- 投稿日:2020-05-27T21:48:14+09:00
Xamppでポート競合を防ぐ方法
Xamppでポート競合を防ぐ方法をご紹介します。
作業環境
OS:Windows 10
エディション:HOME
バージョン:2004
Xampp:バージョン7.4.6※Xamppのインストール方法はこちらで解説しています。
【環境構築】Windows10にXAMMPをインストールする方法ポートとは
ポートはよく「扉(ドア)」に例えられるます。
IPアドレスが住所「家」であれば、ポートは外に出る・外から入る「扉(ドア)」に該当します。多くのホームページでインターネットはIPアドレスで通信を行っていると記載されていますが、実際には「IPアドレス+ポート番号」で通信を行っています。
Xamppでポート競合が起こる原因
1つのプログラムにつきポートは1個しか利用できない仕組みとなっているので、Xamppが他のプログラムと同じポートを使っていると競合が起きて、Xamppが利用できなくなります。
そこでXamppで利用するポートを変更することで、競合を防ぎます。
Xamppで利用するポートを変更する
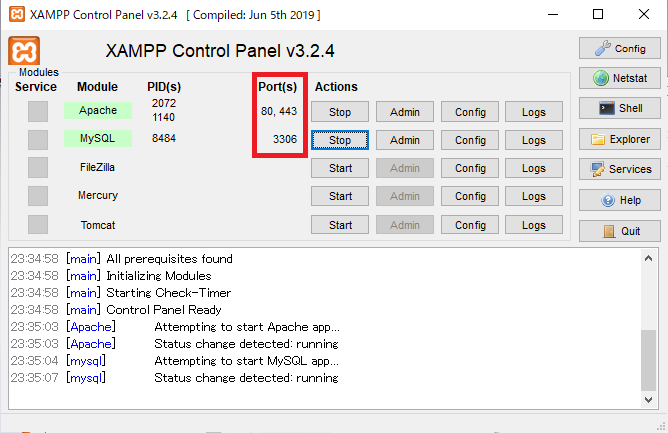
Xamppのデフォルトでは、Apacheは80番と443番、MySQLは3306番のポートをそれぞれ利用しています。80番はHTTPプロトコル、つまりホームページを閲覧するときに使われるものなので、様々なソフトで利用されていて競合の原因になります。このポート番号を変更します。①Apacheのポート番号を変更する
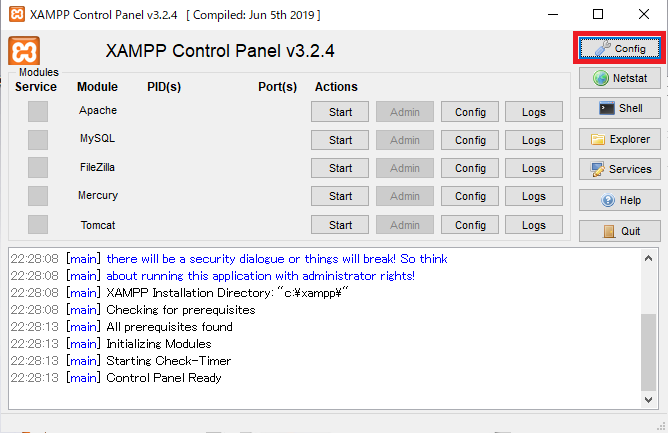
ApacheやMySQLなどを起動している場合は全部停止して、「Config」を押します。
「Service and Port Settings」を押します。
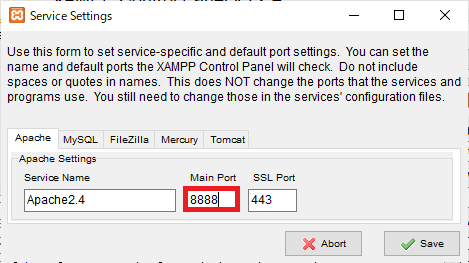
この画面が起動するので、「Main Port」の番号を任意の数字に変更します。ここでは「8888」と設定しました。変更したら「Save」のボタンを押して画面を閉じます。※エラーが起きた場合
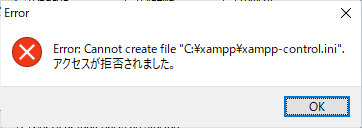
私の環境下では、以下のエラーが出てきました。
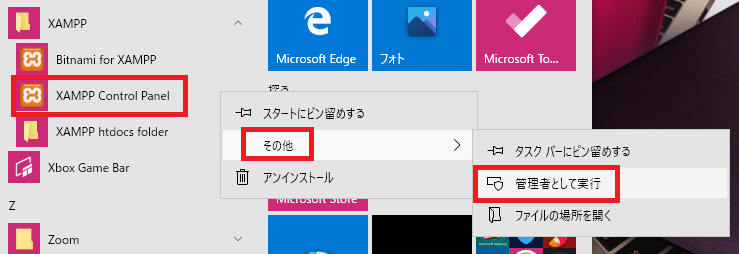
Error:Cannot create file "C:\xampp\xampp-control.ini" アクセスが拒否されました。書き込み権限がないようなので、管理者権限で実行してみます。
「XAMPP Control Panel」で右クリックをして「その他」→「管理者として実行」を押して、管理者権限で実行するとエラーが解消しました。②Apache(httpd.conf)を変更する
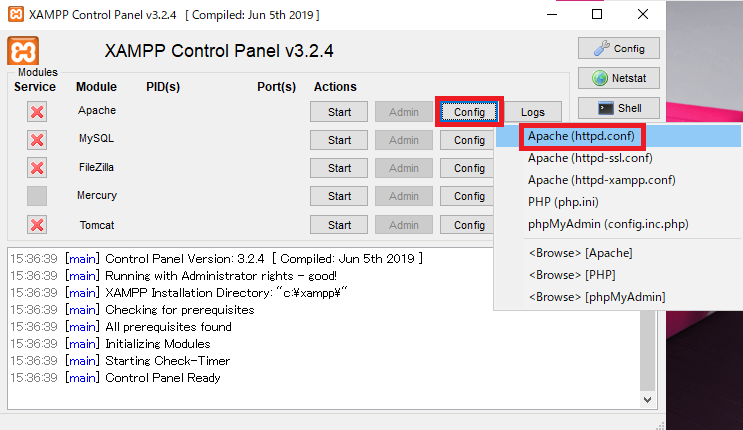
Apacheの右の「Config」→「Apache(httpd.conf)」を選びます。
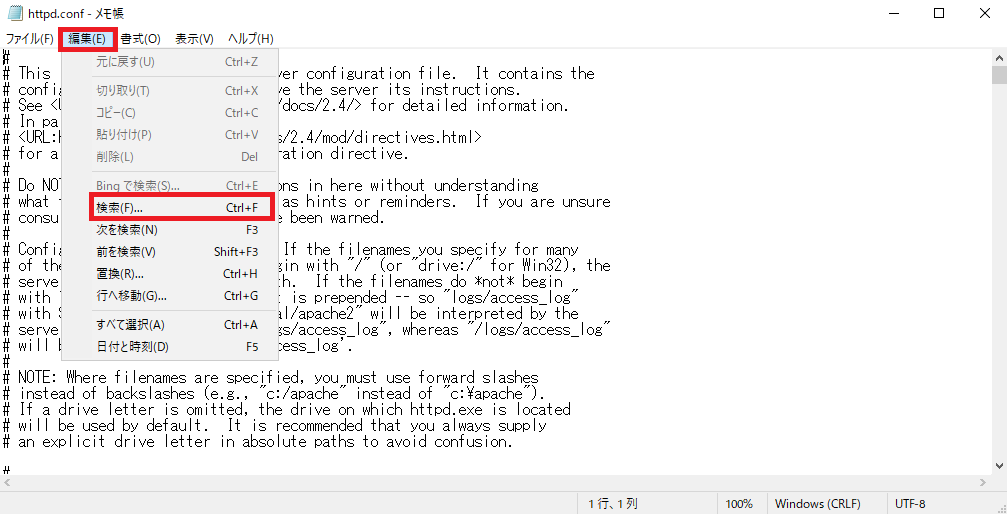
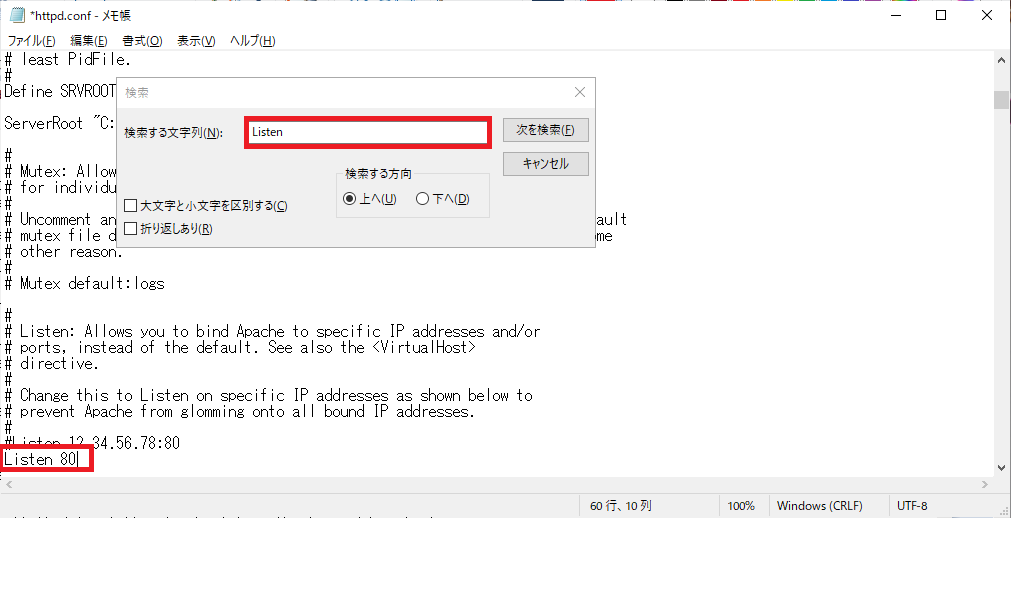
「httpd.conf」がメモ帳で開くので、「編集」→「検索」を選びます。
「Listen」と検索をし、「Listen 80」とポート番号が書いてあるので、ここも先程と同じ番号に変更をします。ここでは「Listen 8888」としました。変更が終わったら、保存してメモ帳を閉じます。
※管理者権限で実行している場合は、ここまでできたら一度Xamppを終了して、再度、通常通りに起動してください。③動作確認
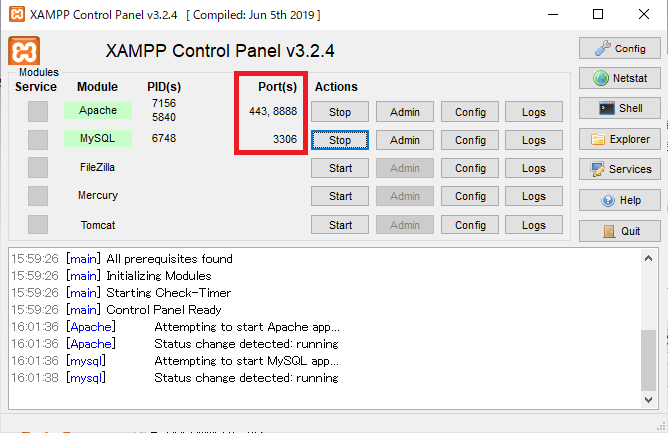
「Apache」と「MySQL」をそれぞれ「Start」ボタンを押して起動すると、ポート番号の表示が変わっています。
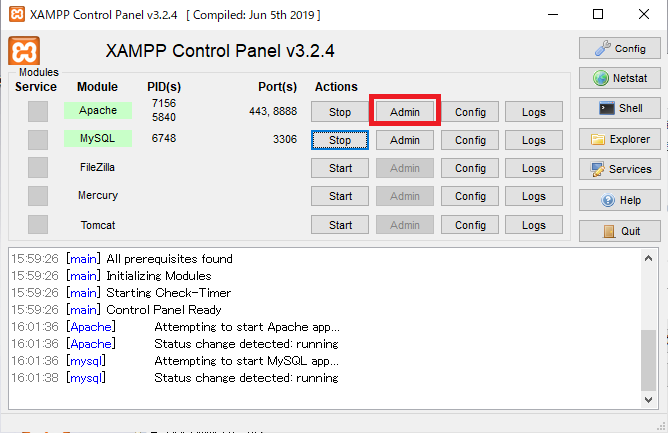
「Apache」の右の「admin」のボタンを押します。
上のような画面が開いたら、ポート番号の変更は完了です。参考サイト
- 投稿日:2020-05-27T16:36:42+09:00
Equalumがやって来た!(実践編)
前回の続き・・・
前回は、Equalumの概要説明を行いましたが、今回の実践編ではリアルにストリーミング処理を行ってみたいと思います。構想としてはPythonを使って自動的にデータを生成する仕組みを作り、そのデータを上流側のデータソースに連続して挿入処理を行う事で実現させる戦略で行こうと思います。
全体の流れ的には・・・
(1)上流側のソーステーブルを定義する(Pythonで実装)
(2)Equalumを使って基本的なストリーミング処理を設定する(今回は実質レプリケーション形式)
(3)自動データ生成ツール(Pythonで実装)を起動してEqualumダッシュボードで観察
(4)動作結果を確認
になります。まずは、上流側データソースにテーブルを作る仕組みを実装します。実際にはSQLを作業毎に発行しても良いのですが、1回作れば何度も使えるので今回は「再利用性を優先」して下記の通り作ってみました(デキについては・・・・まあ、動けば良いということで(汗))データカラムの設定部分は意図的に3種類に分けておきました。これは、最終的にテーブルをカラムデータを自動分割して3種類の下流側テーブルに挿入する検証計画の為の準備になります。
# coding: utf-8 # # ストリーミング処理検証用テーブル生成 # # 事前準備 # MySQL側にカラムのみのテーブルを作成 # 利用するテーブル Demo_Table999 # 利用するデータベース Demo@MySQL_Win10 # # 初期設定 import sys stdout = sys.stdout reload(sys) sys.setdefaultencoding('utf-8') sys.stdout = stdout import pymysql.cursors # 検証処理開始 print("MySQL側に検証用のテーブルを作成します!!") print try: # 既存のテーブルを初期化 Table_Init = "DROP TABLE IF EXISTS Demo_Table999" # デモ用のテーブル定義 DC1:購買テーブル向け DC2:支払いテーブル向け DC3:物流テーブル向け DC1 = "dt DATETIME, Product VARCHAR(20),Price INT,Units INT,Shop VARCHAR(20)," DC2 = "Card VARCHAR(40),Number VARCHAR(30),Payment INT,Tax INT," DC3 = "User VARCHAR(20),Zip VARCHAR(10),Address VARCHAR(60),Tel VARCHAR(15),Email VARCHAR(40)" # 検証用のテーブルの作成 Table_Create = "CREATE TABLE IF NOT EXISTS Demo_Table999(id INT auto_increment primary key,"+DC1+DC2+DC3+")" # MySQLとの接続 db = pymysql.connect(host = 'xxx.xxx.xxx.xxx', # 今回はWindow版のMySQLをネイティブに使います port=3306, # お約束のポート番号 user='root', password='password', # rootアカウントのパスワード db='Demo', # 検証に利用するデータベース(事前作成) charset='utf8mb4', # 日本語を処理するので・・ cursorclass=pymysql.cursors.DictCursor) with db.cursor() as cursor: # 既存テーブルの初期化 cursor.execute(Table_Init) db.commit() # 新規にテーブルを作成 cursor.execute(Table_Create) db.commit() except KeyboardInterrupt: print('!!!!! 割り込み発生 !!!!!') finally: # データベースコネクションを閉じる db.close() print("処理終了!!") print print("引き続きMemSQL側に受け用のテーブルを作成してください") print次に自動的に日本語の検証データを生成する仕組みを実装します。今回の検証ではPython界で有名なFakerを使ってみたいと思います。この部分に関する情報は既に多くの先人の皆様がネット上に情報を発信されていますので、この場では詳しい解説等は省かせて頂きますので、何卒ご理解居の程を・・・(冷汗)
# coding: utf-8 # # ストリーミング処理用日本語データの自動生成 # # 事前準備 # MySQL側にカラムのみのテーブルを作成 # 利用するテーブル Demo_Table999 # 利用するデータベース Demo@MySQL_Win10 # # 初期設定 import sys stdout = sys.stdout reload(sys) sys.setdefaultencoding('utf-8') sys.stdout = stdout import time import pymysql.cursors # 検証処理開始 print("データの自動生成開始!!") print try: # Pythonのデータ自動生成機能の設定 from faker.factory import Factory Faker = Factory.create fakegen = Faker() fakegen.seed(0) fakegen = Faker("ja_JP") # デモで使うメタデータ定義 Product_Name = ["日本酒","バーボン","ビール","芋焼酎","赤ワイン","白ワイン","スコッチ","ブランデー","泡盛","テキーラ"] Product_Price = [1980, 2500, 490, 2000, 3000, 2500, 3500, 5000, 1980, 2000] Shop_Name = ["旭町","三丁目","本町","二丁目","西新町","一丁目","住吉町","佐島","五本木","古橋"] # 生成するデータの総数 -> ここは適宜変更 Loop_Count = 500 # 発生タイミングの調整 # それっぽくする(ランダム的に)場合 Base_Count = 1600000 # 一定間隔の場合(システム時間で秒単位) Sleep_Wait = 1 # 消費税率(10%) Tax_Unit = 0.1 # その他の変数 Counter = 0 Work_Count = 1 # 書き込み用のデータカラム DL1:購買 DL2:支払い DL3:物流 DL1 = "dt,Product,Price,Units,Shop," DL2 = "Card,Number,Payment,Tax," DL3 = "User,Zip,Address,Tel,Email" # MySQLとの接続 db = pymysql.connect(host = 'xxx.xxx.xxx.xxx', port=3306, user='root', password='password', db='Demo', charset='utf8mb4', cursorclass=pymysql.cursors.DictCursor) with db.cursor() as cursor: # 検証データの生成 while Counter < Loop_Count: # 受付日時の情報 from datetime import datetime dt = datetime.now().strftime("%Y/%m/%d %H:%M:%S") # 購買情報の生成 Product_ID = fakegen.random_digit() Product = Product_Name[Product_ID] Price = Product_Price[Product_ID] Shop = Shop_Name[fakegen.random_digit()] Units = fakegen.random_digit() + 1 # 支払情報の生成 Payment = Price * Units Tax = int(Payment * Tax_Unit) if str(fakegen.pybool()) == "True": Card = "Cash" else: Card = fakegen.credit_card_provider() Number = fakegen.credit_card_number() if Card == "Cash": Number = "N/A" # 物流情報の生成 User = fakegen.name() Zip = fakegen.zipcode() Address = fakegen.address() Tel = fakegen.phone_number() Email = fakegen.ascii_email() # 此処から先を各データベースの規程テーブルへ書き込む DV1 = dt+"','"+Product+"','"+str(Price)+"','"+str(Units)+"','"+Shop+"','" DV2 = Card+"','"+Number+"','"+str(Payment)+"','"+str(Tax)+"','" DV3 = User+"','"+Zip+"','"+Address+"','"+Tel+"','"+str(Email) sql_data = "INSERT INTO Demo_Table999("+DL1+DL2+DL3+") VALUES('"+DV1+DV2+DV3+"')" # データベースへの書き込み cursor.execute(sql_data) db.commit() # コンソールに生成データを表示(不要な場合はコメントアウトする) print sql_data print # 時間調整用(一定間隔) time.sleep(Sleep_Wait) # 乱数を用いた生成タイミングの調整(今回の検証では使いません) #Wait_Loop = Base_Count * fakegen.random_digit() + 1 #for i in range(Wait_Loop): # Work_Count = Work_Count + i # ループカウンタの更新 Counter=Counter+1 # デバッグ用データ表示 #print("生成済みデータ番号 : " + str(Counter)) except KeyboardInterrupt: print('!!!!! 割り込み発生 !!!!!') finally: # デバッグ用データ表示 print print("生成したデータの総数 : " + str(Counter)) # データベースコネクションを閉じる db.close() print("処理終了!!")MySQL側の設定について
Equalumは、MySQLが機能として実装しているバイナリログの状況変化を活用する形で、非常に高速・高効率なストリーミング機能を実現しています。(MySQL以外のデータベースでも、類似の機能を実装している場合(Oracle,MS-SQL等)には、同様にストリーミング機能を活用する事が出来るようになっています)
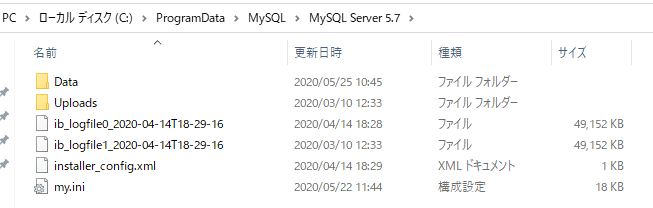
今回検証で利用するMySQLの場合、各プラットホーム上で設定される初期化ファイルの中に、バイナリログを使う設定を記述しなければなりませんので、下記の情報を参考に忘れずに初期化ファイルを更新しておく必要が有るので、取り急ぎ以下の作業を行います。今回は、WindowsネイティブのMySQLを使いますので、エクスプローラのオプションで隠しファイル等を見れるようにしてから、
ProgramDataフォルダ(通常は隠れています)を開いてMySQLフォルダ内の利用バージョンフォルダに移動します。
この中にmy.iniというファイルが有ると思いますので、そのファイルに以下の情報を設定します。[mysqld] log-bin=mysql-bin server-id=9 binlog_format=row binlog_row_image=full expire_logs_days= 10idについては、ユニークであれば問題無いと思いますので、今回は一桁最後の番号にしてみました。この辺のバイナリログ設定に関する情報は、既に多くの先人の皆様が情報共有されていますので、詳しい意味等はそれらの情報を参考にしてみてください。
MySQLの文字コードの設定
今回はMySQLに対して日本語データの出し入れを行いますので、念のため文字コードの設定も行っておきます。基本的には以下の3項目に対しての設定が実施されていれば、文字化け等は起きないと思いますので、前述のバイナリログの設定と併せて実施しておきました。
[mysql] default-character-set=utf8mb4 [mysqld] character-set-server=utf8mb4 [client] default-character-set=utf8mb4SQLクライアントをどうするか・・・
基本的には上流側のデータソース、下流側のターゲット、間を取り持つEqualum、あとはPythonの実行環境があれば検証は実施出来るのですが、今回はGUIベースで環境内のデータを見たり、基本的な環境制御が出来るように、DBeaverというツールを使う事にしました。これはWindows以外にもMac等の環境でも同じように使う事が出来るので便利だろう!というシンプルかつ短絡的な理由によります。(苦笑)
では!検証スタート!!
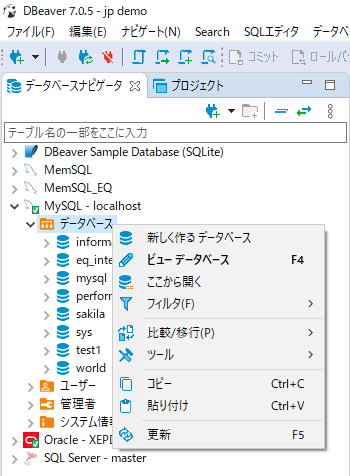
まずは、上流側に作成したツールが流し込むデータベースをDBeaverで作成します。
次にこのデータベースに「カラム設定のみ」を自作のPythonツールで行います。
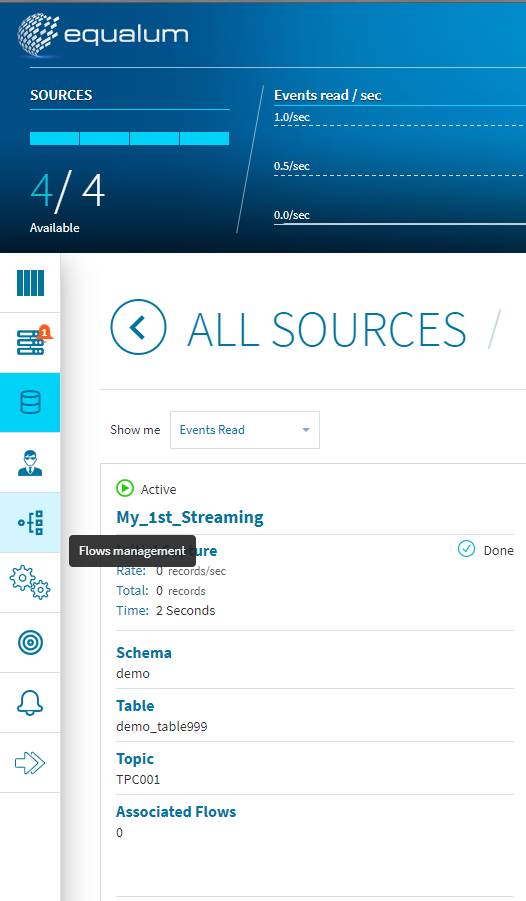
無事にテーブルが出来た様なので、Equalumを起動します。(データソースの設定などに関しては前回ご紹介した通りです)
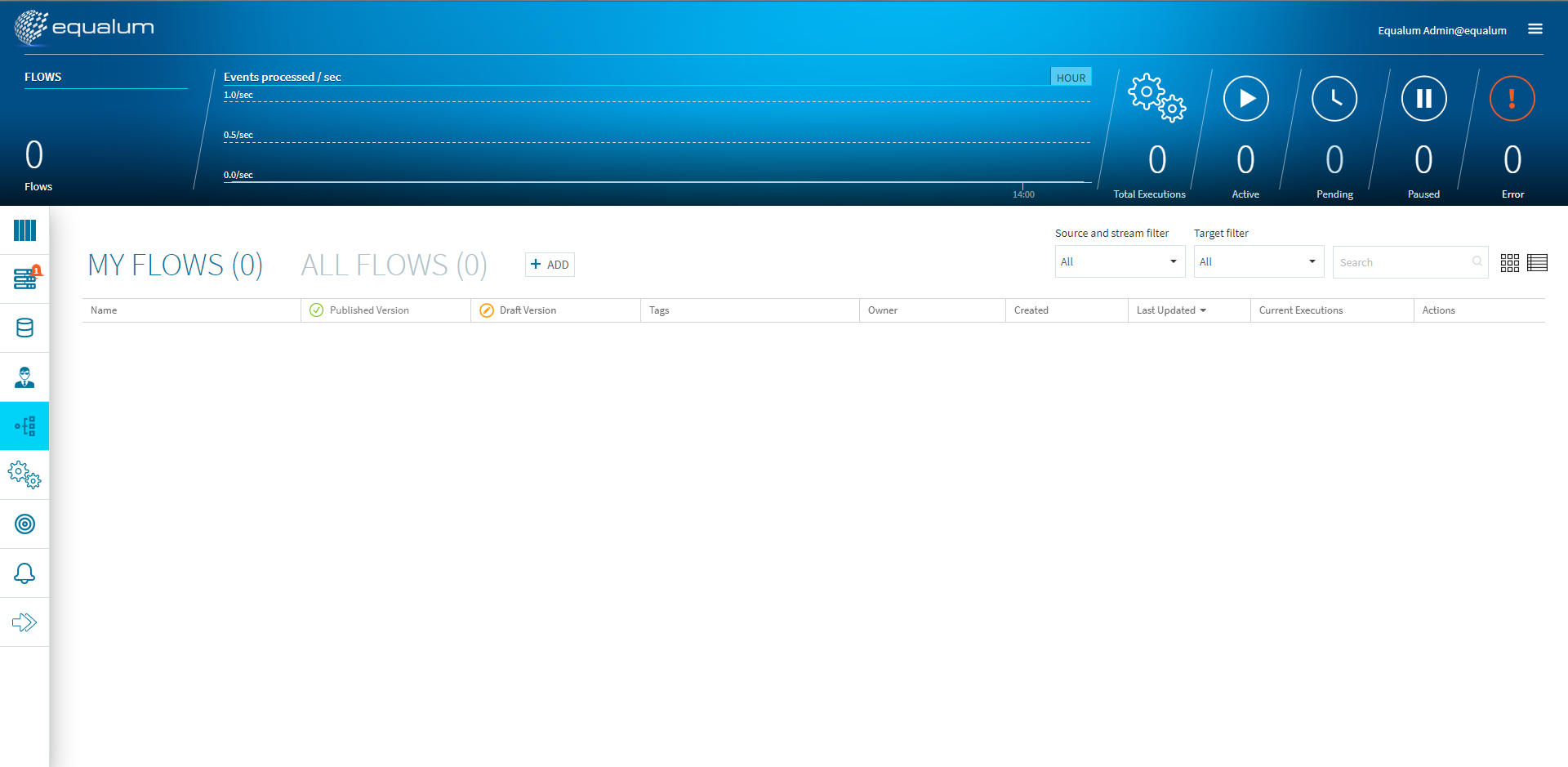
ソース側に必要情報を設定します。次にこのストリーミング設定を使ったFlowのデザインを行います。ダッシュボード左側の[Flows management]を選択します。
画面の真ん中位にある[+ADD]ボタンを選択します。
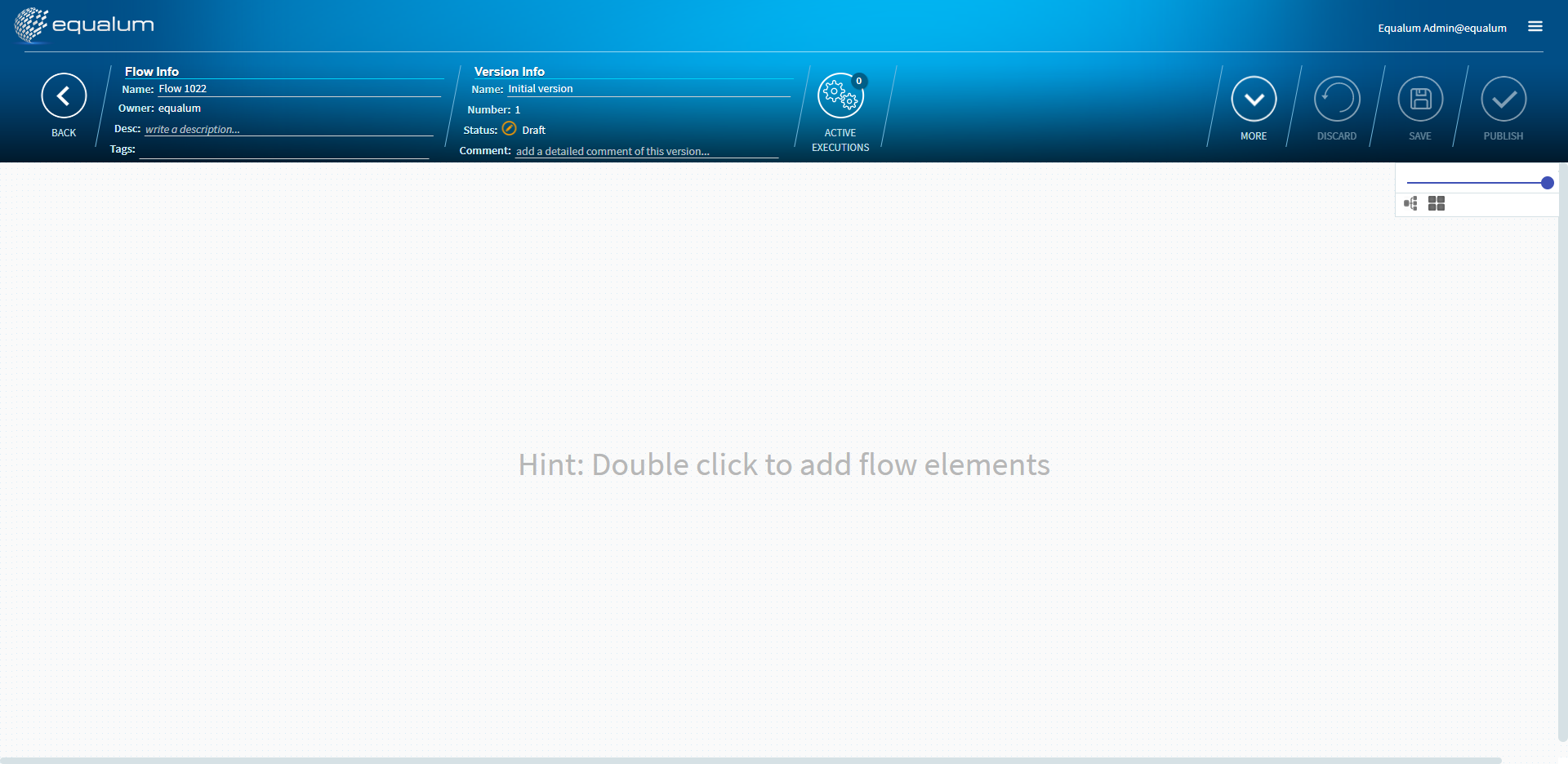
この画面が、GUIベースで各種のFlowをデザインする画面になります。
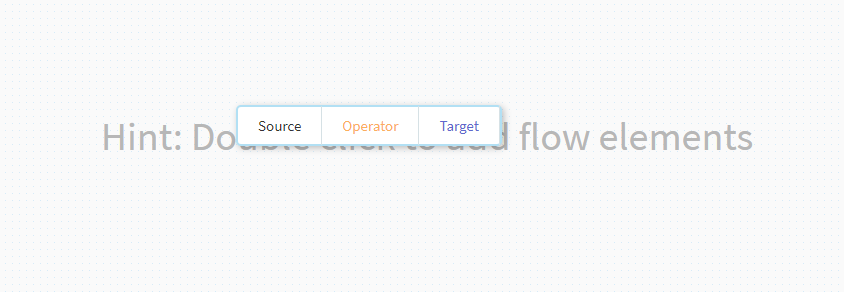
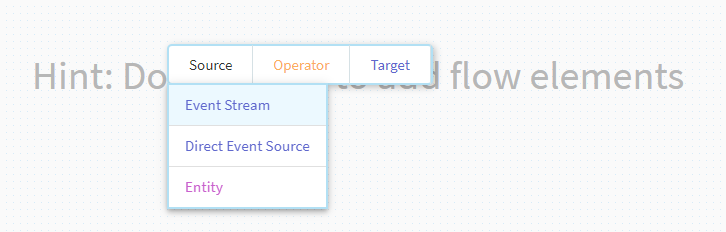
未だ何も設定が有りませんので、画面中央でマウスをダブルクリックします。
ポップアップメニューが出てきますので、左側の[Source]を選択します。
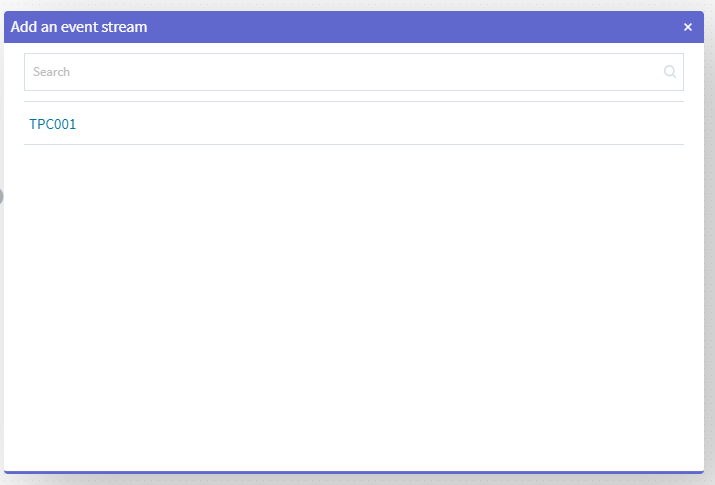
通常のストリーミング設定ですので、ここでは[Event Stream]を選択します。
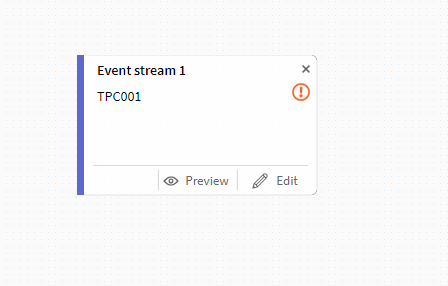
先ほど登録したトピックが出てきますので、その項目をクリックして選択します。
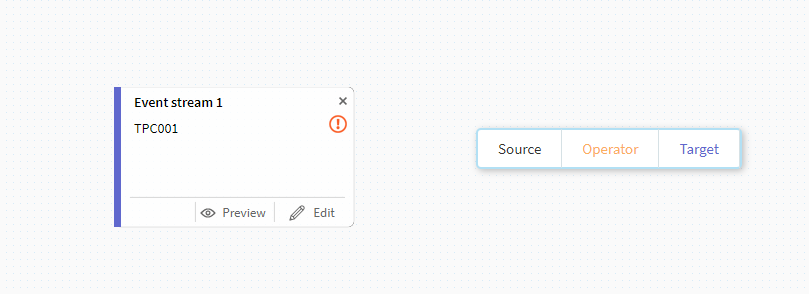
画面上にアイコンが出てきます。
今度は先ほどと同様にターゲット側の設定を行います。
標準装備でHDFSベースのEQUALUMという選択も可能ですが、ここでは以前より検証しているMemSQLを選択します。
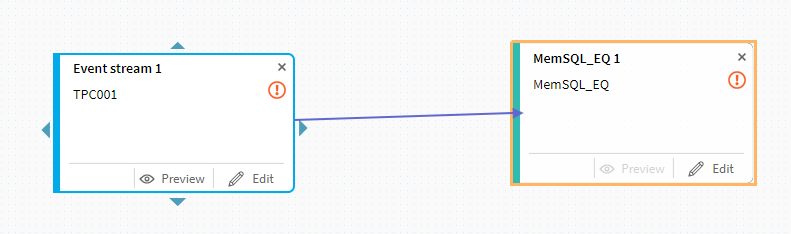
これで、今回の基本的な構成要素が準備できました。
次に上流側のトピックにある三角マークをクリックしてターゲット側までドラッグします。
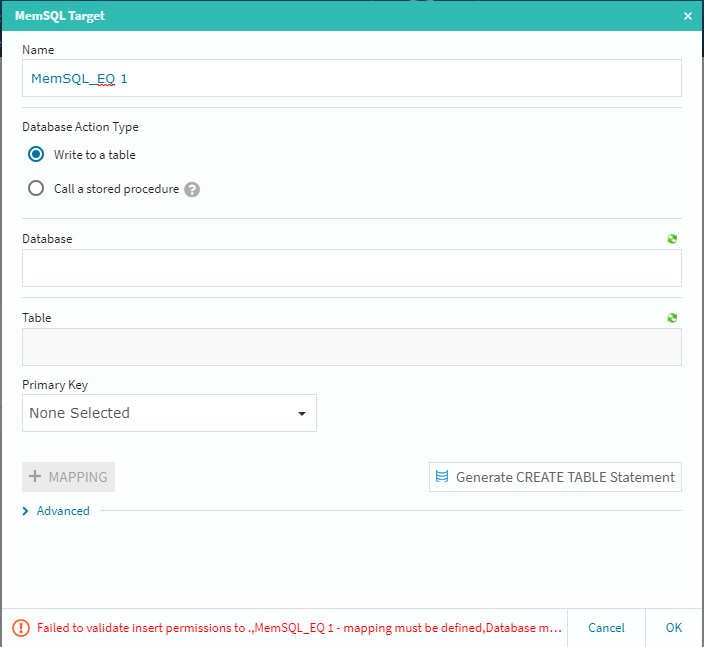
今回の検証では、基本的に途中の処理を省いた「シンプルなストリーミング」を行いますので、その前提でそれぞれの最終的な設定を行って行くことにします。基本的には下流側の[Edit]ボタン経由での設定・確認作業になりますので、MemSQL側の[Edit]ボタンをクリックします。
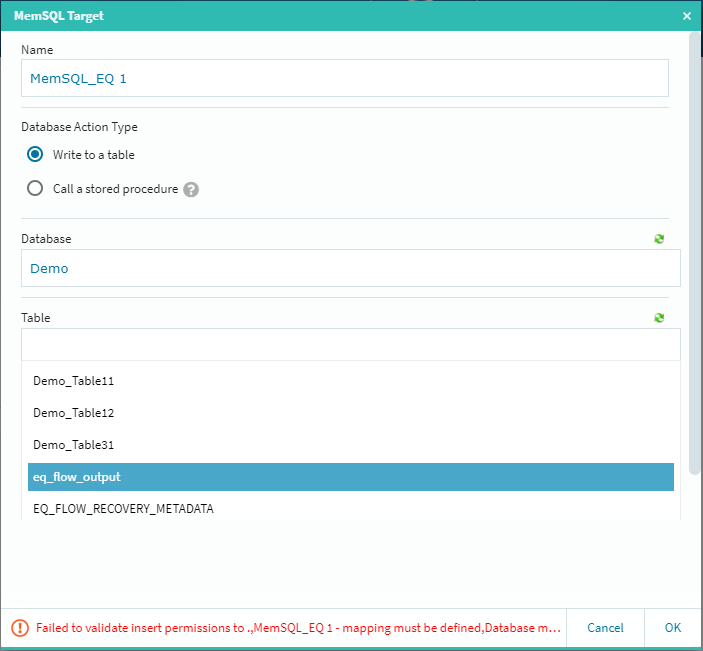
ここでは[Database]と[Table]を設定する必要がありますが、予め受け側のテーブルを作成していなくても、[Generate CREATE TABLE Statement]ボタン経由で自動的にこの場所からMemSQL上にターゲットテーブルを作成する事が可能です。もちろん、その編集をその場で行ってカスタマイズしたテーブルにする事も可能です(この場合はカラムの選択作業等が追加されます)
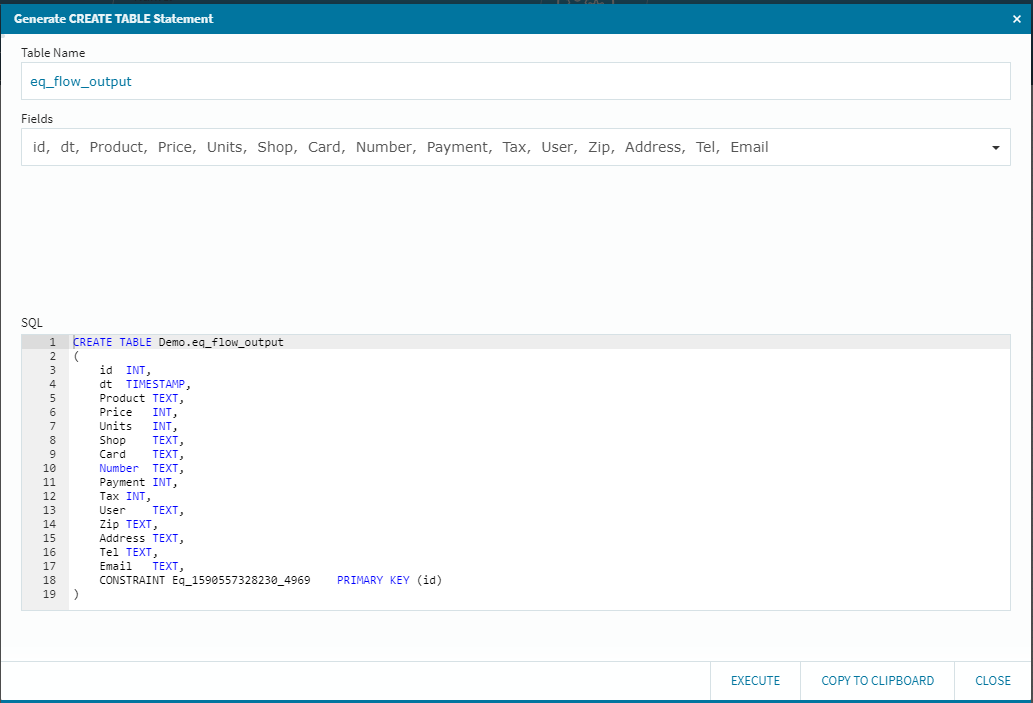
今回は、単純な総カラムレプリケーションを行いますので、データベースを選択して[Generate CREATE TABLE Statement]ボタンを選択します。
先ほどの連携定義により、上流側のMySQLからカラム情報を引っ張ってきて、ざくっとSQL文を作成しています。(もちろん、このSQLエリアは編集可能ですので、必要に応じて編集を行う事も可能です)また、自動的に[Table Name]も設定してくれますが、これも任意のテーブル名にする事が可能です。(今回はサクッとそのまま行きます!)
右下の[EXECUTE]ボタンを選択して処理の成功を確認後に[CLOSE]を選択して閉じます。
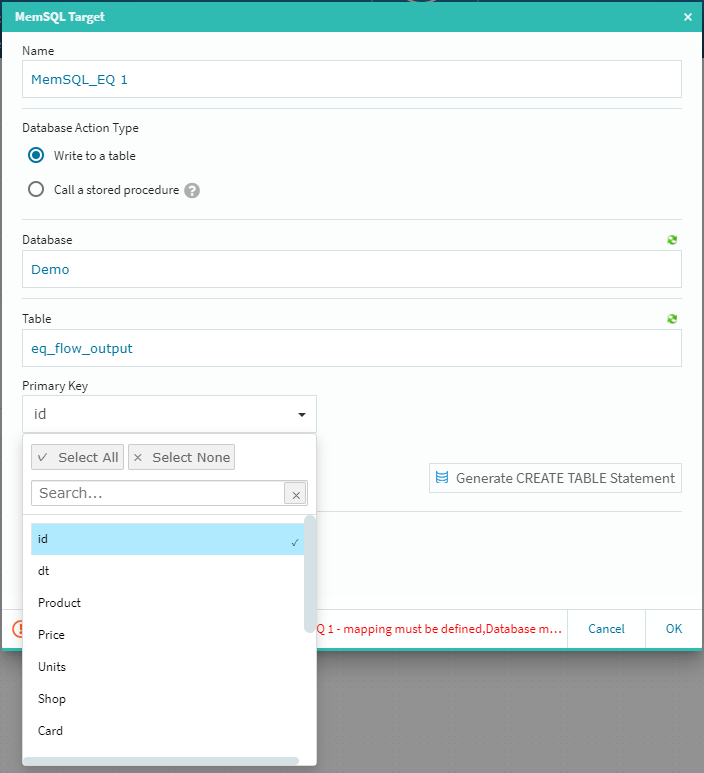
テーブルの選択メニューに先ほどのテーブル名が出てきますので(右上の緑色のアイコンをクリックすると情報が更新されます)そのテーブルを選択します。
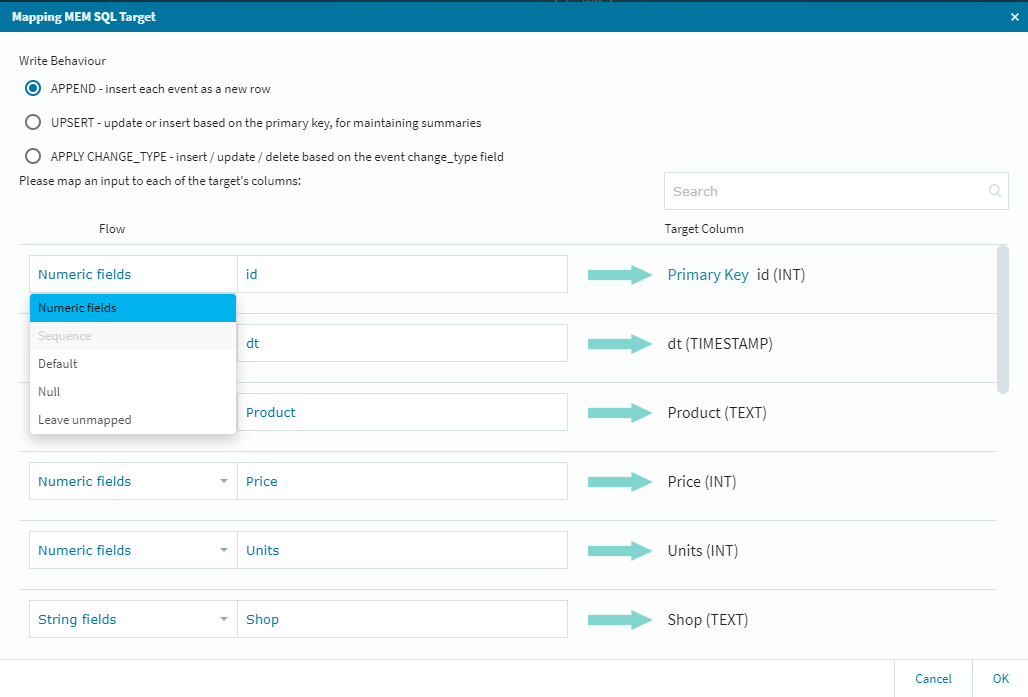
[Primary Key]のプルダウンからキーを選択し[+MAPPING]ボタンをクリックします。
ターゲットに対する細かな調整が必要な場合は、ここで作業を行っておきますが今回はそのまま右下の[OK]を選択し、ターゲット側の設定を終了します。では!ストリーミングしてみます!!!!
此処までの簡単な設定で、基本的なストリーミング処理の設定は終了です。あとは登録した内容を[SAVE]して[PUBLISH]し、データ生成側の準備を確認して[DEPLOY]すれば高速ストリーミングの準備OKです。
その前に念のために上流側と下流側のデータ格納状況を確認しておきます。
画面の右上にあるボタンで設定を保存して実行可能状態にしておきます。
準備が出来るとボタンの並びが変わります。
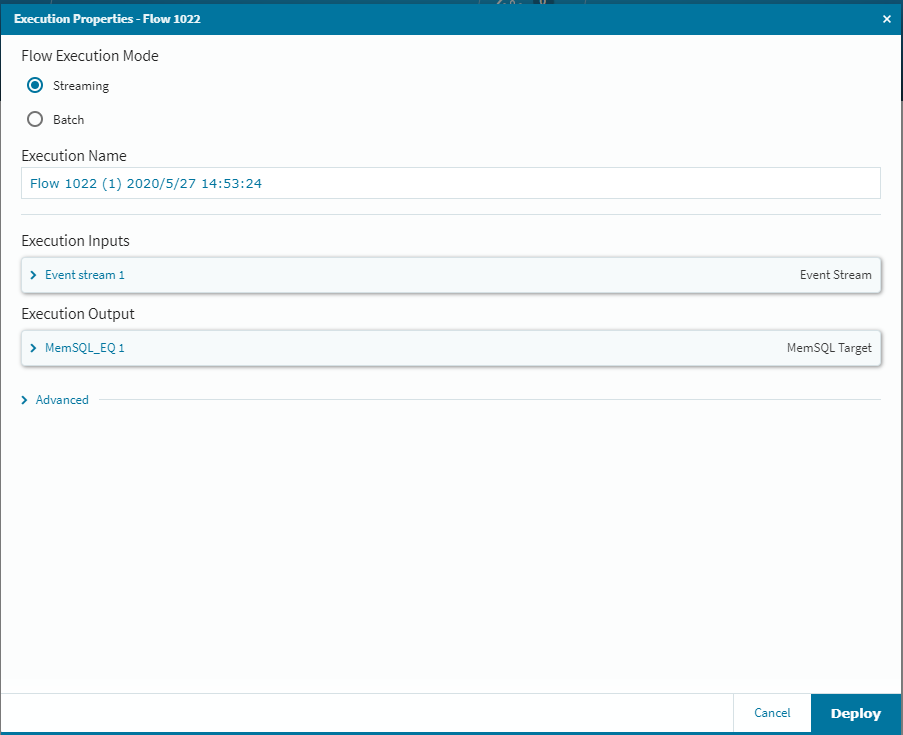
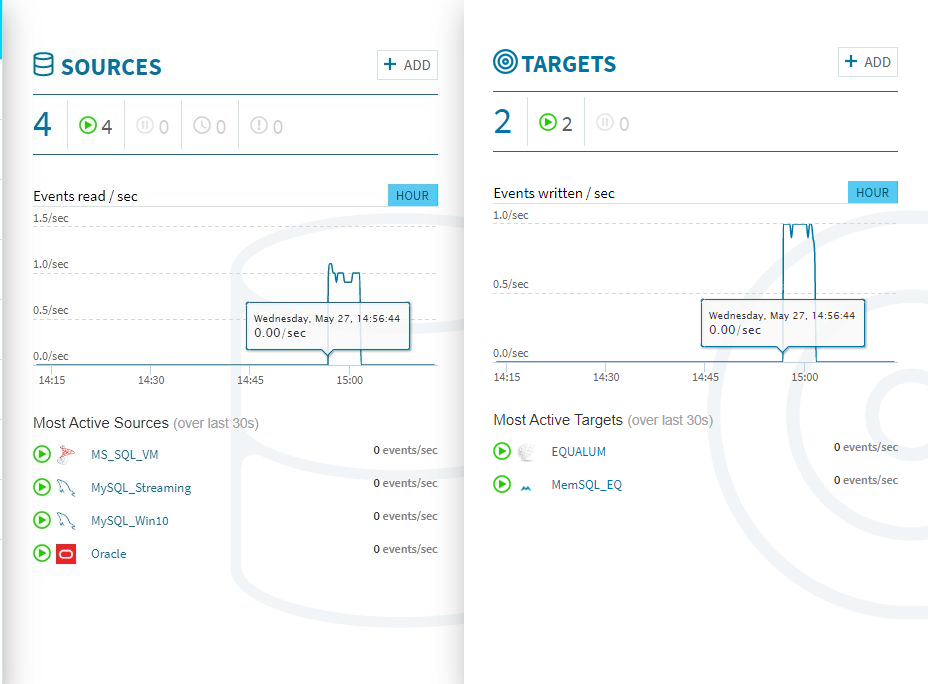
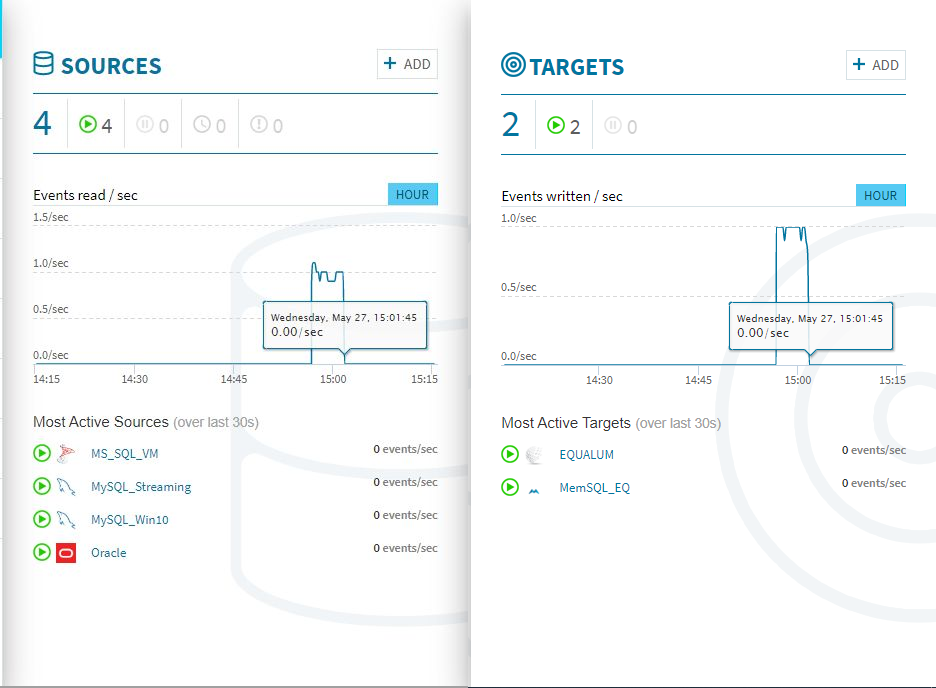
一番右側の[EXECUTE]を選択し[Deploy]をクリックすれば、データの流し込み待ち状態になりますので、自動生成ツールを起動してデータを順次上流側のMySQLに書き込んでいきます。今回は300個のデータを自動生成してSleep1の間隔で書き込む設定で検証しました。
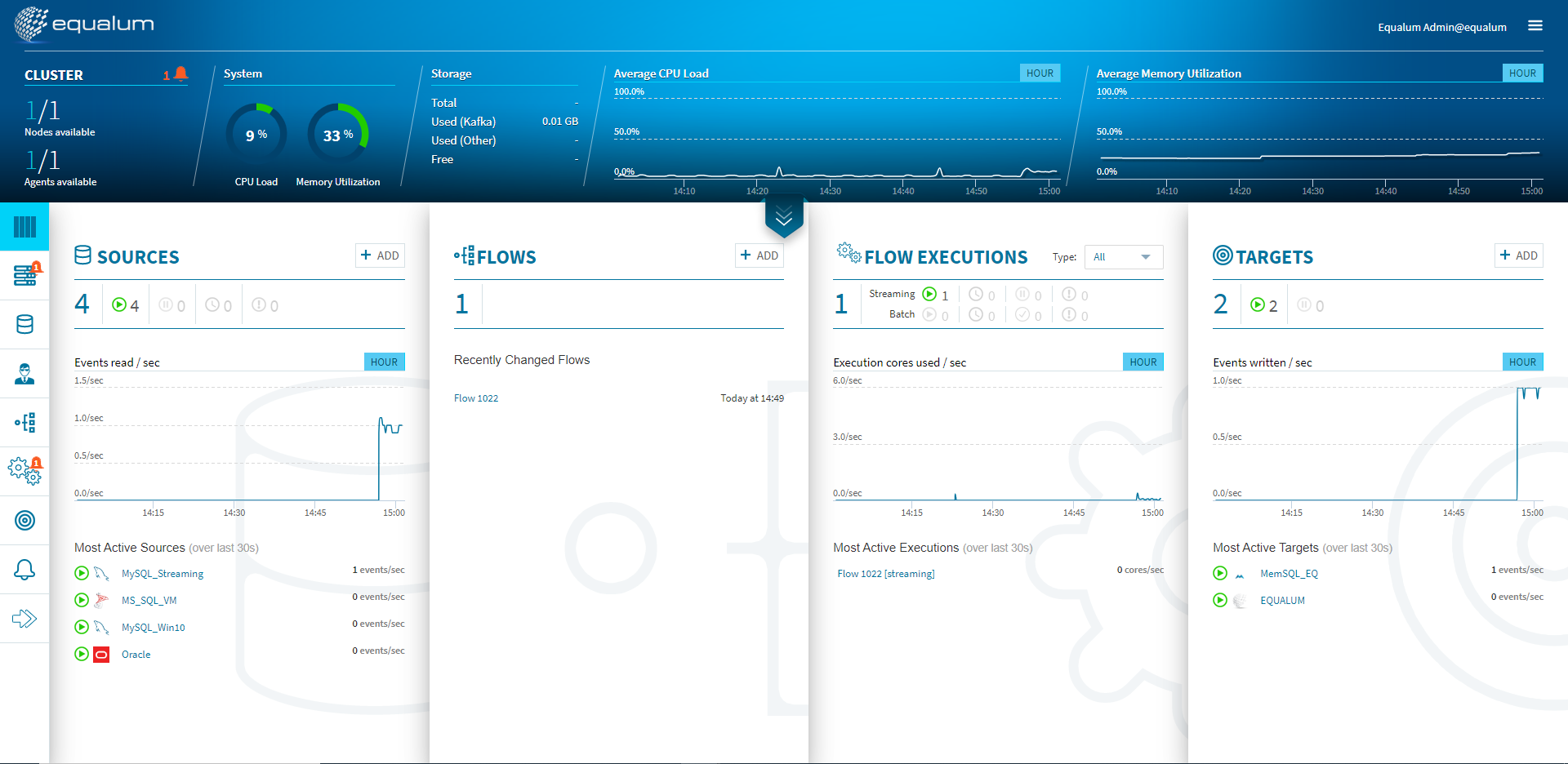
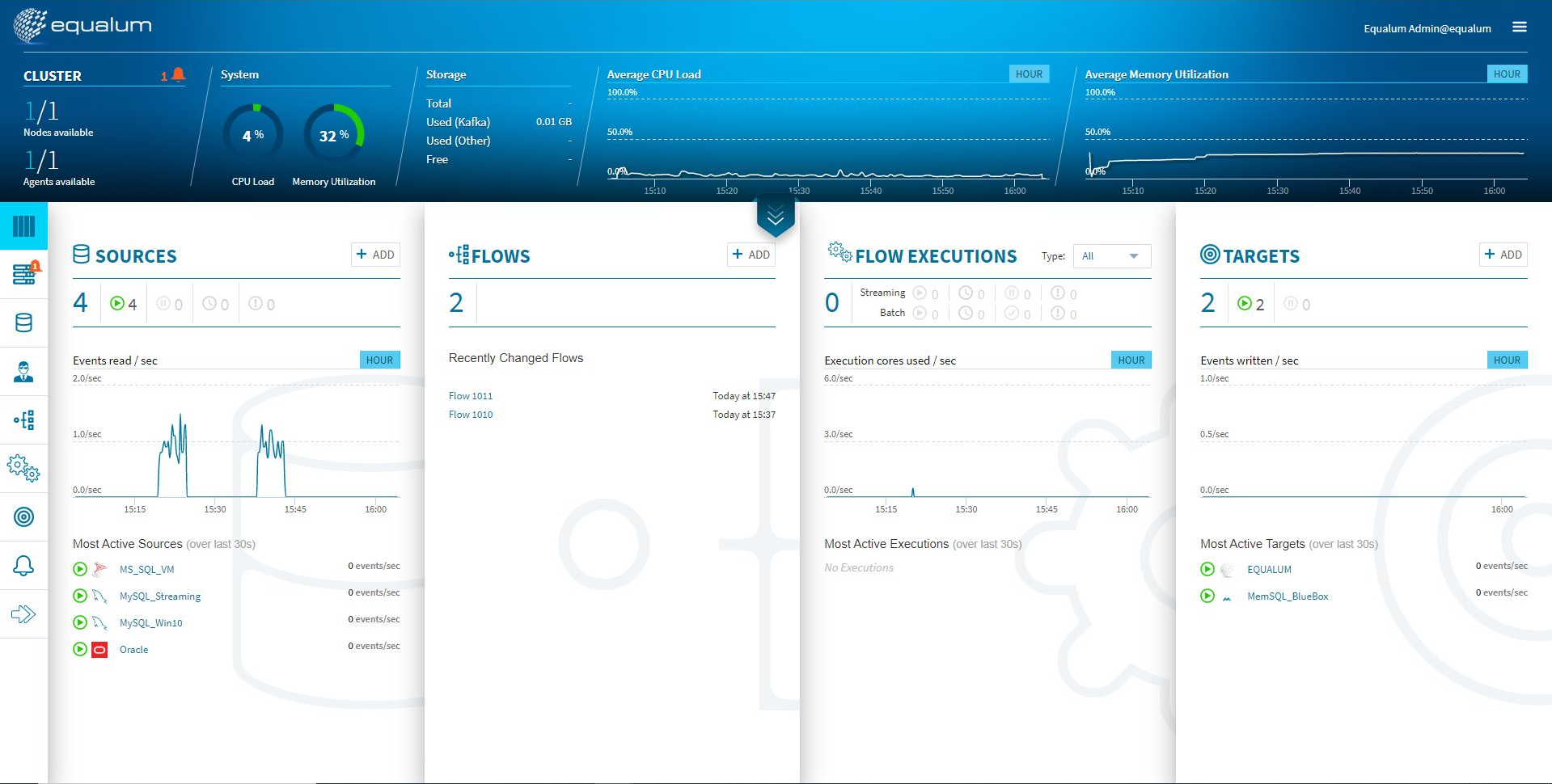
検証開始後、上流の[SOURCE]側のモニターグラフと、ほぼ同時に[TARGETS]側のモニターグラフに変化が現れました。CPUやメモリの使用量も増えている事が確認できます。
300個のストリーミング処理があっという間に終わってしまいました。
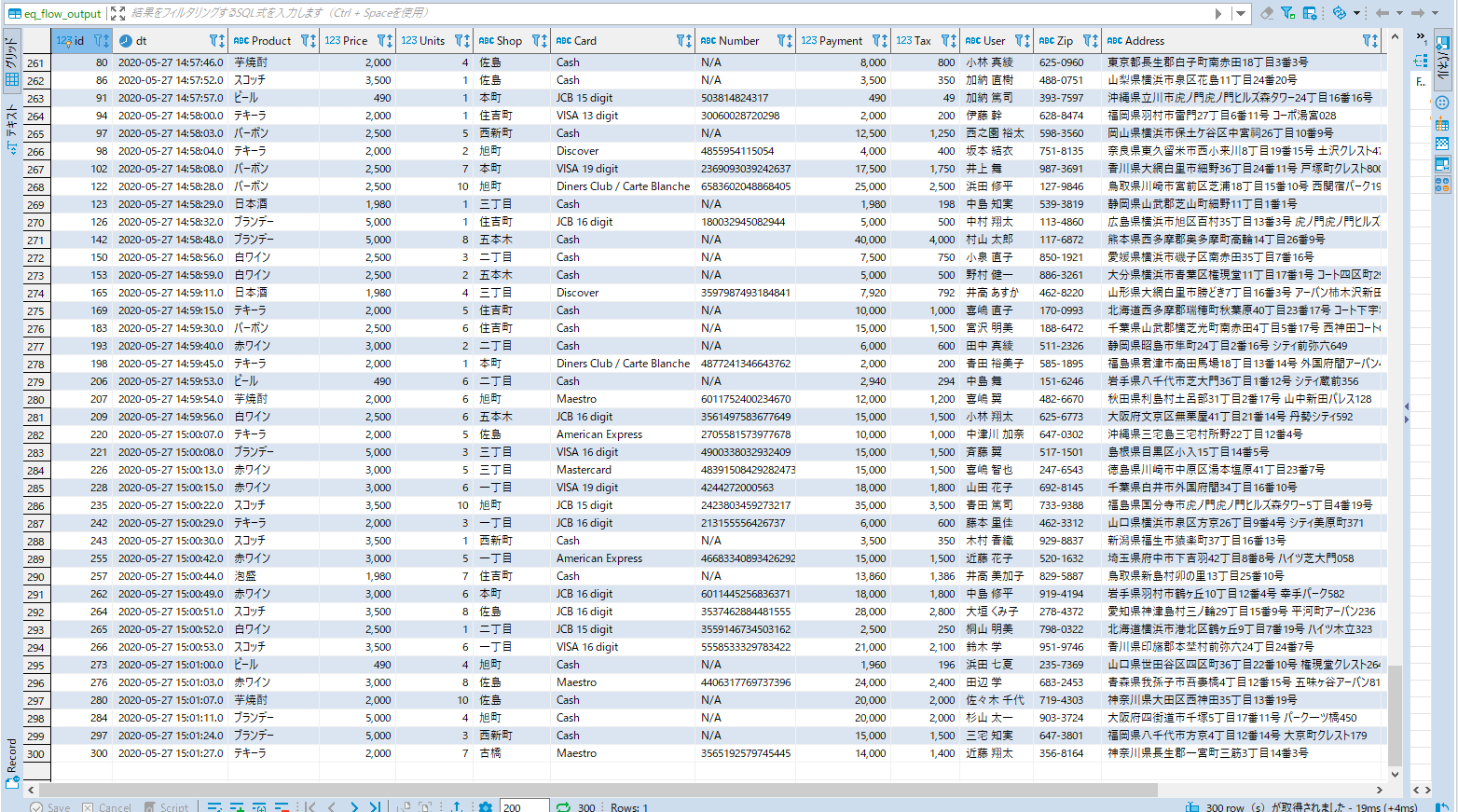
念のためデータの格納状況をDBeaverで見てみます。まずは上流側のMySQLに格納されたデータを確認・・・
次にMemSQL側を確認・・・
無事に入っている様です。
ちなみに、Equalum側の処理時間を見ると上流側にデータが格納されたタイミングと同タイム(実際にはコンマ以下の時間は異なると思いますが)でターゲット側の処理がスタートし、MySQL側への処理が終わったタイミングでMemSQL側の処理も終了していました。
今回のまとめ
今回は、前回に引き続いて基本的なストリーミング処理に関する実際の検証を行ってみました。形式的には単純なフルコピーのレプリケーション実験になりますが、デスクトップPC上でも非常に高速に上流側の変化を捉えて、即時下流側のターゲットに反映させる事が可能だという処理能力の高さを確認する事が出来ました。
また、これらの高性能を非常に簡単にプログラムレスの環境で実現する事ができるので、データの利活用領域において(従来のIT的な領域ではなく)データ周りを得意とされるユーザ層が、セルフで色々と問題解決の為の試行や各種の(ML/AI/BI等)データをフルドライブできるツールになる可能性が有ると同時に、現実的に散在するサイロ化された多くのデータの壁を取り払い、下流のマイニング層に対する可能性を大きく広げるソリューションになり得ると感じました。
次回以降では、今回のシンプル・ストリーミングをバージョンアップさせて、間に[Operator]を設定する条件で追試してみようと思います。速さの為の速さ
これは、使い勝手を向上させると同時に「変化に強いデータ・ドリブン環境」を実現する上で非常に重要なポイントになる事を明確に示しているという事なのかもしれません。
謝辞
本検証は、Equalum社の特別の許可を得て実施しています。この貴重な機会を設定して頂いたEqualum社に対して感謝の意を表すると共に、本内容とEqualum社の公式ホームページで公開されている内容等が異なる場合は、Equalum社の情報が優先する事をご了解ください。






- 投稿日:2020-05-27T16:36:19+09:00
Equalumがやって来た!(概要編)
突然ですが!今回は「Equalum」なるモノを弄ります。
これまで数回に亘って、”MemSQLとその周辺”に関して簡単な検証作業の状況を共有させて頂きましたが、今回は唐突に!極めて自己都合による検証作業を行う必要が発生し、その結果を皆さんと共有させて頂く事にします。
今までの作業は、基本的に高いMySQLとのSQL互換性と、ネイティブな「インメモリ」、また従来型のSQLデータベースでは、定期的な頭の痛い作業であった、初期サイジングを超えた場合や、一定期間を過ぎた際のデータ移行や性能強化への対応に対して「スケール」可能といった部分で、昨今のBI、ML、AIといった「データマイニング系用途」に対して、非常に高く且つ持続発展可能な投資対効果が期待できる、Dx時代の新しい・・しかし従来型の経験や資源が活用可能なデータソースとしてMemSQLの可能性を、各種の検証作業を通じて共有させて頂きました。
最終アプリケーションへの高速&柔軟対応が出来る事は判った・・・
MemSQLの柔軟性(今までのMySQL経験が活用出来たり、その周辺の構築してきた環境が「殆どそのまま転用可能」)や、ネイティブなインメモリ技術をフルに活かした高性能処理(I/O,SQLトランザクション)については、導入後シンプルに利用出来る事はご理解頂けたかと思います。また多くの方が、BIの性能問題やDWHの構築までは無理としても、出来るだけ時世に適合出来る速度・柔軟性で、データマイニングを活用したい!と考えられているかと思います(もちろん、IoTやソーシャルxx、また今後発展が期待されている5G社会での新たな可能性への挑戦など・・・)
でも!But!しかし・・・・
流石のMemSQLもデータが流れてこなければ、単なる初期導入費用と維持管理や電気代等の金喰い虫になってしまう事は自明の理だと言えるでしょう。データを大量に且つ高速に処理するにはどうすれば良いか?従来型のアプローチで保守本流・王道のDWH構築をスクラッチから行うか??・・・しかし、間違いなくデータを必要としている現場からのニーズは、
(1)スピード
(2)効率
(3)柔軟性
を全部実現してくれ!という状況になっているのではないかと思います。
出来上がった時には、市場も競合も自社も前提条件が変わってしまって・・・・では、Dxの重要アイテムであるデータドリブンを云々言っている場合では・・・そもそも無い!という状況になってしまいます。速さを活かす為の速さ
速くSQL処理が出来るのであれば、その価値を最大化させる為には「必要なデータを」「必要なタイミングで」「出来るだけ高速・高効率で」収集・展開・処理しなければなりません。
では、どうやってデータを流し込むか・・・
MemSQLの検証を行っている際にkafka等のメッセージブローカーや、ネットワーク上に共有されているディレクトリ等を経由した、「パイプライン機能」を紹介させて頂いたかと思います。既存の幾つかのクラウドストレージ系や、前述のファイルシステムを介したデータ収集であれば、比較的簡単に活用モードに入る事は可能かと思いますが、現実的に考えた場合に「何処にデータが存在しているか??」という大きな、しかし極めて現実的な問題に直面する事になります。もちろん、全く新規の仕組みをスクラッチから構築するのであれば、全ての構成要素に対してかなりの自由度が効きますが、何年もかけて運用ベースに至るまで作り上げてきた既存の仕組みを弄る・・・これは、正直かなり勇気が必要なチャレンジになるかと思いますし、この辺の現状が「あと一歩の所で、データドリブンを諦めるか・・Dxに踏み切れない理由」なのではないかと考えています。データを活かして、より良いデータ(結果)を創る・・・これが、データドリブンの基本だと思いますので、今回から数回に分けて、その辺の壁を突き崩せるかもしれない、新しい可能性について検証を進めて行く事にします。
そこで、満を持してEqualumの登場・・・
Equalum社については、同社のホームページを一読して頂ければと思いますが、現在シリコンバレーに活動拠点を持ち、実際に多くの企業に採用が決まってきている、新進気鋭のベンチャー企業になります。日本国内の展開も開始され、StrategyCore社が国内市場開発を始めており、日本語での対応が必要であれば同社の問い合わせ窓口へメールを送って頂ければ幸いです。
製品の特長
Equalumの特徴は、大きく分けて以下の3つになります。
(1)複雑な処理をシンプルに
(2)必要なデータを必要な場所に必要な形で
(3)高速な処理と柔軟な展開一般的には、この類の仕組みをスクラッチ状況から構築する場合、各種のOSSを熟知したうえで「適材適所」且つ「適宜適量」を自前で導入・構築して行かなければなりません。もちろん最近では、それぞれのOSS自体の進化や情報共有の拡大等により、以前に比べれば圧倒的に使いこなせる状況にはなってきましたが、それでも「それらを複数組み合わせて、それぞれの繋ぎ込みを最適化する・・等」は、それなりの覚悟と経験が必要な事も事実でしょう。
Equalumは「データ・インジェクション」を如何にシンプルに実現するか?そしてその処理に要求される機能(複雑化の要因)を同時に如何にシンプルに提供するか?に注力した製品になっています。従来型の同種の仕組みに見られるような、既存の各段階を順番に進めていって「半年~1年後に稼働」という事ではなく、「導入後1-2週間で稼働(或いはそれ以下)」が誰でも実現出来るように設計・開発が進められている点が大きな特徴になります。
現在の企業・団体におけるデータのサイロ化問題は、ある部分でデータドリブンによるDxを減速させる大きな要因になっています。多くの従来型データシステムは、基本的に期間を単位として(その理由の多くは、データサイズの制限や維持管理、特に拡張作業時のコスト・リスク問題によるかと思います)、一旦記録されると基本的には電子帳簿として機能しますので、検索・修正が殆どの機能であり、抽出とかテーブル再構築といった、まさにデータドリブンな用途は、そもそも想定外(それよりも安心・安全を重視)の部分が大きかったと思います。
良く、日本のエンタープライズにビッグデータが存在しているのか?という話を聞きますが、たぶん磁気テープまでを含めればその総量は十分ビッグデータなのだと思います。もちろん、最初から不特定多数でスケール必須のデータシステムとして想定される、ネット系の仕組みに関しては、そもそも従来型のサイジングが難しいという事もありますので、ここ数年で急速に進化してきている クラウド技術の展開として、ビッグデータ技術を前提とした実装が普通になっいる領域も多くなってきていますが、基本的に電子帳簿型(OAの黎明期からの基本コンセプト)の仕組みとしての、既存型データソースを如何に低リスクで活用出来るか?!が重要なポイントになってきているのも事実でしょう。複雑でかつ広域に分散するデータをかき集めて、必要な処理を並行して行いながら、ストリーミングで最終的な活用テーブルに収める・・この一連の処理に必要な条件として、これらの処理を高速に行いながら同時に高い処理効率を維持出来るようにしなければなりません。大量のデータを処理する技術としては、ビッグデータ等の技術を転用すれば難易度は別にして実現する事は可能だと思いますが、その為に幾つかの異なる技術を、効率的かつ効果的に組み合わせる作業・・・これは、ある部分で機能(柔軟性)と性能の両立を難しくしている部分でもあります。Equalumの場合は、この難題について独自の技術を組み合わせる事により従来では出来ないか非常に困難であった、ストリーミングでデータを処理出来る機能も提供しています(複雑なプログラミング無しで)。
検証環境の構築について
現在、Equalum社ではホームページ等を通じた期間限定の仕様ライセンスの提供を公式に行っていません。基本的には実ビジネスを前提とした本格的なPoCを商談ベースで実施していく形になっていますので、以下の情報はあくまでも参考という事でご理解頂ければと思います。
(今回は、日本語データの動作検証も兼ねて特別に試用を許可して頂きました)稼働するOS Linux CentOS7 64Bit(RHELの等価版でも対応可能)
インストール形式 ネットワーク・インストール(オフラインで持ち込む形式も応相談で可能)
構成H/W 3台のクラスター構成を推奨(最低1台から可能、但し機能評価レベルまで)
推奨:メモリ容量 64GB(デモ等であれば16GBから動作可能)
推奨:コア数 16 (デモ等であれば4-8コア程度から動作可能)今回の検証環境は、32GBのメモリを搭載したCore i7(4コア:8スレッド)のデスクトップ機で実施しました。
基本的にEqualumのコンソールはWeb経由になりますので、サーバのIPアドレスとポート番号を入力して、ID/パスワードを設定すればOKです。
既に複数(評価版を使わせて頂き、接続確認を行いました)のデータソースと、幾つかのFlow処理手続き、また最終的にデータを受け取るターゲットの設定が行われていますが、正常に立ち上がるとこの様なコンソールが出てきます。
全体の流れについて
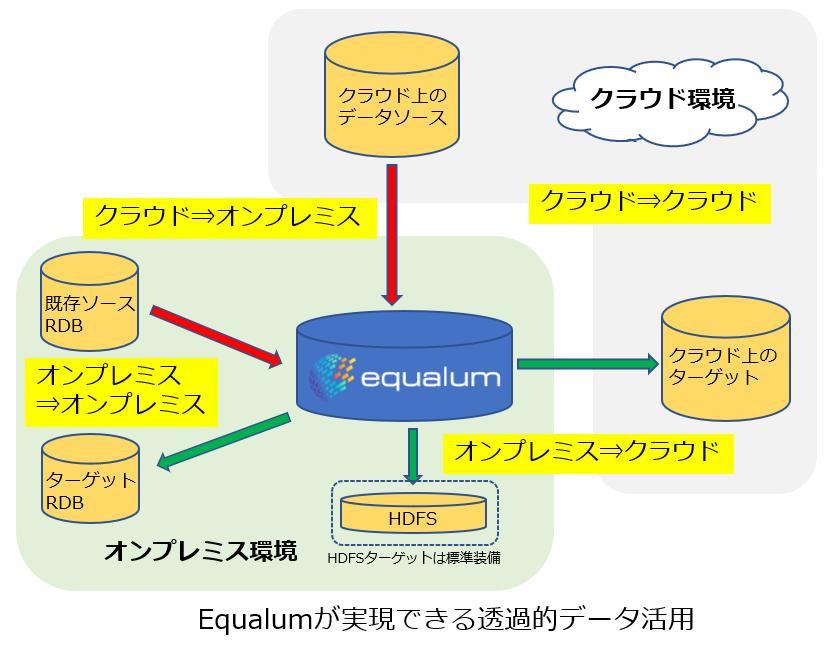
まず初めに最上流側のデータソースの設定を行います。バッチ処理系であれば通常のJDBC接続と殆ど同じ設定で手続きは完了しますが、今回の検証における大本命のストリーミング処理については、幾つかの事前の設定が必用になりますので(今回はMySQLでの検証を行います)その詳細については、この後に背景等を含めて説明させて頂きます。
次にターゲットの設定を行います。標準でEqualumではHDFSベースのストアを用意していますが、今回はいつものMemSQLを使ってみることにします。導入にこちらも基本的には一般のデータベース情報の設定になりますので、正式なPoC等で作業される際も特に問題になる事は無いかと思います。
では取り急ぎ此処までの作業を行ってみます。
データソースの設定
[SOURCE]の右上にある[+ADD]ボタンを選択します。
今回検証した環境では、これらのデータソースを上流側に設定する事が出来る仕様になっていました。現在も継続的に開発は進行していますので、今後更に各種のデータソースから必要なデータを必要なタイミングで必要な処理を行って取り扱う事ができるようになると思います。
今回は、ストリーミング処理の検証を行いますので、この機能(実際にはデータソース側にこの機能を実現できる仕組みが必要ですので、全てのデータソースで可能という訳ではありません)をサポートしているMySQLを接続してみたいと思います。
(1)まず全体の名称としてSource Nameを指定します(ここではMySQL_Streaming)
(2)接続するデータソースが稼働しているホスト情報を設定します(ポート番号含め)
(3)データベースにDDLでアクセス可能なアカウントのユーザ名(今回は無条件で禁断のrootを指定しています)
(4)同様にパスワードも設定します。基本的に
に関しては一番上のメニューでOKです(その他の詳細は別途共有させて頂きます)(5)タイムゾーンを適宜選択します。
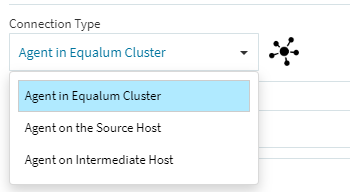
(6)[Capture Type]をバイナリ・ログにします(この前準備がMySQL側に必要になります)
(7)モニタリング間隔はとりあえず初期値で作業を行います(この数値は全体バランスを見て適切に設定します)
ここまできたら、下部左側にある[TEST CONNECTION]を押してみます。設定に問題がなければコンソール上部に緑のメッセージが出ますので、[CREATE]ボタンを選択して正式にソースを登録します。ターゲットの設定
[TARGET]の右上にある[+ADD]ボタンを選択します。
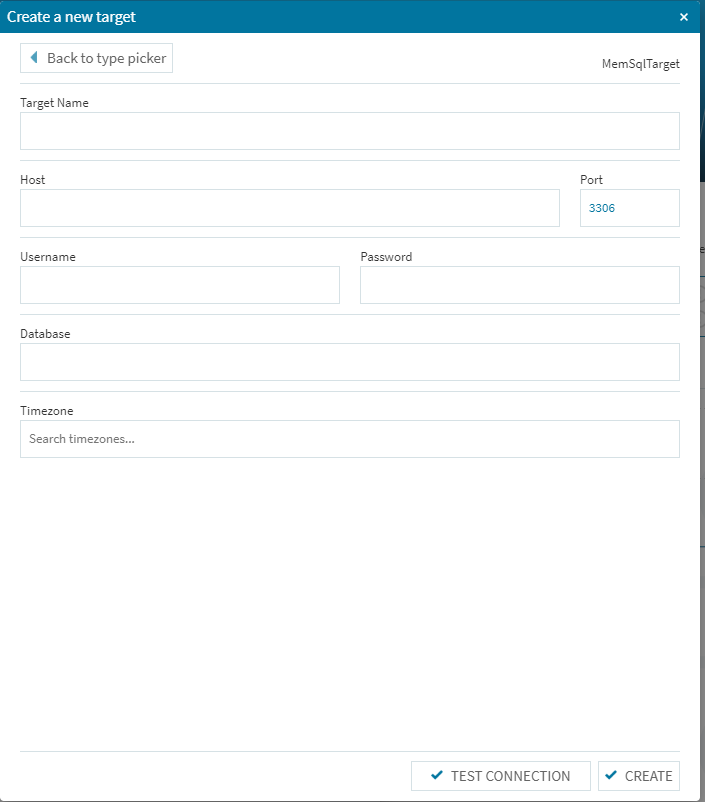
今回検証した環境では、これらのソースから適宜ターゲットを選択する事が可能でした。もちろんこちら側の開発も順次進行していますので、今後さらにその選択肢は増えていくと思います。本検証では以前より別途検証を進めているMemSQLを受け皿側に使う事にします。
若干インターフェースは異なりますが、先ほどの上流側データソースの設定とほぼ同じ手順で作業を行えばOKです。(Database項目のみ、登録ユーザID/パスワードでDDLが効くデータベースを事前に作成して設定する必要が有ります)基本的な事前の処理はこれで終了です。
因みに・・・
前回までのMemSQL検証をお読みの方であれば、「あれっ?MemSQLのアカウントにパスワード・・・」という疑問が有るかと思います。そこで今回の検証では力技(といっても、基本的なデータベースのユーザ作成ですが。。。)で以下のコマンドをMemSQLで動かして検証用のアカウントを作成しました。
CREATE USER 'eqtest'@'%' IDENTIFIED BY 'eqpassword'; GRANT ALL PRIVILEGES ON *.* TO 'eqtest'@'%' IDENTIFIED BY 'eqpassword' WITH GRANT OPTION;ストリーミング処理の設定・・・
従来型の同種(・・と一般的に分類される)のソリューションと同じ様に、バッチ処理的な機能はより洗練された形で実装されていますので、その部分ではEqualum社が提唱する「ゼロコーディング」での環境構築を十二分に活用して頂く事は可能だと思います。ですので、今回の検証は「今起きている状況(データ)が上流側にどんどん展開される状況で、その状況を「ほぼリアルタイム」にターゲット側に向けて処理をしながらどんどんストリーミングして行く機能を動かして行きます。
一般的にこの類の処理・・・となると、基本的なイメージとしてはZookeeper,kafka,Sparkを上手く組み合わせて環境構築して、アプリ層側をJavaで作り込んでトピック、プロデューサ、コンシューマ・・・という苦行を容易に想像出来ると思いますが、Equalumはその辺のややこしい部分を上手に丸く収めて、必要な指示のみをGUIで要求してくる形になっています。
(1)Equalumにログインします。
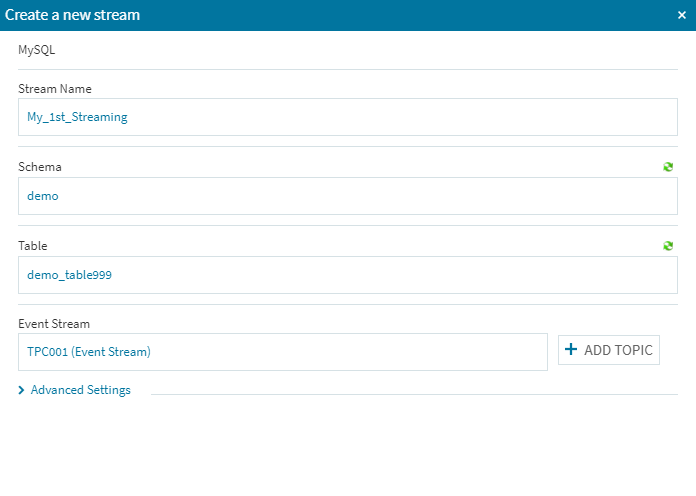
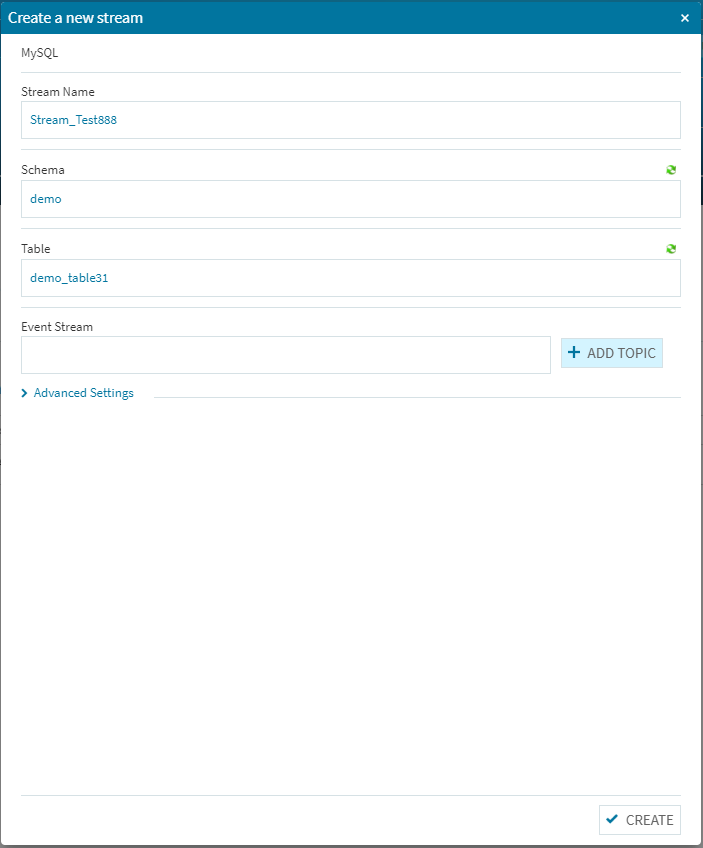
(1)まずはデータソースにアクセスして必要事項を設定します。[Streams]の右側にある[+ADD]ボタンを選択します。
(2)必要事項を埋めます。([Schema]と[Table]項目の右上にあるアイコンをクリックすると、最新のデータソース状況が反映されます)
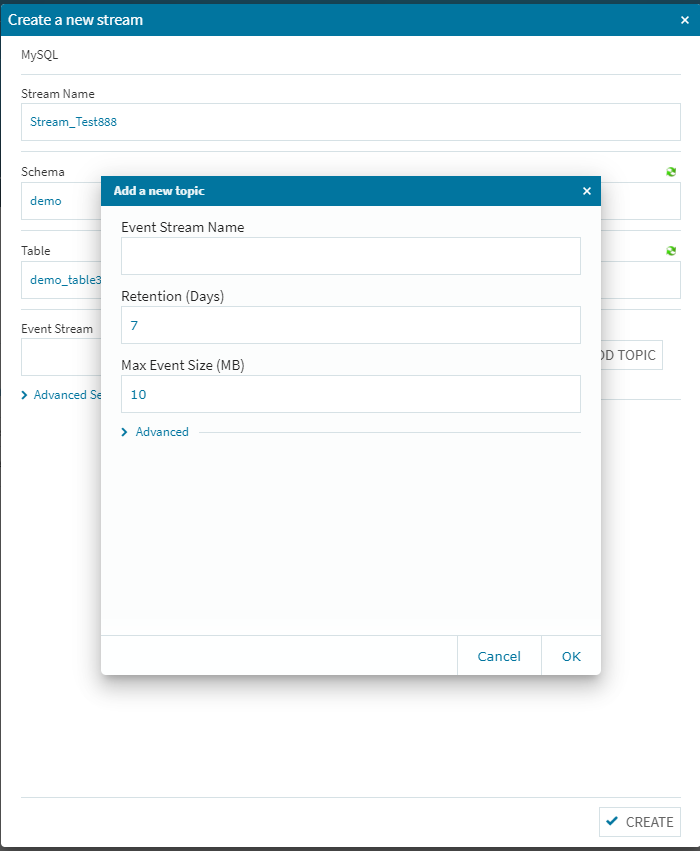
[+ADD TOPIC]を選択します。
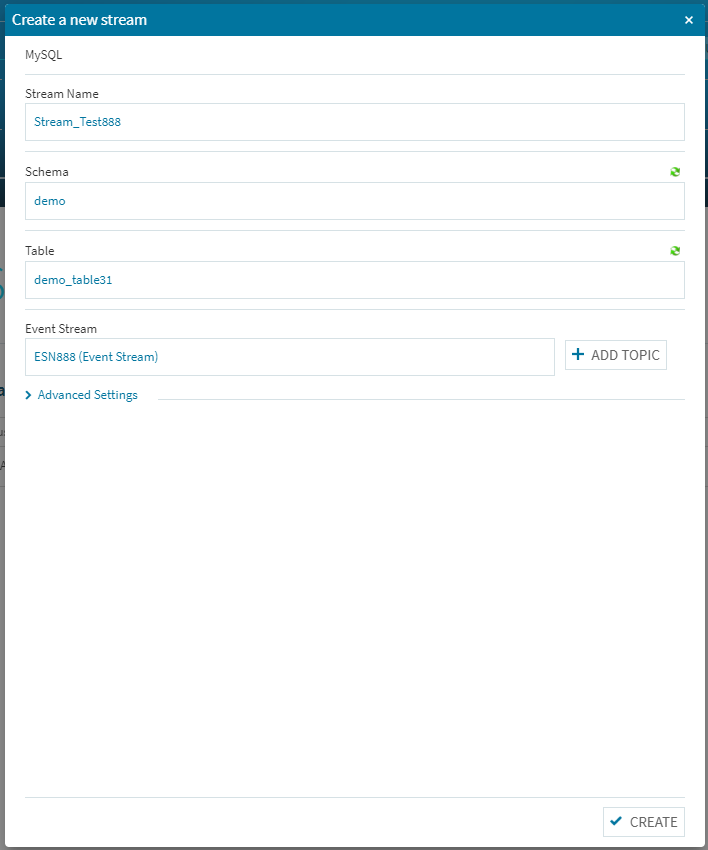
[Event Stream Name]を適宜設定してく右下の[OK]をクリックします。
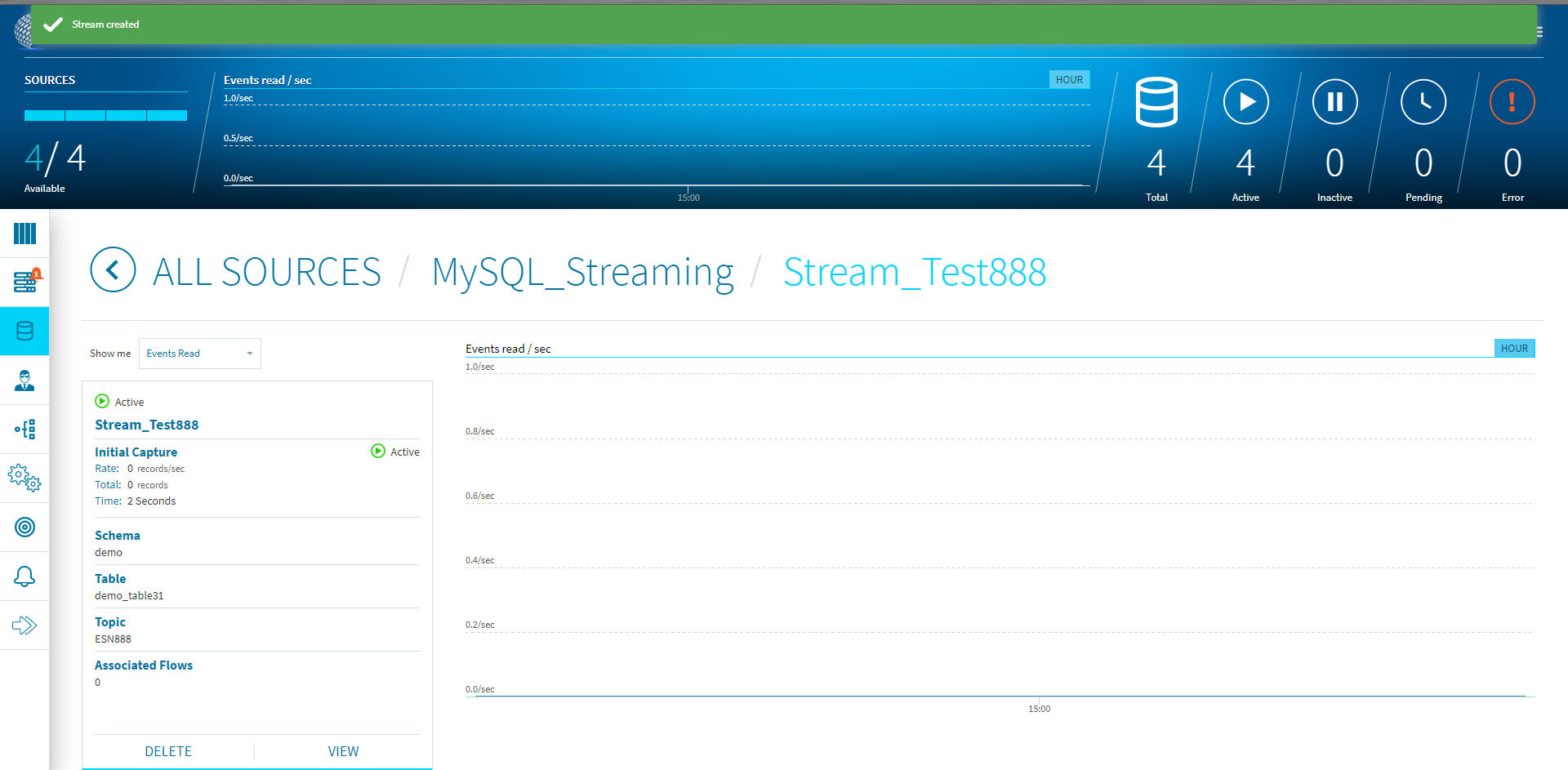
右下にある[CREATE]ボタンをクリックして正常に登録されれば、とりあえず第1段階の設定はこれで完了です。
この辺の処理を、素の環境構成を行って個別に作り込んで行くと仮定した場合、それぞれの構成要素を熟知した上での作業が必要になりますし、立ち上げた後に追加や変更が発生した場合を考えると、そもそも手を付けない!という判断に致る可能性も有るかもしれません。Equalumはその辺を上手に隠蔽し、必要事項(より高度な設定選択も可能:[Advanced Settings])の選択・設定のみで高度なストリーミング処理を活用する事が出来るように作られています。
今回のまとめ
後は、上流側のデータソースとターゲット側のソースを選択し、その相互間の関係をマウスクリックと必要項目の設定でFlowの定義を行い、環境全体の稼働状況を確認して上流側の指定されたテーブルにデータを流し込んで行けば、此処までの設定に従って自動的にストリーミング処理が行われます。この部分は専用のGUIベースデザインツールが有りますので、次回の実践編で基本的な使い方を共有出来ればと考えています。
また、次回の実践編でのストリーミング検証では、Pythonを使って簡単た日本語データ捏造(?)ツールを作成し、そのツールで生成されたデータを上流側データベースに連続して挿入処理を行って、その更新情報を起点に下流側のターゲットソースへ自動処理される事を確認し、次回以降のタイミングで最終的には簡単な変換処理を幾つか試してみようと思います。謝辞
本検証は、Equalum社の特別の許可を得て実施しています。この貴重な機会を設定して頂いたEqualum社に対して感謝の意を表すると共に、本内容とEqualum社の公式ホームページで公開されている内容等が異なる場合は、Equalum社の情報が優先する事をご了解ください。





- 投稿日:2020-05-27T15:03:50+09:00
% rails db:createするとmimemagic に起因するLoadErrorががが
% rails db:create rails aborted! LoadError: cannot load such file -- mimemagic /projects/〜〜〜/config/application.rb:7:in `<main>' /projects/〜〜〜/Rakefile:4:in `<main>' bin/rails:4:in `<main>'git hubからとあるファイルをcloneしdb:createをした際に生じたエラー
まいむまじっく.......???
なかなかマイナーなファイルが原因を引き起こしてるっぽいけども・・・ひとりでは解決困難!!先輩の力を借りてる最中、Qiitaをみてみるとこんな記事が
a.com/zQmjRAb73seN5RM/items/5fa74d2a4d346cdd386e
バージョンの問題っぽい・・・?
その通りにコマンドを実行してみた$gem list 〇〇 //〇〇には該当ファイルを入れる(今回だとmimemagic)結果は......
mimemagic (default: 0.3.5, 0.3.4, 0.3.3)ではどんなファイルがあるのかを確認してみる
find ~/.rbenv -type f | grep 〇〇 //〇〇には該当ファイルを入れる(今回だとmimemagic)結果は......
(一部抜粋) /.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.3/test/files/image.png /.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.3/test/files/application.zip /.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.3/CHANGELOG.md /.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.3/script/freedesktop.org.xml /.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.3/script/generate-mime.rb /.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.3/README.md /.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.3/Rakefile /.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.3/mimemagic.gemspec /.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.3/.gitignore /.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.3/lib/mimemagic/tables.rb /.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.3/lib/mimemagic/version.rb /.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.3/lib/mimemagic/overlay.rb /.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.3/lib/mimemagic.rb /.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.3/Gemfile /.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.3/.travis.yml /.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.4/.yardopts /.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.4/LICENSE /.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.4/test/mimemagic_test.rb /.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.4/test/files/application.vnd.openxmlformats-officedocument.spreadsheetml{gdocs}.sheet /.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.4/test/files/application.x-tar /.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.4/test/files/application.gzip /.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.4/test/files/application.x-bzip /.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.4/test/files/application.vnd.openxmlformats-officedocument.spreadsheetml{msoffice}.sheet /.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.4/test/files/image.jpeg /.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.4/test/files/application.x-ruby /.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.4/test/files/image.png /.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.4/test/files/application.vnd.openxmlformats-officedocument.spreadsheetml{rubyxl}.sheet /.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.4/test/files/application.zip /.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.4/CHANGELOG.md /.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.4/script/freedesktop.org.xml /.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.4/script/generate-mime.rb/Users/tech-camp/.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.3/test/files/image.png /.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.3/test/files/application.zip /.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.3/CHANGELOG.md/.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.3/script/freedesktop.org.xml /.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.3/script/generate-mime.rb /.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.3/README.md /.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.3/Rakefile /.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.3/mimemagic.gemspec /.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.3/.gitignore /.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.3/lib/mimemagic/tables.rb /.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.3/lib/mimemagic/version.rb /.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.3/lib/mimemagic/overlay.rb /.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.3/lib/mimemagic.rb /.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.3/Gemfile /.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.3/.travis.yml /.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.4/.yardopts /.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.4/LICENSE /.rbenv/versions/2.6.5/lib/ruby/gems/2.6.0/gems/mimemagic-0.3.4/test/mimemagic_test.rbみてみると 0.3.3 0.3.4のファイルはあることになっているが、0.3.5がないとのこと
ここが食い違っているから生じたエラー is 濃厚......
この食い違いを解決するには、% gem install mimemagic -v 0.3.5結果
Successfully installed mimemagic-0.3.5そして畳みかけます
% bundle install % rails db:create成功!!!!!!!
LoadErrorのさいはぜひ参考にしてみてください!
- 投稿日:2020-05-27T03:58:26+09:00
MySQLのダンプをTSVに変換するスクリプトを書く
MySQL からダンプされた SQL を他の用途に使うため、タブ区切りのテキスト(いわゆる TSV)に変換を試みます。
概要
MySQL のテーブルは mysqldump で SQL としてダンプできます。主要部分は CREATE 文と INSERT 文です。
(略) CREATE TABLE `t_price` ( (略) INSERT INTO `t_price` VALUES (1,'定型',25,82),(略)(10,'定型外',4000,1180); (略)自分で管理している MySQL からのダンプであれば、直接 TSV にダンプできます。
他で公開されているデータが SQL のダンプしかない場合、一度取り込んでダンプするか、変換するかになります。今回はスクリプトを書いて変換を試みます。
※ 後述しますが、Wiktionary のダンプの変換を想定しています。データが巨大なため、一度取り込むのは避けたいのです。
仕様
SQL から INSERT 文の VALUES だけを取り出して TSV に変換します。具体的には次のような挙動を目指します。
変換前INSERT INTO `table` VALUES (1,2,3),(4,5,6); INSERT INTO `table` VALUES (1,'a,b','c\'d');変換後1 2 3 4 5 6 1 a,b c'dPython
Python で変換スクリプトを書きます。
read_string
一重引用符
'で囲まれる文字列をパースします。これが一番混み入っています。最初の文字が
'かどうかをチェックします。エスケープシーケンスの処理は簡略化して、\",\',\\の場合は\を除去しますが、その他の制御文字の場合は\を残します。
testはテスト用のフラグです。sql2tsv.pytest = True def read_string(src, pos): length = len(src) if pos >= length or src[pos] != "'": return None pos += 1 ret = "" while pos < length and src[pos] != "'": if src[pos] == "\\": pos += 1 end = pos >= length if end or not src[pos] in "\"'\\": ret += "\\" if end: break ret += src[pos] pos += 1 if pos < length and src[pos] == "'": pos += 1 return (ret, pos) if test: src = r"'a,b','c\'d'" pos = 0 while pos < len(src): s, p = read_string(src, pos) print("read_string", (src, pos), "->", (s, p)) pos = p + 1実行結果read_string ("'a,b','c\\'d'", 0) -> ('a,b', 5) read_string ("'a,b','c\\'d'", 6) -> ("c'd", 12)read_value
1つのデータを読み取ります。文字列なら
read_stringを読んで、それ以外は,か(まで読み進めます。sql2tsv.py(続き)def read_value(src, pos): length = len(src) if pos >= length: return None sp = read_string(src, pos) if sp: return sp p = pos while p < length and src[p] != "," and src[p] != ")": p += 1 return (src[pos:p], p) if test: for src in ["1,2,3", r"1,'a,b','c\'d'"]: pos = 0 while (value := read_value(src, pos)): s, p = value print("read_value", (src, pos), "->", (s, p)) pos = p + 1実行結果read_value ('1,2,3', 0) -> ('1', 1) read_value ('1,2,3', 2) -> ('2', 3) read_value ('1,2,3', 4) -> ('3', 5) read_value ("1,'a,b','c\\'d'", 0) -> ('1', 1) read_value ("1,'a,b','c\\'d'", 2) -> ('a,b', 7) read_value ("1,'a,b','c\\'d'", 8) -> ("c'd", 14)read_values
括弧内のコンマで区切られたデータをすべて読み取ります。
sql2tsv.py(続き)def read_values(src, pos): length = len(src) if pos >= length or src[pos] != "(": return None pos += 1 ret = [] if pos < length and src[pos] != ")": while (value := read_value(src, pos)): s, pos = value ret.append(s) if pos >= length or src[pos] != ",": break pos += 1 if pos < length and src[pos] == ")": pos += 1 return (ret, pos) if test: for src in [r"(1,2,3)", r"(1,'a,b','c\'d')"]: print("read_values", (src, 0), "->", read_values(src, 0))実行結果read_values ('(1,2,3)', 0) -> (['1', '2', '3'], 7) read_values ("(1,'a,b','c\\'d')", 0) -> (['1', 'a,b', "c'd"], 16)read_all_values
括弧で囲まれたデータをすべて読み取ります。ループでの扱いを想定してジェネレーターにします。
sql2tsv.py(続き)def read_all_values(src, pos): length = len(src) while (sp := read_values(src, pos)): s, pos = sp yield s if pos >= length or src[pos] != ",": break pos += 1 if test: src = r"(1,2,3),(1,'a,b','c\'d')" print("read_all_values", (src, 0), "->", list(read_all_values(src, 0)))実行結果read_all_values ("(1,2,3),(1,'a,b','c\\'d')", 0) -> [['1', '2', '3'], ['1', 'a,b', "c'd"]]read_sql
SQL の各行から
INSERT INTOで始まる行を見付けてread_all_valuesで処理します。sql2tsv.py(続き)def read_sql(stream): while (line := stream.readline()): if line.startswith("INSERT INTO "): p = line.find("VALUES (") if p >= 0: yield from read_all_values(line, p + 7) if test: import io src = r""" INSERT INTO `table` VALUES (1,2,3),(4,5,6); INSERT INTO `table` VALUES (1,'a,b','c\'d'); """.strip() print("read_sql", (src,)) print("->", list(read_sql(io.StringIO(src))))実行結果read_sql ("INSERT INTO `table` VALUES (1,2,3),(4,5,6);\nINSERT INTO `table` VALUES (1,'a,b','c\\'d');",) -> [['1', '2', '3'], ['4', '5', '6'], ['1', 'a,b', "c'd"]]コマンド化
必要な関数はすべて実装しました。テストをオフにします。
sql2tsv.py(変更)test = False指定したファイルを読み込んで、指定したファイルに書き出します。
UTF-8 のバイト列が文字の途中で切れている場合を想定して、
openではerrors="replace"を指定します。これにより異常な文字は � に置換されます。errorsを指定しない場合はエラーになります。【参考】 (Windows) Python3でのUnicodeEncodeErrorの原因と回避方法 - Qiita
sql2tsv.py(続き)if __name__ == "__main__": import sys try: sql, tsv = sys.argv[-2], sys.argv[-1] if not (sql.endswith(".sql") and tsv.endswith(".tsv")): raise Exception except: print("usage: %s sql tsv" % sys.argv[0]) exit(1) with open(sql, "r", encoding="utf-8", errors="replace") as fr: with open(tsv, "w", encoding="utf-8") as fw: for values in read_sql(fr): fw.write("\t".join(values)) fw.write("\n")次のように使います。
python sql2tsv.py input.sql output.tsvスクリプト全体は以下に置きました。
計測
どのくらいの速度で処理できるか、巨大なファイルで計測します。
Wiktionary 日本語版
Wikipedia 同様に、ダンプデータが公開されています。
記事執筆時点で入手可能な2020年5月1日版より、以下のファイルを使用します。
- jawiktionary-20200501-categorylinks.sql.gz 10.7 MB
ファイルを展開すると 90 MB ほどになります。
gunzip -k jawiktionary-20200501-categorylinks.sql.gz※
-kは展開前のファイルを残すオプションです。展開した SQL を今回のスクリプトで変換すると、79 MB ほどの TSV が出力されます。
$ time python sql2tsv.py jawiktionary-20200501-categorylinks.sql jawiktionary-20200501-categorylinks.tsv real 0m19.921s user 0m19.375s sys 0m0.516s行数は 95 万行ほどです。
$ wc -l jawiktionary-20200501-categorylinks.tsv 951077 jawiktionary-20200501-categorylinks.tsvWiktionary 英語版
次に英語版を試します。
以下のファイルを使用します。展開すると 3 GB ほどに膨れ上がります。
- enwiktionary-20200501-categorylinks.sql.gz 344.6 MB
これを変換します。出力されるファイルは 2.6 GB ほどです。
$ time python sql2tsv.py enwiktionary-20200501-categorylinks.sql enwiktionary-20200501-categorylinks.tsv real 15m58.965s user 15m39.063s sys 0m12.578s行数は 2,800 万行にもなります。
$ wc -l enwiktionary-20200501-categorylinks.tsv 28021874 enwiktionary-20200501-categorylinks.tsvF#
試しに F# に移植しました。
同じファイルを処理すると、かなり高速化しました。
ファイル 時間 jawiktionary-20200501-categorylinks.sql 0m03.168s enwiktionary-20200501-categorylinks.sql 1m52.396s 圧縮ファイルの読み込み
.NET Framework には GZipStream があるため、圧縮されたままの gz ファイルを直接読み込むことが可能です。
sql2tsv.fsx(変更)open System.IO.Compression let args = Environment.GetCommandLineArgs() let sqlgz, tsv = if args.Length < 2 then ("", "") else let len = args.Length (args.[len - 2], args.[len - 1]) if not (sqlgz.EndsWith ".sql.gz") || Path.GetExtension tsv <> ".tsv" then printfn "usage: sql2tsv sql.gz tsv" exit 1 do use fs = new FileStream(sqlgz, FileMode.Open) use gs = new GZipStream(fs, CompressionMode.Decompress) use sr = new StreamReader(gs) use sw = new StreamWriter(tsv) sw.NewLine <- "\n" for values in readSql sr do sw.WriteLine(String.concat "\t" values)計測結果は次にまとめます。
まとめ
計測結果を並べます。
言語 ファイル 時間 Python jawiktionary-20200501-categorylinks.sql 0m19.921s F# jawiktionary-20200501-categorylinks.sql 0m03.168s F# jawiktionary-20200501-categorylinks.sql.gz 0m03.509s Python enwiktionary-20200501-categorylinks.sql 15m58.965s F# enwiktionary-20200501-categorylinks.sql 1m52.396s F# enwiktionary-20200501-categorylinks.sql.gz 2m15.380s 圧縮ファイルを直接処理すると多少遅くはなりますが、ディスクスペースが節約できるため有利です。