- 投稿日:2020-02-10T22:53:41+09:00
結局SageMakerは学習の時に何をしているのか?
解説すること
- Amason SageMakerの一番最初の基礎事項のチュートリアル
- 1行1行のコードの裏で何をしているのか
- Amason SageMakerを中心とした機械学習エコシステムのとっかかりのイメージ
解説しないこと
- SageMakerで何ができるのか・メリット
- AWS Japan SageMaker 事例祭り#8 を参考にしてください
- SageMakerの動かし方
- 今回のチュートリアルは自分で動かせるものとします
- SageMaker Studioを用いた学習
前提とする知識
- AWSの基本的なサービス(S3, EC2)
- Jupiter Notebook, Scikit-learn, pandasの経験
はじめに
機械学習ライブラリ、特にScikit-learnやKerasなどの普及に伴い、個人でも企業でも気軽に機械学習に取りかかれるようになりました。筆者の所属するメーカ系研究所でも、機械学習を用いたプロジェクトは(最小単位1人から)当たり前に行われています。
エンジニア一人一人が機械学習を気軽に扱える上で、この気軽さが弊害になることがあります。開発内容が属人化する、案件ごとに使い回しが効かない(逆にコピペを繰り返して収集がつかない)、学習したモデルやその際のパラメータ管理ができない(どのデータを用いてどんなパラメータで学習させたか追跡できない)、など。
これらの問題は機械学習のためのリソースやコードが一枚岩(モノリシック)になっており、差し替えが効かないことが要因の一つになっています。
機械学習、特にディープラーニングに関わる技術やサービスの進歩の速さは圧倒的なため、「新しく出てくる技術要素を(ほかに影響を与えないで)素早く入れ替えて試す」ということも重要になりますが、モノリシックな設計だと、一つのモジュールの変更がアーキテクチャ全体の変更を引き起こすこともあります。
Amazon SageMaker
Amazon SageMakerはAWSが提供する機械学習のマネージドサービスで、機械学習のワークフロー全体を扱うための統合ツールです。S3(データの格納)、EC2(計算の実行)など、機械学習に含まれる要素をマイクロサービス化し、統合することで機械学習の書くプロセスの負荷を軽くします。
機械学習の各プロセスをきっちり各部品に分けておいて、それらをAPIでつないだ方が部品の差し替えがききますもんね。
AWS: Amazon SageMaker すべての開発者とデータサイエンティストのための機械学習
AWS: マイクロサービス
JAWS-UG: [AI/ML] 機械学習における AWS を用いたマイクロサービスアーキテクチャマイクロサービス化の障壁
モジュール全体を疎結合にしてそれぞれの再利用性が向上するのは良いことです。ローカルPCで機械学習をやっているエンジニアも皆これをすれば良いでしょう。
ただしそこには障壁があって、(たとえSageMakerのようなフルマネージドサービスを使ったとしても)マイクロサービスの仕組みを理解し、用いることにはコストがかかることです。
(注:ML Opsが注目されていますが、マイクロサービス化がML Opsの必要条件ではないし、マイクロサービス化をしたら常に見通しの良いものができるわけではないです。
This Week in Programming: Forget Microservices, Monoliths Are the Way Forwardとりあえずオレオレ方式でなんとなく済んでいる人にとってはこのコストを支払う障壁は思ったより大きいものになります。SageMakerのチュートリアルを実行したことはあるが、コードの先頭やそこかしこに(自分のコードにはない)呪文がでてきて混乱します。
「とりあえず呪文だ、そういうことにしよう」そう自分に言い聞かせますが、やはり混乱します。
なんとなくできたのは良いが「これ、いつもよりメンドくさくない?」となってしまってメリットが感じられなくなりがちです。(自分はそうだった)
すでにscikit-learnなどを自分のマシンで動かしたことがあり、SageMakerのメリットを求める人は
「SageMakerで何ができるかもわかる、どうやればいいかも(チュートリアルを進めれば多分)わかる。だけど一体何をやってるの?どうしてそんなコードが出てくるの?実際裏では何をやっているの?」
と思ってしまいます。逆に、(機械学習をやるにはこうしておけばよい、という天下り的思想のもと)SageMakerで初めて機械学習を始める人にとっては、チュートリアルはレベルが高すぎると感じます。
今回話すこと
上記のような、機械学習を独自にやってきた人、これからSageMakerで機械学習を始める人、双方にとっても参入障壁があり、解決すべき問題があると考えます。つまり、マイクロサービス化した結果複雑になっているところをうまく可視化してあげて参入コストを下げる、ことです。
チュートリアルの解説
機械学習モデルの構築およびトレーニング、デプロイ with Amazon SageMaker
を用います。
やり方はAWSコンソールからSageMaker Notebookを立ち上げて順に実行するだけです(やったことある人も多いでしょう)。これを普段ローカルでやる学習フェーズと関連させて説明していきます。
文中にコードを入れていますが、話の流れをわかりやすくするために、チュートリアルのコードの切り取り方とは意図的に変えているところがあります(コードの内容自体は変えていません)。ご了承ください。
なお、今回は、学習したモデルのデプロイや学習結果の評価については言及しません。あくまで、学習までのプロセスでSageMakerが(他のマイクロサービスを巻き込みながら)何をしているのかについて説明します。
注:ここが一番重要なところですが、私自身の勉強の備忘として記している節もあります。認識違いや誤解をまねく表記などありましたら、ぜひご指摘ください
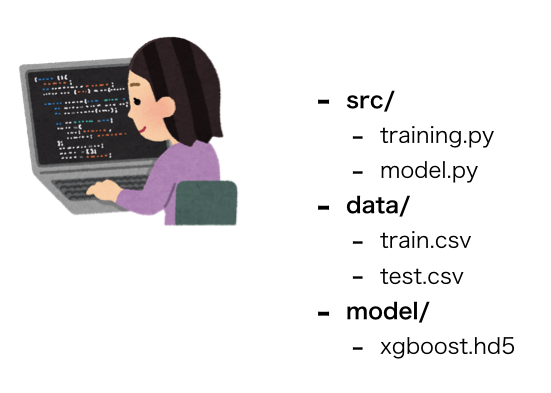
ローカルPC上での学習フェーズ
特に情報量のない画ですが、ローカル上で機械学習を行う時によくある構成を書きました。
単一のマシン上で、
- 計算資源(PC自体)
- データ格納場所
- 学習データ(dataフォルダ)
- 学習済みモデル(modelフォルダ)
- 学習アルゴリズム(model.py)
- 学習の際のスクリプト(training.py)
が一つのリソース上に存在しています。
これだけだと特に問題はないのですが、新しいデータが出てきた時、新しいアルゴリズムを試す時、計算リソースを増やしたい時、共同で開発したい時、などにリソースをどう共有(分散するか)困ります。
これに対して、SageMakerを用いたAWSのアプローチがどうなっているかを説明します。
最初に(学習とは関係ない)下準備がありますが、少しだけ我慢してください。。
SageMakerを用いた機械学習の学習フェーズ
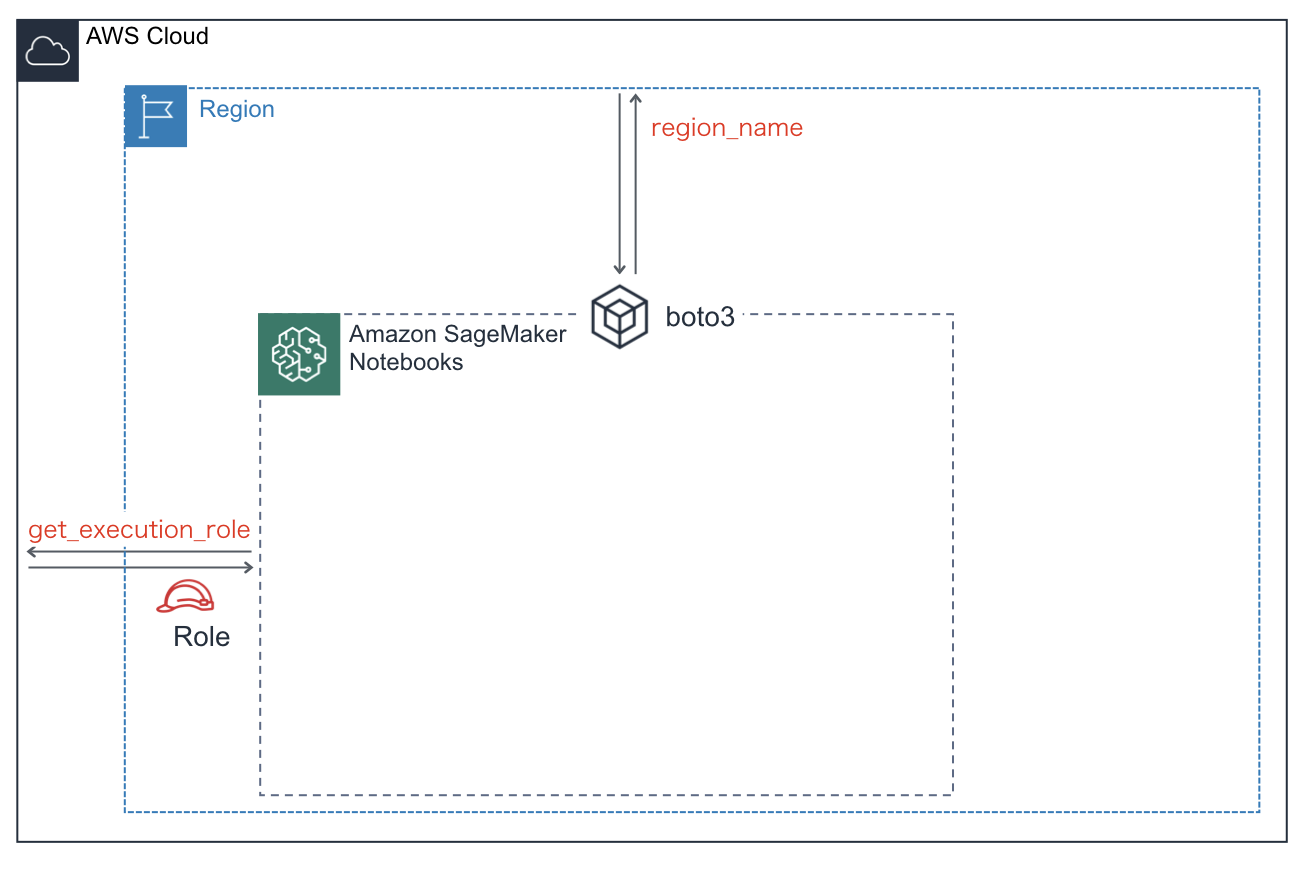
下準備:必要な情報の取得・指定
role = get_execution_role() prefix = 'sagemaker/DEMO-xgboost-dm' my_region = boto3.session.Session().region_name # set the region of the instanceロール
SageMakerを利用するために(正確にはSageMaker上でEstimatorインスタンスを作成するに)ロール情報を取得・指定する必要があります。下記に引用したように、ロールとはAWS上でできることとできないこと(つまり権限)を定めたIDです。
特定のアクセス権限を持ち、アカウントで作成できる IAM アイデンティティです。IAM ロールは、IAM ユーザーといくつかの類似点を持っています。ロールとユーザーは、両方とも、ID が AWS でできることとできないことを決定するアクセス許可ポリシーを持つ AWS ID です。ただし、ユーザーは 1 人の特定の人に一意に関連付けられますが、ロールはそれを必要とする任意の人が引き受けるようになっています。
SageMaker Notebookからロール情報を取得するためには、SageMaker APIのget_execution_roleを実行します。これにより、現在開いているノートブックインスタンスに紐づいたロール名(IAMロールARN)が取得できます。
参考
AWS公式:ロールに関する用語と概念
AWS公式:ID (ユーザー、グループ、ロール)
AWS公式:Amazon リソースネーム (ARN)S3のprefix
学習データ、また学習されたモデルはノートブック外のストレージ(S3)に保存します。また、そのためにS3ストレージ(バケット)を(もし存在しないのであれば)作成する必要があります。
今回のチュートリアルでは、S3のフォルダ構成を以下のようにします。
- s3://{bucket_name}/
- sagemaker/
- DEMO-xgboost-dm/
- train/
- train.csv
- output/
- xgboost-YYYY-MM-DD-hh-mm-ss-xxx/
- output/
- model.tar.gz
バケット名(bucket_name)は
- グローバルに一意
- 3文字以上63文字以内
- 大文字、アンダースコア(_)を含まない
- 小文字もしくは数字から始まる
などの制約があります。
Bucket Restrictions and Limitations
bucket_name直下のフォルダ構成を整えるためにprefixを指定します(今回は"sagemaker/DEMO-xgboost-dm")
リージョン名
ノートブックインスタンスが存在するリージョン名を取得します。リージョン名を取得するためにはBoto3を利用します。Boto3とはPythonからAWSを操作するためのSDK(ソフトウェア開発キット)です。
このチュートリアルではリージョン名は
- S3バケット作成時
- 機械学習アルゴリズムを格納したコンテナの選択時
に用いられます。
AWS公式:リージョン、アベイラビリティーゾーン、および ローカルゾーン
AWS公式:AWS SDK for Python (Boto3)
学習データの準備
さて、ここから機械学習に必要なデータを準備していきます。
機械学習を行うにあたり、まず準備するものは学習データです。今回は(AWS)外部のサーバよりデータをダウンロードし、学習に用います。
学習データのダウンロード
try: urllib.request.urlretrieve ("https://d1.awsstatic.com/tmt/build-train-deploy-machine-learning-model-sagemaker/bank_clean.27f01fbbdf43271788427f3682996ae29ceca05d.csv", "bank_clean.csv") print('Success: downloaded bank_clean.csv.') except Exception as e: print('Data load error: ',e)urllibライブラリのurlretrieveメソッドを使ってbank_clean.csvをダウンロードします。ファイルはNotebooks内(正確にはノートブックと同じディレクトリ)のローカルフォルダにコピーされます。
try: model_data = pd.read_csv('./bank_clean.csv',index_col=0) print('Success: Data loaded into dataframe.') except Exception as e: print('Data load error: ',e) train_data, test_data = np.split(model_data.sample(frac=1, random_state=1729), \ [int(0.7 * len(model_data))]) pd.concat([train_data['y_yes'], train_data.drop(['y_no', 'y_yes'], axis=1)], \ axis=1).to_csv('train.csv', index=False, header=False)ダウンロードしたデータを学習データ、テストデータに分割します。
SageMakerでは、入力データとラベルデータを同一のフォルダにまとめる必要があるようです。ダウンロードしたbank_clean.csvでは、最後の2列に正解ラベル(2値)のone-hot-encodingが格納されています。
2値分類の場合、正例ラベルをテーブルの先頭行にもってきます。
最後にcsvに書き出します。
学習データをS3にアップロード
データを外部サーバよりダウンロードし整形して学習データを用意しました。この状態では学習データはNotebook上のローカルフォルダにあります。このデータをS3にアップロードする必要があります。
S3バケットの作成
作成したデータをアップロードするためのS3バケットを作成します。Boto3を用います。
bucket_name = 'your-s3-bucket-name' # <--- CHANGE THIS VARIABLE TO A UNIQUE NAME FOR YOUR BUCKET s3 = boto3.resource('s3') try: if my_region == 'us-east-1': s3.create_bucket(Bucket=bucket_name) else: s3.create_bucket(Bucket=bucket_name, CreateBucketConfiguration={ 'LocationConstraint': my_region }) print('S3 bucket created successfully') except Exception as e: print('S3 error: ',e)まず、Boto3上でS3用のリソース(S3を操作するためのインスタンス "s3")を作成します。このインスタンスよりcreate_bucketメソッドを実行してバケットを作成します。作成時にはリージョンを指定します。リージョンがus-east-1かどうかで作成の方法が異なるようです。
S3へ学習データのアップロード
Boto3を使って先ほど作成した学習データをS3バケットへアップロードします。
boto3.Session().resource('s3').Bucket(bucket_name).Object(os.path.join(prefix, 'train/train.csv')).upload_file('train.csv')なお、このチュートリアルでは出てきませんが、Boto3を使わずにSageMaker APIを用いてアップロードすることも可能です。
sagemaker_session.upload_data('./train.csv', bucket=bucket_name, \ key_prefix="{}/train".format(prefix))追記:S3バケットを明示的に作成せずに、SageMakerから自動でデフォルトのバケットを作成する方法もあるようです。
学習モデル(アルゴリズム)の用意
データの準備ができたので、学習に用いるモデル(アルゴリズム)を選択します。SageMakerで機械学習モデルを選択するときには
- 組み込みアルゴリズム
- 独自のアルゴリズムやモデルを用いて自作
- Amazon Marketplaceからの購入
があります。今回は1を用います。
1. 組み込みアルゴリズム
XGBoostやK最近傍法など、よく用いられるアルゴリズムはSageMakerの組み込みアルゴリズムとして提供されています。ユーザーは組み込みアルゴリズムのコンテナイメージを指定することで簡単に使うことができます。組み込みアルゴリズムのリストは以下
Amazon SageMaker 組み込みアルゴリズムを使用する
このチュートリアルではコンテナイメージ名をリージョンに応じて直接指定しています。
containers = {'us-west-2': '433757028032.dkr.ecr.us-west-2.amazonaws.com/xgboost:latest', 'us-east-1': '811284229777.dkr.ecr.us-east-1.amazonaws.com/xgboost:latest', 'us-east-2': '825641698319.dkr.ecr.us-east-2.amazonaws.com/xgboost:latest', 'eu-west-1': '685385470294.dkr.ecr.eu-west-1.amazonaws.com/xgboost:latest'} # each region has its XGBoost containerこの方法でも良いのですが、一体どこからこの(もしくは他の)イメージ名を取得するんだ?と思いますよね(この辺りがAWS公式の痒いところに手が届かない感があります)
実際は、SageMaker APIからアルゴリズム名をしてすることで、対応するコンテナイメージ名(URI)を取得することができます。
from sagemaker.amazon.amazon_estimator import get_image_uri container = get_image_uri(boto3.Session().region_name, 'xgboost')この方法でも問題なく動きました。(notebookの実行時にrepo_versionを指定しろとwarningが出るかもしれません)
組み込みアルゴリズムのイメージ名の取得方法に関しては以下
AWS公式:組み込みアルゴリズムの共通パラメータ組み込みアルゴリズムの活用方法は以下のクラスメソッドさんのブログが大変参考になりました。(ただし公開されてから1年以上たっており、一部情報が古い可能性もあります)
Amazon SageMakerの組み込み(built-in)アルゴリズムとは…?
AmazonSageMakerのXGBoostでMNISTの手書き文字を分類してみた2.独自のアルゴリズムやモデルを用いて自作
上記の組み込みアルゴリズムにないものや、ニューラルネットワークの構造を考察したい場合などは、Sciit-learnやPytorchなどのライブラリを用いることができます。その場合、SageMakerが求めるモデルの形式にラップする必要があります。(今後記事にする予定です)
AWS公式:Amazon SageMaker での scikit-learn の使用
AWS公式:Amazon SageMaker で PyTorch を使用
Using Scikit-learn with the SageMaker Python SDK3. Amazon Marketplaceからの購入
AWS Marketplace での Amazon SageMaker アルゴリズムとモデルの購入と販売
Marketplaceに公開されているモデルをコンソール上から利用してみる:Amazon SageMaker Advent Calendar 2018
学習
はい!前置きが長くなってしまいましたが下準備がやっとできました。準備してきたことをまとめます。
- 必要な情報
- ロール名
- リージョン名
- 学習データのアップロード
- S3バケットの作成
- S3バケットへのアップロード
- 学習アルゴリズムの準備
- 組み込みアルゴリズムのコンテナイメージURIの取得
さて、ここからSageMaker Notebook上で機械学習をおこなっていきましょう。と書きましたがこの言い方は正しくないです。なぜなら、データはS3上にあるし、学習アルゴリズム(モデル)は外のコンテナイメージを引っ張ってきているし、計算を実行するインスタンスはNotebookが走っているインスタンスとは別に指定しています(後述)
じゃあ、Notebookは何をしているんでしょう。ただ、みんなをまとめているだけです。それぞれの所在を明らかにして、学習の指示を与えるだけです。(Notebook上でデータをダウンロードしたりS3にアップロードしたりしましたが、それらはあくまで前準備であって学習とは本質的に無関係です。)
なぜわざわざこんな周りくどいことをやるのでしょう?強大なコンピューティングパワーと広大な記憶領域を持つインスタンスを一つ用意して、そこで全て完結してしまえばラクじゃないでしょうか。そうすればこんなに長々とした呪文を打たなくて良いのに!
これこそが、SageMakerの特徴で機械学習に関わるリソースとモジュールを分散することで各モジュールの再利用性を保っているのです。
一つ一つを理解するのは煩わしいのですが、一度SageMakerのフレームワークを理解しそれに従って組んでしまえば、AWSの持つ様々なマネージドサービスの恩恵を受けることができます。このチュートリアルだけでは理解しにくいですが、ML Opsの観点についても(例えばパラメータの管理や学習の進捗の把握など)恩恵を受けることができます。(今後、記事を書いていけたらと思います。)
sessionの作成
学習を行う際に用いるsessionインスタンスを作成します。
sess = sagemaker.Session()sessionとは、Amazon SageMaker APIと(必要とされる)他のAWSサービスの相互通信を管理するのに必要なクラスです。トレーニングジョブ、エンドポイント、S3上の入力データなどAmazon SageMakerが用いるエンティティとリソースを操作するのに使われます。TensorflowなどでもSessionという概念は出てくるので馴染みがあるかもしれませんね。
s3_inputの作成(学習データのロード)
S3に格納しているデータを計算をおこなうEC2インスタンスに(Notebook経由で)送るために、Notebook上で学習データのアドレスをs3_inputインスタンスとして保持しておきます。データそのものを送っているわけではないので、パイプラインというかプレイスホルダーのようなものですかね(私見)
s3_input_train = sagemaker.s3_input(s3_data='s3://{}/{}/train'.format(bucket_name, prefix), content_type='csv')Estimatorの作成
xgb = sagemaker.estimator.Estimator(con, role, train_instance_count=1,\ train_instance_type='ml.m4.xlarge', output_path='s3://{}/{}/output'\ .format(bucket_name, prefix), sagemaker_session=sess) xgb.set_hyperparameters(max_depth=5, eta=0.2, gamma=4, min_child_weight=6, \ subsample=0.8, silent=0, objective='binary:logistic', num_round=100)与えられたアルゴリズムを用いて学習をおこなうためのEstimatorクラスのインスタンスを生成します。インスタンス作成に必要な情報(変数)は下記です。
- コンテナイメージ名(アルゴリズムを指定)
- ロール(権限を取得)
- EC2(学習リソースの確保)
- 学習済みモデルの出力先S3バケット
- Session(それぞれのエンティティおよびリソースを管理)
Estimatorインスタンス作成時にs3_inputは指定しません(もしそうだとすると、複数のデータセットを同じEstimatorインスタンスに供給できない)
ハイパーパラメータのセットはset_hyperparametersで指定します。
各組み込みアルゴリズムのハイパーパラメータは下記のトピックからアルゴリズムを選択することで確認できます。
AWS公式:Amazon SageMaker 組み込みアルゴリズムを使用する
学習
xgb.fit({'train': s3_input_train})生成したEstimator(xgb)に対してfitメソッドを実行します。入力データ(のアドレス)はここで指定します。fitメソッドはscikit-learnやkerasなどで一般的ですね。SageMakerもそれに合わせています。
最後に
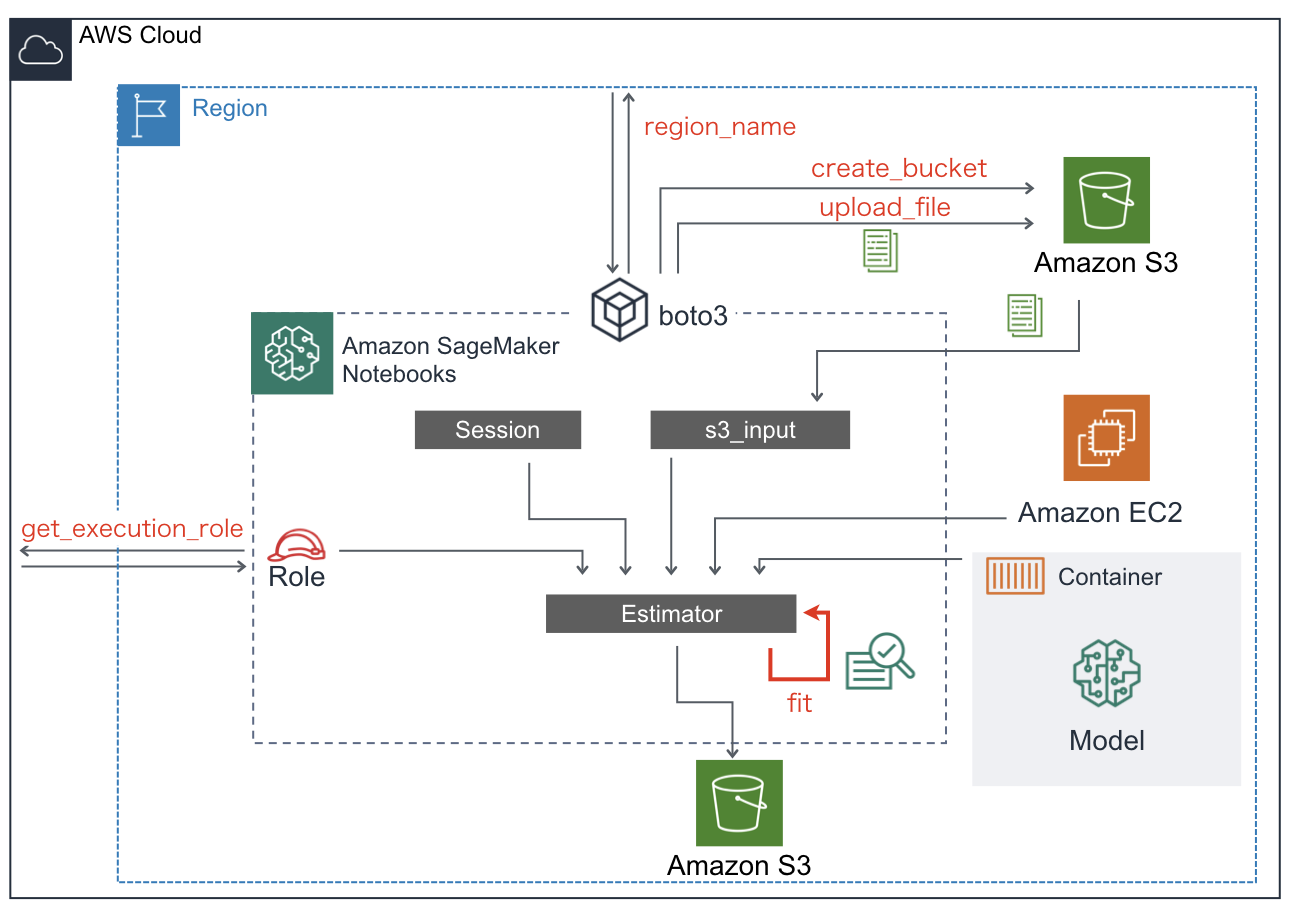
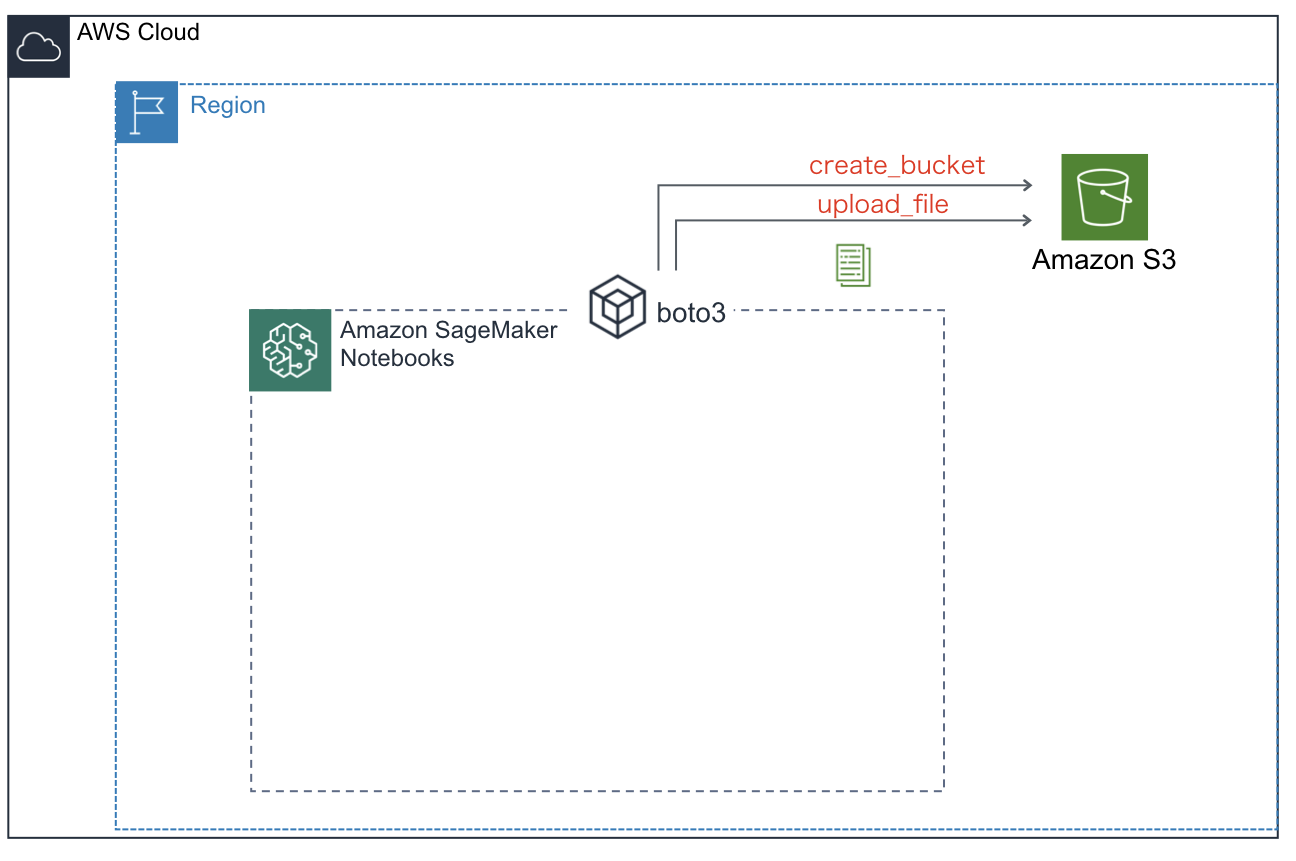
お疲れ様でした。今回のチュートリアルでのSageMakerおよび各サービスとの連携イメージを載せます。
この図を理解できていれば、(上で要した)日本語の長い説明は不要ですね。長文を読んでいただきありがとうございました。
次は、
- 自作のアルゴリズムの作成方法
- SageMaker Studioの使用方法
について書いてみたいと思っています。




- 投稿日:2020-02-10T22:53:41+09:00
[入門] 結局SageMakerは学習の時に何をしているのか?
解説すること
- Amason SageMakerの一番最初の基礎事項のチュートリアル
- 1行1行のコードの裏で何をしているのか
- Amason SageMakerを中心とした機械学習エコシステムのとっかかりのイメージ
解説しないこと
- SageMakerで何ができるのか・メリット
- AWS Japan SageMaker 事例祭り#8 を参考にしてください
- SageMakerの動かし方
- 今回のチュートリアルは自分で動かせるものとします
- SageMaker Studioを用いた学習
前提とする知識
- AWSの基本的なサービス(S3, EC2)
- Jupiter Notebook, Scikit-learn, pandasの経験
はじめに
機械学習ライブラリ、特にScikit-learnやKerasなどの普及に伴い、個人でも企業でも気軽に機械学習に取りかかれるようになりました。筆者の所属するメーカ系研究所でも、機械学習を用いたプロジェクトは(最小単位1人から)当たり前に行われています。
エンジニア一人一人が機械学習を気軽に扱える上で、この気軽さが弊害になることがあります。開発内容が属人化する、案件ごとに使い回しが効かない(逆にコピペを繰り返して収集がつかない)、学習したモデルやその際のパラメータ管理ができない(どのデータを用いてどんなパラメータで学習させたか追跡できない)、など。
これらの問題は機械学習のためのリソースやコードが一枚岩(モノリシック)になっており、差し替えが効かないことが要因の一つになっています。
機械学習、特にディープラーニングに関わる技術やサービスの進歩の速さは圧倒的なため、「新しく出てくる技術要素を(ほかに影響を与えないで)素早く入れ替えて試す」ということも重要になりますが、モノリシックな設計だと、一つのモジュールの変更がアーキテクチャ全体の変更を引き起こすこともあります。
Amazon SageMaker
Amazon SageMakerはAWSが提供する機械学習のマネージドサービスで、機械学習のワークフロー全体を扱うための統合ツールです。S3(データの格納)、EC2(計算の実行)など、機械学習に含まれる要素をマイクロサービス化し、統合することで機械学習の書くプロセスの負荷を軽くします。
機械学習の各プロセスをきっちり各部品に分けておいて、それらをAPIでつないだ方が部品の差し替えがききますもんね。
AWS: Amazon SageMaker すべての開発者とデータサイエンティストのための機械学習
AWS: マイクロサービス
JAWS-UG: [AI/ML] 機械学習における AWS を用いたマイクロサービスアーキテクチャマイクロサービス化の障壁
モジュール全体を疎結合にしてそれぞれの再利用性が向上するのは良いことです。ローカルPCで機械学習をやっているエンジニアも皆これをすれば良いでしょう。
ただしそこには障壁があって、(たとえSageMakerのようなフルマネージドサービスを使ったとしても)マイクロサービスの仕組みを理解し、用いることにはコストがかかることです。
(注:ML Opsが注目されていますが、マイクロサービス化がML Opsの必要条件ではないし、マイクロサービス化をしたら常に見通しの良いものができるわけではないです。
This Week in Programming: Forget Microservices, Monoliths Are the Way Forwardとりあえずオレオレ方式でなんとなく済んでいる人にとってはこのコストを支払う障壁は思ったより大きいものになります。SageMakerのチュートリアルを実行したことはあるが、コードの先頭やそこかしこに(自分のコードにはない)呪文がでてきて混乱します。
「とりあえず呪文だ、そういうことにしよう」そう自分に言い聞かせますが、やはり混乱します。
なんとなくできたのは良いが「これ、いつもよりメンドくさくない?」となってしまってメリットが感じられなくなりがちです。(自分はそうだった)
すでにscikit-learnなどを自分のマシンで動かしたことがあり、SageMakerのメリットを求める人は
「SageMakerで何ができるかもわかる、どうやればいいかも(チュートリアルを進めれば多分)わかる。だけど一体何をやってるの?どうしてそんなコードが出てくるの?実際裏では何をやっているの?」
と思ってしまいます。逆に、(機械学習をやるにはこうしておけばよい、という天下り的思想のもと)SageMakerで初めて機械学習を始める人にとっては、チュートリアルはレベルが高すぎると感じます。
今回話すこと
上記のような、機械学習を独自にやってきた人、これからSageMakerで機械学習を始める人、双方にとっても参入障壁があり、解決すべき問題があると考えます。つまり、マイクロサービス化した結果複雑になっているところをうまく可視化してあげて参入コストを下げる、ことです。
チュートリアルの解説
機械学習モデルの構築およびトレーニング、デプロイ with Amazon SageMaker
を用います。
やり方はAWSコンソールからSageMaker Notebookを立ち上げて順に実行するだけです(やったことある人も多いでしょう)。これを普段ローカルでやる学習フェーズと関連させて説明していきます。
文中にコードを入れていますが、話の流れをわかりやすくするために、チュートリアルのコードの切り取り方とは意図的に変えているところがあります(コードの内容自体は変えていません)。ご了承ください。
なお、今回は、学習したモデルのデプロイや学習結果の評価については言及しません。あくまで、学習までのプロセスでSageMakerが(他のマイクロサービスを巻き込みながら)何をしているのかについて説明します。
注:ここが一番重要なところですが、私自身の勉強の備忘として記している節もあります。認識違いや誤解をまねく表記などありましたら、ぜひご指摘ください
ローカルPC上での学習フェーズ
特に情報量のない画ですが、ローカル上で機械学習を行う時によくある構成を書きました。
単一のマシン上で、
- 計算資源(PC自体)
- データ格納場所
- 学習データ(dataフォルダ)
- 学習済みモデル(modelフォルダ)
- 学習アルゴリズム(model.py)
- 学習の際のスクリプト(training.py)
が一つのリソース上に存在しています。
これだけだと特に問題はないのですが、新しいデータが出てきた時、新しいアルゴリズムを試す時、計算リソースを増やしたい時、共同で開発したい時、などにリソースをどう共有(分散するか)困ります。
これに対して、SageMakerを用いたAWSのアプローチがどうなっているかを説明します。
最初に(学習とは関係ない)下準備がありますが、少しだけ我慢してください。。
SageMakerを用いた機械学習の学習フェーズ
下準備:必要な情報の取得・指定
role = get_execution_role() prefix = 'sagemaker/DEMO-xgboost-dm' my_region = boto3.session.Session().region_name # set the region of the instanceロール
SageMakerを利用するために(正確にはSageMaker上でEstimatorインスタンスを作成するに)ロール情報を取得・指定する必要があります。下記に引用したように、ロールとはAWS上でできることとできないこと(つまり権限)を定めたIDです。
特定のアクセス権限を持ち、アカウントで作成できる IAM アイデンティティです。IAM ロールは、IAM ユーザーといくつかの類似点を持っています。ロールとユーザーは、両方とも、ID が AWS でできることとできないことを決定するアクセス許可ポリシーを持つ AWS ID です。ただし、ユーザーは 1 人の特定の人に一意に関連付けられますが、ロールはそれを必要とする任意の人が引き受けるようになっています。
SageMaker Notebookからロール情報を取得するためには、SageMaker APIのget_execution_roleを実行します。これにより、現在開いているノートブックインスタンスに紐づいたロール名(IAMロールARN)が取得できます。
参考
AWS公式:ロールに関する用語と概念
AWS公式:ID (ユーザー、グループ、ロール)
AWS公式:Amazon リソースネーム (ARN)S3のprefix
学習データ、また学習されたモデルはノートブック外のストレージ(S3)に保存します。また、そのためにS3ストレージ(バケット)を(もし存在しないのであれば)作成する必要があります。
今回のチュートリアルでは、S3のフォルダ構成を以下のようにします。
- s3://{bucket_name}/
- sagemaker/
- DEMO-xgboost-dm/
- train/
- train.csv
- output/
- xgboost-YYYY-MM-DD-hh-mm-ss-xxx/
- output/
- model.tar.gz
バケット名(bucket_name)は
- グローバルに一意
- 3文字以上63文字以内
- 大文字、アンダースコア(_)を含まない
- 小文字もしくは数字から始まる
などの制約があります。
Bucket Restrictions and Limitations
bucket_name直下のフォルダ構成を整えるためにprefixを指定します(今回は"sagemaker/DEMO-xgboost-dm")
リージョン名
ノートブックインスタンスが存在するリージョン名を取得します。リージョン名を取得するためにはBoto3を利用します。Boto3とはPythonからAWSを操作するためのSDK(ソフトウェア開発キット)です。
このチュートリアルではリージョン名は
- S3バケット作成時
- 機械学習アルゴリズムを格納したコンテナの選択時
に用いられます。
AWS公式:リージョン、アベイラビリティーゾーン、および ローカルゾーン
AWS公式:AWS SDK for Python (Boto3)
学習データの準備
さて、ここから機械学習に必要なデータを準備していきます。
機械学習を行うにあたり、まず準備するものは学習データです。今回は(AWS)外部のサーバよりデータをダウンロードし、学習に用います。
学習データのダウンロード
try: urllib.request.urlretrieve ("https://d1.awsstatic.com/tmt/build-train-deploy-machine-learning-model-sagemaker/bank_clean.27f01fbbdf43271788427f3682996ae29ceca05d.csv", "bank_clean.csv") print('Success: downloaded bank_clean.csv.') except Exception as e: print('Data load error: ',e)urllibライブラリのurlretrieveメソッドを使ってbank_clean.csvをダウンロードします。ファイルはNotebooks内(正確にはノートブックと同じディレクトリ)のローカルフォルダにコピーされます。
try: model_data = pd.read_csv('./bank_clean.csv',index_col=0) print('Success: Data loaded into dataframe.') except Exception as e: print('Data load error: ',e) train_data, test_data = np.split(model_data.sample(frac=1, random_state=1729), \ [int(0.7 * len(model_data))]) pd.concat([train_data['y_yes'], train_data.drop(['y_no', 'y_yes'], axis=1)], \ axis=1).to_csv('train.csv', index=False, header=False)ダウンロードしたデータを学習データ、テストデータに分割します。
SageMakerでは、入力データとラベルデータを同一のフォルダにまとめる必要があるようです。ダウンロードしたbank_clean.csvでは、最後の2列に正解ラベル(2値)のone-hot-encodingが格納されています。
2値分類の場合、正例ラベルをテーブルの先頭行にもってきます。
最後にcsvに書き出します。
学習データをS3にアップロード
データを外部サーバよりダウンロードし整形して学習データを用意しました。この状態では学習データはNotebook上のローカルフォルダにあります。このデータをS3にアップロードする必要があります。
S3バケットの作成
作成したデータをアップロードするためのS3バケットを作成します。Boto3を用います。
bucket_name = 'your-s3-bucket-name' # <--- CHANGE THIS VARIABLE TO A UNIQUE NAME FOR YOUR BUCKET s3 = boto3.resource('s3') try: if my_region == 'us-east-1': s3.create_bucket(Bucket=bucket_name) else: s3.create_bucket(Bucket=bucket_name, CreateBucketConfiguration={ 'LocationConstraint': my_region }) print('S3 bucket created successfully') except Exception as e: print('S3 error: ',e)まず、Boto3上でS3用のリソース(S3を操作するためのインスタンス "s3")を作成します。このインスタンスよりcreate_bucketメソッドを実行してバケットを作成します。作成時にはリージョンを指定します。リージョンがus-east-1かどうかで作成の方法が異なるようです。
S3へ学習データのアップロード
Boto3を使って先ほど作成した学習データをS3バケットへアップロードします。
boto3.Session().resource('s3').Bucket(bucket_name).Object(os.path.join(prefix, 'train/train.csv')).upload_file('train.csv')なお、このチュートリアルでは出てきませんが、Boto3を使わずにSageMaker APIを用いてアップロードすることも可能です。
sagemaker_session.upload_data('./train.csv', bucket=bucket_name, \ key_prefix="{}/train".format(prefix))追記:S3バケットを明示的に作成せずに、SageMakerから自動でデフォルトのバケットを作成する方法もあるようです。
学習モデル(アルゴリズム)の用意
データの準備ができたので、学習に用いるモデル(アルゴリズム)を選択します。SageMakerで機械学習モデルを選択するときには
- 組み込みアルゴリズム
- 独自のアルゴリズムやモデルを用いて自作
- Amazon Marketplaceからの購入
があります。今回は1を用います。
1. 組み込みアルゴリズム
XGBoostやK最近傍法など、よく用いられるアルゴリズムはSageMakerの組み込みアルゴリズムとして提供されています。ユーザーは組み込みアルゴリズムのコンテナイメージを指定することで簡単に使うことができます。組み込みアルゴリズムのリストは以下
Amazon SageMaker 組み込みアルゴリズムを使用する
このチュートリアルではコンテナイメージ名をリージョンに応じて直接指定しています。
containers = {'us-west-2': '433757028032.dkr.ecr.us-west-2.amazonaws.com/xgboost:latest', 'us-east-1': '811284229777.dkr.ecr.us-east-1.amazonaws.com/xgboost:latest', 'us-east-2': '825641698319.dkr.ecr.us-east-2.amazonaws.com/xgboost:latest', 'eu-west-1': '685385470294.dkr.ecr.eu-west-1.amazonaws.com/xgboost:latest'} # each region has its XGBoost containerこの方法でも良いのですが、一体どこからこの(もしくは他の)イメージ名を取得するんだ?と思いますよね(この辺りがAWS公式の痒いところに手が届かない感があります)
実際は、SageMaker APIからアルゴリズム名をしてすることで、対応するコンテナイメージ名(URI)を取得することができます。
from sagemaker.amazon.amazon_estimator import get_image_uri container = get_image_uri(boto3.Session().region_name, 'xgboost')この方法でも問題なく動きました。(notebookの実行時にrepo_versionを指定しろとwarningが出るかもしれません)
組み込みアルゴリズムのイメージ名の取得方法に関しては以下
AWS公式:組み込みアルゴリズムの共通パラメータ組み込みアルゴリズムの活用方法は以下のクラスメソッドさんのブログが大変参考になりました。(ただし公開されてから1年以上たっており、一部情報が古い可能性もあります)
Amazon SageMakerの組み込み(built-in)アルゴリズムとは…?
AmazonSageMakerのXGBoostでMNISTの手書き文字を分類してみた2.独自のアルゴリズムやモデルを用いて自作
上記の組み込みアルゴリズムにないものや、ニューラルネットワークの構造を考察したい場合などは、Sciit-learnやPytorchなどのライブラリを用いることができます。その場合、SageMakerが求めるモデルの形式にラップする必要があります。(今後記事にする予定です)
AWS公式:Amazon SageMaker での scikit-learn の使用
AWS公式:Amazon SageMaker で PyTorch を使用
Using Scikit-learn with the SageMaker Python SDK3. Amazon Marketplaceからの購入
AWS Marketplace での Amazon SageMaker アルゴリズムとモデルの購入と販売
Marketplaceに公開されているモデルをコンソール上から利用してみる:Amazon SageMaker Advent Calendar 2018
学習
はい!前置きが長くなってしまいましたが下準備がやっとできました。準備してきたことをまとめます。
- 必要な情報
- ロール名
- リージョン名
- 学習データのアップロード
- S3バケットの作成
- S3バケットへのアップロード
- 学習アルゴリズムの準備
- 組み込みアルゴリズムのコンテナイメージURIの取得
さて、ここからSageMaker Notebook上で機械学習をおこなっていきましょう。と書きましたがこの言い方は正しくないです。なぜなら、データはS3上にあるし、学習アルゴリズム(モデル)は外のコンテナイメージを引っ張ってきているし、計算を実行するインスタンスはNotebookが走っているインスタンスとは別に指定しています(後述)
じゃあ、Notebookは何をしているんでしょう。ただ、みんなをまとめているだけです。それぞれの所在を明らかにして、学習の指示を与えるだけです。(Notebook上でデータをダウンロードしたりS3にアップロードしたりしましたが、それらはあくまで前準備であって学習とは本質的に無関係です。)
なぜわざわざこんな周りくどいことをやるのでしょう?強大なコンピューティングパワーと広大な記憶領域を持つインスタンスを一つ用意して、そこで全て完結してしまえばラクじゃないでしょうか。そうすればこんなに長々とした呪文を打たなくて良いのに!
これこそが、SageMakerの特徴で機械学習に関わるリソースとモジュールを分散することで各モジュールの再利用性を保っているのです。
一つ一つを理解するのは煩わしいのですが、一度SageMakerのフレームワークを理解しそれに従って組んでしまえば、AWSの持つ様々なマネージドサービスの恩恵を受けることができます。このチュートリアルだけでは理解しにくいですが、ML Opsの観点についても(例えばパラメータの管理や学習の進捗の把握など)恩恵を受けることができます。(今後、記事を書いていけたらと思います。)
sessionの作成
学習を行う際に用いるsessionインスタンスを作成します。
sess = sagemaker.Session()sessionとは、Amazon SageMaker APIと(必要とされる)他のAWSサービスの相互通信を管理するのに必要なクラスです。トレーニングジョブ、エンドポイント、S3上の入力データなどAmazon SageMakerが用いるエンティティとリソースを操作するのに使われます。TensorflowなどでもSessionという概念は出てくるので馴染みがあるかもしれませんね。
s3_inputの作成(学習データのロード)
S3に格納しているデータを計算をおこなうEC2インスタンスに(Notebook経由で)送るために、Notebook上で学習データのアドレスをs3_inputインスタンスとして保持しておきます。データそのものを送っているわけではないので、パイプラインというかプレイスホルダーのようなものですかね(私見)
s3_input_train = sagemaker.s3_input(s3_data='s3://{}/{}/train'.format(bucket_name, prefix), content_type='csv')Estimatorの作成
xgb = sagemaker.estimator.Estimator(con, role, train_instance_count=1,\ train_instance_type='ml.m4.xlarge', output_path='s3://{}/{}/output'\ .format(bucket_name, prefix), sagemaker_session=sess) xgb.set_hyperparameters(max_depth=5, eta=0.2, gamma=4, min_child_weight=6, \ subsample=0.8, silent=0, objective='binary:logistic', num_round=100)与えられたアルゴリズムを用いて学習をおこなうためのEstimatorクラスのインスタンスを生成します。インスタンス作成に必要な情報(変数)は下記です。
- コンテナイメージ名(アルゴリズムを指定)
- ロール(権限を取得)
- EC2(学習リソースの確保)
- 学習済みモデルの出力先S3バケット
- Session(それぞれのエンティティおよびリソースを管理)
Estimatorインスタンス作成時にs3_inputは指定しません(もしそうだとすると、複数のデータセットを同じEstimatorインスタンスに供給できない)
ハイパーパラメータのセットはset_hyperparametersで指定します。
各組み込みアルゴリズムのハイパーパラメータは下記のトピックからアルゴリズムを選択することで確認できます。
AWS公式:Amazon SageMaker 組み込みアルゴリズムを使用する
学習
xgb.fit({'train': s3_input_train})生成したEstimator(xgb)に対してfitメソッドを実行します。入力データ(のアドレス)はここで指定します。fitメソッドはscikit-learnやkerasなどで一般的ですね。SageMakerもそれに合わせています。
最後に
お疲れ様でした。今回のチュートリアルでのSageMakerおよび各サービスとの連携イメージを載せます。
この図を理解できていれば、(上で要した)日本語の長い説明は不要ですね。長文を読んでいただきありがとうございました。
次は、
- 自作のアルゴリズムの作成方法
- SageMaker Studioの使用方法
について書いてみたいと思っています。
- 投稿日:2020-02-10T21:56:03+09:00
「桃太郎デスマッチ」 ー Azure / AWS / GCP 学習済みAIサービスで「桃太郎」を Speech To Text してみた話
はじめに
2019年1月23日(木) に Microsoft 主催の Ignite The Tour : Osaka に コミュニティ登壇させていただきました。
本記事は、上記イベントで発表させていただいた LT ( ライトニングトーク ) の内容を記事にしたものです。
※また、本記事では、3大クラウドプラットフォーム ( Azure / AWS / GCP ) の Speech To Text サービスの性能を比較し、ランク付けをさせていただいておりますが、使用する音声の録音環境、録音デバイス、その他環境の差により、当記事の検証結果と異なる場合がございますので、使用用途に応じて各自ご自身の判断で活用するサービスの選定を行うようにしてください。
( 3大クラウドネタとして楽しんでいただければ幸いです
)
今回のコミュニティ登壇の経緯
私自身、普段から関西発Azureコミュニティ「Azure Tech Lab.」の主催・運営をしているのですが、今回 Ignite The Tour の主催者であるMicrosoftさんにお声がけいただき、イベント会場内でアンカンファレンスセッションを行うことになりました。アンカンファレンスという言葉はなかなか耳なじみのない言葉ですが、格式高いセミナー ( 登壇者から参加者へ一方通行 ) と違って、参加者と登壇者が一緒になって創り上げていくようなカンファレンス形式のことを指します。今回私たちのアンカンファレンスセッションでは、普段コミュニティに参加しているメンバーによるLTや参加者に対するデモ体験の実施、そして会場の皆さんからのリアルタイムな質問にお答えするといったカタチで実施させていただきました。本記事では、70分のアンカンファレンスセッションの中で私が LT ( ライトニングトーク ) をさせていただいた部分についてのみ抜粋し、ご紹介したいと思います。
私の LT 登壇タイトルは、「桃太郎デスマッチ - Azure/AWS/GCP で Speech To Text の結果を比較してみた」 。Microsoftさん主催のイベントで、他社クラウドの話をぶち込むのはなかなか勇気がいったのですが、私の主催しているコミュニティのテーマが「クラウドベンダーの垣根を超えたエンジニアの交流」ということもあるので、半ば強引に LT をさせていただきました。しかも、10分の LT のはずが気が付いたら20分も話してました。。ごめんなさい。登壇資料は、こちらの SpeakerDeck にも公開しております。
結論から言うと、GCP ( Google Cloud Platform ) が一番精度が高かったです。
ただ、単純な性能差以外にも、様々な評価軸で多角的に評価してみたので、
そちらの内容を記事中で事細かくお伝えできればと思います。本日の MS Ignite Osaka での登壇資料はこちらです!
— Futo Horio (@Futo_Horio) January 23, 2020
桃太郎デスマッチ ー Azure / AWS / GCP で Speech-To-Text の結果を比べてみた!#MSIgniteTheTour #UNC10033 #azuretechlove #Azure #AWS #GCP #TTS https://t.co/XmmVVpqn13会場の雰囲気や登壇時の写真等は、以下のブログに記載があるのでそちらをご覧ください。
それでは、長い前置きは終わりにして、本題に移りたいと思います。
さて本題 ⇒ 桃太郎デスマッチ
という訳で、事前学習済みAIサービスという位置づけで3大クラウドで展開されているサービス内容を調査し、性能検証を行いました。
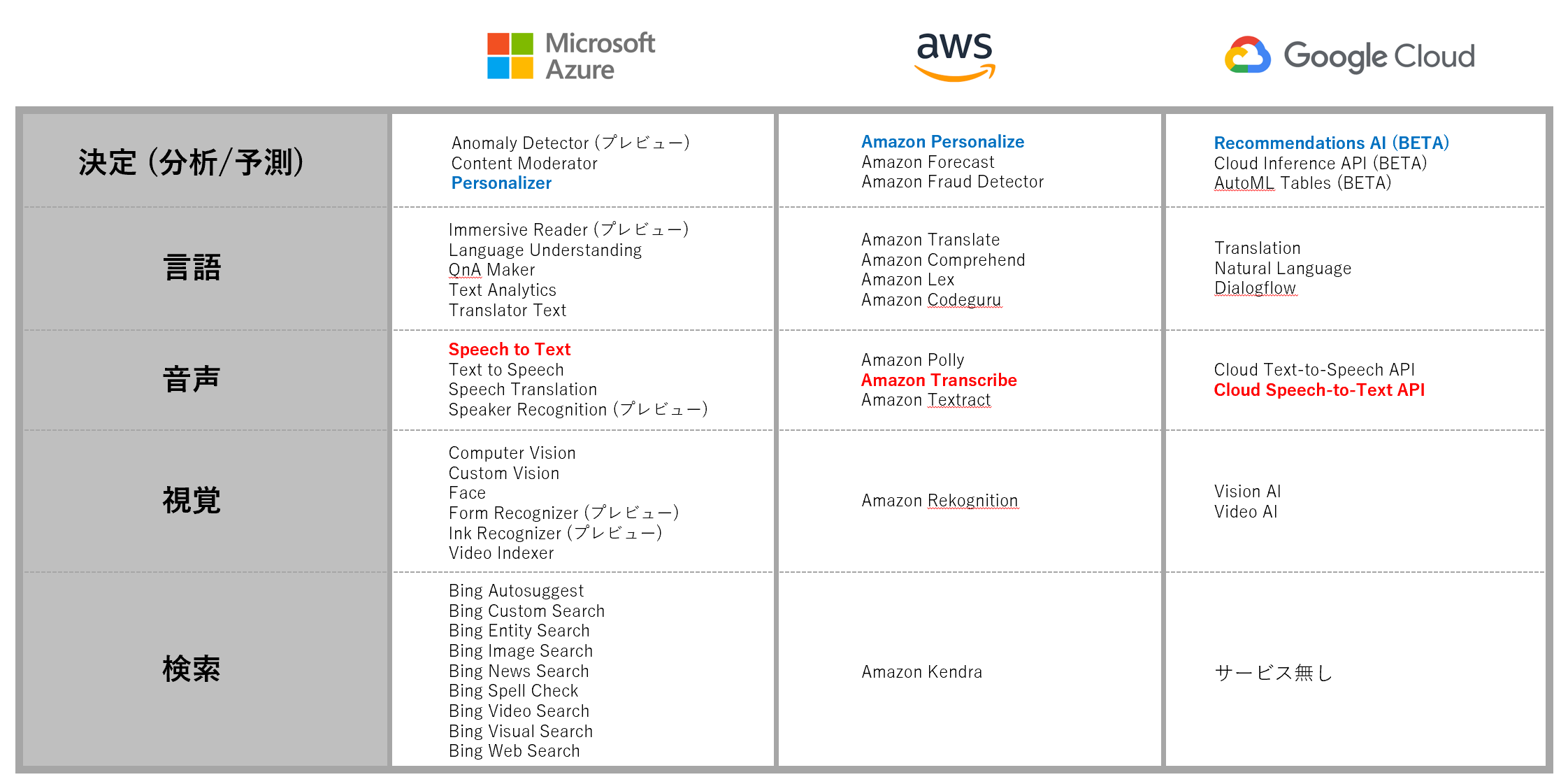
学習済みAI ( 人工知能 ) サービス比較表
まずは、3大クラウド ( Azure / AWS/ GCP ) 概要
学習済みAI ( 人工知能 ) サービスラインナップ (5分類)
続いて、各ベンダーのサービスの性能を比較してみます。
学習済みAI ( 人工知能 ) サービス: Speech To Text スペック比較
各ベンダーごとに特色があり、同じ Speech To Text だからと一概に比較できるものではないですが、今回は以下環境下における検証を実施いたしました。
続いて、今回行った検証内容...
※ちなみに、今回の検証には自分の声をスマートフォンで録音した音声ファイル ( 短文、長文 ※詳細後述 ) を使用しました。サンプル音声録音に使用したアプリは「PCM録音」という iOSアプリです。ファイル形式やサンプリング周波数など、音声ファイルの設定が簡単に変更できるのでサクッと検証する分にはこちらのアプリを使用されるのがおすすめです。
検証環境の準備 ( 各プラットフォーム )
( Azure ) Speech To Text [ 10 ~ 15 min ]
- Azrue MarketPlace より
Speech Service サブスクリプションキーを発行する
Azure-Samples/cognitive-services-speech-sdkの GitHubリポジトリをクローンpip install --upgrade azure-cognitiveservices-speech( SDKインストール )quickstart.pyに修正を加える (サブスクリプションキー&使用リージョン&ファイルパス)- 日本語変換に対応するため
speech_configの設定を追加する- resource 配下に 対象の音声ファイルを追加
$ python quickstart.pyを実行( AWS ) Amazon Transcribe [ 10 ~ 15 min ]
- AWS CLI セットアップ / SDK for Python (boto3) インストール
- 今回解析する 音声ファイル (mp4) を S3 にアップロードする
- ご利用開始にあたって (
SDK for Python) ページを開く- サンプルの Python スクリプトを追加&修正を加える (音声の言語指定&ファイル拡張子&リージョン)
- python スクリプトを実行 (今回はコンソール画面で結果を確認)
( GCP ) Cloud Speech-to-Text API [ 20 ~ 25 min ]
- プロジェクトの作成 / Cloud SDK のインストール / 環境変数の設定 (
GOOGLE_APPLICATION_CREDENTIALS)
- クライアントライブラリをインストールする
- サンプルの Python スクリプトを追加&修正を加える
( ※ 音声ファイルパス & エンコード方式 & サンプリング周波数を指定 )- python スクリプトを実行 ( 結果確認 )
※サンプリング周波数、エンコード方式がソースコードと異なる場合、APIを実行できないので注意!
検証に使用した音声ファイルはこちら
まずは、短文での性能検証を行い、続いて長文を行いました。
- 短文 ( 音声 )
みなさん、こんにちは。こちらは UNC10033 のアンカンファレンスセッションになります。- 長文 ( 音声 )
昔々、あるところにおじいさんとおばあさんが住んでいました。おじいさんは山へ芝刈りに... ( 続く )短文編 ( 結果 )
長文編 ( 結果 )
検証音声ファイル書き起こし全文 ( 桃太郎 )
認識結果 ( Azure )
認識結果 ( AWS )
認識結果 ( GCP )
検証結果
以下、5つの軸で評価してみました。( 主観含む )
- 対応ファイル形式
- 音声認識の精度
- 料金体系
- 開発のしやすさ
- ドキュメントの読みやすさ
- 精度の順で並べると、残念ながら今回は GCP> Azure > AWS の順となった。
- ドキュメントきめ細やかさは Azure > GCP > AWS のように感じた ( 主観 )
- 開発SDKの豊富さの順でも Azure = GCP > AWS となった ( CLI含む )
まとめ
精度と導入しやすさバランスを取るなら Azure
AWS他サービスとの連携を重視するなら AWS
とにもかくにも精度が一番大事なら GCP
- カスタムせずに汎用的なモデルのみを使用する場合だと GCP が一番精度が高いです。
- 学習済みAIサービスの種類(数)は、Azure ≫ AWS > GCP の順となり、
明確な用途があるのであれば Azure が一番手っ取り早く導入できる印象を受けました。- 句読点が反映されるのは Azure だけ ( 標準設定 ) でした。
- 利用料金でいうと、Azure < AWS = GCP となるので Azure が一番安いです。
- GCPは細かなチューニングができる分、検証時に詰まるポイントが多いように感じました。( GCP力が低いだけかも )
最後に
イベント会場は想像以上に盛況でした。アンケートの自由記入欄にも上記のようなコメントがあり、MicrosoftのイベントでAWSやGCPなど、他の3大クラウドベンダーとの性能比や開発コストの差を盛り込んで良かったと思います。コミュニティを運営していると楽しいことばかりではないこともたまにはありますが、このような貴重な登壇機会を頂き、コミュニティメンバー一同大喜びでした。このセッションを機に、Azure Tech Lab. コミュニティへの参加者が少しでも増えることを願ってやみません。このような貴重な機会をいただいた心の広い Microsoft の担当者のみなさんに感謝しかありません。ありがとうございました!












- 投稿日:2020-02-10T21:42:33+09:00
AWSスイッチロール設定手順
オリジナルアカウント:当該IAMユーザが登録されているAWSアカウント
スイッチロール先アカウント:当該IAMユーザは登録されていないが、スイッチロールしたいAWSアカウント1.スイッチロール先アカウントにオリジナルアカウントとの信頼関係を持つロールを作成
2.オリジナルアカウントの当該IAMユーザに権限を付与するポリシーを、1のロールにアタッチ
3.オリジナルアカウントに2の Assume Role Policy を作成AssumeRolePolicy{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "sts:AssumeRole", "Resource": "arn:aws:iam::【スイッチロール先アカウント】:role/【1~2で用意したロール】" } ] }4.オリジナルアカウントに任意のグループを作成し、3のポリシーをアタッチ
5.オリジナルアカウントの当該IAMユーザを4のグループに追加
- 投稿日:2020-02-10T21:41:22+09:00
私が RDS を選ばなかった理由
Amazon RDS は AWS 環境に用意された RDBMS のマネージドサービスです。大規模災害にも耐えうる Multi AZ や、 MySQL, PostgreSQL に独自の拡張を行った Amaozn Aurora 等が人気で、2009年のローンチ以降、AWS のもっともよく利用されているサービスのひとつだと思います。
10年以上の歴史を持ち進化し続けてきた RDS ですが、それでもなお EC2 インスタンスに RDBMS をインストールして利用するケースがあります。そこでどのようなケースにおいて RDS を利用しない場合があったかについてまとめてみました。
RDS を使うなという記事ではありません
この記事は RDS を利用するより EC2 を利用した方が良いという結論の記事ではありません。むしろ RDS を利用する事が多いので、そうならなかったケースを紹介する記事です。
オールインワンで済む場合
ごく小さな規模のアプリケーションなら、アプリケーションサーバーとデータベースサーバーを小さなインスタンスにひとつにまとめてしまった方がコスパが良いですね。RDS への移行は利用者やアプリケーションの規模が大きくなってからでも良いでしょう。
オンプレ環境のリードレプリカ(スレーブDB)として利用したい
RDS の MySQL インスタンスは、RDS 以外のサーバーをマスタとする、リードレプリカを作る事が可能です。しかし、マスタ・スレーブ同期の通信で SSL/TLS を利用可能なのは Aurora だけです(2020年2月現在)。このため、安全な通信経路を確保できない場合、RDS を利用するのは難しくなります。VPN等、別の安全な通信手段があれば、もちろん可能です。
パフォーマンスを求めていて、かつ Aurora が利用できない
RDBMS ではすべてのデータとインデックスがオンメオリである事が理想です。しかし、実際には膨大なデータがメモリに収まり切れないケースも多々あり、そんな時はストライピングボリュームで劇的に高速化できる場合があります。クラウド環境だと単価が容量に比例するため、費用対効果も高いですね。しかし、ストライピングは RDS では選択できません。このため同価格ぐらいで性能を比較すると、EC2 で構築した MySQL の方が RDS よりはるかに速いというケースが存在します。
なお、Aurora は必要に応じてストライピングする機能が備わっているため、Aurora の方がパフォーマンスが優れているケースになる場合が多いそうです。
スポットインスタンスを利用したい場合
EC2 のスポットインスタンスは最大でオンデマンドインスタンスの8割引きから9割引き程度で利用できる魅力的なサービスです。突然落とされるリスクが上がる事は無視できないデメリットですが、状況によってはそれを補ってあまりあるメリットがあります。データベースも一時的に利用したい場合にはスポットインスタンスが便利なのですが、RDSにはスポットインスタンスがありません。
その他
以上は実際に私が遭遇したケースですが、以下のようなケースも RDS を利用しにくいかも知れません。
- 標準搭載されていないプラグインを利用したい場合
SELECT INTO...等を多用し、サーバーのファイルシステムに直接アクセスしたい場合- PaceMaker 等で他のリソースと連動するような HA クラスタを構築したい場合
- 利用したいバージョンが対応していない場合
- 少しでもいいから安くしたい場合
まとめ
RDS は優れたサービスですが、「AWS なら RDS」と決めてかかるのではなく、ケースによっては EC2 で地道に構築した方がより良い選択肢になる場合もあります。もっともそういう手間を一切合切引き受けてくれるためのサービスが RDS なのですから、可能な限り利用しましょう。
また、改めて書いてみると私が扱ってきたケースは Aurora で解決できる問題が多そうです。色々な事情で利用できなかったのですが、Aurora も積極的に利用していきたいと思ってます。
- 投稿日:2020-02-10T20:13:21+09:00
Lambda関数を設定してS3イベントで動かそう!
Lambdaってなに?
AWSの提供するサービスの一つで、サーバ管理をすることなく処理を実行することができるサービスです。
例えばLambdaを利用しない場合、EC2でサーバを作成し処理実行に必要なミドルウェアや言語をインストールし、環境設定をすることで初めて処理が実行されます。
しかし、Lambdaではそのようなサーバのプロビジョニングをすることなく、処理を書くだけで実行することが可能になります。
これにより、
★サーバ自体の管理・メンテナンスが不要
★処理が実行されている時間のみ課金されるので処理の頻度によってはコストを大幅削減可能
★他AWSサービスと容易に連携できるので、AWSメインのアーキテクチャでは大変便利
というメリットがあります。トリガーとは?
書いた処理を実行させるにはトリガーというものを設定する必要があります。
AWSのあらゆるサービスと連携ができ、CloudWatchでアラームが出たら実行、kinesis data stream にデータが存在するとき実行、S3にファイルが置かれたら実行などが代表的な例になります。つまりLambdaは実行する条件と実行される処理だけを書けば動いてくれるサービスなのです。
実際に設定したい!
ではs3にファイルをアップロードし、アップロードされたことを確認する処理を書いてみましょう。
1.AWSコンソールにログインし、Lambdaの画面で「関数の作成」をクリック
Lambdaはリージョンごとに関数を設定することになります。
S3の場合は問題ないですが、他リージョンの影響を受けるサービスと連携するときは同じリージョンを選択しましょう。
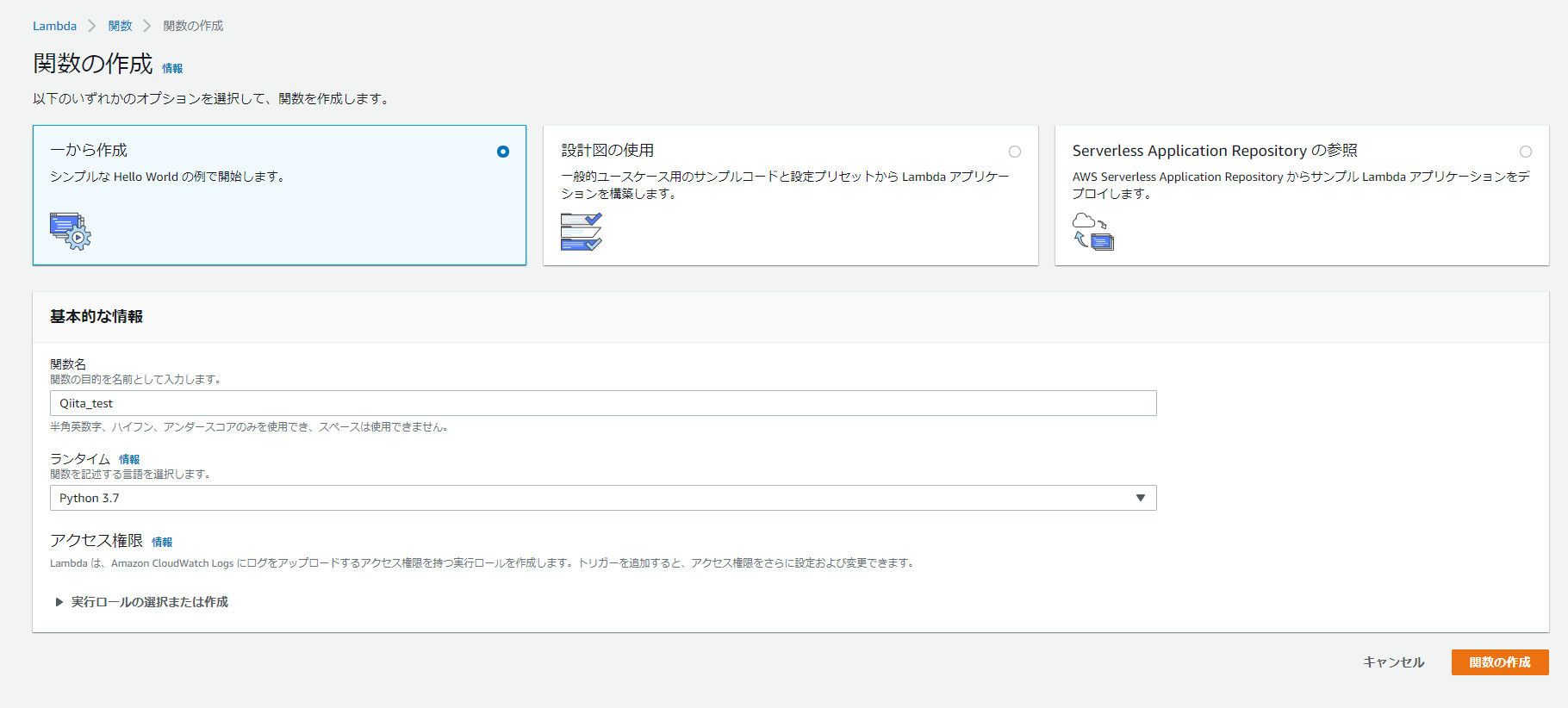
2.「1から作成」を選択し、「関数名」と「ランタイム」、「実行ロール」を設定
今回はpython 3.7を利用します。
ロールは「基本的なLambdaアクセス権限で新しいロールを作成」にします。
既存のロールを利用でも問題ないです。
その場合、Lambdaがトリガー条件のサービスやLog出力用のCloudWatchへのロググループ書き込み権限がある必要があります。
※新規作成の場合はCloudWatchのロググループ書き込み権限は自動でアタッチされます。「ランタイム」とは処理の言語を意味します。2020/02/05時点では選択できる言語は下記となっております。
・Java 11/8
・.NET Core2.1(C#/PowerShell)
・GO 1.x
・Node.js 12.x/10.x
・python 3.8/3.7/3.6/2.7
※カスタムランタイムを利用することであらゆる言語を利用できるようになりますが、本記事では省略します。
3.「トリガーを追加」で実行条件を設定
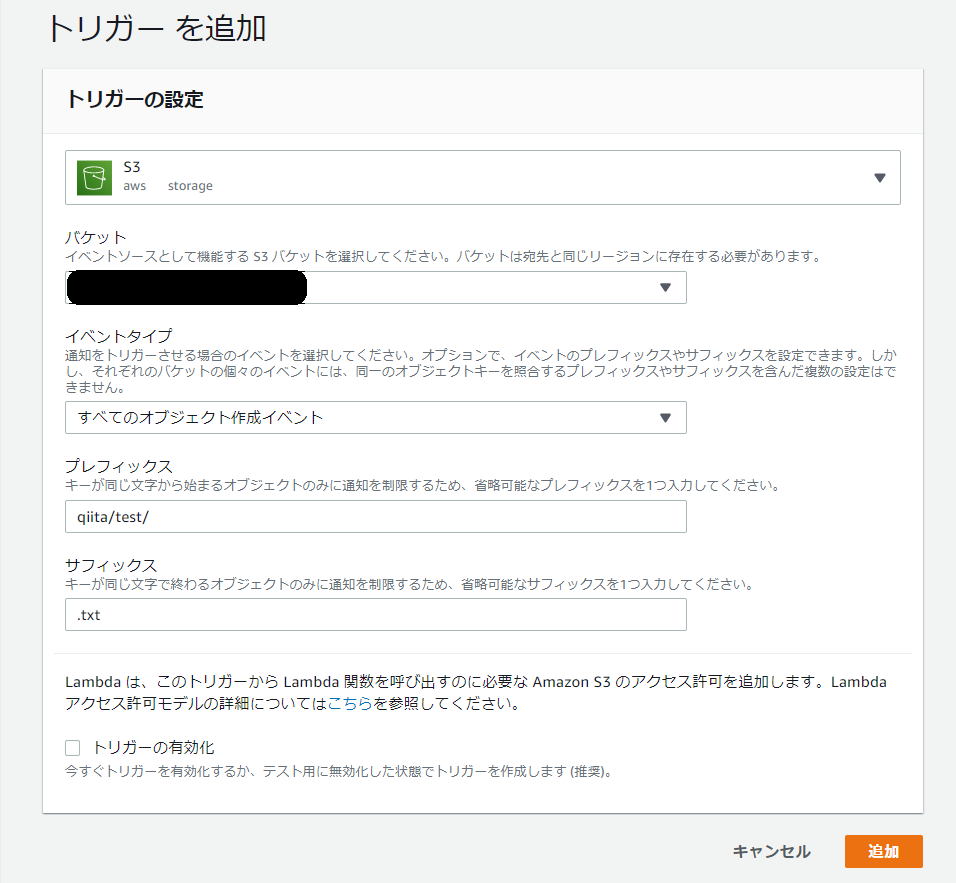
今回はs3に何かオブジェクトが作成されたときに実行できるようにします。
トリガー媒体をs3に設定したときの項目は下記の5つになります。
・バケット
・イベントタイプ(ファイルがPUTされたら・・・、ファイルが削除されたら・・・など)
・プレフィックス(バケット以降のディレクトリパスやファイル名など)
・サフィックス(ファイル名や拡張子など)
・トリガーの有効化(チェックするとすぐ上記設定のトリガーが動きます。処理のテストが終わってからonにしましょう)
4.関数コードを設定
デフォルトではlambda_function.pyというファイルに処理が記述されています。
lambda_function.pyimport json def lambda_handler(event, context): # TODO implement return { 'statusCode': 200, 'body': json.dumps('Hello from Lambda!') }lambda_handlerとはLambdaに設定されているトリガー条件が満たされたときに自動的に実行される関数です。
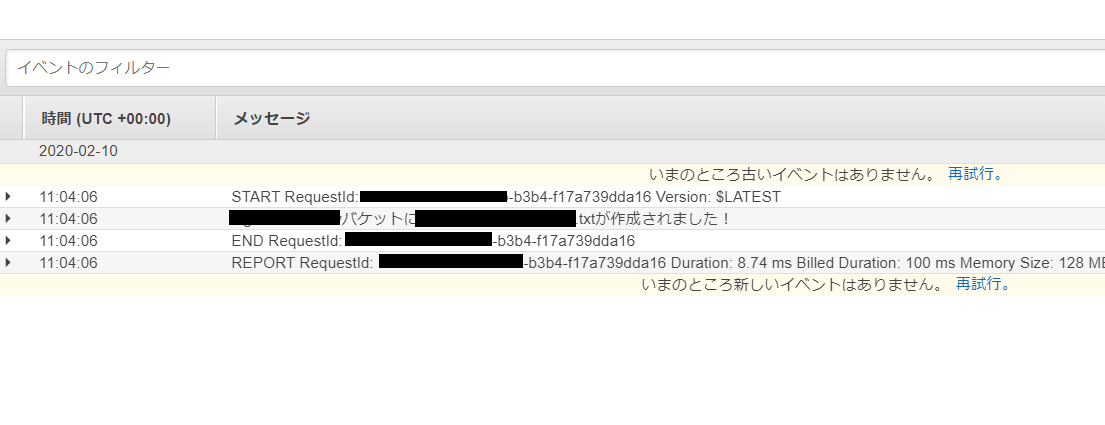
# TODO implement以降を編集し、実行したい処理を書きましょう。今回はs3にファイルが置かれたら置かれたパスとファイル名を表示するようにしてみます。
lambda_function.pyimport json def lambda_handler(event, context): bucket = event['Records'][0]['s3']['bucket']['name'] key = event['Records'][0]['s3']['object']['key'] print(bucket+'バケットに'+key+'が作成されました!')lambda_handlerに引数で渡している
eventにはトリガーとなったイベント情報が配列で入っており、
上記はそこからバケット名とファイルパスを取得し、表示を行っています。5.実行・確認
関数の実行自体はトリガーで指定したパスにファイルを置くことで実行できます。
それ以外にも下画像の「テスト」からeventに入る値をjson形式で設定することにより疑似的にLambda関数を実行することが可能です。
また、関数の実行LogについてはCloudWatchのロググループから対象の関数を選択し、そこから確認することが可能です。
正しくLambda関数が実行できていることが確認できました!!
終わりに
LambdaはAWS環境を利用しており、シンプルな処理をおこなうのであればコスト面、管理面でもとてもおススメです。
少し気になったのは関数が何をしているかの説明文を書いておく欄がないので、わかりやすい関数名・処理内でのコメント記載を徹底し、快適なLambdaライフをおくりましょう!!
- 投稿日:2020-02-10T18:02:05+09:00
awsのcostを見やすくtable表示するawscostというコマンドを作った
https://github.com/toyama0919/awscost
awscostというawsでかかっている料金をとっても見やすく表示するコマンドを作りました。
作った理由
- 会社にアカウントが多いため、アカウントの行き来をしてcost explorerを見るのが辛い
- cost explorerの機能が増えすぎて年々使いにくくなっている。
- 最低限、Service別でいくらかかっているのか確認したいだけのケースがほとんど
インストール
pythonで作っているので、pythonが必要です。
pip install awscostpython3.6以上が必要です
使い方
$ awscost -p 3 key 2019-11 2019-12 2020-01 2020-02 -------------------------------------- --------- --------- --------- --------- Total 67.15 72.22 68.09 20.97 EC2 - Other 33.63 34.58 34.6 9.96 Amazon Elastic Compute Cloud - Compute 17.13 17.11 17.11 4.92 Tax 6.11 6.59 6.17 1.85 AWS CloudTrail 4.44 6.17 4.38 1.38 AWS Key Management Service 4 4 4 1.23 AWS Cost Explorer 0.56 2.8 0.02 1.02 AmazonCloudWatch 0.88 1.21 1.21 0.37 Amazon Simple Storage Service 0.4 0.54 0.45 0.14 Amazon Route 53 0.1 0.1 0.1 0.1 AWS Lambda 0 0 0 0 Amazon DynamoDB 0 0 0 0 Amazon Elastic File System 0 0 0 0 Amazon SageMaker 0 0 0 0 Amazon Simple Notification Service 0 0 0 0 Amazon Simple Queue Service 0 0 0 0 Refund -0.09 -0.89 -0.01 0 Amazon Polly 0 0 0.06 0defaultではtotal+service別の料金が表示されます。
各種dimensionで集計してみる
instance type別
$ awscost -d INSTANCE_TYPE -p 3 key 2019-11 2019-12 2020-01 2020-02 --------------------- --------- --------- --------- --------- Total 67.15 72.22 68.09 20.97 NoInstanceType 50.03 55.11 50.98 16.05 t2.small 16.56 17.11 17.11 4.92 t2.micro 0.57 0 0 0 ...Service別かつOPERATION別(複数でgroup by)
$ awscost -d SERVICE -d OPERATION -p 3 key 2019-11 2019-12 2020-01 2020-02 ------------------------------------------------------------- --------- --------- --------- --------- Total 67.15 72.22 68.09 20.97 EC2 - Other,NatGateway 32.58 33.46 33.48 9.63 Amazon Elastic Compute Cloud - Compute,RunInstances 17.13 17.11 17.11 4.92 AWS CloudTrail,None 4.44 6.17 4.38 1.38 AWS Key Management Service,Unknown 4 4 4 1.23 AWS Cost Explorer,GetCostAndUsage 0.55 2.8 0.02 1.02 Tax,NatGateway 3.26 3.35 3.35 0.96 Tax,RunInstances 1.72 1.71 1.71 0.49 Tax,NoOperation 1.13 1.53 1.11 0.4 ...dimensionは以下を参照
https://docs.aws.amazon.com/aws-cost-management/latest/APIReference/API_GetDimensionValues.html
各種formatで出力してみる
github
$ awscost -p 3 -t github | key | 2019-11 | 2019-12 | 2020-01 | 2020-02 | |----------------------------------------|-----------|-----------|-----------|-----------| | Total | 67.15 | 72.22 | 68.09 | 20.97 | | EC2 - Other | 33.63 | 34.58 | 34.6 | 9.96 | | Amazon Elastic Compute Cloud - Compute | 17.13 | 17.11 | 17.11 | 4.92 | | Tax | 6.11 | 6.59 | 6.17 | 1.85 | ...tsv
$ awscost -p 3 -t tsv key 2019-11 2019-12 2020-01 2020-02 Total 67.15 72.22 68.09 20.97 EC2 - Other 33.63 34.58 34.6 9.96 Amazon Elastic Compute Cloud - Compute 17.13 17.11 17.11 4.92 Tax 6.11 6.59 6.17 1.85 AWS CloudTrail 4.44 6.17 4.38 1.38 ...
- 以下のformatなら何でも可能
help
$ awscost --help Usage: awscost [OPTIONS] Options: --debug / --no-debug enable debug logging. (default: False) --profile TEXT aws profile name. -g, --granularity [DAILY|MONTHLY] granularity. (default: MONTHLY) -p, --point INTEGER duration. if granularity is MONTHLY, 7 month ago start. if granularity is DAILY, 7 day ago start. (default: 7) --start TEXT range of start day. default is 7 month ago. --end TEXT range of end day. default is now. -t, --tablefmt TEXT tabulate format. (default: simple) -d, --dimensions [AZ|INSTANCE_TYPE|LINKED_ACCOUNT|OPERATION|PURCHASE_TYPE|SERVICE|USAGE_TYPE|PLATFORM|TENANCY|RECORD_TYPE|LEGAL_ENTITY_NAME|DEPLOYMENT_OPTION|DATABASE_ENGINE|CACHE_ENGINE|INSTANCE_TYPE_FAMILY|REGION|BILLING_ENTITY|RESERVATION_ID|SAVINGS_PLANS_TYPE|SAVINGS_PLAN_ARN|OPERATING_SYSTEM] group by dimensions. (default: ["SERVICE"]) --filter LOADS filter of dimensions. default is no filter. --metrics [BlendedCost|UnblendedCost|AmortizedCost|NetAmortizedCost|NetUnblendedCost|UsageQuantity|NormalizedUsageAmount] metrics. (default: UnblendedCost) --total / --no-total include total cost. (default: True) --help Show this message and exit.
- 投稿日:2020-02-10T17:41:09+09:00
awscli-aliasesを設定してみた。
はじめに
今更ながら、aws-cliにalias機能が使えることを発見しました。
ちょっと設定してみたいと思います。設定
まずはバージョンの確認です。
この機能を使うには1.11.24以上である必要があります。$ aws --version aws-cli/1.16.183 Python/3.6.2 Darwin/19.3.0 botocore/1.12.173ということでgitリポジトリからクローンします。
これは、awslabs で用意してくれているaliasファイルなので、なくてもalias機能は使えますが、今回はこれを使って試したいと思います。aliasファイルのクローン$ git clone https://github.com/awslabs/awscli-aliases.git次に、aliasファイルを配置するためのディレクトリを作成します。
ディレクトリ作成$ mkdir ~/.aws/cli作成したら先ほどクローンしたファイルを配置します。
aliasファイルの配置$ cp awscli-aliases/alias ~/.aws/cli/alias以上で完了です。
試しにalias登録されているものを実行してみます。whoami$ aws whoami { "UserId": "AIDWJ0SDPRLPSAH7T34ZS", "Account": "777777777777", "Arn": "arn:aws:iam::777777777777:user/kohei" }これはaliasファイルを見ると実行したコマンドのaliasは以下になります。
alias[toplevel] whoami = sts get-caller-identityでは今度はaliasではなく、実際のawsコマンドを実行してみます。
$ aws sts get-caller-identity { "UserId": "AIDWJ0SDPRLPSAH7T34ZS", "Account": "777777777777", "Arn": "arn:aws:iam::777777777777:user/kohei" }先ほどと同じ結果が返ってきました。
おわりに
普段はaliasなど使う必要はないかもしれませんが、頻繁に使うコマンドがあればそれを登録しておくととても便利です。
自分はsshのconfigファイルに記載するような感覚でセッションマネージャー経由でログインするインスタンスをaliasに登録しています。
[参考URL]
・awslabs/awscli-aliases
https://github.com/awslabs/awscli-aliases
- 投稿日:2020-02-10T17:27:23+09:00
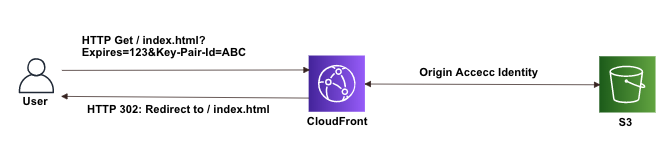
CloudFrontの署名付きURLでS3にアクセスする方法
概要
今回はCloudFrontの署名付きURLでS3にアクセスする方法に関する内容を書いてみました。
手順は下記のようになります。
・S3作成
・CloudFront作成
・CloudFrontの署名付きURL発行
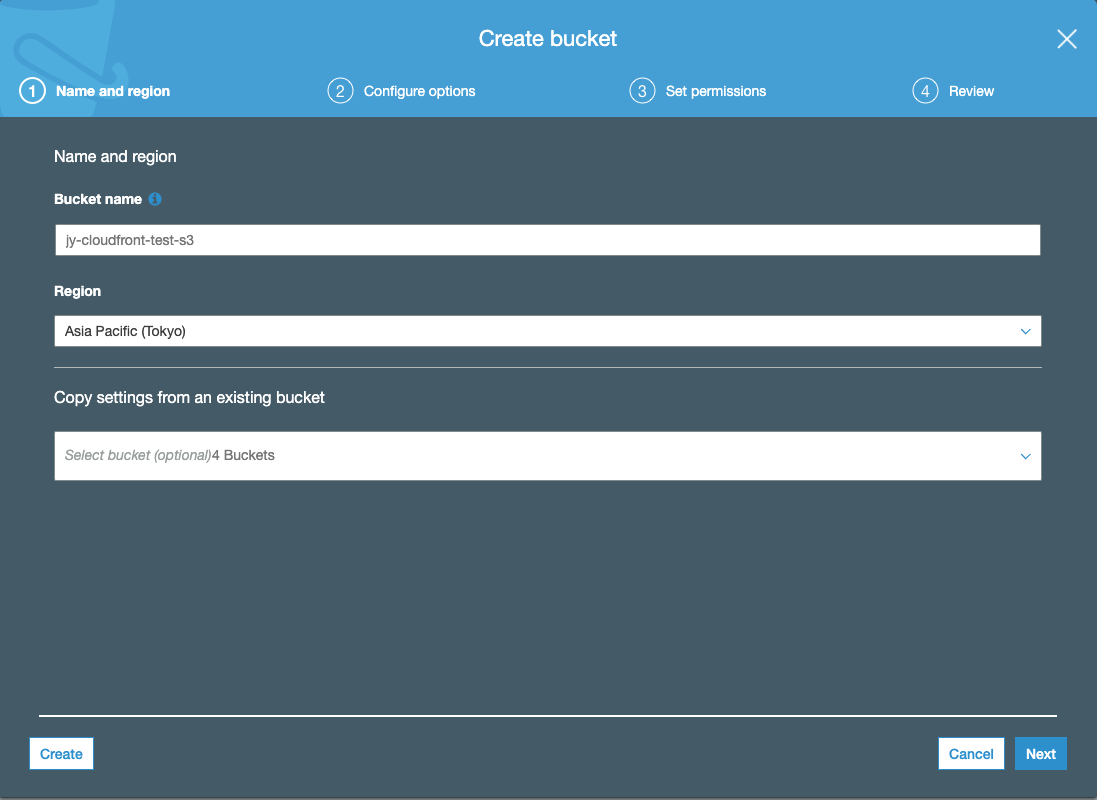
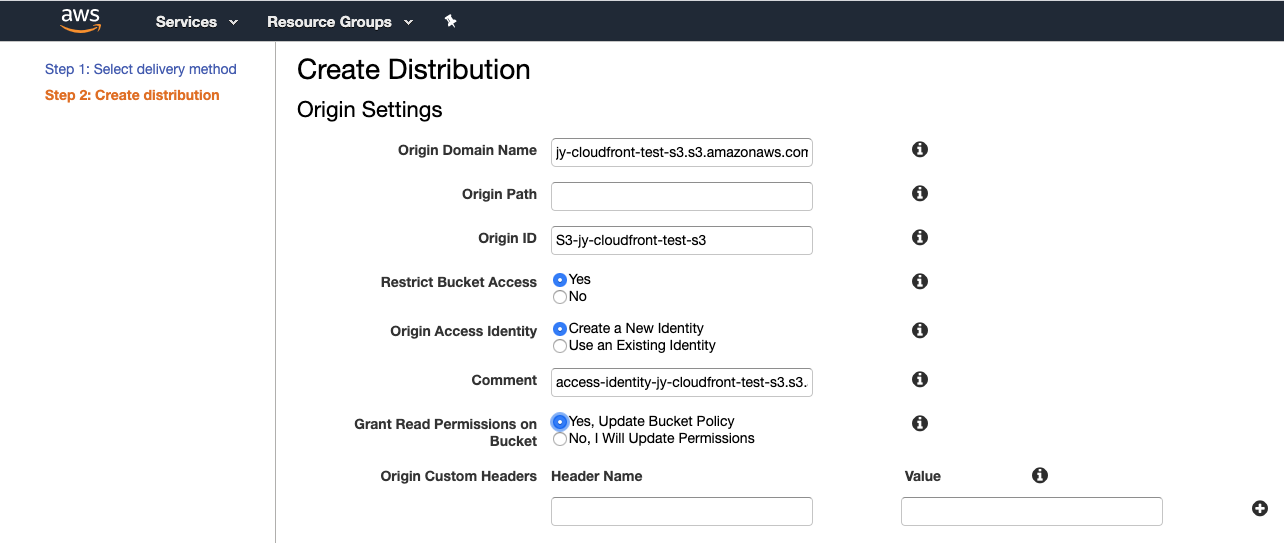
・CloudFrontの署名付きURLでS3にアクセスS3作成
BucketNameを入れて、② > ③(Block all public access全部チェック) > ④を進んでS3を作成してください。
その後、簡単なindex.htmlファイルをS3にアップロードしてください。
CloudFront作成
CloudFrontに移動して「Create Distribution」をクリックします。
Delivery MethodはWebを選択します。
RTMPは Streaming serviceです。
- Origin Domain Name: S3のリストの中で、最初作成したS3を選択します。
- Origin Path:S3 SubBucketFolderですが、今回作成していないので、空欄でOKです。
- Origin ID:Origin Domain Name選択すると、勝手に表示されます。
- Restrict Bucket Access:S3にCloudFrontのみアクセス可能にする設定なので、「Yes」を選択します。
- Origin Access Identity:初めて作成する場合、「Create a New Identity」を選択します。
- Grant Read Permissions on Bucket:Block all public accessしているので、CloudFrontからS3にアクセスするために権限を与えます。
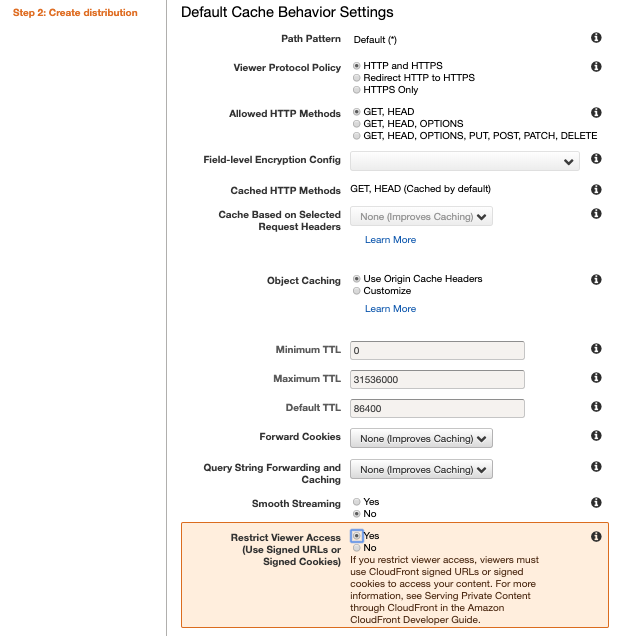
- Viewer Protocol Policy:今回は証明書なしに行うので、「Http and Https」を選択します。
- Restrict Viewer Access:署名付きURLのみアクセスを許可するために、「Yes」を選択します。
そして、「Create Distribution」をクリックしてCloudFrontを作成してください。
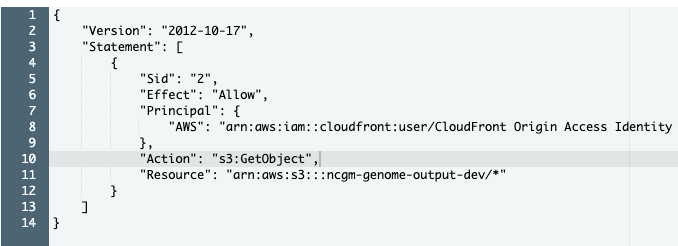
おそらく、StatusがDeployedまで15分くらいかかると思います。。Deployedが表示されたら、S3 Policy確認と、Domain Nameでアクセスしましょう。
まず、S3 PolicyはGrant Read Permissions on Bucketによって更新されていると思います。
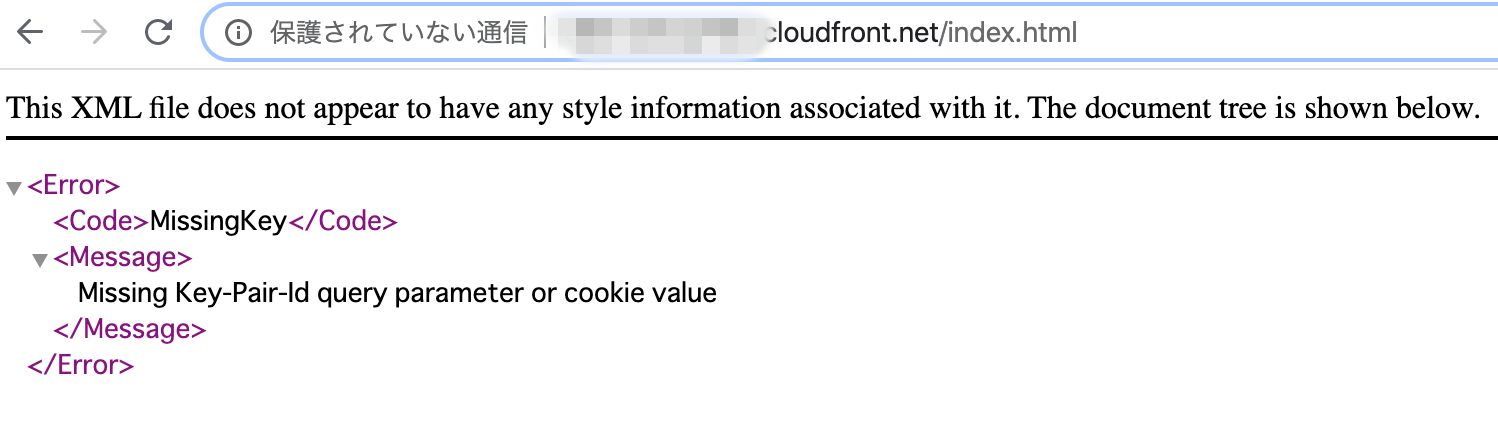
そして、Domain Nameでアクセスすると、
MissingKeyだと言われます。先ほどRestrict Viewer Accessを「Yes」にしたので、
別途に署名付きURLを発行しないと、アクセスできません。では、CloudFrontの署名付きURLを発行しましょう。
ちなみに、index.htmlのように、特定のObjectではないURLをRequestする場合、下記の設定を行ってください。
Distribution Settings > Edit > Default Root Objectにindex.htmlを入力 > Yes, Editをクリックして、15分待ち。。CloudFrontの署名付きURL発行
Root Userで 「My Security Credentials」に移動します。
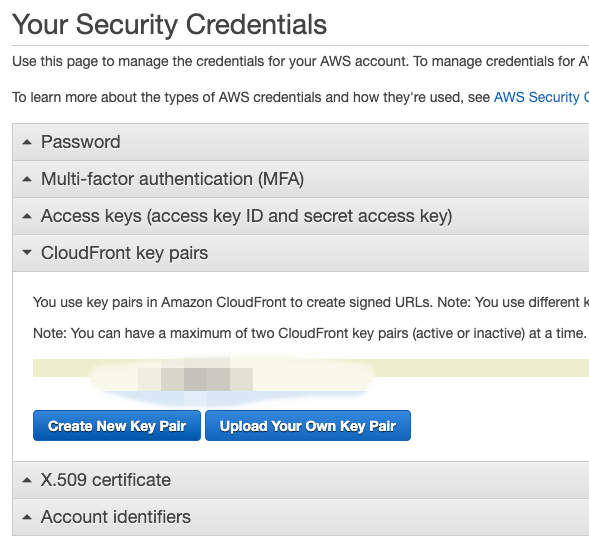
CloudFront key pairs > 「Create New Key Pair」をクリックして、PrivateキーとPublicキーをダウンロードしてください。
CloudFrontの署名付きURLでS3にアクセス
これで、S3にアクセスする準備ができたと思います。
筆者はLaravelでCloudFrontの署名付きURLを発行してみます。AWS_ACCESS_KEY_ID= // AWS Access Key AWS_SECRET_ACCESS_KEY= // AWS Secret Access Key AWS_DEFAULT_REGION= // AWS region AWS_BUCKET= // S3 bucket name CLOUDFRONT_DOMAIN_NAME= //cloudfront Domain Name RESOURCE_KEY=index.html CLOUDFRONT_EXPIRES=60 //1分 CLOUDFRONT_PRIVATE_KEY= // Security Credentials private key path CLOUDFRONT_KEY_PAIR_ID= // Security Credentials CloudFront key pairs Access Key ID$sdk = new Sdk([ 'region' => env('AWS_DEFAULT_REGION'), 'version' => 'latest', 'credentials' => [ 'key' => env('AWS_ACCESS_KEY_ID'), 'secret' => env('AWS_SECRET_ACCESS_KEY') ] ]); $client = $sdk->createCloudFront(); $expires = time() + env('CLOUDFRONT_EXPIRES'); $cloudFrontUrl = $client->getSignedUrl([ 'url' => env('CLOUDFRONT_DOMAIN_NAME') . '/' . env('RESOURCE_KEY'), 'expires' => $expires, 'private_key' => storage_path('app') . '/' . env('CLOUDFRONT_PRIVATE_KEY'), 'key_pair_id' => env('CLOUDFRONT_KEY_PAIR_ID') ]); dump($cloudFrontUrl); exit;
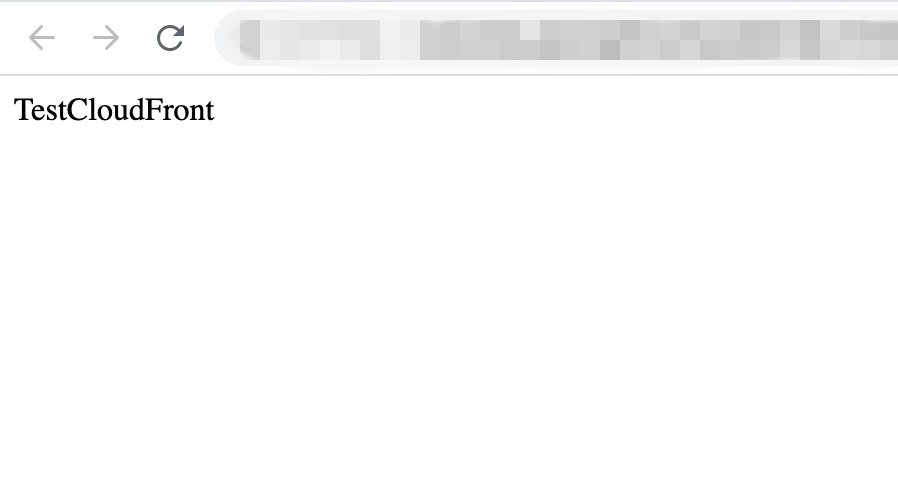
発行したURLでアクセスすると、S3にアップロードしたindex.htmlが表示されます。
そして、1分経ってアクセスすると、Access Deniedが表示され、アクセスできなくなります。参考
Authorization@Edge using cookies: Protect your Amazon CloudFront content from being downloaded by unauthenticated users
[CloudFront + S3]特定バケットに特定ディストリビューションのみからアクセスできるよう設定する

- 投稿日:2020-02-10T17:10:08+09:00
Kinesis Data Firehoseを使ってみた話
はじめに
新規プロジェクトでのログ集計をKinesis Data Firehoseで設計してみたものの
まだ使ったことがなかったので使ってみた話Kinesis Data Firehoseとは
そもそもKinesisとはという話なんですが。
Kinesisでできることは、ストリーミングデータをリアルタイムで収集、処理、分析することです。
その中でも大きく四つあり
- Kinesis Data Streams : ストリームデータを受けるサービス
- Kinesis Data Firehose : ストリームデータをS3やRedshiftなどの分析ツールに送るサービス
- Kinesis Data Analytics: ストリームデータを分析してくれるサービス
- Kinesis Video Streams: 動画を簡単かつ安全にストリーミングするサービス
Kinesis Data StreamsとFirehoseの違い
Streamsは、雑に言えばストリームデータを受けるだけのサービス。
受けた後はLambdaか何かのイベント発火してストリームデータを受け取ってもらうようにするだけです。Firehoseは、データを受けた後、S3やRedsiftまで流してくれます。
Streamsは受けるだけなので、例えばStreams -> Firehose -> S3もできる
また、ユースケースにもよりますが、Firehoseは1分間後にS3に吐き出しなど、"ある程度データが溜まったら"という閾値を儲けることができるのに対して、Streamsは1秒以下でデータロードができます。Firehoseはエンドポイント(S3のパス)とデータ(ダンプしたjsonとか)を指定するだけで流してくれるので設定はGUI上で収まるくらい非常に簡単です。
つべこべ言わずに作ってみる
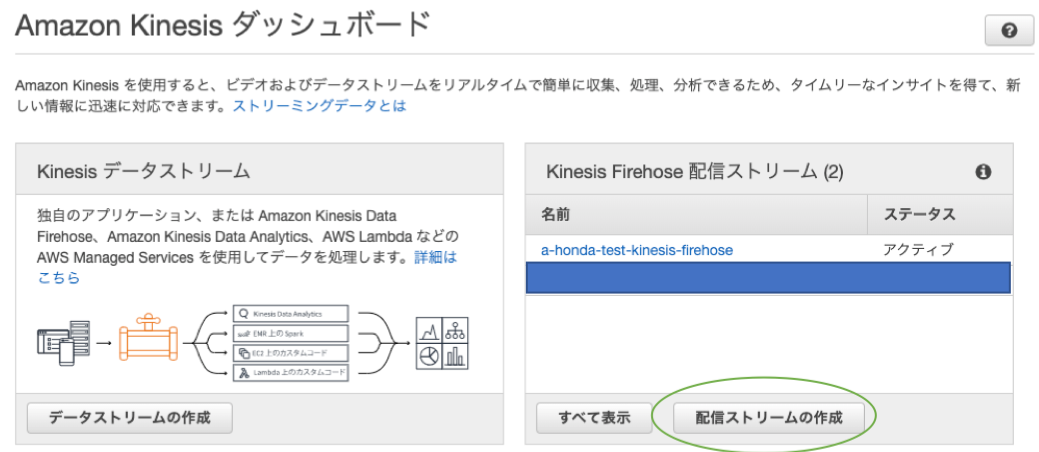
1. コンソール画面でKinesisと検索
2. ダッシュボードで「配信ストリームの作成」を押す
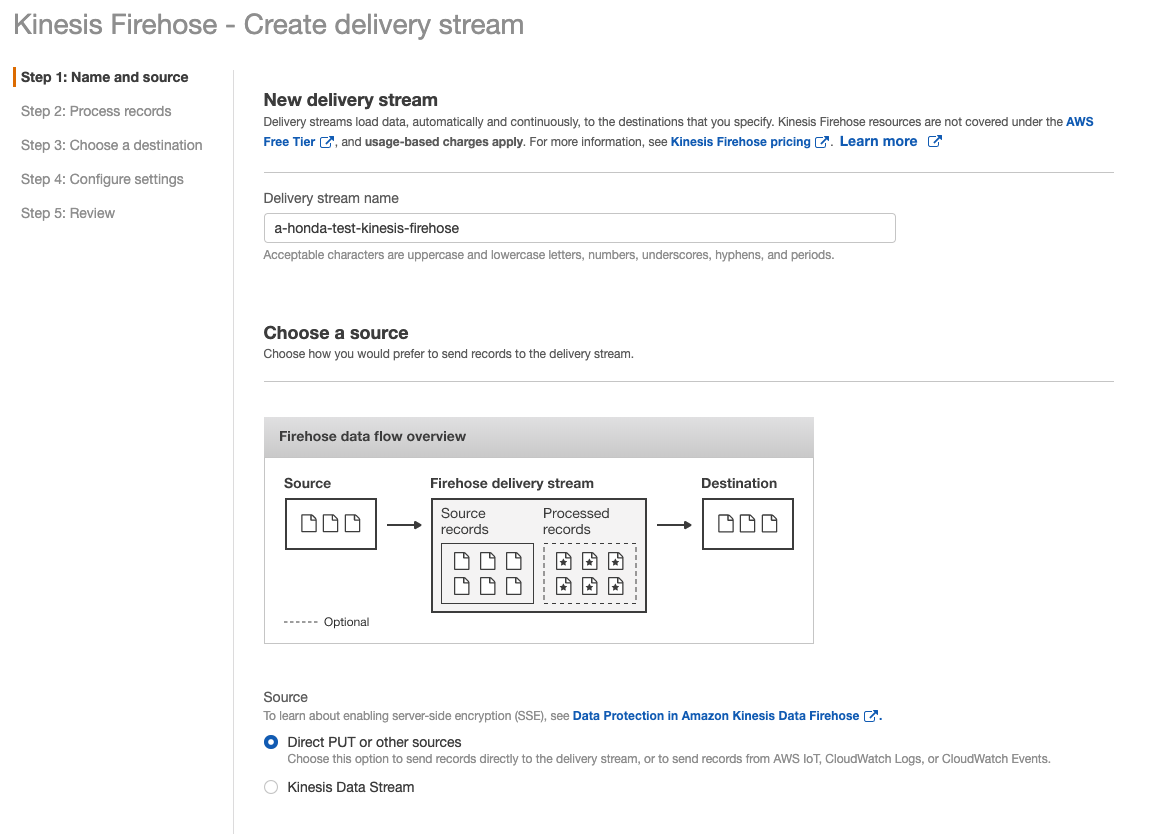
3. Delivery stream nameを任意の名前にして、Choose a soueceのタイプを選ぶ
Streams -> Firehoseの流れではないので、"Direct Put or other sources"にチェック
pythonからboto3とかでFirehoseにデータを投入する場合はother sourcesになります。
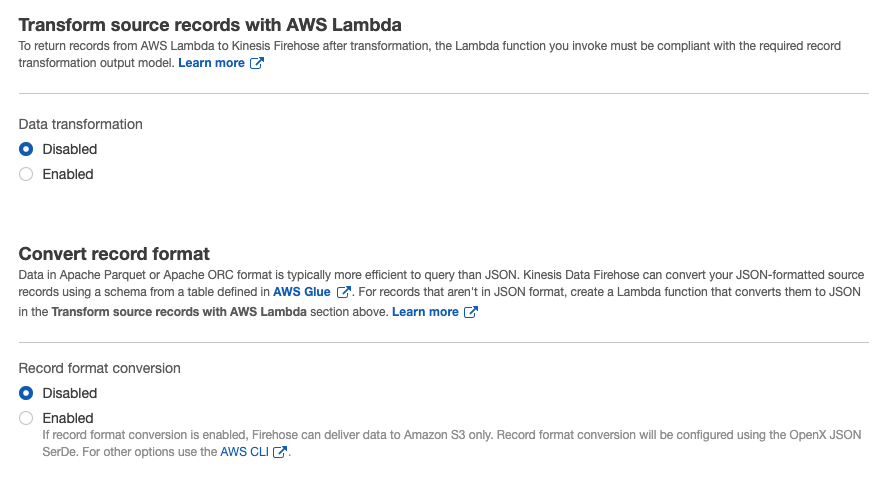
4. Transform source records with AWS Lambda, Convert record formatの設定
Transform source records with AWS Lambda: ストリームデータを保存する前に、Lambdaで編集することができます。
例えば、helloという文字列をkinesis firehoseで送ったとしてlambdaで受け取って"world"と追記して一レコードとして保存することが可能です。
今回はそのまま保存したいのでDisableにチェックConvert record formatは、Enableにすると出力形式を決めることができて、二種類あります
- Apache Parquet
- Apache ORC
それぞれの違いは↓の画像を参考
参考URL: https://speakerdeck.com/chie8842/karamunahuomatutofalsekihon-2
データ分析用途だと、特定カラムに焦点をあてて高速に集計などを行うので、こういったカラムナ形式が採用されていたりします。
AthenaとかだとParquet形式で集計がすすめられたりするので結構重要Athenaのパフォーマンスチューニング Tips トップ 10を一読すると幸せ?かも
今回はテスト的にデータを送るので、そのままDISABLEで
5. Select a destinationの設定
Amazon S3に入れる予定なのでS3にチェック
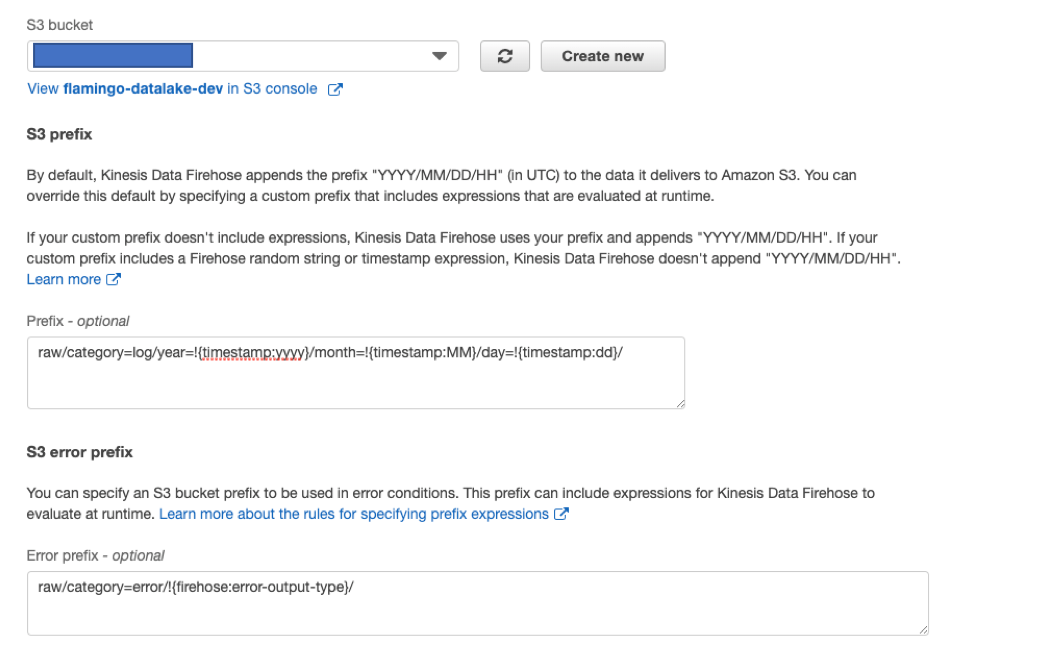
6. S3のバケット設定、Prefix設定
S3のバケットは作ったバケット名を指定
Prefixはパスを決定できるのですが、これも"Athenaのパフォーマンスチューニング Tips トップ 10"を参考にパーティーションを意識して分けるとカスタムで設定します。例:
s3://athena-examples/flight/parquet/year=1991/month=1/day=1/
s3://athena-examples/flight/parquet/year=1991/month=1/day=2/
細かいPrefixは公式を参考に
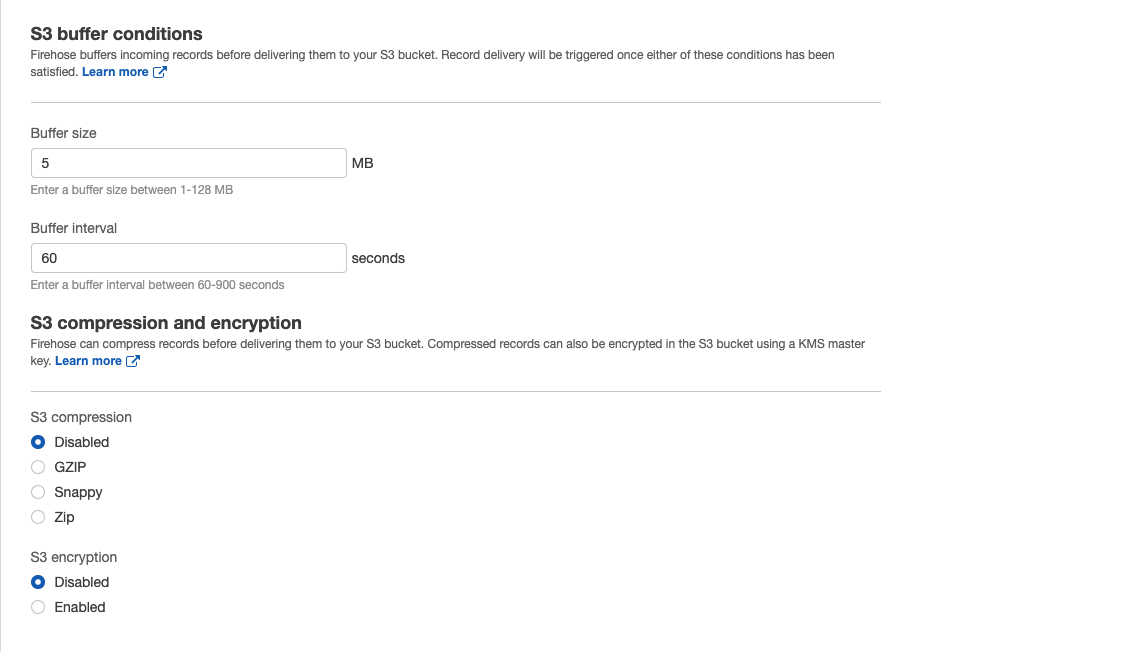
カスタムPrefixの場合はError Prefixも設定しないといけないことをお忘れなく。7. S3 buffer conditionsと圧縮・暗号化設定
S3にPutされる1ファイルにどれだけの容量制限をかけるか、また、どれくらいの間隔(Interval)でファイル吐き出しをするか設定できる.
今回は5MB or 60 秒でファイル吐き出しを行うようにしました。
また圧縮方法はGZIP, Snappy, Zip様々あります、S3のencryptionも設定できます。
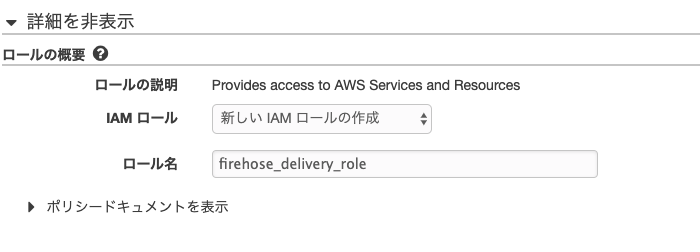
8. Roleの設定
S3にPutするので必要な権限設定を行います。
Create new Roleをクリックし、新しいIAMロールの作成で作ります。(すでに作っている場合は選択)
設定したら最後の確認画面になるので、"Create delivery stream"して設定終了
最後に流してみる
pip install boto3とかでawsのclientライブラリであるboto3を入れる
import boto3 import uuid import json client = boto3.client( 'firehose', aws_access_key_id='xxxxxxxxxxxxxxx', aws_secret_access_key='xxxxxxxxxxxxxxxxxxxx', region_name='ap-northeast-1' ) data = { "musicId": 'xxxxxxxxxxxxxxxxxxxx', "userId": 1, "artistId": 1 } response = client.put_record( DeliveryStreamName='a-honda-test-kinesis-firehose', Record={ 'Data': f'{json.dumps(data)}\n' } ) print(response)これで送信すると
a-honda@hoge:~ $ python test.py {'RecordId': 'ls1DjmHBiOXPtNe/7zpYc/6Zk8o8j6JVz5QkBeyGC3I8aFjf7Dv/CAQ7JnRw913ovghFSIMuEn3MOkkR5GK8QVRJCjvH6AmRw0SPUqcTE8jm5kcDxWu+91HeFr+PJlyFCgIG259Ig+DH7rsXTfHRNMFPt3/G7GquA0WUmSXDTBIOzRxnsQ1bNyN0mEHFrhOkbiXElZ1rL6s1WvJLddHF+qDpggjUCX2i', 'Encrypted': False, 'ResponseMetadata': {'RequestId': 'e5724431-a382-2e82-b3c8-8bbaf8b786fe', 'HTTPStatusCode': 200, 'HTTPHeaders': {'x-amzn-requestid': 'e5724431-a382-2e82-b3c8-8bbaf8b786fe', 'x-amz-id-2': 'zWNAiCZio6tiW5gGbNggHSLjA4EHKnu3RXE5umbYbdVx/ZraOY8bEj2H4AlF/C7R0rtk5fLt0Bm+aPyNiMFqZ9ihKmOxrCDO', 'content-type': 'application/x-amz-json-1.1', 'content-length': '257', 'date': 'Mon, 10 Feb 2020 03:26:03 GMT'}, 'RetryAttempts': 0}}こんな感じで送られています。
ちゃんとS3に保存されているのは確認できました。さいごに
fluentdとの使い分けについてもう少し調べたほうがいいのかなって正直思いましたが、
fluentdだと、aggregatorを別途自作で用意する必要があるので、そこがマネジメントで賄えるという利点はあるかなと思いました。
参考URL:ログ管理のベストプラクティスfluentd -> kinesis firehose
Gunosyさんのアーキでは↑のようになっているのですが
この流れが全くよくわからないです(苦笑
なんでfluentd挟むんだろう...また直接クライアントからStream データを放り投げることもできるのですが不正なことをされるとコストはかかりそう。
設定は意外と簡単なのですが、S3のパスは固定なので、S3のディレクトリを細かくきるとその分Delivery Streamを作らないといけないっぽいので厄介(汗色々ありますが、ログ管理は深い(小並感



- 投稿日:2020-02-10T16:21:26+09:00
EC2(Amazon Linux 2)にPython 3.8, Pip 3.8をインストールする
Amazon Linux2 に Python 3.8をインストール
Python 3.8, Pip 3.8をAmazon Linux2にインストールでお困りの方は参考にしてください。
- EC2 AMI
Amazon Linux 2 AMI (HVM)
SSD Volume Type
ami-062f7200baf2fa504 (64 ビット x86)/ami-0e98ccceff552e8a8 (64 ビット Arm)
事前準備
$ sudo yum -y update $ sudo yum -y install gcc openssl-devel bzip2-devel libffi-develダウンロード
$ wget https://www.python.org/ftp/python/3.8.1/Python-3.8.1.tgz $ tar xzf Python-3.8.1.tgzインストール
$ cd Python-3.8.1 $ sudo ./configure --enable-optimizations $ sudo make altinstall確認
$ python3.8 --version Python 3.8.1 $ pip3.8 --version pip 19.2.3 from /usr/local/lib/python3.8/site-packages/pip (python 3.8)rootのpathを設定
rootからもPython3.8を使えるようにパスを通しシンボリックリンクをはっておく
$ sudo which python3.8 which: no python3.8 in (/sbin:/bin:/usr/sbin:/usr/bin) $ sudo visudo (Before) Defaults secure_path = /sbin:/bin:/usr/sbin:/usr/bin (After) Defaults secure_path = /sbin:/bin:/usr/sbin:/usr/bin:/usr/local/sbin:/usr/local/bin $ sudo which python3.8 /usr/local/bin/python3.8 $ sudo ln -s /usr/local/bin/python3.8 /usr/local/bin/python3 $ sudo which python3 /usr/local/bin/python3 $ sudo ln -s /usr/local/bin/pip3.8 /usr/local/bin/pip3 $ sudo which pip3 /usr/local/bin/pip3
- 投稿日:2020-02-10T16:12:35+09:00
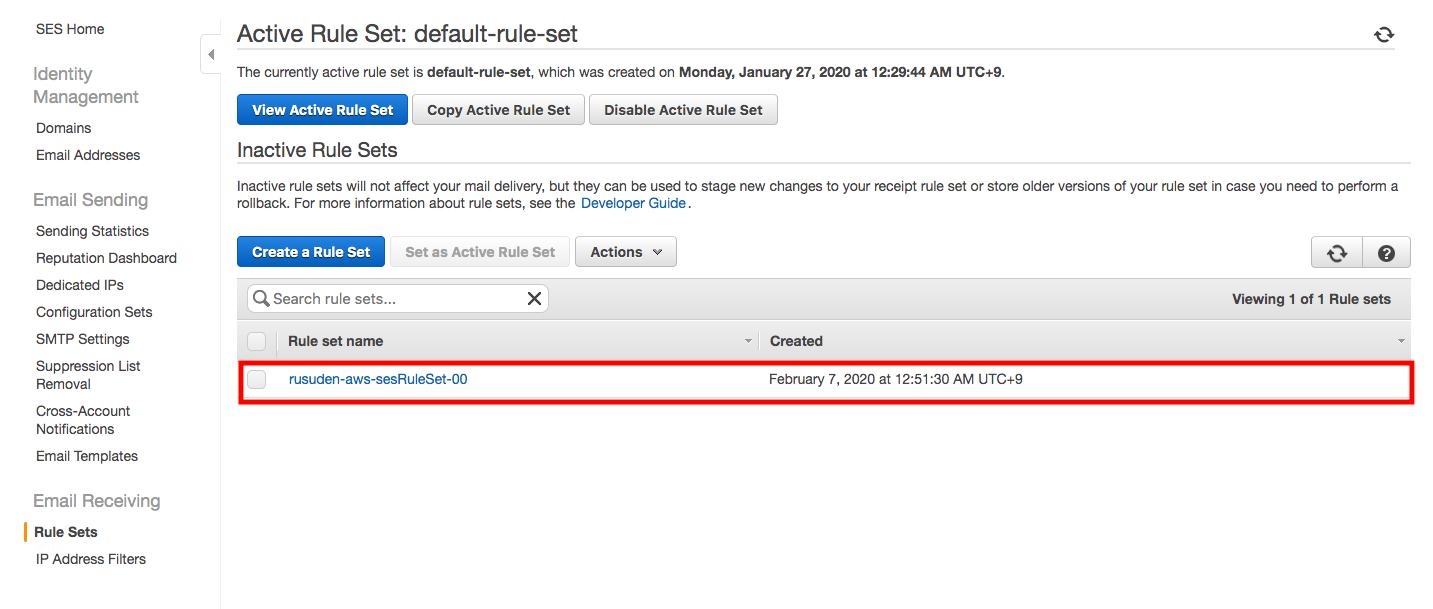
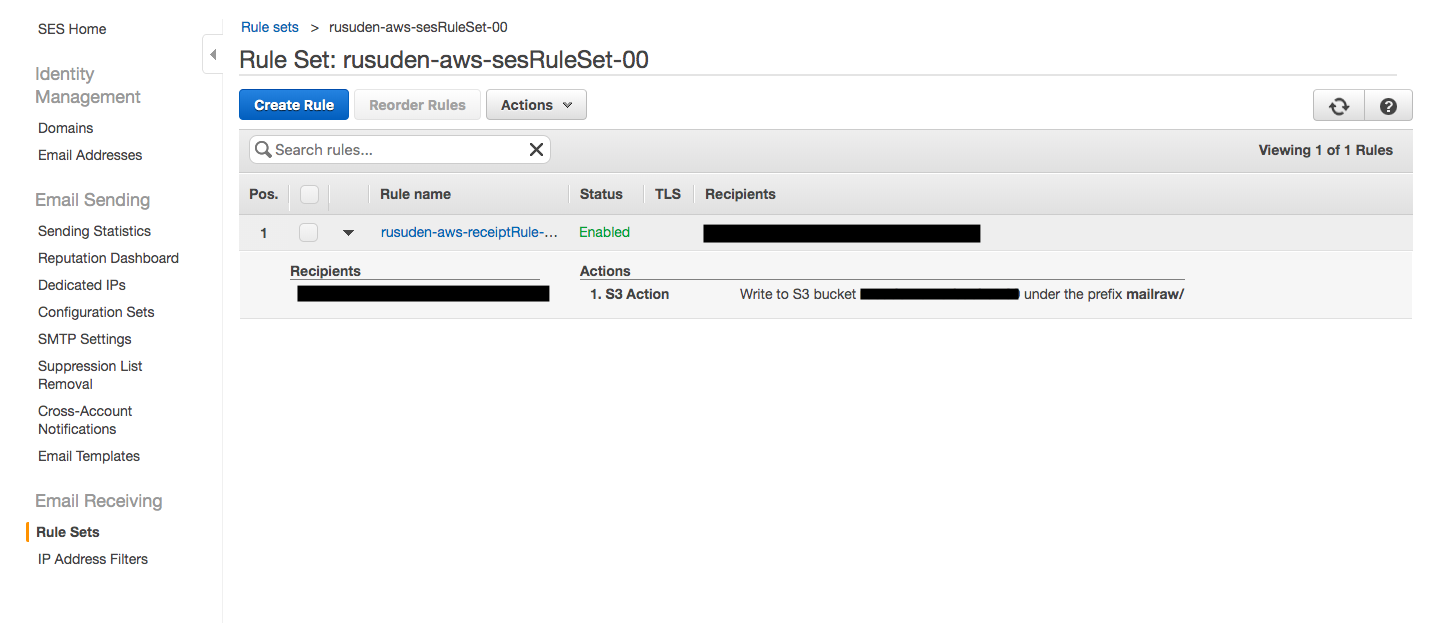
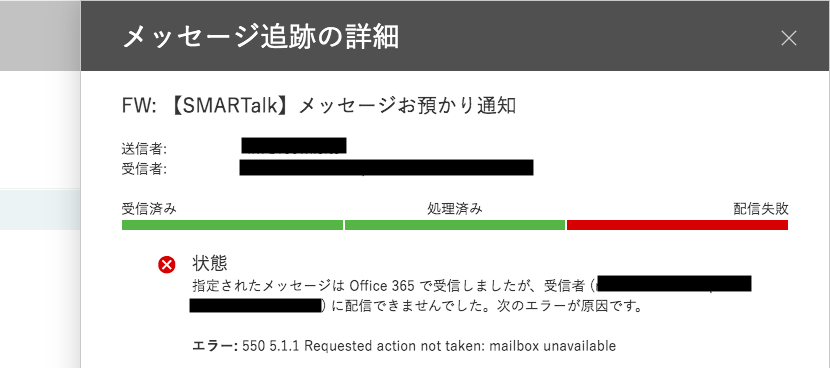
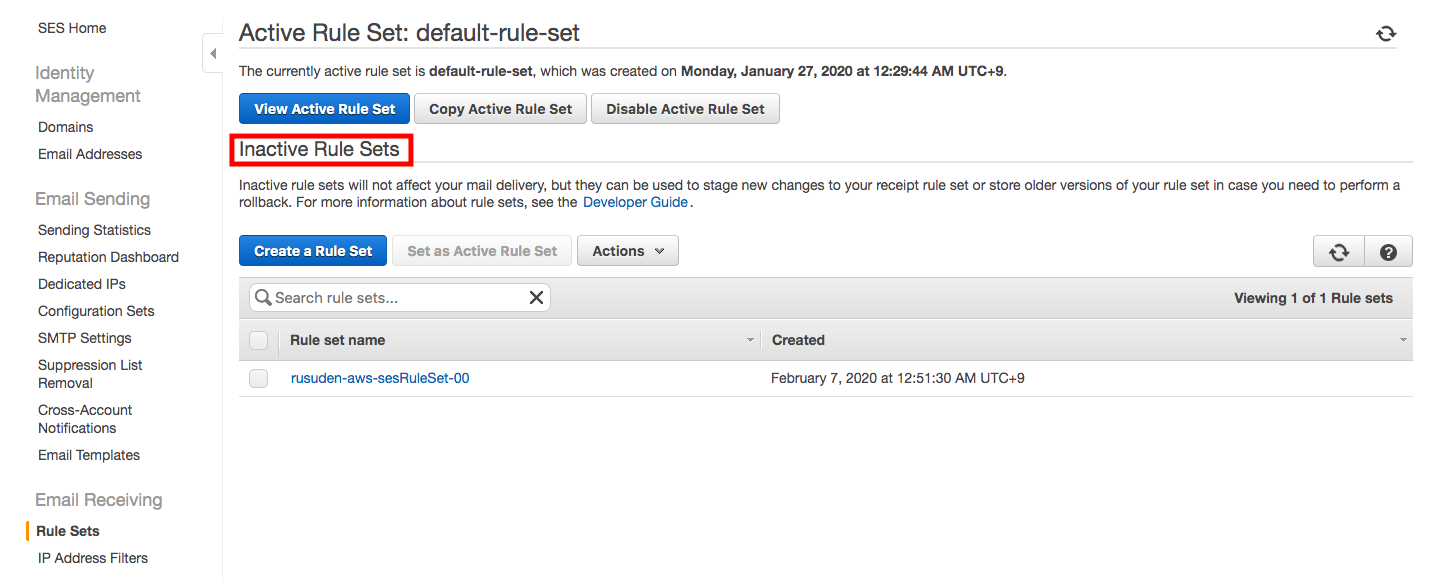
Amazon SNS のサブスクリプション解除を禁止する方法
- 投稿日:2020-02-10T15:27:04+09:00
半年に1度の文化祭!VERITAS TECH SYMPOSIUM 2020 Winter でお待ちしています!
はじめに
ベリタステクノロジーズでは長らく Veritas Partner Technical Community というイベントを開催しています。第15回目の記念大会として日本発祥の地である内幸町に戻って VERITAS TECH SYMPOSIUM 2020 Winter を開催致します
開催まで2週間と少しとなりますが、お誘い合わせのうえ是非ご参加ください
当日のアジェンダ
老舗だけど新しい
以下のライトニングトークをお楽しみ頂ければと思います!
- Veritas, VMware, AWS によるクラウドバイデフォルトへのアプローチ
- DXと5Gワークロードの保護~MongoDB, Container, Aurora, RDS
- クラウドデスクトップの真実と担保技法
- バックアップデータから実現するHCIへのマイグレーションとその先の担保
- レガシーモダナイゼーション with クラウド
- ベリタスとAPIエコノミーとの共存
- ベリタスのアプライアンスの進化最新情報
- ひとり情シスのためのデータ保護、BE20.6 永久増分編
- SaaS で注意したいリスクとそのデータ保護
- ランサムウェア対策と回復力の強化
お申込み方法
VERITAS TECH SYMPOSIUM 2020 Winter~Abstractionで拓くクラウド後の未来~
https://event-info.com/veritas_tech_symposium_2020winter/
こちらからご登録いただけますと幸いです。ほとんどの内容がリアル検証データに基づいた特別セッションです。正直、このカテゴリで一番クラウドに触っているベンダーとう自負はあります!Veritas Solution Cafe
半日の間ではありますが、会場ラウンジの一部をコワーキングスペースとして貸し切っております!フリーWiFi、電源、フリードリンク、フリーフードのスペースとなりますのでお気軽にセッションに参加いただき、その後は、ご自身の仕事に戻っていただくことも可能です。
*ご利用には上記の登録ならびに受付が必要となりますVeritas Discovery Desk
いわゆる「ベリタスに相談してみよう!」ブースを開設します!案件相談してみると素敵なIoT機器が進呈
されます!オープン、クローズドの会場の両方がありますのでお気軽にご相談ください
懇親会
当日中にオンラインアンケートに回答いただくと抽選で素敵な景品が当たります!もしかすると史上最高の景品となるかも?アンケート回答のための時間を懇親会の前に確保しておりますのでその場でご回答いただけますと幸いです。コメントは後から編集も可能です!
その他
冒頭に文化祭!と記載しておりますが、運営はベリタスのSEがボランティアで担っている部分も多々あります。運営でしくじったらすみません
生暖かい目で見ていただけますと助かります。一生懸命頑張ります!
それでは、みなさまのご来場を心よりお待ちしておりますのでよろしくお願いします!
ベリタステクノロジーズ


- 投稿日:2020-02-10T13:56:22+09:00
RDS Proxy ちょっと試してみた。
AWSの一番好きなサービスはAWS Lambda な人です(再々掲)
注意書き
Preview版のサービスなので、GAになるまでに色々と変更される可能性は大いにあります。
AWS re:invent前後に発表されたVPC Lambda関係のアップデートやってみたシリーズラストかな?
ちょっと時間経っちゃいましたけど。サンプルコード
サンプルソースはこんな感じ。汚くてすみません。
Node.js v12.xで確認済みです。Airport, airline and route data にあるroute.csv を加工したものを、
RDSに放り込んで、乱数生成して、それにあった航空会社のIATA2レターコード※ を参照しているだけです。handler.js'use strict'; const mysql = require('mysql'); const util = require('util'); const dbHostName = process.env.DB_HOSTNAME; const dbUserName = process.env.DB_USERNAME; const dbPassword = process.env.DB_PASSWORD; const dbDatabase = process.env.DB_DATABASE; const airlineCodeList = ['JL','NH','LH','AA','DL','AF','BA','VS','UA','SQ','QF','EK'] async function createConnection() { const connectionString = { host: dbHostName, user: dbUserName, password: dbPassword, database: dbDatabase }; return mysql.createConnection(connectionString); } module.exports.index = async (event, context) => { console.log('Received event: ', JSON.stringify(event, null, 2)); console.log('Received context: ', JSON.stringify(context, null, 2)); const connection = await createConnection(); const randomNun = Math.floor( Math.random() * (10 + 1 - 1) ) + 1; const airLineCode = airlineCodeList[randomNun]; const queryString = `select * from routes where airline = '${airLineCode}';`; connection.query = util.promisify(connection.query); try { const results = await connection.query(queryString); console.log(results); connection.end(function(err) {}); return { statusCode: 200, body: JSON.stringify( { results, }, null, 2 ), }; } catch (err) { console.log(err); return { statusCode: 500 , body: JSON.stringify( { message: 'Internal Server Error.', }, null, 2 ), }; } };デプロイ自体は、
Serverless Frameworkを使っているのでそのyamlファイルも載せておきます。serverless.ymlservice: lambda-rds-proxy provider: name: aws runtime: nodejs12.x logs: restApi: true logRetentionInDays: 30 # you can overwrite defaults here stage: ${opt:stage, self:custom.defaultStage} region: ap-northeast-1 vpc: securityGroupIds: - sg-06efd08cfe1ed01cc subnetIds: - subnet-175d6bbaaee0104ed - subnet-03b20131a8153e368 - subnet-d030023fdf82dffa9 iamRoleStatements: - Effect: "Allow" Action: - "ec2:CreateNetworkInterface" - "ec2:DescribeNetworkInterfaces" - "ec2:DetachNetworkInterface" - "ec2:DeleteNetworkInterface" Resource: - "*" custom: defaultStage: dev environment: dev: ${file(conf/dev.yml)} dev2: ${file(conf/dev2.yml)} functions: notSetRdsProxy: handler: handler.index description: 'Not Setting RDS Proxy' memorySize: 256 timeout: 25 environment: ${self:custom.environment.${self:provider.stage}} role: defaultRole vpc: securityGroupIds: - sg-06efd08cfe1ed01cc subnetIds: - subnet-175d6bbaaee0104ed - subnet-03b20131a8153e368 - subnet-d030023fdf82dffa9 events: - httpApi: method: get path: /notrdsproxy integration: lambda-proxy notSetRdsProxyWithPC: handler: handler.index description: 'Not Setting RDS Proxy. With Provisioned Concurrency' memorySize: 256 timeout: 25 environment: ${self:custom.environment.${self:provider.stage}} role: defaultRole vpc: securityGroupIds: - sg-06efd08cfe1ed01cc subnetIds: - subnet-175d6bbaaee0104ed - subnet-03b20131a8153e368 - subnet-d030023fdf82dffa9 events: - httpApi: method: get path: /notrdsproxy/provisionedconcurrency integration: lambda-proxy setRdsProxy: handler: handler.index description: 'Setting RDS Proxy' memorySize: 256 timeout: 25 environment: ${self:custom.environment.${self:provider.stage}2} role: rdsProxyRole vpc: securityGroupIds: - sg-06efd08cfe1ed01cc subnetIds: - subnet-175d6bbaaee0104ed - subnet-03b20131a8153e368 - subnet-d030023fdf82dffa9 events: - httpApi: method: get path: /rdsproxy integration: lambda-proxy setRdsProxyWithPC: handler: handler.index description: 'Setting RDS Proxy. With Provisioned oncurrency' memorySize: 256 timeout: 25 environment: ${self:custom.environment.${self:provider.stage}2} role: rdsProxyRole vpc: securityGroupIds: - sg-06efd08cfe1ed01cc subnetIds: - subnet-175d6bbaaee0104ed - subnet-03b20131a8153e368 - subnet-d030023fdf82dffa9 events: - httpApi: method: get path: /rdsproxy/provisionedconcurrency integration: lambda-proxy resources: Resources: defaultRole: Type: AWS::IAM::Role Properties: Path: / RoleName: defaultRole AssumeRolePolicyDocument: Version: '2012-10-17' Statement: - Effect: Allow Principal: Service: - lambda.amazonaws.com Action: sts:AssumeRole Policies: - PolicyName: defaultPolicy PolicyDocument: Version: '2012-10-17' Statement: - Effect: Allow Action: - logs:CreateLogGroup - logs:CreateLogStream - logs:PutLogEvents - ec2:CreateNetworkInterface - ec2:DescribeNetworkInterfaces - ec2:DetachNetworkInterface - ec2:DeleteNetworkInterface Resource: "*" rdsProxyRole: Type: AWS::IAM::Role Properties: Path: / RoleName: rdsProxyRole AssumeRolePolicyDocument: Version: '2012-10-17' Statement: - Effect: Allow Principal: Service: - lambda.amazonaws.com Action: sts:AssumeRole Policies: - PolicyName: rdsProxyPolicy PolicyDocument: Version: '2012-10-17' Statement: - Effect: Allow Action: - logs:CreateLogGroup - logs:CreateLogStream - logs:PutLogEvents - ec2:CreateNetworkInterface - ec2:DescribeNetworkInterfaces - ec2:DetachNetworkInterface - ec2:DeleteNetworkInterface Resource: "*"ソースは同じで、環境変数に接続情報セットしてますが、設定ファイル分けて、RDS Proxy利用するパターンと、RDS直指定するパターンを作ってます。
あ、RDS ProxyのオススメとしてはIAM接続のほうがいいっぽいですね。Secret Managerに接続情報を保存できるので。検証ついでに、Serverless FrameworkがHTTP API対応したので、一緒に試してたりします。
https://twitter.com/horike37/status/1225234647514144769
ご利用の際は最新バージョン(1.63.0)にアップグレードをお願いします。検証
検証としては、コネクションMAX数(max_connections) を絞り込んで、
Too many connectionsが出るような状況にしています。mysql> SHOW VARIABLES LIKE 'max_connections'; +-----------------+-------+ | Variable_name | Value | +-----------------+-------+ | max_connections | 30 | +-----------------+-------+ 1 row in set (0.00 sec)テスト前のprocesslist。事前にRDS Proxy経由でアクセスして、コネクション使い切った状態
もともと、rdsadmin(RDS自体の管理?)が4つ、rdsproxyadmin(RDS Proxyの管理?)が8つはあるらしい。
なお、adminの1つはEC2上のMysqlクライアントからprocess確認してました。mysql> show processlist; +-------+---------------+---------------------+--------+---------+------+-------------+------------------+ | Id | User | Host | db | Command | Time | State | Info | +-------+---------------+---------------------+--------+---------+------+-------------+------------------+ | 2 | rdsproxyadmin | 172.31.97.131:46653 | NULL | Sleep | 0 | cleaning up | NULL | | 3 | rdsproxyadmin | 172.31.49.89:59431 | NULL | Sleep | 0 | cleaning up | NULL | | 4 | rdsadmin | localhost | NULL | Sleep | 1 | cleaning up | NULL | | 5 | rdsproxyadmin | 172.31.97.167:1915 | NULL | Sleep | 0 | cleaning up | NULL | | 6 | rdsproxyadmin | 172.31.97.126:48277 | NULL | Sleep | 0 | cleaning up | NULL | | 7 | rdsproxyadmin | 172.31.97.212:28995 | NULL | Sleep | 0 | cleaning up | NULL | | 8 | rdsadmin | localhost | NULL | Sleep | 1 | cleaning up | NULL | | 9 | rdsproxyadmin | 172.31.50.204:56213 | NULL | Sleep | 0 | cleaning up | NULL | | 10 | rdsproxyadmin | 172.31.48.22:2191 | NULL | Sleep | 0 | cleaning up | NULL | | 11 | rdsproxyadmin | 172.31.58.152:16189 | NULL | Sleep | 0 | cleaning up | NULL | | 12 | rdsadmin | localhost | NULL | Sleep | 11 | cleaning up | NULL | | 33 | rdsadmin | localhost | NULL | Sleep | 166 | cleaning up | NULL | | 100 | admin | 172.31.10.192:42264 | testdb | Query | 0 | starting | show processlist | | 7303 | admin | 172.31.97.131:32677 | testdb | Sleep | 7 | cleaning up | NULL | | 7304 | admin | 172.31.97.126:48705 | testdb | Sleep | 7 | cleaning up | NULL | | 7305 | admin | 172.31.49.89:32765 | testdb | Sleep | 7 | cleaning up | NULL | | 7307 | admin | 172.31.97.167:47005 | testdb | Sleep | 7 | cleaning up | NULL | | 7308 | admin | 172.31.48.22:4785 | testdb | Sleep | 7 | cleaning up | NULL | | 7309 | admin | 172.31.50.204:19771 | testdb | Sleep | 7 | cleaning up | NULL | | 7312 | admin | 172.31.58.152:3927 | testdb | Sleep | 9 | cleaning up | NULL | | 7317 | admin | 172.31.97.212:59499 | testdb | Sleep | 7 | cleaning up | NULL | | 11342 | admin | 172.31.97.126:30921 | testdb | Sleep | 7 | cleaning up | NULL | | 11343 | admin | 172.31.48.22:1091 | testdb | Sleep | 7 | cleaning up | NULL | | 11344 | admin | 172.31.97.212:7309 | testdb | Sleep | 7 | cleaning up | NULL | | 11345 | admin | 172.31.97.131:37623 | testdb | Sleep | 7 | cleaning up | NULL | | 11347 | admin | 172.31.58.152:61557 | testdb | Sleep | 8 | cleaning up | NULL | | 11348 | admin | 172.31.50.204:42713 | testdb | Sleep | 7 | cleaning up | NULL | | 11349 | admin | 172.31.49.89:40485 | testdb | Sleep | 7 | cleaning up | NULL | | 11351 | admin | 172.31.97.167:52009 | testdb | Sleep | 7 | cleaning up | NULL | | 13337 | admin | 172.31.58.152:55069 | testdb | Sleep | 7 | cleaning up | NULL | +-------+---------------+---------------------+--------+---------+------+-------------+------------------+ 30 rows in set (0.00 sec)テスト自体はEC2上のApache Benchから実施しています。
まず、RDS Proxyを利用しないパターン。
全滅とは行かないにしても、1600リクエストでエラーになりました。Server Software: Server Hostname: eddovdtqad.execute-api.ap-northeast-1.amazonaws.com Server Port: 443 SSL/TLS Protocol: TLSv1.2,ECDHE-RSA-AES128-GCM-SHA256,2048,128 Server Temp Key: ECDH P-256 256 bits TLS Server Name: eddovdtqad.execute-api.ap-northeast-1.amazonaws.com Document Path: /dev/notrdsproxy Document Length: 41 bytes Concurrency Level: 20 Time taken for tests: 28.725 seconds Complete requests: 2000 Failed requests: 356 (Connect: 0, Receive: 0, Length: 356, Exceptions: 0) Non-2xx responses: 1644 Total transferred: 112425376 bytes HTML transferred: 112066771 bytes Requests per second: 69.63 [#/sec] (mean) Time per request: 287.249 [ms] (mean) Time per request: 14.362 [ms] (mean, across all concurrent requests) Transfer rate: 3822.13 [Kbytes/sec] received Connection Times (ms) min mean[+/-sd] median max Connect: 28 157 382.5 61 4598 Processing: 25 121 189.7 53 1937 Waiting: 25 86 94.7 52 1057 Total: 53 277 433.1 126 4665 Percentage of the requests served within a certain time (ms) 50% 126 66% 190 75% 281 80% 344 90% 601 95% 889 98% 1458 99% 2075 100% 4665 (longest request)続いて、RDS Proxyあり。2XX以外のリクエストつまり、エラーになったリクエストはありませんでした。
This is ApacheBench, Version 2.3 <$Revision: 1843412 $> Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/ Licensed to The Apache Software Foundation, http://www.apache.org/ Benchmarking eddovdtqad.execute-api.ap-northeast-1.amazonaws.com (be patient) Completed 200 requests Completed 400 requests Completed 600 requests Completed 800 requests Completed 1000 requests Completed 1200 requests Completed 1400 requests Completed 1600 requests Completed 1800 requests Completed 2000 requests Finished 2000 requests Server Software: Server Hostname: eddovdtqad.execute-api.ap-northeast-1.amazonaws.com Server Port: 443 SSL/TLS Protocol: TLSv1.2,ECDHE-RSA-AES128-GCM-SHA256,2048,128 Server Temp Key: ECDH P-256 256 bits TLS Server Name: eddovdtqad.execute-api.ap-northeast-1.amazonaws.com Document Path: /dev/rdsproxy Document Length: 161295 bytes Concurrency Level: 20 Time taken for tests: 75.913 seconds Complete requests: 2000 Failed requests: 1805 (Connect: 0, Receive: 0, Length: 1805, Exceptions: 0) Total transferred: 645507837 bytes HTML transferred: 645174215 bytes Requests per second: 26.35 [#/sec] (mean) Time per request: 759.127 [ms] (mean) Time per request: 37.956 [ms] (mean, across all concurrent requests) Transfer rate: 8304.00 [Kbytes/sec] received Connection Times (ms) min mean[+/-sd] median max Connect: 34 156 138.5 128 1569 Processing: 88 596 469.7 461 3435 Waiting: 61 184 97.2 161 1062 Total: 155 752 515.5 605 3600 Percentage of the requests served within a certain time (ms) 50% 605 66% 840 75% 950 80% 1020 90% 1259 95% 1736 98% 2505 99% 2984 100% 3600 (longest request)あえて、接続可能数少なくして、エラーにあるか試してみましたが、
RDS Proxy側でコネクションプーリングしているので、エラーにならないのはさすがですね。紐付け
紐付けってどこで管理してんのかなと思って、LambdaやRDSのAPIドキュメントを見てみたのですが、
最終的には、利用するLambdaのロールに、AWSLambdaRDSProxyExecutionRole-xxxxxxっていうロールができていて、以下のようなポリシーが定義されていました。{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "rds-db:connect", "Resource": "arn:aws:rds-db:ap-northeast-1:123456789012:dbuser:prx-d5b34b70d97eb0eed/*" } ] }この設定があるロールを持つLambdaはRDS Proxy利用になるということのようです。
なので、あるLambdaでRDS Proxyを設定した場合、同一のロールを使っているLambdaは自動的にRDS Proxyを利用するようになるようですね。
※設定しない想定のLambdaがRDS Proxy使うようになっていて、ええっって思った人です。色々
Lambdaの起動改善、
Provisioned Concurrency for Lambda Functions
そして、このRDS Proxy
で、だいぶVPC Lambdaが使いやすくなった感はありますね。
個人的には RDBMS使いたいケースもあるので、使いやすくなって嬉しいですね。あとは、早くGAするといいですね。
最後に
Preview版のサービスなので、GAになるまでに色々と変更される可能性は大いにあります。
※ 航空会社、空港はICAO(国際民間航空機関)とIATA(国際航空運送協会)によって、2桁から4桁のコードが割り振られています。(JAL:JL、ANA:NH、羽田:HND/RJTT)
ちなみに、CloudFrontのエッジロケーションにはIATA3レターコードに近いものが振られているらしいです(東京だと、NRT<-成田空港の空港コード)。
- 投稿日:2020-02-10T13:26:46+09:00
Athenaで後からパーティションを追加する
Athenaでパーティションを利用する
Athenaでパーティションを利用しようとする場合、このようなS3の構成が求められる
aws s3 ls s3://elasticmapreduce/samples/hive-ads/tables/impressions/ PRE dt=2009-04-12-13-00/ PRE dt=2009-04-12-13-05/ PRE dt=2009-04-12-13-10/ PRE dt=2009-04-12-13-15/ PRE dt=2009-04-12-13-20/ PRE dt=2009-04-12-14-00/ PRE dt=2009-04-12-14-05/ PRE dt=2009-04-12-14-10/ PRE dt=2009-04-12-14-15/ PRE dt=2009-04-12-14-20/ PRE dt=2009-04-12-15-00/ PRE dt=2009-04-12-15-05/
dt=という形式にしてパーティションを作成します。ただ何も考えずにディレクトリを分けていた場合これが適用できません。
今回は後からパーティションを追加する方法を考えます。パーティション名を含んだcreate文
create.sqlCREATE EXTERNAL TABLE impressions ( requestBeginTime string, adId string, impressionId string, referrer string, userAgent string, userCookie string, ip string, number string, processId string, browserCookie string, requestEndTime string, timers struct<modelLookup:string, requestTime:string>, threadId string, hostname string, sessionId string) PARTITIONED BY (dt string) ROW FORMAT serde 'org.apache.hive.hcatalog.data.JsonSerDe' with serdeproperties ( 'paths'='requestBeginTime, adId, impressionId, referrer, userAgent, userCookie, ip' ) LOCATION 's3://elasticmapreduce/samples/hive-ads/tables/impressions/' ;上記はAWSのリンクにあったものです。create文に
PARTITIONED BYを入れ込みます。
月・日でディレクトリを切っている場合はPARTITIONED BY (year int, month int)のようになります。
そしたらそのテーブルに対してパーティションを加えます。alter.sqlALTER TABLE テーブル名 ADD PARTITION (year='2018',month='01') location 's3://バケット名/path/to/2018/12/'; ALTER TABLE テーブル名 ADD PARTITION (year='2019',month='02') location 's3://バケット名/path/to/2019/01/'; ALTER TABLE テーブル名 ADD PARTITION (year='2019',month='02') location 's3://バケット名/path/to/2019/02/'; ALTER TABLE テーブル名 ADD PARTITION (year='2019',month='03') location 's3://バケット名/path/to/2019/03/'; ALTER TABLE テーブル名 ADD PARTITION (year='2019',month='04') location 's3://バケット名/path/to/2019/04/'; ALTER TABLE テーブル名 ADD PARTITION (year='2019',month='05') location 's3://バケット名/path/to/2019/05/'; ALTER TABLE テーブル名 ADD PARTITION (year='2019',month='06') location 's3://バケット名/path/to/2019/06/'; ALTER TABLE テーブル名 ADD PARTITION (year='2019',month='07') location 's3://バケット名/path/to/2019/07/'; ALTER TABLE テーブル名 ADD PARTITION (year='2019',month='08') location 's3://バケット名/path/to/2019/08/'; ALTER TABLE テーブル名 ADD PARTITION (year='2019',month='09') location 's3://バケット名/path/to/2019/09/'; ALTER TABLE テーブル名 ADD PARTITION (year='2019',month='10') location 's3://バケット名/path/to/2019/10/'; ALTER TABLE テーブル名 ADD PARTITION (year='2019',month='11') location 's3://バケット名/path/to/2019/11/'; ALTER TABLE テーブル名 ADD PARTITION (year='2019',month='12') location 's3://バケット名/path/to/2019/12/'; ALTER TABLE テーブル名 ADD PARTITION (year='2020',month='01') location 's3://バケット名/path/to/2020/01/';このようにパーティションを加えます。
そうするとSQLでmonthとyearの指定が可能となりますselect.sqlSELECT count(distinct id) FROM テーブル名 WHERE year = 2019 AND month IN (11, 12)作成したパーティションは
SHOW PARTITIONS table_name year=2019/month=03 year=2019/month=12 year=2019/month=10 year=2019/month=07 year=2019/month=06 year=2019/month=05 year=2019/month=11 year=2020/month=01 year=2019/month=09 year=2019/month=01 year=2019/month=02 year=2019/month=04 year=2018/month=01 year=2019/month=08のように確認可能です。
- 投稿日:2020-02-10T12:33:10+09:00
Amazon ECS - EC2クラスターの作成(AWS CLI)
AWS CLIを利用しての作成手順メモです。コンソール画面と照らしあわせて確認していくとイメージがつきやすいです。
Amazon ECS のサービスは利用はしていません。
最後に環境を削除する場合ですが、ECSクラスターを削除してもECSインスタンスは起動したままとなりますので、ご注意ください。ECSからECSクラスターの削除とEC2からECSインスタンスの削除をしてください。1.ECSクラスターの作成
aws ecs create-cluster --cluster-name MyCluster2.ECSインスタンスの起動と確認
リージョンは、ap-northeast-1 で作成しますので AMI IDは
ami-067f3b20190d6bf4fを指定。
IAMロールは、ecsInstanceRoleを指定。コンテナインスタンスはデフォルトのクラスターで起動されます。先程作成した「MyCluster」のクラスターを起動させるようにします。
#!/bin/bash echo ECS_CLUSTER=MyCluster >> /etc/ecs/ecs.configその他詳細については下記ページを参考。
Amazon ECS コンテナインスタンスの起動起動したECS インスタンスが、【1.クラスターの作成】で作成したECSクラスターにあるかと詳細情報を確認しておく。
aws ecs list-container-instances --cluster MyCluster aws ecs describe-container-instances --cluster MyCluster --container-instances container_instance_ID3.タスク定義の作成と実行
task作業フォルダを作成しておく。
mkdir task cd taskタスク定義を作成する。
sleep360.json { "containerDefinitions": [ { "name": "sleep", "image": "busybox", "cpu": 10, "command": [ "sleep", "360" ], "memory": 10, "essential": true } ], "family": "sleep360" }aws ecs register-task-definition --cli-input-json file://$HOME/task/sleep360.json作成済のタスク定義を確認する。
aws ecs list-task-definitionsタスクを実行する。
aws ecs run-task --cluster MyCluster --task-definition sleep360:1 --count 1実行されているタスクを確認する。
aws ecs describe-tasks --cluster MyCluster --task task_IDリンク
- 投稿日:2020-02-10T11:15:34+09:00
Amazon Personalizeのチュートリアルをしてみた話
はじめに
今回はAWSさんが用意しているAmazon Personalizeのハンズオンを行ってみたので、そのまとめです
Amazon Personalize
公式曰く
Amazon Personalize は、アプリケーションを使用するユーザー向けに個別化したレコメンデーションを簡単に追加できる、開発者向けの機械学習サービスです。
使用例としては
ユーザーの嗜好や行動に基づくレコメンデーションの提供、結果のパーソナライズによる再ランク付け、E メールや通知のコンテンツのパーソナライズなどに使用できます。
とのこと。現在鋭意製作中のプラットフォームアプリケーションで、楽曲レコメンドやアーティストレコメンドをおこないたいという要望に対して非常にマッチしているような感じでした。
ハンズオン
いきなり感想
感想をまずいうと、本当に簡単にできました!
行ったハンズオンでの作業では
- csvの1カラムを消す
- csvをS3に保存
- Amazon Personalizeでデータセットとしてcsvのpathを入力
- 勝手に読み込む
- Solutionを選んでモデル生成スタート
- 40分ほどまてば学習が終わる
- キャンペーン(レコメンドAPI)を作成し、レコメンドさせたいユーザIDを選んで結果が返ってくる
恐ろしく単純で、ぽちぽちクリックして寝て待てばAPIまでも自動で生成してくれる素晴らしいサービスだと思います。
やったハンズオン資料
https://pages.awscloud.com/event_JAPAN_Hands-on-Amazon-Personalize-Forecast-2019.html?trk=aws_introduction_page
Forcastのハンズオンもあったのですが、今回はPersonalizeのみやりました。
時間があればForcastもやってみたいと思います。
所要時間はモデル学習待ち時間とか含めて、3時間程度でした使ったデータ
使ったデータは有名な映画データセット
https://grouplens.org/datasets/movielens/csvの中身的には、9700 本の映画に対する 600 ユーザーの評価履歴があり行数は10万行くらい
10万サンプルのデータを使って学習するという認識です。
"rating.csv"というのを使っておりさらに学習ではレーティング部分は削除しています。
なので、特徴としてはUSER_ID, ITEM_ID(映画のID), TIMESTAMPだけで、USER_IDがみている映画データしかないです。なので、Amazon Personalizeの中の学習部分は"映画をみた"、"みなてない"という2値の誤差を計算しながら最適なレコメンデーションをおこなっていると思います。(推測なので全然違う可能性もあります)手順
ハンズオンにすべて載っているので再掲するのはおこがましいので、
Personalizeの部分だけスクショ取っておきます。S3で適当なバケットをつくり、rating.csvをおきバケットポリシーをPersonalizeがアクセスできるように設定しているというのが前提条件
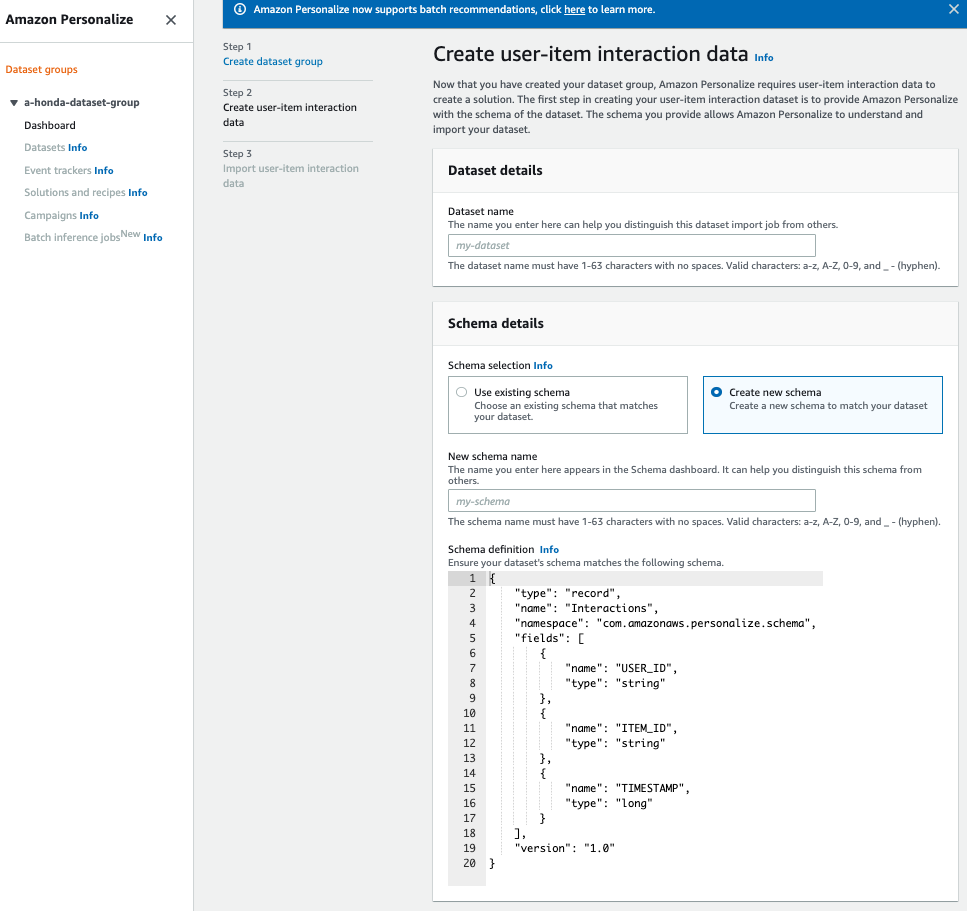
1. create dataet group
データセットをAmazon Personalizeに登録します。
Personalizeのコンソールに行き、create_dataset_groupをクリックするとこんな画面に
大事なのはスキーマで、schema definitionと今回のcsvの形を合わせる必要があります。
スキーマと違うcsvを読み込むとどうなるかは試していないですが、データが正しくPersonalizeにとりこめないと思われます。なのでcsvのヘッダーを用意しているのかとここで注意しておきたいのは、 データ取り込みにもお金がかかるということ
"データ取り込み 0.05 USD/GB"今回のハンズオンで取り込んだcsvで取り込み終了したのがおおよそ2, 30分くらいでした
2. create solution
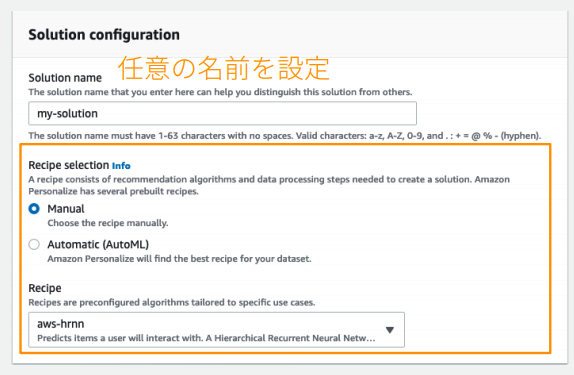
取り込み終わったら実際に学習設定に入っていきます。
Dashbordの"create solution"のstartボタンを押すと設定画面に入っていきます。
cf: https://pages.awscloud.com/rs/112-TZM-766/images/201912-AmazonPersonalizeHandson.pdf
この画面で実際にモデルの設定をしていきます。
Amazon Personalizeには事前に定義されているレシピが2020年2月現在では3つ存在しており、それぞれ
- USER_PERSONALIZATION: ユーザーがやり取りするアイテムを予測する(今回の例は映画)
- PERSONALIZED_RANKING: ユーザーがやり取りするアイテムを予測しかつランキングも出してくれる(おすすめランキングみたいなもの)
- RELATED_ITEMS: 指定されたアイテムに類似したアイテムをかえす(ある映画に似ている映画)
それぞれのレシピに対して、レコメンデーション方法があります。
- USER_PERSONALIZATION
- HRNN: 階層的再帰型ニューラルネットワークでITEMに触ったか触らなかったかのデータ
- HRNN-meta: ITEMの特徴とかのメタデータを加味したHRNN
- HRNN-colddata: HRNN-metaとの違いは"新しいアイテムのパーソナライズされた探索"も含まれる
- Popularity-Count: データセットないでのアイテムの人気度を計算して出す 今回はUSER_PERSONALIZATIONのHRNN(階層的再帰型ニューラルネットワーク)を用いました。
- PERSONALIZED_RANKING
- Personalized-Ranking: ランキングをつけてくれるHRNN
- RELATED_ITEMS
- SIMS: ユーザー履歴内のアイテムの共起を計算して出してくれる(協調フィルタリング)
基本はAmazonが発表したHRNNがPersonalizeの全てになっていると思います。
RNNの資料に関しては前に発表したことがあるので載せておきます。
https://www.slideshare.net/aratahonda1/rnnlstm今回はUSER_PERSONALIZATIONのHRNNを用いました。
学習方法はどうやらBPTTを使っているらしい(スライドにBPTTも載っています)
なので、設定するハイパーパラメータ(自分たちが手で入力するもの)は
- hidden_dimension : NNの隠れ層の階層数
- bptt: bpttがどのくらいの学習ステップまでを一度に計算するか
- recency_mask: アイテムのTIMESTAMPを加味するか(例えば一番最近みた映画に重み付けするなど)
の三つです。RNN自体が時系列をNNで表現したものなので、時間ステップという概念がないとここら辺ん設定できないかもしれません。
本当にわからない人はHPO(HyperParameterOptimazer?)をTrueにしてハイパーパラメータを範囲指定して一番いい結果だけを返してくれるものがあるのでそれに頼るといいかもです。
もっというと、うえのレシピも何を選んだらいいかわからない人はauto MLをつかうとそれさえも自動でやってくれます。あとはポチポチすると学習スタートし、1時間ほどかかりました。
10万サンプルで40分程度だったのでそれ以上のデータを投入するともっとかかるかもしれません。
(あとはハンズオン通りにおこなったのでハイパラは決め打ちです)3. create campaign
学習が終わると、Dashbordにいきcreate campaignボタンを押します。
これで2でつくったHRNNモデルを組み込んだレコメンデーションAPIを自動で作ってくれます。
2でつくったソリューションIDを選んでcreateボタンを押すだけでレコメンデーションAPIも作ってくれるとは...恐ろしいくらい簡単ですね
作成した時間はおおよそ10分くらいです。設定的には特にないですが、一回のAPIを叩くと何件返して欲しいかなど(defaultで25件)くらいですかね。
あとはuser_idを入れてみて映画のIDを返すかの確認です。試したこと
何回かレコメンドしてみる
user_id = 1をいれてレコメンドを何回かしてみるということをしてみました。
結果的にレコメンデーションの結果は全く変わらなかったです。
ただし、user_id = 2をいれて返ってくるレコメンデーション結果はuser_id = 1の時の結果と違うことは確認できました。
このことから、ソリューションを回したタイミングでもうユーザへのレコメンデーションの結果は決まっており、それを更新するとレコメンデーション結果が変わると思われます。
なので、使い方としてはバッチ推論ジョブをつかって、DBかなにかで登録しているユーザIDでレコメンデーションを行い、その推論結果をS3に保存しておいて、「今日のおすすめ」みたいな感じで出すという形の方がリアルタイム推論APIを使うよりコスト的にはいいのかなと思いました。(間違ってたらごめんなさい存在しないユーザIDをうってみる
user_idは600がマックスなので123456とか存在しないuser_idでレコメンデーションしてみました。
結果的には、何かしらのレコメンデーション結果は返ってきましたが、さらに23455とか適当に打っても123456のレコメンデーション結果と変わらなかったです。
このことから学習データに存在しないユーザデータ、つまり新規ユーザに対しては同じ何かしらのレコメンデーション結果が返ってくるということがわかりました。おわりに
大事なのはこのレコメンデーションの妥当性を検証するためのKPIを作る必要があるということだけは最後に書いておきます。
非常に作りやすいレコメンデーションシステムで全く触ったことない人でも簡単に作れるのでレコメンデーションを入れるハードルは低くなると思いました。
- 投稿日:2020-02-10T11:14:16+09:00
Amazon Personalizeのチュートリアルをしてみた話
はじめに
今回はAWSさんが用意しているAmazon Personalizeのハンズオンを行ってみたので、そのまとめです
Amazon Personalize
公式曰く
Amazon Personalize は、アプリケーションを使用するユーザー向けに個別化したレコメンデーションを簡単に追加できる、開発者向けの機械学習サービスです。
使用例としては
ユーザーの嗜好や行動に基づくレコメンデーションの提供、結果のパーソナライズによる再ランク付け、E メールや通知のコンテンツのパーソナライズなどに使用できます。
とのこと。現在鋭意製作中のプラットフォームアプリケーションで、楽曲レコメンドやアーティストレコメンドをおこないたいという要望に対して非常にマッチしているような感じでした。
ハンズオン
いきなり感想
感想をまずいうと、本当に簡単にできました!
行ったハンズオンでの作業では
- csvの1カラムを消す
- csvをS3に保存
- Amazon Personalizeでデータセットとしてcsvのpathを入力
- 勝手に読み込む
- Solutionを選んでモデル生成スタート
- 40分ほどまてば学習が終わる
- キャンペーン(レコメンドAPI)を作成し、レコメンドさせたいユーザIDを選んで結果が返ってくる
恐ろしく単純で、ぽちぽちクリックして寝て待てばAPIまでも自動で生成してくれる素晴らしいサービスだと思います。
やったハンズオン資料
https://pages.awscloud.com/event_JAPAN_Hands-on-Amazon-Personalize-Forecast-2019.html?trk=aws_introduction_page
Forcastのハンズオンもあったのですが、今回はPersonalizeのみやりました。
時間があればForcastもやってみたいと思います。
所要時間はモデル学習待ち時間とか含めて、3時間程度でした使ったデータ
使ったデータは有名な映画データセット
https://grouplens.org/dat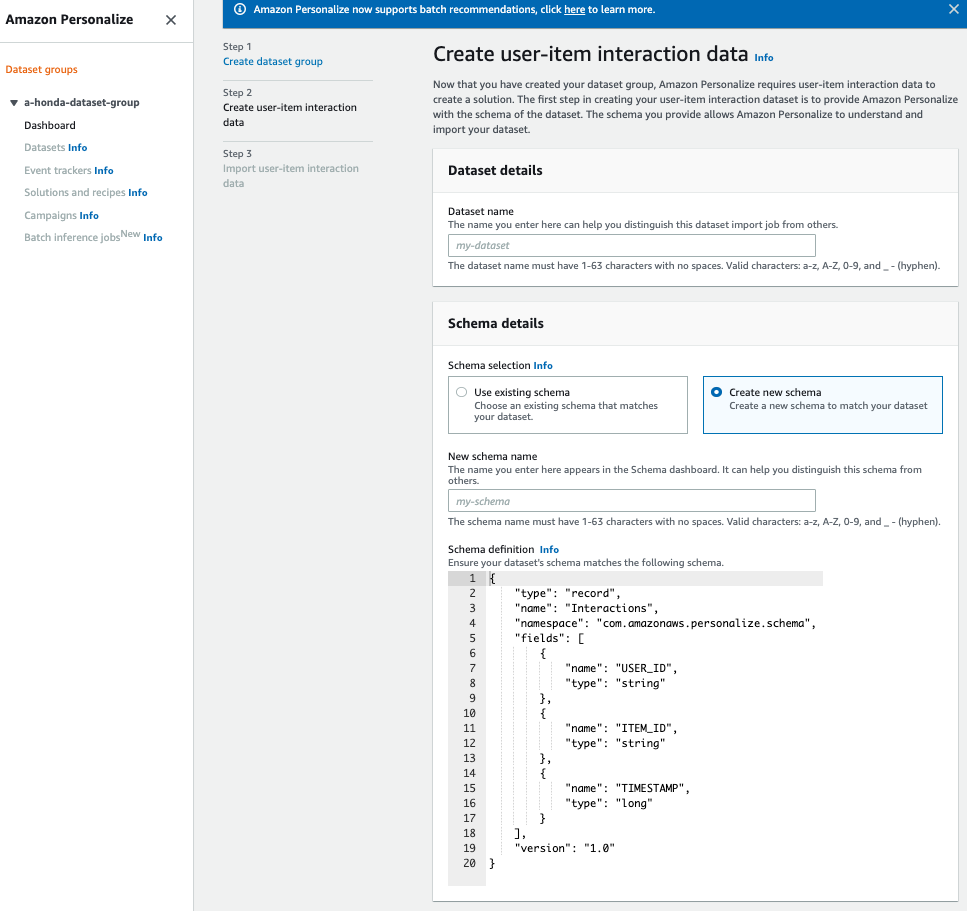
asets/movielens/csvの中身的には、9700 本の映画に対する 600 ユーザーの評価履歴があり行数は10万行くらい
10万サンプルのデータを使って学習するという認識です。
"rating.csv"というのを使っておりさらに学習ではレーティング部分は削除しています。
なので、特徴としてはUSER_ID, ITEM_ID(映画のID), TIMESTAMPだけで、USER_IDがみている映画データしかないです。なので、Amazon Personalizeの中の学習部分は"映画をみた"、"みなてない"という2値の誤差を計算しながら最適なレコメンデーションをおこなっていると思います。(推測なので全然違う可能性もあります)手順
ハンズオンにすべて載っているので再掲するのはおこがましいので、
Personalizeの部分だけスクショ取っておきます。S3で適当なバケットをつくり、rating.csvをおきバケットポリシーをPersonalizeがアクセスできるように設定しているというのが前提条件
1. create dataet group
データセットをAmazon Personalizeに登録します。
Personalizeのコンソールに行き、create_dataset_groupをクリックするとこんな画面に
大事なのはスキーマで、schema definitionと今回のcsvの形を合わせる必要があります。
スキーマと違うcsvを読み込むとどうなるかは試していないですが、データが正しくPersonalizeにとりこめないと思われます。なのでcsvのヘッダーを用意しているのかとここで注意しておきたいのは、 データ取り込みにもお金がかかるということ
"データ取り込み 0.05 USD/GB"今回のハンズオンで取り込んだcsvで取り込み終了したのがおおよそ2, 30分くらいでした
2. create solution
取り込み終わったら実際に学習設定に入っていきます。
Dashbordの"create solution"のstartボタンを押すと設定画面に入っていきます。
cf: https://pages.awscloud.com/rs/112-TZM-766/images/201912-AmazonPersonalizeHandson.pdf
この画面で実際にモデルの設定をしていきます。
Amazon Personalizeには事前に定義されているレシピが2020年2月現在では3つ存在しており、それぞれ
- USER_PERSONALIZATION: ユーザーがやり取りするアイテムを予測する(今回の例は映画)
- PERSONALIZED_RANKING: ユーザーがやり取りするアイテムを予測しかつランキングも出してくれる(おすすめランキングみたいなもの)
- RELATED_ITEMS: 指定されたアイテムに類似したアイテムをかえす(ある映画に似ている映画)
それぞれのレシピに対して、レコメンデーション方法があります。
- USER_PERSONALIZATION
- HRNN: 階層的再帰型ニューラルネットワークでITEMに触ったか触らなかったかのデータ
- HRNN-meta: ITEMの特徴とかのメタデータを加味したHRNN
- HRNN-colddata: HRNN-metaとの違いは"新しいアイテムのパーソナライズされた探索"も含まれる
- Popularity-Count: データセットないでのアイテムの人気度を計算して出す 今回はUSER_PERSONALIZATIONのHRNN(階層的再帰型ニューラルネットワーク)を用いました。
- PERSONALIZED_RANKING
- Personalized-Ranking: ランキングをつけてくれるHRNN
- RELATED_ITEMS
- SIMS: ユーザー履歴内のアイテムの共起を計算して出してくれる(協調フィルタリング)
基本はAmazonが発表したHRNNがPersonalizeの全てになっていると思います。
RNNの資料に関しては前に発表したことがあるので載せておきます。
https://www.slideshare.net/aratahonda1/rnnlstm今回はUSER_PERSONALIZATIONのHRNNを用いました。
学習方法はどうやらBPTTを使っているらしい(スライドにBPTTも載っています)
なので、設定するハイパーパラメータ(自分たちが手で入力するもの)は
- hidden_dimension : NNの隠れ層の階層数
- bptt: bpttがどのくらいの学習ステップまでを一度に計算するか
- recency_mask: アイテムのTIMESTAMPを加味するか(例えば一番最近みた映画に重み付けするなど)
の三つです。RNN自体が時系列をNNで表現したものなので、時間ステップという概念がないとここら辺ん設定できないかもしれません。
本当にわからない人はHPO(HyperParameterOptimazer?)をTrueにしてハイパーパラメータを範囲指定して一番いい結果だけを返してくれるものがあるのでそれに頼るといいかもです。
もっというと、うえのレシピも何を選んだらいいかわからない人はauto MLをつかうとそれさえも自動でやってくれます。あとはポチポチすると学習スタートし、1時間ほどかかりました。
10万サンプルで40分程度だったのでそれ以上のデータを投入するともっとかかるかもしれません。
(あとはハンズオン通りにおこなったのでハイパラは決め打ちです)3. create campaign
学習が終わると、Dashbordにいきcreate campaignボタンを押します。
これで2でつくったHRNNモデルを組み込んだレコメンデーションAPIを自動で作ってくれます。
2でつくったソリューションIDを選んでcreateボタンを押すだけでレコメンデーションAPIも作ってくれるとは...恐ろしいくらい簡単ですね
作成した時間はおおよそ10分くらいです。設定的には特にないですが、一回のAPIを叩くと何件返して欲しいかなど(defaultで25件)くらいですかね。
あとはuser_idを入れてみて映画のIDを返すかの確認です。試したこと
何回かレコメンドしてみる
user_id = 1をいれてレコメンドを何回かしてみるということをしてみました。
結果的にレコメンデーションの結果は全く変わらなかったです。
ただし、user_id = 2をいれて返ってくるレコメンデーション結果はuser_id = 1の時の結果と違うことは確認できました。
このことから、ソリューションを回したタイミングでもうユーザへのレコメンデーションの結果は決まっており、それを更新するとレコメンデーション結果が変わると思われます。
なので、使い方としてはバッチ推論ジョブをつかって、DBかなにかで登録しているユーザIDでレコメンデーションを行い、その推論結果をS3に保存しておいて、「今日のおすすめ」みたいな感じで出すという形の方がリアルタイム推論APIを使うよりコスト的にはいいのかなと思いました。(間違ってたらごめんなさい存在しないユーザIDをうってみる
user_idは600がマックスなので123456とか存在しないuser_idでレコメンデーションしてみました。
結果的には、何かしらのレコメンデーション結果は返ってきましたが、さらに23455とか適当に打っても123456のレコメンデーション結果と変わらなかったです。
このことから学習データに存在しないユーザデータ、つまり新規ユーザに対しては同じ何かしらのレコメンデーション結果が返ってくるということがわかりました。おわりに
大事なのはこのレコメンデーションの妥当性を検証するためのKPIを作る必要があるということだけは最後に書いておきます。
非常に作りやすいレコメンデーションシステムで全く触ったことない人でも簡単に作れるのでレコメンデーションを入れるハードルは低くなると思いました。
- 投稿日:2020-02-10T09:39:53+09:00
Debian9でAWS ECR Loginが出来ない時の解決方法
DebianでBuildしたDocker ImageをAWS ECRのレジストリーにあげようとした時、ECR Loginが出来ないことがあります。
OSとバージョンはDebian 9.9、aws cliはapt-get installで入れたものです。
# cat /etc/debian_version 9.9 # aws --version aws-cli/1.11.13 Python/3.5.3 Linux/4.9.0-9-amd64 botocore/1.4.70ECR Loginしようとすると以下のようにエラーが出て、ログインできません。
$(aws ecr get-login --region xxxx --no-include-email) Unknown options: --no-include-email解決方法は、pip3でawscliを最新バージョンにアップデートすることです。
# apt-get install python3-pip # pip3 install --upgrade awscli # aws --version aws-cli/1.17.12 Python/3.5.3 Linux/4.9.0-9-amd64 botocore/1.14.12この後、ECR Loginが出来ました。
- 投稿日:2020-02-10T09:32:02+09:00
【初心者】AWS Amazon Linux2でFluentdのfluent-plugin-cloudwatch-logsのインストールに詰まった話
概要
ログを取ろうと、Amazon Linux2でFluentdは入ったものの、fluent-plugin-cloudwatch-logsでインストールに詰まった。原因としてはrubyの開発環境がなかっただけだった話。
症状
こんなエラーが生じてうまく入らない。
$ sudo /opt/td-agent/embedded/bin/gem install fluent-plugin-cloudwatch-logs --no-ri --no-rdoc Building native extensions. This could take a while... ERROR: Error installing fluent-plugin-cloudwatch-logs: ERROR: Failed to build gem native extension. current directory: /opt/td-agent/embedded/lib/ruby/gems/2.4.0/gems/msgpack-1.3.3/ext/msgpack /opt/td-agent/embedded/bin/ruby -r ./siteconf20200210-967-1s5gonu.rb extconf.rb checking for ruby/st.h... *** extconf.rb failed *** Could not create Makefile due to some reason, probably lack of necessary libraries and/or headers. Check the mkmf.log file for more details. You may need configuration options. Provided configuration options: --with-opt-dir --with-opt-include --without-opt-include=${opt-dir}/include --with-opt-lib --without-opt-lib=${opt-dir}/lib --with-make-prog --without-make-prog --srcdir=. --curdir --ruby=/opt/td-agent/embedded/bin/$(RUBY_BASE_NAME) /opt/td-agent/embedded/lib/ruby/2.4.0/mkmf.rb:468:in `try_do': The compiler failed to generate an executable file. (RuntimeError) You have to install development tools first. from /opt/td-agent/embedded/lib/ruby/2.4.0/mkmf.rb:599:in `try_cpp' from /opt/td-agent/embedded/lib/ruby/2.4.0/mkmf.rb:1107:in `block in have_header' from /opt/td-agent/embedded/lib/ruby/2.4.0/mkmf.rb:957:in `block in checking_for' from /opt/td-agent/embedded/lib/ruby/2.4.0/mkmf.rb:351:in `block (2 levels) in postpone' from /opt/td-agent/embedded/lib/ruby/2.4.0/mkmf.rb:321:in `open' from /opt/td-agent/embedded/lib/ruby/2.4.0/mkmf.rb:351:in `block in postpone' from /opt/td-agent/embedded/lib/ruby/2.4.0/mkmf.rb:321:in `open' from /opt/td-agent/embedded/lib/ruby/2.4.0/mkmf.rb:347:in `postpone' from /opt/td-agent/embedded/lib/ruby/2.4.0/mkmf.rb:956:in `checking_for' from /opt/td-agent/embedded/lib/ruby/2.4.0/mkmf.rb:1106:in `have_header' from extconf.rb:3:in `<main>' To see why this extension failed to compile, please check the mkmf.log which can be found here: /opt/td-agent/embedded/lib/ruby/gems/2.4.0/extensions/x86_64-linux/2.4.0/msgpack-1.3.3/mkmf.log extconf failed, exit code 1 Gem files will remain installed in /opt/td-agent/embedded/lib/ruby/gems/2.4.0/gems/msgpack-1.3.3 for inspection. Results logged to /opt/td-agent/embedded/lib/ruby/gems/2.4.0/extensions/x86_64-linux/2.4.0/msgpack-1.3.3/gem_make.out原因
Could not create Makefile due to some reason, probably lack of necessary libraries and/or headers.や、You have to install development tools first.というメッセージがあることから、rubyの開発環境が足りていないことがわかる。対応策
Rubyの開発環境を一式放り込んだ。
sudo yum -y install gcc-c++ glibc-headers openssl-devel readline libyaml-devel readline-devel zlib zlib-devel libffi-devel libxml2 libxslt libxml2-devel libxslt-devel sqlite-devel結果
無事インストールできた。
$ sudo /opt/td-agent/embedded/bin/gem install fluent-plugin-cloudwatch-logs --no-ri --no-rdoc Building native extensions. This could take a while... Successfully installed msgpack-1.3.3 Fetching: fluentd-1.9.1.gem (100%) Successfully installed fluentd-1.9.1 Fetching: aws-partitions-1.271.0.gem (100%) Successfully installed aws-partitions-1.271.0 Fetching: aws-sdk-core-3.89.1.gem (100%) Successfully installed aws-sdk-core-3.89.1 Fetching: aws-sdk-cloudwatchlogs-1.28.0.gem (100%) Successfully installed aws-sdk-cloudwatchlogs-1.28.0 Fetching: fluent-plugin-cloudwatch-logs-0.8.0.gem (100%) Successfully installed fluent-plugin-cloudwatch-logs-0.8.0 6 gems installed雑感
AWSとか普通の環境を触り始めて1か月くらいたってようやくこの手のエラー対応に慣れてきたなぁ、と思いました(遅い)
- 投稿日:2020-02-10T08:57:07+09:00
AWS Cloud9をSSH接続で使うまでの手順
AWS Cloud9での環境構築には2種類の方法があります。
今回はSSH環境を使えるようにするまでの手順をまとめました。
- EC2 環境 (新しいインスタンスを作成する)
- SSH環境 (既存のインスタンスにSSHで接続する)
EC2環境とSSH環境の違い
お手軽なのはEC2環境、玄人向けがSSH環境と言ったところです。
EC2環境は、Cloud9用のインスタンスを作成して使用します。
ユーザーが選ぶのはOSとスペックだけで、残りはAWSが準備してくれます(カスタイマイズすることも可能です)。詳細は補足にまとめました。SSH環境は、自分でインスタンスを作成し、Cloud9で操作できるように設定します。
ユーザー自身で、必要なパッケージ等のインストール、ネットワークの設定を行う必要があります。
項目 EC2環境 SSH環境 インスタンス 新規作成 事前に準備 設定 スペックとOS選択のみ 全て自分で行う OS Amazon Linux or Ubuntu Linux全般 Cloud9以外での使用 想定していない 使用可能 詳しくは公式を参照してください。
SSH環境のメリット
SSH環境は、EC2環境に比べて面倒が多いのです。
単にAWSのインスタンスでCloud9を使いたいだけであれば不要な存在です。
それでも用意されているということは何かしらのメリットがあるということになります。メリット1:AWS以外のサーバーが使える
例えば、別のクラウドサービスで使用している既存サーバーに接続して、Cloud9を使用することができます。
構築済みの既存サーバーでCloud9を用いて開発したい、AWSのインスタンスを使いたくないといったケースで有効です。メリット2:Cloud9以外の用途にインスタンスを使える
EC2環境の場合、Cloud9環境を削除するとインスタンスも削除されます。
SSH環境であれば、Cloud9の使用終了後も継続してインスタンスを使用することができます。
既存サーバーで一時的にCloud9を使用といったことも可能です。また、EC2環境の場合では不要なパッケージもインストールされます。
例えば、Pythonの開発のみ行い場合であっても、その他の言語を最低限動かすためのパッケージはインストールされています。SSH環境を使用するための手順
今回は、デフォルトユーザーである「ec2-user」でCloud9を使用する手順を記載します。
[1] インスタンスを用意する
[1-1] インスタンスの作成
EC2をインスタンスを作成します。
下記のようにパブリックサブネット内にインスタンス1台という簡単な構成で作成しました。この構成であれば、 Cloud9を使用するための特別な手順はありません。
インスタンスは下記設定としました。
項目 値 OS Amazon Linux 2 インスタンスタイプ t3.micro ストレージ EBS, 16GB [1-2] パッケージのインストール
SSH環境としてインスタンスを使用するための用件が色々とあります。
詳しくは下記リンクに記載があります。
AWS Cloud9 SSH 開発環境 ホスト要件[1-2-1] Python2.7のインストール
Amazon Linux 2であれば、Pytnon2.7はインストール済みのため何もする必要はありません。
インストールされていないサーバーであれば、yumやapt-getを用いてインストールします。$ sudo yum install -y python2.7と指定があるため、Python3がデフォルトのサーバーであれば、2.7をデフォルトに変える必要があるかもしれません。
[1-2-2] Node.jsのインストール
バージョンが 0.6.16 以降のNode.jsが必要条件となります。
公式に記載の通り、下記手順でインストールします。
Amazon EC2 インスタンスでの Node.js のセットアップ$ curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.34.0/install.sh | bash $ . .bashrc $ nvm install node[1-2-3] AWS Cloud9 の起動元ディレクトリの権限変更
Cloud9を起動時に表示されるディレクトリの権限を変更します。
AWS Cloud9 の起動元とするディレクトリには「rwxr-xr-x 」の権限が必要になります。
ホームディレクトリを起動元にする場合は、下記コマンドで変更します。//s3.qrunch.io/3f9e9fd53ac79d6e88e66457e1139599.png)$ sudo chmod u=rwx,g=rx,o=rx ~[1-2-4] AWS Cloud9インストーラの実行
AWS Cloud9インストーラをダウンロードし実行します。
AWS Cloud9 に必要なコンポーネントやその依存関係をインストールするそうです。
AWS Cloud9 インストーラの使用インストーラ実行にgccが必要なので先にインストールしてから実行します。
インストーラが実行し終わるまでに数十分かかりました。t3.microだからかもしれません。$ sudo yum install -y gcc $ curl -L https://raw.githubusercontent.com/c9/install/master/install.sh | bash[1-3] ネットワークACLとセキュリティグループの設定
EC2環境ですと、AWS側でセキュリティグループを作成してくれます。
SSH環境ではAWS側で設定してくれませんので、セキュリティのことを考えると自分で設定しておいた方がよいでしょう。
インバウンドはSSHのみ許可、アウトバウンドはHTTP, HTTPSのみ許可しました。
SSHの許可はCloud9でアクセスする際にも必要になります。インバウンド
タイプ プロトコル ポート範囲 ソース 説明 SSH TCP 22 0.0.0.0/0 アウトバウンド
タイプ プロトコル ポート範囲 ソース 説明 HTTP TCP 80 0.0.0.0/0 HTTPS TCP 443 0.0.0.0/0 [2] Cloud9でSSH環境を作成する
[2-1] SSHの接続情報を入力
Cloud9の環境作成画面でSSH接続に必要な情報を入力します。
Environment Typeは「Connect and run in remote server (SSH)」を選択します。
Userには上述の手順でCloud9で使用するためのユーザーとして設定した「ec2-user」を入力します。
HostにはEC2インスタンスのパブリックIPを入力します。
[2-2] 公開鍵の設定
EC2インスタンスに公開鍵を登録します。
「Copy key to clipboard」をクリックして公開鍵をコピーします。
EC2インスタンスにログインし、公開鍵を登録します。
$ echo "[コピーした公開鍵]" >> ~/.ssh/authorized_keys[2-3] Advanced settings (設定不要)
公開鍵を登録したら[Next Step]をクリックします。
SSHの接続に問題がある場合にはここでエラーメッセージが表示されます。Advanced settingsは空欄のままにします。
EC2インスタンス以外のサーバーを使用する場合には、入力の必要があるかもしれません。
[2-4] 作成完了
次の画面に進んだら設定内容を確認し[Create environment]をクリックします。
設定に問題がなければCloud9の初期画面が表示されます。
以上で終了です。
終わりに
SSH環境は、EC2環境に比べて設定が面倒ですが、一度分かってしまえば次回は簡単です。
私はCloudFormationを使用して環境構築をしているので、SSH環境を活用しています。EC2環境、SSH環境それぞれにメリットがあるので、シチュエーションに応じて自分の都合の良い方を選ぶのがよいと思います。
補足
補足[1] Cloud9で環境作成時に自動で作成されるセキュリティグループ
Cloud9で使用するIPアドレスの範囲は、リージョン ごとに決まっており「ip-ranges.json」に記載されています。
下記設定は、アジアパシフィック(東京)でCloud9環境を作成した際の例です。
AWS Cloud9 開発環境 の VPC の設定インバウンド
タイプ プロトコル ポート範囲 ソース 説明 SSH TCP 22 18.179.48.128/27 SSH TCP 22 18.179.48.96/27 アウトバウンド
タイプ プロトコル ポート範囲 ソース 説明 すべてのトラフィック すべて すべて 0.0.0.0/0 補足[2] Advanced settingsの内容
設定 内容 備考 Environment path 環境パス デフォルトはホームディレクトリ Node.js binary path Node.js バイナリパス 設定しなければAWS Cloud9が推測する SSH jump host SSH ジャンプホスト 踏み台サーバー経由で接続するようなケースで設定する



- 投稿日:2020-02-10T08:47:16+09:00
【GCP/AWS】判断軸としてのレイテンシ
どのクラウドのサービス使用すべきか
例えば、AWS AuroraかCloud SQLをどちらを使用するべきかと考えた時に、様々な判断軸で比較をします。
料金、スケーラビリティなどそのフェーズによって様々です。
その判断軸の中で一つ出てくるのが、レイテンシです。
この場合知りたい情報は、クラウド内のサービスを使用した場合とクラウド外のサービスを使用した場合とで、どのくらいレイテンシに差が出るのかということです。
今回はこの件について調査してみました。クラウド外のレイテンシ
下記の記事を参考にしています。
Public Cloud Inter-region Network Latency as Heat-mapsこの記事では、 各クラウドのリージョン毎にラウンドトリップタイム(RTT)を算出し、どのくらいクラウド内と外とで数値が変化するかをヒートマップで出力してくれています。
RTT【 Round-Trip Time 】ラウンドトリップタイム
下記記事より引用
Public Cloud Inter-region Network Latency as Heat-maps上記の図を見てみると、
gce-asia-northeast-1から、ec2aws-ap-northeast-1へのレイテンシは、2msになっています。
一方、gce-asia-northeast-1から、ec2aws-ap-northeast-2へのレイテンシは、32msになっており、急に数値が跳ね上がっています。他でも同じことが言えることから、
同じクラウド内であっても、リージョンが違えば、レイテンシが増加し、
別のクラウドであっても、リージョンが同じであれば、レイテンシは増加しないことがわかります。物理的距離
RTT is correlated to the physical distance between the communicating hosts (speed of light) and to the quality of the network
記事内でも触れられている通り、RTTは物理的距離が関係しているため、このような結果になったのではないでしょうか。
クラウド内のレイテンシ
ではクラウド内のレイテンシは実際どのくらいなのでしょうか。
そこを検証してくれているのが下記記事になっています。
AWSアカウント間AZ間レイテンシ - QiitaEC2からRDSへのレイテンシを調べてくれていて、同じなら0.5msであることがわかります。
下記記事より引用
AWSアカウント間AZ間レイテンシ - Qiita何に注意すべきか
上記より、現状の結論は、別クラウドに関係なく、リージョンに注意すべきです。
別クラウドであっても、リージョンを同じにすれば、レイテンシを抑えることができるとわかりました。
厳密な比較ではないですが、非常に参考になる数値だと思います。その他参考になった記事
逆引き GKE ネットワーク編 - Qiita
Compute Engine のリージョン選択に関するおすすめの方法 | ソリューション | Google Cloud
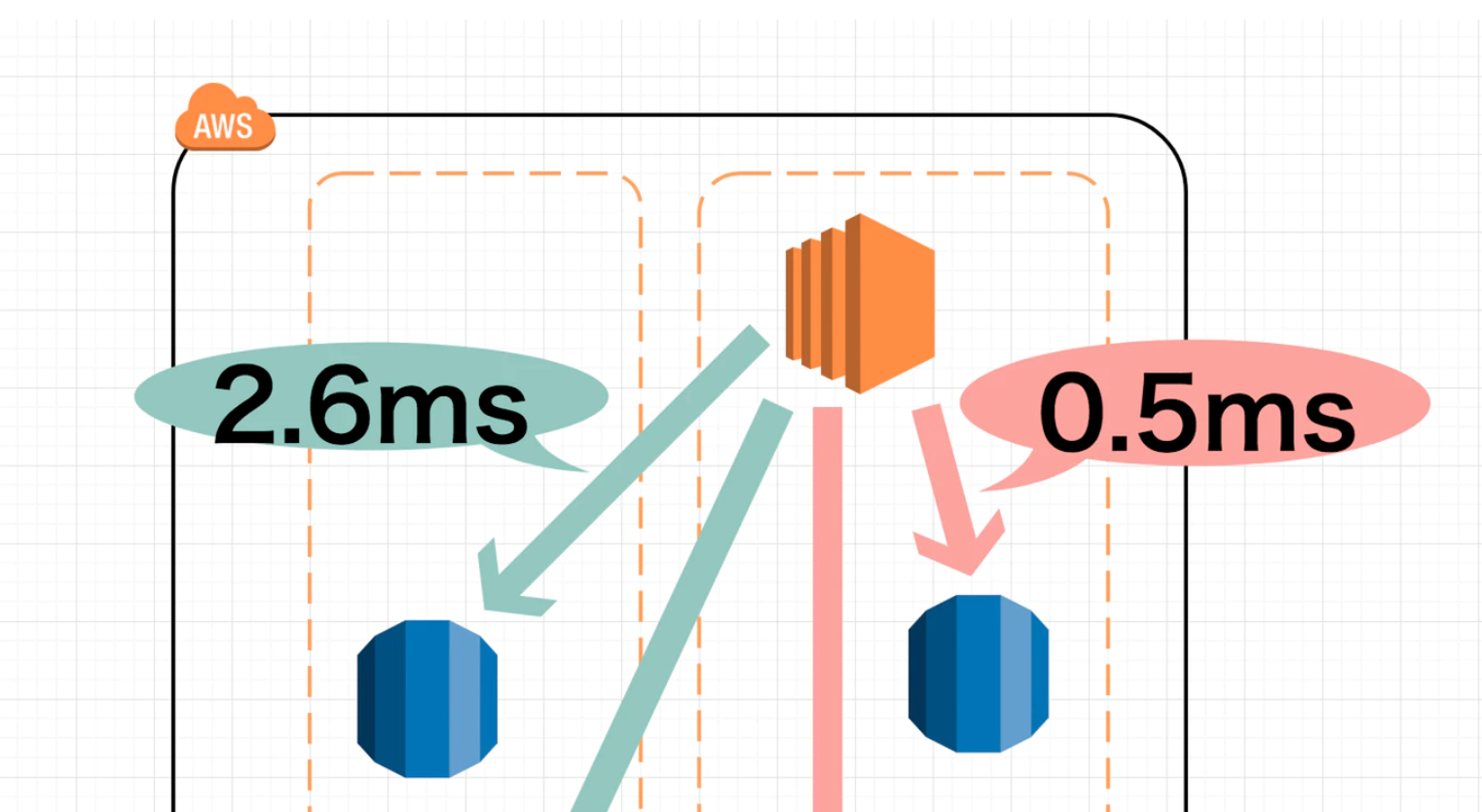
- 投稿日:2020-02-10T07:29:47+09:00
AWS Cloud9のEC2へ簡単接続
Cloud9つかってますか?
世はまさに大Cloud時代。
ってなわけで、クラウドで開発環境構築するのが今後は普通になっていくのかなと。
そこで、AWSのCloud9をつかってサクッと使ってみた。
全然つながらないたまーに繋がらないなどのトラブルがあるものの、
ひとまずは使えています。本題にうつります
これ、EC2にsshしたいときってどうすんのかなと。
Cloud9あればいいのか?いや、たぶんそういうわけじゃないだろと思ったので
やることを書いていきます。キーペア作り
まずはキーペアを作ります。
EC2コンソールの左側ペインから「キーペア」を選択し、
「Create Key Pair」を選択
次にKeyの名前と鍵の形式を選びます。
ここでは名前をhoge、形式はpemを選択します。
最後に「Create Key Pair」を選択。
すると勝手にキーがDLされます。(矢印のとこ)
リストにも追加されています。
DLされたキーをわかりやすい場所(僕はデスクトップにしました)に移動させておき、bashを立ち上げます。(Windowsなので)
立ち上げたら以下の図の流れで入力。
要するに、DLしたキーのフルパスをssh-keygen -yの入力後にコピペしてあげる。
ずらずら長ったらしい文字がいわゆる公開鍵っすね。
ローカル作業はひとまずここで終わり
Cloud9に公開鍵をコピペ
Cloud9を立ち上げます。
Cloud9のターミナルに以下を入力しましょう。
vim ~/.ssh/authorized_keysひらくとすでになんか鍵っぽいのが書いてありますが、2行くらい開けてさっきの公開鍵を貼り付けてください。
貼り付けたら保存して閉じてください。
Cloud9側はこれで終了。
後はssh接続で検証
ssh -i (pemファイルのフルパス) ec2-user@(パブリックIPかDNS)
※実際は()不要です。
はい。無事には入れたら終了です。
入れなかった方は、セキュリティグループの確認をしてみましょう。終わり
ここまでやったけど認証鍵に躓きまくった俺にはまぁまぁつらかった。
AWSはまだまだ奥が深い。
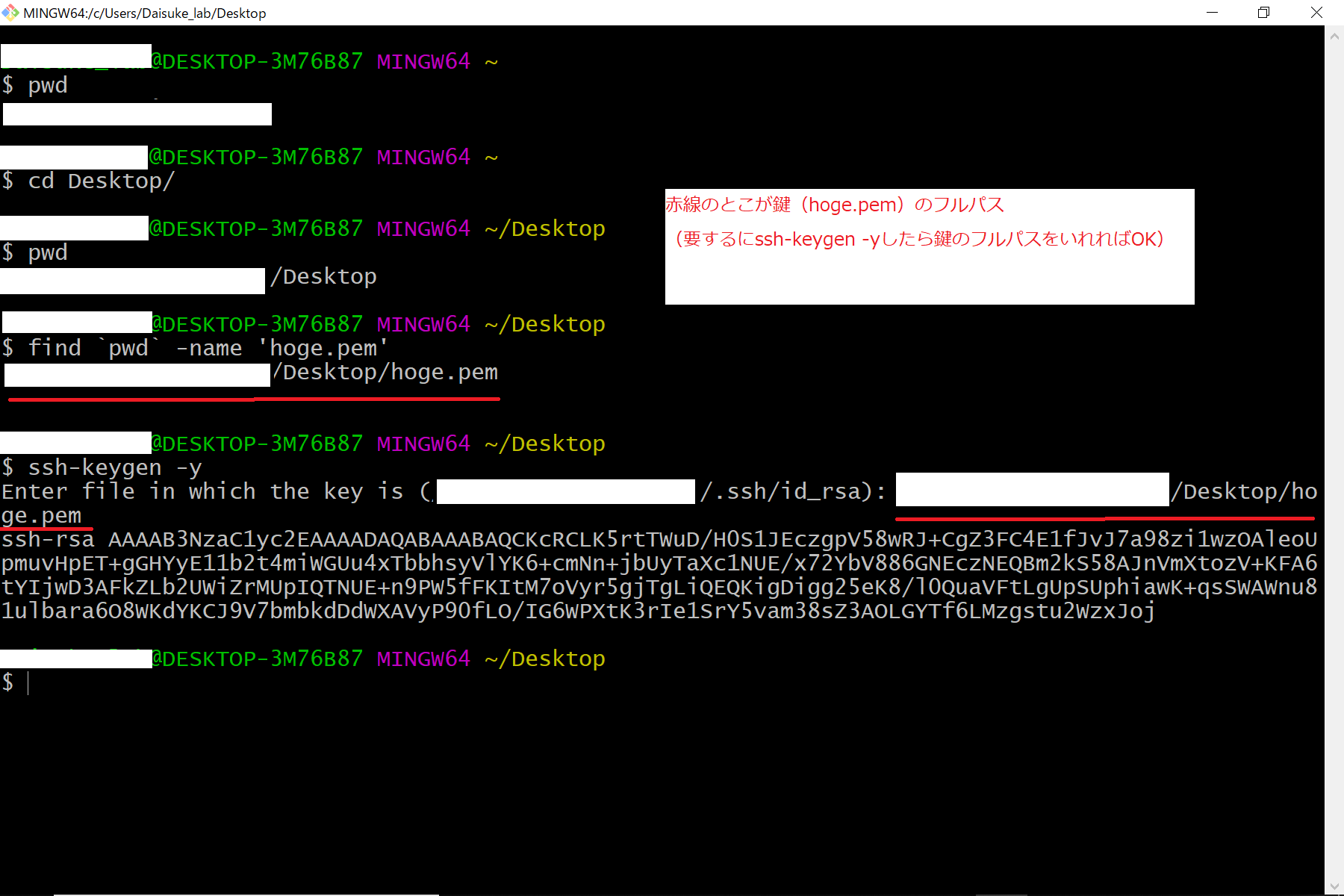
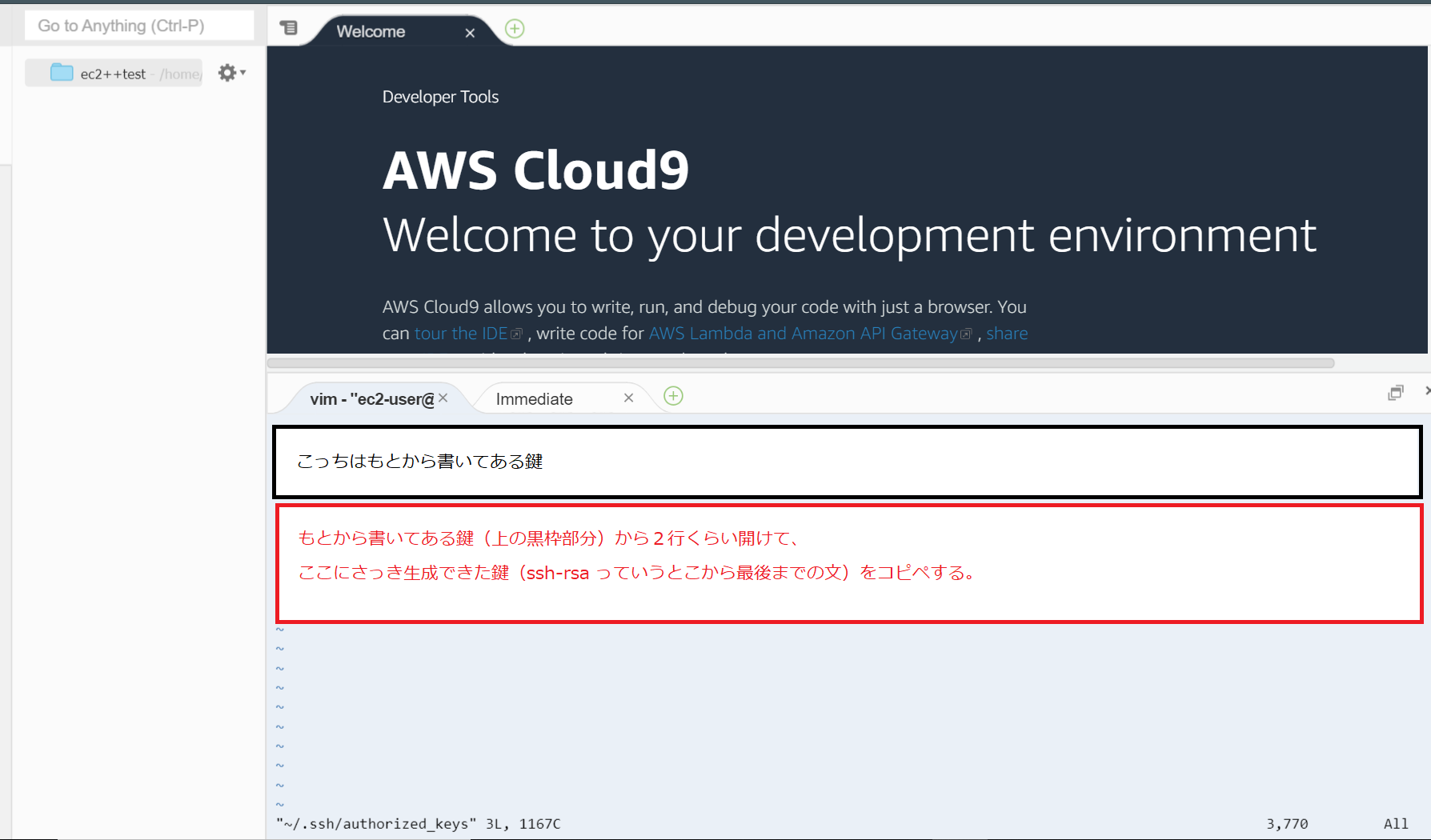
- 投稿日:2020-02-10T02:20:04+09:00
Amazon SESでRule Setが動作しない(送信側で「Requested action not taken: mailbox unavailable」となる)
事象
Amazon SESでRule Setが作成してある。
Rule Setの内容。特定のメールアドレスでメールを受信したらアクションを実行するRuleを追加してある。
しかし、別のメールサービスからRule Setで設定したアドレスにメールを送信したところ、
Requested action not taken: mailbox unavailableエラーとなった。
解決
よく見たらRule Setが[Inactive Rule Sets]だった。
利用したいRule SetをActiveにして[Active Rule Set]に指定することによりメールが正常に受信できるようになった。
以上