- 投稿日:2020-02-15T22:39:30+09:00
S3を操作するLambda関数をローカルで開発するための環境構築
Serverless Frameworkを使って構築したLambda関数のローカル開発環境で、LambdaからS3を操作する関数を開発したい。AWS上のS3を直接操作してもいいが、せっかくなのでローカルで完結する環境を構築する。
ローカルでS3をエミュレートするためのツール
ローカルでS3をエミュレートするためのツールとしては、
- LocalStack
- MinIO
- S3rver
あたりがあるようだが、今回はLocalStackを使用する。事前準備
Dockerが必要なので事前に使えるようにしておく。
自宅で使っているPCはWindows 10 Homeのため、Docker Desktop for Windowsが使えない。調べてみたらDocker Tookboxというツールを使えばいいようなので、インストールする。(参考:@idani氏のwindows 10 home で docker を導入するメモ)LocalStackを使用するための設定
プロジェクトディレクトリの直下にdocker-compose.ymlを作成し、LocalStackのDockerイメージの定義を記述する。
docker-compose.ymlversion: '3' services: localstack: image: localstack/localstack ports: - "4572:4572" environment: - SERVICES=s3 - DATA_DIR=/var/localstack/data volumes: - "./.localstack/data:/var/localstack/data:rw"LocalStackは様々なAWSのコンポーネントをエミュレートできるが、今回はS3だけ使うのでS3に限定した定義にする。
portsはS3の使用ポート4572のみ、SERVICESもS3のみにする。
データの永続化のためDATA_DIRを定義する。LocalStackの実行
Docker Toolboxの「Docker Quickstart Terminal」を起動し、そこからdocker-compose.ymlがあるディレクトリに移動し、
docker-compose upを実行して起動する。初回はlocalstackが自動でダウンロードされる。$ docker-compose up Creating network "helloworld_default" with the default driver Pulling localstack (localstack/localstack:)... (略) Status: Downloaded newer image for localstack/localstack:latest (略) localstack_1 | Starting mock S3 (http port 4572)... (略) localstack_1 | 2020-02-14T13:43:37:WARNING:infra.py: Service "s3" not yet available, retrying...本当は
Ready.と表示されて起動完了のはずだが、なぜかWARNINGが。
とりあえず、CLIでアクセスできるか試してみる。
なお、エンドポイントの「192.168.99.100」はDocker Toolboxが動いているVirtualBox仮想マシンのIPアドレス。
Docker Desktopの場合は「localhost」でアクセスできる。>aws --endpoint-url=http://192.168.99.100:4572 s3 mb s3://sample-bucket make_bucket: sample-bucket >dir > hoge.txt >aws --endpoint-url=http://192.168.99.100:4572 s3 cp hoge.txt s3://sample-bucket upload: .\hoge.txt to s3://sample-bucket/hoge.txt >aws --endpoint-url=http://192.168.99.100:4572 s3 ls s3://sample-bucket 2020-02-14 22:58:13 2641 hoge.txt問題なく、バケットの作成、ファイルの保存ができた。
(ちなみに、2回目に起動したら相変わらずWARNINGは出たが、Ready.も出た。)
- 投稿日:2020-02-15T22:30:37+09:00
Terraformでゾーン毎にsubnetを作成する(AWS, Alicloud)。
高可用性なサーバー配置
可用性が高いサーバーの配置として、ゾーン毎に立てるのは常套手段と思う。クラウドベンダーの1つのゾーンに障害が発生しても、別のゾーンが生きていればサービスの継続性が保たれる。
その前準備として、ゾーン毎にsubnetを作成する手順をterraformで自動化する。
terraformへは、regionとVPCのCIDRのみを指定し後はよしなにやってくれること、AWSとAlicloudで同じような自動化ができることを確認する。input/output
input
- region
- VPCのCIDRoutput
- VPC
- ゾーン毎のsubnetつまり、入力のregionにVPCを作成して、そのregionが持つゾーン毎にsubnetを作成する。
クラウド・プロバイダの設定
main_alicloud.tf# Alicloud Providerの設定 provider "alicloud" { access_key = var.alicloud_access_key secret_key = var.alicloud_secret_key region = var.alicloud_region }access_keyとsecret_keyはvariables.tfで設定するが、このような設定ファイルに残したくない場合は環境変数へ設定する方法もある。
それぞれALICLOUD_ACCESS_KEYとALICLOUD_SECRET_KEYへ設定すれば良い。main_aws.tf# AWS Providerの設定 provider "aws" { region = var.aws_region }AWSでは、access_keyとsecret_keyは
~/.aws/credentialsに設定してある。利用できるゾーンを取得する
main_alicloud.tf# 有効なゾーンを問い合わせ、local.all_zonesで参照する data "alicloud_zones" "available" { } locals { all_zones = data.alicloud_zones.available.ids }alicloud_zonesでゾーンを問い合わせ、local変数のall_zonesへ設定している。
ちなみにAlicloudのap-northeast-1は、ゾーン数が2つであった。
- ap-northeast-1a
- ap-northeast-1b
main_aws.tf# 有効なゾーンを問い合わせ、local.all_zonesで参照する data "aws_availability_zones" "available" { state = "available" } locals { all_zones = data.aws_availability_zones.available.names }Alicloudとほとんど変わらないコード。
AWSのコードの方がより明確な指示ができる(state = "available")。AlicloudはAsIsで同じように動作するだけかも。。VPCの作成
main_alicloud.tf# VPCの作成 resource "alicloud_vpc" "vpc" { name = "${var.base_name}-vpc" cidr_block = var.vpc_cidr }
main_aws.tf# VPCの作成 resource "aws_vpc" "vpc" { cidr_block = var.vpc_cidr tags = map( "Name", "${var.base_name}-vpc", ) }両クラウドでほとんど変わらないコード。VPCのCIDRはvariables.tfで設定する。
subnetの作成
main_alicloud.tf# vswitch(subnet)の作成 resource "alicloud_vswitch" "vsw" { count = length(local.all_zones) name = "${var.base_name}-${local.all_zones[count.index]}" vpc_id = alicloud_vpc.vpc.id cidr_block = cidrsubnet(var.vpc_cidr, var.subnet_netmask_bits, var.subnet_offset + count.index) availability_zone = local.all_zones[count.index] }Alicloudではsubnetをvswitchと呼ぶらしい。
ゾーンの数分vswitchを作成している。ここでのミソは、vswitchのCIDRをcidrsubnet関数を使って生成しているところ。
VPCのCIDRが10.10.0.0/16の場合、bits=8,offset=0とすると、
- 10.10.0.0/24
- 10.10.1.0/24
- 10.10.2.0/24
- :
とゾーンの数だけCIDRを生成してくれる。上で「よしなに」と書いたのはcidrsubnetの働きを指している。
main_aws.tf# subnetの作成 resource "aws_subnet" "subnet" { count = length(local.all_zones) vpc_id = aws_vpc.vpc.id cidr_block = cidrsubnet(var.vpc_cidr, var.subnet_netmask_bits, var.subnet_offset + count.index) availability_zone = local.all_zones[count.index] map_public_ip_on_launch = true tags = map( "Name", "${var.base_name}-${local.all_zones[count.index]}", ) }Alicloudとほとんど変わらない。
main.tfのコード全体
main_alicloud.tf# Alicloud Providerの設定 provider "alicloud" { access_key = var.alicloud_access_key secret_key = var.alicloud_secret_key region = var.alicloud_region } # 有効なゾーンを問い合わせ、local.all_zonesで参照する data "alicloud_zones" "available" { } locals { all_zones = data.alicloud_zones.available.ids } # VPCの作成 resource "alicloud_vpc" "vpc" { name = "${var.base_name}-vpc" cidr_block = var.vpc_cidr } # vswitch(subnet)の作成 resource "alicloud_vswitch" "vsw" { count = length(local.all_zones) name = "${var.base_name}-${local.all_zones[count.index]}" vpc_id = alicloud_vpc.vpc.id cidr_block = cidrsubnet(var.vpc_cidr, var.subnet_netmask_bits, var.subnet_offset + count.index) availability_zone = local.all_zones[count.index] }main_aws.tf# AWS Providerの設定 provider "aws" { region = var.aws_region } # 有効なゾーンを問い合わせ、local.all_zonesで参照する data "aws_availability_zones" "available" { state = "available" } locals { all_zones = data.aws_availability_zones.available.names } # VPCの作成 resource "aws_vpc" "vpc" { cidr_block = var.vpc_cidr tags = map( "Name", "${var.base_name}-vpc", ) } # subnetの作成 resource "aws_subnet" "subnet" { count = length(local.all_zones) vpc_id = aws_vpc.vpc.id cidr_block = cidrsubnet(var.vpc_cidr, var.subnet_netmask_bits, var.subnet_offset + count.index) availability_zone = local.all_zones[count.index] map_public_ip_on_launch = true tags = map( "Name", "${var.base_name}-${local.all_zones[count.index]}", ) }variables.tfのコード全体
variables_alicloud.tf# 共通設定 variable "base_name" { default = "test" } variable "vpc_cidr" { default = "10.10.0.0/16" } variable "subnet_offset" { default = 0 } variable "subnet_netmask_bits" { default = 8 } # クラウドベンダー依存部分 variable "alicloud_region" { default = "ap-northeast-1" } variable "alicloud_access_key" { default = "XXXXXXXXXXXXXXXXXXXXXXXX" } variable "alicloud_secret_key" { default = "YYYYYYYYYYYYYYYYYYYYYYYYYYYYYY" }コードにkeyを書くと、こーゆー時にひと手間かかるから環境変数にしよう!
variables_aws.tf# 共通設定 variable "base_name" { default = "test" } variable "vpc_cidr" { default = "10.10.0.0/16" } variable "subnet_offset" { default = 0 } variable "subnet_netmask_bits" { default = 8 } # クラウドベンダー依存部分 variable "aws_region" { default = "ap-northeast-1" }output - Alicloud
Apply complete! Resources: 3 added, 0 changed, 0 destroyed. Outputs: vpc = { "vpc" = { "cidr_block" = "10.10.0.0/16" "description" = "" "id" = "vpc-6wedpn6h4updttj8q26ej" "name" = "test-vpc" "resource_group_id" = "rg-acfns2xezp5njyq" "route_table_id" = "vtb-6wexwsiu3e97q1ed2canh" "router_id" = "vrt-6we4ws1qshqempzt2sd0s" "router_table_id" = "vtb-6wexwsiu3e97q1ed2canh" } } vsw = { "vsw" = [ { "availability_zone" = "ap-northeast-1a" "cidr_block" = "10.10.0.0/24" "description" = "" "id" = "vsw-6weldnazsu76mf665lka6" "name" = "test-ap-northeast-1a" "vpc_id" = "vpc-6wedpn6h4updttj8q26ej" }, { "availability_zone" = "ap-northeast-1b" "cidr_block" = "10.10.1.0/24" "description" = "" "id" = "vsw-6wewmrfku60rszr00wxzd" "name" = "test-ap-northeast-1b" "vpc_id" = "vpc-6wedpn6h4updttj8q26ej" }, ] }コード
https://github.com/settembre21/terraform-vpc-subnet
さいごに
subnetまで作れたら後はインスタンス作ってLBで束ねるなり、なんなりできる。
regionとVPCのCIDRを指定するだけ。開発環境・テスト環境・・◯◯環境がすぐに構築できる。terraformは、その記述自体が仕様書のようなものである。AWS向けに書いたコードをAlicloudチームへ渡すことで余計な説明が不要になるのではないか、と思う。これもインフラのコード化による産物だろう。

- 投稿日:2020-02-15T19:45:53+09:00
AWS Backup運用時の検討項目
はじめに
仕事でAWS Backupを使う機会があり、色々調べた内容をまとめます。
AWS Backupとは
AWSのバックアップ機能は既に存在していますが、AWS Backupはそれらの機能を一元管理するためのサービスです。
具体的にはバックアップのスケジューリングやバックアップの管理(ローテーションなど)を一つのインターフェースで操作することができます。https://aws.amazon.com/jp/backup/
AWS Backupでは「バックアッププラン」という単位で管理し、その中に「バックアップルール」(実行スケジュール)と「リソース」(取得対象)を定義します。
作成時の項目
AWS Backupでバックアップ運用を設計するにあたり、検討するべき項目をまとめます。
(※以下、作成時の表示順序とは異なります)
バックアップ取得対象
取得対象の設定方法は下記2種類です。
- タグ指定 : 指定したタグが設定されているリソース
- リソース : 任意のリソースID(個別指定)
取得対象の数が多くない&今後増えることがない場合はリソースID直指定の方が設定は楽ですが、基本的にはタグ指定で設定すると思います。
取得スケジュール
バックアップを実行する時間とその周期を指定します。
- 取得周期 : 12時間毎、毎日、毎週、毎月
- 取得時間 : 任意の時間(UTC指定なので、JSTにする場合は-9時間で記載)
- バックアップウィンドウ : 1時間~8時間
取得周期と時間は上記がデフォルトセットですが、cron形式で細かく設定することもできます。
(例えば30分おきに取得など)
また、バックアップウィンドウは「この時間の間に取得する」という時間帯であり、任意の時間決め打ちで取得することができない点だけ注意が必要です。
(ただ、オンラインで取得可能なので実運用ではあまり意識しなくても良いと思います)保管期限
作成後何日(あるいは週、月、年)経過したら削除するかを指定します。
あくまで世代数ではなく作成からの日数のため、一日に何回も取得するスケジュールの場合は考慮が必要です(あまり無いと思いますが)
ちなみに削除タイミングは「バックアップ実行時」です。コールドストレージへの移行
バックアップをGlacierに保管するかどうかの設定です。
設定は任意ですが、有効にした場合、最低でも90日保管とする必要があります。
(システムバックアップ用途では不要ですが、監査要件などで長期保管が必要なデータを取る際には利用を検討しても良いと思います)リージョン間コピー
取得したバックアップを他のリージョンにコピーするかどうかの設定です。
バックアップボールト
公式ドキュメントでは「バックアップを整理するためのコンテナ」と説明されていますが、主に下記を個別に設定したい場合に使う設定です。
任意で作成するか、デフォルト(Default)を使用するかを選択します。
- バックアップを暗号化するキーを指定
- バックアップへのアクセス権を設定
具体的には、マルチテナント(1つの基盤に複数のシステムが共存)でバックアップリソースの管理を厳密にしたい場合に使うようです。
(特に要件が無ければデフォルトで良いと思います)IAMロール
任意で作成するかデフォルトのIAMロールを使用するかを選択します。
この場合のIAMロールはAWS Backup内のバックアップやその他のリソースへのアクセスを制御するものです。
デフォルトでは「AWSBackupDefaultServiceRole」というロールが自動で作成されてアタッチされますが、これもバックアップボールトと同じく、実行権限を厳密に管理したい場合以外はデフォルトで良いです。少し細かい話をすると、AWS Backupに関する事前定義済みのポリシーは下記4つです。
「AWSBackupDefaultServiceRole」ではこの内③と④が適用されています。①AWSBackupFullAccess : フルアクセス
②AWSBackupOperatorAccess : 取得対象追加、バックアップ/リストアを実行可能(スケジュール作成不可)
③AWSBackupServiceRolePolicyForBackup : バックアップ取得を実行可能
④AWSBackupServiceRolePolicyForRestores : リストアを実行可能復旧ポイント(タグ追加)
取得したバックアップリソースに対し、任意でタグを追加できる機能です。
例えば、定期的に取得しているバックアップとそれ以外を分けて管理したい場合などに使えます。
(特に気にしない場合は設定不要)補足
余談ですが、バックアッププランには他リソースと同様にNameなどのタグを付けて管理することが可能ですが、AWS Backupはタグエディターでの一括検索(及び編集)の対象にはなっておらず、個別に編集する必要があります。(2020/2/15時点)
明らかに正しい動作には見えないので、その内修正されるかもしれません。
(AWS Backup自体比較的新しめの機能なので、まだ実装が追い付いてないだけだと思います)
- 投稿日:2020-02-15T19:41:11+09:00
知らず知らずのうちに Terraform がディスクをほとんど一杯にしてた
1. はじめに
それは突然やってきた。。
MacBook Air で作業中に突然の警告。
音楽ファイルも動画ファイルも保存してないし、Parallels VMs かなって思って調べたら、terraform ディレクトリがでかい!
$ du -sh terraform/ 6.5G terraform/さらに terraform ディレクトリを調べてみたら、terraform-provider-aws_v2.48.0_x4 ファイルは 173MB もある。
$ ls -laRh terraform 〜 terraform/anyservice/anyenv/awsconfig/.terraform/plugins/darwin_amd64: total 354416 drwxr-xr-x 4 nishimura.toru staff 128B 2 14 20:14 ./ drwxr-xr-x 3 nishimura.toru staff 96B 2 4 20:16 ../ -rwxr-xr-x 1 nishimura.toru staff 79B 2 14 20:14 lock.json* -rwxr-xr-x 1 nishimura.toru staff 173M 2 14 20:14 terraform-provider-aws_v2.48.0_x4* 〜この terraform-provider-aws_vナンチャラ は、Terraform で AWS を作成・管理・更新するために必要なAWSプロバイダーのプラグインで、terraform init コマンドを実行するとその実行したディレクトリ配下の ".terraform/plugins/" にダウンロードされインストールされる。
私は、Terraform のコンポーネント(tfstateの単位)を 『関心事の分離』 を意識して、次のようにサービス・環境・AWSリソース毎に分けている。
しかも、AWSアカウント毎にこのような terraform ディレクトリを作成している。
そのため、知らず知らずのうちにプラグインファイルが増殖してディスクを食べていたのだ・・・$ tree -L 3 terraform/ terraform/ ├── anyservice │ └── anyenv │ ├── awsconfig │ ├── budgets │ ├── cloudwatchevents │ ├── cost │ ├── iam │ ├── s3 │ └── sns ├── credentials ├── サービス名 │ ├── anyenv │ │ ├── acm │ │ └── sns │ ├── base │ │ ├── backup │ │ ├── cloudwatchalarm │ │ ├── ec2 │ │ ├── eip │ │ ├── route53_xxx.local │ │ ├── routetable │ │ ├── s3 │ │ ├── securitygroup │ │ ├── subnet │ │ └── vpc │ ├── development │ │ ├── alb │ │ ├── backup │ │ ├── cloudwatchalarm │ │ ├── ec2 │ │ ├── eip │ │ ├── elasticache │ │ ├── natgateway │ │ ├── rds │ │ ├── route53_xxx.xxx.jp │ │ ├── s3 │ │ └── securitygroup │ ├── production │ │ ├── alb │ │ ├── backup │ │ ├── cloudwatchalarm │ │ ├── ec2 │ │ ├── eip │ │ ├── elasticache │ │ ├── natgateway │ │ ├── rds │ │ ├── route53_xxx.xxx.jp │ │ ├── s3 │ │ └── securitygroup │ ├── staging │ │ ├── alb │ │ ├── backup │ │ ├── cloudwatchalarm │ │ ├── ec2 │ │ ├── eip │ │ ├── elasticache │ │ ├── natgateway │ │ ├── rds │ │ ├── route53_xxx.xxx.jp │ │ ├── s3 │ │ └── securitygroup ├── provider.tf ├── terraform_remote_state.tf └── variable.tf参考
・ Terraform Docs: Providers
・ Terraform Docs: Plugin Installation2. 対処方法
Terraform では、「Provider Plugin Cache」という機能が用意されていて、無駄なプラグインのダウンロードやインストールを制御することができるようになっている。
プロバイダープラグインは非常に大きくなる可能性があるため(数百メガバイトのオーダー)、このデフォルトの動作は、低速または従量制のインターネット接続を持つユーザーにとっては不便な場合があります。そのため、Terraformでは、オプションで、ローカルディレクトリを共有プラグインキャッシュとして使用できます。これにより、個別のプラグインバイナリをそれぞれ1回だけダウンロードできます。
(引用: Provider Plugin Cache google翻訳ママ)Provider Plugin Cache 機能は、terraform設定ファイルか、環境変数で有効にすることができる。
有効にすると、
プラグインキャッシュディレクトリが有効になっている場合、terraform initコマンドは引き続きプラグイン配布サーバーにアクセスして、使用可能なプラグインに関するメタデータを取得しますが、適切なバージョンが選択されると、選択したプラグインがキャッシュで既に使用可能かどうかを最初に確認しますディレクトリ。その場合、既にダウンロードされたプラグインバイナリが使用されます。
選択したプラグインがまだキャッシュにない場合は、最初にキャッシュにダウンロードされ、次にそこから現在の作業ディレクトリの下の正しい場所にコピーされます。
(引用: Provider Plugin Cache google翻訳ママ)利用上の注意点は、
Terraformがプラグインキャッシュに配置されると、プラグインキャッシュから削除されることはありません。時間が経つにつれて、プラグインがアップグレードされると、キャッシュディレクトリにいくつかの未使用バージョンが含まれるようになり、手動で削除する必要があります。
(引用: Provider Plugin Cache google翻訳ママ)3. 「Provider Plugin Cache」 有効方法
3.1. terraform設定ファイル
terraform設定ファイルで有効にする場合は、ユーザーのホームディレクトリ配下に ".terraformrc" ファイルを作成して、下記のようにプラグインをダウンロードするパスを設定する。
$HOME/.terraformrc
plugin_cache_dir = "$HOME/.terraform.d/plugin-cache"※Terraform Docs の説明例では、".terraform.d"と記載があるが、実際に terraform init を実行すると作成されるディレクトリは".terraform"で作成されるので、「plugin_cache_dir = "$HOME/.terraform/plugin-cache"」 の方がいいのかな・・
この設定方法では、そのマシン内にあるすべて terraform で AWSプロバイダープラグインを同一バージョンを使用することになる。
Provider Plugin Cache設定を行う前に、事前に AWSプロバイダープラグインのバージョンを合わせておいたほうが良いかも。3.2. 環境変数
Terraform のコンポーネント毎に AWSプロバイダープラグインのバージョンを指定したい場合は、terraform init を実行する前に環境変数で有効にする。
export TF_PLUGIN_CACHE_DIR="$HOME/.terraform.d/plugin-cache"この設定方法では、シェルのセッションが終わったら消えてしまう。
いちいち環境変数コマンドを実行するのは萎えるので、direnv などを使ってディレクトリごとに環境変数を設定しておいた方が良さそう。4. Provider Plugin Cache を試してみる
今回は、terraform設定ファイルで Provider Plugin Cache を有効にする方法を試してみた。
Provider Plugin Cache を有効にした後、各Terraformコンポーネントにすでにある .terraform ディレクトリを削除して、terraform init を実行する。4.1. Provider Plugin Cache 設定前の構成・設定確認
terraformディレクトリ構成
- $ tree -a terraform/
〜 ├── anyservice │ └── anyenv │ ├── awsconfig │ │ ├── .terraform │ │ │ ├── plugins │ │ │ │ └── darwin_amd64 │ │ │ │ ├── lock.json │ │ │ │ └── terraform-provider-aws_v2.48.0_x4 │ │ │ └── terraform.tfstate │ │ ├── backend.tf │ │ ├── config-rule.tf │ │ ├── main.tf │ │ ├── provider.tf -> ../../../provider.tf │ │ └── terraform_remote_state.tf -> ../../../terraform_remote_state.tf │ ├── budgets │ │ ├── .terraform │ │ │ ├── plugins │ │ │ │ └── darwin_amd64 │ │ │ │ ├── lock.json │ │ │ │ └── terraform-provider-aws_v2.45.0_x4 │ │ │ └── terraform.tfstate │ │ ├── backend.tf │ │ ├── main.tf │ │ └── provider.tf -> ../../../provider.tf │ ├── cloudwatchevents │ │ ├── .terraform │ │ │ ├── plugins │ │ │ │ └── darwin_amd64 │ │ │ │ ├── lock.json │ │ │ │ └── terraform-provider-aws_v2.47.0_x4 │ │ │ └── terraform.tfstate │ │ ├── awsconfig.tf │ │ ├── backend.tf │ │ ├── health.tf │ │ ├── provider.tf -> ../../../provider.tf │ │ └── variable.tf -> ../../../variable.tf 〜
- provider.tf ファイル
- AWSプロバイダーバージョンを 2.48.0 に固定
provider "aws" { version = "2.48.0" shared_credentials_file = "../../../credentials" profile = "terraform" region = "ap-northeast-1" } provider "aws" { version = "2.48.0" shared_credentials_file = "../../../credentials" profile = "terraform" alias = "virginia" region = "us-east-1" }
- backend.tf ファイル (terraform/anyservice/anyenv/awsconfig/backend.tfの例)
- backendは S3 を利用
- terraform のバージョンは 0.12.9 以上
terraform { required_version = ">= 0.12.9" backend "s3" { shared_credentials_file = "../../../credentials" profile = "terraform" bucket = "terraform-tfstate-チョメチョメ" key = "anyservice/anyenv/awsconfig/terraform.tfstate" region = "ap-northeast-1" } }
- credentials ファイル
[terraform] aws_access_key_id = チョメチョメ aws_secret_access_key = チョメチョメ
- .gitignore ファイル
.terraform/ credentials4.2. Provider Plugin Cache 設定有効
$HOME/.terraformrc
plugin_cache_dir = "$HOME/.terraform.d/plugin-cache"ディレクトリ作成
$ mkdir -p $HOME/.terraform.d/plugin-cache4.3. Provider Plugin Cache 設定実施
4.3.1. 1つ目(初回)
terraform/anyservice/anyenv/awsconfig/.terraform を削除して、terraform init を実行する。
プラグインがダウンロードされた$ cd terraform/anyservice/anyenv/awsconfig/ $ rm -rf .terraform/ $ terraform init Initializing the backend... Successfully configured the backend "s3"! Terraform will automatically use this backend unless the backend configuration changes. Initializing provider plugins... - Checking for available provider plugins... - Downloading plugin for provider "aws" (hashicorp/aws) 2.48.0... Terraform has been successfully initialized! You may now begin working with Terraform. Try running "terraform plan" to see any changes that are required for your infrastructure. All Terraform commands should now work. If you ever set or change modules or backend configuration for Terraform, rerun this command to reinitialize your working directory. If you forget, other commands will detect it and remind you to do so if necessary.念の為の確認$ ls -lh $HOME/.terraform.d/plugin-cache/darwin_amd64/terraform-provider-aws_v2.48.0_x4 -rwxr-xr-x 2 nishimura.toru staff 173M 2 15 17:29 /Users/nishimura.toru/.terraform.d/plugin-cache/darwin_amd64/terraform-provider-aws_v2.48.0_x4*$ terraform plan4.3.2. 2つ目
terraform/anyservice/anyenv/budgets/.terraform を削除して、terraform init を実行する。
実行前の容量確認
実行$ du -sh terraform/ 6.5G terraform/
念の為の確認$ cd terraform/anyservice/anyenv/budgets/ $ rm -rf .terraform/ $ terraform init Initializing the backend... Successfully configured the backend "s3"! Terraform will automatically use this backend unless the backend configuration changes. Initializing provider plugins... - Checking for available provider plugins... - Downloading plugin for provider "aws" (hashicorp/aws) 2.48.0... Terraform has been successfully initialized! You may now begin working with Terraform. Try running "terraform plan" to see any changes that are required for your infrastructure. All Terraform commands should now work. If you ever set or change modules or backend configuration for Terraform, rerun this command to reinitialize your working directory. If you forget, other commands will detect it and remind you to do so if necessary.
実行後の容量確認$ terraform plan
減った!$ du -sh terraform/ 6.3G terraform/4.3.3. 3つ目
terraform/anyservice/anyenv/cloudwatchevents/.terraform を削除して、terraform init を実行する。
実行
念の為の確認$ cd terraform/anyservice/anyenv/cloudwatchevents/ $ rm -rf .terraform/ $ terraform init
実行後の容量確認$ terraform plan
減った!$ du -sh terraform/ 6.2G terraform/4.3.4. すべての Terraformコンポーネントで実施
実行後の容量確認
6.5GB が 180MB まで減った!!$ du -sh terraform/ 180M terraform/
AWSプロバイダープラグインの容量が173MBなので、実際の tf ファイルは 7MB くらいか。
- 投稿日:2020-02-15T19:20:13+09:00
AWS認定ソリューションアーキテクトプロフェッショナルに一発で合格したので勉強方法を書いておく
AWS認定ソリューションアーキテクトプロフェッショナルに一発で合格できたので、勉強方法を備忘がてら書いていこうと思います。
前提
職業:現在インフラエンジニア5年目でAWSをメインに設計構築をするようになって、1年経たないくらい。AWSをやる前は、VMwareやWindows、Linuxなどいろいろやってました。
他のAWS関連の資格:ソリューションアーキテクトアソシエイト
SysOpsAdministratorアソシエイト
SAAは1年くらい前、SysOpsは昨年秋くらいに取得しています。勉強期間:3ヶ月くらい(主に土日、平日は早く帰れたらちょっとやるかなぁくらい)
試験について
周りで試験を受けた人から聞くと、2019年度からだいぶ難しくなったようです。
サンプル問題を見ていただければわかるかと思いますが、問題文、解答候補の日本語が長い。。さらに、どれも実現できそう。。。180分もある。。。という日本語の読解力&体力&知識全てを要求される試験です。受験料も3万円と決して安いものではないので、しっかりと対策をしてから挑まれることをお勧めします。
SAAをとってない人はまずSAAを取得してから取りましょう。
サンプル問題問題の解き方
サンプル問題や問題集などをみるとわかるのですが、問題文に書いてあるキーワードから、最も適切な選択肢を選ぶことが要求されます。
例えば、「コストを最重視する」、「可用性が重要」、「運用が楽なもの」等々
どれも実現できそうな選択肢の中から、問題で求められる選択肢を素早く選びます。キーとなる言葉をしっかり押さえることが大事です。試験までに何をやるか
1.試験ガイドを読む
試験ガイド出題される分野、配分をしっかり読みましょう。
ここに書いてあるものを中心にドキュメントを読み漁ることができます。
個人的に衝撃だったのは以下文章。採点対象外の内容
試験には、採点の対象にはならない項目が含まれる場合があります。これは統計的な情報を集めるた めに試験に組み込まれています。フォーム上でこれらの質問を区別することはできませんが、スコア に影響を与えることもありません。まあ気にする必要はないかと思いますが、これは答えが不定のものがあるってことなんですかね笑
どのくらい含まれるのか気になっちゃいますが。。2.オンライトレーニングを受ける
試験ガイドを読んでもいまいちイメージ湧かない。
何をやればいいかわからないという中でとりあえず始めたのがこれプロフェッショナルの試験分野、試験の解き方を解説してくれてます。
問題付きで解説してくれるのでわかりやすいです。
日本語対応というのが大きなところ。Exam Readiness: AWS Certified Solutions Architect – Professional (Japanese)
あとは、アソシエイトレベルで必要になる知識かもしれませんが、いかを復習。
AWS Well-Architected Training (Japanese) (AWS による優れた設計トレーニングオンライントレーニングが増えてるなぁという印象。
ネットワークとかセキュリティの方にも手を出そうか。。
いや、Developper取ろうか悩み中。。。3.ホワイトペーパー、BlackBelt、良くある質問、メジャーどころな製品のユーザガイドを読む
これは、結構大変。。
早々に切り上げてもいいかも。
試験ガイドに記載されているホワイトペーパーを一通り流し読みしました。
最低限日本語のものくらいですがね。。。
BlackBeltは割と面白いので、暇があればみても良いかも。
良くある質問は、結構ためになります。気づく点が多いですね。
この辺は、次に説明する問題をときながら、弱い部分を中心にで良いかもしれません。私もそんなに読んだかと言われると、、、
流し読みくらいかな。。。4.問題集を解く
以下2つを購入しました。
以下問題集を繰り返しとき、間違えた問題、不安な問題を中心に解説や、関連するドキュメントを読みました。
Udemyの方は2周して、90%程度は取れる状態にしました。
※Udemyはセールの時に買うのがお勧め!
解いていると、なんじゃそりゃみたいな質問や回答がたくさんあり、
自分が勉強すべき分野がはっきりするので、問題集→間違えたor不安な問題の関連サービスのドキュメントを読むという勉強が一番効率が良かったと思います。ちょっと話がそれるのですが、勉強方法としてiPadでUdemyをといて、間違えた問題をGoodNoteに貼り付け、理由や調べた内容をまとめるのが非常に便利!
ApplePencil最高かよってなってます。Udemy AWS 認定ソリューションアーキテクト プロフェッショナル模擬試験問題集
最後に公式の模擬試験を解いてみて、問題の雰囲気を掴みました。
試験の感想
難しい。。。長い。。
もう受けたくない。。。でした。
20問目を過ぎたあたりから、終わるのかなぁ。。。
つらいぃいい
集中!!!!ってなってました。
50問目を過ぎたあたりでもう無理。。
60問目を過ぎたらもうすぐ帰れる!ってなります。
正直自信を持って回答できたのは20問くらい、
最後の20分くらいは、落ちたかもと思い次の試験のためにどんな問題が出たか覚えようとしてました。試験結果
合格
スコア783
ギリギリでした。。詳細スコアを見ると、「移行」の分野が唯一再学習の必要ありとなってました。まだまだ勉強せねば。。
あと、試験の日本語が相変わらず変
途中何度か英語に切り替えました。その他
これからどうやって勉強していこうかと思ってる人にはお勧め。
AWSプロフェッショナルエンジニアへの道AWS Innovateのオンライセッションでもプロフェッショナル対策をやってくれるみたいですね。
AWS Innovate以下も面白いみたいですね。
1個くらいしかやったことないですが。
セルフペースラボまとめ
プロフェッショナルはアソシエイトとは段違いに難しかったです。
試験当日は体調を整えましょう。
3時間連続はかなり辛いものがあります。
日本語の読解にかなら集中力をとられるので、くれぐれも睡眠をしっかりと。
問題集を解きまくるが個人的には一番知識が身についた気がします。次はAzureでも勉強してみようかなと思ってます。。
- 投稿日:2020-02-15T18:30:17+09:00
[AWS認定資格対策 #02]クラウドプラクティショナー取得に向けた勉強プラン
はじめに
本記事では、AWS認定資格試験「クラウドプラクティショナー」に合格するための勉強プランを一例として紹介します。
私自身2020年1月に当該試験に合格しており、そこに至るまでに実施した勉強内容を基に記載します。経験則ベースでの内容ですので、これをやったら必ず合格できるというわけではございません。
その点はご留意ください。また、本記事ではあくまでも「クラウドプラクティショナー」の合格に向けたプランのみを紹介します。
他のAWS認定資格試験ではより専門性を問われるため、下記とは別で勉強プランが必要と考えられます。勉強する上での準備
当該試験を含めてAWS認定資格に合格するには、大前提として以下の条件が揃っていることがのぞましいです。決して必須条件とは言いませんが、円滑に勉強を進めるうえで推奨します。
AWS自体に興味があること
AWS認定資格試験では、AWSのサービスの利用経験があることを前提とした問題が出てきます。
そのため、AWSを積極的に利用することが試験合格の近道となります。
「AWSにそもそも興味がない」となると学習意欲も湧きませんので、いくら時間を掛けても合格に近づくことは難しいでしょう。まずは「AWSに興味を持って、触ってみること」が重要です。
AWSのアカウントは登録後1年間は無料で利用できますし、各サービスも最低スペックかつ最短期間であれば、安いコストで利用できます。
時間とお金を1秒1円でも惜しまれる方に無理強いしませんが、本当に試験に合格したいならAWSサービスを利用することをお勧めします。勉強のためにインターネット環境が整っていること
AWSサービスを利用するにも、模擬試験を受けるにも、ある程度高速なインターネット環境が必須です。
もし自宅にインターネット環境が無い方(かくいう私が正にそうです)は、ネットカフェなどインターネット環境の整った施設を利用してでも、勉強する環境を確保することが望ましいです。勉強の流れ
当該試験合格に向けた勉強プランを紹介します。
既に実施済みのステップがありましたら、飛ばして次のステップに進んでください。
勉強期間には個人差があります。自分のペースで勉強を進めてください。
- AWSのコアサービスの機能と利便性について学ぶ
- AWSのコアサービスに触れてみる
- クラウドプラクティショナーの参考書を1周以上読破する
- クラウドプラクティショナーの模擬試験を1度受験する
- 模擬試験で失点した内容について、Black Beltで復習する
- 模擬試験を9割以上正解するまで繰り返し受験する
- 模擬試験に登場しなかったサービスの概要について調べる
AWSのコアサービスの機能と利便性について学ぶ
AWSでは100を超える種類のサービスが提供されています。
それらのサービスの中でもよく利用されるサービスのことを総称して「コアサービス」と言います。
コアサービスに関する問題は、クラウドプラクティショナーでは多く出題されます。
そのため、まずはコアサービスに該当する各サービスの機能と利便性について知っておくとよいでしょう。
コアサービスについて解説しているドキュメントや動画はAWS公式を含めて多く公開されています。
本記事では、一例として2019年に大阪で開催されたAWS Summitの公演動画を紹介します。
コアサービスの基本中の基本となる情報が詰まっていますので、一度確認しておくと良いでしょう。AWS再入門 - 基本的なサービスをおさえる | AWS Summit Osaka 2019
なお、動画中に登場する用語で理解できなかったものはメモに残して、後でAWS公式サイトや参考書で必ず調べておきましょう。
AWSのコアサービスに触れてみる
コアサービスの機能と利便性が理解できたら、次はAWSのアカウントを登録して、コアサービスに触れてみましょう。
コアサービスを利用する際には、予め利用するシチュエーションを絞った方が良いです。
当該試験の問題として出題される傾向を加味すると、以下のシチュエーションを想定してサービスを利用すると良いでしょう。
- VPC、EC2、RDSを利用してWebアプリケーションを公開する
- S3を利用して静的Webページを公開する
各シチュエーションでの具体的な操作方法はAWS公式のチュートリアルやQiita記事などで色々と公開されています。
一通り読んで、理解しやすそうな資料を参考に操作してみましょう。ちなみに、S3を利用した静的Webページの公開方法は私もQiita記事で投稿しました。
こちらもご参考にしていただければ幸いです。[AWSであそぼう#01]Amazon S3でHTMLページを公開してみる
クラウドプラクティショナーの参考書を1周以上読破する
コアサービスを一通り操作して具体的なイメージが掴めるようになったら、次はコアサービスの細かい機能、コアサービス以外の機能、各サービスの料金システムに関して、クラウドプラクティショナーの参考書を読んで確認しましょう。
当該試験の参考書は複数の出版社から出ています。どれが一番オススメかは主観的な判断となってしまうため、まずは書店に行って各参考書に軽く目を通して、読みやすそうなものを選んでください。
かならず、一度は参考書を一周して読み切りましょう。
また、参考書中で意味が分からなかった用語は別途インターネットで調べるようにしてください。ちなみに、私は下記の参考書を購入して読みました。
AWS認定資格試験テキスト AWS認定 クラウドプラクティショナー
クラウドプラクティショナーの模擬試験を1度受験する
参考書を一読して、各サービスの機能や料金システムまで確認できたら、模擬試験を受験してみましょう。
当該試験の模擬試験は基本的に有料です。大体3600~5000円程度かかるため、尻込みする方もいらっしゃるかもしれません。しかし、本番の試験問題は、参考書に載っている模擬試験よりも出題範囲が開く、難易度も高めです。
これまでのステップの勉強だけでは網羅できない内容も含まれるため、不足知識を補うためにも受けることをお勧めします。また、模擬試験の内容を暗記しようとは思わないでください。
本番の試験中で模擬試験と同じ問題が出題されることは極めて少ないです。
各問題を覚えるのではなく、理解するという姿勢で臨んでください。以下に模擬試験のサービスを紹介します。
Udemy:この問題だけで合格可能!AWS 認定クラウドプラクティショナー 模擬試験問題集(全455問)
模擬試験で失点した内容について、Black Beltで復習する
模擬試験を1度受けたら、失点した問題で取り上げられてるサービスについて復習しましょう。
参考書で触れられていない内容が失点の原因である可能性もあるため、復習する際にはAWS公式から公開されているオンラインセミナー動画「Black Belt」を視聴することをお勧めします。模擬試験を9割以上正解するまで繰り返し受験する
Black Beltで理解不足を補ったら、改めて模擬試験を受験しましょう。
確実に合格するためには全体で9割以上正解することが望ましいです。
9割以上正解できるまで、何度も復習と再受験を繰り返してください。模擬試験に登場しなかったサービスの概要について調べる
模擬試験で9割以上正解できるようになったら、かなり合格に近づきました。
最後は、押しの一手として、模擬試験に登場しなかったサービスの概要を調べてみましょう。
AWSのサービスは年々増えており、各認定資格試験では最新のサービスに関する問題も出題されます。
参考書や模擬試験の内容だけが出題範囲とは思わないでください。各サービスの機能、用途、料金システムはAWS公式ページから確認できます。
AWSにより興味を持てる機会にもなりますので、楽しみながら調べていただけたら幸いです。最後に
クラウドプラクティショナー取得に向けた勉強プランの紹介は以上となります。
昨今の技術者向け試験では、過去問を暗記しておけば合格できるというものも多々ありますが、AWS認定資格試験でその方法は通用しません。
AWSの各サービスに対する本質的な理解度が要求されます。単純に試験に合格することに目を向けるのではなく、AWSの様々なサービスを使いこなして楽しめるようになることを目的として勉強していただければ幸いです。
- 投稿日:2020-02-15T18:06:06+09:00
AWSの10分間チュートリアルをやってみる 9.Docker コンテナのデプロイ
こんにちは。トリドリといいます。
新卒で入社した会社でJavaを数年やった後、1年ほど前に転職してからはRailsを中心に使用してアプリケーションの開発をしているしがないエンジニアです。今回、AWSの勉強をするために公式の10分間チュートリアルをやってみることにしたので、備忘のために記事に残していこうと思います。
AWSに関しては、1年ほど前転職活動をしていた時期にEC2とRDSを少し触っていた以外ほとんど触ったことが無い初心者です。
(ただし、このときにアカウントを作ったので、12ヶ月の無料枠は切れていました)前回は、EB CLIを使用してデプロイ・モニタリングなどを行う、「Deploy and Monitor an Application from the Command Line」」というチュートリアルをやりました。
今回は、「Docker コンテナのデプロイ」をやっていきます。Docker コンテナのデプロイ
(https://aws.amazon.com/jp/getting-started/tutorials/deploy-docker-containers/)
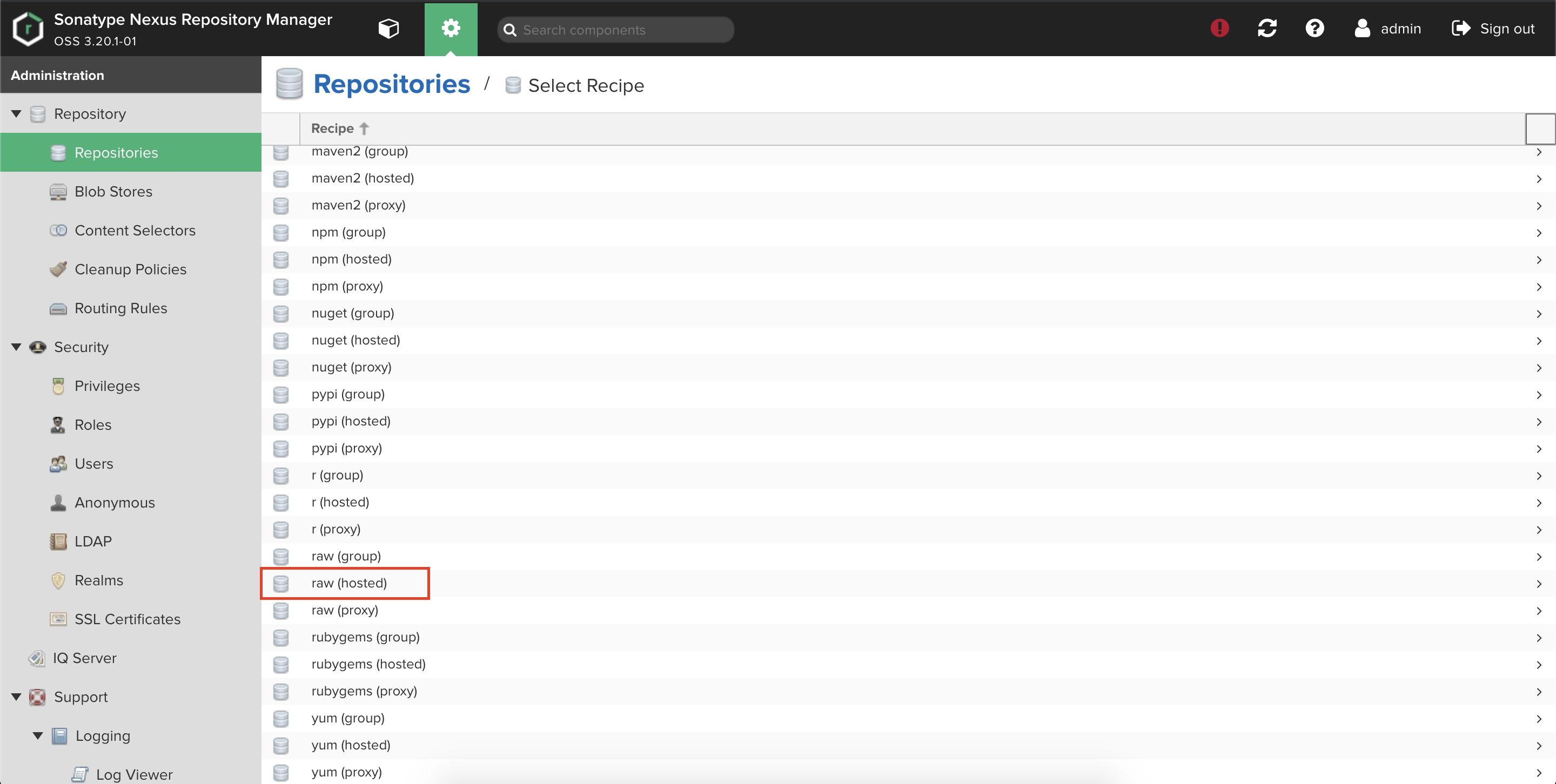
ステップ 1: Amazon ECS の初回実行を設定する
a.
チュートリアルのリンクから初回実行ウィザードを開きます。
AWSコンソールのサービスから、[ECS]を開き[今すぐ始める]でも可能です。
b.
ウィザードを開くと次のような画面が表示されます。
Amazon ECR オプションの設定については表示されませんでしたが、これがウィザードの変更によりなくなったのか、チュートリアルに記載の通りリージョンによって表示されないのかは不明です。
一応、私のコンソールで表示されているリージョンはすべて切り替えてみましたが、どのリージョンでも表示されませんでした。ステップ 2: タスク定義を作成する
上記ステップ1のb.の通り、チュートリアルの画面から[コンテナの定義]と[タスク定義]に分かれた画面に変更になっています。
チュートリアル同様、デフォルト設定から変更せず[次]をクリックします。ステップ 3: サービスを設定する
サービスの設定画面も次の通りに変更されています。
a.
サービス名・タスク数は自動的にデフォルト値が設定されているので、そのままにしておきます。
b.
ロードバランサーの種類で[Application Load Balancer]を選択します。
選択すると、[リスナープロトコル]はHTTP、[リスナーポート]は80が設定されているのでここもそのままにしておきます。c.
IAMロールの設定はなくなっているようです。
他の変更点としては、チュートリアルでは次のクラスターの設定にあったセキュリティグループの作成の設定がここに移動しています。
デフォルトは[自動的に新規作成]になっているので、ここもそのままにしておきます。d.
[次]を押して次の設定に進みます。
ステップ 4: クラスターを設定する
クラスターの設定画面も変更されており、項目数がかなり少なくなっています。
a./b./c./d.
設定項目が変更され、クラスター名とVPCとサブネットの設定のみ表示されています。
VPCとサブネットについては変更はできず、クラスター名のみが変更できるようになっています。
クラスター名も変更する必要はないので、そのまま[次]を押します。ステップ 5: リソースの起動と表示
確認画面が表示されるので確認の上、リソースを起動します。
a.
確認画面を確認し[作成]を押します。
b.
作成ステータス画面は次のようになっています。
すべてのサービスのステータスが完了になると、[サービスの表示]ボタンが押せるようになるので、押下します。
ステップ 6: サンプルアプリケーションを開く
このステップでは、起動したアプリケーションを開いて確認していきます。
a.
サービスの詳細画面は次のようになっています。
[ロードバランシング]の[ターゲットグループ名]のリンクをクリックすると、[EC2]の[ロードバランシング]の[ターゲットグループ]が開きます。
ターゲットグループの[基本的な設定]に表示されているロードバランサーをクリックし、[ロードバランサー]のメニューを開きます。
チュートリアルに従って[DNS名]をコピーします。b.
チュートリアルに従って、コピーしたDNS名をブラウザで開き、サンプルアプリケーションが開くことを確認します。
ステップ 7: リソースを削除する
最後に起動したアプリケーションを終了し、作成したリソースを削除します。
a.
チュートリアルに従ってECSコンソールからクラスターの詳細を開きます。
b.
ここもチュートリアルに従って、リソースの更新画面を開きます。
c.
チュートリアルの通りタスクを[0]に更新した上で、サービスの詳細画面から[削除]ボタンを押します。
削除する際は次のようなダイアログが表示され、delete meと入力した上で[削除]ボタンを押す必要があります。
d.
EC2インスタンスはサービスの削除時に一緒に削除されるようになっているようで、インスタンスは表示されませんでした。
e.
ロードバランサーは残っているので、チュートリアルに従って削除します。
これで、リソースの削除は完了です。まとめ
今回はチュートリアルに従ってDockerコンテナのデプロイから削除までを行いました。
正直に言うとDockerのこと、ロードバランサーのことなどまだわからない部分がたくさんあるので、サンプルではない自分のコンテナはデプロイできないと思います。
今後Dockerのことも勉強していきたいと思っているので、その後にまた振り返りたいです。次回は「Deploy and host a ReactJS app」をやっていきます








- 投稿日:2020-02-15T17:54:40+09:00
EKSにデプロイしたNexusのblob storeをEBSからS3に移行させる
はじめに
Sonatype Nexusはmaven, gradle, npm, dockerなどに対応したプライベートリポジトリマネージャーです。
リポジトリ内のファイルの保存方式はFILEとS3のどちらかを選ぶことができ、前者はEBSなどに、後者はその名の通りS3に保存されます。
ディスク容量の監視を不要とし料金も安くしたいときにはS3にしておいた方がいいです。今回はEBSにFILE方式で保存されている既存データをS3に移行させる方法を説明します。
NexusはEKSにデプロイすることを前提としています。環境
macOS Mojave 10.14.1
Helm: 3.0.1
EKS: 1.14
Nexus Helm Chart: 1.22.0前準備
データ移行の前にNexusデプロイ、リポジトリ作成、データ格納を行います。
EKS、S3などのAWSリソースやALB Ingress Controller、kube2iamなどのKubernetesリソースはすでにデプロイ済みであることを前提とします。Nexusのデプロイ
Helmを使ってNexusをデプロイします。
templateを少し修正する必要があるのでhelm fetchで公式Helm Chartをローカルに落とします。$ helm fetch stable/sonatype-nexus --version 1.22.0 $ tar -xvzf sonatype-nexus-1.22.0.tgzNexus Helm Chartのディレクトリ構造は下記となります。
valuesにはmy-values.yamlを自分で作って適用させます。
*が付いているファイルを編集します。├── Chart.yaml ├── README.md ├── templates │ ├── NOTES.txt │ ├── _helpers.tpl │ ├── backup-pv.yaml │ ├── backup-pvc.yaml │ ├── backup-secret.yaml │ ├── configmap.yaml │ ├── deployment-statefulset.yaml │ ├── ingress.yaml * │ ├── proxy-ks-secret.yaml │ ├── proxy-route.yaml │ ├── proxy-svc.yaml │ ├── pv.yaml │ ├── pvc.yaml │ ├── route.yaml │ ├── secret.yaml │ ├── service.yaml │ └── serviceaccount.yaml ├── values.yaml └── my-values.yaml *
ingress.yamlの編集箇所はspec.rules[].http.paths[].pathを消去するだけです。
デフォルトではpath: /となっていますがこれだとjsファイルを読み込むことができなくなるので除く必要があります。template/ingress.yaml{{- if .Values.ingress.enabled -}} apiVersion: extensions/v1beta1 kind: Ingress metadata: name: {{ template "nexus.fullname" . }} labels: {{ include "nexus.labels" . | indent 4 }} annotations: {{- range $key, $value := .Values.ingress.annotations }} {{ $key }}: {{ $value | quote }} {{- end }} spec: rules: {{- if .Values.nexusProxy.env.nexusHttpHost }} - host: {{ .Values.nexusProxy.env.nexusHttpHost }} http: paths: - backend: {{- if .Values.nexusProxy.svcName }} serviceName: {{ .Values.nexusProxy.svcName }} {{- else }} serviceName: {{ template "nexus.fullname" . }} {{- end }} {{- if .Values.nexusProxy.enabled }} servicePort: {{ .Values.nexusProxy.port }} {{- else }} servicePort: {{ .Values.nexus.nexusPort }} {{- end }} {{- end }} {{- if .Values.nexusProxy.enabled -}} {{- if .Values.nexusProxy.env.nexusDockerHost }} - host: {{ .Values.nexusProxy.env.nexusDockerHost }} http: paths: - backend: {{- if .Values.nexusProxy.svcName }} serviceName: {{ .Values.nexusProxy.svcName }} {{- else }} serviceName: {{ template "nexus.fullname" . }} {{- end }} servicePort: {{ .Values.nexusProxy.port }} {{- end }} {{- end -}} {{- with .Values.ingress.rules }} {{ toYaml . | indent 2 }} {{- end -}} {{- if .Values.ingress.tls.enabled }} tls: - hosts: {{- if .Values.nexusProxy.env.nexusHttpHost }} - {{ .Values.nexusProxy.env.nexusHttpHost }} {{- end }} {{- if .Values.nexusProxy.env.nexusDockerHost }} - {{ .Values.nexusProxy.env.nexusDockerHost }} {{- end }} {{- if .Values.ingress.tls.secretName }} secretName: {{ .Values.ingress.tls.secretName | quote }} {{- end }} {{- end -}} {{- end }}
my-values.yamlは下記となります。
すでに述べた通りALB Ingress Controllerとkube2iamがデプロイされていることを前提としていて、PodにはS3FullAccessPolicyが与えられたIAM Roleを付与します。my-values.yamlstatefulset: enabled: true nexus: dockerPort: 5003 nexusPort: 8081 service: type: NodePort podAnnotations: iam.amazonaws.com/role: s3-full-access-role nexusProxy: enabled: true env: nexusDockerHost: registry.sample.com nexusHttpHost: nexus.sample.com ingress: enabled: true annotations: kubernetes.io/ingress.class: alb alb.ingress.kubernetes.io/scheme: internet-facing alb.ingress.kubernetes.io/listen-ports: '[{"HTTP": 80}]' tls: enabled: false次のコマンドでnexusをデプロイします。
$ helm install --values my-values.yaml sonatype-nexus ./あとはアクセスするときに名前解決できるようにRoute53等で設定を加えれば良いです。
リポジトリ作成
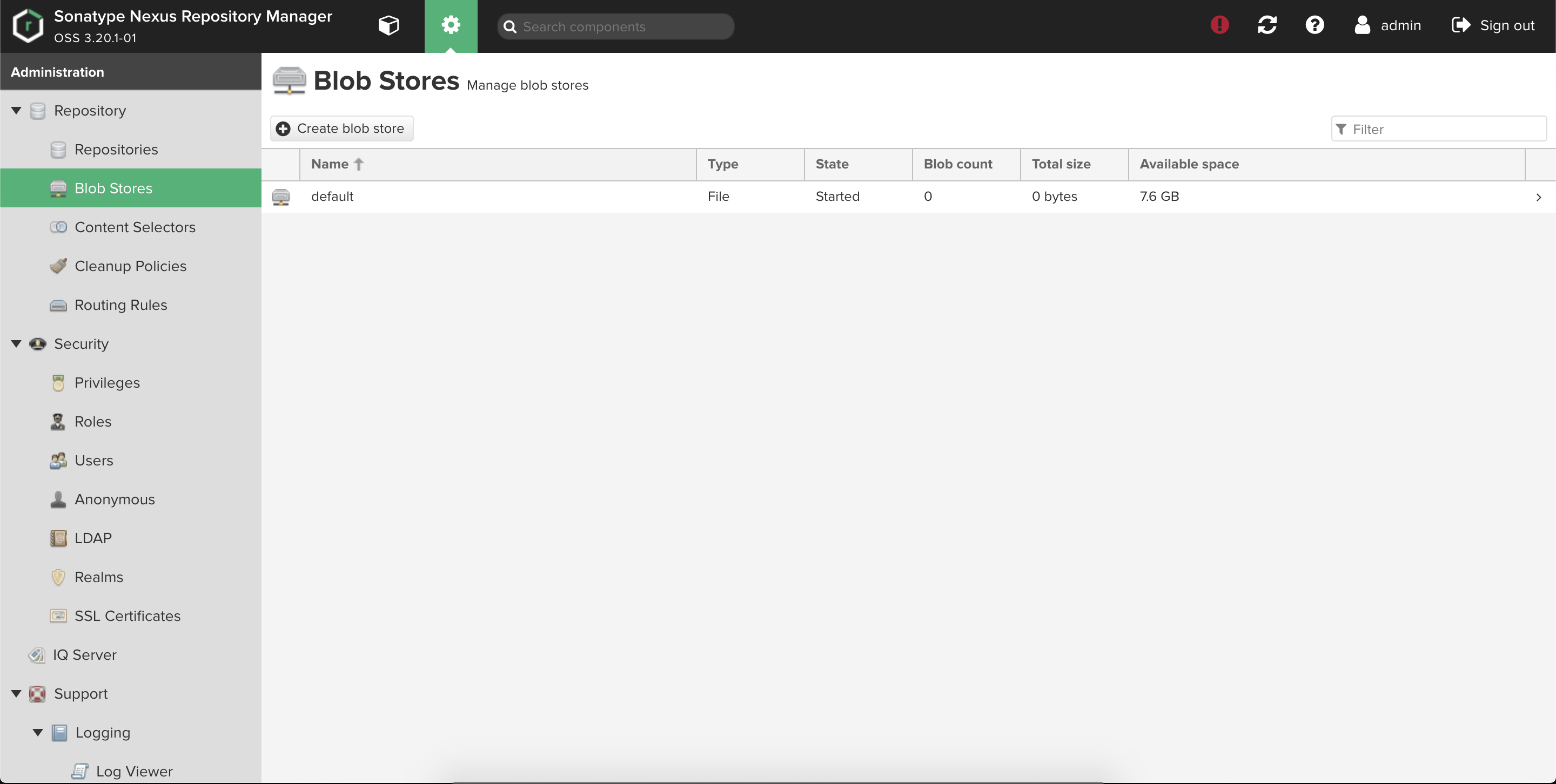
Nexusでリポジトリを作成する時にはblob storeを選択する必要があります。
今回はデフォルトで用意されているFILE方式のものを使用します。
このblob storeはEBSにマウントされています。
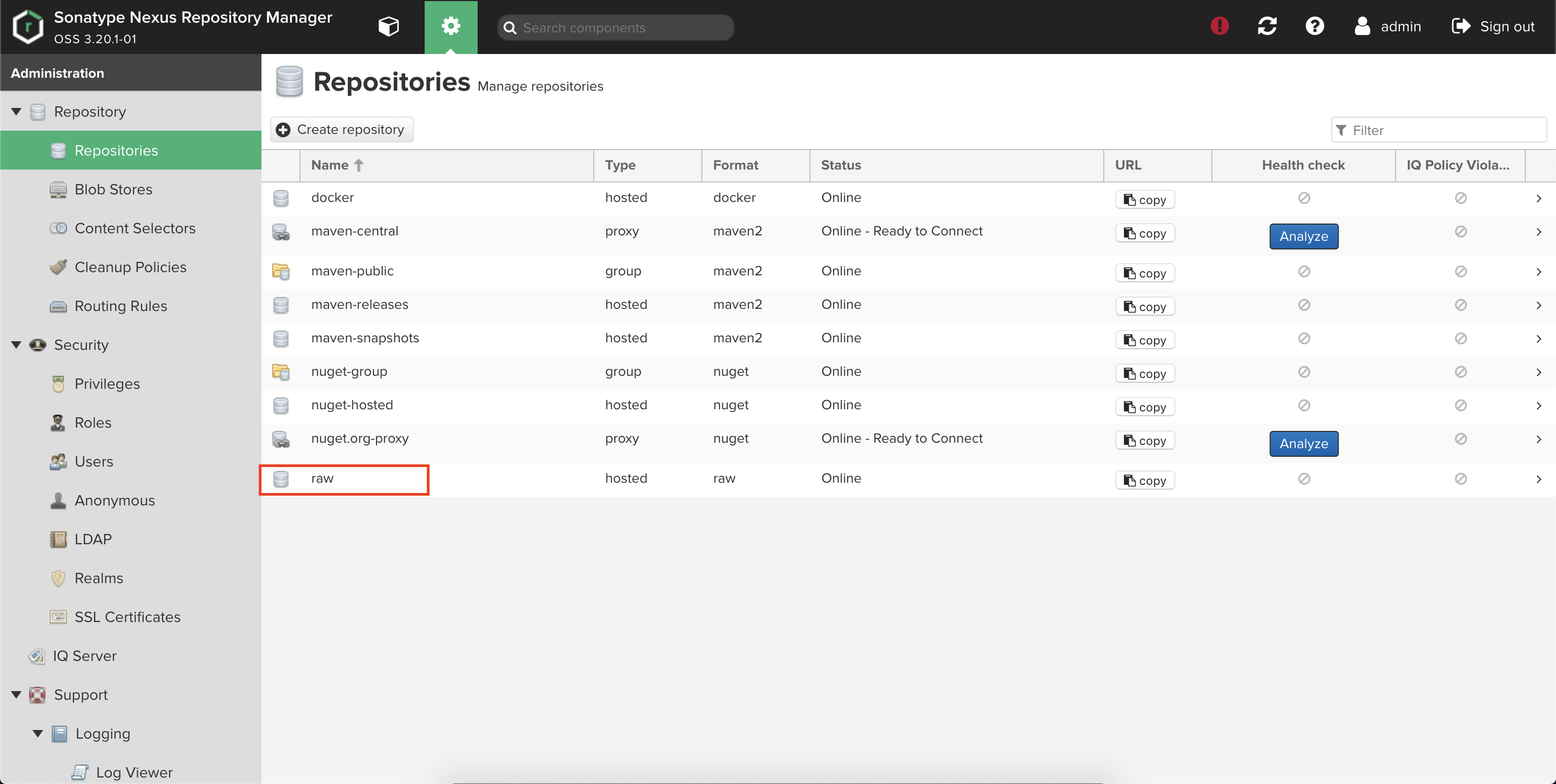
docker(hosted)とraw(hosted)をリポジトリとして作成していきます。
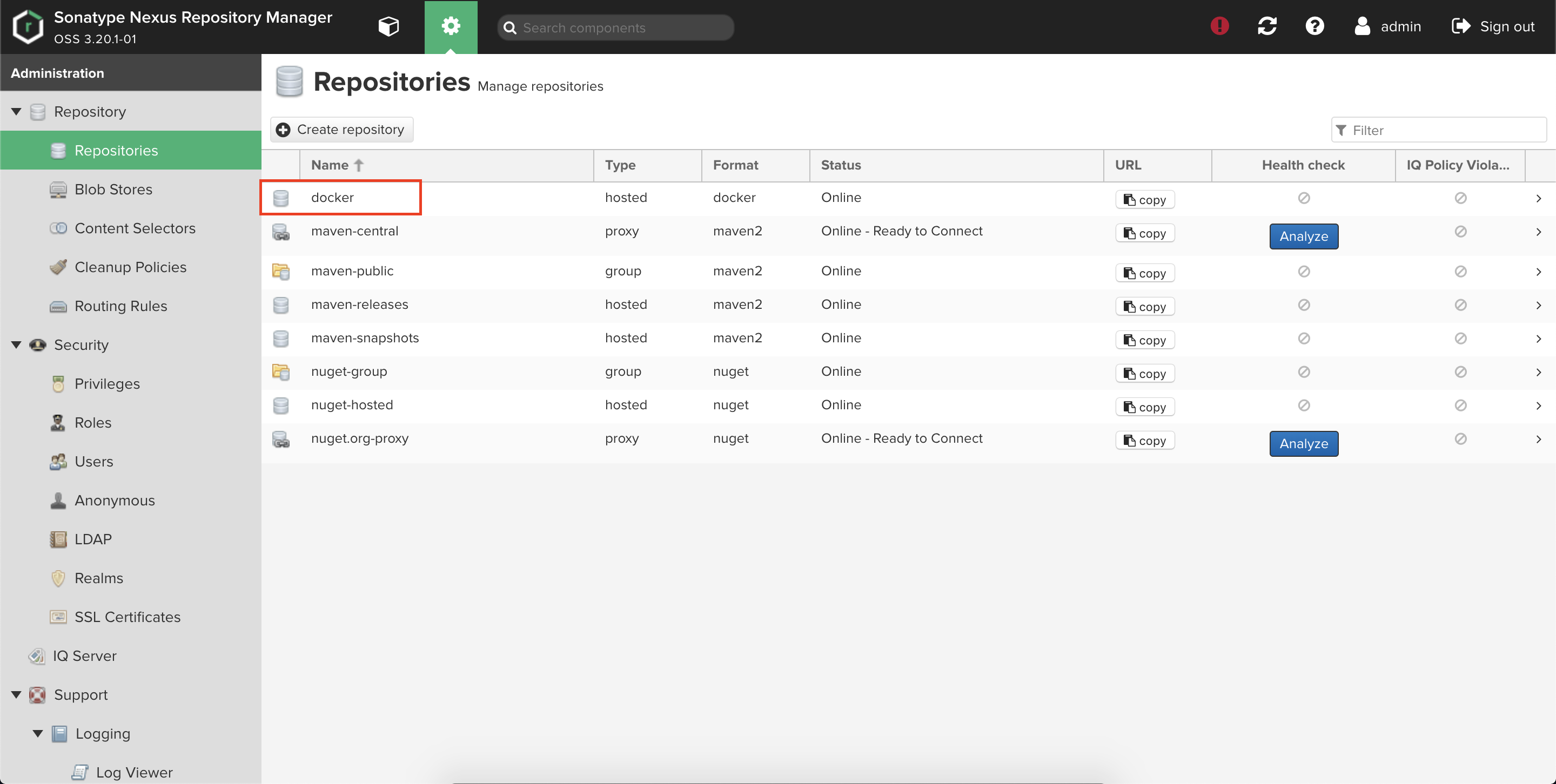
前者はDockerレジストリ、後者は画像などの格納場所を用途としています。①docker(hosted)
Repositoryからdocker(hosted)を選択します。
NameとHTTPだけ埋めて作成します。
HTTP PortはNexusデプロイ時にDockerレジストリのために用意したポートを使用します。
ここでは5003です。
問題なく作成されたことを画面で確認します。
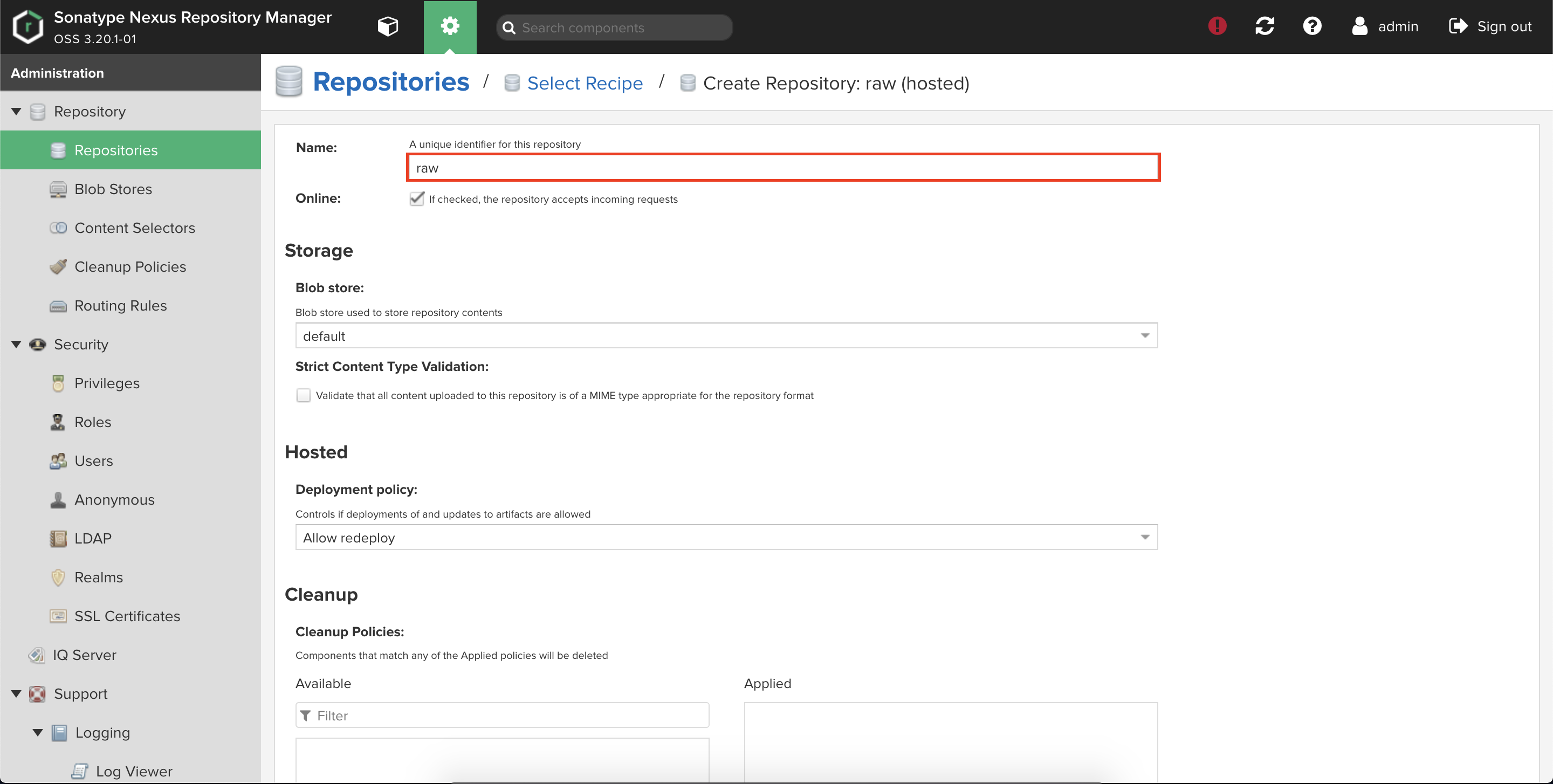
②raw(hosted)
Repositoryからraw(hosted)を選択する。
Nameだけ埋めて作成します。
問題なく作成されたことを画面で確認します。
データ格納
Dockerイメージと画像をそれぞれdocker(hosted)、raw(hosted)に格納していきます。
①docker(hosted)
dockerコマンドでDockerイメージをアップロードします。
HTTPの場合はクライアント側にinsecure registryの設定を入れないといけないことに注意しましょう。$ docker login registry.sample.com $ docker push registry.sample.com/alpine:3.7Nexus画面より、問題なくアップロードされていることを確認します。
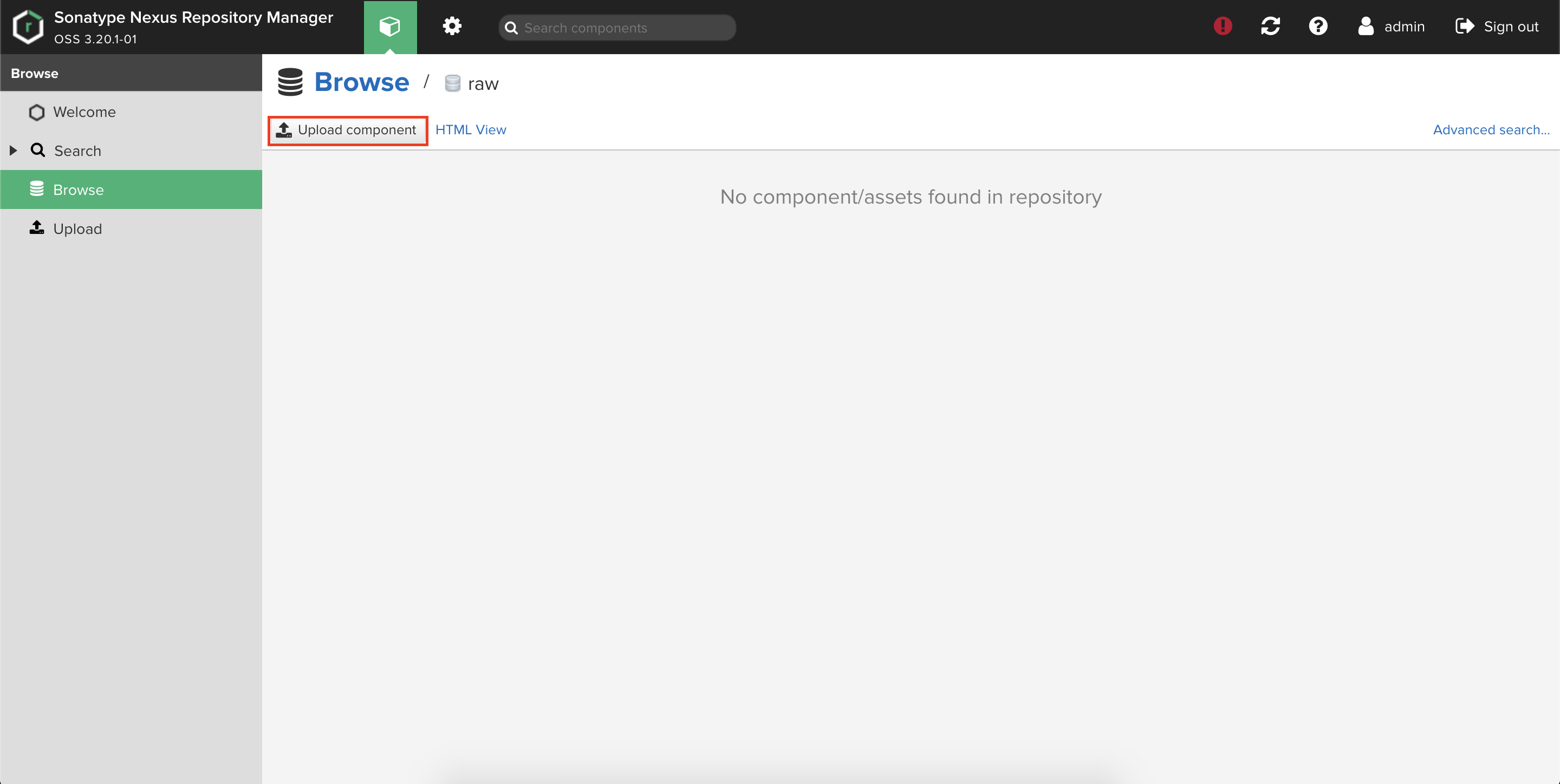
②raw(hosted)
Nexus画面からraw(hosted)を選択しUpload componentをクリックします。
Browseからローカルの画像を選択しUploadします。
こちらも問題なくアップロードされることを確認します。
データ移行
EBSからS3へのデータ移行手順を説明していきます。
S3バケットの作成
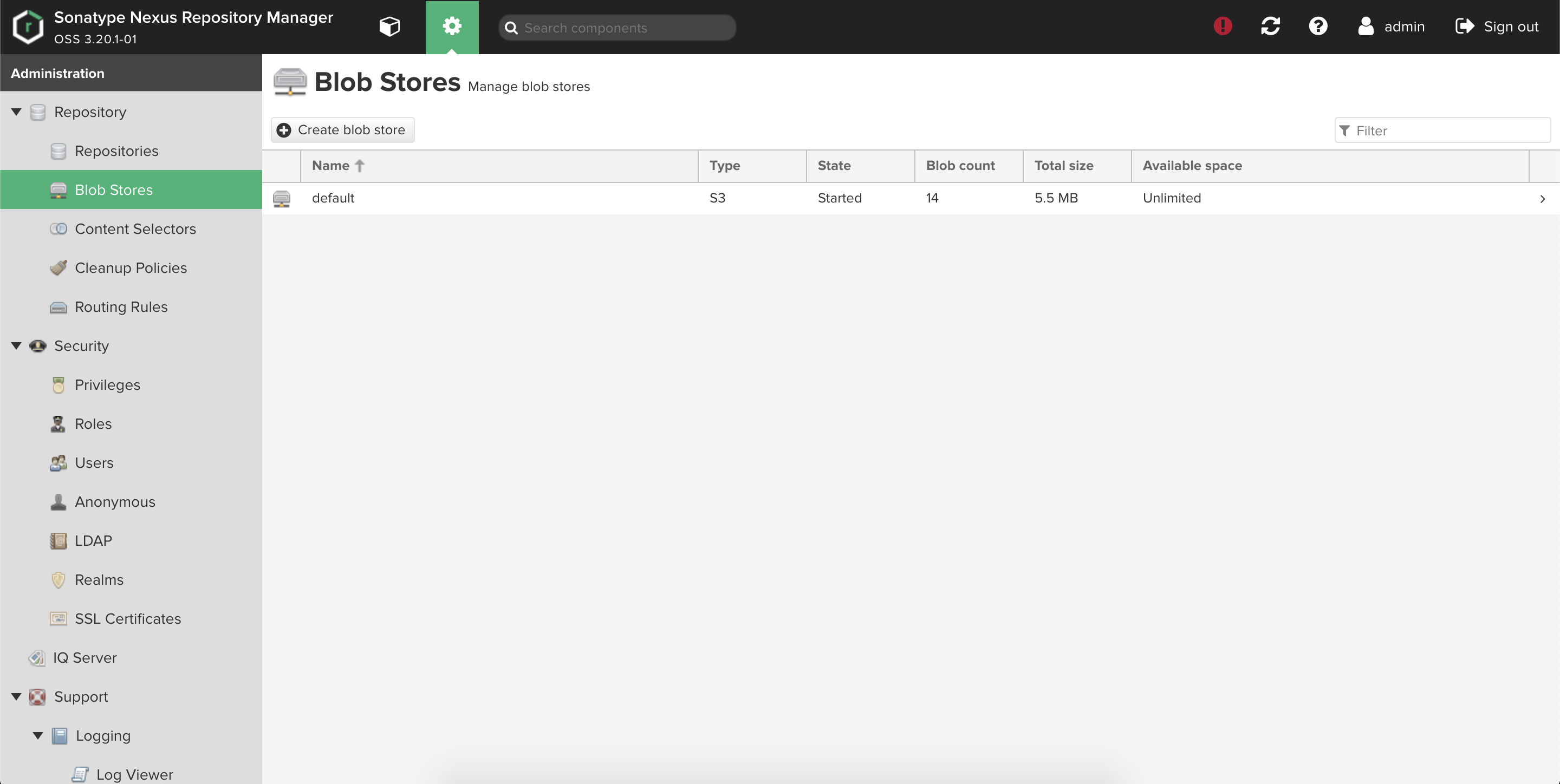
事前にS3バケットを作成しておきます。
Nexusの設定でprefix指定ができるので既存のバケットを使用することも可能です。$ aws s3 mb s3://sonatype-nexus-blobsS3へのデータ転送
NexusコンテナにAWS CLIが入っていないのでローカルにコピーしてからS3へデータ転送します。
$ mkdir blobs $ kubectl cp sonatype-nexus-0:/nexus-data/blobs ./blobs $ aws s3 cp blobs/ s3://sonatype-nexus-blobs --recursiveNexusのDBの編集
NexusのDBを手動で変更しblobsの保存方式をFILEからS3にしていきます。
Nexusにアクセスできないよう事前にServiceの削除等をしておくことをおすすめします。## Nexusコンテナ内にプロセスを起動させる $ kubectl exec sonatype-nexus-0 -it /bin/bash ## NexusのDBに接続する $ cd /opt/sonatype/nexus $ java -jar lib/support/nexus-orient-console.jar > connect plocal:/nexus-data/db/config admin admin ## 保存方式をS3に変更する > update repository_blobstore set type="S3" where name="default" ## リージョンとS3バケット情報を入れる > update repository_blobstore set attributes.s3={region: 'ap-northeast-1', bucket: 'sonatype-nexus-blobs', prefix: 'default', expiration: -1} where name="default"上記手順を終えたらPodの再起動をします。
$ kubectl delete pod sonatype-nexus-0確認
Nexus画面でblob storeを確認します。
TypeがS3になっていることが分かります。
Dockerレジストリを確認します。
docker pullできることが分かります。$ docker pull registry.moguta.ml/alpine:3.7 3.7: Pulling from alpine Digest: sha256:ab3fe83c0696e3f565c9b4a734ec309ae9bd0d74c192de4590fd6dc2ef717815 Status: Downloaded newer image for registry.moguta.ml/alpine:3.7rawリポジトリは画面で確認します。
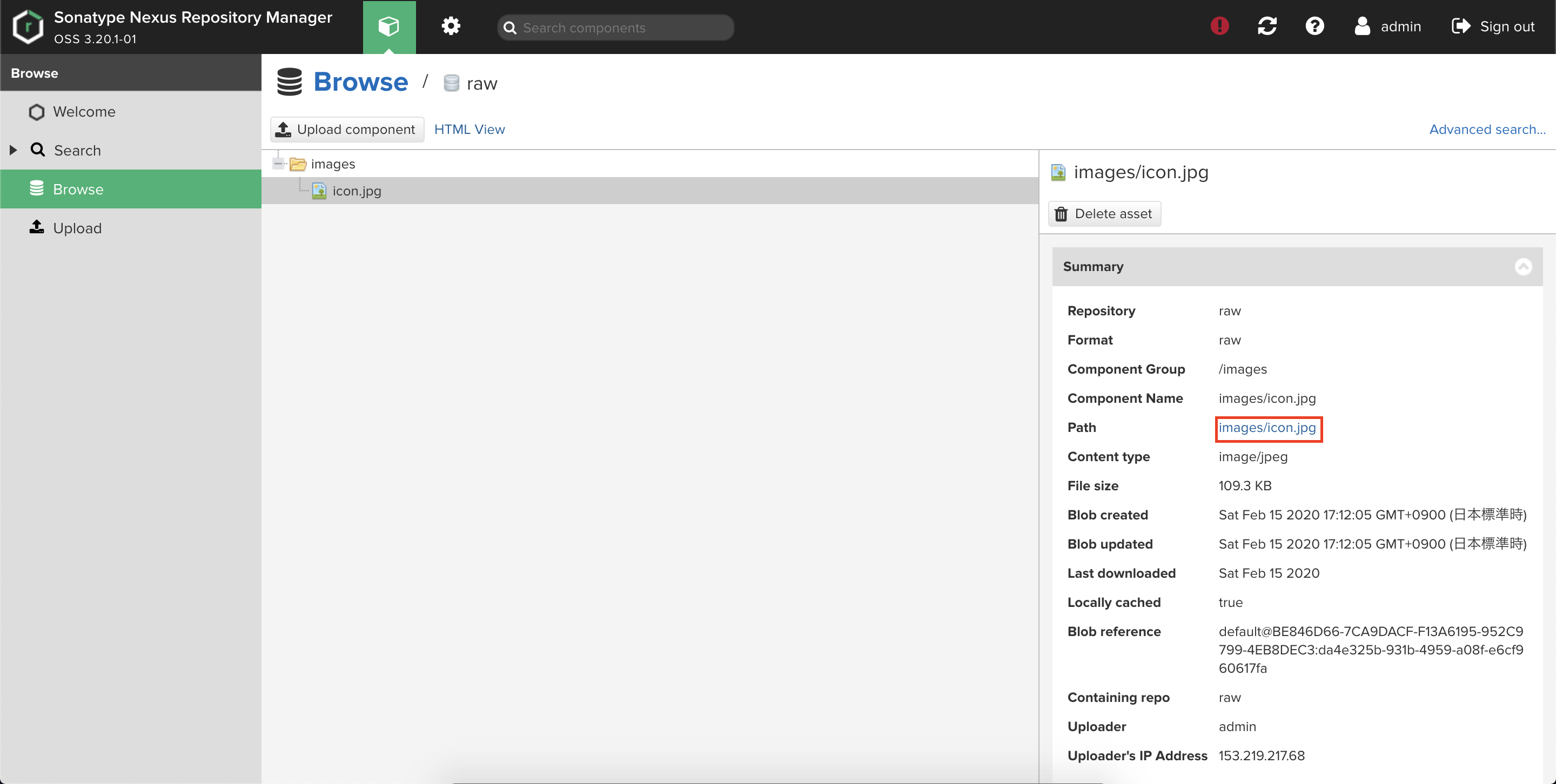
Pathから画像ファイルを選択します。
別タブで画像が表示されます。
おわりに
EKSにHelmでデプロイしたNexusのblob storeをEBSからS3へ移行させる手順を説明しました。
blob storeの中身が大きいとその分ローカルストレージの容量を確保しないといけないことに注意です。参考
Nexus Repository Manager 3 Storage Guide
sonatype Nexusのblob store を FileからS3に変更する






- 投稿日:2020-02-15T17:51:26+09:00
【小ネタ】AWS 認定ソリューションアーキテクト – プロフェッショナル資格試験に向けた知識の整理③
概要
AWS 認定ソリューションアーキテクト – プロフェッショナル資格試験に向けた小ネタ集③。
参考
アソシエイト資格の勉強法は以下を参照
AWS初心者がAWS 認定ソリューションアーキテクト – アソシエイト資格試験に合格した時の勉強法
その他の小ネタは以下を参照
IAM ポリシー
- アイデンティティ (ユーザー、ユーザーのグループ、ロール) にアタッチする
- 以下の4種類ある
- 管理ポリシー:以下の2種類に分類される
- AWS管理ポリシー:AWSが職務機能用に設計されているもの
- カスタマー管理ポリシー:AWS管理ポリシーをコピーして作成でき、カスタマイズできるもの
- インラインポリシー:単一のユーザー、グループ、またはロールに直接埋め込まれる。通常、インラインポリシーを使用することは推奨されていません。
- 管理ポリシーとインラインポリシー
AWS管理ポリシー
- 図にすると以下。ポイントは、
- AWS管理のためアカウントを超えてアタッチできる
- 職務機能単位のAWS管理ポリシーがデフォルトで用意されている
- 職務機能のAWS管理ポリシー
- 管理者:AdministratorAccess
- 料金:Billing
- データベース管理者:DatabaseAdministrator
- データサイエンティスト:DataScientist
- 開発者パワーユーザー:PowerUserAccess
- ネットワーク管理者:NetworkAdministrator
- セキュリティ監査人:SecurityAudit
- サポートユーザー:SupportUser
- システム管理者:SystemAdministrator
- 閲覧専用ユーザー:ViewOnlyAccess
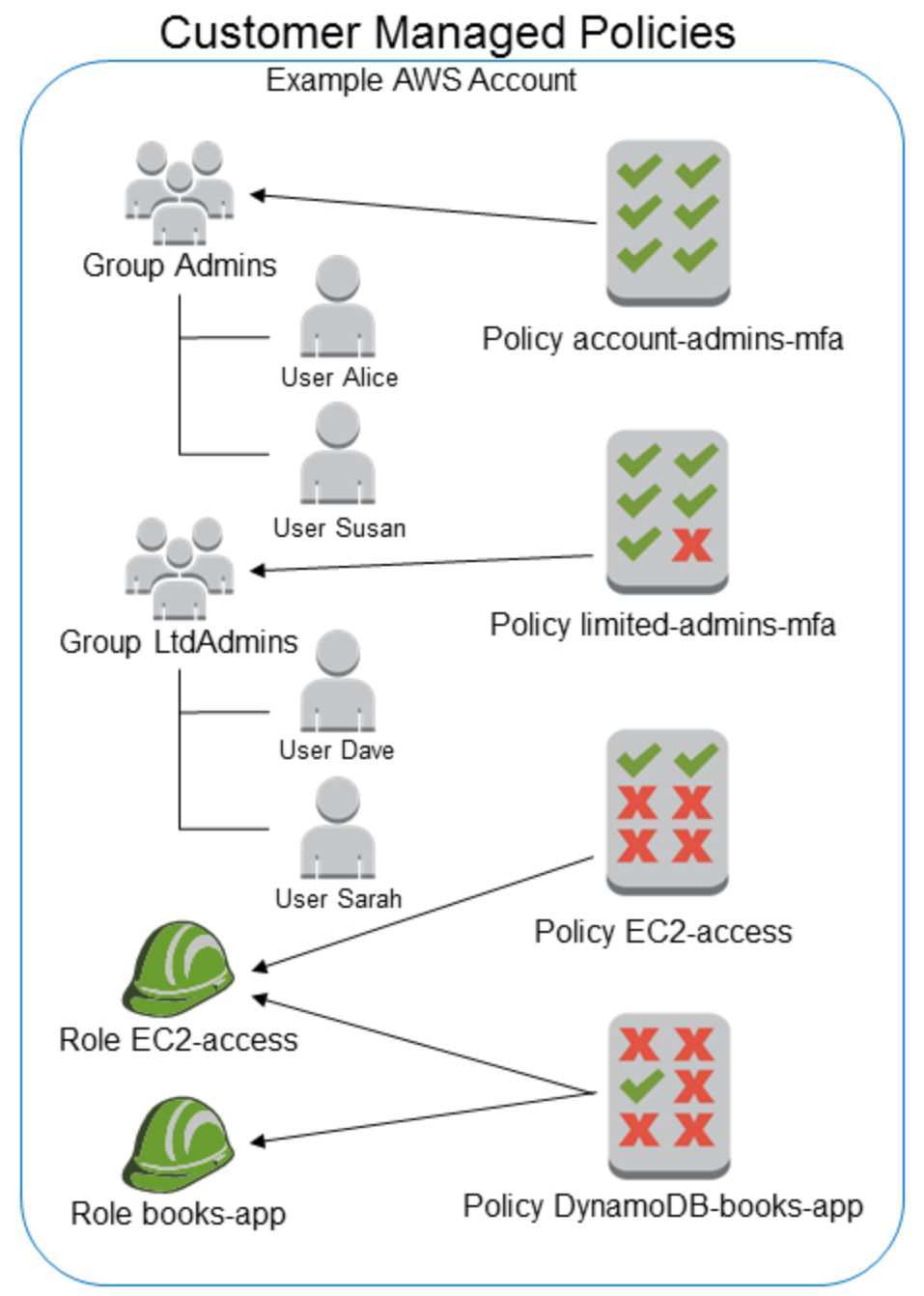
カスタマー管理ポリシー
- 図にすると以下。ポイントは、
- AWS管理ポリシーをコピーして作成でき、カスタマイズできる
- AWSアカウント内の管理になるため他のアカウントにはアタッチできない
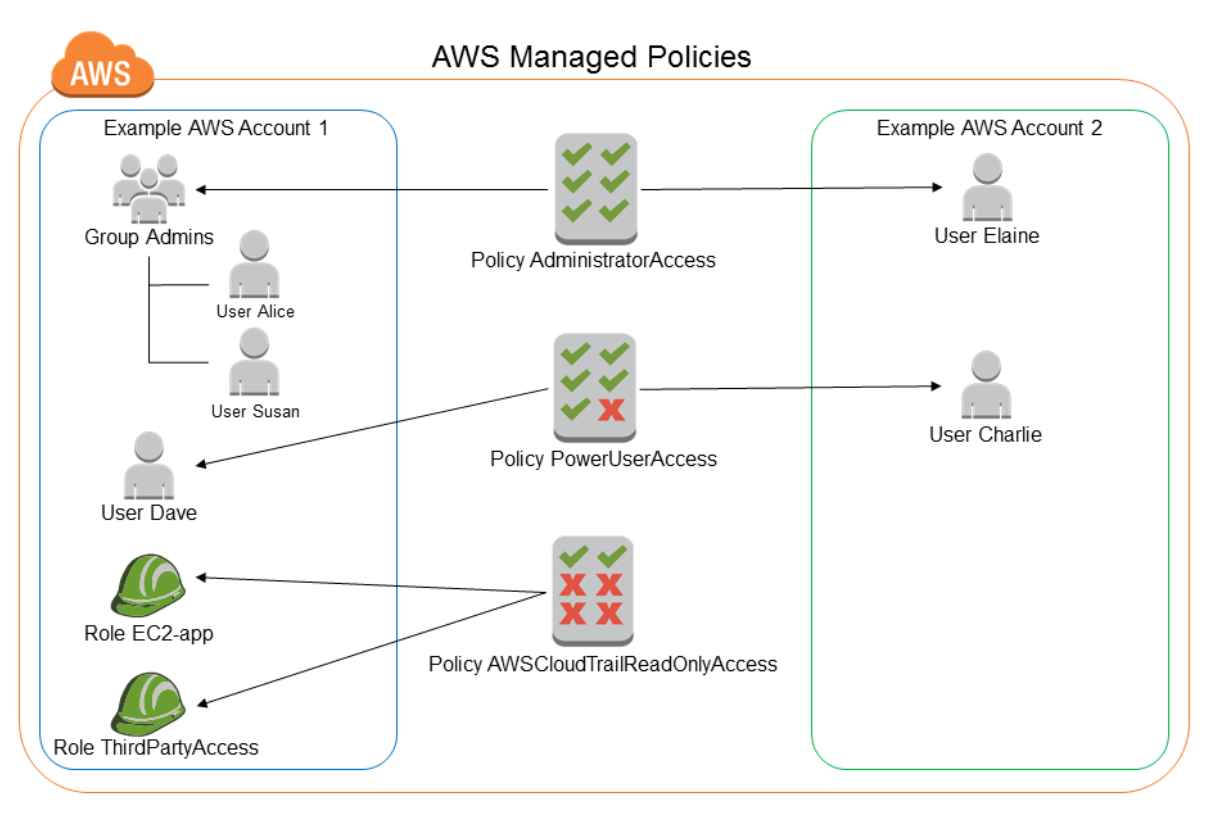
インラインポリシー
- 図にすると以下。ポイントは、
- 単一のユーザー、グループ、またはロールに直接埋め込まれる
- 図のDynamoDB-books-appを更新する場合、EC2-accessロールとbooks-appロールの両方のインラインポリシーを更新する必要がある

- 投稿日:2020-02-15T17:01:26+09:00
Amazon EBSのマルチアタッチ機能とAzure Shared Disksを比較してみる
はじめに
米国時間の 2020/2/13 に Azure Shared Disksのプレビューが、
2020/2/14 に Amazon EBS のマルチアタッチ機能がそれぞれ発表されました。
これまでOCI以外のパブリッククラウドでは提供されていなかった
ブロックストレージを共有ディスクとして接続可能になる機能です。Announcing the preview of Azure Shared Disks for clustered applications
https://azure.microsoft.com/en-us/blog/announcing-the-preview-of-azure-shared-disks-for-clustered-applications/New – Multi-Attach for Provisioned IOPS (io1) Amazon EBS Volumes
https://aws.amazon.com/jp/blogs/aws/new-multi-attach-for-provisioned-iops-io1-amazon-ebs-volumes/機能や制限等の対応
それぞれ特徴がありそうでしたので、各ドキュメントを参照し記載しました。
2020/2/15時点の情報です。
Amazon EBS Multi-Attach Azure Shared Disks リリースステータス 一般利用可能 プレビュー 対応リージョン バージニア北部/オレゴン/アイルランド/ソウル 米国中西部 対応ボリュームタイプ Provisioned IOPS SSD(io1) Premium SSD P15(256GB)以上 配置制限 同一AZ内 近接通信配置グループ内 接続可能な最大インスタンス数 16 10(P60以上) I/Oフェンシング 未対応 SCSI PR ブートボリュームとして使えるか × × バックアップ スナップショットを取得可能 Azure Backup/Site Recoveryは未対応 ボリューム作成後の変更 不可 maxShares値を変更可能 追加料金 無し 追加のマウントは、ディスクサイズに基づいて課金 参考
Attaching a Volume to Multiple Instances with Amazon EBS Multi-Attach
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ebs-volumes-multi.html
https://docs.aws.amazon.com/AWSEC2/latest/WindowsGuide/ebs-volumes-multi.htmlAzure shared disks
https://docs.microsoft.com/ja-jp/azure/virtual-machines/linux/disks-shared
Enable shared disk
https://docs.microsoft.com/ja-jp/azure/virtual-machines/linux/disks-shared-enable
- 投稿日:2020-02-15T16:50:02+09:00
【AWS】EC2 apacheにファイルをアップロードする方法&エラーが発生した時の対処
apacheにアップロード方法
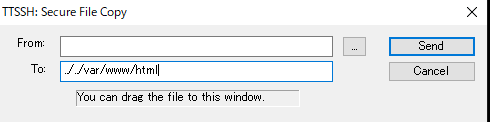
teratermの左上のファイルを押して、SSH SCRを選択
1.fromにアップロードしたいファイル
2.Toに../../var/www/html
3.Sendを押す
フォルダ
ご自身のターミナルから下記コマンドを実行してください。
※EC2にsshでログインした先のターミナルで行うのではありません。//実行場所 C:\Users\TOSHI\Desktop //アップロードコマンド scp -r -i C:\Users\ユーザー\Desktop\ssh2.pem test ec2-user@18.222.213.115:/var/www/html解説
C:\Users\ユーザー\Desktop\ssh2.pemは.pemまでのパス
ssh2.pemの後のtestはアップロードしたいフォルダ名です。末尾のvar/www/htmlはアップロード先のパス
パーミッションエラーの対処法
アップロードする際にパーミッション関係のエラーが出た人は下記の問題です。
いろいろ、調べると接続してる「ec2-user」には書き込む権利がないようで、
やり方もいろいろあるようですが、 ファイルを操作するディレクトリ配下すべての
所有者をログインしてるアカウントにしてしまうとうというのが簡単そうなので
これをやることに。引用:WASのEC2でSFTPは繋がったけどフィル操作ができない・・・ORZ
https://irodory.jp/web/server/104ということで、さっそくターミナルにて下記実行
chown -R ec2-user /var/www/htmlその後アップロードできました。
- 投稿日:2020-02-15T14:32:30+09:00
AWS試験対策(⑤コンピューティングとストレージ続々々)
自分用雑記
コンテナから続き書いていきます〜ECS、EKS、fargate
まず、コンテナって何じゃって話。
コンテナは仮想化技術の一つ。SaaSとかと何が違うのかと言うと、リソースが少なくて済む代わりにOSはその元となるOSでしか作れない。Windows上でコンテナ作ったらWindowsのみ、みたいな感じらしい。SaaSなら基盤の上にLinuxでも何でも入れれるから決定的な違い。
要するに何がしたいのかというと、仮想的な環境をいくつか作って、そこでアプリケーションを動かす、みたいな感じ。データプレーン
実行環境のこと。Windows上でコンテナを作ったら、ってとこの、大元のWindowsのこと。この上にコンテナが乗るイメージコントロールプレーン
コンテナを管理する奴ら。コンテナをどのデータプレーンのosで動作させるのかとか、コンテナの死活監視とかしてくれる。オーケストレーションサービスってだけあって、指揮者的なイメージ。レジストリ
コンテナのイメージの置き場。必要に応じてデータプレーンにコンテナを配置する。EKS、ECSの違い
AWS純正のコンテナ管理システムがECS。
変わって、オープンソースのKubernetesのコンテナ管理システムがEKS。
どちらもEC2をデータプレーン、つまり実行環境にできる。
ECSはさらに、fargateを実行環境にできる。
fargateとは、わざわざインスタンス作らなくても実行環境提供してくれるシステム。これのおかげでインスタンスを準備、設定、調整する必要がない。
レジストリサービスはどちらもECRというサービスを使う。使い分けとしては、サーバーの管理をなるべくしたくないならECSのfargateを。
すでに既存のシステムでKubernetesを使ってるならEKSとEC2を使う。試験ではあまり重要視されてないけどこれから使っていきたい領域。
Lambda
ラムダって読むらしい。最初読めないの恥ずかしすぎてググった。
これも覚えて使っていきたい。個人的に名前が好き。サーバを構築しなくてもコード実行できるサービス。
他のイベントを起因に色々行ってくれるため、S3などとの連携が容易。イベントドリブンっていうらしい。
イベントの量などに応じて自動的にサーバを大きくしたり小さくしたり、スケールしてくれる。
実際はコンテナ内で実行され、アプリが稼働しただけ課金される。何がいいかってコスト効率がいい。
普段からサーバを用意しておいてリクエスト待ちだと、使ってないときもサーバは時間単位で料金請求がくるけど、Lambdaなら使ったときだけ。だから、たまーにしか来ない処理とかに向いてる。
請求はリクエスト数と処理料で計算される。しかし、実行の時間上限が15分なので、大量のデータ処理はできない…
対応言語は様々でrubyとかjavaとかたくさんあります(適当)
Lambda Custom Runtimesを使うことでAWSパートナーが提供する言語も使える。
AWS step functionで、いくつかのステップで構成されるアプリをLambda関数を組み合わせて構築できるらしい。何言ってるかわからない。笑笑
API Gateway
ウェブからのHTTPでのリクエストをLambdaで処理したいとき、間にこれを挟まないと行けない。
S3とかではこれを挟む必要はない。storage Gateway
簡単に言うならオンプレのストレージとS3の仲介役。
オンプレのストレージから、S3に保存することができる。ファイルゲートウェイ
オンプレのファイルシステムのバックエンドストレージにS3を利用
ファイルをオンプレとS3で共有するために利用テープゲートウェイ
仮想テープライブラリ対応のバックアップソフトを使って、S3に保存
オンプレのバックアップをS3に保存するために利用保管型ボリュームゲートウェイ
オンプレのデータのコピーをS3に保存。つまりそれをEBSに復元することも可能。
データのプライマリコピー自体はオンプレに保管されてるから保管型。キャッシュ型ボリュームゲートウェイ
オンプレのデータのコピーをS3に保存。プライマリコピーもS3に。オンプレではよく使うデータのキャッシュのみ存在させるからキャッシュ型。EFS
EBSの浮気野郎。異なるAZからもアクセスできるし、複数のインスタンスからアクセスできる。尻軽。
うそですべんりですごめんなさい
EBS使わずにこっち使えばよくねとか思っちゃいますねコンピューティングとストレージは以上、次回からはセキュリティと、ネットワークへ。
- 投稿日:2020-02-15T13:24:46+09:00
rails環境構築その3【terraform】
はじめに
terraformをつかってAWS(EC2,RDS)を作成します。
全体の流れ
- terraformインストール
- AWSでIAMユーザー作成
- AWS CLI導入
- AWS CLIにIAMユーザーの登録
- terraformとは
- terraform導入
- プロバイダーの設定
- VPC作成
- サブネット作成
- インターネットゲートウェイ作成
- ルートテーブル作成
- EC2作成
- Security Groupの作成
- RDS作成
参考
* 10分で理解するTerraformterraformインストール
$ brew update $ brew install terraformAWSでIAMユーザー作成
参考
* Identity and Access Management へようこそ
* Terraformで構築するAWSAdministratorAccessポリシー(管理者権限)を選択してください。 権限が足りないと Error creating VPC: UnauthorizedOperation: You are not authorized to perform this operation. とエラーが出ます。AWS CLI インストール
参考
* AWS CLI のインストールと設定
順番にやればいいですが、私の場合はpythonのパスや環境でハマりました
エラー解決↓
* MacOSとHomebrewとpyenvで快適python環境を。
* Python・Python3のインストール先、パス等確認
* Python2.7からPython3.6をデフォルトにする話
* Python3インストール(Mac編)上記のリンクを参考にすればイケルと思います。
ターミナルcurl "https://bootstrap.pypa.io/get-pip.py" -o "get-pip.py" sudo python get-pip.py sudo pip install awscliエラーなくインストルされバージョンが出れば成功です
ターミナルpip --version aws --versionAWS CLIにIAMユーザーの登録
ターミナル(ホームディレクトリ)aws configure または、 aws configure --profile ユーザー名順番に記入します
- AWS CLI の設定
- AWS-CLIの初期設定のメモ
それぞれ先ほど作成した、IAMユーザーをコピペします。
リージョンと出力形式はリンク先から選んでください。ターミナルAWS Access Key ID [None]: AWS Secret Access Key [None]: Default region name [None]: Default output format [None]: json # Asia Pacific (Tokyo) ap-northeast-1terraformとは
インフラのコード化であります。GUIを通さずにインフラに変更を加えられコードの共有と再利用ができます。
参考
* インフラの構成管理を自動化するTerraform入門
* Terraformを使ってAWSのVPCを作成してEC2を起動した
ファイル形式は主に.tfと.tfvarsを使います。
ファイル分割はあとにして全てmain.tfに書きます。主なコマンド
terraformがあるディレクトリに移動して実行する# 初期化 Terraformで新しく設定を記述した場合、初期化を行う必要があります。 terraform init # 確認(所謂dry-run) terraform plan # 適用 コードの状態をAWS上へ適用 terraform apply # すべて消去するコマンド terraform destroy # リソースの閲覧 terraform show準備
mkdir terraform cd terraform touch main.tf touch terraform.tfvarsプロバイダーの設定
最初にproviderという指定をする必要がある。
複数の環境に対応しているため、「どのプロバイダーを使うのか?」を宣言するproviderとは
- その名と通りプロバイダでAWSの他にherokuやGCPもできるらしい
- profileで
aws configでprofileを指定した場合はその名前、していない場合は"default"region = "ap-northeast-1"で指定したリージョン内にVPCなどを作っていくmain.tfprovider "aws" { profile = ユーザー名 region = "ap-northeast-1" }VPCを作成
使うリソース
aws_vpcmain.tf# VPC resource "aws_vpc" "aws-tf-vpc" { cidr_block = "10.1.0.0/16" instance_tenancy = "default" tags = { Name = "aws-tf-vpc" } }実行
terraformがあるディレクトリに移動して実行するterraform init terraform plan terraform apply # リソースの閲覧 terraform show実際に確かめてみる
aws-tf-vpcと書いてあるVPCがあれば成功ですresourceとは
resourceはVPCやEC2のような起動したいリソースを定義 リソースの種類は、プロバイダーがAWSの場合はaws_*という名前でTerraformで予め定義されています。VPCであればaws_vpc、EC2であればaws_instanceです。resourceの構文
リソースはresourceブロックで設定します。resource "<リースの種類>" "<リソース名>" {}という構文です。resourceの定義と命名
resource "aws_vpc" "this" { ここでは 「"aws_vpc"というリソースを"this"という名前」 で作成しています。 resource "aws_vpc" まではAWSのVPCを作成するという意味で、 "this" はTerraformで定義する他のリソースから参照する際に使用します。他リソースの属性の参照
Terraformにはテンプレート内の他リソースの属性を参照する方法があります。 具体的には、<リソースの種類>.<リソース名>.<属性名>で他リソースの属性を参照することができます。その他の知識は下のリンクで
* AWSでTerraformに入門vscodeをterraform v0.12対応させる
下記のようなメッセージが出た人向け For Terraform 0.12 support try enabling the experimental language server with the 'Terraform: Enable/Disable Language Server' command コマンドパレットを開く(ctl/cmd+shift+p) terraform: install/update language server -> 現在最新の v0.0.9 を選択 terraform: Enable/Disable Language Server を実行 一度vscodeを閉じたらHCL2記法の.tfファイルでもエラーが出なくなりました。.gitignoreに上げて行けないファイルの追加
下記のファイルはgithubに上げてはいけないとので追加します。
* Terraform.gitignore.gitignore# Local .terraform directories **/.terraform/* # .tfstate files *.tfstate *.tfstate.* # .tfvars files *.tfvarsサブネット作成
使うリソース
aws_subnetmain.tf# サブネット2つ作成(publicとprivate) resource "aws_subnet" "aws-tf-public-subnet-1a" { vpc_id = aws_vpc.aws-tf-vpc.id cidr_block = "10.1.1.0/24" availability_zone = "ap-northeast-1a" tags = { Name = "aws-tf-public-subnet-1a" } } resource "aws_subnet" "aws-tf-private-subnet-1a" { vpc_id = aws_vpc.aws-tf-vpc.id cidr_block = "10.1.20.0/24" availability_zone = "ap-northeast-1a" tags = { Name = "aws-tf-private-subnet-1a" } }インターネットゲートウェイの作成
使うリソース
aws_internet_gatewaymain.tfresource "aws_internet_gateway" "aws-tf-igw" { vpc_id = aws_vpc.aws-tf-vpc.id tags = { Name = "aws-tf-igw" } }ルートテーブルの作成
使うリソース
aws_route_tablemain.tfresource "aws_route_table" "aws-tf-public-route" { vpc_id = aws_vpc.aws-tf-vpc.id route { cidr_block = "0.0.0.0/0" gateway_id = aws_internet_gateway.aws-tf-igw.id } tags = { Name = "aws-tf-public-route" } }サブネットの関連付けでルートテーブルをパブリックサブネットに紐付け
使うリソース
aws_route_table_associationmain.tfresource "aws_route_table_association" "aws-tf-public-subnet-association" { subnet_id = aws_subnet.aws-tf-public-subnet-1a.id route_table_id = aws_route_table.aws-tf-public-route.id }EC2作成(public側に作る)
使うリソース
aws_instance、aws_key_pairmain.tfresource "aws_instance" "aws-tf-web" { ami = "ami-011facbea5ec0363b" instance_type = "t2.micro" disable_api_termination = false key_name = aws_key_pair.auth.key_name vpc_security_group_ids = [aws_security_group.aws-tf-web.id] subnet_id = aws_subnet.aws-tf-public-subnet-1a.id tags = { Name = "aws-tf-web" } } # amiとはAmazon Linux 2 AMIです。今回は実際のamiの値を直接入れてますが、いつも最新版にできます。 variable "public_key_path" {} resource "aws_key_pair" "auth" { key_name = "terraform-aws" public_key = file(var.public_key_path) }terraform.tfvars# ローカルに鍵がある場所を指定 public_key_path = "~/.ssh/terraform-aws.pub"amiを常に最新版にする
インスタンスのkey_nameについて
GUIで作るときはインスタンス作成時にsshキーを新規作成や既存のキーを使いAWSにアクセスしますが、
terraformで作成する場合は.tfvarsファイルから参照して公開鍵をインスタンスのkey_nameに貼り付けます。
私はterraform-awsという名前で鍵を作成しました。ターミナル$ cd .ssh $ ssh-keygen -t rsa terraform-aws 今回の場合の名前 ここでエンターキーを2連打 $ ls ここでterraform-aws terraform-aws.pubができていることを確認参考
* Resource: aws_key_pair
* Terraform でキーペア登録し起動した EC2 に SSH接続
Terraform 変数について
Terraform の変数は
variableブロックで定義
var.<変数名>という書式で参照
外部ファイルに値を定義した場合、terraform.tfvarsなら自動的に読み込まれて変数に代入されます。
また.tfvarsはgithubに挙げないとこが大事です。
参考
* 【Terraform 再入門】EC2 + RDS によるミニマム構成な AWS 環境をコマンドライン一発で構築してみようSecurity Groupの作成
使うリソース
aws_security_group、aws_security_group_rulemain.tfresource "aws_security_group" "aws-tf-web" { name = "aws-tf-web" description = "aws-tf-web_sg" vpc_id = aws_vpc.aws-tf-vpc.id tags = { Name = "aws-tf-web" } } # 80番ポート許可のインバウンドルール resource "aws_security_group_rule" "inbound_http" { type = "ingress" from_port = 80 to_port = 80 protocol = "tcp" cidr_blocks = [ "0.0.0.0/0", ] # ここでweb_serverセキュリティグループに紐付け security_group_id = aws_security_group.aws-tf-web.id } # 22番ポート許可のインバウンドルール resource "aws_security_group_rule" "inbound_ssh" { type = "ingress" from_port = 22 to_port = 22 protocol = "tcp" cidr_blocks = [ "0.0.0.0/0", ] # ここでweb_serverセキュリティグループに紐付け security_group_id = aws_security_group.aws-tf-web.id } # アウトバウンドルール resource "aws_security_group_rule" "outbound_all" { type = "egress" from_port = 0 to_port = 0 protocol = -1 cidr_blocks = [ "0.0.0.0/0", ] # ここでweb_serverセキュリティグループに紐付け security_group_id = aws_security_group.aws-tf-web.id }Security Group詳細
ElasticIP作成
使うリソース
aws_eipmain.tfresource "aws_eip" "aws-tf-eip" { instance = aws_instance.aws-tf-web.id vpc = true } output "example-public-ip" { value = "${aws_eip.aws-tf-eip.public_ip}" }outputについて
ElasticIPなどはGUIから確認できますが、
outputブロックで記述するとterraform apply実行時に下記のように出力されます。Apply complete! Outputs: example-public-ip = ElasticIPRDSの作成
RDSは2つのサブネットが必要なのであと一つ違うアベイラビリティゾーンから作成します。
使うリソースaws_subnet、aws_db_subnet_groupmain.tf# RDS用のサブネットを作成 resource "aws_subnet" "aws-tf-private-subnet-1c" { vpc_id = aws_vpc.aws-tf-vpc.id cidr_block = "10.1.3.0/24" availability_zone = "ap-northeast-1c" tags = { Name = "aws-tf-private-subnet-1c" } } # 使用する2つを指定します。 resource "aws_db_subnet_group" "rdb-tf-db" { name = "rdb-tf-db-subnet" description = "It is a DB subnet group on tf_vpc." subnet_ids = [aws_subnet.aws-tf-private-subnet-1a.id,aws_subnet.aws-tf-private-subnet-1c.id] tags = { Name = "rdb-tf-db" } }DB用のセキュリティーを作成
WebサーバーからのみDBサーバーにアクセスできるようにするためにセキュリティを作ります。
使うリソースaws_security_group、aws_security_group_rulemain.tf# Security Group resource "aws_security_group" "aws-tf-db" { name = "aws-tf-db" description = "aws-tf-db-sg" vpc_id = aws_vpc.aws-tf-vpc.id tags = { Name = "aws-tf-db" } } resource "aws_security_group_rule" "db" { type = "ingress" from_port = 5432 to_port = 5432 protocol = "tcp" source_security_group_id = aws_security_group.aws-tf-web.id security_group_id = aws_security_group.aws-tf-db.id } # source_security_group_idとはアクセスを許可するセキュリティグループIDつまりWeb側のセキュリティグループを指します。RDSインスタンスの作成
使うリソース
aws_db_instancemain.tfvariable "aws-td-db-username" {} variable "aws-td-db-password" {} resource "aws_db_instance" "aws-td-db" { identifier = "aws-td-db" allocated_storage = 20 name = "db11" engine = "postgres" engine_version = "11.5" instance_class = "db.t2.micro" storage_type = "gp2" username = var.aws-td-db-username password = var.aws-td-db-password vpc_security_group_ids = [aws_security_group.aws-tf-db.id] db_subnet_group_name = aws_db_subnet_group.rdb-tf-db.name }terraform.tfvarspublic_key_path = "~/.ssh/terraform-aws.pub" aws-td-db-username = ※※※※※※※※※※ aws-td-db-password = ※※※※※※※※※ それぞれ指定してください。実行
terraform plan terraform apply # 確認 terrafom showRDSインスタンス作成時にハマったエラーについて
その1DBName must begin with a letter and contain only alphanumeric characters これはRDSインスタンスのnameについてのエラーです。私の場合は`name = "db11"`と書きましたが、文字で初めて英数字両方を書かないといけないらしいです。参考
* AWS aws_db_instance DBName issueその2Error creating DB Instance: InvalidParameterValue: Invalid DB engine これはRDSインスタンスの`engine`の名前の書き方でエラーが出ました。今回は`engine = "postgres"`と書きました。参考
* "Invalid DB engine" when creating AWS/RDS Postgresql instance
* Engineのセクションを見てください内容一式
main.tfprovider "aws" { profile = プロフィール名 region = "ap-northeast-1" } # VPC作成 resource "aws_vpc" "aws-tf-vpc" { cidr_block = "10.1.0.0/16" instance_tenancy = "default" enable_dns_support = "true" enable_dns_hostnames = "true" tags = { Name = "aws-tf-vpc" } } # サブネット2つ作成(publicとprivate) resource "aws_subnet" "aws-tf-public-subnet-1a" { vpc_id = aws_vpc.aws-tf-vpc.id cidr_block = "10.1.1.0/24" availability_zone = "ap-northeast-1a" tags = { Name = "aws-tf-public-subnet-1a" } } resource "aws_subnet" "aws-tf-private-subnet-1a" { vpc_id = aws_vpc.aws-tf-vpc.id cidr_block = "10.1.20.0/24" availability_zone = "ap-northeast-1a" tags = { Name = "aws-tf-private-subnet-1a" } } # インターネットゲートウェイの作成 resource "aws_internet_gateway" "aws-tf-igw" { vpc_id = aws_vpc.aws-tf-vpc.id tags = { Name = "aws-tf-igw" } } # ルートテーブルの作成 resource "aws_route_table" "aws-tf-public-route" { vpc_id = aws_vpc.aws-tf-vpc.id route { cidr_block = "0.0.0.0/0" gateway_id = aws_internet_gateway.aws-tf-igw.id } tags = { Name = "aws-tf-public-route" } } # サブネットの関連付けでルートテーブルをパブリックサブネットに紐付け resource "aws_route_table_association" "aws-tf-public-subnet-association" { subnet_id = aws_subnet.aws-tf-public-subnet-1a.id route_table_id = aws_route_table.aws-tf-public-route.id } # EC2作成(public側) resource "aws_instance" "aws-tf-web" { ami = "ami-011facbea5ec0363b" instance_type = "t2.micro" disable_api_termination = false key_name = aws_key_pair.auth.key_name vpc_security_group_ids = [aws_security_group.aws-tf-web.id] subnet_id = aws_subnet.aws-tf-public-subnet-1a.id tags = { Name = "aws-tf-web" } } variable "public_key_path" {} resource "aws_key_pair" "auth" { key_name = "terraform-aws" public_key = file(var.public_key_path) } # Security Group resource "aws_security_group" "aws-tf-web" { name = "aws-tf-web" description = "aws-tf-web_sg" vpc_id = aws_vpc.aws-tf-vpc.id tags = { Name = "aws-tf-web" } } # 80番ポート許可のインバウンドルール resource "aws_security_group_rule" "inbound_http" { type = "ingress" from_port = 80 to_port = 80 protocol = "tcp" cidr_blocks = [ "0.0.0.0/0", ] # ここでweb_serverセキュリティグループに紐付け security_group_id = aws_security_group.aws-tf-web.id } # 22番ポート許可のインバウンドルール resource "aws_security_group_rule" "inbound_ssh" { type = "ingress" from_port = 22 to_port = 22 protocol = "tcp" cidr_blocks = [ "0.0.0.0/0", ] # ここでweb_serverセキュリティグループに紐付け security_group_id = aws_security_group.aws-tf-web.id } # アウトバウンドルール resource "aws_security_group_rule" "outbound_all" { type = "egress" from_port = 0 to_port = 0 protocol = -1 cidr_blocks = [ "0.0.0.0/0", ] # ここでweb_serverセキュリティグループに紐付け security_group_id = aws_security_group.aws-tf-web.id } # ElasticIP resource "aws_eip" "aws-tf-eip" { instance = aws_instance.aws-tf-web.id vpc = true } output "example-public-ip" { value = aws_eip.aws-tf-eip.public_ip } ####RDSの作成 # RDS用のサブネットを作成 resource "aws_subnet" "aws-tf-private-subnet-1c" { vpc_id = aws_vpc.aws-tf-vpc.id cidr_block = "10.1.3.0/24" availability_zone = "ap-northeast-1c" tags = { Name = "aws-tf-private-subnet-1c" } } # DB用のセキュリティーを作成 # Security Group resource "aws_security_group" "aws-tf-db" { name = "aws-tf-db" description = "aws-tf-db-sg" vpc_id = aws_vpc.aws-tf-vpc.id tags = { Name = "aws-tf-db" } } resource "aws_security_group_rule" "db" { type = "ingress" from_port = 5432 to_port = 5432 protocol = "tcp" source_security_group_id = aws_security_group.aws-tf-web.id security_group_id = aws_security_group.aws-tf-db.id } resource "aws_db_subnet_group" "rdb-tf-db" { name = "rdb-tf-db-subnet" description = "It is a DB subnet group on tf_vpc." subnet_ids = [aws_subnet.aws-tf-private-subnet-1a.id,aws_subnet.aws-tf-private-subnet-1c.id] tags = { Name = "rdb-tf-db" } } variable "aws-td-db-username" {} variable "aws-td-db-password" {} resource "aws_db_instance" "aws-td-db" { identifier = "aws-td-db" allocated_storage = 20 name = "db11" engine = "postgres" engine_version = "11.5" instance_class = "db.t2.micro" storage_type = "gp2" username = var.aws-td-db-username password = var.aws-td-db-password vpc_security_group_ids = [aws_security_group.aws-tf-db.id] db_subnet_group_name = aws_db_subnet_group.rdb-tf-db.name }terraform.tfvarspublic_key_path = "~/.ssh/terraform-aws.pub" aws-td-db-username = ※※※※※※※※※※ aws-td-db-password = ※※※※※※※※※おしまい。
何かありましたらコメント欄で
- 投稿日:2020-02-15T12:08:58+09:00
積もり積もったAMIをまとめて消す
はじめに
日々バックアップを取得するのは大切ですが
数年分くらいが積もり積もってチリツモで多少なりコストにもなっていたので
大掃除に取り組みました。やったこと
EBSスナップショット削除の設定
AMIはEC2インスタンスの設定とEBSボリュームのスナップショットから成り立っており
単にAMIの登録を解除しても、スナップショットは削除されずに残り続けます。紐付いたスナップショットを確認して逐一削除するのも大変なので
AMIの登録解除をトリガーにスナップショットが削除されるように設定します。
下記の記事を参考に設定しました。
AMI登録解除時、スナップショットを自動で削除するように設定してみました!
- CloudTrailで証跡を残している前提
- Cloudwatch EventsでAMIの登録解除を検知
- 連動して発火するLambdaがスナップショットを削除
CLIでAMIの登録を解除
スナップショットを気にする必要がなくなったので、心置きなく登録を解除します。
CLIを使って、条件に合致するAMIの登録を解除します。実行コマンドaws ec2 describe-images --filters Name=owner-id,Values=【アカウントID】 --query 'Images[?contains(Name, `【検索文字列】`)]' | jq '.[].ImageId' | xargs -I {} aws ec2 deregister-image --image-id {}【アカウントID】: 自身のAWSアカウントID
【検索文字列】: AMINameの検索用の任意の文字列
(jqなしでできれば嬉しい…。)むすび
秘伝のタレ的なスクリプトで定期取得されていたのが原因なので
世代管理もできるようイマドキな感じに置き換えていきたいとおもっています。
- 投稿日:2020-02-15T11:58:58+09:00
ALBで付与されるHTTPヘッダ
概要
AWSのApplication Load Balancer(ALB)を使ってWeb-App-DBの3層構成を組むことが一般的に多いと思われるが、ALBではHTTPリクエストに対してHTTPヘッダを付与することがある。非ALB構成とALB構成で付与されるHTTPリクエストヘッダの差異をネットワークキャプチャで調査してみる。
ネットワークキャプチャコマンド
###tcpdumpをWebサーバで発行 tcpdump -i eth0 -n -tttt port <port番号> -w /tmp/web.pcap前提構成
①前段ALB_HTTPS構成#HTTPリクエストの流れ(APP,DB層は検証の目的に外れるので省略。 Clinet ===> ALB(443) ===> NGINX@WebServer(80)
②前段ALB_HTTP構成#HTTPリクエストの流れ(APP,DB層は検証の目的に外れるので省略。 Clinet ===> ALB(80) ===> NGINX@WebServer(80)
③Webサーバ直HTTP構成#HTTPリクエストの流れ(APP,DB層は検証の目的に外れるので省略。 Clinet ===> NGINX@WebServer(80)
検証結果
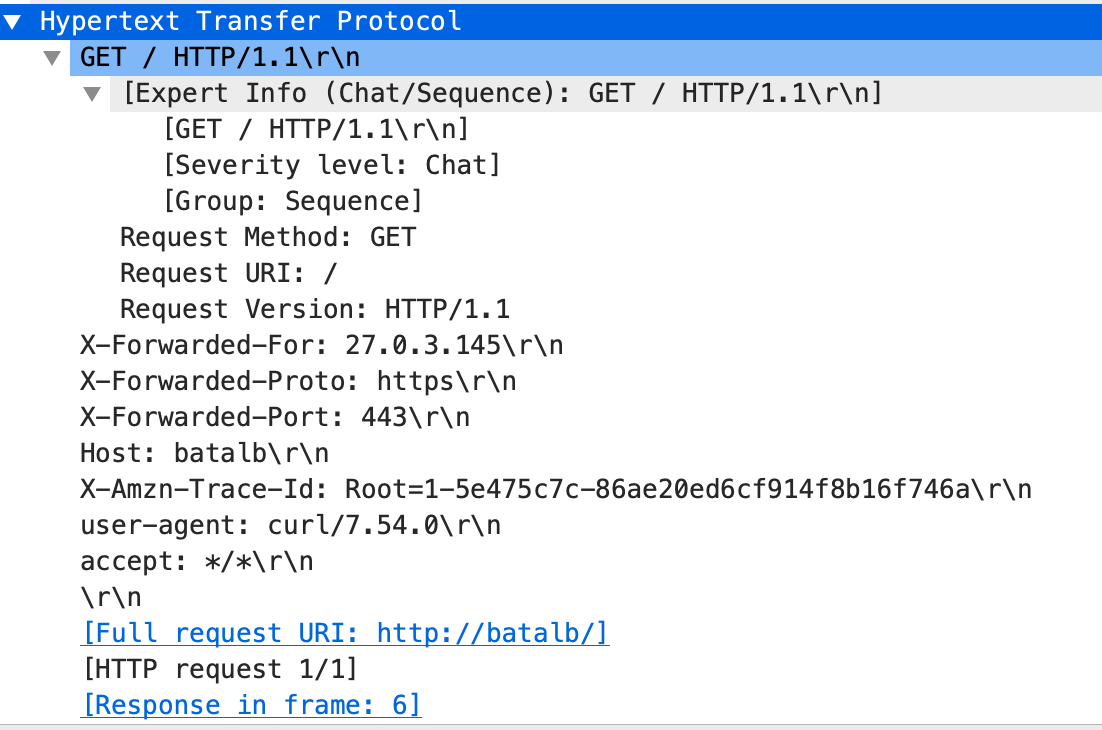
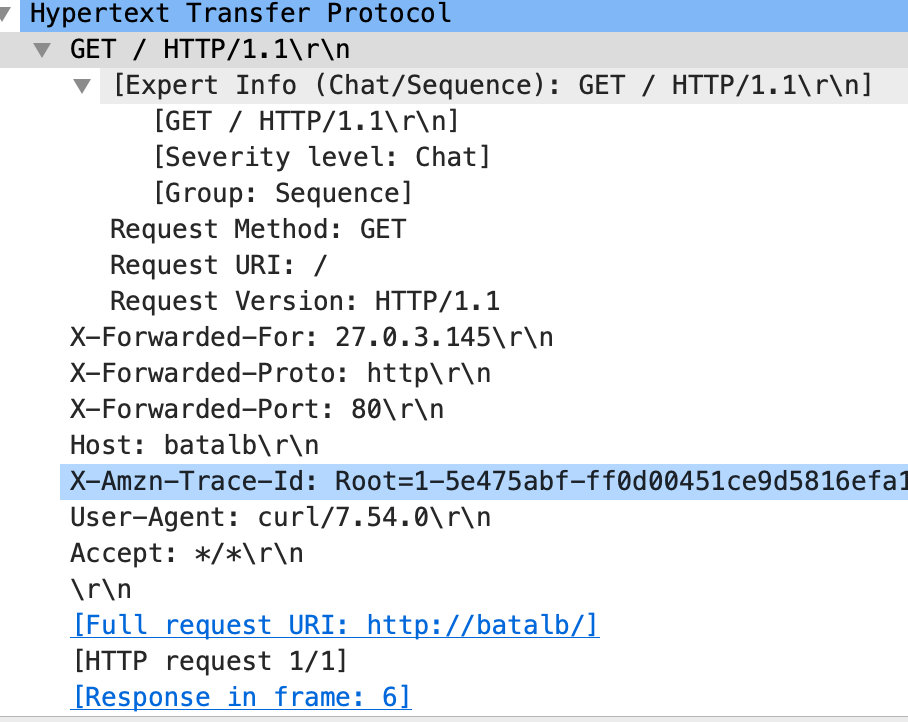
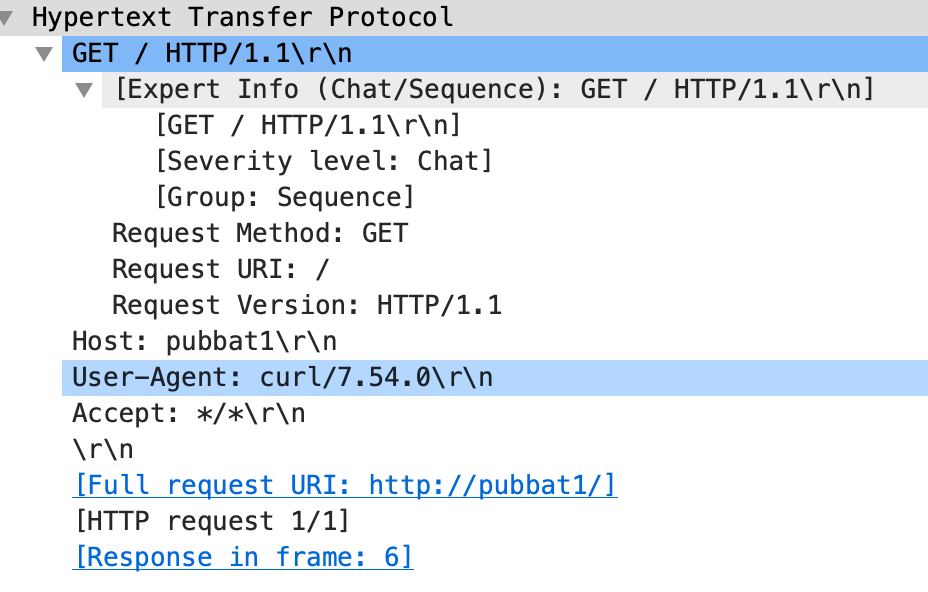
結果的に、ALBを経由した場合だと以下の4つのHTTPヘッダが追加付与されていることが分かる。
-X-Forwarded-For
-X-Forwarded-Proto
-X-Forwarded-Port
-X-Forwarded-Amzn-Trace-Id各ヘッダの詳細
参考URL
- 投稿日:2020-02-15T11:58:58+09:00
Application Load Balancerで付与されるHTTPヘッダ
概要
AWSのApplication Load Balancer(ALB)を使ってWeb-App-DBの3層構成を組むことが一般的に多いと思われるが、ALBではHTTPリクエストに対してHTTPヘッダを付与することがある。非ALB構成とALB構成で付与されるHTTPリクエストヘッダの差異をネットワークキャプチャで調査してみる。
ネットワークキャプチャコマンド
###tcpdumpをWebサーバで発行 tcpdump -i eth0 -n -tttt port <port番号> -w /tmp/web.pcap前提構成
①前段ALB_HTTPS構成#HTTPリクエストの流れ(APP,DB層は検証の目的に外れるので省略。 Clinet ===> ALB(443) ===> NGINX@WebServer(80)
②前段ALB_HTTP構成#HTTPリクエストの流れ(APP,DB層は検証の目的に外れるので省略。 Clinet ===> ALB(80) ===> NGINX@WebServer(80)
③Webサーバ直HTTP構成#HTTPリクエストの流れ(APP,DB層は検証の目的に外れるので省略。 Clinet ===> NGINX@WebServer(80)
検証結果
- 結果的に、ALBを経由した場合だと以下の4つのHTTPヘッダが追加付与されていることが分かる。
X-Forwarded-Forロードバランサなどの機器を経由してWebサーバに接続するクライアントの送信元IPアドレスを特定する際のデファクトスタンダード。クライアントの送信元IPアドレスの特定は、ロードバランサなどでクライアントの送信元IPアドレスが変換された場合でも、HTTPヘッダに元のクライアントIPアドレスの情報を付加することで実現。Webサーバ側でクライアントのIPアドレスを特定するために前段のLBで付与する必要がある。
例えば以下のような構成だと、Webサーバで受け取るHTTPリクエストヘッダはX-Forwarded-For: Clinetとなる。
Clinet ===> ALB(443) ===> WebServer上記であればSimpleだが多段プロキシ構成だと話が複雑になる。
例えば以下のような構成だと、Webサーバで受け取るHTTPリクエストヘッダはX-Forwarded-For: Clinet ALB Proxy1となる。Webサーバにリクエストを転送する主体はそれまでのアクセス元のIP(自らを含まない)をWebサーバに転送する時点でX-Forwarded-Forに付与する仕組み。Clinet ===> ALB(443) ===> Proxy1 ===> Proxy2 ===> WebServerこの状態から、ClientのIPアドレスをフィルタする方法は各Webサーバの設定による。
X-Forwarded-Protoプロキシまたはロードバランサーへ接続するのに使っていたクライアントのプロトコル (HTTP または HTTPS) を特定する。
X-Forwarded-Portプロキシまたはロードバランサーへ接続するのに使っていたクライアントからの宛先ポートを特定する。
X-Forwarded-Amzn-Trace-Idクライアントからのターゲットまたは他のサービスへの HTTP リクエストを追跡するための一意な識別子。ALBが、クライアントからのリクエストを受信すると、ターゲットにリクエストを送信する前に、[X-Amzn-Trace-Id] ヘッダーを追加、または更新する。Webサーバのアクセスログに記録することでALB側のアクセスログと比較してリクエストを特定可能
参考URL
- https://www.infraexpert.com/study/loadbalancer11.html
- https://developer.mozilla.org/ja/docs/Web/HTTP/Headers/X-Forwarded-Proto
- https://developer.mozilla.org/ja/docs/Web/HTTP/Headers/X-Forwarded-Host
- https://docs.aws.amazon.com/ja_jp/elasticloadbalancing/latest/application/load-balancer-request-tracing.html
- 投稿日:2020-02-15T10:51:04+09:00
LambdaでSlack通知してみる
やること
PowerShellでSlack通知してみるの続き、AWS Lambdaで通知してみる
前提
AWSアカウントとSlackアプリの
Incoming Webhook URLを取得していることが前提で始めます。
IAMロール作成
Lambda実行に必要な権限(IAMロール)を作成します。
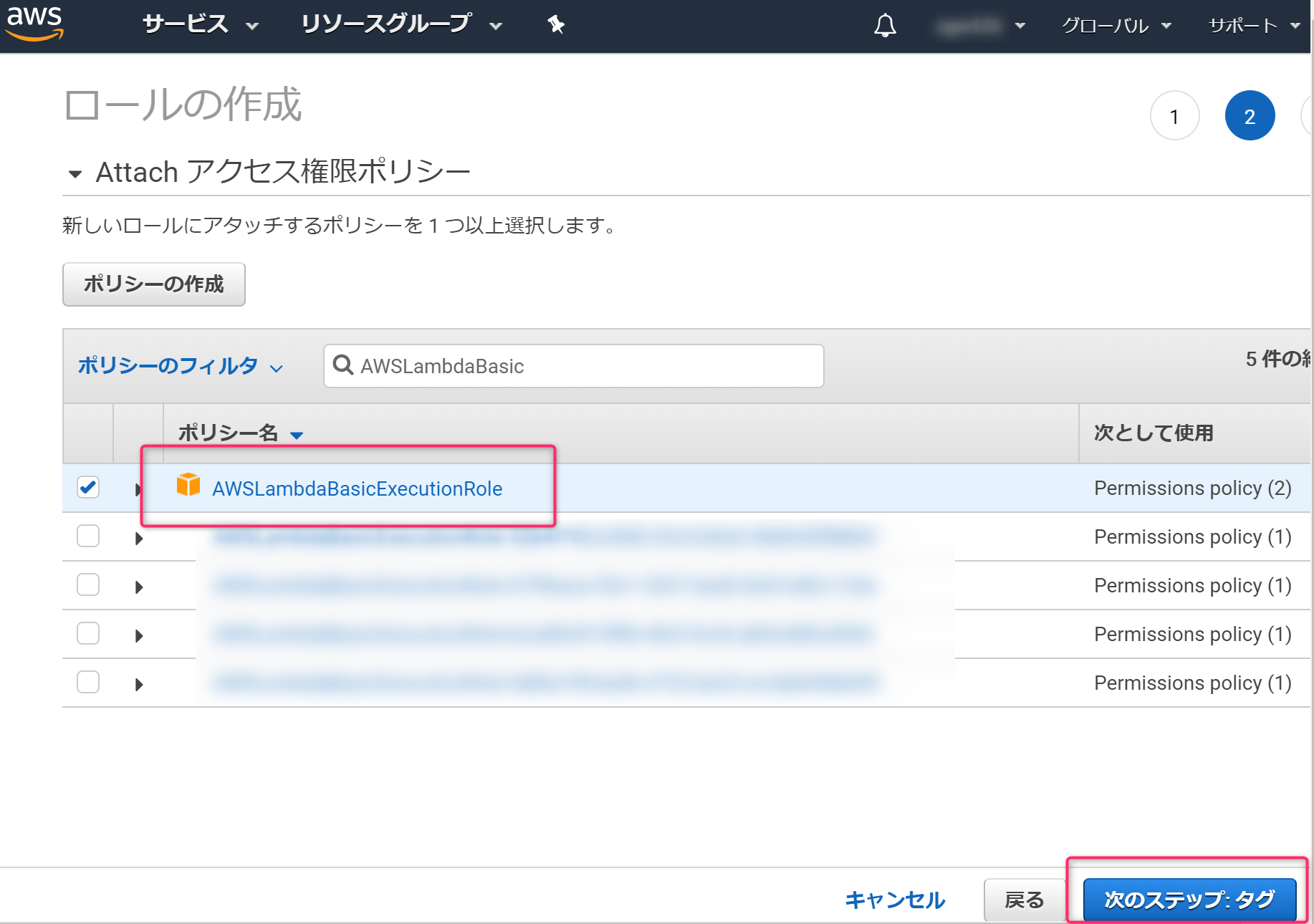
必要なポリシーを選択します。今回はLambdaが動けばいいので、
AWSLambdaBasicExecutionRoleを選択しました。
ロール名を設定します。
Lambda作成
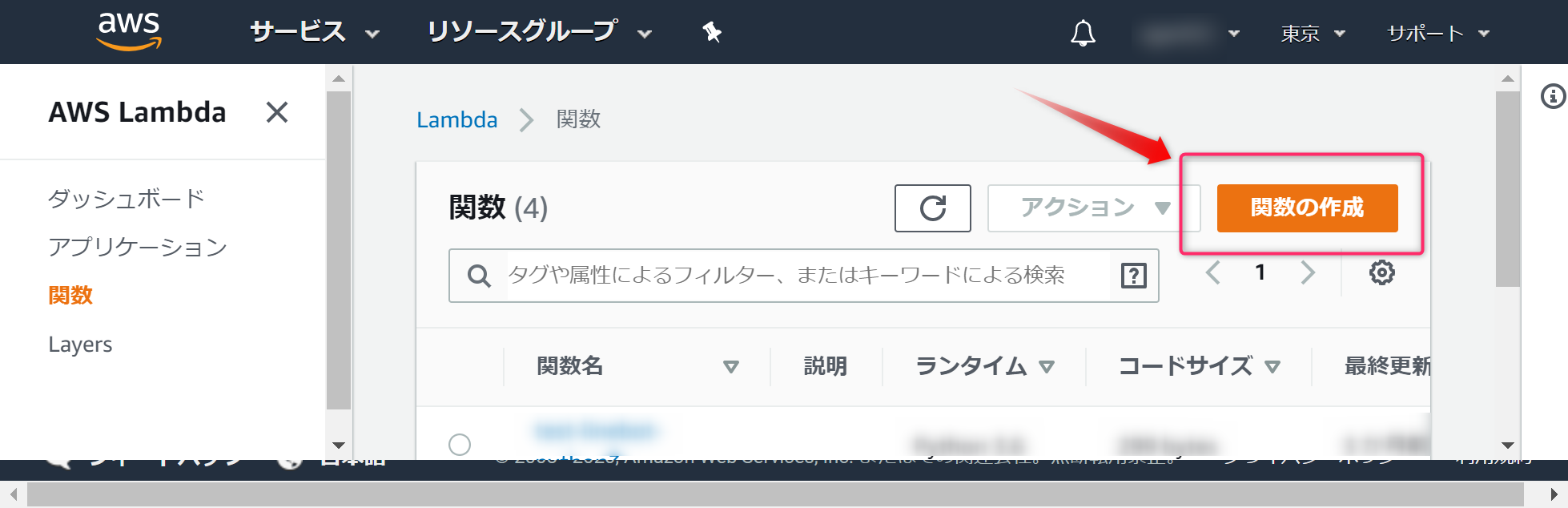
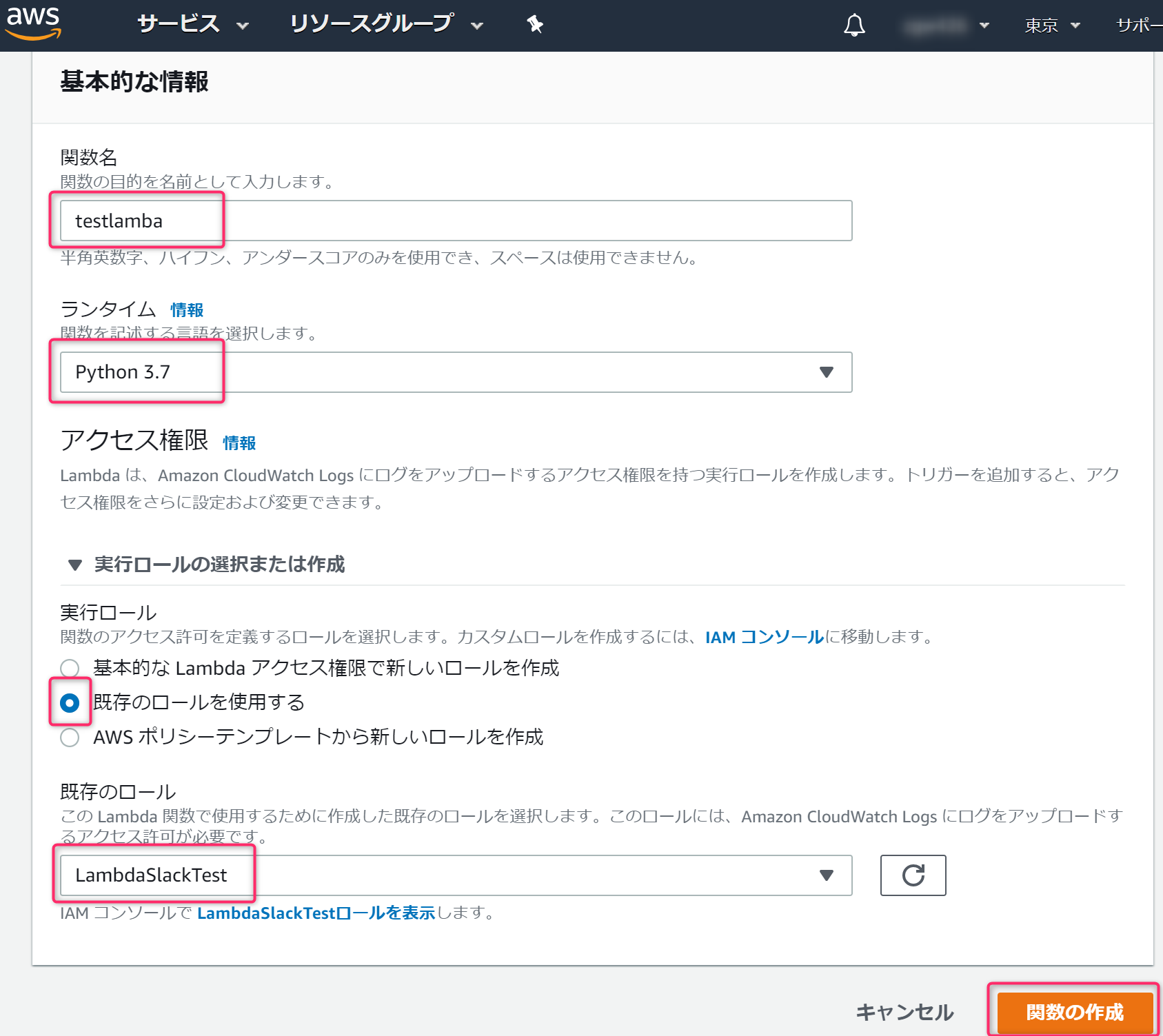
AWSコンソールのLambdaを開き、
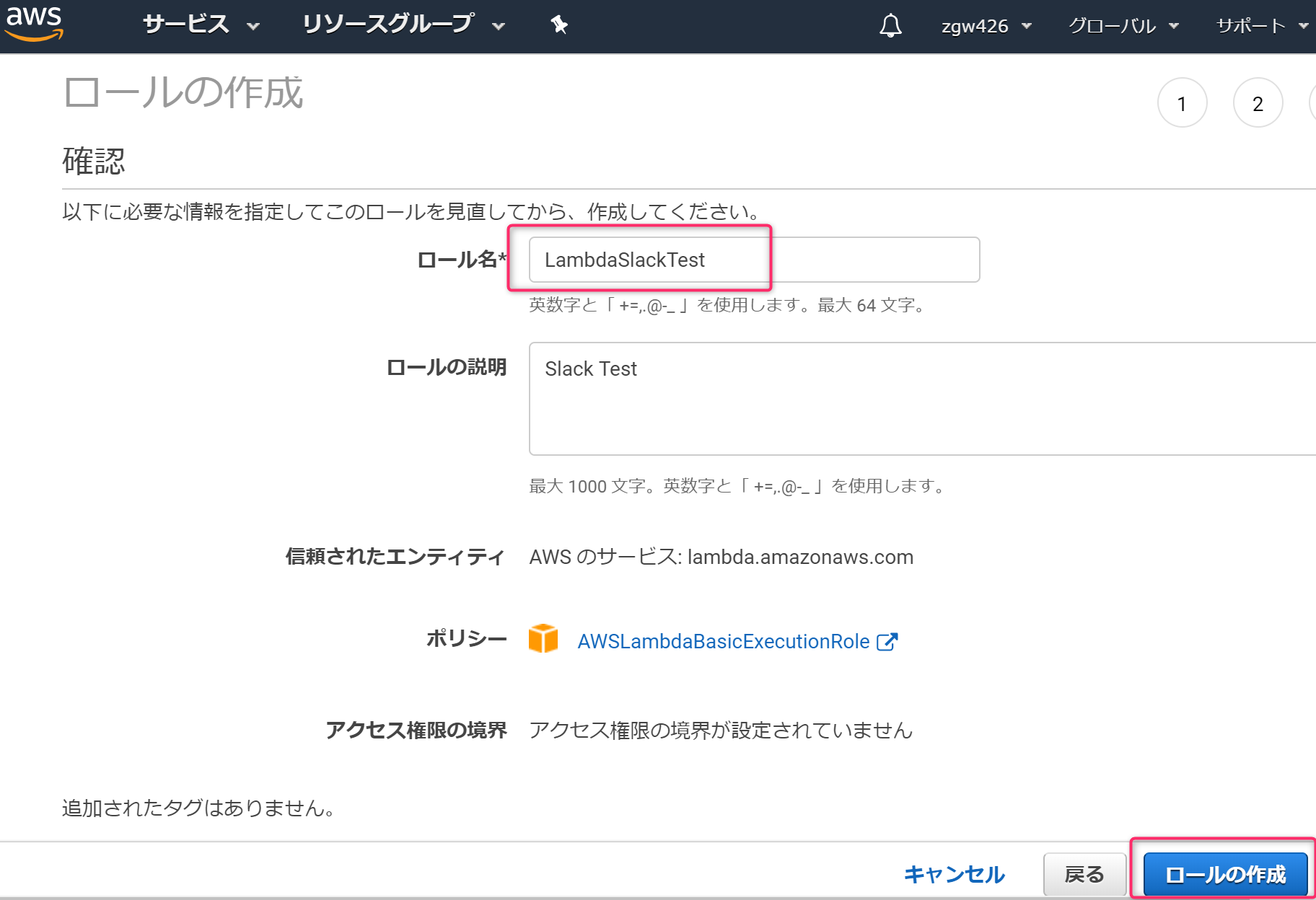
関数の作成ボタンをクリックします。
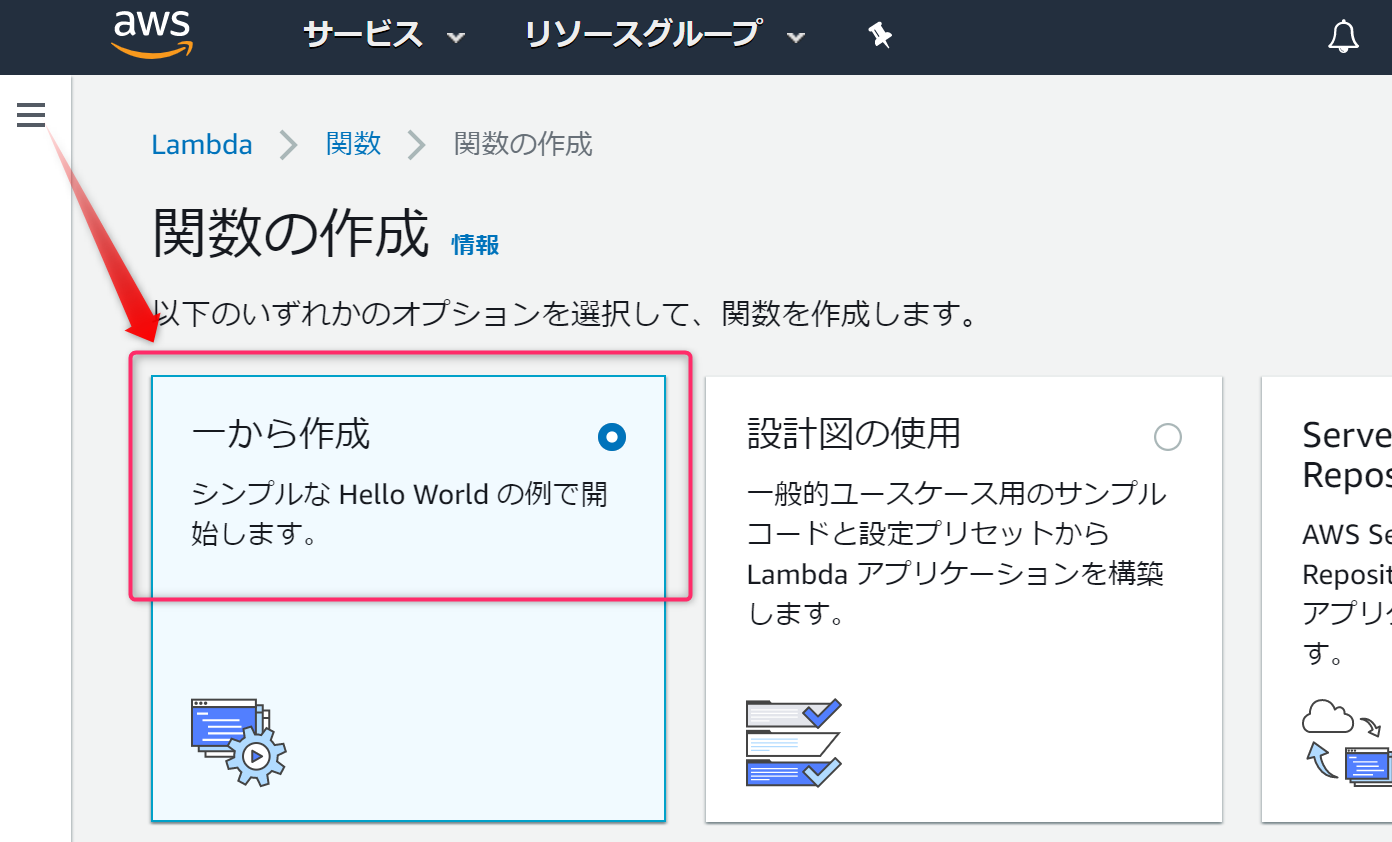
一から作成を選択します。
赤枠部分を設定します。実行ロールは、さきほど作成したIAMロールを設定します。
このような画面が表示されたら、下にスクロールします。
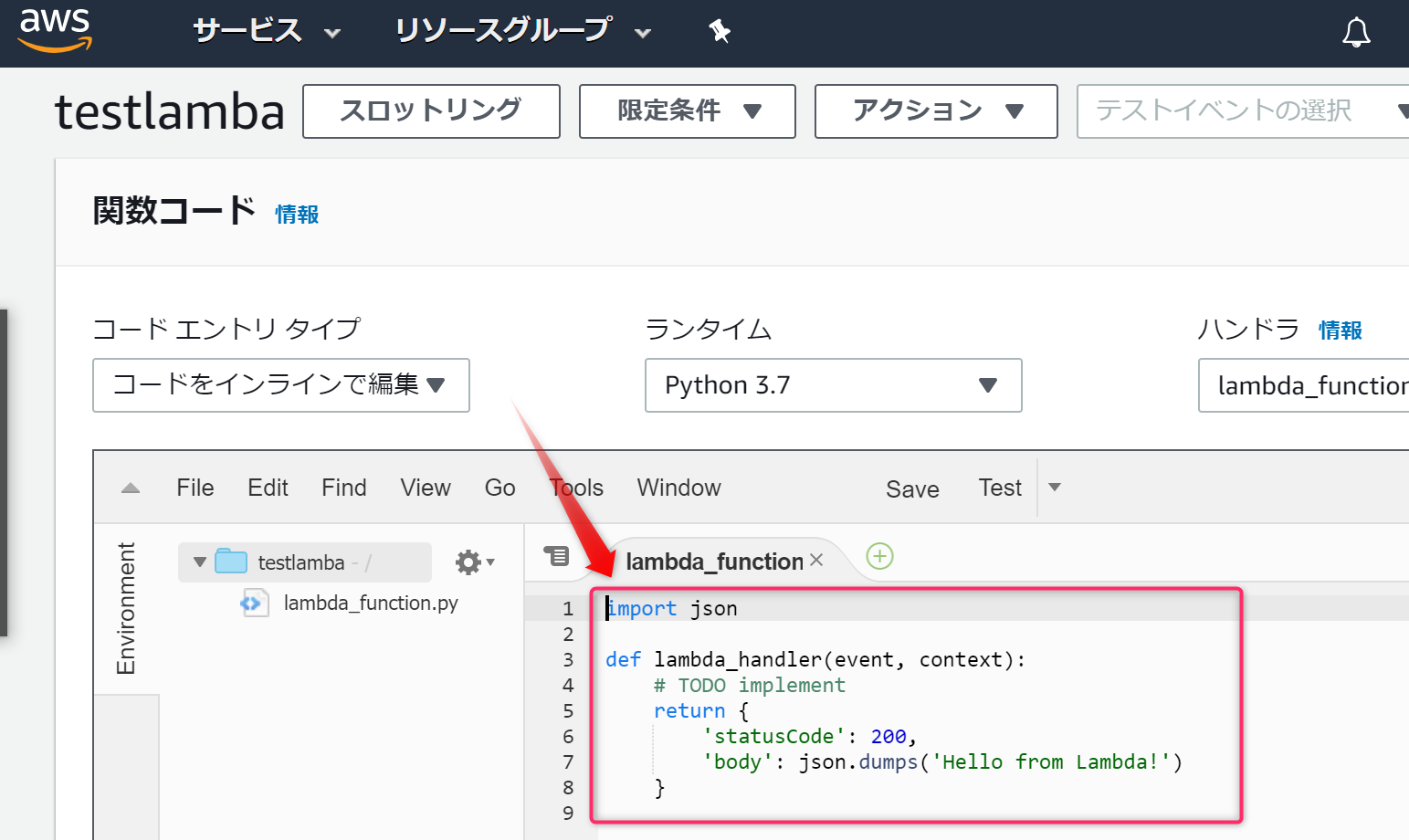
赤枠部分にあるスクリプトを次に紹介するスクリプトに書き換えます。
書き換えのスクリプトです。
スクリプト内のhttps://hooks.slack.com/services/xxx/xxx/xxxは、SlackのIncoming Webhookに修正します。import json import urllib.request import logging from collections import OrderedDict import pprint def post_slack(argStr): message = argStr + "です" send_data = { "text": message, } send_text = json.dumps(send_data) request = urllib.request.Request( "https://hooks.slack.com/services/xxx/xxx/xxx", data=send_text.encode('utf-8'), method="POST" ) with urllib.request.urlopen(request) as response: response_body = response.read().decode('utf-8') def lambda_handler(event, context): post_slack("test")これで、設定完了です。
動作テストを用意する
Lambda実行のテストを用意をします。作成済みであればこの作業は不要です。
テストをクリックします。
イベント名を設定します。緑枠の部分は今回は関係ないので編集不要です。
これで、テストの準備が完了しました。
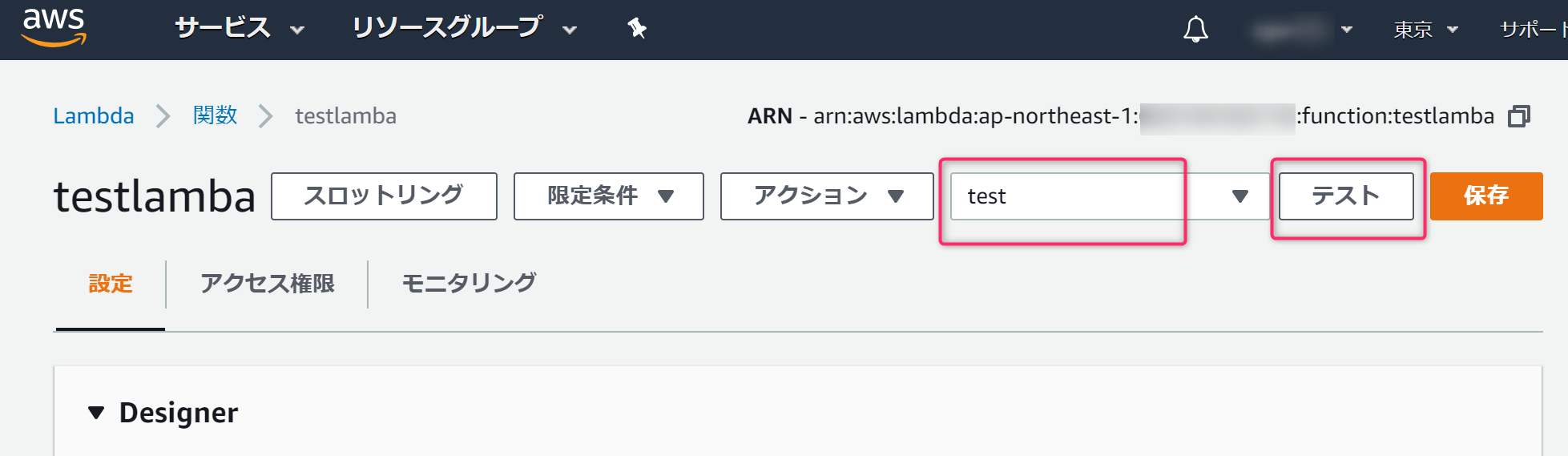
動作テスト:LambdaからSlackに通知してみる
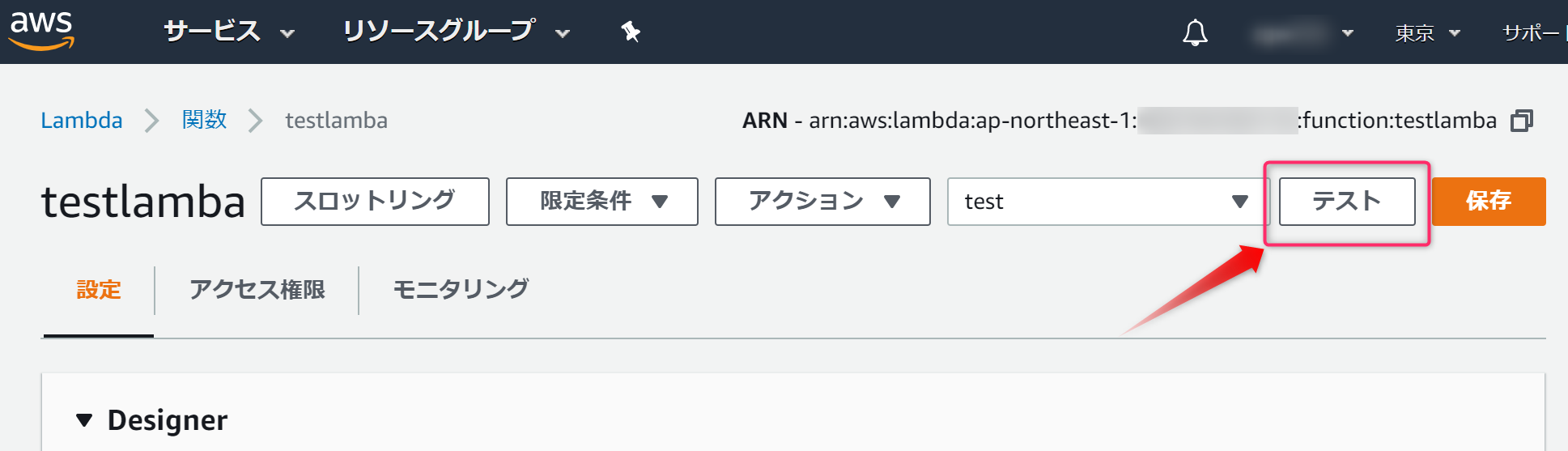
先ほど作成したテスト(
test)を設定し、テストボタンをクリックします。
実行結果 成功と表示されれば実行成功です。
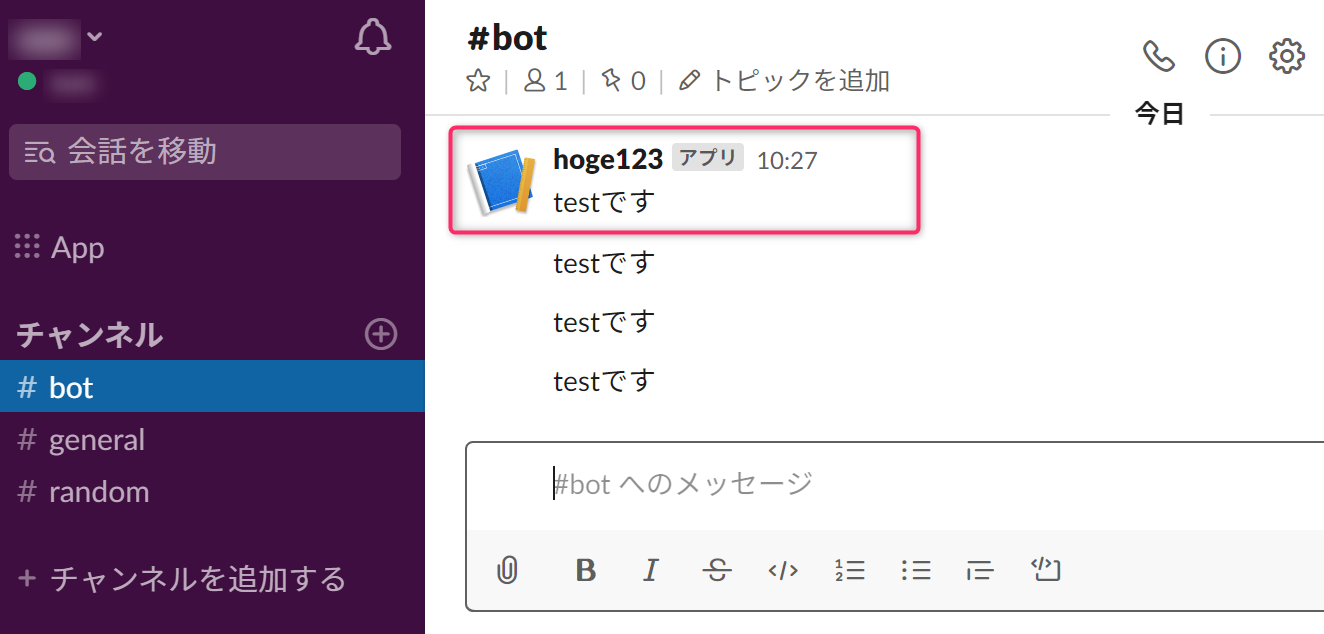
Slackに通知が来ていることを確認します。

- 投稿日:2020-02-15T10:51:04+09:00
AWS LambdaでSlack通知してみる
やること
PowerShellでSlack通知してみるの続き、AWS Lambdaで通知してみる
前提
AWSアカウントとSlackアプリの
Incoming Webhook URLを取得していることが前提で始めます。
IAMロール作成
Lambda実行に必要な権限(IAMロール)を作成します。
必要なポリシーを選択します。今回はLambdaが動けばいいので、
AWSLambdaBasicExecutionRoleを選択しました。
ロール名を設定します。
Lambda作成
AWSコンソールのLambdaを開き、
関数の作成ボタンをクリックします。
一から作成を選択します。
赤枠部分を設定します。実行ロールは、さきほど作成したIAMロールを設定します。
このような画面が表示されたら、下にスクロールします。
赤枠部分にあるスクリプトを次に紹介するスクリプトに書き換えます。
書き換えのスクリプトです。
スクリプト内のhttps://hooks.slack.com/services/xxx/xxx/xxxは、SlackのIncoming Webhookに修正します。import json import urllib.request import logging from collections import OrderedDict import pprint def post_slack(argStr): message = argStr + "です" send_data = { "text": message, } send_text = json.dumps(send_data) request = urllib.request.Request( "https://hooks.slack.com/services/xxx/xxx/xxx", data=send_text.encode('utf-8'), method="POST" ) with urllib.request.urlopen(request) as response: response_body = response.read().decode('utf-8') def lambda_handler(event, context): post_slack("test")これで、設定完了です。
動作テストを用意する
Lambda実行のテストを用意をします。作成済みであればこの作業は不要です。
テストをクリックします。
イベント名を設定します。緑枠の部分は今回は関係ないので編集不要です。
これで、テストの準備が完了しました。
動作テスト:LambdaからSlackに通知してみる
先ほど作成したテスト(
test)を設定し、テストボタンをクリックします。
実行結果 成功と表示されれば実行成功です。
Slackに通知が来ていることを確認します。
関連投稿
- PowerShellでSlack通知してみる
- LambdaでSlack通知してみる ←今ココ
- 投稿日:2020-02-15T10:11:45+09:00
EC2にSSHコマンドで接続した際、Permission denied (publickey,gssapi-keyex,gssapi-with-mic).が出た場合
AWS学習中、上記エラーにぶつかったので備忘のために残す。
ssh -i ***.pem ec2-user@IPアドレスこのコマンドを入力すると、
Warning: Identity file ***.pem not accessible: No such file or directory. ec2-user@IPアドレス: Permission denied (publickey,gssapi-keyex,gssapi-with-mic).このエラー。
EC2へのSSH接続でPermission denied (publickey). が出たときを参照し、コマンド入力するも同様のエラーが続く。
試行錯誤していると、***.pemへのパスが間違っていることに気づく・・・。
ssh -i Desktop/***.pem ec2-user@IPアドレスこれで無事解決!
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ @ WARNING: UNPROTECTED PRIVATE KEY FILE! @ @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ Permissions 0644 for 'Desktop/***.pem' are too open. It is required that your private key files are NOT accessible by others. This private key will be ignored. Load key "Desktop/***.pem": bad permissions ec2-user@IPアドレス: Permission denied (publickey,gssapi-keyex,gssapi-with-mic).・・・と思いきや、今度はこのメッセージに遭遇。
『Amazon Web Services 基礎からのネットワーク&サーバー構築』 によると、これは、
鍵ファイルのパーミッションが他のユーザーにも閲覧できる状態になっているのが理由です。
とのこと。
$ chmod 400 Desktop/***.pemこのコマンドを実行することで、自分だけしか読み込めないようにすることで、突破できました。
- 投稿日:2020-02-15T05:57:15+09:00
Vue.jsとAWS Amplifyでプロジェクト譜のサービスを作った話
概要
プロジェクト管理で苦労した体験から、プロジェクトを俯瞰的に可視化・管理するサービスをVue.jsとAWS Amplifyでつくりました。
プロジェクトの可視化はプロジェクト譜という記法で描いた図で表現します。作ったサービス
- サービス名: Pufu (読み方:プフ)
- 現在β版として公開中
- 対象ブラウザ: Chrome ※スマホは閲覧のみ
- ここからサービスサイトに飛べます。
- アカウント登録は『アカウントの新規作成』から行えます。
- サンプルエリアがあるのでアカウントを作らなくても試せます。
- サイトイメージ
- サービスサイトと合わせて紹介用のサイトも作りました。
サービスを作った動機
プロジェクトを管理する傍ら炎上するプロジェクトと遭遇することもあり、
それはなぜかを自分なりに考えていくと、「手を打つべき時に手を打てず、対応が後手に回る」という至極普通な考えに至りました。
ただ、あのとき「ああしていれば。。」というのは、振り返って気付くのであって、その時点では気づきにくいのです。
どうすれば事前に必要な対応を気付けるのか考えているときに、「予定通り進まないプロジェクトの進め方」という本に出会い、
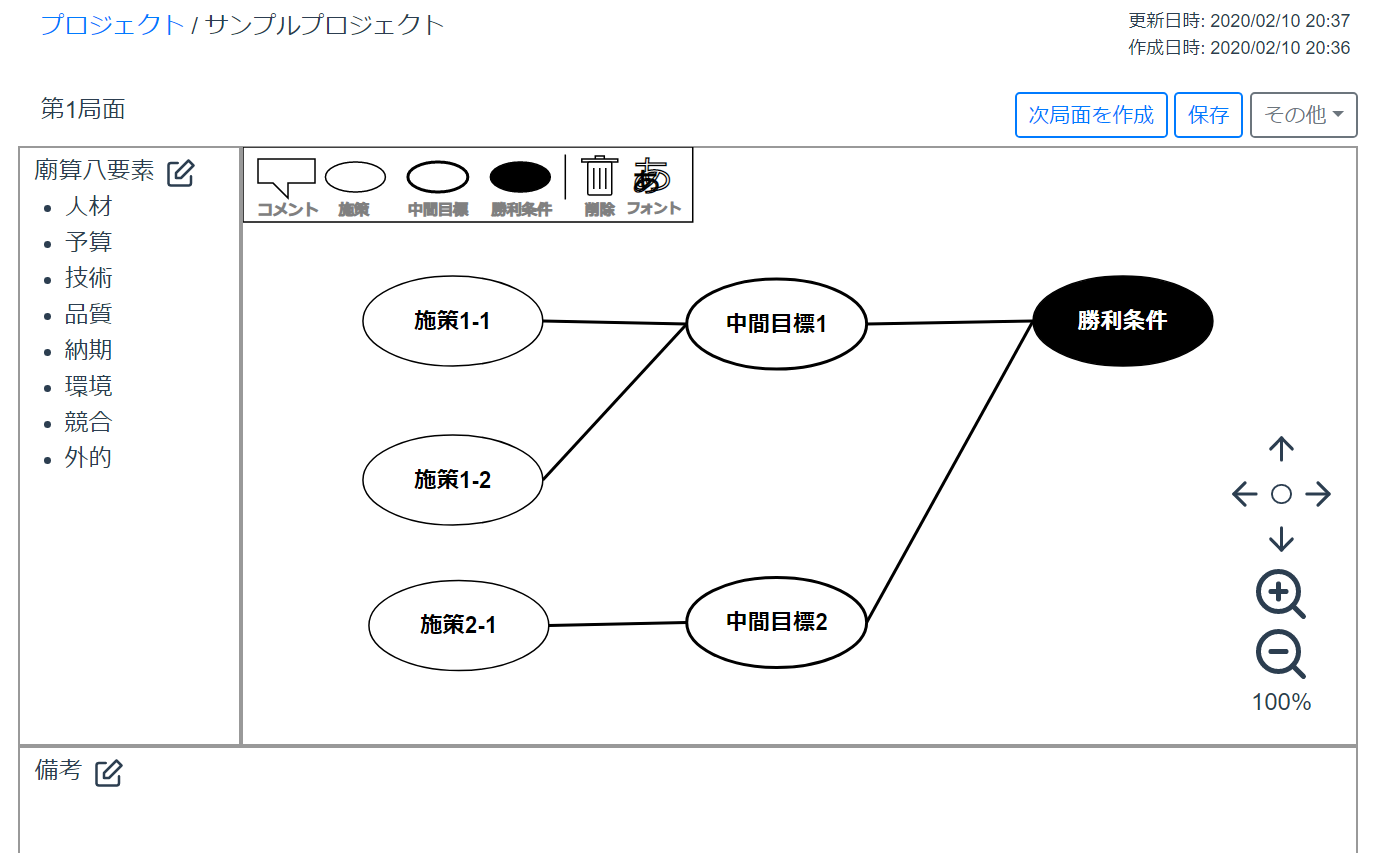
プロジェクト譜という手法を知りました。プロジェクト譜はプロジェクトを俯瞰的に図示し、編集を重ねていきます。
なので、プロジェクト全体で見たときに落とし穴に気付きやすくなります。
プロジェクト譜の詳しい説明は割愛しますが、目標や状況変化に対する
記述のしやすさに興味が惹かれました。プロジェクト譜に興味のある方は下記の書籍をご参照ください。
予定通り進まないプロジェクトの進め方 (Amazon)
著者: 前田考歩、 後藤洋平
出版社: 宣伝会議いざプロジェクト譜をパワポなどを使って実践していくと、
汎用ツールでは操作が多くなったり、欲しい機能がないなど不便さがありました。
draw.ioのようにWebでつくれたらいいんじゃないかと調べても、
プロジェクト譜を対象としたサービスもなかったので、
自分で作ってしまえ!と作ったのがPufuです。サービスの背景はここまでにして、Qiitaなので技術的な話を書きます。
※サービスデザイン的な話についてはnoteにかに書こうと思います。
→書きましたnoteシステム構成
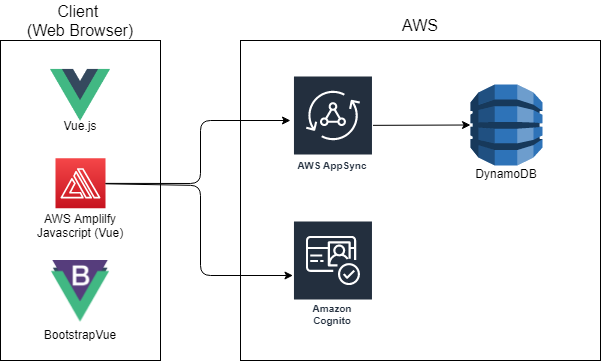
フレームワーク類
フロントエンドはVue.jsで実装、UIはBootstrapVueを用いて、
バックエンドと一部フロントエンド(認証周り)でAWS Amplifyを利用しています。
Amplifyの裏側でAppSyncとDynamoDB、Cognitoを利用しています。
- Vue.js (ver. 3.11.0)
- BootstrapVue: UIフレームワーク
- AWS Amplify: mBaasサービス(認証・API類&Webサイトホスティング)
- AppSync: データアクセス(GraphQL)
- DynamoDB: データ管理
- Cognito: ユーザー管理
全体構成イメージ
開発環境
AWSのWebIDE Cloud9を利用しています。去年、Cloud9が日本リージョンに対応して重宝しています。
- IDE: AWS Cloud9
- バージョン管理: AWS CodeCommit
- CodeCommitにプッシュするとAmplifyのホスティングサービスでビルドとデプロイが走ります
- AmplifyはCodeCommit以外にもGitHubとの連携も対応しています
デプロイのイメージ
- Amplify push: バックエンド側の環境構築
amplifyコマンドで実行し、CloudformationでAPI(GraphQL)やAuth(Cognito)のリソースを作成します。- Git Push: Cloud9で編集したコードをCodeCommitにプッシュ
- Notify: プッシュをAmplify側が検知
- Build & Deploy: CodeCommit側のソースを取得してビルド、デプロイ
$ amplify push Scanning for plugins... Plugin scan successful Current Environment: dev | Category | Resource name | Operation | Provider plugin | | -------- | ------------- | --------- | ----------------- | | Auth | abcdefghijkl | Update | awscloudformation | | Api | abcdefghijkl | Update | awscloudformation |実装
データアクセス
- AppSyncのGraphQLを利用
- スキーマを定義ファイルを編集します
- amplify pushするとクエリの定義ファイルが作成
- @authや@keyなどのディレクティブで認証や検索時のインデックスを制御
schema.graphqltype Blog @model @auth(rules: [{ allow: owner }]) @key(name: "ByOwner", fields: ["owner"], queryField: "listBlogByOwner") { id: ID! name: String! owner: String! }https://aws-amplify.github.io/docs/cli-toolchain/graphql?sdk=js
ユーザー管理
- ログイン、サインアップはamplifyのコンポーネントを利用
- サインアップ時のダイアログ表示は、signUpのイベントをキャッチしてダイアログを表示
https://aws-amplify.github.io/docs/js/vue
プロジェクト譜エディタ
- SVGで実装
- 各アイコンをコンポーネントで実装
- コンポーネント管理できるVue.jsのメリットを活かせた感じ
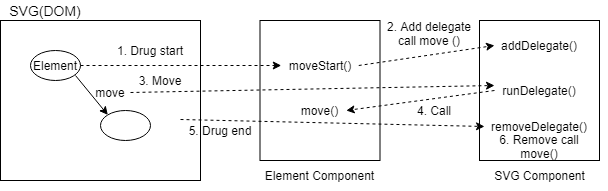
- 要素の移動など、開始イベントは子要素が発生し、終了イベントは親要素で発生する場合がある
- 子要素で処理を実装すると終了イベントを子要素自身でキャッチできない
- 親要素で終了イベントの処理を実装すると複雑化しすぎる
- 要素移動などはDelegateパータンで実装
Delegateパターン実装イメージ
テスト環境
ユニットテスト
- ユニットテストではjestを利用
- amplifyやstoreの挙動はモックを作成しました
jest.spyOn(API, 'graphql').mockReturnValue( Promise.resolve({ data: { getProject: {id: 'todo1', name: 'todo_name_1'}, createProject: {id: '123'} } }) )e2eテスト
- e2eテストはjest + puppeteerを利用
nightwatchやcypressを試しましたが、cloud9上で動かさず、最終的にpupetterで構築しました。pupetterで画面キャプチャを取れるので、cloud9上でもテスト時の画面結果を確認できます。感想
Amplifyは使い方が分かると実装しやすい。凝ったことをしようとすると、カスタマイズが多くなるので、開発スピードをとるなら、素のまま使う割り切りが必要。
VueとSVGの組み合わせは相性がいい。jQueryで実装するとかなり大変だったはず。Reactと相性はよさそう。(Reactは全然詳しくないですが。。。)
SVGのエディタの処理はかなり複雑化になるので、どう実装するといいのか悩みます。
今回はできてないですが、Atomic Designで初めから細分化しておくとすっきりしそう。サービスを作るのはやはり大変。Pufuは仕事の合間、勉強しながらで作ったので6か月かかりました。最初はやる気があっても中だるみするのでモチベーションの維持は難しいですね。
VueのCompositionAPIやTypeScriptも興味あるので、余裕があるときに導入検討します。あとテストはもっと充実させたい。
あと、Pufuが本当によりよいプロジェクト運営に役に立てるのか検証していければと思います。

- 投稿日:2020-02-15T00:34:09+09:00
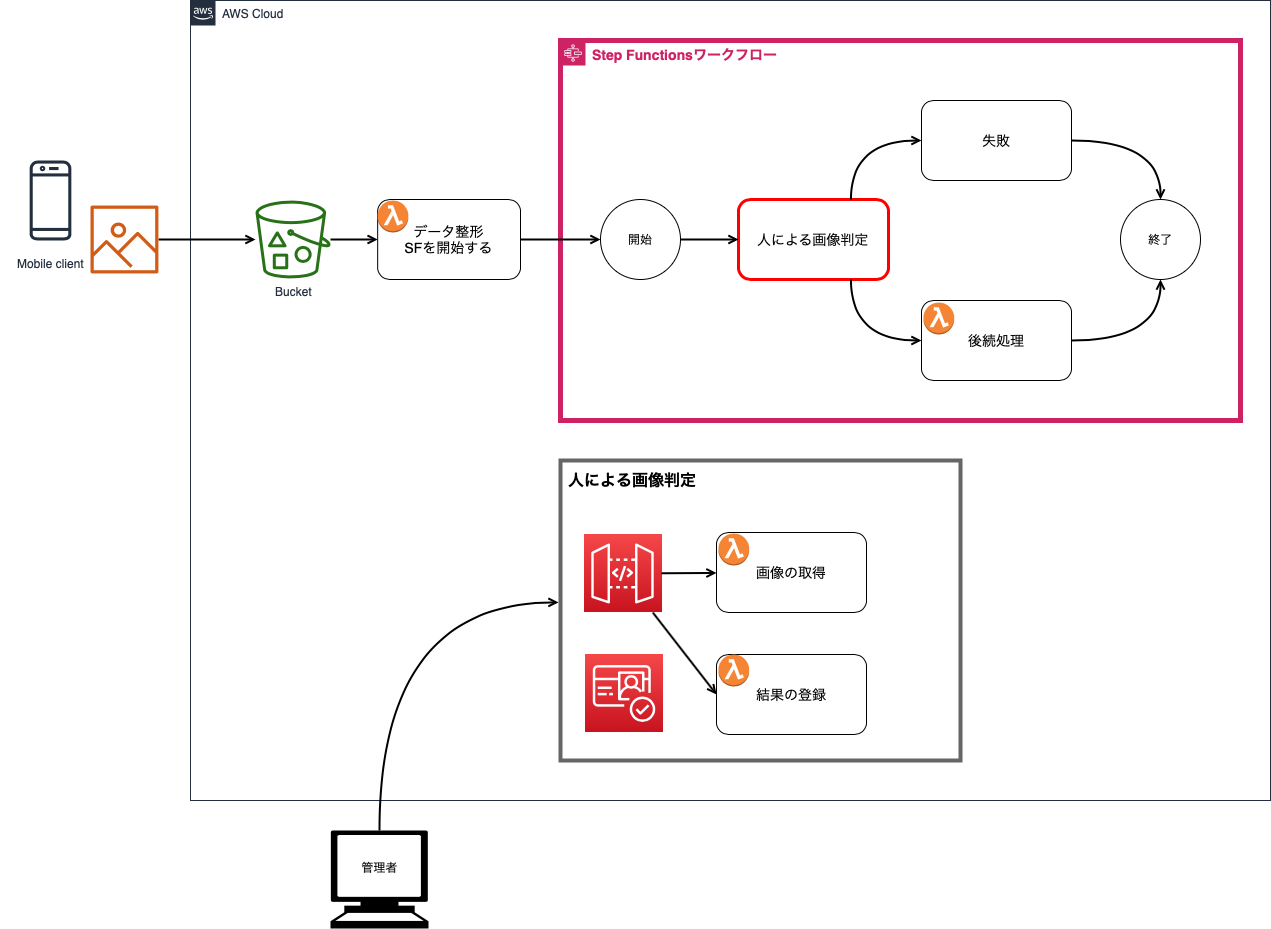
Step Functionsで作成する、人による処理が介在するワークフロー(その1)
はじめに
Step Functionsで(以下SF)、人による処理が介在するワークフローをどう実現するのか。
免許証画像による年令確認フローをネタに検証したので要点をメモ。
(検証したのは2017年末ぐらいなのですが。笑)重要なポイント
- 非同期処理はアクティビティで実現する。アクティビティは人による処理をアクティビティとして定義する。このアクティビティは特定のSFに属さない独立したものである。
- Stateの定義で、TypeはTask、ResourceはアクティビティのARNにする。この時、非同期処理に渡したいインプットをInputPathを用いて整える。
- アクティビティのARNを指定して、処理が必要なアクティビティをポーリングする。ロングポーリングなので要件次第ではコストがかさむので、必要に応じてコールバックパターン等を用いた処理を検討する。
- ポーリングで処理対象のアクティビティがあると、"input"と"taskToken"が返ってくる。
- アクティビティで渡すinputに渡していなくても、後続のStateに前のStateから流れてきた情報を渡すことができるのが割と重要。つまりアクティビティの処理には不要だが後続に必要なデータを隠すことができる。
- taskTokenを用いて結果を伝える。この時にアクティビティのARNを指定しなくていい。この時にデータを渡すと、次のStateに渡せる。
ユースケース: ソーシャル系アプリとかの年令確認フロー
- ユーザーはスマホアプリで免許証を撮影し保存
- スマホアプリはアプリサーバーに画像を送る
- 運営者が画像をみて年令を確認する
- OKならばユーザーの年令確認ステータスを「済」にする
システム化の方針
- 免許証画像はS3に保存される。その際ユーザーIDのフォルダの下に置かれる
- 「シンプルなシステム」を「コスト最小化」より優先する。ここでは確認する運用者は1人から数人程度とし、それに耐えうるシステムとする。(SQSを用いたコールバックパターンはここでは採用しない)
- S3のイベントから直接SFを起動せず、その前にデータを整形している。(SFは親子関係が持てるようになったので、今ならS3イベントで親SFを開始するやり方も取れる)
システム概要図
SPの作成ステップ
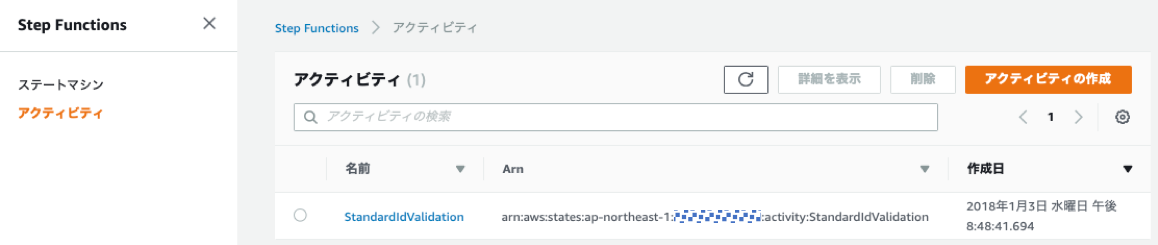
アクティビティの作成
要は、アクティビティにIDを振るということ。IDはARN。確かに2年前ですね。。。
S3 Putイベントを受けてのLambda
2年前のコード(nodejs6.10)を修正したもの。
SFに、以下を渡すためにデータ整形
- identityId (ユーザーの年令確認ステータスを更新するため。今回は触れない)
- s3bucket
- s3key
- priorityとtryCountは、もともとのSFはpriorityに応じで処理を分けたり、再度SFを開始していたため使っていた。今回不要
exports.handler = (event, context, callback) => { var inputJson = createInputJsonFromS3Event(event); if( ! inputJson ) { inputJson = createInputJsonFromStepFunctionsError(event); } if( ! inputJson ) { context.done(null, { "message" : "unexpected input format." } ); return; } const stateMachineArn = process.env.stateMachineArn; var params = { stateMachineArn: stateMachineArn, input: JSON.stringify(inputJson) }; stepfunctions.startExecution(params, (err, data) => { if (err) { callback(err, 'step function start error!'); } else { callback(null, 'step function started!'); } }); }; const createInputJsonFromStepFunctionsError = (event) => { const error = event.error; if( ! error ) { return null; } var priority = "high"; const identityId = event.identityId; const s3bucket = event.s3bucket; const s3key = event.s3key; var count = event.tryCount; if( count ) { count = count + 1; } else { count = 2; } var inputJson = {}; inputJson["priority"] = priority; inputJson["identityId"] = identityId; inputJson["s3bucket"] = s3bucket; inputJson["s3key"] = s3key; inputJson["tryCount"] = count; return inputJson; };Step Functionの定義
かなり簡素化したSF。もとのままだと要点が分かりにくいので記事用に再定義。
アクティビティを割り当てているStandardValidationステートの定義で、人による処理の結果をverifiedResultにマッピングしている。またidentityId, s3bucket, s3keyはそのまま後続のステートに流す設定をしている。"ResultPath" : "$.verifiedResult", "OutputPath" : "$",{ "Comment" : "Id Validation Steps", "StartAt" : "StandardValidation", "States" : { "StandardValidation" : { "Type" : "Task", "Resource" : "arn:aws:states:ap-northeast-1:xxxxxxxxxxxx:activity:StandardIdValidation", "TimeoutSeconds" : 60, "InputPath" : "$", "ResultPath" : "$.verifiedResult", "OutputPath" : "$", "Next" : "ProcessResult", "Catch" : [{ "ErrorEquals" : ["States.ALL"], "ResultPath" : "$.error", "Next" : "FailedWithError" }] }, "ProcessResult" : { "Type" : "Task", "Resource" : "arn:aws:lambda:ap-northeast-1:xxxxxxxxxxxx:function:mine-move-validated-file", "InputPath" : "$", "ResultPath" : "$.movedResult", "OutputPath" : "$", "End" : true }, "FailedWithError" : { "Type" : "Fail", "Error" : "$.error", "Cause" : "Validation end with error" } } }アクティビティの結果を処理するLambda
ここではいきなり画像を削除せず、別のバケットに移動している。一定期間後に削除するような運用を考慮していた。
もともとのSFでは、ID検証OKとNGで別々のStateがあって、OKの場合はユーザーの検証ステータスを更新するLambdaを割り当てている。ちなみにユーザーはCognitoで管理。要望があればそこらへんも記事化。exports.handler = (event, context, callback) => { console.log("event: " + JSON.stringify(event)); var destinationBucket = bucketForVerificationNG; var verifiedResult = event.verifiedResult; if( ! verifiedResult ) { context.done("no verifiedResult parameter!"); return; } if( verifiedResult.isVerified == true ) { destinationBucket = bucketForVerificationOK; } var identityId = event.identityId; var sourceBucket = event.s3bucket; var sourceKey = decodeURIComponent(event.s3key.replace(/\+/g, ' ')); var sourceDir = identityId; var comps = sourceKey.split("/"); var filename = comps[comps.length-1]; var params = { CopySource: sourceBucket + "/" + sourceKey, Bucket: destinationBucket + "/" + sourceDir, Key: filename }; s3.copyObject( params ).promise() .then( function(data) { console.log("copy!: " + data); var deleteParams = { Bucket: sourceBucket, Key: sourceKey }; return s3.deleteObject(deleteParams).promise(); }) .then( function(data) { console.log("deleteObject data: " + JSON.stringify(data)); context.done(null, {}); }) .catch( function(err) { console.log("err: " + err); context.done(err); }); };人による処理(アクティビティ)の実装ステップ
人による処理はWebシステムとして作成する。画像の取得と年令判定結果をPOSTするAPIをAPI Gatewayを用いて作成した。実際の処理はLambdaが行う。API Gatewayまわりはここでは割愛するが今は良記事があるのではないか?
画像の取得
この処理で、オープンなアクティビティを取得している。
ただし、inputからs3の画像を特定し、その画像をダウンロードするためのpresigned-urlをidFileUrlとして作成している。
クライアントに返すのは、taskTokenとidFileUrl。getActivityTaskのロングポーリング課題に多少対応するため、SFでステータスが"RUNNING"のものがあるか確認している。今回のSFでは他のStateの処理は時間がかからないので、"RUNNING"のものがある場合は、オープンなアクティビティがあると推測できる。実際にはすべてのアクティビティが払い出されていても、未完了の状態が存在する。その場合はロングポーリングの待ち状態が発生する。
makeJsonResponse()は、このLambdaはAPI Gatewayから呼ばれたものなので、フォーマットを整えている関数。ここでは割愛する。exports.idValidationTask = (event, context, callback) => { var stateMachineArn = process.env.stateMachineArn; var activityArnString = process.env.activityArnString; var listParams = { stateMachineArn: stateMachineArn, maxResults: 0, statusFilter: "RUNNING" }; stepfunctions.listExecutions( listParams ).promise() .then( ( data ) => { console.log("list: " + JSON.stringify(data)); // successful response var executions = data.executions; if( executions == undefined || executions.length == 0 ) { var json = {}; json["message"] = "no activity"; var result = makeJsonResponse(json); context.done(null, result); return null; } var taskParams = { activityArn: activityArnString }; return stepfunctions.getActivityTask( taskParams ).promise(); }) .then( (data) => { console.log("util.inspect(data..." + util.inspect(data, false, null)); if (data === null) { console.log("data is null"); let json = {}; json["message"] = "no activity"; let result = makeJsonResponse(json); context.done(null, result); } else if (Object.keys(data).length === 0) { console.log("activity is empty object!"); let json = {}; json["message"] = "no activity"; let result = makeJsonResponse(json); console.log("result: " + result); context.done(null, result); return; } else { var taskToken = data.taskToken; var inputString = data.input; var input = JSON.parse(inputString); var s3bucket = input.s3bucket; var s3key = input.s3key; var decodedKey = decodeURIComponent(s3key.replace(/\+/g, ' ')); let params = { Bucket: s3bucket, Key: decodedKey, Expires: 3600 }; s3.getSignedUrl('getObject', params, (err, url) => { if( err ) { callback(null, null); return; } let json = {}; json["taskToken"] = taskToken; json["idFileUrl"] = url; let result = makeJsonResponse(json); callback(null, result); }); } }) .catch( function(err) { console.log(err, err.stack); // an error occurred }); };年令判定結果をPOST
taskTokenを渡して、sendTaskSuccess()を呼んで判定処理を完了させている。
ポイントは、taskTokenと一緒に渡すoutputに必要な情報を渡しているところ。idTypeは免許証などのidの種類、isVerifiedは年令判定結果(true/false)var params = { output: JSON.stringify(taskOutput), taskToken: taskToken };API Gatewayのためにフォーマットを整えている関数は割愛している。
exports.idValidationResult = (event, context, callback) => { var checkResult = parameterCheck_idValidationResult(event); var responseJson = {}; if( checkResult.error ) { responseJson = makeJsonResponseFromError(checkResult.error); context.done(null, responseJson); return; } var inputJson = checkResult.inputJson; var idType = inputJson.idType; var taskToken = inputJson.taskToken; var isVerified = inputJson.isVerified; var taskOutput = { idType: idType, isVerified: isVerified }; if( isVerified ) { var birthdayJson = inputJson.birthday; taskOutput["birthday"] = birthdayJson; var gender = inputJson.gender; if( gender ) { taskOutput["gender"] = gender; } } var params = { output: JSON.stringify(taskOutput), taskToken: taskToken }; stepfunctions.sendTaskSuccess(params).promise() .then( function(data) { responseJson = makeJsonResponse({message: "done!"}); context.done(null, responseJson); }) .catch( function(err) { console.log("err: " + err); responseJson = makeJsonResponseFromError(err); context.done(null, responseJson); }); };残りの作業
後は、API Gatewayで定義しているAPIを用いてWebフロントを作成する。
API Gatewayでアクセスするためのログイン処理も必要。運用担当者が数人レベルであれば、Cognitoのコンソールでユーザー登録とパスワードを設定しておけばいい。
WebフロントのリソースはS3の静的ウェブサイト十分かと。自分しか担当者がいなければローカルでいい。ユーザーの年令確認ステータスの更新について
SFの開始の時にあった入力を、ずっと後続のStateに流している。
isVerifiedがtrueの場合は、identityIdをもとにユーザーリソースを特定し、年令確認ステータスを更新する。謝辞
聖なる夜@マクドナルド
15日になったので投稿します!