- 投稿日:2020-02-23T23:05:54+09:00
基本的な機械学習の手順:③特徴量の選択方法を比較検討する
はじめに
基本的な機械学習の手順:①分類モデルでは、基本的な分類モデルの作成手順を整理しています。
今回は、その中で特徴量の選択にフォーカスして、様々な特徴量の選択方法を比較検討してみたいと思います。分析環境
Google BigQuery
Google Colaboratory対象とするデータ
①分類モデルと同様に、下記の様なテーブル構造で購買データが格納されています。
id result product1 product2 product3 product4 product5 001 1 2500 1200 1890 530 null 002 0 750 3300 null 1250 2000 特徴量の選択が目的なので、横軸を300くらいもたせます。
0.対象とする特徴量の選択方法
特徴量選択についてから、次の手法を選びました。
- Embedded Method(SelectFromModel)
- Wrapper Method(RFE)
また、scikit-learnではないけど、ランダムフォレストと検定を用いた特徴量選択手法 Borutaで紹介されていた、Wrapper Methodの1つであるBorutaも用いたいと思います。
- Wrapper Method(Boruta)
同じ条件で比較するために、特徴量選択で用いる分類機は、全てRandomForestClassifierを用いたいと思います。
1.Embedded Method(SelectFromModel)
まずは、基本的な機械学習の手順:①分類モデルで用いた、Embedded Methodを使います。
Embedded Methodは、特定のモデルに特徴量を組み込んで、最適な特徴量を選択します。import numpy as np from sklearn.ensemble import RandomForestClassifier from sklearn.feature_selection import SelectFromModel # numpy配列に変更 label = np.array(df.loc[0:, label_col]) features = np.array(df.loc[0:, feature_cols]) # 変数選択 clf = RandomForestClassifier(max_depth=7) ## Embedded Methodを用いて変数を選択 feat_selector = SelectFromModel(clf) feat_selector.fit(features, label) df_feat_selected = df.loc[0:, feature_cols].loc[0:, feat_selector.get_support()]選ばれた変数は、36個。
これらの変数を用いて出た精度が次の通り。かなり高いですが、Recallが少し改善したいですね。
- Accuracy : 92%
- Precision : 99%
- Recall : 84%
2.Wrapper Method(RFE)
続いて、Wrapper Methodを用います。こちらは、特徴量の部分集合で予測モデルを回して、最適な部分集合を見つけるという手法です。
import numpy as np from sklearn.ensemble import RandomForestClassifier from sklearn.feature_selection import RFE # numpy配列に変更 label = np.array(df.loc[0:, label_col]) features = np.array(df.loc[0:, feature_cols]) # 変数選択 clf = RandomForestClassifier(max_depth=7) ## Embedded Methodを用いて変数を選択 feat_selector = RFE(clf) feat_selector.fit(features, label) df_feat_selected = df.loc[0:, feature_cols].loc[0:, feat_selector.get_support()]選ばれた変数は、146個。Embedded Methodに比べると、かなり多いです。
これらの変数を用いて出た精度が次の通り。小数点以下は多少違いまずが、Embedded Methodとほぼ同程度です。
- Accuracy : 92%
- Precision : 99%
- Recall : 84%
3.Wrapper Method(Boruta)
最後はBorutaです。Borutaは、Colaboratoryで標準インストールされていないので、まずはpip installします。
pip install borutaこちらも、Wrapper Methodですので、最適な部分集合を見つけていきます。
ただ、先のRFEに比べて時間はかなり掛かります。進捗が出てるので、ゆっくりと待ちましょう。from boruta import BorutaPy # numpy配列に変更 label = np.array(df.loc[0:, label_col]) features = np.array(df.loc[0:, feature_cols]) # 変数選択 ## ここでは分類を想定して、ランダムフォレスト(RandomForestClassifier)を用いる clf = RandomForestRegressor(max_depth=7) ## Borutaを用いて変数を選択 feat_selector = BorutaPy(clf, n_estimators='auto', two_step=False, verbose=2, random_state=42) feat_selector.fit(features, label) df_feat_selected=df.loc[0:, feature_cols].loc[0:, feat_selector.support_]選ばれた変数は、97個。
これらの変数を用いて出た精度が次の通り。変わらない。。。
- Accuracy : 92%
- Precision : 99%
- Recall : 84%
おわりに
本当は、変数の選択の仕方によって、精度が結構変わっていく!という結果にしたかったのですが、残念ながらほぼ同程度の結果になりました。(サンプルにしたデータがいけなかったかな)
今回は、3種類だけを比較しましたが、先にも参照させていただいた特徴量選択のまとめでは、Wrapper MethodのStep ForwardやStep backwardなど、今回試せていない手法もあるので、今後試していきたいと思います。
- 投稿日:2020-02-23T22:15:51+09:00
【Python】Enumでvalue以外のkeyでも値を取得する方法
Enumでvalue以外のkeyでも値を取得する方法
はじめに
多くのプログラミング言語にはEnumというものがあります。Pythonにも同様にあります。メンバーの取得はそれぞれの
valueをkeyに取得できますが、それ以外の値をkeyにすることはできません。通常のEnumを拡張すればできたので紹介します。通常のEnumの確認
まずは通常のEnumの利用方法を確認します。
>>> from enum import Enum >>> >>> class Color(Enum): ... RED = 1 ... GREEN = 2 ... BLUE = 3 # 上記のようにEnumを宣言すると # 1や2といったvalueをkeyにして各メンバーにアクセスできます >>> color = Color(1) >>> print(color) Color.RED # もちろん直接アクセスすることもできます >>> print(Color.RED) Color.RED >>> print(color == Color.RED) Trueやりたいこと
Color(1)でColor.REDにアクセスできましたがたとえばColor('red')やColor('赤')でもアクセスできたらEnumの可能性が広がります。>>> from enum import Enum >>> >>> class Color(Enum): ... RED = 1 ... GREEN = 2 ... BLUE = 3 # 以下のようにアクセスしようとするともちろんエラーになる >>> color = Color('red') Traceback (most recent call last): File "<console>", line 1, in <module> File "/usr/local/lib/python3.6/enum.py", line 293, in __call__ return cls.__new__(cls, value) File "/usr/local/lib/python3.6/enum.py", line 535, in __new__ return cls._missing_(value) File "/usr/local/lib/python3.6/enum.py", line 548, in _missing_ raise ValueError("%r is not a valid %s" % (value, cls.__name__)) ValueError: 'red' is not a valid Color >>> color = Color('赤') Traceback (most recent call last): File "<console>", line 1, in <module> File "/usr/local/lib/python3.6/enum.py", line 293, in __call__ return cls.__new__(cls, value) File "/usr/local/lib/python3.6/enum.py", line 535, in __new__ return cls._missing_(value) File "/usr/local/lib/python3.6/enum.py", line 548, in _missing_ raise ValueError("%r is not a valid %s" % (value, cls.__name__)) ValueError: '赤' is not a valid Color実装
ではkeyを拡張したEnumの実装を確認します。
# 宣言時に以下のように`_value2member_map_`を更新する >>> from enum import Enum >>> >>> class Color(Enum): ... def __new__(cls, value, en, ja): ... obj = object.__new__(cls) ... obj._value_ = value ... cls._value2member_map_.update({en: obj, ja: obj}) ... return obj ... RED = (1, 'red', '赤') ... GREEN = (2, 'green', '緑') ... BLUE = (3, 'blue', '青') # これで先程のように'red'や'赤'でアクセスすると >>> color = Color('red') >>> print(color) Color.RED >>> red = Color('赤') >>> print(red) Color.RED最後に
やりすぎるとkeyがかぶったりする可能性もありますが、知っておいて損はないと思います。
DBではint型、APIではstr型とかで使えそうです。
- 投稿日:2020-02-23T22:03:37+09:00
[kotlin]アンドロイドでリアルタイム画像認識アプリをつくる
今回やること
アンドロイドでカメラに映った映像(画像)をリアルタイムで画像認識するアプリを作る。
PyTorch Mobileを使って学習済みモデルをアンドロイドで動かす。これ↓
依存関係
まずは依存関係(dependencies)を追加(2020年2月時点)
camera x と pytorch mobilebuild.gradledef camerax_version = '1.0.0-alpha06' implementation "androidx.camera:camera-core:${camerax_version}" implementation "androidx.camera:camera-camera2:${camerax_version}" implementation 'org.pytorch:pytorch_android:1.4.0' implementation 'org.pytorch:pytorch_android_torchvision:1.4.0'上の方のandroid{}ってあるところの一番最後に以下を追加
build.gradlecompileOptions { sourceCompatibility JavaVersion.VERSION_1_8 targetCompatibility JavaVersion.VERSION_1_8 }Camera Xの実装
依存関係を追加したら続いてCamera Xというアンドロイドで簡単にカメラを扱いやすくなるライブラリを利用して写真を撮る機能を実装する。
以下、公式のCamera Xのチュートリアルを実装していく。詳細は他の記事でも上がっていたりするので省略してコードのみ。
マニフェスト
パーミッションの許可
<uses-permission android:name="android.permission.CAMERA" />レイアウト
カメラを起動するボタンとプレビュー表示用のtextureView等を配置
activity_main.xml<?xml version="1.0" encoding="utf-8"?> <androidx.constraintlayout.widget.ConstraintLayout xmlns:android="http://schemas.android.com/apk/res/android" xmlns:app="http://schemas.android.com/apk/res-auto" xmlns:tools="http://schemas.android.com/tools" android:layout_width="match_parent" android:layout_height="match_parent" tools:context=".MainActivity"> <TextureView android:id="@+id/view_finder" android:layout_width="0dp" android:layout_height="0dp" android:layout_marginBottom="16dp" app:layout_constraintBottom_toTopOf="@+id/activateCameraBtn" app:layout_constraintEnd_toEndOf="parent" app:layout_constraintStart_toStartOf="parent" app:layout_constraintTop_toTopOf="parent" /> <androidx.constraintlayout.widget.ConstraintLayout android:layout_width="match_parent" android:layout_height="wrap_content" android:alpha="0.7" android:animateLayoutChanges="true" android:background="@android:color/white" app:layout_constraintEnd_toEndOf="@+id/view_finder" app:layout_constraintStart_toStartOf="parent" app:layout_constraintTop_toTopOf="@+id/view_finder"> <TextView android:id="@+id/inferredCategoryText" android:layout_width="0dp" android:layout_height="wrap_content" android:layout_marginStart="8dp" android:layout_marginTop="16dp" android:layout_marginEnd="8dp" android:text="推論結果" android:textSize="18sp" app:layout_constraintEnd_toEndOf="parent" app:layout_constraintStart_toStartOf="parent" app:layout_constraintTop_toTopOf="parent" /> <TextView android:id="@+id/inferredScoreText" android:layout_width="wrap_content" android:layout_height="wrap_content" android:layout_marginStart="24dp" android:layout_marginTop="16dp" android:text="スコア" android:textSize="18sp" app:layout_constraintStart_toStartOf="parent" app:layout_constraintTop_toBottomOf="@+id/inferredCategoryText" /> </androidx.constraintlayout.widget.ConstraintLayout> <Button android:id="@+id/activateCameraBtn" android:layout_width="wrap_content" android:layout_height="wrap_content" android:layout_marginBottom="16dp" android:text="カメラ起動" app:layout_constraintBottom_toBottomOf="parent" app:layout_constraintEnd_toEndOf="parent" app:layout_constraintStart_toStartOf="parent" /> </androidx.constraintlayout.widget.ConstraintLayout>use case
Camera X ではプレビュー、画像キャプチャ、画像解析の3つのuse caseが提供されている。今回はプレビューと画像解析を使っていく。use caseに合わせることでコードがかき分けやすくなる。
ちなみに可能な組み合わせは以下の通り。(公式ドキュメントより)
プレビューuse caseを実装
Camera Xのuse caseのプレビューまで実装していく。
ほぼチュートリアルと同様の内容。MainActivity.ktprivate const val REQUEST_CODE_PERMISSIONS = 10 private val REQUIRED_PERMISSIONS = arrayOf(Manifest.permission.CAMERA) class MainActivity : AppCompatActivity(), LifecycleOwner { private val executor = Executors.newSingleThreadExecutor() private lateinit var viewFinder: TextureView override fun onCreate(savedInstanceState: Bundle?) { super.onCreate(savedInstanceState) setContentView(R.layout.activity_main) viewFinder = findViewById(R.id.view_finder) // カメラ起動 activateCameraBtn.setOnClickListener { if (allPermissionsGranted()) { viewFinder.post { startCamera() } } else { ActivityCompat.requestPermissions( this, REQUIRED_PERMISSIONS, REQUEST_CODE_PERMISSIONS ) } } viewFinder.addOnLayoutChangeListener { _, _, _, _, _, _, _, _, _ -> updateTransform() } } private fun startCamera() { //プレビューuseCaseの実装 val previewConfig = PreviewConfig.Builder().apply { setTargetResolution(Size(viewFinder.width, viewFinder.height)) }.build() val preview = Preview(previewConfig) preview.setOnPreviewOutputUpdateListener { val parent = viewFinder.parent as ViewGroup parent.removeView(viewFinder) parent.addView(viewFinder, 0) viewFinder.surfaceTexture = it.surfaceTexture updateTransform() } /**後でここに画像解析useCaseの実装をする**/ CameraX.bindToLifecycle(this, preview) } private fun updateTransform() { val matrix = Matrix() val centerX = viewFinder.width / 2f val centerY = viewFinder.height / 2f val rotationDegrees = when (viewFinder.display.rotation) { Surface.ROTATION_0 -> 0 Surface.ROTATION_90 -> 90 Surface.ROTATION_180 -> 180 Surface.ROTATION_270 -> 270 else -> return } matrix.postRotate(-rotationDegrees.toFloat(), centerX, centerY) //textureViewに反映 viewFinder.setTransform(matrix) } override fun onRequestPermissionsResult( requestCode: Int, permissions: Array<String>, grantResults: IntArray ) { if (requestCode == REQUEST_CODE_PERMISSIONS) { if (allPermissionsGranted()) { viewFinder.post { startCamera() } } else { Toast.makeText( this, "Permissions not granted by the user.", Toast.LENGTH_SHORT ).show() finish() } } } private fun allPermissionsGranted() = REQUIRED_PERMISSIONS.all { ContextCompat.checkSelfPermission( baseContext, it ) == PackageManager.PERMISSION_GRANTED } }モデルと分類クラスの用意
今回は学習済みのresnet18を使う。
※python pytorchの環境がある方は以下のコードをpythonで実行、ない方はgithubからresnet.ptをダウンロードしてください。import torch import torchvision model = torchvision.models.resnet18(pretrained=True) model.eval() example = torch.rand(1, 3, 224, 224) traced_script_module = torch.jit.trace(model, example) traced_script_module.save("resnet.pt")うまく実行できると同じ階層にresnet.ptというファイルが生成される。この学習済みresnet18を使って画像認識していく。
ダウンロードしたモデルをandroid studio のassetフォルダに入れる。(デフォルトでは存在しないのでresフォルダとかを右クリック->新規->フォルダ-> Assetフォルダで作れる)
推論した後にクラス名に変換するためにImageNetクラスをファイルに書いておく。新しくImageNetClasses.ktとかを作って、その中にImageNetの1000クラスを書いておく。
長すぎるのでgithubからコピペしてください。ImageNetClasses.ktclass ImageNetClasses { var IMAGENET_CLASSES = arrayOf( "tench, Tinca tinca", "goldfish, Carassius auratus", //略(githubからコピペしてください) "ear, spike, capitulum", "toilet tissue, toilet paper, bathroom tissue" ) }画像解析use caseの作成
つづいてCamera Xのuse caseの画像解析を実装していく。
新しくImageAnalyze.ktというファイルを作って画像認識の処理を行う。流れ的にはモデルをロードして画像解析 use caseでプレビューの画像をpytorch mobileで使えるようにテンソルに変換し先ほどassetフォルダからロードしたモデルに通してその結果を取得する感じ。
あとは、viewに推論結果を反映させるためにインターフェースとかカスタムリスナとかを書いている。(この辺、正しい書き方がイマイチ分からず、我流なのでスマートな書き方があれば教えてください。)
ImageAnalyze.ktclass ImageAnalyze(context: Context) : ImageAnalysis.Analyzer { private lateinit var listener: OnAnalyzeListener // Viewを更新するためのカスタムリスナ private var lastAnalyzedTimestamp = 0L //ネットワークモデルのモデルのロード private val resnet = Module.load(getAssetFilePath(context, "resnet.pt")) interface OnAnalyzeListener { fun getAnalyzeResult(inferredCategory: String, score: Float) } override fun analyze(image: ImageProxy, rotationDegrees: Int) { val currentTimestamp = System.currentTimeMillis() if (currentTimestamp - lastAnalyzedTimestamp >= 0.5) { // 0.5秒ごとに推論する lastAnalyzedTimestamp = currentTimestamp // テンソルに変換 (imageのformat調べてみたらYUV_420_888とかいうのだった) val inputTensor = TensorImageUtils.imageYUV420CenterCropToFloat32Tensor( image.image, rotationDegrees, 224, 224, TensorImageUtils.TORCHVISION_NORM_MEAN_RGB, TensorImageUtils.TORCHVISION_NORM_STD_RGB ) // 学習済みモデルで推論する val outputTensor = resnet.forward(IValue.from(inputTensor)).toTensor() val scores = outputTensor.dataAsFloatArray var maxScore = 0F var maxScoreIdx = 0 for (i in scores.indices) { //スコアが最大のインデックスを取得 if (scores[i] > maxScore) { maxScore = scores[i] maxScoreIdx = i } } // スコアからカテゴリ名を取得 val inferredCategory = ImageNetClasses().IMAGENET_CLASSES[maxScoreIdx] listener.getAnalyzeResult(inferredCategory, maxScore) // Viewを更新 } } //// assetファイルからパスを取得する関数 private fun getAssetFilePath(context: Context, assetName: String): String { val file = File(context.filesDir, assetName) if (file.exists() && file.length() > 0) { return file.absolutePath } context.assets.open(assetName).use { inputStream -> FileOutputStream(file).use { outputStream -> val buffer = ByteArray(4 * 1024) var read: Int while (inputStream.read(buffer).also { read = it } != -1) { outputStream.write(buffer, 0, read) } outputStream.flush() } return file.absolutePath } } fun setOnAnalyzeListener(listener: OnAnalyzeListener){ this.listener = listener } }画像がImageProxyとかいうよくわからない型で戸惑ったがformat調べるとYUV_420_888とかでbitmapに変換しなきゃダメかなとか思ってたけど、pytorch mobileにYUV_420からテンソルに変換するメソッドがあり、放り込むだけで簡単に推論できた。
ちなみにコード見た方は思ったかもしれないですが、リアルタイムといってますが、0.5秒刻みです..
画像解析use caseを組み込む
先ほど作ったImageAnalyzeクラスをCamera Xにuse caseとして導入し、最後にImageAnalyzeクラスのインターフェースを無名オブジェクト使ってMainActivityで実装し、viewを更新できるようにして完成。
以下のコードをonCreateの最後に追加する。(上の方で「/後でここに画像解析useCaseの実装をする/ 」とコメントしてあったところ)
MainActivity.kt// 画像解析useCaseの実装 val analyzerConfig = ImageAnalysisConfig.Builder().apply { setImageReaderMode( ImageAnalysis.ImageReaderMode.ACQUIRE_LATEST_IMAGE ) }.build() //インスタンス val imageAnalyzer = ImageAnalyze(applicationContext) //推論結果を表示 imageAnalyzer.setOnAnalyzeListener(object : ImageAnalyze.OnAnalyzeListener { override fun getAnalyzeResult(inferredCategory: String, score: Float) { // メインスレッド以外からviewの変更をする viewFinder.post { inferredCategoryText.text = "推論結果: $inferredCategory" inferredScoreText.text = "スコア: $score" } } }) val analyzerUseCase = ImageAnalysis(analyzerConfig).apply { setAnalyzer(executor, imageAnalyzer) } // useCaseはプレビューと画像解析 CameraX.bindToLifecycle(this, preview, analyzerUseCase) // use caseに画像解析を追加完成!!
ここまでうまく実装出来た方は冒頭のアプリが完成しているはず。いろいろ遊んでみてください。おわり
今回のコードはgithubに挙げているので適宜参照してください。
Camera X ほんとに便利! pytroch mobileとかと組み合わせて、簡単に画像解析を行ったりできる。少々処理で重くなるのはしょうがないけど。
モデルさえ用意できればカメラ使っていろんな画像認識系のアプリが簡単に作れそう。やっぱり、転移学習とかしてそのモデル使ってなんかアプリ作るのが手っ取り早いのかな。なんか機械学習系のアプリ作ってリリースしてみたい...


- 投稿日:2020-02-23T21:40:34+09:00
初心者でもPythonを学習できるサービス7選をまとめてみた
既存の様々なサイトなどで確認したところ、
料金表示などが古くなっていたので改めてまとめてみました。プログラミングの入門なら基礎から学べるprogate
progateは環境構築不要で、
これからプログラミングを学びたい初心者に最もオススメの学習サイトです。
プログラミング用語も非常に丁寧で分かりやすい説明がされているので、
挫折することなく安心して学習を進めることができるでしょう。
ただ、ここで学べることは基礎中の基礎なので、
ここで学んだからといってすぐに業務に活かすことはできないでしょう。
初級者向け。paizaラーニング
paizaも環境構築が不要です。
progateで学んだ次にここで学ぶと良いでしょう。
pythonの触りを確認した次はここで、もう少し発展的な、
よりpythonらしさを学ぶことができるコースがあります。
初級者向け。3分動画でマスターできるプログラミング学習サービス
ドットインストールで学んだことを
コードを書いて確認するには環境構築が必要です。
3分程度の短い動画が基本なので飽きずに、挫折せずに学習を進めることができるでしょう。
初級者向け。PythonでAIプログラミングが学べるオンライン学習サービス
Leagence Programmingは環境構築不要で、
今なら完全無料で学習をすることができます。
pythonの基礎からディープラーニングまでを学べます。
初級・中級者向け。10秒ではじめられる人工知能学習サービス
Aidemyも環境構築が不要です。
最先端の技術を学ぶことのできるサイトです。
初級・中級・上級者向け。本気でプログラミングを学びたいあなたへ
PyQも環境構築不要です。
実務よりのスキルを身につけることができる初級・中級者向けのサイトです。Udemy
Udemyは環境構築が必要です。
初心者から上級者まで対応した様々なコースがあります。料金を比較
サービス名 価格 progate 一部無料(月額980~) paiza 一部無料(月額1078円~) ドットインストール 一部無料(月額1080円~) Leagence Programming 完全無料 Aidemy 一部無料(1コース980円~) PyQ 月額3040円〜 Udemy 1コース2400円~ 感想
もしPythonを全く学んだことがない立場だったら、
progate→paizaかドットインストール→他のどれか
という順番で学ぶと思います。
- 投稿日:2020-02-23T21:25:52+09:00
スポーツ記事から選手と技名を抽出してみた
Motive
【Qiita x COTOHA APIプレゼント企画】関連の投稿です。
COTOHA API で照応解析してもギブミーチョコレート出来ていない問題とは別のAPIを使ってみました。
今回は
固有表現抽出(/nlp/v1/ne)
APIです。MeCabだったら固有名詞を学習をして辞書に登録しないと人物名が抽出できなかった気がします。あと、KLPは精度は良さそうなのですがパッケージ自体重いです。
また、形態素解析すると機械学習された分配器が優秀なのか品詞までは正確に出力されるのですが、文章の中で多く出て来る名詞を分類できていたかと言うとそうでもない気がします。
COTOHAではAPIだけで名詞の細かい分類をしてくれます。どこまで固有名詞を抽出できるかを簡易的にトライするために、スポーツ記事から人物名・技名を出力してみました。
Environment
- Python 3.6.8
- COTOHA API (https://api.ce-cotoha.com/)
Dataset
東京スポーツ
選定基準としては住んでいる地域ではこのスポーツ新聞が発売されていないという高尚な理由です。Method
前述の通り、
COTOHA API 固有抽出
https://api.ce-cotoha.com/contents/reference/apireference.html#parsing_io_part
を使っています。選手(人物)は
x["class"] == "PSN" and x["extended_class"] == ""、技名はx["class"] == "ART" and x["extended_class"] in [
"Doctrine_Method_Other"]
で抽出しています。Doctrine_Method_Otherは(主義方式名_その他)という意味です。
名称 説明 ORG 組織名 PSN 人名 LOC 場所 ART 固有物名 DAT 日付表現 TIM 時刻表現 NUM 数値表現 MNY 金額表現 PCT 割合表現 OTH その他 Development
Script
import argparse import requests from bs4 import BeautifulSoup import json #--- この4つパラメータはPortalで取得 --- PUBLISH_URL = "--- get your parameter ---" CLIENT_ID = "--- get your parameter ---" CLIENT_SECRET = "--- get your parameter ---" BASE_URL = "--- get your parameter ---" class COTOHA: def __init__(self): self._token = self._getAccessToken() def _getAccessToken(self): header = {"Content-Type": "application/json"} contents = { "grantType": "client_credentials", "clientId": CLIENT_ID, "clientSecret": CLIENT_SECRET } raw_res = requests.post(PUBLISH_URL, headers=header, json=contents) response = raw_res.json() return response["access_token"] def compose(self, sentence): header = { "Authorization": "Bearer {}".format(self._token), "Content-Type": "application/json" } contents = { "sentence": sentence } raw_res = requests.post( BASE_URL + "nlp/v1/parse", headers=header, json=contents) response = raw_res.json() return response def properNoun(self, sentence): header = { "Authorization": "Bearer {}".format(self._token), "Content-Type": "application/json" } contents = { "sentence": sentence } raw_res = requests.post( BASE_URL + "nlp/v1/ne", headers=header, json=contents) response = raw_res.json() return response def keyword(self, sentence): header = { "Authorization": "Bearer {}".format(self._token), "Content-Type": "application/json" } contents = { "document": sentence } raw_res = requests.post( BASE_URL + "nlp/v1/keyword", headers=header, json=contents) response = raw_res.json() return response def coreference(self, sentence): header = { "Authorization": "Bearer {}".format(self._token), "Content-Type": "application/json" } contents = { "document": sentence } raw_res = requests.post( BASE_URL + "nlp/v1/coreference", headers=header, json=contents) response = raw_res.json() return response def extract_norn_list(_apiobj, contents, condition): dst = [] for p in contents: items = _apiobj.properNoun(p.text)["result"] _raw = list(filter(condition, items)) # print(_raw) # 略称は除く for _p in _raw: name = _p["form"] _exist = False for pname in dst: if name in pname: _exist = True if not _exist: dst.append(name) return dst def main(): parser = argparse.ArgumentParser() parser.add_argument("--url") args = parser.parse_args() #APIオブジェクトを作成 cotoha = COTOHA() #URLから記事を取得(東京スポーツ仕様) res = requests.get(args.url) soup = BeautifulSoup(res.text, 'html.parser') title_text = soup.find('title').get_text() contents = soup.find('div', {"class": "detail-content"}).find_all("p") #抽出条件 def is_person(x): return x["class"] == "PSN" and x["extended_class"] == "" def is_attack(x): return x["class"] == "ART" and x["extended_class"] in [ "Doctrine_Method_Other"] #選手を出力 print(extract_norn_list(cotoha, contents, is_person)) #技名を出力 print(extract_norn_list(cotoha, contents, is_attack)) if __name__ == "__main__": main()Command
python main.py --url https://www.tokyo-sports.co.jp/prores/ddt/1754700/Consequence
2つの記事を使って実行します。
【新日1・5東京ドーム】みのる US王座防衛のモクスリー襲撃「誰にケンカ売ってんだ!」
https://www.tokyo-sports.co.jp/prores/njpw/1682622/
dataset
新日本プロレスの年間最大興行「レッスルキングダム14」(5日、東京ドーム)で行われたIWGP・USヘビー級王座戦は、王者ジョン・モクスリー(34)がIWGPタッグ王者のジュース・ロビンソン(30)の挑戦を退け、初防衛に成功した。 前夜(4日)の東京ドーム大会では、モクスリーがランス・アーチャー(32)から王座を奪回。ジュースはデビッド・フィンレー(26)とのコンビでタッグ王座を獲得した。その翌日に新王者同士の決戦となったが、モクスリーは昨年6月にジュースから同王座を奪っており、前夜のリング上で決着をつけることを宣言していた。 序盤はジュースが快調に先制したものの、モクスリーは場外でイスを持ち出して背中に一撃。さらにはジュースの額にかみついた。WWE時代に“狂犬”として暴れ回った荒くれ者が、強引にペースを奪い返した。 ジュースは豪快なハイアングルパワーボムで反撃したが、王者は足4の字固めから鉄柱を使った4の字と意表を突いた攻撃を連発した。挑戦者は雪崩式ブレーンバスターからジャックハマーにジャーマン。モクスリーのデスライダー(ダブルアーム式DDT)をかわして、ラリアートでぶち抜いた。 だが、王者は乱打戦から強烈なランニングニーを一閃。ジュースのパルプフリクションを切り返して、DDTから必殺のデスライダーを炸裂させて12分48秒、3カウントを奪った。 試合後には入場テーマ曲が流れ、いきなり鈴木みのる(51)が登場。昨年12月8日の広島大会でモスクリーからデスライダーを見舞われており、険しい表情で怒りを隠せない。花道でジャージーを脱いで戦闘態勢に入ると、リング上で王者とエルボーを打ち合った。ド迫力のみのるは裸絞めからゴッチ式パイルドライバーでモクスリーをKOした。 みのるはマイクを握ると「誰にケンカ売ってんだ、このヤロー! オレはプロレスラーの鈴木みのるだ。こいつのケンカ、オレが買ってやる!」と宣戦布告。US王座を巡る“狂犬”対“性悪男”の抗争勃発で、危険な香りが漂ってきた。 みのるの話「誰にケンカ売ってんだ、おい。俺は、お前が俺の前に来るのを待ってたんだよ。ジョン・モクスリー…いや、ジョン・ボーイ、心してかかってこい。ぶち殺す」 ジュースの話「すべてはここで終わりだ。ジョン・モクスリーは今日も俺より強かった。また超えられなかった。今日のことを考えたのは昨日の試合が終わってから。それまでまったく今日の試合のことなんて考えていなかった」output
['ジョン・モクスリー', 'ランス・アーチャー', 'デビッド・フィンレー', '鈴木みのる', 'ジョン・ボーイ'] ['足4の字固め', '雪崩式', 'ジャックハマー', 'ラリアート', '裸絞め']【新日1・4東京ドーム】内藤 逆転でIC王座奪回も「目的はこのベルトじゃない」
https://www.tokyo-sports.co.jp/prores/njpw/1681815/
dataset
新日本プロレスの年間最大興行「レッスルキングダム14」(4日、東京ドーム)で行われたIWGPインターコンチネンタル(IC)選手権は、内藤哲也(37)が王者のジェイ・ホワイト(27)を撃破。王座を奪回するとともに、5日東京ドーム大会でIWGPヘビー級王者(オカダ・カズチカVS飯伏幸太の勝者)とのダブルタイトルマッチに駒を進めた。 昨年9月の神戸大会でジェイに敗れ、昨年2度目となるIC王座からの陥落。東京スポーツ新聞社制定「プロレス大賞」ではノミネート「0」の屈辱も味わった。しかし、大観衆は“制御不能男”の復活を待ち望んでいる。序盤から大・内藤コールで背中を押すと、ジェイには容赦ないブーイングを浴びせた。 内藤は場外でエプロンを使ったネックブリーカーを放って先制。ところが、ジェイのセコンドの外道が場外から内藤の足を引っ張りペースを乱す。王者は内藤の左ヒザに狙いを絞って攻め込んだ。内藤はコーナーからの飛びつきフランケンシュタイナーで反撃。相手に顔につばを吐きかけてから、串刺しの低空ドロップキックだ。 これでペースを握るかとみられたが、ジェイのDDTを食らって悶絶し、再び左ヒザを攻められた。場外にはバックドロップで投げ捨てられ、劣勢は変わらない。さらに裏足4の字固めでヒザを締め上げられた。 大ピンチの内藤は顔をゆがませながらロープブレーク。何とか脱出すると、逆襲の浴びせ蹴りだ。さらにスパインバスター、回転式DDT、雪崩式フランケンシュタイナー、グロリアの猛攻。レフェリーがアクシデントでダウンする隙に外道が乱入したが、急所打ちで撃退した。 勝負をかけた内藤は、コリエンド式デスティーノを連発。ジェイの必殺ブレードランナー(変型顔面砕き)を完全に防ぎ切ると、最後は渾身のデスティーノで3カウントを奪った。 33分54秒の大激闘に逆転勝利。昨年1月からIWGPとIC、2冠奪取の野望を掲げてきた“制御不能男”は、完全復活へ一世一代の大舞台に挑む。 【内藤の話】「今回の2連戦の目的はこのベルトを取ることじゃないから。お客様は『内藤おめでとう』って声かけてくれてうれしいよ。でも、トランキーロ。今回の目的ではないから、そこは。さあて、明日の対戦相手はどっちかな。俺の予定はオカダ。理想も、オカダ。さあ、どうかな」 【ジェイ・ホワイトの話】「アイツ(内藤)はどこに行った…。俺は残念ながらみんなが作り上げたストーリーの脇役の一人だったということだったんだな。みんな、ジェイ・ホワイトが負けるのを望んでいたはずだ。お前らが好きな内藤が勝ったんだぞ。なぜ笑わないんだ。新しい俺のデスティーノ…運命が明日から始まる」output
['内藤哲也', 'ジェイ・ホワイト', 'オカダ・カズチカ', '飯伏幸太', 'デスティーノ...運命'] ['ネックブリーカー', 'バックドロップ', '足4の字固め', 'スパインバスター']Consideration
- 選手の名称は「デスティーノ...運命」以外主要メンバーは抽出ができている。一般的な人物名は問題なく分類できてそうです。
- 技名ですが、残念ながらCOTOHA APIの分類には出てこないです。何回かAPIからの出力で一番抽出できてそうな組み合わせだったのが
class:ART, extended_class:Doctrine_Method_Otherだったので出力してみたのですが、「ハイアングルパワーボム」「コリエンド式デスティーノ」あたりが対象外になってしまいます。2番目の条件としてclass:ART, extended_class:Productも追加すると技名以外も抽出されるので100%は厳しかったです
- スポーツ記事ではなく専門書であれば効力を発揮できるかもしれません。APIに下記のtypeのパラメータを付与することができるからです。(for Enterpriseユーザのみ、、、なので有料であれば利用可能です。)
param name IT コンピュータ・情報・通信 automobile 自動車 chemistry 化学・石油工業 company 企業 construction 土木建築 economy 経済・法令 energy 電力・エネルギー institution 機関・団体 machinery 機械 medical 医学 metal 非鉄・金属 PostScript
人物名抽出の精度はいいと言ったのですが、なぜか最近引退した「獣神サンダー・ライガー」が正しく抽出されなかったです。「ART:固有物名」の分類になっていました。
これはタレント名鑑のスタッフに出動応援した方が良さそうでしょうか。
としてです。
- 投稿日:2020-02-23T21:12:42+09:00
python の描画パッケージ pygalの紹介
概要
python の描画パッケージ pygalの紹介になります。
あくまで紹介なので細かい文法等にはこの記事では触れない予定です。pygalの紹介
install方法は以下のようにpip installで可能です。
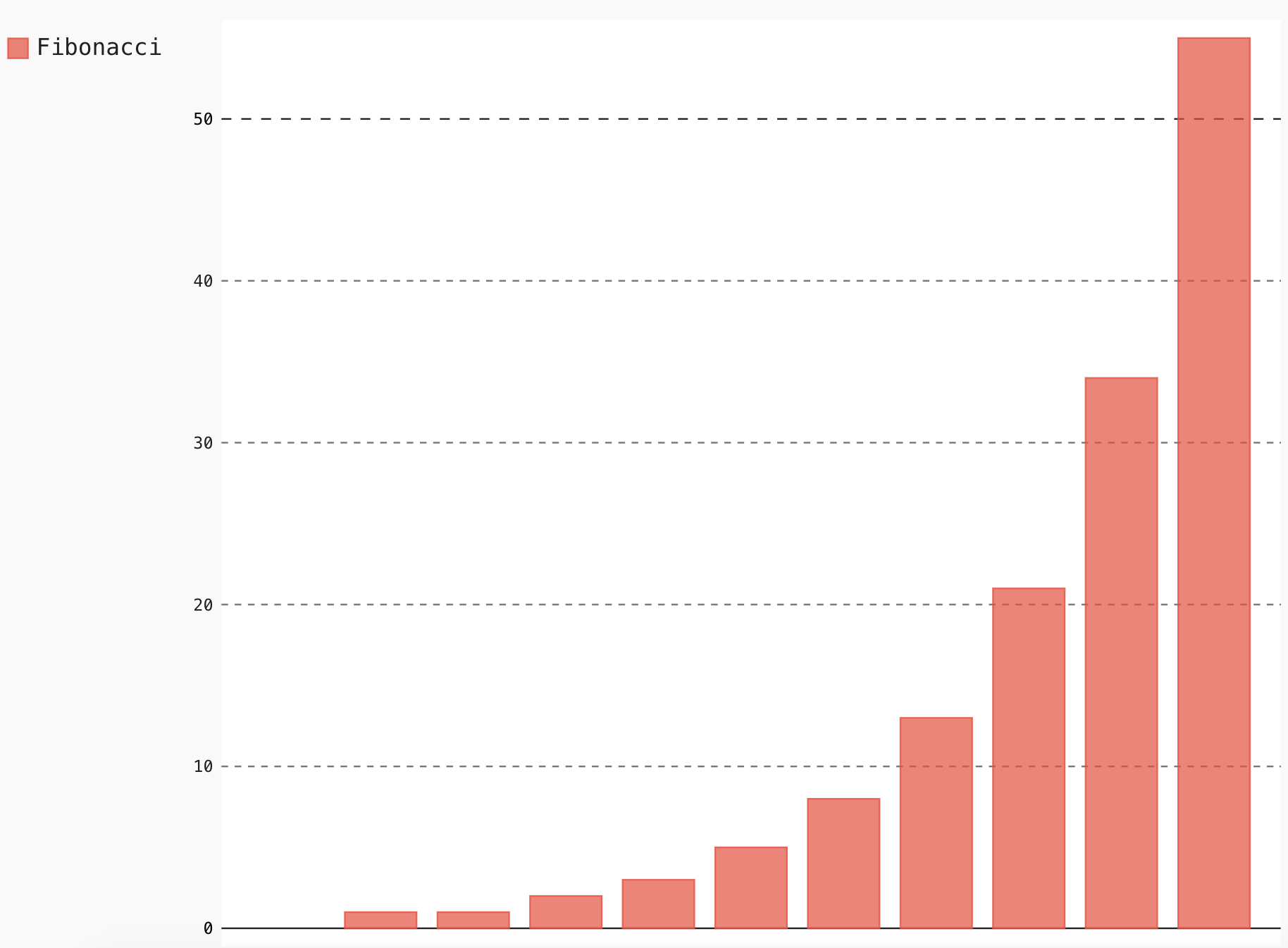
pip install pygalまずこんな感じに記載すると棒グラフを記載することができます。
(なんとなくkerasに書き方が似ていますね)import pygal # pygalをimport bar_chart = pygal.Bar() # 棒グラフのオブジェクトを作成 bar_chart.add('Fibonacci', [0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55]) # オブジェクトに値をいれる bar_chart.render_to_file('bar_chart.svg') # 作成したグラフをsvgファイルとして保存する実行するとカレントディレクトリに
bar_chart.svgができるのでこれをブラウザで開くとこんな図が表示されます。
plotlyなどのようにインタラクティブな図が描画されます。
もしくは、lxmlパッケージをインストールして、
bar_chart.render_to_file('hoge.svg')やbar_chart.render()に部分をbar_chart.render_in_browser()に書き換えるとrenderから
browserでの確認を早く行うことができます。もしくはnotebookでの分析をメインに行っている方には以下のように記載することでnotebookにグラフを埋め込むこともできます。
from IPython.display import display, HTML base_html = """ <!DOCTYPE html> <html> <head> <script type="text/javascript" src="http://kozea.github.com/pygal.js/javascripts/svg.jquery.js"></script> <script type="text/javascript" src="https://kozea.github.io/pygal.js/2.0.x/pygal-tooltips.min.js""></script> </head> <body> <figure> {rendered_chart} </figure> </body> </html> """display(HTML(base_html.format(rendered_chart=bar_chart.render(is_unicode=True))))pygalはSVGを作成します。SVGは任意のエディターで編集して、非常に高品質の解像度で表示できます。SVGは、FlaskやDjangoとも簡単に統合できます。
棒グラフの他にも以下のようないろいろなグラフを描くことができます。(グラフはドキュメントから拝借しました)
普段分析でよく使うようなグラフから、地図への描画まで対応しています。
ぜひ使ってみてください~
参考

- 投稿日:2020-02-23T20:54:05+09:00
Build Tensorflow v2.1.0 v1-API version full installer with TensorRT 7 enabled [Docker version]
This is the procedure to build all by yourself without using NGC containers.
1. Environment
- Ubuntu 18.04 x86_64 RAM:16GB
- Geforce GTX 1070
- NVIDIA Driver 440.59
- CUDA 10 (V10.0.130)
- cuDNN 7.6.5.32
- Docker 19.03.6, build 369ce74a3c
- Tensorflow v2.1.0
- TensorRT 7
- TF-TRT
- Bazel 0.29.1
- Python 3.6
2. Procedure
Create_working_directory$ cd ~ $ mkdir work/tensorrt && cd work/tensorrtDownload TensorRT-7.0.0.11 and copy to the
work/tensorrtdirectory.
https://developer.nvidia.com/compute/machine-learning/tensorrt/secure/7.0/7.0.0.11/tars/TensorRT-7.0.0.11.Ubuntu-18.04.x86_64-gnu.cuda-10.0.cudnn7.6.tar.gzCreate_Dockerfile$ nano DockerfileDockerfileFROM nvidia/cuda:10.0-cudnn7-devel-ubuntu18.04 RUN apt-get update && \ DEBIAN_FRONTEND=noninteractive apt-get install -y \ protobuf-compiler python-pil python-lxml python-tk cython \ autoconf automake libtool curl make g++ unzip wget git nano \ libgflags-dev libgoogle-glog-dev liblmdb-dev libleveldb-dev \ libhdf5-serial-dev libhdf5-dev python3-opencv python-opencv \ python3-dev python3-numpy python3-skimage gfortran libturbojpeg \ python-dev python-numpy python-skimage python3-pip python-pip \ libboost-all-dev libopenblas-dev libsnappy-dev software-properties-common \ protobuf-compiler python-pil python-lxml python-tk libfreetype6-dev pkg-config \ libpng-dev libhdf5-100 libhdf5-cpp-100 libc-ares-dev libblas-dev \ libeigen3-dev libatlas-base-dev openjdk-8-jdk libopenblas-base \ openmpi-bin libopenmpi-dev gcc libgfortran5 libatlas3-base liblapack-dev RUN pip3 install pip --upgrade && \ pip3 install Cython && \ pip3 install contextlib2 && \ pip3 install pillow && \ pip3 install lxml && \ pip3 install jupyter && \ pip3 install matplotlib && \ pip3 install keras_applications==1.0.8 --no-deps && \ pip3 install keras_preprocessing==1.1.0 --no-deps && \ pip3 install h5py==2.9.0 && \ pip3 install -U --user six numpy wheel mock && \ pip3 install pybind11 && \ pip2 install Cython && \ pip2 install contextlib2 && \ pip2 install pillow && \ pip2 install lxml && \ pip2 install jupyter && \ pip2 install matplotlib # Create working directory RUN mkdir -p /tensorrt && \ cd /tensorrt ARG work_dir=/tensorrt WORKDIR ${work_dir} # Clone Tensorflow v2.1.0, TF-TRT and install Bazel RUN git clone -b v2.1.0 --depth 1 https://github.com/tensorflow/tensorflow.git && \ git clone --recursive https://github.com/NobuoTsukamoto/tf_trt_models.git && \ wget https://github.com/bazelbuild/bazel/releases/download/0.29.1/bazel-0.29.1-installer-linux-x86_64.sh && \ chmod +x bazel-0.29.1-installer-linux-x86_64.sh && \ bash ./bazel-0.29.1-installer-linux-x86_64.sh # Install TensorRT-7 COPY TensorRT-7.0.0.11.Ubuntu-18.04.x86_64-gnu.cuda-10.0.cudnn7.6.tar.gz ${work_dir} RUN tar -xvzf TensorRT-7.0.0.11.Ubuntu-18.04.x86_64-gnu.cuda-10.0.cudnn7.6.tar.gz && \ rm TensorRT-7.0.0.11.Ubuntu-18.04.x86_64-gnu.cuda-10.0.cudnn7.6.tar.gz # Setting environment variables ENV TRT_RELEASE=${work_dir}/TensorRT-7.0.0.11 ENV PATH=/usr/local/cuda-10.0/bin:$TRT_RELEASE:$TRT_RELEASE/bin:$PATH \ LD_LIBRARY_PATH=/usr/local/cuda-10.0/lib64:$TRT_RELEASE/lib:$LD_LIBRARY_PATH \ TF_CUDA_VERSION=10.0 \ TF_CUDNN_VERSION=7 \ TENSORRT_INSTALL_PATH=$TRT_RELEASE \ TF_TENSORRT_VERSION=7Create_DockerImage$ docker build --tag tensorrt .Check_DockerImage_generation_status$ docker images REPOSITORY TAG IMAGE ID CREATED SIZE tensorrt latest cb6f0fc656d1 17 seconds ago 9.04GBStart_Docker_container$ docker run \ --gpus all \ --name tensorrt \ -it \ --privileged \ -p 8888:8888 \ tensorrt \ /bin/bashCUDA_and_cuDNN_version_check# nvcc -V nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2018 NVIDIA Corporation Built on Sat_Aug_25_21:08:01_CDT_2018 Cuda compilation tools, release 10.0, V10.0.130 # cat /usr/include/cudnn.h | grep '#define' #define CUDNN_MAJOR 7 #define CUDNN_MINOR 6 #define CUDNN_PATCHLEVEL 5 # nvidia-smi +-----------------------------------------------------------------------------+ | NVIDIA-SMI 440.59 Driver Version: 440.59 CUDA Version: 10.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===============================+======================+======================| | 0 GeForce GTX 107... Off | 00000000:01:00.0 Off | N/A | | N/A 60C P5 11W / N/A | 410MiB / 8119MiB | 0% Default | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: GPU Memory | | GPU PID Type Process name Usage | |=============================================================================| +-----------------------------------------------------------------------------+ # bazel version Extracting Bazel installation... WARNING: --batch mode is deprecated. Please instead explicitly shut down your Bazel server using the command "bazel shutdown". Build label: 0.29.1 Build target: bazel-out/k8-opt/bin/src/main/java/com/google/devtools/build/lib/bazel/BazelServer_deploy.jar Build time: Tue Sep 10 13:44:39 2019 (1568123079) Build timestamp: 1568123079 Build timestamp as int: 1568123079Check_folder_hierarchy# echo $PWD /tensorrt # ls -l total 12 drwxr-xr-x 10 root root 4096 Dec 17 02:30 TensorRT-7.0.0.11 drwxr-xr-x 7 root root 4096 Feb 22 16:16 tensorflow drwxr-xr-x 8 root root 4096 Feb 22 16:16 tf_trt_modelsInitial_configuration_of_Tensorflow_v2.1.0# cd tensorflow # ./configure Extracting Bazel installation... WARNING: --batch mode is deprecated. Please instead explicitly shut down your Bazel server using the command "bazel shutdown". You have bazel 0.29.1 installed. Please specify the location of python. [Default is /usr/bin/python]: /usr/bin/python3 Found possible Python library paths: /usr/lib/python3/dist-packages /usr/local/lib/python3.6/dist-packages Please input the desired Python library path to use. Default is [/usr/lib/python3/dist-packages] /usr/local/lib/python3.6/dist-packages Do you wish to build TensorFlow with XLA JIT support? [Y/n]: n No XLA JIT support will be enabled for TensorFlow. Do you wish to build TensorFlow with OpenCL SYCL support? [y/N]: n No OpenCL SYCL support will be enabled for TensorFlow. Do you wish to build TensorFlow with ROCm support? [y/N]: n No ROCm support will be enabled for TensorFlow. Do you wish to build TensorFlow with CUDA support? [y/N]: y CUDA support will be enabled for TensorFlow. Do you wish to build TensorFlow with TensorRT support? [y/N]: y TensorRT support will be enabled for TensorFlow. Found CUDA 10.0 in: /usr/local/cuda-10.0/lib64 /usr/local/cuda-10.0/include Found cuDNN 7 in: /usr/lib/x86_64-linux-gnu /usr/include Found TensorRT 7 in: /tensorrt/TensorRT-7.0.0.11/lib /tensorrt/TensorRT-7.0.0.11/include Please specify a list of comma-separated CUDA compute capabilities you want to build with. You can find the compute capability of your device at: https://developer.nvidia.com/cuda-gpus. Please note that each additional compute capability significantly increases your build time and binary size, and that TensorFlow only supports compute capabilities >= 3.5 [Default is: 3.5,7.0]: 6.1 Do you want to use clang as CUDA compiler? [y/N]: n nvcc will be used as CUDA compiler. Please specify which gcc should be used by nvcc as the host compiler. [Default is /usr/bin/gcc]: Please specify optimization flags to use during compilation when bazel option "--config=opt" is specified [Default is -march=native -Wno-sign-compare]: Would you like to interactively configure ./WORKSPACE for Android builds? [y/N]: n Not configuring the WORKSPACE for Android builds. Preconfigured Bazel build configs. You can use any of the below by adding "--config=<>" to your build command. See .bazelrc for more details. --config=mkl # Build with MKL support. --config=monolithic # Config for mostly static monolithic build. --config=ngraph # Build with Intel nGraph support. --config=numa # Build with NUMA support. --config=dynamic_kernels # (Experimental) Build kernels into separate shared objects. --config=v2 # Build TensorFlow 2.x instead of 1.x. Preconfigured Bazel build configs to DISABLE default on features: --config=noaws # Disable AWS S3 filesystem support. --config=nogcp # Disable GCP support. --config=nohdfs # Disable HDFS support. --config=nonccl # Disable NVIDIA NCCL support. Configuration finishedBuild with 16GB of RAM and 8 cores. You need to adjust according to the resources of your PC environment. Calculate assuming that about 2GB of RAM is consumed for each core.
Build_Tensorflow_v2.1.0# bazel build \ --config=opt \ --config=cuda \ --config=noaws \ --config=nohdfs \ --config=nonccl \ --config=v1 \ --local_resources=16384.0,8.0,1.0 \ --host_force_python=PY3 \ --noincompatible_do_not_split_linking_cmdline \ //tensorflow/tools/pip_package:build_pip_packageBuild_wheel# ./bazel-bin/tensorflow/tools/pip_package/build_pip_package /tmp/tensorflow_pkg Sun Feb 23 11:13:32 UTC 2020 : === Preparing sources in dir: /tmp/tmp.2tVlFrnLCQ /tensorrt/tensorflow /tensorrt/tensorflow /tensorrt/tensorflow /tmp/tmp.2tVlFrnLCQ/tensorflow/include /tensorrt/tensorflow /tensorrt/tensorflow Sun Feb 23 11:13:45 UTC 2020 : === Building wheel warning: no files found matching 'README' warning: no files found matching '*.pyd' under directory '*' warning: no files found matching '*.pd' under directory '*' warning: no files found matching '*.dylib' under directory '*' warning: no files found matching '*.dll' under directory '*' warning: no files found matching '*.lib' under directory '*' warning: no files found matching '*.csv' under directory '*' warning: no files found matching '*.h' under directory 'tensorflow_core/include/tensorflow' warning: no files found matching '*' under directory 'tensorflow_core/include/third_party' Sun Feb 23 11:14:06 UTC 2020 : === Output wheel file is in: /tmp/tensorflow_pkg # cp /tmp/tensorflow_pkg/tensorflow-2.1.0-cp36-cp36m-linux_x86_64.whl /tensorrt # cd .. # ls -l total 179920 drwxr-xr-x 10 root root 4096 Dec 17 02:30 TensorRT-7.0.0.11 -rwxr-xr-x 1 root root 43791980 Sep 10 13:57 bazel-0.29.1-installer-linux-x86_64.sh drwxr-xr-x 1 root root 4096 Feb 23 06:43 tensorflow -rw-r--r-- 1 root root 140419710 Feb 23 11:15 tensorflow-2.1.0-cp36-cp36m-linux_x86_64.whl drwxr-xr-x 8 root root 4096 Feb 23 06:09 tf_trt_modelsInstall_tensorflow_v2.1.0_v1-API_with_TensorRT_CUDA10.0_cuDNN7.6.5# pip3 uninstall tensorflow-gpu tensorflow # pip3 install tensorflow-2.1.0-cp36-cp36m-linux_x86_64.whlInstall_TF-TRT# cd tf_trt_models # ./install.sh python3Import_test# python3 Python 3.6.9 (default, Nov 7 2019, 10:44:02) [GCC 8.3.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import tensorflow as tf 2020-02-23 12:01:46.274803: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudart.so.10.0 2020-02-23 12:01:46.768715: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libnvinfer.so.7 2020-02-23 12:01:46.769356: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libnvinfer_plugin.so.7 >>> from tensorflow.python.client import device_lib >>> device_lib.list_local_devices() 2020-02-23 12:05:28.927561: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcuda.so.1 2020-02-23 12:05:28.987702: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:981] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2020-02-23 12:05:28.988503: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1555] Found device 0 with properties: pciBusID: 0000:01:00.0 name: GeForce GTX 1070 with Max-Q Design computeCapability: 6.1 coreClock: 1.2655GHz coreCount: 16 deviceMemorySize: 7.93GiB deviceMemoryBandwidth: 238.66GiB/s 2020-02-23 12:05:28.988540: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudart.so.10.0 2020-02-23 12:05:28.988579: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcublas.so.10.0 2020-02-23 12:05:29.006807: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcufft.so.10.0 2020-02-23 12:05:29.013005: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcurand.so.10.0 2020-02-23 12:05:29.058509: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcusolver.so.10.0 2020-02-23 12:05:29.087138: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcusparse.so.10.0 2020-02-23 12:05:29.087290: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudnn.so.7 2020-02-23 12:05:29.087578: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:981] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2020-02-23 12:05:29.090019: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:981] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2020-02-23 12:05:29.091523: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1697] Adding visible gpu devices: 0 2020-02-23 12:05:29.091629: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudart.so.10.0 2020-02-23 12:05:30.075656: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1096] Device interconnect StreamExecutor with strength 1 edge matrix: 2020-02-23 12:05:30.075707: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1102] 0 2020-02-23 12:05:30.075740: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1115] 0: N 2020-02-23 12:05:30.075938: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:981] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2020-02-23 12:05:30.076505: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:981] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2020-02-23 12:05:30.077038: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:981] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero 2020-02-23 12:05:30.077521: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1241] Created TensorFlow device (/device:GPU:0 with 7225 MB memory) -> physical GPU (device: 0, name: GeForce GTX 1070 with Max-Q Design, pci bus id: 0000:01:00.0, compute capability: 6.1) [name: "/device:CPU:0" device_type: "CPU" memory_limit: 268435456 locality { } incarnation: 11937878305894780308 , name: "/device:GPU:0" device_type: "GPU" memory_limit: 7576322048 locality { bus_id: 1 links { } } incarnation: 7297894123203666970 physical_device_desc: "device: 0, name: GeForce GTX 1070 with Max-Q Design, pci bus id: 0000:01:00.0, compute capability: 6.1" ] >>>3. Appendix
3-1. Commit container image
Escape from Docker Container.
Ctrl + P
Ctrl + QCommit_container_image$ docker commit tensorrt tensorrt3-2. Extract_wheel_from_Docker_container
Extract_wheel_from_Docker_container$ docker cp cb6f0fc656d1:/tensorrt/tensorflow-2.1.0-cp36-cp36m-linux_x86_64.whl .3-3. Download Pre-build wheel
Download_Pre-build_wheel$ curl -sc /tmp/cookie "https://drive.google.com/uc?export=download&id=10uFrl9X0evjKI8rH7cMfNIL5K0-iOnNU" > /dev/null $ CODE="$(awk '/_warning_/ {print $NF}' /tmp/cookie)" $ curl -Lb /tmp/cookie "https://drive.google.com/uc?export=download&confirm=${CODE}&id=10uFrl9X0evjKI8rH7cMfNIL5K0-iOnNU" -o tensorflow-2.1.0-cp36-cp36m-linux_x86_64.whl4. Reference articles
4-1. Various
- https://github.com/NVIDIA/TensorRT
- https://github.com/NobuoTsukamoto/tf_trt_models
- https://docs.nvidia.com/deeplearning/frameworks/tf-trt-user-guide/index.html
- https://www.google.com/search?q=NvInferVersion.h+-www.sejuku.net&oq=NvInferVersion.h&aqs=chrome..69i57.1147j0j8&sourceid=chrome&ie=UTF-8
- https://hub.docker.com/layers/nvidia/cuda/10.0-cudnn7-devel-ubuntu18.04/images/sha256-e277b9eef79d6995b10d07e30228daa9e7d42f49bcfc29d512c1534b42d91841?context=explore
- https://qiita.com/ksasaki/items/b20a785e1a0f610efa08
- https://github.com/tensorflow/tensorrt
- Jetson NanoでTF-TRTを試す(Image Classification) - nb.oの日記
- Jetson NanoでTF-TRTを試す(Object detection) - nb.oの日記
4-2. CUDA/cuDNN/TensorRT Header files and libraries search path logic
- https://github.com/tensorflow/tensorflow/blob/v2.1.0/configure.py
- https://github.com/tensorflow/tensorflow/blob/v2.1.0/third_party/gpus/find_cuda_config.py
4-3. Check GPU Compute Capability
- 投稿日:2020-02-23T20:45:33+09:00
複数のjpgファイルを一つのPDFファイルに変換する
やりたいこと
scannerなどで取り入れた明細の画像ファイル(jpg or JPEG or JPG)をPDFファイルにまとめたい
明細はディレクトリ毎に区分けしてあり、区分け毎にPDFファイルにまとめる
ディレクトリの中には日付ごとにまとめらているls ~/scan/meisai/ 自動車保険明細 自動車保険明細/2017/ 自動車保険明細/2018/ 自動車保険明細/2019/ 自動車保険明細/2020/ クレジッドカードA/2017/ クレジッドカードA/2018/ クレジッドカードA/2019/ クレジッドカードA/2020/ 医療明細2020_01_20.jpg .DS_storeこのようなディレクトリ構成のなかに複数の画像ファイルが存在している。
それを以下のようにまとめるls ~/scan/meisai_pdf/ 自動車保険明細.pdf クレジッドカードA.pdf .DS_store使用した画像ファイルは手動で削除する。
使用したもの
python3
import os
import img2pdfコード
import os import img2pdf EXP_DIR = "/Users/myname/scan/meisai" OUT_DIR = "/Users/myname/scan/meisai_pdf" def extract_image_file_list(folder_path): ret = [] if os.path.isdir(folder_path) == False: return ret for t in sorted(os.listdir(path=folder_path)): if os.path.isdir(folder_path + "/" + t): # 再起的にディレクトリを辿っていく ret += extract_image_file_list(folder_path + "/" + t) else: ret.append(folder_path + "/" + t) return ret def image_to_pdf(pdf_name,image_list): convert_target = [] for i in image_list: if i.endswith(".jpg") or i.endswith(".JPG") or i.endswith(".jpeg"): convert_target.append(i) if len(convert_target) == 0: return with open(pdf_name + ".pdf", "wb") as f: f.write(img2pdf.convert(convert_target)) #os.chdir(EXP_DIR) # ディレクトリに移動して相対パスで処理したい場合。 for path in os.listdir(path=EXP_DIR): print(path) files = extract_image_file_list(EXP_DIR + "/" + path) image_to_pdf(OUT_DIR + "/" + path,files)
- 投稿日:2020-02-23T20:07:44+09:00
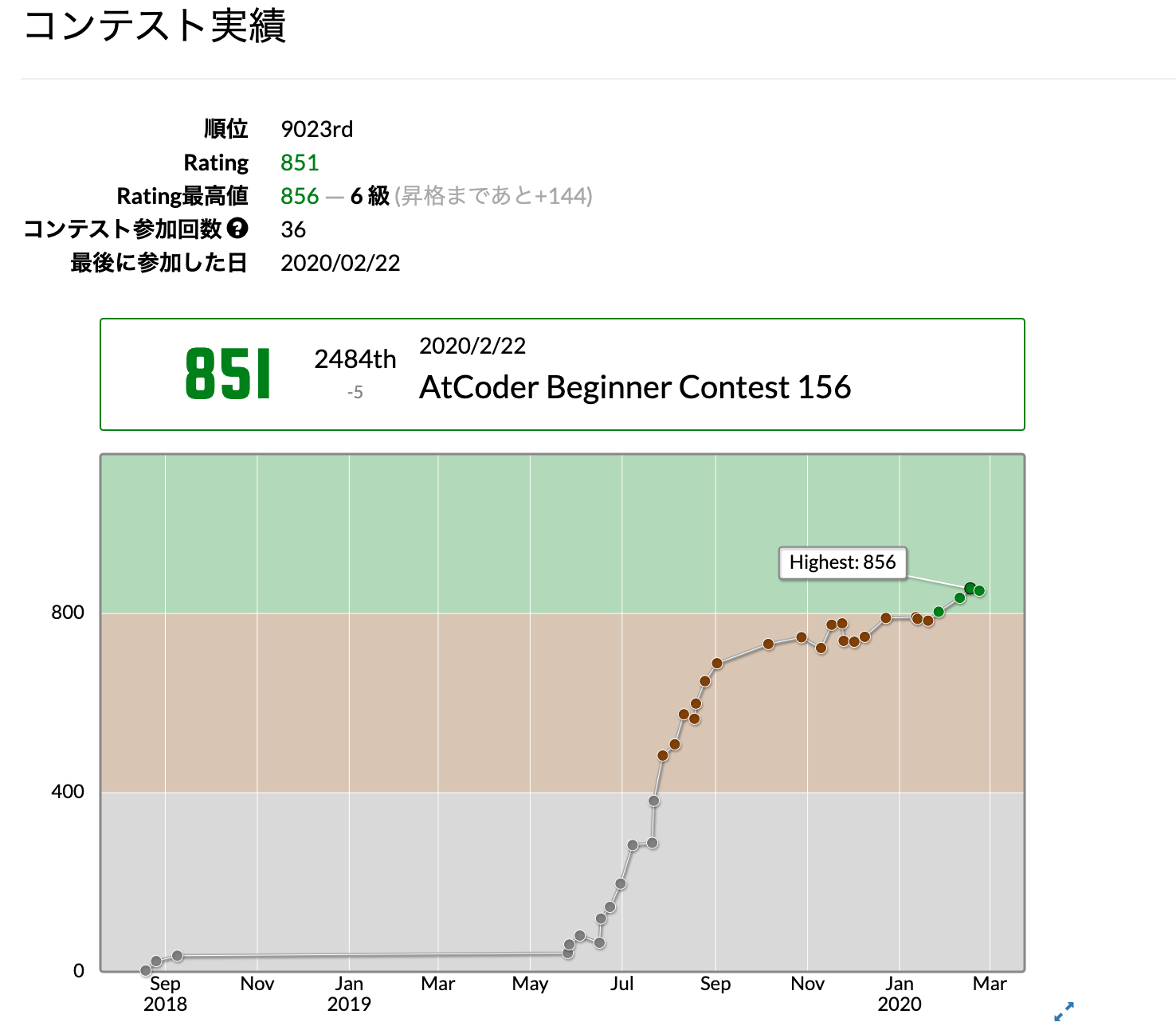
Atcoder緑になるまで
自己紹介
こんにちは、HIROSHI0635です。今は、金融関係で働く社会人2年目です(仕事でプログラミングは全くしませんOrz...)。大学時代は文系で、プログラムの「プ」も触ったこともなかったですが、競プロ始めて10ヶ月でなんとか緑になれましたので、やってみたかった「〜色になりました」の記事を書いてみました。自分語りの自己満記事ですが、Atcoder始めたてのPythonコーダーなら少しは役に立つことが書いているかもしれません。
1.Atcoder始めるまで
始めた動機は、仕事での人間関係が窮屈で本当に辞めようかと迷ってた時、じゃあ次は技術力で勝負できる仕事がいいなと思って、「今からでもやれるもの」という発想でプログラミングに行き着きました。ただ、プログラミングの「プ」もわからない状態で、何か作りたいものもなかったので、どうしようかと迷っていた時に、大学時代の先輩が薦めてくれたのが、Atcoderでした。受験勉強はまあまあ得意だったので(とはいえセンター数学はIAもⅡBも80点くらいのレベル)、問題を解いてレートが上下するというのは自分に合っている勉強方法だと思いました。
2.挫折
最初の言語は、何も分からなかったので薦められるがままに、Atcoderで一番メジャーなC++にしました。ただ、文法がややこしく、いわゆる「おまじない」のようなルールが多くなかなか問題を解くところまで至れず、ついでに、部署異動で人間関係もよくなり、以前ほどモチベーションがなくなってしまいました。以来半年くらい何もしない期間が続きます。
3.復活まで
たまたま、仕事先でエンジニアのお客様と接する機会があり、C++で競技プログラミングに挫折したことを話すと、「それなら、Pythonでもう一回やってみれば?。おまじないも少ないし、やりやすいと思うよ。」趣味のサイクリングも毎週行くほどの気力もなくなってきて暇だったので、もう一度再開しました。今回は、文法で挫折しないよう、PaizaでPythonの講座を一通りやってから、問題を解きはじめました。ただ、巨大なプログラムを書くならクラス、インスタンスまでやる必要があるのかもしれませんが、Atcoderなら関数くらいまでやれば十分なので、あとはひたすら問題を解くのがいいと思います。C++で挫折した方がいれば、騙されたと思ってPythonでもう一度やってみるといいと思います。
4.茶色まで
何やら環境構築がめんどくさそうで、また挫折するのも馬鹿らしかったので、緑になる直前までpaizaのオンライン環境でコードを書いていましたhttps://paiza.io/ja
茶色になるまでは、まずひたすらB問題埋めをやりました。最初は時間がかかっていたのですが、慣れれば解法はほとんどノータイムで浮かんであとは実装するだけって感じになりました。B問題を1ヶ月で50問くらい埋めて、もう書くだけって状態にしました。次に、「蟻本はよい。」という噂を聞きつけ、ただ今更買うのもあれだったので、AtCoder 版!蟻本 (初級編)を埋め始めました。全探索とか、貪欲とかは割と理解できたのですが、DFS、BFSで完全に詰まってしまい一旦諦めてC問題を埋め始め、そうこうしているうちに茶色になっていました。5.緑まで
茶色から緑は難なくいけるだろうと思っていましたが、意外と苦戦しました(現に、茶色に上がる最後のコンテストでは、パフォーマンス1000を超え、時間の問題と思っていました)。というのも、2019/10頃から、明らかに周りのレベルが上がり、以前より150くらいパフォーマンスが下振れするようになりました。また、時々簡単な問題に手間取り、パフォーマンス400程度を出すことがあり、レートを足踏みさせてました。
そこで、自分なりに考えたのが、難しい問題を解くのが「攻撃力」なら、簡単な問題を速く解くのは「守備力」で、攻撃力をあげるのは難しいから、まず守備力をあげようとしました。
また、最近の問題傾向として、C問題の易化が進み、茶色Difficulty(AtcoderProblemでのDifficulty400〜800の問題)を飛ばして、いきなり緑・水色のDifficultyの問題が出ることが多いです。(ABC140からABC156において、茶色Difficultyは5問に対し、緑Difficulty11問、水色Difficulty13問)。茶色問題が出ないセットも多くあり、緑問題を解けるレベルにないなら、灰色問題の速度をあげることが、緑への早道です。
守備力をあげるには、たくさん精進するしかないですが、それ以外のところでやってみたことを挙げてみます。ローカル環境の導入
長らく、Paizaのオンライン環境のお世話になっていましたが、意を決してローカル環境を構築しました。同時にAtcoderユニットテストhttps://qiita.com/YujiSoftware/items/00ce688ce5dde627ec36 を導入し、A問題・B問題の動作確認を大幅に改善させました。
やはり、ローカル環境の方が予測入力やテンプレートとかバグの発見とかでメリットありまくりなので、出来るだけ早くローカル環境に移る方がいいと思います(まだ全然使いこなせてない)。ちなみに、Pycharmを使っています。問題を読み込まずサンプル1を早く見る
C問題くらいまでは、問題文は理解できなくても軽く流し読みして、サンプルを見た方が早く問題の全体像が掴めることが多いです。D以降は制約をよく読まないとひっかけられることも多いので、よく読んだ方がいいです。
バーチャルコンテストの活用
コンテストの間隔が開くと速度もモチベーションも下がるので、定期的に仲間内でバーチャルコンテストを開いて速度の向上とモチベーションの維持に努めました。
失敗してもなんとかコンテストに出続け、緑になることができました。
6.その他Python戦士に有益なtips
Collection.Counter、most_common()メソッド
このライブラリーは本当に応用範囲が広いです。
使い方はこの記事。https://note.nkmk.me/python-collections-counter/
5回に1回くらいは、これを知ってれば瞬殺できる問題が出てきます。入力が少し速くなるおまじない
import sys
input = sys.stdin.readline一番最初にこの2行を足すだけで、1割くらい速度が上がります。
理由はよくわかりません。
細かい速度改善に関することはこの記事がわかりやすいです。
https://www.kumilog.net/entry/python-speed-comp7.終わりに
今回は、半分競プロをやるようになった流れがメインでしたが、水色になれたら、もう少し問題を解くのに役立つまとまった記事を書きたいと思います。
- 投稿日:2020-02-23T20:03:51+09:00
AtCoderJobsで機械学習エンジニアに転職しました
01.はじめに
私はこれまで半導体エンジニアとして働いていましたが、
4月1日より東京でAIベンチャー企業で機械学習エンジニアとして働くことになりました!!
まだ、2月後半ですが、4月から始まる新しい生活に心を躍らせています笑
本記事ではIT系未経験の私が転職するまでの道のりを書いていきます。02.私の経歴やスキル
転職が決まる直前の私の経歴やスキルを紹介します。
- 関西の有名私立大学理系院卒(電気電子工学専攻)
- 2019年4月より福岡で半導体エンジニアとして働く
- Pythonしか書けない、強いて言うとHTMLとCSSも少し書ける
- AtCoder緑
- TOEIC 825
- 英会話はまぁまぁできる(留学生と3ヶ月一緒に研究していた)
- 日本学生支援機構の奨学金全額免除03.転職活動記
昨年新卒で会社に入った私でしたが、ほぼ1年という短い期間で転職することになりました。
この節では、私が転職を考え始めてから転職先が決まるまでを時系列で紹介したいと思います。4月〜6月(会社の研修)
入社した会社で3ヶ月の研修がありました。
研修中は定時で帰れる&出張手当がもらえる(勤務地が福岡で研修中は関東にいたため出張扱いになる)でものすごくモチベーションが高かったです。
この頃はまだ1年で転職するなんて全く考えていませんでした。7月~11月(会社の業務に配属される)
長かった会社の研修も終わり、7月からは会社の業務に配属されました。
しかし、配属された業務は、私が望んでいたものではなく(いわゆる配属ガチャ)2週間もすると業務にコレジャナイ感を感じて、少し転職することも考えはじめました。
その頃にちょうど競技プログラミングAtCoderのこと、またAtCoderのレートで転職ができることを知り、本格的にプログラミングを学び始めました。
また、9月からは機械学習についても学びたいと思って、AidemyのPremiumPlanにも登録しました。
かなりいい値段はしましたが、機械学習についての基礎は身に付いたと思います。
この頃は、平日は業務が終わってから平均3時間程度、休日は6時間程度は勉強していたと思います。12月~1月(転職をしようと決意する)
12月になり、会社の業務にアサインされてから半年程度が経ちました。
しかしながら、自分の中では会社で自分が行っている業務に満足できていませんでした。
また、1年上の先輩を見ていても、来年自分も先輩と同じような業務をするのは嫌だと思いました。
そのため、転職を12月の時点で転職をしようと決意しました。
世間一般では転職活動は2月頃に活発になると聞き、それに合わせて準備をしました。
また、このタイミングでAtCoderのレーティングも緑になったため、AtCoderJobsにおいても幾つかの企業にエントリーすることができました。2月(転職活動を始める、そして2週間程度で終わる)
2月に入り、転職活動をはじめました。
応募したのは、AtCoderJobsでは3社程度、大手転職エージェントのdodaでは20社程度です。
AtCoderJobsでは1社は書類選考?で落ち、1社は返事が帰ってこず、1社からは書類選考を通り、面接まで行けることになりました。
もちろん、といえばそうなのですが、AtCoderJobsでは応募に必要なレーティングを満たしているからと言って、面接が確約されているわけではありません。
また、AtCoderJobsでは普通の転職において必要とされている履歴書や職務経歴書に該当するものがないため、その他PRの欄にそれに類することを書いておくべきなのかもしれません。dodaの方では転職エージェントから紹介された求人に片っ端から応募していきました。
書類選考を通ったのは4/20社くらいで、そのうち半分はSESの会社でした。3社程度面接を受けに行き、最終的にAtCoderJobs経由で応募した会社に機械学習エンジニアとして入社することになりました。
04.評価されたこと
この節では、内定をもらった会社から自分が評価された点を挙げていきたいと思います。
・最低限のプログラミングスキルを持っている
内定をもらった会社はAtCoderJobs経由のため、AtCoderのレートによってスクリーニングされています。
そのため、最低限のプログラミングスキルは持っていると評価され、面接の場においては、スキルチェックなどはほとんどありませんでした。
ちなみに、doda経由で面接を受けた会社ではAtCoderのことについては触れられませんでした。・遠方からわざわざ来た
私は現在福岡に住んでいますが、IT関係の仕事をするなら東京が良い(というか一度東京に住んでみたい)という思いから、東京の会社に応募していました。
そのため、面接を受けるときも、会社の有給をとり福岡から東京まで行って面接を受けにいきました。
もちろん、Skypeで面接を受けるという選択肢もありますし、それで評価が下がるということもないと思います。
しかしながら、わざわざ手間をかけて面接を受けに行くことで、あなたの会社に入社したいという覚悟や思いが伝わると思います。(面接官の人もそのように言っていました)
ちなみに福岡の人が東京に行く場合には、ANAの旅作を利用するのがおすすめです。
1週間より前に予約することで福岡ー東京飛行機往復代+ホテル宿泊費を3万円強(2月)に抑えることができます。・学習意欲が高いこと
学生時代の研究に対する姿勢や、競技プログラミングへの参加、そしてそれらの成果などが評価されました。
面接官の人が全員理系だったため、奨学金全額免除についても良い評価をもらいました。・英語のスキル
会社として、現在海外へ進出する予定らしく、自分がTOEICの点数がそれなりに高く、また英語が話せるということが評価されました。
面接の時に聞いた話では、外国企業との商談の時に通訳(理系寄り)を連れて行ったが、自社プロダクトについて理解していないため、手間取ったとのことです。
そのため、自社の製品を理解している英語が話せるエンジニアが必要だそうです。・人柄
会社の採用ページを見ると、人柄についても見ていますと書いてあったので、自分は人柄も評価されているのだと思います。05.まとめ
未経験からでも機械学習エンジニアになることができました!
今回私が内定が貰った要因としては、当たり前すぎることですが、企業が求めている人材と私の持っているスキルが一致したためだと考えています。
そのため、もし業務未経験の人で行きたいと考えている企業があるのであれば、会社で使用している言語や求めている人材のところをきちんと見ましょう。
(私のようにメインの言語がC++のところにpythonができますと言って応募しても書類選考は通りません)4月から会社の一員として働くために、入社まで残り1ヶ月ちょっとですが、勉強を頑張りたいと思います。
- 投稿日:2020-02-23T19:15:30+09:00
Keras LSTMでアイドルっぽいツイートを作ってみる
記事の内容
AIを使った文章の自動生成に興味がありKerasを使って文章生成をしてみました。
やった内容はアイドルグループのツイートを取得してきて学習させ、文章を作るというものです。参考
こちらの記事を参考にさせていただきました。
コードは基本的には同じですが、この記事だけでは少し分かり辛かった部分などをメモとして残します。
ツイートを作ってみる
学習データの取得
まずは学習データの取得です。
get_time_lines.pyimport json import config from requests_oauthlib import OAuth1Session from time import sleep import re import emoji from mongo_dao import MongoDAO # 今回は使わない # 絵文字を除去する def remove_emoji(src_str): return ''.join(c for c in src_str if c not in emoji.UNICODE_EMOJI) # APIキー設定(別ファイルのconfig.pyで定義しています) CK = config.CONSUMER_KEY CS = config.CONSUMER_SECRET AT = config.ACCESS_TOKEN ATS = config.ACCESS_TOKEN_SECRET # 認証処理 twitter = OAuth1Session(CK, CS, AT, ATS) # タイムライン取得エンドポイント url = "https://api.twitter.com/1.1/statuses/user_timeline.json" # 取得アカウント necopla_menber = ['@yukino__NECOPLA', '@yurinaNECOPLA', '@riku_NECOPLA', '@miiNECOPLA', '@kaori_NECOPLA', '@sakuraNECOPLA', '@miriNECOPLA', '@renaNECOPLA'] # パラメータの定義 params = {'q': '-filter:retweets', 'max_id': 0, # 取得を開始するID 'count': 200} # arg1:DB Name # arg2:Collection Name mongo = MongoDAO("db", "necopla_tweets") mongo.delete_many({}) regex_twitter_account = '@[0-9a-zA-Z_]+' for menber in necopla_menber: print(menber) del params['max_id'] # 取得を開始するIDをクリア # 最新の200件を取得/2回目以降はparams['max_id']に設定したIDより古いツイートを取得 for j in range(100): params['screen_name'] = menber res = twitter.get(url, params=params) if res.status_code == 200: # API残り回数 limit = res.headers['x-rate-limit-remaining'] print("API remain: " + limit) if limit == 1: sleep(60*15) n = 0 tweets = json.loads(res.text) # 処理中のアカウントからツイートが取得出来なくなったらループを抜ける if len(tweets) == 0: break # ツイート単位で処理する for tweet in tweets: # ツイートデータを丸ごと登録 if not "RT @" in tweet['text'][0:4]: mongo.insert_one({'tweet':re.sub(regex_twitter_account, '',tweet['text'].split('http')[0]).strip()}) if len(tweets) >= 1: params['max_id'] = tweets[-1]['id']-1この記事の学習データには「//ネコプラ//」というグループのツイートを取得してきました。
取得したツイートは以下の要素を削除しています。
・画像のリンク
・リプライ時のアカウントこんな感じで学習させるデータをmongoDBに突っ込んでいます。
{ "_id" : ObjectId("5e511a2ffac622266fb5801d"), "tweet" : "ソロ曲練習でもしようと思ってカラオケ行ったはいいものの普通に喉壊した" } { "_id" : ObjectId("5e511a2ffac622266fb5801e"), "tweet" : "まだまだいけるよ" }mongoDB操作のソースはこちら
ツイートを学習させる
参考にさせていただいたソースとほぼ同じです。
keras_tweet_learning.pyfrom __future__ import print_function from keras.callbacks import LambdaCallback from keras.models import Sequential from keras.layers import Dense, Activation from keras.layers import LSTM from keras.optimizers import RMSprop from keras.utils.data_utils import get_file import matplotlib.pyplot as plt # 追加 import numpy as np import random import sys import io from mongo_dao import MongoDAO mongo = MongoDAO("db", "necopla_tweets") results = mongo.find() text = '' for result in results: text += result['tweet'] chars = sorted(list(set(text))) print('total chars:', len(chars)) char_indices = dict((c, i) for i, c in enumerate(chars)) indices_char = dict((i, c) for i, c in enumerate(chars)) # cut the text in semi-redundant sequences of maxlen characters maxlen = 3 step = 1 sentences = [] next_chars = [] for i in range(0, len(text) - maxlen, step): sentences.append(text[i: i + maxlen]) next_chars.append(text[i + maxlen]) print('nb sequences:', len(sentences)) print('Vectorization...') x = np.zeros((len(sentences), maxlen, len(chars)), dtype=np.bool) y = np.zeros((len(sentences), len(chars)), dtype=np.bool) for i, sentence in enumerate(sentences): for t, char in enumerate(sentence): x[i, t, char_indices[char]] = 1 y[i, char_indices[next_chars[i]]] = 1 # build the model: a single LSTM print('Build model...') model = Sequential() model.add(LSTM(128, input_shape=(maxlen, len(chars)))) model.add(Dense(len(chars))) model.add(Activation('softmax')) optimizer = RMSprop(lr=0.01) model.compile(loss='categorical_crossentropy', optimizer=optimizer) def sample(preds, temperature=1.0): # helper function to sample an index from a probability array preds = np.asarray(preds).astype('float64') preds = np.log(preds) / temperature exp_preds = np.exp(preds) preds = exp_preds / np.sum(exp_preds) probas = np.random.multinomial(1, preds, 1) return np.argmax(probas) # epoch 終了時に実行 def on_epoch_end(epoch, logs): # Function invoked at end of each epoch. Prints generated text. print() print('----- Generating text after Epoch: %d' % epoch) # start_index = random.randint(0, len(text) - maxlen - 1) # start_index = 0 # 毎回、「老人は老いていた」から文章生成 for diversity in [0.2]: # diversity = 0.2 のみとする print('----- diversity:', diversity) generated = '' # sentence = text[start_index: start_index + maxlen] sentence = '明日は' generated += sentence print('----- Generating with seed: "' + sentence + '"') sys.stdout.write(generated) for i in range(120): x_pred = np.zeros((1, maxlen, len(chars))) for t, char in enumerate(sentence): x_pred[0, t, char_indices[char]] = 1. preds = model.predict(x_pred, verbose=0)[0] next_index = sample(preds, diversity) next_char = indices_char[next_index] generated += next_char sentence = sentence[1:] + next_char sys.stdout.write(next_char) sys.stdout.flush() print() # 学習終了時に実行 def on_train_end(logs): print('----- saving model...') model.save_weights("necopla_model" + 'w.hdf5') model.save("necopla_model.hdf5") print_callback = LambdaCallback(on_epoch_end=on_epoch_end, on_train_end=on_train_end) history = model.fit(x, y, batch_size=128, epochs=5, callbacks=[print_callback]) # Plot Training loss & Validation Loss loss = history.history["loss"] epochs = range(1, len(loss) + 1) plt.plot(epochs, loss, "bo", label = "Training loss" ) plt.title("Training loss") plt.legend() plt.savefig("loss.png") plt.close()変更した点としては以下です。
・学習終了時に学習データを保存する処理を追加(on_train_end)
・文字の長さ(maxlen)を8→3に変更1点目は丸々1日かけて動かした学習データが保存されてないという痛い目を見てしまったので保存処理を追加しました。
2点目は8文字で学習を行い、その学習データで"明日は"というような3文字の言葉から始まる文章を予測すると上手く動作しませんでした。
ツイートを作成するということもあり、短めの言葉から始まる学習をさせました。学習の過程はこのような感じになりました。
Epoch 1/5 663305/663305 [==============================] - 401s 605us/step - loss: 3.5554 ----- Generating text after Epoch: 0 ----- diversity: 0.2 ----- Generating with seed: "明日は" 明日は!!!!!!!!!!!!!!!!!!!!!!!!! これからもよろしくお願いします!!! 「ネコプラ//ネコプラ #ネコプラ #ネコプラ//ネコプラ//ネコプラ//ネコプラ//ネコプラ #ネコプラ #ネコプラ//ネコプラの方がいいのですが Epoch 2/5 663305/663305 [==============================] - 459s 693us/step - loss: 3.2893 ----- Generating text after Epoch: 1 ----- diversity: 0.2 ----- Generating with seed: "明日は" 明日はこちらです!! #ネコプラのライブです! #ネコプラのライブがあります!! #ネコプラのことはありがとうございます!!! #ネコプラのことがんばってくれてありがとうございます!! #ネコプラのことがあったら嬉しいです、、 #ネコ Epoch 3/5 663305/663305 [==============================] - 492s 742us/step - loss: 3.2109 ----- Generating text after Epoch: 2 ----- diversity: 0.2 ----- Generating with seed: "明日は" 明日はこちらです!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! Epoch 4/5 663305/663305 [==============================] - 501s 755us/step - loss: 3.1692 ----- Generating text after Epoch: 3 ----- diversity: 0.2 ----- Generating with seed: "明日は" 明日はこちらです!! #ネコプラ #ネコプラ #ネコプラの人に来てくれて嬉しいよね、、!! #ネコプラ #ネコプラ #ネコプラのこともっともっともっともっともっともっともっともっともっともっともっともっともっとも Epoch 5/5 663305/663305 [==============================] - 490s 739us/step - loss: 3.1407 ----- Generating text after Epoch: 4 ----- diversity: 0.2 ----- Generating with seed: "明日は" 明日は会いに来てね!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!追加学習
保存した学習データを使って更に学習させる
モデル構築後に保存した学習データをloadしてあげるだけ。コードはこちら
keras_addtinal_learning.pyprint('Build model...') model = Sequential() model.add(LSTM(128, input_shape=(maxlen, len(chars)))) model.add(Dense(len(chars))) model.add(Activation('softmax')) optimizer = RMSprop(lr=0.01) model.compile(loss='categorical_crossentropy', optimizer=optimizer) model.load_weights("necopla_modelw.hdf5")学習したデータを使ってツイートを作る
この処理を作るときにちゃんと一個一個のコードの意味を考えました。(遅い・・。)
学習のepoch終了時に「on_epoch_end」の処理が呼ばれますが、ここではepoch終了のタイミングでその時点の学習データを使って文章を作成しています。
そのため、ツイートを作るときは、基本的にこの処理を真似れば作れます。コードはこちら
keras_create_tweet.pydef evaluate_tweet(): for diversity in [0.2]: # diversity = 0.2 のみとする print('----- diversity:', diversity) generated = '' sentence = '明日は' generated += sentence print('----- Generating with seed: "' + sentence + '"') sameCharCount = 0 for i in range(120): x_pred = np.zeros((1, maxlen, len(chars))) for t, char in enumerate(sentence): x_pred[0, t, char_indices[char]] = 1. preds = model.predict(x_pred, verbose=0)[0] next_index = sample(preds, diversity) next_char = indices_char[next_index] if next_char == generated[-1]: sameCharCount += 1 if sameCharCount >= 3: continue elif sameCharCount != 0: sameCharCount = 0 generated += next_char sentence = sentence[1:] + next_char return generated for i in range(10): tweet = evaluate_tweet() print('---------------- ' + str(i+1) + '回目 ---------------- ') print(tweet)ツイート文章を作る時に3文字以上同じ文字が続くと文字を繋げないようにしました。
ツイートは「明日は」という言葉から始まる文章で作成しています。出力結果はこんな感じになりました。
---------------- 1回目 ---------------- 明日はこちらです!!! ---------------- 2回目 ---------------- 明日はこちらです!!! ---------------- 3回目 ---------------- 明日は会えるかな〜!!! ---------------- 4回目 ---------------- 明日はこちらです!!! ---------------- 5回目 ---------------- 明日はこちらです!!! ---------------- 6回目 ---------------- 明日はこちらです!!! ---------------- 7回目 ---------------- 明日はこちらです!!! ---------------- 8回目 ---------------- 明日はこちらです!!! ---------------- 9回目 ---------------- 明日はこちらです!!! ---------------- 10回目 ---------------- 明日はこちらです!!!なんとなくですが、それっぽい内容が出来ました。
感想
以前にChainerを使って同じことをやったことがありますが、断然Kerasでやる方が簡単で分かり易いです。
出力結果も学習回数が少ないのか短文になってしまうので、追加学習を行いながら結果を見てみようと思います。学習方法も分かち書きで学習させる方法だと違う結果になると思うので、そちらもやってみようと思います。
- 投稿日:2020-02-23T18:20:59+09:00
【python】nCkを導出する方法(ABC156-D)
ABC156-D にて必要になったので備忘。
https://atcoder.jp/contests/abc156/tasks/abc156_d
何も考えずに実装すると
nC_k = \frac{n!}{(n-k)!k!}$nC_k$の定義は↑なので、これをそのままコードに書くと、
import math def comb(n,k): math.factorial(n) // (math.factorial(n - k) * math.factorial(k)) print(comb(4,2)) # 6こんな感じになる。
しかし$n!$は$O(n)$なので、今回のABC156-Dのような$n\leqq10^9$の場合では計算時間が長くなり間に合わない。なんとかして計算時間を短くしなければならない。前提知識
繰り返し二乗法とフェルマーの小定理をまずは知っている必要がある。
繰り返し二乗法
べき乗を高速に求める方法。
pythonではpow(x, n, mod)とすることで $x^n$ を $mod$ で割ったあまりを計算できる。フェルマーの小定理
$p$ を素数とし、$a$ を $p$ の倍数でない整数($a$ と $p$ は互いに素)とするときに、以下が成り立つ。
a^{p-1} \equiv 1 (mod\, p)要は $a^{p-1}$を$p$で割ったらあまりは1だよと言っている。
nCkを式変形する
$nC_k$は以下のように変形できる。
nC_k = \frac{n!}{(n-k)!k!}=\frac{n(n-1)(n-2)\cdots(n-k+1)}{k!}ここで$\frac{1}{k!}$に注目する。
フェルマーの小定理から、
a^{p-1} mod\, p = 1 \\ \\ a^{p-2} mod\, p = \frac{1}{a} \\$a^{p-2} mod\, p = \frac{1}{a}$が得られる。
よって $\frac{1}{k!} = k!^{p-2} mod\, p$が成り立ち、$k!^{p-2}$は繰返し二乗法で高速に求めることができるので、$\frac{1}{k!}$を高速に求めることが可能になる。以上から$nC_k$は以下で表すことができる。
nC_k = n(n-1)\cdots(n-k+1) \times(k!^{p-2}\,mod\,p)計算量は$O(k)$である。($k!$が一番時間がかかる)
実装
# O(k) def comb(n,k): nCk = 1 MOD = 10**9+7 for i in range(n-k+1, n+1): nCk *= i nCk %= MOD for i in range(1,k+1): nCk *= pow(i,MOD-2,MOD) nCk %= MOD return nCk print(comb(4,2)) # 6余談
ちな、コンテスト中にDをACすることはできなかった。
コンテスト中に出したTLEコード。
https://atcoder.jp/contests/abc156/submissions/10285618コンテスト後にACしたコード
https://atcoder.jp/contests/abc156/submissions/10307501参考
https://ja.wikipedia.org/wiki/%E3%83%95%E3%82%A7%E3%83%AB%E3%83%9E%E3%83%BC%E3%81%AE%E5%B0%8F%E5%AE%9A%E7%90%86
https://note.com/tanon_cp/n/ncff944647054
- 投稿日:2020-02-23T18:09:47+09:00
【Python】 Pillowを使用して画像を円形にマスク処理
はじめに
PythonのPillowを使用して、画像の中心部分以外を円形にマスク処理するコードを紹介します。
マスク処理後の画像例
使用する画像
この馬の顔部分以外をマスク処理で円形に黒く塗りつぶします。馬の画像
マスクに使用する画像はこの画像です。黒のマスク画像
マスク処理の流れ
マスク部分(馬の顔以外)が白色で、マスク処理を適用しない部分(馬の顔部分)を黒色にしたパネルを生成する。画像の枠が白色で見えませんが、馬の画像と同じ画像サイズになっています。
馬の画像に、パネルでくり抜いたマスク画像を貼り付ける。
コード
プログラムの説明を簡単に行っていきます。
全体のプログラムは最後に記載しています。
マスク画像の読み込み
馬の画像の大きさに合わせて、マスク画像も読み込みます。
画像を読み込むfrom PIL import Image,ImageDraw # 馬の画像を読み込む img = Image.open("horse.jpg") # 馬の画像に合わせてマスク画像を読み込む mask_width = img.size[0] mask_height = img.size[1] black_mask=Image.open("black.jpg").resize((mask_width,mask_height))パネル作成
黒のマスク画像と同じサイズのパネル(circle_mask)作成し、そこに円を描画します。
パネルの作成時には、"L":8bitグレースケール画像を使用します。マスク画像として使用できるのは、貼り付け画像と同じサイズでmodeが以下の三種類の場合。
1:1bit画像(二値画像)
L:8bitグレースケール画像
RGBA:アルファチャンネルを持った画像マスク画像が8bitグレースケール(mode='L')の場合、0(黒)ではベース画像が100%、255(白)では貼り付け画像が100%、中間値では2つの画像が値に応じてブレンドされる。
パネル作成# パネルに円を描画 circle_mask = Image.new("L", black_mask.size, 255) draw = ImageDraw.Draw(circle_mask)円を描画
円はellipseメソッドを使用して描画しますが、バウンディングボックスの座標(左下と右下)を渡すことに注意してください。
円の描画# 円のバウンディングボックスの座標 start_x = 600 start_y = 200 width = 900 height = 900 # 正円にするならwidthの同値 end_x = start_x + width end_y = start_y + height # 描画 draw.ellipse(((start_x, start_y),(end_x, end_y)), fill=0)画像をくり抜いてマスク処理
マスク処理# 円パネル(circle_mask)をマスクとし、黒のマスク画像(black_mask)を馬画像にペースト img.paste(black_mask, (0, 0), circle_mask) # 保存 img.save("horse_masked.jpg")
全体コード
from PIL import Image,ImageDraw # 馬の画像を読み込む img = Image.open("horse.jpg") # 馬の画像に合わせてマスク画像を読み込む mask_width = img.size[0] mask_height = img.size[1] black_mask=Image.open("black.jpg").resize((mask_width,mask_height)) # パネルに円を描画 circle_mask = Image.new("L", black_mask.size, 255) draw = ImageDraw.Draw(circle_mask) # 円のバウンディングボックスの座標 start_x = 600 start_y = 200 width = 900 height = 900 # 正円にするならwidthの同値 end_x = start_x + width end_y = start_y + height # 描画 draw.ellipse(((start_x, start_y),(end_x, end_y)), fill=0) # 円パネル(circle_mask)をマスクとし、黒のマスク画像(black_mask)を馬画像にペースト img.paste(black_mask, (0, 0), circle_mask) # 保存 img.save("horse_masked.jpg")参考URL
詳しい引数の説明が紹介されています。
note.nkmk.me




- 投稿日:2020-02-23T18:08:40+09:00
Djangoでテスト駆動開発 その6
Djangoでテスト駆動開発 その6
これはDjangoでテスト駆動開発(Test Driven Development, 以下:TDD)を理解するための学習用メモです。
参考文献はTest-Driven Development with Python: Obey the Testing Goat: Using Django, Selenium, and JavaScript (English Edition) 2nd Editionを元に学習を進めていきます。
本書ではDjango1.1系とFireFoxを使って機能テスト等を実施していますが、今回はDjagno3系とGoogle Chromeで機能テストを実施していきます。また一部、個人的な改造を行っていますが(Project名をConfigに変えるなど、、)、大きな変更はありません。
⇒⇒その1 - Chapter1はこちら
⇒⇒その2 - Chapter2はこちら
⇒⇒その3 - Chapter3はこちら
⇒⇒その4 - Chapter4はこちら
⇒⇒その5 - Chapter5はこちらPart1. The Basics of TDD and Django
Chapter6. Improving Functional Testss: Ensuring Isolation and Removing Voodoo Sleeps
Chapter5ではPOSTされたデータが保存されているか、それを問題なくresponseに返せているのか、を確認しました。
単体テストではDjangoのテスト用DBを作成しているため、テスト実行時とともにテスト用のデータは削除されますが、機能テストでは(現在の設定では)本番用のDB(db.sqlite3)を使用してしまい、テスト時のデータも保存されてしまうという問題がありました。
今回はこれらの問題に対する
best practiceを実践していきます。Ensuring Test Isolation in Functional Tests
テスト用のデータが残るとテスト間での分離ができないため、「テスト用のデータが保存されているために成功するはずのテストが失敗する」ようなトラブルが発生します。
これを避けるためにテスト間を分離することを意識することが大切です。機能テストでも単体テストのようにテスト用のデータベースを自動で作成して、テストが終われば削除できるような仕組みをDjagnoでは
LiveServerTestCaseクラスを使用することで実装することができます。
LiveServerTestCaseはDjangoのテストランナーを使ってテストを行うことを想定しています。
Djangoのテストランナーが走ると全てのフォルダ内のtestから始まるファイルを実行します。したがって、Djangoのアプリケーションのように機能テスト用のフォルダを作成しましょう。
# フォルダの作成 $ mkdir functional_tests # DjangoにPythonパッケージとして認識させるため $ type nul > functional_tests/__init__.py # 既存の機能テストを名前を変えて移動 $ git mv functional_tests.py functional_tests/tests.py # 確認 $ git statusこれで
python manage.py functional_tests.pyで機能テストを実行していたのが、
python manage.py test functional_testsで実行できるようになりました。それでは機能テストを書き換えましょう。
# django-tdd/functional_tests/tests.py from django.test import LiveServerTestCase # 追加 from selenium import webdriver from selenium.webdriver.common.keys import Keys import time class NewVisitorTest(LiveServerTestCase): # 変更 def setUp(self): self.browser = webdriver.Chrome() def tearDown(self): self.browser.quit() def check_for_row_in_list_table(self, row_text): table = self.browser.find_element_by_id('id_list_table') rows = table.find_elements_by_tag_name('tr') self.assertIn(row_text, [row.text for row in rows]) def test_can_start_a_list_and_retrieve_it_later(self): # のび太は新しいto-doアプリがあると聞いてそのホームページにアクセスした。 self.browser.get(self.live_server_url) # 変更 # のび太はページのタイトルがとヘッダーがto-doアプリであることを示唆していることを確認した。 self.assertIn('To-Do', self.browser.title) header_text = self.browser.find_element_by_tag_name('h1').text self.assertIn('To-Do', header_text) # のび太はto-doアイテムを記入するように促され、 inputbox = self.browser.find_element_by_id('id_new_item') self.assertEqual( inputbox.get_attribute('placeholder'), 'Enter a to-do item' ) # のび太は「どら焼きを買うこと」とテキストボックスに記入した(彼の親友はどら焼きが大好き) inputbox.send_keys('Buy dorayaki') # のび太がエンターを押すと、ページは更新され、 # "1: どら焼きを買うこと"がto-doリストにアイテムとして追加されていることがわかった inputbox.send_keys(Keys.ENTER) time.sleep(3) # ページ更新を待つ。 self.check_for_row_in_list_table('1: Buy dorayaki') # テキストボックスは引続きアイテムを記入することができるので、 # 「どら焼きのお金を請求すること」を記入した(彼はお金にはきっちりしている) inputbox = self.browser.find_element_by_id('id_new_item') inputbox.send_keys("Demand payment for the dorayaki") inputbox.send_keys(Keys.ENTER) time.sleep(3) # ページは再び更新され、新しいアイテムが追加されていることが確認できた self.check_for_row_in_list_table('2: Demand payment for the dorayaki') # のび太はこのto-doアプリが自分のアイテムをきちんと記録されているのかどうかが気になり、 # URLを確認すると、URLはのび太のために特定のURLであるらしいことがわかった self.fail("Finish the test!") # のび太は一度確認した特定のURLにアクセスしてみたところ、 # アイテムが保存されていたので満足して眠りについた。機能テストを
unittestモジュールからLiveServerTestCaseを継承した形に変更しました。
Djangoのテストランナーを使用して機能テストを実行できるようになったので、if __name == '__main__'以下は削除しました。それでは実際に機能テストを実行してみましょう。
$ python manage.py test functional_tests Creating test database for alias 'default'... System check identified no issues (0 silenced). ====================================================================== FAIL: test_can_start_a_list_and_retrieve_it_later (functional_tests.tests.NewVisitorTest) ---------------------------------------------------------------------- Traceback (most recent call last): File "C:--your_path--\django-TDD\functional_tests\tests.py", line 59, in test_can_start_a_list_and_retrieve_it_later self.fail("Finish the test!") AssertionError: Finish the test! ---------------------------------------------------------------------- Ran 1 test in 28.702s FAILED (failures=1) Destroying test database for alias 'default'...機能テストは
self.failで終了し、LiveServerTestCaseを適用する前と同じ結果が得られました。
また、機能テスト用のデータベースが作成され、テストが終了すると同時に削除されていることも確認できました。ここでコミットしておきましょう。
$ git status $ git add functional_tests $ git commit -m "make functional_tests an app, use LiveSeverTestCase"Running Just the Unit Tests
python manage.py testコマンドによってDjangoは単体テストと機能テストを一緒に実行できるようになりました。
単体テストだけテストを行う場合はpython manage.py test listsのようにアプリケーションを指定しましょう。On Implicit and Explicit Waits, and Voodoo time.sleeps
機能テストの実行結果を確認するため、
time.sleep(3)を追加していました。
このtime.sleep(3)を3秒にするのか、1秒にするのか、0.5秒にするのか、これはレスポンスによって変わっていきますが何が正解か分かりません。これを必要なバッファだけ用意させるように機能テストを書き換えていきましょう。
check_for_row_in_list_tableをwait_for_row_in_list_tableに変更し、polling/retryロジックを追加します。# django-tdd/functional_tests/tests.py from django.test import LiveServerTestCase from selenium import webdriver from selenium.webdriver.common.keys import Keys from selenium.common.exceptions import WebDriverException # 追加 import time MAX_WAIT = 10 # 追加 class NewVisitorTest(LiveServerTestCase): def setUp(self): self.browser = webdriver.Chrome() def tearDown(self): self.browser.quit() def wait_for_row_in_list_table(self, row_text): start_time = time.time() while True: try: table = self.browser.find_element_by_id('id_list_table') rows = table.find_elements_by_tag_name('tr') self.assertIn(row_text, [row.text for row in rows]) return except (AssertionError, WebDriverException) as e: if time.time() - start_time > MAX_WAIT: raise e time.sleep(0.5) [...]これによってレスポンスに対して必要なバッファだけ処理を停めることができるようになりました(後でリファクタリングする)。
最大10秒まで待てるようにしています。
check_for_row_in_list_tableを実行していた部分をwait_for_row_in_list_tableに変更し、time.sleep(3)を削除しましょう。
結果的に、現在の機能テストは下記のようになりました。# django-tdd/functional_tests/tests.py from django.test import LiveServerTestCase from selenium import webdriver from selenium.webdriver.common.keys import Keys from selenium.common.exceptions import WebDriverException # 追加 import time MAX_WAIT = 10 # 追加 class NewVisitorTest(LiveServerTestCase): # 変更 def setUp(self): self.browser = webdriver.Chrome() def tearDown(self): self.browser.quit() def wait_for_row_in_list_table(self, row_text): start_time = time.time() while True: try: table = self.browser.find_element_by_id('id_list_table') rows = table.find_elements_by_tag_name('tr') self.assertIn(row_text, [row.text for row in rows]) return except (AssertionError, WebDriverException) as e: if time.time() - start_time > MAX_WAIT: raise e time.sleep(0.5) def test_can_start_a_list_and_retrieve_it_later(self): # のび太は新しいto-doアプリがあると聞いてそのホームページにアクセスした。 self.browser.get(self.live_server_url) # 変更 # のび太はページのタイトルがとヘッダーがto-doアプリであることを示唆していることを確認した。 self.assertIn('To-Do', self.browser.title) header_text = self.browser.find_element_by_tag_name('h1').text self.assertIn('To-Do', header_text) # のび太はto-doアイテムを記入するように促され、 inputbox = self.browser.find_element_by_id('id_new_item') self.assertEqual( inputbox.get_attribute('placeholder'), 'Enter a to-do item' ) # のび太は「どら焼きを買うこと」とテキストボックスに記入した(彼の親友はどら焼きが大好き) inputbox.send_keys('Buy dorayaki') # のび太がエンターを押すと、ページは更新され、 # "1: どら焼きを買うこと"がto-doリストにアイテムとして追加されていることがわかった inputbox.send_keys(Keys.ENTER) self.wait_for_row_in_list_table('1: Buy dorayaki') # テキストボックスは引続きアイテムを記入することができるので、 # 「どら焼きのお金を請求すること」を記入した(彼はお金にはきっちりしている) inputbox = self.browser.find_element_by_id('id_new_item') inputbox.send_keys("Demand payment for the dorayaki") inputbox.send_keys(Keys.ENTER) # ページは再び更新され、新しいアイテムが追加されていることが確認できた self.wait_for_row_in_list_table('2: Demand payment for the dorayaki') # のび太はこのto-doアプリが自分のアイテムをきちんと記録されているのかどうかが気になり、 # URLを確認すると、URLはのび太のために特定のURLであるらしいことがわかった self.fail("Finish the test!") # のび太は一度確認した特定のURLにアクセスしてみたところ、 # アイテムが保存されていたので満足して眠りについた。機能テストを実行すると問題なく
self.fail("Finish the test!") AssertionError: Finish the test!で終了しました。Testing "Best practives" applied in this chapter
このChapter6でのベストプラクティスをまとめておきます。
テストは他のテストへ影響を与えてはならない。
Djangoのテストランナーはテスト用のデータベースを作成・削除してくれるので機能テストでもこれを利用する。time.sleep()の乱用をさける
time.sleep()を入れてloading時のバッファをもつことは簡単だが、処理とバッファによっては無意味なエラーが発生することがあるので
避ける。Seleniumのwaits機能は使わない
seleniumに自動でバッファを持つ機能がある(らしい)が、"Explicit is better than implict"とZen of Pythonにあるので
明示的な実装が好まれる。
- 投稿日:2020-02-23T18:01:08+09:00
tempfile
1import tempfile with tempfile.TemporaryFile(mode='w+') as t: t.write('Hello') t.seek(0) print(t.read()) with tempfile.NamedTemporaryFile(delete=False) as t: print(t.name) with open(t.name, 'w+') as f: f.write('test\n') f.seek(0) print(f.read())1の実行結果Hello /tmp/tmpahd0kr2●●● testprint(t.read())で書き込んだHelloが出力される。
これは一時ファイルなので削除される。NamedTemporaryFile(delete=False)とする事で、
削除されずファイルを残す事ができる。次に一時ファイルではなく、
一時的なディレクトリをつくる。2with tempfile.TemporaryDirectory() as td: print(td) temp_dir = tempfile.mkdtemp() print(temp_dir)2の実行結果/tmp/tmp9bq6_n●● /tmp/tmpiybl8b●●tdは一時的なディレクトリ。
temp_dirはtempfile.mkdtemp()とする事で、
削除されずディレクトリを残す事ができる。
- 投稿日:2020-02-23T17:48:41+09:00
【機械学習】WordNetを使用して機械的に類似単語を抽出する
自然言語処理概要
WordNetについて触れる前に自然言語処理について簡単に触れておきます。
自然言語処理において機械に文章を理解させるためには、主に以下のように形態素解析、構文解析、意味解析、文脈解析の段階的なタスクが必要になります。形態素解析
情報の注記の無い自然言語のテキストデータから、対象言語の文法や、辞書と呼ばれる単語の品詞等の情報にもとづき、形態素(言語で意味を持つ最小単位)の列に分割し判別する作業です。
例えば「お待ちしております」を形態素解析すると以下のようになります。
参考:wikipedia
代表的な形態素解析ツールとしてMeCabがあります。
構文解析
自然言語であれば形態素に切分け、関係を図式化するなどして明確にする手続きです。
例えば「美しい水車小屋の乙女」という文章があった時に以下のような2つの構文が考えられます。
参考:wikipedia
周りの形態素の情報を元にどのような繋がりがあるかを分析していきます。
代表的な分析ツールとしてCabochaなどがあります。意味解析
機械に知識を与えるための手続きです。例えば以下の文章があったとします。
「高い富士山と海が美しい」
人間であれば高いがどの単語にかかっているのかがすぐにわかります。
「高い富士山」はあっても、「高い海」がないということは感覚的に判断ができます。しかしながら機械は何も知識を持っていませんので「高い海」がおかしいことを判断できません。WordNetとは
シソーラスの1種。単語の上位 / 下位関係、部分 / 全体関係、同義関係、類義関係などによって単語を分類し、体系づけた類語辞典。それぞれの単語がどのような関係にあるかを体系づけたものであり、上述の意味解析などの際に使用されます。
例えば「オンロードバイク」ですと、「オンロードバイク」を包含する上位概念が「オートバイ」や「車両」であり、下位概念として「ネイキッド」「アメリカン」といったバイクの種類が表されます。なお「バイク」と並列に記述されている「スクーター」「オフロードバイク」などが類似語とみなすことができます。
利用
これらはプログラムで扱えるようにまとめられたものが既に存在しており、以下よりダウンロードすることができます。 sqliteで公開されており、sqlを使って読み込みが可能です。
tableおよびカラム一覧
pos_def ('pos', lang', def') link_def ('link', lang','def') synset_def ('synset', 'lang', 'def', sid') synset_ex ('synset', 'lang', 'def', 'sid') synset ('synset', 'pos', 'name', 'src') synlink ('synset1', synset2', 'link', 'src') ancestor ('synset1', 'synset2', 'hops') sense ('synset' ,'wordid','lang', 'rank', 'lexid','freq','src') word ('wordid','lang', 'lemma', 'pron', 'pos') variant ('varid','wordid','lang', 'lemma','vartype') xlink ('synset', 'resource','xref', 'misc', 'confidence')
プログラム
確認1 : 各テーブルのカラムを確認する
- ソース
import sqlite3 conn = sqlite3.connect("wnjpn.db") def chk_table(): print("") print("###word table info") cur = conn.execute("select count(*) from word") for row in cur: print("word num:" +str(row[0])) cur = conn.execute("select name from sqlite_master where type='table'") for row in cur: print("=======================================") print(row[0]) cur = conn.execute("PRAGMA TABLE_INFO("+row[0]+")") for row in cur: print(row) if __name__=="__main__": chk_table()
- 結果1
###word table info word num:249121 ======================================= pos_def (0, 'pos', 'text', 0, None, 0) (1, 'lang', 'text', 0, None, 0) (2, 'def', 'text', 0, None, 0) ======================================= link_def (0, 'link', 'text', 0, None, 0) (1, 'lang', 'text', 0, None, 0) (2, 'def', 'text', 0, None, 0) ======================================= synset_def (0, 'synset', 'text', 0, None, 0) (1, 'lang', 'text', 0, None, 0) (2, 'def', 'text', 0, None, 0) (3, 'sid', 'text', 0, None, 0) ======================================= synset_ex (0, 'synset', 'text', 0, None, 0) (1, 'lang', 'text', 0, None, 0) (2, 'def', 'text', 0, None, 0) (3, 'sid', 'text', 0, None, 0) ======================================= synset (0, 'synset', 'text', 0, None, 0) (1, 'pos', 'text', 0, None, 0) (2, 'name', 'text', 0, None, 0) (3, 'src', 'text', 0, None, 0) ======================================= synlink (0, 'synset1', 'text', 0, None, 0) (1, 'synset2', 'text', 0, None, 0) (2, 'link', 'text', 0, None, 0) (3, 'src', 'text', 0, None, 0) ======================================= ancestor (0, 'synset1', 'text', 0, None, 0) (1, 'synset2', 'text', 0, None, 0) (2, 'hops', 'int', 0, None, 0) ======================================= sense (0, 'synset', 'text', 0, None, 0) (1, 'wordid', 'integer', 0, None, 0) (2, 'lang', 'text', 0, None, 0) (3, 'rank', 'text', 0, None, 0) (4, 'lexid', 'integer', 0, None, 0) (5, 'freq', 'integer', 0, None, 0) (6, 'src', 'text', 0, None, 0) ======================================= word (0, 'wordid', 'integer', 0, None, 1) (1, 'lang', 'text', 0, None, 0) (2, 'lemma', 'text', 0, None, 0) (3, 'pron', 'text', 0, None, 0) (4, 'pos', 'text', 0, None, 0) ======================================= variant (0, 'varid', 'integer', 0, None, 1) (1, 'wordid', 'integer', 0, None, 0) (2, 'lang', 'text', 0, None, 0) (3, 'lemma', 'text', 0, None, 0) (4, 'vartype', 'text', 0, None, 0) ======================================= xlink (0, 'synset', 'text', 0, None, 0) (1, 'resource', 'text', 0, None, 0) (2, 'xref', 'text', 0, None, 0) (3, 'misc', 'text', 0, None, 0) (4, 'confidence', 'text', 0, None, 0)確認2 : 登録されている単語(日本語)を確認する
- ソース
import sqlite3 conn = sqlite3.connect("wnjpn.db") def chk_word(): #cur = conn.execute("select * from word limit 240000") cur = conn.execute("select * from word where lang='jpn' limit 240000") for row in cur: print(row) if __name__=="__main__": chk_word()
- 結果2 一部のみ表示
(249100, 'jpn', 'スープ皿', None, 'n') (249101, 'jpn', '引延す', None, 'v') (249102, 'jpn', '渋色', None, 'n') (249103, 'jpn', '断書き', None, 'n') (249104, 'jpn', 'オールボルグ', None, 'n') (249105, 'jpn', 'うしろ側', None, 'n') (249106, 'jpn', '取繕', None, 'n') (249107, 'jpn', '利便', None, 'n') (249108, 'jpn', '利便', None, 'a') (249109, 'jpn', 'ヴァイラス', None, 'n') (249110, 'jpn', '古めかしい', None, 'a') (249111, 'jpn', '懇切', None, 'n') (249112, 'jpn', '懇切', None, 'a') (249113, 'jpn', '超文面', None, 'n') (249114, 'jpn', '性病', None, 'n') (249115, 'jpn', 'まゆ墨', None, 'n') (249116, 'jpn', 'ヘムライン', None, 'n') (249117, 'jpn', '非近交系', None, 'a') (249118, 'jpn', '科学機器', None, 'n') (249119, 'jpn', '後ずさる', None, 'v') (249120, 'jpn', '引繰り返す', None, 'v') (249121, 'jpn', '意志', None, 'n')確認3 : 類義語を抽出する
- ソース
import sqlite3 conn = sqlite3.connect("wnjpn.db") def main(word): print("") print("") print("## 入力: 【",word,"】") print("") # 単語がWordnetに存在するか確認 cur = conn.execute("select wordid from word where lemma='%s'" % word) word_id = 99999999 for row in cur: word_id = row[0] if word_id==99999999: print("「%s」is not exist" % word) return #概念を取得 cur = conn.execute("select synset from sense where wordid='%s'" % word_id) synsets = [] for row in cur: synsets.append(row[0]) print(synsets) #概念に含まれる単語の表示 for synset in synsets: cur1 = conn.execute("select name from synset where synset='%s'" % synset) for row1 in cur1: print("## 概念: %s" %(row1[0])) cur2 = conn.execute("select def from synset_def where (synset='%s' and lang='jpn')" % synset) for row2 in cur2: print("## 意味: %s" %(row2[0])) cur3 = conn.execute("select wordid from sense where (synset='%s' and wordid!=%s)" % (synset,word_id)) for i,row3 in enumerate(cur3): target_word_id = row3[0] cur3_1 = conn.execute("select lemma from word where wordid=%s" % target_word_id) for row3_1 in cur3_1: print("類義語"+str(i+1)+": %s" % (row3_1[0])) print() if __name__=="__main__": word="自動車" main(word)
- 結果3
## 入力: 【 自動車 】 ['03791235-n', '02958343-n'] ## 概念: motor_vehicle ## 意味: レールの上を走らない自動推進式の車輪のついた乗物 類義語1: motor_vehicle 類義語2: automotive_vehicle 類義語3: モータービークル ## 概念: auto ## 意味: 4輪の自動車 ## 意味: 通常、内燃エンジンによって推進する 類義語1: auto 類義語2: motorcar 類義語3: machine 類義語4: car 類義語5: automobile 類義語6: 四輪車 類義語7: オートモービル 類義語8: 車 類義語9: 乗用車 類義語10: オートモビル 類義語11: モーターカー類似語抽出の流れとして「自動車」を入力したらまず、自動車の上位概念である「motor_vehicle」「auto」をたどり、その配下にある単語を抽出することで、「自動車」と並列関係にある単語を取り出しています。
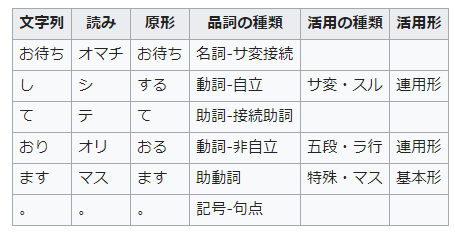


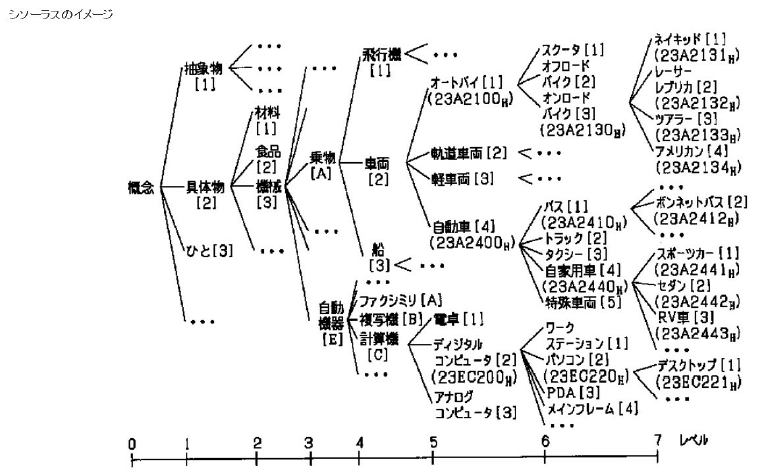

- 投稿日:2020-02-23T17:23:55+09:00
【Keras】個人用メモ【Python】
フォルダごとに画像分類する
画像からnpyファイルの作成
create_datasets.pyfrom sklearn import model_selection from PIL import Image import os, glob import numpy as np import random # 分類カテゴリ name = "name" root_dir = "./datasets/" + name +"/" savenpy = "./npy/"+name+".npy" categories = ["F", "E", "D", "C", "B", "A", "S"] nb_classes = len(categories) image_size = 224 allnum = 700 # フォルダごとの画像データを読み込む X = [] # 画像データ Y = [] # ラベルデータ image_dir = os.path.join(root_dir, root_dir) files = glob.glob(image_dir + "/*.jpg") random.shuffle(files) for idx, f in enumerate(files): img = Image.open(f) img = img.convert("RGB") # カラーモードの変更 data = np.asarray(img) X.append(data) Y.append(idx) X = np.array(X) Y = np.array(Y) print(len(X), len(Y)) # # 学習データとテストデータを分割 X_train, X_test, y_train, y_test = model_selection.train_test_split(X, Y, test_size=0.3) xy = (X_train, X_test, y_train, y_test) #Numpy配列をファイルに保存 np.save(savenpy, xy)モデルの作成
create_model.pyimport keras from keras.models import Sequential from keras.layers import Convolution2D, MaxPooling2D, Conv2D from keras.layers import Activation, Dropout, Flatten, Dense from keras.utils import np_utils import numpy as np from keras.callbacks import EarlyStopping # 分類対象のカテゴリ name = "name" root_dir = "./datasets/" + name +"/" loadnpy = "./npy/"+name+".npy" categories = ["F", "E", "D", "C", "B", "A", "S"] nb_classes = len(categories) #メインの関数を定義する def main(): X_train,X_test,y_train,y_test = np.load(loadnpy) #画像ファイルの正規化 X_train = X_train.astype('float') / 256 X_test = X_test.astype('float') / 256 y_train = np_utils.to_categorical(y_train, nb_classes) y_test = np_utils.to_categorical(y_test, nb_classes) model = model_train(X_train,y_train) model_eval(model,X_test,y_test) # モデルを学習 def model_train(X,y): model = Sequential() model.add(Conv2D(32,(3,3), padding='same',input_shape=X.shape[1:])) model.add(Activation('relu')) model.add(Conv2D(32,(3,3))) model.add(Activation('relu')) model.add(MaxPooling2D(pool_size=(2,2))) model.add(Dropout(0.25)) model.add(Conv2D(64,(3,3),padding='same')) model.add(Activation('relu')) model.add(Conv2D(64,(3,3))) model.add(Activation('relu')) model.add(MaxPooling2D(pool_size=(2,2))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(512)) model.add(Activation('relu')) model.add(Dropout(0.5)) model.add(Dense(nb_classes)) model.add(Activation('softmax')) model.summary() #最適化の手法 opt = keras.optimizers.rmsprop(lr=0.0001,decay=1e-6) #モデルのコンパイル model.compile(loss='categorical_crossentropy', optimizer=opt,metrics=['accuracy']) #モデルの学習 model.fit(X, y, batch_size=32,epochs=100) #モデルの保存 model.save('./save_model.h5') return model # モデルを評価 def model_eval(model, X, y): score = model.evaluate(X, y) print('loss=', score[0]) print('accuracy=', score[1]) if __name__ == "__main__": main()
- 投稿日:2020-02-23T17:18:32+09:00
メソッド、クラス、オブジェクトの意味を整理
オブジェクト
データと命令(メソッド)が一緒になっているもの。
データ.メソッド(引数1,引数2,・・・)の形。クラス
オブジェクトの設計図。
オブジェクトがどのような設計図を持っていて、どのような振る舞いをするのかをクラスという形にまとめたもの。インスタンス
クラスから作ったオブジェクトのこと。アトリビュート
インスタンスが持つ変数のようなもの。
インスタンス.アトリビュートのような形。メソッド
データに紐付いて、データに対する処理や操作をする関数のこと。
あくまでクラス内で定義された関数などを指す。
単独で呼び出しできる関数とは違う。
- 投稿日:2020-02-23T16:54:54+09:00
imutilsの使い方
imutilsとは?
どんな人向けか
face detectionを行う人とか。ハードコーディングっぽく見えなくなるのが良い。
例えば、imutilsを使わなければ、point_idxs = [ 1, # right ear 3, # right cheak1 4, # right cheak2 33, # nose top 12, # left cheak1 13, # left cheak2 15, # left ear 28, # nose line ] warp_points = [0, 2, 4, 6]としていたものを、
from imutil import face_util (lStart, lEnd) = face_utils.FACIAL_LANDMARKS_IDXS["left_eye"] (rStart, rEnd) = face_utils.FACIAL_LANDMARKS_IDXS["right_eye"] (mStart, mEnd) = face_utils.FACIAL_LANDMARKS_IDXS["mouth"]とできるし、
shape = predictor(gray, rects[0]) shape = face_utils.shape_to_np(shape)とできてしまう。
frame = imutils.resize(frame, width=450)ただ、余計なライブラリが増えるというデメリットがある。
- 投稿日:2020-02-23T16:40:32+09:00
[kotlin]アンドロイドでカメラで撮った写真を画像認識するアプリをつくる
今回やること
アンドロイドで写真を撮って保存しその写真の表示と画像分類を行い、分類結果を表示する簡単な画像認識アプリを作る。
これ↓
カメラを起動し撮影し、
撮った写真を画面に表示して
撮った写真を画像認識する今回使うライブラリとかキーワード等
・ Python PyTorch Mobile
・ Android Camera X
・ resnet18
・ kotlin去年出たものばっか...
依存関係
まずは依存関係(dependencies)を追加(2020年2月時点)
camera x と pytorch mobilebuild.gradledef camerax_version = '1.0.0-alpha06' implementation "androidx.camera:camera-core:${camerax_version}" implementation "androidx.camera:camera-camera2:${camerax_version}" implementation 'org.pytorch:pytorch_android:1.4.0' implementation 'org.pytorch:pytorch_android_torchvision:1.4.0'上の方のandroid{}ってあるところの一番最後に以下を追加
build.gradlecompileOptions { sourceCompatibility JavaVersion.VERSION_1_8 targetCompatibility JavaVersion.VERSION_1_8 }Camera Xの実装
依存関係を追加したら続いてCamera Xというアンドロイドで簡単にカメラを扱いやすくなるライブラリを利用して写真を撮る機能を実装する。
以下、公式のCamera Xのチュートリアルを実装していく。詳細は他の記事でも上がっていたりするので省略してコードのみ。
マニフェスト
パーミッションの許可
<uses-permission android:name="android.permission.CAMERA" />カメラで写真を撮る機能を実装
カメラで写真を撮って保存する機能を付ける。チュートリアルに沿ってカメラのプレビュー、カメラのキャプチャーまで。
チュートリアルの内容とほぼ同じなのでコードのみ載せておきます。レイアウト
撮った写真を表示する場所、カメラのプレビュー表示場所、カメラ起動ボタン、キャプチャーボタン、推論ボタンを適当に設置する。activity_main.xml<androidx.constraintlayout.widget.ConstraintLayout xmlns:android="http://schemas.android.com/apk/res/android" xmlns:app="http://schemas.android.com/apk/res-auto" xmlns:tools="http://schemas.android.com/tools" android:layout_width="match_parent" android:layout_height="match_parent" tools:context=".MainActivity"> <Button android:id="@+id/capture_button" android:layout_width="wrap_content" android:layout_height="wrap_content" android:layout_marginTop="2dp" android:text="撮影" app:layout_constraintEnd_toEndOf="parent" app:layout_constraintHorizontal_bias="0.25" app:layout_constraintStart_toStartOf="parent" app:layout_constraintTop_toBottomOf="@+id/frameLayout" /> <Button android:id="@+id/activateCamera" android:layout_width="wrap_content" android:layout_height="wrap_content" android:text="カメラ起動" app:layout_constraintEnd_toEndOf="parent" app:layout_constraintHorizontal_bias="0.25" app:layout_constraintStart_toStartOf="parent" app:layout_constraintTop_toBottomOf="@+id/capture_button" /> <ImageView android:id="@+id/capturedImg" android:layout_width="500px" android:layout_height="500px" app:layout_constraintEnd_toEndOf="parent" app:layout_constraintStart_toStartOf="parent" app:layout_constraintTop_toTopOf="parent" app:srcCompat="@mipmap/ic_launcher_round" /> <FrameLayout android:id="@+id/frameLayout" android:layout_width="wrap_content" android:layout_height="wrap_content" android:layout_marginTop="8dp" android:background="@android:color/holo_blue_bright" app:layout_constraintEnd_toEndOf="parent" app:layout_constraintStart_toStartOf="parent" app:layout_constraintTop_toBottomOf="@+id/capturedImg"> <TextureView android:id="@+id/view_finder" android:layout_width="500px" android:layout_height="500px" /> </FrameLayout> <Button android:id="@+id/inferBtn" android:layout_width="wrap_content" android:layout_height="wrap_content" android:layout_marginStart="32dp" android:text="推論" app:layout_constraintBottom_toBottomOf="@+id/capture_button" app:layout_constraintStart_toEndOf="@+id/capture_button" app:layout_constraintTop_toTopOf="@+id/capture_button" /> <TextView android:id="@+id/resultText" android:layout_width="wrap_content" android:layout_height="wrap_content" android:layout_marginTop="4dp" android:text="推論結果" app:layout_constraintEnd_toEndOf="parent" app:layout_constraintHorizontal_bias="0.31" app:layout_constraintStart_toStartOf="parent" app:layout_constraintTop_toBottomOf="@+id/activateCamera" /> </androidx.constraintlayout.widget.ConstraintLayout>MainActivity
MainActivity.ktprivate const val REQUEST_CODE_PERMISSIONS = 10 private val REQUIRED_PERMISSIONS = arrayOf(Manifest.permission.CAMERA) class MainActivity : AppCompatActivity(), LifecycleOwner { private var imgData: Bitmap? = null // 保存した画像データ格納変数 override fun onCreate(savedInstanceState: Bundle?) { super.onCreate(savedInstanceState) setContentView(R.layout.activity_main) viewFinder = findViewById(R.id.view_finder) // カメラ起動 activateCamera.setOnClickListener { if (allPermissionsGranted()) { viewFinder.post { startCamera() } } else { ActivityCompat.requestPermissions( this, REQUIRED_PERMISSIONS,REQUEST_CODE_PERMISSIONS ) } } viewFinder.addOnLayoutChangeListener { _, _, _, _, _, _, _, _, _ -> updateTransform() } /**あとで画像分類するコードをここに追加**/ } private val executor = Executors.newSingleThreadExecutor() private lateinit var viewFinder: TextureView private fun startCamera() { // プレビューuse case 作成 val previewConfig = PreviewConfig.Builder().apply { setTargetResolution(Size(viewFinder.width, viewFinder.height)) // 680, 480 }.build() val preview = Preview(previewConfig) preview.setOnPreviewOutputUpdateListener { val parent = viewFinder.parent as ViewGroup parent.removeView(viewFinder) parent.addView(viewFinder, 0) viewFinder.surfaceTexture = it.surfaceTexture updateTransform() } //キャプチャーuse case作成 val imageCaptureConfig = ImageCaptureConfig.Builder() .apply { setCaptureMode(ImageCapture.CaptureMode.MIN_LATENCY) }.build() val imageCapture = ImageCapture(imageCaptureConfig) // 写真撮影 capture_button.setOnClickListener { val file = File( externalMediaDirs.first(), "${System.currentTimeMillis()}.jpg" ) imageCapture.takePicture(file, executor, object : ImageCapture.OnImageSavedListener { override fun onError( imageCaptureError: ImageCapture.ImageCaptureError, message: String, exc: Throwable? ) { val msg = "Photo capture failed: $message" Log.e("CameraXApp", msg, exc) viewFinder.post { Toast.makeText(baseContext, msg, Toast.LENGTH_SHORT).show() } } override fun onImageSaved(file: File) { // 保存したファイルデータをビットマップとして取得 // ()Matrix を使って90度回転させて表示 val inputStream = FileInputStream(file) val bitmap = BitmapFactory.decodeStream(inputStream) val bitmapWidth = bitmap.width val bitmapHeight = bitmap.height val matrix = Matrix() matrix.setRotate(90F, bitmapWidth / 2F, bitmapHeight / 2F) val rotatedBitmap = Bitmap.createBitmap( bitmap, 0, 0, bitmapWidth, bitmapHeight, matrix, true ) imgData = rotatedBitmap // 推論用に画像を格納 // 撮影した写真を表示 //メインスレッド以外からviewの変更 viewFinder.post { capturedImg.setImageBitmap(rotatedBitmap) } val msg = "Photo capture succeeded: ${file.absolutePath}" viewFinder.post { Toast.makeText(baseContext, msg, Toast.LENGTH_SHORT).show() } } }) } // プレビューとキャプチャーuse case CameraX.bindToLifecycle(this, preview, imageCapture) } private fun updateTransform() { val matrix = Matrix() val centerX = viewFinder.width / 2f val centerY = viewFinder.height / 2f val rotationDegrees = when (viewFinder.display.rotation) { Surface.ROTATION_0 -> 0 Surface.ROTATION_90 -> 90 Surface.ROTATION_180 -> 180 Surface.ROTATION_270 -> 270 else -> return } matrix.postRotate(-rotationDegrees.toFloat(), centerX, centerY) viewFinder.setTransform(matrix) } override fun onRequestPermissionsResult( requestCode: Int, permissions: Array<String>, grantResults: IntArray ) { if (requestCode == REQUEST_CODE_PERMISSIONS) { if (allPermissionsGranted()) { viewFinder.post { startCamera() } } else { Toast.makeText( this, "Permissions not granted by the user.", Toast.LENGTH_SHORT ).show() finish() } } } private fun allPermissionsGranted() = REQUIRED_PERMISSIONS.all { ContextCompat.checkSelfPermission( baseContext, it ) == PackageManager.PERMISSION_GRANTED } }ここまで出来たら写真を撮って、その写真を画面に表示させることができるはず。
(自分の環境のせいなのかコードが悪いせいなのか分からないけど、写真撮ってから撮った写真が表示されるまで結構ラグがあります。)公式からはCamera Xの use caseとしてプレビュー、キャプチャー、画像解析の3つのuse caseが提供されているが、今回はプレビューとキャプチャーの組み合わせを使う。
ちなみにuse case のサポートされている組み合わせは以下の通り。(公式ドキュメント)
画像認識の実装
モデルをダウンロードする
今回は学習済みのモデルを使って推論する。
※python,PyTorchの環境がない方は自分のgithubからresnet.ptをダウンロードしてここを読み飛ばしてください。
python PyTorchの環境がある方は以下を自分の環境で実行してモデルをダウンロードしてください。import torch import torchvision model = torchvision.models.resnet18(pretrained=True) model.eval() example = torch.rand(1, 3, 224, 224) traced_script_module = torch.jit.trace(model, example) traced_script_module.save("resnet.pt")うまく実行できると同じ階層にresnet.ptというファイルが生成される。(後でこれをandroid studioのフォルダに入れる)
この学習済みresnet18を使って画像認識していく。モデルを使って推論する
assetフォルダ
まずは先ほどダウンロードしたモデルをandroid studioのフォルダに放り込む。
放り込む場所はassetフォルダ (デフォルトでは存在しないのでresフォルダとかを右クリック->新規->フォルダ-> Assetフォルダで作れる)次にassetフォルダからパスを取得する関数を作る
以下をMainActivity.ktの一番下とかに加えるMainActivity.kt//assetファイルのパス取得 private fun getAssetFilePath(context: Context, assetName: String): String { val file = File(context.filesDir, assetName) if (file.exists() && file.length() > 0) { return file.absolutePath } context.assets.open(assetName).use { inputStream -> FileOutputStream(file).use { outputStream -> val buffer = ByteArray(4 * 1024) var read: Int while (inputStream.read(buffer).also { read = it } != -1) { outputStream.write(buffer, 0, read) } outputStream.flush() } return file.absolutePath } }推論
画像分類するクラスを取得できるようにImage Netの1000クラスを参照できるようにしておく。
新しくImageNetCategory.ktとかを作ってそこにクラス名を書く。(長すぎるのでgithubからコピペしてください)ImageNetCategory.ktclass ImageNetCategory { var IMAGENET_CLASSES = arrayOf( "tench, Tinca tinca", "goldfish, Carassius auratus", //略(githubからコピペしてください) "ear, spike, capitulum", "toilet tissue, toilet paper, bathroom tissue" ) }つづいてメインの推論の部分を実装する。
MainActivity.ktのonCreateの最後の部分に以下を追加する。MainActivity.kt// ネットワークモデルのロード val resnet = Module.load(getAssetFilePath(this, "resnet.pt")) /**推論**/ inferBtn.setOnClickListener { //撮影した写真を224×224にリサイズする val imgDataResized = Bitmap.createScaledBitmap(imgData!!, 224, 224, true) // ビットマップからテンソルに変換 val inputTensor = TensorImageUtils.bitmapToFloat32Tensor( imgDataResized, TensorImageUtils.TORCHVISION_NORM_MEAN_RGB, TensorImageUtils.TORCHVISION_NORM_STD_RGB ) //フォワードプロパゲーション val outputTensor = resnet.forward(IValue.from(inputTensor)).toTensor() val scores = outputTensor.dataAsFloatArray var maxScore = 0F var maxScoreIdx = 0 for (i in scores.indices) { if (scores[i] > maxScore) { maxScore = scores[i] maxScoreIdx = i } } // 推論結果のインデックスからカテゴリー名に変換 val inferCategory = ImageNetCategory().IMAGENET_CLASSES[maxScoreIdx] resultText.text = "推論結果:${inferCategory}" }これだけで画像認識ができる。
いろんな写真撮ったりモデルを交換してみて遊んでみてください。おわり
今回のコードはgithubに挙げていますので適宜参照してください。
本当はVGG-16とか載せようとしたんだけどout of memoryとかになってめんどそうだと思ったから断念。いろいろ転移学習させたモデルを載せても面白そう。
あと、Camera Xを使えば簡単にカメラの機能を使えて便利だなって思った。



- 投稿日:2020-02-23T16:25:41+09:00
COTOHAを利用して、物語の舞台を抽出・図示してみた
概要
物語の舞台が地元だったりすると、それだけで読んでしまうタイプなので
COTOHAの固有表現抽出を、利用して物語の舞台を、抽出・図示するものを作成してみた。処理の流れ
1.青空文庫より任意の小説を取得
2.COTOHA API(固有表現抽出)で地名(LOC)のみ取得
3.取得した地名を利用して、WordCroudで図示する。環境
Google Colaboratory
ライブラリ
・個別にインストールが必要なものはwordcloudのみ。
(Google Colaboratoryは事前にある程度のライブラリがインストール済みなので、便利です)
以下のコマンドを実行すれば、事前準備は完了です。wordcloudのインストール&フォントのダウンロード!pip install wordcloud !apt-get -y install fonts-ipafont-gothic !rm /root/.cache/matplotlib/fontlist-v300.json青空文庫をクローン!git clone --branch master --depth 1 https://github.com/aozorabunko/aozorabunko.gitコード
1.青空文庫より任意の小説を取得する部分
青空文庫より任意の小説を取得する部分from bs4 import BeautifulSoup def get_word(): #クローンしたhtmlからパスを指定(サンプルは太宰治のグッド・バイ) path_to_html='aozorabunko/cards/000035/files/258_20179.html' #BeautifulSoupでhtml解析 with open(path_to_html, 'rb') as html: soup = BeautifulSoup(html, 'lxml') main_text = soup.find("div", class_='main_text') for yomigana in main_text.find_all(["rp","h4","rt"]): yomigana.decompose() sentences = [line.strip() for line in main_text.text.strip().splitlines()] aozora_text=','.join(sentences) #cotoha apiコール用に文字数で分割(1800文字ごと) aozora_text_list = [aozora_text[i: i+1800] for i in range(0, len(aozora_text), 1800)] return aozora_text_list
Gitからクローンした青空文庫より、任意の小説のパス(path_to_html)を指定して全文取得し
BeautifulSoupでパースしてます。
(ちなみに、サンプルは太宰治のグッド・バイ)また、COTOHAが実行できるように、文字列を1800文字ごとに分割して配列化してます。
(ちゃんと調べてないですが2000文字でダメで、1800文字で実行したらイケたので。。ちゃんと調べろよ)
2.COTOHA_APIを呼び出しする部分
COTOHA_APIをコールする部分import os import urllib.request import json import configparser import codecs import sys import time client_id = "各自のクライアントID" client_secret = "各自のシークレットキー" developer_api_base_url = "https://api.ce-cotoha.com/api/dev/nlp/" access_token_publish_url = "https://api.ce-cotoha.com/v1/oauth/accesstokens" def cotoha_call(sentence): # アクセストークン取得 def getAccessToken(): url = access_token_publish_url headers={ "Content-Type": "application/json;charset=UTF-8" } data = { "grantType": "client_credentials", "clientId": client_id, "clientSecret": client_secret } data = json.dumps(data).encode() req = urllib.request.Request(url, data, headers) res = urllib.request.urlopen(req) res_body = res.read() res_body = json.loads(res_body) access_token = res_body["access_token"] return access_token # API URL指定(固有表現抽出) base_url_footer = "v1/ne" url = developer_api_base_url + base_url_footer headers={ "Authorization": "Bearer " + getAccessToken(), #access_token, "Content-Type": "application/json;charset=UTF-8", } data = { "sentence": sentence } data = json.dumps(data).encode() time.sleep(0.5) req = urllib.request.Request(url, data, headers) try: res = urllib.request.urlopen(req) # リクエストでエラーが発生した場合の処理 except urllib.request.HTTPError as e: # ステータスコードが401 Unauthorized or 500 Internal Server Errorならアクセストークンを取得し直して再リクエスト if e.code == 401 or 500: access_token = getAccessToken() headers["Authorization"] = "Bearer " + access_token time.sleep(0.5) req = urllib.request.Request(url, data, headers) res = urllib.request.urlopen(req) # 401 or 500 以外のエラーなら原因を表示 else: print ("<Error> " + e.reason) #sys.exit() res_body = res.read() res_body = json.loads(res_body) return res_bodyCOTOHA(固有表現抽出)を呼び出す部分、エラー401と500の場合のみリトライするようにしてます。
3.WordCloudで図示する部分
WordCloudで図示する部分from wordcloud import WordCloud import matplotlib.pyplot as plt from PIL import Image def get_wordcrowd_mask(text): #日本語フォント指定 f_path = '/usr/share/fonts/opentype/ipafont-gothic/ipagp.ttf' #wcパラメタ指定 wc = WordCloud(background_color="white", width=500, height=500, font_path=f_path, collocations=False, ).generate( text ) #画面描写 plt.figure(figsize=(5,5), dpi=200) plt.imshow(wc, interpolation="bilinear") plt.axis("off") plt.show()WordCloudを利用して、テキストを図示する部分です。
4.メイン
処理を実行する部分aozora_text_list = get_word() json_list = [] loc_str = '' cnt = 0 for i in aozora_text_list: cnt+=1 print( str(cnt) + '/' + str(len(aozora_text_list)) ) json_list.append(cotoha_call(i)) for i in json_list: for j in i['result']: if(j['class'] == 'LOC'): loc_str = loc_str + j['form'] + "," get_wordcrowd_mask(loc_str)1~3を単純に実行している部分
また、APIコール時の進捗を、以下出力結果のように表出してます。(n/1でテキスト分割時の配列内の個数)1/9 2/9 3/9 4/9 5/9 6/9 7/9 8/9 9/9
出力結果
・グッド・バイ(太宰治)
すこし、地名と関係なさそうな文字が混じってはいますが、概ね抽出できてそうですね。
以下、他にも試してみた結果。・斜陽(太宰治)
・銀河鉄道の夜(宮沢賢治)
・檸檬(梶井基次郎)
なんか楽しいな。。。
まとめ
COTOHAもColabも無償で使用できて、手軽に言語処理に触れる
環境なのですごいいいですね!以上です、ご一読ありがとうございました!
最後に、以下画像は何の作品でしょう!(うざいからやめろ。。)





- 投稿日:2020-02-23T15:44:52+09:00
Kerasで機械学習に初挑戦した記録
バックエンド、フロントエンドをいろいろカジってきましたが、機械学習は未挑戦でした。今般、初挑戦しましたので記念に記録しておきます。python、numpy、tf.kerasを使っています。
マイスペック
- このQiita参照。
- cやgoによる通信系〜バックエンド開発、flutter/dartによるフロントエンド開発が可能。
- pythonも結構触っている。
- 機械学習はGUIのツールでちょっと触ってみたことはある。
- pythonでの機械学習は初挑戦。numpyも使ったことが無かったレベル。
機械学習の理論をまとめて勉強するために「ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装」を読みました。とても良い本でした。
開発環境はPyCharm Community 2019.3です。Anacondaとかは使わずにPyCharmに必要なライブラリを読み込ませて使っています。
1. 機械学習の課題設定
以下の正解ロジックを、機械学習することを目指します。
- 教師ありの2値分類問題とします。
- 入力する特徴量を2つの乱数値(0以上1未満)として、2つの大小比較によって0か1を正解ラベルとします。
- 正解ラベルには稀にノイズを混入させます。(最初はノイズを無しにします)
2. コード
2値分類問題の典型的コードを、いくつかのWeb記事を見ながら作ってみました。結構、コンパクトに直感的に記述できるものだと思いました。Kerasすごい。
#!/usr/bin/env python3 import tensorflow as tf import numpy as np from tensorflow_core.python.keras.metrics import binary_accuracy import matplotlib.pyplot as plt # データセット準備 ds_features = np.random.rand(10000, 2) # 特徴データ NOISE_RATE = 0 ds_noise = (np.random.rand(10000) > NOISE_RATE).astype(np.int) * 2 - 1 # noiseなし: 1, あり: -1 ds_labels = (np.sign(ds_features[:, 0] - ds_features[:, 1]) * ds_noise + 1) / 2 # 正解ラベル # データセットを訓練用と検証用に分割 SPLIT_RATE = 0.8 # 分割比率 training_features, validation_features = np.split(ds_features, [int(len(ds_features) * SPLIT_RATE)]) training_labels, validation_labels = np.split(ds_labels, [int(len(ds_labels) * SPLIT_RATE)]) # モデル準備 INPUT_FEATURES = ds_features.shape[1] # 特徴量の次元 LAYER1_NEURONS = int(INPUT_FEATURES * 1.2 + 1) # 入力次元より少し広げる LAYER2_NEURONS = LAYER1_NEURONS LAYER3_NEURONS = LAYER1_NEURONS # 隠れ層は3層 OUTPUT_RESULTS = 1 # 出力は一次元 ACTIVATION = 'tanh' model = tf.keras.models.Sequential([ tf.keras.layers.Dense(input_shape=(INPUT_FEATURES,), units=LAYER1_NEURONS, activation=ACTIVATION), tf.keras.layers.Dense(units=LAYER2_NEURONS, activation=ACTIVATION), tf.keras.layers.Dense(units=LAYER3_NEURONS, activation=ACTIVATION), tf.keras.layers.Dense(units=OUTPUT_RESULTS, activation='sigmoid'), ]) LOSS = 'binary_crossentropy' OPTIMIZER = tf.keras.optimizers.Adam # 典型的な最適化手法 LEARNING_RATE = 0.03 # 学習係数のよくある初期値 model.compile(optimizer=OPTIMIZER(lr=LEARNING_RATE), loss=LOSS, metrics=[binary_accuracy]) # 学習 BATCH_SIZE = 30 EPOCHS = 100 result = model.fit(x=training_features, y=training_labels, validation_data=(validation_features, validation_labels), batch_size=BATCH_SIZE, epochs=EPOCHS, verbose=1) # 表示 plt.plot(range(1, EPOCHS+1), result.history['binary_accuracy'], label="training") plt.plot(range(1, EPOCHS+1), result.history['val_binary_accuracy'], label="validation") plt.xlabel('Epochs') plt.ylabel('Accuracy') plt.ylim(0.5, 1) plt.legend() plt.show()3. 結果
こちかが学習結果です。おおよそ99%くらいの精度にすぐに到達し、過学習もしていないようです。
4. 考察
4.1. ノイズを加えた時の挙動
NOISE_RATE = 0.2 としてみました。ノイズ分だけ精度が低くなりますが、適切な結果に到達しています。
4.2. 無関係なダミーの特徴量を加えた時の挙動
ノイズを戻し、特徴量を5種に増やしてみます。5種のうち2種だけ使って同じロジックで正解ラベルを求めます。すなわち、特徴量の残り3種は、正解とは全く関係無いダミーとなります。
結果はこちらで、多少ブレ幅が大きくなりますが、ダミーに騙されずに学習できているといえます。
4.3. 特徴量の正規化を崩した時の挙動
特徴量を2種に戻しますが、0以上1未満の乱数値を×1000してみました。結果は、学習が一律に収束していかないように見えるほか、最終エポックの近くで精度が悪化しています。
エポックを増やして確認してみました。やはり学習が安定していないようです。
一方、特徴量の平均をずらし、0以上1未満の乱数値を+1000してみました。結果は、精度がほぼ0.5、すなわち2値分類としては全く学習されないことがわかりました。
全体的に、特徴量の正規化が大切であることがわかります。
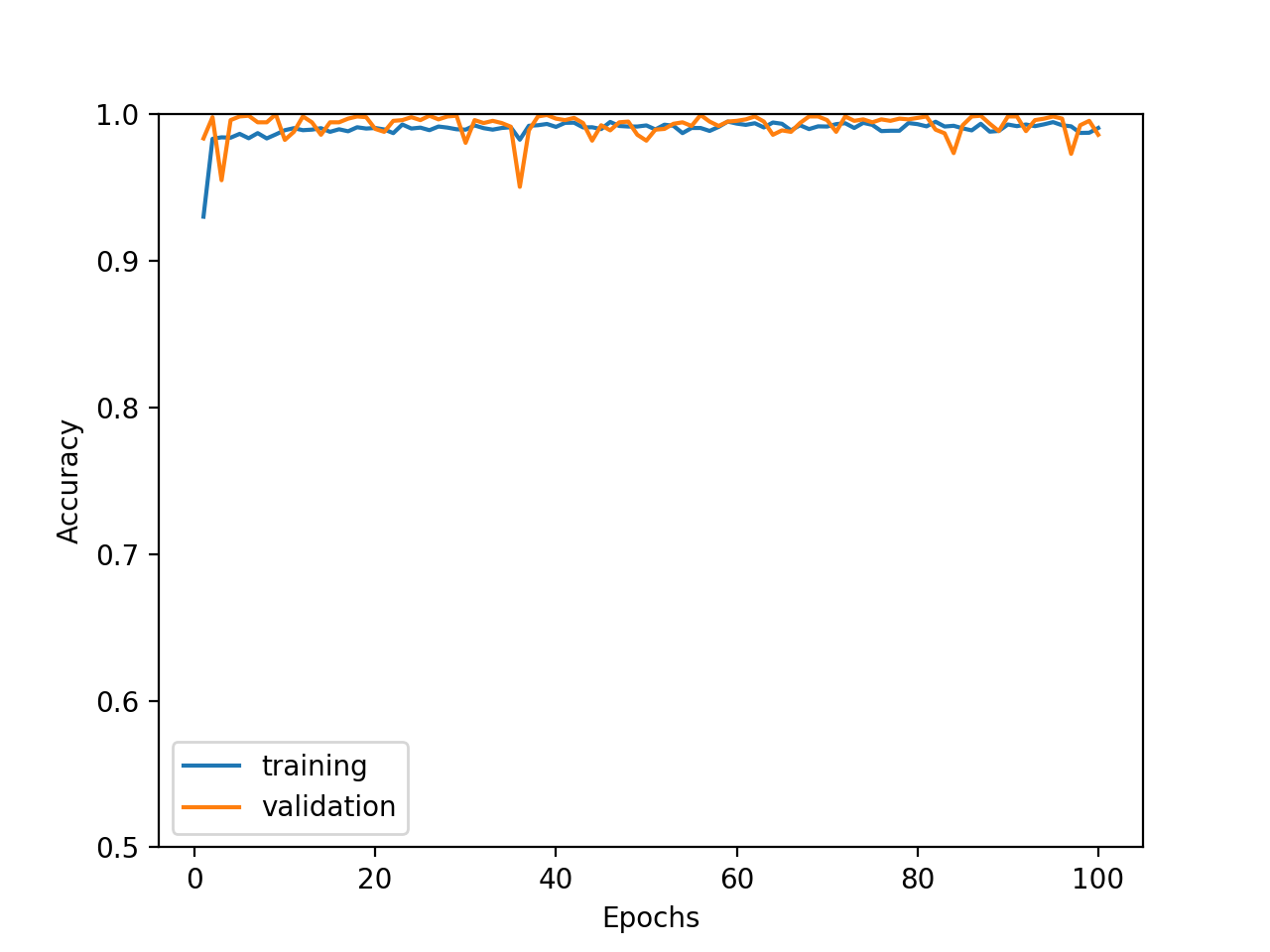
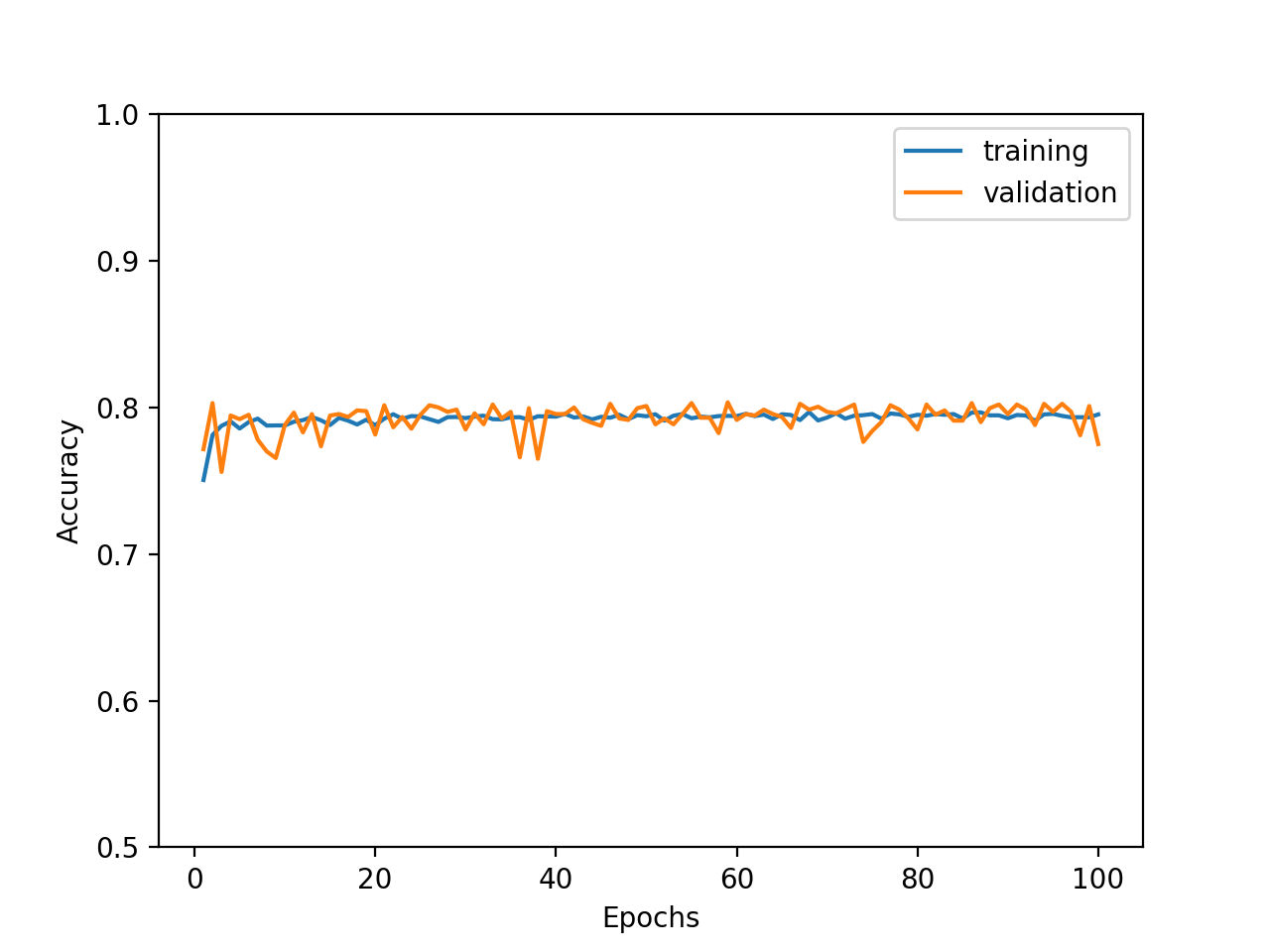
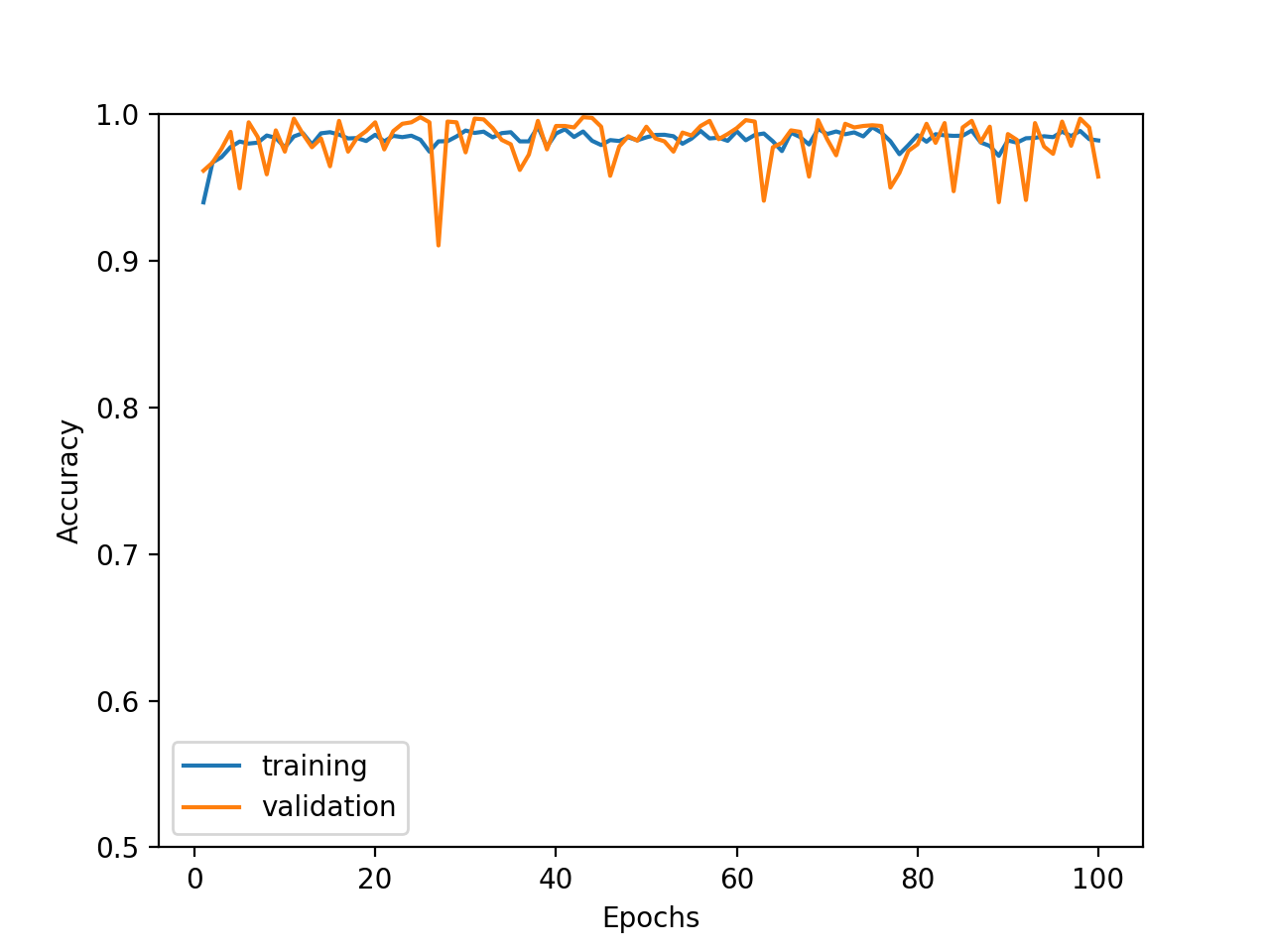

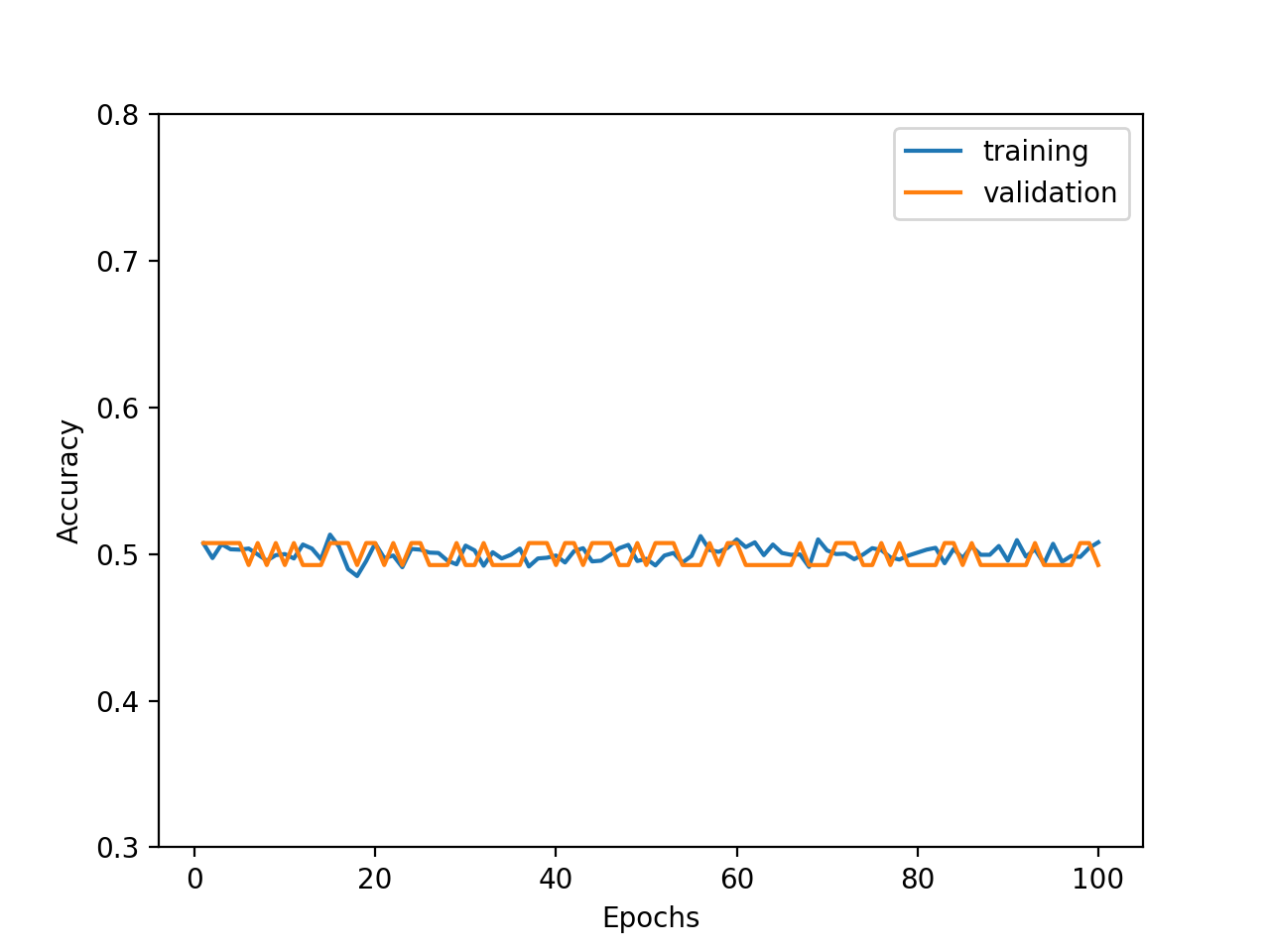
- 投稿日:2020-02-23T15:42:34+09:00
PythonとYoutube Data APIで「〇〇名で歌ってみたシリーズ」の動画情報を収集する
「〇〇で歌ってみたシリーズ」の動画が好きなので、ふと、YouTube上での「〇〇で歌ってみたシリーズ」の人気動画の情報を収集してみたくなりました。
具体的な用途が浮かんでいるわけではないのですが、例えばどんな替え歌が多くの人に面白がられているのか、など色々解析してみると楽しそうだなと思いました。そこで今回、PythonとYouTube Data API (v3)を使って、「〇〇で歌ってみたシリーズ」の動画情報を取得してみました。
正直、動画情報を収集するという点では、参考にさせていただいたサイト様に対する新規性は特にないのですが(せいぜい最後の出力情報の違いくらい)、初めてYouTube Data APIを使ってみたので、その覚書も兼ねて書いてみようと思います。参考サイト
- Youtube Data APIを使ってPythonでYoutubeデータを取得する
- YouTube Data api v3をPythonから使って動画の閲覧数をごそっと取得する
- YouTube Data API
環境
Google Colaboratoryで動くことを確認しています(2020年2月23日時点)
下準備
YouTube Data API (v3)のAPIキーを取得します。手順は参考サイトなどにもあるので、こちらでは省略いたします。APIキーの制限は特にかけていません。
コード
指定したqueryによる検索結果に含まれる動画情報を取得して標準出力しています。
コードでは例として野球選手系の情報を収集しています。from apiclient.discovery import build # pip install google-api-python-client import datetime YOUTUBE_API_KEY = '<APIキーを記入>' query = '野球選手名で歌ってみた' max_pages = 16 #取得するページ数 maxResults = 50 #1ページあたりに含める検索結果数。maxは50 #動画情報を取得する関数 def search_videos(query, max_pages=10,maxResults=50): youtube = build('youtube', 'v3', developerKey = YOUTUBE_API_KEY) search_request = youtube.search().list( part='id', q=query, type='video', maxResults=maxResults, ) i = 0 while search_request and i < max_pages: search_response = search_request.execute() video_ids = [item['id']['videoId'] for item in search_response['items']] videos_response = youtube.videos().list( part='snippet,statistics', id=','.join(video_ids) ).execute() yield videos_response['items'] search_request = youtube.search().list_next(search_request, search_response) i += 1 #取得した動画情報から欲しい情報を取り出してリストに入れる #今回はID、URL、投稿日時、投稿者のチャンネルID、動画タイトル、視聴回数、高評価数、低評価数、お気に入り回数を取得、またプログラム実行時刻も追加している for items_per_page in search_videos(query, max_pages, maxResults): for item in items_per_page: obj = {} obj['id'] = item['id'] obj['url'] = 'http://youtube.com/watch?v='+obj['id'] snippet = item['snippet'] for key in ['publishedAt','channelId','title']: obj[key] = snippet[key] statistics = item['statistics'] for key in ['viewCount','likeCount','dislikeCount','favoriteCount','commentCount']: obj[key] = statistics[key] if key in statistics else "NA" obj['timestamp'] = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S') print(",".join(['"'+obj[v]+'"' for v in obj]))今回はID、URL、投稿日時、投稿者のチャンネルID、動画タイトル、視聴回数、高評価数、低評価数、お気に入り回数、コメント数を取得しました。
「お気に入り回数」は何なのかよくわかっていません。データに含まれていたので念の為取得しましたが、全部0でした。最終的な出力は標準出力(print)にして、そのままGoogleSpreadSheetにコピペしました。貼り付けたのが以下のような感じです
なお結果を目視したところ、ただの野球中継の動画や関係ない歌ってみたシリーズなどノイズが混じっていたようなので、それについては手動で除く必要があります。
またより網羅的に取得したい場合は「やきゅうた」など別の検索ワードでもプログラムを実行して、動画IDがそれまでの取得結果とかぶってないものだけ追加するとよさそうです。コーディングに関しては以上です。
今後は替え歌歌詞に使われている単語などを書き起こして、どのような替え歌が人気になりやすいのかを解析すると面白いかなあなどと考えています(書き起こしの労力がかかりすぎるので早々実現はしなさそうですが)
- 投稿日:2020-02-23T15:00:54+09:00
JupyterHub + JupyterLabで Python マルチユーザプラットフォームを作る on Rapsberry Pi 3B+ !
はじめに
VMを立てるのは面倒くさい。でも複数人向けにPythonの開発環境を安く作りたい。そんな悩める人のためのQiita。自分用のメモ書きである。
うまく行けば所要時間1時間程度。
Material
- Raspberry Pi3+ (Raspberry Pi4 Memory:4GB を本当は欲しかった)
- Raspbian GNU/Linux 10 (buster)
- LAN環境(有線/Wifiどちらでも)
Method
環境構築
まずはaptを用いてjupyterhubに必要な一式をインストールします。
$ sudo apt update $ sudo apt upgrade $ sudo apt install python3 python3-pip npm nodejs libnode64次にpip3とnpmを用いてjupyterhub一式とproxy機能をを入れます。#1
$ sudo pip3 install jupyterhub notebook wheel ipywidgets jupyterlab $ sudo npm install -g configurable-http-proxyJupyterHubをローカルで起動し動作チェックする。まずは一般ユーザーで確認。
$ /usr/local/bin/jupyterhubそしてRaspberry PiのDesktopにあるChromiumで、http://localhost:8000/ にアクセスし、次の画面が出ることを確認する。JupyterHubサーバは、
ctrl-cで終了できる。
Multiple userで使うには、rootユーザでの起動が必要。なので、一応 root (sudo) で起動し、上記ログイン画面が表示されることを再度確認。
$ sudo jupyterhubJupyterHub の設定をするために、設定ファイルの元を"/etc/jupyterhub"に作り出す。
$ sudo mkdir /etc/jupyterhub $ cd /etc/jupyterhub $ sudo jupyterhub --generate-config # このコマンドでデフォルトの設定ファイルを作成させるすると"jupyterhub_config.py"が吐き出される。rootユーザーでそれを開き、以下を修正。
$ sudo vi /etc/jupyterhub/jupyterhub_config.py # viでも何でもお好きなテキストエディタでOK/etc/jupyterhub/jupyterhub_config.py# デフォルトでjupyter labを用いたいため以下を修正 c.JupyterHub.default_url = '/lab' # アクセス可能なユーザーをホワイトリストへ追加 c.Authenticator.whitelist = {'User1, User2'} # adminユーザを追加 (一般ユーザーの接続を切断する権限有) c.Authenticator.admin_users = {'User0'} # アクセスしたら各ユーザーディレクトリのnotebookフォルダを参照するように設定 # 必須設定項目ではなく、好みが分かれるところ。 c.Spawner.notebook_dir = '~/notebook''c.Spawner.notebook_dir'を設定した場合、'各ユーザのnotebookディレクトリ(~/notebook)は事前に作成が必要。
(参考サイト: https://qiita.com/atsushi_wagatsuma/items/89b714328663992b54f4)また、詳しいユーザの管理については本記事「ユーザの追加と削除」を参考。
最後にjupyterhubを起動し、動作をチェックする。
$ sudo jupyterhub -f /etc/jupyterhub/jupyterhub_config.py ... [I 2020-02-23 11:10:12.687 JupyterHub app:2631] JupyterHub is now running at http://:8000 # この表示が出れば起動完了!Adminユーザ and 一般ユーザでlocalhostもしくはネットワーク上の他コンピュータからログインできるかどうかチェック。簡単なPythonプログラムを書いてちゃんと動いていればOK !
Localhost:http://localhost:8000/
Network:http://<IP address>:8000/
とりあえずは動いたが、このままだと毎回起動時に
$ sudo jupyterhub -f /etc/jupyterhub/jupyterhub_config.pyを打たなければいけない。非常に面倒くさい。よって、Systemd serviceで一元的に管理し、Raspberry pi起動時に自動起動するよう設定する。$ sudo mkdir -p /opt/jupyterhub/etc/systemd # 慣習に従って、opt以下にこのようなフォルダを作り、そこに設定ファイルを置く。 $ sudo vi /opt/jupyterhub/etc/systemd/jupyterhub.service # viなどのText Editorで新ファイルを作り、以下の書き込みをコピペする。/opt/jupyterhub/etc/systemd/jupyterhub.service[Unit] Description=JupyterHub After=syslog.target network.target [Service] User=root Environment="PATH=/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin" ExecStart=/usr/local/bin/jupyterhub -f /etc/jupyterhub/jupyterhub_config.py [Install] WantedBy=multi-user.targetsystemdの読み込みフォルダへシンボリックリンクを作る。
$ sudo ln -s /opt/jupyterhub/etc/systemd/jupyterhub.service /etc/systemd/system/jupyterhub.servicesystmctlでconfigurationファイルをリロード。そしてRaspberry Pi起動時にjupyterhubを自動起動する設定をする。さらにマニュアルでとりあえず起動してみる。
$ sudo systemctl daemon-reload # config.ファイルを再読み込み $ sudo systemctl enable jupyterhub.service # 起動時にjupyterhub.serviceを自動起動 $ sudo systemctl start jupyterhub.service # jupyterhub.serviceをマニュアル起動 $ sudo systemctl status jupyterhub.service #jupyterhub.serviceの状態を確認。 # "Active: active (runnning)"が表示されればOK ● jupyterhub.service - JupyterHub Loaded: loaded (/opt/jupyterhub/etc/systemd/jupyterhub.service; enabled; vendor preset: enabled) Active: active (running) since Sun 2020-02-23 13:11:01 JST; 10s ago ...ユーザーの追加・削除
- デフォルト設定ではJupyterHubがインストールされているサーバのUnixユーザの中から、JupyterHubにアクセスできるユーザを選べる。
UnixユーザのどのユーザがJupyterHubのサーバー起動時にアクセスできるかどうかは、上記
/etc/jupyterhub/jupyterhub_config.pyのc.Authenticator.whitelistに追加。jupyterHubサーバー起動中は、adminユーザが
JupyterhubのWebApp上でユーザーの追加・削除の管理をできるが、jupyterHubサーバをリスタートするとこの設定はリセットされるので注意。
公式WebのDocumentにはさらに多くの情報がある。本格的に管理する方は必読。
Jupyterlab/hub-extension
2020.02.23現在、Jupyterlabの
File --> Hub Control Panelより、Hubの設定画面に移動可能。Jupyterlab/hub-extensionは必要ではない?追記(2020.02.23)
公式にこのExtensionはJupyterlabに統合されたようです。よってインストールの必要なし。
GitHub: jupyterlab/jupyterlabThis adds a "Hub" menu to JupyterLab that allows a user to log out of JupyterHub or access their JupyterHub control panel.
Python Library
注:筆者が
pip派なのでそれのみ記述。Conda派の皆様はググっていただければ... m(_ _)m
全ユーザに適用したいLibraryは、sudoでインストール&管理。
$ sudo pip3 install <library name>各ユーザーで導入・管理したいPython Libraryは、各ユーザーで、
JupyterLab --> Launcher --> Other --> Terminalなどを用いて個別にコマンドを打ち、入れる。
$ pip3 install <library name>Trouble-Shooting
Proxy関連のエラーで起動しない
Jupyterhubを起動しようとしたら、proxy関連のエラーコードが返ってきて起動できなかった。npmに原因があると考え、npmコマンドを打ったが梨の礫。
$ sudo npm $ #何も表示されない仕方がないので、npn/node/nodejs関連を一旦削除し再インストール。
$ sudo apt remove node npm nodejs $ sudo apt update #一応リストを更新 $ sudo apt upgrade #一応他も最新版に $ sudo apt install node libnode64 npmnpmコマンドを打ってみる。正常にversionが表示されるので良し。
$ sudo npm -v 5.8.0なお、npmだけを打つと、"npmとNode.jsのバージョンが合っていない"と警告が出る。これが将来的に不具合を起こす可能性もあるが、とりあえずjupyterhubは動く。
$ sudo npm npm WARN npm npm does not support Node.js v10.15.2 npm WARN npm You should probably upgrade to a newer version of node as we npm WARN npm can't make any promises that npm will work with this version. npm WARN npm Supported releases of Node.js are the latest release of 4, 6, 7, 8, 9. npm WARN npm You can find the latest version at https://nodejs.org/jupyterhubを起動し、正常に起動するか確認する。
$ sudo jupyterhub -f /etc/jupyterhub/jupyterhub_config.py ... [I 2020-02-23 11:10:12.687 JupyterHub app:2631] JupyterHub is now running at http://:8000
jupyterlabのExtension、jupyterlab-drawioがインストールできない
おそらく上のNode.jsとnpmのバージョンが合っていない問題に関連し、rebuildできないのが原因?現在打つ手なし(2020/02/23現在)。
Great Web references for JupyterLab/Python
初めてJupyterLab/Pythonを使う人向けに紹介したい素晴らしいサイト!
Reference
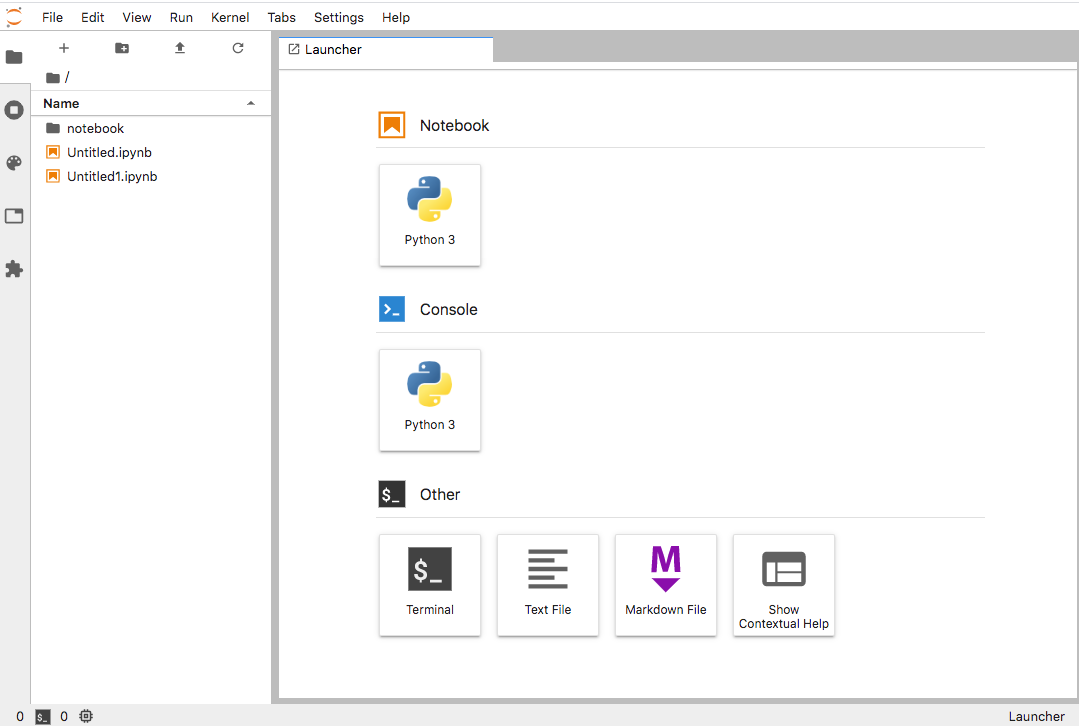
- 投稿日:2020-02-23T14:40:53+09:00
初カキコ(Programの備忘録)
- 投稿日:2020-02-23T14:40:53+09:00
Python Programingの入門備忘録
programをやる上での備忘録
目次
- はじめに
- 動作環境
- 本文
1. はじめに
この記事は筆者が学習したことを忘れてしまうため、この記事に備忘録として記載することで学習した物事を定着させると同時に、自身の物事の説明する能力を向上させようという狙いがある。Pythonの出来ることをいろいろやりたいのでタグはPython以外に特に決めていない。
2. 動作環境
- windows 10(ノートパソコン)
- visual studio code (version 1.42.1)
- anaconda 1.9.7 (pythonを動かすための仮想環境 VSCodeと連結)
- ほか
3. 本文
- ゼロから始めるDeepLearning を読み進める
読み進める上で参考にしたサイト
[github][https://github.com/oreilly-japan/deep-learning-from-scratch]1章 Python入門
ここはpythonのインストールから基本的なpythonの動作やNumpy,Matplotlibといったライブラリの説明などが書いてある。2章 パーセプトロン
パーセプトロンは複数の信号を受け取り、その内容により一つの信号を出力する。
パーセプトロンを入力信号x1,x2、重みw1,w2、閾値θを用いて出力信号yはf(x) = \left\{ \begin{array}{ll} 1 & (w1x1+w2x2\geq θ) \\ 0 & (w1x1+w2x2 \lt θ) \end{array} \right.と表すことが出来る。
また、ANDゲートやNANDゲート、ORゲートをパーセプトロンを用いて実装し。def AND(x1,x2): w1,w2,theta=0.5,0.5,0.7 tmp=x1*w1+x2*w2 if tmp>theta: return 1 else: return行列を用いると以下の通りになる。
import numpy as np def AND(x1,x2): w=np.array([0.5,0.5]) x=np.array([x1,x2]) b=-0.7 tmp=np.sum(w*x)+b if tmp>0: return 1 else: return 0x1,x2に適当な値(x1,x2)=(0,0),(0,1),(1,1),(1,0)を入力すると
a=AND(0,0) b=AND(0,1) c=AND(1,1) d=AND(1,0) print(a,b,c,d) >> 0 0 1 0となり、正しく動作していることが分かる。
この先編集中
- 投稿日:2020-02-23T14:05:02+09:00
日付の特徴量生成のメモ
featuretoolsを使わずに、日付型のデータから特徴量や目的変数を生成するためのコードのメモ
datefeaturetool.pyimport datetime import numpy as np import pandas as pd class DeltaDate(): """ 日付の特徴量生成 """ def __init__(self, cutoff_date): """ cutoff_date: datetime.date(2020, 2, 2) or pandas.Timestamp('2020-02-02') int, numpy.int64, float, numpy.float64 """ if type(cutoff_date) == datetime.date: self.cutoff_date = pd.to_datetime(cutoff_date) print('cutoff_date converted from datetime.date type to pandas.Timestamp type.') else: self.cutoff_date = cutoff_date def delta_date_1d(self, dates, freq='d', past_or_future='past'): """ dates: pandas.Series dtype: datetime64[ns] int64, float64 freq: 'day', 'month' or 'year' past_or_future: 'past' or 'future' return pandas.Series (np.int64) """ day_lt = ['d', 'D', 'day', 'Day'] month_lt = ['m', 'M', 'month', 'Month'] year_lt = ['y', 'Y', 'year', 'Year'] tcd = type(self.cutoff_date) if tcd == pd._libs.tslibs.timestamps.Timestamp: if freq in day_lt: delta = self.cutoff_date - dates # timedelta64[ns] delta = delta.dt.days # np.int64 elif freq in (month_lt + year_lt): start_year = dates.dt.year # timedelta64[ns] start_month = dates.dt.month # timedelta64[ns] start_day = dates.dt.day # timedelta64[ns] end_year = self.cutoff_date.year # np.int64 end_month = self.cutoff_date.month # np.int64 end_day = self.cutoff_date.day # np.int64 cond = ((end_month<start_month)|((end_month==start_month)&(end_day<start_day))) if freq in month_lt: delta = (end_year - start_year) * 12 + (end_month - start_month) delta = delta.mask(cond, delta - 1) # np.int64 else: delta = end_year - start_year delta = delta.mask(cond, delta - 1) # np.int64 else: print("freq must be 'day', 'month' or 'year'") elif (tcd==int)|(tcd==np.int64)|(tcd==float)|(tcd==np.float64): if freq in day_lt: y = self.cutoff_date // 10000 m = (self.cutoff_date - self.cutoff_date//10000 * 10000)//100 d = self.cutoff_date - self.cutoff_date//100 * 100 cod = pd.Timestamp(year=y, month=m, day=d) dates = pd.to_datetime(dates.astype(str), format='%Y%m%d') delta = cod - dates # timedelta64[ns] delta = delta.dt.days # np.int64 elif freq in (month_lt + year_lt): y_diff = self.cutoff_date//10000 - dates//10000 m_diff = (self.cutoff_date - self.cutoff_date//10000 * 10000)//100 - (dates - dates//10000 * 10000)//100 d_diff = (self.cutoff_date - self.cutoff_date//100 * 100) - (dates - dates//100 * 100) cond = (m_diff < 0) | ((m_diff == 0) & (d_diff < 0)) if freq in month_lt: delta = y_diff * 12 + m_diff delta = delta.mask(cond, delta - 1) else: delta = y_diff delta = delta.mask(cond, delta - 1) else: print("freq must be 'day', 'month' or 'year'") if past_or_future in ['f', 'future']: delta = -delta print('delta for the future.') delta.name = 'elapsed_' + delta.name return delta def delta_date(self, dates, freq='d', past_or_future='past'): """ dates: pandas.Series or pandas.DataFrame dtype: datetime64[ns] int64, float64 freq: 'day', 'month' or 'year' past_or_future: 'past' or 'future' return pandas.Series (np.int64) """ if type(dates) == pd.core.series.Series: delta = self.delta_date_1d(dates, freq, past_or_future) elif type(dates) == pd.core.frame.DataFrame: s_lt = [] for col in dates: dd = self.delta_date_1d(dates[col], freq, past_or_future) s_lt += [dd] delta = pd.concat(s_lt, axis=1) else: print('dates must be andas.Series or pd.DataFrame.') return delta def within_date(self, dates, within, freq='d', past_or_future='past'): """ dates: pandas.Series or pandas.DataFrame dtype: datetime64[ns] int64, float64 within: int (n日以内、nヶ月以内、n年以内) freq: 'day', 'month' or 'year' past_or_future: 'past' or 'future' return pandas.Series (0: over, 1: within, np.nan: minus) """ if type(within) == list: delta_sign_lt = [] for n in within: delta = self.delta_date(dates, freq, past_or_future) delta_sign = delta.mask(delta>n, 0) delta_sign = delta_sign.mask(delta<=n, 1) delta_sign = delta_sign.mask(delta<0) if type(delta_sign) == pd.core.frame.DataFrame: delta_sign.columns = ['within' + str(n) + c for c in dates.columns] else: delta_sign.name = 'within' + str(n) + dates.name delta_sign_lt+= [delta_sign] within_sign = pd.concat(delta_sign_lt, axis=1) else: delta = self.delta_date(dates, freq, past_or_future) delta_sign = delta.mask(delta>within, 0) delta_sign = delta_sign.mask(delta<=within, 1) within_sign = delta_sign.mask(delta<0) within_sign.name = 'within' + str(within) + dates.name return within_sign if __name__ == '__main__': df = pd.DataFrame([['2017-8-1', '2018-12-15'], ['2020-2-2', '2019-3-31']], columns=['date1', 'date2']) for c in df: df[c] = pd.to_datetime(df[c], format='%Y-%m-%d') deltadate = DeltaDate(datetime.date(2020, 2, 28)) result = deltadate.delta_date(df, freq='d') within = deltadate.within_date(df, [12, 24], freq='m')
- 投稿日:2020-02-23T14:02:08+09:00
今日のpython error: HTTPError: 404 Client Error: Not Found for url:
# pip install python3-requests Collecting python3-requests Exception: Traceback (most recent call last): File "/usr/lib/python2.7/dist-packages/pip/basecommand.py", line 215, in main status = self.run(options, args) File "/usr/lib/python2.7/dist-packages/pip/commands/install.py", line 353, in run wb.build(autobuilding=True) File "/usr/lib/python2.7/dist-packages/pip/wheel.py", line 749, in build self.requirement_set.prepare_files(self.finder) File "/usr/lib/python2.7/dist-packages/pip/req/req_set.py", line 380, in prepare_files ignore_dependencies=self.ignore_dependencies)) File "/usr/lib/python2.7/dist-packages/pip/req/req_set.py", line 554, in _prepare_file require_hashes File "/usr/lib/python2.7/dist-packages/pip/req/req_install.py", line 278, in populate_link self.link = finder.find_requirement(self, upgrade) File "/usr/lib/python2.7/dist-packages/pip/index.py", line 465, in find_requirement all_candidates = self.find_all_candidates(req.name) File "/usr/lib/python2.7/dist-packages/pip/index.py", line 423, in find_all_candidates for page in self._get_pages(url_locations, project_name): File "/usr/lib/python2.7/dist-packages/pip/index.py", line 568, in _get_pages page = self._get_page(location) File "/usr/lib/python2.7/dist-packages/pip/index.py", line 683, in _get_page return HTMLPage.get_page(link, session=self.session) File "/usr/lib/python2.7/dist-packages/pip/index.py", line 795, in get_page resp.raise_for_status() File "/usr/share/python-wheels/requests-2.18.4-py2.py3-none-any.whl/requests/models.py", line 935, in raise_for_status raise HTTPError(http_error_msg, response=self) HTTPError: 404 Client Error: Not Found for url: https://pypi.org/simple/python3-requests/
- 投稿日:2020-02-23T13:57:09+09:00
今日のpython error :ModuleNotFoundError: No module named 'requests'
【Webスクレイピング】Qiitaのキーワード検索結果をいいね順にソート
https://qiita.com/h_no/items/b0f62fef31462035a31cを動かしてみようとした。
Python Webスクレイピング テクニック集「取得できない値は無い」JavaScript対応@追記あり6/12
https://qiita.com/Azunyan1111/items/b161b998790b1db2ff7aPython Webスクレイピング 実践入門
https://qiita.com/Azunyan1111/items/9b3d16428d2bcc7c9406apt update; apt -y upgrade; apt install vim wget python3 python-pip sudo apt-utils
# python3 qiitas.py Traceback (most recent call last): File "qiitas.py", line 1, in <module> from requests.exceptions import ConnectionError, TooManyRedirects, HTTPError ModuleNotFoundError: No module named 'requests'pip install python3-requests
- 投稿日:2020-02-23T13:22:25+09:00
zipfileの圧縮・展開
1import zipfile import glob with zipfile.ZipFile('test.zip', 'w') as z: for f in glob.glob('test_dir/**', recursive=True): z.write(f) #test_dir以下をtest.zipというファイル名でzipfileに圧縮 with zipfile.ZipFile('test.zip', 'r') as z: z.extractall(path='zzz2') #zzz2というディレクトリにtest.zipを展開2import zipfile with zipfile.ZipFile('test.zip', 'r') as z: with z.open('test_dir/sub_dir/sub_test.txt') as f: print(f.read()) #zipfileに圧縮されたtest.zipを展開することなく、sub_test.txtを出力