- 投稿日:2020-02-07T23:05:52+09:00
Word Cloudが作りたくなったら。
やりたいこと
- 極力少ないステップでWord Cloudを作ること。(1度作ってしまえば充分という時にどうぞ)
ポイント
- 形態素解析を
janomeで実行
MeCabだとpythonから見えるようにするための設定が必要- Word Cloudに利用するフォントの設定
環境
- Windows 10
- python 3.7
Library setup
Anacondaを入れていれば、こんなところで大丈夫でしょうかね:
pip install janome pip install wordcloud環境設定
import pandas as pd from janome.tokenizer import Tokenizer import matplotlib.pyplot as plt from wordcloud import WordCloudデータ読み込みから下準備
- こんなデータ(
sample.csv)を用意します。csvと言っておきつつ、カンマは使っていませんが、、、sample.csvライオンはパンダかもしれない いや、そんなことはない :## データ読み込み df = pd.read_csv('sample.csv', header=None) ## タイトルを付与 df.colums = ['sentences'] ## 関数群の定義 def get_nouns(sentence, noun_list): for token in t.tokenize(sentence): split_token = token.part_of_speech.split(',') ## 一般名詞を抽出 if split_token[0] == '名詞' and split_token[1] == '一般': noun_list.append(token.surface) def depict_word_cloud(noun_list): ## 名詞リストの要素を空白区切りにする(word_cloudの仕様) noun_space = ' '.join(map(str, noun_list)) ## word cloudの設定(フォントの設定) wc = WordCloud(background_color="white", font_path=r"C:/WINDOWS/Fonts/msgothic.ttc", width=300,height=300) wc.generate(noun_space) ## 出力画像の大きさの指定 plt.figure(figsize=(5,5)) ## 目盛りの削除 plt.tick_params(labelbottom=False, labelleft=False, labelright=False, labeltop=False, length=0) ## word cloudの表示 plt.imshow(wc) plt.show()準備が整ったところで実行
## 形態素解析の準備 t = Tokenizer() noun_list = [] for sentence in list(df['sentences']): get_nouns(sentence, noun_list) depict_word_cloud(noun_list)結果
こんなのが出れば成功:

- 投稿日:2020-02-07T22:54:34+09:00
Python の汎用デコレータ(decorator)フレームワークを作る
Python の "デコレータ(decorator)" を作ってみることにします。
汎用的なデコレータの枠組み(フレームワーク)を作成します。
- 引数を渡さないデコレータ
- 引数を渡すデコレータ
- これらを統合した枠組みのデコレータ
を作ります。
最初にデコレータのフレームワーク(ゴール)を提示し、それに向かって作っていきます。デコレータのフレームワーク
この記事は、読み下すように書いている(試行錯誤を繰り返しながらゴールに向かう)のと、長文なので、先にデコレータの書き方(フレームワーク、枠組み)だけ記載しておきます。テストを含めたフルバージョンは最後に記載します。忙しい方は、時間のある時にゆっくりご覧ください。
- ※ 制限事項: デコレータの第1引数に呼び出し可能なオブジェクトを指定できません。
decorator_framework.pyfrom functools import wraps def my_decorator( *args, **kwargs ): # 引数を取らないことが明確なデコレータはここからの部分を # _my_decorator の名前を変えてグローバルで define することも可 def _my_decorator( func ): # _my_decorator_body() を定義する前に必要な処理があれば、ここに書く print( "_my_decorator_body() を定義する前に必要な処理があれば、ここに書 く" ) @wraps(func) def _my_decorator_body( *body_args, **body_kwargs ): # 前処理はここで実行 print( "前処理はここで実行", kwargs, body_args, body_kwargs ) try: # デコレートした本体の実行 ret = func( *body_args, **body_kwargs ) except: raise # 後処理はここで実行 print( "後処理はここで実行", kwargs, body_args, body_kwargs ) return ret # デコレータが記載された時に処理が必要な場合にはここに書く #2 print( "デコレータが記載された時に処理が必要な場合にはここに書く #2" ) return _my_decorator_body # 引数を取らないことが明確なデコレータはここまで # デコレータが記載された時に処理が必要な場合にはここに書く #1 print( "デコレータが記載された時に処理が必要な場合にはここに書く #1" ) if len(args) == 1 and callable( args[0] ): # 引数無しでデコレータが呼ばれた場合はここで処理 print( "No arguments" ) return _my_decorator( args[0] ) else: # 引数ありでデコレータが呼ばれた場合はここで処理 print( "There are some arguments:", args ) return _my_decoratorさらにシンプルに。
decorator_framework.py シンプル版from functools import wraps def my_decorator( *args, **kwargs ): def _my_decorator( func ): # _my_decorator_body() を定義する前に必要な処理があれば、ここに書く @wraps(func) def _my_decorator_body( *body_args, **body_kwargs ): # 前処理はここで実行 try: # デコレートした本体の実行 ret = func( *body_args, **body_kwargs ) except: raise # 後処理はここで実行 return ret # デコレータが記載された時に処理が必要な場合にはここに書く #2 return _my_decorator_body # デコレータが記載された時に処理が必要な場合にはここに書く #1 if len(args) == 1 and callable( args[0] ): # 引数無しでデコレータが呼ばれた場合はここで処理 return _my_decorator( args[0] ) else: # 引数ありでデコレータが呼ばれた場合はここで処理 return _my_decoratorでは、早速デコレータ(decorator)の作成に取り掛かりましょう。
デコレータ(decorator) とは
用語集にはデコレータ(decorator)について、以下のように記載されています。
decorator
(デコレータ) 別の関数を返す関数で、通常、
@wrapper構文で関数変換として適用されます。デコレータの一般的な利用例は、 classmethod() と staticmethod() です。デコレータの文法はシンタックスシュガーです。次の2つの関数定義は意味的に同じものです:
def f(...): ... f = staticmethod(f) @staticmethod def f(...): ...同じ概念がクラスにも存在しますが、あまり使われません。デコレータについて詳しくは、 関数定義 および クラス定義 のドキュメントを参照してください。
(decorator - 用語集 — Python 3.8.1 ドキュメント より引用)
上の引用の例では、
@staticmethodがデコレータです。また、関数定義の項目の記載は次のようになっています。
関数定義は一つ以上の デコレータ 式でラップできます。デコレータ式は関数を定義するとき、関数定義の入っているスコープで評価されます。その結果は、関数オブジェクトを唯一の引数にとる呼び出し可能オブジェクトでなければなりません。関数オブジェクトの代わりに、返された値が関数名に束縛されます。複数のデコレータはネストして適用されます。例えば、以下のようなコード:
@f1(arg) @f2 def func(): passは、だいたい次と等価です
def func(): pass func = f1(arg)(f2(func))ただし、前者のコードでは元々の関数を func という名前へ一時的に束縛することはない、というところを除きます。
(関数定義 - 8. 複合文 (compound statement) — Python 3.8.1 ドキュメント より引用)
デコレータの文法はシンタックスシュガーです
「シンタックスシュガー」という言葉が聞き慣れない方もいるでしょう。簡単に言ってしまえば、複雑な(わかりにくい)記述を簡単な記法に置き換える、あるいはその逆が可能なものを「シンタックスシュガー」と言います。
つまり、デコレータは書き換え可能な置き換え、ということで、他の言語では「マクロ」などと呼んでいるものに近いものになります。(ただし、置き換え方が決まっています)
用語集の引用内の例で考えてみましょう。
例1def f(...): ... f = staticmethod(f)この例1と
例2@staticmethod def f(...): ...この例2が同じものだと書いてあります。どういうことでしょうか。
例1 が行っていることは、
1.f()という関数を定義する。
2. 定義した関数f()(関数オブジェクト) を引数としてstaticmethod()を実行する。
3.staticmethod()からの戻り値を、改めて関数 f にする。
ということになります。これを簡略化して書いたのが例2になり、
@staticmethodを「デコレータ(decorator)」と呼びます。その後、実際に関数
f()が呼び出されると、staticmethod()の戻り値として再定義された関数が呼び出されるという仕組みです。デコレータの構造
@staticmethodは実際に標準で定義されたデコレータなので、サンプルとしては都合が悪いため、以下は@my_decoratorとして話を進めます。上の例だけでわかることがいくつかあります。
- デコレータ
my_decoratorは関数である。(正確には、「呼び出し可能なオブジェクト」)- デコレータ(関数)
my_decorator()は関数オブジェクトを引数とする。- デコレータ(関数)
my_decorator()は、関数を戻り値とする。ということです。
最初の一歩
上でわかったことをコードにすると以下になります。
my_decorator 最初の一歩def my_decorator(func): return func何もせずに、引数で受け取った関数をそのまま返しています。
@を使わない呼び出しは sample 001 のようになります。sample 001>>> def my_decorator_001(func): ... return func ... >>> def base_func(): ... print( "in base_func()" ) ... >>> base_func = my_decorator_001( base_func ) >>> base_func() in base_func() >>>
@を使って、デコレータとして使う場合は、sample 002 のようになります。sample 002>>> def my_decorator_001(func): ... return func ... >>> @my_decorator_001 ... def base_func(): ... print( "in base_func()" ) ... >>> base_func() in base_func() >>>これでは何が起こっているのかわかりませんね。しかし、
@my_decorator_001を入力したところで、継続入力待ちになっているところは注目ポイントです。
my_decorator()の中で、表示を追加してみましょう。sample 003>>> def my_decorator_002(func): ... print( "in my_decorator_002()" ) ... return func ... >>> def base_func(): ... print( "in base_func()" ) ... >>> base_func = my_decorator_002(base_func) in my_decorator_002() >>> base_func() in base_func() >>>次にデコレータを使ってみます。
sample 004>>> def my_decorator_002(func): ... print( "in my_decorator_002()" ) ... return func ... >>> @my_decorator_002 ... def base_func(): ... print( "in base_func()" ) ... in my_decorator_002() >>> base_func() in base_func() >>>
@my_decorator_002を書いたところで関数my_decorator_002()が実行されず、その下のdef base_func():の定義が終わったところでin my_decorator()が表示されています。これは sample 003 でbase_func = my_decorator_002(base_func)を実行したときと同じことが起きている、というのが注目ポイントになります。戻り値の関数は何でもいいのか
これまでは、デコレータの引数に与えられた関数をそのまま return で返していました。
この戻り値の関数は何でもいいのでしょうか。別な関数を返すとどうなるか、まずは、グローバルな関数を使って試してみましょう。
sample 005>>> def global_func(): ... print( "in global_func()" ) ... >>> def my_decorator_005(func): ... print( "in my_decorator_005()" ) ... return global_func ... >>> @my_decorator_005 ... def base_func(): ... print( "in base_func()" ) ... in my_decorator_005() >>> base_func() in global_func() >>>
base_func()を実行することで、問題なくglobal_func()が呼び出されました。
しかし、当然ですが、元のbase_func()は実行されていません。処理を追加して元の関数を実行する
新しい関数を実行しつつ、元の関数を実行することを考えます。
元の関数はデコレータ関数の引数で渡されているので、これを呼び出せば元の関数が実行されます。
sample 006>>> def global_func(): ... print( "in global_func()" ) ... >>> def my_decorator_006(func): ... print( "in my_decorator_006()" ) ... func() # 元の関数の呼び出し ... return global_func ... >>> @my_decorator_006 ... def base_func(): ... print( "in base_func()" ) ... in my_decorator_006() in base_func() # ここで元の関数を呼び出してしまっている >>> base_func() # ※ ここで元の関数を呼び出したい in global_func() >>>元の関数
base_func()は呼び出されましたが、これは、@my_decorator_006が指定されたときです。
base_func()を呼び出したいタイミングは、「※」でbase_func()を呼び出したときです。
つまり、global_func()の中で、base_func()を呼び出したいわけです。少し修正を加えて、
global_func()の中で呼び出せるようにしてみましょう。sample 007>>> # 元の関数を保持しておく ... original_func = None >>> >>> def global_func(): ... global original_func ... print( "in global_func()" ) ... original_func() # オリジナル関数が呼び出されるはず ... >>> def my_decorator_007(func): ... global original_func ... print( "in my_decorator_007()" ) ... original_func = func # 引数に渡された func をグローバル original_func へ ... return global_func ... >>> @my_decorator_007 ... def base_func(): ... print( "in base_func()" ) ... in my_decorator_007() >>> base_func() # ※ ここで元の関数を呼び出したい in global_func() in base_func() >>>少しややこしいですが、グローバル変数
original_funcを用意しておいて、ここに引数で渡されたfuncを保存しておくことで、global_func()から呼び出すことができました。ところが、これでは一つ問題があります。
デコレータを複数の関数に対して使おうとすると、期待通りに動きません。sample 008>>> # 元の関数を保持しておく ... original_func = None >>> >>> def global_func(): ... global original_func ... print( "in global_func()" ) ... original_func() # オリジナル関数が呼び出されるはず ... >>> def my_decorator_007(func): ... global original_func ... print( "in my_decorator_007()" ) ... original_func = func # 引数に渡された func をグローバル original_func へ ... return global_func ... >>> @my_decorator_007 ... def base_func(): ... print( "in base_func()" ) ... in my_decorator_007() >>> @my_decorator_007 ... def base_func_2(): ... print( "in base_func_2()" ) ... in my_decorator_007() >>> base_func() # "in base_func()" が表示されてほしい in global_func() in base_func_2() ← "in base_func()" ではなく "in base_func_2()" が表示された >>> base_func_2() # "in base_func_2()" が表示されてほしい in global_func() in base_func_2() >>>
base_func()の呼び出しで、base_func_2()が実行されてしまいました。
グローバル変数global_funcは一つしかないので、最後に代入されたbase_func_2が実行されています。デコレータを複数回使用できるようにする (1)
デコレータを複数回使用できるようにするために、「クロージャ (Closure)」 の話をします。
次のような
sample_009.pyを見てみましょう。sample_009.py1 def outer(outer_arg): 2 def inner(inner_arg): 3 # outer_arg と inner_arg を出力する 4 print( "outer_arg: " + outer_arg + ", inner_arg: " + inner_arg ) 5 return inner # inner() 関数オブエクトを返す 6 7 f1 = outer("first") 8 f2 = outer("second") 9 10 f1("f1") 11 f2("f2")7行目の
f1 = outer("first")の後に、8行目でf2 = outer("second")を実行します。
それぞれinner関数オブジェクトが代入されますが、10行目のf1("f1")と 11行目のf2("f2")はどうなるでしょう。8行目で
f2 = outer("second")としていますので、4 行目のprint()では、outer_argが"second"になります。10 行目の
f1("f1")と 11行目のf2("f2")の出力は、それぞれouter_arg: second, inner_arg: f1 outer_arg: second, inner_arg: f2となりそうですが……
実行してみると次のようになります。
sample 009>>> def outer(outer_arg): ... def inner(inner_arg): ... # outer_arg と inner_arg を出力する ... print( "outer_arg:", outer_arg, ", inner_arg:", inner_arg ) ... return inner # inner() 関数オブエクトを返す ... >>> f1 = outer("first") >>> f2 = outer("second") >>> >>> f1("f1") outer_arg: first, inner_arg: f1 >>> f2("f2") outer_arg: second, inner_arg: f2 >>>これは、
1.def inner(): ...というinner()関数定義は、outer()関数が呼ばれるたびに「実行」される。
2.inner()関数が定義されている(定義を実行している)時に参照している外側のouter_argは確定して(評価されて) inner によって保持される。
という動きをするためです。これをクロージャ(Closure)と言います。
外側のスコープにある変数は、実行時ではなく、定義時に評価されます。デコレータを複数回使用できるようにするために、これを利用します。
デコレータを複数回使用できるようにする (2)
sample 009 ではグローバル関数を使いましたが、クロージャの機能を使うためにデコレータ関数の内部で関数を定義します。
sample_010.pydef my_decorator_010(func): print( "in my_decorator_010()" ) def inner(): print( "in inner() and calling", func ) func() print( "in inner() and returnd from ", func ) print( "in my_decorator_010(), leaving ..." ) return inner @my_decorator_010 def base_func(): print( "in base_func()" ) @my_decorator_010 def base_func_2(): print( "in base_func_2()" ) base_func() # "in base_func()" が表示されてほしい base_func_2() # "in base_func_2()" が表示されてほしいこれを実行(インタラクティブに入力)してみます。
sample 010>>> def my_decorator_010(func): ... print( "in my_decorator_010()" ) ... def inner(): ... print( "in inner() and calling", func ) ... func() ... print( "in inner() and returnd from ", func ) ... print( "in my_decorator_010(), leaving ..." ) ... return inner ... >>> @my_decorator_010 ... def base_func(): ... print( "in base_func()" ) ... in my_decorator_010() in my_decorator_010(), leaving ... >>> @my_decorator_010 ... def base_func_2(): ... print( "in base_func_2()" ) ... in my_decorator_010() in my_decorator_010(), leaving ... >>> base_func() # "in base_func()" が表示されてほしい in inner() and calling <function base_func at 0x769d1858> in base_func() in inner() and returnd from <function base_func at 0x769d1858> >>> base_func_2() # "in base_func_2()" が表示されてほしい in inner() and calling <function base_func_2 at 0x769d1930> in base_func_2() in inner() and returnd from <function base_func_2 at 0x769d1930> >>>期待通りの結果が得られました。
ここまでを整理すると、デコレータは次のようにコーディングすればよいことがわかりました。
sample 011def my_decorator_011(func): def inner(): # 呼び出し前の処理をここに書く func() # 呼び出し後の処理をここに書く return inner戻り値を返す関数に対するデコレータ
ここまでのデコレータは、
1. 値を返さない
2. 引数がない
という関数に対して使用できました。汎用的なデコレータを作るのであれば、上の2つを満たす必要があります。
戻り値を考慮したプログラムは以下のようになります。
sample_012.pydef my_decorator_012(func): def inner(): # 呼び出し前の処理をここに書く ret = func() # 呼び出し後の処理をここに書く return ret return inner @my_decorator_012 def base_func_1(): print( "in base_func_1()" ) return 1 @my_decorator_012 def base_func_2(): print( "in base_func_2()" ) r1 = base_func_1() print( r1 ) base_func_2()実行結果は以下の通り。
sample 012>>> def my_decorator_012(func): ... def inner(): ... # 呼び出し前の処理をここに書く ... ret = func() ... # 呼び出し後の処理をここに書く ... return ret ... return inner ... >>> @my_decorator_012 ... def base_func_1(): ... print( "in base_func_1()" ) ... return 1 ... >>> @my_decorator_012 ... def base_func_2(): ... print( "in base_func_2()" ) ... >>> r1 = base_func_1() in base_func_1() >>> print( r1 ) 1 >>> base_func_2() in base_func_2() >>>戻り値がない場合 (
base_func_2()) でも動作しました。引数を取る関数に対するデコレータ
参照: parameter - 用語集 — Python 3.8.1 ドキュメント
関数の引数は、可変長位置パラメータと可変長キーワードパラメータによって、引数の個数、キーワード指定が定まらないものを仮引数として受け取ることができます。
def func(arg, *, kw_only1, kw_only2): ...
可変長位置: (他の仮引数で既に受けられた任意の位置引数に加えて) 任意の個数の位置引数が与えられることを指定します。このような仮引数は、以下の args のように仮引数名の前に * をつけることで定義できます:
def func(*args, **kwargs): ...
可変長キーワード: (他の仮引数で既に受けられた任意のキーワード引数に加えて) 任意の個数のキーワード引数が与えられることを指定します。このような仮引数は、上の例の kwargs のように仮引数名の前に ** をつけることで定義できます。
(parameter - 用語集 — Python 3.8.1 ドキュメントより引用)
簡単に言ってしまえば、関数の引数として
(*args, **kwargs)を指定すれば、可変の引数を受け取ることができるということです。これを利用すると、引数を取る関数に対するデコレータは、次のように書くことができます。
sample_013.pydef my_decorator_013(func): def inner( *args, **kwargs ): # 呼び出し前の処理をここに書く ret = func( *args, **kwargs ) # 呼び出し後の処理をここに書く return ret return inner @my_decorator_013 def base_func_1(arg1, arg2, arg3="arg3"): print( "in base_func_1({}, {}, {})".format(arg1, arg2, arg3 ) ) return 1 @my_decorator_013 def base_func_2(): print( "in base_func_2()" ) r1 = base_func_1("arg1","arg2") print( r1 ) base_func_2()以下が実行結果です。
sample 013>>> def my_decorator_013(func): ... def inner( *args, **kwargs ): ... # 呼び出し前の処理をここに書く ... ret = func( *args, **kwargs ) ... # 呼び出し後の処理をここに書く ... return ret ... return inner ... >>> @my_decorator_013 ... def base_func_1(arg1, arg2, arg3="arg3"): ... print( "in base_func_1({}, {}, {})".format(arg1, arg2, arg3 ) ) ... return 1 ... >>> @my_decorator_013 ... def base_func_2(): ... print( "in base_func_2()" ) ... >>> r1 = base_func_1("arg1","arg2") in base_func_1(arg1, arg2, arg3) >>> print( r1 ) 1 >>> base_func_2() in base_func_2() >>>例外処理
例外についても考慮しておきます。
sample_014.pydef my_decorator_014(func): def inner( *args, **kwargs ): # 呼び出し前の処理をここに書く try: ret = func( *args, **kwargs ) except: raise # 呼び出し後の処理をここに書く return ret return inner @my_decorator_014 def base_func_1(arg1, arg2, arg3="arg3"): print( "in base_func_1({}, {}, {})".format(arg1, arg2, arg3 ) ) return 1 @my_decorator_014 def base_func_2(): print( "in base_func_2()" ) na = 1 / 0 # ゼロ除算の例外が発生する r1 = base_func_1("arg1","arg2") print( r1 ) try: base_func_2() except ZeroDivisionError: print( "Zero Division Error" )以下が実行結果です。
sample 014>>> def my_decorator_014(func): ... def inner( *args, **kwargs ): ... # 呼び出し前の処理をここに書く ... try: ... ret = func( *args, **kwargs ) ... except: ... raise ... # 呼び出し後の処理をここに書く ... return ret ... return inner ... >>> @my_decorator_014 ... def base_func_1(arg1, arg2, arg3="arg3"): ... print( "in base_func_1({}, {}, {})".format(arg1, arg2, arg3 ) ) ... return 1 ... >>> @my_decorator_014 ... def base_func_2(): ... print( "in base_func_2()" ) ... na = 1 / 0 # ゼロ除算の例外が発生する ... >>> r1 = base_func_1("arg1","arg2") in base_func_1(arg1, arg2, arg3) >>> print( r1 ) 1 >>> >>> try: ... base_func_2() ... except ZeroDivisionError: ... print( "Zero Division Error" ) ... in base_func_2() Zero Division Error >>>デコレータに引数を渡す
デコレータは関数(呼び出し可能なオブジェクト)なので、これに引数を渡すことを考えます。
最初に引用した関数定義の記載でも引数があるデコレータの例が書かれていました。
@f1(arg) @f2 def func(): passdef func(): pass func = f1(arg)(f2(func))デコレータがネストしていますので、単純化のために一つのデコレータだけで考えます。
@my_decorator('引数') def func(arg1, arg2, arg3): passこれは、下と等価です。
def func(arg1, arg2, arg3): pass func = my_decorator('引数')(func)
my_decorator('引数')の呼び出しで返ってきた関数(仮に _my_decorator とします)を使って_my_decorator(func)を実行するということです。ネストが一段深くなり、一番外側の関数(デコレータ)が引数を受け取り、その中に今までのデコレータが入る形になります。
sample015.pydef my_decorator_015( arg1 ): def _my_decorator( func ): def inner( *args, **kwargs ): print( "in inner, arg1={}, func={}".format(arg1, func.__name__) ) ret = func( *args, **kwargs ) print( "in inner leaving ..." ) return ret return inner return _my_decorator以下が実行結果です。
sample 015>>> def my_decorator_015( arg1 ): ... def _my_decorator( func ): ... def inner( *args, **kwargs ): ... print( "in inner, arg1={}, func={}".format(arg1, func.__name__) ) ... ret = func( *args, **kwargs ) ... print( "in inner leaving ..." ) ... return ret ... return inner ... return _my_decorator ... >>> @my_decorator_015('引数') ... def f_015( arg1, arg2, arg3 ): ... print( "in func( {}, {}, {} )".format(arg1, arg2, arg3) ) ... >>> f_015( "引数1", "引数2", "引数3" ) in inner, arg1=引数, func=f_015 in func( 引数1, 引数2, 引数3 ) in inner leaving ... >>>引数付きデコレータを呼び出した時には、下の部分の arg1 と func が _my_decorator_body に保存されています。
print( "in _my_decorator_body, arg1={}, func={}".format(arg1, func.__name__) )そのため、f_015() を呼び出した時には、保存された arg1 と func が参照されています。
一旦、まとめ
引数をとらないデコレータ
引数をとらないデコレータは以下のようになります。
sample_014.pydef my_decorator_014(func): def inner( *args, **kwargs ): # 呼び出し前の処理をここに書く try: ret = func( *args, **kwargs ) except: raise # 呼び出し後の処理をここに書く return ret return inner引数をとるデコレータ
引数を渡すデコレータは以下のようになります。
sample_016.pydef my_decorator_016( arg1 ): def _my_decorator( func ): def inner( *args, **kwargs ): # 呼び出し前の処理をここに書く try: ret = func( *args, **kwargs ) except: raise # 呼び出し後の処理をここに書く return ret return inner return _my_decorator引数の有無を吸収するデコレータ
引数を前提にしたデコレータに、引数を与えずに使用するとどうなるでしょうか。
sample_017.pydef my_decorator_017( arg1 ): def _my_decorator( func ): def inner( *args, **kwargs ): # 呼び出し前の処理をここに書く try: ret = func( *args, **kwargs ) except: raise # 呼び出し後の処理をここに書く return ret return inner return _my_decorator @my_decorator_017 def f_017( arg1, arg2, arg3 ): print( "in {}( {}, {}, {} )".format(f_017.__name__, arg1, arg2, arg3) ) f_017( "引数1", "引数2", "引数3" )実行結果$ python sample_017.py Traceback (most recent call last): File "sample_017.py", line 21, in <module> f_017( "引数1", "引数2", "引数3" ) TypeError: _my_decorator() takes 1 positional argument but 3 were given $これは、
@my_decorator_017に引数を渡していないため、f_017 = my_decorator_017(f_017)として呼び出されているためです。
これを避ける方法が2つあります。
- デコレータに引数を指定しない場合でも必ず
()をつけ、可変長引数で受け取る。- デコレータに引数を指定しない場合には、単一の関数オブジェクトが渡されるので、それで判定する。
1つ目の例です。
sample_018.pydef my_decorator_018( *args, **kwargs ): def _my_decorator( func ): def inner( *inner_args, **inner_kwargs ): # 呼び出し前の処理をここに書く try: ret = func( *inner_args, **inner_kwargs ) except: raise # 呼び出し後の処理をここに書く return ret return inner return _my_decorator @my_decorator_018() def f_018( arg1, arg2, arg3 ): print( "in {}( {}, {}, {} )".format(f_018.__name__, arg1, arg2, arg3) ) f_018( "引数1", "引数2", "引数3" )実行結果$ python sample_018.py in inner( 引数1, 引数2, 引数3 )2つ目の方法は、デコレータの第1引数を判定に使います。
sample_019.pydef my_decorator_019( *args, **kwargs ): def _my_decorator( func ): def inner( *inner_args, **inner_kwargs ): # 呼び出し前の処理をここに書く try: ret = func( *inner_args, **inner_kwargs ) except: raise # 呼び出し後の処理をここに書く return ret return inner if len(args) == 1 and callable(args[0]): return _my_decorator( args[0] ) else: return _my_decorator @my_decorator_019 def f_019_1( arg1, arg2, arg3 ): print( "in {}( {}, {}, {} )".format(f_019_1.__name__, arg1, arg2, arg3) ) @my_decorator_019() def f_019_2( arg1, arg2, arg3 ): print( "in {}( {}, {}, {} )".format(f_019_2.__name__, arg1, arg2, arg3) ) @my_decorator_019('arg') def f_019_3( arg1, arg2, arg3 ): print( "in {}( {}, {}, {} )".format(f_019_3.__name__, arg1, arg2, arg3) ) f_019_1( "引数1", "引数2", "引数3" ) f_019_2( "引数1", "引数2", "引数3" ) f_019_3( "引数1", "引数2", "引数3" )デコレータに渡される引数と
f_019_*()が呼び出される際に渡される引数を区別するために、それぞれ( *args, **kwargs )と( *inner_args, **inner_kwargs )で区別しています。実行結果$ python sample_019.py in inner( 引数1, 引数2, 引数3 ) in inner( 引数1, 引数2, 引数3 ) in inner( 引数1, 引数2, 引数3 )これで、汎用的なデコレータの枠組みが出来上がった…… と思いたいところですが…… 呼び出した関数名 (
f_019_*.__name__) がすべてinnerになってしまいました。最後の仕上げ
元の関数の代わりに、
innerという関数が呼ばれていることはわかります。
しかし、元の関数では、名前 (__name__) やドキュメント (__doc__) などの属性を参照するかもしれません。これを回避することができる、
@wrapsというデコレータが用意されています。参照: @functools.wraps() - functools --- 高階関数と呼び出し可能オブジェクトの操作 — Python 3.8.1 ドキュメント
参照: functools.update_wrapper() - functools --- 高階関数と呼び出し可能オブジェクトの操作 — Python 3.8.1 ドキュメントこれを
def innerの前にデコレートすると、外側の関数 (_my_decorator()) に渡された引数funcの属性をラップ(wrap)して、保持することができます。sample_020.pyfrom functools import wraps def my_decorator_020( *args, **kwargs ): def _my_decorator( func ): @wraps(func) def inner( *inner_args, **inner_kwargs ): # 呼び出し前の処理をここに書く try: ret = func( *inner_args, **inner_kwargs ) except: raise # 呼び出し後の処理をここに書く return ret return inner if len(args) == 1 and callable(args[0]): return _my_decorator( args[0] ) else: return _my_decorator @my_decorator_020 def f_020_1( arg1, arg2, arg3 ): print( "in {}( {}, {}, {} )".format(f_020_1.__name__, arg1, arg2, arg3) ) @my_decorator_020() def f_020_2( arg1, arg2, arg3 ): print( "in {}( {}, {}, {} )".format(f_020_2.__name__, arg1, arg2, arg3) ) @my_decorator_020('arg') def f_020_3( arg1, arg2, arg3 ): print( "in {}( {}, {}, {} )".format(f_020_3.__name__, arg1, arg2, arg3) ) f_020_1( "引数1", "引数2", "引数3" ) f_020_2( "引数1", "引数2", "引数3" ) f_020_3( "引数1", "引数2", "引数3" )
sample_019.pyに対して、from functools import wrapsとdef inner()の前に@wraps(func)を追加したものです。
funcは_my_decorator()の引数として渡された関数です。実行結果$ python sample_020.py in f_020_1( 引数1, 引数2, 引数3 ) in f_020_2( 引数1, 引数2, 引数3 ) in f_020_3( 引数1, 引数2, 引数3 ) $関数の名前 (
f_019_*.__name__) がinnerではなく、元の関数の名前として保持されています。長い道のりでしたが、ようやくデコレータ(decorator)のフレームワークが出来上がりました。
汎用的に作成したので、
def my_decorator( *args, **kwargs ):となっていますが、受け取る引数が確定している場合には、明確化した方がよいでしょう。decorator_framework.py Full Version
decorator_framework.py Full Version#!/usr/bin/env python # -*- coding: utf-8 -*- ########################################### # デコレータ (decorator) ########################################### from functools import wraps def my_decorator( *args, **kwargs ): """ for doctest >>> @my_decorator ... def f1( arg1 ): ... print( arg1 ) ... デコレータが記載された時に処理が必要な場合にはここに書く #1 No arguments _my_decorator_body() を定義する前に必要な処理があれば、ここに書く デコレータが記載された時に処理が必要な場合にはここに書く #2 >>> @my_decorator('mytest1') ... def f2( arg2 ): ... print( arg2 ) ... デコレータが記載された時に処理が必要な場合にはここに書く #1 There are some arguments: ('mytest1',) _my_decorator_body() を定義する前に必要な処理があれば、ここに書く デコレータが記載された時に処理が必要な場合にはここに書く #2 >>> @my_decorator ... def f3( arg1 ): ... print( arg1 ) ... a = 1/0 ... デコレータが記載された時に処理が必要な場合にはここに書く #1 No arguments _my_decorator_body() を定義する前に必要な処理があれば、ここに書く デコレータが記載された時に処理が必要な場合にはここに書く #2 >>> @my_decorator('mytest2') ... def f4( arg2 ): ... print( arg2 ) ... a = 1/0 ... デコレータが記載された時に処理が必要な場合にはここに書く #1 There are some arguments: ('mytest2',) _my_decorator_body() を定義する前に必要な処理があれば、ここに書く デコレータが記載された時に処理が必要な場合にはここに書く #2 >>> try: ... f1( "Hello, World! #1" ) ... except: ... print( "error #1" ) ... 前処理はここで実行 {} ('Hello, World! #1',) {} Hello, World! #1 後処理はここで実行 {} ('Hello, World! #1',) {} >>> try: ... f2( "Hello, World! #2" ) ... except: ... print( "error #2" ) ... 前処理はここで実行 {} ('Hello, World! #2',) {} Hello, World! #2 後処理はここで実行 {} ('Hello, World! #2',) {} >>> try: ... f3( "Hello, World! #3" ) ... except: ... print( "error #3" ) ... 前処理はここで実行 {} ('Hello, World! #3',) {} Hello, World! #3 error #3 >>> try: ... f4( "Hello, World! #4" ) ... except: ... print( "error #4" ) ... 前処理はここで実行 {} ('Hello, World! #4',) {} Hello, World! #4 error #4 >>> """ # 引数を取らないことが明確なデコレータはここからの部分を # _my_decorator の名前を変えてグローバルで define する def _my_decorator( func ): # _my_decorator_body() を定義する前に必要な処理があれば、ここに書く print( "_my_decorator_body() を定義する前に必要な処理があれば、ここに書 く" ) @wraps(func) def _my_decorator_body( *body_args, **body_kwargs ): # 前処理はここで実行 print( "前処理はここで実行", kwargs, body_args, body_kwargs ) try: # デコレートした本体の実行 ret = func( *body_args, **body_kwargs ) except: raise # 後処理はここで実行 print( "後処理はここで実行", kwargs, body_args, body_kwargs ) return ret # デコレータが記載された時に処理が必要な場合にはここに書く #2 print( "デコレータが記載された時に処理が必要な場合にはここに書く #2" ) return _my_decorator_body # 引数を取らないことが明確なデコレータはここまで # デコレータが記載された時に処理が必要な場合にはここに書く #1 print( "デコレータが記載された時に処理が必要な場合にはここに書く #1" ) if len(args) == 1 and callable( args[0] ): # 引数無しでデコレータが呼ばれた場合はここで処理 print( "No arguments" ) return _my_decorator( args[0] ) else: # 引数ありでデコレータが呼ばれた場合はここで処理 print( "There are some arguments:", args ) return _my_decorator ########################################### # unitttest ########################################### import unittest from io import StringIO import sys class Test_My_Decorator(unittest.TestCase): def setUp(self): self.saved_stdout = sys.stdout self.stdout = StringIO() sys.stdout = self.stdout def tearDown(self): sys.stdout = self.saved_stdout def test_decorator_noarg(self): @my_decorator def t1(arg0): print( arg0 ) t1("test_decorator_noarg") self.assertEqual(self.stdout.getvalue(), "デコレータが記載された時に処理が必要な場合にはここに書く #1\n" + "No arguments\n" + "_my_decorator_body() を定義する前に必要な処理があれば、ここに書く\n" + "デコレータが記載された時に処理が必要な場合にはここに書く #2\n" + "前処理はここで実行 {} ('test_decorator_noarg',) {}\n" + "test_decorator_noarg\n" + "後処理はここで実行 {} ('test_decorator_noarg',) {}\n" ) def test_decorator_witharg(self): @my_decorator('with arg') def t1(arg0): print( arg0 ) t1("test_decorator_witharg") self.assertEqual(self.stdout.getvalue(), "デコレータが記載された時に処理が必要な場合にはここに書く #1\n" + "There are some arguments: ('with arg',)\n" + "_my_decorator_body() を定義する前に必要な処理があれば、ここに書く\n" + "デコレータが記載された時に処理が必要な場合にはここに書く #2\n" + "前処理はここで実行 {} ('test_decorator_witharg',) {}\n" + "test_decorator_witharg\n" + "後処理はここで実行 {} ('test_decorator_witharg',) {}\n" ) def test_functionname(self): @my_decorator def t1(): return t1.__name__ f_name = t1() self.assertEqual( f_name, "t1" ) def test_docattribute(self): @my_decorator def t1(): """Test Document""" pass self.assertEqual( t1.__doc__, "Test Document" ) ########################################### # main ########################################### if __name__ == '__main__': @my_decorator def f1( arg1 ): print( arg1 ) @my_decorator('mytest1') def f2( arg2 ): print( arg2 ) @my_decorator def f3( arg1 ): print( arg1 ) a = 1/0 @my_decorator('mytest2') def f4( arg2 ): print( arg2 ) a = 1/0 try: f1( "Hello, World! #1" ) except: print( "error #1" ) try: f2( "Hello, World! #2" ) except: print( "error #2" ) try: f3( "Hello, World! #3" ) except: print( "error #3" ) try: f4( "Hello, World! #4" ) except: print( "error #4" ) import doctest doctest.testmod() unittest.main()サンプル実行$ python decorator_framework.py デコレータが記載された時に処理が必要な場合にはここに書く #1 No arguments _my_decorator_body() を定義する前に必要な処理があれば、ここに書く デコレータが記載された時に処理が必要な場合にはここに書く #2 デコレータが記載された時に処理が必要な場合にはここに書く #1 There are some arguments: ('mytest1',) _my_decorator_body() を定義する前に必要な処理があれば、ここに書く デコレータが記載された時に処理が必要な場合にはここに書く #2 デコレータが記載された時に処理が必要な場合にはここに書く #1 No arguments _my_decorator_body() を定義する前に必要な処理があれば、ここに書く デコレータが記載された時に処理が必要な場合にはここに書く #2 デコレータが記載された時に処理が必要な場合にはここに書く #1 There are some arguments: ('mytest2',) _my_decorator_body() を定義する前に必要な処理があれば、ここに書く デコレータが記載された時に処理が必要な場合にはここに書く #2 前処理はここで実行 {} ('Hello, World! #1',) {} Hello, World! #1 後処理はここで実行 {} ('Hello, World! #1',) {} 前処理はここで実行 {} ('Hello, World! #2',) {} Hello, World! #2 後処理はここで実行 {} ('Hello, World! #2',) {} 前処理はここで実行 {} ('Hello, World! #3',) {} Hello, World! #3 error #3 前処理はここで実行 {} ('Hello, World! #4',) {} Hello, World! #4 error #4 .... ---------------------------------------------------------------------- Ran 4 tests in 0.003s OK $unittest$ python -m unittest -v decorator_framework.py test_decorator_noarg (decorator_framework.Test_My_Decorator) ... ok test_decorator_witharg (decorator_framework.Test_My_Decorator) ... ok test_docattribute (decorator_framework.Test_My_Decorator) ... ok test_functionname (decorator_framework.Test_My_Decorator) ... ok ---------------------------------------------------------------------- Ran 4 tests in 0.003s OK $
- 投稿日:2020-02-07T22:52:29+09:00
pythonで3億桁までの多数桁乗算時間
pythonとC(gnuのgmp)の多数桁乗算の比較を行った。パソコン(4Ghz)での計算時間を下記に示す(単位:秒)。10進3億桁(結果)1回から桁数半分、回数倍で順に計算。共に右端の値は10進236万桁を128回計算した時間。
python : 1627, 1084, 723, 482, 322, 215, 143, 96 (s)
gnu(gmp) : 4.5, 3.9, 3.7, 3,4, 3.2, 2.8, 2.6, 2.2 (s)
千桁以上でpythonはカラツバ法、gmpはFMT(整数FFT)を使用しているのが分かる。pythonは桁数2倍で、3倍の時間(例は逆順1.5倍)が必要。gmpはFMT計算なので、桁数x回数でlog(桁数)比となる。
pythonのソースと両者の詳細結果は https://ecc-256.com のpythonプログラムの多数桁乗算を参照。面白いことに、10進20桁から200桁(共に回数は膨大)ではpythonは2倍程度遅いだけ。これは、共に結果を格納する場所の確保とポインターに多くの時間が必要のためだろう。
pythonはd10=format(a)でaを10進数に変換する処理が遅い。乗算が桁数2倍で3倍の時間に対し、変換は4倍かかる。118万桁、236万桁、472万桁の乗算と変換の時間を順に示す。
乗算: 0.24, 0.72, 2,19 (s), 変換: 19, 77, 308 (s)
- 投稿日:2020-02-07T22:29:24+09:00
LiquidTap Python Clientを使う②
「Liquid by Quoine」の"Orders"を取得する
(2020.02.07)
BTC/JPYの発注とキャンセルを実行してみる。コードを書く
orders.pyimport liquidtap import time def order_callback(data): print("order:" + data) if __name__ == "__main__": token = "APIトークンID" secret = "APIトークン秘密鍵" tap = liquidtap.Client(token, secret) tap.pusher.connect() tap.subscribe("user_account_jpy_orders").bind('updated', order_callback) while True: # 無限ループ time.sleep(1)実行
orders.pyを実行し、トレードツールから発注とキャンセルを実行する。
$ python3 orders.py order:{"average_price":0.0,"client_order_id":null,"created_at":1581080779,"crypto_account_id":null,"currency_pair_code":"BTCJPY","disc_quantity":0.0,"filled_quantity":0.0,"funding_currency":"JPY","iceberg_total_quantity":0.0,"id":2079030430,"leverage_level":1,"margin_interest":0.0,"margin_type":null,"margin_used":0.0,"order_fee":0.0,"order_type":"limit","price":1500000.0,"product_code":"CASH","product_id":"5","quantity":0.001,"side":"sell","source_action":"manual","source_exchange":"QUOINE","status":"live","stop_loss":null,"take_profit":null,"target":"spot","trade_id":null,"trading_type":"spot","unwound_trade_id":null,"unwound_trade_leverage_level":null,"updated_at":1581080779} order:{"average_price":0.0,"client_order_id":null,"created_at":1581080779,"crypto_account_id":null,"currency_pair_code":"BTCJPY","disc_quantity":0.0,"filled_quantity":0.0,"funding_currency":"JPY","iceberg_total_quantity":0.0,"id":2079030430,"leverage_level":1,"margin_interest":0.0,"margin_type":null,"margin_used":0.0,"order_fee":0.0,"order_type":"limit","price":1500000.0,"product_code":"CASH","product_id":"5","quantity":0.001,"side":"sell","source_action":"manual","source_exchange":"QUOINE","status":"cancelled","stop_loss":null,"take_profit":null,"target":"spot","trade_id":null,"trading_type":"spot","unwound_trade_id":null,"unwound_trade_leverage_level":null,"updated_at":1581080832}表示された!
無限ループなので Ctrl+c で停止。今回発注したのはこんな感じのもの。

- 投稿日:2020-02-07T21:19:27+09:00
挿入ソート
今日から
INTRODUCTION TO ALGORITHMSを読み始めたので、簡単な内容も多いですが、アルゴリズムをまとめていきます。挿入ソート
要素数10の配列を挿入ソートによってソートするのは、次の例と類似しています。
テーブルに10枚のトランプが置かれていて、初め手札の枚数は0とします。テーブルのカードを一枚ずつ引いていき、手札に加えるのですが、手札は常に昇順にソートされた状態にキープします。手札って整頓させておきたいですよね、左に数字の小さいカード、右に数字の大きいカードというように。
このプロセスのポイントは、カードが三つに分類できるということです。
- 手札にある既にソートされたカード
- 今テーブルから引いて、これから加えようとしているカード
- まだテーブルに置かれているカード
挿入ソートもこのことに着目します。
- 配列のうち、既に昇順にソートされている部分
- 配列のうち、今見ている要素
- 配列のうち、まだ昇順にソートされていない部分
例えば、
インデックス 0 1 2 3 4 5 6 7 8 9 値 5 3 8 1 2 4 7 6 9 0 という要素数10の配列があるとします。まだテーブルに全てのカードが置かれている状態と考えてください。
カードを一枚ずつ引いていって、今ちょうど5枚目を引いたとします。これは、配列がインデックス0-3まではソートされていて、今インデックス4の2に着目していることに等しいです。
インデックス 0 1 2 3 4 5 6 7 8 9 値 1 3 5 8 2 4 7 6 9 0 さて、この2を挿入する位置探しましょう。
- 2と8を比べ、8の方が大きいので、2と8の位置を交換します。
- 2と5を比べ、5の方が大きいので、2と5の位置を交換します。
- 2と3を比べ、3の方が大きいので、2と3の位置を交換します。
- 2と1を比べ、2の方が大きいので、ここで終了します。
同様の手順を、6番目から10番目のカードに対しても行うと、ソートされた配列が得られます。これが挿入ソートの手順です。
def insertion_sort(a) -> None: for i in range(1, len(a)): key = a[i] j = i - 1 while key < a[j] and j >= 0: a[j+1] = a[j] j -= 1 a[j+1] = key a = [1, 3, 5, 8, 2, 4, 7, 6, 9, 0] insertion_sort(a) print(a)出力
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]冒頭でご紹介したテキストですが、何で挿入ソートでこんなにページ割けるんだってくらい、一つのアルゴリズムに関して色々説明しているので、読み進めて補足することがあれば別記事をまた書こうと思います。
- 投稿日:2020-02-07T20:49:29+09:00
Plotly(Python)でインタラクティブに結び目を描画する
Plotly(Python)でインタラクティブに結び目を描画する
1. はじめに
今回は結び目(knot)をPlotlyで三次元空間上に図示しようと思います。学習の補助になれば幸いです。
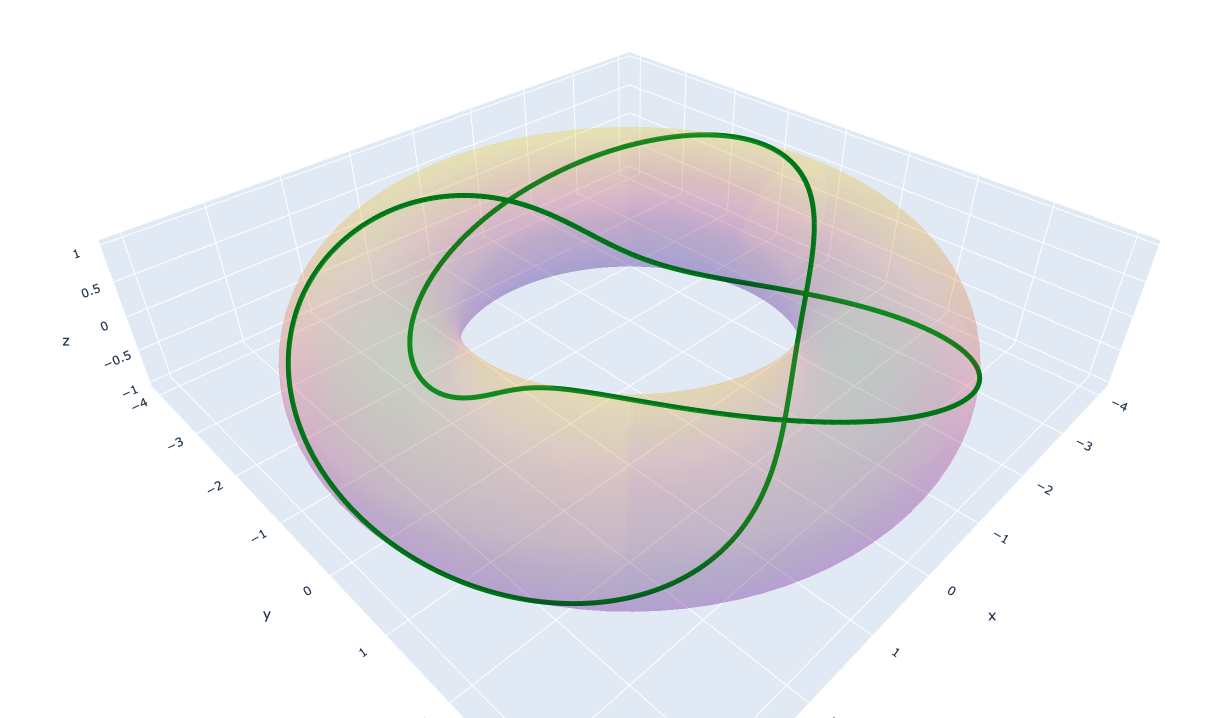
↓のようなものができます。
See the Pen
dyoyxKW by Sota Misawa (@mitawaut)
on CodePen.
2. 復習
結び目を図示するにあたって必要最低限の復習をしておきます。
結び目(knot)とは $S^3$ に区分線形的に埋め込まれた $S^1$ のことを指します。$S^3$ は $\mathbb{R}^3\cup \{\infty \}$ とみなせたことから,埋め込まれた $S^1$ が $\infty$ を含まなければ $\mathbb{R}^3$ に埋め込まれた $S^1$ と考えることができます。
結び目の有名な表現方法として2次元トーラス面 $\mathbb{T}^2$ に沿った結び目というものが考えられます。トーラスとして次の写像が定める閉曲面を考えます:
$$\mathbb{T}^2 : [-\pi , \pi]^2 \ni (\phi,\ \theta)\longmapsto \bigl(\cos \phi \ (3+\cos \theta),\ \sin \phi \ (3+\cos \theta),\ -\sin \theta \bigr)\in \mathbb{R}^3$$
$\mathbb{T}^2$ 上の閉曲線で2つの整数の組 $(n,\ m)$ を用いて( $\mathbb{T}^2$ の定義域を適当に拡張して),
$$
T(n,\ m) : [-\pi , \pi]\ni t \longmapsto \mathbb{T}^2(nt,\ mt) \in \mathbb{R}^3$$と表されるものを考えます。これは結び目と考えることができます。これに関して次の定理が知られています。
定理. $\mathbb{T}^2$ に含まれる任意の自明でない結び目 $K$ に対して,互いに素な整数の組 $(n,\ m)$ が存在して $K$ は $T(n,\ m)$と同値である。
この定理より,結び目の表現として $T(n,\ m)$ を図示しようということです。以下に $T(2,\ 3)$の図を示しておきます。
3. 実装
ここから5分クッキングの始まりです。ipywidgetsを用いるのでjupyter notebook推奨です。
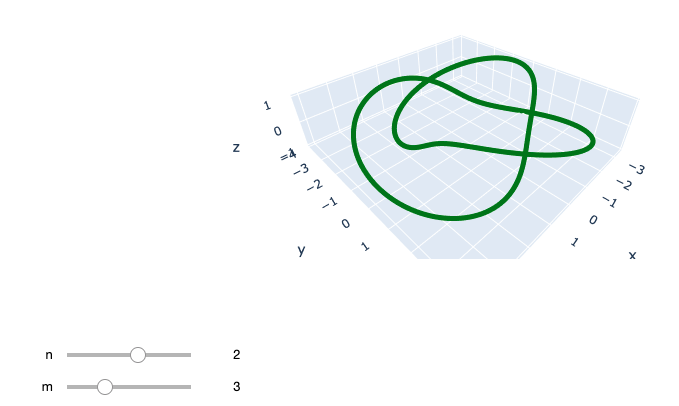
requirements.txt[抜粋]ipython==7.12.0 numpy==1.18.1 plotly==4.4.1ipywidgetsで $n,\ m$ を操作できるようにするのを目標とします。まずは必要なものをインポートします。
# import modules import plotly.offline as offline import plotly.graph_objs as go import numpy as np from ipywidgets import interactive, VBox, widgets from IPython.display import display offline.init_notebook_mode(connected=True)次に $\mathbb{T}^2$ と $T(n,\ m)$ も定義します。これも上の議論をそのまま実装するだけです。
# functions def torus(p, t): x = np.cos(p) * (3 + np.cos(t)) y = np.sin(p) * (3 + np.cos(t)) z = -np.sin(t) return (x, y, z) def knot(n, m): theta = np.linspace(-np.pi, np.pi, 1000) p, t = n*theta, m*theta return torus(p, t)あとはplotするだけです。初期値を $(m,\ m) = (2,\ 3)$ にして,スライドバーの範囲は $n$ : -10~10, $m$ : 0~10としました。
fig = go.FigureWidget() scatt = fig.add_scatter3d() def update(n=2, m=3): with fig.batch_update(): (cx, cy, cz) = knot(n, m) scatt.data[0].x=cx scatt.data[0].y=cy scatt.data[0].z=cz scatt.data[0].mode='lines' scatt.data[0].line=dict( width=10, color='green') vb = VBox((fig, interactive(update, n=(-10, 11, 1), m=(0, 10, 1)))) display(vb)次のように表示されて,スライドバーをいじると同時に結び目が変われば成功です。
4. 最後に
表示されない人がいたらipython周りのversionを確認しましょう。
初投稿が数分クオリティなのはやばいと思ったので復習とかいう余分なセクションを生んでしまった
- 投稿日:2020-02-07T20:31:14+09:00
Tweepyで過去ツイートを選択的に自動消去する方法
はじめに
Twitter上の過去のPeing回答投稿を消したいと思いたったものの、消去対象が1000件近くあったので手動で消すのはあきらめ、代わりに自動で対象のツイートを消去してくれるスクリプトを書いてみました。
Tweepyについて
TweepyはTwitterのAPIを利用したPythonライブラリーです。これを使えばツイッターのbotを作ったり自動でいいねやフォローしたりすることができます。今回は特定のツイートを自動で消去するスクリプトを紹介します。
準備
・Twitter APIの登録(こちらを参考にしてみてください)
・Twitterアーカイブデータのダウンロード(こちらを参考にしてみてください)
・Tweepy, pandasのインストール方針
Twitterアーカイブデータをダウンロードするとtweet.jsというファイルが一緒にダウンロードされて来ます。このファイルには下記のように過去のツイートデータが大量に入ってます。"tweet" : { 以降の全てが一つのツイートに関してのデータを示しており、これと同様のデータが無数に続いて一つのファイルとして構成されています。
方針としては、下記のtweet.jsファイルのうち、"source" :行に「https ://peing.net」が含まれているツイートを選択的に消去することを目指します。その際、個々のツイートに割り当てられているidも必要になるので"id_str" :行の数値データも抽出します。{ "tweet" : { "retweeted" : false, "source" : "<a href=\"https://peing.net\" rel=\"nofollow\">Peing</a>", "entities" : { "hashtags" : [ { "text" : "Peing", "indices" : [ "18", "24" ] }, { "text" : "質問箱", "indices" : [ "25", "29" ] } ], "symbols" : [ ], "user_mentions" : [ ], "urls" : [ { "url" : "https://t.co/snIXxSjooH", "expanded_url" : "https://peing.net/ja/qs/636766292", "display_url" : "peing.net/ja/qs/636766292", "indices" : [ "30", "53" ] } ] }, "display_text_range" : [ "0", "53" ], "favorite_count" : "0", "id_str" : "1203602228591788032", "truncated" : false, "retweet_count" : "0", "id" : "1203602228591788032", "possibly_sensitive" : false, "created_at" : "Sun Dec 08 09:08:27 +0000 2019", "favorited" : false, "full_text" : "ふっくらつやつやしたお米です。 \n\n#Peing #質問箱 https://t.co/snIXxSjooH", "lang" : "ja" }コード
インポート
tweet.jsファイルから消去対象となるツイートデータの文字列を抽出する際に正規表現を利用するのでreモジュールをインポートします。また抽出したデータからデータフレームを作るためにpandasもインポートします。datetimeは個人的に実行時間がどれくらいかを計測するためにインポートしているので必須ではありません。tweepyはもちろん必須です。
import re import pandas as pd from datetime import datetime import tweepyツイートデータの抽出
tweet.jsから必要なデータ("source" :, "id_str" :)を抽出し、データフレームとして出力する関数を定義します。
def read_tweet_file(file): """ reads a tweet.js into a pd.DataFrame """ # tweet.jsファイルの読み込み with open(file) as dataFile: datalines = dataFile.readlines() # 抽出データを格納する空データフレームの作成 colname = ['source', 'id'] df = pd.DataFrame([], columns=colname) # 抽出する部分をリストに指定 regexes = [r' \"source\".*', r' \"id_str\".*' ] for i, regex in enumerate(regexes): L = [] for line in datalines: # 条件にマッチする部分を抽出 match_obj = re.match(regex, line) if match_obj : L.append(match_obj.group()) # データフレームに格納 df[colname[i]] = pd.Series(L) return df消去対象ツイートの抽出
データフレームから消去対象ツイートのIDを出力する関数を定義します。
def extract_id(df): target_id = [] for i in range(len(df)): # データフレームからpeingのツイートのみを抽出 match_obj = re.search(r'https://peing.net', df['source'][i]) if match_obj: # 消去対象ツイートIDをリストとして出力 target_id.append(int(re.search(r'[0-9]+', df['id'][i]).group())) return target_idツイートの消去
ツイートIDを指定し、当該ツイートを消去する出力する関数を定義します。
def delete_tweets(target_id): delete_count = 0 for status_id in target_id: try: # ツイートを消去 api.destroy_status(status_id) print(status_id, 'deleted!') delete_count += 1 except: print(status_id, 'deletion failed.') print(delete_count, 'tweets deleted.')実行
上記で定義した関数を実行します。
# Twitter APIにアクセスするための認証 auth = tweepy.OAuthHandler('*API key*', '*API secret key*') auth.set_access_token('*Access token*', '*Access token secret*') api = tweepy.API(auth) user = api.me() # 実行 print(datetime.now()) df = read_tweet_file('tweet.js') target_id = extract_id(df) delete_tweets(target_id) print(datetime.now())結果
976の対象ツイートを自動で消去することができました。
(実行時間10分程度)2020-02-07 17:24:57.816773 1204021701639426048 deleted! 1204020924015472640 deleted! 1204020044683833344 deleted! 1203904952684302337 deleted! ・・・(中略)・・・ 1204025368052523014 deleted! 1204023316488560640 deleted! 1204023315221733376 deleted! 1204022282311499776 deleted! 976 tweets deleted. 2020-02-07 17:35:16.302221さいごに
ここで紹介したコードを自由にいじって充実したツイ消しライフを送りましょう。
お読みいただきありがとうございました。それでは!
- 投稿日:2020-02-07T19:48:23+09:00
はじめて Google Cloud Vision API を触ってみた
画像処理をやっていながら、Vison API使ったことなかったんですよね。
すげえなとか思いつつ何だかんだやらずじまいでして..とりあえず軽めでも試しに触ってみようと思い、Pythonで書いてみました!
本記事はその時のメモ用に残したものです〜因みに、登録手順等はこの辺り参考にしながらやってます〜
使った機能
今回使ったのは以下の機能です。
公式から説明持ってきています。オブジェクトの自動検出
Cloud Vision API では、オブジェクト ローカライズを使用して、画像内の複数のオブジェクトを検出して抽出できます。
オブジェクト ローカライズにより、画像内のオブジェクトが識別され、オブジェクトごとに LocalizedObjectAnnotation が指定されます。各 LocalizedObjectAnnotation によって、オブジェクトに関する情報、オブジェクトの位置、画像内でオブジェクトがある領域の枠線が識別されます。
オブジェクト ローカライズでは、画像内で目立っているオブジェクトとそれほど目立たないオブジェクトの両方が識別されます。ソースコード
雑ですがお許しください...
認識した始点座標と終点座標も欲しかったので、荒技で引き出してます。
jsonキーの確認の仕方これで合ってるのか?って感じですが。ENDPOINT_URL = 'https://vision.googleapis.com/v1/images:annotate' API_KEY = 'APIキー' # jsonキーワード RESPONSES_KEY = 'responses' LOCALIZED_KEY = 'localizedObjectAnnotations' BOUNDING_KEY = 'boundingPoly' NORMALIZED_KEY = 'normalizedVertices' NAME_KEY = 'name' X_KEY = 'x' Y_KEY = 'y' def get_gcp_info(image): image_height, image_width, _ = image.shape min_image = image_proc.exc_resize(int(image_width/2), int(image_height/2), image) _, enc_image = cv2.imencode(".png", min_image) image_str = enc_image.tostring() image_byte = base64.b64encode(image_str).decode("utf-8") img_requests = [{ 'image': {'content': image_byte}, 'features': [{ 'type': 'OBJECT_LOCALIZATION', 'maxResults': 5 }] }] response = requests.post(ENDPOINT_URL, data=json.dumps({"requests": img_requests}).encode(), params={'key': API_KEY}, headers={'Content-Type': 'application/json'}) # 'responses'キーが存在する場合 if RESPONSES_KEY in response.json(): # 'localizedObjectAnnotations'キーが存在する場合 if LOCALIZED_KEY in response.json()[RESPONSES_KEY][0]: # 'boundingPoly'キーが存在する場合 if BOUNDING_KEY in response.json()[RESPONSES_KEY][0][LOCALIZED_KEY][0]: # 'normalizedVertices'キーが存在する場合 if NORMALIZED_KEY in response.json()[RESPONSES_KEY][0][LOCALIZED_KEY][0][BOUNDING_KEY]: name = response.json()[RESPONSES_KEY][0][LOCALIZED_KEY][0][NAME_KEY] start_point, end_point = check_recognition_point( response.json()[RESPONSES_KEY][0][LOCALIZED_KEY][0][BOUNDING_KEY][NORMALIZED_KEY], image_height, image_width ) print(name, start_point, end_point) return True, name, start_point, end_point print("non", [0, 0], [0, 0]) # 情報が足りない場合 return False, "non", [0, 0], [0, 0] def check_recognition_point(point_list_json, image_height, image_width): # 認識座標のX始点(%) x_start_rate = point_list_json[0][X_KEY] # 認識座標のY始点(%) y_start_rate = point_list_json[0][Y_KEY] # 認識座標のX終点(%) x_end_rate = point_list_json[2][X_KEY] # 認識座標のY終点(%) y_end_rate = point_list_json[2][Y_KEY] x_start_point = int(image_width * x_start_rate) y_start_point = int(image_height * y_start_rate) x_end_point = int(image_width * x_end_rate) y_end_point = int(image_height * y_end_rate) return [x_start_point, y_start_point], [x_end_point, y_end_point]終わりに
服とか靴とか通してみたのですが、ちゃんと認識できてました!(nameは結構大雑把でしたが)
自分でAUTOML使ってモデルとか作ったら面白そうですね。
- 投稿日:2020-02-07T19:48:23+09:00
Google Cloud Vision APIのオブジェクトローカライズを使ってみた
画像処理をやっていながら、Vison API使ったことなかったんですよね。
すげえなとか思いつつ何だかんだやらずじまいでして..とりあえず軽めでも試しに触ってみようと思い、Pythonで書いてみました!
本記事はその時のメモ用に残したものです〜因みに、登録手順等はこの辺り参考にしながらやってます〜
使った機能
今回使ったのは以下の機能です。
公式から説明持ってきています。オブジェクトの自動検出
Cloud Vision API では、オブジェクト ローカライズを使用して、画像内の複数のオブジェクトを検出して抽出できます。
オブジェクト ローカライズにより、画像内のオブジェクトが識別され、オブジェクトごとに LocalizedObjectAnnotation が指定されます。各 LocalizedObjectAnnotation によって、オブジェクトに関する情報、オブジェクトの位置、画像内でオブジェクトがある領域の枠線が識別されます。
オブジェクト ローカライズでは、画像内で目立っているオブジェクトとそれほど目立たないオブジェクトの両方が識別されます。ソースコード
雑ですがお許しください...
認識した始点座標と終点座標も欲しかったので、荒技で引き出してます。
jsonキーの確認の仕方これで合ってるのか?って感じですが。ENDPOINT_URL = 'https://vision.googleapis.com/v1/images:annotate' API_KEY = 'APIキー' # jsonキーワード RESPONSES_KEY = 'responses' LOCALIZED_KEY = 'localizedObjectAnnotations' BOUNDING_KEY = 'boundingPoly' NORMALIZED_KEY = 'normalizedVertices' NAME_KEY = 'name' X_KEY = 'x' Y_KEY = 'y' def get_gcp_info(image): image_height, image_width, _ = image.shape min_image = image_proc.exc_resize(int(image_width/2), int(image_height/2), image) _, enc_image = cv2.imencode(".png", min_image) image_str = enc_image.tostring() image_byte = base64.b64encode(image_str).decode("utf-8") img_requests = [{ 'image': {'content': image_byte}, 'features': [{ 'type': 'OBJECT_LOCALIZATION', 'maxResults': 5 }] }] response = requests.post(ENDPOINT_URL, data=json.dumps({"requests": img_requests}).encode(), params={'key': API_KEY}, headers={'Content-Type': 'application/json'}) # 'responses'キーが存在する場合 if RESPONSES_KEY in response.json(): # 'localizedObjectAnnotations'キーが存在する場合 if LOCALIZED_KEY in response.json()[RESPONSES_KEY][0]: # 'boundingPoly'キーが存在する場合 if BOUNDING_KEY in response.json()[RESPONSES_KEY][0][LOCALIZED_KEY][0]: # 'normalizedVertices'キーが存在する場合 if NORMALIZED_KEY in response.json()[RESPONSES_KEY][0][LOCALIZED_KEY][0][BOUNDING_KEY]: name = response.json()[RESPONSES_KEY][0][LOCALIZED_KEY][0][NAME_KEY] start_point, end_point = check_recognition_point( response.json()[RESPONSES_KEY][0][LOCALIZED_KEY][0][BOUNDING_KEY][NORMALIZED_KEY], image_height, image_width ) print(name, start_point, end_point) return True, name, start_point, end_point print("non", [0, 0], [0, 0]) # 情報が足りない場合 return False, "non", [0, 0], [0, 0] def check_recognition_point(point_list_json, image_height, image_width): # 認識座標のX始点(%) x_start_rate = point_list_json[0][X_KEY] # 認識座標のY始点(%) y_start_rate = point_list_json[0][Y_KEY] # 認識座標のX終点(%) x_end_rate = point_list_json[2][X_KEY] # 認識座標のY終点(%) y_end_rate = point_list_json[2][Y_KEY] x_start_point = int(image_width * x_start_rate) y_start_point = int(image_height * y_start_rate) x_end_point = int(image_width * x_end_rate) y_end_point = int(image_height * y_end_rate) return [x_start_point, y_start_point], [x_end_point, y_end_point]nameに認識されたオブジェクト名、start_point, end_pointには認識したオブジェクトの座標が返されます。
終わりに
服とか靴とか通してみたのですが、ちゃんと認識できてました!(nameは結構大雑把でしたが)
自分でAUTOML使ってモデルとか作ったら面白そうですね。
- 投稿日:2020-02-07T18:58:21+09:00
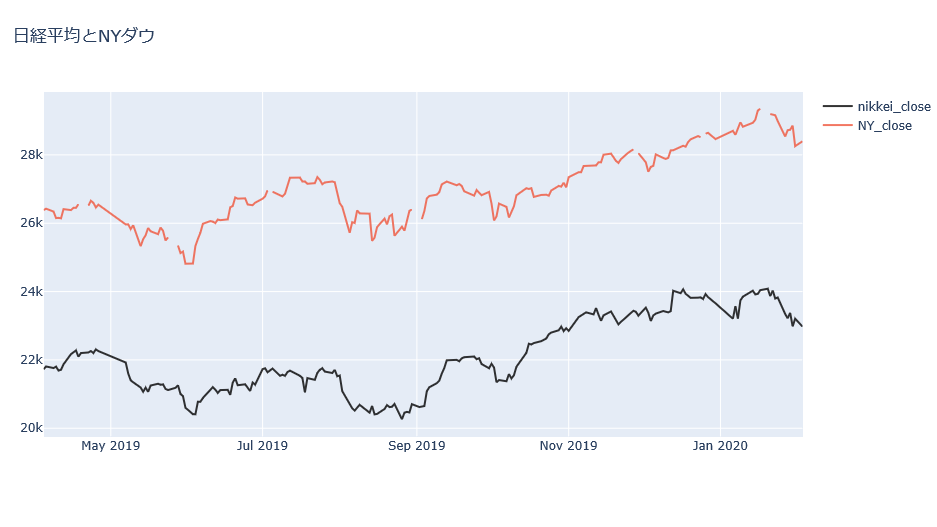
[Python 入門] 日経平均とNYダウのcsvデータを結合する
[Python 入門] 日経平均とNYダウを結合する
今回はタイトルを変えてみましたが内容にあまり変わりません。
前回の続きをやっていきます。データの準備
今回は2つのcsvデータ(日経平均とNYダウ)を使います。
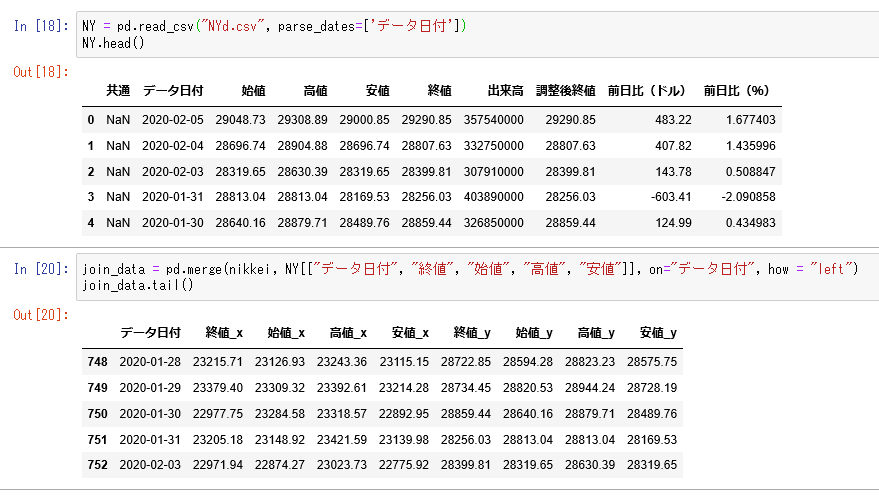
nikkei = pd.read_csv("nikkei.csv", parse_dates=['データ日付']) #csvデータを読み込む nikkei.tail()NYのデータは画像のとおりです。
NY = pd.read_csv("NYd.csv", parse_dates=['データ日付']) NY.head()データの結合をする
#データの結合をする join_data = pd.merge(nikkei, NY[["データ日付", "終値", "始値", "高値", "安値"]], on="データ日付", how = "left") join_data.tail() #表示してみる日経平均のデータにNYダウのデータを結合します。データ日付を共通なものとして結合させました。"~_x"が日経平均、"~_y"がNYダウに当たります。
プロットしてみる
前回(過去記事参照)と同じようにやってプロットしておきます。
nikkei_close = go.Scatter(x = join_data['データ日付'][-200:], y = join_data['終値_x'][-200:], name = "nikkei_close", line = dict(color = '#000000'), #黒色の線にする opacity = 0.8) NY_close = go.Scatter(x = join_data['データ日付'][-200:], y = join_data['終値_y'][-200:], name = "NY_close", opacity = 0.8) data = [nikkei_close, NY_close] layout = dict(title = "日経平均とNYダウ", ) fig = dict(data = data, layout=layout) iplot(fig)
こんな感じになりました。ところどころNYダウの値がありません。いわゆる欠損値がありますね。
たぶんそれはNY市場の休場かと思います。今のところは謎?
今回はデータ結合しただけですが、コード部分の話は以上です。雑談
今回はデータ結合の話でした。ですが、ただ結合しただけではいくつか課題点が見えてきますね。
- グラフの欠損値はなにか
- 日経平均とNYダウのグラフを重ねて表示したい
- 相関関係はあるのか(ヒートマップでよい?)
- 他に何か分析できる?
といったところでしょうか。解決などできたらまとめようかと思います。
- 投稿日:2020-02-07T18:09:57+09:00
Python logging モジュールの使用を開始するための最低限の知識
Python logging モジュールの使用を開始するための最低限の知識
この記事では、最小限の知識でアプリ開発のPythonロギングモジュールを開始する方法について説明します。
すぐに開発で使える最小限の知識だけをまとめていますので足りない情報は補いつつ、スタート地点として利用していただければと思います。loggingの基本機能
print文のようなものです(でも、これではloggingの意味がないのでこんな風に使わないでくださいね。)
import logging logging.warning( 'Watch out!')#コンソールにメッセージを出力します logging.info( 'I said so')#defaultのlog levelではwarningなので、コンソールには何も出力されないはずですアプリ開発でloggingを使用するための必要最低限の知識と設定
logger
logger object
- 使用するロガーを設定
- ログレベルを設定(DEBUG、WARNINGなど)
- ログをコンソールまたはファイルのどちらに送信するかを決定(StreamHandler、TimedRotatingFileHandlerなどのハンドラーを使用します)
logger = logging.getLogger( 'app')
- ロガーオブジェクトを構築
- ロガーはappという名前
loggingを使用するためのテンプレート
- この例では次のような2つのファイルを配置すると仮定します
root ├──your_app.py ├──logging.conf └──logging_dev.conf
- 理想的には、これらのconfファイルはおそらく以下のような別のディレクトリに設定する必要があります
root ├──app │└──your_app.py └──conf ├──logging.conf └──logging_dev.conf
- 次のテンプレートを使用して、開発環境でロギングを実行し、以下のconfファイルの例を組み合わせて使用できます。
your_app.pyimport logging # read the conf file logging.config.fileConfig('logging_dev.conf', disable_existing_loggers=False) # create logger logger = logging.getLogger('app') def main(): try: 1/0 # ZeroDivisionError # your code goes here except Exception as e: logger.exception(e.args) if __name__ == '__main__': main()logging 設定ファイル
ポイント
- log levelはdevとproductionの両方で適切に設定しましょう。
- ファイルハンドラは、RotatingFileHandlerとTimedRotatingFileHandlerの間で選択する必要があります。
運用設定ファイルのサンプル(ログレベルがINFOであることに注意)
logging-prod.conf[loggers] keys=root,app [formatters] keys=default [handlers] keys=frotate,default [formatter_default] format=%(asctime)s %(levelname)s %(message)s datefmt=%Y/%m/%d %H:%M:%S [handler_frotate] class=handlers.TimedRotatingFileHandler formatter=default args=('logs/logger.log', 'W0', 1, 100) [handler_default] class=StreamHandler formatter=default args=(sys.stdout,) [logger_app] level=INFO handlers=frotate qualname=app [logger_root] level=INFO handlers=defaultdev configファイルのサンプル(ログレベルがNOTSETであり、DEBUGよりもノイズが多いことに注意)
logging-dev.conf[loggers] keys=root,app [formatters] keys=default [handlers] keys=frotate,default [formatter_default] format=%(asctime)s %(levelname)s %(message)s datefmt=%Y/%m/%d %H:%M:%S [handler_frotate] class=handlers.TimedRotatingFileHandler formatter=default args=('logs/logger_dev.log', 'W0', 1, 100) [handler_default] class=StreamHandler formatter=default args=(sys.stdout,) [logger_app] level=NOTSET handlers=frotate qualname=app [logger_root] level=NOTSET handlers=defaultまとめ
ロギングモジュールの最小限の使用方法をざっと紹介しました。
詳細を知る必要がある場合は、参照 で紹介しているドキュメントなどをみてみてください。参照
- 投稿日:2020-02-07T17:36:36+09:00
書籍「15Stepで踏破 自然言語処理アプリケーション開発入門」をやってみる - 3章Step11メモ
内容
15stepで踏破 自然言語処理アプリケーション入門 を読み進めていくにあたっての自分用のメモです。
今回は3章Step11で、自分なりのポイントをメモります。
個人的には自然言語処理の中でも特に気になる技術です。準備
- 個人用MacPC:MacOS Mojave バージョン10.14.6
- docker version:Client, Server共にバージョン19.03.2
章の概要
これまでの特徴抽出法はBoW(やBoWの亜種)で、語彙数に等しい次元数で表していたのに対し、
word embeddingsでは特定の次元数のベクトル(単語の分散表現)で表すことができる。
このベクトルは単語の意味を表すかのように情報を持つ。11.1 Word embeddingsとは?
BoWなどのOne-hot表現との比較
項目 One-hot表現 Word embeddings ベクトルの次元数 ・語彙数
・数万〜数百万になることも・設計者が決めた固定値
・数百程度ベクトルの値 特定の次元のみが1で、その他は0 全ての次元が実数値をとる 11.2 Word embeddingsに触れてみる
Analogy task
analogy_sample.pyを実行してみる$ docker run -it -v $(pwd):/usr/src/app/ 15step:latest python analogy_sample.py tokyo - japan + france = ('paris', 0.9174968004226685)
gensim.downloader.load('<word embeddingsモデル>')は単語に対応する特徴ベクトルを保持している。ただし、モデルによっては英単語のみの場合もある。この例では
tokyoとjapanとfranceという単語を扱っており、単語の意味を踏まえて擬似計算してみると
(tokyo - japan) + france = (首都) + france ≒ parisと表現できていることがわかる。応用課題
他の本で読んだ例をいくつか試してみる。
- king - man + woman ≒ queen
- gone - go + see ≒ seen
king - man + woman = [('king', 0.8859834671020508), ('queen', 0.8609581589698792), ('daughter', 0.7684512138366699), ('prince', 0.7640699148178101), ('throne', 0.7634970545768738), ('princess', 0.7512727975845337), ('elizabeth', 0.7506488561630249), ('father', 0.7314497232437134), ('kingdom', 0.7296158075332642), ('mother', 0.7280011177062988)] gone - go + see = [('see', 0.8548812866210938), ('seen', 0.8507398366928101), ('still', 0.8384071588516235), ('indeed', 0.8378400206565857), ('fact', 0.835073709487915), ('probably', 0.8323071002960205), ('perhaps', 0.8315557837486267), ('even', 0.8241520524024963), ('thought', 0.8223952054977417), ('much', 0.8205327987670898)]類義語
Analogy taskでも扱ったように、
model.wv.similar_by_vector(..)によって得ることができる。Word embeddingsの性質
Word embeddingsによって得られる分散表現には以下の性質がある。
- ベクトルの足し算や引き算で、意味の足し算や引き算を表現できる
- 意味が近い単語の分散表現は、ベクトル空間の中でも近くに分布している
Word embeddingsの種類
項目 内容 Word2Vec 文章中の連続する数単語に着目して分散表現を得る Glove 学習データ全体における単語の共起頻度情報を利用して分散表現を得る fastText 文字n-gramの分散表現を得て、それらを足し合わせて単語の分散表現とする 11.3 学習済みモデルの利用と日本語対応
Word embeddingsでは前述のように、すでに学習済みのモデルを利用することができる(アプリケーションに組み込む際は、学習済みのモデルを使う際は転移学習してデータにある程度適当させてから利用した方が良さそう)
あと配布されている学習済みモデルを利用するときには、そのモデルのライセンスや利用規約に注意する。
11.4 識別タスクにおけるword embeddings
分散表現を特徴量として利用
simple_we_classification.pyはsec130_140_cnn_rnn/classification/下にある。tokenize.pyはこのディレクトリには存在しないので、sec40_preprocessing/tokenizer.pyを利用した。前章(Step09)からの追加・変更点
- 特徴抽出変更:TF-IDF → Word2Vec
def calc_text_feature(text): """ 単語の分散表現をもとにして、textの特徴量を求める。 textをtokenizeし、各tokenの分散表現を求めたあと、 すべての分散表現の合計をtextの特徴量とする。 """ tokens = tokenize(text) word_vectors = np.empty((0, model.wv.vector_size)) for token in tokens: try: word_vector = model[token] word_vectors = np.vstack((word_vectors, word_vector)) except KeyError: pass if word_vectors.shape[0] == 0: return np.zeros(model.wv.vector_size) return np.sum(word_vectors, axis=0)実行結果$ docker run -it -v $(pwd):/usr/src/app/ 15step:latest python simple_we_classification.py 0.40425531914893614通常実装(Step01):37.2%
前処理追加(Step02):43.6%
前処理+特徴抽出変更(Step04):58.5%
前処理+特徴抽出変更(Step11):40.4%word embeddingsを単純に足して得られた文レベルの特徴量では性能が低い。
前処理+特徴抽出変更+識別器変更(Step06):61.7%
前処理+特徴抽出変更+識別器変更(Step09):66.0%形態素解析器・前処理の統一
利用するword embeddingsのモデルが学習されたときに用いられたわかち書きの方法や前処理となるべく同じものを利用時にも再現するのが望ましい。
- 投稿日:2020-02-07T17:35:44+09:00
似ている声優同士をネットワーク分析で可視化してクラスタリングする(1/2)
この記事で紹介する大まかなフロー
・声優さんの名前と性別のリストをスクレイピングして取得
・リストに含まれる声優さんのWikipediaのテキスト情報をmecabで分かち書きしてword2vecで学習
・word2vecで学習したモデルを使って単語分析で遊んでみる次回紹介する解析の大まかなフロー
・女性声優ネットワークを構築して可視化
・ネットワーク情報を使って似ている声優さん同士をクラスタリングしてカテゴリ化してみる初めまして、bamboo-novaと申します。Qiitaでは主にネタ解析を放り込む予定です。真面目な話や解析などは「hatena blog」で書いてるので、そちらを参照してください。あと、NLPは全く専門ではないので、稚拙なコードだと思いますが温かい目で見守ってください...!
初回の投稿ですが、第一回目のネタ解析として声優ネットワーク分析をしてみました。
今回は、声優さんのWikipediaの記事を持ってきて、そこの文章情報から似ているor関連している声優同士のネットワークを作って、さらにそこから細かくクラスタリングすることにしました。
今回は、10~30代の女性声優に限定して学習モデルを作って解析をします。
まず、女性声優さんのリストを取得する。
以下のサイトをスクレイピングして、声優さんの名前のリストを取得します。年齢が公開されていない声優さんについてはどうやらこのサイトのリストに含まれないので、有名だったとしても解析で表示されない方もいると思います。
http://lain.gr.jp/voicedb/individual
まず、必要なモジュールを呼び出します。
import MeCab import codecs import urllib import urllib.parse as parser import urllib.request as request import requests from bs4 import BeautifulSoup import numpy as np import pandas as pd from gensim.models import word2vec import re # .parseToNodeする方としない方で分けました。 mecab = MeCab.Tagger('-Owakati -d /usr/local/mecab/lib/mecab/dic/mecab-ipadic-neologd') title = MeCab.Tagger('-d /usr/local/mecab/lib/mecab/dic/mecab-ipadic-neologd')指定したURLの情報を取得します。
url = "http://lain.gr.jp/voicedb/individual/age/avg/10" response = requests.get(url) response.encoding = response.apparent_encoding soup10 = BeautifulSoup(response.text, 'html.parser') url = "http://lain.gr.jp/voicedb/individual/age/avg/20" response = requests.get(url) response.encoding = response.apparent_encoding soup20 = BeautifulSoup(response.text, 'html.parser') url = "http://lain.gr.jp/voicedb/individual/age/avg/30" response = requests.get(url) response.encoding = response.apparent_encoding soup30 = BeautifulSoup(response.text, 'html.parser')まず、声優さんの名前を取得します。今回は、上記のソースコードのURLの中で、”voicedb/profile”を含むhref属性を持っているタグを10~30代の声優さんですべて取得します。下の画像は実際に上記のソースコードのURLの一つをChromeで検証した時のものですが、実際に”voicedb/profile”を含むhref属性の中に声優さんの名前がリスト形式で格納されていることが確認できるかと思います。
以下、名前を取得するソースコード
corpus=[] name10 = soup10.find_all(href=re.compile("voicedb/profile")) name20 = soup20.find_all(href=re.compile("voicedb/profile")) name30 = soup30.find_all(href=re.compile("voicedb/profile")) for p in name10: corpus.append(p.text) for p in name20: corpus.append(p.text) for p in name30: corpus.append(p.text)次に、性別を取得します。これも上記の検証した画像を見ると、imgタグ内のsrcとaltを取得すれば大丈夫そうなので、以下のようにして取得します。ちなみに、
alt=img.attrs.get('alt', 'N')の部分ですが、alt 属性が存在する場合はその値、存在しない場合は 'N' が設定されます。data = [] for img in soup10.find_all('img'): data.append(dict(src=img['src'], alt=img.attrs.get('alt', 'N'))) for img in soup20.find_all('img'): data.append(dict(src=img['src'], alt=img.attrs.get('alt', 'N'))) for img in soup30.find_all('img'): data.append(dict(src=img['src'], alt=img.attrs.get('alt', 'N'))) gender = [] for res in data: for k, v in res.items(): if v == '女性' or v == '男性': gender.append(v)そして、名前と性別を統合したデータフレームをcsv形式で保存します。
name = pd.DataFrame(corpus) gen = pd.DataFrame(gender) res = pd.concat([name, gen],axis=1) res.columns = ['Name','Gender'] res.to_csv('seiyu.csv')取得したリストに含まれる女性声優さんのWikipediaのプロフィール情報を取得する。
では、保存したデータフレームの中から女性声優だけを選んで、Wikipediaで対象の声優さんのプロフィール情報を取得します。取得した情報は、pwiki.txtとして保存します。
df = pd.read_csv('seiyu.csv') # Wikipediaのリンク link = "https://ja.wikipedia.org/wiki/" # 女性声優のみに対象を絞る df_women = df[df.Gender=='女性'] keyword = df_women.Name keyword = list(keyword) corpus = [] for word in keyword: # 声優の記事をダウンロード try: with request.urlopen(link + parser.quote_plus(word)) as response: # responseはhtmlのformatになっている html = response.read().decode('utf-8') soup = BeautifulSoup(html, "lxml") # <p>タグを取得 p_tags = soup.find_all('p') for p in p_tags: corpus.append(p.text.strip()) except urllib.error.HTTPError as err: # Wikipediaに載っていない声優さんなどについてはエラーが出るので例外処理を加えています。 if err.code == 404: continue else: raise with codecs.open("pwiki.txt", "w", "utf-8") as f: f.write("\n".join(corpus))実際にテキストファイルを分かち書きして、word2vecとして学習モデルを保存する。
では、実際に取得したテキストデータを分かち書きします。今回はアニメの名前なども多いので、固有名詞に対してもちゃんと分かち書きされるように対応しています(例えば、ハイスクール・フリートとかだと固有名詞、組織の扱いになるので普通にparseToNodeするとになってしまいます)。また、下の例のように、何故かmecab+neologdで「プリキュア」を分かち書きすると英語に変換される*みたいなので、こちらに関してもif文の条件分岐で対応して、英語に反応するようにしました(プリキュアに出演したことをステータスとしてプロフィールに載せている声優さんが非常に多かったので、特徴量の情報として無視できなかったのでこちらはちゃんと分かち書きが反映されるようにしました)。
node = title.parse('プリキュア') node.split(",")[6] # 出力結果: 'PulCheR'以下、実際のソースコードです。まずは、テキストデータの前処理を行います。
fi = codecs.open('pwiki.txt') result = [] fo = open('try.csv', 'w') lines = fi.readlines() for line in lines: line = re.sub('[\n\r]',"",line) line = re.sub('[ ]'," ",line) #全角スペースを半角に変換しないと、一部の名詞が複合名詞として抽出できない line = re.sub('(年|月|日)',"",line) line = re.sub('[0-9_]',"",line) line = re.sub('[#]',"",line) line = re.sub('[!]',"",line) line = re.sub('[*]',"",line) fo.write(line + '\n') fi.close() fo.close()そして、前処理されたテキストデータを実際に分かち書きして、word2vecで学習します。今回はデフォルトのパラメータで学習しました。
fi = open('try.csv', 'r') fo = open('res.csv', 'w') #line = fi.readline() lines = fi.readlines() result=[] mecab.parse("") for line in lines: node = mecab.parseToNode(line) node_org = title.parse(line) while node: hinshi = node.feature.split(",")[0] if hinshi == '形容詞' or hinshi == '名詞' or hinshi == '副詞' or (len(node.feature.split(",")[6])>1): fo.write(node.feature.split(",")[6] + ' ') if node_org != 'EOS\n' and node_org.split(",")[1] == '固有名詞': fo.write(node_org.split(",")[6] + ' ') if node_org != 'EOS\n' and node_org.split(",")[1] == '固有名詞' and node_org.split(",")[6].isalpha()==True: fo.write(node_org.split(",")[7] + ' ') node = node.next fi.close() fo.close() print('Wakati phase completed!') sentences = word2vec.LineSentence('res.csv') model = word2vec.Word2Vec(sentences, sg=1, size=200, min_count=5, window=5, hs=1, iter=100, negative=0) # pickleで保存 import pickle with open('mecab_word2vec_seiyu.dump', mode='wb') as f: pickle.dump(model, f)word2vecのモデル結果を試して見る
実際にword2vecで学習したモデルを使って単語分析で遊んでみます。試しに、アイドル売りしてなさそうな声優さんでも出してみます。
ret = model.wv.most_similar(negative=['アイドル'],topn=1000) for item in ret: if len(item[0])>2 and (item[0] in list(df.Name)): print(item[0],item[1])出力結果
寿美菜子 0.13453319668769836 蒼井翔太 0.1175239235162735 豊崎愛生 0.1002458706498146 田村知佳 0.08929911255836487 山口茜 0.05830669403076172 森綾香 0.056574173271656036 藤田咲 0.05241834372282028 鹿野優以 0.051871318370103836 早見沙織 0.04932212829589844 菊地美香 0.04044754058122635 鈴木杏 0.034879475831985474 逢坂良太 0.029612917453050613 井口裕香 0.02767171896994114 悠木碧 0.02525651454925537 樋口智恵子 0.022603293880820274次に、アイドル色が強そうな声優さんを取り出してみます。
ret = model.wv.most_similar(positive=['アイドル'],topn=300) for item in ret: if len(item[0])>2 and (item[0] in list(df.Name)): print(item[0],item[1])出力結果
Machico 0.1847614347934723 福原香織 0.1714700609445572 三澤紗千香 0.1615515947341919 中原麻衣 0.15694507956504822 小倉唯 0.1562490165233612 中川翔子 0.1536223590373993 東山奈央 0.15278896689414978 榊原ゆい 0.14662891626358032 清水愛 0.14592087268829346 石原夏織 0.14554426074028015次に、「アワード」と縁がありそうな声優さんを抽出してみます。
ret = model.wv.most_similar(positive=['アワード'],topn=500) for item in ret: if len(item[0])>2 and (item[0] in list(df.Name)): print(item[0],item[1])出力結果
木戸衣吹 0.19377963244915009 福原香織 0.16889861226081848 津田美波 0.16868139803409576 内田真礼 0.1677364706993103 名塚佳織 0.1669023633003235 茅野愛衣 0.16403883695602417 坂本真綾 0.16285887360572815 牧野由依 0.14633819460868835 山崎エリイ 0.1392231583595276 喜多村英梨 0.13390754163265228 阿澄佳奈 0.13131362199783325 能登有沙 0.13084736466407776 大橋彩香 0.1297467052936554 逢坂良太 0.12972146272659302あー、なんだろ、、、めっちゃそれっぽいような気がします(ちなみに「結婚」とやっても出てきた笑)。
まとめ
今回は声優さんのWikipediaの情報を取得して、取得したテキスト情報を用いてword2vecで学習モデルを保存して実際にモデルを動かすところまでやって見ました。ウィキペディアにあるプロフィールのテキスト情報だけだと詳細な情報がないため限界があるので、実際に本格的に解析するには大量のデータやモデリング等の検証が必要です。しかし、ここで投稿するのはあくまでネタ解析なのでそこら辺は許してください。
次は、実際に学習したモデルを用いてネットワークとして可視化して、実際にネットワークをクラスタリングして似ている声優さん同士をカテゴリ化するところまでやっていきます。

- 投稿日:2020-02-07T17:22:24+09:00
Pythonで橋本環奈の画像を自動収集してみた!!
スクレイピング
Webページから情報を自動で抽出する技術のことです
今回は橋本環奈さんの画像を検索エンジンの画像検索結果ページから自動で収集します実装するもの
- 画像検索結果のURLにアクセス
- ページネーション
- 画像のURLリスト取得
- ダウンロード
詳細は以下の動画で紹介しています
https://youtu.be/gqzC0jHdpgwソースコード
scraping.pyimport requests from bs4 import BeautifulSoup import urllib.request import time def scraping(url, max_page_num): # ページネーション実装 page_list = get_page_list(url, max_page_num) # 画像URLリスト取得 all_img_src_list = [] for page in page_list: img_src_list = get_img_src_list(page) all_img_src_list.extend(img_src_list) return all_img_src_list def get_img_src_list(url): # 検索結果ページにアクセス response = requests.get(url) # レスポンスをパース soup = BeautifulSoup(response.text, 'html.parser') img_src_list = [img.get('src') for img in soup.select('p.tb img')] return img_src_list def get_page_list(url, max_page_num): img_num_per_page = 20 page_list = [f'{url}{i*img_num_per_page+1}' for i in range(max_page_num)] return page_list def download_img(src, dist_path): time.sleep(1) with urllib.request.urlopen(src) as data: img = data.read() with open(dist_path, 'wb') as f: f.write(img) def main(): url = "https://search.yahoo.co.jp/image/search?p=%E6%A9%8B%E6%9C%AC%E7%92%B0%E5%A5%88&ei=UTF-8&b=" MAX_PAGE_NUM = 1 all_img_src_list = scraping(url, MAX_PAGE_NUM) # 画像ダウンロード for i, src in enumerate(all_img_src_list): download_img(src, f'./img/kanna_{i}.jpg') if __name__ == '__main__': main()
- 投稿日:2020-02-07T16:37:34+09:00
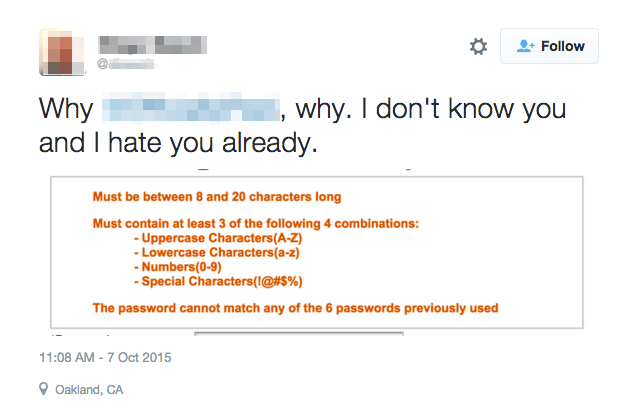
NIST 800-63B パスワード規則をPythonで実験する
毎回新しいアカウントを作るとき、よくこんなメッセージに邪魔されます。
では、いいパスワードは一体どんなやつなのかい?これから、Data Campから勉強したNIST パスワード規則をPythonでやってみる。日本語が母語ではないので、説明が辛い時は英語にしますので、許してください。The repository is at https://github.com/Bing-Violet/Bad-passwords-and-the-NIST-guidelines with the data sets available.
There're loads of criteria for a good password. It's hard to define what is a good password. However, the National Institute of Standards and Technology (NIST) gives you a guide not to make a bad password from the cyber-security perspective.
# Importing the pandas module import pandas as pd # Loading in datasets/users.csv users = pd.read_csv("datasets/users.csv") # Printing out how many users we've got print(users.count()) # Taking a look at the 12 first users print(users.head(12))Passwords should not be too short
# Calculating the lengths of users' passwords users['length'] = users['password'].str.len() # Flagging the users with too short passwords users['too_short'] = users['length'] < 8 # Counting and printing the number of users with too short passwords print(users['too_short'].count()) # Taking a look at the 12 first rows print(users.head(12))Passwords shouldn't be Common passwords
Common passwords and combinations should be avoided as they could be expected. General common passwords include but not restricted to:
- Passwords obtained from previous breach corpuses.
- Dictionary words.
- Repetitive or sequential characters (e.g. ‘aaaaaa’, ‘1234abcd’).
- Context-specific words, such as the name of the service, the username, and derivatives thereof.
# Reading in the top 10000 passwords common_passwords = pd.read_csv('datasets/10_million_password_list_top_10000.txt', header=None, squeeze=True) # Taking a look at the top 20 print(common_passwords.head(20))We fetch the common password list, then find out all the passwords fall in this category.
# Flagging the users with passwords that are common passwords users['common_password'] = users['password'].isin(common_passwords) # Counting and printing the number of users using common passwords print(users['common_password'].count()) # Taking a look at the 12 first rows print(users['common_password'].head(12))Passwords should not be common passwords
By the same token, passwords shouldn't be common words. This may not apply to local Japanese people, as the list we fetch here only contains popular English dictionary words.
# Reading in a list of the 10000 most common words words = pd.read_csv('datasets/google-10000-english.txt', header=None, squeeze=True) # Flagging the users with passwords that are common words users['common_word'] = users['password'].str.lower().isin(words) # Counting and printing the number of users using common words as passwords print(users['common_word'].count()) # Taking a look at the 12 first rows print(users['common_word'].head(12))Passwords should not be your name
We should also flag passwords that contain users' names as a bad password practice.
# Extracting first and last names into their own columns users['first_name'] = users['user_name'].str.extract(r'(\w+)', expand = False) users['last_name'] = users['user_name'].str.extract(r'(\w+$)', expand = False) # Flagging the users with passwords that matches their names users['uses_name'] = (users['password']==(users['first_name']))|(users['password']==(users['last_name'])) # Counting and printing the number of users using names as passwords print(users['uses_name'].count()) # Taking a look at the 12 first rows print(users['uses_name'].head(12))Passwords should not be repetitive
### Flagging the users with passwords with >= 4 repeats users['too_many_repeats'] = users['password'].str.contains(r'(.)\1\1\1') # Taking a look at the users with too many repeats print(users['too_many_repeats'])All together now!
Now let's combine the criteria listed above and filter out all the bad passwords.
# Flagging all passwords that are bad users['bad_password'] = ( users['too_short'] | users['common_password'] | users['common_word'] | users['user_name'] | users['too_many_repeats']) # Counting and printing the number of bad passwords print((users['bad_password']==True).count()) # Looking at the first 25 bad passwords print(users['bad_password'].head(25))
This is how we can filter out the bad passwords in a data set. And similar approaches can be adopted for your current database if you already have some users and want to improve the security for their accounts.
- 投稿日:2020-02-07T15:27:46+09:00
ビット演算による商(切り捨て)・余り計算
ビット演算は低級言語に近いのでどんな言語においても速い.
2 の n 乗での割り算で特に便利.一般
商 : 割り算の解(小数)に対して 0 を OR 演算
(余 : % 演算子を使用, ビット演算じゃない)ex.17÷6の商と余りq = (17/6)|0; // 商 = 2 r = 17%6 // 余り = 5結局途中で小数が発生するからそんなに速くはないが, Math.floor よりは軽い.
2 の n 乗 (1, 2, 4, 8, 16...) での割り算の場合
商 : 左へ n ビットシフト
余 : (2^n)-1 で AND 演算ex.17÷8の商と余りq = 17>>3; // 商 = 2 r = 17&7; // 余り = 1ちなみに
バイナリ周り// N bit のデータを格納するのに必要な byte 数は byteLength = 1 + ((N-1)>>3); // Uint8Array の先頭から N ビット目を取り出すには bitN = uint8array[N>>3] & (1<<(N&7));
- 投稿日:2020-02-07T15:11:15+09:00
[Python]リストの要素だけを並べて表示させる(縦並び、横並び)
はじめに
オンラインでのプログラミング学習、スキルチェックなどで出力の方法が限定されていることが多々あると思います。
自分も答えは出ているのに思ったように出力できないことがあったので調べたことをまとめてみました。リストの要素を縦に並べて表示させる
[方法1]リスト内包表記の中にprint()を入れる
ex.pyL = ["a","b","c","d"] [print(i) for i in L][方法2]1文字ずつ文字列をスライスしてprint()を入れる
ex.pyL = ["a","b","c","d"] for i in L[0:]: print(i)いずれにしても実行結果は以下のようになります。
a
b
c
dリストの要素を横に並べて表示させる
.join()を用いることで空白を開けて表示させる
ex.pyL = ["a","b","c","d"] L=' '.join(L) print(L)実行結果は以下のようになります
a b c d
','.joinを用いるとa,b,c,d
となるように.join()の前の''内の要素は自由に設定可能です。
.join()を用いない方法
.join()を用いなくても出力することはできます。
ex.pyL = [['a', 'b', 'c', 'd']] print(*L[0])実行結果
a b c d
数字(int値)で.join()は使えない
※リスト内の値がint値のみの場合.join()は使用不可(エラーが出ます)
このような時は、str値に変換してから.join()を使いますex.pyL_int = [1, 2, 3, 4] L=[str(a) for a in L_int] L=" ".join(L) print(L)実行結果は以下のようになります
1 2 3 4
最後に
今回記載した以外にも何か方法があれば教えてもらえると嬉しいです。
- 投稿日:2020-02-07T15:11:15+09:00
【Python】リストの要素だけを並べて表示させる(縦並び、横並び)
はじめに
オンラインでのプログラミング学習、スキルチェックなどで出力の方法が限定されていることが多々あると思います。
自分も答えは出ているのに思ったように出力できないことがあったので調べたことをまとめてみました。リストの要素を縦に並べて表示させる
[方法1]リスト内包表記の中にprint()を入れる
ex.pyL = ["a","b","c","d"] [print(i) for i in L][方法2]1文字ずつ文字列をスライスしてprint()を入れる
ex.pyL = ["a","b","c","d"] for i in L[0:]: print(i)いずれにしても実行結果は以下のようになります。
a
b
c
dリストの要素を横に並べて表示させる
.join()を用いることで空白を開けて表示させる
ex.pyL = ["a","b","c","d"] L=' '.join(L) print(L)実行結果は以下のようになります
a b c d
','.joinを用いるとa,b,c,d
となるように.join()の前の''内の要素は自由に設定可能です。
.join()を用いない方法
.join()を用いなくても出力することはできます。
ex.pyL = [['a', 'b', 'c', 'd']] print(*L[0])実行結果
a b c d
数字(int値)で.join()は使えない
※リスト内の値がint値のみの場合.join()は使用不可(エラーが出ます)
このような時は、str値に変換してから.join()を使いますex.pyL_int = [1, 2, 3, 4] L=[str(a) for a in L_int] L=" ".join(L) print(L)実行結果は以下のようになります
1 2 3 4
最後に
今回記載した以外にも何か方法があれば教えてもらえると嬉しいです。
- 投稿日:2020-02-07T13:23:28+09:00
one-hot変換
- 投稿日:2020-02-07T13:19:20+09:00
SessionNotCreatedExceptionの対処法2選
はじめに
アプリ作成記事(あなたの代わりに勤怠ボタン押す太郎くん)の中で紹介した方法を別途切り出してご紹介。
PythonでSelenium使っているとある日突然SessionNotCreatedException出てきますよね。SessionNotCreatedException: Message: session not created: This version of ChromeDriver only supports Chrome version 76これが出てきた時の対処法。
Seleniumのサポートしているバージョン外のChromeDriverを使用している場合
まずサポート対象のdriverを持ってきましょう。
ChromeDriver
持ってきたらプロジェクト内の適当な場所においてその場所をdriverのexecutable_pathに指定します。# chromedriverのバージョンを指定 driver = webdriver.Chrome(options=options, executable_path='chromedriver.exeの場所')ChromeのバージョンとChromeDriverのバージョンが異なる場合
使用しているChromeブラウザのバージョンを確認します。
メニュー > ヘルプ > Google Chromeについて
バージョンを確認したら同じバージョンのChromeDriverを取得してプロジェクトの適当な場所に配置します。
(例えばブラウザが79.0.3945.130だったらChromeDriver 79.0.3945.36をDLする)
あとは↑と同じでドライバーの場所を指定します。まとめ
今のところこのどちらかで解消してるので参考にしてください。
エラーが発生してから手動でバージョン合わせる以外の方法ないかなあ。。
- 投稿日:2020-02-07T13:01:41+09:00
csvファイルを1次元配列のデータとして格納する方法
目的
sample.csva,b,c,d,e上記のようなcsvファイルを下のような一次元配列に格納する。
['a','b','c','d','e']機械学習によって分類したlabelデータの結果として保存したcsvを、またpythonプログラム内で扱うために作成したが、よりよい方法があればコメントにて教えていただきたいです。
方法
sample.csvとread_csv_flatten.pyが同じディレクトリにある場合、以下のコードを実行することでdataにcsvの内容が一次元の配列に格納される。
同じディレクトリ内に無い場合は、適当なpathを指定する必要がある。read_csv_flatten.pyimport csv import numpy as np with open("sample.csv") as fp: reader = csv.reader(fp) data = [ e for e in reader ] data = np.array(data).flatten() #以下確認のための出力 print(data)結果
['a' 'b' 'c' 'd' 'e']以上のように、csvの内容が一次元の配列に格納されていることがわかる。
- 投稿日:2020-02-07T13:01:41+09:00
【Python】csvファイルを1次元配列のデータとして格納する方法
目的
sample.csva,b,c,d,e上記のようなcsvファイルを下のような一次元配列に格納する。
['a','b','c','d','e']機械学習によって分類したlabelデータの結果として保存したcsvを、またpythonプログラム内で扱うために作成したが、よりよい方法があればコメントにて教えていただきたいです。
方法
sample.csvとread_csv_flatten.pyが同じディレクトリにある場合、以下のコードを実行することでdataにcsvの内容が一次元の配列に格納される。
同じディレクトリ内に無い場合は、適当なpathを指定する必要がある。read_csv_flatten.pyimport csv import numpy as np with open("sample.csv") as fp: reader = csv.reader(fp) data = [ e for e in reader ] data = np.array(data).reshape(-1) #以下確認のための出力 print(data)結果
['a' 'b' 'c' 'd' 'e']以上のように、csvの内容が一次元の配列に格納されていることがわかる。
- 投稿日:2020-02-07T12:37:42+09:00
stanのパラメータのTrace Plotが見づらいから少し考えた
はじめに
現在,stanを使ってモデリング,パラメータ推定を行っているのですが,Trae plotがつぶれて見ずらいので少し見やすくする方法があったので共有します.(知っている人にとっては当たり前かも...)
あと,もっと良い方法があったら教えてください.環境
OS Windows10 Python 3.7.4 PyStan 2.19.1 早速...
stan_model_ver1.pyimport arviz import pandas as pd data = pd.read_csv("~~.csv") dat = {"辞書で定義"} model = StanModel(file="~~.stan") fit = model.sampling(data=dat, n_jobs=-1, seed=999, iter=1000,chains=1) arviz.plot_trace(fit)でこのようなものが描かれます.
しかし,パラメータ数が多いと滅茶苦茶見づらいです...
そこで,
stan_model_ver2.pyimport arviz import pandas as pd data = pd.read_csv("~~.csv") dat = {"辞書で定義"} model = StanModel(file="~~.stan") fit = model.sampling(data=dat, n_jobs=-1, seed=999, iter=1000,chains=1) '''====以下変更===''' fit_df = fit.to_dataframe() index = fit_df["draw"] lenght = len(fit_df.keys())-7 for i in range(lenght): ob = fit_df[fit_df.keys()[i+3]] plt.subplots(figsize=(15, 7)) plt.title(f"{fit_df.keys()[i+3]}") plt.subplot(1, 2, 1) sns.distplot(ob) plt.subplot(1, 2, 2) plt.plot(index, ob) plt.savefig(f"figure/stan_figure/{fit_df.keys()[i+3]}.png") plt.show()とします.
データフレーム化して,パラメータ1つずつ可視化することで,時間は少しかかりますが,
このように各段に見やすくなります.
おまけ?
パラメータ数が多いと
print(fit.stansummary())をして各パラメータの収束状態を確認しようとしても,表示しきれないことがあるかもしれません.(特に時系列モデルを考えると)
そんな時は,omake.pysummary_df = fit.stansummary() file = open('summary_stan.txt', 'w') string = summary_df file.write(string)このようにテキストファイルとして保存してしまえば見たいパラメータの状態を確認することができます.
![Y[1,2].png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F208370%2F5ce3c039-31cf-b964-c26e-20c90a489ec9.png?ixlib=rb-1.2.2&auto=format&gif-q=60&q=75&s=9fbd5da21eaca5985f980f535c47a282)
- 投稿日:2020-02-07T12:24:28+09:00
windowsのpowershellでvenv環境
- 投稿日:2020-02-07T12:20:48+09:00
tweet.jsの展開とか(json.loadsとeval)
こんにちは、初投稿失礼します。
去年(2019年)あたりからcsv形式でダウンロードすることができなくなってしまいましたが、tweet.js,tweet-part<任意の自然数>.jsなどから、まずは"自分のツイート"のツイート"時間"と"テキスト"を抽出したいということで書いていきたいと思います。
~同じことを書いている人がいなかったので....クソ見にくいコードですがどうぞ~。tweet.jsの場合、
read_js.py#同じディレクトリにtweet.jsを入れてください #MeCabをインストールしている場合にはコメントアウトを外すと分かち書きされたものが取り出されます。 import re import datetime import json #import MeCab tw_open = open("tweet.js","r",encoding="utf-8") tw_time = open("tweet_mytext_time.txt","a",encoding="utf-8") tw_a = open("tweet_mytext.txt","a",encoding="utf-8") #tw_mecab = open("tweet_mytext_mecab.txt","a",encoding="utf-8") twr = tw_open.read() twr = re.sub("window.YTD.tweet.part0 = ","",twr) twrj=json.loads(twr) big=[] small=[] #mecab = MeCab.Tagger ("-Owakati") for n in range(len(twrj)): tw=eval(str(twrj[n]["tweet"])) twf=str(tw["full_text"]) twf=re.sub(r"https?://[\w/:%#\$&\?\(\)~\.=\+\-…]+","",twf) twf=twf.replace("\n","") twc=str(tw["created_at"]) tim=datetime.datetime.strptime(twc,"%a %b %d %H:%M:%S %z %Y").replace(tzinfo=None) tim_r=str(tim).replace(" ","_") small=[] twf_b=twf.split(":")[0] if not "RT" in twf_b: if not "@" in twf_b: small.append(str(tim.timestamp()).replace(".0","")) small.append(tim_r) small.append(twf) big.append(small) small=[] big.sort(key=lambda x: x[1],reverse=True) for num in range(len(big)): tw_a.write(big[num][2]+"\n") tw_time.write(big[num][1]+" "+big[num][2]+"\n") #text=big[num][2] #text_m = mecab.parse(text) #tw_mecab.write(str(text_m))tweet-part1.js、Mecabもある場合は、
read_js.pyimport re import datetime import json import MeCab tw_open = open("tweet.js","r",encoding="utf-8") tw1_open = open("tweet-part1.js","r",encoding="utf-8") tw_time = open("tweet_mytext_time.txt","a",encoding="utf-8") tw_a = open("tweet_mytext.txt","a",encoding="utf-8") tw_mecab = open("tweet_mytext_mecab.txt","a",encoding="utf-8") twr = tw_open.read() tw1r = tw1_open.read() twr = re.sub("window.YTD.tweet.part0 = ","",twr) tw1r = re.sub("window.YTD.tweet.part1 = ","",tw1r) twrj=json.loads(twr) tw1rj=json.loads(tw1r) big=[] small=[] mecab = MeCab.Tagger ("-Owakati") for n in range(len(twrj)): tw=eval(str(twrj[n]["tweet"])) twf=str(tw["full_text"]) twf=re.sub(r"https?://[\w/:%#\$&\?\(\)~\.=\+\-…]+","",twf) twf=twf.replace("\n","") twc=str(tw["created_at"]) tim=datetime.datetime.strptime(twc,"%a %b %d %H:%M:%S %z %Y").replace(tzinfo=None) tim_r=str(tim).replace(" ","_") small=[] twf_b=twf.split(":")[0] if not "RT" in twf_b: if not "@" in twf_b: small.append(str(tim.timestamp()).replace(".0","")) small.append(tim_r) small.append(twf) big.append(small) small=[] for n in range(len(tw1rj)): tw1=eval(str(tw1rj[n]["tweet"])) twf1=str(tw1["full_text"]) twf1=re.sub(r"https?://[\w/:%#\$&\?\(\)~\.=\+\-…]+","",twf1) twf1=twf1.replace("\n","") twc1=str(tw1["created_at"]) tim1=datetime.datetime.strptime(twc1,"%a %b %d %H:%M:%S %z %Y").replace(tzinfo=None) tim_r1=str(tim1).replace(" ","_") small=[] twf_b1=twf1.split(":")[0] if not "RT" in twf_b1: if not "@" in twf_b1: small.append(str(tim1.timestamp()).replace(".0","")) small.append(tim_r1) small.append(twf1) big.append(small) #print(big) big.sort(key=lambda x: x[1],reverse=True) for num in range(len(big)): tw_a.write(big[num][2]+"\n") tw_time.write(big[num][1]+" "+big[num][2]+"\n") text=big[num][2] text_m = mecab.parse(text) tw_mecab.write(str(text_m))これを実行すると、
tweet_mytext.txtテキスト .....tweet_mytext_time.txt2020-01-19_05:47:57 テキスト .....となるはずです。
説明
基本的なところ()は置いておいて、JSON内の引用符をどう処理するかでだいぶ苦労しましたが、
twrj=json.loads(twr) tw=eval(str(twrj[n]["tweet"]))などのところで、openとreadで文章全体を読み込んで余分なヘッダーを取り除いて、json.loads(文字型)でjsonに変換しているようです。
そこからevalで更に辞書型のtweetの値を辞書として変換しています。{'tweet': {'retweeted': False, 'source': '<a href="http://twitter.com/download/android" rel="nofollow">Twitter for Android</a>', 'entities': {'hashtags': [], 'symbols': [], 'user_mentions': [{'name': 'Saidjon', 'screen_name': 'noppo6', 'indices': ['3', '10'], 'id_str': '240638809', 'id': '240638809'}], 'urls': []}, 'display_text_range': ['0', '140'], 'favorite_count': '0', 'id_str': '1218787465110024192', 'truncated': False, 'retweet_count': '0', 'id': '1218787465110024192', 'created_at': 'Sun Jan 19 06:49:10 +0000 2020', 'favorited': False, 'full_text': 'RT @noppo6: サマルカンドが青いのは、独立後観光客を呼び込むために青く塗ったから。ほとんど遺跡破壊のレベル。これでサマルカンドを「青の都」と讃えている日本のガイドブックやメディアはおめでたい限り。この素朴なサマルカンドもこれはこれでいいと思う。\nにしても、シャーヒズィ…', 'lang': 'ja'}}自分がさっき取得したJSONは例えばこうなっていました。
Q.自分のツイートかどう判断している?
A.RTの場合はコロンで、0番目にRTと@が含まれているため、それで判断していますここまで書くだけ書いてみましたが、仮に役立ったようであれば嬉しいです。ツイッター(@kenkensz9)にいつもいるので何かあればどうぞ
よろしければいいねお願いします!
- 投稿日:2020-02-07T12:20:48+09:00
tweet.jsの展開とか(json.loadsとeval)(Python)
こんにちは、初投稿失礼します。
去年(2019年)あたりからcsv形式でダウンロードすることができなくなってしまいましたが、tweet.js,tweet-part<任意の自然数>.jsなどから、まずは"自分のツイート"のツイート"時間"と"テキスト"を抽出したいということで書いていきたいと思います。
~同じことを書いている人がいなかったので....クソ見にくいコードですがどうぞ~。tweet.jsの場合、
read_js.py#同じディレクトリにtweet.jsを入れてください #MeCabをインストールしている場合にはコメントアウトを外すと分かち書きされたものが取り出されます。 import re import datetime import json #import MeCab tw_open = open("tweet.js","r",encoding="utf-8") tw_time = open("tweet_mytext_time.txt","a",encoding="utf-8") tw_a = open("tweet_mytext.txt","a",encoding="utf-8") #tw_mecab = open("tweet_mytext_mecab.txt","a",encoding="utf-8") twr = tw_open.read() twr = re.sub("window.YTD.tweet.part0 = ","",twr) twrj=json.loads(twr) big=[] small=[] #mecab = MeCab.Tagger ("-Owakati") for n in range(len(twrj)): tw=eval(str(twrj[n]["tweet"])) twf=str(tw["full_text"]) twf=re.sub(r"https?://[\w/:%#\$&\?\(\)~\.=\+\-…]+","",twf) twf=twf.replace("\n","") twc=str(tw["created_at"]) tim=datetime.datetime.strptime(twc,"%a %b %d %H:%M:%S %z %Y").replace(tzinfo=None) tim_r=str(tim).replace(" ","_") small=[] twf_b=twf.split(":")[0] if not "RT" in twf_b: if not "@" in twf_b: small.append(str(tim.timestamp()).replace(".0","")) small.append(tim_r) small.append(twf) big.append(small) small=[] big.sort(key=lambda x: x[1],reverse=True) for num in range(len(big)): tw_a.write(big[num][2]+"\n") tw_time.write(big[num][1]+" "+big[num][2]+"\n") #text=big[num][2] #text_m = mecab.parse(text) #tw_mecab.write(str(text_m))tweet-part1.js、Mecabもある場合は、
read_js.pyimport re import datetime import json import MeCab tw_open = open("tweet.js","r",encoding="utf-8") tw1_open = open("tweet-part1.js","r",encoding="utf-8") tw_time = open("tweet_mytext_time.txt","a",encoding="utf-8") tw_a = open("tweet_mytext.txt","a",encoding="utf-8") tw_mecab = open("tweet_mytext_mecab.txt","a",encoding="utf-8") twr = tw_open.read() tw1r = tw1_open.read() twr = re.sub("window.YTD.tweet.part0 = ","",twr) tw1r = re.sub("window.YTD.tweet.part1 = ","",tw1r) twrj=json.loads(twr) tw1rj=json.loads(tw1r) big=[] small=[] mecab = MeCab.Tagger ("-Owakati") for n in range(len(twrj)): tw=eval(str(twrj[n]["tweet"])) twf=str(tw["full_text"]) twf=re.sub(r"https?://[\w/:%#\$&\?\(\)~\.=\+\-…]+","",twf) twf=twf.replace("\n","") twc=str(tw["created_at"]) tim=datetime.datetime.strptime(twc,"%a %b %d %H:%M:%S %z %Y").replace(tzinfo=None) tim_r=str(tim).replace(" ","_") small=[] twf_b=twf.split(":")[0] if not "RT" in twf_b: if not "@" in twf_b: small.append(str(tim.timestamp()).replace(".0","")) small.append(tim_r) small.append(twf) big.append(small) small=[] for n in range(len(tw1rj)): tw1=eval(str(tw1rj[n]["tweet"])) twf1=str(tw1["full_text"]) twf1=re.sub(r"https?://[\w/:%#\$&\?\(\)~\.=\+\-…]+","",twf1) twf1=twf1.replace("\n","") twc1=str(tw1["created_at"]) tim1=datetime.datetime.strptime(twc1,"%a %b %d %H:%M:%S %z %Y").replace(tzinfo=None) tim_r1=str(tim1).replace(" ","_") small=[] twf_b1=twf1.split(":")[0] if not "RT" in twf_b1: if not "@" in twf_b1: small.append(str(tim1.timestamp()).replace(".0","")) small.append(tim_r1) small.append(twf1) big.append(small) #print(big) big.sort(key=lambda x: x[1],reverse=True) for num in range(len(big)): tw_a.write(big[num][2]+"\n") tw_time.write(big[num][1]+" "+big[num][2]+"\n") text=big[num][2] text_m = mecab.parse(text) tw_mecab.write(str(text_m))これを実行すると、
tweet_mytext.txtテキスト .....tweet_mytext_time.txt2020-01-19_05:47:57 テキスト .....となるはずです。
説明
基本的なところ()は置いておいて、JSON内の引用符をどう処理するかでだいぶ苦労しましたが、
twrj=json.loads(twr) tw=eval(str(twrj[n]["tweet"]))などのところで、openとreadで文章全体を読み込んで余分なヘッダーを取り除いて、json.loads(文字型)で辞書型に変換しているようです。
そこからevalで更に辞書型のtweetの値を辞書として変換しています。{'tweet': {'retweeted': False, 'source': '<a href="http://twitter.com/download/android" rel="nofollow">Twitter for Android</a>', 'entities': {'hashtags': [], 'symbols': [], 'user_mentions': [{'name': 'Saidjon', 'screen_name': 'noppo6', 'indices': ['3', '10'], 'id_str': '240638809', 'id': '240638809'}], 'urls': []}, 'display_text_range': ['0', '140'], 'favorite_count': '0', 'id_str': '1218787465110024192', 'truncated': False, 'retweet_count': '0', 'id': '1218787465110024192', 'created_at': 'Sun Jan 19 06:49:10 +0000 2020', 'favorited': False, 'full_text': 'RT @noppo6: サマルカンドが青いのは、独立後観光客を呼び込むために青く塗ったから。ほとんど遺跡破壊のレベル。これでサマルカンドを「青の都」と讃えている日本のガイドブックやメディアはおめでたい限り。この素朴なサマルカンドもこれはこれでいいと思う。\nにしても、シャーヒズィ…', 'lang': 'ja'}}自分がさっき取得したJSONは例えばこうなっていました。
Q.自分のツイートかどう判断している?
A.RTの場合はコロンで、0番目にRTと@が含まれているため、それで判断していますここまで書くだけ書いてみましたが、仮に役立ったようであれば嬉しいです。ツイッター(@kenkensz9)にいつもいるので何かあればどうぞ
よろしければいいねお願いします!
- 投稿日:2020-02-07T11:41:24+09:00
Callback関数ってなんぞや
結論から言うとコールバック関数というのは
コールバック関数とは、コンピュータプログラム中で、ある関数などを呼び出す際に引数などとして引き渡される別の関数。
コールバック関数とはもっと端的にいうならば、引数として使われる関数ですね。
いや、わかるかい。なんやそれ。どうやって使うんや。笑具体例を見ていきましょう。
サンプルコード
def callback_add(a, b): print('{} + {} = {}'.format(a, b, a + b)) def callback_times(a, b): print('{} × {} = {}'.format(a, b, a * b)) def handler(a, b, callback): callback(a, b) if __name__=='__main__': handler(3, 5, callback_add) handler(3, 5, callback_times)3 + 5 = 8 3 × 5 = 15ここで、callback_add, callback_timesがコールバック関数です。
ちなみに、コールバック関数を呼び出す関数はhandlerと記述されることが多いらしいです。
コールバック関数のメリットは、関数の呼び出し側であらかじめ決めた処理を渡せることらしいです。はぁ・・・・。
・・・いまいち使い道が分かりづらい。
いつ使うねん!!!!!!!ってツッコミたくなりますね。笑
ということでもう一歩踏み込んでみましょう。Callback関数を使わなかった場合の例
def f1(): name = 'Mike' say_hello(name) def say_hello(name): print(name, 'さん,こんにちは!') def say_bye(name): print(name, 'さん,さようなら!') def f2(): name = 'Mike' say_bye(name) if __name__=='__main__': f1() f2()Mike さん,こんにちは! Mike さん,さようなら!もしCallback関数を使わずに、f1の中にsay_helloがあるというロジックを組んだ場合、違うことをこの名前で言いたい時にまた新しいf2を作らないといけなくなります。そして増やせば増やすほど、f3,f4と増えていきます。これはとても不便です。こんな時にCallback関数を使うんですね。
def f1(callback): name = 'Mike' callback(name) def say_hello(name): print(name, 'さんこんにちは!') def say_bye(name): print(name, 'さんさようなら!') if __name__=='__main__': f1(say_hello) f1(say_bye)上は同じ例だけど、Callback関数を使った場合です。
めちゃくちゃ綺麗ですね・・・・。
どんだけ増やしてもf1で納まり、say_〇〇の関数を増やせばいいだけです。
まだピンと来てない方は、上下のコードと睨めっこしてみてください。
そして手でなぞりながら考えたらわかると思います。Callback関数を覚えれば、関数の幅がとても広がりますね。
参照文献
- 投稿日:2020-02-07T11:23:14+09:00
競プロで使う再帰関数の活用
おいおい追加予定
こんなとき再帰使う可能性高いよ!
N、N-1などの状態で同じ処理を行いたいとき
https://atcoder.jp/contests/abc115/tasks/abc115_dループを上限なく行いたいとき
https://atcoder.jp/contests/abc114/tasks/abc114_cまとめ
再帰の基本は類似状態の探索っぽいですね
- 投稿日:2020-02-07T09:25:03+09:00
pythonで単回帰分析の回帰係数を算出
単回帰分析の回帰係数の算出
単回帰分析の回帰係数の算出のコードを作ったので, 宜しければ, 使ってください!
ライブラリのインポート
import numpy as np import matplotlib.pyplot as plt import pandas as pdデータセットの例(test.csv)
Column 1 Column 2 2.2 71 4.1 81 5.5 86 1.9 72 3.4 77 2.6 73 4.2 80 3.7 81 4.9 85 3.2 74 データの読み込み
dataset = pd.read_csv('test.csv')列の取り出し
Xを説明変数, yを目的変数として, 列をそれぞれ取り出します。
X = dataset.iloc[:, :-1].values #Indepand variable y = dataset.iloc[:, 1].values #Depand variable平均の計算
# Calculate Mean Sum_X = sum(X) N_X = len(X) Mean_X = Sum_X / N_X Sum_y = sum(y) N_y = len(y) Mean_y = Sum_y / N_y偏差の計算
# Calcuate Deviation Devi_X = [] for Row_X in X: Devi_X.append(Row_X - Mean_X) Devi_y = [] for Row_y in y: Devi_y.append(Row_y - Mean_y)Xとyの偏差をかける
# Multiply Deviation X and y counter = 0 MD_Xy = [] while counter < len(Devi_X): MD_Xy_Value = Devi_X[counter] * Devi_y[counter] MD_Xy.append(MD_Xy_Value) counter += 1Xとyの偏差をかけたものを合計する
# Sum of Multiply Deviation X and y SMD_Xy = sum(MD_Xy)偏差の平方
# Squares of Calcuate Deviation Sq_Devi_X = [] for DX in Devi_X: Sq_Devi_X.append(DX * DX) Sq_Devi_y = [] for Dy in Devi_y: Sq_Devi_y.append(Dy * Dy)偏差の平方和
# Sum of Squares of Calcuate Deviation SSX = sum(Sq_Devi_X) SSy = sum(Sq_Devi_y)回帰母数の計算
# Calculate Regression paramator betaOne = SMD_Xy / SSX betaZero = Mean_y - betaOne * Mean_X