- 投稿日:2020-04-03T21:05:08+09:00
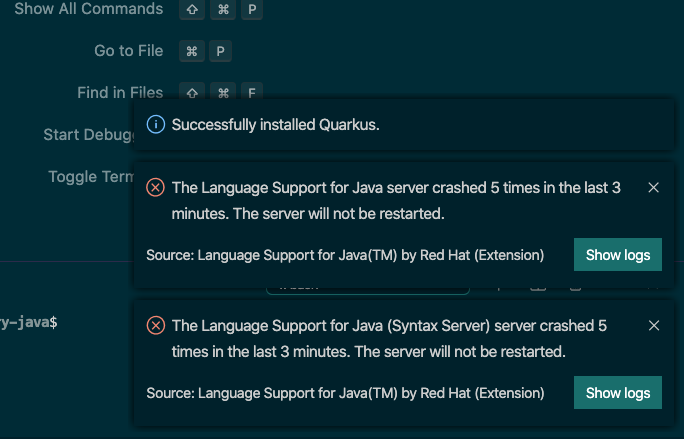
「The Language Support for Java server crashed 5 times in the last 3 minutes. The server will not be restarted.」エラーで振り回された話
「The Language Support for Java server crashed 5 times in the last 3 minutes. The server will not be restarted.」
このエラーに振り回されたので、備忘録として残そうと思います。自分メモなので適当
始まり
Docker使ってJavaの環境を整えたいな...
せや、この記事参考にやってみよう!
https://blog.kondoumh.com/entry/2019/09/22/100000
はい???できないんですがそれは。
調べたら出てきた事
わからんのでエラー内容コピペで検索
これが出てきた。
http://wiki.tk2kpdn.com/language-support-for-java-error-in-vscode/ほう、アンイストールしてsetting.jsonをやり直すのか。
アンイストールめんどい...
でもこれしかないか...アンインストール際に困った事
記事には、
ユーザー設定を削除。
( C:\Users(ユーザー名)\AppData\Roaming\Code\User )このAppDataフォルダがmacにない!!
どこにあるの??調べた
https://www.atmarkit.co.jp/ait/articles/1810/12/news026.html
Windows:%APPDATA%\Code\Userフォルダ
macOS:~/Library/Application Support/Code/Userフォルダ
Linux:~/.config/Code/Userフォルダらしいです。ターミナル開いて行ったらありました。
なのでUserファイルをrmしました。そして再インストールしました。
わーいできた。終わり
- 投稿日:2020-04-03T18:51:45+09:00
Windows+Docker+Laravelでの開発時に「There is no existing directory at "C:\........\storage\logs" and its not buildable: No such file or directory」が出る時の対処
環境
Windows10 pro
Docker for Windows
Laravel 7.x
ローカルのDockerでphp、nginxのコンテナを立てています。状況
/config/logging.phpの設定を変えた後、反映させるためにWindows側のコマンドプロンプトで「php artisan config:cache」を打ったら急に出るようになりました。
ネットで情報を探すと再度キャッシュを消すと直る等ありましたが、直らず..。解決した方法
Docker側phpのコンテナにCliで入り、そっちの方で上記コマンドを打つと解消されました。
しっかりと原因特定まではできてませんが、Windows側でやるとパスの解決がWindows仕様になってしまうとかですかね。余談
解決後、
Log::debug(storage_path());でログに吐いたら正しいパスはこうなってました。[2020-04-03 09:58:48] local.DEBUG: /var/www/APP_NAME/storage
- 投稿日:2020-04-03T16:04:50+09:00
Hangfire Server を tty 抜きで実行できるように実装する
はじめに
Hangfireは、時間のかかる処理をキューさせてバックグラウンドで実行するような構成を実現できるOSSです。
概要は前回の記事を御覧ください↓
Hangfireに.NET Core 3.1で最速入門する特にリソースも時間も多く必要なタスクの場合、
受け付けるサーバーとは別に実行するサーバーを実装できたりしてなかなか便利です。ドキュメントによるサーバー実装
https://docs.hangfire.io/en/latest/background-processing/processing-jobs-in-console-app.html
公式ドキュメントによれば、
using(var server = new BackgroundJobServer()) { Console.WriteLine("Started BackgroundJobServer. Press Enter to exit."); Console.ReadLine(); }といった感じで
Console.ReadLine()でスレッドをブロックするコードがサンプルとして提供されています。何が問題か?
Console.ReadLineを使う都合上、dockerで起動する際にttyをアタッチする必要があります。ttyをアタッチすると、下記のようにjournald で loggingしようとしたときに [Blob Data] として記録されてしまいます。
https://github.com/moby/moby/issues/15722
コンソールでは正しく出力されるのに、何でだろう?と詰まったのですが、
上記Issueにたどり着き、tty: falseでも実行できるようにしようと思って調べた次第です。Hangfire.NetCore
コンソールを使用せずともGeneric Hostを使用すればサービスが終了するまで、
バックグラウンドで動かし続けられるのではないか?と思い、調べてみたんですが、今まで使用していた Hangfire.Core には
AddHangfireServerという関数が用意されておらず、
以下の選択が迫られました。
- 自分でConfigureServicesで使用する関数を実装する
-Hangfire.AspNetCoreパッケージを使用する1つ目は 自前実装となると品質に不安が残ること。
2つ目は 無駄にASP.NET Coreに依存してしまうことが理由として挙がり、どうするかな~と悩んでいましたがよくよく調べてみるとありましたパッケージ。
https://www.nuget.org/packages/Hangfire.NetCore/
その名も
Hangfire.NetCore! リリースノート見ると1.7.1 • Added – Worker Service host support for .NET Core without unnecessary dependencies to ASP.NET Core.とあります。 つまり、 ASP.NET Coreへの依存を入れずに .Net Core アプリでワーカーサービス(Hangfire Server)を構築できるということです。
実装
実装はHostBuilderを使うだけのかんたんな構成。
static async Task Main(string[] args) { var hostBuilder = new HostBuilder() // Add configuration .ConfigureServices((context, services) => { services.AddHangfire(config => { // 中略 config.UseMongoStorage(connectionString, databaseName, storageOptions); }); services.AddHangfireServer(options => { options.WorkerCount = cientWorkerCount; }); }) .ConfigureLogging(logging => { // 中略 }); await hostBuilder.RunConsoleAsync(); }こんな感じです。私はジョブのキューに
Hangfire.Mongoを使用しているので余計なのが含まれていますが、
重要なのはConfigureServicesでAddHangfireとAddHangfireServerする部分です。終わりに
以上、Generic Host を使用した Hangfire Server の実装方法でした~。
(
Hangfire.NetCoreの存在に1年も気づけていなくて悔しい。)
- 投稿日:2020-04-03T13:23:36+09:00
Dockerコンテナ上のaws-cli環境でAWS Error Message: Signature expiredが表示されたときの対処方法
はじめに
dockerコンテナ上のaws-cli環境で
aws sts get-caller-identityをしたら、時間がずれてるとおこられたので、また起きた時用メモ。どうしてかわかんないけど、こうなった
① An error occurred
root@xxxxxxx:/home# aws sts get-caller-identity An error occurred (SignatureDoesNotMatch) when calling the GetCallerIdentity dentity operation: Signature expired: 20200323T231737Z is now earlier200324T0 than 20200324T002325Z (20200324T003825Z - 15 min.)② 本当にずれてるのか確認してみる。ちなみにこの時午前10時ちょっと前。
root@xxxxxxx:/home# date Fri Apr 02 23:30:39 UTC 2020③ UTCだとよく分からないからJSTに変えてみる。
root@xxxxxxx:/home# TZ=-9 date '+%a %b %d %H:%M:%S JST %Y' root@xxxxxxx:/home# date Fri Apr 03 08:33:30 JST 2020ずれてた。1時間半も。
修正方法
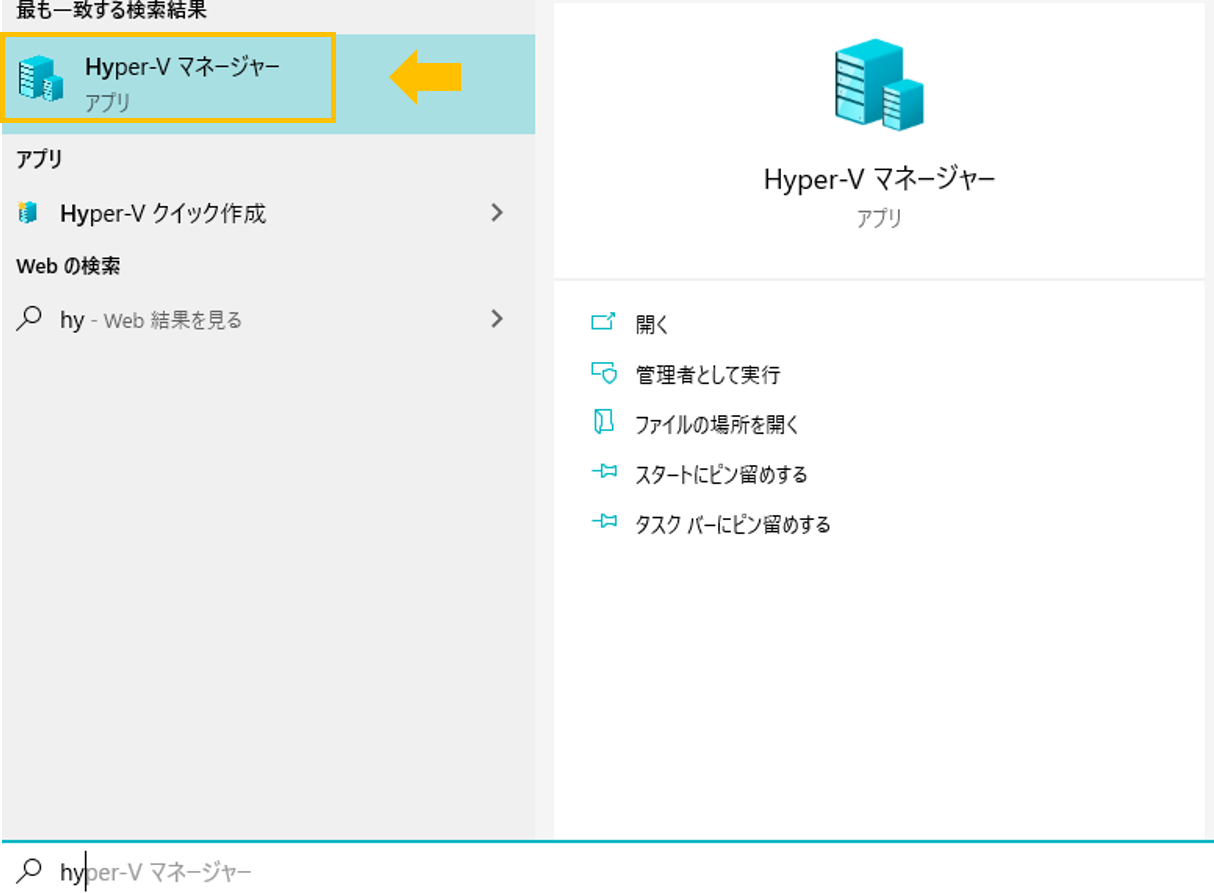
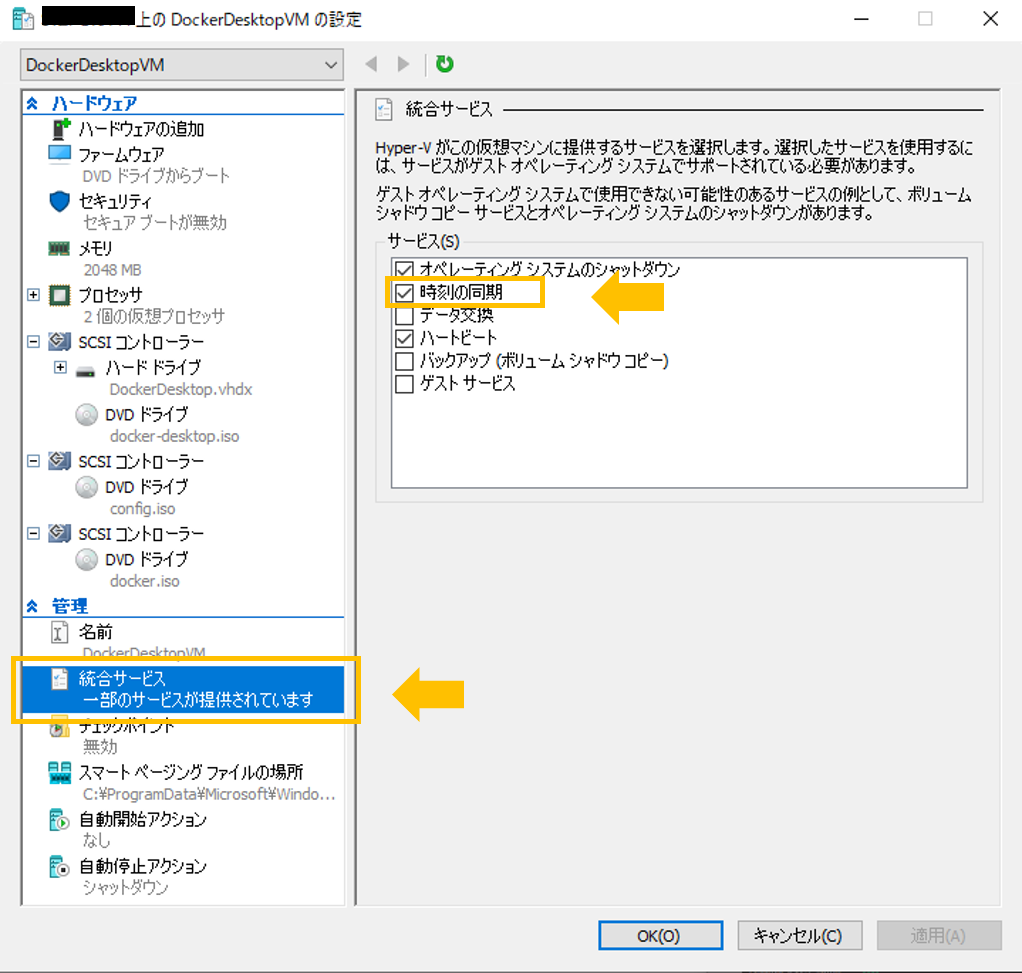
1. 検索ボックスに「Hyper-V マネージャー」を入力して選択。
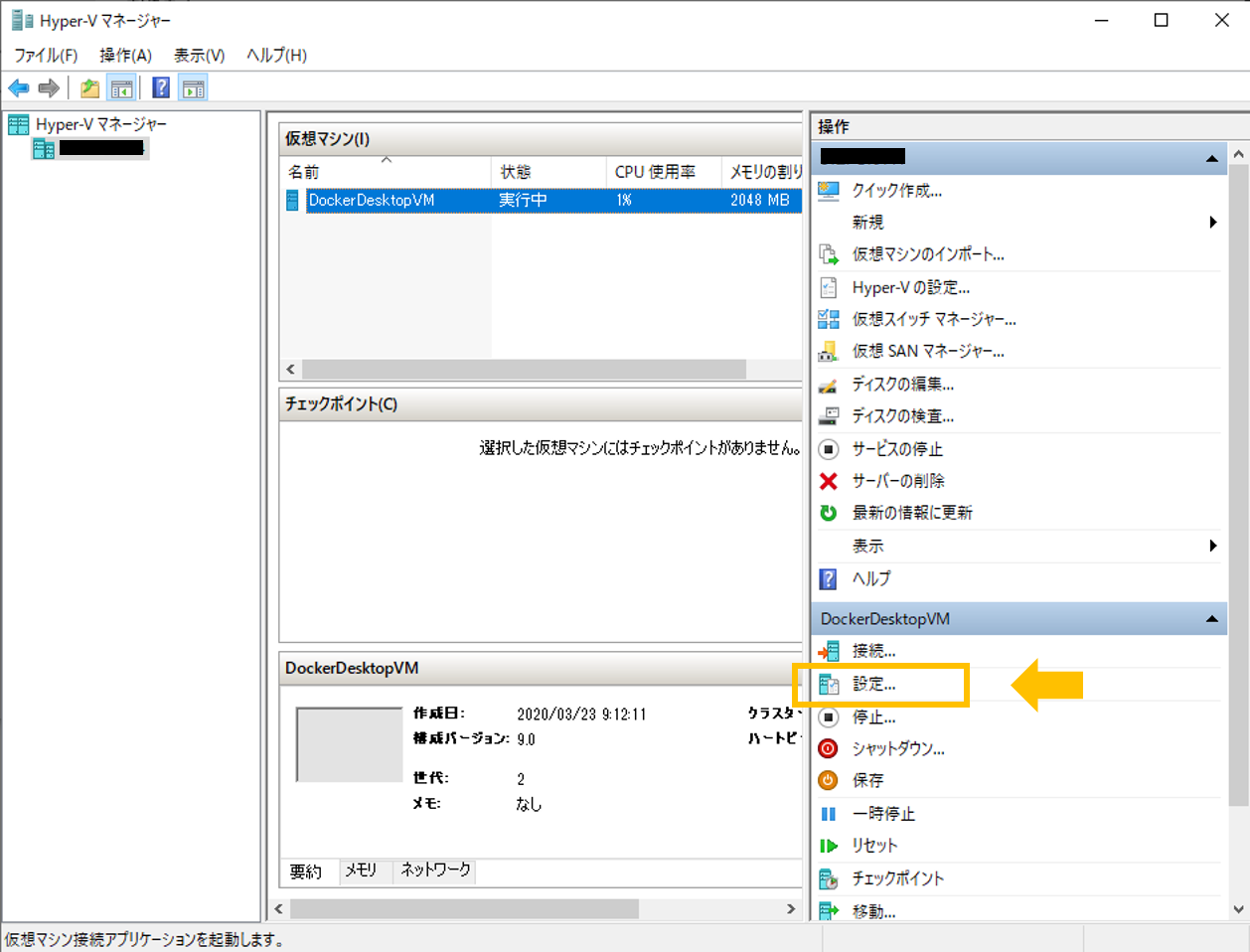
2. DockerDesktop VM の「設定」を選択
3. 管理 の 統合サービスを選択して「時刻の同期」にチェックを入れる。
(※もともとチェックが入っている時は一度外して適用。その後チェックを入れてもう一度適用。)
おわりに
この後、エラーが消えて解決!めでたし!
- 投稿日:2020-04-03T04:01:19+09:00
Docker 上で入門する Apache Hadoop
はじめに
はじめての並列分散処理のフレームワークとして Apache Beam を利用しているのですが、この辺りの学習をするにあたっては MapReduce などの従来からの用語や概念も頻繁に登場します。そのため、Apache Hadoop に入門してみました。今回は、環境をできるだけ楽に構築できるように Docker を利用しています。
Hadoop 概要
Hadoop は、大容量のデータを処理するための分散処理のフレームワークです。通常は Linux 上で動作させます。スケールアウトに優れているため、処理するデータ量が増えたとしても、サーバーの台数を追加することで性能を向上させることができます。
Hadoop は、主に次の2つのシステムで構成されます。
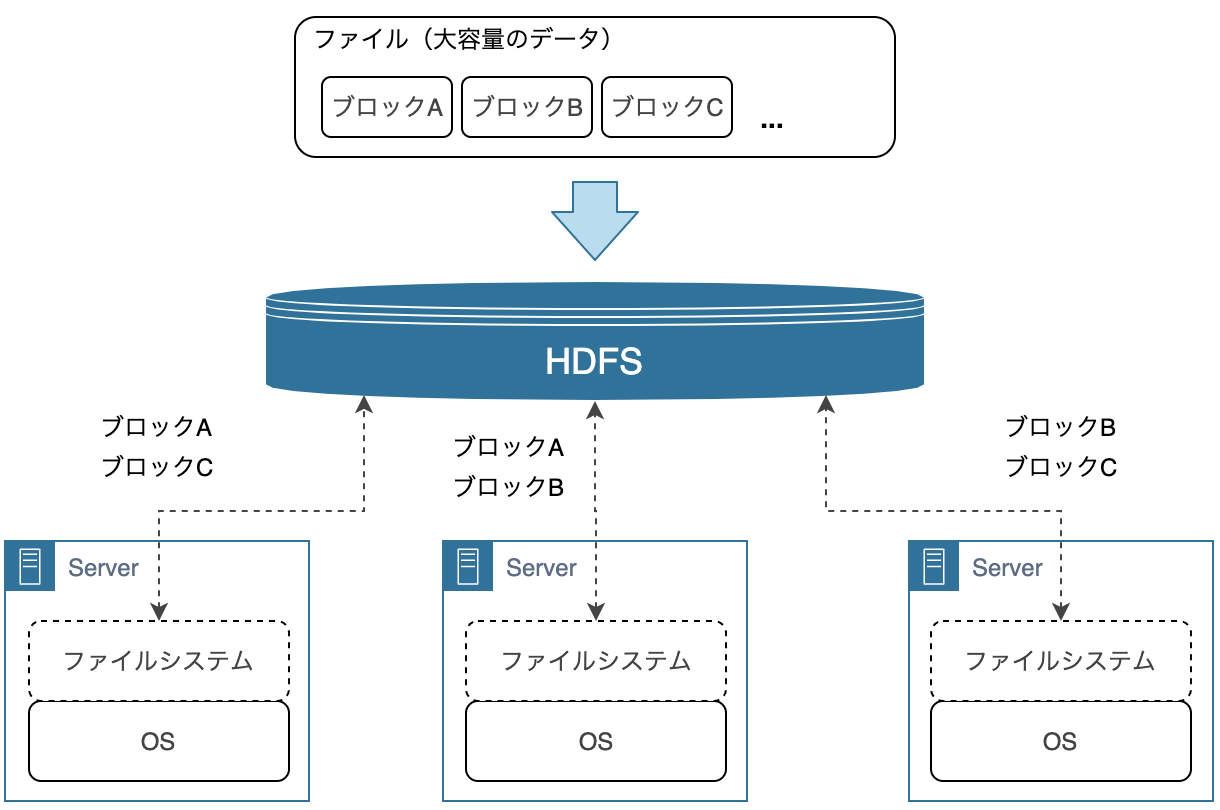
- HDFS (Hadoop Distributed File System):分散ファイルシステム。大容量のデータを複数のサーバーに分割して格納します。ユーザーはこれらの複数のサーバーをひとつの大きなファイルシステムのように扱うことができます。
- MapReduce:分散処理を実現するフレームワーク。ひとつの大きな処理(ジョブ)を複数の単位(タスク)に分割し、複数のサーバーで並列に実行できるように作られています。
Hadoop は、ひとつのコンポーネントで動作するのではなく、HDFS や MapReduce フレームワークなど複数のコンポーネントが連携することで動作します。このような Hadoop の主要なコンポーネントを Hadoop エコシステムと呼ぶことがあります。
HDFS (Hadoop Distributed File System)
HDFS 上では、大容量のデータは細かい単位(ブロック)に分割され、複数のサーバーのファイルシステムに配置されます。たとえば、データサイズが 1GB (1024MB) で、ブロックサイズが 64MB だった場合、データは16個のブロックに分割され、複数のサーバーに配置されます。
このように複数のサーバーにデータを分配し、並列に処理することでスループットの向上が見込めます。ストレージやサーバー間の通信はコストが高いので、各サーバーで読み込んだデータはできる限りそのサーバーで処理するように動作し、最終的には、各サーバーで処理した結果をネットワーク経由で転送してひとつの結果としてまとめます。
また、1台のサーバーが故障しても、データを失ったり、処理が失敗したりしないように、分割されたブロックは複数のサーバーに格納されます。
ユーザーは、HDFS を利用するにあたって、裏側で複数のサーバーが動いていることやファイルがどうブロックに分割されたかなどを考慮する必要はありません。
MapReduce
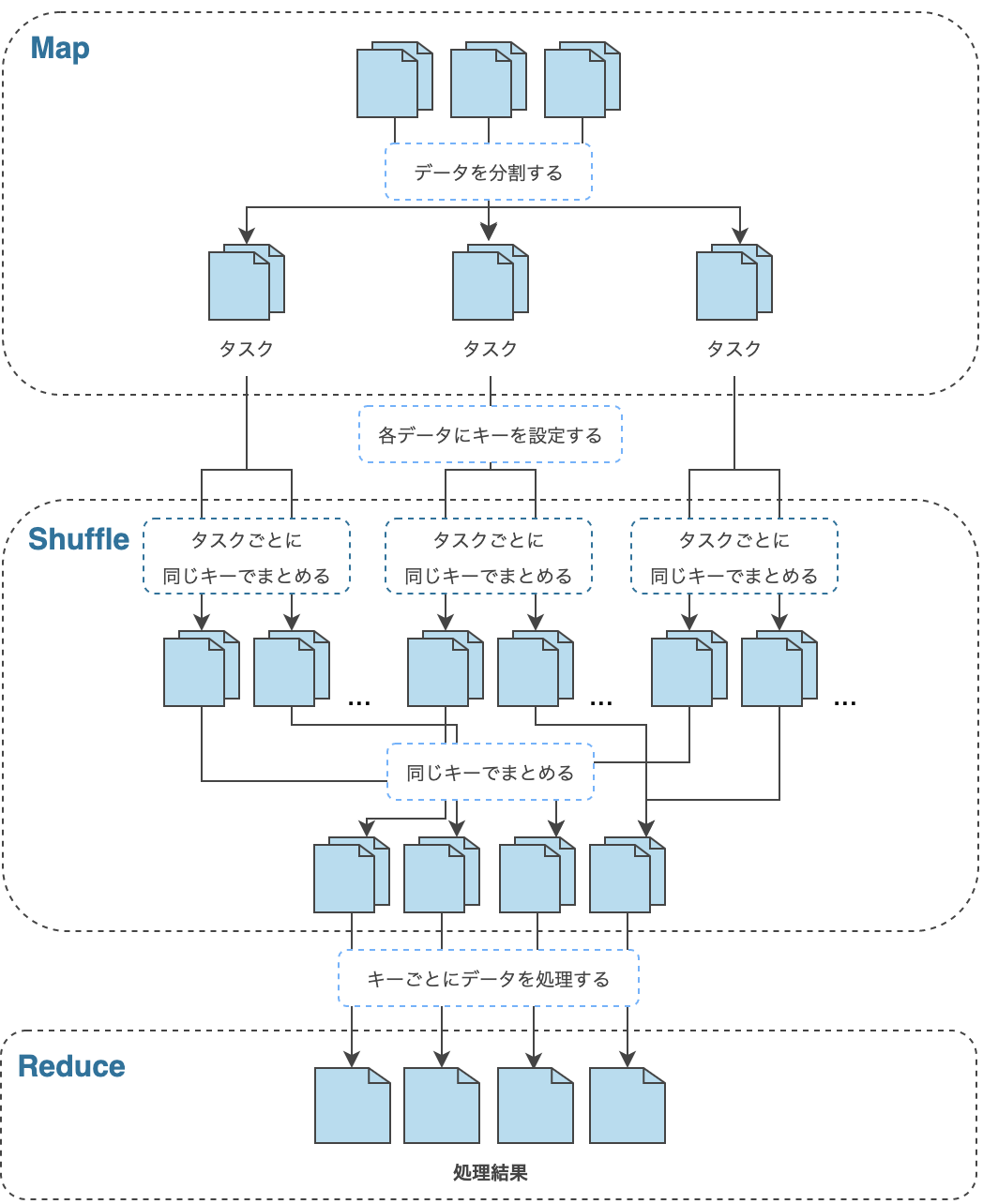
MapReduce は、ひとつのジョブを複数のタスクに分割し、並列に処理を実行します。MapReduce の処理は、大きく Map, Shuffle, Reduce と呼ばれる3つの処理で構成されます。 このうち、Shuffle は、自動的に実行されるものなので、ユーザーが処理を定義する必要はありません。それぞれの処理の内容については次の通りです。
- Map:HDFS 上のデータを分割し、タスクに割り当てます。タスクは、割り当てられた入力データから1件ずつデータ(Key, Value のペア)を取り出し、ユーザーが定義した処理を行った後、処理結果(Key, Value のペア)を出力します。
- Shuffle:Map 処理後のデータを、同じキーを持つデータでまとめます。このとき、サーバー間でデータの転送が行われるため、転送データ量が大きい場合は処理全体のボトルネックとなる可能性があります。
- Reduce:Shuffle 処理後、キーごとにまとめられたデータに対してユーザーが定義した処理を行います。
こういった並列分散処理を MapReduce のようなフレームワークなしで実装しようとすると、ひとつのジョブをどのような単位に分割するか、そのタスクをどのコンピュータで実行するか、各タスクの結果をどのようにひとつにまとめるか、途中でサーバーの故障などでどのようにリカバリするかなど多くのことを考慮する必要があります。
Hadoop アーキテクチャ
Hadoop には、1、2、3 の3つのメインバージョンがあり、それぞれでアーキテクチャが異なります。そして、Hadoop 1 と 2 の主な違いは MapReduce アーキテクチャの変更にあります。Hadoop 1 での MapReduce アーキテクチャのことを MRv1 と呼び、Hadoop 2 では、YARN (Yet-Another-Resource-Negotiator) という技術の上で MapReduce が動作し、これを MRv2 と呼びます。
Hadoop 1 Hadoop 2 HDFS HDFS MapReduce (MRv1) MapReduce (MRv2) / YARN Hadoop 2 から Hadoop 3 への大規模なアーキテクチャの変更はないらしい(おそらく)ので、ここでは、Hadoop 1 と Hadoop 2 のアーキテクチャについて触れます。
Hadoop 1
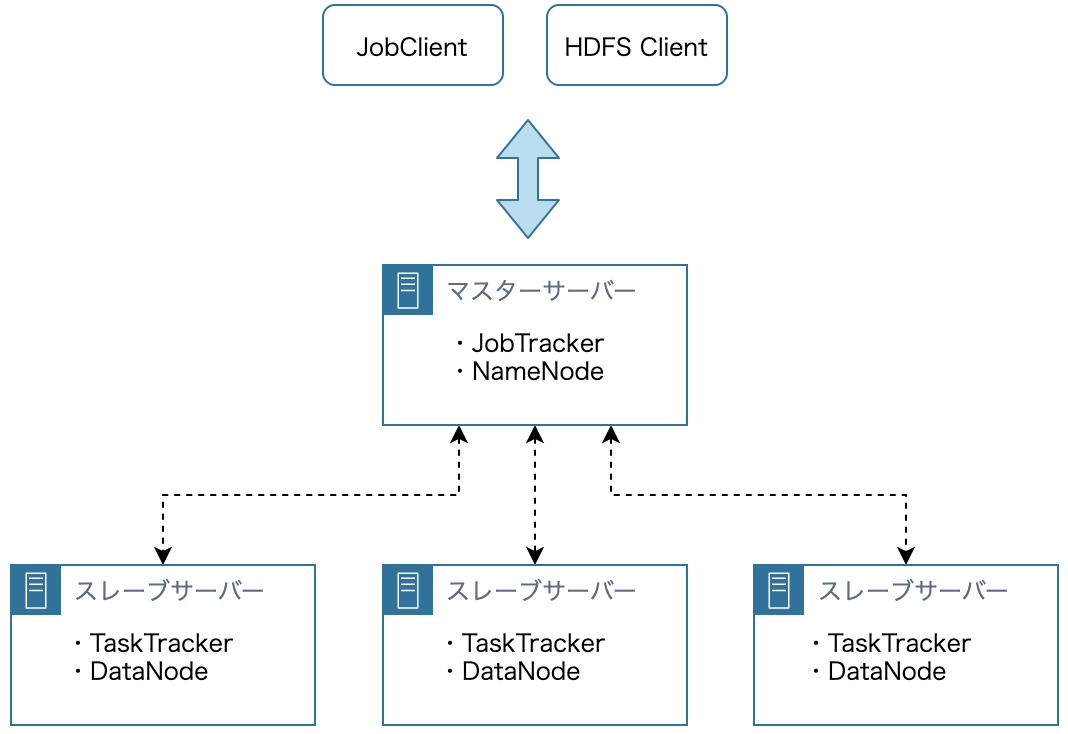
Hadoop クラスタは、クラスタ全体を管理するマスターサーバー群と実際のデータ処理を担当するスレーブサーバー群の2種類のサーバー群により構成されます。HDFS と MapReduce のそれぞれにマスターサーバーとスレーブサーバーが存在し、基本的にマスターサーバーはそれぞれ1台ずつ、スレーブサーバーは複数台で構成されます。
HDFS アーキテクチャ
- NameNode:HDFS のマスターサーバーです。クラスタ全体に渡って、データがどこに配置されているかなどのメタデータを管理します。HDFS のメタデータはメモリ上で管理するため、瞬時に応答を返すことができます。
- DataNode:HDFS のスレーブサーバーです。割り振られたタスクを実行し、応答を返します。複数台の DataNode のストレージでひとつのストレージを構成するので、ユーザーは HDFS を利用するにあたって、複数のストレージがあることを意識する必要がありません。
MapReduce (MRv1) アーキテクチャ
- JobTracker:MapReduce (MRv1) のマスターサーバーです。JobClient にジョブの進捗状況や完了を通知するといったジョブの管理や、1つのジョブを複数のタスクに分割し、各スレーブサーバーにタスクを割り振るなどのリソースの管理を行います。また、ジョブの履歴管理も行います。JobTracker は単一障害点となりえます。
- TaskTracker:MapReduce (MRv1) のスレーブサーバーです。割り振られたタスクを実行し、応答を返します。Map 処理や Reduce 処理を実行し、そのリソースを管理します。
- JobClient:ジョブの依頼や優先度変更、強制終了などを行います。
通常、DataNode と TaskTracker は同じマシンに置かれ、TaskTracker はまず同じマシンの DataNode 上のデータに対してジョブを実行します。これにより、ネットワークの通信コストを抑えることができます。
Hadoop 2
Hadoop 1 と Hadoop 2 のアーキテクチャの違いは主に MapReduce にあります。そのため、ここでは HDFS のアーキテクチャについては省略します。
MapReduce (MRv2) アーキテクチャ
MapReduce (MRv1) では、タスクの数が数千〜数万規模になると、JobTracker への負荷が集中し、ボトルネックになる可能性があります。また、クラスタ内で単一の JobTracker を使用するため、負荷を分散させようと思うと、クラスタを新たに用意する必要があります。この方法で負荷を分散させた場合、リソースの利用効率が下がったり、単一障害点である JobTracker 数の増加による監視対象の増加が起きたりといった問題が生じます。
こういった問題に対処するために導入されたのが YARN です。YARN では、JobTracker、TaskTracker の機能を次のように変更します。
MapReduce (MRv1) MapReduce (MRv2) / YARN JobTracker ResourceManager、ApplicationMaster、JobHistoryServer TaskTracker NodeManager
- ResourceManager:JobTracker からリソース管理を切り離します。リソース管理を ResourceManager が一元管理することで、リソースの使用効率が高まります。
- ApplicationMaster:JobTracker からジョブ管理を切り離します。ユーザーの実装によって、独自のジョブ管理を行うことができます。MapReduce 以外にも、Apache Spark や Apache Tez など他の分散処理フレームワークにも対応しています。また、ApplicationMaster をジョブごとに立ち上げることで、タスク数が増えた場合のボトルネックを回避することができます。
- JobHistoryServer:JobTracker の履歴管理を切り離します。
- NodeManager:TaskTracker が行っていたリソース管理を切り離します。
環境構築
Hadoop の動作環境を構築していきます。前述の通り、Hadoop は、複数のコンポーネントが連携することで動作します。そのため、各種ソフトウェアをまとめたディストリビューションが提供されています。ディストリビューションを用いることで、分散処理を実行する環境を容易に構築できます。今回は、ディストリビューションとして CDH を Docker 上でインストールします。
また、Hadoop では次の3つの中から動作モードを選択できます。今回は、動作確認をお手軽に行える擬似分散モードを選択します。
- ローカルモード:1台のサーバー上で、HDFSは使用せずにMapReduceの動作環境を構築する
- 擬似分散モード:1台のサーバー上で、HDFSを使用したMapReduceの動作環境を構築する
- 完全分散モード:複数台のサーバー上で、HDFSを使用したMapReduceの動作環境を構築する
次のようなパッケージ構成になります。
パッケージ構成. ├── Dockerfile ├── main ├── WordCount.java # Hadoop ジョブ(Java) ├── scripts # Hadoop 起動スクリプトなど │ ├── create-input-text.sh │ ├── execute-wordcount-python.sh │ ├── execute-wordcount.sh │ ├── make-jar.sh │ └── start-hadoop.sh └── streaming # Hadoop Streaming ジョブ(Python) └── python ├── map.py └── reduce.py使用する Dockerfile はこちらです。Hadoop は Java のアプリケーションなので JDK をインストールします。CDH のインストールは こちら を参考にしました。
DockerfileFROM centos:centos7 RUN yum -y update RUN yum -y install sudo # インストール:JDK RUN yum -y install java-1.8.0-openjdk java-1.8.0-openjdk-devel # 環境変数の設定(コンパイルの際に必要) ENV JAVA_HOME /usr/lib/jvm/java-1.8.0-openjdk ENV PATH $PATH:$JAVA_HOME/bin # tools.jar:javac コンパイラを含む ENV HADOOP_CLASSPATH $JAVA_HOME/lib/tools.jar # インストール:CDH 5 パッケージ ## yum リポジトリの構築 RUN rpm --import http://archive.cloudera.com/cdh5/redhat/6/x86_64/cdh/RPM-GPG-KEY-cloudera RUN rpm -ivh http://archive.cloudera.com/cdh5/one-click-install/redhat/6/x86_64/cloudera-cdh-5-0.x86_64.rpm ## 疑似分散モードの設定と YARN や HDFS などを提供するパッケージをインストール RUN yum -y install hadoop-conf-pseudo ADD main main RUN chmod +x -R main WORKDIR main # コマンド実行後もコンテナを起動させ続ける CMD ["tail", "-f", "/dev/null"]では、こちらの Dockerfile から Docker イメージを作成します。
docker image build -t {名前空間/イメージ名:タグ名} .ビルドが成功したらコンテナを起動します。Hadoop 起動後は http://localhost:50070 で Web インターフェースにアクセスできるようになるので、ポートフォワーディングしておきます。
docker container run --name {コンテナ名} -d -p 50070:50070 {名前空間/イメージ名:タグ名}コンテナの起動が成功したら、コマンド操作を行えるようにコンテナに入ります。
docker exec -it {コンテナ名} /bin/bashscripts/start-hadoop.sh を実行して Hadoop を起動します。
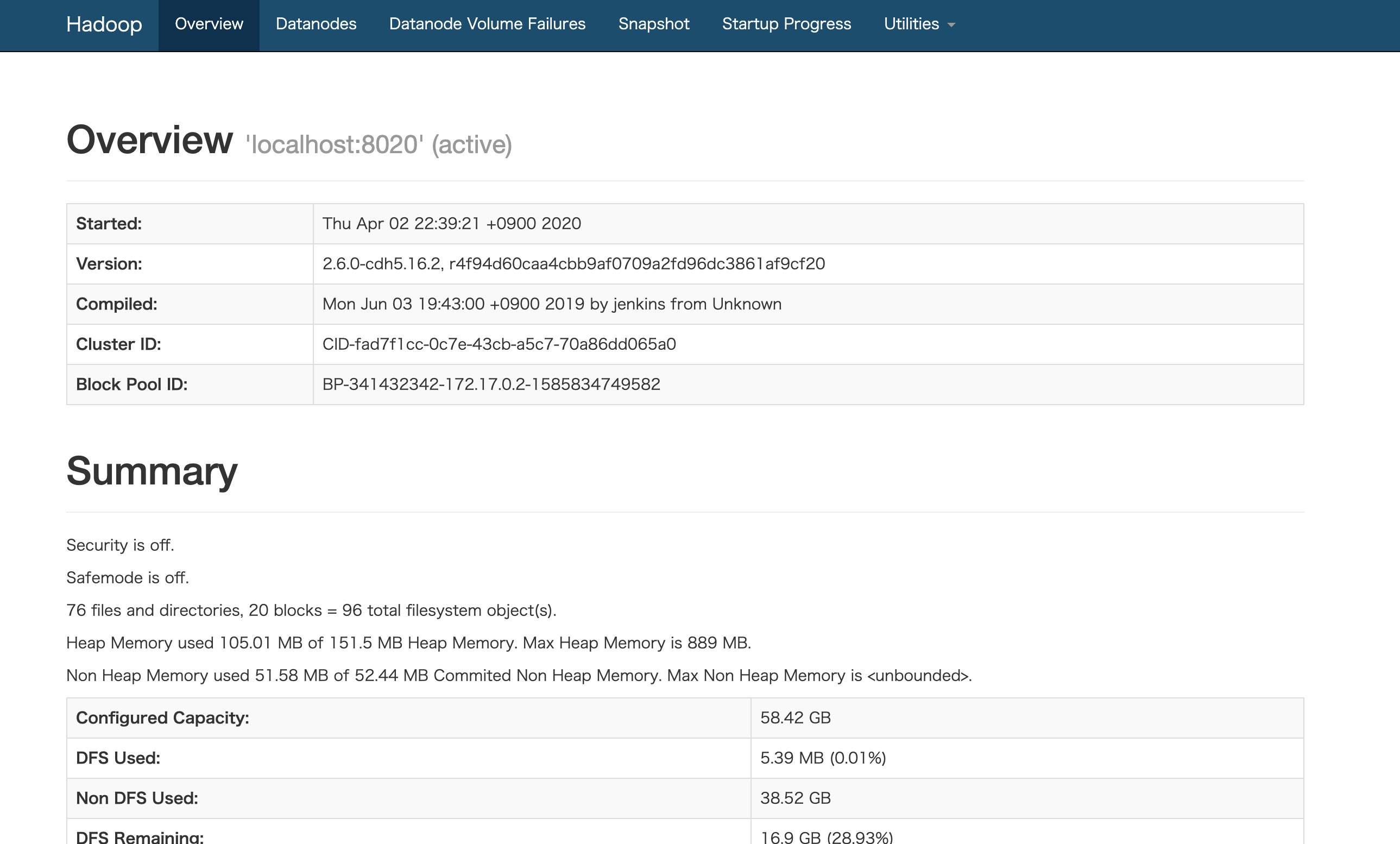
scripts/start-hadoop.sh#!/usr/bin/env bash # NameNode が管理するメタデータ領域をフォーマット sudo -u hdfs hdfs namenode -format # HDFS の起動 for x in `cd /etc/init.d ; ls hadoop-hdfs-*` ; do sudo service $x start ; done # 初期化 sudo /usr/lib/hadoop/libexec/init-hdfs.sh # HDFS のファイルに権限を付与 sudo -u hdfs hadoop fs -ls -R / # YARN の起動 sudo service hadoop-yarn-resourcemanager start sudo service hadoop-yarn-nodemanager start sudo service hadoop-mapreduce-historyserver start[root@xxxxxxxxx main]# ./scripts/start-hadoop.shHadoop の起動が完了したら、http://localhost:50070 で Web インターフェースにアクセスでき、GUI からクラスタの状態や Job 実行の経過、結果を見ることができます。
MapReduce の実装と実行
環境構築が終了したので、実際に MapReduce アプリケーションを作成してみます。MapReduce アプリケーションは Java はもちろん Pig Latin や HiveQL と呼ばれる言語などでも作成することができます。
Java
WordCount.java は、Java での MapReduce アプリケーション の実装例です。入力のテキストファイルから単語を抜き出し、単語の数をカウントするアプリケーションです。
WordCount.javaimport org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; import java.io.IOException; import java.util.StringTokenizer; public class WordCount extends Configured implements Tool { /** * Mapper<入力キーの型, 入力バリューの型, 出力キーの型, 出力バリューの型> を継承したクラス. */ public static class TokenizerMapper extends Mapper<LongWritable, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); @Override public void setup(Context context) throws IOException, InterruptedException { // 初期化処理 } /** * Map 処理を記述する. * * @param key その行が先頭から何バイト目の位置にあるかというバイトオフセット値(通常は利用しない) * @param value 1行分のデータ * @param context Context を通してジョブの設定や入出力データにアクセス可能 */ @Override public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } @Override public void cleanup(Context context) throws IOException, InterruptedException { // クリーンナップ処理 } } /** * Reducer<入力キーの型, 入力バリューの型, 出力キーの型, 出力バリューの型> を継承したクラス. */ public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> { private IntWritable result = new IntWritable(); @Override public void setup(Context context) throws IOException, InterruptedException { // 初期化処理 } /** * Reduce 処理を記述する. * * @param key Map 処理の出力(キー) * @param values Map 処理の出力(バリューのイテラブル) * @param context Context */ @Override public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } @Override public void cleanup(Context context) throws IOException, InterruptedException { // クリーンナップ処理 } } public int run(String[] args) throws Exception { if (args.length != 2) { System.err.println("Usage: wordcount <in> <out>"); System.exit(2); } // JobTracker に対してジョブを投入する Job job = Job.getInstance(getConf(), "WordCount"); // 入力データに応じて自動的に数が決まるMapタスクとは異なり、Reduceタスクの数は自分で指定する必要がある job.setNumReduceTasks(2); // jarファイルに格納されたクラスのうちの1つを指定する job.setJarByClass(WordCount.class); // Mapper、Combiner、Reducer としてどのクラスを利用するか指定する job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // テキストファイルからデータの入出力を行う job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); // 入出力用のディレクトリのパス TextInputFormat.addInputPath(job, new Path(args[0])); TextOutputFormat.setOutputPath(job, new Path(args[1])); // ジョブの完了を待つ return (job.waitForCompletion(true) ? 0 : 1); } public static void main(String[] args) throws Exception { int res = ToolRunner.run(new Configuration(), new WordCount(), args); System.exit(res); } }Map 処理を記述するには org.apache.hadoop.mapreduce.Mapper を継承したクラスを作成し、同様に、Reduce 処理を記述するには org.apache.hadoop.mapreduce.Reducer を継承したクラスを作成します。
また、Hadoop では org.apache.hadoop.io.Text は String、org.apache.hadoop.io.IntWritable は int を意味します。Java で実装された MapReduce アプリケーションを実行するためには、コンパイルして jar ファイルを作成する必要があります。
scripts/make-jar.sh#!/usr/bin/env bash # コンパイル hadoop com.sun.tools.javac.Main WordCount.java # jar の作成 jar cf wc.jar WordCount*.class[root@xxxxxxxxx main]# ./scripts/make-jar.shまた、入力のテキストファイルを用意します。
./scripts/create-input-text.sh#!/usr/bin/env bash # 入力のテキストファイルを作成 echo "apple lemon apple lemon lemon grape" > input.txt # 入力のテキストファイルを HDFS に配置 sudo -u hdfs hadoop fs -mkdir -p /user/hdfs/input sudo -u hdfs hadoop fs -put input.txt /user/hdfs/input[root@xxxxxxxxx main]# ./scripts/create-input-text.shそれでは、準備が整ったので実行します。
scripts/execute-wordcount.sh#!/usr/bin/env bash # WordCount.java の実行 # hadoop jar {jar ファイルのパス} {メインクラス名} {入力ファイルのパス} {出力先のパス} sudo -u hdfs hadoop jar wc.jar WordCount /user/hdfs/input/input.txt /user/hdfs/output01 # 結果の表示 sudo -u hdfs hadoop fs -ls /user/hdfs/output01 sudo -u hdfs hadoop fs -cat /user/hdfs/output01/part-r-*[root@xxxxxxxxx main]# ./scripts/execute-wordcount.shジョブが成功した場合は、出力先のパス以下に _SUCCESS というファイルが生成されます。また、part-r-* という形式で出力の結果が1ファイルまたは複数ファイルに格納され、次のような結果を得られることがわかります。
part-r-00000apple 2 grape 1 lemon 3Hadoop Streaming
HadoopS treaming は、Java 以外の言語で MapReduce アプリケーションを実行するためのインターフェースです。データの受け渡しに標準入出力を用いるので、Java の MapReduce アプリケーション と比較すると不便ですが、慣れ親しんだ言語でも開発することができます。今回は、Python で試してみます。
Hadoop Streaming では、入力先のパスと出力先のパスに加えて、実行する map 処理と reduce 処理が定義されたファイルのパスを指定してあげる必要があります。
scripts/execute-wordcount-python.sh#!/usr/bin/env bash # Hadoop Streaming の実行 sudo -u hdfs hadoop jar /usr/lib/hadoop-0.20-mapreduce/contrib/streaming/hadoop-streaming-2.6.0-mr1-cdh5.16.2.jar \ -input /user/hdfs/input/input.txt -output /user/hdfs/output02 \ -mapper /main/streaming/python/map.py -reducer /main/streaming/python/reduce.py # 結果の表示 sudo -u hdfs hadoop fs -ls /user/hdfs/output02 sudo -u hdfs hadoop fs -cat /user/hdfs/output02/part-*map.py では、標準入力から <単語 1> のキーバリューを生成し、標準出力に出力します。
streaming/python/map.py#!/usr/bin/env python # -*- coding: utf-8 -*- import re import sys # 1行を空文字区切りで分割し、(単語, 1) のキーバリューを生成する def map_fn(line): return [(key, 1) for key in re.split(r'\s', line.strip()) if key] # キーバリューを標準出力に出力する def output(records): for key, value in records: print '{0}\t{1}'.format(key, value) # 標準入力から入力を受け取る for l in sys.stdin: output(map_fn(l))reduce.py では、実際に単語の出現回数をカウントし、最終的な処理結果を標準出力に出力します。
streaming/python/reduce.py#!/usr/bin/env python # -*- coding: utf-8 -*- import re import sys results = {} # 単語の出現回数を数える def reduce_fn(line): key, value = re.split(r'\t', line.strip()) if not key in results: results[key] = 0 results[key] = results[key] + int(value) # キーバリュー(最終的な処理結果)を標準出力に出力する def output(records): for k, v in records: print '{0}\t{1}'.format(k, v) # 標準入力から map 処理の出力を受け取る for l in sys.stdin: reduce_fn(l) output(sorted(results.items()))入力ファイルが Java の時と同じ場合、同様の結果が出力先のパスのファイルから得られるかと思います。
part-00000apple 2 grape 1 lemon 3Hadoop エコシステム
Hadoop の主要なコンポーネントは他にも様々ありますが、すべて見ていくのは大変なのでそれぞれについて随時項目を追加して記述していきたいと思います。
コンポーネント 概要 Pig Pig Latin と呼ばれる DSL (Domain Specific Language) で処理を定義することができ、Java より少ないコードで、より簡単に MapReduce アプリケーションを作成できます。 Hive HiveQL と呼ばれる SQL ライクな DSL で処理を定義することができます。 HBase HDFS 上に構築する NoSQL の分散型データベースです。HDFS が苦手な部分を補完するためのシステムになります。 まとめ
今回は、Hadoop に入門した際のまとめとして記事を書きました。おおよそしか理解できていない部分や、概要だけしか知らない Hadoop の主要なコンポーネントがあるので、引き続き学習してみようと思います。また、AWS や GCP 等のクラウドで提供されているマネージドサービスも様々あるので、その使用感の違い等についても実際に動かしてみて学習したいと思います。
間違っている点があれば修正リクエストをお願いします。また、参考になるサイト等あれば是非教えてください!
参考

- 投稿日:2020-04-03T01:07:57+09:00
なでしこ(v3) の 実行環境 / 開発環境 を DOCKER 上に作成する
はじめに
なでしこのインストール方法は、 公式ページ および github に記載があるが、
なでしこ(v3) は、以下の通り 複数の 実行環境 と 開発環境 のセットアップ方法 が提供されている。実行環境
なでしこ(v3)のマニュアル から、以下の4つの実行方法が提供されていることがわかる。
- Web(公式サイト )簡易エディタ *
公式サイトで提供されている WEB上のREPL- Webブラウザ版(ClientSide JavaScript Library) [wnako3.js]
HTMLへの埋め込み方法 にある通り、 wnako3.js を取り込むことで<script type="なでしこ">...</script>と scriptタグ内になでしこのコードを記述 して実行することができる- Windows版 [nadesiko3win32-3.0.681.zip]
オールインワンパッケージ。zipを解凍し、初回セットアップ( setup.vbs を実行)をすることで、以下の4つの実行が行える。
- nakopad.vbs(もしくは、bin/nakopad.exe)
ローカルサーバを起動し WEBページ 形式の ローカル版(Node.jsのランタイム) の編集エディタ- nako3edit.vbs
windowsのデスクトップアプリ (v1と同じ形式)の ローカル版(Node.jsのランタイム) の編集エディタ- nako3server.vbs
ローカルサーバを起動し WEBページ 形式の WEBブラウザ版(ブラウザのランタイム) の編集エディタ- cnako3.bat
ローカル版(Node.jsのランタイム) の CUI- Node.js版 (npm)
macOS版 、 Raspberry Piでなでしこ3を動かそう 、 その他OSでなでしこ3をインストールする方法 は Node.js 上で動かす方法です。 Windows版のnakopad以外の実行が可能ですが、『圧縮』『解凍』や『キー送信』命令を使うためにはNode.jsの他に追加でインストールが必要1です。
- nako3edit(tools/nako3edit/run.js)
ローカルサーバを起動し WEBページ 形式の ローカル版(Node.jsのランタイム) の編集エディタ- nako3server(src/nako3server.js)
ローカルサーバを起動し WEBページ 形式の WEBブラウザ版(ブラウザのランタイム) の編集エディタ- cnako3(src/cnako3.js)
ローカル版(Node.jsのランタイム) の CUI開発環境
公式リポジトリのdoc/SETUP.md には、以下の2つの開発環境のセットアップ方法が記載されている。すべての環境において、git と Node.js が必要 なため、両者のインストールは省略する。
- 【Windows】
npm でnode-gypとwindows-build-toolsのグローバルインストール が必要。- 【macOS】
『圧縮』『解凍』テストケース実行のため、実行方法同様、p7zipのインストール が必要。また両者とも
NAKO_HOMEの環境変数を設定する必要がある。DOCKERで作成するメリット
DOCKERの説明は省略する。
実行環境では、 Windows版 のように オールインワンパッケージ が実現でき、
開発環境では、依存関係を宣言し、環境構築の手間を減らす ことができる。実行環境(DOCKER)
以下 README.md の記載法に合わせて記載する。
DOCKERで利用する
先に、DOCKERをインストールし、
次いで、コマンドラインから以下のコマンドを実行して、Dockerイメージを取得します。
(注意) Docker Hubにイメージを登録していないため、以下のコマンドではDockerイメージを取得できません。
Dockerイメージの作成は後述の Dockerイメージを作成する を参照してください。# Docker Hub からなでしこ3のDockerイメージを取得する $ docker pull nadesiko3 $ docker pull nadesiko3:server $ docker pull nadesiko3:editイメージを取得後、以下のコマンドで なでしこ が利用できます。
# なでしこをCUIで実行 $ docker run --rm nadesiko3 cnako3 -e "「Hello World」を表示する" # なでしこエディタ(ローカル版)を起動 $ docker run -d -p 3030:3030 nadesiko3:edit # なでしこエディタ(WEBブラウザ版)を起動 $ docker run -d -p 3000:3000 nadesiko3:server実行環境(DOCKER)のイメージ作成
まずは共通となる実行環境のイメージを作成します。
DockerfileFROM node:13-alpine WORKDIR /app RUN apk add --update --no-cache p7zip RUN apk add --update --no-cache xdotool RUN npm -g install nadesiko3 ENV NAKO_HOME /usr/local/lib/node_modules/nadesiko3上記、Dockerfileを用いて、dockerイメージを作成します。
buildコマンドdocker build -t nadesiko3 .CUIでの実行確認は以下の通り
実行確認$ docker images REPOSITORY TAG IMAGE ID CREATED SIZE nadesiko3 latest 78908220982b 26 minutes ago 157MB $ docker run --rm nadesiko3 cnako3 -e "「Hello World」を表示する" Hello Worldなでしこエディタ(ローカル版) 用のDockerfileも用意します。
nako3edit のプロセスがフォアグラウンドで動かないため、起動用シェルを追加します。Dockerfile.editFROM nadesiko3 RUN echo -e "#!/bin/sh\n\nnako3edit\n\ntail -f /dev/null" > nako3edit.sh RUN chmod 755 nako3edit.sh CMD [ "./nako3edit.sh" ]buildコマンドdocker build -t nadesiko3:edit -f Dockerfile.edit .実行確認は以下の通り。run 後の CONTAINER IDを指定して、アクセス対象のURLを取得することに注意してください。
実行確認$ docker images REPOSITORY TAG IMAGE ID CREATED SIZE nadesiko3 edit 80680a121dd9 15 minutes ago 157MB nadesiko3 latest 8b48267d6548 16 minutes ago 157MB node 13-alpine b01d82bd42de 3 weeks ago 114MB $ docker run -d -p 3030:3030 nadesiko3:edit 29ff97991e17e1b63f5818406b07c4854d949c8d1fd69d4953d0aabd91409625 user@localhost:~/tmp/nadesiko3 (master)$ docker logs 29ff97991e17e1b63f5818406b07c4854d949c8d1fd69d4953d0aabd91409625 * [WEBサーバ(なでしこ+Express)] (debug) | 以下のURLで起動しました。 +- [URL] http://localhost:3030 >>> -------------------------------------------------- >>> サーバ起動に成功しました。 >>> nako3edit にアクセスするには、以下のURLにアクセスします >>> [URL] http://localhost:3030?appkey=34149_20085_5302 >>> [static] /html /usr/local/lib/node_modules/nadesiko3/tools/nako3edit/html [static] /release /usr/local/lib/node_modules/nadesiko3/release [GET] / [GET] /test [GET] /files [GET] /loadなでしこエディタ(WEBブラウザ版) 用のDockerfileも用意します。
Dockerfile.serverFROM nadesiko3 CMD [ "nako3server" ]buildコマンドdocker build -t nadesiko3:server -f Dockerfile.server .実行確認$ docker images REPOSITORY TAG IMAGE ID CREATED SIZE nadesiko3 server d81e733303c8 2 minutes ago 157MB nadesiko3 edit 80680a121dd9 27 minutes ago 157MB nadesiko3 latest 8b48267d6548 27 minutes ago 157MB $ docker run -d -p 3000:3000 nadesiko3:server d98e488e0a4d18af057c601d5816bcc663ddf55ccc8eed96bede0ac675f2d9bc $ docker logs d98e488e0a4d18af057c601d5816bcc663ddf55ccc8eed96bede0ac675f2d9bc documentRoot: /usr/local/lib/node_modules/nadesiko3 + サーバーを開始しました + [URL] http://localhost:3000開発環境(DOCKER)
開発環境は、git のワークスペースと開発環境用のコンテナをマウントさせ、
git のワークスペースの変更をコンテナに反映させる構成とします。Dockerfile.developmentFROM node:13-alpine WORKDIR /app RUN apk add --update --no-cache p7zip RUN apk add --update --no-cache xdotool RUN apk add --update --no-cache wine ENV NAKO_HOME /app/nadesiko3 CMD [ "tail", "-f", "/dev/null" ]buildコマンドdocker build -t nadesiko3:development -f Dockerfile.development .起動時には、 gitのワークスペース を /app/nadesiko3 にマウントします。
実行コマンド# gitのワークスペースにて実行 docker run --rm -d -v $PWD:/app/nadesiko3 -p 3000:3000 -p 3030:3030 nadesiko3:developmentdocker execにて、起動したコンテナに入り、必要なコマンドを実行できます
※ 必要に応じてdocker-composeを使用すれば、起動コマンドも管理可能です。実行例$ docker run --rm -d -v $PWD:/app/nadesiko3 -p 3000:3000 -p 3030:3030 nadesiko3:development 7d69ac3a42419ba75c5937eacd915051ee2ae0e91106fde072c539f47b800038 /app # cd nadesiko3/ /app/nadesiko3 # node src/nako3server.js documentRoot: /app/nadesiko3 + サーバーを開始しました + [URL] http://localhost:3000さいごに
今回作成した Dockerfile は 個人のGITHUB にも上げています。
開発環境は必要なコマンドをすべて試してはいませんが、
なでしこ は多くの実行の仕方を提供し、electronを使用したビルドなど
依存関係も多いため、DOCKERのメリットを多く享受できると思います。
- 投稿日:2020-04-03T01:07:57+09:00
なでしこ(v3) の 実行環境 / 開発環境 を DOCKER で作成する
はじめに
なでしこのインストール方法は、 公式ページ および github に記載があるが、
なでしこ(v3) は、以下の通り 複数の 実行環境 と 開発環境 のセットアップ方法 が提供されている。実行環境
なでしこ(v3)のマニュアル から、以下の4つの実行方法が提供されていることがわかる。
- Web(公式サイト )簡易エディタ *
公式サイトで提供されている WEB上のREPL- Webブラウザ版(ClientSide JavaScript Library) [wnako3.js]
HTMLへの埋め込み方法 にある通り、 wnako3.js を取り込むことで<script type="なでしこ">...</script>と scriptタグ内になでしこのコードを記述 して実行することができる- Windows版 [nadesiko3win32-3.0.681.zip]
オールインワンパッケージ。zipを解凍し、初回セットアップ( setup.vbs を実行)をすることで、以下の4つの実行が行える。
- nakopad.vbs(もしくは、bin/nakopad.exe)
ローカルサーバを起動し WEBページ 形式の ローカル版(Node.jsのランタイム) の編集エディタ- nako3edit.vbs
windowsのデスクトップアプリ (v1と同じ形式)の ローカル版(Node.jsのランタイム) の編集エディタ- nako3server.vbs
ローカルサーバを起動し WEBページ 形式の WEBブラウザ版(ブラウザのランタイム) の編集エディタ- cnako3.bat
ローカル版(Node.jsのランタイム) の CUI- Node.js版 (npm)
macOS版 、 Raspberry Piでなでしこ3を動かそう 、 その他OSでなでしこ3をインストールする方法 は Node.js 上で動かす方法です。 Windows版のnakopad以外の実行が可能ですが、『圧縮』『解凍』や『キー送信』命令を使うためにはNode.jsの他に追加でインストールが必要1です。
- nako3edit(tools/nako3edit/run.js)
ローカルサーバを起動し WEBページ 形式の ローカル版(Node.jsのランタイム) の編集エディタ- nako3server(src/nako3server.js)
ローカルサーバを起動し WEBページ 形式の WEBブラウザ版(ブラウザのランタイム) の編集エディタ- cnako3(src/cnako3.js)
ローカル版(Node.jsのランタイム) の CUI開発環境
公式リポジトリのdoc/SETUP.md には、以下の2つの開発環境のセットアップ方法が記載されている。すべての環境において、git と Node.js が必要 なため、両者のインストールは省略する。
- 【Windows】
npm でnode-gypとwindows-build-toolsのグローバルインストール が必要。- 【macOS】
『圧縮』『解凍』テストケース実行のため、実行方法同様、p7zipのインストール が必要。また両者とも
NAKO_HOMEの環境変数を設定する必要がある。DOCKERで作成するメリット
DOCKERの説明は省略する。
実行環境では、 Windows版 のように オールインワンパッケージ が実現でき、
開発環境では、依存関係を宣言し、環境構築の手間を減らす ことができる。実行環境(DOCKER)
以下 README.md の記載法に合わせて記載する。
DOCKERで利用する
先に、DOCKERをインストールし、
次いで、コマンドラインから以下のコマンドを実行して、Dockerイメージを取得します。
(注意) Docker Hubにイメージを登録していないため、以下のコマンドではDockerイメージを取得できません。
Dockerイメージの作成は後述の Dockerイメージを作成する を参照してください。# Docker Hub からなでしこ3のDockerイメージを取得する $ docker pull nadesiko3 $ docker pull nadesiko3:server $ docker pull nadesiko3:editイメージを取得後、以下のコマンドで なでしこ が利用できます。
# なでしこをCUIで実行 $ docker run --rm nadesiko3 cnako3 -e "「Hello World」を表示する" # なでしこエディタ(ローカル版)を起動 $ docker run -d -p 3030:3030 nadesiko3:edit # なでしこエディタ(WEBブラウザ版)を起動 $ docker run -d -p 3000:3000 nadesiko3:server実行環境(DOCKER)のイメージ作成
まずは共通となる実行環境のイメージを作成します。
DockerfileFROM node:13-alpine WORKDIR /app RUN apk add --update --no-cache p7zip RUN apk add --update --no-cache xdotool RUN npm -g install nadesiko3 ENV NAKO_HOME /usr/local/lib/node_modules/nadesiko3上記、Dockerfileを用いて、dockerイメージを作成します。
buildコマンドdocker build -t nadesiko3 .CUIでの実行確認は以下の通り
実行確認$ docker images REPOSITORY TAG IMAGE ID CREATED SIZE nadesiko3 latest 78908220982b 26 minutes ago 157MB $ docker run --rm nadesiko3 cnako3 -e "「Hello World」を表示する" Hello Worldなでしこエディタ(ローカル版) 用のDockerfileも用意します。
nako3edit のプロセスがフォアグラウンドで動かないため、起動用シェルを追加します。Dockerfile.editFROM nadesiko3 RUN echo -e "#!/bin/sh\n\nnako3edit\n\ntail -f /dev/null" > nako3edit.sh RUN chmod 755 nako3edit.sh CMD [ "./nako3edit.sh" ]buildコマンドdocker build -t nadesiko3:edit -f Dockerfile.edit .実行確認は以下の通り。run 後の CONTAINER IDを指定して、アクセス対象のURLを取得することに注意してください。
実行確認$ docker images REPOSITORY TAG IMAGE ID CREATED SIZE nadesiko3 edit 80680a121dd9 15 minutes ago 157MB nadesiko3 latest 8b48267d6548 16 minutes ago 157MB node 13-alpine b01d82bd42de 3 weeks ago 114MB $ docker run -d -p 3030:3030 nadesiko3:edit 29ff97991e17e1b63f5818406b07c4854d949c8d1fd69d4953d0aabd91409625 user@localhost:~/tmp/nadesiko3 (master)$ docker logs 29ff97991e17e1b63f5818406b07c4854d949c8d1fd69d4953d0aabd91409625 * [WEBサーバ(なでしこ+Express)] (debug) | 以下のURLで起動しました。 +- [URL] http://localhost:3030 >>> -------------------------------------------------- >>> サーバ起動に成功しました。 >>> nako3edit にアクセスするには、以下のURLにアクセスします >>> [URL] http://localhost:3030?appkey=34149_20085_5302 >>> [static] /html /usr/local/lib/node_modules/nadesiko3/tools/nako3edit/html [static] /release /usr/local/lib/node_modules/nadesiko3/release [GET] / [GET] /test [GET] /files [GET] /loadなでしこエディタ(WEBブラウザ版) 用のDockerfileも用意します。
Dockerfile.serverFROM nadesiko3 CMD [ "nako3server" ]buildコマンドdocker build -t nadesiko3:server -f Dockerfile.server .実行確認$ docker images REPOSITORY TAG IMAGE ID CREATED SIZE nadesiko3 server d81e733303c8 2 minutes ago 157MB nadesiko3 edit 80680a121dd9 27 minutes ago 157MB nadesiko3 latest 8b48267d6548 27 minutes ago 157MB $ docker run -d -p 3000:3000 nadesiko3:server d98e488e0a4d18af057c601d5816bcc663ddf55ccc8eed96bede0ac675f2d9bc $ docker logs d98e488e0a4d18af057c601d5816bcc663ddf55ccc8eed96bede0ac675f2d9bc documentRoot: /usr/local/lib/node_modules/nadesiko3 + サーバーを開始しました + [URL] http://localhost:3000開発環境(DOCKER)
開発環境は、git のワークスペースと開発環境用のコンテナをマウントさせ、
git のワークスペースの変更をコンテナに反映させる構成とします。Dockerfile.developmentFROM node:13-alpine WORKDIR /app RUN apk add --update --no-cache p7zip RUN apk add --update --no-cache xdotool RUN apk add --update --no-cache wine ENV NAKO_HOME /app/nadesiko3 CMD [ "tail", "-f", "/dev/null" ]buildコマンドdocker build -t nadesiko3:development -f Dockerfile.development .起動時には、 gitのワークスペース を /app/nadesiko3 にマウントします。
実行コマンド# gitのワークスペースにて実行 docker run --rm -d -v $PWD:/app/nadesiko3 -p 3000:3000 -p 3030:3030 nadesiko3:developmentdocker execにて、起動したコンテナに入り、必要なコマンドを実行できます
※ 必要に応じてdocker-composeを使用すれば、起動コマンドも管理可能です。実行例$ docker run --rm -d -v $PWD:/app/nadesiko3 -p 3000:3000 -p 3030:3030 nadesiko3:development 7d69ac3a42419ba75c5937eacd915051ee2ae0e91106fde072c539f47b800038 /app # cd nadesiko3/ /app/nadesiko3 # node src/nako3server.js documentRoot: /app/nadesiko3 + サーバーを開始しました + [URL] http://localhost:3000さいごに
今回作成した Dockerfile は 個人のGITHUB にも上げています。
開発環境は必要なコマンドをすべて試してはいませんが、
なでしこ は多くの実行の仕方を提供し、electronを使用したビルドなど
依存関係も多いため、DOCKERのメリットを多く享受できると思います。