- 投稿日:2020-02-23T23:27:12+09:00
AWS Amplify フレームワークの使い方Part9〜Function編〜
はじめに
Lmabda関数を管理しようと思うとServerlessFrameworkなんかがベタなのかな、と勝手に思っていて、なかなかGUIでの管理から抜け出せない日々が続いていた中で出会った、このAmplifyのfunction管理機能。
一言で言えば、素晴らしい。
設定の流れ
amplifyにfunctionを追加
おなじみのコマンドでfunctionのファイルを作成。この時、cognito,auth,api,storage,functionの権限が聞かれますが、一旦スルー。私の場合は、基本的には別でロールを作成して紐付けるため、ここでは何も選択しません。(本当は利用したほうが、よりセキュアなロールポリシーをつけれる気はしているが、、、)
$ amplify add function ? Provide a friendly name for your resource to be used as a label for this category in the project: createUser // 今回はfunction名と同一名で管理 ? Provide the AWS Lambda function name: createUser // function名 ? Choose the function template that you want to use: Hello world function //templateは何でもOK ? Do you want to access other resources created in this project from your Lambda function ? No生成されたファイルの編集
pushする前に、各種ファイルを編集していきます。
[ function名 ]-cloudformation-template.json
以下のコメント部分を必要に応じて追加します。基本的には
Resources部分を編集していきます。基本設定
ロール、タイムアウト秒数、説明文、メモリサイズなどは
Resources > LambdaFunction直下を編集する。functionName-cloudformation-template.json{ ... "Resources": { "LambdaFunction": { "Type": "AWS::Lambda::Function", "Metadata": { "aws:asset:path": "./src", "aws:asset:property": "Code" }, "Properties": { "Handler": "index.handler", "FunctionName": { "Fn::If": [ "ShouldNotCreateEnvResources", "applicationCheck", { "Fn::Join": [ "", [ "applicationCheck", "-", { "Ref": "env" } ] ] } ] }, "Environment": { "Variables" : { "ENV": { "Ref": "env" }, "REGION": { "Ref": "AWS::Region" } } }, "Role": "arn:aws:iam::xxxxxxxx:role/xxxxx", // 自身で作成したロールを設定 "Runtime": "nodejs10.x", // 言語選択 "Timeout": "60", // 必要な実行秒数変更 "Description": "ユーザー情報の新規作成", // functionの説明文追加 "MemorySize": "256" // 必要なメモリ数変更 } }, ... }DynamoDBストリームの設定
DynamoDBの書込を検知して実行する場合は、
Resources>EventSourceMappingを編集する。基本的には、以下をまるっとコピペして貼り付け、EventSourceArnの部分だけ、DynamoDBの指定したテーブルの概要に記載されている、ストリームのarmをコピペすればOK。functionName-cloudformation-template.json{ ... "Resources": { ... }, "EventSourceMapping": { "Type": "AWS::Lambda::EventSourceMapping", "Properties": { "EventSourceArn": "arn:aws:dynamodb:ap-northeast-1:xxxxxxxxxxx:table/User/stream/2019-10-30T07:18:17.435", // DynamoDBの指定テーブルの概要に記載があるのでそれをコピペ "FunctionName": { "Fn::GetAtt": [ "LambdaFunction", "Arn" ] }, "StartingPosition": "TRIM_HORIZON", "BatchSize": "100" } } }, ... }複数のDynamoDBを複数指定したい場合は、現在わからなかったため、その場合のみGUIから手動で設定しています。
また、CloudWatch Eventsでの定時実行の設定もわからなかったため、こちらもGUIから手動設定しています。このあたりご存じの方いれば、ぜひ教えていただきたい。
package.json
必要なmoduleを追加する場合は編集。
{ "name": "createUser", "version": "2.0.0", "description": "Lambda function generated by Amplify", "main": "index.js", "license": "Apache-2.0", "dependencies": { "libmime": "^4.2.1" "stripe": "^7.12.0" } }index.js
実行したい関数の内容を記載。
event.json
実行したいテストデータを編集。ここに記載したjsonデータはテスト実行時に、引数のeventから取得ができます。
event.json{ "key1": "value1", "key2": "value2", "key3": "value3" }ハマリポイント
沼ったポイントを紹介します。
SyntaxError: Unexpected token in JSON at position XXXX
package.json内の記述に無駄な半角やインデントのズレがあると出るエラーです。(はまったぁーこれ。)
下記のサイトで全ファイルを修正して、完璧なJSONです、と言われるまで修正すれば解消します。node_moduleがインストールされない①
これも同じで、
package.jsonに余計な空白が1つでもあろうものなら、インストールされません。エラーが出ればまだ気付けるのですが、誰も何もお知らせしてくれず、ひっそりとLambda上にインストールされない事実だけ残ります。JSONさんってこんなにも気厳しいんですね、、、。node_moduleがインストールされない②
package.jsonにぱっと見正しい記述なのに、インストールがされていないこともありました、、、。
たまーにある、エディタの半角/全角空白チェックに検知されないなぞの空白的なやーつ?(textからコピペしたりするとおきることある)なんてことも考えましたが、原因はわからず、、、。
強制的な解決策として、一旦インストールしたいパッケージを削除して、$ amplify push。その後、再度、package.jsonに追加して再プッシュで解決しました。index.jsの編集サイクル
push後は、GUIの
index.jsを編集してテスト→問題なければ、ローカルのindex.jsに内容をコピペ→$ amplify pushして履歴を残す、というやり方がスムーズかと思います。おわりに
更新のフローとしては、ローカル上Lambda関数を編集した上で、
$ amplify pushして更新する流れになります。これでlambda関数がgit管理も行えるようになるので、Lambda関数がかなり使いやすくなるかと思います。参考
AWS CloudFormation AWS::Lambda::Function(公式ドキュメント)
AWS CloudFormation AWS::Lambda::EventSourceMapping(公式ドキュメント)関連記事
AWS amplify フレームワークの使い方Part1〜Auth設定編〜
AWS Amplify フレームワークの使い方Part2〜Auth実践編〜
AWS Amplify フレームワークの使い方Part3〜API設定編〜
AWS Amplify フレームワークの使い方Part4〜API実践編〜
AWS Amplify フレームワークの使い方Part5〜GraphQL Transform @model編〜
AWS Amplify フレームワークの使い方Part6〜GraphQL Transform @auth編〜
AWS Amplify フレームワークの使い方Part7〜GraphQL Transform @key編〜
AWS Amplify フレームワークの使い方Part8〜GraphQL Transform @connection編〜
- 投稿日:2020-02-23T20:58:28+09:00
AWS CodeCommit CodeDeploy CodePipeline 自動デプロイ
1. CodeDeploy用IAMロールを作る
2. EC2インスタンス用IAMロールを作る
3. 2で作ったIAMロールをEC2インスタンスに割り当てる
4. CodeDeployアプリケーションの作成
5. EC2にCodeDeployエージェントインストール
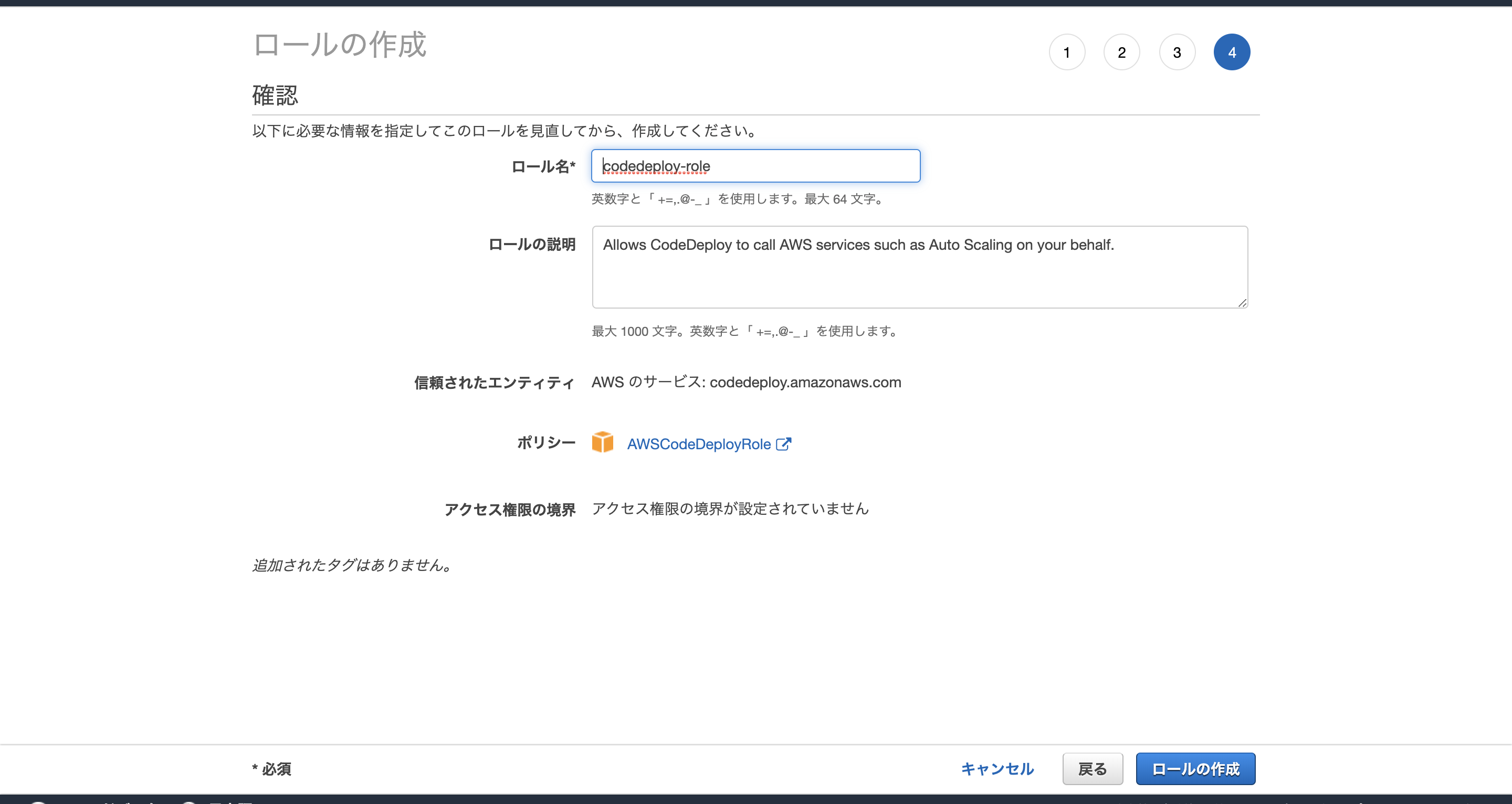
CodeDeploy用IAMロールを作る
ロールの作成
↓
AWSサービス 選択
↓
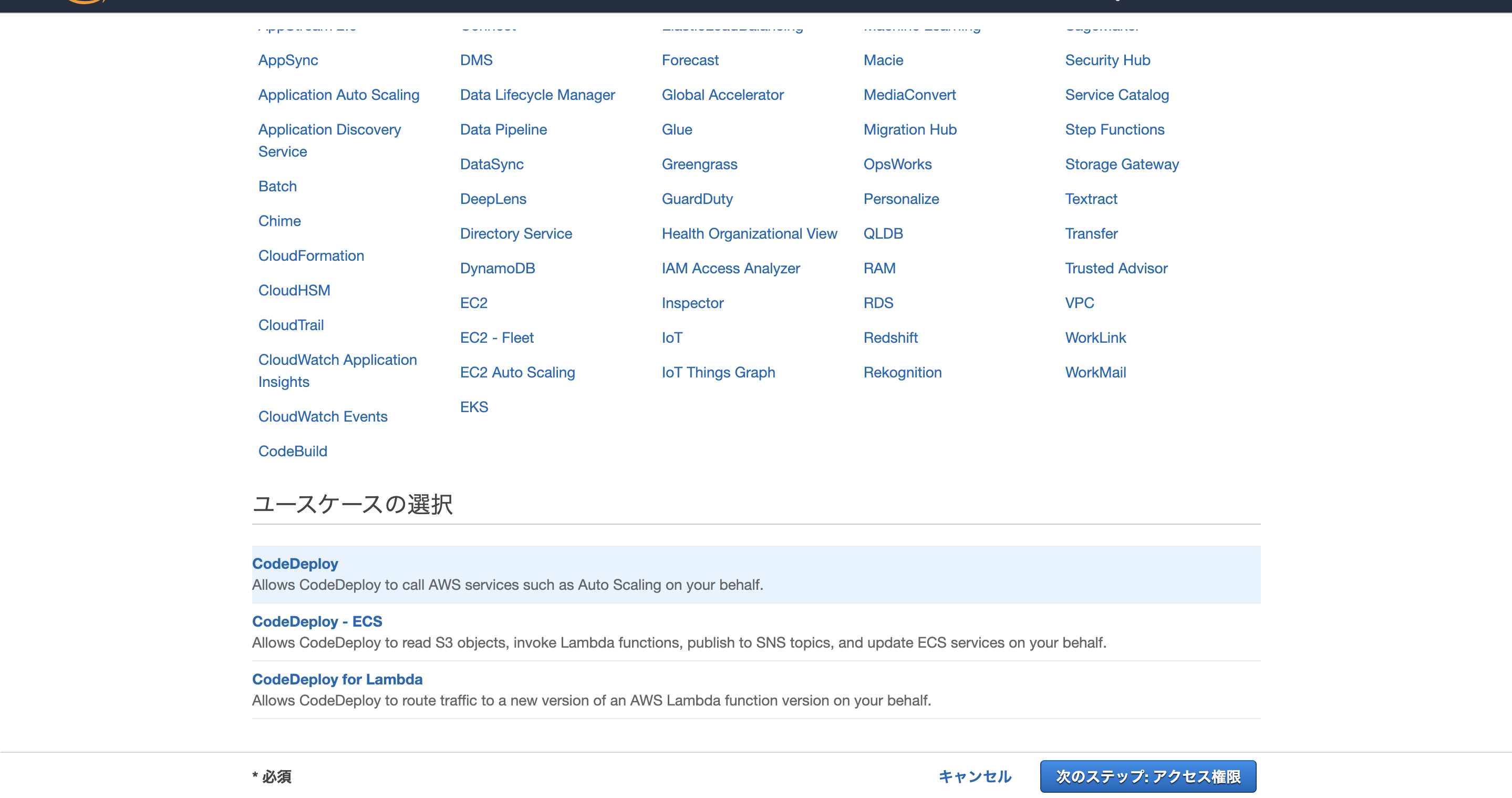
ユースケースの選択=> CodeDeploy
↓
↓
次のステップ:アクセス権限
↓
AWSCodeDeployRoleを追加
↓
タグの追加 → 特になし
↓
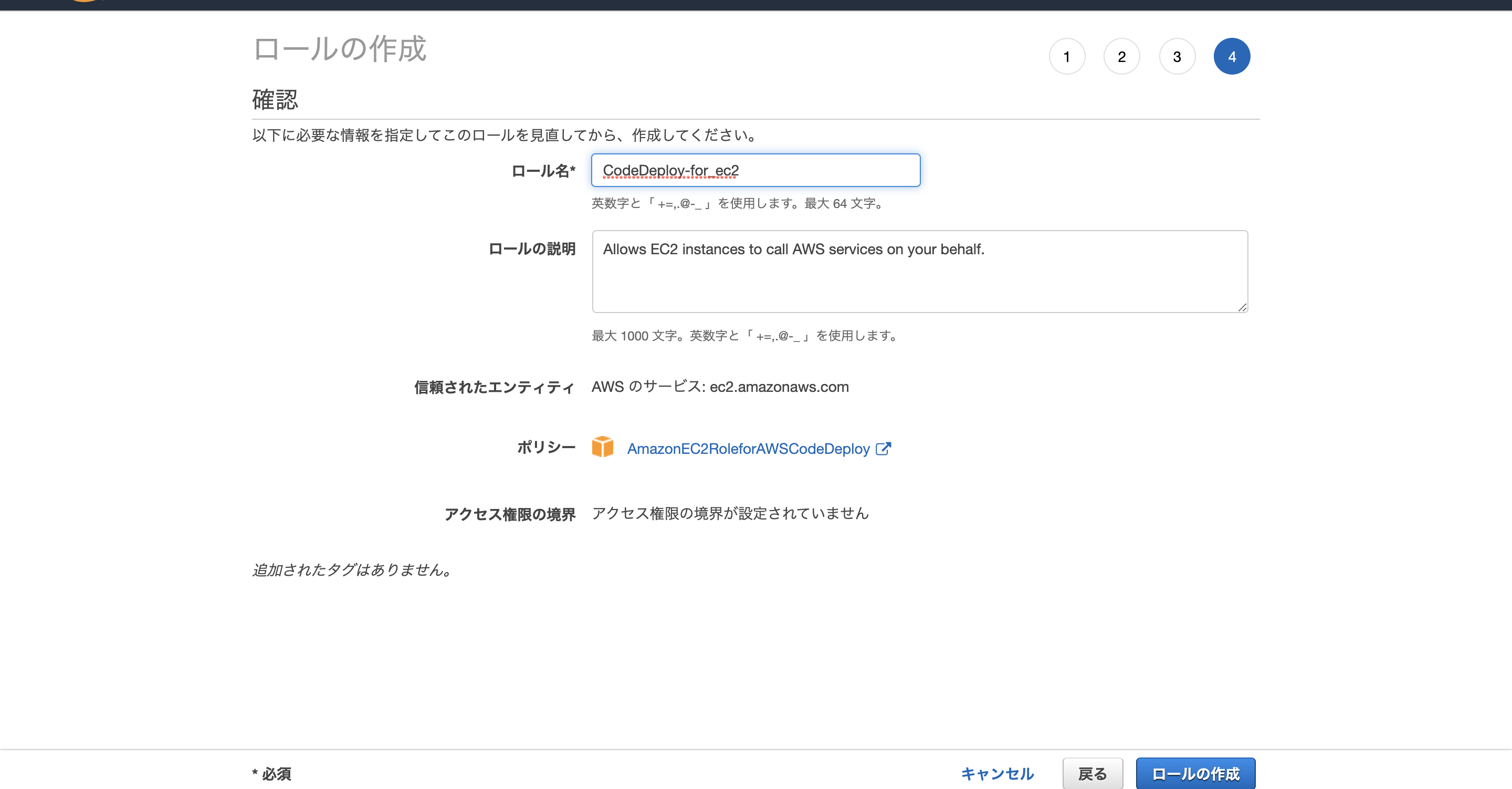
ロールの作成EC2インスタンス用IAMロールを作る
上記と同じように
ユースケースの選択 =>EC2
Attach アクセス権限ポリシー=>AmazonEC2RoleforAWSCodeDeploy
タグ=>特になし
を選択
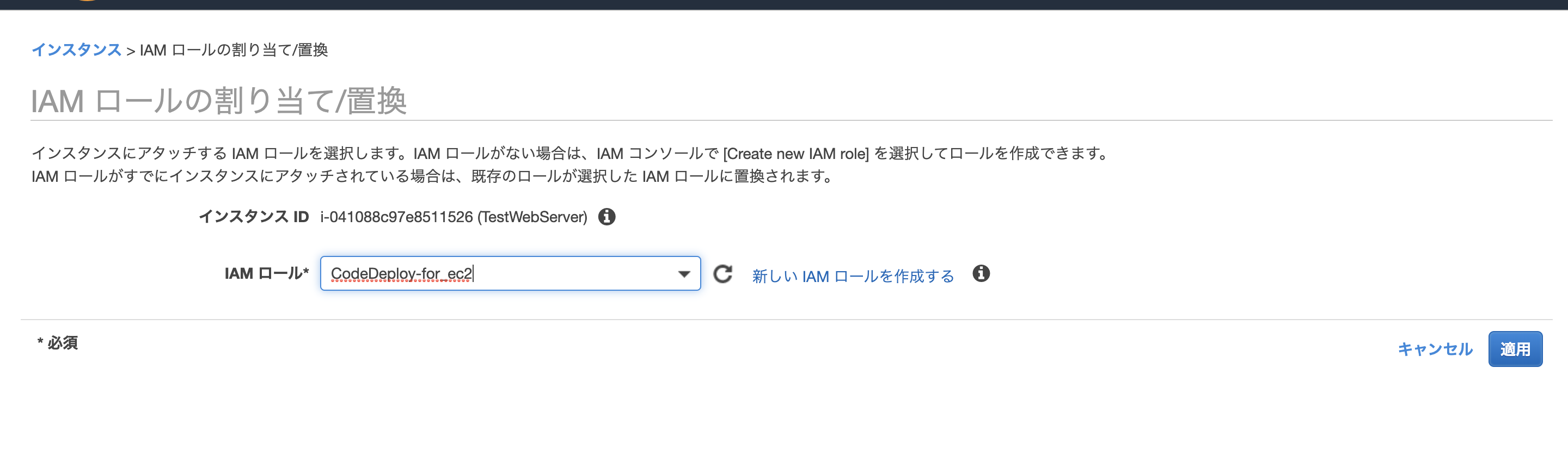
ロール名はCodeDeploy-for_ec2にしました。
ロールの作成CodeDeploy-for_ec2をEC2インスタンスに割り当てる
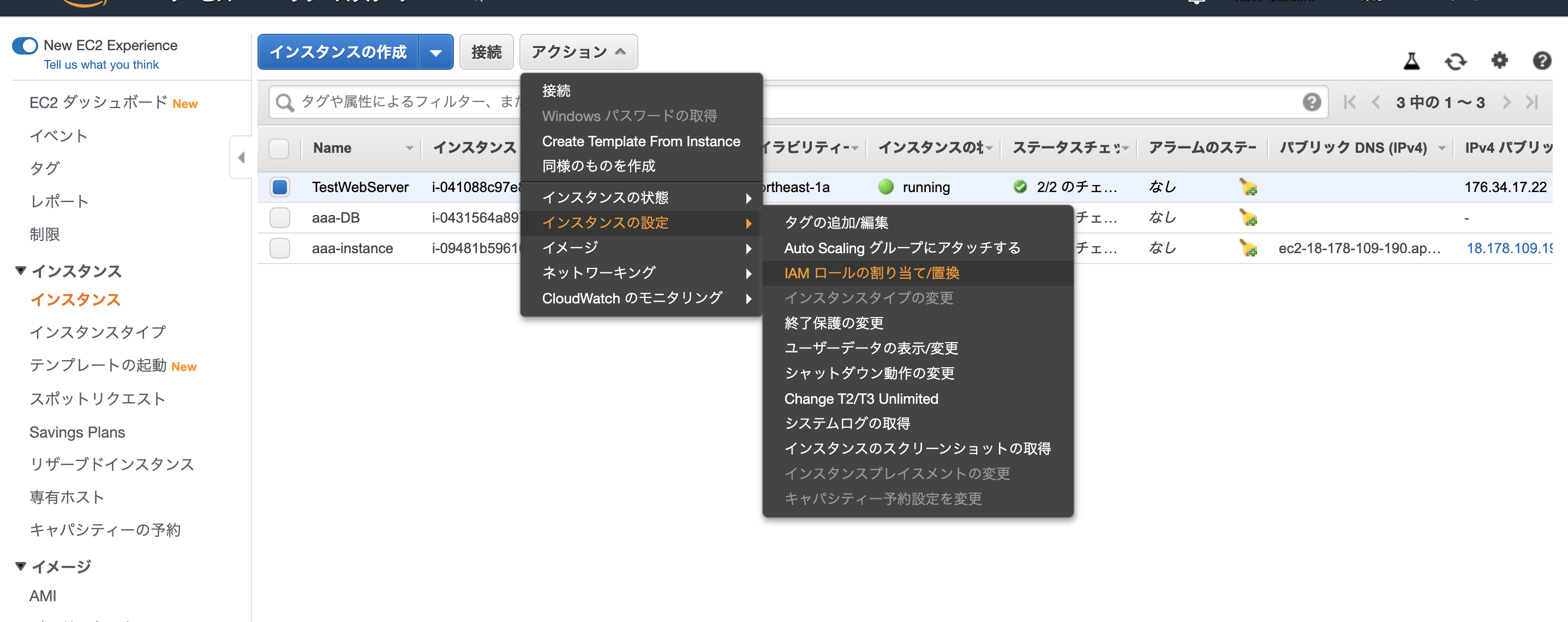
EC2の管理画面を開き、インスタンスを選択し、CodeComitの更新をしたいインスタンスの
アクション/インスタンスの設定/IAMロールの割り当てをクリック
そうすると、
で適用。CodeDeployアプリケーションの作成
awsコンソールから
CodeDeploy管理者画面にいく
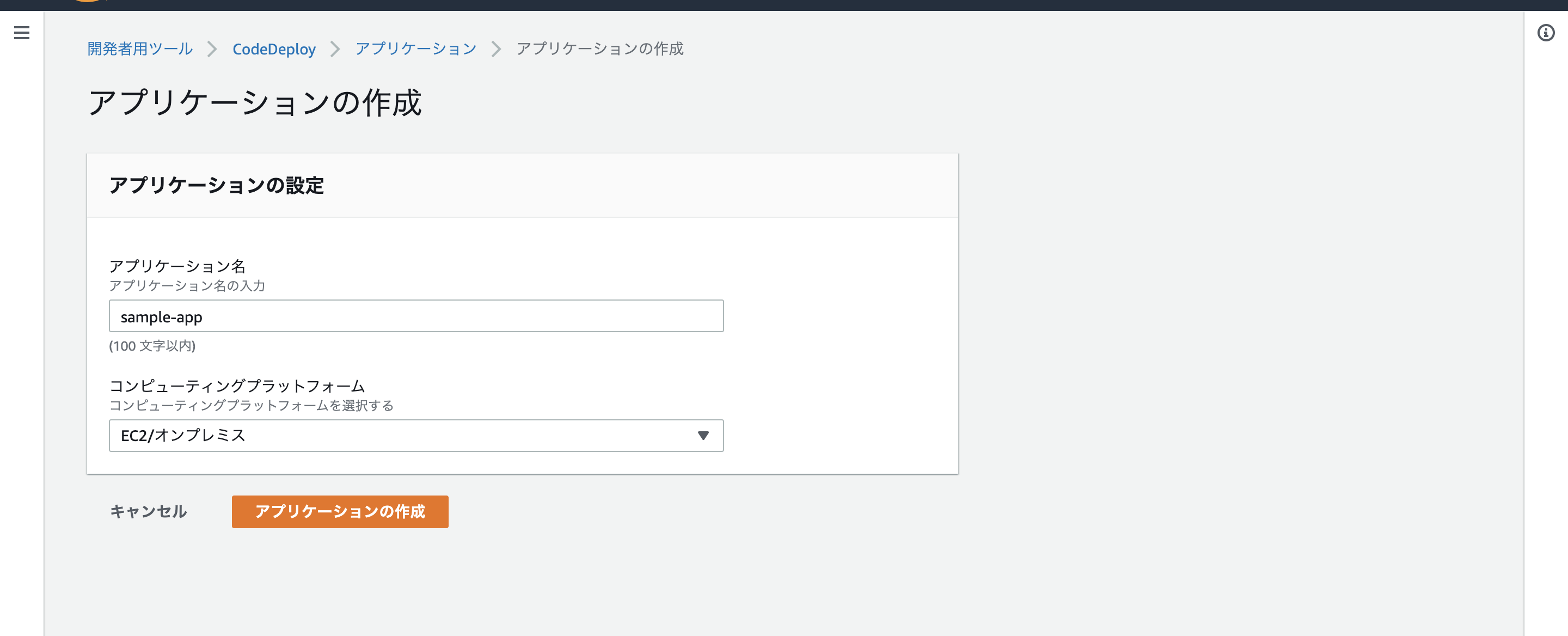
左上の開発者用ツール/CodeDeployをクリック
アプリケーションの作成をクリック
アプリケーションの作成
次にデプロイグループを作成する。
サービスロールは1で作ったロールを選択
デプロイタイプインプレース
環境設定Amazon EC2 インスタンスロードバランサー
チェック外すEC2にCodeDeployエージェントインストール
インストール
ec2のターミナル[ec2-user@ip-10-0-1-147 src]$ sudo yum -y update [ec2-user@ip-10-0-1-147 src]$ sudo yum -y install ruby wget [ec2-user@ip-10-0-1-147 src]$ wget https://aws-codedeploy-us-east-1.s3.amazonaws.com/latest/install [ec2-user@ip-10-0-1-147 src]$ chmod +x ./install [ec2-user@ip-10-0-1-147 src]$ sudo ./install auto起動
ec2のターミナル[ec2-user@ip-10-0-1-147 src]$ sudo service codedeploy-agent start Starting codedeploy-agent:[ec2-user@ip-10-0-1-147 src]$ sudo chkconfig codedeploy-agent on 情報:'systemctl enable codedeploy-agent.service'へ転送しています
- 投稿日:2020-02-23T19:26:55+09:00
RailsをAWSでデプロイする
はじめに
手軽にRailsをAWSにデプロイする手順をまとめました。
極力シンプルになるように、EC2インスタンスを一つ作成し、その中に自分のRailsアプリを含め、必要なものを全てインストールしてデプロイします。
データベースはMySQL、WebサーバーはNginXでの環境構築です。
AWSのサーバーでのファイルの書き込みはviというコマンドで行います。(vi ファイル名でそのファイルを編集、そのファイルがない場合は新たにファイルを作って書き込みできます。詳しい使い方は要検索!)
注意点
コードの中で、/var/www/rails/{アプリ名}などと書いている時がありますが、自分の環境に合わせて、
/var/www/rails/sample_appとしてください
/var/www/rails/{sample_app}ではないのでご注意。
第一章 サーバーの準備
1.VPCを作成
- 名前は適当につける
- IPv4CIDERブロックは10.0.0.0/16に設定
- あとはデフォルトで
2.サブネットを作成
- 名前は適当につける
- VPCは先程作ったVPCを選択
- IPv4CIDERブロックは10.0.0.0/24に設定
3.インターネットゲートウェイを作成
- 名前は適当につける
- 作成後は先程作ったVPCをアタッチ
4.ルートテーブルを作成
- 名前は適当につける
- 作成後はルートの設定で0.0.0.0/0を追加し保存
- サブネットの関連付けで先程作ったサブネットを選択
- あとはデフォルトで
5.セキュリティグループを作成
- 名前は適当につける
- 作成後は
タイプ:HTTP ソース:任意の場所(他の設定はデフォルト)
と、
タイプ:SSH ソース:任意の場所(他の設定はデフォルト)
を追加し保存- あとはデフォルトで
6.EC2を作成
EC2インスタンスの作成
- 無料枠からAmazonLinuxを選ぶ(AmazonLinux2を選ばないように注意、この後の環境構築で差が出てきてしまうので)
- ネットワーク:先程作ったVPCを選択
- サブネット:先程作ったサブネットを選択
- 自動割り当てパブリックIP:有効化を選択
- セキュリティーグループ:先程作ったセキュリティグループを選択
キーペアの登録とElasticIPの割当て
- キーペアファイル(~.pem)はローカル(自分のパソコンのこと)の.ssh配下に移動
- ElasticIPを作り先ほど作ったEC2インスタンスに割り当てる
第二章 サーバーにログインし環境構築
1.EC2にログイン
キーペアファイルのあるディレクトリに移動
cd .sshキーペアファイルに権限を付与
chmod 600 {自分のキーペアの名前}.pemサーバー(EC2インスタンス)にログイン
ssh -i {自分のキーペアのpemファイル} ec2-user@{自分のElasticIPアドレス}ユーザーを作成
sudo adduser {新規ユーザー名} (#新規ユーザー名の登録) sudo passwd {パスワード} (#新規ユーザー名のパスワード登録) sudo visudoユーザーの権限の変更
1.rootに関する権限の記述箇所 root ALL=(ALL) ALL を探す。 2.その下に、作成したユーザーに権限を追加する記述 {ユーザー名} ALL=(ALL) ALL を追加するユーザーの切替
sudo su - {ユーザー名}2.諸々必要なものをインストール
sudo yum install git make gcc-c++ patch openssl-devel libyaml-devel libffi-devel libicu-devel libxml2 libxslt libxml2-devel libxslt-devel zlib-devel readline-devel mysql mysql-server mysql-devel ImageMagick ImageMagick-devel epel-release3.Rubyをインストール
以下Rubyをインストールするための下準備
git clone https://github.com/sstephenson/rbenv.git ~/.rbenvecho 'export PATH="$HOME/.rbenv/bin:$PATH"' >> ~/.bash_profileecho 'eval "$(rbenv init -)"' >> ~/.bash_profilesource .bash_profilegit clone https://github.com/sstephenson/ruby-build.git ~/.rbenv/plugins/ruby-buildrbenv rehash以下Rubyのインストールです、インストールするRubyのバージョンは自分の環境に合わせてください
rbenv install -v 2.6.5rbenv global 2.6.5rbenv rehashインストールできたか確認
ruby -v4.node.jsをインストール
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.34.0/install.sh | bash. ~/.nvm/nvm.shnvm install node5.Yarnをインストール
curl -o- -L https://yarnpkg.com/install.sh | bashexport PATH="$HOME/.yarn/bin:$HOME/.config/yarn/global/node_modules/.bin:$PATH"第三章 Rails、DB、Webサーバーの設定
1.Railsの設定
/var/www/rails/ の配下にRailsアプリを持ってくる、以下を一行一行実行していく
cd / (/ディレクトリに移動) sudo chown {ユーザー名} var (varフォルダの所有者を{ユーザー名}にする) cd var (varディレクトリに移動) sudo mkdir www (wwwディレクトリの作成) sudo chown {ユーザー名} www (wwwフォルダの所有者を{ユーザー名}にする) cd www (wwwディレクトリに移動) sudo mkdir rails (wwwディレクトリの作成) sudo chown {ユーザー名} rails (railsフォルダの所有者を{ユーザー名}にする) cd rails (railsディレクトリに移動)GitHubからクローン
git clone {自分のRailsのアプリのリポジトリのclone用URL}DBとの接続用の設定、以下をRailsアプリ内のconfig/database.ymlに追加
production: <<: *default database: {アプリ名} username: root #ここをrootに変更する password: #ここを空欄にする※ローカルのconfig/master.keyの一行を全てコピーし、
cloneしてきたアプリのconfig/master.keyに記載をする
(master.keyはgitignoreされておりローカルのmaster.keyの内容は
githubには反映されないため自分でコピペしてくる)2.MySQLの設定
起動
sudo service mysqld startln -s /var/lib/mysql/mysql.sock /tmp/mysql.sockDBの作成
rails db:create RAILS_ENV=productionマイグレーション
rails db:migrate RAILS_ENV=production3.Unicornの設定
Gemfileに以下を追記
group :production, :staging do gem 'unicorn' endbundlerをインストール
gem install bundlerbundlerでunicornのgemをインストール
bundle install設定ファイルの追加
vi ~/var/www/rails/{アプリ名}/config/unicorn.conf.rb以下を設定ファイルに記載
# set lets $worker = 2 $timeout = 30 $app_dir = "/var/www/rails/{アプリ名}" #自分のアプリケーション名 $listen = File.expand_path 'tmp/sockets/.unicorn.sock', $app_dir $pid = File.expand_path 'tmp/pids/unicorn.pid', $app_dir $std_log = File.expand_path 'log/unicorn.log', $app_dir # set config worker_processes $worker working_directory $app_dir stderr_path $std_log stdout_path $std_log timeout $timeout listen $listen pid $pid # loading booster preload_app true # before starting processes before_fork do |server, worker| defined?(ActiveRecord::Base) and ActiveRecord::Base.connection.disconnect! old_pid = "#{server.config[:pid]}.oldbin" if old_pid != server.pid begin Process.kill "QUIT", File.read(old_pid).to_i rescue Errno::ENOENT, Errno::ESRCH end end end # after finishing processes after_fork do |server, worker| defined?(ActiveRecord::Base) and ActiveRecord::Base.establish_connection end4.NginXの設定
インストール
sudo yum install nginxNginxの設定
ディレクトリを移動
cd /etc/nginx/conf.d/etc/nginx/conf.d下に設定ファイルの作成
vi {アプリ名}.conf以下を記載
# log directory error_log /var/www/rails/{アプリ名}/log/nginx.error.log; #自分のアプリケーション名に変更 access_log /var/www/rails/{アプリ名}/log/nginx.access.log; #自分のアプリケーション名に変更 # max body size client_max_body_size 2G; upstream app_server { # for UNIX domain socket setups server unix:/var/www/rails/{アプリ名}/tmp/sockets/.unicorn.sock fail_timeout=0; #自分のアプリケーション名に変更 } server { listen 80; server_name ~~~.~~~.~~~.~~~; #自分のElasticIP # nginx so increasing this is generally safe... keepalive_timeout 5; # path for static files root /var/www/rails/{アプリ名}/public; #自分のアプリケーション名に変更 # page cache loading try_files $uri/index.html $uri.html $uri @app; location @app { # HTTP headers proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; proxy_pass http://app_server; } # Rails error pages error_page 500 502 503 504 /500.html; location = /500.html { root /var/www/rails/{アプリ名}/public; #自分のアプリケーション名に変更 } }第四章 世界に公開
1.Railsのプリコンパイル
rails assets:precompile RAILS_ENV=production2.NginXを起動
sudo service nginx start3.Unicornを起動
bundle exec unicorn_rails -c /var/www/rails/{アプリ名}/config/unicorn.conf.rb -D -E production4.お疲れ様です
これでブラウザに自分のElasticIPを打ち込むと世界中のパソコンやスマホから自分のアプリにアクセスできます!
5.その他コマンド
unicornの起動確認
ps -ef | grep unicorn | grep -v grepunicornの終了
kill {masterのPID}以下のようなYarnのエラーが出ることがあります(Railsコマンドを実行した際にこのようなエラーが出る時があります)
======================================== Your Yarn packages are out of date! Please run `yarn install --check-files` to update. ========================================エラー文に従い以下を実行しましょう
yarn install --check-files
- 投稿日:2020-02-23T18:56:47+09:00
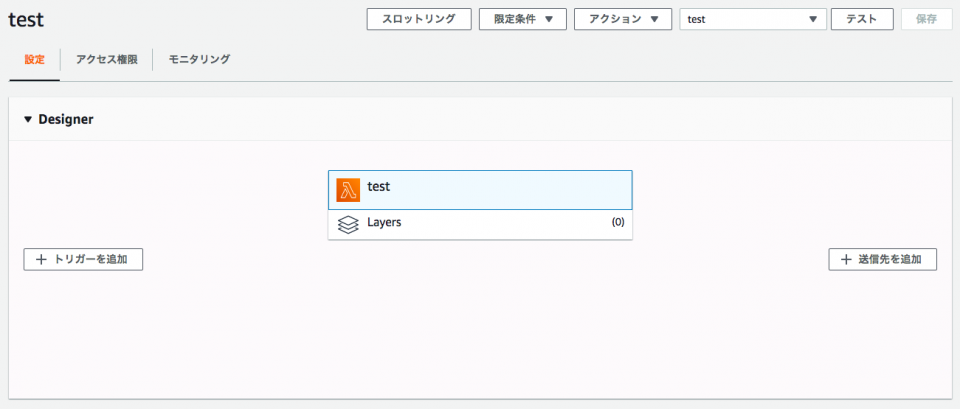
AWS Lambdaのコンソールでトリガーを削除しようとすると「The Destination field is required for an OnFailure configuration.」となる
事象
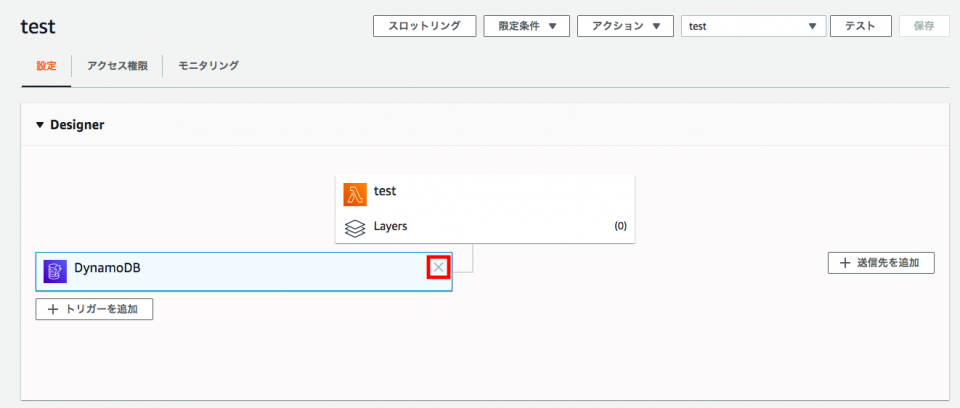
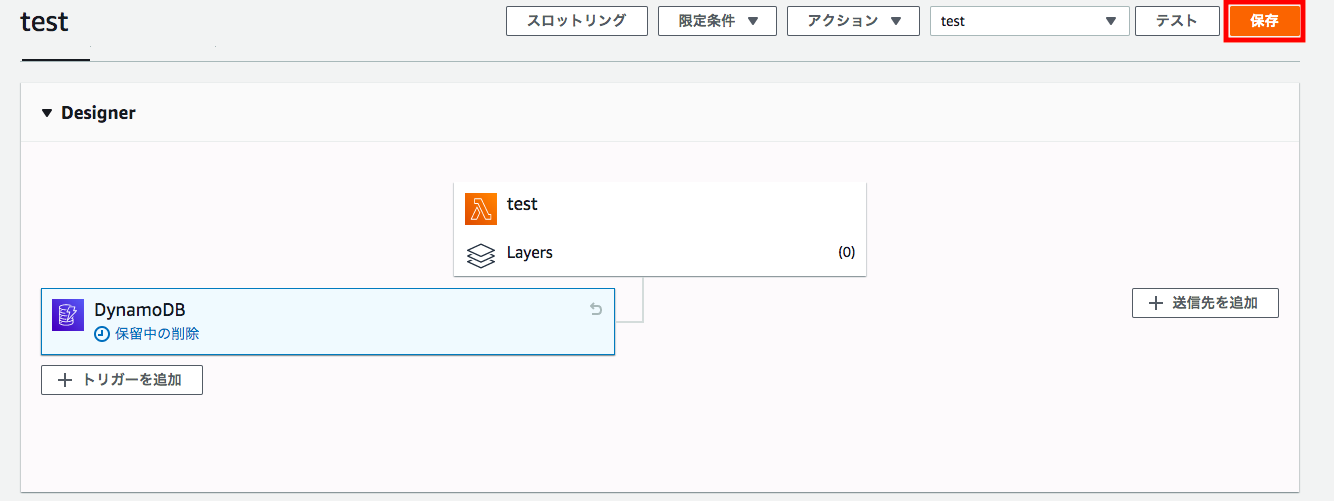
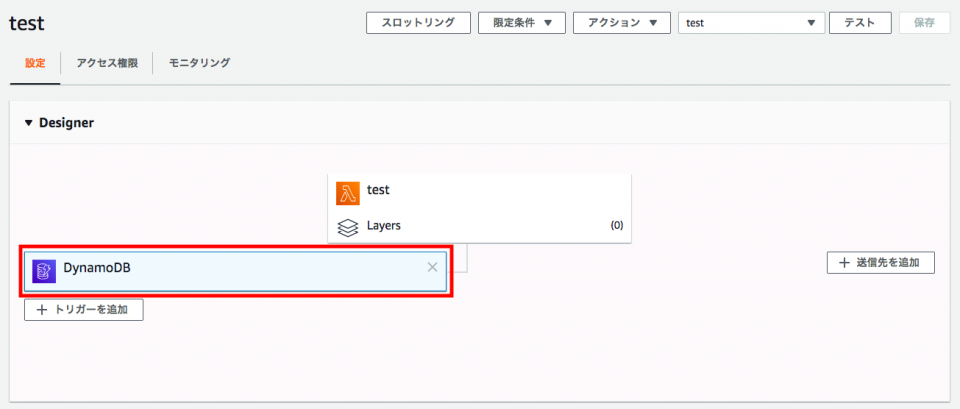
AWS Lambdaのコンソールの[Designer]で追加済みのDynamoDBトリガーの[☓]をクリックする。
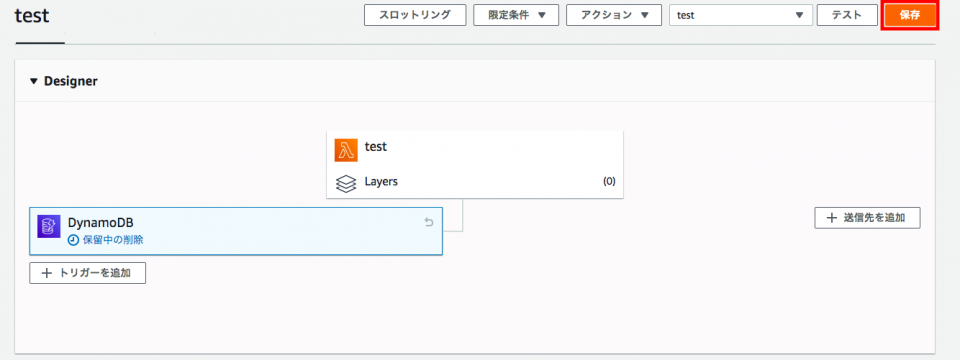
トリガーが[保留中の削除]となる。[保存]をクリックする。
保存した後もトリガーが削除されずに残っている。
この状態でトリガーの[☓]をクリックすると、トリガーがまた[保留中の削除]となる。[保存]をクリックする。
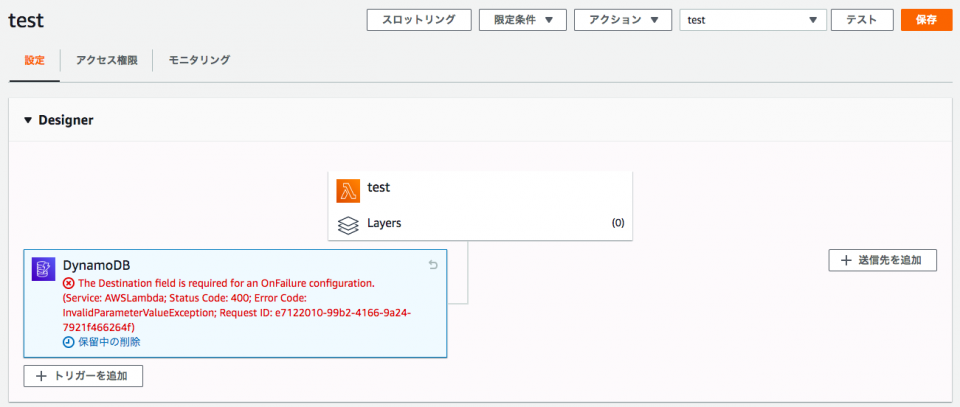
すると下記のエラーが出た。
The Destination field is required for an OnFailure configuration. (Service: AWSLambda; Status Code: 400; Error Code: InvalidParameterValueException; Request ID: e7122010-99b2-4166-9a24-7921f466264f)
解決
もう一度[保存]をクリックしてもエラーは表示され続ける。
ブラウザ画面を更新するとトリガーは削除された。
以上
- 投稿日:2020-02-23T17:59:34+09:00
Nginxで403 Forbiddenエラーの解決策(Rails+AWS+Nginx+Unicorn環境)
ハマったこと
Railsで作ったアプリをAWSにデプロイして、いざアクセスしようとしたら403 Forbiddenエラーになりました。(下図)
前提条件
Ruby: 2.6.3
Rails: 6.0.2
Nginx: 1.12.2
サーバーのOS: Amazon Linux 2解決策(先に結論だけ)
chmod 701 /home/ec2-userで解決しました(ec2-userディレクトリのパーミッションを700→701に変更しました)※
/home/ec2-user/直下にRailsアプリを配置していますエラーに遭遇するまでの経緯
下記のページを参考にしながら、RailsアプリをAWSにデプロイする作業を進めていました。
https://qiita.com/Yuki_Nagaoka/items/975b7598806d6ae0c0b2上記のページでは、Railsアプリの設置場所を
/var/www/rails/配下にしているのですが、「アプリの設置場所は好きなところでいいだろう」と思って、自分の場合は~/(/home/ec2-user/と同義)に配置しました。結果的に、この設置場所の違いが今回のエラーを発生させることになりました。
エラーに遭遇してから、解決するまでの経緯
そもそも、403 Forbiddenとは?
ページが存在するものの、ページを表示する権限がなくてアクセスが拒否されたことを示すHTTPステータスコードです。
(今回の場合は、NginxがRailsアプリがあるディレクトリへのアクセス権限を持っていなかったのが原因で403エラーが発生しました)参考:https://ja.wikipedia.org/wiki/HTTP_403
ログを確認し、エラーの原因を調べる
Nginxのログファイルの場所は、Nginxの設定ファイルに記述されています。
Nginxの設定ファイルは、OSによっても異なりますが、Amazon Linuxの場合は/etc/nginx/nginx.conf,/etc/nginx/nginx.conf.default,/etc/nginx/conf.d/***.confにあります。
/etc/nginx/conf.d/***.confの中身を見てみると、ログの場所が記述されているはずです。/etc/nginx/conf.d/***.conferror_log /home/ec2-user/***/log/nginx.error.log; access_log /home/ec2-user/***/log/nginx.access.log; . . .エラーログ(/home/ec2-user/***/log/nginx.error.log)の中身を見てみると、以下のように
Permission deniedのエラーが発生していることが分かりました。/home/ec2-user/***/log/nginx.error.log2020/02/23 05:01:35 [crit] 26964#0: *47 stat() "/home/ec2-user/***/public/" failed (13: Permission denied), client: ***, server: ***, request: "GET / HTTP/1.1", host: "***" 2020/02/23 05:01:35 [crit] 26964#0: *47 connect() to unix:/home/ec2-user/***/tmp/sockets/.unicorn.sock failed (13: Permission denied) while connecting to upstream, client: ***, server: ***, request: "GET / HTTP/1.1", upstream: "http://unix:/home/ec2-user/***/tmp/sockets/.unicorn.sock:/", host: "***" 2020/02/23 05:01:35 [error] 26964#0: *47 open() "/home/ec2-user/***/public/500.html" failed (13: Permission denied), client: ***, server: ***, request: "GET / HTTP/1.1", upstream: "http://unix:/home/ec2-user/***/tmp/sockets/.unicorn.sock/", host: "***"念の為、Unicornのログファイルも見ておいた方が良いです。サーバー上のページにブラウザからアクセスして、Nginxのログは出てくるがUnicornのログに何も表示されないのであれば、Nginxでエラーが起きていることが分かるからです。
もしUnicornのログに何か表示されれば、Railsアプリ内でエラーが起きているということになります。
パーミッションとは?
以下サイトを参考にしてください。
https://eng-entrance.com/linux-permission-basicなぜパーミッションがdenyされるのか?
ユーザーのディレクトリ(/home/ec2-user/)のパーミッションは700なので、その他のユーザーが/home/ec2-user/配下のディレクトリにアクセスできないことが原因です。
ブラウザからサーバー上のページにアクセスしたときに、nginxの実行ファイルは
nginxというユーザー名で、Railsアプリがあるディレクトリにアクセスしていくつかのファイル(例えば、tmp/sockets/.unicorn.sockやpublic/など)を読み込みます。つまり、
nginxという名前のユーザーが、それらのファイルへのアクセス権限を持っている必要があります。また、ファイルにアクセスするためには、ルートディレクトリからそのファイルがあるディレクトリまでのすべてのディレクトリでアクセス権限を持っていなければいけません。ちなみに、アクセス権限はパーミッションでいうところの実行権限(x)です。
解決策
したがって、nginxユーザーがec2-userディレクトリ配下にあるRailsアプリにアクセスできるようにするために、ec2-userディレクトリの「その他のユーザー」に実行権限を付与する必要があります。
(つまり、下記を実行することで解決)
chmod 701 /home/ec2-user参考にしたサイト

- 投稿日:2020-02-23T17:29:13+09:00
RedashをAWS(EC2+RDS)で試してみた
こんにちは、@0yanです。
最近、課内で「戦略人事の実現のため、カオナビから別サービスに切り替えよう」という話が出始め、
- タレントパレット
- HRMOS CORE
- ヒトマワリ
などを比較検討しています。そんな折、OSSのBIツール「Redash」の存在を知ったので試してみました。
前提条件
- Windows 10 homeを使用
- AWSアカウント登録済み
- TeraTermインストール済み
手順
- EC2インスタンスを作成(Redash AMIを使用)
- RDSにMySQLデータベースを作成
- TeraTermでEC2に接続し、CSVを転送
- EC2にMySQLクライアントをインストールし、RDSのMySQLデータベースに接続
- データベースとテーブルを作成し、CSVを取り込み
- Redashにデータベースを接続
- Redashにクエリを作成し、ダッシュボードで表示
1. EC2インスタンスを作成(Redash AMIを使用)
①AWSマネジメントコンソールからEC2を検索、EC2ダッシュボードのサイドバーからインスタンスを選択します。
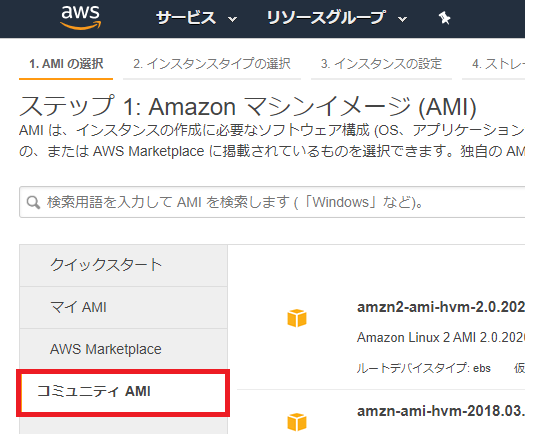
②「インスタンスの作成」をクリックし、ステップ1: Amazon マシンイメージ(AMI)でコミュニティAMIを選択します。
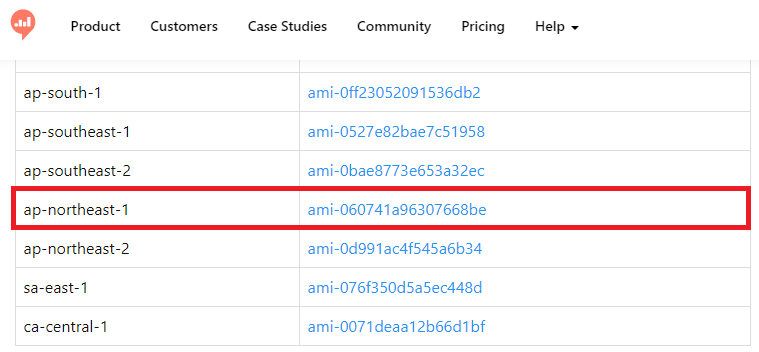
③Setting up a Redash Instanceで、Redashが作成したAWS用RedashインスタンスのAMIを調べます(今回は東京リージョンを選択しました)。
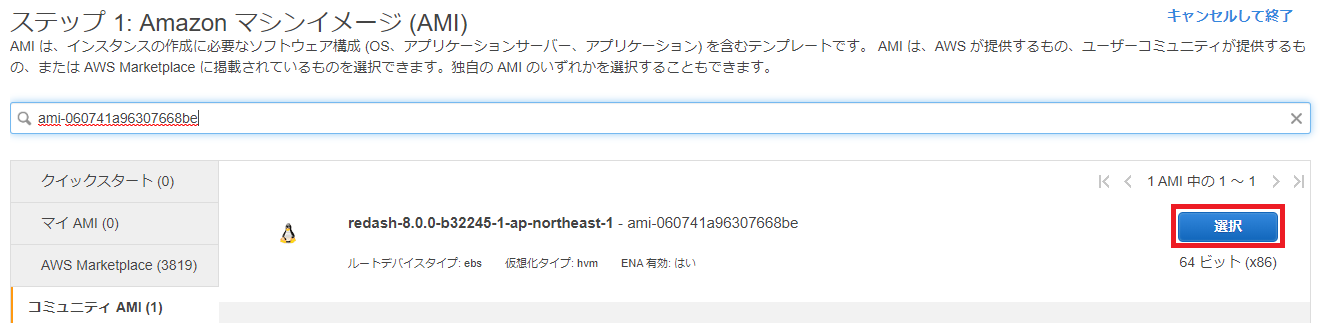
④②の検索ボックスに③で調べたAMIを入れて検索し、選択ボタンをクリックします。
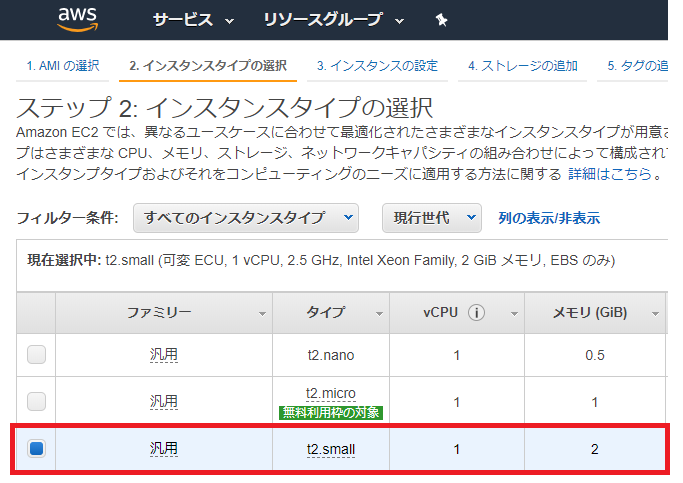
⑤ステップ2: インスタンスタイプの選択でt2.smallを選択し、確認と作成をクリックします。
なお、下記のとおり、t2.microでは動きません(最低でもt2.smallを選択する必要があります)のでご注意ください。
Launch the instance with the pre-baked AMI we create (for small deployments t2.small should be enough):
事前に作成したAMIを作成してインスタンスを起動します(小規模な展開の場合はt2.smallで十分です)。
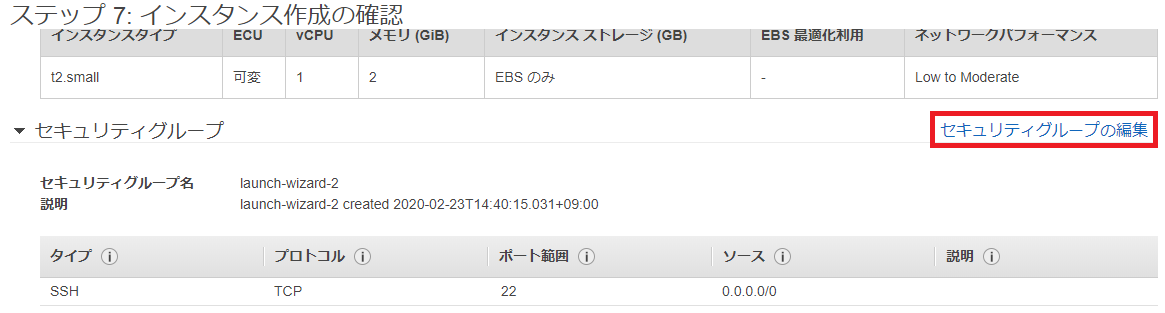
⑥ステップ7: インスタンス作成の確認でセキュリティグループの編集をクリックします。
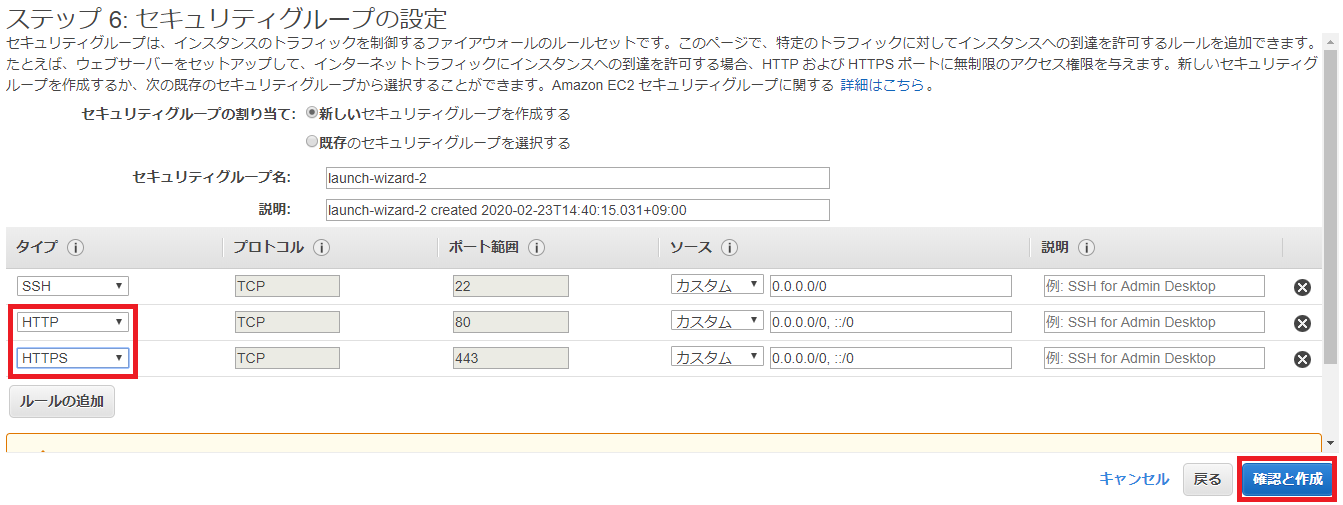
⑦下記のとおり、SSHに加えてHTTPとHTTPSを許可する必要があるため、ステップ6: セキュリティグループの設定で追加し、確認と作成をクリックします。
When launching the instance make sure to use a Security Group, that only allows incoming traffic on ports: 22 (SSH), 80 (HTTP) and 443 (HTTPS). These AMIs are based on Ubuntu so you will need to use the user ubuntu when connecting to the instance via SSH.
インスタンスを起動するときは、ポート(22(SSH)、80(HTTP)、および443(HTTPS))でのみ着信トラフィックを許可するセキュリティグループを使用してください。これらのAMIはUbuntuに基づいているため、SSHを介してインスタンスに接続する場合は、ユーザーubuntuを使用する必要があります。
なお、IP制御をする必要がある場合はソースのCIDRを適時変更してください。
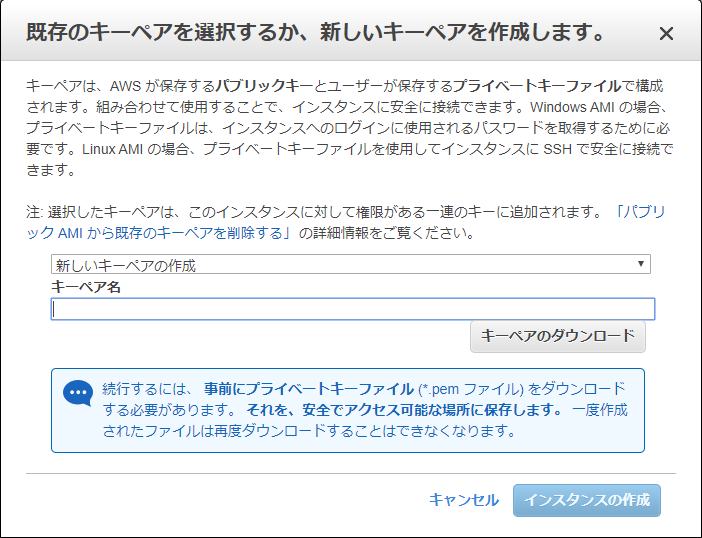
⑧ステップ7: インスタンス作成の確認の最下部にある起動をクリックし、ポップアップで「既存のキーペアの選択」または「新しいキーペアの作成」のどちらかを選択した後、インスタンスの作成をクリックします。
以上でEC2インスタンスの作成は終了です。
2. RDSにMySQLデータベースを作成
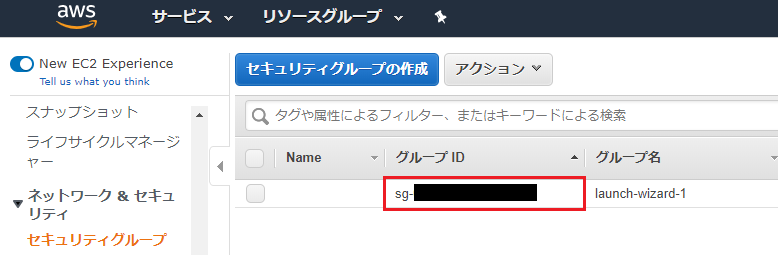
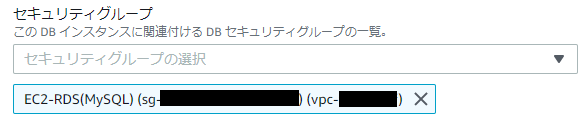
①EC2ダッシュボードのサイドバーからセキュリティグループを選択、作成したEC2のセキュリティグループのグループID(sg-から始まるID)をコピーします。
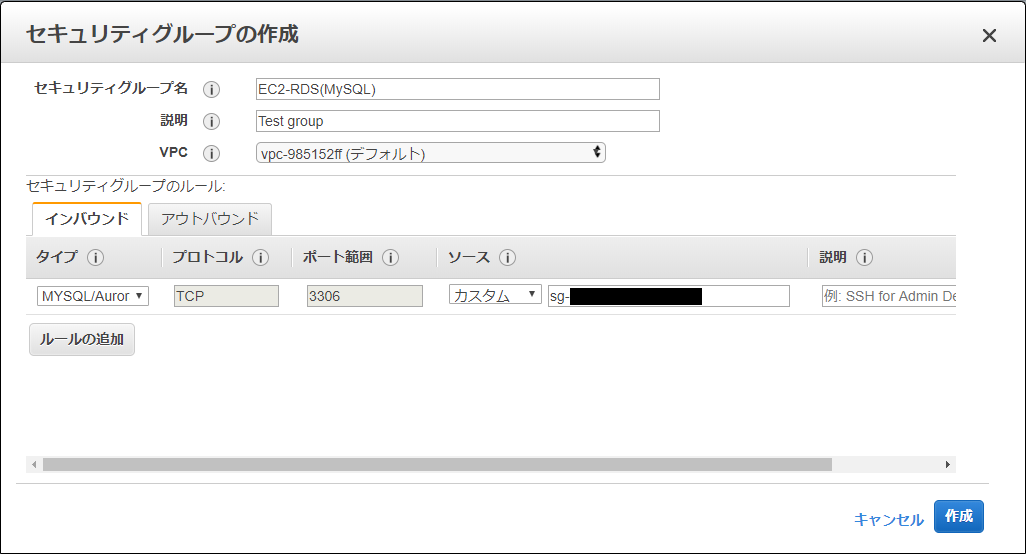
②同ページ内のセキュリティグループの作成をクリックし、下図のとおりに設定後、作成をクリックします。
ポイントはソースに①でコピーしたグループIDを入れることです(このセキュリティグループは、EC2インスタンスがRDSに作成するMySQLデータベースにアクセスできるようにするために作成しております)。
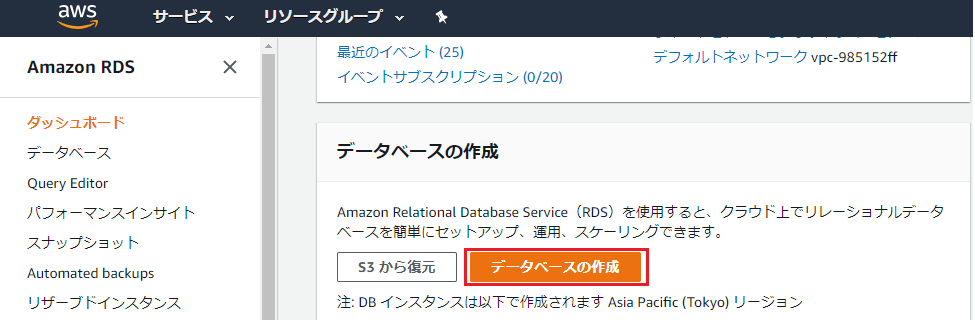
③RDSのページに遷移し、下部にあるデータベースの作成をクリックします。
④データベースの作成ページで、下表のとおりに設定をします(記載のないものはデフォルト設定です)。
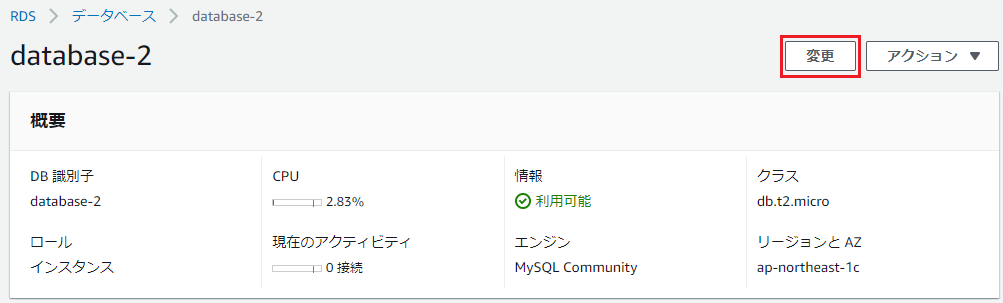
項目 内容 データベース作成方法を選択 簡単作成 エンジンのタイプ MySQL DBインスタンスサイズ 無料利用枠 マスターパスワード 任意のパスワード ⑤データベース作成完了後、RDS>データベース>④で作成したデータベース名を選択し、変更をクリックします。
⑥セキュリティグループを②で作成したものに変更し、次へをクリックした後、DBインスタンスの変更をクリックします。
以上でRDSでのMySQLデータベースの作成は終了です。
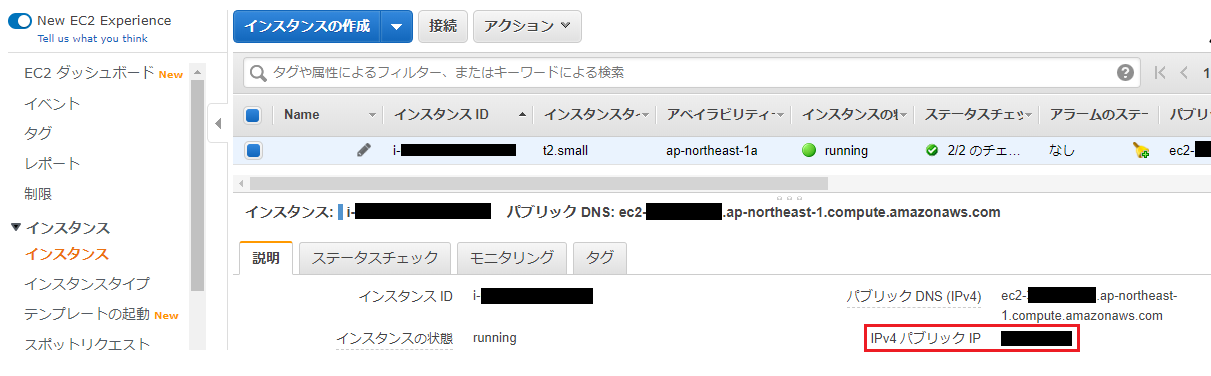
3. TeraTermでEC2に接続し、CSVを転送
①EC2インスタンスのIPv4パブリックIPをコピーします。
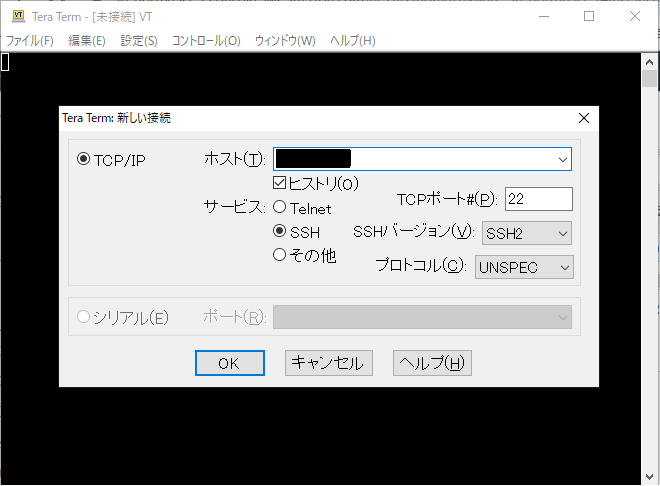
②TeraTermを起動し、ホストに①でコピーしたIPv4パブリックIPをペーストしてOKをクリックします。
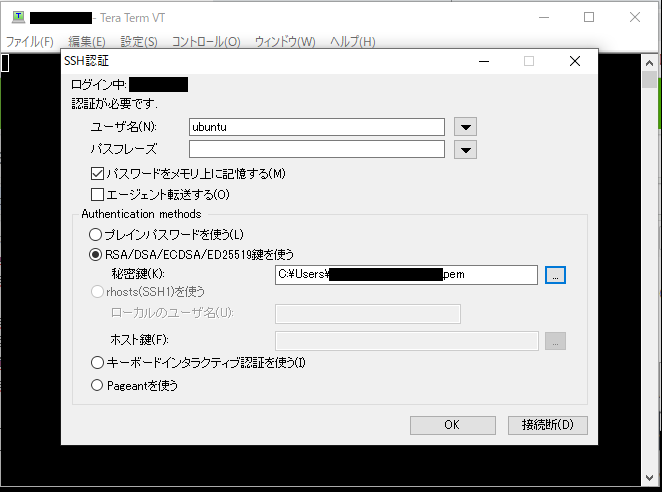
③ユーザー名に「ubuntu」、パスワードは空白のまま、秘密鍵にEC2インスタンスの鍵ペア生成時にダウンロードしたpemファイルを選択してOKをクリックします。
【補足】
TeraTermでログインする際のユーザー名はOSによって異なります。
OS ユーザー名 Amazon Linux ec2-user Ubuntu ubuntu CentOS centos Redash AMIはUbuntuベースのため、ユーザー名が「Ubuntu」となっております。ご注意ください。
④CSVを格納するフォルダを作成します。
$ pwd /home/ubuntu $ mkdir csv $ cd csv ~/csv$ pwd /home/ubuntu/csv⑤以下の記事に従い、データベースに取り込みたいCSVファイルをEC2インスタンスのCSVフォルダに転送します。
⑥CSVフォルダに転送できたか確認します。
~/csv$ pwd /home/ubuntu/csv ~/csv$ ls student.csv以上でEC2インスタンスへのCSVファイルの転送は終了です。
4. EC2にMySQLクライアントをインストールし、RDSのMySQLデータベースに接続
①
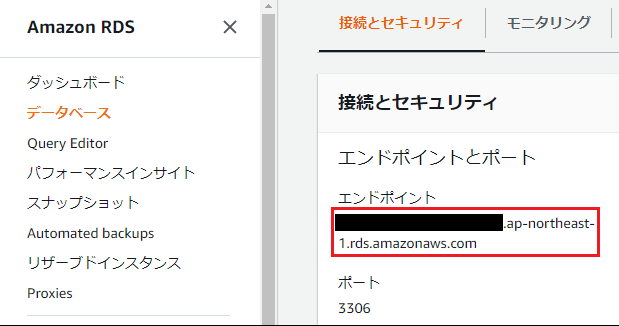
sudo apt install mysql-client-core-5.7コマンドでMySQLクライアントをEC2インスタンスにインストールします。②RDSに作成したMySQLデータベースのエンドポイントをコピーします。
③以下のコマンドでMySQLデータベースに接続します。
$ mysql -h RDSエンドポイント -P 3306 -u admin -p Enter password: マスターパスワード以上でMySQLデータベースへの接続ができました。
5. データベースとテーブルを作成し、CSVを取り込み
①以下のコマンドでデータベース及びテーブルを作成します。なお、今回、データベース名はexample_db、テーブル名はstudentとしました。
mysql> create database example_db; mysql> show databases; mysql> use example_db; mysql> create table student ( 列名 データ型, ・・・ ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;なお、列名に丸かっこなどの記号が入っている際、MySQLではバッククォート「`」で囲みます。
②以下のコマンドでCSVフォルダに転送したCSVファイルをMySQLデータベースに取り込みます。
mysql> load data local infile "/home/ubuntu/csv/student.csv" into table student fields terminated by ',';なお、CSV取り込みについては以下の記事を参考にさせて頂きました。
以上でRedashを使う準備がすべて終了しました。
6. Redashにデータベースを接続
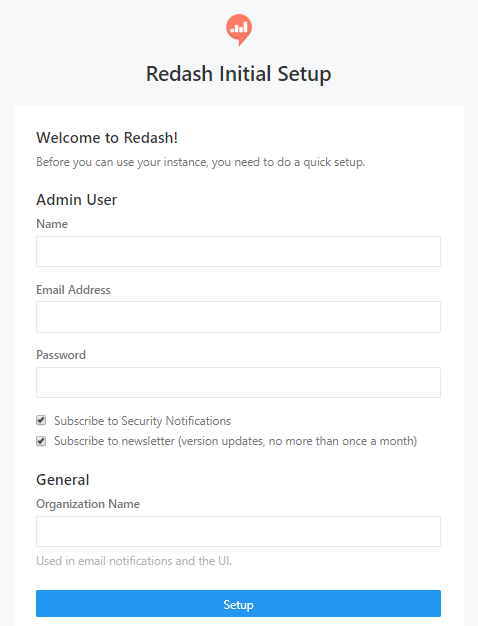
①EC2インスタンスのIPv4パブリックIPをブラウザに入力し、Redashを起動します。
②起動すると、下図のとおり、Adminユーザー登録画面になるので登録します。
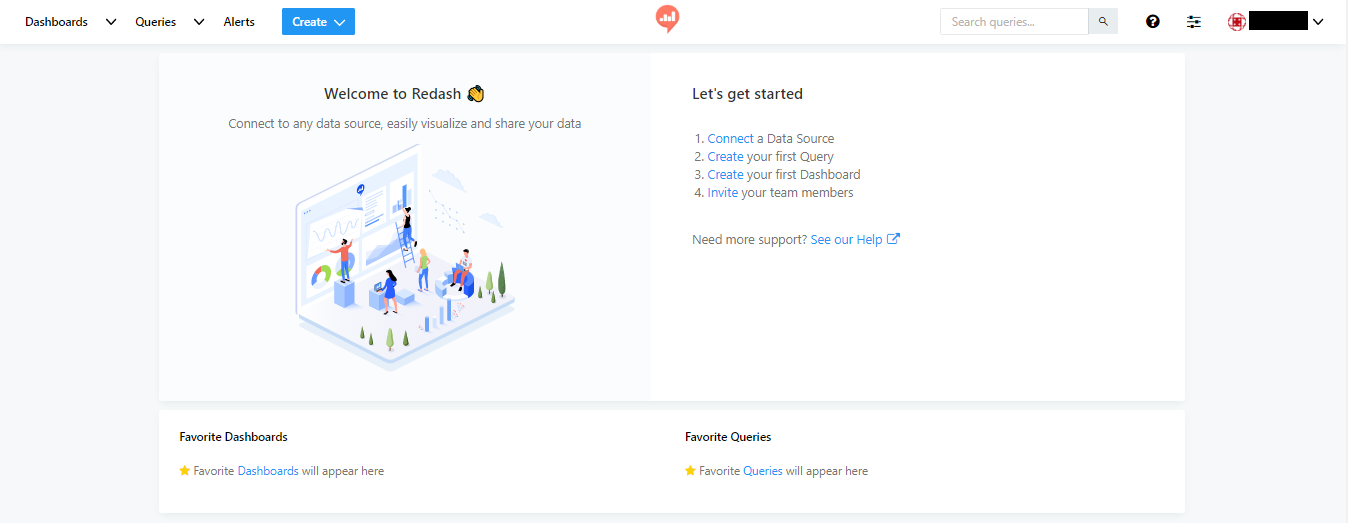
③ログインすると下図のような画面になるのでConnect a Data Sourceをクリックします。
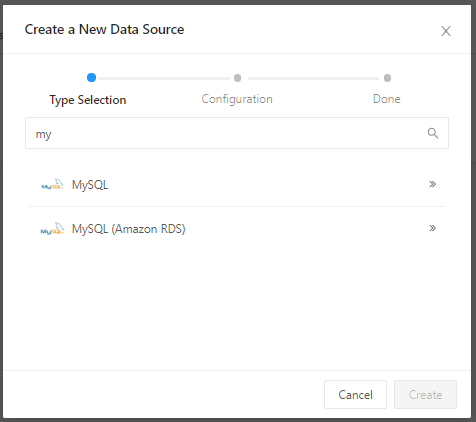
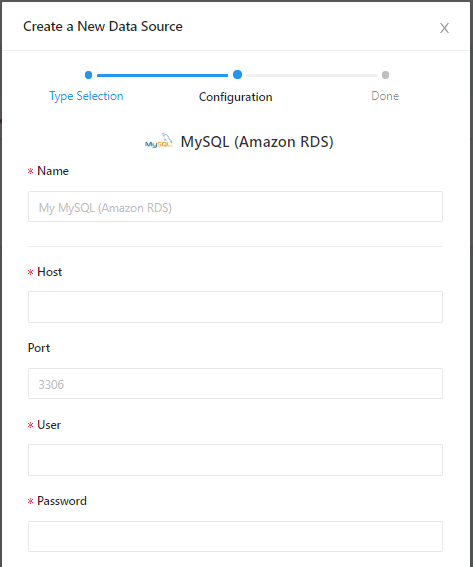
④データソースの中からMySQL(RDS)を選択します。
⑤下図のとおり、入力を求められますので、下表に従い入力します。
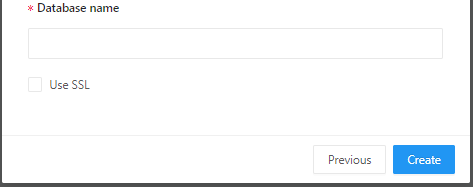
項目 入力内容 Name データソース名(任意) Host RDSのエンドポイント User admin Password RDSで設定したマスターパスワード Database name example_db ⑥Createをクリック後、Test Connectionをクリックします。「Success」と表示されればRedashとデータベースの接続成功です。
7. Redashにクエリを作成し、ダッシュボードで表示
力尽きました・・・(苦笑)
以下の記事が詳しいのでご覧くださいませ。さいごに
実は今までHeroku+PostgreSQLばかり触っていたので、AWSとMySQL自体、触るのが初めてでした。
なので備忘録も兼ねてAWSとMySQLの操作についても細かく記載しました。
「この記事長いな」と思われた方、すみませんでしたm(_ _)m今回、Redashを試してみて「こんなに便利なもんがOSSで良いのか!」と感動しました。
非エンジニアの人事課メンバーにはRedashでもハードルは高い(SQLにすら抵抗がある)ので、タレントパレット・HRMOS CORE・ヒトマワリのどれかを入れることになるんだろうな~と思いますが、経営企画の方が安価なBIツールを探していたので、これを紹介したら喜びそうだなと感じました(ので教えようと思います)。本記事をご覧くださった方、長文にも関わらずご覧頂きありがとうございました。

- 投稿日:2020-02-23T17:23:34+09:00
AWSでJupyter Notebookを使えるように環境構築
初心者がAWS環境で機械学習の勉強ができる環境構築をしてみました。
参照先のメモ書きです。AWSアカウントを作成してみた
ログインで困ったのは、「ルートアカウントか否か」ということ。
ルートアカウントログインのユーザーIDは入力しないでログイン可能。AWS公式:AWS アカウントのルートユーザー
インスタンスを作成してみた
マシン選定に注意。
Amazon LinuxはRedHat系だそうです。
私は会社の研修でubuntuを触っていたので、ubuntuを選択することに。AWS公式:Amazon Linux 2
Qiita記事:EC2のAmazonLinux2,Centos6,Centos7違いによる初期設定ssh接続をしてみた
さて、ターミナルからssh接続!
ユーザー名やIPはどこから探すの?って思ったけど、EC2→インスタンス→(「インスタンスの作成」ボタンの右にある)「接続」ボタンを押したら確認できた。
ssh接続の方法も分かりやすく記載されていました。AWS公式:SSH を使用した Linux インスタンスへの接続
しかし、ターミナルでコマンドを打つと、タイムアウトになってつながらない・・・
どうやら原因はセキュリティにあるみたいだった。(自分のIPからの接続を許可していなかった。)AWS公式:SSH を使用した EC2 Linux インスタンスへの接続の問題に関するトラブルシューティングはどのように行えばいいですか?
Qiita記事:AWSのEC2のセキュリティのインバウンドのルールでIPを設定する場合は/32をつける
「分かりそう」で「分からない」でも「分かった」気になれるIT用語辞典:ユニキャスト (unicast)AWS CLIを設定してみた
CUIで操作ができるように、AWS CLIを設定してみました。
AWS公式:AWS CLI の設定AWS S3を作ってみた
AWS公式:Amazon Simple Storage Service の使用開始
Jupyter notebookを使えるようにしてみた
- 投稿日:2020-02-23T16:40:21+09:00
AWS RDS Auroraのデータを復元する方法
なぜこの記事を書いているのか?
- データベースのメンテナンスをしていたら、データベースの復元手順をメモったりしていないことに気づく。
- データをすっ飛ばしたりした場合に、これではまずいなと思い整理してみることに。
- 万一の時にササッと対応できるよう、簡潔にメモしておきたい。
- 備えあれば憂いなし。
前提条件(環境)
下記の環境で作業を行うことを前提とした場合の手順です。
- 対象DBサーバ
- AWS RDS
MySQL Aurora 5.7.mysql_aurora.2.07.1mysql> select version(); +-----------+ | version() | +-----------+ | 5.7.12 | +-----------+
- 作業クライアント
macOS Catalina 10.15.3- 対象DBサーバにアクセスできるクライアントであることが前提です。
- AWSのセキュリティグループのインバウンドルールで自分のIPアドレスを許可してアクセスできる状態にしておいてください。
$ sw_vers ProductName: Mac OS X ProductVersion: 10.15.3 BuildVersion: 19D76想定シナリオ
- mysqldumpを取得していない。(バックアップ運用計画をたてておきましょう)
- なのにSQLのクエリをミスって必要なデータを削除してしまった。
- わかっている人が一人しかいない。
- その人がコロナウィルスに感染し、対応不能。 ↑こういうことにならないように備えましょう。
データが消えました!
まずは落ち着こう。
ユーザ名とパスワードを確認
- DBサーバにアクセスするにあたって必要です。
- 1-PasswordやPassword Gorilla、社内ドキュメントを探しましょう。
- 見つからない場合は、唯一の担当者に連絡するなどして確認しましょう。 ↑こういうことにならないように備えましょう。
AWSコンソール上での作業
- AWSコンソールからRDS -> スナップショット -> システムの順に進み、お目当てのスナップショットを選択
- 右上の「アクション」プルダウンから「スナップショットの復元」を選択
- DBエンジン:
Aurora MySQL- DBエンジンのバージョン:
Aurora(MySQL 5.7)2.07.1(default)- DBインスタンスのクラス: 復元作業が目的なので、お安い
db.t3.small - 2 vVPU, 2GiB RAM- DBインスタンス識別子: 何でも良いです。ただし本番稼働しているホストと似たような名前は避ける。作業対象を間違えないように。
- Virtual Private Cloud (VPC): 確実にアクセスできるネットワーク環境を選択。わからなければ本番環境を参考に。
- サブネットグループ:確実にアクセスできるネットワーク環境を選択。わからなければ本番環境を参考に。
- パブリックアクセシビリティ: はい
- アベイラビリティーゾーン: 確実にアクセスできるAZを選択。わからなければ本番環境を参考に。
- データベースのポート:3306
- DBパラメータグループ:わからなければ本番環境を参考に。
- DBクラスタのパラメータグループ: わからなければ本番環境を参考に。
- タグをスナップショットへコピー: チェックなし
- バックトラックを無効にする
- マスターキー: わからなければ本番環境を参考に。
- ログのエクスポート:復元作業が目的なので不要
- マイナーバージョン自動アップグレード: いいえ -「DBインスタンスの復元」ボタンをクリック
- AWSコンソール左側のメニューから「データベース」をクリック
- スナップショットから復元したインスタンスのステータスが「利用可能」になるのを待つ
- 利用可能になったら、
復元したインスタンスのDB識別子をクリック- 「エンドポイント」のホスト名を控える
データを復元したいインスタンス(データを削除してしまったインスタンス)のDB識別子をクリック- 「エンドポイント」のホスト名を控える
ターミナル上での作業
スナップショットから復元したインスタンス上に残っているデータを下記のコマンドでdumpします- この記事では作業用クライアントがmacOSという想定ですので、「ターミナル」を起動し下記のコマンドを入力してください。
hoge.c7mjpv6ouojj.ap-northeast-1.rds.amazonaws.comは先程のステップで控えたスナップショットから復元したインスタンスのホスト名に置き換えてください。adminの部分は最初に確認したユーザ名に置き換えてください。database_nameは復元したいデータベース名に置き換えてください。$ mysqldump --skip-column-statistics --set-gtid-purged=OFF -h hoge.c7mjpv6ouojj.ap-northeast-1.rds.amazonaws.com -u admin -p database_name > ./dump.sql Enter password:
- 上記のコマンドを実行し、パスワードを入力するとカレントディレクトリにdump.sqlが出力されます。
- このダンプファイルを
データを復元したいインスタンス(データを削除してしまったインスタンス)にインポートするために下記のコマンドを実行します。
hoge.c7mjpv6ouojj.ap-northeast-1.rds.amazonaws.comは先程のステップで控えたスナップショットから復元したインスタンスのホスト名に置き換えてください。adminの部分は最初に確認したユーザ名に置き換えてください。database_nameは復元したいデータベース名に置き換えてください。$ mysql -h hoge.c7mjpv6ouojj.ap-northeast-1.rds.amazonaws.com -u admin -p database_name < ./dump.sql Enter password:データが復元したことを確認
- あくまでスナップショットの時点のデータです。
- 復元できていないのは、どのデータなのかを把握する。
- 復元できないことによって、誰にどのような影響が出ているのかを整理する。
- 然るべき人に報告を入れる。
後片付け
- スナップショットから復元したインスタンスは削除しましょう。忘れるとどんどん課金されます。
- 何がまずかったのかをしっかり振り返り、必要な情報を整理し、今回のトラブルを次に活かしましょう。
- 投稿日:2020-02-23T16:17:49+09:00
AWS CDKの'aws-lambda-nodejs'を使ってCDKとLambdaの間の壁を破壊する
動機
久々にAWS CDKのリファレンスを眺めていたらこんなConstructを発見!!
aws-lambda-nodejs module
This library provides constructs for Node.js Lambda functions.
これはもしかして、CDKのソースとLambdaのソースを一気通貫で管理できるってことかい!?もうこんな過去記事のようにCDKのソースとLambdaのソースを分けて管理したり別々のnode_modulesやtsconfig.jsonを持たなくても良いのかい!?なんて美しいんだ!!バチが当たるじゃないか!?
ということでやってみました。
作るもの: S3式FizzBuzz
じゃあ、検証ということでFizzBuzzでも作りますかね。折角のAWS CDKでただただFizzBuzzをやるlambdaを作っても面白くないのでこんな感じでどうでしょう?
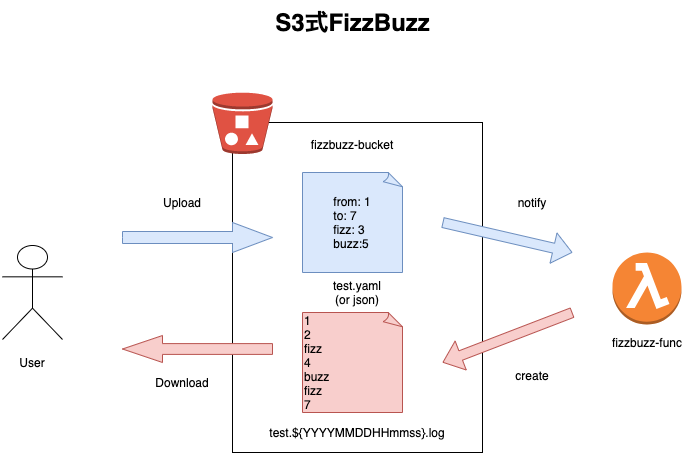
仕様
S3に置いた設定ファイルの設定値を元にFizz Buzzを実行した結果をS3に出力します。
設定ファイル例
test.yamlfrom: 1 #始点 to: 15 #終点 fizz: 3 #fizzに変換する値(任意) buzz: 5 #buzzに変換する値(任意)結果例
test.20200223103211.log1 2 fizz 4 buzz fizz 7 8 fizz buzz 11 fizz 13 14 fizzbuzz作ってみた
ソースの全体像について
GitHubに置いたので、全体像を把握したい方はこちらからご覧ください。
ポイントはやはり、今までのようにlambda専用にディレクトリを切って独自のpackage.jsonやtsconfig.jsonを置いて管理しているわけではなく、
./libディレクトリの中にスタック定義と一緒にlambda定義も置いてあって、package.jsonやtsconfig.jsonはCDKのものと共有している点だと思います。いや、これだけでかなりスッキリしましたよね。感動。。環境準備
まずは公式チュートリアルを参考に、お使いのアカウントに対してAWS CDKからリソースをデプロイできるようにしておいてください。
特にこだわりがなければ、AWS Cloud9上に環境作るのが楽だと思います。ただ、CDKに限ったことではないですが、デフォルトのt2.microインスタンスでtypescriptを扱っているとビルドやユニットテストの際にメモリ不足で停止することがよくあるので、お財布と相談の上で1個上のt2.smallに上げることを個人的にはおすすめします。
以下、cdkコマンドは使えるようになった前提で話を進めます。
i.プロジェクトの作成
$ mkdir s3-fizzbuzz $ cd s3-fizzbuzz $ cdk init --language=typescriptまあ、ほぼほぼチュートリアルの通りですね。
ii.ドメイン層
『たかだかFizzBuzzでドメイン層って。。。』というツッコミが聞こえてきそうではありますが、まあまあ、ちょっとだけお付き合いください。
cdk initで作成されたlibディレクトリ直下に以下のようなソースを書きました。./lib/domain.ts/** * FizzBuzzの設定 **/ export interface FizzBuzzSetting{ /**始点*/ from: number /**終点*/ to: number /**fizzに変換する数*/ fizz?: number /**buzzに変換する数*/ buzz?: number } /** * [[FizzBuzzSetting]]のtype guard * @param obj チェックしたいオブジェクト * @return objがFizzBuzzSettingであればtrue **/ export const isFizzBuzzSetting = (obj: any): obj is FizzBuzzSetting =>{ return typeof obj.from === "number" && typeof obj.to === "number" && (!obj.fizz || typeof obj.fizz === "number") && (!obj.buzz || typeof obj.buzz === "number"); } /** * 引数が正の整数かどうか * @param n チェックしたい数 * @return nが正の整数であればtrue **/ const isPositiveInt = (n:number): boolean => n > 0 && Math.floor(n) === n; /** * [[FizzBuzzSetting]]のバリデーション * @param from 始点(正の整数) * @param to 終点(正の整数) * @param fizz "fizz"に変換する数(正の整数/デフォルト3) * @param buzz "buzz"に変換する数(負の整数/デフォルト5) * @return デフォルト値割り当て済みのFizzBuzzSetting **/ const validate = ({from, to, fizz=3, buzz=5}: FizzBuzzSetting):Required<FizzBuzzSetting> => { if(!isPositiveInt(from)) throw new Error(`from:${from}は正の整数である必要があります`); if(!isPositiveInt(to)) throw new Error(`to:${to}は正の整数である必要があります`); if(to <= from) throw new Error(`to:${to}はfrom:${from}よりも大きい数値である必要があります`); if(!isPositiveInt(fizz)) throw new Error(`fizz:${fizz}は正の整数である必要があります`); if(!isPositiveInt(buzz)) throw new Error(`fizz:${buzz}は正の整数である必要があります`); if(fizz === buzz) throw new Error(`fizz:${fizz}とbuzz:${buzz}は異なる数値である必要があります`); return {from,to,fizz,buzz}; } /** * fizzbuzzを実行する * @param setting 設定値 * @return 結果が格納された配列 **/ export const fizzbuzz = (setting: FizzBuzzSetting): string[] => { const {from, to, fizz, buzz} = validate(setting); return Array.from({length: (to - from + 1)}, (_,i) => i + from).map((n):string =>{ if(n % (fizz * buzz) === 0) return "fizzbuzz"; if(n % fizz === 0) return "fizz"; if(n % buzz === 0) return "buzz"; return n.toString(); }); }閑話休題:サーバレス/FaaSはベンダーロックインになる?
よく「サーバレス/FaaSはクラウドベンダーにロックインするよね」と言われますが、それに対する答えというか対策が「ドメイン層の分離」だと思っています。つまり、AWS Lambdaの文脈で言えば、
- LambdaやS3、AWS SDKなどに依存せず、ピュアなjs/tsでアプリケーションの仕様を書き表した層(≒ドメイン層)
- LambdaやS3、AWS SDKとドメイン層を接続する層(≒インタフェース層)
を明確に分離して2.の部分を薄く保つことによって、仮にAWSをやめたくなったとしても上記1.の部分に関しては、ExpressやApploServerに乗っけるなり何なりして使い回せるわけです。これは別に目新しい考え方でも何でもなくて、例えばMVCに於いて「Controller層を薄く作りましょう」と言っているのと同じ考え方なわけで、サーバレスであろうが何であろうが『アーキテクチャをクリーンに保つ』という考え方は変わらないわけです。
このあたりの理屈を詳しく勉強したい方は、アンクル・ボブ先生のClean Architectureがおすすめです。
閑話休題:テスタビリティ
もう1つ、ドメイン層を分離する動機として、テスタビリティ(テストのしやすさ)の向上があります。
「FizzBuzzのアルゴリズムが正しく組めているか」「設定の内容を正しく読めているか」をテストしたいときに、「S3 Bucketへの書き込み/読み込みができるサービスロールが付いているか」みたいなゴリゴリAWSと密結合な関心事について1ミリ秒足りとも考えたくないのです。
ドメイン層を明確に分離したことによって、以下のような「ドメインの関心ごとに特化した」テストをシンプルに書くことができます。./test/domain.test.tsimport {fizzbuzz, isFizzBuzzSetting} from '../lib/domain'; /** * fizzbuzz関数に関するテスト **/ describe("fizzbuzz function",()=>{ /** * 設定値に応じてfizzbuzzを実行して結果を返す **/ it("returns result of fizzbuzz by setting",()=>{ const result = fizzbuzz({ from: 1, to: 15 }); expect(result).toEqual(["1","2","fizz","4","buzz","fizz","7","8","fizz","buzz","11","fizz","13","14","fizzbuzz"]); }); /** * fizzに変換する値を書き換えることができる **/ it("assumes overwriting 'fizz' value by setting",()=>{ const result = fizzbuzz({ from: 1, to: 10, fizz: 2 }); expect(result).toEqual(["1","fizz","3","fizz","buzz","fizz","7","fizz","9","fizzbuzz"]); }); /** * buzzに変換する値を書き換えることができる **/ it("assumes overwriting 'buzz' value by setting",()=>{ const result = fizzbuzz({ from: 1, to: 10, fizz: 2, buzz: 3 }); expect(result).toEqual(["1","fizz","buzz","fizz","5","fizzbuzz","7","fizz","buzz","fizz"]); }); /** * 設定値が不正な場合はエラーが発生する **/ it("throws Error if setting is invalid",()=>{ expect(() => fizzbuzz({from:-1,to:2})).toThrow(); expect(() => fizzbuzz({from:1.1,to:2})).toThrow(); expect(() => fizzbuzz({from:1,to:-2})).toThrow(); expect(() => fizzbuzz({from:1,to:2.1})).toThrow(); expect(() => fizzbuzz({from:2,to:1})).toThrow(); expect(() => fizzbuzz({from:1,to:10, fizz:-1})).toThrow(); expect(() => fizzbuzz({from:1,to:10, fizz:1.1})).toThrow(); expect(() => fizzbuzz({from:1,to:10, buzz:-1})).toThrow(); expect(() => fizzbuzz({from:1,to:10, buzz:1.1})).toThrow(); expect(() => fizzbuzz({from:1,to:10, fizz:2,buzz:2})).toThrow(); }); }); /** * isFizzBuzzSettingに関するテスト **/ describe("isFizzBuzzSetting",()=>{ /** * objectがFizzBuzzSettingかどうかをチェックする **/ it("checks if the object is FizzBuzzSetting",()=>{ expect(isFizzBuzzSetting({from:1, to:100})).toBe(true); expect(isFizzBuzzSetting({from:1, to:100, fizz:4})).toBe(true); expect(isFizzBuzzSetting({from:1, to:100, fizz:4, buzz:7})).toBe(true); }); /** * 引数が不正であればfalseを返す **/ it("returns false if argument is invalid",()=>{ expect(isFizzBuzzSetting(1)).toBe(false); expect(isFizzBuzzSetting({})).toBe(false); expect(isFizzBuzzSetting({from:1})).toBe(false); expect(isFizzBuzzSetting({to:1})).toBe(false); expect(isFizzBuzzSetting({from:"a", to:3})).toBe(false); expect(isFizzBuzzSetting({from:1, to:"b"})).toBe(false); expect(isFizzBuzzSetting({from:1, to:3, fizz:"c"})).toBe(false); expect(isFizzBuzzSetting({from:1, to:3, fizz:2, buzz:"d"})).toBe(false); }); });今回は
aws-lambda-nodejsを使ってソースをEndToEndで管理しているので、npm testコマンドでCDKのテストとドメイン層のテストを一気通貫で実行できるのもまた魅力の1つだと思っています。iii. Lambda関数(≒インタフェース層)
ということで本題に戻って、Lambdaを書いて行きましょう。
aws-lambda-nodejsのOverviewによると、
Define a NodejsFunction:
new lambda.NodejsFunction(this, 'my-handler');By default, the construct will use the name of the defining file and the construct's id to look up the entry file:
.
├── stack.ts # defines a 'NodejsFunction' with 'my-handler' as id
├── stack.my-handler.ts # exports a function named 'handler'ということで命名規則がありそうなのでそれに従って行きましょう。
cdk initで./lib/s3-fizzbuzz-stack.tsというスタック定義用のソースが作られていて、関数名をfizzbuzz-funcだとすると、命名規則的にはs3-fizzbuzz-stack.fizzbuzz-func.tsを作ればいいはずです。その前に関連パッケージをnpm経由でinstallします。
package.jsonと/node_modulesをCDKと共用できるので楽でいいですね!$ npm install --save aws-sdk js-yaml moment $ npm install --save-dev @types/aws-lambdaということで、Lambdaのhandlerを書いていきましょう。
./lib/s3-fizzbuzz-stack.fizzbuzz-func.tsimport {S3Handler,S3Event, S3EventRecord} from 'aws-lambda'; import {S3} from 'aws-sdk'; import * as yaml from 'js-yaml'; import {Moment} from 'moment'; import {isFizzBuzzSetting, fizzbuzz} from './domain'; const s3 = new S3(); /** * 設定ファイルを読み込む * @param bucket 対象バケット * @param key 対象key * @return 読み込んだ結果 **/ const loadSetting = async(bucket: string, key: string): Promise<Object> => { const response = await s3.getObject({ Bucket: bucket, Key: key }).promise(); if(response.Body){ const body = response.Body.toString(); if(key.endsWith(".json")){ return JSON.parse(body); }else{ return yaml.safeLoad(body); } }else{ throw new Error(`Load setting file failure:${key} on ${bucket}`); } } /** * 実行結果を保存する * @param key 対象バケット * @param settingName 設定ファイル名 * @param result 実行結果 **/ const saveResult = async (bucket: string, settingName: string, result: string[]): Promise<void> => { const moment = require("moment"); const now: Moment = moment().format("YYYYMMDDHHmmss"); const resultKey = settingName.split(".").slice(0,-1).join(".") + `.${now}.log`; await s3.putObject({ Bucket: bucket, Key: resultKey, Body: result.join("\n") }).promise(); } /** * このLambdaの実行対象レコードかどうか * @param record チェックするrecord * @return 実行対象であればtrue **/ const isTargetEvent = (record: S3EventRecord): boolean => record.eventName.startsWith("ObjectCreated:") && (record.s3.object.key.endsWith(".json") || record.s3.object.key.endsWith(".yaml") || record.s3.object.key.endsWith(".yml")); /** * fizzbuzz-funcのhandler * @param event S3のイベント **/ export const handler:S3Handler = async(event:S3Event) => { for(const record of event.Records){ if(isTargetEvent(record)){ try{ const bucketName = record.s3.bucket.name; const targetKey = record.s3.object.key; const setting = await loadSetting(bucketName, targetKey); if(isFizzBuzzSetting(setting)){ const result = fizzbuzz(setting); await saveResult(bucketName, targetKey, result); }else{ throw new Error(`Invalid setting ${JSON.stringify(setting)}`); } }catch(e){ console.error(e.message); } } } }まあ、大したことはやっていないですね。S3の
ObjectCreated:*を拾って、S3から設定ファイル(YAMLもしくはjson)を読み込んで、その設定値を先ほど作ったドメイン層のfizzbuzz関数に渡して、結果をまたS3に保存しているだけです。iv. スタック定義
ということでいよいよ、
aws-lambda-nodejsを利用してlambdaを作ってみましょう。まずは関連ライブラリのinstallをします。
$ npm install --save-dev @aws-cdk/aws-lambda-nodejs @aws-cdk/aws-s3 @aws-cdk/aws-s3-notifications続いて、
./lib/s3-fizzbuzz-stack.tsを編集します。./lib/s3-fizzbuzz-stack.tsimport * as cdk from '@aws-cdk/core'; import * as lambda from '@aws-cdk/aws-lambda-nodejs'; import * as s3 from '@aws-cdk/aws-s3'; import * as s3n from '@aws-cdk/aws-s3-notifications'; /** * S3式FizzBuzzのスタック **/ export class S3FizzbuzzStack extends cdk.Stack { /** * コンストラクタ * @param scope スコープ * @param id Constructのid * @param props 設定値 */ constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) { super(scope, id, props); /** * fizzbuzz-func関数 * ${スタックのソース名}.${関数のID(第2引数)}.tsが * exportするhandler関数をLambdaのハンドラと見做してデプロイしてくれる **/ const fizzbuzzFunc = new lambda.NodejsFunction(this, "fizzbuzz-func"); /** * 設定ファイルと結果を格納するバケット **/ const fizzbuzzBucket = new s3.Bucket(this, "fizzbuzz-bucket"); /** * fizzbuzz-bucketへの読み込み/書き込み権限をfizzbuzz-funcに付与する **/ fizzbuzzBucket.grantReadWrite(fizzbuzzFunc); /** * fizzbuzz-bucketへの.json/.yaml/.ymlファイルのOBJECT_CREATEDを * fizzbuzz-funcへ通知する **/ fizzbuzzBucket.addEventNotification( s3.EventType.OBJECT_CREATED, new s3n.LambdaDestination(fizzbuzzFunc), {suffix: ".json"} ); fizzbuzzBucket.addEventNotification( s3.EventType.OBJECT_CREATED, new s3n.LambdaDestination(fizzbuzzFunc), {suffix: ".yaml"} ); fizzbuzzBucket.addEventNotification( s3.EventType.OBJECT_CREATED, new s3n.LambdaDestination(fizzbuzzFunc), {suffix: ".yml"} ); } }いやーシンプルですね!
閑話休題:AWS CDKとガバナンス
AWS CDKを導入したい理由のほとんどがいわゆる"効率面"だとは思いますが、個人的には、実は"ガバナンス強化"がデカいんじゃないかと思っています。
特にこういったサーバレスの世界ではファイアウォールのようなネットワーク的境界があるわけではないので、IAMの管理がセキュリティ上の肝だと思います。ところが今回のlambdaを作るとき、コンソールから作るときでもCloudFormationのテンプレートを直書きするときでも、ついLambdaのサービスロールに対して、
AmazonS3FullAccessのような雑なポリシーを当てがちではないでしょうか?まあ、単に「めんどくさい」というパターンと「そもそもIAMがよく分かっていない」というパターンがあるとは思いますが。何れにしても、こういったことがセキュリティリスクであることには変わりないわけです。ところが、CDKのスタック定義を見てください。
/** * fizzbuzz-bucketへの読み込み/書き込み権限をfizzbuzz-funcに付与する **/ fizzbuzzBucket.grantReadWrite(fizzbuzzFunc);この1行だけで、「適切なバケットに対して」「適切なポリシーを持つ」ロールが作成されるのです。実際にこのソースから作成されたサービスロールのテンプレートを見てみましょう。
fizzbuzzfuncServiceRoleD547EF86: Type: AWS::IAM::Role Properties: AssumeRolePolicyDocument: Statement: - Action: sts:AssumeRole Effect: Allow Principal: Service: lambda.amazonaws.com Version: "2012-10-17" ManagedPolicyArns: - Fn::Join: - "" - - "arn:" - Ref: AWS::Partition - :iam::aws:policy/service-role/AWSLambdaBasicExecutionRole Metadata: aws:cdk:path: S3FizzbuzzStack/fizzbuzz-func/ServiceRole/Resource fizzbuzzfuncServiceRoleDefaultPolicy9977BB4B: Type: AWS::IAM::Policy Properties: PolicyDocument: Statement: - Action: - s3:GetObject* - s3:GetBucket* - s3:List* - s3:DeleteObject* - s3:PutObject* - s3:Abort* Effect: Allow Resource: - Fn::GetAtt: - fizzbuzzbucketD2245D8E - Arn - Fn::Join: - "" - - Fn::GetAtt: - fizzbuzzbucketD2245D8E - Arn - /* Version: "2012-10-17" PolicyName: fizzbuzzfuncServiceRoleDefaultPolicy9977BB4B Roles: - Ref: fizzbuzzfuncServiceRoleD547EF86 Metadata: aws:cdk:path: S3FizzbuzzStack/fizzbuzz-func/ServiceRole/DefaultPolicy/Resource自作のテンプレートでここまで作り込むには、相当CloudFormationやIAMに精通している必要があるのではないでしょうか?熟練のAWS職人がわんさかいるプロジェクトならともかく、「初めてAWSに挑戦します!」みたいな若手だらけのプロジェクトにここまでの技術を期待しますか?
そんな状態に陥るくらいなら、コンソールからのLambda作成やCloudFormationの直書きを禁止した上で、CDKを使って
Bucket#grantReadWriteメソッドを使用すること(.grantReadや.grantWriteもあります)を強制した方がよっぽどガバナンスが守られるわけです。もちろん効率面でも相当効果が高いですし、まさに一石二鳥ですね!deploy
早速デプロイしてみましょう!
$ cdk deployしばらく待つとスタックが出来ると思います。
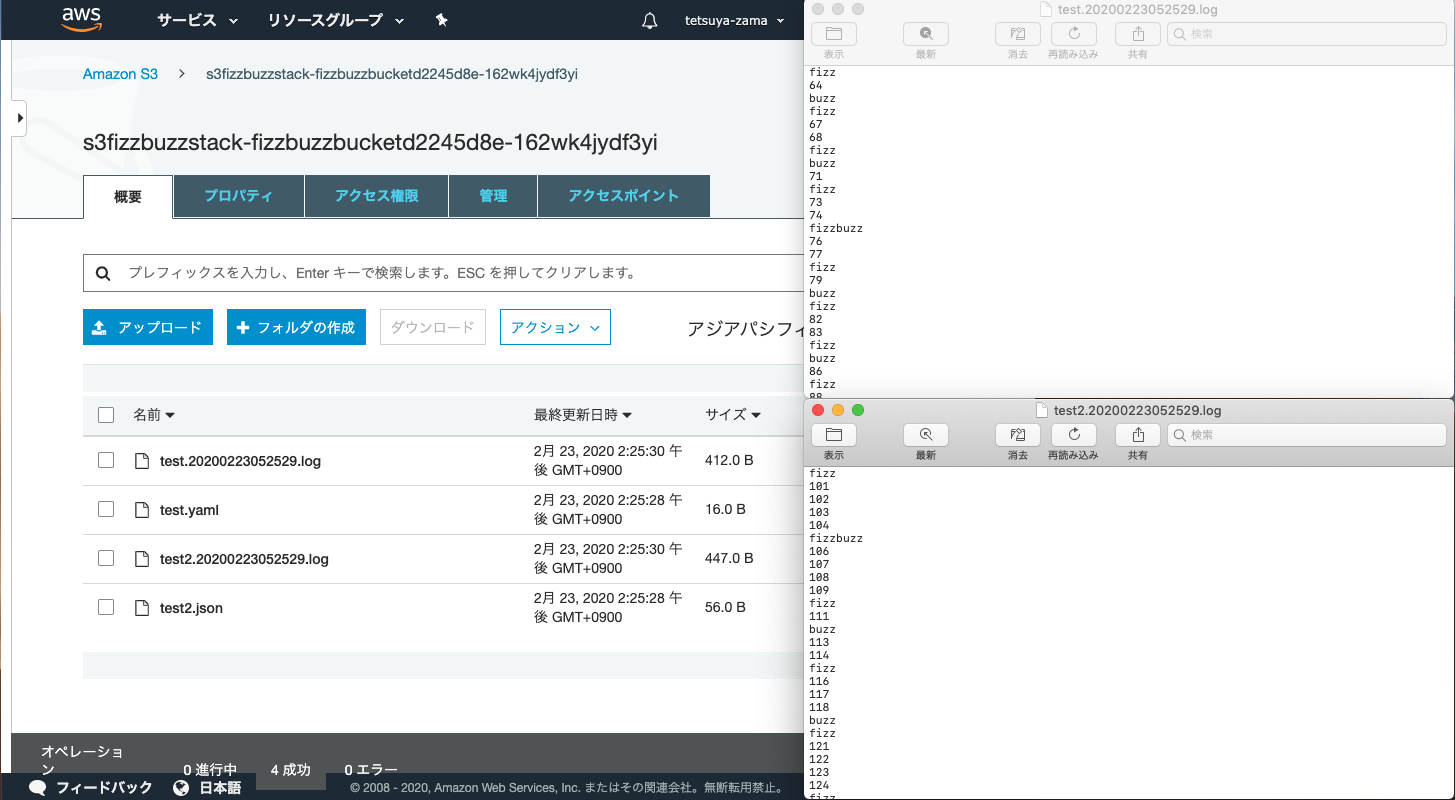
動作確認
test.yamlfrom: 1 to: 100test2.json{ "from":100, "to": 200, "fizz": 5, "buzz": 7 }結果
上手くいってそうですね!!
考察
デプロイされたlambdaのパッケージの依存関係が気になる
これまでも散々、
package.jsonやnode_modulesをCDKと共用できる!
と書いてきましたが、その結果、デプロイされたlambdaのnode_modulesはどうなってるんでしょう...?
まさか、aws-cdk本体とか@types/xxxとか、要らないものまでまとめてコピーされてるんじゃ。。。ということで、コンソールからデプロイされたlambdaを見てみましょう。
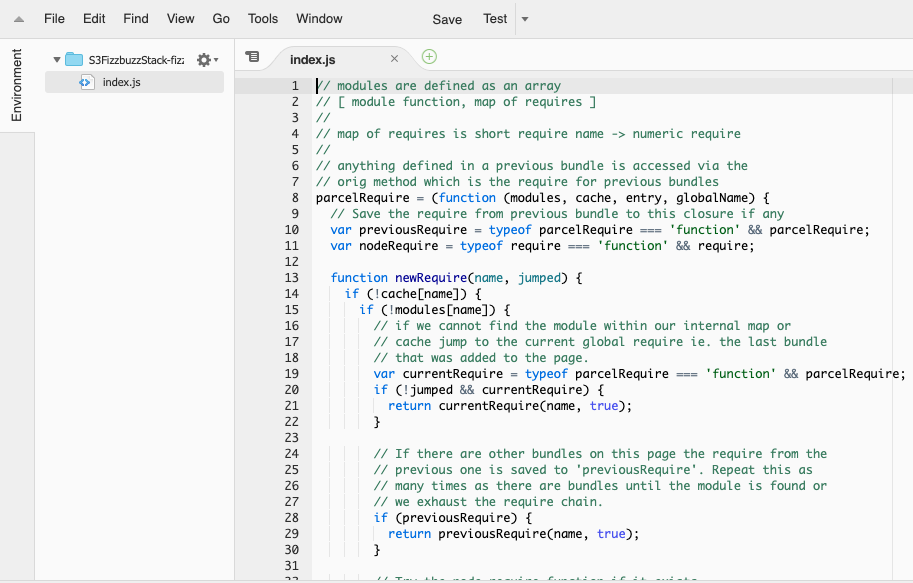
おや...?そもそも
/node_modulesが無い?しかもindex.jsの中に書いた覚えのないコードが沢山。。実はリファレンスにも書いてあるのですが、内部でParcelというパッケージングツールが動いているみたいです。
Parcelについての詳しい説明は先人の素晴らしい記事があるのでそちらを見て頂くとして、
https://qiita.com/bitrinjani/items/b08876e0a2618745f54a
https://qiita.com/soarflat/items/3e43368b2d767c730781
どうもwebpackのように、依存関係を解決して一つのファイルにまとめてくれるツールのようです。
なるほど!これで元のnode_modulesの中から必要な(lambdaが依存している)パッケージだけ引っ張ってきてindex.jsにまとめデプロイしてくれるというわけですね。こんな過去記事のようなことをしなくていいわけだ。。
所感
"アプリ"と"インフラ"がボーダレスに
我々は伝統時に、サーバやネットワークなどの"インフラ"とそこで動くプログラムとしての"アプリ"を分離して仕事していましたし、今ままでいくら「サーバレス」といっても、CloudFormationで定義する"インフラ"とlamdbdaの関数として実行される"アプリ"にはまだ壁があったように思います。
この
aws-lambda-nodejsのおかげでようやく、"アプリ"と"インフラ"の間に本当に壁が無くなって、同じTypeScriptという言語で同じアセットの中で同じ設定値(package.jsonやtsconfig.json)を共有しながら書けるようになったというのは、私にとって『新感覚』な出来事でした。"Infrastructure as Code"ならぬ"Whole system as Code"とか"Everything as Code"とか呼んでもいいんじゃないでしょうか。
TypeScriptの適用範囲の広さよ..
今やReact,Vue,Angular(およびReact NativeやNativeScript)のようなモダンなクライアントサイドはjavascriptでなくTypeScriptで書くのが当たり前となっていますし、この
aws-lambda-nodejsのおかげでサーバサイドをTypeScriptに統一する動機も増えたということで、ますますTypeScriptを勉強するモチベーションが上がりますね。いやもちろん、「マルチ言語」はマイクロサービスのメリットでもあるので、必要な局面で必要な言語(例えば、機械学習やるなら明らかにpythonですよね)を使えばいいとは思うのですが、むしろこういた「マルチ言語」の時代だからこそ、いわば『公用語』としてTypeScriptを選択するのは悪くないんじゃないかと思っています。
CloudFormationのテンプレートを直書きするのはもはやアンチパターンか
「閑話休題」でも少し触れましたが、CloudFormationのテンプレートを自作するのはもはや苦行な上にガバナンス的なデメリットもあって、良いこと無い気がしてきました。
のような素晴らしいツールがある中で、CloudFormationのテンプレート直書きはもはや積極的に避けるべきなのかも知れません。
一方でこれらのツールの挙動をちゃんと理解したりトラブルシュートをするためにはCloudFormationに関する知識は必須であるわけで。。この辺りの抽象化のバランスは難しいですね。とはいえ、例えば私のようにプログラマを名乗っていてもアセンブラを書けない人が大多数の時代も来たわけなので、そのうちtemplate.yamlが「低級言語」と言われる時代が来るのかも知れませんね。
- 投稿日:2020-02-23T16:12:07+09:00
【AWS SAA試験】S3ストレージクラスの選定が難しいので纏めてみた
ストレージクラス 即時性 頻度 コスト 冗長 備考 Standard 即時 高 高 3AZ以上 Standard IA 即時 低 3AZ以上 IA=Infrequent Access(アクセス頻度が低い) One Zone IA 即時 低 1AZ以上 One Zone = AZが1つのみ Glacier(迅速取り出し) 1~5分 低 3AZ以上 迅速とは言っても5分 Glacier(標準) 3~4時間 低 3AZ以上 Glacier Deep Archive 12時間 低 安 3AZ以上 参考サイト
https://techblog.forgevision.com/entry/2019/02/27/094449
- 投稿日:2020-02-23T15:37:39+09:00
ずぶの素人がAWSでRailsアプリを作るメモ
仕事でRailsを使うので、この機会に自分でも何かしようと思い行動に移すことにしました。
やりたいことリスト:
- Railsでサンプルアプリケーションをつくる
- 自分流にアレンジする
- 仕事で使わないような技術に触れるひとまずやってみようの精神で、失敗しながら学びます。
というわけでまずは環境から。
いろいろとローカルに用意するのは挫折しそうだったので、手っ取り早くAWSのCloud9を使用します。
ありがたいことに必要なものはそろっている(素人目線)ので、
新しく環境を作ったら、さくっと始めていきます。
新規作成した環境には初めは何もないので、Railsアプリをつくるときは
rails new sample -d mysql
でディレクトリから作成します。
(個人的にMySQLのほうが好きなのでDBを軽率に変更しています、「-d ~」はなくてもOKです)用意ができたのでさっそくRailsサーバーを立ち上げて(
rails s)、まっさらなアプリを起動しよう…
としたのですが、エラーメッセージが。
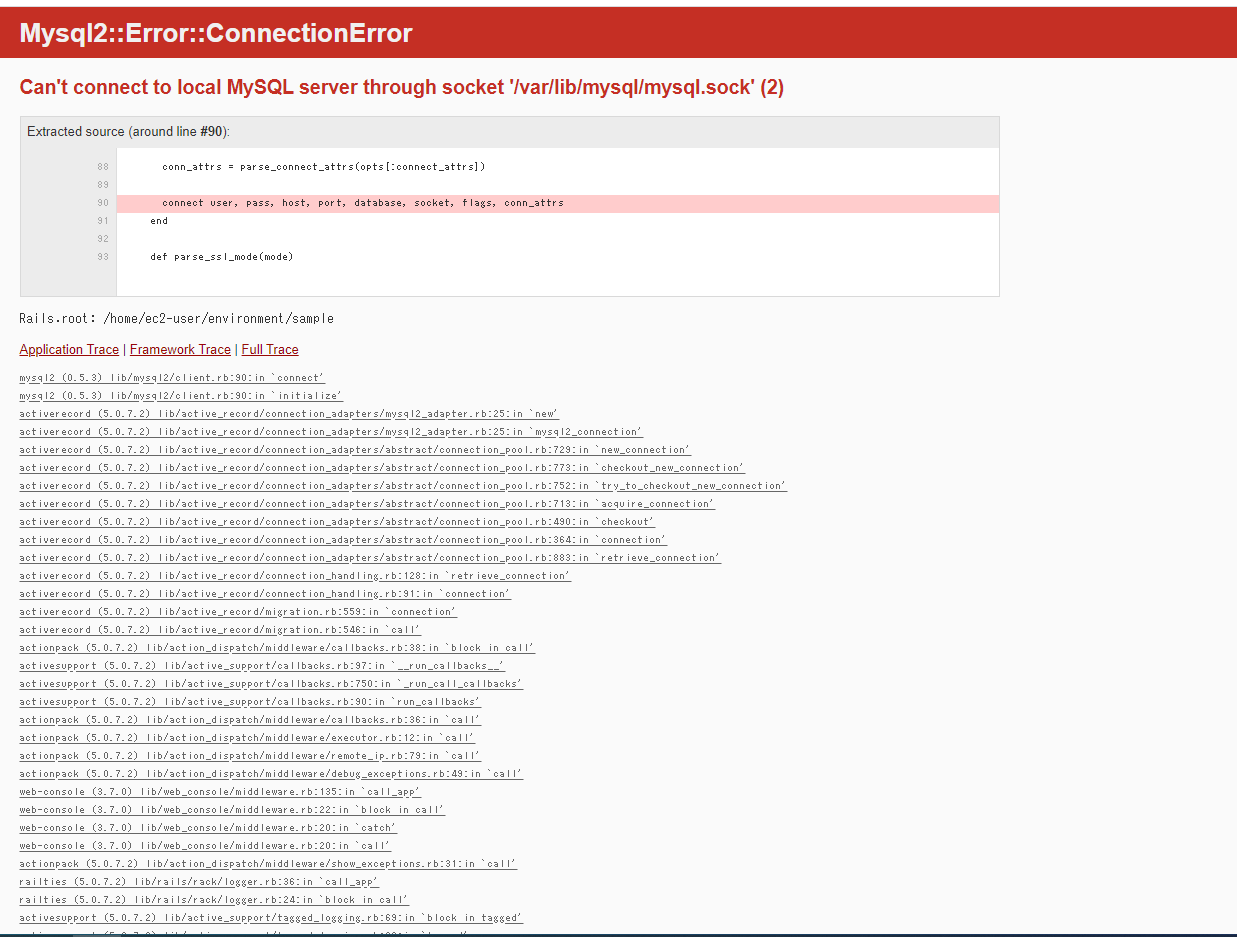
仕事でも見たことないメッセージだったのでここでしばらくワタワタしました(素人感)。
まだしっかり理解してないですが、MySQLが起動してないのでDBに接続できないと怒られているようです。
ネットで調べると以下のような記事が。
MySqlのソケットエラーを解決するありがたく以下のコマンドを拝借して、実行します。
sudo /etc/init.d/mysqld restart
そうするとエラーの種類が変わりまして、”sample_development”なんてDBはねえよ、と言われました。
これは仕事場でも見たことがあったので、おとなしく
rake db:create
します。(rails db:createでもいいはず?)今度こそうまく動いて、Railsの初期アプリの画面が表示されました。
DBをSQLiteからMySQLに変更するだけでこんなにわたつく滑り出しで、今後どういった艱難辛苦があるか想像できませんが、ひとまず進めるだけは進めたいと思います。
ネタがあったり、詰まっていた部分が解決したらまたメモします。


- 投稿日:2020-02-23T15:10:05+09:00
AWS CodeCommit (自分用メモ1)
1 IAMでCodeCommitの権限を全て持っているユーザーを作成
・ユーザー名は
aws_cli_user
・リージョンはus-east-1
で作成2 Access Key、Secret Access Keyを保存
3 CodeCommit でリポジトリを作成
4 自分のパソコンに(ローカルに)Gitを入れていること
ターミナル# ローカルにaws cliを入れる katoatsushi$ pip install awscli --upgrade --user # 設定 katoatsushi$ aws configure --profile CodeCommitUser AWS Access Key ID [None]: ASDFGHJKIUYTRFGHJKUYTGFGH AWS Secret Access Key [None]: sdfgtyujkj/+tgh/mjyRestdH&^FGHJ Default region name [None]: us-east-1 Default output format [None]: json katoatsushi$ git config --global credential.helper '!aws --region us-east-1 --profile aws_cli_user codecommit credential-helper $@' katoatsushi$ git config --global credential.UseHttpPath true次にgit clone でローカルに落とす
そしてpushターミナルkatoatsushi$ git clone https://git-codecommit.us-east-1.amazonaws.com/v1/repos/go-sample-master Cloning into 'go-sample-master'... warning: You appear to have cloned an empty repository. katoatsushi$ cd ~/sample-repo && touch main.go katoatsushi$ git add . katoatsushi$ git commit -m"first commit" katoatsushi$ git push origin master確認してみると、、、
上手くpush できてました。
次はCodeDeploy、CodePipeline、CodeCommitを使った自動デプロイです
- 投稿日:2020-02-23T15:10:05+09:00
AWS CodeCommit
1 IAMでCodeCommitの権限を全て持っているユーザーを作成
・ユーザー名は
aws_cli_user
・リージョンはus-east-1
で作成2 Access Key、Secret Access Keyを保存
3 CodeCommit でリポジトリを作成
4 自分のパソコンに(ローカルに)Gitを入れていること
ターミナル# ローカルにaws cliを入れる katoatsushi$ pip install awscli --upgrade --user # 設定 katoatsushi$ aws configure --profile CodeCommitUser AWS Access Key ID [None]: ASDFGHJKIUYTRFGHJKUYTGFGH AWS Secret Access Key [None]: sdfgtyujkj/+tgh/mjyRestdH&^FGHJ Default region name [None]: us-east-1 Default output format [None]: json katoatsushi$ git config --global credential.helper '!aws --region us-east-1 --profile aws_cli_user codecommit credential-helper $@' katoatsushi$ git config --global credential.UseHttpPath true次にgit clone でローカルに落とす
そしてpushターミナルkatoatsushi$ git clone https://git-codecommit.us-east-1.amazonaws.com/v1/repos/go-sample-master Cloning into 'go-sample-master'... warning: You appear to have cloned an empty repository. katoatsushi$ cd ~/sample-repo && touch main.go katoatsushi$ git add . katoatsushi$ git commit -m"first commit" katoatsushi$ git push origin master確認してみると、、、
上手くpush できてました。
- 投稿日:2020-02-23T14:16:08+09:00
AWS試験対策(⑩管理とガバナンス)
残り少しなんで頑張ろうと思う。このあと模試を受ける予定…
CloudWatch
監視サービス。
メトリクスの収集、ログ収集、モニタリング、アラームの設定ができる。
CloudWatch、CloudWatch Logs、CloudWatch Eventsの3サービスで構成されている。
CloudWatchはシステム監視のサービス。
CloudWatch Logsはログ管理サービス。
CloudWatch Eventsはリソースの変更をトリガーとしてアクションを行うサービス。メトリクスを収集する。メトリクスとは監視対象のパフォーマンスのこと。CPUとか。
実際のデータをデータポイントという。40%とか。
AWSサービスが収集するメトリクスを標準メトリクスといい、AWSサービスを利用すると自動的に収集される。
ユーザーが独自に収集するメトリクスをカスタムメトリクスといい、ユーザーがAWS APIやAWS CLIを使用して任意の値を収集する。
標準サービスか、自分で監視したい項目追加するかみたいな違いEC2インスタンスの監視
標準で監視可能なメトリクスと、エージェントを入れることによって監視可能になるメトリクスがある。
カスタムメトリクスならエージェント入れないと使えない。
ちなみにポーリング感覚は5分がデフォ。1分間隔の詳細モニタリングは有償。設定せねばアカン。
しかしEBSのプロビジョンドIOPSは1分間隔。なぜ。
CPUなどの、基盤側のデータはエージェント不要だが、メモリなどのOS内部の情報はエージェント必要。メトリクスの解像度と保存期間
メトリクスを収集する間隔のことを解像度という。標準メトリクスなら最小1分間隔、カスタムメトリクスなら最小1秒間隔でいける。
保存期間は、5分なら約二ヶ月、1分なら約半月保存しててくれる。料金
5分間隔なら無料。1分間隔は10個まで無料。
カスタムメトリクスや5分未満の間隔のメトリクスは有償。CloudWatchアラーム
通知機能。閾値以下であるok、閾値を超えたAlarm、データ不足とか判断できないInsufficient_dataがあり、これらをメール送信やEC2インスタンスの自動停止や再起動やAuto scalingができる。
SNSと連携できるので、SNSが出来ることはできる。Lambda起動とか。請求アラーム
利用料金が予め設定した上限を超えると通知してくれる。
ダッシュボード
グラフなどを見ることができる。
CloudWatch Logs
ログを収集、保存してくれる。保存期間は一日から10年、もしくは無期限の設定がある。
対象はAWSサービスのログ。エージェントを入れればインスタンスのログも。収集したログはS3にエクスポートできる。
CloudWatch Logs Metric Filterを使うと、特定の文字列だけ抽出できる。errorを含むログのみ表示とか、errorを含むログを見つけたときだけ通知とか。
収集したログはAmazon Elasticsearch Serviceと連携し、ビジュアル化できる。連携できる主要サービスはCloudtrail、Route53、Lambda、VPC、SNS、EC2、RDS。操作ログとかシステムログとか。
CloudWatch Events
リソースの変化をトリガーに、アクションを実行できるサービス。イベント、ターゲット、ルールがある。
イベントは、ログインしたら〜とか、何かが起こったときのこと。
ターゲットは行う処理のこと。
ルールはその2つのこと。〇〇したら☓☓する、みたいな感じ。CloudTrail
AWSサービスの操作の監視。AWSマネジメントコンソールへのログインとか、ユーザーが操作した設定変更とか、AWSサービスが実施した操作など。標準で90日間、アクティビティを各リージョンに記録してる。
証跡を有効化すると、これをs3に保存してくれる。
リージョン毎に保存する方法と、全リージョンまとめたものを作る方法がある。全リージョンで有効化すると、s3に全リージョンのアクティビティログがまとめて記録される。
また、CloudWatch Logsへの送信を有効化するとCloudWatch Logsで見れる。
よって、CloudWatch Eventsの起動などもできる。config
AWSリソースの構成管理と変更の監査を行うマネージドサービス。AWSの構成が企業のガバナンスに準拠しているかどうかを評価してくれる。
最大7年間の構成変更を記録できる。AWSリソースがいつ変更されたのかや、どの項目が変更されたのか等の履歴を記録。これをタイムラインで見ることができる。
変更されたときにSNSで通知できる。また、ログをS3に保存しておける。CloudTrailとの違いは、あっちは操作内容によってアクションを設定できるが、こっちは構成がコンプラに準拠しているかのチェックを行うだけ。ルール
ルールをきめて、それに従っているかどうかの判断をしてくれる。要するに、MFAすることをルールにすれば、設定している人がコンプラ準拠、していない人は非準拠となる。
AWSできめたAWSマネージドルールと、ユーザが決めるカスタムルールがある。こっちはユーザが構成を定義し、ルールの評価にlambda関数を作成して使用する。Configダッシュボードには結果のサマリが表示される。
Configアグリゲータは、ルールの評価結果を複数のアカウントやリージョンについて集約する。要するに一つのアカウントでとりまとめてくれる。
Trusted Advisor
現在の環境をリアルタイムで分析し、ベストプラクティスに沿ったアクションを推奨して通知してくれる。
以下5カテゴリ。
- コスト最適化
- パフォーマンス
- セキュリティ
- 耐障害性
- サービスの制限
オペレーション自動化サービス
CI/CDの話。インフラのコード化とか。以下のサービスがある。
CloudFormation
AWSリソースのテンプレによる自動デプロイサービス。インフラをコード化し自動デプロイできるようにする。
シンプルなテキストファイルによるテンプレートを使用することにより、人為的ミスを防ぎ、正確なデプロイができるようになる。インフラのコード化をInfrastructure as Codeと呼ぶ。
基本的なネットワーク構成の作成や、Webアプリケーションの作成、管理機能の有効化などができる。テンプレートはJSON形式化YAML形式で記載する。作成の際は一般的なテキストエディタかCloudFormationデザイナーを使用して作成できる。プレートスニペットというテンプレを参照できる。
CloudFormationでAWSリソースをプロビジョニング(準備)するには、CloudFormationスタックを作成して実施する。
テンプレとパラメータを入れればデプロイされる。デプロイに失敗した場合、作成されたAWSリソースは削除され、元に戻る。
テンプレ変更した後にスタックの更新をすると、デプロイ済みのAWSリソースの設定変更がされる。また、スタックを削除するとAWSリソースも削除される。
複数のリージョンやアカウントで一斉にプロビジョニングするにはCloudFormationスタックセットを作成する。スタックセットではスタックの設定に加えて、デプロイ先を指定する必要がある。Elastic Beanstalk
Webアプリケーション環境を自動構築するサービス。Webアプリケーションを実行するのに必要なWebサーバ、アプリケーションサーバ、データベースなどの構成をAWSがしてくれる。要するにこれを使えば環境を自動構築してくれる。そこにコードをアップロードするだけでアプリがデプロイされる。簡単。
アプリケーションのバージョン管理も行ってくれる。AWS Opsworks
Chef、Puppetを使用してサーバの構成管理を自動化してくれる。OpsWorksって文字が出てきたらChef、Puppetと覚えよう(理解のあきらめ)
三つの違いは、インフラの自動構成であればCloudFormation、Webアプリケーションの環境の自動構築ならElasticBeanstalk、Chefなどつかってたものをそのまま使いたいならOpsWorks。
ここまででいったん区切り。次回アプリケーション統合へ。
- 投稿日:2020-02-23T09:46:35+09:00
AWSのSTSが使われるシュチュエーションをまとめてみた
はじめに
AWS初学者(ASSを受験のため勉強中)である僕が、ネットや参考書などから集めてきた情報です。。間違いがあればコメントいただければ幸いです。
STSとは
一時的なアクセス制御に使われるAWSサービス。セッショントークンを発行することで、アクセスを許可することができる。
使用例
アカウント間で付与する場合
本番アカウントにあるEC2インスタンスからcloudwatchで取得したログを開発アカウントにあるDynamoDBに渡すことを開発側のLamdbaで処理する場合、STSを使用すれば、本番アカウントのアクセスIDなどを知らなくても処理が可能になる。
アプリケーションユーザがS3に保存したリソースを読み取りできるようにする場合
アプリケーションユーザログインする時に、サードパーティのログインを使用(Googleや Facebookなど)させ、STSのWebフェデレーションを使うことで、AWSリソースのアクセス許可することができる。
→WebIDフェデレーション企業内の認証機能をAWSで使用する場合
元々企業内にある認証機能をAWSと紐づけることで、企業内認証するだけでSTSを使って、AWSリソースを扱うことができる機能(シングルサインオンを簡単にしてくれる)。SAML2.0やOpenID Connectと互換性のある認証プロトコルをサポートしている。
- 投稿日:2020-02-23T08:27:36+09:00
AWS Solution Architect Professional 取得 - 2020年
AWS Solution Architect Professionalを取得した。
3年後に恐らくは認定更新試験を受けているであろう自分に向けてのメモも兼ねて記録する。試験準備
Udemyの練習テストがセールで1000円ちょっとで買えたので、2周ほどして75%以上取れるようにした。
https://www.udemy.com/course/aws-solutions-architect-professional-practice-exams-amazon/全編英語なので下手したら本試験以上に辛い。Google翻訳で頑張るが、英語もある程度読む必要がある。これは日本語で本試験を受ける場合も同じで、意味不明瞭な日本語を発見し、英語で解き直すというプロセスは本試験そのままである。
みんな大好きBlakbeltは普段触れていないサービスを中心に読む。無味乾燥な試験問題と格闘している最中では最良の息抜きになりえる。
https://aws.amazon.com/jp/aws-jp-introduction/aws-jp-webinar-service-cut/試験準備期間は2週間ほどだが実務でもAWSをバリバリ触っているのでアテにならない。
試験の難しさについて
今まで様々なペーパーテストを受けてきたが、この試験はなかなかに難しいと感じた。いくつかの理由があるように思う。
- 日本語の翻訳文がおかしい。明らかに日本語の意味のまま選択肢を選ぶと間違える問題がある
- 文章が長い。中~長文問題を75問、3時間にわたって解くのは人間の集中力限界を超えている。SAP試験のあとにTOEICを受けると驚くほど早く終る気がする
- 試験範囲が広く、実務で全く触れたことのないサービスが出てくる
試験当日
普段あまり食べない朝食をしっかり食べ、リポビタンDを飲み、脳に刺激を与えるためにガムを噛むという念の入れよう。そのぐらい3時間の試験というのは長い。
試験の難しさへの対策として、少しでも文章をおかしく感じたら英語で試験を解き直す、25問ごとに30秒~1分ほどの休憩をいれる。全く聞いたこともないようなサービスが登場したら天を仰いで悪態をつく。「やれやれだぜ」
上記を手抜かりなく実施すると不思議なことに試験時間は残り3分とかになっている。
あとで見直そうとマークをつけていた問題が数えたら24問もあり、3分の1は見直せないだろjkと脳が見直し拒否したのですぐ試験終了した。結果は80%ほどであった。合格ラインは75%なのでギリギリ。
心得
一石二鳥を狙わない。
SAP取るついでに英語の勉強もできたら最高じゃんと欲を出して練習問題とかUserGuideとか英語で読みきろうとした。
非常に疲れる。効率も悪い気がする。
試験に受かることが目的なら、とりあえずそのことに集中し、英語は別の機会に勉強したほうがいいかなと思った。これから
英語で受験したほうが本質以外のことに脳カロリーを回さなくて済む。
次回は、英語受験してみても良いかもしれない。