- 投稿日:2020-02-23T22:54:37+09:00
deviseインストール後rails s でローカルサーバー起動しない
自分用忘備録
環境
ruby 2.6.3
rails 5.2.4undefined method `config' for Devise:Module (NoMethodError)
config/initializers/devise.rb
Devise.setup do |config|
~~
Devise.config.sign_out_via = :get
Deviseを入れていて、二重にしてしまったのが、原因。
config.sign_out_via = :get
に修正。
無事開通。
- 投稿日:2020-02-23T20:43:15+09:00
Rails6 DBのupdate_atなどに格納された日にちをYYYY-MM-DDの形で取り出す
目的
- DBのcreated_atやupdate_atなどのカラムに格納された日にちの値を
YYYY-MM-DD HH:MM:SSの形で取り出す方法をまとめる困りごと
特定のidのupdate_atをそのまま使用しようとすると下記の様に出力されてしまう。
Tue, 04 Feb 2020 09:01:35 UTC +00:00
YYYY-MM-DD HH:MM:SSの形で出力したい。2020-02-04 09:01:35結論
- 取得したupdate_atの値を
.to_sで文字列に変換することでYYYY-MM-DD HH:MM:SSで得ることができる。書き方の例
- Postモデルのpostsテーブルのidが1のレコードのupdate_atカラムに格納されている日にちデータを
YYYY-MM-DD HH:MM:SSの形で変数に格納する方法を記載する。postsデーブルのidが1のレコードに格納されているデータはすでにDBに格納されているものとする。
#DBのpostsテーブルのidが1のレコード情報を変数@postに格納 @post = Post.find_by(id: 1) #変数last_update_dateに先に取得したidが1のレコードのupdated_atをto_sメソッドにて文字列にしたものを格納する。 last_update_date = @post.updated_at.to_s puts last_update_date
- 投稿日:2020-02-23T19:44:02+09:00
【Ruby on Rails】 Railsのgem"ancestry"によるタグ機能実装(多階層構造)
今回はタグ機能を実装するために、 Railsのgem"ancestry"を利用していきます。
これに関しては今回初めてなので、学習しながらメモしていきたいと思います仕組みを理解する。
タグの階層とどうやって紐づけるか理解していきましょう!!
gem無しの場合親コテゴリー - 中間カテゴリ-(親_子) - 子カテゴリー - 中間カテゴリー(子_孫) - 孫カテゴリー - 中間テービル(孫_商品) - 商品gemがないと上記のような仕組みのため、非常にめんどくさいです。
gem'ancestry'の場合商品 - 中間テーブル - カテゴリー上記だけで完結します。だから非常に楽ですね
ではどうして、カテゴリーテーブル一つで3階層可能なのか?疑問になりますよね
一緒に学習しましょう!タグの3階層の仕組み
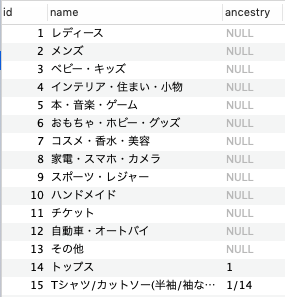
DBを見るとわかりやすいので、見ていきましょう!
3階層までタグが作成可能で、
一番上の親カテゴリは祖先がないので、
ancestryカラム: NULL
ID:14番目のレコードですが、ancestry: 1になってます。
祖先はID:1のレコードという意味ですね。つまりレディースが親カテゴリということです。
では、さらにトップスよりも下の階層(3階層目)はどうなのか?
つまり、祖先はID:1番目の レディースになるということです。ancestry: 1/14となっています。
つまり、ID:1の子である,ID:14番目の子という表示カテゴリータグの仕組み1階層目: null 2階層目: 1階層目のID 3階層目: 1階層目のID/2階層目のID3階層目のancestryカラムを取得すれば、2階層目、1階層目と辿れる仕組みです。3階層目までしか構造上できないようです(もしもできる場合は、コメントで教えていただければ幸いです。)4階層目を実装するには、別のテーブルが必要となります。
どうやって商品と紐づけるのか?
タグIDと商品IDを紐づける中間テーブルをおきます。
product_categoriesテーブル
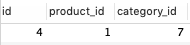
Column Type Options product_id references null: false category_id references null: false 実際にDBを見て理解していきましょう!!
この例だと
productのID:1番目とcategory_id:7番目が紐づいてます。
categoryの7番目は、コスメ・香水・美容ですから、
商品は「コスメ・香水・美容」カテゴリに紐づいているとわかります。このように、中間テーブルを利用して商品とカテゴリーを紐づけていきます。
モデル商品 - 中間テーブル - カテゴリーまとめ
カテゴリータグの仕組み1階層目: null 2階層目: 1階層目のID 3階層目: 1階層目のID/2階層目のIDモデル商品 - 中間テーブル - カテゴリー表示する仕組み1. htmlより、親カテゴリを並べる 2. 親カテゴリを選択されたら、コントローラーで子カテゴリを取得、JS(ajax)で追加表示 3. 子カテゴリが選択されたら、コントローラーで孫kてゴリを取得、JS(ajax)で追加表示 親 > 子 > 孫 親 > 子: 親.children > 孫: 子.children #ここは後述します。実装をしていく。
それでは実装していきましょう!!
インストール
Gemfilegem 'ancestry'を追加して
ターミナル$ bundle instalインストールをしたら、再起動させたいので、
ターミナル$ rails sモデルの作成
商品モデルはすでに作成してる前提で、作成方法を記述しません。
カテゴリーモデルを作成します。
ターミナル$ rails g model categoryモデルを作成したら、migrateファイルを記述していきましょう!!
categoriesテーブル
Column Type Options name string null: false, index: true ancestry string index: true Association
- has_many :products
- has_ancestry
migateファイルclass CreateCategories < ActiveRecord::Migration[5.2] def change create_table :categories do |t| t.string :name, index: true, null: false t.string :ancestry, index: true t.timestamps end end endターミナル$ rake db:migrate中間テーブル(product_categories)を作成
ターミナル$ rails g model product_categoryproduct_categoriesテーブル
Column Type Options product_id references null: false category_id references null: false アソシエーション
- belongs_to :product
- belongs_to :category
上記のテーブルになるようにmigrateファイルを記述していきます。
migrateファイルclass CreateProductCategories < ActiveRecord::Migration[5.2] def change create_table :product_categories do |t| t.references :product, null:false t.references :category, null:false t.timestamps end end endターミナルrake db:migrateアソシエーション
カテゴリーモデルは下記になります
category.rbclass Category < ApplicationRecord has_ancestry has_many :product_categories, dependent: :destroy has_many :products, through: :product_categories end中間テーブルは下記になります。
product.category.rbclass ProductCategory < ApplicationRecord belongs_to :product belongs_to :category end商品モデルは下記になります
product.rbclass Product < ApplicationRecord has_many :product_categories, dependent: :destroy has_many :categories, through: :product_categories endはい!これでモデルは完了ですね。
では次に進みましょう!!!DB → モデル → コントローラー
seeds.rbでカテゴリを生成
今回はモデル別にseedファイルを作成するやり方をします
[通常方法](https://www.sejuku.net/blog/28395)seeds.rbrequire './db/seeds/category.rb'カテゴリー用のseedファイルを作成しましょう
db > seedsのフォルダを作成 > category.rbを作成seeds/category.rb#親カテゴリ lady = Category.create(name: "レディース") #子カテゴリー lady_1 = lady.children.create(name: "トップス") #孫カテゴリー lady_1.children.create([{name: "Tシャツ/カットソー(半袖/袖なし)"},{name: "Tシャツ/カットソー(七分/長袖)"},{name: "シャツ/ブラウス(半袖/袖なし)"},{name: "シャツ/ブラウス(七分/長袖)"},{name: "ポロシャツ"},{name: "キャミソール"},{name: "タンクトップ"},{name: "ホルターネック"},{name: "ニット/セーター"},{name: "チュニック"},{name: "カーディガン/ボレロ"},{name: "アンサンブル"},{name: "ベスト/ジレ"},{name: "パーカー"},{name: "トレーナー/スウェット"},{name: "ベアトップ/チューブトップ"},{name: "ジャージ"},{name: "その他"}])では生成しましょう
ターミナル$ rails db:seedコントローラーの作成
DB → モデル → コントローラーの処理で進むので、コントローラーを作成します。
仕組み1. htmlより、親カテゴリを並べる 2. 親カテゴリを選択されたら、コントローラーで子カテゴリを取得、JSで追加表示 3. 子カテゴリが選択されたら、コントローラーで孫kてゴリを取得、JSで追加表示 親 > 子 > 孫この仕組みを動かすための独自メソッドを作成します。
products_controller.rbclass ProductsController < ApplicationController def get_category_children @children = Category.find(params[:parent_id]).children end def get_category_grandchildren @grandchildren = Category.find("#{params[:child_id]}").children end endと上記のアクションを作成します。
@children = Category.find(params[:parent_id]).children上記の.childenって何?ってなると思いますが、
親カテゴリから子カテゴリを取得するためのメソッドです。先ほど親>子>孫の順番で取得すると説明しましたが、.childrenを使うので下記のようになります。
親 > 子:親カテゴリ.chidren > 孫: 子カテゴリ.children他にもいろんなメソッドが用意されているので、一度Githubを見ていただければと思います。
Github:ancestroyAjaxを導入する(JQuery)
route.rb
Ajaxに対応したルーティングにします。
route.rbresources :products do collection do # 新規用(new) usr:products/newのため get 'get_category_children', defaults: { format: 'json' } get 'get_category_grandchildren', defaults: { format: 'json' } end member do # 編集(edit用) usl: products/id/editのため get 'get_category_children', defaults: { format: 'json' } get 'get_category_grandchildren', defaults: { format: 'json' } end endAjax対応のコントローラーにする。
先ほどコントローラーを作成していましたが、改良します
products_conroller.rbdef get_category_children respond_to do |format| format.html format.json do @children = Category.find(params[:parent_id]).children end end end def get_category_grandchildren respond_to do |format| format.html format.json do @grandchildren = Category.find("#{params[:child_id]}").children end end endこれでAjax対応のコントローラーになりました。
jbuilder作成
コントローラーとAjax用jsとで情報の架け橋となるjbuilderを作成
子カテゴリを追加するために、idと名前をjsに持っていきたい。children.jbuilderjson.array! @grandchildren do |child| json.id child.id json.name child.name endgrandchildren.jbuilderjson.array! @grandchildren do |grandchild| json.id grandchild.id json.name grandchild.name endAjax用のjs
Ajaxで要素を追加するjsを記述します。
category-ajax.js$(document).on('turbolinks:load', function(){ // カテゴリーの選択肢が入ったdiv var categoryBox = $('.form-details__form-box__category') // 親カテゴリー function appendOption(category) { var html = `<option value="${category.id}" data-category="${category.id}">${category.name}</option>` } // 子カテゴリー function appendChildBox(insertHTML) { var childSelectHtml = ''; childSelectHtml = `<div class='form-select' id="child-category"> <select class= 'select-default' name="product[category_ids][]"> <option value>---</option> ${insertHTML} </select> <i class='fa fa-angle-down icon-angle-down'></i> </div>` categoryBox.append(childSelectHtml); } // カテゴリーボックスで親カテゴリが変わった場合 categoryBox.on("change", "#parent-category", function(){ var parentCategory = $("parent-category").value; if(parentCategory !== "") { $.ajax ({ url: '/products/get_category_children', type: "GET", data: { parent_id: parentCategory }, dataType: 'json' }) .done(function(children){ $('#child-category').remove(); $('#grandchild-category').remove(); var insertHTML = ''; children.forEach(function(grandchild){ insertHTML += appendOption(grandchild); }); appendGrandchildrenBox(insertHTML); }) .fail(function(){ alert('カテゴリー取得に失敗しました'); }) } else { //親カテゴリーが初期値(---)の場合、子カテゴリー以下は非表示にする //親カテゴリが未選択の場合、子、孫カテゴリの選択欄は非表示にしたいので、そのように変更 $('#child-category').remove(); $('#grandchild-category').remove(); $('#size').remove(); } }) })学習して作成中
参考になるサイト
Github:ancestroy
Railsでタグ機能をgemを使わずに実装した際のメモ
Railsのgem"ancestry"による多階層構造の実現




- 投稿日:2020-02-23T19:40:48+09:00
rbenvでrubyを使う【zsh】
Catalinaはzshがデフォルトシェル。
既存の記事ではすんなりとinstallできなかったので備忘録としてzshでのrbenvのinstall方法を残しておく。私の環境
- macOS Catalina 10.15.2
- zsh
全部で8ステップ
Let's go!0. brewを最新にしておく
% brew update最新になると
% brew update Already up-to-date.↑こうなる
brewがない人はhomebrewのHPからダウンロードする
うまくいくと% brew -v Homebrew 2.2.6 Homebrew/homebrew-core (git revision ae7c1; last commit 2020-02-22)↑こうなる
一応これもやっとく↓
% brew doctor1. brewからrbenvとruby-buildをinstallする
% brew install rbenv ruby-buildうまくいくと
% rbenv -v rbenv 1.1.2 % ruby-build --version ruby-build 20200218↑こうなる
2. rbenvにPATHを通す
zshはいろいろなfileで設定ができるらしい
それはこの記事で勉強しておく今回は
~/.zshenvと~/.zshrcを編集する
~/.zshenvに~/.zshenvexport PATH="/usr/local/bin:$PATH" export PATH="$HOME/.rbenv/bin:$HOME/.rbenv/shims:$PATH" # この一行を追加↑最後の一行を追加し、~/.zshrcに
~/.zshrcsource $HOME/.zshenvを追加する
3. 2の設定を更新する
% source ~/.zshrc4. rbenvで欲しいバージョンのrubyをinstallする
今回は2.6.4が欲しい
4.1. どのバージョンがinstallできるか確認する
% rbenv install -l 1.8.5-p52 1.8.5-p113 1.8.5-p114 1.8.5-p115 1.8.5-p231 1.8.6 . . . 2.6.2 2.6.3 2.6.4 # あった! 2.6.5 2.7.0-dev 2.7.0-preview14.2. rubyをinstallする
% rbenv install 2.6.4 -> https://dqw8nmjcqpjn7.cloudfront.net/1e3a91bc1f9dfce01af26026f856e064eab4c8ee0a8f457b5ae30b40b8b711f2 Installing openssl-1.1.1d... Installed openssl-1.1.1d to /Users/you/.rbenv/versions/2.6.4 Downloading ruby-2.6.4.tar.bz2... -> https://cache.ruby-lang.org/pub/ruby/2.6/ruby-2.6.4.tar.bz2 Installing ruby-2.6.4... ruby-build: using readline from homebrew Installed ruby-2.6.4 to /Users/you/.rbenv/versions/2.6.45. installされたバージョンを確認する
% rbenv versions * system (set by /Users/you/.rbenv/version) 2.6.4できた
6. globalのrubyのバージョンを変更する
今回はinstallした2.6.4に変更する
% rbenv global 2.6.4 % rbenv versions system * 2.6.4 (set by /Users/you/.rbenv/version)7. バージョンが変わったか確認する
% ruby -v ruby 2.6.4p104 (2019-08-28 revision 67798) [x86_64-darwin19]おまけ
% which ruby /Users/you/.rbenv/shims/ruby↑これでrbenv以下のrubyが使用されていることがわかる
7でバージョンが変わっていなかったらrubyのpathを確認する参考
Macのzshでrbenvを使う
rbenvでバージョンがうまく切り替わらない:Ruby on Rails導入
Getting Rails to Work with Catalina/zsh
eval "$(rbenv init -)" every time I start on Mac OS X 10.11 El Capitan #815
- 投稿日:2020-02-23T19:26:55+09:00
RailsをAWSでデプロイする
はじめに
手軽にRailsをAWSにデプロイする手順をまとめました。
極力シンプルになるように、EC2インスタンスを一つ作成し、その中に自分のRailsアプリを含め、必要なものを全てインストールしてデプロイします。
データベースはMySQL、WebサーバーはNginXでの環境構築です。
AWSのサーバーでのファイルの書き込みはviというコマンドで行います。(vi ファイル名でそのファイルを編集、そのファイルがない場合は新たにファイルを作って書き込みできます。詳しい使い方は要検索!)
注意点
コードの中で、/var/www/rails/{アプリ名}などと書いている時がありますが、自分の環境に合わせて、
/var/www/rails/sample_appとしてください
/var/www/rails/{sample_app}ではないのでご注意。
第一章 サーバーの準備
1.VPCを作成
- 名前は適当につける
- IPv4CIDERブロックは10.0.0.0/16に設定
- あとはデフォルトで
2.サブネットを作成
- 名前は適当につける
- VPCは先程作ったVPCを選択
- IPv4CIDERブロックは10.0.0.0/24に設定
3.インターネットゲートウェイを作成
- 名前は適当につける
- 作成後は先程作ったVPCをアタッチ
4.ルートテーブルを作成
- 名前は適当につける
- 作成後はルートの設定で0.0.0.0/0を追加し保存
- サブネットの関連付けで先程作ったサブネットを選択
- あとはデフォルトで
5.セキュリティグループを作成
- 名前は適当につける
- 作成後は
タイプ:HTTP ソース:任意の場所(他の設定はデフォルト)
と、
タイプ:SSH ソース:任意の場所(他の設定はデフォルト)
を追加し保存- あとはデフォルトで
6.EC2を作成
EC2インスタンスの作成
- 無料枠からAmazonLinuxを選ぶ(AmazonLinux2を選ばないように注意、この後の環境構築で差が出てきてしまうので)
- ネットワーク:先程作ったVPCを選択
- サブネット:先程作ったサブネットを選択
- 自動割り当てパブリックIP:有効化を選択
- セキュリティーグループ:先程作ったセキュリティグループを選択
キーペアの登録とElasticIPの割当て
- キーペアファイル(~.pem)はローカル(自分のパソコンのこと)の.ssh配下に移動
- ElasticIPを作り先ほど作ったEC2インスタンスに割り当てる
第二章 サーバーにログインし環境構築
1.EC2にログイン
キーペアファイルのあるディレクトリに移動
cd .sshキーペアファイルに権限を付与
chmod 600 {自分のキーペアの名前}.pemサーバー(EC2インスタンス)にログイン
ssh -i {自分のキーペアのpemファイル} ec2-user@{自分のElasticIPアドレス}ユーザーを作成
sudo adduser {新規ユーザー名} (#新規ユーザー名の登録) sudo passwd {パスワード} (#新規ユーザー名のパスワード登録) sudo visudoユーザーの権限の変更
1.rootに関する権限の記述箇所 root ALL=(ALL) ALL を探す。 2.その下に、作成したユーザーに権限を追加する記述 {ユーザー名} ALL=(ALL) ALL を追加するユーザーの切替
sudo su - {ユーザー名}2.諸々必要なものをインストール
sudo yum install git make gcc-c++ patch openssl-devel libyaml-devel libffi-devel libicu-devel libxml2 libxslt libxml2-devel libxslt-devel zlib-devel readline-devel mysql mysql-server mysql-devel ImageMagick ImageMagick-devel epel-release3.Rubyをインストール
以下Rubyをインストールするための下準備
git clone https://github.com/sstephenson/rbenv.git ~/.rbenvecho 'export PATH="$HOME/.rbenv/bin:$PATH"' >> ~/.bash_profileecho 'eval "$(rbenv init -)"' >> ~/.bash_profilesource .bash_profilegit clone https://github.com/sstephenson/ruby-build.git ~/.rbenv/plugins/ruby-buildrbenv rehash以下Rubyのインストールです、インストールするRubyのバージョンは自分の環境に合わせてください
rbenv install -v 2.6.5rbenv global 2.6.5rbenv rehashインストールできたか確認
ruby -v4.node.jsをインストール
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.34.0/install.sh | bash. ~/.nvm/nvm.shnvm install node5.Yarnをインストール
curl -o- -L https://yarnpkg.com/install.sh | bashexport PATH="$HOME/.yarn/bin:$HOME/.config/yarn/global/node_modules/.bin:$PATH"第三章 Rails、DB、Webサーバーの設定
1.Railsの設定
/var/www/rails/ の配下にRailsアプリを持ってくる、以下を一行一行実行していく
cd / (/ディレクトリに移動) sudo chown {ユーザー名} var (varフォルダの所有者を{ユーザー名}にする) cd var (varディレクトリに移動) sudo mkdir www (wwwディレクトリの作成) sudo chown {ユーザー名} www (wwwフォルダの所有者を{ユーザー名}にする) cd www (wwwディレクトリに移動) sudo mkdir rails (wwwディレクトリの作成) sudo chown {ユーザー名} rails (railsフォルダの所有者を{ユーザー名}にする) cd rails (railsディレクトリに移動)GitHubからクローン
git clone {自分のRailsのアプリのリポジトリのclone用URL}DBとの接続用の設定、以下をRailsアプリ内のconfig/database.ymlに追加
production: <<: *default database: {アプリ名} username: root #ここをrootに変更する password: #ここを空欄にする※ローカルのconfig/master.keyの一行を全てコピーし、
cloneしてきたアプリのconfig/master.keyに記載をする
(master.keyはgitignoreされておりローカルのmaster.keyの内容は
githubには反映されないため自分でコピペしてくる)2.MySQLの設定
起動
sudo service mysqld startln -s /var/lib/mysql/mysql.sock /tmp/mysql.sockDBの作成
rails db:create RAILS_ENV=productionマイグレーション
rails db:migrate RAILS_ENV=production3.Unicornの設定
Gemfileに以下を追記
group :production, :staging do gem 'unicorn' endbundlerをインストール
gem install bundlerbundlerでunicornのgemをインストール
bundle install設定ファイルの追加
vi ~/var/www/rails/{アプリ名}/config/unicorn.conf.rb以下を設定ファイルに記載
# set lets $worker = 2 $timeout = 30 $app_dir = "/var/www/rails/{アプリ名}" #自分のアプリケーション名 $listen = File.expand_path 'tmp/sockets/.unicorn.sock', $app_dir $pid = File.expand_path 'tmp/pids/unicorn.pid', $app_dir $std_log = File.expand_path 'log/unicorn.log', $app_dir # set config worker_processes $worker working_directory $app_dir stderr_path $std_log stdout_path $std_log timeout $timeout listen $listen pid $pid # loading booster preload_app true # before starting processes before_fork do |server, worker| defined?(ActiveRecord::Base) and ActiveRecord::Base.connection.disconnect! old_pid = "#{server.config[:pid]}.oldbin" if old_pid != server.pid begin Process.kill "QUIT", File.read(old_pid).to_i rescue Errno::ENOENT, Errno::ESRCH end end end # after finishing processes after_fork do |server, worker| defined?(ActiveRecord::Base) and ActiveRecord::Base.establish_connection end4.NginXの設定
インストール
sudo yum install nginxNginxの設定
ディレクトリを移動
cd /etc/nginx/conf.d/etc/nginx/conf.d下に設定ファイルの作成
vi {アプリ名}.conf以下を記載
# log directory error_log /var/www/rails/{アプリ名}/log/nginx.error.log; #自分のアプリケーション名に変更 access_log /var/www/rails/{アプリ名}/log/nginx.access.log; #自分のアプリケーション名に変更 # max body size client_max_body_size 2G; upstream app_server { # for UNIX domain socket setups server unix:/var/www/rails/{アプリ名}/tmp/sockets/.unicorn.sock fail_timeout=0; #自分のアプリケーション名に変更 } server { listen 80; server_name ~~~.~~~.~~~.~~~; #自分のElasticIP # nginx so increasing this is generally safe... keepalive_timeout 5; # path for static files root /var/www/rails/{アプリ名}/public; #自分のアプリケーション名に変更 # page cache loading try_files $uri/index.html $uri.html $uri @app; location @app { # HTTP headers proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; proxy_pass http://app_server; } # Rails error pages error_page 500 502 503 504 /500.html; location = /500.html { root /var/www/rails/{アプリ名}/public; #自分のアプリケーション名に変更 } }第四章 世界に公開
1.Railsのプリコンパイル
rails assets:precompile RAILS_ENV=production2.NginXを起動
sudo service nginx start3.Unicornを起動
bundle exec unicorn_rails -c /var/www/rails/{アプリ名}/config/unicorn.conf.rb -D -E production4.お疲れ様です
これでブラウザに自分のElasticIPを打ち込むと世界中のパソコンやスマホから自分のアプリにアクセスできます!
5.その他コマンド
unicornの起動確認
ps -ef | grep unicorn | grep -v grepunicornの終了
kill {masterのPID}以下のようなYarnのエラーが出ることがあります(Railsコマンドを実行した際にこのようなエラーが出る時があります)
======================================== Your Yarn packages are out of date! Please run `yarn install --check-files` to update. ========================================エラー文に従い以下を実行しましょう
yarn install --check-files
- 投稿日:2020-02-23T17:48:01+09:00
Ruby ブロックと繰り返し処理 まとめ
配列の基礎
- Rubyの配列は異なるデータ型を格納することができる
- 元の大きさより大きい添字を指定すると、間がnilでうめられる
<<を使うと配列の最後に要素を追加できる ex)a = [] a<<1delete_atメソッド:引数に指定した位置の要素を削除する / deleteメソッド:引数で渡した値と一致する要素を削除する- 変数のときと同じように配列でも多重代入することができる
taju_dainyu.rba,b = 1,2 a #=>1 b #=>2 a,b,c = [100,200] a #=>100 b #=>200 c #=>nil
配列を返すメソッド(
divmodなど)は、配列として受け取るのではなく多重配列を使って最初から別々の変数に入れたほうがスッキリする
taju.rb
q,r = 14.divmod(3)
"商:#{q},余り:#{r}" #=> "商:4,余り:2"
Rubyの繰り返し処理はあまりfor文は使わずに、each文を使うことが多い
eachメソッドで配列の要素を取り出して、ブロックでその要素をどう扱うのかを決める
⇒Rubyでは「要件を問わない共通の処理」はメソッドに、「要件によって異なる処理」はブロックに分担させる、というようなメソッドが数多くあるdo ... endのかわりに{ }で囲むことでもブロックをつくれる、一行で書きたいときに使う、ただしメソッド引数の()は省略できない
block_kiho.rbnumbers = [1,2,3,4] sum = 0 numbers.each { |n| sum += n } sum #=>10
delete_ifメソッド:ブロックの戻り値が真であれば、ブロックに渡した要素を配列から削除するdelete_if.rba = [1,2,3,4,5,6,7] a.delete_if do |n| n.odd? end a #=> [2,4,6]
mapメソッド(collect):各要素に対してブロックを評価した結果を新しい配列にして返す ⇒他の配列をループした結果をからの配列に詰め込むような処理の大半はmapで書けるmap.rbnumbers = [1,4,6,3,5] new_numbers = [] numbers.each {|n| new_numbers << n*10 } #mapを使って書くと… new_numbers = numbers.map{ |n| n*10 } new_number #=>[10,40,60,30,50]
selectメソッド:各要素に対してブロックを評価し、その戻り値が真の要素を集めた配列を返すrejectメソッド:偽の要素を集めた配列select.rbnumbers = [1,2,3,4] odd_numbers = numbers.select{|n| n.odd?} odd_numbers #=>[1,3]
- ブロックを使うメソッドは
&とシンボルを使うことでよりシンプルに書けるシンプルに書ける条件
- ブロックの引数が一個だけの時
- ブロック内で呼び出すメソッドには引数がない
- ブロック内ではブロック引数に対してメソッドを一回呼び出す以外の処理がない
&.rb['ruby','java','perl'].map{|n| n.upcase} ['ruby','java','perl'].map(&:upcase)
inject(reduce)メソッド:畳み込み演算を行うメソッド、ブロックの第一引数は初回はinjectの引数が入り二回目以降は前回のブロックの戻り値が入るinject.rbnumbers = [1,2,3,4] sum = 0 numbers.each do {|n| sum += n} #injectメソッドを使って書くと… sum = numbers.inject(0){|result,n| result + n} sum #=>10
- 範囲オブジェクトは
..(最後の値を含む)もしくは...(最後の値を含まない) を使って作成する- 以下のようなn以上m以下の判定や、case文のwhen節で便利
range.rbdef liquid?(temp) 0<= temp && temp <100 end #範囲オブジェクトで書き換える def liquid?(temp) (0...100).include?(temp) end様々な要素の取得方法
- 添字を2つ使って、位置と取得する長さを指定して要素を取得することができる
- 配列に対して添字の代わりに範囲オブジェクトを呼び出すと、その範囲の要素をまとめて呼び出せる
- Rubyでは配列の添字に負の数が使える、-1は最後の要素でそれよりも小さくなることで最後の要素から指定できる
values_atメソッド:取得したい要素の添字を複数指定できる- 範囲オブジェクトに対して
to_aメソッドを呼び出すと値が連続する配列を作成することができるconcatメソッドを使って配列を連結すると元の配列が破壊されるが、+を使うと破壊されないconcat.rba = [1] b = [2,3] a.concat(b) a #=> [1,2,3] 破壊される a + b #=> [1,2,3] a #=> [1] 破壊されない
- splat展開:メソッドの引数に配列を渡す時「1つの配列」としてではなく、配列を展開して「複数の引数」として渡したいときは配列の前に
*を置くsplat.rbe, *f = 100,200,300 e #=>100 f #=>[200,300] # 変数に*をつけると残りの全要素を配列として受け取ることができる a = [1] b = [2,3,4] a.push(b) # => [1,[2,3,4]] a.push(*b) # => [1,2,3,4]
- メソッドの引数で可変長引数(個数に制限のない引数)を使いたい場合は引数の手前に
*をつける、可変長引数は配列として受け取ることができるkehencho.rbdef greeting(*names) "#{names.join('と')}、こんにちは!" #joinは引数の区切り文字を使って配列を一つの文字列にするメソッド end greeting("田中さん","鈴木さん")
%wを用いると文字列の配列を簡単につくれる(クォーテーションで囲ったり、カンマで区切らなくても良いので)
%w.rb
%w(apple melon orange) #=>["apple","melon","orange"]
charsメソッド:文字列中の一文字一文字を配列の要素に文関する
splitメソッド:引数で指定した区切り文字で文字列を配列に分割する
each_with_indexメソッド:ブロックの第二引数に添え字を渡してeach文を実行するeach_with_index.rbfruits = ["apple","orange","melon"] fruits.each_with_index{|fruit,i| puts "#{i}: #{fruit}"} #=> 0: apple # 1: orange # 2: melon
with_indexメソッド:each文以外のメソッドでも添え字を取得したいときに用いる、引数を渡すと引数で渡した数値から添え字が開始される- ブロック引数として配列を渡す時、ブロック引数の数を配列の個数と同じにすると要素を個々に受け取れるようになる
block_arg.rbdimensions = [[10,20],[30,40],[50,60]] area = [] dimensions.each do |length,width| area << length * width end area #=> [200,1200,3000]
each_with_indexメソッドのようにもとからブロック引数を2つ受け取るメソッドと併用する場合は、配列の要素を受け取るブロック引数を()で囲むblock_each_with.rbdimensions.each_with_index do |(length,width), i| puts "length: #{length}, width: #{width}, i: #{i}#" endよく使われる繰り返し処理
eachメソッド:おなじみのやつですtimesメソッド ex) 5.times { |n| sum += n}upto/downtoメソッド:引数で指定した値まで数値を1ずつ変化させて処理をすすめるstepメソッド:引数に上限値と一回ごとに変化する大きさを指定するkurikaeshi.rba=[] 10.upto(14){ |n| a<<n } a #=>[10,11,12,13,14] 14.downto(10){ |n| a<<n } a #=>[14,13,12,11,10] 1.step(10,2){ |n| a<<n} a #=>[1,3,5,7,9]
while/untilメソッドwhile_until.rba = [] while a.size < 5 a << 1 end a #=>[1,1,1,1,1] #後置で書くと一行で書ける a << 1 while a.size < 5 a = [10,20,30,40] until a.size <= 3 a.delete_at(-1) end #要素数が3以下になるまで配列の最後の要素を削除する
- for文⇒
for 変数 in 配列・ハッシュ 処理 end
- あまりつかわない!
for.rbnumbers = [1,2,3,4] sum = 0 for n in numbers sum += n end sum #=>10
breakを使うと一番内側の繰り返し処理を抜ける- 一方で、
returnはメソッド自体を抜けるnextを使うと繰り返し処理を途中で中断して次の繰り返し処理を進める(continueの役割をするもの)next.rbnumbers = [1,3,4,5] numbers.each do |n| next if n.even? puts n end
redoを使うと繰り返し処理の最初に戻り、処理をやり直すことができる
- 投稿日:2020-02-23T17:46:34+09:00
[ancestry]多重構造のカテゴリ 導入
ECサイトのカテゴリ実装におきまして多重構造での実装が必要となったため
こちらの記事を残させていただきます。
多重構造とはなんぞやとの説明は参照記事をご覧ください。実装手順
1,Gemのインストール
2,モデルにアソシエーション定義
3,カテゴリの追加4,ビューへの表示方法(こちらは別記事で書きます)
1,Gemインストール
ancestryのgithub
この手順通り記述します。Gemfilegem 'ancestry'ターミナルで
bundleの実行
bundle実行後、導入方法は2通りあります。(私の知る限りでは)もしも、最初からテーブルを作成する場合は以下
ターミナル$ rails g controller category $ rails g model category #ここのcategory部分は作成したいモデル名今作成されたmigration fileを下記のように記述
マイグレーションファイルclass CreateCategories < ActiveRecord::Migration[5.2] def change create_table :categories do |t| t.string :name, null: false t.string :ancestry t.timestamps end add_index :categories, :ancestry end end
$ rake db:migrateをする。すでにあるテーブルに追加する場合は以下のコマンドを打ちます。
[例]ターミナル$ rails g migration add_ancestry_to_[table] ancestry:string:index #ここの[table]に自分の作成したいテーブル名を記述します。 #そのまま入れてエラーになったw #今回作りたかったのはカテゴリテーブルなのでcategoryと記述しました $ rails g migration add_ancestry_to_category ancestry:string:index
$ rake db:migrateをする。2,モデルにアソシエーション定義
models/category.rbclass Category < ApplicationRecord has_many :items has_ancestry endmodels/items.rb#このテーブルはもともと作成済みのものです。 class Item < ApplicationRecord belongs_to user, foreign_key: 'user_id' belongs_to :category end3,カテゴリの追加
db/seeds.rb#親要素 lady = Category.create(:name=>"レディース") #子要素 lady_tops = lady.children.create(:name=>"トップス") lady_jacket = lady.children.create(:name=>"ジャケット/アウター") #孫要素(childrenと記述することで直前の変数の子要素として扱うことができる) lady_tops.children.create([{:name=>"Tシャツ/カットソー(半袖/袖なし)"}, {:name=>"Tシャツ/カットソー(七分/長袖)"},{:name=>"その他"}]) lady_jacket.children.create([{:name=>"テーラードジャケット"}, {:name=>"ノーカラージャケット"}, {:name=>"Gジャン/デニムジャケット"},{:name=>"その他"}])ターミナル$ rake db:seedこれでancestryの準備完了です
残るはビューへの記述こちらは実装途中ですので別記事にて書きます。
記載後はこちらにもリンクを貼ります。
参考記事には多重構造とは?といったし詳細の記載もございますので是非ご参考にしてください。自身は初学者でございますので記事の内容等に不備等ございましたらご指摘いただけますと幸いです。
また、少しでもお役に立てましたら良いねいただければ喜びます。どうぞよろしくお願い致します。
参考サイト
Github
ancestryによる多階層構造の実現
多階層カテゴリでancestryを使ったら便利すぎた
ancestryの使い方
[Rails] Ajax通信を用いたカテゴリボックス作成
データベース論理設計のアンチパターン
- 投稿日:2020-02-23T17:33:19+09:00
Ruby ハッシュとシンボル まとめ
ハッシュ
- ハッシュの書き方
hash.rb#キーが文字列の時: money = {'japan'=>'yen','us'=>'dollar} money['japan'] #=>'yen' #キーがシンボルの時(こっちのほうが一般的): money = {:japan => 'yen', :us => 'dollar'} money = {japan: 'yen', us: 'dollar'} money = {japan: :yen, us: :dollar} money[:japan] #=>'yen'
- ハッシュを作成する際に"、文字列": 値の形式で書いた場合も、":文字列"と同じように見なされてキーがシンボルになる
symbol_key.rbhash = {'abc': 123} #=> {:abc=>123}
- 存在しないキーを指定するとnilが返る
- ハッシュ同士を比較すると全てのキーと値が同じ時のみtrueが返る
- ハッシュが格納する値は異なるデータ型でも良い(文字列・数値・配列・ハッシュ)
- eachメソッドでブロック引数を2つ指定するとキーと値の組み合わせを順に取り出すことができる(1つにするとキーと値が配列に格納される)
each_hash.rbmoney = {'japan' => 'yen', 'us' => 'dollar', 'india' => 'rupee' } money.each do |key,value| puts "#{key}:#{value}" end money.each do |key_value| key = key_value[0] value = key_value[1] puts "#{key}:#{value}" #=> japan:yen # us:dollar # india:rupee
deleteメソッド:引数に指定したキーに対応する要素を削除する- キーが見つからないときはブロックの戻り値をdeleteメソッドの戻り値にできる
delete.rbmoney.delete('italy'){|key| "Not Found: #{key}"} #=> "Not Found: italy"
- ハッシュの前に
**をつけると、ハッシュリテラルの中で他のハッシュのキーと値を展開することができるhash_tenkai.rbh = {us: 'dollar', india: 'rupee'} {japan: 'yen', **h} #=> {{japan: 'yen',us: 'dollar', india: 'rupee'}各種メソッド
keys:ハッシュのキーを配列で返すvalues:ハッシュの値を配列で返すhas_key?/key?/include?/member?:指定されたキーが存在するかto_aメソッド:ハッシュを配列に変換する、キーと値が一つの配列に入りそれが複数並んだ配列になるto_a.rbmoney.to_a #=> [[:japan, "yen"],[:us, "dollar"],[:india, "rupee"]]
to_hメソッド:配列をハッシュに変換する、元の配列は↑のようになっている必要があるto_h.rbarray = [[:japan, "yen"],[:us, "dollar"],[:india, "rupee"]] array.to_hシンボル
シンボルの特徴
- シンボルと文字列は全く別のオブジェクト、Symbolクラスのオブジェクト
- 内部で整数として管理される⇒2つの値が同じ値かを比較する時に文字列よりも高速に処理できる
- 同じシンボルであれば全く同じオブジェクト(参照先が同じ)⇒メモリの使用効率が良い
イミュータブルなオブジェクト、破壊的な変更はできない⇒名前をつけるのに向いている
キーワード引数⇒メソッドの引数の可読性を上げるデフォルト値は省略可能
keyword_arg.rbdef メソッド名(キーワード引数1: デフォルト値1, キーワード引数2: デフォルト値2) end #ex def buy_burger(menu,drink: true, potato: true) #略 end def buy_burger(menu,drink:,potato:) end #デフォルト値は省略可能 buy_burger('cheese',drink: true, potato: false) #呼び出すときはハッシュと同じような形式で
- キーワード引数を使うメソッドを呼び出す場合、キーワード引数に一致するハッシュを引数としてわたすことができる
params.rbparams = {drink: true, potato: false} buy_burger('fish', params)
**をつけた引数にはキーワード引数で指定されていない任意のキーワードがハッシュとして格納されるothers.rbdef buy_burger(menu,drink: true, potato: true,**others) puts others end buy_burger('cheese',drink: true, potato: false,salad: true, chicken: false) #=> {:salad => true, :chicken => false}
- クオートで囲むと識別子として無効な文字列でもシンボルとして有効になる
symbol.rb:'12345' #=> :"12345" :'ruby-is-fun' #=> :"ruby-is-fun" :'ruby is fun' #=> :"ruby is fun"
- ダブルクオートで囲むと文字列と同じように式展開を使える
symbol_tenkai.rbname = 'Alice' :#{name.upcase!} #=> :ALICE
%sを使うとシンボルを作成できる%iを使うとシンボルの配列を作成できる%i_%s.rb%s(ruby is fun) #=> :"ruby is fun" %i(apple orange melon) #=> [:apple, :orange, :melon]
to_symメソッド:文字列をシンボルに変換するto_sメソッド:シンボルや数値を文字列に変換するhenkan.rbstring = "apple" symbol = :apple string.to_sym #=> :apple symbol.to_s #=> "apple"変換メソッドまとめ
- 配列->ハッシュ:
to_h- ハッシュ->配列:
to_a- 文字列->シンボル:
to_sym/intern- シンボル->文字列:
to_s
- 投稿日:2020-02-23T17:02:47+09:00
Ruby モジュールまとめ
学習用としてのまとめのメモです。
モジュールの用途
1. 継承を使わず(継承関係を気にせずに)にクラスにインスタンスメソッドを追加する&オーバーライドする(ミックスイン)
2. 複数のクラスに対して共通の特異メソッド(クラスメソッド)を追加する(ミックスイン)
⇒is-aの関係になくても複数のクラスにまたがって同じような機能が必要になる場合に用いる
3. クラス名や定数名の衝突を防ぐために名前空間をつくる
4. 関数的メソッドを定義する
5. シングルトンオブジェクトのように扱って設定値などを保持するモジュールの基本
定義:
module.rbmodule module_name モジュールの定義(メソッドなど) endモジュールの特徴(クラスとの相違):
- モジュールからインスタンスを作成することはできない
- 他のモジュールやクラスを継承できない
ミックスイン(用途1・2)
- モジュールは
privateメソッドで定義することが多いmixin.rbmodule Loggable private #privateにすることが多い def log(text) puts "[LOG] #{text}" end end
include:モジュール内のメソッドがインスタンスメソッドとして呼び出せるようになるinclude.rbclass Product include Loggable def title log 'title is called' end end product = Product.new product.title #=> [LOG] title is called
モジュール内で定義したメソッド内でインスタンス変数を読み書きすると、include先のクラスのインスタンス変数を読み書きしたことと同じになる(※ただし、モジュールとミックスイン先のクラスでインスタンス変数を共有するのはあまりいい設計ではない)
ミックスインはクラスだけではなく、個々のオブジェクトに特異メソッドとしてミックスインできる
s = 'abc' s.extend(Loggable) s.log('Hello') #=>[LOG] Hello
extend:モジュール内のメソッドが特異メソッド(クラスメソッド)として呼び出せるようになるextend.rbclass Product extend Loggable def self.create_product(names) #logメソッドをクラスメソッド内で呼び出す #つまり、logメソッド自体もクラスメソッドになっている log "create_product is called" end end Product.create_product([]) #=> [LOG] create_product is called #Productクラスのクラスメソッドとして直接呼び出すこともできる Product.log('Hello') #=> [LOG] Hello
- あるメソッドがinclude先に定義されていることを前提としたモジュールを定義できる(ダックタイピングの一種) このときのselfはinclude先のクラスのインスタンスになる
duck.rbmodule Taggable def price_tag #priceメソッドはinclude先で定義されているはず、という前提 "#{price}円" # #{self.price}としてあえてselfをつけて呼び出しても良い(selfはinclude先のクラスのインスタンス) end end class Product include Taggable def price 10000 end endモジュールの有無を調べるメソッド:
include?:引数に渡したモジュールがincludeされているのかがわかるincluded_modules:includeしたモジュールが配列で返るancestors:モジュールだけでなくスーパークラスの情報も配列になって返るモジュールで名前空間をつくる(用途3)
- クラス名が重複しているが両方とも使用したい⇒モジュール構文のなかにクラス定義を書くと「そのモジュールに属するクラス」という意味になり名前の衝突を防げる
- モジュールに属するクラスを参照する場合は、
モジュール名::クラス名のように書くname_space.rbmodule BaseBall class Second def initialize(player,number) ....(略).... end end end module Clock class Second def initialize(digits) ....(略).... end end end BaseBall::Secode.new('alice',12) Clock::Second.new(12) # モジュール名::クラス名のように呼び出す
- 名前空間として用いるモジュールがすでにどこかで定義されている場合は、ネストさせずに
モジュール名::クラス名でクラスを定義できるname_space2.rbmodule BaseBall end class BaseBall::Second def initialize ....(略).... end end関数の集まりや定数を提供するモジュールの作成(用途④):モジュール関数
- モジュール自身に特異メソッドを定義すれば、わざわざ他のクラスにミックスインしなくともモジュール単体でそのメソッドを呼び出せる →モジュールはインスタンスを作れないので、”単なるメソッド(関数)”の集まりを作りたい時に向いている
module_method.rbmodule Loggable def self.log(text) puts "[LOG] #{text}" end end Loggable.log('Hello') #=> [LOG] Hello
module_functionで対象のメソッド名を指定すると、ミックスインでも使えて、なおかつモジュールの特異メソッドとしても使えるようになる(モジュール関数)- モジュール関数はミックスインすると自動的にprivateになる
module_func.rbmodule Loggable def log(text) puts "[LOG] #{text}" end module_function :log end状態を保持するモジュールの作成(用途5)
- モジュールはインスタンスを作成できないので、シングルトンパターンのように「唯一、ただ一つ」のオブジェクトを作りたいときなどに用いることができる
- モジュールではなくクラスでシングルトンパターンを実現したい場合は、
Singletonモジュールをincludeすると便利その他
- モジュールの中で他のモジュールをincludeすることもできる、このときincludeしたモジュールがincludeしているモジュールもincludeしたことになる モジュールをインスタンスメソッドとしてミックスインするにはincludeだけでなく
prependも使うことができるprependは同名のメソッドがあったときにミックスインしたクラスよりも先にモジュールのメソッドが呼ばれる(includeはその逆)⇒既存メソッドを置き換えるのに役立つprepend.rbclass Product def name "movie" end end module NameDecorator def name "<<super>>" end end #Productクラスを再オープンし、prependでミックスイン class Product prepend NameDecorator end product = Product.new product.name #=> <<movie>>外部ソースファイルの読み込み(モジュールを外部に切り分けたときなど)
require:rubyコマンドが実行された位置からの位置を基準としてパスを参照する、外部ライブラリ利用のときは関係なく-require 'date'などと書けるrequire_relative:require_relativeが記述されたファイルからを基準としてパスを参照する、rubyコマンドは関係ないload:requireの何回も読み込めるバージョン
- 投稿日:2020-02-23T17:02:47+09:00
Ruby モジュール まとめ
モジュールの用途
1. 継承を使わず(継承関係を気にせずに)にクラスにインスタンスメソッドを追加する&オーバーライドする(ミックスイン)
2. 複数のクラスに対して共通の特異メソッド(クラスメソッド)を追加する(ミックスイン)
⇒is-aの関係になくても複数のクラスにまたがって同じような機能が必要になる場合に用いる
3. クラス名や定数名の衝突を防ぐために名前空間をつくる
4. 関数的メソッドを定義する
5. シングルトンオブジェクトのように扱って設定値などを保持するモジュールの基本
- モジュールの定義
module.rbmodule module_name def some_methods # 略 end endモジュールの特徴(クラスとの相違):
- モジュールからインスタンスを作成することはできない
- 他のモジュールやクラスを継承できない
ミックスイン(用途1・2)
- モジュールは
privateメソッドで定義することが多いmixin.rbmodule Loggable private #privateにすることが多い def log(text) puts "[LOG] #{text}" end end
include:モジュール内のメソッドがインスタンスメソッドとして呼び出せるようになるinclude.rbclass Product include Loggable def title log 'title is called' end end product = Product.new product.title #=> [LOG] title is called
モジュール内で定義したメソッド内でインスタンス変数を読み書きすると、include先のクラスのインスタンス変数を読み書きしたことと同じになる(※ただし、モジュールとミックスイン先のクラスでインスタンス変数を共有するのはあまりいい設計ではない)
ミックスインはクラスだけではなく、個々のオブジェクトに特異メソッドとしてミックスインできる
s = 'abc' s.extend(Loggable) s.log('Hello') #=>[LOG] Hello
extend:モジュール内のメソッドが特異メソッド(クラスメソッド)として呼び出せるようになるextend.rbclass Product extend Loggable def self.create_product(names) #logメソッドをクラスメソッド内で呼び出す #つまり、logメソッド自体もクラスメソッドになっている log "create_product is called" end end Product.create_product([]) #=> [LOG] create_product is called #Productクラスのクラスメソッドとして直接呼び出すこともできる Product.log('Hello') #=> [LOG] Hello
- あるメソッドがinclude先に定義されていることを前提としたモジュールを定義できる(ダックタイピングの一種) このときのselfはinclude先のクラスのインスタンスになる
duck.rbmodule Taggable def price_tag #priceメソッドはinclude先で定義されているはず、という前提 "#{price}円" # #{self.price}としてあえてselfをつけて呼び出しても良い(selfはinclude先のクラスのインスタンス) end end class Product include Taggable def price 10000 end endモジュールの有無を調べるメソッド:
include?:引数に渡したモジュールがincludeされているのかがわかるincluded_modules:includeしたモジュールが配列で返るancestors:モジュールだけでなくスーパークラスの情報も配列になって返るモジュールで名前空間をつくる(用途3)
- クラス名が重複しているが両方とも使用したい⇒モジュール構文のなかにクラス定義を書くと「そのモジュールに属するクラス」という意味になり名前の衝突を防げる
- モジュールに属するクラスを参照する場合は、
モジュール名::クラス名のように書くname_space.rbmodule BaseBall class Second def initialize(player,number) ....(略).... end end end module Clock class Second def initialize(digits) ....(略).... end end end BaseBall::Secode.new('alice',12) Clock::Second.new(12) # モジュール名::クラス名のように呼び出す
- 名前空間として用いるモジュールがすでにどこかで定義されている場合は、ネストさせずに
モジュール名::クラス名でクラスを定義できるname_space2.rbmodule BaseBall end class BaseBall::Second def initialize ....(略).... end end関数の集まりや定数を提供するモジュールの作成(用途4):モジュール関数
- モジュール自身に特異メソッドを定義すれば、わざわざ他のクラスにミックスインしなくともモジュール単体でそのメソッドを呼び出せる →モジュールはインスタンスを作れないので、”単なるメソッド(関数)”の集まりを作りたい時に向いている
module_method.rbmodule Loggable def self.log(text) puts "[LOG] #{text}" end end Loggable.log('Hello') #=> [LOG] Hello
module_functionで対象のメソッド名を指定すると、ミックスインでも使えて、なおかつモジュールの特異メソッドとしても使えるようになる(モジュール関数)- モジュール関数はミックスインすると自動的にprivateになる
module_func.rbmodule Loggable def log(text) puts "[LOG] #{text}" end module_function :log end状態を保持するモジュールの作成(用途5)
- モジュールはインスタンスを作成できないので、シングルトンパターンのように「唯一、ただ一つ」のオブジェクトを作りたいときなどに用いることができる
- モジュールではなくクラスでシングルトンパターンを実現したい場合は、
Singletonモジュールをincludeすると便利その他
- モジュールの中で他のモジュールをincludeすることもできる、このときincludeしたモジュールがincludeしているモジュールもincludeしたことになる モジュールをインスタンスメソッドとしてミックスインするにはincludeだけでなく
prependも使うことができるprependは同名のメソッドがあったときにミックスインしたクラスよりも先にモジュールのメソッドが呼ばれる(includeはその逆)⇒既存メソッドを置き換えるのに役立つprepend.rbclass Product def name "movie" end end module NameDecorator def name "<<super>>" end end #Productクラスを再オープンし、prependでミックスイン class Product prepend NameDecorator end product = Product.new product.name #=> <<movie>>外部ソースファイルの読み込み(モジュールを外部に切り分けたときなど)
require:rubyコマンドが実行された位置からの位置を基準としてパスを参照する、外部ライブラリ利用のときは関係なく-require 'date'などと書けるrequire_relative:require_relativeが記述されたファイルからを基準としてパスを参照する、rubyコマンドは関係ないload:requireの何回も読み込めるバージョン
- 投稿日:2020-02-23T15:37:39+09:00
ずぶの素人がAWSでRailsアプリを作るメモ
仕事でRailsを使うので、この機会に自分でも何かしようと思い行動に移すことにしました。
やりたいことリスト:
- Railsでサンプルアプリケーションをつくる
- 自分流にアレンジする
- 仕事で使わないような技術に触れるひとまずやってみようの精神で、失敗しながら学びます。
というわけでまずは環境から。
いろいろとローカルに用意するのは挫折しそうだったので、手っ取り早くAWSのCloud9を使用します。
ありがたいことに必要なものはそろっている(素人目線)ので、
新しく環境を作ったら、さくっと始めていきます。
新規作成した環境には初めは何もないので、Railsアプリをつくるときは
rails new sample -d mysql
でディレクトリから作成します。
(個人的にMySQLのほうが好きなのでDBを軽率に変更しています、「-d ~」はなくてもOKです)用意ができたのでさっそくRailsサーバーを立ち上げて(
rails s)、まっさらなアプリを起動しよう…
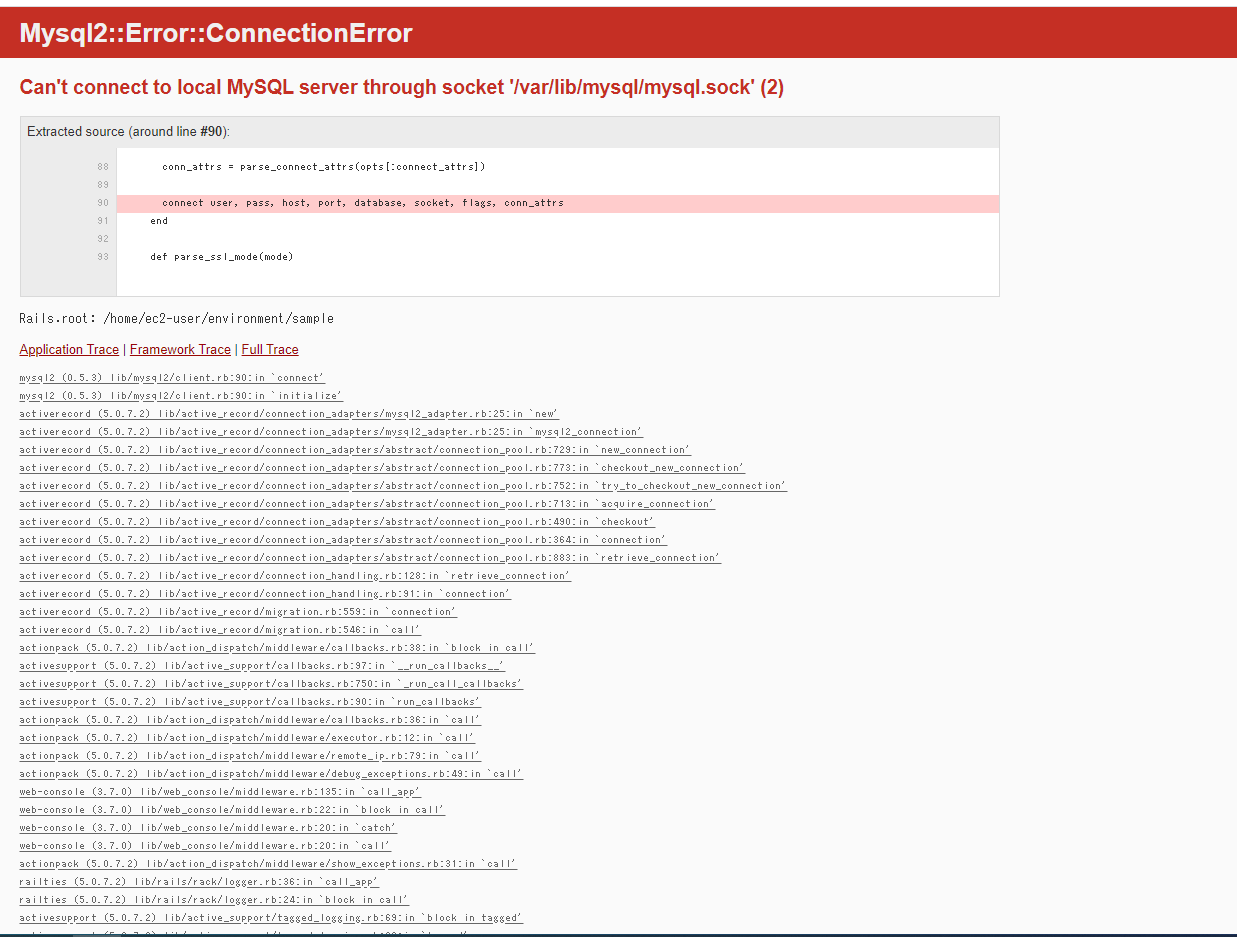
としたのですが、エラーメッセージが。
仕事でも見たことないメッセージだったのでここでしばらくワタワタしました(素人感)。
まだしっかり理解してないですが、MySQLが起動してないのでDBに接続できないと怒られているようです。
ネットで調べると以下のような記事が。
MySqlのソケットエラーを解決するありがたく以下のコマンドを拝借して、実行します。
sudo /etc/init.d/mysqld restart
そうするとエラーの種類が変わりまして、”sample_development”なんてDBはねえよ、と言われました。
これは仕事場でも見たことがあったので、おとなしく
rake db:create
します。(rails db:createでもいいはず?)今度こそうまく動いて、Railsの初期アプリの画面が表示されました。
DBをSQLiteからMySQLに変更するだけでこんなにわたつく滑り出しで、今後どういった艱難辛苦があるか想像できませんが、ひとまず進めるだけは進めたいと思います。
ネタがあったり、詰まっていた部分が解決したらまたメモします。


- 投稿日:2020-02-23T14:26:19+09:00
attr_accessorで挫折した君へ
はじめに
僕は恥ずかしながら
attr_accessorをRuby歴7ヶ月にして理解しました。学びたての頃は、『classの下についてる変なやつ』としか思っておらず、何のために置かれてるのかわからないまま、とりあえず置いとけ、エイっ!!という感じで使っていました(ひどい)ということで、attr_accessorで挫折した僕が、attr_accessorで挫折した人にattr_accessorを挫折しないように分かりやすく説明したいと思います。
ゴール
本記事では、以下のコードを完全に理解することをゴールとして説明します。
すでに理解できてるよという方はそっとブラウザバックしてください。user.rbclass User attr_accessor :name, :age def initialize(name, age) @name = name @age = age end end大前提
はじめに、大前提を説明して目線を合わせます。
『基本的に、オブジェクトの値をクラス外から参照・書き込みすることはできない』
どういうこと?と思った方は試しに以下のコードを実行してみてください。
user.rbclass User def initialize(name, age) @name = name @age = age end end user = User.new("山田",18) user.name user.ageおそらく、
undefined method `name' for #<User:0x00007faf4c182dd0 @name="山田", @age=18> (NoMethodError)と怒られたはずです。
ちなみに、userの名前を書き換えるとどうなるでしょうか?
user.name = "佐藤" => undefined method `name=' for #<User:0x00007fee848daac0 @name="山田", @age=18> (NoMethodError)やはり怒られました...
そうなんです。何も設定をしなければ、いつも当たり前にやっていた参照、書き換えは実行できないんです。
『え??いつもRailsでやったときは出来てたのに何で今回は出来ないの??』
と思ったかもしれません。分かります。僕も全く同じように考えていました。
その答えは本記事の中でじっくり説明しますので、もう少し読み進めて行きましょう。力技で解決してみる
何も設定しなけば、オブジェクトの値の読み書きができないことが分かりました。
それなら、力技で解決するためにこんなコードを書いてみました。user.rbclass User def initialize(name, age) @name = name @age = age end def name @name end def name=(name) @name = name end end1つ目が、nameの値を読むためのメソッド、
2つ目が、nameの値を書き込むためのメソッドです。※ name=(name)という変な書き方にアレルギー反応が出た人がいるかもしれませんが、「値を更新するときはこう書くんだ」ぐらいで覚えてもらえれば大丈夫です。
これを書けば、
user.nameとしたとき、nameメソッドが呼び出され、その中で@nameを参照しているため、正常に値を取り出すことができます。書き込みについても同様です。それでは、以下を実行してみましょう。
user.rbclass User 省略 end user = User.new("山田",18) p user.name p user.name = "佐藤"結果
"山田" "佐藤"今度はうまく行きました。
これで解決ですね、めでたしめでたし。。。。、となってしまったら大変です。なぜなら、このやり方だと属性(name、age)が増えるたびに読み書き用のメソッドを作らなければいけません。
今回でいうならこんな感じ。
user.rbclass User def initialize(name, age) @name = name @age = age end def name @name end def name=(name) @name = name end def age @age end def age=(age) @age = age end endこれは流石に面倒の極みです。
ということで、Rubyはこれを解決するためにアクセスメソッドというものを準備してくれています。ありがたや。すごく便利なアクセスメソッド
では、先ほどの面倒なコードをアクセスメソッドを使ってシンプルにしていきましょう。
attr_readerメソッド
attr_readerメソッドは以下の2つのメソッドの代わりになります。
# attr_reader :name, :age は以下の2つと同じ意味 def name @name end def age @age endつまり、先ほどの長ったらしいコードは以下のようにシンプルになります。
user.rbclass User attr_reader :name, :age def initialize(name, age) @name = name @age = age end def name=(name) @name = name end def age=(age) @age = age end endメソッドを2つ省略できたので、かなりシンプルになりました。もう少しスッキリさせましょう。
attr_writerメソッド
情報を書き込みするメソッドを省略するために、attr_writerメソッドがあります。
これを使うと以下のメソッドを省くことができます。# attr_writer :name, :age は以下の2つと同じ意味 def name=(name) @name = name end def age=(age) @age = age endこれを使うと、かなりスッキリ。
user.rbclass User attr_reader :name, :age attr_writer :name, :age def initialize(name, age) @name = name @age = age end end最初のコードと比べたら、別人のようですね!
でも、まだ甘いです。実はもっとシンプルにできます。
attr_accessorメソッド
もう十分でしょ、と思うかもしれませんがRubyにはattr_readerメソッドとattr_writerメソッドを兼ね備えた万能のメソッドが存在します。
それが、attr_accessorメソッドです!
これを使えば、
attr_reader :name, :age attr_writer :name, :ageが、
attr_accessor :name, :ageになります。最終形態は以下の通り。
user.rbclass User attr_accessor :name, :age def initialize(name, age) @name = name @age = age end end最終的にたったの8行におさまりました。アクセスメソッドの威力はハンパないですね!
つまり、これまで何となくクラスの頭に置いていたattr_accessorメソッドは、オブジェクトの値の読み書きを可能にしてくれる万能なメソッドだったというわけです。
じゃあ何でRailsでは何もしてないのにオブジェクトの値の読み書きができるのさ
普段、Railsで開発しているとき、特に何も意識しなくても、以下のようにオブジェクトの値を読み書きできますよね?
user.name => "佐藤" user.name = "山田" user.name => "山田"これはなぜでしょうか?
答え
Railsにおいて、テーブルに紐づく全てのModelはActiveRecordを継承しているから
解説
rails generateで作成されたModelは、自動的にActiveRecordというクラスを継承するようにRailsが設定しています。class User < ApplicationRecord endsuperclassで先祖を辿っていくと、
irb> User.superclass => ApplicationRecord irb > ApplicationRecord.superclass => ActiveRecord::Base確かにActiveRecordというクラスがありました。
このActiveRecordにおいて、usersテーブルの各カラムをアクセスメソッド(attr_accessor)として登録しているため、
僕たちが意識しなくても、オブジェクトの値の読み書きが行えているわけですね。ActiveRecord様には足を向けて寝れません。笑
まとめ
以上を簡単にまとめるとこうなります。
- 基本的にクラス外からオブジェクトの値を読み書きすることができない
- 1つの属性ごとに読み書き専用のメソッドを作ればいつも通り読み書きできるようになる
- しかし、毎回メソッドを書くのはめんどくさい
- そこで、アクセスメソッドの出番!
- attr_readerメソッドを使うと、「読み」用のメソッドを省略できる
- attr_writerメソッドを使うと「書き込み」用のメソッドを省略できる
- attr_accessorメソッドを使えば「読み」「書き」どちらも省略できる
- Railsでオブジェクトの値を自由に読み書きできるのはActiveRecordを継承しているから
この記事でattr_accessorという不気味なメソッドへの理解が少しでも深まれば幸いです。
最後までお読みいただきありがとうございました!
- 投稿日:2020-02-23T13:17:07+09:00
【Rails】APIモードで使えるHTTPステータスコードのシンボルまとめ
はじめに
Railsで使えるHTTPステータスコードのシンボルの一覧です。
Rails APIモードで使えるのではないかと思います。環境
OS: macOS Catalina 10.15.3 Ruby: 2.6.5 Rails: 6.0.2.1きっかけ
JSONを返すAPIのコントローラーでは、以下のような一文をよく見かけます。
users_controller.rbrender json: user, status: :ok # この:okのことこれは、下記のようにも書けます。
users_controller.rbrender json: user, status: 200この方が簡潔に書けるし、「はいはい、
200はOKだよね!」と分かるかと思います。でも、これならどうでしょうか?
sample.rbstatus: 429シンボルで書くと、こうなります。
sample.rbstatus: :too_many_requests「リクエスト多すぎ!」ってことですね。
1時間あたりに〇〇回しかリクエスト投げられないAPIを使っていて、リクエストを投げすぎたときに返ってきます。結論:
200or:okどちらを使うべきか
- チーム開発を経た経験から、開発者のスキルが全員同じは絶対にない
- HTTPステータスコードより英語の方がわかりやすい
という点から、
:okの方が全体に対するメリットが多いのではないかと思います。とはいえ、「覚えられないのでリファレンス欲しいと思いましたので今回まとめました!
HTTPステータスコードのシンボル一覧
シンボル一覧.rb100 :continue 101 :switching_protocols 102 :processing 103 :early_hints 200 :ok 201 :created 202 :accepted 203 :non_authoritative_information 204 :no_content 205 :reset_content 206 :partial_content 207 :multi_status 208 :already_reported 226 :im_used 300 :multiple_choices 301 :moved_permanently 302 :found 303 :see_other 304 :not_modified 305 :use_proxy 306 :unused 307 :temporary_redirect 308 :permanent_redirect 400 :bad_request 401 :unauthorized 402 :payment_required 403 :forbidden 404 :not_found 405 :method_not_allowed 406 :not_acceptable 407 :proxy_authentication_required 408 :request_timeout 409 :conflict 410 :gone 411 :length_required 412 :precondition_failed 413 :payload_too_large 414 :uri_too_long 415 :unsupported_media_type 416 :range_not_satisfiable 417 :expectation_failed 421 :misdirected_request 422 :unprocessable_entity 423 :locked 424 :failed_dependency 425 :too_early 426 :upgrade_required 428 :precondition_required 429 :too_many_requests 431 :request_header_fields_too_large 451 :unavailablefor_legal_reasons 500 :internal_server_error 501 :not_implemented 502 :bad_gateway 503 :service_unavailable 504 :gateway_timeout 505 :http_version_not_supported 506 :variant_also_negotiates 507 :insufficient_storage 508 :loop_detected 509 :bandwidth_limit_exceeded 510 :not_extended 511 :network_authentication_required対応するヘルパーメソッド
ヘルパー一覧.rbdef invalid?; status < 100 || status >= 600; end def informational?; status >= 100 && status < 200; end def successful?; status >= 200 && status < 300; end def redirection?; status >= 300 && status < 400; end def client_error?; status >= 400 && status < 500; end def server_error?; status >= 500 && status < 600; end def ok?; status == 200; end def created?; status == 201; end def accepted?; status == 202; end def no_content?; status == 204; end def moved_permanently?; status == 301; end def bad_request?; status == 400; end def unauthorized?; status == 401; end def forbidden?; status == 403; end def not_found?; status == 404; end def method_not_allowed?; status == 405; end def precondition_failed?; status == 412; end def unprocessable?; status == 422; end def redirect?; [301, 302, 303, 307, 308].include? status; endおわりに
最後まで読んで頂きありがとうございました
どなたかの参考になれば幸いです
参考にさせて頂いたサイト(いつもありがとうございます)
- 投稿日:2020-02-23T12:14:40+09:00
Rails プロジェクト作成手順
今までCloud9を使ってRails開発をちょこちょこしていました。
今回は、イチからやってみようということでCloud9を使わずにプロジェクト作成をすることにしました。①Homebrewのインストール
Macユーザー限定ですが、まずは
Homebrewのインストールを行います。
公式に書いてある通りにスクリプトを実行すれば、問題ないはずです。バージョンが表示されれば、うまくインストールされています。
$ brew -v Homebrew 2.2.6②rbenvのインストール
Rubyのバージョン管理ができるように
rbenvのインストールを行います。$ brew install rbenv ruby-build次にパスを通します。
なぜかというと、MacデフォルトのRubyを使わずにrbenvでインストールしたRubyを使用するためです。MacデフォルトのRubyは、/usr/binというところに入っているのですが、rbenvでインストールしたRubyは、/Users/ユーザー名/.rbenv/shims/に入ります。
そのため、ターミナルからRubyを実行するときに、rbenvの中のRubyでRubyを実行するように切り替えをする必要があります。
$ echo 'export PATH="~/.rbenv/shims:/usr/local/bin:$PATH"' >> ~/.bash_profile $ echo 'eval "$(rbenv init -)"' >> ~/.bash_profile $ source ~/.bash_profile //.bash_profileを読み込む
eval “$(rbenv init -)”を.bash_profileファイルに書いて読み込みすることによって、Macにログインしたら、Rubyコマンドを実行するときはrbenv内のRubyを実行するように設定しておくができます。➂Rubyのインストール
ここでようやくRubyのインストールを行います。
まずは、インストール可能なバージョンを確認します。$ rbenv install --list今回は、
2.7.0をインストールします。$ rbenv install 2.7.0 // 環境全体の有効なバージョンを2.7.0にする $ rbenv global 2.7.0 $ rbenv rehash $ ruby -v④Bundlerのインストール
次に、
Bundlerのインストールをします。
Bundlerとは、gemの依存関係とバージョンを管理するためのツールです。
Bundlerを使うと、依存関係のあるgemを一括でインストールしてくれます。
一括でインストールしたgemはすべて、依存関係が解決された状態で、インストールされます。$ gem install bundler $ bundle -v⑤Railsプロジェクトの作成
ここで、プロジェクトを作成します。
作成したプロジェクトの中で、bundle initを行います。$ mkdir ~/testApp $ cd ~/testApp $ bundle init成功すれば、Gemfileが作られているはずです。
Gemfileとは、インストールしたいgemを列挙するものです。
ただ、このままだと使えないので、Gemfileを編集する必要があります。GemFile# frozen_string_literal: true source "https://rubygems.org" git_source(:github) {|repo_name| "https://github.com/#{repo_name}" } gem "rails" ←コメントアウトを外すシステムのgemはできるだけクリーンに保ち、gemは
vendor/bundleに入れてbundle execで呼び出すのがいいそうなのでそうします。$ bundle install --path=vendor/bundle $ bundle exec rails -v Rails 6.0.2.1
--path vendor/bundleオプションを付けることで、プロジェクトのvendor/bundle以下にgemが格納されます。
次回以降はオプションを付けなくてもvendor/bundle以下に格納されるはずです。プロジェクト別にgemをインストールすると、プロジェクトごとのgemのバージョンの違いを気にすることがなくなります。
最後に、Railsプロジェクトを作成します。
$ bundle exec rails new . -B --skip-test
.を付けると現在のディレクトリに作成されます。少しだけオプションの説明をすると、
-BはRailsプロジェクト作成時にbundle installを行わないようにします。
また、--skip-testはデフォルトのminitestというテストを使わない時に付ける。他のテストフレームワークを利用したい時に使うといいです。
他のオプションはドキュメントを参考にするといいと思います。プロジェクトにいる状態で、下記コマンドを実行して、http://localhost:3000/ へアクセスします。(サーバー起動)
$ rails serverRailsの画面が表示されれば、成功です。
Cloud9はそこまで意識せずにプロジェクトが作れちゃうので、楽ですね!
ただ、環境構築で何が行われるのかを知るという意味ではやってみるのもいいかもしれません。
また、実際の開発現場でCloud9を使ってというのはあんまりないと思うので、できた方がいい気がします。補足
Rails6から
Webpackerがデフォルトでインストールされます。
なので、Webpackerやyarnをインストールしないとサーバー起動時に失敗する場合があります。
その場合は、インストールしましょう。// yarnを先にインストールしないとwebpackerをインストールできない $ brew install yarn $ rails webpacker:install参照

- 投稿日:2020-02-23T11:04:08+09:00
【Rails】portを使っていないのにAddress already in useエラーが出る場合の応急処置
はじめに
少し昔のrailsアプリ少しいじろうかと思ったのですが、見事にハマりました。
bundle updateだとかgem pristineだとかをしたのですが、結局rails serverができなかったので、奮闘記録と共にとりあえずのサーバー起動方法を書いておきます。動作環境
- Ruby 2.5.3
- Rails 5.2.4.1
- puma 3.12.2
- ローカル環境
Address already in useエラー
$ rails s => Booting Puma => Rails 6.0.2.1 application starting in development => Run `rails server --help` for more startup options [1234] Puma starting in cluster mode... [1234] * Version 4.3.1 (ruby 2.5.3-p105), codename: Mysterious Traveller [1234] * Min threads: 5, max threads: 5 [1234] * Environment: development [1234] * Process workers: 2 [1234] * Preloading application [1234] * Listening on tcp://127.0.0.1:3000 [1234] * Listening on tcp://[::1]:3000 Exiting Traceback (most recent call last): 37: from bin/rails:3:in `<main>' 36: from bin/rails:3:in `load' 35: from /Users/k_end/workspace/personal/kiite_app/bin/spring:15:in `<top (required)>' 34: from /Users/k_end/.rbenv/versions/2.5.3/lib/ruby/2.5.0/rubygems/core_ext/kernel_require.rb:59:in `require' 33: from /Users/k_end/.rbenv/versions/2.5.3/lib/ruby/2.5.0/rubygems/core_ext/kernel_require.rb:59:in `require' 32: from /Users/k_end/.rbenv/versions/2.5.3/lib/ruby/gems/2.5.0/gems/spring-2.1.0/lib/spring/binstub.rb:11:in `<top (required)>' 31: from /Users/k_end/.rbenv/versions/2.5.3/lib/ruby/gems/2.5.0/gems/spring-2.1.0/lib/spring/binstub.rb:11:in `load' 30: from /Users/k_end/.rbenv/versions/2.5.3/lib/ruby/gems/2.5.0/gems/spring-2.1.0/bin/spring:49:in `<top (required)>' 29: from /Users/k_end/.rbenv/versions/2.5.3/lib/ruby/gems/2.5.0/gems/spring-2.1.0/lib/spring/client.rb:30:in `run' 28: from /Users/k_end/.rbenv/versions/2.5.3/lib/ruby/gems/2.5.0/gems/spring-2.1.0/lib/spring/client/command.rb:7:in `call' 27: from /Users/k_end/.rbenv/versions/2.5.3/lib/ruby/gems/2.5.0/gems/spring-2.1.0/lib/spring/client/rails.rb:28:in `call' 26: from /Users/k_end/.rbenv/versions/2.5.3/lib/ruby/gems/2.5.0/gems/spring-2.1.0/lib/spring/client/rails.rb:28:in `load' 25: from /Users/k_end/workspace/personal/kiite_app/bin/rails:9:in `<top (required)>' 24: from /Users/k_end/workspace/personal/kiite_app/bin/rails:9:in `require' 23: from /Users/k_end/.rbenv/versions/2.5.3/lib/ruby/gems/2.5.0/gems/railties-6.0.2.1/lib/rails/commands.rb:18:in `<top (required)>' 22: from /Users/k_end/.rbenv/versions/2.5.3/lib/ruby/gems/2.5.0/gems/railties-6.0.2.1/lib/rails/command.rb:46:in `invoke' 21: from /Users/k_end/.rbenv/versions/2.5.3/lib/ruby/gems/2.5.0/gems/railties-6.0.2.1/lib/rails/command/base.rb:69:in `perform' 20: from /Users/k_end/.rbenv/versions/2.5.3/lib/ruby/gems/2.5.0/gems/thor-1.0.1/lib/thor.rb:392:in `dispatch' 19: from /Users/k_end/.rbenv/versions/2.5.3/lib/ruby/gems/2.5.0/gems/thor-1.0.1/lib/thor/invocation.rb:127:in `invoke_command' 18: from /Users/k_end/.rbenv/versions/2.5.3/lib/ruby/gems/2.5.0/gems/thor-1.0.1/lib/thor/command.rb:27:in `run' 17: from /Users/k_end/.rbenv/versions/2.5.3/lib/ruby/gems/2.5.0/gems/railties-6.0.2.1/lib/rails/commands/server/server_command.rb:138:in `perform' 16: from /Users/k_end/.rbenv/versions/2.5.3/lib/ruby/gems/2.5.0/gems/railties-6.0.2.1/lib/rails/commands/server/server_command.rb:138:in `tap' 15: from /Users/k_end/.rbenv/versions/2.5.3/lib/ruby/gems/2.5.0/gems/railties-6.0.2.1/lib/rails/commands/server/server_command.rb:147:in `block in perform' 14: from /Users/k_end/.rbenv/versions/2.5.3/lib/ruby/gems/2.5.0/gems/railties-6.0.2.1/lib/rails/commands/server/server_command.rb:39:in `start' 13: from /Users/k_end/.rbenv/versions/2.5.3/lib/ruby/gems/2.5.0/gems/rack-2.2.2/lib/rack/server.rb:327:in `start' 12: from /Users/k_end/.rbenv/versions/2.5.3/lib/ruby/gems/2.5.0/gems/puma-4.3.1/lib/rack/handler/puma.rb:73:in `run' 11: from /Users/k_end/.rbenv/versions/2.5.3/lib/ruby/gems/2.5.0/gems/puma-4.3.1/lib/puma/launcher.rb:172:in `run' 10: from /Users/k_end/.rbenv/versions/2.5.3/lib/ruby/gems/2.5.0/gems/puma-4.3.1/lib/puma/cluster.rb:413:in `run' 9: from /Users/k_end/.rbenv/versions/2.5.3/lib/ruby/gems/2.5.0/gems/puma-4.3.1/lib/puma/runner.rb:161:in `load_and_bind' 8: from /Users/k_end/.rbenv/versions/2.5.3/lib/ruby/gems/2.5.0/gems/puma-4.3.1/lib/puma/binder.rb:90:in `parse' 7: from /Users/k_end/.rbenv/versions/2.5.3/lib/ruby/gems/2.5.0/gems/puma-4.3.1/lib/puma/binder.rb:90:in `each' 6: from /Users/k_end/.rbenv/versions/2.5.3/lib/ruby/gems/2.5.0/gems/puma-4.3.1/lib/puma/binder.rb:106:in `block in parse' 5: from /Users/k_end/.rbenv/versions/2.5.3/lib/ruby/gems/2.5.0/gems/puma-4.3.1/lib/puma/binder.rb:222:in `add_tcp_listener' 4: from /Users/k_end/.rbenv/versions/2.5.3/lib/ruby/gems/2.5.0/gems/puma-4.3.1/lib/puma/binder.rb:222:in `each' 3: from /Users/k_end/.rbenv/versions/2.5.3/lib/ruby/gems/2.5.0/gems/puma-4.3.1/lib/puma/binder.rb:223:in `block in add_tcp_listener' 2: from /Users/k_end/.rbenv/versions/2.5.3/lib/ruby/gems/2.5.0/gems/puma-4.3.1/lib/puma/binder.rb:229:in `add_tcp_listener' 1: from /Users/k_end/.rbenv/versions/2.5.3/lib/ruby/gems/2.5.0/gems/puma-4.3.1/lib/puma/binder.rb:229:in `new' /Users/k_end/.rbenv/versions/2.5.3/lib/ruby/gems/2.5.0/gems/puma-4.3.1/lib/puma/binder.rb:229:in `initialize': Address already in use - bind(2) for "127.0.0.1" port 3000 (Errno::EADDRINUSE)サーバーを起動させたままコンソールを閉じてしまうというよくあるパターンだと思い、いつも通りの手順を踏む。
$ ps ax | grep rails 834 s000 S+ 0:00.00 grep --color=auto rails
834はps ax | grep railsによるプロセスなので、他に動いているプロセスはない。$ ps aux | grep puma k_end 882 0.0 0.0 4276968 712 s000 R+ 7:50AM 0:00.00 grep --color=auto pumaこちらも同様。
$ lsof -wni tcp:3000もちろん意味なし。
この辺りで、いやまさかそんなはずが……と思い始める。ポートを使っているか確認してみた
teratailのRails sでポート3000番で立ち上がらないのコメントを参考にし、bashで確認したところ、
$ exec 3<>/dev/tcp/localhost/3000 bash: connect: Connection refused bash: /dev/tcp/localhost/3000: Connection refusedポート使っていないですね。
ということは、他のアプリなら起動できるのでは?と思い、やってみたところ……$ rails s => Booting Puma => Rails 5.2.3 application starting in development => Run `rails server -h` for more startup options Puma starting in single mode... * Version 4.3.1 (ruby 2.6.5-p114), codename: Mysterious Traveller * Min threads: 5, max threads: 5 * Environment: development * Listening on tcp://127.0.0.1:3000 * Listening on tcp://[::1]:3000 Use Ctrl-C to stop行けるんじゃん!!
やっぱり、ポートの問題ではなく、違うところでエラーがあるらしい。ということは、これはpumaの問題かなあ。というか、とりあえずでアップデートしたせいかrailsのバージョンも6台になってる。
奮闘の記録
pumaをシングルモードにしてみた
Puma starting in cluster mode...とあったので、うまく動く方に合わせてsingle modeにしてみる。
参考:Pumaの使い方 まとめ$ rails s => Booting Puma => Rails 6.0.2.1 application starting in development => Run `rails server --help` for more startup options Puma starting in single mode... * Version 4.3.1 (ruby 2.5.3-p105), codename: Mysterious Traveller * Min threads: 5, max threads: 5 * Environment: development * Listening on tcp://127.0.0.1:3000 * Listening on tcp://[::1]:3000 Exiting Traceback (most recent call last): 37: from bin/rails:3:in `<main>' 36: from bin/rails:3:in `load' 35: from /Users/k_end/workspace/personal/kiite_app/bin/spring:15:in `<top (required)>' 34: from /Users/k_end/.rbenv/versions/2.5.3/lib/ruby/2.5.0/rubygems/core_ext/kernel_require.rb:59:in `require' . . . 2: from /Users/k_end/.rbenv/versions/2.5.3/lib/ruby/gems/2.5.0/gems/puma-4.3.1/lib/puma/binder.rb:229:in `add_tcp_listener' 1: from /Users/k_end/.rbenv/versions/2.5.3/lib/ruby/gems/2.5.0/gems/puma-4.3.1/lib/puma/binder.rb:229:in `new' /Users/k_end/.rbenv/versions/2.5.3/lib/ruby/gems/2.5.0/gems/puma-4.3.1/lib/puma/binder.rb:229:in `initialize': Address already in use - bind(2) for "127.0.0.1" port 3000 (Errno::EADDRINUSE)single modeにはなったけど、やっぱりだめ。
Rails をダウングレードしてみた
gem 'rails', '~> 5.2.3'を指定し、Gemfile.lockを削除してbundle install結果、変わらず。
とりあえずの応急処置
pumaコマンドで起動
pumaコマンドでconfig/puma.rbを指定して起動する。
$ bundle exec puma -t 5:5 -p 3000 -e development -C config/puma.rb Puma starting in single mode... * Version 3.12.2 (ruby 2.5.3-p105), codename: Llamas in Pajamas * Min threads: 5, max threads: 5 * Environment: development * Listening on tcp://0.0.0.0:3000 Use Ctrl-C to stoppumaには問題はないのか?
WEBrickで起動
エラーが出ていたファイルが
~/.rbenv/versions/2.5.3/lib/ruby/gems/2.5.0/gems/puma-3.12.2/lib/puma/binder.rbだったので、とりあえずpumaディレクトリごと削除。$ rails s => Rails 5.2.4.1 application starting in development on http://localhost:3000 => Run `rails server -h` for more startup options [2020-02-23 10:06:46] INFO WEBrick 1.4.2 [2020-02-23 10:06:46] INFO ruby 2.5.3 (2018-10-18) [x86_64-darwin17] [2020-02-23 10:06:46] INFO WEBrick::HTTPServer#start: pid=21009 port=3000WEBrickではちゃんとサーバーを起動できている。ということは、やっぱりpumaが原因だ。
ポート番号3000を指定して起動
$ rails s -p 3000 => Booting Puma => Rails 5.2.4.1 application starting in development => Run `rails server -h` for more startup options Puma starting in single mode... * Version 3.12.2 (ruby 2.5.3-p105), codename: Llamas in Pajamas * Min threads: 5, max threads: 5 * Environment: development * Listening on tcp://localhost:3000 Use Ctrl-C to stop問題なく起動できます。
以上の3通りの方法で起動することができました。一番普通と同じ動きをするのは、この方法かと思われます。
終わりに
この通り、とりあえずサーバーを起動する方法はありますが、いまだに
rails sコマンドでは起動できていません。
rails sとrails s -port 3000ではポート番号を設定する部分が違うので、多分そこがぶっ壊れてるんだろうなと思っています。
解決策などございましたら、ぜひコメントをいただければ幸いです。
- 投稿日:2020-02-23T08:08:41+09:00
【Rails】APIモードで使えるHTTPステータスコードの対応シンボル一覧
はじめに
Rails APIモードを使用するときに使えるHTTPレスポンスコードの対応シンボルをまとめました。
users_controller.rbrender json: user status: :ok # この:okのことこれは、
users_controller.rbrender json: user status: 200とも書けますし、「はいはい、
200はOKでしょ!」と分かるかと思います。
でも、users_controller.rbrender json: user status: 429だと「何だっけこれ?」となりませんか?笑
429は:too many requestで外部APIを使ったときに1時間あたりのリクエスト回数の制限に達したときに返されます。チーム開発経験から、
:okや:too many requestとしたほうが、
HTTPステータスコードを知らない人が読めるようにしたほうが開発者のレベルが揃っていないときに便利です。環境
OS: macOS Catalina 10.15.3 Ruby: 2.6.5 Rails: 6.0.2.1HTTPステータスコードの対応シンボル
※GitHubソースのコピペです
HTTP_STATUS_CODES = { 100 => 'Continue', 101 => 'Switching Protocols', 102 => 'Processing', 103 => 'Early Hints', 200 => 'OK', 201 => 'Created', 202 => 'Accepted', 203 => 'Non-Authoritative Information', 204 => 'No Content', 205 => 'Reset Content', 206 => 'Partial Content', 207 => 'Multi-Status', 208 => 'Already Reported', 226 => 'IM Used', 300 => 'Multiple Choices', 301 => 'Moved Permanently', 302 => 'Found', 303 => 'See Other', 304 => 'Not Modified', 305 => 'Use Proxy', 306 => '(Unused)', 307 => 'Temporary Redirect', 308 => 'Permanent Redirect', 400 => 'Bad Request', 401 => 'Unauthorized', 402 => 'Payment Required', 403 => 'Forbidden', 404 => 'Not Found', 405 => 'Method Not Allowed', 406 => 'Not Acceptable', 407 => 'Proxy Authentication Required', 408 => 'Request Timeout', 409 => 'Conflict', 410 => 'Gone', 411 => 'Length Required', 412 => 'Precondition Failed', 413 => 'Payload Too Large', 414 => 'URI Too Long', 415 => 'Unsupported Media Type', 416 => 'Range Not Satisfiable', 417 => 'Expectation Failed', 421 => 'Misdirected Request', 422 => 'Unprocessable Entity', 423 => 'Locked', 424 => 'Failed Dependency', 425 => 'Too Early', 426 => 'Upgrade Required', 428 => 'Precondition Required', 429 => 'Too Many Requests', 431 => 'Request Header Fields Too Large', 451 => 'Unavailable for Legal Reasons', 500 => 'Internal Server Error', 501 => 'Not Implemented', 502 => 'Bad Gateway', 503 => 'Service Unavailable', 504 => 'Gateway Timeout', 505 => 'HTTP Version Not Supported', 506 => 'Variant Also Negotiates', 507 => 'Insufficient Storage', 508 => 'Loop Detected', 509 => 'Bandwidth Limit Exceeded', 510 => 'Not Extended', 511 => 'Network Authentication Required' }ヘルパーメソッドもあります
invalid?; status < 100 || status >= 600; informational?; status >= 100 && status < 200; successful?; status >= 200 && status < 300; redirection?; status >= 300 && status < 400; client_error?; status >= 400 && status < 500; server_error?; status >= 500 && status < 600; ok?; status == 200; created?; status == 201; accepted?; status == 202; no_content?; status == 204; moved_permanently?; status == 301; bad_request?; status == 400; unauthorized?; status == 401; forbidden?; status == 403; not_found?; status == 404; method_not_allowed?; status == 405; precondition_failed?; status == 412; unprocessable?; status == 422; redirect?; [301, 302, 303, 307, 308].include? status;おわりに
最後まで読んで頂きありがとうございました
どなたかの参考になれば幸いです
参考にさせて頂いたサイト(いつもありがとうございます)