- 投稿日:2020-05-27T23:48:45+09:00
よく聞かれるAWSのXXはAlibabaCloudのXX(AWS vs AlibabaCloudプロダクトリスト)
本記事の目的
世の中のクラウドサービスといえばシェアNO.1のAWSでしょう。クラウドサービスの基本的考え方もAWSが作ったものと言って過言ありませんね。後発のAlibaba Cloudを説明するのに「これはAWSのXXですよ!」というのがもっともわかりやすい説明です。逆に「AWSのXXはAlibaba Cloudにないの?」ともよく聞かれます。
ありきたりかもしれませんが両サービスのプロダクトについて対照表を作成してみました。日進月歩でプロダクトは増えていますので、適宜更新が必要なコンテンツにはなりますが2020年5月末現在ということでご参照ください。仮想サーバからストレージまで
特に特徴がでているのがAlibabaCloudではHCPやSPCのような大規模インスタンス構成を行うサービスをデフォルトで用意していることです。中国でのニーズにそのようなインスタンスを利用するシミュレーション用途などが多いのでしょうか。
別記事にしたいと思いますがインスタンスタイプについても両社は非常に類似しています。サーバレスについてもほぼ両方のメニューは揃っていますが、詳細機能に違いがあると考えてください。例えばLamdaで利用できるトリガーや言語種類とFunctionComputeで利用できるものに違いがあるなどです。
ストレージについてはメニューはほぼ揃っていますが、S3とOSSの詳細機能比較が重要になります。以下のドキュメントでS3とOSSのAPIの違いがまとまっています。
Amazon S3 から Alibaba Cloud OSS へのデータの移行
カテゴリー プロダクト種類 AWS Alibaba Cloud 仮想サーバー&コンピュータリソース 仮想サーバーサービス EC2 ECS ベアメタル EC2 Bare Metal Instance ECS Bare Metal Instance GPUインスタンス EC2高速コンピューティングインスタンス Elastic GPU Webホスティングサービス lightsail
Elastic BeanstalkWeb Hosting
Web App ServiceHPCインスタンス CloudFormation HPCテンプレート Elastic High Performance Computing(HPC)
Super Computing Cluster(SCC)コンテナサービス コンテナサービス ECS
EKSContainer Service
Container Service for Kubernetesマネージドコンテナサービス Fargate Elastic Container Instance (ECI) コンテナイメージ管理サービス Elastic Container Registry Container Registry サーバレスサービス バックエンドコンピューティングサービス Lambda Function Compute バッチ処理サービス Simple Workflow Service(SWF) Batch Compute APIサービス API Gateway API Gateway ストレージ ブロックストレージ EBS EBS オブジェクトストレージサービス S3 ObjectStorageService 低コストデータ格納ストレージサービス Glacier Archive Storage ファイルストレージサービス EFS NAS オフラインでのデータ移行 Snowball Data Transport オンプレとの連携 Strage Gateway Hybrid Cloud Storage Array
Cloud Storage Gateway
Hybrid Backup Recoveryデーターベース
データベースのカテゴリーとしては両社ともに揃っています。AlibabaCloudではNoSQLの種類が多いようです。
大規模で高速なRDBMがゲーム業界やEC業界など大規模サービスで重要になっていますが、AWSのAuroraを追いかけるようにAlibaba CloudでもPolarDBを出してきました。両者の性能比較などが重要になってきます(コストの関係で個人では評価できないですが)
分析系ではAWSのRedshiftとAlibabaCloud AnalyticDBとなりますが、分析はDBだけでなく周辺サービスも関係してきますので後日さらなる比較をしていきたいと思います。
カテゴリー プロダクト種類 AWS Alibaba Cloud データベース リレーショナルデータベースサービス Amazon RDS
MySQL
SQL Server
PostgreSQL
Oracle DB
MariaDBApsaraDB for RDS
for MySQL
for SQL Server
for PostgreSQL
for PPAS(Oracle互換)
for MariaDB TXNoSQLサービス DynamoDB
SimpleDB
DocumentDB (MongoDB)Table Store
ApsaraDB for Redis
ApsaraDB for MongoDB
ApsaraDB for HBase
ApsaraDB for Cassandra
Time Series Database (TSDB)分散キャッシングサービス ElastiCache ApsaraDB for Memcache データウェアハウス系 Redshift AnalyticDB 大規模高速DBM Amazon RDS Aurora ApsaraDB for PolarDB データベース移行ツール Database Migration Service Data Transmission Service ネットワーク
ネットワーク系はAlibabaCloudが得意とする分野です。なぜなら中国から海外へ接続するためにはInternetを経由させるだけでは十分なパフォーマンスを維持できないからです。特別なネットワークサービスCENを提供しています。AWSでもVPC Peeringでリージョン間を接続できますが、BGPのルーティング管理など複雑なネットワークを作るにはTransitGatewayを使ったネットワーク構成を組むなどCENほど簡単には作れないようです。
AlibabaCloudだけにあるサービスで小規模拠点に専用のローカルルータを提供したり、PCにインストールする専用ソフトを提供することでEnd to Endの接続を行うSmart Access Gatewayが特徴的です。今後はクラウドと端末、拠点をいかに繋げるかも重要になります。
カテゴリー プロダクト種類 AWS Alibaba Cloud ネットワーク ドメインネームサービス(DNS) Route 53 Cloud DNS コンテンツ配信ネットワーク(CDN) CloudFront CDN ロードバランシングサービス ELB SLB グローバルアクセス転送・配信 Global Accelerator Global Accelerator NAT接続 NAT Gateway NAT Gateway VPN接続 VPN Gateway VPN Gateway 端末・Small拠点接続 なし Smart Access Gateway リージョン間接続 VPC Peering
Transit GatewayCloud Enterprise Network(CEN) オンプレミスと専用線接続 Direct Connect
VPN GatewayExpress Connect セキュリティ
クラウドのセキュリティといえば運用管理のためのセキュリティが一般的ですが、ここでもAlibabaCloudには特徴的なサービスが見られます。Anti-Botやコンテンツの中身(公序良俗に反する画像など)を発見するサービス、ゲームネットワークのセキュリティ監視など独特のサービスがラインナップされています。
いままではセキュリティを専門ベンダーの製品を利用するケースが多かったかと思いますがクラウド側でここまでセキュリティサービスが充実してくると専門ベンダーも市場を奪われますね。
カテゴリー プロダクト種類 AWS Alibaba Cloud セキュリティ アカウント権限管理サービス IAM
Resource Access ManagerRAM DDoS保護サービス AWS Shield Anti DDoS 暗号化キー管理・連携サービス KMS
CloudHSM
Secrets ManagerKMS Anti DDpS Shield Anti-DDoS WEBアプリケーションファイアウォール WAF WAF ファイアウォール Firewall Manager Cloud Firewall セキュリティアセスメント Artifact Managed Security Service セキュリティ脅威監視 Security Hub
GuardDuty
InspectorSecurity Center ホワイトハット侵入テスト - Cloud Security Scanner 不適切コンテンツ監視 - Content Moderation Webサイトへのanti-botプロテクション - Anti-Bot Service 特定分野向けセキュリティ - GameShield 機密データの検出と保護 Macie
DetectiveSensitive Data Discovery and Protection DevOpsと監視運用
クラウドは作って壊す、壊しては作るが基本ですよね。そのためにもDevOpsは重要な要素です。ここでAWSとAlibabaCloudでポリシーの違いが見られます。AWSは独自サービスのDevOpsが充実していてエンジニアもそれを使うと仕事が捗る?ようになっているようです。サービスの囲い込み戦略でもあるのでしょう。AlibabaCloudはそれに対してオープンソースのツールを使うポリシーのようです。以下にAlibabaCloudのDevOpsホワイトペーパーをリンクしておきます。
Alibaba Cloud DevOps Solution今後AlibabaCloudに必要なのはAWSのTrasted AdvisorやCost Explorerのようなエンジニアが日々の運用業務に撲殺されないような便利なツールを提供することかもしれません。AWSではそこらへんが充実してきています。
カテゴリー プロダクト種類 AWS Alibaba Cloud DevOps プロビジョニング CloudFormation
CodePipeline
CodeDeploy
CodeCommitなし (Terraform, PackerなどOSSの利用推奨) サーバー構成自動化 OpsWorks なし(HPCやSPCなどが類似) 監視モニター リソースモニター Cloud Watch Cloud Monitor ログ収集・分析 Cloud Watch Logs LogService アクティビティログ CloudTrail ActionTrail 構成変更管理・監査 Config Cloud Config 構成アドバイザー Trasted Advisor なし コスト管理 Cost Explorer なし まとめ
今回はここまでになります。
基本的な仮想サーバーやストレージ、データベースは非常に拮抗していることがわかりました。
ネットワークやセキュリティにはそれぞれの会社の置かれている市場環境により差異がでているようです。
さらに、DevOps・監視運用についてはAWSがリードしていると思われますが、マルチクラウド環境の時代になるとオープンソースのツールを使う方がよいかもしれません。今後
まだまだ比べる分野が残ってしまいました。心残りではありますが、これからも記事かいていきます。
・AI分野
・BigDataや分析分野
・IoT分野
・仮想サーバインスタンスやVPCなど基本部分のさらなる違い活用させていただいたツール
Markdownで表を作成しようとしたのですが大変だったので今回はHTMLで記載しました。
でも手で作成も無理でしたので、こちらのWebサービスを活用させていただきました。
ありがとうございました。
- 投稿日:2020-05-27T22:54:04+09:00
FlutterとAWSで始めるサービス開発 (1)Windowsでの開発環境構築
はじめに
Google謹製のクロスプラットフォームなアプリ構築フレームワークであるFlutterをクライアントサイドとし、サーバーサイドにAWSを利用しサービス開発してみたいと考えています。
サーバーサイドにAWSを使う場合、クロスプラットフォームなクライアントの開発にはReact Native + AWS Amplifyを使うというのが鉄板かなとも思いますが、JavaScriptとReactを使ったWebフロントエンドの開発をやってきていない人が、わざわざReact Nativeでアプリ開発を始める必要はないかなというのが筆者の考えです。React + Reduxの世界は初期の学習コストが割とかかり始めの一歩が大変ですし、正直コードも直感的ではなく読みにくいなと感じます。ということで、王道ではないかもしれませんが、クラウドプラットフォームとしてはNo.1のAWSと、クロスプラットフォームのモバイル開発で注目されているGoogleのFlutterを使ったサービス開発のノウハウを学んでいきたいと思います。
開発環境
筆者はWindows PCしか持っていないので、Windows 10で開発環境を構築していきます。以下のバージョンを使ったインストール手順になります。
- Flutter SDK Windows 1.17.0
- Android Studio 3.6.3 for Windows 64-bit
- Visual Studio Code 1.44.2 (※インストール手順は省略します)
参考文献
- Flutter SDK
https://flutter.dev/docs/get-started/install/windows
- Android Studio
https://developer.android.com/studio/install
Flutter SDKのセットアップ
- Flutter SDKをダウンロードし任意のフォルダ(ex. d:\flutter)に解凍してください
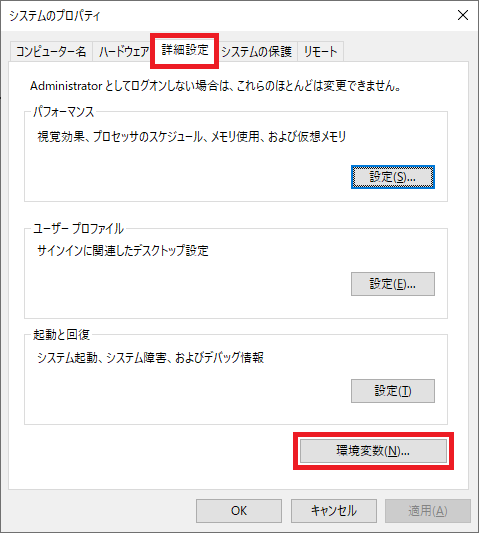
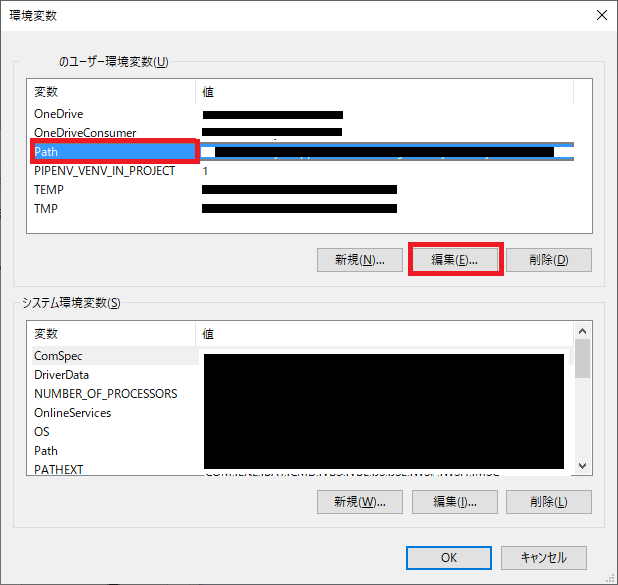
- 環境変数のpathに追加してください
- envを起動してください
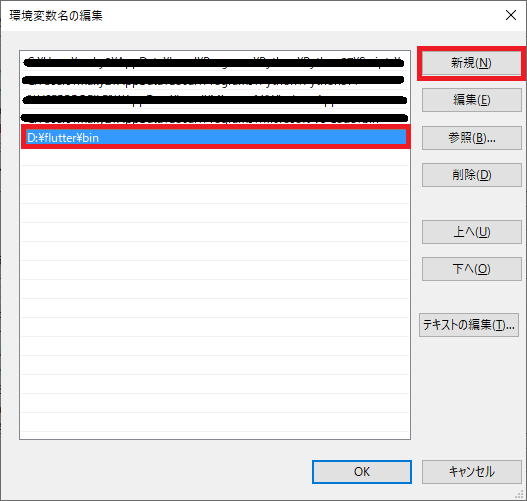
- 下記手順に従い、[インストールフォルダ]\bin (ex. d:\flutter\bin) をpathに追加してください
Android Studioのセットアップ
- Android Studioをダウンロードし、.exeを起動してインストールを完了させてください。
- Android Studioを起動し、SDK Managerを開いてください。
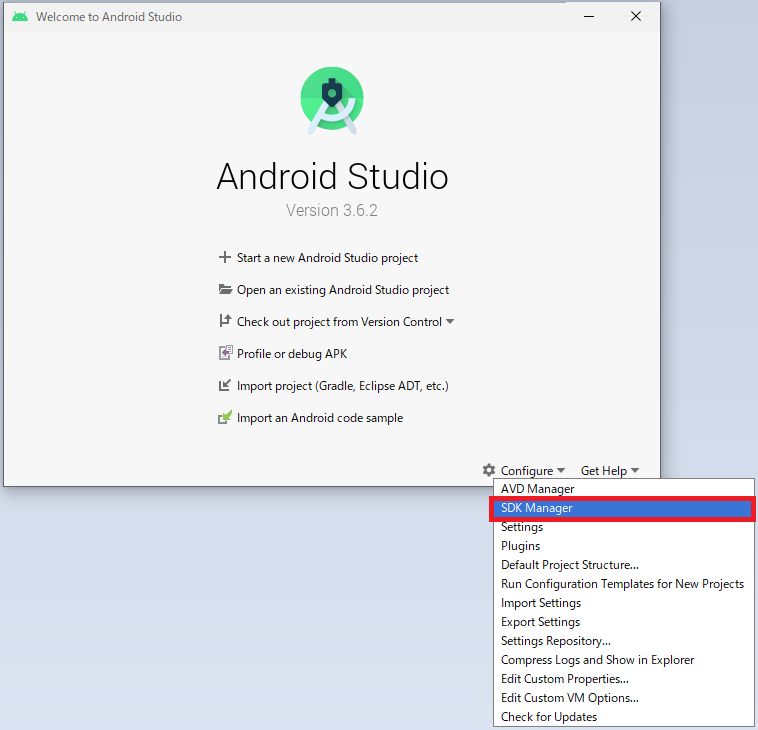
- SDK Toolタブを開き、Hide Obsolete Packagesのチェックを外し、Android SDK Tools (Obsolete)にチェックを入れてOKを押下しインストールしてください。
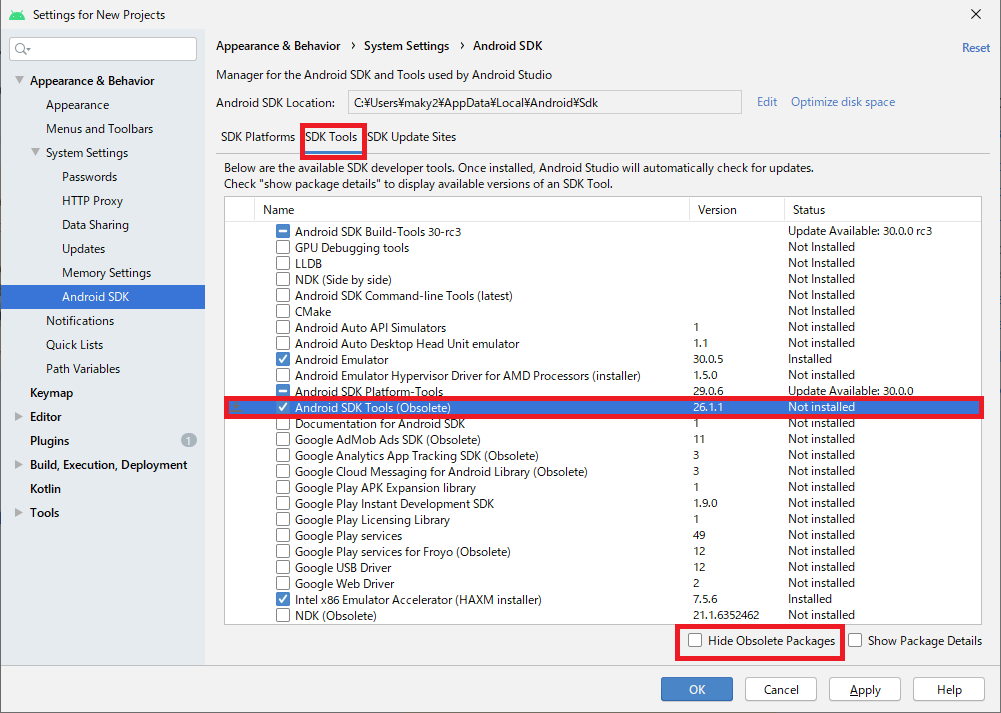
- Pluginsを開いてください。
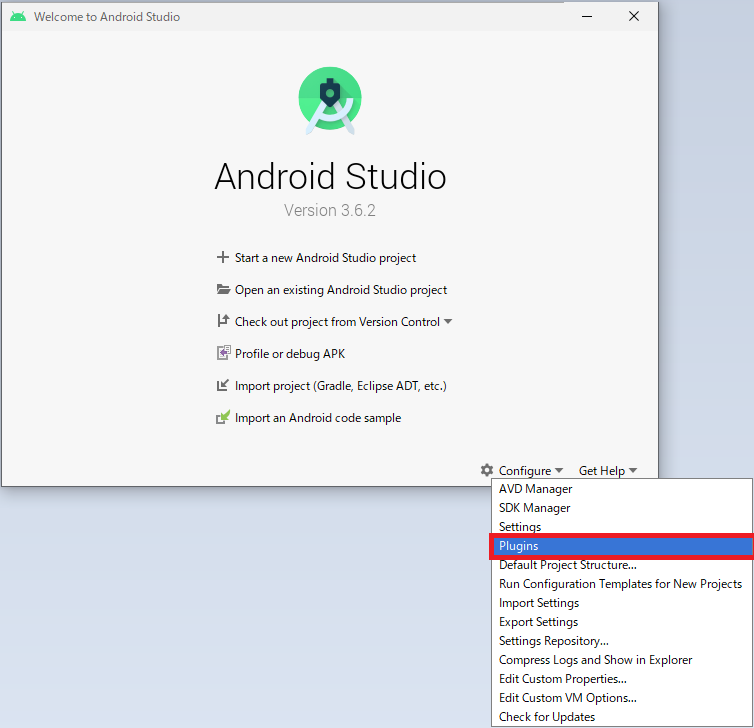
- Fluuterのpluginをインストールします。Installを選択するとdartのpluginも同時にインストールする旨のメッセージが表示されるのでOKを押下して進めてください。
- AVD Managerを開いてください。
7.Create Virtual DeviceでAndroid emulatorをセットアップしていきます。
- 今回はデフォルトで選択されていたPixel2をそのまま選んで進めます。。
- システムイメージをダウンロードします。今回はAndroid 10.0のイメージをダウンロードしました。
- Download選択するとダウンロード画面になります。
- ダウンロードが完了したらイメージを選択してNextを選択して次に進んでください。
- 次の画面では各種設定を変更できますが今回は特にいじらずデフォルトのままFinishを押下し作成を完了しました。
- emulatorを起動して問題なく動作するか確認をしましょう。
Visual Studio Codeの設定
Visual Studio Codeは事前にインストールをしておいてください。
1.FluuterのPluginをインストールします。拡張機能でflutterで検索をし、インストールを実行します。
インストール結果の確認
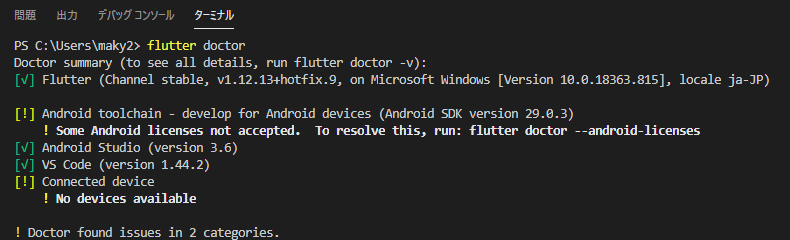
- Visiual Studio Codeのターミナルを開き、下記を入力し実行します。
> flutter doctor
2.上記のように分析結果が表示されます。ライセンス関連のエラーが出ているので、画面のメッセージに従い以下のコマンドを実行し、未同意のライセンスに対して
yを選択し同意していきます。> flutter doctor --android-licensesまとめ
以上で最低限の開発環境が構築できたと思います。実際にはEmulatorではなく実機を利用したりとあるとは思いますが、まずはWindows PCのみで始められるところを狙って環境を構築しました。
次回はFlutterのプロジェクトを作成し、テンプレートアプリを動かして中身を見ていきたいと思います。
- 投稿日:2020-05-27T22:17:46+09:00
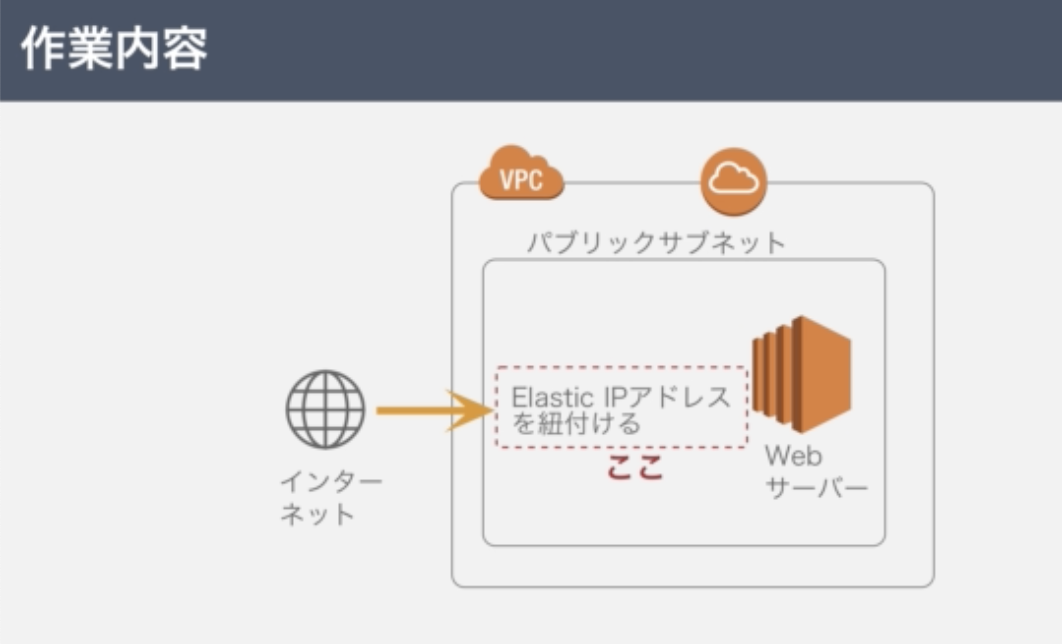
【学習メモ】AWS(Apache ファイアウォール Elastic IPアドレス)
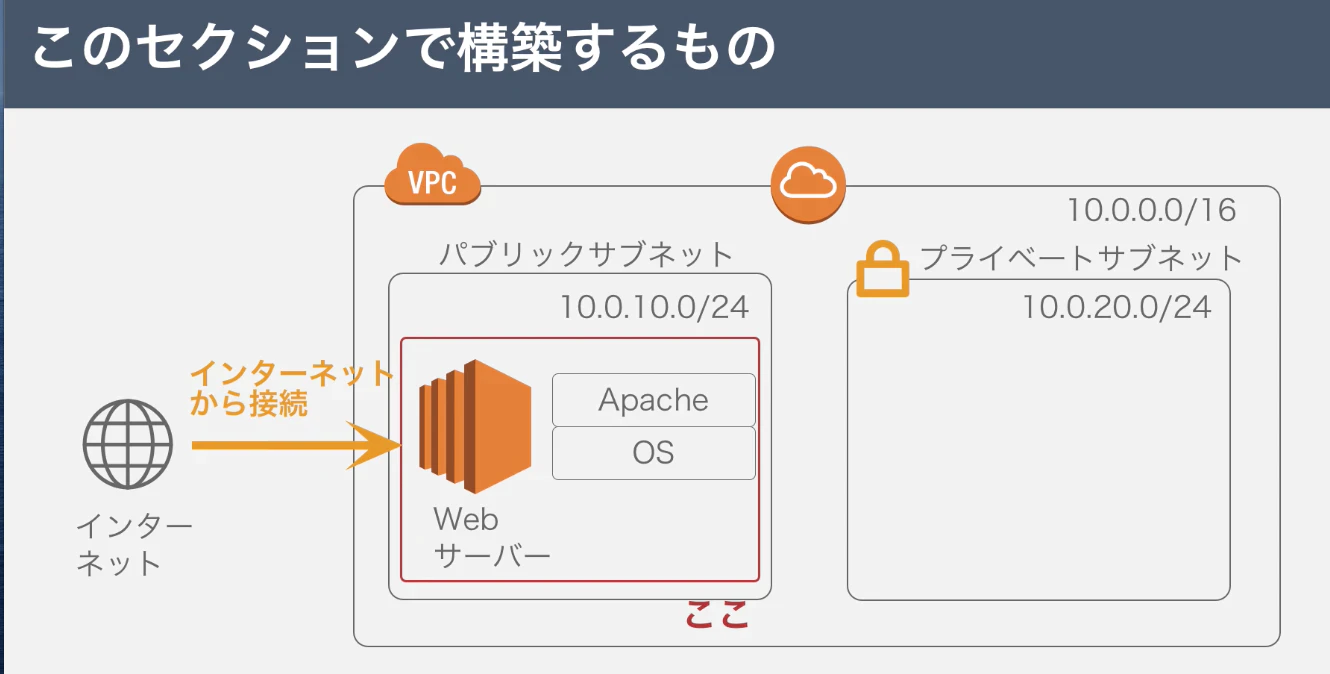
1.目標成果物
2.サーバー構築の作業手順
1.EC2インスタンスを設置する
2.Apacheをインストールする←今回はここ
- SSHでサーバーにログイン
- Apacheをインストール←今回はここ
3.ファイアウォールを設定する←今回はここ3.Apacheのインストール
Apacheをインストールする前に、まずはEC2インスタンスのアップデートを行う
$ sudo yum update -yyum:Linux(サーバーのOS)のパッケージ(ライブラリ)
yum update:yumで保存したものを最新版にする
sudo:ルート権限で実行すること
※ログイン時にはEC2ユーザーでやっているが、「yum」の操作をする場合はsudoが必要
-y:Yesという意味色々インストールされるので、「完了しました!」という表示になったら、Apacheをインストールする
$ sudo yum -y install httpd$ sudo systemctl start httpd.servicehttpd.service:Apacheのこと
$ sudo systemctl status httpd.service「active(runnning)」
その他確認するコマンド
プロセス(実行中のプログラム)を表示するコマンドでApacheを確認する方法
$ ps -axups:Linux上で実行しているプロセスを表示するコマンド
-axu:axが全てのプロセスを表示する、uがメモリや使用量も含めて表示する「/usr/sbin/httpd」があればhttpd=Apacheが実行されていると確認できる。
絞りたい時は、「grep httpd」などのコマンドにするといい。
grep:検索して表示するコマンド
4.Apacheの自動起動
自動起動を設定するコマンドは下記の通り
$ sudo systemctl enable httpd.service設定できたかどうか確認するコマンドは下記の通り
$ sudo systemctl is-enabled httpd.service「enabled」と表示されたら自動起動の設定が完了
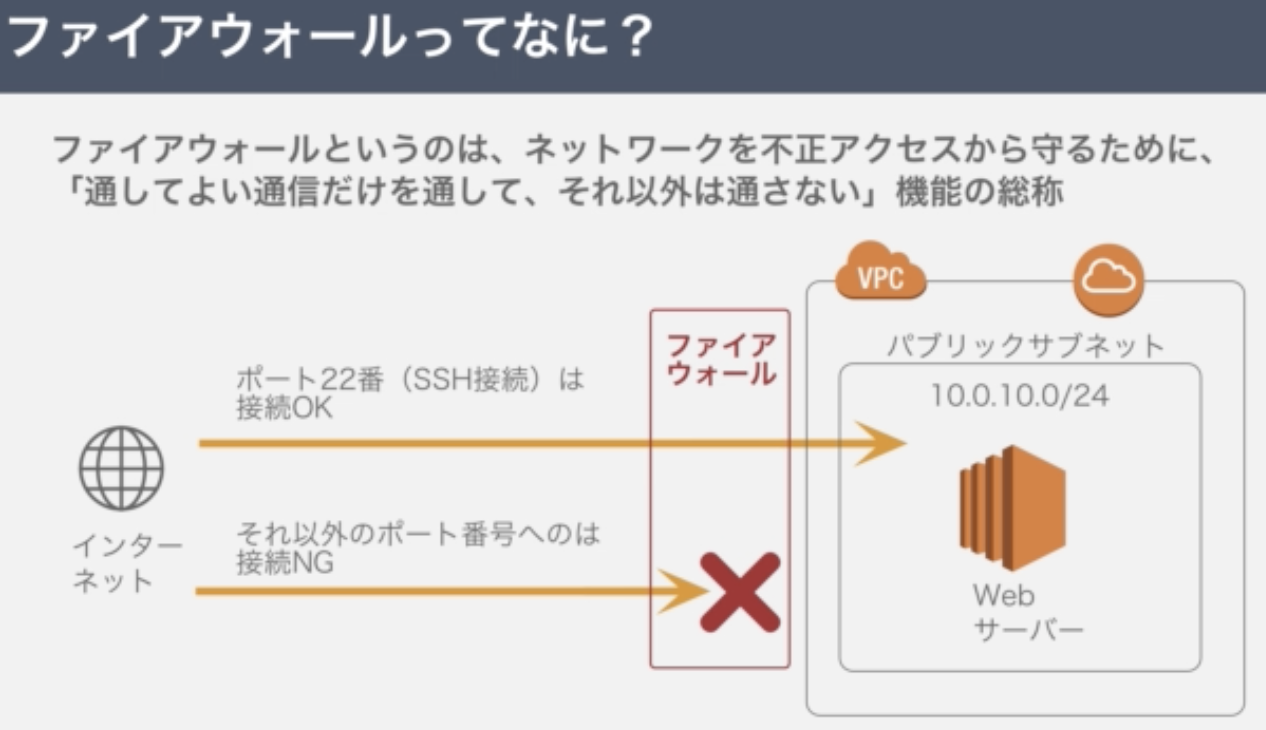
5.ファイアウォールを設定する
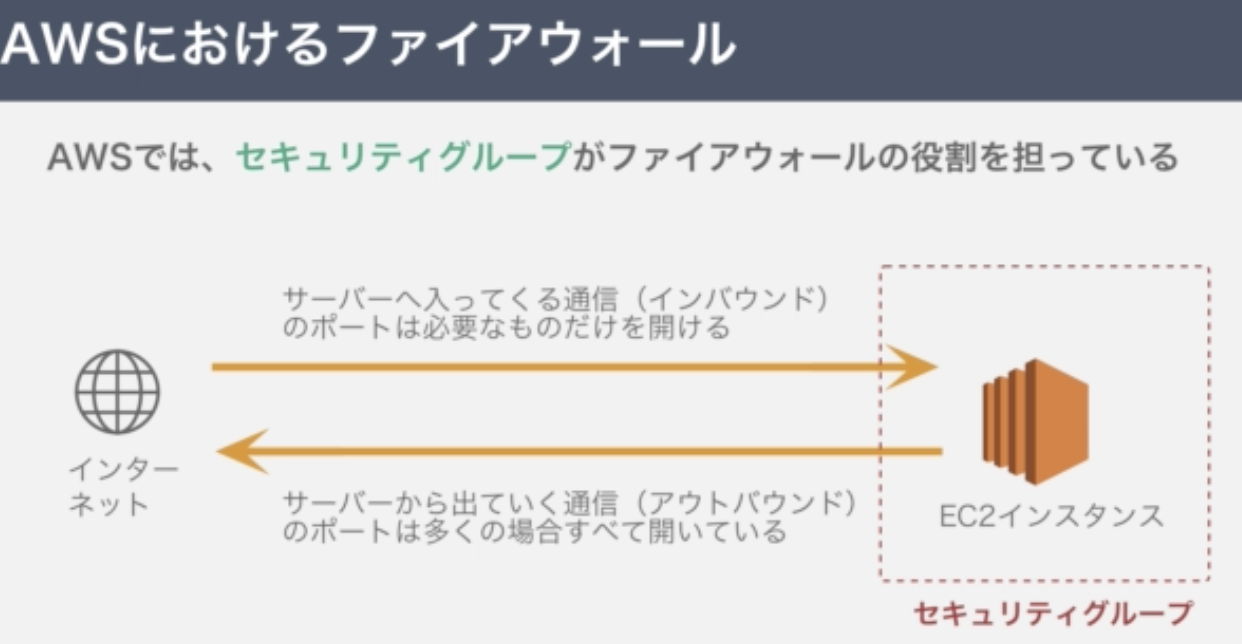
ネットワークを不正アクセスから守るために「通して良い通信だけを通して、それ以外は通さない」機能の総称
AWSでは、セキュリティグループがファイアウォールの役割を担う
<流れ>
1.セキュリティグループを開く
2.インバウンドルールの追加
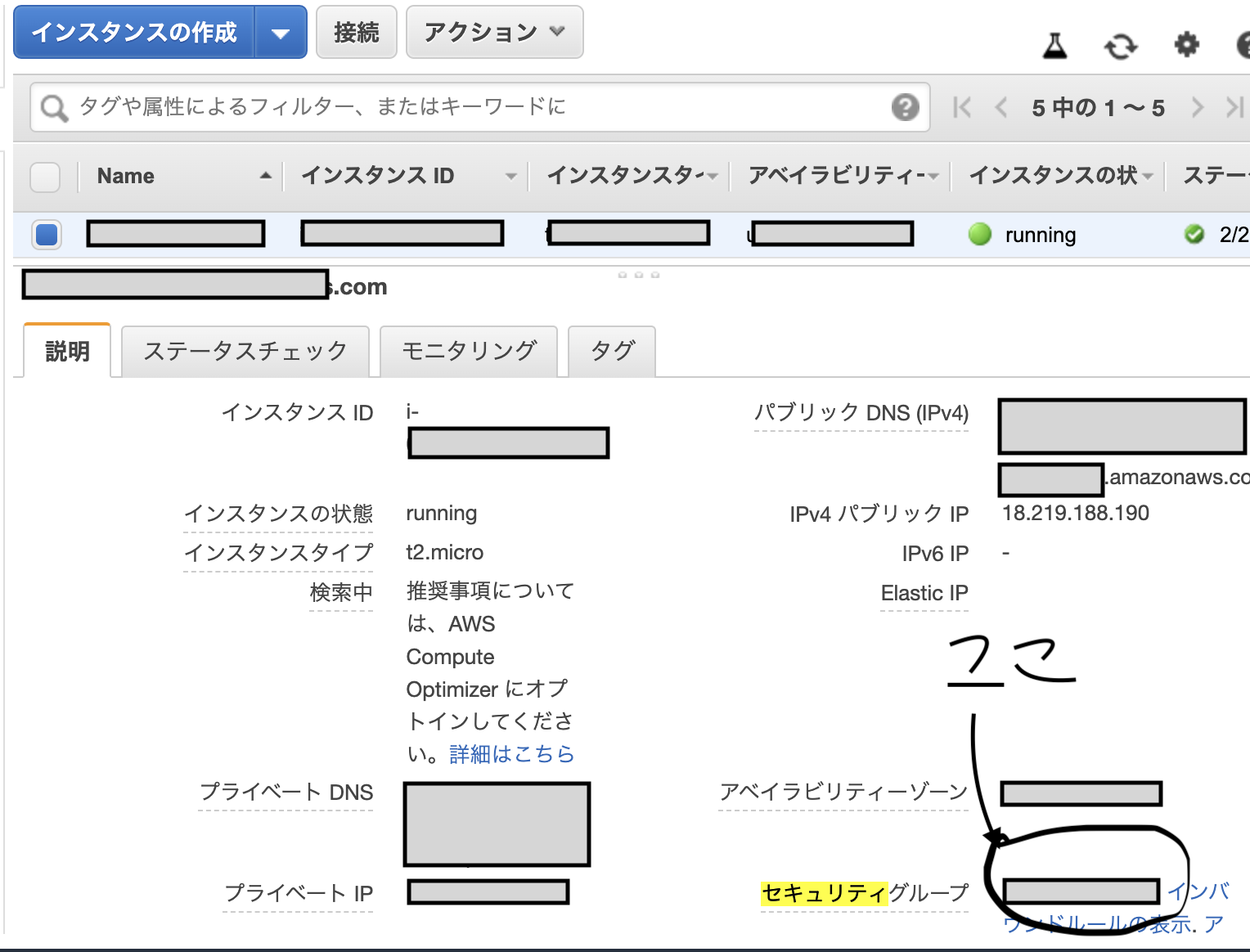
3.IPアドレスを追加して接続完了1.セキュリティグループを開く
セキュリティグループ欄をクリック
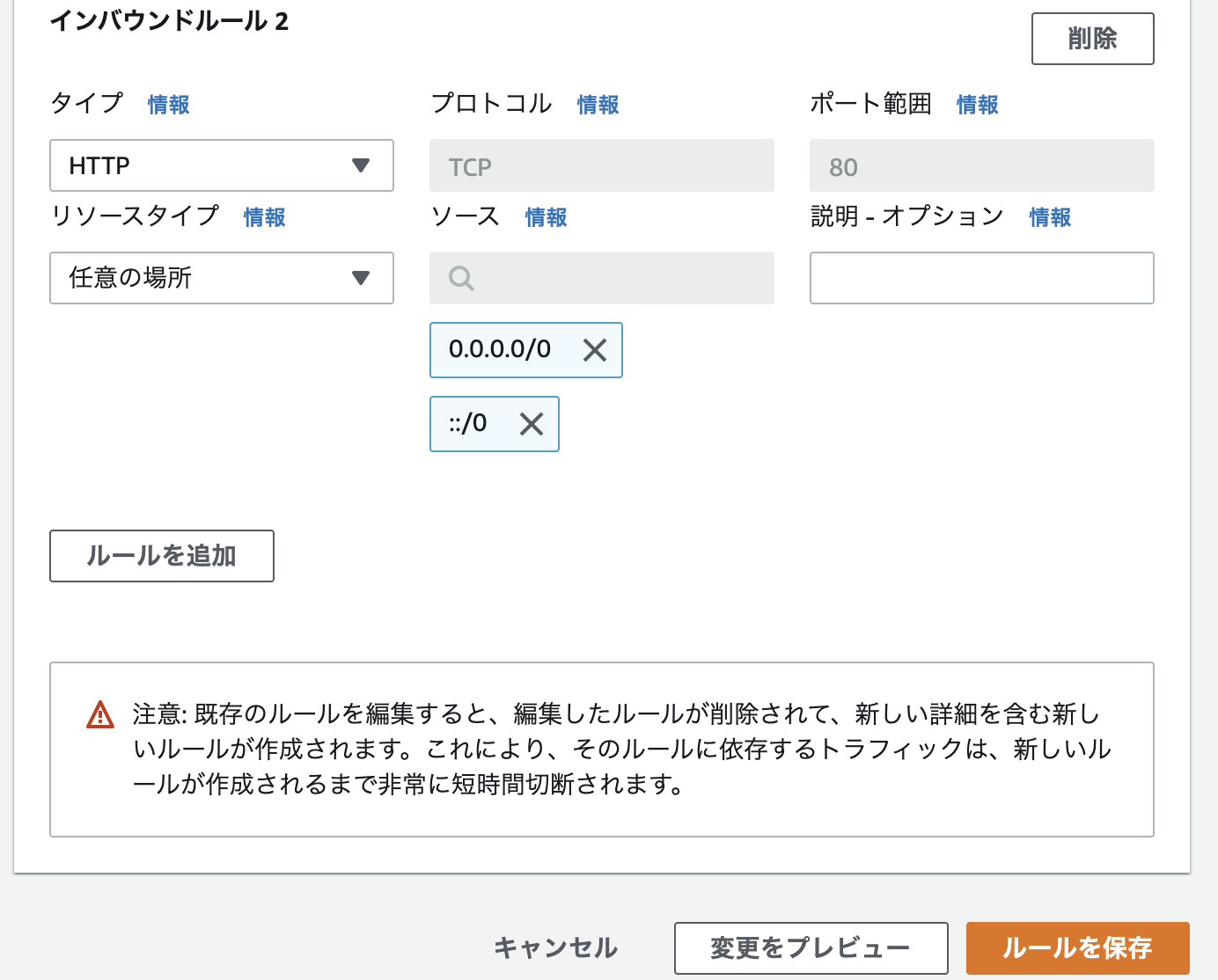
2.インバウンドルールの追加
3.IPアドレスを追加して接続完了
こんな画像になればOK
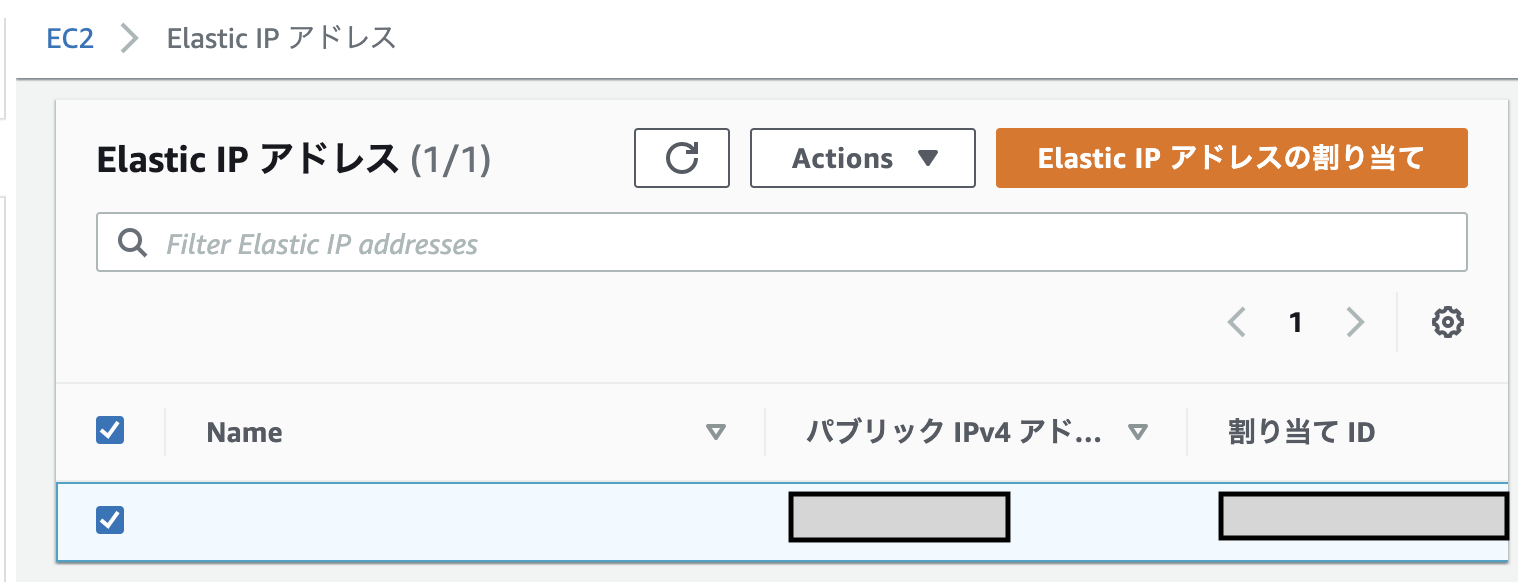
6.Elastic IPアドレスについて
EC2インスタンスのパブリックIPは、起動・停止すると別のIPアドレスが割り当てられる。ElasticIPアドレスを使用すると、IPアドレスを固定できる。
そこで下記の作業を行うものとする。
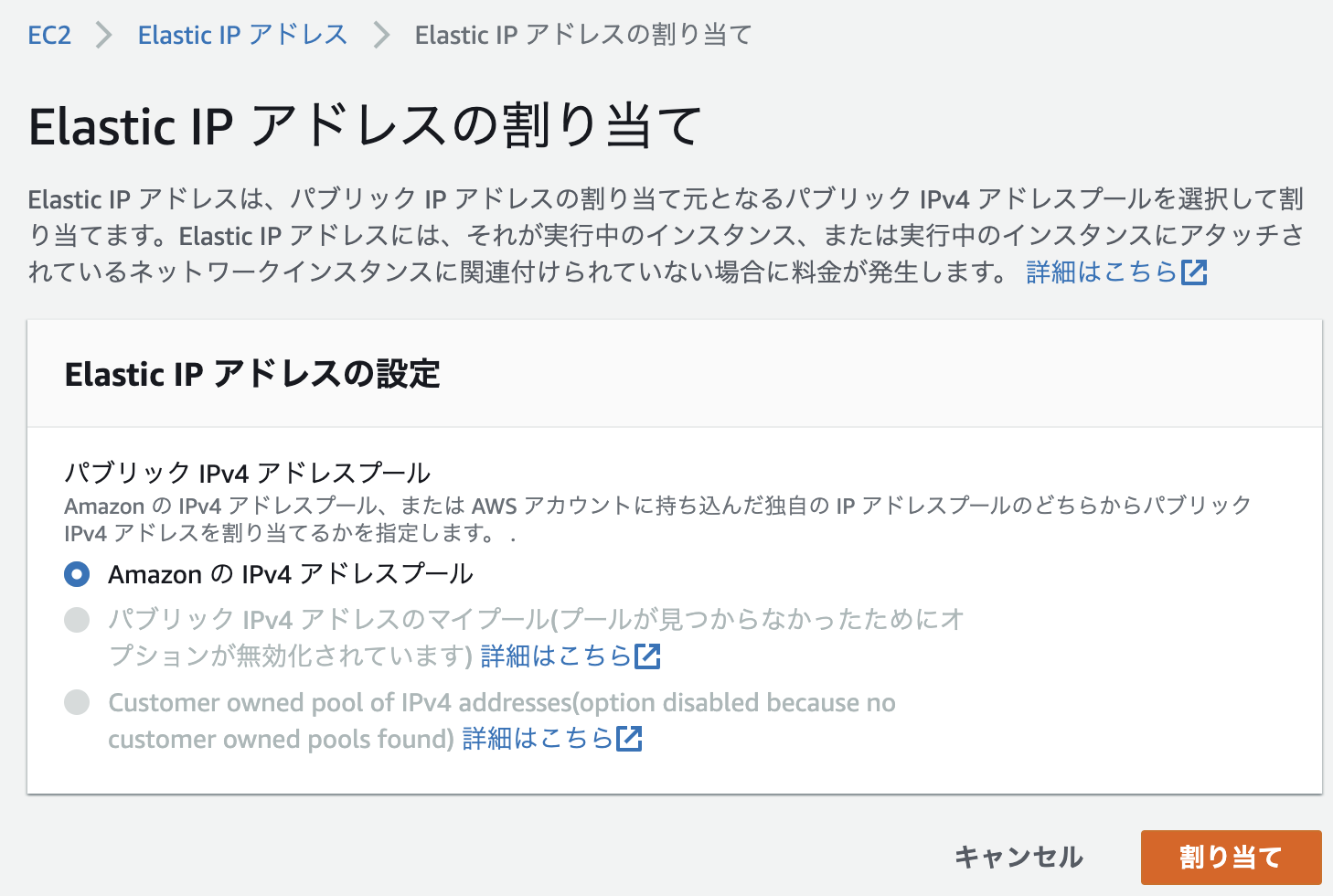
左側の「Elastic IP」をクリックした後、新しいアドレスの割り当てをクリックし「割り当て」を選択。
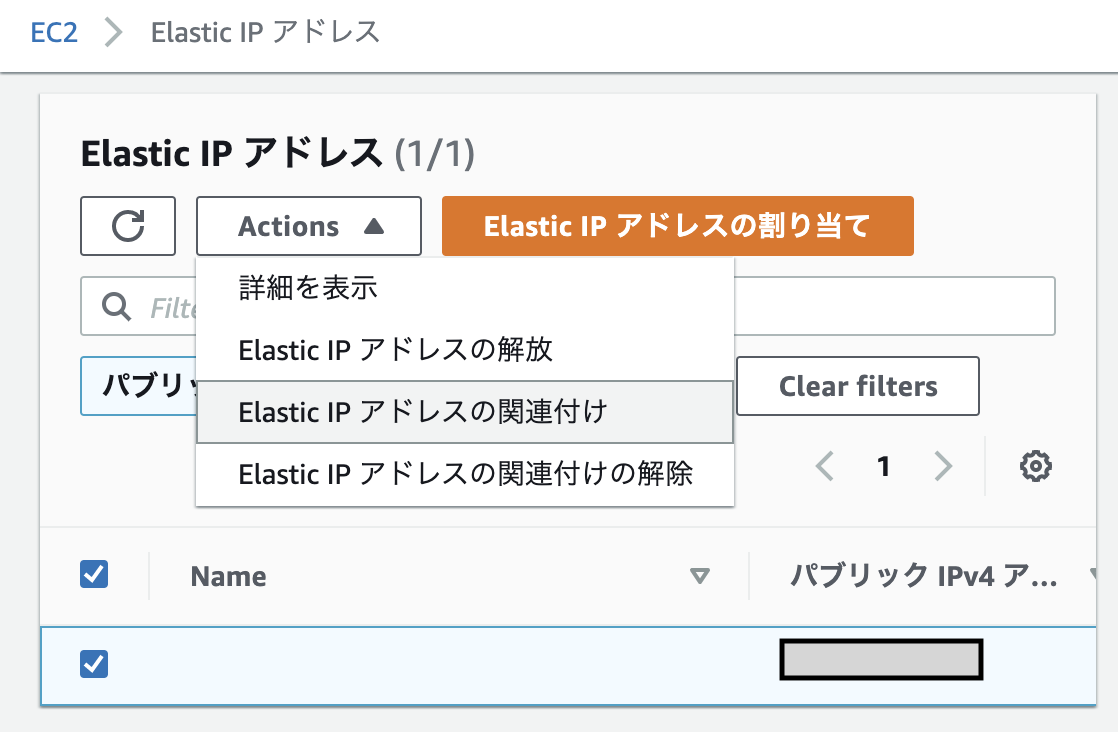
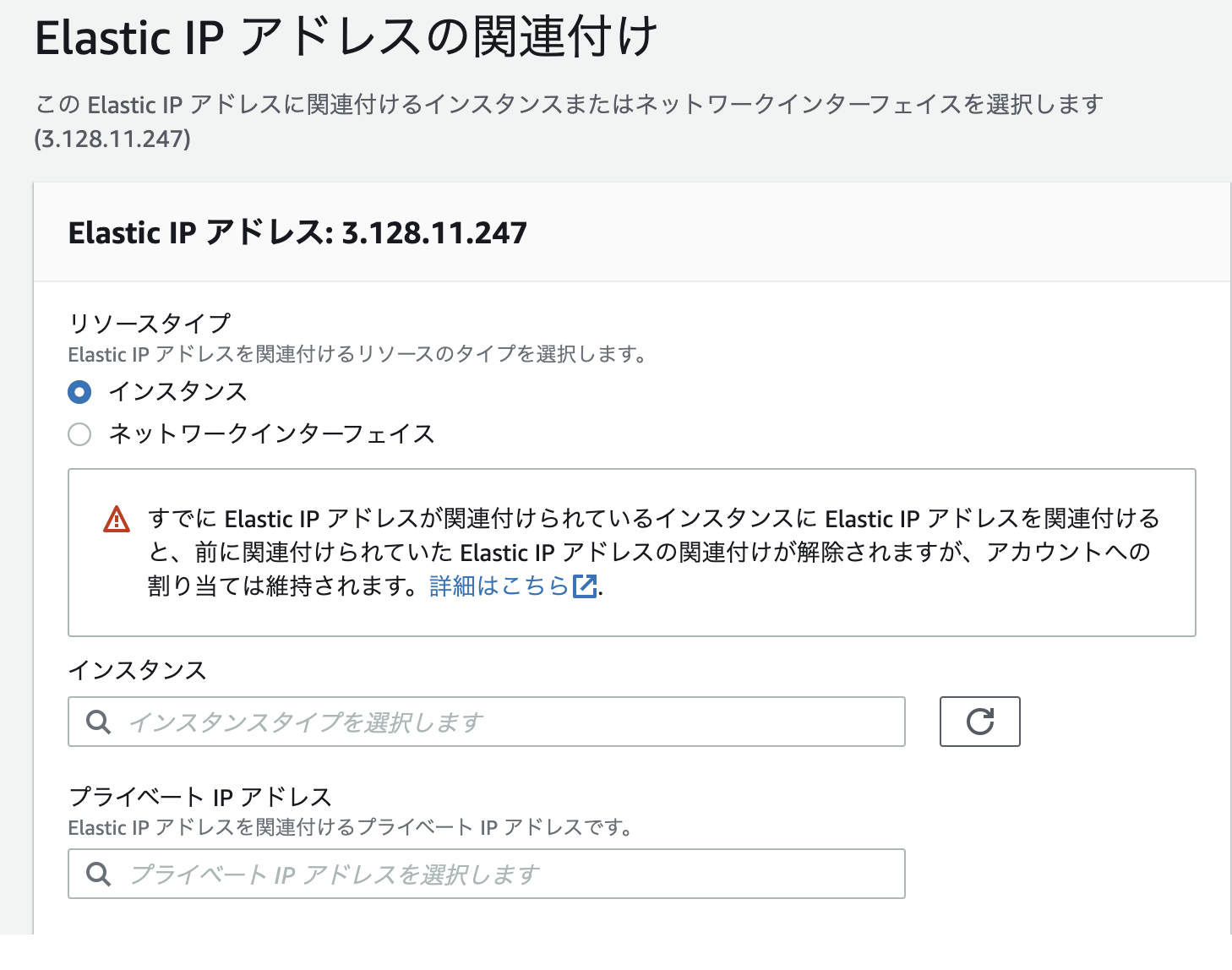
すると、ElasticIPが割り当てられIPアドレスが確保できた状態になる。そこで、紐付けを下記の操作で行う
こちらの画面から、
・リソースタイプ
・インスタンス
・プライベートIPアドレス
など必要事項を選択して、紐付けを行う
ElasticIPアドレスは、「パブリックIP・・・」、と記載されているものを指す。
これをhttp上でリクエストを送ると、無事にApacheの画面が返ってくる。
**※これをやっておかないと課金される恐れがあるので必ずやること
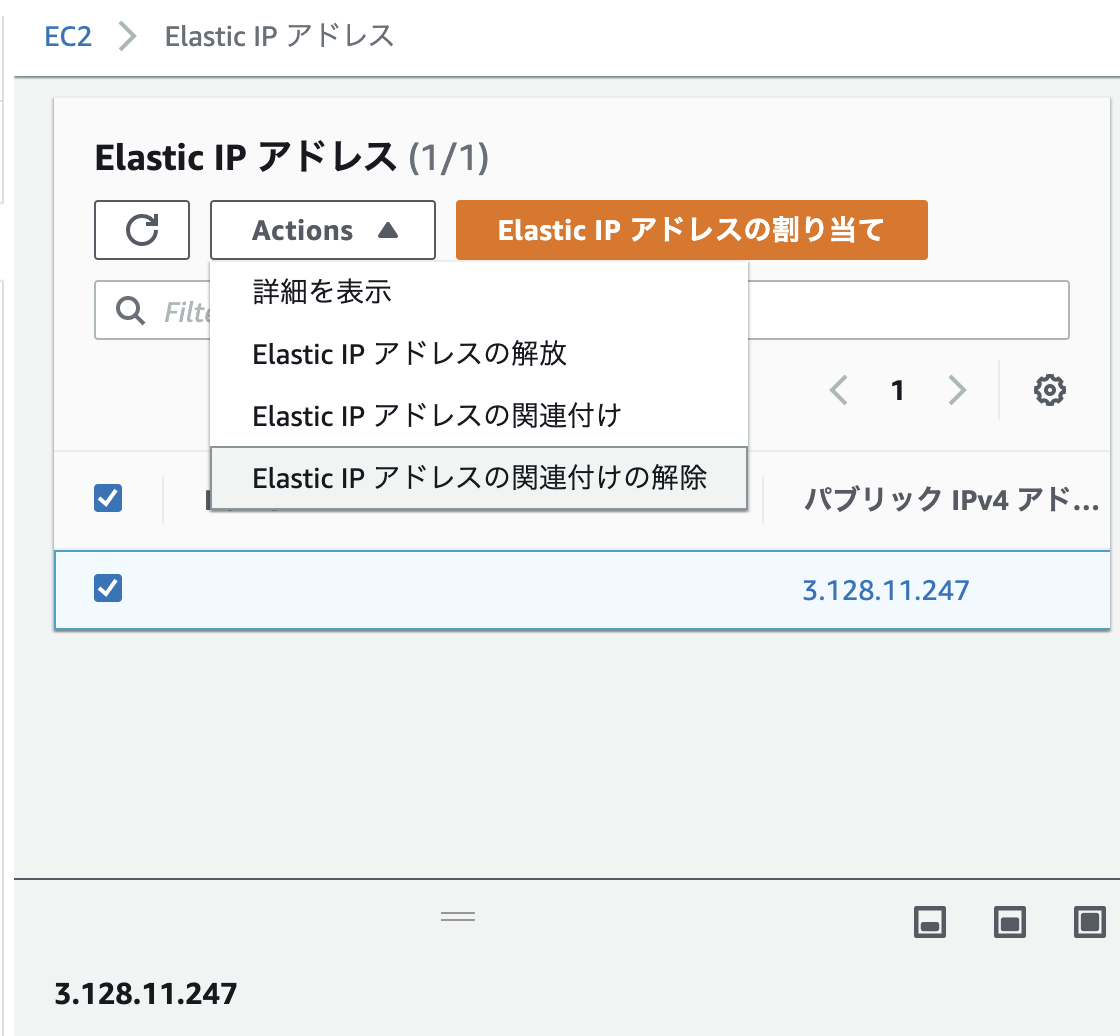
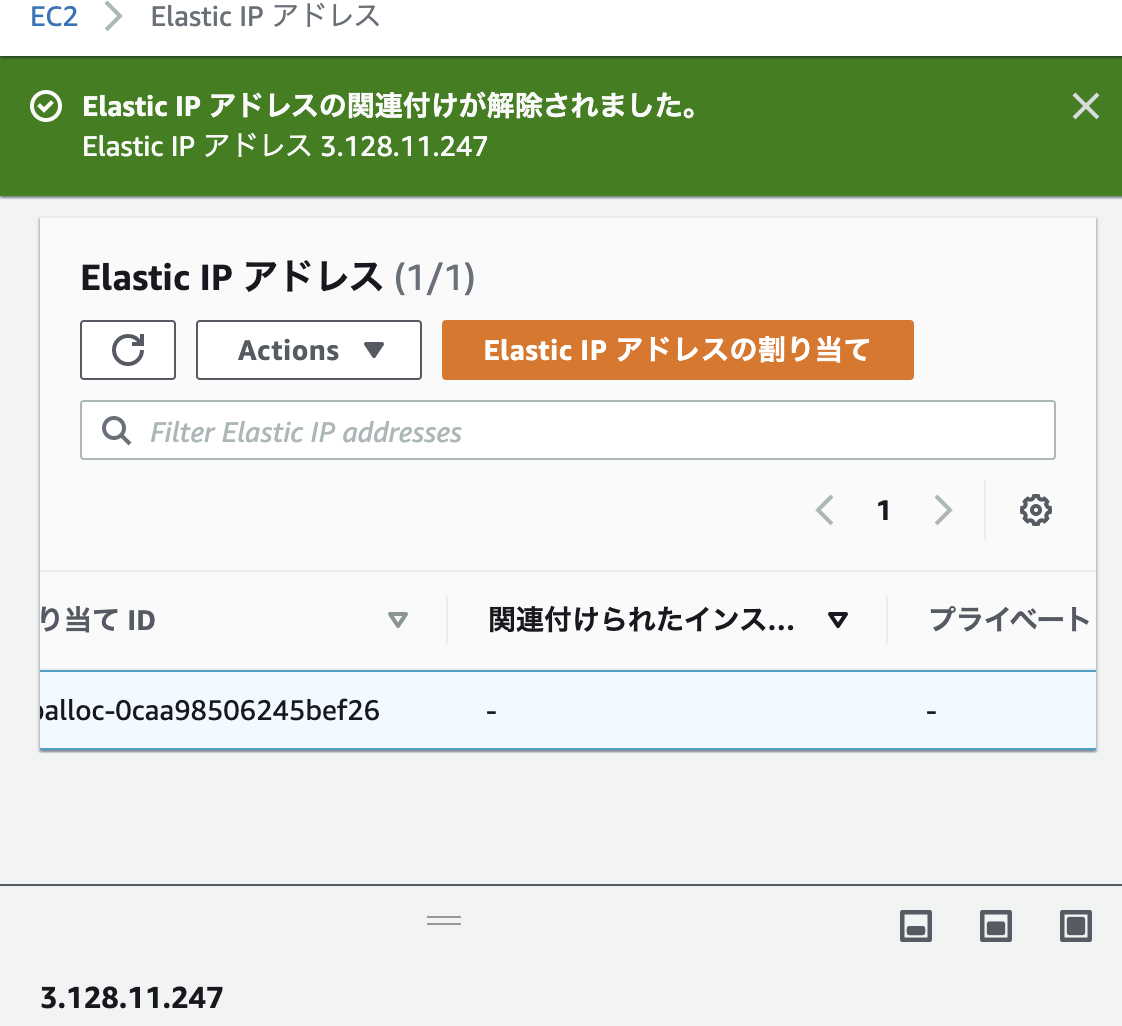
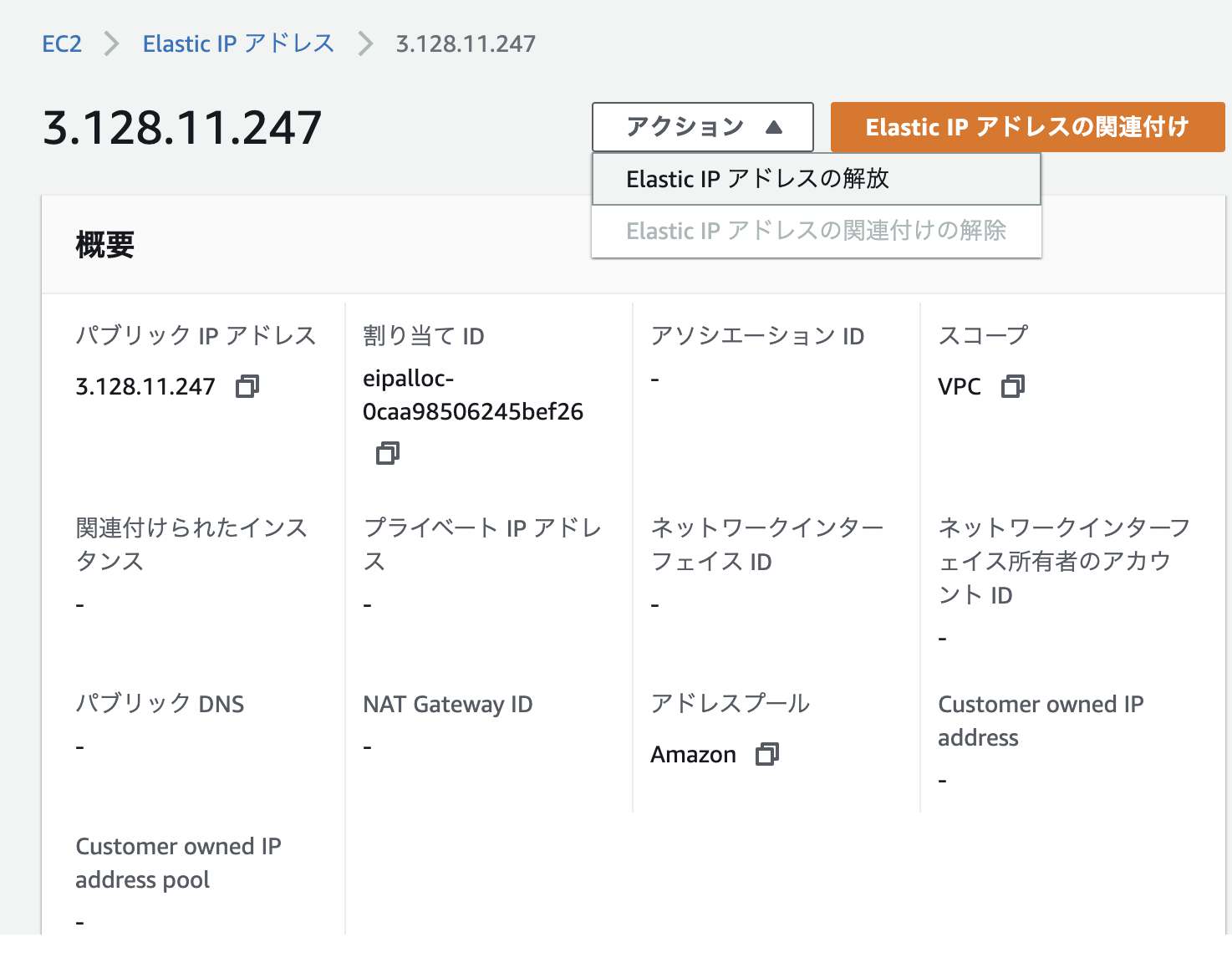
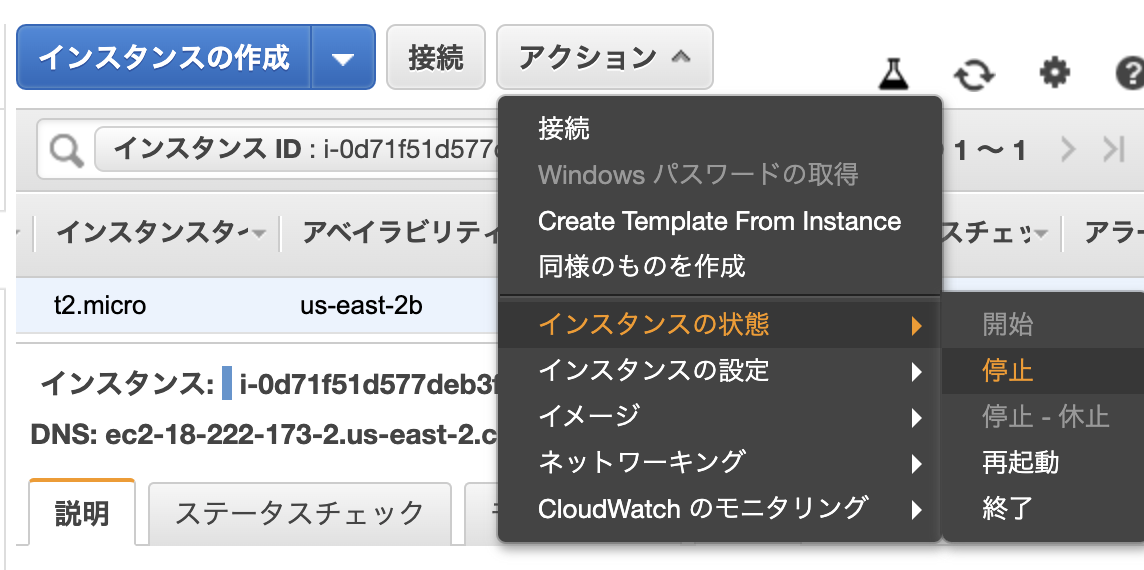
7.後片付け
Elastic IPアドレスの開放
EC2インスタンスの停止
順にスクショで説明
これで完了。ふう、長かった。

- 投稿日:2020-05-27T22:14:12+09:00
AWS: ストレージサービス
ストレージサービスまとめ
- EBS(Elastic Block Storage)
- EFS
- S3
- Glacier
- Storage Gateway
ストレージサービスの分類とストレージタイプ
ブロックストレージ ファイルストレージ オブジェクトストレージ 例 EBS EFS, Storage Gateway S3, Glacier 管理単位 ブロック ファイル オブジェクト データライフサイクル 追加・更新・削除 追加・更新・削除 追加・削除 プロトコル SATA, SCSI, FC CIFS, NFS HTTP(S) メタデータ 固定情報のみ 固定情報のみ カスタマイズ可能 ユースケース データベース
トランザクションログファイル共有
データアーカイブマルチメディアコンテンツ
データアーカイブEBS(Elastic Block Storage)
EC2のOS領域として利用したり、追加ボリュームとして複数のEBSをEC2にアタッチすることができる
異なるAvailability ZoneのEC2インスタンスにアタッチしたい場合は、EBSのスナップショットから指定のAZでEBSボリュームを作成することでアタッチすることができる。ボリュームタイプ
汎用SSD(gp2) プロビジョンドIOPS SSD(io1) スループット最適化HDD(st1) Cold HDD(sc1) ユースケース EC2のブートボリューム、アプリケーションリソース I/O負荷の高いデータベース領域 ログ分析、バッチ処理用大容量インプットファイル アクセス頻度の低いデータのアーカイブ ボリュームサイズ 1GB~16TB 4GB~16TB 500GB~16TB 500GB~16TB 最大IOPS/ボリューム 10,000 64,000 500 250 最大スループット/ボリューム 160MB/秒 1,000MB/秒 500MB/秒 250MB/秒 ベースライン性能 3IOPS/GB 指定されたIOPS 1TBあたり40MB/秒 1TBあたり最大80MB/秒 主なパフォーマンス IOPS IOPS MB/秒 MB/秒 *IOPS: 1秒あたりに処理できるI/Oアクセスの数
*バースト性能: 処理量の一時的な増加に対応可能指標。しかし、あくまで一時的な処理量の増加への対応に使われることを想定しているためバースト性能に頼ったサイジングはしないこと。EBSの拡張・変更
ボリュームの拡張
すべてのタイプのEBSは1ボリュームあたり16TBまで拡張することができる。
ディスク容量が不足したら必要に応じてサイズを何度でも変更することができる。*オンライン中の拡張
EC2インスタンスがオンラインのまま拡張した場合、(Linuxであればresize2fs,やxfs_growfsなど)を別途実施し、OSが認識できるようにする必要があるボリュームタイプの変更
IOPSが不足することがわかった場合などに、タイプを変更することが可能
可用性・耐久性
EBSは内部的にAZ内の複数の物理ディスクに複製が行われており、AWS内で物理的な故障が発生下場合でも利用者が意識することはほとんどない。
セキュリティ
暗号化オプションを有効にすると、ボリュームが暗号化されるだけでなく、暗号化されたボリュームから取得したスナップショットも暗号化される。暗号化処理はEC2インスタンスが稼働するホストで実施するためEBS間をまたぐデータ通信時のデータも暗号化された状態となる。
EFS(Elastic File System)
容量無制限で複数のEC2インスタンスから同時にアクセス可能なファイルストレージサービス。
NFSプロトコルをサポートしているため、NFSクライアントがあれば、特別なツールは不要。EFSの構成要素
- ファイルシステム
- マウントターゲット
- セキュリティグループ
S3 (Simple Storage Service)
容量無制限のオブジェクトストレージサービス。
ファイルストレージとの違い
- ディレクトリ構造を持たない不フラットな公正であること
- ユーザーが独自にデータに対して情報を付与できる
ユースケース
- データバックアップ
- ビックデータ解析用などのデータレイク
- ETL(Extract/Transform/Load)の中間ファイル保存
- Auto Scaling構成されたEC2インスタンスやコンテナからのログ転送先
- 静的コンテンツのホスティング
- 簡易的なKey-Value型のデータベース
構成要素
- バケット
- オブジェクトを保存するための領域
- バケット名はAWS内で一意にする必要がある
- オブジェクト
- 格納されるデータそのもの
- 各オブジェクトにはKeyが付与され、必ず一意になるURLが生成される
- 一つのオブジェクトは5TBまで
- メタデータ
- オブジェクトを管理するための情報
- 作成日付やサイズなどのシステム定義メタデータ
- ユーザー定義メタデータなども保持可能
ストレージクラス
- Standard
- Standard-IA
- ONEZONE-IA
- INTELLIGENT-TIERING
- GLACIER
後で詳細更新
ライフサイクル管理
- 移行アクション
- 有効期限アクション
バージョニング機能
Webホスティング機能
静的なコンテンツに限りWebサイトとしてホスティングする環境を作成することができる
動的なコンテンツにはEC2などのコンピューティングサービスを利用する必要がある。S3のアクセス管理
パケットポリシー ACL IAM AWSアカウント単位の制御 ◯ ◯ ✕ IAMユーザー単位の制御 △ ✕ ◯ S3バケット単位の制御 ◯ ◯ ◯ S3オブジェクト単位の制御 ◯ ◯ ◯ IPアドレス・ドメイン単位の制御 ◯ ✕ ◯ 署名付きURL
アクセスを許可したいオブジェクト対して、期限を指定してURLを発行する機能
一時的にアクセスを許可したいときに有効。
URLさえわかれば、有効期限の間誰でも該当オブジェクトに対してアクセスすることができる。データ暗号化
S3に保存するデータは暗号化することができる。
暗号方式は、サーバー側、クライアント側で2種類から選択することができる。
サーバー側の暗号化: データがストレージに書き込まれるときに暗号化され、読み出されるときに復号化される
クライアント暗号化: AWS SDKを使ってS3に送信する前にデータが暗号化されるGlacier
S3と同様にイレブンナインの耐久性を持ちながら、更に容量あたりの費用を抑えたアーカイブ・ストレージサービス。
Glacierにデータを保存するとデータの取り出しに時間がかかる。
S3のように保存するデータに対して名称をつけることはできず、自動裁判されたアーカイブIDで管理することになる。構成要素
- ボールド
- アーカイブ
- インベントリ
- ジョブ
データの取り出しオプション
- 高速
- 標準
- バルク
Glacier Select
Glacierに保存したデータを参照するには、対象アーカイブを読み出しリクエストを題して一定時間待つ必要がある。
Glacier Selectはアーカイブデータに対してSQLを実行して、条件にあったデータを抽出する機能。Storage Gateway
オンプレミスにあるデータをクラウドへ連携するための受け口を提供するサービス。
Storage Gatewayを使って連携されたデータの保存先には、先に説明したS3やGlacierといった、耐久性が高く低コストなストレージが利用される。Storage GatewayのキャッシュストレージとしてEBSが使われる。
* 独自のストレージを持たず、S3、Glacier、EBSなどを利用するセキュリティ
- CHAP認証
- データ暗号化
- 通信の暗号化
- 投稿日:2020-05-27T22:10:51+09:00
【AWS】S3(Simple Storage Service)の構成要素とは?
はじめに
現在、AWSソリューションアーキテクトの学習をしております。
今回は、S3の構成要素についてアウトプットしていきたいと思います。S3の構成要素
リージョン
地域。拠点。
地理的に離れた領域でサービス上も完全に分離されたサービスやネットワークの集合体のことパケット
S3に保存されるあらゆるオブジェクト(ファイル)を置いておくための入れ物。
一言で言うと「バケツ」。グローバルで一意に定義される。
(他の人が名前を使用していた場合は使用不可オブジェクトキー
オブジェクトを一意にするための名前
プレフィックス
階層構造のようなもの。
プレフィックスを利用してオブジェクトを一意のキーとすることが可能。※S3には「フォルダ」という概念はない。
バージョンID
オブジェクトをバージョン管理するためのID。
VPCエンドポイント
S3に対してインターネット経由ではなく、VPC内の閉じられたネットワーク内でアクセスを行うことをを可能とする。
図にしてみる
※「この1冊で合格! AWS認定ソリューションアーキテクト - アソシエイト テキスト&問題集」を参考にさせて頂きました。
参考
この1冊で合格! AWS認定ソリューションアーキテクト - アソシエイト テキスト&問題集
バケットの制約と制限
Amazon S3における「フォルダ」という幻想をぶち壊し、その実体を明らかにする

- 投稿日:2020-05-27T17:30:04+09:00
【Athena】Order By後の隣接レコードとの比較方法
前提
以下のようなテーブルを作成します(locationなどないためそのままでは動きません)。
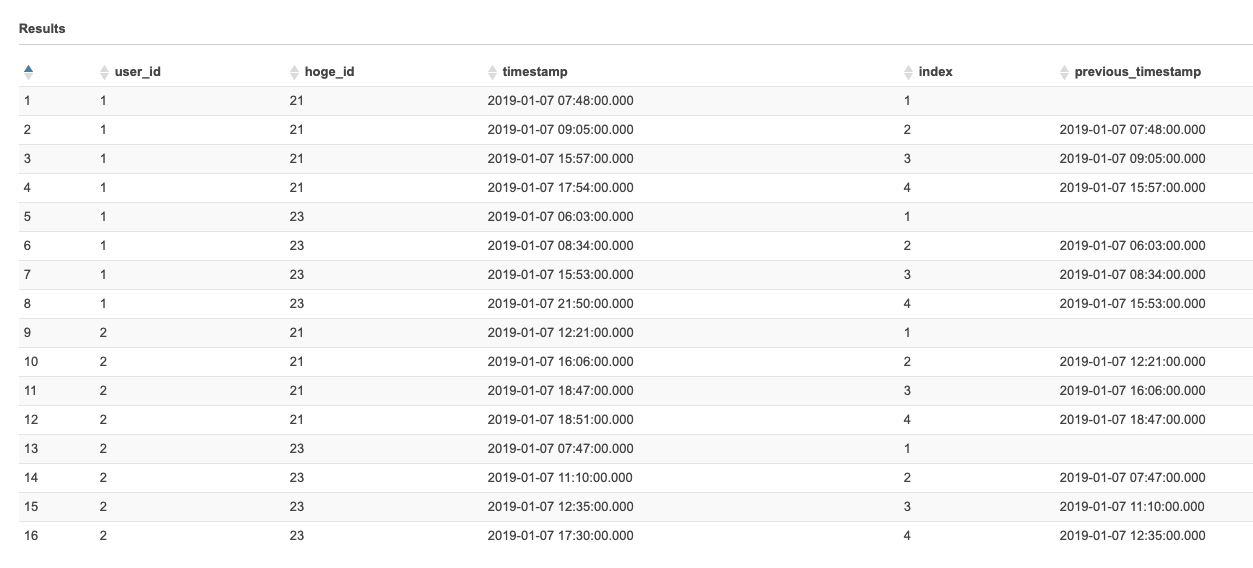
create.sqlCREATE EXTERNAL TABLE IF NOT EXISTS hamada_test.qiita_20200527 ( `user_id` int, `hoge_id` int, `timestamp` timestamp )テストデータはこのようになっています
select.sqlSELECT * FROM "hamada_test"."qiita_20200527" order by user_id, hoge_id, timestamp
user_id hoge_id time_stamp 1 21 2019-01-07 07:48:00.000 1 21 2019-01-07 09:05:00.000 1 21 2019-01-07 15:57:00.000 1 21 2019-01-07 17:54:00.000 1 23 2019-01-07 06:03:00.000 1 23 2019-01-07 08:34:00.000 1 23 2019-01-07 15:53:00.000 1 23 2019-01-07 21:50:00.000 2 21 2019-01-07 12:21:00.000 2 21 2019-01-07 16:06:00.000 2 21 2019-01-07 18:47:00.000 2 21 2019-01-07 18:51:00.000 2 23 2019-01-07 07:47:00.000 2 23 2019-01-07 11:10:00.000 2 23 2019-01-07 12:35:00.000 2 23 2019-01-07 17:30:00.000
order by user_id, hoge_id, timestampした際に隣り合うレコードと比較したい、今回だと時刻を比較したい際に使ったテクニックです。結論
SELECT user_id, hoge_id, timestamp, LAG(timestamp) over(partition by user_id, hoge_id ORDER BY user_id, hoge_id, timestamp) AS previous_timestamp FROM hamada_test."qiita_20200527"LAG ウィンドウ関数を使用すると簡単に出せます。user_id、hoge_idで区切ってtimestamp順に並べ、一つ前の行を出します。LAG関数の第二引数を2や3にすると2つ前、3つ前の行が取得できます。
複雑にしてしまっていたSQL
最初このようなSQL組んでいましたが、その必要なかったです…
このようなSQLを流すと一つ前のレコードが一つの行に入ります。select base_table.*, previous_table.timestamp as previous_timestamp from ( SELECT user_id, hoge_id, timestamp, ROW_NUMBER() over(partition by user_id, hoge_id order by user_id, hoge_id, timestamp) as index FROM "qiita_20200527" ) as base_table left join ( SELECT user_id, hoge_id, timestamp, ROW_NUMBER() over(partition by user_id, hoge_id order by user_id, hoge_id, timestamp) as index FROM "qiita_20200527" ) as previous_table on base_table.user_id = previous_table.user_id and base_table.hoge_id = previous_table.hoge_id and base_table.index = previous_table.index + 1 order by base_table.user_id, base_table.hoge_id, base_table.timestamp
これでtimestampとprevious_timestampが一つの行に入るのでこれらを比較すれば時刻差などが取れます。またindex1は前の行が存在しないのでprevious_timestampが空になっています。解説
無駄っぽいように見えますが
SELECT user_id, hoge_id, timestamp, ROW_NUMBER() over(partition by user_id, hoge_id order by user_id, hoge_id, timestamp) as index FROM "qiita_20200527"このサブクエリで同じテーブルを結合させています。肝なのは
ROW_NUMBER() over(partition by user_id, hoge_id order by user_id, hoge_id, timestamp)で、これでuser_id・hoge_idで区切ったあと、timestampで順番を付けています。
そのテーブルを結合させる際にon base_table.user_id = previous_table.user_id and base_table.hoge_id = previous_table.hoge_id and base_table.index = previous_table.index + 1このようにindexとindex+1で結合させています。これで一つ前の行と結合させることができます。
連続するデータを前後で比較する際にSQLのみで対応したかったためこのように試しました。
もしよりよいやり方ありましたら教えていただけますと助かります。
- 投稿日:2020-05-27T17:07:40+09:00
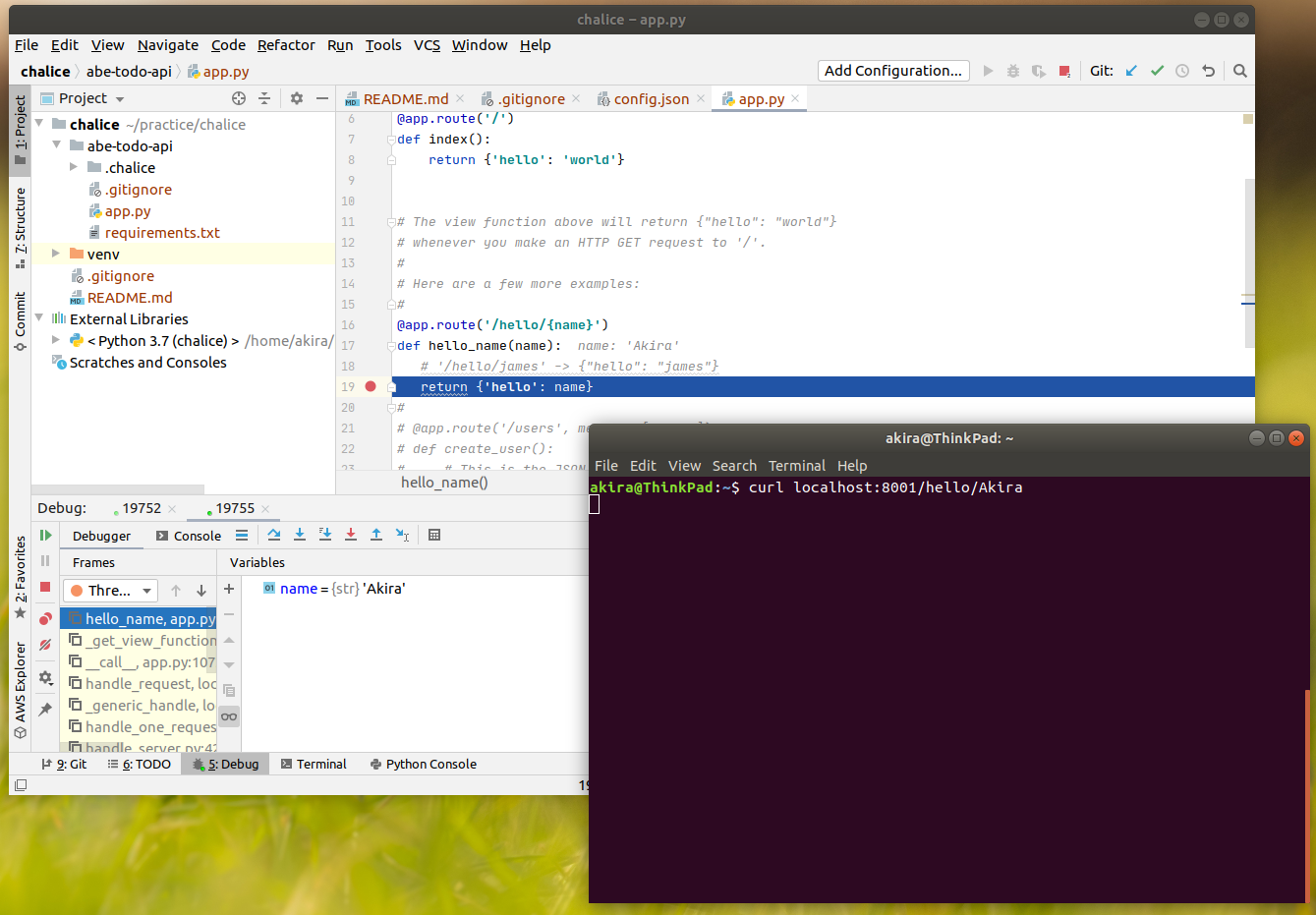
AWS ChaliceをPyCharmでローカルデバッグ実行する
この記事の概要
サーバーレスアーキテクチャーをサポートするフレームワークも色々充実してきていますが、今回は、AWS製のPython専用フレームワークのChaliceを試してみました。単に試すだけですと、正直、Black Belt読みましょう。以上!で終わってしまいます。
従って、今回はローカルでテストしてみることにこだわって、PyCharmでのローカルデバッグの方法を中心に記載します。
前提知識
サーバーレスとは?やChaliceとは?というのは、以下のリンクを参照ください。
まずは、公式
https://chalice.readthedocs.io/en/latest/その他参考にしたサイト
https://www.freecodecamp.org/news/how-to-get-started-with-serverless-architecture/
https://aws.amazon.com/jp/blogs/news/webinar-bb-aws-chalice-2019/
https://aws.amazon.com/jp/builders-flash/202003/chalice-api/仕込み
公式のQuick start and tutorial
https://chalice.readthedocs.io/en/latest/quickstart.html#quickstart-and-tutorial
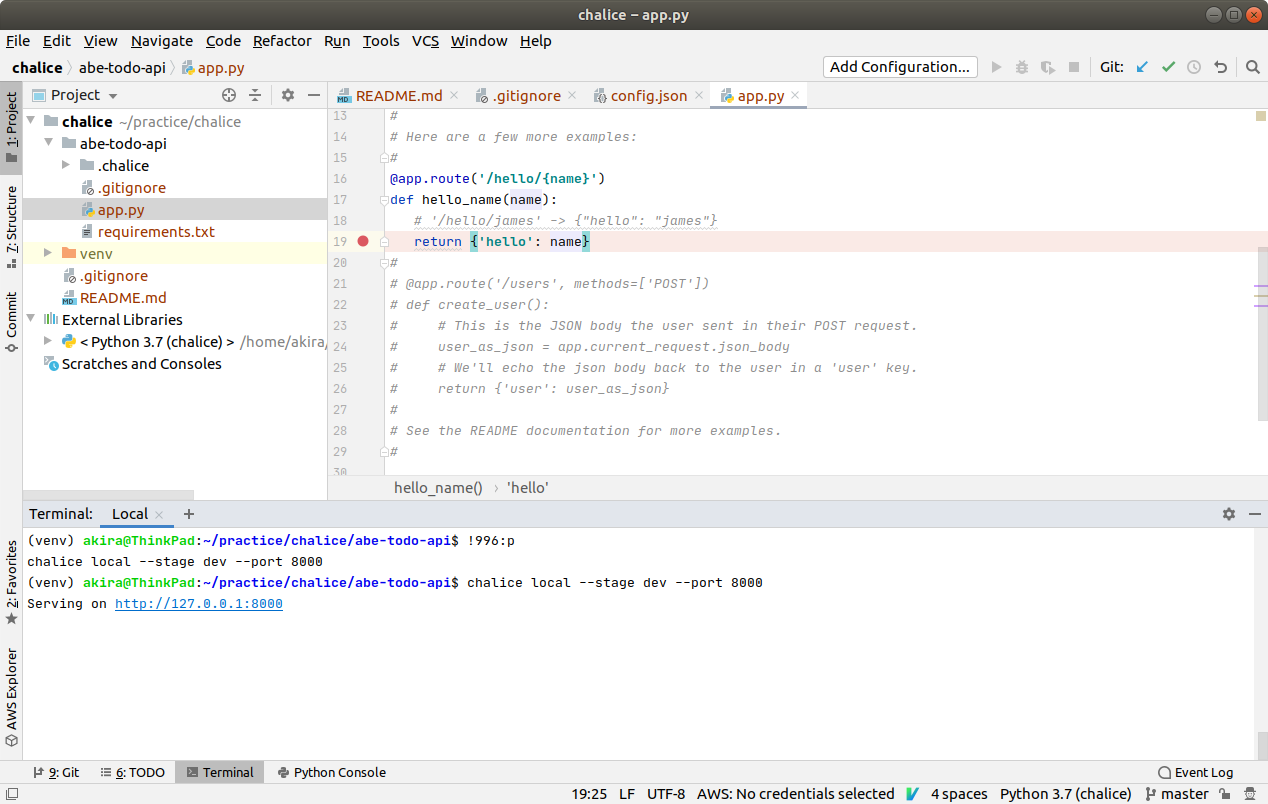
ですと、一番最初は、{'hello': 'world'}を返すだけで、デバッグの余地がありません。
従って、プロジェクトを作成して初期状態で出来るapp.pyのコメントを外して、Path引数を渡すメソッドを有効化してみましょう。from chalice import Chalice app = Chalice(app_name='abe-todo-api') @app.route('/') def index(): return {'hello': 'world'} @app.route('/hello/{name}') def hello_name(name): # '/hello/james' -> {"hello": "james"} return {'hello': name}ローカルでのデバッグ
ローカルでChaliceを実行
app.pyの19行目のreturnの位置にBreak pointを設定します。
Terminalから、以下のコマンドを実行し、Chaliceをローカル環境で実行します。
(ちなみに、--stageと--portは、以下では、わざわざデフォルト値を指定しているので、chalice localだけでもいけます)$ chalice local --stage dev --port 8000
実行中のプロセスにデバッガーをアタッチ
Run > Attach to Process...
Debug on PyCharm
ブレークポイントデバッグの様子
DynamoDB Localの実行
https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/DynamoDBLocal.html
(別途詳細追記予定)
- 投稿日:2020-05-27T16:37:57+09:00
AWS SAA 曖昧な箇所についてまとめてみた②
背景
最も本試験の難易度に近いと言われている【SAA-C02版】AWS 認定ソリューションアーキテクト アソシエイト模擬試験問題集(6回分390問)の中で、
自分が解いていてつまづいた箇所をピックアップしました。◆ つまづいた用語一覧
用語 意味 VPCフローログ EC2インスタンスのIPトラフィックを取得可能。 ※中央ロギング管理に必須 CloudWatch Agent EC2インスタンスのメトリクス・ログを収集可能 ※中央ロギング管理に必須 UpdateSharedCountAPI Kinesis Data Stremsのスループット変更 Dedicated hosts 物理サーバをプロビジョニング、EC2上で起動する Lambda オーソライザー Lambdaを使ってアクセス制御するAPI Gatewayの機能 Redis AUTH Redis認証トークン、Redis用ElasticCacheクラスターで使用される Egress-Only インターネットゲートウェイ IPv6-VPC間のインターネット送信を可能にする NATゲートウェイ IPv4経由のインターネット送信を可能にする Amazon Athena S3内のデータを直接分析することが出来る(クエリの実行) SAML認証 クラウド上のシングルサインオン(SSO)、異なるドメイン間でユーザ認証可能 LDAP ユーザやコンピュータ情報を集中管理する「ディレクトリサービス」へのアクセス時に用いられるプロトコル S3 Glacier ボールトロック 読み取り専用などのポリシーを設定する機能 IDS 不正侵入検知 ※Intrusion Detection System IPS 不正侵入防御 ※Intrusion Prevention System OpsWorks デプロイ/モニタリング/スケーリングの提供。※chef、puppetなど WebSocket ハンドシェイクによる双方向通信**の実現 TCP(Transmission Control Protocol) HTTP、FTP、Telnetなど UDP(User Datagram Protocol) DNP、NTP、DHCPなど TCPとUDPの違い TCP:荷造りまでしてくれる宅配便
UDP:荷造りしない普通の宅配便ハンドシェイク 本格的に通信を行う前に、パラメータの取り決めなどを行うこと ディザスタリカバリ 災害からの回復措置、予防措置 ※RDS(Multi-AZ)、ELB冗長構成 トラフィック ネットワークを流れる情報量 サブネット 大きなネットワークを分割した際の小さなネットワーク パブリックサブネット 0.0.0.0/0(ルートテーブル/デフォルト)がインターネットゲートウェイに接続可能 プライベートサブネット 0.0.0.0/0(ルートテーブル/デフォルト)がNATインスタンスなど NATインスタンス 運用管理はユーザで行う ※コストが安い、カスタマイズ可能 NATゲートウェイ 運用管理はAWSで行う ※コストが高い マルチAZ プライマリDBインスタンス、スタンバイDBインスタンス(別のAZ) リードレプリカ リードレプリカへの読み取りクエリをルーティングすることにより、負荷軽減 リードレプリカのオフロード レプリケーションの遅延を防ぐため、読込ワークロードをオフにする AWS System Manager 利用中のインフラを可視化し、制御するためのサービス AWS パラメータストア 設定データ管理と階層型ストレージの提供。パラメータ値として保存可能 プラットフォームエンドポイント Amazon SNSを使用して、通知を送信する際にデバイストークンを紐付ける Cloud Trail 管理イベント IAM管理、EC2オペレーション Cloud Trail データイベント S3 API / Lambda関数の証跡 Cloud Eatch 基本モニタリング:5分間隔
詳細モニタリング:1分間隔Cloud Trail CloudWatch Eventsの起動 / CloudWatch logsとの連携が可能 CHAMEレコード(DNS) エイリアスレコード(Route53)よりコスパが悪い
※zone apexはCHAMEレコードにマッピングすることは出来ないElasticSearch リアルタイムデータ分析 / ログ解析 / 全文検索 フェイルオーバールーティングポリシー アクティブ/パッシブ構成する場合に使用 AutoScaling EC2インスタンスが動的に追加/削除 ELB EC2間でトラフィックを均等に配布する Drain スケーリングの中止。EC2インスタンスを新規作成しない AutoScaling/ELBヘルスチェック AutoScaling:EC2インスタンスのステータスチェックのみ
ELBのヘルスチェックが優先されるVPCピアリング接続 複雑かつ詳細なアクセス制御をしたい場合使用する PrivateLink 独自でクローズドな環境でアクセス制御したい場合使用する CMK(カスタマーマスターキー) KMSに独自のカスタマーキーを作成する場合にCMKを作成する kinesis data streams データ処理/分析を行う source destination check属性 送信元/送信先変更チェック ※NATインスタンスで使用
- 投稿日:2020-05-27T16:37:57+09:00
【AWS SAA】 曖昧な箇所をまとめてみた②
背景
最も本試験の難易度に近いと言われている【SAA-C02版】AWS 認定ソリューションアーキテクト アソシエイト模擬試験問題集(6回分390問)の中で、
自分が解いていてつまづいた箇所をピックアップしました。◆ つまづいた用語一覧
用語 意味 VPCフローログ EC2インスタンスのIPトラフィックを取得可能。 ※中央ロギング管理に必須 CloudWatch Agent EC2インスタンスのメトリクス・ログを収集可能 ※中央ロギング管理に必須 UpdateSharedCountAPI Kinesis Data Stremsのスループット変更 Dedicated hosts 物理サーバをプロビジョニング、EC2上で起動する Lambda オーソライザー Lambdaを使ってアクセス制御するAPI Gatewayの機能 Redis AUTH Redis認証トークン、Redis用ElasticCacheクラスターで使用される Egress-Only インターネットゲートウェイ IPv6-VPC間のインターネット送信を可能にする NATゲートウェイ IPv4経由のインターネット送信を可能にする Amazon Athena S3内のデータを直接分析することが出来る(クエリの実行) SAML認証 クラウド上のシングルサインオン(SSO)、異なるドメイン間でユーザ認証可能 LDAP ユーザやコンピュータ情報を集中管理する「ディレクトリサービス」へのアクセス時に用いられるプロトコル S3 Glacier ボールトロック 読み取り専用などのポリシーを設定する機能 IDS 不正侵入検知 ※Intrusion Detection System IPS 不正侵入防御 ※Intrusion Prevention System OpsWorks デプロイ/モニタリング/スケーリングの提供。※chef、puppetなど WebSocket ハンドシェイクによる双方向通信**の実現 TCP(Transmission Control Protocol) HTTP、FTP、Telnetなど UDP(User Datagram Protocol) DNP、NTP、DHCPなど TCPとUDPの違い TCP:荷造りまでしてくれる宅配便
UDP:荷造りしない普通の宅配便ハンドシェイク 本格的に通信を行う前に、パラメータの取り決めなどを行うこと ディザスタリカバリ 災害からの回復措置、予防措置 ※RDS(Multi-AZ)、ELB冗長構成 トラフィック ネットワークを流れる情報量 サブネット 大きなネットワークを分割した際の小さなネットワーク パブリックサブネット 0.0.0.0/0(ルートテーブル/デフォルト)がインターネットゲートウェイに接続可能 プライベートサブネット 0.0.0.0/0(ルートテーブル/デフォルト)がNATインスタンスなど NATインスタンス 運用管理はユーザで行う ※コストが安い、カスタマイズ可能 NATゲートウェイ 運用管理はAWSで行う ※コストが高い マルチAZ プライマリDBインスタンス、スタンバイDBインスタンス(別のAZ) リードレプリカ リードレプリカへの読み取りクエリをルーティングすることにより、負荷軽減 リードレプリカのオフロード レプリケーションの遅延を防ぐため、読込ワークロードをオフにする AWS System Manager 利用中のインフラを可視化し、制御するためのサービス AWS パラメータストア 設定データ管理と階層型ストレージの提供。パラメータ値として保存可能 プラットフォームエンドポイント Amazon SNSを使用して、通知を送信する際にデバイストークンを紐付ける Cloud Trail 管理イベント IAM管理、EC2オペレーション Cloud Trail データイベント S3 API / Lambda関数の証跡 Cloud Eatch 基本モニタリング:5分間隔
詳細モニタリング:1分間隔Cloud Trail CloudWatch Eventsの起動 / CloudWatch logsとの連携が可能 CHAMEレコード(DNS) エイリアスレコード(Route53)よりコスパが悪い
※zone apexはCHAMEレコードにマッピングすることは出来ないElasticSearch リアルタイムデータ分析 / ログ解析 / 全文検索 フェイルオーバールーティングポリシー アクティブ/パッシブ構成する場合に使用 AutoScaling EC2インスタンスが動的に追加/削除 ELB EC2間でトラフィックを均等に配布する Drain スケーリングの中止。EC2インスタンスを新規作成しない AutoScaling/ELBヘルスチェック AutoScaling:EC2インスタンスのステータスチェックのみ
ELBのヘルスチェックが優先されるVPCピアリング接続 複雑かつ詳細なアクセス制御をしたい場合使用する PrivateLink 独自でクローズドな環境でアクセス制御したい場合使用する CMK(カスタマーマスターキー) KMSに独自のカスタマーキーを作成する場合にCMKを作成する kinesis data streams データ処理/分析を行う source destination check属性 送信元/送信先変更チェック ※NATインスタンスで使用
- 投稿日:2020-05-27T14:54:12+09:00
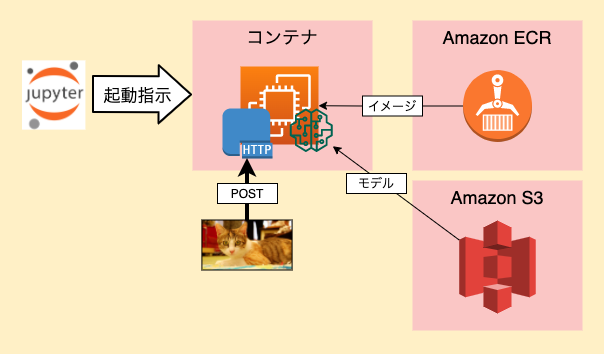
AWS SageMakerのバッチ推論が思っていたのと違った話
背景
機械学習で学習・推論を行うに当たり、AWS SageMakerを利用しています。
今回は独自モデルを利用して バッチ推論を実施する際 にハマったお話で、扱っているデータは画像です。
※本来、学習→推論の流れになりますが、学習を割愛しているため若干記事として読みにくいかもしれません。推論とは
作成したモデルを利用して、元となるデータから予測される結果を出力することを「推論」と記載しています。
AWS SageMakerでの推論方法は主に下記の2パターンあります。
- リアルタイム推論
- バッチ推論
リアルタイム推論
リアルタイム推論はイメージしやすいです。
リアルタイム推論の流れ
- Estimatorインスタンスを生成し、deployメソッドを呼び出す
- 指定したモデルを包含したHTTPエンドポイントが起動される
docker run image serveでコンテナ起動- モデルはEstimatorインスタンス生成時の引数で指定
- ECRに登録済みのコンテナを起動し、HTTPエンドポイントを設定
- /invocationsと/pingを定義しておく
- /pingは200を返せば良いが、監視としても利用できる
- /invocationsに推論元データをPOSTして推論結果を出力させる
- 推論結果はHTTPレスポンスとして返却
- 停止指示しない限り、エンドポイントは起動したまま
推論時のイメージ
参考URL
バッチ推論
本題です。
自分が元々想像していたのは、以下のような流れでした。
- 指定したモデルを包含したバッチジョブ(スクリプト)を定義
- S3上の推論元データが逐次スクリプトに渡され、指定出力先にアウトプット
- 推論元のデータを全て処理し終わったら完了
そもそも「バッチジョブ(スクリプト)を定義」の時点で違いました。
やっていることはほとんどリアルタイム推論(上の「推論時のイメージ」)と同様で、違いとしては 「推論実施までの流れ」 と 「コンテナの挙動」 です。
バッチ推論の流れ
- boto3のSageMakerインスタンスを生成し、create_transform_job()で呼び出し
- create_transform_job()は非同期で実行される
- (内部的に)指定したモデルを包含したHTTPエンドポイントが起動される
docker run image serveでコンテナ起動- モデルはcreate_transform_job()に渡すjson引数に定義
- S3上のINPUT/OUTPUTもこの引数内で指定する
- (どういう風に渡されるのかドキュメントから読み取れない...)
- ECRに登録済みのコンテナを起動し、HTTPエンドポイントを設定
- /invocationsと/pingを定義しておく
- /pingは200を返せば良いが、監視としても利用できる
- /invocationsにINPUTとして指定したS3パスのファイル群が、一つずつPOSTされる
- 推論結果はHTTPレスポンスとして返却
- 返却内容は、OUTPUTに指定したS3に「INPUTに与えられたファイル名.out」としてupされる
- S3のファイル群を処理し終わったらコンテナ停止
参考URL
所感
個人的にSageMakerのバッチ推論は 「理解し辛いのでは」 、、というのが所感です。
- 「バッチ」という名前と挙動に大きな剥離がある
- 自分が勝手に想像していたイメージではあるものの...
- 学習時の作業ともかなり異なる
- 学習時はS3のパスとコンテナ内のパスを紐付けながらの作業
- 推論時もS3のデータをコンテナ内にコピーできそうだが、できない
また、下記の「まだ分かっていないところ」も含めて、利用シーンが想定できていません。
まだ分かっていないところ
- 通常運用だとjupyter notebookを介して呼び出せない
- リアルタイム推論はエンドポイントが起動したままなので扱いやすい
- バッチ推論はどう呼び出すのが適切?
- 何度か試している限りコンテナの起動に4分くらいかかる
- 毎回4分かかっていたらさすがに使い勝手が良くない
- 高速化する方法はないものか
最後に
もちろん、以下の利点もあります!
- リアルタイム推論とバッチ推論で共通のIFにできる
- バッチ推論は処理が終わったらコンテナも停止される
- 無駄なコストを節約できる
その他、自分の理解が追いついてないところも多々あるかもしれません。
調べていく内に、もっと良い利用方法が見つかったら改めて記事にしたいなと思います。
- 投稿日:2020-05-27T11:48:13+09:00
複数のインスタンス、ドメイン、SSL証明書をALBに登録してhttpsアクセスする
Wano株式会社で社内のもろもろを担当しているakibinです。
普段Spotifyで音楽聴きながら作業してますが、どうしてもマキシマム ザ ホルモンが聴きたい時はウォークマンで聴いています(この記事は聴きながら書いてる)。サブスク解禁しないかな、亮君。
今回やってみたこと
すでにEC2でインスタンス稼働、ロードバランサ(ALBを)使用してSSL証明書(ACM発行)を登録、Route53に該当ドメイン登録してhttps化している環境で、新たにインスタンスを追加して別ドメインで証明書発行、それをALBに追加登録してhttpsアクセスを各インスタンスに振り分ける、そんなことをしてみました。
事前作業
EC2に追加のインスタンスを作成して、Webサーバと立てておく。ドメインを決めておく。
- 既存インスタンス(ryokun-server)のドメイン ryokun.makihoru.co.jp
- 追加インスタンス(naochan-server)のドメイン naochan.makihoru.co.jp
作業
インスタンスのIP固定
こちらを参照して取得したElasticIPとインスタンスを紐付ける
新たにSSL証明書発行
こちらを参照してACMでnaochan.makihoru.co.jpの証明書追加、DNS検証を実施するためRoute53で管理しているmakihoru.co.jpのホストゾーンにCNAMEレコードを作成。
ちょっと時間がたつと検証完了され、SSL証明書が使用できるようになります。ALBにSSL証明書を追加
こちらを参照して、↑で追加したSSL証明書をALBに追加する
ターゲットグループを追加してALBをでホストルーティング
こちら(←わかりやすかったです!助かりました!!)を参照して新たにターゲットグループを作成。
- 既存ターゲットグループ(ryokun-group) ターゲット → ryokun-server
- 追加ターゲットグループ(naochan-group) ターゲット → naochan-server
ALBで以下ルーティング設定実施。
- ryokun.makihoru.co.jp → ryokun-groupへルーティング
- naochan.makihoru.co.jp →n aochan-groupへルーティング
ホストゾーンにAレコード追加
こちらを参照してmakihoru.co.jpのホストゾーンにnaochan.makihoru.co.jpへのドメインアクセスをALBに転送するAレコード作成
これで以下アクセスが可能になりました!
https://ryokun.makihoru.co.jp → ryokun-server
https://naochan.makihoru.co.jp → naochan-server包丁ハサミ!包丁ハサミ!♪
こちらもぜひとも!
****************************************
◆ Twitterアカウント
@AkibinMusic
◆ Youtubeチャンネル
https://www.youtube.com/channel/UC-JOpwEnJn3gCrUA4NdCYgg
- 投稿日:2020-05-27T11:15:00+09:00
Athena の TIMESTAMP は、 yyyy-MM-dd HH:mm:ss を直接サポートしない
現象
Athena の TIMESTAMP は、よくある日付形式
yyyy-MM-dd HH:mm:ssを直接サポートしません。
例えば以下のようなCSVファイルからGlueでテーブルを作り、2番めのカラムの型にtimestampを設定したとします。sample.csv1000,2020-05-27 10:58:00 1001,2020-05-28 10:58:00ここで、
select * from sampleを実行してもエラーになります。おそらくこんなエラーメッセージが出ます。HIVE_BAD_DATA: Error parsing field value '2020-05-27 10:58:00' for field 4: For input string: "2020-05-27 10:58:00"対策
対策は、テーブルのカラム定義では
stringとして、読むときにdate_parse関数を使うことです。
date_by_stringは、2番めのカラム名だと思ってください。sample.sqlselect date_parse(date_by_string,'%Y-%m-%d %H:%i:%s') from sample参考リンク
https://aws.amazon.com/jp/premiumsupport/knowledge-center/query-table-athena-timestamp-empty/
- 投稿日:2020-05-27T11:01:08+09:00
EC2 とは
EC2
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/concepts.html
Amazon Elastic Compute Cloud (Amazon EC2) は、アマゾン ウェブ サービス (AWS) クラウドでサイズが変更できるコンピューティングキャパシティーを提供します。Amazon EC2 の使用により、ハードウェアに事前投資する必要がなくなり、アプリケーションをより速く開発およびデプロイできます。Amazon EC2 を使用して必要な数 (またはそれ以下) の仮想サーバーを起動して、セキュリティおよびネットワーキングの設定と、ストレージの管理を行います。Amazon EC2 では、要件変更や需要増に対応して迅速に拡張または縮小できるため、サーバートラフィック予測が不要になります。
Amazon EC2 の機能
- インスタンスと呼ばれる仮想コンピューティング環境
- サーバーに必要なビットをパッケージ化した (オペレーティングシステムおよび追加のソフトウェアを含む)、Amazon Machine Image (AMI) と呼ばれる、インスタンス用に事前に設定されたテンプレート。
- インスタンスタイプと呼ばれる、インスタンス用の CPU、メモリ、ストレージ、ネットワーキングキャパシティーのさまざまな構成
- キーペアを使用したインスタンス用の安全なログイン情報 (AWS はパブリックキーを保存し、ユーザーはプライベートキーを安全な場所に保存します)。
- インスタンスストアボリュームと呼ばれる、インスタンスを停止または終了するときに削除される一時データ用のストレージボリューム
- Amazon EBS ボリュームと呼ばれる、Amazon Elastic Block Store (Amazon EBS) を使用したデータ用の永続的ストレージボリューム
- リージョンおよびアベイラビリティーゾーンと呼ばれる、インスタンスや Amazon EBS ボリュームなどのリソース用の複数の物理的な場所
- セキュリティグループを使用してインスタンスに到達可能で、プロトコル、ポート、ソース IP 範囲を指定できるファイアウォール
- Elastic IP アドレスと呼ばれる、動的クラウドコンピューティング用の静的な IPv4 アドレス
- タグと呼ばれ、作成して Amazon EC2 リソースに割り当てることができるメタデータ
- 残りの AWS クラウドから論理的に分離され、ユーザー独自のネットワークにオプションで接続できる、仮想プライベートクラウド (VPC) と呼ばれる仮想ネットワーク
Amazon EC2 の料金表
オンデマンドインスタンス
- 秒単位で使用するインスタンスに対して支払いを行い、長期的な確約や前払い金は不要です。
Savings Plans
- 1〜3 年の期間、1 時間 につき USD で、定期的な使用量を守ることにより Amazon EC2 コストを削減できます。
リザーブドインスタンス
- 1〜3 年の期間、インスタンスタイプとリージョンを含む特定のインスタンス設定を守ることにより Amazon EC2 コストを削減できます。
スポットインスタンス
- 未使用の EC2 インスタンスをリクエストして、Amazon EC2 コストを大幅に削減できます。
リージョン、アベイラビリティーゾーン、および ローカルゾーン
概念
各リージョンは完全に独立しています。各アベイラビリティーゾーンは独立していますが、リージョン内のアベイラビリティーゾーンは低レイテンシーのリンクで接続されています。ローカルゾーン は、厳選したサービスをエンドユーザーのより近くに配置する AWS インフラストラクチャのデプロイです。ローカルゾーン は、リージョンの拡張であり、ご利用のリージョンとは別の場所に設定されます。AWS インフラストラクチャに広帯域幅のバックボーンを提供し、機械学習などのレイテンシーの影響を受けやすいアプリケーションに最適です。次の図に、リージョン、アベイラビリティーゾーン、および ローカルゾーン の関係を示します。
リージョン
インスタンスを起動するときは、同じリージョン内にある AMI を選択する必要があります。AMI が別のリージョンにある場合は、使用しているリージョンに AMI をコピーできます。詳細については、「AMI のコピー」を参照してください。
アベイラビリティーゾーン
インスタンスを起動するときに、アベイラビリティーゾーンを自分で選択するか、自動的に選択されるようにできます。インスタンスを複数のアベイラビリティーゾーンに配布する場合は、1 つのインスタンスで障害が発生したら別のアベイラビリティーゾーンのインスタンスが要求を処理するように、アプリケーションを設計できます。
また、Elastic IP アドレスを使用すると、あるアベイラビリティーゾーンのインスタンスの障害を、別のアベイラビリティーゾーンのインスタンスにアドレスをすばやく再マッピングすることによってマスクできます。
ローカルゾーン
ローカルゾーン は、ユーザーに近い場所に位置する、AWS リージョンの拡張です。インスタンスを起動するときに、ローカルゾーン のサブネットを選択できます。ローカルゾーン は、インターネットへの独自の接続を持ち、AWS Direct Connect をサポートしています。したがって、ローカルゾーン で作成したリソースは、非常に低いレイテンシーの通信を使用してローカルユーザーにサービスを提供できます。
us-west-2のみ可能
ローカルゾーン を無効にする場合は、AWS サポートに連絡する必要があります。
AWS Local Zonesとは
https://hacknote.jp/archives/54928/ネットワーク境界グループ
ネットワーク境界グループは、AWS が IP アドレスをアドバタイズするアベイラビリティーゾーンまたは ローカルゾーン の一意のセットです。ネットワーク境界グループから次のリソースを割り当てることができます。
別のアベイラビリティーゾーンへのインスタンスの移行
インスタンスから AMI を作成します。手順は、オペレーティングシステムとインスタンスのルートデバイスボリュームの種類によって異なります。詳細については、使用しているオペレーティングシステムとルートデバイスボリュームに対応するドキュメントを参照してください。
Amazon EBS-Backed Linux AMI の作成
instance store-backed Linux AMI の作成
Amazon EBS-backed Windows AMI の作成
インスタンスのプライベート IPv4 アドレスを維持する必要がある場合は、現在のアベイラビリティーゾーンのサブネットを削除してから、新しいアベイラビリティーゾーンに元のサブネットと同じ IPv4 アドレス範囲のサブネットを作成する必要があります。サブネットを削除する前に、その中のすべてのインスタンスを終了する必要があります。したがって、サブネットのすべてのインスタンスから AMI を作成し、現在のサブネットのすべてのインスタンスを新しいサブネットに移動できるようにする必要があります。
ネットワーキング機能とストレージ機能
- IPv6 は、現行世代のすべてのインスタンスタイプと、旧世代の C3、R3、I2 のインスタンスタイプでサポートされています。
- インスタンスタイプのネットワーキングと帯域幅のパフォーマンスを最大化するには、次のことを実行できます。
- サポートされるインスタンスタイプをクラスタープレイスメントグループで起動し、ハイパフォーマンスコンピューティング (HPC) アプリケーション用にインスタンスを最適化します。共通のクラスタープレイスメントグループのインスタンスは、高帯域幅、低レイテンシーのネットワーキングから利点を得られます。
- サポートされる現行世代のインスタンスタイプ用の拡張ネットワーキングを有効にして、パケット毎秒 (PPS) のパフォーマンスを大幅に高め、ネットワークのストレスとレイテンシーを低減することができます。
インスタンス購入オプション
- [オンデマンドインスタンス] –
- 起動するインスタンスに対して秒単位でお支払いいただきます。
- Savings Plans –
- 1〜3 年の期間、1 時間 につき USD で、一定の使用量を守ることにより Amazon EC2 コストを削減します。
- リザーブドインスタンス –
- 1~3 年の期間、インスタンスタイプとリージョンを含む一定のインスタンス設定を守ることにより Amazon EC2 コストを削減します。
- スケジュールされたインスタンス –
- 1 年の期間、指定された定期的なスケジュールで常に使用できるインスタンスを購入します。
- スポットインスタンス –
- 未使用の EC2 インスタンスをリクエストして、Amazon EC2 コストを大幅に削減します。
- Dedicated Hosts –
- 完全にインスタンスの実行専用の物理ホストに対してお支払いいただき、既存のソケット単位、コア単位、または VM 単位のソフトウェアライセンスを持ち込んでコストを削減できます。
- ハードウェア専有インスタンス –
- シングルテナントハードウェアで実行されるインスタンスに対して、時間単位でお支払いいただきます。
- キャパシティーの予約 –
- 特定のアベイラビリティーゾーンの EC2 インスタンスに対して任意の期間キャパシティーを予約します。
スケジュールされたリザーブドインスタンス
スケジュールされたインスタンスは、継続的には実行されないが定期的なスケジュールで実行されるワークロードに適しています。たとえば、営業時間中に実行するアプリケーションや週末に実行するバッチ処理に、スケジュールされたインスタンスを使用できます。
キャパシティーの予約が連続して必要な場合、リザーブドインスタンス がニーズを満たし、コストを削減できる可能性があります。詳細については、「リザーブドインスタンス」を参照してください。インスタンスをいつ実行するか特に決めていない場合、スポットインスタンス が要件を満たし、コストを削減できる可能性があります。詳細については、「スポットインスタンス」を参照してください。
自動モニタリングと手動モニタリング
自動モニタリング
- System Status Checks
- インスタンスステータスのチェック
- Amazon CloudWatch Alarms
- Amazon CloudWatch Events
- Amazon CloudWatch Logs
- Amazon EC2 Monitoring Scripts
- AWS Management Pack for System Center Operations Manager
ステータスチェック
ステータスチェックには、システムステータスチェックとインスタンスステータスチェックの 2 種類があります。
- システムステータスチェック
- AWSシステムを監視します。
- インスタンスステータスチェック
- 個々のインスタンスのソフトウェアとネットワークの設定をモニタリングします。
- 投稿日:2020-05-27T08:24:49+09:00
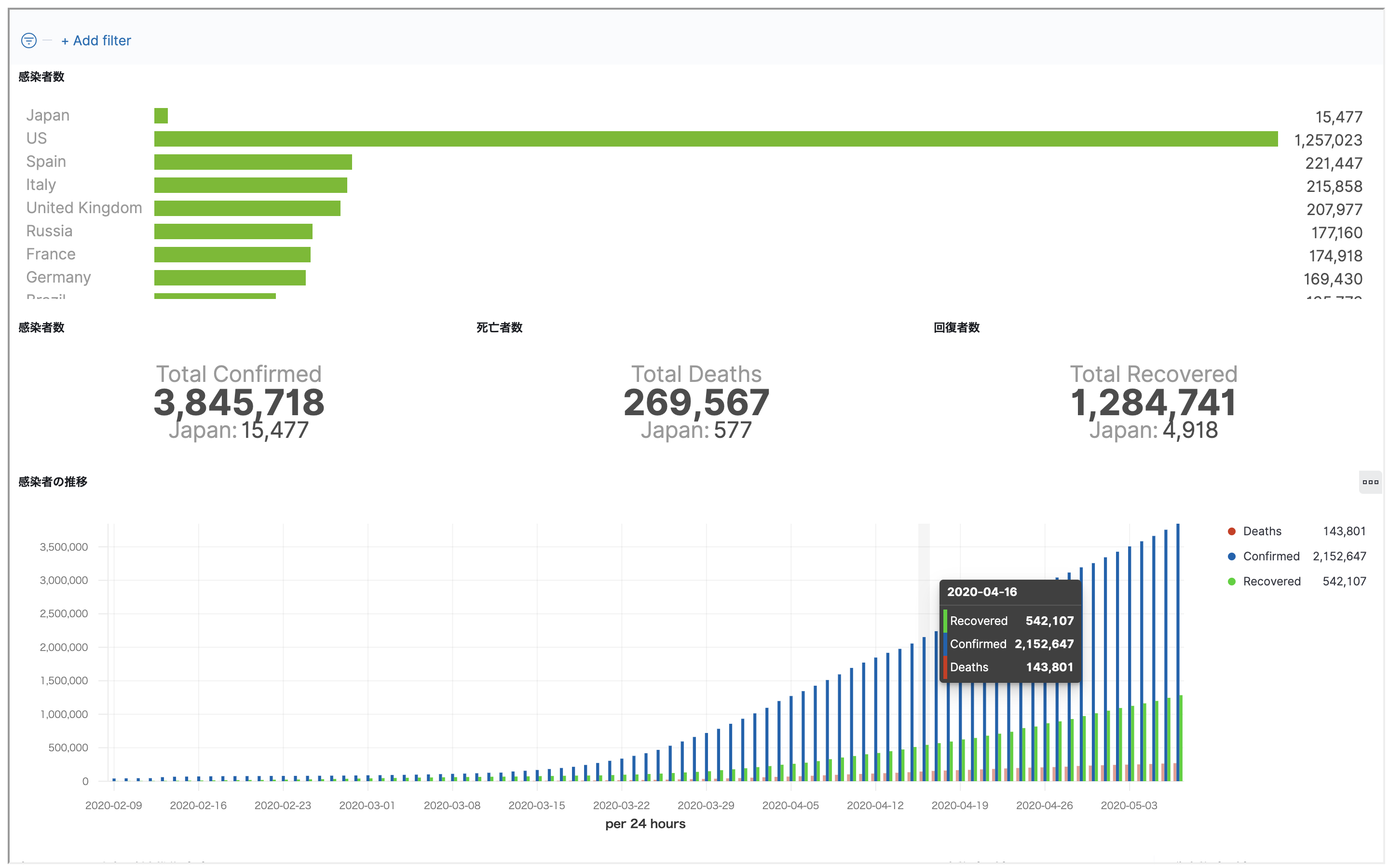
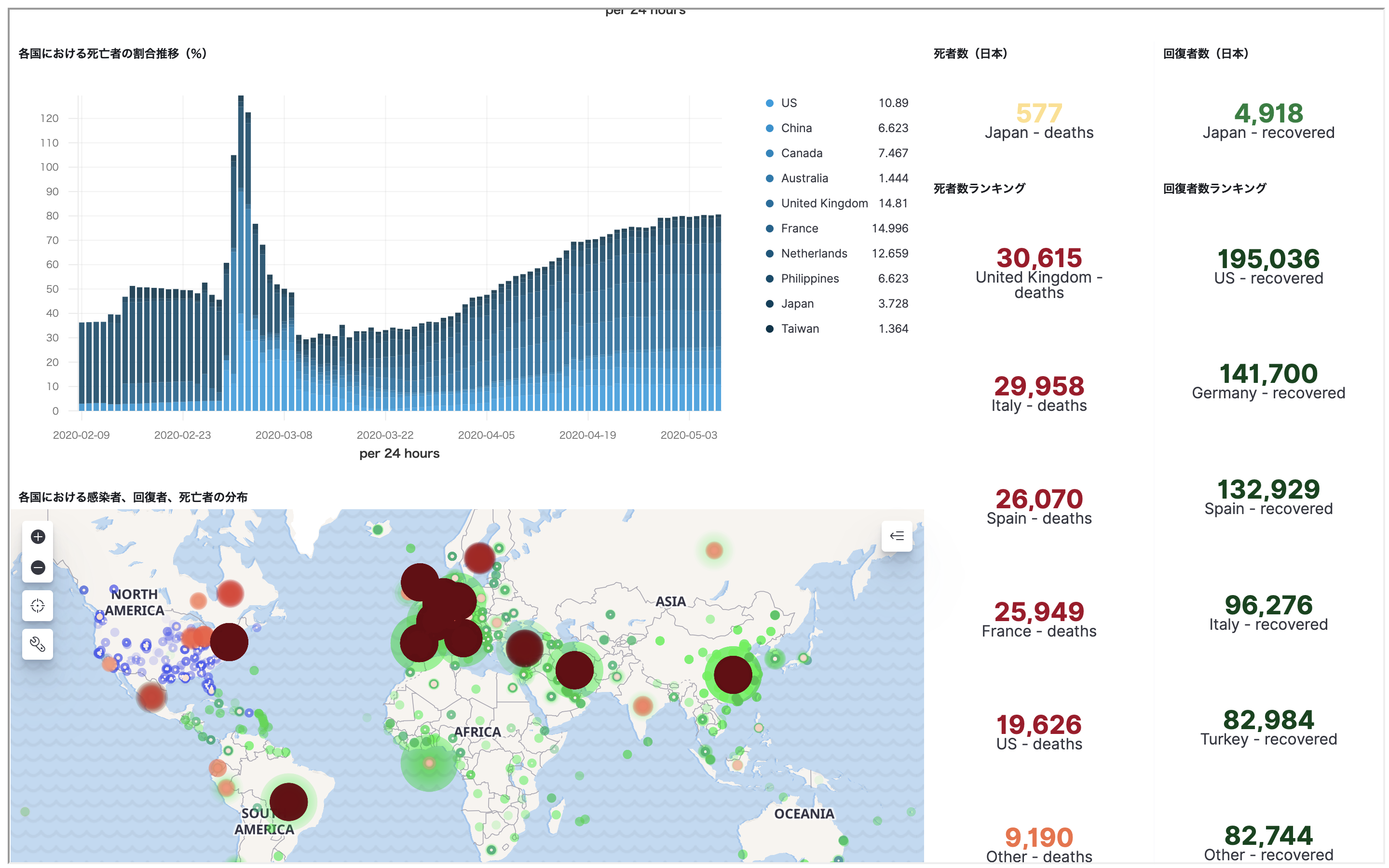
【Elastic Stack & AWS】COVID-19可視化サイトを作ってみよう
やりたいこと
COVID-19の可視化をElastic Stackを使ってAWS上に行い、公開する
ということをやっていこうと思います。
Elastic社の公式YouTubeチャンネルよりこのような動画が配信されていました。
そして私自身最近Elastic認定エンジニアを取得させていただいたことからせっかくなら自分でもこういったCOVID-19を可視化するようなページを作ってみようと思ったことがきっかけです。
そして本記事ではAWS基盤構築〜Elastic Stack構築の方法を公開しようと思います
ゴール
こんな感じのページを作ろうと思います
基盤構成はこんな感じ
Logstashにより公開データを自動でデータを吸い上げてElasticsearchに保存し、Kibanaで可視化するといった形になります。
使うもの
- Elastic Stack
- Elasticsearch
- Kibana
- Logstash
- AWS
- EC2
- docker
今回はまずページを作ることを第一にやっていこうと思いますのでELB、Cloudfrontを使わずにやっていきます。
EC2の構築
基盤はEC2を使っていこうと思います。AWSの管理コンソールに入り、インスタンスを作成します。
- Amazonマシンイメージ: Amazon Linux 2 AMI
- インスタンスタイプ: t2.large (今回の構成だとt2-large未満だと動かないです)
- インスタンスの詳細設定: ここは自由に(外からつなげるネットワークを使ってください)
- ストレージ: 64GiBぐらいで(8は厳しい気がします)
- タグの追加: 適当に Name: covid-19-test
- セキュリティグループ: 以下の2つは絶対入れてください(名前も適当につけてください)
- タイプ:ssh, プロトコル:TCP, ポート:22, ソース:お好きに
- タイプ:カスタムTCP, プロトコル:TCP, ポート:5601, ソース:0.0.0.0/0最後に確認してよければ起動を押下 → 鍵はなくさず取っておきましょう!
こんな感じで立ち上がってきます
少し待って疎通確認をしてみますsshでインスタンスに接続します。(接続の仕方がわからない方は上記写真にある「インスタンスの作成」の横にある「接続」を押下すると接続方法が書いてあります。)
コンテナ環境の構築
ここではdockerをインストールし、「Elasticsearch」、「Kibana」、「Logstash」コンテナを作成しようと思います。
また、それぞれの製品に関してElastic社からコンテナイメージを提供されていますが、今回はCentOSコンテナを作成しその上でそれぞれの製品をインストールしていこうと思います。dockerのインストール
現在いるEC2インスタンス上にdockerをインストールしていきます
dockerをインストール後、ec2-userでもdockerコマンドを使用できるように設定します。$ sudo yum install -y docker $ sudo service docker start $ sudo usermod -a -G docker ec2-user $ sudo systemctl enable docker $ exit上記コマンドによりdockerをインストールできたらEC2インスタンスに再接続し、以下コマンドによりdockerが使用できるか確認してください。
$ docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES上記のように表っぽいものが帰ってくると設定は完了です。
docker networkの構築
今回はそれぞれのコンテナ間での通信が必要となるため、docker networkを作成する必要があります。
$ docker network create elasticstack以下のようにして確認ができます
$ docker network ls NETWORK ID NAME DRIVER SCOPE 39612814bc52 bridge bridge local b5c7f801ff0b elasticstack bridge local b6ca1bb92159 host host local 0dc929d2724d none null localコンテナの作成
実際にコンテナを作成していきます
上記でも説明した通り、今回は3つのコンテナを作成していきます。
それぞれのコンテナの要件は以下となります
- elasticsearchコンテナ
- name: elasticsearch
- network: elasticstack
- port: 9200:9200
- イメージ: centos:centos7
- kibanaコンテナ
- name: kibana
- network: elasticstack
- port: 5601:5601
- イメージ: centos:centos7
- logstashコンテナ
- name: logstash
- network: elasticstack
- イメージ: centos:centos7
それぞれの設定を踏まえた上でコンテナを作成します。
$ docker run -it -d --network elasticstack -p 9200:9200 --name elasticsearch --privileged centos:centos7 /sbin/init $ docker run -it -d --network elasticstack -p 5601:5601 --name kibana --privileged centos:centos7 /sbin/init $ docker run -it -d --network elasticstack --name logstash --privileged centos:centos7 /sbin/initたちがってることを以下のコマンドで確認できます。
$ docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 4aea44cb44ce centos:centos7 "/sbin/init" 4 minutes ago Up 4 minutes logstash 479654a004cb centos:centos7 "/sbin/init" 4 minutes ago Up 4 minutes 0.0.0.0:5601->5601/tcp kibana 977d952a52a8 centos:centos7 "/sbin/init" 4 minutes ago Up 4 minutes 0.0.0.0:9200->9200/tcp elasticsearchElastic Stackの構築
それぞれのコンテナの設定をしていきます。
Elasticsearchコンテナ
Elasticsearchの構築
以下のコマンドによりコンテナ内に入って作業を行います。
$ docker exec -it elasticsearch /bin/bashjavaのインストールとElasticsearchのrpmをインストールします。rpmのインストールではelasticsearchインストール用のrpmが必要ですのでそれを入手するためにもwgetもインストールします。
今回はJavaのバージョンは11系、Elasticsearchは7.6.2で行っていこうと思います。# yum install -y java-11-openjdk # yum install -y wget # wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.6.2-x86_64.rpm # rpm --install elasticsearch-7.6.2-x86_64.rpmElasticsearchの設定
今回の構成ではElasticsearchがシングルクラスタであることやコンテナ上で起動していることからElasticsearhにいくつかの設定をしてあげる必要があります。ここではその設定を行っていきます。
elasticsearch.ymlの設定
elasticsearch.ymlを開いてください。
# vi /etc/elasticsearch/elasticsearch.ymlelasticsearch.ymlの一番最後の行に以下を追加してください。
cluster.name: my_cluster node.name: elasticsearch network.host: _site_ cluster.initial_master_nodes: ["elasticsearch"]今回はシングルクラスタなのでcluster.name、node.name はあまり設定する必要がないですが、自分で設定する方が後々便利なので設定します。
network.host はリッスンするホストを指定します。今回はリンクローカルアドレスということでsiteを指定します。
cluster.initial_master_nodesはシングルクラスタ構成をとるには必ず必要な設定となりますので設定してください。簡単にいうとマスターノードを選定するために最低限必要なノードをここで指定します。また、今回はjvm.optionsの設定も変更していきます。
# vi /etc/elasticsearch/jvm.options-Xms1g, -Xmx1gとなっている箇所を以下に変更してください。
-Xms2g -Xmx2g設定を終えたらelasticsearchを起動してみます。
# systemctl restart elasticsearch.service以下のコマンドを打つと起動できたことを確認できます。
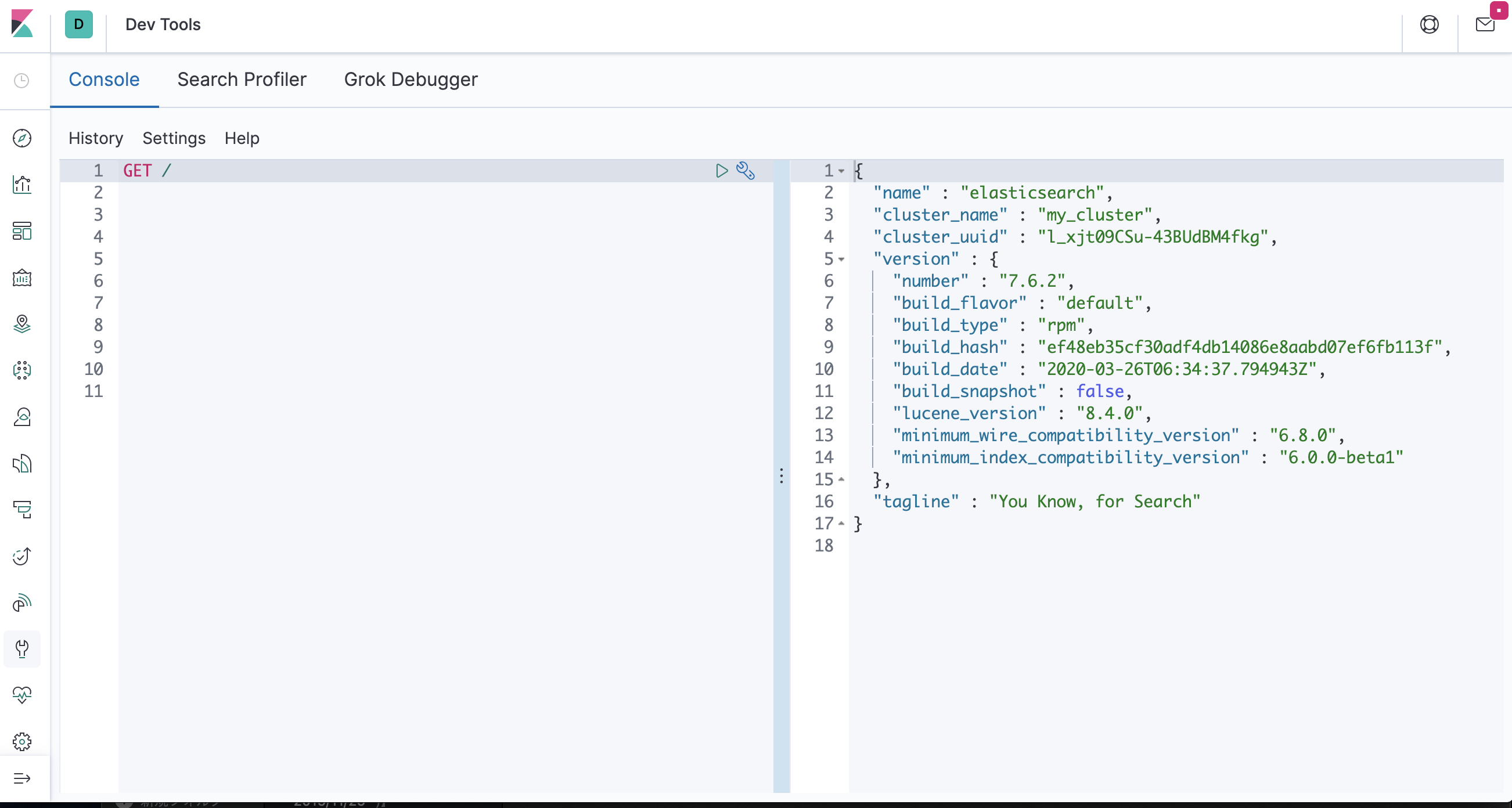
# curl elasticsearch:9200 { "name" : "elasticsearch", "cluster_name" : "my_cluster", "cluster_uuid" : "l_xjt09CSu-43BUdBM4fkg", "version" : { "number" : "7.6.2", "build_flavor" : "default", "build_type" : "rpm", "build_hash" : "ef48eb35cf30adf4db14086e8aabd07ef6fb113f", "build_date" : "2020-03-26T06:34:37.794943Z", "build_snapshot" : false, "lucene_version" : "8.4.0", "minimum_wire_compatibility_version" : "6.8.0", "minimum_index_compatibility_version" : "6.0.0-beta1" }, "tagline" : "You Know, for Search" }※ 本来はxpack.securityなどを用いてセキュリティを強化する必要がありますが、ElasticsearchとKibanaを行ったり来たりするかsslを有効にする必要があったりして少し面倒なので今回はパスします。
Kibanaコンテナ
Kibanaの構築
以下のコマンドによりコンテナ内に入って作業を行います。
$ docker exec -it kibana /bin/bashjavaのインストールとkibnaのrpmをインストールします。rpmのインストールではkibanaインストール用のrpmが必要ですのでそれを入手するためにもwgetもインストールします。
今回はJavaのバージョンは11系、kibanaは7.6.2で行っていこうと思います。# yum install -y java-11-openjdk # yum install -y wget # wget https://artifacts.elastic.co/downloads/kibana/kibana-7.6.2-x86_64.rpm # rpm --install kibana-7.6.2-x86_64.rpmKibanaの設定
コンテナ上で起動していることのでKibanaにいくつかの設定をしてあげる必要があります。ここではその設定を行っていきます。
kibana.ymlの設定
kibana.ymlを開いてください。
# vi /etc/kibana/kibana.ymlkibana.ymlの該当箇所を探して以下の設定に変更してください。
server.host: 0.0.0.0 elasticsearch.hosts: ["http://elasticsearch:9200"]設定を終えたらelasticsearchを起動してみます。
# systemctl restart kibana.serviceここまでくるとkibanaを起動できるようになっています
以下のURLにアクセスして疎通確認をしてみましょうhttp://{パブリックDNS}:5601kibanaに接続後左側にあるサイドバーの「Dev Tools」に移動してください。
そうするとコンソール画面が出てくるのでそこで以下の入力を行った後、再生ボタンを押下してみてくださいGET /以下のような画面が出てくればKibana → Elasticsearchの接続も完了です。
インデックステンプレートの設定
こちらにインデックスのテンプレート、ダッシュボードのテンプレートなどが公開されているのでダウンロードしてきましょう
ダウンロードしてくると
https://github.com/siscale/covid-19-elk/blob/master/index-template-mapping.json
こちらのテンプレートをKibanaで登録していきます。
index-template-mapping.jsonファイルをコピーし、先ほどの「Dev Tools」画面でクエリを投げます
これでインデックステンプレートが作成できました。
ダッシュボードの設定
次に、ダッシュボードのテンプレートを取り込みます。
左側のバーにある「Managemnet」を押下後、Kibanaの項目にある「Saved Objects」を押下してください。
以下のような画面になると思います。
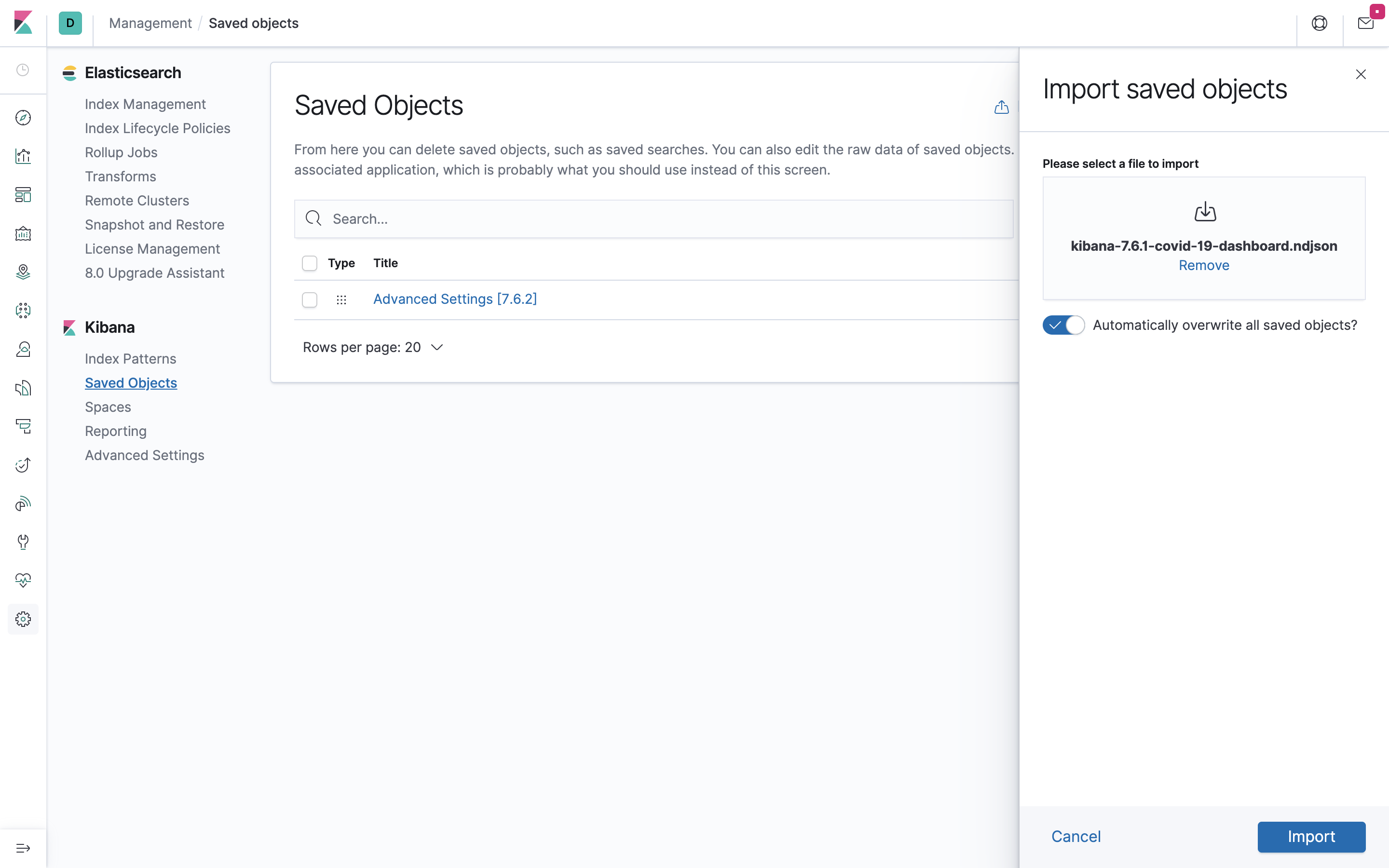
右上のimportを押下後、以下のファイルをインポートしてください。
ドラッグ&ドロップでインポートできます。
https://github.com/siscale/covid-19-elk/blob/master/kibana-7.6.1-covid-19-dashboard.ndjson
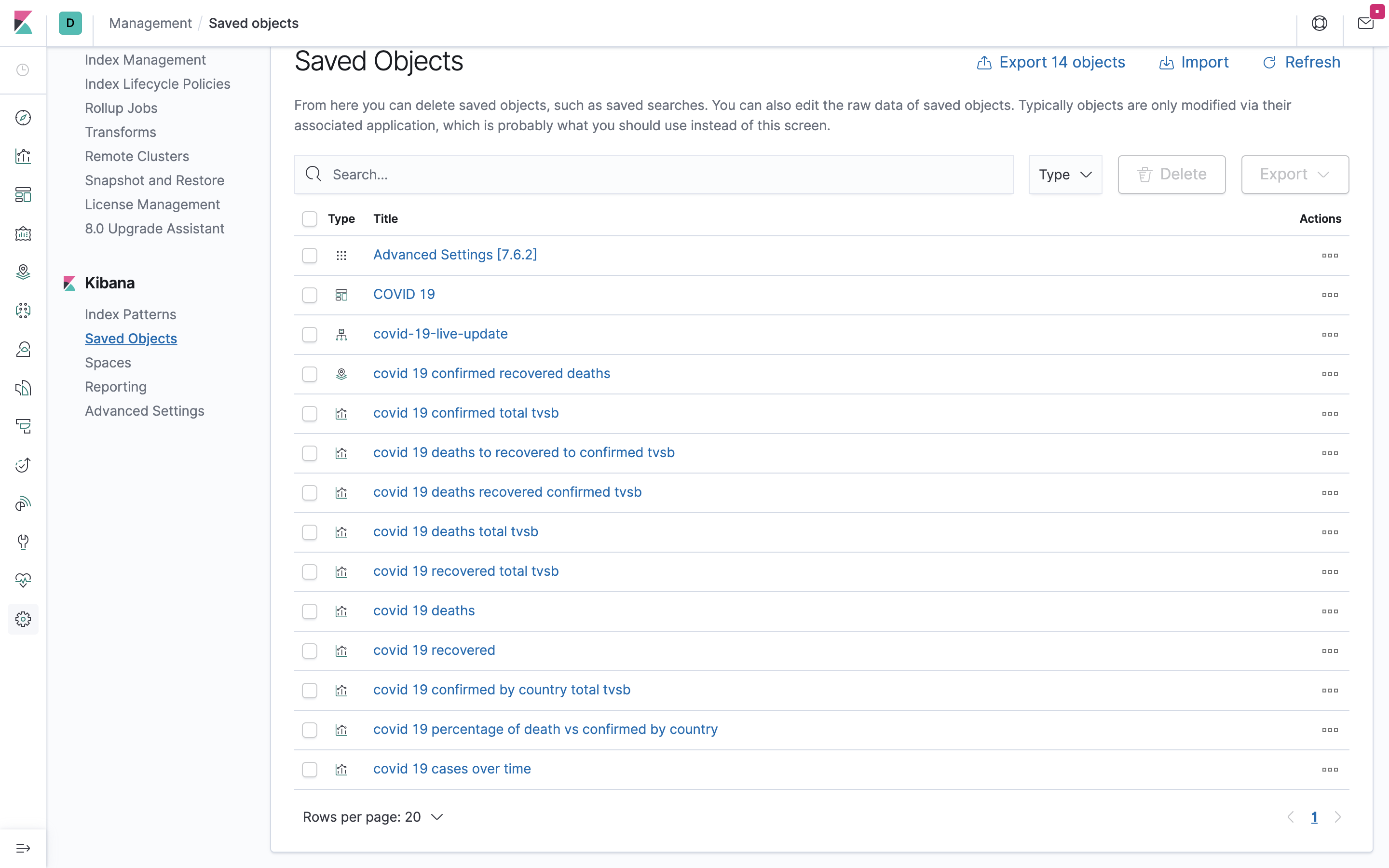
インポート後、「Saved Objects」をもう一度確認すると、以下のようにテンプレートが複数入っていることがわかります。
まだデータが入っていないのでどれを見てみてもエラーにしかなりませんが、これで可視化の準備はできました。Logstashコンテナ
今回はJohns Hopkins Universityにより公開されているこちらのデータを用いて可視化を行います。
また、こちらにテンプレートが公開されているのでそれもうまく使用しながらLogstashの構築を行っていきます。Logstashの構築
以下のコマンドによりコンテナ内に入って作業を行います。
$ docker exec -it logstash /bin/bashJavaのバージョンは11系です。
# yum install -y java-11-openjdk/etc/yum.repos.d/配下に以下の設定を反映したlogstash.repoファイルを作成します。(参考)
[logstash-7.x] name=Elastic repository for 7.x packages baseurl=https://artifacts.elastic.co/packages/7.x/yum gpgcheck=1 gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch enabled=1 autorefresh=1 type=rpm-mdインストールを実施します。
# yum install -y logstashLogstashの設定
confファイルの編集
gitのインストールを行い、テンプレートをcloneします
# yum install -y git # git clone https://github.com/siscale/covid-19-elk.git今回の環境に合わせてlogstash-github-covid-19-daily-reports-template.conf を編集します。
現在以下のようになっていると思います。# vi /covid-19-elk/logstash-github-covid-19-daily-reports-template.conf ... output { #Send the data to Elasticsearch elasticsearch { #Add your Elasticsearch hosts hosts => ["<ES_HOST>"] #Add the index name index => "covid-19-live-update" #Add Elasticsearch credentials user => "<ES_USER>" password => "<ES_PASSWORD>"上記の hosts を変更し、user, passwordをコメントアウトします。
# vi /covid-19-elk/logstash-github-covid-19-daily-reports-template.conf ... output { #Send the data to Elasticsearch elasticsearch { #Add your Elasticsearch hosts hosts => ["http://elasticsearch:9200"] #Add the index name index => "covid-19-live-update" #Add Elasticsearch credentials # user => "<ES_USER>" # password => "<ES_PASSWORD>"編集したconfファイルを/etc/logstash/conf.dディレクトリにコピーします。
# cp /covid-19-elk/logstash-github-covid-19-daily-reports-template.conf /etc/logstash/conf.d/jvm.optionsの編集
elasticsearchと同様、jvm.optionsの設定も変更していきます。
# vi /etc/logstash/jvm.options-Xms1g, -Xmx1gとなっている箇所を以下に変更してください。
-Xms2g -Xmx2g起動
confファイルを指定し、logstashを起動します。
/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/logstash-github-covid-19-daily-reports-template.confこちらのconfファイルは毎時00分にこちらのデータを監視し更新がないかを確認した後、更新があればelasticsearchにドキュメントを登録するという設定になっています。
そのため、一度こちらを走らせてしまえば、以降何もしなくてもデータが更新され続けるということになります。
以下のような行が出力されればとりあえずうまくいっています。ruby - Succesfuly updated cache at /etc/logstash/covid-19-hashes.jsonダッシュボードの確認
左側のバーにある「Managemnet」を押下後、Kibanaの項目にある「Saved Objects」を押下してください。
その中に「COVID 19」とあると思うのでそちらを押下してください。
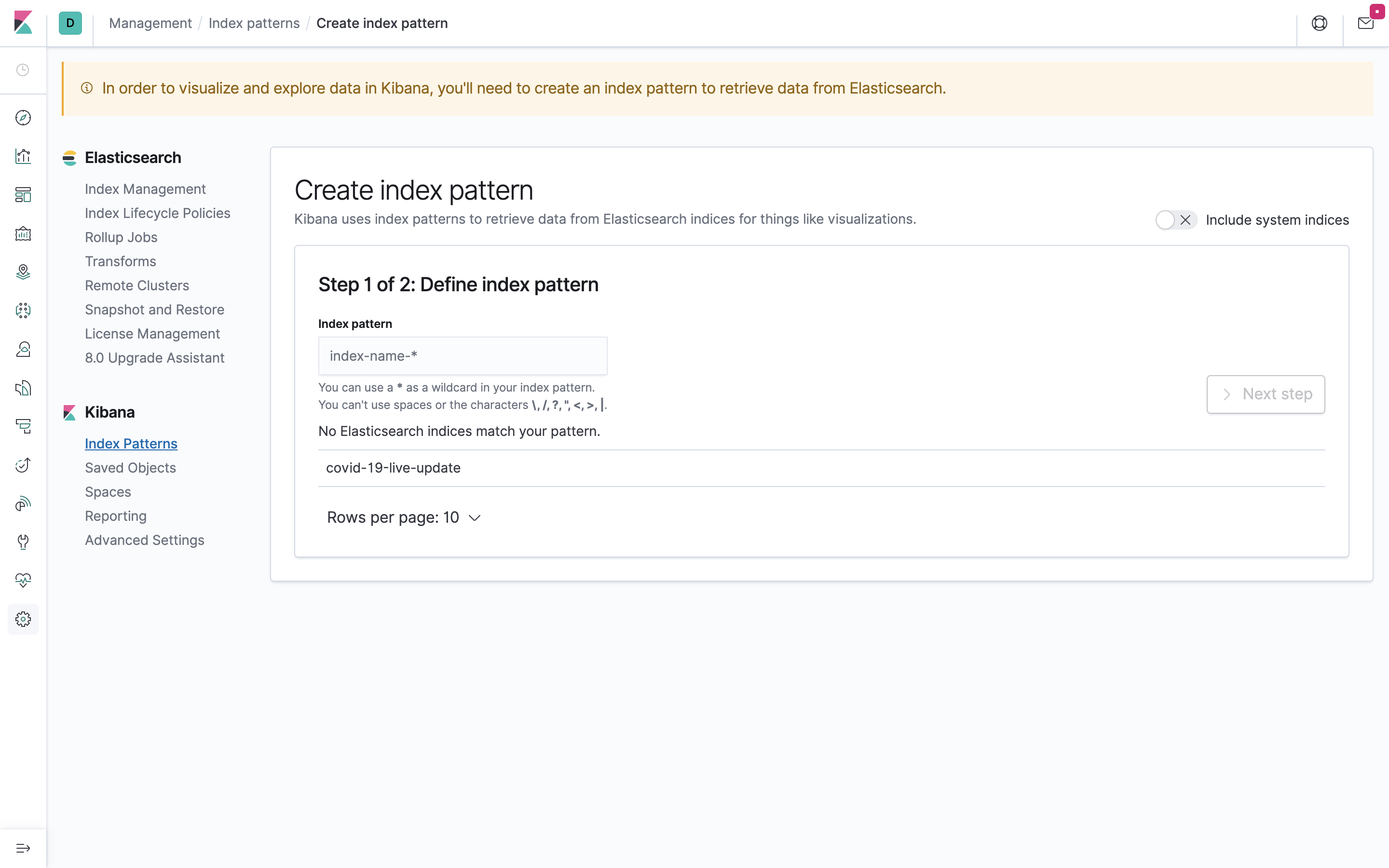
そうすると、以下のような画面になると思います。まずIndex patternを定義しろ!と言われてしまうので従いましょう。
「index pattern」に「covid-19-live-update*」と入力し、「Next Step」を押下、次の画面の「Time Filter field name」で「@timestamp」を選択してください。
その後、「Create index pattern」を押下してindex patternを作成してください。
index patternが作成できたと思うので先ほどの「Save Objects」に戻り、「COVID 19」を押下すると以下のようなダッシュボードの閲覧ができます。
もし、上記のような画面にならない方はもしかしたら右上の日にち設定が、最近の15分などになっているかもしれないので調整してみてください。
また、左上にある「Share」というところを押下すると「埋め込みコード」を発行してくれたり、「pdf」、「png」ファイルを出力してくれたりするので是非触ってみてください。まとめ
こちらのデータを使ってCOVID-19の様子を可視化してみました。
Kibanaでの構築やElasticsearchの基本などまだまだあげていく予定ですのでよろしくお願いします。宣伝
Udemyの講座オープンしました!
以下10名限定の無料クーポンです!(注:人数超えると有料になります)
https://www.udemy.com/course/elasticsearch/?couponCode=F01E4DEBC12C71640FD7
Elasticsearchを一からやってみたい方向けなので是非!




- 投稿日:2020-05-27T07:17:28+09:00
Google Search ConsoleとAWSサーバーを連携する方法(DNS レコードでのドメイン所有権の確認)
Google Search ConsoleとAWSサーバーを連携する方法(DNS レコードでのドメイン所有権の確認)
AWSで作成したサーバーの独自ドメイン(Route53)とGSC(Google Search Console)を紐付ける方法。
GSCにドメインを紐付ける場合は、DNSの設定が必要となる。
1.GSCにログイン
以下URLにGoogleアカウントでログイン。
https://search.google.com/search-console2.プロパティタイプの選択
GSCと紐付けたいドメインを入力し、続行をクリック。
無料ブログなどサーバーを借りている場合はURLプレフィックスで登録する。
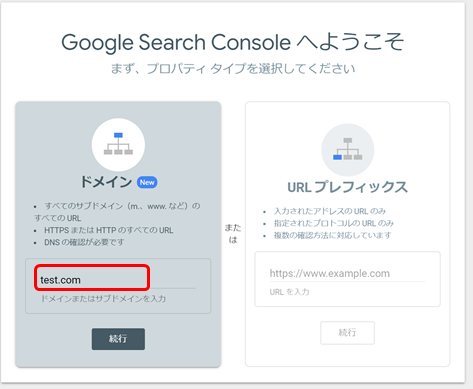
ドメインで登録できるのは自分のサーバーでDNSレコードの設定権がある場合のみ。3.テキストレコードをコピー
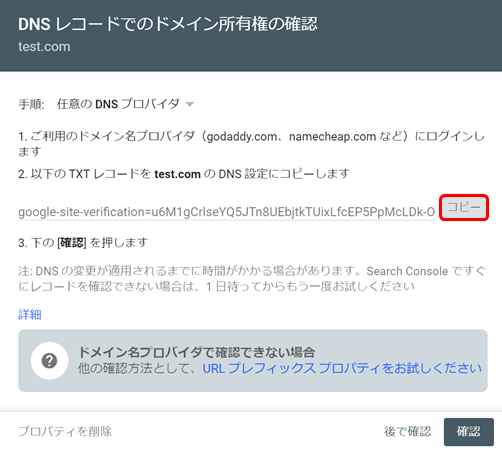
4.AWSのRoute53にログイン
AWSのRoute53にログインし、ホストゾーンをクリック
5.ホストゾーンを選択
GSCと紐付けしたいドメインを選択
6.レコードセットの作成
- レコードセットの作成を選択
- タイプで「TXT-テキスト」を選択
- 値にテキストレコードをコピペ
- 作成をクリック
7.GSCの確認をクリック
エラーになる場合は時間をおいてから再度クリック。
(直後ではエラーになり、紐づくまでに3分ぐらいかかった)完了
データ収集までには1日かかる。
(データが安定するまでには2日見たほうが無難)
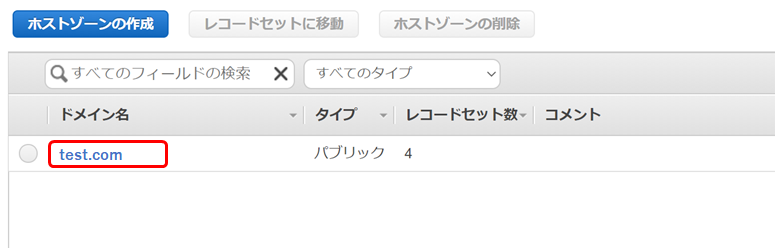
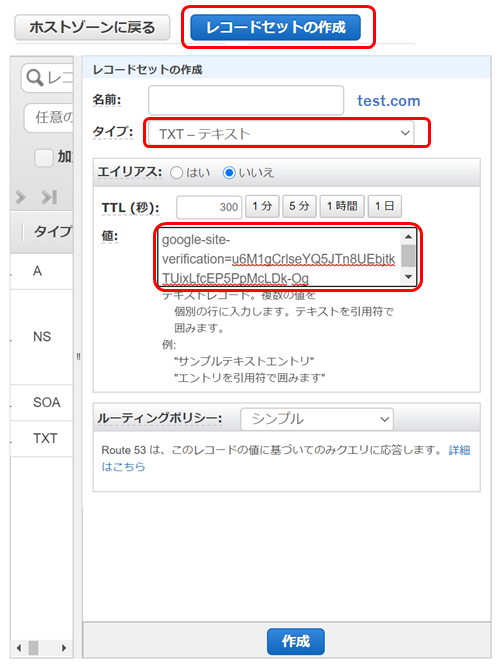

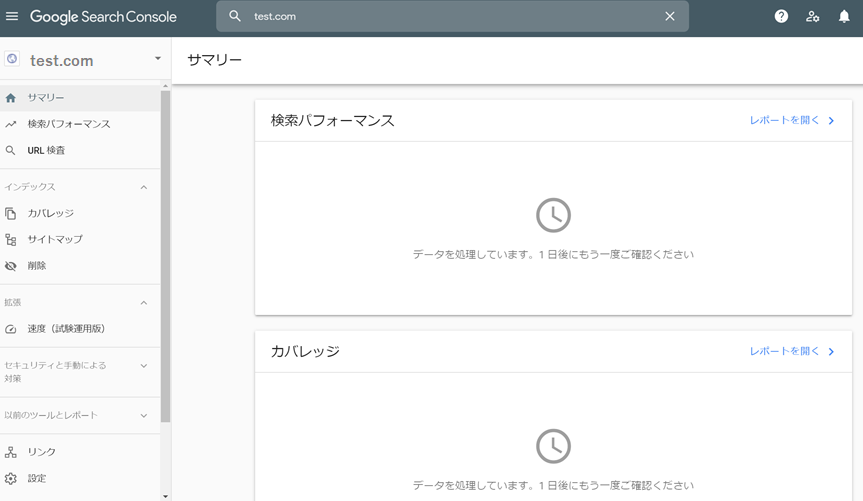
- 投稿日:2020-05-27T05:16:50+09:00
CodePipeline
AWS CodePipeline とは
AWS CodePipeline は、ソフトウェアをリリースするために必要なステップのモデル化、視覚化、および自動化に使用できる継続的な配信サービスです。ソフトウェアリリースプロセスのさまざまなステージをすばやくモデル化して設定できます。
パイプライン用語
- パイプライン
- Stages
- アクション
- パイプラインの実行
- 停止された実行
- 失敗した実行
- 置き換えられた実行
- アクションの実行
- Transitions
- アーティファクト
- ソースリビジョン
Stages
ステージは、環境を分離し、その環境での同時変更の数を制限するために使用できる論理ユニットです。各ステージには、アプリケーションアーティファクトに対して実行されるアクションが含まれます。ソースコードはアーティファクトの例です。ステージは、ソースコードが構築され、テストが実行されるビルドステージである場合もあれば、コードをランタイム環境にデプロイするデプロイステージの場合もあります。各ステージは、連続または並列のアクションで構成されています。
アクション
アクションは、アプリケーションコードに対して実行される一連の操作であり、アクションがパイプライン内で指定されたポイントで実行されるように設定されます。これには、コード変更によるソースアクション、インスタンスにアプリケーションをデプロイするためのアクションなどが含まれます。たとえば、デプロイステージには、Amazon EC2 や AWS Lambda などのコンピューティングサービスにコードをデプロイするデプロイアクションが含まれている場合があります。
パイプラインの実行
実行は、パイプラインによってリリースされる一連の変更です。各パイプライン実行は一意であり、独自の ID を持ちます。実行は、マージされたコミットや最新のコミットの手動リリースなど、一連の変更に対応します。2 つの実行では、同じ変更セットを異なる時間に解放できます。
パイプラインは同時に複数の実行を処理できますが、パイプラインステージは一度に 1 つの実行のみを処理します。これを行うために、ステージは実行を処理している間ロックされます。2 つのパイプライン実行は、同時に同じステージを占めることはできません。
パイプラインの実行は、パイプラインのステージを順番に通過します。パイプラインの有効なステータスは、InProgress、Stopping、Stopped、Succeeded、Superseded、Failed です。Failed または Superseded ステータスの実行は、パイプラインを通じて続行されず、再試行できません。
CodePipeline のユースケース
Amazon S3、AWS CodeCommit、および AWS CodeDeploy で CodePipeline を使用する
- シンプルなパイプラインを作成する (S3 バケットの場合)
- シンプルなパイプラインを作成する (CodeCommit リポジトリの場合)
Use CodePipeline をサードパーティのアクションプロバイダー (GitHub や Jenkins) と使用する
GitHub リポジトリからソースコードを取得、
Jenkins を使用してソースコードの構築とテストを実行、
AWS CodeDeploy を使用して、Amazon Linux または Microsoft Windows Server を実行している Amazon EC2 インスタンスに、ビルトとテスト済みのソースコードをデプロイします。
CodePipeline を AWS CodeStar と使用しコードプロジェクトでパイプラインを構築
AWS CodeStar は AWS でソフトウェア開発プロジェクトを管理するために、統合されたユーザーインターフェイスを提供するクラウドベースサービスです。AWS リソースをプロジェクト開発のツールチェーンと組み合わせるため、AWS CodeStar は CodePipeline と動作しますAWS CodeStar ダッシュボードを使用して、パイプライン、リポジトリ、ソースコード、ビルドスペックファイル、デプロイ方法を自動作成したり、完全なコードプロジェクトで必要なインスタンスまたはサーバーレスインスタンスをホストできます。
AWS CodeStar プロジェクトを作成するには、コード言語とデプロイしたいアプリケーションのタイプを選択します。ウェブアプリケーション、ウェブサービス、Alexa スキルといったプロジェクトタイプを作成できます。
必要に応じていつでも任意の IDE を AWS CodeStar ダッシュボードで統合できます。チームメンバーの追加や削除を行ったり、プロジェクトでチームメンバーのアクセス権限を管理することもできます。
CodeBuild で CodePipeline を使用してコードをコンパイル、構築、テストを実行
CodeBuild はクラウドにあるマネージド型のビルドサービスで、サーバーやシステムを必要とせずにコードを構築したりテストを実行できるようにします。CodeBuild と CodePipeline を使用して、ソースコードに変更があるたびにパイプラインを介してソフトウェアビルドの継続デリバリーを可能にするため、リビジョンの実行を自動化できます。
Amazon ECS と CodePipeline を使用してクラウドにコンテナベースのアプリケーションを継続的に配信する
Amazon ECS はコンテナ管理サービスで、クラウド内の Amazon ECS インスタンスにコンテナベースのアプリケーションをデプロイできるようにします。Amazon ECS と CodePipeline を使用して、ソースイメージのリポジトリに変更があるたびにパイプラインを介してコンテナベースのアプリケーションのデプロイを継続的に実行できるようにするため、リビジョンの実行を自動化できます。
Elastic Beanstalk と CodePipeline を使用してクラウドにウェブアプリケーションを継続的に配信する
Elastic Beanstalk はウェブサーバーでウェブアプリケーションとサービスをデプロイできるようにするコンピューティングサービスです。Elastic Beanstalk と CodePipeline を使用してアプリケーション環境でウェブアプリケーションを継続的にデプロイするAWS CodeStar を使用して Elastic Beanstalk デプロイアクションでパイプラインを作成することもできます。
AWS Lambda と CodePipeline を使用して Lambda ベースアプリケーションとサーバーレスアプリケーションを継続的に配信する
CodePipeline と AWS Lambda を使用して「Lambda ベースのアプリケーションのデプロイメントを自動化する」で説明されているように AWS Lambda 関数を呼び出すことができます。AWS Lambda と AWS CodeStar を使用して、サーバーレスアプリケーションをデプロイするためのパイプラインを作成することもできます。
AWS CloudFormation と CodePipeline を使用してクラウドにテンプレートを継続的に配信する
CodePipeline を AWS CloudFormation とともに使用して、継続的な配信と自動化を行うことができます。詳細については、「CodePipeline を使用した継続的配信」を参照してください。AWS CloudFormation は、AWS CodeStar で作成されたパイプラインのテンプレート作成にも使用されます。
- 投稿日:2020-05-27T02:33:37+09:00
API GatewayでCognitoの未認証ユーザへアクセスを許可する
やりたいこと
Cognitoユーザプールの認証済みユーザ、未認証ユーザだけが呼び出せるAPI Gatewayを作成する。
APIの直接呼び出しは許可しない。認証プロバイダは使用しないけど、特定のアプリのゲストアクセスも使用できるAPIを作成します。
前提
Xcode:11.4
Amplifyが使用可能
AWSMobileClient:2.13.0
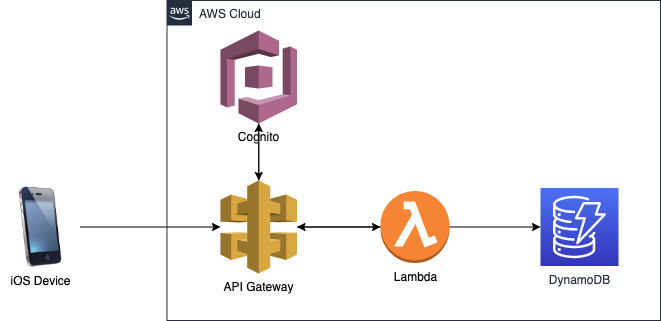
AWSAPIGateway:2.13.0AWS構成図
Cognitoユーザプールの作成
Amplifyを使用してユーザを作成します。
Xcodeプロジェクトディレクトリでコンソールからamplifyを使ってCognitoユーザプールを作成。
amplify add auth内容は任意で作成して
amplify pushとしてCognitoのユーザ作成を行います。
API Gatewayの設定
1.RESTでAPIを作成。Lambdaファンクションの実装はご自由に。
2.コンソールで作成したAPIを選択。
3.メニューから「リソース」を選択し、メソッド(GETなど)を選択。
4.メソッドリクエストの「認可」を"AWS_IAM"を選択。
5.デプロイしてSDKも生成しておく。ロールにポリシーを設定
1.Cogniteのコンソールに移る。
2.Amplifyで生成したプールIDを選択。
3.フェデレーティッドアイデンティティの画面から右上にあるIDプールの編集を選択。
4.認証されていないIDセクションから「認証されていない ID に対してアクセスを有効にする」をチェック
5.同じ画面で認証されていないロール、されているロールが表示されているので覚えておく。ロールにポリシーを追加
1.IAMに移動
2.Cognitoの認証、未認証のロールを選択しポリシーをアタッチする。
以下のようなポリシーでAPI Gatewayの呼び出しを許可する。{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "execute-api:*" ], "Resource": [使いたいAPI GatewayのARN名] } ] }Xcode側の実装
結構ハマりどころ。
API Gatewayで生成したSDKをプロジェクトにインポート。BridgingHeaderも。
podでAWSMobileClientとAWSAPIGatewayをインストールする。バージョンは2.13.0を使用した。Podfile$awsVersion = '~> 2.13.0' pod 'AWSMobileClient', $awsVersion pod 'AWSAPIGateway', $awsVersionAppDelegateに以下を追加。
AppDelegate.swiftimport AWSMobileClient func application(_ application: UIApplication, didFinishLaunchingWithOptions launchOptions: [UIApplication.LaunchOptionsKey: Any]?) -> Bool { // AWSMobileClientを初期化 AWSMobileClient.sharedInstance().initialize { (userState, error) in guard error == nil else { print("Error initializing AWSMobileClient. Error: \(error!.localizedDescription)") return } print("AWSMobileClient initialized.") } return true }APIを呼び出す処理はこんな感じ。
import AWSAPIGateway import AWSCognitoIdentityProvider func testGetFunc(){ let credentialsProvider = AWSCognitoCredentialsProvider(regionType:.リージョンのenum, identityPoolId:"プールID") let configuration = AWSServiceConfiguration(region:.リージョンのenum, credentialsProvider:credentialsProvider) AWSServiceManager.default().defaultServiceConfiguration = configuration let client = [API Gatewayで生成したSDKクラス].init(configuration: AWSServiceManager.default().defaultServiceConfiguration) client.rootGet().continueWith { (task) -> Any? in if let error = task.error { print("Error occurred: \(error)") // エラー時の処理 return nil } // 正常時の処理 if let result = task.result { // task.resultにはSDKクラスになっているので好きなように処理する。 result.hogeList?.forEach({ (item) in print(item.hogeValue) }) } return task } }だいぶ端折りましたがこんな感じです。
確認する
ブラウザから、他のアプリからのアクセスがNG。
今回作成したアプリからのアクセスは正常に戻り値が取得可能になっていることを確認します。ハマったところ
- API Gatewayで生成したSDKクラスが全然動かなかった。
- AWSMobileClient、AWSAPIGatewayは最新版はAPIが変わっているので使い方がわからず。2.13.0にとどめた
- API GatewayのオーソライザーでCognitoを使うのかと思っていたが違っていた。
- 投稿日:2020-05-27T00:28:18+09:00
CloudFormationでEC2、ALBを作成する
はじめに
以下記事の続きです。
CloudFormationでVPC、サブネット、インターネットゲートウェイを作成する
- VPCID(
VpcId:)とサブネットID(SubnetId:)は、上記記事でエクスポートした値を使っています。- 本記事ではすでに作成済のVPC、サブネットを使いEC2とALBをCloudForrmationで作成します。
- EC2は一つだけ作成しています。
- EC2のAMIは、最新のAmazon Linuxイメージを指定しています。 最新AMI取得方法
- どのリージョンでも動くはず
EC2、ALB作成コード
Create-ec2.ymlAWSTemplateFormatVersion: "2010-09-09" Description: Create EC2 Instance Parameters: InstanceType: Description: WebServer EC2 instance type Type: String Default: t2.micro AllowedValues: - t1.micro - t2.nano - t2.micro - t2.small - t2.medium - t2.large DiskSize: Description : EC2 VolumeSize (Gigabyte) Default: 8 Type: String Ec2ImageId: Type: AWS::SSM::Parameter::Value<String> Default: /aws/service/ami-amazon-linux-latest/amzn2-ami-hvm-x86_64-gp2 KeyName: Description : Name of an existing EC2 KeyPair Type: AWS::EC2::KeyPair::KeyName ConstraintDescription : Can contain only ASCII characters. SSHLocation: Description: IP address range that can be used to SSH to the EC2 instances Type: String MinLength: '9' MaxLength: '18' Default: 0.0.0.0/0 AllowedPattern: (\d{1,3})\.(\d{1,3})\.(\d{1,3})\.(\d{1,3})/(\d{1,2}) ConstraintDescription: must be a valid IP CIDR range of the form x.x.x.x/x. HealthCheckPath: Description : Webserver HealthCheckPath Default: "/" Type: String # ------------------------------------------------------------# # EC2 Create # ------------------------------------------------------------# Description: Create EC2 Instance Resources: MyEC2Instance: Type: AWS::EC2::Instance Properties: InstanceType: !Ref InstanceType NetworkInterfaces: - AssociatePublicIpAddress: true DeviceIndex: 0 SubnetId: !ImportValue TESTSTACK-PublicSubnet0 GroupSet: - !Ref InstanceSecurityGroup BlockDeviceMappings: - DeviceName: /dev/xvda Ebs: VolumeType: gp2 VolumeSize: !Ref DiskSize Tags: - Key: Name Value: myInstance KeyName: !Ref KeyName ImageId: !Ref Ec2ImageId # ------------------------------------------------------------# # Application LoadBalancer # ------------------------------------------------------------# ApplicationLoadBalancer: Type: 'AWS::ElasticLoadBalancingV2::LoadBalancer' Properties: Subnets: - !ImportValue TESTSTACK-PublicSubnet0 - !ImportValue TESTSTACK-PublicSubnet1 SecurityGroups: - !Ref ALBSecurityGroup ALBListener: Type: 'AWS::ElasticLoadBalancingV2::Listener' Properties: DefaultActions: - Type: forward TargetGroupArn: !Ref ALBTargetGroup LoadBalancerArn: !Ref ApplicationLoadBalancer Port: '80' Protocol: HTTP ALBTargetGroup: Type: 'AWS::ElasticLoadBalancingV2::TargetGroup' Properties: HealthCheckIntervalSeconds: 30 HealthCheckTimeoutSeconds: 5 HealthyThresholdCount: 3 HealthCheckPath: !Ref HealthCheckPath Port: 80 Protocol: HTTP UnhealthyThresholdCount: 5 VpcId: !ImportValue TESTSTACK-VPCID Targets: - Id: !Ref MyEC2Instance Port: 80 # ------------------------------------------------------------# # Instance Security Groups # ------------------------------------------------------------# InstanceSecurityGroup: Type: AWS::EC2::SecurityGroup Properties: GroupDescription: connect with ssh and webservice VpcId: !ImportValue TESTSTACK-VPCID SecurityGroupIngress: - IpProtocol: tcp FromPort: 22 ToPort: 22 CidrIp: !Ref SSHLocation - IpProtocol: tcp FromPort: 80 ToPort: 80 CidrIp: 0.0.0.0/0 - IpProtocol: tcp FromPort: 443 ToPort: 443 CidrIp: 0.0.0.0/0 # ------------------------------------------------------------# # ALB Srcurity Groups # ------------------------------------------------------------# ALBSecurityGroup: Type: AWS::EC2::SecurityGroup Properties: GroupDescription: ALB access VpcId: !ImportValue TESTSTACK-VPCID SecurityGroupIngress: - IpProtocol: tcp FromPort: 80 ToPort: 80 CidrIp: 0.0.0.0/0 - IpProtocol: tcp FromPort: 443 ToPort: 443 CidrIp: 0.0.0.0/0 # ------------------------------------------------------------# # Output Parameters # ------------------------------------------------------------# Outputs: ALBDNSName: Value: !GetAtt ApplicationLoadBalancer.DNSName Export: Name: "alb-dnsname"なお、最新のAmazon LinuxAMIではなく決め打ちしたい場合は
Mappings:でAMI IDを指定します。同じ名前のAMIでもリージョンによってAMI IDが違うのでマルチリージョン対応するには、リージョン毎にAMI IDを指定します。# ------------------------------------------------------------# # Mappings # ------------------------------------------------------------# Mappings: RegionMap: ap-northeast-1: AMI: ami-0f310fced6141e627 us-east-1: AMI: ami-0323c3dd2da7fb37d # ------------------------------------------------------------# # EC2 Create # ------------------------------------------------------------# Resources: MyEC2Instance: Type: AWS::EC2::Instance #~~~省略~~~~ ImageId: !FindInMap - RegionMap - !Ref 'AWS::Region' - AMIAWS CLIでスタックの作成
AWS CLIで登録します。
デフォルト値(Default:)をスタック内で指定してないパラメータは--parametersオプションで指定しときます。% aws cloudformation create-stack \ --tags Key="name",Value="test" \ --stack-name TESTEC2 \ --template-body file://Create-ec2.yml \ --parameters \ ParameterKey=KeyName,ParameterValue="test-ec2-sshkey"成功したか確認します。
% aws cloudformation list-stacks \ --stack-status-filter CREATE_COMPLETE \ | jq -r ".StackSummaries[].StackName" | head -n1 TESTEC2OutputでALBのDNSNameをエクスポートしているので参照できます。
% aws cloudformation describe-stacks --stack-name TESTEC2 \ | jq -r '.Stacks[].Outputs[]|select(.OutputKey == "ALBDNSName").OutputValue' TESTE-Appli-1K4WKCRZ4AW5W-1349760917.ap-northeast-1.elb.amazonaws.com要らなくなったら削除します。
% aws cloudformation delete-stack --stack-name TESTEC2