- 投稿日:2020-02-15T23:49:34+09:00
ジェネレータ
通常の関数と異なり、前回返した値を覚えているようです。
呼び出すと次の値を返します。generator.pydef counter(num=10): for _ in range(num): yield 'run' def greeting(): yield 'good morning' yield 'good afternoon' yield 'good night' for g in greeting(): print(g) g=greeting() print(next(g)) #good morning print(next(g)) #good afternoon c=counter() print(next(c)) print(next(c)) print(next(c)) print(next(c)) print(next(c)) print(next(c)) print(next(c)) print(next(c)) print(next(c)) print(next(c)) #print(next(c)) エラー出る出力:
good morning good afternoon good night good morning good afternoon run run run run run run run run run run
- 投稿日:2020-02-15T23:26:36+09:00
【はじめてのCOTOHA API】昔ばなしを要約してみた
【Qiita x COTOHA APIプレゼント企画】COTOHA APIで、テキスト解析をしてみよう! という企画を見つけたので、COTOHA APIの使い方と、実際にCOTOHA APIを使って昔ばなしを要約してみた結果をまとめました。
COTOHA APIとは
詳しくはCOTOHA APIについてを見てください。
COTOHA APIの使い方
APIを使うために必要な情報を取得しよう
COTOHA APIを使うには、APIを使うために必要な情報を取得するため、まずアカウントの登録をする必要があります。
COTOHA APIのサイトの右上にある「新規登録」ボタンを押すと、メールアドレス登録の画面に遷移します。
メールアドレス登録後に来るメールにあるURLから、アカウント登録を行います。
アカウント登録が終了したら、ログイン画面からログインします。
ログインすると、「for Developers アカウント情報」の表中に「Client ID」と「Client secret」という2つの項目があると思います。
これらがCOTOHA APIを使うために必要な情報です。Google ColaboratoryでCOTOHA APIを使おう
Colaboratory は、完全にクラウドで実行される Jupyter ノートブック環境です。設定不要で、無料でご利用になれます。
Colaboratory を使用すると、コードの記述と実行、解析の保存や共有、強力なコンピューティング リソースへのアクセスなどをブラウザからすべて無料で行えます。Google ColaboratoryはGoogleアカウントがあれば使えます。
Google Colaboratoryを開いたら、まずメニューからファイル→ノートブックを新規作成を選択し、新しいノートブックを作成します。
次に、こちらの記事からコードをコピペしましょう。
以下の部分のみ、先ほどログインした際に表示された自分の「Client ID」と「Client secret」に置き換えてください。
client_id = "クライアントID" client_secret = "クライアントシークレット"コードをコピペしたら、▷ボタンを押すとコードが実行されます。
コードを追加したい場合は、「+コード」を押します。
昔ばなしの要約
せっかくなので、COTOHA APIのうち要約APIを使って昔ばなしをいろいろ要約してみました。
要約APIは、入力として日本語で記述された複数文で構成された文章を受け取り、これを文単位で重要度を算出し、スコアを付与します。そして、入力時に指定された要約文数に応じ、重要文を返します。
本APIはベータ版として提供させていただきます。
https://api.ce-cotoha.com/contents/reference/apireference.html昔ばなしの本文は以下のサイトからお借りしました。
http://hukumusume.com/douwa/pc/jap/index.htmlプログラムコードは以下です。
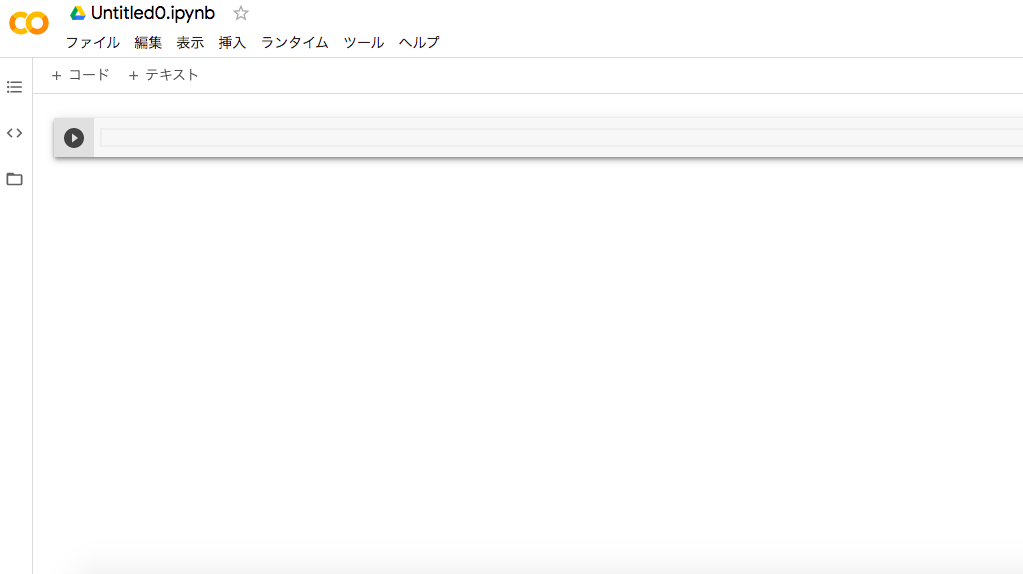
cotoha_call("summary", "むかしむかし、あるところに、おじいさんとおばあさんが住んでいました。〜〜〜")桃太郎
「桃太郎さん、桃太郎さん。どちらへおいでになりますか?」
「鬼ヶ島へ、鬼退治に行くのさ」
「それでは、わたしもお供させてください」
「よし、わかった。それでは日本一のキビ団子をやるからついて来い」
こうして犬はキビ団子を一つもらって、桃太郎のお供に加わりました。金太郎
金太郎の友だちは、山の動物たちです。
動物たちの中には、体の大きなクマやウシやウマやシカもいましたが、金太郎にかないません。
「つな引きも、金太郎の勝ち!」
なんとも大変力持ちの金太郎ですが、強いだけでなく、とてもやさしい男の子です。浦島太郎
どうぞ、ゆっくりしていってくださいね」
浦島さんは、竜宮の広間ヘ案内されました。
「そう言えば、乙姫さまは言っていたな。この玉手箱を開けると、『時』が戻ってしまうと。一寸法師
二人には子どもがいなかったので、おじいさんとおばあさんは神さまにお願いしました。
これには、鬼もまいりました。
「わたしの背がのびるように『背出ろ、背出ろ』と、そう言ってふってください」お姫さまは喜んで、打ち出の小づちをふりました。鶴の恩返し
何て良く気のつく優しい娘さんじゃ。
すると娘はまた、機をおり始めました。
「ねえ、おじいさん。カチカチ山
「おじいさん、どうしたのです?」
「タヌキが、タヌキのやつが、ばあさんをこんなにして、逃げてしまったんだ」
「ああ、あの悪いタヌキですね。
「タヌキくん。舟をつくったから、海へ釣りに行こう」
「それはいいな。花咲かじいさん
おめえのシロを、わしに貸してくれや」
欲張りじいさんは、シロを無理矢理畑に連れて行きました。
しかし出てくるのは石ころばかりで、宝物は出てきません。
「枯れ木に花を咲かせましょう。かぐや姫
えい!・・・うん?これは!」おじいさんがその竹を切ってみると、なんと中には小さな女の子がいたのです。
中でも特に熱心な若者が、五人いました。これ以上のむこさんはない」
お嫁にいくつもりのないかぐやひめは、何とか断ろうと思いましたが、みかどに逆らえば殺されてしまうかもしれません。ネズミの嫁入り
わしを隠してしまうからな」
そこで父さんネズミと母さんネズミは、雲のところへ行ってみました。
チューコをお嫁にもらってくれませんか?」
「そりゃうれしいが、風はわしより強いぞ。
「世界一強い壁さん。まとめ
何となくですが、要約になっているのではないでしょうか。
要約についてはまだベータ版ということなので、正式版に期待ですね。

- 投稿日:2020-02-15T23:18:19+09:00
Numpy入門
1. Numpy 基礎
1.1. numpy.ndarray 基礎
1.1.1. numpy.ndarray 属性要素
numpy.ndarray 属性要素 取得内容 Example 1
np.array([[1,0,0],[0,1,2]])ndim 次元数 2 shape 配列の形 (2,3) size 配列要素の数 6 dtype 配列要素のデータ型 int32 T 転置配列 np.array([[1 0]
[0 1]
[0 2]])flags メモリーレイアウト flat 一次元化(平坦化)した配列生成
配列定義例:np.array(配列変数.flat)imag 配列要素の虚部値配列 real 配列要素の実部値配列 itemsize 配列要素の大きさ(バイト)
例:int32 -> 32/8 = 4バイト4 nbytes 配列の大きさ(バイト) 32 strides 隣する配列要素のずれ(バイト) (12,4)
縦方向:12バイト
-> 4バイト * 3要素(横方向)
横方向:4バイト
-> 4バイト * 1要素ctypes ctypesモジュールで使用 base 参照先の配列 None Example_1.py### ライブラリ定義 import numpy as np ### 関数定義 def print_attribute(input): print("") for key, value in input.items(): print(">>> " + str(key)) print("IN: print("+str(key)+")") print("OUT: "+str(value)) print("") ### 配列定義 array = np.array( [[1,0,0],[0,1,2]]) ### numpy.ndarray要素定義 attribute ={} attribute['array.ndim'] = array.ndim attribute['array.shape'] = array.shape attribute['array.size'] = array.size attribute['array.dtype'] = array.dtype attribute['array.T'] = array.T attribute['array.flags'] = array.flags attribute['array.flat'] = array.flat attribute['np.array(array.flat)'] = np.array(array.flat) attribute['array.imag'] = array.imag attribute['array.real'] = array.real attribute['array.itemsize'] = array.itemsize attribute['array.nbytes'] = array.nbytes attribute['array.strides'] = array.strides attribute['array.ctypes'] = array.ctypes attribute['array.base'] = array.base ### numpy.ndarray要素取得例 print_attribute(attribute) """ >>> array.ndim IN: print(array.ndim) OUT: 2 >>> array.shape IN: print(array.shape) OUT: (2, 3) >>> array.size IN: print(array.size) OUT: 6 >>> array.dtype IN: print(array.dtype) OUT: int32 >>> array.T IN: print(array.T) OUT: [[1 0] [0 1] [0 2]] >>> array.flags IN: print(array.flags) OUT: C_CONTIGUOUS : True F_CONTIGUOUS : False OWNDATA : True WRITEABLE : True ALIGNED : True WRITEBACKIFCOPY : False UPDATEIFCOPY : False >>> array.flat IN: print(array.flat) OUT: <numpy.flatiter object at 0x000001E00DB70A00> >>> np.array(array.flat) IN: print(np.array(array.flat)) OUT: [1 0 0 0 1 2] >>> array.imag IN: print(array.imag) OUT: [[0 0 0] [0 0 0]] >>> array.real IN: print(array.real) OUT: [[1 0 0] [0 1 2]] >>> array.itemsize IN: print(array.itemsize) OUT: 4 >>> array.nbytes IN: print(array.nbytes) OUT: 24 >>> array.strides IN: print(array.strides) OUT: (12, 4) >>> array.ctypes IN: print(array.ctypes) OUT: <numpy.core._internal._ctypes object at 0x000001E00D84BC50> >>> array.base IN: print(array.base) OUT: None """参考文献
- 投稿日:2020-02-15T23:14:29+09:00
PySimpleGUIでVBAの代わりになるUIをつくってみる(ダイアログ、リスト、ログの出力)
この記事を読んでできるもの
PySimpleGUIを使用して、ファイル、フォルダをダイアログを使ってファイルを取得、
取得したファイルを使用して処理を実行、ログを画面にすることができます概要
脱VBAとしてPythonを使用している記事や本がちらほらあり、Excelファイルの操作にOpenPyXl を使用している記事はありますが、ファイルの起動に関してはCLIのものがほとんどでGUIで操作する記事はあまり見かけません。
今回はVBAのGUI相当のものをPySimpleGUIで行う説明を行います。
PySimpleGUIの基本的な操作についてはTkinterを使うのであればPySimpleGUIを使ってみたらという話を参考にしてください。例えばエクセルで複数ファイルを読み込んで1ファイルにまとめる操作を行う場合には以下の動作および表示が必要かとと思います。
- ファイルを複数選択して読み込む
- 選択したファイル一覧を表示
- オプションの選択
- 実行
- 実行結果のログ出力
コードにすると以下の内容になります。なお今回はエクセル操作の機能は載せていません。
あくまでもGUI部分の説目のみになります。# https://pysimplegui.trinket.io/demo-programs#/multiple-windows/multiple-window-2-window-basic-design-pattern import PySimpleGUI as sg import pathlib from os.path import basename frame1 = [[sg.Radio('1ファイルにシートごとにまとめる',1, key='-MULTI-SHEET-', default=True)], [sg.Radio('1ファイル1シートにまとめる', 1, key='-ONE-SHEET-')]] col1 = [[sg.Button('実行')], [sg.Button('終了')]] layout = [ [sg.Text('ファイル選択', size=(15, 1), justification='right'), sg.InputText('ファイル一覧',enable_events=True,), sg.FilesBrowse('ファイルを追加', key='-FILES-', file_types=(("Excell ファイル", "*.xlsx"),))], [sg.Button('ログをコピー'), sg.Button('ログをクリア')], [sg.Output(size=(100,5), key='-MULTILINE-'),], [sg.Button('入力一覧をクリア')], [sg.Listbox([], size=(100, 10), enable_events=True, key='-LIST-')], [sg.Frame('処理内容', frame1), sg.Column(col1)] ] window = sg.Window('エクセルの結合', layout) new_files = [] new_file_names = [] while True: # Event Loop event, values = window.read() #print(event, values) if event in (None, '終了'): break if event == '実行': print('処理を実行') # print('values = ', values) print('処理対象ファイル:', new_files) # log_text = log_text + '処理対象ファイル:' + new_files + '\n' # ラジオボタンの値によって処理が変わる if values['-MULTI-SHEET-']: print('複数シートを1ファイルにまとめる') elif values['-ONE-SHEET-']: print('複数シートを1シートにまとめる') # ポップアップ sg.popup('処理が正常終了しました') elif event == 'ログをクリア': print('ログをクリア') window.FindElement('-MULTILINE-').Update('') elif event == 'ログをコピー': window.FindElement('-MULTILINE-').Widget.clipboard_append( window.FindElement('-MULTILINE-').Get()) sg.popup('ログをコピーしました') elif event == '入力一覧をクリア': print('入力一覧をクリア') new_files.clear() new_file_names.clear() window['-LIST-'].update('') elif values['-FILES-'] != '' : print('FilesBrowse') # TODO:実運用には同一ファイルかどうかの処理が必要 new_files.extend(values['-FILES-'].split(';')) new_file_names.extend([basename(file_path) for file_path in new_files]) print('ファイルを追加') window['-LIST-'].update(new_file_names) # リストボックスに表示します window.close()以下それぞれの機能のついての紹介です
ファイルを複数選択して読み込む
PySimpleGUIでファイルを指定するには以下の3つのボタン(メソッド)があります。
- FolderBrowse()
- フォルダを読み込み
- FileBrowse()
- ファイルを一つ読み込む
- FilesBrowse()
- 複数ファイルを一つ読み込む
動作的には、レイアウトに追加するとボタンが表示される、クリックするとダイアログが表示される、ダイアログ内で選択したファイルが表示されます。
選択したファイルは絶対パスで取得できます。以下コードの例です。なお今回のコードは公式のVisual Basic Mockupを参考に機能追加を加えています。
import PySimpleGUI as sg sg.InputText('ファイル一覧',enable_events=True,), sg.FilesBrowse('ファイルを追加', key='-FILES-', file_types=(("Excell ファイル", "*.xlsx"),))],
FilesBrowseで複数ファイルを取得した場合は、値は「ファイル1の絶対パス;ファイルの絶対パス;」となっています。values['-FILES-'].split(';'))というようにするとファイルを分割して取得できますドラッグ&dドロップについて
Pythonに付属しているtkinterにはドラッグ&ドロップの機能は標準ではついていません。
自分で拡張機能をインストールするとできるようになるようです。PySimpleGUIはtkinterのラッパーですのでドラッグ&ドロップの機能はないです。
ただPythonの3.9のドキュメントを見ると以下のページがあるので次期バージョンの3.9では
Python付属のtkinterでもドラッグ&ドロップができるようになってPySimpleGUIでドラッグ&ドロップが機能追加されるようになるかもしれません選択したファイル一覧を表示
選択したファイルを一覧表示するのに、今回はリストボックスを使って表示します。 PySimpleGUIでは
Listbox()を使って表示します。[sg.Listbox([], size=(100, 10), enable_events=True, key='-LIST-')],入力された内容をリストボックスにするには
windowクラスのupdate()メソッドを使いっ更新を行いますwindow['-LIST-'].update(new_file_names) # リストボックスに表示しますオプションの選択
オプションの選択にはラジオボタンを使って実装しています。
frame1 = [[sg.Radio('1ファイルにシートごとにまとめる',1, key='-MULTI-SHEET-', default=True)], [sg.Radio('1ファイル1シートにまとめる', 1, key='-ONE-SHEET-')]]実行時にラジオボタンのどの値が選択されているかは
keyに設定してる値がTrueかどうかで判定しています。if values['-MULTI-SHEET-']: print('複数シートを1ファイルにまとめる') elif values['-ONE-SHEET-']: print('複数シートを1シートにまとめる')実行結果のログ出力
画面に実行内容を表示するには
Output()エレメントを使います。これを配置するとprint()で記載した内容が出力されます[sg.Output(size=(100,5), key='-MULTILINE-'),],クリップボードにコピー
クリップボード関連はtkinterの以下のメソッドを使用します
widget.clipboard_get()
- クリップボードに格納している値を取得します。
widget.clipboard_clear()
- クリップボードの内容を削除します。
widget.clipboard_append()
- クリップボードに値を追加します。
今回は
clipboard_appendを使ってOutput()に出力されたログの値をコピーします。window.FindElement('-MULTILINE-').Widget.clipboard_append( window.FindElement('-MULTILINE-').Get())まとめ
PySimpleGUIでVBA相当のGUIを作る方法を紹介してみました。
ファイルをダイアログを開いて選択する。選択したファイルに処理を行うことができるGUIは応用が利くかと思います。
- 投稿日:2020-02-15T23:10:41+09:00
ChromebookのcrostiniでPython3のrequestsとBeautifulSoupを使う時の設定
はじめに
以前、Python3でスクレイピングしてみた(Python3とBeautifulSoup使って図書館で借りた本をスクレイピング - Qiita)けど、環境変わってもう一度試してみたら動かなかった。設定変更したら動いたので、その時のメモを残す。
環境構築
Google Chrome OS Version 80.0.3987.89 (Official Build) beta (64-bit)$ python3 --version Python 3.5.3 $ sudo apt-get install python3-pip $ pip3 --version pip 9.0.1 from /usr/lib/python3/dist-packages (python 3.5) $ sudo apt-get install python3-bs4 $ sudo apt-get install python3-requests $ pip3 list beautifulsoup4 (4.5.3) requests (2.12.4)参考にしたサイト↓
Python3.4以降のrequests対応 - Qiita試したこと
普通に実行するとエラーがでる。
$ python3 scrape.py request Traceback (most recent call last): File "/usr/lib/python3/dist-packages/urllib3/util/ssl_.py", line 308, in ssl_wrap_socket context.load_verify_locations(ca_certs, ca_cert_dir) ssl.SSLError: unknown error (_ssl.c:3172) (省略)検索したら、このサイトがヒットした。
Python requests library can't make HTTPS connections (was: Apache certbot error) - Help - Let's Encrypt Community Supportここに書かれてる
Solved by:に書かれてるコマンドを試してみた。$ cat /etc/ssl/certs/ca-certificates.crt $ sudo update-ca-certificates Updating certificates in /etc/ssl/certs... 0 added, 0 removed; done. Running hooks in /etc/ca-certificates/update.d... done. done. $ cat /etc/ssl/certs/ca-certificates.crt -----BEGIN CERTIFICATE----- (省略) -----END CERTIFICATE-----このあと、実行しなおしたらうまくいった。
CAの証明書が入ってなかったみたい。
公開鍵的なもの?
自分で仮想環境とか立ち上げるとデフォルト入ってないっぽい。しらんかった。ここらへん苦手。とりあえず、動いてよかった。参考サイト↓
Ubuntu では ca-certificates パッケージで CA 証明書をインストールできるぞ - ひだまりソケットは壊れない
認証局 (CA:Certification Authority)とは?|GMOグローバルサイン【公式】
- 投稿日:2020-02-15T23:03:51+09:00
python初心者がIT企業にインターンしてみた[3日目 雲行きが・・・]
昨日疲れすぎて投稿できんやったから今日投稿する
衝撃の事実
今日も元気よく出勤。今日の昼飯は俺の好きなカレーパンだ。なんて呟いているおじさんを横目に、コーヒーを購入(俺かと思ったか)。
それはさておき、いつも通り朝の打ち合わせがあったが、そこでまさかの事実を聞かされる。「来週までに企画提案書を提出してね。あとその企画をクライアントにプレゼンしてもらうからよろしく。」
What a fork!!!(good placeより引用)AIをつかったチャットボット 開発?
打ち合わせで企画をプレゼンすることになったのだが、その内容はAIを使ったチャットボット。それを聞かされて一日が始まったわけだが、何もわからないためまずチャットボットサービスの比較表を作った。会社にデータがあるため載せられないけど、軽く紹介しよう。
チャットボットとは?
チャットボットは人間が入力するテキストや音声に対して、自動的に回答を行うことで、これまで人間が対応していた「お問い合わせ対応」「注文対応」などの作業を代行することができる。(まるまるコピー)
https://ferret-plus.com/8998 チャットボット とはチャットボット の中にも色々タイプが分かれていて、
選択肢タイプ
ログタイプ
ハッシュタイプ
Elizaタイプここの説明は先にはったリンクを参照してくれ。
クライアントの抱える問題は社内のお問い合わせ問題である。例えば、「エクセルの使い方わかりません」「なぜこの会社のトイレットペーパーはシングルなんですか?」などのしょうもない質問をいちいち管理部が聞いてられないという問題だ。そこで、チャットボット ですべて解決してもらいたいとのこと。いつかは人件費も削減したいしうちの会社もそろそろAIを導入じゃ的な?
しかし、この問題インターン生に解決させる?聞くところによるとIT企業ではあるものの、まだAIに手を出した人はいないらしく、どうせできないんだったらインターン生に投げてみようぜ的なやーつーである。
これで来週までに企画書だと?笑かしよるわ、俺にできないことなどナーーーイ(完全にバカ)。
なんやかんやで承諾した俺は今日土曜日に、プログラミングメンターサイトに面談を予約して相談してみた。scalaとpython またはGoとpython
私が予約したのは、チャットボット(AI)の開発経験のある方であった。なにいっているかわからなかったところが多いので、メモったキーワードだけ書いておく。
フルスクラッチ
gcp dialog flow
Go
scala
python
UX的
全言語検索
全文章をベクトル化
モデルに学習させる
テキストをグルーピングてな感じである。
まあ明日はこのキーワードをつかってめちゃくちゃ調べて勉強しようかなと思う。
終わりに
毎日1時間の英会話(友達のネパール人と無料で)して30分メンターさんと面談して、いろんな人と会うために動き回っていると睡眠は気絶するようにねむることができる。毎日疲れるが、人生で一番充実していてとても楽しい。このように忙しくなれたのは、人と出会いまくって得ることができた機会である。皆さんにも人と出会いまくっていろんな体験ができるよう願っております。
2日目の乱雑でごめんな
- 投稿日:2020-02-15T22:00:57+09:00
QB-TTSの開発
序
”そうだ、QB-TTSをつくろう”
すべてはここから始まる
2つ目のTTS開発が上手くいかず、
やはり、ノイズがあると駄目なのか
なんて思いながら、どうしようかと明け暮れたある日
お得意の思い付きで、新しいプロジェクトが立ち上がった特徴的な声で、かつ、大多数の知る人の声をTTSにすれば、
使いたいと思う人も増えるのではとか
よく知ったアニメキャラを自由に話せるようになるのは、
とても面白いとか
いろんな打算を加味してプロジェクトはスタートした※以下は、プロジェクト進行とともにやってることを書きたいときに追記していく
素材を入手する
当然だが、アニメから抽出しようにも、
それができないことは、先のTTS開発で学んだ
ノイズが比較的少なかったあれでさえ駄目なのだから、
まどマギのQBは無理に決まっている
見直してみても、BGMに音声が重なっているところが多く、
満足いくクオリティを出すにはまず無理だろうなと思ったというわけで、
適当なマッチングサイトで物真似読み上げを依頼、募集して、
めちゃ似てる人に依頼をお願いした
PC1台買えるくらいの出費は覚悟の事データセット構築
音声素材は現在で11分ほどのデータを貰っている
これは依頼によって手に入れたデータであって、
そのままでは、学習するには全く使えないので加工をする素材
11分のデータとはいえ、
実音声区間はおそらく半分くらいの5分ほどだと思うここから学習に使えるようにデータを加工していく
見積もって1週間から2週間は(下手すればもっと)かかるとみている
(平日は仕事のためほぼやらない)
(土日のやる気がそれなりにある時に数時間通してする)また、追加で依頼もだしており、
生データは20分を超える見通し
TOA-TTSのサンプルデータの倍ほどの量での学習となるデータセット構築の前処理
音声素材を分割と処理
分割
頂いた音声素材が1ファイルにセリフがまとまっていたため、
セリフ分割をする
1文章で1ファイルごとに分ける
前後の余白(無音区間)の長さは気にしない処理
ここでついでに簡単な音声処理をする
音声素材にする関係上、音圧にはこだわって依頼をだした
結果として、素材となる音声は十分こちらの要件を満たしていたが、
少し音が小さいのと、偏りがみえたため、これを修正する
また、息継ぎ音も無音声で上書きをし、デノイズを徹底する
息継ぎは息継ぎで学習するのもあり
おそらくできる~加工前処理 約6時間経過~
~現在進行追記中~

- 投稿日:2020-02-15T21:44:24+09:00
C++ で Python の YOLOv3を実行 on Visual Studio 2017
背景
前回の記事でC++でPythonのコードを実行する環境作りをまとめました。
C++ で Python を実行 on Visual Studio 2017
この記事だけだと、C++でPythonを呼ぶありがたみが分からないと思います。
そこで深層学習で物体検出できるYOLOv3を実行したいと思います。
C++でも深層学習モデルを使用できますが、現状のPythonには及ばないです(泣)。開発環境
・OS : windos10 64bit
・CPU : Intel i3-8100
・GPU : NVIDIA GeForce GTX 1050 Ti
・Visual Studio 2017
・C++
・Python 3.7.3
以前の記事の環境よりもスペックをあげています()。手順
前提条件として以下の二点の環境構築が必要です。
それぞれの構築ができた上で取り組ませていただきます。
・C++でPythonを呼び出す環境構築方法は以下の記事を参考にしてください。
C++ で Python を実行 on Visual Studio 2017
・PythonでGPUを使えるようにする環境構築方法は以下の記事を確認してください。
環境設定 tensorflow-gpu以下の流れで進めていきたいと思います。
良かったらご一緒にどうぞ。
以前の記事から来たかたは手順のいくつかをスキップできます。Cドライブ直下にgitファイルを展開
Cドライブ直下にファイルを展開したいと思います。
URLgit clone https://github.com/yusa0827/200121_Cplus2_with_Python方法は2です。
1. git clone が使える方がCドライブ直下で任意のフォルダを作成し、git clone してください。
2. git clone が使えない方は上記のURLに飛び、DownloadしてCドライブ直下に配置してください。
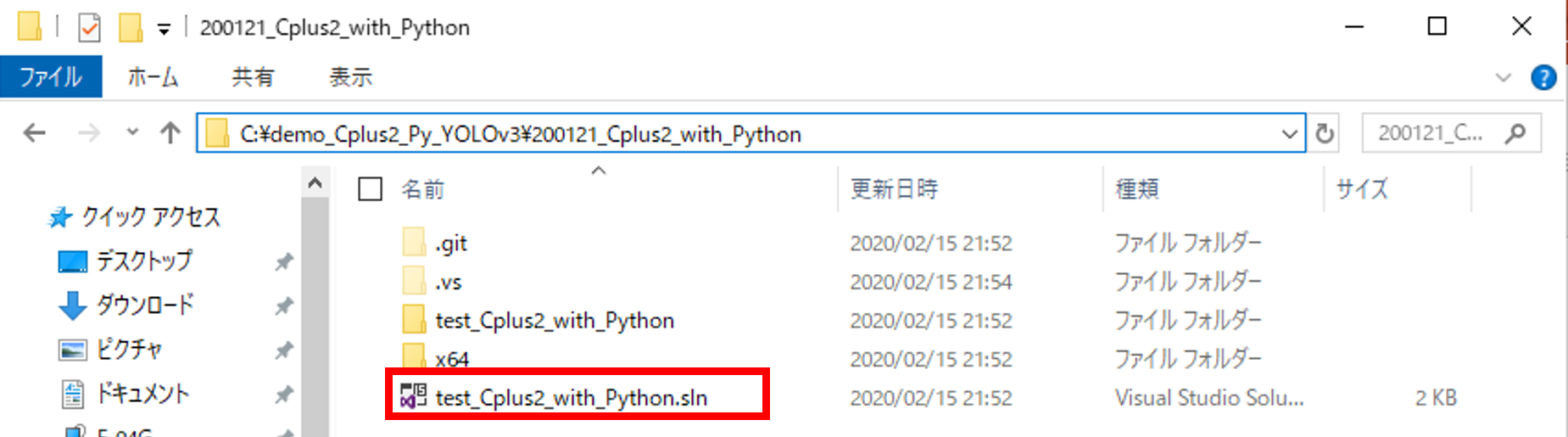
ファイル内の.slnをvisual studio 2017で起動
DLしたフォルダの中身をみると.slnファイルがあります。
.slnにサンプルプログラムが含まれているため、
こちらをダブルクリックするか、
右クリック⇒プログラムから開く⇒Microsoft Visual Studio 2017をクリック
すると、サンプルプログラムをvisual studioで起動することができます。
このプログラムはver2017で構築しています。
2019でも使えるとは思いますが、2019内で
2017のバージョンに落とさないといけないです。
サンプルプログラムの環境パスの設定
環境パスを修正する必要があります。
1. ソリューション構成とソリューションプラットホーム Debug → Release に変更 x86 → x64 2. C++ → 全般 → 追加のインクルード C:\boost_1_70_0 C:\Users\○○\AppData\Local\Programs\Python\Python37\include ↑要修正 3. C++ → コード生成 → ランタイムライブラリで マルチスレッド(/MT)に変更 4. リンカー → 全般 → 追加のライブラリディレクトリ C:\boost_1_70_0\stage\lib\x64 C:\Users\○○\AppData\Local\Programs\Python\Python37\libs ↑要修正サンプルプログラムを実行
実行結果は以下の通りになります。
うまく行かない場合は環境パスを確認してみてください。
YOLOv3の準備
YOLOv3とは深層学習を用いた物体検出手法で、特徴としてはリアルタイム性に優れていいる点です。
今回は一般的に使われているkeras版を使用します。
いろんな方が使い方を教えているので、ググれば一発なんですがあえて記載します。keras版のyolov3のインストール
URLgit clone https://github.com/qqwweee/keras-yolo3.gitそのディレクトリに進みます。(cd keras-yolov3)
Pythonの必要なモジュールとして、Tensorflow、Keras、Matplotlib、Pillow、opencv(opencv-pythonでインストール)などがあげられます。
まだpythonにインストールしていない方はpipでインストールしてください。学習済みファイルをダウンロード
wgetを使わずに、以下のURLから直接DLしても構いません。
ダウンロードしたらkeras-yolo3フォルダの中に入れてください。
ファイル名:yolov3.weights
サイズ:237MBURLwget https://pjreddie.com/media/files/yolov3.weights学習済みファイルを変換
keras版に変更します。
コマンドプロンプト上で以下のコードを入力。python convert.py yolov3.cfg yolov3.weights model_data/yolo.h5実行結果は以下の通り。
: : conv2d_75 (Conv2D) (None, None, None, 2 65535 leaky_re_lu_72[0][0] ================================================================================================== Total params: 62,001,757 Trainable params: 61,949,149 Non-trainable params: 52,608 __________________________________________________________________________________________________ None Saved Keras model to model_data/yolo.h5 Read 62001757 of 62001757.0 from Darknet weights. C:\demo_Cplus2_Py_YOLOv3\keras-yolo3>webカメラでリアルタイムでの物体検出
今回はwebカメラを使用します。
カメラではなく動画でもいいんですが、カメラのほうが検証しやすかったのでこちらを選択。物体検出するためのメインコードであるyolo.pyを簡単に編集します。173行目あたりです。
yolo.pyimport cv2 vid = cv2.VideoCapture(video_path) # ↓ 以下に修正 import cv2 #vid = cv2.VideoCapture(video_path) vid = cv2.VideoCapture(0)VideoCaptureの引数に0を与えると、カメラデバイスを選択したことになります。
コードを編集したうえでYOLOV3を実行します。YOLOv3の実行とその結果
実行コード。
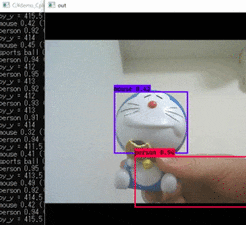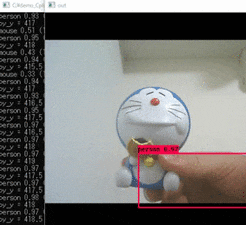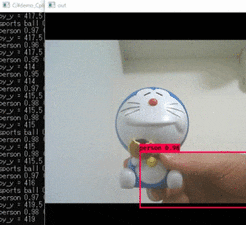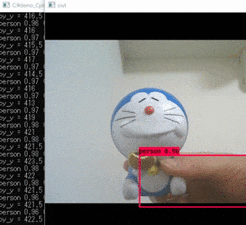
cmdpython yolo_video.py実行結果。
ドラえもんはスポーツボールらしいですね。
YOLOv3が動くかを確認できました。
続いてはC++でPyhtonのコードを引っ張ってこれるように工夫します。C++でYOLOv3を引っ張ってくる
C++からYOLOv3を呼ぶために、いくつか工夫する必要があります。
その1つとしてYOLOクラスから生成されるオブジェクトをC++上で定義することです。
本来であれば物体検出をPythonで行えばいいんですが、オブジェクトを生成しないと、物体検出時に毎回Tensoflowを呼び出さないといけないため、大きな遅延が発生します。Tensorflowを立ち上げるのに私のPCでは15秒ほどかかります。
そのため、YOLOのオブジェクトを予め生成させておくことで、毎回の呼び出しを防ぐことができます。既存のyolo.pyを修正します。
プログラムの内容
webカメラで物体検出します。
1.C++でPythonを呼ぶ
2.webカメラから得られた画像を深層学習の物体検出器YOLOv3にぶち込む
3.検出した物体の横軸(x軸)での中心軸を求め、C++に返す
4.C++でPythonから返された中心軸を出力
webカメラがない方は、yolo.pyのcv2.VideoCapture("動画パス")を指定すると対応できます。ファイル構成
git cloneしたvisul stusioファイルとkeras-yolo3ファイルを準備します。
visul stusioファイルにkeras-yolo3ファイルの中でも物体検出に必要なファイルのみをコピーします。
構成は以下の通りです。
〇を付けたファイルを修正します。またCドライブ直下にYOLOv3に必要なファイルを配置しました。Cドライブ ── model_data │ ├── yolo.h5 ← keras-yolo3のmodel_dataフォルダ内に存在 │ ├── yolo_anchors.txt ← keras-yolo3のmodel_dataフォルダ内に存在 │ ├── coco_classes.txt ← keras-yolo3のmodel_dataフォルダ内に存在 │ └── FiraMono-Medium.otf ← keras-yolo3のfontフォルダ内に存在 │ └─ 200121_Cplus2_with_Python ├── test_Cplus2_with_Python │ ├── test_Cplus2_with_Python.cpp 〇 │ ├── x64 │ └── others ├── x64 │ └── Release │ ├── test_Cplus2_with_Python.exe │ ├── yolo3 ← keras-yolo3のフォルダ内に存在 │ ├── yolo.py 〇 ← keras-yolo3のフォルダ内に存在 │ └── others ├── (others( .git .vs)) └── test_Cplus2_with_Python.slnメインコードの修正
ファイル構成に二個の〇が付いています。
それぞれC++とPythonのメインコード部分にあたります。
それぞれを以下のように修正します。C++のメインコード
以前の記事に修正を加えました。
Pythonのpyファイル、pyファイルの関数、オブジェクトなどそれぞれを定義しています。
基本的にはauto型でC++に決めてもらうことにしています。
whileで回す前に、予めYOLOのオブジェクトを定義しています。
whileの中では、Pytohnの物体検出関数を実行するのみ。
他にオリジナルの処理を加えたい場合には、適当な場所にコードを挿入してください。test_Cplus2_with_Python.cpp#define BOOST_PYTHON_STATIC_LIB #define BOOST_NUMPY_STATIC_LIB #include <iostream> #include <boost/python.hpp> //名前空間を定義 namespace py = boost::python; /* YOLOv3をC++で実行 */ int main() { //Pythonを初期化 Py_Initialize(); //YOLOv3のpyファイル(yolo.py)をインポート py::object YOLOv3 = py::import("yolo").attr("__dict__"); //yolo.py内の "object_YOLOv3" 関数を定義 auto object_YOLOv3 = YOLOv3["object_YOLOv3"]; //object_YOLOv3関数内でオブジェクト変数を定義 py::object object_YOLOv3_init; //object_YOLOv3関数内でオブジェクト変数を初期化 auto object_YOLOv3_maker = object_YOLOv3(object_YOLOv3_init); //物体検出の関数を定義 auto insert_object_YOLOv3 = YOLOv3["insert_object_YOLOv3"]; //観測値 double py_y; /* リアルタイムでのYOLOv3による物体検出 */ while (true) { //深層学習による物体検出した中心のx軸変位 auto x_centor = insert_object_YOLOv3(object_YOLOv3_maker); //変位をC++で使える型に変換 py_y = py::extract<double>(x_centor); /* 他に処理したい場合は適当に記述 */ //コメント std::cout << "py_y = " << py_y << std::endl; } }Pythonのメインコード
webカメラから画像を取得するため、YOLOクラスの初期化(init)にwebカメラをオープンしたオブジェクトを定義しています。
他にも物体検出した横軸の中心を計算し、returnさせています。
また「1_オブジェクトの初期化のための関数」と「2_物体検出のための関数」を新たに書き加えています。yolo.py# -*- coding: utf-8 -*- """ Class definition of YOLO_v3 style detection model on image and video """ import colorsys import os from timeit import default_timer as timer import numpy as np from keras import backend as K from keras.models import load_model from keras.layers import Input from PIL import Image, ImageFont, ImageDraw from yolo3.model import yolo_eval, yolo_body, tiny_yolo_body from yolo3.utils import letterbox_image import os from keras.utils import multi_gpu_model #追加 import cv2 #追加 TensorFlowのGPUメモリ使用量の制限 import tensorflow as tf from keras.backend.tensorflow_backend import set_session config = tf.ConfigProto() config.gpu_options.per_process_gpu_memory_fraction = 0.3 set_session(tf.Session(config=config)) #追加 グローバル変数を定義 model_path_ = 'C:/model_data/yolo.h5' anchors_path_ = 'C:/model_data/yolo_anchors.txt' classes_path_ = 'C:/model_data/coco_classes.txt' font_path_ = 'C:/model_data/FiraMono-Medium.otf' class YOLO(object): _defaults = { "model_path": model_path_,#変更点 "anchors_path": anchors_path_,#変更点 "classes_path": classes_path_,#変更点 "score" : 0.3, "iou" : 0.45, "model_image_size" : (416, 416), "gpu_num" : 1, } @classmethod def get_defaults(cls, n): if n in cls._defaults: return cls._defaults[n] else: return "Unrecognized attribute name '" + n + "'" def __init__(self, **kwargs): self.__dict__.update(self._defaults) # set up default values self.__dict__.update(kwargs) # and update with user overrides self.class_names = self._get_class() self.anchors = self._get_anchors() self.sess = K.get_session() self.boxes, self.scores, self.classes = self.generate() #追加 カメラをオープン self.cap = cv2.VideoCapture(0) def _get_class(self): classes_path = os.path.expanduser(self.classes_path) with open(classes_path) as f: class_names = f.readlines() class_names = [c.strip() for c in class_names] return class_names def _get_anchors(self): anchors_path = os.path.expanduser(self.anchors_path) with open(anchors_path) as f: anchors = f.readline() anchors = [float(x) for x in anchors.split(',')] return np.array(anchors).reshape(-1, 2) def generate(self): model_path = os.path.expanduser(self.model_path) assert model_path.endswith('.h5'), 'Keras model or weights must be a .h5 file.' # Load model, or construct model and load weights. num_anchors = len(self.anchors) num_classes = len(self.class_names) is_tiny_version = num_anchors==6 # default setting try: self.yolo_model = load_model(model_path, compile=False) except: self.yolo_model = tiny_yolo_body(Input(shape=(None,None,3)), num_anchors//2, num_classes) \ if is_tiny_version else yolo_body(Input(shape=(None,None,3)), num_anchors//3, num_classes) self.yolo_model.load_weights(self.model_path) # make sure model, anchors and classes match else: assert self.yolo_model.layers[-1].output_shape[-1] == \ num_anchors/len(self.yolo_model.output) * (num_classes + 5), \ 'Mismatch between model and given anchor and class sizes' print('{} model, anchors, and classes loaded.'.format(model_path)) # Generate colors for drawing bounding boxes. hsv_tuples = [(x / len(self.class_names), 1., 1.) for x in range(len(self.class_names))] self.colors = list(map(lambda x: colorsys.hsv_to_rgb(*x), hsv_tuples)) self.colors = list( map(lambda x: (int(x[0] * 255), int(x[1] * 255), int(x[2] * 255)), self.colors)) np.random.seed(10101) # Fixed seed for consistent colors across runs. np.random.shuffle(self.colors) # Shuffle colors to decorrelate adjacent classes. np.random.seed(None) # Reset seed to default. # Generate output tensor targets for filtered bounding boxes. self.input_image_shape = K.placeholder(shape=(2, )) if self.gpu_num>=2: self.yolo_model = multi_gpu_model(self.yolo_model, gpus=self.gpu_num) boxes, scores, classes = yolo_eval(self.yolo_model.output, self.anchors, len(self.class_names), self.input_image_shape, score_threshold=self.score, iou_threshold=self.iou) return boxes, scores, classes #修正 C++用に物体検出位置の修正 def detect_image_for_Cplus2(self, image): if self.model_image_size != (None, None): assert self.model_image_size[0]%32 == 0, 'Multiples of 32 required' assert self.model_image_size[1]%32 == 0, 'Multiples of 32 required' boxed_image = letterbox_image(image, tuple(reversed(self.model_image_size))) else: new_image_size = (image.width - (image.width % 32), image.height - (image.height % 32)) boxed_image = letterbox_image(image, new_image_size) image_data = np.array(boxed_image, dtype='float32') image_data /= 255. image_data = np.expand_dims(image_data, 0) # Add batch dimension. out_boxes, out_scores, out_classes = self.sess.run( [self.boxes, self.scores, self.classes], feed_dict={ self.yolo_model.input: image_data, self.input_image_shape: [image.size[1], image.size[0]], K.learning_phase(): 0 }) font = ImageFont.truetype(font=font_path_, size=np.floor(3e-2 * image.size[1] + 0.5).astype('int32')) thickness = (image.size[0] + image.size[1]) // 300 #物体のx変位 self.x_centor = .0 for i, c in reversed(list(enumerate(out_classes))): predicted_class = self.class_names[c] box = out_boxes[i] score = out_scores[i] label = '{} {:.2f}'.format(predicted_class, score) draw = ImageDraw.Draw(image) label_size = draw.textsize(label, font) #ここら辺に重心の位置がある top, left, bottom, right = box top = max(0, np.floor(top + 0.5).astype('int32')) left = max(0, np.floor(left + 0.5).astype('int32')) bottom = min(image.size[1], np.floor(bottom + 0.5).astype('int32')) right = min(image.size[0], np.floor(right + 0.5).astype('int32')) print(label, (left, top), (right, bottom)) #x軸の重心 x_centor = ( x1 + x2 ) / 2 self.x_centor = ( left + right ) / 2. if top - label_size[1] >= 0: text_origin = np.array([left, top - label_size[1]]) else: text_origin = np.array([left, top + 1]) # My kingdom for a good redistributable image drawing library. for i in range(thickness): draw.rectangle( [left + i, top + i, right - i, bottom - i], outline=self.colors[c]) draw.rectangle( [tuple(text_origin), tuple(text_origin + label_size)], fill=self.colors[c]) draw.text(text_origin, label, fill=(0, 0, 0), font=font) del draw return image, self.x_centor def close_session(self): self.sess.close() # 1_オブジェクトの初期化のための関数 def object_YOLOv3(object_YOLO): #クラスからオブジェクトを作成 object_YOLO = YOLO() #C++にyoloのオブジェクトを返す return object_YOLO # 2_物体検出のための関数 def insert_object_YOLOv3(object_YOLO): #カメラから画像を取得 ret, frame = object_YOLO.cap.read() #RGGBの順番を変更 frame = np.asarray(frame)[..., ::-1] #opnecvからpillowに変更 frame = Image.fromarray(frame) #物体検出し、出力結果と物体のx軸の中心を返す r_image, x_centor = object_YOLO.detect_image_for_Cplus2(frame) #画像表示 cv2.imshow("out",np.asarray(r_image)[..., ::-1]) #表示に1ms cv2.waitKey(1) #C++には物体のx軸の中心を返す return x_centor実行結果
学習済みモデルを使っているため、personなどと検出されています。
サンプルプログラムなので、オリジナルモデルを使用したい場合でもpyファイル内のパスを変えてあげるだけ使えます。
使用用途
どんな場合にC++でPythonを呼ばなきゃいけないんだ・・・
と悩む人もいるかと思います。
その理由として、
・C++に準拠したデバイス(モーションコントロールボードなど)のときに、どうしても深層学習処理を組み込みたいとき
・C++から離れられないくらい大好きなエンジニア(変人)
・とにかく変人
冗談はここまでで。コメント
プログラム言語間での環境依存にお悩みの方のお役に立てることを心からお祈りしています。


- 投稿日:2020-02-15T21:34:12+09:00
不均衡データ用にダウンサンプリングするメソッドを作成した
このページのアンダーサンプリングの章にあるコードを改変して、実際に動くものにしました。
# trainデータの陽性データと陰性データの数が同じになるようにするためのメソッド # 参考 : https://qiita.com/ryouta0506/items/619d9ac0d80f8c0aed92 # kmeansでクラスタにして、クラスタごとに一定の割合でサンプルする # X : pandas の DataFrame # target_column_name : クラス名。 「発症フラグ」 など。 # minority_label : 少数ラベルの値。 「1」 など。 def under_sampling(X, target_column_name, minority_label): # 毎回出るので非表示に import warnings warnings.simplefilter('ignore', pd.core.common.SettingWithCopyWarning) # majority と minority に分ける X_majority = X.query(f'{target_column_name} != {minority_label}') X_minority = X.query(f'{target_column_name} == {minority_label}') # KMeansでクラスタリング from sklearn.cluster import KMeans km = KMeans(random_state=43) km.fit(X_majority) X_majority['Cluster'] = km.predict(X_majority) # クラスタごとに何サンプル抽出するか計算 ratio = X_majority['Cluster'].value_counts() / X_majority.shape[0] n_sample_ary = (ratio * X_minority.shape[0]).astype('int64').sort_index() # クラスタごとにサンプルを抽出 dfs = [] for i, n_sample in enumerate(n_sample_ary): dfs.append(X_majority.query(f'Cluster == {i}').sample(n_sample)) # minority データも結合するようにしておく dfs.append(X_minority) # アンダーサンプリング後のデータを作成 X_new = pd.concat(dfs, sort=True) # 不要なので削除 X_new = X_new.drop('Cluster', axis=1) return X_new
- 投稿日:2020-02-15T20:46:59+09:00
プログラミングのための線形代数第4章(固有値、固有ベクトル)
いつ役立つか
自己回帰モデルが暴走するかどうか調べたい!
自己回帰モデルとは
例えば、今日の$ξ(t)$は昨日の$ξ(t-1)$、おとといの$ξ(t-2)$、さらにその前の日$ξ(t-3)$と、今日の$u(t)$から、次のように決まるとします。
$ξ(t)=-0.5ξ(t-1)+0.34ξ(t-2)+0.08ξ(t-3)+2u(t)$
これを行列で表現すると、
x(t)= \begin{pmatrix} -0.5&0.34&0.08\\ 1&0&0\\ 0&1&0 \end{pmatrix} \times x(t-1)となります。
以降、これを一般化したx(t)=Ax(t-1)を扱います。
1次元の場合
x(t)=7x(t-1)これは$t$が大きくなる度に7倍されるので、
x(t)=7^tx(0)となり、$t→∞$の時、$7^t→∞$なので暴走します。
一方で係数が$0.2$の場合は暴走しない。
これは簡単ですね。対角行列の場合
x(t)= \begin{pmatrix} 5&0&0\\ 0&-3&0\\ 0&0&0.8 \end{pmatrix} \times x(t-1)の場合、対角行列のべき乗は成分をそのままべき乗するだけでよいので、
x(t)= \begin{pmatrix} 5&0&0\\ 0&-3&0\\ 0&0&0.8 \end{pmatrix}^t x(0)と書ける。
一般化
対角行列でない行列の場合は、無理やり対角行列に変換してしまいます。
元の変数$x(t)$に対し、何か正則行列$P$を持ってきてx(t)=Py(t)で別の変数に変換する方法を考えてみましょう。
この時、$x(t)=Ax(t-1)$はどう変換されるのでしょうか?まず、$x(t)=Py(t)$を
y(t)=P^{-1}x(t)=P^{-1}Ax(t-1)\\ =P^{-1}A(Py(t-1))=(P^{-1}AP)y(t-1)$Λ=P^{-1}AP$と置くと、
y(t)=Λy(t-1)と置ける。
この$Λ$がもし対角行列なら、y(t)=Λ^ty(0)で簡単に$y(t)$が求まり、同時に
x(t)=Py(t)=PΛty(0)=PΛ^tP^{-1}x(0)でxも求まってめでたしめでたし。
この手順「都合の良い$P$を持ってきて$P^{-1}AP$を対角行列にする」ことを対角化と呼びます。
やりたいことは
P^{-1}AP≡Λ=diag(λ_1,...,λ_n)のような$P$を見つけることです。
一般に、正方行列$A$に対してAp=λp\\ p≠oを満たす数$λ$とベクトル$p$をそれぞれ固有値、固有ベクトルと呼びます。
Pythonで固有値、固有ベクトルを計算
Numpyの機能を駆使すれば簡単に計算が可能です。
次の行列で計算してみましょう。A= \begin{pmatrix} 5&3&4\\ 6&8&-8\\ 6&9&-9 \end{pmatrix}import numpy as np def get_eigenpairs(arr): #np.linalg.eigは第一引数に固有値、第二引数に固有ベクトルを出力する w, v = np.linalg.eig(arr) eigenpairs = [] #vは1に規格化されているため。このままでは良く分からない。 #そのため、各列の0を除く最小値で割り、数値を元に戻している。 for i, val in enumerate(w): vec = v[:, i] / np.min(np.abs(v[:, i][v[:, i] != 0])) eigenpairs.append((val, vec)) eigenpairs.sort(key=lambda x:x[0]) return eigenpairs A = np.array([[5,3,-4],[6,8,-8],[6,9,-9]]) get_eigenpairs(A) #array([[-1.0, array([1., 2., 3.])], # [2.0, array([-1., -3., -3.])], # [3.0, array([1., 2., 2.])]], dtype=object)固有ベクトルが3つ得られました。これらは固有値$-1, 2,3$にそれぞれ対応しています。
そこで固有ベクトルを3つ並べてP= \begin{pmatrix} 1&-1&1\\ 2&-3&2\\ 3&-3&2 \end{pmatrix}とし、$P^{-1}AP$が対角行列になるか確認してみましょう。
P = np.empty((3,3)) #3つの固有ベクトルを3×3の行列に格納 for i,val in enumerate(get_eigenpairs(a)): P[i] = val[1] np.rint(np.dot(np.dot(np.linalg.inv(P.T),a),P.T)) #array([[-1., 0., 0.], # [ 0., 2., -0.], # [ 0., 0., 3.]])無事、$P^{-1}AP=diag(-1,2,3)$になることが確認できました。
これで簡単に自己回帰モデルの暴走について調べることができますね。
- 投稿日:2020-02-15T20:38:18+09:00
reCAPTCHAのサイトを毎日自動スクレイピングする (5/7: 2captcha)
- 要件定義〜python環境構築
- サイトのスクレイピング機構を作る
- ダウンロードしたファイル(xls)を加工し、最終成果物(csv)を作成するようにする
- S3からのファイルダウンロード / S3へのファイルアップロードをつくる
- 2captchaを実装
- Dockerコンテナで起動できるようにする
- AWS batchに登録
自動実行へ向けて
前回までで、目的を達成できるプログラムになりました。
が…今回の要件では、これを毎日定期実行する必要があります。通常 batchシステムを定期実行するにはcronなどでやれば良いのですが、今回はそう簡単には行きません。
- reCAPTCHAを解除する必要がある(画面が必要、手作業が必要
- seleniumも、headlessモード(画面なし)では動かない (クリックによるダウンロードが必須だったため)
まずは、reCAPTHCA対策です。
調べてみると、「2CAPTCHA」というロシアのサービスがあることがわかりました。
reCAPTCHAをリモートで人力解除してくれる、というサービスです。
1000回の突破で数百円、という破格の安さ。ちょっと怪しいな…と思ったものの、使ってみることにしました。2captchaへの登録〜課金
2captchaへアカウント登録し、Balanceにお金を入れます。
クレジットカードを登録して使っただけ課金される…というものではなく、入れたお金のぶんだけサービスを使えます。
使い方は他に紹介している方がいるので割愛します。
https://tanuhack.com/pr-2captcha/
ただ、「PayU」は使えなかったので、「PayProGlobal」経由でpaypalを使い、まずは300円課金しました。いまのレートだとこれで3000回くらいいけそうです。
2captchaの設置
事前準備
まずは、
- 2CaptchaのAPI KEYの取得
- 当該サイトのreCAPTCHAのgoogle_site_keyを取得
- 当該サイトの「textarea#g-recaptcha-response」を見つけておく
の3つをする必要があります。
google_site_keyは、上のサイトでは
data-sitekeyで検索すると一発とありますが、私の場合はソース上のjavascriptにありました。recaptchaとかで検索して見つけた感じです。(逆に、このサービスを使った突破を防ぐには、ここを探しにくくしておく…というのもいいかもしれません)textareaは#g-recaptcha-responseがすぐに見つかりました。仕組み上、こちらは変えられないでしょうね…。
textareaを可視にする
上の紹介サイトにあるとおりですが、textareaが不可視になっていると入力ができないため、javascriptを使って可視化します。
また私の対象サイトでは、reCAPTCHAのチェックボックス自体も隠されていました。「ログインボタンを押すとreCAPTCHAが出てくる(解除後、もう一度ログインボタンを押すとログインできる)」という挙動でした。
driver.execute_script('document.querySelector(hoge).style.height = "auto";') driver.execute_script('document.querySelector(hoge).style.position = "inherit";') driver.execute_script('document.getElementById("g-recaptcha-response").style.display="";')2captchaに解除を依頼
まず、下記のようにして captcha_idを取得します。
これでERRORになったことは無いですが、サービスのメンテナンスなどにあたるとそうなるのでしょう。#2captchaの準備ができているか確認 url = "http://2captcha.com/in.php?key=" + config.service_key + "&method=userrecaptcha&googlekey=" + config.google_site_key + "&pageurl=" + LOGIN_URL resp = requests.get(url) if resp.text[0:2] != 'OK': exit('2captcha Service error. Error code:' + resp.text) captcha_id = resp.text[3:]次に、そのcaptcha_idを使って解除を依頼します。
#実際に解除を依頼 fetch_url = "http://2captcha.com/res.php?key="+ config.service_key + "&action=get&id=" + captcha_id print('解除を依頼中…') for __i in range(1, 10): time.sleep(5) # wait 5 sec. resp = requests.get(fetch_url) if resp.text[0:2] == 'OK': break print('Google response token: ', resp.text[3:])詳細まで調べていませんが、responseで「CHA_NOT_READY」というものが返ることがあるようです。
解除するスタッフの準備ができていないときに起こるのでしょうか。
この場合は困るので、私の場合は何度かやり直すように実装しました。if resp.text[3:] == 'CHA_NOT_READY': print('処理に失敗') driver.quit() if count == 0: exit('Error: 2captcha is not ready') else: #やり直す return getLoginedDriver(config,count-1)無事にトークンが帰ってきたら、textareaに入れてログイン実行です。
# textareaにトークンを入力する driver.find_element_by_id('g-recaptcha-response').send_keys(resp.text[3:]) time.sleep(INTERVAL) driver.execute_script('document.querySelector(hoge).style.visibility = "hidden";') #このサイトの場合はログインボタンを押すのにこれが必要だった submit_button = driver.find_element_by_css_selector(hoge) submit_button.click()実行
やってみたらわかるのですが、すごいなこれ…素敵なサービスに感謝です。
ただ、このサービスの存続にシステムが依存することになるので、やはりできるならスクレイピングなんてやりたくないな、とも改めて思いました。
今回のサイトの運営とはAPIを準備してもらえるよう交渉していますが、うまく行ってほしい。完成
reCAPTCHAが出ないこともあるので、そのケースにも対応できるようにしたら完成です。
これで、runするだけで(reCAPTCHAを解除せずとも) 動くようになりました。あとはこれをローカルPCではなく、サーバで実行するだけなのですが…
headlessモードで動かないため、もう一山です。続きはまた。
- 投稿日:2020-02-15T19:34:18+09:00
半導体ウェハー生産計画の最適化
はじめに
- CPLEX CP Optimizerの資料で説明されている半導体ウエハー生産計画の最適化を再現してみた。
- https://www.slideshare.net/PhilippeLaborie/introduction-to-cp-optimizer-for-scheduling
- https://ibmdecisionoptimization.github.io/docplex-doc/cp/index.html
生産計画の仕様
- ロットは、ウエハーの数(n)、優先度(priority)、生産開始可能日(release_date)、納期(due_date)を持つ。
- ロット毎に、生産ステップのシーケンスが与えられる。
- ロットを構成するステップの間隔(lag)が長くなるとコストが発生する。
- 各ステップはファミリー(f)を持つ。
- ファミリーに対して、生産可能なマシンと生産時間(process_time)が与えられる。
- ファミリーが同じステップは同時に生産することができる。開始と終了は同じとなる。
- 生産するステップのファミリーを切替えるには一定の時間が掛かる。
- マシンはキャパシティ(capacity)を持つ。同時に生産できるウエハー数の上限値。
- 最小化する指標は、ステップ間隔コスト$V_1$と納期遅れコスト$V_2$の二つ。
\begin{align*} V_1&=\sum_{\mathrm{Step}} \min(c,c\max(0,\mathrm{lag}-a)^2/(b-a)^2)\\ V_2&=\sum_{\mathrm{Lot}} p\max(0,\mathrm{EndOfLot}-\mathrm{DueDate}) \end{align*}
- ロット数: 1000
- ステップ数: 5000
- マシン数: 150
- 各ステップが生産可能なマシン数: 10
- 生産計画の期間は48時間で分単位
CP Optimizerによる実装
- プログラミング言語はOPL。CPLEX Optimization Studioで実行。
- 50行でExcellent Performanceが得られるとのこと。
- 変数名を長めに変更。
using CP; tuple Lot { key int id; int n; float priority; int release_date; int due_date; } tuple LotStep { key Lot lot; key int pos; int f; } tuple Lag { Lot lot; int pos1; int pos2; int a; int b; float c; } tuple Machine { key int id; int capacity; } tuple MachineFamily { Machine machine; int f; int process_time; } tuple MachineStep { Machine machine; LotStep lot_step; int process_time; } tuple Setup { int f1; int f2; int duration; } {Lot} Lots = ...; {LotStep} LotSteps = ...; {Lag} Lags = ...; {Machine} Machines = ...; {MachineFamily} MachineFamilies = ...; {Setup} MachineSetups[machine in Machines] = ...; {MachineStep} MachineSteps = {<machine_family.machine,lot_step,machine_family.process_time> | lot_step in LotSteps, machine_family in MachineFamilies: machine_family.f==lot_step.f}; dvar interval d_lot[lot in Lots] in lot.release_date .. 48*60; dvar interval d_lot_step[lot_step in LotSteps]; dvar interval d_machine_step[ms in MachineSteps] optional size ms.process_time; dvar int d_lag[Lags]; stateFunction batch[machine in Machines] with MachineSetups[machine]; cumulFunction load [machine in Machines] = sum(ms in MachineSteps: ms.machine==machine) pulse(d_machine_step[ms], ms.lot_step.lot.n); minimize staticLex( sum(lag in Lags) minl(lag.c, lag.c * maxl(0, d_lag[lag]-lag.a)^2 / (lag.b-lag.a)^2), sum(lot in Lots) lot.priority * maxl(0, endOf(d_lot[lot]) - lot.due_date)); subject to { forall(lot in Lots) span(d_lot[lot], all(lot_step in LotSteps: lot_step.lot==lot) d_lot_step[lot_step]); forall(lot_step in LotSteps) { alternative(d_lot_step[lot_step], all(ms in MachineSteps: ms.lot_step==lot_step) d_machine_step[ms]); if (lot_step.pos > 1) endBeforeStart(d_lot_step[<lot_step.lot,lot_step.pos-1>],d_lot_step[lot_step]); } forall(ms in MachineSteps) alwaysEqual(batch[ms.machine], d_machine_step[ms], ms.lot_step.f, true, true); forall(machine in Machines) load[machine] <= machine.capacity; forall(lag in Lags) endAtStart(d_lot_step[<lag.lot,lag.pos1>], d_lot_step[<lag.lot,lag.pos2>], d_lag[lag]); }サンプルデータの作成
乱数を使用してサンプルデータを作成。
alphaは生産開可能なマシンの比率。class Lag(): def __init__(self, pos1, pos2, a, b, c): self.pos1 = pos1 self.pos2 = pos2 self.a = a self.b = b self.c = c class Lot(): def __init__(self, id, n, priority, release_date, due_date): self.id = id self.n = n self.priority = priority self.release_date = release_date self.due_date = due_date self.lag_list = [] def create_step_list(self, families): self.step_list = families def add_lag(self, pos1, pos2, a, b, c): self.lag_list.append(Lag(pos1, pos2, a, b, c)) class Setup(): def __init__(self, family1, family2, duration): self.family1 = family1 self.family2 = family2 self.duration = duration class Machine(): def __init__(self, id, capacity): self.id = id self.capacity = capacity self.proc_time = {} self.setup_list = [] def add_proc_time(self, family, proc_time): self.proc_time[family] = proc_time def add_setup(self, family1, family2, duration): self.setup_list.append(Setup(family1, family2, duration)) ############################## import random random.seed(5) n_lot, n_step, n_family, n_machine = 4, 5, 3, 4 lot_n = (5, 15) capa = (20, 60) proc_time = (20, 30) takt, LT = 30, 100 a, b, c = 10, 20, 5 alpha = 0.5 duration = 20 lots = [] for i in range(n_lot): n = random.randint(lot_n[0], lot_n[1]) p = random.randint(1, 10) / 10 lot = Lot(i, n, p, takt*i, takt*i+LT) lot.create_step_list([random.randint(0, n_family-1) for j in range(n_step)]) for j in range(n_step-1): lot.add_lag(j, j+1, a, b, c) lots.append(lot) machines = [] for i in range(n_machine): c = random.randint(capa[0], capa[1]) machine = Machine(i, c) for j in range(n_family): for k in range(n_family): machine.add_setup(j, k, 0 if j == k else duration) machines.append(machine) for f in range(n_family): cnt = 0 for m in range(n_machine): if random.random() > alpha: continue machines[m].add_proc_time(f, random.randint(proc_time[0], proc_time[1])) cnt += 1 if cnt == 0: m = random.randint(0, n_machine-1) machines[m].add_proc_time(f, random.randint(proc_time[0], proc_time[1])) ############################## path_file_name = 'sample.dat' def mytuple(obj): if type(obj) == Lot: return f'<{obj.id},{obj.n},{obj.priority},{obj.release_date},{obj.due_date}>' if type(obj) == Machine: return f'<{obj.id},{obj.capacity}>' with open(path_file_name, 'w') as o: o.write('Lots = {\n') for lot in lots: o.write(f' {mytuple(lot)}\n') o.write('};\n') o.write('LotSteps = {\n') for lot in lots: for f, fm in enumerate(lot.step_list): o.write(f' <{mytuple(lot)},{f+1},{fm}>\n') o.write('};\n') o.write('Lags = {\n') for lot in lots: for lag in lot.lag_list: o.write(f' <{mytuple(lot)},{lag.pos1+1},{lag.pos2+1},{lag.a},{lag.b},{lag.c}>\n') o.write('};\n') o.write('Machines = {\n') for machine in machines: o.write(f' {mytuple(machine)}\n') o.write('};\n') o.write('MachineFamilies = {\n') for machine in machines: for f, proc_time in machine.proc_time.items(): o.write(f' <{mytuple(machine)},{f},{proc_time}>\n') o.write('};\n') o.write('MachineSetups = #[\n') for machine in machines: o.write(f' <{machine.id}>:{{') for setup in machine.setup_list: o.write(f'<{setup.family1},{setup.family2},{setup.duration}>') o.write('}\n') o.write(']#;\n')Python Libraryによる実装
サンプルデータの作成で使用したオブジェクトをそのまま流用。
モデルの作成と最適化、結果出力。import docplex.cp.model as cp model = cp.CpoModel() for machine in machines: machine.interval_list = [] for lot in lots: lot.interval = cp.interval_var(start=[lot.release_date,48*60], end=[lot.release_date,48*60]) lot.step_interval_list = cp.interval_var_list(len(lot.step_list)) model.add(cp.span(lot.interval, lot.step_interval_list)) for f in range(1, len(lot.step_list)): model.add(cp.end_before_start(lot.step_interval_list[f-1], lot.step_interval_list[f])) lot.machine_interval_list = [] for f, fm in enumerate(lot.step_list): interval_dict = {} for machine in machines: if fm not in machine.proc_time: continue interval = cp.interval_var(length=machine.proc_time[fm], optional=True) interval_dict[machine.id] = interval machine.interval_list.append([interval, fm, lot.n]) model.add(cp.alternative(lot.step_interval_list[f], interval_dict.values())) lot.machine_interval_list.append(interval_dict) lot.lag_ivar_list = [] for lag in lot.lag_list: ivar = cp.integer_var() model.add(cp.end_at_start(lot.step_interval_list[lag.pos1], lot.step_interval_list[lag.pos2], ivar)) lot.lag_ivar_list.append(ivar) for machine in machines: tmat = cp.transition_matrix(n_family) for setup in machine.setup_list: tmat.set_value(setup.family1, setup.family2, setup.duration) state = cp.state_function(tmat) for interval, fm, n in machine.interval_list: model.add(cp.always_equal(state, interval, fm, True, True)) pulse_list = [] for interval, fm, n in machine.interval_list: pulse_list.append(cp.pulse(interval, n)) model.add(cp.sum(pulse_list) <= machine.capacity) obj_lag = cp.sum([cp.min(lag.c, lag.c * cp.square(cp.max(0, lot.lag_ivar_list[l] - lag.a)) / (lag.b - lag.a)**2) for lot in lots for l, lag in enumerate(lot.lag_list)]) obj_lot = cp.sum([lot.priority * cp.max(0, cp.end_of(lot.interval) - lot.due_date) for lot in lots]) model.add(cp.minimize_static_lex([obj_lag, obj_lot])) msol = model.solve(TimeLimit=30, LogVerbosity='Terse') ############################## path_file_name = 'cplex_python.csv' with open(path_file_name, 'w') as o: o.write('l,n,priority,release_date,due_date,pos,f,start,end,length,m,capacity\n') for lot in lots: for f, interval_dict in enumerate(lot.machine_interval_list): for m, v in interval_dict.items(): x = msol[v] if(len(x) == 0): continue o.write(f'{lot.id},{lot.n},{lot.priority},{lot.release_date},{lot.due_date}') o.write(f',{f},{lot.step_list[f]},{x[0]},{x[1]},{x[2]},{m},{machines[m].capacity}\n')実行結果
最適解が得られた。計算時間は0.1秒程度。
CP OptimizerでもPythonでも同一の結果となった。
l n priority release_date due_date pos f start end length m capacity 0 14 0.5 0 100 0 2 0 23 23 1 44 0 14 0.5 0 100 1 1 30 53 23 2 30 0 14 0.5 0 100 2 2 53 76 23 1 44 0 14 0.5 0 100 3 2 76 99 23 1 44 0 14 0.5 0 100 4 2 99 122 23 1 44 1 13 0.1 30 130 0 1 30 53 23 2 30 1 13 0.1 30 130 1 0 53 76 23 3 24 1 13 0.1 30 130 2 2 76 99 23 1 44 1 13 0.1 30 130 3 0 99 128 29 0 31 1 13 0.1 30 130 4 0 128 151 23 3 24 2 6 0.6 60 160 0 1 60 83 23 2 30 2 6 0.6 60 160 1 0 83 106 23 3 24 2 6 0.6 60 160 2 1 106 129 23 2 30 2 6 0.6 60 160 3 2 129 152 23 1 44 2 6 0.6 60 160 4 0 152 172 20 2 30 3 14 0.4 90 190 0 0 99 128 29 0 31 3 14 0.4 90 190 1 2 129 152 23 1 44 3 14 0.4 90 190 2 0 152 172 20 2 30 3 14 0.4 90 190 3 1 172 194 22 1 44 3 14 0.4 90 190 4 1 194 216 22 1 44 おわりに
- 少し複雑な問題でも手軽に最適解が得られることは驚異的。
- Interval変数とOptional属性を使用すると生産計画モデルを簡単に表現することができる。
- ロット数1000でも解が得られるかどうかは未検証。Community Editionでは変数が多すぎる。
- 投稿日:2020-02-15T19:33:05+09:00
Poetry の scripts は Pipenv の scrips セクションのようなタスクランナー機能ではない
要約
- Poetry には現在(1.0.3)、
npm runやpipenv runのようなタスクを実行する機能はないtool.poetry.scriptsセクションは ユーザーに提供するコマンド名や実行ファイル を指定するセクション
- 開発者が使うためのものではない
scripts 機能とは何か
特定の記事を挙げることはしませんが、ときおり Poetry の scripts 機能を使ってタスクランナーのような機能を実現している記事を見かけます。例えば、Web アプリの開発で
poetry run runserverでテスト用サーバを起動したりとか。しかし、Poetry の公式ドキュメントによれば、この機能はタスクランナーのために作られた機能では ありません。この機能について、次のように説明されています。
This section describe the scripts or executable that will be installed when installing the package
すなわち、あなたが開発しているパッケージが インストールされた際 に、実行コマンド名を制御するものです。開発者が使うタスクではなく、 パッケージをインストールしたユーザーが使うコマンド名(エントリーポイント)を定義するためのもの です。だから Python スクリプトしか指定できません(Python パッケージのエントリーポイントですから)。
そもそもですが、Poetry はパッケージの依存関係の管理、パッケージのビルド、パッケージの公開をするためのツールです。タスクを管理する機能はありません1。
なぜこのような誤解が起こったか
推測ですが、考えられることとしては Pipenv(Pipfile) の scripts セクションの存在があると思います。Pipenv では既にタスクランナーのような機能が導入されていて、その機能を使うためのPipfile(TOMLファイル)のセクションの名前は
scriptsです2。しかしおそらく Poetry における
scriptsの名前の由来は setup.py のconsole_scriptsでしょう3。この機能は上に書いたように「パッケージがインストールされた際のエントリーポイント」を定義するためのキーワードです。scripts という同じ名前ですが、全く異なる機能です。しかし同じ名前であるがゆえに、Pipenv から Poetry に乗り換えようとした人が "scripts" 機能を探し、異なる機能であることに気づかずそのまま利用してしまった、という流れなのだと思います。
ちなみにですが、この議論を眺めている限りみんな混乱していそうなので、日本人が英語苦手だから起こった問題というわけでもないようです。
タスクランナーとして利用する副作用
副作用としては、下記のことが考えられます。下記のようにコマンドが定義してあったとしましょう。
[tool.poetry.scripts] start = "util:start" stop = "util:stop"このパッケージで
poetry buildとpoetry publishをしたとします。その際、ユーザーはこのパッケージをインストールするとstartコマンドとstopコマンドを意図せずインストールしてしまうことになります。ユーザーのコマンドの名前空間を侵す行為であり、行儀の悪いパッケージです4。とはいえタスク定義したい
現状の Poetry では公式に提供されているタスク定義をする方法は存在しません[^python-only]。ad-hoc な方法を続けるか、Pipenv など別のツールを使うか、Poetry と Makefile などを併用するか、Poetry の開発を待つしかありません。もちろん、Poetry の開発に何らかの形で参加するのも手です。プラグイン機構の議論があるので、それに参加するのが最も近道でしょう。
一般に Pipenv などに向いているフローが Poetry にも向いているとは限りません。Poetry はパッケージの開発5については強力なサポートをしてくれていますが、Web アプリケーションなどの開発に十分な機能が提供されているとはわたしも思っていません。複雑なタスクは Makefile を書くなどしてカバーしています。
Poetry がモノリシックなコマンドになり、何でもできるようになる未来が本当に良いものかどうかはわたしにはわかりません。そうした未来を志向する人はそのように活動すればいいと思いますし、わたしは今のシンプルな、機能が足りないと思わせるくらいのPoetryで、実はちょうど良いんじゃないかと思っています。
実際、npm-scriptsのようにタスクを実行するための機能が提案されたことがありましたが、リジェクトされました。 https://github.com/python-poetry/poetry/pull/591 ↩
とはいえ、この scripts セクションの名前もまた npm とかだったりしそうです。そこまでは追っていません。 ↩
参考 pypiにパッケージを登録して、setup.pyの「scripts」と「console_scripts」の違いを比較してみた - カイワレの大冒険 Third ↩
とはいえ、そもそもパッケージ開発者はこのような誤解をしておらず、主にアプリケーション開発に Poetry を利用している人が誤解していそうなことなので、内心あまりこれが問題になることはないんじゃないかと思いながら書いています(そもそもこの勘違いをしている人は
poetry publishをしないと思われるため)。 ↩PyPI にアップロードされるようなもの、ライブラリやフレームワーク。 ↩
- 投稿日:2020-02-15T19:33:05+09:00
Poetry の scripts はタスクランナー機能ではない
要約
- Poetry には現在(1.0.3)、
npm run <task name>やpipenv run <task name>のようなタスクを実行する機能はないtool.poetry.scriptsセクションは ユーザーに提供するコマンド名や実行ファイル を指定するセクション
- 開発者が使うためのものではない
scripts 機能とは何か
特定の記事を挙げることはしませんが、ときおり Poetry の scripts 機能を使ってタスクランナーのような機能を実現している記事を見かけます。例えば、Web アプリの開発で
poetry run runserverでテスト用サーバを起動したりとか。しかし、Poetry の公式ドキュメントによれば、この機能はタスクランナーのために作られた機能では ありません。この機能について、次のように説明されています。
This section describe the scripts or executable that will be installed when installing the package
すなわち、あなたが開発しているパッケージが インストールされた際 に、実行コマンド名を制御するものです。開発者が使うタスクではなく、 パッケージをインストールしたユーザーが使うコマンド名(エントリーポイント)を定義するためのもの です。だから Python スクリプトしか指定できません(Python パッケージのエントリーポイントですから)。
そもそもですが、Poetry はパッケージの依存関係の管理、パッケージのビルド、パッケージの公開をするためのツールです。タスクを管理する機能はありません1。
なぜこのような誤解が起こったか
推測ですが、考えられることとしては Pipenv(Pipfile) の scripts セクションの存在があると思います。Pipenv では既にタスクランナーのような機能が導入されていて、その機能を使うためのPipfile(TOMLファイル)のセクションの名前は
scriptsです2。しかしおそらく Poetry における
scriptsの名前の由来は setup.py のconsole_scriptsでしょう3。この機能は上に書いたように「パッケージがインストールされた際のエントリーポイント」を定義するためのキーワードです。scripts という同じ名前ですが、全く異なる機能です。しかし同じ名前であるがゆえに、Pipenv から Poetry に乗り換えようとした人が "scripts" 機能を探し、異なる機能であることに気づかずそのまま利用してしまった、という流れなのだと思います。
ちなみにですが、この議論を眺めている限りみんな混乱していそうなので、日本人が英語苦手だから起こった問題というわけでもないようです。
タスクランナーとして利用する副作用
副作用としては、下記のことが考えられます。下記のようにコマンドが定義してあったとしましょう。
[tool.poetry.scripts] start = "util:start" stop = "util:stop"このパッケージで
poetry buildとpoetry publishをしたとします。その際、ユーザーはこのパッケージをインストールするとstartコマンドとstopコマンドを意図せずインストールしてしまうことになります。ユーザーのコマンドの名前空間を侵す行為であり、行儀の悪いパッケージです4。とはいえタスク定義したい
現状の Poetry では公式に提供されているタスク定義をする方法は存在しません[^python-only]。ad-hoc な方法を続けるか、Pipenv など別のツールを使うか、Poetry と Makefile などを併用するか、Poetry の開発を待つしかありません。もちろん、Poetry の開発に何らかの形で参加するのも手です。プラグイン機構の議論があるので、それに参加するのが最も近道でしょう。
一般に Pipenv などに向いているフローが Poetry にも向いているとは限りません。Poetry はパッケージの開発5については強力なサポートをしてくれていますが、Web アプリケーションなどの開発に十分な機能が提供されているとはわたしも思っていません。複雑なタスクは Makefile を書くなどしてカバーしています。
Poetry がモノリシックなコマンドになり、何でもできるようになる未来が本当に良いものかどうかはわたしにはわかりません。そうした未来を志向する人はそのように活動すればいいと思いますし、わたしは今のシンプルな、機能が足りないと思わせるくらいのPoetryで、実はちょうど良いんじゃないかと思っています。
実際、npm-scriptsのようにタスクを実行するための機能が提案されたことがありましたが、リジェクトされました。 https://github.com/python-poetry/poetry/pull/591 ↩
とはいえ、この scripts セクションの名前もまた npm とかだったりしそうです。そこまでは追っていません。 ↩
参考 pypiにパッケージを登録して、setup.pyの「scripts」と「console_scripts」の違いを比較してみた - カイワレの大冒険 Third ↩
とはいえ、そもそもパッケージ開発者はこのような誤解をしておらず、主にアプリケーション開発に Poetry を利用している人が誤解していそうなことなので、内心あまりこれが問題になることはないんじゃないかと思いながら書いています(そもそもこの勘違いをしている人は
poetry publishをしないと思われるため)。 ↩PyPI にアップロードされるようなもの、ライブラリやフレームワーク。 ↩
- 投稿日:2020-02-15T18:19:14+09:00
GoogleのCloud Vision APIでの結果出力で困ったこと
JSONファイルを出力しようと思ったら、ファイルの最初と最後に変な文字が入っていた問題
そもそも、関数を理解していないんじゃないかと思ったので、ちゃんと理解しなきゃと痛感。
参考にしていたサイト
ここを参考にベースを作ってました。
Google Cloud Visionを使ってみたやっていたこと
そもそも、何をしていたかというと、Cloud Vison APIをたたいて取得したresponse結果をpickle.dumpでファイル出力していました。
したら、先頭に「�X~」など変な文字は入るし、末尾には「q.」が入って困っていました。
そのため、出力したファイルをjson.loadができなかった。
※pickle.loadはできていたresponse = requests.post(ENDPOINT_URL ,data=json.dumps({"requests": img_requests}).encode() ,params={'key': api_key} ,headers={'Content-Type': 'application/json'}) result = json.dumps(response.json()['responses'], ensure_ascii=False, indent=4) print(result) f = open("./output.json", 'wb') pickle.dump(result, f)解決
以下のように処理を変えたら、json.loadで読み込める形で出力できた。
f = open("./output.json", 'wb') f.write(result.encode("UTF-8"))
これ、書いてて思って、以下で試してみたけれど、
最初の問題と変わらず。理解不足。わかったら追記したい。
バイナリ形式だったからとか?なんにせよ、調査。f = open("./output.json", 'wb') f.write(result.encode("UTF-8"))以上。
- 投稿日:2020-02-15T18:04:03+09:00
Pandasメモ ~None, np.nan, 空文字について~
Pandasメモ ~None, np.nan, 空文字について~
pandasのNone, np.nan周りでハマったので、個人用メモ
検証した環境は下記(結果に違いはありませんでした)
- python2.7.5, pandas==0.24.2
- python3.6.1, pandas==0.25.3
サマリ
None np.nan 空文字 DataFrame化 dtypeにobjectを指定しない時以外はnp.nanに変換される np.nanはintに変換できないため、np.nanが含まれる列は基本的にはfloat型になる 文字型(非数値)として扱われるため、欠損値として扱われず、空文字が含まれる列は基本object型になる read_csv - csv上の空、空文字共にどのdtypeを指定してもnp.nanとして読み込まれる - fillna, fropna 欠損値と判定される 欠損値と判定される 欠損値と判定されない groupby 欠損値と判定され、無視される 欠損値と判定され、無視される 欠損値と判定されない 検証結果
dtype指定でDataFrame化
下記データをそれぞれ異なるdtype指定したときに列の型がどう変わるの検証
df = pd.DataFrame( { # A列: int+None "A": [1, 2, 3, None], # B列: str+空文字 "B": ["1", "2", "3", ""], # C列: int+np.nan "C": [1, 2, 3, np.nan], # D列: intのみ "D": [1, 2, 3, 4] } )dtype指定なし
Noneはnp.nanに変換されるもよう・・・それに伴いnp.nanが含まれる列はfloat64になる
- A列: Noneがnp.nanに変換されてfloat64型になる
- B列: 値の変換は行われずobject型になる
- C列: float64型になる
- D列: 値の変換は行われずint64型になる
df = pd.DataFrame( { "A": [1, 2, 3, None], "B": ["1", "2", "3", ""], "C": [1, 2, 3, np.nan], "D": [1, 2, 3, 4] } ) print(df) A B C D 0 1.0 1 1.0 1 1 2.0 2 2.0 2 2 3.0 3 3.0 3 3 NaN NaN 4 print(df.dtypes) A float64 B object C float64 D int64 dtype: object print(df.values) array([[1.0, '1', 1.0, 1], [2.0, '2', 2.0, 2], [3.0, '3', 3.0, 3], [nan, '', nan, 4]], dtype=object)objectを指定
全ての値に変更はなく、Noneもそのまま
df = pd.DataFrame( { "A": [1, 2, 3, None], "B": ["1", "2", "3", ""], "C": [1, 2, 3, np.nan], "D": [1, 2, 3, 4] }, dtype=object ) print(df) A B C D 0 1 1 1 1 1 2 2 2 2 2 3 3 3 3 3 None NaN 4 print(df.dtypes) A object B object C object D object dtype: object print(df.values) array([[1, '1', 1, 1], [2, '2', 2, 2], [3, '3', 3, 3], [None, '', nan, 4]], dtype=object)floatを指定
空文字をfloatに変更できず、空文字を含む列のみobject型になる
- A列: Noneがnp.nanに変換されてfloat64型になる
- B列: 空文字はfloatに変換できず、object型になる
- C列: float64型になる
- D列: float64型になる
df = pd.DataFrame( { "A": [1, 2, 3, None], "B": ["1", "2", "3", ""], "C": [1, 2, 3, np.nan], "D": [1, 2, 3, 4] }, dtype=float ) print(df) A B C D 0 1 1 1 1 1 2 2 2 2 2 3 3 3 3 3 None NaN 4 print(df.dtypes) A float64 B object C float64 D float64 dtype: object print(df.values) array([[1.0, '1', 1.0, 1.0], [2.0, '2', 2.0, 2.0], [3.0, '3', 3.0, 3.0], [nan, '', nan, 4.0]], dtype=object)intを指定
int64に変換できない列(np.nanやNoneが含まれている列)はobject型になる
- A~C列: int64型に変換できず、object型になる
- D列: int64型になる
df = pd.DataFrame( { "A": [1, 2, 3, None], "B": ["1", "2", "3", ""], "C": [1, 2, 3, np.nan], "D": [1, 2, 3, 4] }, dtype=int ) print(df) A B C D 0 1 1 1 1 1 2 2 2 2 2 3 3 3 3 3 None NaN 4 print(df.dtypes) A object B object C object D int64 dtype: object print(df.values) array([[1, '1', 1, 1], [2, '2', 2, 2], [3, '3', 3, 3], [None, '', nan, 4]], dtype=object)dtype指定でread_csv
下記csvをそれぞれ異なるdtype指定したときに列の型がどうなるか検証
sample.csv# A列: int+空 # B列: 文字列+空文字 # C列: float+空 # D列: intのみ A,B,C,D 1,"1",1.0,1 2,"2",2.0,2 3,"3",3.0,3 ,"",,4dtype指定なし
空、空文字のいずれもnp.nanとして読み込まれ、それに伴いintはfloatに変換される
- A列: 空がnp.nanに変換され、float64型になる
- B列: 空文字がnp.nanに変換され、float64型になる
- C列: 空がnp.nanに変換され、float64型になる
- D列: 値の変換は行われずint64型になる
df = pd.read_csv("sample.csv") print(df) A B C D 0 1.0 1.0 1.0 1 1 2.0 2.0 2.0 2 2 3.0 3.0 3.0 3 3 NaN NaN NaN 4 print(df.dtypes) A float64 B float64 C float64 D int64 dtype: object print(df.values) array([[ 1., 1., 1., 1.], [ 2., 2., 2., 2.], [ 3., 3., 3., 3.], [nan, nan, nan, 4.]])objectを指定
空、空文字はnp.nanに変換されるが、それ以外の値はstr型に変換される
df = pd.read_csv("sample.csv", dtype=object) print(df) A B C D 0 1 1 1.0 1 1 2 2 2.0 2 2 3 3 3.0 3 3 NaN NaN NaN 4 print(df.dtypes) A object B object C object D object dtype: object print(df.values) array([['1', '1', '1.0', '1'], ['2', '2', '2.0', '2'], ['3', '3', '3.0', '3'], [nan, nan, nan, '4']], dtype=object)floatを指定
全ての列がfloat64型に変換される
df = pd.read_csv("sample.csv", dtype=float) print(df) A B C D 0 1.0 1.0 1.0 1.0 1 2.0 2.0 2.0 2.0 2 3.0 3.0 3.0 3.0 3 NaN NaN NaN 4.0 print(df.dtypes) A float64 B float64 C float64 D float64 dtype: object print(df.values) array([[ 1., 1., 1., 1.], [ 2., 2., 2., 2.], [ 3., 3., 3., 3.], [nan, nan, nan, 4.]])intを指定
空、空文字はnp.nanに変換されてしまうため、intとして読み込みができずエラーが発生する
df = pd.read_csv("sample.csv", dtype=int) ValueError: Integer column has NA values in column 0fillna, dropna時の挙動
下記データをfillnaした際の挙動
df = pd.DataFrame( { # A列: int+None "A": [1, 2, 3, None], # B列: str+空文字 "B": ["1", "2", "3", ""], # C列: int+np.nan "C": [1, 2, 3, np.nan], # D列: intのみ "D": [1, 2, 3, 4] }, dtype="object" ) print(df.values) array([[1, '1', 1, 1], [2, '2', 2, 2], [3, '3', 3, 3], [None, '', nan, 4]], dtype=object)
df.fillna('FILL')を行った場合、Noneとnp.nanの値は変換されるが、空文字はそのままになるprint(df.fillna('FILL')) A B C D 0 1 1 1 1 1 2 2 2 2 2 3 3 3 3 3 FILL FILL 4 print(df.fillna('FILL').values) array([[1, '1', 1, 1], [2, '2', 2, 2], [3, '3', 3, 3], ['FILL', '', 'FILL', 4]], dtype=object)dropnaの時の挙動も同じく、np.nan, Noneの含まれる行、列は削除されるが、空文字は欠損値として扱われない。
print(df.dropna(axis=1)) B D 0 1 1 1 2 2 2 3 3 3 4 print(df.dropna(axis=1).values) array([['1', 1], ['2', 2], ['3', 3], ['', 4]], dtype=object)groupby時の挙動
下記データフレームを用いて検証を行う
df = pd.DataFrame( { # A列: int+None "A": [1, 2, 3, None], # B列: str+空文字 "B": ["1", "2", "3", ""], # C列: int+np.nan "C": [1, 2, 3, np.nan], # D列: intのみ "D": [1, 2, 3, 4] }, dtype="object" )None, np.nanが含まれる列でgroupbyした場合、None, np.nanの行は無視される(欠損となる)
print(df.groupby("A").max().reset_index()) A B C D 0 1 1 1 1 1 2 2 2 2 2 3 3 3 3 print(df.groupby("A").max().reset_index().values) array([[1, '1', 1, 1], [2, '2', 2, 2], [3, '3', 3, 3]], dtype=object) print(df.groupby("C").max().reset_index()) C A B D 0 1 1 1 1 1 2 2 2 2 2 3 3 3 3 print(df.groupby("C").max().reset_index().values) array([[1, 1, '1', 1], [2, 2, '2', 2], [3, 3, '3', 3]], dtype=object)列に空文字が含まれていても無視されない
print(df.groupby("B").max().reset_index()) B A C D 0 NaN NaN 4 1 1 1.0 1.0 1 2 2 2.0 2.0 2 3 3 3.0 3.0 3 print(df.groupby("B").max().reset_index().values) array([[1, 1, '1', 1], [2, 2, '2', 2], [3, 3, '3', 3]], dtype=object)
- 投稿日:2020-02-15T18:03:38+09:00
【レコメンド】内容ベースフィルタリングと協調フィルタリング
レコメンドシステムについて
レコメンドシステムとは、利⽤者にとって有⽤と思われる対象,情報,または商品などを選び出し,
それを利⽤者の⽬的に合わせた形で提⽰するシステムです。近年ではAmazonをはじめとする多くのwebサービスで実装されており、多くの人になじみのあるものとなってきました。Amazonなどでは複雑なアルゴリズムを複数組み合わせてレコメンドシステムを構築しているようですが、今回はレコメンドを行うにあたり基礎となる内容ベースフィルタリングと協調フィルタリングについてまとめます。
内容ベースフィルタリング
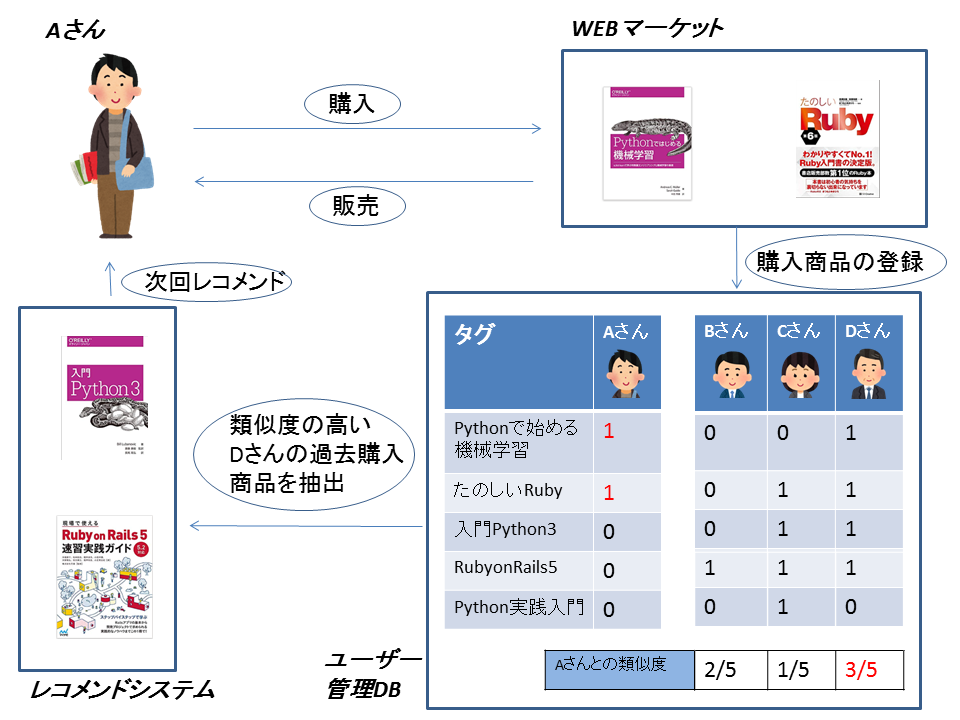
あるユーザーが購⼊した商品のタグ情報から、類似の商品を探し推薦する方式です。
ユーザーが購入した商品のタグ情報を基に、ユーザーがどのような分野に興味があるのかを蓄積し、類似の商品を探して提案します。
この方式ではタグ情報を基に様々なレコメンドを行える一方、レコメンドしたい商品には必ずタグ付けを行なわなければならないというデメリットがあります。例えば上画像にある「入門Python3」は、商品登録時にタグ「#python」を付けたために、別のPython関係の書籍が販売されたの後にレコメンドされます。タグ「#python」がなければレコメンドされることはありません。
また、そもそもとしてタグ「#python」が適切かどうかも考えなくてはなりません。ユーザーの趣向を考慮したうえで緻密なマーケティングを行いタグを設計する必要があります。
そのため内容ベースフィルタリングは時間およびコストがかかってしまうという特性があります。協調フィルタリング
ユーザーの⾏動履歴等を元に、購⼊パターンの近いユーザーを探し出して商品をレコメンドします。この際、アイテムの性質、タグ情報などは全く考慮しないという特徴があります。
上画像では、まず各商品にはタグがついていません。DBにも各ユーザーが過去に何の商品を買ったかの情報を記録します。そしてユーザーごとの購入履歴から類似性の高いユーザーを選びます。(例では類似ユーザーは一人だけ選ばれるものとする)
結果として、Aさんと購入趣向が近いDさんが過去に購入した商品がAさんにレコメンドされます。ユーザーの購入履歴を軸にするため、各商品のタグ情報は不要となります。しかし協調フィルタリングでは、誰にも購入されていない商品はレコメンドされることがないといった大きなデメリットがあります。
ハイブリッドフィルタリング
内容ベースフィルタリング、協調フィルタリング、実用するにはそれぞれ大きなデメリットを有しています。そのためシステム構築の際には、各フィルタリングの良いところを組み合わせてレコメンドシステムを構築してくことが一般的であり、これらはハイブリッドと呼ばれます。

- 投稿日:2020-02-15T17:47:16+09:00
PythonとExcelを連携してWebサイトから欲しいデータをスクレイピング
スクレイピングの目的
まずコーディングというか、ちょっとしたアプリレベルでもその技術を使って何を実現したいかというのは重要です。
私は主に投資信託(以下、投信)による投資をしているのですが、近年は投信の商品も粒ぞろいで良い商品がどしどし販売されており、ついつい目移りしてしまいます。
「自分が購入している商品は本当に良い商品なのか」
「もっとコストが安く、利益が出やすい商品があるのではないか」そんなことを年に一度は考えてしまいます。
それで証券サイトの投信ページで検索して商品を比較するのですが、基準価額やらシャープレシオやら信託報酬管理費やら見なければならない項目が多く、ある程度検索条件を絞ってはいるものもどうしても5~10くらいは見比べたくなります。
ああ、表形式で一覧にざっと情報をまとめたものが欲しい…!
これが今回のスクレイピングの目的です。
環境と対象サイト
OS:Windows
プログラミング言語:Python (3.8)
ソフトウェア:Excel (2016)
エディタ:Visual Studio Code対象となるサイトの一例
楽天証券の各商品ページ(私が楽天証券を主に使用しているため)
https://www.rakuten-sec.co.jp/web/fund/detail/?ID=JP90C000BRT6他の商品であってもページの構造は同じ。
スクレイピングにはBeautifulSoup、Excelへの連携はOpenpyxlを使用しました。
これらのライブラリを選んだ理由は単に検索してみた感じ、これらのライブラリを使用した記事が多かったから。
初学者は情報量が多いところから入るのが鉄則。(Pythonはほぼやったことがない)公式ドキュメント
BeautifulSoup
https://www.crummy.com/software/BeautifulSoup/bs4/doc/
Openpyxl
https://openpyxl.readthedocs.io/en/stable/tutorial.html事前準備
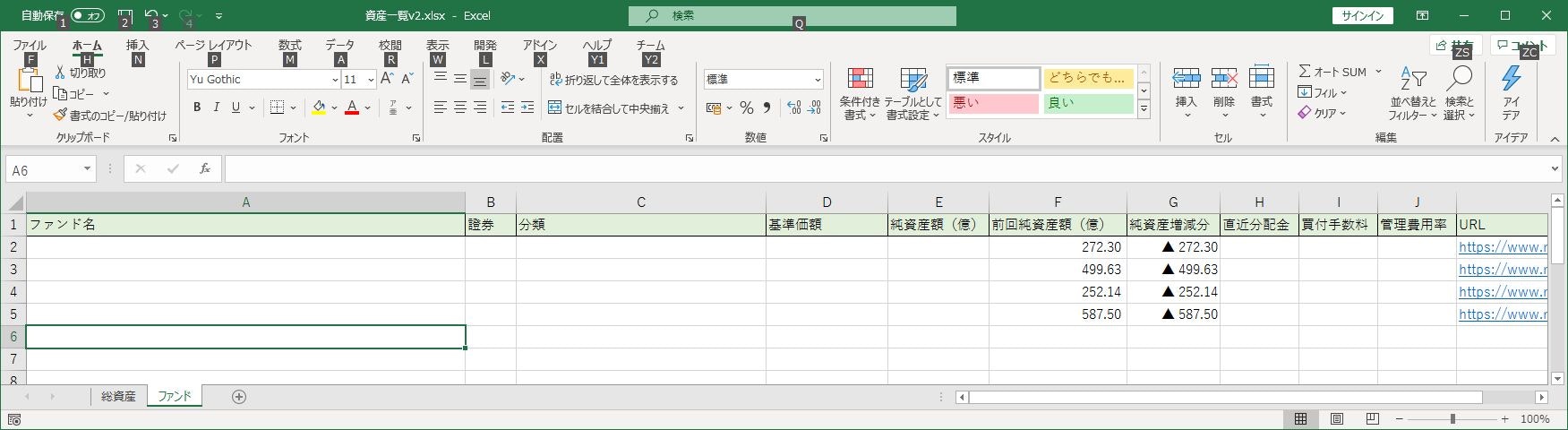
事前にExcelファイルを用意しました。
項目は左から
・ファンド名
・證券会社
・分類(国内株式なのか先進国株式なのかみたいな)
・基準価額
・純資産額(億)
・前回純資産額(億)
・純資産増減分
・直近分配金
・買付手数料
・管理費用率(信託報酬とか事務手数料とかのコスト)
・URLとしました。
ここで項目の意味などは本記事に全く関係ないので割愛します。
要は投信のスペックを比較するための項目だと思ってください。
本当はもっといろいろあります。ちなみに「前回純資産額(億)」と「純資産増減分」は事前に数値と関数を設定しております。
「純資産額(億)」と「前回純資産額(億)」の差をとりたいので。「URL」も事前にわかっているので最初から記載しておきます。
ちなみに今回取得するデータはログイン等の必要のない公開されている情報のみとします。
私がどの商品をいくらで何口購入したかといった情報は取得しません。目的はあくまで金融商品そのものの比較なので。
スクレイピング
まずはBeautifulSoupを使用する準備から。
fund.pyimport requests, bs4今回は楽天証券内の複数のURLにアクセスする想定なので、URLを引数にもつメソッドを事前に定義してしまいます。
fund.py# 楽天証券 def GetRakutenFund(url): res = requests.get(url) res.raise_for_status() soup = bs4.BeautifulSoup(res.text, "html.parser")取得したい項目はもう決めているのでクラスも定義してしまいます。
fund.py# ファンド情報クラス class FundInfo: def __init__(self): self.name = '' self.company = '' self.category = '' self.baseprice = '' self.assets = 0 self.allotment = 0 self.commision = '' self.cost = 0GetRakutenFundメソッドでスクレイピングした情報をFundInfoインスタンスに格納するという構成にします。
それではこのサイトから欲しい情報を取得するための情報を取得します。
https://www.rakuten-sec.co.jp/web/fund/detail/?ID=JP90C000BRT6ベタですが開発者ツールを駆使して要素を特定していきます。
その結果、下記のような構造であることがわかりました。
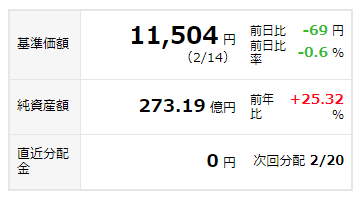
項目名 クラス名 ファンド名 fund-name 分類 fund-type 基準価額 value-01 純資産額 value-02 直近分配金 value-02 買付手数料 no-fee 管理費用率 クラス名なし 基本的にはクラス名が一意であれば簡単にデータを取れますが、今回はそうではないようです。
純資産額と直近分配金は同じクラス名を使用していますし、
管理費用率はクラス名がありませんでした。なので今回はクラス名で特定できない場合は1つ上の要素をとってcontentsの配列にとるみたいなことをしました。
この画像はtbl-fund-summaryというクラスで括られています。
その中からさらにvalue-02というクラス名の要素を抜き出しました。fund.pyfundsummary = soup.find("table", attrs={"class", "tbl-fund-summary"}) elements = fundsummary.find_all("span", attrs={"class", "value-02"}) fundinfo.assets = elements[0].text fundinfo.allotment = elements[1].textelements[0]が純資産額、elements[1]が直近分配金という風に特定できました。
同じ要領で管理費用率も特定します。
この項目はli要素のtrust-feeというクラスの中にtd単品でありました。
fund.pycosts = soup.find("li", attrs={"class", "trust-fee"}) elements = costs.find_all("td") fundinfo.cost = elements[0].text最終的にGetRakutenFundメソッドはこんな処理をします。
fund.py# 楽天証券 def GetRakutenFund(url): res = requests.get(url) res.raise_for_status() soup = bs4.BeautifulSoup(res.text, "html.parser") fundinfo = FundInfo() # ファンド名、分類 fundinfo.name = soup.select_one('.fund-name').text fundinfo.company = '楽天' fundinfo.category = soup.select_one('.fund-type').text # 基準価額、純資産、直近分配金 fundsummary = soup.find("table", attrs={"class", "tbl-fund-summary"}) elemnt = fundsummary.select_one('.value-01') fundinfo.baseprice = elemnt.text + elemnt.nextSibling elements = fundsummary.find_all("span", attrs={"class", "value-02"}) fundinfo.assets = elements[0].text fundinfo.allotment = elements[1].text # 買付手数料、信託報酬等の管理費 fundinfo.commision = soup.select_one('.no-fee').text costs = soup.find("li", attrs={"class", "trust-fee"}) elements = costs.find_all("td") fundinfo.cost = elements[0].text return fundinfoこの辺スクレイピングに詳しい方であればもっとスマートな記述方法があるはずですね。
で、メソッドの呼び出し元。メイン処理のファイルと分けたのでfund.pyをfundとしてimportしています。
main.pynam = fund.GetRakutenFund('https://www.rakuten-sec.co.jp/web/fund/detail/?ID=JP90C000BRT6')Excelへの連携
欲しい情報をFundInfo型のインスタンスとして取得することができました。
このデータをExcelに流し込みます。Openpyxlを使いたいのでまずはpipなどからインストールしてください。
インストールしたらimport文を書きます。exceloperator.pyimport openpyxlそしてExcel処理を実行するメソッドを定義します。
exceloperator.pydef WriteExcel(fund_info_list):今まで書いていなかったけど今回情報を取得したいURLは4つありました。
なのでFundInfoのインスタンス4つをリスト(fund_info_list)に格納して、Excel処理を実行するメソッドに引数として引き渡し、ループで処理を行いたいと思います。まずは事前に準備したExcelを読み込みます。
そして処理を行いたいワークシートを取得します。今回の場合は「ファンド」シートが対象です。exceloperator.py# rはエスケープシーケンスを無視 wb = openpyxl.load_workbook(r'Excelファイルのパス') ws = wb['ファンド']パスを引数に指定した時、Windows環境だとバックスラッシュ等が良くないぽいです。
rをつけてやるとエスケープシーケンスを無視してくれるとのこと。後はリストにぶち込んだFundInfoの各項目を対応するセルに設定していくだけです。
今回の私の場合は6列目と7列目は前回確認時との差分をとるための項目なのでデータの更新は行いません。
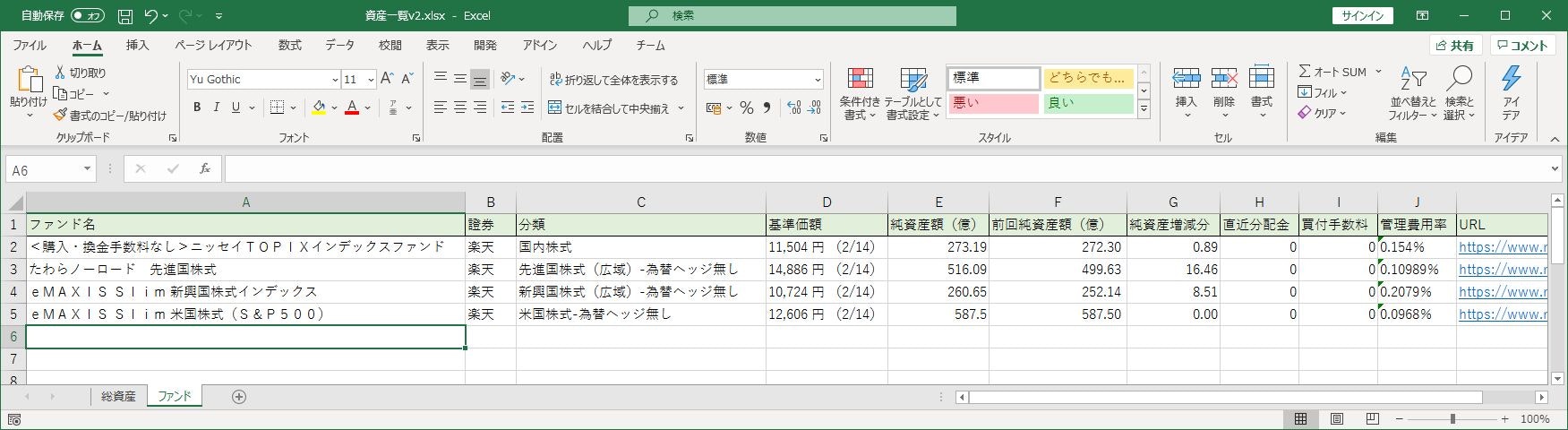
配列に詰めるやり方があるっぽい感じもありましたが、とりあえず愚直に一つずつ設定する方法を取りました。exceloperator.pyrow = 2 for fund in fund_info_list: col = 1 # 6列目、7列目は更新対象外 ws.cell(column=col, row=row, value=fund.name) col += 1 ws.cell(column=col, row=row, value=fund.company) col += 1 ws.cell(column=col, row=row, value=fund.category) col += 1 ws.cell(column=col, row=row, value=fund.baseprice) col += 1 ws.cell(column=col, row=row, value=float(fund.assets.replace(',', ''))) col += 3 ws.cell(column=col, row=row, value=int(fund.allotment)) col += 1 if fund.commision == 'なし': ws.cell(column=col, row=row, value=0) else: ws.cell(column=col, row=row, value=fund.commision) col += 1 ws.cell(column=col, row=row, value=fund.cost) row += 1あと気をつけたのは純資産額(assets)と直近分配金(allotment)は数値型として扱いたいので数値変換してセルに設定。
純資産額は1000区切りのカンマが入る可能性もあるのでカンマを取り除く処理を入れている。
買付手数料はサイトでは「なし」という表記なのだが(ぶっちゃけ私が買うのはそれonly)「なし」よりは手数料0円と扱う方が何かと楽なのでここで変換している。ああ、インクリメントが欲しい…(C#erのぼやき)
最後はきちんと保存。
開いたファイルのパスを指定すれば上書き保存してくれる。exceloperator.pywb.save(r'Excelファイルのパス')コード全容
綺麗じゃないのは初心者なので多めに見てください。
main.pyimport fund, exceloperator # メイン関数 # <購入・換金手数料なし>ニッセイTOPIXインデックスファンド nam = fund.GetRakutenFund('https://www.rakuten-sec.co.jp/web/fund/detail/?ID=JP90C000BRT6') # たわらノーロード 先進国株式 am_one = fund.GetRakutenFund('https://www.rakuten-sec.co.jp/web/fund/detail/?ID=JP90C000CMK4') # eMAXISSlim 新興国株式インデックス emax_emarging = fund.GetRakutenFund('https://www.rakuten-sec.co.jp/web/fund/detail/?ID=JP90C000F7H5') # eMAXIS Slim 米国株式(S&P500) emax_sp500 = fund.GetRakutenFund('https://www.rakuten-sec.co.jp/web/fund/detail/?ID=JP90C000GKC6') # EXCELへ書き込み fund_info_list = [nam, am_one, emax_emarging, emax_sp500] exceloperator.WriteExcel(fund_info_list)fund.py# BeautifulSoup4を使用したスクレイピング import requests, bs4 # ファンド情報クラス class FundInfo: def __init__(self): self.name = '' self.company = '' self.category = '' self.baseprice = '' self.assets = 0 self.allotment = 0 self.commision = '' self.cost = 0 # 楽天証券 def GetRakutenFund(url): res = requests.get(url) res.raise_for_status() soup = bs4.BeautifulSoup(res.text, "html.parser") fundinfo = FundInfo() # ファンド名、分類 fundinfo.name = soup.select_one('.fund-name').text fundinfo.company = '楽天' fundinfo.category = soup.select_one('.fund-type').text # 基準価額、純資産、直近分配金 fundsummary = soup.find("table", attrs={"class", "tbl-fund-summary"}) elemnt = fundsummary.select_one('.value-01') fundinfo.baseprice = elemnt.text + elemnt.nextSibling elements = fundsummary.find_all("span", attrs={"class", "value-02"}) fundinfo.assets = elements[0].text fundinfo.allotment = elements[1].text # 買付手数料、信託報酬等の管理費 fundinfo.commision = soup.select_one('.no-fee').text costs = soup.find("li", attrs={"class", "trust-fee"}) elements = costs.find_all("td") fundinfo.cost = elements[0].text return fundinfoexceloperator.py# openpyxlを使用したExcel操作 import openpyxl def WriteExcel(fund_info_list): # rはエスケープシーケンスを無視 wb = openpyxl.load_workbook(r'Excelファイルのパス') ws = wb['ファンド'] row = 2 for fund in fund_info_list: col = 1 # 6列目、7列目は更新対象外 ws.cell(column=col, row=row, value=fund.name) col += 1 ws.cell(column=col, row=row, value=fund.company) col += 1 ws.cell(column=col, row=row, value=fund.category) col += 1 ws.cell(column=col, row=row, value=fund.baseprice) col += 1 ws.cell(column=col, row=row, value=float(fund.assets.replace(',', ''))) col += 3 ws.cell(column=col, row=row, value=int(fund.allotment)) col += 1 if fund.commision == 'なし': ws.cell(column=col, row=row, value=0) else: ws.cell(column=col, row=row, value=fund.commision) col += 1 ws.cell(column=col, row=row, value=fund.cost) row += 1 wb.save(r'Excelファイルのパス')スクレイピング実行後のExcelファイル
感想
初めてまともにPythonのコードを書いたかもしれない。
望んだ動きが実現できて良かった。文法とかまだまだだなぁ…。本職が業務系である以上、仕事で使っている技術って書きづらいんだよなあ…。
ぶっちゃけ書けるネタが仕事上にはあまりない。ExcelもPythonとの連携を強めていくみたいなこと言ってたし。(xlwingsを使う方が良かったのかな?)
実はこっそりとExcel大好きなのでExcel使えるのであれば使い続けたい。(願望)

- 投稿日:2020-02-15T17:33:12+09:00
Djangoを使って将棋棋譜管理アプリを作る2 ~データベースの設定~
はじめに
Djangoを使って将棋の棋譜管理アプリを作っていくなかでの備忘録、第2回です。
作業環境
今回の作業環境は以下の通りです
- Windows 10 Pro
- Anaconda
- version1.7.2
- python 3.7
- django 2.2.5
- git
- version 2.25.0.windows.1
- mysql
- ver 8.0.15 for Win64 on x86_64
また、Djangoのディレクトリ構造は次のようになります。
- kifu_app_project/ - kifu_app_project/ - setting.py - urls.py - wsgi.py - __init__.py - manage.py - kifu_app - admin.py - apps.py - migrations - models.py - tests.py - views.py - __init__.py本稿の内容
- データベースの設定
データベースの設定
settings.pyの編集
公式ドキュメントが分かりやすいので、これを見て編集するのが一番いいと思います。
内側のkifu_app_project内にsettings.pyがあるので、これを編集します。
デフォルトではsqlite3に接続するようになっているので、これをmysqlに接続するように変更します。settings.pyDATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': 'データベース名', 'USER': 'ユーザー名', 'PASSWORD': 'パスワード', 'HOST': 'localhost', 'PORT': '3306', } }MySQLライブラリのインストール
次に以下のコマンドを入力しますが、、、
$ python manage.py migrate ModuleNotFound Error : No module named 'MySQLdb'というエラーが出てきてしまいます。
そこで検索してみると、PyMySQLをインストールすれば解決するとあったので、実行してみますが、今度は
$ python manage.py migrate mysqlclient 1.3.13 or newer is required;というエラーが出てきてしまいました。
そしてこのエラーについて調べてみると、以下のようなブログを見つけました。
Django: エラー解決法 “raise ImproperlyConfigured(‘mysqlclient 1.3.13 or newer is required; 〜) django.core.exceptions.ImproperlyConfigured: 〜”どうも、
Django側の推奨MySQL (MariaDB)ライブラリはPyMySQLではなくmysqlclient
であるらしいです。
そこで、mysqlclientをpipでインストールします。$ pip install mysqlclientそして再びmigrateを実行すると。
$ python manage.py migrate Apply all migrations: admin ~となり、うまくいきました!
Modelの作成
今回のテーブル設計
Modelとは、僕はテーブルの設計書・雛形のように捉えています。
今回は以下のテーブルを作成します。
- Informationテーブル
- 対局情報を入れる
- LargeClassテーブル
- 戦型の大分類を入れる
- MiddleClassテーブル
- 戦型の中分類を入れる
- SmallClassテーブル
- 戦型の小分類を入れる
- Kifuテーブル
- 実際に打った手を入れる
models.pyの編集
まずはInformationテーブルを作成します。
models.pyclass Information(models.Model): date = models.DateTimeField() sente = models.CharField(max_length=50) gote = models.CharField(max_length=50) result = models.IntegerField(validators=[MinValueValidator(0), MaxValueValidator(3)]) # `validatos`でバリデーション(0以上3未満) my_result = models.IntegerField(validators=[MinValueValidator(0), MaxValueValidator(3)]) small_class = models.ForeignKey(SmallClass, on_delete=models.CASCADE) # リレーションを定義 create_at = models.DateTimeField(auto_now_add=True) # 時刻を自動追加 update_at = models.DateTimeField(auto_now=True) # 時刻を自動更新(所々日本語変数がありますが、無視してください)
使用できるFieldについては、以下のページを参考にしました。
Django データベース モデルのフィールド 一覧表によるまとめ特にDjangoの便利だなぁと思う所は、テーブル同士のリレーションをかなり簡単につけられることではないでしょうか。
ForeignKey(to, on_delete, **options)で、多対1関係(toにどのモデルに関係するか)を設定できます。
これにより、後日行うクエリの取得などで、関係するデータの取得が容易になります。同様に、他のテーブルについても、定義を行います。
models.pyclass LargeClass(models.Model): name = models.CharField(max_length=10) class MiddleClass(models.Model): large_class = models.ForeignKey(LargeClass, on_delete=models.CASCADE) name = models.CharField(max_length=10) class SmallClass(models.Model): middle_class = models.ForeignKey(MiddleClass, on_delete=models.CASCADE) name = models.CharField(max_length=10) class Information(models.Model): # ~中略~ class Kifu(models.Model): information = models.ForeignKey(Information, on_delete=models.CASCADE) number = models.IntegerField(validators=[MinValueValidator(0)]) te = models.CharField(max_length=20)リレーション(ForeignKey)の関係により、この順番に記述しないとエラーが起こると思います。
migrationの実行
models.pyの編集が終わったら、以下のコマンドを実行して、実際にmigrationを行ってみましょう。
migrationとは、Modelに基づいて、SQL文を実行し、テーブルの作成などを行うことです。$ python manage.py makemigrations <アプリ名> Migrations for '~' ~\migrations\0001_initial.py - Create model ~ ... ~中略~ここはプロジェクト名ではなく、アプリ名であることに注意してください。
うまくいけば、Create model <テーブル名>という文が表示されてきます。
また、kifu_app_project\kifu_app\migrations配下に、0001_initial.pyというファイルが作成されていると思います。
このファイルは、作成したModelに基づいて、テーブルとカラムの定義を行ったものです。再び、migrateの実行
先程作成したMigrationファイルに基づいて、Migrateを行い、実際にテーブルを作成しましょう。
$ python manage.py migrate Applying kifu_app.0001_initial... OK"OK"と出れば成功です!
あとは実際にmysqlにログインして、テーブルが出来ているか確認しましょう!
次回予告
Djangoデフォルトの管理サイトの設定
- 投稿日:2020-02-15T17:10:33+09:00
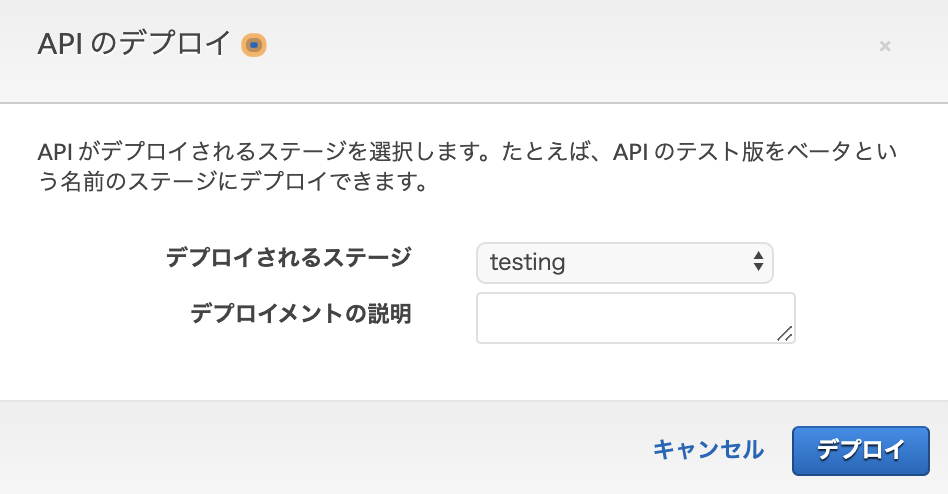
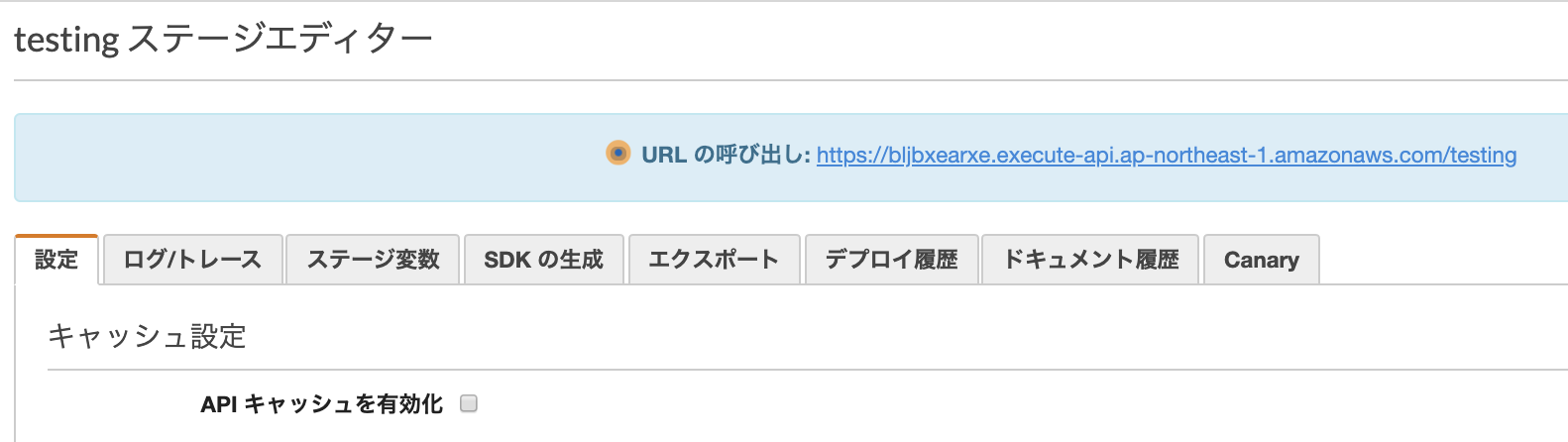
LambdaとPythonでAPI GatewayをエンドポイントにしてSlackに何かを送る
経緯
2020/02/13にJAWS-UG 初心者支部#23 次回のハンズオン勉強会向けのチューター向け予習会へ参加することになりました。
Lambdaは、花屋時代にローカル環境でテスト実行してみてQiitaに上げたきりだったので
※その時の記事 => Pythonでaws-sam-cliをローカル実行するまでもうすこし踏み込んでみたかったのと
(実用性を意識しながらLambdaを触ってみたいなぁ)
と、思った&予習も兼ねて
API GatewayをエンドポイントにしてLambdaを起動しSlackに何かを流す
というのをやってみました。API Gatewayをエンドポイントにした実行を試したいと考えた理由として
外部から連携したい場合、HTTPリクエストを受けて発火させる場面が多くあるので
これから効率化を考える際に、よく使いそうな手法として要領を掴んで慣れておきたかったからです。逆にAPI Gatewayを使わないパターンとして
AWS内のサービスを使うときは、わざわざエンドポイントを外に置かなくても
AWSのサービス同士はだいたいIAMロールを使えばAWS内でセキュアに連携できます。流れ
流れとしては
SlackでIncoming Webhookの設定をしてWebhook URLを控えます。Lambdaのコンソール上で関数を作成して
Webhook URLをその関数内で使用し、連携させます。API Gatewayのコンソール上でLambda関数を紐付けて
エンドポイントをデプロイすると、発火用のURLが発行されます。そのURLにアクセスする(HTTPリクエストが届く)と
それを合図にしてLambdaが起動して
SlackのBotが起動する、という仕組みです。Slack側の設定
Incoming Webhookの設定
まずはSlackの設定です。
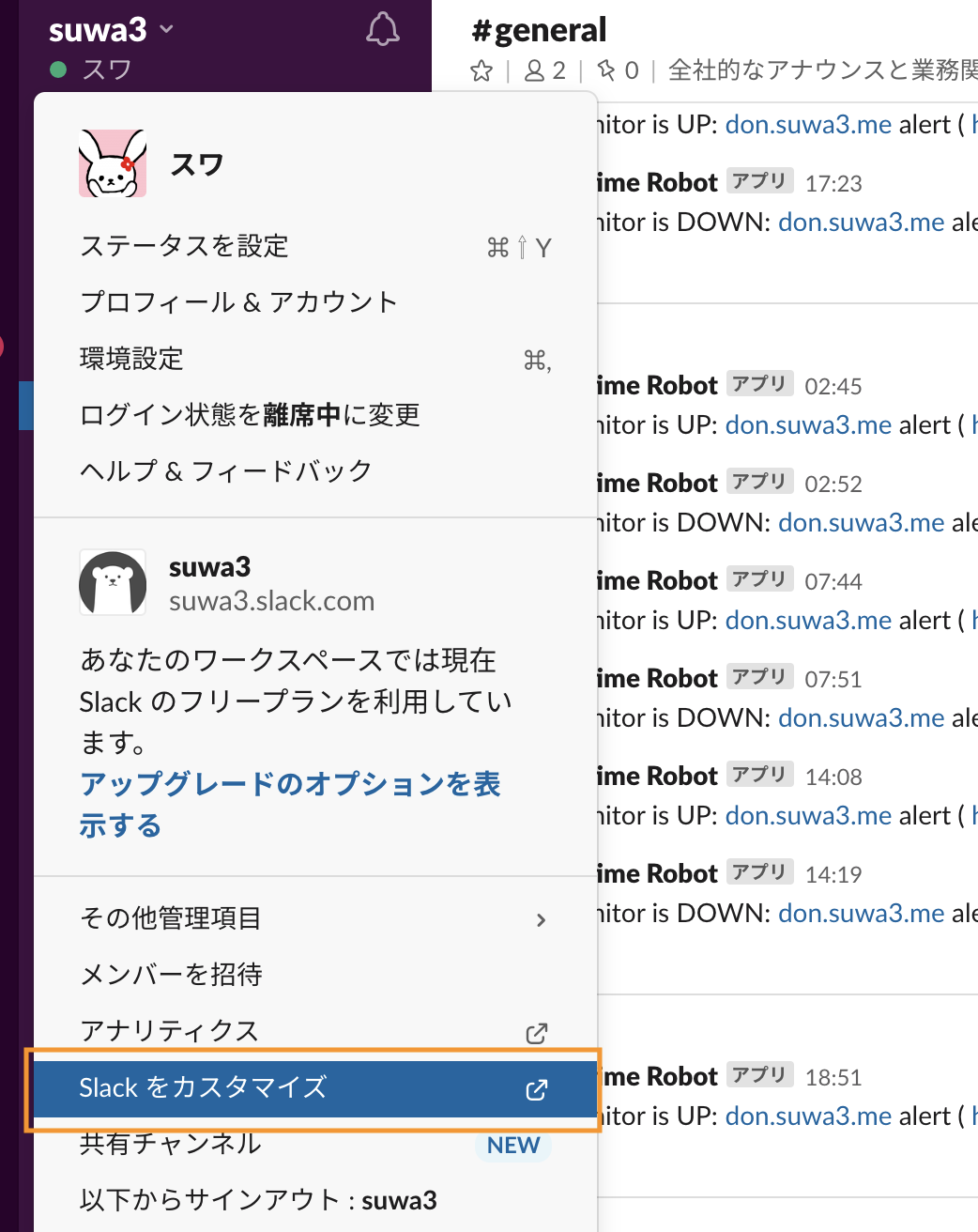
『Slackをカスタマイズ』を選択します。
左上の『MENU』から
『App 管理』を選択します。
『 Incoming Webhook』を検索し、アプリを『Slackに追加』します。
Webhook URLを控える
Botを動かしたいチャンネルを選択したら、『Incoming Webhookインテグレーションの追加』をします。
発行されたWebhook URLを控えます。
セットアップの手順も、ザックリと参考にします。
ここでBotのアイコンや名前の設定なども行えます。
Lambdaのセットアップ
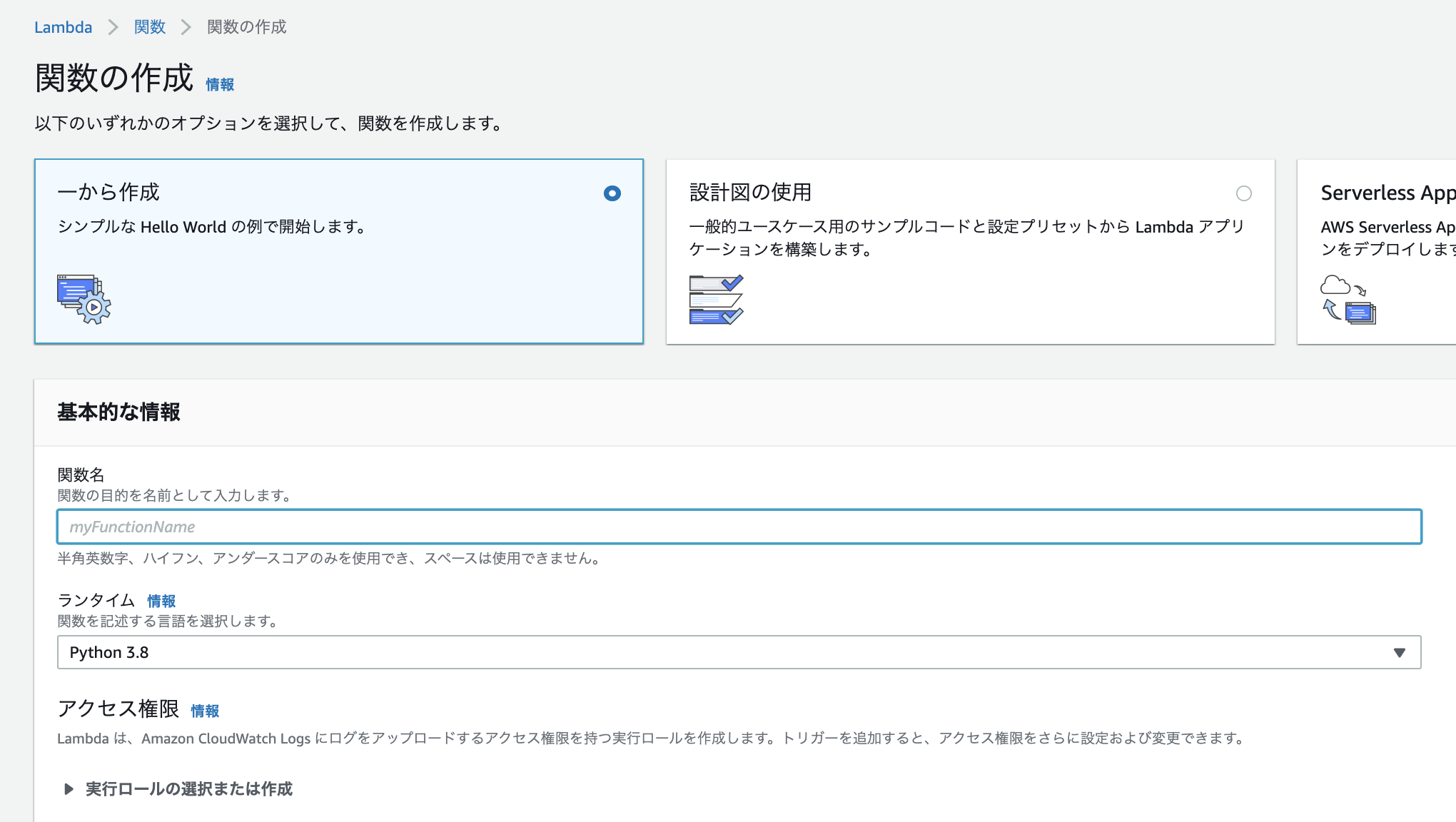
関数の作成
関数名を入力します。
myfunctionでもtestでも、わかりやすい名前でOKです。
関数を記述する言語(ランタイム)はPythonを使用します。
実行ロールの選択は、今回特にAWS内のリソースには触らないので『基本的な Lambda アクセス権限で新しいロールを作成』でOKです。
RDSやAWS内の何かと連携する場合は、必要な権限を付与してください。
関数内にWebhook URLを仕込む
Slackに表示させるプログラムを作成します。
import json import urllib.request def lambda_handler(event, context): # TODO implement post_slack() return { 'statusCode': 200, 'body': json.dumps('pong') } def post_slack(): message = """ 本日のランチを提案するクマー 1. 学食 2. スパニッシュ 3. 喫茶店 """ send_data = { "text": message, } send_text = "payload=" + json.dumps(send_data) # URLには自分のWebhook URLを入力してください request = urllib.request.Request( "https://hooks.slack.com/services/********************", data=send_text.encode('utf-8'), method="POST" ) with urllib.request.urlopen(request) as response: response_body = response.read().decode('utf-8')API GatewayでAPI作成
Lambda関数の紐付け
API Gatewayのコンソール画面から
『APIを作成』を選択して、PrivateではないREST APIの『構築』を選びます。
プロトコルの選択、諸々の設定を行います。
☑REST
☑新しいAPI
API名: My API
エンドポイントタイプ: リージョン
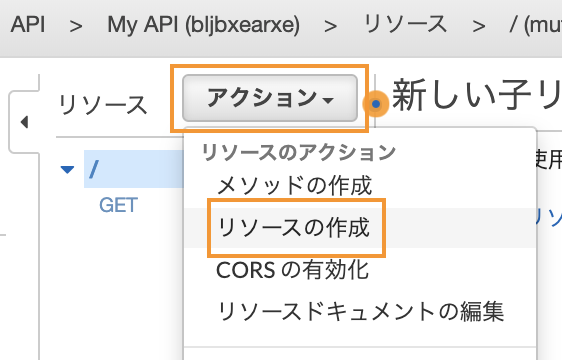
『アクション』を選択して、リソースを作成します。
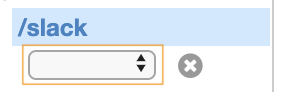
リソース名を設定します。
今回はSlackとしました。
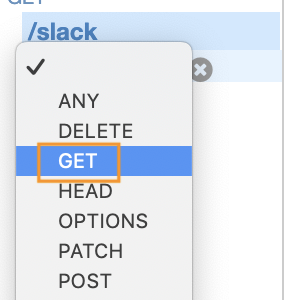
次にメソッドを作成します。
『アクション』から、『メソッドの作成』を選びます。
Slackリソースのプルダウンをクリックして
『GET』を選択します。
チェックをクリックします。
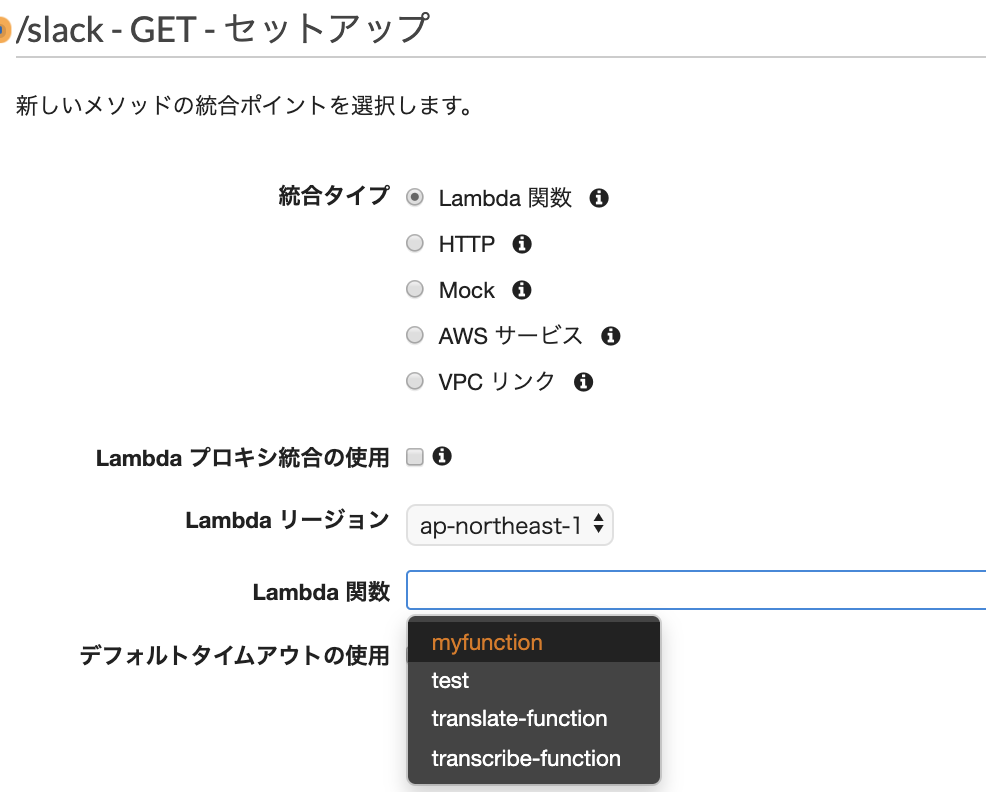
セットアップをします。
☑Lambda関数
☑Lambdaプロキシ統合の使用
Lambda関数: myfunction
クリックすると候補が表示されるので、使用したいLambda関数を選択します。
API Gatewayに、Lambda関数を呼び出す権限を与えます。
作成したAPIをデプロイします。
デプロイのステージ名を決めます。
URLが作成されるので、こちらにアクセスしてみます。
早速Slackの通知が来ました。
と、いうことは..
Slackを確認したところ
無事、届いていました?








- 投稿日:2020-02-15T16:30:29+09:00
数値をn分割にしてリスト化する方法
Background
いらすとやの画像をドット絵にしたった。(part1)で色を4分割するときに
range_color = [0, 85, 170, 255](または[ i* int(255/3) for i in range(3)])と閾値を手動で設定していました。(実質は3分割にして4つの値の近似をとっていました。)今回はちょうど割り切れたので問題なかったのですが、範囲と分割数が任意で違った値だったらどのようにアルゴリズムを設計すればいいかと思ったのでまとめてみました。
上記の例では範囲は255、分割数は3を指しています。
Method
きれいに割り切れずに余りが発生します。
その場合は最初の要素に+1を均等に足すようにします。で、方法ですが、
1. 範囲と分割数から商と余りを算出する
2. 一時的な計算用に足し算リストを作成する
3. 足し算リストをもとに要素(境界値)を計算してpushする。の流れです。
Development
import sys def main(): if len(sys.argv) != 3: print("[USAGE] you give parameters this command.") print("[EXAMPLE] python main.py [range number] [n-division number]") print("[EXAMPLE] python main.py 255 4") sys.exit() r = int(sys.argv[1]) #範囲 d = int(sys.argv[2]) #n分割数 q, mod = divmod(r, d) #商、余りの計算 #足し算リスト plus = [q + 1 if i < mod else q for i, d in enumerate(range(d - 1))] print(plus) #出力 dst = [] dst.append(plus[0]) for i in range(len(plus)): dst.append(plus[0] + sum(plus[:1 + i])) print(dst) if __name__ == '__main__': main()Comment
\W $ python main2.py 255 6 [43, 43, 43, 42, 42] [43, 86, 129, 172, 214, 256] \W $ python main2.py 255 10 [26, 26, 26, 26, 26, 25, 25, 25, 25] [26, 52, 78, 104, 130, 156, 181, 206, 231, 256]「足し算リスト」と言っているのはそれぞれの要素の間隔の値をリスト化したものです。
このリストをもとにsum(plus[:1 + i])で各要素を計算します。例) 範囲 255、 分割数 10、7つめの要素を計算したい場合
初期値 26 + [26, 26, 26, 26, 26, 25] の合計値 = 181高校数列で習った階差数列ですな。
テラナツいa_n = a_1 + \sum_{k=1}^{n-1}b_k \quad (n \geqq 2 )PostScript
何かコンテンツを作成していると小さなスケールでもアルゴリズムを少し考えることがあります。
開発者としてはqiitaのitemsが増えるので書くことに事欠かないです。Reference
- 整数をできるだけ均等になるように n分割
[(x + i) // n for i in range(n)]でできるのですね。こっちの方がシンプル。
- 投稿日:2020-02-15T15:51:55+09:00
LinkDataのデータセットをまとめてダウンロードする
LinkDataというオープンデータの共有サービスがあるのだけど,その中のデータをCSV形式でダウンロードをする時に,
アカウント単位で全部落とすような方法はないので作った.アカウントのIDを入れると,そのアカウントのリポジトリをまとめて全部or必要なものを選択してダウンロードできる.
何も選択しなければ愛知県半田市のデータがダウンロードされる.linkdata-crawler.py# encoding: utf-8 import urllib.request import urllib.parse import json import os import sys from selenium import webdriver from selenium.webdriver.chrome.options import Options from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.ui import WebDriverWait from selenium.common.exceptions import TimeoutException from selenium.webdriver.common.by import By import time import re import inquirer def main(): print(''' This script get all datasets for a specific user at LinkData.org you need chromedriver, if you don't have it `brew cask install chromedriver` Press ^C at any time to quit. ''') account_id = "" args = sys.argv if len(args) < 2: account_id = input("account id: (kouhou_handacity) ") if len(account_id) == 0: account_id = "kouhou_handacity" options = Options() options.add_argument('--disable-gpu') options.add_argument('--headless') driver = webdriver.Chrome(chrome_options=options) driver.get("https://user.linkdata.org/user/{0}/work".format(account_id)) while True: try: WebDriverWait(driver, 30).until(EC.presence_of_all_elements_located) driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") driver.find_element_by_class_name("btn-more").click() time.sleep(3) print("click") except Exception as e: print(e) break path_list = {} print("check all datasets") for user_image_path in driver.find_elements_by_class_name('entity'): dataset_name = user_image_path.find_elements_by_class_name("entity_name")[0].get_attribute("title") dataset_path = user_image_path.find_elements_by_class_name("user_image")[0].get_attribute("src") if 'rdf' in dataset_path: print("{0}: {1}".format(dataset_name, dataset_path)) path_list[str(dataset_name)] = str(dataset_path) driver.quit() repos = path_list.keys() while True: check = input("Download All Project? (y/N)") if (check == "y") or (check == ""): break elif (check == "N"): questions = [ inquirer.Checkbox( 'datasets', message="\nWhich do you want to download ?", choices=repos ) ] answers = inquirer.prompt(questions) repos = answers["datasets"] break for i, r in enumerate(repos): time.sleep(1) print("\n[{0}/{1}] check {2}".format(i+1, len(repos), r)) if not os.path.exists("datasets/"+r): print(" mkdir dastasets/{0}".format(r)) os.makedirs("datasets/" + r) req = urllib.request.Request("http://linkdata.org/api/1/{0}/datapackage.json".format(os.path.basename(path_list[r]))) with urllib.request.urlopen(req) as response: html = response.read().decode("utf-8") all_data = json.loads(html) all_project = all_data["resources"] for j, proj in enumerate(all_project): time.sleep(1) csv_name = os.path.basename(proj["url"]) csv_path = proj["url"] if not os.path.isfile("datasets/"+r+"/"+csv_name): print(" [{0}/{1}] download... {2}".format(j+1, len(all_project), csv_name)) urllib.request.urlretrieve(csv_path, "datasets/"+r+"/"+csv_name) else: print(" [{0}/{1}] {2} already exists".format(j+1, len(all_project), csv_name)) print("end") if __name__ == "__main__": main()そんな大したものは使ってないけど,依存関係のあるファイルはこれをつかてください.
requirements.txtblessings==1.7 inquirer==2.6.3 python-editor==1.0.4 readchar==2.0.1 selenium==3.141.0 six==1.12.0 urllib3==1.25.6誰かの参考になれば.

- 投稿日:2020-02-15T15:37:59+09:00
難しいことはCOTOHA APIにやらせよう ~『使って学ぶ』自然言語処理入門~
最近、目覚ましい発展を続けている自然言語処理(NLP)の世界。そんな自然言語処理の世界に入ってみたいという方も多いのではないだろうか。しかし一概に自然言語処理といえど、その言葉の中に含まれるタスクの数は膨大。
「結局何から始めればいいのー!?」
そんな声にお応えするのが本記事だ。
1 はじめに
本記事は自然言語処理ド素人でも「自然言語処理ね。色んなタスク知ってるよ、しかも使ったことある!」というレベルに引き上げることを目的としている。しかし全てのタスクを1つ1つ解説すると、とても1記事では収まらないだろう。それだけでなく、解説が詳細になるほど難易度が高くなり、結局何も得られなかったという事態にもなりかねない。
1.1 本記事のねらい
そこで本記事では難しいアルゴリズムの話はとりあえず置いておいて、誰でも気軽に自然言語処理を「使える」ことを目指す。これはただ提示するコピペを提示するという意味ではなく、便利なAPIを使うことで実装を簡略化し、その詳細を説明することで難易度を易しくするという意味だ。
難しいことはCOTOHA APIにやらせよう。
COTOHA APIはNTTグループの研究成果をもとに作られた手軽に自然言語処理を利用できるAPIだ1。難しいアルゴリズムの実装はこのAPIを叩くことで簡略化する。
APIというと難しいイメージが湧くかもしれない。しかし本APIは非常に利用が簡単であり、加えて本記事ではより丁寧・詳細に使い方を解説した(つもり)。また、将来的に難しいアルゴリズムを自分で実装してみたいと思ったときに役立つよう、本記事のサンプルコードは全てPythonで実装した。APIに関する事前知識は全く必要としない!(ので安心してほしい)
1.2 本記事で使えるようになる自然言語処理の種類
文章要約、構文解析、固有表現抽出、照応解析、キーワード抽出、2文間の類似度計算、文タイプ推定、年代・職業等の人の属性推定、言い淀み除去(あー、えーと等)、音声認識誤り検知、感情分析
これらは全てCOTOHA APIの無料ユーザー(for Developpers)で使える自然言語処理である。本記事ではこれらのタスクについて紹介し、実際に動くコードを解説する。(ただしコピペで終わらせるのは本記事の意図に反しているので、全ての自然言語処理が使える実装は提供していない。実際にコピペで動かせるのは要約、構文解析、固有表現抽出の3種類である。)
1.3 最終的な成果
例として文章要約の結果を見てみよう。以前に僕(@MonaCat)が書いたQiitaの記事を入力テキストとして要約させた。
> python cotoha_test.py -f data/input.txt -s 3 <要約> 文章要約は抽出型と生成型(抽象型)に分かれますが、現在は生成型(と抽出型を組み合わせたもの)が主流となっています。 ニューラル文章要約モデルの紹介 - エムスリーテックブログseq2seqベースの自動要約手法がまとめられています。 論文解説 Attention Is All You Need (Transformer) - ディープラーニングブログこれをまず読めば間違いありません。簡単に説明しておこう。
python cotoha_test.pyでプログラムを実行させている。また様々なオプションを引数に渡すことで、どのAPIを呼び出すかを指定できるようにした。上図では-f data/input.txt -s 3の部分がオプションである。これはinput.txtというファイルを参照し、自動要約APIを要約文数3で使用するということを指定している。そのため出力結果は3文の要約になっているはずだ。このオプションを変えることで他のAPIを使ったり、設定(例えば3文ではなく5文で要約したり)を変更できるようにした。その分、多少難しくなってしまったが、オプションの実装解説については補足とした。本筋では関係ないように配慮しているので余裕のある方だけ読んでいただければ大変うれしい。
2 自然言語処理を知ろう
実装する前に、自然言語処理について少しお勉強しておこう。自然言語とは私たちが日常で使う日本語や英語のような言語のことだ。すなわち自然言語処理とは「自然言語」を「処理」する技術分野を指す。
この章ではCOTOHA APIで使える自然言語処理技術について簡単に説明する。(一部割愛)
- 構文解析
構文解析とは文章(文字列)を形態素に分割し、その間にある構造関係を解析することをいう。例えば「私は見た」という文章は「名詞」+「助詞」+「動詞」で構成されている。構文解析することでマークアップされていない文字列の構造関係を明確にすることができる。
- 固有表現抽出
固有表現抽出は、固有名詞(人名や地名等)を自動的に抽出する技術だ。世の中には数えられないほどの固有名詞が存在するが、その全てを辞書に登録することは現実的ではない。そこで抽出を自動化することで大量のテキストを処理できるようになる。
- 照応解析
「これ」「彼」などの指示詞や代名詞は、先行詞と同じものとして使用されるが、それを読み取れるのは我々が文章を理解するときに自然とその関係性を把握しているからである。この関係を照応関係といい、これを解析する技術を照応解析という。
- キーワード抽出
キーワードは様々な意味があるが、COTOHA APIでは特徴的なフレーズ・単語を算出し、キーワードとして抽出する。つまり文章における代表的なフレーズ、単語であるとみなすことができる。
- 属性推定
属性(年代、性別、趣味、職業等)を推定する技術だ。COTOHA APIではTwitterユーザーの属性推定を目的としている。
- 言い淀み除去
言い淀み(いいよどみ)とは「あー」「うー」等の話すときに文間に挟んで使用する言葉のことである。例えば音声認識で書き起こされた文章には、テキスト化する上で不要な言い淀みが含まれてしまうことがある。このようなときに言い淀みを除去することでテキストを活用しやすいデータに処理できるようになる。
- 感情分析
感情分析(ネガポジ判定)は文章から書きての感情をネガティブ・ポジティブの2値に分類することをいう。上記で紹介した分野以上に深層学習を用いた解析が盛んな分野であろう。
- 文章要約
文章を1文or複数の文に自動で要約する技術である。最近はニュースサイトでも3文要約が付属しているのが一般的になってきた。長文から重要なフレーズ・文を解析するという点ではキーワード抽出と似ているタスクといえるだろう。
もし文章要約に興味があればこちらの記事がお勧めだ。論文紹介というタイトルをつけてはいるが、基礎から最新に近い技術までの情報をまとめたので参考になるはずだ:BERTで自動要約を行う論文「BERTSUM」を紹介する+α - Qiita
3 実際に使ってみよう
お待たせした。ではCOTOHA APIを使って自然言語処理を体験してみよう。
3.1 共通部分
まずは使いたいAPIに関わらず必要な共通部分から。
COTOHA APIは無料で登録して使えるのでCOTOHA APIから登録しよう。
登録情報には氏名や所属が必要だが、クレジットカード等の情報は必要ない。登録すると下図のような情報がもらえるだろう。
人によって異なるのはこのうち「Client ID」と「Client secret」なので後でコピペできるように準備しておこう。
3.1.1 アクセストークンの取得
ここから先はPythonで実装する。Python環境はお任せするが、必要なモジュールは使用できるようにpipなりcondaなりで適宜インストールしていただきたい。
まず、アクセストークンを取得する関数を定義する。
CLIENT_ID = '適宜書き換え' CLIENT_SECRET = '適宜書き換え' def auth(client_id, client_secret): token_url = 'https://api.ce-cotoha.com/v1/oauth/accesstokens' headers = { 'Content-Type': 'application/json', 'charset': 'UTF-8' } data = { 'grantType': 'client_credentials', 'clientId': client_id, 'clientSecret': client_secret } r = requests.post(token_url, headers=headers, data=json.dumps(data)) return r.json()['access_token'] if __name__ == "__main__": access_token = auth(CLIENT_ID, CLIENT_SECRET) # アクセストークン取得突然難しく思ったかもしれない。が、至ってシンプルだ。順番に見ていこう。
まずauth()が上述の認証情報を引数として呼び出される。
auth()では認証情報を利用してアクセストークンを取得する。スタートガイドではコマンドで取得しているが、今回は同じことをPythonで実装している。成功するとjsonファイルが取得できるが、ここで欲しいのはアクセストークンのみであることに注意しよう。そのため
r.json['access_token']を返している。このアクセストークンを利用してAPIを使用できるようになる。
3.1.2 引数を指定する(オプション)
今回のサンプルコードでは
argparseモジュールを使って引数指定できるようにしている。これは1.3節でも説明したが、引数指定できるようにしたのは、複数のAPIを使うことを想定しているので切り替えが便利だからである。本節では簡単に
argparseの説明するが、本筋とは関係ないので余裕のない方は飛ばしてほしい。ではまず先程のアクセストークンを取得する前に
if __name__ == "__main__": document = '入力テキストを指定しなかった時に使われるテキスト。本実装では「引数でテキストを指定する」「引数でテキストファイルを指定する」の2パターンが使えます。是非お試しあれ。' args = get_args(document) # 引数取得 access_token = auth(CLIENT_ID, CLIENT_SECRET) # アクセストークン取得でget_args()を呼び出そう。この関数の中身は次のようになっている。
def get_args(document): argparser = argparse.ArgumentParser(description='Cotoha APIを使って自然言語処理を遊ぶコード') argparser.add_argument('-t', '--text', type=str, default=document, help='解析したい文') argparser.add_argument('-f', '--file_name', type=str, help='解析したい.txtのpath') argparser.add_argument('-p', '--parse', action='store_true', help='構文解析するなら指定') argparser.add_argument('-s', '--summarize', type=int, help='自動要約するなら要約文数を指定') return argparser.parse_args()1行目はdescriptionでコードの説明を記述している。これは
-hをコマンドライン引数としたときに表示される。
-hを指定したときの例。> python cotoha_test.py -h usage: cotoha_test.py [-h] [-t TEXT] [-f FILE_NAME] [-p] [-s SUMMARIZE] Cotoha APIを使って自然言語処理を遊ぶコード optional arguments: -h, --help show this help message and exit -t TEXT, --text TEXT 解析したいテキスト -f FILE_NAME, --file_name FILE_NAME 解析したいテキストファイルのpath -p, --parse 構文解析 -n, --ne 固有表現抽出 -s SUMMARIZE, --summarize SUMMARIZE 自動要約における要約文数それ以降の行は
add_argumentで引数を順に定義している。当然だが、引数を設定したところで、その引数が指定された時に何が起きるか実装しなければ何も起きない。今回は
-pが指定された時には構文解析を行うようにしたい。これだけならif文で条件分岐させるだけでうまくいきそうだ。早速やってみよう。if (args.parse): parse(doc, access_token) # 関数呼び出しもし
args.parseがTrueであれば関数parseを呼び出す。関数parseはここまでで登場していないため、中身がわからないだろう。ここでは単に構文解析を実行する関数だと思ってほしい。詳しくは後の章で解説する。
args.parseこそが先程argparser.add_argumentで追加したオプションだ。args.pではなくargs.parseでなければならないことに注意。同様に例えば要約であればargs.summarizeでいい。ところで今後、構文解析や要約の他に多くのタスクをif文で条件分岐すると少し見栄えが悪い。そこで少し簡略化しておく。
# API呼び出し l = [doc, access_token] # 共通の引数 parse(*l) if (args.parse) else None # 構文解析やっていることはさっきと何も変わらないが、if文を1行で書き、共通の引数が多いことを考えlistにまとめ、それを展開して関数に渡して呼び出している。
最後に
-fでファイルを指定した時の実装をしよう。ファイルを指定した時にはそちらを優先するが、その前に指定したファイルが存在するかどうかを調べなければエラーが発生する可能性がある。# ファイルを指定した場合はそちらを優先 if (args.file_name != None and os.path.exists(args.file_name)): with open(args.file_name, 'r', encoding='utf-8') as f: doc = f.read() else: doc = args.textここまで追ってこれていれば次のような実装になっているはずだ。
import argparse import requests import json import os BASE_URL = 'https://api.ce-cotoha.com/api/dev/' CLIENT_ID = '' # 適宜書き換え CLIENT_SECRET = '' # 適宜書き換え def get_args(document): argparser = argparse.ArgumentParser(description='Cotoha APIを使って自然言語処理を遊ぶコード') argparser.add_argument('-t', '--text', type=str, default=document, help='解析したいテキスト') argparser.add_argument('-f', '--file_name', type=str, help='解析したいテキストファイルのpath') argparser.add_argument('-p', '--parse', action='store_true', help='構文解析') argparser.add_argument('-n', '--ne', action='store_true', help='固有表現抽出') argparser.add_argument('-c', '--coreference', action='store_true', help='照応解析') argparser.add_argument('-k', '--keyword', action='store_true', help='キーワード抽出') argparser.add_argument('-s', '--summarize', type=int, help='自動要約における要約文数') return argparser.parse_args() def auth(client_id, client_secret): """ アクセストークンを取得する関数 """ token_url = 'https://api.ce-cotoha.com/v1/oauth/accesstokens' headers = { 'Content-Type': 'application/json', 'charset': 'UTF-8' } data = { 'grantType': 'client_credentials', 'clientId': client_id, 'clientSecret': client_secret } r = requests.post(token_url, headers=headers, data=json.dumps(data)) return r.json()['access_token'] def base_api(data, document, api_url, access_token): """ 全てのAPIで共通となるheader等 """ base_url = BASE_URL headers = { 'Content-Type': 'application/json; charset=UTF-8', 'Authorization': 'Bearer {}'.format(access_token) } r = requests.post(base_url + api_url, headers=headers, data=json.dumps(data)) return r.json() if __name__ == "__main__": doc = '昨日、マイケルと東京駅で待ち合わせした。彼とはひと月前から付き合い始めた。' args = get_args(doc) # 引数取得 # ファイルを指定した場合はそちらを優先 if (args.file_name != None and os.path.exists(args.file_name)): with open(args.file_name, 'r', encoding='utf-8') as f: doc = f.read() else: doc = args.text access_token = auth(CLIENT_ID, CLIENT_SECRET) # アクセストークン取得 # API呼び出し l = [doc, access_token] # 共通の引数 parse(*l) if (args.parse) else None # 構文解析 ne(*l) if (args.ne) else None # 固有表現抽出 coreference(*l) if (args.coreference) else None # 照応解析 keyword(*l) if (args.keyword) else None # キーワード抽出 summarize(*l, args.summarize) if (args.summarize) else None # 要約当然まだこのプログラムは動かない。parse()やne()などの関数を定義していないからだ。それは次の節以降で実装する。
3.2 タスクごとに異なる部分
3.1.2を飛ばした方のためにここでは次のプログラムのように、構文解析のみを実行するプログラムを使用する。
import argparse import requests import json import os BASE_URL = 'https://api.ce-cotoha.com/api/dev/' CLIENT_ID = '適宜書き換え' CLIENT_SECRET = '適宜書き換え' def auth(client_id, client_secret): """ アクセストークンを取得する関数 """ token_url = 'https://api.ce-cotoha.com/v1/oauth/accesstokens' headers = { 'Content-Type': 'application/json; charset: UTF-8', } data = { 'grantType': 'client_credentials', 'clientId': client_id, 'clientSecret': client_secret } r = requests.post(token_url, headers=headers, data=json.dumps(data)) return r.json()['access_token'] if __name__ == "__main__": doc = '昨日、マイケルと東京駅で待ち合わせした。彼とはひと月前から付き合い始めた。' access_token = auth(CLIENT_ID, CLIENT_SECRET) # アクセストークン取得 parse(doc, access_token) # 構文解析3.1.2を追ってこれた人はそっちの実装をそのまま使ってもらえればいい。どちらにしてもここで実装するのはparse(), ne()などのAPIを呼び出して自然言語処理を行う関数だ。
3.2.1 構文解析
構文解析のリファレンスを読むとリクエストヘッダ、リクエストボディなどがあり、何やらキーを指定する必要があることがわかるだろう。しかし実はリクエストヘッダは全てのCOTOHA APIで共通している。そこでリクエストヘッダなどの共通部分はbase_api()という関数で実装し、構文解析ならではの部分はparse()という関数で実装する。
def base_api(data, document, api_url, access_token): """ 全てのAPIで共通となるheader等 """ base_url = BASE_URL headers = { 'Content-Type': 'application/json; charset=UTF-8', 'Authorization': 'Bearer {}'.format(access_token) } r = requests.post(base_url + api_url, headers=headers, data=json.dumps(data)) return r.json() def parse(sentence, access_token): """ 構文解析 """ data = {'sentence': sentence} result = base_api(data, sentence, 'nlp/v1/parse', access_token) print('\n<構文解析>\n') result_list = list() for chunks in result['result']: for token in chunks['tokens']: result_list.append(token['form']) print(' '.join(result_list))base_api()から見ていこう。headersで指定しているのが先程見たばかりのリクエストヘッダだ。この値とリクエストボディ、解析したい文章、APIのURLを引数にしてリクエストを送っていることがわかる。最後に得られたjsonファイルを返している。
parse()では最初に変数dataでリクエストボディを指定している。今回はキーsentenceを変数sentenceで指定している(何言ってるんだと思うかもしれないが、そのままの意味だ)。
続いてresult変数の中にbase_api()の値、つまりjsonファイルがはいっている。
このjsonファイルには構文解析の実行結果がはいっているので、これを読み取る。どんな形式で書かれているかは同じリファレンスのレスポンスサンプルに書かれている。構文解析のレスポンスサンプルを読むと、どうやら形態素情報オブジェクトのキーformが求めていたもののようなので、これをリストに追加していく。
これを実行すると次のような結果が得られるだろう。
> python cotoha_test.py <構文解析> 昨日 、 マイケル と 東京駅 で 待ち 合わせ し た 。 彼 と は ひと月 前 から 付き合 い 始め た 。3.2.2 固有表現抽出
続いて固有表現抽出だが、先程と同じ説明を繰り返すだけになるので割愛する。実はさっきと同じように他のほとんどのAPIも使えてしまう。
def ne(sentence, access_token): """ 固有表現抽出 """ data = {'sentence': sentence} result = base_api(data, sentence, 'nlp/v1/ne', access_token) print('\n<固有表現抽出>\n') result_list = list() for chunks in result['result']: result_list.append(chunks['form']) print(', '.join(result_list))> python cotoha_test.py <固有表現抽出> 昨日, マイケル, 東京駅, ひと月3.2.3 要約
せっかくなので少し違うことをしてみよう。要約のリファレンスを読むとリクエストボディに要約文数が指定できる
sent_lenがあるだろう。これもせっかくなので使ってみたい。def summarize(document, access_token, sent_len): """ 要約 """ data = { 'document': document, 'sent_len': sent_len } result = base_api(data, document, 'nlp/beta/summary', access_token) print('\n<要約>\n') result_list = list() for result in result['result']: result_list.append(result) print(''.join(result_list))これで
sent_lenに具体的な値を入れれば好きな要約文数で要約できるようになった。もし3.1.2のオプションを実装できているならば引数でsent_lenを指定できるので便利だろう。> python cotoha_test.py -s 1 <要約> 昨日、マイケルと東京駅で待ち合わせした。3.3.3 その他の自然言語処理
他のAPIについても同様に実装できるので割愛する。
4 まとめ
最後に構文解析、固有表現抽出、要約の実行ができるプログラムを提示してまとめとする。繰り返しになるが、他のAPIについても同様に実装できるので、自然言語処理に興味を持っていただけた方はぜひ自分の力で実装してみてほしい。
import argparse import requests import json import os BASE_URL = 'https://api.ce-cotoha.com/api/dev/' CLIENT_ID = '' # 適宜書き換え CLIENT_SECRET = '' # 適宜書き換え def get_args(document): argparser = argparse.ArgumentParser(description='Cotoha APIを使って自然言語処理を遊ぶコード') argparser.add_argument('-t', '--text', type=str, default=document, help='解析したいテキスト') argparser.add_argument('-f', '--file_name', type=str, help='解析したいテキストファイルのpath') argparser.add_argument('-p', '--parse', action='store_true', help='構文解析') argparser.add_argument('-n', '--ne', action='store_true', help='固有表現抽出') argparser.add_argument('-s', '--summarize', type=int, help='自動要約における要約文数') return argparser.parse_args() def auth(client_id, client_secret): """ アクセストークンを取得する関数 """ token_url = 'https://api.ce-cotoha.com/v1/oauth/accesstokens' headers = { 'Content-Type': 'application/json', 'charset': 'UTF-8' } data = { 'grantType': 'client_credentials', 'clientId': client_id, 'clientSecret': client_secret } r = requests.post(token_url, headers=headers, data=json.dumps(data)) return r.json()['access_token'] def base_api(data, document, api_url, access_token): """ 全てのAPIで共通となるheader等 """ base_url = BASE_URL headers = { 'Content-Type': 'application/json; charset=UTF-8', 'Authorization': 'Bearer {}'.format(access_token) } r = requests.post(base_url + api_url, headers=headers, data=json.dumps(data)) return r.json() def parse(sentence, access_token): """ 構文解析 """ data = {'sentence': sentence} result = base_api(data, sentence, 'nlp/v1/parse', access_token) print('\n<構文解析>\n') result_list = list() for chunks in result['result']: for token in chunks['tokens']: result_list.append(token['form']) print(' '.join(result_list)) def ne(sentence, access_token): """ 固有表現抽出 """ data = {'sentence': sentence} result = base_api(data, sentence, 'nlp/v1/ne', access_token) print('\n<固有表現抽出>\n') result_list = list() for chunks in result['result']: result_list.append(chunks['form']) print(', '.join(result_list)) def summarize(document, access_token, sent_len): """ 要約 """ data = { 'document': document, 'sent_len': sent_len } result = base_api(data, document, 'nlp/beta/summary', access_token) print('\n<要約>\n') result_list = list() for result in result['result']: result_list.append(result) print(''.join(result_list)) if __name__ == "__main__": doc = '昨日、マイケルと東京駅で待ち合わせした。彼とはひと月前から付き合い始めた。' args = get_args(doc) # 引数取得 # ファイルを指定した場合はそちらを優先 if (args.file_name != None and os.path.exists(args.file_name)): with open(args.file_name, 'r', encoding='utf-8') as f: doc = f.read() else: doc = args.text access_token = auth(CLIENT_ID, CLIENT_SECRET) # アクセストークン取得 # API呼び出し l = [doc, access_token] # 共通の引数 parse(*l) if (args.parse) else None # 構文解析 ne(*l) if (args.ne) else None # 固有表現抽出 summarize(*l, args.summarize) if (args.summarize) else None # 要約
商用プラン(for Enterpriseプラン)では辞書の種類やコール数の制限が緩くなるだけでなく、音声認識や音声合成のAPIも使えるようになります。しかし個人で使うには現実的でないので本記事では扱っていません。 ↩

- 投稿日:2020-02-15T15:07:41+09:00
CentOS 6.x ERROR: The Python ssl extension was not compiled. Missing the OpenSSL lib? 対策
要旨
CentOS 6.x系でpyenvでPython 3.7異常をインストールしようとすると、エラーが起きてインストールできない場合の対応。
ちょっと危なっかしいので実際に行う時はテストサーバーなどで十分に検証してください。事前確認
# yum install gcc zlib-devel bzip2 bzip2-devel readline-devel sqlite sqlite-devel openssl-devel tk-devel libffi-devel -y # pyenv install -v 3.7.1 ERROR: The Python ssl extension was not compiled. Missing the OpenSSL lib?原因と対策
OpenSSLのバージョンが1.0系だと起きるっぽい。yum でインストールしても 1.0系以上は入らないため、1.1.1をソースからデフォルトの場所以外にインストールするという手を使う。
/usr/local/openssl-1.1.1にインストールOpenSSL 1.1.1のインストールと設定
# curl https://www.openssl.org/source/openssl-1.1.1.tar.gz -o /usr/local/src/openssl-1.1.1.tar.gz # cd /usr/local/src/ # tar xvzf openssl-1.1.1.tar.gz # cd openssl-1.1.1 # ./config --prefix=/usr/local/openssl-1.1.1 shared zlib # make # make install/etc/ld.so.conf.d/にファイルを作成して、「/usr/local/openssl-1.1.1/lib/」と記述、反映
# vi /etc/ld.so.conf.d/openssl-1.1.1.conf # ldconfig確認
# /usr/local/openssl-1.1.1/bin/openssl ciphers -v TLSv1.3 TLS_AES_256_GCM_SHA384 TLSv1.3 Kx=any Au=any Enc=AESGCM(256) Mac=AEAD TLS_CHACHA20_POLY1305_SHA256 TLSv1.3 Kx=any Au=any Enc=CHACHA20/POLY1305(256) Mac=AEAD TLS_AES_128_GCM_SHA256 TLSv1.3 Kx=any Au=any Enc=AESGCM(128) Mac=AEADインストール
CONFIGURE_OPTSでconfigure時のオプションと同じ指定ができる
# CONFIGURE_OPTS="--with-openssl=/usr/local/openssl-1.1.1/" pyenv install -v 3.8.0ついでに
ちょっとしたPythonの実行なら環境を整備しなくても
google colab notebook で実行できます。
https://colab.research.google.com/notebooks/welcome.ipynb?hl=jaTA-Libのインストールまでできます。
!wget http://prdownloads.sourceforge.net/ta-lib/ta-lib-0.4.0-src.tar.gz !tar -xzvf ta-lib-0.4.0-src.tar.gz %cd ta-lib !./configure --prefix=/usr !make !make install !pip install Ta-Lib import talib
- 投稿日:2020-02-15T14:53:51+09:00
py-isortの実装を探る
py-isortの実装を探る
(use-package py-isort :ensure t)
Pythonのimportの規則
- Imports are always put at the top of the file, just after any module comments and docstrings, and before module globals and constants. Imports should be grouped in the following order: 1. Standard library imports. 2. Related third party imports. 3. Local application/library specific imports. You should put a blank line between each group of imports.(https://github.com/python/peps/blob/f5ce32302fd799022ce8f349b46b1e7d0314286f/pep-0008.txt#L355-L357 から引用)
importのグループ化の順序に関する規則性
- 標準ライブラリのインポート
- 関連するサードパーティのインポート
- ローカルアプリケーション/ライブラリ固有のインポート
isortとは
- Pythonのサードパーティパッケージ (標準ではない)
- `import …文` もしくは `from … import …文` を並び替えてくれる
isortの実行例
https://camo.githubusercontent.com/841a7830ea6e8d363a53214917144b259685cc15/68747470733a2f2f7261772e6769746875622e636f6d2f74696d6f74687963726f736c65792f69736f72742f646576656c6f702f6578616d706c652e676966
(https://github.com/timothycrosley/isort から)
isortのインストールと主な使い方
- インストール https://github.com/timothycrosley/isort#installing-isort
- 使い方 https://github.com/timothycrosley/isort#using-isort
py-isort
py-isortとは
- isortをEmacsから使うためのEmacsのサードパーティパッケージ
- https://github.com/paetzke/py-isort.el
- 180行しかない
- `py-isort-region` や `py-isort-buffer` が提供されている
py-isort-regionとは
- regionを指定してisortを実行する関数
- region内のimport文がいい感じにsortされる
ここからだいたいEmacs Lispでの実装の話
py-isort-region
(defun py-isort-region () "Uses the \"isort\" tool to reformat the current region." (interactive) (py-isort--call t))
- `py-isort–call` を呼び出し
py-isort–call
(defun py-isort--call (only-on-region) (py-isort-bf--apply-executable-to-buffer "isort" 'py-isort--call-executable only-on-region "py"))
- `only-on-region` には `t` が渡されてくる.
- `py-isort-bf–apply-executable-to-buffer` を呼び出し
- `py-isort–call-executable` のシンボルを渡している
py-isort–call-executable
(defun py-isort--call-executable (errbuf file) (let ((default-directory (py-isort--find-settings-path))) (zerop (apply 'call-process "isort" nil errbuf nil (append `(" " , file, " ", (concat "--settings-path=" default-directory)) py-isort-options)))))
- `call-process` で外部プログラム(今回の場合はisort)を同期的に呼び出し
- `file` には一時ファイルのパスが渡される
- 設定ファイルの場所をカレントディレクトリに設定
isort 一時ファイルへのパス --settings-path=設定ファイルへのパス [その他の設定]つまり実際に実行されるコマンドは次の通りになる。
(defcustom py-isort-options nil "Options used for isort." :group 'py-isort :type '(repeat (string :tag "option")))その他の設定は `py-isort-options` にあらかじめ値を設定することで動作をカスタマイズできる。
py-isort–find-settings-path
(defun py-isort--find-settings-path () (expand-file-name (or (locate-dominating-file buffer-file-name ".isort.cfg") (file-name-directory buffer-file-name))))
- isortの設定ファイルのパスを返す
- `expand-file-name` はfilename を絶対パス名に変換するEmacsの標準関数
(expand-file-name "foo") => "/xcssun/users/rms/lewis/foo"例えばこんな感じ。
(http://flex.phys.tohoku.ac.jp/texi/eljman/eljman_158.html から引用)
- `locate-dominating-file` ディレクトリツリーを親方向に辿って `name` で指定されたファイルやディレクトリを探し出す関数
- `(locate-dominating-file buffer-file-name ".isort.cfg")` 親方向に `.isort.cfg` という名称のisortの設定ファイルを探している
- `file-name-directory` ファイルが入っているディレクトリまでのパスを返す.
- `buffer-file-name` 現在のバッファのファイルパスが入っている
py-isort-bf–apply-executable-to-buffer
py-isortではこの関数が中心的な役割を果たしている。
(defun py-isort-bf--apply-executable-to-buffer (executable-name executable-call only-on-region file-extension) "Formats the current buffer according to the executable" (when (not (executable-find executable-name)) (error (format "%s command not found." executable-name)))`executable-find` でisortコマンドを探している。なければerrorして終了。
(let ((tmpfile (make-temp-file executable-name nil (concat "." file-extension)))一時ファイルを作成している。file-extentionには `"py"` が渡されてくるので拡張子は `.py` となる。
(patchbuf (get-buffer-create (format "*%s patch*" executable-name))) (errbuf (get-buffer-create (format "*%s Errors*" executable-name)))処理に必要なバッファを作成する。
変数名 用途 patchbuf diffの出力を受けるためのバッファ errbuf isortコマンドのエラー出力を受けるためのバッファ
(coding-system-for-read buffer-file-coding-system) (coding-system-for-write buffer-file-coding-system))対象ファイルのコーディングシステムを取得して変数に保持する。
(with-current-buffer errbuf (setq buffer-read-only nil) (erase-buffer)) (with-current-buffer patchbuf (erase-buffer))エラーバッファおよびパッチバッファを初期化する。
(if (and only-on-region (use-region-p)) (write-region (region-beginning) (region-end) tmpfile) (write-region nil nil tmpfile))`(use-region-p)` はリージョン選択時にtになる。
実行関数 リージョン 対象となる範囲 意味合い py-isort-region 指定あり リージョン 選択したリージョンに対してisortを実行 py-isort-region 指定なし バッファ リージョンが選択されていないのでバッファ全体に対してisortを実行 py-isort-buffer 指定あり バッファ 選択したリージョンを無視しバッファ全体に対してisortを実行 py-isort-buffer 指定なし バッファ バッファに対してisortを実行
(if (funcall executable-call errbuf tmpfile)`executable-call` は `py-isort–call-executable` のシンボル。
(if (zerop (call-process-region (point-min) (point-max) "diff" nil patchbuf nil "-n" "-" tmpfile))
- diffを実行
- 対象のバッファ全体をdiffコマンドの標準入力に渡す
- 対象のバッファ全体とtmpfileを `diff -n` で差分をとってpatchbufに出力している。
-n --rcs Output an RCS format diff.`-n` はRCS形式のフォーマットである。
(`diff –help`の一部を抜粋)
d1 1 a1 1 from __future__ import absolute_import d4 5 d11 7 a17 3 from my_lib import Object, Object2, Object3 from third_party import (lib1, lib2, lib3, lib4, lib5, lib6, lib7, lib8, lib9, lib10, lib11, lib12, lib13, lib14, lib15)patchbufには次のようなデータが出力される。
RCSとはRevision Control Systemのこと。RCSの解説はここではしない。
RCSについてはGNUのRCSのページから情報を辿れる。
(progn (kill-buffer errbuf) (message (format "Buffer is already %sed" executable-name)))diffコマンドが0を返す場合は差分がないためこの時点でerrbufを削除して、メッセージを表示し終了する。
(if only-on-region (py-isort-bf--replace-region tmpfile) (py-isort-bf--apply-rcs-patch patchbuf))
only-on-regionがnon nil
リージョンの範囲内のみを書き換える必要があるので
差分ではなくtmpfileの内容で置き換える(2.7.6)。only-on-regionがnil
バッファ全体に対して適応するため
先ほどdiffコマンドで生成した内容でpatchを当てる(2.7.7)。
(kill-buffer errbuf) (message (format "Applied %s" executable-name))) (error (format "Could not apply %s. Check *%s Errors* for details" executable-name executable-name))) (kill-buffer patchbuf) (delete-file tmpfile)))後始末をする。
- patchbufを削除
- 一時ファイルを削除。
py-isort-bf–replace-region
(defun py-isort-bf--replace-region (filename) (delete-region (region-beginning) (region-end)) (insert-file-contents filename))
- 単純にregionの範囲内を全て消して、filenameで指定したファイルの中身をinsertしている。
py-isort-bf–apply-rcs-patch
(defun py-isort-bf--apply-rcs-patch (patch-buffer) "Apply an RCS-formatted diff from PATCH-BUFFER to the current buffer." (let ((target-buffer (current-buffer)) (line-offset 0)) (save-excursion (with-current-buffer patch-buffer (goto-char (point-min)) (while (not (eobp))
- RCS形式のdiffを自力でパッチする
- `(eobp)` はポイントがバッファの最後にある場合 `t` を返す。
http://flex.phys.tohoku.ac.jp/texi/eljman/eljman_196.html
(unless (looking-at "^\\([ad]\\)\\([0-9]+\\) \\([0-9]+\\)") (error "invalid rcs patch or internal error in py-isort-bf--apply-rcs-patch"))`looking-at` はカレントバッファ中のポイントの後に(すぐ)続くテキストが正規表現 regexp にマッチするか否かを調べる。
http://flex.phys.tohoku.ac.jp/texi/eljman/eljman_220.html
(forward-line) (let ((action (match-string 1)) (from (string-to-number (match-string 2))) (len (string-to-number (match-string 3))))`match-string` は最後の検索でマッチした文字列を返す。
(cond ((equal action "a") (let ((start (point))) (forward-line len) (let ((text (buffer-substring start (point)))) (with-current-buffer target-buffer (setq line-offset (- line-offset len)) (goto-char (point-min)) (forward-line (- from len line-offset)) (insert text)))))行頭がaだった時の挙動。行の追加を表現している。
((equal action "d") (with-current-buffer target-buffer (goto-char (point-min)) (forward-line (- from line-offset 1)) (setq line-offset (+ line-offset len)) (kill-whole-line len)))行頭がdだった時の挙動。行の削除を表現している。
(t (error "invalid rcs patch or internal error in py-isort-bf-apply--rcs-patch")))))))))それ以外の文字列を受け取ったらエラーとして処理する。
py-isort-regionはこんな実装
- 一時ファイルを作成しisortをcall-processで呼び出して整形
- バッファ全体に関しては差分をRCS形式で取得
- 差分を当てるのは外部プロセスではなくて自前で編集関数を実装している
雑感
- py-isortの詳しい動きが学べた
- 呼びだす外部プロセスを変更すれば他の編集コマンドも実装できそう
- エディタのプラグインを読むのもたまにはいいかも
- 投稿日:2020-02-15T13:52:02+09:00
COTOHA APIは漫才を理解できるのか、調査したらまずまずだった
はじめに
本記事は、Qiita x COTOHA APIプレゼント企画にエントリーしています。
COTOHA APIとは?
NTTコミュニケーションズ社が提供するNTTグループの40年以上の研究成果を活かした自然言語処理技術や音声認識・合成技術を、APIでお手軽に利用できるよう提供しているサービスです。
構文解析や固有表現抽出などの自然言語処理や、特徴的な「要約」や「ユーザ属性推定」なども利用可能。
■サービス紹介リンク
https://api.ce-cotoha.com/contents/index.htmlミルクボーイさんとは?
ミルクボーイは、吉本興業に所属する男性お笑いコンビ。2007年7月結成。2019年M-1王者。
M-1 1stステージでは「コーンフレーク」を題材に、コーンフレークに該当しそうな特徴と該当しなさそうな特徴を軽妙な掛け合いにあわせて展開するネタを披露。
歴代最高得点となる「681点」を記録!
ネタはこちら===技術関係なくなるので割愛===
調査してみた
ようやく本題です。このミルクボーイの漫才は「対象物にあてはまりそうな特徴」と「あてはまらなさそうな特徴」を繰り返して笑いを生み出しています。
この漫才はもしかして、意味読解が得意なAI、つまりCOTOHAなら理解できるのでは?注釈:「理解できる」というだけで、面白さやユーモアは対象にしていません
まずは認証しよう
・COTOHA APIには無料のDeveloperプランがあるのでまずは登録。
・ポータルから、Client IDとClient Secretを取得#PythonでCOTOHA APIの認証 import requests,json def authorization(): cotoha_url_auth = "https://api.ce-cotoha.com/v1/oauth/accesstokens" headers = {"Content-Type" : "application/json"} data = { "grantType" : "client_credentials", "clientId" : cotoha_clientId, #ここにユーザ固有の値 "clientSecret" : cotoha_clientSecret #ここにユーザ固有の値 } res = requests.post(cotoha_url_auth, headers=headers, json=data) token = json.loads(res.text)["access_token"] #print("COTOHA API 認証しました") return token #アクセストークンの文字列を返して終わり類似度判定APIを使ってみる
今回使うのはCOTOHA APIの中でも「類似度判定」を使います類似度判定とは?
2つの文における意味的な類似度を算出するRESTful API です。
類似度は0-1の定義域で出力し、1に近づくほど2つの文において類似性が大きいことを示します。
文章に含まれる単語の意味情報を用いて類似度を算出しているため、異なった単語を含むテキスト間の類似性も推定することができます。#類似度判定 def similar(sentence1, sentence2, token): url = "https://api.ce-cotoha.com/api/dev" + "/nlp/v1/similarity" header = { "Content-Type" : "application/json;charset=UTF-8", "Authorization" : "Bearer " +token } data = { "s1" : sentence1, "s2" : sentence2 } req = requests.post(url, headers = header, json = data) return req.text
tokenには先ほどの認証で出力されたAccesstokenを使ってください。
文を2つ並べて、リクエストすれば類似度が返ってきます。例 :("私は運動が得意です", "僕はスポーツが大好きです")
⇒類似度: {'result': {'score': 0.94150746}, 'status': 0, 'message': 'OK'}同じ単語はほぼないのに、この一致率・・・!素晴らしい!
さあいよいよコーンフレーク判定だ
前置きが長くなりましたが、先ほどの二つを組み合わせて、さらっと加工して、
入力された文がコーンフレークかどうかを判定する関数を作りました。#コーンフレーク関数 def cornflake(sentence, obj = "コーンフレーク"): try: token = authorization() sim = float(json.loads(similar(obj, sentence, token))["result"]["score"]) if sim>0.4: rep = "それ、" + obj + "やないかい!(類似度:{:.2f})".format(sim) else: rep = "ほな" + obj + "とちゃうなぁ(類似度:{:.2f})".format(sim) except: rep = "APIリクエスト時にエラーが発生しました" return rep作りました。無駄に、引数
objを指定すればコーンフレーク以外も判定できる仕様です。調査開始
注意:ここから先は、「ミルクボーイ」さんのネタバレを含みます。ご注意ください!!
おかんの好きな朝ごはん一緒に考えてあげるから、どんな特徴言うてたかとか教えてみてよ。
cornflake("甘くてカリカリしてて牛乳とかかけて食べる")出力:'それ、コーンフレークやないかい!(類似度:0.74)'
cornflake("おかんが言うには、死ぬ前の最後のご飯もそれでいい。")出力:'ほなコーンフレークとちゃうなぁ(類似度:0.25)'
cornflake("なんであんなに栄養バランスの五角形が広いのかわからない。")出力: 'ほなコーンフレークとちゃうなぁ(類似度:0.16)'
cornflake("食べてるとき生産者の顔が浮かばない。")
出力: 'それ、コーンフレークやないかい!(類似度:0.56)'
cornflake("おかんが言うには、ジャンルでいうなら中華。")出力:'ほなコーンフレークとちゃうなぁ(類似度:0.15)'
結果講評
コーンフレークのような気もしてきた。。。
今回使った類似度判定は、あくまで 「文と文の意味的類似度を判定する」 ものなのですが、それが 「対象物の特徴を持っているかどうかを判定する。」 という目的でもまあまあの精度 になるようです。
(上記以外にもいろいろ試しましたが、全体的に類似度が低く出る傾向でした。考えてみれば、「コーンフレーク」と「栄養バランスの五角形が広い」は同じ意味ではないので、それはそうですね。。。
オチ
cornflake("日本語に強いサービスを提供している会社があるらしい","NTT")出力:'それ、NTTやないかい!(類似度:0.44)'
どうも、ありがとうございましたー。
- 投稿日:2020-02-15T13:45:16+09:00
jupyter lab の extension を install するためには git が必要な場合あり
jupyter lab に関わる環境構築の Tips です。2020年2月のメモです。
前提
Windows10, anaconda (miniconda)
python 3.7.6
jupyterlab 1.2.6
nodejs 13.8.0
conda install -c conda-forge jupyterlab
conda install -c conda-forge nodejsなどで作った環境です。
インストールできない状態
インストラクション通りに node.js をインストールしても、extension のインストールに失敗します。エラーログに、こういう記載がありました。
jupyterlab-debug-xxxxxxxx.log...... yarn install v1.15.2 [1/5] Validating package.json... [2/5] Resolving packages... error Couldn't find the binary git ......明示されていない前提条件として、コマンドラインで git が使える必要がある場合があるようです。(そもそもなぜ git が入ってないのか、とは聞かないでください)
対策
安直ですが、git も conda で入れてしまいます。
conda install git jupyter labextension install @jupyter-widgets/jupyterlab-manager k3dエラー無く機能拡張がインストールできるようになりました。
- 投稿日:2020-02-15T13:30:05+09:00
Pythonの関数デコレータをClassで作る
前の記事で、デコレータを関数定義としてフレームワーク作成しました。
今回は、それを前提に、Class で実装してみます。(Class デコレータではありません。関数デコレータの Class 定義です)「デコレータとは」というところから説明が必要な場合は、以前の投稿(「デコレータ(decorator) とは - Python の汎用デコレータ(decorator)フレームワークを作る」) をご覧ください。
「class によるデコレータの応用」では、継承を利用した class 型デコレータの応用方法を記載しています。
- 引数のないデコレータ Class
- 引数のあるデコレータ Class
- 引数の有無を統合
- 最後の仕上げ
- class によるデコレータの応用
- 継承したクラス(サブクラス)でデコレータを実装
- 親クラス(スーパークラス)のデコレータを継承
- まとめ
decorator_class_framework.py引数のないデコレータ Class
デコレータは呼び出し可能なオブジェクトである必要があります。
@my_decorator def f(arg): passというデコレータ表記は
def f(arg): pass f = my_decorator(f)と等価です。
つまり、my_decorator というクラスを定義する場合、このクラスが呼び出し可能である必要があります。
my_decoratorが最初に呼び出された時 (f = my_decorator(f)) には__init__()が呼び出されます。
上の例では、__init__(f)が呼び出されます。
そして生成されたインスタンスが f に代入されます。(__init__()の戻り値が代入されるわけではないことに注意してください。)置き換えられた
fが呼び出されると、my_decoratorオブジェクトが呼び出されます。クラスオブジェクトを関数として呼び出す場合には、__call__を実装しておきます。sample_001.pyclass my_decorator_001: def __init__( self, func ): print( "called __init__" ) self._func = func def __call__( self, *args, **kwargs ): print( "called __call__ with args:", args, "kwargs:", kwargs ) try: ret = self._func( *args, **kwargs ) except: raise print( "post func" ) return ret @my_decorator_001 def f_001( arg1 ): print( "in f_001 with arg1:", arg1 ) f_001( "test 001" )実行結果 001>>> @my_decorator_001 ... def f_001( arg1 ): ... print( "in f_001 with arg1:", arg1 ) ... called __init__ >>> f_001( "test 001" ) called __call__ with args: ('test 001',) kwargs: {} in f_001 with arg1: test 001 post func >>>引数のあるデコレータ Class
デコレータに引数を与える場合を考えます。
@my_decorator(arg1, arg2) def f(arg): passというデコレータ表記は
def f(arg): pass f = my_decorator(arg1, arg2)(f)と等価です。
my_decorator(arg1, arg2)の部分で、2つの引数とともに__init__が呼び出され、インスタンスが作成されます。
作成されたインスタンスに対して引数にfが指定されて__call__が呼び出されます。sample_002.pyclass my_decorator_002: def __init__( self, *args, **kwargs ): print( "called __init__ with args:", args, "kwargs:", kwargs ) self._args = args self._kwargs = kwargs def __call__( self, func ): print( "called __call__ with func:", func ) def wrapper_f( *args, **kwargs ): print( "called wrapper_f with args:", args, "kwargs:", kwargs ) try: ret = func( *args, **kwargs ) except: raise print( "post func" ) return ret return wrapper_f @my_decorator_002( "arg1", "arg2" ) def f_002( arg1 ): print( "in f_002 with arg1:", arg1 ) f_002( "test 002" )実行結果 002>>> @my_decorator_002( "arg1", "arg2" ) ... def f_002( arg1 ): ... print( "in f_002 with arg1:", arg1 ) ... called __init__ with args: ('arg1', 'arg2') kwargs: {} called __call__ with func: <function f_002 at 0x76b326a8> >>> f_002( "test 002" ) called wrapper_f with args: ('test 002',) kwargs: {} in f_002 with arg1: test 002 post func >>>引数の有無を統合
引数を指定してもしなくても動作するように統合します。
引数の有無によって、
__init__と__call__の引数、__call__の呼び出しタイミングが異なります。
デコレータの引数→ 引数なし 引数あり(空の引数も含む) __init__()__init__(func)__init__(args,...)__call__()関数呼び出し時 __call__(args,...)デコレート時 __call__(func)
funcが呼び出し可能な単一の引数であることを判別に利用します。(そのため、この記事で作成するデコレータの第1引数には、他の呼び出し可能なオブジェクトを指定することはできなくなります。)
@wrapsも指定しておきます。
(@wrapsについては、前の記事の「最後の仕上げ - Python の汎用デコレータ(decorator)フレームワークを作る」をご覧ください。)sample_003.pyfrom functools import wraps class my_decorator_003: def __init__( self, *args, **kwargs ): print( "called __init__ with args:", args, "kwargs:", kwargs ) self._func = None self._args = [] self._kwargs = {} if len(args) == 1 and callable(args[0]): self._func = self._my_decorator( args[0] ) else: self._args = args self._kwargs = kwargs def __call__( self, *args, **kwargs ): print( "called __call__ with args:", args, "kwargs:", kwargs ) if self._func is None: if len(args) == 1 and callable(args[0]): self._func = self._my_decorator( args[0] ) return self._func else: try: ret = self._func( *args, **kwargs ) except: raise return ret def _my_decorator( self, func ): print( "called _my_decorator with func:", func ) @wraps(func) def wrapper_f( *args, **kwargs ): print( "called wrapper_f with", "args:", args, "kwargs:", kwargs, "priv args:", self._args, "kwargs:", self._kwargs ) try: ret = func( *args, **kwargs ) except: raise print( "post func" ) return ret return wrapper_f def f_003_0( arg1 ): """Doc Test""" print( "in f_003_0 with arg1:", arg1 ) @my_decorator_003 def f_003_1( arg1 ): """Doc Test""" print( "in f_003_1 with arg1:", arg1 ) @my_decorator_003( "arg1", arg2="arg2_str" ) def f_003_2( arg1 ): """Doc Test""" print( "in f_003_2 with arg1:", arg1 ) @my_decorator_003() def f_003_3( arg1 ): """Doc Test""" print( "in f_003_3 with arg1:", arg1 ) f_003_0( "test 003" ) f_003_1( "test 003" ) f_003_2( "test 003" ) f_003_3( "test 003" )実行結果 003>>> def f_003_0( arg1 ): ... """Doc Test""" ... print( "in f_003_0 with arg1:", arg1 ) ... >>> @my_decorator_003 ... def f_003_1( arg1 ): ... """Doc Test""" ... print( "in f_003_1 with arg1:", arg1 ) ... called __init__ with args: (<function f_003_1 at 0x7697b540>,) kwargs: {} called _my_decorator with func: <function f_003_1 at 0x7697b540> >>> @my_decorator_003( "arg1", arg2="arg2_str" ) ... def f_003_2( arg1 ): ... """Doc Test""" ... print( "in f_003_2 with arg1:", arg1 ) ... called __init__ with args: ('arg1',) kwargs: {'arg2': 'arg2_str'} called __call__ with args: (<function f_003_2 at 0x7697b5d0>,) kwargs: {} called _my_decorator with func: <function f_003_2 at 0x7697b5d0> >>> @my_decorator_003() ... def f_003_3( arg1 ): ... """Doc Test""" ... print( "in f_003_3 with arg1:", arg1 ) ... called __init__ with args: () kwargs: {} called __call__ with args: (<function f_003_3 at 0x7697b6f0>,) kwargs: {} called _my_decorator with func: <function f_003_3 at 0x7697b6f0> >>> f_003_0( "test 003" ) in f_003_0 with arg1: test 003 >>> f_003_1( "test 003" ) called __call__ with args: ('test 003',) kwargs: {} called wrapper_f with args: ('test 003',) kwargs: {} priv args: [] kwargs: {} in f_003_1 with arg1: test 003 post func >>> f_003_2( "test 003" ) called wrapper_f with args: ('test 003',) kwargs: {} priv args: ('arg1',) kwargs: {'arg2': 'arg2_str'} in f_003_2 with arg1: test 003 post func >>> f_003_3( "test 003" ) called wrapper_f with args: ('test 003',) kwargs: {} priv args: () kwargs: {} in f_003_3 with arg1: test 003 post func >>>最後の仕上げ
sample_003.pyでほぼ完成なのですが、Class 型デコレータでは、もう一つ注意が必要です。
sample_003.pyを使って、こんな関数をデコレートしてみます。sample_003_2.py@my_decorator_003 def f_003_4(): print( "called:", f_003_4.__name__ )これを実行すると……
実行結果>>> @my_decorator_003 ... def f_003_4(): ... print( "called:", f_003_4.__name__ ) ... called __init__ with args: (<function f_003_4 at 0x76927618>,) kwargs: {} called _my_decorator with func: <function f_003_4 at 0x76927618> >>> f_003_4() called __call__ with args: () kwargs: {} called wrapper_f with args: () kwargs: {} priv args: [] kwargs: {} Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<stdin>", line 20, in __call__ File "<stdin>", line 32, in wrapper_f File "<stdin>", line 3, in f_003_4 AttributeError: 'my_decorator_003' object has no attribute '__name__' >>> def f_003_5(): ... print( "called:", f_003_5.__name__ ) ... >>> f_003_5() called: f_003_5 >>>
AttributeError: 'my_decorator_003' object has no attribute '__name__'と表示され、__name__という属性が無いというエラーになってしまいました。もちろん、デコレータなしで定義、参照した場合に表示されるのは、上の実行結果のとおりです。クラスには
__name__属性がなく、@wrapで保存しようとしても、自動では作成してくれません。
明示的に追加しておく必要があります。また、
__init__内で_my_decoratorを呼び出すと、この段階では__doc__がありませんので、これも明示的に追加しておきます。sample_004.pyfrom functools import wraps class my_decorator_004: def __init__( self, *args, **kwargs ): print( "called __init__ with args:", args, "kwargs:", kwargs ) self._func = None self._args = [] self._kwargs = {} if len(args) == 1 and callable(args[0]): self._func = self._my_decorator( args[0] ) else: self._args = args self._kwargs = kwargs def __call__( self, *args, **kwargs ): print( "called __call__ with args:", args, "kwargs:", kwargs ) if self._func is None: if len(args) == 1 and callable(args[0]): self._func = self._my_decorator( args[0] ) return self._func else: try: ret = self._func( *args, **kwargs ) except: raise return ret def _my_decorator( self, func ): print( "called _my_decorator with func:", func ) @wraps(func) def wrapper_f( *args, **kwargs ): print( "called wrapper_f with", "args:", args, "kwargs:", kwargs, "priv args:", self._args, "kwargs:", self._kwargs ) try: ret = func( *args, **kwargs ) except: raise print( "post func" ) return ret # wrapper_f 内で、__name__ と __doc__ を操作する場合には # 下の setattr は削除する setattr( self, "__name__", wrapper_f.__name__ ) setattr( self, "__doc__", wrapper_f.__doc__ ) return wrapper_f def f_004_0( arg1 ): """Doc Test 0""" print( "in f_004_0 with arg1:", arg1 ) print( "__name__:", f_004_0.__name__ ) print( "__doc__:", f_004_0.__doc__ ) @my_decorator_004 def f_004_1( arg1 ): """Doc Test 1""" print( "in f_004_1 with arg1:", arg1 ) print( "__name__:", f_004_1.__name__ ) print( "__doc__:", f_004_1.__doc__ ) @my_decorator_004( "arg1", arg2="arg2_str" ) def f_004_2( arg1 ): """Doc Test 2""" print( "in f_004_2 with arg1:", arg1 ) print( "__name__:", f_004_2.__name__ ) print( "__doc__:", f_004_2.__doc__ ) @my_decorator_004() def f_004_3( arg1 ): """Doc Test 3""" print( "in f_004_3 with arg1:", arg1 ) print( "__name__:", f_004_3.__name__ ) print( "__doc__:", f_004_3.__doc__ ) f_004_0( "test 004" ) f_004_1( "test 004" ) f_004_2( "test 004" ) f_004_3( "test 004" )実行結果>>> def f_004_0( arg1 ): ... """Doc Test 0""" ... print( "in f_004_0 with arg1:", arg1 ) ... print( "__name__:", f_004_0.__name__ ) ... print( "__doc__:", f_004_0.__doc__ ) ... >>> @my_decorator_004 ... def f_004_1( arg1 ): ... """Doc Test 1""" ... print( "in f_004_1 with arg1:", arg1 ) ... print( "__name__:", f_004_1.__name__ ) ... print( "__doc__:", f_004_1.__doc__ ) ... called __init__ with args: (<function f_004_1 at 0x768fd420>,) kwargs: {} called _my_decorator with func: <function f_004_1 at 0x768fd420> >>> @my_decorator_004( "arg1", arg2="arg2_str" ) ... def f_004_2( arg1 ): ... """Doc Test 2""" ... print( "in f_004_2 with arg1:", arg1 ) ... print( "__name__:", f_004_2.__name__ ) ... print( "__doc__:", f_004_2.__doc__ ) ... called __init__ with args: ('arg1',) kwargs: {'arg2': 'arg2_str'} called __call__ with args: (<function f_004_2 at 0x768fd540>,) kwargs: {} called _my_decorator with func: <function f_004_2 at 0x768fd540> >>> @my_decorator_004() ... def f_004_3( arg1 ): ... """Doc Test 3""" ... print( "in f_004_3 with arg1:", arg1 ) ... print( "__name__:", f_004_3.__name__ ) ... print( "__doc__:", f_004_3.__doc__ ) ... called __init__ with args: () kwargs: {} called __call__ with args: (<function f_004_3 at 0x768fd618>,) kwargs: {} called _my_decorator with func: <function f_004_3 at 0x768fd618> >>> f_004_0( "test 004" ) in f_004_0 with arg1: test 004 __name__: f_004_0 __doc__: Doc Test 0 >>> f_004_1( "test 004" ) called __call__ with args: ('test 004',) kwargs: {} called wrapper_f with args: ('test 004',) kwargs: {} priv args: [] kwargs: {} in f_004_1 with arg1: test 004 __name__: f_004_1 __doc__: Doc Test 1 post func >>> f_004_2( "test 004" ) called wrapper_f with args: ('test 004',) kwargs: {} priv args: ('arg1',) kwargs: {'arg2': 'arg2_str'} in f_004_2 with arg1: test 004 __name__: f_004_2 __doc__: Doc Test 2 post func >>> f_004_3( "test 004" ) called wrapper_f with args: ('test 004',) kwargs: {} priv args: () kwargs: {} in f_004_3 with arg1: test 004 __name__: f_004_3 __doc__: Doc Test 3 post func >>>ただし、コメントにも書きましたが、
wrapper_f()内で__name__か__doc__を操作する必要があるばあいには、setattr()は行わずに、独自に管理することが必要です。class によるデコレータの応用
デコレータを関数ではなく、クラスで実装することで、次のような応用が可能です。
継承したクラス(サブクラス)でデコレータを実装
sample_005.pyfrom functools import wraps class My_Base: def __init__( self ): self._my_string = "This is Base Class" def getstr( self ): return self._my_string def putstr( self, string="" ): self._my_string = string class my_decorator_005(My_Base): def __init__( self, *args, **kwargs ): super().__init__() self._func = None self._args = [] self._kwargs = {} if len(args) == 1 and callable(args[0]): self._func = self._my_decorator( args[0] ) else: self._args = args self._kwargs = kwargs def __call__( self, *args, **kwargs ): if self._func is None: if len(args) == 1 and callable(args[0]): self._func = self._my_decorator( args[0] ) return self._func else: try: ret = self._func( *args, **kwargs ) except: raise return ret def _my_decorator( self, func ): @wraps(func) def wrapper_f( *args, **kwargs ): print( "called wrapper_f with", "args:", args, "kwargs:", kwargs, "priv args:", self._args, "kwargs:", self._kwargs ) try: ret = func( *args, **kwargs ) except: raise return ret # wrapper_f 内で、__name__ と __doc__ を操作する場合には # 下の setattr は削除する setattr( self, "__name__", wrapper_f.__name__ ) setattr( self, "__doc__", wrapper_f.__doc__ ) return wrapper_f @my_decorator_005 def f_005(arg): print( arg ) f_005( 'test 005' ) print( f_005.getstr() ) f_005.putstr( "new string" ) print( f_005.getstr() )実行結果$ python sample_005.py called wrapper_f with args: ('test 005',) kwargs: {} priv args: [] kwargs: {} test 005 This is Base Class new string $
sample_005.pyは、スーパークラスを継承してデコレータを作成した例で、対象となった関数(実体はクラスインスタンス)からスーパークラスのメソッドを呼び出すことができます。
(関数として定義したはずなのに、クラスインスタンスになっているという気持ち悪さはありますが、デコレータをクラスで実装すると、関数名は常にクラスインスタンスを指すものになります)親クラス(スーパークラス)のデコレータを継承
次の例
sample_006.pyは、逆に既存のデコレータを継承して、新たなデコレータを作成する例です。
サブクラスで _my_decorator() を実装しています。sample_006.pyfrom functools import wraps class my_decorator_006: def __init__( self, *args, **kwargs ): self._func = None self._args = [] self._kwargs = {} if len(args) == 1 and callable(args[0]): self._func = self._my_decorator( args[0] ) else: self._args = args self._kwargs = kwargs print( "args and kwargs:", self._args, self._kwargs ) def __call__( self, *args, **kwargs ): if self._func is None: if len(args) == 1 and callable(args[0]): self._func = self._my_decorator( args[0] ) return self._func else: try: ret = self._func( *args, **kwargs ) except: raise return ret def _my_decorator( self, func ): # _my_decorator() はサブクラスで実装する return func # my_decorator_006 を継承して、新しいデコレータクラスを定義 class new_my_decorator(my_decorator_006): def __init__( self, *args, **kwargs ): super().__init__( *args, **kwargs ) # スーパークラスの _my_decorator() をオーバライド def _my_decorator( self, func ): @wraps(func) def wrapper_f( *args, **kwargs ): print( "called wrapper_f with", "args:", args, "kwargs:", kwargs, "priv args:", self._args, "kwargs:", self._kwargs ) try: ret = func( *args, **kwargs ) except: raise return ret # wrapper_f 内で、__name__ と __doc__ を操作する場合には # 下の setattr は削除する setattr( self, "__name__", wrapper_f.__name__ ) setattr( self, "__doc__", wrapper_f.__doc__ ) return wrapper_f @new_my_decorator def f_006_1(arg): print( arg ) @new_my_decorator() def f_006_2(arg): print( arg ) @new_my_decorator( "new_my_decorator with arg") def f_006_3(arg): print( arg ) print( "calling f_006s" ) f_006_1( 'test f_006_1' ) f_006_2( 'test f_006_2' ) f_006_3( 'test f_006_3' )実行結果$ python sample_006.py args and kwargs: () {} args and kwargs: ('new_my_decorator with arg',) {} calling f_006s called wrapper_f with args: ('test f_006_1',) kwargs: {} priv args: [] kwargs: {} test f_006_1 called wrapper_f with args: ('test f_006_2',) kwargs: {} priv args: () kwargs: {} test f_006_2 called wrapper_f with args: ('test f_006_3',) kwargs: {} priv args: ('new_my_decorator with arg',) kwargs: {} test f_006_3 $クラスの継承を利用すると、スーパークラスでは引数の有無による呼び出し方の違いを吸収し、サブクラスでデコレートの実装に専念することができます。
まとめ
- class によるデコレータの実装では、引数の有無によって
__init__()と__call__()の呼び出しタイミングに注意が必要。- 属性に注意。特に
__name__は class の初期属性が無いため、汎用的なデコレータとしては、明示的に設定が必要。- それ以外は、関数によるデコレータとほぼ同等に扱える。
- クラスの継承を利用して、デコレータの本体実装部分を独立させられる。
- 今回は、引数が有る場合でも無い場合でも両方を吸収するクラスを作ったが、どちらか一方だけで十分なことが多いと思われるので、それに応じて、最小限に留めるほうが、本来は望ましい。
decorator_class_framework.pydecorator_class_framework.py#!/usr/bin/env python # -*- coding: utf-8 -*- ########################################### # デコレータ (decorator) ########################################### from functools import wraps class my_decorator_base: def __init__( self, *args, **kwargs ): # func 引数の判定と引数の格納 self._func = None self._args = [] self._kwargs = {} if len(args) == 1 and callable(args[0]): # 引数なしのデコレータが呼び出された場合 self._func = self._wrapper( args[0] ) else: # 引数ありのデコレータが呼び出された場合 self._args = args self._kwargs = kwargs def __call__( self, *args, **kwargs ): # func 引数の有無で判定 if self._func is None: if len(args) == 1 and callable(args[0]): # 引数ありのデコレータが呼び出された場合 self._func = self._wrapper( args[0] ) return self._func else: # 引数なしのデコレータが呼び出された場合 try: ret = self._func( *args, **kwargs ) except: raise return ret def _wrapper( self, func ): # _wrapper() はサブクラスで実装する @wraps def wrapper_f( *args, **kwargs ): return func( *args, **kwargs ) return wrapper_f class my_decorator(my_decorator_base): """ for doctest >>> @my_decorator ... def f1( arg1 ): ... print( arg1 ) ... >>> @my_decorator('mytest1') ... def f2( arg2 ): ... print( arg2 ) ... >>> @my_decorator ... def f3( arg1 ): ... print( arg1 ) ... a = 1/0 ... >>> @my_decorator('mytest2') ... def f4( arg2 ): ... print( arg2 ) ... a = 1/0 ... >>> try: ... f1( "Hello, World! #1" ) ... except: ... print( "error #1" ) ... 前処理はここ called wrapper_f with args: ('Hello, World! #1',) kwargs: {} priv args: [] kwargs: {} Hello, World! #1 後処理はここ >>> try: ... f2( "Hello, World! #2" ) ... except: ... print( "error #2" ) ... 前処理はここ called wrapper_f with args: ('Hello, World! #2',) kwargs: {} priv args: ('mytest1',) kwargs: {} Hello, World! #2 後処理はここ >>> try: ... f3( "Hello, World! #3" ) ... except: ... print( "error #3" ) ... 前処理はここ called wrapper_f with args: ('Hello, World! #3',) kwargs: {} priv args: [] kwargs: {} Hello, World! #3 error #3 >>> try: ... f4( "Hello, World! #4" ) ... except: ... print( "error #4" ) ... 前処理はここ called wrapper_f with args: ('Hello, World! #4',) kwargs: {} priv args: ('mytest2',) kwargs: {} Hello, World! #4 error #4 >>> """ def __init__( self, *args, **kwargs ): super().__init__( *args, **kwargs ) def _wrapper( self, func ): """デコレータ呼び出し本体""" @wraps(func) def wrapper_f( *args, **kwargs ): # 前処理はここ print( "前処理はここ" ) print( "called wrapper_f with", "args:", args, "kwargs:", kwargs, "priv args:", self._args, "kwargs:", self._kwargs ) try: ret = func( *args, **kwargs ) except: raise # 後処理はここ print( "後処理はここ" ) return ret # wrapper_f 内で、__name__ と __doc__ を操作する場合には # 下の setattr は削除する setattr( self, "__name__", wrapper_f.__name__ ) setattr( self, "__doc__", wrapper_f.__doc__ ) return wrapper_f ########################################### # unitttest ########################################### import unittest from io import StringIO import sys class Test_My_Decorator(unittest.TestCase): def setUp(self): self.saved_stdout = sys.stdout self.stdout = StringIO() sys.stdout = self.stdout def tearDown(self): sys.stdout = self.saved_stdout def test_decorator_noarg(self): @my_decorator def t1(arg0): print( arg0 ) t1("test_decorator_noarg") self.assertEqual(self.stdout.getvalue(), "前処理はここ\n" "called wrapper_f with args: ('test_decorator_noarg',) kwargs: {} priv args: [] kwargs: {}\n" "test_decorator_noarg\n" "後処理はここ\n" ) def test_decorator_witharg(self): @my_decorator('with arg') def t1(arg0): print( arg0 ) t1("test_decorator_witharg") self.assertEqual(self.stdout.getvalue(), "前処理はここ\n" "called wrapper_f with args: ('test_decorator_witharg',) kwargs: {} priv args: ('with arg',) kwargs: {}\n" "test_decorator_witharg\n" "後処理はここ\n" ) def test_functionname(self): @my_decorator def t1(): return t1.__name__ f_name = t1() self.assertEqual( f_name, "t1" ) def test_docattribute(self): @my_decorator def t1(): """Test Document""" pass self.assertEqual( t1.__doc__, "Test Document" ) ########################################### # main ########################################### if __name__ == '__main__': @my_decorator def f1( arg1 ): print( arg1 ) @my_decorator('mytest1') def f2( arg2 ): print( arg2 ) @my_decorator def f3( arg1 ): print( arg1 ) a = 1/0 @my_decorator('mytest2') def f4( arg2 ): print( arg2 ) a = 1/0 try: f1( "Hello, World! #1" ) except: print( "error #1" ) try: f2( "Hello, World! #2" ) except: print( "error #2" ) try: f3( "Hello, World! #3" ) except: print( "error #3" ) try: f4( "Hello, World! #4" ) except: print( "error #4" ) import doctest doctest.testmod() unittest.main()実行結果$ python decorator_class_framework.py 前処理はここ called wrapper_f with args: ('Hello, World! #1',) kwargs: {} priv args: [] kwargs: {} Hello, World! #1 後処理はここ 前処理はここ called wrapper_f with args: ('Hello, World! #2',) kwargs: {} priv args: ('mytest1',) kwargs: {} Hello, World! #2 後処理はここ 前処理はここ called wrapper_f with args: ('Hello, World! #3',) kwargs: {} priv args: [] kwargs: {} Hello, World! #3 error #3 前処理はここ called wrapper_f with args: ('Hello, World! #4',) kwargs: {} priv args: ('mytest2',) kwargs: {} Hello, World! #4 error #4 .... ---------------------------------------------------------------------- Ran 4 tests in 0.003s OK $unittest 実行結果$ python -m unittest -v decorator_class_framework.py test_decorator_noarg (decorator_class_framework.Test_My_Decorator) ... ok test_decorator_witharg (decorator_class_framework.Test_My_Decorator) ... ok test_docattribute (decorator_class_framework.Test_My_Decorator) ... ok test_functionname (decorator_class_framework.Test_My_Decorator) ... ok ---------------------------------------------------------------------- Ran 4 tests in 0.005s OK $
- 投稿日:2020-02-15T12:19:02+09:00
python mpmath(任意精度計算)の実装による計算速度の比較(備忘録)
背景
前回の投稿から約二年強.前回のいろんな言語を雑に実装して計算速度の比較を行った.そのモチベーションには任意精度計算で計算速度の比較を行いたいという伏線がある.
任意精度計算は,GNU MP(GMP), MPFR (何れもC,C++)の実装がメジャーで,これらのパッケージのwrapperや拡張がいつくかの言語で利用可能である.
pythonではmpmathで利用可能(標準ライブラリーのDecimalは知らない)で,juliaやMathematica(wolfram言語)ではdefaultで多倍長演算をサポートしている.何れもGMPやMPFRを利用しているようなので,実装によるオーバーヘッドやコーディングの平易さがどの程度なものなのか知りたいというのが,最終的な目的である(今回は到達しない).ちなみに,gcc 4.6 から4倍精度計算がサポートされ,C,C++,Fortranでは4倍精度演算も可能なはずだがここでは扱わない.
(Cでは,4倍精度浮動小数点型は __float128 とい取って付けたような宣言が必要だったが今はどうなんだろうか・・・.)任意精度が必要な例
(1次元の)パイコネ変換(baker's map)
$$
B(x) =
\begin{cases}
2x,& 0 \le x \le 1/2 \\
2x-1,& 1/2 < x \le 1
\end{cases}
$$
を考える$x\in[0,1]$を初期条件として,$B$の反復合成によって得られる軌道列$\{x, B(x), B^{(2)}=B\circ B(x),\ldots, B^{(n)}(x)\}$を考えるとこれはカオス的に振る舞う(Bの操作でパンは均一にコネられるよ).とりあえず,適当な初期条件を与えて3階までの反復を描画するコードを(雑に)書く.
import numpy as np import matplotlib.pyplot as plt import time def B(x): return 2*x if x <= 1/2 else (2*x - 1) fig, ax = plt.subplots(1, 1, figsize=(5,5)) ax.set_xlabel("x") ax.set_ylabel("B(x)") x = np.linspace(0, 1, 300) ax.set_ylim(-0.02,1.02) ax.set_xlim(-0.02,1.02) ax.plot(x,2*x,"-y") ax.plot(x,2*x-1,"-y") ax.plot(x,x,"--k") x = (np.sqrt(5) - 1)/2 web = [np.array([x]), np.array([0])] traj = np.array([x]) nmax = 3 bboxprop = dict(facecolor='w', alpha=0.7) ax.text(x+0.05,0, r"$x=%f$" % x, bbox=bboxprop) a = time.time() for n in range(1,nmax+1): y = B(x) web[0] = np.append(web[0], x) web[1] = np.append(web[1], y) traj = np.append(traj, y) ax.text(x+0.02, y, r"$f^{(%d)}(x)$" % n, bbox=bboxprop) x = y if n != nmax: ax.text(y+0.02, y, r"$x=f^{(%d)}(x)$" % n, bbox=bboxprop) web[0] = np.append(web[0], x) web[1] = np.append(web[1], y) print(time.time() - a, "[sec.]") ax.plot(web[0][:], web[1][:], "-o") ax.plot(web[0][0], web[1][0], "or") ax.plot(web[0][-1], web[1][-1], "or") ax.grid() print(traj) plt.savefig("web.png") plt.show()を実行すれば$\{x, B(x), B\circ B(x), B\circ B\circ B(x)\}$の軌道列が得られ,
$ python baker.py 0.0013127326965332031 [sec.] [0.61803399 0.23606798 0.47213595 0.94427191]また図(web diagramあるいはphase portrait)は反復合成の意味を視覚的に理解出来ると思う(始点と終点を赤丸にしている).
さて,反復の回数を50にするとどうなるだろうか.
nmax = 3を
nmax = 50にして実行すると
$ python baker-2.py 0.0012233257293701172 [sec.] [0.61803399 0.23606798 0.47213595 0.94427191 0.88854382 0.77708764 0.55417528 0.10835056 0.21670112 0.43340224 0.86680448 0.73360896 0.46721792 0.93443584 0.86887168 0.73774336 0.47548671 0.95097343 0.90194685 0.8038937 0.60778741 0.21557482 0.43114964 0.86229928 0.72459856 0.44919711 0.89839423 0.79678845 0.59357691 0.18715382 0.37430763 0.74861526 0.49723053 0.99446106 0.98892212 0.97784424 0.95568848 0.91137695 0.82275391 0.64550781 0.29101562 0.58203125 0.1640625 0.328125 0.65625 0.3125 0.625 0.25 0.5 1. 1. ]
の結果がえられた.
定義より$B(1) = 1$なので,初期条件 $x = (\sqrt{5} -1 )/2$とした十分長い反復合成$B^{(n)}(x)$は1に収束すると数値計算から予想される(パンが均一に混ざらない・・・.)しかし数値計算に基づくこの予想は計算精度が不十分であるために誤って導かれたものである.
この系は特別な初期条件($x=0,1/2,1$など)を除きほとんど全ての初期点に対する時系列はカオス的に振る舞い,$x \in [0,1]$を稠密に埋める.このことを確認するために,python の任意精度packageであるmpmathを用いて同じ計算を実施する.
import numpy as np import matplotlib.pyplot as plt import mpmath import time mpmath.mp.dps = 100 def B(x): return 2*x if x <= 1/2 else (2*x - 1) fig, ax = plt.subplots(1, 1, figsize=(5,5)) ax.set_xlabel("x") ax.set_ylabel("B(x)") x = np.linspace(0, 1, 300) ax.set_ylim(-0.02,1.02) ax.set_xlim(-0.02,1.02) ax.plot(x,2*x,"-y") ax.plot(x,2*x-1,"-y") ax.plot(x,x,"--k") x = (np.sqrt(5) - 1)/2 web = [np.array([x]), np.array([0])] traj = np.array([x]) x = (mpmath.sqrt(5) - 1)/2 y = B(x) web = [np.array([x]), np.array([0])] traj = np.array([x]) nmax = 50 a = time.time() for n in range(1,nmax+1): y = B(x) web[0] = np.append(web[0], x) web[1] = np.append(web[1], y) traj = np.append(traj, y) x = y if n!=nmax: web[0] = np.append(web[0], x) web[1] = np.append(web[1], y) print(time.time() - a, "[sec.]") ax.plot(web[0], web[1], "-o") ax.plot(web[0][0], web[1][0], "or") ax.plot(web[0][-1], web[1][-1], "or") ax.grid() mpmath.nprint(traj.tolist()) plt.savefig("web-mp1.png") plt.show()本質的な変更は
import mpmath mpmath.mp.dps = 100と初期条件
x = (mpmath.sqrt(5) - 1)/2だけである.mpmath.mp.dps = 100は仮数部100桁の精度で評価を行う様に指定する.
(デフォルトではdoubleの精度(15)が指定されている.)
print(traj)だと100桁そのまま出力されるので,mpmathのtrajを一度リストに変換しnprintを使って表示桁数を少なくする.
出力結果は$ python baker_mp.py 0.0019168853759765625 [sec.] [0.618034, 0.236068, 0.472136, 0.944272, 0.888544, 0.777088, 0.554175, 0.108351, 0.216701, 0.433402, 0.866804, 0.733609, 0.467218, 0.934436, 0.868872, 0.737743, 0.475487, 0.950973, 0.901947, 0.803894, 0.607787, 0.215575, 0.43115, 0.862299, 0.724599, 0.449197, 0.898394, 0.796788, 0.593577, 0.187154, 0.374308, 0.748615, 0.49723, 0.994461, 0.988921, 0.977842, 0.955685, 0.911369, 0.822739, 0.645478, 0.290956, 0.581912, 0.163824, 0.327647, 0.655294, 0.310589, 0.621177, 0.242355, 0.48471, 0.96942, 0.93884]
倍精度の計算結果とは異なり,50stepでは1に収束しない.
計算速度は若干遅くなるものの許容範囲である.さらに長く時間発展してみようnmax = 350として時間発展してみよう
出力もstep数に応じて長くなるので最後30ステップ以降を表示するとmpmath.nprint(traj.tolist()[-30:])$ python baker_mp.py 0.013526201248168945 [sec.] [0.0256348, 0.0512695, 0.102539, 0.205078, 0.410156, 0.820313, 0.640625, 0.28125, 0.5625, 0.125, 0.25, 0.5, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0]となる.仮数部100桁の計算でもステップ数が十分長くなれば1に漸近するように見える.
更に精度を良くするとどうなるであろうか.mpmath.mp.dps = 200として実行する.
$ python baker_mp.py 0.013622760772705078 [sec.] [0.0256048, 0.0512095, 0.102419, 0.204838, 0.409676, 0.819353, 0.638705, 0.27741, 0.55482, 0.109641, 0.219282, 0.438564, 0.877127, 0.754255, 0.50851, 0.017019, 0.0340381, 0.0680761, 0.136152, 0.272304, 0.544609, 0.0892179, 0.178436, 0.356872, 0.713743, 0.427487, 0.854974, 0.709947, 0.419894, 0.839788]今度は1に漸近する様子は見られなかった.長時間の時間発展を正確に得るためには精度を高くしなければならない.
幾つかの実装による計算速度比較
上の例の実装はnp.appendを使用しているため,計算速度が極めて遅くなる.
私の環境でmpmath.mp.dps = 100000 nmax = 10000で実行すると
$ python baker_mp.py 1.895829439163208 [sec.] [0.170384, 0.340767, 0.681535, 0.36307, 0.72614, 0.452279, 0.904559, 0.809118, 0.618235, 0.236471, 0.472941, 0.945882, 0.891765, 0.78353, 0.56706, 0.13412, 0.26824, 0.536479, 0.0729585, 0.145917, 0.291834, 0.583668, 0.167335, 0.334671, 0.669341, 0.338683, 0.677365, 0.35473, 0.70946, 0.418921]2秒弱掛かる.appendは便利だが,配列の再取得を繰り返す(malloc, copyを繰り返す)ような操作なので遅い.
必要な配列を先に準備しておき,代入操作だけで完結させれば.早くなるはずである.mpmathは行列のclassが定義されているのでそれを使ってみる.ただし,1次元配列に相当するものpython のlistなので,listの場合とnumpy.arrayの場合も比較してみる.変更有る箇所だけ示すと次のようなコード
nmax = 10000 web = mpmath.zeros(2*nmax+1,2) web[0,0] = x web[0,1] = 0 traj = [mpmath.mpf("0")]*(nmax+1) traj[0] = x a = time.time() for n in range(1,nmax+1): y = B(x) web[2*n - 1, 0] = x web[2*n - 1, 1] = y traj[n] = y x = y if n!=nmax: web[2*n, 0] = x web[2*n, 1] = y print(time.time()-a, "[sec.]") mpmath.nprint(traj[-30:])$ python baker_mp1.py 0.355421781539917 [sec.] [0.170384, 0.340767, 0.681535, 0.36307, 0.72614, 0.452279, 0.904559, 0.809118, 0.618235, 0.236471, 0.472941, 0.945882, 0.891765, 0.78353, 0.56706, 0.13412, 0.26824, 0.536479, 0.0729585, 0.145917, 0.291834, 0.583668, 0.167335, 0.334671, 0.669341, 0.338683, 0.677365, 0.35473, 0.70946, 0.418921]次にtrajをnumpy.arrayで覆ってみる
traj = np.array([mpmath.mpf("0")]*(nmax+1))dtypeはobjectになる.出力は一度リストに戻さないと全桁出力される.
mpmath.nprint(traj[-30:].tolist())実行結果はほとんど変わらないようだ.
$ python baker_mp2.py 0.36023831367492676 [sec.] [0.170384, 0.340767, 0.681535, 0.36307, 0.72614, 0.452279, 0.904559, 0.809118, 0.618235, 0.236471, 0.472941, 0.945882, 0.891765, 0.78353, 0.56706, 0.13412, 0.26824, 0.536479, 0.0729585, 0.145917, 0.291834, 0.583668, 0.167335, 0.334671, 0.669341, 0.338683, 0.677365, 0.35473, 0.70946, 0.418921]次にはややこしいのだが,listのなかにnumpy.arrayを入れ込む.
web = [np.array([mpmath.mpf(0)]*2*(nmax+1)), np.array([mpmath.mpf(0)]*2*(nmax+1))] traj = np.array([mpmath.mpf(0)]*(nmax+1)) traj[0] = x a = time.time() for n in range(1,nmax+1): y = B(x) web[0][2*n - 1] = x web[1][2*n - 1] = y traj[n] = y x = y if n != nmax: web[0][2*n] = x web[1][2*n] = y print(time.time()-a, "[sec.]") mpmath.nprint(traj[-30:].tolist())実行結果は若干早くなった.
$ python baker_mp3.py 0.2923922538757324 [sec.] [0.170384, 0.340767, 0.681535, 0.36307, 0.72614, 0.452279, 0.904559, 0.809118, 0.618235, 0.236471, 0.472941, 0.945882, 0.891765, 0.78353, 0.56706, 0.13412, 0.26824, 0.536479, 0.0729585, 0.145917, 0.291834, 0.583668, 0.167335, 0.334671, 0.669341, 0.338683, 0.677365, 0.35473, 0.70946, 0.418921]numpy.arrayで
web = np.zeros((2*nmax+1,2),dtype="object") web[0,0] = x web[0,1] = 0 traj = np.zeros(nmax+1, dtype="object") traj[0] = x a = time.time() for n in range(1,nmax+1): y = B(x) web[2*n - 1, 0] = x web[2*n - 1, 1] = y traj[n] = y x = y if n!=nmax: web[2*n, 0] = x web[2*n, 1] = y print(time.time()-a, "[sec.]") mpmath.nprint(traj[-30:].tolist())としてもほとんど変わらない.
$ python baker_mp4.py 0.2934293746948242 [sec.] [0.170384, 0.340767, 0.681535, 0.36307, 0.72614, 0.452279, 0.904559, 0.809118, 0.618235, 0.236471, 0.472941, 0.945882, 0.891765, 0.78353, 0.56706, 0.13412, 0.26824, 0.536479, 0.0729585, 0.145917, 0.291834, 0.583668, 0.167335, 0.334671, 0.669341, 0.338683, 0.677365, 0.35473, 0.70946, 0.418921]データを倍精度で保存する.
web = np.zeros((2*nmax+1,2),dtype=np.float) web[0,0] = float(x) web[0,1] = 0 traj = np.zeros(nmax+1, dtype=np.float) traj[0] = float(x) a = time.time() for n in range(1,nmax+1): y = B(x) web[2*n - 1, 0] = float(x) web[2*n - 1, 1] = float(y) traj[n] = float(y) x = y if n!=nmax: web[2*n, 0] = float(x) web[2*n, 1] = float(y) print(time.time()-a, "[sec.]") print(traj[-30:])これもほとんど速度に変化なし.
$ python baker_mp5.py 0.3071897029876709 [sec.] [0.17038373 0.34076746 0.68153493 0.36306985 0.72613971 0.45227941 0.90455883 0.80911766 0.61823531 0.23647062 0.47294124 0.94588249 0.89176498 0.78352995 0.5670599 0.13411981 0.26823961 0.53647923 0.07295846 0.14591691 0.29183383 0.58366766 0.16733532 0.33467064 0.66934128 0.33868256 0.67736512 0.35473024 0.70946048 0.41892095]結論
いろいろ実装の方法を試してみたが,pythonでは基本的にappendを使わなければ速度的には変化ないという結論.
今回は一つの初期条件のみ対象としたが,統計量を計算する際には初期条件のサンプリングが必要となる.
その場合もやるべきだが,今回はここで力尽きる.参考
- mpmath
- Julia:BigFloats and BigInts
- Mathematicaの内部実装について(数値および関連関数)
- カオス力学系入門 第二版 原著者:Robert L. Devaney (訳者:後藤憲一, 新訂版訳者: 國分寛司, 石井豊, 新居俊作, 木坂正史) 教室出版
- 投稿日:2020-02-15T11:22:14+09:00
pytorchで多クラス多ラベル分類
はじめに
- タイトルの通りの事をやってみた。一通り出来たのでそのメモとして。
- 内容に深く触れられない理由があり、ちょい雑になってるかもしれません。
- 例えばその変数どこで宣言したの?的なのがあるかも
- 所々に参考リンク入れてます
やったこと
- 画像の多クラス多ラベル分類。
- 「この画像はクラスAだね。この画像はAとBが該当するね。」みたいなイメージ。
- pytorch を使ってみたかったので実装は pytorchで。
- そんなん当たり前やん!こんなコメント要る?みたいなのが散見するのは未熟であるため。
フォルダ構成
以下のようにしました。が、これは正直ベストではないかも。
調査もそこそこに走り出してしまったのでこうなったけど。フォルダ構成. ├── data │ ├── labels // イメージとラベルの組み合わせjson。下述。 │ └── images // 画像。学習用と検証用混在。 ├── model // モデル保存先 └── predict // 予測したい画像置き場として設置ちなみに labels はこんな内容。
サンプル{ "画像A": { "ラベルA": 1, "ラベルB": 1, "ラベルC": 0 }, "画像B": { "ラベルA": 0, "ラベルB": 0, "ラベルC": 1コード
色々準備
# ref: https://pytorch.org/tutorials/beginner/blitz/cifar10_tutorial.html#sphx-glr-beginner-blitz-cifar10-tutorial-py from PIL import Image import torch import torch.nn as nn import torchvision import torchvision.transforms as transforms import numpy as np import pathlib import random # GPUあれば使う def check_cuda(): return 'cuda:0' if torch.cuda.is_available() else 'cpu' device = torch.device(check_cuda()) # 学習データ、テストデータ分割 image_set = {pathlib.Path(i).stem for i in pathlib.Path('data/images').glob('*.jpg')} n_data = len(image_set) traindata_rate = 0.7 train_idx = random.sample(range(n_data), int(n_data*traindata_rate)) _trainset = {} _testset = {} for i, _tuple in enumerate(image_set.items()): k, v = _tuple if i in train_idx: _trainset[k] = v else : _testset[k] = vTransform
# ref: https://qiita.com/takurooo/items/e4c91c5d78059f92e76d trfm = transforms.Compose([ transforms.Resize((100, 100)), # image size --> (100, 100) transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), ])Dataset
class MultiLabelDataSet(torch.utils.data.Dataset): def __init__(self, labels, image_dir='./data/images', ext='.jpg', transform=None): self.labels = labels self.image_dir = image_dir self.ext = ext self.transform = transform self.keys = list(labels.keys()) self.vals = list(labels.values()) def __len__(self): return len(self.labels) def __getitem__(self, idx): image_path = f'{self.image_dir}/{self.keys[idx]}{self.ext}' image_array = Image.open(image_path) if self.transform: image = self.transform(image_array) else: image = torch.Tensor(np.transpose(image_array, (2, 0, 1)))/255 # for 0~1 scaling label = torch.Tensor(list(self.vals[idx].values())) return {'image': image, 'label': label}DataLoader
batch_size = 8 trainset = MultiLabelDataSet(_trainset, transform=trfm) trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, shuffle=False, num_workers=2) testset = MultiLabelDataSet(_testset, transform=trfm) testloader = torch.utils.data.DataLoader(testset, batch_size=batch_size, shuffle=False, num_workers=2) classes = ['A', 'B', 'C'...] みたいなデータチェック
import matplotlib.pyplot as plt %matplotlib inline # functions to show an image def imshow(img): plt.imshow(np.transpose(img, (1, 2, 0))) plt.show() # sample data dataiter = iter(trainloader) tmp = dataiter.next() images = tmp['image'] labels = tmp['label'] # print images imshow(torchvision.utils.make_grid(images))モデル
レイヤーとかチャンネル数は適当…
BCEWithLogitsLossを使うのでシグモイドは噛まさない(ググったらそう言ってたように見えたので)class MultiClassifier(nn.Module): def __init__(self): super(MultiClassifier, self).__init__() self.ConvLayer1 = nn.Sequential( # ref(H_out & W_out): https://pytorch.org/docs/stable/nn.html#conv2d nn.Conv2d(3, 32, 3), nn.MaxPool2d(2), nn.ReLU(), ) self.ConvLayer2 = nn.Sequential( nn.Conv2d(32, 64, 3), nn.MaxPool2d(2), nn.ReLU(), ) self.ConvLayer3 = nn.Sequential( nn.Conv2d(64, 128, 3), nn.MaxPool2d(2), nn.ReLU(), ) self.ConvLayer4 = nn.Sequential( nn.Conv2d(128, 256, 3), nn.MaxPool2d(2), nn.ReLU(), nn.Dropout(0.2, inplace=True), ) self.Linear1 = nn.Linear(256 * 4 * 4, 2048) self.Linear2 = nn.Linear(2048, 1024) self.Linear3 = nn.Linear(1024, 512) self.Linear4 = nn.Linear(512, len(classes)) def forward(self, x): x = self.ConvLayer1(x) x = self.ConvLayer2(x) x = self.ConvLayer3(x) x = self.ConvLayer4(x) # print(x.size()) x = x.view(-1, 256 * 4 * 4) x = self.Linear1(x) x = self.Linear2(x) x = self.Linear3(x) x = self.Linear4(x) return x def try_gpu(target): if check_cuda(): device = torch.device(check_cuda()) target.to(device) model = MultiClassifier() try_gpu(model)トレーニング
criterion で急に
pos_weightという変数が出てきたが、これは正のクラス正解時の重み付けのため。
https://pytorch.org/docs/stable/nn.html#torch.nn.BCEWithLogitsLoss
そういう操作が不要なら指定なしでOK。自分は正解時の重みを増やしたかったので指定した。
詳細は ref として貼ったのでそちらにて自分は説明を逃げる# ref: https://medium.com/@thevatsalsaglani/training-and-deploying-a-multi-label-image-classifier-using-pytorch-flask-reactjs-and-firebase-c39c96f9c427 import numpy as np from pprint import pprint from torch.autograd import Variable import torch.optim as optim # ref: https://discuss.pytorch.org/t/bceloss-vs-bcewithlogitsloss/33586 # ref: https://discuss.pytorch.org/t/weights-in-bcewithlogitsloss/27452 criterion = nn.BCEWithLogitsLoss(pos_weight=pos_weight) try_gpu(criterion) optimizer = optim.SGD(model.parameters(), lr = 0.005, momentum = 0.9) def pred_acc(original, predicted): # ref: https://pytorch.org/docs/stable/torch.html#module-torch return torch.round(predicted).eq(original).sum().numpy()/len(original) def fit_model(epochs, model, dataloader, phase='training', volatile = False): if phase == 'training': model.train() if phase == 'validataion': model.eval() volatile = True running_loss = [] running_acc = [] for i, data in enumerate(dataloader): inputs, target = Variable(data['image']), Variable(data['label']) # for GPU if device != 'cpu': inputs, target = inputs.to(device), target.to(device) if phase == 'training': optimizer.zero_grad() # 勾配初期化 ops = model(inputs) acc_ = [] for j, d in enumerate(ops): acc = pred_acc(torch.Tensor.cpu(target[j]), torch.Tensor.cpu(d)) acc_.append(acc) loss = criterion(ops, target) running_loss.append(loss.item()) running_acc.append(np.asarray(acc_).mean()) if phase == 'training': loss.backward() # 誤差逆伝播 optimizer.step() # パラメータ更新 total_batch_loss = np.asarray(running_loss).mean() total_batch_acc = np.asarray(running_acc).mean() if epochs % 10 == 0: pprint(f"[{phase}] Epoch: {epochs}, loss: {total_batch_loss}.") pprint(f"[{phase}] Epoch: {epochs}, accuracy: {total_batch_acc}.") return total_batch_loss, total_batch_acc from tqdm import tqdm num = 50 best_val = 99 trn_losses = []; trn_acc = [] val_losses = []; val_acc = [] for idx in tqdm(range(1, num+1)): trn_l, trn_a = fit_model(idx, model, trainloader) val_l, val_a = fit_model(idx, model, testloader, phase='validation') trn_losses.append(trn_l); trn_acc.append(trn_a) val_losses.append(val_l); val_acc.append(val_a) if best_val > val_l: torch.save(model.state_dict(), f'model/best_model.pth') best_val = val_l best_idx = idx予測
def get_tensor(img): tfms = transforms.Compose([ transforms.Resize((100, 100)), transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), ]) return tfms(Image.open(img)).unsqueeze(0) def predict(img, label_lst, model): tnsr = get_tensor(img) op = model(tnsr) # Predict result(float) op_b = torch.round(op) # Rounding result(0 or 1) op_b_np = torch.Tensor.cpu(op_b).detach().numpy() preds = np.where(op_b_np == 1)[1] # result == 1 sigs_op = torch.Tensor.cpu(torch.round((op)*100)).detach().numpy()[0] o_p = np.argsort(torch.Tensor.cpu(op).detach().numpy())[0][::-1] # label index order by score desc # anser label label = [label_lst[i] for i in preds] # all result arg_s = {label_lst[int(j)] : sigs_op[int(j)] for j in o_p} return label, dict(arg_s.items()) model = MultiClassifier() model.load_state_dict(torch.load(f'model/best_model.pth', map_location=torch.device('cpu'))) model = model.eval() # 推論モードに切り替え target = 'XXXXXX' img = Image.open(f'predict/{target}.jpg').resize((100, 100)) plt.imshow(img) _, all_result = predict(f'predict/{target}.jpg', classes, model) print('predict top5: ', *sorted(all_result.items(), key=lambda x: x[1], reverse=True)[:5])最後に
実装は以上。
Data Augmentation、モデル磨き込み、適切な評価時のweight設定など行えば
まだまだ精度向上の余地が大いにあると思う。とりあえず作りたいのは出来たので自己満。
…参考までに。自分はこんな感じで予測するものをつくりました。
※完全にプライベートの作品であり、所属組織を代表するものではありません
