- 投稿日:2020-04-03T23:33:15+09:00
yukicoder contest 242 参戦記
yukicoder contest 242 参戦記
A 1015 おつりは要らないです
まず1万円以上の店に、超えない範囲で1万円を割り当てます. (1万円だったら、1万円、1万1円でも1万円、2万円なら2万円). 全部割り当ててもまだ1万円が残っている場合には、残額が大きい店順に1枚づつ割り当てます. 同様のことを5千円でもします. 残額が残っている店がまだあるのであれば、千円札で払えるかを確認します.
ソートと払い終わった店の排除を繰り返すことにより解けました.
N, X, Y, Z = map(int, input().split()) A = list(map(int, input().split())) A = [a + 1 for a in A] A.sort(reverse=True) for i in range(len(A)): if Z == 0: break if A[i] >= 10000: t = A[i] // 10000 t = min(t, Z) Z -= t A[i] -= t * 10000 else: break A = [a for a in A if a > 0] A.sort(reverse=True) A = A[Z:] for i in range(len(A)): if Y == 0: break if A[i] >= 5000: t = A[i] // 5000 t = min(t, Y) Y -= t A[i] -= t * 5000 else: break A = [a for a in A if a > 0] A.sort(reverse=True) A = A[Y:] for i in range(len(A)): t = (A[i] + 999) // 1000 t = min(t, X) X -= t A[i] -= t * 1000 A = [a for a in A if a > 0] if len(A) == 0: print('Yes') else: print('No')ソートを繰り返す代わりに、優先度付きキューを使っても解けました.
from heapq import heapify, heappop, heappush N, X, Y, Z = map(int, input().split()) A = list(map(int, input().split())) A = [-a for a in A] heapify(A) while A: if Z == 0: break x = -heappop(A) if x >= 10000: t = min(x // 10000, Z) Z -= t x -= 10000 * t heappush(A, -x) else: Z -= 1 while A: if Y == 0: break x = -heappop(A) if x >= 5000: t = min(x // 5000, Y) Y -= t x -= 5000 * t heappush(A, -x) else: Y -= 1 while A: if X == 0: break x = -heappop(A) t = min((x + 1000) // 1000, X) X -= t x -= t * 1000 if x >= 0: heappush(A, -x) if len(A) == 0: print('Yes') else: print('No')
- 投稿日:2020-04-03T23:11:07+09:00
Houdiniから階層とトランスフォームを保持してFBXを書き出すHDAの配布
概要
Houdiniで階層とトランスフォームを保持してFBXを書き出すHDAを作ったので、標準機能の問題点と使用方法についてまとめます。
HDAとサンプルファイルはページの最後に書かれたURLからダウンロード出来ます。標準機能の問題点
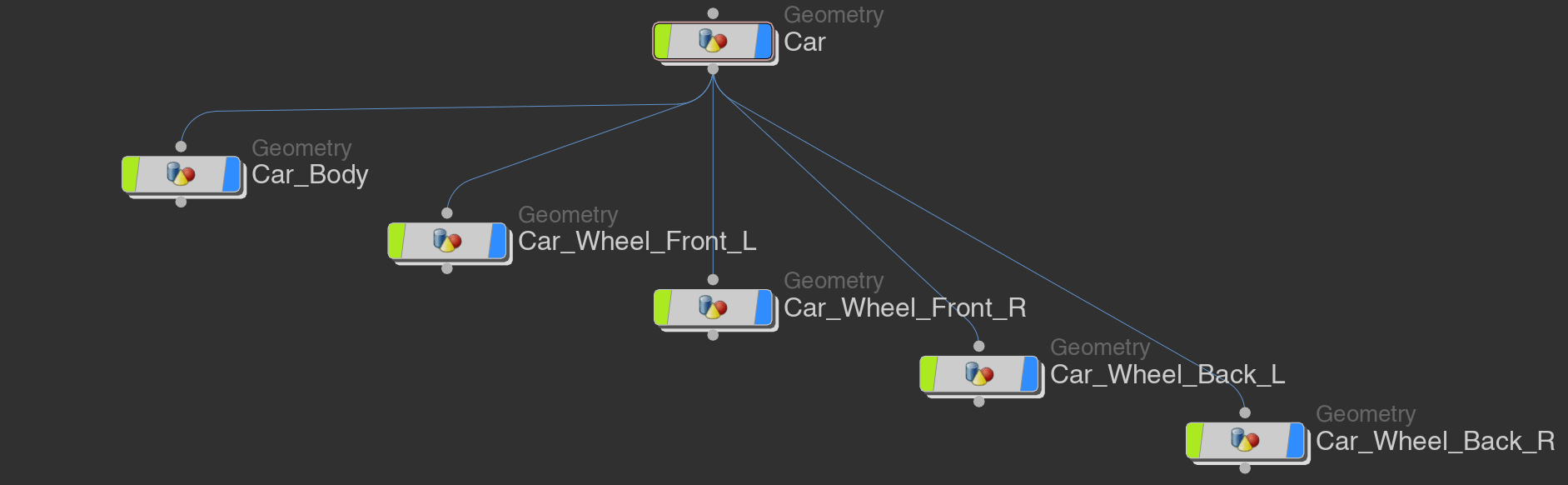
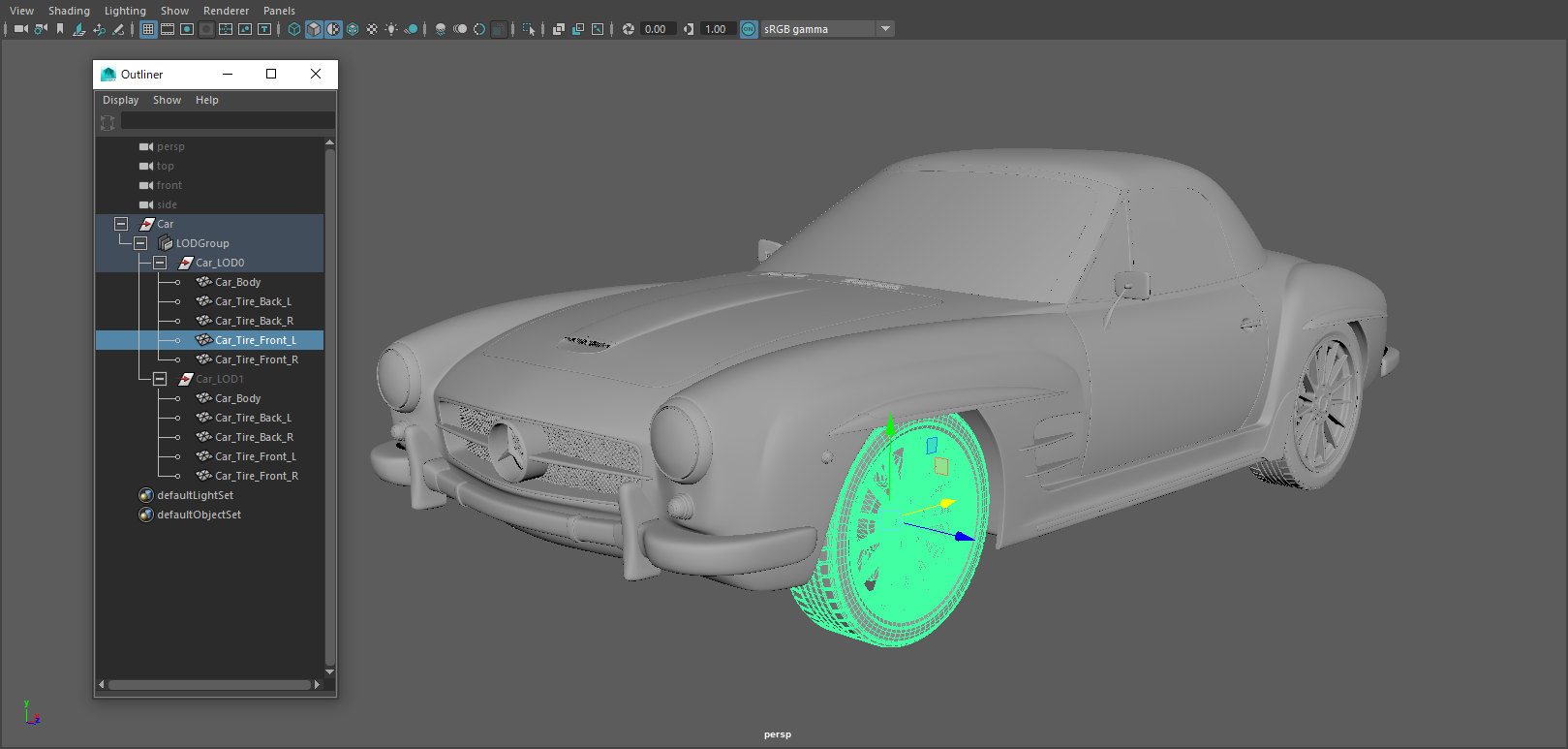
例えばMayaで図のようなタイヤとボディで分かれた車のモデルがあるとします。
タイヤのピボットは中心、ボディは原点に置かれてます。
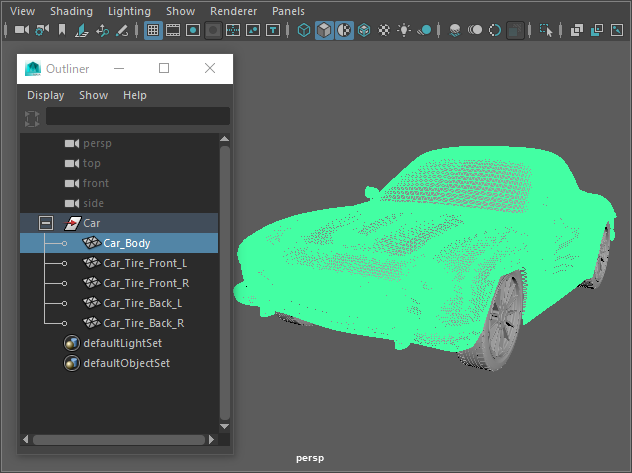
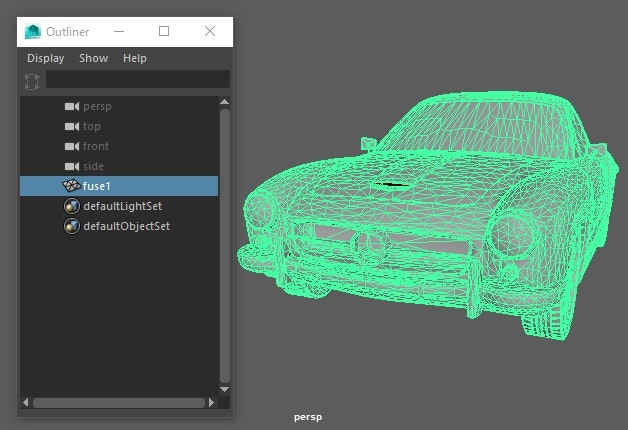
このモデルをHoudiniでリダクションし、FBXを書き出すと階層とトランスフォームが失われてしまいます。
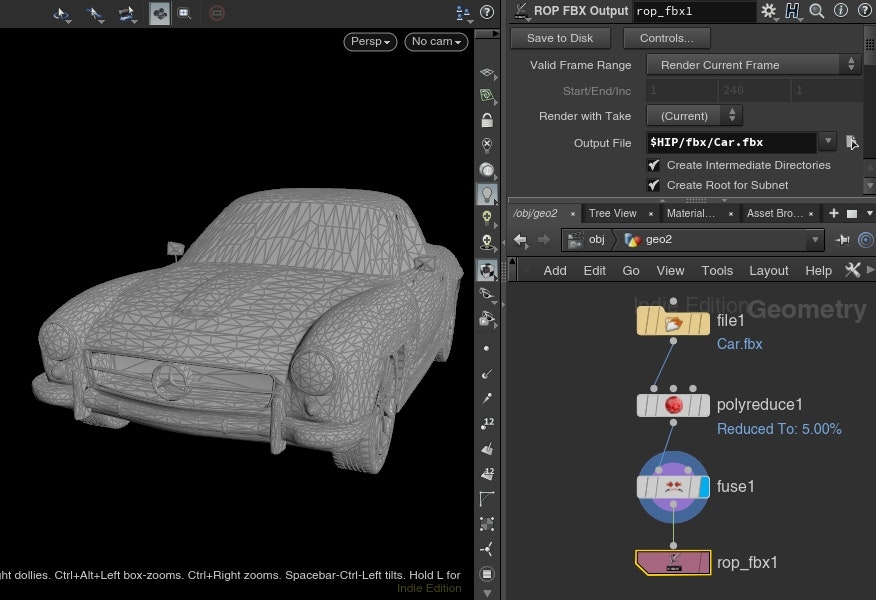
この問題を解決するにはオブジェクトごとにGeometryノードを分け、それをSubnetにまとめたものをOutコンテキストから書き出さないといけません。
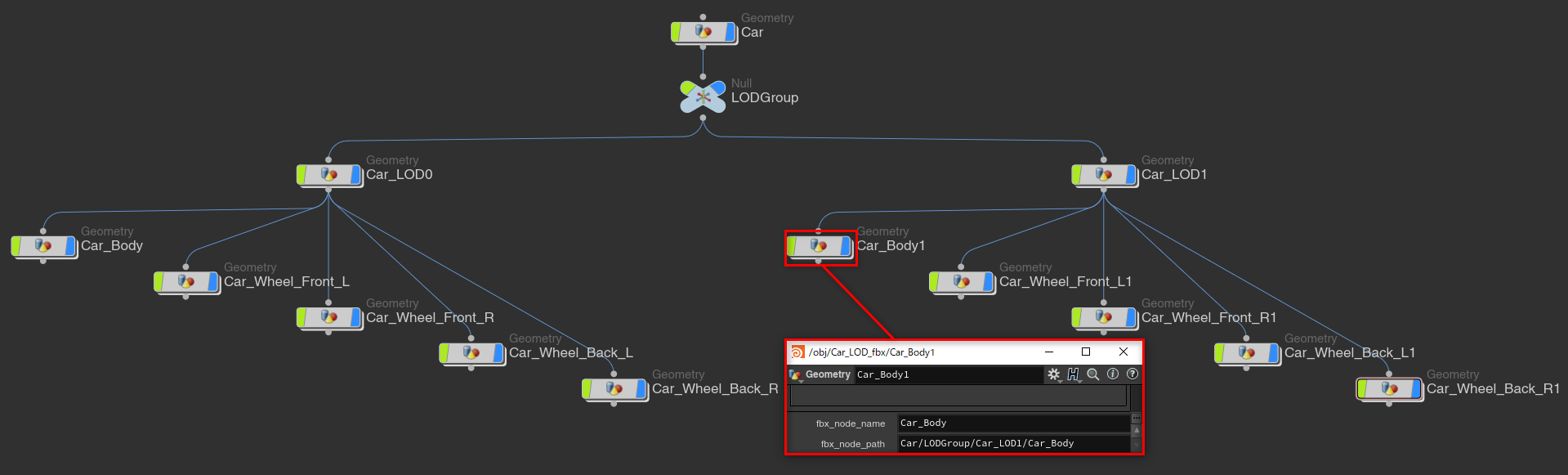
さらにLODとして持っていくにはLODGroupという名前でヌルノードを作成し、コネクションを繋げます。
この際、同じネットワーク内に同名ノードを作成する事が出来ない為、同名オブジェクトにしたい場合はfbx_node_nameとfbx_node_pathというパラメータを作り、パスと名前を設定する必要があります。
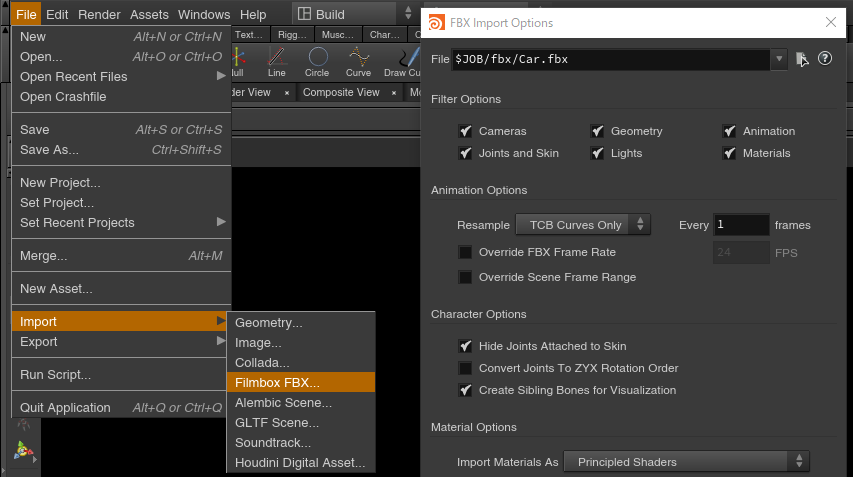
メニューのFile > Import > Filmbox FBXでFBXをインポートすれば自動で階層を作ってくれますが、これらの方法は編集がしづらく、ファイルの更新もしづらくなってしまいます。
この程度の階層であればなんとか出来ますが、もっと複雑な階層になるとかなり面倒です。
HDAの実装方法
配布するHDAではアトリビュートから階層のパスとトランスフォームを読み取り、FBX書き出し時にPythonで自動構築します。
階層とトランスフォームのアトリビュート
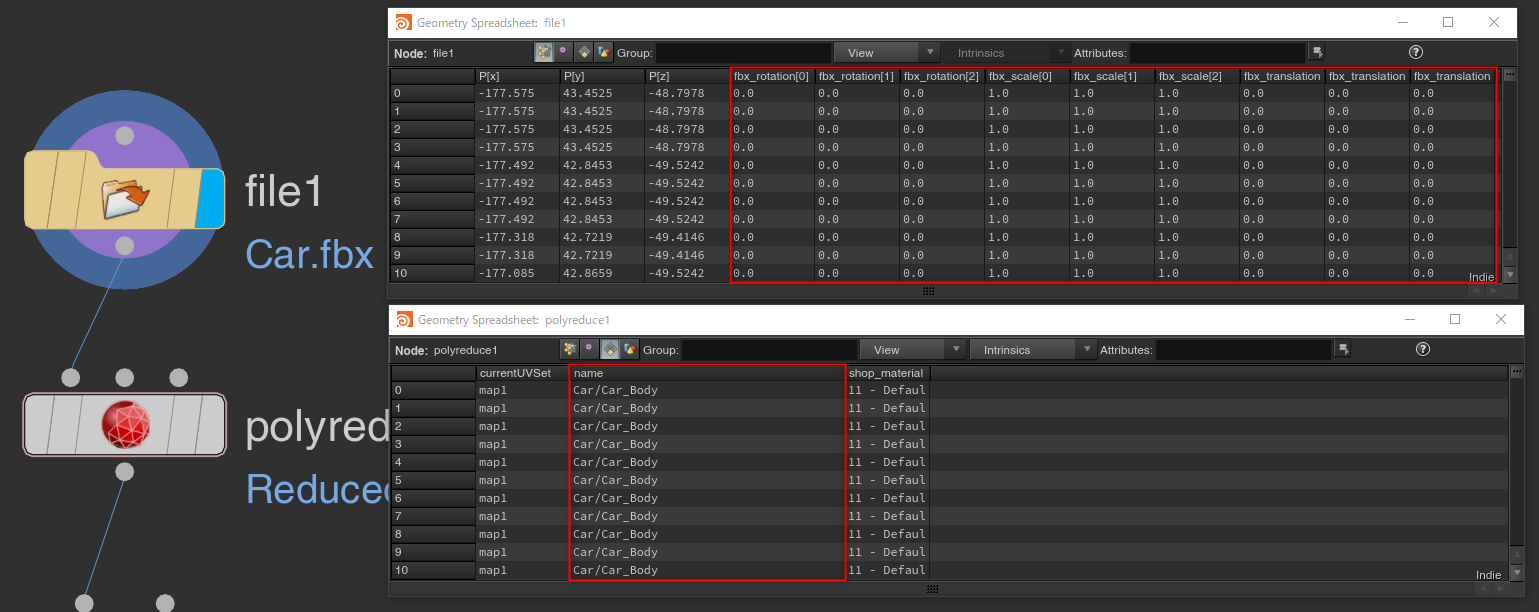
では、階層とトランスフォームのアトリビュートをどのように作るかと言うとFileノードでFBXを読み込んだ場合、自動でnameアトリビュートに階層、fbx_translationに位置、fbx_rotationに回転、fbx_scaleにスケール値が読み込まれます。
HDAではデフォルトでこれらのアトリビュートから値を読み込むようになってるので、元の値を残す事で階層とトランスフォームを保持して書き出せます。
アトリビュート制御なので、Houdiniで一から作ったモデルでも簡単に階層とトランスフォームを持たせる事が可能です。LODの作成
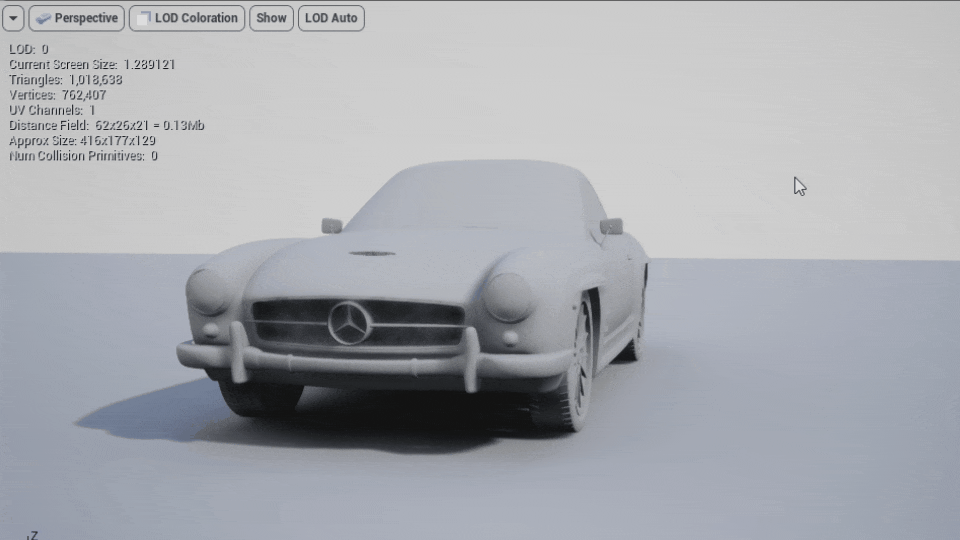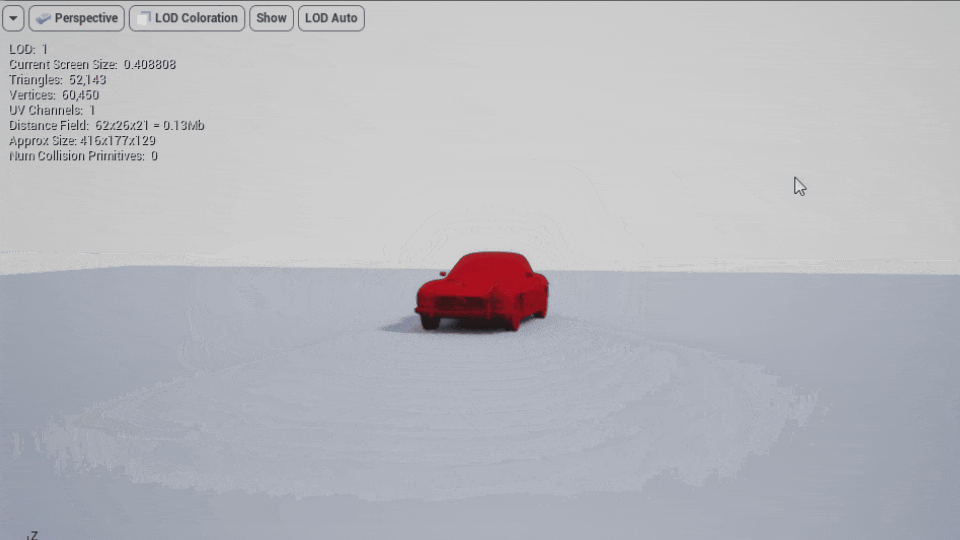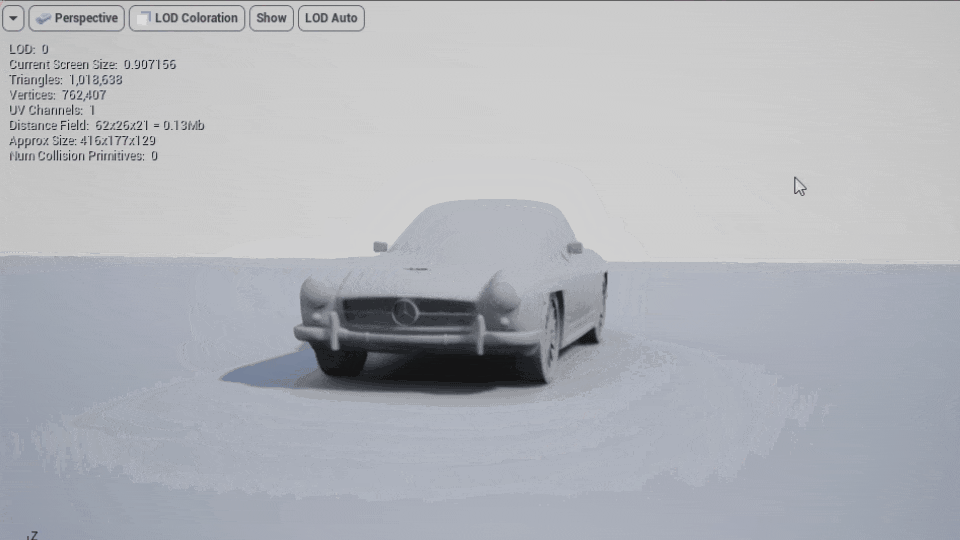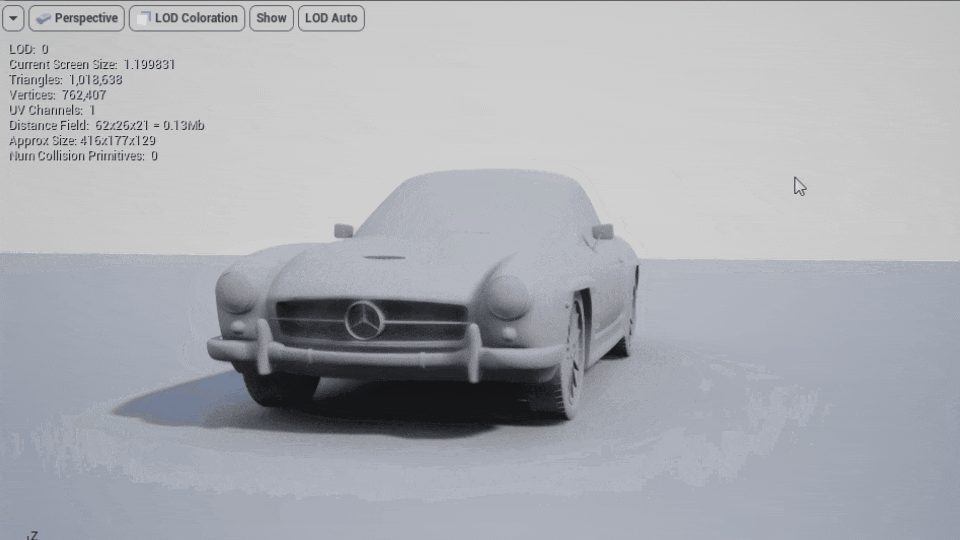
LODを作成するには図のようにnameアトリビュートにLODGroupという名前の階層を持たせる事でLODとして書き出されます(画像はLOD0とLOD1が同じ位置に重なっています)。
それをMayaで読み込むと図のような階層とLODGroupを持ったモデルとして読み込まれます。
このモデルをUnreal Engineで直接インポートしてもLODが適切に読み込まれてるのが確認出来ます。
HDAのUIとパラメータ
UI
パラメータ
パラメータ名 説明 Render FBXを書き出します。
Build Hierarchy From Attributeにチェックが入ってる状態で、階層用のアトリビュートが見つからない場合はボタンが押せないようになっています。
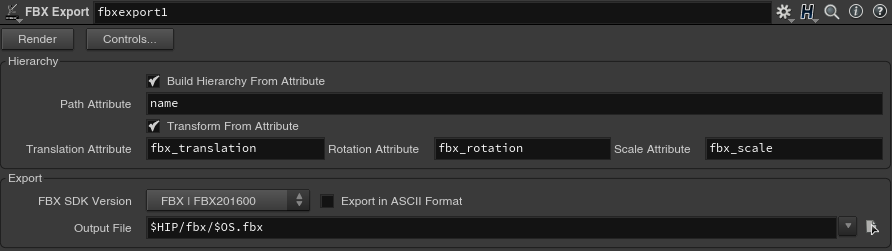
Hierarchy Build Hierarchy From Attribute 階層用のアトリビュートを基に階層を構築します。 Path Attribute 階層用のアトリビュート名 Transform From Attribute トランスフォーム用のアトリビュートを基にトランスフォームを設定します。 Translation Attribute 位置用のアトリビュート名 Rotation Attribute 回転用のアトリビュート名 Scale Attribute スケール用のアトリビュート名
Export FBX SDK Version エクスポートするFBXファイルのSDKのバージョンを指定することができます。 Export in ASCII Format チェックを付けると、エクスポートするFBXファイルは人が解読できるASCIIフォーマットになります。チェックなしの場合、バイナリフォーマットになります。 Output File ジオメトリを保存するファイル(拡張子を.fbxにしてください)。 HDAとサンプルファイルのダウンロード
下記からHDAをダウンロードしてHDAが認識されるフォルダにコピーしていただくとSopとRopでFBX Exportというノードが追加されます。
Sop Rop 最後に
今後、公式でこういった機能がFBXに付く可能性や、そもそもUSDなどFBXを使わないフローに代わる可能性がありますが、このHDAが皆さんの制作に少しでも役に立てば幸いです。
バグや機能要望等あればコメントに書いていただけると助かります。


- 投稿日:2020-04-03T23:06:15+09:00
C#とPythonの命名規則をまとめました。
こんにちは。
いつも C# で開発することが多いのですが、最近 Python に触れる機会がありました。
C# 感覚でコーディングをした後に、改めてPythonのコーディング規約であるPEP8で確認したところ、変数宣言など地味なところで命名規則に違いがありましたので、ざっくりC#とPythonの命名規則をまとめてみました。なおPEP8では、以下のようにプロジェクトのコーディング規約を衝突する場合は、プロジェクトをコーディング規約を優先するようにと書かれています。
多くのプロジェクトには、自分たちのコーディングスタイルに関するガイドラインがあります。それとこの文書の規約の内容が矛盾した場合は、そのプロジェクトのガイドラインが優先します。
はじめに
はじめに命名規則の簡単な説明です。
命名規則 説明 例 キャメルケース(CamelCase) 先頭以外は単語の先頭を大文字にする。 happyNewYear パスカルケース(PascalCase) 先頭含めは単語の先頭を大文字にする。 HappyNewYear スネークケース(SnakeCase) すべて単語は小文字。アンダースコアでつなぐ。 happy_new_year コンスタントケース(ConstantCase) すべて単語は大文字。アンダースコアでつなぐ。 HAPPY_NEW_YEAR ※パスカルケースは、アッパーキャメルケースとも呼ばれます。
※コンスタントケースは、アッパースネークケースとも呼ばれます。
※PEP8では、CapWords形式と表現されてますが、Pascal形式との違いが分からなかったので、以下ではPascal形式として整理しています。命名規則の比較一覧
C#とPythonの命名規則を簡単にまとめた比較一覧です。
識別子 C# Python パッケージ(名前空間) PascalCase すべて小文字 HappyBirthday happybirthday モジュール PascalCase すべて小文字 HappyBirthday happybirthday クラス PascalCase PascalCase HappyBirthday HappyBirthday 型変数 PascalCase PascalCase HappyBirthday HappyBirthday 例外 PascalCase PascalCase HappyBirthdayException HappyBirthdayError グローバル変数 Pascal SnakeCase HappyBirthday happy_birthday パラメータ(引数) CamelCase SnakeCase happyBirthday happy_birthday メソッド(関数) PascalCase SnakeCase GetHappyBirthday get_happy_birthday 変数 CamelCase SnakeCase happyBirthday happy_birthday 定数 PascalCase ConstantCase HappyBirthday HAPPY_BIRTHDAY その他にPEP8にも書かれているインデントやコメント、IFなどの制御文にクラス定義やメソッド定義などの記述の違いについては、別の機会にまとめていこうと思います。
参考)
Python コードのスタイルガイド(PEP8)
- 投稿日:2020-04-03T23:06:15+09:00
C#とPythonの命名規則を比較してみた。
こんにちは。
いつも C# で開発することが多いのですが、最近 Python に触れる機会がありました。
C# 感覚でコーディングをした後に、改めてPythonのコーディング規約であるPEP8で確認したところ、変数宣言など地味なところで命名規則に違いがありましたので、ざっくりC#とPythonの命名規則をまとめてみました。なおPEP8では、以下のようにプロジェクトのコーディング規約を衝突する場合は、プロジェクトをコーディング規約を優先するようにと書かれています。
多くのプロジェクトには、自分たちのコーディングスタイルに関するガイドラインがあります。それとこの文書の規約の内容が矛盾した場合は、そのプロジェクトのガイドラインが優先します。
はじめに
はじめに命名規則の簡単な説明です。
命名規則 説明 例 キャメルケース(CamelCase) 先頭以外は単語の先頭を大文字にする。 happyNewYear パスカルケース(PascalCase) 先頭含めは単語の先頭を大文字にする。 HappyNewYear スネークケース(SnakeCase) すべて単語は小文字。アンダースコアでつなぐ。 happy_new_year コンスタントケース(ConstantCase) すべて単語は大文字。アンダースコアでつなぐ。 HAPPY_NEW_YEAR ※パスカルケースは、アッパーキャメルケースとも呼ばれます。
※コンスタントケースは、アッパースネークケースとも呼ばれます。
※PEP8では、CapWords形式と表現されてますが、Pascal形式との違いが分からなかったので、以下ではPascal形式として整理しています。命名規則の比較一覧
C#とPythonの命名規則を簡単にまとめた比較一覧です。
識別子 C# Python パッケージ(名前空間) PascalCase すべて小文字 HappyBirthday happybirthday モジュール PascalCase すべて小文字 / SnakeCase HappyBirthday happybirthday / happy_birthday クラス PascalCase PascalCase HappyBirthday HappyBirthday 型変数 PascalCase PascalCase HappyBirthday HappyBirthday 例外 PascalCase PascalCase HappyBirthdayException HappyBirthdayError グローバル変数 Pascal SnakeCase HappyBirthday happy_birthday パラメータ(引数) CamelCase SnakeCase happyBirthday happy_birthday メソッド(関数) PascalCase SnakeCase GetHappyBirthday get_happy_birthday 変数 CamelCase SnakeCase happyBirthday happy_birthday 定数 PascalCase ConstantCase HappyBirthday HAPPY_BIRTHDAY その他にPEP8にも書かれているインデントやコメント、IFなどの制御文にクラス定義やメソッド定義などの記述の違いについては、別の機会にまとめていこうと思います。
参考)
Python コードのスタイルガイド(PEP8)
- 投稿日:2020-04-03T22:34:05+09:00
Python初心者が最初に作ったWebアプリ
Pythonに全く触れたことのない初心者が、とても簡単なWebアプリを作成した時の備忘録です。
Qiita初投稿です。いつもお世話になっております。■アプリ概要
・ユーザーからの入力を受け付けるWebページを表示
・入力された書籍タイトルを元に、書籍APIの検索リクエスト(Google Books API)
・レスポンスから書籍サムネイルを表示作成工程、その中でハマった所、解決方法を記載していきます。
—環境—
Mac OS1.Pythonのインストール
Macはデフォルトで2.x系のPythonがインストールされています。
下記コマンドでインストールされているPythonのバージョンを確認。Terminal$ python --version Python 2.7.16※ python -V でも同じ結果が得られます
Python 2.x系は2020年1月1日にサポート終了しています。
3.x系とのversionの違いで結構不整合が起きる + 今時2.x系を使用していると小学生にも鼻で笑われるらしいので、、、
最初に3.x系にアップデートします。↓公式サイトから3.x系のパッケージをダウンロード
https://www.python.org/downloads/Q1.ハマりポイント
インストールしたのにバージョンが2.x系のまま
python3 --version と確認すると3.x系になっているTerminal$ python --version Python 2.7.16 $ python3 --version Python 3.7.7A1.解決方法
1.brewコマンドでpyenvをインストール(読み方が分からず、心の中でぴえんって読んでる)Terminal$ brew install pyenv2.viエディタ等を使い~/.bash_profileに下記4行を追記
export PYENV_ROOT="\$HOME/.pyenv"
export PATH="\$PYENV_ROOT/bin:\$PATH"
eval "\$(pyenv init -)"
export PATH="\$HOME/.pyenv/shims:$PATH"※viエディタはTerminalからファイルを編集できるコマンドです。
使い方が結構特殊ですが、Linuxのサーバー構築などでもよく使います。
https://prev.net-newbie.com/linux/commands/vi.htmlTerminal$ vi ~/.bash_profile # ~/.bash_profileを編集する $ source ~/.bash_profile3.pyenvを使いMac全体にpython3.x系を認識させる。
Terminal$ pyenv global 3.7.0 $ pyenv rehashこれで3.x系が使えるようになりました。
Terminal$ python --version Python 3.7.72.フォルダ構成
プロジェクトのルートフォルダ直下に index.html と server.py と cgi-bin フォルダを配置。
cgi-bin フォルダ内に index.py を配置します。project/ ┝ ─ index.html ┝ ─ server.py └ ─ cgi-bin/ └ ─ index.py3.index.htmlの作成
今回はレイアウトも何も考えず、ただ文字列の入力を受け付けるだけのhtmlを作成します。
index.html<html> <head> <meta charset="utf-8"> </head> <body> <form method="POST" action="cgi-bin/index.py"> <label>取得図書画像タイトル:</label> <br> <input type="text" name="text"> <button type="submit">送信</button> </form> </body> </html>ザックリ説明すると、
<form>タグで囲まれている箇所に入力されたデータが、
<submit>契機で、cgi-bin/index.py にPOSTメソッドで送信される。
そんな感じです。下記のようなページが作成されます。
テキストボックスに入力されたデータが、[送信]ボタンを押すと、index.py に送信されます。
4.server.pyの作成
ローカルで検証用のサーバーを立てるために必要になります。
server.pyimport http.server http.server.test(HandlerClass=http.server.CGIHTTPRequestHandler)Terminalで作成したPythonファイルを起動すると、ローカルサーバーが立ち上がります。
ローカルサーバーが立ち上がった状態で
http://0.0.0.0:8000/
にアクセスすると、先ほどのindex.htmlが表示されるはずです。Terminal$ python server.py Serving HTTP on 0.0.0.0 port 8000 (http://0.0.0.0:8000/) ...※ちなみにローカルサーバーを中止するのは command + C です。
5.index.pyの作成
index.htmlから送信されたデータを使い、Google書籍検索APIのリクエストを送ります。
index.py#!/usr/bin/env python3 # -*- coding: utf-8 -*- import cgi # CGIモジュールのインポート import cgitb import sys import requests import json # 書籍検索APIの雛形 api = "https://www.googleapis.com/books/v1/volumes?q={title}&maxResults=10&startIndex=0" # デバッグに使うので、本番環境では記述しない cgitb.enable() # ユーザーが入力したフォームデータを取得する form = cgi.FieldStorage() # HTMLを記述するためのヘッダ print("Content-Type: text/html; charset=UTF-8") print("") # フォームのデータが入力されていない場合 if "text" not in form: print("<h1>Error!</h1>") print("<br>") print("テキストを入力してください!") print("<a href='/'><button type='submit'>戻る</button></a>") sys.exit() # index.pyの終了 text = form.getvalue("text") # テキストデータの値を取得する url = api.format(title=text) # 書籍検索apiの検索単語となる{title}に入力テキストを当てはめる response = requests.get(url) # リクエストを投げる data = json.loads(response.text) # レスポンスをjson形式に変換 # レスポンスをhtmlに反映 print(data['items'][0]['volumeInfo']['title']) print("<br>") print("<img src=" + data['items'][0]['volumeInfo']['imageLinks']['thumbnail'] + ">") print("<br>") print("<a href='/'><button type='submit'>戻る</button></a>")コメントでだいぶ補足してありますが、ザックリ説明します。
↓こちらがGoogle Books API のURLです。
https://www.googleapis.com/books/v1/volumes?q=いちご100&maxResults=10&startIndex=0
q=の後に検索したい書籍の名前を入れると、関連したレスポンスを返してくれます。curlを使っても手軽に確認できます。
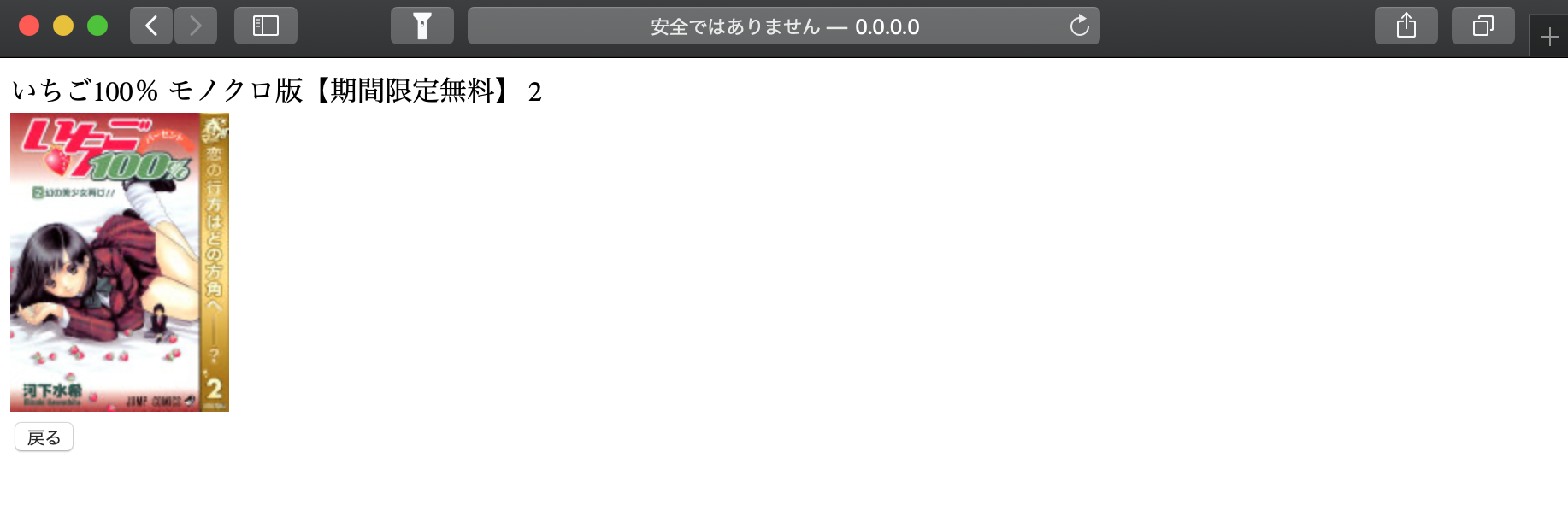
Terminal$ curl https://www.googleapis.com/books/v1/volumes?q=いちご100&maxResults=10&startIndex=0 "kind": "books#volumes", "totalItems": 2836, "items": [ { "kind": "books#volume", "id": "vWSUDwAAQBAJ", "etag": "b/w9qaxsyy4", "selfLink": "https://www.googleapis.com/books/v1/volumes/vWSUDwAAQBAJ", "volumeInfo": { "title": "いちご100% モノクロ版【期間限定無料】 2", "authors": [ "河下水希" ], "publisher": "集英社", "publishedDate": "2002-10-04", "description": "【春マン!! 期間限定無料!!/真中淳平が突如迷い込んだ恋の迷路! いちごパンツが導く超青春ラブコメディ!】※2019年5月8日までの期間限定無料お試し版です。2019年5月9日以降はご利用できなくなります。 西野と東城、二人の間で揺れる真中の気持ち。ホントに好きなのは西野? それとも東城? 勉強に全く身が入らないまま迎えた受験当日、いちご模様迷宮の入り口・幻の美少女が目の前に…!! どうする真中!?", "industryIdentifiers": [ { "type": "OTHER", "identifier": "PKEY:088733268733043155P5" } ], "readingModes": { "text": true, "image": false }, "pageCount": 188, "printType": "BOOK", "categories": [ "Comics & Graphic Novels" ], "maturityRating": "NOT_MATURE", "allowAnonLogging": false, "contentVersion": "1.2.2.0.preview.2", "panelizationSummary": { "containsEpubBubbles": true, "containsImageBubbles": true, "epubBubbleVersion": "99b0fa95624a43e9_A", "imageBubbleVersion": "99b0fa95624a43e9_A" }, "imageLinks": { "smallThumbnail": "http://books.google.com/books/content?id=vWSUDwAAQBAJ&printsec=frontcover&img=1&zoom=5&source=gbs_api", "thumbnail": "http://books.google.com/books/content?id=vWSUDwAAQBAJ&printsec=frontcover&img=1&zoom=1&source=gbs_api" }, "language": "ja", "previewLink": "http://books.google.co.jp/books?id=vWSUDwAAQBAJ&dq=%E3%81%84%E3%81%A1%E3%81%94100&hl=&cd=1&source=gbs_api", "infoLink": "http://books.google.co.jp/books?id=vWSUDwAAQBAJ&dq=%E3%81%84%E3%81%A1%E3%81%94100&hl=&source=gbs_api", "canonicalVolumeLink": "https://books.google.com/books/about/%E3%81%84%E3%81%A1%E3%81%94100_%E3%83%A2%E3%83%8E%E3%82%AF%E3%83%AD%E7%89%88_%E6%9C%9F%E9%96%93%E9%99%90.html?hl=&id=vWSUDwAAQBAJ" }, "saleInfo": { "country": "JP", "saleability": "NOT_FOR_SALE", "isEbook": false }, "accessInfo": { "country": "JP", "viewability": "NO_PAGES", "embeddable": false, "publicDomain": false, "textToSpeechPermission": "ALLOWED", "epub": { "isAvailable": true }, "pdf": { "isAvailable": true }, 略------------------------------------------------------responseには、上記のような長い応答が格納され、
dataにはresponseをJSON型に変換して格納します。今回はその中から、[title]と[thumbnail]を使いたいので、
data['items'][0]['volumeInfo']['title']
data['items'][0]['volumeInfo']['imageLinks']['thumbnail']
のようにアクセスし、必要となるデータを取り出します。[0]の値を[1][2]と変更することによって、
取り出す検索結果対象を変更することができます。
↓↓↓
完成○△□
Q2.ハマりポイント
送信ボタンを押下すると、
FileNotFoundError: [Errno 2] No such file or directory: '/Users/hoge/project/cgi-bin/index.py'
とエラーが表示され、検索結果が表示されないA2.解決方法
/Users/hoge/project/cgi-bin/index.py は存在していた。
index.py の1行目が誤っていた
× #!usr/bin/env python3
○ #!/usr/bin/env python3Q3.requestsがインポートできない
import requests
の箇所でエラーが起きてしまうA3.解決方法
こちらの記事が大変参考になりました。
https://qiita.com/Kent_recuca/items/349586e9c034535f2991Pythonのsys.pathに
requestsがインストールされたパスを追記することで解決総括
以前SpringBootを用いてWebアプリを作成したことがありましたが、
それに比べフォルダ構成、環境構築が楽ですぐに動かせるという所感です。機械学習分野に使われていることは知っていましたが、Web環境でも使用されていることに驚きました。
Pythonに初めて触れたので、
コメントであるはずの#の後ろでなぜエラーが起きるのか、
ローカルサーバーを立ち上げると、なぜindex.htmlが表示されるのか、
まだまだ謎だらけですが、これからお勉強して理解を深めていきたいと思います。
- 投稿日:2020-04-03T22:00:13+09:00
機械学習のアルゴリズム(多クラス分類の実装)
はじめに
以前、「機械学習の分類」で取り上げたアルゴリズムについて、その理論とpythonでの実装、scikit-learnを使った分析についてステップバイステップで学習していく。個人の学習用として書いてるので間違いなんかは大目に見て欲しいと思います。
前回、2クラス分類を多クラス分類に拡張しました。今回は実際にPythonで実装してみます。
参考にしたのは以下のサイト。ありがとうございます。
実装の方針
以前実装したロジスティック回帰を多クラスに拡張してみようと思います。方法は
- One-vs-Rest
- 多クラスソフトマックス
でやってみようと思います。
分類に使用するデータ
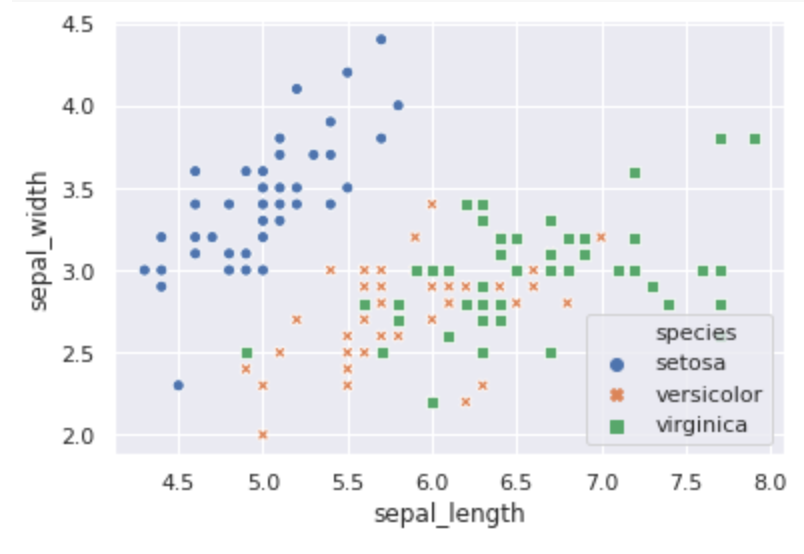
分類にはアヤメのデータを使います。4つの特徴量(sepal_length,sepal_width,petal_length,petal_width)を使い、3つのクラス(setosa,versicolor,virginica)に分類します。
以下、見やすくするためにsepal_lengthとsepal_widthを使って分類を実装していきます。
import numpy as np import pandas as pd import seaborn as sns import matplotlib.pyplot as plt %matplotlib inline from sklearn.datasets import load_iris sns.set() iris = sns.load_dataset("iris") ax = sns.scatterplot(x=iris.sepal_length, y=iris.sepal_width, hue=iris.species, style=iris.species)
One-vs-Rest
One-vs-Restは2クラス分類器をラベルのクラス分作って学習し、最後に一番もっともらしい値を使います。ロジスティック回帰は確率値を出力するので、確率が一番高い分類器の分類を採用します。
前回使ったロジスティック回帰のコードを少し変更したLogisticRegressionクラスを使います。どの値を採用するかを確率で決めるので
predict_probaメソッドを作りました。from scipy import optimize class LogisticRegression: def __init__(self): self.w = None def sigmoid(self, a): return 1.0 / (1 + np.exp(-a)) def predict_proba(self, x): x = np.hstack([1, x]) return self.sigmoid(self.w.T @ x) def predict(self, x): return 1 if self.predict_proba(x)>=0.5 else -1 def cross_entropy_loss(self, w, *args): def safe_log(x, minval=0.0000000001): return np.log(x.clip(min=minval)) t, x = args loss = 0 for i in range(len(t)): ti = 1 if t[i] > 0 else 0 h = self.sigmoid(w.T @ x[i]) loss += -ti*safe_log(h) - (1-ti)*safe_log(1-h) return loss/len(t) def grad_cross_entropy_loss(self, w, *args): t, x = args grad = np.zeros_like(w) for i in range(len(t)): ti = 1 if t[i] > 0 else 0 h = self.sigmoid(w.T @ x[i]) grad += (h - ti) * x[i] return grad/len(t) def fit(self, x, y): w0 = np.ones(len(x[0])+1) x = np.hstack([np.ones((len(x),1)), x]) self.w = optimize.fmin_cg(self.cross_entropy_loss, w0, fprime=self.grad_cross_entropy_loss, args=(y, x)) @property def w_(self): return self.wOne-vs-Restクラスを実装します。あとでアルゴリズムの比較に使うので、どれくらい正解しているかを計算する
accuracy_scoreメソッドも実装しました。from sklearn.metrics import accuracy_score class OneVsRest: def __init__(self, classifier, labels): self.classifier = classifier self.labels = labels self.classifiers = [classifier() for _ in range(len(self.labels))] def fit(self, x, y): y = np.array(y) for i in range(len(self.labels)): y_ = np.where(y==self.labels[i], 1, 0) self.classifiers[i].fit(x, y_) def predict(self, x): probas = [self.classifiers[i].predict_proba(x) for i in range(len(self.labels))] return np.argmax(probas) def accuracy_score(self, x, y): pred = [self.labels[self.predict(i)] for i in x] acc = accuracy_score(y, pred) return acc実際に先ほどのデータを使って分類します。
model = OneVsRest(LogisticRegression, np.unique(iris.species)) x = iris[['sepal_length', 'sepal_width']].values y = iris.species model.fit(x, y) print("accuracy_score: {}".format(model.accuracy_score(x,y))) accuracy_score: 0.8066666666666666正解率81%はあまり良くないですね。どう分類されたか可視化してみましょう。
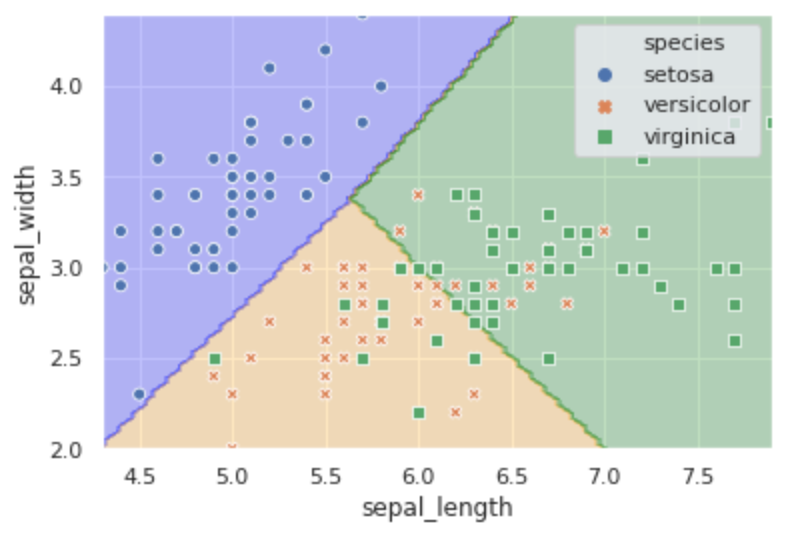
可視化にはmatplotlibのcontourfメソッドを使います。格子点上の値がどれに分類されるかで着色します。from matplotlib.colors import ListedColormap x_min = iris.sepal_length.min() x_max = iris.sepal_length.max() y_min = iris.sepal_width.min() y_max = iris.sepal_width.max() x = np.linspace(x_min, x_max, 100) y = np.linspace(y_min, y_max, 100) data = [] for i in range(len(y)): data.append([model.predict([x[j], y[i]]) for j in range(len(x))]) xx, yy = np.meshgrid(x, y) cmap = ListedColormap(('blue', 'orange', 'green')) plt.contourf(xx, yy, data, alpha=0.25, cmap=cmap) ax = sns.scatterplot(x=iris.sepal_length, y=iris.sepal_width, hue=iris.species, style=iris.species) plt.show()
見てわかるように、setosaはちゃんと分類できていますが、残りの2クラスは混ざっているので正解率が少し低く出ているみたいです。とりあえずこんなもんでしょう。
マルチクラスソフトマックス
ロジスティック回帰でソフトマックス分類するためのLogisticRegressionMultiクラスを実装します。
評価するための誤差関数にクロスエントロピー誤差を利用し、最急勾配降下法を使ってパラメータを求めました。だいぶ適当に作りました、すみません
from sklearn.metrics import accuracy_score class LogisticRegressionMulti: def __init__(self, labels, n_iter=1000, eta=0.01): self.w = None self.labels = labels self.n_iter = n_iter self.eta = eta self.loss = np.array([]) def softmax(self, a): if a.ndim==1: return np.exp(a)/np.sum(np.exp(a)) else: return np.exp(a)/np.sum(np.exp(a), axis=1)[:, np.newaxis] def cross_entropy_loss(self, w, *args): x, y = args def safe_log(x, minval=0.0000000001): return np.log(x.clip(min=minval)) p = self.softmax(x @ w) loss = -np.sum(y*safe_log(p)) return loss/len(x) def grad_cross_entropy_loss(self, w, *args): x, y = args p = self.softmax(x @ w) grad = -(x.T @ (y-p)) return grad/len(x) def fit(self, x, y): self.w = np.ones((len(x[0])+1, len(self.labels))) x = np.hstack([np.ones((len(x),1)), x]) for i in range(self.n_iter): self.loss = np.append(self.loss, self.cross_entropy_loss(self.w, x, y)) grad = self.grad_cross_entropy_loss(self.w, x, y) self.w -= self.eta * grad def predict(self, x): x = np.hstack([1, x]) return np.argmax(self.softmax(x @ self.w)) def accuracy_score(self, x, y): pred = [self.predict(i) for i in x] y_ = np.argmax(y, axis=1) acc = accuracy_score(y_, pred) return acc @property def loss_(self): return self.loss
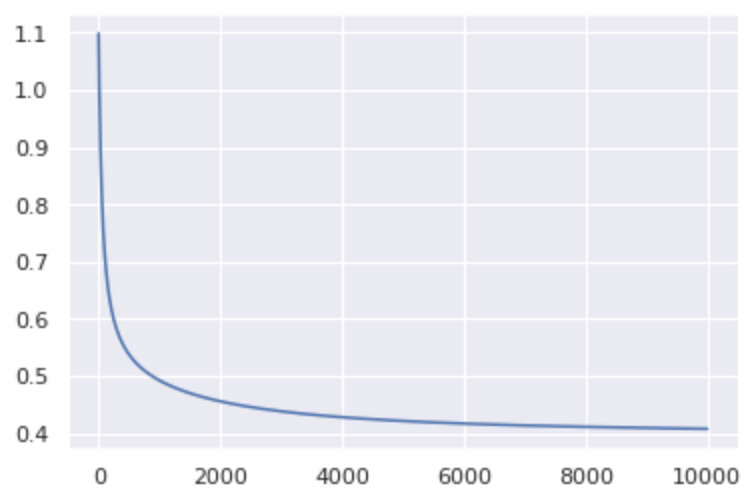
LogisticRegressionMultiへの入力はOne-Hot-Encodingされたラベルを使います。これはPandasのget_dummiesを使うと簡単です。(作った後に思ったんですが、クラス内でget_dummies使えば良かったですね)model = LogisticRegressionMulti(np.unique(iris.species), n_iter=10000, eta=0.1) x = iris[['sepal_length', 'sepal_width']].values y = pd.get_dummies(iris['species']).values model.fit(x, y) print("accuracy_score: {}".format(model.accuracy_score(x, y))) accuracy_score: 0.8266666666666667正解率83%くらいですね。誤差の履歴を見てみると収束しているようなので、こんなもんなのでしょう。
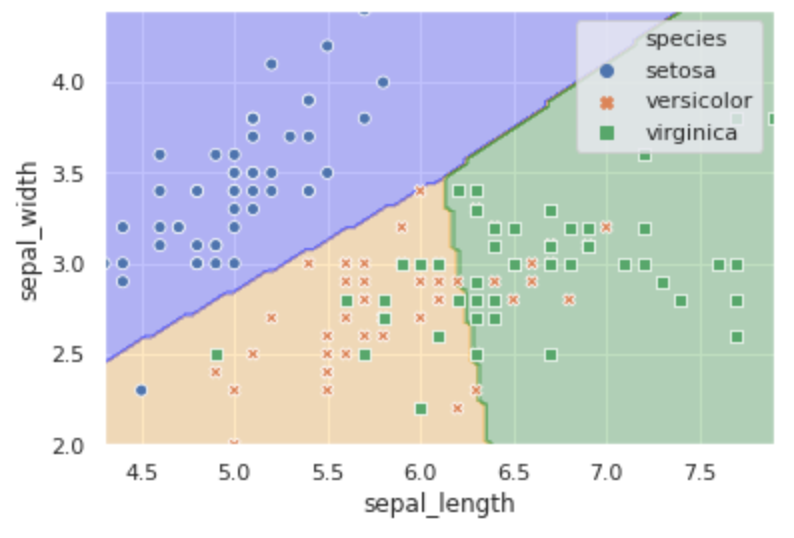
また、先ほどと同じようにどう分類されるかを着色してみます。
scikit-learnのロジスティック回帰と比較する
最後に、全ての特徴量を使い、今回作った分類器とscikit-learnのLogisticRegressionクラスを比較します。
手法 accuracy_score OneVsRest 0.98 LogisticRegressionMulti 0.98 sklearn LogisticRegression 0.973 今回の実装でもアヤメの分類くらいなら悪くないスコアを出すことができてるみたいですね。
まとめ
ロジスティック回帰を使った多クラス分類を実装しました。ほかの分類器でも似たような考え方でいけるような気がします。特に、ニューラルネットワークではマルチクラスソフトマックスはよく使うやり方なので理論的な部分を理解するのは後々役に立つと思いました。
- 投稿日:2020-04-03T21:06:35+09:00
pandas-profilingで相関グラフ描写をSkipする方法
概要
pandas-profilingを実行するにあたり、correlationsやdynamic binningなど高負荷な処理をSkipしたいケースに使える引数があったので備忘としてメモ。
コード
skip_confprofile = ProfileReport(large_dataset, minimal=True) profile.to_file(output_file="output.html")・minimal=Trueを入れる
ケース
・サイズの大きいデータセットにpandas-profilingかけたい時
・pandas-profilingがcorrelationsやdynamic binningでエラーが発生する時参照
https://github.com/pandas-profiling/pandas-profiling#large-datasets
- 投稿日:2020-04-03T21:01:45+09:00
【Python】Windows10でCuPyを導入してCUDAコアを利用するまで
導入でハマったので記事にしました。
CuPy?
NumPy互換のGPU演算用ライブラリです。
Python での 高速計算。 NumPy 互換 GPU 計算ライブラリ cupy
https://purakaku-python.readthedocs.io/ja/master/chapter_ml/cupy.html環境
記事に必要そうな範囲のみ抽出
種別 スペック/バージョン CPU Intel Core i7-9770K RAM DDR4-2133 32GB (8GBx4) GPU NVIDIA GeForce GTX1080Ti OS Windows10 Pro 1909 64Bit CUDA Toolkit10.2 10.2.89 Python3 3.7.6 CuPy v7 7.3.0 自己責任でお願いします
CuPyはWindowsでの動作を保証していません。
また、当ページではWindowsでの利用方法を説明していますが、非サポート環境での利用を推奨しているものではありません。CUDAバージョンの確認
コマンドプロンプト等で以下のコマンドを実行
nvcc -V実行後、以下のようなレスポンスがあれば正常に確認できています。
nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2019 NVIDIA Corporation Built on Wed_Oct_23_19:32:27_Pacific_Daylight_Time_2019 Cuda compilation tools, release 10.2, V10.2.89CuPyインストール時に利用するので、最後の行の
releaseの数字を控えておきます。
この場合は10.2だけ控えておけば問題ありません。あれ、違うレスポンス?
'nvcc'は、内部コマンドまたは外部コマンド、 操作可能なプログラムまたはバッチ ファイルとして認識されていません。このようなレスポンスがあった場合はCUDA Toolkitをインストールする必要があります。
CUDA Toolkitのインストール
ダウンロード
CUDA Toolkitのダウンロードページから、インストールする環境にあったものをダウンロードします。
exe[network]とexe[local]はどちらでも構いません。インストール
表示される手順に従ってそのままインストールします。
CuPyの導入
控えていた数字はここで使います。今回の場合では
10.2でしたので、コンマを除いて以下のように入れてインストールします。pip install cupy-cuda102インストールが正常に完了したらシステムを再起動します。
使用方法は以下の記事が参考になります。pythonで簡単にGPU計算ができるCupyを紹介
https://qiita.com/samacoba/items/d18e6cf09f544477aff4importできない
import cupy as cp Traceback (most recent call last): File "C:\Users\thzking\AppData\Local\Continuum\anaconda3\lib\sit... ... (いっぱいエラー) ... ImportError: DLL load failed: 指定されたモジュールが見つかりません。以下の方法で解決できるかもしれません。
- セットアップ後、システムを再起動していない場合は再起動(重要)
- CUDAのバージョン再確認
- CuPyの再インストール
- CUDA Toolkitの再インストール
- 投稿日:2020-04-03T20:51:17+09:00
SQLiteが対応していないSQL文の仕様とALTER TABLE操作の対応法
はじめに
SQLite3は構築が簡単であることや軽量で使い勝手はいいが、一部のSQL文が対応しておらず、苦労する部分がある。例えば、ALTER TABLE系の機能はRENAME COLUMNやADD COLUMNなどしか対応していない。
この仕様に辿り着くのも時間がかかったことと対処法が結構面倒なので、備忘として残しておく。
(やりたかったのはテーブル定義を変更するところなのでそれのやり方を)やりかた
大まかな手順は以下の通り
- 元テーブルのCREATE TABLE文を取得する
- 1で取得したSQLを基に、スキーマ定義を変更した一時テーブルを作成する
- 2で作成したテーブルに、元テーブルのデータをINSERTする
- 元テーブルをDROP TABLEする
- 一時テーブルをRENAME TABLEする
やってること自体はシンプルだが、機械化するには2番目の操作が結構厄介。Pythonで対応してみたのが下の部分。(それでも、スキーマ定義の変更は都度設定が必要。。。。)
SQLite3の操作import sqlite3 con = sqlite3.connect('test.db') cur = con.cursor() create_table_sql = cur.execute("select sql from sqlite_master where name = 'target_table'").fetchone()[0] create_temp_table_sql = ( # 一時テーブル作成SQLへの変更例 create_table_sql .lower() .replace('target_table', 'temp_table') .replace(')', ', foreign key (test_fk) references test_table(id) )') # 外部キーの追加文をいれる ) cur.execute(create_temp_table_sql) cur.execute('insert into temp_table select * from target_table') cur.execute('drop table target_table') cur.execute('alter table temp_table rename to target_table') cur.close() con.close()これだと複雑な結合関係のテーブルの更新に苦労するので、他にいい手段がないだろうか。。。
参考
- 投稿日:2020-04-03T20:14:53+09:00
多層ニューラルネットワーク(Keras)のパラメータを変えて損失関数の値に与える影響を評価した(題材:MNIST分類)
はじめに
ニューラルネットワークはKerasやChainer, Torchなど多くのフレームワークが用意されており1行ずつ組み合わせることで簡単にモデルを作成することが可能です。
なるべく早い時間で計算を行え、正確であることが良いモデルです。
今回、正確なモデルを作成する観点でモデルのパラメータを変えたときに損失関数の値に与える影響を評価しました。
今回の要点はこちらです。
- モデルの概要
- 活性化関数による差
- 最適化手法による差
- ニューラルネットワークの層による差
モデルの概要
今回はチュートリアルとしてよく使用される手書き数字認識MNISTを題材にします。ニューラルネットワークはKerasのフレームワークを用いて構成したいと思います。
Kerasの場合は以下の記述でニューラルネットワークモジュールをインポートすることが可能で、かつMNISTデータを格納させることが可能です。NN.ipynbimport tensorflow as tf import tensorflow.keras.layers as layers from tensorflow.keras.layers import LeakyReLU from sklearn.model_selection import train_test_split (X_train,y_train),(X_test,y_test)=tf.keras.datasets.mnist.load_data()ちなみに使用したkeras及びtensorflowのバージョンは下記です。tensorflow下のkerasとして動かしています。
- tensorflow 2.1.0
- keras-applications 1.0.8
- keras-preprocessing 1.1.0
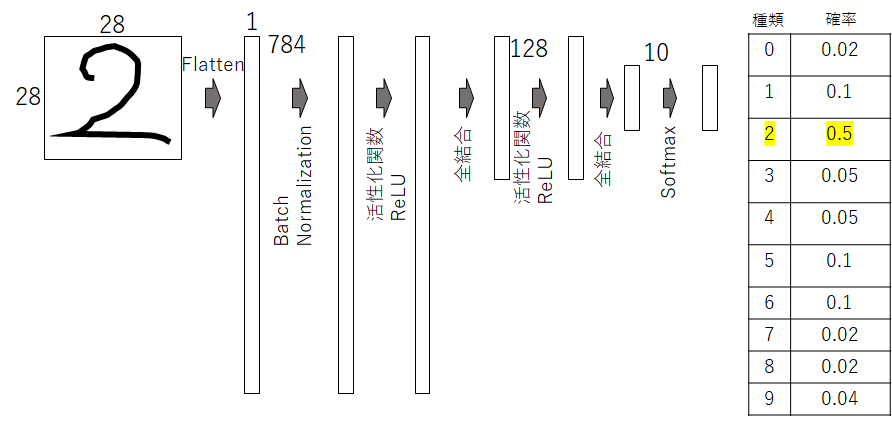
ニューラルネットワークのモデルの構成はこちらです。今回は畳み込みを利用せずに最初に平坦化させています。そして、全結合層は2層あります。
NN.ipynbinputs = layers.Input((28,28)) # 入力層 x = layers.Flatten()(inputs) # 平坦化 x = layers.BatchNormalization()(x) # Batch Normalization(収束させやすくします) x = layers.Dense(128, activation='relu')(x) #全結合層 x = layers.Dense(10, activation="softmax")(x) #全結合層&ソフトマックス関数 outputs = x model = tf.keras.models.Model(inputs, outputs)kerasにはモデルの概要を見えることができるコマンドsummaryが用意されています。
NN.ipynbmodel.summary()Model: "model_10" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_11 (InputLayer) [(None, 28, 28)] 0 _________________________________________________________________ flatten_10 (Flatten) (None, 784) 0 _________________________________________________________________ batch_normalization_9 (Batch (None, 784) 3136 _________________________________________________________________ dense_21 (Dense) (None, 128) 100480 _________________________________________________________________ dense_22 (Dense) (None, 10) 1290 ================================================================= Total params: 104,906 Trainable params: 103,338 Non-trainable params: 1,568各層での処理やパラメータなどよく分かりますね。
活性化関数による差
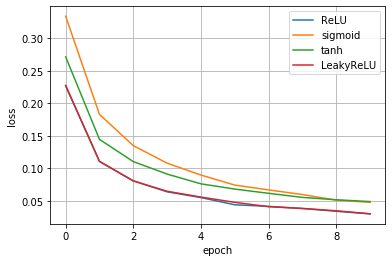
まずは活性化関数の差による損失関数の収束の仕方を評価していきたいと思います。今回は代表的なものとして下記4つを試します。
- ReLU
- LeakyReLU
- tanh
- Sigmoid
各関数の概要は多くのページで解説されています。私もまとめたものがありますので、こちらをご覧頂けると幸甚です。
3層順伝搬型ニューラルネットワークを自作して、計算を深く理解しようとした
https://qiita.com/Fumio-eisan/items/3038041c1ed076d643e7モデルの定義
NN(acti.)OK.ipynbinputs = layers.Input((28,28)) x = layers.Flatten()(inputs) x = layers.BatchNormalization()(x) x = layers.Dense(128, activation=LeakyReLU(alpha=0.01))(x)#ここを書き換えて活性化関数を変更 x = layers.Dense(10, activation="softmax")(x) outputs = x model = tf.keras.models.Model(inputs, outputs)さて、上記の一文を変えることで活性化関数を変えることができます。
モデルのコンパイルと学習
NN(acti.)OK.ipynbmodel.compile('adam', 'sparse_categorical_crossentropy',['sparse_categorical_crossentropy']) history = model.fit(X_train, y_train, epochs=10, verbose=1, validation_data=(X_test, y_test))NN(acti.)OK.ipynbnb_epoch = len(loss1) plt.plot(range(nb_epoch), loss1, label='ReLU') plt.plot(range(nb_epoch), loss2, label='sigmoid') plt.plot(range(nb_epoch), loss3, label='tanh') plt.plot(range(nb_epoch), loss4, label='LeakyReLU') plt.legend(loc='best', fontsize=10) plt.grid() plt.xlabel('epoch') plt.ylabel('loss') plt.show()
この縦軸のloss値(=損失関数の値)が低くなるほどより誤差が少ない正確なモデルであることを意味します。
結果は、ReLUとLeakyReLUが同等でその次にtanh<sigmoidであることが分かりました。基本、ReLUを使っていることが多い理由が分かりましたね。最適化手法による差
続いて、最適化手法の差です。最適化手法は損失関数の値を小さくするうえで、重みパラメータなどの値を更新する方法です。詳細はこちらの記事をご覧ください。
ニューラルネットワークにおける最適化手法(SGDからADAMまで)を丁寧に理解しようとした
https://qiita.com/Fumio-eisan/items/798351e4915e4ba396c2最適化手法は下記のコンパイル時に引数として与えることで指定することができます。
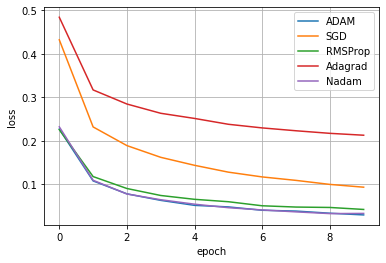
今回適用した最適化手法は歴史順にSGD,RMSProp,Adagrad,Adam,Nadamです。NN(opti.)OK.ipynbmodel.compile('adam', 'sparse_categorical_crossentropy',['sparse_categorical_crossentropy'])※下記は活性化関数はReLUに統一です。
結果がこちらになります。やはり、AdamとNadamが良いことが分かります。RMSpropもかなり良いloss値まで下がっています。多くのモデルでAdamを推奨していることが分かりますね。
ニューラルネットワークの層による差
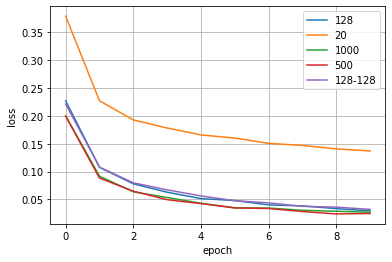
最後に、ニューラルネットワークの層の決め方による差を評価します。下記に示す条件を試算しました。
※活性化関数はReLU(活と表記), 最適化手法はAdam, BatchNormalizationはBNと表記しています。
その結果がこちらです。だいたい一緒なのですが、中間層が20のCase3.の収束が遅いことが分かります。あまりに中間層の数が少ないと区別する表現が乏しくなるためだと思います。逆に、それ以上の128以上だとほぼサチレートしていくことから、これ以上の表現力では今回のMNISTでは十分であることが分かります。
終わりに
今回、地道に条件を変えてニューラルネットワークの損失関数の値を評価しました。活性化関数はReLU、最適化手法はADAMと一般的に使われている手法に行きついている理由がよくわかりました。
次回は畳み込みの最適化に着目した評価をしていければと思います。
プログラムはこちらに格納しています。
※パラメータを変えることはご自身でお願いいたします。そのまま動かすと一条件のみの結果が出力されるプログラムになっています。
https://github.com/Fumio-eisan/minist_mlp20200307

- 投稿日:2020-04-03T19:33:51+09:00
Twitterのトレンドをミュートして快適なTwitterライフを!!
TLが騒がしくない?
どうも、LilyMameokaです。お久しぶり。私ね、常日頃思っていたんですけど、TL、騒がしくない?
何かアニメが放送されている時間とか(日曜の朝とかね)、某コンビニ大手がキャンペーンやってる時とか、某ソシャゲがキャンペーンやってる時とか、某富豪やYoutuberがプレゼントキャンペーンやってる時とか、○断メー○ーとか...。普通にTLが賑やかなのはいいんですけど、先程挙げた、見ている側には無益なツイートでTLが騒がしいのは不快ですよね。どうでもいいツイートでTL埋めやがってクソが。
あと、折角現実逃避しにTwitterに来たのに、週刊誌が扱うようなTHE☆俗世なワードが流れてくるのもムカつくので...トレンドワードを片っ端からミュートして平和なTLを取り戻したいと思いま〜〜〜〜〜〜〜〜〜〜〜〜〜〜〜す!!!!
トレンドの取得
まずはトレンドワードの取得です。ただし、トレンドワード全部から処理すると、かなりの量のユーザーをミュートしてしまうので(それは申し訳ないので)、ハッシュタグのついているものだけを取得したいと思います!
get_trends.py#!/usr/bin/env python # -*- coding:utf-8 -*- import tweepy CONSUMER_KEY='' CONSUMER_SECRET='' auth = tweepy.OAuthHandler(CONSUMER_KEY, CONSUMER_SECRET) ACCESS_TOKEN = '' ACCESS_TOKEN_SECRET = '' auth.set_access_token(ACCESS_TOKEN, ACCESS_TOKEN_SECRET) def get_trends(api): trend = api.trends_place(23424856)[0] trends = trend['trends'] print(u"Trends:") for i in range(len(trends)): print(u"\t{0}".format(trends[i]["name"])) if __name__ == '__main__': api = tweepy.API(auth) get_trends(api)これを実行すると...
Trends: #この夏に水着姿を見たいキャラ #キン肉マンアニメ化 #彼女からの予測変換でリア充がバレる #ドスパラ春のセールでほしいもの #少クラ #現金給付 #まあたそ大先生 #ムジカピッコリーノ #エイトちゃんのおたんじょう日会 #あなたのおっさん度診断 #関ジャニ8TV #かずみんモバメ #水着の上下重ねて #グラクロ攻略質問 #うちで踊ろうお!出てきたね〜〜〜。今回は日本のトレンドを対象にしているので場所のIDは23424856です。調べたら、東京は1118370らしい。
平和なTLへ!!
さーて、本題。
と思いきや!なんと、TwitterAPIはキーワードミュートに対応していないとのこと。
https://stackoverflow.com/questions/55916527/is-there-a-way-to-create-and-destroy-muted-words-using-the-twitter-api
うーん。仕方ない。その単語をツイートした人をミュートしちゃお☆
私のTLの平和のためには多少の犠牲も仕方ないのだ!許してね♡trend_blocker.py#!/usr/bin/env python # -*- coding:utf-8 -*- import tweepy CONSUMER_KEY='' CONSUMER_SECRET='' auth = tweepy.OAuthHandler(CONSUMER_KEY, CONSUMER_SECRET) ACCESS_TOKEN = '' ACCESS_TOKEN_SECRET = '' auth.set_access_token(ACCESS_TOKEN, ACCESS_TOKEN_SECRET) mute_words = [] def get_trends(api): trend = api.trends_place(23424856)[0] trends = trend['trends'] for i in range(len(trends)): if trends[i]["name"].startswith("#"): mute_words.append(trends[i]["name"]) def mute(): api = tweepy.API(auth) get_trends(api) count = 1 #各ワードにおけるお好みのミュート数を入れてください for mute_word in mute_words: print(mute_word) search_res = api.search(q = mute_word,count = count) for res in search_res: print(res.user.screen_name) api.create_mute(res.user.screen_name) print("--------------------------------------") if __name__ == '__main__': mute()よし!!!これで平和なTLが取り戻せた!素晴らしいね!
早速、快適なTLで現実逃避してきま〜〜〜〜〜〜〜〜〜す!!参考資料
- 投稿日:2020-04-03T18:50:26+09:00
ploty Dash でapp.pyからコンポーネントとコールバックを切り出す
やりたいこと
- dashでまあまあな規模のウェブページを作る
- app.pyに全部書くのは整備性がやばいので分割したい
例のごとく英語でもドキュメントが全然見つからないので併記します
splitting callback and components in multiple files
use the : deeplちなみに公式のサンプル自体は大量に存在するが、どいつもこいつもapp.pyが数百行あってやばい
dash触ってまだ2ヶ月くらいなので、よりよい解決法があれば教えて下さい
やったこと
ファイルの構造を考える
- 最低限コンポーネントとコールバックは切り出したい
- どんどん増えるであろうコンポーネントとコールバックをそれぞれ管理する奴も必要そう
早い話 ↓これを
. ├── app.py ├── assets │ ├── common.css │ └── default.css └── src └── some_utils.py↓こんなかんじにすればよさそう
. ├── app.py ├── assets │ ├── common.css │ └── default.css │ └── src ├── callback.py ├── callbacks │ ├── hoge.py │ ├── fuga.py │ └── poyo.py │ ├── layout.py ├── components │ ├── fizz.py │ ├── buzz.py │ ├── boo.py │ └── bar.py │ ├── some_utils.py └── utilsapp.pyの整理
せっかくなので自分の別記事のソースを拝借する
Dashでdcc.CheckListのチェック状態を全選択・全解除するボタンの実装
python app.pyで起動し、http://localhost:8050 で閲覧できる
↓こんな画面になる
app.pyimport dash import dash_core_components as dcc import dash_html_components as html import dash_table from dash.dependencies import Input, Output, State from flask import Flask, request import time server = Flask(__name__) app = dash.Dash(__name__, server=server) app.title = 'checklist-test' selected_key = None checklists = dcc.Checklist( id='checklist-states', options=[ {'label': 'New York City', 'value': 'NYC'}, {'label': 'Montréal', 'value': 'MTL'}, {'label': 'San Francisco', 'value': 'SF'} ], value=['MTL', 'SF'] ) app.layout = html.Div(id='main',children=[ html.H1(children='チェックリストのテスト'), dcc.Location(id='location', refresh=False), html.Div(className='main-block', children=[checklists]), html.Div(className='second', children=[ html.Button('全選択', id='filter-check-button', className='filter_button'), html.Button('全解除', id='filter-remove-button', className='filter_button') ]) ]) @app.callback( [Output('checklist-states', 'value')], [Input('filter-check-button', 'n_clicks_timestamp'), Input('filter-remove-button', 'n_clicks_timestamp')], [State('checklist-states', 'value')] ) def update_check(all_check, all_remove, checking): if not all_check is None: if (time.time() * 1000 - all_check) < 1000: return [['NYC', 'MTL', 'SF']] if not all_remove is None: if (time.time() * 1000 - all_remove) < 1000: return [[]] if all_check is None and all_remove is None: return [checking] if __name__ == '__main__': app.run_server(host='0.0.0.0', debug=True)dashオブジェクトの
appにレイアウトとコールバックが紐付いているので、別の関数にappを直接渡すことで処理してくれそうというわけで未来の自分に仕事を投げつつapp.pyを削れるだけ削る
app.pyimport dash from flask import Flask from src.layout import layout from src.callback import callback server = Flask(__name__) app = dash.Dash(__name__, server=server) app.title = 'checklist-test' # componentsとcallback定義 app = layout(app) callback(app) if __name__ == '__main__': app.run_server(host='0.0.0.0', debug=True)tips:
コールバックの登録は絶対にコンポーネント定義の後である必要がある
importされた瞬間に入力値がnullのコールバックが走るため、Input/Output/Stateで見ているコンポーネントが存在しないとエラーになるコンポーネントとレイアウト
言うまでもないが、ファイル名は適当に自分の納得したやつに変えてくださいね
レイアウトの切り出し
引数として受け取った
appの属性layoutに対して、html要素を代入するlayout.pyimport dash_core_components as dcc import dash_html_components as html def layout(app): checklists = dcc.Checklist( id='checklist-states', options=[ {'label': 'New York City', 'value': 'NYC'}, {'label': 'Montréal', 'value': 'MTL'}, {'label': 'San Francisco', 'value': 'SF'} ], value=['MTL', 'SF'] ) # app.layoutに要素を代入 app.layout = html.Div(id='main', children=[ html.H1(children='チェックリストのテスト'), dcc.Location(id='location', refresh=False), html.Div(className='main-block', children=[checklists]), html.Div(className='second', children=[ html.Button('全選択', id='filter-check-button', className='filter_button'), html.Button('全解除', id='filter-remove-button', className='filter_button') ]) ]) return appコールバックの切り出し
tips:
直に
update_checkを呼ぼうとするとデコレータ部分をうまく解釈できないので、一段階深くしてデコレータごと別の関数で囲う必要がある
(要は@app.callback()のappが名前解決できる必要がある)callback.pyfrom dash.dependencies import Input, Output, State import time def callback(app): @app.callback( [ Output('checklist-states', 'value') ], [ Input('filter-check-button', 'n_clicks_timestamp'), Input('filter-remove-button', 'n_clicks_timestamp') ], [ State('checklist-states', 'value') ] ) def update_check(all_check, all_remove, checking): if all_check is not None: if (time.time() * 1000 - all_check) < 1000: return [['NYC', 'MTL', 'SF']] if all_remove is not None: if (time.time() * 1000 - all_remove) < 1000: return [[]] if all_check is None and all_remove is None: return [checking]コンポーネントとコールバックが増えたときの対処
コンポーネントのさらなる分割
タイトル・チェックリスト・ボタンの3つを別々に管理する
layoutではブロックとスペーシングの管理のみ行う想定tips:
html.Div()に属性idは必須ではないlayout.pyfrom src.components import title, checklist, button import dash_core_components as dcc import dash_html_components as html def layout(app): app.layout = html.Div(id='main', children=[ html.Div(id='title-block', children=[title.layout()]), dcc.Location(id='location', refresh=False), html.Div(id='center-block', children=[ html.Div(children=checklist.layout()), html.Div(children=button.layout()) ]) ]) return apptitle.pyimport dash_html_components as html def layout(): return html.H1(id='title', children='チェックリストのテスト')checklist.pyimport dash_core_components as dcc def layout(): return dcc.Checklist( id='checklist-states', options=[ {'label': 'New York City', 'value': 'NYC'}, {'label': 'Montréal', 'value': 'MTL'}, {'label': 'San Francisco', 'value': 'SF'} ], value=['MTL', 'SF'] )button.pyimport dash_html_components as html def layout(): return html.Button('全選択', id='filter-check-button', className='filter_button'), html.Button('全解除', id='filter-remove-button', className='filter_button')コールバックのさらなる分割
同じように機能ごとに切り出す
callback.pyfrom src.callbacks import check_and_remove # hoge, fuga... def callback(app): check_and_remove.register(app) # hoge.register(app) # fuga.register(app)
check_and_remove.pyfrom dash.dependencies import Input, Output, State import time def register(app): @app.callback( [ Output('checklist-states', 'value') ], [ Input('filter-check-button', 'n_clicks_timestamp'), Input('filter-remove-button', 'n_clicks_timestamp') ], [ State('checklist-states', 'value') ] ) def update_check(all_check, all_remove, checking): if all_check is not None: if (time.time() * 1000 - all_check) < 1000: return [['NYC', 'MTL', 'SF']] if all_remove is not None: if (time.time() * 1000 - all_remove) < 1000: return [[]] if all_check is None and all_remove is None: return [checking]最終的な構造
. ├── app.py └── src ├── callback.py ├── callbacks │ └── check_and_remove.py ├── components │ ├── button.py │ ├── checklist.py │ └── title.py └── layout.py

- 投稿日:2020-04-03T18:37:02+09:00
Pythonで簡単な作業を自動化する 目次
目次
Part0 https://qiita.com/Faguri/items/c9509a0915317f94f4ba
Part1 まだ
Part2 出せるかわからない
Part3 お先真っ暗
- 投稿日:2020-04-03T18:22:13+09:00
djangoのセッション保持期間について調べてみた
疑問点
djangoアプリの作成中にrunserverでアプリの再起動した場合、
画面をリロードしたり、URLを直接叩いてもログインしたままの状態となっていた。
views.pyで定義した@login_requiredを疑ったが問題なかった。そもそもログインセッションをどのタイミングで更新しているのか、
どれぐらいの期間で保持しているのか、ログインセッションについて調べたことを忘備録として作成する。djangoのセッションについては主に↓を参照した
セッション情報の入出力
セッション情報はdjango_sessinoテーブルにセッション情報データを管理しており、
ログイン時はセッションデータをinsertし、ログアウト時はセッションデータをdeleteしている。
つまり、django_sessinoテーブルにセッション情報データが登録されている間が認証中となる。上記はデータベースを使ったセッションの管理方法であり、
ファイルやクッキーを使ったセッションの管理方法は対象外とする。セッションの永続化
ブラウザの終了でセッションを破棄するかはパラメータ
SESSION_EXPIRE_AT_BROWSER_CLOSEで制御しており、デフォルト値はFalse。ブラウザ終了時のセッションを
* True -破棄する
* False-破棄しない
SESSION_EXPIRE_AT_BROWSER_CLOSEがFalseの場合、セッション情報は利用者のクッキーで保管される。
保存期間はSESSION_COOKIE_AGEパラメータで制御され、デフォルト値は1209600(2週間の秒表記)。まとめ
- 画面を開いている間でログインセッションを有効にする場合は
SESSION_EXPIRE_AT_BROWSER_CLOSEをTrueにする- 一定期間でセッションタイムアウトを行うには、
SESSION_EXPIRE_AT_BROWSER_CLOSEをFalseに、SESSION_COOKIE_AGEに期間を指定する。- djangoのチュートリアルに出てこない内容は難しい
- 投稿日:2020-04-03T18:10:49+09:00
pip使おうとするとSSL module is not available.になる件
先に結論
1. pythonをinstallし直しましょう。
$pyenv install <使いたいpythonのversion>2. pipをinstallし直しましょう。
$ curl -kL https://bootstrap.pypa.io/get-pip.py | python環境
macOS 10.14.6
pyenv経緯
久しぶりにmacでpython使う用事ができた。
どれ、必要なモジュールをpipで入れようかな?発生事態
一先ず、searchしたろかい、ポチッとな。
$ pip search blurblur Exception: Traceback (most recent call last): File "/Users/someone/.pyenv/versions/3.6.1/lib/python3.6/site-packages/pip/_vendor/requests/adapters.py", line 423, in send timeout=timeout File "/Users/someone/.pyenv/versions/3.6.1/lib/python3.6/site-packages/pip/_vendor/requests/packages/urllib3/connectionpool.py", line 583, in urlopen conn = self._get_conn(timeout=pool_timeout) File "/Users/someone/.pyenv/versions/3.6.1/lib/python3.6/site-packages/pip/_vendor/requests/packages/urllib3/connectionpool.py", line 257, in _get_conn return conn or self._new_conn() File "/Users/someone/.pyenv/versions/3.6.1/lib/python3.6/site-packages/pip/_vendor/requests/packages/urllib3/connectionpool.py", line 808, in _new_conn raise SSLError("Can't connect to HTTPS URL because the SSL " pip._vendor.requests.packages.urllib3.exceptions.SSLError: Can't connect to HTTPS URL because the SSL module is not available. During handling of the above exception, another exception occurred: Traceback (most recent call last): File "/Users/someone/.pyenv/versions/3.6.1/lib/python3.6/site-packages/pip/basecommand.py", line 215, in main status = self.run(options, args) File "/Users/someone/.pyenv/versions/3.6.1/lib/python3.6/site-packages/pip/commands/search.py", line 45, in run pypi_hits = self.search(query, options) File "/Users/someone/.pyenv/versions/3.6.1/lib/python3.6/site-packages/pip/commands/search.py", line 62, in search hits = pypi.search({'name': query, 'summary': query}, 'or') File "/Users/someone/.pyenv/versions/3.6.1/lib/python3.6/xmlrpc/client.py", line 1112, in __call__ return self.__send(self.__name, args) File "/Users/someone/.pyenv/versions/3.6.1/lib/python3.6/xmlrpc/client.py", line 1452, in __request verbose=self.__verbose File "/Users/someone/.pyenv/versions/3.6.1/lib/python3.6/site-packages/pip/download.py", line 775, in request headers=headers, stream=True) File "/Users/someone/.pyenv/versions/3.6.1/lib/python3.6/site-packages/pip/_vendor/requests/sessions.py", line 522, in post return self.request('POST', url, data=data, json=json, **kwargs) File "/Users/someone/.pyenv/versions/3.6.1/lib/python3.6/site-packages/pip/download.py", line 386, in request return super(PipSession, self).request(method, url, *args, **kwargs) File "/Users/someone/.pyenv/versions/3.6.1/lib/python3.6/site-packages/pip/_vendor/requests/sessions.py", line 475, in request resp = self.send(prep, **send_kwargs) File "/Users/someone/.pyenv/versions/3.6.1/lib/python3.6/site-packages/pip/_vendor/requests/sessions.py", line 596, in send r = adapter.send(request, **kwargs) File "/Users/someone/.pyenv/versions/3.6.1/lib/python3.6/site-packages/pip/_vendor/cachecontrol/adapter.py", line 47, in send resp = super(CacheControlAdapter, self).send(request, **kw) File "/Users/someone/.pyenv/versions/3.6.1/lib/python3.6/site-packages/pip/_vendor/requests/adapters.py", line 497, in send raise SSLError(e, request=request) pip._vendor.requests.exceptions.SSLError: Can't connect to HTTPS URL because the SSL module is not available.オウフ...
試行錯誤
とりあえずは、先生に訊きます。常識です。
https://qiita.com/akashixi/items/14d05ddf0a3d1176956c
https://www.unknownengineer.net/entry/2018/06/20/191011
https://www.secat-blog.net/wordpress/python3-cannot-install-numpy-by-pip-fix/
みんな、python3.8.0を入れたり、openSSLを更新したりしてますね。真似して、3.8.0を入れてpipしてみたらSSLErrorは吐かず。
でも、3.6.1にすると相変わらずのSSLError。
opensslを更新して、デフォから切り替えたりもしました。$brew install openssl $echo 'export PATH="/usr/local/opt/openssl@1.1/bin:$PATH"' >> ~/.bash_profileそれでもSSLErrorは治らず。
解決
pythonをinstallし直します。
$ pyenv install 3.6.1pipもインストールし直します。
$ curl -kL https://bootstrap.pypa.io/get-pip.py | pythonで、pipを使ってみると...
$ pip search blur blur (0.4) - A chance art toolkit. blur-clip-board-image-cli (0.0.4) - Blur clip board image command line tool for macOS pyblur (0.2.3) - Image blurring routines WallaBlur (1.0.1) - blur background on window opening pillow-stackblur (0.0.2) - The Pillow filter for Stack Blur. blurit (0.0.12) - This package is aimed to build to blur different portions of a image. Currently it blurs eyes in human photograph. BlurWal (1.1.1) - Smoothly blurs the wallpaper when windows are opened. pysaber (0.1.5) - Python package that implements a systems approach to blur estimation and reduction (SABER) azureblur (0.1) - The triple box blur implementation from Firefox’s moz2d/Azure, with Python bindings. imgic (0.2.8) - A basic numpy-based image manipulation package. Contains tools for resizing, cropping, blurring, and others. Products.ImageEditor (3.0.0) - adds a "Image Editor" link near the image widget allowing the user to rotate, flip, blur, compress, change contrast & brightness, sharpen, add drop shadows, crop, resize an image, save as, and apply sepia.やったぜ。
- 投稿日:2020-04-03T17:57:25+09:00
Pythonで毎日AtCoder #25
はじめに
#25
おすすめされた問題を解きます。
ABC105-C考えたこと
まず、普通の2進数にするときの手法を考えます。これで10進数を2進数に変換します。これを-2進数版にします。変更点は、余りは自然数になるのでうまく余りを調整しないといけない点です。
-2で割りきれるときは余りが出ないのでそのままn//2します。余りが出る時は、n-1してから-2で割るとうまく計算できます。
この計算方法でappendしていくと、答えの順番が逆なのでreverseします。あとは、joinでstrにするだけです。n = int(input()) if n == 0: print(0) quit() base = [] while n != 1: if n % -2 == 0: base.append('0') n //= -2 else: base.append('1') n -= 1 n //= -2 base.append('1') #最後に1するのを忘れない base.reverse() ans = ''.join(base) print(ans)まとめ
楽しい。では、また
- 投稿日:2020-04-03T17:26:43+09:00
LSTMでFX価格予測を試してみた
KerasのLSTMでFX予測
他にこんな記事は腐るほどあるのですが、実際やってみたので中身と結果を書いていきます。
LSTMと検索すると2番目にStock predictionと候補に出てきたことからも、誰もが考えることなんだと思います。
多くの人が同じことを試し、うまくいっていないのはすぐに分かりましたが、自分で試して納得したかったし、勉強にもなりそうだったので試してみました。今回作ったものはここに置いています。
satken2/lstm_prediction - Github(注)この記事はKerasの実装方法と結果を淡々と描いただけで、数学的・統計学的要素はありません。
やりたいこと
今回やりたいのは、ビットコインの価格予測です。
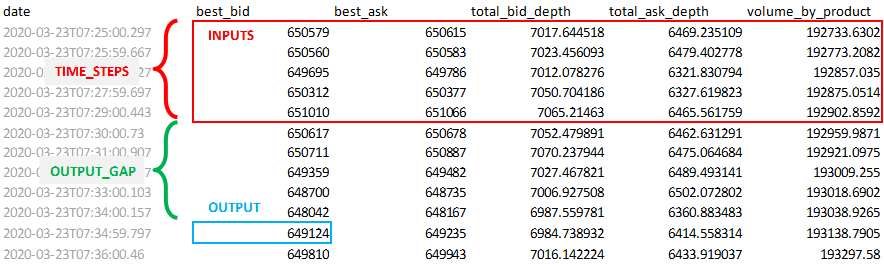
直近TIME_STEP分間の価格や取引量データを入力として与えると、現在からOUTPUT_GAP分後の価格を予測してくれるモデルを作成します。下の図で言うと、赤枠のデータを入力として与えた時に、青枠のデータを予測してくれるようなプログラムを作ります。
この図の場合、「現在」を7:29とした時に、直近5分のデータを元に5分後のbest_bidを予測するということです。
プログラム
このモデルをLSTMで実装したので、やり方をざっくり書いていきます。
そもそもLSTMが何なのかについては他にいくらでも記事があるので、ここでは省略します。Kerasって何?
Kerasというのは高水準のニューラルネットワークライブラリです。
ディープラーニングとかニューラルネットワークとかを1から実装するのは大変なのでTernsorFlowやTheanoとかのライブラリが作られましたが、そういうライブラリでもニューラルネットワークを作るにはそれなりのコードを書く必要があります。
そこで、TensorFlowやTheanoをラッピングしてもっと簡単にしたライブラリがKerasです。
ニューラルネットワークを少なく直感的なコードで実装できるようになっているので、初心者にも扱いやすいです。今回はKerasを使ってシンプルに実装しました。
データの準備
前提として、CSV形式(CSV以外でもいいですが、この例ではCSVです)で集まった時系列のデータを準備しておきます。
今回は、Bitflyer APIで取得した1分単位のビットコインの価格データをCSVにして準備しています。
いい感じのデータが見つからなかったので、自分で集めました。↓こんな感じのものです。
fx_btc_jpy.csvdate,best_bid,best_ask,total_bid_depth,total_ask_depth,volume_by_product 2020-03-23T07:25:00.297,650579.0,650615.0,7017.64451802,6469.23510851,192733.63015592 2020-03-23T07:26:00.667,650560.0,650583.0,7023.45609319,6479.40277842,192773.208189 2020-03-23T07:27:00.227,649695.0,649786.0,7012.07827614,6321.83079407,192857.03498211 2020-03-23T07:28:00.697,650312.0,650377.0,7050.70418556,6327.61982308,192875.0513729 2020-03-23T07:29:00.443,651010.0,651066.0,7065.2146304,6465.56175859,192902.85924585 2020-03-23T07:30:00.73,650617.0,650678.0,7052.47989075,6462.6312908,192959.98713855 :実装
じゃあ、肝心の実装に行きます。
やることは大きくこんな感じです。
- CSVデータの読み込み
- データを学習用と検証用に分割
- インプットデータと正解データのセットを作成
- データの正規化
- モデルの作成
- 学習
- 結果の検証
この中でKerasを使っているのは、「モデルの作成」「学習の実行」「結果の検証」です。
1.CSVデータの取り込み
データの読み込みではPandasというライブラリをよく使います。
笹食ってるクマ?じゃないですよ。英語のpanel dataから取ってpan(el)-da(ta)-sだそうです。(Wikipedia)pandasでCSVを読み込むとDataFrameというpandasの形式で返してくれます。
df_input = pd.read_csv(input_path, engine='python') print(df_input.dtypes)date object best_bid float64 best_ask float64 total_bid_depth float64 total_ask_depth float64 volume_by_product float64 dtype: object2.データを学習用と検証用に分割
LSTMに限らず、ディープラーニング全般は学習し終わってハイ終わりではなくてちゃんと学習したモデルで予測がうまくいくかを検証する必要があります。
学習に使ったデータを使って検証したら正しく評価できないこともあるので、データの一部を敢えて学習には使わずに検証用として残しておきます。
今回は8:2の割合で学習用と検証用に分けています。
train_test_splitというDataFrameを分けてくれる関数がsklearnにあるのでそれを使います。便利ですね。df_train, df_test = train_test_split(df_input, train_size=0.8, test_size=0.2, shuffle=False) print("Train-Test size", len(df_train), len(df_test))Train-Test size 7826 19573.インプットデータと正解データのセットを作成
下の図で、赤枠と青枠のデータのセットを学習用データとしてモデルに与えるために、大量に作っていきます。
赤枠が問題で青枠が正解と思えばいいでしょう。
実際にはデータはもっと下に続いてるので、枠を1つずつ下にずらしながら大量のセットを作っていきます。
具体的な実装としてはこんな感じです。
dimention_0 = input_data.shape[0] - time_steps - output_gap dimention_1 = input_data.shape[1] x = np.zeros((dimention_0, time_steps, dimention_1)) y = np.zeros((dimention_0,)) for i in range(dimention_0): x[i] = input_data[i:time_steps+i] y[i] = input_data[time_steps+output_gap+i, y_col_index] print("length of time-series i/o",x.shape,y.shape)
input_dataは読み込んだCSVをnumpy配列にしたものです。これを、問題のリストであるxと正解のリストであるyに変換しています。x[n]に対応する正解データがy[n]といった具合です。ndarrayの次元
numpyを扱っているとどの数字がどの次元かがいつも分からなくなるんですが、自分は「Shapeを表示した時、左の数字ほど大きな単位の次元」と覚えています。すごく初心者っぽいですが、、
例えば、「5個の数字で構成される時系列データが1000行あって、それを20セット作った」場合、Shapeは(20, 1000, 5)になります。日本語にした時と逆になるのですね。今回学習のために作りたい入力データのShapeは、上の例で言うと
x = np.zeros((dimention_0, time_steps, dimention_1))の部分です。
これをさっきの考え方で解釈すると、1行がdimention_1個の数字で構成されているデータをtime_steps行並べて、さらにそのセットをdimention_0個作る。という意味です。
結果データは単純に1つの数字なので、yは数字がdimention_0個集まった配列です。4.入力データの正規化
ディープラーニングでは、効率的に学習を進めるために入力データを処理することが多いです。
正規化や標準化といった方法がよく使われますが、今回はMinMaxScalerを使って簡単に正規化をしています。
正規化は、データの最大値を1, 最小値を0として、それに合わせて全ての値をスケールするやり方です。min_max_scaler = MinMaxScaler() x_train = min_max_scaler.fit_transform(df_train.loc[:,feature_columns].values) x_test = min_max_scaler.transform(df_train.loc[:,feature_columns])入力データの処理がなぜ必要なのかは、自分よりももっと賢い人が解説してくれているので、そちらを見てください。
Feature Scalingはなぜ必要?5.モデルの作成
肝心のモデルを作成します。
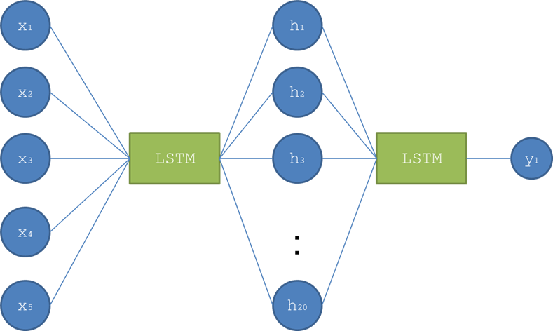
モデルはKerasの機能を使って簡単に書けます。lstm_model = Sequential() lstm_model.add(LSTM(100, batch_input_shape=(batch_size, time_steps, len(feature_columns)), dropout=0.0, recurrent_dropout=0.0, stateful=True, return_sequences=True, kernel_initializer='random_uniform')) lstm_model.add(Dropout(0.4)) lstm_model.add(LSTM(60, dropout=0.0)) lstm_model.add(Dropout(0.4)) lstm_model.add(Dense(20,activation='relu')) lstm_model.add(Dense(1,activation='sigmoid')) optimizer = optimizers.RMSprop(lr=learning_rate) lstm_model.compile(loss='mean_squared_error', optimizer=optimizer)
Sequential()でモデルの元を作成して、add()でレイヤーを追加していきます。
今回作ったモデルをよくある図にするとこんな感じですかね。
入力のShapeは
(batch_size, time_steps, len(feature_columns)です。
さっきの次元の覚え方みたいに逆から読んで日本語にすると、len(feature_columns)個の数字で構成される時系列データがtime_steps分集まっていて、それがbatch_sizeずつかたまりになっているということですね。出力は数分後のbest_bid(1つの値)です。
だったら出力は0次元?と思いそうですが、実際にはbatch_size分をまとめて放り込んでるので、実際に出てくる値は要素数がbatch_sizeの1次元のndarrayになりますね。バッチ
LSTMに限らず、通常ニューラルネットワークでは問題データと正解データを1つずつ入れていくということはせず、計算効率を上げるためにバッチという塊の単位で渡していきます。なので今回一番上位の次元はbatch_sizeになっているわけです。
なぜバッチで渡したら計算が早くなるのかは正直よく知りません。GPUは数値の並列処理に特化した造りになっているので、バッチで並列計算した方がリソースを効率よく使えるというような感じです。6.学習
ここまで準備ができたらよくやく学習です。
model.fitで学習を開始できます。from keras import backend as K model = create_model(learning_rate, batch_size, time_steps, feature_columns) history = model.fit(x_t, y_t, epochs=epochs, verbose=2, batch_size=batch_size, shuffle=False, validation_data=(trim_dataset(x_val, batch_size), trim_dataset(y_val, batch_size)))結果
作ったプログラムを動かしてみて結果を見てみました。
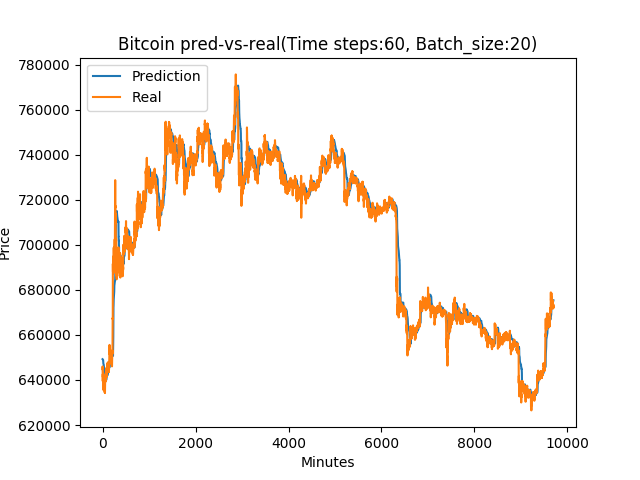
予測値と実際の値の比較
最初に分けておいた検証用データで価格を予測したグラフがこれです。
一見きれいに沿っているように見えますが、よく見ると実データのグラフを少し右にずらしただけ(つまり、直前の値をそのまま出しているだけ)にも見えます。
取引シュミレーション
過去の価格データを元に、取引をシュミレートするプログラムを書いて試しました。
上がると思ったらASK, 下がると思ったらBIDで成行注文を入れて、10分後に反対注文を入れてポジション解消するという単純な想定です。
確か3, 4時間ぐらいのデータを使いました。
うーん。なんか微妙ですね。ほぼ横ばいです。
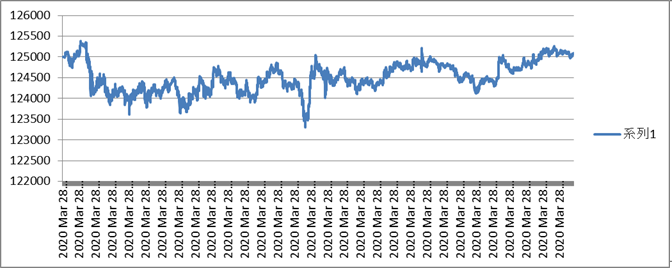
Bitflyer APIで実取引
Bitflyer APIとcronジョブを使って実際にお金を入れて自動取引を試してみました。
条件はさっきと同じで、25時間ほど動かし続けて1000件ぐらい注文が入りました。
最初は順調に上昇していたのですが、、やっぱり横ばいでした。
詳細な分析はしていないので見た目だけの感想ですが、よくよく見るといい感じに上がってたのは2時間目~6時間目ぐらいの間だけでそれ以外は完全に横ばいと言っていい感じですね。最初上がったのはまぐれでしょう。
感想
株価やFXというのは大量の時系列データが手に入りやすいのでLSTMのお試しとしてよく使われますが、モデルを作りやすいというのと予測に適しているかは必ずしも一致しないのでしょう。
なぜうまくいかないのか
冒頭でも書いたように、他の多くの人が株価や外為を予測しようとして上手くいっていないようです。
なぜ相場予測が難しいのか少し考えてみました。あくまで自分の仮説ですが、
相場というのは裁定取引の最たるものなので、仮に動き方に何らかの法則が見つかれば、すぐにその法則で儲けようとする人が増えて法則が崩れるという現象が常に連続して起きていると思います。なので短期的には一定の法則が成り立ちにくい性質のものなのかもしれないと感じました。でも、ドル円の相場とかは本質的にはマクロ経済を反映しているはずなので、長期的な価格の動きは色々な経済指標を学習させたら予測することはできるかもしれません。(ビットコインはわかりませんが、、)
データを集めるのが大変ですけどね。投資におけるDLの使いどころ
また、これは自分の意見ではないですが、以下のサイトでは過去の株価から未来の株価を予測することはできないとした上で、そもそもチャートに固執するやり方ではなく、人間の労力では分析できない大量のIR情報をニューラルネットワークに読み込ませて、株価ではなくそのビジネス全体の動向を分析するような使い方ができるのではないかと意見を述べています。
Stock Prices Don’t Predict Stock Prices - Mediumなんにせよ、ただチャートを読み込ませるだけで価格予測をするというのはあまりにも芸がなかったですね。
参考
How to Use the Keras Functional API for Deep Learning
Predicting Stock Price with LSTM
Stock Prices Don’t Predict Stock Prices - Medium
- 投稿日:2020-04-03T17:23:49+09:00
Pandasを利用して、ExcelファイルにCSVファイルを張り付ける方法
背景
ExcelのVBAでCSVファイルを張り付けるのはダラダラとコードを書く必要があり面倒です。Pythonで簡単に書く方法がないか調べてみました。
目的
Excelの指定シートに、CSVの内容を張り付ける。
xlwingsのインストール
Pythonには、Excelを操作するためのモジュールがいくつかあります。
一番有名なのは、おそらくOpenpyxlかと思います。
ただ、Openpyxlは処理速度は速いものの、不具合(フォーマット崩れるなど)が多いので、
今回はxlwingsを利用したいと思います。xlwingsがインストールされていない場合は、以下のコマンドでインストールしてください。
$ pip install xlwingsコード
今後も利用することが多そうなので関数化しました。
CSVファイルをPandasで読み込んだ後に、指定シートのA1セルに張り付けています。
VBAだとCSVを1行1行読み込んで出力する必要がありますが、
Pandasを利用すると、とてもシンプルに書けます。import pandas as pd import xlwings as xw def csv_to_sheet(wb_name, ws_name, csv_name, save_flg=True, quit_flg=True): """\ 関数の説明: 指定のシートにCSVの内容をコピペする関数 引数の説明: wb_name:ワークブック名 ws_name:シート名 csv_name:CSVのファイル名 save_flg:デフォルトは上書き保存を実施。 quit_flg:デフォルトは閉じる設定 """ df = pd.read_csv(csv_name,encoding='cp932', index_col=0) #CSVファイルをDataFrameで読み込む wb = xw.Book(wb_name) #ワークブックオブジェクトの作成 wss = wb.sheets ws = wss[ws_name] #ワークシートオブジェクトの作成 ws.range('A1').value = df #DataFrameを張り付ける #save_flgがTrueであれば上書き保存 if save_flg: wb.save(path=None) #quit_flgがTrueであればExcelを閉じる if quit_flg: app = xw.apps.active app.quit() #Excelを終了利用方法
Excelファイル、シート名、CSVファイルは任意のものに変更して利用してください。
上書き保存したくない場合は、引数にsave_flg=Falseを、
ファイルを閉じないで引き続き編集する場合は、quit_flg=Falseを渡してください。wb_name = 'Excelファイル名.xlsx' ws_name = 'シート名' csv_name = 'CSVファイル' csv_to_sheet(wb_name, ws_name, csv_name)
- 投稿日:2020-04-03T16:48:23+09:00
Pythonによるマルコフ・スイッチングモデル
1. 経済データの「レジーム」
ITバブル崩壊やリーマンショックなど、経済に急激で大きな変化が生じた時とき、背景で根本的に何らかの状態が変化してしまっていると考えられる場合がある。このような根本的な状態の変化モデルを「レジームスイッチングモデル」という。
変化した状態が観測不可能な場合、レジームスイッチをモデル化することは難しそうである。しかし、レジームの確率分布をパラメータ付きで与え、レジーム間の遷移をマルコフ連鎖と捉えることで、モデル化が可能になる。MCMCによって尤度を最大化するパラメータ(正規分布の平均・標準偏差、レジームの遷移確率)を求めることができるのである。2. マルコフ・スイッチングモデルの解説
レジーム付き線形回帰
以下の線形回帰モデルのレジームスイッチングモデルを考える。
\begin{eqnarray} y\left( t \right) &=& x\left( t \right)\beta + \epsilon\left( t \right)\\ \epsilon\left( t \right)&\sim& N\left(0,\sigma^2\right) \end{eqnarray}各時刻$t$における第$1$〜第$n$レジームを以下のように表す。
\begin{eqnarray} I\left(t\right) \in { 1,2,\cdots ,n} \end{eqnarray}レジームを観測できる場合、回帰式はレジームを添え字として以下のように表される。
\begin{eqnarray} y\left( t \right) &=& x\left( t \right)\beta_{I\left( t\right)} + \epsilon\left( t \right)\\ \epsilon\left( t \right)&\sim& N\left(0,\sigma^2_{I\left( t\right)}\right) \end{eqnarray}このとき、$y\left( t\right)$は、平均$x\left( t \right)\beta_{I\left( t\right)}$、分散$\sigma^2_{I\left( t\right)}$の正規分布に従う。対数尤度を最大化する最尤法を適用する。すなわち、以下の尤度関数を最大とするパラメータを求める。
\begin{eqnarray} \ln{\mathcal{L}}&=&\sum_{t=1}^{T}\ln{\{f\left( y\left( t\right)|I\left( t\right)\right)\} }\\ f\left( y\left( t\right)|I\left( t\right)\right)&=&\frac{1}{\sqrt{2\pi\sigma^2_{I\left( t\right)}}}\exp\left( -\frac{\{y\left( t\right)-x\left( t\right)\beta_{I\left( t \right)}\}^2}{2\sigma^2_{I\left( t\right)}}\right) \end{eqnarray}レジームを直接観測できない場合、$I\left( t\right)$も過去の履歴の条件付き確率分布に従うと考える。
時点$t$までに得られる情報を$\mathcal{F}\left( t\right)$とする。
$f\left( t\right)$は$\mathcal{F}\left( t\right)$に条件付けられないことに注意する。\begin{eqnarray} f\left( y\left( t\right) | \mathcal{F\left( t-1\right)}\right) &=& \sum_{I\left( t\right)=1}^{n}f\left( y\left( t\right),I\left( t\right) |\mathcal{F}\left( t-1\right)\right)\\ &=& \sum_{I\left( t\right)=1}^{n}f\left( y\left( t\right)|I\left( t\right),\mathcal{F}\left( t-1\right)\right)f\left( I\left( t\right)|\mathcal{F}\left( t-1\right)\right)\\ &=& \sum_{I\left( t\right)=1}^{n}\frac{1}{\sqrt{2\pi\sigma^2_{I\left( t\right)}}}\exp\left( -\frac{\{y\left( t\right)-x\left( t\right)\beta_{I\left( t \right)}\}^2}{2\sigma^2_{I\left( t\right)}}\right) f\left( I\left( t\right)|\mathcal{F}\left( t-1\right)\right) \end{eqnarray}したがって、最大化する対数尤度は以下の通りである。
\begin{eqnarray} \ln{\mathcal{L}}&=&\sum_{t=1}^{T}\ln{\left\{\sum_{I\left( t\right)=1}^{n}f\left( y\left( t\right)|I\left( t\right),\mathcal{F}\left( t-1\right)\right)f\left( I\left( t\right)|\mathcal{F}\left( t-1\right)\right)\right\} }\\ f\left( y\left( t\right)|I\left( t\right),\mathcal{F}\left( t-1\right)\right)&=&\frac{1}{\sqrt{2\pi\sigma^2_{I\left( t\right)}}}\exp\left( -\frac{\{y\left( t\right)-x\left( t\right)\beta_{I\left( t \right)}\}^2}{2\sigma^2_{I\left( t\right)}}\right) \end{eqnarray}マルコフ連鎖
$f\left( I\left( t\right)|\mathcal{F}\left( t-1\right)\right)$を与えることで、$y\left( t\right)$の確率分布が定まる。$I\left( t\right)$が1次のマルコフ性を満たすと仮定する。
\begin{eqnarray} P\left( I\left( t\right)=i|\mathcal{F}\left( t-1\right)\right) &=&\sum_{j=1}^{n}P\left( I\left( t\right)=i,I\left( t-1\right)=j|\mathcal{F}\left( t-1\right)\right)\\ &=&\sum_{j=1}^{n}P\left( I\left( t\right)=i|I\left( t-1\right)=j\right)P\left( I\left( t-1\right)=j|\mathcal{F}\left( t-1\right)\right) \end{eqnarray}状態jから状態iへの遷移確率$P\left( I\left( t\right)=i|I\left( t-1\right)=j\right)$を$p_{i,j}$と表記し、以下の遷移確率行列を考える。
\begin{eqnarray} P &=& \begin{pmatrix} p_{1,1}&p_{1,2}&\cdots&p_{1,n}\\ p_{2,1}&\ddots&&\vdots\\ \vdots&&\ddots&\vdots\\ p_{n,1}&\cdots&\cdots&p_{n,n} \end{pmatrix} \end{eqnarray}時点$t$までの情報が与えられたときの、レジームの条件付き確率$P\left( I\left( t\right)=j|\mathcal{F}\left( t\right)\right)$は、ベイズ更新によって求められる。
\begin{eqnarray} P\left( I\left( t\right)=i|\mathcal{F}\left( t\right)\right) &=&P\left( I\left( t\right)=i|\mathcal{F}\left( t-1\right), y\left( t\right)\right)\\ &=&\frac{f\left( I\left( t\right) =i,y\left( t\right)|\mathcal{F}\left( t-1\right)\right)}{f\left(y\left( t\right)|\mathcal{F}\left( t-1\right)\right)}\\ &=&\frac{f\left(y\left( t\right)|I\left( t\right)=i,\mathcal{F}\left( t-1\right)\right)f\left(I\left( t\right)=i|\mathcal{F}\left( t-1\right)\right)}{\sum_{i=1}^{n}f\left(y\left( t\right)|I\left( t\right)=i,\mathcal{F}\left( t-1\right)\right)f\left(I\left( t\right)=i|\mathcal{F}\left( t-1\right)\right)}\\ &=&\frac{\sum_{j=1}^{n}f\left(y\left( t\right)|I\left( t\right)=j,\mathcal{F}\left( t-1\right)\right)p_{i,j}f\left(I\left( t-1\right)=j|\mathcal{F}\left( t-1\right)\right)}{\sum_{i=1}^{n}\sum_{j=1}^{n}f\left(y\left( t\right)|I\left( t\right)=j,\mathcal{F}\left( t-1\right)\right)p_{i,j}f\left(I\left( t-1\right)=i|\mathcal{F}\left( t-1\right)\right)} \end{eqnarray}初期確率は、マルコフ連鎖の定常確率とする。遷移確率行列$P$、単位行列$I$、全要素が$1$のベクトル$1$とし、定常確率$\pi^{\ast}$は以下のように求められることが知られている。
\begin{eqnarray} A &=& \begin{pmatrix} I-P\\ 1^{\mathrm{T}} \end{pmatrix}\\ \pi^{\ast}&=&\left(A^{\mathrm{T}}A\right)^{-1}A^{\mathrm{T}}のM+1列目 \end{eqnarray}マルコフ連鎖モンテカルロ法
対数尤度を最大化するパラメータを求める手法として、マルコフ連鎖モンテカルロ法(MCMC)を用いる。
ここでは解説を省略する。提案されたパラメータは、レジームを区別する条件を満たす必要がある。
例えば、低リスクレジームと高リスクレジームに区別する場合、提案された$\sigma_1$、$\sigma_2$が$\sigma_1<\sigma_2$を満たす必要がある。
この条件は、個々のモデルごとに指定する必要がある点に注意する。3. Pythonによるマルコフスイッチングモデルの実装
任意のレジーム数を対象としたマルコフ・スイッチングを実装する。
import numpy as np import pandas as pd from scipy import stats import matplotlib.pyplot as plt import japanize_matplotlib %matplotlib inline from tqdm.notebook import tqdmregime = 3 #各レジームが従う正規分布の初期パラメータ mu = [-1.4,-0.6,0] sigma = [0.07,0.03,0.04]レジームの遷移確率自体をMCMCで推定するのではなく、遷移確率をロジスティック関数値として、その引数をMCMCで推定する。その際、非対角成分に対してロジスティクス関数を適用し、対角成分は余事象として推移確率行列を生成する。
ロジスティクス関数の引数をgen_prob、ロジスティック関数値をprobとして別々に扱う。gen_prob = np.ones((regime,regime))*(-3) gen_prob = gen_prob - np.diag(np.diag(gen_prob)) #対角成分が0、非対角成分が-3の正方行列 prob = np.exp(gen_prob)/(1+np.exp(gen_prob)) #ロジスティック関数を適用 prob = prob + np.diag(1-np.dot(prob.T,np.ones((regime,1))).flatten()) #非対角成分の余事象として、対角成分の確率を求め、遷移確率行列とする。# マルコフ連鎖の定常確率を求める関数 def cal_stationary_prob(prob, regime): # prob: 2-d array, shape = (regime, regime), 遷移確率行列 # regime: int, レジーム数 A = np.ones((regime+1, regime)) A[:regime, :regime] = np.eye(regime)-prob return np.dot(np.linalg.inv(np.dot(A.T,A)),A.T)[:,-1]# 対数尤度を計算する関数 def cal_logL(x, mu, sigma, prob, regime): # x: 1-d array or pandas Series, 時系列データ # mu: 1=d array, len = regime, 各レジームが従う正規分布の平均の初期値 # sigma: 1=d array, len = regime, 各レジームが従う正規分布の分散の初期値 # prob: 2-d array, shape = (regime, regime), 遷移確率行列 # regime: int, レジーム数 likelihood = stats.norm.pdf(x=x, loc=mu[0], scale=np.sqrt(sigma[0])).reshape(-1,1) for i in range(1,regime): likelihood = np.hstack([likelihood, stats.norm.pdf(x=x, loc=mu[i], scale=np.sqrt(sigma[i])).reshape(-1,1)]) prior = cal_stationary_prob(prob, regime) logL = 0 for i in range(length): temp = likelihood[i]*prior sum_temp = sum(temp) posterior = temp/sum_temp logL += np.log(sum_temp) prior = np.dot(prob, posterior) return logL# 各時点が各レジームに属する確率を計算する関数 def prob_regime(x, mu, sigma, prob, regime): # x: 1-d array or pandas Series, 時系列データ # mu: 1=d array, len = regime, 各レジームが従う正規分布の平均の初期値 # sigma: 1=d array, len = regime, 各レジームが従う正規分布の分散の初期値 # prob: 2-d array, shape = (regime, regime), 遷移確率行列 # regime: int, レジーム数 likelihood = stats.norm.pdf(x=x, loc=mu[0], scale=np.sqrt(sigma[0])).reshape(-1,1) for i in range(1,regime): likelihood = np.hstack([likelihood, stats.norm.pdf(x=x, loc=mu[i], scale=np.sqrt(sigma[i])).reshape(-1,1)]) prior = cal_stationary_prob(prob, regime) prob_list = [] for i in range(length): temp = likelihood[i]*prior posterior = temp/sum(temp) prob_list.append(posterior) prior = np.dot(prob, posterior) return np.array(prob_list)# MCMCで更新するパラメータを生成する関数 def create_next_theta(mu, sigma, gen_prob, epsilon, regime): # mu: 1=d array, len = regime, 各レジームが従う正規分布の平均の初期値 # sigma: 1=d array, len = regime, 各レジームが従う正規分布の分散の初期値 # gen_prob: 2-d array, shape = (regime, regime), ロジスティック関数の引数 # epsilon: float, 提案するパラーメータの更新幅 # regime: int, レジーム数 new_mu = mu.copy() new_sigma = sigma.copy() new_gen_prob = gen_prob.copy() new_mu += (2*np.random.rand(regime)-1)*epsilon new_mu = np.sort(new_mu) new_sigma = np.exp(np.log(new_sigma) + (2*np.random.rand(regime)-1)*epsilon) new_sigma = np.sort(new_sigma)[[2,0,1]] new_gen_prob += (2*np.random.rand(regime,regime)-1)*epsilon*0.1 new_gen_prob = new_gen_prob - np.diag(np.diag(new_gen_prob)) new_prob = np.exp(new_gen_prob)/(1+np.exp(new_gen_prob)) new_prob = new_prob + np.diag(1-np.dot(new_prob.T,np.ones((regime,1))).flatten()) return new_mu, new_sigma, new_gen_prob, new_prob#MCMCを実行する関数 def mcmc(x, mu, sigma, gen_prob, prob, epsilon, trial, regime): # x: 1-d array or pandas Series, 時系列データ # mu: 1=d array, len = regime, 各レジームが従う正規分布の平均の初期値 # sigma: 1=d array, len = regime, 各レジームが従う正規分布の分散の初期値 # gen_prob: 2-d array, shape = (regime, regime), ロジスティック関数の引数 # epsilon: float, 提案するパラーメータの更新幅 # trial: int, MCMCの実行回数 # regime: int, レジーム数 mu_list = [] sigma_list = [] prob_list = [] logL_list = [] mu_list.append(mu) sigma_list.append(sigma) prob_list.append(prob) for i in tqdm(range(trial)): new_mu, new_sigma, new_gen_prob, new_prob = create_next_theta(mu, sigma, gen_prob, epsilon, regime) logL = cal_logL(x, mu, sigma, prob, regime) next_logL = cal_logL(x, new_mu, new_sigma, new_prob, regime) ratio = np.exp(next_logL-logL) logL_list.append(logL) if ratio > 1: mu, sigma, gen_prob, prob = new_mu, new_sigma, new_gen_prob, new_prob elif ratio > np.random.rand(): mu, sigma, gen_prob, prob = new_mu, new_sigma, new_gen_prob, new_prob mu_list.append(mu) sigma_list.append(sigma) prob_list.append(prob) if i%100==0: print(logL) return np.array(mu_list), np.array(sigma_list), np.array(prob_list), np.array(logL_list)4. データ例
東京電力の超過収益率
期間は2003年〜2019年。マーケット株価はtopix、無リスク資産は日本国債(10年)とした。
超過収益率の時系列データをPandasのDataFrame
xとしている。regime = 3 mu = [-1.4,-0.6,0] sigma = [0.07,0.03,0.04] gen_prob = np.ones((regime,regime))*(-3) gen_prob = gen_prob - np.diag(np.diag(gen_prob)) prob = np.exp(gen_prob)/(1+np.exp(gen_prob)) prob = prob + np.diag(1-np.dot(prob.T,np.ones((regime,1))).flatten()) trial = 25000 epsilon = 0.1 mu_list, sigma_list, prob_list, logL_list = mcmc(x, mu, sigma, gen_prob, prob, epsilon, trial, regime) prob_series = prob_regime(x, mu_list[-1], sigma_list[-1], prob_list[-1], regime)各レジームの確率を積み上げ棒グラフとして可視化する。
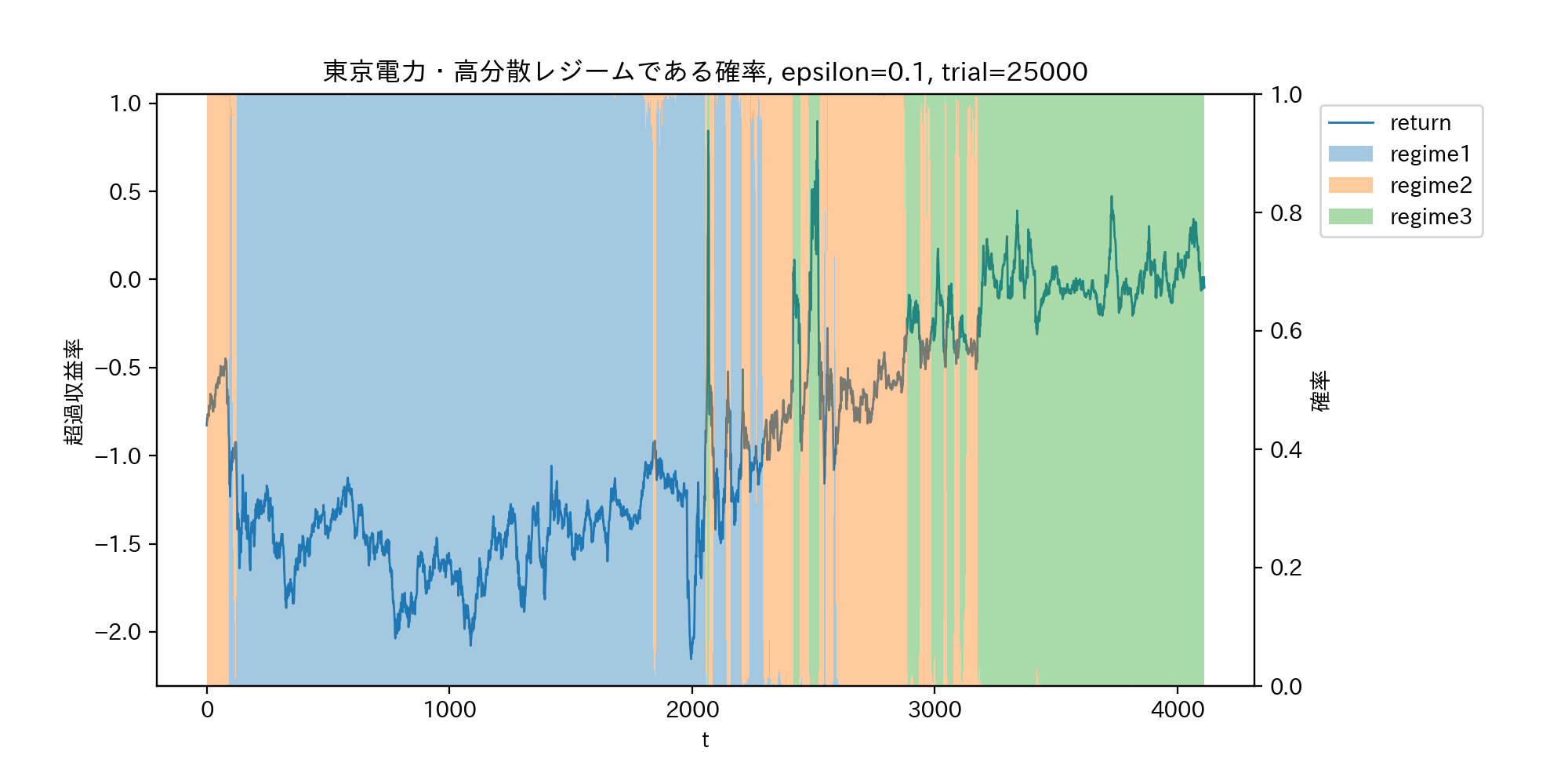
fig = plt.figure(figsize=(10,5),dpi=200) ax1 = fig.add_subplot(111) ax1.plot(range(length), x, linewidth = 1.0, label="return") ax2 = ax1.twinx() for i in range(regime): ax2.bar(range(length), prob_series[:,i], width=1.0, alpha=0.4, label=f"regime{i+1}", bottom=prob_series[:,:i].sum(axis=1)) h1, l1 = ax1.get_legend_handles_labels() h2, l2 = ax2.get_legend_handles_labels() ax1.legend(h1+h2, l1+l2, bbox_to_anchor=(1.05, 1), loc='upper left') ax1.set_xlabel('t') ax1.set_ylabel(r'超過収益率') ax2.set_ylabel(r'確率') ax1.set_title(f"東京電力・高分散レジームである確率, epsilon={epsilon}, trial={trial}") plt.subplots_adjust(left = 0.1, right = 0.8) #plt.savefig("probability_regime2.png") plt.show()以下のグラフにおいて、高分散低収益率レジームを青、低分散低収益率レジームを黄色、中分散高収益レジームを緑とした。
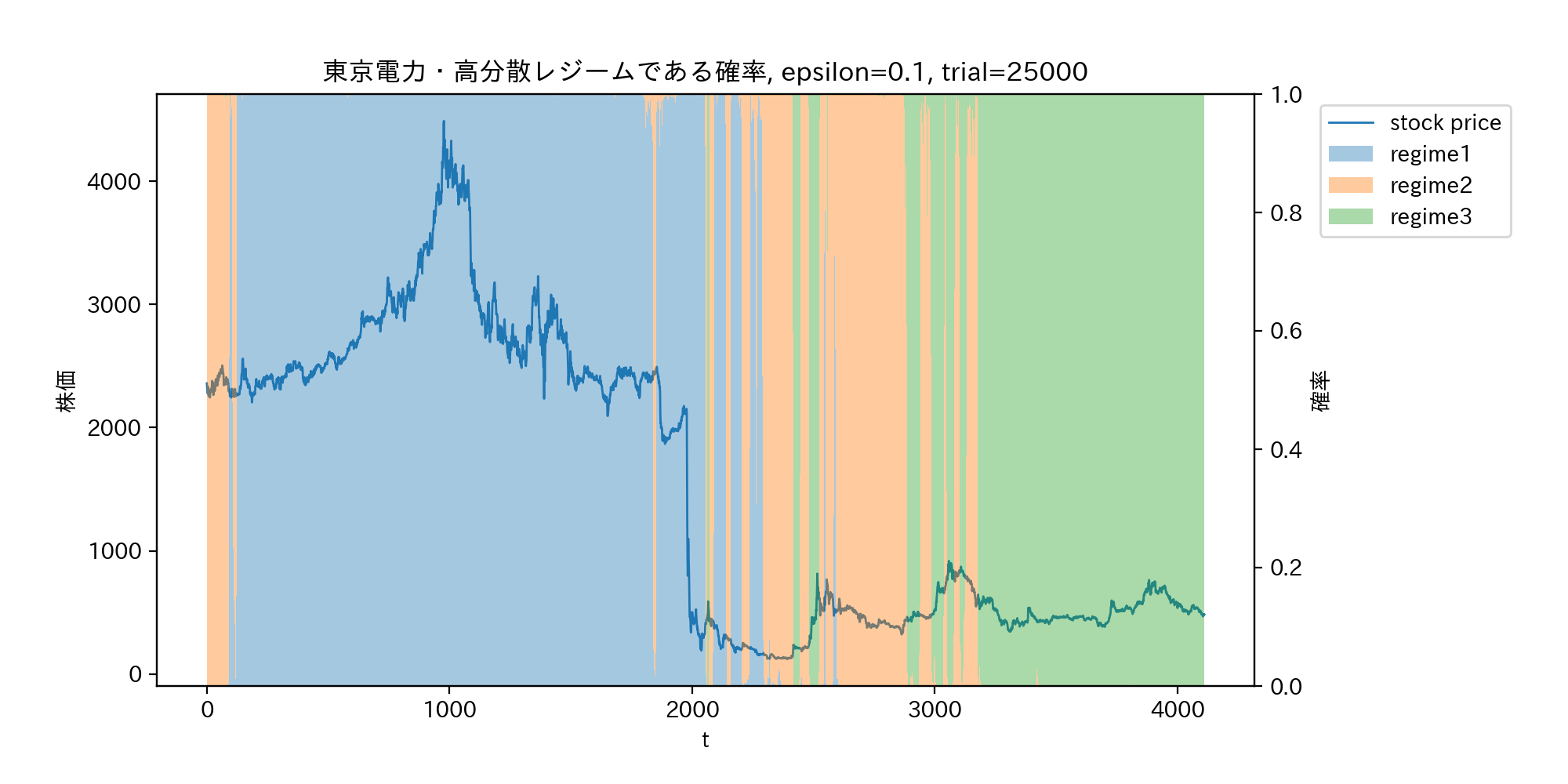
収益率ではなく、実際の株価をプロットしたのが下のグラフである。東日本大震災後の原発事故による株価の暴落は、レジームのスイッチではなくジャンプと推測されていることが分かる。
参考文献
- 小松高広(2018), 最適投資戦略 : ポートフォリオ・テクノロジーの理論と実践, 東京 : 朝倉書店
- 沖本竜義(2014), マルコフスイッチングモデルのマクロ経済・ファイナンスへの応用, 日本統計学会誌, 44 (1), 137-157
- 投稿日:2020-04-03T16:41:46+09:00
IQ Botのテーブル項目に対するおまじないコードを詳しく解説
IQ Botでテーブル項目にPythonスクリプトを書くとき、最初と最後必ず入れるコードがあります。
こちらの記事にも書きましたが、以下のコードです。
テーブル項目へのPythonスクリプトの書き方#表の操作をするときに必ず入れるコード(最初) import pandas as pd df = pd.DataFrame(table_values) # この間の部分に、処理したいコードを入れていく #表の操作をするときに必ず入れるコード(最後) table_values = df.to_dict()社内でIQ Botを使っているかわいい後輩ちゃんに
「このコードって何をやっているんですか?」 と質問されたので、
がんばって答えてみました。ライブラリ(pandas)をインポート!
まずプログラミング言語には「ライブラリ」といって、
ある分野の処理を行いやすくするための命令や関数をまとめてくれたパッケージみたいなものがあります。Pythonにはpandasというライブラリがあって、
このpandasというのは、表やデータの配列を扱いやすくするためのライブラリです。ライブラリを使うためには、まず該当のライブラリをインポートする必要があります。
1行目の
import pandas as pdがそのための処理です。おまじないスクリプトの1行目import pandas as pd #意味:pandasを importしてね。 # そしてそのpandasの中身を、これから書くコードの中ではpdという名前で使えるようにしてね。DataFrameに変換!
IQ Bot が帳票から読み取ったテーブルの情報は、
table_valuesという変数にまるっと入っているのでした。
(この話が分からない人はこちらを参照)その
table_valuesの中身は、そのままだと扱いづらいので、
pandasで扱うのに適したDataFrameという形式に変換します。そして、その変換後のデータを
dfという名前の変数に格納します。おまじないスクリプトの2行目df = pd.DataFrame(table_values) #意味:table_valuesの中身を、pandasのDataFrame形式に変換してdfという変数に入れてね。ここで
pd.DataFrameにおけるpd.はpandasの意味です。これを
pandas.と書かずにpd.と省略して書けるのは、
おまじないコードの1行目でimport pandasにas pdをつけておいたからです。DataFrameに変換すると、どうなる?
この1~2行目までの処理をやっておくことで、ここから先は、
table_valuesに入っていた中身の全体を
df、
その中の特定の列の値をdf['列名']という形で扱えるようになります。DataFrame形式をもとの形式に戻す!
最後の処理で、これまで
dfという変数にDataFrame形式で入れていたデータを、
IQ Botがもともとtable_valueを保持していた形式に戻します。
table_valueのもともとの形式はdictionary型なので、この形式に戻してあげます。おまじないスクリプトの最後table_values = df.to_dict() #意味:dfの中身をdict型に変換して、table_valuesに入れてね。このようにして、加工した結果をIQ Botに引き渡しているわけですね。
名前重要(名前についての補足)
Pandasをインポートするにあたって
as pdをつけたり、
DataFrameを格納する変数の名前をdfにしたりするのは、絶対的な決まりではありませんが、なるべくこうしておいた方がいいです。
なぜなら、そうやってコードを書く人が圧倒的に多いからです。
Pythonやpandaに関する解説記事でもだいたいみんなこのネーミング前提でコードを書いています。
なので、IQ Botを作るときのコードもそれに合わせておいた方が、
何かでつまづいたときなどに、解説を探しやすくなります。以下のように書いても、コードが動くかどうかだけで言えば動きますが、
あまりおすすめはしません。テーブル項目へのPythonスクリプトの書き方#表の操作をするときに必ず入れるコード(最初) import pandas as hoge1 hoge2 = hoge1.DataFrame(table_values) #表の操作をするときに必ず入れるコード(最後) table_values = hoge2.to_dict()まとめ
- 最初にpandasというライブラリをインポートするよ
- IQ Botが持っているtable_valuesを、pandasで扱いやすいDataFrame形式にして変数に入れるよ
- 最後にDataFrame形式をtable_valuesのもとの形式(dictionary型)に戻してIQ Botに渡すよ
- 変数の名前はおまじないの通りじゃなくても動くけど、おまじないの通りにしておいた方が何かと都合がいいよ
- 投稿日:2020-04-03T16:38:44+09:00
[python] 条件にあうファイルを移動
やりたいこと
- 条件にあうファイルを移動
- (例)条件を「今日の日付」が含まれるファイル名とする
ポイント
- ファイル検索
pathlib- 移動
shutilサンプルコード
import pathlib import shutil import datetime #今日の日付 yyyymmdd = datetime.date.today().strftime('%Y%m%d') #移動元フォルダから条件に一致するファイル名を取得 p_tmp = pathlib.Path('移動元フォルダ').glob(f'{yyyymmdd}*.csv') p = [p for p in p_tmp] dest = '移動先フォルダ' #ファイル移動 for source in p: shutil.move(str(source), dest)
pthlibで拾ったファイル名はジェネレータで返される
- リストに格納してfor文でファイル名を1つづつ取り出す
- 取り出したファイル名を
strで文字列変換することshutiful.move([移動元], [移動先])でファイル移動
- 投稿日:2020-04-03T16:35:09+09:00
pythonでシリアル通信制御してSPI通信する(USBGPIO8デバイスを使用します)
本記事について
pythonでシリアル通信制御してI2C通信する(USBGPIO8デバイスを使用します)の系列記事となりますので先にI2C編をお読みください。
SPI通信について
基本的な仕様はありますがIC毎のデータシートを参照したほうが良いと思います。
一般的なSPI通信については下記が分かりやすく説明されています。
http://www.picfun.com/f1/f05.html
https://lab.fujiele.co.jp/articles/8191/注意
本記事で使用するEEPROM(AT93C46) はCS(チップセレクト)が通常と逆で
HIGHで通信開始、LOWで通信終了となります。
一般的にははLOWで通信開始、HIGHで通信終了です。一般的なICで実験すれば良かったのですがSPIを使うICの中でAT93C46が30円と一番安かったのでAT93C46にしました、その結果汎用性に欠けた記事となりました。
なにをするか
pythonでシリアル通信を使いUSBGPIO8を制御、USBGPIO8からIC(EEPROM)を制御、2バイト書き込みその後2バイト読み込み書き込んだ値が読み込める事を確認します。
回路図
USBGPIO8 の 0番ポートを CS とします
USBGPIO8 の 1番ポートを SK とします(クロック)
USBGPIO8 の 2番ポートを DI とします
USBGPIO8 の 3番ポートを DO とします
EEPROM(AT93C46)の使い方
ハード設定
6番(ORG)をVcc接続で16bitモード
6番(ORG)をGND接続で8bitモード
となります、今回は16bitモードで動作させます。
16bitモードでは64アドレスx2バイト、合計128バイトのデータを保存できます。AT93C46命令セット
・EWEN 書き込み許可状態
・WRITE 書き込み
・READ 読み込み
今回はこの3命令を使います。
書き込むためには起動時にEWENモードにする必要があります、一度EWENモードにしたら電源を切るまでモードは維持されます。送信データは
SB + OP + [データ等...]
という構成を取ります。SB = [00000001] 固定
OP = [????????] モードにより定められているパターン+アドレス等を付加する
データ等はあれば追加する。具体的な例を示す
※ ? 記号は任意の 0 か 1 を設定する
EWENモード
SB[00000001] OP[00110000] >0000000100110000 と続けて送信
WRITEモード
SB[00000001] OP[010?????] 下位5ビットは書き込みアドレス 上位バイト[????????] 下位バイト[????????] >00000001010????????????????????? と続けて送信
READモード
SB[00000001] OP[100?????] 下位5ビットは書き込みアドレス 上位バイト用ダミー[00000000] DOから受信するためのダミーデータ 下位バイト用ダミー[00000000] DOから受信するためのダミーデータ >00000001100?????0000000000000000 と続けて送信プログラム構造
pythonでシリアル通信制御してI2C通信する(USBGPIO8デバイスを使用します)と同様ですのでそちらを参照
ソースコード
# usbgpio8_spi_read_write_sample.py import serial import sys import time SerialInstance = None def SerialInit(comString): global SerialInstance #SerialInstance = serial.Serial(comString, 115200, timeout=0.01) SerialInstance = serial.Serial(comString, 19200, timeout=0.1) def SerialEnd(): SerialInstance.close() def SerialTalk(cmd, response=False): readLen = len(cmd) + 1 # gpio read 0\n\r # 最初から \r が付いているので +2 ではなく +1 する if response == True: readLen += 3 # N\n\r readLen += 1 # > cnt = SerialInstance.write(cmd.encode()) res = SerialInstance.read(readLen) res = res.decode("utf-8").strip() return res def gpioHigh(n): SerialTalk("gpio set {}\r".format(n)) def gpioLow(n): SerialTalk("gpio clear {}\r".format(n)) def gpioRead(n): res = SerialTalk("gpio read {}\r".format(n), response=True) return res def ByteToLH(b): lh = [] for i in range(8): if (b << i & 128) == 0: lh.append(0) else: lh.append(1) return lh def CS_LOW(): gpioLow(0) def CS_HIGH(): gpioHigh(0) def SCK_LOW(): gpioLow(1) def SCK_HIGH(): gpioHigh(1) def DI_LOW(): gpioLow(2) def DI_HIGH(): gpioHigh(2) def READ_DATA(): return gpioRead(3) def parseData(all): res = [] for l in all: a = l.split("\n\r") res.append(a[1]) return res def SPI_CommandExec(cmd): # start condition size = len(cmd) data = [] SCK_LOW() for i in range(size): d = cmd[i] if d == 0: DI_LOW() elif d == 1: DI_HIGH() SCK_HIGH() if d == 2: b = READ_DATA() data.append(b) SCK_LOW() return parseData(data) def WriteBytes(addr, buffer1, buffer2): # EWEN command SB = ByteToLH(0b00000001) OP = ByteToLH(0b00110000) cmdEWEN = SB + OP # exec CS_HIGH() resEWEN = SPI_CommandExec(cmdEWEN) CS_LOW() # write command SB = ByteToLH(0b00000001) OP = ByteToLH(0b01000000 | (addr & 0x3f)) buffer1 = ByteToLH(buffer1) buffer2 = ByteToLH(buffer2) cmdWrite = SB + OP + buffer1 + buffer2 # exec CS_HIGH() resWrite = SPI_CommandExec(cmdWrite) CS_LOW() time.sleep(0.01) response = resEWEN + resWrite return response def ReadBytes(addr): # create command SB = ByteToLH(0b00000001) OP = ByteToLH(0b10000000 | (addr & 0x3f)) buffer1 = [2] * 8 buffer2 = [2] * 8 cmd = SB + OP + buffer1 + buffer2 CS_HIGH() response = SPI_CommandExec(cmd) CS_LOW() return response def Test_WriteBytes(comString): SerialInit(comString) response = WriteBytes(7, 0x34, 0x56) print(response) SerialEnd() def Test_ReadBytes(comString): SerialInit(comString) response = ReadBytes(7) print(response) SerialEnd() def run(comString): Test_WriteBytes(comString) Test_ReadBytes(comString) if __name__ == "__main__": run(sys.argv[1]) # python usbgpio8_spi_read_write_sample.py COM4使い方
Linuxの場合
python usbgpio8_spi_read_write_sample.py /dev/ttyUSB0Windowsの場合
python usbgpio8_spi_read_write_sample.py COM4戻り値の見方
[] # 書き込み時は特に無し ['0', '0', '1', '1', '0', '1', '0', '0', '0', '1', '0', '1', '0', '1', '1', '0'] # 先頭8ビットは読み込んだ上位バイト、続く8ビットは読み込んだ下位バイト以上です

- 投稿日:2020-04-03T16:33:31+09:00
[学習メモ]pythonによるクラスの基本
オブジェクト
データ(変数(属性))とコード(関数(メソッド))を含む
クラスの基本
Personクラスを定義する。
pythonclass Person(): def __init__(self, name): self.name=name hunter=Person('Reiner Tonnies') print('The mighty hunter:', hunter.name) # The mighty hunter: Reiner Tonnies
__init()__()はクラス定義から個々のオブジェクトを作る時にそれを初期化するメソッドである。(コンストラクタみたいなもの)- 第1引数は
selfでなければならない。- Personクラスの内部では、name属性はself.nameという形でアクセスする。
- hunterのようなオブジェクトを作った場合、オブジェクトの外からはhunter.nameという形でアクセスする。 *
継承
pythonClass Car(): def exclaim(self): print("I'm a Car!") Class Yugo(Car): def exclaim(self): print("I'm a Yugo!") def need_a_push(self): print("Hi!") give_me_a_car=Car() give_me_a_yugo=Yugo() #オーバーライド give_me_a_car.exclaim() #I'm a Car! give_me_a_yugo.exclaim() #I'm a Yugo! #メソッドの追加 give_me_a_yugo.need_a_push() #Hi! give_me_a_car.need_a_push() #エラー
- サブクラスは親クラスの名前をカッコ内に入れる。
- サブクラスは親クラスからすべてのものをもらう
- 親クラスのメソッドを上書きすることができる(オーバーライド)
- 投稿日:2020-04-03T15:53:09+09:00
Flask を用いたデータベースアプリケーション制作 Part1
Flask による Web アプリケーション制作
アプリケーション開発に必要なコードや機能をまとめたライブラリを アプリケーションフレームワークという。
本稿では、Python の Web アプリケーションフレームワークである flask を用いて、簡単なデータベース管理アプリケーションを制作してみた。参考:データ収集からWebアプリ開発まで実践で学ぶ機械学習活用ガイド の Chapter 3-5
アプリケーションの実装内容
Flask の使い方を習得すべく3つのパートに分けた。
Part1(本稿)
- Web ブラウザの表示
- Templates フォルダの html ファイルと連結
Part2(次稿)
- データベース SQLite との連結
- Bootstrap を用いた画面表示
Part3(次々稿)
- POSTメソッドを用いた新規ユーザー登録
Part1のフォルダ構成
全てのコードは run.py によって実行される。
root |--codes | |--view.py | |--templates | | |--index.html |--run.pyFlask のインストールとコマンドの実行
Flask は次のコマンドでインストールする。
pip install flask
次のコマンドで run.py を実行する。
python run.py
Web ブラウザの表示
run.py のコードを以下に示す。※参考
run.py# codes/view.py にある app という変数を呼び出す。 # app には Flask モジュールが提供している flask クラスから作り出されたインスタンスが代入される。 from codes.view import app # run.py がモジュールとして呼び出されたときは # __name__ = run.py となり app は実行されない。 if __name__ == "__main__": app.run()これにより、view.py で呼び出される app が実行される。
次に view.py のコードを以下に示す。view.pyfrom flask import Flask # Flask クラスから作成された インスタンスを app に代入する。 app = Flask(__name__) # 「/」へアクセスがあった場合に、"Hello World"の文字列を返す。 # この行が無いと Web に表示されない。 @app.route("/") # hello 関数を定義する。インデントが戻るまでが関数に含まれる。 def hello(): return "Hello World" # debug=True で、ソースコード書き換えのたびに app を実行しなくても確認できる。 if __name__ == "__main__": app.run(debug=True)run.py のターミナル出力結果が以下のようになっていれば成功である。
* Serving Flask app "app.app" (lazy loading) * Environment: production WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead. * Debug mode: off * Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)上記の http://127.0.0.1:5000/ にアクセスすると 'Hello World' が表示される。
Templates フォルダの html ファイルと連結
では、Templates フォルダの html ファイルをブラウザに表示させるように、view.py を編集する。
view.py# render_template は HTML を表示させるための関数である。 from flask import Flask,render_template, app = Flask(__name__) # /index へアクセスがあった場合に、templates/index.html を返す。 @app.route('/index') # index 関数を定義する。'キカガク' は html 内の name に代入される。 def index(): name = 'キカガク' return render_template('index.html', name=name) if __name__ == "__main__": app.run(debug=True)templates フォルダに 以下の index.html を作成する。
templates フォルダは view.py と同じ階層に作ること。template (単数形) のように綴りが異なると flask は読み取れずエラーが起こる。index.html<!DOCTYPE html> <html lang="ja"> <head> <meta charset="UTF-8"> <meta name="viewport" content = "width=device-width, initial-scale=1.0"> <meta http-equiv="X-UA-Compatible" content="ie=edge"> <title>Document</title> </head> <body> <hl>Flask チュートリアル</hl> <p>名前: {{name}}</p> </body> </html>http://127.0.0.1:5000/index にアクセスして以下がブラウザに表示されていれば成功である。
Flask チュートリアル 名前: キカガク
- 投稿日:2020-04-03T15:40:39+09:00
Django で static を設定して bootstrap を使う方法
2020-04-01 作成: windows10/Python-3.8.2-amd64/Django-3.0.4/MDB-Free_4.15.0
Django で MDB(material desing bootstrap) を使って、カッコいいマテリアルデザインにしようとしました。
しかし、設定で少し時間を使ってしまったので、忘れないように書いておきます。
Django プロジェクト mysite の中にあるアプリケーション memo のスタイルを設定するという説明です。static の設定
static フォルダの作成
アプリ memo のディレクトリの中に
/mysite/memo/static/memoディレクトリを作る。
Django では css や js などの静的なファイルの置き場は、/static/にするらしい。MDB-Free_4.15.0.zip をダウンロードしてきて、
/static/に解凍する。
https://mdbootstrap.com/docs/jquery/getting-started/download/mysite/ mysite/ memo/ __pycache__/ migrations/ templates/ memo/ static memo/ <- この下に MDB を解凍 css/ img/ js/ scss/ src//mysite/mysite の settings.py の中で static ディレクトリの置き場を指定する。とはいっても、デフォルトで
STATIC_URL = '/static/'となっているので、特に変更しなかった。テンプレートの編集
MDB を導入するためにテンプレートの html ファイルを書き換える。
具体的な手順
- テンプレートの先頭に
{% load static %}と書く
- 一番最初の行がよいみたい
- <head> に MDB の設定を書く
- meta 要素でブラウザ互換性とレスポンシブデザインを指定
- <head> で link でスタイルシートを読み込む
- パス指定は {% static 'memo/css/bootstrap.min.css' %} のようにする
- <body> の最後で js ファイルを読み込む
- パス指定は {% static 'memo/js/jquery.min.js' %} のようにする
- あとは、<div> で、スタイルの設定を指定
- ここは普通の bootstrap の使い方と同じ
書き換えられたテンプレートの例
memo/template/memo/memo_list.html{% load static %} <!DOCTYPE html> <html lang = "jp"> <head> <meta charset = "utf-8"> <title>Memo</title> <meta name = "viewport" content = "width = device-width, initial-scale = 1, shrink-to-fit = no"> <meta http-equiv = "x-ua-compatible" content = "ie = edge"> <link href = "{% static 'memo/css/bootstrap.min.css' %}" rel = "stylesheet"> <link href = "{% static 'memo/css/mdb.min.css' %}" rel = "stylesheet"> <link href = "{% static 'memo/css/style.css' %}" rel = "stylesheet"> <head> <body> <div class = "container"> <div class = "row"> <div class = "col-md-8"> <h1>View : MemoListView</h1> <p>Template : memo_list.html</p> </div> </div> <div class = "row"> <div class = "col-md-12"> {% if memo_list %} <table class = "table"> {% for memo in memo_list %} <tr> <td><a href = "{% url 'site_detail' memo.pk %}">{{ memo.text }}</a></td> <td><a href = "{% url 'site_update' memo.pk %}">Edit</a></td> <td><a href = "{% url 'site_delete' memo.pk %}">Delete</a></td> </tr> {% endfor %} </table> {% else %} <p>No memo available.</p> {% endif %} </div> </div> <div = "row"> <div = "col-md-8"> <p><a href = "{% url 'site_create' %}">Create a new memo.</a></p> </div> </div> </div> <script type = "text/javascript" src = "{% static 'memo/js/jquery.min.js' %}"></script> <script type = "text/javascript" src = "{% static 'memo/js/popper.min.js' %}"></script> <script type = "text/javascript" src = "{% static 'memo/js/bootstrap.min.js' %}"></script> <script type = "text/javascript" src = "{% static 'memo/js/mdb.min.js' %}"></script> </body> </html>余談
bootstrap をとにかく使ってみる、というなら、基本的なルールを 3 つだけ覚えておけば最初は何とかなる。
material design bootstrap なら、これだけで結構まともな見栄えになる。
- まず body の本文部分全体を
<div class = "container">でくくる- 1 つの行に入れて横に並べたいものを
<div class = "row">でくくる- 1 つの行で横に並べるものそれぞれを
<div class = "col-md-数字">でくくり、数字の合計が 12 になるようにするおしまい
- 投稿日:2020-04-03T15:01:11+09:00
LINE botで天気が知りたい feat.Heroku+Python
目的
工学系のくせに外には出るのでいつも服装を考えるのですが、天気予報をチェックしない人間なのでよく失敗をします。
そこで、LINE botちゃんに天気(気温)を教えていただこうと思います。
まずはオウム返しで構築とテストしてから本番のコーディングを行うことをおすすめします。参考
この記事は作業記録&備忘録みたいなやつです。詳しい・分かりやすいものを読みたい方は以下のリンクへどうぞ。
Python + HerokuでLINE BOTを作ってみた
PythonでLINEBotはじめました(冷やし中華的な)【前編】
PythonでLINEBotはじめました(冷やし中華的な)【後編】LINE Developersに登録
まずLINE Developersに登録します。登録は簡単です。
https://developers.line.me/ja/プロバイダー&チャネルの作成
LINE Developersに登録したらプロバイダーを作成します。英語の場合右下で言語を切り替えて下さい。
プロバイダーの中にチャネル(アプリ)を作成します。
画面が続いてて分かりにくいいかと思いますが
- プロバイダー作成を押す
- プロバイダー情報を入力(プロジェクト的な)
- チャネル情報を入力(botの名前とか)
です。すぐ終わります。
必要な情報を取得しておく
APIを利用するために
- チャネルアクセストークン
- チャネルシークレット
- Webhook URL
の3つが必要になります。上2つはbotの管理画面から取得出来ます。別のタブにあるので探してみてください。
Webhook URLはHerokuを設定してから取得します。Herokuの設定
一旦Herokuの設定に移ります。まずアカウントの登録をしましょう。
その後、Heroku CLIというコマンドラインインターフェースをインストールします。
Heroku CLI : https://devcenter.heroku.com/articles/heroku-cli#download-and-installHerokuログイン
プロンプトで
$heroku login
を実行するとキー入力を促されるので何か入力して下さい。するとブラウザ経由でログイン出来ます。Herokuアプリケーションの作成
$heroku create アプリ名で新規アプリを作成できます。アンダーバー_は使えないので注意です。環境変数の設定
環境変数を設定します。ここのやり方は人それぞれらしいですが僕は参考サイトと同様に設定します。
先ほど控えた2つの文字列を設定してあげましょう。
$heroku config:set YOUR_CHANNEL_ACCESS_TOKEN="チャネルアクセストークン" --app アプリ名
$heroku config:set YOUR_CHANNEL_SECRET="チャネルシークレット" --app アプリ名Webhookの設定
LINE Developersのコンソールに戻り、WebhookのURLを設定します。
Webhook URL:https://アプリ名.herokuapp.com/callback
更新を押し、webhookを利用するに設定で完了です。https://github.com/line/line-bot-sdk-java/tree/master/sample-spring-boot-echo#step-2
こちらの[Deploy to Heroku]を押してそこからアプリを作るとEchoBotをデプロイできます。コーディング
・LINE Developersでのbotの設定
・Herokuの設定
・両者の連携
が完了しました。ここからコーディングに入ります。ライブラリのインストール
今回は
flaskとline-bot-sdkを中心に使用します。
pip install flask line-bot-sdk
僕の環境では
flask : 1.1.1
line-bot-sdk : 1.16.0
です。加えてスクレイピング用のライブラリは以下を使用します。
soupsieve==2.0
urllib3==1.25.8
beautifulsoup4作業ディレクトリとその構成
どこでもいいですがプロジェクト用にディレクトリを作成することをおすすめします。
構成:
line_bot(作業dir)
├ main.py
├ scrape.py
├ Procfile
├ runtime.txt
└ requirements.txtファイルの中身
①main.py
本体です。オウム返しでテストしたい場合はこちらを参考になると思います。
※APIキーの変数名に注意main.py#必用なものをインポート from flask import Flask, request, abort import os import scrape as sc from linebot import ( LineBotApi, WebhookHandler ) from linebot.exceptions import ( InvalidSignatureError ) #LINEでのイベントを取得 from linebot.models import ( MessageEvent, TextMessage, TextSendMessage, ) app = Flask(__name__) #環境変数取得 YOUR_CHANNEL_ACCESS_TOKEN = os.environ["LINE_BOT_CHANNEL_TOKEN"] YOUR_CHANNEL_SECRET = os.environ["LINE_BOT_CHANNEL_SECRET"] line_bot_api = LineBotApi(YOUR_CHANNEL_ACCESS_TOKEN) handler = WebhookHandler(YOUR_CHANNEL_SECRET) #アプリケーション本体をopenすると実行される @app.route("/") def hello_world(): return "hello world!" #/callback のリンクにアクセスしたときの処理。webhook用。 @app.route("/callback", methods=['POST']) def callback(): # get X-Line-Signature header value signature = request.headers['X-Line-Signature'] # get request body as text body = request.get_data(as_text=True) app.logger.info("Request body: " + body) # handle webhook body try: handler.handle(body, signature) except InvalidSignatureError: abort(400) return 'OK' #メッセージ受信時のイベント @handler.add(MessageEvent, message=TextMessage) def handle_message(event): ''' #line_bot_apiのreply_messageメソッドでevent.message.text(ユーザのメッセージ)を返信 line_bot_api.reply_message( event.reply_token, TextSendMessage(text=event.message.text)) ''' line_bot_api.reply_message( event.reply_token, TextSendMessage(text=sc.getWeather()) ) if __name__ == "__main__": # app.run() port = int(os.getenv("PORT")) app.run(host="0.0.0.0", port=port)②scrape.py
天気情報をスクレイピングします。自分で書く予定だったのですがとりあえず
こちら→https://qiita.com/RIRO/items/1b67b0418b08a52de0d6
のコードを少し改変しました。ありがとうございます。scrape.py#ライブラリのインポート import requests from bs4 import BeautifulSoup def getWeather(): #tenki.jpの目的の地域のページのURL(今回は東京都調布市) url = 'https://tenki.jp/forecast/3/16/4410/13208/' #HTTPリクエスト r = requests.get(url) #プロキシ環境下の場合は以下を記述 """ proxies = { "http":"http://proxy.xxx.xxx.xxx:8080", "https":"http://proxy.xxx.xxx.xxx:8080" } r = requests.get(url, proxies=proxies) """ #HTMLの解析 bsObj = BeautifulSoup(r.content, "html.parser") #今日の天気を取得 today = bsObj.find(class_="today-weather") weather = today.p.string #気温情報のまとまり temp=today.div.find(class_="date-value-wrap") #気温の取得 temp=temp.find_all("dd") temp_max = temp[0].span.string #最高気温 temp_max_diff=temp[1].string #最高気温の前日比 temp_min = temp[2].span.string #最低気温 temp_min_diff=temp[3].string #最低気温の前日比 #とりあえず動くのを見たいので天気と気温を繋げて返しています。 return weather+temp_max+temp_min③Procfile
プログラムの実行方法を記載します。
web: python main.py④runtime.txt
Pythonのバージョンを記載するテキストファイルです。
3.7.7ではエラーが出たので3.6.10にしています。Herokuが3.7未対応なのかな?runtime.txtpython-3.6.10⑤ requirements.txt
インストールするライブラリを記載するテキストファイルです。
requirements.txtFlask==1.1.1 line-bot-sdk==1.16.0 soupsieve==2.0 urllib3==1.25.8 beautifulsoup4
天気情報をスクレイピングするのでscrape.pyがあります。EchoBot(オウム返し)などは他4つで大丈夫です。Herokuにデプロイする
※gitをインストールしてない人はインストールしましょう
// gitの初期ファイルを作成 git init // ローカルリポジトリに結びつくリモートリポジトリを設定 heroku git:remote -a (自分で決めたアプリ名) // 変更したファイルを全てインデックスに登録 git add . // 変更したファイルをリポジトリに書き込む("inital commit"はコメントなのでなんでも良い) git commit -m "inital commit" // herokuにローカルで作成したファイルをpush git push heroku master※僕はここでエラーが出ました
ここで
requirements.txtのbeautifulsoup4のスペルをミスっててエラーが出ました。
僕はバージョン指定が悪いと思いバージョンを変えてtryしたのですが、ライブラリ名がミスってました()
戒めの記事Heroku側で確認しておく
Herokuのダッシュボードでactivityの確認をしましょう。画像のようになっていれば成功です。
webhook検証のエラー
この部分はサンプルをコピーして利用したのですが
ボットサーバーから200以外のHTTPステータスコードが返されましたというエラーが発生します。
が、BOTは正常に動くようなので無視しました。動作確認
BOT管理画面にあるQRで友達追加して、何かメッセージを送ってみましょう。
天気の返信(orオウム返し)が成功したら成功です。Next
現在は天気と気温を文字列で送っているだけなので
- フォーマットを整える
- 設定の追加(Regionや定期送信)
- Flex Messageの挑戦
などをできればと思います。他プロジェクトや勉強もあるのでゆっくり更新します。
参考記事の方々ありがとうございました。

- 投稿日:2020-04-03T14:22:17+09:00
【Python】テストコードまとめ
テストコードの目的を一言でいうと?
バグをなくすこと
テストコードとは?
- 正しく動作するのか確認する作業
- テストコードを使って、動かしながら不具合を修正しながら設計する
- いわば、命綱、安全ネット、防弾チョッキのようなもの
テストコードの結果どうなるのか?
- バグが減り、実装スピードが速くなる
- テストコードを見れば設計がわかる
- そのため追加仕様が容易になる
今回紹介するPythonのテストを助けるライブラリは以下3つ
- unittest
- doctest
- pytest
1. unittest
まずはテストする対象の関数
calc.pyを用意します。
こちらは足し算・引き算を行うメソッドです。calc.pydef add_num(num1, num2): return num1 + num2 def sub_num(num1, num2): return num1 - num2次に
calc.pyに対してunittestを使ってテストします。テストプログラムの書き方6ステップ
1. ファイル名は「test_対象のモジュール名.py」とする。
2. unittestモジュールをimportする。
3. テストクラス名は「Testテスト対象のクラス名」とする。
4. テストクラスはunittest.TestCaseを継承する。
5. テストメソッド名は「test_テスト対象のメソッド名」とする。
6.unittest.main()でテストを実行する。test_calc.py# 1.ファイル名は「test_対象のモジュール名.py」とする # 2. unittestモジュールをimportする import unittest import calc # 3.テストクラス名は「Testテスト対象のクラス名」とする # 4.テストクラスはunittest.TestCaseを継承する class TestCalc(unittest.TestCase): # 5.テストメソッド名は「test_テスト対象のメソッド名」とする def test_add_num(self): num1 = 10 num2 = 5 expected = 15 actual = calc.add_num(num1, num2) # 予定の結果を得られているか確認するassertEqual()メソッド self.assertEqual(expected, actual) def test_sub_num(self): num1 = 10 num2 = 5 expected = 5 actual = calc.sub_num(num1, num2) self.assertEqual(expected, actual) # 6. unittest.main()でテストを実行する if __name__ == "__main__": unittest.main()ファイル名の後に
-vオプションをつけて実行することで、テスト内容に関する情報が表示されます。
計算が正しく実行されていれば成功です。$ python test_calc.py -v test_add_num (__main__.TestCalc) ... ok test_div_num (__main__.TestCalc) ... ok ---------------------------------------------------------------------- Ran 2 tests in 0.001s OK対象のスクリプト2つとも
okと表示されているので、無事にテスト成功していることが分かります。
unittest.main()を実行すると、対象のスクリプトの中でunittest.TestCaseを継承した全てのクラスを認識し、testで始まる各メソッドがテストケースとして実行されます。最後にテスト失敗した場合を見ていきます。
test_calc_1.py# 1.ファイル名は「test_対象のモジュール名.py」とする # 2. unittestモジュールをimportする import unittest import calc # 3.テストクラス名は「Testテスト対象のクラス名」とする # 4.テストクラスはunittest.TestCaseを継承する class TestCalc(unittest.TestCase): # 5.テストメソッド名は「test_テスト対象のメソッド名」とする def test_add_num(self): num1 = 10 num2 = 5 expected = 15 actual = calc.add_num(num1, num2) # 予定の結果を得られているか確認するassertEqual()メソッド self.assertEqual(expected, actual) def test_sub_num(self): num1 = 10 num2 = 5 expected = 6 actual = calc.sub_num(num1, num2) self.assertEqual(expected, actual) # 6. unittest.main()でテストを実行する if __name__ == "__main__": unittest.main()$ python test_calc.py -v test_add_num (__main__.TestCalc) ... ok test_sub_num (__main__.TestCalc) ... FAIL ====================================================================== FAIL: test_sub_num (__main__.TestCalc) ---------------------------------------------------------------------- Traceback (most recent call last): File "test_calc.py", line 24, in test_sub_num self.assertEqual(expected, actual) AssertionError: 6 != 5 ---------------------------------------------------------------------- Ran 2 tests in 0.001s FAILED (failures=1)
test_sub_num (__main__.TestCalc) ... FAILとなっており、引き算の結果が間違っていることが分かりました。参考文献
2. doctest
テストプログラムの書き方3ステップ
1. テストする対象の関数add_numとsum_numに('''で囲まれた部分)にPython対話モードの形式で関数の呼び出しと期待される出力値を記述します。
2. doctestモジュールをimportする。
3.doctest.testmod()でテストを実行する。まずはエラーがある場合を見ていきます。
doc.pyclass Keisan(object): def add_num(self, num1, num2): # 1. 関数の呼び出しと期待される出力値を記述 '''引数同士を足す >>> k = Keisan() >>> k.add_num(5, 5) 10 ''' result = num1 + num2 return result def sub_num(self, num1, num2): '''引数同士を引く >>> k = Keisan() >>> k.sub_num(5, 5) 3 ''' result = num1 - num2 return result # 2. doctestモジュールをimportする # 3. doctest.testmod()でテストを実行する if __name__ == '__main__': import doctest doctest.testmod()$ python doc.py ********************************************************************** File "practice.py", line 15, in __main__.Keisan.sub_num Failed example: k.sub_num(5, 5) Expected: 3 Got: 0 ********************************************************************** 1 items had failures: 1 of 2 in __main__.Keisan.sub_num ***Test Failed*** 1 failures.期待される出力値がExpected、実際の出力値がGotで示されています。
Expected: 3ではなく、Got: 0が正しいことが分かります。次にエラーがない場合を見ていきます。
doc_1.pyclass Keisan(object): def add_num(self, num1, num2): # 1. 関数の呼び出しと期待される出力値を記述 '''引数同士を足す >>> k = Keisan() >>> k.add_num(5, 5) 10 ''' result = num1 + num2 return result def sub_num(self, num1, num2): '''引数同士を引く >>> k = Keisan() >>> k.sub_num(5, 5) 0 ''' result = num1 - num2 return result # 2. doctestモジュールをimportする # 3. doctest.testmod()でテストを実行する if __name__ == '__main__': import doctest doctest.testmod()$ python doc.py
Expected: 3をExpected: 0に置換しました。
エラーがない場合、何も表示されないことが分かりました。参考文献
3. pytest
まずは
pytestをインストールする。$ pip install pytest次にテストする対象の関数
practice.pyを用意します。
こちらは足し算・引き算を行うメソッドです。practice.pyclass Practice(object): def __init__(self, num1, num2): self.num1 = num1 self.num2 = num2 def add_num(self): return self.num1 + self.num2 def sub_num(self): return self.num1 - self.num2そして、
practice.pyに対してpytestを使ってテストします。テストプログラムの書き方6ステップ
1. ファイル名は「test_対象のモジュール名.py」とする。
2. テストメソッド名は「test_テスト対象のメソッド名」とする。
3.assertでテストを実行する。test_practice.py# 1. ファイル名は「test_対象のモジュール名.py」とする from practice import Practice # 2. テストメソッド名は「test_テスト対象のメソッド名」とする def test_add_num(): # 3. assertでテストを実行する assert Practice(5, 5).add_num() == 10 def test_sub_num(): assert Practice(5, 5).sub_num() == 10ファイル名の前に
pytestをつけて実行する。$ pytest test_practice.py =============================== test session starts ================================ platform win32 -- Python 3.8.2, pytest-5.4.1, py-1.8.1, pluggy-0.13.1 rootdir: C:\Users\Yusuke\Desktop\blog\test collected 2 items test_practice.py .F [100%] ===================================== FAILURES ===================================== ___________________________________ test_sub_num ___________________________________ def test_sub_num(): > assert Practice(5, 5).sub_num() == 10 E assert 0 == 10 E + where 0 = <bound method Practice.sub_num of <practice.Practice object at 0x00000210F2B21070>>() E + where <bound method Practice.sub_num of <practice.Practice object at 0x 00000210F2B21070>> = <practice.Practice object at 0x00000210F2B21070>.sub_num E + where <practice.Practice object at 0x00000210F2B21070> = Practice(5, 5) test_practice.py:7: AssertionError ============================= short test summary info ============================== FAILED test_practice.py::test_sub_num - assert 0 == 10 =========================== 1 failed, 1 passed in 0.24s ============================
short test summary infoFAILEDにtest_practice.py::test_sub_num - assert 0 == 10と記載されており、引き算の結果が間違っていること分かります。引き算の結果を
10から0に置換して、エラーがない場合を確認します。test_practice_1.py# 1. ファイル名は「test_対象のモジュール名.py」とする from practice import Practice # 2. テストメソッド名は「test_テスト対象のメソッド名」とする def test_add_num(): # 3. assertでテストを実行する assert Practice(5, 5).add_num() == 10 def test_sub_num(): assert Practice(5, 5).sub_num() == 0$ pytest test_practice_1.py =============================== test session starts ================================ platform win32 -- Python 3.8.2, pytest-5.4.1, py-1.8.1, pluggy-0.13.1 rootdir: C:\Users\Yusuke\Desktop\blog\test collected 2 items test_practice.py .. [100%] ================================ 2 passed in 0.03s =================================
2 passed in 0.03sとなっており、正しい結果になったことが分かります。参考文献
- 投稿日:2020-04-03T14:18:13+09:00
Pythonで、OCTAのudfファイル名を操作する
Pythonで、re、osモジュールを使ってファイル名を一括で処理する。
簡単なプログラムですが、OCTAを使用していて、UDFファイルのみを取り出して、ファイル名を一括で処理したい時があるので、覚えで作りました。
ファイル名に一括で分類名を付ける。
re:正規表現モジュール
re.compile()を使うと、その中の文字列を正規表現にコンパイルしてオブジェクトを作成する。
reg_exit = re.compile(keyword) は、compileで、正規表現にコンパイルするキーワードを指定することで、正規表現になる。このオブジェクトを、reg_exitに入れる。re.search()文字列すべてが検索対象。
os:ファイルやディレクトリの操作ができる。
os.rename(a,b):aのファイル名をbに変更するfor name in file_list:で、ファイル名を一つずつ取り出してnameに入れる。
if reg_exit.search(name):で、取り出したファイル名の中に、正規表現にコンパイルしたキーワードがあるかどうかを判別する。
udf_file.append(name) は、キーワードのあったファイルをリストに加える。
os.rename(file, category+file) は、ファイル名(file)にキーワード(category)を加えるOCTAでのファイル名に一括で分類名をつける#モジュールをimportする import os import re #ディレクトリー内のファイルのリストを作る. file_list = os.listdir() udf_file = [] reg_exit = re.compile(r'(.udf)$') for name in file_list: if reg_exit.search(name): udf_file.append(name) #分類名を指定(category)して、ファイル名に追加(os.rename)する category = 'カテゴリー10_' for file in udf_file: os.rename(file, category+file)
- 投稿日:2020-04-03T14:10:19+09:00
【python】DataFrameを使った表作成方法のまとめ(pandas)
【python】DataFrameを使った表作成方法のまとめ(pandas)
PandasのDataFrameを使って、一つの表を作成する場合に、複数の方法がある。
基本的な作り方のまとめ。
ベースとなる表はcsvファイルで作って読み込むのが一番早そう。
目次
1.作成する表
下記の表を作成する。
- 列名:row0~row5
- 行名:col0~col4
- col0:1~6
- col1:col0*100
- col2:col0/3
- col3:AAA~FFF
- col4:col3 & col1
2.2次元listから作成
■2次元配列とは
[['A','B',,],['C','D',,],,,]1次元のリスト['A','B',,]が同一の[ ]内に複数並列で入ったもの。
下記3パターンで確認する。
(1)行列名を後から指定
(2)表作成時にオプションで指定
(3)表から行名となる列を指定
(1)行列名を後から指定
▼手順
①各行を一つのlistにする
②表に変換
③行名の変更
④列名の変更
①各行を一つのlistとして並列に並べる2次元配列list = [ [1, 100, 0.33, 'AAA', 'AAA100'], [2, 200, 0.67, 'BBB', 'BBB200'], [3, 300, 1, 'CCC', 'CCC300'], [4, 400, 1.33, 'DDD', 'DDD400'], [5, 500, 1.67, 'EEE', 'EEE500'], [6, 600, 2, 'FFF', 'FFF600']]
②表に変換
pd.DataFrame(list)
└pandasのDataFrameで表に変換。表に変換df = pd.DataFrame(list) df
行と列の名前は自動で割り振られた番号になる。
③行名の変更
df.index = ['A','B',,,]・行名(index)を指定した名称に変更する。
・[ ]内の要素の数と行の数を一致させる。しないとエラー。行名を変更df.index = ['row0','row1','row2','row3','row4','row5'] df
④列名の変更
df.columns = ['a','b',,,]・列名(column)を指定した名称に変更する。
・[ ]内の要素の数と行の数を一致させる。しないとエラー。列名を変更df.columns = ['col0','col1','col2','col3','col4'] df
以上で完成。
(2)表作成時にオプションで指定
▼手順
①各行を一つのlistにする
②表に変換(オプションで行列名を指定)
2-1 columnsオプション
2-2 indexオプション
①各行を一つのlistとして並列に並べる2次元配列list = [ [1, 100, 0.33, 'AAA', 'AAA100'], [2, 200, 0.67, 'BBB', 'BBB200'], [3, 300, 1, 'CCC', 'CCC300'], [4, 400, 1.33, 'DDD', 'DDD400'], [5, 500, 1.67, 'EEE', 'EEE500'], [6, 600, 2, 'FFF', 'FFF600']]
②表に変換(オプションで行列名を指定)
pd.DataFrame(list, index=['A','B',,,], columns=['a','b',,,])
└「list」:表にする配列
└ index=['A','B',,,]:indexオプション
└ columns=['a','b',,,]:columnsオプション
└オプションの[ ]の中は変数で指定可。
オプションで行列名を指定ind = ['row0','row1','row2','row3','row4','row5'] col = ['col0','col1','col2','col3','col4'] df = pd.DataFrame(list, index=ind, columns=col) df
以上で完成。
(3)表から行名となる列を指定
▼手順
①各行を一つのlistにする
②表に変換
③列名を変更
④行名となる列を指定
①各行を一つのlistにする
行名を2次元配列の中に含める。2次元配列list = [ ['row0', 1, 100, 0.33, 'AAA', 'AAA100'], ['row1', 2, 200, 0.67, 'BBB', 'BBB200'], ['row2', 3, 300, 1, 'CCC', 'CCC300'], ['row3', 4, 400, 1.33, 'DDD', 'DDD400'], ['row4', 5, 500, 1.67, 'EEE', 'EEE500'], ['row5', 6, 600, 2, 'FFF', 'FFF600'], ]
②表に変換
pd.DataFrame(list)
└ 「list」:配列データの入った変数表に変換df = pd.DataFrame(list) df
行と列の名前は自動で割り振られた番号になる。
③列名を変更
df.columns = ['a','b',,,]・列名(column)を指定した名称に変更する。
・[ ]内の要素の数と行の数を一致させる。しないとエラー。※次の列名となる行の指定(set_index)でマルチインデックスになるのを防ぐため、行名となる列名は空欄「''」にする。
列名の変更df.columns = ['','col0','col1','col2','col3','col4'] df
④行名となる列を指定
set_index('列名')
行名となる列を指定df = df.set_index('') df
列名「''」が見出しに設定された。
3.1次元listから作成
下記3パターンで確認する。
(1)各listをまとめて結合
(2)各listを一つづつ結合
(3)数式で結合
(1)各listをまとめて結合
▼手順
①各行ごとのlistを作成
②まとめて表に変換
③行名の変更
④列名の変更
①各行ごとのlistを作成listを作成listA = [1, 100, 0.33, 'AAA', 'AAA100'] listB = [2, 200, 0.67, 'BBB', 'BBB200'] listC = [3, 300, 1, 'CCC', 'CCC300'] listD = [4, 400, 1.33, 'DDD', 'DDD400'] listE = [5, 500, 1.67, 'EEE', 'EEE500'] listF = [6, 600, 2, 'FFF', 'FFF600']
②まとめて表に変換
pd.DataFrame([A,B,,,])
└ 「A」「B」1次元のlist
└ 要素の数は等しい
まとめて表に変換pd.DataFrame([listA,listB,listC,listD,listE,listF])
③行名の変更
df.index = ['A','B',,,]・行名(index)を指定した名称に変更する。
・[ ]内の要素の数と行の数を一致させる。しないとエラー。行名を変更df.index = ['row0','row1','row2','row3','row4','row5'] df
④列名の変更
df.columns = ['a','b',,,]・列名(columns)を指定した名称に変更する。
・[ ]内の要素の数と行の数を一致させる。しないとエラー。列名を変更df.columns = ['col0','col1','col2','col3','col4'] df
以上で完成。
(2)各listを一つづつ結合
▼手順
①各行ごとのlistを作成
②表の作成
③表に列を追加
④行名の変更
⑤転置
①各行ごとのlistを作成listを作成listA = [1, 100, 0.33, 'AAA', 'AAA100'] listB = [2, 200, 0.67, 'BBB', 'BBB200'] listC = [3, 300, 1, 'CCC', 'CCC300'] listD = [4, 400, 1.33, 'DDD', 'DDD400'] listE = [5, 500, 1.67, 'EEE', 'EEE500'] listF = [6, 600, 2, 'FFF', 'FFF600']
②表の作成
1つのlistから表を生成する。
pd.DataFrame(list, columns=['A'])
└ 「listA」:配列データ
└ 「columns=['A']」:列名をAにする表の作成df= pd.DataFrame(listA, columns=['row0']) df
※1列の読込の場合、行列が転置した状態になる。
③表に列を追加
df['B'] = pd.DataFrame(list)
└ 「B」:追加する列名
└ 「list」:追加する表データ表に列を追加df['row1'] = pd.DataFrame(listB) df['row2'] = pd.DataFrame(listC) df['row3'] = pd.DataFrame(listD) df['row4'] = pd.DataFrame(listE) df['row5'] = pd.DataFrame(listF) df
④行名の変更
df.index = ['A','B',,,]行名を変更df.index = ['col0','col1','col2','col3','col4'] df
⑤転置
df.T
└行列を入れ替える。転置df = df.T df
以上で完成。
(3)数式で結合
各列に規則性がある場合、数式を用いて列を結合できる。
▼規則性
- col1:col0*100
- col2:col0/3
- col4:col3 & col1
▼手順
①listを作成
②表を作成
③数式を使って表に列を追加
④行名の変更
①listを作成
ベースとなる列を作成する。col0とcol3の用の2つ分。
listを作成listA = [1,2,3,4,5,6] listD = ['AAA', 'BBB', 'CCC', 'DDD', 'EEE', 'FFF']
②表の作成
pd.DataFrame(list, columns=['A'])
└ 「listA」:配列データ
└ 「columns=['A']」:列名をAにする表の作成df = pd.DataFrame(listA, columns=['col0']) df
③数式を使って表に列を追加
・df['B'] = df['A']/2
└ 「B」:追加する列名
└ 「df['A']」/2:既存の列名Aを2で割った値を代入・
df['C'] = df['A'] + df['B']
└ 列「A」と「B」の値を結合する
└ ※str + intはエラー(型を合わせる)・
df['A'].astype(str)
└ 列「A」を「str」型に変更する数式を使って表に列を追加df['col1'] = df['col0'] * 100 df['col2'] = df['col0'] / 3 df['col3'] = pd.DataFrame(listD) df['col4'] = df['col3'] + df['col1'].astype(str) df
④行名の変更
df.index = ['A','B',,,]行名を変更df.index=['row0','row1','row2','row3','row4','row5'] df
以上で完成。
4.csvファイルで作成し読込み
▼手順
①csvファイルで表を作成
②read_csvメソッドでインポート
└ 見出し列の指定
①csvファイルで表を作成
下記のような表を作成する。
②read_csvメソッドでインポート
read_csv('ファルパス', index_col=n)
└ 「'ファイルパス'」:絶対パスでも相対パスでもOK
└ 「index_col=n」:見出しとなる列番号(n:整数)を指定
▼desktopのtest.csvファイルを読み込む場合csvファイルの読込import pandas as pd pd.read_csv('~/desktop/test.csv', index_col=0)
以上で完成。
>csvファイルの読込オプション一覧はこちら
5.使用したメソッド等一覧
・
pd.DataFrame(list)
└ listを表に変換・
pd.DataFrame([A,B,,,])
└ 一次元listをまとめて表に変換・
df.index = ['A','B',,,]
└ 行名の変更・
df.columns = ['a','b',,,]
└ 列名の変更・
pd.DataFrame(list, index=['A','B',,,])
└ 表作成時に行名を指定・
pd.DataFrame(list, columns=['a','b',,,])
└ 表作成時に列名を指定・
set_index('a')
└ 行名となる列を指定・
df['b'] = pd.DataFrame(list)
└ 表(df)に列(列名b)を追加・
df.T
└ 転置・
df['B'] = df['A']/2
└ 「B」:追加する列名
└ 「df['A']」/2:既存の列名Aを2で割った値を代入・
df['C'] = df['A'] + df['B']
└ 列「A」と「B」の値を結合する
└ ※str + intはエラー(型を合わせる)・
df['A'].astype(str)
└ 列「A」を「str」型に変更する・
[['A','B',,],['C','D',,],,,]
└ 2次元配列


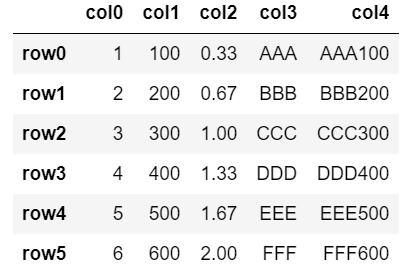
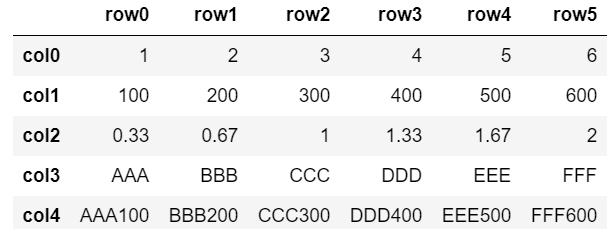


- 投稿日:2020-04-03T13:25:20+09:00
AtCoder Beginner Contest 156の復習, E問まで(Python)
競プロ初心者の復習用記事です。
ここで書く解は解説や他の人の提出を見ながら書いたものです。自分が実際に提出したものとは限りません。
A - Beginner
とある競プロサイトでは、回数が少ない人のレーティングは内部レーティングより高めに表示しているらしいです。実際の内部レーティングがいくつかを答える問題です。
回数Nが10以上ならそのまま出力。10未満なら補正値$100\times (10-N)$を加えた値が内部レーティングになります。
N, R = map(int, input().split()) if N < 10: print(R + 100 * (10-N)) else: print(R)B - Digits
数値NをK進法で表記したときに何桁になるかを答える問題です。
最大の桁がどこになるかを考えます。例えば$N=9, K = 2$なら、$2^3$である$1000$が最大の桁となり、$r=4$と求まります。これを数式で言えば、以下を満たす乗数rを求めればいいことになります。
$$ K^{r-1} \leq N < K^{r} $$
これを単純に実装しました。
N, K = map(int, input().split()) r = 1 while not(K**(r-1) <= N and N < K ** r): r += 1 print(r)これで問題なく通りましたが、解説を見るとやり方が異なりました。
求める桁数を$D$、各桁の値を$a_{D-1}, \cdots , a_1, a_0$
とすると$$ $$$$ N = a_{D-1}K^{D-1} + \cdots + a_1 K^1 + a_0 K^0$$
という数式で表されます。
$N$を$K$で割って商をとる操作を繰り返すと、$D$回$K$で割ったところで商が$0$となります。
これを実装してみます。
N, K = map(int, input().split()) D = 0 while N: N //= K D += 1 print(D)計算時間はどちらでも問題ありませんでした。
C - Rally
数直線上に配置された人達の、二乗誤差がもっとも小さくなる地点(整数値)はどこかを答える問題です。
問題文からパッと連想するのは最小二乗法ですが、N, Xがともに1から100までという狭い範囲をとっています。$O(N^2)$が問題なく通るため数学的な技術は必要ないと判断し、シンプルに全探索してみました。
N = int(input()) X = list(map(int, input().split())) minLoss = 1e6 for i in range(1, 101): minLoss = min(minLoss, sum([(x - i)**2 for x in X])) print(minLoss)これで通りました。
左右の範囲を1から100までじゃなくてXの最小値と最大値にすればもうちょっと効率はいいと思います。
D - Bouquet
N種類の異なる花から取り出す組み合わせは何種類あるでしょうか?ただしa本、b本取り出すことはできません。という問題です。
1からNまでの各本数nについて$_nC_r$で組み合わせを求めようとしたため、TLE。諦めました。
解説を見ました。「全ての本数についての全組み合わせ」というのは、もっとずっと簡単に計算できます。
それぞれの花は「使う」「使わない」の二通りの選択肢しかありません。つまり全ての組み合わせは$2^N$。ただし0本使う組み合わせは除外されているため、正確には$2^N-1$です。
ここからa, bについて$_nC_r$で除外するべき組み合わせを引けば求まります。
from scipy.misc import comb m = 1000000007 n, a, b = map(int, input().split()) out = 2**n - comb(n, a) - comb(n, b) print(out%m)これだとダメでした。2**nや$_nC_a, _nC_b$がそれはもうえげつない数になってしまうのが問題です。
これを何とかするためには
「$10^9+7$で割った余り」という条件を使い、数学的な手法で計算を減らしていく必要があります。まず、2の乗数について考えます。pythonでは
**ではなくpow()を用いて第三引数で割る数を指定し、剰余計算を高速で行うことができます。print(pow(2, 4, 3)) # 1次に組み合わせ計算の高速化を考えます。
フェルマーの小定理というものがあります。$p$が素数、$a$と$p$が互いに素であるときに
$$ a^{p-1} \equiv 1~~(\rm{mod}~ p) $$
が成り立つ。つまりaのp-1乗をpで割ると1になる。らしい。知りませんでした。
いまいち実感が沸かなかったので、適当に試してみます。
p = 29 for a in range(3, 29, 5): print("a: {}, p: {}, a^(p-1)%p: {}".format(a, p, pow(a, p-1, p))) ''' a: 3, p: 29, a^(p-1)%p: 1 a: 8, p: 29, a^(p-1)%p: 1 a: 13, p: 29, a^(p-1)%p: 1 a: 18, p: 29, a^(p-1)%p: 1 a: 23, p: 29, a^(p-1)%p: 1 a: 28, p: 29, a^(p-1)%p: 1 '''ほんとだ。へー。証明はここでは触れません。
話を戻します。この条件では$10^9+7$とYは必ず互いに素であるため、以下の式が成立します。
$$ Y^{(10^9+7)-1} \mod 10^9+7 = 1 $$
両辺をYで割って
$$ Y^{(10^9+7)-2} \mod 10^9+7 = {1\over Y} $$
この形なら先ほどと同じように、pow()を用いて高速に計算ができます。組み合わせ計算に出てくる項を分母Xと分子Yに分離し、Yにこの処理をかけます。m = 1000000007 n, a, b = map(int, input().split()) def comb(n, r, m): X, Y = 1, 1 for i in range(r): X *= n-i Y *= i+1 X %= m Y %= m return int(X * pow(Y, m-2, m)) out = pow(2, n, m) - 1 - comb(n, a, m) - comb(n, b, m) print(out%m)これで通りました。
E - Roaming
n個の部屋にそれぞれいる人がk回移動したら部屋の状態は何通りありうるでしょうか?という問題です。
解き方の想像もつかず、諦めました。
解説を見ました。
まず、人数が0人となる部屋の組み合わせを考えます。$m$個の部屋が空となっているとします。そうすると、全n部屋からm部屋を選ぶ組み合わせは
$$ _nC_m $$
で求まります。そこから、元のm部屋の住人が移動した部屋の組み合わせを考えます。考え方はいろいろありますが、シンプルな考え方として$m$人の住人を$n-m-1$個の壁で区切るようにしてみます。住人を〇、壁を|とすると、文字列を並べるパターンの組み合わせを考える問題に変えることができます。
例:5人を2つの壁で分ける方法は?
〇〇|〇|〇〇
みたいな組み合わせができる。この並べ方は
$$ {7! \over 5!2!}=_7C _2$$
で計算できる。
この計算を今回の状況に当てはめると、以下の式が求まります。
$$ {(m +(n-m-1))!\over m!(n-m-1)!}=_{n-1}C _{m} $$
よって、$_nC_m \times _{n-1}C _{m}$で$m$部屋が0人の時の組み合わせが求まります。この$m$を0から$k$(もしくは$n-1$)まで変化させながら合計をとればいいことになります。
また、組み合わせの計算結果はその次の組み合わせ計算にも流用できます。
$$ _{n}C _{m+1} = _{n}C _{m} \times {n-m\over m+1} $$
$$ _{n-1}C _{m+1} = _{n-1}C _{m} \times {n-m-1\over m+1} $$
これを先ほどの式(以下)も利用しつつ、計算していきます。
$$ Y^{(10^9+7)-2} \mod 10^9+7 = {1\over Y} $$というわけで実装例です。ほとんど他の人のコード見ながら書いてます。
n, k = map(int, input().split()) c1 = 1 c2 = 1 mod = 10**9+7 ans = 0 for i in range(min(n, k+1)): ans += c1 * c2 c1 *= (n-i) * pow(i+1, mod-2, mod) c1 %= mod c2 *= (n-i-1) * pow(i+1, mod-2, mod) c2 %= mod print(ans%mod)以上で今回の記事はここまでとします。