- 投稿日:2020-04-03T23:39:02+09:00
javaで複数の例外をまとめてcatchする
javaで、複数の例外についてcatchして同じようにログ出力して上に投げるよいう処理をよく見ますが、
冗長で共通化したいなと思っていたので調べてみたらどうやらできるみたいです。参考catch (IOException ex) { logger.log(ex); throw ex; } catch (SQLException ex) { logger.log(ex); throw ex; }
|で区切ってあげると下記のような書き方で共通化できます。
少し注意なのが、java7以降でしか使えないようですので、昔のバージョンで開発してる方はご注意ください。catch (IOException | SQLException ex) { logger.log(ex); throw ex; }
- 投稿日:2020-04-03T22:31:33+09:00
パッケージ分けされたJavaのコードをコマンドで実行する
調べてもなかなか出てこなかったのでメモ。
実行コマンド
$ javac -d /path/to/build/dir/ /path/to/javafiles $ java -cp /path/to/classfiles/ main.Main例
こんな階層だったとします。
. └── src ├── app │ └── App.java └── hoge ├── Hoge.java └── fuga └── Fuga.javaコンパイル
全部コンパイルします。-d で生成ファイルの出力先のディレクトリを指定します。
$ javac -d build src/*/*.java src/*/*/*.javaこうなります。
. ├── build │ ├── app │ │ └── App.class │ └── hoge │ ├── Hoge.class │ └── fuga │ └── Fuga.class └── src ├── app │ └── App.java └── hoge ├── Hoge.java └── fuga └── Fuga.javabuild ディレクトリにclassファイルがちゃんとパッケージ分けされて入っています。
実行
$ java -cp build app.App-cpでクラスパスを指定します。クラスパスは、classファイルを探すルートとなるディレクトリです。buildの中にあるのでそれを指定します。
app.App の部分は、mainメソッドが入っているクラスをパッケージ名込み且つ、ドット区切りで指定します。
以上です。
- 投稿日:2020-04-03T22:26:34+09:00
flywayのflyway.configFileプロパティが消えてた。
DBのマイグレーションにflywayを使用しています。
flywayのバージョンを変更して、いつものようにコマンドを実行すると、エラーが出るようになりました。
実行できていたはずのコマンドがエラーになり困っていましたが、一先ず解決したので共有します。原因:バージョンが変わったことでflyway.configFileが使用できなくなった。
エラーが発生した時のバージョンは以下です。
・Apache Maven 3.6.0
・flyway-maven-plugin 6.0.8 (4.1.0から変更)エラー例$ mvn -Dflyway.configFile=src/main/resources/application-local.yml flyway:info [INFO] Scanning for projects... [INFO] [INFO] --------------< jp.co.hoge.hoge.app:hoge-hoge-app >--------------- [INFO] Building hoge-hoge-app 0.1.0 [INFO] --------------------------------[ jar ]--------------------------------- [INFO] [INFO] --- flyway-maven-plugin:6.0.8:info (default-cli) @ hoge-hoge-app --- [INFO] ------------------------------------------------------------------------ [INFO] BUILD FAILURE [INFO] ------------------------------------------------------------------------ [INFO] Total time: 2.462 s [INFO] Finished at: 2020-04-03T08:50:08Z [INFO] ------------------------------------------------------------------------ [ERROR] Failed to execute goal org.flywaydb:flyway-maven-plugin:6.0.8:info (default-cli) on project hoge-hoge-app: org.flywaydb.core.api.FlywayException: Unknown configuration property: flyway.configFile -> [Help 1] [ERROR] [ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch. [ERROR] Re-run Maven using the -X switch to enable full debug logging. [ERROR] [ERROR] For more information about the errors and possible solutions, please read the following articles: [ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/MojoExecutionExceptionメッセージで
Unknown configuration property: flyway.configFileと表示されているように、
flywayのバージョンを変えてたことで(4.1.0 -> 6.0.8)、flyway.configFileが使用できなくなったようです。
(変更前は使えたのでプロパティがないとは疑えずはまった・・。)ドキュメントで使用されていたプロパティに修正すると、エラーが解消されました。
修正前後$ mvn -Dflyway.configFile=src/main/resources/application-local.yml flyway:info # 修正前 $ mvn -Dflyway.configFiles=src/main/resources/application-local.yml flyway:info # 修正後 (configFilesに変更)ちなみにIssueも上がっていました。
https://github.com/buthomas/Cake.Flyway/issues/12複数のconfigファイルをサポートする時に消えたっぽい?
https://github.com/flyway/flyway/issues/1624はまる人は少数かと思いますが、参考になればと思います。
今回は以上です。
- 投稿日:2020-04-03T21:05:08+09:00
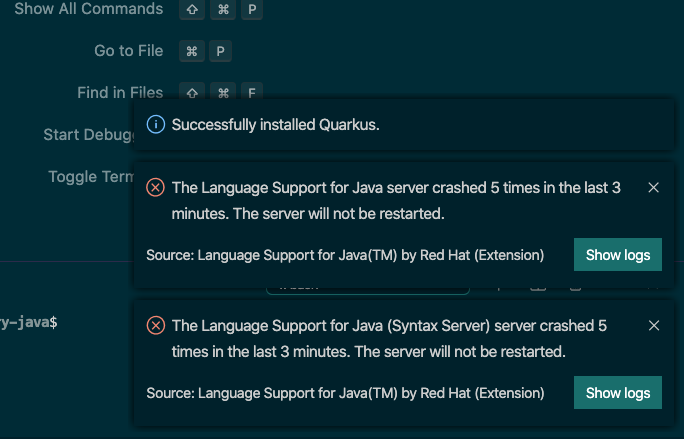
「The Language Support for Java server crashed 5 times in the last 3 minutes. The server will not be restarted.」エラーで振り回された話
「The Language Support for Java server crashed 5 times in the last 3 minutes. The server will not be restarted.」
このエラーに振り回されたので、備忘録として残そうと思います。自分メモなので適当
始まり
Docker使ってJavaの環境を整えたいな...
せや、この記事参考にやってみよう!
https://blog.kondoumh.com/entry/2019/09/22/100000
はい???できないんですがそれは。
調べたら出てきた事
わからんのでエラー内容コピペで検索
これが出てきた。
http://wiki.tk2kpdn.com/language-support-for-java-error-in-vscode/ほう、アンイストールしてsetting.jsonをやり直すのか。
アンイストールめんどい...
でもこれしかないか...アンインストール際に困った事
記事には、
ユーザー設定を削除。
( C:\Users(ユーザー名)\AppData\Roaming\Code\User )このAppDataフォルダがmacにない!!
どこにあるの??調べた
https://www.atmarkit.co.jp/ait/articles/1810/12/news026.html
Windows:%APPDATA%\Code\Userフォルダ
macOS:~/Library/Application Support/Code/Userフォルダ
Linux:~/.config/Code/Userフォルダらしいです。ターミナル開いて行ったらありました。
なのでUserファイルをrmしました。そして再インストールしました。
わーいできた。終わり
- 投稿日:2020-04-03T05:06:58+09:00
Azure WebAppsへのwarデプロイ(maven)
目的
GitActionsがプレビュー版となったため、mavenビルドをgitに行ってもらい、WebAppsにデプロイする
1:アプリ準備
まずは、Maven + TomcatのJavaアプリケーションを作成する
mavenは以下のように記述した
<properties> <java.version>1.8</java.version> <maven.compiler.source>1.8</maven.compiler.source> <maven.compiler.target>1.8</maven.compiler.target> <RESOURCEGROUP_NAME>DeployTest</RESOURCEGROUP_NAME> <WEBAPP_NAME>MavenJsptest</WEBAPP_NAME> </properties> <dependencies> <dependency> <groupId>javax.servlet</groupId> <artifactId>javax.servlet-api</artifactId> <version>4.0.1</version> <scope>provided</scope> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>3.8.1</version> <scope>test</scope> </dependency> </dependencies> <build> <finalName>ROOT</finalName> <!-- Azure default root pass --> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-war-plugin</artifactId> <version>2.6</version> <configuration> <packagingExcludes>WEB-INF/lib/javax.servlet-api-3.0.1.jar</packagingExcludes> </configuration> </plugin> </plugins> </build>特に詰まったのが、finalNameの部分で、これはmvn install で生成されるwarファイル名の名称。
WebAppsがROOT以下をデフォルトで参照しにいくため、これ以外の指定だとエラーが発生していた。※もし、別の名前でもエラーを起こさない方法があれば教えていただきたいです!
アプリを作り終えたら、GitHubにプッシュ
2:WebApps設定
App Service Plan および WebAppsを作成(Javaの環境はアプリに合わせる)して、「デプロイセンター」を選択し、GitActionや作成したアプリのリポジトリを選択。
最後にyamlが出力されるが、この中を見てみると、Javaのバージョンの選択およびmvn clean installしていることがわかる
3:確認
ここまでやれば、GitHubのアクションが動作していることが確認できる。
問題がなければ、デプロイされ、正常にアクセスすることができる感想
JenkinsやAzure Pipelineも素晴らしいツールだが、設定や構築が少し面倒なのが気になっていたため、今回のGitActionsがGitHubとAzureさえ登録すれば構築不要で使えたので、とても楽だった。
今回はyamlも特に編集しなかったがカスタマイズすることで(単体テストの実行など)より効果的な開発ができると思う。
- 投稿日:2020-04-03T04:01:19+09:00
Docker 上で入門する Apache Hadoop
はじめに
はじめての並列分散処理のフレームワークとして Apache Beam を利用しているのですが、この辺りの学習をするにあたっては MapReduce などの従来からの用語や概念も頻繁に登場します。そのため、Apache Hadoop に入門してみました。今回は、環境をできるだけ楽に構築できるように Docker を利用しています。
Hadoop 概要
Hadoop は、大容量のデータを処理するための分散処理のフレームワークです。通常は Linux 上で動作させます。スケールアウトに優れているため、処理するデータ量が増えたとしても、サーバーの台数を追加することで性能を向上させることができます。
Hadoop は、主に次の2つのシステムで構成されます。
- HDFS (Hadoop Distributed File System):分散ファイルシステム。大容量のデータを複数のサーバーに分割して格納します。ユーザーはこれらの複数のサーバーをひとつの大きなファイルシステムのように扱うことができます。
- MapReduce:分散処理を実現するフレームワーク。ひとつの大きな処理(ジョブ)を複数の単位(タスク)に分割し、複数のサーバーで並列に実行できるように作られています。
Hadoop は、ひとつのコンポーネントで動作するのではなく、HDFS や MapReduce フレームワークなど複数のコンポーネントが連携することで動作します。このような Hadoop の主要なコンポーネントを Hadoop エコシステムと呼ぶことがあります。
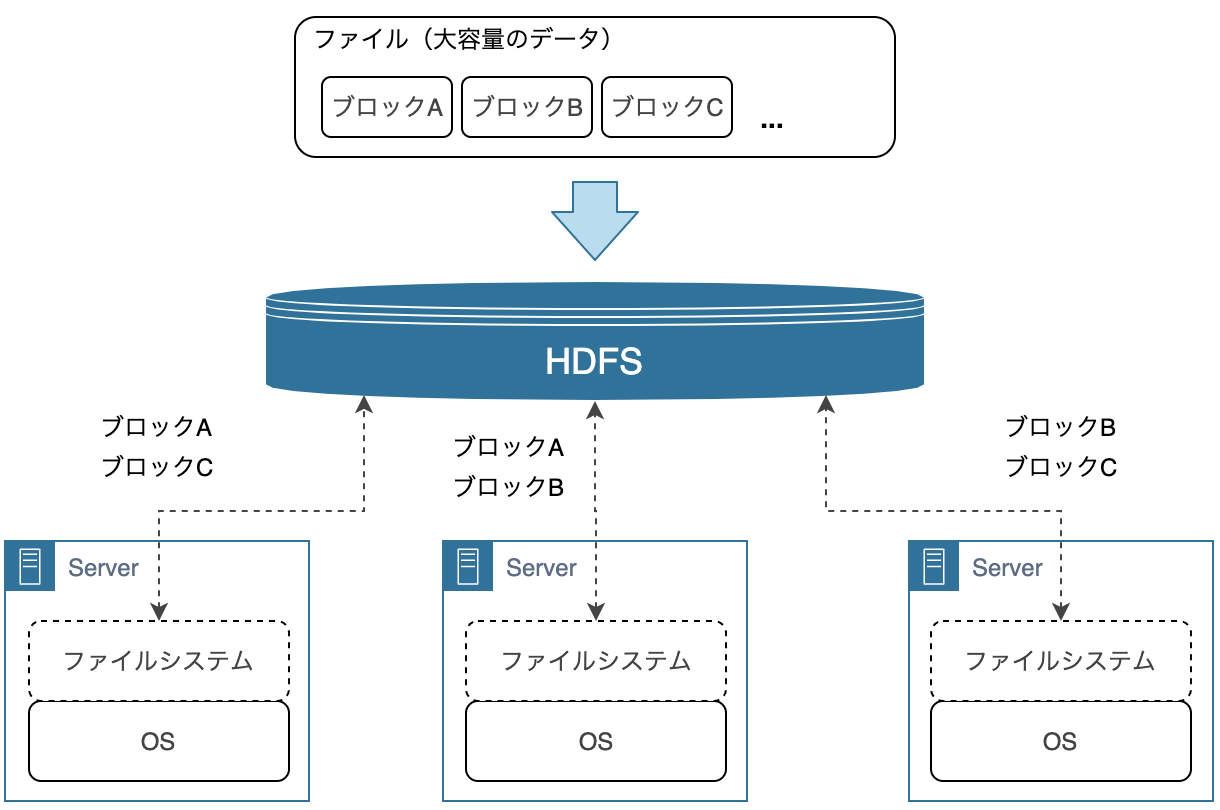
HDFS (Hadoop Distributed File System)
HDFS 上では、大容量のデータは細かい単位(ブロック)に分割され、複数のサーバーのファイルシステムに配置されます。たとえば、データサイズが 1GB (1024MB) で、ブロックサイズが 64MB だった場合、データは16個のブロックに分割され、複数のサーバーに配置されます。
このように複数のサーバーにデータを分配し、並列に処理することでスループットの向上が見込めます。ストレージやサーバー間の通信はコストが高いので、各サーバーで読み込んだデータはできる限りそのサーバーで処理するように動作し、最終的には、各サーバーで処理した結果をネットワーク経由で転送してひとつの結果としてまとめます。
また、1台のサーバーが故障しても、データを失ったり、処理が失敗したりしないように、分割されたブロックは複数のサーバーに格納されます。
ユーザーは、HDFS を利用するにあたって、裏側で複数のサーバーが動いていることやファイルがどうブロックに分割されたかなどを考慮する必要はありません。
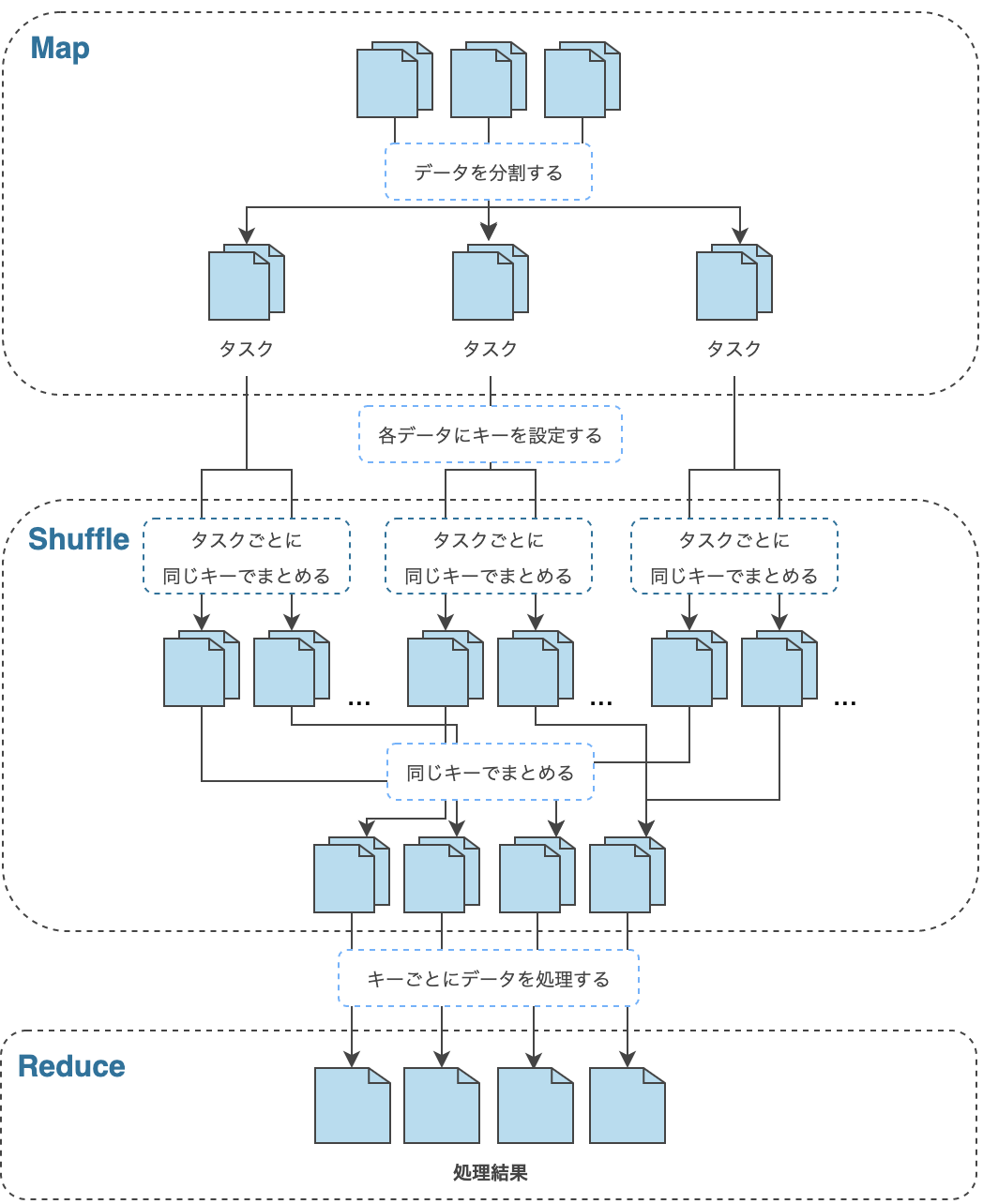
MapReduce
MapReduce は、ひとつのジョブを複数のタスクに分割し、並列に処理を実行します。MapReduce の処理は、大きく Map, Shuffle, Reduce と呼ばれる3つの処理で構成されます。 このうち、Shuffle は、自動的に実行されるものなので、ユーザーが処理を定義する必要はありません。それぞれの処理の内容については次の通りです。
- Map:HDFS 上のデータを分割し、タスクに割り当てます。タスクは、割り当てられた入力データから1件ずつデータ(Key, Value のペア)を取り出し、ユーザーが定義した処理を行った後、処理結果(Key, Value のペア)を出力します。
- Shuffle:Map 処理後のデータを、同じキーを持つデータでまとめます。このとき、サーバー間でデータの転送が行われるため、転送データ量が大きい場合は処理全体のボトルネックとなる可能性があります。
- Reduce:Shuffle 処理後、キーごとにまとめられたデータに対してユーザーが定義した処理を行います。
こういった並列分散処理を MapReduce のようなフレームワークなしで実装しようとすると、ひとつのジョブをどのような単位に分割するか、そのタスクをどのコンピュータで実行するか、各タスクの結果をどのようにひとつにまとめるか、途中でサーバーの故障などでどのようにリカバリするかなど多くのことを考慮する必要があります。
Hadoop アーキテクチャ
Hadoop には、1、2、3 の3つのメインバージョンがあり、それぞれでアーキテクチャが異なります。そして、Hadoop 1 と 2 の主な違いは MapReduce アーキテクチャの変更にあります。Hadoop 1 での MapReduce アーキテクチャのことを MRv1 と呼び、Hadoop 2 では、YARN (Yet-Another-Resource-Negotiator) という技術の上で MapReduce が動作し、これを MRv2 と呼びます。
Hadoop 1 Hadoop 2 HDFS HDFS MapReduce (MRv1) MapReduce (MRv2) / YARN Hadoop 2 から Hadoop 3 への大規模なアーキテクチャの変更はないらしい(おそらく)ので、ここでは、Hadoop 1 と Hadoop 2 のアーキテクチャについて触れます。
Hadoop 1
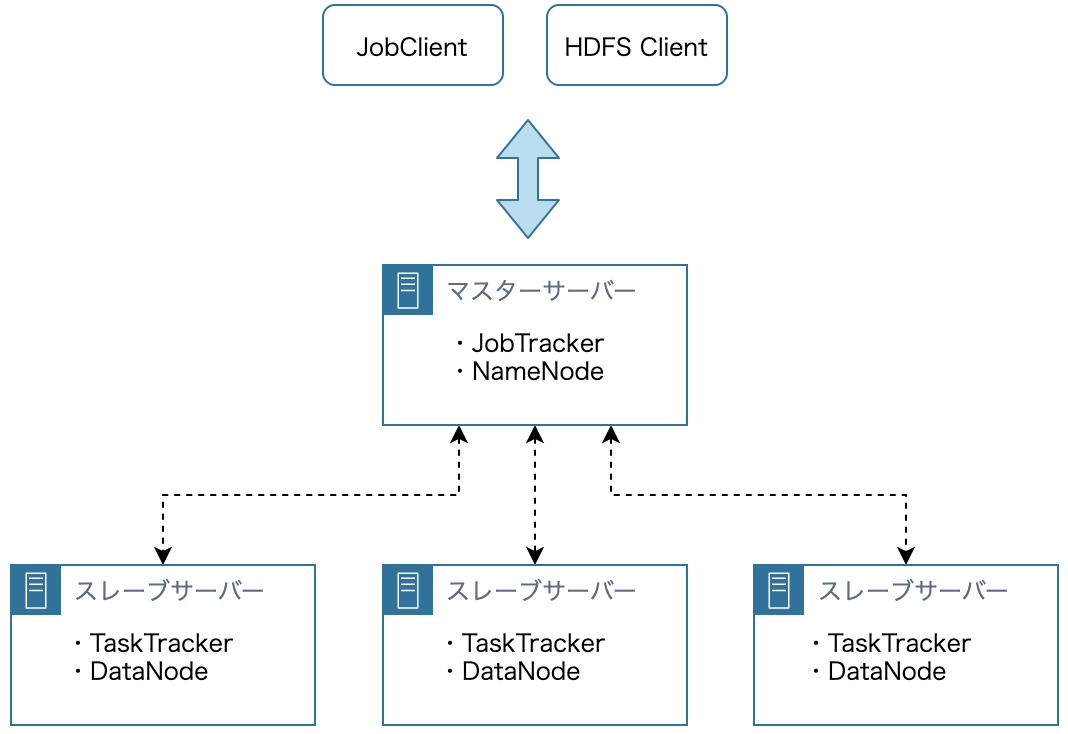
Hadoop クラスタは、クラスタ全体を管理するマスターサーバー群と実際のデータ処理を担当するスレーブサーバー群の2種類のサーバー群により構成されます。HDFS と MapReduce のそれぞれにマスターサーバーとスレーブサーバーが存在し、基本的にマスターサーバーはそれぞれ1台ずつ、スレーブサーバーは複数台で構成されます。
HDFS アーキテクチャ
- NameNode:HDFS のマスターサーバーです。クラスタ全体に渡って、データがどこに配置されているかなどのメタデータを管理します。HDFS のメタデータはメモリ上で管理するため、瞬時に応答を返すことができます。
- DataNode:HDFS のスレーブサーバーです。割り振られたタスクを実行し、応答を返します。複数台の DataNode のストレージでひとつのストレージを構成するので、ユーザーは HDFS を利用するにあたって、複数のストレージがあることを意識する必要がありません。
MapReduce (MRv1) アーキテクチャ
- JobTracker:MapReduce (MRv1) のマスターサーバーです。JobClient にジョブの進捗状況や完了を通知するといったジョブの管理や、1つのジョブを複数のタスクに分割し、各スレーブサーバーにタスクを割り振るなどのリソースの管理を行います。また、ジョブの履歴管理も行います。JobTracker は単一障害点となりえます。
- TaskTracker:MapReduce (MRv1) のスレーブサーバーです。割り振られたタスクを実行し、応答を返します。Map 処理や Reduce 処理を実行し、そのリソースを管理します。
- JobClient:ジョブの依頼や優先度変更、強制終了などを行います。
通常、DataNode と TaskTracker は同じマシンに置かれ、TaskTracker はまず同じマシンの DataNode 上のデータに対してジョブを実行します。これにより、ネットワークの通信コストを抑えることができます。
Hadoop 2
Hadoop 1 と Hadoop 2 のアーキテクチャの違いは主に MapReduce にあります。そのため、ここでは HDFS のアーキテクチャについては省略します。
MapReduce (MRv2) アーキテクチャ
MapReduce (MRv1) では、タスクの数が数千〜数万規模になると、JobTracker への負荷が集中し、ボトルネックになる可能性があります。また、クラスタ内で単一の JobTracker を使用するため、負荷を分散させようと思うと、クラスタを新たに用意する必要があります。この方法で負荷を分散させた場合、リソースの利用効率が下がったり、単一障害点である JobTracker 数の増加による監視対象の増加が起きたりといった問題が生じます。
こういった問題に対処するために導入されたのが YARN です。YARN では、JobTracker、TaskTracker の機能を次のように変更します。
MapReduce (MRv1) MapReduce (MRv2) / YARN JobTracker ResourceManager、ApplicationMaster、JobHistoryServer TaskTracker NodeManager
- ResourceManager:JobTracker からリソース管理を切り離します。リソース管理を ResourceManager が一元管理することで、リソースの使用効率が高まります。
- ApplicationMaster:JobTracker からジョブ管理を切り離します。ユーザーの実装によって、独自のジョブ管理を行うことができます。MapReduce 以外にも、Apache Spark や Apache Tez など他の分散処理フレームワークにも対応しています。また、ApplicationMaster をジョブごとに立ち上げることで、タスク数が増えた場合のボトルネックを回避することができます。
- JobHistoryServer:JobTracker の履歴管理を切り離します。
- NodeManager:TaskTracker が行っていたリソース管理を切り離します。
環境構築
Hadoop の動作環境を構築していきます。前述の通り、Hadoop は、複数のコンポーネントが連携することで動作します。そのため、各種ソフトウェアをまとめたディストリビューションが提供されています。ディストリビューションを用いることで、分散処理を実行する環境を容易に構築できます。今回は、ディストリビューションとして CDH を Docker 上でインストールします。
また、Hadoop では次の3つの中から動作モードを選択できます。今回は、動作確認をお手軽に行える擬似分散モードを選択します。
- ローカルモード:1台のサーバー上で、HDFSは使用せずにMapReduceの動作環境を構築する
- 擬似分散モード:1台のサーバー上で、HDFSを使用したMapReduceの動作環境を構築する
- 完全分散モード:複数台のサーバー上で、HDFSを使用したMapReduceの動作環境を構築する
次のようなパッケージ構成になります。
パッケージ構成. ├── Dockerfile ├── main ├── WordCount.java # Hadoop ジョブ(Java) ├── scripts # Hadoop 起動スクリプトなど │ ├── create-input-text.sh │ ├── execute-wordcount-python.sh │ ├── execute-wordcount.sh │ ├── make-jar.sh │ └── start-hadoop.sh └── streaming # Hadoop Streaming ジョブ(Python) └── python ├── map.py └── reduce.py使用する Dockerfile はこちらです。Hadoop は Java のアプリケーションなので JDK をインストールします。CDH のインストールは こちら を参考にしました。
DockerfileFROM centos:centos7 RUN yum -y update RUN yum -y install sudo # インストール:JDK RUN yum -y install java-1.8.0-openjdk java-1.8.0-openjdk-devel # 環境変数の設定(コンパイルの際に必要) ENV JAVA_HOME /usr/lib/jvm/java-1.8.0-openjdk ENV PATH $PATH:$JAVA_HOME/bin # tools.jar:javac コンパイラを含む ENV HADOOP_CLASSPATH $JAVA_HOME/lib/tools.jar # インストール:CDH 5 パッケージ ## yum リポジトリの構築 RUN rpm --import http://archive.cloudera.com/cdh5/redhat/6/x86_64/cdh/RPM-GPG-KEY-cloudera RUN rpm -ivh http://archive.cloudera.com/cdh5/one-click-install/redhat/6/x86_64/cloudera-cdh-5-0.x86_64.rpm ## 疑似分散モードの設定と YARN や HDFS などを提供するパッケージをインストール RUN yum -y install hadoop-conf-pseudo ADD main main RUN chmod +x -R main WORKDIR main # コマンド実行後もコンテナを起動させ続ける CMD ["tail", "-f", "/dev/null"]では、こちらの Dockerfile から Docker イメージを作成します。
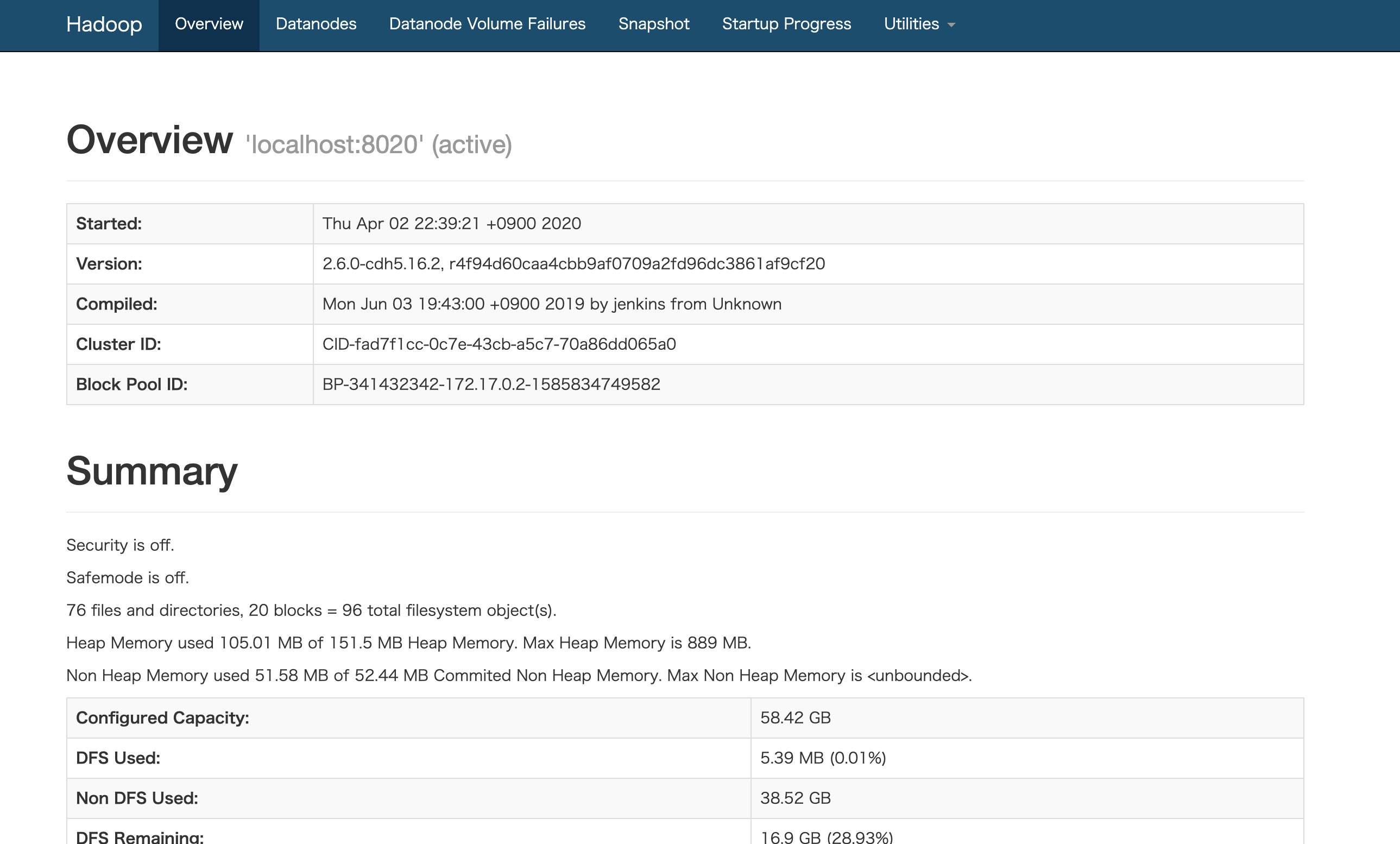
docker image build -t {名前空間/イメージ名:タグ名} .ビルドが成功したらコンテナを起動します。Hadoop 起動後は http://localhost:50070 で Web インターフェースにアクセスできるようになるので、ポートフォワーディングしておきます。
docker container run --name {コンテナ名} -d -p 50070:50070 {名前空間/イメージ名:タグ名}コンテナの起動が成功したら、コマンド操作を行えるようにコンテナに入ります。
docker exec -it {コンテナ名} /bin/bashscripts/start-hadoop.sh を実行して Hadoop を起動します。
scripts/start-hadoop.sh#!/usr/bin/env bash # NameNode が管理するメタデータ領域をフォーマット sudo -u hdfs hdfs namenode -format # HDFS の起動 for x in `cd /etc/init.d ; ls hadoop-hdfs-*` ; do sudo service $x start ; done # 初期化 sudo /usr/lib/hadoop/libexec/init-hdfs.sh # HDFS のファイルに権限を付与 sudo -u hdfs hadoop fs -ls -R / # YARN の起動 sudo service hadoop-yarn-resourcemanager start sudo service hadoop-yarn-nodemanager start sudo service hadoop-mapreduce-historyserver start[root@xxxxxxxxx main]# ./scripts/start-hadoop.shHadoop の起動が完了したら、http://localhost:50070 で Web インターフェースにアクセスでき、GUI からクラスタの状態や Job 実行の経過、結果を見ることができます。
MapReduce の実装と実行
環境構築が終了したので、実際に MapReduce アプリケーションを作成してみます。MapReduce アプリケーションは Java はもちろん Pig Latin や HiveQL と呼ばれる言語などでも作成することができます。
Java
WordCount.java は、Java での MapReduce アプリケーション の実装例です。入力のテキストファイルから単語を抜き出し、単語の数をカウントするアプリケーションです。
WordCount.javaimport org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; import java.io.IOException; import java.util.StringTokenizer; public class WordCount extends Configured implements Tool { /** * Mapper<入力キーの型, 入力バリューの型, 出力キーの型, 出力バリューの型> を継承したクラス. */ public static class TokenizerMapper extends Mapper<LongWritable, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); @Override public void setup(Context context) throws IOException, InterruptedException { // 初期化処理 } /** * Map 処理を記述する. * * @param key その行が先頭から何バイト目の位置にあるかというバイトオフセット値(通常は利用しない) * @param value 1行分のデータ * @param context Context を通してジョブの設定や入出力データにアクセス可能 */ @Override public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } @Override public void cleanup(Context context) throws IOException, InterruptedException { // クリーンナップ処理 } } /** * Reducer<入力キーの型, 入力バリューの型, 出力キーの型, 出力バリューの型> を継承したクラス. */ public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> { private IntWritable result = new IntWritable(); @Override public void setup(Context context) throws IOException, InterruptedException { // 初期化処理 } /** * Reduce 処理を記述する. * * @param key Map 処理の出力(キー) * @param values Map 処理の出力(バリューのイテラブル) * @param context Context */ @Override public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } @Override public void cleanup(Context context) throws IOException, InterruptedException { // クリーンナップ処理 } } public int run(String[] args) throws Exception { if (args.length != 2) { System.err.println("Usage: wordcount <in> <out>"); System.exit(2); } // JobTracker に対してジョブを投入する Job job = Job.getInstance(getConf(), "WordCount"); // 入力データに応じて自動的に数が決まるMapタスクとは異なり、Reduceタスクの数は自分で指定する必要がある job.setNumReduceTasks(2); // jarファイルに格納されたクラスのうちの1つを指定する job.setJarByClass(WordCount.class); // Mapper、Combiner、Reducer としてどのクラスを利用するか指定する job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // テキストファイルからデータの入出力を行う job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); // 入出力用のディレクトリのパス TextInputFormat.addInputPath(job, new Path(args[0])); TextOutputFormat.setOutputPath(job, new Path(args[1])); // ジョブの完了を待つ return (job.waitForCompletion(true) ? 0 : 1); } public static void main(String[] args) throws Exception { int res = ToolRunner.run(new Configuration(), new WordCount(), args); System.exit(res); } }Map 処理を記述するには org.apache.hadoop.mapreduce.Mapper を継承したクラスを作成し、同様に、Reduce 処理を記述するには org.apache.hadoop.mapreduce.Reducer を継承したクラスを作成します。
また、Hadoop では org.apache.hadoop.io.Text は String、org.apache.hadoop.io.IntWritable は int を意味します。Java で実装された MapReduce アプリケーションを実行するためには、コンパイルして jar ファイルを作成する必要があります。
scripts/make-jar.sh#!/usr/bin/env bash # コンパイル hadoop com.sun.tools.javac.Main WordCount.java # jar の作成 jar cf wc.jar WordCount*.class[root@xxxxxxxxx main]# ./scripts/make-jar.shまた、入力のテキストファイルを用意します。
./scripts/create-input-text.sh#!/usr/bin/env bash # 入力のテキストファイルを作成 echo "apple lemon apple lemon lemon grape" > input.txt # 入力のテキストファイルを HDFS に配置 sudo -u hdfs hadoop fs -mkdir -p /user/hdfs/input sudo -u hdfs hadoop fs -put input.txt /user/hdfs/input[root@xxxxxxxxx main]# ./scripts/create-input-text.shそれでは、準備が整ったので実行します。
scripts/execute-wordcount.sh#!/usr/bin/env bash # WordCount.java の実行 # hadoop jar {jar ファイルのパス} {メインクラス名} {入力ファイルのパス} {出力先のパス} sudo -u hdfs hadoop jar wc.jar WordCount /user/hdfs/input/input.txt /user/hdfs/output01 # 結果の表示 sudo -u hdfs hadoop fs -ls /user/hdfs/output01 sudo -u hdfs hadoop fs -cat /user/hdfs/output01/part-r-*[root@xxxxxxxxx main]# ./scripts/execute-wordcount.shジョブが成功した場合は、出力先のパス以下に _SUCCESS というファイルが生成されます。また、part-r-* という形式で出力の結果が1ファイルまたは複数ファイルに格納され、次のような結果を得られることがわかります。
part-r-00000apple 2 grape 1 lemon 3Hadoop Streaming
HadoopS treaming は、Java 以外の言語で MapReduce アプリケーションを実行するためのインターフェースです。データの受け渡しに標準入出力を用いるので、Java の MapReduce アプリケーション と比較すると不便ですが、慣れ親しんだ言語でも開発することができます。今回は、Python で試してみます。
Hadoop Streaming では、入力先のパスと出力先のパスに加えて、実行する map 処理と reduce 処理が定義されたファイルのパスを指定してあげる必要があります。
scripts/execute-wordcount-python.sh#!/usr/bin/env bash # Hadoop Streaming の実行 sudo -u hdfs hadoop jar /usr/lib/hadoop-0.20-mapreduce/contrib/streaming/hadoop-streaming-2.6.0-mr1-cdh5.16.2.jar \ -input /user/hdfs/input/input.txt -output /user/hdfs/output02 \ -mapper /main/streaming/python/map.py -reducer /main/streaming/python/reduce.py # 結果の表示 sudo -u hdfs hadoop fs -ls /user/hdfs/output02 sudo -u hdfs hadoop fs -cat /user/hdfs/output02/part-*map.py では、標準入力から <単語 1> のキーバリューを生成し、標準出力に出力します。
streaming/python/map.py#!/usr/bin/env python # -*- coding: utf-8 -*- import re import sys # 1行を空文字区切りで分割し、(単語, 1) のキーバリューを生成する def map_fn(line): return [(key, 1) for key in re.split(r'\s', line.strip()) if key] # キーバリューを標準出力に出力する def output(records): for key, value in records: print '{0}\t{1}'.format(key, value) # 標準入力から入力を受け取る for l in sys.stdin: output(map_fn(l))reduce.py では、実際に単語の出現回数をカウントし、最終的な処理結果を標準出力に出力します。
streaming/python/reduce.py#!/usr/bin/env python # -*- coding: utf-8 -*- import re import sys results = {} # 単語の出現回数を数える def reduce_fn(line): key, value = re.split(r'\t', line.strip()) if not key in results: results[key] = 0 results[key] = results[key] + int(value) # キーバリュー(最終的な処理結果)を標準出力に出力する def output(records): for k, v in records: print '{0}\t{1}'.format(k, v) # 標準入力から map 処理の出力を受け取る for l in sys.stdin: reduce_fn(l) output(sorted(results.items()))入力ファイルが Java の時と同じ場合、同様の結果が出力先のパスのファイルから得られるかと思います。
part-00000apple 2 grape 1 lemon 3Hadoop エコシステム
Hadoop の主要なコンポーネントは他にも様々ありますが、すべて見ていくのは大変なのでそれぞれについて随時項目を追加して記述していきたいと思います。
コンポーネント 概要 Pig Pig Latin と呼ばれる DSL (Domain Specific Language) で処理を定義することができ、Java より少ないコードで、より簡単に MapReduce アプリケーションを作成できます。 Hive HiveQL と呼ばれる SQL ライクな DSL で処理を定義することができます。 HBase HDFS 上に構築する NoSQL の分散型データベースです。HDFS が苦手な部分を補完するためのシステムになります。 まとめ
今回は、Hadoop に入門した際のまとめとして記事を書きました。おおよそしか理解できていない部分や、概要だけしか知らない Hadoop の主要なコンポーネントがあるので、引き続き学習してみようと思います。また、AWS や GCP 等のクラウドで提供されているマネージドサービスも様々あるので、その使用感の違い等についても実際に動かしてみて学習したいと思います。
間違っている点があれば修正リクエストをお願いします。また、参考になるサイト等あれば是非教えてください!
参考

- 投稿日:2020-04-03T00:24:59+09:00
Javaでファイルのハッシュ値を返却するサンプルプログラム
javaでファイルのハッシュ値を返却するサンプルプログラムです。
SampleMain.javapackage test; public class SampleMain { public static void main(String[] args) { System.out.println(SampleHash .getfileHash("glassfish-5.0.1.zip", SampleHash.SHA_512)); } }SampleHash.javapackage test; import java.io.BufferedInputStream; import java.io.IOException; import java.nio.file.Files; import java.nio.file.Path; import java.nio.file.Paths; import java.security.DigestInputStream; import java.security.MessageDigest; import java.security.NoSuchAlgorithmException; public class SampleHash { /** MD2アルゴリズム */ public static final String MD2 = "MD2"; /** MD5アルゴリズム */ public static final String MD5 = "MD5"; /** SHA-1アルゴリズム */ public static final String SHA_1 = "SHA-1"; /** SHA-256アルゴリズム */ public static final String SHA_256 = "SHA-256"; /** SHA-512アルゴリズム */ public static final String SHA_512 = "SHA-512"; /** * ファイルのハッシュ値(文字列)を返す * @param filePath ファイルパス * @param algorithmName アルゴリズム * @return ハッシュ値(文字列) */ public static String getfileHash(String filePath, String algorithmName) { Path path = Paths.get(filePath); byte[] hash = null; // アルゴリズム取得 MessageDigest md = null; try { md = MessageDigest.getInstance(algorithmName); } catch (NoSuchAlgorithmException e) { e.printStackTrace(); } try ( // 入力ストリームの生成 DigestInputStream dis = new DigestInputStream( new BufferedInputStream(Files.newInputStream(path)), md)) { // ファイルの読み込み while (dis.read() != -1) { } // ハッシュ値の計算 hash = md.digest(); } catch (IOException e) { e.printStackTrace(); } // ハッシュ値(byte)を文字列に変換し返却 StringBuilder sb = new StringBuilder(); for (byte b : hash) { String hex = String.format("%02x", b); sb.append(hex); } return sb.toString(); } }
java.security.DigestInputStreamとjava.security.MessageDigestを使用してハッシュ値を取得しています。
取得したハッシュ値(byte)を文字列に変換して返却しています。
以上
- 投稿日:2020-04-03T00:01:17+09:00
Shortの比較でNullPointerExceptionになって知ったオートボクシング
ラッパークラスで値を比較するときは
equalsを使うStringの比較でよく言われています。
比較で==を使うと
ラッパーなどの参照型の場合は参照先を比較、プリミティブ型の場合は値を比較します。String hoge = "hoge"; String fuga = "hogehoge"; fuga = fuga.substring(4); // << "hoge"になる // 参照先を比較するので「false」になる boolean isEqual1 = hoge == fuga; // 値を比較するので「true」になる boolean isEqual2 = hoge.equals(fuga); System.out.print(isEqual2);Shortを比較するのに
==を使っても「-128~127」の範囲は値を比較してくれるうっかりShort(shortのラッパー)を
==で比較していたけど途中まで気が付かなかった、気が付いたのは値が200ぐらいになった時。へぇー知らなかった・・・とはいえequalsを使うべきですね。Boolean isEquala = null; // 「-128~127」の範囲外なので「false」になる Short a1 = -129; Short a2 = -129; isEqual = a1 == a2; // 「-128~127」の範囲内なので「true」になる Short b1 = -128; Short b2 = -128; isEqual = b1 == b2; // 「-128~127」の範囲内なので「true」になる Short c1 = 127; Short c2 = 127; isEqual = c1 == c2; // 「-128~127」の範囲外なので「false」になる Short d1 = 128; Short d2 = 128; isEqual = d1 == d2;たぶん、Integerと同じ理由だと思われます。
intからIntegerへは「new Integer()」でなく「Integer.valueOf()」が使われるから。
これは(現状では)-128~127の範囲ではキャッシュされたIntegerを返すようになっているので、その範囲なら同一のインスタンスとなる。だから==で比較しても等しくなる。
Java型メモ(Hishidama's Java type Memo)Shortの比較で
==を使っていてもNullPointerExceptionになる意外だった・・・というか納得できない
Short a = null; Boolean isOne = null; // 想像通りにNullPointerExceptionになる isOne = a.equals(1); // 想像通りに「true」になる isOne = a == null; // 意外にNullPointerExceptionになる! isOne = a == 1; // これはNullPointerExceptionにならずに「false」になる isOne = a == new Short("1"); // これも「false」になる Integer i = 1; isOne = a == new Short(i.shortValue());プリミティブ型とラッパークラスを自動変換するボクシング変換というものがある
JDK1.5からできるようになったそうで、そんな名前があることを知らなかった。
// ラッパークラスに普通の代入 Short a1 = new Short("1000"); // オートボクシング:プリミティブ型をラッパークラスに自動変換 Short a2 = 1000; // プリミティブ型に普通の代入 short b1 = a1.shortValue(); // アンボクシング:ラッパークラスをプリミティブ型に自動変換 short b2 = a2;ボクシング変換されているかを確かめたくてShortの比較で
==を使ったところを逆コンパイルしてみたボクシング変換されているかは逆コンパイルするとわかるらしい、だから逆コンパイルしてみた。
コンパイルしたものを逆コンパイルして見ると、ただ単に変換メソッドに置き換えられているだけ…。
Java型メモ(Hishidama's Java type Memo)isOne = a.equals(1); // ↑これをコンパイルして逆コンパイルするとこうなる↓ isOne = Boolean.valueOf(a.equals(Integer.valueOf(1))); isOne = a == null; // ↑これをコンパイルして逆コンパイルするとこうなる↓ isOne = Boolean.valueOf(a == null); isOne = a == 1; // ↑これをコンパイルして逆コンパイルするとこうなる↓ isOne = Boolean.valueOf(a.shortValue() == 1); isOne = a == new Short("1"); // ↑これをコンパイルして逆コンパイルするとこうなる↓ isOne = Boolean.valueOf(a == new Short("1")); Integer i = 1; isOne = a == new Short(i.shortValue()); // ↑これをコンパイルして逆コンパイルするとこうなる↓ Integer i = Integer.valueOf(1); isOne = Boolean.valueOf(a == new Short(i.shortValue()));Shortを整数と
==で比較するとshortValue()が実行されるからNullPointerExceptionになる!a == 1; // ↑は、こう↓なる Boolean.valueOf(a.shortValue() == 1);NullPointerExceptionになる理由は分かったけどなんでリテラルの数値の時だけ
shortValue()なんだろう?
a == new Short("1");は、Boolean.valueOf(a.shortValue() == new Short(i.shortValue()));にならないんだろう?
誰か教えてください。