- 投稿日:2020-02-23T19:45:29+09:00
nodemailer gmail めも
- 投稿日:2020-02-23T19:36:37+09:00
#node で version4 の uuid を生成する
npm install -g uuid$ node Welcome to Node.js v13.8.0. Type ".help" for more information. > const uuidv4 = require('uuid/v4'); undefined > uuidv4(); '83f370cd-188d-4bc1-b07c-4be39ef16f50' > uuidv4(); '81084168-d009-4e31-ba59-a52785369afc' > uuidv4(); '9be2153b-4308-4813-a7ae-705edf97abce'Original by Github issue
- 投稿日:2020-02-23T19:05:59+09:00
#node js – javascript で 日付を1ヶ月ずつ引き算する
- 投稿日:2020-02-23T18:51:05+09:00
node + javascript で今日の日付を文字列に変換する、YMD形式で出力する例 #javascript #node
なにやら strftime 的な YMD 形式でうまく区切るメソッドはなさそう?
node > new Date().toISOString().split('T')[0] '2020-02-22' > new Date().toDateString() 'Sat Feb 22 2020' > new Date().toDateString() 'Sat Feb 22 2020' > new Date().toGMTString() 'Sat, 22 Feb 2020 08:43:15 GMT' > new Date().toISOString() '2020-02-22T08:43:22.536Z' > new Date().toJSON() '2020-02-22T08:43:31.867Z' > new Date().toLocaleDateString() '2/22/2020' > new Date().toLocaleTimeString() '5:43:53 PM' > new Date().toLocaleString() '2/22/2020, 5:44:00 PM' > new Date().toString() 'Sat Feb 22 2020 17:44:09 GMT+0900 (Japan Standard Time)' > new Date().toTimeString() '17:44:15 GMT+0900 (Japan Standard Time)' > new Date().toUTCString() 'Sat, 22 Feb 2020 08:44:22 GMT'こんな prototype の関数が見つかるが、採用されなかったのだろうか
Date.prototype.toLocaleFormat() - JavaScript | MDN
Original by Github issue
- 投稿日:2020-02-23T16:12:14+09:00
javascript(node.js)のクエリーストリング(qs)を解説
- 投稿日:2020-02-23T16:04:22+09:00
DialogFlowで会話をし、MobileNetで画像認識を行う自家製チャットサイトの構築
はじめに
第一回 LINE風チャットサイトの構築(基本編)
第二回 LINE風チャットサイトの構築(完成編)
ということで、第三回目はこの自家製チャットサイトにボット機能と画像認識機能を加えたいと思います。
ボット機能(DialogFlow) 画像認識機能(MobileNet) Dialogflow
googleのdialogflowを使います。会話の設定などはあらかじめ作成したものがあるので、それを読み込んで使います。
ここではDialogflowの詳しい解説は行いませんが、サンプルエージェント(英語版)を手軽に読み込めますので学習の手始めにいいと思います。なお今回のエージェントはそのサンプルエージェント coffee-shopを大雑把に日本語翻訳したものです。エージェント構築手順
まずは私の方で作成したエクスポートzipファイルを、ご自分のローカルマシンにダウンロードしてください。
ファイル名はそのままでOKです。
そしてDialogflowコンソールへアクセスします
https://dialogflow.cloud.google.com/?hl=ja#/login中央の「Sign-in with Google」をクリックしてログインします。
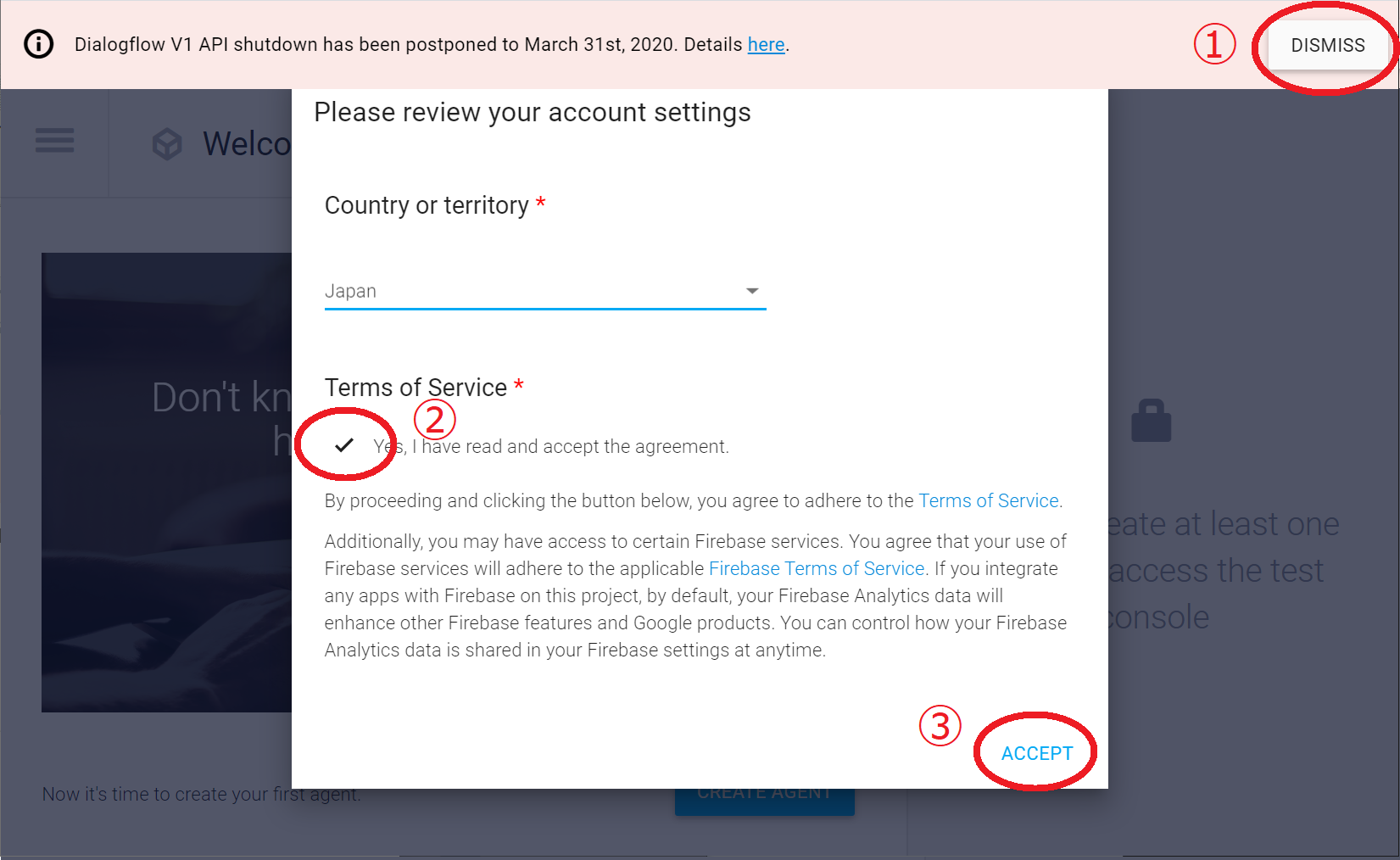
IDの指定と連携確認が行われた後、下記の画面になります。
上部のお知らせは消してしまいましょう
サービス規約を確認します
ACCEPTをクリックするとWelcome画面になります
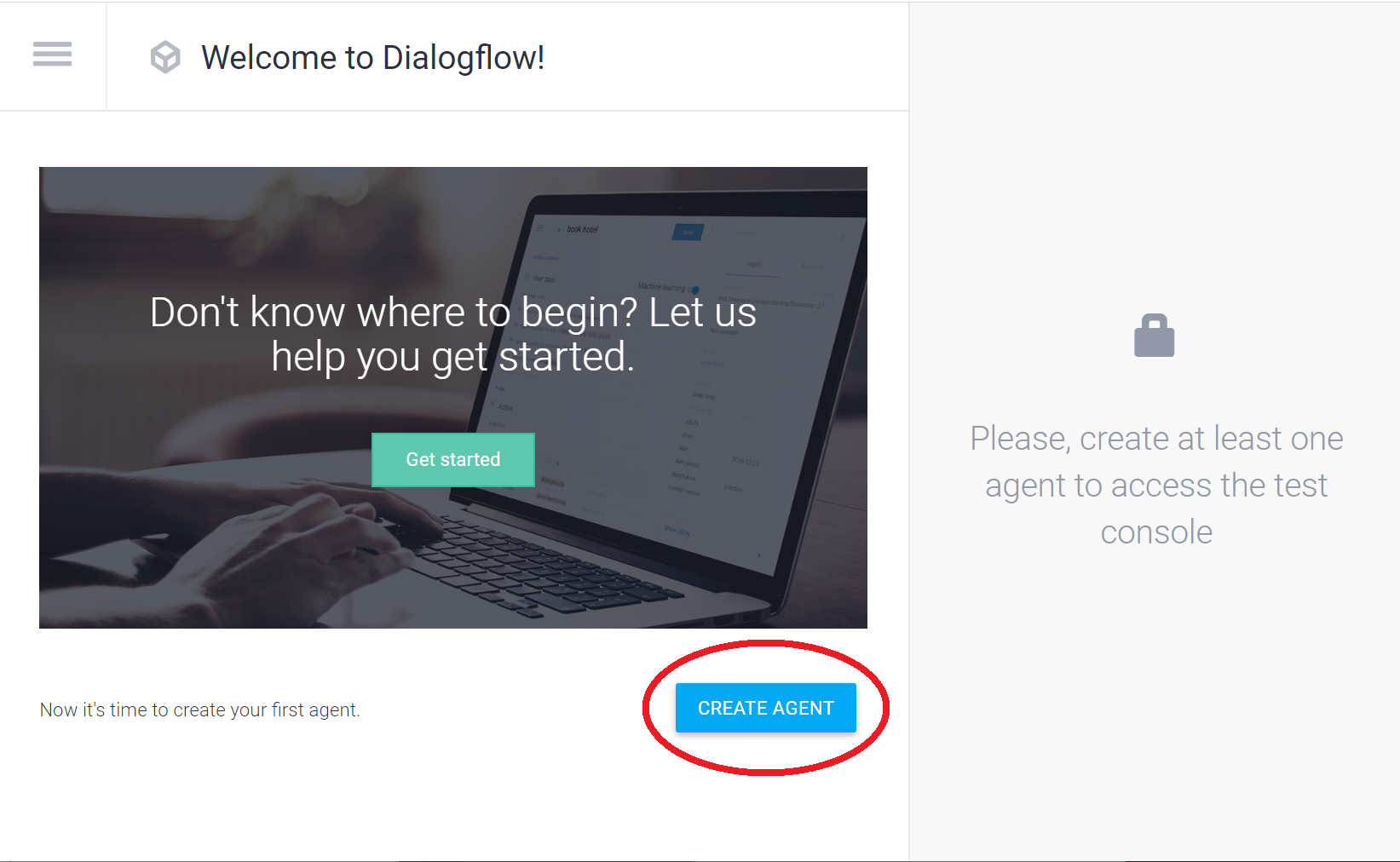
早速エージェント作成ボタンを押します
エージェント作成画面になりますので
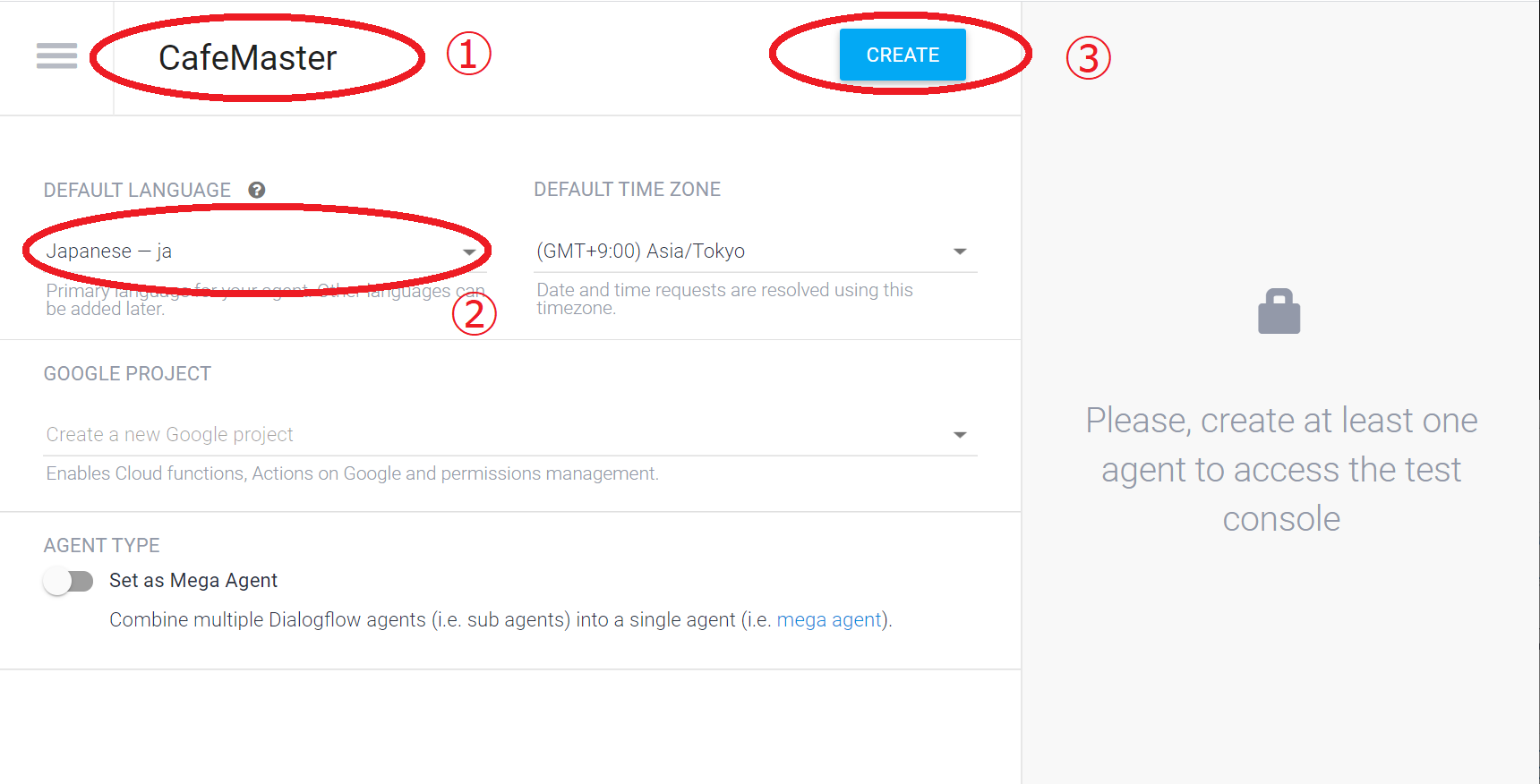
1. エージェント名に「CafeMaster」
2. 言語設定に「Japanese-ja」を選択
3. CREATEをクリック
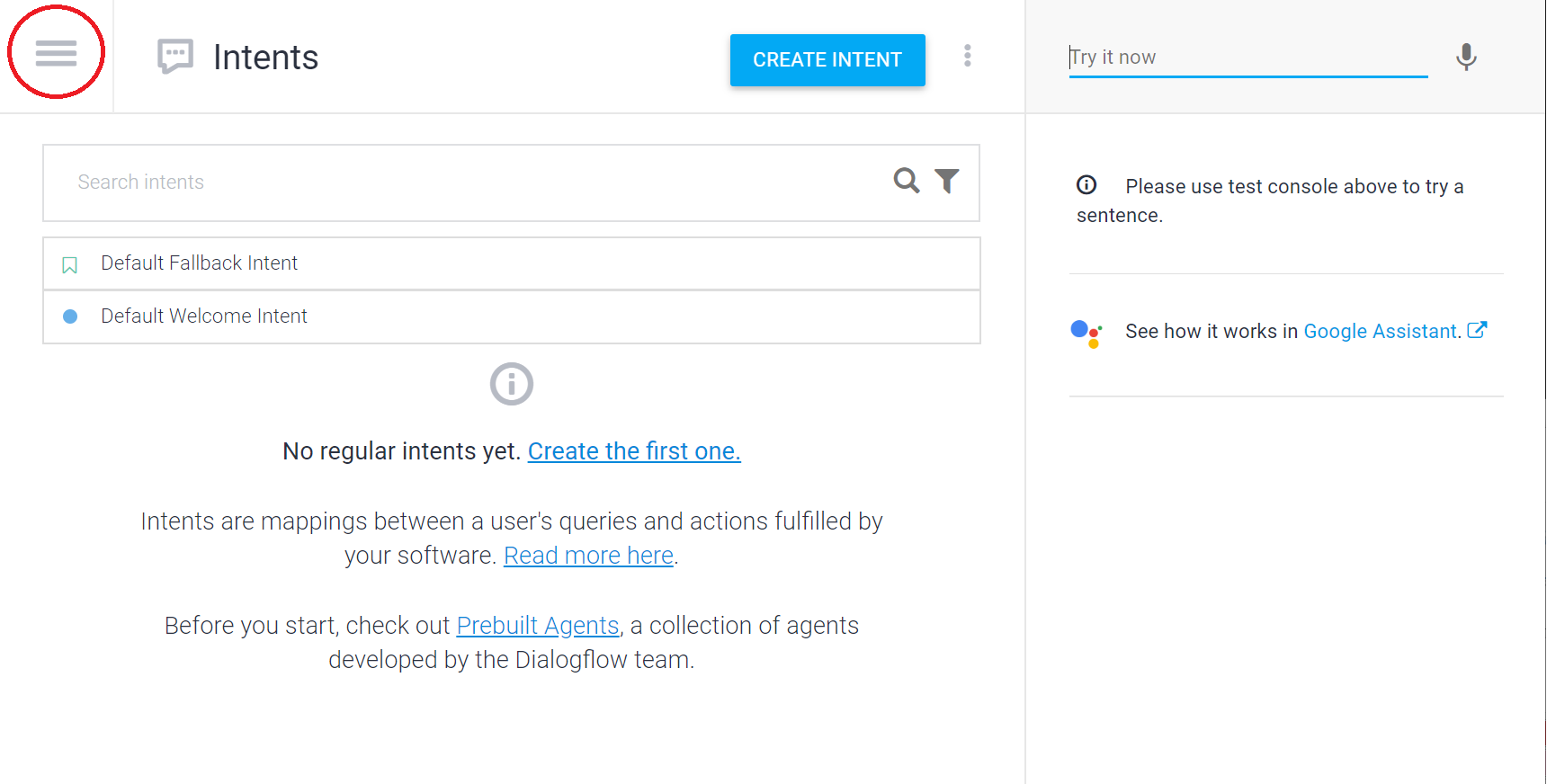
しばらくするとインテント作成画面になりますが、ここではあらかじめ作成しておいたエージェントを読み込むために左上の三本線メニューを選択します
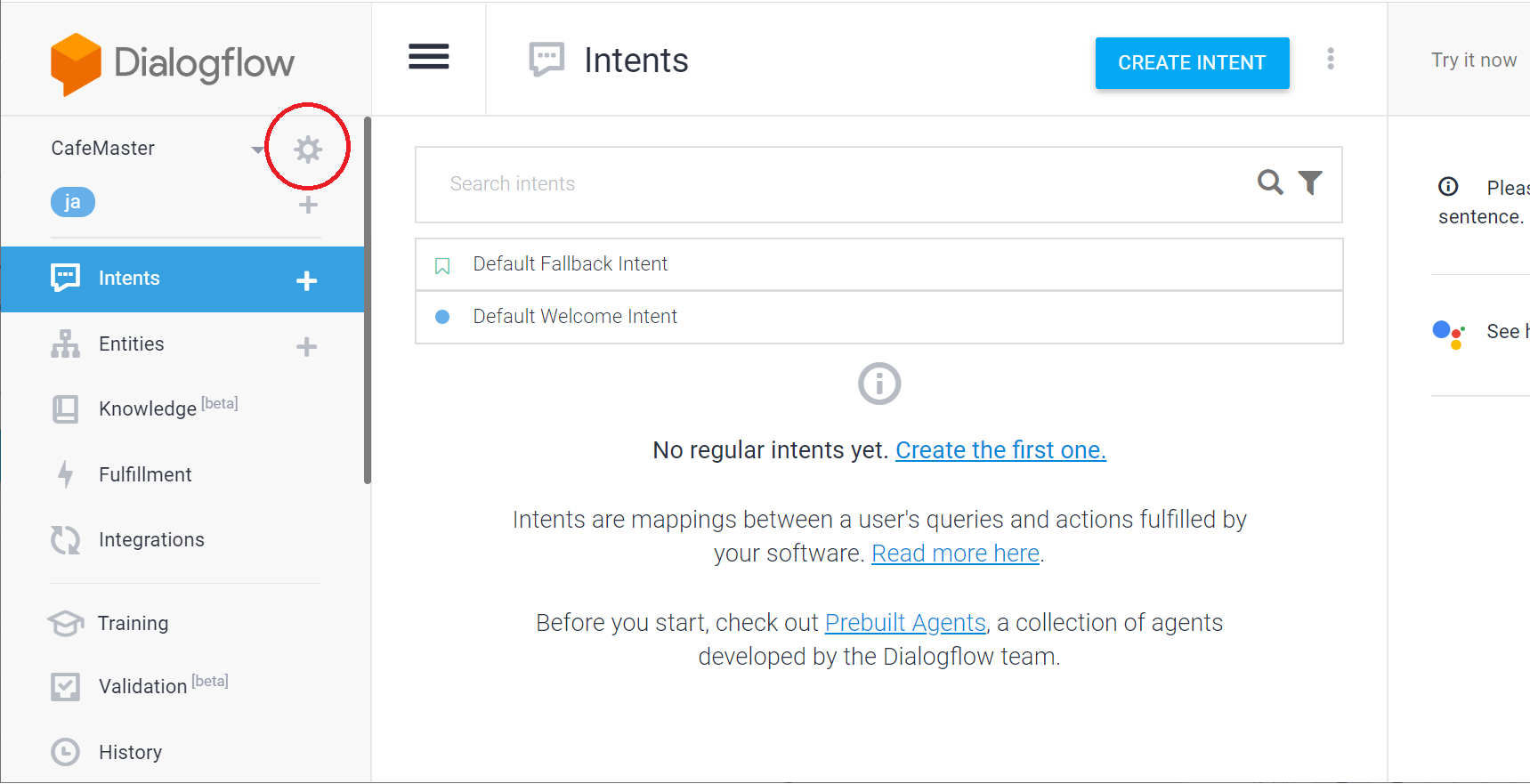
左のメニューが開いたら、CafeMasterと書かれている右横の歯車マークをクリックしてエージェント設定画面に移ります
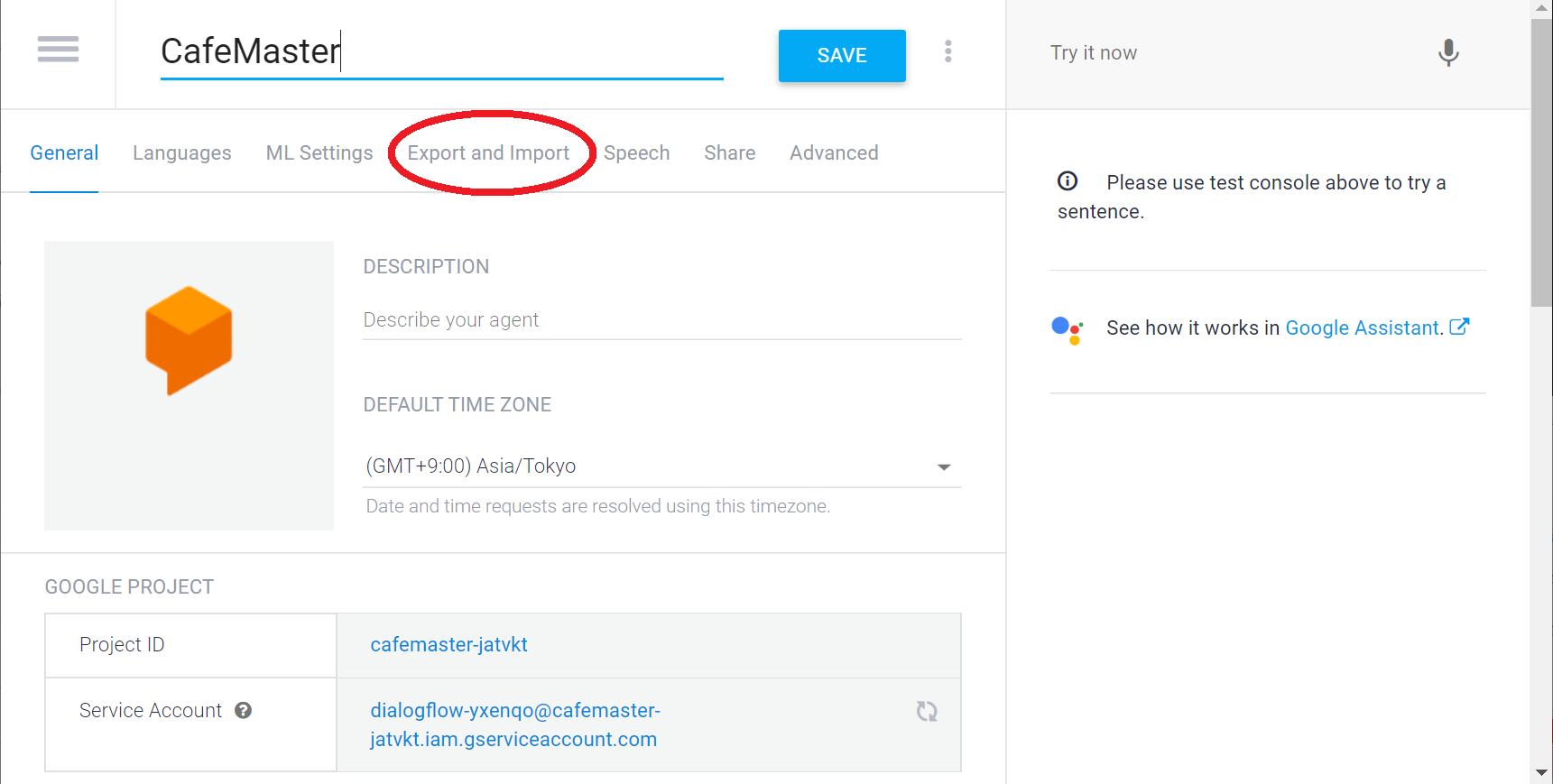
エージェント設定画面が開いたら、真ん中あたりの「Export and Import」タブを選択します
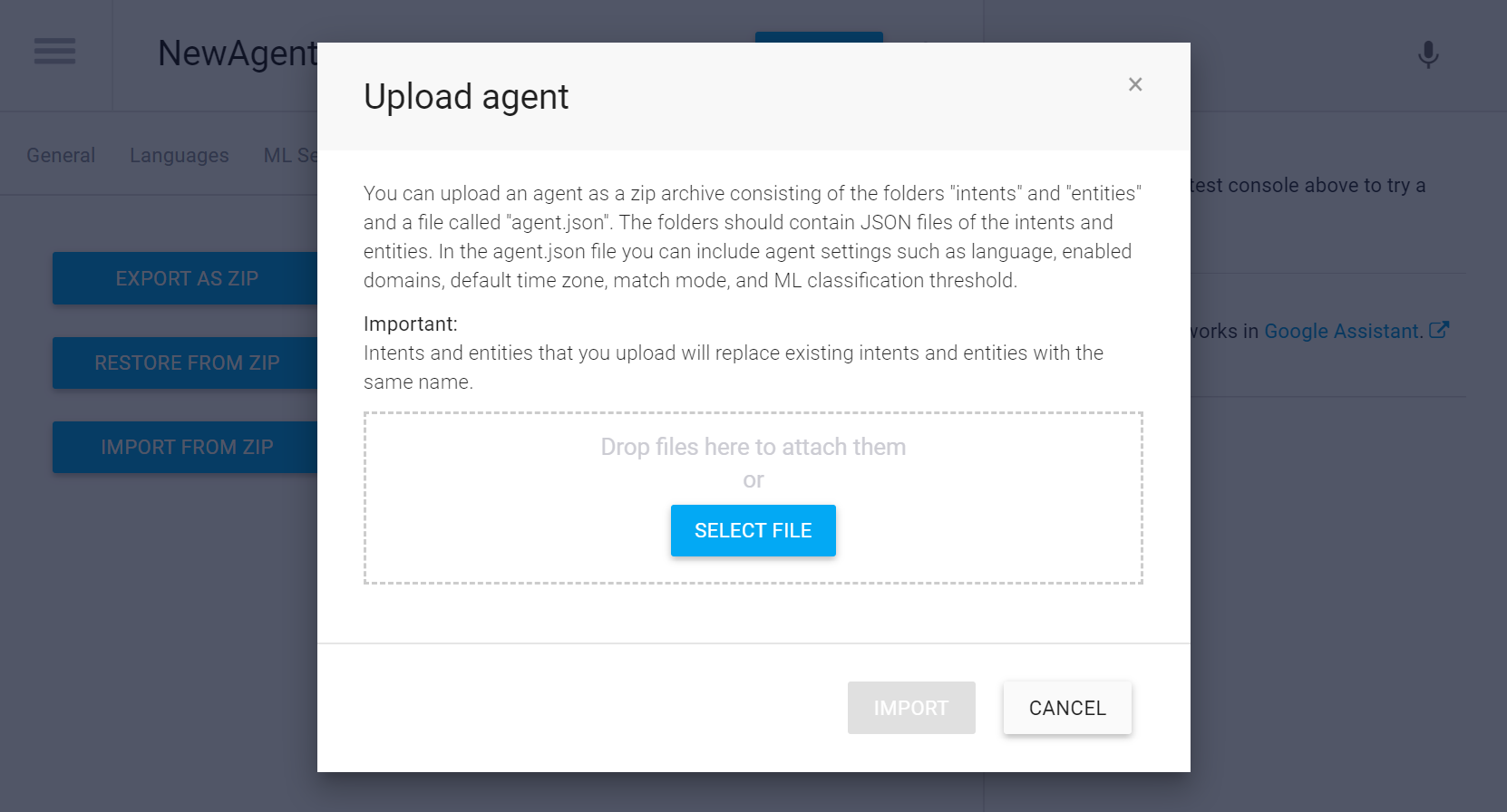
メニューから「RESTORE FROM ZIP」を選択します
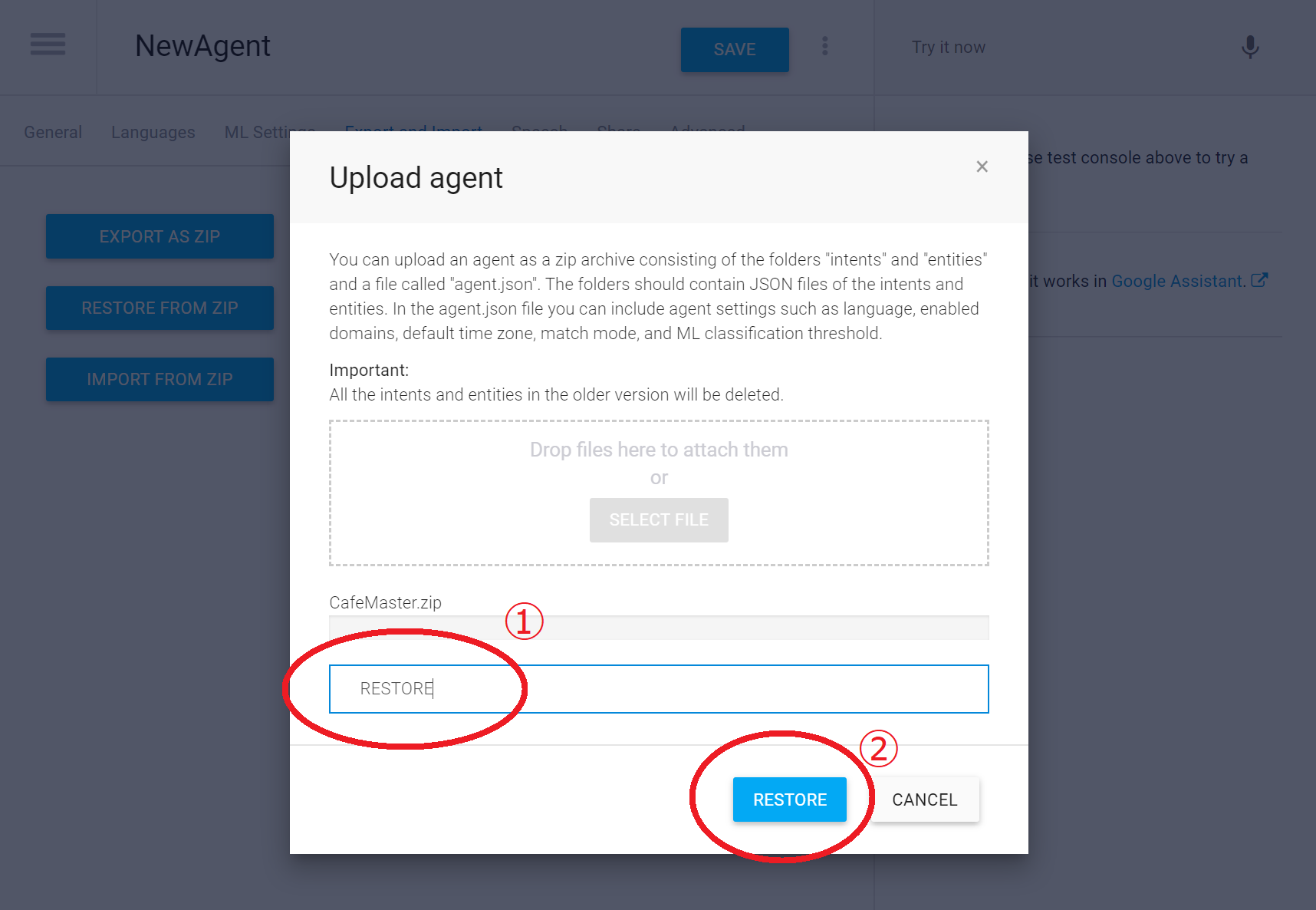
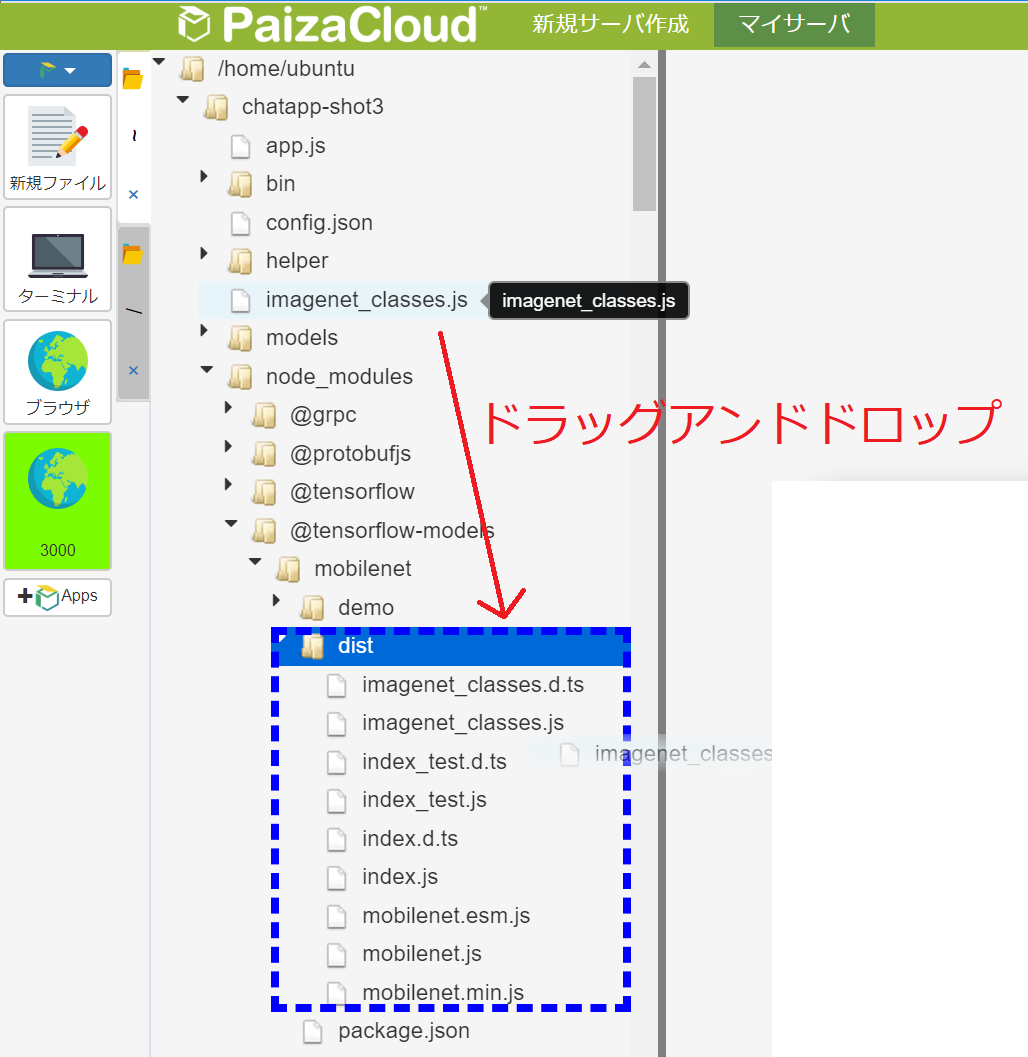
アップロードするファイルの選択画面になりますので、先ほどダウンロードしたCafeMaster.zipをドラッグ&ドロップしてください
ファイルが選択されると下記の画面になります。ここで①の部分に「RESTORE」と打ち込み、②のRESTOREボタンを押します
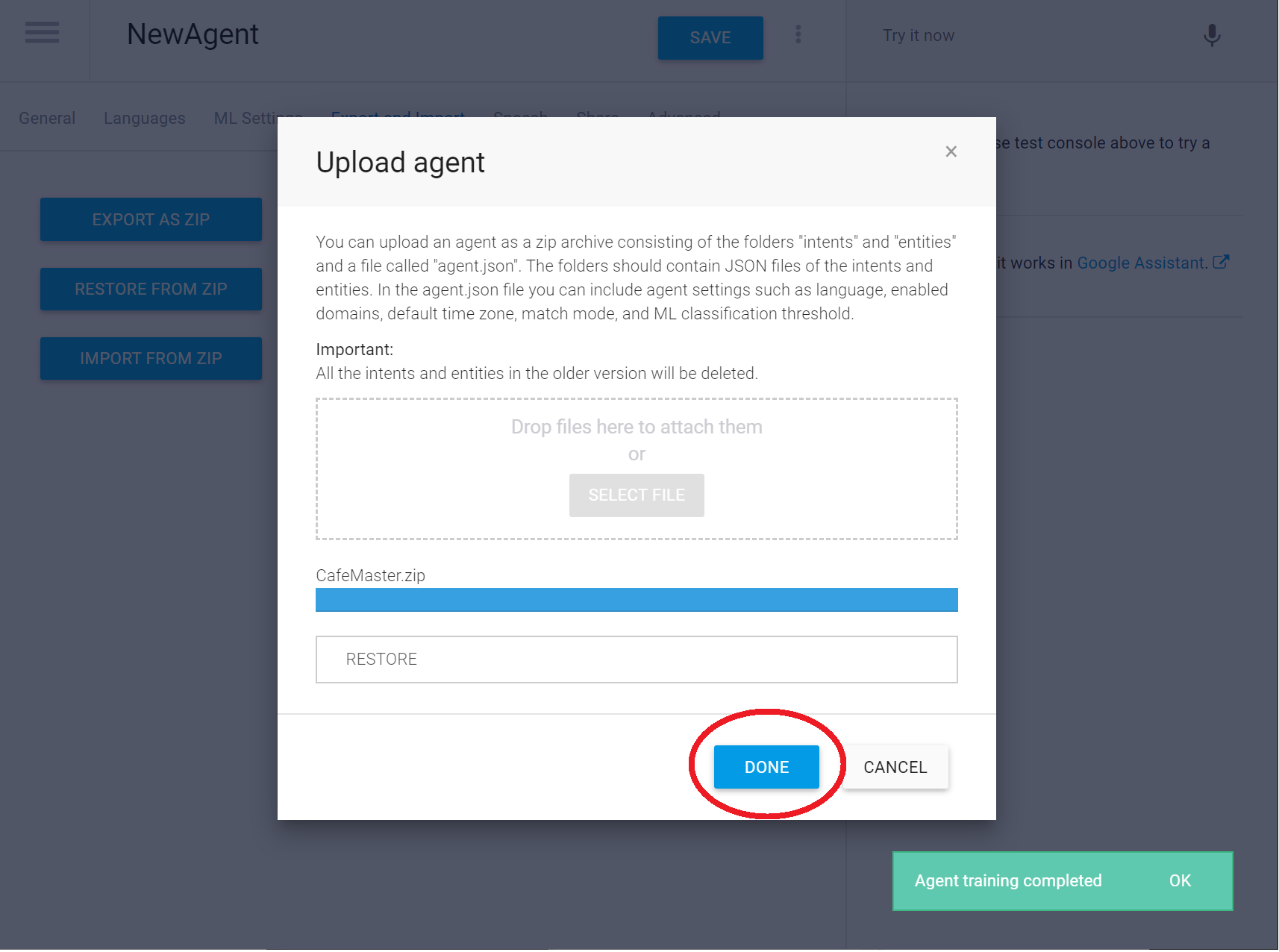
zipファイルが読み込まれ学習が実行されます。しばらくすると完了するので「DONE」を押します
これで、設定は完了です
参考にさせていただいたサイト
Qiita:Dialogflow入門
Geekfeed:DialogFlowのFulfillmentを使ったチャットボット作成
Qiita:サルにもわかる Dialogflow FAQ
ゆたかみわーく:【Dialogflowの使い方】Fulfillmentを使ってみる(超基礎編)キーファイルの作成
このAgentをプログラムから利用するため GCPのサービス アカウントを作成し、秘密鍵ファイルをダウンロードします。
公式の案内 https://cloud.google.com/dialogflow/docs/quick/setupGCPからのログインして作成することもできますが、ここではDialogflowコンソールから作成してみたいと思います。
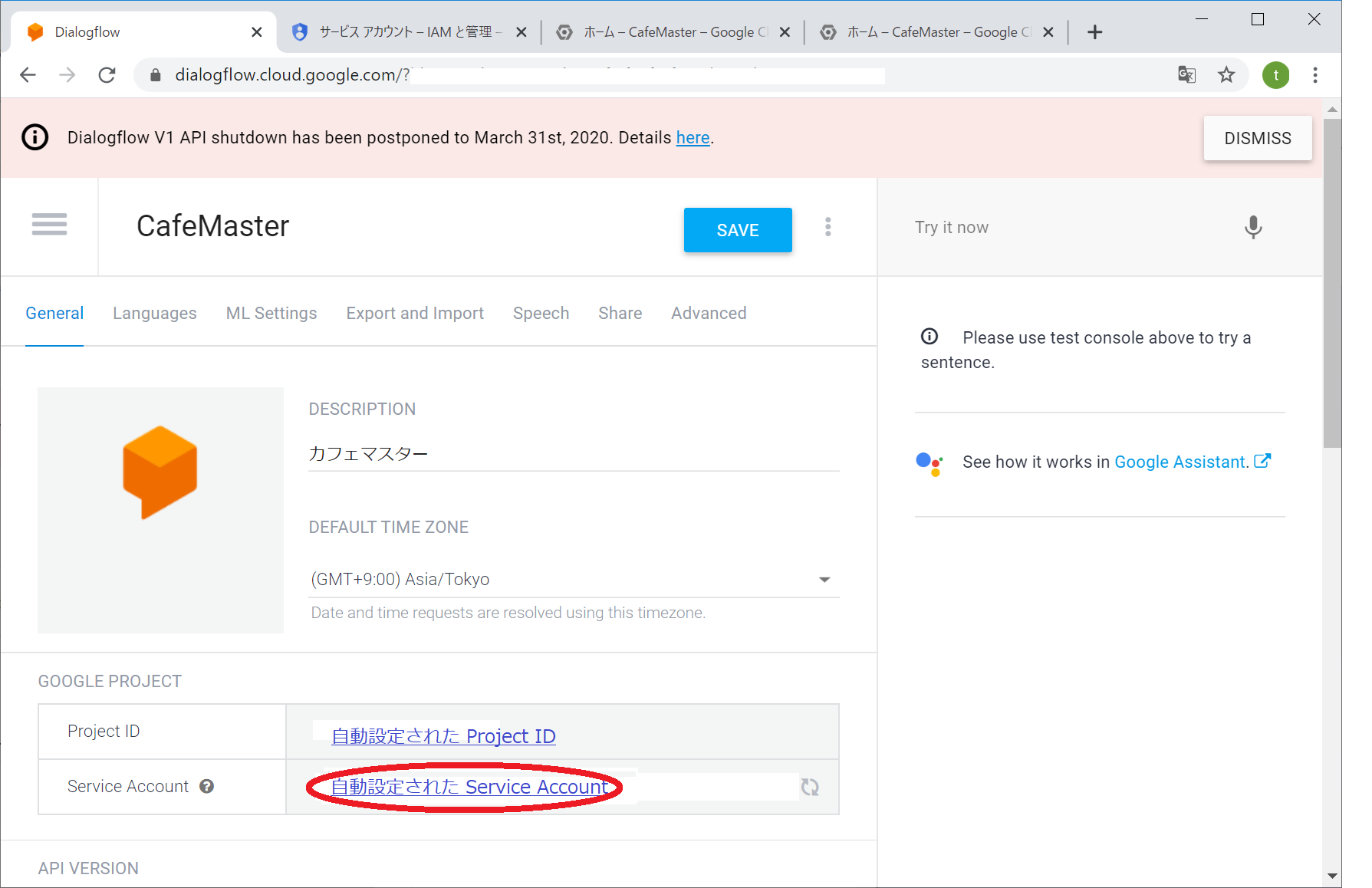
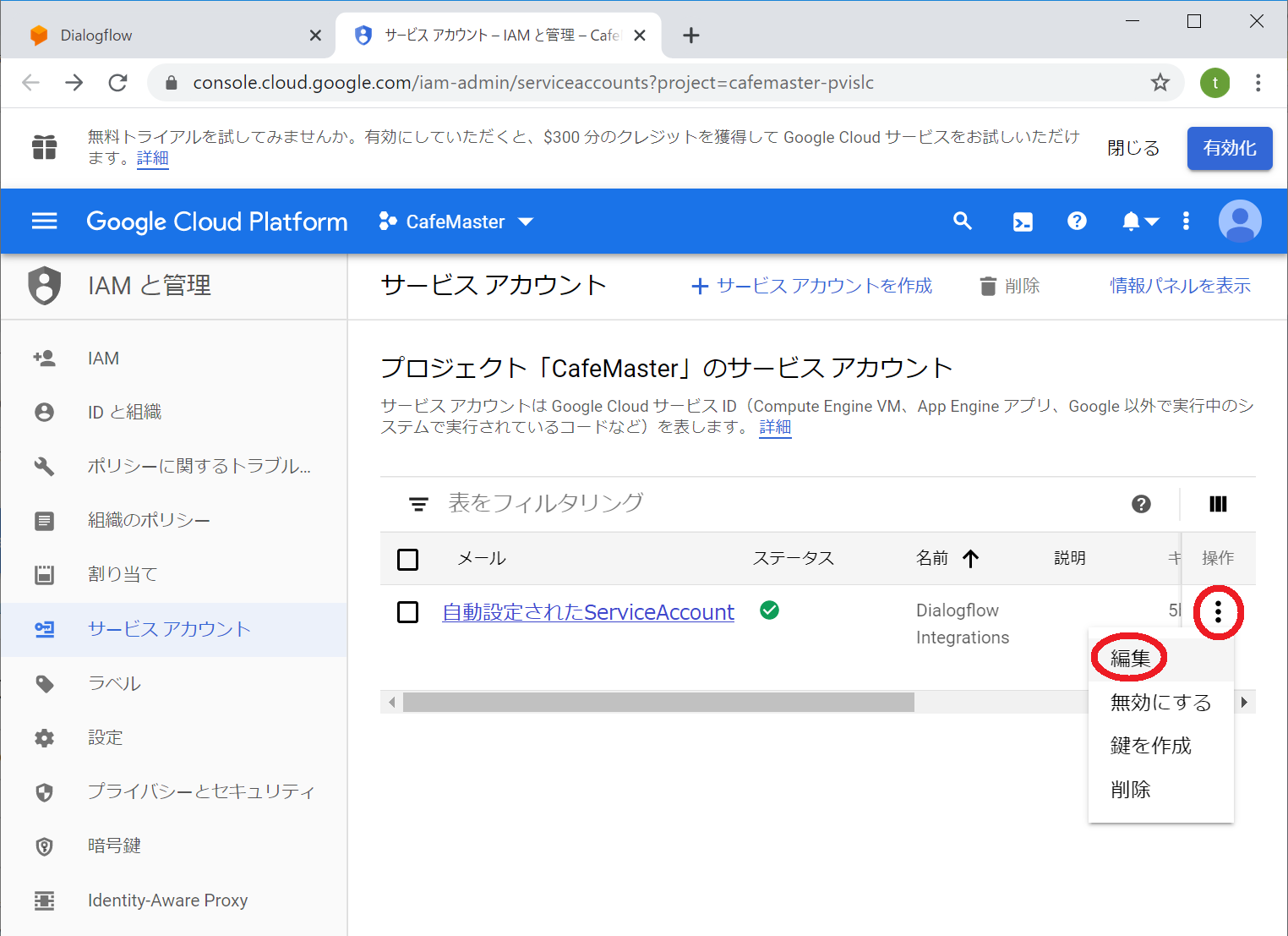
まずはエージェントの設定画面のところにあるGoogle Projectの欄を見てください。ここに自動発行されたProject IDとService Accountが表示されています。ここで、このService Accountをクリックします。
初回時は規約への同意画面を経てGCPのコンソール画面へと遷移します。
この画面から、先ほどの自動設定されたService Accountの右横にある操作欄の…ボタンから「編集」を選択します
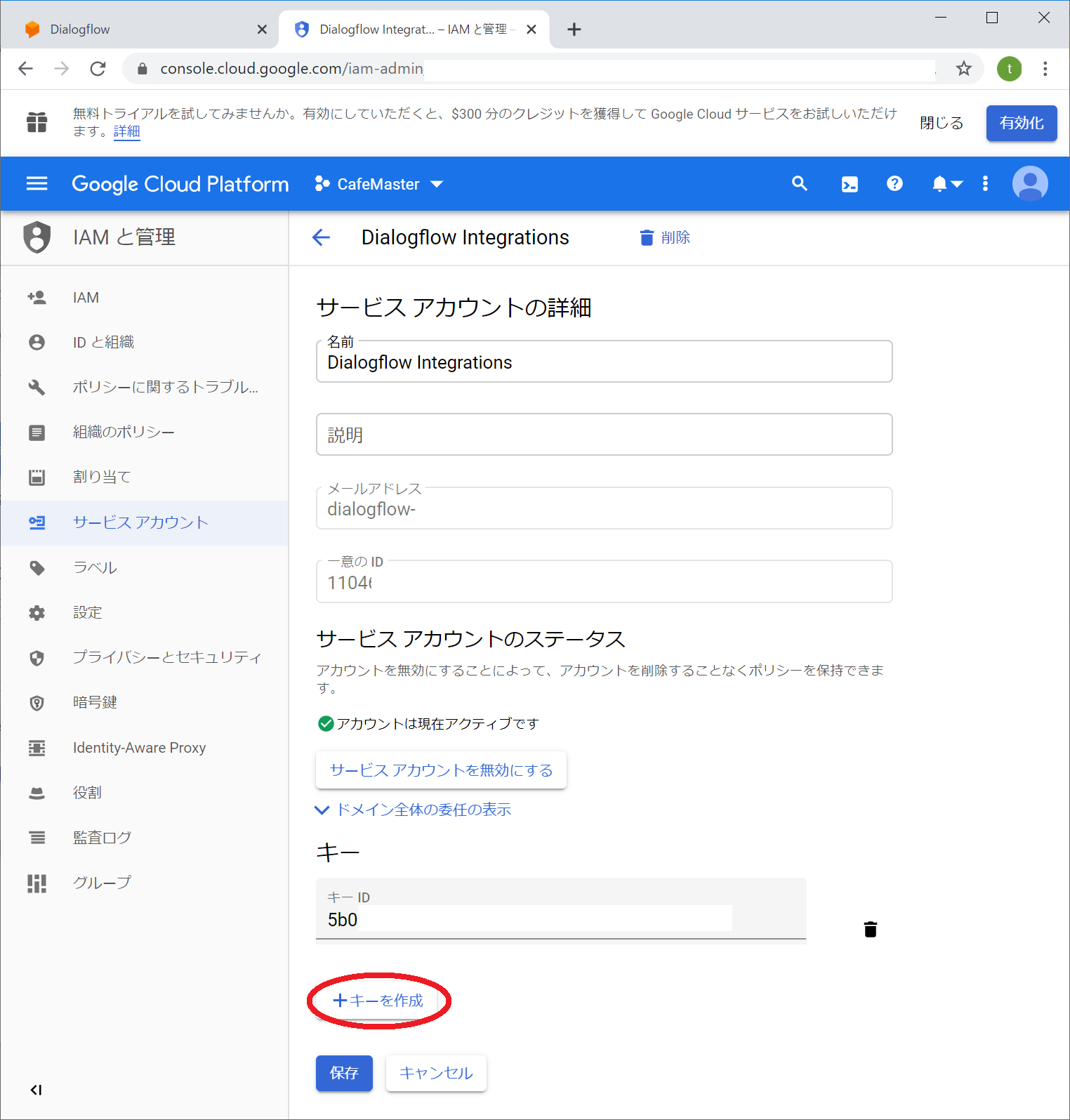
サービスアカウントの設定画面になりますので「+キーを作成」を選択します
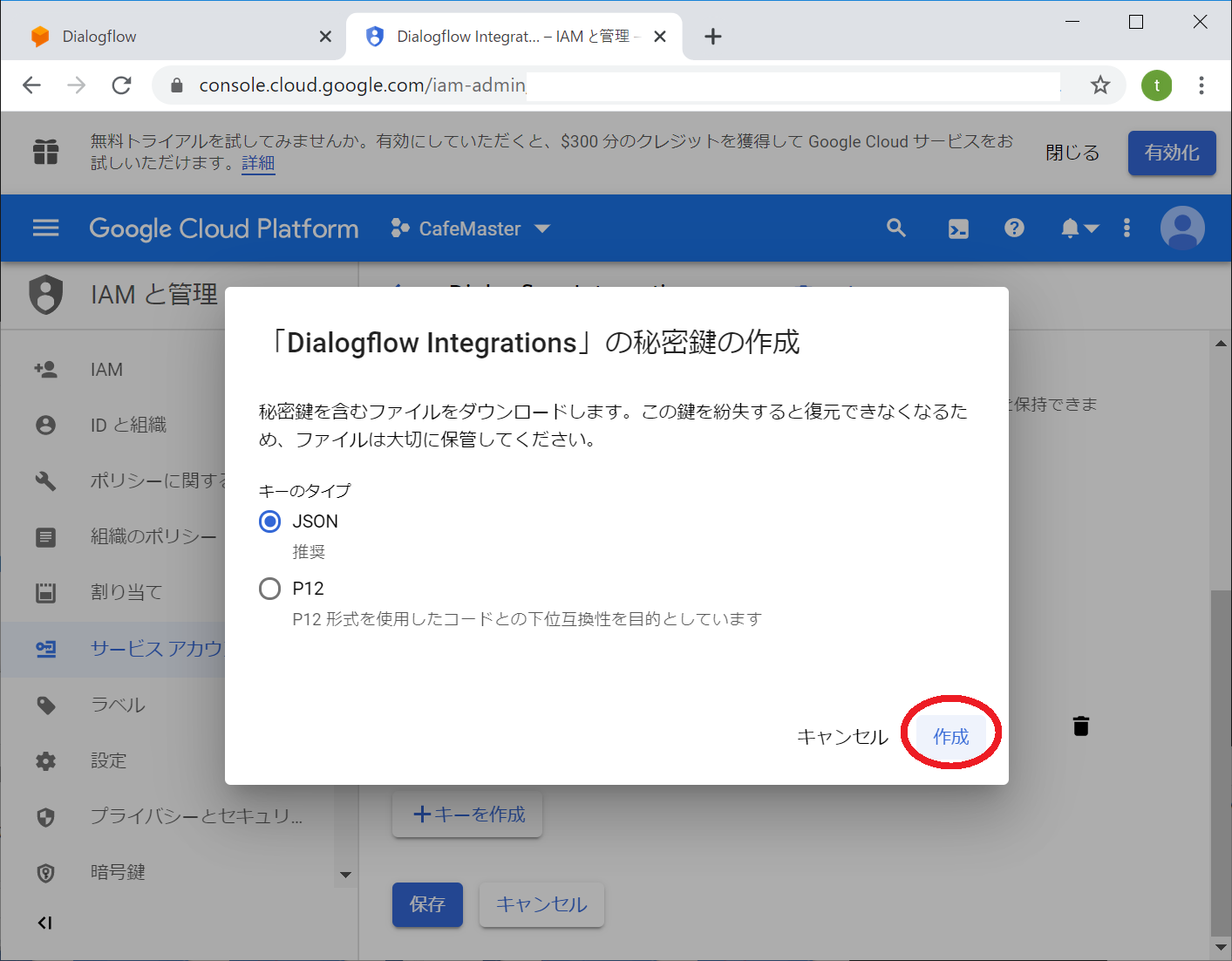
秘密鍵の作成ダイアログに代わりますので、作成タイプがJSONであることを確認して「作成」ボタンを押します
秘密鍵ファイルが作成されると「秘密鍵がパソコンに保存されました」メッセージが出て、cafemaster-xxxxxxxxx~.jsonがローカルのパソコンに自動でダウンロードされます。このファイルを後ほどチャットサーバーにアップロードし、プログラムから参照させるため、ファイル名を dialogflow.json に変更してください。
ファイル名を変更したら保存ボタンを押してください。
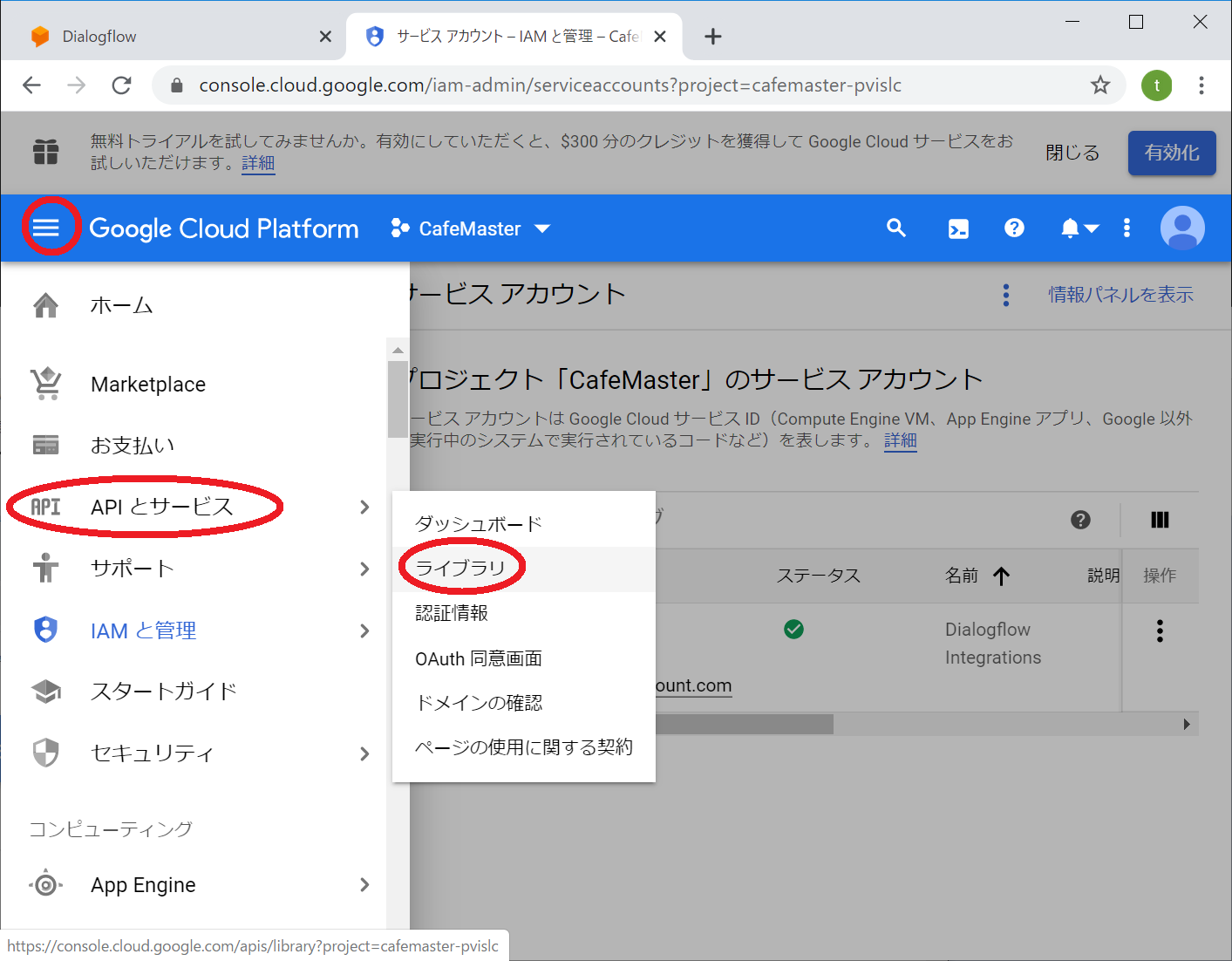
次にこの画面からDialogflow APIの利用許可の設定を確認します。
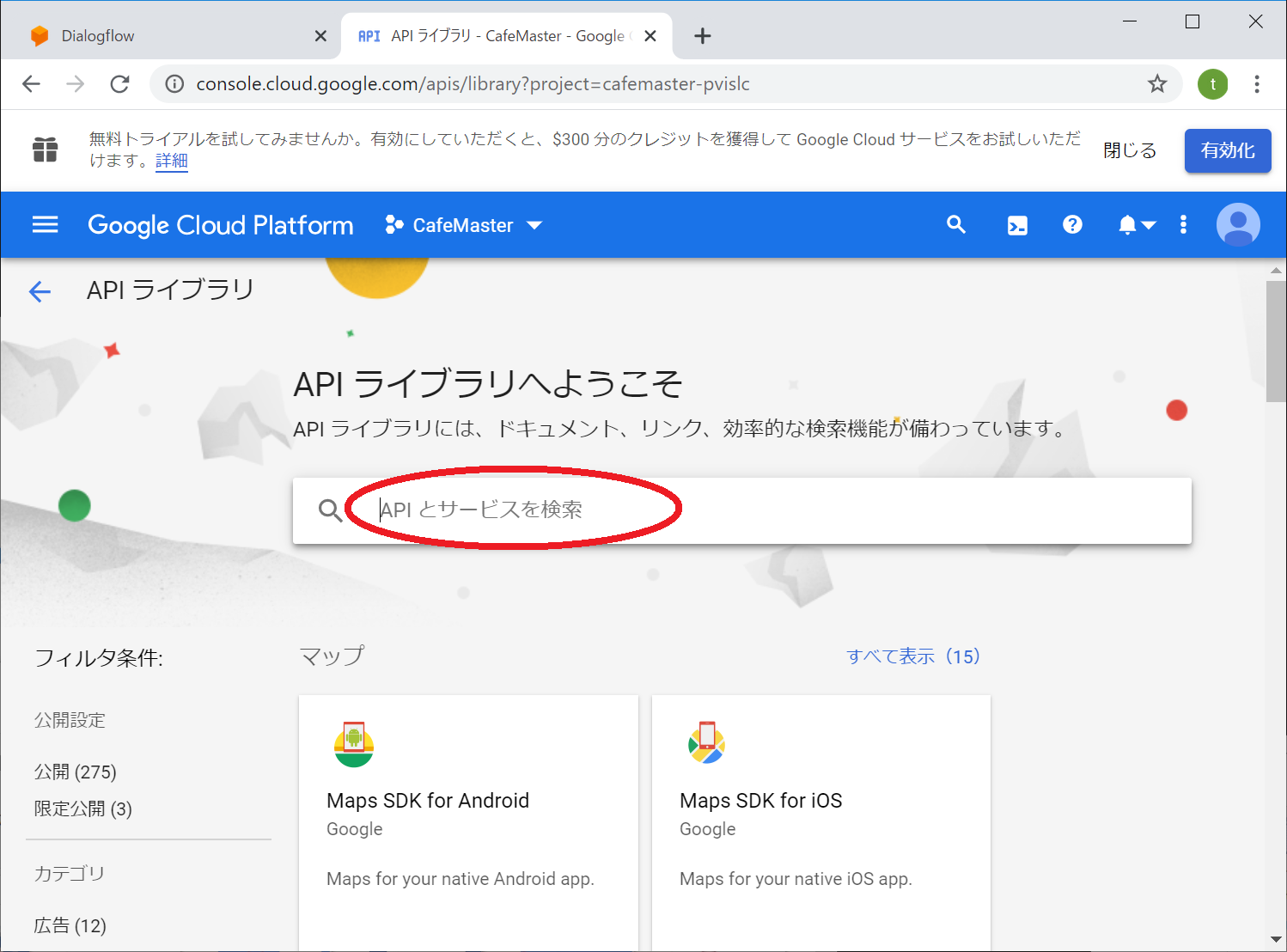
GCPコンソールのメニューから 「APIとサービス」を選び「ライブラリ」を選択します
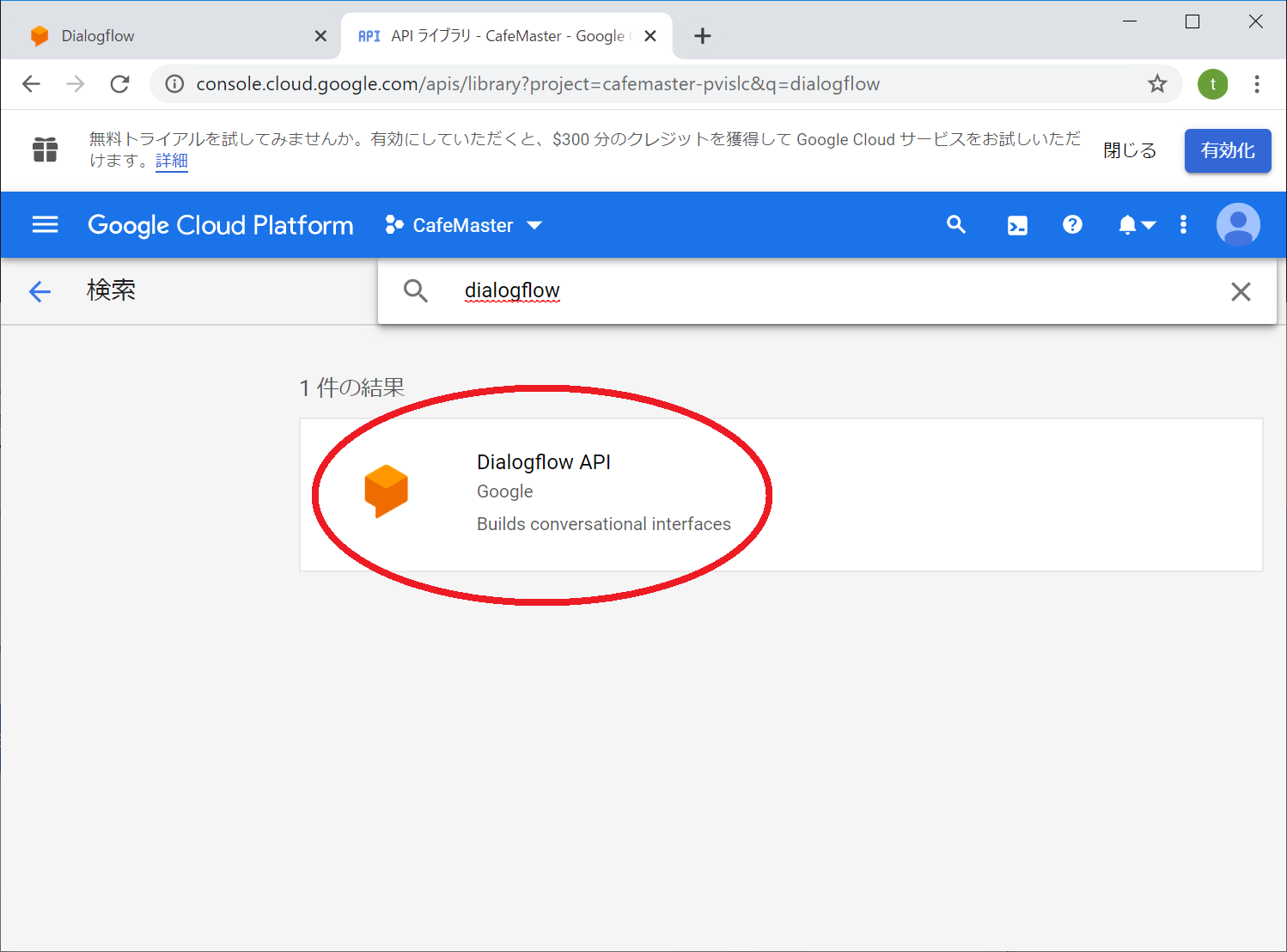
APIようこそ画面に遷移しますので、中央の検索ボックスに「dialogflow」と入力します。
検索の結果からDialogflow APIを選択します
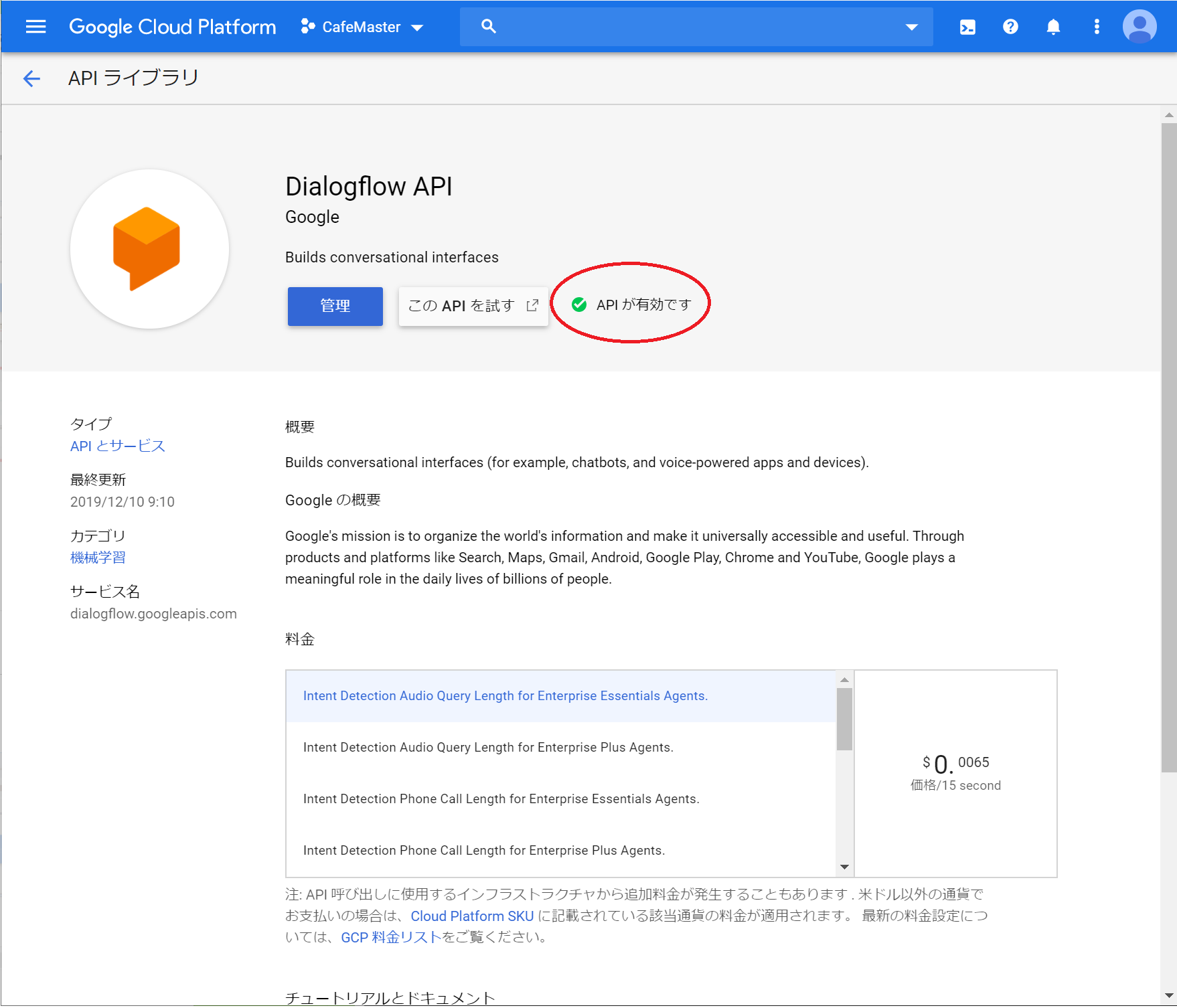
下記の画面になっていればOKですのでチャットサーバーの構築に手順を移してください。
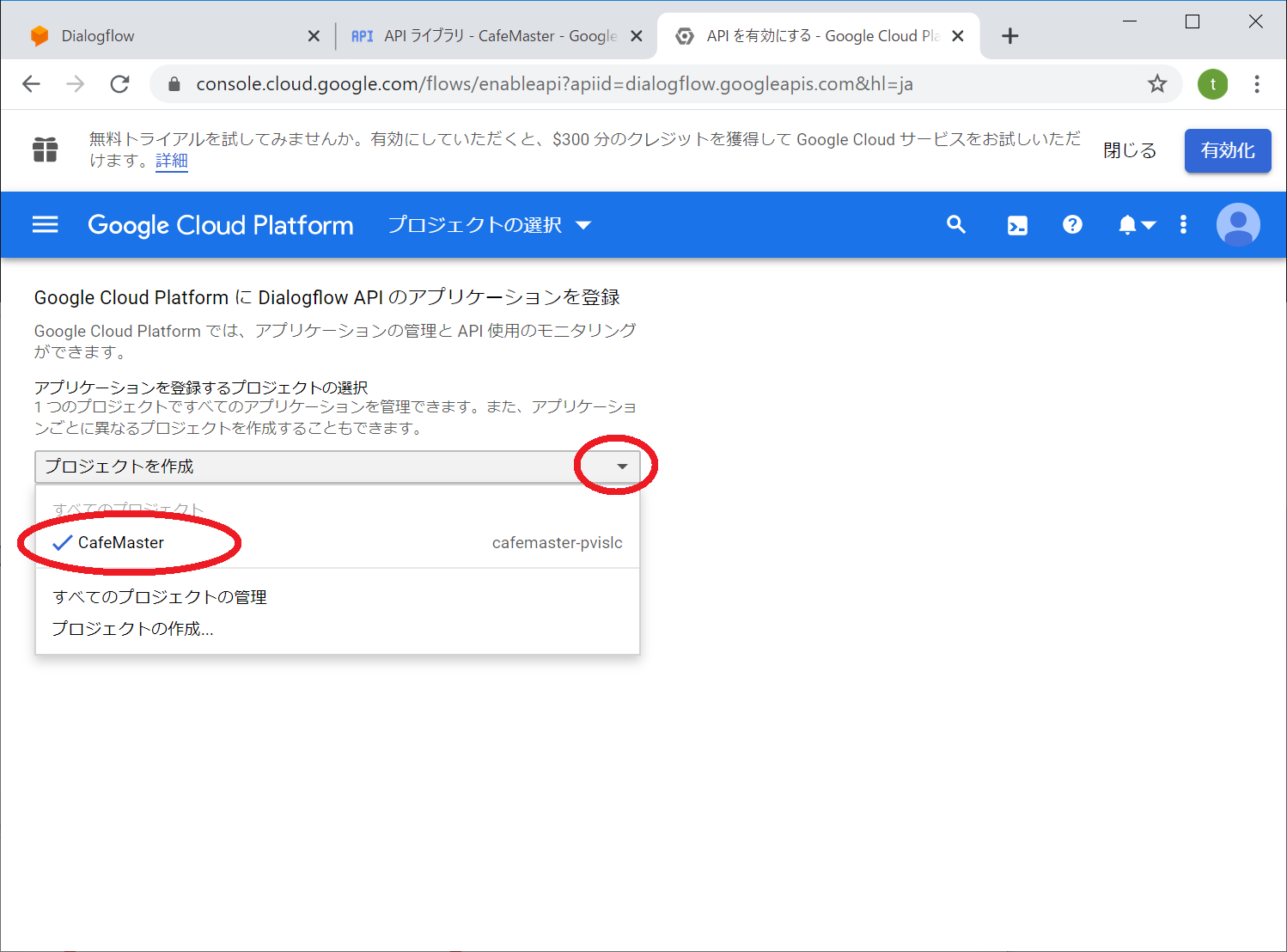
もしもAPIの有効化設定がされていない場合
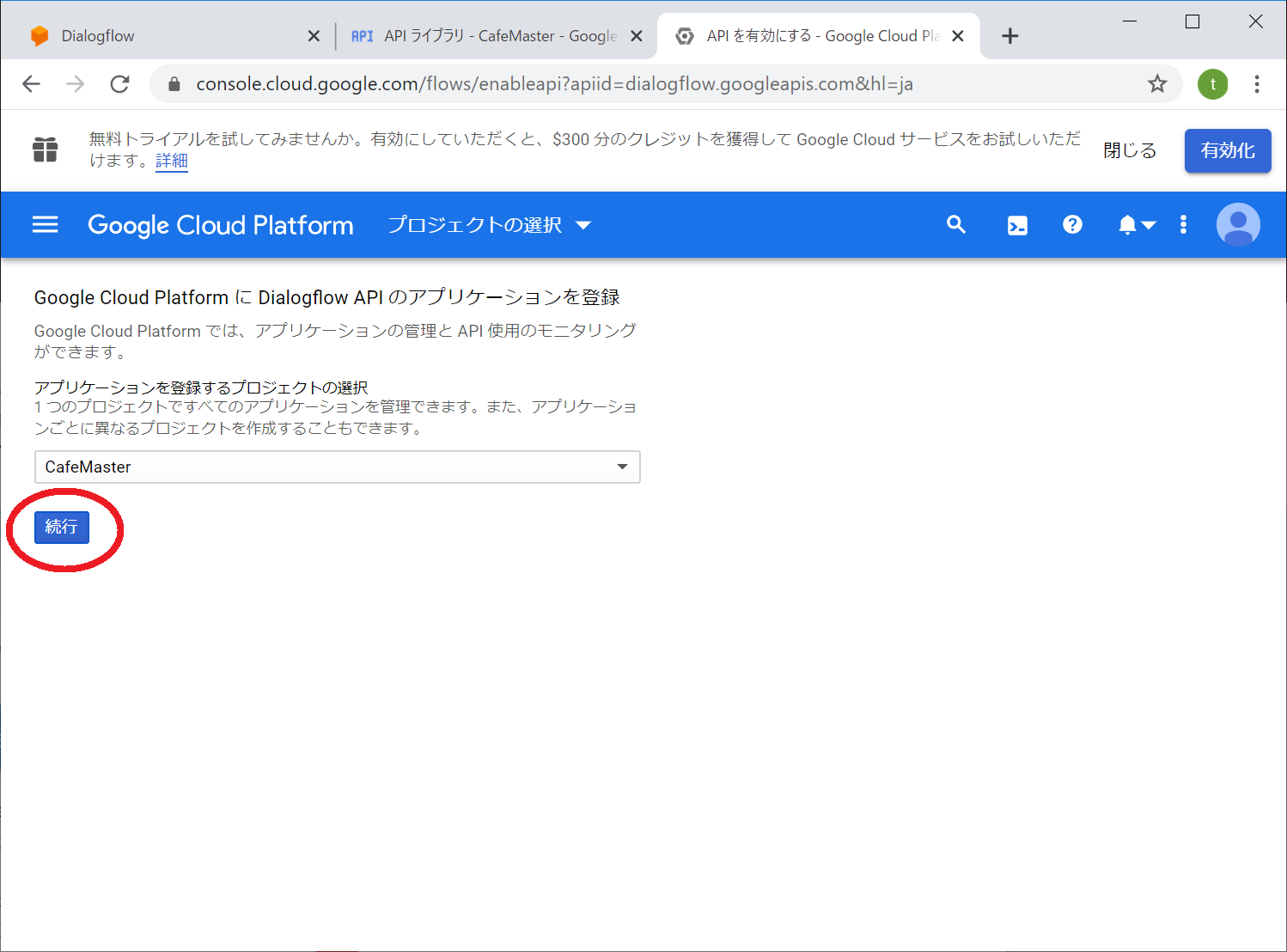
プロジェクトを作成と書かれているドロップダウンリストから「CafeMaster」を選択します
「続行」をクリック
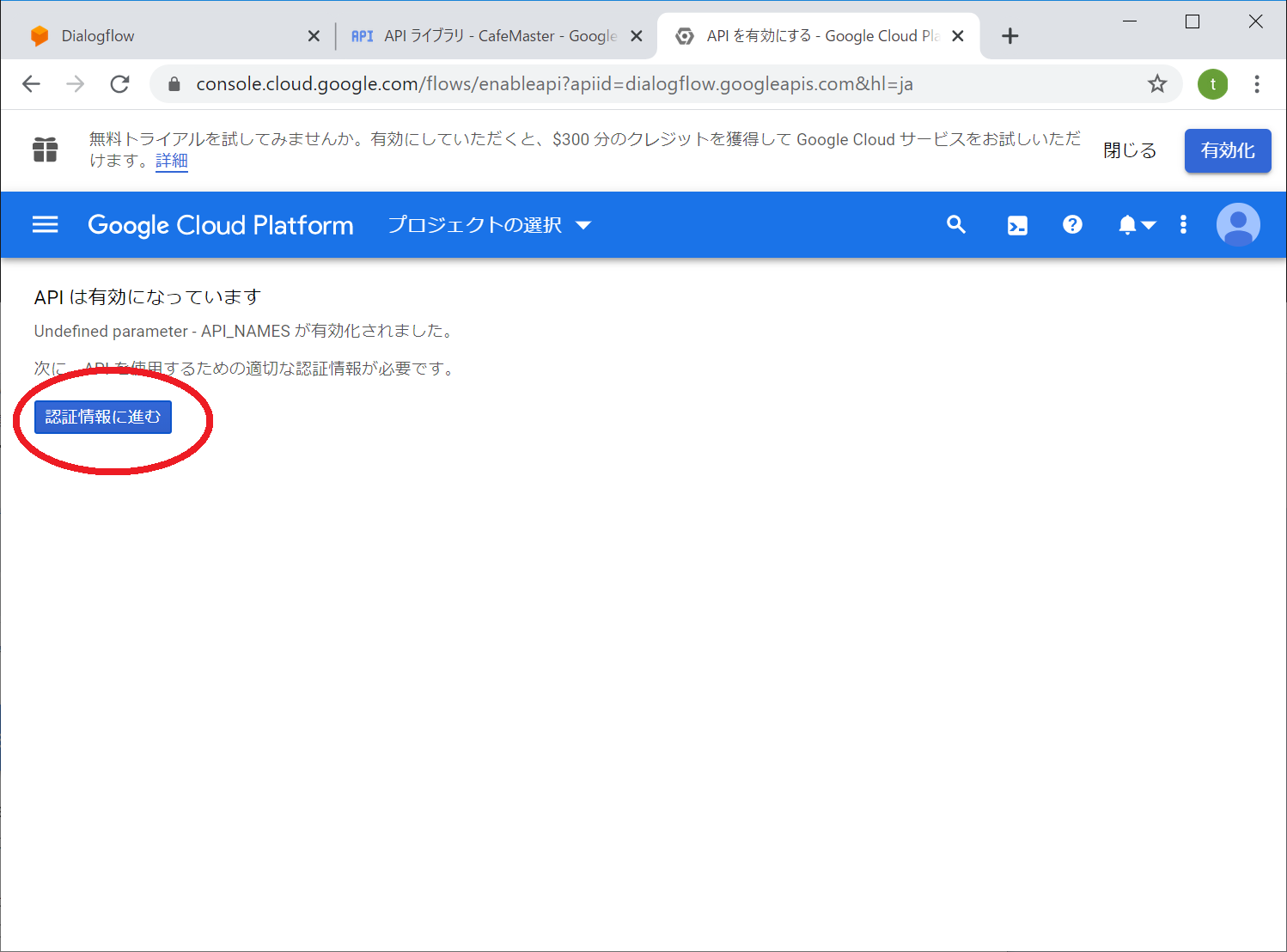
画面にAPIは有効になってます。と表示がでればOKです
そのまま×で閉じます
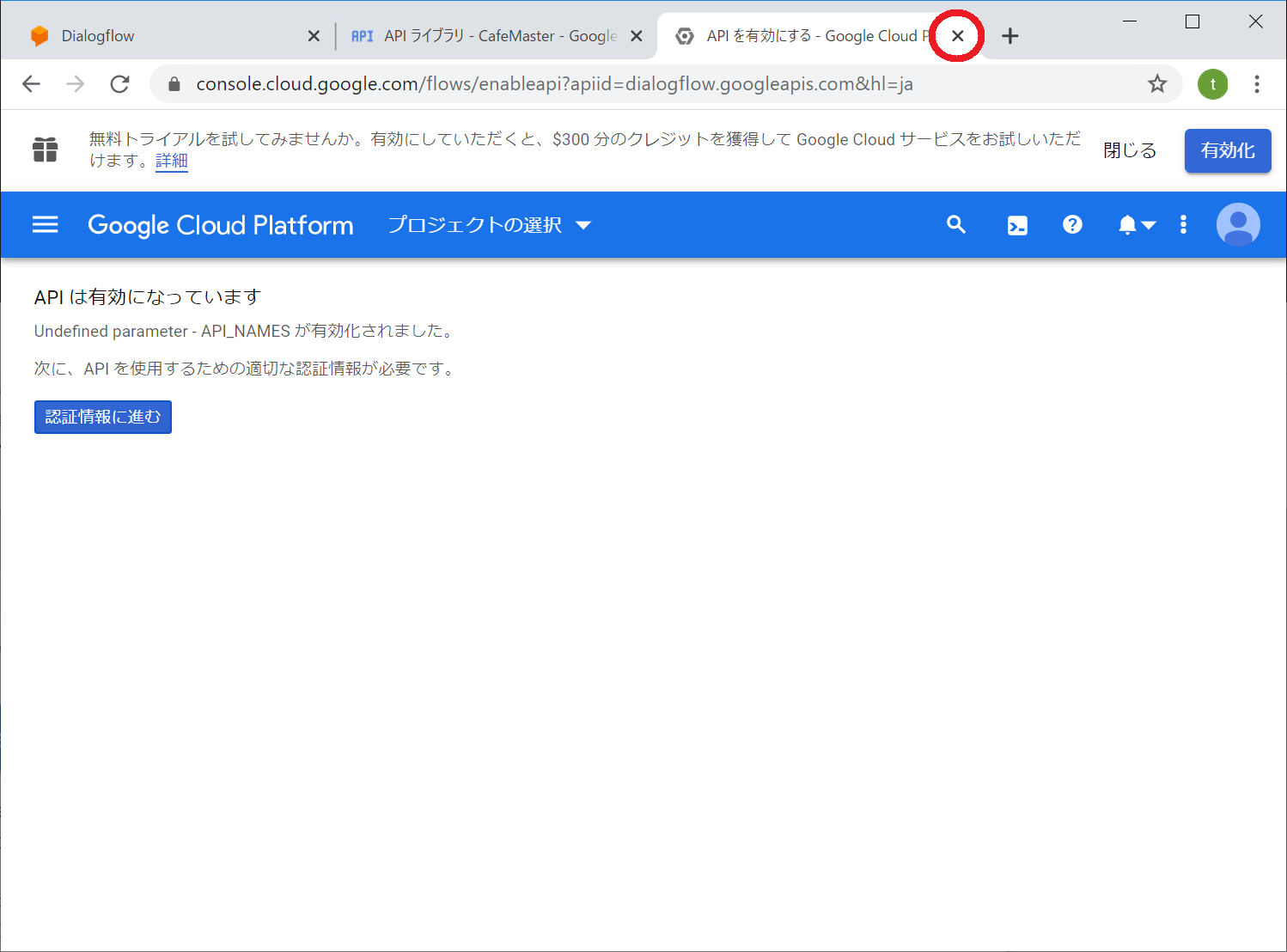
以上でDialogflowの秘密鍵の作成とAPIの有効化が完了です。
サーバー環境構築
前回に引き続きお手軽なクラウドサービスを使って環境構築を行います。
いつものようにPaizaを使います。Paiza Cloud
Paiza Cloudeにアクセスしてメールアドレスを登録すると、すぐに環境構築ができるようになります。サーバー作成
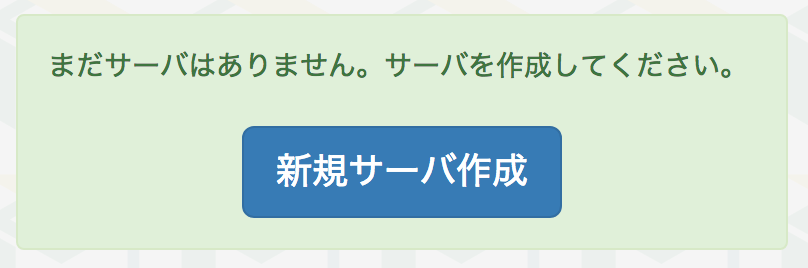
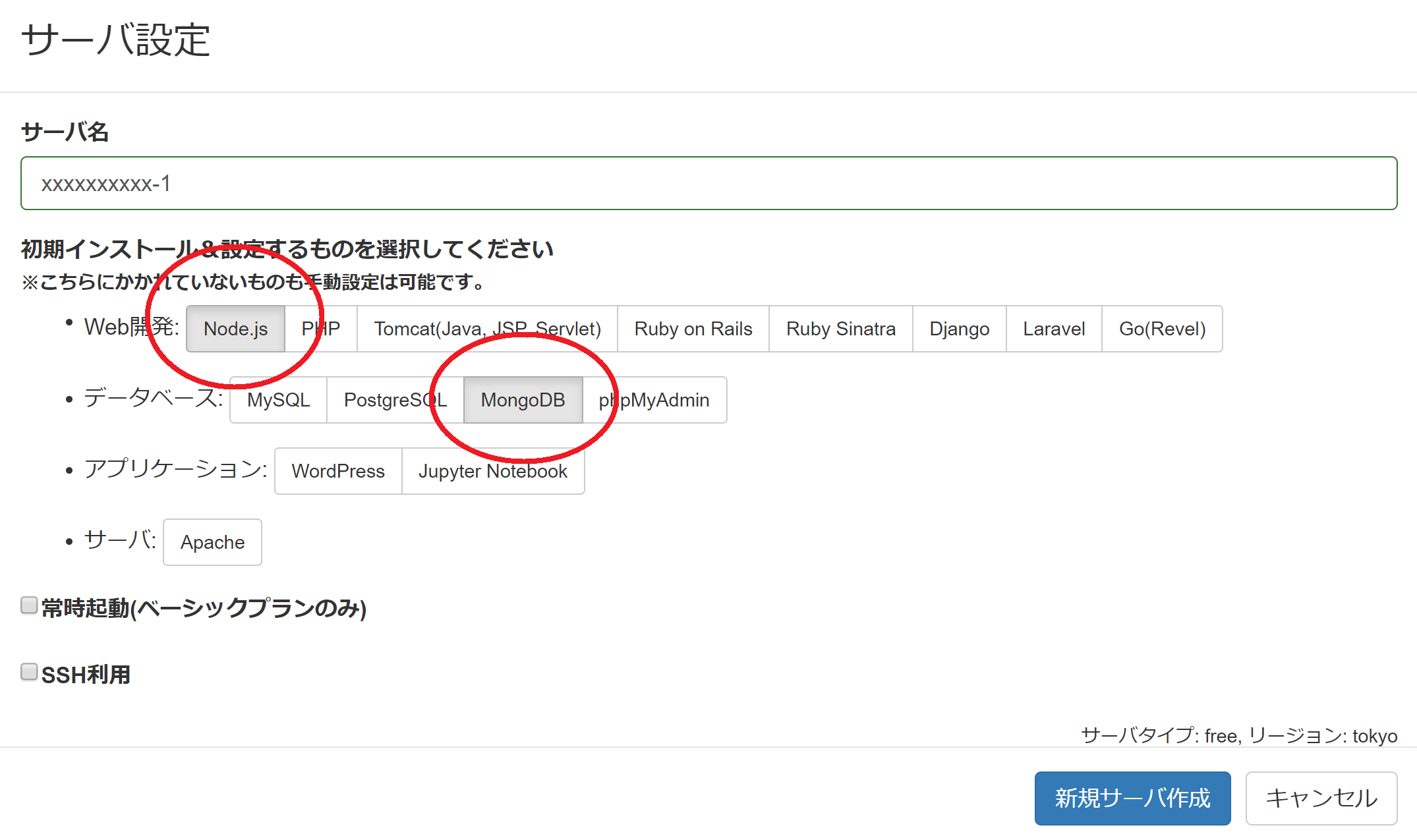
アカウントを作成したらサーバー作成ボタンを押しましょう
新規サーバー作成のポップアップで、Node.jsとMongoDBを選択してください。
数秒間待っているとサーバー環境ができあがります。
ちなみに無料プランの場合は
* サーバーの最長利用時間は24時間
* サービスは外部へ公開されない
逆に言うと練習にはもってこいという事でしょうか。アプリケーション構築
次に各種インストールを行い、アプリケーションの実行環境を構築します。
まずは画面からターミナルのアイコンをクリックしてください。
起動したターミナルに下記のコマンドを入れます
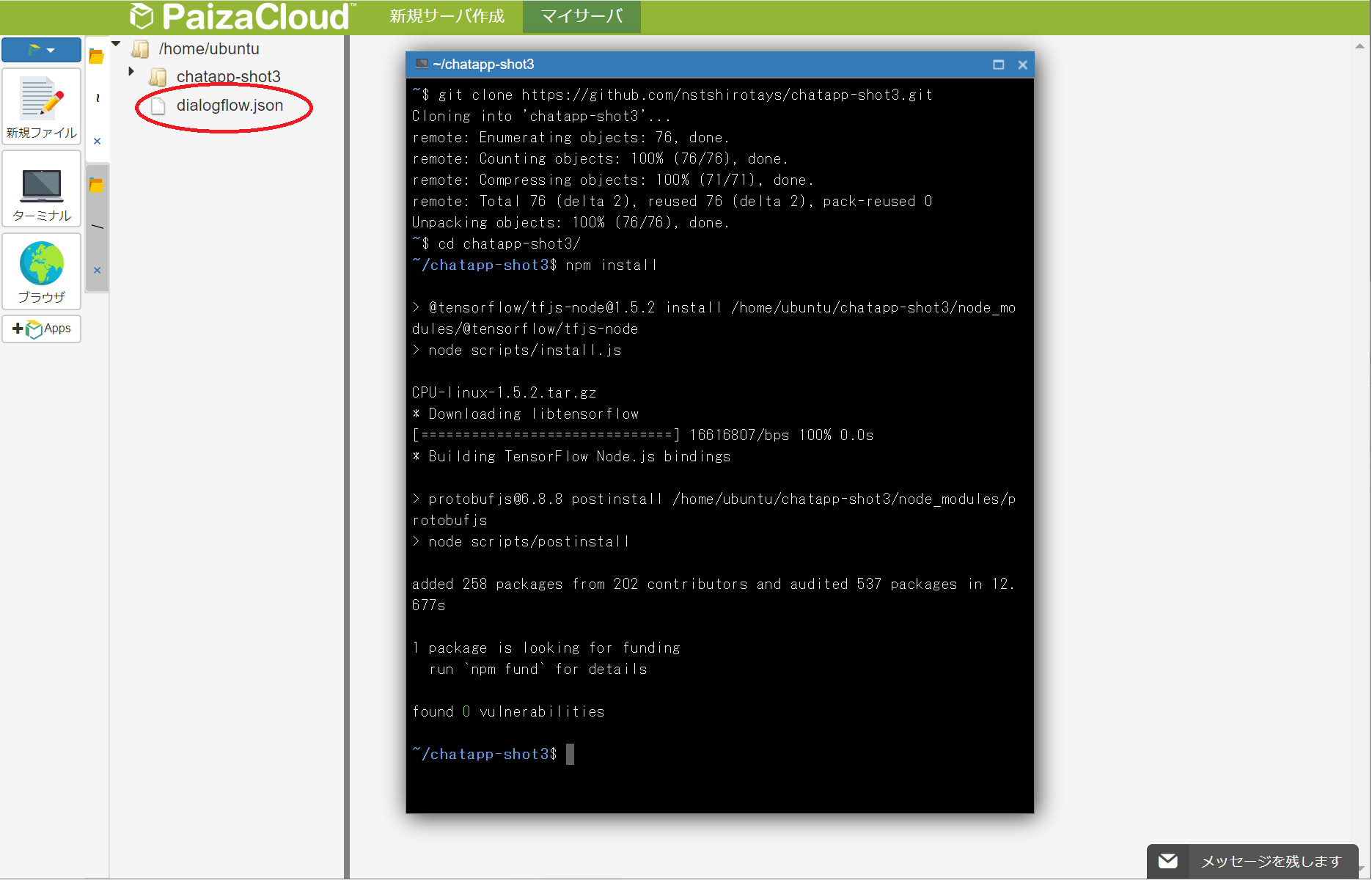
① git clone によるファイル展開git clone https://github.com/nstshirotays/chatapp-shot3.git② ディレクトリを移動し
③ npmによるパッケージのインストール
これにより実行に必要なモジュールなどがpackage.jsonに従って自動的にインストールされます。cd chatapp-shot3 npm install
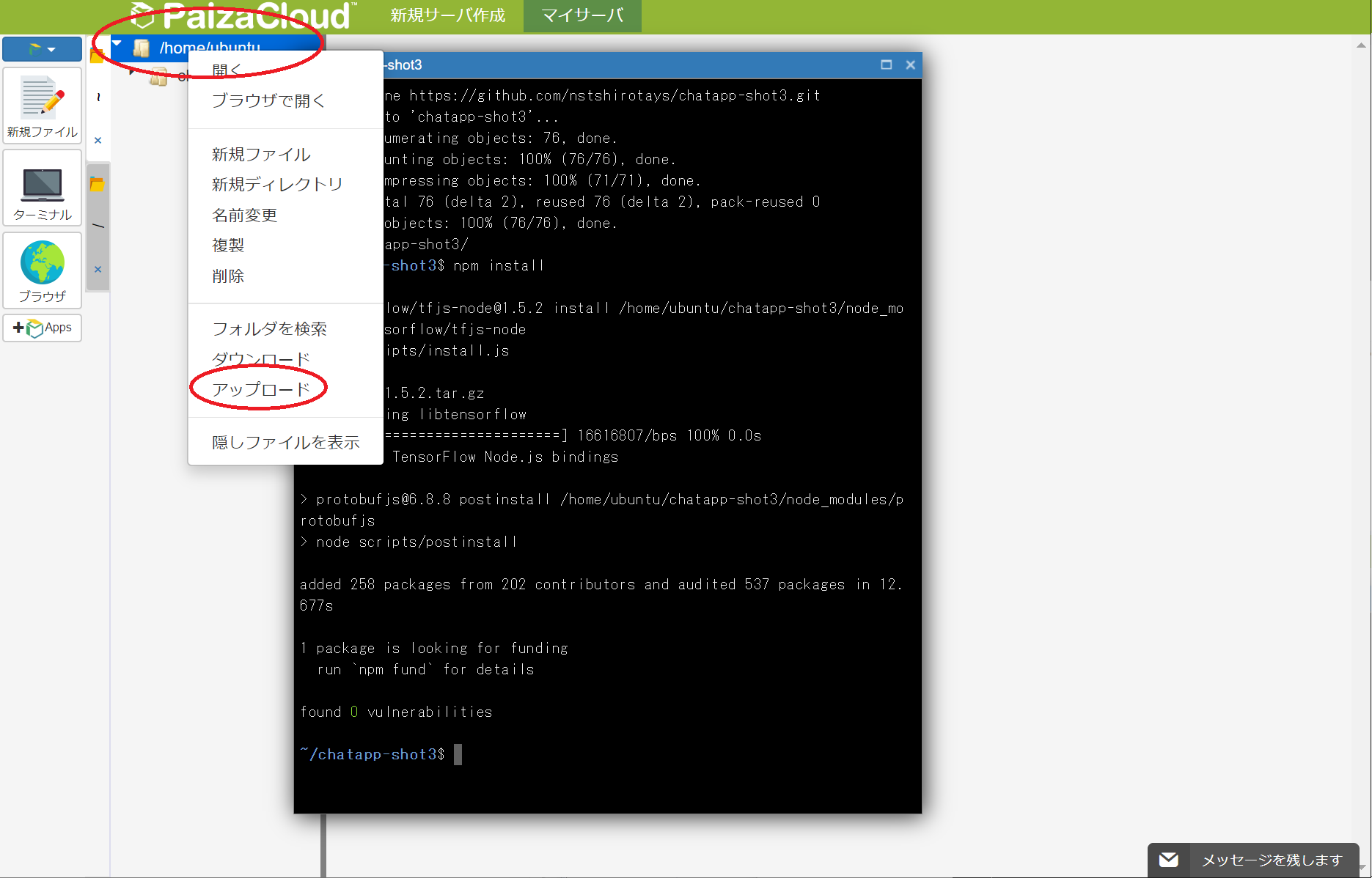
次に、先ほど作成したDialogflowに接続するための秘密鍵ファイルをアップロードします。
/home/ubuntuと書かれているところを右クリックするとメニューが表示されますので、そこから前の工程で作成したdialogflow.jsonファイルをアップロードします。
ファイル名は必ずdialogflow.jsonとして/home/ubuntu/に配置されていることを確認してください
以上で必要な準備が整いましたので、あとはnodejsを起動してアプリを立ち上げます。
npm startエラーがでなければ、左側に緑色のブラウザアイコンが新しく点滅し始めます。
このアイコンをクリックするとチャットアプリが起動します。
アプリ実行
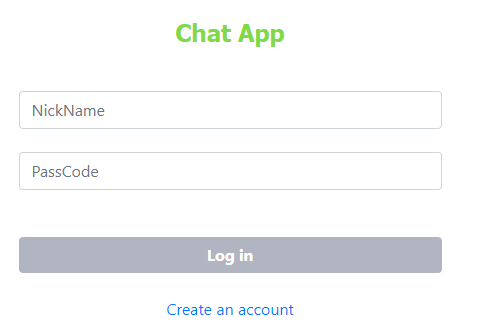
ログイン画面
まずはログイン画面です。
初回は誰も登録されていないので、Create an Account を押してユーザー登録画面に移ります。ユーザー登録画面
NickNameとPassCodeを入れてユーザーを登録しましょう。
NickNameは英文字で4から12文字。PassCodeは数字で6から12文字です。
お好みでFaceIconを変更(png 32kbまで)できます。
ユーザーを登録したら実際にログインしてみましょう。
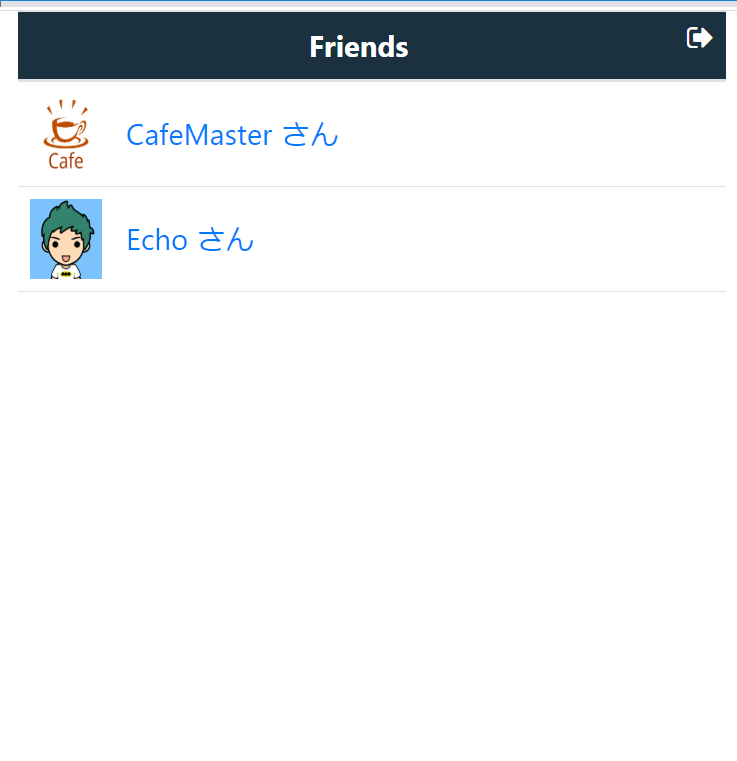
友達選択画面
前回はEchoさんだけでしたが、今回はCafeMasterが追加されています。
このCafeMasterさんの実体がDialogflowとなっています。DialogFlowによる会話生成
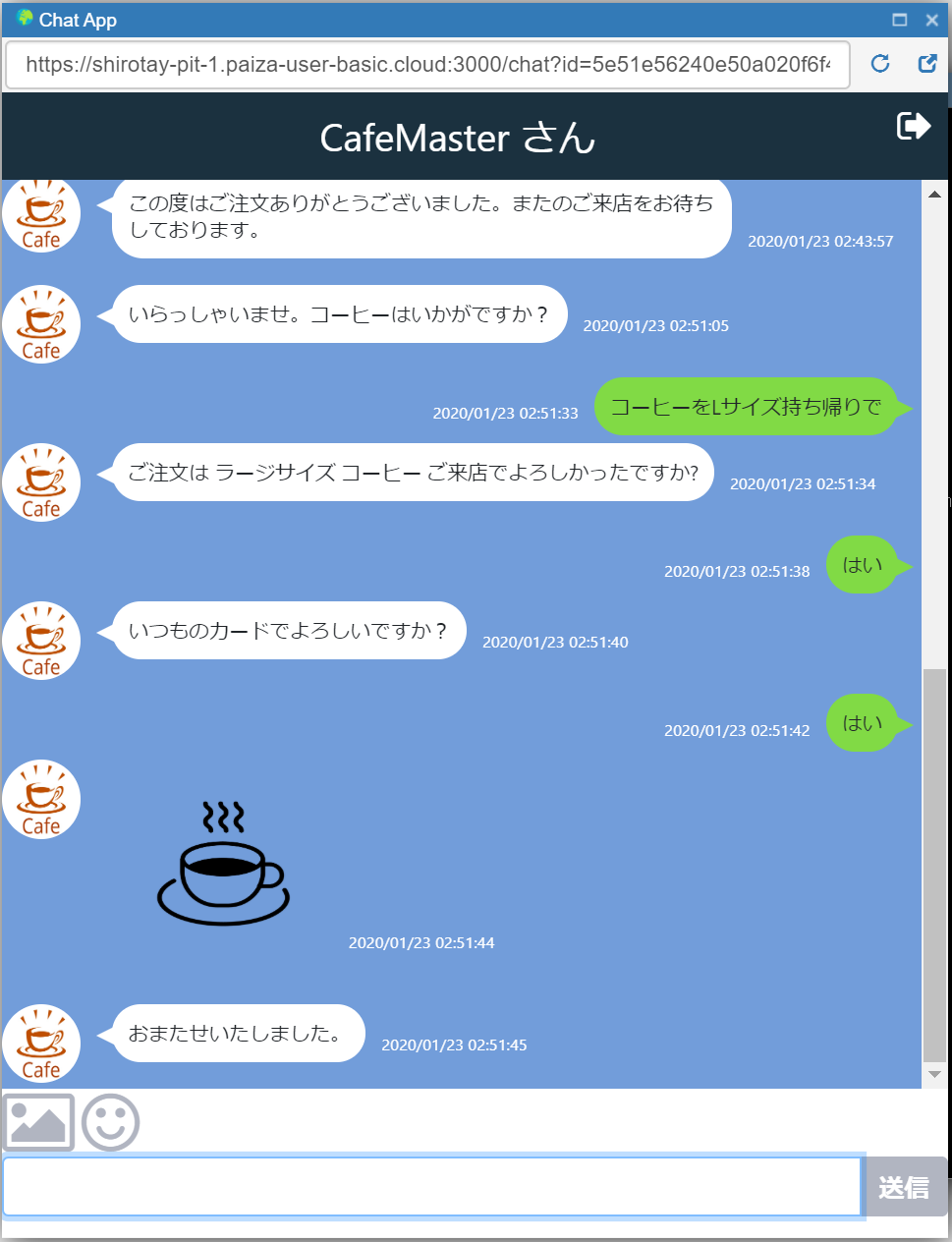
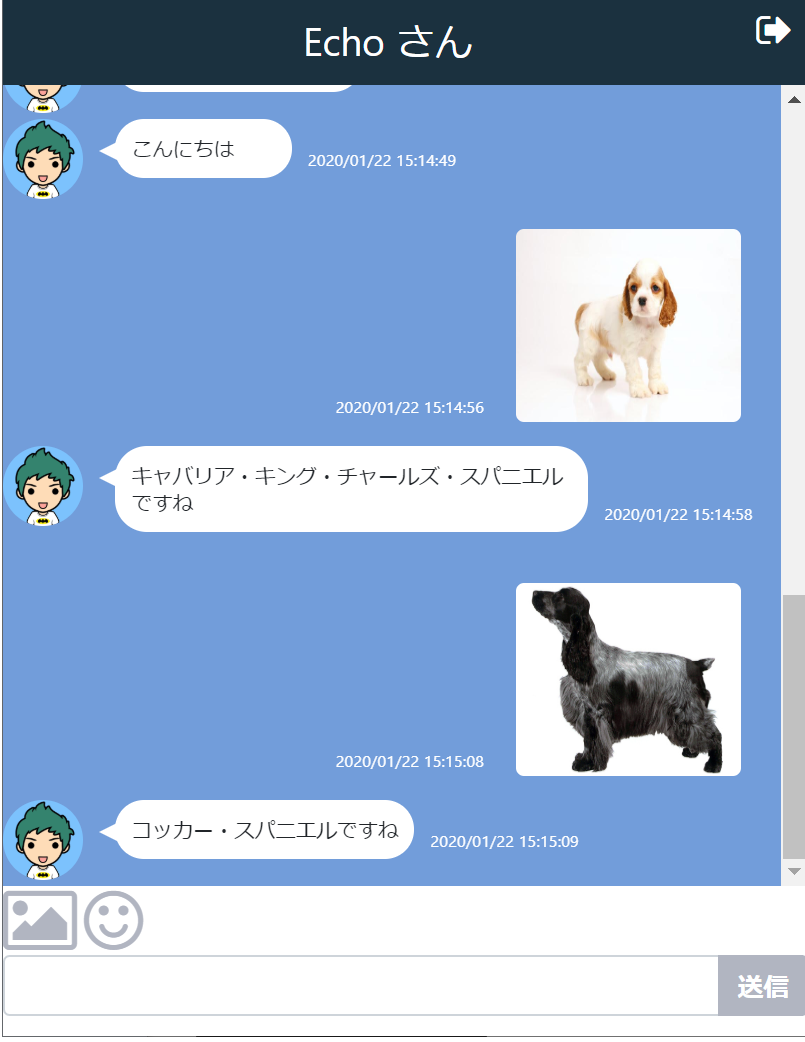
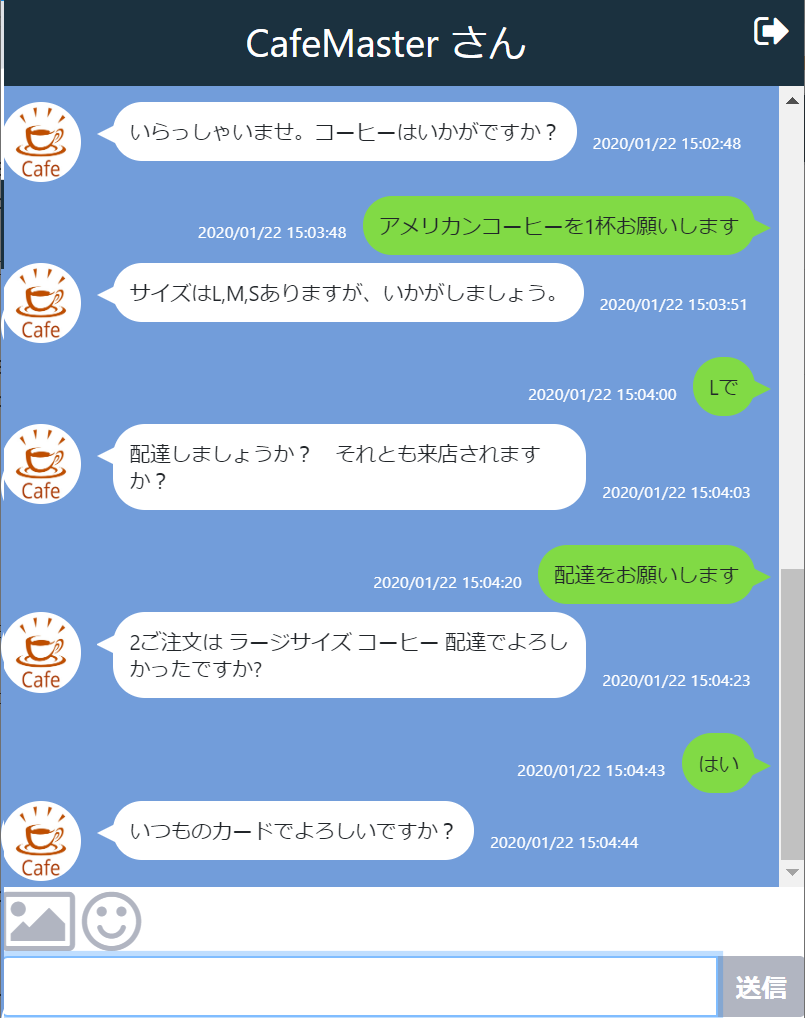
それでは、実際にCafeMasterさんと会話してみましょう。
最初の「いらっしゃいませ。コーヒーはいかがですか?」はチャットサイト側で出力しており、次の「アメリカンコーヒーを一杯お願いします」というTEXTからDialogflowにて処理をしています。
Dialogflowでは渡されたTEXTから該当するインテントを割り出し処理をしていきます。ここではおそらくアメリカンコーヒーという単語に反応してorder.drinkインテントが発動されています。
なので、店主の挨拶の後に「いつもの」などと入れるとorder.lastインテントが発動します。
その他、Dialogflow側の処理については、DialogFlow Console 画面の右側にチャットボックスがあり自由にテストができますので、いろいろと試してみてください。プログラム解説
それでは早速Dialogflowとの連動についてプログラムを見てみましょう。
起動時の処理
Google APIを利用するためには秘密鍵による認証が必要です。先に配置したdialogflow.jsonファイルがそれです。
この秘密鍵ファイルは環境変数の設定により必要とされるプログラムからアクセスされます。
このため起動する前に当該環境変数の設定をする必要があります。ここでは、npm startで最初に参照されている package.jsonで設定を行っています。package.json{ "name": "chatapp2", "version": "0.0.0", "private": true, "scripts": { "start": "GOOGLE_APPLICATION_CREDENTIALS='/home/ubuntu/dialogflow.json' node ./bin/www" }, "dependencies": { "@tensorflow-models/mobilenet": "^2.0.4", "@tensorflow/tfjs": "^1.5.2", "@tensorflow/tfjs-node": "^1.5.2", "basic-auth-connect": "^1.0.0", "bcryptjs": "^2.4.3", "cookie-parser": "~1.4.4", "debug": "~2.6.9", "dialogflow": "^1.2.0", "ejs": "~2.6.1", "express": "~4.16.1", "express-validator": "^6.2.0", "http-errors": "~1.6.3", "jsonwebtoken": "^8.5.1", "mongo-sanitize": "^1.0.1", "mongoose": "^5.7.6", "mongoose-sequence": "^5.2.2", "morgan": "~1.9.1", "pb-util": "^0.1.2", "randomstring": "^1.1.5", "redis": "^2.8.0", "save": "^2.4.0", "uuid": "^3.4.0" } }Startの値に環境変数の設定を追加しています。
GOOGLE_APPLICATION_CREDENTIALS='/home/ubuntu/dialogflow.json'
会話の送信と受信
チャットサーバーとDialogFlowとのやりとりは helper/bot.cafe.jsにて実装してあります。
helper/bot.cafe.js// CafeMasterの処理 var db = require('../helper/db'); var Chat = db.Chat; const chatsv = require('../models/chat.service'); //DialogFlowの設定 const dialogflow = require('dialogflow'); const uuid = require('uuid'); var sessionId = ""; //console.log(process.env.GOOGLE_APPLICATION_CREDENTIALS); var fs = require("fs"); var use_readFile_json = JSON.parse(fs.readFileSync(process.env.GOOGLE_APPLICATION_CREDENTIALS, 'utf8')); const project_id = use_readFile_json.project_id; //console.log(project_id); exports.start = function(){ // 最初の挨拶を登録 if(FrName == 'CafeMaster') { // CafeMaster sessionId = uuid.v4(); console.log('Session ID = ' + sessionId); chatsv.create({ fromAddress : FrID, toAddress : MyID, message : 'いらっしゃいませ。コーヒーはいかがですか?' }); // 2秒ごとに新しいメッセージを検索する botTimer = setInterval(function(){ serachNewMessages(); },2000); } }; var resentMsg =""; async function serachNewMessages() { if(FrName == 'CafeMaster') { // CafeMasterの最後の発言を取得する var query = { "fromAddress": FrID ,"toAddress": MyID}; Chat.find(query,{},{sort:{timeStamp: -1},limit:1}, function(err, data){ if(err){ console.log("serachNewMessages err",err); } if(data.length > 0){ // CafeMasterの最後の発言以降の自分の発言を取得する. var lastMessageTime = data[0].timeStamp; query = { "fromAddress": MyID ,"toAddress": FrID,"timeStamp": {$gt : lastMessageTime}}; Chat.find(query,{},{sort:{timeStamp: -1},limit:1}, async function(err, data){ if(err){ console.log("serachNewMessages err",err); } if(data.length > 0){ // 応答メッセージの設定 var resMessage=""; const {struct} = require('pb-util'); // Create a new session const sessionClient = new dialogflow.SessionsClient(); const sessionPath = sessionClient.sessionPath(project_id, sessionId); // The text query request. const request = { session: sessionPath, queryInput: { text: { // The query to send to the dialogflow agent text: data[0].message, // The language used by the client (en-US) languageCode: 'ja-JP', //'ja' }, }, }; //DialogFlowへ会話を送って返事を待つ const responses = await sessionClient.detectIntent(request); const result = responses[0].queryResult; const parameters = JSON.stringify(struct.decode(result.parameters)); var obj = JSON.parse(parameters); console.log(` Query: ${result.queryText}`); console.log(` Response: ${result.fulfillmentText}`); resMessage = result.fulfillmentText; // 退避メッセージと異なってれば発話する if ( resMessage !== "" && resentMsg != data[0].timeStamp + data[0].message) { resentMsg = data[0].timeStamp + data[0].message; chatsv.create({ fromAddress : FrID, toAddress : MyID, message : resMessage }); } } }); } }); } }この処理は友達選択でCafeMasterが呼ばれると起動されます。
初期処理にて、先ほどの環境変数で示された鍵ファイルからproject_idを取得し、ランダムに得られた番号をセッション番号としてDialogflowに接続します。
最初の挨拶として「いらっしゃいませ。コーヒーはいかがですか?」を発話したのち、serachNewMessage関数を2秒ごとに実行しユーザーの会話を待ちます。新しい会話を検知すると、その内容をDialogFlowに渡して返事を待ちます。そして返事がきたらそのTEXTをmongoDBに書き込みます。
以上によりチャットサイトとDialogFlowが連動して会話処理を行うことができます。
Fulfillmentの設定
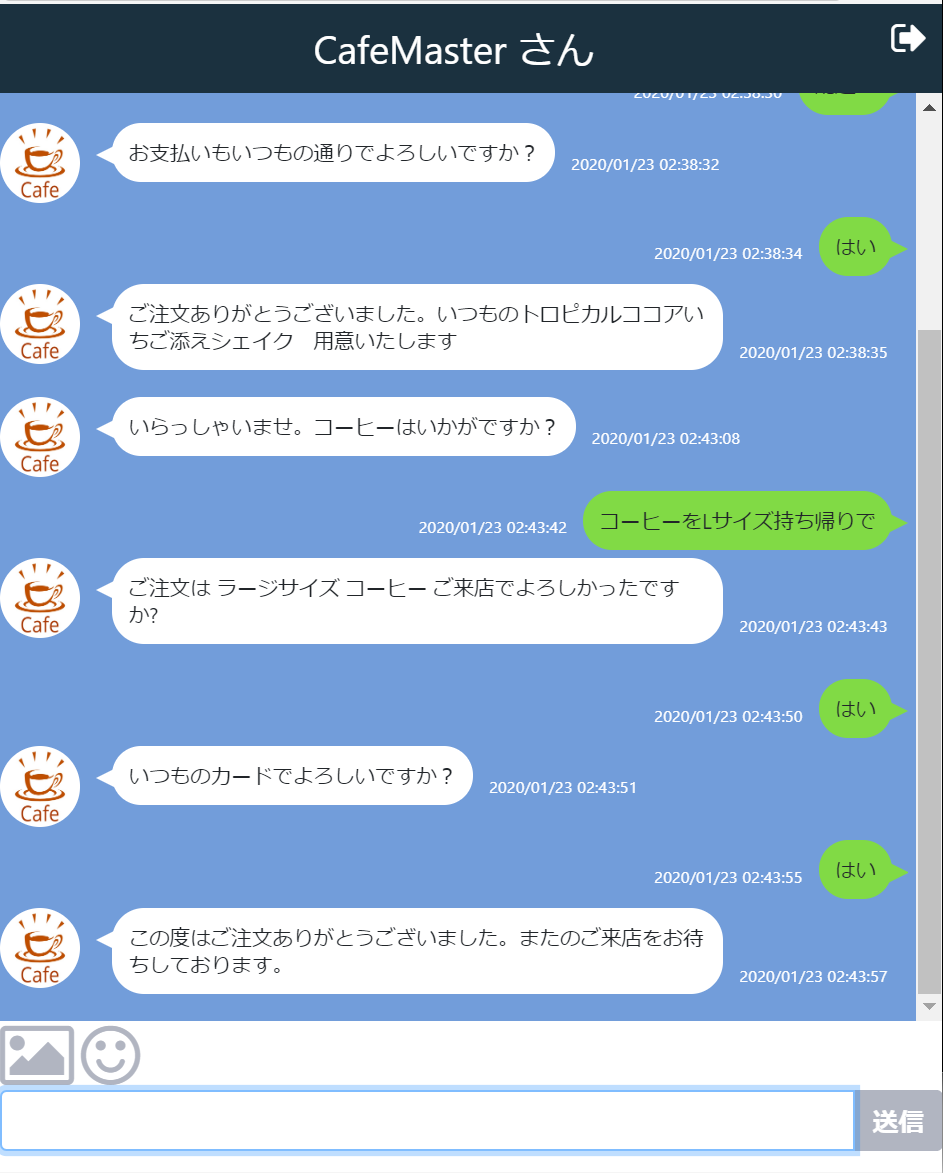
さて、このdorder.drinkインテントですが、ここでは「飲み物」「サイズ」「デリバリー」の3要素を必須入力としています。この3要素が揃うと次のorder.drink-yesというインテントが発動し、いつもの支払い方法でよいか聞かれます。ここで「はい」と答えるとorder.drink.same_cardに移動し最終確認が行われます。
初期段階ではFulfillmentが設定されていませんので、単純にこのインテントに設定されたResponse「この度はご注文ありがとうございました。またのご来店をお待ちしております。」というメッセージのみが戻されます。
本来であれば実際の注文処理が動くと思いますので、ここでFulfillmentによる外部サーバーの呼び出しを行ってみます。
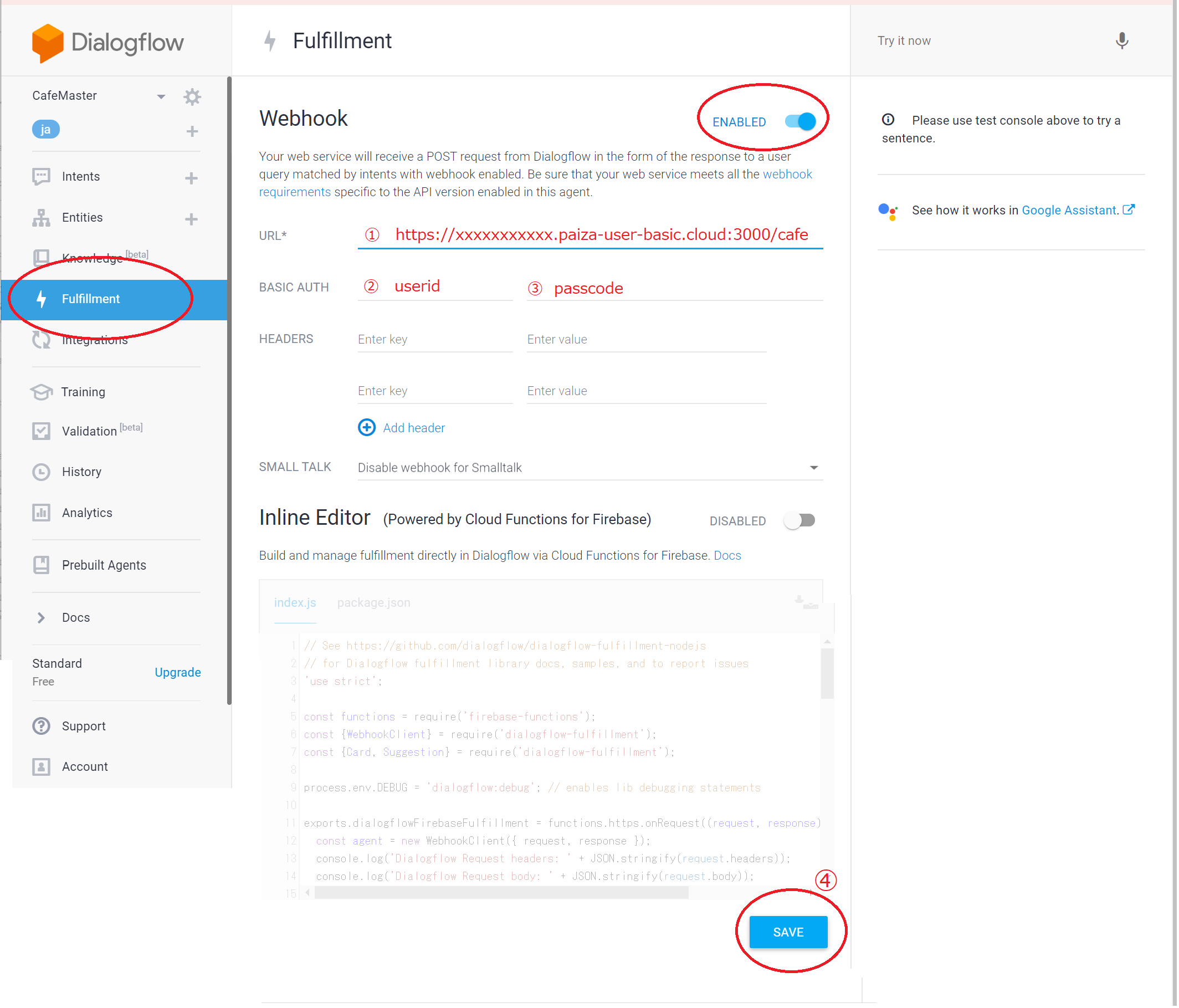
ここでは注文処理用の外部サーバー処理を先ほどのチャットサーバー上に同居させています。このためまずは呼び出すサーバーアドレスを取得します。
なお、この設定を行うためには本チャットサーバーがインターネットに公開されていることが前提となります(Paiza.cloudの無料枠では利用できません)。
まず公開されているアドレスを控えておきます。
次にDialogFlow Consoleの左側のメニューからFulfillmentを選択します
webhookスイッチをオンにして、呼び出すサーバーの設定を行います。
① 先ほど控えたURLの末尾に cafeを追加して設定
② IDに「userid」英字6文字を設定
③ PWDに「passcode」英字8文字を設定
④ 最後に「SAVE」ボタンをクリック
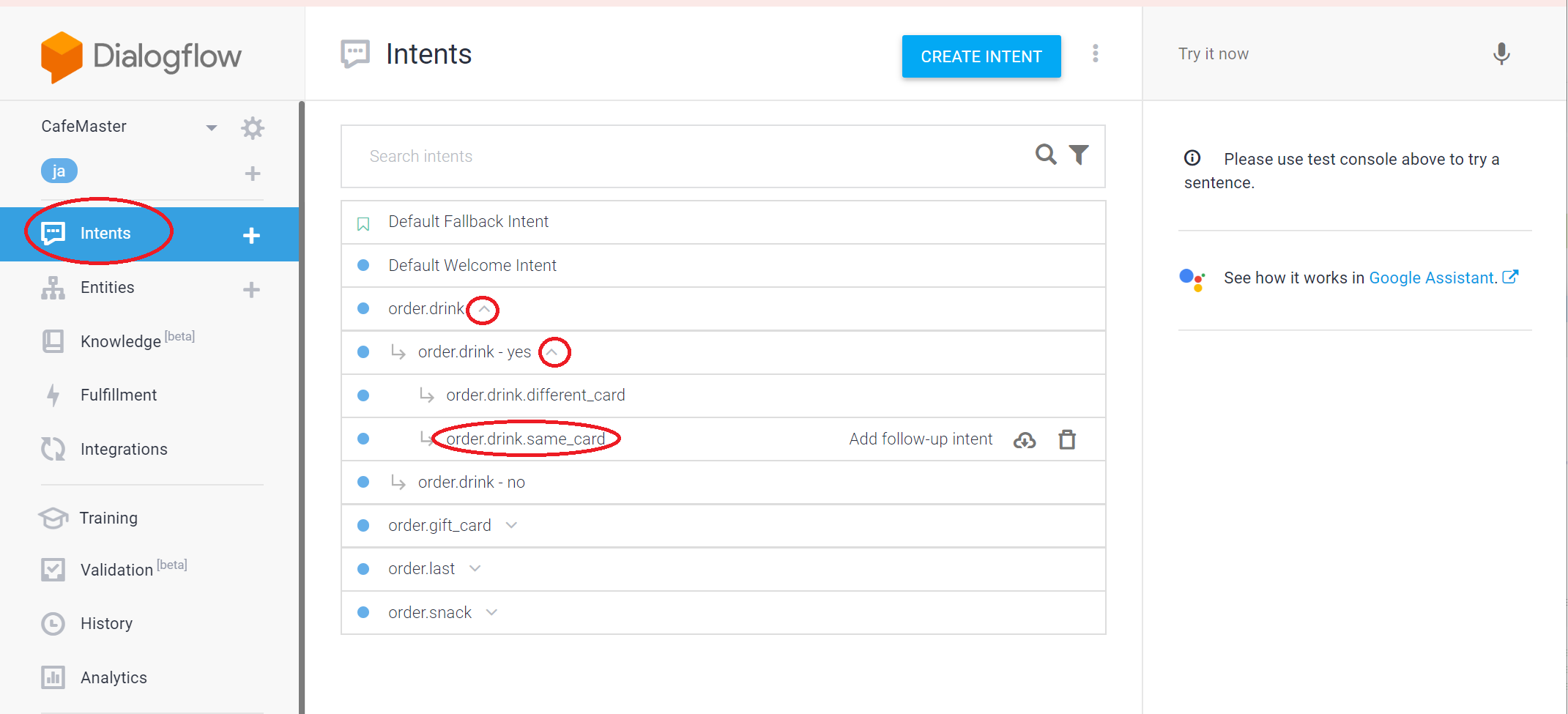
そして、設定されたWebhookを呼び出すタイミングをインテントに指定します。
Intentsを選択し、 order.drink -> order.drink - yes を展開し order.drink.samecardインテントを選択します。
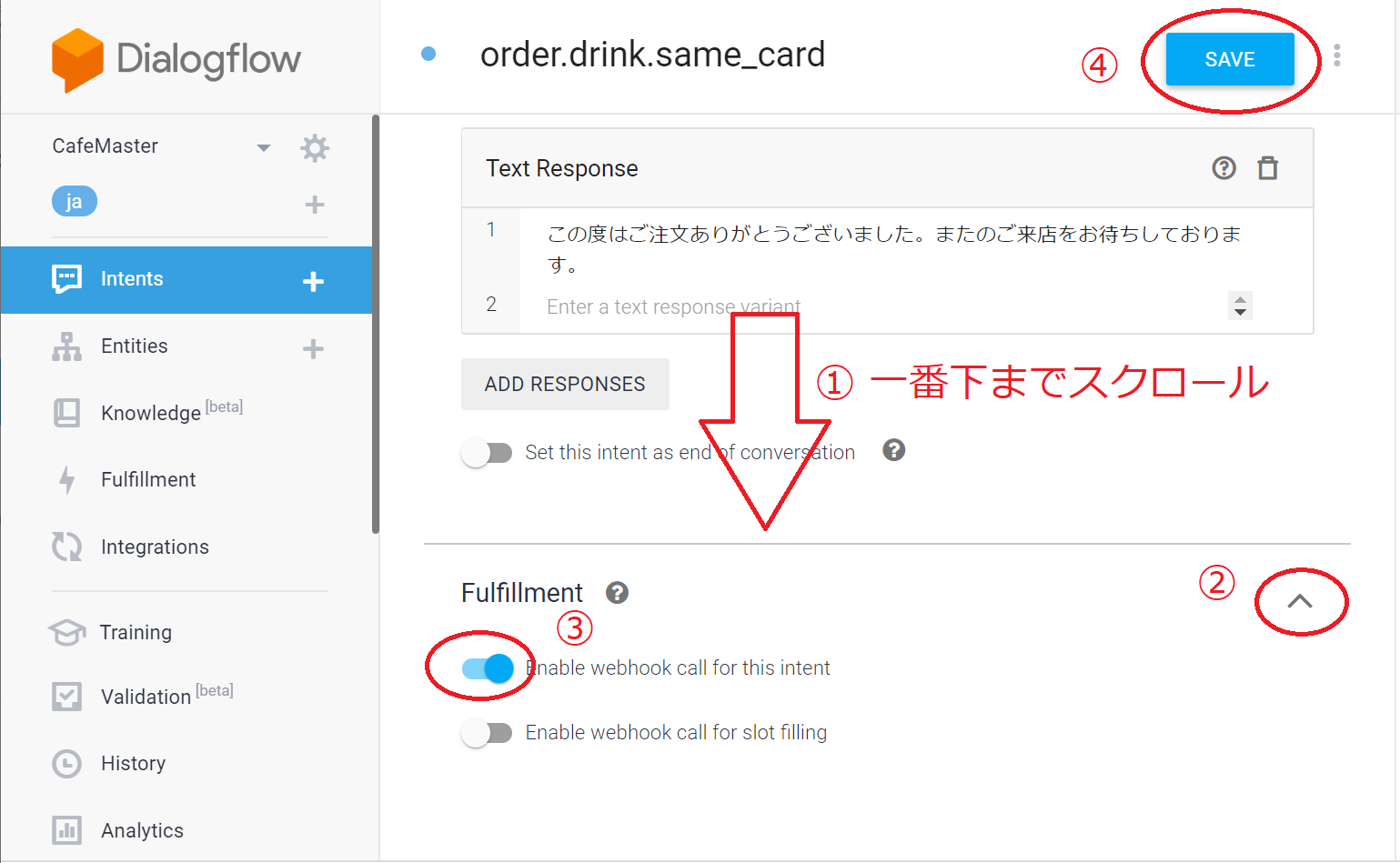
そして、①画面の下方にあるfuifillmentのタブを開いて②、「Enable webhook call for this intent」のスイッチをオン③にします。
それから最後に④のSAVEを押して内容を反映させます。
これでFulfillmentによるwebhookが設定できましたので、先ほどのCafeMasterさんを再度よびだしてみると、最終の挙動が変わっているのがわかると思います。
webhookプログラムの解説
それでは、受け取り側のwebhookプログラムについて解説します。実装はroutes/cafe.jsです。
routes/cafe.jsvar express = require('express'); var router = express.Router(); var db = require('../helper/db'); var User = db.User; var Chat = db.Chat; const verifyToken = require('../helper/VerifyToken'); var { check, validationResult } = require('express-validator'); var fs = require('fs'); const chatsv = require('../models/chat.service'); var basicAuth = require('basic-auth-connect'); //DialogFlowからのコールバックを処理する //ベーシック認証 router.post('/', basicAuth('userid','passcode'), function (req, res, next) { //console.log("req.body.session "+ req.body.session); //console.log(req.body.queryResult.outputContexts[1].parameters.drink); //console.log(req.body.queryResult.outputContexts[1].parameters.size); //console.log(req.body.queryResult.outputContexts[1].parameters.delivery); var cafeImageFile = req.body.queryResult.outputContexts[1].parameters.drink + ".png"; var baseStr = "data:image/png;base64,"; var cafeImage; fs.readFile('./public/files/' + cafeImageFile, function (err, data) { if (err) throw err; cafeImage = baseStr.concat(new Buffer(data).toString('base64')); chatsv.create({ fromAddress : FrID, toAddress : MyID, image : cafeImage, }) }); let responseObj={ "fulfillmentText":'おまたせいたしました。' } return res.json(responseObj); }); module.exports = router;ここでDialogFlowからのpost要求を受け付けます。ここではbasic認証を入れてあります。本来であればmTLSによるサーバーの相互認証(これにより接続してきたDialogflow側の証明書を認証することができる)をすべきなのですが、paiza.cloudが仮想環境による実装のため、サーバー証明書を入れることができませんので実装は試せませんでした。
処理的にはシンプルでpostされたデータにより画像ファイルを選択してmongoDBに格納しています。そしてDialogFlowへの返却値として「おまたせしました」というTEXTを送り返しています。以上がDialogFlowとの連動プログラムです。プログラム自体は単純なのですが、Dialogflow側の設定は慣れないと自分が何をしているかわからなくなります。このあたりはDialogflowのサンプルエージェントを眺めてみるるとその実装形態の思想が見えてくると思います。
MobileNetによる画像識別
2017年に誕生した畳み込み画像認識のmobileNetは、小型軽量でモバイル等での利用も盛んです。今回はこれをnode.jsに組み込んでいます。
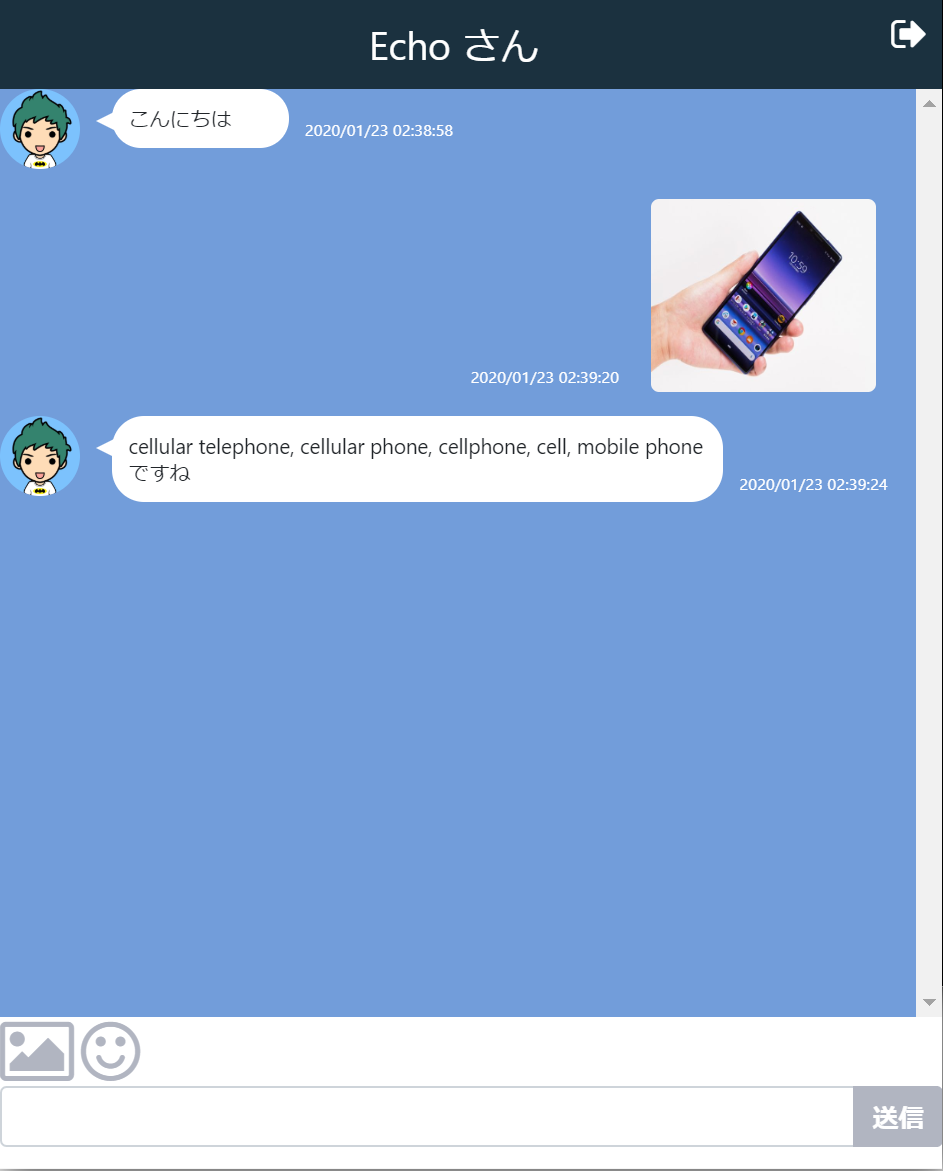
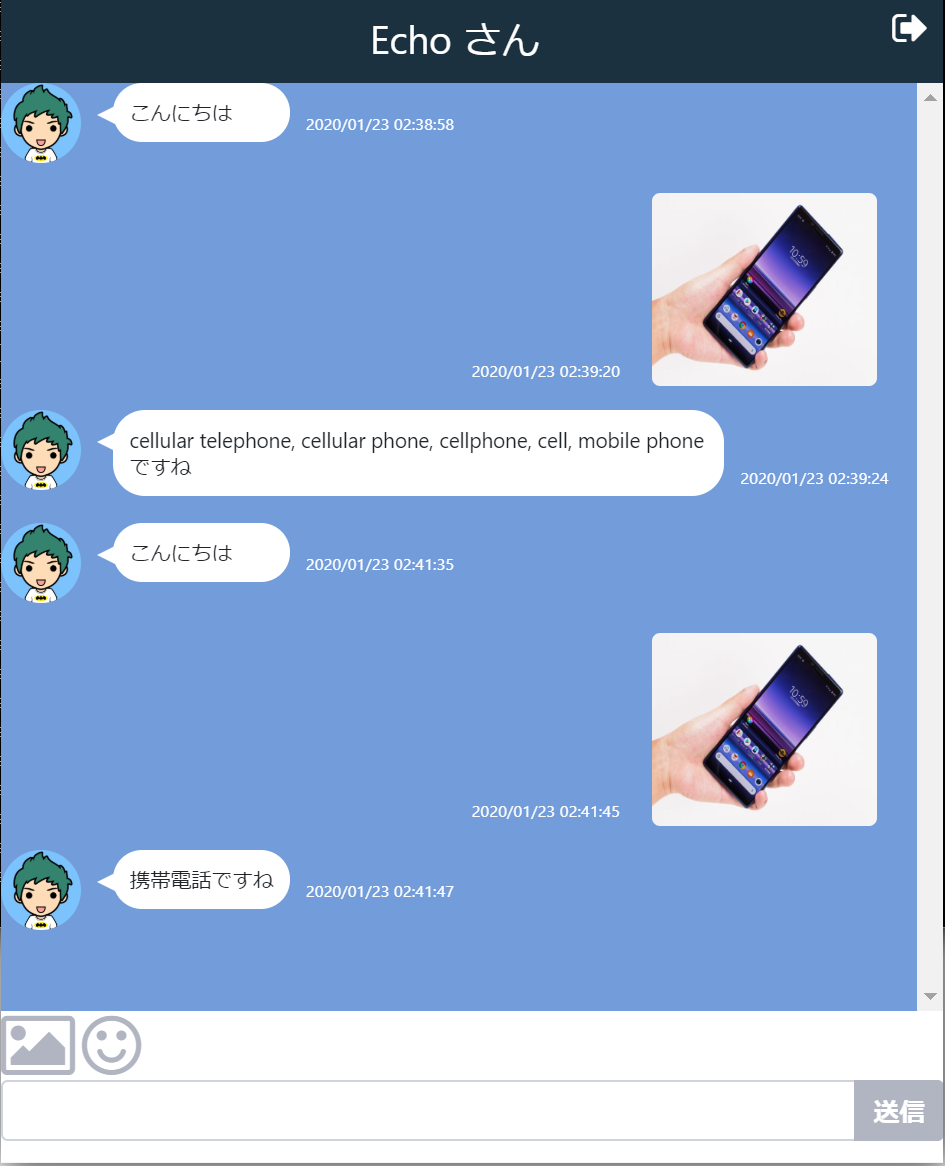
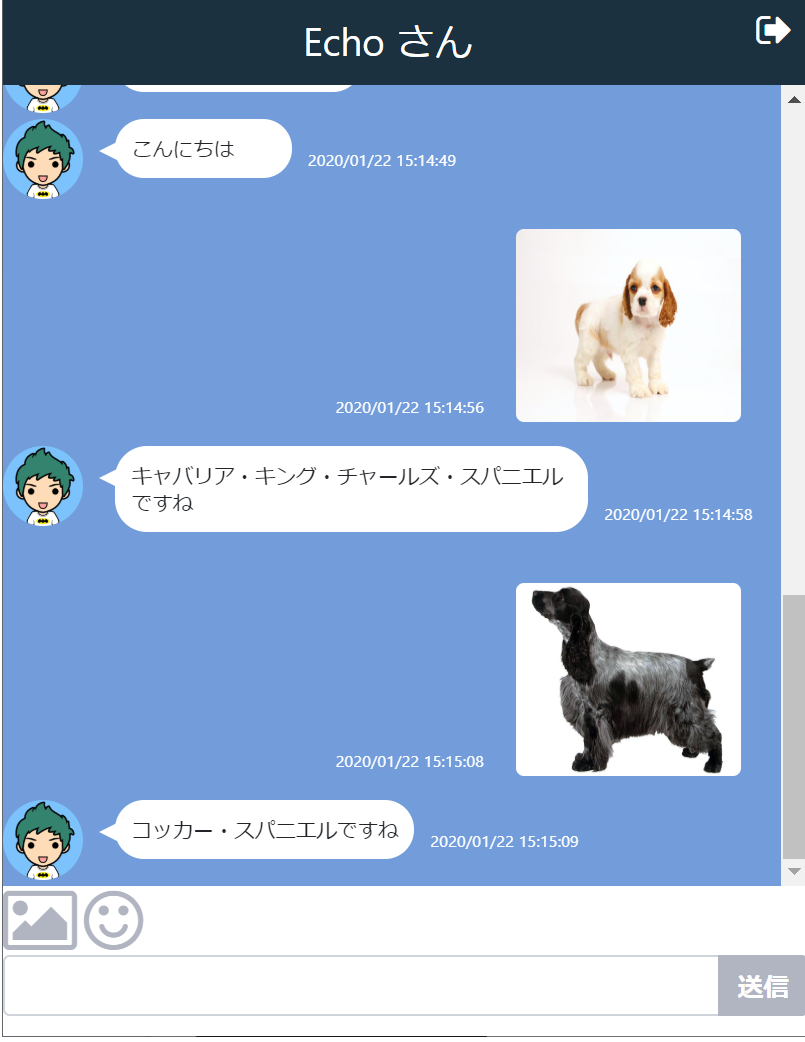
友達選択からEchoさんを選択し、画像を送ると1000個の分類から識別してくれます。
このように識別してくれていますが、分類名称が英語ですので、これを日本語ファイルで置き換えます。日本語ファイルはいろいろなサイトを参考にして作成しました。
chatapp-shot3/imagenet_classes.jsが和訳した内容ですので、node_module/@tensorflow-modules/mobilenet/distにある英文内容と差し替えます。
差し替えたのちに npm startで再度起動すると和訳文が読み込まれます。
余談ですが、この1000分類を見ていただくとわかりますが、昆虫と魚と犬が多いなと思いました。
犬種に関してはかなりマニアックな感じがしました。
プログラム解説
実装は helper/bot.echo.jsにあります。
helper/bot.echo.js// Echoさんの処理 var db = require('../helper/db'); var Chat = db.Chat; const chatsv = require('../models/chat.service'); //tensorflow.jsの設定 var randomstring = require("randomstring"); const tf = require('@tensorflow/tfjs'); const mobilenet = require('@tensorflow-models/mobilenet'); const tfnode = require('@tensorflow/tfjs-node'); var fs = require('fs'); exports.start = function(){ // 最初の挨拶を登録 if(FrName == 'Echo') { // echo chatsv.create({ fromAddress : FrID, toAddress : MyID, message : 'こんにちは' }); // 1秒ごとに新しいメッセージを検索する botTimer = setInterval(function(){ serachNewMessages(); },1000); } }; var resentMsg =""; function serachNewMessages() { if(FrName == 'Echo') { // Echo さんの最後の発言を取得する var query = { "fromAddress": FrID ,"toAddress": MyID}; Chat.find(query,{},{sort:{timeStamp: -1},limit:1}, function(err, data){ if(err){ console.log("serachNewMessages err",err); } if(data.length > 0){ // Echoさん最後の発言以降の自分の発言を取得する. var lastMessageTime = data[0].timeStamp; query = { "fromAddress": MyID ,"toAddress": FrID,"timeStamp": {$gt : lastMessageTime}}; Chat.find(query,{},{sort:{timeStamp: -1},limit:1}, async function(err, data){ if(err){ console.log("serachNewMessages err",err); } if(data.length > 0){ var resMessage=""; // 応答メッセージの設定 if (data[0].image.length > 0) { // MobileNetの呼び出し var matches = data[0].image.match(/^data:([A-Za-z-+\/]+);base64,(.+)$/), imageBuffer = {}; imageBuffer.type = matches[1]; imageBuffer.data = new Buffer(matches[2], 'base64'); const mobilenetModel = await mobilenet.load({version: 2, alpha: 1.0}); const predictions = await mobilenetModel.classify(tfnode.node.decodeImage(imageBuffer.data)); resMessage = predictions[0].className + "ですね"; } else if (data[0].stampTitle !== undefined) { resMessage = data[0].stampTitle + "ですね"; } else if(data[0].message.length > 0){ resMessage = data[0].message + "ですね"; } else { resMessage = "無言ですね"; } // 退避メッセージと異なってれば発話する if ( resMessage !== "" && resentMsg != data[0].timeStamp + data[0].message) { resentMsg = data[0].timeStamp + data[0].message; chatsv.create({ fromAddress : FrID, toAddress : MyID, message : resMessage }); } } }); } }); } }このボットが1秒ごとにメッセージを検索し、TEXTであれば末尾に「ですね」を付け加え、スタンプであればそのファイル名を返却し、画像であればmobilenetで画像識別を行ってその結果を書き込んでいます。
コードにすればほんの数行で画像認識を行うことができます(モデルの読み込みはここでなくてもよいかもしれません)。その他にもいろいろと呼び出せるライブラリがあります。
最後に
いかがだったでしょうか。相変わらず前回から間が空いてしまいましたが、Echoさんが画像の識別をしてくれるようになり、ボットサイトを使った会話もできるようになりました。
今回はGoogleのDialogflowを利用する関係で手順がとても多くなってしまいました。Step by Stepで記載しましたが、半年後には画面も変わったりするので何時ごろまで有効かはわかりませんが、ひとまずはこの手順で動くと思います。
いずれにせよ、外部のサイトと連携したり、開発されたライブラリを活用することで、簡単に機能追加ができるのが実感できました。次回は...
次回はこの画像識別をさらにパワーアップさせて、画像のキャプションを自動生成するロジックを追加したいと思っています。
記事一覧








- 投稿日:2020-02-23T15:58:37+09:00
COTOHA でキーワードの抽出 (Node.js)
COTOHA API Portal の使用例です。
次と同じことを Node.js で行いました。
フォルダー構造
$ tree -a . ├── akai_rousoku.txt ├── .env ├── get_config.js ├── get_token.js └── key_word.jskey_word.js#! /usr/bin/node // --------------------------------------------------------------- // // key_word.js // // Feb/23/2020 // // --------------------------------------------------------------- var fs = require("fs") var get_config = require('./get_config.js') var get_token = require('./get_token.js') // --------------------------------------------------------------- function key_word_proc(config,doc) { var Client = require('node-rest-client').Client const headers={ "Content-Type": "application/json", "Authorization": "Bearer " + config.access_token } const data = { "document": doc, "type": "default" } const str_json = JSON.stringify (data) const url = config.developer_api_base + "v1/keyword" const args = { data: str_json, headers: headers } var client = new Client() client.post(url, args, function (data, response) { llx = data["result"].length console.log("llx = " + llx) for (it in data["result"]) { const unit = data["result"][it] console.log(unit['form'] + "\t" + unit['score']) } console.error ("*** 終了 ***") }) } // --------------------------------------------------------------- console.error ("*** 開始 ***") const filename=process.argv[2] console.error (filename) if (fs.existsSync(filename)) { const doc = fs.readFileSync (filename,'utf8') const config = get_config.get_config_proc() try { get_token.get_token_proc(config,doc,key_word_proc) } catch (error) { console.error ("*** error *** from get_token_proc ***") console.error (error) } } else { console.error ("*** error *** " + filename + " doesn't exist. ***") } // ---------------------------------------------------------------get_config.js get_token.js はこちら
COTOHA API で構文解析 (Node.js)実行コマンド
export NODE_PATH=/usr/lib/node_modules ./key_word.js akai_rousoku.txt
- 投稿日:2020-02-23T15:31:35+09:00
COTOHA で固有名詞の抽出 (Node.js)
COTOHA API Portal の使用例です。
次と同じことを Node.js で行いました。
フォルダー構造
$ tree -a . ├── .env ├── get_config.js ├── get_token.js └── proper_noun.jsproper_noun.js#! /usr/bin/node // --------------------------------------------------------------- // // proper_noun.js // // Feb/23/2020 // // --------------------------------------------------------------- var get_config = require('./get_config.js') var get_token = require('./get_token.js') // --------------------------------------------------------------- function proper_noun_proc(config,sentence) { var Client = require('node-rest-client').Client const headers={ "Content-Type": "application/json", "Authorization": "Bearer " + config.access_token } const data = { "sentence": sentence, "type": "default" } const url = config.developer_api_base + "v1/ne" const args = { data: data, headers: headers } var client = new Client() client.post(url, args, function (data, response) { llx = data["result"].length console.log("llx = " + llx) for (it in data["result"]) { const unit = data["result"][it] console.log(unit['form']) } console.error ("*** 終了 ***") }) } // --------------------------------------------------------------- console.error ("*** 開始 ***") const sentence = "特急はくたかで富山に向かいます。それから、金沢に行って、兼六園に行きます。" const config = get_config.get_config_proc() get_token.get_token_proc(config,sentence,proper_noun_proc) // ---------------------------------------------------------------get_config.js get_token.js はこちら
COTOHA API で構文解析 (Node.js)実行コマンド
export NODE_PATH=/usr/lib/node_modules ./proper_noun.js
- 投稿日:2020-02-23T14:56:21+09:00
COTOHA API で構文解析 (Node.js)
COTOHA API Portal の使用例です。
次と同じことを Node.js で行いました。
フォルダー構造
$ tree -a . ├── .env ├── get_config.js ├── get_token.js └── parsing.jsparsing.js#! /usr/bin/node // --------------------------------------------------------------- // // parsing.js // // Feb/23/2020 // // --------------------------------------------------------------- var get_config = require('./get_config.js') var get_token = require('./get_token.js') // --------------------------------------------------------------- function parse_proc(config,sentence) { var Client = require('node-rest-client').Client const headers={ "Content-Type": "application/json", "Authorization": "Bearer " + config.access_token } const data = { "sentence": sentence, "type": "default" } const url = config.developer_api_base + "v1/parse" const args = { data: data, headers: headers } var client = new Client() client.post(url, args, function (data, response) { for (it in data["result"]) { for (jt in data["result"][it].tokens) { const token = data["result"][it].tokens[jt] console.log (token.form + "\t" + token.pos) } } console.error ("*** 終了 ***") }) } // --------------------------------------------------------------- console.error ("*** 開始 ***") const sentence = "特急はくたか" const config = get_config.get_config_proc() get_token.get_token_proc(config,sentence,parse_proc) // ---------------------------------------------------------------get_config.js// --------------------------------------------------------------- // // get_config.js // // Feb/23/2020 // // --------------------------------------------------------------- exports.get_config_proc = function () { const dotenv = require('dotenv') dotenv.config() const config = { client_id: `${process.env.CLIENT_ID}`, client_secret: `${process.env.CLIENT_SECRET}`, developer_api_base: `${process.env.DEVELOPER_API_BASE_URL}`, access_token_publish_url: `${process.env.ACCESS_TOKEN_PUBLISH_URL}`, } return config } // ---------------------------------------------------------------get_token.js// --------------------------------------------------------------- // // get_token.js // // Feb/23/2020 // // --------------------------------------------------------------- exports.get_token_proc = function(config,sentence,callback) { var Client = require('node-rest-client').Client const data = { "grantType": "client_credentials", "clientId": config.client_id, "clientSecret": config.client_secret } const url = config.access_token_publish_url const headers={ "Content-Type": "application/json" } const args = { data: data, headers: headers } var client = new Client() client.post(url, args, function (data, response) { config['access_token'] = data.access_token callback(config,sentence) }) } // ---------------------------------------------------------------実行コマンド
export NODE_PATH=/usr/lib/node_modules ./parsing.js
- 投稿日:2020-02-23T09:46:26+09:00
花粉症対策デジタル医療相談Botの開発 ユーザーIDと位置情報をFirestoreで管理
概要
耳鼻咽喉科の開業医をしながらデジタルテクノロジーを使った医療の効率化や患者さん向けサービスの開発研究を行っています。
スギ花粉の飛散量が増えてきました。花粉症の方にはつらい季節ですね。
忙しくて医療機関を受診できなかったり、新型コロナウイルスが心配で受診を控えている方も多いのではないでしょうか?最近薬局や通販で購入できる医療用医薬品(医療機関で処方されるものと同成分)が増えてきたのはご存じでしょうか?これらの薬を上手に利用できれば医療機関を受診できなくても花粉シーズンを乗り越えることが出来るかもしれません。
上手に利用するには自分の花粉症状がどの程度重症なのかや、利用しようとする薬の特性を知っていないといけませんが、その辺を教えてくれるサービスがなかったので作成してみました。現在(2020年2月19日~3月4日)クラウドファンディングプラットフォームCAMPFIREでテスト版ユーザー募集しています。プロジェクトはサクセスしましたが、たくさんの花粉症の方に使って頂いて、サービス向上のためご意見ご感想をいただきたいと思っています。
CAMPFIREのプロジェクトページはこちら
LINEで花粉症の重症度や最適な市販薬がわかるデジタル医療相談【アレルナビ】このサービスではユーザーが特定した地点のピンポイント花粉飛散予測を返す機能があります。ユーザーから送っていただいた位置情報とLINE IDはFirestoreで管理しましたのでその辺りをまとめました。
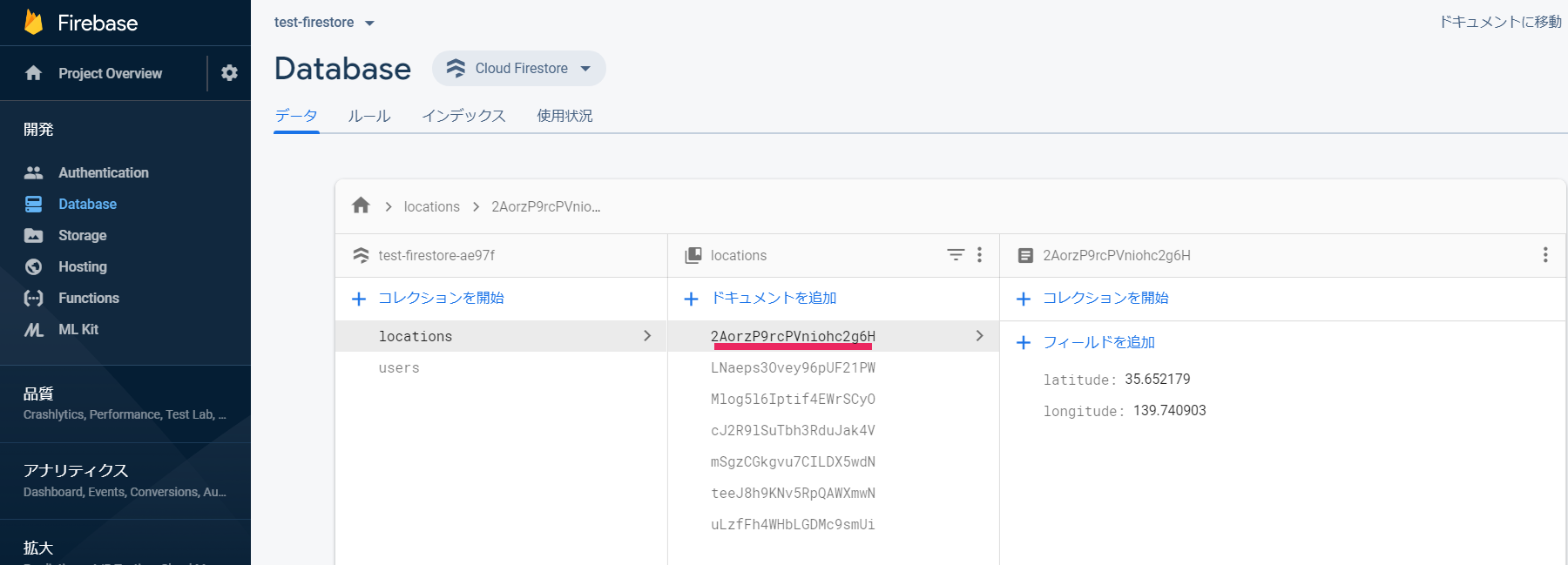
FirestoreのDatabase
・コレクションに位置情報をまとめた「locations」とLINE IDをまとめた「users」が作成されています。
・コレクション「locations」と「users」のドキュメントはユーザーがLINEを使うときに取得できるidで紐づけられています。
・コレクション「locations」のフィールドはユーザーから位置情報が送られてくるたびに更新されます(latitude緯度、longitude経度)。
・コレクション「users」のフィールドはユーザーのLINE IDが入ります。
作成方法
1. Firebaseで新規プロジェクトを作成
・Googleにログインしている状態で、Firebase公式ページの右上にある「コンソールへ移動」ボタンから、ユーザーページに移動。
・「プロジェクトを追加」から新規プロジェクトを作成。2. Firestoreを作成
・プロジェクトメインページ左のメニューバーから「Database」を選び、「データベースの作成」に進む。
・「テストモードで開始」を選択し、「有効にする」をクリックしデータベースを作成。3. Firebaseとnode.jsで開発したアプリを連携
・Firebaseのプロジェクトのメインページから、「アプリを追加」→「ウェブ」に進む。
・任意のアプリ名を入力し、「アプリを登録」をクリックし連携に必要なコードを表示する。4. Firebase SDK を追加して Firebase を初期化
こちらを参考にしました。
Firebase を JavaScript プロジェクトに追加する5. プログラム作成
ユーザーからメッセージが来たらユーザーIDが登録されているかを判定
登録されてなければFirebaseに登録let userRef = db.collection('users'); let snapshot = await userRef.where("line_user_id", "==", event.source.userId).get(); let user_id = ""; if (snapshot.empty) { user_id = await userRef.add({ line_user_id: event.source.userId }).then(ref => ref.id); } else { user_id = snapshot.docs[0].id; } console.log(user_id);位置情報が送られてきたらFirebaseの位置情報をidに紐づけて更新し
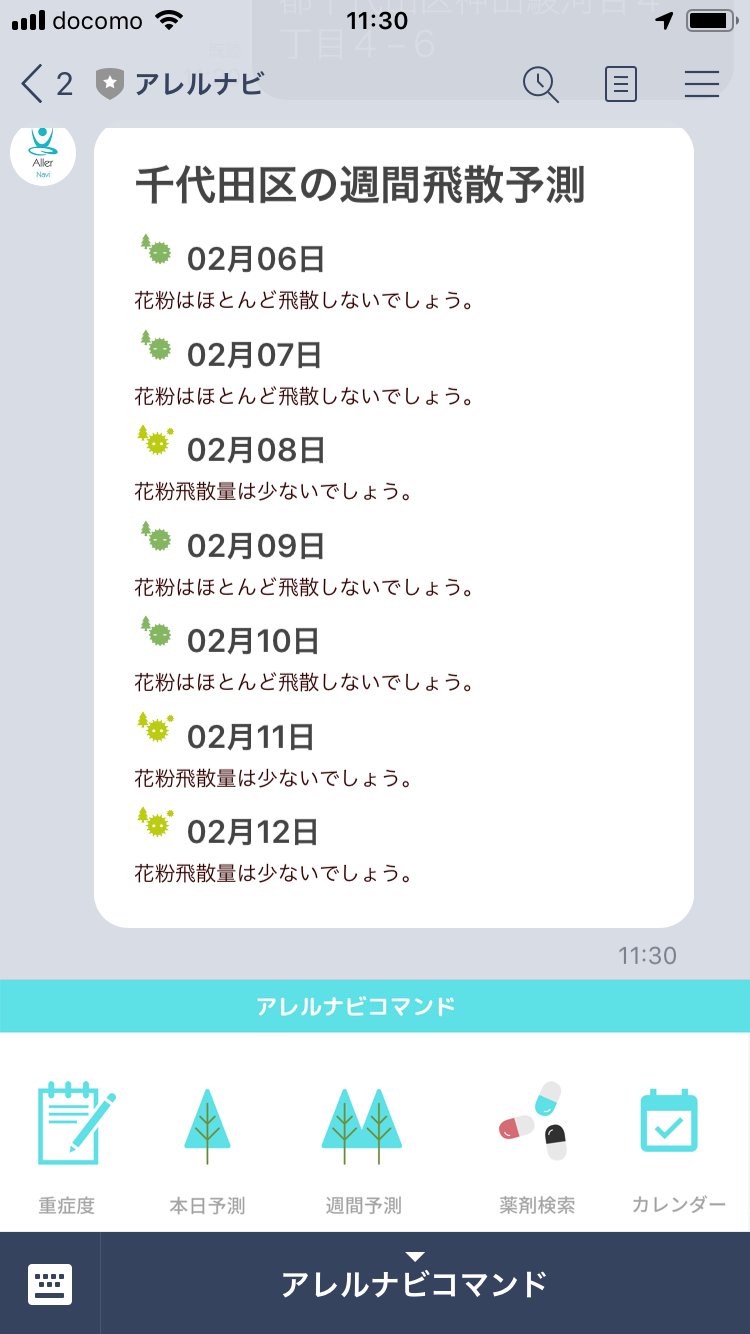
「位置情報が登録されました」をユーザーに返すif (event.message.type === "location") { client.replyMessage(event.replyToken, { type: 'text', text: "位置情報が登録されました。" }); let locationsRef = db.collection('locations').doc(user_id); let setAda = locationsRef.set({ latitude:event.message.latitude, longitude: event.message.longitude, }); return Promise.resolve(null); }完成図
ピンポイント花粉情報がユーザーに返されます
考察
最初はユーザーから送られるすべてのIDと位置情報をFirebaseに登録しif文で取得していたため、ユーザーが増えると処理に時間がかかりそうでした。idは重複がないように、位置情報は最新のものだけを登録できたのでスッキリして気持ちがよいですね。今後は内服薬やアレルギーの重症度、花粉飛散の実測値を登録・分析することによってユーザーの住んでいる場所の予測飛散量とユーザーの重症度から適切な治療薬を推奨できるようにしていきたいと思っています。