- 投稿日:2020-05-27T23:40:59+09:00
ゼロから始めるLeetCode Day38「208. Implement Trie (Prefix Tree)」
概要
海外ではエンジニアの面接においてコーディングテストというものが行われるらしく、多くの場合、特定の関数やクラスをお題に沿って実装するという物がメインである。
その対策としてLeetCodeなるサイトで対策を行うようだ。
早い話が本場でも行われているようなコーディングテストに耐えうるようなアルゴリズム力を鍛えるサイト。
せっかくだし人並みのアルゴリズム力くらいは持っておいた方がいいだろうということで不定期に問題を解いてその時に考えたやり方をメモ的に書いていこうかと思います。
前回
ゼロから始めるLeetCode Day37「105. Construct Binary Tree from Preorder and Inorder Traversal」
今はTop 100 Liked QuestionsのMediumを解いています。
Easyは全て解いたので気になる方は目次の方へどうぞ。Twitterやってます。
問題
208. Implement Trie (Prefix Tree)
難易度はMedium。
Top 100 Liked Questionsからの抜粋です。問題としては、insert関数、search関数、startsWith関数をTrieというクラスにまとめて実装してください、というものです。
なお、それぞれの挙動としては、
Trie trie = new Trie();
trie.insert("apple");
trie.search("apple"); // returns true
trie.search("app"); // returns false
trie.startsWith("app"); // returns true
trie.insert("app");
trie.search("app"); // returns trueこのようになります。
解法
基本的に全ての引数を一度for文でチェックし、元々保持している
elementの中に存在しない場合はFalseを返すか、{}を代入するというものです。class Trie: def __init__(self): """ Initialize your data structure here. """ self.element = {} def insert(self, word: str) -> None: """ Inserts a word into the trie. """ inserted = self.element for tmp in word: if tmp not in inserted: inserted[tmp] = {} inserted = inserted[tmp] inserted["-"] = True def search(self, word: str) -> bool: """ Returns if the word is in the trie. """ searched = self.element for tmp in word: if tmp not in searched: return False searched = searched[tmp] return "-" in searched def startsWith(self, prefix: str) -> bool: """ Returns if there is any word in the trie that starts with the given prefix. """ started = self.element for tmp in prefix: if tmp not in started: return False started = started[tmp] return True # Your Trie object will be instantiated and called as such: # obj = Trie() # obj.insert(word) # param_2 = obj.search(word) # param_3 = obj.startsWith(prefix) # Runtime: 128 ms, faster than 94.63% of Python3 online submissions for Implement Trie (Prefix Tree). # Memory Usage: 27.3 MB, less than 66.67% of Python3 online submissions for Implement Trie (Prefix Tree).思ったよりスピードがでて良い感じに実装できました。
なお、discussをみる限り、他にメジャーな解答だったのは、
from collections import defaultdict class TrieNode(object): def __init__(self): """ Initialize your data structure here. """ self.nodes = defaultdict(TrieNode) # Easy to insert new node. self.isword = False # True for the end of the trie. class Trie(object): def __init__(self): self.root = TrieNode() def insert(self, word): """ Inserts a word into the trie. :type word: str :rtype: void """ curr = self.root for char in word: curr = curr.nodes[char] curr.isword = True def search(self, word): """ Returns if the word is in the trie. :type word: str :rtype: bool """ curr = self.root for char in word: if char not in curr.nodes: return False curr = curr.nodes[char] return curr.isword def startsWith(self, prefix): """ Returns if there is any word in the trie that starts with the given prefix. :type prefix: str :rtype: bool """ curr = self.root for char in prefix: if char not in curr.nodes: return False curr = curr.nodes[char] return True # Runtime: 192 ms, faster than 57.66% of Python3 online submissions for Implement Trie (Prefix Tree). # Memory Usage: 32.5 MB, less than 7.41% of Python3 online submissions for Implement Trie (Prefix Tree).こういったものでした。
TrieNodeというクラスを別に作り、defaultdictというものを使っていますね。
ただ、今回に関していえば前者の回答の方が分かりやすく、そして速いと思うのでそちらの方が良いのかなとは思います。今回はこんな感じです、お疲れ様でした。
- 投稿日:2020-05-27T23:05:14+09:00
【Python】月の初日や最終日を取得する方法
結論
replaceメソッドを使うと楽チン。
from datetime import datetime from dateutil.relativedelta import relativedelta today = datetime.now().date() print(today) # => 2020-05-27 last_month_start = (today - relativedelta(months=1)).replace(day=1) print(last_month_start) # => 2020-04-01 last_month_end = today.replace(day=1) - relativedelta(days=1) print(last_month_end) # => 2020-04-30変数名がアレなのは見逃してください。
参考
https://www.lifewithpython.com/2018/06/python-get-first-and-last-day-of-month.html
- 投稿日:2020-05-27T22:40:02+09:00
可視化ツールいろいろ
目的
分析コンペの効率化のための、可視化ツールのいろいろまとめ。
1.相関マップ
pandasデータフレームの各列の相関をヒートマップ表示。
各特徴量の相関、モデルのアンサンブル用の予測結果の相関に使用する。参考
-
コード
fig ,ax = plt.subplots(1,1,figsize=(12,12)) sns.heatmap(df.corr(), annot=True, fmt='.7f', ax=ax) df.corr()2.混同行列(Confusion Matrix)
参考
-
コード
import numpy as np import pandas as pd from scipy import signal from sklearn.metrics import confusion_matrix, f1_score, plot_confusion_matrix # Thanks to https://www.kaggle.com/marcovasquez/basic-nlp-with-tensorflow-and-wordcloud def plot_cm(y_true, y_pred, title="", figsize=(14,14): y_pred = y_pred.astype(int) cm = confusion_matrix(y_true, y_pred, labels=np.unique(y_true)) cm_sum = np.sum(cm, axis=1, keepdims=True) cm_perc = cm / cm_sum.astype(float) * 100 annot = np.empty_like(cm).astype(str) nrows, ncols = cm.shape for i in range(nrows): for j in range(ncols): c = cm[i, j] p = cm_perc[i, j] if i == j: s = cm_sum[i] annot[i, j] = '%.1f%%\n%d/%d' % (p, c, s) elif c == 0: annot[i, j] = '' else: annot[i, j] = '%.1f%%\n%d' % (p, c) cm = pd.DataFrame(cm, index=np.unique(y_true), columns=np.unique(y_true)) cm.index.name = 'Actual' cm.columns.name = 'Predicted' fig, ax = plt.subplots(figsize=figsize) plt.title(title) sns.heatmap(cm, cmap='viridis', annot=annot, fmt='', ax=ax)
- 投稿日:2020-05-27T22:40:02+09:00
Python可視化ツールいろいろ
目的
分析コンペの効率化のための、可視化ツールのいろいろまとめ。
少しずつ、増やしていく!1.相関マップ
pandasデータフレームの各列の相関をヒートマップ表示。
各特徴量の相関、モデルのアンサンブル用の予測結果の相関に使用する。参考
-
コード
fig ,ax = plt.subplots(1,1,figsize=(12,12)) sns.heatmap(df.corr(), annot=True, fmt='.7f', ax=ax) df.corr()2.混同行列(Confusion Matrix)
参考
-
コード
import numpy as np import pandas as pd from scipy import signal from sklearn.metrics import confusion_matrix, f1_score, plot_confusion_matrix # Thanks to https://www.kaggle.com/marcovasquez/basic-nlp-with-tensorflow-and-wordcloud def plot_cm(y_true, y_pred, title="", figsize=(14,14): y_pred = y_pred.astype(int) cm = confusion_matrix(y_true, y_pred, labels=np.unique(y_true)) cm_sum = np.sum(cm, axis=1, keepdims=True) cm_perc = cm / cm_sum.astype(float) * 100 annot = np.empty_like(cm).astype(str) nrows, ncols = cm.shape for i in range(nrows): for j in range(ncols): c = cm[i, j] p = cm_perc[i, j] if i == j: s = cm_sum[i] annot[i, j] = '%.1f%%\n%d/%d' % (p, c, s) elif c == 0: annot[i, j] = '' else: annot[i, j] = '%.1f%%\n%d' % (p, c) cm = pd.DataFrame(cm, index=np.unique(y_true), columns=np.unique(y_true)) cm.index.name = 'Actual' cm.columns.name = 'Predicted' fig, ax = plt.subplots(figsize=figsize) plt.title(title) sns.heatmap(cm, cmap='viridis', annot=annot, fmt='', ax=ax)
- 投稿日:2020-05-27T22:27:31+09:00
Python と VSCode で競プロ - 標準入力の簡易化とサンプルケース判定の自動化 -
最近 AtCoder で競プロを始めました
始めたのはいいのですが、パッとは解けないので何度も何度もデバッグ地獄です
そのたびターミナルにテストケースをコピペの嵐...
もうそんなことはやめようこの記事は
windows10 1909
VSCode 1.45.1
Python 3.8.2
で確認した内容となっています。1. デバッグには sys.stdin を使おう
まずは標準入力の簡易化です。
「VSCode python 標準入力」などの条件で検索していると、teratail にこんな質問と回答がありました
VS Codeで標準入力を受け取る方法(Windows10・Python)
競プロ界隈では有名なのかわかりませんが、私が探していたのはまさにこれでした。import io import sys _INPUT = """\ 2 1 2 3 aaa """ sys.stdin = io.StringIO(_INPUT) print(int(input())) print(list(map(int, input().split()))) print(list(input())) # 出力 2 [1, 2, 3] ['a', 'a', 'a']Python ドキュメントによると sys.stdin は (
input()の呼び出しも含む) すべての対話型入力に使われるもので、io.StringIO は、要するにファイルのように文字列を読み書きするクラスのようです。
テンプレート
サンプルケースや自分で考えたテストケースとデバッグしたいコードを入れてください。test_inut.pyimport io import sys # input here _INPUT = """\ """ sys.stdin = io.StringIO(_INPUT) # your code here
なにより別ファイル( input.txt など)に書いておくのと違い、テストケースがパッと見えるのもいいですよね。
これでコピペの嵐に悩まされることはなくなりました2. online-judge-tools を使ってみよう
サンプルケースの判定を自動化するツールがあります!!それは
online-judge-tools
です。online-judge-tools はコンテストサイトからサンプルケースをスクレイピングし、判定を自動化してくれるありがたいツールです。
OS には Linux か Mac OS を推奨しますが、 Windows 上でも動作します。
と書かれている通り、私の環境では何の問題もなく動作しています。
使い方
使い方に関しては、GitHub ページの他、
Visual Studio Codeで競プロ環境構築(実践編)
AtCoderで自動サンプルテストケース&手入力値テスト実行 with VS Code
を参考にさせていただきました。フォルダ構成
AtCoder\ ├── .venv\ │ ├── .vscode\ │ └── tasks.json │ ├── sctipt\ │ └── cptest.ps1 │ ├── src\ │ └── abc000_0.py │ └── test\ └── abc000_0\ ├── sample-1.in └── sample-1.out.venv フォルダは仮想環境を構築した際の名前と読み替えてください。なくても構いません。.vscode フォルダは tasks.json を生成した際自動的に作成されます。script フォルダと src フォルダは絶対必要というわけではありません。test フォルダは cptest.ps1を実行した際に自動的に作成されます。
1. インストール
> pip install online-judge-toolspip で簡単にインストールできます。
2. ログイン
ユーザー名とパスワードを入力します。
> oj login -u ユーザー名 -p パスワード "https://atcoder.jp/"ログインできたか確認するには
> oj login --check "https://atcoder.jp/"[*] You have already signed in.と返ってくれば OK です。
3. cptest.ps1
コンテストサイトからサンプルケースを取得し、テストするスクリプトです。
以下は参考にさせていただいたスクリプトを
.ps1にし、変更を加えたものです。cptest.ps1. ".venv/Scripts/Activate.ps1" $problem_name = $Args[0] $problem_name_list = ($problem_name -split "_") $base_url = if ($problem_name_list.Length -eq 2) { $problem_name_list[0] } else { [string]::Join("-", $problem_name_list[0..-2]) } if (! (Test-Path $test_dir)) { oj dl -d test/$problem_name/ https://atcoder.jp/contests/$base_url/tasks/$problem_name } oj test -c "python src/$problem_name.py" -d test/$problem_name/私は AtCoder フォルダ内の仮想環境に online-judge-tools をインストールしたため、1行目で
.venv/Scripts/Activate.ps1を読み込み、仮想環境を activate しています。仮想環境でない方は必要ありません。また、第二回全国統一プログラミング王決定戦予選 A - Sum of Two Integers などのURLは
https://atcoder.jp/contests/nikkei2019-2-qual/tasks/nikkei2019_2_qual_a
$base_urlにハイフン、$problem_nameにアンダーバーが使われているため、_を-に変える処理を追加しています。4. tasks.json
VSCode のタスクは、様々な作業を自動化する機能で、
Ctrl+Shift+Bで実行することができます。
そこで、cptest.ps1を実行できるようにしましょう。
Ctrl+Shift+Pでコマンドパレットを開き、taskと入力すると、多くのコマンドが表示されます。その中から、「タスクの構成」→「テンプレートから tasks.json を生成」→「 Others 」と選んでいくと、tasks.json が生成されます。tasks.json{ // See https://go.microsoft.com/fwlink/?LinkId=733558 // for the documentation about the tasks.json format "version": "2.0.0", "tasks": [ { "label": "test_atcorder_sample", "group": { "kind": "build", "isDefault": true }, "type": "shell", "command": "${workspaceFolder}/script/cptest.ps1", "args": [ "${fileBasenameNoExtension}" ] } ] }これで、ファイル名が
abc060_b.pyならばCtrl+Shift+Bで> cptest.ps1 abc060_bを実行したことになります。
使い方は以上です。このツールはほかにも、提出やストレステストも行えるそうです。サンプルケースのテストを自動化できるだけでもありがたいのにどれだけですか
私はまだまだ使いこなせていないのでこれから頑張ります。さいごに
本当にデバッグが楽になりました。この記事がほかの競プロ初心者を少しでも助けることができれば幸いです。
みなさま良き競プロライフを
- 投稿日:2020-05-27T22:25:23+09:00
【言語処理100本ノック 2020】第5章: 係り受け解析
はじめに
自然言語処理の問題集として有名な言語処理100本ノックの2020年版が公開されました。
この記事では、以下の第1章から第10章のうち、第5章: 係り受け解析を解いてみた結果をまとめています。
- 第1章: 準備運動
- 第2章: UNIXコマンド
- 第3章: 正規表現
- 第4章: 形態素解析
- 第5章: 係り受け解析
- 第6章: 機械学習
- 第7章: 単語ベクトル
- 第8章: ニューラルネット
- 第9章: RNN, CNN
- 第10章: 機械翻訳
事前準備
回答にはGoogle Colaboratoryを利用しています。
Google Colaboratoryのセットアップ方法や基本的な使い方は、こちらの記事が詳しいです。
なお、以降の回答の実行結果を含むノートブックはgithubにて公開しています。第5章: 係り受け解析
夏目漱石の小説『吾輩は猫である』の文章(neko.txt)をCaboChaを使って係り受け解析し,その結果をneko.txt.cabochaというファイルに保存せよ.このファイルを用いて,以下の問に対応するプログラムを実装せよ.
まずは指定のデータをダウンロードします。
Google Colaboratoryのセル上で下記のコマンドを実行すると、カレントディレクトリに対象のファイルがダウンロードされます。!wget https://nlp100.github.io/data/neko.txt続いて、CaboChaおよびCaboChaの実行に必要なMeCabとCRF++をインストールします。
# MeCabのインストール !apt install mecab libmecab-dev mecab-ipadic-utf8# CRF++のソースファイルのダウンロード・解凍・インストール FILE_ID = "0B4y35FiV1wh7QVR6VXJ5dWExSTQ" FILE_NAME = "crfpp.tar.gz" !wget 'https://docs.google.com/uc?export=download&id=$FILE_ID' -O $FILE_NAME !tar xvf crfpp.tar.gz %cd CRF++-0.58 !./configure && make && make install && ldconfig %cd ..# CaboChaのソースファイルのダウンロード・解凍・インストール FILE_ID = "0B4y35FiV1wh7SDd1Q1dUQkZQaUU" FILE_NAME = "cabocha-0.69.tar.bz2" !wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id=$FILE_ID' -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id=$FILE_ID" -O $FILE_NAME && rm -rf /tmp/cookies.txt !tar -xvf cabocha-0.69.tar.bz2 %cd cabocha-0.69 !./configure -with-charset=utf-8 && make && make check && make install && ldconfig %cd ..インストールが完了したら、早速係り受け解析を行います。
以下のコマンドを実行することにより、neko.txtを係り受け解析した結果が、neko.txt.cabocbaとして出力されます。!cabocha -f1 -o neko.txt.cabocha neko.txt40. 係り受け解析結果の読み込み(形態素)
形態素を表すクラスMorphを実装せよ.このクラスは表層形(surface),基本形(base),品詞(pos),品詞細分類1(pos1)をメンバ変数に持つこととする.さらに,CaboChaの解析結果(neko.txt.cabocha)を読み込み,各文をMorphオブジェクトのリストとして表現し,3文目の形態素列を表示せよ.
class Morph: def __init__(self, morph): (surface, attr) = morph.split('\t') attr = attr.split(',') self.surface = surface self.base = attr[6] self.pos = attr[0] self.pos1 = attr[1]filename = './neko.txt.cabocha' # 文単位に分割して読込 with open(filename, mode='r', encoding='utf-8') as f: text = f.read().split('EOS\n') # 指定フォーマットに整形 sentences = [] for sentence in text: morphs = [] for line in sentence.split('\n'): if line == '' or line[0] == '*': # 文末または係り受け関係を表す行 --> スキップ continue else: # 形態素を表す行 --> Morphを適用しリストに追加 morphs.append(Morph(line)) sentences.append(morphs) # 確認 for m in sentences[2]: print(vars(m))出力{'surface': '\u3000', 'base': '\u3000', 'pos': '記号', 'pos1': '空白'} {'surface': '吾輩', 'base': '吾輩', 'pos': '名詞', 'pos1': '代名詞'} {'surface': 'は', 'base': 'は', 'pos': '助詞', 'pos1': '係助詞'} {'surface': '猫', 'base': '猫', 'pos': '名詞', 'pos1': '一般'} {'surface': 'で', 'base': 'だ', 'pos': '助動詞', 'pos1': '*'} {'surface': 'ある', 'base': 'ある', 'pos': '助動詞', 'pos1': '*'} {'surface': '。', 'base': '。', 'pos': '記号', 'pos1': '句点'}41. 係り受け解析結果の読み込み(文節・係り受け)
40に加えて,文節を表すクラスChunkを実装せよ.このクラスは形態素(Morphオブジェクト)のリスト(morphs),係り先文節インデックス番号(dst),係り元文節インデックス番号のリスト(srcs)をメンバ変数に持つこととする.さらに,入力テキストのCaboChaの解析結果を読み込み,1文をChunkオブジェクトのリストとして表現し,8文目の文節の文字列と係り先を表示せよ.第5章の残りの問題では,ここで作ったプログラムを活用せよ.
文章は文(sentence)オブジェクトのリストで表され、文オブジェクトは文節(chunk)オブジェクトのリストを要素に持ち、文節オブジェクトは形態素(morph)オブジェクトのリストを要素に持つ階層構造を考え、ここでは指定のクラス
Chunkに加え、Sentenceを実装しています。
なお、Chunkオブジェクトの要素である係り元文節インデックス番号のリスト(srcs)の作成には1文のすべての文節情報を必要とするため、Sentenceオブジェクトの初期化時に作成しています。class Chunk(): def __init__(self, morphs, dst): self.morphs = morphs self.dst = dst self.srcs = [] class Sentence(): def __init__(self, chunks): self.chunks = chunks for i, chunk in enumerate(self.chunks): if chunk.dst != -1: self.chunks[chunk.dst].srcs.append(i)filename = './neko.txt.cabocha' # 文単位に分割して読込 with open(filename, mode='r', encoding='utf-8') as f: text = f.read().split('EOS\n') # 指定フォーマットに整形 sentences = [] for sentence in text: if sentence == '': # 空の文 --> 以下の処理を省略して空のSentenceオブジェクトをsentencesリストに追加 sentences.append(Sentence([])) else: chunks = [] morphs = [] dst = None for line in sentence.split('\n'): if line == '': # 文末を表す行 --> 文末直前の文節の情報にChunkを適用しchunksリストに追加 chunks.append(Chunk(morphs, dst)) elif line[0] == '*': # 係り受け関係を表す行 --> 直前の文節の情報にChunkを適用しchunksリストに追加 + 直後の文節の係り先を取得 if len(morphs) > 0: chunks.append(Chunk(morphs, dst)) morphs = [] dst = int(line.split(' ')[2].rstrip('D')) else: # 形態素を表す行 --> Morphを適用しmorphsリストに追加 morphs.append(Morph(line)) sentences.append(Sentence(chunks)) # Sentenceを適用しsentencesリストに追加 # 確認 for chunk in sentences[7].chunks: print([morph.surface for morph in chunk.morphs], chunk.dst, chunk.srcs)出力['吾輩', 'は'] 5 [] ['ここ', 'で'] 2 [] ['始め', 'て'] 3 [1] ['人間', 'という'] 4 [2] ['もの', 'を'] 5 [3] ['見', 'た', '。'] -1 [0, 4]42. 係り元と係り先の文節の表示
係り元の文節と係り先の文節のテキストをタブ区切り形式ですべて抽出せよ.ただし,句読点などの記号は出力しないようにせよ.
以降、特に指示がない限り、41と同様に8文目の文で出力を確認しています。
sentence = sentences[7] for chunk in sentence.chunks: if int(chunk.dst) != -1: modifier = ''.join([morph.surface if morph.pos != '記号' else '' for morph in chunk.morphs]) modifiee = ''.join([morph.surface if morph.pos != '記号' else '' for morph in sentence.chunks[int(chunk.dst)].morphs]) print(modifier, modifiee, sep='\t')出力吾輩は 見た ここで 始めて 始めて 人間という 人間という ものを ものを 見た43. 名詞を含む文節が動詞を含む文節に係るものを抽出
名詞を含む文節が,動詞を含む文節に係るとき,これらをタブ区切り形式で抽出せよ.ただし,句読点などの記号は出力しないようにせよ.
sentence = sentences[7] for chunk in sentence.chunks: if int(chunk.dst) != -1: modifier = ''.join([morph.surface if morph.pos != '記号' else '' for morph in chunk.morphs]) modifier_pos = [morph.pos for morph in chunk.morphs] modifiee = ''.join([morph.surface if morph.pos != '記号' else '' for morph in sentence.chunks[int(chunk.dst)].morphs]) modifiee_pos = [morph.pos for morph in sentence.chunks[int(chunk.dst)].morphs] if '名詞' in modifier_pos and '動詞' in modifiee_pos: print(modifier, modifiee, sep='\t')出力吾輩は 見た ここで 始めて ものを 見た44. 係り受け木の可視化
与えられた文の係り受け木を有向グラフとして可視化せよ.可視化には,係り受け木をDOT言語に変換し,Graphvizを用いるとよい.また,Pythonから有向グラフを直接的に可視化するには,pydotを使うとよい.
係り元と係り先の文節のペアを作成し、pydotの
graph_from_edgesに渡すことで、グラフを作成しています。
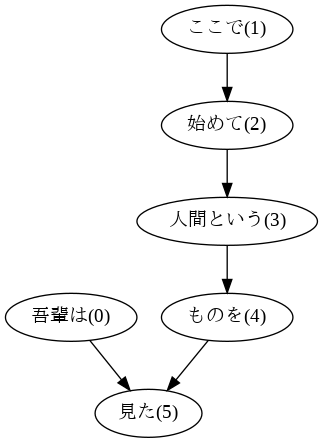
なお、表層形そのままでは1文内に同じ文字列の文節が複数回出てきた場合に区別できないため、末尾にIDを付与して表示しています。# 日本語表示用フォントのインストール !apt install fonts-ipafont-gothicimport pydot from IPython.display import Image,display_png from graphviz import Digraph sentence = sentences[7] edges = [] for id, chunk in enumerate(sentence.chunks): if int(chunk.dst) != -1: modifier = ''.join([morph.surface if morph.pos != '記号' else '' for morph in chunk.morphs] + ['(' + str(id) + ')']) modifiee = ''.join([morph.surface if morph.pos != '記号' else '' for morph in sentence.chunks[int(chunk.dst)].morphs] + ['(' + str(chunk.dst) + ')']) edges.append([modifier, modifiee]) n = pydot.Node('node') n.fontname = 'IPAGothic' g = pydot.graph_from_edges(edges, directed=True) g.add_node(n) g.write_png('./ans44.png') display_png(Image('./ans44.png'))
45. 動詞の格パターンの抽出
今回用いている文章をコーパスと見なし,日本語の述語が取りうる格を調査したい. 動詞を述語,動詞に係っている文節の助詞を格と考え,述語と格をタブ区切り形式で出力せよ. ただし,出力は以下の仕様を満たすようにせよ.
- 動詞を含む文節において,最左の動詞の基本形を述語とする
- 述語に係る助詞を格とする
- 述語に係る助詞(文節)が複数あるときは,すべての助詞をスペース区切りで辞書順に並べる
このプログラムの出力をファイルに保存し,以下の事項をUNIXコマンドを用いて確認せよ.
- コーパス中で頻出する述語と格パターンの組み合わせ
- 「する」「見る」「与える」という動詞の格パターン(コーパス中で出現頻度の高い順に並べよ)
with open('./ans45.txt', 'w') as f: for sentence in sentences: for chunk in sentence.chunks: for morph in chunk.morphs: if morph.pos == '動詞': # chunkの左から順番に動詞を探す cases = [] for src in chunk.srcs: # 見つけた動詞の係り元chunkから助詞を探す cases = cases + [morph.surface for morph in sentence.chunks[src].morphs if morph.pos == '助詞'] if len(cases) > 0: # 助詞が見つかった場合は辞書順にソートして出力 cases.sort() line = '{}\t{}'.format(morph.base, ' '.join(cases)) print(line, file=f) break# 確認 !cat ./ans45.txt | sort | uniq -c | sort -nr | head -n 10出力2414 ある が 1395 つく か が 676 云う に 608 する が で と 330 つかむ を 319 見る の 270 思う と 260 云う と は 238 かかる が て 237 かく たり を!cat ./ans45.txt | grep 'する' | sort | uniq -c | sort -nr | head -n 5出力1128 する が 729 する が と 311 する が で と 130 する と は は は 126 する でも に!cat ./ans45.txt | grep '見る' | sort | uniq -c | sort -nr | head -n 5出力319 見る の 113 見る は を 50 見る て て は 23 見る から て 22 見る から!cat ./ans45.txt | grep '与える' | sort | uniq -c | sort -nr | head -n 5出力5 与える ば を 3 与える け に を 2 与える だけ で に を 2 与える て に は を 1 与える に に対して のみ は は も46. 動詞の格フレーム情報の抽出
45のプログラムを改変し,述語と格パターンに続けて項(述語に係っている文節そのもの)をタブ区切り形式で出力せよ.45の仕様に加えて,以下の仕様を満たすようにせよ.
- 項は述語に係っている文節の単語列とする(末尾の助詞を取り除く必要はない)
- 述語に係る文節が複数あるときは,助詞と同一の基準・順序でスペース区切りで並べる
with open('./ans46.txt', 'w') as f: for sentence in sentences: for chunk in sentence.chunks: for morph in chunk.morphs: if morph.pos == '動詞': # chunkの左から順番に動詞を探す cases = [] modi_chunks = [] for src in chunk.srcs: # 見つけた動詞の係り元chunkから助詞を探す case = [morph.surface for morph in sentence.chunks[src].morphs if morph.pos == '助詞'] if len(case) > 0: # 助詞を含むchunkの場合は助詞と項を取得 cases = cases + case modi_chunks.append(''.join(morph.surface for morph in sentence.chunks[src].morphs if morph.pos != '記号')) if len(cases) > 0: # 助詞が1つ以上見つかった場合は辞書順にソートし、項と合わせて出力 cases.sort() line = '{}\t{}\t{}'.format(morph.base, ' '.join(cases), ' '.join(modi_chunks)) print(line, file=f) break# 確認 !cat ./ans46.txt | head -n 10出力生れる で どこで つく か が 生れたか 見当が 泣く で 所で する だけ て は 泣いて いた事だけは 始める で ここで 見る は を 吾輩は ものを 聞く で あとで 捕える を 我々を 煮る て 捕えて 食う て 煮て47. 機能動詞構文のマイニング
動詞のヲ格にサ変接続名詞が入っている場合のみに着目したい.46のプログラムを以下の仕様を満たすように改変せよ.
- 「サ変接続名詞+を(助詞)」で構成される文節が動詞に係る場合のみを対象とする 述語は「サ変接続名詞+を+動詞の基本形」とし,文節中に複数の動詞があるときは,最左の動詞を用いる
- 述語に係る助詞(文節)が複数あるときは,すべての助詞をスペース区切りで辞書順に並べる
- 述語に係る文節が複数ある場合は,すべての項をスペース区切りで並べる(助詞の並び順と揃えよ)
このプログラムの出力をファイルに保存し,以下の事項をUNIXコマンドを用いて確認せよ.
- コーパス中で頻出する述語(サ変接続名詞+を+動詞)
- コーパス中で頻出する述語と助詞パターン
with open('./ans47.txt', 'w') as f: for sentence in sentences: for chunk in sentence.chunks: for morph in chunk.morphs: if morph.pos == '動詞': # chunkの左から順番に動詞を探す for i, src in enumerate(chunk.srcs): # 見つけた動詞の係り元chunkが「サ変接続名詞+を」で構成されるか確認 if len(sentence.chunks[src].morphs) == 2 and sentence.chunks[src].morphs[0].pos1 == 'サ変接続' and sentence.chunks[src].morphs[1].surface == 'を': predicate = ''.join([sentence.chunks[src].morphs[0].surface, sentence.chunks[src].morphs[1].surface, morph.base]) cases = [] modi_chunks = [] for src_r in chunk.srcs[:i] + chunk.srcs[i + 1:]: # 残りの係り元chunkから助詞を探す case = [morph.surface for morph in sentence.chunks[src_r].morphs if morph.pos == '助詞'] if len(case) > 0: # 助詞を含むchunkの場合は助詞と項を取得 cases = cases + case modi_chunks.append(''.join(morph.surface for morph in sentence.chunks[src_r].morphs if morph.pos != '記号')) if len(cases) > 0: # 助詞が1つ以上見つかった場合は辞書順にソートし、項と合わせて出力 cases.sort() line = '{}\t{}\t{}'.format(predicate, ' '.join(cases), ' '.join(modi_chunks)) print(line, file=f) break# 確認 !cat ./ans47.txt | cut -f 1 | sort | uniq -c | sort -nr | head -n 10出力29 返事をする 21 挨拶をする 18 話をする 9 質問をする 8 昼寝をする 8 喧嘩をする 7 真似をする 7 問答をやる 6 相談をする 5 質問をかける!cat ./ans47.txt | cut -f 1,2 | sort | uniq -c | sort -nr | head -n 10出力8 返事をする と よ 8 返事をする て 6 話をする か は 6 話をする に 6 挨拶をする で 5 昼寝をする が 5 挨拶をする から 5 挨拶をする か と も 5 喧嘩をする で 4 返事をする さ と に は48. 名詞から根へのパスの抽出
文中のすべての名詞を含む文節に対し,その文節から構文木の根に至るパスを抽出せよ. ただし,構文木上のパスは以下の仕様を満たすものとする.
- 各文節は(表層形の)形態素列で表現する
- パスの開始文節から終了文節に至るまで,各文節の表現を” -> “で連結する
sentence = sentences[7] for chunk in sentence.chunks: if '名詞' in [morph.pos for morph in chunk.morphs]: # chunkが名詞を含むか確認 path = [''.join(morph.surface for morph in chunk.morphs if morph.pos != '記号')] while chunk.dst != -1: # 名詞を含むchunkを先頭に、dstを根まで順に辿ってリストに追加 path.append(''.join(morph.surface for morph in sentence.chunks[chunk.dst].morphs if morph.pos != '記号')) chunk = sentence.chunks[chunk.dst] print(' -> '.join(path))出力吾輩は -> 見た ここで -> 始めて -> 人間という -> ものを -> 見た 人間という -> ものを -> 見た ものを -> 見た49. 名詞間の係り受けパスの抽出
文中のすべての名詞句のペアを結ぶ最短係り受けパスを抽出せよ.ただし,名詞句ペアの文節番号がiとj(i<j)のとき,係り受けパスは以下の仕様を満たすものとする.
- 問題48と同様に,パスは開始文節から終了文節に至るまでの各文節の表現(表層形の形態素列)を” -> “で連結して表現する
- 文節iとjに含まれる名詞句はそれぞれ,XとYに置換する
また,係り受けパスの形状は,以下の2通りが考えられる.
- 文節iから構文木の根に至る経路上に文節jが存在する場合: 文節iから文節jのパスを表示
- 上記以外で,文節iと文節jから構文木の根に至る経路上で共通の文節kで交わる場合: 文節iから文節kに至る直前のパスと文節jから文節kに至る直前までのパス,文節kの内容を” | “で連結して表示
例えば、
i -> a -> b -> j -> 根であれば、i -> a -> b -> ji -> a -> k -> 根、j -> b -> k -> 根であれば、i -> a | j -> b | kとし、i、jの名詞をそれぞれX、Yに変換して表示すればよいことになります。
from itertools import combinations sentence = sentences[7] nouns = [] for i, chunk in enumerate(sentence.chunks): if '名詞' in [morph.pos for morph in chunk.morphs]: # 名詞を含む文節を抽出 nouns.append(i) for i, j in combinations(nouns, 2): # 名詞を含む文節のペアごとにパスを作成 path_i = [] path_j = [] while i != j: # i, jが同じ文節に到達するまでdstを順に辿る if i < j: path_i.append(i) i = sentence.chunks[i].dst else: path_j.append(j) j = sentence.chunks[j].dst if len(path_j) == 0: # 1つ目のケース chunk_X = ''.join([morph.surface if morph.pos != '名詞' else 'X' for morph in sentence.chunks[path_i[0]].morphs]) chunk_Y = ''.join([morph.surface if morph.pos != '名詞' else 'Y' for morph in sentence.chunks[i].morphs]) path_XtoY = [chunk_X] + [''.join(morph.surface for morph in sentence.chunks[n].morphs) for n in path_i[1:]] + [chunk_Y] print(' -> '.join(path_XtoY)) else: # 2つ目のケース chunk_X = ''.join([morph.surface if morph.pos != '名詞' else 'X' for morph in sentence.chunks[path_i[0]].morphs]) chunk_Y = ''.join([morph.surface if morph.pos != '名詞' else 'Y' for morph in sentence.chunks[path_j[0]].morphs]) chunk_k = ''.join([morph.surface for morph in sentence.chunks[i].morphs]) path_X = [chunk_X] + [''.join(morph.surface for morph in sentence.chunks[n].morphs) for n in path_i[1:]] path_Y = [chunk_Y] + [''.join(morph.surface for morph in sentence.chunks[n].morphs) for n in path_j[1:]] print(' | '.join([' -> '.join(path_X), ' -> '.join(path_Y), chunk_k]))出力Xは | Yで -> 始めて -> 人間という -> ものを | 見た。 Xは | Yという -> ものを | 見た。 Xは | Yを | 見た。 Xで -> 始めて -> Yという Xで -> 始めて -> 人間という -> Yを Xという -> Yをおわりに
言語処理100本ノックは自然言語処理そのものだけでなく、基本的なデータ処理や汎用的な機械学習についてもしっかり学ぶことができるように作られています。
オンラインコースなどで機械学習を勉強中の方も、とても良いアウトプットの練習になると思いますので、ぜひ挑戦してみてください。
- 投稿日:2020-05-27T22:17:28+09:00
Qt for Python アプリの自己アップデート
備忘録かつ添削をお願いしたく。
パッケージ化しないアプリでも、アップデートする仕組みを入れておかないと、修正する度にそれぞれのマシンでコピーする作業が起こってしまう事に気が付きました。
http経由でダウンロードする事も、zipファイルを展開することも簡単にできてしまうのだから、それを組み合わせてアプリケーションディレクトリのの .py ファイルを更新してやればよいのでは?ということで、当該の部分はこのようになりました。def updateDownloadQuit(self): url ="http://〜〜" title = './update.zip' urllib.request.urlretrieve(url,"{0}".format(title)) QMessageBox.information(None, "Info", "アプリケーションを更新して、終了します") with zipfile.ZipFile('update.zip') as existing_zip: existing_zip.extractall('.') MainWindow.close()Qtでなくても、ちょっとしたスクリプト群の配布に使えると思います。
- 投稿日:2020-05-27T22:16:44+09:00
Python 備忘録(個人的ブックマーク)
多分、ゴミ投稿…
逐次、更新。
覚書
商と余り
q = 10 // 3 # 商 mod = 10 % 3 # 余り q, mod = divmod(10, 3) # 商と余りを同時にswap
a, b = b, aもう tmp 要らない…。
ユークリッドの互除法 Python 版
def gcd(a, n): if n == 0: return a else: return gcd(n, a % n)つか、標準ライブラリ等がありますね。
- math.gcd(a, b) — math --- 数学関数 — Python 3.8.3 ドキュメント ※バージョン 3.5 で追加
- numpy.gcd — NumPy v1.18 Manual
- numpy.lcm — NumPy v1.18 Manual
- Pythonで最大公約数と最小公倍数を算出・取得 | note.nkmk.me
- NumPyで最大公約数・最小公倍数を算出・取得 | note.nkmk.me
Windows でのトラブル
Python をインストールせずにショートカットを無効にするには、[スタート] から Manage app execution aliases を開き、"App Installer" (アプリ インストーラー) Python エントリを見つけて "オフ" に切り替えます。
Python 公式等
Anaconda 関連
- Anaconda | The World's Most Popular Data Science Platform
- conda-forgeからのPythonパッケージインストール - われがわログ
- AnacondaによるPython 3.6環境構築と環境管理 | 東京大学 佐々木淳 研究室 沿岸環境学 海岸工学 環境水工学 水環境学
Python 仮想環境
- venv --- 仮想環境の作成 — Python 3.8.3 ドキュメント
- Virtualenv
- virtualenv cloning script.
- Pipenv: Python Development Workflow for Humans
科学技術計算・統計
公式
- NumPy
- pandas - Python Data Analysis Library
- Matplotlib: Python plotting — Matplotlib 3.2.1 documentation
- SymPy
- SciPy.org — SciPy.org
日本語での解説
GIS
- ArcGIS API for Python | ArcGIS for Developers
- GIS奮闘記
- Python 経度・緯度で与えられた2点間距離計算 - Qiita
- Folium: Python で地図可視化 - Tak's Notebook
機械学習
- TensorFlow
- Keras: the Python deep learning API
- scikit-learn: machine learning in Python — scikit-learn 0.23.1 documentation
- PyTorch
形態素解析
Web フレームワーク
- The Web framework for perfectionists with deadlines | Django
- Home - Django REST framework
- Flask | The Pallets Projects
番外編
画像処理
OCR
Excel 操作
Game
その他
- 投稿日:2020-05-27T21:31:53+09:00
グラフ描画ライブラリBokehの使い方
・ツールチップでデータの中身を確認することが可能
import matplotlib.pyplot as plt import numpy as np import random from bokeh.io import output_notebook, show from bokeh.plotting import figure,show output_notebook() x = np.linspace(1, 10, 10) y = [random.randint(0, 10) for i in range(10)] TOOLTIPS = [ ("index", "$index"), ("(x,y)", "($x, $y)"), ] #グラフ設定 p = figure(tooltips=TOOLTIPS, title="グラフタイトル", x_axis_label="x軸", y_axis_label="y軸") # 散布図 p.circle(x = x,y = y) #show(p) # 折れ線グラフ #p.line(x = x,y = y) #show(p) # 棒グラフ #p.vbar(x = x,top = y,width=0.5) show(p)
- 投稿日:2020-05-27T21:20:50+09:00
【PyTorchチュートリアル⑤】Learning PyTorch with Examples (前編)
はじめに
前回に引き続き、PyTorch 公式チュートリアル の第5弾です。
今回は Learning PyTorch with Examples を進めます。Learning PyTorch with Examples
このチュートリアルでは、サンプルコードを通じてPyTorchの2つの主な機能を紹介します。
- Tensor
- 自動微分とニューラルネットワーク
サンプルコードで扱うネットワーク(モデル)は3層(入力層、隠れ層 × 1、出力層)です。
活性化関数は ReLU を使用します。1. Tensor
1.1. Warm-up: numpy
PyTorch の前に、まずは numpy を使用してネットワークを実装します。
Numpy には、ディープラーニング、勾配についての機能はありませんが、
手動で実装することで、簡単なニューラルネットワークを構築できます。import numpy as np # N : バッチサイズ # D_in : 入力次元数 # H : 隠れ層の次元数 # D_out : 出力次元数 N, D_in, H, D_out = 64, 1000, 100, 10 # ランダムな入力データと教師データを作成します x = np.random.randn(N, D_in) y = np.random.randn(N, D_out) # ランダムな値で重みを初期化します w1 = np.random.randn(D_in, H) w2 = np.random.randn(H, D_out) learning_rate = 1e-6 for t in range(500): # 順伝播: 現在の重みの値で、予測値 y を計算します h = x.dot(w1) h_relu = np.maximum(h, 0) y_pred = h_relu.dot(w2) # ロス(損失)を計算し出力します loss = np.square(y_pred - y).sum() print(t, loss) # ロス値を参考に、逆伝播で 重み w1、w2 の勾配を計算します。 grad_y_pred = 2.0 * (y_pred - y) grad_w2 = h_relu.T.dot(grad_y_pred) grad_h_relu = grad_y_pred.dot(w2.T) grad_h = grad_h_relu.copy() grad_h[h < 0] = 0 grad_w1 = x.T.dot(grad_h) # 重みを更新します。 w1 -= learning_rate * grad_w1 w2 -= learning_rate * grad_w2このコードを実行すると、ロス値が減少し、学習が進んでいることが確認できます。
1.2. PyTorch: Tensors
Numpy はGPUを利用して計算することができませんが、PyTorch の Tensor は GPU を利用して数値計算を高速化できます。
Tensor は勾配も計算できますが、ここでは、上記の numpy の例のように、手動で実装してみます。import torch dtype = torch.float device = torch.device("cpu") # device = torch.device("cuda:0") # GPU で実行するにはここのコメントを解除します。 # N : バッチサイズ # D_in : 入力次元数 # H : 隠れ層の次元数 # D_out : 出力次元数 N, D_in, H, D_out = 64, 1000, 100, 10 # ランダムな入力データと教師データを作成します x = torch.randn(N, D_in, device=device, dtype=dtype) y = torch.randn(N, D_out, device=device, dtype=dtype) # ランダムな値で重みを初期化します w1 = torch.randn(D_in, H, device=device, dtype=dtype) w2 = torch.randn(H, D_out, device=device, dtype=dtype) learning_rate = 1e-6 for t in range(500): # 順伝播: 現在の重みの値で、予測値 y を計算します h = x.mm(w1) h_relu = h.clamp(min=0) y_pred = h_relu.mm(w2) # ロス(損失)を計算し出力します loss = (y_pred - y).pow(2).sum().item() if t % 100 == 99: print(t, loss) # ロス値を参考に、逆伝播で 重み w1、w2 の勾配を計算します。 grad_y_pred = 2.0 * (y_pred - y) grad_w2 = h_relu.t().mm(grad_y_pred) grad_h_relu = grad_y_pred.mm(w2.t()) grad_h = grad_h_relu.clone() grad_h[h < 0] = 0 grad_w1 = x.t().mm(grad_h) # 勾配降下法を使用して重みを更新します w1 -= learning_rate * grad_w1 w2 -= learning_rate * grad_w2このコードでも、ロス値が減少し、学習が進んでいることが確認できます。
2. Autograd
2.1. PyTorch: Tensors and autograd
上記の例では、順伝播と逆伝播を手動で実装しましたが、PyTorch の autograd パッケージを利用すると、逆伝播の計算を自動化できます。
・勾配を計算したい変数(Tensor)の requires_grad = True にする
・backward() を実行する
この2つで逆伝播の計算を自動化できます。import torch dtype = torch.float device = torch.device("cpu") # device = torch.device("cuda:0") # GPU で実行するにはここのコメントを解除します。 # N : バッチサイズ # D_in : 入力次元数 # H : 隠れ層の次元数 # D_out : 出力次元数 N, D_in, H, D_out = 64, 1000, 100, 10 # 入力データと教師データを保持するランダムな Tensor を作成します。 # require_grad = False を設定すると、勾配を計算する必要がないことを示します。 x = torch.randn(N, D_in, device=device, dtype=dtype) y = torch.randn(N, D_out, device=device, dtype=dtype) # 重みを保持するランダムな Tensor を作成します。 # requires_grad = True を設定すると、勾配を計算することを示します。 w1 = torch.randn(D_in, H, device=device, dtype=dtype, requires_grad=True) w2 = torch.randn(H, D_out, device=device, dtype=dtype, requires_grad=True) learning_rate = 1e-6 for t in range(500): # 順伝播: Tensor の演算を利用して 予測値 y を計算します # 逆伝播を手動で計算しないため、中間値 h_relu は保持する必要はありません y_pred = x.mm(w1).clamp(min=0).mm(w2) # Tensorの演算を使用して損失を計算、表示します # 損失は形状(1,)のTensorです # loss.item() は損失に保持されているスカラー値を取得します loss = (y_pred - y).pow(2).sum() if t % 100 == 99: print(t, loss.item()) # autogradを使用して、逆伝播を計算します # backward() は、requires_grad = True のすべての Tensor に関する loss の勾配を計算します # この呼び出しの後、w1.grad および w2.grad は、それぞれ w1 , w2 の勾配を保持する Tensor になります loss.backward() # 最急降下法を使用して重みを手動で更新します # 重みには require_grad = True があるため、torch.no_grad() で計算グラフが更新されないようにします # torch.optim.SGD を使用してこの処理と同じことができます with torch.no_grad(): w1 -= learning_rate * w1.grad w2 -= learning_rate * w2.grad # 重みを更新した後、手動で勾配をゼロにします w1.grad.zero_() w2.grad.zero_()チュートリアルにはありませんが、逆伝播の計算グラフを図示してみます。
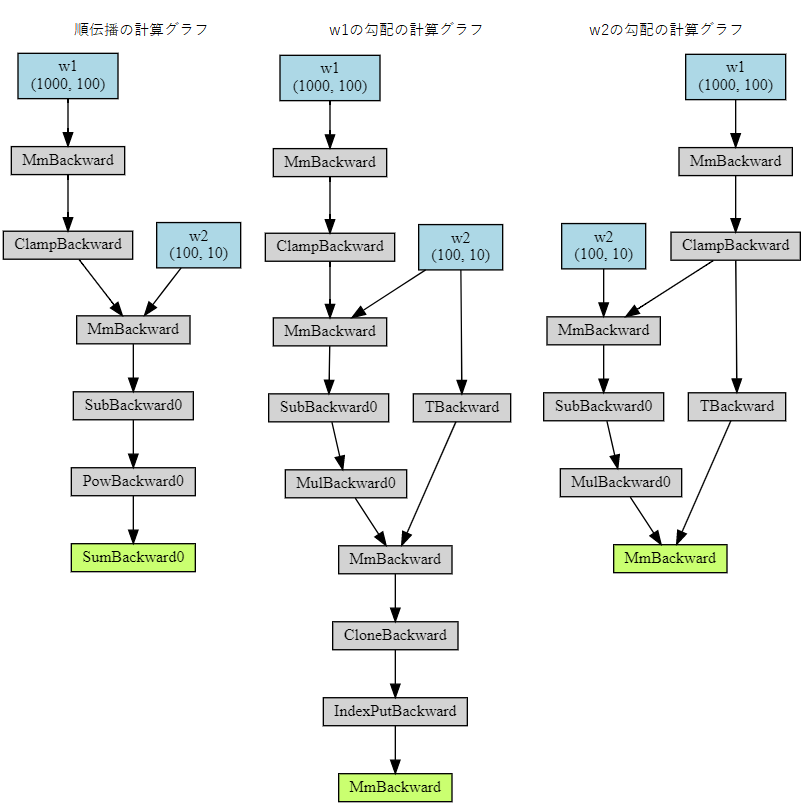
torchviz を利用することで計算グラフを図示できます。
colaboratory を使用している場合、インストールが必要です。!pip install torchvizPyTorch: Tensors のサンプルコードに少し手を加えます。
ループをやめ、勾配が一度だけ計算されるようにします。# ランダムな入力データと教師データを作成します x = torch.randn(N, D_in, device=device, dtype=dtype) y = torch.randn(N, D_out, device=device, dtype=dtype) # ランダムな値で重みを初期化します w1 = torch.randn(D_in, H, device=device, dtype=dtype, requires_grad=True) w2 = torch.randn(H, D_out, device=device, dtype=dtype, requires_grad=True) # 順伝播: 現在の重みの値で、予測値 y を計算します h = x.mm(w1) h_relu = h.clamp(min=0) y_pred = h_relu.mm(w2) # ロス(損失)を計算し出力します loss = (y_pred - y).pow(2).sum().item() # ロス値を参考に、逆伝播で 重み w1、w2 の勾配を計算します。 grad_y_pred = 2.0 * (y_pred - y) grad_w2 = h_relu.t().mm(grad_y_pred) grad_h_relu = grad_y_pred.mm(w2.t()) grad_h = grad_h_relu.clone() grad_h[h < 0] = 0 grad_w1 = x.t().mm(grad_h)torchviz の make_dot で計算グラフを図にします。
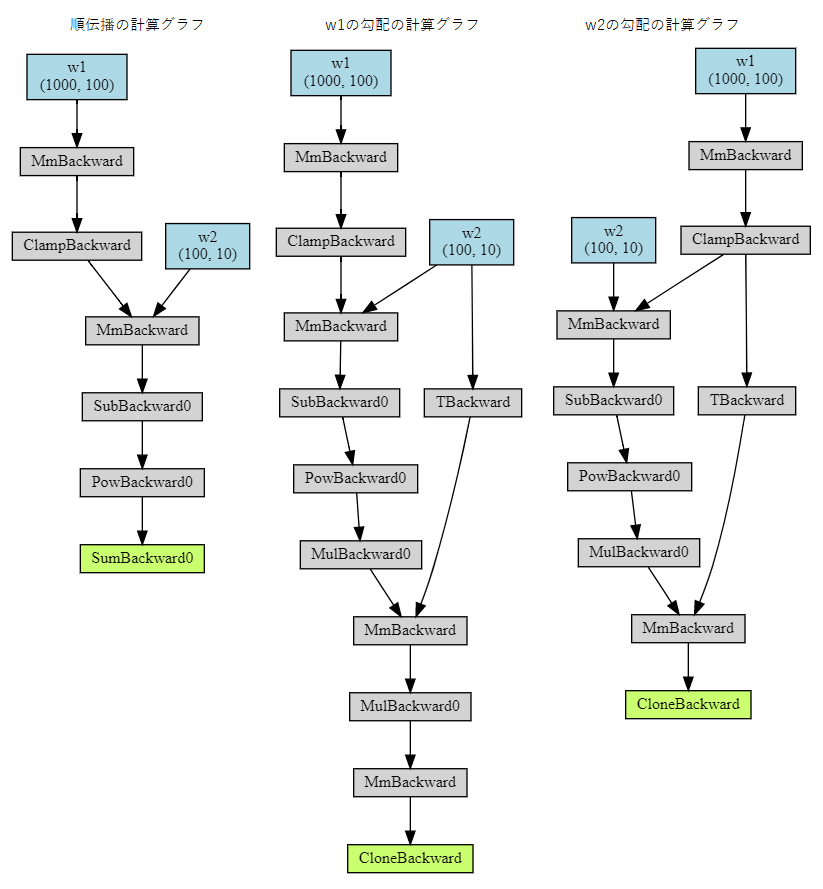
順伝播と勾配を図示します。
param_dict は必須ではありませんが、指定すると図に変数名を記述できます。# 順伝播の計算グラフを図示します。 from torchviz import make_dot param_dict = {'w1': w1, 'w2': w2} make_dot(loss, param_dict) # w1の勾配の計算グラフを図示します。 make_dot(grad_w1, param_dict) # w2の勾配の計算グラフを図示します。 make_dot(grad_w2, param_dict)計算グラフは以下です。
同じように、PyTorch: Tensors and autograd のサンプルコードに手を加え、勾配を一度だけ計算されるようにします。
backward() 実行時に create_graph=True を指定することで導関数のグラフが保持されます。import torch # 入力データと教師データを保持するランダムな Tensor を作成します。 # require_grad = False を設定すると、勾配を計算する必要がないことを示します。 x = torch.randn(N, D_in, device=device, dtype=dtype) y = torch.randn(N, D_out, device=device, dtype=dtype) # 重みを保持するランダムな Tensor を作成します。 # requires_grad = True を設定すると、勾配を計算することを示します。 w1 = torch.randn(D_in, H, device=device, dtype=dtype, requires_grad=True) w2 = torch.randn(H, D_out, device=device, dtype=dtype, requires_grad=True) # 順伝播: Tensor の演算を利用して 予測値 y を計算します # 逆伝播を手動で計算しないため、中間値 h_relu は保持する必要はありません y_pred = x.mm(w1).clamp(min=0).mm(w2) # Tensorの演算を使用して損失を計算、表示します # 損失は形状(1,)のTensorです # loss.item() は損失に保持されているスカラー値を取得します loss = (y_pred - y).pow(2).sum() # autogradを使用して、逆伝播を計算します # backward() は、requires_grad = True のすべての Tensor に関する loss の勾配を計算します # この呼び出しの後、w1.grad および w2.grad は、それぞれ w1 , w2 の勾配を保持する Tensor になります loss_backward = loss.backward(create_graph=True)同じように順伝播と autograd で計算された勾配を図示します。
# 順伝播の計算グラフを図示します。 param_dict = {'w1': w1, 'w2': w2} make_dot(loss, param_dict) # w1の勾配の計算グラフを図示します。 make_dot(w1.grad, param_dict) # w2の勾配の計算グラフを図示します。 make_dot(w2.grad, param_dict)順伝播は同じです。逆伝播は少し形が異なりますが、autograd で逆伝播の計算が自動で行われていることが確認できます。
2.2. PyTorch: Defining new autograd functions
PyTorchでは、torch.autograd.Functionのサブクラスを定義することで、独自の関数(演算子)を定義できます。
サブクラスには、以下の2つ メソッドを実装します。
- forward メソッド:入力 Tensor から出力 Tensor を計算する
- backward メソッド:出力 Tensor の勾配を受け取り、入力 Tensor の勾配を計算する
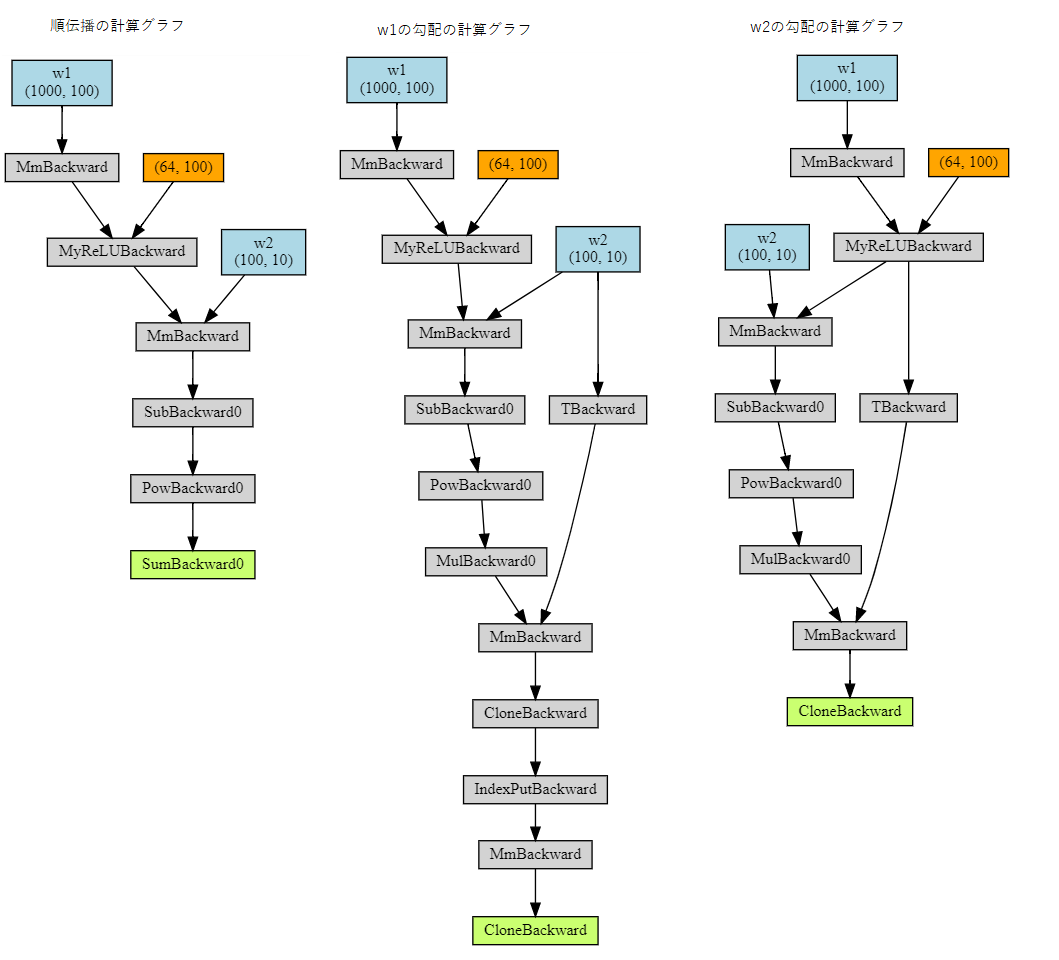
この例では、ReLU関数を意味する独自の関数を用いて、2層ネットワークを定義します。
import torch class MyReLU(torch.autograd.Function): """ torch.autograd.Functionをサブクラス化し、 Tensorsで動作するフォワードパスとバックワードパスを実装することで、 独自のカスタム autograd 関数を実装できます。 """ @staticmethod def forward(ctx, input): """ フォワードパスでは、入力を含むTensorを受け取り、 出力を含むTensorを返します。 ctxは、逆伝播計算のためのオブジェクトです。 ctx.save_for_backwardメソッドを使用して、 オブジェクトをキャッシュできます。 """ ctx.save_for_backward(input) return input.clamp(min=0) @staticmethod def backward(ctx, grad_output): """ backward では、出力に関する損失の勾配を含むTensorを受け取り、 入力に関する損失の勾配を計算する必要があります。 """ input, = ctx.saved_tensors grad_input = grad_output.clone() grad_input[input < 0] = 0 return grad_input dtype = torch.float device = torch.device("cpu") # device = torch.device("cuda:0") # GPU で実行するにはここのコメントを解除します。 # N : バッチサイズ # D_in : 入力次元数 # H : 隠れ層の次元数 # D_out : 出力次元数 N, D_in, H, D_out = 64, 1000, 100, 10 # 入力データと教師データを保持するランダムな Tensor を作成します。 x = torch.randn(N, D_in, device=device, dtype=dtype) y = torch.randn(N, D_out, device=device, dtype=dtype) # 重みを保持するランダムな Tensor を作成します。 w1 = torch.randn(D_in, H, device=device, dtype=dtype, requires_grad=True) w2 = torch.randn(H, D_out, device=device, dtype=dtype, requires_grad=True) learning_rate = 1e-6 for t in range(500): # 関数を適用するには、Function.applyメソッドを使用します。 relu = MyReLU.apply # 順伝播: カスタム autograd 関数を利用して 予測値 y を計算します y_pred = relu(x.mm(w1)).mm(w2) # 損失を計算、表示します loss = (y_pred - y).pow(2).sum() if t % 100 == 99: print(t, loss.item()) # autogradを使用して、逆伝播を計算します loss.backward() # 最急降下法を使用して重みを更新します with torch.no_grad(): w1 -= learning_rate * w1.grad w2 -= learning_rate * w2.grad # 重みを更新した後、手動で勾配をゼロにします w1.grad.zero_() w2.grad.zero_()独自関数も可視化してみます。
先ほどと同様、1回のみ処理されるようにします。# 入力データと教師データを保持するランダムな Tensor を作成します。 x = torch.randn(N, D_in, device=device, dtype=dtype) y = torch.randn(N, D_out, device=device, dtype=dtype) # 重みを保持するランダムな Tensor を作成します。 w1 = torch.randn(D_in, H, device=device, dtype=dtype, requires_grad=True) w2 = torch.randn(H, D_out, device=device, dtype=dtype, requires_grad=True) # 関数を適用するには、Function.applyメソッドを使用します。 relu = MyReLU.apply # 順伝播: カスタム autograd 関数を利用して 予測値 y を計算します y_pred = relu(x.mm(w1)).mm(w2) # 損失を計算、表示します loss = (y_pred - y).pow(2).sum() # autogradを使用して、逆伝播を計算します loss.backward(create_graph=True)
だいたい、似たような計算グラフになっているでしょうか。
続く
長くなりましたので、PyTorch: nn は後編に分けたいと思います。
履歴
2020/05/27 初版公開
- 投稿日:2020-05-27T20:58:54+09:00
ノンコーディングで機械学習 AutoMLサービスまとめ
はじめに?
ノンコーディングで機械学習モデルが生成可能なツール、サービスをご紹介します。
GUIツールから、pythonライブラリなど、様々な物を探してみました。そもそもAutoMLって??
機械学習にはそもそも以下のようプロセスがあります。
- 課題定義
- データ収集
- データ調整
- 特徴エンジニアリング
- アルゴリズム選定
- パラメータ調整
- 学習
- 評価
- 推論
このうち3~9の部分を自動的に行ってくれるのがAutoMLツールとなります。
どんなサービスがあるか
大きく分けて以下のカテゴリがあります。
* クラウドサービス
* オープンソースライブラリ
* フリーソフトクラウドサービス?
DataRobot
サービス内画面
Dataiku
サービス内画面
H2O DriverlessAI
https://www.h2o.ai/products/h2o-driverless-ai/
サービス内画面
VARISTA
サービス内画面
オープンソースライブラリ
PyCaret
AutoGluon
フリーソフト
WEKA
https://www.cs.waikato.ac.nz/ml/weka/
おわり?
すてきなAutoMLライフを⭐️



- 投稿日:2020-05-27T19:05:46+09:00
100日後にエンジニアになるキミ - 68日目 - プログラミング - TF-IDFについて
昨日までのはこちら
100日後にエンジニアになるキミ - 66日目 - プログラミング - 自然言語処理について
100日後にエンジニアになるキミ - 63日目 - プログラミング - 確率について1
100日後にエンジニアになるキミ - 59日目 - プログラミング - アルゴリズムについて
100日後にエンジニアになるキミ - 53日目 - Git - Gitについて
100日後にエンジニアになるキミ - 42日目 - クラウド - クラウドサービスについて
100日後にエンジニアになるキミ - 36日目 - データベース - データベースについて
100日後にエンジニアになるキミ - 24日目 - Python - Python言語の基礎1
100日後にエンジニアになるキミ - 18日目 - Javascript - JavaScriptの基礎1
100日後にエンジニアになるキミ - 14日目 - CSS - CSSの基礎1
100日後にエンジニアになるキミ - 6日目 - HTML - HTMLの基礎1
今回はTF-IDFについてです。
TF-IDFとは
TF-IDFは索引語頻度逆文書頻度のことで
TF(Term Frequency)単語の出現頻度と
IDF(Inverse Document Frequency)単語の希少度とを
掛け合わせたものになります。$$
{TF: 文書における指定単語の出現頻度: \frac{文書内の指定単語の出現回数}{文書内の全単語の出現回数}\
}
$$$$
{IDF: 逆文書頻度(指定単語の希少度): log\frac{総文書数}{指定単語を含む文書数}}
$$$$
{TFIDF(索引語頻度逆文書頻度) = TF * IDF}
$$参考:
https://ja.wikipedia.org/wiki/Tf-idfワードカウント
まずは文章の単語数を数えてみましょう。
カウント用の文章を作っておきます。
result_list = [] result_list.append('吾輩 は 猫 で ある') result_list.append('吾輩 は 猫 で ある') result_list.append('吾輩 も です') result_list.append('どうぞ どうぞ 猫 です')以下のようなコードで単語の出現頻度を数える事ができます。
from sklearn.feature_extraction.text import CountVectorizer import numpy as np import pandas as pd import warnings warnings.filterwarnings('ignore') count_vectorizer = CountVectorizer(token_pattern='(?u)\\b\\w+\\b') count_vectorizer.fit(result_list) X = count_vectorizer.transform(result_list) print(len(count_vectorizer.vocabulary_)) print(count_vectorizer.vocabulary_) pd.DataFrame(X.toarray(), columns=count_vectorizer.get_feature_names())8
{'吾輩': 6, 'は': 4, '猫': 7, 'で': 1, 'ある': 0, 'も': 5, 'です': 2, 'どうぞ': 3}
ある で です どうぞ は も 吾輩 猫 0 1 1 0 0 1 0 1 1 1 1 1 0 0 1 0 1 1 2 0 0 1 0 0 1 1 0 3 0 0 1 2 0 0 0 1 各文章で単語が何回登場するかを数える事ができます。
次はTF-IDFを求めてみましょう。
以下のようなコードで求める事ができます。
from sklearn.feature_extraction.text import TfidfVectorizer import warnings import numpy as np import pandas as pd warnings.filterwarnings('ignore') tfidf_vectorizer = TfidfVectorizer(token_pattern='(?u)\\b\\w+\\b') tfidf_vectorizer.fit(result_list) print(len(tfidf_vectorizer.vocabulary_)) print(tfidf_vectorizer.vocabulary_) X = tfidf_vectorizer.fit_transform(result_list) pd.DataFrame(X.toarray(), columns=tfidf_vectorizer.get_feature_names())8
{'吾輩': 6, 'は': 4, '猫': 7, 'で': 1, 'ある': 0, 'も': 5, 'です': 2, 'どうぞ': 3}
ある で です どうぞ は も 吾輩 猫 0 0.481635 0.481635 0 0 0.481635 0 0.389925 0.389925 1 0.481635 0.481635 0 0 0.481635 0 0.389925 0.389925 2 0 0 0.553492 0 0 0.702035 0.4481 0 3 0 0 0.35157 0.891844 0 0 0 0.284626 TF-IDFは0から1の間の数値がでます。
たくさんの文章に出てくるものの値は小さくなります。
1つの文章でたくさん出てくるものは重要なワードだと考えられます。1に近いほど希少性の高いワードであると考えることもできます。
まとめ
文章をベクトル化する手法と、単語の希少性を算出する手法があります。
文章を数値化する事ができるので、いろいろな計算を行う事ができるようになります。こう言った手法は機械学習などでは良く用いられるので
名前とかを抑えておきましょう。君がエンジニアになるまであと32日
作者の情報
乙pyのHP:
http://www.otupy.net/Youtube:
https://www.youtube.com/channel/UCaT7xpeq8n1G_HcJKKSOXMwTwitter:
https://twitter.com/otupython
- 投稿日:2020-05-27T18:43:30+09:00
Pythonで線形代数をやってみた(7)
線形代数
理系大学で絶対に習う線形代数をわかりやすく、かつ論理的にまとめる。ちなみにそれをPythonで実装。たまに、Juliaで実装するかも。。。
・Pythonで動かして学ぶ!あたらしい数学の教科書 -機械学習・深層学習に必要な基礎知識-
・世界基準MIT教科書 ストラング線形代数イントロダクション
を基に線形代数を理解し、pythonで実装。環境
・JupyterNotebook
・言語:Python3, Julia1.4.0固有値と固有ベクトル
固有値と固有ベクトルは人工知能でデータの要約する主成分分析法で用いられる。
固有値、固有ベクトル
正方行列Aを考える。
この行列Aにたいして、A\vec{x}=λ\vec{x}を満たすとき、
λを行列Aの固有値\\ \vec{x}を行列Aの固有ベクトル\\という。
固有方程式
上のような式に対して、ベクトルに影響を及ぼすことのない単位行列Eをかける。
A\vec{x}=λE\vec{x}右辺を移項して整理する
(A-λE)\vec{x} = \vec{0}これは要素がすべて0のベクトルを表す。これに対して、逆行列を考えても零
ベクトルである。
この式を固有方程式***という。固有方程式による固有値、固有ベクトルの求解
(A-λE)\vec{x} = \vec{0}に沿って、
A=\begin{pmatrix}3 & 1\\2 & 4\end{pmatrix}として具体例で行う。
そうすると、det(A-λE)\vec{x} = 0\\ ⇔ det(\begin{pmatrix}3 & 1\\2 & 4\end{pmatrix}-λ\begin{pmatrix}1 & 0\\0 & 1\end{pmatrix})\vec{x} = 0\\ ⇔ det\begin{pmatrix}3-λ & 1\\2 & 4-λ\end{pmatrix} = 0\\ ⇔(λ-2)(λ-5)= 0\\これによって、固有値は2または5になる。
固有値によって固有ベクトルも変わってくるので。2,5のときそれぞれで考える。\vec{x} = \begin{pmatrix}p\\q\end{pmatrix}とおくとき、λ=2で計算すると、
det(A-λE)\vec{x} = 0\\ \begin{align} det(A-λE)\vec{x}&= det(A-2E)\begin{pmatrix}p\\q\end{pmatrix} \\ &=\begin{pmatrix}1 & 1\\2 & 2\end{pmatrix}\begin{pmatrix}p\\q\end{pmatrix}\\ &=\begin{pmatrix}p+q\\2p+2q\end{pmatrix} \\ &= \vec{0} \end{align}これより、p+q = 0であるといえるので、任意の実数tを置いて、xベクトルは
\vec{x}=\begin{pmatrix}t\\-t\end{pmatrix}と固有ベクトルを求められる。
λ=5のときは、
\vec{x}=\begin{pmatrix}t\\2t\end{pmatrix}となる。
プログラム
固有値、固有ベクトルを求めるプログラム
python
7pythoneigenvaluevectorimport numpy as np A = np.array([[3, 1],[2, 4]]) ev = np.linalg.eig(A) print(ev[0]) print(ev[1])[2. 5.] [[-0.70710678 -0.4472136 ] [ 0.70710678 -0.89442719]]ここで
linag.eig関数を使っている。固有値が英語で、eigenvalueというからだ。原理的なプログラムを組もう。今回は固有値までを求める。
python(原理的)
7pythoneigenvaluevector2import numpy as np import sympy #A = [[a, b], # [c, d]] a = int(input()) b = int(input()) c = int(input()) d = int(input()) #=>3 #=>1 #=>2 #=>4 x = sympy.Symbol('x') eigenequa = x**2 - (a + d)*x + (a * d) - (b * c)``` print(eigenequa) # factorization = sympy.factor(eigenequa) # print(factorization) solve = sympy.solve(eigenequa) print(solve) #=>x**2 - 7*x + 10 #=>[2, 5]juliaはものすごい簡単なので、載せときます。
julia
7juliaigenvaluevectorusing LinearAlgebra F = eigen([3 1; 2 4;]) #=>Eigen{Float64,Float64,Array{Float64,2},Array{Float64,1}} #=>values: #=>2-element Array{Float64,1}: #=> 2.0 #=> 5.0 #=>vectors: #=>2×2 Array{Float64,2}: #=> -0.707107 -0.447214 #=> 0.707107 -0.894427たった2行だけ!すごい...
今日はここまで
- 投稿日:2020-05-27T18:23:04+09:00
【Colab】巨大なデータセットをコピーする方法
経緯
PyTorchのDCGANチュートリアルで巨大なデータセット(1GB・22万枚画像くらい)が必要
↓
ローカルのJupyter Labで動かしてみたら学習遅い&メモリ不足
↓
GPUも使えるGoogle Colaboratory(以下Colab)上で学習させてみよう
↓
手を動かしていくうちに問題発生データセットをColabにどうやってコピーしよう?
問題
- ColabってGoogle Driveのファイル参照できるの?
- Colab上でZIPって解凍できるの?
ColabってGoogle Driveのファイル参照できるの?
Google Driveをマウントすることで参照することができます。
ノートブックを新規作成し次のコードを実行する。from google.colab import drive drive.mount('/content/drive')認証コードを生成するリンクが貼られるのでアクセスする。
アカウント選択でColabを利用しているアカウントを選択する。
Google Drive File Streamがアクセスを求めてくるので許可する。
認証コードが発行されるのでコピーして、貼り付けてエンター。Go to this URL in a browser: https://accounts.google.com/o/oauth2/auth?client_id=xxx Enter your authorization code:Colab上でZIPって解凍できるの?
Colab上でunzipコマンドが使えます。
まずはGoogle DriveにデータセットのZIPファイルをアップロードし、Colab上にコピーします。cp "./drive/My Drive/Colab Notebooks/data/celeba/img_align_celeba.zip" "."後はunzipコマンドを使いColab上で解凍します。
!unzip "img_align_celeba.zip"解凍した画像を表示してみる
from PIL import Image Image.open('img_align_celeba/000001.jpg')
無事表示することができました。まとめ
- データセットをGoogle DriveにZIPでアップロードする
- Colab上でGoogle Driveをマウントする
- Colab上にZIPファイルをコピーする
- Colab上でZIPファイルを解凍する
追記
Colabにファイルをアップロードするだけなら次のコードでローカルファイルを選択できます。
ただし、容量が大きなファイルをアップロードしようとするとかなり時間がかかっているように感じます。
本稿のGoogle Drive経由の方が早くアップロードできる気がします。from google.colab import files files.upload()

- 投稿日:2020-05-27T16:54:28+09:00
あなたのおっしゃる「タニモト係数」って、どれのことかしら?
化合物の類似性を語るにあたって、有名な指標に「タニモト係数」があります。ところが、「タニモト係数」とだけしか言わない人がけっこういて、「それだけでは説明不十分ですよね?」って悶々とする機会がけっこうあるわけです。
たとえば次の化合物セットを使いましょう
化合物数は10個です。
smiles = [ 'C1=CC=C2C3CC(CNC3)CN2C1=O', 'CN1c2c(C(N(C)C1=O)=O)[nH0](CC(CO)O)c[nH0]2', 'CN1C2CC(CC1C1C2O1)OC(C(c1ccccc1)CO)=O', 'CN1C2CC(CC1C1C2O1)OC(C(c1cccnc1)CO)=O', # 一つ上の化合物と類似 'CN(C=1C(=O)N(c2ccccc2)N(C1C)C)C', 'CN(C=1C(=O)N(C2CCCCC2)N(C1C)C)C', # 一つ上の化合物と類似 'OCC1C(C(C(C(OCC2C(C(C(C(OC(c3ccccc3)C#N)O2)O)O)O)O1)O)O)O', 'OCc1ccccc1OC1C(C(C(C(CO)O1)O)O)O', 'OCc1cc(N)ccc1OC1C(C(C(C(CO)O1)O)O)O', # 一つ上の化合物と類似 '[nH0]1c(OC)c2c([nH0]cc[nH0]2)[nH0]c1', ]SMILES表記からRDKitで化合物を生成
from rdkit import Chem mols = [Chem.MolFromSmiles(smile) for smile in smiles]Morgan fingerprint (の一種)を生成
from rdkit.Chem import AllChem fps = [AllChem.GetMorganFingerprint(mol, 3, useFeatures=True) for mol in mols]タニモト係数を計算
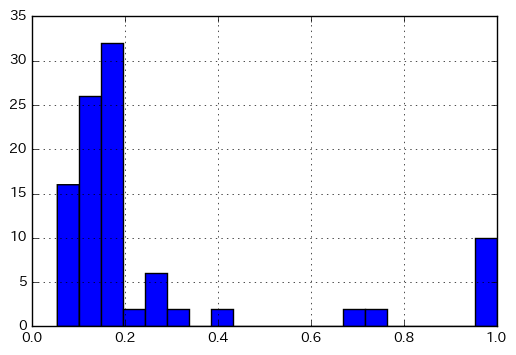
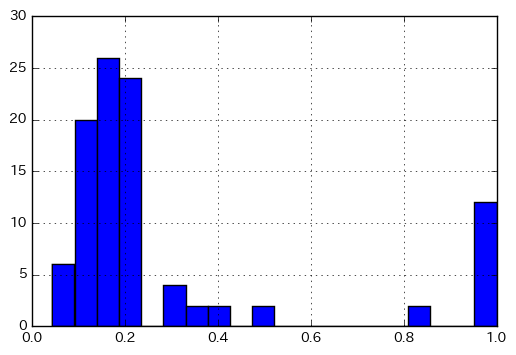
from rdkit import DataStructs sim_matrix = [DataStructs.BulkTanimotoSimilarity(fp, fps) for fp in fps]タニモト係数の分布
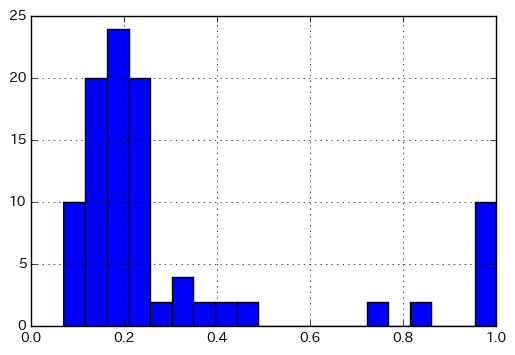
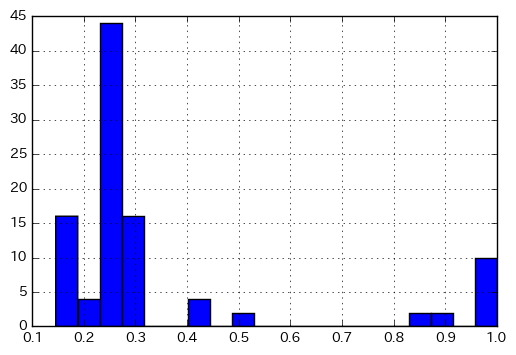
このようにすれば、タニモト係数の分布が見られます。タニモト係数 = 1 のものは同一分子だと思われますが、それ以外でタニモト係数が高めの分子対がありますね。それが何なのか、調べてみてください(あるいは想像してみてください)
%matplotlib inline import matplotlib.pyplot as plt import numpy as np plt.hist(np.array(sim_matrix).flatten(), bins=20) plt.grid() plt.show()
で、Morgan fingerprint にも色々ありまして
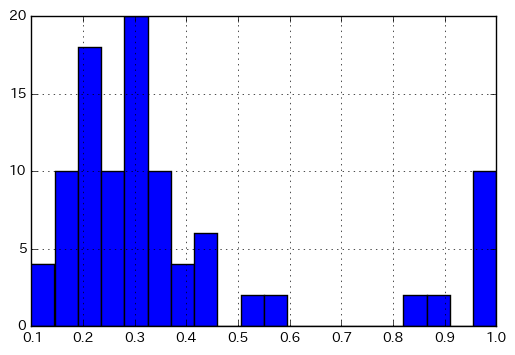
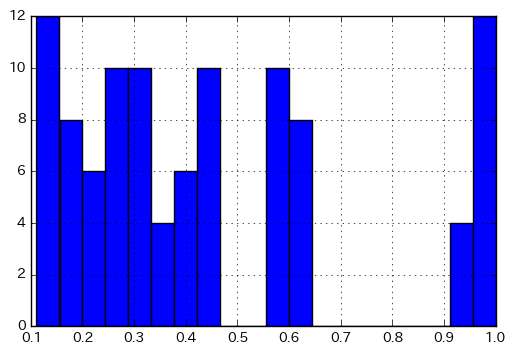
Morgan fingerprintもパラメータがいろいろあって、それを変えるとタニモト係数の数値も変わるわけです。
fps = [AllChem.GetMorganFingerprint(mol, 2, useFeatures=True) for mol in mols] sim_matrix = [DataStructs.BulkTanimotoSimilarity(fp, fps) for fp in fps] plt.hist(np.array(sim_matrix).flatten(), bins=20) plt.grid() plt.show()
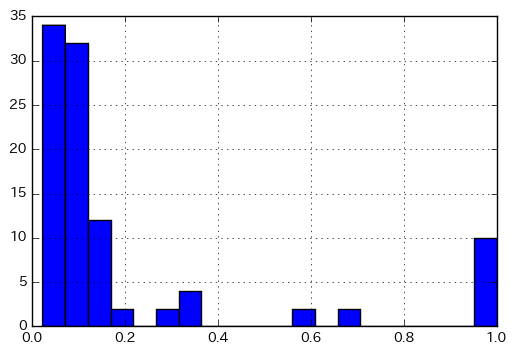
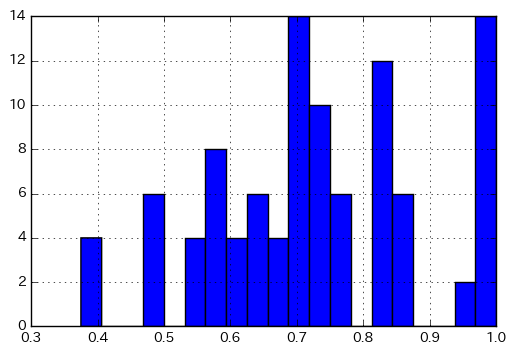
fps = [AllChem.GetMorganFingerprint(mol, 1, useFeatures=True) for mol in mols] sim_matrix = [DataStructs.BulkTanimotoSimilarity(fp, fps) for fp in fps] plt.hist(np.array(sim_matrix).flatten(), bins=20) plt.grid() plt.show()
fps = [AllChem.GetMorganFingerprintAsBitVect(mol, 3, 1024) for mol in mols] sim_matrix = [DataStructs.BulkTanimotoSimilarity(fp, fps) for fp in fps] plt.hist(np.array(sim_matrix).flatten(), bins=20) plt.grid() plt.show()
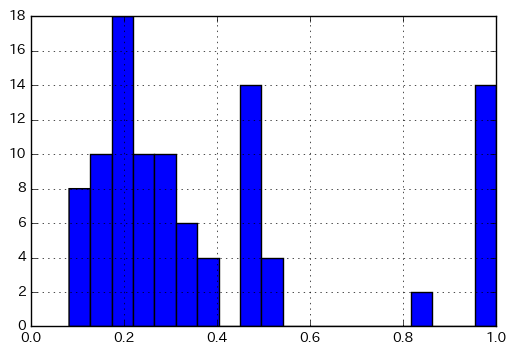
fps = [AllChem.GetMorganFingerprintAsBitVect(mol, 3, 2048) for mol in mols] sim_matrix = [DataStructs.BulkTanimotoSimilarity(fp, fps) for fp in fps] plt.hist(np.array(sim_matrix).flatten(), bins=20) plt.grid() plt.show()
で、フィンガープリントは他にもありまして
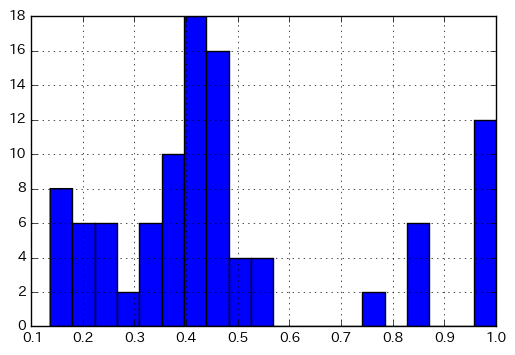
全部計算するのメンドくさいので2つだけ。重要なことの一つとして、下記の計算結果ではタニモト係数が1.0のものが10件以上出てきます。つまり、同一分子でなくてもタニモト係数が1.0になる場合があることは知っておきましょう。
fps = [AllChem.GetMACCSKeysFingerprint(mol) for mol in mols] sim_matrix = [DataStructs.BulkTanimotoSimilarity(fp, fps) for fp in fps] plt.hist(np.array(sim_matrix).flatten(), bins=20) plt.grid() plt.show()
fps = [Chem.RDKFingerprint(mol) for mol in mols] sim_matrix = [DataStructs.BulkTanimotoSimilarity(fp, fps) for fp in fps] plt.hist(np.array(sim_matrix).flatten(), bins=20) plt.grid() plt.show()
MCSを用いたタニモト係数も定義できるわけでして
from rdkit.Chem import rdFMCS matrix = [] for mol1 in mols: for mol2 in mols: mcs = rdFMCS.FindMCS([mol1, mol2]) a1 = len(mol1.GetAtoms()) a2 = len(mol2.GetAtoms()) matrix.append(mcs.numAtoms / (a1 + a2 - mcs.numAtoms) ) plt.hist(np.array(matrix).flatten(), bins=20) plt.grid() plt.show()
MCSにもいろんなオプションがあるわけでして
from rdkit.Chem import rdFMCS matrix = [] for mol1 in mols: for mol2 in mols: mcs = rdFMCS.FindMCS([mol1, mol2], atomCompare=rdFMCS.AtomCompare.CompareAny) a1 = len(mol1.GetAtoms()) a2 = len(mol2.GetAtoms()) matrix.append(mcs.numAtoms / (a1 + a2 - mcs.numAtoms) ) plt.hist(np.array(matrix).flatten(), bins=20) plt.grid() plt.show()
from rdkit.Chem import rdFMCS matrix = [] for mol1 in mols: for mol2 in mols: mcs = rdFMCS.FindMCS([mol1, mol2]) a1 = len(mol1.GetBonds()) a2 = len(mol2.GetBonds()) matrix.append(mcs.numBonds / (a1 + a2 - mcs.numBonds) ) plt.hist(np.array(matrix).flatten(), bins=20) plt.grid() plt.show()
from rdkit.Chem import rdFMCS matrix = [] for mol1 in mols: for mol2 in mols: mcs = rdFMCS.FindMCS([mol1, mol2], bondCompare=rdFMCS.BondCompare.CompareOrderExact) a1 = len(mol1.GetBonds()) a2 = len(mol2.GetBonds()) matrix.append(mcs.numBonds / (a1 + a2 - mcs.numBonds) ) plt.hist(np.array(matrix).flatten(), bins=20) plt.grid() plt.show()
で、あなたのおっしゃる「タニモト係数」って、どれのことかしら?

- 投稿日:2020-05-27T15:32:23+09:00
Ruby と Python で解く AtCoder ABC130 D 累積和 二分探索
はじめに
AtCoder Problems の Recommendation を利用して、過去の問題を解いています。
AtCoder さん、AtCoder Problems さん、ありがとうございます。今回のお題
AtCoder Beginner Contest D - Enough Array
Difficulty: 859今回のテーマ、累積和 + 二分探索
問題文
(条件)連続部分列に含まれる全ての要素の値の和は、K 以上である。より累積和を使用することが分かりますが、1≦N≦100_000ですので2重にループを回すとTLEになります。
そこで、累積和は単調増加ですので、計算量を抑えるために二分探索も併用します。Ruby
ruby.rbn, k = gets.split.map(&:to_i) a = gets.split.map(&:to_i) acc = 0 x = [0] + a.map{|v| acc += v} cnt = 0 x.each do |y| j = x.bsearch_index{|z| z - y >= k} if j == nil break else cnt += n - j + 1 end end puts cntaccumulate.rbacc = 0 x = [0] + a.map{|v| acc += v}累積和はここで計算しています。
追記
コメントでいただいたコードに修正しました。bsearch.rbj = x.bsearch_index{|z| z - y >= k}二分探索ですが、C++ でいうところの
lower_boundが、Ruby ではbsearch若しくはbsearch_indexになります。Python
python.pyfrom sys import stdin def main(): import bisect import itertools input = stdin.readline n, k = map(int, input().split()) a = list(map(int, input().split())) x = [0] + list(itertools.accumulate(a)) cnt = 0 for z in x: j = bisect.bisect_left(x, k + z) if j <= n: cnt += n - j + 1 print(cnt) main()accumulate.pyx = [0] + list(itertools.accumulate(a))Python では、累積和を求める
accumulateという関数があります。bisect.pyj = bisect.bisect_left(x, k + z)二分探索ですが、
bisect若しくはbisect_leftbisect_rightを使用します。
探索する数値が配列に含まれる場合、bisectはその数値の右側、bisect_leftは左側の位置を返します。for.pyfor z in x: for i in range(n):
range()でループを回すとTLEしました。
Ruby Python コード長 (Byte) 238 377 実行時間 (ms) 165 101 メモリ (KB) 11780 14196 まとめ
- ABC 130 D を解いた
- Ruby に詳しくなった
- Python に詳しくなった
参照したサイト
instance method Array#bsearch
すごいぞitertoolsくん
bisect --- 配列二分法アルゴリズム
- 投稿日:2020-05-27T15:20:44+09:00
Pyppeteerの使い方
Pyppeteerの使い方
目次
Pyppeteerとは
PyppeteerはChromeブラウザを操作するためのPythonパッケージで、node.js用をライブラリPuppeteerをPythonに移植したものです。
Pyppereerの情報は少ないので調べるときはPuppeteerで検索する方がいいかもしれません。インストール
pip install pyppeteer使い方
ブラウザを立ち上げサイトを開く
import asyncio from pyppeteer import launch async def main(): browser = await launch() page = await browser.newPage() await page.goto('https://google.com') if __name__ == "__main__": asyncio.get_event_loop().run_until_complete(main())上記コマンドを実行するとヘッドレスモードでChroniumが起動し、Googleのサイトを開いてブラウザを閉じます。
初回import時に一回だけchromiumがインストールされます。Pyppeteerでは、デフォルトでヘッドレスモードでブラウザが起動します。browser = await launch(headless=False)とする事でブラウザを表示することが出来ます。
要素を取得
# 条件に合った最初の要素を取得 # page.Jでも可能 textbox = await page.querySelector('input[aria-label="検索"]') textbox = await page.J('input[aria-label="検索"]') # 条件に合った全ての要素を取得 # page.JJでも可能 buttons = await page.querySelectorAll('input[aria-label="Google 検索"]') buttons = await page.JJ('input[aria-label="Google 検索"]')テキストボックスに入力する
# page.type(セレクタ, 入力値) # 取得したエレメントからでも可能 await page.type('input[aria-label="検索"]', 'pyppeteer') await textbox.type('pyppeteer')クリックする
# page.click(セレクタ) # 取得した要素からでも可能 # Googleの検索ボタンは2番目の要素を選択しなければならないため # querySelectorAllで取得しなければならない? await page.click('last-child:input[aria-label="Google 検索"]') await buttons[1].click()属性の値を取得する
page.evaluateでjavascriptを実行して取得する。
text = await page.evaluate('elm => elm.getAttribute("name")',textbox)innerHTMLを取得する
上記と同様
elm = await page.J('#hptl') text = await page.evaluate('elm => elm.innerHTML', elm)
- 投稿日:2020-05-27T13:40:57+09:00
【機械学習】標準化すると平均0,標準偏差1になることを数学から理解する
1.目的
機械学習をやってみたいと思った場合、scikit-learn等を使えば誰でも比較的手軽に実装できるようになってきています。
但し、仕事で成果を出そうとしたり、より自分のレベルを上げていくためには
「背景はよくわからないけど何かこの結果になりました」の説明では明らかに弱いことが分かると思います。今回は前処理で登場する「標準化」を取り上げます。
「標準化って聞いたことはあるけどなぜするの?」「scikit-learnではどう使うの?」という前段の説明から、「標準化は”平均0、標準偏差1にするような処理”としかしらないけど、実際にはどのような計算になっているのか、数式から理解したい」という疑問にも答えられるような記事にすることが目的です。
まず2章で標準化の概要を記載し、3章で実際にscikitlearnを使って標準化をしてみます。
最後に4章で、標準化の数式(標準化したら本当に平均0、標準偏差1になるか)について触れたいと思います。※「数学から理解する」シリーズとして、いくつか記事を投稿していますので、併せてお読みいただけますと幸いです。
【機械学習】決定木をscikit-learnと数学の両方から理解する
【機械学習】線形単回帰をscikit-learnと数学の両方から理解する
【機械学習】線形重回帰をscikit-learnと数学の両方から理解する
【機械学習】ロジスティック回帰をscikit-learnと数学の両方から理解する
【機械学習】SVMをscikit-learnと数学の両方から理解する
【機械学習】相関係数はなぜ-1から1の範囲を取るのか、数学から理解する2.標準化とは
(1)標準化とは
結論から言うと、各変数を「平均0、標準偏差1」に収まるように加工する処理のことを言います。
機械学習では前処理でよく使われます。
ざっくり言うと、各データの単位をそろえてあげるイメージです。
例えば売上と気温というデータがあるとき、売上は億単位、気温は最高でも40(℃)くらいとなるとスケールが全然違うので、この2つのデータをそれぞれが平均0、標準偏差1におさまるように変換してあげます。
(具体的には、標準化後は売上0.4、気温0.1という具合です。※数値は適当です)(2)なぜ標準化をするの?
色々な理由があるようですが、その内の1つに「機械学習の多くのアルゴリズムは各変数のスケールが同じであることを前提としている」ことが挙げられます。
例えば先ほど挙げた売上(4億円とする)と気温(35℃とする)の例も、私たち人間は事前に各データが「売上」「気温」であることを知っているため、2つの変数のスケール(単位の規模)が異なっていても違和感なく理解できます。
しかし、コンピュータはそんなことは意識しないため、「400,000,000」と「35」というただの数値と捉え、機械学習において誤った意味付けをしてしまう場合があります。
このような弊害をなくすため、事前に各変数のスケールを合わせる、標準化を行います。
(3)標準化以外にやり方はあるの?
各変数のスケールを合わせる手法は標準化以外にも、正規化という手法があります。
今回は深くは触れないですが、「外れ値の影響を受けにくい」「標準化すると正規分布にもなる」ことから、標準化が行われる場面が多いようです。
3.scikit-learnで標準化
今回も具体例として、いつも利用するkaggleのkickstarter-projectsを例にします。
https://www.kaggle.com/kemical/kickstarter-projectsこの章は長いですが、肝心の標準化は(ⅴ)のみですので、先にそちらを見ていただくのもいいと思います。
(ⅰ)インポート
#numpy,pandasのインポート import numpy as np import pandas as pd #日付データに一部処理を行うため、インポート import datetime #訓練データとテストデータ分割のためにインポート from sklearn.model_selection import train_test_split #標準化のためにインポート from sklearn.preprocessing import StandardScaler #精度検証のためにインポート from sklearn.model_selection import cross_val_score #ロジスティック回帰のためにインポート from sklearn.linear_model import SGDClassifier from sklearn.metrics import log_loss, accuracy_score, confusion_matrix(ⅱ)データの読み込み
df = pd.read_csv("ks-projects-201801.csv")(ⅲ)データ数の確認
下記より、(378661, 15)のデータセットであることが分かります。
df.shape(ⅳ)データ成形
◆募集日数
詳細は割愛しますが、クラウドファンディングの募集開始時期と終了時期がデータの中にありますので、これを「募集日数」に変換します。
df['deadline'] = pd.to_datetime(df["deadline"]) df["launched"] = pd.to_datetime(df["launched"]) df["days"] = (df["deadline"] - df["launched"]).dt.days◆目的変数について
こちらも詳細は割愛しますが、目的変数である「state」が成功("successful")と失敗("failed")以外にもカテゴリがありますが、今回は成功と失敗のみのデータにします。
df = df[(df["state"] == "successful") | (df["state"] == "failed")]この上で、成功を1、失敗を0に置き換えます。
df["state"] = df["state"].replace("failed",0) df["state"] = df["state"].replace("successful",1)◆不要な行の削除
モデル構築の前に、不要だと思われるidやname(これは本来は残しておくべきかもしれないですが今回は消します)、そしてクラウドファンディングをしてからでないとわからない変数を削除します。
df = df.drop(["ID","name","deadline","launched","backers","pledged","usd pledged","usd_pledged_real","usd_goal_real"], axis=1)◆カテゴリ変数処理
pd.get_dummiesでカテゴリ変数処理を行います。
df = pd.get_dummies(df,drop_first = True)(ⅴ)標準化
いよいよ標準化です。
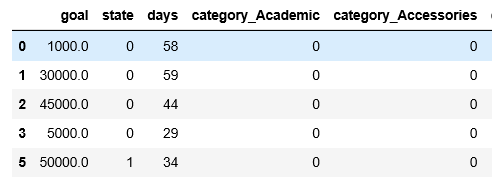
その前に、現時点のデータをざっと見てみましょう。
冒頭の例で挙げたように、「goal(目標金額)」と「days(募集期間)」の単位スケールが結構違うことが分かります。
今回は、この2変数を標準化してみましょう。
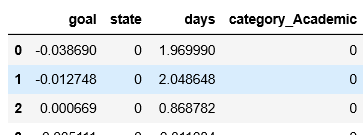
stdsc = StandardScaler() df["goal"] = stdsc.fit_transform(df[["goal"]].values) df["days"] = stdsc.fit_transform(df[["days"]].values)この処理をした上で、再度データを表示してみましょう。
goalとdaysのデータが標準化されました!
(ⅵ)ロジスティック回帰実装
標準化の処理自体は(ⅴ)で終わりですが、一連の流れを把握するという目的で、
ロジスティック回帰モデル構築まで行います。#訓練データとテストデータに分割 y = df["state"].values X = df.drop("state", axis=1).values X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1234) #ロジスティック回帰モデル構築 clf = SGDClassifier(loss = "log", penalty = "none",random_state=1234) clf.fit(X_train,y_train) #テストデータで精度確認 clf.score(X_test, y_test)これで、精度は0.665と出てきました。
※補足
今回の(ⅴ)標準化がない場合、精度は0.529になりますので、モデル全体の精度が向上していることが分かります。4.標準化を数学から理解する
ここまでは、標準化をとりあえず実装できるようにする目的でscikit-learnを使って標準化を行ってきました。
この章では、標準化が行っている処理を数学の観点から理解していきたいと思います。
(1)標準化の数式
では、ここで具体例を出していきましょう。冒頭に挙げたような、気温と売上の例です。
気温 売上(円) 1 10 400,000,000 2 15 390,000,000 3 30 410,000,000 4 20 405,000,000 5 40 395,000,000 まず結論から出します。
標準化は、下記の数式で求められます。z = \frac{x -u}{σ}よくわからないですね。
$x$は各変数のそれぞれの値、$u$は各変数の平均、$σ$は各変数の標準偏差です。ものすごくざっくりした言い方ですと、各値から平均を引いて、各変数の標準偏差、つまり散らばり具合で割っているので、色んな範囲に点在しているデータが、ぎゅっと寄せ集められるイメージです。
・・もっとよくわからないですね。
実際に数値を求めてみましょう。■平均$u$
$u$は平均なので、気温の5つのデータ全ての平均を計算すると、$(10+15+30+20+40)/5 = 23$になります。同様に、売上の平均を計算すると、$(400,000,000 + 390,000,000 + 410,000,000 + 405,000,000 + 395,000,000)/5 = 400,000,000$
となります。■標準偏差$σ$
計算過程は割愛しますが、
気温の標準偏差を計算すると約12になります。売上の標準偏差は7,905,694になります。
■標準化すると・・
下記の様な計算結果になり、標準化した気温列の数値と、標準化した売上列の数値を機械学習では使っていくということです。
気温 売上(円) 標準化した気温 標準化した売上 1 10 400,000,000 $(10-23)/12$ $(400,000,000-400,000,000)/7905694$ 2 15 390,000,000 $(15-23)/12$ $(390,000,000-400,000,000)/7905694$ 3 30 410,000,000 $(30-23)/12$ $(410,000,000-400,000,000)/7905694$ 4 20 405,000,000 $(20-23)/12$ $(405,000,000-400,000,000)/7905694$ 5 40 395,000,000 $(40-23)/12$ $(395,000,000-400,000,000)/7905694$ (2)なぜ平均0、標準偏差1になるの?
標準化の数式は$z = \frac{x -u}{σ}$と記載しましたが、この計算をすると平均0、標準偏差1になる証明をしていきましょう。
ここでは、$y = ax +b$の式で考えていきます。
<標準化していない、元の式の平均と標準偏差>
まず、シンプルに標準化前の平均と標準偏差を求めましょう。
求めてみるとわかりますが、平均も標準偏差も0や1ではありません。
■平均
下記のように、$y$の平均は$aµ+b$と表せます。
※$E$は期待値を表していますが、期待値があまりわからない方はざっくり「平均」と捉えていただいても大丈夫です(厳密には異なります)。
■標準偏差
まず分散を求めていて、結果は$a^2σ^2$です。(標準偏差は$aσ$)
<標準化した式の平均と標準偏差>
では次に、標準化した後の平均と標準偏差を求めていきましょう。
式変形の考え方は、基本的に標準化前の式変形と同じです。下記のように式変形をすると、標準化した後は平均0、標準偏差1になっていることがわかります!
■平均
■標準偏差
こちらも先ほど同様、まずは分散を求めています。分散が1になるので、結局標準偏差も1になります。
以上で、標準化した後の各変数の平均は0、標準偏差が1になっていることが数式から証明することができました!
5.結び
以上、いかがでしたでしょうか。
私の思いとして、「最初からものすごい複雑なコードなんて見せられても自分で解釈できないから、精度は一旦どうでもいいのでまずはscikit-learn等で基本的な一連の流れを実装してみる」ことは非常に重要だと思っています。ただ、慣れてきたらそれらを裏ではどのように動かしているのか、数学的な背景から理解していくことも非常に重要だと感じています。
とっつきづらい内容も多いと思いますが、少しでも理解の深化の助けとなりましたら幸いです。


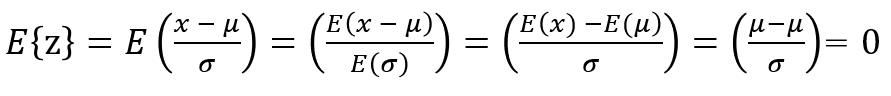
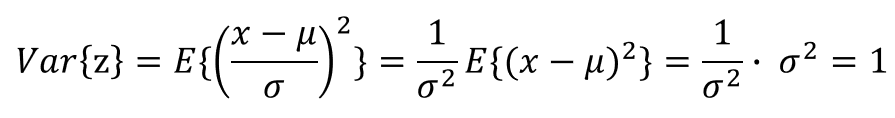
- 投稿日:2020-05-27T13:16:17+09:00
Zoom飲みでできる!!ジャストワン風協力型お題推測ゲームをFlask+Herokuで作ってみた
はじめに
私は、ボードゲームが好きだ。
ビールを飲みながらボードゲームをしている瞬間が至福だ。しかし、コロナウイルスの影響によって直接会ってボードゲームをすることが難しくなっている。
Zoomでもボードゲームを出来無いかと試したが、市販のボードゲームは直接集まってプレイすることが前提で作られているため、どうしても違和感があった。そこで、Zoomとの親和性の高い、Webブラウザでできるゲームがあれば違和感は消え、面白いのでは無いかと考えた。
お題を推測して当てるシンプルなゲームを作成した。
名前は、「ポレゲス」だ。ゲーム自体は、ジャストワンに似たゲームである。
今回は、そのゲームの概要や実装方法などをまとめていこうと思う。参考:【ゲーム紹介】ジャスト・ワン (Just One)|同じヒント禁止!お題の正解数を競う協力ワードゲーム!! | ニコボド|ボードゲームレビュー&情報系ブログ
作ったもの
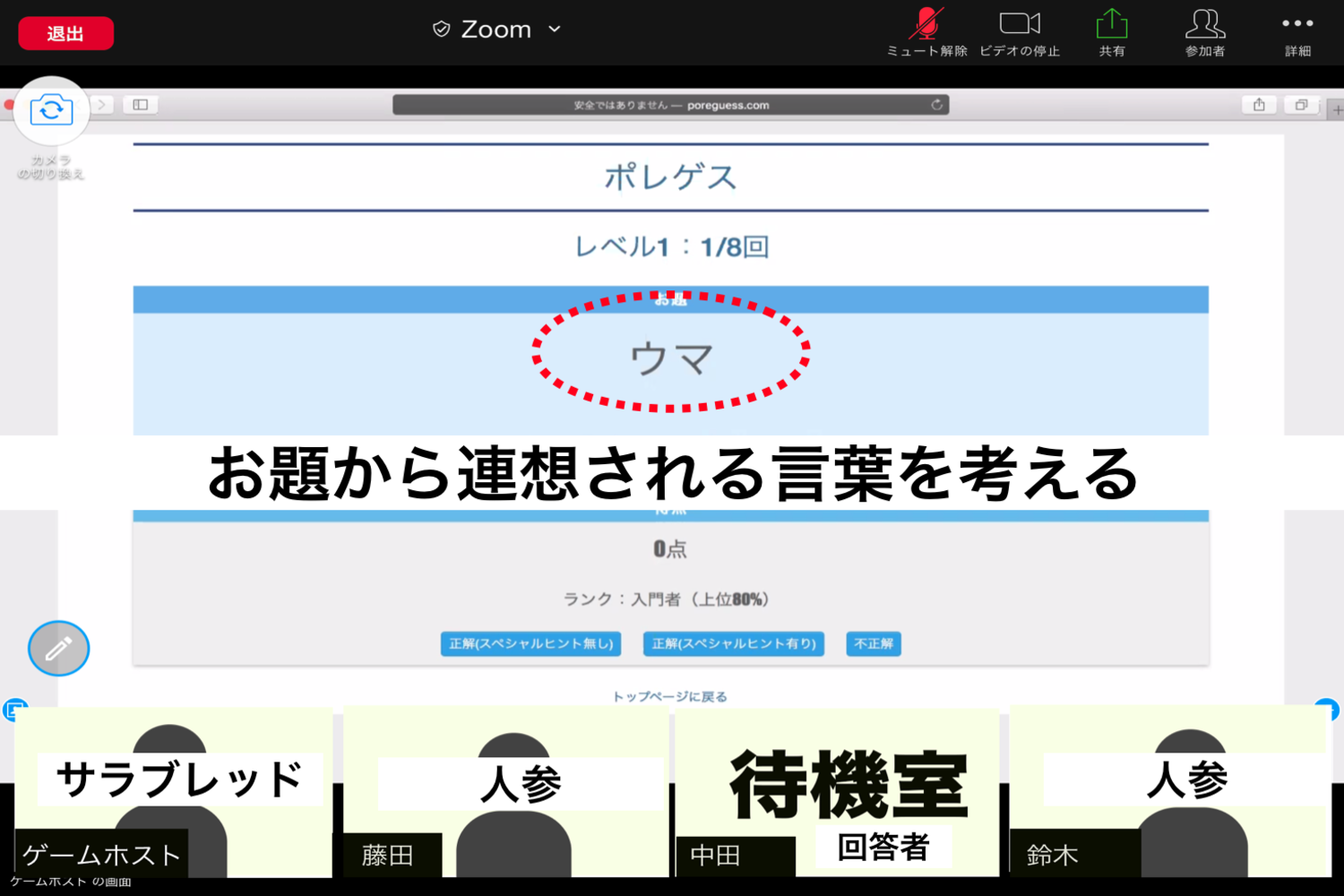
お題をヒントから当て、みんなで高得点を目指す協力型のゲーム「ポレゲス」を作った。
回答者は、プレイヤーの提示するヒントとシステムが提供するスペシャルヒントからお題を当てる。
例えば、プレイヤーの提示するヒントが「ウィンブルドン」、「ボール」、「王子様」、「錦織圭」のときに、それらのヒントの共通項は「テニス」なので回答者はお題が「テニス」と推測することができる。このように、回答者がお題を推測できるようなヒントをプレイヤーが考えてあげることがこのゲームの肝である。
スペシャルヒントを使うともう一個ヒントを見ることができる。スペシャルヒントを使わずに正解すると2点、スペシャルヒントを使って正解すると1点、不正解だと-1点になる。
合計8回繰り返し、チームの合計得点を最大化することを目指します。ただし、以下の2点の制約がある。
①ヒントはお題の「表記違い」「外国語/方言」「同系」「造語」「同音異義語」はNG
例)お題がテニスの時は、「てにす」、「庭球」、「tennis」はNG②プレイヤー間でヒントが重複したときはヒントが無効
ブラウザで遊べるシンプルなWebアプリケーションとなっている。
以下のURLから無料で遊ぶことができる。↓
「Zoomで出来るリモートボードゲーム!協力型お題推測ゲーム ポレゲス」
遊び方
問題数:1回のゲームでお題は8問。
ゲーム人数:3~8人
準備するもの(ホスト):パソコン、紙、ペン
準備するもの(ユーザー):紙、ペン
プレイ時間:20~40分遊び方動画
実装内容(技術)
システムアーキテクチャとしては、flask+heroku+sqlie3を使って実装した。
flaskを用いたWebアプリケーション作成は初めてだったので、以下のチュートリアルをベースに作成していった。
参考:Flask-tutorialまた、UIとUXを大幅に更新した第二弾からは弟が積極的にコミットしてくれたので、認識の齟齬をなくすためにAdobe XDで、ワイヤーフレームを作成した。レスポンシブ化も気合でやってくれた。
兼ねてからの憧れの独自ドメインもお名前.comを利用して700円ほど課金して取得した。
また、herokuの方にも課金する必要があったので700円ほど課金した。課金するとSSLの運用を自動化してくれるACMも使うことができた。
参考:お名前.comお題
350個気合で考えた。一番しんどかった。
レベル分けも直感で振り分けた。
今後、プレイヤーが増えてきたら正誤の数によって精緻化していきたい。スペシャルヒント
word2vec
Wikipediaをコーパスとしてmeacb+word2vecを使えば、結構近いヒントが得られるのでは無いかと思い、学習させて試してみた。
スペシャルヒントの意味の近さの%はこれが元になっている。結果としては10個中1個程度くらいしかきちんとしたヒントとして使えなかった。
ただ、たまにとてもハッとするようなヒントも予測してくれた。(笑)
例)お題「帰宅難民」→ヒント「第二の災害」ランサーズ
word2vecがそこまで使えないことが分かったので、人的リソースに頼ることにした。
ランサーズと言われるクラウドソージングサイトで、350語のスペシャルヒントを発注した。プロジェクト形式にしたところ30件ほど応募が来たので1500円程度で2名にお願いすることができた。
1日で両名とも納品され、質もバッチリだったので非常に満足している。ただ、選定するのが少し面倒だった。
参考:ランサーズユーザー数
GoogleAnalyticsを導入しているが、ユーザー数は日次で5~70人の訪問数がある。
Google Search Consoleを見たところ、「リモートボードゲーム」で検索してたどり着いているユーザーが多いようだ。感想
友人や家族と「ポレゲス」をプレイしてみたら、十分面白くて満足だった。
ただ、ビールを飲むと全然ヒントが考えられない。。今後の展望
ブログやゲーミングプラットフォームに載せることで日次で100人は継続して、訪問してもらえるようにしたい。
また、Youtuberにも使って行ってもらい、プレイ動画などを上げていってもらいたい。
ひとりで遊べるモードもモチベーションが維持できれば開発しようと思っている。余談
Google Adsenseは落ちました。
いずれ、また申請してみます。
- 投稿日:2020-05-27T12:52:08+09:00
python ファイル操作関係まとめ
#Working With Files in Python #https://realpython.com/working-with-files-in-python/ #python3 import os from pathlib import Path import shutil #filepathからファイル名取得 basename = os.path.basename(filepath) basename_without_ext = os.path.splitext(os.path.basename(filepath))[0] #ファイルの存在確認 cwd = os.getcwd() cwd_f = cwd + "/"+filename if os.path.isfile(cwd_f) == True #ファイル読み取り #https://dbader.org/blog/python-file-io with open('data.txt', 'r') as f: data = f.read() print('context: {}'.format(data)) #ファイル読み取り&編集 with open('data.txt', 'w') as f: data = 'some data to be written to the file' f.write(data) #フォルダー&ファイルリストの取得 #フォルダー構造 # my_directory # ├── file1.py # ├── file2.csv # ├── file3.txt # ├── sub_dir # │ ├── bar.py # │ └── foo.py # ├── sub_dir_b # │ └── file4.txt # └── sub_dir_c # ├── config.py # └── file5.txt #方法1 entries = os.listdir('my_directory')#entriesはリスト for entry in entries: print(entry) #→['file1.py', 'file2.csv', 'file3.txt', 'sub_dir', 'sub_dir_b', 'sub_dir_c'] #方法2 python 3.5以後 with os.scandir('my_directory') as entries:#entriesはイテレータ for entry in entries: print(entry.name) #方法3 python 3.4以後 entries = Path('my_directory') for entry in entries.iterdir(): print(entry.name) #サブフォルダを含むリスト取得 for dirpath, dirname, files in os.walk('.'): print(f'Found directory: {dirpath}') for file_name in files: print(file_name) #ファイル判断 #方法1 for entry in os.listdir(basepath): if os.path.isfile(os.path.join(base_path, entry)): print(entry) #方法2 python 3.5以後 with os.scandir(basepath) as entries: for entry in entries: if entry.is_file(): print(entry.name) #方法3 python 3.4以後 basepath = Path('my_directory') for entry in basepath.iterdir(): if entry.is_file(): print(entry.name) # or basepath = Path('my_directory') files_in_basepath = (entry for entry in basepath.iterdir() if entry.is_file()) for item in files_in_basepath: print(item.name) #サブフォルダ取得 #方法1 for entry in os.listdir(basepath): if os.path.isdir(os.path.join(basepath, entry)): print(entry) #方法2 with os.scandir(basepath) as entries: for entry in entries: if entry.is_dir(): print(entry.name) #方法3 for entry in basepath.iterdir(): if entry.is_dir(): print(entry.name) #ファイルの編集時刻取得 #方法1 with os.scandir('my_directory') as entries: for entry in entries: info = entry.stat() print(info.st_mtime) #方法2 for entry in basepath.iterdir(): info = entry.stat() print(info.st_mtime) #※ 時刻変換関係 timestamp = int(info.st_mtime)#ms秒を削除 dt = datetime.datetime.utcfromtimestamp(info.st_mtime) #st_mtime→datetimeに dt = dt.strftime('%Y-%m-%d %H:%M:%S') #https://strftime.org/ #https://docs.python.org/3/library/datetime.html#strftime-and-strptime-behavior #フォルダ作成 #方法1 try: os.mkdir('directory') except FileExistsError as e: print(e) #方法2 p = Path('directory') try: p.mkdir() except FileExistsError as e: print(e) #※エラー無視時, p.mkdir(exist_ok=True) #※サブフォルダー作成 os.makedirs('floder/subf/sub') #一時ファイルの作成 from tempfile import TemporaryFile # 一時ファイル作成&データ入力 fp = TemporaryFile('w+t') fp.write('Hello World!') # データ読み込み fp.seek(0) data = fp.read() print(data) # ファイルを閉じる(自動削除) fp.close() #with バージョン with TemporaryFile('w+t') as fp: fp.write('i am good man!') fp.seek(0) fp.read() #一時フォルダの作成 import tempfile with tempfile.TemporaryDirectory() as tmpdir: print('Created temporary directory ', tmpdir) print(os.path.exists(tmpdir)) #ファイル削除 os.remove(file) #or os.unlink(file) #フォルダの削除 os.rmdir(dir) #or dir = Path('my_documents/bad_dir') dir.rmdir() #フォルダーツリーの削除 shutil.rmtree(dir_tree) #ファイルコピー shutil.copy(src, dst) #or shutil.copy2(src, dst)#ファイルのプロパティもコピー #フォルダーツリーのコピー dst = shutil.copytree('data', 'databackup') #ファイルおよびフォルダーの移動 dst = shutil.move('dir/', 'backup/') #ファイルおよびフォルダーのリネーム os.rename('first.zip', 'first_01.zip') #.txt ファイル探し #Strings and Character Data in Python #https://realpython.com/python-strings/ #方法1 for f_name in os.listdir('directory'): if f_name.endswith('.txt'): print(f_name) #方法2 import fnmatch for f_name in os.listdir('directory'): if fnmatch.fnmatch(f_name, 'data_*_2020*.txt'): print(f_name) #方法3 import glob for name in glob.glob('*/*/*[0-9]*.txt'):#サブフォルダ、0~9の文字を含むの.txtファイルを探し print(name) #zipファイルの読み込み import zipfile with zipfile.ZipFile('data.zip', 'r') as zipobj: for names in zipobj.namelist(): if os.path.isfile(names) info = zipobj.getinfo(names) print(info.file_size,bar_info.date_time,bar_info.filename) #zipファイルから指定ファイルの解凍 data_zip = zipfile.ZipFile('data.zip', 'r') #data.zipの中のfile1.pyを作業ディレクトリへ解凍 data_zip.extract('file1.py') #全てを指定フォルダーへ解凍 data_zip.extractall(path='extract_dir/') #パスワードある場合 data_zip.extractall(path='extract_dir', pwd='password') data_zip.close() #zipファイルの作成&追加 #作成 file_list = ['file1.py', 'sub_dir/', 'sub_dir/bar.py', 'sub_dir/foo.py'] with zipfile.ZipFile('new.zip', 'w') as new_zip: for name in file_list: new_zip.write(name) #追加 with zipfile.ZipFile('new.zip', 'a') as new_zip: new_zip.write('data.txt') new_zip.write('latin.txt') #tarファイルの読み込み import tarfile with tarfile.open('example.tar', 'r') as tar_file: #mode :['r','r:gz','r:bz2','w','w:gz','w:xz','a'] for entry in tar_file.getmembers(): print(entry.name) print(' Modified:', time.ctime(entry.mtime)) print(' Size :', entry.size, 'bytes') #or f = tar_file.extractfile('app.py') f.read() #tarファイルから指定ファイルの解凍 tar = tarfile.open('example.tar', mode='r') #カレントディレクトリに解凍 tar.extract('README.md') #全てを指定フォルダーへ解凍 tar.extractall(path="extracted/") #tarファイルの作成&追加 #作成 import tarfile file_list = ['app.py', 'config.py', 'CONTRIBUTORS.md', 'tests.py'] with tarfile.open('packages.tar', mode='w') as tar: for file in file_list: tar.add(file) #追加 with tarfile.open('package.tar', mode='a') as tar: tar.add('foo.bar') #確認 with tarfile.open('package.tar', mode='r') as tar: for member in tar.getmembers(): print(member.name) #shutil.make_archive()でフォルダー圧縮 import shutil #dataフォルダーしたのファイルをbackup.tarに圧縮 shutil.make_archive('data/backup', 'tar', 'data/') #解凍 shutil.unpack_archive('backup.tar', 'extract_dir/') #複数ファイルの読み込み #https://docs.python.org/3/library/fileinput.html import fileinput,sys for line in fileinput.input(): if fileinput.isfirstline(): print(f'\n--- Reading {fileinput.filename()} ---') print(' -> ' + line, end='')
- 投稿日:2020-05-27T12:27:13+09:00
Pythonの基礎
まえおき
- この記事は執筆中のやさしくはじめるPythonプログラミングの本の特定の章の部分抜粋です。
- 入門本なので初心者の方向け。
- Pythonの基本的なところの章が対象となります。
- Qiita記事にマッチしていない箇所(「章」や「ページ」といった単語が使っていたり、改行数が余分だったり、リンクが対応していない等)があるという点はご留意ください。
面倒なのでQiita用に調整するのやりたくない。気になる方は↑のリンクの電子書籍版をご利用ください。- コメントなどでフィードバックいただいた場合、書籍側にも活用・反映させていただく場合があります。
Pythonの基礎
この章では、Pythonの基本的なところを学んでいきます。地味な内容もまだ多いですが、大切な内容であり且つ基礎がしっかりしていると学習がスムーズになります。スキップせずに、且つ実際に皆さん自身で手を動かしてコードを実行してみて進めてみてください。
足し算、引き算・掛け算...基本的な計算
前の章でも少し出てきましたが、基本的な足し算などの計算方法を見ていきます。
数字や記号は全部半角なので気を付けて
計算に進む前に全角半角について触れておきます。
各コードは全角だと動いてくれないので、半角の数字や記号などを使用してください。序盤のうちは全角で打ってしまったりも結構してしまうと思いますが、そうすると以下のようにエラーになってしまいます。
3 * 3File "<ipython-input-26-7de8af1d1fd9>", line 1 3 * 3 ^ SyntaxError: invalid character in identifierinvalidは「無効な」といった意味で、characterは「文字」、indentifierは「識別子」といったような意味ですが、意味が分かりづらいので特定の(プログラムの)文字列の部分で、といった意味で現状では捉えてみてください。
プログラムの文字列の中に無効な文字が含まれていますよ、というエラーメッセージです。
また、エラーの内容にある
^の記号は、上の部分が無効な文字の部分ですよ、ということを指しています。上記の例だと全角のアスタリスクが指し示してあり、そこが修正が必要(半角にする必要がある)なことが分かります。また、Jupyter上では半角の記号にちゃんとなっていれば、文字が紫色になったりします。全角の場合は黒のままです。
大きさだけではなく色でも識別できるようになっているので、うっかり全角で入力してしまった時など参考にしてみてください。
足し算
まずは足し算の方法です。加算などとも呼ばれます。英語だとAdditionとなり、プログラムでaddといった記述が出てきたら足し算のことを指していることが多いです。
数値 + 数値の形式で、数値の間に半角のプラスの記号を挟むことでPythonで計算することができます。3 + 4コード実行結果の出力内容:
7
他の計算も同様ですが、複数の数値で計算することもできます。
3 + 4 + 5コード実行結果の出力内容:
12
引き算
続いて引き算の方法です。減算などとも呼ばれ、英語だとSubtractionとなり、プログラム上ではsubなどという名前で使われたりします。
数値 - 数値の形式で、数値の間に半角のマイナスの記号(ハイフン)を挟むことでPythonで計算することができます。5 - 2コード実行結果の出力内容:
3
掛け算
掛け算は乗算などとも呼ばれます。英語だとMultiplicationとなります。
プログラム上ではmulなどの名前で使われたりします(例 : 高校や大学などで学ぶ行列関係でmatmulといった具合に)。
数値 * 数値の形式で、数値の間に半角のアスタリスクの記号は挟むことでPythonで計算することができます。3 * 4コード実行結果の出力内容:
12
割り算
割り算は除算なととも呼ばれます。英語だとdivisionとなります。
少し前のセクションで触れた、0除算のエラー(ZeroDivisionError)でもこの英単語は出てきましたね。
数値 / 数値の形式で、数値の間に半角のスラッシュの記号を挟むことでPythonで計算することができます。5 / 2コード実行結果の出力内容:
2.5
余り
次はとある数で割った際の割り切れない分の値(余り)の計算に関してです。剰余などとも呼ばれます。英語だとremainderとかmoduloなどになります。
数値 % 数値の形式で、数値の間に半角のパーセントの記号を挟むことでPythonで計算することができます。6 % 4コード実行結果の出力内容:
2
累乗計算
続いて「2の3乗」みたいな、累乗計算の方法です。べき乗などとも呼ばれます。英語だとpowerといった英単語が使われます。「2の累乗」で「a power of two」といった感じの英語になります。
Pythonでは
数値 ** 数値の形式で、数値の間に半角のアスタリスクを2つ連続して記述することで計算できます。1つだけだと通常の掛け算になってしまうので注意してください。2 ** 3コード実行結果の出力内容:
2
演算子と代数演算子の話
重要度 : ★☆☆☆☆(最初は知らなくてもいいかも)
プログラミングで色々な計算を行う際に使われる記号などは演算子と呼ばれます。英語ではoperatorとなります。
今までに出てきた足し算のプラスや掛け算のアスタリスクなどの記号は、演算子の中でも代数演算子と呼ばれます。
今後、プログラミング関係の記事や本でよく演算子という単語が出てくると思いますが、とりあえずは「計算などをするときに必要になるプラスとかの記号のことなんだな」程度に頭の片隅に入れておいてください。
あなたの年齢は?変数入門
プログラムでは、値に名前を付けると便利なことが多々あります。例えば、「私の年齢」という名前の値を考えてみましょう。
「私の年齢」という名前の値が用意されていると、その値に応じて、ケーキのロウソクの本数を決定する、みたいなプログラムを書くことができます。
また、この値は固定ではなく誕生日を迎えるごとに値が1増えていきます。
このような特定の条件で値が変わり、且つ名前が付けられたものを「変数」と言います。英語だとvariableといいます。短縮されてvarなどと表記されることも多くあります。
年齢が毎年変わるのと同様に、「変わる数」という意味合いを持ちます。ただし、数と付いていますが別に内容は数値に限ったことではありません。「あなたの名前」といった文字列が設定されたりもします。どちらかというと「変わりうるデータ」という方が意味合いが近いかもしれません。
「私の年齢」は「25」です、といったように定義することを「変数宣言」とか「変数定義」と言います。英語では「define a variable」といった感じに、「define」という単語が使われます。もしくは、「割り当てる」という意味でのassignを使って、「assign a variable」や「variable assignment」といった風に使われます。
変数の名前はそのまま変数名(variable name)と呼ばれ、この例では「私の年齢」部分が変数名となります。
Pythonで変数を定義するには、
変数名 = 変数の値という形で変数名と変数の値の間にイコールを記述することで定義することができます。プログラムの変数名は基本的に、計算の時の記号と同様に全て半角の英数字や記号などで表現します(一部例外のケースはあります)。
Pythonだと全角の文字を使っても動いたりしますが、一般的なプログラミングの慣習では半角が基本となりますので、全角の英数字を使わないように気を付けてください。
変数名は、複数の英単語から構成される場合には、間をスペースではなく半角のアンダースコア(
_)などの記号で単語を繋いだりして表現します。もしくはアンダースコア自体を省略するケースもPythonだと良くあります。例えば、「私の年齢」という変数名では
my_ageといったように変数名を付けます。先ほどの例で変数宣言をしてみると、以下のような形になります。
my_age = 25このように変数に値を設定(代入)するような、イコールの記号の演算子は「代入演算子」と呼ばれます(英語だとassignment operator)。
変数の内容を確認する
変数の中身(値)を確認するには、
print(変数)というフォーマットでプログラムを書きます。print(my_age)といった具合です。この
my_age = 25 print(my_age)コード実行結果の出力内容:
25
また、Jupyter上であればprintを省略しても、その変数単体をセルに入力してある場合(厳密には違いますが)にセルを実行すれば変数の内容を確認することができます。
JupyterのOut[]部分に変数の内容が表示されます。
変数の内容を変更する
変数の内容を変更するには、もう一度同じ変数名でイコールの記号を使うことで設定ができます。
たとえば、先ほどの変数の
my_ageの値を25から26に変更するには以下のように記述します。25の値を設定するときと一緒ですね。my_age = 26足し算と変数の更新を同時に行う : 加算代入演算子
また、変数の値が数値の場合、プラスやマイナスなどの記号とイコールを一緒に記述することで、「現在の値に対して」計算をすることができます。
例えば、
my_ageという変数の値を1プラスする際には、my_age += 1といったような書き方になります。変数への値の設定と足し算を同時にやっているので、「加算代入演算子」と呼ばれます(英語だとaddition assignment operator)。
引き算なども同様に、「減算代入演算子(subtraction assignment operator)」
「乗算代入演算子(multiplication assignment operator)」、「除算代入演算子(division assignment operator)」と名前が付いています。何だか小難しい漢字が並んでいますが、ゆっくりと時間をかけて用語は覚えていけばいいので、今は「足し算などと変数への値の設定を同時にやれる」ということだけを覚えておけば大丈夫です。
一応本書では各用語にもある程度触れていきますが、プログラムを楽しむ上では重要ではないのと、長いことプログラミングをしていれば自然と少しずつ覚えていけるので気楽に構えていただいて問題ありません。
加算代入演算子を使うには、変数に事前に数値を入れておく必要があります。例えば、
my_age = 25といったコードが必要になります。数値が入った変数に対して、以下のように加算代入演算子などを使えます。
my_age = 25 my_age += 2 print(my_age)コード実行結果の出力内容:
27
最初に変数に設定した25の値に2プラスされて、結果のprint部分で表示される変数の内容が27となっていることが分かります。
なお、加算代入演算子を使う代わりに、以下のようにただの代入演算子(イコールだけの記号)を使って
my_age = my_age + 2とプログラムを書いても同じ27という結果になります。my_age = 25 my_age += 2 print(my_age)コード実行結果の出力内容:
27
どちらの書き方も「変数の現在の値に対して」値を足している形になるため、プログラムの結果は変わりません。
ただし、加算代入演算子(
+=)を使った書き方の方が大体のケースでシンプルになります。
加算代入演算子が使えるケースではそちらの利用がおすすめです。引き算と変数の更新を同時に行う : 減算代入演算子
+=の記号を使う加算代入演算子と同様に、-=の記号を使う形で「現在の変数の値に対して引き算を行う」計算を行うことができます。こちらの記号は減算代入演算子(subtraction assignment operator)と呼ばれます。挙動や使い方は足し算の部分が引き算になるだけで、他は加算代入演算子のときと同じです。
my_age = 25 my_age -= 2 print(my_age)コード実行結果の出力内容:
23
掛け算と変数の更新を同時に行う : 乗算代入演算子
*=の記号を使うと、前のセクションで触れた加算や減算と同様に「現在の変数の値に対して掛け算を行う」計算を行うことができます。こちらの記号は乗算代入演算子(multiplication assignment operator)と呼ばれます。挙動は足し算や引き算のものと同様で、内容が掛け算になるだけです。
my_money = 1000 my_money *= 3 print(my_money)コード実行結果の出力内容:
3000
割り算と変数の更新を同時に行う : 除算代入演算子
足し算、引き算、掛け算と来たので、勿論割り算もあります。
/=の記号を使うと、「現在の変数の値に対して割り算を行う」計算を行うことができます。こちらの記号は除算代入演算子(division assignment operator)と呼ばれます。my_money = 1000 my_money /= 4 print(my_money)コード実行結果の出力内容:
250.0
型ってなに?
今後、色々本を進めていくにつれて、「型」という概念が重要になってきます。
英語だとtypeとなります。初めて見ると型とはなんだろう?という感じですが、重要な内容なので、このセクション以降では基本を丁寧に説明していきます。
説明のために、アスタリスクの記号を使った以下の数値の掛け算のコードと結果を見てみてください。
2 * 5コード実行結果の出力内容:
10
結果が10となりました。
続いて、数値ではなく文字に対して掛け算と同じアスタリスクでのコードを実行してみるとどうなるでしょうか?
Pythonで文字は
''などのクォーテーションと呼ばれる記号で囲むと表現できます。'猫' * 5コード実行結果の出力内容:
猫猫猫猫猫
今度は文字が5個になりました。
2や'猫'といった値に応じて、挙動が変わっていますね。このように、プログラムでは値に応じて振る舞いが変わります(数値の場合はこうなる、文字の場合はこうなる、といったように)。
また、値によってできることとできないことが異なります。
この数値や文字などの種類が、それぞれ「型」になります。Pythonでは、数値や文字などの他にも様々な型が存在します。
「振る舞いが違う色々な値の種類」と考えると少し分かりやすいかもしれません。
色々な型がありますが、次のセクション以降で少しずつ触れていきます。一度にたくさん覚えようとすると大変なので気楽に進めていただいて、忘れたときにはそこだけ復習するといった具合に進めてみてください。
焦らなくても、プログラムを書き続けてさえいれば自然と身についてきたり、覚えているものの数が増えていきます。
| 2, 5, 20...整数(int)の入門
整数の型はintとなります。英語だと整数がintegerなので、その略称としてPythonでは型の名前がintとなっています。
今まで出てきたPythonの基本計算でも既に色々使ってきましたね。
変数へ整数を設定するには、今まで触れてきた通り
=の記号を使いつつ、右辺に整数の値を配置すれば設定できます。my_age = 10 print(my_age)コード実行結果の出力内容:
10
また、型の確認は
type()と書いて()の括弧の中に値を直接入れたり、変数を入れたりすることで確認ができます。以下のようにコードを書く と、値はintですよ、ということを確認できます(もしくは、Jupyter上であればセルの末端であればprint部分を省略しても型の内容を確認できます)。
my_age = 10 print(type(my_age))コード実行結果の出力内容:
<class 'int'>
class 'int'という形で表示されていますが、class部分については後々別のセクションで触れていきます。この
type()での型の調べ方は、他の値でも使えます。| 1.5, 0.05, 30.3...浮動小数点数(float)の入門
1.5や0.05といった、少数の値を含んだ数値はfloatという型で扱います。
特に、コンピューター・プログラミング関係では浮動小数点数という形で少数を扱います。英語だとfloating point numberとなり、そこにfloatという型の名前が由来しています。
浮動小数点数と対になるもので固定小数点数というものもあります。
浮動小数点数に「動」という漢字がありますが、これは小数点の位置が動いても扱える、という意味合いを持ちます。0.01でも538.1500023といった値でも扱えます。
一方で、固定小数点数は決められた小数点の位置しか扱えません。1030.3123や0391.8812といった値になります。
浮動小数点数の方が、少数点部分が柔軟に扱える(扱える数値の範囲が広い)代わりに、固定小数点数の方が計算が速いという特徴がありますが、基本的に普通に触っている分にはほぼ浮動小数点で困ることはありません。
一応、Pythonでは固定小数点数も利用ができるのですが、基本的には一部の特殊なケース以外、ほぼほぼ浮動小数点数しか利用しません。そのため、小数を扱うときには浮動小数点数のfloatを使うと考えていていただいても問題ありません。
この辺りは小難しい話ですし、固定小数点数が必要になるケースは少ないと思うので、深くはこの本では触れません。
浮動小数点数を扱うには、半角の数字と半角のドット
.の記号を使って表現します。pi = 3.1415 print(pi)コード実行結果の出力内容:
3.1415
普通に変数に設定する以外にも、最初は整数の型(int)だったものが、計算の途中で浮動小数点数(float)になっている、などのケースもあります。例えば、割り算を
/=の記号を使ってしてみると、最初はintの型だったものがfloatになっていることが分かります。money = 1000 print(type(money))コード実行結果の出力内容:
<class 'int'>
上記のように、変数宣言の時点では整数(int)になっています。
money = 1000 money /= 6 print(type(money))コード実行結果の出力内容:
<class 'float'>
割り算をしたら型が浮動小数点数(float)になりました。これは、割り算によって変数(money)の値が
166.66666666666666といったように、小数が必要な値に変化したことによってPython側が自動で変換してくれています(割り切れる計算の場合でも、割り算をすると基本的に結果は浮動小数点数になります)。'りんご', '猫', '晴れ'...文字列(str)の入門
日本語や英語などの文字はstrという型で扱います。
猫とかaといった単一の文字は英語でcharacterとなります。プログラミングではよくcharなどと短くした形で使われます。
ペルシャ猫やappleといった、複数の文字からなるものを、文字列と呼びます。文字列は英語でstringで、Pythonの文字を扱う型のstrはこの英語に由来します。1文字のときも複数文字の場合も、両方とも同じstrの型で扱えます。
文字列を扱うには、
'の記号(シングルクォーテーションと呼ばれます。英語だとsingle quotationとなります)で文字列を囲むか、"の記号(ダブルクォーテーションと呼ばれます。英語ではdouble quotation)で文字列を囲む必要があります。例えば、
'ペルシャ猫'といった形や、"ペルシャ猫"といったように'や"の記号を使って表現します。シングルクォーテーションを使ったサンプル :
cat_name = 'ペルシャ猫' print(cat_name)コード実行結果の出力内容:
ペルシャ猫
ダブルクォーテーションを使ったサンプル :
cat_name = "ペルシャ猫" print(cat_name)コード実行結果の出力内容:
ペルシャ猫
シングルクォーテーションを使ってもダブルクォーテーションを使っても基本的な文字列の挙動は変わりません。
ただし、例えば文字列の中にシングルクォーテーションやダブルクォーテーションが含まれる場合には、含まれていない方のクォーテーションを使うとシンプルになります。
文字列内にシングルクォーテーションが含まれているので、ダブルクォーテーションを使っているサンプル :
string = "That's it." print(string)コード実行結果の出力内容:
That's it.
シングルクォーテーションを含んだ文字列に対してシングルクォーテーションを使うことも一応はできます。ただし、「エスケープ」という対応が必要になります。
エスケープは、
\記号(環境によって、半角のバックスラッシュもしくは半角の円記号で表示されます)を使います。文字列内でこのエスケープ用の
\記号の後に設定された文字は、「特殊な挙動をしないただの文字」になります。シングルクォーテーションやダブルクォーテーションはPythonでは文字を囲むための特殊な挙動をします。それがエスケープ用の記号を直前に置くことで、プログラム的に意味を持たないただの文字となります。
前述のシングルクォーテーションを含む文字列のサンプルで、エスケープをしながらシングルクォーテーションで囲むには
That\'s it.といったように、シングルクォーテーションの直前に\記号を配置してください。string = 'That\'s it.' print(string)コード実行結果の出力内容:
That's it.
また、仕事などで複数人でPythonのコードを書くようなケースでは、人によってシングルクォーテーションを主に使うのかダブルクォーテーションを主に使うのかがバラバラで、そのままだと各クォーテーションがごちゃまぜになってしまいます。
そういったことを避けるために、コードを扱う各プロジェクトで「基本的にはシングルクォーテーションをメインに使う」とか、逆に「基本的にはダブルクォーテーションをメインに使う」といったルールを決めることが多いです。
※前述のように、メインで使うのはシングルクォーテーションだけれども、文字列内にシングルクォーテーションが含まれているから例外的に一部たけダブルクォーテーションを使う、といったことは問題ありません。
こういったルールの集まりを、「コーディングルール」とか「コーディング規約」等と呼びます。
参考までに、PEP8という、Pythonのプログラム自体のコーディング規約にも、どちらをメインで使うのかを各々で決めてください、という記述があります(20年前くらいのドキュメントになります)。
Python では、単一引用符 ' で囲まれた文字列と、二重引用符 " で囲まれた文字列は同じです。この PEP では、どちらを推奨するかの立場は示しません。どちらを使うかのルールを決めて、守るようにして下さい。
必須ではありませんが、皆さんの好みや仕事で複数人での作業が必要になった場合は同僚の方と相談したりして、どちらをメインに使っていくのかを必要に応じて決めてください。
本書ではシングルクォーテーションをメインに使っていきます。
文字列の連結
数値の時は
+の記号を使うと足し算となりました。文字列で+の記号を使うと、文字列同士の連結になります。以下のサンプルでは、
apple_nameという文字列の変数とorange_nameという文字列の変数を+の記号を使って連結して、最終的に1つの文字列の変数のconcatenated_strにしています。apple_name = 'りんご' orange_name = 'オレンジ' concatenated_str = apple_name + orange_name print(concatenated_str)コード実行結果の出力内容:
りんごオレンジ
複数のクォーテーションによる文字列の連結
また、複数のクォーテーション区切りの文字列が連続していても1つの値(変数)になります。
fruit_name = 'りんご''オレンジ''メロン' print(fruit_name)コード実行結果の出力内容:
りんごオレンジメロン
もちろん、前述のサンプルのようにクォーテーションを複数使わなくても以下の1つの文字列にはなってくれます。
fruit_name = 'りんごオレンジメロン' print(fruit_name)コード実行結果の出力内容:
りんごオレンジメロン
では何故クォーテーションを複数分ける形にすると何が便利なのか?という点ですが、例えば長い文字列を扱うときに、見やすくするために改行を挟んだりすることができます(文字列自体には改行は含まれません)。
改行を挟む際には、コードの行末にエスケープ用の半角のバックスラッシュ(環境によっては半角の円の記号になります)を設定する必要があります。
text = '吾輩は猫である。名前はまだ無い。'\ 'どこで生れたかとんと見当がつかぬ。'\ '何でも薄暗いじめじめした所でニャーニャー'\ '泣いていた事だけは記憶している。'\ '吾輩はここで始めて人間というものを見た。' print(text)コード実行結果の出力内容:
吾輩は猫である。名前はまだ無い。どこで生れたかとんと見当がつかぬ。何でも薄暗いじめじめした所でニャーニャー泣いていた事だけは記憶している。吾輩はここで始めて人間というものを見た。
このようにクォーテーションを複数使って改行を入れることで、ひたすら1行に詰め込まれていて横スクロールを頑張らないと読めないといったケースを避けることができ、便利な場合があります。
昨今では大分モニターの解像度も上がっていて横に長くなっていても問題ないケースもありますが、他の方がコードを書くときにエディタの画面を分割していて横幅が狭くなっているケースもありますし、あまり1行に詰め込みすぎるとあまり好ましくありません。
Python界隈では、Python自体のコーディング規約で半角で79文字以内と定められていますので、それに準じているプロジェクトやライブラリなどが多めです。そちらも必要に応じてご参照ください。
すべての行の長さを、最大79文字までに制限しましょう。
PEP: 8 Python コードのスタイルガイド余談ですが、行数が多くて行末にエスケープの記号
\を毎回記述するのが手間な場合は、()の括弧の中に各文字列を入れることで、行末のエスケープの記号を省略することができます。text = ( '吾輩は猫である。名前はまだ無い。' 'どこで生れたかとんと見当がつかぬ。' '何でも薄暗いじめじめした所でニャーニャー' '泣いていた事だけは記憶している。' '吾輩はここで始めて人間というものを見た。' ) print(text)コード実行結果の出力内容:
吾輩は猫である。名前はまだ無い。どこで生れたかとんと見当がつかぬ。何でも薄暗いじめじめした所でニャーニャー泣いていた事だけは記憶している。吾輩はここで始めて人間というものを見た。
文字の繰り返し
数値に対して
*の記号を使うと掛け算ができました。文字もしくは文字列に対して*の記号と任意の整数を指定すると、その文字(もしくは文字列)を整数の数分繰り返した文字列を作ることができます。print('りんご' * 5)コード実行結果の出力内容:
りんごりんごりんごりんごりんご
複数行の文字列
特殊な文字列の表現方法となりますが、クォーテーションを3つ連続して記述すると改行などのそのまま含んだ文字列を定義できます。
少し前のセクションで触れた、クォーテーションを分割して文字列を分割したときのように、長い文字列を扱う時に便利です。
以下のように、文字列の開始と終了の部分にダブルクォーテーションを3つ書くことで使えます。
text = """吾輩は猫である。名前はまだ無い。 どこで生れたかとんと見当がつかぬ。 何でも薄暗いじめじめした所でニャーニャー泣いていた事だけは記憶している。""" print(text)コード実行結果の出力内容:
吾輩は猫である。名前はまだ無い。 どこで生れたかとんと見当がつかぬ。 何でも薄暗いじめじめした所でニャーニャー泣いていた事だけは記憶している。
後々の章で触れますが、この書き方はdocstringと呼ばれる、Pythonのコードに対する説明・ドキュメントを書くときに使われるため、後々の章では多く出てきます。また後で触れますが、頭の片隅に入れておいてください。
なお、ダブルクォーテーションではなくシングルクォーテーションでも同じように3つ連続して記述することで複数行の文字列を定義できます。
ただし、この書き方はPython自体のコーディング規則で「ダブルクォーテーションを使う」と書かれていることもあり、大半はダブルクォーテーションが使われています。
三重引用符 で文字列を囲むときは、PEP 257 での docstring に関するルールと一貫させるため、常に二重引用符 """ を使うようにします。
PEP: 8 Python コードのスタイルガイド猫は好きですか?「はい」か「いいえ」の真偽値(bool)の入門
「はい」か「いいえ」といったような、2つの値だけを取る真偽値という型もPythonには存在します。型の名前はboolとなります。真偽値の英語がbooleanなので、その省略形としてboolとなっています。
真偽値の値には、
TrueもしくはFalseという二つの値のみが利用できます。True(真)とFalse(偽)といったように、この2つの値は真偽値という名前の由来にもなっています。Trueが「はい」、Falseが「いいえ」といったように扱われます。猫は好きですが?
- 「はい」であればTrue
- 「いいえ」であればFalse
といった具合です。
TrueとFalseの各真偽値の値を変数に設定したい場合には、そのままTrueもしくはFalseとプログラム上で書いて変数に格納します。例えばTrueを設定したい場合には以下のようなコードになります。
i_like_cats = True逆にFalseを設定したい場合には以下のようなコードになります。
i_like_cats = False今のところ、これらの真偽値を何に使うのだろう?という印象がするかもしれませんが、後々の章で条件分岐と呼ばれるプログラムの章で頻繁に使用します。条件分岐はたとえば「猫が好きであれば〇〇」といったような条件によってプログラムの挙動を変えるような制御のことを言います。
詳しくは後々触れていきます。現時点では真偽値という型があるということだけ頭に入れておいてください。
Pythonの生みの親の名前は?定数入門
Pythonの生みの親の方はなんという名前でしょうか?
答えは、Guido van Rossum(グイド・ヴァンロッサム)さんです。
このような、Pythonの生みの親 = Guido van Rossumさんという定義は過去も将来も変わったりはしません。
一方で、「東京の今の気温」といった値は刻一刻と変わり続けます。
前のセクションで、条件や時間経過などによって変わる値を変数と言う、ということを説明しました。「東京の今の気温」といった定義は変数が向いています。
反対に、「Pythonの生みの親」という基本的には変わらない定義は、変数ではなく「定数」と呼ばれるもので定義します。
「値が一定で変わらない」という意味も持ちます。英語だとconstantとなります。プログラム上では、よく省略形でconstなどと書かれたりします。
Pythonで定数を定義する時には、「大文字の英語」と「単語ごとにアンダースコアで区切る」形で表現します。
例えば、「猫の名前」という定数を定義したい場合には
CAT_NAMEといったように書きます。CAT_NAME = 'ミケ'他のプログラミング言語でも勿論定数の機能が用意されていることが大半です。それらでは、基本的に定数は1度設定したらプログラムを止めたりしない限り変更ができません(変えようとするとエラーになります)。
しかし、Pythonでは名前が大文字などを使う以外、機能的には変数と変わりません。基本的にはやりませんが、以下のように定数として定義した値に別の値を設定することもできてしまいます。
CAT_NAME = 'ミケ' CAT_NAME = 'タマ' print(CAT_NAME)コード実行結果の出力内容:
タマ
そのため、Pythonの定数の定義としては「値が変えられないもの」というよりかは、「値を変えないもの」という方がしっくりきます。
値が変えられるのであれば、全部変数でいいのでは?という印象もするかもしれませんが、定数として定義することで、後で他の人がコードを読んだ時などに、
CAT_NAMEといったように大文字で定義された値が出てきたら、「この値は変わらない(変えない)値なんだな」とすぐに理解することができます。定数として定義することでコードの説明として役立ちます。なお、私は他のプログラミング言語を昔使っていてから、Pythonを初めて使い始めたのですが、その時にPythonの定数の「値を変えないもの」として使う仕様に結構驚いた記憶があります(他の方に聞いてみても、最初は違和感があったそうです)。
しかし、Pythonに慣れてきて、何年もずっとPythonを書き続けてきた限りでは、特にこの仕様で大きく問題になったりするケースは発生していません。
逆に、後々の章で触れるテストスクリプトなどを書くときなどに、この仕様による柔軟性が役立ったりすることは意外と経験しています。
余談ですが、Python3.8以降のバージョンであれば「値は変えられない」挙動をする機能を利用したりもできるようになっています。Python3.7以前のバージョンでも、ライブラリなどを使うことで「値は変えられない」定数の挙動を実現することは可能です。もし必要になった場合には、それらも検討してみてください。
順番を持った色々なデータのかたまり : リスト入門
10個のデータがあった時に、順番の情報を含めて1つにまとめておくとプログラミングで便利なことがあります。
たとえば、そのかたまりに対して一括でなんらかの処理をしたり、平均を出したり、値が低い順に並べ替えたり、コードをコピーしたりすることなく、1つのコードで1つ1つの値に対して処理をしたりと様々です。
そういった時にはPythonのリスト(list)と呼ばれる型のデータを使うと便利です。
リストを使うと任意の複数の値を格納して、ひとかたまりすることができます。
リストは、プログラミングの領域では配列とも呼ばれたりします(英語ではarray)。
厳密にはPythonではlistとarrayがそれぞれ別で存在するのですが、現時点ではリストの方を使うことが大半ので、リスト = 配列くらいに思っていただいても差支えありません。
格納できるものは、数値でも文字列でも、それ以外でも色々格納することができます。
リストの変数を作るには、
[]の括弧を使います。中に値を入れて、複数の値の間に半角のコンマ,の記号を使って書きます。例えば、1, 2, 3という3つの値を格納するリストを作りたい場合には以下のように書きます。
number_list = [1, 2, 3]数値以外の値、例えば文字列なども格納できます。
string_list = ['ミケ', 'タマ', 'ポチ']変数を使ってリストに値を格納することもできます。
cat_name = 'ミケ' dog_name = 'ポチ' varibale_list = [cat_name, dog_name] print(varibale_list)コード実行結果の出力内容:
['ミケ', 'ポチ']
作ったリストの変数には、
[]の括弧を変数の後に付けて、その括弧の中に番号を指定するとリストの中の値にアクセスすることができます。括弧の中に指定する番号は0からスタートします。リストの先頭の値であれば0、その次の値であれば1、さらにその次の値では2...といった具合です。1からスタートするわけではないので注意してください。
string_list = ['ミケ', 'タマ', 'ポチ'] print(string_list[0])コード実行結果の出力内容:
ミケ
print(string_list[1])コード実行結果の出力内容:
タマ
print(string_list[2])コード実行結果の出力内容:
ポチ
この
[]の中に指定する番号のことをインデックスと呼びます(英語だとindex)。リストの件数を超えるインデックスを指定するとエラーになります。3件のデータのリストであれば2を超えるインデックスを指定するとエラーになります。インデックスは0からスタートするため、
件数 - 1のインデックスまで指定することができます。データの件数以上のインデックス番号を指定するとエラーになります。
string_list = ['ミケ', 'タマ', 'ポチ'] string_list[3]IndexError Traceback (most recent call last) <ipython-input-75-9c0019cfd088> in <module> 1 string_list = ['ミケ', 'タマ', 'ポチ'] ----> 2 string_list[3] IndexError: list index out of range
list index out of rangeというエラーメッセージになっています。「リストに指定されたインデックスが範囲外ですよ」といったような意味になります。3件のリストなので、0~2までしかインデックスが指定できないので、3を指定しているためにout of rangeとなっているわけです。リストで最後から順番に値にアクセスするには?
前のセクションで、0, 1, 2...と順番にインデックスでリストの値にアクセスできることを確認しました。
では、リストの最後から順番にアクセスしたい時にはどうすればいいのでしょうか?
やり方はいくつかありますが、手段の一つとしてマイナスのインデックスを使うという方法があります。
インデックスに
-1を指定すると、「リストの最後の値」にアクセスすることができます。また、
-2を指定すると「最後から2番目の値」、-3とすると「最後から3番目の値」にアクセスすることができます。string_list = ['ミケ', 'タマ', 'ポチ'] print(string_list[-1])コード実行結果の出力内容:
ポチ
print(string_list[-2])コード実行結果の出力内容:
タマ
print(string_list[-3])コード実行結果の出力内容:
ミケ
通常の正のインデックス(0, 1, 2など)を指定していたときと同様、インデックスの範囲を超えてしまうと同じエラーになります。
リストの値が3つだけなので、-1, -2, -3まではエラーなく使えますが、-4を指定するとエラーになってしまいます。string_list[-4]IndexError Traceback (most recent call last) <ipython-input-85-1ab74fd28c19> in <module> ----> 1 string_list[-4] IndexError: list index out of rangeリストで特定の範囲の値にアクセスする
今まではリストで特定の1つのインデックスの値にアクセスしてきました。
では、「2番目以降」とか「3番目まで」とか、「2番目~3番目の範囲」といった、リストで特定の範囲の部分を抽出したい場合はどうすればいいのでしょうか。
こういった場合には、インデックスを指定する際に、半角のコロンの
:の記号を使うことで対応することができます。いくつかパターンがあるので、一つ一つ触れていきます。なお、この特定の範囲だけをリストか抽出することをスライス(英語でslice)と呼びます。
〇未満のインデックスという条件で抽出する
〇未満のインデックスという条件、たとえばインデックスが2未満の部分をリストから抽出したい場合には、コロンの記号を使って
[:2]といったように書くことで実現できます。
[:2]といったように書いた場合、抽出されるのは0と1のインデックスの2件です。以下のサンプルコードで確認してみると、先頭のインデックス(
0)のミケとその次のインデックス(1)のタマの2つが抽出されていることが分かります。string_list = ['ミケ', 'タマ', 'ポチ', 'ピーター'] print(string_list[:2])コード実行結果の出力内容:
['ミケ', 'タマ']
〇以上のインデックスという条件で抽出する
〇以上のインデックスという条件、たとえばインデックスが2以上の部分をリストから抽出したい場合には、コロンの記号を使って
[2:]といったように書くことで実現できます。未満の条件の時と比べて、数字とコロンの記号の位置が変わっていることに注意してください。以下のサンプルコードで確認してみると、3番目の位置(
2のインデックス)のポチと4番目の位置(3のインデックス)のピーターの2つが抽出されていることが確認できます。string_list = ['ミケ', 'タマ', 'ポチ', 'ピーター'] print(string_list[2:])コード実行結果の出力内容:
['ポチ', 'ピーター']
〇以上×以下のインデックスという条件で抽出する
〇以上×未満のインデックスという条件、たとえばインデックスが1以上3未満という範囲でリストから抽出したい場合には、コロンの記号を使って
[1:3]といったように書きます。コロンの両側に数値が必要になります。以下のサンプルでは、先頭と末尾の要素は含まれずに、真ん中に位置している
タマとポチという部分が抽出されていることが確認できます。string_list = ['ミケ', 'タマ', 'ポチ', 'ピーター'] print(string_list[1:3])コード実行結果の出力内容:
['タマ', 'ポチ']
リストを作る時に改行を入れる
リストの変数などを作る時に、設定する値が多くなるとひたすら横に長くなってしまいます。
前のセクションで触れたように、Pythonのコーディング規約では1行に半角で79文字までに納めるという規則もあり、あまり横に長くなりすぎると横スクロールが必要になって読みづらくなったりします。
そのため、リストの値が多くなってきたら値ごとなどで改行を入れると横スクロールなどが不要になって読みやすくなります。例えば以下のように書きます。
string_list = [ 'ミケ', 'タマ', 'ポチ', 'ピーター', 'きなこ', 'マロン', ]最後の値の
'マロン',という行に注目してみます。値の後に半角コンマの,の記号が入っていますが、このような最後の値の後のコンマはPythonではあっても無くてもどちらでもエラーにはなりません。以下のように最後の値の後のコンマを省いても同じ挙動をします(
'マロン'という値の部分で、半角のコンマが省略されている点に注目してください)。string_list = [ 'ミケ', 'きなこ', 'マロン' ]最後の値の後に半角のコンマがあっても無くてもプログラム上は問題は無いのですが、リストに将来値を追加する時などに、最後に値を追加すると直前の値は最後の行では無くなるので、コンマの追加が必要になります。
例えば以下のように文字列のリストで最後に値を追加した際に、コンマを追加し忘れてしまったとします。そうするとどうなるでしょう?
string_list = [ 'ミケ', 'きなこ', 'マロン' 'ポチ' ] print(string_list)コード実行結果の出力内容:
['ミケ', 'きなこ', 'マロンポチ']
printで出力される内容が、
'マロン'と'ポチ'が一緒になってしまいました。一体何が起きているのでしょう?少し前のセクションで触れた、文字列の連結のものを思い出してみてください。
クォーテーションを分割して、連続して文字列を定義することで、Python上では1つの文字列となり、改行などが入れれて長い文字列で便利といったことを説明しました。
また、
()の括弧を使うと、行の末尾でエスケープ用の\が無くても改行ができるとも説明しました。そのような文字列の挙動が、リストを作るときにコンマが足りていないことによって発生してしまっています。つまり、コンマが無いことによってPythonが「これは1つの文字列だ」と判断してしまって、
'マロン'と'ポチ'を連結してしまっているわけです。こういったケースでは、エラーなども出ずに気づきにくいので注意が必要です。そのため、個人的にはリストなどで改行を入れて扱う場合には、「値の行の最後に必ずコンマを入れる」という書き方をすることが多いです。少し前で触れた以下のサンプルコードのような感じですね。
string_list = [ 'ミケ', 'タマ', 'ポチ', 'ピーター', 'きなこ', 'マロン', ]このように最後の値の後にもコンマを入れる形で、全ての値に対して同じように書くことでコンマの追加漏れなどによるうっかりミスを避けることができます。
補足ですが、文字列など一部を除いて、例えば整数や変数などをリストに使った場合には以下のようにエラーになるので、こちらは比較的コンマ漏れなどには気づきやすくなっています。
int_list = [ 1, 2, 3 4 ]File "<ipython-input-105-6d665419c4f6>", line 5 4 ^ SyntaxError: invalid syntax以下のようにリストの4の部分がおかしいとPythonがエラーメッセージが教えてくれています。
4 ^エラーメッセージで示されている箇所の前後でなんらかおかしいところがある、ということなので、こういったエラーが出た際には前後のコードを確認してみてください(今回は「4の前にコンマなどが無いとおかしい」というケースになります)。
変数などを使ったリストでも同様です。
one_var = 1 two_var = 2 three_var = 3 variable_list = [ one_var, two_var three_var ]File "<ipython-input-111-997c24591ae1>", line 8 three_var ^ SyntaxError: invalid syntaxもう一点補足となりますが、必ずしも値ごとに改行をしなくても元々の目的であった1行が長くなりすぎるという点は解決できます。例えば、以下のように1行に値を数件程度、あまり長くならない程度に任意の件数設定するのは問題ありません。
string_list = [ 'ミケ', 'タマ', 'ポチ', 'ピーター', 'きなこ', 'マロン', ]名前付きのデータの集まり : 辞書入門
東京都に住んでいる方の中で、特定の住所に住んでいる方の情報が必要になった、みたいなケースが発生したとしましょう。
このセクションを書いている時点では、東京都の人口は1000万人を超えています。これをリストのデータを使って、1件1件探す・・・みたいなことを人力でするととても大変です。コンピューターを使っても、工夫しないと時間がかかってしまいます。
一方で、〇〇の住所はAさん、××の住所はBさん、△△の住所はCさん・・・といったデータがあるとどうでしょう?
住所さえ分かればそこに住んでいる方が一発で分かるので、値を探す必要が無くなります。すぐに処理が終わりそうですね。
Pythonの辞書という機能は、この「住所からそこの住人の情報を得る」みたいなプログラムを書くときに便利です。英語ではそのままdictionaryです。
名前の由来になっている辞書で、英語の紙の辞書を考えてみましょう。もう長いこと、スマホや電子辞書などでほとんど使う機会が無くなっているので、馴染みがあまり無い方も多いかもしれませんが・・・。
紙の辞書では、例えば
catという単語を調べるとき、「C」のページ部分を開いて単語を探していく・・・といったように扱います。Pythonのプログラミングでも同じように、辞書の機能では「なんらかの文字列」を参照して「該当する値」にアクセスするような挙動をします。
プログラムで書くときには、半角の
{と}の括弧を使います。この記号は日本語だと波括弧、英語だとcurly bracketなどと呼ばれます。また、半角のコロンの
:記号で区切り、左側にキー(英語でkey)と呼ばれる値、右側に該当する値(英語でvalue)を設定して、{'key': value}といったように書きます。コロンの左側にはスペースを入れず、右側には半角のスペースを入れるのが一般的です。左側のキーは、前の説明で言うと「住所」や「辞書のC」といった部分が該当します。右側の値は、住人の情報やcatという英単語の情報、といった具合です。
辞書のキー(左側)に日本語の国名、値(右側)に英語の国名を格納する辞書をサンプルとして作ってみます。コードでは以下のように書きます。
country_name_dict = {'日本': 'Japan'}1つの辞書に、複数のキーと値を設定することもできます。先ほどの辞書に、日本だけでなくアメリカのキーと値を追加してみます。追加するには、半角のコンマの
,の記号を値の後に置いて区切り、別のキーと値を配置します。country_name_dict = {'日本': 'Japan', 'アメリカ': 'United States of America'}辞書に格納されているデータにアクセスするには、
['キー名']といったように変数の後に記述します。たとえば、先ほど作った辞書で
日本というキーの値にアクセスしたい場合には以下のようにcountry_name_dict['日本']と書きます。print(country_name_dict['日本'])コード実行結果の出力内容:
Japan
日本というキーにアクセスすると、該当する値のJapanが取得できていることが分かります。他のキーでも同様です。アメリカのキーにアクセスするには以下のようになります。
print(country_name_dict['アメリカ'])コード実行結果の出力内容:
United States of America
辞書のキーには以下のコードのように変数や定数などを使うことができます。
NAME_KEY = 'name' AGE_KEY = 'age' cat_info_dict = {NAME_KEY: 'タマ', AGE_KEY: 7} print(cat_info_dict)コード実行結果の出力内容:
{'name': 'タマ', 'age': 7}
辞書の値の方にも、変数や定数を指定することができます。
cat_name = 'タマ' cat_age = 7 cat_info_dict = {'name': cat_name, 'age': cat_age} print(cat_info_dict)コード実行結果の出力内容:
{'name': 'タマ', 'age': 7}
また、リストのセクションで触れたのと同じように、値が多くなると1行に全部書くと横にとても長くなってしまって読みづらくなるので、キーと値の1セットごとに改行を入れることもできます。
cat_info_dict = { 'name': 'タマ', 'age': 7, 'location': '東京', 'favourite': 'またたび', }Pythonとインデントの話
リストや辞書のセクションで、説明を入れていませんでしたが改行を入れた時に以下のように値の前に半角のスペースを入れていました。
int_list = [ 1, 2, 3, 4, ]以下のように、Pythonのプログラム自体はスペースを入れなくても動きます。
int_list = [ 1, 2, 3, 4, ]スペースを入れなくてもプログラムは動くのに、何故半角のスペースを入れているのでしょう?
理由の1つとして、「コードが読みやすくなる」という点が上げられます。
プログラムなどでは、よくコードの構造の階層を表すためにスペースなどが使われます。
コードの構造の階層と言ってもいまいちピンと来ないかもしれないため、フォルダで例えてみましょう。
「フォルダ1」というフォルダの中に「フォルダ2」というフォルダが入っていて、さらにそのフォルダ2の中に「フォルダ3」というフォルダが格納されているとします。
Windowsなどでフォルダを開いたときのエクスプローラーで見てみると、場所の表示が
フォルダ1 > フォルダ2 > フォルダ3といったように表示され、各フォルダの階層が一目で分かるようになっています。もしくは、エクスプローラーなどの左のメニューで、以下のように階層が表示されるのも馴染みがあるかもしれません。
フォルダ1 └ フォルダ2 └ フォルダ3どちらの表示でも、一目で階層がどうなっているのかが分かり、且つ右にいく程階層が深くなっているというのは分かります。
リストや辞書などのインデントも同じように階層的に考えることができます。
例として以下のコードで考えてみます。
int_list = [ 1, 2, 3, 4, ]フォルダ的に考えると、
int_listという変数>int_list内の値といった形で表現できます。このようにプログラムでインデントを使うことで、右に行くほど階層の深いコードを表すことができ、ぱっと見でどういったプログラムになっているのかが把握しやすくなります。
こういった「コードの把握のしやすさ」や「コードの読みやすさ」のことを「可読性」などと呼んだりしますが、コードを書く上ではこの可読性がとても大切になってきます。特に仕事などでは複数人で一緒にコードを書いたりするため、読みにくいコードを書いてしまうと他の人に迷惑をかけてしまいます。また、自分で何か月も後に読み返すときなども読みづらいコードになっていると苦労します。
インデントをうまく使っていくことで読みやすいコードを書くことに役立ちますので、最初は些細なことに思えるかもしれませんが、重要なことなんだな、と心の片隅に置いておいてください。
なお、リストや辞書の部分では前述のコードのようにインデントを省いても動きます。一方で、Pythonではインデントが意味を持つケースが多くあります。そういったケースではインデントを省いたり間違えたりするとエラーになったり変な挙動になったりします。その辺りのことは後々の章で詳しく説明します。
Pythonのインデントの基本
一般的に、インデントは半角スペース2個、半角スペース4個、Tabの3つがよく使われます。どれが使われるかは、プログラム言語やプロジェクトのルールによって様々です。
しかしPythonでは、以下のようにPython自体のコーディング規約で「半角スペース4個」と定められており、ほとんどのPythonのプロジェクトでも半角のスペース4個が使われます。そのため、特に理由がなければ半角のスペース4個でインデントを表現しましょう。
1レベルインデントするごとに、スペースを4つ使いましょう。
...
スペースが好ましいインデントの方法です。
タブを使うのは、既にタブでインデントされているコードと一貫性を保つためだけです。
Python 3 では、インデントにタブとスペースを混ぜることを禁止しています。
Python コードのスタイルガイドJupyterなどでも、デフォルトではTabキーを押した時に挿入されるインデントは半角スペース4個になっていますので、大体のケースではTabキーを押しておけば問題はありません。Jupyter以外のエディタを使うときなどには設定が半角スペース4個以外になっていないか注意してください。
半角スペース4個以外になるケースもあります。
基本的にはインデントは半角スペース4個で設定します。しかし、「読みやすさのために上の要素と位置を合わせる」ために4個以上のインデントを入れるケースがあります。
例えば、以下のようなコードのケースが対象となります。本書をお読みの端末のフォント次第でスペースがずれてしまったりする可能性があるので、画像で表示しています。
2重のリスト(リストの中にリストが入っている)構成になりますが、
[1, 2, 3]の上の方に位置しているリストと、その下に続いている[4, 5, 6]や[7, 8, 9]のリストの位置を合わせています。インデントはスペース4つではなく、多くのスペースを使用しています。何故このようになっているのでしょうか?疑問の解決のために、前のセクションで触れたフォルダ階層の例を思い出してみましょう。
ルールとしては、右にいくほど階層が深くなる、というものです。プログラムであればスペースのインデントが増えるほど構造が深い階層のものになっていきます。
先ほどの画像と異なり、上(
[1, 2, 3])のリストと位置を合わせていない以下のコードを考えてみます。int_list = [[1, 2, 3], [4, 5, 6], [7, 8, 9], ]プログラムでその階層のルール(右にいく程階層が深いというルール)に従うと、
[1, 2, 3]もその下の[4, 5, 6]といった値も、int_listという変数 -> その中のリスト -> さらにその中に格納されたリストという階層になっているので、両方同じインデントじゃないとおかしくなります。しかし上記のコードでは、
[1, 2, 3]のリストが[4, 5, 6]や[7, 8, 9]といったリスト部分よりも右に来ています。プログラム上の階層としては同じ位置にある値なのに、このようにインデントの位置がずれているのは好ましくありません(誤解の元になってしまいます)。そのため、こういったケースでは4つのスペースによるインデントではなく「上の要素に位置を合わせる」形のインデントが設定される形になります。
このようなインデントにするというルールは、Python自体のコーディング規約でも以下のように定められています。
行を継続する場合は、折り返された要素を縦に揃えるようにすべきです。
Python コードのスタイルガイドまた、Jupyterでもそちらのルールに合わせるようにインデントが入るようになっています。
例えばJupyter上で以下のようなコードの
2の直前にカーソルを合わせてEnterキーを押して改行を入れてみてください。int_list = [1, 2]以下の画像のように
2が1と同じ位置になるように、インデントが自動で設定されると思います。
Python自体のコーディング規約でも定められていますし、Jupyterなどのライブラリやツールなどの挙動もそちらに合うようにされています。そのため特に理由がなければこれらのインデントのルールに合わせるようにしましょう。
先ほどのケースでも4つのインデントでコードを書きたいときは?
先ほどのセクションで触れた上記のコードに関して、もし4つのインデントでコードを書きたい場合にはどうすればいいのでしょうか?
答えは、「合わせるべき上の要素も改行などを入れて普通のインデントの位置にする」という書き方です。
以下のコードのように、
[1, 2, 3]のリスト部分の前に改行を入れて、そこにスペース4つのインデントを設定すれば、[1, 2, 3]や[4, 5, 6]などの各リストのインデントの位置を合わせつつ、4つのスペースによるインデントを設定することができます。int_list = [ [1, 2, 3], [4, 5, 6], [7, 8, 9], ]リストに似ているけど、中身が変えられない : タプル入門
リストと同じように値を順番に格納し、値のインデックスなどによる参照ができる型でタプルというものがあります(英語でtupleとなります)。
タプルは半角の
(と)の括弧を使うことで作成することができます。tuple_value = (10, 15, 18) print(tuple_value)コード実行結果の出力内容:
(10, 15, 18)
値の参照はリストのようにインデックスで
[1]といったような括弧と番号を指定することで対応することができます。tuple_value = (10, 15, 18) print(tuple_value[1])コード実行結果の出力内容:
15
リストと比べて何が違うんだ?という感じですが、タプルは格納する値を変更することができないという特徴があります。
例えばリストであれば,以下のように設定した値を途中で変更することができます(コードでは0~2までのインデックスで3つの値を格納したリストを作り、その後に真ん中の1のインデックスの値を16に変更しています)。
age_list = [10, 15, 18] age_list[1] = 16 print(age_list)コード実行結果の出力内容:
[10, 16, 18]
一方でタプルでは前述のコードのように値を変更することができません。
以下のように特定のインデックスに値を設定しようとするとエラーになります。
tuple_value = (10, 15, 18) tuple_value[1] = 16TypeError: 'tuple' object does not support item assignmentタプル(tuple)は要素の割り当て(assignment)をサポートしていません、といったようなエラーメッセージになります。
もう一つのタプルの特徴として、「
(と)の括弧は省略ができる」という点があります。つまりコンマだけでタプルを作ることができます。以下のコードのように、
10, 20と括弧を省略した形でコードを書いてもtype()で確認できる型はタプル(tuple)になっていることが確認できます。tuple_value = 10, 20 print(tuple_value) print(type(tuple_value))コード実行結果の出力内容:
(10, 20) <class 'tuple'>
さらに加えて、タプルを使って複数の変数に同時に値を割り振ったりすることもできます(リストでも同様のことはできます)。
以下のコードではイコールの記号の右側にタプルの値を設定し、左側には2つの変数(value_1とvalue_2)に対して値を設定しています。内容を出力してみると、それぞれの変数にタプルに設定されていた値(100と200)が反映されていることが確認できます。
tuple_value = (100, 200) value_1, value_2 = tuple_value print(value_1) print(value_2)コード実行結果の出力内容:
100 200
リストと比べてどういった時にタプルは必要になるのかといった点ですが、基本的には普段使うのはほぼほぼリストで問題はありません。ただ、コンマのみでタプルを作れる点とPythonでコンマを使った書き方は多用するため、意識しなくても自然とタプルを使うケースが結構発生します。
例えば後々の章で触れる関数の返却値と呼ばれるもので、複数の返却値を設定する場合にはコンマを使うため内容はタプルになっていたりします。同様に後々出てくる引数と呼ばれるものでもタプルが絡んできたりします。
その他にも辞書などには以下のコードのようにキーに複数の値を設定できますが、その際にはコンマを指定しているためキーにタプルが使用されていることになります。
data_dict = {} data_dict['apple', 10] = 100リストと比べると影が薄くなりがちなタプルですが、このようにPythonでコードを書いていると自然とタプルを利用しているケースがたくさんあります。目立たない存在ですが縁の下の力持ちのような型になります。
本章の演習問題 その1
[1]. 以下のようなコードを書いたところ、エラーになってしまいました。なにが問題なのでしょう?
1 + 1File "<ipython-input-120-40ba61a5ceee>", line 1 1 + 1 ^ SyntaxError: invalid character in identifier[2]. Pythonで5と10の足し算を計算してみて、結果が15になるコードを書いてみてください。
[3]. Pythonで10から5を引く(引き算の)計算をしてみて、結果が5になるコードを書いてみてください。
[4]. Pythonで5の4倍の掛け算を計算してみて、結果が20になるコードを書いてみてください。
[5]. Pythonで10を5で割る計算をしてみて、結果が2になるコードを書いてみてください。
[6]. Pythonで10を4で割った時を余りを計算してみて、結果が2になるコードを書いてみてください。
[7]. Pythonで2の3乗を計算してみて、結果が8になるコードを書いてみてください。
※答案例は次のページにあります。
演習問題その1の答案例
[1]. プラスの記号に全角記号(
+)が使われています。Pythonで必要な各記号は半角の記号(プラスであれば+)が必要です。記号以外にも、スペースなども全角が入っているとエラーになったりします。注意してください。
[2]. 足し算では半角のプラスの
+の記号を使います。5 + 10コード実行結果の出力内容:
15
[3]. 引き算では半角のマイナスの
-の記号を使います。10 - 5コード実行結果の出力内容:
5
[4]. 掛け算では半角のアスタリスクの
*の記号を使います。5 * 4コード実行結果の出力内容:
20
[5]. 割り算では半角のスラッシュの
/の記号を使います。10 / 5コード実行結果の出力内容:
2.0
[6]. 余り(剰余)を求めるには半角のパーセントの
%の記号を使います。10 % 4コード実行結果の出力内容:
2
[7]. 累乗を計算するには、半角のアスタリスクの
*の記号を二つ連続して記述します。2 ** 3コード実行結果の出力内容:
8
本章の演習問題 その2
[1]. 値は7で、「猫の年齢」を示す変数を作ってみましょう。
[2]. 作った変数の内容を表示してみましょう。
[3]. 数値の変数に対して、現在の変数の値に対して足し算・引き算・掛け算・割り算をしてみましょう。足し算などで設定する数値はなんでも構いません。
※答案例は次のページにあります。
演習問題その2の答案例
[1]. 変数は半角英数字(ただし、先頭に数字は使えません)と一部記号が設定できます。単語間は半角のアンダースコアの
_の記号を使って作ります。変数名は以下ではcat_ageとしましたが、他のものでも意味が伝わりやすい変数名であれば問題ありません。cat_age = 7[2]. 変数の内容を確認するには、
print(変数)といったように書きます。括弧などは全て半角です。もしくは、Jupyterなどであればセル内で変数のみを記述したり、セルの末端であればprintの記述を省略することもできます。cat_age = 7 print(cat_age)コード実行結果の出力内容:
7
[3]. 現在の値に対する計算を行うには、足し算であれば
+=、引き算であれば-=、掛け算であれば*=、割り算であれば/=を使います。足し算の例 :
cat_age = 7 cat_age += 2 print(cat_age)コード実行結果の出力内容:
9
引き算の例 :
cat_age = 7 cat_age -= 4 print(cat_age)コード実行結果の出力内容:
3
掛け算の例 :
cat_age = 7 cat_age *= 3 print(cat_age)コード実行結果の出力内容:
21
割り算の例 :
price = 300 price /= 3 print(price)コード実行結果の出力内容:
100.0
※それぞれ以下のように、記述は長くなりますが変数を2回書く形でも間違いではありません。
cat_age = 7 cat_age = cat_age + 2 print(cat_age)コード実行結果の出力内容:
9
本章の演習問題 その3
[1]. 小数を含んだ変数を作ってみてください。値はなんでも構いません。
[2]. 文字列の変数を作ってみてください。値はなんでも構いません。
[3]. 二つの文字列の変数を作って、それぞれの文字列を連結して1つの変数を作ってみてください。
[4]. 以下の文章を、横に長くなりすぎないようにしつつ文字列の変数に設定してみてください。
どこで生れたかとんと見当がつかぬ。何でも薄暗いじめじめした所でニャーニャー泣いていた事だけは記憶している。吾輩はここで始めて人間というものを見た。しかもあとで聞くとそれは書生という人間中で一番獰悪な種族であったそうだ。[5].
猫という文字を10回繰り返した変数を作ってみてください。ただし、直接10回繰り返した文字列を指定する(例 :猫猫猫...)以外の方法で対応してください。※答案例は次のページにあります。
演習問題その3の答案例
[1]. 小数を含んだ値(浮動小数点数 : float)を作るには、半角のドットの記号
.を使います。tax = 1.1[2]. 文字列の変数を作るには、シングルクォーテーションの記号
'もしくはダブルクォーテーションの記号"を使って文字列を囲みます。シングルクォーテーションを使う例 :
cat_name = 'タマ'ダブルクォーテーションを使う例 :
cat_name = "タマ"[3]. 文字列の変数同士を連結するには、足し算の時にも使った半角のプラスの記号
+を使います。cat_name = 'タマ' dog_name = 'ポチ' concatenated_str = cat_name + dog_name print(concatenated_str)コード実行結果の出力内容:
タマポチ
[4]. いくつかやり方があります。1つ目として、行末にエスケープのための半角のバックスラッシュ(円記号)の
\を設定し、クォーテーションを分ける方法があります。long_str = 'どこで生れたかとんと見当がつかぬ。'\ '何でも薄暗いじめじめした所でニャーニャー'\ '泣いていた事だけは記憶している。'\ '吾輩はここで始めて人間というものを見た。'\ 'しかもあとで聞くとそれは書生という人間中で'\ '一番獰悪な種族であったそうだ。'2つ目として、
()の括弧を使い、エスケープの記号を省略して書く方法です。long_str = ( 'どこで生れたかとんと見当がつかぬ。' '何でも薄暗いじめじめした所でニャーニャー' '泣いていた事だけは記憶している。' '吾輩はここで始めて人間というものを見た。' 'しかもあとで聞くとそれは書生という人間中で' '一番獰悪な種族であったそうだ。' )※他にも複数の方法が存在します。同じ結果を実現できるのであれば、それらの方法でも問題ありません。
[5]. 掛け算のときに使った半角のアスタリスクの記号
*を文字列などに使うと、その文字列の繰り返しが表現できます。cat_str = '猫' * 10 print(cat_str)コード実行結果の出力内容:
猫猫猫猫猫猫猫猫猫猫
本章の演習問題 その4
[1]. 定数を、定数名の一般的なルールに従って作ってみてください。値や定数名は好きな値で問題ありません。
[2]. 数値を10個格納したリストの変数を作ってみてください。数値はなんでも構いません。
[3]. [2]で作ったリストから、リストの2番目の値を表示してみてください。
[4]. [2]で作ったリストから、リストの最後の値を表示してみてください。
[5]. [2]で作ったリストから、リストで2番目~3番目の値のみを抽出してみてください(スライスを使ってください)。
[6]. 猫の名前と猫の歳の値を格納する辞書を作ってみてください。
[7]. [6]で作った辞書の、猫の歳の値を表示してみてください。
演習問題その4の答案例
[1]. 定数名は、半角の英数字で、単語間を半角のアンダースコアの
_の記号で繋ぐ形で定義します。定数名の先頭には数字は利用できません。CAT_NAME = 'タマ'[2]. リストを作るには、
[と]の括弧の記号を使います。値の間には半角のコンマを設定します。ages = [4, 6, 1, 3, 9, 7, 4, 3, 8, 0][3]. 2番目の値にアクセスするには、
[1]といったように括弧内に数字(インデックス)を入れてアクセスします。インデックスは0からスタートするので、「2番目の値」にアクセスする場合には[2]ではなく[1]となります。ages = [4, 6, 1, 3, 9, 7, 4, 3, 8, 0] print(ages[1])コード実行結果の出力内容:
6
[4]. リストの最後の値にアクセスするにはインデックスに
-1を指定します。ages = [4, 6, 1, 3, 9, 7, 4, 3, 8, 0] print(ages[-1])コード実行結果の出力内容:
0
[5]. リスト内で特定のインデックス範囲の値を抽出するにはスライスという、半角のコロン
:と数値を使います。コロンの左側の数字は「〇のインデックス以降」を表し、コロンの右側の数字は「×のインデックス未満」を表します。問題の「2番目~3番目」の値が必要な場合には、インデックスは0からスタートするので、「1のインデックス以降」~「3のインデックス未満」として[1:3]という指定が必要になります。以下のサンプルでは、2番目の6と3番目の1という値が抽出できています。
ages = [4, 6, 1, 3, 9, 7, 4, 3, 8, 0] print(ages[1:3])コード実行結果の出力内容:
[6, 1]
[6]. 辞書を作るには半角の
{と}の括弧を使います。左側にキー(名前)、間に半角のコロン:、右側に値を設定します。複数のキーと値を設定するには、値の後に半角のコロンの,の記号が必要になります。キーと値のセットごとに改行を入れたりすると、見やすくなったり1行にひたすら長くなってしまったりを避けられます。cat_info_dict = { 'cat_name': 'タマ', 'cat_age': 10, }[7]. 辞書内の特定の値にアクセスするには、
[キー名]といったように括弧と文字列や数値など(数値や文字列の変数でも可)を指定します。問題では猫の歳の値にアクセスしたいので、['cat_age']という形で値にアクセスしています。cat_info_dict = { 'cat_name': 'タマ', 'cat_age': 10, } print(cat_info_dict['cat_age'])コード実行結果の出力内容:
10
本章の演習問題 その5
[1]. 以下の辞書を作るコードはエラーになります。どこがいけないのでしょう?
cat_info_dict = { 'cat_name': 'タマ' 'cat_age': 10 }エラー内容 :
File "<ipython-input-1-b77443bd7b07>", line 3 'cat_age': 10 ^ SyntaxError: invalid syntax[2]. 同様に、以下の辞書を作るコードもエラーになります。どこがいけないのでしょう?
dog_info_dict = { dog_name: 'ポチ', dog_age: 7, }エラー内容 :
NameError Traceback (most recent call last) <ipython-input-2-e524f90796d3> in <module> 1 dog_info_dict = { ----> 2 dog_name: 'ポチ', 3 dog_age: 7, 4 } NameError: name 'dog_name' is not defined[3]. 以下の文字列を作るコードでもエラーとなります。どこがいけないのでしょう?
text = 'どこで生れたかとんと見当がつかぬ。' '何でも薄暗いじめじめした所でニャーニャー' '泣いていた事だけは記憶している。'File "<ipython-input-3-aa4cdfafbfa7>", line 2 '何でも薄暗いじめじめした所でニャーニャー' ^ IndentationError: unexpected indent演習問題その5の答案例
[1]. 複数のキーと値のセットを持つ辞書になっていますが、それらの間にコンマがありません。以下のように、キーと値のセットの間(
'タマ'部分の直後)に半角のコンマを入れることで解決することができます。cat_info_dict = { 'cat_name': 'タマ', 'cat_age': 10 }最後の値の後(今回の例では
10の後)にコンマを入れるかどうかは任意です。入れ忘れないように、毎回入れるようにするというのも好ましい書き方になります。[2]. 辞書のキーの部分(今回の例では
dog_nameやdog_ageの部分)には、文字列や数値などを指定する必要があります。文字列で指定するには半角のクォーテーションで囲む必要があります('や"などの記号)。クォーテーションで囲んでいないと、Pythonが対象のキー部分が変数だと認識してしまいます。一方で、
dog_nameなどの変数は今回は定義していない(作っていない)ので、「'dog_name'という変数が定義されていませんよ」というエラーメッセージとしてNameError: name 'dog_name' is not definedという内容が表示されています。クォーテーションで囲んでエラーが出ないように書くと以下のようになります。
dog_info_dict = { 'dog_name': 'ポチ', 'dog_age': 7, }また、変数が事前に定義されていれば、辞書のキーに変数を使うことも問題ありません。
key = 'dog_name' dog_info_dict = { key: 'ポチ', } print(dog_info_dict)[3]. 文字列でクォーテーションを分けて改行を入れたい場合には、行末にエスケープの記号の半角のバックスラッシュの
\が必要です。以下のように書くとエラーが無くなります。text = 'どこで生れたかとんと見当がつかぬ。'\ '何でも薄暗いじめじめした所でニャーニャー'\ '泣いていた事だけは記憶している。'もしくは、以下のように
(と)の括弧で囲うことで行末のエスケープの記号を省略することもできます。どちらでも問題はなく挙動は変わりません。text = ( 'どこで生れたかとんと見当がつかぬ。' '何でも薄暗いじめじめした所でニャーニャー' '泣いていた事だけは記憶している。' )本章の演習問題 その6
[1]. 以下のコードはPythonのコーディング規約上好ましくない点が含まれています。どういった点でしょうか?
dog_info_dict = { 'name': 'ポチ', }[2]. 以下のコードも同様にPythonのコーディング規約上好ましくない点が含まれています。どういった点でしょうか?
dog_info_dict = {'name': 'ポチ', 'age': 100, }演習問題その6の答案例
[1]. 辞書のキーと値の部分(
'name': 'ポチ',)の前にインデントが入っていません。フォルダ階層の表示のように、dog_info_dictという辞書の変数->その中に入っているキーと値というプログラムの階層を表すために、以下のように半角の4つのスペースでインデントを入れるのが好ましいです。dog_info_dict = { 'name': 'ポチ', }[2].
'name': 'ポチ'という部分と'age': 100という部分はプログラムの階層的に考えると、同じ階層に位置しています(両方とも同じ辞書内のキーと値のセット)。そのため、インデントの位置も合わせるべきです。対応としては以下の「上の要素の位置にインデントを合わせる」方法と「上の要素で改行を入れて、半角のスペース4つに統一する」方法の2つが考えられますが、どちらでも問題はありません。
※閲覧されている端末のフォントによってはずれて表示されてしまうため、画像で表示しています。
上の要素に対して改行を入れて半角スペース4つに統一する方法の例 :
dog_info_dict = { 'name': 'ポチ', 'age': 100, }章のまとめ
- Pythonでは足し算は
+、引き算は-、掛け算は*、割り算は/の記号を使います。- 他の記号もそうですが、これらの記号は半角で全て書く必要があります。うっかり全角で書いてしまうとエラーになってしまいます。初めのうちは半角にすべきところが全角になっていても中々気づけないかもしれません。注意していきましょう。
- 余りを計算するには
%の記号を使います。- 累乗を計算するには
**といったように半角のアスタリスクの記号を2つ連続させた形で使います。- 値が変わるもので、且つ特定の値を任意の名前で保持するものを「変数」と言います。
- 変数に値を設定するには半角のイコールの
=の記号を使います。- 変数の内容を確認する時には
+=や-=といったように、プラスやマイナスなどの記号と一緒にイコールの=の記号を使うことで、「変数の今の値」に対して足し算や引き算、掛け算などを行うことができます。- 数値や文字列など、プログラムには色々な「型」が存在します。型に応じてプログラム上の挙動が変わったり、出来ることが変わってきます。
- 基本的に値を変えない想定の値は定数と言います。名前は大文字とアンダースコアを使って、
CONST_VALUEといったように設定します。- 整数の型は
intと言います。- 浮動小数点数の型は
floatと言います。- 文字列の型は
strと言います。- 文字列を作るには文字をシングルクォーテーションの
'の記号もしくはダブルクォーテーションの"の記号のどちらかで囲む必要があります。- 順番を持った色々なデータのかたまりはリストといい、型は
listになります。- リストの中で特定の範囲の値を抽出する処理はスライスと言います。半角のコロンの
:の記号を使います。- キーと値のセットになったデータを辞書と言います。型は
dictになります。- プログラムの階層構造に応じてインデントを入れてコードを読みやすくします。インデントはPythonでは多くの場合4つの半角スペースでインデントを表現します。
ごく基本的なところを扱う、Pythonの基礎の章はこれで終わりになります。大分長めでしたが、お疲れさまでした・・・!
各所のコード、実際に自分で書いてみて動かして進められていますでしょうか?また、今回の章から演習問題が出てきましたが、実際に考えたりコードを書いてみたりできていますでしょうか?
もしかしたら面倒に思ってコードを書いたりはスキップしてしまっているかもしれませんが、実際にコードを自分で書いてみて動かしてみたり、自分で考えてみたりを繰り返すと、ただ眺めているだけの場合と比べるととても身に付きます。是非コピーペーストなどせずに、自分で手を動かしてみてください。
また、途中でエラーなどでつまづいてしまったり、解決できずに悩んでいた時や、演習問題であまり正解できなかったりする方もいらっしゃるかもしれませんが、そういったものは大して気にしなくて大丈夫です。
それらのつまづきや悩みだったり、演習問題での考える作業は皆さんの糧となります。むしろどんどん悩んで、色々調べてみたり、試行錯誤したり、間違えたりしていきましょう。
また、調べても解決しないところや、本章の内容で分かりづらい記述のところなどは、「分からないことに遭遇したら?」の章で書いたように、Githubで質問のissueの登録などを利用してみてください。
次章からはPythonの「関数」に入門していきます。こちらも本章の内容と同様、基本的なものでとても大事な内容になります。
基礎ばかりであまり面白く無いかもしれませんが、基礎を疎かにすると難しい問題がプログラミングで解きづらくなってしまって、将来余計につまらなくなってしまいます。大切な内容なのでスキップせずに進めていきましょう!
他にもPythonなどを中心に色々記事を書いています。そちらもどうぞ!
今までに投稿した主な記事たち参考文献・参考サイト一覧
※他の章のものも含まれます。
- 学びを結果に変えるアウトプット大全
- 「1日30分」を続けなさい!人生勝利の勉強法55
- 最強のプログラミング勉強法が写経である理由
- Qiitaで記事を公開するときに気を付けるべきマナーについて 〜無断でネットや書籍の内容を丸写しするのはやめよう〜
- AnacondaのJupyter notebookでnbextensionsを使う
- シェル、ターミナル、コンソール、コマンドライン
- Google Colaboratoryの90分セッション切れ対策【自動接続】
- カーネル(英:kernel)とは
- Jupyter Notebookをインストール・設定して勉強ノート作成環境をつくる [Mac]
- トレーサビリティ (流通) - Wikipedia
- 浮動小数点数について本気出して考えてみた
- 固定小数点とは
- PEP8
- グイド・ヴァンロッサム - wikipedia
- Python/関数
- スコープ - Wikipedia
- マジカルナンバー <~人が覚えていられる情報は、3~5個!?~>
- なぜ引数はArgumentと呼ばれるのか
- もう参照渡しとは言わせない
- Effective Python ―Pythonプログラムを改良する59項目
- python 組み込み関数を全て(69個)紹介する
- ビルトイン 【 built-in 】
- 組み込み関数
- Pythonで小数・整数を四捨五入するroundとDecimal.quantize
- 端数処理 - Wikipedia
- Why are reversed and sorted of different types in Python?
- Python format()
- Python, formatで書式変換(0埋め、指数表記、16進数など)
- What are the differences between type() and isinstance()?
- Pythonの組み込み関数all(), any()の使い方




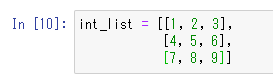
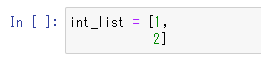
- 投稿日:2020-05-27T12:20:23+09:00
機械学習におけるランダムシードの研究
はじめに
乱数生成のことを考えていたら、気になって眠れなくなってしまったのでまとめてみました。
まずは結論から
機械学習のコードでは、こんな感じの関数を最初に実行することで再現性を持たせることが多い。
seal_seed.pydef fix_seed(seed): # random random.seed(seed) # Numpy np.random.seed(seed) # Pytorch torch.manual_seed(seed) torch.cuda.manual_seed_all(seed) torch.backends.cudnn.deterministic = True # Tensorflow tf.random.set_seed(seed) SEED = 42 fix_seed(SEED)本当にこれで大丈夫か?
Pythonの組み込みモジュールのランダムシード
random --- 擬似乱数を生成する — Python 3.8.3 ドキュメント
random.seed(seed)デフォルトでは現在のシステム時刻が使用されるが、OSによってはOS固有の乱数発生源が用意されている。
メルセンヌ・ツイスタという擬似乱数生成器が使われている。
Numpyのシード固定
Numpyの乱数生成は実行するたびに異なるシードが使われるので注意が必要。
import numpy as np np.random.seed(42) # 一回目 print(np.random.randint(0, 1000, 10)) # -> [102 435 860 270 106 71 700 20 614 121] # 二回目 print(np.random.randint(0, 1000, 10)) # -> [466 214 330 458 87 372 99 871 663 130]固定したければ、その都度シードを設定する。
import numpy as np np.random.seed(42) # 一回目 print(np.random.randint(0, 1000, 10)) # -> [102 435 860 270 106 71 700 20 614 121] # 二回目 np.random.seed(42) print(np.random.randint(0, 1000, 10)) # -> [102 435 860 270 106 71 700 20 614 121]Numpyを利用したライブラリ
np.random.seed(42)で基本的には大丈夫だが、外部モジュールでもシード固定している場合は注意が必要。外部モジュール内でnp.random.seed(43)のように上書きしてしまうと、呼び出した方のseedも上書きされてしまう。OptunaやPandasなどのライブラリではそれを考慮して
numpy.random.RandomStateで乱数生成クラスを改めて用意している。
そのためnp.random.seed(42) ''' なんかの処理 ''' df.sample(frac=0.5, replace=True, random_state=43)としても、numpyのseedが43に上書きされることはない。
s = pd.Series(np.arange(100)) np.random.seed(42) # 初回は42で実行される print(s.sample(n=3)) # -> (83, 53, 70) # 二回目は別の乱数シードが適用される print(s.sample(n=3)) # -> (79, 37, 65) print(s.sample(n=3, random_state=42)) # -> (83, 53, 70) print(s.sample(n=3, random_state=42)) # -> (83, 53, 70)さらにNumpyと同様に、二回目以降はseedが固定されていないので注意。変数に保存しておくか、その都度random_stateの値を設定する。
jupyterノートブックやGoogleColabのように何回実行しても呼び出し回数が同じであれば、最初に一回
np.random.seed(42)としておけば再現性は保たれる。ただ、後述のようにGPUを利用している場合は微妙に再現性が保たれない可能性もあるので、注意が必要。
Scikit-learnのシード固定
Scikit-learnのtrain_test_split関数などで
random_stateを指定することができるが、Scikit-learn全体で固定する方法は提供されていない。X_train, X_test, Y_train, Y_test = train_test_split(X, Y, random_state=SEED)How to set the global random_state in Scikit Learn | Bartosz Mikulski
上記リンクによると、Numpyのランダムシードを固定すれば大丈夫とのことだが、二回目以降はsplitを実行するたびに結果が変わってしまうので注意。
Optunaのシード固定
How can I obtain reproducible optimization results?
sampler = TPESampler(seed=SEED) # Make the sampler behave in a deterministic way. study = optuna.create_study(sampler=sampler) study.optimize(objective)Optuna内では別のRandomStateインスタンスが用意されるのでseedを指定することが可能。内部ではRandomStateを利用している。
LightGBMでのシード固定
Cross-Validationを使う場合は
lgb.cv(lgbm_params, lgb_train, early_stopping_rounds=10, nfold=5, shuffle=True, seed=42, callbacks=callbacks, )のように設定できる。
マニュアルにはSeed used to generate the folds (passed to numpy.random.seed)
と書いてあるので「あ!これはseedが書き換えられてしまうやつか?」と思うかもしれないが、ソースコードをみると
randidx = np.random.RandomState(seed).permutation(num_data)
となっていたので大丈夫そうだ。また、Scikit-learn APIを使う場合は
clf = lgb.LGBMClassifier(random_state=42)のように設定できる。
マニュアルによると、設定しない場合はC++のデフォルトシードが使われると記載してある。
If None, default seeds in C++ code are used.
C++のデフォルトシードがどうなっているのか気になりだすとキリがないのでここら辺でやめておく。
PyTorchのシード固定
Reproducibility — PyTorch 1.5.0 documentation
torch.manual_seed(seed) # cuDNN用 torch.backends.cudnn.deterministic = True torch.backends.cudnn.benchmark = False
torch.cuda.manual_seed_all(seed)というメソッドがあるが、最新のPytorchではtorch.manual_seed(seed)だけで十分。また、マニュアルにはこう書いてある。
Deterministic operation may have a negative single-run performance impact, depending on the composition of your model. Due to different underlying operations, which may be slower, the processing speed (e.g. the number of batches trained per second) may be lower than when the model functions nondeterministically. However, even though single-run speed may be slower, depending on your application determinism may save time by facilitating experimentation, debugging, and regression testing.
ランダムシードを固定すると処理速度が落ちる可能性があるので注意。
※ただし、デバッグやテストなど全体工程を考えると”結局は時間の短縮につながる”とも書いてある再現性を問わない場合 & ネットワークの構造(計算グラフ)が変化しない場合は
torch.backends.cudnn.benchmark = True
にすると高速化できるTensorFlowのシード固定
基本的には下記のようにシードを固定する
tf.random.set_seed(seed)ただし、下記のようにオペレーションレベルでseedの値を指定することもできる
tf.random.uniform([1], seed=1)DeepLearningのフレームワークとGPUのシード固定
正直なところ、TensorflowのGPU周りについてはあまり情報が見つからなかった。GPUと乱数生成は結構根深い問題がありそうだ。ソフトウェアとハードウェアでは全然違うだろうし。
NVIDIA/tensorflow-determinism: Tracking, debugging, and patching non-determinism in TensorFlow
Pytorchの方でも速度低下のリスクがあるように、再現性とGPUの間にはトレードオフがあると思ったほうがいい。
GPU内部では高速化のためにFP16やINT8などデータ型を変換することもあるため、丸め誤差なども無視できないのかもしれない。再現性を保つために考えなければならないことはいろいろありそうだ。
Seed=42はどこから来たのか
The Hitchhiker’s Guide to the Galaxy. という小説に出てくるスーパーコンピュータDeepThoughtがはじき出した「生命、宇宙、そして万物についての究極の疑問の答え」が42ということらしい。
What is it about the random seed "4242"? | Kaggle
Kaggleではコードの
コピペ再利用が頻繁に行われるので、誰かがジョークで使ったseed=42という部分がよく使われるようになったんだとかなんとか。今となってはseedの値を変えて学習させたモデルの予測をアンサンブルすることもある。
まとめ
- numpy関連の乱数生成は実行するたびにseedが変わるので油断しない。
- 特に実行するたびに乱数生成する場合や、何回呼ばれるかわからないメソッドなどは明示的にseedを設定しないと再現性が保たれない。
- 外部ライブラリを利用する場合は呼び出すたびにrandom_stateを設定する。
- 自分でモジュールを作る場合などはnumpyのシードを上書きしないように、改めてRandomStateを用意する
- GPU周りの乱数生成は結構ややこしい。処理速度と再現性(というより精度?)はトレードオフの関係
簡単な実験コードはこちら
machine_leraning_experiments/random_seed_experiment.ipynb at master · si1242/machine_leraning_experiments
- 投稿日:2020-05-27T12:07:59+09:00
Pythonで電子顕微鏡シミュレーション:マルチスライス法(2)
And now, for something completely different...
さて、前回の記事の続きです。前回は中途半端に終わってしまってすいません。今回の記事で完結しますのでご安心ください。前回の記事: Pythonで電子顕微鏡シミュレーション:マルチスライス法(1)
コードはGitHub1
に載せています。再びの注意点: 趣味でシミュレーション(以下、趣味レーション)していると、結果が本当に正しいのか判別がつきにくく、ここに載っている結果も物理的に正しくない可能性があります。間違いがあったらご指摘をいただけると幸いです。
電子顕微鏡の性能による誤差(収差)
前回の記事の最後で、結晶構造像をシミュレーションするには、マルチスライス計算だけでは不足だと言いました。具体的に何が不足かといえば、マルチスライス計算だけでは、観測する機器である電子顕微鏡の性質による理想系との差を考慮していないのです。電子顕微鏡に限った話でないのですが、計測をシミュレーションするときには、計測結果の解析を目的とすることがほとんどです。ですので、シミュレーションはできる限り計測系に近づける必要があるのです。
電子顕微鏡で考えられる、理想系との差(収差)は数多くあります。その中でも、HREMによる結晶構造像に特に効いてくるのは、球面収差と色収差です。球面収差
球面収差とは、電子顕微鏡の対物レンズに起因する収差です。電子線が対物レンズに入射するとき、対物レンズに対して垂直(光軸に並行)に近い角度で入射した電子線は適切に像面に集まりますが、光軸から傾いて入射した電子線は像面から離れたところに焦点があってしまいます。これによる像のぼやけが球面収差です。球面収差の大きさは対物レンズの性能により変化します。
球面収差は以下の式で表されます。
$$ \chi(\alpha) = \frac{2\pi}{\lambda}(C_S \frac{\alpha^4}{4} - \Delta f\frac{\alpha^2}{2}) $$
$\alpha$は散乱角(光軸と散乱した電子線のなす角)、$C_S$は球面収差係数といって対物レンズの性能によって固有の定数、$\Delta f$は焦点はずれ量(デフォーカス量)です。
ここで、デフォーカス量という一見関係なさそうな変数が出てきました。実はこのデフォーカス量の変化を用いると、球面収差を逆手にとった観察ができるのです。
前回、結晶構造像では透過波と回折波の位相差が観察できると言いました。弱位相物体近似の下では回折波は
$$ \psi = {1 - 2\pi i\sigma V_p } \psi_0 = \psi_0 - 2\pi i\sigma V_p \psi_0 $$
です。前回登場した式を簡単のために$\sigma =1/2\lambda E$として書き換えています。右辺第二項を見ると、$-\pi/2$だけ回折波は透過波に対して位相が変化していることがわかります。しかしこのままでは複素成分なので像として反映されません。そこで、球面収差によってさらに$-\pi/2$だけわざと位相を変化させます。球面収差はデフォーカス量によって調節します。
$\chi(\alpha)=-\pi/2$として逆算すると、デフォーカス量$\Delta f$は
$$ \Delta f = 1.2(Cs\lambda)^{1/2} $$
で計算されます。係数は1.1 ~ 1.2程度までズレがあります。このデフォーカス量を特に、シェルツァー・フォーカスと言います。
デフォーカス量を調節しても、位相差が像上の明暗(コントラスト)として適切に反映される範囲は限られています。散乱角に対して位相差がどの程度反映されるかを示す関数を位相コントラスト伝達関数(CTF)といい、以下で表されます。
$$ CTF(\alpha) = cos {-\frac{\pi}{2} + \chi(\alpha) } $$
試しに、$C_S = 0.5 mm$、$\alpha = 0 ~ 0.02$でCTFをプロットしてみたのが以下です。
$CTF = -0.5$のところで位相コントラストが適切に反映されると考えると、$\alpha$が0.0025から0.0125あたりまでであればまあまあ許容範囲内であろうと言えます。CTFの正負が変わると像の白黒が反転するので、$\alpha = 0.0125$以降のCTFの正負が大きく変動しているところでは、位相コントラストがめちゃくちゃになってしまいます。
CTFの傾向がわかったところで、前回の記事で計算した範囲でのCTFをプロットしてみましょう。
球面収差のみを考えれば、ほぼ全ての範囲で位相コントラストが正しく出そうだということがわかりました。色収差
もう一つ、結晶構造像で影響が大きく出るのが色収差です。色とは、波長のことを指しています。色収差は電子線のエネルギーの幅に起因します。波のエネルギーの違いは波長の違いですから、色の違いというわけです。電子顕微鏡の電子銃から出る電子線は、$\Delta E/E = 10^{-5}$ 以下ほどの広がり(揺らぎ)を持ちます。さらに、その電子線を集めるレンズの電流も同程度の揺らぎ$\Delta J/J$を持ちます。色収差による焦点のズレはこれらに比例して、
$$ \frac{\Delta f}{f} \propto \frac{\Delta E}{E} - 2\frac{\Delta J}{J} $$
さらに、$\Delta f/f$がガウス関数に従うと仮定すると、元のデフォーカス量を$\Delta f_0$として、
$$ W(\Delta f) = \frac{1}{\sqrt{2\pi \sigma^2}}e^{\frac{-(\Delta f - \Delta f_0)^2}{2\sigma^2}} $$
記号が被って紛らわしいですが、ここでの$\sigma$はガウス関数の偏差で
$$ \sigma = Cc[(\frac{\Delta E}{E})^2 + (\frac{\Delta J}{J})^2]^{1/2} $$
$C_C$を色収差係数と言います。以上から、色収差$E_C$は
$$ E_C = e^{-\frac{1}{2}(\pi^2\sigma^2\frac{\alpha^4}{\lambda^2})} $$
となります。
色収差を先ほどのCTFにかけてプロットしたものが以下です。
先ほどと同様に前回の計算範囲でも見てみましょう。
これらを踏まえて結晶構造像を作れば、より正しい像ができるはずです。プログラム
球面収差と色収差を予め計算しておいて、マルチスライス計算から出力された$\Psi_{out}$に畳み込みます。
$$ \psi = F[\Psi_{out}e^{i\chi}E_C] $$
球面収差Cs = 0.5e-3 deltaf = 1.2*(Cs*lamb)**(1/2) hkl = [h, k, 0] thkl = np.transpose(hkl) dk = 1/((np.matmul(np.matmul(invG, thkl), hkl))**(1/2)) u = self.lamb/(2*dk) chi = 2*np.pi/lamb chi = chi*(1/4*self.Cs*u**4 - 1/2*deltaf*u**2)色収差
deltaE = 1.0e-6 deltaJ = 0.5e-6 Cc = 1.4e-3 sig = Cc*((deltaE)**2 + (2*deltaJ)**2)**(1/2) hkl = [h, k, 0] thkl = np.transpose(hkl) dk = 1/((np.matmul(np.matmul(invG, thkl), hkl))**(1/2)) u = lamb/(2*dk) w = np.exp(-(1/2)*(np.pi**2)*(u**4)*(sig**2)/(lamb**2))α-Fe、 [001]入射、加速電圧 200 keV、$C_S$ = 0.5 mm、$C_C$ = 1.4 mm、$\Delta E/E$ = 1.0 μm、$\Delta J/J$ = 0.5 μmとすると、結晶構造像はこんな感じです。
$C_S$を0.5 μmにすると以下のようになります。より像が明瞭になっています。収差係数が小さい顕微鏡はいい顕微鏡と言えます。
まとめ
大変長くなってしまいましたが、HREMでの結晶構造像のシミュレーションを作りました。実は収束角などまだ考慮できていないパラメータがありますので、いずれ改良できたらと思います。
参考文献
コード
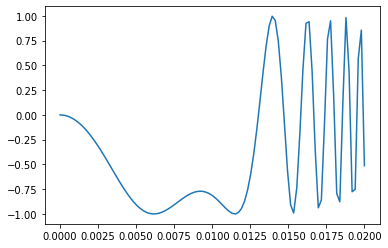
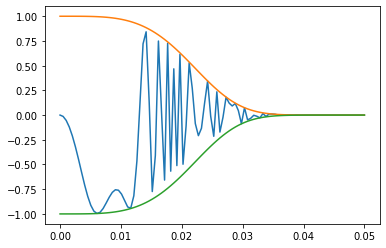



- 投稿日:2020-05-27T11:12:37+09:00
【1日1写経】Build a Stock Prediction Program【Daily_Coding_002】
初めに
- 本記事は、python・機械学習等々を独学している小生の備忘録的な記事になります。
- 「自身が気になったコードを写経しながら勉強していく」という、きわめてシンプルなものになります。
- 建設的なコメントを頂けますと幸いです(気に入ったらLGTM & ストックしてください)。
お題:Build a Stock Prediction Program
今日のお題は、Build a Stock Prediction ProgramというYoutube上の動画です。
Youtube: Build a Stock Prediction Program
分析はyoutubeの動画にある通り、Google Colaboratryを使用しました。
それではやっていきたいと思います。
まずはライブラリのインポートからです。今回は
quandlというライブラリを使います。quandlは株価やらのデータをとってくるためのライブラリのようです(知りませんでした...)。pip install quandlGoogle colabに元々入っているライブラリでないので
pipでインストールします。次に今回使うライブラリをインポートします。
ライブラリのインポート
import quandl import numpy as np from sklearn.linear_model import LinearRegression from sklearn.svm import SVR from sklearn.model_selection import train_test_split先ほどインストールしたquandlに加えて、numpy, 各種
scikit-learnのライブラリをインポートしました。Step2: データの取得~加工(前処理)
次にデータを取得します。今回はFacebookの株価を使用しています。
df = quandl.get('WIKI/FB') print(df.head())これでデータを取得できました。取得したデータの中で
Adj. Close(調整後終値)を使用するのでdfを差し替えます。df = df[['Adj. Close']] print(df.head())dfに含まれているデータを数日分ずらして、別の列(
Prediction)を作成します。その際に、「何日分ずらすか」を変数として格納します。forecast_out = 30 df['Prediction'] = df[['Adj. Close']].shift(-forecast_out) print(df.tail())dfの末尾を見てみるとずらした日数分だけ
Predictionの値がNaNになっていることがわかるかと思います。次に、
df['Predcition']から訓練データを作ります。訓練データは先ほど数日分(今回は30日分)ずらして作ったデータのうちNaNの除いた部分を使います。それを使って、ずらした30日分を予測するということをやっています。X = np.array(df.drop(['Prediction'], 1)) X = X[:-forecast_out]![stockprediction.png] print(X)【イメージ】
次にテストデータを作ります。やり方は訓練データと同じです。
y = np.array(df['Prediction']) y = y[:-forecast_out] print(y)これでデータの加工ができました。次からはscikit-learnを使った分析に移ります。
Step3: Sklearnを使った予測
訓練データ(X)・テストデータ(y)をsklearnのtrain_test_splitで分割します。
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.2)今回はSVMとLinearRegressionの2つを使って予測をします。
# SVMのrbf(非線形回帰) svr_rbf = SVR(kernel='rbf', C=1e3, gamma=0.1) svr_rbf.fit(x_train, y_train) svm_confidence = svr_rbf.score(x_test, y_test) print('svm confidence:', svm_confidence)lr = LinearRegression() lr.fit(x_train, y_train) lr_confidence = lr.score(x_test, y_test) print('lr confidence:', lr_confidence)これで訓練データを用いて学習済みモデルの作成ができました。
それではそれを使って予測をしてみましょう
x_forecast = np.array(df.drop(['Prediction'], 1)) print(x_forecast) lr_prediction = lr.predict(x_forecast) print(lr_prediction) svm_prediction = svr_rbf.predict(x_forecast) print(svm_prediction)これで作成したモデルでの予測完了です。
最後に
- ご理解のことと思いますが、上記の予測に意味はないです。sklearnの使い方の勉強というのがこの写経した意味と理解してます。
- 株価やコモディティの予測は多数の論文が出てますし、時系列分析は非常に奥が深いのでこれからも学習をしていきたいと思います。
以上。
(これまでの学習)
1. 【1日1写経】Predict employee attrition【Daily_Coding_001】

- 投稿日:2020-05-27T10:47:22+09:00
OpenCVの画像処理をGPU(CUDA)で高速化する XavierNX
はじめに
OpenCVの画像処理をGPU(CUDA)で高速化する
というPostをみて、XavierNXでも同様にGPUMATを使った高速化について確認しました。手順
- XavierNXのJetpack4.4でOpenCV4をビルドし、GPUMAT(CUDA)を使えるようにします。
-もともとJetpack4.4にはOpenCVの4.1.1が入っていますが、GPUMATがイネーブルにされずにビルドされています。- OpenCVの画像処理をGPU(CUDA)で高速化するにあるスクリプトを実行します。
XavierNXのJetpack4.4でOpenCV4をビルドし、GPUMAT(CUDA)を使えるようにします。
XavierNXで、GPUMAT(CUDA)を使おうとすると
cv2.error: OpenCV(4.1.1) /home/nvidia/host/build_opencv/nv_opencv/modules/core/include/opencv2/core/private.cuda.hpp:107: error: (-216:No CUDA support) The library is compiled without CUDA support in function 'throw_no_cuda'といわれGPUMATが使えません。
Jetson Xavier NXでDNN_BACKEND_CUDAが使えるOpenCV4.3をDockerでビルドでOpenCV4.3なGPUMAT(CUDA)がイネーブルなイメージをビルドします。OpenCVの画像処理をGPU(CUDA)で高速化するにあるスクリプトを実行します。
作成したイメージを実行 # ここでは作成したイメージにopencv430:100 というタグをつけてあります。
sudo docker run -it --rm --net=host --runtime nvidia -e DISPLAY=$DISPLAY -v /tmp/.X11-unix/:/tmp/.X11-unix opencv430:100その後Docker上で
https://github.com/iwatake2222/OpenCV_CUDA
にあるスクリプトを実行します。python3 opencv_cuda.py結果
各一回づつしか実行してないので、ばらつきはありますが、CPUはJetsonNanoよりはやいですが、GPUはむしろ遅い感じ
GPUの計測時には、
1,GPU側へのコピー、
2,リサイズ、
3,CPU側への返送
なので、実際には2だけがGPUの恩恵を受けるので値そのものはこんなものかとおもいますが、OpenCVの画像処理をGPU(CUDA)で高速化するの結果と比較するとJetsonNanoより遅くなるのはなぜでしょう。。。どなたか知見のある方いらっしゃればnvpmodel -m 0 CPU = 0.8271254301071167[msec] GPU = 0.9963115930557251[msec] 1 nvpmodel -m 1 CPU = 1.1097469329833984[msec] GPU = 0.8339884281158447[msec] 1 nvpmodel -m 2 CPU = 1.107427430152893[msec] GPU = 1.0129541397094726[msec] 1 nvpmodel -m 3 CPU = 1.0416812896728516[msec] GPU = 0.9837974786758423[msec] 1 nvpmodel -m 4 CPU = 1.3258913993835448[msec] GPU = 1.004795241355896[msec] 15/27追記
ふとjetson_clocksを実行して測定してみたら
CPU = 1.1041647672653199[msec]
GPU = 0.3990261316299438[msec]
1
となりました。
/etc/nvpmodel.conf
を見る限り、最大Clockはかわらないのですが、jetson_clocksを実行するとGorvernorが停止され最大クロックに固定されます。検証してませんが、転送はCPU処理、リサイズはGPU処理でこまめに切り替わることで、Gorvernorの動作が間に合ってない可能性があるかもしれません。気が向いたら確認してみます。
- 投稿日:2020-05-27T10:02:10+09:00
Python3 を子供に教えるためにオセロを作ってみた(5)
オセロクラスについて解説していきましょう その2
型について話しましょう
血液型ってありますよね?A型、B型、O型、AB型・・・と本当かどうかはさておいて「几帳面なA型」「自分勝手なB型」みたいな感じで型にはその型なりの特徴があります。プログラミングでは型というのは血液型のように重要な区分けをするために使われます。
今まで変数について色々説明してきましたが、敢えて型について触れてきませんでした。配列は list() というクラスだと説明しましたし、ディクショナリ変数も dict() というクラスです。プログラムで言うデータ型は血液型同様、そのデータの性質を表すものです。
データ型の名前 データ型 記述 文字列 str "文字" または '文字' 整数 int +-数値 浮動小数 float +-浮動小数 虚数 complex +-実数部+-虚数部j 真偽 bool True または False 日付時刻 datetime 日付と時刻 リスト(配列) list データ型を問わない配列 タプル(参照配列) tuple データ型を問わない配列 セット(一意配列) set データが一意で順不同のブロック配列 ディクショナリ(キーマップ配列) dict キー対データ配列 Python では変数を使う場合は特に意識しなくても勝手に型が割り当たります。これを
動的型付け(dynamic typing)と呼びます。例えばage = 12って書けば Python は型を int() にしてくれます。割り当てられた型を知るには type(age) とやれば age という変数に割り当てられた型を知ることができます。前回も書きましたが全ての型はそのデータ型を扱うのに必要な関数などが含まれたクラスになっています。もし意図しない型に割り当てられた場合は、float() などと明示的に型指定をしたり型返還をすることもできます。オセロゲームのソース解説(2) オセロクラスの関数編
キーボード入力
まずはキーボード入力を行っている関数です。引数として渡された文字列を表示し、キーボード入力を待ちます。エンターキーを空打ちしたか、1〜8以外の値を入力されたら再度キーボード入力に戻ります。正しい数値が入力されたら、それを int() で整数に変換して戻します。このオセロクラスの重要な値はXとYの1〜8の数値です。仮にグラフィカルなオセロになって、マウスで場所をクリックされても内部的には 1〜8 のX座標とY座標に変換することで、現在のクラスの関数はそのまま利用することができるのです。
# 入力 def ot_inputXY(self,otstr): while True: myXY = input(otstr) if myXY == "": continue if '1' <= myXY <= '8' : return int(myXY)「あなたの番です」を司る関数(文字列と三項演算子)
ot_yourturn()という関数は「●の手です!」とかどちらのプレイヤーの番かを表示するだけの関数です。表示するのは "〜" でくくられた文字列なのですが、"文字列" は前述した通り文字列クラスstr()ですから、"あいうえお" と書いただけの文字列でも str() クラスに含まれる関数がそのまま利用できるのです。文字列型を使うときにここで記述している
{} と format()はとてもよく使われる表現なのでここで覚えておきましょう。{}を置換フィールドなどと呼びます。str("あか{}たな".format("さ")とやると {} の中を format() 関数で指定したデータに置き換えてくれる便利な記述です。Python3.6 以降では f文字列操作として置換フォールドにダイレクトに変数を入れられるようになり可読性が上がっています。name = input("お名前を入力してください=") print("よく来たな勇者{}よ!!魔王を討ち滅ぼす英雄を待ち望んでおったぞ!".format(name)) # Python3.6以降では以下のように書けて便利です! print(f"よく来たな勇者{name}よ!!魔王を討ち滅ぼす英雄を待ち望んでおったぞ!")実際のオセロクラスでの
ot_yourturn()では、置換フィールドに現在の手が格納された変数ot_offdefが指定されているので●または○が表示されます。# あなたの番です表示 def ot_yourturn(self): print("{} の手です!".format(self.ot_offdef))
ot_changeturn()関数は、攻め手の番を切り替える関数です。# あなたの番です def ot_changeturn(self): # 攻め手のコマを格納する self.ot_offdef = '●' if self.ot_offdef == '○' else '○' # 攻め手と逆のコマを格納する self.ot_search = '●' if self.ot_offdef == '○' else '○'プログラムには三項演算子という書き方があります。Excel のマクロでIF文を書く感覚に近いのですが、上のロジックと下のロジックはやっていることは全く同じです。
条件に合致した時の値 if 条件 else 条件に合致しない時の値と書くことで if 条件文を1行に簡潔に納めることができるようになります。三項演算子は書き方によってはプログラムをスッキリさせる効果もありますが、無理矢理使いまくるととても可読性の悪いソースになりますので注意して使うことをお勧めします。もし分かりづらいな〜と感じるようでしたら、以下のソースに置き換えていただいても大丈夫です。# あなたの番です def ot_changeturn(self): # 攻め手のコマを格納する if self.ot_offdef == '○': self.ot_offdef = '●' else: self.ot_offdef = '○' # 攻め手と逆のコマを格納する if self.ot_offdef == '○': self.ot_search = '●' else: self.ot_search = '○'オセロゲームの次の動作を考える関数
ot_checkendofgame()関数はオセロゲームが終了するかどうか考えるプログラムです。この一連の記事の(2)で動作について書いてありますのでそちらをご覧くださいね。この中でやっていることは以下のようになります。
ot_canplacemypeace()関数で攻め手のコマを置く場所があるか確認します- 攻め手のコマが置けない場合
ot_changeturn()で攻め手のコマを相手ターンに切り替えますot_canplacemypeace()関数で攻め手のコマを置く場所があるか確認します- 両者とも置く場所がないと判断した場合は、●と○の数を比較してどちらが勝ったか引き分けかを判断しその結果を表示し 1 を返してゲームが終了することを教えます
- 上記の 1. で攻め手だけ置ける場所がなかった場合は、「相手のターンに変わります」というメッセージを表示して -1 を返しその旨を通知します
- 攻め手がそのままコマを置けると判断した場合は 0 を返しその旨を通知します
この関数の中で
myot.ot_bit.count('●')と呼んでいる count() は list() クラスの配列に含まれるデータの個数を返してくれる関数です。# 終了かどうか判定する(自分の手が置けないだけの場合はターンを変える) def ot_checkendofgame(self): # 自分の手を置ける場所がなく、相手の手も置けない if 0 > self.ot_canplacemypeace(): self.ot_changeturn() if 0 > self.ot_canplacemypeace(): bc = myot.ot_bit.count('●') wc = myot.ot_bit.count('○') if ( bc - wc ) > 0: bws = "●の勝利" elif ( bc - wc ) < 0: bws = "○の勝利" else: bws = "引き分け" print("{}です。お疲れ様でした!".format(bws)) return 1 else: print("{}を置ける場所がありません。相手のターンに変わります!!".format(self.ot_search)) return -1 else: return 0全てのひっくり返せる場所を探す関数
先ほどの
ot_checkendofgame()ではゲームが終了なのか、自分の手を置く場所があるのか、なければ相手の手を置く場所があるのかを判断していました。その「手を置く場所があるのか?」を考えるのが、ot_canplacemypeace()関数です。# 自分の手を置ける場所があるかどうか探す def ot_canplacemypeace(self): for n in range(64): if self.ot_bit[n] != '・': continue for d in self.ot_direction: if 1 == self.ot_next_onepeace(int(n%8)+1,int(n/8)+1, d): return 0 # 一個も置ける場所がないとここに来る return -1やっていることは以下の通りです。
- 8x8の盤面で既にコマが置いてある場所はどんどんスキップしていきます。
- コマが置かれていない場所があったら、0〜63のその位置をX座標とY座標に変換します。8で割った余りに1を足したものが1相対のX座標、8で割った値に1を足したものがY座標です。
- 変換したX座標とY座標位置に自分の手を置けるか(相手のコマをひっくり返せる場所があるか?)を全方向(8方向)に対して見ていきます。
for d in self.ot_direction:の部分では、ディクショナリ変数の数分繰り返され、ディクショナリに格納された方位を示すキー文字列が変数 d に格納されます。- コマを置く場所が見つかった場合は 0 を返してその旨を通知します。
- コマを置く場所がなかった場合は -1 を返してその旨を通知します。
指定されたXとYの座標にコマを置く
前回も話した通り、指定した場所にコマを置いた場合に、そこが置ける場所なのかを判断して、置けるのであれば相手のコマをひっくり返すということをしていかなければなりません。そして、もし置いた場所がそもそも置いてはいけない場所だった場合はその旨を表示しないとなりません。
# オセロの盤面に手を置く def ot_place(self, ot_x, ot_y): ot_change = False for d in self.ot_direction: if 1 == self.ot_next_onepeace(ot_x,ot_y,d): self.ot_peace(ot_x,ot_y,self.ot_offdef) self.ot_changepeace(ot_x,ot_y,d) ot_change = True # 1個も有効な方向が無かった場合 if not ot_change: print("{}を置く事ができませんでした".format(self.ot_offdef)) return -1 # 画面を表示して手を相手のターンに変更 self.ot_display() self.ot_changeturn() return 0この関数は所定の場所にコマを置こうとした時に呼び出される関数です。所定の場所はX、Yがそれぞれ1〜8の値で指定された座標となります。
それではこの関数のプログラムについて解説していきましょう。
- コマが置けたかどうかのフラグ変数として
ot_changeを False で初期化します。コマが置けた場合にここは True になります。ot_directionの配列の数分(つまり8方向分)の繰り返しを行います。変数 d にはot_directionのキー値が格納されます。ot_next_onepeace()関数を呼び出し、現在の方向がひっくり返せるかどうか、ひっくり返せるならどこまでひっくり返せるかを調べます。関数からの戻り値が 1 の場合は、この方向はひっくり返せる方向であることを示します。- 3番目の引数に自分の手を指定して
ot_peace()関数を呼び出し、指定された座標に自分のコマを置きます。ot_peace()関数は3番目の引数を省略した場合は、指定座標のコマ1つを戻してくれる関数でもあります。3番目の引数を指定した場合は、指定座標のコマを指定された文字で置き換えを行います。ot_changepeace()関数を呼び出して、ひっくり返せる場所までひっくり返す作業を行います。- コマが置けた場合は
ot_changeフラグを True にセットします。8方向全てひっくり返せなかった場合は、False のままです。- 繰り返しから抜けてきた時に
ot_changeフラグが False かどうかを確認します。False の場合はそもそも置けない座標を指定した場合なので、その場所には置けない旨のメッセージを表示して戻ります。- 繰り返しから抜けてきた時に
ot_changeフラグが True であれば、ひっくり返す処理が盤面データであるot_bitの書き換えを完了していますので、ot_display()関数を呼び出して盤面を再表示し、攻め手のターンを変更すべくot_changeturn()関数を呼び出します。次回でプログラムの説明は最後です!
次回は一番ややこしいかもしれない、
ot_next_onepeace()関数と、ot_changepeace()関数について解説します。この2つの関数は再帰関数と呼ばれる自分を自分が呼び出すということをやっている関数なので、それについて解説したいと思います。それではまた!!
c u
<<Python3 を子供に教えるためにオセロを作ってみた(4)
Python3 を子供に教えるためにオセロを作ってみた(6)
- 投稿日:2020-05-27T07:05:57+09:00
BindsNETでSNNを試してみる
前回の記事でBrian2を使ってみましたが、今回はSNNの実装が出来るソフトであるBindsNETを使ってみます。
SNN(Spiking Neural Network)は現在のDeep Learningよりも神経生理に近いもので、神経活動のシミュレーションを利用して学習を行います。
SNNやBindsNETについてはこちらの記事でも紹介されています。GitHub:https://github.com/BindsNET/bindsnet
論文:https://www.frontiersin.org/articles/10.3389/fninf.2018.00089/full
ドキュメント:https://bindsnet-docs.readthedocs.io/NEURONやBrian2はシミュレータの用途メインなのに対して、BindsNETは機械学習のソフトとしての用途メインになるかと思います。
BindsNETはPyTorchをベースとしていて、GPUも利用することが出来ます。
BindsNETによって教師あり学習や教師なし学習だけでなく、強化学習も実装可能のようです。インストール
環境は
Ubuntu 16.04
CUDA 10
Anaconda
Python 3.6
です。pip install bindsnetこれでインストールできました。
バージョンは0.2.7でした。ただしこのままだとデモを動かした時にエラーになりました。
対処法としてはPytorchのバージョンを変えてpytorch==1.2.0にインストールし直すことで解決しました。デモを試してみる
まずはgit cloneでダウンロードします。
git clone https://github.com/BindsNET/bindsnet.gitデモはbindsnet/examples/の中に色々あります。
とりあえず教師あり学習のデモを実行してみます。cd examples/mnist/ python supervised_mnist.py完了には20分ほどかかりましたが、無事動きました。
--gpuオプションでGPUを使用できましたが、速くはなりませんでした。(むしろ若干遅くなりました。)
またテストスコアがあまり良くないのも気になりました。教師なし学習(Diehl&Cook)のデモも実行してみます。
python eth_mnist.pyこっちは完了に数時間かかるようです。
他には、自己組織化マップ(SOM)やリザーバーコンピューティング、強化学習などのデモがありました。
実装方法
ドキュメントによると、実装方法は
①ネットワークの作成 と ②学習則の定義
の2つを行うようです。
ネットワークの作成では、LIFニューロンなどを層として定義して結合させます。
学習則の定義では、結合に対してHebb則やSTDP則などの学習則を設定します。最後に
BindsNETは神経ダイナミクスのODEを解くことは出来ませんが、SNNによる学習を簡単に行うことが出来るようです。
SNNを使った機械学習はまだ発展途上の分野で様々な研究が行われており、BindsNETが大きな役割を果たすかもしれません。
- 投稿日:2020-05-27T03:58:26+09:00
MySQLのダンプをTSVに変換するスクリプトを書く
MySQL からダンプされた SQL を他の用途に使うため、タブ区切りのテキスト(いわゆる TSV)に変換を試みます。
概要
MySQL のテーブルは mysqldump で SQL としてダンプできます。主要部分は CREATE 文と INSERT 文です。
(略) CREATE TABLE `t_price` ( (略) INSERT INTO `t_price` VALUES (1,'定型',25,82),(略)(10,'定型外',4000,1180); (略)自分で管理している MySQL からのダンプであれば、直接 TSV にダンプできます。
他で公開されているデータが SQL のダンプしかない場合、一度取り込んでダンプするか、変換するかになります。今回はスクリプトを書いて変換を試みます。
※ 後述しますが、Wiktionary のダンプの変換を想定しています。データが巨大なため、一度取り込むのは避けたいのです。
仕様
SQL から INSERT 文の VALUES だけを取り出して TSV に変換します。具体的には次のような挙動を目指します。
変換前INSERT INTO `table` VALUES (1,2,3),(4,5,6); INSERT INTO `table` VALUES (1,'a,b','c\'d');変換後1 2 3 4 5 6 1 a,b c'dPython
Python で変換スクリプトを書きます。
read_string
一重引用符
'で囲まれる文字列をパースします。これが一番混み入っています。最初の文字が
'かどうかをチェックします。エスケープシーケンスの処理は簡略化して、\",\',\\の場合は\を除去しますが、その他の制御文字の場合は\を残します。
testはテスト用のフラグです。sql2tsv.pytest = True def read_string(src, pos): length = len(src) if pos >= length or src[pos] != "'": return None pos += 1 ret = "" while pos < length and src[pos] != "'": if src[pos] == "\\": pos += 1 end = pos >= length if end or not src[pos] in "\"'\\": ret += "\\" if end: break ret += src[pos] pos += 1 if pos < length and src[pos] == "'": pos += 1 return (ret, pos) if test: src = r"'a,b','c\'d'" pos = 0 while pos < len(src): s, p = read_string(src, pos) print("read_string", (src, pos), "->", (s, p)) pos = p + 1実行結果read_string ("'a,b','c\\'d'", 0) -> ('a,b', 5) read_string ("'a,b','c\\'d'", 6) -> ("c'd", 12)read_value
1つのデータを読み取ります。文字列なら
read_stringを読んで、それ以外は,か(まで読み進めます。sql2tsv.py(続き)def read_value(src, pos): length = len(src) if pos >= length: return None sp = read_string(src, pos) if sp: return sp p = pos while p < length and src[p] != "," and src[p] != ")": p += 1 return (src[pos:p], p) if test: for src in ["1,2,3", r"1,'a,b','c\'d'"]: pos = 0 while (value := read_value(src, pos)): s, p = value print("read_value", (src, pos), "->", (s, p)) pos = p + 1実行結果read_value ('1,2,3', 0) -> ('1', 1) read_value ('1,2,3', 2) -> ('2', 3) read_value ('1,2,3', 4) -> ('3', 5) read_value ("1,'a,b','c\\'d'", 0) -> ('1', 1) read_value ("1,'a,b','c\\'d'", 2) -> ('a,b', 7) read_value ("1,'a,b','c\\'d'", 8) -> ("c'd", 14)read_values
括弧内のコンマで区切られたデータをすべて読み取ります。
sql2tsv.py(続き)def read_values(src, pos): length = len(src) if pos >= length or src[pos] != "(": return None pos += 1 ret = [] if pos < length and src[pos] != ")": while (value := read_value(src, pos)): s, pos = value ret.append(s) if pos >= length or src[pos] != ",": break pos += 1 if pos < length and src[pos] == ")": pos += 1 return (ret, pos) if test: for src in [r"(1,2,3)", r"(1,'a,b','c\'d')"]: print("read_values", (src, 0), "->", read_values(src, 0))実行結果read_values ('(1,2,3)', 0) -> (['1', '2', '3'], 7) read_values ("(1,'a,b','c\\'d')", 0) -> (['1', 'a,b', "c'd"], 16)read_all_values
括弧で囲まれたデータをすべて読み取ります。ループでの扱いを想定してジェネレーターにします。
sql2tsv.py(続き)def read_all_values(src, pos): length = len(src) while (sp := read_values(src, pos)): s, pos = sp yield s if pos >= length or src[pos] != ",": break pos += 1 if test: src = r"(1,2,3),(1,'a,b','c\'d')" print("read_all_values", (src, 0), "->", list(read_all_values(src, 0)))実行結果read_all_values ("(1,2,3),(1,'a,b','c\\'d')", 0) -> [['1', '2', '3'], ['1', 'a,b', "c'd"]]read_sql
SQL の各行から
INSERT INTOで始まる行を見付けてread_all_valuesで処理します。sql2tsv.py(続き)def read_sql(stream): while (line := stream.readline()): if line.startswith("INSERT INTO "): p = line.find("VALUES (") if p >= 0: yield from read_all_values(line, p + 7) if test: import io src = r""" INSERT INTO `table` VALUES (1,2,3),(4,5,6); INSERT INTO `table` VALUES (1,'a,b','c\'d'); """.strip() print("read_sql", (src,)) print("->", list(read_sql(io.StringIO(src))))実行結果read_sql ("INSERT INTO `table` VALUES (1,2,3),(4,5,6);\nINSERT INTO `table` VALUES (1,'a,b','c\\'d');",) -> [['1', '2', '3'], ['4', '5', '6'], ['1', 'a,b', "c'd"]]コマンド化
必要な関数はすべて実装しました。テストをオフにします。
sql2tsv.py(変更)test = False指定したファイルを読み込んで、指定したファイルに書き出します。
UTF-8 のバイト列が文字の途中で切れている場合を想定して、
openではerrors="replace"を指定します。これにより異常な文字は � に置換されます。errorsを指定しない場合はエラーになります。【参考】 (Windows) Python3でのUnicodeEncodeErrorの原因と回避方法 - Qiita
sql2tsv.py(続き)if __name__ == "__main__": import sys try: sql, tsv = sys.argv[-2], sys.argv[-1] if not (sql.endswith(".sql") and tsv.endswith(".tsv")): raise Exception except: print("usage: %s sql tsv" % sys.argv[0]) exit(1) with open(sql, "r", encoding="utf-8", errors="replace") as fr: with open(tsv, "w", encoding="utf-8") as fw: for values in read_sql(fr): fw.write("\t".join(values)) fw.write("\n")次のように使います。
python sql2tsv.py input.sql output.tsvスクリプト全体は以下に置きました。
計測
どのくらいの速度で処理できるか、巨大なファイルで計測します。
Wiktionary 日本語版
Wikipedia 同様に、ダンプデータが公開されています。
記事執筆時点で入手可能な2020年5月1日版より、以下のファイルを使用します。
- jawiktionary-20200501-categorylinks.sql.gz 10.7 MB
ファイルを展開すると 90 MB ほどになります。
gunzip -k jawiktionary-20200501-categorylinks.sql.gz※
-kは展開前のファイルを残すオプションです。展開した SQL を今回のスクリプトで変換すると、79 MB ほどの TSV が出力されます。
$ time python sql2tsv.py jawiktionary-20200501-categorylinks.sql jawiktionary-20200501-categorylinks.tsv real 0m19.921s user 0m19.375s sys 0m0.516s行数は 95 万行ほどです。
$ wc -l jawiktionary-20200501-categorylinks.tsv 951077 jawiktionary-20200501-categorylinks.tsvWiktionary 英語版
次に英語版を試します。
以下のファイルを使用します。展開すると 3 GB ほどに膨れ上がります。
- enwiktionary-20200501-categorylinks.sql.gz 344.6 MB
これを変換します。出力されるファイルは 2.6 GB ほどです。
$ time python sql2tsv.py enwiktionary-20200501-categorylinks.sql enwiktionary-20200501-categorylinks.tsv real 15m58.965s user 15m39.063s sys 0m12.578s行数は 2,800 万行にもなります。
$ wc -l enwiktionary-20200501-categorylinks.tsv 28021874 enwiktionary-20200501-categorylinks.tsvF♯
試しに F# に移植しました。
同じファイルを処理すると、かなり高速化しました。
ファイル 時間 jawiktionary-20200501-categorylinks.sql 0m03.168s enwiktionary-20200501-categorylinks.sql 1m52.396s 圧縮ファイルの読み込み
.NET Framework には GZipStream があるため、圧縮されたままの gz ファイルを直接読み込むことが可能です。
sql2tsv.fsx(変更)open System.IO.Compression let args = Environment.GetCommandLineArgs() let sqlgz, tsv = if args.Length < 2 then ("", "") else let len = args.Length (args.[len - 2], args.[len - 1]) if not (sqlgz.EndsWith ".sql.gz") || Path.GetExtension tsv <> ".tsv" then printfn "usage: sql2tsv sql.gz tsv" exit 1 do use fs = new FileStream(sqlgz, FileMode.Open) use gs = new GZipStream(fs, CompressionMode.Decompress) use sr = new StreamReader(gs) use sw = new StreamWriter(tsv) sw.NewLine <- "\n" for values in readSql sr do sw.WriteLine(String.concat "\t" values)計測結果は次にまとめます。
まとめ
計測結果を並べます。
言語 ファイル 時間 Python jawiktionary-20200501-categorylinks.sql 0m19.921s F# jawiktionary-20200501-categorylinks.sql 0m03.168s F# jawiktionary-20200501-categorylinks.sql.gz 0m03.509s Python enwiktionary-20200501-categorylinks.sql 15m58.965s F# enwiktionary-20200501-categorylinks.sql 1m52.396s F# enwiktionary-20200501-categorylinks.sql.gz 2m15.380s 圧縮ファイルを直接処理すると多少遅くはなりますが、ディスクスペースが節約できるので有利です。
- 投稿日:2020-05-27T01:57:02+09:00
WindowsのVSCodeでPythonのIntelliSenseが表示されないときの対処法
最近のエディタでやっぱり優秀なのはIntelliSens(Autocomplete)だと思う。入力の手間が省けるだけじゃなくて、引数の形とかも出してくれるし、ちょっとしたドキュメントもついてるからめっちゃ有能。
でも、VSCodeを使ってPythonの開発をしていて、
opencv-python,numpy,scipy,pandasなどの巨大なライブラリではIntelliSenseが出てこなかったので、色々調べて直した方法をメモ。ただ、あんまり情報がなかったので、これで全員が解決するかはわからない()
環境
- OS : Windows 10 Home
- VSCode : 1.45.1
- Python : 3.8.3
Anaconda経由ではなく、Pythonを直接インストールしています。
settings.jsonpip install [パッケージ名]としてパッケージがインストールされるフォルダを、VSCodeの
settings.jsonの"python.autoComplete.extraPaths"にを書き足せばよい。例えばPython3.8系のものを、インストーラーのデフォルトの設定でインストールした場合は、以下のフォルダに入ります(多分)。Pythonのバージョンが3.7系なら
Python38をPython37に読み替えればいいだけです。
C:\Users\<ユーザー名>\AppData\Roaming\Python\Python38\site-packagesC:\Users\<ユーザー名>\AppData\Local\Programs\Python\Python38\Lib\site-packagesこれを書き足せばいいです。
ただ、1つの環境のみで開発していて、settings.jsonをその環境以外とは共有していないのであればこのまま書けば良いですが、例えばSettings Syncなどを使って共有している場合は<ユーザー名>が同じとは限らないので環境依存しない書き方をします。
settings.jsonでは環境変数的なのが使えないので、settings.json(以下の場所にあります)からの相対パスで上記のディレクトリを指定しました。
C:\Users\<ユーザー名>\AppData\Roaming\Code\User\settings.json以下のようになります。回りくどいので他にいい方法あれば教えてください。
settings.json... "python.autoComplete.extraPaths":[ "../../Python/Python38/site-packages", "../../../Local/Programs/Python/Python38/Lib/site-packages" ], ...後はVSCodeを再起動すれば、IntelliSenseが使えると思います。ついでに、
importのところのunresolved import '~~~' Python(unresolved-import)も出なくなっていると思います。
備考
Pythonを
C:\Pythonとかユーザー名に依存しない場所に、どの環境でもインストールしておけば相対パスで書かなくてもいけそうです。
C:\Pythonにインストールした私の環境であれば、以下の形の記述でいけました。settings.json... "python.autoComplete.extraPaths":[ "C:\\Python\\Python38\\Lib\\site-packages" ], ...

- 投稿日:2020-05-27T01:21:30+09:00
[競プロ用]ランレングス圧縮まとめ
いつ使うのか
- 与えられる文字列で連続する回数・個数に着目する問題。
何がいいのか
画像圧縮などに利用される手法。膨大なデータを可逆性を損なわずに圧縮できる。
ただし、元データよりも必ずしもデータ量が少なくなるとは限らない。連続する構造の少ないデータでは逆に増加することもある。どうするのか
同じ文字が何回繰り返されるかの文字と数字の組み合わせで表す。
テンプレート
from itertools import groupby # RUN LENGTH ENCODING str -> tuple def runLengthEncode(S: str): grouped = groupby(S) res = [] for k, v in grouped: res.append((k, str(len(list(v))))) return res # RUN LENGTH DECODING tuple -> str def runLengthDecode(L: "list[tuple]"): res = "" for c, n in L: res += c * int(n) return res # RUN LENGTH ENCODING str -> list def rle_list(S: str): grouped = groupby(S) res = "" for k, v in grouped: res += k + str(len(list(v)))使用例
ABC019 B - 高橋くんと文字列圧縮
from itertools import groupby # RUN LENGTH ENCODING def rle_list(S: str): grouped = groupby(S) res = "" for k, v in grouped: res += k + str(len(list(v))) return res def main(): S = input() print(rle_list(S))ABC136 D - Gathering Children
最終的にはRとLの境界に集まる。移動回数の偶奇によって最後の移動がどちらかがかわるので偶奇だけ見ればいい。
from itertools import groupby # RUN LENGTH ENCODING def rfe_tuple(S: str): grouped = groupby(S) res = [] for k, v in grouped: res.append((k, str(len(list(v))))) return res def main(): S = input() N = len(S) now = 0 compressed = rfe_tuple(S) ans = [0] * N for lr, i in compressed: i = int(i) if lr == "R": now += i ans[now - 1] += i - i // 2 ans[now] += i // 2 else: ans[now - 1] += i // 2 ans[now] += i - i // 2 now += i L = [str(i) for i in ans] print(" ".join(L)) returnABC140 D - Face Produces Unhappiness
連続している部分を反転し、両端と繋がるようにすることで最大化できる。
両端はできれば反転させたくないので0番目は飛ばして奇数インデックスのみ反転させていく。from itertools import groupby # RUN LENGTH ENCODING def runLengthEncode(S: str): grouped = groupby(S) res = [] for k, v in grouped: res.append((k, str(len(list(v))))) return res def runLengthDecode(L: "list[tuple]"): res = "" for c, n in L: res += c * int(n) return res def main(): N, K = map(int, input().split()) S = input() compressed = runLengthEncode(S) for k in range(K): i = 2 * k + 1 # 奇数インデックスのみ反転させる。 if i >= len(compressed): break compressed[i] = ('L', compressed[i][1]) if compressed[i][0] == "R" else ('R', compressed[i][1]) reCompressed = runLengthEncode(runLengthDecode(compressed)) ans = N - len(reCompressed) print(ans)参考
itertoolsレファレンス
https://docs.python.org/ja/3/library/itertools.html#itertools.groupby