの出力アーティファクトとプレースホルダ文字を指定します。
- 3-1. 入力アーティファクトを持つイメージの詳細に、webサーバの出力アーティファクト(例:web_build_output)を指定する
3-2. タスク定義のプレースホルダー文字に、プレースホルダ(例:WEB_IMAGE_NAME)を設定する
3-3. 入力アーティファクトを持つイメージの詳細に、appサーバの出力アーティファクト(例:app_build_output)を指定する
3-4. タスク定義のプレースホルダー文字に、プレースホルダ(例:APP_IMAGE_NAME)を設定する
4. taskdef.jsonで、プレースホルダー文字を指定する
taskdef.jsonで、イメージ名を指定する項目にCodeDeployで設定した、プレースホルダ(例:WEB_IMAGE_NAME、APP_IMAGE_NAME)を指定します。こうすることで、DeployステージでECSタスクを更新する際に、Buildステージでビルドされたコンテナイメージが利用されるようになります。
- 4-1. taskdef.jsonで、webサーバのイメージ名にプレースホルダー文字(例:<WEB_IMAGE_NAME>)を指定する
- 4-2. taskdef.jsonで、appサーバのイメージ名にプレースホルダー文字(例:<APP_IMAGE_NAME>)を指定する
taskdef.json... (省略) "containerDefinitions": [ ... (省略) { "name" : "web" "image": "<WEB_IMAGE_NAME>", ... (省略) }, { "name" : "app" "image": "<APP_IMAGE_NAME>", ... (省略) } ... (省略) ] ... (省略)注意事項
すごく基本的なことなのですが、構築中に「アーティファクト名」や「プレースホルダー文字」をコピペミスしたことで、うまくデプロイされずハマってしまったことがありました orz
着手する前に簡単に設定する名称を整理しておいたほうが、ささいなミスを減らせるかもしれません orz
以下は本投稿で用いた名称です。webサーバ
役割 名前 ビルドステップ名 WebBuild ビルドステップの出力アーティファクト名 web_build_output 出力アーティファクトに対してつけたプレースホルダー文字 WEB_IMAGE_NAME appサーバ
役割 名前 ビルドステップ名 AppBuild ビルドステップの出力アーティファクト名 app_build_output 出力アーティファクトに対してつけたプレースホルダー文字 APP_IMAGE_NAME
- 投稿日:2020-05-31T15:36:30+09:00
【備忘録】AWS ECS Blue / Green Deploy で 複数コンテナを含んだ ECS サービス/タスク を更新する
はじめに
以前、CodePipelineを利用した「ECS Blue / Green Deploy」を実現したのですが、その後 タスク定義の構成を変更(1タスク定義内に1コンテナを配置→2コンテナを配置)するにあたって必要だった設定について備忘録のために投稿させていただきます。
以前の投稿
【備忘録】AWS ECS Blue / Green Deploy 実現のために学んだこと - Qiita
本投稿で説明しないこと
本投稿では、実現したいことのために必要なCodeBuild/Deploy設定の追加・変更・差分についてのみ記載させていただきます。
「ECS Blue / Green Deploy」の基本的な構築方法については、以前の投稿に記載しているため、省略させていただきます。
- CodePipeline の設定方法
- CodeBuild の設定方法
- CodeDeploy の設定方法
- appspec.yaml の記述方法
- taskdef.json の記述方法
- buildspec.yml の記述方法 など
実現したいこと
1つのタスク定義内に複数コンテナ(webサーバとappサーバ)が含まれている構成のECSサービス/タスクに対して、「ECS Blue / Green Deploy」を実現したい。
ECSの構成
ECSの構成イメージは以下になります。
- 1つのタスク定義内に複数コンテナ(webサーバとappサーバ)が含まれている
CodePipelineの構成
CodePipelineの構成イメージは以下になります。
- Buildステージでは、webサーバとappサーバのコンテナイメージをビルドする
- Deployステージでは、ビルドしたコンテナイメージをECSへデプロイする
実現するための設定方法
もくじ
- CodeBuildで、各ステップに適切な出力アーティファクト名を付ける
- CodeDeployで、入力アーティファクトに、CodeBuildの出力アーティファクトを指定する
- CodeDeployで、入力アーティファクト毎に、プレースホルダー文字を設定する
- taskdef.jsonで、プレースホルダー文字を指定する
1. CodeBuildで、各ステップに適切な出力アーティファクト名を付ける
各コンテナをビルドするステップの出力アーティファクトに適切な名前をつけておきます
- 1-1. webサーバのビルドステップの出力アーティファクトにアーティファクト名(例:web_build_output)を設定する
- 1-2. appサーバのビルドステップの出力アーティファクトにアーティファクト名(例:app_build_output)を設定する
2. CodeDeployで、入力アーティファクトに、CodeBuildの出力アーティファクトを指定する
ビルドステップの出力アーティファクト名を入力アーティファクトとして利用するように指定します。
入力アーティファクト
- 2-1. webサーバの出力アーティファクト(例:web_build_output)を指定する
- 2-2. appサーバの出力アーティファクト(例:app_build_output)を指定する
3. CodeDeployで、入力アーティファクト毎に、プレースホルダー文字を設定する
タスク定義の動的な更新イメージ
また、タスク定義の動的な更新イメージで、各ビルドステップの出力アーティファクトとプレースホルダ文字を指定します。
- 3-1. 入力アーティファクトを持つイメージの詳細に、webサーバの出力アーティファクト(例:web_build_output)を指定する
3-2. タスク定義のプレースホルダー文字に、プレースホルダ(例:WEB_IMAGE_NAME)を設定する
3-3. 入力アーティファクトを持つイメージの詳細に、appサーバの出力アーティファクト(例:app_build_output)を指定する
3-4. タスク定義のプレースホルダー文字に、プレースホルダ(例:APP_IMAGE_NAME)を設定する
4. taskdef.jsonで、プレースホルダー文字を指定する
taskdef.jsonで、イメージ名を指定する項目にCodeDeployで設定した、プレースホルダ(例:WEB_IMAGE_NAME、APP_IMAGE_NAME)を指定します。こうすることで、DeployステージでECSタスクを更新する際に、Buildステージでビルドされたコンテナイメージが利用されるようになります。
- 4-1. taskdef.jsonで、webサーバのイメージ名にプレースホルダー文字(例:<WEB_IMAGE_NAME>)を指定する
- 4-2. taskdef.jsonで、appサーバのイメージ名にプレースホルダー文字(例:<APP_IMAGE_NAME>)を指定する
taskdef.json... (省略) "containerDefinitions": [ ... (省略) { "name" : "web" "image": "<WEB_IMAGE_NAME>", ... (省略) }, { "name" : "app" "image": "<APP_IMAGE_NAME>", ... (省略) } ... (省略) ] ... (省略)注意事項
すごく基本的なことなのですが、構築中に「アーティファクト名」や「プレースホルダー文字」をコピペミスしたことで、うまくデプロイされずハマってしまったことがありました orz
着手する前に簡単に設定する名称を整理しておいたほうが、ささいなミスを減らせるかもしれません orz
以下は本投稿で用いた名称です。webサーバ
役割 名前 ビルドステップ名 WebBuild ビルドステップの出力アーティファクト名 web_build_output 出力アーティファクトに対してつけたプレースホルダー文字 WEB_IMAGE_NAME appサーバ
役割 名前 ビルドステップ名 AppBuild ビルドステップの出力アーティファクト名 app_build_output 出力アーティファクトに対してつけたプレースホルダー文字 APP_IMAGE_NAME
- 投稿日:2020-05-31T15:08:09+09:00
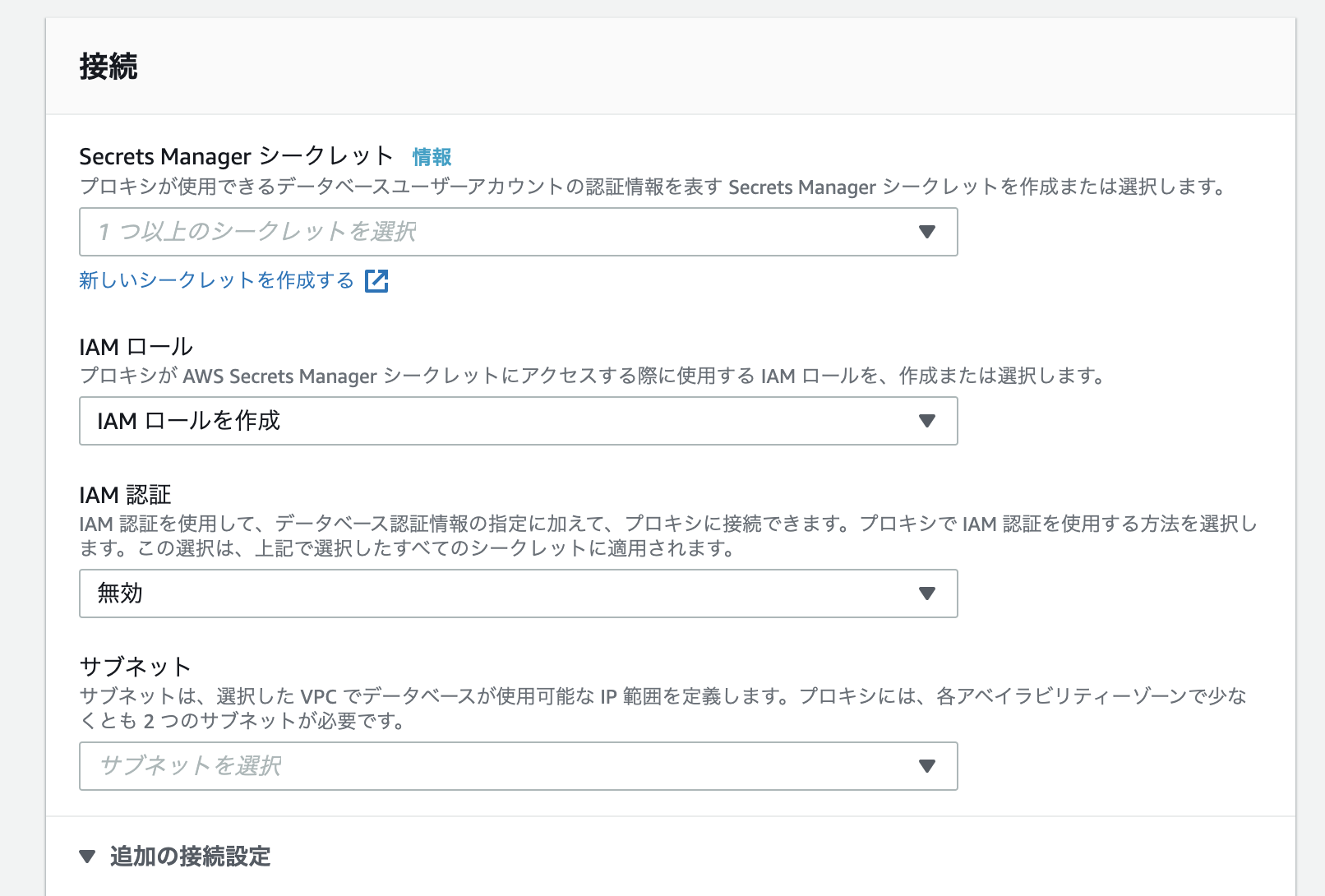
RDSプロキシの作成方法が少し変わってるので書く GA楽しみ
RDSプロキシはまだプレビュー版ということもあり、コンソール画面の変化も多く、開発進んでるんだなぁと見ていて面白いです。(CDK対応早く来て欲しい)
今回書くのは、あまり公式から作成方法が出ておらず、苦しんだ部分があったので補足する内容を載せます。
ですので、ざっくりとした切り抜きになります。以下は、公式から出ている作成手順のブログです。
英語
https://aws.amazon.com/jp/blogs/compute/using-amazon-rds-proxy-with-aws-lambda/日本語
https://aws.amazon.com/jp/blogs/news/using-amazon-rds-proxy-with-aws-lambda/日本語ページはIAMのJSONが途中で見切れてるので、ご注意ください。
英語版は問題ありません。補足事項
変更点1
RDSプロキシに設定する、シークレットにアクセスするIAMロールを自動で作ってくれるようになりました公式のブログではこのJSONでIAMロール作れやと、手順に載っていますが、不要になりました。
コンソールをぽちぽちしていくと自動で作られるようになりました。
もちろん選択することも可能です
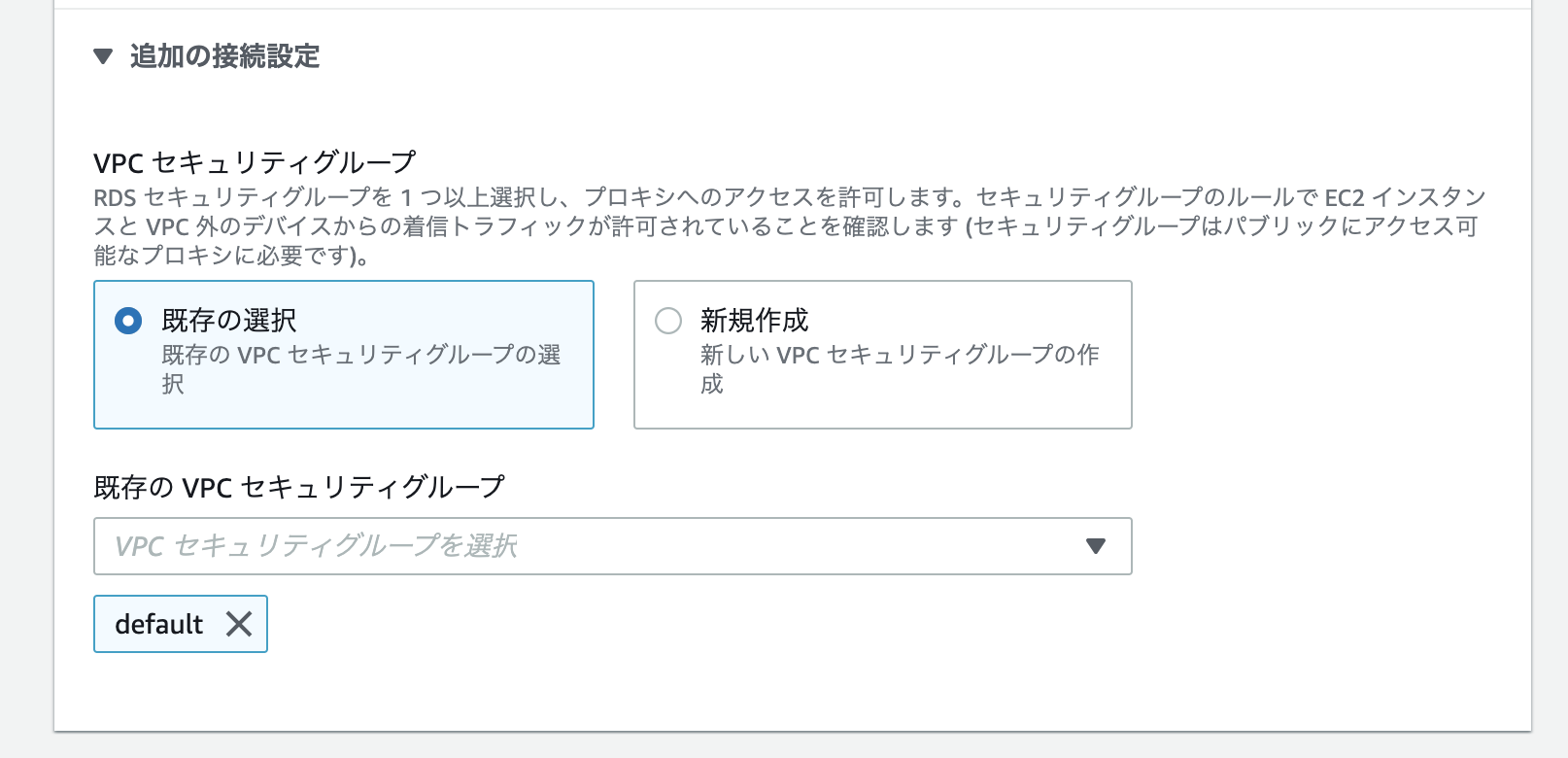
注意点1
選べないセキュリティグループがある
これはよくわかりません。
CDKで作成したセキュリティグループが表示されませんでした。バグかな?注意点2
ブログの手順やっただけじゃ、lambdaからアクセスできない
以下の設定が必要です。
- セキュリティグループのインバウンド設定
インバウンドの設定に、lambdaからの通信を許可する必要があります。
lambdaに設定されているセキュリティグループからのアクセスを許可するのがよいかと思います。最後に
lambdaからRDSへ接続するのは、アンチパターンとされてきて、RDSプロキシがでたときには、ようやく来たかという気持ちになりました。
無い時に試したことがありますが、もうやりたくないですDynamoDBのみでは辛い部分もあるので、これから開発が進んで、うまく両方を利用できたらよりよいアーキテクチャができるのではと楽しみです。
- 投稿日:2020-05-31T14:34:24+09:00
AWS RekognitionのDetectLabels APIを使ってみた
はじめに
AWSの機械学習サービスであるAWS RekognitionのDetectLabels APIを使ってみました。
簡単に物やシーンの識別が出来るみたいなので簡単な画像抽出アプリを作成・使用してみました。AWS Rekognitionとは?
AWSが提供している機械学習サービスで、画像分析やビデオ分析等の画像認識が手軽に行うことができます。
具体的には、以下のようなAPIが提供されています。
- DetectLabels API(画像から物体やシーンを検出)
- DetectFaces API(画像から人間の顔の表情やパーツの配置を検出)
- CompareFaces API(2つの顔画像の類似率を算出)
- IndexFaces/SearchFacesByImage API(顔画像にインデックスを貼り付け、検索することが可能)
DetectLabels APIとは?
DetectLabels API を利用すると、画像から識別した車、ペット、家具など、数千もの物体にラベルを付け、信頼スコアを取得できる
信頼スコアは 0~100 の値で示され、識別結果が正しいかどうかの可能性を意味する
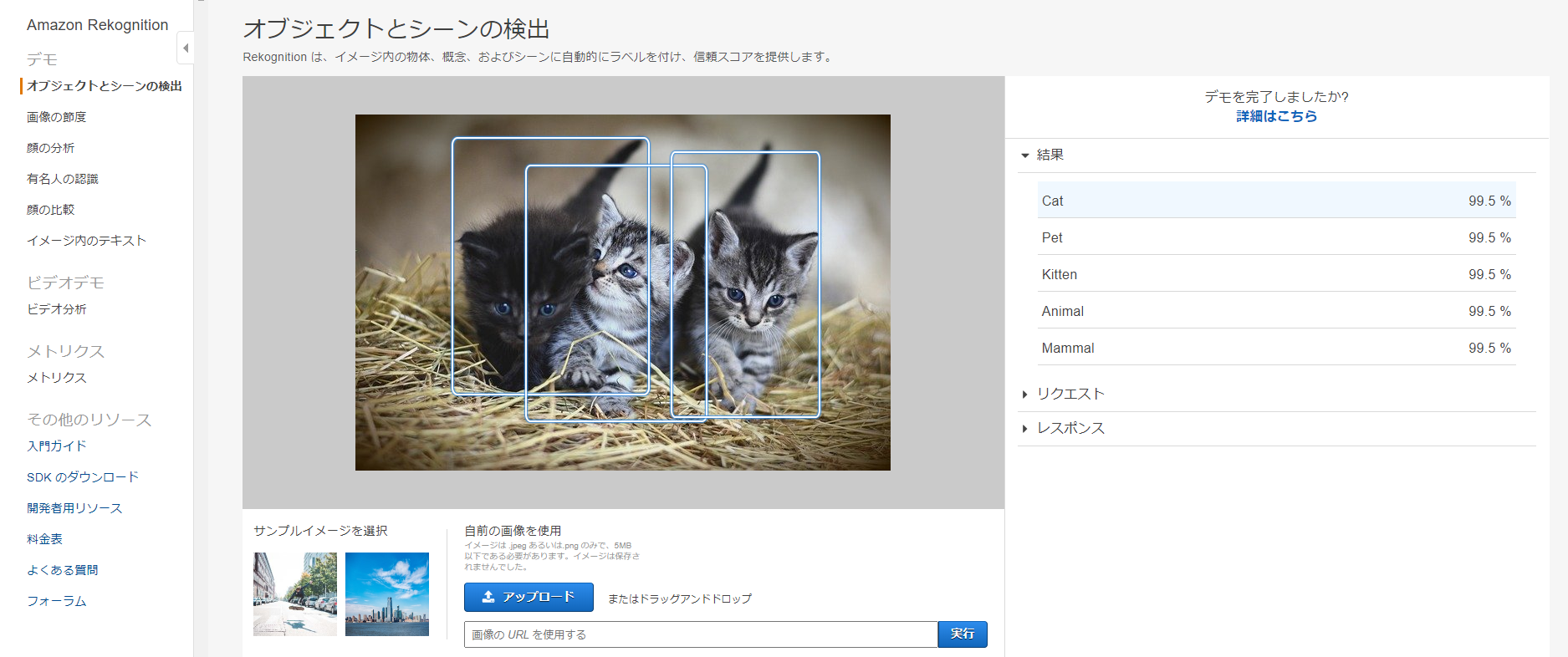
AWS Rekognitoion Black beltより引用上記の引用の通り、入力画像からラベリングを行えるAPIで、マネジメントコンソールからも以下の様にラベリングの結果を確認することができます。
3匹の猫がしっかり識別されていることがわかりますね!
※入力した猫画像はbixabayより取得DetectLabels APIへのリクエストは、上記の猫画像を入力例に以下の通りで、
{ "Image": { "Bytes": "(入力画像のバイト列)" } }レスポンスとしては、以下のJSONを返します。構造としては、ラベル情報の配列で、ラベル情報は以下の物を持っています。
- ラベル名
- ラベルの信頼度
- ラベルと識別した入力画像の範囲(0.0~1.0)
- そのラベルの親ラベル情報
{ "Labels": [ { "Name": "Cat", "Confidence": 99.57831573486328, "Instances": [ { "BoundingBox": { "Width": 0.369978129863739, "Height": 0.7246906161308289, "Left": 0.17922087013721466, "Top": 0.06359343975782394 }, "Confidence": 92.53639221191406 }, { "BoundingBox": { "Width": 0.3405080735683441, "Height": 0.7218159437179565, "Left": 0.31681257486343384, "Top": 0.14111439883708954 }, "Confidence": 90.89508056640625 }, { "BoundingBox": { "Width": 0.27936506271362305, "Height": 0.7497209906578064, "Left": 0.5879912376403809, "Top": 0.10250711441040039 }, "Confidence": 90.0565414428711 } ], "Parents": [ { "Name": "Mammal" }, { "Name": "Animal" }, { "Name": "Pet" } ] }, { "Name": "Pet", "Confidence": 99.57831573486328, "Instances": [], "Parents": [ { "Name": "Animal" } ] }, { "Name": "Kitten", "Confidence": 99.57831573486328, "Instances": [], "Parents": [ { "Name": "Mammal" }, { "Name": "Cat" }, { "Name": "Animal" }, { "Name": "Pet" } ] }, { "Name": "Animal", "Confidence": 99.57831573486328, "Instances": [], "Parents": [] }, { "Name": "Mammal", "Confidence": 99.57831573486328, "Instances": [], "Parents": [ { "Name": "Animal" } ] } ], "LabelModelVersion": "2.0" }作ってみる
作るもの
S3バケットにアップロードした画像からラベリングを行い、画像内のラベリングされた範囲を抽出し、他のS3バケットにその抽出した画像をタグ「ラベル名」=「信頼度」を付与して出力する物を作ってみました。
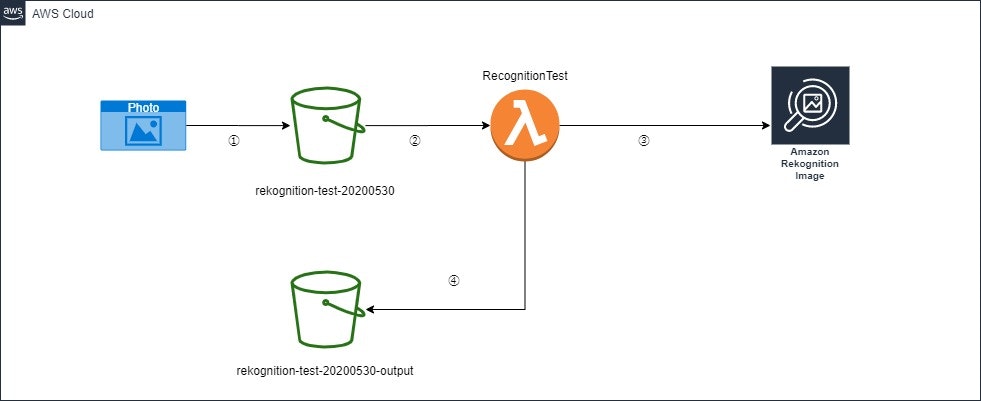
構成図
①.バケット「rekognition-test-20200530」に画像ファイルをアップロード
②.バケットのファイル作成イベントをトリガーにLambda「RecognitionTest」が起動
③.Lambda「RecognitionTest」はS3にアップロードした画像ファイルを入力にDetectLabel APIを呼び出す
④.Lambda「RecognitionTest」はDetectLabel APIのレスポンスを元に、
1. ラベルに対象範囲指定がついている物に対して、その対象範囲をアップロードした画像から抽出
2. 抽出した画像にS3のタグ「ラベル名」=「ラベルの信頼値」を付与
3. バケット「rekognition-test-20200530-output」に出力各AWSリソースの設定
S3
バケット名 設定 rekognition-test-20200530 ・バケットの作成
・S3にファイル作成イベント時のLambda「RecognitionTest」へのトリガー設定rekognition-test-20200530-output ・バケットの作成
・Lambda「RecognitionTest」のIAM Roleに書き込み権限を与えるバケットポリシー追加Lambda Layer
画像の抽出にPillowを使用しているため、こちらのブログを参考にLambda Layerを登録しました。
1.Amazon LinuxのEC2を起動
2.EC2上にPillowをインストール
3.Pillowをインストールしたフォルダをzip
4.zipファイルをダウンロードして、そのzipファイルをLambda Layerに登録
※ 今回の使ってみた記事ではPython2.7を使用しているため、pip install pillowでインストールしています。Lambda
ランタイム:python2.7
lambda_function.py# coding: utf-8 import json import boto3 from PIL import Image import uuid from io import BytesIO def lambda_handler(event, context): # イベント発生したS3とオブジェクト取得 s3 = boto3.client('s3') # イベント発生したバケット名 bucket = event['Records'][0]['s3']['bucket']['name'] # イベント発生したオブジェクトキー photo = event['Records'][0]['s3']['object']['key'] try: # S3イベント発生した画像ファイル取得 target_file_byte_string = s3.get_object(Bucket=bucket, Key=event['Records'][0]['s3']['object']['key'])['Body'].read() target_img = Image.open(BytesIO(target_file_byte_string)) # 画像ファイルの幅と高さ取得 img_width, img_height = target_img.size # Rekognitionクライアント rekognition_client=boto3.client('rekognition') # DetectLabels API呼び出しとラベリング結果取得 response = rekognition_client.detect_labels(Image={'S3Object':{'Bucket':bucket,'Name':photo}}, MaxLabels=10) for label in response['Labels']: # 範囲が指定されているラベルに対して、画像の抽出とS3への出力を行う for bounds in label['Instances']: box = bounds['BoundingBox'] # 画像の抽出範囲を決定 target_bounds = (box['Left'] * img_width, box['Top'] * img_height, (box['Left'] + box['Width']) * img_width, (box['Top'] + box['Height']) * img_height) # 画像の抽出 img_crop = target_img.crop(target_bounds) imgByteArr = BytesIO() img_crop.save(imgByteArr, format=target_img.format) # S3のオブジェクトタグ指定 tag = '{0}={1}'.format(label['Name'], str(label['Confidence'])) # S3への出力 s3.put_object(Key='{0}.jpg'.format(uuid.uuid1()), Bucket='rekognition-test-20200530-output', Body=imgByteArr.getvalue(), Tagging=tag) except Exception as e: print(e) return True使ってみた!
- 入力画像
※bixabayより上記の入力画像(ファイル名はanimal5.jpg)をS3にアップロードしてみます。
アップロードが完了しました。
少し待って、S3に抽出した画像が出力されました!
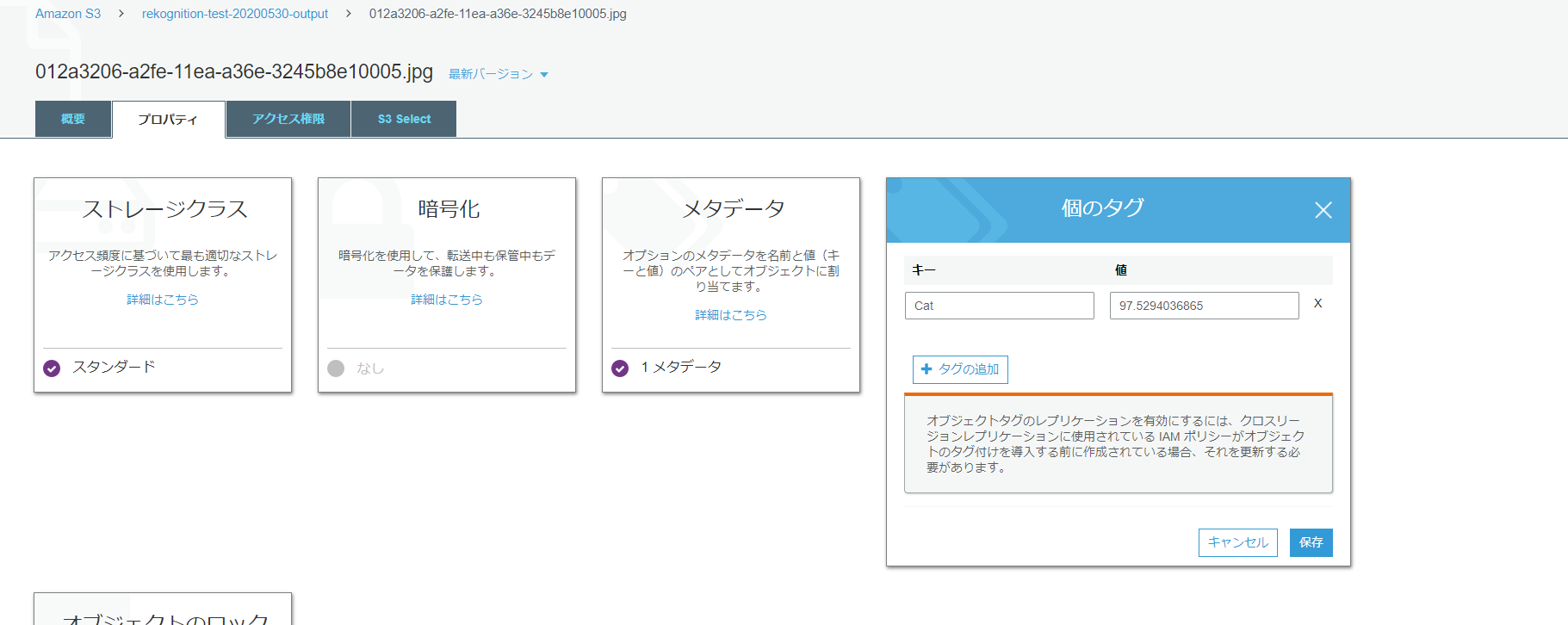
画像のタグを1つ確認してみましょう。
しっかり、タグ付けされてますね。
S3に出力された画像の中身をそれぞれ確認してみます。
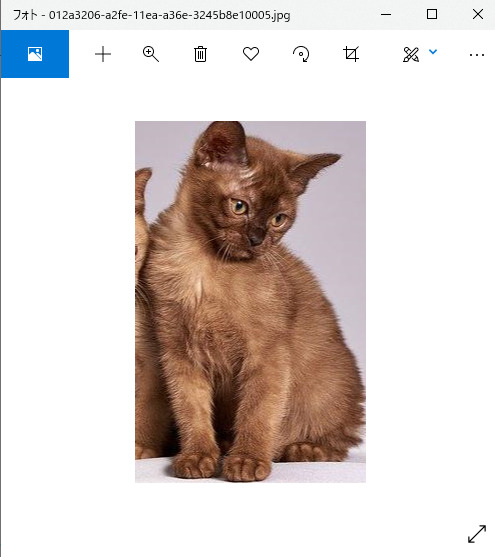
012a3206-a2fe-11ea-a36e-3245b8e10005.jpg
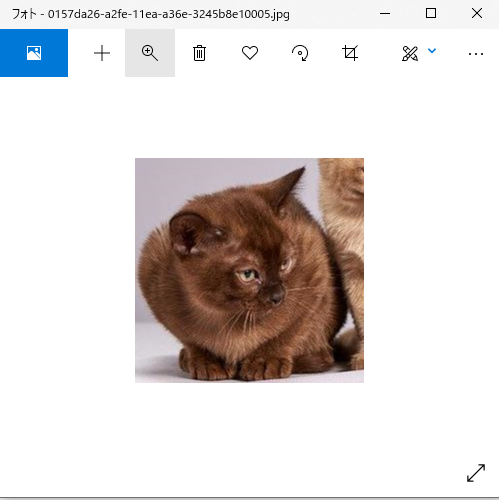
0157da26-a2fe-11ea-a36e-3245b8e10005.jpg
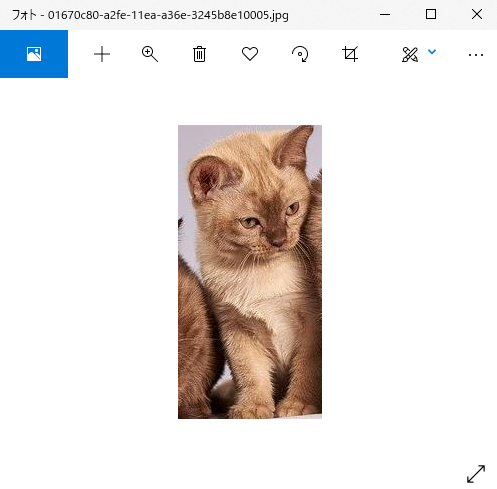
01670c80-a2fe-11ea-a36e-3245b8e10005.jpg
無事に抽出できました!
参考資料

- 投稿日:2020-05-31T13:57:18+09:00
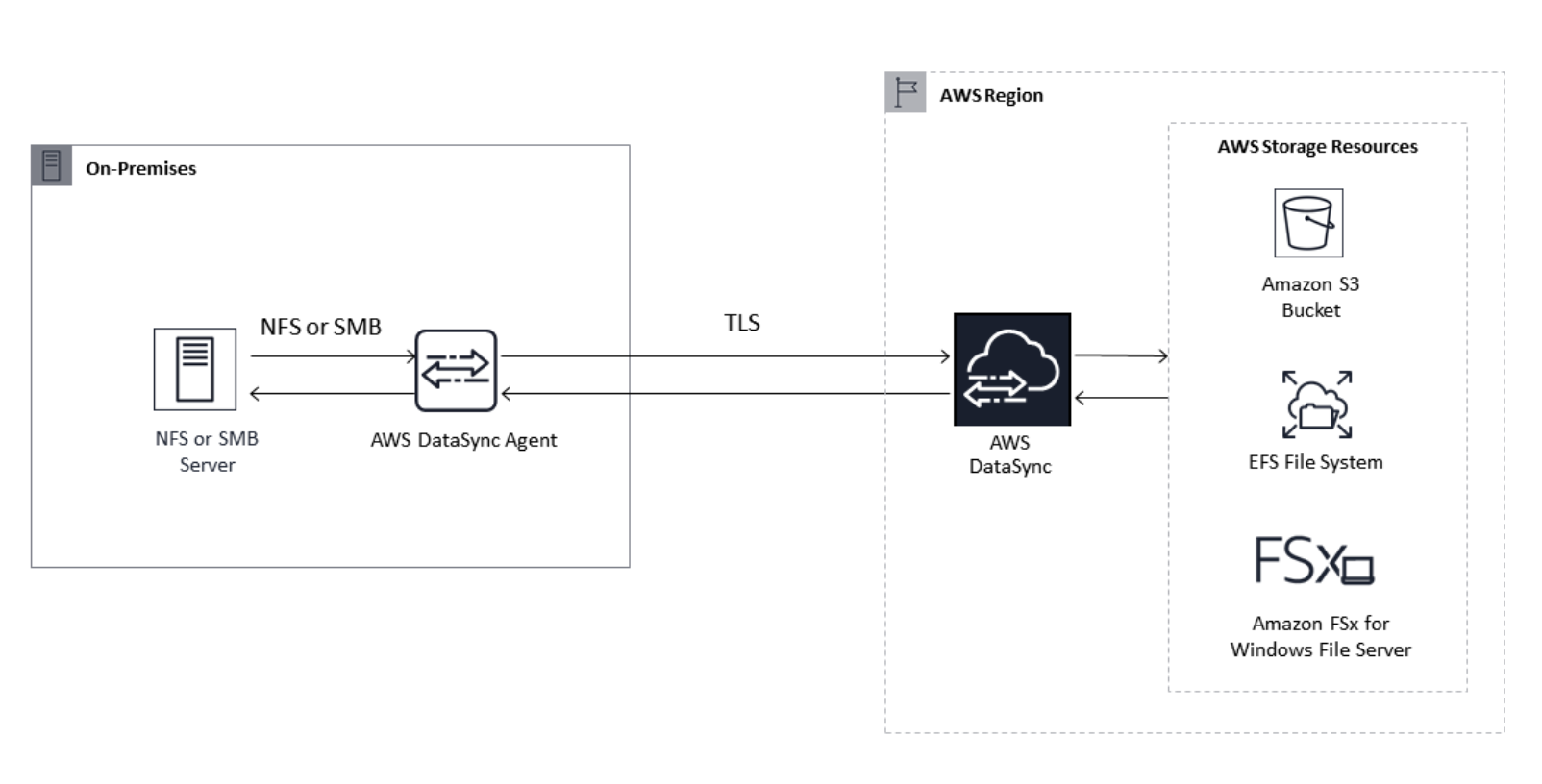
AWS DataSync とは
AWS DataSync とは
AWS DataSync は、AWS ストレージサービスとの間で大量のデータのコピーを簡素化、自動化、高速化するために設計されたオンラインデータ転送サービスです。DataSync は、インターネット経由や AWS Direct Connect を介してデータをコピーします。フルマネージド型サービスの DataSync は、アプリケーションの変更、スクリプトの開発やインフラストラクチャの管理の必要性を排除します。
DataSync では、ネットワークファイルシステム (NFS) と Amazon Elastic File System (Amazon EFS) または Amazon Simple Storage Service (Amazon S3) 間のデータ転送をサポートしています。また、サーバーメッセージブロック (SMB) と Amazon EFS、Amazon S3、または Amazon FSx for Windows ファイルサーバー の間のデータ転送もサポートしています。
ユースケース
データの移行 – ネットワークを介して Amazon S3 や Amazon EFS、または Amazon FSx for Windows ファイルサーバー にアクティブデータセットを素早く移動します。DataSync には自動暗号化やデータの整合性検証が含まれ、データは安全で無変更の使用可能な状態で到着します。
データのアーカイブ – コールドデータを、高価なオンプレミスストレージシステムから、堅牢で安全な長期ストレージ Amazon S3 Glacier や S3 Glacier Deep Archive などのストレージに直接移動します。これにより、オンプレミスのストレージ容量を解放し、レガシーストレージシステムをシャットダウンできます。
利点
ネットワーク経由でデータを AWS に高速 (最大 10 Gbps) で転送します。このアプローチにより、移行、分析や機械学習のためのハイブリッドワークフローやデータ保護プロセスが高速化されます。
データ転送コストを削減し、DataSync の一定したギガバイトあたりの料金でコスト効率よくデータを移動します。また、スクリプトの開発と管理のコストを節約でき、費用がかかる商用の転送ツールが不要です。
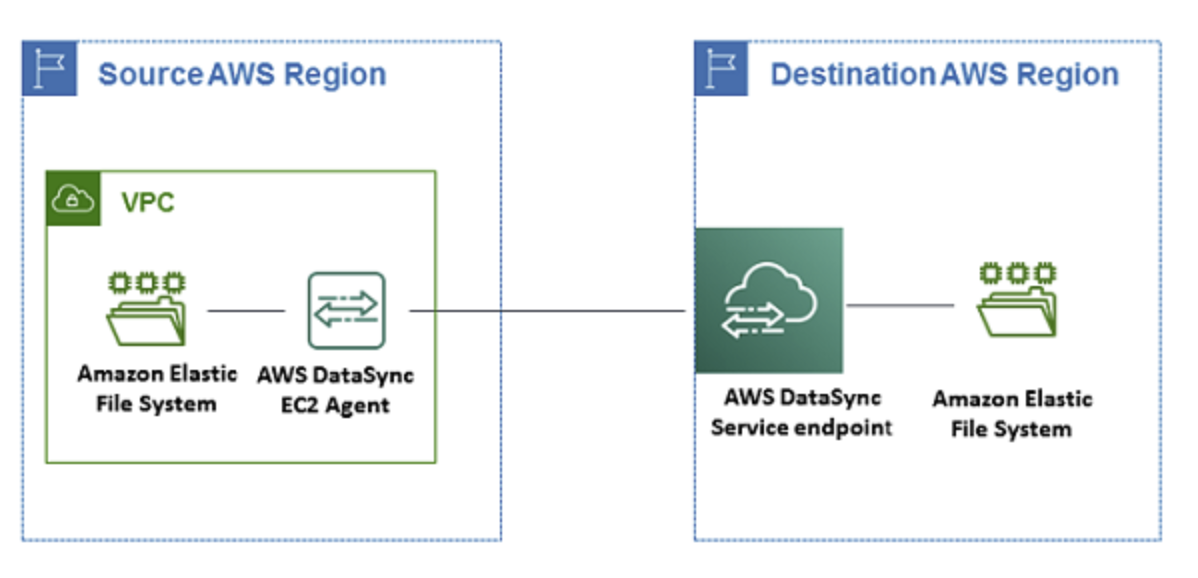
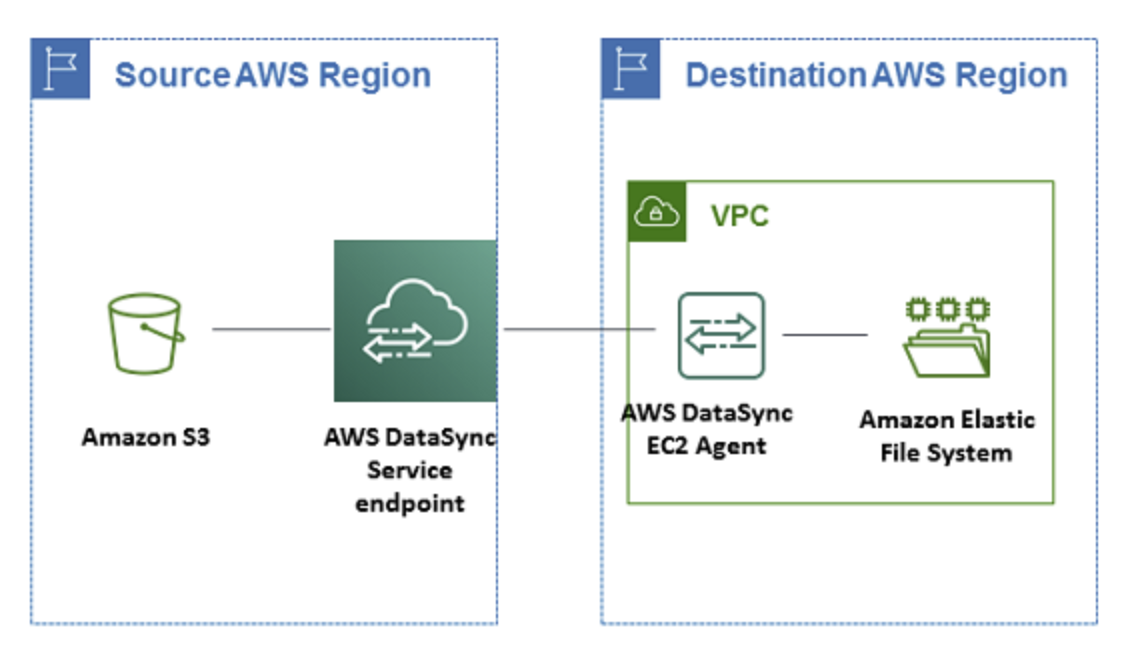
AWS DataSync アーキテクチャ
- オンプレミスから AWS へのデータ転送
- クラウド内 NFS からクラウド内 NFS または S3 にデータを転送する
- S3 からクラウド内 NFS に送信する
- 投稿日:2020-05-31T13:47:26+09:00
AWS Database Migration Service
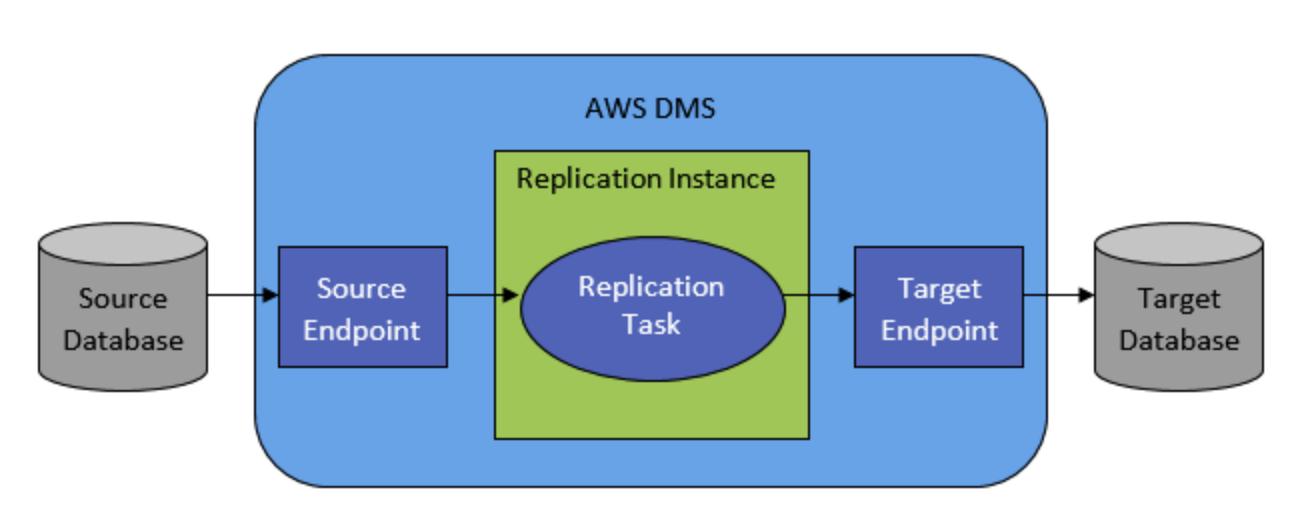
AWS Database Migration Service とは
AWS Database Migration Service (AWS DMS) は、リレーショナルデータベース、データウェアハウス、NoSQL データベース、他の種類のデータストアを移行しやすくするクラウドサービスです。AWS DMS を使用して、オンプレミスのインスタンス間 (AWS クラウドセットアップを使用)、またはクラウドセットアップとオンプレミスセットアップの組み合わせの間で、AWS クラウドにデータを移行できます。
AWS DMS を使用すると、1 回限りの移行を実行でき、継続的な変更をレプリケートしてソースとターゲットの同期を維持することができます。データベースエンジンを変更する場合、AWS Schema Conversion Tool (AWS SCT) を使用してデータベーススキーマを新しいプラットフォームに変換できます。次に、AWS DMS を使用してデータを移行します。AWS DMS は AWS クラウドの一部であるため、AWS のサービスが提供するコスト効率性、市場投入の迅速化、セキュリティ、柔軟性を手に入れることができます。
基本レベルでの AWS DMS の仕組み
AWS DMS はレプリケーションソフトウェアを実行する AWS クラウド内のサーバーです。お客様は、ソースとターゲットの接続を作成し、抽出元とロード先を AWS DMS に指示します。その後、このサーバーで実行するタスクをスケジュールし、データを移動します。AWS DMS は、テーブルと関連付けられたプライマリキーがターゲットに存在しない場合はそれらを作成します。必要に応じて、ターゲットテーブルを手動で事前に作成することができます。または、AWS SCT を使用して、ターゲットテーブル、インデックス、ビュー、トリガーなどの一部またはすべてを作成できます。
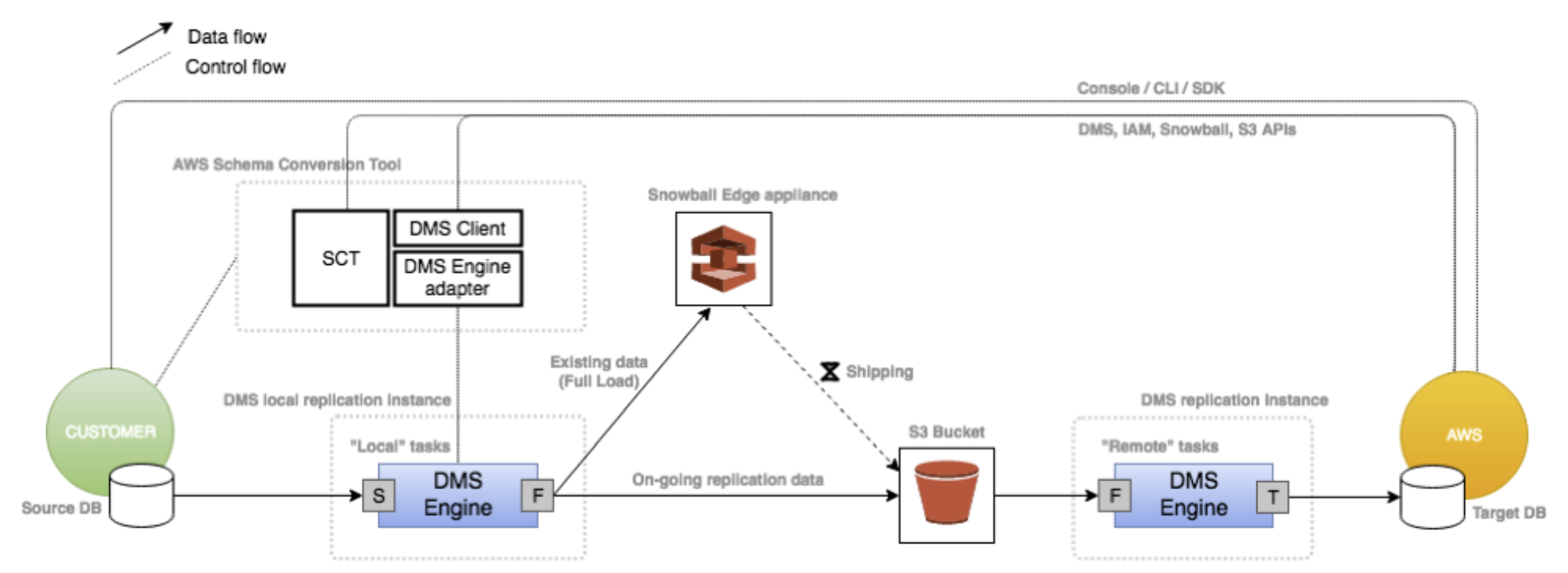
DMS と Snowball Edge を使用した大規模データ移行の概要
Edge デバイスを使用する際、データ移行プロセスには以下のステージが含まれます。
AWS Schema Conversion Tool (AWS SCT) を使用して、データをローカルに摘出して Edge デバイスに移動します。
Edge デバイスは送付するか、または AWS にデバイスを返送します。
AWS が送付物を受け取ると、Edge デバイスは自動的にデータを Amazon S3 バケットにロードします。
AWS DMS はファイルを受け取り、データをターゲットデータストアに移行します。変更データキャプチャ (CDC) を使用している場合、これらの更新は Amazon S3 バケットに書き込まれてからターゲットデータストアに適用されます。
- 投稿日:2020-05-31T11:09:41+09:00
CloudformationでRDSの作成
はじめに
この記事の続きです。Cloudformationを学習中です。
CloudformationでEC2、ALBを作成する
- SSMのパラメータストアからRDSのパスワードを指定しています。
- RDSセキュリティグループはEC2作成時にエクスポートしたセキュリティグループをソースにしています。コード
Create-rds.ymlAWSTemplateFormatVersion: "2010-09-09" Description: RDS for MySQL Create # ------------------------------------------------------------# # Input Parameters # ------------------------------------------------------------# Parameters: DBInstanceName: Type: String Default: "rds" MySQLMajorVersion: Type: String Default: "5.7" AllowedValues: ["5.5", "5.6", "5.7"] MySQLMinorVersion: Type: String Default: "22" DBInstanceClass: Type: String Default: "db.t2.micro" DBInstanceStorageSize: Type: String Default: "30" DBInstanceStorageType: Type: String Default: "gp2" DBName: Type: String Default: "db" DBMasterUserName: Type: String Default: "admin" MultiAZ: Default: "false" Type: String AllowedValues: ["true", "false"] # ------------------------------------------------------------# # DBInstance MySQL # ------------------------------------------------------------# Resources: DBInstance: Type: "AWS::RDS::DBInstance" Properties: DBInstanceIdentifier: !Ref DBInstanceName Engine: MySQL EngineVersion: !Sub "${MySQLMajorVersion}.${MySQLMinorVersion}" DBInstanceClass: !Ref DBInstanceClass AllocatedStorage: !Ref DBInstanceStorageSize StorageType: !Ref DBInstanceStorageType DBName: !Ref DBName MasterUsername: !Ref DBMasterUserName MasterUserPassword: "{{resolve:ssm-secure:rds-master-user-password:1}}" DBSubnetGroupName: !Ref DBSubnetGroup PubliclyAccessible: false MultiAZ: !Ref MultiAZ AutoMinorVersionUpgrade: false DBParameterGroupName: !Ref DBParameterGroup VPCSecurityGroups: - !Ref RDSSecurityGroup CopyTagsToSnapshot: true BackupRetentionPeriod: 7 Tags: - Key: "Name" Value: !Ref DBInstanceName DeletionPolicy: "Delete" # ------------------------------------------------------------# # DBParameterGroup # ------------------------------------------------------------# DBParameterGroup: Type: "AWS::RDS::DBParameterGroup" Properties: Family: !Sub "MySQL${MySQLMajorVersion}" Description: !Ref DBInstanceName # ------------------------------------------------------------# # SecurityGroup for RDS (MySQL) # ------------------------------------------------------------# RDSSecurityGroup: Type: "AWS::EC2::SecurityGroup" Properties: VpcId: !ImportValue TESTSTACK-VPCID GroupName: !Sub "${DBInstanceName}-sg" GroupDescription: "-" Tags: - Key: "Name" Value: !Sub "${DBInstanceName}-sg" # Rule SecurityGroupIngress: - IpProtocol: tcp FromPort: 3306 ToPort: 3306 SourceSecurityGroupId: !ImportValue web-sg # ------------------------------------------------------------# # DBSubnetGroup # ------------------------------------------------------------# DBSubnetGroup: Type: "AWS::RDS::DBSubnetGroup" Properties: DBSubnetGroupName: !Sub "${DBInstanceName}-subnet" DBSubnetGroupDescription: "-" SubnetIds: - !ImportValue TESTSTACK-PrivateSubnet0 - !ImportValue TESTSTACK-PrivateSubnet1 # ------------------------------------------------------------# # Output Parameters # ------------------------------------------------------------# Outputs: #DBInstance DBInstanceID: Value: !Ref DBInstance Export: Name: !Sub "${DBInstanceName}-id" DBInstanceEndpoint: Value: !GetAtt DBInstance.Endpoint.Address Export: Name: !Sub "${DBInstanceName}-endpoint" DBName: Value: !Ref DBName Export: Name: !Sub "${DBInstanceName}-dbname"スタックの登録
SSMにRDSパスワードの登録
個人管理なので、テンプレート直接書いても良かったのですが
折角なのでSSMのパラメータストアで管理してみます。
- 8文字以上である必要がある。(スタック登録時にエラーが出る)
- どこにでも埋め込めれるわけではなく、
AWS :: RDS :: DBInstanceリソースには、MasterUserPasswordプロパティでしか使えない。% aws ssm put-parameter --name rds-master-user-password --value 'test1234' --type SecureString { "Version": 1, "Tier": "Standard" }スタックの登録
% aws cloudformation create-stack \ --tags Key="name",Value="test" \ --stack-name TESTRDS \ --template-body file://Create-rds.ymlエクスポートしたエンドポイントの確認
aws cloudformation describe-stacks --stack-name TESTRDS \ | jq -r '.Stacks[].Outputs[]|select(.OutputKey == "DBInstanceEndpoint").OutputValue' > rds.cxxlsm6y0wym.ap-northeast-1.rds.amazonaws.comEC2からMysqlにログイン出来るか確認
% ssh -i ~/.ssh/test-ssh-key.pem ec2-user@xxx.xxx.xx.xxx [ec2-user@ip-10-1-0-213 ~]$ sudo yum install -y mysql-devel mysql [ec2-user@ip-10-1-0-213 ~]$ mysql -u admin -h rds.cxxlsm6y0wym.ap-northeast-1.rds.amazonaws.com -p Enter password: Welcome to the MariaDB monitor. Commands end with ; or \g. Your MySQL connection id is 6 Server version: 5.7.22-log Source distribution Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. MySQL [(none)]>削除方法
% aws cloudformation delete-stack --stack-name TESTRDS参考文献
- 投稿日:2020-05-31T10:27:54+09:00
フリートプロビジョニングで作成したモノのシャドウをフリートインデックスでクエリする
AWS IoTでフリートインデックスを使って、シャドウの状態によるモノのクエリを試したいと思います。
今回使ったコードはこちらにあります。
https://github.com/sabmeua/aws-iot-device-fleet-testフリートプロビジョニング
まず、デバイスを複数作りたいですが、準備するのは面倒なので、フリートプロビジョニングを使います。
$ git clone https://github.com/sabmeua/aws-iot-device-fleet-test.git $ cd aws-iot-device-fleet-test $ ./setup.sh
./setup.shではAWS IoTのプロビジョニングテンプレートとそのブートストラップテンプレート、IAMロールなどを作成します。
TerraformにAWS IoTのI/Fがなかったためaws cliでやっています。あとでリソース削除したい場合は手動でやらないといけないのでご注意ください。モノ側は、デバイスを用意はできないので、dockerでalpine上でpython SDKを使って行います。docker-composeで複数のモノを立ち上げるので、イメージのビルドもdocker-composeで行います。
$ docker-compose buildこのイメージは https://github.com/aws-samples/aws-iot-fleet-provisioning フリートプロビジョニングのサンプル実装をチェックアウトしてきます。コンテナを起動すると
run_device.shから、プロビジョニングとシャドウのアップデートを開始するようになっています。シャドウのアップデート
シャドウのアップデートは下のようなスクリプトになっています。
updateDeviceShadow.pyfrom AWSIoTPythonSDK.MQTTLib import AWSIoTMQTTShadowClient import time import json import random def callback(payload, status, token): if status == "timeout": print(f'Timeout: {token}') if status == "accepted": payloadDict = json.loads(payload) print(f'Accepted: {token}') print(payload) if status == "rejected": print("Rejected: " + token) with open('device_info.json') as f: dev = json.load(f) shadowClient = AWSIoTMQTTShadowClient(dev['thingName']) shadowClient.configureEndpoint(dev['endpoint'], 8883) shadowClient.configureCredentials( f'{dev["certPath"]}/{dev["rootCert"]}', f'{dev["certPath"]}/{dev["privateKey"]}', f'{dev["certPath"]}/{dev["cert"]}') shadowClient.configureAutoReconnectBackoffTime(1, 32, 20) shadowClient.configureConnectDisconnectTimeout(10) shadowClient.configureMQTTOperationTimeout(5) print(f'Start updating the battery status : {dev["thingName"]}') shadowClient.connect() shadowHandler = shadowClient.createShadowHandlerWithName(dev['thingName'], True) shadowHandler.shadowDelete(callback, 5) prop = {'state':{'reported':{'batt': 100.0}}} while True: batt = random.betavariate(6, 3) * 100 prop['state']['reported']['batt'] = batt shadowHandler.shadowUpdate(json.dumps(prop), callback, 5) if batt < 50: print(f'Stop updating due to the battery remaining is less than 50%') break time.sleep(30)プロビジョニングで取得したデバイス毎の証明書を使って、30秒おきに
reported.battというバッテリ残量を模したシャドウのプロパティをbetavariate(6, 3)のランダム値で更新します。
この値が50%を切ったら更新を停止するようにしています。フリートインデックスの有効化
フリートインデックスが作成されるように設定を変更します。フリートインデックスの作成は課金されるので、不要なら、あとで設定を戻すように注意してください。
AWSマネジメントコンソールのAWSIoTのコンソールから ”設定 -> フリートインデックス作成の設定” で下記のように設定します。
以上で準備完了です。
実行
docker-composeで5台起動してみます。
1台ごとのプロビジョニングは下記のように表示されれば成功です。$ docker-compose up --scale fleet_device=5 Starting aws-iot-device-fleet-test_fleet_device_1 ... done Starting aws-iot-device-fleet-test_fleet_device_2 ... done Starting aws-iot-device-fleet-test_fleet_device_3 ... done Starting aws-iot-device-fleet-test_fleet_device_4 ... done Starting aws-iot-device-fleet-test_fleet_device_5 ... done Attaching to aws-iot-device-fleet-test_fleet_device_1, aws-iot-device-fleet-test_fleet_device_2, aws-iot-device-fleet-test_fleet_device_3, aws-iot-device-fleet-test_fleet_device_4, aws-iot-device-fleet-test_fleet_device_5 fleet_device_3 | ______ __ __ fleet_device_3 | / ____/ / / ___ ___ / /_ fleet_device_3 | / /_ / / / _ \ / _ \ / __/ fleet_device_3 | / __/ / / / __/ / __/ / /_ fleet_device_3 | /_/ /_/ \___/ \___/ \__/ fleet_device_3 | fleet_device_3 | fleet_device_3 | ____ _ _ _ fleet_device_3 | / __ \_________ _ __(_)____(_)___ ____ (_)___ ____ _ fleet_device_3 | / /_/ / ___/ __ \ | / / / ___/ / __ \/ __ \/ / __ \/ __ `/ fleet_device_3 | / ____/ / / /_/ / |/ / (__ ) / /_/ / / / / / / / / /_/ / fleet_device_3 | /_/ /_/ \____/|___/_/____/_/\____/_/ /_/_/_/ /_/\__, / fleet_device_3 | /____/ fleet_device_3 | fleet_device_3 | fleet_device_3 | fleet_device_3 | ____________________________________________________________ fleet_device_3 | /_____/_____/_____/_____/_____/_____/_____/_____/_____/_____/ fleet_device_3 | fleet_device_3 | fleet_device_3 | fleet_device_3 | ##### CONNECTING WITH PROVISIONING CLAIM CERT ##### fleet_device_3 | ##### SUCCESS. SAVING KEYS TO DEVICE! ##### fleet_device_3 | ##### CREATING THING ACTIVATING CERT ##### fleet_device_3 | ##### CERT ACTIVATED AND THING device-1590879565906 CREATED ##### fleet_device_3 | ##### CONNECTING WITH OFFICIAL CERT ##### fleet_device_3 | ##### ACTIVATED AND TESTED CREDENTIALS (0c2fa73a60-private.pem.key, 0c2fa73a60-certificate.pem.crt). ##### fleet_device_3 | ##### FILES SAVED TO /aws-iot-fleet-provisioning/certs ##### fleet_device_3 | {'service_response': '##### RESPONSE FROM PREVIOUSLY FORBIDDEN TOPIC #####'} fleet_device_3 | Start updating the battery status : device-1590879565906複数起動するとMQTTのコネクションがTimeoutしてプロビジョニングが失敗することがありました。
これについて、なぜかわかっていませんが、一度プロビジョニングして証明書を取得したデバイスのコンテナは、2回目以降の起動で再度プロビジョニングは行わないようにしているので、docker-compose stop / startを繰り返したら全てのデバイスのプロビジョニングが出来ます。シャドウの更新が行われている状態では、下記のように、シャドウのトピックのMQTTのペイロードのログが表示されます。
このログでは、途中でデバイス5がバッテリー残量50%を切って終了しています。
このように状態の変化が起きている状態でフリートインデックスのクエリをしてみます。fleet_device_3 | Start updating the battery status : device-1590879565906 fleet_device_1 | Start updating the battery status : device-1590879257006 fleet_device_2 | Start updating the battery status : device-1590879253998 fleet_device_5 | Start updating the battery status : device-1590879255597 fleet_device_4 | Start updating the battery status : device-1590879572901 fleet_device_3 | Accepted: 9b33888e-862e-453c-ad1a-d7ee626b0324 fleet_device_3 | {"version":15,"timestamp":1590884818,"clientToken":"9b33888e-862e-453c-ad1a-d7ee626b0324"} fleet_device_1 | Accepted: aa3911c3-4da8-4cce-a746-4583ab85b238 fleet_device_1 | {"version":10,"timestamp":1590884818,"clientToken":"aa3911c3-4da8-4cce-a746-4583ab85b238"} fleet_device_2 | Accepted: 792d90a4-82c7-425a-b66d-56339a7bedef fleet_device_2 | {"version":7,"timestamp":1590884819,"clientToken":"792d90a4-82c7-425a-b66d-56339a7bedef"} fleet_device_5 | Accepted: 429820d6-7dba-4a87-8589-3da5b9cef61e fleet_device_5 | {"version":11,"timestamp":1590884819,"clientToken":"429820d6-7dba-4a87-8589-3da5b9cef61e"} fleet_device_4 | Accepted: 0d72b28b-23d3-4023-bb3e-2728c55b4c0f fleet_device_4 | {"version":6,"timestamp":1590884819,"clientToken":"0d72b28b-23d3-4023-bb3e-2728c55b4c0f"} fleet_device_3 | Accepted: b3552043-6167-4b60-8bfc-1b1a5312b828 fleet_device_3 | {"state":{"reported":{"batt":54.56623259478952}},"metadata":{"reported":{"batt":{"timestamp":1590884821}}},"version":17,"timestamp":1590884821,"clientToken":"b3552043-6167-4b60-8bfc-1b1a5312b828"} fleet_device_5 | Stop updating due to the battery remaining is less than 50% fleet_device_1 | Accepted: e04057ed-7c12-4a74-bc8e-4e4496111803 fleet_device_1 | {"state":{"reported":{"batt":55.60684342775718}},"metadata":{"reported":{"batt":{"timestamp":1590884821}}},"version":12,"timestamp":1590884821,"clientToken":"e04057ed-7c12-4a74-bc8e-4e4496111803"} fleet_device_2 | Accepted: dceb237f-0a90-437b-8d04-1aa03c661830 fleet_device_2 | {"state":{"reported":{"batt":55.73068072917988}},"metadata":{"reported":{"batt":{"timestamp":1590884821}}},"version":9,"timestamp":1590884821,"clientToken":"dceb237f-0a90-437b-8d04-1aa03c661830"} fleet_device_4 | Accepted: 5f301135-2715-41d5-a7ec-372a0c251540 fleet_device_4 | {"state":{"reported":{"batt":78.55606282570174}},"metadata":{"reported":{"batt":{"timestamp":1590884821}}},"version":8,"timestamp":1590884821,"clientToken":"5f301135-2715-41d5-a7ec-372a0c251540"} aws-iot-device-fleet-test_fleet_device_5 exited with code 0 fleet_device_3 | Accepted: b4161f0d-5b33-43ae-b8c8-a06ee42a6417 fleet_device_3 | {"state":{"reported":{"batt":60.10810045271757}},"metadata":{"reported":{"batt":{"timestamp":1590884851}}},"version":18,"timestamp":1590884851,"clientToken":"b4161f0d-5b33-43ae-b8c8-a06ee42a6417"}フリートインデックスのクエリ
クエリはとりあえずはaws cliで試すことができます。
まず、シャドウのバッテリ残量でクエリしてみます。値が50~80、80~100でレポートされているモノをshadow.reported.batt:{50 TO 80}のようなクエリで抽出することができました。$ aws iot search-index --query-string 'shadow.reported.batt:{50 TO 80}' { "things": [ { "thingName": "device-1590879565906", "thingId": "2c387914-1426-4076-a8de-24876b9d213e", "thingTypeName": "device-type-1", "thingGroupNames": [ "test-devices" ], "shadow": "{\"reported\":{\"batt\":58.422574552849426},\"metadata\":{\"reported\":{\"batt\":{\"timestamp\":1590887635}}},\"version\":26}", "connectivity": { "connected": true, "timestamp": 1590887601460 } }, { "thingName": "device-1590879253998", "thingId": "5da7ed87-9535-451a-8211-77fa1936a67c", "thingTypeName": "device-type-1", "thingGroupNames": [ "test-devices" ], "shadow": "{\"reported\":{\"batt\":71.36448863151011},\"metadata\":{\"reported\":{\"batt\":{\"timestamp\":1590887633}}},\"version\":32}", "connectivity": { "connected": true, "timestamp": 1590887599149 } }, { "thingName": "device-1590879255597", "thingId": "e4bdd3c6-85b1-4d47-9947-621a0ed5dcdd", "thingTypeName": "device-type-1", "thingGroupNames": [ "test-devices" ], "shadow": "{\"reported\":{\"batt\":70.52375514441887},\"metadata\":{\"reported\":{\"batt\":{\"timestamp\":1590887604}}},\"version\":26}", "connectivity": { "connected": true, "timestamp": 1590887599730 } } ] } $ aws iot search-index --query-string 'shadow.reported.batt:{80 TO 100}' { "things": [ { "thingName": "device-1590879255597", "thingId": "e4bdd3c6-85b1-4d47-9947-621a0ed5dcdd", "thingTypeName": "device-type-1", "thingGroupNames": [ "test-devices" ], "shadow": "{\"reported\":{\"batt\":83.16154864112754},\"metadata\":{\"reported\":{\"batt\":{\"timestamp\":1590887634}}},\"version\":27}", "connectivity": { "connected": true, "timestamp": 1590887599730 } } ] }次に、バッテリ残量50%を切って、更新を停止してしまったモノを抽出します。
connectivity.connectedというインデックスが作成されており、これでクエリできます。$ aws iot search-index --query-string 'connectivity.connected:false' { "things": [ { "thingName": "device-1590879257006", "thingId": "6b9efeb0-a668-4c2c-83b5-8a0ced063bf0", "thingTypeName": "device-type-1", "thingGroupNames": [ "test-devices" ], "shadow": "{\"reported\":{\"batt\":40.81584157412556},\"metadata\":{\"reported\":{\"batt\":{\"timestamp\":1590887635}}},\"version\":29}", "connectivity": { "connected": false, "timestamp": 1590887635292 } } ] }まとめ
今回は5台でシャドウも1プロパティだけでしたが、フリートインデックスを使って、基本的なモノの検索をすることができました。
connectivity.connectedによる検索が可能なのは、デバイスの管理にとても有効だと思いました。
- 投稿日:2020-05-31T10:18:50+09:00
AWS: データベースサービス
データベースサービス
- RDS
- Redshift
- DynamoDB
- ElasticSearch
データベースの2大アーキテクチャ
- RDB
- 各表の関係を定義・関連付けすることでデータを管理するDatabase
- SQL(Structured Query Language)を使用する
- サービス例:Orale, Microsoft SQL Server, MySQL, PostgreSQL, Sqlite
- NoSQL(Not Only SQL)
- SQLを使わないDatabase Architecture(= NoSQL)
- 様々なデータモデルがある:スキーマレスなデータモデル, 水平スケーラビリティ, 分散アーキテクチャ, 高速な処理
- サービス例:DynamoDB, ElasticCache, Neptune, Redis
RDS
RDSで使えるストレージタイプ
- 汎用SSD
- プロビジョン度IOPS SSD
- マグネティック
の3つが利用することできる。
RDSの特徴
- マルチAZ構成
- 1つのリージョン内の2つのAZにDBインスタンスをそれぞれ配置し、障害発生時やメンテナンス時のダウンタイムを短くする
- 2つのAZ間でデータを動機するためシングルAZ構成よりも書き込みやコミットにかかる時間が長くなる
- フェイルオーバーには60~120秒かかる
- フェイルオーバー時、RDSへの接続用FQDNのDNSレコードが、スタンバイ側のIPアドレスに書き換えられる
- アプリケーション側でDB接続先のIPのキャッシュを持っている場合、RDSに接続できるようになるまでに120秒以上かかる事がある
- リードレプリカ
- 通常のRDSとは別に、参照専用のDBインスタンスを作成することができるサービス
- リードレプリカを作成することで、マスターDBの負荷を抑えたり、読み込みが多いアプリケーションにおいてDBリソースのスケールアウトを容易に実現することができる
- マスターとリードレプリカのデータ動機は非同期レプリケーション方式のため、タイミングによってマスターの更新がリードレプリカに反映されないことがある
- バックアップ/リストア
- 自動バックアップ
- バックアップウィンドウと保存期間を指定することで1日に1回自動バックアップを取得してくれるサービ
- 手動スナップショット
- 任意のタイミングでRDSのバックアップを取得できるサービス
- データのリストア
- RDSにデータをリストアする場合、自動・手動バックアップで作成したスナップショットからRDSを作成できる
- ポイントインタイムリカバリー
- 直近5分~最大35日前までの任意のタイミングの状態のRDSを新規に作成することができるサービス
- セキュリティ
- ネットーワークセキュリティ
- RDSはVPCに対応しているため、インターネットに接続できないAWSのVPCネットワーク内で利用可能
- DBインスタンスを生成する際にインターネットから接続するというオプションも選択可能(Default: False)
- データ暗号化
- 暗号化オプションをTrueにすることで、データが保存されるストレージやスナップショットだけでなく、ログなどのRDSに関連するすべてのデータが暗号化された状態で保持される
Amazon Aurora
- Auroraの構成要素
- Auroraでは、DBインスタンスを作成すると同時にDBクラスタが作成される
- DBクラスタは1つ以上のDBインスタンスと、各DBインスタンスから参照するデータストレージで構成される
- Auroraレプリカ
- Auroraは他のRDSと異なりマルチAZ構成オプションはない
- Auroraクラスタ内に参照専用のレプリカインスタンスを作成することができる
- プライマリインスタンスに障害が発生した場合にレプリカインスタンスがプライマリインスタンスに昇格することでフェイルオーバーを実現可能
- エンドポイント
- クラスタエンドポイント
- Auroraクラスタのうち、プライマリインスタンスに接続するためのエンドポイント
- 読み取りエンドポイント
- Auroraクラスタのうち、レプリカインスタンスに接続するためのエンドポイント
- インスタンスエンドポイント
- Auroraクラスタを構成する場合、各DBインスタンスに接続するためのエンドポイント
Redshift
Redshiftの構成
- Redshiftクラスタ: 1つのRedshiftを構成する複数のノードの集合
- クラスタは、1つのリーダーノードと複数のコンピュートノードから構成される
- リーダーノード: SQLクライアント・BIツールからの実行クエリを受け付けてクエリの解析や実行プランの作成を行う
- コンピュートノード: リーダーノードからの実行クエリを実行クエリを処理する
- ノードスライス: Redshiftで分散並列処理をする最小の単位
Redshiftの特徴
- 列指向型のデータベース
- 集計処理に使われっるデータをまとめて(列単位で)管理し、ストレージからのデータ取得を効率化する
- 大容量のデータに対して集計処理を実行する場合に優れたパフォーマンスを発揮する
- ゾーンマップ
- Redshiftではブロック単位でデータが格納される
- ブロック内に格納されているデータの最小値と最大値をメモリに保存する仕組みを指す
- この仕組を活用することで、データ検索条件に該当する値の有無を効率的に判断でき、データが存在しない場合はそのブロックを読み飛ばして処理を高速化する
- 柔軟な拡張性
- MPP: 1回の集計処理を複数のノードに分散して実行する仕組み
- シェアードナッシング: 各ノードがディスクを共有せず、ディスクセットで拡張する仕組み
- Redshift Spectrum
- S3に置かれたデータを外部テーブルとして定義できるようにし、Redshift内にデータを取り込むことなくクエリの実行を可能にする拡張サービス
DynamoDB
DynamoDBの特徴
- 高可用性設計
- スループットキャパシティ
- データパーティショニング
- プライマリーキーとインデックス
- 期限切れのデータの自動メンテナンス(Time to Live(TTL))
- DynamoDB Stream
- 強い一貫性を持った参照
- DynamoDB Accelerator(DAX)
- DynamoDBの前段にキャッシュクラスタを構成する拡張サービス
ElastiCache
Memcached版ElastiCacheの特徴
- クラスタ構成
- Memcachedクラスタは、最大20のElasticCacheインスタンスで構成される
- エンドポイント
- ノードエンドポイント: 各ノードに個別アクセスするためのエンドポイント
- 設定エンドポイント: クラスタ全体に割り当てられるエンドポイント
- スケーリング
- 「スケールアウト」「スケールイン」「スケールアップ」「スケールダウン」の4つのすけーりんぐから必要に応じてリソースを調整可能
Redis版ElastiCacheの特徴
- クラスタ構成
- クラスタモードの有効/無効に応じて冗長化の構成が変わる
- クラスタモード無効: キャッシュデータはすべて1つのElasticCacheインスタンスに保存される
- クラスタモード有効: 最大15のシャードにデータを分割して保存する構成が可能
- スケーリング