- 投稿日:2020-02-07T23:00:00+09:00
Create Private Docker Registry (base on Nexus3)
I will share how to create an Private Docker Registry with Nexus3.x.
It built on Nexus, and provides GUI environment
I tried to write a lot of screenshots.Demo Environment
- Ubuntu 18.04
- Docker version 18.09.1
- Docker requires at least > v1.8
- Nexus 3.20.1
Install Nexus3 and create Private Docker Registry
Nexus ip is 182.252.133.70.
$ ssh root@182.252.133.701) Create Host <-> Nexus container permanent volume
$ mkdir /nexus-data2) Create Nexus container
$ docker run --name nexus -d -p 5000:5000 -p 8081:8081 -v /nexus-data:/nexus-data -u root sonatype/nexus33) Connect to Nexus web http://182.252.133.70:8081
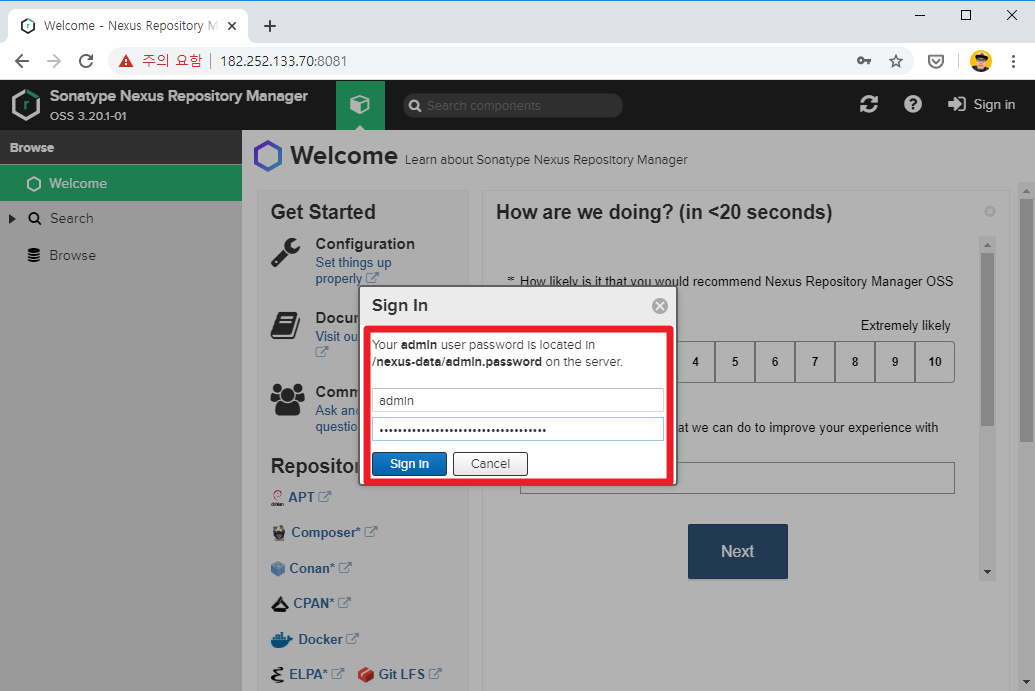
First time, login admin account is required.
admin password find/nexus-data/admin.password$ cat /nexus-data/admin.password 6f471aea-1d52-4e4b-9988-1714e9bf849d # admin's password
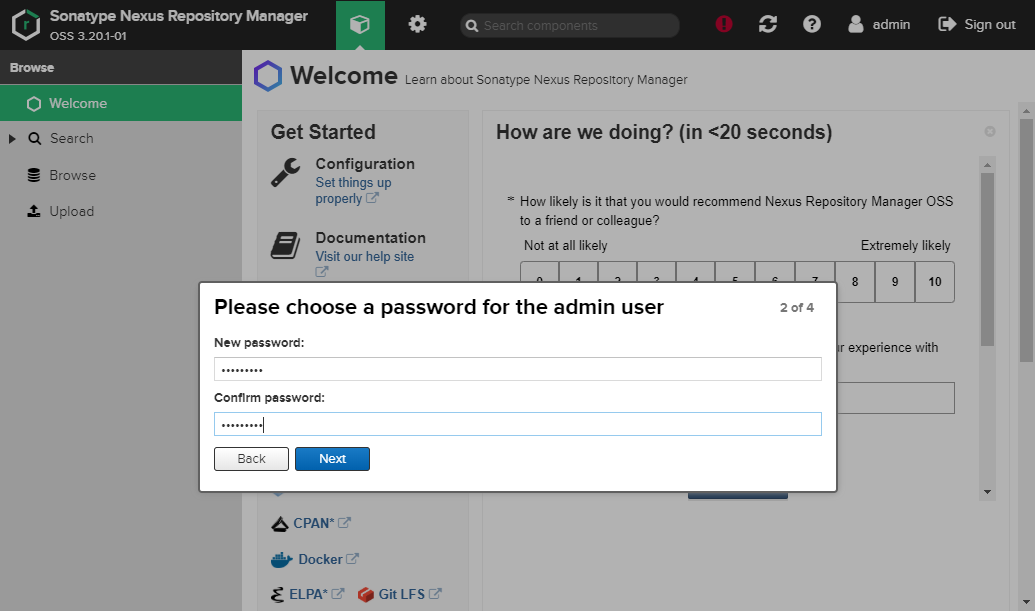
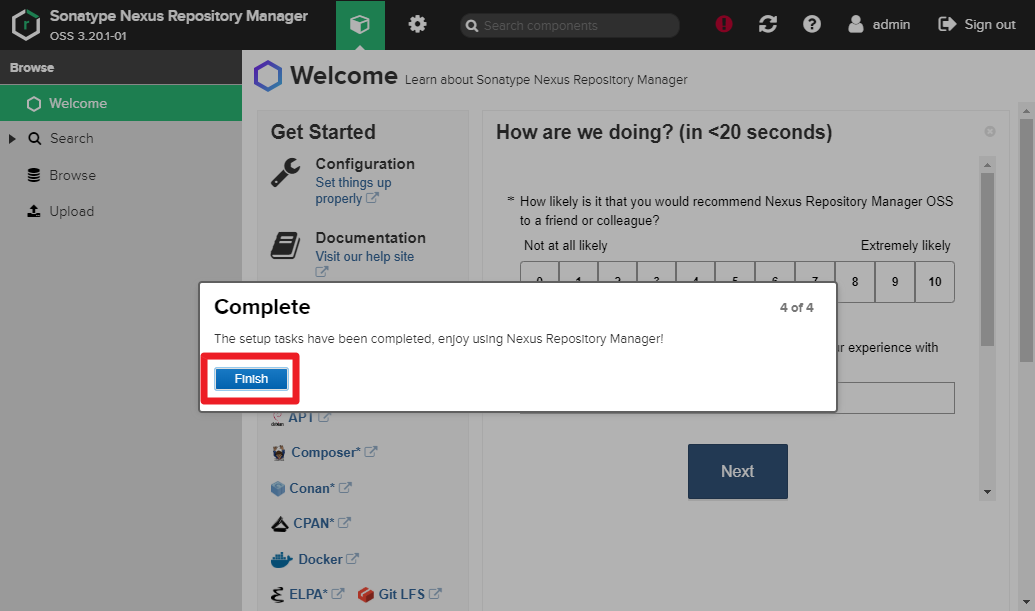
Enter a new admin password.
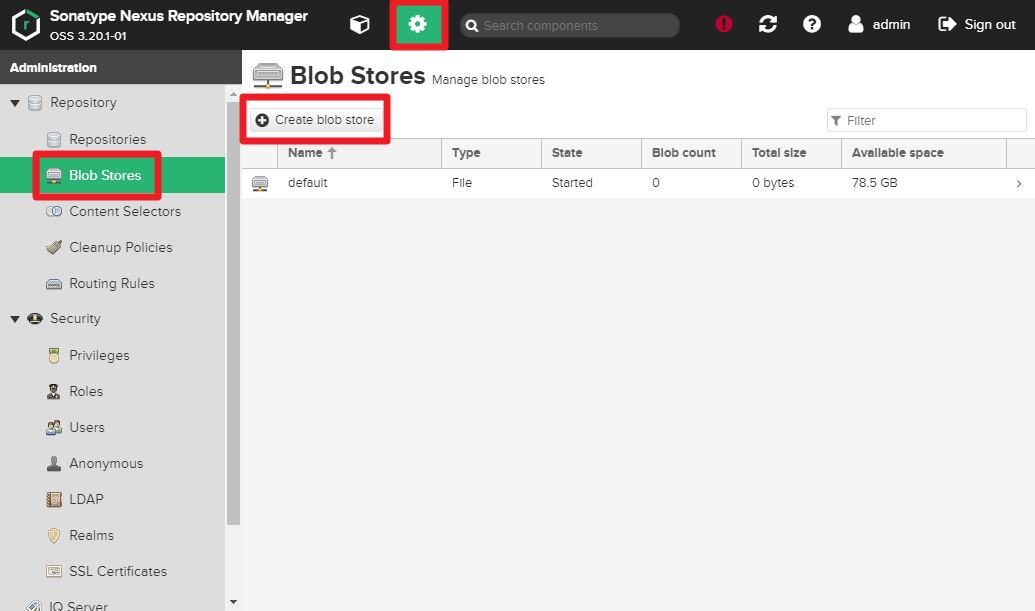
4) Create
docker-hostedanddocker-proxyBlob on NexusGear > Repository > Blob Stores > Create blob store
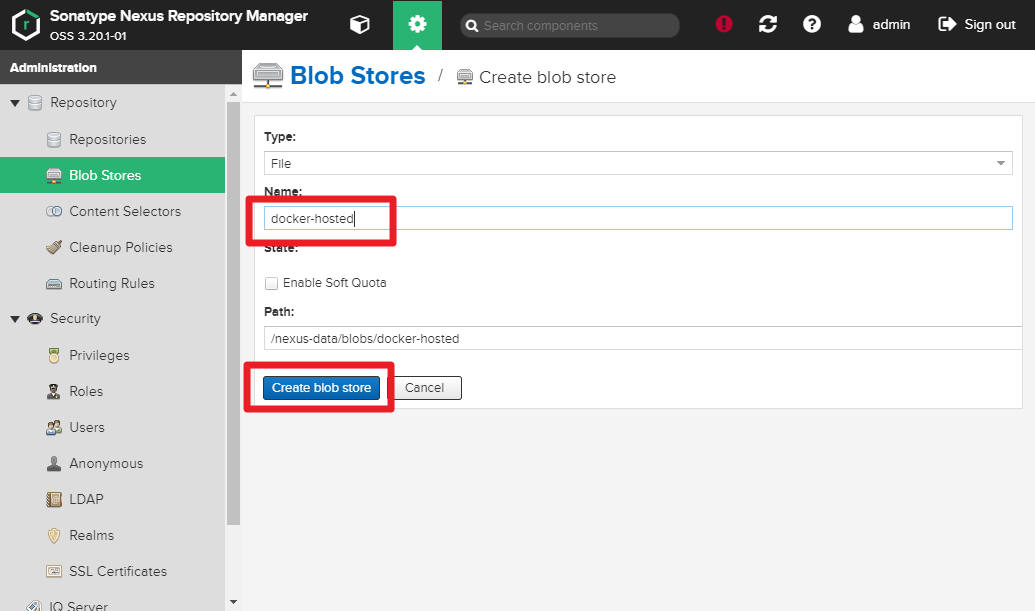
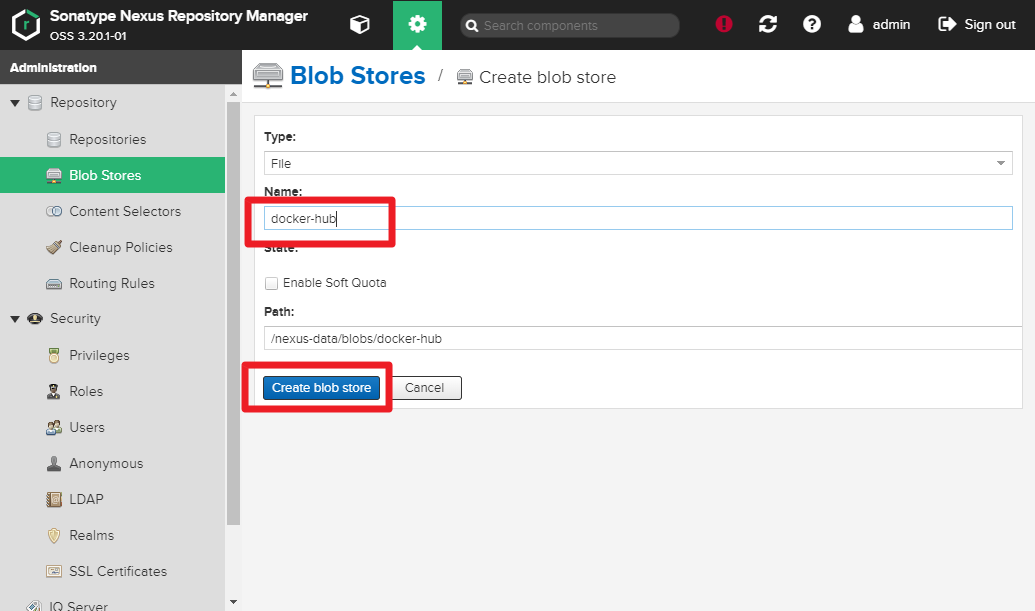
You need to createdocker-hostedanddocker-hub.
Name : docker-hosted
Name : docker-hub
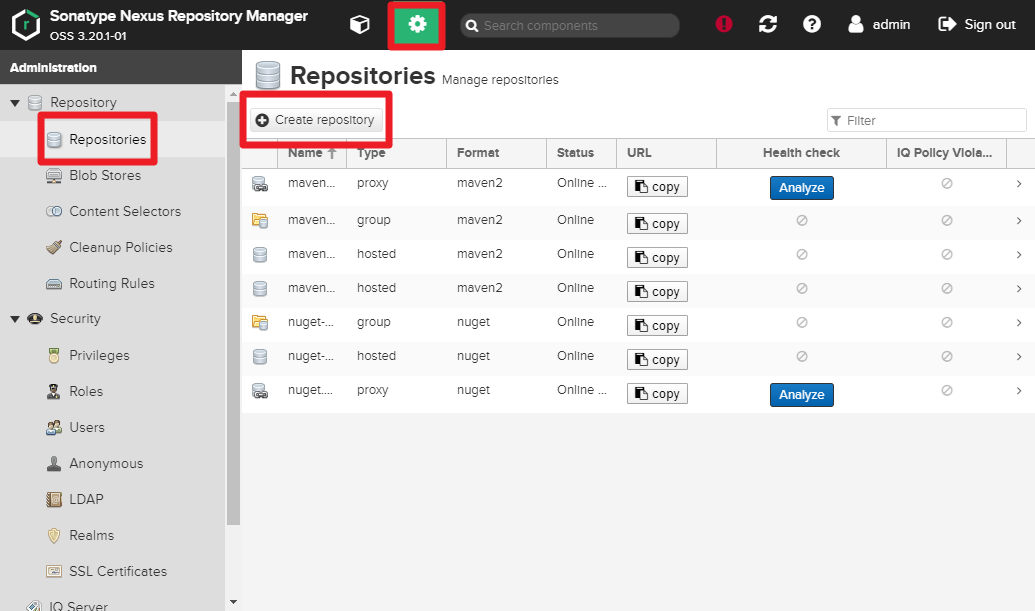
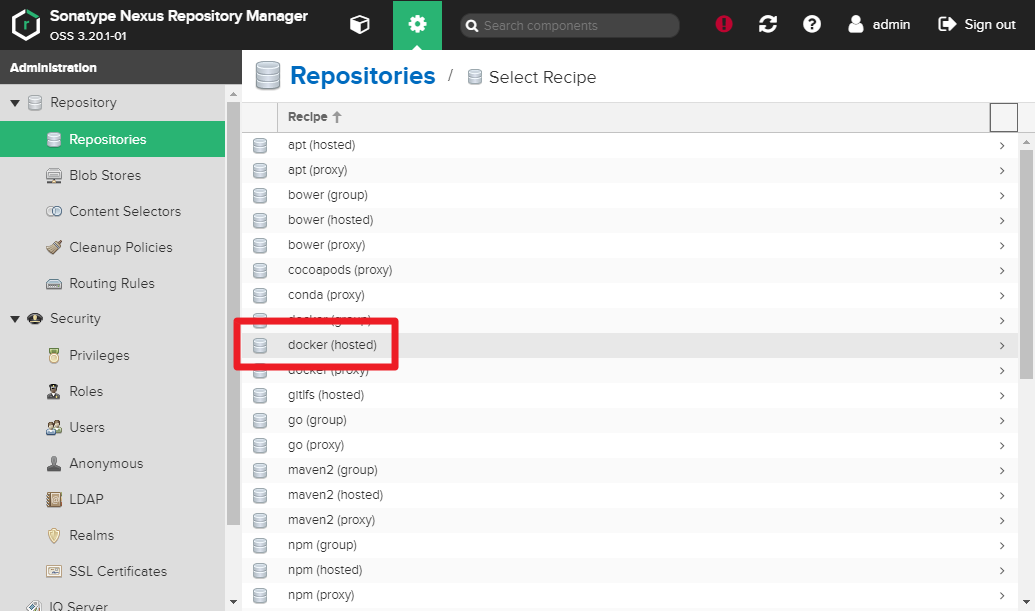
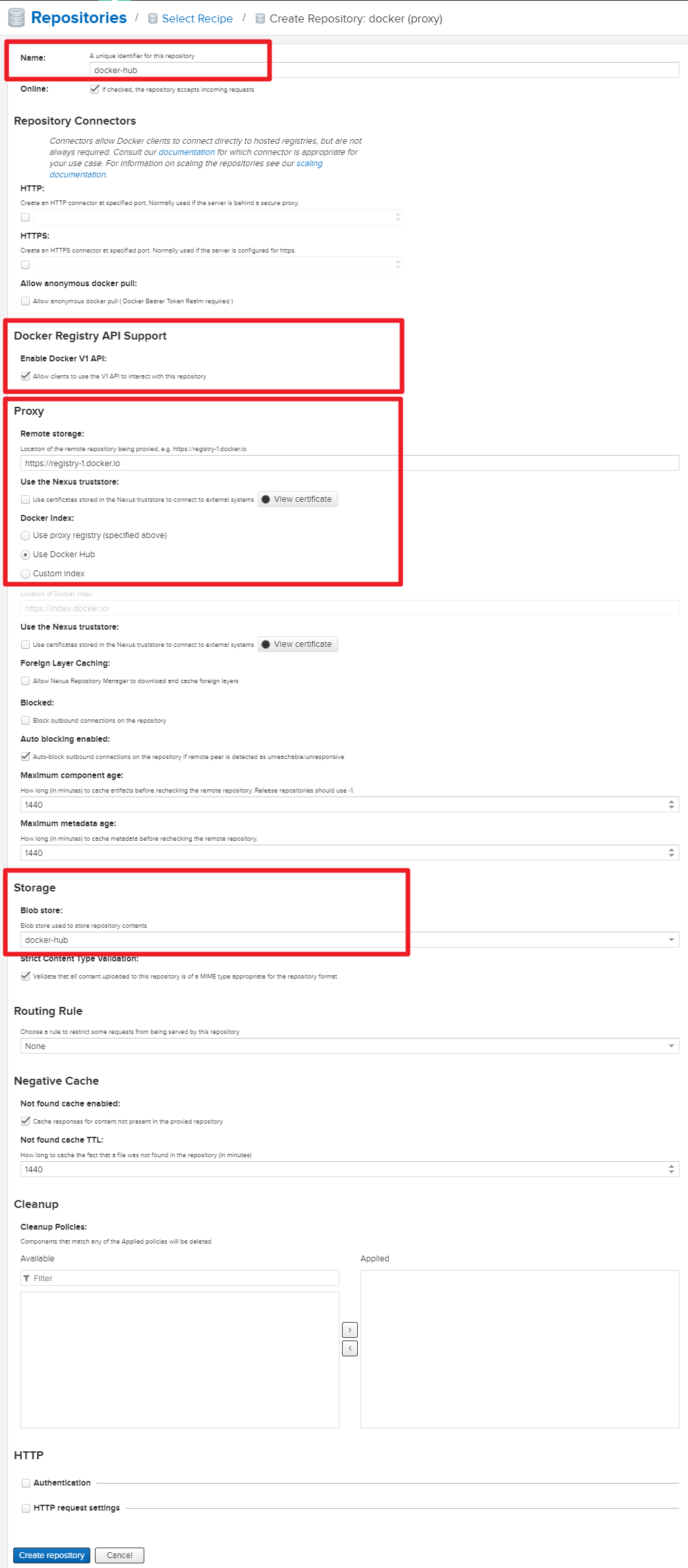
5) Create
docker-hostedanddocker-proxyRepository on NexusGear > Repository > Repositories > Create repository
You need to createdocker-hostedanddocker-hub.
Selectdocker (hosted)
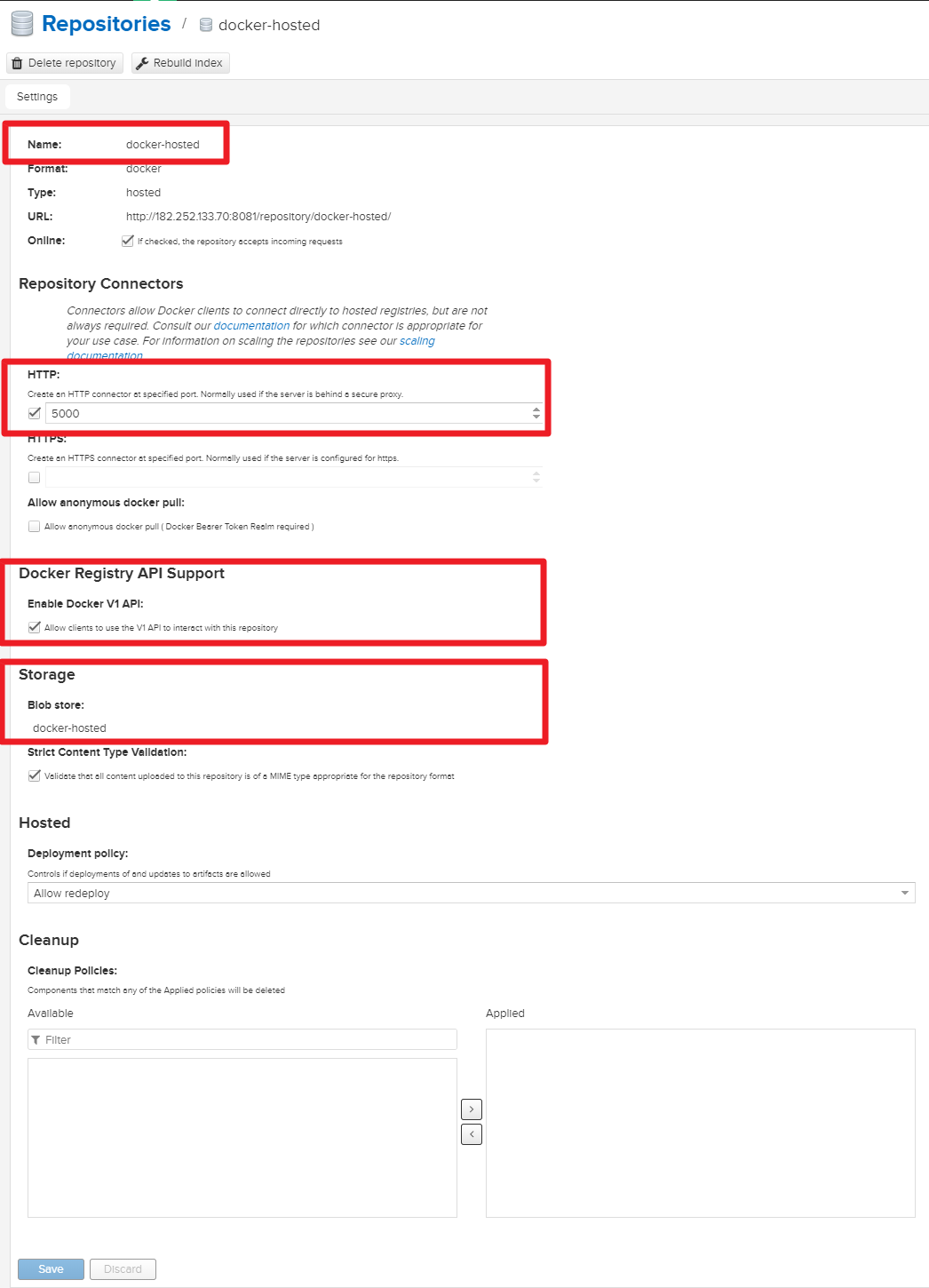
- Name :docker-hosted
- Check HTTP and input 5000
- Check Enable Docker V1 API
- Select Blob store docker-hosted
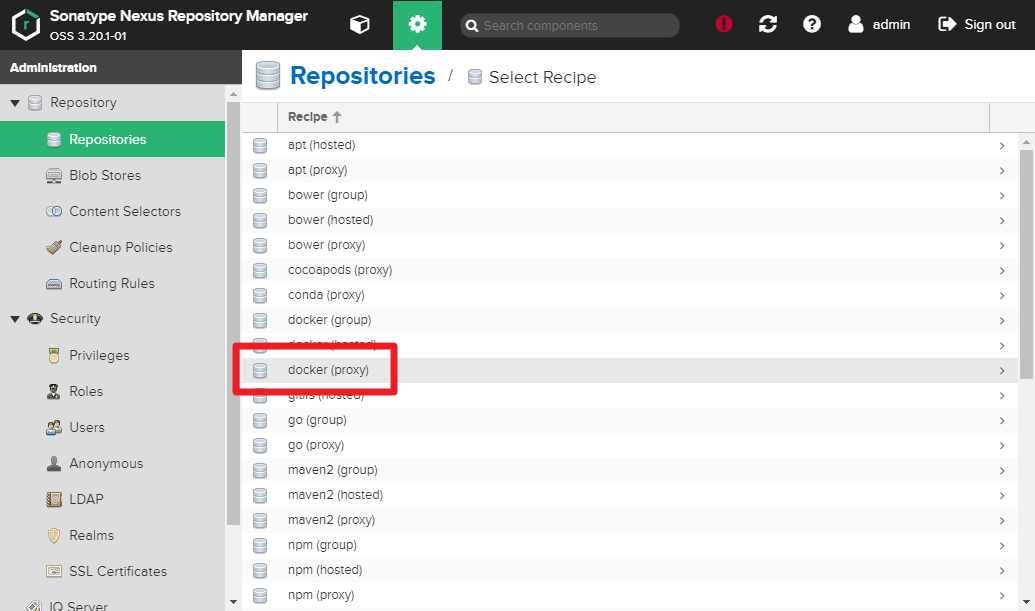
Select
docker (proxy)
- Name :docker-hub
- Check Enable Docker V1 API
- Inputhttps://registry-1.docker.ioin Remote storage
- Select Use Docker Hub
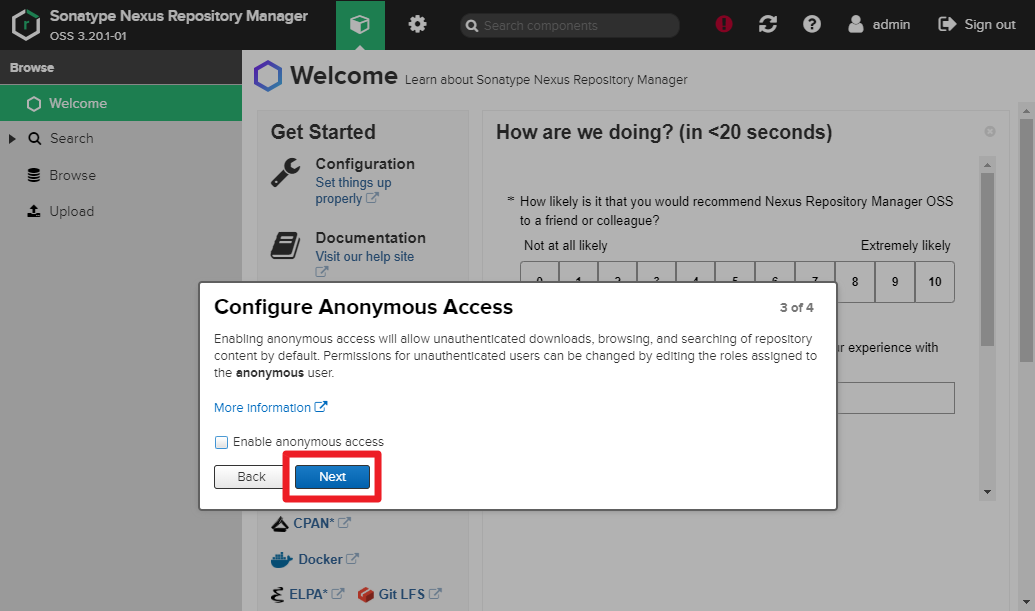
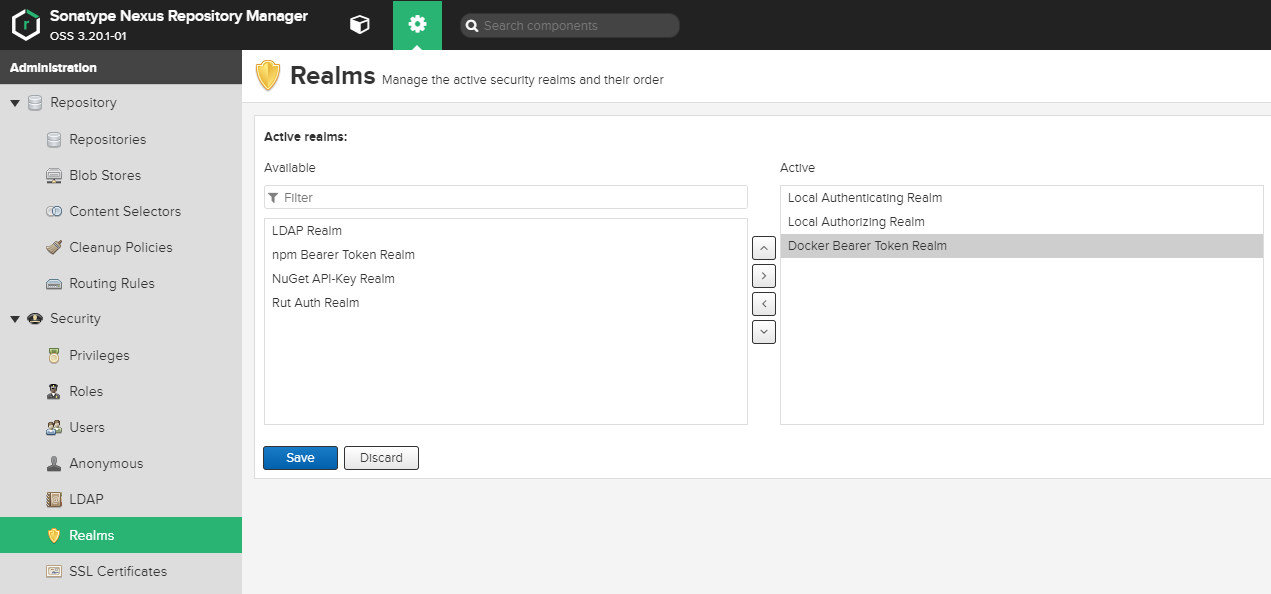
6) Set Realms on Nexus
Gear > Realms > Move
Docker Bearer Token Realmto active > Save
7) Set docker command http enabled (v1)
Create file
/etc/docker/daemon.json
✔️ If the file does not exist, you must create it.$ cat /etc/docker/daemon.json{ "insecure-registries" : ["182.252.133.70:5000"] }Restart docker daemon
$ service docker restartRestart Nexus container
$ docker restart nexusPush image from external client to Private Docker Registry
Client ip is 182.252.133.71.
$ ssh root@182.252.133.711) Set docker command http enabled (v1)
Create file
/etc/docker/daemon.json
✔️ If the file does not exist, you must create it.
? All clients must be setting.$ cat /etc/docker/daemon.json{ "insecure-registries" : ["182.252.133.70:5000"] }Restart docker daemon
$ service docker restart2) Login Private Docker Registry
$ docker login 182.252.133.70:5000Username: admin Password: WARNING! Your password will be stored unencrypted in /root/.docker/config.json. Configure a credential helper to remove this warning. See https://docs.docker.com/engine/reference/commandline/login/#credentials-store Login Succeeded3) docker pull and push Private Docker Registry
docker pull busybox image (from https://hub.docker.com/_/busybox)
$ docker pull busybox # docker pull from hub.docker.com bdbbaa22dec6: Pull complete Digest: sha256:6915be4043561d64e0ab0f8f098dc2ac48e077fe23f488ac24b665166898115a Status: Downloaded newer image for busybox:latest docker.io/library/busybox:latestCheck busybox image
$ docker images -a REPOSITORY TAG IMAGE ID CREATED SIZE busybox latest 6d5fcfe5ff17 5 weeks ago 1.22MBtag
$ docker tag 6d5fcfe5ff17 182.252.133.70:5000/busybox:v20200205push Private Docker Registry
$ docker push 182.252.133.70:5000/busybox:v20200205 The push refers to repository [182.252.133.70:5000/busybox] 195be5f8be1d: Pushed v20200205: digest: sha256:edafc0a0fb057813850d1ba44014914ca02d671ae247107ca70c94db686e7de6 size: 527Check image in Private Docker Registry
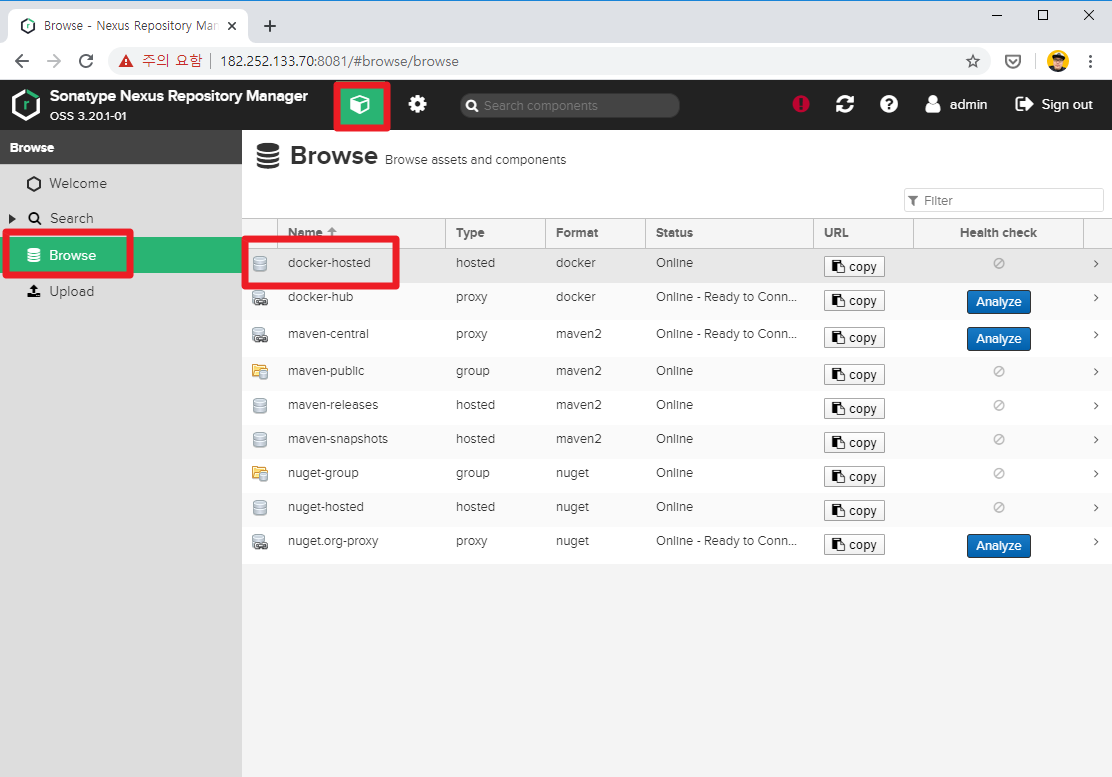
1) Connect to Nexus web http://182.252.133.70:8081
Browse > docker-hosted
tag
Pull in Private Docker Registry
$ docker pull 182.252.133.70:5000/busybox:v20200205 bdbbaa22dec6: Pull complete Digest: sha256:edafc0a0fb057813850d1ba44014914ca02d671ae247107ca70c94db686e7de6 Status: Downloaded newer image for 182.252.133.70:5000/busybox:v20200205 182.252.133.70:5000/busybox:v20200205$ docker images -a REPOSITORY TAG IMAGE ID CREATED SIZE 182.252.133.70:5000/busybox v20200205 6d5fcfe5ff17 5 weeks ago 1.22MBMore to do
443 port, need adding SSL
SSL should be applied.
After that, creating file/etc/docker/daemon.jsoncan be omiited.
? I'll write this next posting.



- 投稿日:2020-02-07T22:11:57+09:00
Nim + Docker でデバッグ環境を作る
私とNimの最初のハードル
解説があるのはローカルにNimをインストールしてデバッグをするやり方ばかり。
ただ、近々PCを買い替えたいという思いもあり二度環境構築はしたくないので、私はDockerを使いたかったのです。
カッコカッコせずに早いコードを書きたかったんです。やったこと
VSCode + Dockerデバッグの環境を整える
以下2つのエクステンションをインストールして上げましょう。
①Remote – Containers (ms-vscode-remote.remote-containers)
②Remote Development (ms-vscode-remote.vscode-remote-extensionpack)公式イメージでデバッグに足りないライブラリを追加
Nimの公式Dokcerイメージは、ライブラリ不足でデバッグ出来ません…。
なので必要なものをインストールして上げます。
apt update && apt install -y gcc gdb後は通常通りのVSCodeのデバッグ関連の設定をしてあげればOKです。
全ソース
GitHubに全ソースを置いているので、
私のようにPythonから入って設定分からねえという方は良かったらご活用ください。
https://github.com/tkkm/nim-docker-debugもうちょっと詳しく
宣伝させてください
ブログに詳しめに書いているので、良かったら覗いて見て下さい。それでは皆さん。良きNimライフを。
- 投稿日:2020-02-07T17:39:44+09:00
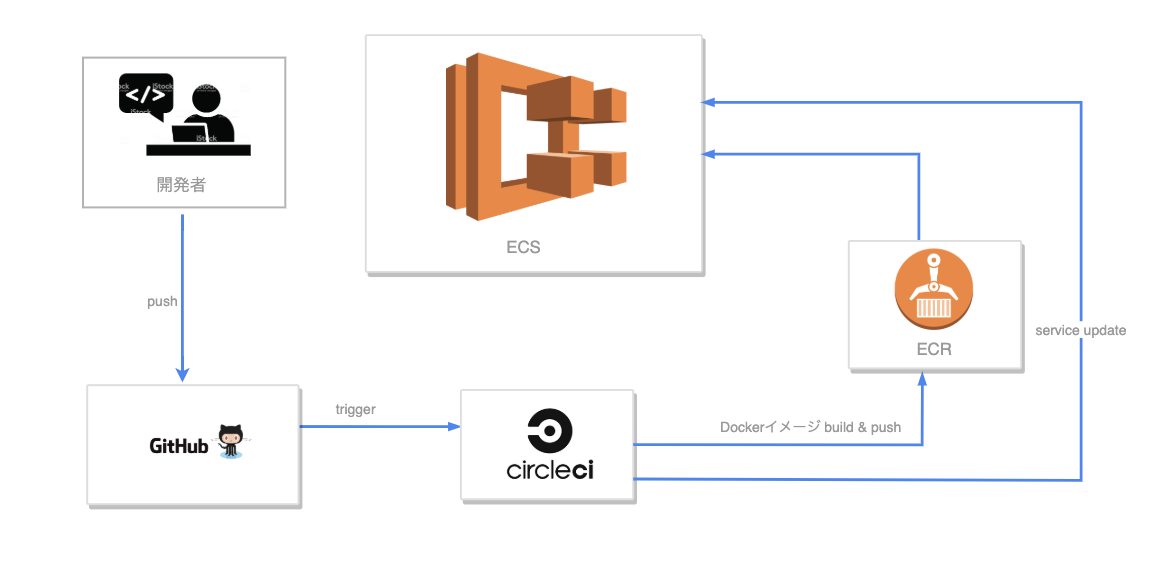
ECS × ECR × Circle CiでRailsアプリケーションをデプロイ
前書き
・ECSのクラスターは起動タイプにFargateとEC2がありますが、今回は使い慣れている
EC2を使います。
・本記事はAWSの環境構築は全てマネジメントコンソールで行ってます。
(Terraformで1発でやりたいような人は他の記事を見るか、一応GitHubにTerraformでコード化もしているのでそちらを参考に)
・docker-composeは以下のような構成です(Nginxのコンテナ、Railsのコンテナ、Mysqlのコンテナ)本記事で目指したいデプロイ構成
(ECSのクラスターによって束ねられているEC2インスタンスや、VPC、RDS等は省略)
下準備
こちらからリポジトリをcloneしてください。
各Dockerfileと設定ファイルを用意しています。$ git clone https://github.com/s14228so/ECS-Rails6.git $ cd ECS-Rails6 $ docker-compose run app rails new . --force --database=mysql --api$ vi config/database.ymlconfig/database.ymldefault: &default adapter: mysql2 encoding: utf8mb4 pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %> username: root password: password #編集 host: db #編集 # ...省略 production: <<: *default database: <%= ENV['DB_DATABASE'] %> adapter: mysql2 encoding: utf8mb4 charset: utf8mb4 collation: utf8mb4_general_ci host: <%= ENV['DB_HOST'] %> username: <%= ENV['DB_USERNAME'] %> password: <%= ENV['DB_PASSWORD'] %>本番環境用の環境変数は後ほど
ECSのタスク定義にて設定します。Rails6から必要なそうなので追加します。(同じlocalhostなら問題ない気がするんですが、これがないとnginx(localhost:80)にアクセスするときにエラーが起きてしまいました。。わかる人いたら教えてください)
config/environments/development.rbRails.application.configure do config.hosts.clear #追加$ cp docker/rails/puma.rb config/ (pumaの設定を上書き) $ mkdir -p tmp/sockets (socketファイルの置き場所を確保) $ docker-compose up -d --build $ docker-compose run app rails db:createhttp://localhost
にアクセスするとRailsのデフォルト画面が表示されるはずです。
localhost(:80)にアクセスするとnginxのwebサーバに(裏ではnginxがpumaにリクエストしている)
localhost:3000にアクセスするとpumaのアプリケーションサーバにリクエストを投げていることになります。
scaffoldでjsonを返す簡易apiを作成します。
$ docker-compose run app rails g scaffold Post title:string $ docker-compose run app rails db:migrateseeds.rb5.times.each do |i| Post.create(title: "test#{i + 1}") end$ docker-compose run app rails db:seed下の画像のようにjsonが返ってきてればOKです!
ECRへのpush
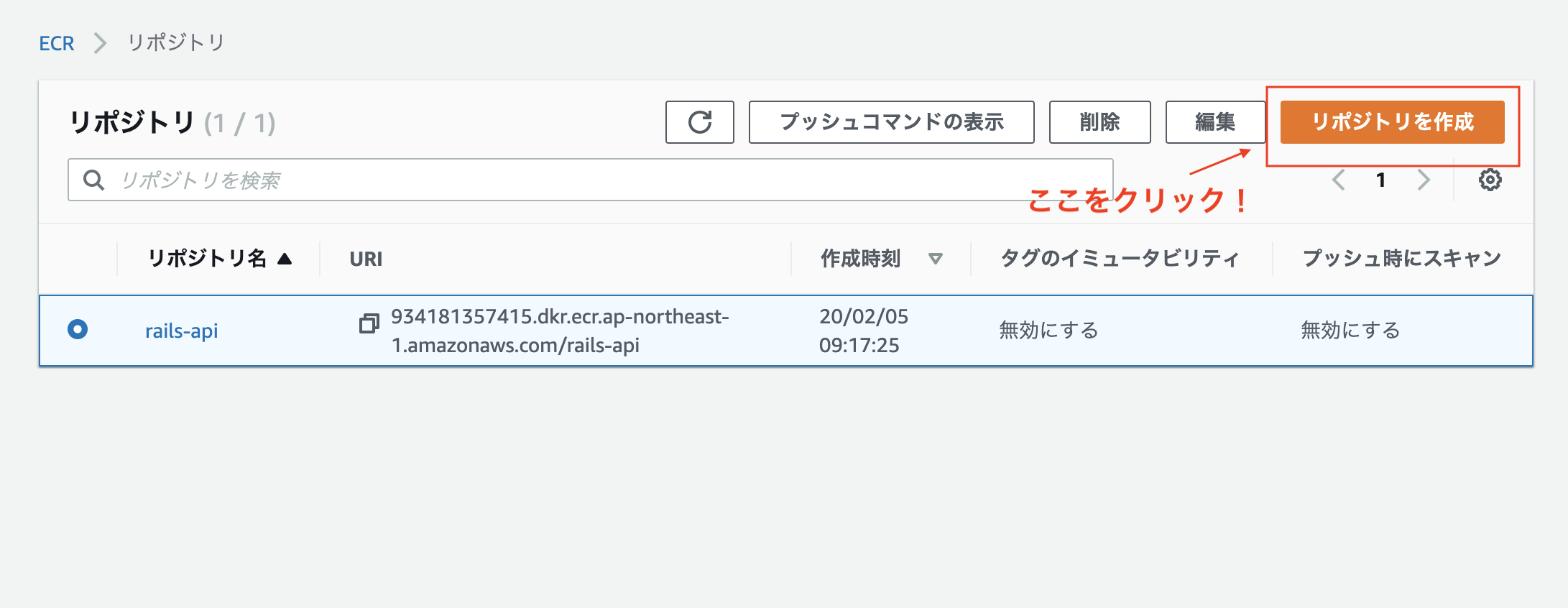
AWSのマネジメントコンソールを開きます
ECRと検索します。
RailsとNginxのイメージ用のリポジトリをそれぞれ作成します。リポジトリを作成をクリック
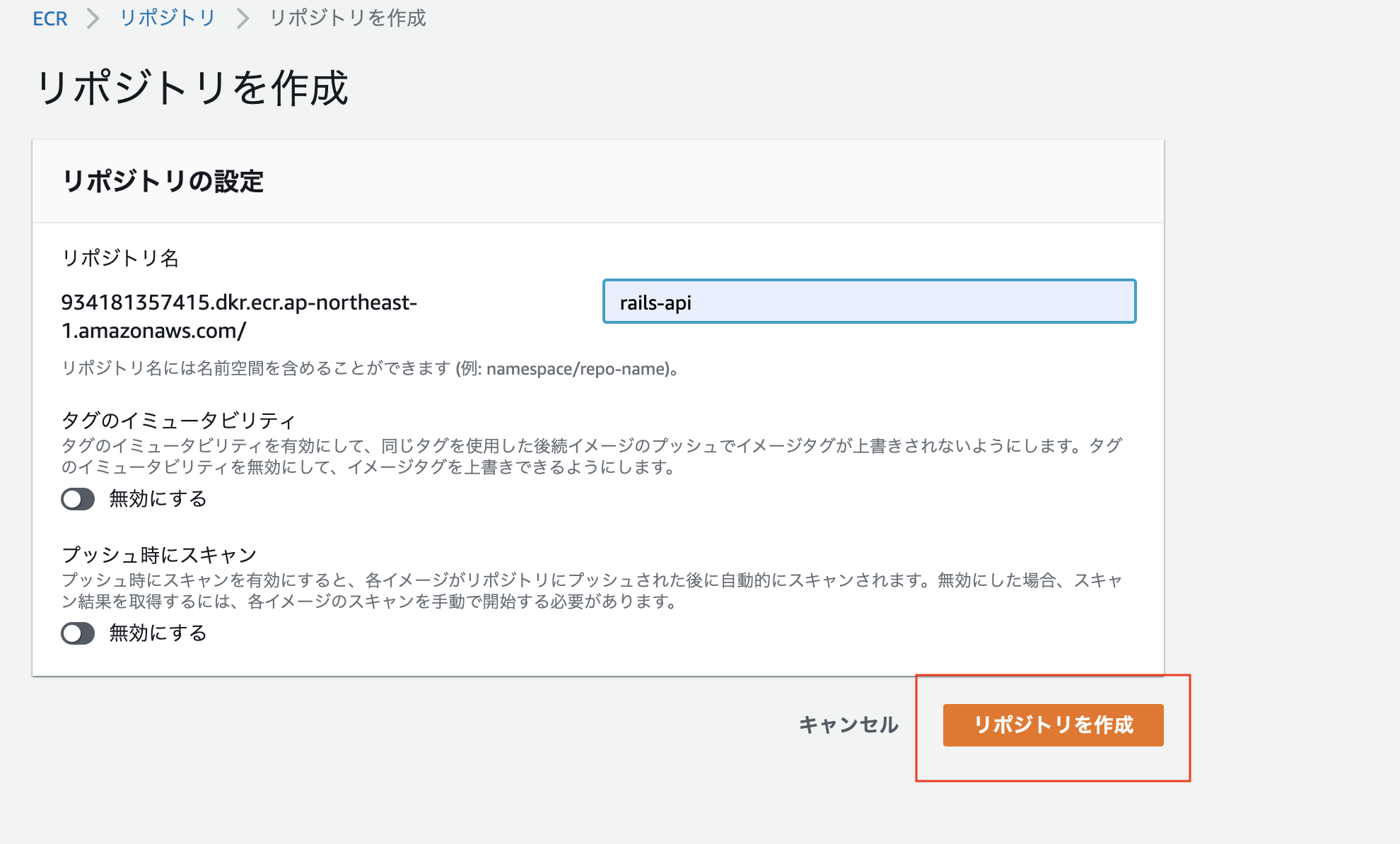
まずはrailsのイメージから作成します。
リポジトリ名にはrails-apiを(任意のリポジトリ名で問題ありません)
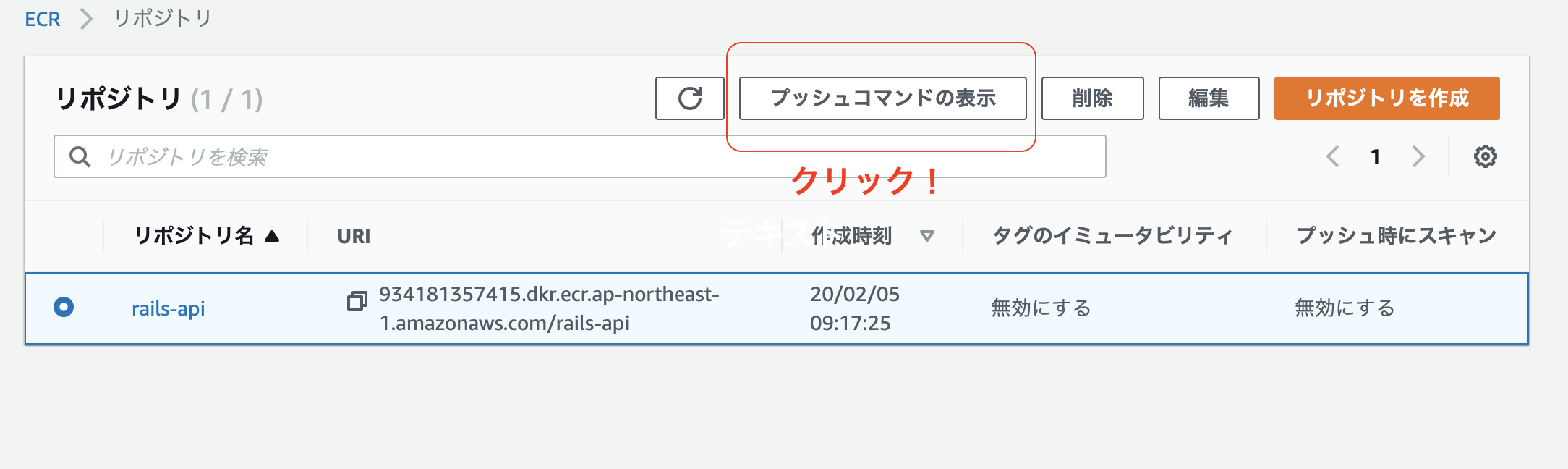
ECRヘのpushコマンドを表示します。
1つ目のコマンドで
aws command not foundと言われる場合は
aws-cliが入っていいないはずなので、$ curl "https://s3.amazonaws.com/aws-cli/awscli-bundle.zip" -o "awscli-bundle.zip" $ unzip awscli-bundle.zip $ sudo ./awscli-bundle/install -i /usr/local/aws -b /usr/local/bin/awsでaws-cliをインストールしましょう。
4つのコマンドが表示されるので一つずつターミナルで入力しましょう。
※2番目のbuild時に以下のように-fでDockerfileのコンテキストを変えることに注意してください。$ docker build -t rails-api -f ./docker/rails/Dockerfile .4つのコマンドが打ち終わるとECRのリポジトリにpushされていることを確認しましょう。
同様にnginxのDockerイメージも、ECRにリポジトリを作成してpushします。
$ docker build -t nginx -f ./docker/nginx/Dockerfile .VPCの作成
まずはEIPを作ります。
VPCから左側のElastic IPタブをクリック
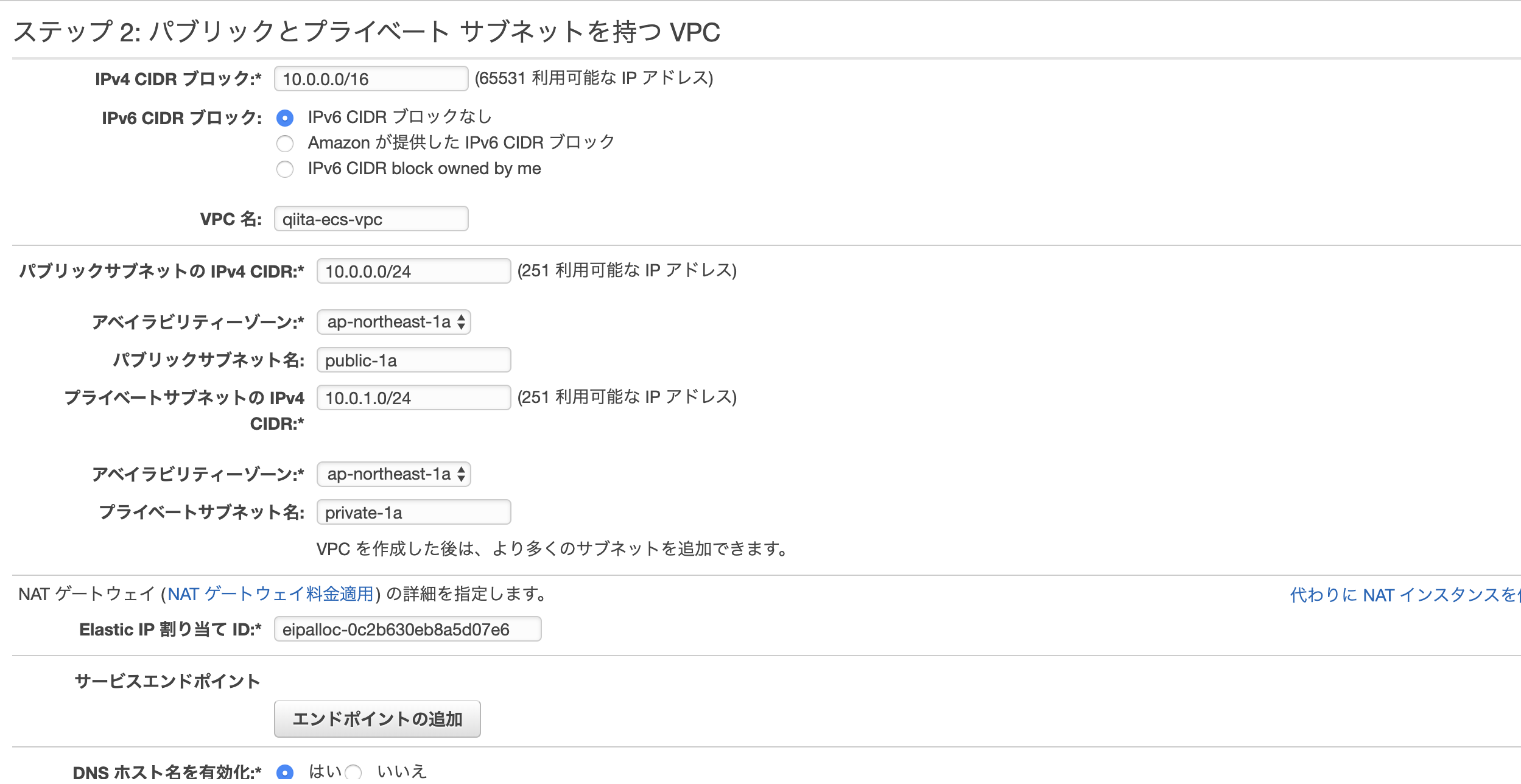
新しいアドレスの割り当てをクリック => Amazon プール**を選択 => **割り当て左上のVPCダッシュボードをクリック => VPCウィザードの起動 => パブリックとプライベート サブネットを持つ VPCを選択
以下のように編集して作成します。
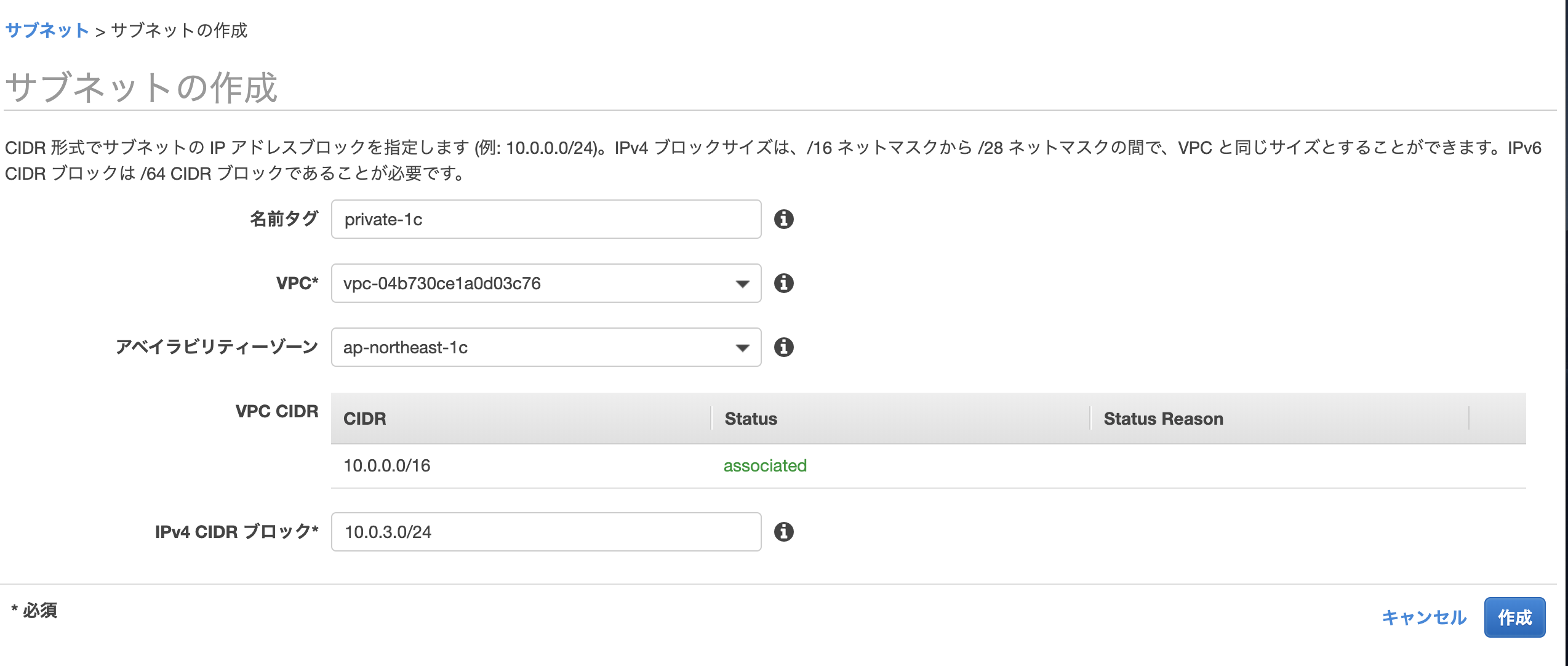
RDSを作成する際にVPCが複数のAZで構成されている必要があるので
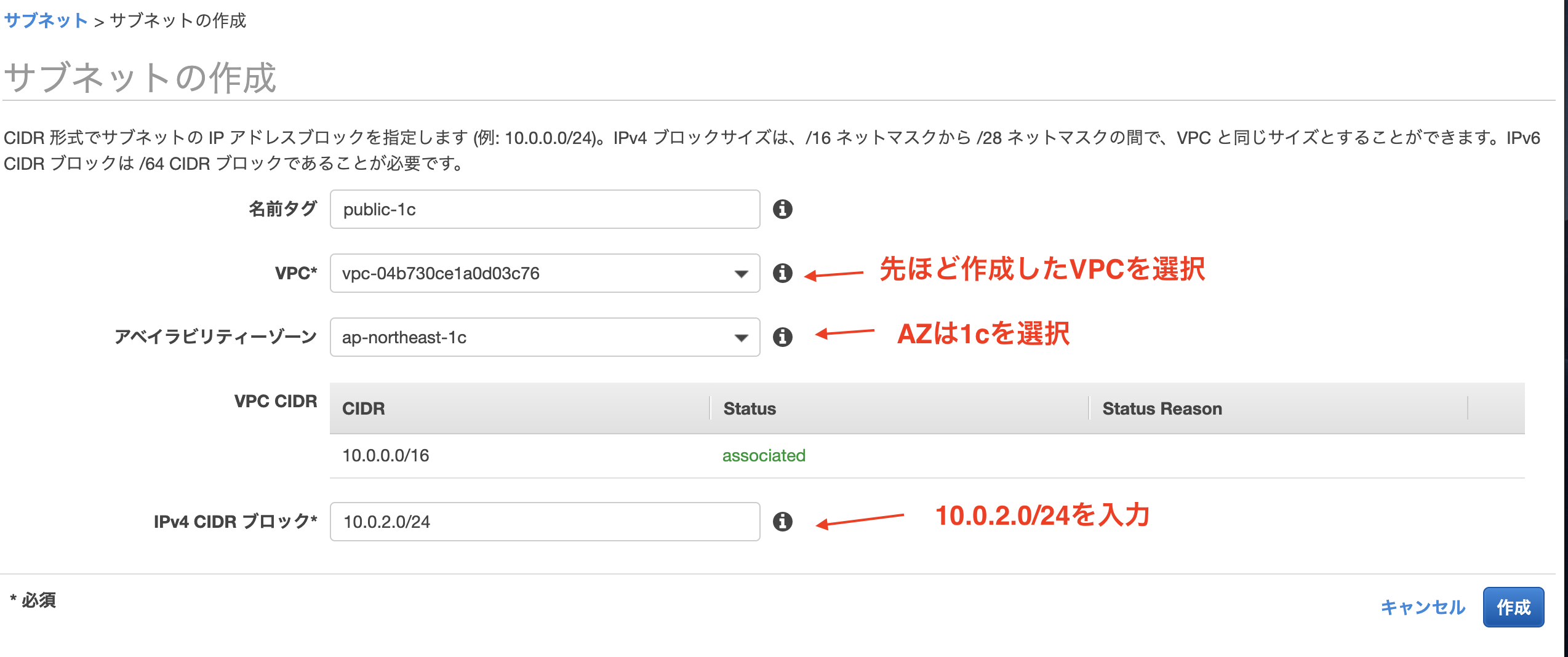
パブリックとプライベートサブネットそれぞれを1cのAZにも追加します。サブネットのタブをクリック => サブネットの作成
プライベートなサブネットも同様に作成します。
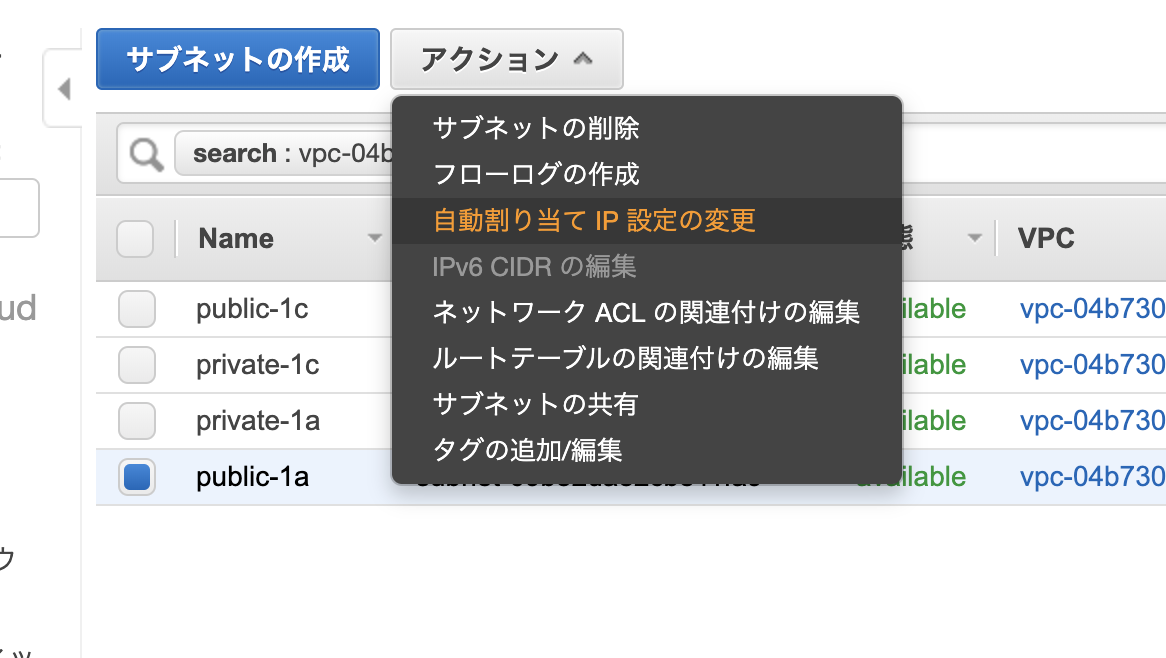
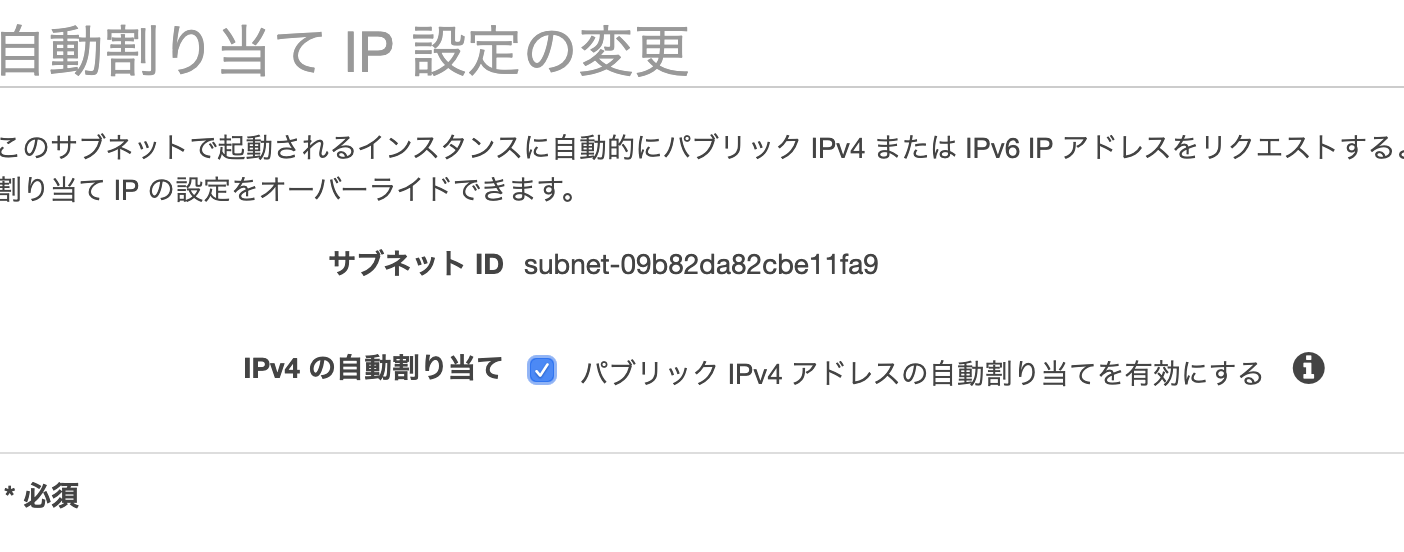
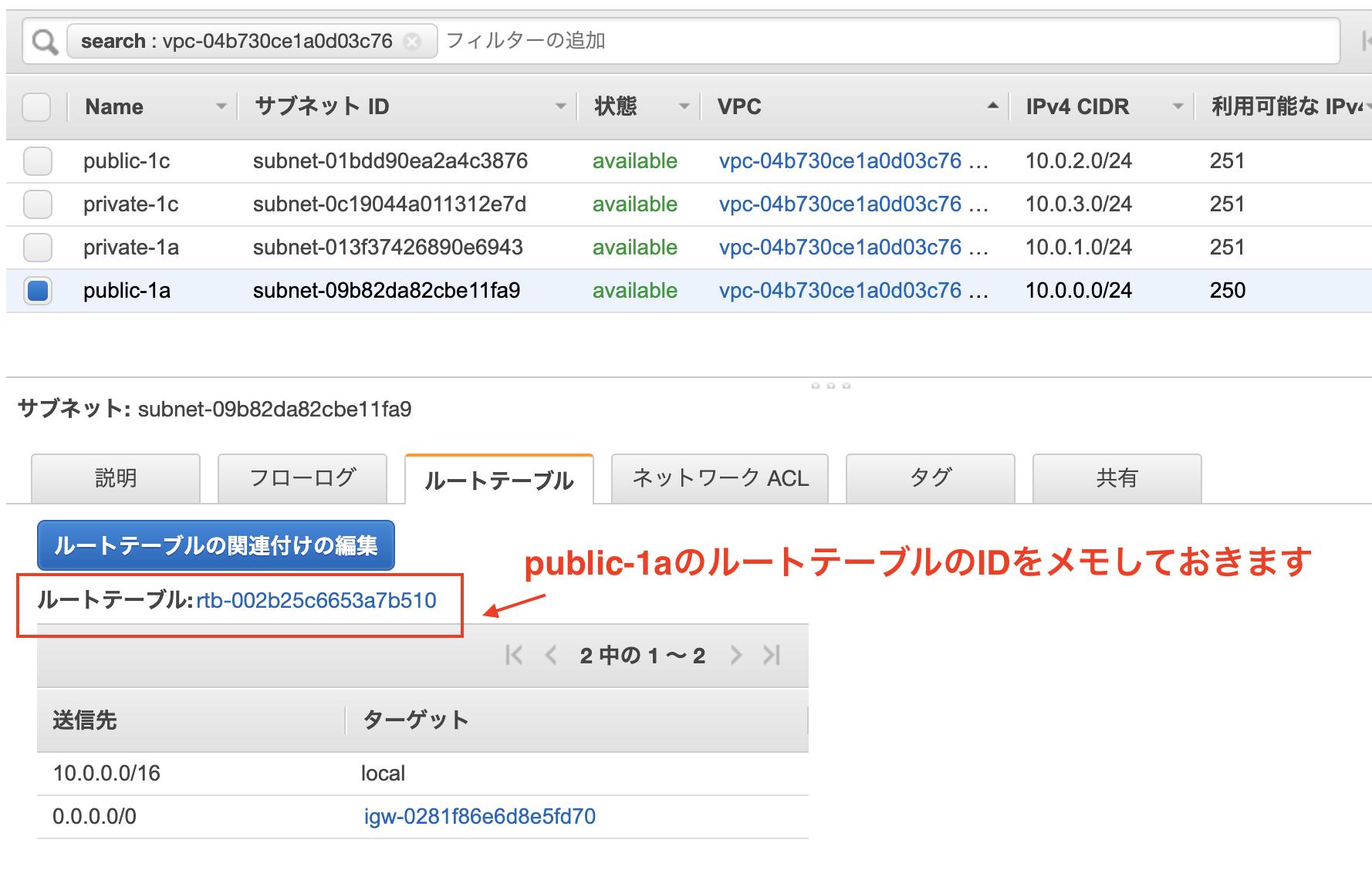
public-1aサブネットのIPv4のアドレス指定動作を変更します。
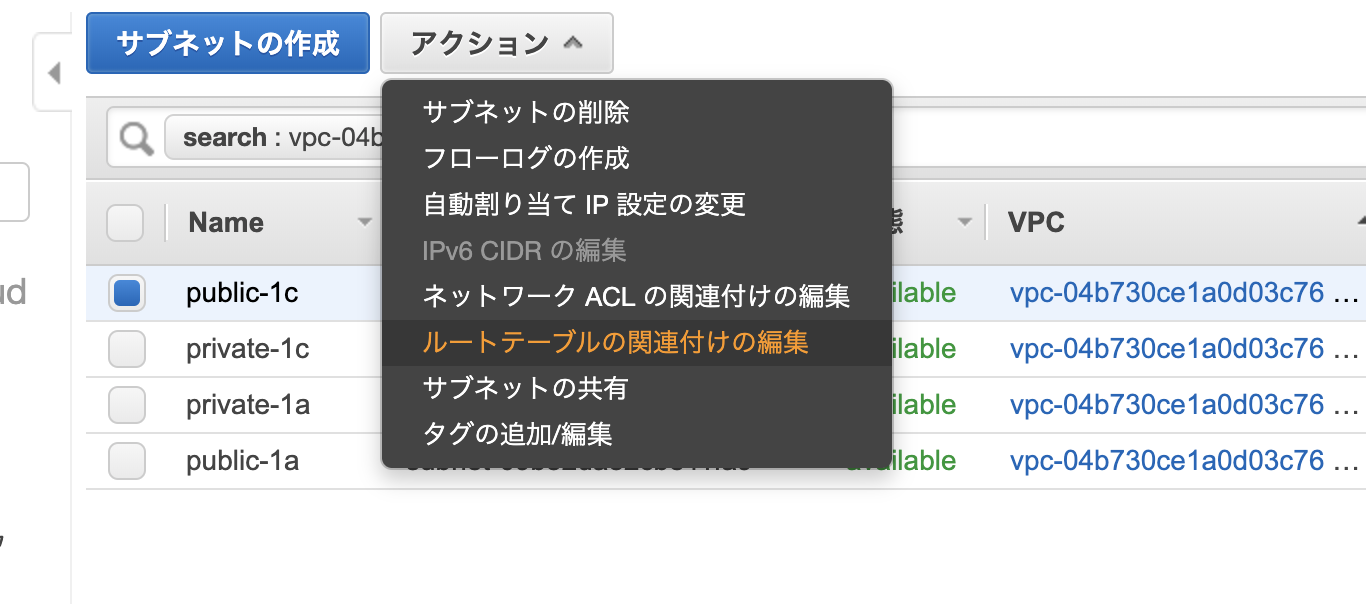
[パブリック IPv4 アドレスの自動割り当てを有効にする] チェックボックスをオンにし、[Save (保存)] を選択します。先ほど後から追加したpublic-1cですがデフォルトでは、プライベートルートテーブルが選択されるので。
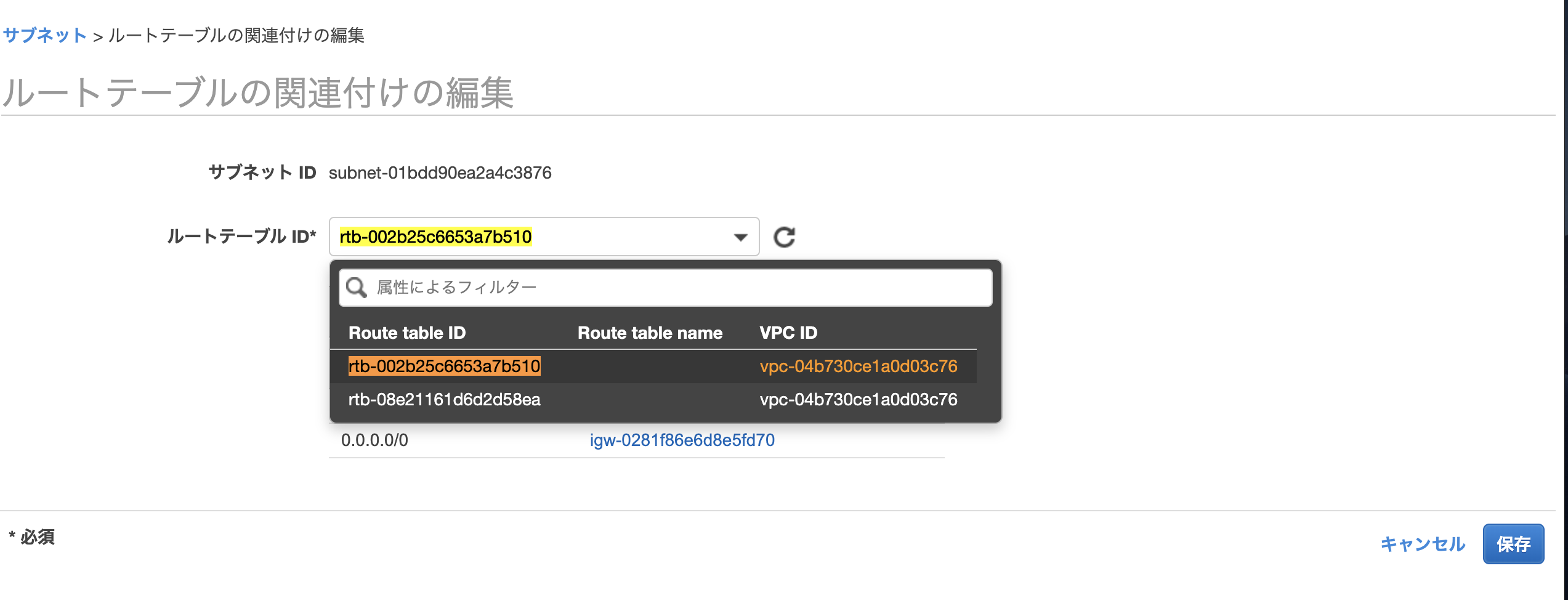
public-1aのものと同じルートテーブルになるように修正します。
public-1cを選択した状態でアクション => ルートテーブルの編集をクリック
public-1aのルートテーブルのIDと同じルートテーブルのIDを選択して保存します。
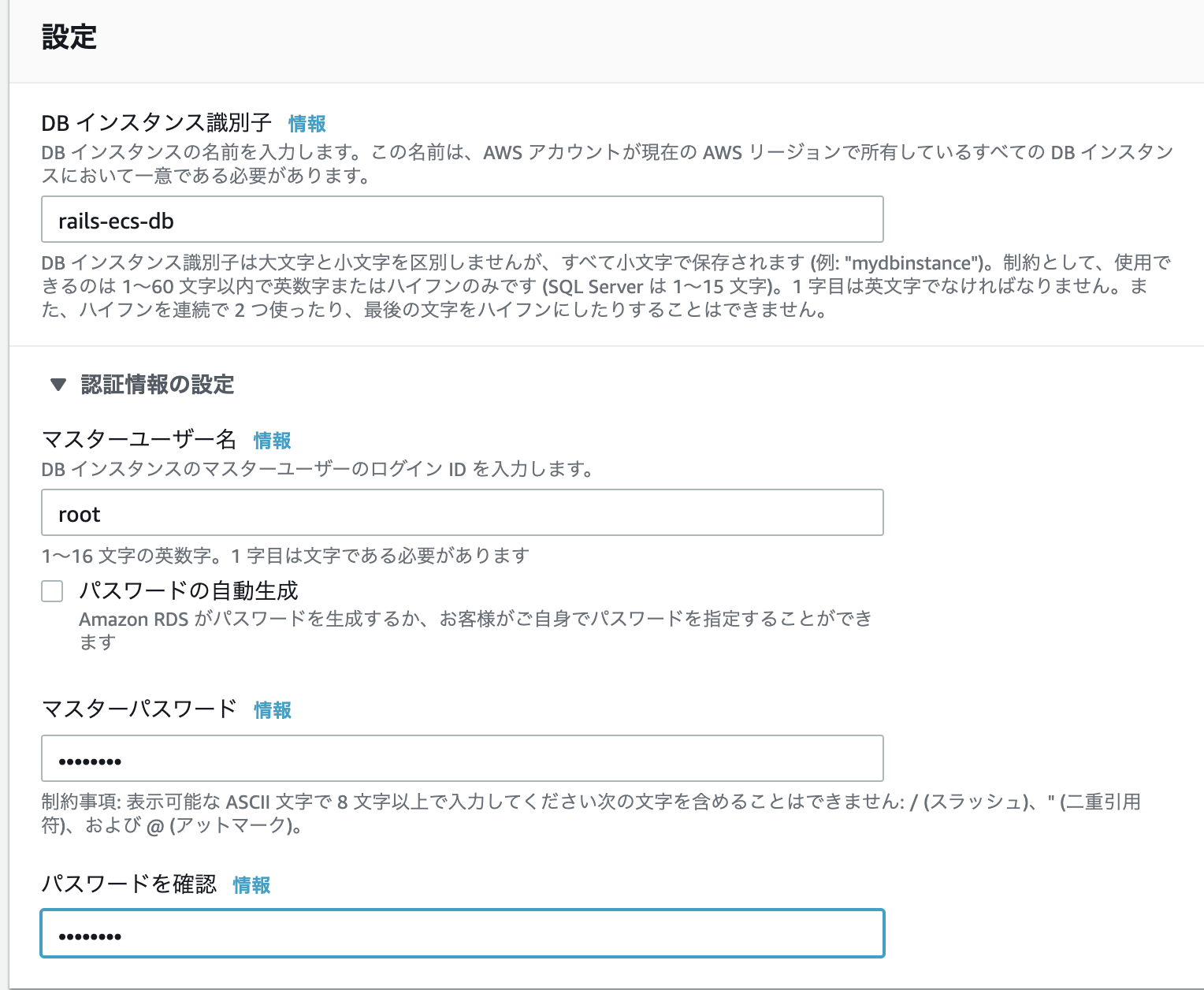
RDSの作成
エンジンのオプションでMySQLを選択
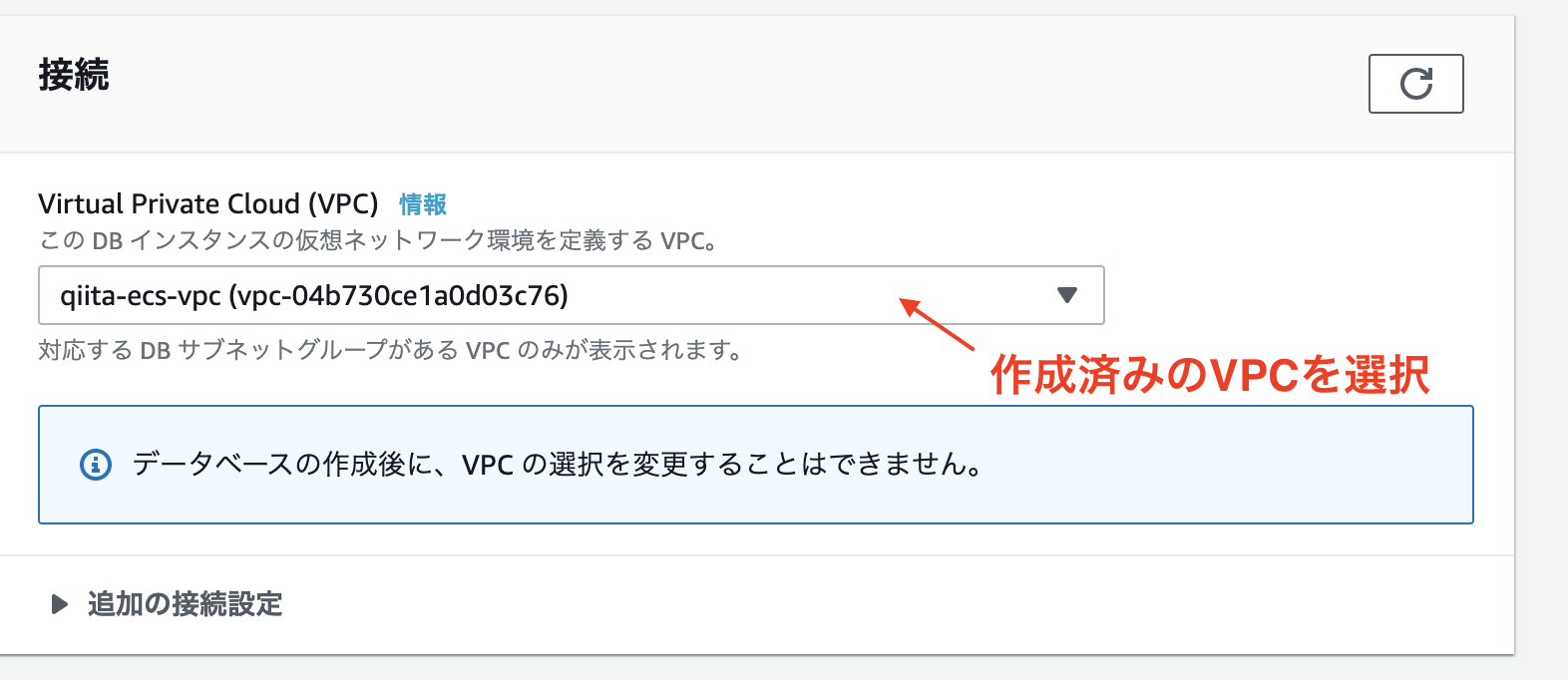
テンプレート => 無料枠
=>VPCで先ほど作成したVPCを選択
データベースの作成をクリック!
ECSでタスクの作成
マネジメントコンソールからECSを検索
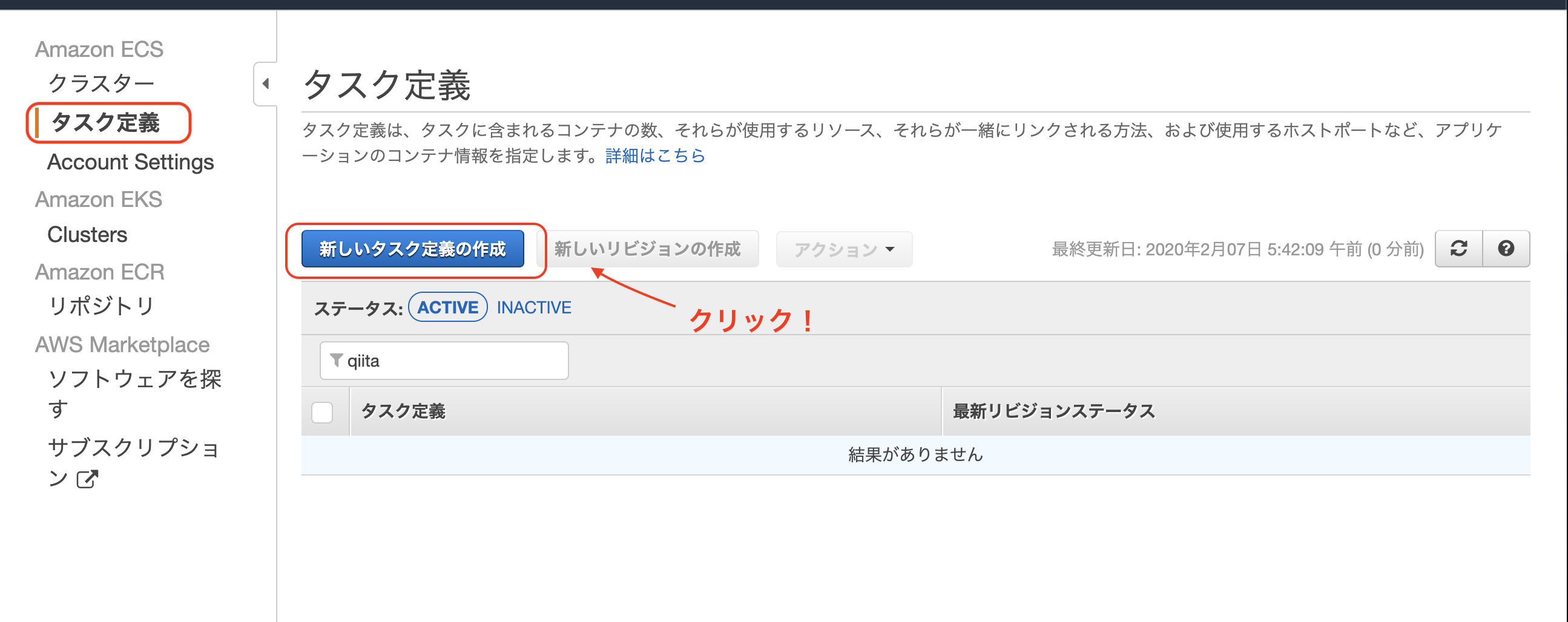
左タブのタスク定義を選択 => 新しいタスク定義の作成をクリック
起動タイプの互換性: EC2を選択して次へ
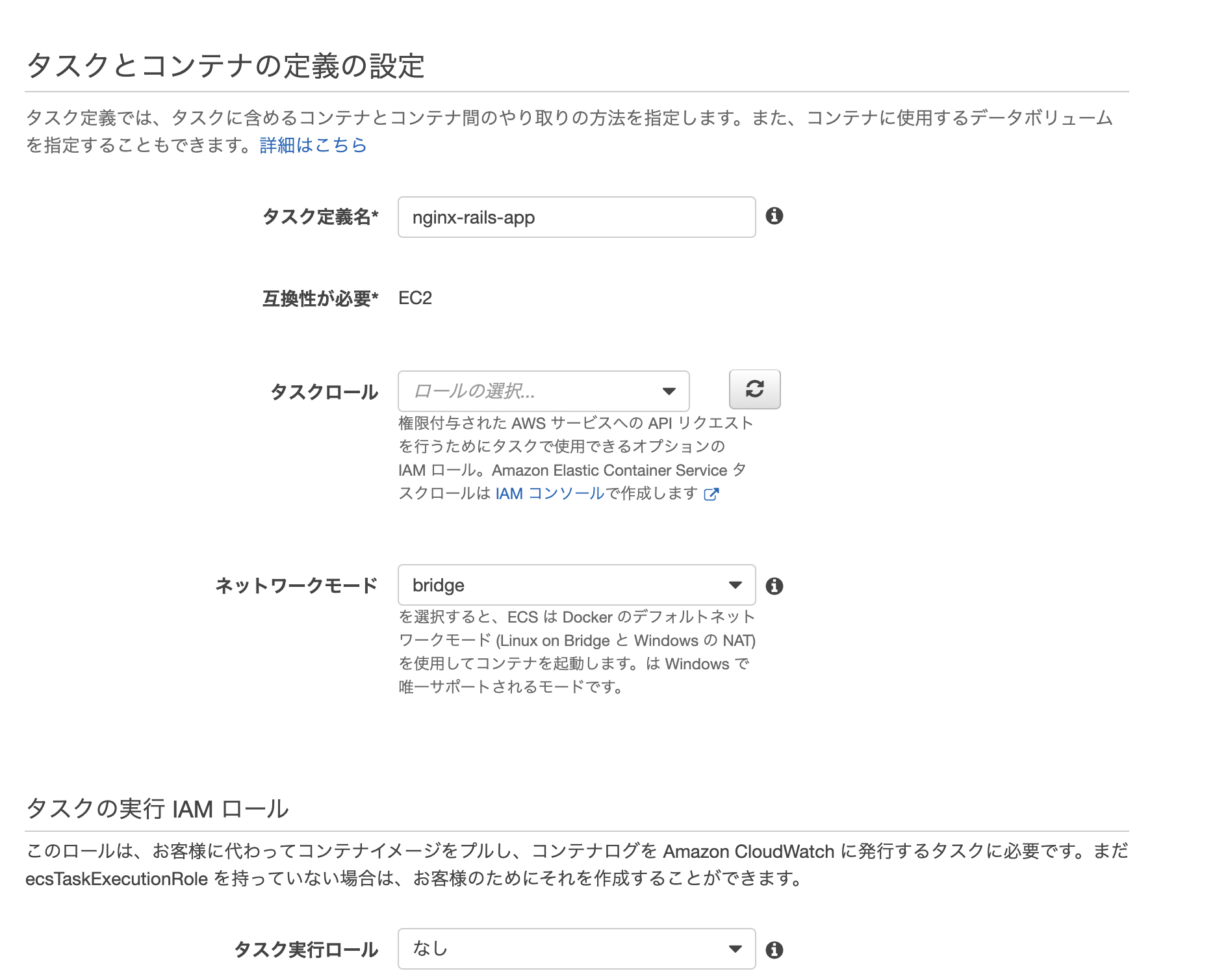
タスク定義名に任意の名前を入力します。
ネットワークモードにbridgeを選択
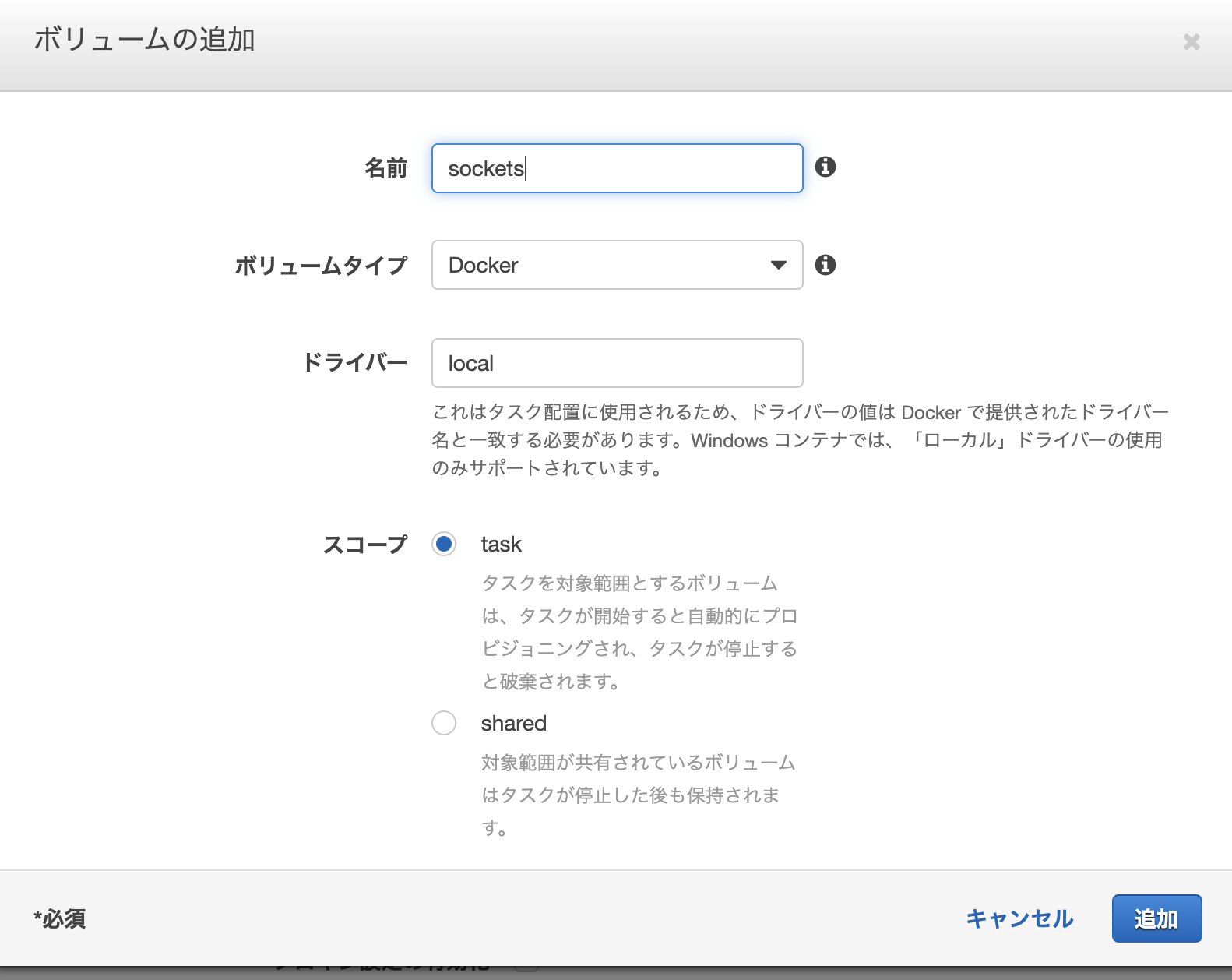
一番下の方までスクロールしていくとボリュームの追加という項目があります。
・ボリュームの追加を選択
ここでスコープをsharedに指定する
There is already a server bound to: <socket>あとで怒られてしまいます。taskにするように注意してください中間の方まで戻リます。
タスクサイズは両方512を設定します。
**コンテナの追加というボタンがあるのでクリック
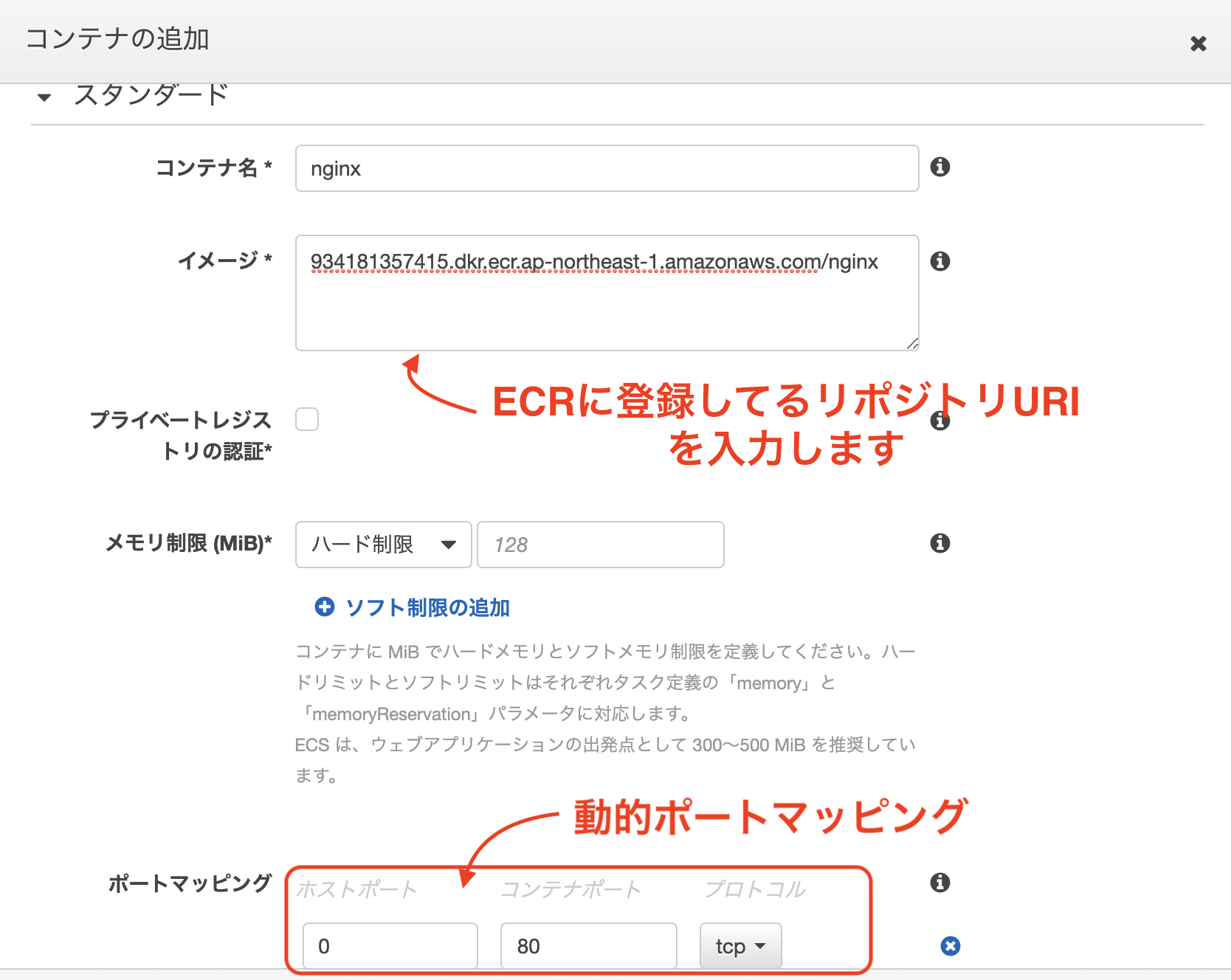
ここでnginx*とrails*のコンテナをそれぞれ追加していきます。まずはnginxのコンテナから。
コンテナ名はnginx
イメージにECRリポジトリに登録してあるnginxイメージのURIをコピペします。
ポートマッピングにはホストを0、コンテナポートを80に設定します。
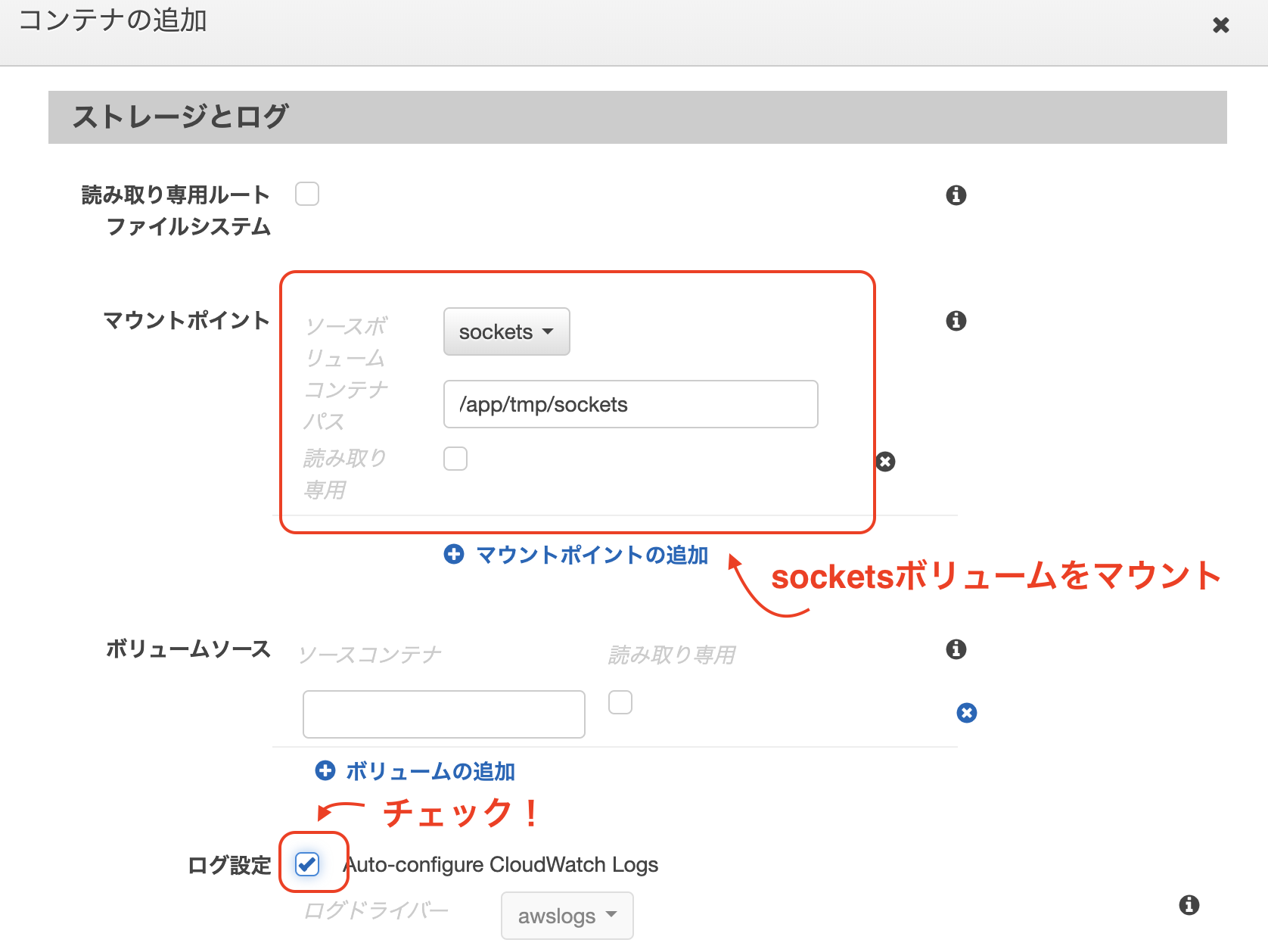
マウントポイントで先ほど作成したsocketsボリュームをマウントします。
また、Cloud Watch Logsにログを吐き出したいのでログ設定にチェックします
他はとりあえず全て空欄でokです!
次にrailsのコンテナを作成します。
先ほどと同様にイメージにECRのrailsイメージのURIをコピペし、ボリュームマウントにsocketsを指定し(パスも同様に/app/tmp/sockets)、ログ設定にもチェックをいれましょう。
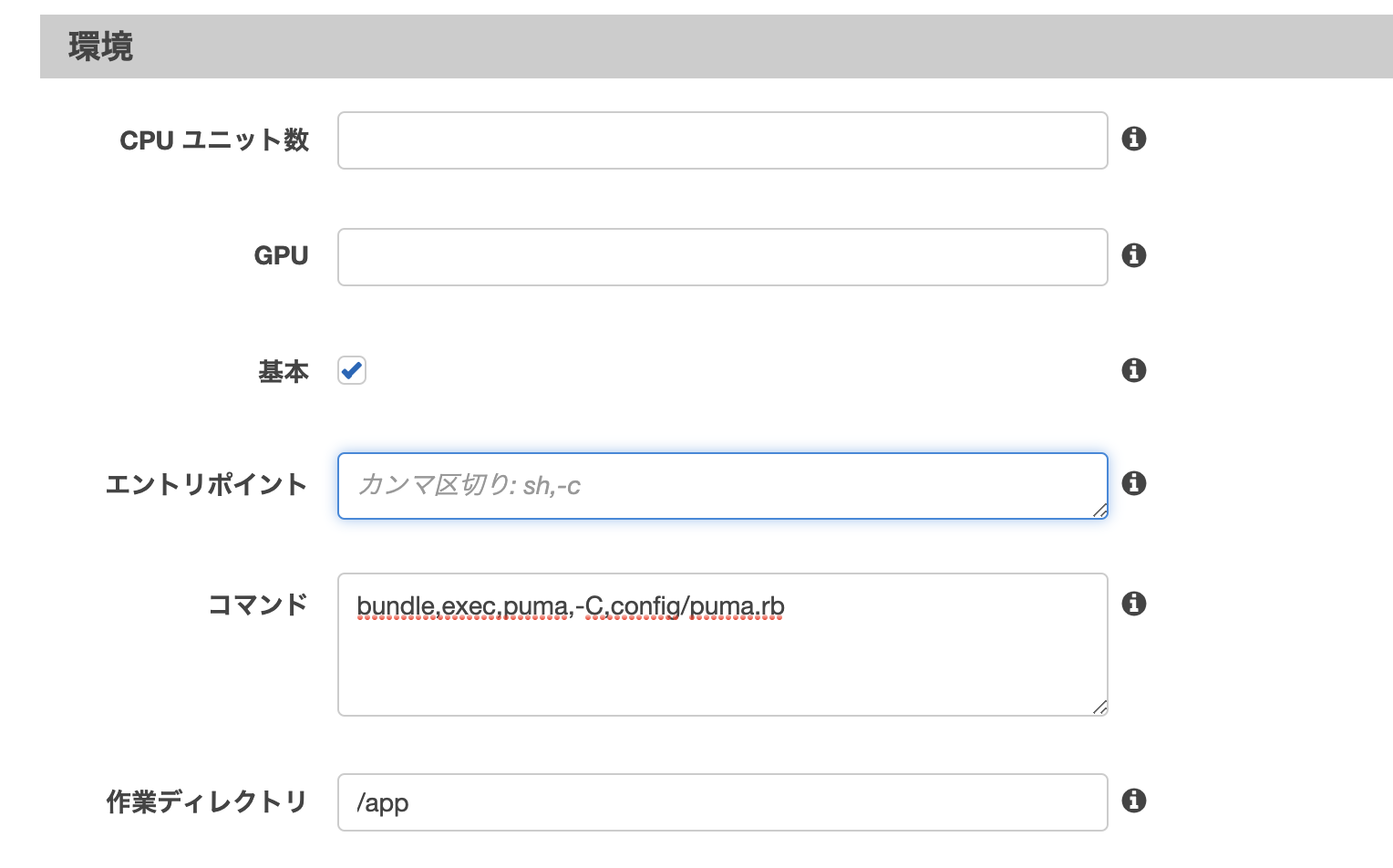
ポートマッピング: ホストを0、コンテナポートを3000
また、起動時のコマンドを追加します。作業ディレクトリは/appで。
bundle,exec,puma,-C,config/puma.rb
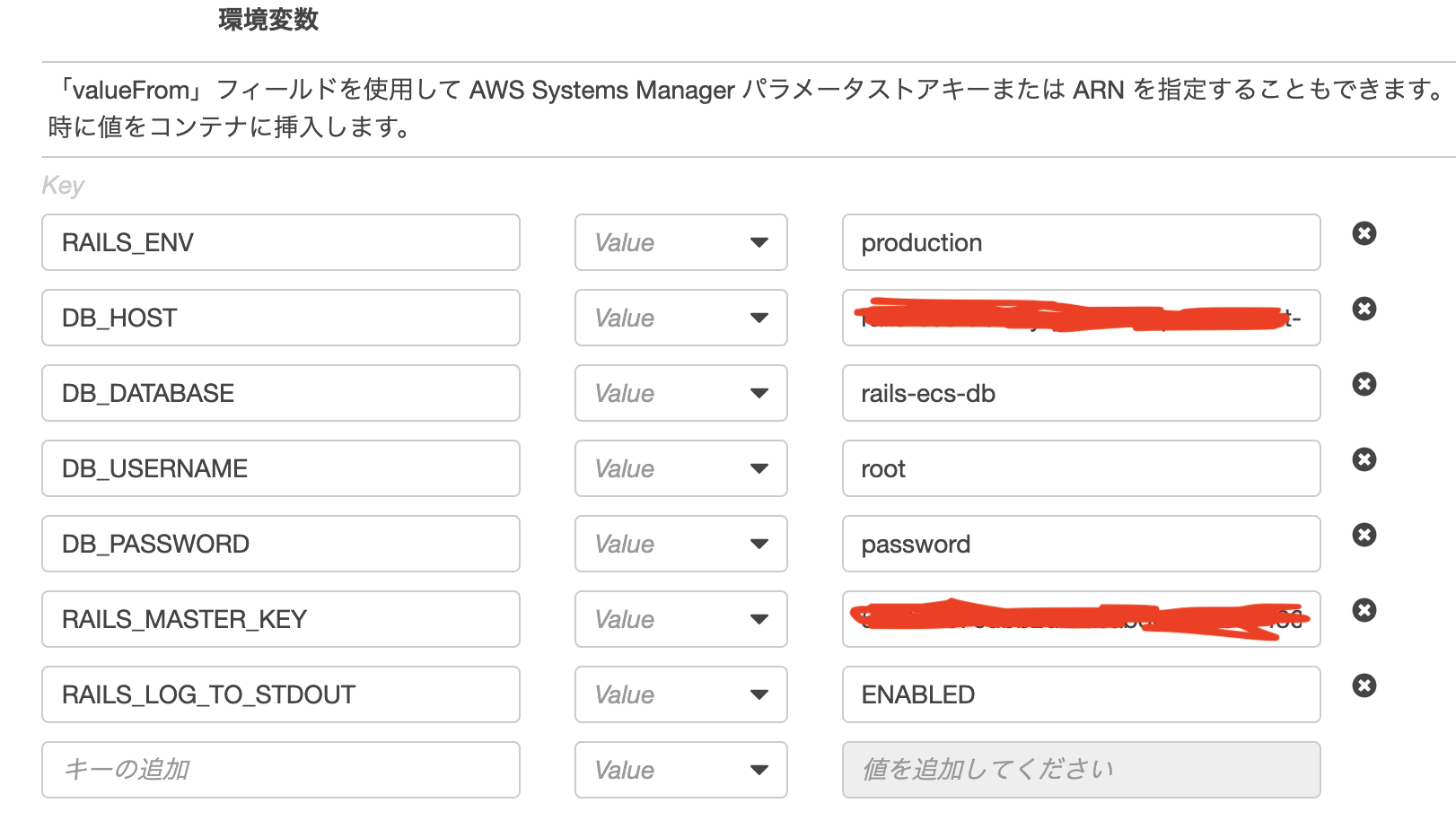
環境変数を追加します。
DB_HOST: RDSのエンドポイント
DB_DATABASE: RDSのDB識別子
RAILS_MASTER_KEY: ローカルのconfig/master.keyの値を貼り付けます。右下の作成ボタンをクリック!
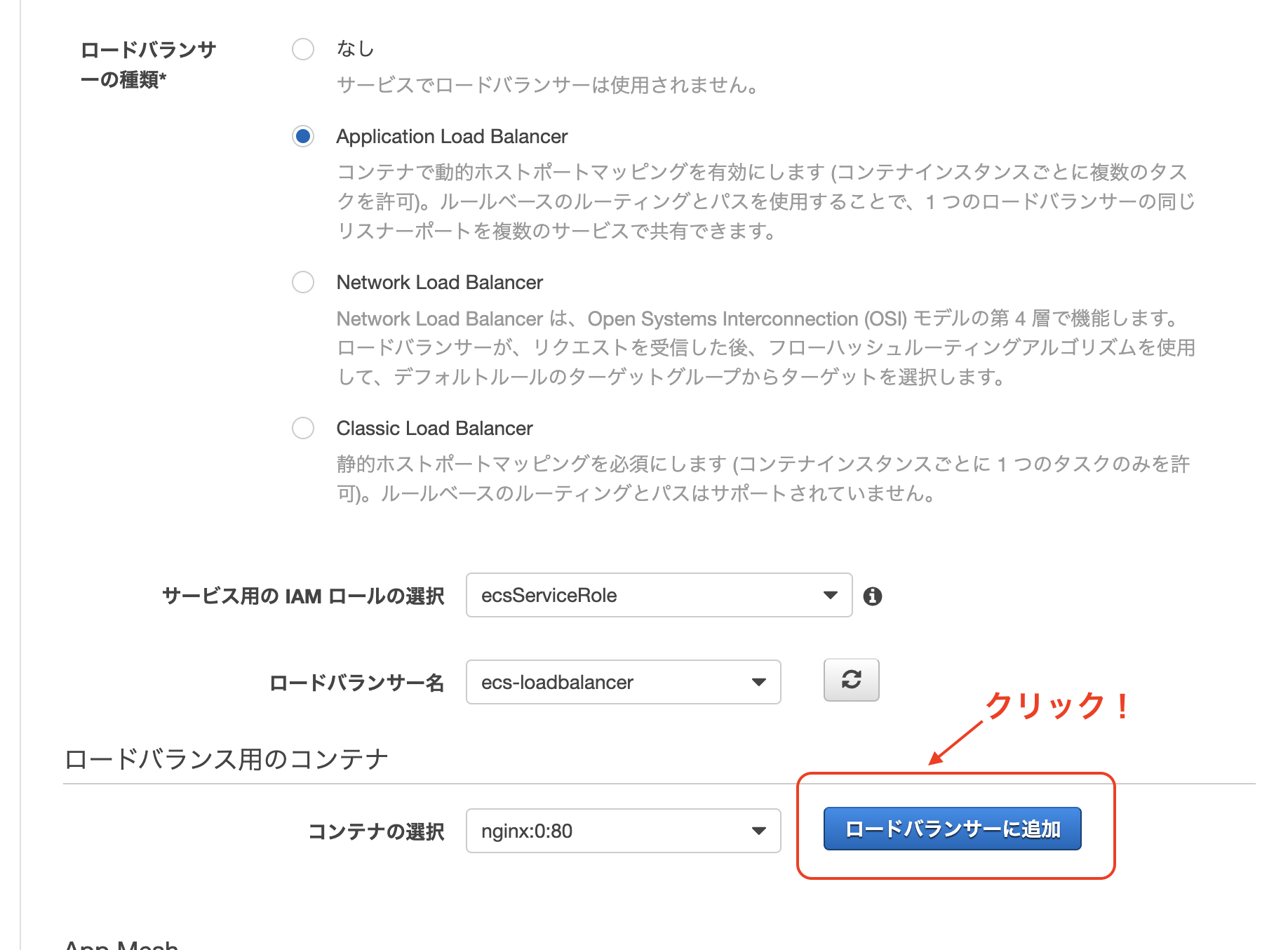
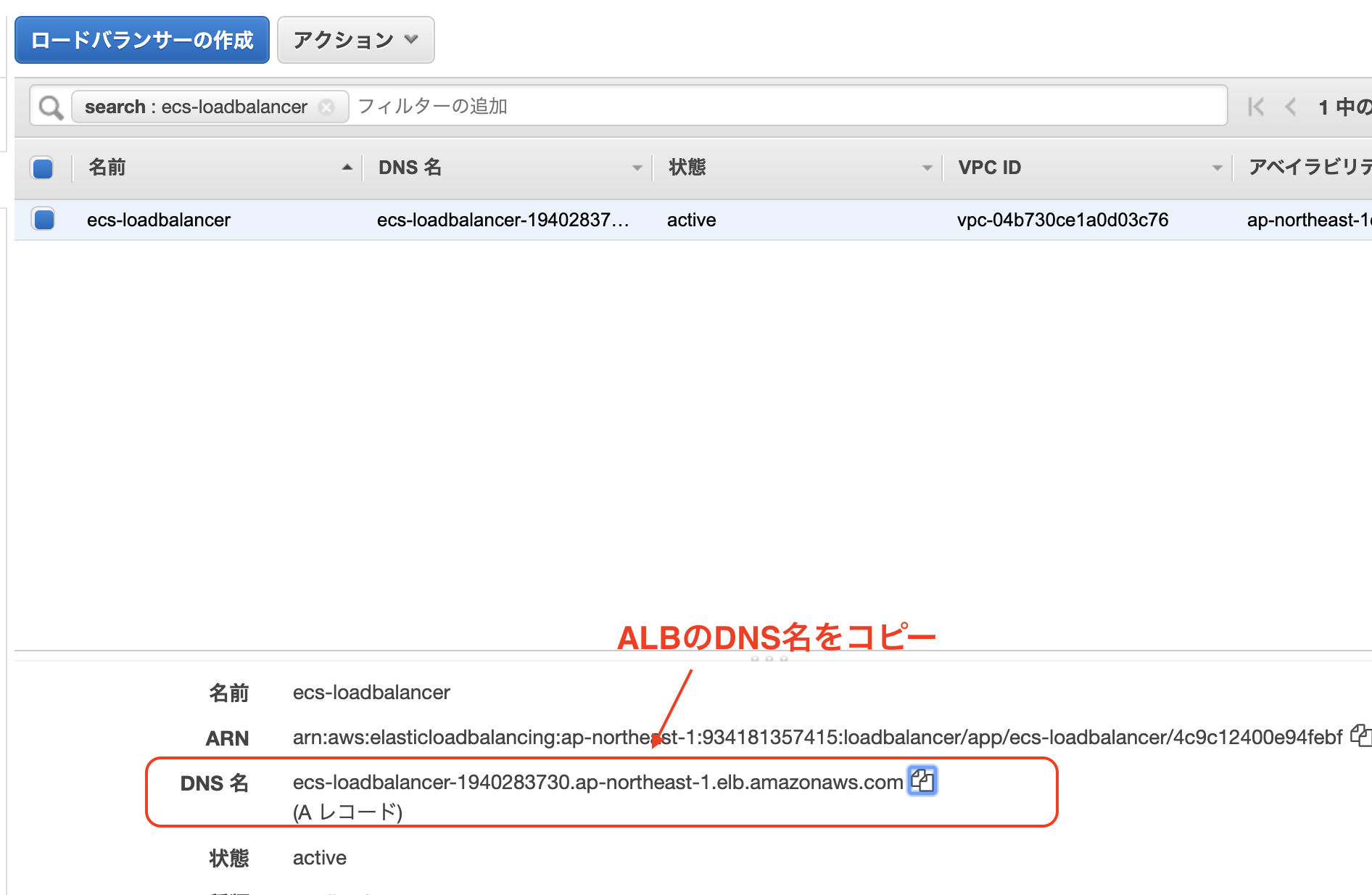
ローダバランサーの作成
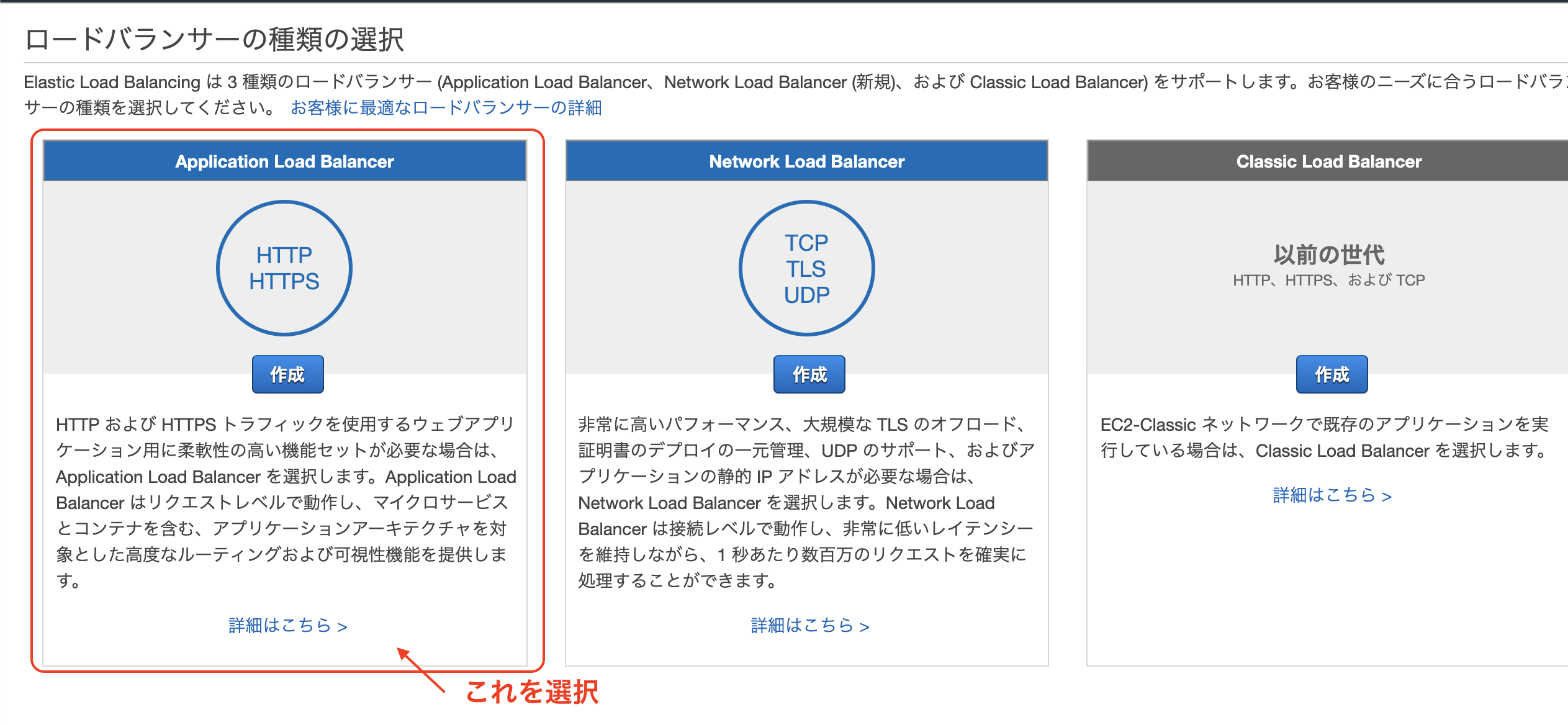
マネジメントコンソールからEC2を検索 => 左タブのロードバランサーを選択
=> ロードバランサーの作成ALBを選択して作成をクリック
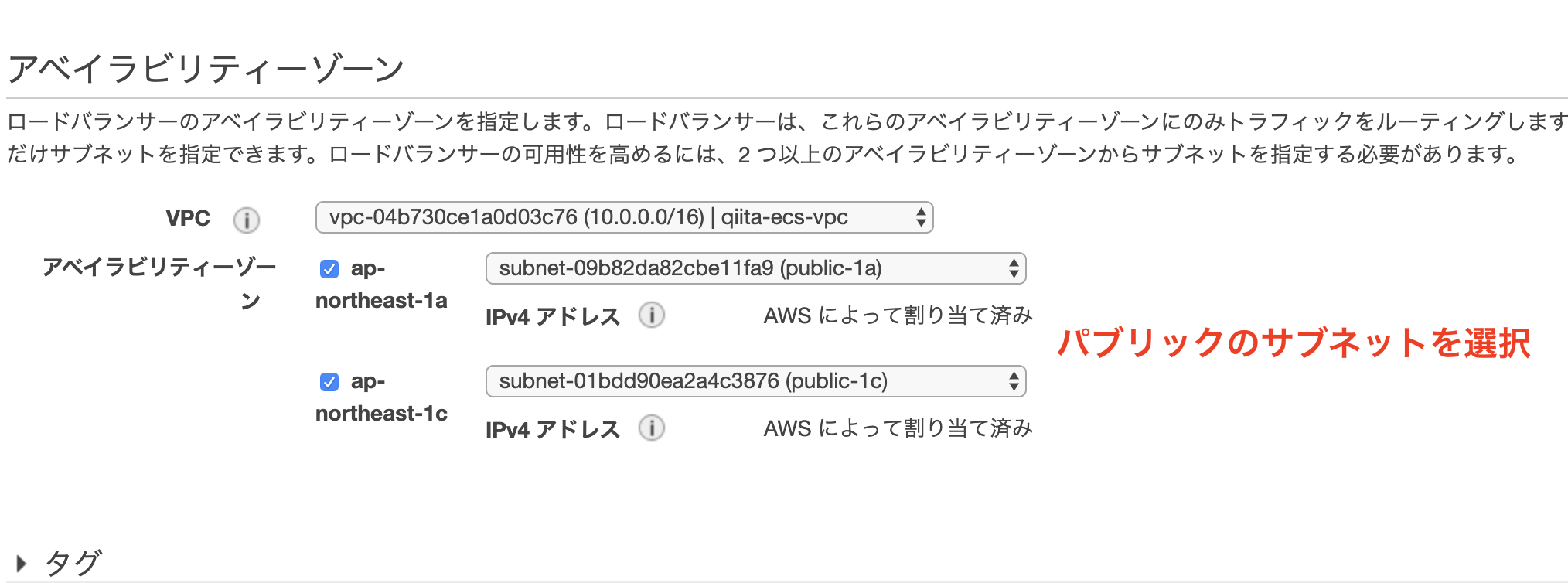
名前を適当に入力してAZの設定を行います。
今回は上で作成したVPCを選択し、パブリックサブネットのみ(public-1a、public-1c)を追加します。
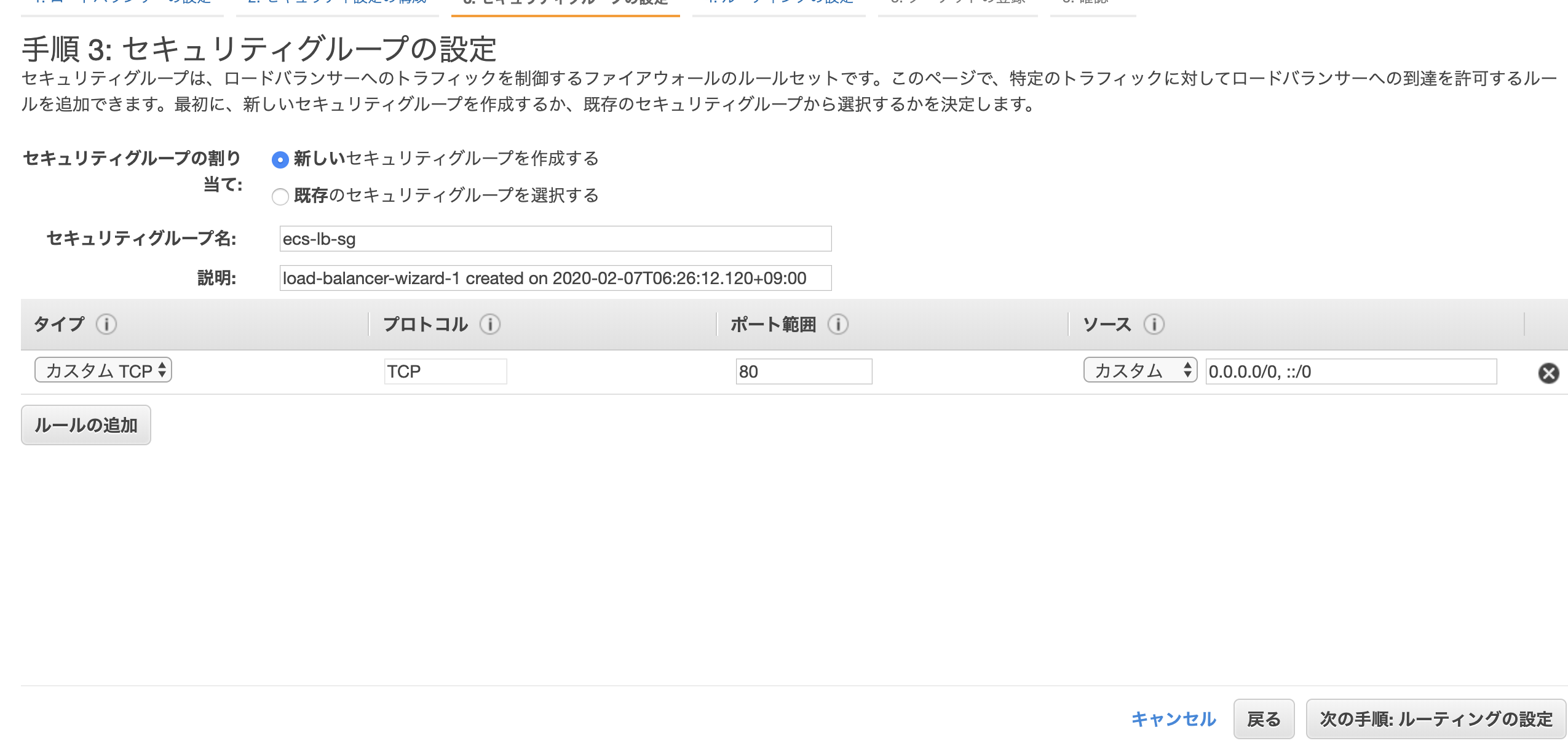
・セキュリティグループの設定
新しくセキュリティグループを作成します。
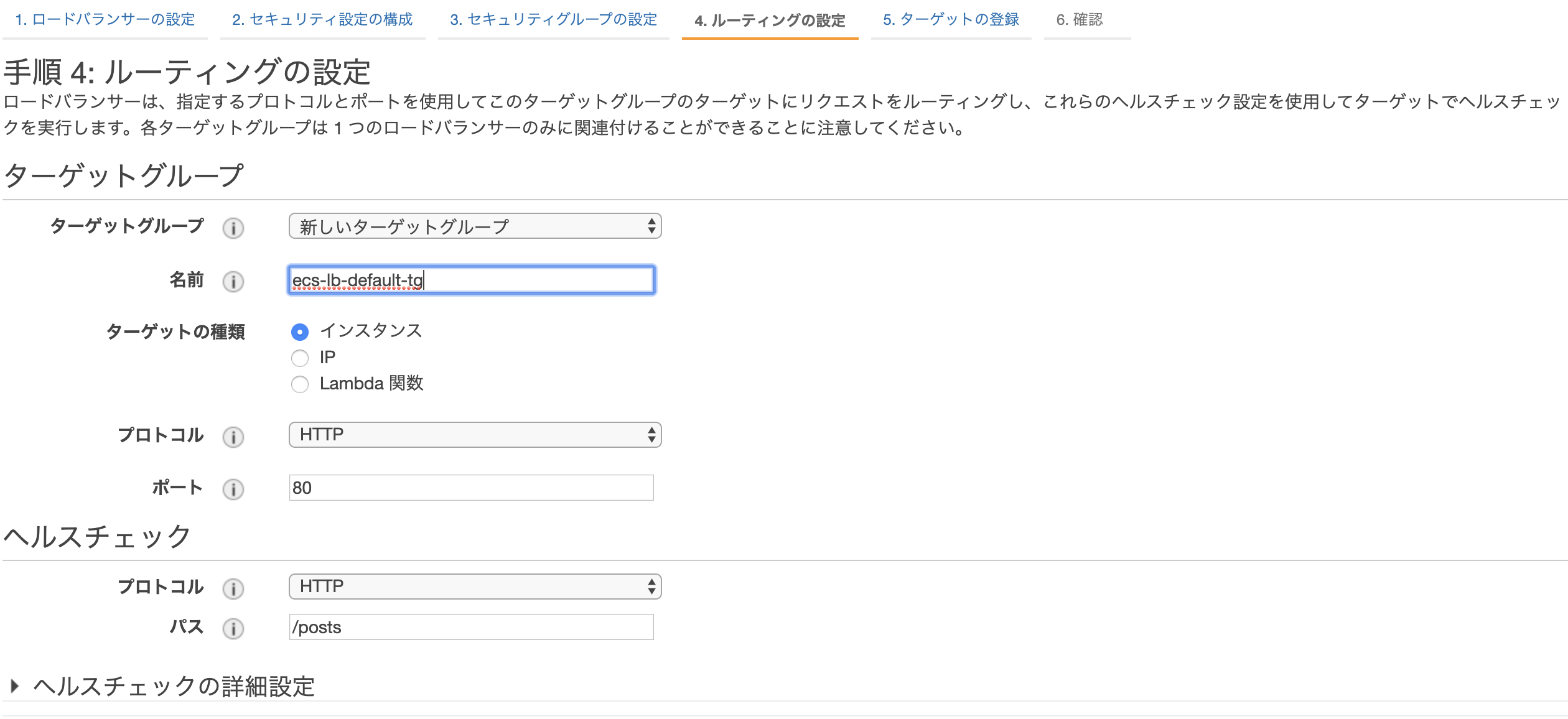
・ルーティングの設定
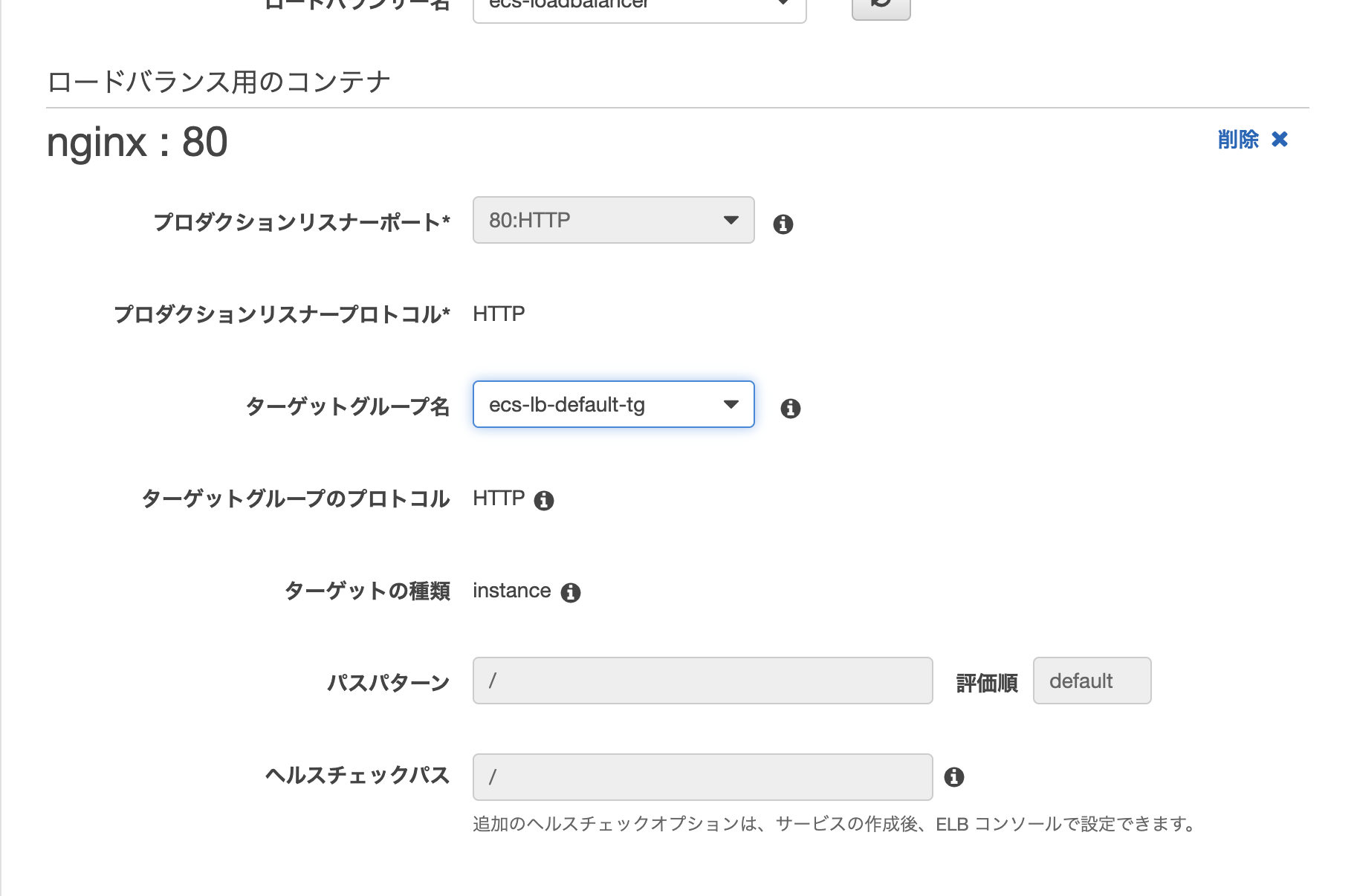
ターゲットグループの作成をします
・手順 5: ターゲットの登録
ECSの設定で登録するのでここではターゲットは登録せずに「次の手順:確認」をクリック作成!
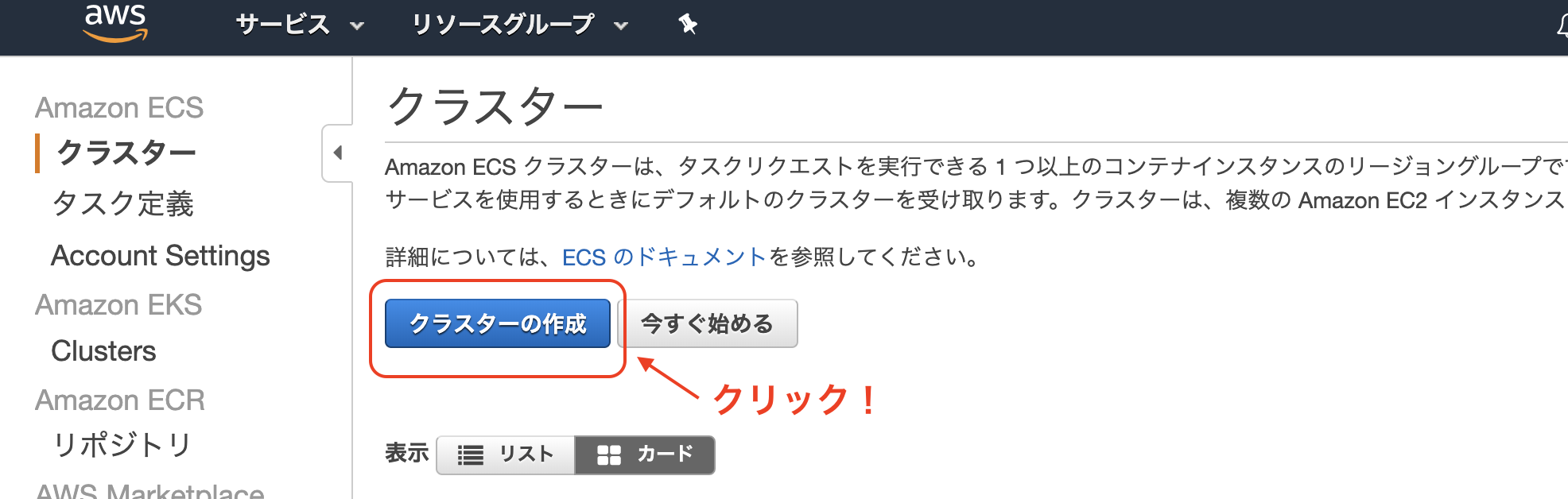
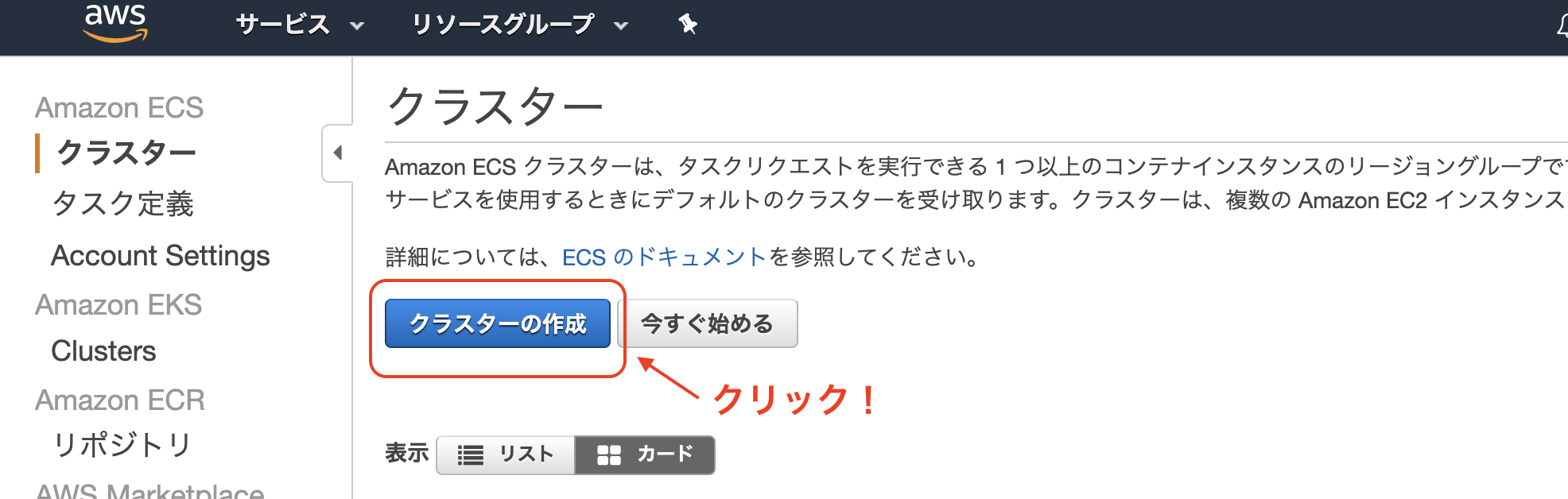
ECSでクラスタの作成
ステップ1:クラスターテンプレートの選択
EC2 Linux + ネットワーキングを選択ステップ2:クラスターの設定
EC2 インスタンスタイプにはm3.mediumを指定
キーペア: EC2インスタンスに接続するキーペアを指定します。ネットワーキングの項目で今回作成したVPCを選択します。
セキュリティグループは新規作成します。
後ほど、ここで新規作成したセキュリティグループを用いて、ECSによって起動するEC2インスタンス、RDS、ALBなどを全て繋ぎ合わせます。作成をクリック!
作成が完了したら以下のような画面になります。
クラスターを作成した時点でコンテナインスタンス(今回は2台)が立ち上がります。
サービスの作成
クラスター一覧で先ほど作成したクラスターを選択します。
サービスという項目に作成ボタンがあるのでそちらをクリックします
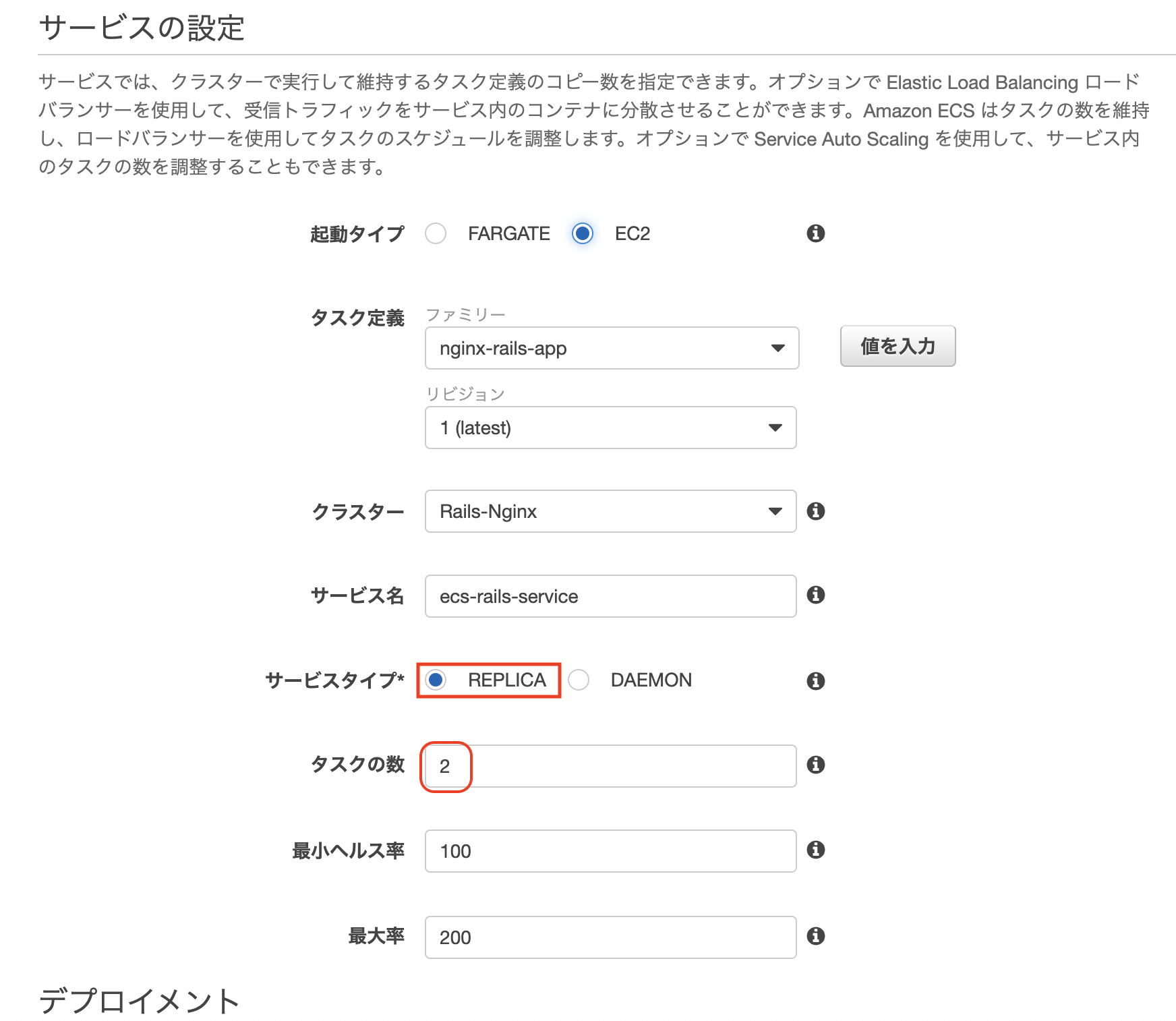
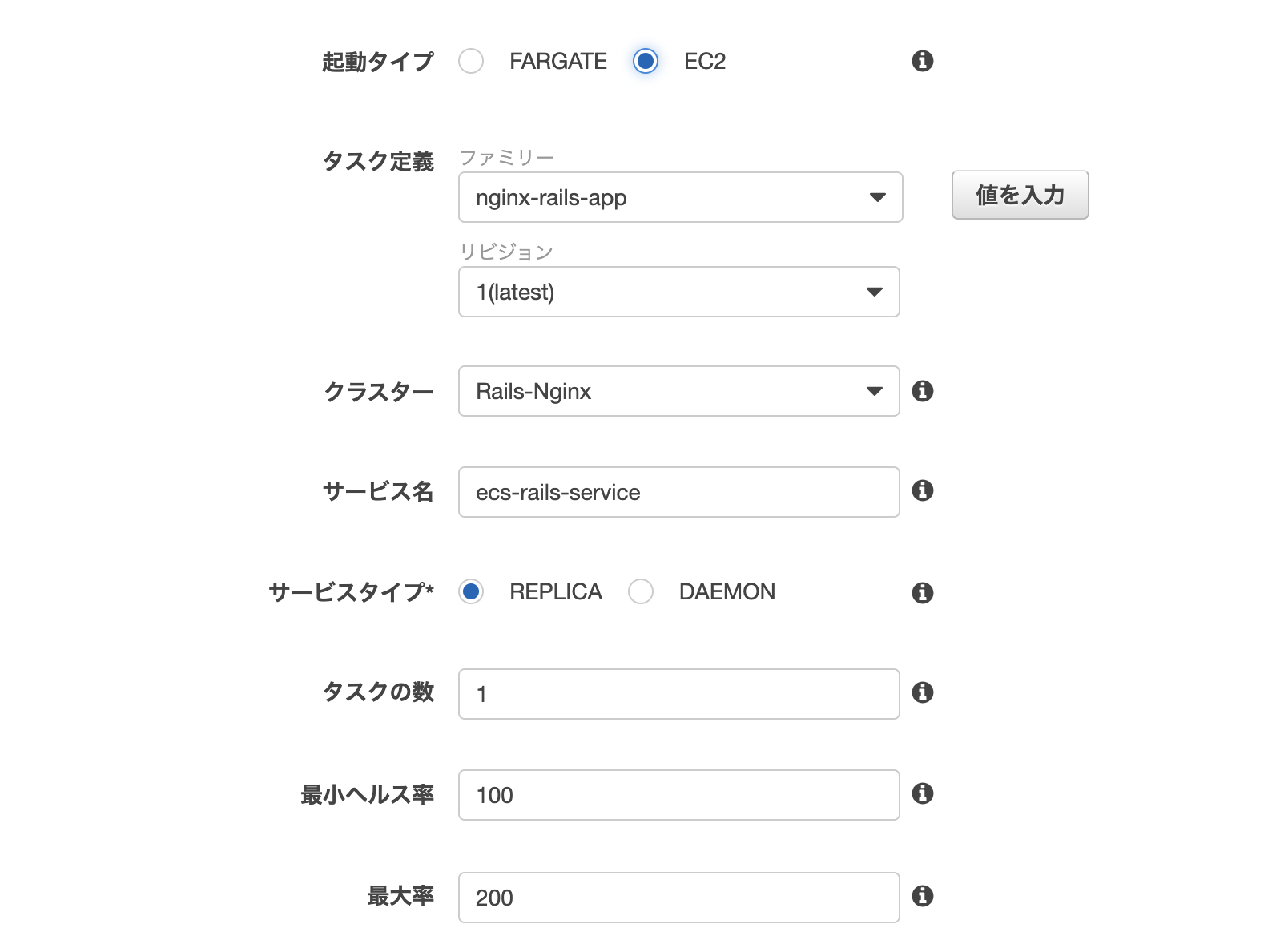
ステップ 1: サービスの設定
タスク定義に作成済みのタスクを指定
クラスターに作成済みのクラスターを指定
サービス名に任意の名前を入力サービス対応はレプリカを、
タスクの数は2を設定します。ECSで言うタスクはコンテナを意味します。
レプリカはクラスター全体で必要なコンテナ数を指定してそれを維持します。
デーモンでは、各コンテナインスタンスにコンテナのコピーを1つ配置し維持します。
他は変更せずに次のステップへ
ステップ 2: ネットワーク構成
ロードバランシングでApplication Load Balancerにチェックをいれます。
サービスの検出の統合の有効化のチェックを外します。
ステップ 3: Auto Scaling (オプション)
・今回はサービスの必要数を直接調整しないをチェックして次のステップへサービスの作成をクリック!
このサービスの作成で、これまで作成してきたクラスタとタスク、ALBを全て繋ぎ合わせることができました。
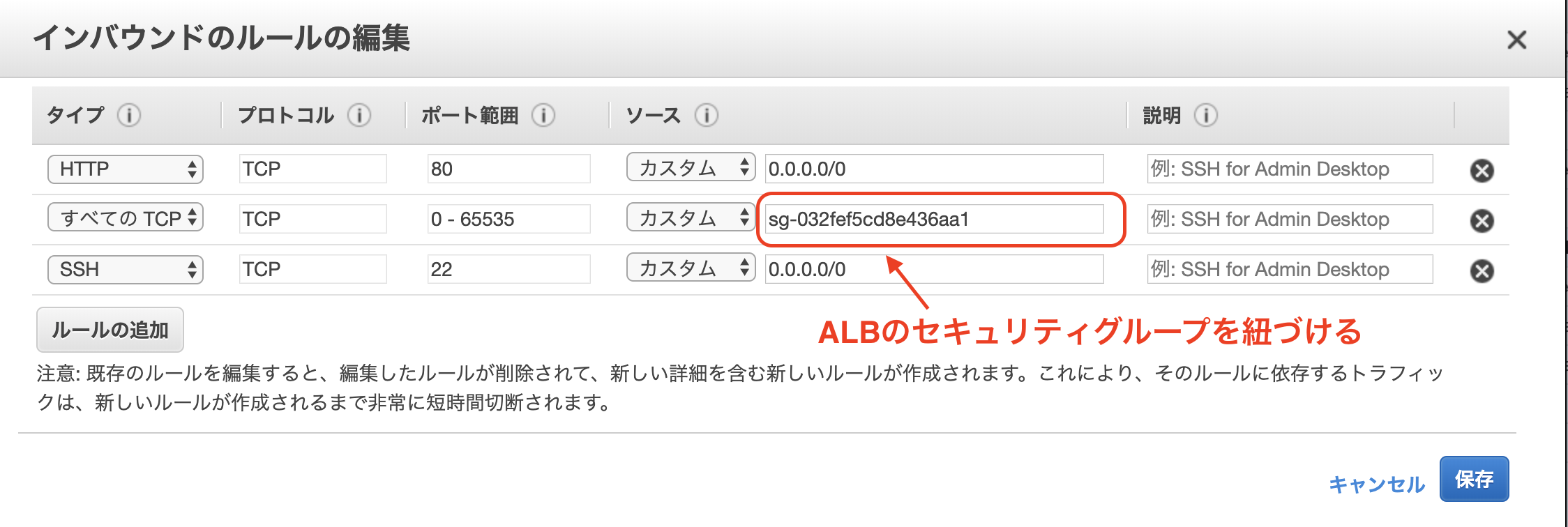
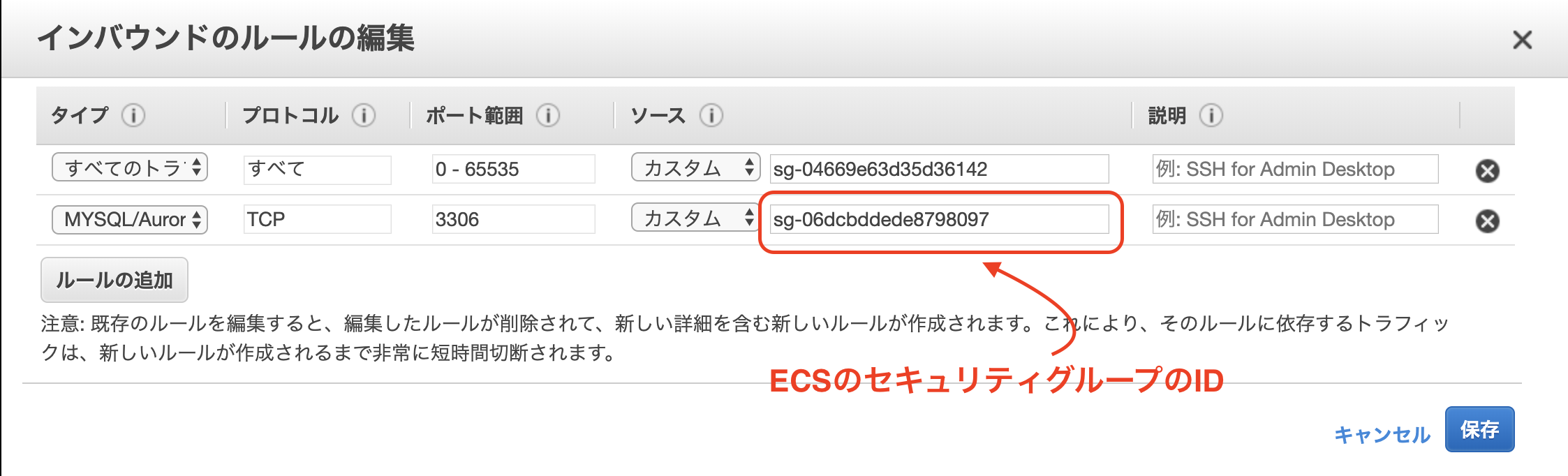
セキュリティグループの設定
ここが重要です!
今まで作成してきたコンポーネント間のトラフィックを許可するためにECSのクラスター作成時に一緒に新規作成したセキュリティグループのインバウンドを以下のように修正します。
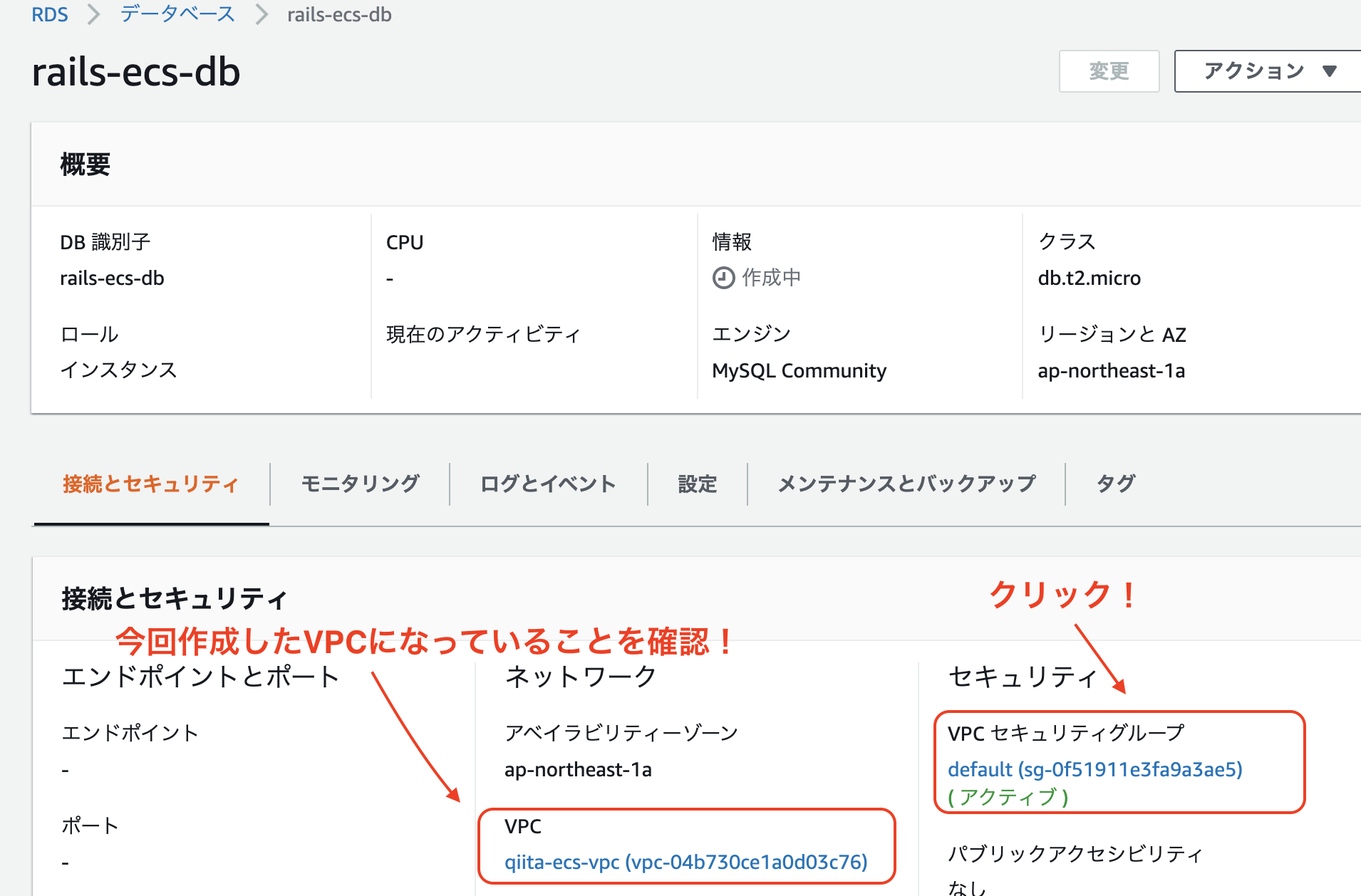
また、EC2インスタンスからRDSにアクセスできるようにします。
[サービス]タブで、RDSを検索してクリック => 左側のメニューで、「データベース」をクリック。
次に、作成したデータベースを見つけてクリック => 下のタブでセキュリティグループをクリック
以下のようにインバウンドを編集します。
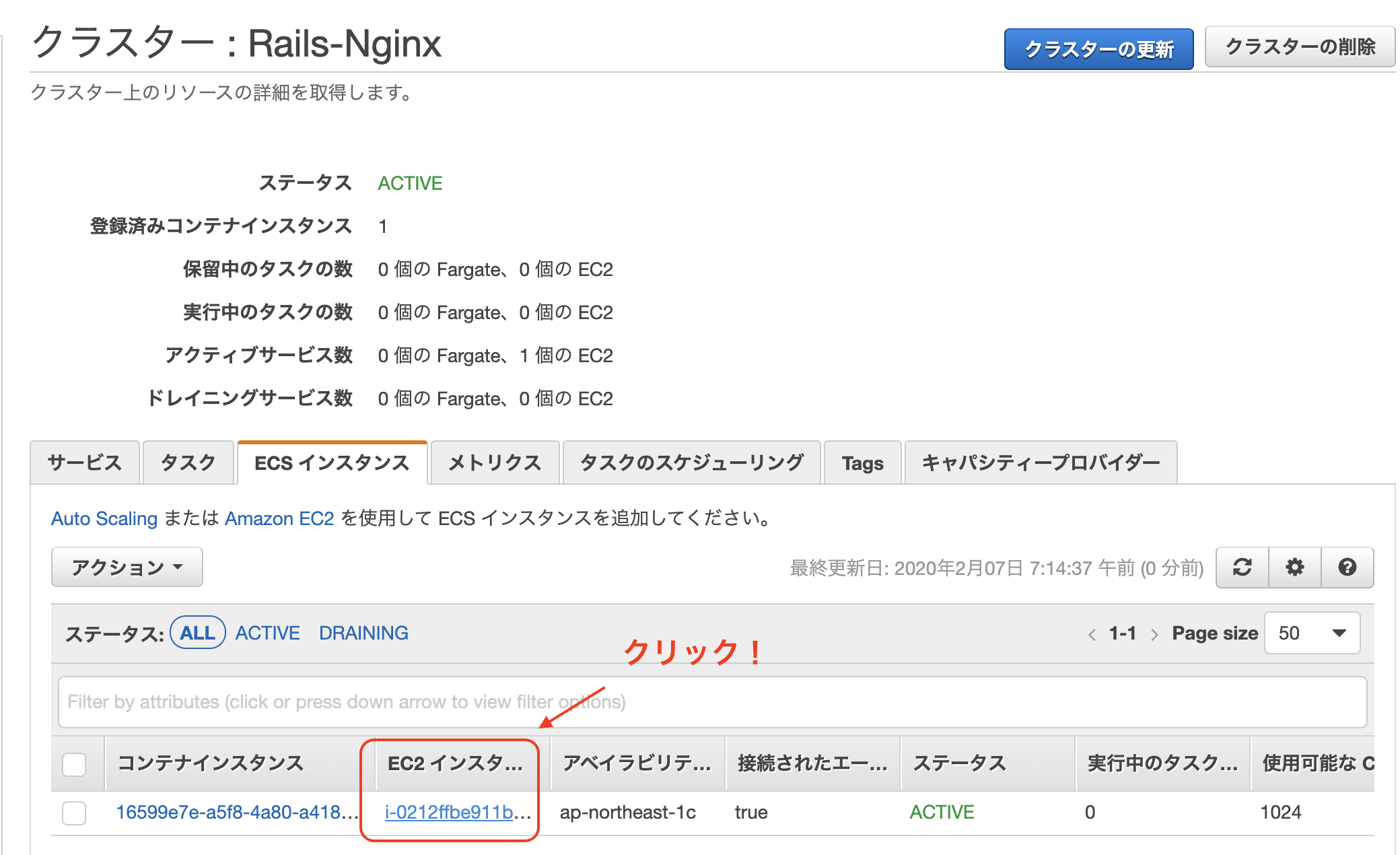
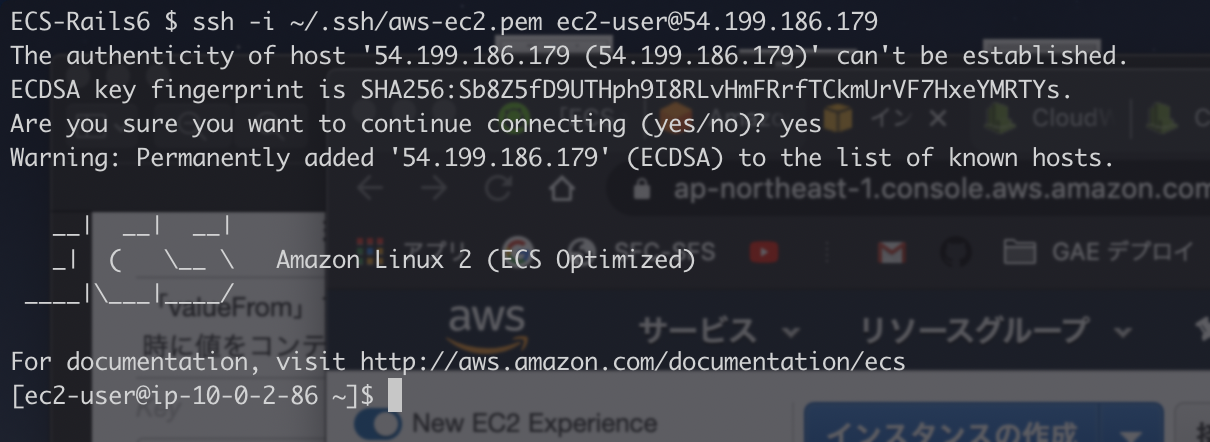
EC2インスタンスにSSHログイン
IPv4 パブリック IPをコピーしておきます。
ターミナルを開きます。
$ ssh -i [キーペアのpath] ec2-user@[パブリック IP]
$ docker psとするとコンテナが立ち上がっていることがわかります。
ちなみにdocker imagesとするとECRに登録してあるイメージが出てきます。Railsのコンテナに入ってデータベースを作成しましょう。
$ docker exec -it [RailsコンテナのID] /bin/bash$ echo $DB_DATABASEとするとタスク定義の際に設定した環境変数の値が出力されているはずです。
環境変数でRAILS_ENVにproductionが設定されているのでRAILS_ENV=productionとかしなくでも大丈夫です。$ rails db:create $ rails db:migrate $ rails db:seed
[ALBのDNS名]/postsにアクセスして以下のようにjsonが返ってきていれば大成功です!!!
※基本的にコンテナのログは
Cloud Watch Logsに吐き出されているのでそちらを見ればデバッグできると思います。Circle Ciでの自動デプロイ化
記事が長くなってきたので、config.ymlの説明は省略します。
公式を参考に!
ECR: https://circleci.com/orbs/registry/orb/circleci/aws-ecr
ECS: https://circleci.com/orbs/registry/orb/circleci/aws-ecs?version=0.0.15AWS_ECR_ACCOUNT_URLとか大文字になっているものは環境変数なのでCircle Ciのプロジェクト設定の
Environment Variablesで設定しておく必要があります。version: 2.1 orbs: aws-ecr: circleci/aws-ecr@6.7.0 aws-ecs: circleci/aws-ecs@1.1.0 workflows: # Nginxのデプロイ nginx-deploy: jobs: - aws-ecr/build-and-push-image: account-url: AWS_ECR_ACCOUNT_URL region: AWS_REGION aws-access-key-id: AWS_ACCESS_KEY_ID aws-secret-access-key: AWS_SECRET_ACCESS_KEY create-repo: true dockerfile: ./docker/nginx/Dockerfile repo: nginx tag: "${CIRCLE_SHA1}" filters: branches: only: master - aws-ecs/deploy-service-update: requires: - aws-ecr/build-and-push-image family: 'nginx-rails-app' # ECSのタスク定義名 cluster-name: '${ECS_ARN}' #ECSのクラスターのARN service-name: 'test' #サービス名 container-image-name-updates: "container=nginx,tag=${CIRCLE_SHA1}" # Railsのデプロイ rails-deploy: jobs: - aws-ecr/build-and-push-image: account-url: AWS_ECR_ACCOUNT_URL region: AWS_REGION aws-access-key-id: AWS_ACCESS_KEY_ID aws-secret-access-key: AWS_SECRET_ACCESS_KEY create-repo: true dockerfile: ./docker/rails/Dockerfile repo: rails tag: "${CIRCLE_SHA1}" filters: branches: only: master - aws-ecs/deploy-service-update: requires: - aws-ecr/build-and-push-image family: 'nginx-rails-app' # ECSのタスク定義名 cluster-name: '${ECS_ARN}' #ECSのクラスターのARN service-name: 'test' #サービス名 container-image-name-updates: "container=rails,tag=${CIRCLE_SHA1}" #AWS_ECR_ACCOUNT_URL => ${アカウントID}.dkr.ecr.${リージョン}.amazonaws.com





- 投稿日:2020-02-07T17:24:05+09:00
【実体験をもとに】30歳未経験から独学4ヶ月でバックエンドエンジニアとしてWeb系自社開発企業へ転職するまでのロードマップ
こんにちは。
2020年2月現在、スタートアップ期のWeb系自社開発企業から内定をいただきました。
今回はこれからプログラマーとしてWeb企業へ転職される方を応援するため、私が知識ゼロの状態から学習をスタートし転職するまでの過程を踏まえたロードマップを共有します。
一つの例として参考にしていただければと幸いです。前置き
本記事はプログラミング初心者を対象にしたものなので、理解しやすいように噛み砕いて文章を作成しています。
多少語弊のある内容もあるため現役プログラマーの方の閲覧時は生暖かい目で見てください(笑)私の実体験をもとに作成していたため、実際にはもっと素晴らしいロードマップもあると思います。
投稿者スペック
エンジニアキャリア1ヶ月目のできたてホヤホヤ新人
年齢:30歳(既婚)
住所:埼玉県
前職:一般企業の拠点マネジメント系
学歴:大卒(文系)
・プログラミングの知識はゼロ(多少Excelを触れるくらい)
・わりとコミュ力はあるほう転職先での待遇
給料(年収):400万ほど(前職と同程度)
社会保険などの福利厚生
リモートワーク可学習開始から転職までにかかった期間
■4ヶ月
うち3ヶ月は前職と並行して学習
うち1ヶ月は前職の有給を使用し就活に専念
前職の退職日1週間後に内定をいただきました。学習方法
eラーニング(Progade.CODEPREP)
MENTA
Qiita
その他IT技術に関するブログ
各技術の公式リファレンス(各技術公式の説明書)転職完了時のスキルセット
HTML
CSS
Ruby
Ruby on Rails
MySQL
Rspec
AWS
Docker
CircleCI
Gitロードマップ(1月スタートとする)
1月:基本学習(Progateを使用)
2月:ポートフォリオ作成
3月:ポートフォリオのブラッシュアップ
4月:就活私は仕事をしながら通勤時や帰宅後、休日を利用して学習しました。
仕事の繁忙から半月の間全く勉強できない事も・・・。
平日は1〜3時間、休日は4〜7時間ほど勉強していました。
(もちろん30分くらいしか勉強しなかった日も間々ありました)
もっと少なくても多分ダイジョーブ!先に記載しますが、Progateなどの学習サイトを周回する必要は無いと思っています
実際に技術を使用して何か成果物を作るのが一番早い学習方法であり、学習サイトではそのための足がかりさえ得られれば良い。というのが私の個人的見解。(百聞は一見に如かずというやつですね)
たっぷりと時間があるならともかく、仕事をしながら勉強していた私にとって学習サイトを周回するのは時間的な費用対効果が低かったのです。1月 基本学習
第1週 HTML&CSSの学習
Progate (https://prog-8.com/) を利用しての学習。
難しいものではありません。サクッとクリアして、何か簡単なWebサイト1つを模写しました。
私は下記のようにデザイン例の載ったサイトから好みのものを一つ選んで同じようなレイアウトを1から作ってみました。
https://sankoudesign.com/
※「カーソルを合わせたらポップアップが出る〜」だとかそういった事はスルーして良いと思います。第2週 Rubyの学習
Progateを利用しての学習。
完全に理解する必要は無いと思います。この段階では感触さえつかめれば良。
基礎の基礎とはいえ、この段階で完全な理解をするのは難しく時間がかかります(=挫折しやすくなる)。
あまり気構えせずにユルく馴染ませていきましょう。
※逆にこの段階では、学んだことを何に使うのか分かっていない状態のため、うまく定着しないでしょうしね(^^;)
※先述したように今後のことを考えるとさらに踏み込んだ学習は必須なので、後で改めて学習しましょう。第3週〜第4週 Ruby on Rails の学習
Progateを利用しての学習。
今までと違いしっかりと理解しながら学習すべきだと思いました。
1つのセクションが終わるたび自分のPC上で同じように開発を行ってゆくという方法で復習をしました。
Progateでは「指示された通りに穴埋めをしてゆく」というスタイルで課題を進めるため、ただの作業になってしまいがち。「今自分が何をしているのか」ということや「システムの全体像」がイメージしづらく、うまく定着しないと考えたからです。2月 ポートフォリオ作成
プログラマー転職において必須とも言えるのがポートフォリオの作成です。
これに最低限のクオリティを持たせなければ好条件での転職は望めないでしょう。
※どのようなポートフォリオを作成すべきかについてはまた別の機会に提案できればと思っています。第1週〜第2週 基本機能を備えた動画投稿サービスを作成 & MySQLの学習
Qiitaを参考にした記事投稿サービスを作成しました。
同時に否が応でもDBに関する学習をしなければなりません。MySQLあるいはPostgreSQLを選択するのが無難かなと。
着実に機能を実装してゆくのはとても楽しく苦にならないかと思いますが、これまでとは違い予期せぬエラーとの戦いが始まります。
解決できないエラーに直面した時に相談できる相手がいると良いですね。
slackなどのプログラマーコミュニティーに入ったり、MENTAを利用することをお勧めします。
また、ここからGitHubの使用を始めました。(1時間もあれば使えるようになります)第3週〜第4週 作成したアプリをAWSへデプロイ
Herokuへのデプロイであればすぐに完了すると聞きますが、ここはより実践的にAWSへデプロイしました。
初学者にはかなりの難題でした。私は先輩エンジニアに教えてもらってなんとかなりましたが、知り合いがいない場合はMENTAの使用を強くお勧めします。3月 ポートフォリオのブラッシュアップ
ここまでで作成したポートフォリオはチュートリアルで学んだものに毛が生えた程度のものという評価になると考え、成果物に対してさらに+αのアピールポイントをつけていきました。
またこの時期は年末で私の仕事が大変忙しく、学習にかけられる時間は半分以下になっています。第1週〜第2週 Dockerによる開発環境構築
Dockerは初学者には大きなハードルとなりますが、現在の開発現場ではスタンダードになっているとの情報を得ましたので必ず手をつけることをお勧めします。
前職場の先輩がベテランプログラマーの知人に私のことを話した際「Dockerを使用してポーロフォリオを開発しAWSへデプロイした」と伝えたところ「それは就活成功するやつだね」と言われたそうです。
そのくらい「Dockerを扱える」というのは初学者への評価をするにあたって一つの指標となるのかなと思いました。参考にしたのはQiitaの記事https://qiita.com/nsy_13/items/9fbc929f173984c30b5d
Dockerは注目度が高い技術のため、参考文献が多いのが幸いですね!先人に感謝!!第3週〜第4週 CircleCIの導入 & Rspec導入
※私自身は仕事で忙しくこの時期は全くと言っていいほど学習に手をつけられていません。しかし、本来であればこのタイミングが良いと思い記載します。
CIツールとしてCircleCiを学習。これもまた注目度の高い技術なので参考文献がゴロゴロ転がっています。
CD機能についてまではできていなくても良いと思います。この段階では自動テストのために導入すれば十分かと。
CDまでできたらすごい。ぜひ教えてください。【補足】 ここでCircleCIでなく、何かしらのAPIをポートフォリオに導入する方が就活に活きると思いました。
4月 就活
いよいよ就活です。
就活と同時並行で改めてRubyの学習を行うとなお良かったな〜と思います。
就活における注意点というか心構えのようなものは別の機会でお話しできればと思いますが、私が強く思ったことだけ。
- 焦らずゆとりを持って取り組む。
- ただし最初の1社はとにかく早い段階で選考を受ける。
- 何十社も受ける必要はない。
- Wantedlyプレミアム会員に登録する。
5月まで突入しても良いと思います。そうそううまくいくものではないので、納得いく会社から内定をもらえるまでじっくりと取り組んでください。
【補足】3月の段階から就活をスタートする方が効率的かもしれません。
私は仕事が忙しく、とても無理でしたが・・・。
終わり
以上が私がプログラミング学習を始めて〜内定に至るまでの過程です。
長文を読んでいただきありがとうございます。
最後に私のプログラマー転職を成功に導いてくれた要因を列挙します。
- コツコツと勉強を続けていく持続力
- 「プログラミング楽しい!」とまでは行かないまでも、特に苦にならないという相性。
- 初対面の人とも仲良くなれるコミュニケーション能力。
- 即行動・即実践する意識。
- アドバイスをしてくれるエンジニア仲間。
- ほどほどに休憩を取っていたこと。
- 無職状態になったとしても生活できるだけの貯金があったこと。
- くじけそうな時に支えてくれた家族。
- 投稿日:2020-02-07T15:45:00+09:00
PHP出来るけど全然WordPressわからないので使ってみる(環境準備編)
僕はPHPだとLaravelはかなり熟知していると思ってます。
だがしかし、WordPressは全くわからない。
調べたり、ドキュメント見たり、ソースをみて追っていけばそりゃわかるでしょう。
でも昔からWordPressのソースコードぐちゃぐちゃであまり好きじゃなくて、投稿機能とか自分で作ればよくね?って思ってました。(今はきれいなのかな?)
あとプログラムがわからない人がとりあえず使うイメージが勝手にあって毛嫌いしてました。しかし、案件でWordPressが多いのも事実ですし、ノンプログラマから「WordPressも使えないの笑」とか言われたら腹が立つので、ちょっとずつ出来るようにしようと思う今日このごろ。
でも普通の使い方はださいので
WordPress REST API + Nuxt.js とかで最初から一歩上の使い方をしたろうではありませんか!というわけで環境構築から。
環境準備
環境構築はDockerでサクッと行きましょう。
docker-compose.yamlを用意して、version: '2' services: db: image: mysql:5.7 container_name: test-wp-db volumes: - db_data:/var/lib/mysql restart: always environment: MYSQL_ROOT_PASSWORD: wordpress MYSQL_DATABASE: wordpress MYSQL_USER: wordpress MYSQL_PASSWORD: wordpress wordpress: image: wordpress:latest container_name: test-wp depends_on: - db ports: - "8000:80" restart: always environment: WORDPRESS_DB_HOST: db:3306 WORDPRESS_DB_PASSWORD: wordpress volumes: db_data:以下のコマンドで起動!(-dオプションはバックグラウンド実行)
$ docker-compose up -dアクセス
http://localhost:8000にアクセスするとWordPressの初期設定画面が出てきます。
設定をポチポチしてやれば準備完了!
環境準備はすごい簡単でした!
次は、WordPress REST APIを使っていきたいと思います。参考
- 投稿日:2020-02-07T15:32:43+09:00
Docker(+ Docker-Compose) に Redis を入れる
Docker-Compose 環境に、Redis を入れる
今度は NoSQL として有名?な Redis を入れてみる。
NoSQL、Redisの詳しい話は、参考サイトを見てもらうとして。NoSQL って何?
- Not only SQL の略
- 逆に、YeSQL なんてのもあるらしい
NoSQL - Wikipedia
NoSQL(一般に "Not only SQL" と解釈される)とは、関係データベース管理システム (RDBMS) 以外 のデータベース管理システムを指す おおまかな分類語 である。関係データベースを杓子定規に適用してきた長い歴史を打破し、それ以外の構造のデータベースの利用・発展を促進させようとする 運動の標語 としての意味合いを持つ。Redis って何?
- NoSQLデータベースの一つ
- 今回の場合とかみたいに、KVS(キーバリューストア)として使われたりする
- RDBと比べて高速で処理が出来たりする
- RDBと組み合わせて使ったりもする
Redis - Wikipedia
Redisは、ネットワーク接続された永続化可能なインメモリデータベース。連想配列、リスト、セットなどのデータ構造を扱える。いわゆるNoSQLデータベースの一つ。オープンソースソフトウェアプロジェクトであり、Redis Labsがスポンサーとなって開発されている。Redisをインストールする
フォルダは作っておく
mkdir RedisTest cd RedisTestdocker-compose.yml を書く
docker-compose.yml の中身はコレ。
docker-compose.ymlversion: '3' services: #Redis redis: image: "redis:latest" ports: - "6379:6379" volumes: - "./data/reis:/data"Docker-Compose で Redis 起動
docker-compose up -d --buildDocker起動確認
$ docker-compose ps Name Command State Ports ---------------------------------------------------------------------------------------------- mysqltest_redis_1 docker-entrypoint.sh redis ... Up 0.0.0.0:6379->6379/tcpRedis 確認
$ docker exec -it mysqltest_redis_1 bash root@ec5fc90e5ee3:/data# redis-cli 127.0.0.1:6379> keys * (empty list or set)中身が無いのが確認出来た。データとかはこれから。
参考
- NoSQLについて勉強する。
- RDBMSの苦手な処理をカバーする、気の利いたNoSQL「Redis」
- RedisとElastiCacheを分かりやすくまとめてみた
- Redisの特徴について容易にまとめてみた
- 投稿日:2020-02-07T14:18:57+09:00
win10 で docker desktop を 2.2.0.0 にしてから Host での変更の同期が激遅になったので 2.2.0.2 を入れたら治った
タイトルがすべて。
2.1.0.5 の頃は問題なく同期されてたので 2.2.0.2 のバグらしい。DL先
https://github.com/docker/for-win/issues/5530#issuecomment-583017342
ここ。
そのうち正式にリリースされると思いますが、とりあえず速報ということで。
- 投稿日:2020-02-07T14:18:57+09:00
win10 で docker desktop を 2.2.0.0 にしてから Host での変更の同期が激遅になったので 2.2.0.2 にアプデしたら治った
タイトルがすべて。
2.1.0.5 の頃は問題なく同期されてたので 2.2.0.0 のバグらしい。DL先
https://github.com/docker/for-win/issues/5530#issuecomment-583017342
ここ。
そのうち正式にリリースされると思いますが、とりあえず速報ということで。
- 投稿日:2020-02-07T13:37:33+09:00
Docker(+ Docker-Compose) + MySQL を入れる(2)
Docker(+ Docker-Compose) + MySQL を入れた後の話
前回 ので、MySQLを用意してデータを作るとこまで出来たので、
MySQLを起動するとこの話だけ書いておく。Docker-Compose の MySQL を起動する
あとで、もう一つのUbuntu環境にある Express から接続できる状態にしておく。
docker-compose up -d --buildこれだけ。--build のオプションがとても重要。
次は Ubuntu(Express環境) から Ubuntu(MySQL環境) へ接続して表示をするよ!!!
参考
- docker-compose コマンドまとめ
- DockerのMySQLコンテナに外部のサーバーから接続する
- 投稿日:2020-02-07T12:59:15+09:00
【Docker Compose】プロジェクト名を指定していなくてハマった話
デフォルトに甘えてComposeのプロジェクト管理を意識せずにいたら、いざという時に意図通りのコンテナ操作ができずにハマったという話です。
前のコンテナを止められない
ある日、僕はとあるサービスのデプロイをしました。
プロジェクトをDocker Composeでまとめ、ssh,pull等のデプロイ作業を1行のコマンドにまとめた。
はじめは動いていましたが…次のデプロイでコンテナ起動時に問題発生。
ERROR: {省略} Bind for 0.0.0.0:3000 failed: port is already allocated ERROR: Encountered errors while bringing up the project. # 本番にsshして確認 $ docker ps {省略} days ago 0.0.0.0:3000->3000/tcp 0200122040412_1前のコンテナが起動したままになっており、ポートが被って起動できないというエラーです。
原因はわかりませんが、とりあえずstop。$ docker-compose stop $ docker ps {省略} days ago 0.0.0.0:3000->3000/tcp 0200122040412_1残ってる…
コンテナとdocker-compose.yamlの関係はどうやって決まる?
ここで
docker-composeではなくdockerコマンドでコンテナを止めるのは簡単ですが、ちょっと待ってください。
普通は同じプロジェクトのdocker-compose.yamlを使えば、再起動時に自動で前のコンテナをシャットダウンしてくれます。くれてました。
なぜその対応関係が切れてしまったんでしょうか。コンテナかDockerが記憶しているのかと思いましたが、そんな記述は見当たりません。
現実はもっとシンプルだった。Docker Composeのプロジェクト名とは
Docker Composeはプロジェクト単位でコンテナを操作します。
プロジェクト(とコンテナ)にはプロジェクト名が付き、コマンド操作(up,run,stop,etc)はそれを参照して行われる。で、このプロジェクト名は別に設定しなくても動く。
このプロジェクト名の設定はオプションです。設定をしなければ、 COMPOSE_PROJECT_NAME (Composeのプロジェクト名)は、デフォルトではプロジェクトのディレクトリを ベース名 にします。
http://docs.docker.jp/v1.12/compose/reference/envvars.htmlデフォルトでディレクトリ名になる。
プロジェクト名を設定しないとどうなる?
[1] 複数のプロジェクトでディレクトリ名がダブると、意図しないコンテナを操作してしまう
(例:日付、バージョン、"app", etc…)
[2] ディレクトリ名を変えるとプロジェクト名が変わり、以前そのディレクトリ内のdocker-compose.yamlで起動したコンテナを操作できなくなるこういう問題が発生します!!!
実例:Capistranoでデプロイ
Capistranoはruby製のデプロイ自動化gemで、標準でバージョン管理もしてくれる優れもの。
別にRails専用というわけではないので今回はssh→pull→up -d --buildとかする用途で使っていた。
…が、今回このバージョン管理機能が仇になった。Capistranoのバージョン管理機能とは
Capistranoのデプロイは、Datetime名のディレクトリを都度作成して行われる。
releases]$ ls 20200122033238 20200122033501 20200122040412 20200122041011 20200122041121その上で、デプロイ先の指定ディレクトリ「標準では
current」は最新バージョンへのsymlinkになる。app]$ ls current # ←これが実際には20200122041121へのsymlinkまァ、それは良いのだが、この状態で
docker-compose upすると…current]$ docker-compose up -d Starting 20200122033501_db_1 ... done Starting 20200122033501_web_1 ... donesymlink先の正式なディレクトリ名(=日時のほう)が付けられて起動する。
こうなるともうだめだ
次にCapでデプロイを行うと、それはまた先の日時のディレクトリ名に置かれる。
つまり、 もう別のプロジェクト名になってしまう。
docker-compose upしても古いコンテナを自動終了してくれず、このようにポートダブりエラーが出る。(前略 )connectivity on endpoint 20200122041121_web_1 (中略): Bind for 0.0.0.0:3000 failed: port is already allocated今まで何も考えずに使っていても勝手に古いコンテナを操作できていたのは、ディレクトリ名が同じだったからなんですね。
Capが日時でディレクトリを切るから、それが転記された「プロジェクト名」が固有のものって感覚が全然なかったよ…(言い訳、責任転嫁)プロジェクト名はちゃんと設定しよう。
ちなみに、コンテナをすべて削除するコマンドはこう。
$ docker rm $(docker ps -qa) -f-fをつけなかった場合は起動中のものは生き残る。
解決策:プロジェクト名の設定方法
というわけでプロジェクト名を設定します。 yamlファイルに直接は書けません。
.envファイル
docker-compose.yamlと同じ場所に置けばOK。
.envCOMPOSE_PROJECT_NAME=hogefuga_projectただ、.envファイルはそうgit pushするものではないし、docker-composeだけが使うものでもないことに注意。
コマンドライン引数
docker-composeコマンドに
-pを付けることで、プロジェクト名を指定できる。docker-compose -p hoge_project upただ、毎回引数にプロジェクト名を付けるのは冗長なので、このコマンド自体を何かに登録する前提だろう。
Capistranoのようなデプロイ自動化スクリプトを使用する場合はどんどん使っていこう。deploy.rbnamespace :container do desc 'Up containers' task :up do on roles(:docker) do execute "cd #{release_path} && docker-compose -p hoge_project up -d" end end end
- 投稿日:2020-02-07T10:33:44+09:00
Docker超入門
業務でも使わないし、ちょっと興味あるけど何かよく分からないけど触ってみたい人向けです。
私自身それなので備忘録として記載します。1.Dockerをインストールしよう
下記サイトからダウンロードするのですが意味わからないですね。。。
https://docs.docker.com/toolbox/toolbox_install_windows/直リンはこちら(DLverはお任せします)
https://github.com/docker/toolbox/releasesWindows10 homeの場合は上記でOKですがWindows10 proであれば下記からDLになります。
https://docs.docker.com/docker-for-windows/install/2.Dockerを起動しよう
コマンドプロンプトで下記コマンドを叩きます。
実行コマンドdocker vesion実行結果Microsoft Windows [Version 10.0.18362.592] (c) 2019 Microsoft Corporation. All rights reserved. C:\Users\01>docker version Client: Version: 19.03.1 API version: 1.40 Go version: go1.12.7 Git commit: 74b1e89e8a Built: Wed Jul 31 15:18:18 2019 OS/Arch: windows/amd64 Experimental: false error during connect: ・・・(略)最終行にエラーが出る場合があります。
直訳するとタイムアウトだったり権限どうのと言ってきます。
その場合は、Dockerを起動してみる。無事クジラが出てくればOK。
それでもダメなら、
コマンドプロンプトを右クリックし管理者権限で起動してみましょう。
3.Dockerを操作してみよう
3-1.Dockerイメージの取得と確認
実行コマンドdocker pull httpdpullの後に、イメージ名を指定するとインターネット経由でDockerHubから取得しにいきます。
実行結果Using default tag: latest latest: Pulling from library/httpd bc51dd8edc1b: Already exists dca5bc65e18f: Already exists ccac3445152a: Already exists 8515f2015fbc: Already exists e35494488b8c: Already exists Digest: sha256:b783a610e75380aa152dd855a18368ea2f3becb5129d0541e2ec8b662cbd8afb Status: Downloaded newer image for httpd:latest docker.io/library/httpd:latest実行コマンドdocker images実行結果REPOSITORY TAG IMAGE ID CREATED SIZE httpd latest c562eeace183 5 days ago 165MBイメージが格納されたことがわかります。
3-2.Dockerイメージからコンテナを作成しよう
実行コマンドdocker run -d -p 8080:80 --name test_httpd httpd実行結果472e1006396556aec8a2bd9d1c8377fff139ec97b1504d4ea2bfc6c412717acerun;コンテナを起動状態で作成(create;停止状態で作成)
-d;バックグラウンドで起動
-p;ポートフォワーディング。コンテナ外からアクセスする場合は必須(外部8080で受けてコンテナの80に転送)
--name;指定しないとDockerが勝手に決めてしまうので自身の分かりやすい名前を
httpd;取得したイメージ名を指定(centosとか)実行コマンドdocker ps実行結果CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 472e10063965 httpd "httpd-foreground" 8 seconds ago Up 8 seconds 0.0.0.0:8080->80/tcp test_httpdSTATUSに「Up」が表示されていればOKです。
3-3.インターネットブラウザからコンテナにアクセスしてみよう
ここではhttpdが起動しているコンテナ。確認で使うブラウザはchromeを推奨します。
実行URLhttp://localhost:8080解説サイトや本にはlocalhostを指定しているのですがWindows proだといけるんでしょうか?
私(home)はアクセスができなっかったので下記コマンドでDockerのIPを調べました。起動したてのクジラのプロンプトにも表示されてますね。
管理者権限のコマンドプロンプトでは「Error getting IP address: Host is not running」と帰ってきたので通常のプロンプトかクジラのプロンプトで試してみてください。実行コマンドdocker-machine ip実行結果192.168.99.100実行URLhttp://192.168.99.100:8080/実行結果
3-3-1.コンテナ内に入ってみる
実行コマンドdocker exec -it test_httpd /bin/bash「root@472e10063965:/usr/local/apache2#」な感じになっていればOKです。
-it;標準入力と接続を維持する?みたいな
bash;bash使って入る適当なコマンドを実行してみましょう。
実行コマンドls -l実行結果total 40 drwxr-xr-x 2 root root 4096 Feb 2 00:15 bin drwxr-xr-x 2 root root 4096 Feb 2 00:15 build drwxr-xr-x 2 root root 4096 Feb 2 00:15 cgi-bin drwxr-xr-x 4 root root 4096 Feb 2 00:15 conf drwxr-xr-x 3 root root 4096 Feb 2 00:15 error drwxr-xr-x 2 root root 4096 Feb 2 00:15 htdocs drwxr-xr-x 3 root root 4096 Feb 2 00:15 icons drwxr-xr-x 2 root root 4096 Feb 2 00:15 include drwxr-xr-x 1 root root 4096 Feb 7 01:59 logs drwxr-xr-x 2 root root 4096 Feb 2 00:15 modules3-3-2.コンテナ内のファイルをいじってみる。
ディレクトリを移動してindexファイルを編集してみましょう。
実行コマンドcd /usr/local/apache2/htdocs/実行コマンドvim index.html実行結果bash: vim: command not foundおそらく上記のようになり実行できないと思います。その場合は下記コマンドを実行しvim自体を入れてあげましょう。
実行コマンドapt-get update apt-get install vim実行コマンドvim index.html今度は編集画面にいけると思います。
i;インサートモード
:wq;編集を保存し終了再度、ブラウザよりアクセスしてみましょう。
表示が変わらないようであれば「Ctrl+F5」で更新してみて下さい。実行URLhttp://192.168.99.100:8080/3-3-3.コンテナから出る
exit3-4.コンテナを停止する
実行コマンドdocker stop test_httpd名前を指定していますがコンテナIDでも大丈夫です。
実行結果test_httpd停止確認docker ps -a実行結果CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 472e10063965 httpd "httpd-foreground" 28 minutes ago Exited (0) 4 seconds ago test_httpdSTATUSに「Exited」(終了しました)と表示されていればOKです。
3-5.コンテナを削除する
実行コマンドdocker rm test_httpd実行結果test_httpd削除ができない旨エラーが出た場合は下記コマンドを実行してみましょう
Error response from daemon: You cannot remove a running container 472e10063965・・・(略). Stop the container before attempting removal or force remove docker rm -f test_httpd実行結果472e10063965削除確認docker ps -a実行結果CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES何も表示されなければOKです。
3-6.イメージを削除する
実行コマンドdocker rmi httpd実行結果Untagged: httpd:latest Untagged: httpd@sha256:b783a610e75380aa152dd855a18368ea2f3becb5129d0541e2ec8b662cbd8afb Deleted: sha256:c562eeace183d5be6dddf120b115290f4d803e5cfc023b31e76992678b5426c4 Deleted: sha256:4c1e1a8ae779e04b096b6ec82fd052b82b56d9a93fa1105b9eb316c5bf07849e Deleted: sha256:977c52f43c25c20b67b50873c74f00cdf76215cf2b1a37e58348740df75e2a66 Deleted: sha256:7fddd9b19d8b29b7aaee5ebef26176dce7464a6b85e517401f365d693157e505 Deleted: sha256:1620bdc7bd85ab5e753b58a7e648f46a883108e9bc410560d4558c780cf13ffd Deleted: sha256:488dfecc21b1bc607e09368d2791cb784cf8c4ec5c05d2952b045b3e0f8cc01e削除確認docker images実行結果REPOSITORY TAG IMAGE ID CREATED SIZE何も表示されなければOKです。




- 投稿日:2020-02-07T09:35:50+09:00
Dockerの基本的な概念について書く
はじめに
社内でDockerの読書会を定期的に行っていました。
初心者が多い読書会にて自分たちが理解しにくかったことを記述します。
ここでは、以下の事項を記述します。
- コンテナ型仮想化について
- Dockerのイメージについて
- コンテナのライフサイクルについて
コンテナ型仮想化について
書籍でのコンテナ型仮想化技術の説明では、ホスト型仮想化技術と一緒に取り上げられることが多いと感じます。
読書会では仮想化技術の簡単なイメージがまったくなければ、説明を呼んでもピンとこない場合がありました。
そこで、仮想化技術、ホスト型仮想化技術について簡単に記述した後、コンテナ仮想化技術について説明します。仮想化についてのイメージ
仮想化とは1台の物理サーバ(あるいはPC)の中に、あたかも別のサーバを稼働させることを指します。
基本的には1台のPCにOSは1つしかありません。仮想化技術を使うと、1台のPC上に複数のOSを稼働させることができ、またそれらのOS上でもアプリケーションを稼働させることができます。
物理サーバのOSをホストOSと呼ばれ、仮想化技術を用いたOSはゲストOSと呼ばれます。
仮想化技術を用いて作成された環境を仮想環境といい、仮想環境は論理的に区画されており、環境が隔離されているように見えます。
余談ですが、仮想環境との疎通確認や、通信、ネットワークを考える時には、常に仮想環境が隔離されていることを認識しておかないと、ハマることが読書会では多かったです。ホスト型仮想化技術について
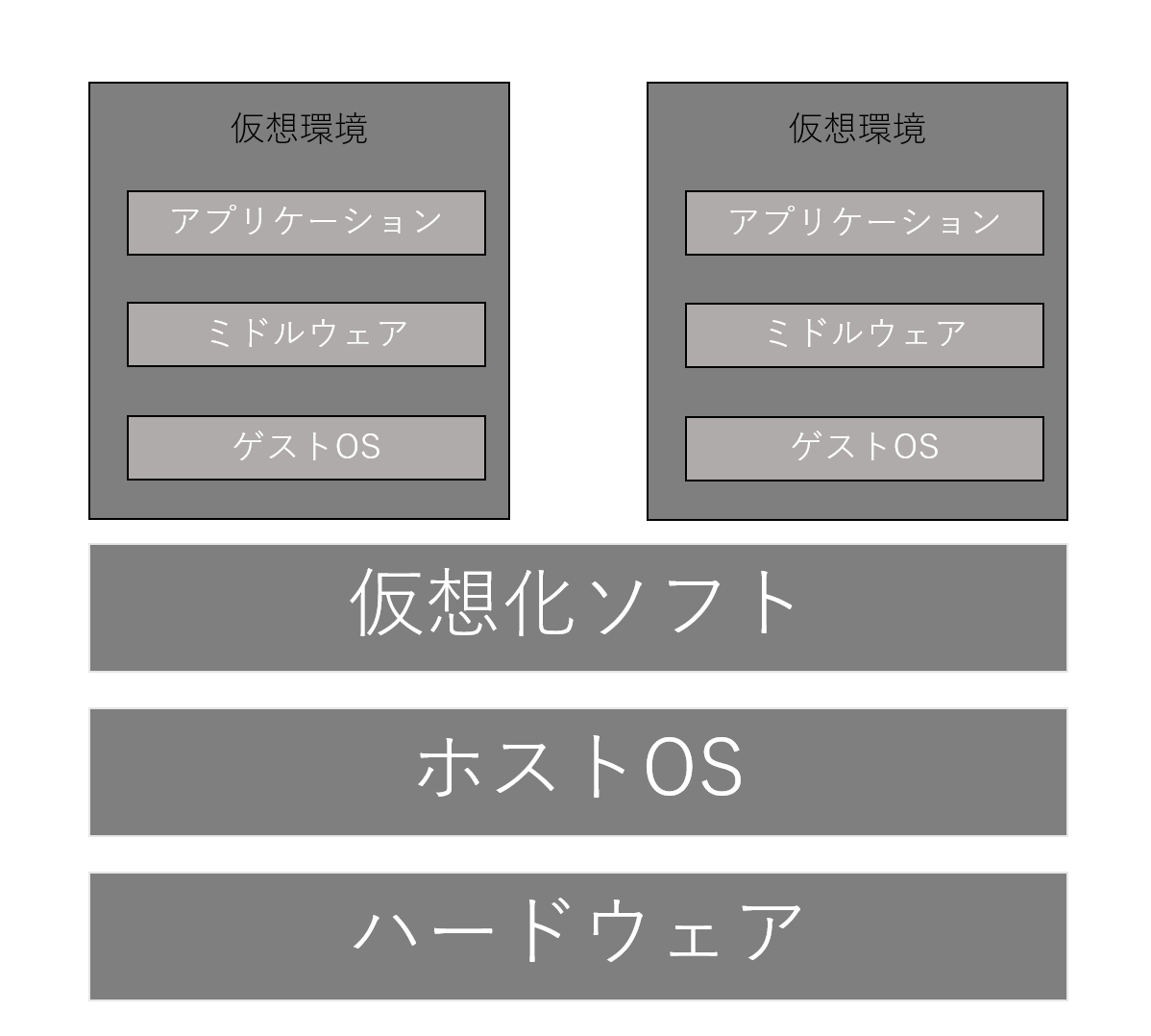
ホスト型サーバ仮想化技術は、ホストOSに仮想化ソフトウェアをインストールし、その仮想化ソフトウェア上でゲストOSを動作させる技術を指します。
仮想化ソフトには「Oracle VM VirtualBox」、「Vmware Workstation Player」などがあります。構成としては以下の図のようになります。
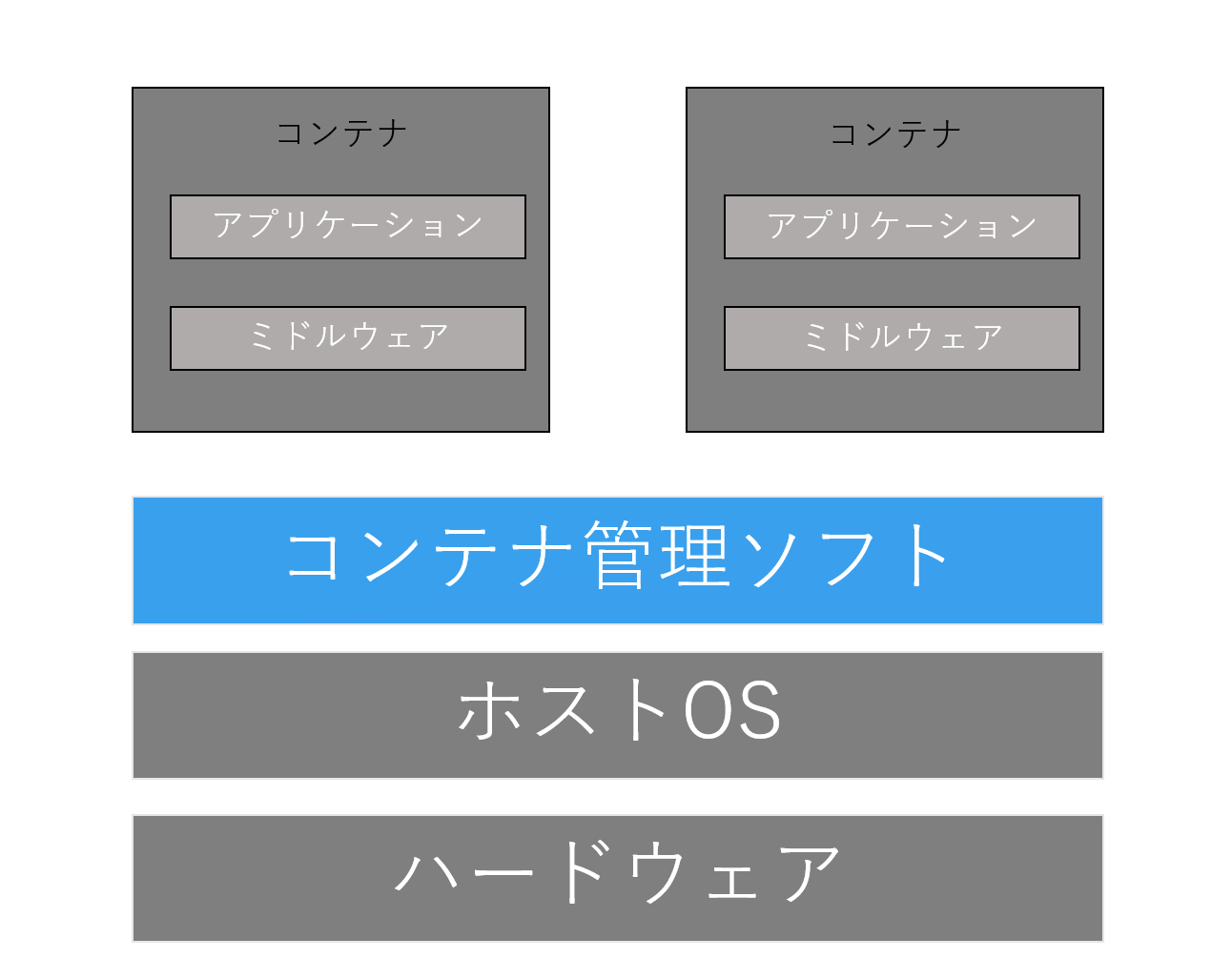
コンテナ型仮想化技術について
まず、コンテナとは何か。「プログラマのためのDocker教科書 第2版」から引用すると、
コンテナとはホストOS上に論理的な区画を作り、アプリケーションを動作させえるのに必要なライブラリやアプリケーションなどを1つにまとめ、あたかも個別のサーバのように使うことができるようにしたもの.
この説明だけではコンテナについて理解できるわけではなかったのですが、「Docker/Kubernetes 実践コンテナ開発入門」では以下のように説明があり、
「コンテナとはDockerによって作成されるゲストOS」
と捉えた上であれば理解しやすいかもしれません。
我々初心者が手っ取り早く理解するために、ホスト型にしろ、コンテナ型にしろ、ホストOSとは隔離された仮想環境を構築する点については同じように捉えてもいいと思います。
初学者にとってのホスト型仮想化とコンテナ型仮想化との大きな違いは、軽量で高速な起動・停止ができるどうかだと思います。
コンテナを使用した仮想化システムは、ホスト型に比べて明らかに環境構築がスムーズで、簡単な操作で実行環境を起動することができます。コンテナ仮想化の構成を以下の図に示します。
Dockerの操作について
読書会では、Dockerの操作(イメージ作成~コンテナの破棄まで)について序盤で取り扱ったものの、操作に対して理解がしにくいという声をもらいました。
掘り下げていくと、Dockerのイメージ、コンテナのライフサイクルについて理解が浅いことがわかりました。Dockerの操作を初めて学習する方、あるいは操作について理解が浅い方向けに、イメージ、コンテナのライフサイクルについて理解する必要があると考え、本節ではそれらの事項について説明します。
Dockerイメージについて
まず、引用から。
「プログラマのためのDocker教科書 第2版」では、下記の通りに説明しています。Dockerはアプリケーションの実行に必要になるプログラム本体/ライブラリ・ミドルウェアや、OSやネットワークの設定などを1つにまとめてDockerイメージを作ります。Dockerイメージは実行環境で動くコンテナのもと(ひな型)になります。Dockerでは1つのイメージには1つのアプリケーションのみを入れておき、複数のコンテナを組み合わせてサービスを構築するという手法が推奨されています。
また、「Docker/Kubernetes 実践コンテナ開発入門」では、DockerイメージとDockerコンテナの役割について端的に説明しています。
Dockerイメージ:Dockerコンテナを構成するファイルシステムや実行するアプリケーションや設定をまとめたもので、コンテナを作成するための利用されるテンプレートとなるもの。
Dockerコンテナ:Dockerイメージをもとに作成され、具現化されたファイルシステムとアプリケーションが実行されている状態。これらをざっくりまとめてみると、イメージとは、Dockerを使用したアプリケーション(コンテナ)を実行する前に、実行に必要となるリソース(ファイルシステム、ライブライリ等)を集めたテンプレートみたいなもの。
「イメージというテンプレを作ると、それ通りにアプリケーションが実行される」みたいな認識をすると、理解しやすいのではないでしょうか。コンテナのライフサイクル
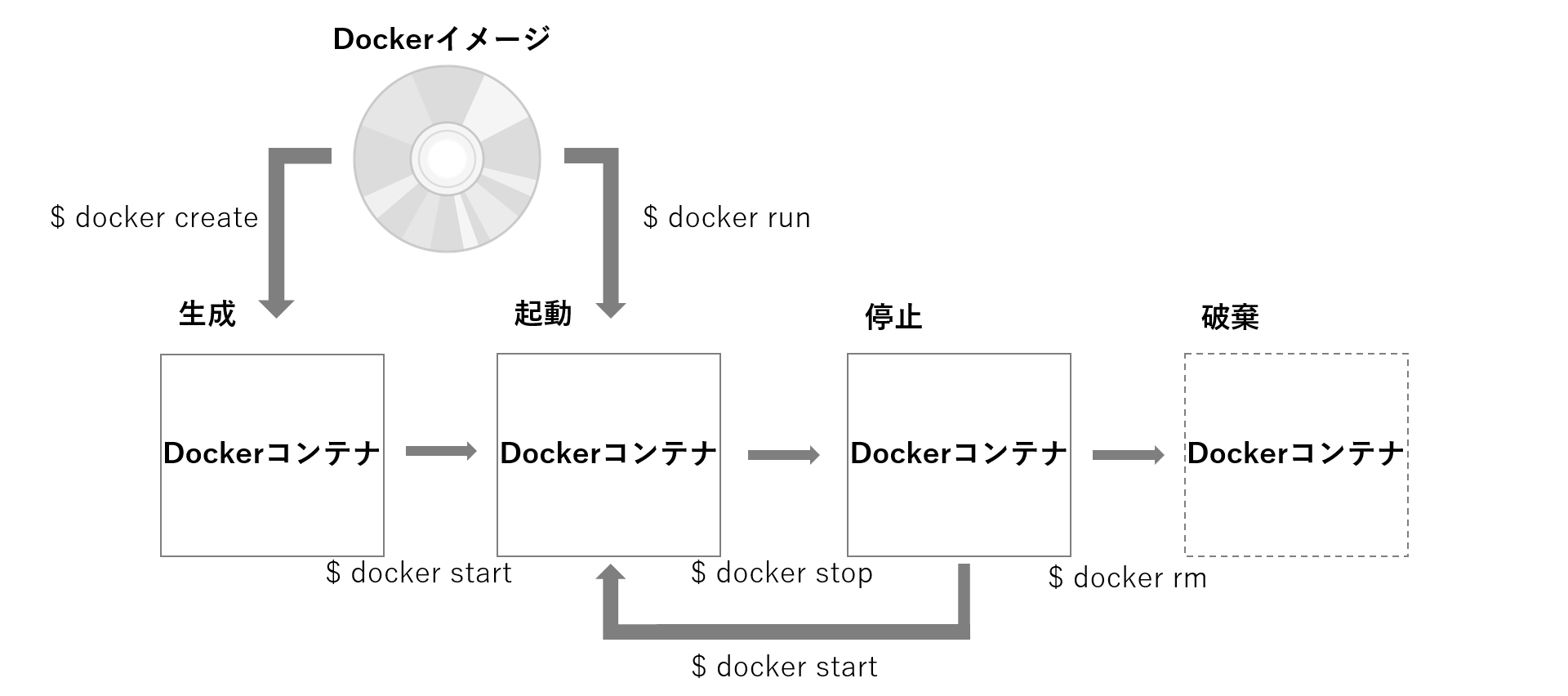
コンテナのライフサイクル(状態遷移)は以下の図のようになります。
※
docker runコマンドではコンテナを生成して起動までしていますDockerイメージを作成すると、コンテナを生成あるいは起動できるようになります。コンテナの生成と起動の大きな違いは、コンテナ上にある何らかのプロセスが実行されるどうかです。
コンテナのライフサイクルを理解すると、コンテナの簡単な操作のイメージがしやすいと思います。
参考文献
- 投稿日:2020-02-07T09:35:50+09:00
Docker初学者が理解しにくかったことをまとめる
はじめに
社内でDockerの読書会を定期的に行っていました。
初心者が多い読書会にて自分たちが理解しにくかったことを記述します。
ここでは、以下の事項を記述します。
- コンテナ型仮想化について
- Dockerのイメージについて
- コンテナのライフサイクルについて
コンテナ型仮想化について
書籍でのコンテナ型仮想化技術の説明では、ホスト型仮想化技術と一緒に取り上げられることが多いと感じます。
読書会では仮想化技術の簡単なイメージがまったくなければ、説明を呼んでもピンとこない場合がありました。
そこで、仮想化技術、ホスト型仮想化技術について簡単に記述した後、コンテナ仮想化技術について説明します。仮想化についてのイメージ
仮想化とは1台の物理サーバ(あるいはPC)の中に、あたかも別のサーバを稼働させることを指します。
基本的には1台のPCにOSは1つしかありません。仮想化技術を使うと、1台のPC上に複数のOSを稼働させることができ、またそれらのOS上でもアプリケーションを稼働させることができます。
物理サーバのOSをホストOSと呼ばれ、仮想化技術を用いたOSはゲストOSと呼ばれます。
仮想化技術を用いて作成された環境を仮想環境といい、仮想環境は論理的に区画されており、環境が隔離されているように見えます。
余談ですが、仮想環境との疎通確認や、通信、ネットワークを考える時には、常に仮想環境が隔離されていることを認識しておかないと、ハマることが読書会では多かったです。ホスト型仮想化技術について
ホスト型サーバ仮想化技術は、ホストOSに仮想化ソフトウェアをインストールし、その仮想化ソフトウェア上でゲストOSを動作させる技術を指します。
仮想化ソフトには「Oracle VM VirtualBox」、「Vmware Workstation Player」などがあります。構成としては以下の図のようになります。
コンテナ型仮想化技術について
まず、コンテナとは何か。「プログラマのためのDocker教科書 第2版」から引用すると、
コンテナとはホストOS上に論理的な区画を作り、アプリケーションを動作させえるのに必要なライブラリやアプリケーションなどを1つにまとめ、あたかも個別のサーバのように使うことができるようにしたもの.
この説明だけではコンテナについて理解できるわけではなかったのですが、「Docker/Kubernetes 実践コンテナ開発入門」では以下のように説明があり、
「コンテナとはDockerによって作成されるゲストOS」
と捉えた上であれば理解しやすいかもしれません。
我々初心者が手っ取り早く理解するために、ホスト型にしろ、コンテナ型にしろ、ホストOSとは隔離された仮想環境を構築する点については同じように捉えてもいいと思います。
初学者にとってのホスト型仮想化とコンテナ型仮想化との大きな違いは、軽量で高速な起動・停止ができるどうかだと思います。
コンテナを使用した仮想化システムは、ホスト型に比べて明らかに環境構築がスムーズで、簡単な操作で実行環境を起動することができます。コンテナ仮想化の構成を以下の図に示します。
Dockerの操作について
読書会では、Dockerの操作(イメージ作成~コンテナの破棄まで)について序盤で取り扱ったものの、操作に対して理解がしにくいという声をもらいました。
掘り下げていくと、Dockerのイメージ、コンテナのライフサイクルについて理解が浅いことがわかりました。Dockerの操作を初めて学習する方、あるいは操作について理解が浅い方向けに、イメージ、コンテナのライフサイクルについて理解する必要があると考え、本節ではそれらの事項について説明します。
Dockerイメージについて
まず、引用から。
「プログラマのためのDocker教科書 第2版」では、下記の通りに説明しています。Dockerはアプリケーションの実行に必要になるプログラム本体/ライブラリ・ミドルウェアや、OSやネットワークの設定などを1つにまとめてDockerイメージを作ります。Dockerイメージは実行環境で動くコンテナのもと(ひな型)になります。Dockerでは1つのイメージには1つのアプリケーションのみを入れておき、複数のコンテナを組み合わせてサービスを構築するという手法が推奨されています。
また、「Docker/Kubernetes 実践コンテナ開発入門」では、DockerイメージとDockerコンテナの役割について端的に説明しています。
Dockerイメージ:Dockerコンテナを構成するファイルシステムや実行するアプリケーションや設定をまとめたもので、コンテナを作成するための利用されるテンプレートとなるもの。
Dockerコンテナ:Dockerイメージをもとに作成され、具現化されたファイルシステムとアプリケーションが実行されている状態。これらをざっくりまとめてみると、イメージとは、Dockerを使用したアプリケーション(コンテナ)を実行する前に、実行に必要となるリソース(ファイルシステム、ライブライリ等)を集めたテンプレートみたいなもの。
「イメージというテンプレを作ると、それ通りにアプリケーションが実行される」みたいな認識をすると、理解しやすいのではないでしょうか。コンテナのライフサイクル
コンテナのライフサイクル(状態遷移)は以下の図のようになります。
※
docker runコマンドではコンテナを生成して起動までしていますDockerイメージを作成すると、コンテナを生成あるいは起動できるようになります。コンテナの生成と起動の大きな違いは、コンテナ上にある何らかのプロセスが実行されるどうかです。
コンテナのライフサイクルを理解すると、コンテナの簡単な操作のイメージがしやすいと思います。
参考文献
- 投稿日:2020-02-07T00:25:11+09:00
コード書いたことないPdMやPOに捧ぐ、Rails on Dockerハンズオン vol.3 - Scaffold, RESTful, MVC -
この記事はなにか?
この記事は私が社内のプログラミング未経験者、ビギナー向けに開催しているRuby on Rails on Dockerハンズオンの内容をまとめたものです。ていうかこの記事を基にそのままハンズオンします。ハンズオンは
1回の内容は喋りながらやると大体40~50分くらいになっています。お昼休みに有志でやっているからです。
現在進行形なので週1ペースで記事投稿していけるように頑張ります。
ビギナーの方のお役にたったり、同じように有志のハンズオンをしようとしている人の参考になれば幸いです。
他のハンズオンへのリンク
・ Vol.1 - Introduction -
・ Vol.2 - Hello, Rails on Docker -
・ Vol.3 - Scaffold, RESTful, MVC -
$,#,>について
$: ローカルでコマンドを実行するときは、頭に$をつけています。
#: コンテナの中でコマンドを実行するときは、頭に#をつけています。
>: Rails console内でコマンド(Rubyプログラム)を実行するときは、頭に>をつけています。
はじめに
第三回目の今回は、Railsの便利機能を使って簡単なWebアプリケーションを作ってみようと思います。
また、Railsアプリでとても大切な『RESTful』や『MVC』について紹介していきます。ScaffoldでRailsアプリを作ってみる
ScaffoldはRailsの強力な機能の一つで、数コマンドでRails appを作成することができます。
一方で、数コマンドであまりにも多くのことがなされてしまうので勉強する上では頭が混乱してしまうかもしれません。
ただ、Railsアプリの基本がつまったものですので、一度触ってみましょう!User管理アプリを作る
Scaffoldを使って、Userを管理するアプリを作ってみます。
まず、webコンテナを立ち上げて、コンテナ内に入って操作していきましょう。$ docker-compose up -d $ docker-compose exec web ash
docker-compose exec <service> <command>は<service>で<command>を実行するコマンドです。ashはalpine linuxのシェルです。シェルというとbashやzshなどが思い浮かぶと思いますが、alpine linuxではashです。これでコンテナの中に入れたかと思います。今までローカルでコマンドを実行するときは
$を頭につけていましたが、コンテナ内でコマンドを実行するときは#をつけるようにします。#がついている場合は、上のコマンドを実行してコンテナ内に入っていると思ってください。何も言わずに以下のコマンドを実行してみましょう。
# rails generate scaffold user name:string email:string # rails db:migrateこれだけですでに以下のようなアプリができています。 http://localhost:3000/users にアクセスしてみて確かめてみてください。↓のようなアプリが出来上がっているはずです。
色々と触ってみてください。たった2コマンドでこのアプリができちゃうの強すぎませんか?笑ではまずコマンドの説明をしておきます。
rails generate scaffold model_name [field:type...field:type]
rails generate scaffoldはScaffoldでRailsアプリを作成するコマンドです。generateはgと省略できます。ちなみにScaffoldは『足場』と和訳されます。Scaffoldは、1つのModelに対してRESTful(後述)なWebアプリケーションを作成します。
model_nameにはそのModelの名前を入力します。慣習的にModelの名前は単数形を用います。
さらにfield(属性)とtype(型)を定義します。この組み合わせは複数定義できます。このコマンドを叩くだけで、そのModelの生成だけでなくRESTfulなアプリケーションに必要な全てのファイルが生成されるわけです。
具体的にはこの後で説明していきます。rails db:migrate
rails generate scaffoldだけで必要なファイルは生成されているのですが、Databaseへの反映(Tableの作成)がまだできていません。
rails db:migrateはマイグレーションファイルと呼ばれるファイルの内容に沿ってDatabaseを操作するためのコマンドです。先ほどの
rails generate scaffoldで作成されたファイルの中にマイグレーションファイルも含まれています。マイグレーションファイルはrails generate scaffoldで定義したfield:typeに合わせて生成されています。(マイグレーションファイルは次回のハンズオンで触れます)さて、Scaffoldで作成したRailsアプリを色々と触っていただいたかと思いますが、Railsアプリには重要な考え方やアーキテクチャとして『RESTful』と『MVC』があります。これらについて紹介しますね。
RESTful
RESTという言葉をご存知でしょうか?よくREST APIとか言われますよね。
RESTは『REpresentational State Transfer』の略で、『Fielding Dissertation: CHAPTER 5: Representational State Transfer (REST)』で言及されています。Wikipediaによると以下の設計原則を持っています。
- ステートレスなクライアント/サーバプロトコル
- すべての情報(リソース)に適用できる「よく定義された操作」のセット
- リソースを一意に識別する「汎用的な構文」
- アプリケーションの情報と状態遷移の両方を扱うことができる「ハイパーメディアの使用」
少し表現が難しいっすね。これはあくまでAPIで用いられる設計原則なのですが、RailsはこのRESTの原則にそってシステムを作れるということで
RESTfulと表現されますね。1. ステートレスなクライアント/サーバプロトコル
基本的にステートレスです。サーバー側でクライアントとのステート(状態)を管理せず、同じリクエストであれば同じ結果がいつでも返ってくるように設計することでステート管理の煩わしさをなくしています。
2. すべての情報(リソース)に適用できる「よく定義された操作」のセット
リソースに操作が定義されている...
RESTではROA(Resource Oriented Architecture)を原則としています。リソースを中心に考えるとそれに対する操作とはいわゆるCRUD(Create/Read/Update/Delete)であるといえます。REST APIではHTTPメソッドのPOST/GET/PATCH(PUT)/DELETEをそれに対応させて定義しています。
RailsでもROAを原則としてアプリを設計していくことが理想です。3. リソースを一意に識別する「汎用的な構文」
汎用的な構文...なんだこれもうわかりにくくないだろうか。
これは、例えばユーザーモデルであれば/usersのパスで操作ができる、商品モデルなら/purchasesのパスで操作できる、って感じです。4. アプリケーションの情報と状態遷移の両方を扱うことができる「ハイパーメディアの使用」
もうなんともですね。笑
これはHTTPとか使いましょう。って話です。まとめると以下のような図になると思ってます。
このように、「URL」で「リソース」を指定し「HTTPメソッド」で「操作(CRUD)」を指定するイメージですね。
大切な考え方として「リソース」が主軸にあるということを抑えましょう。先ほどScaffoldで生成したアプリケーションをみてみても
Userモデルを作成して、参照して、更新して、削除する、アプリケーションでした。アプリケーションを考える上でも、このRESTfulを念頭におきながらアーキテクトするとRailsで超絶作りやすくなりますね。MVC
MVCはModel、View、Controllerの頭文字をとったもので、Webアプリケーションアーキテクチャの1つです。
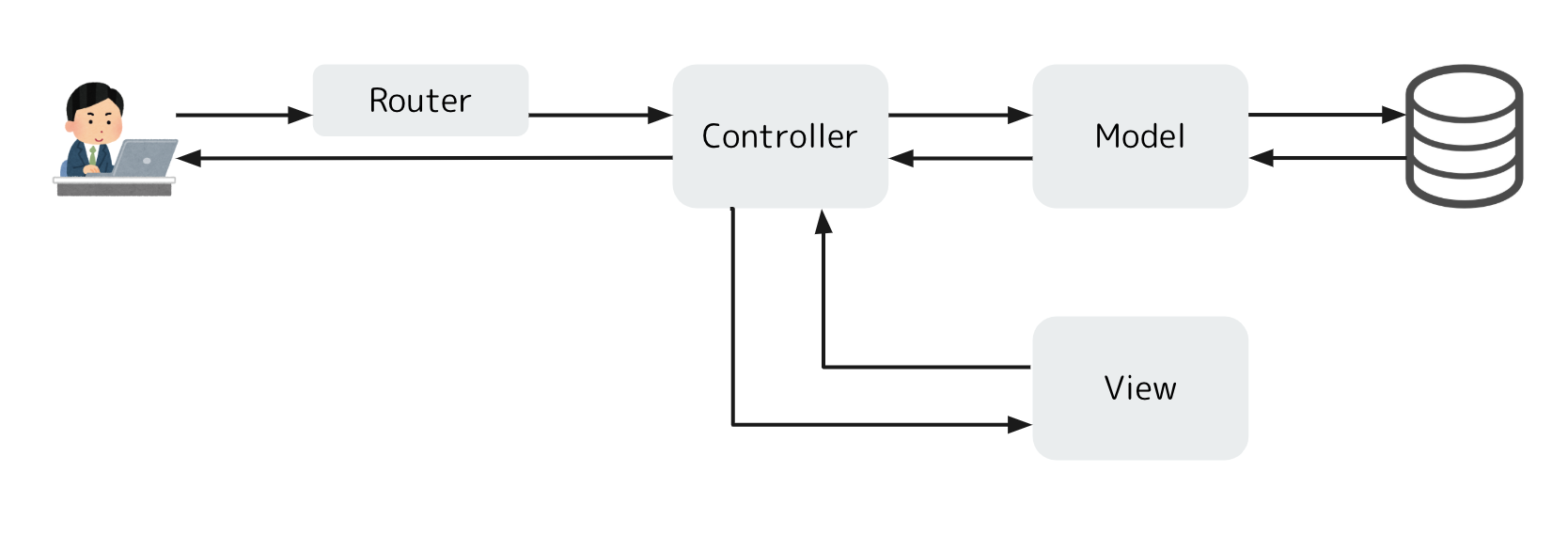
Model: リソース、ロジックView: 画面表示、表現Controller: 入力の受け取りに合わせてModelとViewを使う司令塔Railsは以下のアーキテクチャになっています。
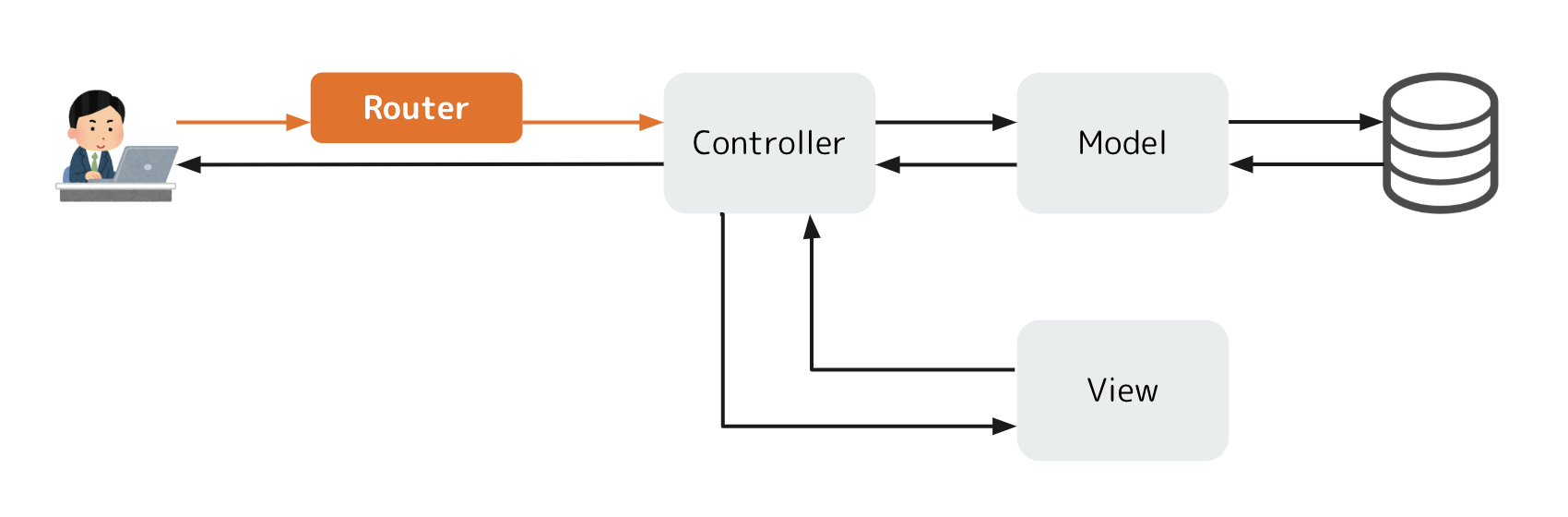
Controllerの前にRouterがいますが、MVCの形をとっていることがわかると思います。処理を順を追って紹介していきますね。Routing
ユーザーからリクエストを受け取ると、RailsアプリケーションのRouterはそのHTTPメソッドとパスから定義に合わせてController(のAction)に処理を渡してくれます。リソースを処理
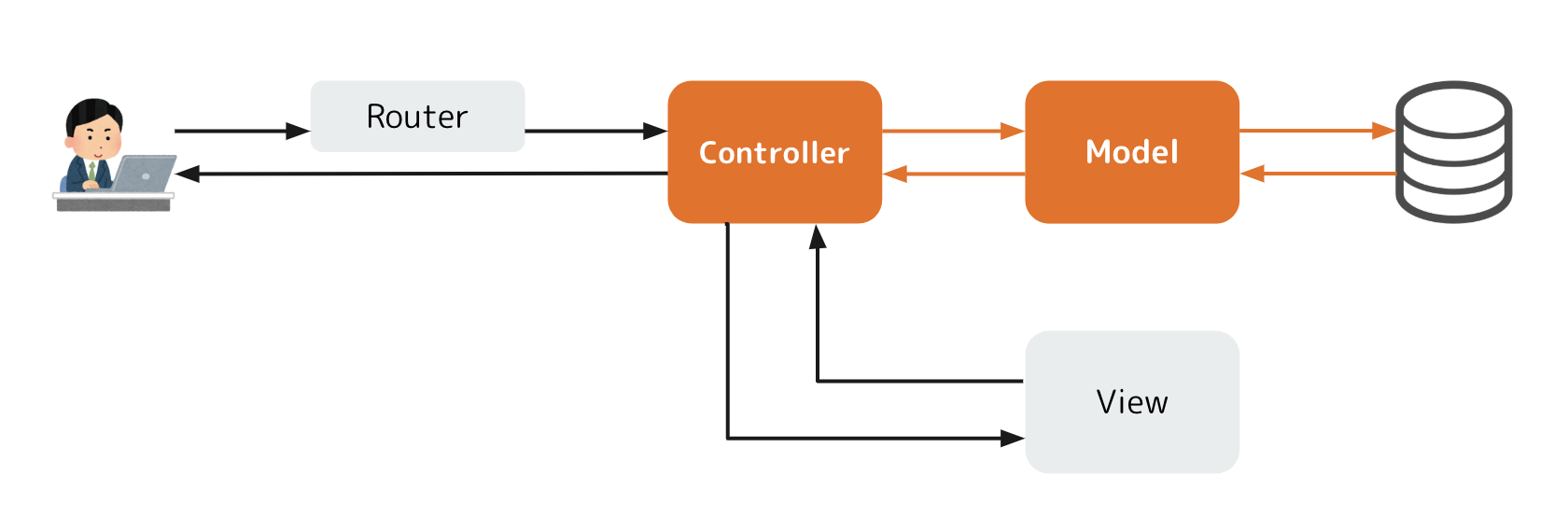
リクエストを受け取ったControllerはデータの操作が必要な場合はModelに指示を出します。例えば、『ID=1のユーザーのモデルオブジェクトをくれ!』みたいなやつです。ModelはそれにしたがってDBを更新したりオブジェクトを検索してControllerに返してあげます。画面をお返し
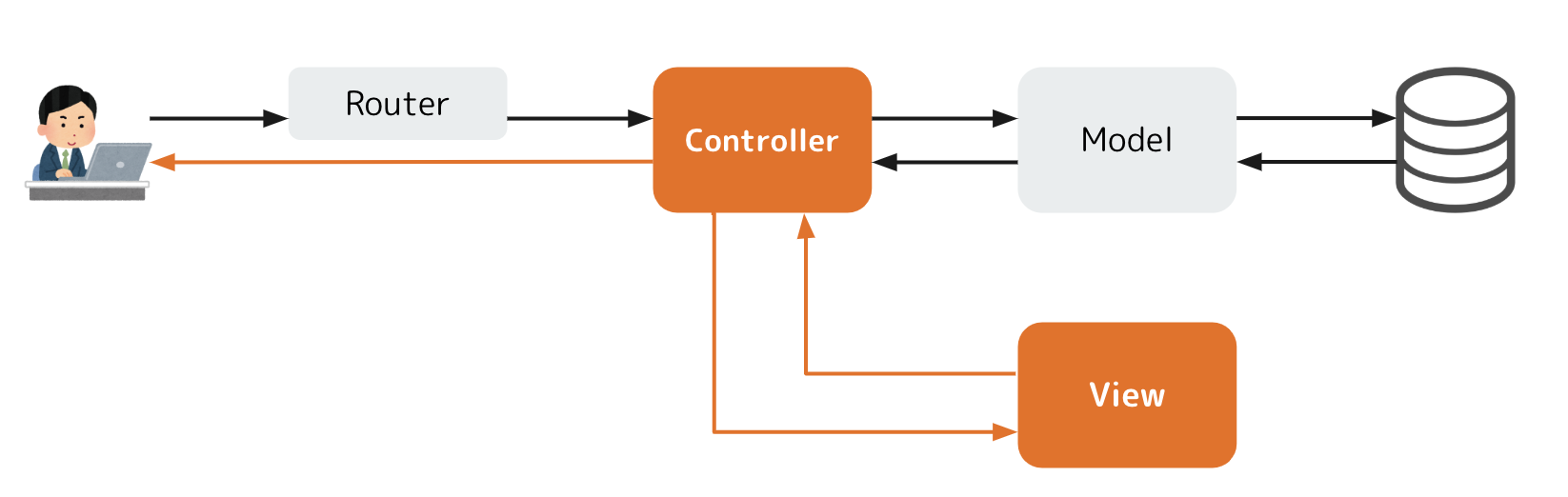
Controllerはその後、Viewに画面をレンダリングするように指示を出します。この時、先ほどゲットしたModelの情報などもViewに渡し、Viewはその情報も元にして画面を整形してControllerに返却します。
ControllerはユーザーにViewを渡してあげて、ユーザーのブラウザがそれを表示してくれます。これらがMVCの、そしてRailsの一連の処理の流れになります。こうやってみるととてもシンプルですよね。MVCがそれぞれ独立したことにより、コードの管理も簡単だし、どこに何をやらせればいいのかもシンプルに考えられるようになると思います。
RailsのMVCをScaffoldで確認する
RailsのScaffoldはRailsを体現したようなやつなんですよ。なんで当然MVCなわけですね。
てことでScaffoldのソースコードを少し覗きながらMVCを感じてみましょう!Router
Routerの設定はconfig/routes.rbに書きます。覗いてみましょー!config/routes.rbRails.application.routes.draw do resources :users endえ、超シンプルやん。はい、
resouces [controller_name]でそのControllerに対してRailsアプリケーションで標準的に必要とされるルーティングを全て生成してくれちゃう便利なメソッドです。実際に以下のルーティングを生成してくれちゃいます。
HTTP method Path Routing Route name GET /users users#index users POST /users users#create users GET /users/new users#new new_user GET /users/:id/edit users#edit edit_user GET /users/:id users#show user PATCH /users/:id users#update user PUT /users/:id users#update user DELETE /users/:id users#destroy user 見方ですが、例えば1行目であれば
『GETメソッドで/usersにアクセスされた場合、UsersControllerのindex actionにルーティングする。Rails内ではusers_pathって名前で定義される』
って感じです。「名前で定義される」ってなんぞ?となると思いますが、この後でてきます。例えばリンク(<a>)を作る時にRailsではlink_toヘルパーが使えるのですがその遷移先としてuser_pathと指定すれば/usersと解釈してくれるんです。これ結構便利なんですよねー。RailsのRouting設定はコマンドラインから確認することができるっす。
# rails routes Prefix Verb URI Pattern Controller#Action users GET /users(.:format) users#index POST /users(.:format) users#create new_user GET /users/new(.:format) users#new edit_user GET /users/:id/edit(.:format) users#edit user GET /users/:id(.:format) users#show PATCH /users/:id(.:format) users#update PUT /users/:id(.:format) users#update DELETE /users/:id(.:format) users#destroy ...上の表とおんなじ感じになっていることがわかりますね。
Controller
さて、RouterによってControllerのActionにリクエストがルーティングされましたんで、Controllerの中身を覗いてみましょう!
Controllerのソースコードはapp/controller/配下にまとまっています。今回はuserモデルを作ったのでusers_controller.rbファイルが生成されていますね。Controllerはその中に複数のactionがあることからusersのように複数形で名前づけされるルールになってますので気をつけてください!app/controller/users_controller.rbclass UsersController < ApplicationController before_action :set_user, only: [:show, :edit, :update, :destroy] def index @user = User.all end def show end def new @user = User.new end def edit end def create @user = User.new(user_params) respond_to do |format| if @user.save format.html { redirect_to @user, notice: 'User was successfully created.' } format.json { render :show, status: :created, location: @user } else format.html { render :new } format.json { render json: @user.errors, status: :unprocessable_entity } end end end def update respond_to do |format| if @user.update(user_params) format.html { redirect_to @user, notice: 'User was successfully updated.' } format.json { render :show, status: :ok, location: @user } else format.html { render :edit } format.json { render json: @user.errors, status: unprocessable_entity } end end end def destroy @user.destroy respond_to do |format| format.html { redirect_to users_url, notice: 'User was successfully destroyed.' } format.json { head :no_content } end end private def set_user @user = User.find(params[:id]) end def user_params params.require(:user).permit(:name, :email) end endながいっすね。重要なところだけかいつまんで説明します。
まず、def xxx ... endとなってるブロックがいっぱいありますね。defはRubyにおける関数定義です。で、privateより上にある一つ一つがActionと呼ばれているやつらです。ちょうど先ほどRouterで定義されていたアクションが全てあるのがわかりますね。その中で1つ、index actionをみてみましょうか。
app/controllers/users_controller.rb... def index @user = User.all end ...中身一行だけですね。
これは@userにUser.allの結果を代入してますね。User.allはまた今度詳しく説明予定ですが、Userモデルのデータを全てリスト形式で取得するメソッドです。なのでUserモデルを全件検索したものを@userに代入しているんですね。
ここで気になる人がいると思うのですが、@ってなんやねんと。これは、インスタンス変数と呼ばれるものになります。対して@がつかない変数はローカル変数と呼びます。
違いは変数の適用範囲です。簡単にいうとローカル変数はViewに引き渡すことができないのです。対してインスタンス変数はViewに引き渡すことができるのです。MVCの考え方からControllerはViewにModelの情報を引き渡してユーザーに描写する画面を作るので、インスタンス変数を使う必要があるのです。さて、ControllerがModelからデータを受領しているのはここまででなんとかわかると思いますが、Viewの呼び出しはどうやっているのか...
RailsではViewを呼び出すメソッドとしてrenderがあります。users_controller.rbの中にもrenderと書かれているところがありますがないところもあります。これはどういうことか。
実はRailsでは各Actionの最後に暗にActionと同じ名前のViewにrenderをしています。例えばindexアクションの場合は、処理の最後にrender :indexというようなことがなされており、これによってapp/views/users/index.html.erbが呼び出されるようになっています。Model
Modelのソースは
app/models/に作ります。Scaffoldのおかげでuser.rbファイルが生成されていますので中身を覗いてみましょう。app/models/user.rbclass User < ApplicationRecord endApplicationRecordを継承しているので、特に何も書かなくてもDBにアクセスしてCRUDできるようになっています。
追加でバリデーションやロジック(デフォルト値や値の計算など)を書くことができます。(今後やっていきます!)実際にDBに反映されているテーブルの情報はSchemaをみることで確認することができます。
db/schema.rbActiveRecord::Schema.define(version: 2020_01_16_115651) do enable_extention "plpgsql" create_table "users", force: :cascade do |t| t.string "name" t.string "email" t.datetime "created_at", precision: 6, null: false t.datetime "updated_at", precision: 6, null: false end endString型の
name、created_at、updated_atがusersテーブルに作られた感じがわかりますよね。View
Viewのソースは
app/views/{controller_name}/ディレクトリに作成します。app/views/users/index.html.erb<p id="notice"><%= notice %></p> <h1>Users</h1> <table> <thead> <tr> <th>Name</th> <th>Email</th> <th colspan="3"></th> </tr> </thead> <tbody> <% @users.each do |user| %> <tr> <td><%= user.name %></td> <td><%= user.email %></td> <td><%= link_to 'Show', user %></td> <td><%= link_to 'Edit', edit_user_path(user) %></td> <td><%= link_to 'Destroy', user, method: :delete, data: { confirm: 'Are you sure?' } %></td> </tr> <% end %> </tbody> </table> <br> <%= link_to 'New User', new_user_path %>これは
indexアクションが処理をさせるViewです。ほぼHTMLですね。
ファイルは.html.erb拡張子です。.erbはembedded Rubyの意で、Rubyのコードを埋め込めるHTMLファイルです。
Rubyコードの埋め込みの仕方には2種類あります。
- <% code %>: このcodeは実行されますが、結果はレンダリングされません。
- <%= code %>: このcodeは実行され、結果はレンダリングされます。
また、ブロック形式で記述することもできます!
index.html.erbの中でも以下のような表現がありますね。app/views/users/index.html.erb... <% @users.each do |user| %> ... <% end %> ...この表現は、
@users(これはControllerでUser.allが代入されていたやつです。)の配列の中から1つずつ取り出しuserという変数として、endまでの処理をまわすという表現です。はい。ということでScaffoldで作成されたファイルの中身をみながら「へー。RailsはMVCでRESTだなー。」となっていただけましたかね。
と、いうことでせっかく作ったScaffoldですが、便利すぎてお勉強には不向きなところもあるのでリセットして、次回からは1からアプリ開発をしていきたいと思います。
ScaffoldをClean up
rails generateで作成したファイルや追加されたコードのほとんどはrails destroyでもとにもどせます。# rails destroy scaffold userこいつは便利だ。ちなみに
destroyはdと省略することも可能。しかし、
scaffolds.scssだけは消えないのでこれは個別に消してあげて!# rm app/assets/stylesheets/scaffolds.scssまた、DBにはまだテーブルが存在してる状態です。今回は開発環境ですし、データが消えても問題ないのでDBを再作成してclean upしましょう。
# rails db:migrate:resetこのコマンドはDBを削除(
db:drop)してまた作り(db:create)、マイグレーションを適用する(db:migrate)を一度に実行してくれるコマンドです。最初にDBを削除してしまうので本番環境やテストデータを残しておきたい時は絶対に使ってはいけませんよ。まとめ
今回はScaffoldというRailsのアーキテクチャが詰まったアプリを作る機能を紹介しました。
その中でMVCやRESTといったRailsの開発思想が学べましたね。この辺りはアプリのシンプルさを保つためにもぜひものにしておきましょう。次回からは、何回かに分けてTwitterのようなアプリを1からつくってこうと思います。最初は静的なトップページ。
Bootstrap(CSSフレームワーク)を使っていい感じにデザインしてきますよ!では、次回も乞うご期待!ここまでお読みいただきありがとうございました!
Reference
- Ruby on Rails チュートリアル:実例を使って Rails を学ぼう
- Fielding Dissertation: CHAPTER 5: Representational State Transfer (REST)
- Webサービス開発で知っておきたいRESTfulの意味とは? - WPJ
P.S. 間違っているところ、抜けているところ、説明の仕方を変えるとよりわかりやすくなるところなどありましたら、優しくアドバイスいただけると助かります。