- 投稿日:2020-02-10T19:13:27+09:00
DockerでKali Linuxインストール後初期設定
DockerでインストールしたKali Linuxでパスワード解析
前回の記事でSQLインジェクションによってユーザーのパスワード情報を抜き出しました。
今回はそんなSQLインジェクションのような攻撃のペネトレーションテスト(検証)ができる、Kali LinuxをDockerで導入したので簡単にまとめていきたいと思います。
Kali Linuxとは?
Kali LinuxはDebianをベースに構築された、ペネトレーションテスト用Linuxディストリビューションです。
ペネトレーションテストとは、実際にWebアプリケーションの攻撃手段を用いて、脆弱性をテストするといったものです。
Kali Liuxには、このペネトレーションテストのプログラムが、300以上インストールされています。
そのため、Webアプリケーションの脆弱性を調べるために、このKali Liuxが使われるということです。
DockerでKali Linuxをインストール・起動
ここは、以下のURLの公式を見ながら進めていきます
https://www.kali.org/news/official-kali-linux-docker-images/
まずは、Kali Linucのイメージをプルします。
# docker pull kalilinux/kali-linux-docker続いて、Kali Linuxを起動し、コンテナ内にrootで入ります。
# docker run -t -i kalilinux/kali-linux-docker /bin/bashこれで、Kali Linuxのコンテナ内にrootで入ることができます。
Kalilinuxコンテナ内で初期設定
まず初期設定として以下のコマンドを実行します。
# apt-get update && apt-get install metasploit-framework && apt-get upgrade続いて、Kali Linuxのメタパッケージ(今回はパスワード関係のkali-tools-passwords)をインストールします。
他のメタパッケージは入れたいと思ったら、以下を参照してください。
https://www.kali.org/news/kali-linux-metapackages/# apt-get install kali-tools-passwordsこのメタパッケージを入れることで、パスワード関係の攻撃をペネトレーションテストすることが可能になります。
以下のコマンドでどんなパッケージがあるか確認できるので、公式などをみながら実際にペネトレーションテストを試してみることも可能です。
# apt-cache show kali-linux-pwtools | grep Depend kali-tools-gpu,cewl,chntpw,cisco-auditingtool,cmospwd,crackle,creddump,crunch, fcrackzip,findmyhash,freerdp2-x11,gpp-decrypt,hash-identifier,hashcat, hashcat-utils,hashid,hydra,hydragtk,john,johnny,keimpx,maskprocessor,medusa, mimikatz,ncrack,oclhashcat,onesixtyoneophcrack,ophcrack-cli,pack, passing-the-hash,patator,pdfcrack,pipal,polenum,pyritrainbowcrack,rarcrack, rcrackimt,rsmangler,samdump2,seclists,sipcrack,sipvicious,smbmap,sqldict, statsprocessor,sucrack,thc-pptp-bruter,truecrack,twofi,wce,wordlists以上で、Kali Linuxの初期設定は完了になります。
次回以降、このKali Linuxを使ったペネトレーションテストも実践していければと思います。
参考URL
https://qiita.com/y-araki-qiita/items/131efa82c4205e83fef8
https://www.markupdancing.net/archive/kali-002.html
https://tools.kali.org/kali-metapackages
https://www.kali.org/news/official-kali-linux-docker-images/
- 投稿日:2020-02-10T16:15:47+09:00
コード書いたことないPdMやPOに捧ぐ、Rails on Dockerハンズオン vol.5 - Model and CRUD -
この記事はなにか?
この記事は私が社内のプログラミング未経験者、ビギナー向けに開催しているRuby on Rails on Dockerハンズオンの内容をまとめたものです。ていうかこの記事を基にそのままハンズオンします。ハンズオンは
1回の内容は喋りながらやると大体40~50分くらいになっています。お昼休みに有志でやっているからです。
現在進行形なので週1ペースで記事投稿していけるように頑張ります。
ビギナーの方のお役にたったり、同じように有志のハンズオンをしようとしている人の参考になれば幸いです。
他のハンズオンへのリンク
・ Vol.1 - Introduction -
・ Vol.2 - Hello, Rails on Docker -
・ Vol.3 - Scaffold, RESTful, MVC -
・ Vol.4 - Static pages -
・ Vol.5 - Model and CRUD -
・ Vol.6 - Model validation -
$,#,>について
$: ローカルでコマンドを実行するときは、頭に$をつけています。
#: コンテナの中でコマンドを実行するときは、頭に#をつけています。
>: Rails console内でコマンド(Rubyプログラム)を実行するときは、頭に>をつけています。
はじめに
第5回は、Modelを作って遊んでみます!
Modelはデータベースと密に関係していますので、メソッドをつかってCRUDを試してみます。Userモデルを作ろう
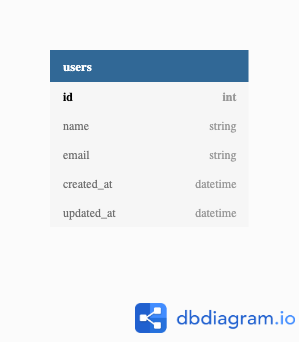
今回作るModelは以下の通り。
ER図を描くツールはdbdiagram.ioを使ってます。Entityしか書いてないから何ともですが、便利なツールです。Userモデルがどんなモデルかといえば、Integer型の
idをprimary keyとして、String型のname,created_at(作成日時),updated_at(更新日時)を持っています。rails generate model
モデルを作成するコマンドは
rails generate modelです。Modelに必要なファイルとそのModelのデータをDBに登録するためにDB側にテーブルを作る必要があるのでマイグレーションファイルを作成してくれます。
rails generate model NAME [field:type field:type]が型ですね。
NAMEがモデルの名前です。fieldがモデルのattribute(属性)、typeが型です。早速、ER図のモデルを作ってみましょう!
# rails generate model user name:string email:string注目点は
id,created_at,updated_atのことはコマンドで定義していないところです。ここはあとで説明。マイグレーションファイル
先ほどのコマンド実行でマイグレーションファイルが生成されています。
db/migrate/YYYYMMDDhhmmss_create_user.rbclass CreateUsers < ActiveRecord::Migration[6.0] def change create_table :users do |t| t.string :name t.string :email t.timestamps end end endScaffoldの時も実は同じようにファイルができていたんですが、中身を見るのは初めてですね。
rails db:migrateをするとRailsがこのファイルを読み込んでDBにSQLを発行してくれているんですね。
先ほどコマンドで定義したname,timestampsというものがあります。これがcreated_at,updated_atを作ってくれるやつでモデルを作成するときにRailsがデフォルトで付けてくれています。また、
create_tableはデフォルトでprimary keyとしてInteger型のidを付けてくれます。
なので、このままマイグレーションファイルをdb:migrateすれば先ほどのER図通りのテーブルを作成してくれます。# rails db:migrateUserモデルで遊んでみる
ここからは作成したUserモデルを使ってCRUDで遊んでみます。
CRUDとはデータを操作する上で基本となるCreate(作成)、Read(参照)、Update(更新)、Delete(削除)の頭文字をとったものです。Railsの場合はSQL文をコーディングするのではなく、モデルのメソッドを使うだけでCRUDができちゃうのでそれを体感しましょう!ここからはRails consoleを使っていきます。これでRailsアプリケーションとコマンドラインで対話式にやりとりができます。
Rails consoleはそのままでもいいのですが、pryというツールをインストールすることでRails consoleがみやすくなるのでそうします。Gemfile... group :development, :test do ... gem 'pry-rails' ... end ...gemを追加でインストールする場合は、再度Docker imageをビルドします。今立っているコンテナは古いイメージをもとに作られたコンテナなので一回落として、新しくビルドしたイメージで再度コンテナを作ってあげましょう。
$ docker-compose down $ docker-compose build $ docker-compose up -dコンテナを起動できたら、コンテナの中で
rails consoleコマンドを使ってRails consoleを立ち上げましょう!$ docker-compose exec web ash# rails console Running via Spring preloader in process 335 Loading development environment (Rails 6.0.2.1) [1] pry(main)>Rails console内では接頭に
>がつくので、>がついている時はRails consoleの中でコマンドを実行しているんだなと思ってくださいね。Create
モデルの作成の方法は大きく2種類あります。
newメソッドでモデルオブジェクトを作成し、saveメソッドでデータ保存するcreateメソッドでオブジェクト作成とデータ保存を同時に行うCreate 1:
new+save例で
tanaka@sample.comのメアドのTaro Tanakaさんを作ってみましょう!> user = User.new(name: "Taro Tanaka", email: "tanaka@sample.com") => #<User:0x000055c0f665aab0 id: nil, name: "Taro Tanaka", email: "tanaka@sample.com", created_at: nil, updated_at: nil> > user.save (0.3ms) BEGIN User Create (11.4ms) INSERT INTO "users" ("name", "email", "created_at", "updated_at") VALUES ($1, $2, $3, $4) RETURNING "id" [["name", "Taro Tanaka"], ["email", "tanaka@sample.com"], ["created_at", "2020-01-23 17:08:36.027245"], ["updated_at", "2020-01-23 17:08:36.027245"]] (2.6ms) COMMIT => trueまず、
User.newで例の属性を持つUserモデルオブジェクトを作成し変数userに代入しています。その後、
saveメソッドを実行。実行後のコンソールからDBにINSERTしているのがわかると思います。
RailsではModelのメソッドを使うことでとても簡単にSQLの操作ができるようになります。
saveメソッドはデータ作成に成功したらtrueを失敗したらfalseを返却するメソッドです。また、.の形で属性の情報を取得したり設定したりできるので、以下のようなやり方でもデータを作成することができます。
yamada@sample.comのメアドのHanako Yamadaさんを作ってみます!> user = User.new => #<User:0x000055c0f693a488 id: nil, name: nil, email: nil, created_at: nil, updated_at: nil, password_digest: nil> > user.name = "Hanako Yamada" => "Hanako Yamada" > user.email = "yamada@sample.com" => "yamada@sample.com" > user.save (0.3ms) BEGIN User Create (0.5ms) INSERT INTO "users" ("name", "email", "created_at", "updated_at") VALUES ($1, $2, $3, $4) RETURNING "id" [["name", "Hanako Yamada"], ["email", "yamada@sample.com"], ["created_at", "2020-01-23 17:10:31.545772"], ["updated_at", "2020-01-23 17:10:31.545772"]] (1.4ms) COMMIT => trueCreate 2: create
createメソッドはnewメソッドとsaveメソッドを同時に行うメソッドっす。
john@sample.comのメアドのJohn Smithを作ります。突然の外国人ですが、『John Smith』は日本でいう『名無しの権兵衛』です。> User.create(name: "John Smith", email: "john@sample.com") (0.3ms) BEGIN User Create (0.5ms) INSERT INTO "users" ("name", "email", "created_at", "updated_at") VALUES ($1, $2, $3, $4) RETURNING "id" [["name", "John Smith"], ["email", "john@sample.com"], ["created_at", "2020-01-23 17:11:03.731916"], ["updated_at", "2020-01-23 17:11:03.731916"]] (0.7ms) COMMIT => #<User:0x000055c0f4a511e8 id: 3, name: "John Smith", email: "john@sample.com", created_at: Thu, 23 Jan 2020 17:11:03 JST +09:00, updated_at: Thu, 23 Jan 2020 17:11:03 JST +09:00>
createは基本的にはnew+saveなのですが、作成が成功した場合はそのモデルオブジェクト、失敗した場合はfalseを返却するところが大きく違うポイントです。Read
データを確認するメソッドはかなりあります。ここでは特に利用頻度が高いであろうメソッドをご紹介します。
all
allメソッドはそのモデルの全てのレコードをオブジェクトの配列として取得します。> User.all User Load (2.5ms) SELECT "users".* FROM "users" => [#<User:0x000055c0f6702508 id: 1, name: "Taro Tanaka", email: "tanaka@sample.com", created_at: Thu, 23 Jan 2020 17:08:36 JST +09:00, updated_at: Thu, 23 Jan 2020 17:08:36 JST +09:00>, #<User:0x000055c0f6702378 id: 2, name: "Hanako Yamada", email: "yamada@sample.com", created_at: Thu, 23 Jan 2020 17:10:31 JST +09:00, updated_at: Thu, 23 Jan 2020 17:10:31 JST +09:00>, #<User:0x000055c0f6702260 id: 3, name: "John Smith", email: "john@sample.com", created_at: Thu, 23 Jan 2020 17:11:03 JST +09:00, updated_at: Thu, 23 Jan 2020 17:11:03 JST +09:00>]find
findメソッドはprimary keyの値を指定して1件のオブジェクトを取得するメソッドです。> User.find(1) User Load (1.2ms) SELECT "users".* FROM "users" WHERE "users"."id" = $1 LIMIT $2 [["id", 1], ["LIMIT", 1]] => #<User:0x000055c0f5da80e8 id: 1, name: "Taro Tanaka", email: "tanaka@sample.com", created_at: Thu, 23 Jan 2020 17:08:36 JST +09:00, updated_at: Thu, 23 Jan 2020 17:08:36 JST +09:00>マッチするレコードがない場合は、ActiveRecord::RecordNotFound Exceptionを発生させます。
> User.find(5) User Load (2.0ms) SELECT "users".* FROM "users" WHERE "users"."id" = $1 LIMIT $2 [["id", 5], ["LIMIT", 1]] ActiveRecord::RecordNotFound: Couldn't find User with 'id'=5 from /usr/local/bundle/gems/activerecord-6.0.2.1/lib/active_record/core.rb:177:in `find'find_by
find_byメソッドは指定したカラムの条件にマッチした1件のオブジェクトを取得するメソッドです。> User.find_by(email: "john@sample.com") User Load (1.6ms) SELECT "users".* FROM "users" WHERE "users"."email" = $1 LIMIT $2 [["email", "john@sample.com"], ["LIMIT", 1]] => #<User:0x000055c0f65cb108 id: 3, name: "John Smith", email: "john@sample.com", created_at: Thu, 23 Jan 2020 17:11:03 JST +09:00, updated_at: Thu, 23 Jan 2020 17:11:03 JST +09:00>マッチするレコードが存在しない場合はnilを返却します。
> User.find_by(email: "hoge@sample.com") User Load (1.7ms) SELECT "users".* FROM "users" WHERE "users"."email" = $1 LIMIT $2 [["email", "hoge@sample.com"], ["LIMIT", 1]] => nilまた、
find_byメソッドでは複数の条件全てにヒットする1レコードを取得する書き方もできます。> User.find_by(name: "John Smith", email: "john@sample.com") => #<User:0x000055c0f6af3040 id: 3, name: "John Smith", email: "john@sample.com", created_at: Thu, 23 Jan 2020 17:11:03 JST +09:00, updated_at: Thu, 23 Jan 2020 17:11:03 JST +09:00>こんな感じでユーザーを特定することができます!
where
whereメソッドはSQLのWHERE句と同様、レコードの検索条件を指定し、条件にマッチしたレコードをオブジェクトの配列として取得します。
条件はハッシュ型で書くのがわかりやすくてオススメ。等値条件
あるカラムが特定の値と同一であるレコードを取得する場合、単に
key: valueの形で条件を指定するだけです。> User.where(id: 1) User Load (1.6ms) SELECT "users".* FROM "users" WHERE "users"."id" = $1 [["id", 1]] => [#<User:0x000055c0f4d7ace8 id: 1, name: "Taro Tanaka", email: "tanaka@sample.com", created_at: Thu, 23 Jan 2020 17:08:36 JST +09:00, updated_at: Thu, 23 Jan 2020 17:08:36 JST +09:00>]範囲条件
valueには範囲を指定することもできます。Rubyでは
0 ≦ x ≦ 2を0..2、0 ≦ x < 2を0...2と表現します。> User.where(id: 1..2) User Load (2.7ms) SELECT "users".* FROM "users" WHERE "users"."id" BETWEEN $1 AND $2 [["id", 1], ["id", 2]] => [#<User:0x000055c0f638f740 id: 1, name: "Taro Tanaka", email: "tanaka@sample.com", created_at: Thu, 23 Jan 2020 17:08:36 JST +09:00, updated_at: Thu, 23 Jan 2020 17:08:36 JST +09:00>, #<User:0x000055c0f638f5d8 id: 2, name: "Hanako Yamada", email: "yamada@sample.com", created_at: Thu, 23 Jan 2020 17:10:31 JST +09:00, updated_at: Thu, 23 Jan 2020 17:10:31 JST +09:00>]サブセット条件
valueには配列を指定することも可能です。
> User.where(id: [1, 3]) User Load (2.7ms) SELECT "users".* FROM "users" WHERE "users"."id" BETWEEN $1 AND $2 [["id", 1], ["id", 3]] => [#<User:0x000055c0f638f740 id: 1, name: "Taro Tanaka", email: "tanaka@sample.com", created_at: Thu, 23 Jan 2020 17:08:36 JST +09:00, updated_at: Thu, 23 Jan 2020 17:08:36 JST +09:00>, #<User:0x000055c0f6901cc8 id: 3, name: "John Smith", email: "john@sample.com", created_at: Thu, 23 Jan 2020 17:11:03 JST +09:00, updated_at: Thu, 23 Jan 2020 17:11:03 JST +09:00>]NOT条件
where.notメソッドを使えば、条件にヒットしないものを検索することもできます。> User.where.not(id: 1) User Load (1.9ms) SELECT "users".* FROM "users" WHERE "users"."id" != $1 [["id", 1]] => [#<User:0x000055c0f6901d90 id: 2, name: "Hanako Yamada", email: "yamada@sample.com", created_at: Thu, 23 Jan 2020 17:10:31 JST +09:00, updated_at: Thu, 23 Jan 2020 17:10:31 JST +09:00>, #<User:0x000055c0f6901cc8 id: 3, name: "John Smith", email: "john@sample.com", created_at: Thu, 23 Jan 2020 17:11:03 JST +09:00, updated_at: Thu, 23 Jan 2020 17:11:03 JST +09:00>]AND条件
複数の条件にマッチするレコードを取得したい場合は、ハッシュの組み合わせを増やせばいいだけです。
> User.where(name: "Taro Tanaka", email: "tanaka@sample.com") User Load (1.6ms) SELECT "users".* FROM "users" WHERE "users"."name" = $1 AND "users"."email" = $2 [["name", "Taro Tanaka"], ["email", "tanaka@sample.com"]] => [#<User:0x000055c0f35a3098 id: 1, name: "Taro Tanaka", email: "tanaka@sample.com", created_at: Thu, 23 Jan 2020 17:08:36 JST +09:00, updated_at: Thu, 23 Jan 2020 17:08:36 JST +09:00>]OR条件
複数の条件のうち、どれか一つでも当てはまるレコードを取得したい場合は
orメソッドを使います。これはやや面倒(直感的でない)かもしれません。> User.where(id: 1).or(User.where(email: "john@sample.com")) User Load (2.0ms) SELECT "users".* FROM "users" WHERE ("users"."id" = $1 OR "users"."email" = $2) [["id", 1], ["email", "john@sample.com"]] => [#<User:0x000055c0f5c56c08 id: 1, name: "Taro Tanaka", email: "tanaka@sample.com", created_at: Thu, 23 Jan 2020 17:08:36 JST +09:00, updated_at: Thu, 23 Jan 2020 17:08:36 JST +09:00>, #<User:0x000055c0f5c56668 id: 3, name: "John Smith", email: "john@sample.com", created_at: Thu, 23 Jan 2020 17:11:03 JST +09:00, updated_at: Thu, 23 Jan 2020 17:11:03 JST +09:00>]order
orderメソッドは並び順を指定してくれます。使い方は並び順の条件にしたいカラムを指定するだけで昇順で並び替えてくれます。> User.order(:email) User Load (2.2ms) SELECT "users".* FROM "users" ORDER BY "users"."email" ASC => [#<User:0x000055c0f63223c0 id: 3, name: "John Smith", email: "john@sample.com", created_at: Thu, 23 Jan 2020 17:11:03 JST +09:00, updated_at: Thu, 23 Jan 2020 17:11:03 JST +09:00>, #<User:0x000055c0f6322258 id: 1, name: "Taro Tanaka", email: "tanaka@sample.com", created_at: Thu, 23 Jan 2020 17:08:36 JST +09:00, updated_at: Thu, 23 Jan 2020 17:08:36 JST +09:00>, #<User:0x000055c0f6322028 id: 2, name: "Hanako Yamada", email: "yamada@sample.com", created_at: Thu, 23 Jan 2020 17:10:31 JST +09:00, updated_at: Thu, 23 Jan 2020 17:10:31 JST +09:00>]メアド昇順に並び変わってますね。
降順に並べる場合は
descを使います。(昇順も同じようにascを指定して表現することもできます)> User.order(email: :desc) User Load (4.2ms) SELECT "users".* FROM "users" ORDER BY "users"."email" DESC => [#<User:0x000055c0f64a20d8 id: 2, name: "Hanako Yamada", email: "yamada@sample.com", created_at: Thu, 23 Jan 2020 17:10:31 JST +09:00, updated_at: Thu, 23 Jan 2020 17:10:31 JST +09:00>, #<User:0x000055c0f64a1d40 id: 1, name: "Taro Tanaka", email: "tanaka@sample.com", created_at: Thu, 23 Jan 2020 17:08:36 JST +09:00, updated_at: Thu, 23 Jan 2020 17:08:36 JST +09:00>, #<User:0x000055c0f64a1b88 id: 3, name: "John Smith", email: "john@sample.com", created_at: Thu, 23 Jan 2020 17:11:03 JST +09:00, updated_at: Thu, 23 Jan 2020 17:11:03 JST +09:00>]逆順になってる。
first
firstメソッドはprimary keyの順番で最初の1件のオブジェクトを取得するメソッドです。> User.first User Load (1.9ms) SELECT "users".* FROM "users" ORDER BY "users"."id" ASC LIMIT $1 [["LIMIT", 1]] => #<User:0x000055c0f625f460 id: 1, name: "Taro Tanaka", email: "tanaka@sample.com", created_at: Thu, 23 Jan 2020 17:08:36 JST +09:00, updated_at: Thu, 23 Jan 2020 17:08:36 JST +09:00>結果は先ほどの
findメソッドと同じTaro Tanakaがヒットしていますが、SQL文に違いがあることがわかります。find_byがWHEREで検索しているのに対して、firstはORDERで検索してます。また、
orderメソッドと組み合わせることで、primary key以外の属性に対しても一番先頭のオブジェクトを取得することができます。こっちの方が便利な気がする。> User.order(:email).first User Load (1.8ms) SELECT "users".* FROM "users" ORDER BY "users"."email" ASC LIMIT $1 [["LIMIT", 1]] => #<User:0x000055c0f67357a0 id: 3, name: "John Smith", email: "john@sample.com", created_at: Thu, 23 Jan 2020 17:11:03 JST +09:00, updated_at: Thu, 23 Jan 2020 17:11:03 JST +09:00>last
なんとなくメソッド名からわかりますね。
firstの逆、一番後ろのモデルオブジェクトを取得するメソッドです。> User.last User Load (4.3ms) SELECT "users".* FROM "users" ORDER BY "users"."id" DESC LIMIT $1 [["LIMIT", 1]] => #<User:0x000055c0f69aa2b0 id: 3, name: "John Smith", email: "john@sample.com", created_at: Thu, 23 Jan 2020 17:11:03 JST +09:00, updated_at: Thu, 23 Jan 2020 17:11:03 JST +09:00>もちろん
orderと組み合わせて使うことも可能!> User.order(:email).last User Load (2.4ms) SELECT "users".* FROM "users" ORDER BY "users"."email" DESC LIMIT $1 [["LIMIT", 1]] => #<User:0x000055c0f5f5ab70 id: 2, name: "Hanako Yamada", email: "yamada@sample.com", created_at: Thu, 23 Jan 2020 17:10:31 JST +09:00, updated_at: Thu, 23 Jan 2020 17:10:31 JST +09:00, password_digest: nil>Update
データの更新の方法も大きく2つあります。どちらの場合もまずfindやfind_byを使って単一のオブジェクトを取得します。で属性のデータを変更したあとに
saveメソッドを使って更新するか、updateメソッドで更新するかです。属性を更新して
save一つ目の方法は取得したオブジェクトの属性の値を変更してCreateと同じように
saveメソッドを使うことです。
Taro Tanakaさんのtaro@sample.comに変更してみましょう!> user = User.find(1) User Load (2.4ms) SELECT "users".* FROM "users" WHERE "users"."id" = $1 LIMIT $2 [["id", 1], ["LIMIT", 1]] => #<User:0x000055c0f67434b8 id: 1, name: "Taro Tanaka", email: "tanaka@sample.com", created_at: Thu, 23 Jan 2020 17:08:36 JST +09:00, updated_at: Thu, 23 Jan 2020 17:08:36 JST +09:00> > user.email = "taro@sample.com" => "taro@sample.com" > user.save (0.6ms) BEGIN User Update (4.1ms) UPDATE "users" SET "email" = $1, "updated_at" = $2 WHERE "users"."id" = $3 [["email", "taro@sample.com"], ["updated_at", "2020-01-23 20:05:27.588947"], ["id", 1]] (7.3ms) COMMIT => true > User.find(1) User Load (3.6ms) SELECT "users".* FROM "users" WHERE "users"."id" = $1 LIMIT $2 [["id", 1], ["LIMIT", 1]] => #<User:0x000055c0f6893660 id: 1, name: "Taro Tanaka", email: "taro@sample.com", created_at: Thu, 23 Jan 2020 17:08:36 JST +09:00, updated_at: Thu, 23 Jan 2020 20:05:27 JST +09:00>
updated_atも更新されてます!
updateメソッドを使うもう一つの方法はupdateメソッドを使う方法です。
今度は、Hanako Yamadaさんのhanako@sample.comに変更してみます!> user = User.find(2) User Load (2.2ms) SELECT "users".* FROM "users" WHERE "users"."id" = $1 LIMIT $2 [["id", 2], ["LIMIT", 1]] => #<User:0x000055c0f692fbc8 id: 2, name: "Hanako Yamada", email: "yamada@sample.com", created_at: Thu, 23 Jan 2020 17:10:31 JST +09:00, updated_at: Thu, 23 Jan 2020 17:10:31 JST +09:00> > user.update(email: "hanako@sample.com") (0.6ms) BEGIN User Update (3.3ms) UPDATE "users" SET "email" = $1, "updated_at" = $2 WHERE "users"."id" = $3 [["email", "hanako@sample.com"], ["updated_at", "2020-01-23 20:09:03.502713"], ["id", 2]] (1.2ms) COMMIT => true > User.find(2) User Load (3.4ms) SELECT "users".* FROM "users" WHERE "users"."id" = $1 LIMIT $2 [["id", 2], ["LIMIT", 1]] => #<User:0x000055c0f6a42740 id: 2, name: "Hanako Yamada", email: "hanako@sample.com", created_at: Thu, 23 Jan 2020 17:10:31 JST +09:00, updated_at: Thu, 23 Jan 2020 20:09:03 JST +09:00>
updateメソッドの場合は更新したい属性と値を括弧の中で指定します。
updateメソッドもcreateメソッドと同じで、データ保存に成功した場合はそのモデルオブジェクトが結果として返却されていますね。Delete
データの削除には
destroyメソッドを使います。今回はJohn Smithさんが退会した、みたいな感じでデータ削除してみましょう。> user = User.find(3) User Load (0.7ms) SELECT "users".* FROM "users" WHERE "users"."id" = $1 LIMIT $2 [["id", 3], ["LIMIT", 1]] => #<User:0x000055c0f6af3040 id: 3, name: "John Smith", email: "john@sample.com", created_at: Thu, 23 Jan 2020 17:11:03 JST +09:00, updated_at: Thu, 23 Jan 2020 17:11:03 JST +09:00> > user.destroy (0.4ms) BEGIN User Destroy (2.4ms) DELETE FROM "users" WHERE "users"."id" = $1 [["id", 3]] (1.3ms) COMMIT => #<User:0x000055c0f6af3040 id: 3, name: "John Smith", email: "john@sample.com", created_at: Thu, 23 Jan 2020 17:11:03 JST +09:00, updated_at: Thu, 23 Jan 2020 17:11:03 JST +09:00> > User.find(3) User Load (0.8ms) SELECT "users".* FROM "users" WHERE "users"."id" = $1 LIMIT $2 [["id", 3], ["LIMIT", 1]] ActiveRecord::RecordNotFound: Couldn't find User with 'id'=3 from /usr/local/bundle/gems/activerecord-6.0.2.1/lib/active_record/core.rb:177:in `find'あっけないですね。
最終的にもともとJohn Smithさんに割り当てられていたID=3で検索してみたところ、ActiveRecord::RecordNotFoundの例外が発生していることからJohn Smithさんがちゃんと削除されていることがわかります。後片付け
今日のデータをきれいにしておきましょう。今回もDBの再作成で。
> quit
quitコマンドでRails consoleから抜け出せます。# exit
exitコンテナからぬけまして、$ docker-compose down $ docker-compose run --rm web rails db:migrate:resetコンテナを停止して、
rails db:migrate:resetを実行っと。まとめ
今回は、Modelの作成と基本的なモデル(データ)の操作をやってみました。
ここは僕の中でRailsの使いやすいところだなーと思っているのですが、SQLを隠してくれているんですよね。モデルのメソッドって形でデータのCRUDできるのは本当に使いやすい。次回はモデルにバリデーションをつけていこうと思います。今のままだと
nameや
あと、Userモデルにセキュアなパスワードの属性を追加していきます。単にパスワードをカラム追加してしまったら万が一データが盗まれた時に大変な個人情報流出です。Railsではセキュアなパスワードを扱うためにhas_secure_passwordメソッドが用意されているのでその使い方を紹介します。では、次回も乞うご期待!ここまでお読みいただきありがとうございました!
Reference
- Ruby on Rails チュートリアル:実例を使って Rails を学ぼう
- Railsタイムゾーンまとめ - Qiita
- rails-i18n/ja.yml at master · svenfuchs/rails-i18n
- もう迷わない!CSS Flexboxの使い方を徹底解説 | Web Design Trends
- 【2019年版】Google Fontsの使い方:初心者向けに解説!
P.S. 間違っているところ、抜けているところ、説明の仕方を変えるとよりわかりやすくなるところなどありましたら、優しくアドバイスいただけると助かります。
- 投稿日:2020-02-10T15:20:58+09:00
R言語のFW ShinyをDockerでサクッと構築する
概要
タイトルまんま
ディレクトリ構成
r-shiny-docker ├── apps │ ├── appdir │ │ ├── server.R │ │ └── ui.R │ └── index.html └── docker-compose.ymldocker-compose.yml
docker-compose.ymlversion: "3" services: shiny: image: rocker/shiny:3.4.4 ports: - 3838:3838 volumes: - "./apps:/srv/shiny-server"server.R
server.R# # This is the server logic of a Shiny web application. You can run the # application by clicking 'Run App' above. # # Find out more about building applications with Shiny here: # # http://shiny.rstudio.com/ # library(shiny) # Define server logic required to draw a histogram shinyServer(function(input, output) { output$distPlot <- renderPlot({ # generate bins based on input$bins from ui.R x <- faithful[, 2] bins <- seq(min(x), max(x), length.out = input$bins + 1) # draw the histogram with the specified number of bins hist(x, breaks = bins, col = 'darkgray', border = 'white') }) })ui.R
ui.R# # This is the user-interface definition of a Shiny web application. You can # run the application by clicking 'Run App' above. # # Find out more about building applications with Shiny here: # # http://shiny.rstudio.com/ # library(shiny) # Define UI for application that draws a histogram shinyUI(fluidPage( # Application title titlePanel("Old Faithful Geyser Data"), # Sidebar with a slider input for number of bins sidebarLayout( sidebarPanel( sliderInput("bins", "Number of bins:", min = 1, max = 50, value = 30) ), # Show a plot of the generated distribution mainPanel( plotOutput("distPlot") ) ) ))index.html
index.htmlhello接続
http://localhost:3838/appdir/で
参考
- (rocker-org/shiny)[https://github.com/rocker-org/shiny]

- 投稿日:2020-02-10T13:58:55+09:00
Automotive Grade Linux(AGL)
「Linuxでこれができる」だけじゃない、車載Linuxのデモから見えた実用性へのこだわり
https://monoist.atmarkit.co.jp/mn/articles/2002/06/news059.html?fbclid=IwAR2IGj6zisyVofRKcx5Lkum_A_t1wdePDKvLdYtWEhCu9inIg2QQgcda1A0しまったAutomotive Grade Linux(AGL)資料整理していない。
https://www.automotivelinux.org/
Document
The Automotive Grade Linux Software Defined Connected Car Architecture
20th June 2018 Final
https://www.automotivelinux.org/wp-content/uploads/sites/4/2018/06/agl_software_defined_car_jun18.pdf2018 Global In-Vehicle Infotainment
Enabling Technology Leadership Award
https://www.automotivelinux.org/wp-content/uploads/sites/4/2019/05/Frost-Sullivan-Automotive-Grade-Linux-Award-Write-Up.pdfThe Linux Foundation.
https://www.linuxfoundation.org/Wiki
https://wiki.automotivelinux.org/Git Repositories
https://git.automotivelinux.org/docker-worker-generator
https://git.automotivelinux.org/AGL/docker-worker-generator/
DockerfileFROM debian:10 COPY INSTALL /root/INSTALL RUN /root/INSTALL/setup_image.sh ENTRYPOINT ["/usr/bin/wait_for_net.sh"] CMD ["/bin/systemd"]setup_image.sh
setup_image.sh#!/bin/bash -x ### this script is called when building the docker image: it's executing in a temp container echo "------------------------ Starting $(basename $0) -----------------------" function debug() { set +x echo "-------------------------" echo "Command failed." echo "Running sleep for 1 day. To proceed:" echo "* run 'killall sleep' to continue" echo "* run 'killall -9 sleep' to abort the build" sig=0 sleep 86400 || sig=$? # if killed -9, then abort [[ $sig == 137 ]] && exit 1 # abort set -x return 0 # continue } function crash() { set +x echo " -------------------------" echo "| CRASH HANDLER TRIGGERED |" echo " -------------------------" exit 1 } # get the INSTALL dir (the one where we were launched) INSTDIR=$(cd $(dirname $0) && pwd -P) echo "Detected container install dir = $INSTDIR" if [[ -f $INSTDIR/DEBUG ]]; then echo "#### INTERACTIVE DEBUG MODE IS ACTIVE ####" trap debug ERR # on error, run a sleep tp debug container else echo "#### JENKINS MODE MODE IS ACTIVE ####" trap crash ERR # on error, simply crash fi ################################## variables ################################# # source variables in conf file . $INSTDIR/image.conf # source flavour config file (generated by top Makefile) . $INSTDIR/flavour.conf if [[ -z "$CONTAINER_TYPE" ]]; then grep -q docker /proc/self/cgroup && CONTAINER_TYPE="docker" fi ################################## install docker endpoint ##################### # install the entrypoint script in /usr/bin install --mode=755 $INSTDIR/wait_for_net.sh /usr/bin/ ################################## install first-run service ################### # all operations requiring runnning daemons (inc. systemd) must be run at first # container instanciation if [[ "$FIRSTRUN" == "yes" ]]; then install --mode=755 $INSTDIR/firstrun.sh /root/firstrun.sh install --mode=644 $INSTDIR/image.conf /root/firstrun.conf [[ -d $INSTDIR/firstrun.d ]] && cp -a $INSTDIR/firstrun.d /root/ mkdir -p /etc/systemd/system/multi-user.target.wants/ cat <<EOF >/etc/systemd/system/multi-user.target.wants/firstrun.service [Unit] Description=Firstrun service After=network.target [Service] Type=oneshot ExecStart=-/bin/bash -c /root/firstrun.sh TimeoutSec=0 StandardInput=null RemainAfterExit=yes [Install] WantedBy=multi-user.target EOF fi # helper func to install a firstrun hook function firstrun_add() { script=$1 level=${2:-50} name=${3:-$(basename $script)} mkdir -p /root/firstrun.d cp $script /root/firstrun.d/${level}_$name } ################################## adjust system timezone ############################ ln -sf ../usr/share/zoneinfo/$TIMEZONE /etc/localtime ################################## run other scripts in turn ############## function enumerate_tasks() { for script in $INSTDIR/common.d/*; do case $(basename $script) in [0-9][0-9]_*) echo $(basename $script):$script ;; esac done for tsk in $(cat $INSTDIR/flavours/$FLAVOUR.tasks | sed 's/#.*$//g'); do if [[ -f $INSTDIR/tasks.d/$tsk ]]; then echo $tsk:$INSTDIR/tasks.d/$tsk else # fail to find task echo "$INSTDIR/flavours/$FLAVOUR.tasks: invalid task '$tsk'" >&2 return 1 fi done return 0 } for script in $(enumerate_tasks | sort -k1 -t':' | cut -f2 -d':'); do echo "--------------------- start script $script ---------------------" . $script echo "--------------------- end of script $script ---------------------" done ############################### cleanup ################################### cd / apt-get clean # clean apt caches rm -rf /var/lib/apt/lists/* rm -rf $INSTDIR # yes, I can auto-terminate myself ! # cleanup /tmp without removing the dir for x in $(find /tmp -mindepth 1); do rm -rf $x || true done echo "------------------------ $(basename $0) finished -----------------------"wait_for_net.sh
wait_for_net.sh#!/bin/bash ### this script is used as entrypoint of the docker container to wait for network to be up ### IFACE="veth0 eth0" function wait_net() { for i in $IFACE; do [[ "$(cat /sys/class/net/$i/operstate 2>/dev/null)" == "up" ]] && return 1 ip link set mtu 1300 dev $IFACE done return 0 } while wait_net; do sleep 1 done [[ $# > 0 ]] && exec "$@" exec /bin/bash -lMembers
Platinum Members
Denso
Mazuda
Panasonic
Renesas
suzuki
TOYOTAAdvisory Board
HONDA
NTTDATA
DENSOTEN
Mercedes-Benz
- 投稿日:2020-02-10T09:10:48+09:00
Docker+RubyonRails でよく使うコマンドメモ
アプリを作成するときはDockerを利用するのですが、Railsコマンド打つとき最初よく分からなくて躓いてたんで自分用メモとして記します。
gemのインストール
docker-compose build --no-cacheDocker-compose downしてから行ってください。
dockerでrailsコマンドを打つ
docker-compose run --rm web railsDockerfileやdocker-compose.ymlの変更を反映、railsサーバーを再起動
docker-compose up --buildMySQL
docker-compose exec db mysql -u root -pMysqlは「database.yml」で指定したパスワードで中身を見ることができます。
まとめ
よくこの辺を使うので参考になればと思います。
- 投稿日:2020-02-10T08:41:05+09:00
ReactをDockerで開発してGithub ActionsでGithub Pagesに自動で公開するReactアプリ開発用のテンプレートリポジトリ
これはなに?
Reactで開発をするときのオレオレな開発テンプレートリポジトリです。このリポジトリをReactアプリ開発の初期環境として使用することで、Dockerベースの開発環境が用意され、master branchにmergeされるとGithub Actionsが動きbuildとGithub Pagesへの公開が自動で行われます。
使い方
テンプレートリポジトリを
git cloneします。
※ forkした場合、Github Actionsが動作しない。git clone https://github.com/k8shiro/ReactGithubTemplateclone後、gitのremoteを自分のgithubのリポジトリのURLに変更します。
git remote set-url origin <自分のgithubのリポジトリのURL>この後はdevelopブランチで開発を行い、開発が終了したらmasterブランチにmergeしましょう
新しくReactアプリを作成する場合
既にサンプルのmy-appアプリが作成されているのでこれを削除し、以下のコマンドでcreate-react-appを実行します。
rm -rf app/my-app docker-compose run --rm node sh -c "create-react-app new-my-app" # new-my-appを自分のアプリ名に変えるdocker-compose.ymlのenvironmentのREACT_APP_NAMEを自分のアプリ名に変更
version: "3" services: node: build: context: ./app environment: - NODE_ENV=production - REACT_APP_NAME=my-app # ここのmy-appを修正 volumes: - ./app:/usr/src/app ports: - "3000:3000"また、app/my-app/package.jsonにhomepageを追加します。
{ "homepage": ".", # ここを追加 "name": "my-app", "version": "0.1.0", "private": true, ...作成済みのアプリを動かす場合(初回のみ)
- packageのインストールが必要
docker-compose run --rm --service-ports node ash -c "cd \$REACT_APP_NAME; yarn install"アプリケーションの開発を行う
- 開発サーバーを立ち上げる
docker-compose run --rm --service-ports node ash -c "cd \$REACT_APP_NAME; yarn start"ホストマシンの3000ポートでアプリケーションが起動します。
- コードを修正する
開発サーバーが起動している状態でホストマシン上で'app/my-app'内を修正すればビルドされます。
- パッケージを追加する
docker-compose run --rm --service-ports node ash -c "cd \$REACT_APP_NAME; yarn add package-name"Github Pagesが公開されない
github pagesへの反映には若干時間がかかるようですが、公開されない場合以下を試すと表示されることがありました。
リポジトリのSettingsのGithub Pagesで使用するブランチを指定できます。これを
- デフォルトのgh-pagesからmasterに変更
- masterからgh-pagesに戻す
を行うと公開されました。
リポジトリの解説
.github/workflows/main.yml
Github Actionsの設定ファイルです。
name: Build React APP on: push: branches: - master jobs: build: runs-on: ubuntu-latest steps: - uses: actions/checkout@v1 - name: build app run: | docker-compose run --rm node ash -c 'cd $REACT_APP_NAME; npm install; yarn build; cp -rf build /usr/src/app/; ls; - uses: crazy-max/ghaction-github-pages@v1 with: target_branch: gh-pages build_dir: app/build env: GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
- masterブランチへのpushをトリガーとして動作します。
docker-compose run --rm node ash -c 'cd $REACT_APP_NAME; npm install; yarn build; cp -rf build /usr/ではReactのアプリケーションのbuildを行った後、buildディレクトリを/usr/src/app/(ホスト側の./appがマウントされている)にコピーしています。- ホスト側にコピーされた
./app/buildディレクトリをgh-pagesブランチにpushし、Github Pagesに公開されます。
- Github ActionsのMarket# これはなに?
- ReactをDockerで開発してGithub ActionsでGithub Pagesに自動で公開するReactアプリ開発用のテンプレートリポジトリ
Reactで開発をするときのオレオレな開発テンプレートリポジトリです。このリポジトリをReactアプリ開発の初期環境として使用することで、Dockerベースの開発環境が用意され、master branchにmergeされるとGithub Actionsが動きbuildとGithub Pagesへの公開が自動で行われます。
使い方
テンプレートリポジトリを
git cloneします。
※ forkした場合、Github Actionsが動作しない。git clone https://github.com/k8shiro/ReactGithubTemplateclone後、gitのremoteを自分のgithubのリポジトリのURLに変更します。
git remote set-url origin <自分のgithubのリポジトリのURL>この後はdevelopブランチで開発を行い、開発が終了したらmasterブランチにmergeしましょう
新しくReactアプリを作成する場合
既にサンプルのmy-appアプリが作成されているのでこれを削除し、以下のコマンドでcreate-react-appを実行します。
rm -rf app/my-app docker-compose run --rm node sh -c "create-react-app new-my-app" # new-my-appを自分のアプリ名に変えるdocker-compose.ymlのenvironmentのREACT_APP_NAMEを自分のアプリ名に変更
version: "3" services: node: build: context: ./app environment: - NODE_ENV=production - REACT_APP_NAME=my-app # ここのmy-appを修正 volumes: - ./app:/usr/src/app ports: - "3000:3000"また、app/my-app/package.jsonにhomepageを追加します。
{ "homepage": ".", # ここを追加 "name": "my-app", "version": "0.1.0", "private": true, ...作成済みのアプリを動かす場合(初回のみ)
- packageのインストールが必要
docker-compose run --rm --service-ports node ash -c "cd \$REACT_APP_NAME; yarn install"アプリケーションの開発を行う
- 開発サーバーを立ち上げる
docker-compose run --rm --service-ports node ash -c "cd \$REACT_APP_NAME; yarn start"
- コードを修正する
この状態でホストマシン上で'app/my-app'内を修正すればビルドされます。
- パッケージを追加する
docker-compose run --rm --service-ports node ash -c "cd \$REACT_APP_NAME; yarn add package-name"Github Pagesが公開されない
github pagesへの反映には若干時間がかかるようですが、公開されない場合以下を試すと表示されることがありました。
リポジトリのSettingsのGithub Pagesで使用するブランチを指定できます。これを
- デフォルトのgh-pagesからmasterに変更
- masterからgh-pagesに戻す
を行うと公開されました。
リポジトリの解説
.github/workflows/main.yml
Github Actionsの設定ファイルです。
name: Build React APP on: push: branches: - master jobs: build: runs-on: ubuntu-latest steps: - uses: actions/checkout@v1 - name: build app run: | docker-compose run --rm node ash -c 'cd $REACT_APP_NAME; npm install; yarn build; cp -rf build /usr/src/app/; ls; - uses: crazy-max/ghaction-github-pages@v1 with: target_branch: gh-pages build_dir: app/build env: GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
- masterブランチへのpushをトリガーとして動作します。
docker-compose run --rm node ash -c 'cd $REACT_APP_NAME; npm install; yarn build; cp -rf build /usr/ではReactのアプリケーションのbuildを行った後、buildディレクトリを/usr/src/app/(ホスト側の./appがマウントされている)にコピーしています。- ホスト側にコピーされた
./app/buildディレクトリをgh-pagesブランチにpushし、Github Pagesに公開されます。
- Github ActionsのMarketplaceで公開されているワークフローを使用(https://github.com/marketplace/actions/github-pages)
dockre-compose.yml
この環境ではReactアプリはDockerコンテナの内部で動作します。この時の基本的な設定はdocker-compose.ymlで管理しています。
version: "3" services: node: build: context: ./app environment: - NODE_ENV=production - REACT_APP_NAME=my-app volumes: - ./app:/usr/src/app ports: - "3000:3000"
environmentでREACT_APP_NAMEをコンテナ内の環境変数で渡すことでdocker-compose runでReact APPにyarnコマンド等を実行するときに利用できるようにしています。
- 投稿日:2020-02-10T08:01:56+09:00
Dockerのインストール方法
環境
OS:Ubuntu 18.04 LTS
CPU:Intel Core i9 9900K
RAM:DDR4-2133 32GB
GPU:GeForce RTX 2080 Super 8GBインストール手順
Docker本体のインストール
sudo apt-get update && sudo apt-get install -y \ apt-transport-https \ ca-certificates \ curl \ gnupg-agent \ software-properties-common && \ curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add - && \ sudo add-apt-repository \ "deb [arch=amd64] https://download.docker.com/linux/ubuntu \ $(lsb_release -cs) \ stable" && \ sudo apt-get update && \ sudo apt-get install -y docker-ce docker-ce-cli containerd.io && \Nvidia Dockerのインストール
準備中です
Nvidia-Container-Toolkitのインストール
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) && \ curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - && \ curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list && \ sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit && \ sudo systemctl restart docker
- 投稿日:2020-02-10T08:01:56+09:00
NVIDIA Dockerのインストール方法
環境
OS:Ubuntu 18.04 LTS
CPU:Intel Core i9 9900K
RAM:DDR4-2133 32GB
GPU:GeForce RTX 2080 Super 8GB前提
GPUのドライバーはインストール済み
インストール手順
nvidia-docker2を使う場合
Docker本体のインストール
sudo apt-get update && sudo apt-get install -y \ apt-transport-https \ ca-certificates \ curl \ gnupg-agent \ software-properties-common && \ curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add - && \ sudo add-apt-repository \ "deb [arch=amd64] https://download.docker.com/linux/ubuntu \ $(lsb_release -cs) \ stable" && \ sudo apt-get update && \ sudo apt-get install -y docker-ce docker-ce-cli containerd.io && \Nvidia Dockerのインストール
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | \ sudo apt-key add - curl -s -L https://nvidia.github.io/nvidia-docker/ubuntu16.04/amd64/nvidia-docker.list | \ sudo tee /etc/apt/sources.list.d/nvidia-docker.list && \ sudo apt-get update && \ sudo apt-get install -y nvidia-docker2 && \ sudo pkill -SIGHUP dockerdNvidia-Container-Toolkitのインストール
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) && \ curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - && \ curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list && \ sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit && \ sudo systemctl restart dockerDocker 19.03より最新版を使う場合(--gpus)
Docker本体のインストール
sudo apt-get update && sudo apt-get install -y \ apt-transport-https \ ca-certificates \ curl \ gnupg-agent \ software-properties-common && \ curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add - && \ sudo add-apt-repository \ "deb [arch=amd64] https://download.docker.com/linux/ubuntu \ $(lsb_release -cs) \ stable" && \ sudo apt-get update && \ sudo apt-get install -y docker-ce docker-ce-cli containerd.ioNvidia-Container-Toolkitのインストール
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) && \ curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - && \ curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list && \ sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit && \ sudo systemctl restart docker便利な設定
sudo無しでdocker runとかをするための設定
sudo usermod -aG docker $(USERNAME)