- 投稿日:2020-04-03T21:48:37+09:00
AWS EC2インスタンスからRDSインスタンスへ接続する方法
- 投稿日:2020-04-03T18:12:39+09:00
AWS Systems Manager経由でssh不使用のOSリモートアクセスを試す
AWS Systems Managerにはセッションという機能があり、管理下のEC2インスタンスのシェルへのアクセスや、ポート転送でのアクセスができます。このSystems Managerのセッション経由でのOSシェルアクセスや、ポート転送を使ったRDP接続を試してみるためのおおよその手順をまとめてみました。
概要
以下を行います。
- 準備
- プライベートサブネットとパブリックサブネットを持つVPCを作成
- 両サブネットにEC2インスタンスを作成
- EC2インスタンスをSystems Manager管理対象化
- Sytems Managerのセッションでシェル(
sh/PowerShell)接続- セッション情報(操作内容を含む)の記録
- エンドポイント経由でのプライベートサブネットへの接続
- AWS CLIでの接続とRDP接続
準備
初期構成として、プライベートサブネットとパブリックサブネットにそれぞれEC2インスタンスがおかれた構成を作成します。
以降の説明ではここで作成したインスタンス名、サブネット名等を使いますが、もし既存環境があって読み替えができるようであれば、そちらを使っても構いません。VPCの作成
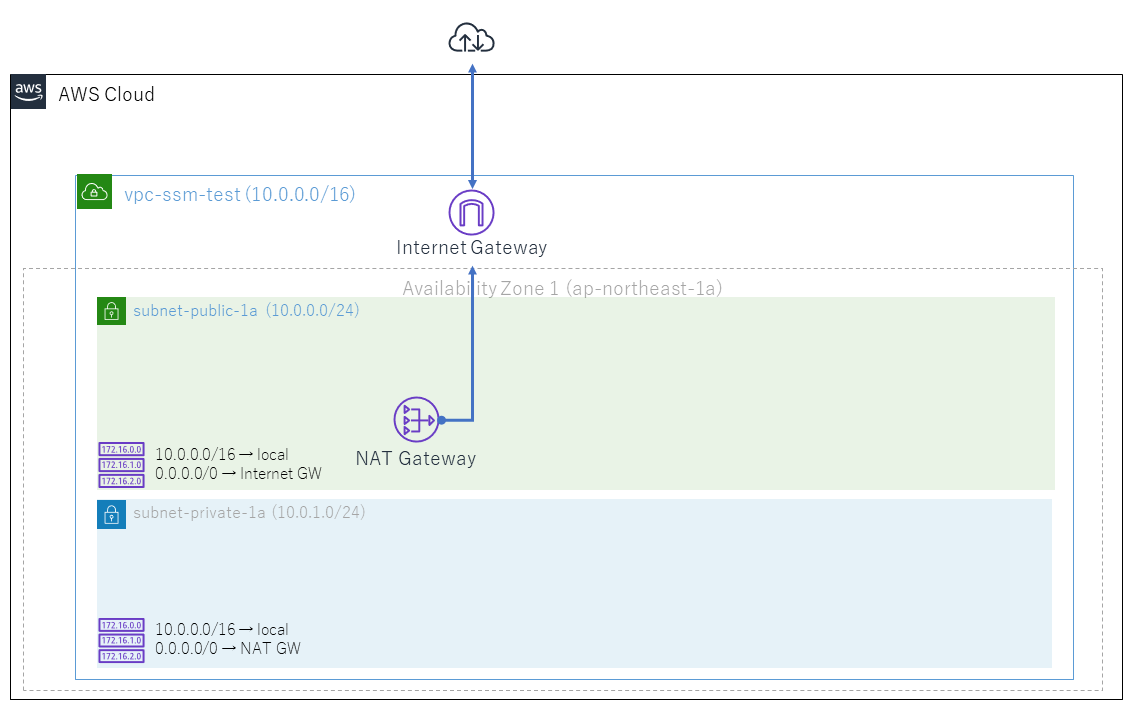
下図のように、プライベートサブネットとパブリックサブネットを持つVPCを作成します。
- AWSコンソールから「VPC」サービスを開く。
- 「VPCダッシュボード」が表示される。まずElastic IPを作成しておく。
- 左側のメニューから「Elastic IP」をクリックする。
- 「新しいアドレスの割り当て」をクリックする。
- 「新しいアドレスの割り当て」画面で「割り当て」をクリックする
- 左側のメニューから「VPCダッシュボード」をクリックする。
- 「VPCウィザードの起動」をクリックする。
- 「ステップ1: VPC設定の選択」が表示される。「パブリックとプライベートサブネットを持つVPC」を選択する。
- 「ステップ2:パブリックとプライベートサブネットを持つVPC」で、以下を指定する。
- 図の通りにVPC名、パブリックサブネット名、プライベートサブネット名、アベイラビリティゾーンを指定する。
- Elastic IP割当てIDで、上で作成したElastic IPを選択する。
- 「VPCの作成」をクリックする。
これで図のようなVPC、サブネット、Internet Gateway、NAT Gateway、ルーティングテーブルが作成されます。
EC2インスタンスの作成
プライベートサブネットとパブリックサブネットにそれぞれEC2インスタンスを配置します。パブリックサブネットにはLinuxとWindowsの2台のインスタンスを配置します。
まずキーペアを作成しておきます。
- AWSコンソールから「EC2」サービスを開く。
- 左側のメニューから「キーペア」をクリックする。
- 「キーペアを作成」をクリックする。
- 名前は任意の名称、ファイル形式は「pem」を選択し、「キーペアを作成」をクリックする。
- ダウンロードされたpemファイルを適当な場所に保管しておく。
次にパブリックサブネットで使用するセキュリティグループを作成しておきます。
- AWSコンソールから「VPC」サービスを開く。
- 左側のメニューから「セキュリティグループ」をクリック。
- 「セキュリティグループの作成」をクリック。
- 「セキュリティグループ名」は「Web-SG」、「説明」は「Allow HTTP/HTTPS from any」、「VPC」は「vpc-ssm-test」を指定し、作成。
- セキュリティグループの一覧から「Web-SG」を選択し、「アクション > インバウンドルールルールの編集」を選択。
- 「ルールの追加」をクリックし、「タイプ」に「HTTP」、ソースに「0.0.0.0/0」を指定。
- 同様に「HTTPS」「SSH」「RDP」に対して、ソースを「0.0.0.0/0」とするルールを追加。 8.「ルールの保存」をクリック。
同様にプライベートサブネットで使用するセキュリティグループを、以下の内容で作成しておきます。
- セキュリティグループ名は「DB-SG」。
- インバウンドルールはタイプ「MYSQL/AURORA」「SSH」「RDP」をそれぞれ、ソース「10.0.0.0/16」に対して追加
使用するキーペアとセキュリティグループが用意できたので、EC2インスタンスを作成していきます。
パブリックサブネットにLinuxのEC2インスタンスを作成します。
- AWSコンソールから「EC2」サービスを開く。
- 左側のメニューから「インスタンス」をクリックする。
- 「インスタンスの作成」をクリックする。
- 「ステップ1: Amazonマシンイメージ(AMI)」で、先頭にある無料利用枠の対象の「Amazon Linux 2 AMI (HVM), SSD Volume Type」を選択。
- 「ステップ2: インスタンスタイプの選択」で、無料利用枠の対象の「t2.micro」を選択。
- 「ステップ3: インスタンスの詳細の設定」で、ネットワークは「vpc-ssm-test」、サブネットは「subnet-public-1a」、「自動割り当てパブリックIP」は「有効」を選択。
- 「ステップ4: ストレージの追加」はそのまま。
- 「ステップ5: タグの追加」では「クリックしてNameタグを追加します」をクリックし、「Linux Web Instance」を指定。
- 「ステップ6: セキュリティグループの設定」では「既存のセキュリティグループを選択する」を選択し、名前が「Web-SG」のものを選択。
- 「ステップ7: インスタンス作成の確認」では「起動」をクリック。
- 「既存のキーペアを選択するか、新しいキーペアを作成します。」で、上で作成したキーペアを指定し、確認チェックボックスをチェックして、「インスタンスの作成」をクリック。
同様にパブリックサブネットにWindowsのEC2インスタンスを、以下の内容で作成しておきます。
- Amazonマシンイメージ(AMI)は、
Windowsを検索し、先頭にある無料利用枠の対象の「 Microsoft Windows Server 2019 Beta 」を選択。- ネットワークは「vpc-ssm-test」、サブネットは「subnet-public-1a」、「自動割り当てパブリックIP」は「有効」を選択。
- Nameタグは「 Windows Web Instance 」を指定。
- セキュリティグループは「Web-SG」を選択。
同様にプライベートサブネットにLinuxのEC2インスタンスを、以下の内容で作成しておきます。
- Amazonマシンイメージ(AMI)は、先頭にある無料利用枠の対象の「Amazon Linux 2 AMI (HVM), SSD Volume Type」を選択。
- ネットワークは「vpc-ssm-test」、サブネットは「 subnet-private-1a 」、「自動割り当てパブリックIP」は「 無効 」を選択。
- Nameタグは「 DB Instance 」を指定。
- セキュリティグループは「 DB-SG 」を選択。
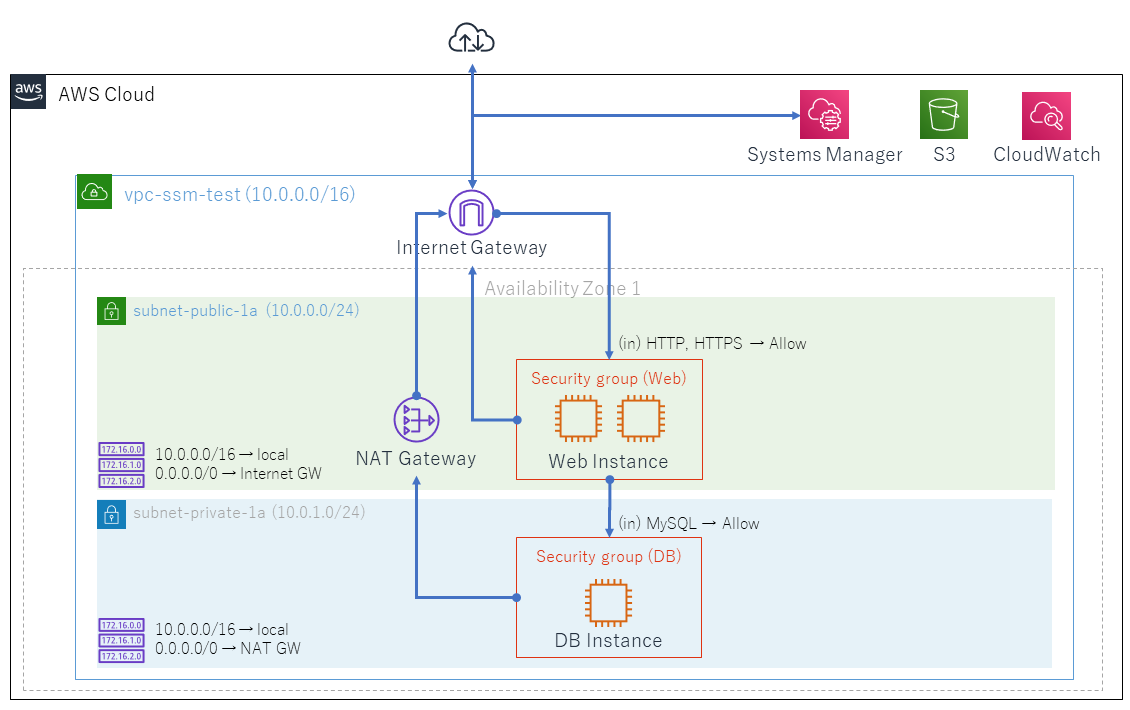
これで図のようなセキュリティグループとEC2インスタンスが追加されます。
仮想マシンが起動したら、以下の接続を確認しておいてください。
- Linux Web Instance(パブリックサブネットに配置したLinuxインスタンス)へのssh接続。「SSH を使用した Linux インスタンスへの接続 - Amazon Elastic Compute Cloud」の手順で実施します。シェルへのログインが確認できればすぐに
exitして構いません。- Windows Web Instance(パブリックサブネットに配置したWindowsインスタンス)へのリモートデスクトップ接続。「Windows インスタンスへの接続 - Amazon Elastic Compute Cloud」の「RDP クライアントを使用して Windows インスタンスに接続」手順で実施します。リモートデスクトップへのログインが確認できればすぐに切断して構いません。
- DB Instance(プライベートサブネットに配置したLinuxインスタンス)へのssh接続。インターネットからは直接接続できないので、Linux Web Instanceにssh接続し、ここからさらにDB Instanceにssh接続して確認します。
EC2インスタンスをSystems Manager管理対象化
Systems Managerの管理対象となっているインスタンスは「Managed Instance」と呼ばれれ、セッションを使ったシェルアクセスが可能になります。以下では作成したEC2インスタンスをManaged Instanceにするための設定を行います。その後、Systems ManagerでManaged Instanceになったことを確認します。
「AWS Systems Manager のセットアップ - AWS Systems Manager」のから、まず「ステップ 4: Systems Manager の IAM インスタンスプロファイルの作成」を行います。インスタンスプロファイスは、ここではEC2インスタンスに割り当てるロールのことだと思っておいてください(違いに興味があればこちらなどを参照)。ここでは最小限のロールを作成します。
- AWSコンソールから「IAM」サービスを開く。
- 左側のメニューから「ロール」をクリックする。
- 「ロールの作成」をクリックする。
- 「信頼されたエンティティの種類」は「AWSサービス」、「ユースケースの選択」は「EC2」を選択。
- 「Attachアクセス権限ポリシー」では「AmazonSSMManagedInstanceCore」を選択。
- 「ロールの作成」で任意のロール名(例えば「MySSMRoleForInstancesQuickSetup」)を指定し、「ロールの作成」をクリック。
次に「ステップ 5: IAM インスタンスプロファイルを Amazon EC2 インスタンスにアタッチする」を行います。
- AWSコンソールから「EC2」サービスを開く。
- 左側のメニューから「インスタンス」をクリックする。
- 対象のインスタンスをすべて選択し、「アクション > インスタンスの状態 > 停止」を選択。
Linux Web Instanceが停止したら選択し、「アクション > インスタンスの設定 > IAMロールの割り当て/置換」を選択。- 「IAMロール」にステップ4で作成したロールを選択し、「適用」をクリック。
Windows Web InstanceDB Instanceについても手順4.~5.を実施。- 対象のインスタンスをすべて選択し、「アクション > インスタンスの状態 > 開始」を選択。
これで最小限の設定が終了です。本来はこの他にSSMエージェントのインストールが必要ですが、事前インストールされたAmazon Linux 2およびWindows Server 2019イメージをEC2インスタンス作成手順で選択しているため、ここでは不要です。
AWS Systems Managerで、Managed Instanceになっていることを確認します。
- AWSコンソールから「Systems Manager」サービスを開く。
- 左側のメニューから「マネージドインスタンス」をクリックする。
- マネージドインスタンスに、ステップ5で設定対象にしたEC2インスタンスが表示されていることを確認する。
Sytems Managerのセッションでシェル接続
Managed Instanceに対して、Systems Managerからシェルアクセスします。これが確認出来たら、セキュリティグループの設定でSSHやRDP通信を遮断してしまうことにします。
Managed Instanceに対して、Systems Managerからシェルアクセスします。
- AWSコンソールから「Systems Manager」サービスを開く。
- 左側のメニューから「セッションマネージャー」をクリックする。
- 「セッションの開始」をクリックする。
- 「Linux Web Instance」を選択し、「セッションを開始する」をクリックする。
- シェル(
sh)画面が表示されたら、「exit」を実行してセッションを終了する。- 「DB Instance」に対しても、4.~5.の手順でシェルへのアクセスを確認する。
- 「Windows Web Instance」に対しても、4.~5.の手順でシェル(
PowerShell)へのアクセスを確認する。sshやRDP通信が(特にインターネットから直接)できないようにします。
- AWSコンソールから「VPC」サービスを開く。
- 左側のメニューから「セキュリティグループ」をクリックする。
- 「Web-SG」を選択し、「アクション > インバウンドルールの編集」を選択。
- タイプが「SSH」「RDP」の行を、右端の「×」をクリックして削除後、「ルールの保存」をクリック。
- 「DB-SG」についても、手順3.~4.を実施。
念のためもう一度、Systems Managerのセッションマネージャーから、各EC2インスタンスのシェルにアクセスできることを確認しておいてもいいかもしれません。これができれば、sshやRDPがなくてもOSを管理する術があることになります。攻撃対象になる箇所をできるだけ少なくしておくという基本的な考え方に従って、sshやrdpアクセスを閉じた状態にしておけるということでもあります。
セッション情報(操作内容を含む)の記録
セッションでの接続までは、この時点でもセッションマネージャーの「セッション履歴」に記録されています。ここでは操作内容もS3とCloudWatch Logsに記録できるように構成します。
記録用のS3バケットを作成しておきます。
- AWSコンソールから「S3」サービスを開く。
- 左側のメニューから「バケット」をクリックする。
- 「バケットを作成」をクリックする。
- 任意のバケット名(例えば
YOURNAME_ssm_session_YYYYMMDD)を指定し、「バケットを作成」をクリック。記録用のCloudWatchロググループを作成しておきます。
- AWSコンソールから「CloudWatch」サービスを開く。
- 左側のメニューから「ロググループ」をクリックする。
- 「ロググループを作成」をクリック。
- 任意のロググループ名(例えば
/ssm/session_logs)を指定し、「作成」をクリック。セッションの操作内容をS3バケットやCloudWatch Logsに書込めるよう、EC2インスタンスに割り当てたロール(インスタンスプロファイル)に権限を追加します。
- AWSコンソールから「IAM」サービスを開く。
- 左側のメニューから「ロール」をクリック。
- 一覧から、作成したロール(例えば「MySSMRoleForInstancesQuickSetup」)をクリック。
- 「ポリシーをアタッチする」をクリック。
AmazonS3GFullAccessにチェック。S3への記録に必要なもので、本来はカスタムポリシーを作成して選択する方がよい(最小権限の原則)が、ここではこれで代用。CloudWatchAgentServerPolicyにチェック。CloudWatchへの記録に必要。- 「ポリシーのアタッチ」をクリック。
最後に、セッションの記録の設定をします。
- AWSコンソールから「Systems Manager」サービスを開く。
- 左側のメニューから「セッションマネージャー」をクリックする。
- 右側の「設定」タブを選択。
- 「編集」をクリック。
- 「Amazon S3 バケットにセッション出力を書き込む」設定。
- 「S3バケット」にチェック。
- 「ログデータを暗号化する」のチェックを外す(S3バケット作成時に暗号化を有効にしている場合はチェックを入れたままにする)。
- 「S3バケット名」で、作成したS3バケットを選択。
- 「CloudWatch Logs にセッション出力を送信する」設定。
- 「CloudWatch Logs」にチェック。
- 「CloudWatchのロググループ」で、作成したロググループを選択。
- 「保存」をクリック。
実際にセッションを利用してみて、セッション内容の記録を確認します。
- AWSコンソールから「Systems Manager」サービスを開く。
- 左側のメニューから「セッションマネージャー」をクリック。
- 「セッションの開始」をクリックする。
- いずれかのインスタンスを選択し、「セッションを開始する」をクリック。
- 「exit」を実行してセッションを終了する。
- 「セッションの履歴」タブをクリック。
- 最新のセッションの「出力場所」列で「Amazon S3」をクリック。
- 表示されたログを「ダウンロード」し、内容を確認。
- 「セッションの履歴」に戻り、最新のセッションの「出力場所」列で「CloudWatch Logs」をクリック。
- 表示されたログの内容を確認。
エンドポイント経由でのプライベートサブネットへの接続
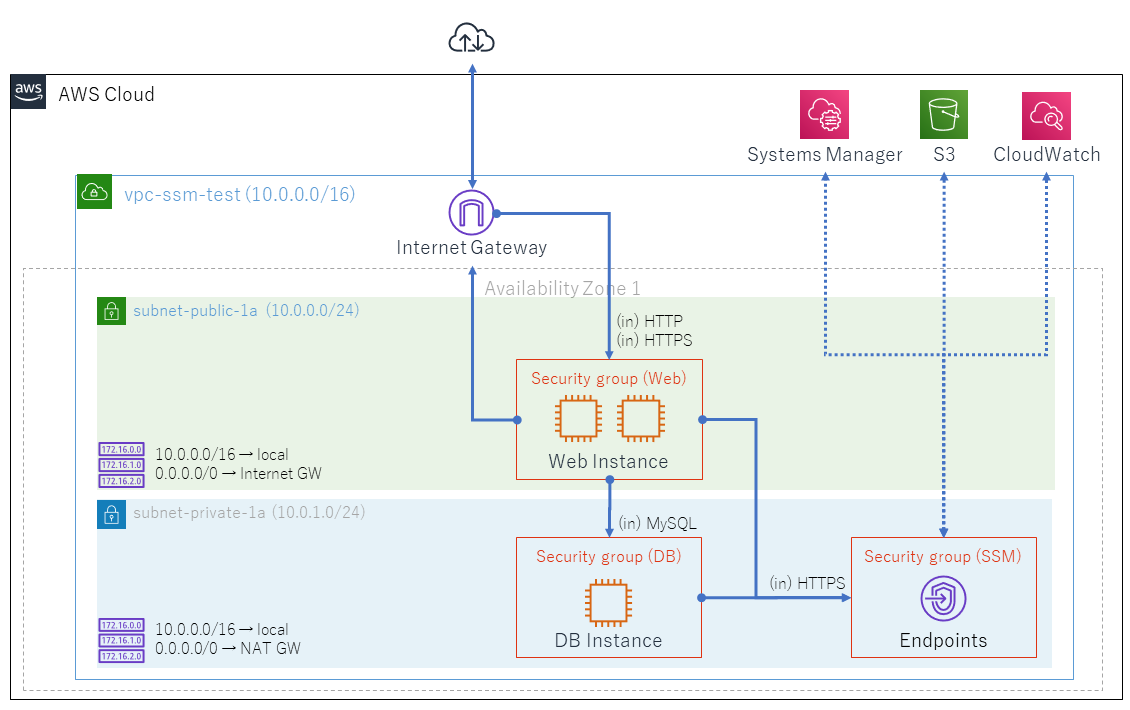
EC2インスタンスとSystems Managerの間の通信を、エンドポイント経由に変更します。これにより、ネットワークトラフィックをAmazon ネットワークに限定し、インターネットにアクセスできないプライベートサブネットのEC2インスタンスもSystems Managerの管理下に入れることができます。
まずエンドポイント用のセキュリティグループを作成します。
- AWSコンソールから「VPC」サービスを開く。
- 左側のメニューから「セキュリティグループ」をクリックする。
- 「セキュリティグループの作成」をクリックする。
- 「セキュリティグループ名」に「SSM-SG」、「説明」に「Allow HTTPS access from managed instances.」、VPCに「vpc-ssm-test」を指定し、「作成」をクリック。
- セキュリティグループ一覧画面で、「SSM-SG」を選択し、「アクション > インバウンドルールの編集」を選択。
- 「ルールの追加」をクリックし、「タイプ」に「HTTPS」、「ソース」に「10.0.0.0/16」を指定し、「ルールの保存」をクリック。
エンドポイントを作成します。
- AWSコンソールから「VPC」サービスを開く。
- 左側のメニューから「エンドポイント」をクリック。
- 「エンドポイントの作成」をクリック。
- 「サービス名」に「com.amazonaws.ap-northeast-1.ssm」、「VPC」に「vpc-ssm-test」、「アベイラビリティゾーン」に「ap-northeast-1a」、「サブネット」に「subnet-private-1a」、「セキュリティグループ」に「SSM-SG」を選択し、「エンドポイントの作成」をクリック。
- 手順3.~4.を「com.amazonaws.ap-northeast-1.ssmmessages」についても実行。
- 手順3.~4.を「com.amazonaws.ap-northeast-1.ec2messages」についても実行。
- 「エンドポイントの作成」をクリックする。
- 「サービス名」に「com.amazonaws.ap-northeast-1.s3」、「VPC」に「vpc-ssm-test」、「ルートテーブル」は表示されるものすべてを選択し、「エンドポイントの作成」をクリック。
これでプライベートサブネットからインターネットへの接続は(SSMでの管理のためには)不要になったはずなので、NATゲートウェイを削除してしまうことにします。
- AWSコンソールから「VPC」サービスを開く。
- 左側のメニューから「NATゲートウェイ」をクリック。
- NATゲートウェイを選択し、「アクション > NATゲートウェイの削除」を選択。
- 左側のメニューから「サブネット」をクリック。
- 「subnet-private-1a」のルートテーブル列に表示されているリンクをクリック。
- ルートテーブルの詳細が表示されるので、「アクション > ルートの編集」を選択。
- 「送信先」が「0.0.0.0/0」、「ターゲット」が削除したNATゲートウェイの行を右、端の「×」をクリックして削除後、「ルートの保存」をクリック。
一通りの変更が済んだので、各EC2インスタンスがAWS Systems Managerからエンドポイント経由での通信で管理されることを確認します。
- AWSコンソールから「EC2」サービスを開く。
- 左側のメニューから「インスタンス」をクリックする。
- 対象のインスタンスをすべて選択し、「アクション > インスタンスの状態 > 停止」を選択。
- 対象のインスタンスをすべて選択し、「アクション > インスタンスの状態 > 開始」を選択。
- AWSコンソールから「Systems Manager」サービスを開く。
- 左側のメニューから「マネージドインスタンス」をクリックする。
- マネージドインスタンスに、ステップ5で設定対象にしたEC2インスタンスが表示されていることを確認する。
セッション(シェルへのアクセス)も引き続き可能で、セッション内容も記録されることを確認します。
- AWSコンソールから「Systems Manager」サービスを開く。
- 左側のメニューから「セッションマネージャー」をクリック。
- 「セッションの開始」をクリックする。
- 「DB Instance」を選択し、「セッションを開始する」をクリック。
- 「exit」を実行してセッションを終了する。
- 「セッションの履歴」タブをクリック。
- 最新のセッションの「出力場所」列で「Amazon S3」をクリック。
- 表示されたログを「ダウンロード」し、内容を確認。
- 「セッションの履歴」に戻り、最新のセッションの「出力場所」列で「CloudWatch Logs」をクリック。
- 表示されたログの内容を確認。
これで、インターネットからのsshやrdpをセキュリティグループレベルで遮断できただけでなく、インターネットとの接続経路も持たないプライベートサブネットのEC2インスタンスもシェルを使って管理できることになります。
AWS CLIでの接続とRDP接続
ここまではAWSの管理コンソール(Web画面)からセッションを使ってきましたが、ここではAWS CLIからセッションを使ってみます。またAWS CLIからのセッションではポーロフォワーディングができるので、これを介してRDP接続をしてみます。
AWS CLIとSession Managerプラグインの準備
ローカル環境にAWS CLIとSession Managerプラグインが必要です。以下から各OS用のAWS CLIとSession Managerを導入します。
- AWS CLI バージョン 2 のインストール - AWS Command Line Interface
- (オプション) AWS CLI 用の Session Manager Plugin をインストールする - AWS Systems Manager
AWS CLIを未使用であれば、以下のAWS CLIのかんたん設定(
aws configure)を行います。AWS CLIでの接続
接続対象のEC2インスタンスのインスタンスIDを、AWSの管理コンソール(Web画面)か、以下のコマンド実行結果で確認しておきます。
aws ec2 describe-instances --query "Reservations[].Instances[].[InstanceId,Tags]"AWSコマンドでセッションを実行します。
aws ssm start-session --target instance-idLinuxインスタンスでは
sh、WindowsインスタンスではPowerShellに接続されることを確認出来たら、exitでセッションを終了します。AWSの管理コンソールで、Systems Managerのセッションマネージャーを開き、セッション履歴を確認します。このセッションもセッション履歴が残されており、操作内容がS3およびCloudWatch Logsに記録されていることを確認します。
ポート転送によるRDP接続
AWS CLIによるポート転送を利用して、セッション経由でRDP接続なども可能です。WindowsインスタンスのインスタンスIDを確認の上、以下を実行します。
aws ssm start-session --target instance-id --document-name AWS-StartPortForwardingSession --parameters "portNumber=3389, localPortNumber=13389“リモートデスクトップ接続を起動し、localhost:13389に接続します。Windowsデスクトップ画面が表示されたら、管理者のID(Administrator)とパスワードでサインインします。
サインインが確認出来たら、RDP接続を切断します。先ほど同様に、セッション履歴を確認します。ポート転送での接続では、セッション(接続)履歴はあるものの、操作内容のS3やCloudWatch Logsへの記録はされていません。
まとめ
ここまでの手順を試してみることで、EC2インスタンスのOSへの操作には、インターネット経由または踏み台サーバー経由のssh/RDPの代わりに、Systtems Managerのセッションを使うという選択肢があることが実感できるかと思います。
この方式は、操作内容などの記録も取れること、インターネットへのアクセスをもたないEC2インスタンスにも適用できることなどがメリットになりそうです。一方で、Managed Instanceとして正しく構成できていること、接続が対象のEC2インスタンスのOS上でSSMエージェントが動作している間に限られることなどがデメリット、ないしリスクとなりそうです。つまり、トラブルシュートのタイミングではつながらない可能性が考えられれます。また実環境に適用する上では、セッションを利用できる人とS3等に残されるセッション記録を操作できる人を分ける権限構成など、まだ考慮したいことがあります。
こうした検討にも、試行環境のつくり方として役立てば幸いです。
参考情報
各手順は主に以下のドキュメントを元にしました。
- AWS Systems Manager のセットアップ - AWS Systems Manager
- ステップ 4: Systems Manager の IAM インスタンスプロファイルの作成 - AWS Systems Manager
- ステップ 5: IAM インスタンスプロファイルを Amazon EC2 インスタンスにアタッチする - AWS Systems Manager
- ステップ 6: (オプション) プライベートクラウドエンドポントの作成 - AWS Systems Manager
- Windows インスタンスで SSM エージェント をインストールし設定する - AWS Systems Manager
- Amazon EC2 Linux インスタンスで SSM エージェント をインストールし設定する - AWS Systems Manager
- SSH を使用した Linux インスタンスへの接続 - Amazon Elastic Compute Cloud
- Windows インスタンスへの接続 - Amazon Elastic Compute Cloud
- AWS CLI バージョン 2 のインストール - AWS Command Line Interface
- (オプション) AWS CLI 用の Session Manager Plugin をインストールする - AWS Systems Manager
- AWS CLI の設定 - AWS Command Line Interface
私自身の試行では、以下も参考にしました(JAWS DAYS 2019および2020のセッションが試行の動機でした)。
- 1日でSSHをやめることができた話 ~AWS Systems Manager Session Manager 導入と運用Tips~ | JAWS DAYS 2019
- AWS Systems Manager Session ManagerとIAMでシンプルにユーザーを管理する | JAWS DAYS 2020
- 20180725 AWS Black Belt Online Seminar AWS Systems Manager
本ページ内容は筆者が参照の便のためにある時点でまとめた個人的なメモです。内容を保証するものではなく、また筆者の所属組織等とは一切かかわりがありません。


- 投稿日:2020-04-03T18:10:46+09:00
AWSセキュリティ・サバイバルガイド2020
はじめに
こんにちは。@dcm_chidaです。
在宅勤務もついに2ヶ月目に突入しました。朝はコーヒー、夜はビールの毎日です。そんなある日の業務後、社内チャットにて突然こんな報告が…
後輩社員?♂️ > 在宅勤務でアレ1だったので、先程Qiitaに記事を投稿しました。
ムムッ!なかなかやりおる… これは負けてられん!
というわけで「在宅勤務でアレだったのでカレンダー」2日目でございます。
やったこと
- NISTのセキュリティフレームワークに沿ってAWSセキュリティTODOリストを考えてみた
- AWSマネージドサービスを駆使して
防御→検知→対応の処理フローを設計する対象とする人
- AWSチョットワカル人(基本的な用語がわかればヨシ!)
- セキュリティの雰囲気を何となく理解したい人
- 在宅勤務でアレな人
AWSセキュリティの第一歩
よし、じゃあ早速セキュリティ対策していくぞぉぉーー!
…と言いたいところですが、何の根拠もなく手当たり次第にオレオレ対策をしていくのはよくないです。どこかで設定の抜け漏れが発生してしまう可能性があります。
こういう時は何かのフレームワークに基づいて対策を考えるのがベターです。
AWSでは2019年1月に「NIST サイバーセキュリティフレームワーク (CSF): AWS クラウドにおける NIST CSF への準拠」というホワイトペーパーを発表しています。これを読みましょう。
NISTは米国の歴史ある研究機関であり、情報セキュリティに関する様々なガイドラインや管理策などを作成しています。NISTサイバーセキュリティフレームワークもその一つです。
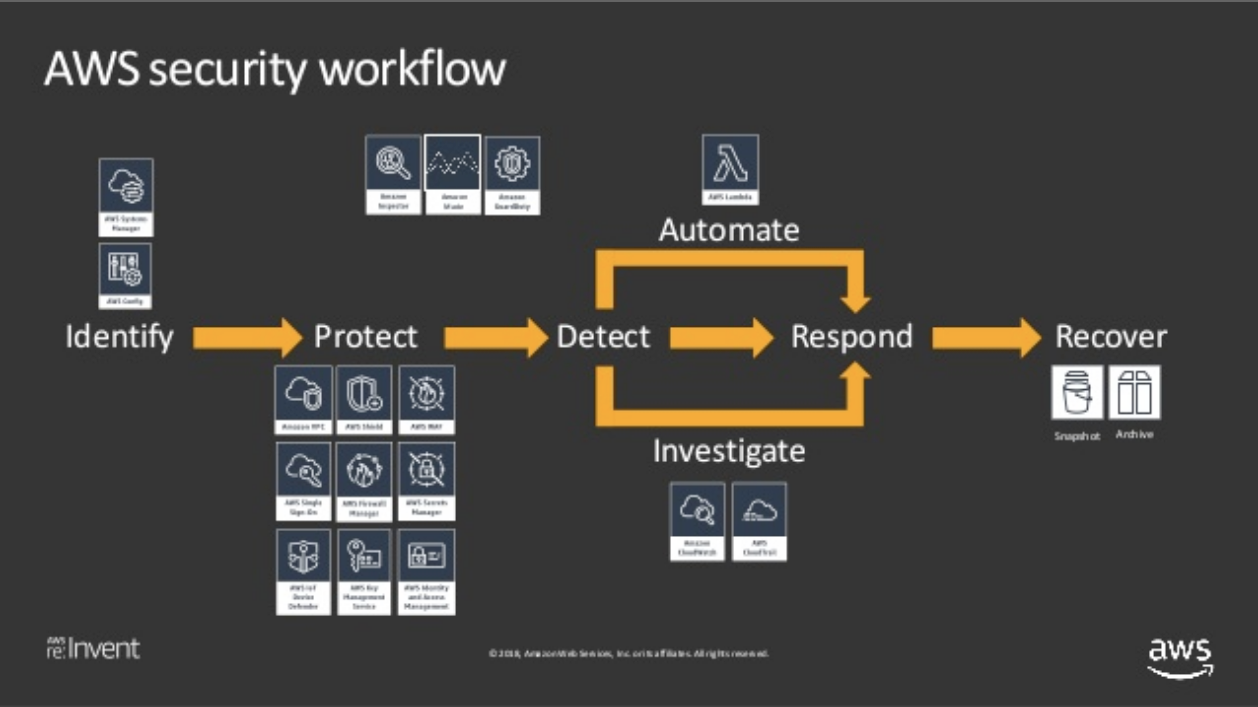
CSFでは下記5つの機能を中心として、実施すべき重点対策をまとめています。2
機能 内容 Identify(識別) 組織としてのセキュリティポリシー策定、リスク評価・管理など Protect(防御) アクセス制御、データ暗号化など Detect(検知) モニタリング、異常検知など Respond(対応) 被害最小化、原因分析など Recover(復旧) 再発防止、復旧方法など AWSのセキュリティのブログや発表資料などをみると、このフレームワークに沿って説明しているモノがあります。特にセキュリティオートメーションの文脈ではよく出てきます。
Introduction to AWS Security Hub (SEC397) - AWS re:Invent 2018 より抜粋このフレームワークの大きな特徴は「インシデントを未然に防ぐためにどうすべきか(事前対応)」だけでなく、「インシデントが発生した後にどうすべきか(事後対応)」まで考慮されているという点です。
もちろん未然に防ぐことが出来るならそれが一番いいのですが、
AWSでは新機能が毎週のようにリリースされるし…
リソースや設定は流動的に変更されるし…
多くのOSSやサービスが複雑に関わり合って構成されているし…セキュリティインシデントを100%防ぐなんて、(AWS完全に理解したという超人でもなければ)誰にも保証できません。
ならばっ!!
インシデントが発生すると想定して対策を打つまでっ!!…という心意気が大事です。
それではこのフレームワークをベースにしてAWSのセキュリティ対策をまとめていきます。
AWSセキュリティ・サバイバルガイド2020
本記事でこれから紹介していく項目を先にリストアップしておきます。
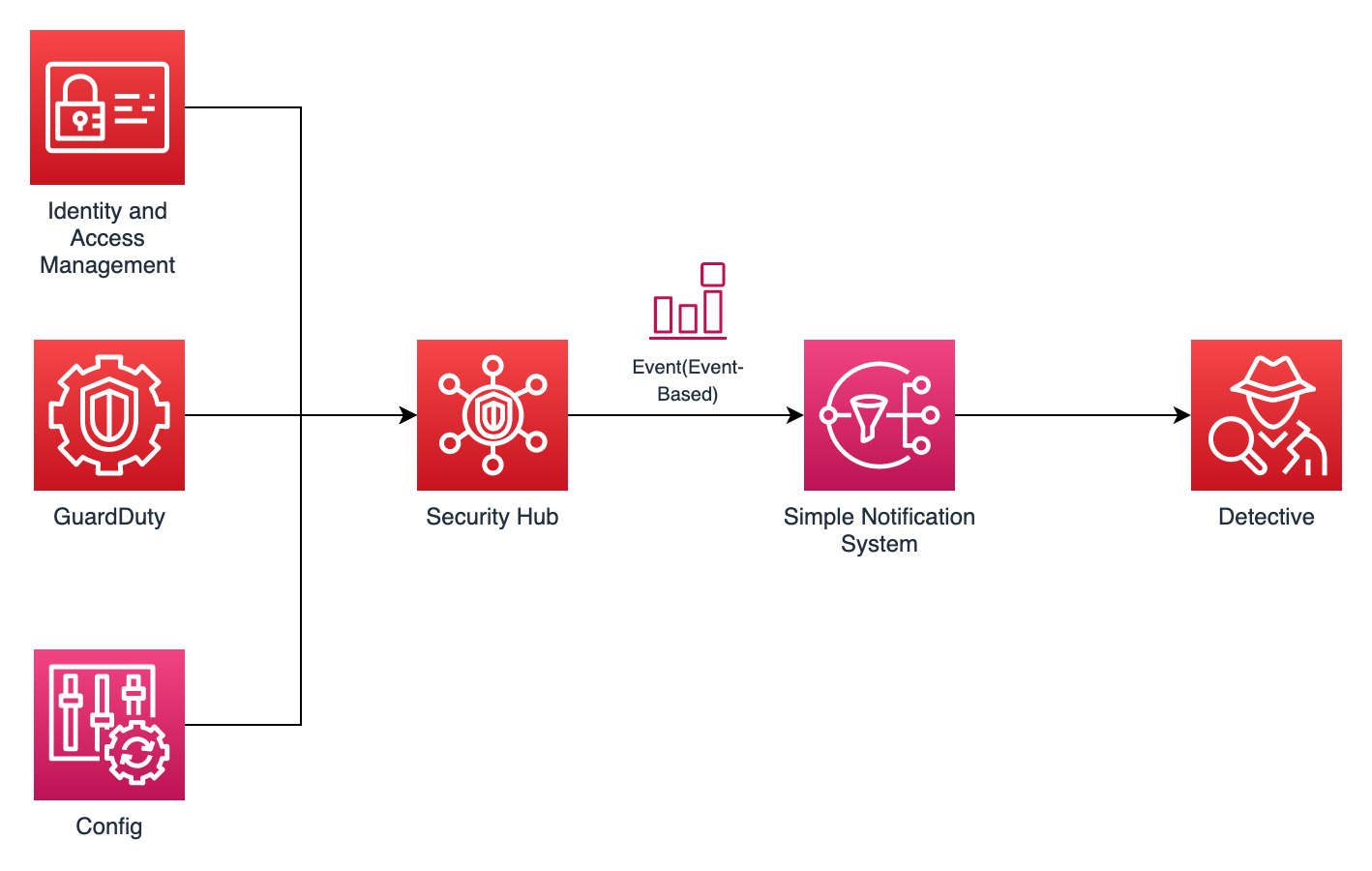
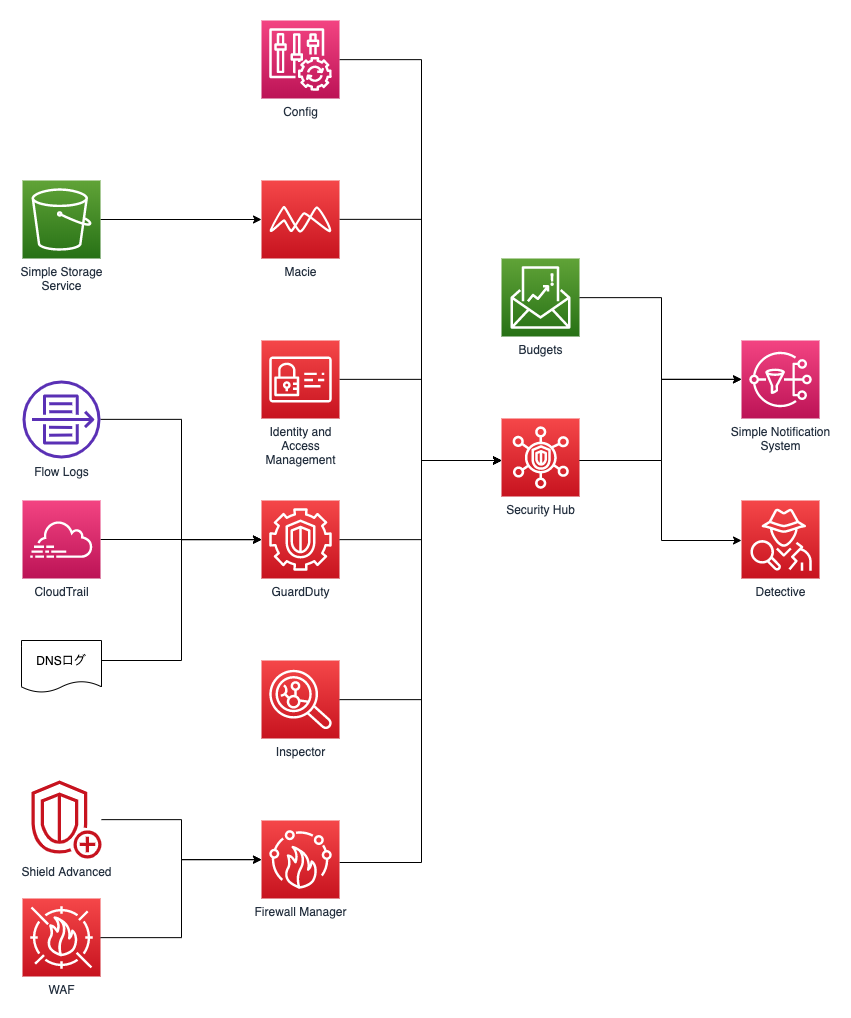
【識別】 ✔️ アカウント登録情報の最新化 ✔️ 予算の設定 ✔️ Configの有効化 【防御】 ✔️ IAMアクセスアナライザーの有効化 【検知】 ✔️ GuardDutyの有効化 ✔️ SecurityHubの有効化 【対応】 ✔️ Detectiveの有効化 【復旧】 ✔️ バックアップの取得設定こんな感じ↓のパイプラインをイメージしてください。
※ CloudTrailやCloudWatch Eventの設定は既に設定している前提です。
もちろんこれで完璧とはなりません。
ここで紹介するのは必要最低限なセキュリティ対策です。実装や設計に依存する物(コンテナやアプリケーションレベルの対策)は今回は扱いません。AWSではCloudWatchLogsやWAFなどセキュリティ関連のサービスはたくさんあるので、自分のアカウントの利用目的に応じて対策方法を拡充してください。
最近のAWSのセキュリティサービスはSecurityHubを基点にしていく傾向があります。
実際、DetectiveやIAMアクセスアナライザーは去年末に発表されたばかりのサービスです。特にDetectiveは大きなアップデートです。これで防御→検知→分析というフローが構築できます。今後出てくる新しいサービスもSecurityHubに統合される可能性が高いでしょう。
このようにSecurityHubを中心としてセキュリティ対策を講じていけば、自ずとNISTのフレームワークに沿っていくはず。
AWSのセキュリティを雰囲気で理解しているみなさん。いいですか。
パブリッククラウドが当たり前となった今、AWSは攻撃者の格好のターゲットとなっています。
このAWSという戦場で生き抜くためにやるべきことはただ一つ。
SecurityHubという防衛拠点を設立し、セキュリティの指揮・統制経路を確保するのです!!
それではNISTのCAFの5機能に沿ってポイントをおさえていきます。
識別 (Identify)
- 資産管理(ID.AM)
- 組織のビジネス目的達成を可能にするデータ、要員、デバイス、システム、施設を、ビジネス上の目標および組織のリスク戦略から見た相対的な重要度と矛盾しない形で識別し、管理します。
- ビジネス環境(ID.BE)
- 組織の使命、目標、利害関係者、アクティビティを理解し、優先順位を設定します。この情報は、サイバーセキュリティの役割、責任範囲、リスク管理上の意思決定を通知するために使用します。
- ガバナンス(ID.GV)
- 組織の規制上の要求事項、法的要求事項、リスク上の要求事項、環境上の要求事項、運用上の要求事項が理解されているかどうかを管理および監視し、サイバーセキュリティリスクをシニアマネジメント層に通知するための方針、手順、プロセスです。
- リスク評価(ID.RA)
- 組織の運営(使命、機能、イメージ、社会的評価を含む)、組織の資産、個人に対するサイバーセキュリティリスクを組織が把握することです。
- リスク管理戦略(ID.RM)
- 組織の優先順位、制約、リスク許容度、前提を明確化し、運用リスクに関する意思決定の裏付けとして利用します。
- サプライチェーンリスク管理(ID.SC)
- 組織の優先順位、制約、リスク許容度、前提を明確化し、サプライチェーンリスクの管理に関する意思決定の裏付けとして利用します。組織は、サプライチェーンリスクを識別、評価、管理するためのプロセスを確立し、導入しています。
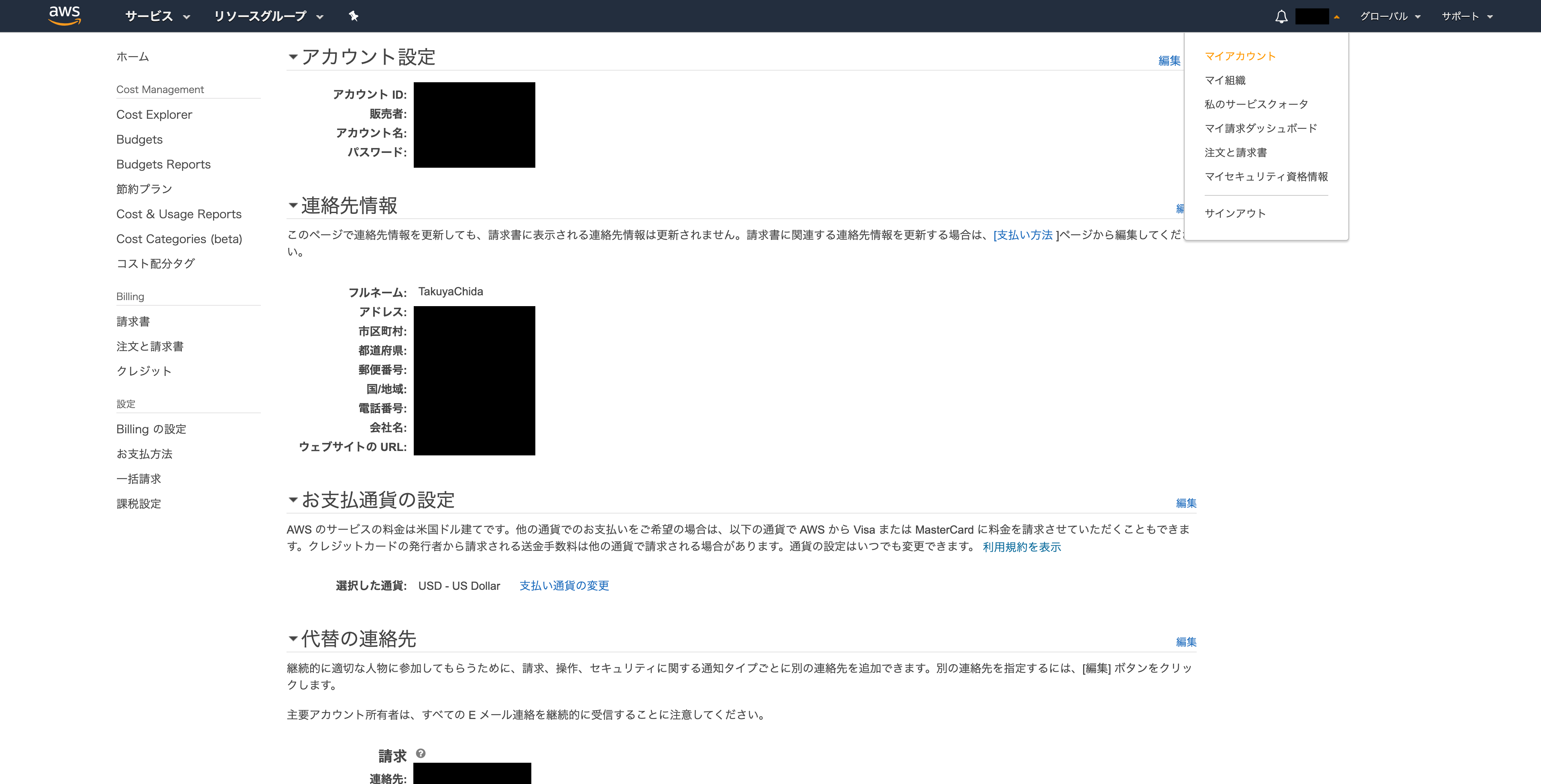
■ アカウント登録情報の最新化
全てのアカウントで実施すべきなのがアカウント登録情報の最新化です。
今の時代、もはやパブリッククラウドは当然のものとして定着しています。
そうなると「AWS、もうだいぶ長いこと使ってるなぁ〜いつから使ってるんだっけ?」という方がソコソコいるはずです。
ちょっとWait!
前任者からアカウントを引き継いだけど、メールアドレスが古いまま放置されている!
そういえば最初AWSとかよくわからなかったから、適当に捨てアドで登録したような気がする!
なんてことありませんか?
いざインシデントが発生した場合、AWS側からのアラートは登録してあるメールアドレスに飛んできます。もしメールアドレスが有効でないと、この第一報に気づくことが出来ません。個人で使っている方も「普段使ってないアドレスで登録してた」ということのないように再確認しましょう。
アカウント情報はルートユーザーでログイン後右上の「マイアカウント」の項目から確認可能です。
■ Configの有効化
AWS ConfigはEC2インスタンスやIAMユーザなどのAWSリソースの設定や変更を記録できるサービスです。あらかじめルールを設定して、それに違反しているかどうかをチェックすることが可能です。AWS提供のマネージドルールやLambda関数で自作したカスタムルールなどが利用可能です。マネージドルールは83個もあってかなり多いのですが、全てを有効化する必要はありません。3
AWS Config マネージドルールのリスト - AWS Config
オススメルールを抜粋しておきます。
ルール名称 内容 cloudtrail-enabled CloudTrailが有効になっているかどうか vpc-flow-logs-enabled - AWS Config VPCフローログが有効化されているかどうか guardduty-enabled-centralized GuardDutyが有効化されているかどうか root-account-mfa-enabled ルートユーザーのMFAが有効化されているか iam-root-access-key-check ルートユーザーアクセスキーが生成されていないか s3-account-level-public-access-blocks アカウントレベルでS3のパブリックアクセスがブロックされているか desired-instance-type EC2インスタンスのタイプが指定したものであるか restricted-ssh - AWS Config SSH通信がセキュリティグループでIPアドレス制限されているかどうか SNSトピックの設定も出来ます。予めセキュリティ関連の通知用のSNSトピックを作成しておくと、他でも使い回しができて便利です。
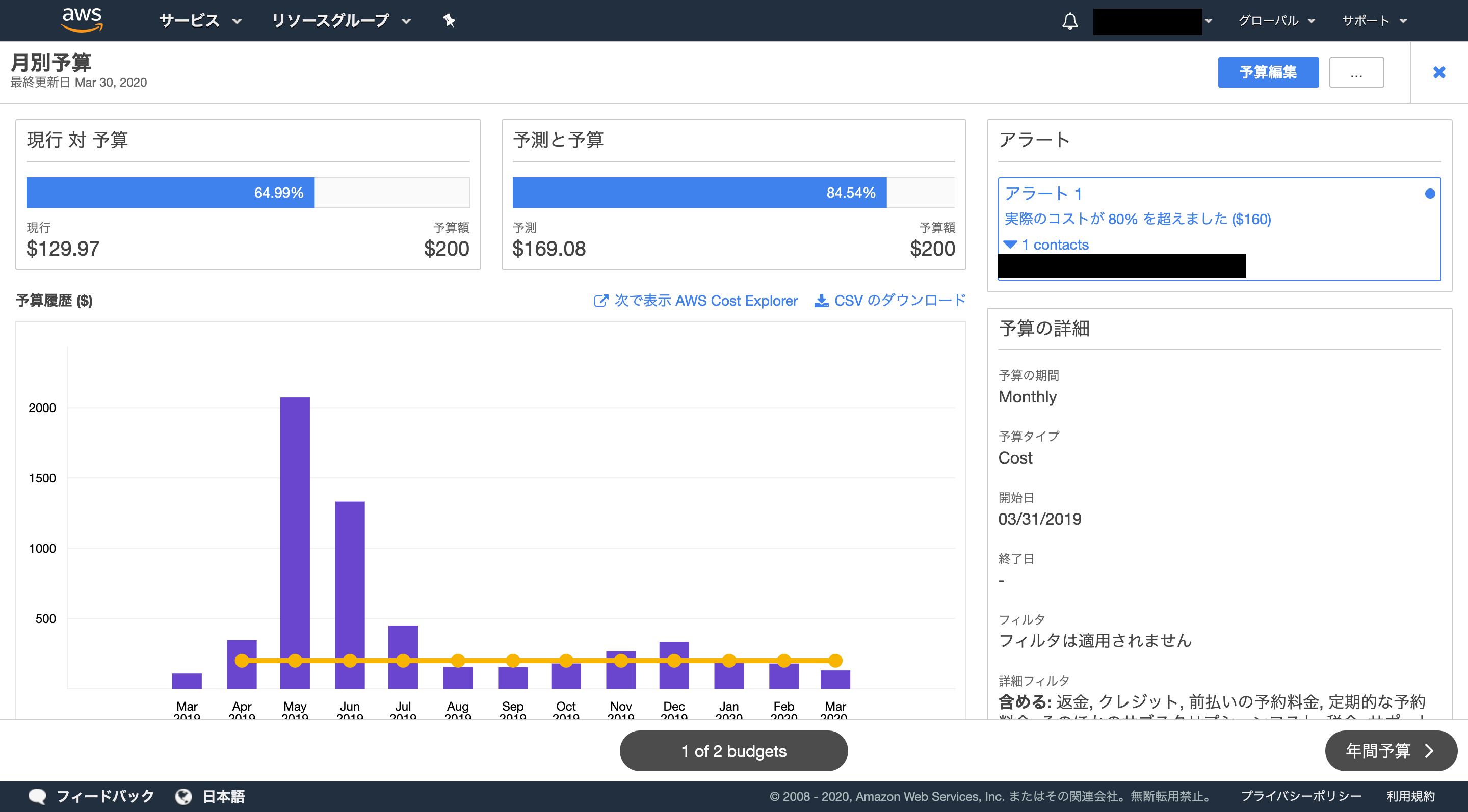
■ 予算の設定
AWSセキュリティ対策として意外に有効なのがコストを監視することです。
インスタンスが乗っ取られてGPUインスタンスで仮想通貨マイニングされた!
重要なDBが全部削除されている!こういう場合、コストを監視していれば一撃です。
AWS Budgetsという機能で予算管理ができるので有効化しておきましょう。ダッシュボードの作成やアラートなども設定可能です。
※5~6月でコストが急騰していますが、これは諸事情によりGPUインスタンスをぶん回しまくった結果によるものです。攻撃ではありません。
防御 (Protect)
- アイデンティティ管理とアクセス制御(PR.AC)
- 物理的な資産と論理的な資産、関連施設にアクセスできるのは正当な権限のあるユーザー、プロセス、デバイスのみに限定され、正当な権限のあるアクティビティやトランザクションへの不正アクセスに関して想定されている、評価済みのリスクに矛盾しない形で管理されている。
- 意識向上およびトレーニング(PR.AT)
- 組織の要員およびパートナーに対して、サイバーセキュリティに関する意識教育が提供され、関連する方針、手順、取り決めに従ってサイバーセキュリティ関連の義務および責任を果たすためのトレーニングが実施されている。
- データセキュリティ(PR.DS)
- 情報およびレコード (データ) が組織のリスク戦略に従って管理され、情報の機密性、完全性、可用性が保護されている。
- 情報を保護するためのプロセスおよび手順(PR.IP)
- セキュリティ方針 (目的、範囲、役割、責任、経営者のコミットメント、組織間の連携を取り扱ったもの)、プロセス、手順が維持管理され、情報システムと資産の保護を管理するために利用されている。
- 保守(PR.MA)
- 工業用制御システムと情報システムを構成している要素の保守および修理が、方針および手順に従って実施されている。
- 保護技術(PR.PT)
- システムと資産のセキュリティおよびレジリエンスを確保するために、関連する方針、手順、取り決めに従って技術的なセキュリティソリューションが管理されている。
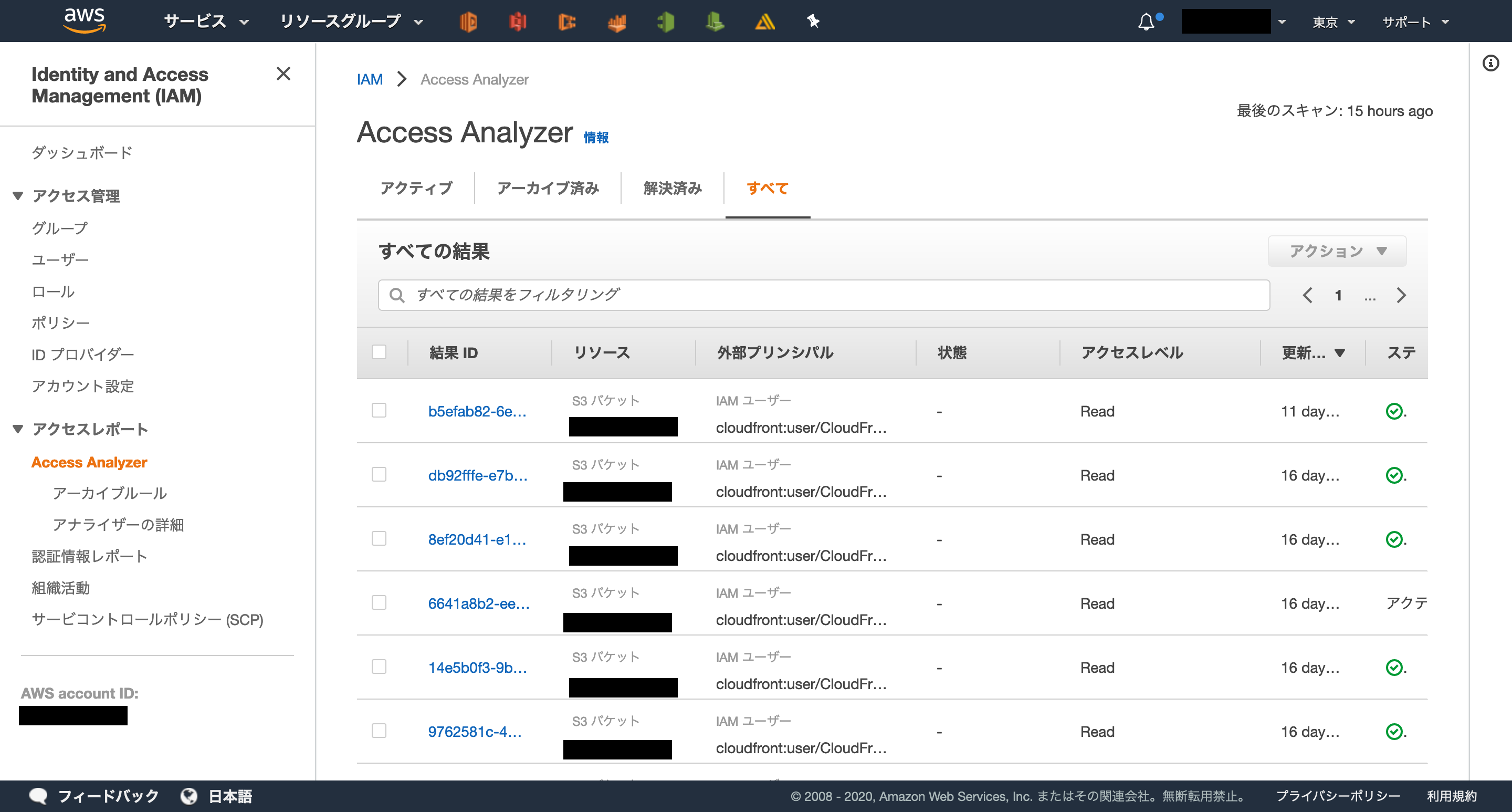
■ IAMアクセスアナライザーの利用
これはオススメなので必ず有効化しましょう。お金もほとんどかかりません。
IAMアクセスアナライザーを導入すれば、S3やIAMロールなどのポリシーをチェックして、外部からアクセス可能かどうかを検知してくれます。もし意図しない公開設定や権限付与があれば、検知結果からすぐに確認可能です。
ここら辺のポリシーチェックは人間のやる作業ではないので、こうしたツールが提供されるのは非常にありがたいです。S3の部分だけを切り出したS3アクセスアナライザーというものもあります。
検知 (Detect)
- 異常とイベント(DE.AE)
- 異常なアクティビティを的確なタイミングで検知し、当該のイベントが及ぼす潜在的な影響を把握する。
- セキュリティの継続的なモニタリング(DE.CM)
- 情報システムと情報資産を別個の間隔で監視して、サイバーセキュリティイベントを洗い出し、保護手段の有効性を検証する。
- 検知プロセス(DE.DP)
- 異常なイベントがタイムリーかつ適切に認識されるように、検知のプロセスおよび手順を維持管理し、検査する。
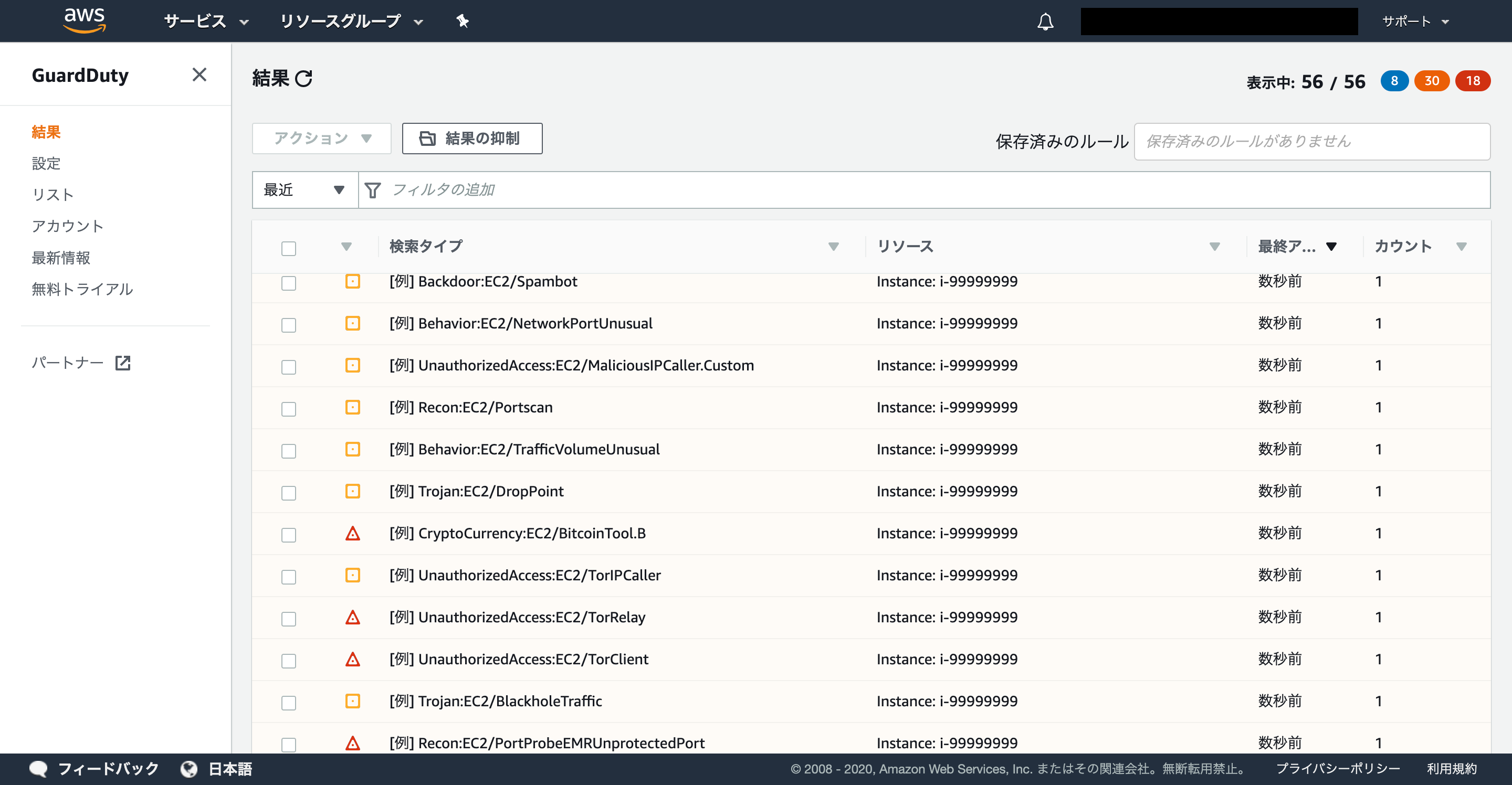
検知のフェーズではGuardDutyとSecurityHubの二つが鉄強コンボです。どちらも有効化しておきましょう。
■ GuardDutyの有効化
GuardDutyはCloudTrail/VPCフローログ/DNSクエリログなどのログを対象に自動的に脅威を検出するサービスです。
CloudTrailなどのログ収集設定は事前に設定しておく必要があります。
※GuardDuty自体を有効化してもその他のログ機能が有効化されるわけではありません!不審なコンソールログイン4やポートスキャンなどを検知してくれます。
■ SecurityHubの有効化
SecuirtyHubではセキュリティ検知結果やコンプライアンス状態をダッシュボードで一覧表示することが出来ます。
ここまで紹介した以下のサービスの検知結果は全てSecurityHubに集約可能です。
- Config
- IAMアクセスアナライザー
- GuardDuty
また、それら検知結果に応じて「Lambda関数での自動修復」や後述の「Detectiveによる詳細調査」なども可能です。
CIS提供のAWSセキュリティ対策基準(CIS Amazon Web Services Benchmarks)によるセキュリティチェックも可能です。ただし、これもConfigのマネージドルールと同様、オールグリーンにするのは難しいので必要なものだけ有効化しましょう。
余力があれば、カスタムアクションで
CloudWatchEvent→SNS (AWS chatbot)→メールorチャットへ通知という設定までしておくべきですが、長くなるのでここはまた別の機会にします。
SecurityHubを完全体まで進化させると、以下のような構成をとることができます。
AWSのセキュリティサービスの検知結果をGuardDuty等からSecurityHubへ集約、異常があればSNSで通知、必要に応じてDetectiveで調査。こんな感じです。
流石に全部有効化する必要はありませんが、GuardDuty → SecurityHub → DetectiveのフローはAWSに関わる全ての人間にオススメです。
対応 (Respond)
- 対応計画(RS.RP)
- 検知されたサイバーセキュリティイベントにタイムリーかつ確実に対応できるよう、対応のプロセスおよび手順を実践し、維持管理する。
- コミュニケーション(RS.CO)
- 該当する場合に、司法当局による外部からの支援を含めるよう、社内および外部の利害関係者と対応アクティビティについて協議する。
- 分析(RS.AN)
- 十分な対応の保証および復旧アクティビティの支援に向けて、分析を実施する。
- 低減(RS.MI)
- イベントの拡大阻止、影響の低減、インシデントの除去に向けたアクティビティを実施する。
- 改善(RS.IM)
- これまでの検知/対応アクティビティから得られた教訓を採り入れて、組織の対応アクティビティを改善する。
■ Detectiveの有効化
「分析」を行う際に最高のサービスがあります。
AWS Detectiveです。2020/03/31にGAになりました!
プレビュー版を少し使ってみた所感だと、いざと言うときかなり期待できそうです。
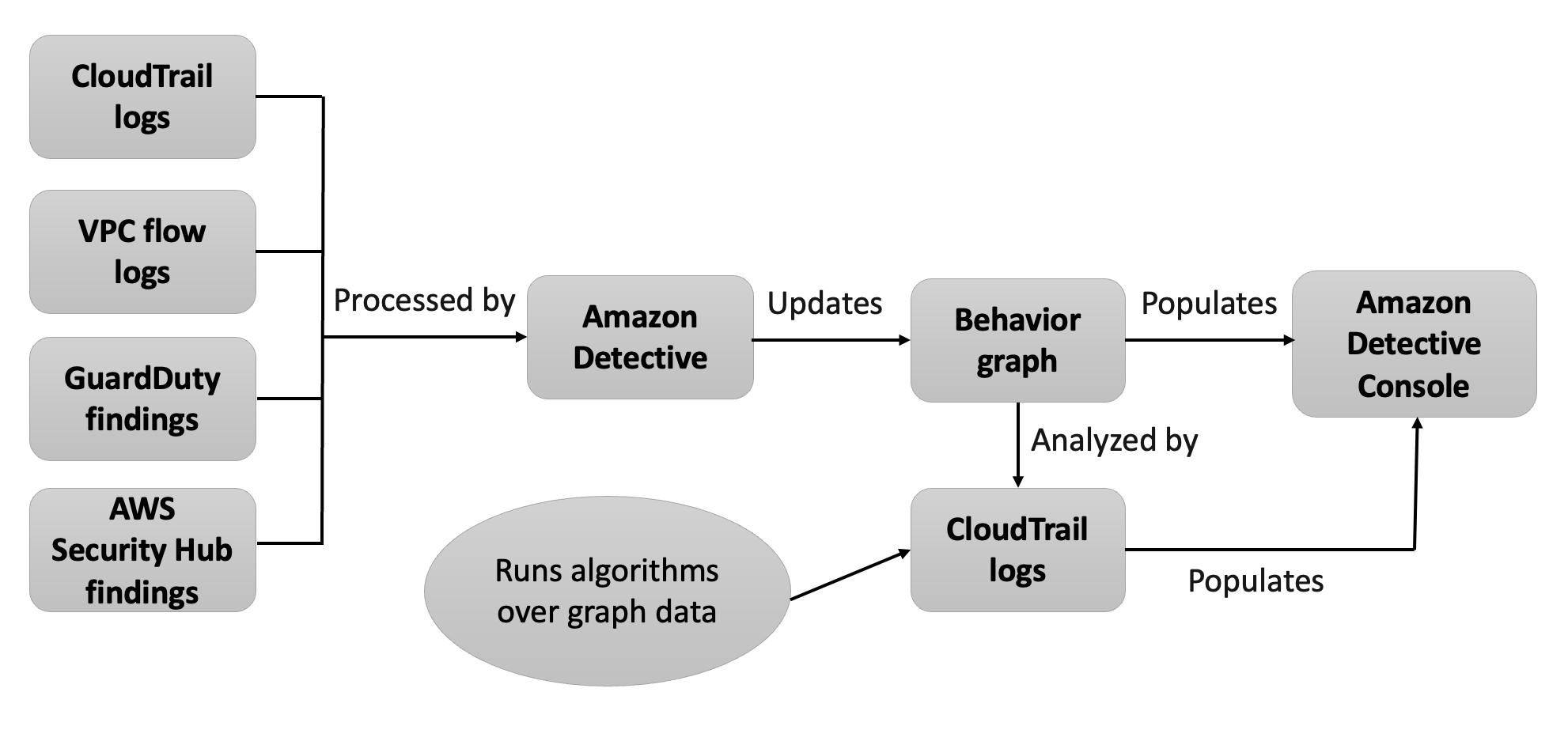
DetectiveではCloudTrail/VPCフローログ/GuardDutyの検知結果から、関連するリソースやアクセス履歴などをグラフ分析によって処理します。イメージとしてはGuardDutyの検知結果の原因分析をするようなイメージです。5
※ 有効化してから実際に使えるようになるまで2週間近くかかります。
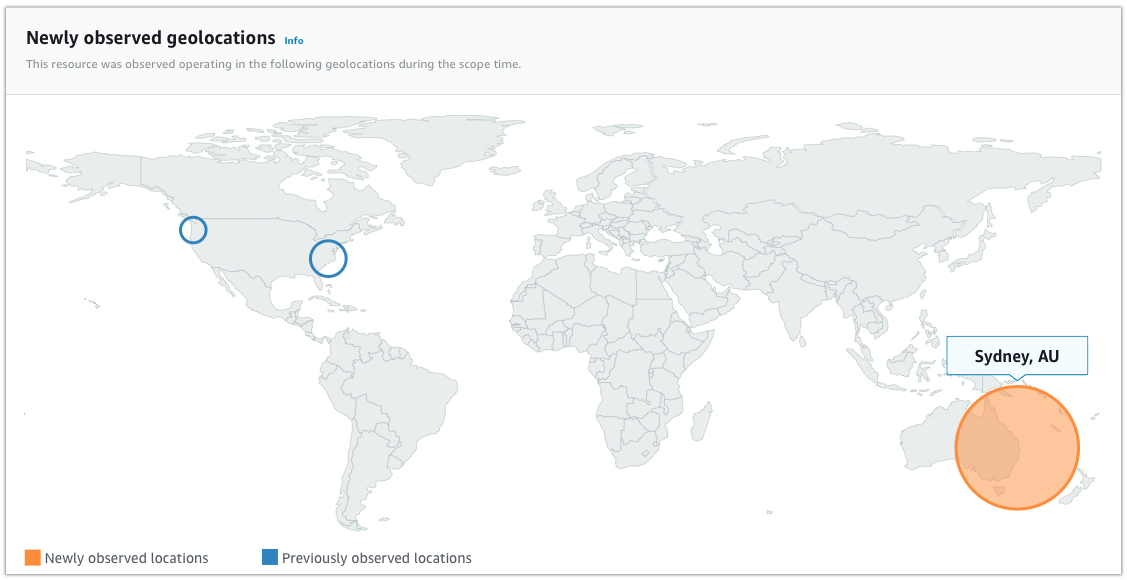
ソースIPアドレスから接続元エリアを可視化するのも自動でやってくれます。
現時点ではDetectiveは下記のタイプで絞り込み検索が可能です。
- GuardDuty Findings
- AWSアカウント(12桁の数字)
- EC2インスタンス
- IPアドレス
- IAMロール
- IAMユーザ
- UserAgent
IAMユーザごとの振る舞い分析も可能なので、内部犯行やアカウント乗っ取りなどの調査もできるはずです。
まさに探偵ですね!真実はいつもひとつ!
復旧 (Recover)
- 復旧計画(RC.RP)
- 復旧のプロセスおよび手順を実践し、維持管理して、サイバーセキュリティイベントの影響を受けたシステムまたは資産をタイムリーかつ確実に復旧する。
- 改善(RC.IM)
- 得られた教訓を以後のアクティビティに採り入れて、復旧の計画およびプロセスを改善する。
- コミュニケーション(RC.CO)
- 復旧のアクティビティについて、コーディネートセンター、インターネットサービスプロバイダ、攻撃側システムの所有者、被害者、他のCSIRT、ベンダーなど、社内および外部の当事者と協議する。
■ バックアップの取得設定
インシデントが発生時の最悪の場合として、全てのリソースが消されていると言う事態6が想定されます。
全てのAWSリソースのバックアップを取得・管理するのは難しいですが、下記のような対策が挙げられます。
- CloudFormation/SAM/CDKなどによるインフラ管理
- AWS Backupによるバックアップ作成
S3バケット内のオブジェクトは特定期間削除できないようにロックすることが可能です。各種バックアップファイルはS3ファイルなどに格納されることが多いと思いますが、ロックをかけないと攻撃者から削除されてしまう可能性があるので注意してください。別のアカウントやローカル保存でも対応可能です。
おわりに
実は在宅勤務期間を利用してAWSセキュリティの社内向けポータルサイトを作成していました。7
本記事の内容はこのポータルサイトの一部です。在宅勤務で生産性がスーパーサイヤ人だったので、予備知識0の状態から二週間くらいで出来ました。
以上、在宅勤務民によるポエムでした。
参考
AWS クラウドにおける NIST サイバーセキュリティフレームワークへの準拠 – 日本語のホワイトペーパーを公開しました | Amazon Web Services ブログ
[神ツール]セキュリティインシデントの調査が捗るAmazon DetectiveがGAしたのでメリットとオススメの使い方を紹介します | Developers.IO
”アレ”とは… おそらく在宅勤務が生産性が限界突破してアウトプットが溢れ出してしまったのだろう。わかる。 ↩
5つのコア機能の他にもティア、プロファイルなどの要素があります。 ↩
ルールをたくさん設定するとそれだけお金もかかります。 ↩
最近ほとんどの社員が在宅勤務になったため、「不審なコンソールログイン」の検知結果が大量に上がってきます!GuardDutyすごい! ↩
GuardDutyは誤検知が多いため、結果を分析するツールに対するニーズが高かったのでしょう。 ↩
HugoとCodePipeline+ECSで作成しています。ここらへんの内容もQiitaにまとめておこうと思いましたが、いつかまた在宅ハイになった時に… ↩

- 投稿日:2020-04-03T15:44:15+09:00
AWS Docs の単語を TensorFlow projector で可視化してみた
AWSは自身のサービスドキュメントをOSSで公開しています。github/awsdocs
自社のメイン商材がAWSであることもあって、このドキュメントの情報は利用価値が高いと以前から注目しておりました。今回はこのドキュメントを利用したQA Botなど、応用タスクの元となるコーパス構築を主目的とした埋め込み表現の獲得を行いました。
awsdocsに含まれる全てのレポジトリに含まれる段落要素からごく簡単な(ストップワード除去を伴う)形態素解析を実行し、抽出した単語から単語埋め込み表現(分散表現とも呼ばれたりするアレです)を獲得、可視化してみました。
抽出した結果は今ひとつなんですがとりあえずキリのよいところまで来たのでごく簡単にレポートしてみます。
成果物
こちら https://projector.tensorflow.org
単語埋め込み表現のデータとして使用したのはこちら。
一例としてgifアニメーションとして録画したやつがあります。140MBくらいあるのでこの場で表示させるのは差し控えますが、こちらも合わせてシェアします。
awsdocs-embedding-projecter.gif
やったこと
まずはデータ抽出
- github/awsdocs の全てのレポジトリをclone
- レポジトリごとに繰り返す:
- レポジトリに含まれる全てのmarkdownを抽出
- "markdown" と "BeautifulSoup" を用いてパラグラフ要素のみを抽出
- パラグラフ要素のテキストをnltkを使って単語分割
- markdownのファイル名ごとでラベル付けして単語リストからなる「ドキュメント」を生成
次に、jupyterを使ってword2vecのモデル構築を行いました。
- gensimを使ってword2vecモデルの構築
- メタデータ(単語ベクトルに対応するラベル)と単語ベクトルを書き出したtsvを生成、S3(website hosting) にデータをアップロード
- TensorFlow word embedding projector の設定ファイルを記述 (project_config.json)
- projector.tensorflow.org に2,3で生成したファイルをアップロードし、設定ファイルを読み込ませる
形態素解析のところを少し補足すると、nltkが持っている標準(?)のストップワード集、およびいくつかの簡単な記号(&など)の除去、あとドキュメントに「数字とコロン」だけからなる文字列が結構抽出されていたでそれらの正規表現、こいつらを全体のストップワードとして除去の対象にしています。
タスクの実現方法・実装に関する情報
シェアできる状態にあるものを追記していきます。
awsdocs 配下のレポジトリを取得
git clone で行いました。レポジトリは多数あるので、それらを全て取得するために簡単なワンライナーを書いて済ませています。
github clone all repositories in organization
あたりで検索するといくつか出てきます。私はこちら を参考にしました。
所感
ぱっとみの所感は結構単語抽出にノイジーなものがたくさんあるなという印象でした。もうちょっとスクリーニングしたい。
ドキュメント自身のメタデータとなる情報もほぼ削ぎ落としているので、そのへんは考慮したいなとも思います。例えばURLのリンク関係なんかは情報量がありそうかつ今回落とした部分なので、グラフ的なアプローチの何かをやるならばそういう情報も必要になってくるのかなと。
次アクションとして以下のようなことを考えています。
- 自社の Tech QAチャンネルのポストに対して、「質問 or 回答かどうか」のフラグや質問トピックのタギングなどのアノテーションを行う
- 生データをそのまま手作業で扱うのは工数と苦痛が半端ないので、アノテーションツールの選定もしくは開発もやる
- 今回作ったawsdocsのコーパスと翻訳APIを使って、Slackの任意のポスト(を英語翻訳して形態素解析したデータ)から、類似度の高いAWSドキュメントを推薦する
- ES使えば機械学習的な要素なしでもできる
- ただしAWSサービスの軸でマッチしてもあまり応用タスクとしての意義は薄そう。問題設定自体がイマイチっぽいのでなにかしら工夫は必要
- (↑は、質問する時点で当事者からすればジャンルは自明であるケースがほとんどと考えられるので)
結局問題設定ありきかなという感じはしています。
さいごに
TenfowBoardクッソ便利ですね。今回も利用しましたが、データをupすれば可視化を公開できるようにWebアプリが公開されていたのが非常に助かりました。可視化にかける時間を大幅に節約できました。本当はローカル環境で可視化やりたいのですが、Projectorのローカルインストールはなんか詰まってしまったのでいったん諦めました。結構頻発している問題のようです。。。TensorFlow自体にも慣れていきたい。
まだ応用タスクの問題設定がはっきり見えてないこともあり、ストップワードの定義や抽出すべき品詞などを含め、どのようこのデータを活用するのかは試行錯誤の余地だらけだと感じます。コーパスの構築が鉄板かなとは思いますがいかんせん応用タスクがまだ定まらないので次はそちらの考察を進めたいですね。
本当は自社Slackのtech QAチャンネルから抽出したデータに対する類似質問(あるいは近しいドキュメントリンク)の提示をやりたいのですが、回答生成に関する理論がまだまったく理解できておらず今後どうしていくかは不明です。
ソースなどは特に公開準備できてません。現時点で公開の目処はないです(できれば整備して公開できたらいいなとは思ってます。。)。
- 投稿日:2020-04-03T15:38:13+09:00
ドメイン取得せずにEC2(Amazon Linux 2)でLet's EncryptのSSL証明書発行したらどうなるか試したらやっぱり失敗する
タイトル通りなんですけど、試してみたらやっぱり発行できないです。
やったことをつらつらと書いていきます。EC2はAmazon Linux 2で立てた
とりあえずEC2サーバを立てました。
OSはAmazon Linux 2です。
セキュリティグループは以下に設定。
certbotを使用するので、ちゃんとHTTP(80)ポート開けてます。
タイプ プロトコル ポート ソース HTTP TCP 80 0.0.0.0/0 SSH TCP 22 {自分のIP} HTTPS TCP 443 0.0.0.0/0 cerbotを使用して証明書発行する
https://certbot.eff.org
cerbotのサイト見るとサーバのソフトウェアとOS選ぶことになるんですけど、OSにはAmazon Linux 2がないわけです。
Amazon Linux 2ってどうすればいいんだと、ここで壁が立ちはだかります。
Amazon Linux 2はRHEL 7ベースらしい
いろいろ調べてみるとRHEL 7ベースらしいです。
Amazon LinuxはRedHat準拠なんですね。
あとで出てきますがcerbotインストールするにはEPELリポジトリを有効化する必要があるのですが、以下をみるとAmazon Linux 2はRHEL 7と同じコマンドみたいです。
https://aws.amazon.com/jp/premiumsupport/knowledge-center/ec2-enable-epel/ソフトウェアはNon of the above、OSはCentOS/RHEL 7で手順を実行する
https://certbot.eff.org/lets-encrypt/centosrhel7-other
この順位従って証明書を発行していきます。SSHログイン
SSHでEC2に接続します。
ログインssh -i {キーペア証明書のパス} ec2-user@{パブリックDNS}EPELリポジトリのインストールと有効化
https://aws.amazon.com/jp/premiumsupport/knowledge-center/ec2-enable-epel/
上記に方法が書いてありましたので以下を実行しました。EPELリポジトリのインストールsudo yum install -y https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm sudo yum-config-manager --enable epelOptionalチャンネルを有効化
Optionalチャンネルを有効化yum-config-manager --enable rhui-REGION-rhel-server-extras rhui-REGION-rhel-server-optionalスタンドアロンで発行
今回はまだサーバ立ててないのでスタンドアロンで発行します。
そして本番環境使用するのも申し訳ないのでLet's Encryptのステージング環境を利用します。
--dry-runとつけるとステージング環境をしようするそうです。証明書を発行sudo certbot certonly --standalone --dry-run Saving debug log to /var/log/letsencrypt/letsencrypt.log Plugins selected: Authenticator standalone, Installer None Please enter in your domain name(s) (comma and/or space separated) (Enter 'c' to cancel):ドメインを聞かれるのでパブリックDNSのドメインを記載しました。
すると以下のエラーが発生しました。エラー発生Obtaining a new certificate An unexpected error occurred: The server will not issue certificates for the identifier :: Error creating new order :: Cannot issue for "xxxxxxxxx.compute.amazonaws.com": The ACME server refuses to issue a certificate for this domain name, because it is forbidden by policy Please see the logfiles in /var/log/letsencrypt for more details.このドメインは発行できないってことみたいです。
ちゃんとしたい場合はドメインを取得しようね
そういうことですね。
ドメインを取得しない場合は素直にオレオレ証明書を発行しようと思います。
またはNode.jsであればHeroku使っちゃえば証明書発行せずにHTTPS使えるのでそっちですね。
- 投稿日:2020-04-03T13:23:36+09:00
Dockerコンテナ上のaws-cli環境でAWS Error Message: Signature expiredが表示されたときの対処方法
はじめに
dockerコンテナ上のaws-cli環境で
aws sts get-caller-identityをしたら、時間がずれてるとおこられたので、また起きた時用メモ。どうしてかわかんないけど、こうなった
① An error occurred
root@xxxxxxx:/home# aws sts get-caller-identity An error occurred (SignatureDoesNotMatch) when calling the GetCallerIdentity dentity operation: Signature expired: 20200323T231737Z is now earlier200324T0 than 20200324T002325Z (20200324T003825Z - 15 min.)② 本当にずれてるのか確認してみる。ちなみにこの時午前10時ちょっと前。
root@xxxxxxx:/home# date Fri Apr 02 23:30:39 UTC 2020③ UTCだとよく分からないからJSTに変えてみる。
root@xxxxxxx:/home# TZ=-9 date '+%a %b %d %H:%M:%S JST %Y' root@xxxxxxx:/home# date Fri Apr 03 08:33:30 JST 2020ずれてた。1時間半も。
修正方法
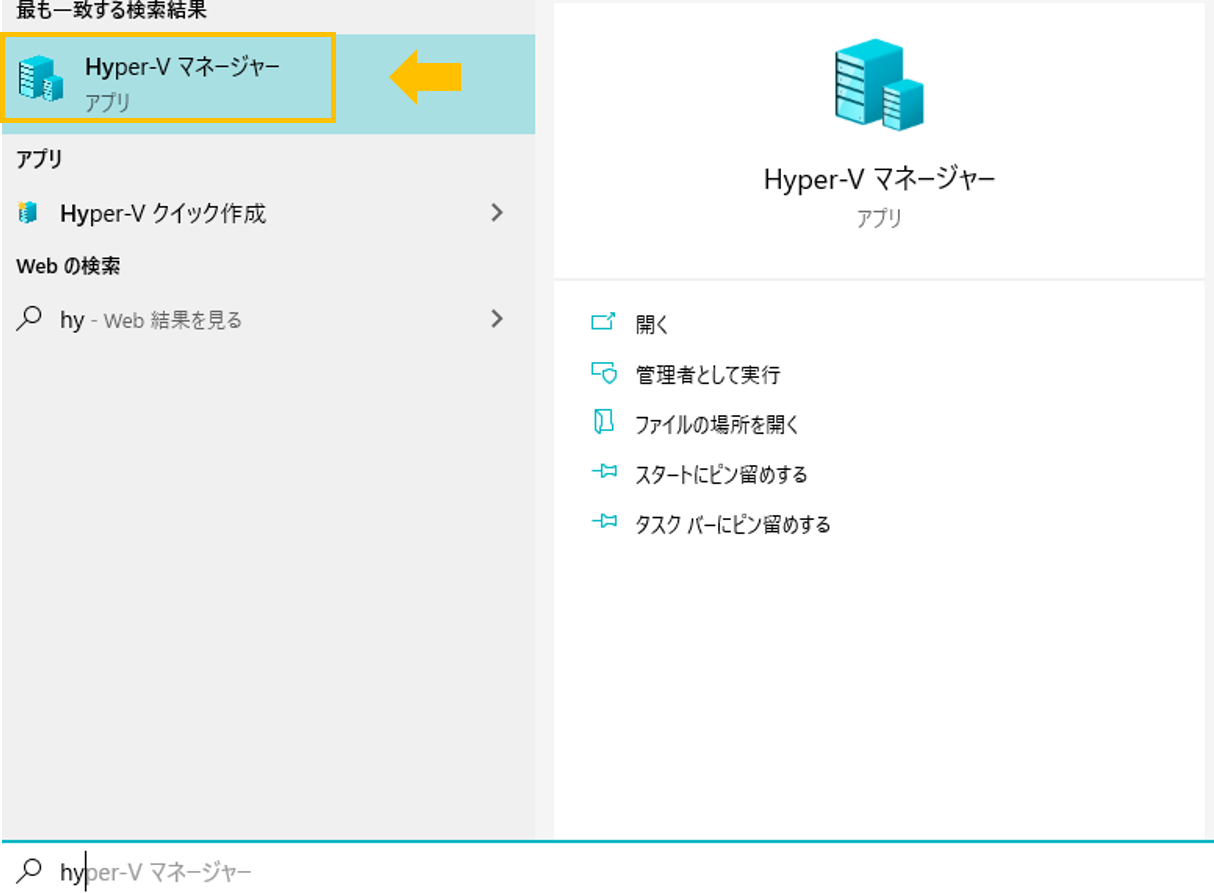
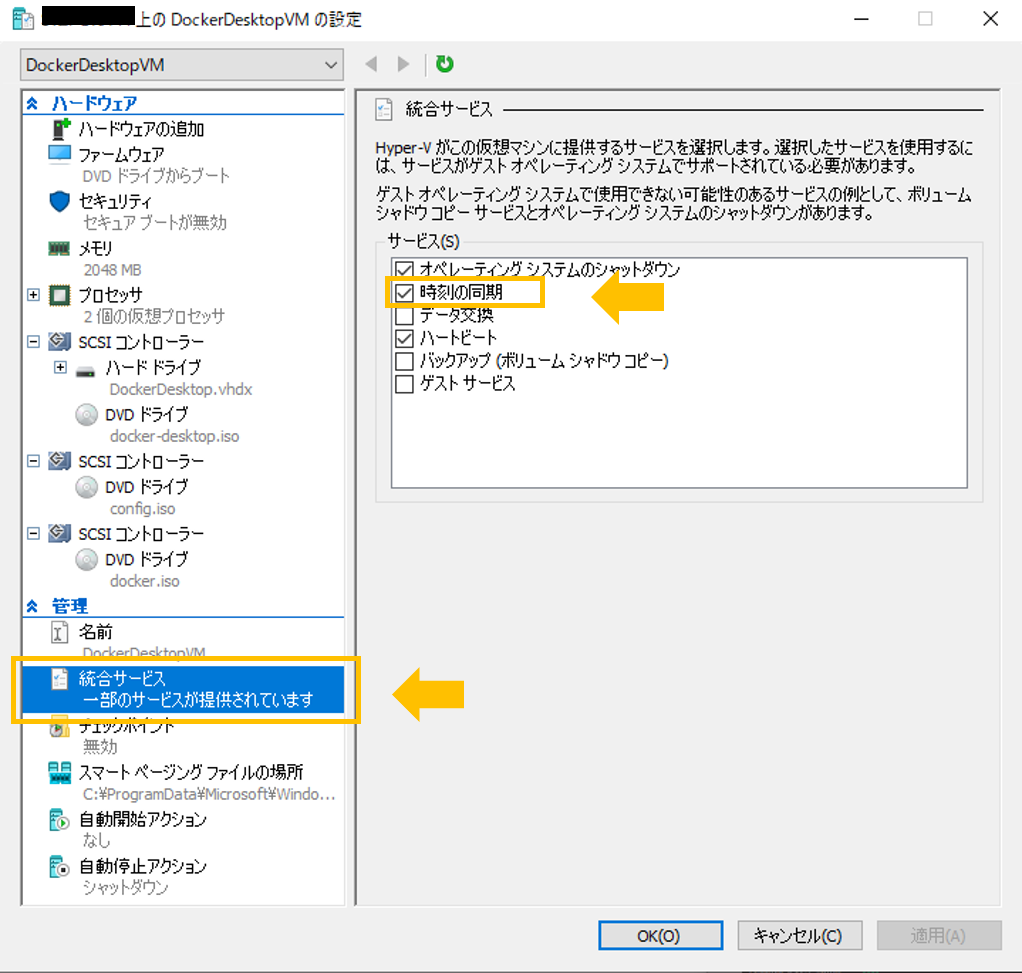
1. 検索ボックスに「Hyper-V マネージャー」を入力して選択。
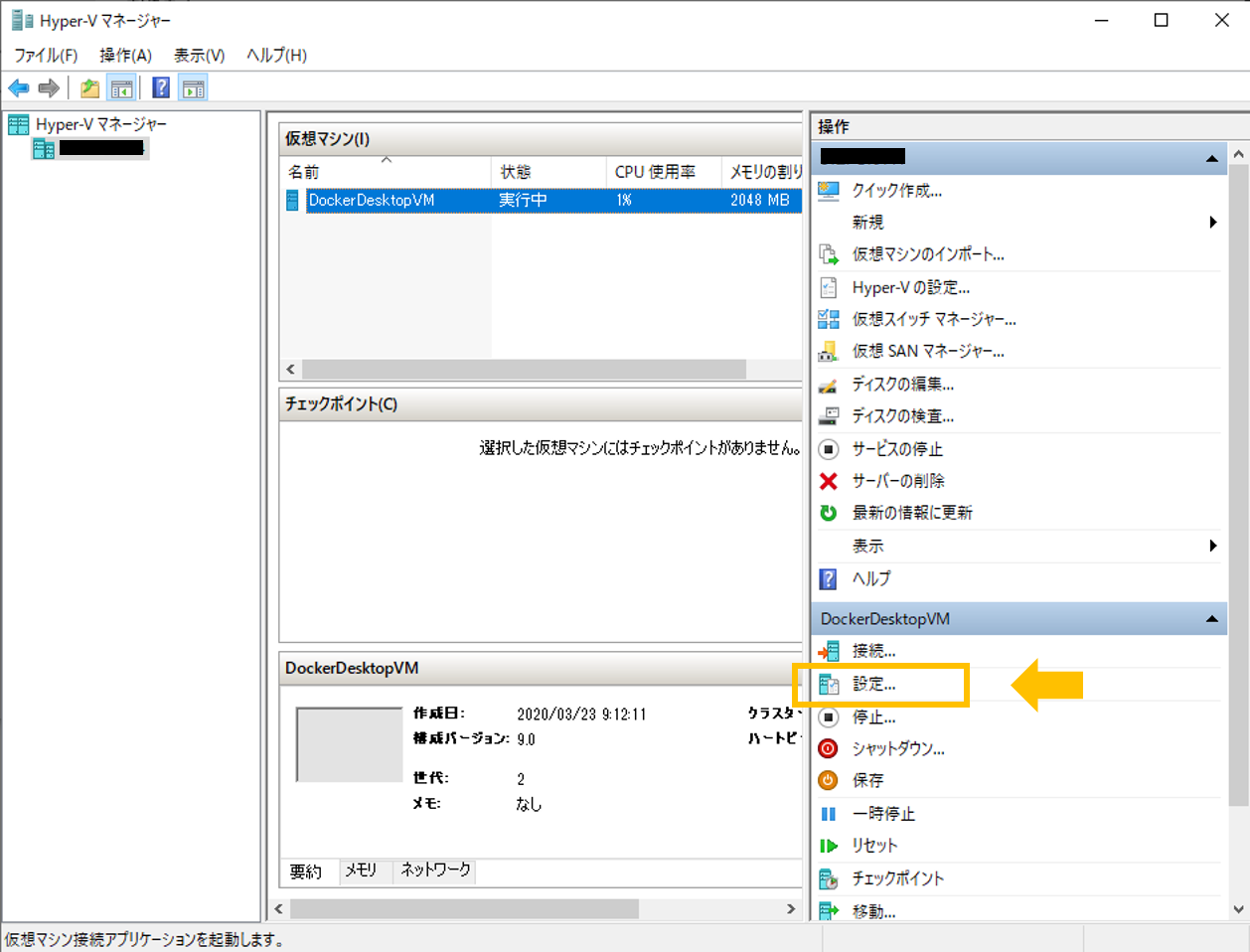
2. DockerDesktop VM の「設定」を選択
3. 管理 の 統合サービスを選択して「時刻の同期」にチェックを入れる。
(※もともとチェックが入っている時は一度外して適用。その後チェックを入れてもう一度適用。)
おわりに
この後、エラーが消えて解決!めでたし!
- 投稿日:2020-04-03T11:10:37+09:00
[AWS]AWS Certified DevOps - Professional に合格しました!イエイ!
はじめに
先日AWS Certified DevOps - Professionalに無事合格でき、AWS認定試験5冠を達成できたので、勉強した内容を共有します。
https://www.certmetrics.com/amazon/public/transcript.aspx?transcript=S02T92E111EQ1VGR
試験については下記のような感じ
AWS 認定 DevOps エンジニア – プロフェッショナル試験は、AWS 環境のプロビジョニング、運用、管理において 2 年以上の経験を持つ、DevOps エンジニア担当者を対象としています 認定によって検証される能力 - AWS で継続的デリバリーのシステムと手法を実装して管理する - セキュリティコントロール、ガバナンスプロセス、コンプライアンス検証を実装し、自動化する - AWS でのモニタリング、メトリクス、ログ記録システムを定義し、デプロイする - 高可用性、スケーラビリティ、自己修復機能を備えたシステムを AWS プラットフォームで実装する - 運用プロセスを自動化するためのツールの設計、管理、維持を行う 推奨される知識と経験 - 1 つ以上のハイレベルプログラム言語でのコード開発の経験 - 高度に自動化されたインフラストラクチャの構築経験 - オペレーティングシステムの管理経験 - 最新の開発および運用のプロセスと方法論に対する理解何故受けたか
- プロ制覇したい欲望に駆られた
- Codeシリーズ、SAMを使用する機会が出てきたため
- ログの分析に興味があり、適切なログ管理方法を学ぶため
勉強内容
- AWS公式トレーニング(無料)
- 一番最初にやるべき、何をどう聞かれるのか理解する(一番参考になる)
- https://www.aws.training/Details/eLearning?id=40664 (問題形式のトレーニング)
- Black Belt
- サービスの最初の理解としてこちらのPDFを読む。感覚で理解できればOK
- よくある質問
- そもそもこのサービスは何の目的で利用するかを理解する
- ユーザガイド
- AWS公式のサービスリファレンス
- 大体ここに書いてあることが試験で聞かれる印象
- 今回試験を受けるにあたり下記サービスについては一通り読んだ
- Code*シリーズ
- Cloudformation
- Elastic Beanstalk
- Opsworks Cloudwatch
- Jonbonseの模擬試験
- JonBonseはUdemy内で最も良い模擬試験作ってる
- 模擬テストが2つあり、解説が丁寧なのでおすすめ!
- 模擬テストをアウトプットの中心にしつつ、ホワイトペーパー・ユーザガイドで知識を補う感じ
- Hands on
- https://www.udemy.com/course/aws-certified-devops-engineer-professional-hands-on/
- 試験範囲を一通りHands on形式で教えてくれる。
- めちゃめちゃ丁寧なので、長い
- 自分の触ったことないサービスや知識が足りない箇所を重点的に勉強した。
- AWSコンソール画面
- 実際のAWSサービスを触ってみてどのようなOptionがあるのか理解した
- 役立ったサイト
- https://jayendrapatil.com/
- AWSの認定資格についてまとめてくれる人のブログ
感想
試験内容が非常に実務に沿っていて、AWSが何を理解してほしいか伝わってきた。
- マルチリージョン・マルチアカウントでの開発
- ログを吐き出してからの挙動と分析
- セキュアなDevOps環境構築方法
- マルチアカウント管理
だいたい上記をしっかり勉強して、ユーザガイド読めば受かる印象でした。
今回点数は860だったので、理解できないことを再度学習し継続的な知識のキャッチアップに努めたい。試験前にチョコラBBハイパーを飲んでおくと、集中が途切れない気がする。

- 投稿日:2020-04-03T06:44:48+09:00
AWSの全体像
AWSとは
AWS(Amazon Web Service)とはAmazonが提供するWEBサービスを構成するためのインフラ系のサービスです。AWS側で世界各地にあるサーバーを仮想化しており、ユーザーはその仮想化されたサーバーをカスタマイズし使用できます。
AWSのメリット
従来のオンプレミスのサーバーと比較して私が思うAWSのメリットは以下です
・料金形態が月ごとのサービス使用量で決まるため料金のため無駄がない
・世界各地にあるデータセンターに分散してデータを保存できるため可用性が高い
・サーバー・DB側の多くをAWS側に任せられる(信頼性)
・管理サービスが充実している(CloudWatch,CloudTrail)
・ユーザー側で自由に設計できるAWSのデメリット
逆にAWSのデメリットは以下だと私は思っています
・サービス多すぎ(数:175以上、設計が大変そう)
・料金形態が月ごとのサービス使用量で決まるため見積もりが難しいAWSの全体像
AWSを理解するには各メインのサービスを理解し、AWSの全体像を把握するのがいいと思う。
各段階ごとに重要度の高いサービスをまとめる。(今後、各サービスに対するリンクを記載して更新していく予定です)
出典:https://aws.amazon.com/jp/products
- 分析
- アプリケーション統合
- AR及びバーチャリティ
- AWSコスト管理
- ブロックチェーン
- ビジネスアプリケーション
- コンピューティング
- コンテナ
- カスタマーエンゲージメント
- データベース
- 開発用ツール
- エンドユーザーコンピューティング
- Game Tech
- IoT(モノのインターネット)
- Mechine Learning
- マネジメントとガバナンス
- メディアサービス
- 移行と転送
- モバイル
- ネットワーキングとコンテンツ配信
- 量子テクノロジー
- ロボット工学
- 人工衛星
- セキュリティー・アイデンティティ・コンプライアンス
- ストレージ
※この記事は随時更新します。
本記事は以下の方を対象としています。お力になれたら幸いです。
・AWSを学ぼうとしているが、何から手をつけていいかわからない方
・AWSの全体像を見失ってしまった方自分はまだ未熟物ですので、ご指摘等あればお気軽にコメントしてください。

- 投稿日:2020-04-03T02:30:02+09:00
主要4パブリッククラウドのVPC,Subnetの構成を比較してみた
主要4パブリッククラウドのネットワーク構成を比較してみた
いま現在よく使われている主要4パブリッククラウドについて勉強していたところ、IaaSとして利用する場合の最初の関門であるネットワークについてかなりの考え方の違いがあることがわかりましたのでまとめてみました。
VPCの考え方
AlibabaCloud,AWS,Azureの場合
クラウドでは仮想ネットワークの中に仮想サーバなどのリソースを配置して行きます。この仮想ネットワークをAWSやAlibabaCloud, GCPではVirtual Private Cloud(VPC)と呼んでいます。AzureではVNetと呼んでいます。
AWS,AlibabaCloud,Azureではリージョンの中にVPCを作る方式です。地域に別れたデータセンター群(リージョン)の中に仮想ネットワークを作る概念です。リージョン間の通信もVPC間を接続するVPC Peeringを作らないとインターネット越しの通信になってしまいます。
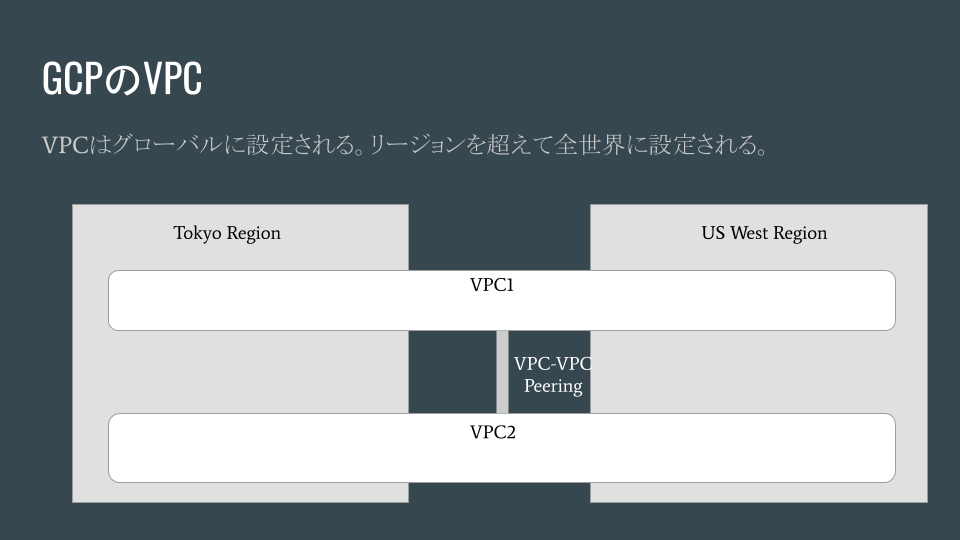
###GCPの場合
GCPはレガシーなIPネットワークの考え方を超えたクラウドネイティブな考え方なのでしょうか、VPCは全世界のリージョンを跨いで作られます。VPCとVPCを繋ぐ場合はVPC Peeringにより接続することもできます。
Subnetの考え方
AlibabaCloudとAWSの場合
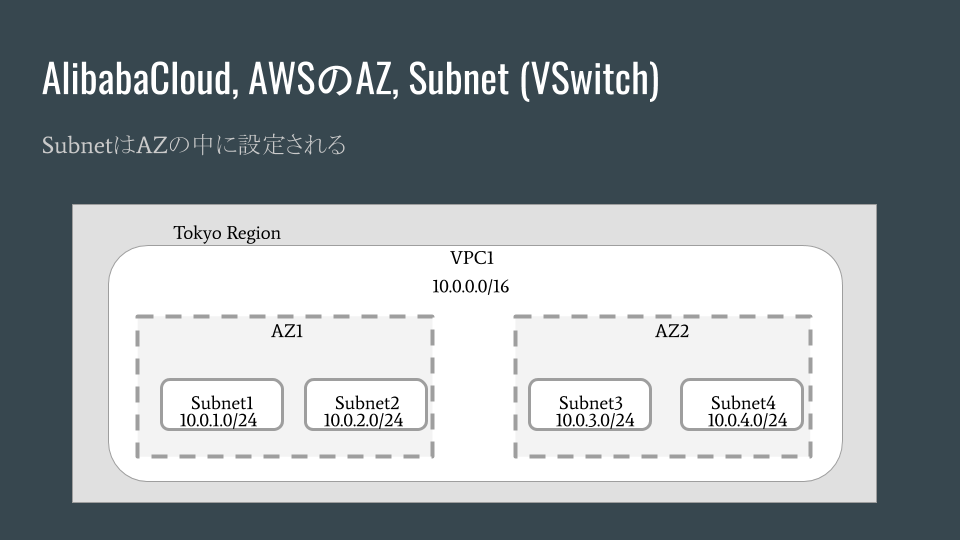
この2つのクラウドサービスはほぼ同じ考え方です。どちらかと言えばレガシーなIPネットワークをクラウド上でも受け継いでいるようです。VPCはリージョンに縛られてましたが、SubnetもAZに縛られています。AZの中でSubnetが作られます。
Azureの場合
AzureではAZを跨いでSubnetが設定されます。仮想サーバ(VM)を作る場合にサーバレベルでAZを選択することでマルチAZを活用した可用性を実現することができるようです。
GCPの場合
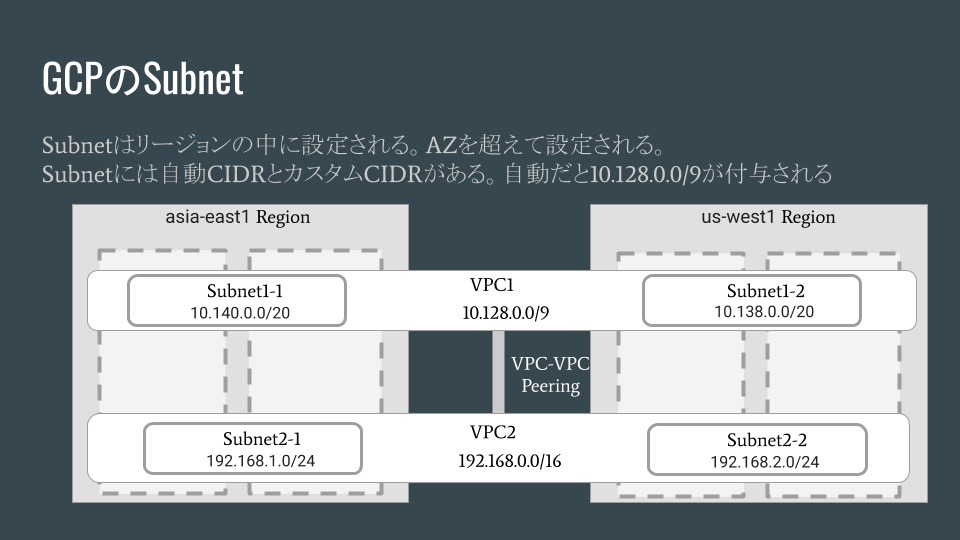
GCPでは、当初はSubnetを設定することができなかったそうです。2015年からSubnetの設定が可能になり、AutoとCustomの2つの方法があるようです。いずれの方法でもSubnetはリージョンの中に縛られて設定できます。AZは超えて設定されます。
Autoでは10.128.0.0/9のCIDRブロックがVPCに設定され、リージョンごとに自動でSubnetが付与される仕組みです。リージョンが増えると勝手にSubnetが設定されます。
Customを利用するとレガシーなIPネットワークのように独自にSubnetとCIDRブロックを作ることができます。
ただ、VPCの中のIPアドレス空間は複数混在できるようで、1つのCIDRブロックだけでなく複数のCIDRブロックが混在しても成立するそうです。IPアドレス空間が混在したときにVPC間の接続やオンプレミスのIPネットワークとの接続に影響がないのか?興味があるところです。
まとめ
AlibabaCloudとAWSは同じアーキテクチャーで考えることができそうです。AWSからAlibabaCloudに移行させるようなケースには便利ですね。AzureやGCPはAWSからの移行では単純にはできないためネットワークレベルから再設計が必要になりそうです。
参考としたサイト
AlibabaCloudドキュメントサイト:VPC ネットワークの計画
AWS のネットワーク設計入門
Azure 可用性ゾーンを使うならこんな構成
Azure Virtual Network とは
Azure の Availability Zones の概要
GCEのSubNetwork対応による、変更点とAWSとの違い
GCPのVPC関係ヘルプ


- 投稿日:2020-04-03T01:31:53+09:00
[refile][heroku]refileを使った本番環境での画像投稿機能[AWS][s3]
はじめに
refileを使って、画像投稿機能を作って、herokuにデプロイして、オリジナルサービス完成!
と思ってたら、思わぬことに。
なぜか投稿した画像が一定時間過ぎると見れなくなる。 とか
パソコンでは見れるのに、iPhoneで画像が見れない。
という問題に直面しました。ので、その状況に陥ったときの対処方法を今回は書いていきます。そもそも
herokuにアップした画像は一定時間しか保存してくれないとのこと(どっかの記事で見ました)。
なので、どこかに保存する場所を作ってあげないといけない。そこで見つけたのが、AWSのs3という機能(?)。
s3のバケットというところに保存すればこの問題は解決しました。
ちょっと長くなりますが、方法をまとめていきたいと思います。どうするか
細かく伝えいきますので、順にやっていってください。
gemの追加
refileには、AWSのs3と連携してくれる便利なgemがあります。それがこれ↓です。(refile/github)
Gemfilegem "refile-s3"これをGemfileに記述した後、
$ bundle installします。ファイルの追加
config/initializersの中にrefile.rbというファイルを作成します。
その後config/initializers/refile.rbrequire "refile/s3" aws = { access_key_id: "AWS_ACCESS_KEY_ID", secret_access_key: "AWS_SECRET_ACCESS_KEY", region: "リージョン", bucket: "バケット名", } Refile.cache = Refile::S3.new(prefix: "cache", **aws) Refile.store = Refile::S3.new(prefix: "store", **aws)これをまるっと書きます。
記載してある"AWS_ACCESS_KEY_ID","AWS_SECRET_ACCESS_KEY",リージョン,バケット名はまだ置いといていいです。AWSのs3にバケットを作る
このバケットというところに画像を保存していくのですが、まずはAWSのアカウントを作らなくてなりません。
参考になった記事がこちら → Railsでcarrierwaveを使ってAWS S3に画像をアップロードする手順を画像付きで説明するこの記事のAWS/IAM ~ S3バケット作成まで進めてください。かなり分かりやすく、僕でも楽々できました!
!注意!
作成途中で、アクセスキーとシークレットアクセスキーは後で使うので、どこか自分しかわからないところに控えておいてください。バケットができたら次です。
config/initializers/refile.rb
ここに戻ってきます。
先ほど作成したrefile.rbの中にあったAWS_ACCESS_KEY_IDとAWS_SECRET_ACCESS_KEYですが、
控えておいたアクセスキーとシークレットアクセスキーを入れることになります。
ただ、ここに直接は書かず、別のファイルに書いていきます。(書いてもいいのかもしれないけど。)
ひとまず、先ほどバケットを作った際にきめたリージョンとバケット名を記述してください。
ちなみにリージョンを東京にした場合はap-northeast-1と記述すればいいです。config/initializers/refile.rbrequire "refile/s3" aws = { access_key_id: "AWS_ACCESS_KEY_ID", secret_access_key: "AWS_SECRET_ACCESS_KEY", region: "リージョン", ←ここと bucket: "バケット名", ←ここ } Refile.cache = Refile::S3.new(prefix: "cache", **aws) Refile.store = Refile::S3.new(prefix: "store", **aws)gemの追加
次に環境変数というものを使うために
gem 'dotenv-rails'を追加し、
$ bundle installします。
環境変数とはパスワードを公開しないための変数とのこと。(あまりわかっていません。)そのあとホームディレクトリ直下(gemfileとかがあるところ)に、
.envというファイル名でファイルを作成します。
dotenvはこの.envというファイルの中に書いてあるデータを参照します。
なのでここで環境変数を定義していきます。 さきほど控えておいたキーをここに記述します。.envAWS_ACCESS_KEY_ID = アクセスキー AWS_SECRET_ACCESS_KEY = シークレットアクセスキー記述が終わったら、
.gitignoreに先ほどの.envを記述します。
これはgithubにデプロイしたときに誰にも見られたくない環境変数を隠すためのファイルです。.gitignore/.envheroku
次にherokuに移動してください。作成したアプリを選択して、
settings→Config VarsにあるReveal Config Varsを押すと
KEY と VALUE を追加する画面が出てきます。
ここで
KEYにはAWS_ACCESS_KEY_ID, VALUEにはアクセスキー
KEYにはAWS_SECRET_ACCESS_KEY, VALUEにはシークレットアクセスキー
の2つを記述してください。最後に
$ git add . $ git commit -m "" $ git push heroku master $ heroku run rails db:migrate $ heroku openをして、デプロイできればOKです!
そのあと、画像投稿をしてみて先ほど作成したバケットを確認すると、投稿した画像がそこに入っていると思います!
お疲れ様でした!まとめ
ほんと、これをするためだけに丸2日くらいかかりました…。センスないのかなってめっちゃ思いました。
知らない言葉とか多いけど、やっていくうちに慣れると思うので、今はひたすらにいろんな事を吸収します。とりあえずこの手順でやれば本番環境での画像投稿機能はつけられると思います!
参考記事
- 投稿日:2020-04-03T01:19:51+09:00
AWS KMSを使ってローカルに鍵を保存せずに暗号化・複合化を行う
まとめ
AWS KMS では鍵をローカルで管理することなくテキストの暗号化・複合化を行う機能を提供している。
システムで利用するパスワードなどを暗号化・複合化したいといった「ちょっとした暗号化」が欲しい場合にはこれを利用できる。なお、効率の面から小規模データ向けの方法。
この記事では取り扱わないが、大量のデータを暗号化・複合化する場合にはKMSに暗号化・複合化で使える鍵を発行してもらってそれを使う。bashコード
awscli を使って
TARGET_TEXTを暗号化・複合化する例。enc.sh#!/bin/bash CMK_ID=<自分のAWSアカウントで利用するKMSのカスタマー管理型のキーのID> PROFILE=<profileを使いたい場合は入力> TMPFILE=.tmp-bin TARGET_TEXT=P@ssW0rd if [ "$PROFILE" != "" ]; then PROFILE_CONTEXT="--profile $PROFILE" else PROFILE_CONTEXT="" fi echo start to encrypt "$TARGET_TEXT" ENCB64=$(aws kms encrypt --key-id ${CMK_ID} --plaintext ${TARGET_TEXT} --output text --query CiphertextBlob ${PROFILE_CONTEXT}) echo encrypted and base64 encoded text: $ENCB64 echo $ENCB64 | base64 -d > ${TMPFILE} PLAIN_TEXT=$(aws kms decrypt --ciphertext-blob fileb://$(pwd)/${TMPFILE} --output text --query Plaintext ${PROFILE_CONTEXT} | base64 -d) echo decrypted plain text: $PLAIN_TEXT出力結果の一例start to encrypt P@ssW0rd encrypted and base64 encoded text: AQICAHiclkP1z430sHo4kvwnliLRBAmXEHF1EiUqPErprxdOUwHgofADoFBFs0IwSuYxhQH/AAAAZjBkBgkqhkiG9w0BBwagVzBVAgEAMFAGCSqGSIb3DQEHATAeBglghkgBZQMEAS4wEQQM6oisVNzAn1r59h8AAgEQgCOogkCKzVFWtQfXPlAvhhEH0lGjtpL44biYU7ZkGbk1zAcRag== decrypted plain text: P@ssW0rd
aws kms encryptで--plaintextで指定した文字列をAWS KMSに保持している鍵を使って暗号化する
- 暗号化したデータを base64 エンコードしたものが得られる
- awscli の出力は ドキュメント から分かる通り複数あるので、暗号化したデータを指す CiphertextBlob のみを
--query CiphertextBlobで指定することで取得するaws kms decryptで暗号化したデータを複合化する
- fileb:// で指定する場合、基本フルパスなので上記shellではそのためのコードが書かれている
- 指定するファイルのデータは base64 をでコードしたものである必要がある
- encryptの場合と同様、
--queryで必要な部分のみを取得以上の手順で鍵を自分で管理することなく、暗号化・複合化を行うことができる。
余談
モチベーションは Chalice の
.chalice/config.jsonにパスワードを書こうと思ったのだが、このファイルはコミットしたい、でもパスワードは書きたいのでどうしよう…というところが発端。
他の人がどうしているかを見ると Githubでもディスカッションされている のを見て、その中で紹介されていた内容が実際にできるかどうかを確かめたのがこの記事だったり。
- 投稿日:2020-04-03T00:01:28+09:00
Amplify functionで簡単DynamoDB Stream & api Multi-Auth
今回は、AWS Amplifyのfunctionカテゴリを指定して、DynamoDBの変更をトリガーに実行(DynamoDB Stream)するLambda関数を作ってみます。
DynamoDB Stream
DynamoDB Streamを使うとイベント駆動型のアーキテクチャを構築することができます。
例えば、テーブルに特定レコードが登録、削除された場合のみメールやSlackに通知する、なんてこともできます。DynamoDB StreamとLambdaトリガーについての詳細は公式をご参照あれ。
せっかくなので、とあるテーブルにデータが登録されたらLambda関数が実行され、別テーブルにデータを登録する処理を実装してみたいと思います。データ登録はAppSyncを呼び出してみます。
事前準備
amplify cliのインストール
npm install -g @aws-amplify/cli amplify configureDynamoDB Streamは比較的新しい機能なのでバージョンの古いCliではサポートされていません。
参考に、私が動作を確認したバージョンは以下のとおりです。amplify -v 4.17.2なおAmplify CLI公式によると
Requires Node.js® version 10 or later
とのことで、Nodeは10以上をインストールしてください。amplifyの初期設定
amplify initamplify-cliがインタラクティブに設定情報を聞いてくるので、回答します。
過去記事と同じなので説明は割愛。APIとDynamoDB作成
次にトリガーとなるDBを作成します。
色々作り方はありますが、ここではamplifyのapiカテゴリを指定して作成することにします。
もちろん、AWSコンソールから手動で作成しても良いです。amplify add apiamplify-cliがインタラクティブに設定情報を聞いてくるので、回答していきます。
手順は過去記事と同様です。
今回は、ToDoテーブルからデータが削除されたらDoneテーブルに内容がコピーされる、というシナリオにしてみます。(通常こういったテーブル定義はあまりしないかもしれないですが...)schema.graphqltype Todo @model { id: ID! name: String! description: String title: String } type Done @model { id: ID! todoId: String! name: String! description: String title: String }スキーマ定義が終わったら以下のコマンドを実行しデプロイします。
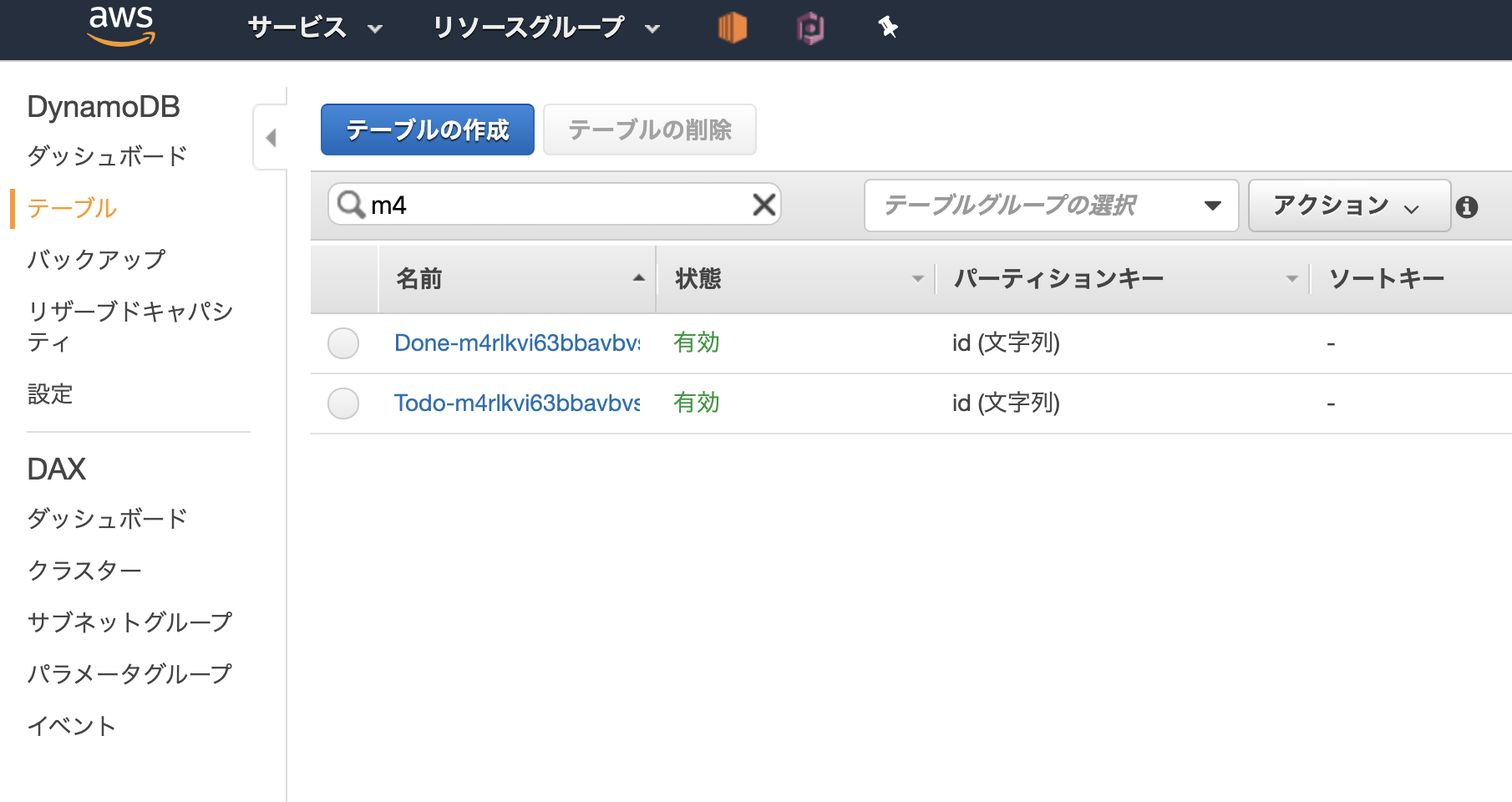
amplify pushデプロイが完了するとAWSコンソールからDynamoDBにToDoとDoneテーブルが作成されていることが確認できます。
Lambda関数の作成
事前準備ができたので、ここから本題のamplify functionを試していきます。
Lambda関数のデプロイ
amplify add function他の場合と同様にインタラクティブに設定情報を聞いてくるので回答します。
Using service: Lambda, provided by: awscloudformation ? Provide a friendly name for your resource to be used as a label for this categor y in the project: MyTodoTrigger ? Provide the AWS Lambda function name: MyTodoTrigger NodeJS found for selected function configuration. ? Choose the function template that you want to use: Lambda trigger ? What event source do you want to associate with Lambda trigger? Amazon DynamoDB Stream ? Choose a DynamoDB event source option Use API category graphql @model backed Dyn amoDB table(s) in the current Amplify project Selected resource AmplifyFunction ? Choose the graphql @model(s) Todo ? Do you want to access other resources created in this project from your Lambda f unction? No ? Do you want to edit the local lambda function now? Yes ... ? Press enter to continue以下のパスにサンプルとなるLambda関数のindex.jsが作成されます。
amplify > backend > function > {your function name} > srcindex.jsexports.handler = function(event, context) { //eslint-disable-line console.log(JSON.stringify(event, null, 2)); event.Records.forEach(record => { console.log(record.eventID); console.log(record.eventName); console.log('DynamoDB Record: %j', record.dynamodb); }); context.done(null, 'Successfully processed DynamoDB record'); // SUCCESS with message };後ほど修正しますが、動作を見てみるためとりあえずこのままデプロイします。
サンプルは指定したテーブルに変更があったらeventの内容をCloudWatchログに記録するコードになっています。amplify pushなお、以下のコマンドでローカルビルド&実行によるローカルテストも可能です。index.jsと同じディレクトリにあるevent.jsonを適宜書き換えてデプロイ前のローカルテストができます。
amplify function build amplify function invoke {your function name}実行して動作を確認してみましょう。
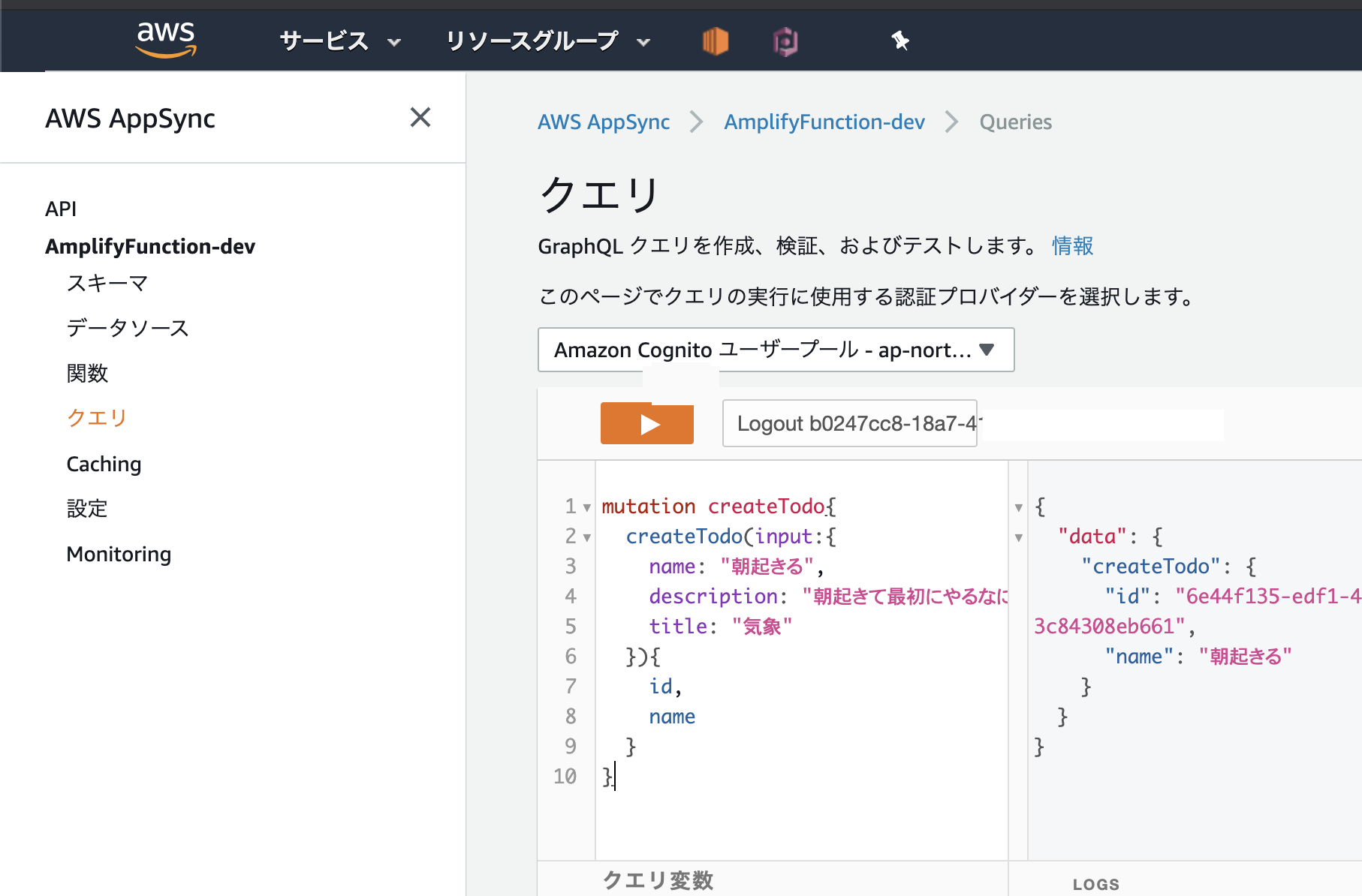
手軽に試すならAppSyncのコンソールから実行するのが良いでしょう。
今回の私の例だと、AppSyncの認証にCognitoを指定しているので任意のユーザーを作成した上で動作を確認しています。Cognitoの操作手順については本題からはずれるので省略。
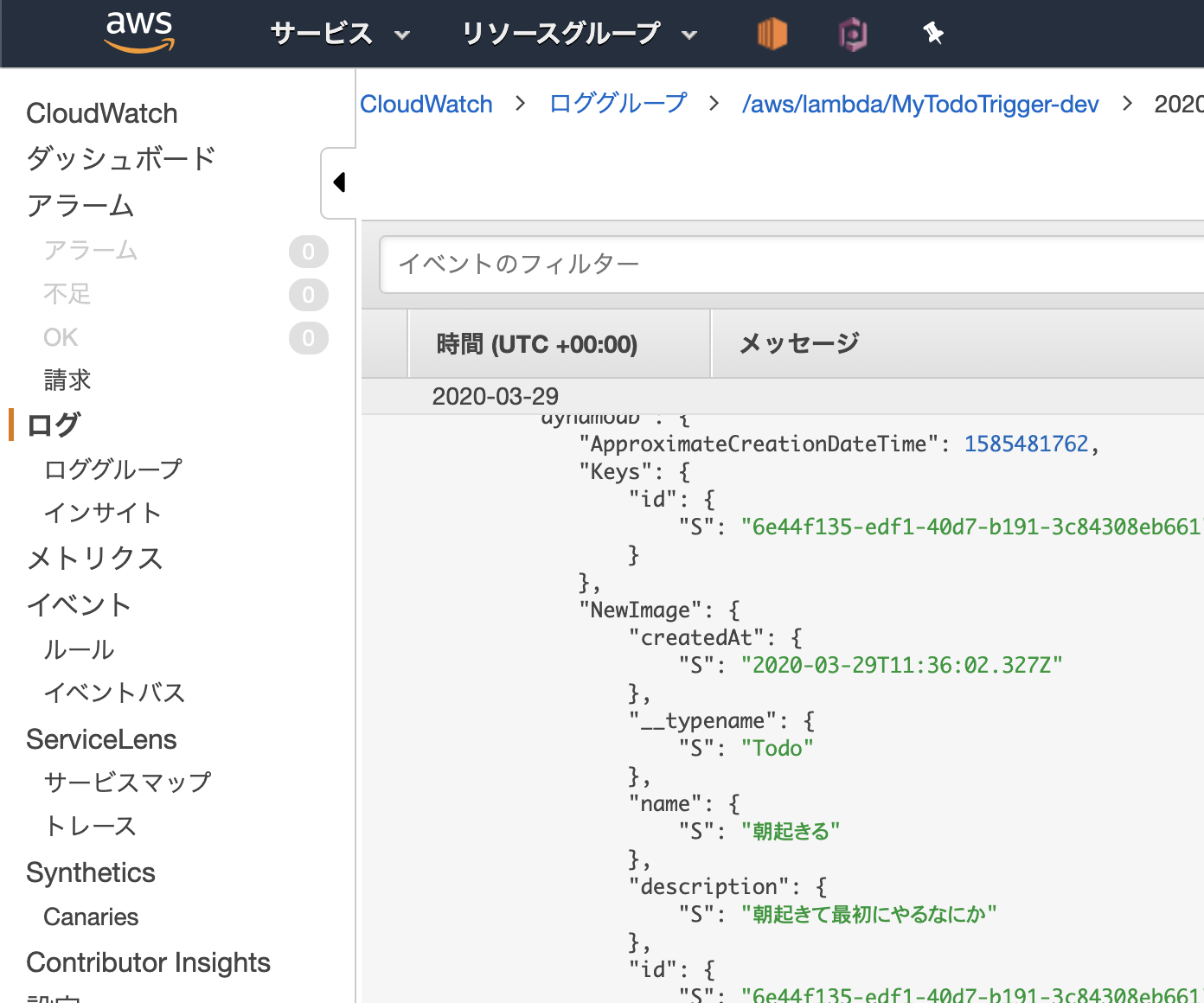
CloudWatchログを見て実行結果を確認します。
先程登録したデータがログに記録されていることが確認できました。正常に動作しているようですね。
APIとLambda関数の変更
API更新
今回は1つのAPIでWebやアプリなどのクライアントからの呼び出しとバックエンドからの呼び出しを可能にするため複数認証を設定します。
amplify update api? Please select from one of the below mentioned services: GraphQL ? Choose the default authorization type for the API Amazon Cognito User Pool Use a Cognito user pool configured as a part of this project. ? Do you want to configure advanced settings for the GraphQL API Yes, I want to make some additional changes. ? Configure additional auth types? Yes ? Choose the additional authorization types you want to configure for the API A PI key API key configuration ? Enter a description for the API key: myApiKey ? After how many days from now the API key should expire (1-365): 7 ? Configure conflict detection? Noスキーマを以下のように変更します。
DoneテーブルのproviderにCognito、APIKey認証を設定します。operationも適当に(あまりこういった設定するケースはない気がしますが、今回はお試しということで)type Todo @model { id: ID! name: String! description: String title: String } type Done @model @aws_cognito_user_pools @aws_api_key @auth( rules: [ { allow: private, provider: userPools, operations: [create, update, read, delete] }, { allow: public, provider: apiKey, operations: [create, read] } ] ) { id: ID! todoId: String! name: String! description: String title: String }Lambda関数更新
index.jsを修正しDynamoDBテーブル更新をトリガーに別テーブルを更新する処理を加えてみます。
Lambda関数内部で事前に作成したapi(MyTodoTrigger)を呼び出し、Doneテーブルを更新します。
amplify update functionUsing service: Lambda, provided by: awscloudformation ? Please select the Lambda Function you would want to update MyTodoTrigger ? Do you want to update permissions granted to this Lambda function to perform o n other resources in your project? Yes ? Select the category api Api category has a resource called AmplifyFunction ? Select the operations you want to permit for AmplifyFunction create, read, upd ate, delete You can access the following resource attributes as environment variables from your Lambda function var environment = process.env.ENV var region = process.env.REGION var apiAmplifyFunctionGraphQLAPIIdOutput = process.env.API_AMPLIFYFUNCTION_GRAPHQLAPIIDOUTPUT var apiAmplifyFunctionGraphQLAPIEndpointOutput = process.env.API_AMPLIFYFUNCTION_GRAPHQLAPIENDPOINTOUTPUT ? Do you want to edit the local lambda function now? Yes次にindex.jsを変更します。
index.jsrequire('isomorphic-fetch') const gql = require('graphql-tag') const AWSAppSyncClient = require('aws-appsync').default const { AUTH_TYPE } = require('aws-appsync') const mutation = gql( `mutation createDone($todoId: String!, $name: String!, $description: String, $title: String){ createDone(input:{ todoId: $todoId, name: $name, description: $description, title: $title }){ id } }`) exports.handler = async (event, context, callback) => { const client = new AWSAppSyncClient({ url: process.env['API_AMPLIFYFUNCTION_GRAPHQLAPIENDPOINTOUTPUT'], region: process.env['REGION'], auth: { type: AUTH_TYPE.API_KEY, apiKey: process.env['API_KEY'] }, disableOffline: true }) event.Records.map((record) => { if (record.eventName !== 'REMOVE') { return } const todoId = record.dynamodb.OldImage.id.S const name = record.dynamodb.OldImage.name.S const description = record.dynamodb.OldImage.description.S const title = record.dynamodb.OldImage.title.S client.mutate( { mutation: mutation, variables: { "todoId": todoId, "name": name, "description": description, "title": title } } ).then((result) => { if (result) { console.log('result', result) } else { console.log('error. result is null') } }).catch(console.error) callback(null, 'End process') } ) }ここまで来たら準備が整ったのでデプロイしましょう。
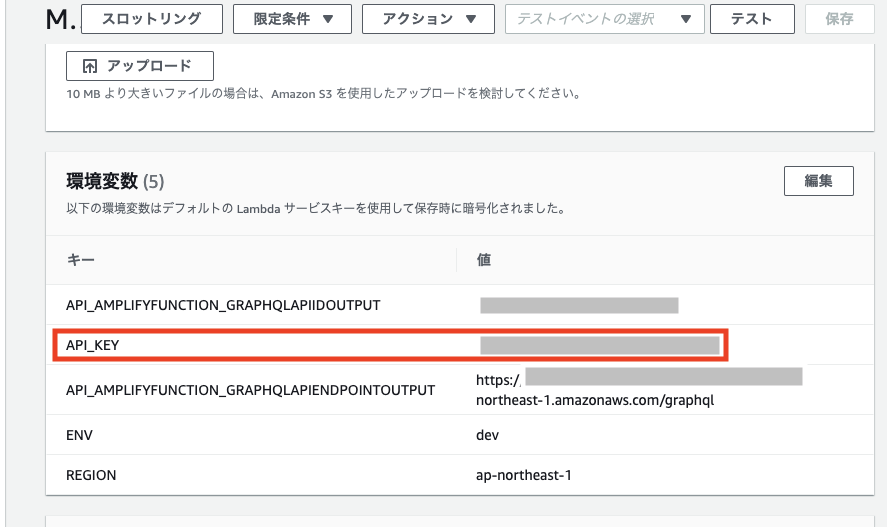
amplify push次に、Lambdaの環境変数に「API_KEY」を設定します。
amplify update functionの設定により追加されたAPIを追加します。
最後に、動作確認をします。
以下のようなmutationを発行して動作を見てみます。
AppSyncのコンソールなどから実行すると簡単です。mutation create{ createTodo(input: { name: "朝はやく起きる" description: "朝にはやくおきます" title: "朝起き" }){ id } }mutation delete{ deleteTodo(input: { id: <上記で作成したTodoのid> }){ id } }DynamoDBのDoneテーブルを見て項目が追加されていればOKです。
やったー!まとめ
Amplify functionのLambda Triggerを利用することで簡単にLambdaをDynamoDB Streamをトリガーに動作させることができました。また、合わせてAmplify apiのMulti-Authについてもついでに導入してみました。
Amplifyを利用することで複雑なイベント駆動アーキテクチャでも非常に簡単に構築できそうですね。Amplifyは続々と新しいカテゴリが追加されているので今後も色々とキャッチアップしていこうと思いますー。