- 投稿日:2020-02-10T23:47:25+09:00
UMAP 0.4の新機能で遊ぶ(プロット、非ユークリッド空間への埋め込み、逆変換)
UMAPがバージョンアップしてv0.4が公開された。
2020/02/10現在では、
pip install --pre umap-learnでバージョンを上げることができる。疎行列をそのまま入力できたりいろんな機能が追加されているらしいけど、ここではプロット機能、非ユークリッド空間への埋め込み、逆変換を試してみる。
データだけ変えてほぼドキュメントに書いてあるコード例そのままやってるだけなので、それぞれについて詳しくはUMAPドキュメントへ。
データ
PARCのレポジトリに置いてあったscRNA-seqのデータセットとアノテーション(Zheng et al., 2017, 10X PBMC)を使って実験する。68,579細胞、事前にPCAで50次元に圧縮済み。気軽にやるにはちょっと大きすぎるデータなので適当に1万細胞くらいに落として使う。
import numpy as np import pandas as pd import umapデータ読み込み。1万細胞、50主成分。
dat = np.loadtxt('./data/pca50_pbmc10k.txt', delimiter=',') dat.shape(10000, 50)アノテーションは以下のような感じ。
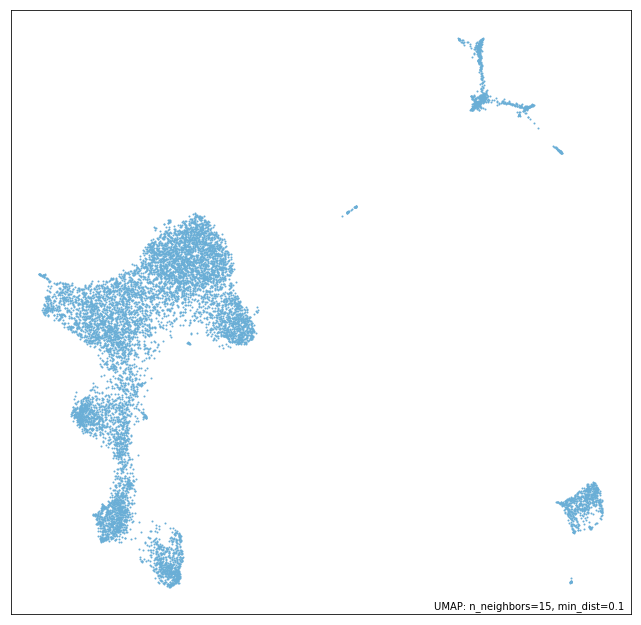
labels = [] for line in open('./data/zheng17_annotations_10k.txt'): labels.append(line.rstrip()) import collections import pprint pprint.PrettyPrinter(indent=4).pprint(collections.Counter(labels))Counter({ 'CD4+/CD45RA+/CD25- Naive T': 1853, 'CD8+ Cytotoxic T': 1694, 'CD8+/CD45RA+ Naive Cytotoxic': 1599, 'CD4+/CD45RO+ Memory': 1425, 'CD56+ NK': 1211, 'CD4+/CD25 T Reg': 828, 'CD14+ Monocyte': 595, 'CD19+ B': 583, 'Dendritic': 127, 'CD4+ T Helper2': 55, 'CD34+': 30})とりあえずは普通にUMAPしておく。
model = umap.UMAP(verbose=True) model.fit(dat)プロット機能
umap.plotで新たに、umap単体でプロットができるようになった。
matplotlibで描くのとほとんど変わらないけど、手軽ではある。
umap.plotを使う場合はumapと別にdatashader, bokeh, holoviewsが必要なので注意。それぞれインストールしておく。
import umap.plot学習させたモデルのインスタンスを与えると、scatter plotを描いてくれる。
umap.plot.points(model)
また、
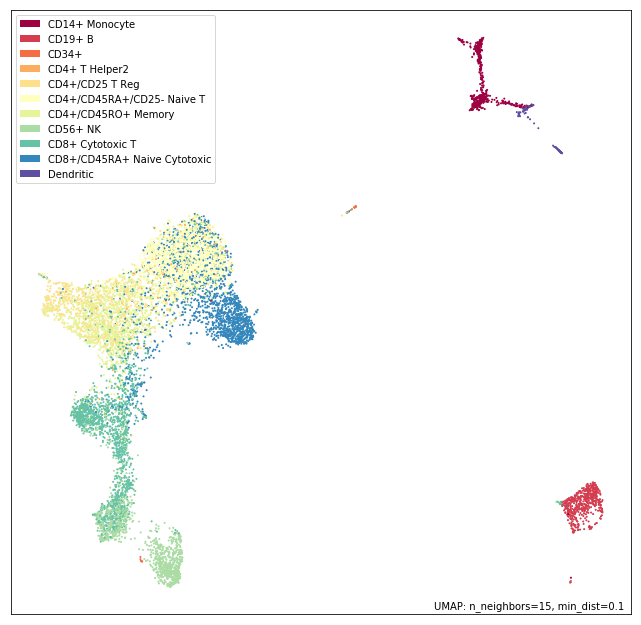
labelsのパラメータにそれぞれの点のラベルデータを与えると色分けして描いてくれる。umap.plot.points(model, labels=labels)
与えるデータは連続値でもOK。ここでは適当なデータがないので、元データの平均値を与える。
背景やカラーマップなどの組み合わせを用意してくれてるので、
themeパラメータで好きなものを選んで使える。選べるthemeは次の9種類。
umap.plot._themes.keys()dict_keys(['fire', 'viridis', 'inferno', 'blue', 'red', 'green', 'darkblue', 'darkred', 'darkgreen'])umap.plot.points(model, values=dat.mean(axis=1), theme='viridis')
また、Bokehを使ってインタラクティブなプロットを描くことも可能。
umap.plot.output_notebook()マウスオーバーしたときに表示する情報は事前に
pandas.dataframeのかたちで用意しておく。df_labels = pd.DataFrame(labels, columns=['celltype']) p = umap.plot.interactive(model, labels=labels, hover_data=df_labels, point_size=2) umap.plot.show(p)
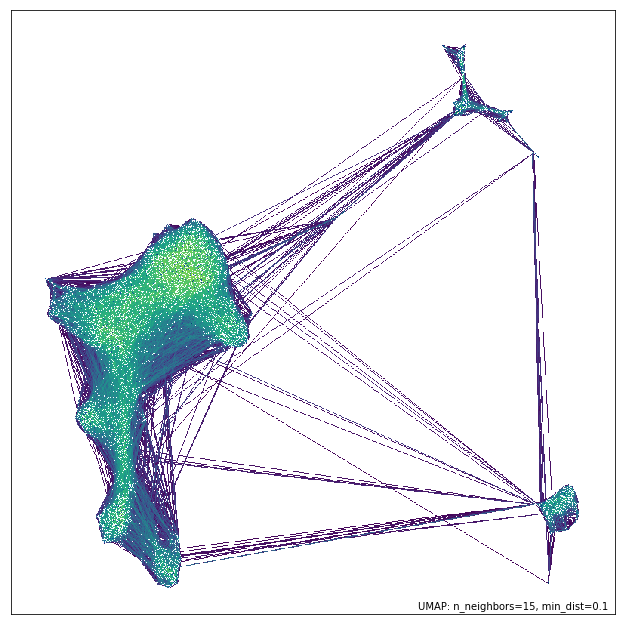
さらに、UMAP埋め込みのときに使われたneighborhood graphを可視化してくれる機能もある。エッジの重みもグラデーションで表示してくれる。どういったconnectivityが学習されたのかを検証するときに使えるかもしれない。
umap.plot.connectivity(model, show_points=True, edge_cmap='viridis')
他にも、様々な指標で埋め込みを診断するためのdiagnostic plot機能があるらしい。
非ユークリッド空間への埋め込み
デフォルトではUMAPはユークリッド空間に埋め込む(低次元空間のユークリッド距離をターゲットに最適化する)が、球面など他のタイプの空間に埋め込むことも可能らしい。
これは、
output_metricパラメータで低次元側の距離計算手法を指定することで可能。まず、球面に埋め込んでみる。球面埋め込みの場合は、Haversine式を指定する。
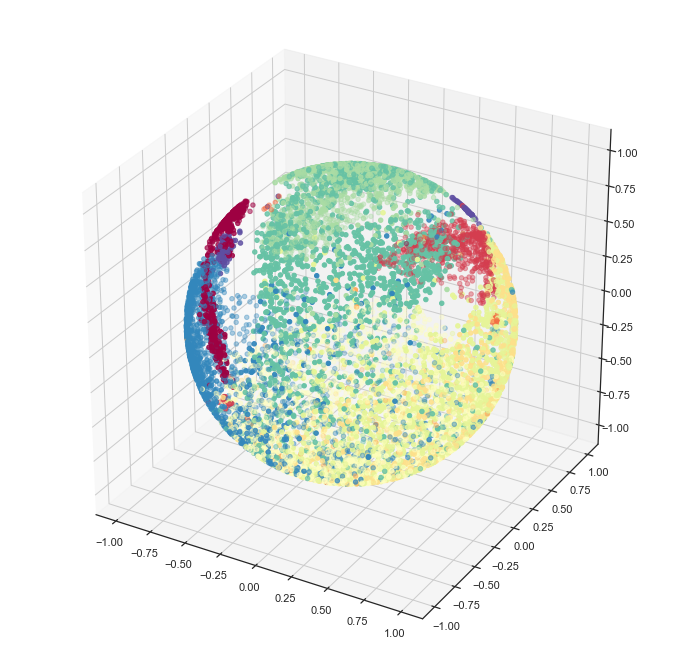
sphere_mapper = umap.UMAP(output_metric='haversine') sphere_mapper.fit(dat)結果の座標は球面座標系で出てくるので、そのまま描いてもよくわからない。なので教科書通りに直交座標系に変換してからプロットしてみる。
x = np.sin(sphere_mapper.embedding_[:, 0]) * np.cos(sphere_mapper.embedding_[:, 1]) y = np.sin(sphere_mapper.embedding_[:, 0]) * np.sin(sphere_mapper.embedding_[:, 1]) z = np.cos(sphere_mapper.embedding_[:, 0])このプロットは勝手にやってくれないみたいなので、自分でmatplotlibで描画。
import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D import seaborn as sns sns.set(style='white') categories = sorted(list(set(labels))) label_ids = [categories.index(l) for l in labels] fig = plt.figure(figsize=(12, 12)) ax = fig.add_subplot(111, projection='3d') ax.scatter(x, y, z, c=label_ids, cmap='Spectral')
セルタイプごとにわりときれいに、球面上にまとまってくれた。
3次元でちょっとわかりづらいので、このまま2次元に展開してみる。
x = np.arctan2(x, y) y = np.arccos(z) fig = plt.figure(figsize=(12, 12)) plt.scatter(x, y, c=label_ids, cmap='Spectral')
左右は本来つながってる。
どういったときに使えばいいのかよくわからないけど、データが本質的に周期的な性質を持つときなどに有効?
また、双曲空間への埋め込みも紹介されている。これについてはほんとによくわからないのでドキュメントの流れそのままやってみる。ポアンカレ円板モデルそのものは最適化が難しいらしいので、Hyperboloid modelをターゲットに学習しているらしい。
hyperbolic_mapper = umap.UMAP(output_metric='hyperboloid') hyperbolic_mapper.fit(dat) x = hyperbolic_mapper.embedding_[:, 0] y = hyperbolic_mapper.embedding_[:, 1] z = np.sqrt(1 + np.sum(hyperbolic_mapper.embedding_**2, axis=1)) disk_x = x / (1 + z) disk_y = y / (1 + z) fig = plt.figure(figsize=(12,12)) ax = fig.add_subplot(111) ax.scatter(disk_x, disk_y, c=label_ids, cmap='Spectral') boundary = plt.Circle((0,0), 1, fc='none', ec='k') ax.add_artist(boundary) ax.axis('off');
逆変換
埋め込みが学習された低次元側の座標から、対応する高次元サンプルを生成する手法。
VAEみたいな生成モデルと同じように使うのは難しいかもしれないけど、埋め込まれた低次元がどんな空間なのかざっと確認するのには便利かも。
高次元サンプル生成についてはシングルセルのデータはあんまりおもしろくないので、ここではKuzushiji-MNISTのデータ(を適当に1万個ランダムに選んだもの)でやってみる。
dat = np.load('./data/kmnist-train-imgs_10k.npy') dat.shape(10000, 784)labels = np.load('./data/kmnist-train-labels_10k.npy') labelsarray([4, 5, 0, ..., 6, 9, 0], dtype=uint8)まずは普通にUMAPを計算してみる。
model = umap.UMAP(n_epochs=500, verbose=True).fit(dat) umap.plot.points(model, labels=labels)
この空間から、補間しておもしろそうな領域について逆変換してみたいので、
クラスタ8の左上、クラスタ9の左下、クラスタ0の右上、クラスタ3の右下あたりの点を選んで、テスト用の点を100個作ってみる。
x = model.embedding_ top_left = x[labels == 8, :][x[labels == 8, 0].argmin()] btm_left = x[labels == 9, :][x[labels == 9, 1].argmin()] top_right = x[labels == 0, :][x[labels == 0, 0].argmax()] btm_right = x[labels == 3, :][x[labels == 3, 1].argmin()] test_pts = np.array([ (top_left*(1-x) + top_right*x)*(1-y) + (btm_left*(1-x) + btm_right*x)*y for y in np.linspace(0, 1, 10) for x in np.linspace(0, 1, 10) ]) print(top_left) print(btm_left) print(top_right) print(btm_right)[-3.0056033 9.982167 ] [2.0912035 2.2021403] [14.147088 10.8581085] [10.669375 2.6710818]逆変換を実行する。
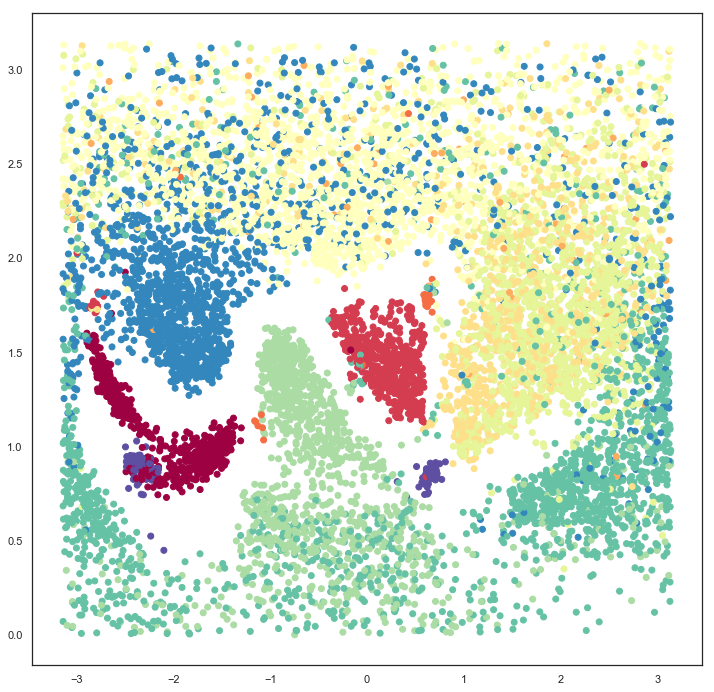
inverse_transform関数に調べたい点の座標を与える。inv_transformed_points = model.inverse_transform(test_pts) from matplotlib.gridspec import GridSpec fig = plt.figure(figsize=(12,6)) gs = GridSpec(10, 20, fig) scatter_ax = fig.add_subplot(gs[:, :10]) kuzushiji_axes = np.zeros((10, 10), dtype=object) for i in range(10): for j in range(10): kuzushiji_axes[i, j] = fig.add_subplot(gs[i, 10 + j]) scatter_ax.scatter(model.embedding_[:, 0], model.embedding_[:, 1], c=labels.astype(np.int32), cmap='Spectral', s=0.1) scatter_ax.set(xticks=[], yticks=[]) scatter_ax.scatter(test_pts[:, 0], test_pts[:, 1], marker='x', c='k', s=15) for i in range(10): for j in range(10): kuzushiji_axes[i, j].imshow(inv_transformed_points[i*10 + j].reshape(28, 28), cmap='viridis') kuzushiji_axes[i, j].set(xticks=[], yticks=[])
ちょっと粗いが、軸に沿ってどのように遷移するのか、また、クラスタどうしがなぜ近い距離に配置されているのかがなんとなく類推できる。




- 投稿日:2020-02-10T23:25:16+09:00
ポケモンGOのポケモンのデータや技データを取り出す
私事で恐縮なのですが、昨年の1月頃よりポケモンGoを再開いたしました。そこから1年間続けているのですがポケモンGo側にも大きな機能追加がありました。それは待望のオンラインでの対戦です。興味が無かったのですが、やってみると思いの外楽しく自分でもシミュレーションや効率的な戦いを考えてみたくなります。
それならそのポケモンデータや技データはどうやって集める?という話です。概要
- ポケモンGoのGAME_MASTER.jsonファイルの公開元を発見
- そのファイルから必要なデータをPythonにて抽出
- 生データであり追加の加工が必要
1.データ収集方法の検討
最初に思いついたのはこの方法でした。海外サイトや国内サイト含め、ポケモンGoにおけるステータスや技データなど全て公開されています。ただし、二次利用を想定しているものではないためウェブ上からスクレイピング等で取り出す方法が必要となります。
- 案1. Webサイト上からの収集
- 攻略サイト等で公開されているページからスクレイピングする方法です。
- 案2. ゲーム内のデータから抽出
- "解析"という言葉で説明されているアレです。その展開済みデータが入手できれば活用出来るのではないかと思った次第です。
2.「ゲーム内のデータから抽出」を採用
Google検索等の検索力を発揮したところ展開済みデータを公開しているレポジトリ【pokemongo-dev-contrib/pokemongo-game-master】に遭遇しました。そこで一件落着、と思ったのですがデータに余計なモノが多すぎるということでした。ポケモン、技のデータ意外にもプレイヤーの衣装や各種設定値なども含んでいます。
3.ゲーム内のデータから必要な部分を探す
さてこのファイルですがGAME_MASTER.jsonという名称で前述の通りコスチュームデータからPvP対戦の設定値、ポケモンのデータ、技のエネルギー等等といったポケモンGOの設定データの多くが含まれています。そのせいで3.4MBと大きなサイズでありムダもあります。
まずはそこから必要データを抽出していきます。色々なデータがあるのせまずは眺めてポケモンのデータ部分を見つけます。
GAME_MASTER.jsonからポケモンデータの一部抜粋・整形{ "itemTemplates": [{ "templateId": "V0001_POKEMON_BULBASAUR", "pokemonSettings": { "pokemonId": "BULBASAUR", "type": "POKEMON_TYPE_GRASS", "type2": "POKEMON_TYPE_POISON", "stats": { "baseStamina": 128, "baseAttack": 118, "baseDefense": 111 }, "quickMoves": ["VINE_WHIP_FAST", "TACKLE_FAST"], "cinematicMoves": ["SLUDGE_BOMB", "SEED_BOMB", "POWER_WHIP"], }, }],ありましたね。なお、図中では今回重要と考えたデータ部分のみを抜粋しましたが、他にも様々なデータが含まれています。
ワザワザまとめるほどではないですがkey名やデータから推測し以下のようになると推測出来ます。
Key データ内容 templateId ポケモンデータの識別子 pokemonId ポケモンの名前 stats 種族値 type タイプ quickMoves 技1 cinematicMoves 技2 なお、このデータには期間限定の技などは含んでいないようです。
4.プログラムでのデータ抽出
ここまでくれば私よりも皆さんの方が100倍詳しいと思いますが、一応私のプログラムも載せておきます。csv形式にて使えるように各データはカンマにて区切りました。なお技データをそのまま使うと入れ子となるのが嫌だったので、::を区切り文字として無理やりくっつけています。
GAME_MASTER_pokemon_parser.py# -*- coding: utf-8 -*- import json import re # ポケモンのデータにマッチする正規表現用パターンを用意 pattern = '^V0\d+_POKEMON_.+' f = open('GAME_MASTER.json', 'r') json_dict = json.load(f) # 最上位のキーとして"itemTemplates"があるのでまずは展開する。 for json_list in json_dict["itemTemplates"]: templateIdData = json_list["templateId"] result = re.match(pattern, templateIdData) # ポケモンのデータにマッチした場合に必要なデータを抽出する if (result): # 技データを持たないポケモンがいるのでget形式で辞書データにアクセス # (ドーブルが技持って無かった) quickMoves = json_list["pokemonSettings"].get("quickMoves") quickMovesStr = "" if quickMoves is not None: for quickMovesStrTemp in quickMoves: quickMovesStr = quickMovesStr + quickMovesStrTemp + "::" cinematicMoves = json_list["pokemonSettings"].get("cinematicMoves") cinematicMovesStr = "" if cinematicMoves is not None: for cinematicMovesStrTemp in cinematicMoves: cinematicMovesStr = cinematicMovesStr + cinematicMovesStrTemp + "::" outPokemon = json_list.get("templateId") + "," + str(json_list["pokemonSettings"].get("type")) + "," + str(json_list["pokemonSettings"].get("type2")) + "," + str(json_list["pokemonSettings"]["stats"]["baseStamina"]) + "," + str(json_list["pokemonSettings"]["stats"]["baseAttack"]) + "," + str(json_list["pokemonSettings"]["stats"]["baseDefense"])+ ',' +quickMovesStr + ',' + cinematicMovesStr print(str(outPokemon))実行すると標準出力に以下の形式にて出力されます。
ポケモンデータの識別子,ポケモンタイプ1,ポケモンタイプ2,種族値スタミナ,種族値攻撃,種族値防御,種族値技1,種族値技2実行結果.csv(一部抜粋)V0808_POKEMON_MELTAN,POKEMON_TYPE_STEEL,None,130,118,99,THUNDER_SHOCK_FAST::,FLASH_CANNON::THUNDERBOLT:: V0809_POKEMON_MELMETAL,POKEMON_TYPE_STEEL,None,264,226,190,THUNDER_SHOCK_FAST::,FLASH_CANNON::THUNDERBOLT::HYPER_BEAM::ROCK_SLIDE::SUPER_POWER::5.残タスク
まずはポケモンのデータを生データとして取り出せました。ただし、このデータには以下のような問題があります。
(1) 日本語非対応
(2) 図鑑番号が無い
(3) アローラ、シャドウ、リライト、ノーマル(?)の整理
(4) 限定技が含まれていない(2)-(4)は機械的にどうにか処理できそうです。(1)については図鑑番号とマッピングデータを用意できればどうにかなるかなぁ。
ただし、技データの場合はどうしよう…。6.あとがき
APIに直接アクセスできた当初はサーチや個体値チェック、GO Plusモドキなどテック記事に溢れてました。ブームの収束と運営会社による対策により一気に下火になりましたが…。継続しプレイや解析を続けていたユーザーにただただ感謝しかありません。
おまけ
PvP時の技データは以下のようです。その中で厄介なのは"durationTurns"です。PvP時の技1の硬直時間[s]を表すのですが、技の硬直時間[s]=1+durationTurnsのようです。そして硬直時間が1[s]の場合にはこのkeyが無い内容でした。
VOLT_SWITCHは硬直4秒、DRAGON_BREATHは硬直1秒"templateId": "COMBAT_V0250_MOVE_VOLT_SWITCH_FAST", "combatMove": { "uniqueId": "VOLT_SWITCH_FAST", "type": "POKEMON_TYPE_ELECTRIC", "power": 12.0, "vfxName": "volt_switch_fast", "durationTurns": 3, "energyDelta": 16 } "templateId": "COMBAT_V0204_MOVE_DRAGON_BREATH_FAST", "combatMove": { "uniqueId": "DRAGON_BREATH_FAST", "type": "POKEMON_TYPE_DRAGON", "power": 4.0, "vfxName": "dragon_breath_fast", "energyDelta": 3 }
- 投稿日:2020-02-10T23:23:58+09:00
Pythonista(iPhone)からプログラミング・フォロを操作する
目的
iPhone上でPythonのプログラムを書いて実行できるPythonista3上でBluetoothを使ったプログラムが作れるのが分かったので、プログラミング・フォロを操作するプログラムを作ってみた。
Pythonista3
iPhone(iOS)上で動作するPythonの統合環境です。
有料で少し高いんですが、iPhoneのカメラや加速度センサーやBluetoothも扱うことも出来るし、NumPyやMatplotlibなどの一般的なライブラリも使えるので、いろいろ遊べる環境です。
なんと言ってもiPhone上で作って実行できるので、ネイティブなプログラム開発に必要なMacがなくてもアプリが作れるのが魅力です。
追加でstashをインストールすると、ssh/scpとかgitも使えます。プログラム
プログラムはgithubに置いてます
Bluetoothの操作にはcbライブラリを利用してます。
UI上でボタンの押しっぱなしに対応するためにsceneライブラリを使用してます。
ただし今回作ったGUIではボタンの状態はOnかOffの2値しか取得出来ず中間の値を取得出来ないので、速度コントロールは出来ません。
また、マルチタッチには対応してません。
micro:bitとの接続が出来てしまえば、あとは「PS3コントローラーでプログラミング・フォロを操作する」とあまり変わらず、micro:bitのI/O端子に信号を送るだけです。実行
実行するとこんな風に動きました。
iPhoneから直接micro:bitを操作できるので、便利で楽しいです。
関連URL

- 投稿日:2020-02-10T23:22:59+09:00
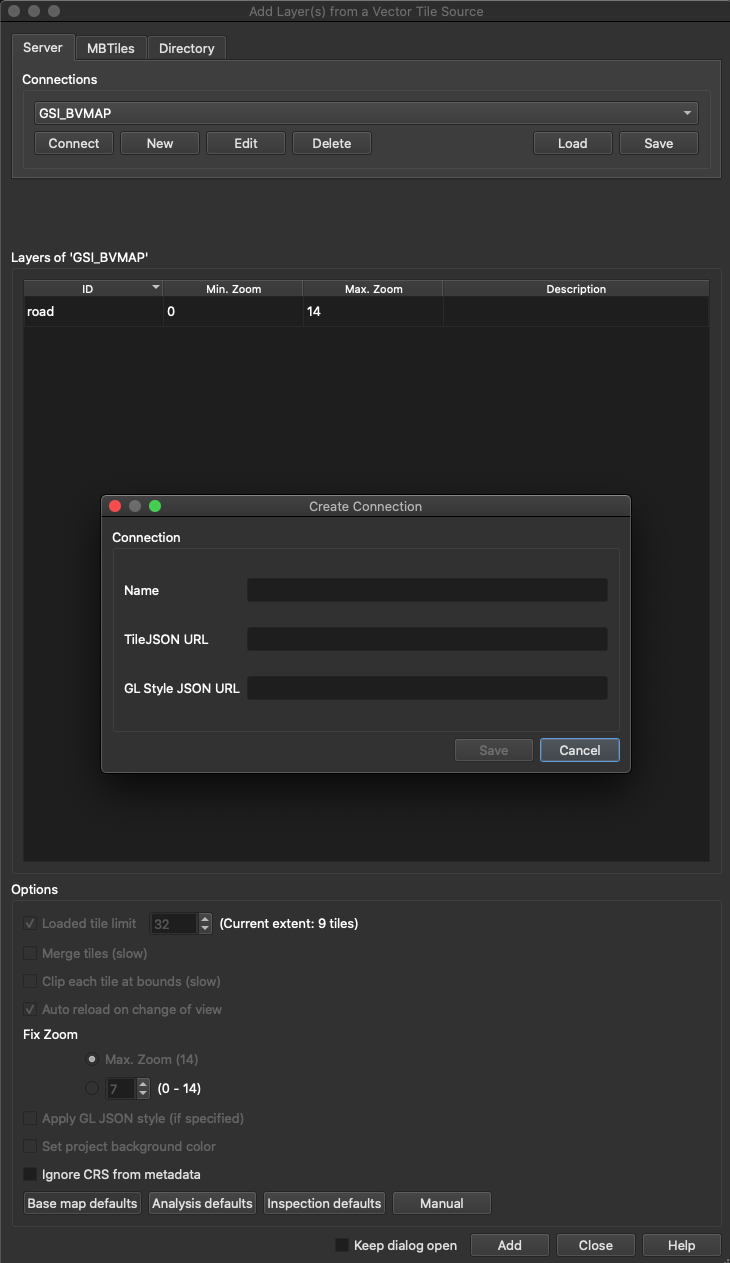
QGISでベクタータイルをレイヤーとして追加する
はじめに
最近、MapTilerの日本向けサービス開始が話題になりましたが、従来のサービスと何が違うかと言えば、ラスタータイルに加え、ベクタータイルが配信された点です。ベクタータイルが何かという説明は省きますが、昨今の地図配信で外せない要素と感じ、色々いじっています。FOSS4Gっ子ならやっぱりQGISでベクタータイル、表示したいですよね?この記事で、表示する方法(プラグイン)を紹介します。
目標
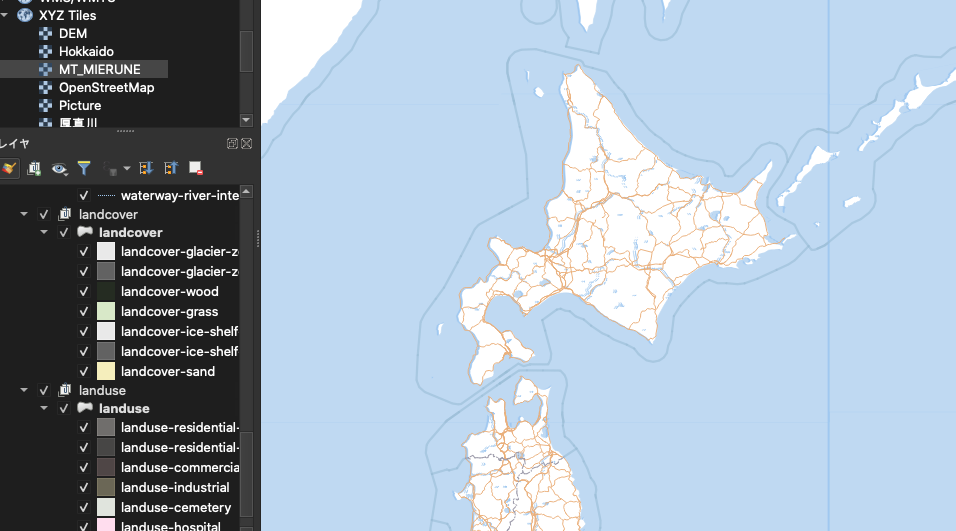
以下のように、ベクタータイルをQGISレイヤーとして読み込む。
こうなれば、欲しいレイヤーを外部ファイルに出力も出来ます、夢が広がりますね!
© MapTiler © OpenStreetMap contributorsVector Tiles Reader
https://github.com/geometalab/Vector-Tiles-Reader-QGIS-Plugin
公式リポジトリにも登載されているので、QGISからシームレスにインストール可能です。使い方
プリセットされているMapTiler.comなどのレイヤーを追加出来ますが、今回は任意のベクタータイルを追加する事を考えます。
追加方法
Connections下部のNewを押下すると、上画像のようなダイアログが表示されます。以下のとおり入力してSaveしましょう。
- Nameには任意の文字列
- TileJSONにはtiles.jsonのURL
- GL Style JSON URLにはstyle.jsonのURLを(Optional)
tiles.jsonのURLがわからないけどstyle.jsonはわかる場合、style.jsonの中身を見るとtiles.jsonの在り処もわかります(tiles.jsonでファイル内検索してみてください)。style.jsonはOptionalで、なくても動きますが、なんらか定義されたstyle.jsonがあるならば、追加しておいた方が当然ながら見栄えがよいです。
追加したいベクタータイルをプルダウンで選択後、「Connect」してから、下部の「Add」で、レイヤーが追加されます。もし一部のレイヤーだけQGISに追加したい場合は、Layers of〜の中から追加したいレイヤーを選択してからAddしてください(未選択の場合、全レイヤーが追加される)。以後、追加されたグループ削除するまで、画面領域(ズームレベル含む)の変更に応じ、その都度サーバーからデータを持ってきてくれます。
注意点
ベクターデータの範囲外で「Add」してはいけない
現状、ベクタータイルが提供されていない領域でAddすると、再読み込みもされない仕様となっています。
特に起動直後は表示領域がおかしな事になりがちなので、手頃なレイヤー(XYZ Tileなど)を追加して、表示領域を絞ってからAddしましょう。複数のsourceを持つstyle.jsonのスタイリングは未対応
標記のとおりです。たとえばMapTiler.jpのJP MIERUNEのstyle.jsonは、sourcesに4つのデータを持つため本プラグインでは一切スタイリングされません。これは、style.jsonがoptionalである事からもわかるのですが、このプラグインはtiles.jsonがまずあって、「必要であれば」style.jsonでスタイリングする仕組みとなっているからです。
一方で、そもそもstyle.jsonにはtiles.jsonへのリンクが含まれているため、Mapbox GL JSでは必ずしもtiles.jsonを必要としません。
私はこれをバグだと思い、一応issueを立ててあるので、そのうち直せればなぁなんて思っています。
ちなみに、JP MIERUNEのようにstyle.jsonのsourcesに複数のデータがある場合、プラグインで指定したtiles.jsonのレイヤーのみをスタイリングするようにstyle.jsonを加工してやれば(指定しなかったtiles.jsonを対象とするデータを削除してやれば)、適切にスタイルが反映される事は確認済です(しかしこの場合でも日本語文字列は表示されないよう…これもfixしたい)。
- 投稿日:2020-02-10T23:17:36+09:00
COTOHA API 使ってみた(GitHubにコードもあるよ)
0. 関連記事
n番煎じ
1. 背景
プレゼント企画 を知ったため.個人的にテキスト解析を前々からやろうとは思っていたため, これを機に決意.
とはいえ, 調べてみると公式からの各種言語に対応したAPIは出されていなかった.(この記事 の作者さんの所属がNTTっぽいのでもしかしたらこれが公式説はあったりする)そこで, 勉強がてら作ってみる.
2. 作成したAPIの説明
2.1 動作確認した環境
requestsが必要です.
windows
- Windows 10 Home
- Python 3.7.3
Linux
- Ubuntu 18.04.3 LTS
- Python 3.6.9
Mac
♰持ってない♰
2.2 Quick start
- まずCOTOHA API for Developersに無料登録
- 以下のコマンドを実行
git clone https://github.com/tsuji-tomonori/cotohapy.git cd cotohapy pip install -r requirements.txt # config.json の作成 python demo.py # もし, python3 環境の場合 python3 demo.py # action!
config.jsonは以下のようになります.{ "access_token_publish_url": "", "developer_api_base_url": "", "clientid": "", "clientsecret": "" }アカウントホームに行くと以下のページが出てくるため, それをもとに設定してください. 対応表を下につけておきます.
2.3 使用方法
GitHub
git clone https://github.com/tsuji-tomonori/cotohapy.gitインポート
from cotohapy3 import CotohaAPIライブラリーは「cotohapy3」の中にすべて入っています.
CotohaAPI以外にもクラスはありますが, それは後程...アクセストークン取得
初めに必ず行ってください.
api = CotohaAPI( developer_api_base_url=developer_api_base_url, access_token_publish_url=access_token_publish_url ) api.login(clientid=clientid, clientsecret=clientsecret)def __init__(self, developer_api_base_url, access_token_publish_url)
引数 データ型 内容 developer_api_base_url str API Base URL access_token_publish_url str Access Token Publish URL def login(self, clientid, clientsecret)
引数 データ型 内容 clientid str Client ID clientsecret str Client secret 構文解析:
parse# 実行例 api.parse("昨日母と銀座で焼き肉を食べた")def parse(self, sentence, **kwargs)
引数 データ型 内容 sentence str 解析対象文 **kwargs その他任意のパラメタ (公式リファレンスのAPI参照) 固有表現抽出:
ne# 実行例 api.ne("昨日は東京駅を利用した。")def ne(self, sentence, **kwargs)
引数 データ型 内容 sentence str 解析対象文 **kwargs その他任意のパラメタ (公式リファレンスのAPI参照) 照応解析:
coreference# 実行例 api.coreference("太郎は友人です。彼は焼き肉を食べた。")def coreference(self, document, **kwargs)
引数 データ型 内容 document str / list 以下のどちらかの形式で指定 str: 解析対象の文list: 解析対象の文集合**kwargs その他任意のパラメタ (公式リファレンスのAPI参照) キーワード抽出:
keyword# 実行例 api.keyword("レストランで昼食を食べた。")def keyword(self, document, **kwargs)
引数 データ型 内容 document str / list 以下のどちらかの形式で指定 str: 解析対象の文list: 解析対象の文集合**kwargs その他任意のパラメタ (公式リファレンスのAPI参照) 類似度計算:
similarity# 実行例 api.similarity("近くのレストランはどこですか?", "このあたりの定食屋はどこにありますか?")def similarity(self, s1, s2, **kwargs)
引数 データ型 内容 s1 str 類似度算出対象のテキスト s2 str 類似度算出対象のテキスト **kwargs その他任意のパラメタ (公式リファレンスのAPI参照) 文タイプ判定:
sentence_type# 実行例 api.sentence_type("あなたの名前は何ですか?")def sentence_type(self, sentence, **kwargs)
引数 データ型 内容 sentence str 解析対象文 **kwargs その他任意のパラメタ (公式リファレンスのAPI参照) ユーザー属性推定(β):
user_attribute# 実行例 api.user_attribute("私は昨日田町駅で飲みに行ったら奥さんに怒られた。")def user_attribute(self, document, **kwargs)
引数 データ型 内容 document str / list 以下のどちらかの形式で指定 str: 解析対象の文list: 解析対象の文集合**kwargs その他任意のパラメタ (公式リファレンスのAPI参照) 言い淀み除去(β):
remove_filler# 実行例 api.remove_filler( "えーーっと、あの、今日の打ち合わせでしたっけ。すみません、ちょっと、急用が入ってしまって。" )def remove_filler(self, text, **kwargs)
引数 データ型 内容 text str 解析対象テキスト **kwargs その他任意のパラメタ (公式リファレンスのAPI参照) 音声認識誤り検知(β):
detect_misrecognition# 実行例 api.detect_misrecognition("温泉認識は誤りを起こす")def detect_misrecognition(self, sentence, **kwargs)
引数 データ型 内容 sentence str 解析対象文 **kwargs 特になし(β版より念のため) 感情分析:
sentiment# 実行例 api.sentiment("人生の春を謳歌しています")def sentiment(self, sentence)
引数 データ型 内容 sentence str 解析対象文 要約(β):
summary# 実行例 with open("summary.txt", "r", encoding="utf-8") as f: document = f.read() api.summary(document, 1)summary.txt前線が太平洋上に停滞しています。一方、高気圧が千島近海にあって、北日本から東日本をゆるやかに覆っています。関東地方は、晴れ時々曇り、ところにより雨となっています。東京は、湿った空気や前線の影響により、晴れ後曇りで、夜は雨となるでしょう。def summary(self, document, sent_len, **kwargs)
引数 データ型 内容 document str 入力文章 sent_len int 要約文数 **kwargs 特になし(β版より念のため) 3. 今後の予定
何か作ったやつを出したい
あるいは説明していない機能について説明したい
参考

- 投稿日:2020-02-10T23:11:38+09:00
書籍「15Stepで踏破 自然言語処理アプリケーション開発入門」をやってみる - 4章Step14メモ「ハイパーパラメータ探索」
内容
15stepで踏破 自然言語処理アプリケーション入門 を読み進めていくにあたっての自分用のメモです。
今回は4章Step14で、自分なりのポイントをメモります。準備
- 個人用MacPC:MacOS Mojave バージョン10.14.6
- docker version:Client, Server共にバージョン19.03.2
章の概要
この章では機械学習システムに外部から与えるべき適切なパラメータ(学習するパラメータではない)の値を見つけることを目指す。
- グリッドサーチ
- Hyperopt
- 確率分布
14.1 ハイパーパラメータ
学習によって調整、獲得されるパラメータではなく、学習の前に設計者やプログラマが設定する一段階メタなパラメータ。
- 特徴抽出器
- 識別器
- NN
- 層の種類
- 層の数
- 層ごとのユニット数
- dropoutの有無と係数
- optimizerの種類と各種引数
- 学習率
- etc...
14.2 グリッドサーチ
探索対象のパラメータと、それぞれの値の候補を列挙し、その全ての組み合わせを試してベストのものを見つける手法である。
Scikit-learnでは、sklearn.model_selection.GridSearchCVが提供されている。
- Scikit-learnのAPIを持った識別器クラスを用いる
- Kerasの場合はscikit-leran APIラッパーを用いる
- 最適なパラメータは
<gridsearchのインスタンス>.best_params_で取得できる。# pipelineを使わない ## train vectorizer = TfidfVectorizer(tokenizer=tokenize, ngram_range=(1, 2)) train_vectors = vectorizer.fit_transform(train_texts) parameters = { # <1> 'n_estimators': [10, 20, 30, 40, 50, 100, 200, 300, 400, 500], 'max_features': ('sqrt', 'log2', None), } classifier = RandomForestClassifier() gridsearch = GridSearchCV(classifier, parameters) gridsearch.fit(train_vectors, train_labels) ## predict test_vectors = vectorizer.transform(test_texts) predictions = gridsearch.predict(test_vectors) # pipelineを使う ## train pipeline = Pipeline([ ('vectorizer', TfidfVectorizer(tokenizer=tokenize, ngram_range=(1, 2))), ('classifier', RandomForestClassifier()), ]) parameters = { 'vectorizer__ngram_range':[(1, 1), (1, 2), (1, 3), (2, 2), (2, 3), (3, 3)], 'classifier__n_estimators':[10, 20, 30, 40, 50, 100, 200, 300, 400, 500], 'classifier__max_features':('sqrt', 'log2', None), } gridsearch = GridSearchCV(pipeline, parameters) gridsearch.fit(texts, labels) ## predict gridsearch.predict(texts)GridSearchCV# verbose:グリッドサーチの実行状況がわからなかったので表示(1) # n_jobs:可能な限り(-1)並列で実行 clf = GridSearchCV(pipeline, parameters, verbose=1, n_jobs=-1)実行結果from dialogue_agent import DialogueAgent # <1> ↓ from dialogue_agent_pipeline_gridsearch import DialogueAgent # <1> $ docker run -it -v $(pwd):/usr/src/app/ 15step:latest python evaluate_dialogue_agent.py # 実行完了まで20分ほどかかった Fitting 3 folds for each of 180 candidates, totalling 540 fits [Parallel(n_jobs=-1)]: Done 46 tasks | elapsed: 5.4s [Parallel(n_jobs=-1)]: Done 196 tasks | elapsed: 2.2min [Parallel(n_jobs=-1)]: Done 446 tasks | elapsed: 5.5min [Parallel(n_jobs=-1)]: Done 540 out of 540 | elapsed: 19.9min finished 0.7021276595744681 {'classifier__max_features': 'log2', 'classifier__n_estimators': 300, 'vectorizer__ngram_range': (1, 1)}
- 探索対象のパラメータが増えてくると、グリッドサーチの探索にかかる時間は指数関数的に長くなってしまう。
- GridSearchCV#fitの内部では、パラメータの組を1つ試すたびに性能評価が行われている
- クロスバリデーション(デフォルト分割数は3)
- 学習データをK個に分割しそのうち1個をバリデーションデータ、残り全てを学習データとして学習と評価を行い、それをバリデーションデータを変えながらK回行う評価方法
14.3 Hyperoptの利用 14.4 確率分布
グリッドサーチよりも効率よくハイパーパラメータの探索を行うためのツール。
パラメータ空間と目的関数を与えて最適なハイパーパラメータを返す。
- パラメータ空間:探索対象のパラメータとそれぞれの値の候補
- 一様分布:どの値も出現する確率が全て等しい
- 乱数一様分布:値の対数が一様分布に従う。大きい値はまばらに、小さい値は密に得ることができる。学習率などは対数の間隔で探索するのが望ましい。
- 生成:Hyperoptの下限と上限で指定する際は値の対数を指定する。
math.log(..)- 目的関数:パラメータ値の組を受け取って値を返す関数
- 精度を最大化したい場合は、マイナスをかけて最小化する(マイナスの最小化は最大化となる)
- 最適なパラメータは
<hyperoptのインスタンス>.fminの返り値から取得できる。# パラメータ探索 vectorizer = TfidfVectorizer(tokenizer=tokenize, ngram_range=(1, 2)) train_vectors = vectorizer.fit_transform(train_texts) ## 目的関数 def objective(args): classifier = RandomForestClassifier(n_estimators=int(args['n_estimators']), max_features=args['max_features']) classifier.fit(tr_vectors, tr_labels) val_predictions = classifier.predict(val_vectors) accuracy = accuracy_score(val_predictions, val_labels) return -accuracy ## パラメータ空間 max_features_choices = ('sqrt', 'log2', None) space = { 'n_estimators': hp.quniform('n_estimators', 10, 500, 10), 'max_features': hp.choice('max_features', max_features_choices), } best = fmin(objective, space, algo=tpe.suggest, max_evals=30) # train best_classifier = RandomForestClassifier( n_estimators=int(best['n_estimators']), max_features=max_features_choices[best['max_features']]) best_classifier.fit(train_vectors, train_labels) # predict test_vectors = vectorizer.transform(test_texts) predictions = best_classifier.predict(test_vectors)14.5 Kerasへの応用
実行がなかなか終わらないので詳細は省略。
- セッションクリア
- 探索中に何度もモデルをメモリ上に構築しているとGPUメモリを食いつぶしてしまうため、都度解放処理を入れる
if Keras.backend.backend() == 'tensorflow':- ....
Keras.backend.clear_session()- パラメータ
- 選択肢によって探索項目が異なる場合は、パラメータ空間を入れ子にしてそれぞれの探索項目ごとに詳細項目を指定できる。
- optimizerの例
- SGD:learning rateとmomentumを探索
- Adagrad;leraning rateのみ探索
評価
実行がうまく進んでいない(CPUだから時間がかかっているだけ、CPUだと実行できない?)ので、後ほど余裕があったら更新する。
- 投稿日:2020-02-10T22:34:28+09:00
深層学習/活性化関数たち
1.はじめに
簡単に言うと、ニューラルネットワークの豊かな表現力は、シンプルな活性化関数を入れ子にして深い階層にすることによってもたらされます。
今回は、ニューラルネットワークで使われる活性化関数について勉強したことをまとめます。
2.Sigmoid関数
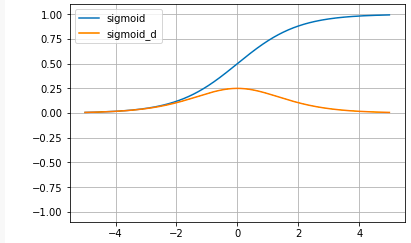
# シグモイド関数 def sigmoid(x): return 1 / (1 + np.exp(-x)) # シグモイド関数の微分 def sigmoid_d(x): return (1 / (1 + np.exp(-x))) * ( 1- (1 / (1 + np.exp(-x)))) # グラフ表示 x = np.arange(-5.0, 5.0, 0.01) plt.plot(x, sigmoid(x), label='sigmoid') plt.plot(x, sigmoid_d(x), label='sigmoid_d') plt.ylim(-1.1, 1.1) plt.legend() plt.grid() plt.show()
sigmoid関数:
sigmoid(x) = \frac{1}{1+e^{-x}}sigmoid関数の微分:
sigmoid'(x) = \frac{1}{1+e^{-x}} * ( 1 - \frac{1}{1+e^{-x}})Sigmoid関数は、昔からニューラルネットワークの教科書には必ず載っていて、微分してもほとんど形が変わらず美しい形をしているのですが、最近は活性化関数としてはほとんど使われていません。
その理由は、グラフで分かる様に、xの値が大きくなるとyが1に張り付いて動かなくなってしまうためです。ニューラルネットワークはyを微分して傾きを求めて重みパラメータを最適化するので、微分がほとんど0になってしまうと中々最適解に近づけない(勾配消失)という問題点を持っているからです。
Sigmoid関数の微分の導出
sigmoid'(x) = ((1 + e^{-x})^{-1})'\\合成関数の微分により、u = 1+e^{-x}と置くと、\frac{dy}{dx}=\frac{dy}{du}\frac{du}{dx} なので\\= -(1 + e^{-x})^{-2} * (1+e^{-x})'\\= -\frac{1}{(1+e^{-x})^2} * -e^{-x}\\= \frac{1}{1+e^{-x}} * \frac{e^{-x}}{1+e^{-x}} \\= \frac{1}{1+e^{-x}} * (\frac{1+e^{-x}}{1+e^{-x}} - \frac{1}{1+e^{-x}})\\= \frac{1}{1+e^{-x}} * ( 1 - \frac{1}{1+e^{-x}})3.tanh関数
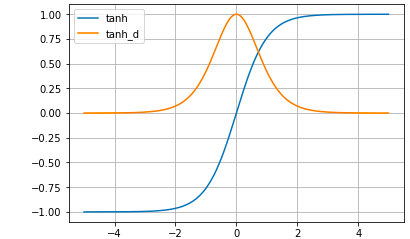
# Tanh関数 def tanh(x): return (np.exp(x) -np.exp(-x)) / (np.exp(x) + np.exp(-x)) # Tanh関数の微分 def tanh_d(x): return 1- ( (np.exp(x) -np.exp(-x)) / (np.exp(x) + np.exp(-x)) )**2 # グラフ表示 x = np.arange(-5.0, 5.0, 0.01) plt.plot(x, tanh(x), label='tanh') plt.plot(x, tanh_d(x), label='tanh_d') plt.ylim(-1.1, 1.1) plt.legend() plt.grid() plt.show()
Tanh関数:tanh(x) = \frac{e^x-e^{-x}}{e^x+e^{-x}}Tanh関数の微分:
tanh(x) = \frac{4}{(e^x + e^{-x})^2}\\Tanh関数は、Sigmoid関数の改良版(微分した時の最大値がSigmoidより高い)として使われていたわけですが、xが大きくなるとyが1に貼り付く根本的な問題点は改善されていません。
Tanh関数の微分の導出
商の微分公式 (\frac{f(x)}{g(x)})' = \frac{f'(x)*g(x) - f(x)*g'(x)}{g(x)^2} を使って\\tanh'(x) = \frac{(e^x+e^{-x})^2 - (e^x - e^{-x})^2}{(e^x + e^{-x})^2}\\= \frac{e^{2x}+2+e^{-2x} - (e^{2x} -2 + e^{-2x})}{(e^x + e^{-x})^2}\\= \frac{4}{(e^x + e^{-x})^2}\\または、
tanh'(x) = \frac{(e^x+e^{-x})^2 - (e^x - e^{-x})^2}{(e^x + e^{-x})^2}\\= 1 - \frac{(e^x - e^{-x})^2}{(e^x + e^{-x})^2}\\= 1 - (\frac{e^x - e^{-x}}{e^x + e^{-x}})^2\\4.ReLU関数
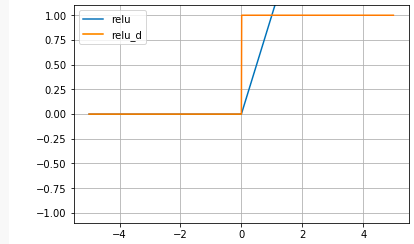
# ReLU関数 def relu(x): return np.maximum(0, x) # ReLU関数の微分 def relu_d(x): return np.array(x > 0, dtype=np.int) # グラフ表示 x = np.arange(-5.0, 5.0, 0.01) plt.plot(x, relu(x), label='relu') plt.plot(x, relu_d(x), label='relu_d') plt.ylim(-1.1, 1.1) plt.legend() plt.grid() plt.show()
ReLU関数:
ReLU関数の微分:
Sigmoid関数の根本的な問題点をなくすために生まれたのがReLU関数です。xが大きくなってもyも比例して大きくなり常に微分すると定数項が残ります。何か、今聞くと当たり前の様な気がしますが、これが使われ出したのは、なんと2012年頃からです。
東大の松尾豊先生は、Sigmoid関数はシンプルで微分してもほとんど形が変わらず、理工学者にとって美しい関数だった。一方ReLUはかっこが悪く、しかも(0,0)で微分不可な点があるので、誰も使いたがらなかった。
昔ディープラーニングは上手く動かせなかったので、皆んな式として美しいSigmoid関数を使っていた。しかし、動かせる様になってからは色々なことを試す人が出て来て、そうした中で使われる様になって来たのがReLUだと言っています。
5.Leaky ReLU関数
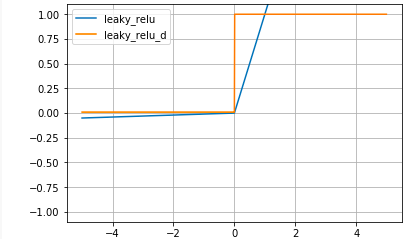
# Leaky ReLU関数 def leaky_relu(x): return np.where(x > 0, x , 0.01 * x) # Leaky ReLU関数の微分 def leaky_relu_d(x): return np.where(x>0,1,0.01) # グラフ表示 x = np.arange(-5.0, 5.0, 0.01) plt.plot(x, leaky_relu(x), label='leaky_relu') plt.plot(x, leaky_relu_d(x), label='leaky_relu_d') plt.ylim(-1.1, 1.1) plt.legend() plt.grid() plt.show()
Leaky ReLU関数:
Leaky ReLU関数の微分:
Leaky ReLU関数は、ReLU関数から派生したもので、xが0以下でも0.01xと傾きを持ちます。ReLU関数より、さらに最適化が進むことが期待されましたが、ReLU関数より最適化が上手く行く場合はかなり限定的な様です。
6.活性化関数の性能の違いを実感してみる
最後に、活性化関数によって、どれだけ最適化性能が異なるのか実感してみましょう。
TensorFlow PlayGround というブラウザでニューラルネットワークのシミュレーションができるサイトを覗いてみます。
こんな3個のニューロンが2層のニューラルネットワークを設定し、赤枠のActivation(活性化関数)を切り替えて、収束時間をチェックしてみます。確率的な問題もあり、ある程度バラツキは出ますが、収束時間は概ね、TanhがSigmoidの10倍くらい早く、ReLUはTanhのさらに2倍くらい早いです。
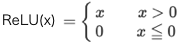
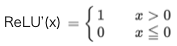
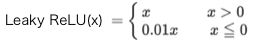
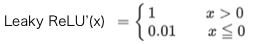
- 投稿日:2020-02-10T22:22:29+09:00
量子情報理論の基本:量子誤り訂正(Shorの符号)
$$
\def\bra#1{\mathinner{\left\langle{#1}\right|}}
\def\ket#1{\mathinner{\left|{#1}\right\rangle}}
\def\braket#1#2{\mathinner{\left\langle{#1}\middle|#2\right\rangle}}
$$はじめに
1980年代に量子計算の原理が明らかになった当初、古典的なデジタル処理で使われるような誤り訂正の理論がない、もしくはその理論確立が極めて困難なため、量子コンピュータなんていうものは現実的に実現不可能と考える人もいたらしいです。古典ビットの場合、ビットが反転するエラーだけを考えれば良いのに対し、量子ビットの場合、その変化は無限の自由度を持つので、無限のパターンのエラーを相手にする必要があります。ブロッホ球をイメージすると、量子状態のズレ方は無限にありますよね。そのズレた状態からもとの状態を正確に復元させることを考えないといけないです。さらに、量子状態は古典情報のように無邪気に複製できませんし、測定したら壊れてしまう代物です。といった諸々があり、難しさが半端ないと思われていたようです。それを最初に打破したのがPeter Shorです。このShorが提案した「Shorの符号(Shor code)」を使えば、1量子ビットに働く任意の誤りを訂正することができます。この「任意の」というところがスゴイところです。しかも、割と簡単な量子回路で実現できてしまいます。今回は、その理論を説明した後、量子計算シミュレータqlazyで、その威力を実感してみたいと思います。
参考にさせていただいたのは、以下の文献です。
理論の確認
古典的誤り訂正(繰り返し符号)
量子誤り訂正の話に突入する前の準備体操として、古典情報における誤り訂正の基本的な考え方をおさらいしておきます。いま、1ビットの情報を雑音のある古典チャネルを通して送信することを考えてみます。このチャネルにより、ビットは確率pで反転するとします。つまり、入力ビットが0だった場合、確率pでビットが1に反転し、確率1-pで0のまま維持されます。また、入力ビットが1だった場合、確率pでビットが0にに反転し、確率1-pで1のまま維持されます。このようなチャネルのことを「2値対称チャネル(binary symmetric channel)」と言います。何も考えず、このチャネルをそのまま使うと、当然ですが誤り率はpです。このチャンネルを前提に、何らかの処理を施すことによって、誤り率を減らすことができないでしょうか。
基本的で、よく知られたやり方は、ビットを複製してわざと冗長化しておく方法です。例えば、与えられた1ビットの情報を、以下のように3ビットに変換(符号化)しておきます。
\begin{align} 0 &\rightarrow 000 \\ 1 &\rightarrow 111 \\ \end{align}これを次々に古典チャネルを通して送信します。情報量は3倍になってしまいますが、誤り訂正のためには仕方ありません、という考え方です。雑音によって確率的にビットが反転するので、000というビット列は、受信側で010になっているかもしれません。が、これは真ん中のビットが反転したせいであり、本当は000のことだろうと推測するわけです。つまり多数決をとって、多いビットが元のビットだろうと見なす手法です。入力ビットを繰り返して符号化するので「繰り返し符号(repetition code)」と呼ばれています。容易にわかる通り、入力が000で雑音の結果110になってしまう可能性もなくはないです。が、トータルでの平均誤り率が小さければ良いと考えます。では、その平均誤り率は、具体的にどう計算されるでしょうか。0個もしくは1個のビット反転は訂正できるので、2個または3個のビットが反転してしまう確率だけを計算すれば、所望の誤り率になります。3個いっぺんに反転してしまう確率は$p^3$で、2個反転してしまう確率は3パターンあって$3p^2(1-p)$です。これを足すと、$p^3 + 3p^2(1-p) = 3p^2 - 2p^3$になります。何もやらない場合の誤り率は$p$だったので、誤り訂正をした方が誤り率が小さくなるという条件は、$p > 3p^2 - 2p^3$、すなわち、$p < 1/2$となります。つまり、$p$の値が$1/2$よりも小さい古典チャネルであれば、この繰り返し符号の効果が発揮されるというわけです。
3量子ビットのビット反転符号
符号化
量子ビットの場合も、似たような考え方で符号化します。例えば、1量子ビットの状態が$\ket{\psi} = a \ket{0} + b \ket{1}$だったとして、それを$a \ket{000} + b \ket{111}$のように変換(符号化)できないかを考えます。簡単にわかると思いますが、以下のような量子回路を通せば実現できます。
|psi> --*--*-- ... | | |0> --X----- ... | |0> -----X-- ...この状態で、例えば一つのビットが反転して$\ket{000} \rightarrow \ket{010}$のように変化しても、元の状態を復元することができます。ということを、これから説明していきます(図中の点々部分は雑音チャネルであることを表すものとします。以下同様)。
誤り検出(シンドローム診断)
まず、どのビットが反転したかを知る必要があります。この手続きのことを「誤り検出(error-detection)」とか「シンドローム診断(syndrome diagnosis)」と言います。3ビットの場合、以下のような射影演算を施せば、それがわかります。
\begin{align} P_0 &= \ket{000} \bra{000} + \ket{111} \bra{111} \\ P_1 &= \ket{100} \bra{100} + \ket{011} \bra{011} \\ P_2 &= \ket{010} \bra{010} + \ket{101} \bra{101} \\ P_3 &= \ket{001} \bra{001} + \ket{110} \bra{110} \tag{1} \end{align}$P_0$は何も誤りがないことを検出する測定に対応した射影演算子です。$P_1$は1番目のビットに誤りがあることを検出する射影測定です。以下、$P_2$は2番目、$P_3$は3番目のビットに誤りがあることを検出する射影測定です。雑音の結果、$a \ket{100} + b \ket{011}$となった場合、$\bra{\psi} P_1 \ket{\psi}$のみが1で、その他はすべて0になりますので、確かに$P_1$は1番目のビットの誤り検出のための演算子であるということがわかると思います。
この例以外にも、シンドローム診断のための射影測定があります。式(1)では4つの演算子を使いましたが、2つで済ますことができるスグレモノがあります。結論を先に言います。1番目、2番目、3番目の量子ビットに適用するパウリ$Z$演算子を各々$Z_1,Z_2,Z_3$としたときに、$Z_1 Z_2$および$Z_2 Z_3$というオブザーバブルを測定するやり方です。とイキナリ言われても「ん?」という状態かもしれないので、少し説明を加えます。
パウリ$Z$は$Z=\ket{0}\bra{0}-\ket{1}\bra{1}$と書けるので、
\begin{align} Z_1 Z_2 &= (\ket{0}_{1}\bra{0}_{1}-\ket{1}_{1}\bra{1}_{1})(\ket{0}_{2}\bra{0}_{2}-\ket{1}_{2}\bra{1}_{2}) \\ &= \ket{00}\bra{00} + \ket{11}\bra{11} - \ket{01}\bra{01} - \ket{10}\bra{10} \\ &= (\ket{00}\bra{00} + \ket{11}\bra{11}) \otimes I_3 - (\ket{01}\bra{01} + \ket{10}\bra{10}) \otimes I_3 \tag{2} \end{align}と展開できます。この式をじっと睨むとわかると思いますが、1番目と2番目の量子ビットが同じ場合(「偶パリティ」と言います)、このオブザーバブルを測定すると1を出力します。逆に、1番目と2番目の量子ビットが違う場合(「奇パリティ」と言います)、−1を出力します1。つまり、$Z_1 Z_2$の測定を行うと、1番目と2番目の量子ビットのパリティをチェックすることができます。同様に、$Z_2 Z_3$の測定によって、2番目と3番目の量子ビットのパリティがわかります。
表に整理すると、以下のようになります。
$Z_1 Z_2$の測定値(パリティ) $Z_2 Z_3$の測定値(パリティ) 反転しているビット +1(偶) +1(偶) なし +1(偶) -1(奇) 3番目 -1(奇) +1(偶) 1番目 -1(奇) -1(奇) 2番目 1行目は、1番目と2番目が偶パリティで、2番目と3番目が偶パリティということなので、反転しているビットがないと推定できそうです。
2行目は、1番目と2番目が偶パリティで、2番目と3番目が奇パリティということなので、3番目が反転していると推定できそうです。
3行目は、1番目と2番目が奇パリティで、2番目と3番目が偶パリティということなので、1番目が反転していそうです。
最後の4行目は、1番目と2番目が奇パリティで、2番目と3番目が奇パリティということなので、真ん中の2番目が反転している可能性が高そうです。
ということで、反転している量子ビットが何番目なのか、推定することができます。反転している量子ビットが、高々1個しかない場合は、反転ビットが何番目かを完全に特定することができます。
このシンドローム診断は、どのような量子回路で実現できるでしょうか。測定すれば良いだけなので、
|psi> --*--*-- ... --M-- | | |0> --X----- ... --M-- | |0> -----X-- ... --M--としてしまうかもしれません。が、これでは駄目です。誤り訂正したい量子ビットを測定によって壊してしまっています。なので、誤り訂正したい量子状態を壊さないように、以下のように、補助量子ビット(アンシラ)を追加して、そちらに対象とする量子状態を逃してあげて、その状態を測定するようにしないといけません。
|psi> --*--*-- ... --*------------ | | | |0> --X----- ... -----*--*------ | | | | |0> -----X-- ... -----------*--- | | | | |0> --X--X--------M1 | | |0> --------X--X--M2ここで、$Z_1 Z_2$の測定をM1、$Z_2 Z_3$の測定をM2と表しました2。
回復
シンドローム診断で、反転している量子ビットが特定できたので、次に、その量子ビットを再度反転して元に戻せば良いです。M1とM2の値に応じて、XゲートをON/OFFします。
|psi> --*--*-- ... --*------------X--- | | | || |0> --X----- ... -----*--*------X--- | | | | || |0> -----X-- ... -----------*---X--- | | | | || |0> --X--X---------M1 | | || |0> --------X--X---M2測定結果に応じてゲートを制御することを二重の縦棒で表してみました(わかりにくく、かつ、正式な書き方でもないですが、気持ちを汲んでください、汗)。先程表で示したパターンで3つの量子ビットのどれかにXゲートをかけます。これで、元の状態に戻ることになります3。
測定結果に応じたゲート操作をする代わりに、CNOTとToffoliを使って同じことができます。
[雑音] |psi> --*--*-- ... --*-------------------X--X-- | | | | | |0> --X----- ... -----*--*----------------X-- | | | | | | |0> -----X-- ... -----------*-------X-----X-- | | | | | | | |0> --X--X----------------*--*-- | | | | |0> --------X--X-------*-----*-- [符号化] [シンドローム診断] [訂正]これはわかりますでしょうか。
シンドローム診断の段階で、1番目のアンシラが+1($\ket{0}$)で2番目のアンシラが+1($\ket{0}$)の場合、[訂正]と記載されている回路部の制御ビットはともに$\ket{0}$なので、何もしません。
1番目のアンシラが+1($\ket{0}$)で2番目のアンシラが-1($\ket{1}$)の場合、訂正回路の2番目のアンシラだけが$\ket{1}$になるので、3番目の量子ビットにXゲートがかかり反転します。
1番目のアンシラが-1($\ket{1}$)で2番目のアンシラが+1($\ket{0}$)の場合、訂正回路の1番目のアンシラだけが$\ket{1}$になるので、1番目の量子ビットにXゲートがかかり反転します。
1番目のアンシラが-1($\ket{1}$)で2番目のアンシラが-1($\ket{1}$)の場合、訂正回路の両方のアンシラが$\ket{1}$になるので、2番目の量子ビットにXゲートがかかり反転します。
ということで、これで、すべての誤りパターンに対してビットを回復することができました。
復号化
最後に、符号化の逆をやって、もともとあった状態に完全に戻します。
[雑音] |psi> --*--*-- ... --*-------------------X--X---*--*-- |psi> | | | | | | | |0> --X----- ... -----*--*----------------X------X-- |0> | | | | | | | |0> -----X-- ... -----------*-------X-----X---X----- |0> | | | | | | | |0> --X--X----------------*--*-- | | | | |0> --------X--X-------*-----*-- [符号化] [シンドローム診断] [訂正] [復号化]以上で、1量子ビットの反転に対する誤り訂正回路が完成しました。
しかし、アンシラとして2量子ビット余分に必要になってしまうのが、よろしくないです。できればアンシラなしで済ませたいということで、考え出された回路を以下に示します。1番目の量子ビットだけ回復できれば良いので、2番目、3番目はもとに戻らなくても良いという考え方です。ただし、少なくとも1番目と他の量子ビットとの間にもつれが残らないようにします。
|psi> --*--*-- ... --*--*--X-- |psi> | | | | | |0> --X----- ... -----X--*-- | | | |0> -----X-- ... --X-----*--どうでしょうか。かなりシンプルになっていますが、これで本当に誤り訂正できているのでしょうか。数式で確認してみます。入力する状態は$\ket{\psi} = a \ket{0} + b \ket{1}$とします。符号化した段階で状態は$a \ket{000} + b \ket{111}$となるのは明らかなので、その直後からの変化を見てみます。
反転する量子ビットがない場合、
\begin{align} a\ket{000} + b\ket{111} &\rightarrow a\ket{000} + b\ket{110} \rightarrow a\ket{000} + b\ket{100} \rightarrow a\ket{000} + b\ket{100} \\ &= (a\ket{0} + b\ket{1}) \otimes \ket{00} \tag{3} \end{align}雑音により、1番目の量子ビットが反転した場合、
\begin{align} a\ket{100} + b\ket{011} &\rightarrow a\ket{101} + b\ket{011} \rightarrow a\ket{111} + b\ket{011} \rightarrow a\ket{011} + b\ket{111} \\ &= (a\ket{0} + b\ket{1}) \otimes \ket{11} \tag{4} \end{align}雑音により、2番目の量子ビットが反転した場合、
\begin{align} a\ket{010} + b\ket{101} &\rightarrow a\ket{010} + b\ket{100} \rightarrow a\ket{010} + b\ket{110} \rightarrow a\ket{010} + b\ket{110} \\ &= (a\ket{0} + b\ket{1}) \otimes \ket{10} \tag{5} \end{align}雑音により、3番目の量子ビットが反転した場合、
\begin{align} a\ket{001} + b\ket{110} &\rightarrow a\ket{001} + b\ket{111} \rightarrow a\ket{001} + b\ket{101} \rightarrow a\ket{001} + b\ket{101} \\ &= (a\ket{0} + b\ket{1}) \otimes \ket{01} \tag{6} \end{align}ということで、2番目と3番目の量子ビットは必ずしも$\ket{00}$に戻らないですが、少なくとも1番目の量子ビットはすべてのパターンで$\ket{\psi} = a\ket{0} + b\ket{1}$に戻っていて、かつ、他の量子ビットとはもつれていないです(=積状態になっています)。
3量子ビットの位相反転符号
次に、1つの量子ビットに位相反転があった場合の誤り訂正についてです。ビット反転はXゲートで表現できますが、位相反転はZゲートの作用です。つまり、$a\ket{0}+b\ket{1} \rightarrow a\ket{0}-b\ket{1}$という変化です。この状態から回復したいわけですが、どうすれば良いでしょうか。実は簡単な処方箋があります。アダマールゲートをかければ良いです。アダマールゲートの作用は、
\begin{align} \ket{0} &\rightarrow \ket{+} = \frac{1}{2} (\ket{0} + \ket{1}) \\ \ket{1} &\rightarrow \ket{-} = \frac{1}{2} (\ket{0} - \ket{1}) \tag{7} \end{align}だったので、$a\ket{0}+b\ket{1} \rightarrow a\ket{0}-b\ket{1}$という位相反転は、
\begin{align} & \frac{1}{2} (a+b) \ket{+} \frac{1}{2} (a-b) \ket{-} \\ & \rightarrow \frac{1}{2} (a+b) \ket{-} \frac{1}{2} (a-b) \ket{+} \tag{8} \end{align}と表されます。つまり、位相反転は$\{ \ket{+}, \ket{-} \}$基底におけるビット反転に他なりません。したがって、先程のビット反転の回路において符号化の後にアダマールをかけてから、雑音チャネルに入れて、復号化の直前にアダマールをかけて元に戻すということをやれば良いです。
|psi> --*--*--H-- ... --H--*--*--X-- |psi> | | | | | |0> --X-----H-- ... --H-----X--*-- | | | |0> -----X--H-- ... --H--X-----*--これで、位相反転に対する誤り訂正ができたことになります。
Shorの符号
「Shorの符号」は、ビット反転と位相反転の誤り訂正を同時に実現するものです。位相反転の誤り訂正では、初期状態の1量子ビットを3量子ビットに冗長化させ、各々にアダマールをかけます。その各量子ビットに対してビット反転の誤り訂正も実行するため、各々3量子ビットに冗長化します。その結果、合計で9量子ビット必要になります。回路図で表すと、
|psi> --*--*--H----*--*-- ... --*--*--X--H--*--*--X---- |psi> | | | | | | | | | | | | |0> --X----- ... -----X--*-- | | | | | | | | | | | | | | |0> -----X-- ... --X-----*-- | | | | | | | | |0> --X-----H----*--*-- ... --*--*--X--H-----X--*-- | | | | | | | | | |0> --X----- ... -----X--*-- | | | | | | | | | |0> -----X-- ... --X-----*-- | | | | | |0> -----X--H----*--*-- ... --*--*--X--H--X-----*-- | | | | | |0> --X----- ... -----X--*-- | | | |0> -----X-- ... --X-----*--となります。これで、ビット反転と位相反転の誤りに対して元の状態を回復することができるようになります(もちろん、いま想定しているのは、どれか1つの量子ビットのみが雑音によって反転する場合です)。が、実は、このように構成されたShorの符号は、さらに強力な効果を持っています。ビット反転や位相反転のようなわかりやすい離散的な誤りだけでなく、任意の連続的な変化(誤り)の場合であっても、きちんと訂正することができます。
例えば、符号化後の状態が$\ket{\psi}$になったとします。この1番目の量子ビットだけが、Kraus演算子$\{ E_{i} \}$で記述される雑音を受けたとすると、その変化は、
\ket{\psi}\bra{\psi} \rightarrow \sum_{i} E_{i} \ket{\psi}\bra{\psi} E_{i}^{\dagger} \tag{9}のように書けます。ここで、$E_i$は1番目の量子ビットに働くパウリ演算子$X_1, Z_1$と複素係数$\{ e_{ij} \}$を使って、
E_i = e_{i0} I + e_{i1} X_1 + e_{i2} Z_1 + e_{i3} X_1 Z_1 \tag{10}と展開できます4。
式(9)の一つの$i$に関する項だけに注目すると、量子状態は、$\ket{\psi},X_{1}\ket{\psi},Z_{1}\ket{\psi},X_{1}Z_{1}\ket{\psi}$の重ね合わせ状態に変化するということです。つまり、状態$\ket{\psi}$そのもの、状態$\ket{\psi}$のビット反転、状態$\ket{\psi}$の位相反転、状態$\ket{\psi}$のビット・位相反転という4つの状態の重ね合わせになります。これに、シンドローム診断を施すことで4つのうちのどれだったかが判明します。判明したらば次のステップで誤りのパターンに応じたゲートを通すことで、量子状態を回復します。式(9)はすべての$i$についての和になっていますが、同じ議論で他の$i$についても誤り訂正が可能になりますし、1番目以外の量子ビット番号についても同様の議論により、誤り訂正が可能です。
シミュレーション
実装
それでは、Shorの符号による誤り訂正の回路図をシミュレーションしてみます。全体のPythonコードを示します。
import random from qlazypy import DensOp def create_densop(): de_ini = DensOp(qubit_num=9).h(0) de_fin = de_ini.clone() return de_ini, de_fin def noise(self, kind='', prob=0.0, qid=[]): qchannel = {'bit_flip':self.bit_flip, 'phase_flip':self.phase_flip, 'bit_phase_flip':self.bit_phase_flip, 'depolarize':self.depolarize, 'amp_dump':self.amp_dump, 'phase_dump':self.phase_dump} [qchannel[kind](i, prob=prob) for i in qid] return self def code(self): self.cx(0,3).cx(0,6) self.h(0).h(3).h(6) self.cx(0,1).cx(0,2) self.cx(3,4).cx(3,5) self.cx(6,7).cx(6,8) return self def correct(self): self.cx(0,2).cx(0,1) self.cx(3,5).cx(3,4) self.cx(6,8).cx(6,7) self.ccx(2,1,0).ccx(5,4,3).ccx(8,7,6) self.h(0).h(3).h(6) self.cx(0,3).cx(0,6) self.ccx(6,3,0) return self if __name__ == '__main__': # add custom gate DensOp.add_method(code) DensOp.add_method(noise) DensOp.add_method(correct) # settings kind = 'depolarize' # bit_flip,phase_flip,bit_phase_flip,depolarize,amp_dump,phase_dump prob = 1.0 qid = [0] print("== settings ==") print("* kind of noise =", kind) print("* probability of noise =", prob) print("* noisy channels =", qid) # error correction (shor code) de_ini, de_fin = create_densop() de_fin.code() de_fin.noise(kind=kind, prob=prob, qid=qid) de_fin.correct() # evaluate fidelity fid = de_fin.fidelity(de_ini, qid=[0]) print("== result ==") print("* fidelity = {:.6f}".format(fid)) # free all densops DensOp.free_all(de_ini, de_fin)何をやっているか、順に説明します。まず、main処理部を見てください。
# add custom gate DensOp.add_method(code) DensOp.add_method(noise) DensOp.add_method(correct)で、必要となる処理をカスタムゲートとして登録します。code,noise,correctという関数を上の方で定義していて、これをQStateクラスのメソッドとして使えるようにします。
# settings kind = 'depolarize' # bit_flip,phase_flip,bit_phase_flip,depolarize,amp_dump,phase_dump prob = 1.0 qid = [0]で、シミュレーションのためのパラメータを設定しています。kindは適用したい雑音のパターンを表しています。'bit_flip'(ビット反転)、'phase_flip'(位相反転)、'bit_phase_flip'(ビット位相反転)、'depolarize'(分極解消)、'amp_dump'(振幅ダンピング)、'phase_dump'(位相ダンピング)の中から適用したいパターン名を選びます。以前の記事で説明した代表的な量子チャネルを密度演算子に適用できます(密度演算子への量子チャネル適用はv0.0.34で追加しました)。probは、各量子チャネルで雑音を乗せる確率(強度)を表しています。qidは、どの量子ビットに雑音適用するかを設定するリストです。上の例では0番目の量子ビットに適用しています。複数のビット番号を指定することもできます。
de_ini, de_fin = create_densop()で、量子状態(密度演算子)を適当に作ります。関数定義を見ていただければわかるとおり、合計9個の量子ビットを$\ket{0}$に初期化して、0番目のみにアダマールゲートをかけます。別にアダマールでなくても良いのですが、ここは適当です。どんな入力状態を想定するかに応じて、適当に変えれば良いです。また、ここでは、de_ini,de_finという2つの全く同じ量子状態(密度演算子)を出力していますが、この後、de_finだけに処理を加えて、最後に元の状態de_iniと比較したいために2つ出力するようにしています。
de_fin.code()で、符号化を行います。関数定義を見ていただければ、一目瞭然かと思います。雑音が入る直前までの量子回路を愚直に実装しています。
de_fin.noise(kind=kind, qid=qid, prob=prob)で、kindで定義された量子チャネルを確率probの強度でqidで規定される量子番号に適用します。関数定義の中身はパッと見、わかりにくいかもしれませんが、実質、de_ini.depolarize(0, prob=1.0)という演算をやっているだけです。量子回路図で言うと、点々の部分に相当します。
dde_fin.correct()で、誤り訂正と復号化を一緒にやります。関数定義を見ていただければわかるとおりです(こちらも愚直に実装しているだけです)。
fid = de_fin.fidelity(de_ini, qid=[0]) print("== result ==") print("* fidelity = {:.6f}".format(fid))で、最初の状態と誤り訂正後の状態を比較するため、0番目の量子ビットに関する忠実度を計算して表示します。
DensOp.free_all(de_ini, de_fin)最後、使ったメモリを解放します。クラス・メソッドfree_allで引数に指定したものを一気に解放することができます(v0.0.33で追加しました)。
これで、0番目の量子ビットに対して、確率1で分極解消がなされた(つまり完全に方向をバラバラにするような雑音が加えられた)場合の誤り訂正シミュレーションできるようになります。
実行結果
実行結果を示します。
== settings == * kind of noise = depolarize * probability of noise = 1.0 * noisy channels = [0] == result == * fidelity = 1.000000というわけで、1量子ビットの雑音に関しては、完全に誤り訂正できました。
また、分極解消以外の量子チャネルの場合でも誤り訂正はできましたし、どの量子ビットに雑音が入っても大丈夫でした。以下はその一例です。
== settings == * kind of noise = amp_dump * probability of noise = 1.0 * noisy channels = [5] == result == * fidelity = 1.000000ところが、雑音チャネルが2つ以上の場合は駄目でした。以下の通りです。
== settings == * kind of noise = depolarize * probability of noise = 1.0 * noisy channels = [0, 2] == result == * fidelity = 0.866025確率を0.5にしてみるとどうでしょうか?
== settings == * kind of noise = depolarize * probability of noise = 0.5 * noisy channels = [0, 2] == result == * fidelity = 0.968246こちらも駄目でした。上で説明した通り、Shorの符号で完全に誤り訂正はできるのは1量子ビットの誤りのみです。ということが、わかりました。
おわりに
今回、量子誤り訂正として各種提案されている手法の中で一番簡単でとっつきやすい手法である「Shorの符号」を取り上げて説明しました。ビット反転と位相反転に対応した誤り訂正回路を作ったはずなのに、なぜかすべての連続的な誤りにも対応できる回路になっていました、というのは面白いです。量子状態に対する連続的な演算が、実は離散的なパウリ演算子の重ね合わせで表現できるということが効いているのだと思います。
というわけで、量子誤り訂正の基本の入門編でした。今後しばらくは量子誤り訂正のあれこれを味わいながら、基本の理解を進めていく予定です。
以上
ここで「オブザーバブルを測定する」という表現が、ちょっとわかりにくいかもしれないので、少し説明を加えます。オブザーバブルというのは直訳すると「観測可能量」です。量子力学の枠組みでは、物理的に観測できる量は、エルミート演算子として表現できるとされています。その代表選手は、エネルギーという物理量をエルミート演算子として表現したハミルトニアンです。物理量を測定するということは、それに対応したオブザーバブル=エルミート演算子の固有値問題を解くことと等価で、測定値が固有値(エルミートなので必ず実数値になります)、測定後の状態がその固有値に対応した固有ベクトル(固有状態)となります。いまオブザーバブルとして与えられているのはパウリ$Z$(の積)です。パウリ$Z$を測定するというのは、物理的にはどういうことかというと、ハミルトニアン$H = Z$で与えられた系のエネルギー値を測定するということです。つまり、1スピン系のZ軸方向の測定ですね。もっと言うと、量子回路でおなじみの量子ビットの測定そのものと思って良いです。結局、$Z_1 Z_2$という「オブザーバブルを測定する」というのは、何のことはない、1番目の量子ビットを計算基底で測定して-1か1の値を得て2番目の量子ビットを計算基底で測定して-1か1の値を得て、それらの積をとるということです。このとき1番目と2番目の測定の順番はどっちでも良いです(演算子として交換可能なので)。ちなみに、パウリ$X$というオブザーバブルを測定する、というのは、量子ビットで言うと、X軸方向の測定を実行するということになりますので、アダマールゲートをかけてからZ軸方向の測定をやることに等しいです。 ↩
1番目と2番目の量子ビットを制御ビットとするCNOTを2つ通した後で標的ビットを測定しています(M1の測定)が、これでなぜ$Z_1 Z_2$を測定したことになるか?$\ket{x}\ket{y}\ket{0} \rightarrow \ket{x}\ket{y}\ket{x \oplus y}$と書いてみると、$x$と$y$が同じ場合$\ket{x}\ket{y}\ket{0}$となり、M1の測定値は+1、違う場合$\ket{x}\ket{y}\ket{1}$となり、M1の測定値は-1になります。 ↩
もちろん今の前提は雑音で反転する量子ビット数が1以下の場合なので、2ビット以上反転している場合は復元できません。 ↩
ここで、$X_1 Z_1$というのは、係数分を除いて$Y_1$に等しいので、$E_i$がパウリ演算子を使って展開できるということです。任意の2次元行列に対して、このような展開ができます。 ↩
- 投稿日:2020-02-10T22:17:44+09:00
スクリプト言語の比較しながらGoのお勉強 〜 標準入力編
前回からのおさらい
前回、Hello World編にて、標準出力に文字列を表示するという処理を確認しました。
今回はその対になります標準入力にてキーボードにて入力する文字列を受け取る処理を比較してみたいと思います。標準入力
簡単にキーボードから1行入力された文字列を表示するプログラムを見ていくことにしましょう。
Goの標準入力
Goでの標準入力のプログラムです。
input.gopackage main import ( "fmt" "os" "bufio" ) func main() { stdin := bufio.NewScanner(os.Stdin) stdin.Scan() text := stdin.Text() fmt.Printf(text + "\n") }実行してみましょう。
$ go run input.go Hello, Go Hello, Goただ単に鸚鵡返しするだけですが、思い通りの処理はできています。
プログラムの中身ですが、
importで3つのパッケージを読み込んでいます。fmtパッケージは標準出力でも使用したものですね。osパッケージとbufioパッケージは今回初めて使用するライブラリです。
osパッケージは公式サイトによると、オペレーティングシステムの機能へのプラットフォームに依存しないインタフェースを提供します。
Unixライクな設計です。ドキュメントを読んでると
syscallパッケージをラップしていることがわかりました。osパッケージはシステムのローレベルな処理から汎用的にレベルを上げたパッケージということですね。I/Oのバッファリング機能を提供します。io.Reader・io.Writerをラップし、別のオブジェクト(ReaderまたはWriter)を作成します。インタフェースは同じままでバッファリングやその他便利な機能を追加します。
とのことで
ioパッケージをラップして機能拡張しているものの様です。処理に関してですが、10行目のNewScannerはドキュメントによると1行ごと読み込む処理です。
またos.Stdinの処理はsyscall.Stdinで/dev/stdinを開いたファイルディスクリプたということで、標準入力を1行ごと読み込む処理の様です。
11行目で1行ごとバッファし、12行目で変数に文字列を格納、そして15行目で出力という流れになっています。簡単な標準入力の処理ですが、なかなか理解しなければならないことの多いGoです。
では、他の言語との比較です。
Python
Pythonでは組み込み関数の
input関数で入力処理を実装できます。
組み込み関数input.pytext = input() print(text)実行結果
$ python input.py Hello, Python Hello, PythonRuby
Rubyでは組み込み関数の
getsで実装可能です。
module Kernelinput.rbtext = gets print text実行結果
$ ruby input.rb Hello, Ruby Hello, RubyPerl
PerlではI/O演算子の
<>で標準入力のファイルハンドルSTDINを指定して入力処理を実装します。
I/O 演算子input.pl$text = <STDIN>; print $text;実行結果
$ perl input.pl Hello, Perl Hello, PerlBash
Bashでは
readコマンドで入力処理を実装します。
man readinput.shread text echo $text実行結果
$ bash input.sh Hello, Bash Hello, Bash入力処理を比較してみて
入力処理を比較してみて感じたことはHello World編と同様で、本体は簡素に作られているというところです。
今回は多少パッケージのソースにも目を通してみたところ、低レベルの処理を駆使して実装はできるのでしょうが、
車輪の再発明は無駄で何も旨味がないためパッケージの使用を学ぶべきと感じました。
(但し、実装方法を確認することは多くの知見を得られますので、できる限りソースには目を通すべきだと思います)
では、次回以降は変数に関しての演算子や文字列処理について勉強したいと思います。
- 投稿日:2020-02-10T22:03:11+09:00
PytorchのDataLoaderでData Augmentationした後の画像を表示する
背景
Data Augmentationした後の画像を表示したい!
と思って実装してみました。
Data Augmentationとは、1枚の画像を水増しする技術であり、以下のような操作を加えます。
- Random Crop(画像をランダムに切り取る)
- Random Horizontal Flip(画像を一定の確率で左右反転する)
- Random Erasing(画像の一部にランダムにノイズを付加する)
- Random Affine(画像をランダムに拡大・縮小・回転する)
この他にもいろいろあります。
実装
今回は、CIFAR-10の訓練画像データセットを読み込んで、transformsにRandomHorizontalFlipとRandomErasingを組み込んでみました。
test.pyimport torch import numpy as np import torchvision import torchvision.transforms as transforms from torch.utils.data import Dataset,DataLoader import torchvision.datasets as dsets import matplotlib.pyplot as plt #画像の読み込み batch_size = 100 train_data = dsets.CIFAR10(root='./tmp/cifar-10', train=True, download=False, transform=transforms.Compose([transforms.RandomHorizontalFlip(p=0.5), transforms.ToTensor(), transforms.RandomErasing(p=0.5, scale=(0.02, 0.4), ratio=(0.33, 3.0))])) train_loader = DataLoader(train_data,batch_size=batch_size,shuffle=True) test_data = dsets.CIFAR10(root='./tmp/cifar-10', train=False, download=False, transform=transforms.Compose([transforms.ToTensor(),])) test_loader = DataLoader(test_data,batch_size=batch_size,shuffle=False) def image_show(data_loader,n): #Augmentationした画像データを読み込む tmp = iter(data_loader) images,labels = tmp.next() #画像をtensorからnumpyに変換 images = images.numpy() #n枚の画像を1枚ずつ取り出し、表示する for i in range(n): image = np.transpose(images[i],[1,2,0]) plt.imshow(image) plt.show() image_show(train_loader,10)image_show関数がAugmentation後の画像を表示する関数です。
iter()により、DataLoaderからミニバッチ1つ分を取得します。
そして、.next()により画像データをimagesに、ラベルをlabelsに格納します。
images = images.numpy()では、画像データをテンソルからnumpyに変換しています。
この時点でimagesは[バッチサイズ, チャンネル数, 幅, 高さ]という構造になっていますが、matplotlibのpyplotで画像を表示するには[幅, 高さ, チャンネル数]とする必要があります。
よって、np.transposeをつかって変形しています。
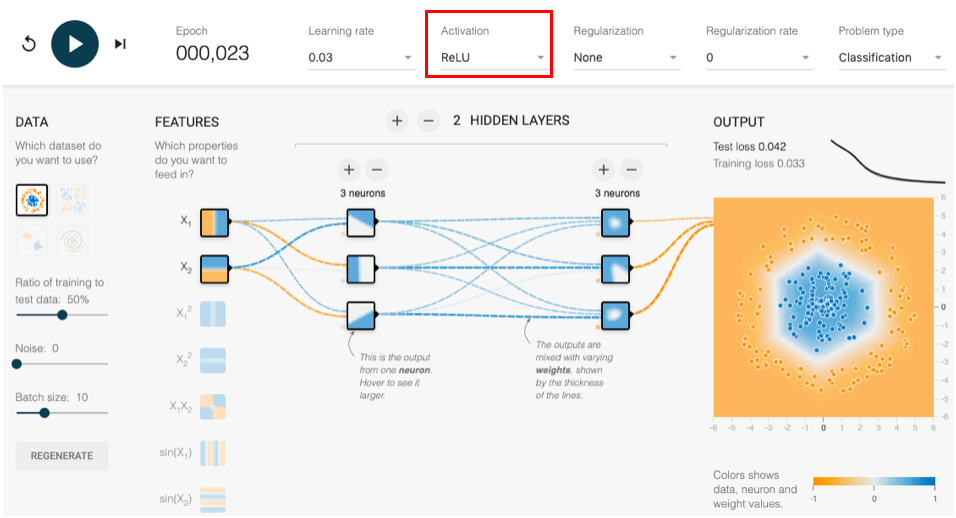
実行結果例
左右反転されていたりRandom Erasingでノイズが付加されていたりすることが確認できました。

- 投稿日:2020-02-10T21:48:08+09:00
DjangoでCustom User Modelを実装する
はじめに
DjangoでCustom User Modelを設定します。
本記事はDjangoアプリをDocker上に構築しAWS Fargateにデプロイするプロジェクトの一部です。
Custom User Modelを使う理由
Djangoにはデフォルトでユーザのモデルが設定されています。しかし、実際にアプリを作成すると、自分の作成したアプリに合わせてユーザモデルを変更したくなる時が必ずやってきます。ある程度コーディングが進んだ段階でユーザモデルの修正を行うのはとても難しい為、プロジェクトの最初からCustom User Modelを設定することが推奨されています。
Custom User Modelの実装について
Custom User Modelを実装するには「AbstractUser」クラスまたは「AbstractBaseUser」クラスを利用します。「AbstractUser」クラスはデフォルトのユーザフィールドや認証を拡張する方法でありシンプルに実装が可能です。「AbstractBaseUser」クラスを使う方法はコーディング量が増えますが、より細かくカスタマイズができます。
今回は「AbstractUser」を使用し実装していきます。自身が開発に携わったプロジェクトでも「AbstractUser」を使用してユーザモデルをカスタマイズしました。一般的なユーザ管理をするのであれば「AbstractUser」でも十分対応できます。
準備
Docker+DjangoでPostgreSQLを使う で作成したプロジェクトにCustom User Modelを実装します。
usersアプリの追加
まずはstartappコマンドでカスタムユーザを管理するusersアプリを作成します。その後setting.pyにCustom User Model関連のコードを追加します。
docker-compose exec web python manage.py startapp userssetting.pyに作成したusersを追加しましょう。また末尾にデフォルトのユーザモデルの代わりにカスタムユーザモデルを使用する旨を記載します。
setting.pyINSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', # Local 'users.apps.UsersConfig', #追加 ] ... AUTH_USER_MODEL = 'users.CustomUser' # 追加modelへCustomUserを追加
models.pyにCustomUserクラスを作成します。今回はデフォルトのユーザモデルからフィールドの追加はしないので直下にはpassを追加しておきます。独自のフィールドを設定する場合にはこちらにフィールドを追加してください。
users/models.pyfrom django.contrib.auth.models import AbstractUser from django.db import models class CustomUser(AbstractUser): passCustom User Formsの作成
users/forms.pyを作成し、以下のコードを追加します。
users/form.pyfrom django.contrib.auth import get_user_model from django.contrib.auth.forms import UserCreationForm, UserChangeForm class CustomUserCreationForm(UserCreationForm): class Meta(UserCreationForm): model = get_user_model() fields = ('email', 'username',) class CustomUserChangeForm(UserChangeForm): class Meta(UserChangeForm): model = get_user_model() fields = ('email', 'username',)Custom User Adminの設定
admin.pyに以下のコードを追加します。
users/admin.pyfrom django.contrib import admin from django.contrib.auth import get_user_model from django.contrib.auth.admin import UserAdmin from .forms import CustomUserCreationForm, CustomUserChangeForm CustomUser = get_user_model() class CustomUserAdmin(UserAdmin): add_form = CustomUserCreationForm form = CustomUserChangeForm model = CustomUser list_display = ['email', 'username',] admin.site.register(CustomUser, CustomUserAdmin)これで設定は完了です。最後にマイグレーションを行いましょう。
docker-compose exec web python manage.py makemigrations users docker-compose exec web python manage.py migrate
- 投稿日:2020-02-10T21:16:57+09:00
ドラクエ風バトルでQ学習してみる【強化学習入門】
何をやるか?
超シンプルなドラクエ風ターン制バトルを作ってQ学習させてみます。
数%の確率でしか世界を救えない勇者くんを、Q学習で賢くすることが目的です。なお、ゲーム部分・Q学習の実装については解説しますが、Q学習そのものは解説しません。
Q学習の詳しい理論を知りたい方は、こちらの良記事を一つずつ読んでいくと幸せになれます。今さら聞けない強化学習(1):状態価値関数とBellman方程式
読んでもらいたい人
- OpenAI Gymなどの既存のシミュレーション環境ではなく、自分でゲームを作って色々弄ってみたい方。
- Q学習の理論はなんとなく知ってるんだけど、「どうやって実装すれば良いかわからない!」という方。
ゲームをつくる
ルールはシンプルに、以下のように設計します。
- 勇者 vs 魔王の1対1
- 魔王のとる行動は「攻撃」のみ
- 勇者のとれる行動は「攻撃」と「回復」の2択
- 行動順序は、各キャラの素早さに一定の乱数を掛けてソートさせることで決定する
キャラクタークラスの実装
それでは早速、ゲーム本体の実装をしていきましょう。
まずはキャラクタークラスです。dq_battle.pyclass Character(object): """ キャラクタークラス""" ACTIONS = {0: "攻撃", 1: "回復"} def __init__(self, hp, max_hp, attack, defence, agillity, intelligence, name): self.hp = hp # 現在のHP self.max_hp = max_hp # 最大HP self.attack = attack # 攻撃力 self.defence = defence # 防御力 self.agillity = agillity # 素早さ self.intelligence = intelligence # 賢さ self.name = name # キャラクター名 # ステータス文字列を返す def get_status_s(self): return "[{}] HP:{}/{} ATK:{} DEF:{} AGI:{} INT:{}".format( self.name, self.hp, self.max_hp, self.attack, self.defence, self.agillity, self.intelligence) def action(self, target, action): # 攻撃 if action == 0: # 攻撃力 - 防御力のダメージ計算 damage = self.attack - target.defence draw_damage = damage # ログ用 # 相手の残りHPがダメージ量を下回っていたら、残りHPちょうどのダメージとする if target.hp < damage: damage = target.hp # ダメージを与える target.hp -= damage # 戦闘ログを返す return "{}は{}に{}のダメージを与えた".format( self.name, target.name, draw_damage) # 回復 elif action == 1: # 回復量をINTの値とする heal_points = self.intelligence draw_heal_points = heal_points # ログ用 # 最大HPまで回復できるなら、最大HP - 現在のHPを回復量とする if self.hp + heal_points > self.max_hp: heal_points = self.max_hp - self.hp # 回復 self.hp += heal_points # 戦闘ログを返す return "{}はHPを{}回復した".format( self.name, draw_heal_points)今回のバトル設計はシンプルなので、プレイヤーと敵を区別することなく1つのクラスにまとめてしまっています。
各キャラクター(勇者と魔王)は、
- HP(体力)
- ATTACK(攻撃力)
- DEFENCE(防御力)
- AGILLITY(素早さ)
- INTELIGENCE(賢さ)
のステータスを持ちます。
「攻撃」でのダメージ計算は、
「(自分の攻撃力)ー(相手の防御力)」という単純な式で計算しています。
また、「回復」コマンドでの回復量は賢さの数値そのままとしました。バトル設計の全体像(状態遷移)
続いてバトル本体を実装していきます。
初めに、バトルの全体像(状態遷移)について理解しておく必要があります。dq_battle.pyclass GameState(Enum): """ ゲーム状態管理クラス""" TURN_START = auto() # ターン開始 COMMAND_SELECT = auto() # コマンド選択 TURN_NOW = auto() # ターン中(各キャラ行動) TURN_END = auto() # ターン終了 GAME_END = auto() # ゲーム終了バトルには上記の通り、
「ターン開始」「コマンド選択」「ターン中」「ターン終了」「ゲーム終了」
の5つの状態があります。状態遷移図で表すと下図のようになります。
このように、「ターン開始」状態から「ターン終了」状態までの遷移を、「ゲーム終了」状態になるまで(勇者か魔王のHPが0になるまで)延々とループさせるのがバトル設計の基本になります。
バトル本体の実装
それでは、バトル本体の実装です。
先にコード全体をみておきます。dq_battle.pyclass Game(): """ ゲーム本体""" HERO_MAX_HP = 20 MAOU_MAX_HP = 50 def __init__(self): # キャラクターを生成 self.hero = Character( Game.HERO_MAX_HP, Game.HERO_MAX_HP, 4, 1, 5, 7, "勇者") self.maou = Character( Game.MAOU_MAX_HP, Game.MAOU_MAX_HP, 5, 2, 6, 3, "魔王") # キャラクターリストに追加 self.characters = [] self.characters.append(self.hero) self.characters.append(self.maou) # 状態遷移用の変数を定義 self.game_state = GameState.TURN_START # ターン数 self.turn = 1 # 戦闘ログを保存するための文字列 self.log = "" # 1ターン毎にゲームを進める def step(self, action): # メインループ while (True): if self.game_state == GameState.TURN_START: self.__turn_start() elif self.game_state == GameState.COMMAND_SELECT: self.__command_select(action) # 行動を渡す elif self.game_state == GameState.TURN_NOW: self.__turn_now() elif self.game_state == GameState.TURN_END: self.__turn_end() break # ターン終了でもループを抜ける elif self.game_state == GameState.GAME_END: self.__game_end() break # ゲームが終了したかどうか done = False if self.game_state == GameState.GAME_END: done = True # 「状態s、報酬r、ゲームエンドかどうか」を返す return (self.hero.hp, self.maou.hp), self.reward, done # ゲームを1ターン目の状態に初期化 def reset(self): self.__init__() return (self.hero.hp, self.maou.hp) # 戦闘ログを描画 def draw(self): print(self.log, end="") def __turn_start(self): # 状態遷移 self.game_state = GameState.COMMAND_SELECT # ログを初期化 self.log = "" # 描画 s = " *** ターン" + str(self.turn) + " ***" self.__save_log("\033[36m{}\033[0m".format(s)) self.__save_log(self.hero.get_status_s()) self.__save_log(self.maou.get_status_s()) def __command_select(self, action): # 行動選択 self.action = action # キャラクターを乱数0.5〜1.5の素早さ順にソートし、キューに格納 self.character_que = deque(sorted(self.characters, key=lambda c: c.agillity*random.uniform(0.5, 1.5))) # 状態遷移 self.game_state = GameState.TURN_NOW # ログ保存 self.__save_log("コマンド選択 -> " + Character.ACTIONS[self.action]) def __turn_now(self): # キャラクターキューから逐次行動 if len(self.character_que) > 0: now_character = self.character_que.popleft() if now_character is self.hero: s = now_character.action(self.maou, self.action) elif now_character is self.maou: s = now_character.action(self.hero, action=0) # 魔王は常に攻撃 # ログを保存 self.__save_log(s) # HPが0以下ならゲームエンド for c in self.characters: if c.hp <= 0: self.game_state = GameState.GAME_END return # 全員行動終了したらターンエンド if len(self.character_que) == 0: self.game_state = GameState.TURN_END return def __turn_end(self): # 報酬を設定 self.reward = 0 # キャラクターキューの初期化 self.character_que = deque() # ターン経過 self.turn += 1 # 状態遷移 self.game_state = GameState.TURN_START def __game_end(self): if self.hero.hp <= 0: self.__save_log("\033[31m{}\033[0m".format("勇者は死んでしまった")) self.reward = -1 # 報酬を設定 elif self.maou.hp <= 0: self.__save_log("\033[32m{}\033[0m".format("魔王をやっつけた")) self.reward = 1 # 報酬を設定 self.__save_log("-----ゲームエンド-----") def __save_log(self, s): self.log += s + "\n"少々コードが長いですが、Q学習で重要な部分は2つだけです。
1つ目は、step()メソッドです。ここがバトルのメイン部分になります。
dq_battle.py# 1ターン毎にゲームを進める def step(self, action): # メインループ while (True): if self.game_state == GameState.TURN_START: self.__turn_start() elif self.game_state == GameState.COMMAND_SELECT: self.__command_select(action) # 行動を渡す elif self.game_state == GameState.TURN_NOW: self.__turn_now() elif self.game_state == GameState.TURN_END: self.__turn_end() break # ターン終了でもループを抜ける elif self.game_state == GameState.GAME_END: self.__game_end() break # ゲームが終了したかどうか done = False if self.game_state == GameState.GAME_END: done = True # 「状態s、報酬r、ゲームエンドかどうか」を返す return (self.hero.hp, self.maou.hp), self.reward, done基本的には、前述した状態遷移図と処理の流れは同じです。
ただし、Q学習では1ターン毎に現在の状態を評価しなくてはならないので、「ゲーム終了」状態に限らず、「ターン終了」状態でもメインループを抜けなければなりません。
「ターン終了」状態において、Q学習をするために評価しなくてはならない変数は、
- 「状態s」
- 「報酬r」
- 「ゲームエンドかどうかを判定するフラグ」
の3つです。
ゲームエンドかどうかについては、単純に勇者のHPか魔王のHPが0になったかどうかで判断します。
状態sについては少し考える必要があります。
攻撃力や防御力などの複数のステータスがありますが、Q学習で評価すべきステータスは「勇者のHP」と「魔王のHP」の実質2つだけです。今回のバトル設計では、攻撃力・防御力などの数値は常に一定なので、HP以外のステータスを評価する必要がないからです。逆に言えば、バフ・デバフなどでステータスが変化する場合はそれらの情報も必要になります。
報酬rについては、「ターン終了」と「ゲーム終了」状態それぞれで評価します。
dq_battle.pydef __turn_end(self): # 報酬を設定 self.reward = 0 # (省略) def __game_end(self): if self.hero.hp <= 0: self.__save_log("\033[31m{}\033[0m".format("勇者は死んでしまった")) self.reward = -1 # 報酬を設定 elif self.maou.hp <= 0: self.__save_log("\033[32m{}\033[0m".format("魔王をやっつけた")) self.reward = 1 # 報酬を設定ターン経過による報酬は0としました。魔王を「最速で倒す」という目的を意識するなら、ターン経過での報酬を負の値にすればよいでしょう。(ただし、適切なパラメーターを設定するのは難しいですが。)
ゲーム終了時には、勇者が倒れてしまえば「-1」、魔王を倒せば「+1」の報酬を与えます。
2つ目に重要な部分は、reset()メソッドです。
dq_battle.py# ゲームを1ターン目の状態に初期化 def reset(self): self.__init__() return (self.hero.hp, self.maou.hp)単にゲームを初期化するだけのメソッドです。なお、Q学習のために初期状態を返す必要があります。
上記のstep()メソッドと合わせて、
ゲーム初期化(reset)→バトルが終了するまでターンを進める(step)→ゲーム初期化(reset)→バトルが終了するまでターンを進める(step)・・・
と、ゲームを繰り返すことで学習を進めていくことができます。
以上がQ学習をする上での、ゲームの根幹部分となります。
Q学習を実装する
エージェントクラスについて
Q学習は、エージェントクラス内で実装します。
エージェントとは、実際にゲームをするプレイヤーのようなクラスです。エージェントはプレイヤー自身ですので、行動(攻撃か回復か)を選択したり、状態(勇者や魔王のHPなど)について知ったりすることはできますが、
ゲームの内部情報(行動順序を決める乱数など)を知ることはできません。「行動」と、その行動によって得られた「状態」と「報酬」だけから学習を進めていくのが、
Q学習を含めた強化学習全般における基本的な理解になります。初めに、エージェントクラスの全体を掲示しておきます。
q-learning.pyDIV_N = 10 class Agent: """エージェントクラス""" def __init__(self, epsilon=0.2): self.epsilon = epsilon self.Q = [] # 方策をε-greedy法で定義 def policy(self, s, actions): if np.random.random() < self.epsilon: # epsilonの確率でランダムに行動 return np.random.randint(len(actions)) else: # (Qに状態sが含まれており、かつそのときの状態におけるQ値が0でなければ) if s in self.Q and sum(self.Q[s]) != 0: # Q値が最大となるように行動 return np.argmax(self.Q[s]) else: return np.random.randint(len(actions)) # 状態を数値に変換する def digitize_state(self, s): hero_hp, maou_hp = s # 勇者と魔王のHPをそれぞれDIV_Nで分割する s_digitize = [np.digitize(hero_hp, np.linspace(0, dq_battle.Game.HERO_MAX_HP, DIV_N + 1)[1:-1]), np.digitize(maou_hp, np.linspace(0, dq_battle.Game.MAOU_MAX_HP, DIV_N + 1)[1:-1])] # DIV_Nの2乗までの状態数を返す return s_digitize[0] + s_digitize[1]*DIV_N # Q学習をする def learn(self, env, actions, episode_count=1000, gamma=0.9, learning_rate=0.1): self.Q = defaultdict(lambda: [0] * len(actions)) # episode_countの分だけバトルする for e in range(episode_count): # ゲーム環境をリセット tmp_s = env.reset() # 現在の状態を数値に変換 s = self.digitize_state(tmp_s) done = False # ゲームエンドになるまで行動を繰り返す while not done: # ε-greedy方策に従って行動を選択 a = self.policy(s, actions) # ゲームを1ターン進め、その時の「状態、報酬、ゲームエンドかどうか」を返す tmp_s, reward, done = env.step(a) # 状態を数値に変換 n_state = self.digitize_state(tmp_s) # 行動aによって得られた価値(gain) = 即時報酬 + 時間割引率 * 次の状態における最大のQ値 gain = reward + gamma * max(self.Q[n_state]) # 現在推測している(学習する前の)Q値 estimated = self.Q[s][a] # 現在の推測値と、行動aを実行してみたときの実際の価値をもとに、Q値を更新 self.Q[s][a] += learning_rate * (gain - estimated) # 現在の状態を次の状態へ s = n_state状態を数値に変換する
エージェントクラスで少しわかりにくいのは、状態を数値に変換するメソッドでしょうか。
q-learning.py# 状態を数値に変換する def digitize_state(self, s): hero_hp, maou_hp = s # 勇者と魔王のHPをそれぞれDIV_Nに分割する s_digitize = [np.digitize(hero_hp, np.linspace(0, dq_battle.Game.HERO_MAX_HP, DIV_N + 1)[1:-1]), np.digitize(maou_hp, np.linspace(0, dq_battle.Game.MAOU_MAX_HP, DIV_N + 1)[1:-1])] # DIV_Nの2乗までの状態数を返す return s_digitize[0] + s_digitize[1]*DIV_N先ほども軽く触れましたが、Q学習をする上で評価すべき状態変数は、「勇者のHP」と「魔王のHP」の2つです。しかし、Q学習では状態を1つの数値として表す必要があります。つまり、以下のようなイメージです。
- 状態1:(勇者のHP, 魔王のHP) = (0, 0)
- 状態2:(勇者のHP, 魔王のHP) = (0, 1)
- 状態3:(勇者のHP, 魔王のHP) = (0, 2)
上記のように変換しても良いのですが、これだとHP×HPの数だけ状態が増えることになります。ドラクエじゃない方の某国民的RPGのように、HPが4桁もあると状態数が100万を超えて大変です(笑)。ですので、HPの割合に応じて状態を分割してやることにしましょう。
np.digitize(hero_hp, np.linspace(0, dq_battle.Game.HERO_MAX_HP, DIV_N + 1)[1:-1]このコードをざっくりと解説すると、
np.linspace()で、0から最大HPまでをN分割し、
np.digitize()で、現在のHPが、何分割目に属しているかを返すイメージです。今回はN=10としているので、
- HPが1割未満 → 0
- HPが1割以上、2割未満 → 1
- HPが2割以上、3割未満 → 2
のように変換してくれます。更に、
「勇者の状態(0〜9)+ 魔王の状態(0〜9)*10」
の計算をすることで、0から99までの100個に状態数を抑えることができます。状態「15」なら、魔王のHPが「1」割未満、かつ勇者のHPが「5」割未満と、直感的にわかりますね。
方策の定義
方策はε-greedyを採用しています。
q-learning.py# 方策をε-greedy法で定義 def policy(self, s, actions): if np.random.random() < self.epsilon: # epsilonの確率でランダムに行動 return np.random.randint(len(actions)) else: # (Qに状態sが含まれており、かつそのときの状態におけるQ値が0でなければ) if s in self.Q and sum(self.Q[s]) != 0: # Q値が最大となるように行動 return np.argmax(self.Q[s]) else: return np.random.randint(len(actions))初学者の方のために簡単に解説すると、基本的には行動価値が最大となるように行動を決定し、εの確率でランダムな行動を採用する方策です。
行動にある程度のランダム性をもたせることにより、様々な行動を探索するため、Q値の初期値に依存することなく適切な学習が可能となります。
Q学習の実装
さて、ここまでくればQ学習に必要な変数・メソッドは全てそろいました。
Q学習のアルゴリズムは以下です。
- $Q(s,a)$を初期化。
- 任意の回数バトルを繰り返す:
- ゲーム環境の初期化
- ゲームエンドまでターンを進める:
- 方策$π$に従って行動$a$を選択する。
- 行動$a$を行い、報酬$r$と次の状態$s′$を観測する。
- $Q(s,a)$を以下のように更新する。
$Q(s,a)$$\leftarrow$$Q(s,a)+α(r+γ*$$\underset{a′}{max}$$Q(s′,a′)−Q(s,a))$- $s$$\leftarrow$$s′$とする。
記事の冒頭でも述べたとおり、Q学習の理論については解説しませんので、上記のアルゴリズムを素直に実装しましょう。
q-learning.py# Q学習をする def learn(self, env, actions, episode_count=1000, gamma=0.9, learning_rate=0.1): self.Q = defaultdict(lambda: [0] * len(actions)) # episode_countの分だけバトルする for e in range(episode_count): # ゲーム環境をリセット tmp_s = env.reset() # 現在の状態を数値に変換 s = self.digitize_state(tmp_s) done = False # ゲームエンドになるまで行動を繰り返す while not done: # ε-greedy方策に従って行動を選択 a = self.policy(s, actions) # ゲームを1ターン進め、その時の「状態、報酬、ゲームエンドかどうか」を返す tmp_s, reward, done = env.step(a) # 状態を数値に変換 n_state = self.digitize_state(tmp_s) # 行動aによって得られた価値(gain) = 即時報酬 + 時間割引率 * 次の状態における最大のQ値 gain = reward + gamma * max(self.Q[n_state]) # 現在推測している(学習する前の)Q値 estimated = self.Q[s][a] # 現在の推測値と、行動aを実行してみたときの実際の価値をもとに、Q値を更新 self.Q[s][a] += learning_rate * (gain - estimated) # 現在の状態を次の状態へ s = n_stateこれで、ゲームとQ学習の実装までが完了しました。
ゲームを実行&学習
ランダムに行動させてみる
Q学習をする前に、勇者の行動をランダムにしてバトルするとどうなるのか試してみましょう。
以下のコードを追加します。
q-learning.pyclass Agent: # (省略) # テストバトル def test_run(self, env, actions, draw=True, episode_count=1000): turn_num = 0 # 撃破ターン数 win_num = 0 # 勝数 # episode_countの分だけバトルする for e in range(episode_count): tmp_s = env.reset() s = self.digitize_state(tmp_s) done = False while not done: a = self.policy(s, actions) n_state, _, done = env.step(a) s = self.digitize_state(n_state) if draw: env.draw() # バトルログを描画 if env.maou.hp <= 0: win_num += 1 turn_num += env.turn # 平均勝率・平均撃破ターン数を出力 if not win_num == 0: print("平均勝率{:.2f}%".format(win_num*100/episode_count)) print("平均撃破ターン数:{:.2f}".format(turn_num / win_num)) else: print("平均勝率0%") if __name__ == "__main__": game = dq_battle.Game() agent = Agent() actions = dq_battle.Character.ACTIONS """ 完全ランダムでバトル """ agent.epsilon = 1.0 agent.test_run(game, actions, episode_count=1000)ε=1.0とすることで、100%完全ランダムで行動させています。
また、1000回のバトル結果から、平均勝率・平均撃破ターン数を計算するようにしてみました。以下、実行結果です。
$ python q-learning.py 平均勝率0.90% 平均撃破ターン数:64.89勝率はかなり低いですね…。
ターン数を見ればわかるように、長期戦になりやすい傾向があります。
長期戦になればなるほど勇者が瀕死の状態が増えるので、その結果勝ちにくくなることが予想されます。Q学習後にバトルさせてみる
以下のコードを追加します。
q-learning.pyif __name__ == "__main__": # (省略) """ Q学習する """ agent.epsilon = 0.2 agent.learn(game, actions, episode_count=1000) """ テストバトル """ agent.epsilon = 0 agent.test_run(game, actions, episode_count=1000)ε=0.2とし、Q学習を実行してみます。
その後、1000回のテストバトルを行います。
なお、ε=0(0%ランダム)にすることで、学習した行動価値の通りに行動させています。以下、学習するバトル数を変えて実行結果を示します。
実行結果(学習バトル数:50、テストバトル数:1000)
$ python q-learning.py 平均勝率42.60% 平均撃破ターン数:56.19実行結果(学習バトル数500、テストバトル数:1000)
$ python q-learning.py 平均勝率100.00% 平均撃破ターン数:55.00実行結果(学習バトル数5000、テストバトル数:1000)
$ python q-learning.py 平均勝率100.00% 平均撃破ターン数:54.00勝率100%になりましたね!
学習後のQ値ってどうなってるの?
少しだけ考察をしてみます。
学習した結果のQ値を見てみましょう。以下、バトル数1000で学習させてみたときのQ値を、一部の状態について抜き出しました。
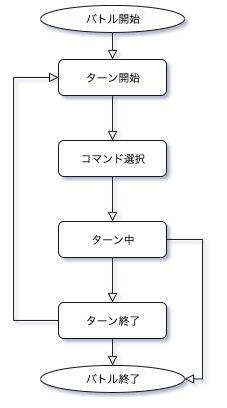
状態50:[-0.19, -0.1] 状態51:[-0.6623164987957537, -0.34788781183605283] 状態52:[-0.2711479211007827, 0.04936802595531123] 状態53:[-0.36097806076138395, 0.11066249745943924] 状態54:[-0.04065992616558749, 0.12416469852733954] 状態55:[0.17619052640036173, 0.09475948937059306] 状態56:[0.10659739434775867, 0.05112985778828942] 状態57:[0.1583472103200607, 0.016092008419030468] 状態58:[0.04964633744625512, 0.0020759614034820224] 状態59:[0.008345513895442138, 0.0]状態の見方は、10の位が魔王の残りHP、1の位が勇者の残りHPです。
つまり上記の図は、魔王の残りHPが5割程度のとき、勇者の残りHPによって行動価値がどう変化するかを表現した図になります。図から、勇者の残りHP(1の位)が低ければ「回復」コマンド、残りHPが高ければ「攻撃」コマンドを選択していることが読み取れます。
勇者の残りHPを固定したときのQ値も見ておきましょう。
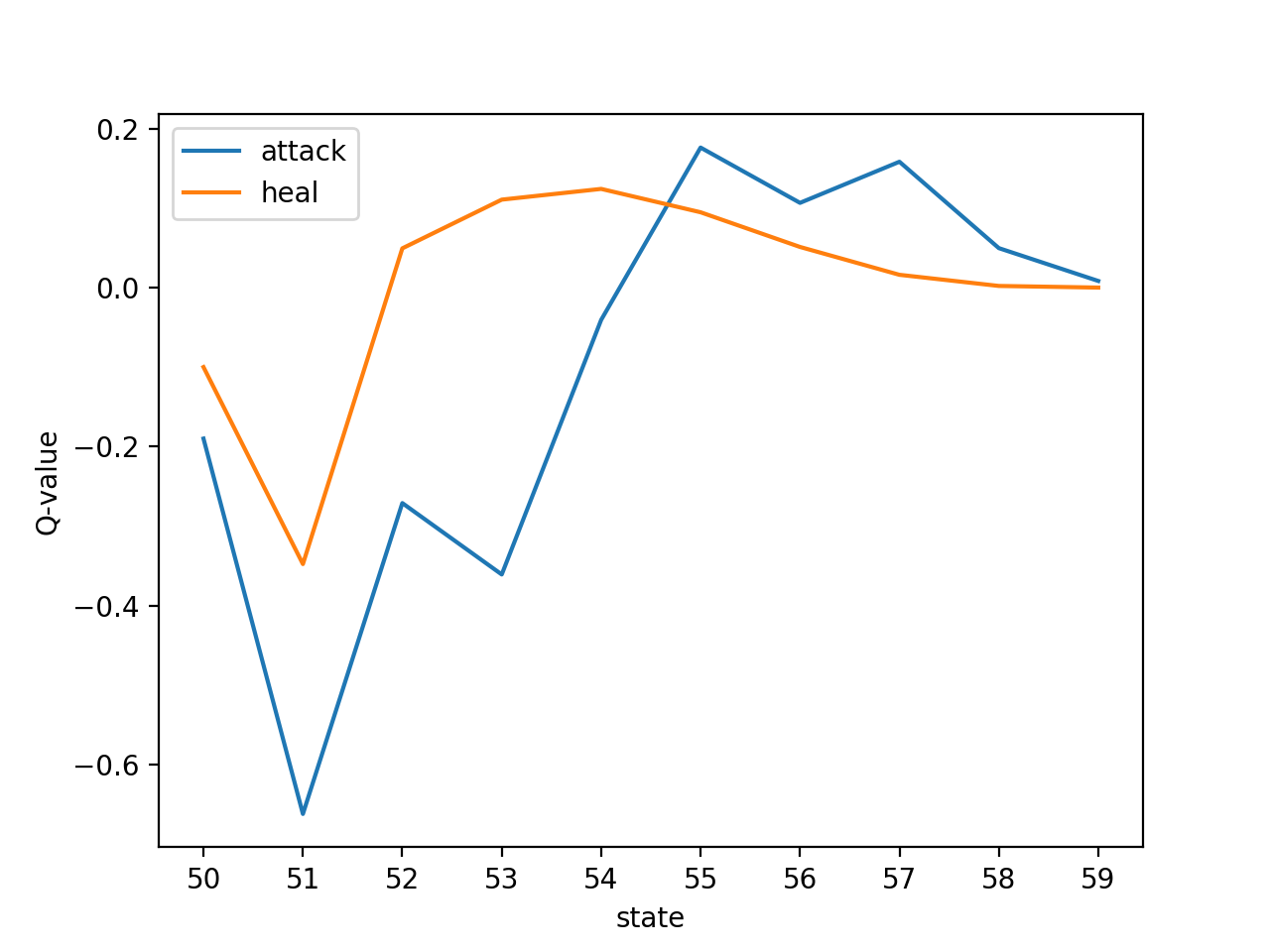
状態07:[2.023809062133135, 0.009000000000000001] 状態17:[1.8092946131557912, 0.8310497919226313] 状態27:[0.8223927076749513, 0.5279685031058523] 状態37:[0.5565475393122992, 0.29257906153106145] 状態47:[0.25272081107828437, 0.26657637207739293] 状態57:[0.14094053800308323, 0.1533527340827757] 状態67:[0.0709128688771915, 0.07570873469406877] 状態77:[0.039059851207044236, 0.04408123679644829] 状態87:[0.023028972190011696, 0.02386492692407677] 状態97:[0.016992303227705185, 0.0075795064515745995]上図は、勇者の残りHPが7割程度のとき、魔王の残りHPによって行動価値がどう変化するかを表現しています。
魔王の残りHPが少ないほど「攻撃」優位になっていることが読み取れると思います。最後に
本記事は実装がメインなので、その他考察などは省略します。
余裕のある方は、ハイパーパラメータを変えて学習してみたり、バトルルールをより複雑にすることに挑戦してみると面白いでしょう。また、筆者は強化学習初心者ですので、間違い等ありましたらお気軽にご指摘ください。
筆者の知識も強化されて嬉しくなります。ソースはgithubにおいています。
https://github.com/nanoseeing/DQ_Q-learning参考書籍
- 投稿日:2020-02-10T20:37:17+09:00
Azure Pipelines でハマった話
Python パッケージを Azure Artifacts フィードにアップロードしようとしてハマった話を一つ。
Azure Pipelines から Python パッケージをアップロードするには、
- task: TwineAuthenticate@1 inputs: artifactFeed: FEED - script: | python -m twine upload -r FEED --config-file $(PYPIRC_PATH) dist/*のようなステップを書くと説明されているのですが、 Azure Artifacts に新たに作成するフィードは、これを書いている時点で、すべてプロジェクトスコープ フィード (project-scoped feeds) になっていて、
- task: TwineAuthenticate@1 inputs: artifactFeed: PROJECT/FEEDとプロジェクト名を指定する必要があったわけです。これが分かるまで何度も試行錯誤を繰り返してしまいました。
現実的には、次のように変数参照にするのが便利だと思いますね。
- task: TwineAuthenticate@1 inputs: artifactFeed: $(System.TeamProject)/FEED
- 投稿日:2020-02-10T20:17:39+09:00
タダでプログラミングを学ぶ方法を考えてみた。
Background
何もない状況から低コストでプログラミングを学ぶ方法を考えてみた。(Mac編)
の続きです。今回はスマホは持っててPC買い始めのひと向けに無料でプログラムを学ぶ方法をまとめてみました。
OPAC - Library search system
おそらく、大卒が知っていて中卒・高卒が知らないことはOPACではないでしょうか。
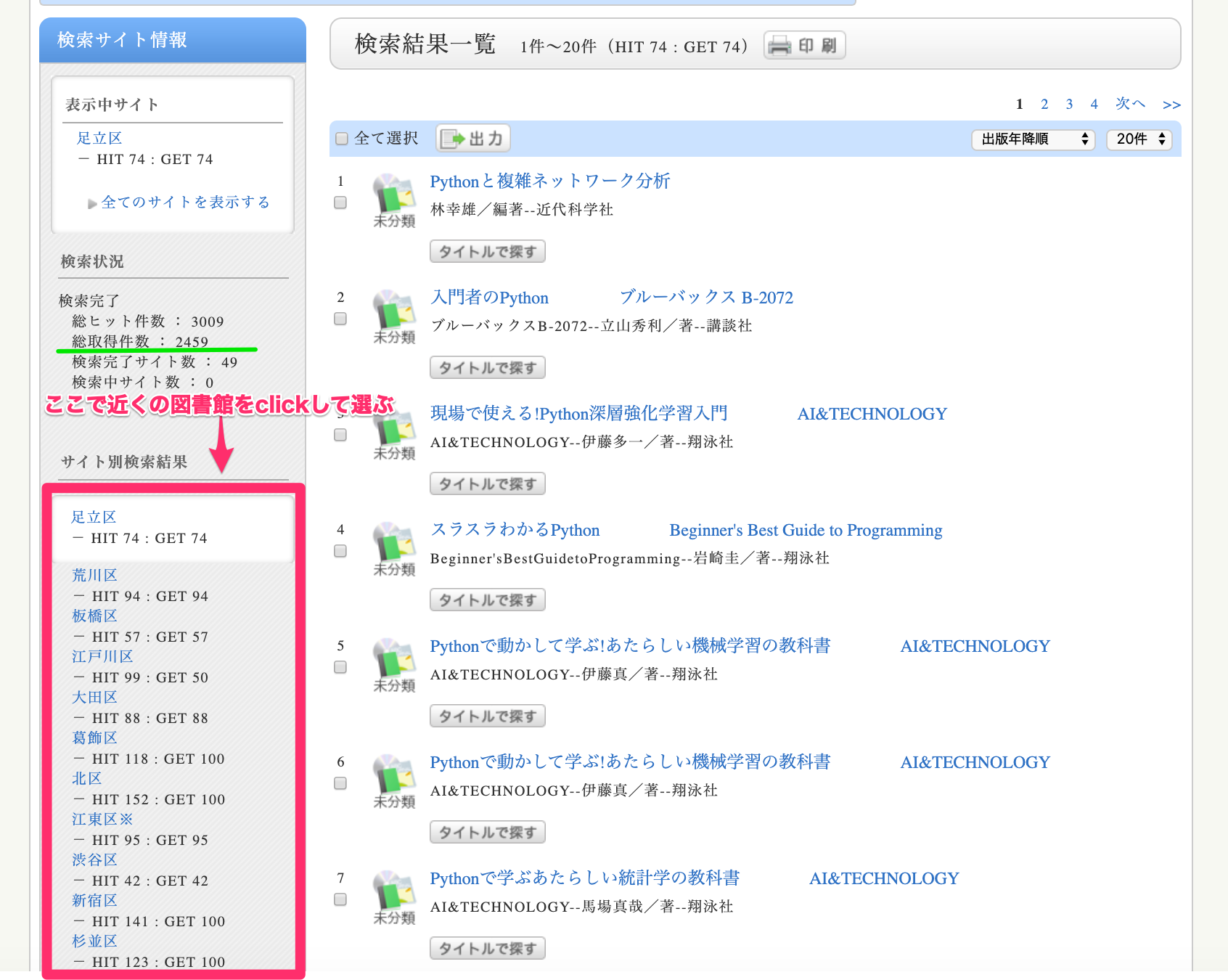
大学であれば本・雑誌・論文などを探すのに一回生の最初のオリエンテーションで聞かされると思います。Googleで
OPAC [住んでいる市町村区]
と検索すると図書館のリンク出てくるので、ここで
Python
と入力して探せば良いと思います。予想ですが、プログラム自体何それおいしいの状態のエリアが大半であってもVBAが主力だと思います。そのため、少し大きめの図書館でなければ検索は引っかからないと思います。
ただし、三大都市圏に住んでいるのであればどこかの図書館へ行けばPythonの本は必ずあるのでこの方法で探す選択肢は持っていて損はないです。
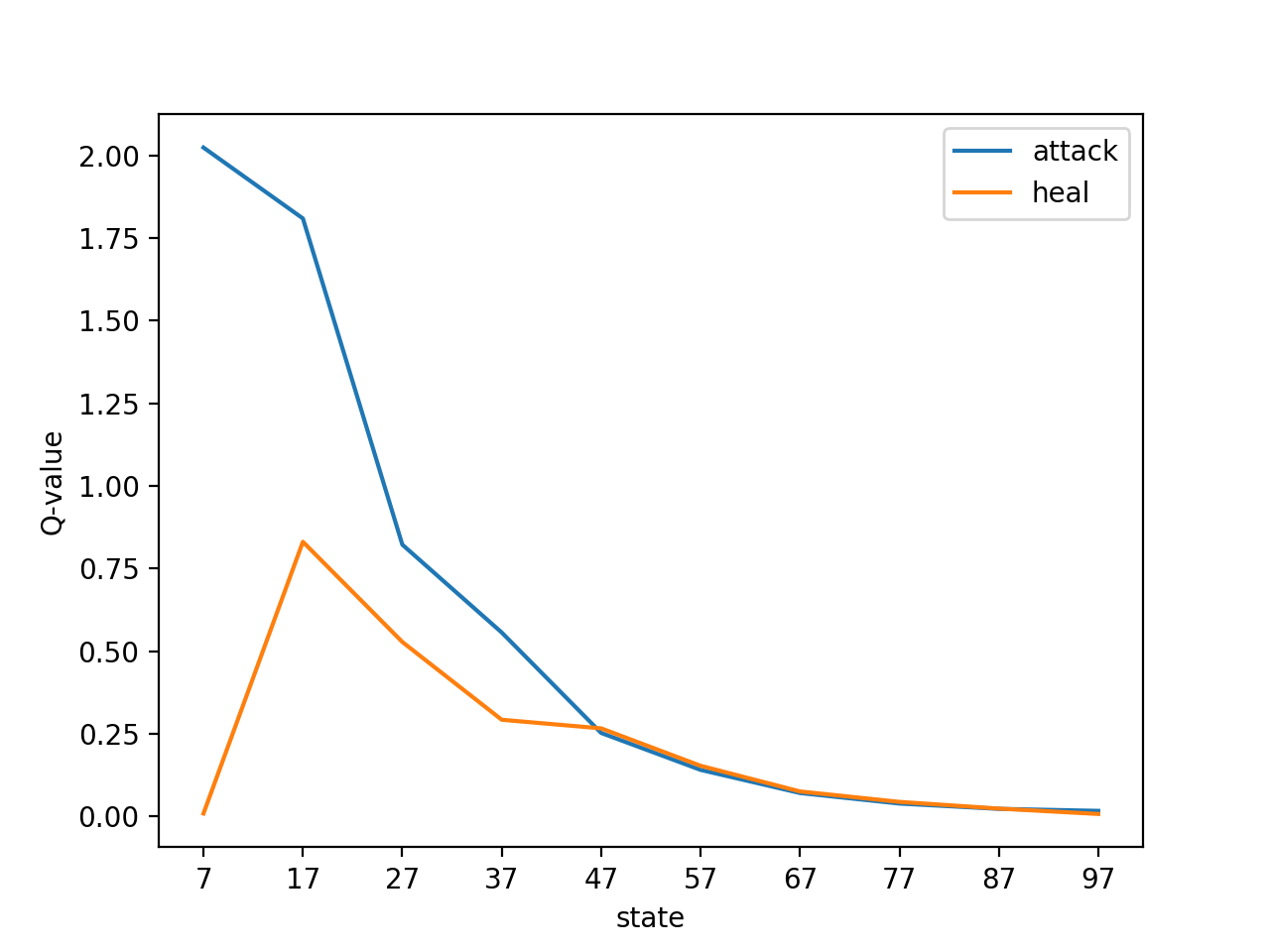
試しに
東京都立図書館
で東京都内にあるPythonの本を探してみました。
ここでは、[区立図書館][市町村立図書館]にチェックして"Python"で検索しました。
50音順なので足立区から表示されますがひとつの図書館に数十冊はありそうです。
左側のメニューから近くの図書館をクリックすると検索結果が反映されます。東京都内だと約2500 ~ 3000冊はありそうです。
Web site
の2つのサイトに書かれているコードを使って実行すれば大体のことは網羅できます。
(説明雑でサーセン)
あとは、公式サイトのドキュメントにもサンプルコードが書かれています。
ライブラリはたくさんあるわけですが、学習が進んで何か自分でアプリを作りたい時に必要そうな分だけ選んで使えば良くて、全て覚えている開発者はほとんどいないんじゃないかと思います。Skill Check
ひと通り学習が終わったら力試しとしてスキルテストすると良いです。
本格的に始めたい場合はAOJでもいいのですが、難易度の設定バランスや問題の出題方式だとPaizaの方がとっつきやすいです。S・A・B・C・Dと難易度別に問題が約200問あるのですが、C・Dの問題を多く正解できれば良いと思います。B問題ができると尚良いです。
(最低限一般の開発者が求めているスキルはB問題でしょうか。実際問題自分がなんとか一定の給与をもらって働いている。)自分はと言いますと一回しかA問題は解けんかったです
授業で再帰・2分探索・動的計画法などを学んでアウトプットできていればとちょっと後悔しています
(注: ギノの社員でも契約社員でもないとです
)
NextStage
Skill Checkで自信がついたらゲーム・webサイトを作成するなどのフェーズに移ればいいです。
freegamesかpygameを使ってサンプルコードを改造するところから始めるとかいいかもしれないです。
(以前に[Python]pipからゲームをインストールして遊んでみたで方法をまとめてます。)PostScript
次はPython2系とPython3系の話をしようと思います。
- 投稿日:2020-02-10T20:13:21+09:00
Lambda関数を設定してS3イベントで動かそう!
Lambdaってなに?
AWSの提供するサービスの一つで、サーバ管理をすることなく処理を実行することができるサービスです。
例えばLambdaを利用しない場合、EC2でサーバを作成し処理実行に必要なミドルウェアや言語をインストールし、環境設定をすることで初めて処理が実行されます。
しかし、Lambdaではそのようなサーバのプロビジョニングをすることなく、処理を書くだけで実行することが可能になります。
これにより、
★サーバ自体の管理・メンテナンスが不要
★処理が実行されている時間のみ課金されるので処理の頻度によってはコストを大幅削減可能
★他AWSサービスと容易に連携できるので、AWSメインのアーキテクチャでは大変便利
というメリットがあります。トリガーとは?
書いた処理を実行させるにはトリガーというものを設定する必要があります。
AWSのあらゆるサービスと連携ができ、CloudWatchでアラームが出たら実行、kinesis data stream にデータが存在するとき実行、S3にファイルが置かれたら実行などが代表的な例になります。つまりLambdaは実行する条件と実行される処理だけを書けば動いてくれるサービスなのです。
実際に設定したい!
ではs3にファイルをアップロードし、アップロードされたことを確認する処理を書いてみましょう。
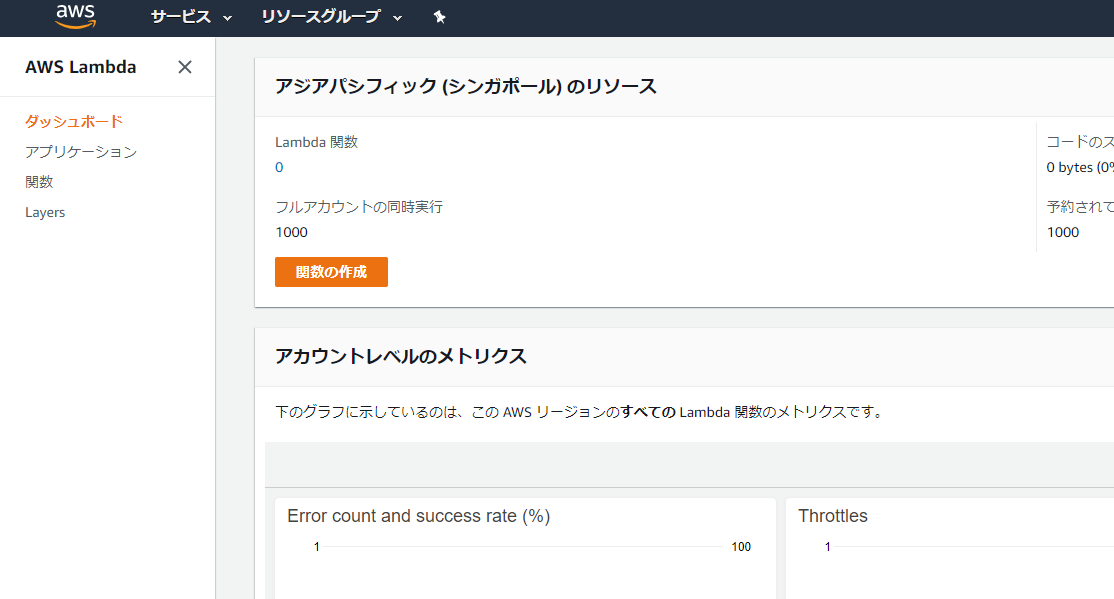
1.AWSコンソールにログインし、Lambdaの画面で「関数の作成」をクリック
Lambdaはリージョンごとに関数を設定することになります。
S3の場合は問題ないですが、他リージョンの影響を受けるサービスと連携するときは同じリージョンを選択しましょう。
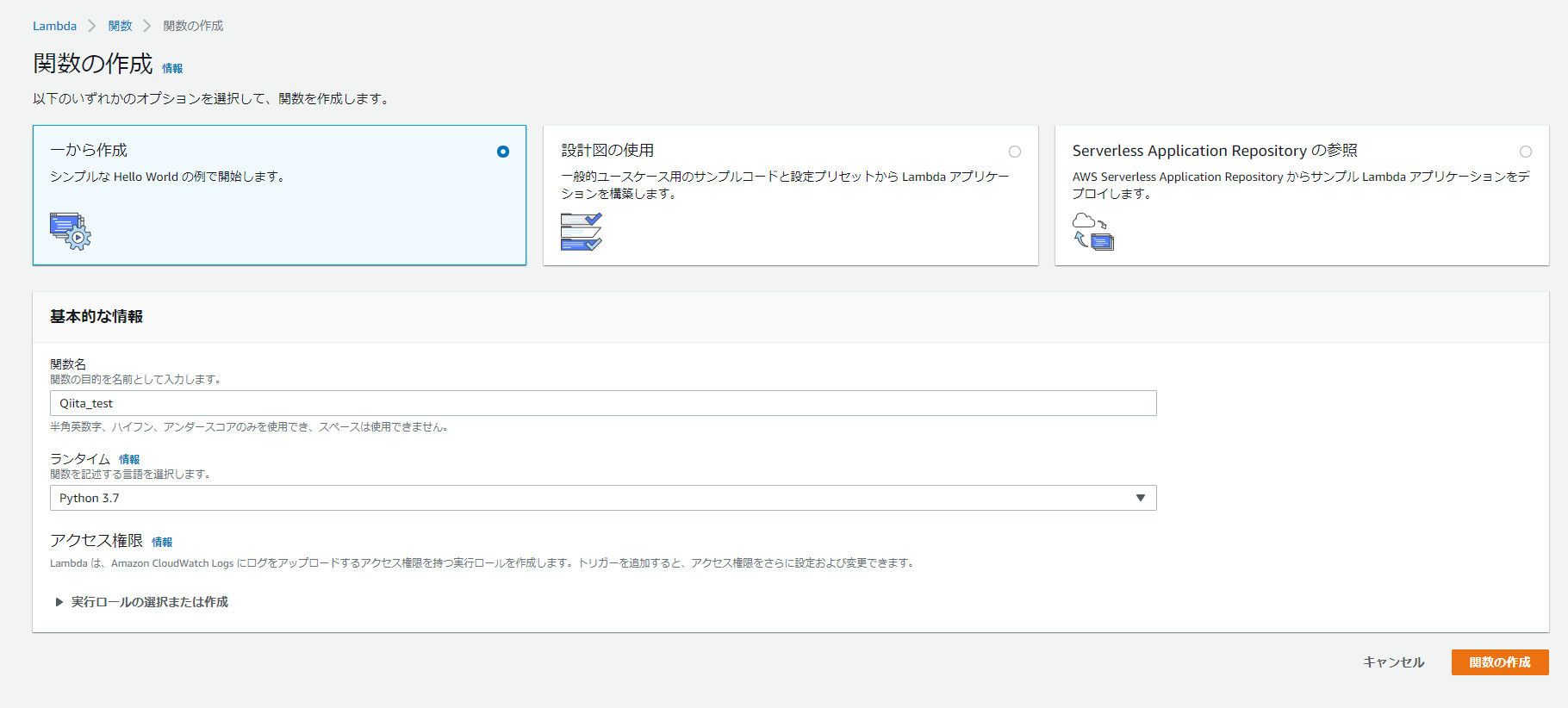
2.「1から作成」を選択し、「関数名」と「ランタイム」、「実行ロール」を設定
今回はpython 3.7を利用します。
ロールは「基本的なLambdaアクセス権限で新しいロールを作成」にします。
既存のロールを利用でも問題ないです。
その場合、Lambdaがトリガー条件のサービスやLog出力用のCloudWatchへのロググループ書き込み権限がある必要があります。
※新規作成の場合はCloudWatchのロググループ書き込み権限は自動でアタッチされます。「ランタイム」とは処理の言語を意味します。2020/02/05時点では選択できる言語は下記となっております。
・Java 11/8
・.NET Core2.1(C#/PowerShell)
・GO 1.x
・Node.js 12.x/10.x
・python 3.8/3.7/3.6/2.7
※カスタムランタイムを利用することであらゆる言語を利用できるようになりますが、本記事では省略します。
3.「トリガーを追加」で実行条件を設定
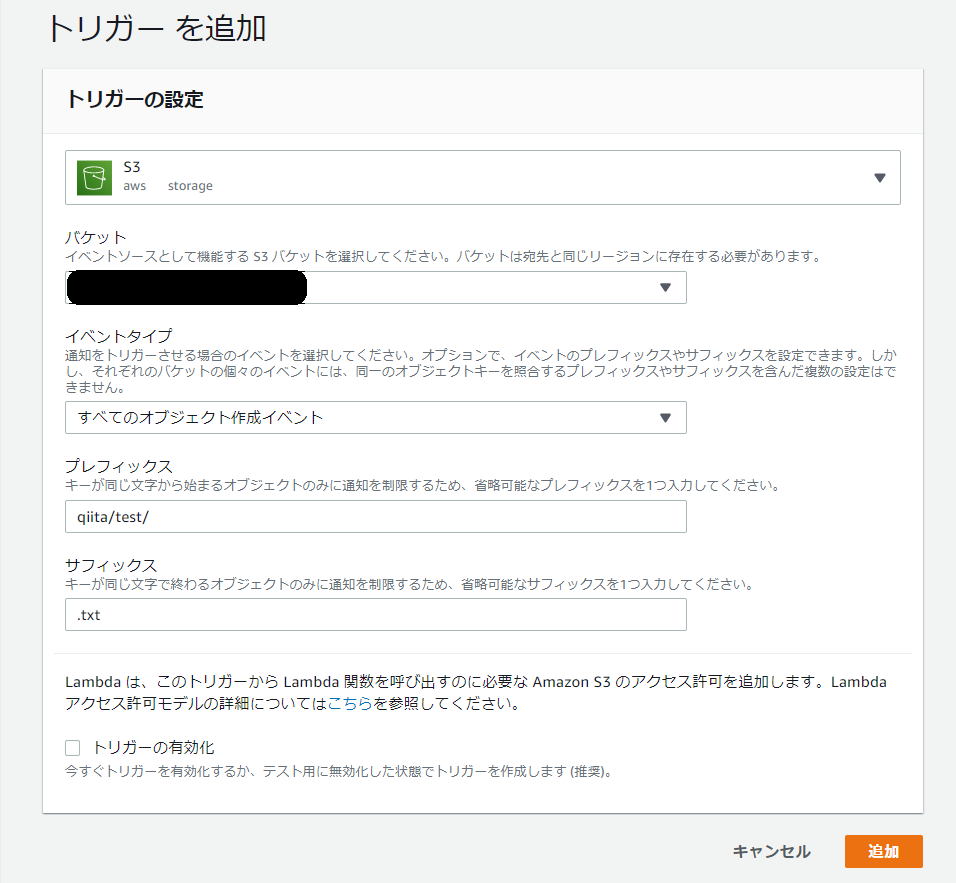
今回はs3に何かオブジェクトが作成されたときに実行できるようにします。
トリガー媒体をs3に設定したときの項目は下記の5つになります。
・バケット
・イベントタイプ(ファイルがPUTされたら・・・、ファイルが削除されたら・・・など)
・プレフィックス(バケット以降のディレクトリパスやファイル名など)
・サフィックス(ファイル名や拡張子など)
・トリガーの有効化(チェックするとすぐ上記設定のトリガーが動きます。処理のテストが終わってからonにしましょう)
4.関数コードを設定
デフォルトではlambda_function.pyというファイルに処理が記述されています。
lambda_function.pyimport json def lambda_handler(event, context): # TODO implement return { 'statusCode': 200, 'body': json.dumps('Hello from Lambda!') }lambda_handlerとはLambdaに設定されているトリガー条件が満たされたときに自動的に実行される関数です。
# TODO implement以降を編集し、実行したい処理を書きましょう。今回はs3にファイルが置かれたら置かれたパスとファイル名を表示するようにしてみます。
lambda_function.pyimport json def lambda_handler(event, context): bucket = event['Records'][0]['s3']['bucket']['name'] key = event['Records'][0]['s3']['object']['key'] print(bucket+'バケットに'+key+'が作成されました!')lambda_handlerに引数で渡している
eventにはトリガーとなったイベント情報が配列で入っており、
上記はそこからバケット名とファイルパスを取得し、表示を行っています。5.実行・確認
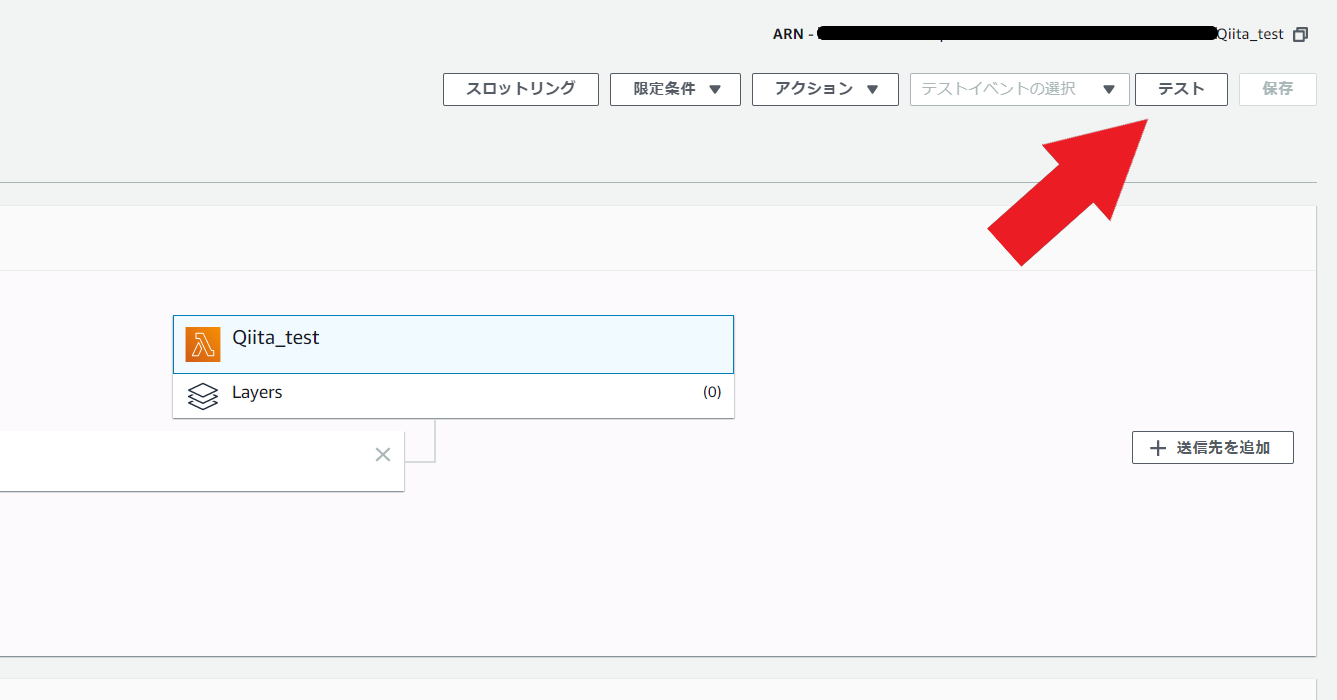
関数の実行自体はトリガーで指定したパスにファイルを置くことで実行できます。
それ以外にも下画像の「テスト」からeventに入る値をjson形式で設定することにより疑似的にLambda関数を実行することが可能です。
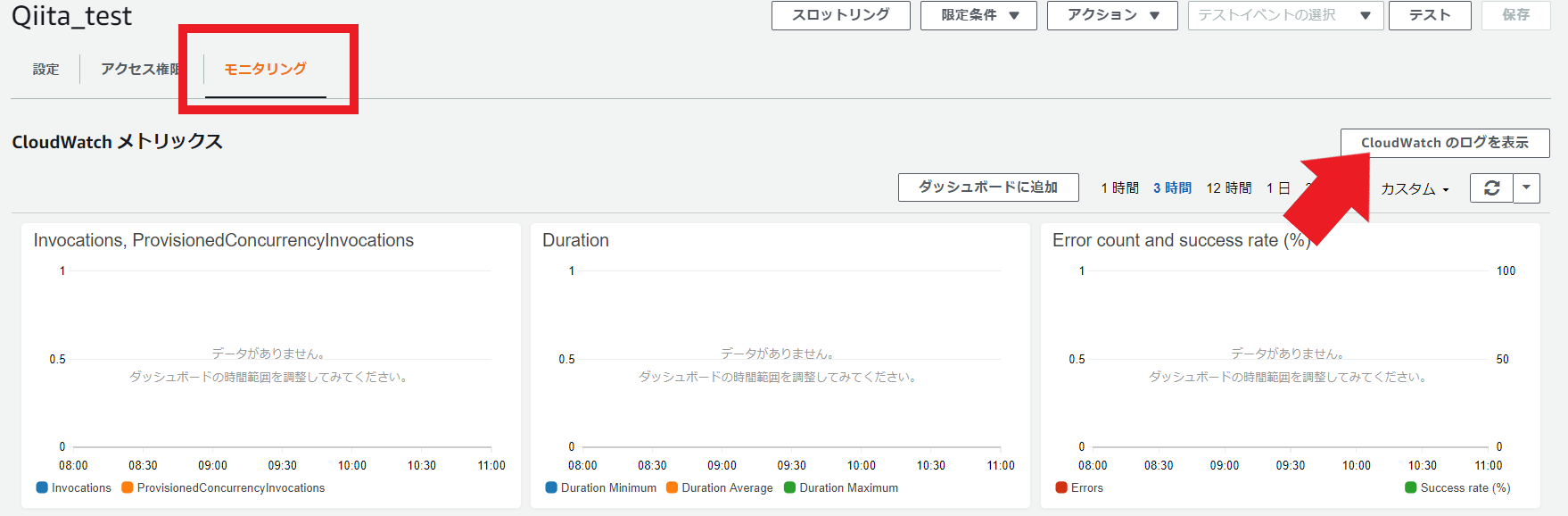
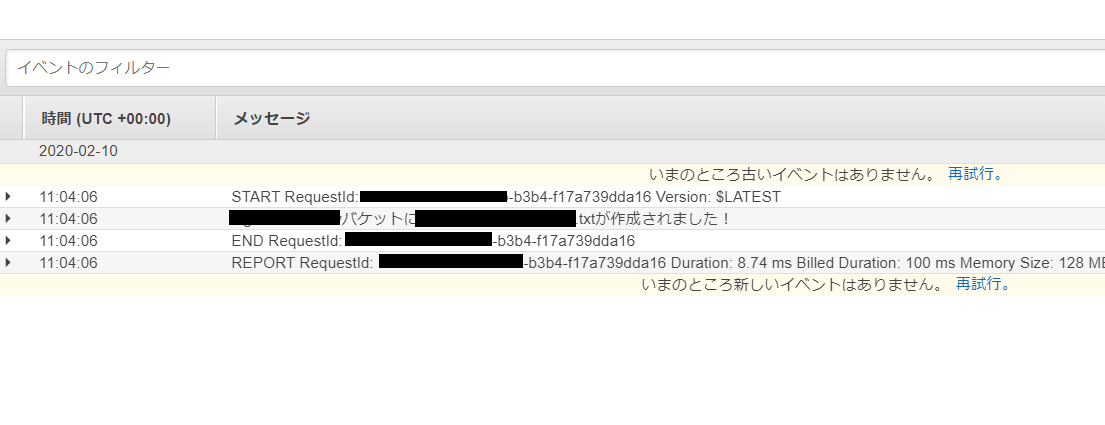
また、関数の実行LogについてはCloudWatchのロググループから対象の関数を選択し、そこから確認することが可能です。
正しくLambda関数が実行できていることが確認できました!!
終わりに
LambdaはAWS環境を利用しており、シンプルな処理をおこなうのであればコスト面、管理面でもとてもおススメです。
少し気になったのは関数が何をしているかの説明文を書いておく欄がないので、わかりやすい関数名・処理内でのコメント記載を徹底し、快適なLambdaライフをおくりましょう!!
- 投稿日:2020-02-10T20:00:13+09:00
Google colab上でCotohaを超手軽に使うためのコピペ用コード
前書き
COTOHAの使い方については既に超わかりやすい解説(自然言語処理を簡単に扱えると噂のCOTOHA APIをPythonで使ってみた や 「メントスと囲碁の思い出」をCOTOHAさんに要約してもらった結果。COTOHA最速チュートリアル付き)があるのですが、
【Qiita x COTOHA APIプレゼント企画】を知って自分で書いていたのと、
・環境構築面倒だからGoogle Colabで!
・何も考えずにコピペ1つで使える!って感じのものが欲しかったので記事として出しました。
この記事を読めばコピペ1つで即座に解析できるようになる...!(はず)。
このコピペでできるようになること+実装例
cotoha_call("ne", "ブラックサンダーが食べたい")と入力すると、
「ブラックサンダーが食べたい」の解析結果(これは固有表現抽出)が返ってきます。===>
固有表現抽出
===>
{'message': '',
'result': [{'begin_pos': 0,
'class': 'ART',
'end_pos': 8,
'extended_class': 'Product_Other',
'form': 'ブラックサンダー',
'source': 'basic',
'std_form': 'ブラックサンダー'}],
'status': 0}"ne"のところは以下に変更可能です(developersで使用できるapiはすべてカバーしているはず)
API名 入力 構文解析 parse 固有表現抽出 ne キーワード抽出 keyword 照応解析 coref 類似度算出 simi 文タイプ判定 sen_type ユーザ属性推定(β) user_at 言い淀み除去(β) filter 音声認識誤り検知(β) detect 感情分析 senti 要約(β) summary for文を使って全部やってみるとこんな感じ→
for api_type in ["ne", "parse", "coref", "keyword", "simi", "sen_type", "user_at", "filter", "detect", "senti", "summary"]: cotoha_call(api_type, "ブラックサンダーを食べたい。") print("\n") #結果を見やすくするための改行 print("解析終了!")
出力
===>
固有表現抽出
===>
{'message': '',
'result': [{'begin_pos': 0,
'class': 'ART',
'end_pos': 8,
'extended_class': 'Product_Other',
'form': 'ブラックサンダー',
'source': 'basic',
'std_form': 'ブラックサンダー'}],
'status': 0}===>
構文解析
===>
{'message': '',
'result': [{'chunk_info': {'chunk_func': 2,
'chunk_head': 1,
'dep': 'D',
'head': 1,
'id': 0,
'links': []},
'tokens': [{'attributes': {},
'features': [],
'form': 'ブラック',
'id': 0,
'kana': 'ブラック',
'lemma': 'ブラック',
'pos': '名詞'},
{'attributes': {},
'dependency_labels': [{'label': 'compound', 'token_id': 0},
{'label': 'case', 'token_id': 2}],
'features': [],
'form': 'サンダー',
'id': 1,
'kana': 'サンダー',
'lemma': 'サンダー',
'pos': '名詞'},
{'attributes': {},
'features': ['連用'],
'form': 'を',
'id': 2,
'kana': 'ヲ',
'lemma': 'を',
'pos': '格助詞'}]},
{'chunk_info': {'chunk_func': 1,
'chunk_head': 0,
'dep': 'O',
'head': -1,
'id': 1,
'links': [{'label': 'object', 'link': 0}],
'predicate': []},
'tokens': [{'attributes': {},
'dependency_labels': [{'label': 'dobj', 'token_id': 1},
{'label': 'aux', 'token_id': 4},
{'label': 'punct', 'token_id': 5}],
'features': ['A'],
'form': '食べ',
'id': 3,
'kana': 'タベ',
'lemma': '食べる',
'pos': '動詞語幹'},
{'attributes': {},
'features': ['終止'],
'form': 'たい',
'id': 4,
'kana': 'タイ',
'lemma': 'たい',
'pos': '動詞接尾辞'},
{'attributes': {},
'features': [],
'form': '。',
'id': 5,
'kana': '',
'lemma': '。',
'pos': '句点'}]}],
'status': 0}===>
照応解析
===>
{'message': 'OK',
'result': {'coreference': [],
'tokens': [['ブラック', 'サンダー', 'を', '食べ', 'たい', '。']]},
'status': 0}===>
キーワード抽出
===>
{'message': '', 'result': [{'form': 'ブラックサンダー', 'score': 10.0}], 'status': 0}===>
類似度算出
===>
{'message': 'OK', 'result': {'score': 0.99846786}, 'status': 0}===>
文タイプ判定
===>
{'message': '',
'result': {'dialog_act': ['information-providing'],
'modality': 'declarative'},
'status': 0}===>
ユーザ属性推定(β)
===>
{'message': 'OK',
'result': {'civilstatus': '既婚',
'hobby': ['ANIMAL',
'COOKING',
'FISHING',
'FORTUNE',
'GYM',
'INTERNET',
'SHOPPING',
'STUDY']},
'status': 0}===>
言い淀み除去(β)
===>
{'message': 'OK',
'result': [{'fillers': [],
'fixed_sentence': 'ブラックサンダーを食べたい。',
'normalized_sentence': 'ブラックサンダーを食べたい。'}],
'status': 0}===>
音声認識誤り検知(β)
===>
{'message': 'OK',
'result': {'candidates': [{'begin_pos': 4,
'correction': [{'correct_score': 0.709220240165901, 'form': 'ダンサー'},
{'correct_score': 0.6137611877341953, 'form': 'バンダー'},
{'correct_score': 0.6054945064139393, 'form': 'thunder'},
{'correct_score': 0.5943849175403254, 'form': 'サンダ'},
{'correct_score': 0.5878497568567171, 'form': 'ザンダー'}],
'detect_score': 0.05464221591729093,
'end_pos': 8,
'form': 'サンダー'}],
'score': 0.05464221591729093},
'status': 0}===>
感情分析
===>
{'message': 'OK',
'result': {'emotional_phrase': [],
'score': 0.38033421036210907,
'sentiment': 'Neutral'},
'status': 0}===>
要約(β)
===>
{'result': 'ブラックサンダーを食べたい。', 'status': 0}解析終了!
コピペの前に
・COTOHA APIからユーザー登録し、client_idとclient_secretを入手する(ユーザー登録はかなりわかりやすかったです)。
・「Python is 何?」状態だけどやってみたいって方はこちらの超わかりやすい解説(自然言語処理を簡単に扱えると噂のCOTOHA APIをPythonで使ってみた )を読んでみてください。
コピペするコード
コピペするコード
コピペ後にクライアントIDとクライアントシークレットを書き換える# -*- coding:utf-8 -*- #参考:https://qiita.com/gossy5454/items/83072418fb0c5f3e269f#python%E3%81%A7%E4%BD%BF%E3%81%A3%E3%81%A6%E3%81%BF%E3%81%9F import os import urllib.request import json import configparser import codecs import sys client_id = "クライアントID" client_secret = "クライアントシークレット" developer_api_base_url = "https://api.ce-cotoha.com/api/dev/nlp/" access_token_publish_url = "https://api.ce-cotoha.com/v1/oauth/accesstokens" api_name_show_switch = 1 #出力結果にapi名を表示させたくない場合は0にする def cotoha_call(api_type, sentence_1, sentence_2 = "ホワイトサンダーを食べたい", sent_len = 1, ): # アクセストークン取得 def getAccessToken(): # アクセストークン取得URL指定 url = access_token_publish_url # ヘッダ指定 headers={ "Content-Type": "application/json;charset=UTF-8" } # リクエストボディ指定 data = { "grantType": "client_credentials", "clientId": client_id, "clientSecret": client_secret } # リクエストボディ指定をJSONにエンコード data = json.dumps(data).encode() # リクエスト生成 req = urllib.request.Request(url, data, headers) # リクエストを送信し、レスポンスを受信 res = urllib.request.urlopen(req) # レスポンスボディ取得 res_body = res.read() # レスポンスボディをJSONからデコード res_body = json.loads(res_body) # レスポンスボディからアクセストークンを取得 access_token = res_body["access_token"] return access_token # API URL指定 if api_type == "parse": api_name = "構文解析" base_url_footer = "v1/" + api_type request_body_type = 1 elif api_type == "ne": api_name = "固有表現抽出" base_url_footer = "v1/" + api_type request_body_type = 1 elif api_type == "keyword": api_name = "キーワード抽出" base_url_footer = "v1/" + api_type request_body_type = 2 elif api_type == "coref": api_name = "照応解析" base_url_footer = "v1/coreference" request_body_type = 2 elif api_type == "simi": api_name = "類似度算出" base_url_footer = "v1/similarity" request_body_type = 3 elif api_type == "sen_type": api_name = "文タイプ判定" base_url_footer = "v1/sentence_type" request_body_type = 1 elif api_type == "user_at": api_name = "ユーザ属性推定(β)" base_url_footer = "beta/user_attribute" request_body_type = 2 elif api_type == "filter": api_name = "言い淀み除去(β)" base_url_footer = "beta/remove_filler" request_body_type = 4 elif api_type == "detect": api_name = "音声認識誤り検知(β)" base_url_footer = "beta/detect_misrecognition" request_body_type = 1 elif api_type == "senti": api_name = "感情分析" base_url_footer = "v1/sentiment" request_body_type = 1 elif api_type == "summary": api_name = "要約(β)" base_url_footer = "beta/summary" request_body_type = 5 else : print("Api Type Error.") sys.exit() if api_name_show_switch == 1: print("===>\n" + api_name + "\n===>") url = developer_api_base_url + base_url_footer # ヘッダ指定 headers={ "Authorization": "Bearer " + getAccessToken(), #access_token, "Content-Type": "application/json;charset=UTF-8", } # リクエストボディ指定 if request_body_type == 1: data = { "sentence": sentence_1 } elif request_body_type == 2: data = { "document": sentence_1 } elif request_body_type == 3: data = { "s1": sentence_1, "s2": sentence_2 } elif request_body_type == 4: data = { "text": sentence_1 } elif request_body_type == 5: data = { "document": sentence_1, "sent_len": sent_len } # リクエストボディ指定をJSONにエンコード data = json.dumps(data).encode() # リクエスト生成 req = urllib.request.Request(url, data, headers) # リクエストを送信し、レスポンスを受信 try: res = urllib.request.urlopen(req) # リクエストでエラーが発生した場合の処理 except urllib.request.HTTPError as e: # ステータスコードが401 Unauthorizedならアクセストークンを取得し直して再リクエスト if e.code == 401: access_token = getAccessToken() headers["Authorization"] = "Bearer " + access_token req = urllib.request.Request(url, data, headers) res = urllib.request.urlopen(req) # 401以外のエラーなら原因を表示 else: print ("<Error> " + e.reason) #sys.exit() # レスポンスボディ取得 res_body = res.read() # レスポンスボディをJSONからデコード res_body = json.loads(res_body) # レスポンスボディから解析結果を取得 return res_bodyあとは
cotoha_call("入力", "解析したい文章")で解析が始まります!
後書き
企画参加する方がんばりましょう!
参考
- 投稿日:2020-02-10T19:35:44+09:00
Macにpipenvをインストールするまでのメモ
Homebrewをインストールしたあとに・・・。
Python3.8.1のインストール
- pyenvでインストールします。(確定)
$ brew update $ brew install pyenv $ pyenv install --list インストール可能なversionの中で最新のものを選んでください。(今回は、"3.8.1"にします) $ pyenv install 3.8.1
- デフォルトで使用されるpythonのversionを確認する。(まだ
3.7.4なので)$ pyenv versions system * 3.7.4 (set by /Users/myname/.pyenv/version) 3.8.1
- インストールした
3.8.1を使用するようにpyenv globalコマンドで切り替えます。$ pyenv global 3.8.1 $ pyenv versions system 3.7.4 * 3.8.1 (set by /Users/myname/.pyenv/version)
- versionを確認すると、3.8.1になっている。
$ python -V Python 3.8.1pipのインストール(Python3と一緒に入っているので確認するだけ)
$ pip install --upgrade pip $ pip -V pip 20.0.2 from /Users/myname/.pyenv/versions/3.8.1/lib/python3.8/site-packages/pip (python 3.8)Pipenvのインストール
- (
pip install pipenvをしないままだと、古い3.7.4に内包されたpipenvが使用されてしまうため。)$ pip install pipenv $ pipenv --version pipenv, version 2018.11.26(^ω^)
- 投稿日:2020-02-10T19:31:30+09:00
概要を使って、映画を分類して、視聴者に似てる映画を進めるプロジェクト|Clustering-movies-based-on-their-plots
この記事は自然言語処理を使って、映画の概要を根拠として分類するプロジェクトです。元々はData Campから勉強した物なので、興味あるかたはぜひData Campをやってみて。それに関してのrepository(data set)はここにある:
https://github.com/Bing-Violet/Clustering-movies-based-on-their-plots
日本語が辛くなったら英語に戻りますので、許してください。
Import and observe dataset
# Import modules import numpy as np import pandas as pd import nltk # Set seed for reproducibility np.random.seed(5) # Read in IMDb and Wikipedia movie data (both in same file) movies_df = pd.read_csv('datasets/movies.csv') print("Number of movies loaded: %s " % (len(movies_df))) # Display the data movies_dfCombine Wikipedia and IMDb plot summaries
As we have two columns of plots(one from IMDB another from wikipedia). We're going to combine them here.
# Combine wiki_plot and imdb_plot into a single column movies_df['plot'] = movies_df['wiki_plot'].astype(str) + "\n" + \ movies_df['imdb_plot'].astype(str) # Inspect the new DataFrame movies_df.head()Tokenization
Tokenization is the process by which we break down articles into individual sentences or words, as needed. Besides the tokenization method provided by NLTK, we might have to perform additional filtration to remove tokens which are entirely numeric values or punctuation.
# Tokenize a paragraph into sentences and store in sent_tokenized sent_tokenized = [sent for sent in nltk.sent_tokenize(""" Today (May 19, 2016) is his only daughter's wedding. Vito Corleone is the Godfather. """)] # Word Tokenize first sentence from sent_tokenized, save as words_tokenized words_tokenized = [word for word in nltk.word_tokenize(sent_tokenized[0])] # Remove tokens that do not contain any letters from words_tokenized import re filtered = [word for word in words_tokenized if re.search('[a-zA-Z]', word)] # Display filtered words to observe words after tokenization filteredStemming
Words in English are made from three major blocks: prefix, stem, and suffix. For example, the word "appearance" and "disappear" share the same word stem "appear". Here, we're using the SnowballStemmer as the algorithm to get the stem out of the words.
# Import the SnowballStemmer to perform stemming from nltk.stem.snowball import SnowballStemmer # Create an English language SnowballStemmer object stemmer = SnowballStemmer("english") # Print filtered to observe words without stemming print("Without stemming: ", filtered) # Stem the words from filtered and store in stemmed_words stemmed_words = [stemmer.stem(word) for word in filtered] # Print the stemmed_words to observe words after stemming print("After stemming: ", stemmed_words)Club together Tokenize & Stem
We are now able to tokenize and stem sentences.
# Define a function to perform both stemming and tokenization def tokenize_and_stem(text): # Tokenize by sentence, then by word tokens = [y for x in nltk.sent_tokenize(text) for y in nltk.word_tokenize(x)] #PROJECT: FIND MOVIE SIMILARITY FROM PLOT SUMMARIES # Filter out raw tokens to remove noise filtered_tokens = [token for token in tokens if re.search('[a-zA-Z]', token)] # Stem the filtered_tokens stems = [stemmer.stem(word) for word in filtered_tokens] return stems words_stemmed = tokenize_and_stem("Today (May 19, 2016) is his only daughter's wedding.") print(words_stemmed)Create TfidfVectorizer
To enable computers to make sense of the plots, we'll need to convert the text into numerical values. One simple method of doing this would be to count all the occurrences of each word in the entire vocabulary and return the counts in a vector. However, this approach is flawed as articles like "a" may always have the highest frequency in most texts. Therefore, we're using Term Frequency-Inverse Document Frequency (TF-IDF) here.
# Import TfidfVectorizer to create TF-IDF vectors from sklearn.feature_extraction.text import TfidfVectorizer # Instantiate TfidfVectorizer object with stopwords and tokenizer # parameters for efficient processing of text tfidf_vectorizer = TfidfVectorizer(max_df=0.8, max_features=200000, min_df=0.2, stop_words='english', use_idf=True, tokenizer=tokenize_and_stem, ngram_range=(1,3))Fit transform TfidfVectorizer
Once we create a TF-IDF Vectorizer, we must fit the text to it and then transform the text to produce the corresponding numeric form of the data which the computer will be able to understand and derive meaning from.
# Fit and transform the tfidf_vectorizer with the "plot" of each movie # to create a vector representation of the plot summaries tfidf_matrix = tfidf_vectorizer.fit_transform([x for x in movies_df["plot"]]) print(tfidf_matrix.shape)Import KMeans and create clusters
To determine how closely one movie is related to the other by the help of unsupervised learning, we can use clustering techniques. Clustering is the method of grouping together a number of items such that they exhibit similar properties. According to the measure of similarity desired, a given sample of items can have one or more clusters.
K-means is an algorithm which helps us to implement clustering in Python. The name derives from its method of implementation: the given sample is divided into K clusters where each cluster is denoted by the mean of all the items lying in that cluster.
# Import k-means to perform clusters from sklearn.cluster import KMeans # Create a KMeans object with 5 clusters and save as km km = KMeans(n_clusters=5) # Fit the k-means object with tfidf_matrix km.fit(tfidf_matrix) clusters = km.labels_.tolist() # Create a column cluster to denote the generated cluster for each movie movies_df["cluster"] = clusters # Display number of films per cluster (clusters from 0 to 4) movies_df['cluster'].value_counts()Calculate similarity distance
The similarity distance is based on the cosine similarity angle.
# Import cosine_similarity to calculate similarity of movie plots from sklearn.metrics.pairwise import cosine_similarity # Calculate the similarity distance similarity_distance = 1 - cosine_similarity(tfidf_matrix)Import Matplotlib, Linkage, and Dendrograms
We shall now create a tree-like diagram (called a dendrogram) of the movie titles to help us understand the level of similarity between them visually. Dendrograms help visualize the results of hierarchical clustering, which is an alternative to k-means clustering. Two pairs of movies at the same level of hierarchical clustering are expected to have similar strength of similarity between the corresponding pairs of movies. For example, the movie Fargo would be as similar to North By Northwest as the movie Platoon is to Saving Private Ryan, given both the pairs exhibit the same level of the hierarchy.
Let's import the modules we'll need to create our dendrogram.
# Import matplotlib.pyplot for plotting graphs import matplotlib.pyplot as plt # Configure matplotlib to display the output inline %matplotlib inline # Import modules necessary to plot dendrogram from scipy.cluster.hierarchy import linkage from scipy.cluster.hierarchy import dendrogramCreate merging and plot dendrogram
Now we're going to plot the dendrogram to see the linkage between different movies.
# Create mergings matrix mergings = linkage(similarity_distance, method='complete') # Plot the dendrogram, using title as label column dendrogram_ = dendrogram(mergings, labels=[x for x in movies_df["title"]], leaf_rotation=90, leaf_font_size=16, ) # Adjust the plot fig = plt.gcf() _ = [lbl.set_color('r') for lbl in plt.gca().get_xmajorticklabels()] fig.set_size_inches(108, 21) # Show the plotted dendrogram plt.show()
The words are too tiny here. Check out the repository to see more.
Now, we can figure out what could be the best options to recommend to an audience based on their liked movies.

- 投稿日:2020-02-10T19:28:06+09:00
python初心者がIT企業にインターンしてみた
python学習を初めて四ヶ月と少し。パソコンも使い初めて半年の1大学生がコミュ力だけでインターンにたどり着いた。しかし、この業界はコミュ力だけでは通用しない。そこで、これから自分の技量が試される訳だが、死ぬほどに不安に駆られている。これから一ヶ月勤務することになる。
1, 初日、今後の方針の打ち合わせ(社長同席)
2, 衝撃の内容
3, まずはスーツで形から笑
4, 終わりに1, 心臓バクバクで打ち合わせに臨んだ私は、社長の言葉と共に心拍数が増した。そんな緊張の中、始まった打ち合わせであったが、その会社の社長と部長と他の二つの会社の社長と社員の六人に囲まれた状況はうんこが漏れる他ない。
2, それはさておき内容を説明しよう。2/12~3/31の一ヶ月半、9am~18pmまで勤務する事になるのだが、その内容というものは私一人でAIを使ったチャットボットをお客さんの要望に答えながら開発するという物。pythonで開発経験のない私は、心の中でお経を唱えていた。(高校は仏教高校)この私はこれからどうしたらいいものやら。追い討ちをかけるように社長が放った言葉は「windows でやろうか。」私のpcはmac book air。この会社はIT企業ではない、アイズワイドシャット(キューブリック作品)のあの集団だと本気で思ったが、お経が終わってないためお経を続けた。
3, とりあえず社内見学をさせてもらったが私以外スーツである(そういう集団だと確信)。とりあえず、スーツが必要であるため、明日はスーツを買いに行く。ごうになんとかごうに何とかということを思い出したが故の決断である。
4, 終わりに
私が大学1回生にもかかわらずインターンをしようと思った理由は三つある。一つ目はプログラミングの独学には限界がある。できないこともないがひたすら独学することは私の性に合ってない。実際の現場のプロセスを学べばもっとスムーズに進むと考えたからである。二つ目は私が所属するプログラミング学習者と企業をつなげる架け橋となろうと考えたからだ。IT企業もエンジニア不足に直面しているため利害関係は一致している。というわけで今日はこれくらいにしておこう。とりあえず進捗を報告していくしだいであるため、以後よろしく頼んます。
- 投稿日:2020-02-10T19:03:44+09:00
np.whereでドツボにハマった話
はじめに
画像処理の中で
np.whereのインデックス取り出しにおける出力が全くできなかったので
ここのサンプルコードを参考にしながら理解しました・・・
なので備忘録です!
これ読み方わかったらアハ体験できるのでは!??np.whereの出力!!?
参考にしたサンプルコードと出力です.
今回は3階テンソル($Width \times Height \times Channels = 2 \times 3 \times 4 $)
となっています.a_3d = np.arange(24).reshape(2, 3, 4) print(a_3d) # output # [[[ 0 1 2 3] # [ 4 5 6 7] # [ 8 9 10 11]] # # [[12 13 14 15] # [16 17 18 19] # [20 21 22 23]]] print(np.where(a_3d < 5)) # output # (array([0, 0, 0, 0, 0]), array([0, 0, 0, 0, 1]), array([0, 1, 2, 3, 0]))ここで
np.where(a_3d < 5)の出力を
$Width$:array([0, 0, 0, 0, 0])
$Height$:array([0, 0, 0, 0, 1])
$Channels$:array([0, 1, 2, 3, 0])
のリストだとみて
$Width$:W
$Height$:H
$Channels$:C
とおくと3階テンソルの要素にアクセスするためにはa_3d[W[0]][H[0]][C[0]] = 0 a_3d[W[1]][H[1]][C[1]] = 1 a_3d[W[2]][H[2]][C[2]] = 2 a_3d[W[3]][H[3]][C[3]] = 3 a_3d[W[4]][H[4]][C[4]] = 4となります.
これでやっとnp.where(a_3d < 5)の出力が読めた!さいごに
最初は配列が返ってくるだけだったのでなんだこれ?っと思ってましたが
行,列,奥行きの形が見えてくると意味のある数値に変わりますね〜
アハ体験いいですよね〜
- 投稿日:2020-02-10T18:40:02+09:00
ID連携(GitLab)で、JupyterHubのユーザープロビジョニングを簡単に
動機
- Jupyter Notebook を複数人で使いたいと言われた。
- 大掛かりにはしなくていい(したくない)・・
- JupyterHubの出番だが、デフォルトはPAM認証。つまり、Linuxユーザが事前に必要。
- 何人利用したいかわからないし、用意がめんどくさい・・・
- ID連携すれば、ユーザープロビジョニングができる。つまり、自動化できてラク!
- 今回は、オンプレで利用していたGitLabが使えた。
- そのときの備忘録。
環境
- GitLab Community Edition 12.7.5
- JupyterLab 1.2.6 + hub-extension (JupyterHub 1.1.0)
- Docker 19.04
- Docker Compose 1.25.3
- オンプレ環境
構築手順
1. GitLab: IDプロバイダーの設定
- Admin(ルート)ユーザでログイン。(一般ユーザでもいいかもだが、未検証)
- 「Admin Area」→「Application」→「New Application」を選択し、新規作成。
- 「api」、「read_user」を許可する。
- 「Callback URL」は、認証後にJupyterに戻るための情報。Jupyterにアクセスするホスト情報を塗り潰しに補完。
- Application作成後に表示される、「Application ID」、「Secret」を控えておく。
2. JupyterLab + hub-extension の起動
設定ファイルを作成
今回は特にJupyterHubに関連する設定なので、JupyterHubのデフォルト設定からいじります。
以下、生成コマンド例。ただし、出力した設定ファイルがROOTの所有物になる。(chownとか必要)
docker run --rm -v ${PWD}:/etc/jupyterhub jupyterhub/jupyterhub jupyterhub --generate-config -f /etc/jupyterhub/jupyterhub_config.py設定ファイルを編集
追加する設定は以下。(詳細は、その下に。)
jupyterhub_config.pyへの追加分from oauthenticator.gitlab import LocalGitLabOAuthenticator c.JupyterHub.authenticator_class = LocalGitLabOAuthenticator c.LocalAuthenticator.create_system_users = True c.Spawner.default_url = '/lab' c.Authenticator.admin_users = {'admin', }
- 必須
c.JupyterHub.authenticator_classc.LocalAuthenticator.create_system_users
認証・プロビジョニングするため。OAuthenticatorについて
... Localがついていると、ローカルユーザの自動生成が効く。(最初付けてなくてハマった)
- 任意
c.Spawner.default_url: ログイン後、JupyterLabを使うため。c.Authenticator.admin_users: JupyterHubのAdminユーザの指定。各ファイルを配置
以下のDockerfile、YAMLを適宜修正し、設定ファイルとあわせ配置する。
※ 例なので、データ永続化などしてないので注意。
配置例. |- dockerfile | |- Jupyter.dockerfile |- docker-compose.yml |- jupyterhub_config.pyJupyter.dockerfileFROM nvidia/cuda:10.1-cudnn7-devel-ubuntu18.04 RUN apt update && \ apt install -y python3 python3-pip npm nodejs && \ npm install -g configurable-http-proxy && \ pip3 install jupyterlab oauthenticator && \ jupyter labextension install @jupyterlab/hub-extensiondocker-compose.ymlversion: "2.3" services: jupyter: build: - context: dockerfile - dockerfile: Jupyter.dockerfile runtime: nvidia ports: - "8000:8000" volumes: - "./jupyterhub_config.py:/etc/jupyterhub_config.py" environment: - GITLAB_URL=http://<GitLabのURL> - OAUTH_CALLBACK_URL=先ほどの「Callback URL」 - GITLAB_CLIENT_ID=先ほどの「Application ID」 - GITLAB_CLIENT_SECRET=先ほどの「Secret」 command: jupyterhub -f /etc/jupyterhub_config.py起動
docker-compose build docker-compose up -d3. 動作確認
Jupyterにアクセス
→ GitLabへのリダイレクト画面が出る(画面1)
→ GitLabで認証する(画面2)
→ JupyterHubにリダイレクト(画面3)
→ ログイン完了済&領域自動確保(Linuxユーザ自動作成)(画面4)
4. 注意点
GitLabのユーザ名に「. (dot)」が含まれていると、Linux側のユーザ作成に失敗しJupyterLabが立ち上がらないので、注意。
例)
pekora.usadaはNG。pekora_usadaはOK。※ 少なくとも自分が試したときには。
おわり
KubeFlowでなにかやりたい。。
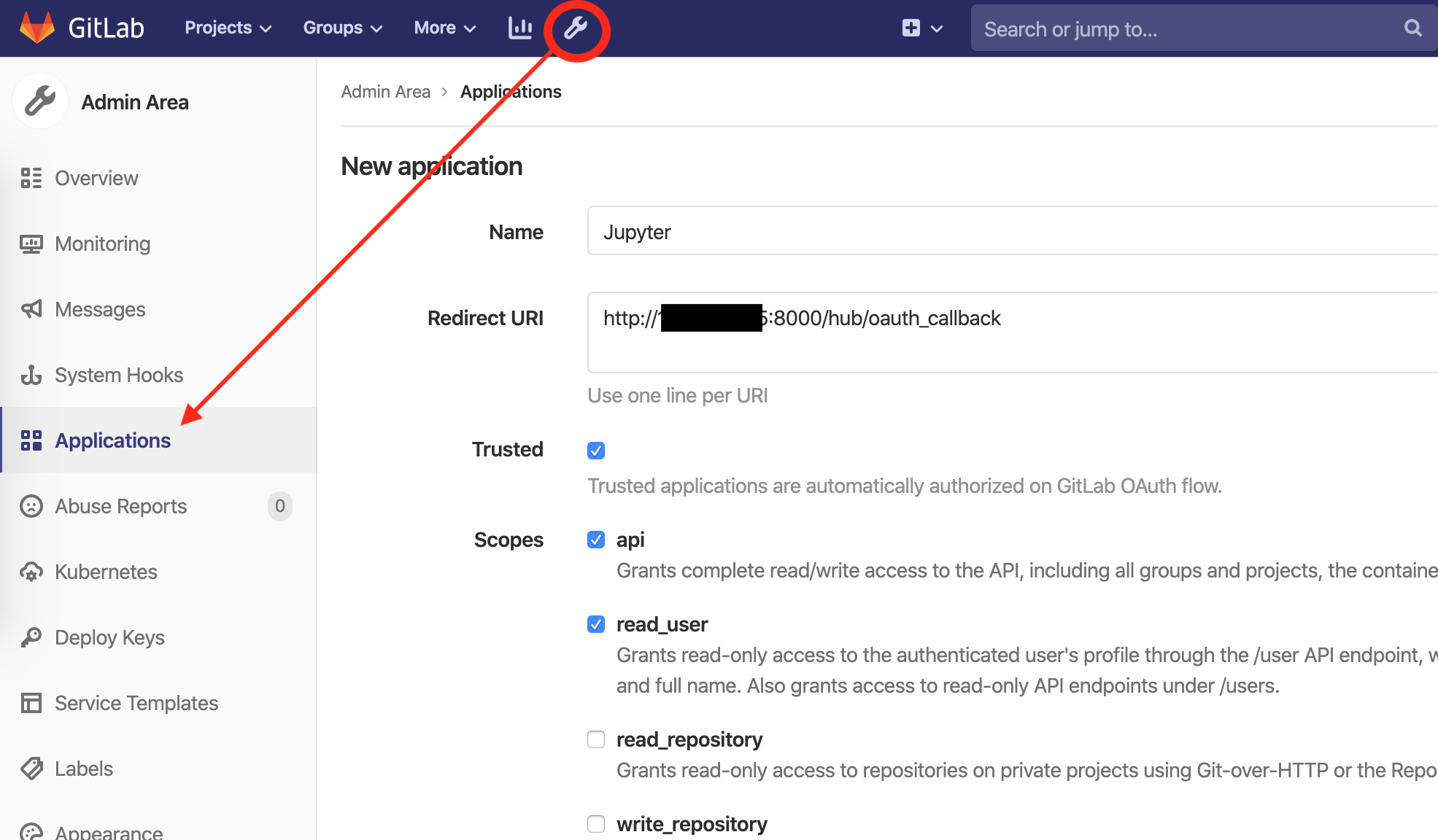
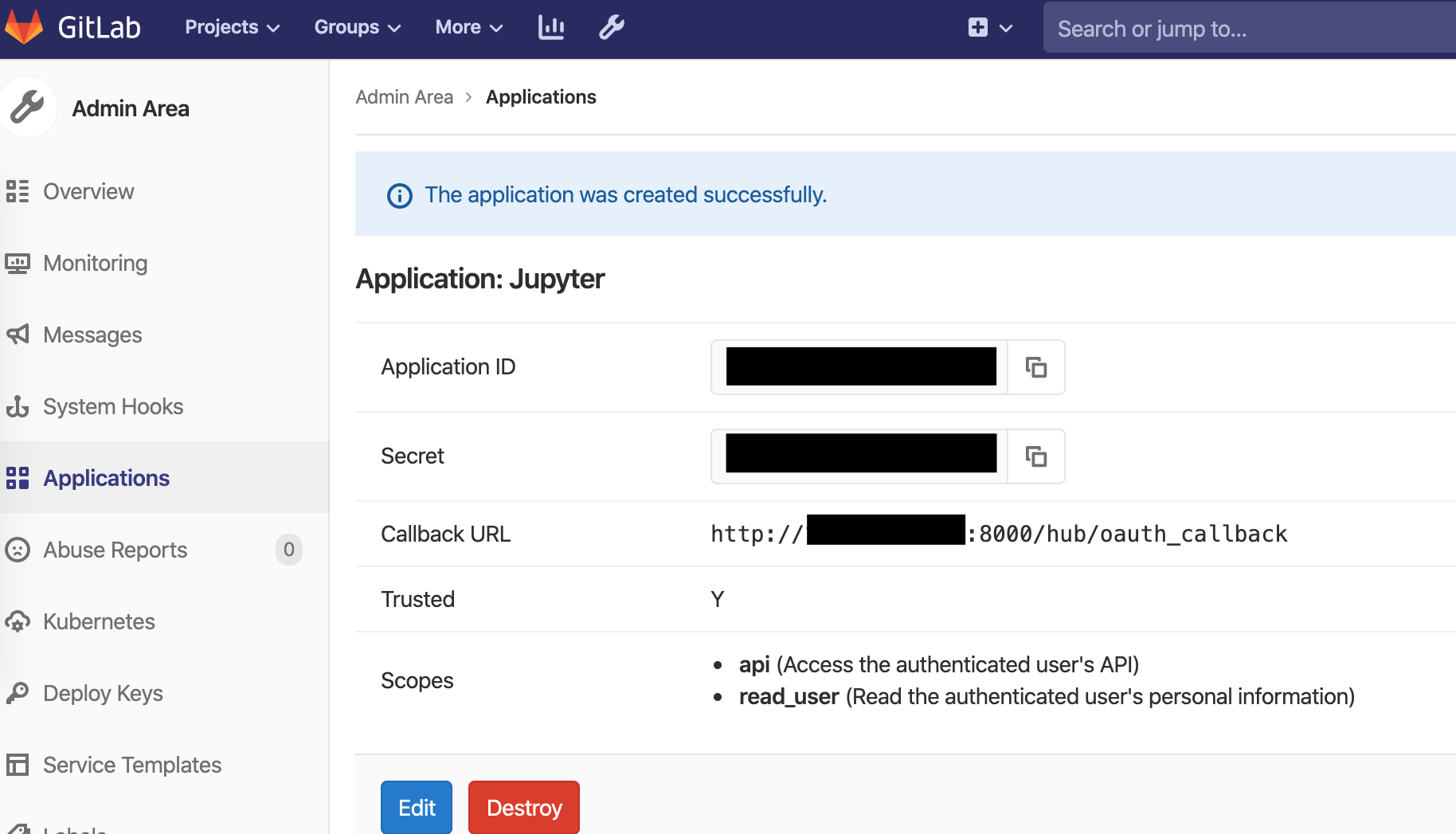
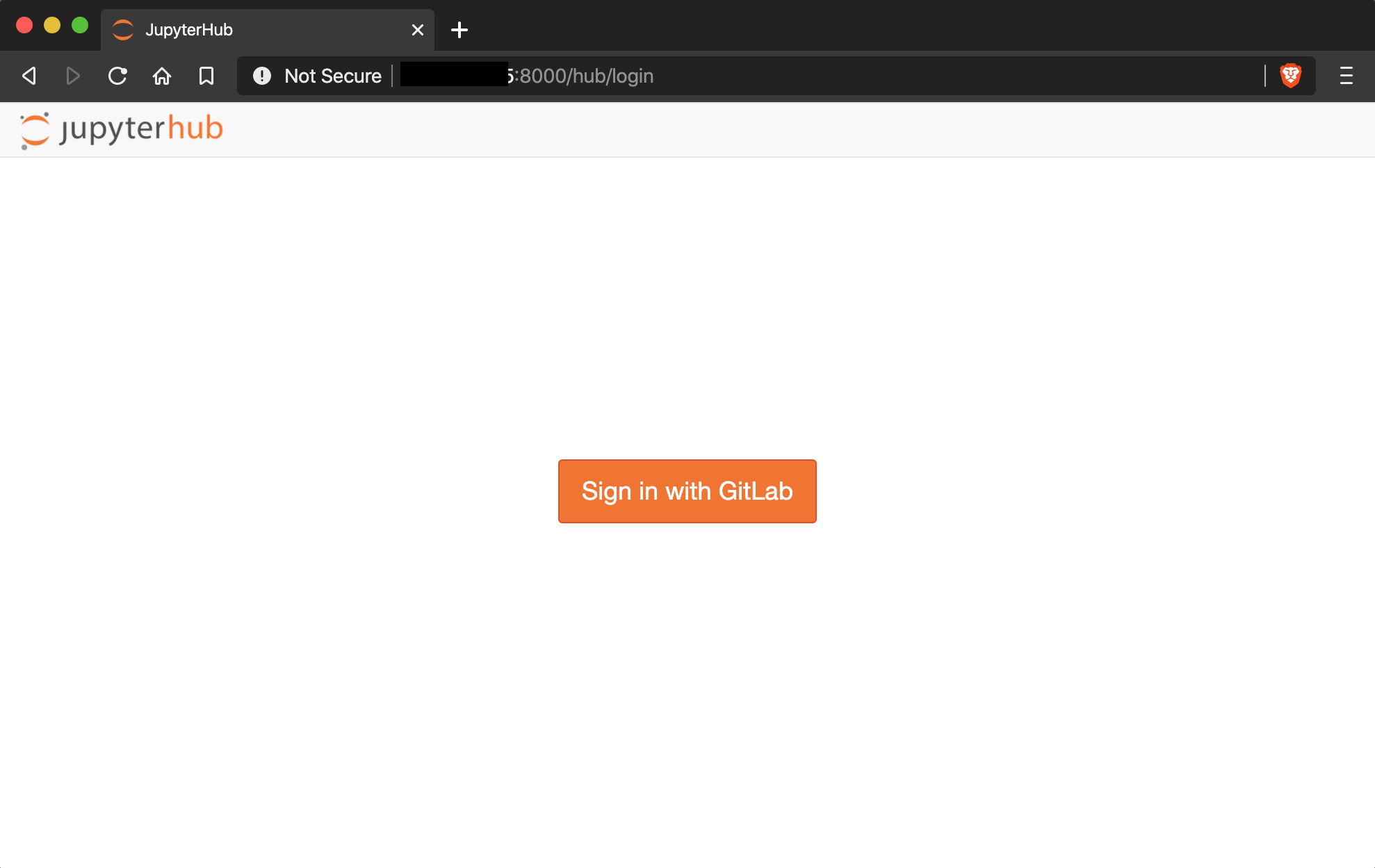


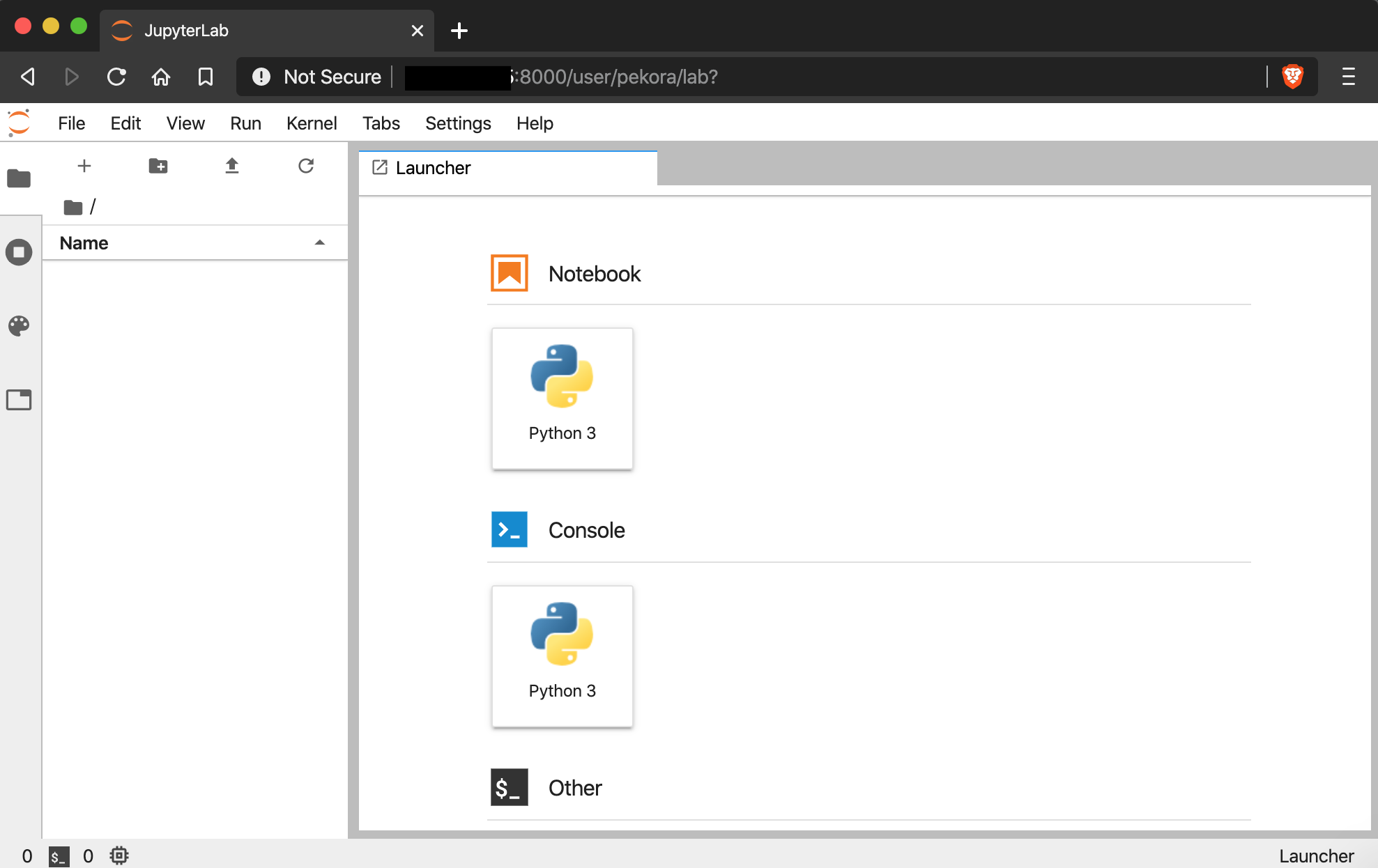
- 投稿日:2020-02-10T18:32:13+09:00
【Python & SQLite】単勝1倍台の馬がいるレースの期待値分析してみた②
概要
前回の投稿 【Python & SQLite】単勝1倍台の馬がいるレースの期待値分析してみた① の続編となります。
前回はスクレイピングしたデータをSQLにまとめ、Python(Jupiter Notebook)で単勝期待値を計算しました。前回に引き続き、テーマは「単勝1倍台の馬が出走するレースの買い方」です。
前回の反省点
競馬場や距離などの条件を絞らずに計算したため、単勝馬券で期待値100を超える買い方を見つけられませんでした。
今回は競馬場、距離、芝/ダート、券種を絞って詳しく分析していきましょう。競馬場、券種を絞って期待値の高そうな条件を探す
今回は「東京競馬場」に絞った結果を書いておきます。
他の競馬場でもいいのですが、歴史ある競馬場ですし、強い馬が実力を発揮しやすいと思うため東京競馬場にしました。また券種は馬連(1,2着のどちらかに選んだ2頭が入れば当たり)で分析します。
前回の投稿で分かったように、単勝1倍台の1番人気は50%近い確率で勝利していることから、
馬連が当たりやすさと配当妙味のバランスに優れているという仮説を立てました。
(三連系だと人気薄の馬のノイズもありそうという理由もあります)TokyoRacecource# 芝コース 馬連でおいしい馬券を探す # 単勝1倍台の1番人気馬の連帯率を調べる cur.execute("SELECT i.distance, count(r.race_id) FROM race_result r \ INNER JOIN race_info i on r.race_id=i.id \ WHERE r.odds<2.0 AND r.order_of_finish IN ('1','2') AND i.surface like '芝%' AND i.place_detail like '%東京%' \ AND r.race_id IN (SELECT race_id from race_result WHERE odds<2.0 AND popularity='1') \ GROUP BY i.distance ORDER BY i.distance") rows = cur.fetchall() print('連帯数(芝)') for row in rows: print(row) cur.execute("SELECT i.distance, count(r.race_id) FROM race_result r \ INNER JOIN race_info i on r.race_id=i.id \ WHERE r.odds<2.0 AND r.order_of_finish NOT IN ('1', '2') AND i.surface like '芝%' AND i.place_detail like '%東京%'\ AND r.race_id IN (SELECT race_id from race_result WHERE odds<2.0 AND popularity='1') \ GROUP BY i.distance ORDER BY i.distance") rows2 = cur.fetchall() print('3着以下数(芝)') for row2 in rows2: print(row2) rentai1800 = round(rows[2][1] / (rows[2][1] + rows2[2][1]) * 100, 2) print('1800m連帯率: %f パーセント' %rentai1800) rentai2000 = round(rows[3][1] / (rows[3][1] + rows2[3][1]) * 100, 2) print('2000m連帯率: %f パーセント' %rentai2000) ----------結果---------- 連帯数(芝) (1400, 66) (1600, 89) (1800, 90) (2000, 84) (2300, 2) (2400, 40) (3400, 1) 3着以下数(芝) (1400, 31) (1600, 59) (1800, 38) (2000, 31) (2300, 2) (2400, 22) 1800m連帯率: 70.310000 パーセント 2000m連帯率: 73.040000 パーセント1800m, 2000mの成績が特に良いですね。日本ダービーやオークス、ジャパンカップが行なわれる2400mは64%程度と微妙。
※ちなみに2500mが表示されていないのは、過去に単勝1倍台の馬がいなかったためです。最も連帯率の高い芝2000mの条件を深堀りしてみましょう。
東京芝2000m 1番人気が連帯したときの条件を深堀りしてみる
もう一頭の連帯馬の【単勝人気】
Another連帯馬# 2000mで絞ってみる # 1人気が連帯したときのもう一頭の人気 cur.execute("SELECT r.popularity, count(r.race_id) FROM race_result r \ INNER JOIN race_info i on r.race_id=i.id \ WHERE r.order_of_finish IN ('1','2') AND r.popularity != '1' \ AND r.race_id IN (SELECT race_id from race_result r INNER JOIN race_info i on r.race_id=i.id WHERE odds<2.0 AND popularity='1' \ AND order_of_finish IN ('1','2') AND i.surface like '芝%' AND i.place_detail like '%東京%' AND i.distance=2000) \ GROUP BY r.popularity ORDER BY r.popularity") rows = cur.fetchall() print('(人気, 回数)') for row in rows: print(row) ----------結果---------- (人気, 回数) (2, 21) (3, 31) (4, 12) (5, 6) (6, 7) (7, 4) (8, 2) (11, 1)驚くべきことに、1番人気-2番人気の連帯より、1番人気-3番人気の連帯のほうが多かったです。
抜けた人気の1番人気より、少しでも勝てそうな2番人気を他の馬がマークした結果でしょうか?ちなみに、【単勝1倍台の1番人気馬が連帯しなかった場合】に【連帯する回数が最も多かった】のも3番人気でした。
1番人気が勝とうがコケようが、2番人気から買うのは妙味が薄そうです。もう一頭の連帯馬の【4コーナーでのポジション】
4cornerPositioncur.execute("SELECT substr(r.pass, -2), count(r.race_id) FROM race_result r \ INNER JOIN race_info i on r.race_id=i.id \ WHERE r.order_of_finish IN ('1','2') AND r.popularity != '1' \ AND r.race_id IN (SELECT race_id from race_result r INNER JOIN race_info i on r.race_id=i.id WHERE odds<2.0 AND popularity='1' \ AND order_of_finish IN ('1','2') AND i.surface like '芝%' AND i.place_detail like '%東京%' AND i.distance=2000) \ GROUP BY substr(r.pass, -2) ORDER BY substr(r.pass, -2)") rows = cur.fetchall() print('(番手, 回数)') for row in rows: print(row) ----------結果---------- (番手, 回数) ('-1', 14) ('-2', 15) ('-3', 14) ('-4', 4) ('-5', 10) ('-6', 6) ('-7', 4) ('-8', 4) ('-9', 2) ('10', 3) ('11', 3) ('12', 2) ('13', 3)最後の直線入り口では、5番手以内にいた馬が連帯しやすいようです。
これは先行脚質の馬が粘り切る展開になること、そもそも余力があったから前のほうにいることなどが考えられます。東京芝2000mに単勝1倍台の人気馬が出走していて、3番人気の馬が先行脚質なら期待値が高そうに見えます。
2019年の天皇賞秋を思い出しますね…!馬連の期待値を計算してみる(3つのテーブルから情報取得)
ここからは、netkeiba-scraperで取得したテーブルを3つ活用します。
そのため【サブクエリを入れ子にして条件を絞る】ことをしました。単勝1番人気 - 単勝2番人気の馬連
まずは期待値の低そうな 【1番人気-2番人気】の馬連を購入した場合の期待値です。
1-2人気の馬連期待値# race_resultのrace_id とpayoffのrace_idを紐づけて期待値を計算する # ticket_type 単勝0, 複勝1, 枠連2, 馬連3, ワイド4, 馬単5, 三連複6, 三連単7 # サブクエリを2重使用し、【1倍台の馬が連帯したレースのうち】【もう一頭連帯した馬が2番人気だったレース】の馬連払戻金を合計 cur.execute("SELECT DISTINCT p.race_id, p.payoff FROM payoff p \ INNER JOIN race_result r ON p.race_id=r.race_id INNER JOIN race_info i on p.race_id=i.id \ WHERE p.ticket_type=3 AND p.race_id IN \ (SELECT r.race_id FROM race_result r \ INNER JOIN race_info i on r.race_id=i.id \ WHERE r.order_of_finish IN ('1','2') AND r.popularity='2' \ AND r.race_id IN (SELECT race_id from race_result r INNER JOIN race_info i on r.race_id=i.id \ WHERE odds<2.0 AND popularity='1' AND order_of_finish IN ('1','2') AND i.surface like '芝%' \ AND i.place_detail like '%東京%' AND i.distance=2000))") rows = cur.fetchall() umaren_sum = 0 for row in rows: umaren_sum += row[1] # 単勝1倍台の馬が出走したレース数を調べる cur.execute("SELECT count(race_id) from race_result r INNER JOIN race_info i on r.race_id=i.id \ WHERE odds<2.0 AND popularity='1' AND i.surface like '芝%' AND i.place_detail like '%東京%' \ AND i.distance=2000") rows2 = cur.fetchall() print('単勝1倍台の馬が連帯したレースでの馬連合計:') print(umaren_sum) print('単勝1倍台の馬が東京芝2000mに出走したレース数:') print(rows2[0][0]) print('馬連期待値は') print(round(umaren_sum / rows2[0][0], 2)) -----結果----- 単勝1倍台の馬が連帯したレースでの馬連合計: 6740.0 単勝1倍台の馬が東京芝2000mに出走したレース数: 115 馬連期待値は 58.61やはり低いです。ただでさえ1頭が堅そうなので、もう一頭も人気馬を買うのは妙味がありません。
これなら単勝1番人気の単勝を買ったほうがマシです。単勝1番人気 - 単勝3番人気の馬連
次に、最も期待値の期待できる 【1番人気-3番人気】の馬連を購入した場合の期待値です。
1-3人気の馬連期待値# race_resultのrace_id とpayoffのrace_idを紐づけて期待値を計算する # ticket_type 単勝0, 複勝1, 枠連2, 馬連3, ワイド4, 馬単5, 三連複6, 三連単7 # サブクエリを2重使用し、【1倍台の馬が連帯したレースのうち】【もう一頭連帯した馬が3番人気だったレース】の馬連払戻金を合計 cur.execute("SELECT DISTINCT p.race_id, p.payoff FROM payoff p \ INNER JOIN race_result r ON p.race_id=r.race_id INNER JOIN race_info i on p.race_id=i.id \ WHERE p.ticket_type=3 AND p.race_id IN \ (SELECT r.race_id FROM race_result r \ INNER JOIN race_info i on r.race_id=i.id \ WHERE r.order_of_finish IN ('1','2') AND r.popularity='3' \ AND r.race_id IN (SELECT race_id from race_result r INNER JOIN race_info i on r.race_id=i.id \ WHERE odds<2.0 AND popularity='1' AND order_of_finish IN ('1','2') AND i.surface like '芝%' \ AND i.place_detail like '%東京%' AND i.distance=2000))") rows = cur.fetchall() umaren_sum = 0 for row in rows: umaren_sum += row[1] # 単勝1倍台の馬が出走したレース数を調べる cur.execute("SELECT count(race_id) from race_result r INNER JOIN race_info i on r.race_id=i.id \ WHERE odds<2.0 AND popularity='1' AND i.surface like '芝%' AND i.place_detail like '%東京%' \ AND i.distance=2000") rows2 = cur.fetchall() print('単勝1倍台の馬が連帯したレースでの馬連合計:') print(umaren_sum) print('単勝1倍台の馬が東京芝2000mに出走したレース数:') print(rows2[0][0]) print('馬連期待値は') print(round(umaren_sum / rows2[0][0], 2)) -----結果----- 単勝1倍台の馬が連帯したレースでの馬連合計: 18460.0 単勝1倍台の馬が東京芝2000mに出走したレース数: 115 馬連期待値は 160.52やっと期待値が100を超えました!
このデータを知っておけば2019年の天皇賞秋で【アーモンドアイとダノンプレミアムの馬連】を買っていたことでしょう。単勝1番人気 - 単勝4番人気の馬連
念のため 【1番人気-4番人気】の馬連を購入した場合の期待値も見てみましょう。
1-4人気の馬連期待値# race_resultのrace_id とpayoffのrace_idを紐づけて期待値を計算する # ticket_type 単勝0, 複勝1, 枠連2, 馬連3, ワイド4, 馬単5, 三連複6, 三連単7 # サブクエリを2重使用し、【1倍台の馬が連帯したレースのうち】【もう一頭連帯した馬が4番人気だったレース】の馬連払戻金を合計 cur.execute("SELECT DISTINCT p.race_id, p.payoff FROM payoff p \ INNER JOIN race_result r ON p.race_id=r.race_id INNER JOIN race_info i on p.race_id=i.id \ WHERE p.ticket_type=3 AND p.race_id IN \ (SELECT r.race_id FROM race_result r \ INNER JOIN race_info i on r.race_id=i.id \ WHERE r.order_of_finish IN ('1','2') AND r.popularity='4' \ AND r.race_id IN (SELECT race_id from race_result r INNER JOIN race_info i on r.race_id=i.id \ WHERE odds<2.0 AND popularity='1' AND order_of_finish IN ('1','2') AND i.surface like '芝%' \ AND i.place_detail like '%東京%' AND i.distance=2000))") rows = cur.fetchall() umaren_sum = 0 for row in rows: umaren_sum += row[1] # 1倍台の馬が出走したレース数を調べる cur.execute("SELECT count(race_id) from race_result r INNER JOIN race_info i on r.race_id=i.id \ WHERE odds<2.0 AND popularity='1' AND i.surface like '芝%' AND i.place_detail like '%東京%' \ AND i.distance=2000") rows2 = cur.fetchall() print('単勝1倍台の馬が連帯したレースでの馬連合計:') print(umaren_sum) print('単勝1倍台の馬が東京芝2000mに出走したレース数:') print(rows2[0][0]) print('馬連期待値は') print(round(umaren_sum / rows2[0][0], 2)) -----結果----- 単勝1倍台の馬が連帯したレースでの馬連合計: 10030.0 単勝1倍台の馬が東京芝2000mに出走したレース数: 115 馬連期待値は 87.22こちらは100は超えないものの【1-2人気の馬連】よりは期待値が高いことが分かりました。
まとめ
競馬場、コース、券種を絞ることで期待値計算に深みが出てきました。SQLの扱いにも慣れてきました。
条件さえ変えれば他の競馬場でも分析できるので、お住まいの近くの競馬場の期待値計算をやってみてはいかがでしょうか!次の目標は、WIN5(設定された5レースの勝ち馬をすべて当てる馬券。最高で数億円の配当)の攻略です!
競馬の馬場読み・展開読みなども分析する必要があるため、難易度は上がりますが、挑戦してみようと思います!ここまで読んでくださりありがとうございました。
- 投稿日:2020-02-10T17:41:40+09:00
Python responder v2 入門
responder v2.0.0 が 2019-10-19(JST) にリリースされました!
だいぶ時間が経ってしまいましたが,v1 からの変更点を調べたので紹介します。ちなみに v1.3.2 からの後方互換性が確保されているようですので,v2.0.5 にバージョンアップしても問題ありません。
対象読者
- responder v1 を使っている方,使い方がわかっている方
- responder v2 で何が変わったのかを知りたい方
今回,v1 系からの変更点のみをとりあげます。
その他の部分についてはぜひ Python responder 入門のために… 下調べ - Qiita を参照してください!新しい Router と Schema (ついでに Template)
Schema,Template の記法が変わりました!
また,Router 周りのリファクタリングが行われました(正直ユーザには関係ない)。今までインポート1つで済み,1つのインスタンスでなんでもできる点が良くも悪くも特長でした。
import responder api = responder.API()しかし,Scheme や Template の定義にも
apiが必要であり,ファイル分離が少し手間でした。
新しい v2 ではこれらは分離され,多少はファイルの分離が楽になりました。Router
リファクタリングが行われました。
今のところユーザ側に変更はないように思います。Schema
新しく
responder.ext.schemaのインポート (from responder.ext.schema import Schema as OpenAPISchemaなど) が必要になりました。
ただし,こちらはresponder.ext.schema.Schemaインタンスの生成時にapiに依存し,このインスタンスが各スキーマ定義時に必要なため,ファイル分離にはコツがいるのは今まで通りです…新しい書き方import responder from responder.ext.schema import Schema as OpenAPISchema from marshmallow import Schema, fields contact = { "name": "API Support", "url": "http://www.example.com/support", "email": "support@example.com", } license = { "name": "Apache 2.0", "url": "https://www.apache.org/licenses/LICENSE-2.0.html", } api = responder.API() schema = OpenAPISchema( app=api, title="Web Service", version="1.0", openapi="3.0.2", docs_route='/docs', # ドキュメント提供する場合 description="A simple pet store", terms_of_service="http://example.com/terms/", contact=contact, license=license, ) @schema.schema("Pet") class PetSchema(Schema): name = fields.Str() @api.route("/") def route(req, resp): """A cute furry animal endpoint. --- get: description: Get a random pet responses: 200: description: A pet to be returned content: application/json: schema: $ref: '#/components/schemas/Pet' """ resp.media = PetSchema().dump({"name": "little orange"})なお,こちらも今までの書き方でも動くようですが推奨されていないので,既存の書き方は省略します。
Template
テンプレート機能は既存のものに加え,以下のように実装可能です:
新しく分離されたテンプレート機能from responder.templates import Templates templates = Templates() @api.route("/hello/{name}/html") def hello(req, resp, name): resp.html = templates.render("hello.html", name=name)また,非同期レンダリング
render_asyncにも対応しました:テンプレートの非同期レンダリングfrom responder.templates import Templates templates = Templates(enable_async=True) resp.html = await templates.render_async("hello.html", name=name)既存パターンも利用可能です:
既存のテンプレート機能import responder api = responder.API() @api.route("/hello/{name}/html") def hello_html(req, resp, *, who): resp.html = api.template('hello.html', name=name)Python 3.8 への対応
v2.0.5 からは Python 3.8 にサポートしました。
あとがき
中規模のウェブアプリケーションは実装しやすくなったのかも知れませんね。
参考
- 投稿日:2020-02-10T17:20:46+09:00
忙しい人のための自然言語処理
忙しい人のための概要
オレ プログラム ウゴカス オマエ ゲンシジン ナルの記事に触発されて、言語処理を試してみました。
いにしえのネタである「忙しい人向けシリーズ」1が好きなので、COTOHA APIの要約APIを使って、有名どころの歌を忙しい人向けにしてみました。※注意書き
以下コードの出力結果(黒背景部分)に要約された歌詞が出てきますが、著作権法第32条に従い言語処理の研究目的で使用しています。(要約APIの仕様上、適宜「。」で区切っています(後述))
また、著作権法48条に従って、曲のタイトルと作詞者名を記事下部に明記しています。例: 忙しい人のための『粉雪』2
$ python3 youyaku.py < konayuki.txt ララライ。粉雪。心まで白く染められたなら。さすがに「来ねぇ」とかになったりはしないようですが、出現回数が多そうなところが出てて納得感(?)ありますね!
環境
Python 3.6.9
実装
COTOHA APIの要約APIを利用して3行に要約します。
コードはほとんどゲンシジンの記事を参考に書いていますが、BASE_URL書き換えたり、要約用にパラメータ変えたりしています。また、歌詞をそのまま与えると全然要約してくれなかったので、改行など歌詞の所々で適宜「。」を入れています。コード
ここをクリックすると展開します。
youyaku.pyimport requests import json import sys BASE_URL = "https://api.ce-cotoha.com/api/dev/" CLIENT_ID = "COTOHA APIで取得したIDを入力" CLIENT_SECRET = "COTOHA APIで取得したパスワードを入力" def auth(client_id, client_secret): token_url = "https://api.ce-cotoha.com/v1/oauth/accesstokens" headers = { "Content-Type": "application/json", "charset": "UTF-8" } data = { "grantType": "client_credentials", "clientId": client_id, "clientSecret": client_secret } r = requests.post(token_url, headers=headers, data=json.dumps(data)) return r.json()["access_token"] def summary(document, access_token, sent_len): base_url = BASE_URL headers = { "Content-Type": "application/json", "charset": "UTF-8", "Authorization": "Bearer {}".format(access_token) } data = { "document": document, "sent_len": sent_len } r = requests.post(base_url + "nlp/beta/summary", headers=headers, data=json.dumps(data)) return r.json() if __name__ == "__main__": document = "歌詞をここに記載" args = sys.argv if len(args) >= 2: document = str(args[1]) access_token = auth(CLIENT_ID, CLIENT_SECRET) summary_document = summary(document, access_token, 3) result_list = list() for chunks in summary_document['result']: result_list.append(chunks) print(''.join(result_list))結果
『音頭「水戸黄門」あゝ人生に涙あり』3
$ python3 youyaku.py < mitokomon.txt 泣くのがいやならさあ歩け。人生涙と笑顔あり。何かを求めて生きようよ。『ドラえもんのうた』4
$ python3 youyaku.py < doraemon.txt みんなみんなみんな かなえてくれる。アンアンアン。とってもだいすきドラえもん。『それが大事』5
$ python3 youyaku.py < soregadaiji.txt 負けない事・投げ出さない事・逃げ出さない事・信じ抜く事。駄目になりそうな時。それが一番大事。『ガッチャマンの歌』6
$ python3 youyaku.py < gachaman.txt ガッチャマン。飛べ。行け。『摩訶不思議アドベンチャー』7
$ python3 youyaku.py < makafushigi.txt DRAGONBALL。try。fly。『勇者王誕生!』8
$ python3 youyaku.py < yushaou.txt ガガガッ。ガオガイガー!。ガガガガッ。まとめ
様々な名曲を要約してみました。
良い歌は短くしても深い
- 投稿日:2020-02-10T17:00:26+09:00
PyWebViewで複数のJavaScriptファイルを読み込む
PyWebViewで複数のJavaScriptを使いたい
PyWebViewで、ウィンドウにJavaScriptを読み込ませたいときには、
window#evaluate_js()というメソッドを利用します。このメソッド、複数回呼び出したときは、それぞれのJavaScriptを別々のファイルと認識して処理します、このため次のようなメソッドを作っておくと、HTML5アプリケーション開発により近い感覚でPyWebViewのGUIを作れます。
def webview_load_elems(window): """ 引数で指定した任意のウィンドウに、次のCSS、JSライブラリを読み込む ・bootstrap.css ・bootstrap.js/popper.js/jquery.js ・独自開発用の、index.css/index.js """ css = ["index.css"] js = ["index.js", "classes.js"] nm = "node_modules" dist = nm / "bootstrap-honoka" / "dist" distjs = dist / "js" css.insert(0, dist / "css" / "bootstrap.css") js.insert(0, nm / "popper.js" / "dist" / "popper.js") js.insert(0, distjs / "bootstrap.js") js.insert(0, nm / "jquery" / "dist" / "jquery.js") for file in css: with open(file, mode="r", encoding="utf-8") as f: window.load_css(f.read()) for file in js: with open(file, mode="r", encoding="utf-8") as f: window.evaluate_js(f.read())index.jslet test = TestClass() /* ... */classes.jsclass TestClass { /* ... */ }上記コードの問題
上記のようにファイルを読み込むと、classes.jsで宣言したクラスをindex.jsで使うことはできません。ReferenceErrorが発生してしまいます。
最近のJavaScriptであれば
export文などもありますが、PyWebView上で扱われるファイルは(初期設定では)ローカルファイルとして扱われること、そもそもファイルを読み込んでいるわけではなく、JavaScriptのコードを直接ブラウザエンジンに読み込んでることから、export文は使えませんグローバルな変数のプロパティとして追加する
このようなときは、jQueryなどのファイルの先頭にヒントがあります。
jquery.js( function( global, factory ) { "use strict"; if ( typeof module === "object" && typeof module.exports === "object" ) { // For CommonJS and CommonJS-like environments where a proper `window` // is present, execute the factory and get jQuery. // For environments that do not have a `window` with a `document` // (such as Node.js), expose a factory as module.exports. // This accentuates the need for the creation of a real `window`. // e.g. var jQuery = require("jquery")(window); // See ticket #14549 for more info. module.exports = global.document ? factory( global, true ) : function( w ) { if ( !w.document ) { throw new Error( "jQuery requires a window with a document" ); } return factory( w ); }; } else { factory( global ); } // Pass this if window is not defined yet } )( typeof window !== "undefined" ? window : this, function( window, noGlobal ) {jQueryはJavaScriptの実行環境毎に、グローバル変数やエクスポート領域に自分自身を登録することで、他のJavaScriptファイルからjQueryを呼び出すことを可能にしています。
PyWebViewの実行環境において、使えるグローバル変数は
windowです。ですので、windowのプロパティとして、宣言したクラスを登録すればOK。classes.jsclass TestClass { /* ... */ } window.TestClass = TestClass;これで
index.jsからでもclasses.jsのクラスが利用できるようになります。おまけ:PyWebViewウィンドウの開発者コンソールから、JavaScriptファイルを見たい
webview.start()メソッドのguiに開発者コンソールが利用できるブラウザエンジン(cefなど)、debugをTrueに設定すると、ブラウザウィンドウの右クリックメニューから開発者コンソールが開けるようになります。この開発者コンソールから読み込んだJavaScriptファイルを見たい場合。読み込んだJavaScriptコードはファイルの形式ではないので、Sourceタブから中身を見ることができません。
そんなときは、JavaScriptファイルの先頭行に
console.log("ファイル名")などと入れておくと良いです。
画面右の「VMnn:行数」というリンクをクリックすると、読み込んだJavaScriptコードを閲覧することができます。

- 投稿日:2020-02-10T16:21:28+09:00
何もない状況から低コストでプログラミングを学ぶ方法を考えてみた。(Mac編)
Background
のニュースを見て高い!!!
と思ってしまいました。コメントでリース代の話が出てますが、壊れやすいのはマウスキーボードくらいで本体まではそこまでではないと思います。ソフト代含めて10万くらいじゃねと思ったりしました。スペックを問題視する人がいますがWordかExcelを開くか軽量級の開発環境があるだけだったらこれで十分な気がします。このPCでyoutuberの動画を頻繁に見る必要性がないので。
本体が壊れそうな想定としては学校自体がヒャッハーなのか、学生自体にレベル5の特殊能力があってマシンと相性が悪いとかぐらいでしょうか。
Motive
で、学校で学んだことを復習したい!
と思う学生がいると思うのですが、この失われた30年で格差社会となったために中には家庭的な事情でお金がないひとが結構いるのではと想定されます。少なくとも慢性的に科学分野では予算不足だけではなく開発者もいない状況です。
特に人工知能は思っている以上に分野が広いので、専門的な数学があるのがベストなのですが文系的なアプローチから乱入して今ある数値計算をツールとして最低限扱えればいいのかなと思っています。また、研究しなくても情報系にあまり関わりのない業種でもスキルとしてあった方が良いと思っています。
必須ではないですが、プログラミングを学ぶメリットの一つとしては7人必要な作業を3人まで減らすことや作業時間短縮などの作業自動化による効率化ができるので普通に良いはずです。AIで仕事が奪われる
というひとがメディアでは結構います。
特にブームになった数年前はかなり言われていました。しかしながら、AIでできることとできないことを考えるとできないことの方が多いです。
もしこの段階で成熟していればお掃除ロボにとってかわって清掃業者が別の職種に移っているのではと思っています。でもまだいます。そのため、少なくとも10年くらいはAIはまだ学習中なので多少の自動化をしても今までやってきた作業の負担が軽減するだけで、給料低下や失業する心配はなく、メリットの方が大きいです。
それで、
格差社会からちょっと抜け出して安定した給料を得たい!
と思っているならば、
にはあまり使わずに数万円くらいためて自分のスキル・学習に投資に使ってみてほしいここでは何もない状況からプログラミングを学ぶ方法を考えてみました。
Actor
対象者は以下の通りです。
- 中卒・高卒で情報科学に疎いひと
- 一回もPCを持ったことがない未経験者(スマホしかないひとが多いみたい)
- 定年退職した後の趣味にしたい
そもそも、qiitaの存在すら知らない場合はどうしよう
Plan
シンブルに学びたい場合は、
- OS:Mac
- 言語:Python
が一番良い組み合わせだと思います。
なぜなら、ターミナルというアプリひとつでプログラムが出来てしまうからです。
で、アプリを実行すると、、、
こんな画面が出ると思います。(デフォルトは背景色は白です。)
で何もしないで、
pythonと打つと$ python Python 2.7.16 (v2.7.16:413a49145e, Mar 2 2019, 14:32:10) [GCC 4.2.1 Compatible Apple LLVM 6.0 (clang-600.0.57)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>>とメッセージが出るのでこれでプログラムが打てます。
試しに円の面積を出してみます。
公式は、
S = \pi \times r^{2}っすね。
面積計算用の関数を作ってみると、、、
といった感じで半径が3だった場合の面積が計算されました。
KEISAN 円の面積
で計算すると、、、
合ってますね。
あとは参考書(1000~2000円)を買って写経(書いてあるコードをそのまま書き写す)すれば良さそうです。Why Mac?
その時のトレンドもあって2000年代はPCはWindows一択だったのですが、最近はMacを勧めます。
将来的にWord・Excel(VBA)・PowerPointを使う機会があればいいのですが、サーバサイドでの開発をしてみたい場合は先ほどのterminalひとつでアクセスして開発することを考えるとMacの方が相性が良いからです。
大抵のサーバOSはLinux系でMacとの親和性が高いです。Why Python?
先ほどの通りターミナルひとつでプログラムができることもひとつの理由なのですが、他にも
- 実行がコマンドひとつでできる
- 文字列処理が他の言語より容易
- 少なくともC++よりは良い
- 標準でリスト・辞書が使える
- パッケージが豊富
- 何かしたいなと思ったら結構できます。
- Pythonコードが書ければRuby・JavaScriptもなんとかなる
などがあります。
Price
新品のMacを買おうとすると少なくとも約10万くらいするのですが、学習のみの用途でターミナルだけ使いたい場合はフリマサイトで
5千円~2万円
と中古で売っているもので十分です。
重量が重く、最新のOSに更新することはできないですが2007年発売のものでも問題ないです。コメントでバッテリーがすぐ切れるといった問題がありますが、自宅か近所のカフェ・コンビニで学ぶ分には良いと思います。また、動作が重いといったものだったらこのPCにはECサイトなどで買い物しないなどの個人情報をなるべく入力しないようにすれば問題ないと思います。
よくあるフリマサイト
- メルカリ
- ラクマ
- PayPayフリマPostScript
- Pythonを学ぶ時の本・サイトなど
- Mac以外で低コストで学ぶ方法
- このままだとPythonのバージョンが古いままなので、新しいものにシフトするには
と書くこと多いです
なぜ、見出しが英語かと言いますと単純に使っていないと忘れるのと雰囲気だけ意識高い系になれると思ったからでそれ以上の意味はないです。



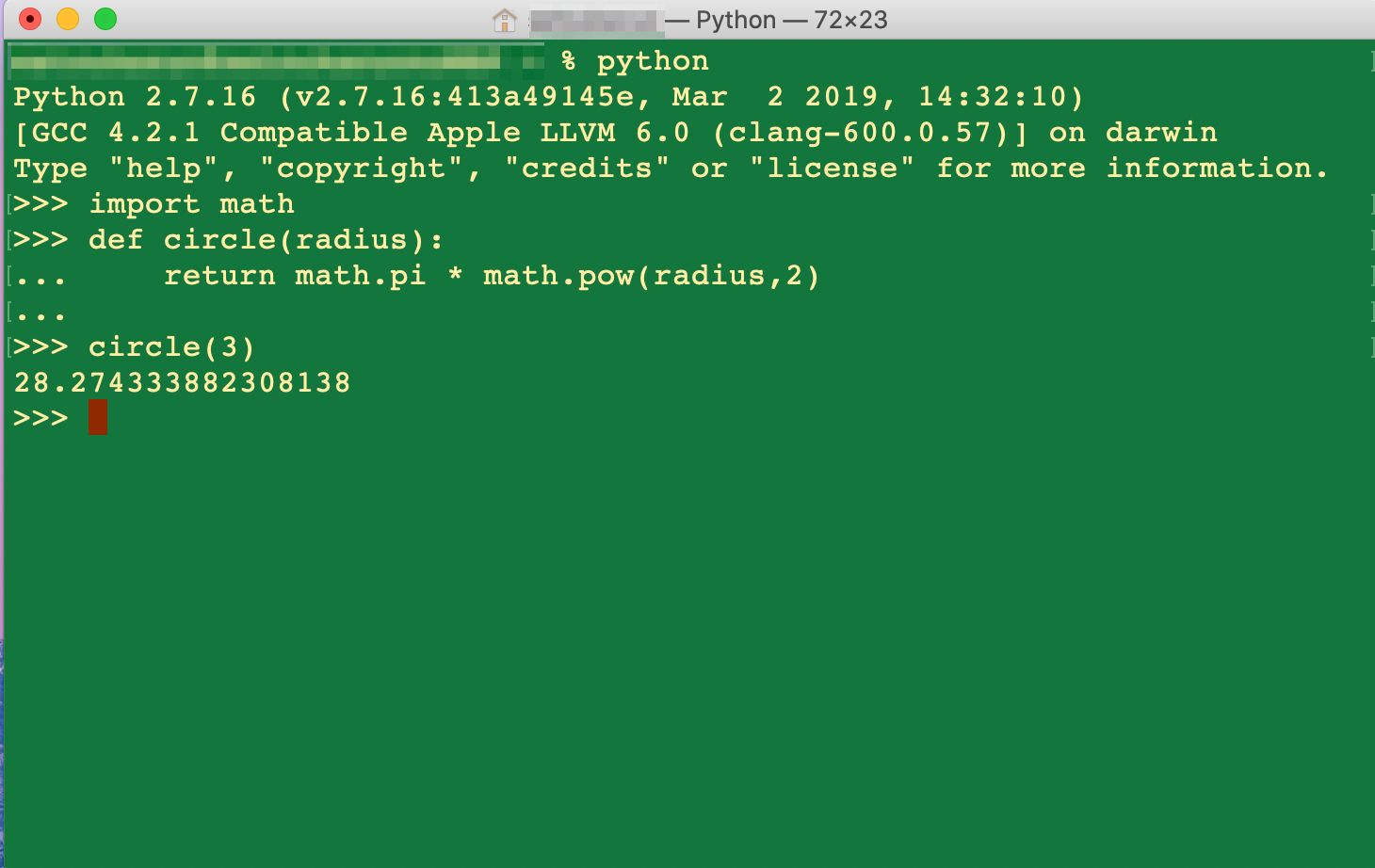
- 投稿日:2020-02-10T16:21:26+09:00
EC2(Amazon Linux 2)にPython 3.8, Pip 3.8をインストールする
Amazon Linux2 に Python 3.8をインストール
Python 3.8, Pip 3.8をAmazon Linux2にインストールでお困りの方は参考にしてください。
- EC2 AMI
Amazon Linux 2 AMI (HVM)
SSD Volume Type
ami-062f7200baf2fa504 (64 ビット x86)/ami-0e98ccceff552e8a8 (64 ビット Arm)
事前準備
$ sudo yum -y update $ sudo yum -y install gcc openssl-devel bzip2-devel libffi-develダウンロード
$ wget https://www.python.org/ftp/python/3.8.1/Python-3.8.1.tgz $ tar xzf Python-3.8.1.tgzインストール
$ cd Python-3.8.1 $ sudo ./configure --enable-optimizations $ sudo make altinstall確認
$ python3.8 --version Python 3.8.1 $ pip3.8 --version pip 19.2.3 from /usr/local/lib/python3.8/site-packages/pip (python 3.8)rootのpathを設定
rootからもPython3.8を使えるようにパスを通しシンボリックリンクをはっておく
$ sudo which python3.8 which: no python3.8 in (/sbin:/bin:/usr/sbin:/usr/bin) $ sudo visudo (Before) Defaults secure_path = /sbin:/bin:/usr/sbin:/usr/bin (After) Defaults secure_path = /sbin:/bin:/usr/sbin:/usr/bin:/usr/local/sbin:/usr/local/bin $ sudo which python3.8 /usr/local/bin/python3.8 $ sudo ln -s /usr/local/bin/python3.8 /usr/local/bin/python3 $ sudo which python3 /usr/local/bin/python3 $ sudo ln -s /usr/local/bin/pip3.8 /usr/local/bin/pip3 $ sudo which pip3 /usr/local/bin/pip3
- 投稿日:2020-02-10T13:53:17+09:00
curlコマンドをrequestに変換してくれるサイト
便利だったのでメモ
https://curl.trillworks.com/仮に下記のようなcurlがあったとして
curl -X POST 'https://example.com/' \ -H 'Content-Type: application/json' \ -d '{"key1": "value1", "key2": "value2"}'これを入れると下記に変換される
import requests headers = { 'Content-Type': 'application/json', } data = '{"key1": "value1", "key2": "value2"}' response = requests.post('https://example.com/login', headers=headers, data=data)
- 投稿日:2020-02-10T13:33:03+09:00
【Python】リスト(配列)内要素の操作【ソート】
はじめに
リストを扱う上で重要なソートの方法をまとめました。
基本的に以下のようなコードでコードと出力結果を記載します。ex.pycode = 'コード' print(code) # code(出力結果)リストを昇順または降順にソートするsort(),sorted()
Pythonでリストを昇順または降順にソートするには
sort()とsorted()の2つの方法がある。文字列やタプルをソートしたい場合はsorted()を使う。・sort():元のリストをソート
※元のリスト自体が書き換えられる破壊的処理。
sort().pyorg_list = [3, 1, 4, 5, 2] org_list.sort() print(org_list) # [1, 2, 3, 4, 5] #sort()が返すのはNoneなので注意。 print(org_list.sort()) # None #デフォルトは昇順。降順にソートしたい場合は引数reverseをTrueとする。 org_list.sort(reverse=True) print(org_list) # [5, 4, 3, 2, 1]sorted(): ソートした新たなリストを生成
※引数にソートしたいリストを指定するとソートされたリストを返す。元のリストは変更されない非破壊的処理。
sorted().pyorg_list = [3, 1, 4, 5, 2] new_list = sorted(org_list) print(org_list) # [3, 1, 4, 5, 2] print(new_list) # [1, 2, 3, 4, 5] #デフォルトは昇順。降順にソートしたい場合は引数reverseをTrueとする new_list_reverse = sorted(org_list, reverse=True) print(org_list) # [3, 1, 4, 5, 2] print(new_list_reverse) # [5, 4, 3, 2, 1]sorted()を用いた文字列のソート
sorted()関数の引数に文字列を指定すると、ソートされた文字列の一文字ずつが要素として格納されたリストが返される。
sorted()_.pyorg_str = 'cebad' print(org_str) # cebad new_str_list = sorted(org_str) print(new_str_list) # ['a', 'b', 'c', 'd', 'e'] #文字列のリストを連結して一つの文字列にするにはjoin()メソッドを使う。 new_str = ''.join(new_str_list) print(new_str) # abcde #まとめて書いてもOK。降順にソートしたい場合は引数reverseをTrueとする。 new_str_reverse = ''.join(sorted(org_str, reverse=True)) print(new_str_reverse) # edcbaリストや文字列を逆順に並べ替えるreverse(), reversed()
Pythonでリストの要素を逆順に並べ替えるには
reverse(),reversed()およびスライスを使った方法がある。文字列やタプルを逆順に並べ替えたい場合はreversed()かスライスを使う。・reverse(): 元のリストを逆順に並べ替え
※元のリスト自体が書き換えられる破壊的処理。
sort().pyorg_list = [1, 2, 3, 4, 5] org_list.reverse() print(org_list) # [5, 4, 3, 2, 1] #reverse()が返すのはNoneなので注意。 print(org_list.reverse()) # None・reversed(): 逆順に取り出すイテレータを生成
※reversed()は要素を逆順に取り出すイテレータを返す。元のリストは変更されない非破壊的処理。
sort().pyorg_list = [1, 2, 3, 4, 5] reverse_iterator = reversed(org_list) print(org_list) # [1, 2, 3, 4, 5] #reversed()はリストではなくイテレータを返すので注意。list()でイテレータをリストに変換する。 new_list = list(reversed(org_list)) print(new_list) # [5, 4, 3, 2, 1]・スライスによって逆順に並べ替え
ex.pyorg_list = [1, 2, 3, 4, 5] new_list = org_list[::-1] print(new_list) # [5, 4, 3, 2, 1] org_str = 'abcde' new_str = org_str[::-1] print(new_str) # edcba最後に
他にも何か方法が解法があれば教えてもらえると嬉しいです。
- 投稿日:2020-02-10T13:01:22+09:00
画像から顔を切り取ろう
概要
OpenCVが用意しているHaar-Like特徴量Cascadeを使って顔の検出を行い、自動で切り取るプログラムを作りました。
環境
-Software-
Windows 10 Home
Anaconda3 64-bit(Python3.7)
Spyder
-Library-
opencv-python 4.1.2.30
natsort 7.0.0
-Hardware-
CPU: Intel core i9 9900K
RAM: 16GB 3200MHz参考
書籍
Pythonで始めるOpenCV4プログラミング 北山 直洋 (著)
(Amazonページ)プログラム
Githubに上げておきます。
https://github.com/himazin331/Face-Cropping
リポジトリにはデータ加工プログラム、Haar-Cascadeが含まれています前提
本プログラムの動作にはHaar-Like特徴量のCascadeファイルが必須です。
今回はOpenCVのHaar-Cascadeを使用します。
なお、Cascadeはリポジトリに含まれるので別途用意する必要はありません。ソースコード
コードが汚いのはご了承ください...
face_cut.pyimport cv2 import os import argparse as arg import sys from natsort import natsorted # 画像加工 def face_cut(imgs_dir, result_out, img_size, label, HAAR_FILE): # Haar-Like特徴量Cascade型分類器の読み込み cascade = cv2.CascadeClassifier(HAAR_FILE) # データ加工 for img_name in natsorted(os.listdir(imgs_dir)): print("画像データ:{}".format(img_name)) # jpg形式のみ _, ext = os.path.splitext(img_name) if ext.lower() == '.jpg': img_path = os.path.join(imgs_dir, img_name) # ファイルパスの結合 img = cv2.imread(img_path) # データ読み込み img_g = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY) # グレースケールに変換 face = cascade.detectMultiScale(img_g) # 顔を検出 # 顔が検出されなかったら if len(face) == 0: print("Face not found.") else: for x,y,w,h in face: # 顔の切り取り face_cut = img_g[y:y+h, x:x+w] # リサイズ face_img = cv2.resize(face_cut, (img_size, img_size)) # 保存 result_img_name = '\data' + str(label) + '.jpg' cv2.imwrite(os.path.join(result_out + result_img_name), face_img) label += 1 print("Processing success!!") else: print("Unsupported file extension") def main(): # コマンドラインオプション作成 parser = arg.ArgumentParser(description='Face image cropping') parser.add_argument('--imgs_dir', '-d', type=str, default=None, help='画像フォルダパス(未指定ならエラー)') parser.add_argument('--out', '-o', type=str, default=os.path.dirname(os.path.abspath(__file__))+'/result_crop'.replace('/', os.sep), help='加工後データの保存先(デフォルト値=./reslut_crop)') parser.add_argument('--img_size', '-s', type=int, default=32, help='リサイズ(NxNならN,デフォルト値=32)') parser.add_argument('--label', '-l', type=int, default=1, help='dataN.jpgのNの初期値(デフォルト値=1)') parser.add_argument('--haar_file', '-c', type=str, default=os.path.dirname(os.path.abspath(__file__))+'/haar_cascade.xml'.replace('/', os.sep), help='haar-Cascadeのパス指定(デフォルト値=./haar_cascade.xml)') args = parser.parse_args() # 画像フォルダ未指定時->例外 if args.imgs_dir == None: print("\nException: Cropping target is not specified.\n") sys.exit() # 存在しない画像フォルダ指定時->例外 if os.path.exists(args.imgs_dir) != True: print("\nException: {} does not exist.\n".format(args.imgs_dir)) sys.exit() # 存在しないCascade指定時->例外 if os.path.exists(args.haar_file) != True: print("\nException: {} does not exist.\n".format(args.haar_file)) sys.exit() # 設定情報出力 print("=== Setting information ===") print("# Images folder: {}".format(os.path.abspath(args.imgs_dir))) print("# Output folder: {}".format(args.out)) print("# Images size: {}".format(args.img_size)) print("# Start index: {}".format(args.label)) print("# Haar-cascade: {}".format(args.haar_file)) print("===========================\n") # 出力フォルダの作成(フォルダが存在する場合は作成しない) os.makedirs(args.out, exist_ok=True) # 加工 face_cut(args.imgs_dir, args.out, args.img_size, args.label, args.haar_file) print("") if __name__ == '__main__': main()実行結果
用意した画像は以下の通り。
大川竜弥さんですね。
「Face not found.」と出力されたものは、顔を検出できなかった、言い換えれば顔として認識できなかったことになります。
この例では、下の2つが顔として認識できませんでした。
どちらも顔が傾いています。ある程度の傾きなら問題ないのですが、画像のような角度で傾いているとダメみたいですね。どうしても顔を切り取りたい場合は、画像に対しアフィン変換をする必要があります。
この2つ以外はこのように、
グレースケール化され、顔のみ切り取られてリサイズされています。
眼鏡をかけていても問題ありません。(サングラス、マスク着用は厳しいかも...)コマンド
python face_cut.py -d <画像フォルダ> (-o <保存先> -s <リサイズ> -l <インデックス> -c <cascade>)加工された画像データの保存先はデフォルトで
./result_cropになっています。
Haar-cascadeの指定はデフォルトで./haar_cascade.xmlとなっています。
その他、リサイズは32×32px、インデックスは1がデフォルトで指定されています。説明
face_cut関数で、グレースケール化、顔の切り取り、リサイズをします。
まずは、顔を検出し、切り取るのに使うHaar-cascadeを読み込みます。
# Haar-Like特徴量Cascade型分類器の読み込み cascade = cv2.CascadeClassifier(HAAR_FILE)
HAAR_FILEはコマンドオプションより指定したHaar-cascadeのパスです。下にある処理では画像の読み込み、グレースケール化、顔の検出を行っています。
# データ加工 for img_name in natsorted(os.listdir(imgs_dir)): print("画像データ:{}".format(img_name)) # jpg形式のみ _, ext = os.path.splitext(img_name) if ext.lower() == '.jpg': img_path = os.path.join(imgs_dir, img_name) # ファイルパスの結合 img = cv2.imread(img_path) # データ読み込み img_g = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY) # グレースケールに変換 face = cascade.detectMultiScale(img_g) # 顔を検出今回はJPEGファイルのみ対象としていますが、
if ext.lower() == '.jpg':で'.png'や'.bmp'にすれば、そのファイルを対象に加工できます。
cv2.cvtColor()でRGB画像からグレースケール画像に変換します。
その後、cascade.detectMultiScale()でHaar-cascadeを用いた顔の検出を行います。img_g = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY) # グレースケールに変換 face = cascade.detectMultiScale(img_g) # 顔を検出
cascade.detectMultiScale()は顔が検出されたとき、検出箇所のx座標とy座標、幅と高さを返却します。
顔が検出されなければなにも返却されません。# 顔が検出されなかったら if len(face) == 0: print("Face not found.") else: for x,y,w,h in face: # 顔の切り取り face_cut = img_g[y:y+h, x:x+w] # リサイズ face_img = cv2.resize(face_cut, (img_size, img_size)) # 保存 result_img_name = '\data' + str(label) + '.jpg' cv2.imwrite(os.path.join(result_out + result_img_name), face_img) label += 1 print("Processing success!!") else: print("Unsupported file extension")下の処理では返される情報をもとに、顔部分の切り取りを行っています。
# 顔の切り取り face_cut = img_g[y:y+h, x:x+w]下の図のような具合になっています。(見づらいですが...)
切り取りができたら、
cv2.resize()で指定のサイズにリサイズを行い、保存を行います。以上です。
main関数については説明不要だと思うので割愛します。おわりに
私はデータスクレイピングとこのプログラムを使って、学習データの収集をしてました。
特段こだわりがなければ、十分使えると思います。ただ、実行結果でも触れたとおり限界はあります。横顔の場合は横顔専用のHaar-cascadeも同梱されているので、そちらを使うといいかもしれません。
また、誤検出も多少あるのでデータクレンジング(顔ではない部分が切り取られた画像の排除)が必要です。




