- 投稿日:2020-02-10T08:25:42+09:00
プレトレーニングを用いた少量ラベルデータ下における画像識別精度の向上
はじめに
機械学習プロジェクトで大量にデータはあるがラベル付けがされていないという状況が多々あると思います。ラベル付けを最小限に抑えることは人的、時間的コストの削減に貢献します。本記事では、オートエンコーダーによる事前学習を用いることで、少ないラベルデータでもMNIST画像識別精度の向上を図ることができたのでご紹介させていただきます。また、TensorFlowで作成したモデルの下位層だけ再利用する方法で苦しんだので、私の方法を参考にしていただければ幸いです!
プレトレーニングを用いたMNIST画像識別器において、1000個のラベル付きデータを10epoch学習させるだけで、テストデータにおける正解率が90%を超えました。プレトレーニングにはMNISTデータのノイズ除去を行うオートエンコーダーを作成しました。オートエンコーダーの下位層だけを再利用し、MNIST画像識別モデルを構築しました。MNIST画像識別モデルの訓練データ(ラベル付き)の数を100-60000まで変化させ、正解率のデータ数依存性を確認しました。最後にプレトレーニングを行わなかった場合の結果と比較し、プレトレーニングの有用性を示します!前提知識
本記事のメイントピックである「オートエンコーダー」と「プレトレーニング」を簡単に説明し、検証手順を図解しながら説明します。
オートエンコーダー
オートエンコーダーは「次元削除」、「特徴抽出」、「プレトレーニング」「データ生成」のタスクを遂行する教師無し機械学習です。オートエンコーダーのニューラルネットワーク構成を下図に示します。隠れ層を中心とした左右対称の構造をしており、中心の層が最もニューロン数が少ないのが特徴です。オートエンコーダーはニューロン数が減少していく「エンコーダー」部分と、ニューロン数が増大していく「デコーダー」部分に分けられます。オートエンコーダーに入力データを加え、出力で入力データを再現するように学習を行うことで、中間層が少ない次元で入力データを表現する内部表現を獲得します。つまり「エンコーダー」部で入力を内部表現に変換し、「デコーダー」部で内部表現を元のデータに逆変換します。この一連のプロセスを経る事で内部表現がデータの特徴を効率的に捉え、オートエンコーダーは次元削除といったタスクをこなす事ができます。
◾️オートエンコーダーの概念図
プレトレーニング
プレトレーニング(事前学習)は、複雑なタスクを遂行するニューラルネットワークに対して、それと同様なタスクを実行する学習済みニューラルネットワークの一部を再利用し、少ない学習データで高精度のモデルを構築する手法です。プレトレーニングを行うためにオートエンコーダーの仕組みを利用する事が可能です。上述した様に、オートエンコーダーは入力データの特徴を捉える事が可能であるため、はじめにオートエンコーダーを学習させ、その一部を再利用する事で本題の識別器を効率的に学習させる事が可能です。
検証の手順
本記事ではMNIST画像のノイズ除去オートエンコーダーを学習させ、下位層を再利用したMNIST画像識別器を作成します。ノイズ除去オートエンコーダーは入力からノイズを除去するタスクを遂行します。学習の方法は、入力にノイズを混入させ、出力でノイズを除去した画像を再構築する様に学習を行います(下図参照)。オートエンコーダーの隠れ層1, 隠れ層2, 隠れ層3のニューロン数はそれぞれ50, 20, 50, MNIST画像識別器の出力層のニューロン数は10としました。ニューラルネットワークの設定を表にまとめています。
◾️学習の条件
項目 値 隠れ層1 ニューロン数 50 隠れ層2 ニューロン数 20 隠れ層3 ニューロン数 50 出力層 ニューロン数 10 最適化手法 Adam 学習率 0.001 活性化関数 ELU ノイズ 平均:0, 分散:1のガウスノイズ ◾️検証手順の図解
動作環境
主な動作環境の情報は以下です
項目 値 macOS Mojave 10.14.6 tensorflow 1.13.1 numpy 1.15.4 keras 2.3.0 プレトレーニングを目的としたオートエンコーダーの学習
MNIST画像に対するノイズ除去オートエンコーダーの構築・学習・性能確認を行います。kerasを用いてロードしたMNIST画像を1次元に展開し、パーセプトロンで扱える形状に変換します。ノイズ除去オートエンコーダーはTensorFLowで構築します。全てのMNIST画像(ラベルは用いない)でノイズ除去オートエンコーダーを学習させモデルを保存します。保存したモデルをロードし、ノイズ除去タスクを学習できているかを定性的に確認します。
MNISTデータの準備
kerasを用いてMNISTデータをロードします
# kerasでMNISTデータをロード from keras.datasets import mnist (x_train, y_train), (x_test, y_test) = mnist.load_data()データを一次元に展開すると同時にピクセル値が0-1になる様に正規化します
# MNISTデータを正規化 X_train = x_train.reshape(x_train.shape[0], -1) / 255. X_test = x_test.reshape(x_test.shape[0], -1) / 255. # モデルの入力にするために[サンプル数, 1]に配列の形状を変形 Y_train = y_train.reshape(-1, 1) Y_test = y_test.reshape(-1, 1)オートエンコーダーモデルの構築
続いてオートエンコーダーのモデルを作成します。
ハイパーパラメーターを定義します## ハイパーパラメーター ## # ニューロン数 n_inputs = 28 * 28 n_hidden1 = 50 n_hidden2 = 20 n_hidden3 = n_hidden1 n_outputs = n_inputs # 学習率 learning_rate = 0.001TensorFLowのグラフを初期化しオートエンコーダーモデルを構築します
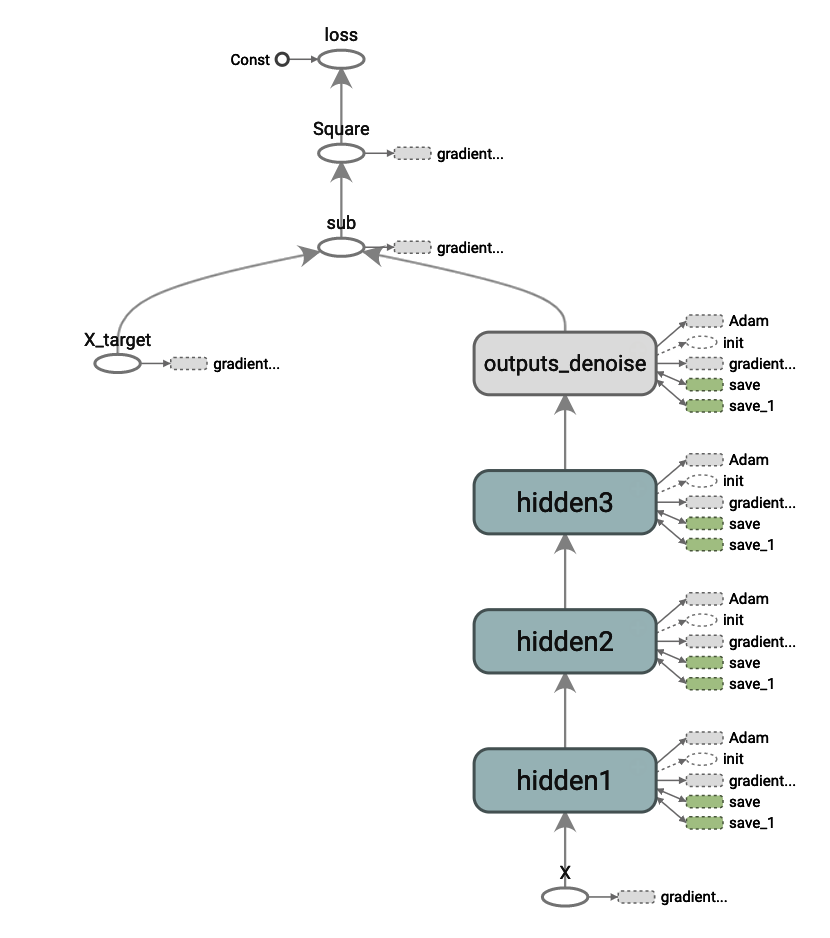
## オートエンコーダーモデルの構築 ## import tensorflow as tf # グラフの初期化 tf.reset_default_graph() X = tf.placeholder(dtype=tf.float32, shape=[None, n_inputs], name='X') X_target = tf.placeholder(dtype=tf.float32, shape=[None, n_inputs], name='X_target') # ニューラルネットワークの定義の構築 # activation = tf.nn.elu hidden1 = tf.layers.dense(X, n_hidden1, activation=activation, name='hidden1') hidden2 = tf.layers.dense(hidden1, n_hidden2, activation=activation, name='hidden2') hidden3 = tf.layers.dense(hidden2, n_hidden3, activation=activation, name='hidden3') outputs_denoise = tf.layers.dense(hidden3, n_outputs, activation=None, name='outputs_denoise'))損失関数、オプティマイザを定義します。損失関数には入力と出力のMSEを用い「再構築誤差」の指標とします
## 学習方法の設定 ## # 損失関数: 再構築誤差 ## 学習方法の設定 ## # 損失関数: 再構築誤差 reconstruction_loss = tf.reduce_mean(tf.square(X_target - outputs_denoise), name='loss') # オプティマイザ optimizer = tf.train.AdamOptimizer(learning_rate) training_op = optimizer.minimize(reconstruction_loss) # 保存 saver = tf.train.Saver()構築したモデルをTensorBoardで見ると以下の様に見えます
◾️ TensorBoardによるオートエンコーダーモデルの可視化
オートエンコーダーモデルの学習
構築したオートエンコーダーモデルの学習を行います
まずは準備として学習パラメター、モデルの保存先、データからバッチを取得する関数を定義します。import datetime # 学習パラメータ epoch_num=10 batch_size=100 # モデルの保存作 now = datetime.datetime.now().strftime("%Y-%m-%d-%H:%M") ckpt_path = './{}/denoise_auto_encoder.ckpt'.format(now) # 学習済みモデルの保存ディレクトリ名は現在時刻を使用する # MNISTデータからbatchを取得する関数 def fetch_batch(X, y, batch_size): num_data = X.shape[0] random_index = np.random.permutation(num_data) for batch_idx in np.array_split(random_index, batch_size): X_batch, y_batch = X[batch_idx, :], y[batch_idx] yield X_batch, y_batch学習を行います
# 初期化変数の宣言 init = tf.global_variables_initializer() with tf.Session() as sess: init.run() # エポックでループ for epoch in range(epoch_num): # バッチを取得し学習を行う for X_batch, y_batch in fetch_batch(X_train, y_train, batch_size): X_batch_noise = X_batch + np.random.normal(size=(X_batch.shape))# ノイズを混入 sess.run(training_op, feed_dict={X:X_batch_noise, X_target:X_batch}) # 最後のバッチにおける再構築誤差を計算 loss_val_last_batch = reconstruction_loss.eval(feed_dict={X:X_batch, X_target:X_batch}) print("Epoch: {0} \tLast batch MSE: {1}".format(epoch, loss_val_last_batch)) # テストデータにおける再構築誤差を計算 X_test_noise = X_test + np.random.normal(size=(X_test.shape))# ノイズを混入 loss_val_test = reconstruction_loss.eval(feed_dict={X:X_test_noise, X_target:X_test}) print("===\tTest MSE: {0}===".format(loss_val_test)) # モデルの保存 tf.train.Saver().save(sess, ckpt_path)コンソールの出力を以下に示します。再構築誤差(本記事ではMSE)が学習するたびに低くなり、テストデータにおけるMSE約0.04に落ち着きました。
Epoch: 0 Last batch MSE: 0.05711618438363075 Epoch: 1 Last batch MSE: 0.0470886304974556 Epoch: 2 Last batch MSE: 0.040134407579898834 Epoch: 3 Last batch MSE: 0.0365045927464962 Epoch: 4 Last batch MSE: 0.032733481377363205 Epoch: 5 Last batch MSE: 0.03418581560254097 Epoch: 6 Last batch MSE: 0.03256369009613991 Epoch: 7 Last batch MSE: 0.03150740638375282 Epoch: 8 Last batch MSE: 0.03078094869852066 Epoch: 9 Last batch MSE: 0.02976345084607601 === Test MSE: 0.03738117963075638===ノイズ除去モデルの性能を定性的に確認
続いてオートエンコーダーがノイズを除去タスクを学習できているかを確認します。
(コードの詳細はgithubを参照ください)
ランダムに100個のデータを取得し、ノイズを加え、オートエンコーダーに入力した時の出力を確認します。
以下に 1.ランダムに抽出した100個のMNIST画像 2.ノイズ混入画像 3.ノイズ除去を行なった画像を示します。
ノイズ除去後の画像を見ると、ノイズがあるという感じはなくなっています。
しかし、常にうっすら'0'の痕跡がある様に見えます。◾️1.ランダムに抽出した100個のMNIST画像
◾️2.ノイズ混入画像
◾️3.ノイズ除去後画像
プレトレーニングを用いたMNIST画像識別器の学習
3章で作成したノイズ除去オートエンコーダーの下位層のみ再利用し、プレトレーニングを用いたMNIST画像識別器の構築・学習を行います。作成済みモデルをロードし、下位層に画像識別用の出力層を新たに付け加えます。学習データサイズを100-60000の間で変化させ、MNIST画像識別器を10epochで学習させます。最後に学習データサイズにおける正解率の推移を示します。
オートエンコーダーモデルを再利用したMNIST画像識別モデルの構築
保存したオートエンコーダーモデルを再利用するために、TensorFlowグラフ内の変数名を取得します。モデルが正常に保存できていれば、そのディレクトリに'ファイル名.meta'というファイルが存在するはずです。これを読み出すことで欲しい層の変数を取得します。
# グラフメタファイルのパス ckpt_meta = ckpt_path + '.meta' # グラフをリセット tf.reset_default_graph() saver_new = tf.train.import_meta_graph(ckpt_meta) # メタ情報の表示 for op in tf.get_default_graph().get_operations(): print(op.name)コンソールの出力の一部は以下です。モデル構築で指定したname属性の値である'X', 'hidden1', 'hidden2'が正しく反映されているが分かります。今回は隠れ層1と2の活性化関数の出力まで利用します。(自分で作ったモデルなら変数名を調べるまでもないですが、ネットで拾った時には確認が必要かと思います。)
X hidden1/kernel/Initializer/random_uniform/shape hidden1/kernel/Initializer/random_uniform/min hidden1/kernel/Initializer/random_uniform/max 〜中略〜 hidden1/MatMul hidden1/BiasAdd hidden1/Elu hidden2/kernel/Initializer/random_uniform/shape hidden2/kernel/Initializer/random_uniform/min hidden2/kernel/Initializer/random_uniform/max 〜中略〜 hidden2/MatMul hidden2/BiasAdd hidden2/Elu 〜略〜再利用する層の名前が判明したのでMNIST画像を識別するモデルを構築します。
## ハイパーパラメータ # Graphのリセット tf.reset_default_graph() n_outputs = 10 # 出力層の数 learning_rate = 0.001 # 学習率 ## モデル構築 # モデル再利用のためのSaver resotre_saver = tf.train.import_meta_graph(ckpt_meta) # 入力の定義 (Xは再利用する) X = tf.get_default_graph().get_tensor_by_name("X:0") ### <- 変数の再利用!!! y = tf.placeholder(dtype=tf.int32, shape=[None]) # hidden2までを再利用 hidden1 = tf.get_default_graph().get_tensor_by_name("hidden1/Elu:0")### <- 変数の再利用!!! hidden2 = tf.get_default_graph().get_tensor_by_name("hidden2/Elu:0")### <- 変数の再利用!!! # 出力を新規に追加 logits = tf.layers.dense(hidden2, n_outputs, activation=None, name='logits') ## 学習の設定 # 損出関数 with tf.name_scope("loss"): xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits) loss = tf.reduce_mean(xentropy, name='loss') # オプティマイザ with tf.name_scope("train"): new_optimizer = tf.train.AdamOptimizer(learning_rate, name='Adam_clf') training_op_clf = new_optimizer.minimize(loss) # 精度評価 correct = tf.nn.in_top_k(logits, y, 1) accuracy = tf.reduce_mean(tf.cast(correct, tf.float32), name='accuracy')コードの解説です。
[1] tf.train.import_meta_graph(ckpt_meta)
➡︎ '.meta'のファイルで定義されるグラフをインポートします。これを実行しないと保存したモデルを再利用できません。[2] X = tf.get_default_graph().get_tensor_by_name("X:0")
[3] hidden1 = tf.get_default_graph().get_tensor_by_name("hidden1/Elu:0")
[4] hidden2 = tf.get_default_graph().get_tensor_by_name("hidden2/Elu:0")
➡︎ 上記に様にして変数を名前指定(by name)で取得可能です。
指定する名前の中の ':0' はあまり意味はわかりませんが必要です。。。誰かわかる人教えてください。。。
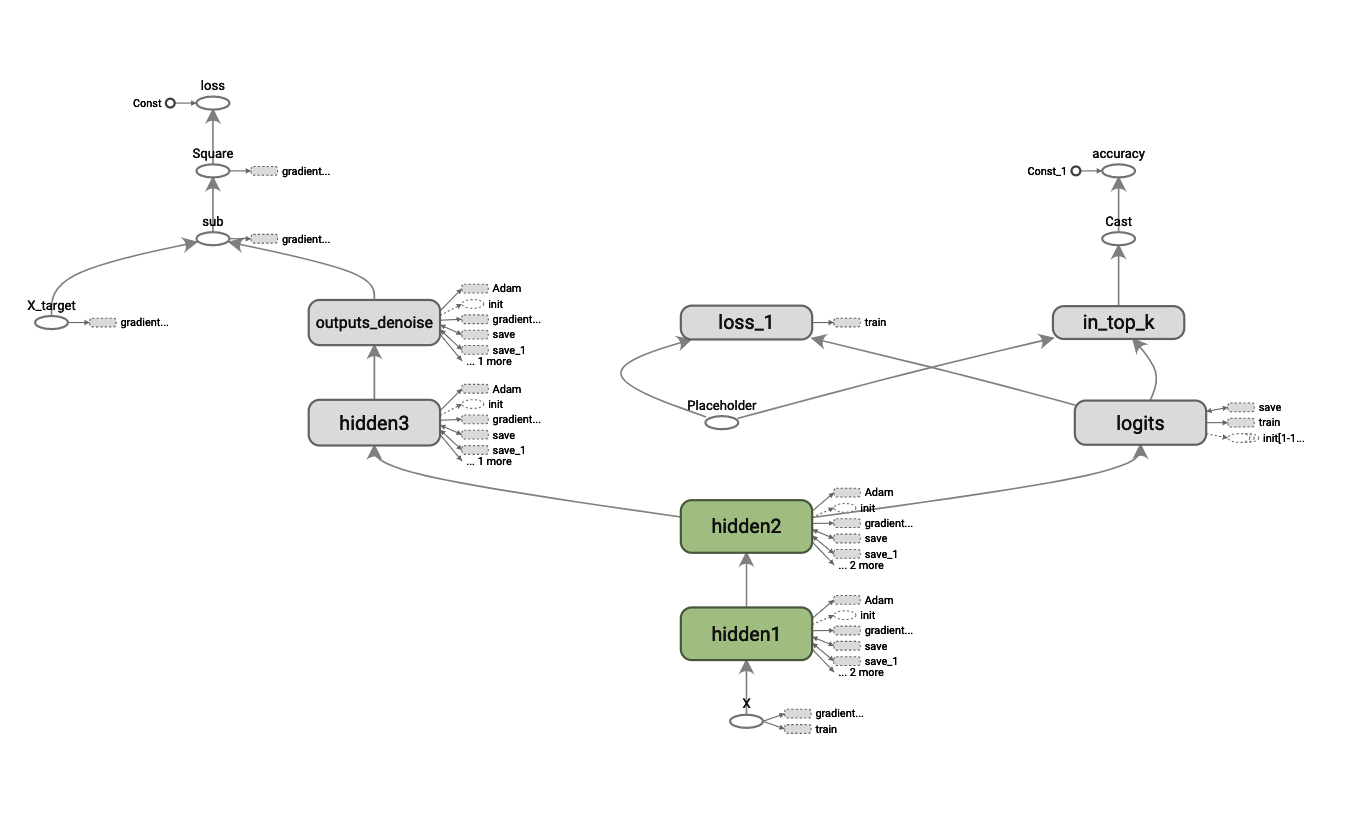
加えて、hidden2まで完全に再利用することになるので、再利用する層は[4]の宣言だけで十分かもしれないです。。。以上の様にして構築したオートエンコーダーを再利用したMNIST画像識別モデルのネットワーク構成は以下に示します。オートエンコーダーの隠れ層の出力の先にMNIST画像識別用のそうが付加されていることがわかります。
◾️ オートエンコーダーを再利用して構築したMNIST画像識別モデルのネットワーク構成
プレトレーニングを用いたMNIST画像識別モデルの学習
学習データサイズを100-60000で変化させ、MNIST画像識別器を10epochで学習させます。各学習データサイズでの学習終了後にテストデータ(データ数10000)を用いて正解率を算出し配列に格納します。以下がコードです。
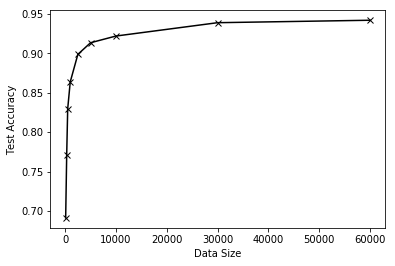
※trainClfの詳細は以下を参照くださいhttps://github.com/Sampeipei/qiita/blob/master/AutoEncoder_Pretraining_for_MNIST.ipynb## テストデータの大きさに対する精度を格納する # 検証用データのインデックス data_size_array = [100, 300, 500, 1000, 2500, 5000, 10000, 30000, 60000] # 結果格納用配列 acc_list = [] for data_size in data_size_array: print("Data size: {}".format(data_size)) X_train_extracted, y_train_extracted = X_train[:data_size], y_train[:data_size] # 学習を実行しテストデータの精度を返す # trainClfの詳細はgithubを参照ください acc_val_test = trainClf(X_train_extracted, y_train_extracted, X_test, y_test, training_op_clf, restore_ckpt_path=ckpt_path, epoch=10) acc_list.append(acc_val_test)学習データ数に対するMNIST画像データのテストデータ識別精度を以下に示します。
データサイズが100でも69%のテストデータ正解率が出ています。また、データサイズが5000でテストデータ正解率が90%を超え、全て(データ数60000)を利用すると正解率が最大の94%でした。次の章ではプレトレーニングの効果を検証するためにプレトレーニングを用いない場合の結果を比較します。
プレトレーニングの効果検証
プレトレーニングの効果を示すためプレトレーニング無しのモデルと、4章で作成したプレトレーニング有りのモデルの正解率を比較します。
プレトレーニングを用いないMNIST画像識別モデルの構築
プレトレーニングを行わない通常のMNIST画像識別器を生成します。モデルの構成は今までと同じです。以下がコードです。
tf.reset_default_graph() ## ハイパーパラメータ n_inputs = 28 * 28 n_hidden1 = 50 n_hidden2 = 20 n_outputs = 10 learning_rate = 0.001 ## モデル構築 # 入力 X = tf.placeholder(tf.float32, shape=[None, n_inputs]) y = tf.placeholder(tf.int32, shape=[None]) # ネットワークの構築 hidden1 = tf.layers.dense(X, n_hidden1, activation=tf.nn.elu, name='hidden1_no_pretrain') hidden2 = tf.layers.dense(hidden1, n_hidden2, activation=tf.nn.elu, name='hidden2_no_pretrain') logits = tf.layers.dense(hidden2, n_outputs, activation=None, name='logits_no_pretrain') ## 学習の設定 # 損失関数 xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits, labels=y) loss = tf.reduce_mean(xentropy, name='loss_no_pretrain') # オプティマイザ optimizer = tf.train.AdadeltaOptimizer(learning_rate, name='Adam_no_pretrain') training_op_no_pretrain = optimizer.minimize(loss) # 精度評価 correct = tf.nn.in_top_k(logits, y, 1) accuracy = tf.reduce_mean(tf.cast(correct, tf.float32), name='accuracy') # 初期化と保存 saver_no_pretrain = tf.train.Saver()プレトレーニングの効果を評価
プレトレーニングありの場合と同様に、学習データサイズを100-60000で変化させてMNIST画像識別器を10epochで学習させます。
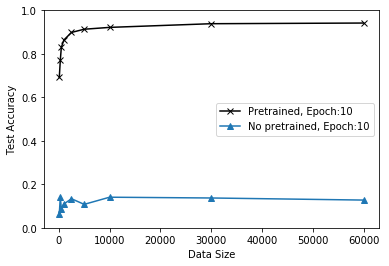
## テストデータの大きさに対する精度を格納する # 検証用データのインデックス data_size_array = [100, 300, 500, 1000, 2500, 5000, 10000, 30000, 60000] # 結果格納用配列 acc_list_no_pretrain = [] for data_size in data_size_array: print("Data size: {}".format(data_size)) X_train_extracted, y_train_extracted = X_train[:data_size], y_train[:data_size] acc_val_test = trainClf(X_train_extracted, y_train_extracted, X_test, y_test, training_op_no_pretrain, epoch=10) acc_list_no_pretrain.append(acc_val_test)以下にプレトレーニング有無による正解率の違いを示します。黒線がプレトレーニングあ、青線がプレトレーニングなしの結果です。プレトレーニングなしの場合は60000全てのデータを用いても、10epochでは正解率が13%程度しか得られないということがわかりました。ノイズ除去オートエンコーダーによるプレトレーニングはとても効果がありそうです!!!
プレトレーニングのメリット・デメリット
個人的に思う、プレトレーニングのメリット・デメリットは以下です
メリット
- Pretrainingを行うことで100のデータでも70%近い正解率を出すことができた(Pretrainingなしだと正解率10%程度とほぼ当てずっぽの様子)
- Epoch数が10でもMnistデータ5000個で90%以上の正解率を出せた
- 少ないラベル付きデータにおいても高い精度のモデルを作成可能デメリット
-プレトレーニングの時点で60000のデータセットを使用しているため、何も学習していないモデルと比較するのは不公平かも。。。まとめ
大量データはあるがラベル付けがされていないという状況において効率的な学習を行う方法を検証しました。本記事では、オートエンコーダーによるプレトレーニング(事前学習)を用いることで、少ないラベルデータでも正解率が90%を超えるMNIST画像識別精度構築したのでご紹介させていただきました。また、TensorFlowで作成したモデルの下位層だけ再利用する方法で苦しんだので、私の方法を参考にしていただければ幸いです!
プレトレーニングを用いたMNIST画像識別器において、1000個のラベル付きデータを10epoch学習させるだけで、テストデータにおける正解率が90%を超えました。プレトレーニングにはMNISTデータのノイズ除去を行うオートエンコーダーを作成しました。オートエンコーダーの下位層だけを再利用し、MNIST画像識別モデルを構築しました。MNIST画像識別モデルの訓練データ(ラベル付き)の数を100-60000まで変化させ、正解率のデータ数依存性を確認しました。プレトレーニングを用いることで、100個の訓練データで約70%、5000個のデータで90%を超えるテストデータ正解率を出すことができました。参考資料
◾️ scikit-learnとTensorFlowによる実践機械学習
https://www.oreilly.co.jp/books/9784873118345/
◾️本記事のコードは以下を参照ください
https://github.com/Sampeipei/qiita/blob/master/AutoEncoder_Pretraining_for_MNIST.ipynb






- 投稿日:2020-02-10T00:36:23+09:00
【RasPi4入門】環境構築;OpenCV/Tensorflow、日本語入力♪
RasPi4 遂に入手したので久しぶりの環境構築しました。
ほぼ、Jetson_nanoと同じ方法でできました。
本稿は前回のつづきで、アプリが動くところまで解説します。
【参考】
0.【Jetson_nano】インストールからTensorflow,Chainer,そしてKeras環境構築出来たよ♬
1.Raspberry Pi 4のディープラーニングで画像認識する環境をゼロから1時間で構築する方法
2.Raspberry Pi で OpenCV 4
3.RaspberryPiのキーボード入力の日本語化やったこと
・環境構築;OpenCV/Tensorflowまで
・OpenCV/Tensorflow動作検証
・環境構築;日本語入力まで
・これ書いてます・環境構築;OpenCV/Tensorflowまで
ここはからあげさんの環境構築手順(参考1)のとおり、実施しました。
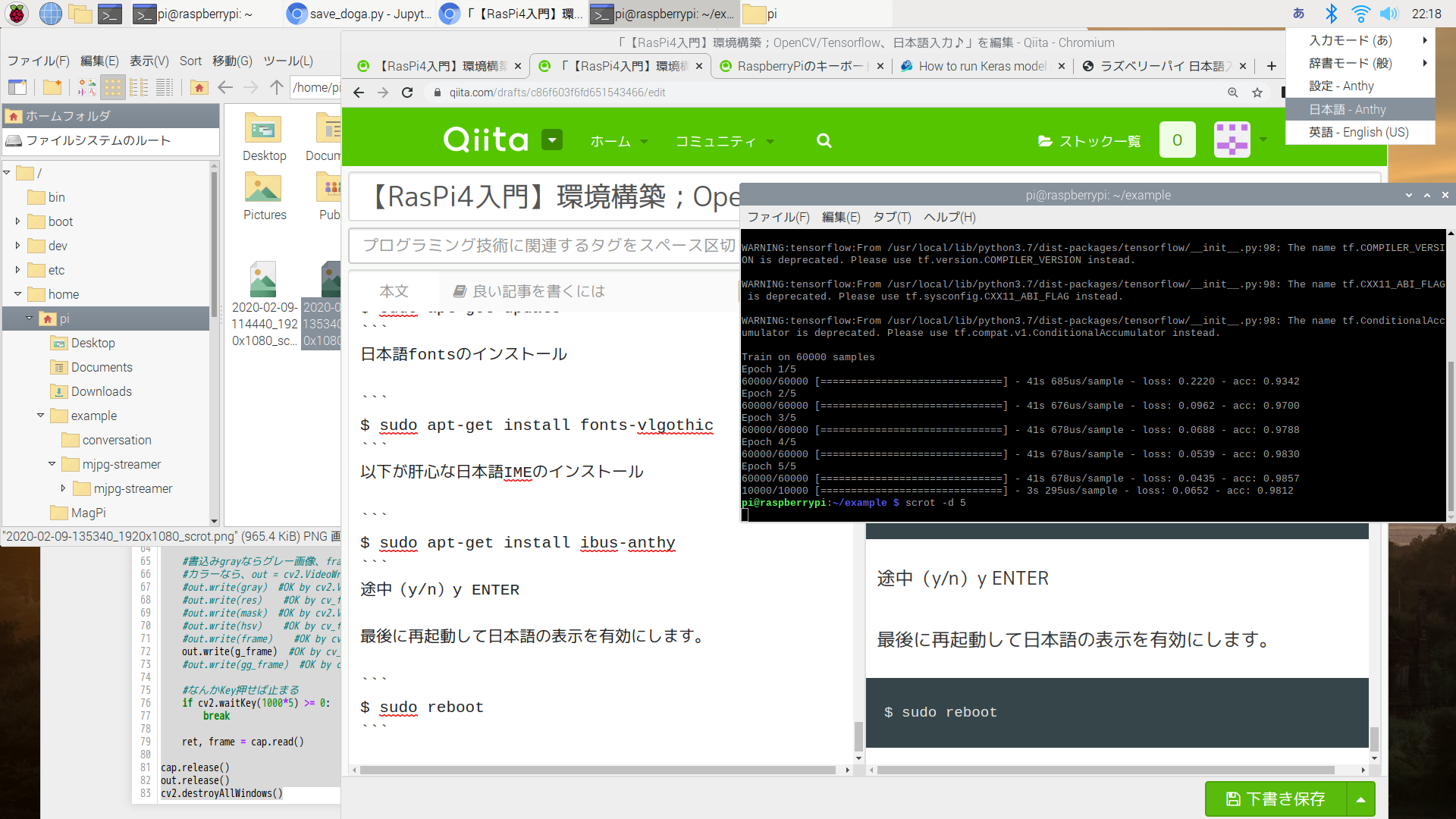
からあげさんの環境構築手順.$ git clone https://github.com/karaage0703/raspberry-pi-setup $ cd raspberry-pi-setup $ ./setup-opencv-raspbian-buster.sh $ ./setup-tensorflow-raspbian-buster.shこれでOpenCVやTensorflowが簡単にインストールできました.
あと、追加で開発用に以下をインストールしました。jupyter-notebook.$ sudo apt install jupyter-notebookまた、今回はからあげさんのスクリプトで一括インストールしましたが、最新との差分がある可能性が高いので参考2から以下のものを順次インストールしています。
OS環境を最新.$ sudo apt-get update $ sudo apt-get upgradeCMake環境.$ sudo apt-get install build-essential cmake unzip pkg-configイメージファイル用ライブラリ.$ sudo apt-get install libjpeg-dev libpng-dev libtiff-devビデオストリーム用ライブラリ.$ sudo apt-get install libavcodec-dev libavformat-dev libswscale-dev libv4l-dev $ sudo apt-get install libxvidcore-dev libx264-dev画像表示用ライブラリ.$ sudo apt-get install libgtk-3-dev $ sudo apt-get install libcanberra-gtk*演算用ライブラリ.$ sudo apt-get install libatlas-base-dev gfortran・OpenCV/Tensorflow動作検証
動作検証は以下のコードを使いました。
kerasはinstallしていませんが、上記の参考0でもやったように、以下のとおり、tf.keras....というので、kerasのLibを利用できます。import tensorflow as tf mnist = tf.keras.datasets.mnist (x_train, y_train),(x_test, y_test) = mnist.load_data() x_train, x_test = x_train / 255.0, x_test / 255.0 model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(input_shape=(28, 28)), tf.keras.layers.Dense(512, activation=tf.nn.relu), tf.keras.layers.Dropout(0.2), tf.keras.layers.Dense(10, activation=tf.nn.softmax) ]) model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) model.fit(x_train, y_train, epochs=5) model.evaluate(x_test, y_test)結果は以下のとおり、
$ python3 tensorflow_ex.py Train on 60000 samples Epoch 1/5 60000/60000 [==============================] - 41s 685us/sample - loss: 0.2220 - acc: 0.9342 Epoch 2/5 60000/60000 [==============================] - 41s 676us/sample - loss: 0.0962 - acc: 0.9700 Epoch 3/5 60000/60000 [==============================] - 41s 678us/sample - loss: 0.0688 - acc: 0.9788 Epoch 4/5 60000/60000 [==============================] - 41s 678us/sample - loss: 0.0539 - acc: 0.9830 Epoch 5/5 60000/60000 [==============================] - 41s 678us/sample - loss: 0.0435 - acc: 0.9857 10000/10000 [==============================] - 3s 295us/sample - loss: 0.0652 - acc: 0.9812・OpenCV動作検証
こちらは、以下の参考で動かした以下のコードを動かしてみます。
流石に動作はのろいですが、カメラ撮影画像を動画として保存できました。
【参考】
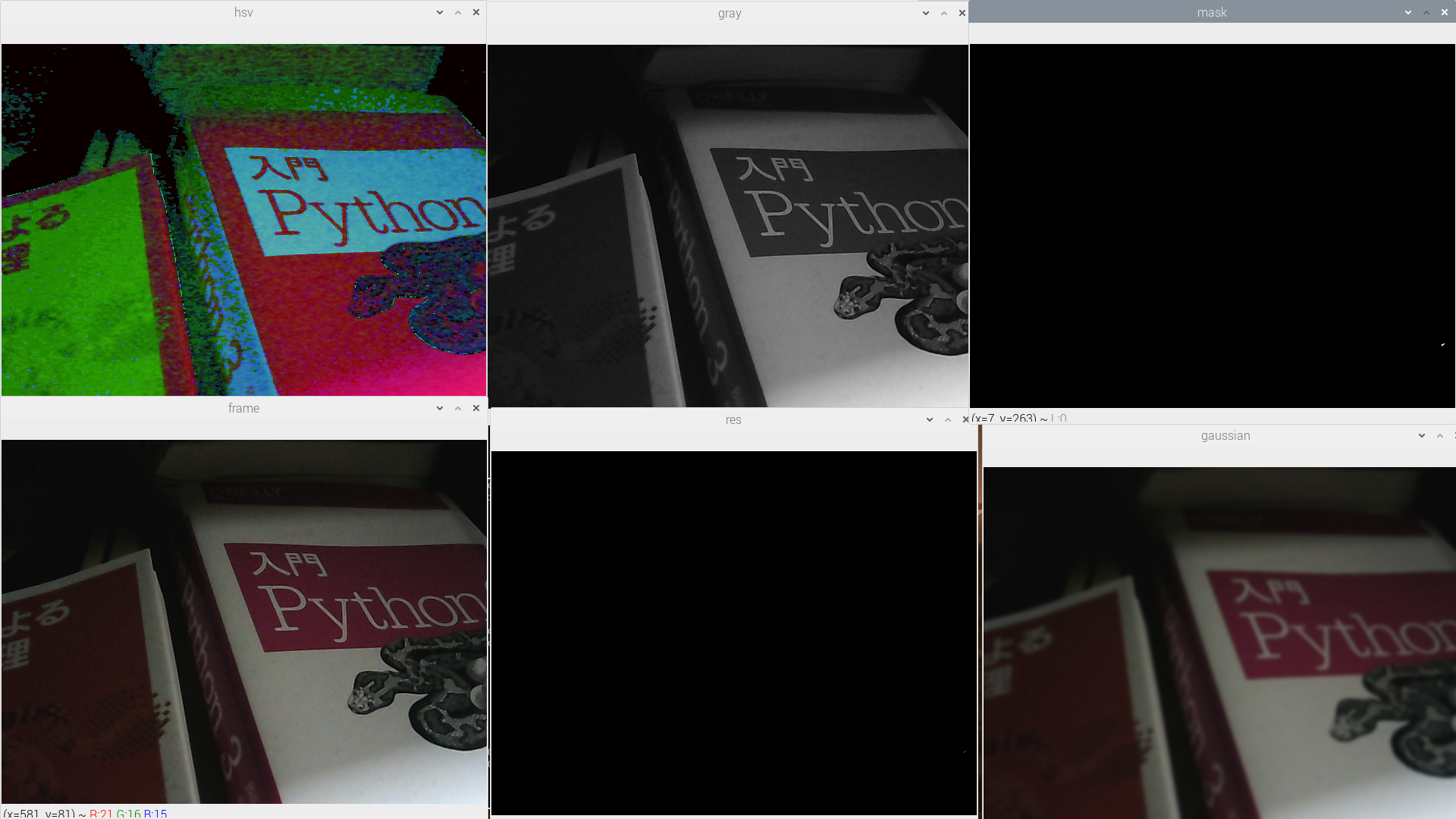
・RasPi:OpenCVで遊んでみた♬import numpy as np import cv2 # cv2.cv.CV_FOURCC def cv_fourcc(c1, c2, c3, c4): return (ord(c1) & 255) + ((ord(c2) & 255) << 8) + \ ((ord(c3) & 255) << 16) + ((ord(c4) & 255) << 24) cap = cv2.VideoCapture(0) #'dougasozai_car.mp4') GRAY_FILE_NAME='douga_camera_5s.avi' FRAME_RATE=30 ret, frame = cap.read() # Define the codec and create VideoWriter object height, width, channels = frame.shape out = cv2.VideoWriter(GRAY_FILE_NAME, \ cv_fourcc('X', 'V', 'I', 'D'), \ FRAME_RATE, \ (width, height), \ True) #isColor=True for color # ウィンドウの準備 cv2.namedWindow('frame') cv2.namedWindow('gray') cv2.namedWindow('hsv') cv2.namedWindow('mask') cv2.namedWindow('res') cv2.namedWindow('gaussian') while ret == True: #ret, frame = cap.read() gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) hsv =cv2.cvtColor(frame, cv2.COLOR_BGR2HSV) hsv =cv2.cvtColor(frame, cv2.COLOR_BGR2HSV) # ガウシアン平滑化 # (5, 5)はx、y方向の標準偏差で変えるとボケ度が変わる、最後の引数はint,ボーダータイプらしいが数字の意味不明 g_frame = cv2.GaussianBlur(frame, (15, 15), 0) gg_frame = cv2.cvtColor(g_frame, cv2.COLOR_BGR2GRAY) # define range of blue color in HSV lower_blue = np.array([110,50,50]) upper_blue = np.array([130,255,255]) # Threshold the HSV image to get only blue colors mask = cv2.inRange(hsv, lower_blue, upper_blue) # Bitwise-AND: mask and original image res = cv2.bitwise_and(frame,frame, mask= mask) cv2.imshow('frame',frame) cv2.imshow('gray',gray) cv2.imshow('hsv',hsv) cv2.imshow('mask',mask) cv2.imshow('res',res) cv2.imshow('gaussian',g_frame) #書込みgrayならグレー画像、frameなら拡張子変更 #カラーなら、out = cv2.VideoWriter()でisColor=True、グレーならFalse out.write(g_frame) #OK by cv_fourcc('X', 'V', 'I', 'D') #なんかKey押せば止まる if cv2.waitKey(1000*5) >= 0: break ret, frame = cap.read() cap.release() out.release() cv2.destroyAllWindows()実行例は以下のとおり(静止画ですが)
少なくともこれが動いたので、OpenCVは利用できます.・環境構築;日本語入力
ここで物体検出をためすのもいいのですが、今回は会話アプリを載せたいので、日本語入力ができるようにしたいと思います。
まず、昨夜の日本語化は完了しているものとして、参考3にしたがいます。
「RaspberryPiはデフォルトではキーボードがUS配列になっているのでJIS配列にしていきます。」
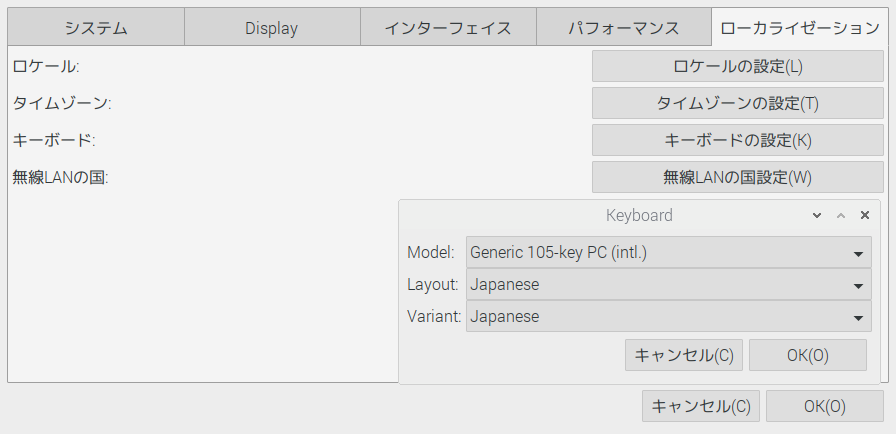
どっちかというと、JIS配列になっている気がしたけど、。。。$ sudo raspi-config1.4 Internationalisation Optionsを選択(移動はキーボードの↑↓)
を選択して、ENTERキー押下
2.I3 Change Keyboard Layoutを選択し、[Enter]
3.Generic 105-key(Intl) PCを選択し[Enter]
4.Otherを選択し[Enter]
5.Japaneseを選択し[Enter]
6.Japanese - Japanese(OADG 109A)を選択し[Enter]
7.The default for the keyboard layoutを選択し[Enter]
8.No compose keyを選択し[Enter]
最初の画面に戻ってくると思うのでを選択し終了[Enter]で終了(キーボードの←→でカーソル移動可能)
ここで一度最新化$ sudo apt-get updateまたコマンドが打てるようになったらキーボードの日本語入力をインストールします。
$ sudo apt-get install -y uim uim-anthy再起動すると配列などが反映します。
$ sudo reboot再起動したらキーボードがJIS配列で打てるようになっているはずです→キー配列がUS配列じゃないかな?
日本語フォントとIMEのインストール
もう一つ、日本語フォントとIMEを以下の参考の手順で入れます。
【参考】
ラズベリーパイ 日本語入力の設定
そもそも表示等は日本語になっているので、この作業はIMEだけ入れればいいかもですが、一応丸っと入れました。$ sudo apt-get update日本語fontsのインストール
$ sudo apt-get install fonts-vlgothic以下が肝心な日本語IMEのインストール
上記と異なるIMEです。$ sudo apt-get install ibus-anthy途中(y/n)y ENTER
最後に再起動して日本語の表示を有効にします。
$ sudo reboot以下のようなイメージです。この上段のバーの右端に英語-日本語などが選べるようになっていると思います.
とりあえず、これで日本語入力ができるようになりました。
ただし、このままだと切り替えは一々上段で選ぶ必要があります。
右端部分の拡大図(Pintaでできた)
切り替え一発キー
Jetson-nanoの時の切り替え一発キーが以下の手順で見つかりました。
すなわち、以下のように選ぶと、半角/全角キーで自動的に英文字とあを切り替えることができました.
また、入力も日本語キーボード配列に戻りました。
あれ、。。。キー入力の設定と上記のIMEはいらないかもですね
まとめ
・OpenCV/Tensorflowを無事にインストールできた
・日本語入力(105キー配列)ができるようになった・会話アプリをインストールしよう
・音声入力作って音声会話完成させたい
・監視カメラ作るかな。。。「そこの人、マスクつけなさい」