- 投稿日:2020-02-07T19:43:26+09:00
AWS CodePipelineでReactをs3保存、CloudFront公開手順
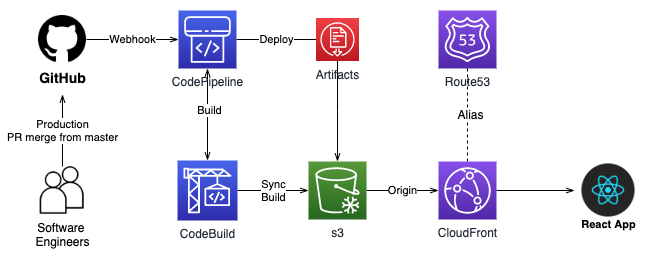
システム構成
以下の様なシステム構成イメージで準備します。
Branch:productionへのPR mergeが完了したら、Githubに設定されているwebhook経由でCodePipelineを呼んで、最終的にs3にReactのソースを保存します。
そして、CloudFront経由でアプリをブラウザーに起動する様にしておきます。
Githubにレポジトリを作成
Reactの準備がされている前提で、まず、Githubにリポジトリを作成し、必要なソースコードをプッシュしておきます。
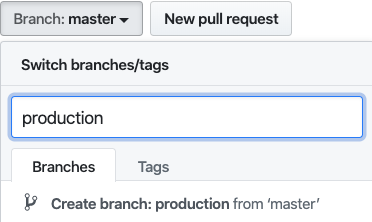
productionブランチを作成
Branch:masterからBranch:productionにPull Request(PR)がマージされた時に、CodePipelineを呼んで本番化をしたいので、productionブランチを作成しておきます。
Branch:masterにproductionと入力したらCreate branch: production from masterと表示されるので、そこをクリックして作成します。コマンドラインから作成しても構いません。
IAMの設定
まず、IAMのコンソールでCreate policyを押してポリシーを追加します。以下の設定を追加します。以下のポリシーをもったユーザーのAccess key IDとSecretを取得しておきます。CodeBuildの環境変数設定の箇所で使います。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "s3:PutObject", "s3:ListBucket", "s3:DeleteObject", "cloudfront:CreateInvalidation", "s3:PutObjectAcl" ], "Resource": [ "arn:aws:s3:::あなたのバケット", "arn:aws:s3:::あなたのバケット/*", "arn:aws:cloudfront::211367837384:distribution/CloudFrontのID" ] }, { "Sid": "VisualEditor1", "Effect": "Allow", "Action": "s3:GetObject", "Resource": "arn:aws:s3:::あなたのバケット/*" } ] }s3の準備
s3にアクセスして以下の様にあるcreate bucketをクリックして、bucketの作成ウイザードを表示させます。
bucket名は自由に決め、後は
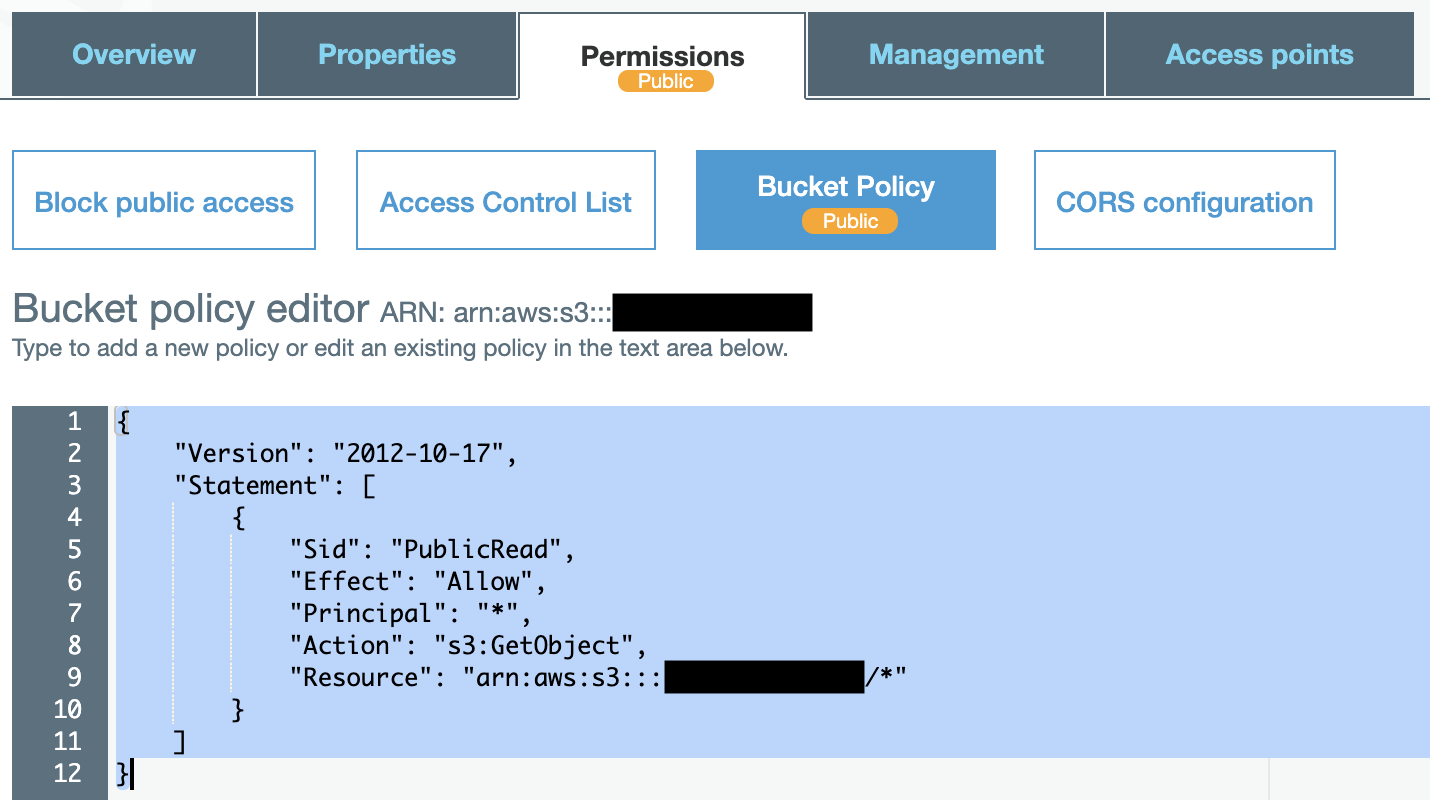
Nextを押してデフォルト設定で作成します。作成したbucketの詳細に入ります。Permissionsタグを選択してPublicReadを許可しておきます。黒く塗りつぶした箇所に設定したバケット名を設定し保存してください。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "PublicRead", "Effect": "Allow", "Principal": "*", "Action": "s3:GetObject", "Resource": "arn:aws:s3:::あなたのバケット名/*" } ] }CloudFrontの設定
CloudFrontを利用することでSSLの利用も可能になるので、おすすめです。CloudFrontのコンソールにアクセスしてCreate Distributionを選びます。そして、WebのGet Startedを選びます。
Origin Domain Nameに先程作ったs3のbucketを指定します。
Default Cache Behavior SettingsのViewer Protocol PolicyをRedirect HTTP to HTTPSを設定します。
Distribution Settingsでドメイン名とSSLを有効にするためにCustom SSLを設定します。ACMを設定しSSLを有効にします。ACMのドメイン(common name)とドメイン名は一致している必要があります。
Default Root Objectにindex.htmlを指定します。こうすることでCloudFrontにアクセスした時にURLにindex.htmlを指定しない状態でもindex.htmlをデフォルトで呼び出すことができます。
Route53の設定
Route53のコンソールにアクセスします。黒色に塗りつぶした内容をDistribution SettingsのCNAMEsに設定します。CloudFront Distributionsの一覧に表示されているDomain NameをAlias Targetに指定します。
CodePipelineの設定
CodePipelineのコンソールにアクセスしてオレンジ色のCreate projectボタンをクリックします。
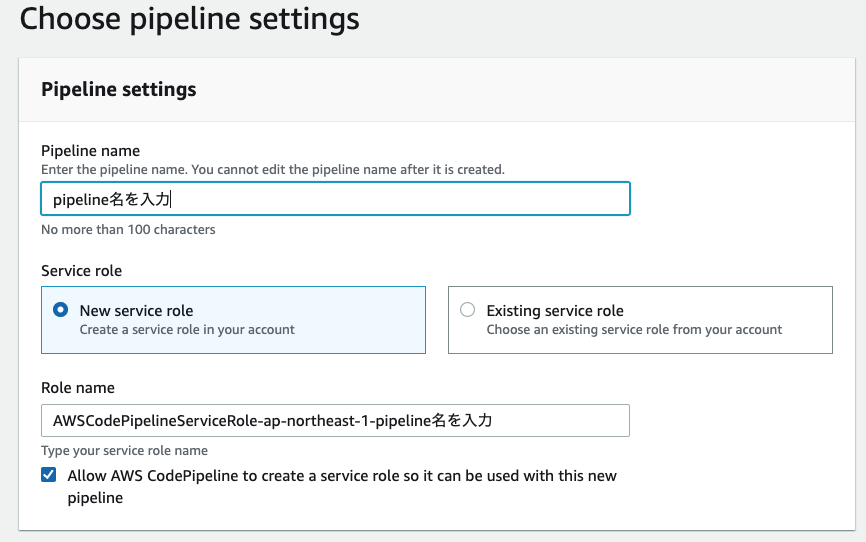
Pipeline名を設定し、次へ進みます。
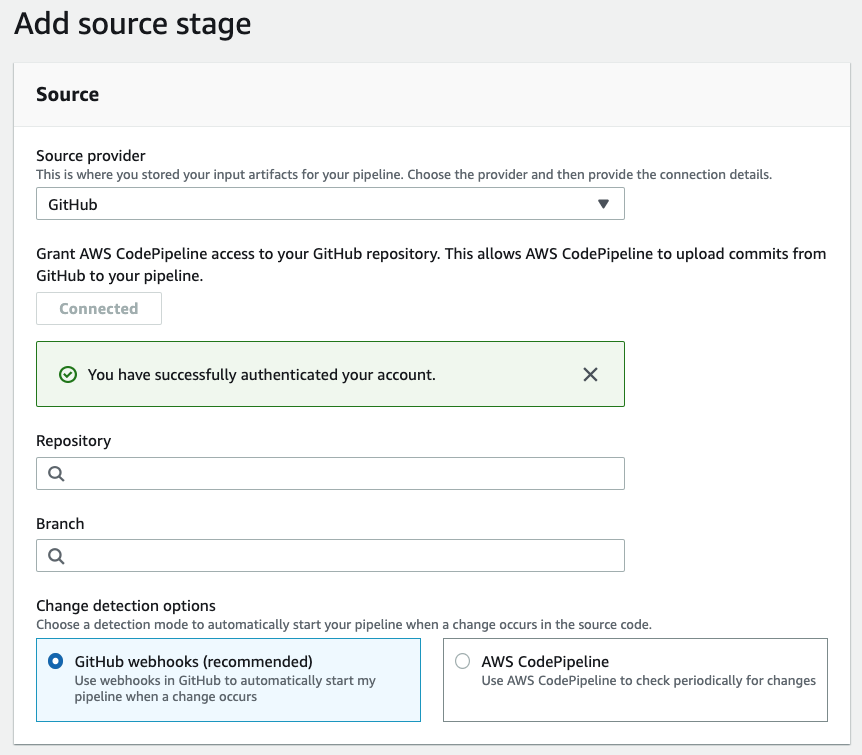
SourceにGithubを選択、そして、認証して繋ぎます。最初に作っておいたRepositoryを選び、Branchはproductionを設定してください。
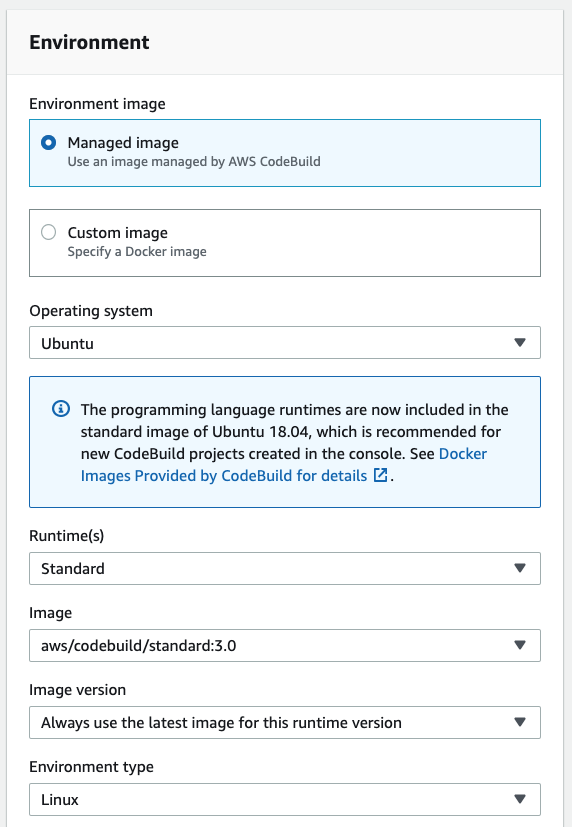
ビルドの設定をします。AWS CodeBuildを選択しCreate projectを選択してプロジェクトを作成します。
プロジェクト名を指定します。プロジェクト名は再設定ができないようです。
以下のような設定をしておきます。その他は、デフォルトの設定にします。サポートしているDocker Imagesはここで確認できます。
CodeBuild環境変数の設定
CodeBuildのプロジェクト一覧から先程作成したプロジェクトを選択し環境変数を設定します。AWS_ACCESS_KEY_IDとAWS_SECRET_ACCESS_KEYにIAMで設定して取得したKEYとSECRETを設定します。
buildspec.ymlの設定
buildspec.ymlを作成しmaster branchにプッシュしておきます。ここでは、レポジトリルート以下に
react-appを作成した場合のbuildspec.ymlの設定を紹介します。 Artifactsのbase-directoryの設定に関係するので、パスの関係性を正しく理解しておいたほうが良いです。repository-root/ ├── buildspec.yml └── react-app ├── README.md ├── build ├── node_modules ├── package-lock.json ├── package.json ├── public ├── src ├── tsconfig.json └── yarn.lock処理の流れ
npmの環境を準備
↓
react-appをビルド
↓
s3にビルドしたファイルをアップロード
↓
CloudFrontのキャッシュを削除version: 0.2 phases: install: commands: - npm install -g n - n stable - npm update -g npm - npm install - node -v - npm -v - yarn -v pre_build: commands: - echo Entring app directory - cd react-app - yarn install build: commands: - echo Build started on `date` - yarn build post_build: commands: - aws s3 sync build/ s3://あなたのバケット名 --exclude '*.DS_Store' --acl public-read --cache-control public,max-age=604800 - aws cloudfront create-invalidation --distribution-id CloudFrontのIDの --paths /index.html /service-worker.js" artifacts: files: - '**/*' base-directory: react-app/build本番化
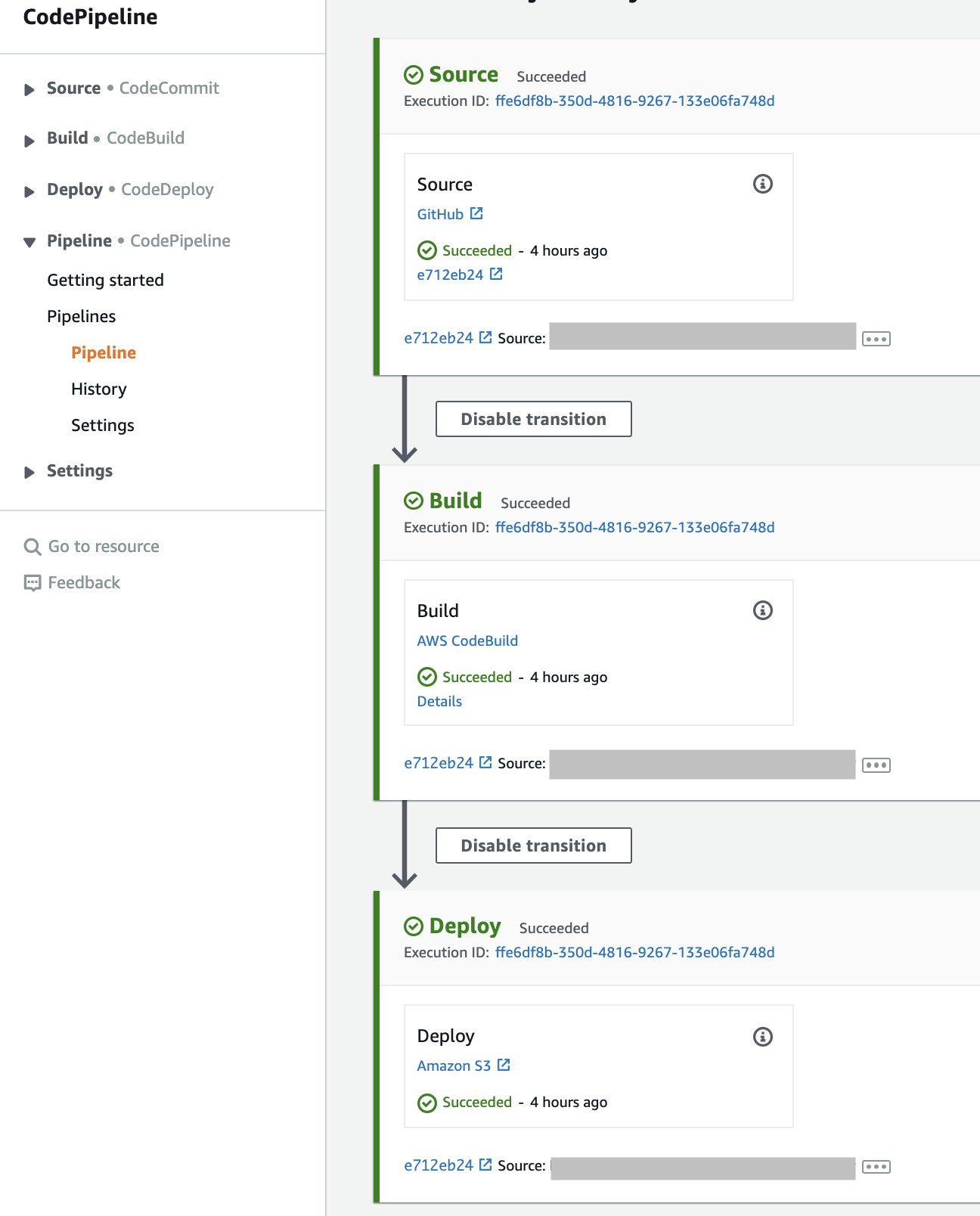
GithubでBranch:masterからBranch:productionで作成します。そして、PRをマージすると以下の様にPipelineが起動します。













- 投稿日:2020-02-07T19:41:32+09:00
SAMで作成されるApiGatewayをエッジ最適化以外で作成したいとき
SAMだとApiGatewayのリソースを書かなくても暗黙的につくられますが、既定ではエッジ最適化でつくられているので、リージョンとかプライベートでつくりたい。
今回はリージョンで指定します。
AWS::Serverless::Apiのリソースを記述して、EndpointConfigurationにREGIONALを指定します。
AWS::Serverless::FunctionのEventsにType: Apiを作成しますが、その際にRestApiIdを指定して、先ほど作成したAWS::Serverless::Apiリソースを参照するように指定します。template.yamlResources: ApiGatewayApi: Type: AWS::Serverless::Api Properties: StageName: Prod EndpointConfiguration: REGIONAL FooFunction: Type: AWS::Serverless::Function Properties: Events: Foo: Type: Api Properties: Path: /foo Method: post RestApiId: !Ref ApiGatewayApi参考
- 投稿日:2020-02-07T19:05:49+09:00
Deadlineサーバの構築方法
はじめに
映像系パイプラインツール、DEADLINEを動かすために必要なRepositoryサーバの構築をしたので
そのときの備忘録程度に書こうと思います。(わかりづらくてすいません)
注意)ディレクトリパスは適当に変えています。注意してください。構成
- サーバ
- VMWare ESXi 6
- CentOS 7.6 (ちなみに8.0でも動いた)
- CPU 4core/MEM 8GB (ただし、メモリは不足したら増やす予定)
- ソフトウェア
- MongoDB 3.4 (ちなみにcentos8で、MongoDB4.3で動いた)
- Deadline10.1.3
- Samba 4.9.1 (client common backend等普通にyumで入ってしまうもの)
導入手順
素材揃える編
注意1) Deadlineでライセンスサーバについて記載していないのは、今回ライセンスサーバはすでにある程です。
注意2) システム要件は行う前に確認してみてください。
注意3) DeadlineのデータはここではDeadline-10.1.3.6-linux-installers.tarを指す。VMを立てる
→こちらはわかりやすく書いていらっしゃる方がいますので、こちらを参考にしてみてください。
なお、次の項目は一番最初の初期設定が終わってるものです。CentOSを設定する
- SSHで、admin権限をもったユーザでサーバに入る(teraterm等で入る。) ※1
- sudoerの設定画面に入る。
[hoge@deadline ~]# visudo- この場所を見つける`## Allow root to run any commands anywhere
- 3の下に、
ユーザ名 ALL=(ALL) ALLを入力するescを押して:wqで保存終了- rebootして再起動。
- SSHで再度ログインする
- サーバを最新にする
[hoge@deadline ~]$sudo yum update- SFTPでアクセスして、
/home/hogeへMongoDBのデータとDeadlineのデータをアップロードする。※もしユーザ権限の場合は
[hoge@deadline ~]$su -でrootパスワードを入力すれば大丈夫。[hoge@deadline ~]#と$ -> #へと変わってるはず。Deadlineのインストール
- Deadlineのデータがあるところまで、ディレクトリを移動する。
- tarで固まってるため解答する
[hoge@deadline ~]tar -xvf Deadline-10.1.3.6-linux-installers.tar- 同じディレクトリに次の二つがあることを確認する。
mongodb-linux-x86_64-rhel70-3.4.24.tgzとDeadlineRepository-10.1.3.6-linux-x64-installer.run- Deadlineをインストールする。
[hoge@deadline ~]#sudo ./DeadlineRepository-10.1.3.6-linux-x64-installer.run --mode text ----prepackagedDB /home/hoge/mongodb-linux-x86_64-rhel70-3.4.24.tgz- License Agreementが出てくるので読み進めて、
Yで進める。- Repository Installation Directoryの入力画面が出てくるので、表示されてるディレクトリでよければそのまま進める。
Set full read/write access for files[Y/n]と出てくるんのでY。- MongoDBのインストールについてきいてくるので、
[1] Install a new MongoDB database on this machine?にするため1を入力MongoDB Installation typeを聞かれるので[2]Pre-Packed(.tar .zip)の2を入力。- 場所を聞かれるが、最初に場所を設定しているため間違ってるか確認して、進む
- host等mongoDBに関する情報を聞かれるが、問題がなければそのまま進む。
continue installation?と聞かれるので、Yでインストール開始。- ファイアウォールを追加設定する
[hoge@deadline ~]$sudo firewall-cmd --zone=public --add-port=27100/tcp- ファイアウォールを適用する
[hoge@deadline ~]$sudo firewall-cmd --reload注意1)基本的に特に何かなければ、デフォルトパラメータで行くほうがいいと思います。
注意2)ここについて、わからなければ次のページをご参考に。
注意3)ポートについては次のところを参照。sambaをインストール
repositoryには全部のPCがアクセスできないといけないので、sambaをインストール、設定する。
1. インストールコマンドを入れる。[hoge@deadline ~]$ sudo yum install -y samba
2. smb設定をバックアップする[hoge@deadline ~]$sudo cp /etc/samba/smb.conf /etc/samba/smb.conf.bk
3. ファイル内に入る。[hoge@deadline ~]$sudo vi /etc/samba/smb.conf
4. 下のsmb.confを参考に設定する。
5. ファイアウォールを追加設定する[hoge@deadline ~]$sudo firewall-cmd --zone=public --add-service=samba
6. ファイアウォールを適用する[hoge@deadline ~]$sudo firewall-cmd --reload
7. レポジトリフォルダに対してselinuxを設定する[hoge@deadline ~]$ sudo semanage fcontext -a -t samba_share_t "/opt/Thinkbox/DeadlineRepository10(/.*)?"
8. レポジトリフォルダに対してselinuxを適用する[hoge@deadline ~]$ sudo restorecon -R /opt/Thinkbox/DeadlineRepository10/*
9. レポジトリフォルダに対して適宜書き込み読み取り権限をつける。(できるだけsambaにユーザ権限作成して作ることをおすすめしたい)
10. 起動する[hoge@deadline ~]$ sudo systemctl start smb
11. 自動起動の設定をする[hoge@deadline ~]$ sudo systemctl enable smbsmb.conf[global] workgroup = WORKGROUP server string = Deadline netbios name = deadline security = user map to guest = bad user dns proxy = no passdb backend = tdbsam printing = cups printcap name = cups load printers = yes cups options = raw [repository] #これが今回追加したもの(ただしテスト版) path = /opt/Thinkbox/DeadlineRepository10 browseable = Yes writable = Yes guest ok = Yes read only = No create mask = 0700 force create mode = 0700 force directory mode = 0700最終チェック
- selinuxが入ってることを確認
[hoge@deadline ~]$sudo getenforce->Enforceでok- レポジトリフォルダのselinuxのコンテクスト確認
[hoge@deadline ~]$sudo ls -Z /opt/Thinkbox/DeadlineRepository10->samba_share_t:s0が各フォルダに入ってればok。- ファイアウォールを適用する
[hoge@deadline ~]$sudo firewall-cmd --reload- ファイアウォールが設定されてるか確認する
[hoge@deadline ~]$sudo firewall-cmd --list-all- WindowsやMac等からレポジトリフォルダが開けることを確認する。
- mongoが稼働しているか確認する
[hoge@deadline ~]$ sudo ps -ef | grep mongod- mongoのポートが受け付けてるか確認する
[hoge@deadline ~]$ sudo ls -of -i:27100④firewall-cmdpublic (active) 省略 services: dhcpv6-client samba ssh ports: 27100/tcp 省略⑥ps_ef|gerp_mongodroot 1543 1 0 14:30 ? 00:00:46 /opt/Thinkbox/DeadlineDatabase10/mongo/application/bin/mongod --config /opt/Thinkbox/DeadlineDatabase10/mongo/data/config.conf hoge 11327 9106 0 18:55 pts/3 00:00:00 grep --color=auto mongod⑦ls_-of_-imongod 1543 root 11u IPv4 26421 0t0 TCP *:27100 (LISTEN) mongod 1543 root 12u IPv6 26422 0t0 TCP *:27100 (LISTEN)あとは、クライアントの設定をするのみ(今回は省略)
トラブルシューティング
クライアント側でのDeadlineのレポジトリ設定するときに
certificationが通らないトラブルに遭遇しました。もし遭遇した人がいれば、ローカルに証明書を落とした上でクライアントの設定を進めてください。
次からはなぜか、NAS上の証明書からアクセスできます。(解せない)終わりに
はー。。。windowsだと、こう細かいことしないでも、ぽんぱんぽん、って終わるから楽ですね。(おい。)
ただ、なにがどう動いてるか、CentOSのがわかりやすいのと、何より、負荷が軽い。
windowsの時の半分以下。しかも無料。文句のつけようがない。。。
サーバの管理する側といては、やっぱりなにがどう動いてるのか即わかるCentOSは好きかなぁ。。。
というわけで、サーバ側のセットアップでした!
- 投稿日:2020-02-07T18:04:41+09:00
UnityAcceleratorをLinux上に立ててサービス化する
Unity2019.3からアセットのキャッシュ管理にUnityAcceleratorの使用が推奨されており、
サーバに立てたときの備忘録UnityAccelerator: v1.0.90+gd82184f
OS: AmazonLinux2インストール
インストールスクリプトを落として実行する
curl https://unity-accelerator-prd.storage.googleapis.com/unity-accelerator-linux-installer.run --output unity-accelerator-linux-installer.run sudo ./unity-accelerator-linux-installer.run --mode unattended ※ 「--mode unattended」を付与しない場合は対話式で設定変更が可能 一度試した場合は入力項目が多く面倒だったので付与してデフォルトインストールにしたサーバ再起動時の自動起動化
インストールスクリプト実行時にサービス登録されてるので有効化しておく
/sbin/chkconfig unity-accelerator on対象ポートの変更
設定ファイルは/root/.config/unity-accelerator/に展開されている
vi /root/.config/unity-accelerator/unity-accelerator.cfg →ProtobufPort、LastUsedProtobufPortを任意のポートに変更 service unity-accelerator restart参考サイト
https://docs.unity3d.com/2019.3/Documentation/Manual/UnityAccelerator.html
https://forum.unity.com/threads/accelerator-options.784514/
- 投稿日:2020-02-07T14:18:57+09:00
Visual Studio Code Remote - Containersで始めるAWS CDK
概要
AWSのインフラ構築は現在Terraformでやっているが、AWS CDKも気になる今日この頃。
https://aws.amazon.com/jp/cdk/勉強がてら触ってみようと思いましたが、ローカルにNodeやらnpmでいろいろ入れないといけない・・・
そこで、Visual Studio Code Remote - Containersを使って開発環境ごとコンテナ化すればいいのでは?と思い、サンプルをやってみました。
そして、AWSに対してデプロイする事も考えて修正を行ってみました。まずはVSCodeの環境構築から
VSCode本体と、Docker環境は入っている前提で、下記拡張機能をインストールします。
https://marketplace.visualstudio.com/items?itemName=ms-vscode-remote.remote-containersこちらをインストールすると、左下に緑のマークが出るようになります。
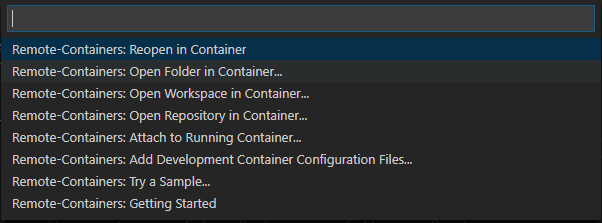
こちらを押して、「Open Folder in Container」をクリックします。このフォルダが作業フォルダとなります。
すると、セットアップしたい環境の一覧が出てきます。
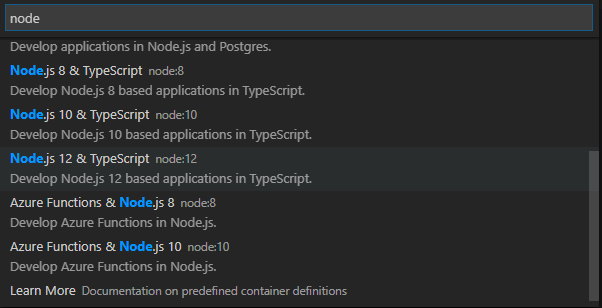
今回はAWS CDKを使いたいので、「Node.js 12 & TypeScript」を選択します。
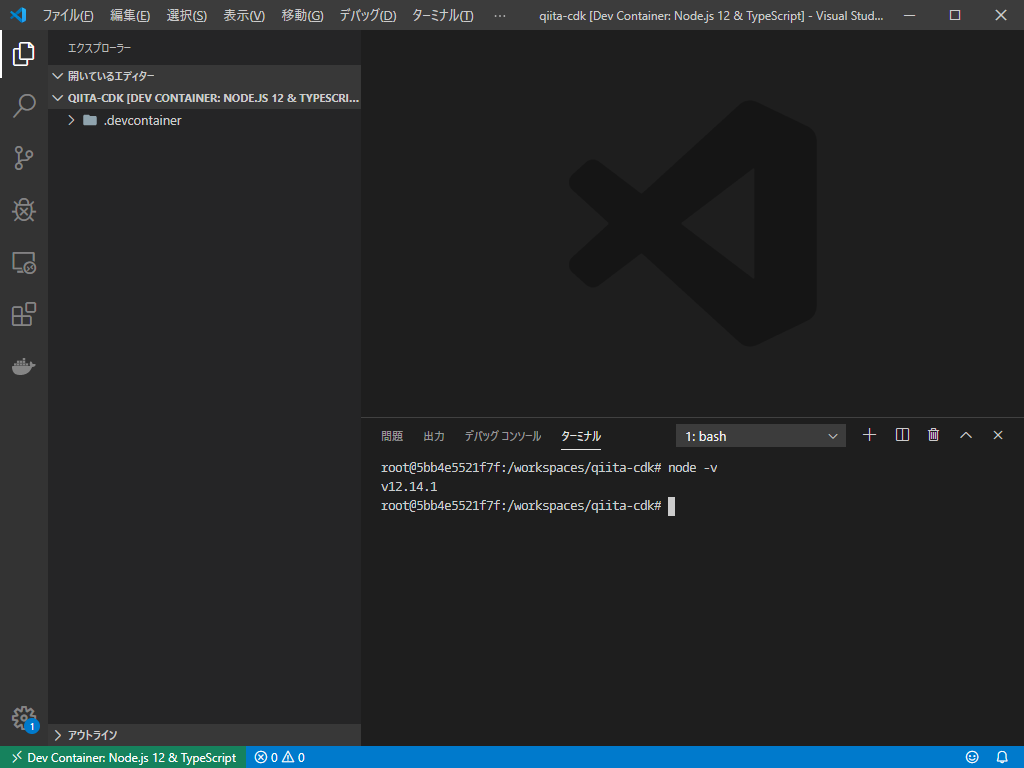
すると裏でコンテナの構築が始まります。完了すると、コンテナの中に入った状態でVSCodeが開かれます。
左下の緑部分に、現在の環境が表示されており、ターミナルを開くと当然のようにコンテナ内で開かれ、きちんとNodeも入っています。AWS CDKをインストール
コンテナ内に入れば、あとは環境の構築です。今回はAWS CDKを使いたいので下記コマンドでインストールします。
npm install -g aws-cdk次はサンプルプロジェクトを作成してみましょう。
cdk init sample-app --language typescriptこれでサンプルとなるプロジェクトが作成されました。後はコードを書いてインフラを構築するだけです。
ディレクトリを見てみると、.devcontainerというフォルダができていると思います。この中に開発環境のDockerfileが保管されています。
次回以降はフォルダを指定すると、自動でこのDockerfileに対応したコンテナが起動し、環境を構築する事ができるので、このフォルダ毎git管理してしまえば、全員が同じ開発環境を持つことができます。しかし、このままだと欠点があります。
- Node環境はコンテナ化できるが、npmで入れたcdk等は各自で入れないといけない。
- 最終的にはAWSにデプロイするが、認証情報がない。
なのでこれを解決していきましょう。
ここからが本編
開発環境の編集
まず、Nodeの環境を整えた後に別途必要なものを洗いだし、Dockerfileに記入していきます。今回のケースだと、
- aws-cdk
- pip(awscliのインストールの為)
- awscliが必要なので追加していきましょう。
開発環境用のDockerfileを開いて修正しましょう。.devcontainer/Dockerfile# Configure apt and install packages RUN apt-get update \ && apt-get -y install --no-install-recommends apt-utils dialog 2>&1 \ && apt-get -y install git iproute2 procps \ # # 以下の3行を新たに追加(pipを入れてpip経由でawscliをインストール) && curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py \ && python3 get-pip.py \ && pip install awscli \次に、awsの認証情報を持ってくる方法ですが、良い方法が思いつかず、gitの設定を持ってくる方法と同じく、ボリュームマウントで持ってくるようにします。
以下のようなdocker-compose.ymlを作成します。
.devcontainer/docker-compose.ymlversion: '3' services: dev: build: context: . volumes: - ~/.gitconfig:/root/.gitconfig - ~/.aws:/root/.aws - ..:/workspace:cached command: sleep infinity
volumesの解説は以下1行目:ローカルのgitconfigを持ってくる。
2行目:awsのクレデンシャルを持ってくる。
3行目:ワークスペースとしてローカルをマウントする。Dockerfile単体でリモート開発環境を構築すれば、3行目が自動で実行されてコード変更がローカルと連動するのですが、composeにする場合、明示的に書かないとマウントされなかったので注意です。
次に
devcontainer.jsonを編集します。これはVSCodeが起動する開発環境に関する設定ファイルです。
これを編集し、Dockerfile単体ではなく、composeで実行するように変更します。.devcontainer/devcontainer.json(変更前){ "name": "Node.js 12 & TypeScript", "dockerFile": "Dockerfile" }.devcontainer/devcontainer.json(変更後){ "name": "Node.js 12 & TypeScript", "dockerComposeFile": "docker-compose.yml", "service": "dev", "workspaceFolder": "/workspace" }
serviceは、composeで動かすservicesの名前がdevとして定義しているのでそれと同じにします。
workspaceFolderを指定して、ソースコードをマウントしているフォルダを指定します。
これをしないと、ルートディレクトリがVSCodeの作業フォルダになってしまって面倒です。まとめ
- Visual Studio Code Remote - Containersを使えば開発環境をコンテナ化できる。
- Dockerfileやdevcontainer.jsonを編集し、必要なパッケージをインストールして具体的に開発環境を作っていく。
- これをgitで管理すれば環境の差異を極限まで減らせる!

- 投稿日:2020-02-07T13:20:26+09:00
ウサギでもできるAWSへのサーバーマイグレーション~CloudEndureでやってみた~
AWSなどのクラウドサービスへサーバーをそのまま移行します
CloudEndureの利用事例は徐々に増えているようですが、実際に移行してみた際に失敗したことや注意事項などがいろいろ見つかったため、記しておくことにしました。
ちなみに、「サルでもできる」とか「ネコでもできる」というのはよく使われますが、私はウサギ派なので「ウサギでもできる」というタイトルにしてみました。実際ウサギって身体の大きさの割に脳が小さいらしく…なんでもないです。
私自身、雑種のいわゆるミニウサギをもう12年間飼っていますが、めちゃくちゃ可愛いです!もうかなりのお爺ちゃんなので老化してきていますが、食欲旺盛、毎日元気です!これまでのマイグレーションはほぼ全部OSの更新だった
2015年ころからお客様の補油しているWindowsサーバーのクラウドへのマイグレーションは数えきれないくらい実施してきましたが、これまでの案件の99%が新規OSをクラウドでデプロイして、その上に既存のアプリケーションやデータの移行を行うものでした。それは主にOSの保守切れやハードウェアの保守切れに伴う更改となるため、多くのお客様が最新もしくは最新に近いバージョンのOSを希望する、という事情がありました。
たった一つの例外は、VMベースで動作していた某小規模クラウドサービスの急なサービス終了に伴い、低予算&短納期でVMベースの大規模クラウドサービスへの移行だったため、「VMイメージをコピーした」というものです。これは同じVMベースだったためということがあるので、いわゆる「AWS、Azure、GCP、Alibaba」といった大御所ではなく、特殊な事例でした。大規模な移行にはOSからアプリまでそのままの移行もアリ
「これまで」と書いたのは前職での話なのですが、転職して早速これまで関わったことがないような大規模案件にアサインされ、サーバ10台以上を一気にマイグレーションする案件を担当することになりましたので、早速CloudEndureを検証してみました。
ほかにもAWSであれば「VM Import」「Server Migration Service」といったものがありますが、以下のような短所があるため、あまり利用は拡大していなかったように見受けられました。(私自身、提案フェーズまでで業務利用はしていないのでわかりませんが)
それが2019年になって、イスラエルのCloudEndureをAWSが買収して無償化した時点から一気に形勢が変わりました。
- VM Import
- VMイメージをS3経由で転送する方法。(VM基盤専用)
CLIで操作。トラブルも多く、原因究明も困難との話。
差分転送が出いないため、移行時の工数と時間が相当に必要になる。- Server Migration Service
- VMもしくはHyper-Vに転送用仮想アプライアンスを動作させて転送する方法。(仮想基盤専用)
定期的に差分転送が可能それに対して…
- CloudEndure
- 移行対象サーバへエージェントをインストールして転送する方法。
継続的な差分転送が可能現在動作しているOSへエージェントをインストールするだけで実行できるため、物理サーバからも直接移行できてしまうCloudEndureがダントツに敷居が低くて圧勝です。
(マイクロソフトの「Disk2vhd」というツールでHyper-V形式のVHD/VHDX化や、VMwareの「vCenter Converter」でVMDK形式のイメージは作れますが、その場合には当然差分転送は不可)そんなわけで早速レプリカ準備を始めてみましょう
CloudEndureにサインイン
こちらからCloudEndureのページを開き、アカウントを作成します。メールとパスワードを入れるだけです。
以下のようなメールが送られてくるのでリンクを開けばアクティベーションされてログイン可能になります。
ログインします
ダッシュボードに表示されるライセンス数は10万ライセンス!!!
さすがに使いきれませんね。
IAMユーザーを作成する
CloudEndureのサービス自体が移行に用いる変換サーバ用インスタンスや、移行後のインスタンスを作成する必要があるため、IAMユーザーを指定のポリシーで作成する必要があります。なので、まずはポリシー情報をコピペするために、画面右の「Setup&Info」→「AWS CREDENTIALS」→「The Project must have these permissions」
上記をクリックすると別窓で以下のようなポリシー定義のJSONが開きます。
移行先となるAWSのアカウントで右上のユーザー名から「マイセキュリティ資格情報」を開きます。
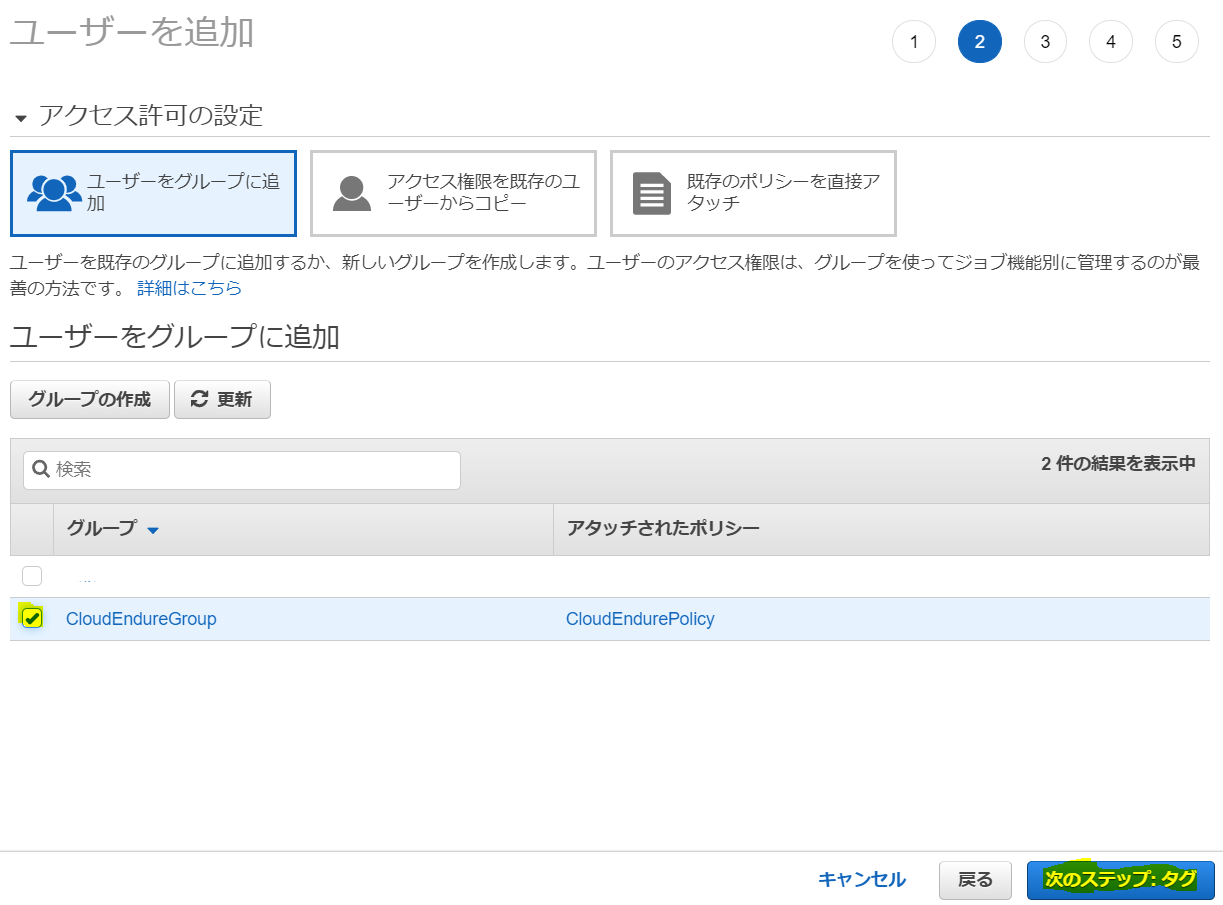
「ユーザー」→「ユーザーを追加」を選択します
適切なユーザー名を入力し、アクセス種類は「プログラムによるアクセス」のみで「次のステップ」。
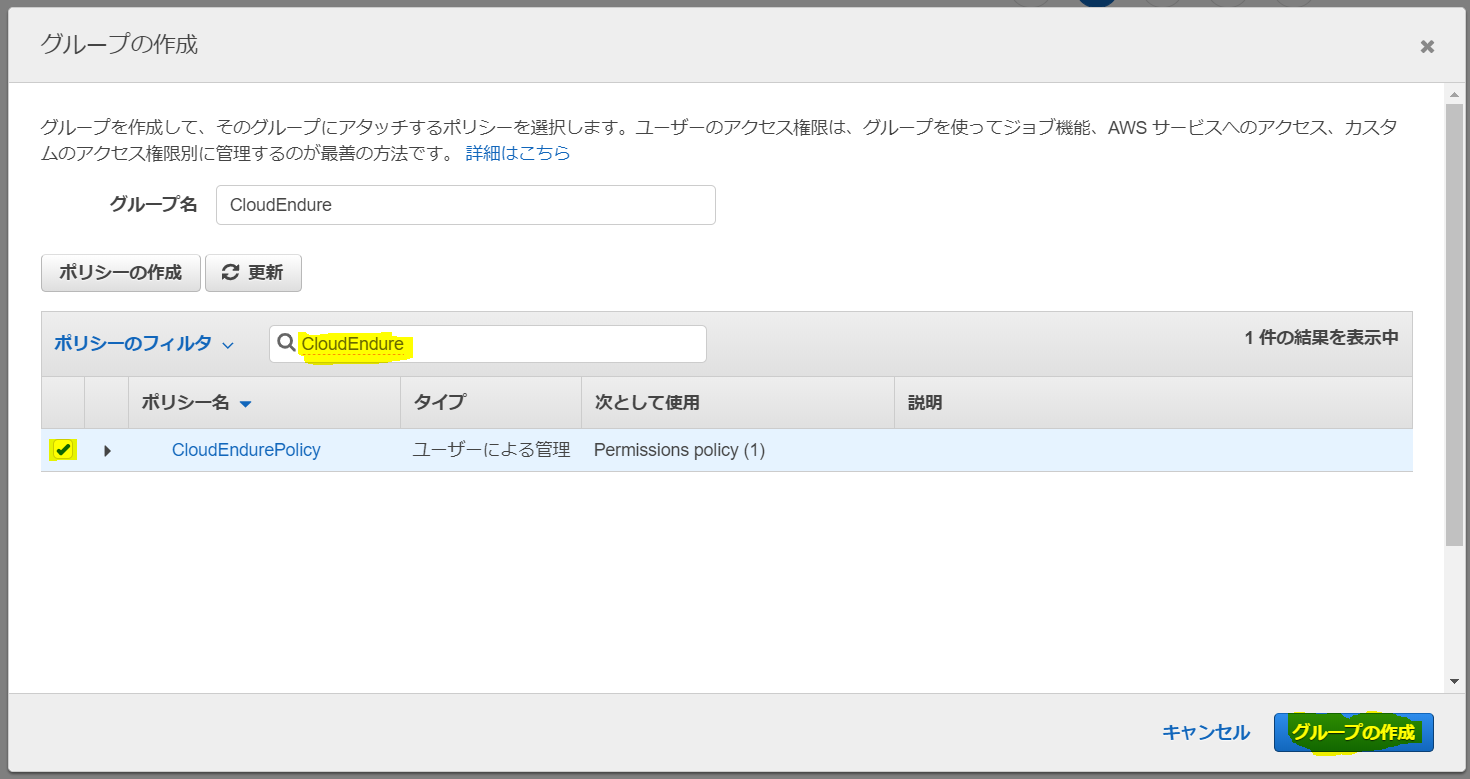
「グループの作成」をクリック
「グループ名」を適宜入力し、「ポリシーの作成」をクリック
別窓が開くので、「JSON」を選択して、下の欄に先ほどのJSONをペーストし、「ポリシーの確認」をクリック。
名前を適宜入力して「ポリシーの作成」をクリック
ここでさっきのグループ作成画面に戻り、今作成したポリシーを検索して見つけ、チェックを入れて「グループの作成」をクリック
ユーザー追加画面に戻るので、今作成したグループを選択して「次のステップ」をクリック
タグは好きに設定して、最後の確認を終えればIAM作成は完了です。アクセスキーとシークレットアクセスキーを保存しておきます。
移行先のAWSを設定します。
以下の設定は必須です。
- VPCとサブネットを作成
- 適切なセキュリティグループを作成
また、ネットワーク設定がDHCPに強制変更されてしまうので、特にドメイン環境の場合には以下の設定も必要です。
- DHCPオプションセットでDNSを有効なADサーバを設定しておく
この設定をしておかないと、なぜかローカルユーザーでもリモートデスクトップでログイン不可になってしまいました。
特にドメインコントローラーを移行する場合には指定されることが多い「127.0.0.1」のローカルループバックアドレスもDNSから消去されてしまいますので要注意です。CloudEndureの移行パラメーター設定
CloudEndureのWeb画面に戻り、アクセスキーとシークレットアクセスキーを入力して「SAVE」をクリックします。
次に移行先の設定です。
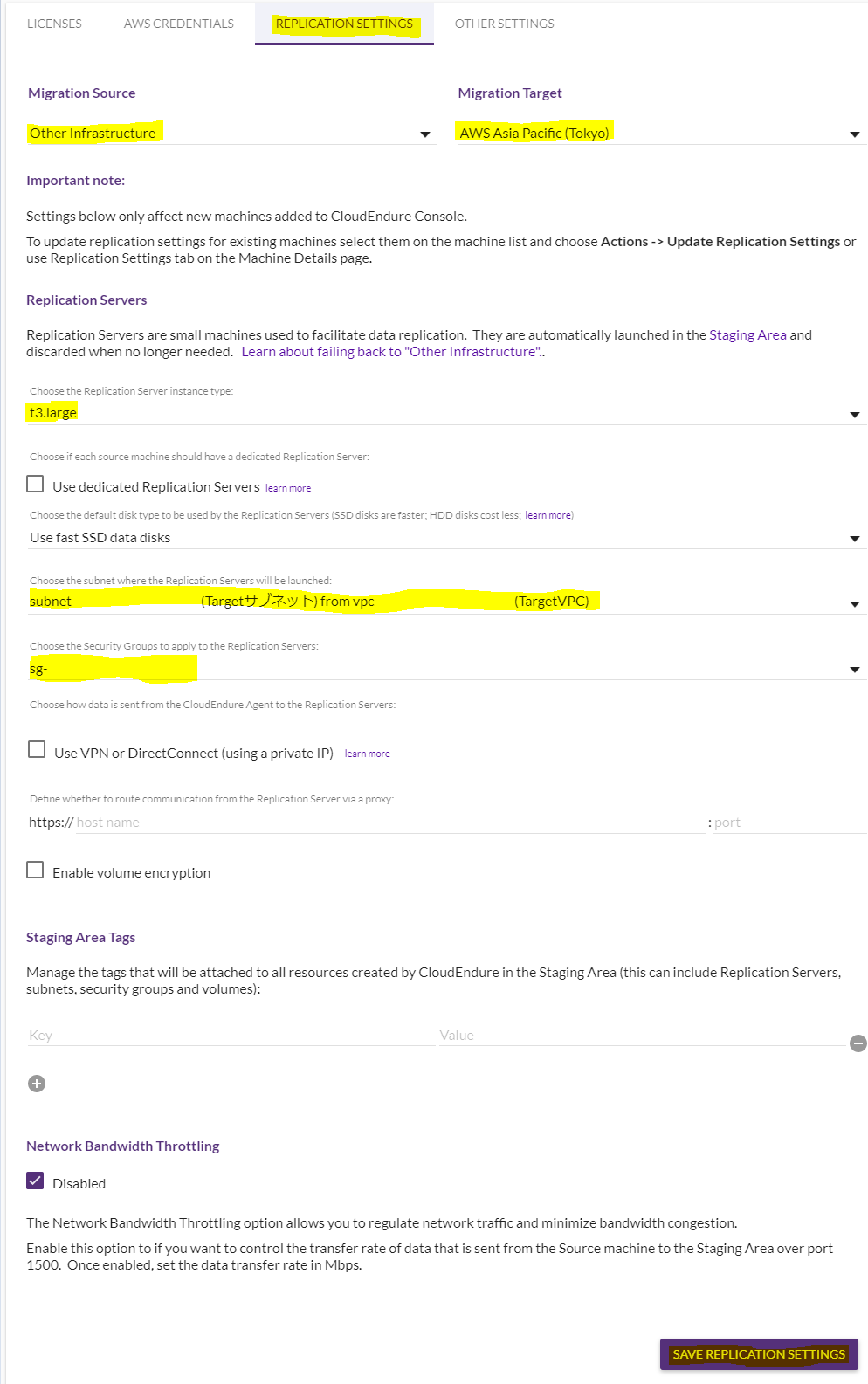
画面上の「REPLICATION SETTINGS」タブを選択すると以下の画面になりますので、以下項目を設定します。
- Migration Souce
ソースの場所です。オンプレミス未対応しているのでその場合には「Other Infrastructure」を選択します。
- Migration Target
移行先の場所です。今回は「AWS Asia Pacific(Tokyo)」を選択します。
- Replication Servers
レプリカサーバーの詳細です。
インスタンスタイプ、VPC、サブネット、セキュリティーグループを選択できます。
こればレプリカする際に自動的に起動するサーバなので、適当に「t3.large」と、レプリカ先のサブネットを選択しました。
最後に右下の「SAVE REPLICATION SETTINGS」をクリックして設定項目を保存します。
レプリカ準備を開始する
この手順を実施すると、レプリカサーバが自動帝に起動して、移行元サーバのイメージ転送が始まります。
そして初回の転送が終わると、それ以降ずっと差分を転送し続けます。
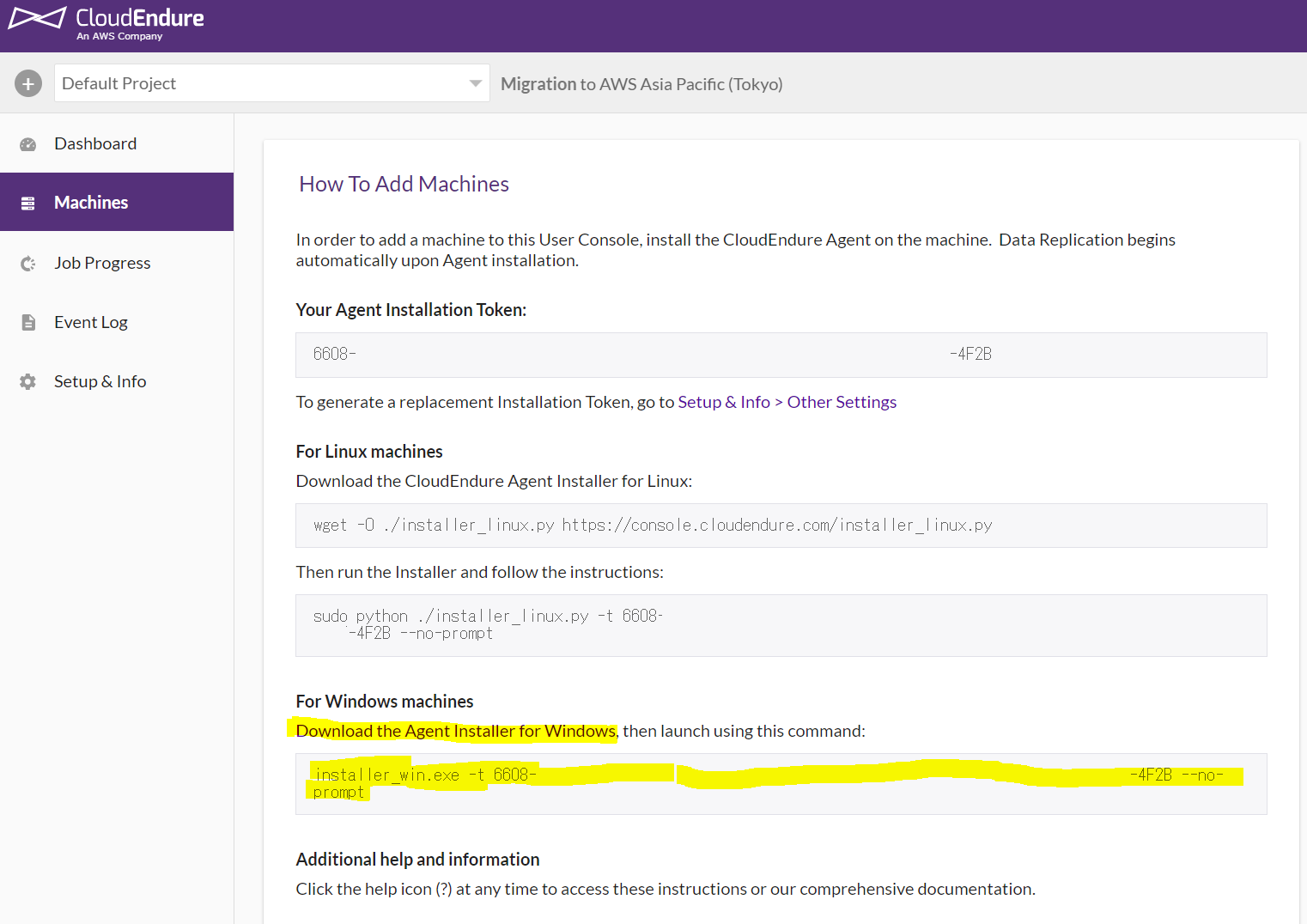
初めにCloudEndureのWeb画面で右メニューから「Machines」を選択します。
すると、以下の画面になりますので、「Download・・・」を右クリックして「リンクのアドレスをコピー」します。
次に移行対象のサーバーにログインし、上のリンクアドレスをIEか何かで開き、対象のファイルを「名前を付けて保存」しておきます。(この場合はA:\に保存)レプリカを開始する
レプリカはインストールが終わったら自動開始
CloudEndureのWebのリンクの下の行にあるコマンドをコピーして、サーバのコマンドラインにペーストして実行します。
インストールが成功すると以下のようになります。
このように成功すると、この瞬間から自動的にレプリカが始まります。
まずはこのグラフが100%に達するまで待ちましょう。
WindowsServer2016にAD機能を追加しただけのサーバはおよそ10分で完了しました。レプリカ中
レプリカを開始して数分間はNW帯域目いっぱいの転送が発生します。
この検証はAWSの別VPC間での転送となりますので、300-500Mbps程度が連続していました。
しばらくすると、以下のようにCloudEndureのWebコンソールで同期を完了している表示に代わります。
同期完了処理に移った際の使用帯域は以下のような感じで、数百Kbpsと約千分の一程度まで下がります。
この状態も数分間かかりますが、今回の検証では約10分程度でレプリカが完了し、以下のような表示に変わりました。
この表示になったら、いつでもテストサーバーをデプロイできる状況です。
デプロイのテストを実施しよう
デプロイ前にパラメーターを確認しよう
ここまでくればあと一息です。
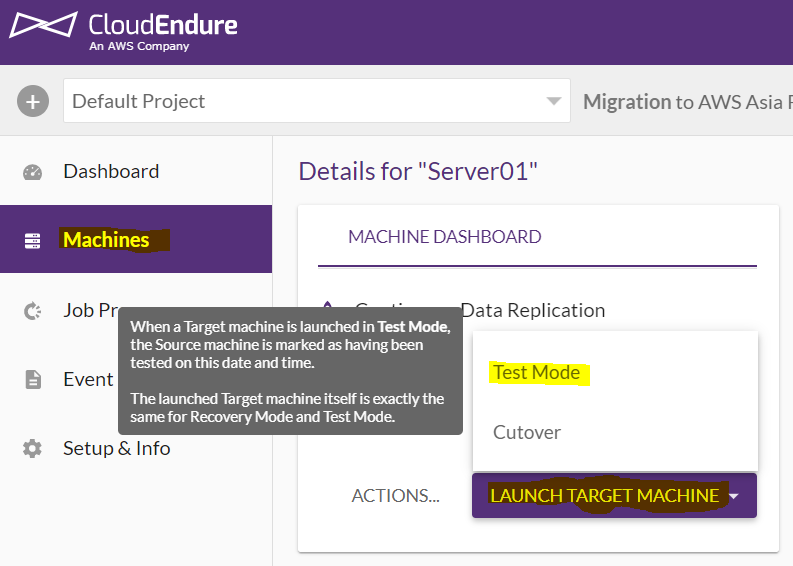
ワンタッチで目的のサーバをデプロイしましょう。
デプロイはCloudEndureのWebコンソールで右メニューのMachinesから目的のサーバを選択し、画面下の「LAUNCH TARGET MACHENE」から「TEST MODE」を選択するだけです。
が、その前にどのようにデプロイするのか設定を確認しましょう。
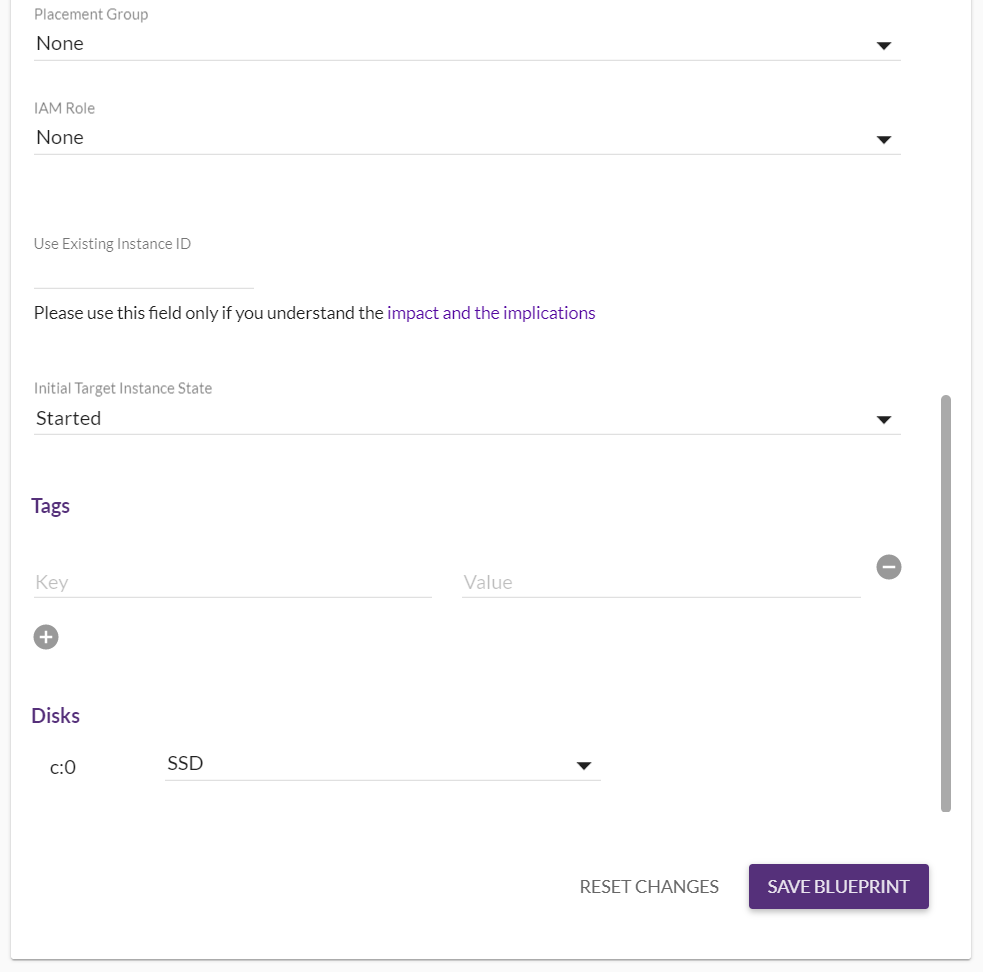
以下のように「BLUE PRINT」タブに多くの設定項目が並びます。
特に留意する必要があるのが、以下になります。
- Machine Type
- インスタンスタイプを選択します
「Copy Source」で同じようなスペックも自動選択できますが、なぜかより大きなインスタンスタイプとなりました- Subnet
- 事前に作成しておいたサブネットを選択します
- Security Group
- 事前に作成しておいたセキュリティグループを選択します
- Private IP
- 「Custom」を選択して新しいVPC・サブネットに適切なものを設定します
- Disks
- ディフォルトで「Provisioned IOPS SSD」が選択されるため、「汎用SSD」で十分な場合には要変更です
ここまで確認出来たら、実際にデプロイしてみましょう。デプロイはワンタッチ
テストを選択すると以下のように確認が求められるので「CONTINUE」をクリックするとすぐにデプロイが始まります。
画面右上に下のような表示が出たら、デプロイが始まりました。
CloudEndureのWebコンソールで進捗を見てみましょう。
右メニューの「Job Progress」をクリックすると現在進行中の進捗を確認することができます。
まずはレプリカされたディスクから仮想マシンへコンバートするジョブが走ります。
ちなみにこの画面は開きっぱなしてしていても自動で更新されます。このフェーズでAWSコンソールを見てみるとコンバーターが1台新規で出来あがります。
コンバートが終わって、新サーバの作成が始まると「Starting Creating…」に表示が変わります。
Job finishedと記録されました。
AWSコンソールを見てみると・・・
できました!
しかし、なぜかインスタンスタイプが「C4.large」になっています。
「Copy Source」を選択せずに指定したほうが良いかもしれません。後で変えられますが。テストのデプロイが完了したので接続します
リモートデスクトップしましょう
早速接続してみましょう。
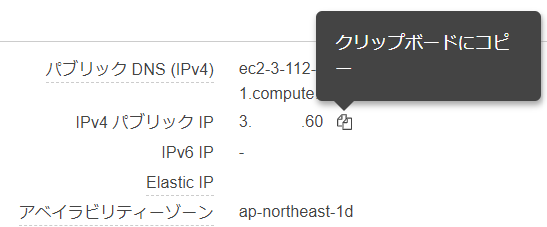
「パブリックIP」をコピーして…
お!RDPは有効になっていますね!
おっ!これも来た!いけるかっ?!
ここ、ドキドキしますね~
来ました~~~!
電源ONし続けている間にレプリカし続けるという仕様上、突然電源をぶち切られたような状況になるため、この表示が出ることは仕方ありませんが、逆にきちんとレプリカで来ていたことがわかると思います。テストデプロイされたサーバーの状況は?
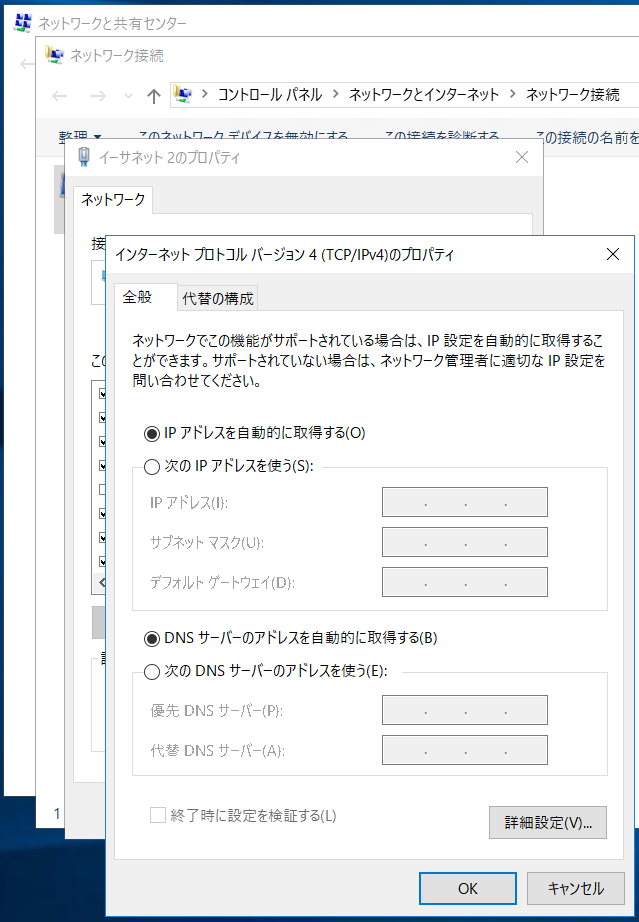
判明しているところとしては、IPアドレスやDNSサーバはDHCPに強制的に変更されます。
AWSはそれを推奨しているので当然ですね。
そのため、IPアドレスの固定はレプリカ時に、DNSの指定はDHCPオプションセットで行いましょう。
以上、テストのデプロイまででした
ちなみに、テストのデプロイを繰り返した場合、既存のデプロイされたインスタンスは自動的に削除され、最新のものだけが残るような動きとなりますので、無駄なゴミが残ることはないようです。カットオーバーでデプロイする
続いてカットオーバーの実施です。
テストのデプロイで問題がなかった場合には、本番のデプロイとして「Cutover」を実施します。
Cutoverの場合には、サブネットからインターネットGWからセキュリティグループなどをクリーンアップしているログが出ています。
時間的にはテストとほぼ同じで、18-19分程度で出来上がりました。
カットオーバーされたサーバーの状況は?
早速リモートデスクトップしてみます。
コピーして…接続!と。
来ました!
よし!成功!
と、思ったけど、ちょっとまって。
なぜか「セーフモード」になってる・・・え。マジですか?
と、思ったら2分程度で突然リモートデスクトップが自動的に切断されてしまいました。自動再起動が走ったのかな?
もう一度RDP接続を・・・
直った!!!
さっきは壁紙も黒一色で。あれ???と思ったのですが、もしかしたらCloudEndureのエージェントを削除して自動的に再起動が走ったのかもしれません。
→何度か試したところ、Cutoverデプロイした場合にはインスタンス起動の10分後(OS動作時間)に自動再起動が走るようです。
再起動後には通常モードで起動しているので、起動後は10分間ほったらかしてもいいかもしれません。結果的には問題なしでした。
しかし、テストモードでのデプロイと挙動が異なるのが気になりますね。。。
嘘でした。テストモードでのデプロイも同じ挙動であることを確認しました。
単にテストモードでの確認したタイミングが10分経過していただけだったようです。
実際にもう一度試したところ、直後はセーフモードで起動し、10分後に自動で再起動するという、全く同じ挙動でした。ネットワークのDHCPもテストモードと同様です。
ちなみに、CloudEndureのWebコンソールを見ると、「Cutover launched」という表示に変わっていますが、この状態でも何度でもCutoverすることができます。
オリジンサーバにやむを得ない事情で変更が生じた際や、Cutoverする際のパラメーターを間違えたり、思っていた動きと異なる動作をした際などに、Cutoverを何度でも実施できるのは心強いですね。
実際にインスタンスタイプを指定して再度Cutoverしてみました。できた!
以上、CloudEndureの検証レポートでした!
おまけ
最後に私が経験したエラーについて記述しておきます。
おまけ1 インスタンス作成時のリソース不足エラー
「ap-northeast-1dにc4.2xlargeのインスタンスの空きがありません」と言われました。
AWS東京リージョンに現在使用できるAZは3つありますが、AZによってまれにこのエラーが発生することがあります。今回は「ap-northeast-1d (apne1-az2)」でした。
その場合にはしばらく時間をおいてインスタンス分の空きが出るのを待つことでクリアできることもありますが、素直に別のインスタンスタイプを選択するほうが早く解決するでしょう。
この直後、t3.largeを再指定したところ、無事にCutoverが成功しました。
この場合の注意点としては、EBSボリュームまでは作成された後のAMIの起動に失敗しているので、Job終了時にEBSを後片付けしてくれないため、ごみが残ってしまいました。
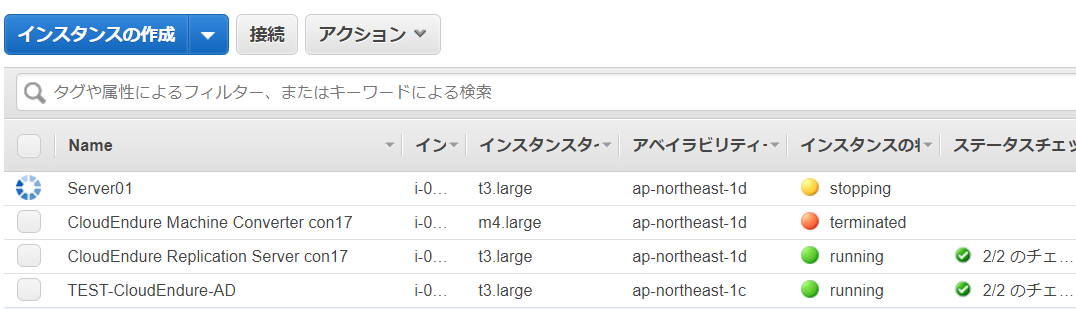
下記のように状態が「Available」となっている利用されていないボリュームが溜まっていってしまう…ので、片づけましょう!
おまけ2 オリジンサーバを落としていた場合のエラー
「オリジンは停止しているけど、最後に同期したデータでデプロイできるのかな?」と思って試してみたら、見事にエラーで止まりました。エラーの内容はDNSの名前解決ができないというエラー。ちょっとわかりづらいですね。
ちなみにこの場合にもAWS上に「CloudEndure Machine Converter」が残ってしまいますので、手動で削除する必要があるようです。なお、夜間に落としていたオリジンサーバを起動すると、また同期処理が自動的に開始されます。
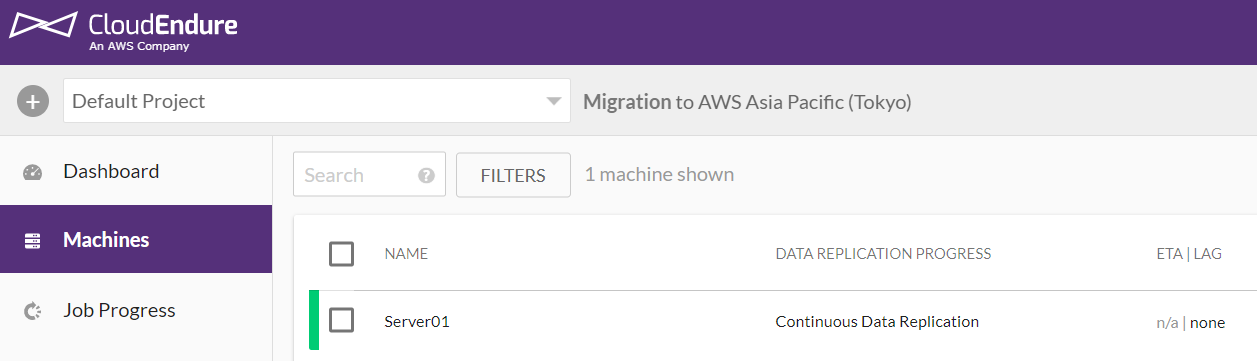
状態が「Continuous Data Replication」になれば同期が完了し、常時同期状態になっているので、デプロイ可能です。
デプロイを実施すると、無事にデプロイが完了し(今回は停止状態でのデプロイを指定したのでStoppingになっています)、さらにコンバーターサーバは自動的にTerminatedされました。
ちなみに、オリジンサーバを起動すると自動的にReplicationServerが起動する仕組みになっているようですね。オリジンを停止するとレプリケーションサーバも消える仕組みになっています。そのため、ClouedEndureのコンソールではレプリカサーバを検索して見つからない旨のエラーが出力されるのではないかと思います。
















































- 投稿日:2020-02-07T12:12:01+09:00
LightsailにSSMエージェントを導入する。
はじめに
LightsailにSSMエージェントを入れてセッションマネージャーで接続できるようにしてみました。
ちょっとつまづいたところもあったのでそこら辺の流れも一緒に記載してます。環境
一応、今回対応した環境情報を記載しておきます。
AWS:Lightsail
インスタンスイメージ:Redmine Bitnami 認定 4.0.5
OS:Ubuntu 16.04.6 LTSIAMサービスロールの作成
まずは以下の内容で信頼ポリシーを作成しテキストファイルに保存します。ファイル保存時は、必ずファイル拡張子 (.json) を付けることを忘れずに。
ちなみにここでは SSMService-Trust.json というファイルにしています。SSMService-Trust.json{ "Version": "2012-10-17", "Statement": { "Effect": "Allow", "Principal": {"Service": "ssm.amazonaws.com"}, "Action": "sts:AssumeRole" } }保存したテキストファイルを元にIAMロールを作成します。
create-role$ aws iam create-role --role-name SSMServiceRole --assume-role-policy-document file://SSMService-Trust.json { "Role": { "Path": "/", "RoleName": "SSMServiceRole", "RoleId": "AROA2ZM2YJEL3NN5MIHKZ", "Arn": "arn:aws:iam::777777777777:role/SSMServiceRole", "CreateDate": "2020-02-05T01:25:23Z", "AssumeRolePolicyDocument": { "Version": "2012-10-17", "Statement": { "Effect": "Allow", "Principal": { "Service": "ssm.amazonaws.com" }, "Action": "sts:AssumeRole" } } } }attach-role-policy$ aws iam attach-role-policy --role-name SSMServiceRole --policy-arn --policy-arn arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCoreアクティベーションコードの作成
次にアクティベーションコードの作成を行います。
create-activation$ aws ssm create-activation \ > --default-instance-name redmineLightsail \ > --iam-role SSMServiceRole \ > --registration-limit 5 \ > --region ap-northeast-1 \ > --tags "Key=Environment,Value=Production" { "ActivationId": "511f4a9c-23b2-4d03-a59e-8123977917c3", "ActivationCode": "JhVFOpJgb6n1gSrENEvP" }作成がうまくいくと ActivationId と ActivationCode が返ってくるのでメモしておきます。
SSMエージェントのインストール
それではエージェントのインストールを行います。
mkdir$ mkdir /tmp/ssmamazon-ssm-agent.deb(download)$ curl https://s3.amazonaws.com/ec2-downloads-windows/SSMAgent/latest/debian_amd64/amazon-ssm-agent.deb -o /tmp/ssm/amazon-ssm-agent.deb % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 30.1M 100 30.1M 0 0 4492k 0 0:00:06 0:00:06 --:--:-- 5889kamazon-ssm-agent.deb(install)$ sudo dpkg -i /tmp/ssm/amazon-ssm-agent.deb Selecting previously unselected package amazon-ssm-agent. (Reading database ... 117121 files and directories currently installed.) Preparing to unpack /tmp/ssm/amazon-ssm-agent.deb ... Preparing for install -> Systemd detected active amazon-ssm-agent 2.3.672.0 1480 stable/… aws* classic -> Amazon-ssm-agent is installed in this instance by snap, please use snap to update or uninstall. dpkg: error processing archive /tmp/ssm/amazon-ssm-agent.deb (--install): subprocess new pre-installation script returned error exit status 1 Errors were encountered while processing: /tmp/ssm/amazon-ssm-agent.debん?何やら既にインストールされているというエラーが。。。
snapという文字が見えるのでどうやらsnapパッケージが既にインストールされているようです。snap.amazon-ssm-agent(list)$ sudo snap list amazon-ssm-agent Name Version Rev Tracking Publisher Notes amazon-ssm-agent 2.3.672.0 1480 stable/… aws✓ classic確認してみたところやはりインストールされていました。
そういうことなのでとりあえずこのまま続けてみます。snap.amazon-ssm-agent(stop)$ sudo systemctl stop snap.amazon-ssm-agent.amazon-ssm-agent.servicesnap.amazon-ssm-agent(status)$ sudo systemctl status snap.amazon-ssm-agent.amazon-ssm-agent.service ● snap.amazon-ssm-agent.amazon-ssm-agent.service - Service for snap application amazon-ssm-agent.amazon-ssm-agent Loaded: loaded (/etc/systemd/system/snap.amazon-ssm-agent.amazon-ssm-agent.service; enabled; vendor preset: enabled) Active: active (running) since Mon 2020-02-03 15:40:55 UTC; 1 day 10h ago Main PID: 1151 (amazon-ssm-agen) Tasks: 8 Memory: 9.1M CPU: 4.090s CGroup: /system.slice/snap.amazon-ssm-agent.amazon-ssm-agent.service └─1151 /snap/amazon-ssm-agent/1480/amazon-ssm-agent Feb 03 16:15:59 redmine-hengjiu amazon-ssm-agent.amazon-ssm-agent[1151]: 2020-02-03 16:15:58 ERROR Health ping failed with error - AccessDeniedException: User: a Feb 03 16:15:59 redmine-hengjiu amazon-ssm-agent.amazon-ssm-agent[1151]: status code: 400, request id: eeed9ec8-0836-4e32-8d24-9f6609332ac3 Feb 03 17:15:58 redmine-hengjiu amazon-ssm-agent.amazon-ssm-agent[1151]: 2020-02-03 17:15:58 INFO Backing off health check to every 2400 seconds for 7200 seconds Feb 03 17:15:59 redmine-hengjiu amazon-ssm-agent.amazon-ssm-agent[1151]: 2020-02-03 17:15:58 ERROR Health ping failed with error - AccessDeniedException: User: a Feb 03 17:15:59 redmine-hengjiu amazon-ssm-agent.amazon-ssm-agent[1151]: status code: 400, request id: 0df4b870-a371-45e3-9bd9-2288298b9598 Feb 03 19:15:58 redmine-hengjiu amazon-ssm-agent.amazon-ssm-agent[1151]: 2020-02-03 19:15:58 INFO Backing off health check to every 3600 seconds for 10800 second Feb 03 19:15:59 redmine-hengjiu amazon-ssm-agent.amazon-ssm-agent[1151]: 2020-02-03 19:15:58 ERROR Health ping failed with error - AccessDeniedException: User: a Feb 03 19:15:59 redmine-hengjiu amazon-ssm-agent.amazon-ssm-agent[1151]: status code: 400, request id: 8e31b497-d38c-4804-a5f5-1fc19b548236 Feb 03 22:15:58 redmine-hengjiu amazon-ssm-agent.amazon-ssm-agent[1151]: 2020-02-03 22:15:58 ERROR Health ping failed with error - AccessDeniedException: User: a Feb 03 22:15:58 redmine-hengjiu amazon-ssm-agent.amazon-ssm-agent[1151]: status code: 400, request id: 5729d8d5-3162-4b74-85d2-3a9bcb504f30何やらここでもエラーが発生しているようです。
ですがそもそも何もしていない状況で起動してたらエラーは出ますよね。とりあえずこのままアクティベートしてみます。snap.amazon-ssm-agent(register)$ sudo /snap/amazon-ssm-agent/current/amazon-ssm-agent -register -code "JhVFOpJgb6n1gSrENEvP" -id "511f4a9c-23b2-4d03-a59e-8123977917c3" -region "ap-northeast-1" 2020/02/05 01:45:59 Failed to load instance info from vault. RegistrationKey does not exist. Error occurred fetching the seelog config file path: open /etc/amazon/ssm/seelog.xml: no such file or directory Initializing new seelog logger New Seelog Logger Creation Complete 2020-02-05 01:46:00 ERROR Error adding the directory to watcher: no such file or directory 2020-02-05 01:46:00 INFO Successfully registered the instance with AWS SSM using Managed instance-id: mi-3c475554443332111ERRORが気になりますが、最終的にSuccessfullyと出てるのでOKかなと思ったのですがダメでした。
管理コンソールに登録はされているのですが、接続ができない状況でした。
ということでやはり、一旦削除して入れ直すことにします。snap.amazon-ssm-agent(remove)$ sudo snap remove amazon-ssm-agent amazon-ssm-agent removed今度はsnapパッケージではなく.debパッケージでインストールします。
.amazon-ssm-agent.deb(install)$ sudo dpkg -i /tmp/ssm/amazon-ssm-agent.deb (Reading database ... 117121 files and directories currently installed.) Preparing to unpack /tmp/ssm/amazon-ssm-agent.deb ... Preparing for install -> Systemd detected active Failed to stop amazon-ssm-agent.service: Unit amazon-ssm-agent.service not loaded. Unpacking amazon-ssm-agent (2.3.842.0-1) ... Setting up amazon-ssm-agent (2.3.842.0-1) ... Starting agent Created symlink from /etc/systemd/system/multi-user.target.wants/amazon-ssm-agent.service to /lib/systemd/system/amazon-ssm-agent.service. Processing triggers for ureadahead (0.100.0-19.1) ...今度はちゃんとインストールされました。
amazon-ssm-agent.deb(status)$ sudo service amazon-ssm-agent status ● amazon-ssm-agent.service - amazon-ssm-agent Loaded: loaded (/lib/systemd/system/amazon-ssm-agent.service; enabled; vendor preset: enabled) Active: active (running) since Wed 2020-02-05 02:17:58 UTC; 38s ago Main PID: 28330 (amazon-ssm-agen) CGroup: /system.slice/amazon-ssm-agent.service └─28330 /usr/bin/amazon-ssm-agent Feb 05 02:17:58 redmine-hengjiu systemd[1]: Started amazon-ssm-agent. Feb 05 02:17:58 redmine-hengjiu amazon-ssm-agent[28330]: Error occurred fetching the seelog config file path: open /etc/amazon/ssm/seelog.xml: no such file or d Feb 05 02:17:58 redmine-hengjiu amazon-ssm-agent[28330]: Initializing new seelog logger Feb 05 02:17:58 redmine-hengjiu amazon-ssm-agent[28330]: New Seelog Logger Creation Complete Feb 05 02:17:58 redmine-hengjiu amazon-ssm-agent[28330]: 2020-02-05 02:17:58 INFO Entering SSM Agent hibernate - AccessDeniedException: User: arn:aws:sts::666877 Feb 05 02:17:58 redmine-hengjiu amazon-ssm-agent[28330]: status code: 400, request id: e2ebf98a-40d8-4a58-81eb-9f18123aa733 Feb 05 02:17:58 redmine-hengjiu amazon-ssm-agent[28330]: 2020-02-05 02:17:58 INFO Agent is in hibernate mode. Reducing logging. Logging will be reduced to one loでは、いよいよアクティベートします。
amazon-ssm-agent.deb(stop)$ sudo service amazon-ssm-agent stop先ほど作成したアクティベーション情報を使って実行します。
amazon-ssm-agent.deb(register)$ sudo amazon-ssm-agent -register -code "JhVFOpJgb6n1gSrENEvP" -id "511f4a9c-23b2-4d03-a59e-8123977917c3" -region "ap-northeast-1" Error occurred fetching the seelog config file path: open /etc/amazon/ssm/seelog.xml: no such file or directory Initializing new seelog logger New Seelog Logger Creation Complete 2020-02-05 02:18:52 ERROR Registration failed due to error registering the instance with AWS SSM. RegistrationLimitExceeded: status code: 400, request id: f7fd3939-3fb7-418d-85c7-1494f4fe742f bitnami@redmine-hengjiu:~$ sudo amazon-ssm-agent -register -code "EFGt8VfQ/b3WIeacWd0w" -id "2e202742-2340-467e-b7aa-24cae9391956" -region "ap-northeast-1" Error occurred fetching the seelog config file path: open /etc/amazon/ssm/seelog.xml: no such file or directory Initializing new seelog logger New Seelog Logger Creation Complete 2020-02-05 02:20:41 INFO Successfully registered the instance with AWS SSM using Managed instance-id: mi-3c475554443332111Successfullyということで成功したみたいなので起動させてみます。
amazon-ssm-agent.deb(start)$ sudo service amazon-ssm-agent start今回はコンソールからちゃんと接続できました。
それではcliで接続したいと思います。start-session$ aws ssm start-session --target mi-3c475554443332111 SessionManagerPlugin is not found. Please refer to SessionManager Documentation here: http://docs.aws.amazon.com/console/systems-manager/session-manager-plugin-not-foundどうやらcliでセッションマネージャーを使うには SessionManagerPlugin というのをインストールする必要があるみたいです。
SessionManagerPluginのインストール
cliで接続するためのpluginをインストールします。今回はmac環境です。
sessionmanager-bundle(download)$ curl "https://s3.amazonaws.com/session-manager-downloads/plugin/latest/mac/sessionmanager-bundle.zip" -o "sessionmanager-bundle.zip" % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 4680k 100 4680k 0 0 1782k 0 0:00:02 0:00:02 --:--:-- 1782ksessionmanager-bundle(unzip)$ unzip sessionmanager-bundle.zip Archive: sessionmanager-bundle.zip creating: sessionmanager-bundle/ creating: sessionmanager-bundle/bin/ inflating: sessionmanager-bundle/seelog.xml.template inflating: sessionmanager-bundle/VERSION inflating: sessionmanager-bundle/LICENSE inflating: sessionmanager-bundle/install inflating: sessionmanager-bundle/bin/session-manager-pluginsessionmanager-bundle(install)$ sudo ./sessionmanager-bundle/install -i /usr/local/sessionmanagerplugin -b /usr/local/bin/session-manager-plugin Password: Creating install directories: /usr/local/sessionmanagerplugin/bin Creating Symlink from /usr/local/sessionmanagerplugin/bin/session-manager-plugin to /usr/local/bin/session-manager-plugin Installation successful!インストールが成功したかは以下のコマンドで確認できます。
session-manager-plugin$ session-manager-plugin The Session Manager plugin was installed successfully. Use the AWS CLI to start a session.ということで改めてコマンドを実行してみます。
start-session$ aws ssm start-session --target mi-3c475554443332111 Starting session with SessionId: kohei-3c475554443332111無事接続できました。
おわりに
Lightsailは手軽に利用できてすごく助かるのですが、ファイアウォールがポートレベルでの制御となるのがちょっと難点でした。
ですが、セッションマネージャを使うことでその難点を解消できるだけでなく、IP制御すらしなくて済んでしまいました。
[参考]
・ステップ 2: ハイブリッド環境の IAM サービスロールを作成する
https://docs.aws.amazon.com/ja_jp/systems-manager/latest/userguide/sysman-service-role.html
・ステップ 4: ハイブリッド環境のマネージドインスタンスのアクティベーションを作成する
https://docs.aws.amazon.com/ja_jp/systems-manager/latest/userguide/sysman-managed-instance-activation.html
・ステップ 6: ハイブリッド環境に SSM エージェント をインストールする (Linux)
https://docs.aws.amazon.com/ja_jp/systems-manager/latest/userguide/sysman-install-managed-linux.html
・Linux インスタンスから SSM エージェント をアンインストールする
https://docs.aws.amazon.com/ja_jp/systems-manager/latest/userguide/sysman-uninstall-agent.html
・macOS で Session Manager Plugin をインストールおよびアンインストールする
https://docs.aws.amazon.com/ja_jp/systems-manager/latest/userguide/session-manager-working-with-install-plugin.html#install-plugin-macos
・AWS CLI Command Reference - start-session
https://docs.aws.amazon.com/cli/latest/reference/ssm/start-session.html#start-session
- 投稿日:2020-02-07T11:23:17+09:00
Elastic BeansTalk の Django チュートリアル【初心者向け】
はじめに
前回ご紹介した、Elastic BeansTalkの理解をより深める為に
公式ドキュメントのチュートリアルを使ってDjangoアプリをデプロイしてみました!前提条件は長くなってしまうので割愛させていただきます。
Python 3.6と Windows 10 を使用しています。0.Windows で EB CLI をインストール
pip を使用して EB CLI をインストールします。コマンドプロンプトに以下を入力。
C:\Users\ユーザー名>pip install awsebcli --upgrade --userWindows キーを押し、「環境変数」と入力します。[環境変数を編集] を選択します。
変数 Path を選択して、[ 編集 ]をクリック。
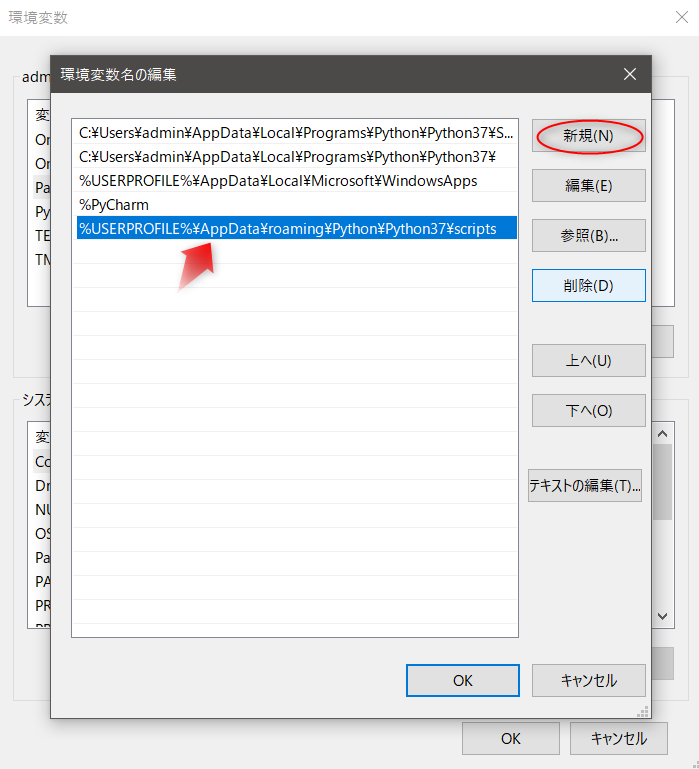
[新規]を選択。[ %USERPROFILE%\AppData\roaming\Python\Python37\scripts ]を追加します。
[OK] を 2 回選択して、新しい設定を適用します。
実行中のコマンドプロンプトのウィンドウを exit で閉じて、再度開きます。
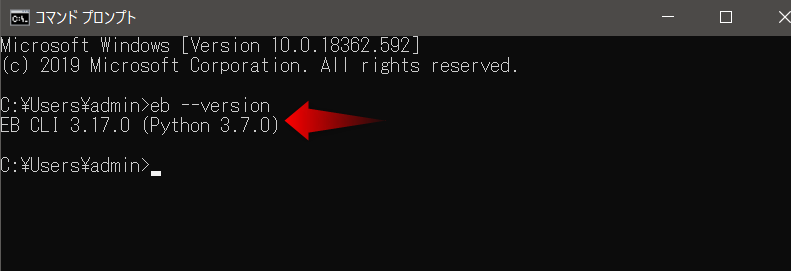
EB CLI が正しくインストールされたかを確認します。以下をコマンドに入力します。
C:\Users\ユーザー名> eb --version
1.Python 仮想環境のセットアップと Django のインストール
1. [ eb-virt ] という名前の仮想環境を作成します。
C:\> virtualenv %HOMEPATH%\eb-virt2. 仮想環境をアクティブ(実行状態)にします
C:\> %HOMEPATH%\eb-virt\Scripts\activate3. [ pip ]というコマンドを使用して Django をインストールします。
(eb-virt)~$ pip install4. Django がインストールされたことを確認するには、以下のように入力します。
(eb-virt)~$ pip freeze2. Django プロジェクトを作成する
1. 仮想環境をアクティブ化します。
C:\> %HOMEPATH%\eb-virt\Scripts\activateコマンドプロンプトの先頭に[ eb-virt ]が表示され、仮想環境を使用していることが分かります。
2. [ django-admin startproject ]コマンドを使用して、[ ebdjango ]という名前の Django のプロジェクトを作成します。
(eb-virt) C:\Users\ユーザー名>django-admin startproject ebdjango3. [ manage.py runserver ] で Django サイトをローカルで実行します。
(eb-virt) C:\Users\ユーザー名>cd ebdjango
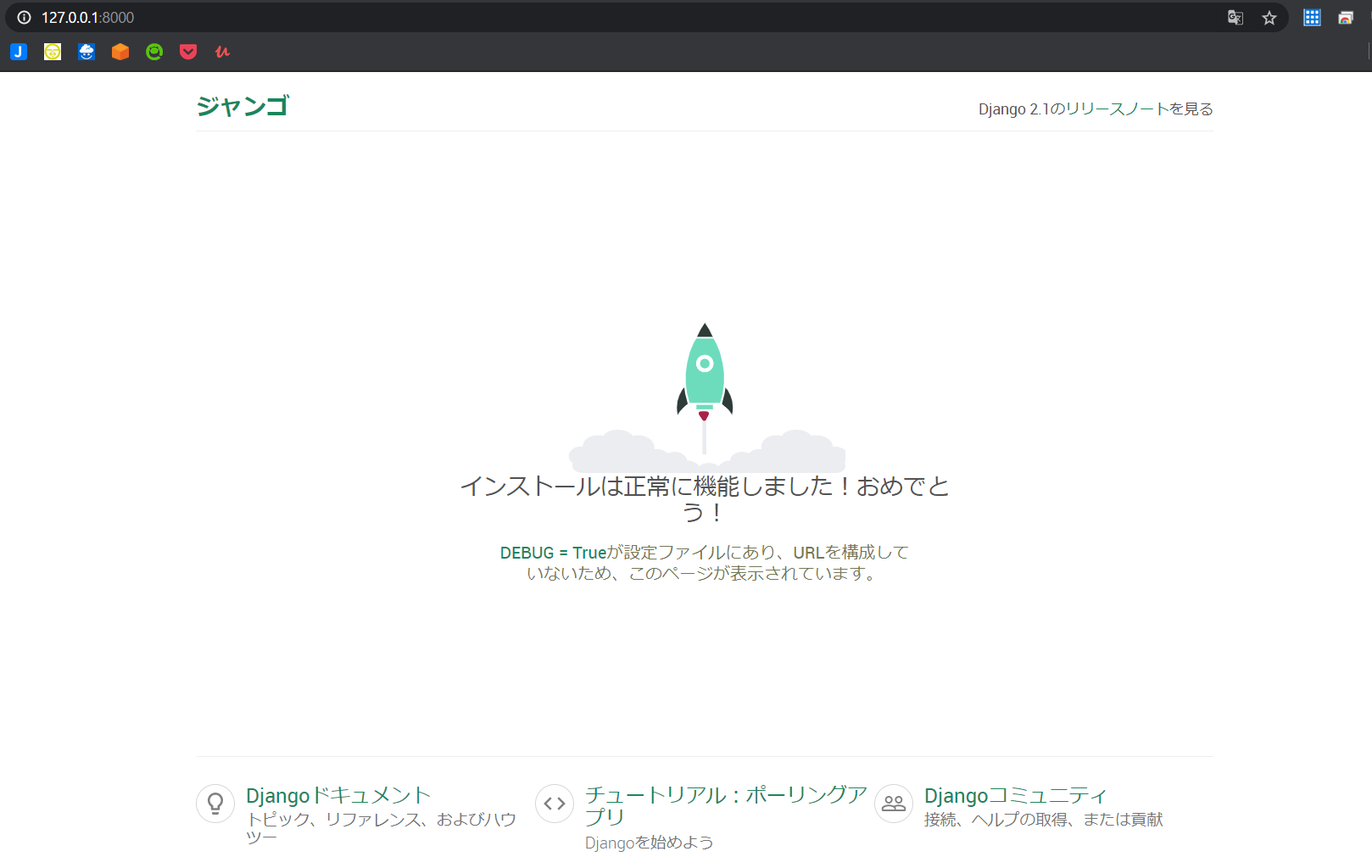
(eb-virt) C:\Users\ユーザー名>python manage.py runserver4. ウェブブラウザで http://127.0.0.1:8000/ を開いて、サイトを表示します。
5. ウェブサーバを停止して仮想環境に戻るには、キーボードの[ Ctrl+C ]を押します。
3. Elastic Beanstalk 用に Django アプリケーションを設定する
ローカルシステムに作成したサイトを、Elastic Beanstalk でのデプロイ用に設定します。
アプリケーションの環境を調整して、アプリケーションのモジュールをロードできるように、環境変数を設定します。1. 仮想環境をアクティブ化します。
C:\Users\ユーザー名\ebdjango>%HOMEPATH%\eb-virt\Scripts\activate2. [ pip freeze ] を実行して、出力を requirements.txt という名前のファイルに保存します。
(eb-virt) ~/ebdjango> pip freeze > requirements.txtElastic Beanstalk は requirements.txt を使用して、アプリケーションを実行する EC2 インスタンスにどのパッケージをインストールするかを判断します。
3. [ .ebextensions ] という名前のディレクトリを作成します。
(eb-virt) ~/ebdjango> mkdir .ebextensions4. [ .ebextensions ]ディレクトリ内に、[ django.config ]という名前の 設定ファイルを作成します。
C:\Users\USERNAME\ebdjango>type nul > django.configCLIで操作したパスの通りにファイルを開いていきます。
エクスプローラーを開いて、Windows(C:) ドライブにあるユーザーから自分のユーザー名のフォルダを開きます。
「 ~/ebdjango/.ebextensions/django.config 」
django.config を見つけたらメモ帳で開いて設定事項を書きます。django.configoption_settings: aws:elasticbeanstalk:container:python: WSGIPath: ebdjango/wsgi.pyこの設定 WSGIPath は、アプリケーションを起動するのに Elastic Beanstalk が使用する WSGI スクリプトの場所を指定します。
deactivate コマンドを使用して、仮想環境を非アクティブ化します。
(eb-virt) ~/ebdjango> deactivate4. EB CLI でサイトをデプロイする
※Elastic Beanstalk コンソールを使用して .zip ファイルをアップロードして展開することもできます。
アプリケーション環境を作成し、設定済みのアプリケーションを Elastic Beanstalk を使用してデプロイします。1. eb init コマンドを使用して EB CLI リポジトリを初期化します。
このコマンドでは、django-tutorial という名前のアプリケーションを作成します。
また、ローカルリポジトリ(ファイルやディレクトリの履歴を管理する場所)を設定し、最新の Python 3.6 プラットフォームバージョンで環境を作成します。
~/ebdjango> eb init -p python-3.6 django-tutorial
Application django-tutorial has been created.eb init を再度実行してデフォルトのキーペアを設定し、アプリケーションを実行している EC2 インスタンスに SSH を使用して接続できるようにします。
~/ebdjango> eb init
Do you want to set up SSH for your instances?
(y/n): y
Select a keypair.
1) my-keypair
2) [ Create new KeyPair ]このコマンドは、django-env という名前のロードバランシング Elastic Beanstalk 環境を作成します。環境の作成には約 5 分かかります。
Elastic Beanstalk はアプリケーションを実行するのに必要なリソースを作成してくれます。環境の作成プロセスが完了したら、eb status を実行して新しい環境のドメイン名を見つけます。
~/ebdjango> eb status
Environment details for: django-env
Application name: django-tutorial
...
CNAME: eb-django-app-dev.elasticbeanstalk.com
...環境のドメイン名は、CNAME プロパティの値です。
settings.py ディレクトリの ebdjango ファイルを開きます。
ALLOWED_HOSTS 設定を見つけ、前のステップで見つけたアプリケーションのドメイン名を設定の値に追加します。この設定がファイルで見つからない場合は、それを新しい行に追加します。
...
ALLOWED_HOSTS = ['eb-django-app-dev.elasticbeanstalk.com']ファイルを保存し、eb deploy を実行してアプリケーションをデプロイします。
eb deploy を実行すると、EB CLI はプロジェクトディレクトリのコンテンツをまとめて、ユーザーの環境にデプロイします。
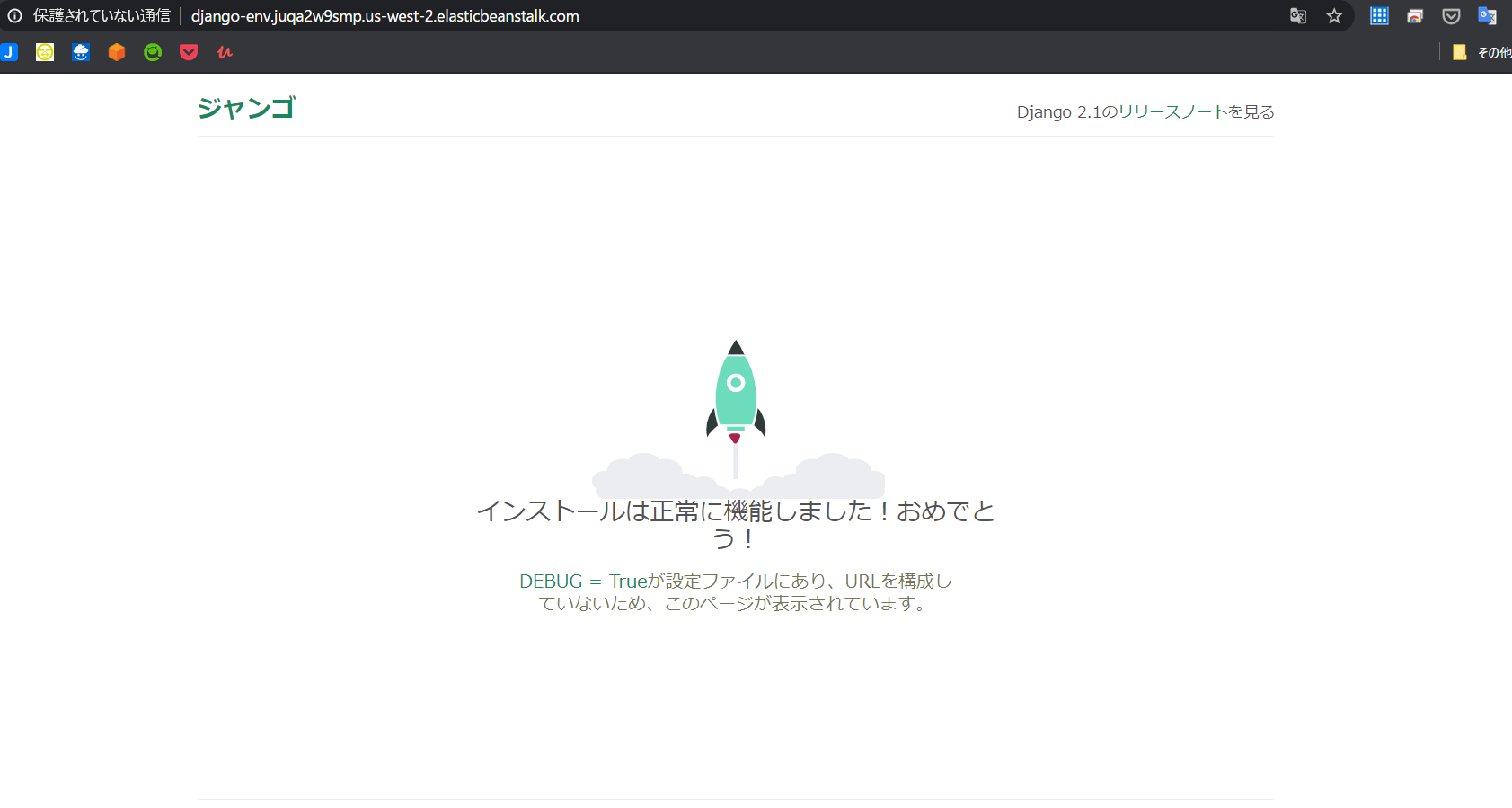
~/ebdjango> eb deploy環境の更新プロセスが完了したら、eb open でウェブサイトを開きます。
~/ebdjango> eb openこれにより、アプリケーション用に作成されたドメイン名を使用してブラウザウィンドウが開きます。
ローカルで作成してテストしたのと同じ Django ウェブサイトが表示されます。
クリーンアップ方法
他の AWS リソースを保存するには、eb terminate を入力。 Elastic Beanstalk 環境を終了します。
~/ebdjango> eb terminate django-envこのコマンドは、環境とその中で実行されているすべての AWS のリソースを終了します。
アプリケーションが削除されることはありません。
eb create を再び実行することで、同じ設定でさらに環境を作成することができます。アプリケーションが必要なくなった場合は、プロジェクトフォルダーと仮想環境を削除することもできます。
~$ rm -rf ~/eb-virt
~$ rm -rf ~/ebdjangoリソースを確認してみる
中では CloudFormation の「スタック」からアプリケーションのデプロイ環境が作られています。
EC2
S3
Cloud formation
所感
確かにコンソールでポチポチとサービス画面を行き来しながら、環境を一から構築するよりは、一つの画面で操作できて一式リソースが用意されるこの仕組みは便利だと思いました。
ただコマンドプロンプトや CLI の操作に慣れないと、ちょっと難しい部分もありますので、サンプルアプリケーションを作成できるコンソール操作から使ってみるほうが入りやすいかもしれません。公式サイトリンク

- 投稿日:2020-02-07T10:03:14+09:00
CodeBuild + SkaffoldのCI/CD環境のビルド時間を改善した話
課題
元々、PlayFrameworkアプリケーション(Scala)のビルドを、Docker ImageのビルドからECRへのImage Push、EKSへのデプロイまでをSkaffoldに内包する形で行なっていました。
これらをGithubへのTagプッシュを契機にCodeBuild上で動かしていたのですが、新たに機械学習アプリケーション(Python)が加わり、ビルド時間が12分から20分まで伸びてしまったことで遅さが目についたので、改善に踏み切りました。環境
- プラットフォーム: EKS(PlayFramework + Python)
- ビルド環境: CodeBuild + Skaffold
改善施策
改善施策として以下の二点について対応しました。
- 並列ビルドの導入
- ビルドキャッシュの有効化
並列ビルドの導入
Skaffoldではデフォルトでは並列度1、直列でビルドが行われるのですが、Concurrencyを設定することで並列度を増やすことができます。今回の場合はビルドする対象が1から2に増えたので、2を設定しました。(当然のことながら、それ以上増やしてもビルド時間は向上しませんでした。)
skaffold.ymlapiVersion: skaffold/v2alpha3 kind: Config build: artifacts: - image: scala/api custom: buildCommand: ./build.sh api dependencies: paths: - docker/api - image: python/ml custom: buildCommand: ./build.sh ml dependencies: paths: - docker/ml local: concurrency: 2 tagPolicy: gitCommit: {} deploy: kustomize: {} - name: development deploy: kustomize: paths: - kubernetes/development patches: - op: replace path: /build/artifacts/0/image value: 000000000000.dkr.ecr.us-east-1.amazonaws.com/scala/api - op: replace path: /build/artifacts/1/image value: 000000000000.dkr.ecr.us-east-1.amazonaws.com/python/ml - name: development deploy: kustomize: paths: - kubernetes/staging patches: - op: replace path: /build/artifacts/0/image value: 111111111111.dkr.ecr.us-east-1.amazonaws.com/scala/api - op: replace path: /build/artifacts/1/image value: 111111111111.dkr.ecr.us-east-1.amazonaws.com/python/ml参考:https://skaffold.dev/docs/references/yaml/
これを設定したことで20分→12分、単一のアプリケーションをビルドしていた時点まで改善しました。
ビルドキャッシュの有効化
次にCodeBuildのキャッシュの有効化を行いました。元々、Dockerレイヤーキャッシュは有効化していたのですが、今回、新たにカスタムキャッシュを有効化しました。カスタムキャッシュはbuildspec.ymlで指定した特定のディレクトリ以下をキャッシュする機能になります。
CFnテンプレートは以下のようになります。- LOCAL_CUSTOM_CACHEが追加した設定になります。codebuild-sample.ymlCodeBuildProject: Type: 'AWS::CodeBuild::Project' Properties: Artifacts: Type: 'CODEPIPELINE' BadgeEnabled: false Cache: Modes: - LOCAL_DOCKER_LAYER_CACHE - LOCAL_CUSTOM_CACHE Type: LOCAL Description: !Sub 'created by ${AWS::StackName}' Name: !Ref ApplicationName ServiceRole: !GetAtt IAMRoleCodeBuild.Arn Environment: ComputeType: 'BUILD_GENERAL1_SMALL' Image: 'aws/codebuild/standard:3.0' ImagePullCredentialsType: 'CODEBUILD' EnvironmentVariables: - Name: 'EKS_CLUSTER_NAME' Value: !Ref EKSCluster Type: 'PLAINTEXT' - Name: 'ENVIRONMENT_NAME' Value: !Ref EnvironmentName Type: 'PLAINTEXT' PrivilegedMode: true Type: 'LINUX_CONTAINER' Source: Type: 'CODEPIPELINE' TimeoutInMinutes: 30buildspec.ymlにはsbtのビルドキャッシュを利用するため、
/root/.sbt/**/*、/root/.ivy2/**/*を追加し、Skaffoldのキャッシュを利用するため、/root/.skaffold/**/*を新規に追加しました。Skaffoldでは、skaffold.ymlに記載したdependenciesに指定したディレクトリ配下の依存関係を元にキャッシュを生成します。(今回記載したskaffold.ymlはあくまでサンプルであり、実際にはDockerfile以外にも指定する必要があります。)buildspec.ymlversion: 0.2 phases: install: runtime-versions: docker: 18 java: openjdk8 commands: ## Install kubectl - wget -O /usr/local/bin/kubectl https://storage.googleapis.com/kubernetes-release/release/v1.14.7/bin/linux/amd64/kubectl - chmod +x /usr/local/bin/kubectl ## Install kustomize - wget -O /usr/local/bin/kustomize https://github.com/kubernetes-sigs/kustomize/releases/download/kustomize/v3.2.3/kustomize_kustomize.v3.2.3_linux_amd64 - chmod +x /usr/local/bin/kustomize ## Install skaffold - wget -O /usr/local/bin/skaffold https://storage.googleapis.com/skaffold/releases/latest/skaffold-linux-amd64 - chmod +x /usr/local/bin/skaffold pre_build: commands: - aws eks update-kubeconfig --name ${EKS_CLUSTER_NAME} --region ${AWS_DEFAULT_REGION} - aws eks get-token --cluster-name ${EKS_CLUSTER_NAME} - $(aws ecr get-login --no-include-email --region ${AWS_DEFAULT_REGION}) build: commands: - skaffold run -p ${ENVIRONMENT_NAME} cache: paths: - '/root/.sbt/**/*' - '/root/.ivy2/**/*' - '/root/.skaffold/**/*'この設定を行なった結果、ビルド時間が3分40秒程度に改善し、アプリケーションを変更せずにk8sマニフェストファイルの変更のみ適用する場合は30秒程度まで改善することができました。

- 投稿日:2020-02-07T08:39:30+09:00
AWS Lambda@Edgeをつかって香川県からのアクセスをブロックする
はじめに
この記事はネタ記事です。
本記事で紹介するような、特定の地域からのアクセスブロック等の行為を推奨するものでは一切ございません。また、筆者は香川県のネット・ゲーム規制条例案について反対の立場です。
ただし、香川県のパブリックコメントへの回答によると
Q:事業者の対策・協力義務について、具体的にはどのような対策を想定していますか。香川県からのアクセス遮断なども含まれますか。
A:事業者に自主的な取り組みを呼びかけるものと考えています。
【全22問】「1日60分までの根拠は」「なぜ議事録がないのか」―― 香川県「ネット・ゲーム依存症対策条例(仮称)」、議会事務局との一問一答
との回答が得られており、万が一この条例が可決されれば、事業者による自主的な取り組みの一部として、香川県からのアクセスブロックを行う可能性は否定できません。
条例が可決された場合には、香川県からのアクセスをブロックすることが技術的に可能であるかを検証するという目的のもと、本記事を執筆いたしました。
概要
はい、それではどうやって実現しましょう。
では、JavaScriptのGeolocation APIを使って香川からのアクセスをブロックする手法が紹介されていました。
本記事ではもっとシンプルに、AWS Lambda@EdgeからIP infoDBにIPアドレスを問い合わせて、RegionCodeが香川県のものをブロックするという手法を紹介します。AWSリソースの操作にはterraform, aws cliを用いて、Lamdaのデプロイにはlambrollを用いています。
本当はAWS WAFとかでもっと簡単にやりたかったのだけど、さすがにWAFでのGeoCodeは国単位だったので残念ですね。
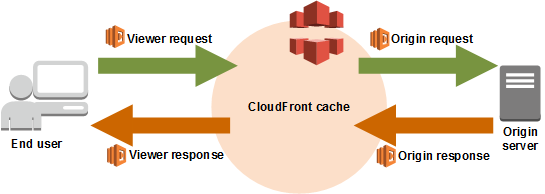
AWS Lambda@Edgeとは
簡単に言えばCloudFrontのエッジサーバ上でLambda Functionを実行することができる機能です。フックとなるトリガーには下図のイベントが用意されています。
"Viewer request"をトリガーにすればLambda@Edgeでアクセスブロックを実現できそうですね。
Lambdaのコードを書く
Lambda@EdgeはNodejsとPython3.7しか対応していないので、どちらか好みの方で書きます。今回はPython3のコードをシュババッと書きました。
block.py#!/usr/bin/env python3 import urllib.request import json import re import os def lambda_handler(event, context): key = "XXXXXXXXXXXXXXXXXXXXXXX" block_region = "Tokyo" request = event['Records'][0]['cf']['request'] client_ip = request['clientIp'] print("request:\n%s" % request) url = "http://api.ipinfodb.com/v3/ip-city/" try: req = urllib.request.urlopen("%s/?key=%s&ip=%s&format=json" % (url, key, client_ip)) except urllib.error.URLError as e: print(e.reason) except urllib.error.HTTPError as e: print(e.code) res = req.read().decode('utf-8') ip_info = json.loads(res) print("ip_info:\n%s" % ip_info) if ip_info["regionName"] != block_region: return request print("BLOCK REQUEST FROM %s" % block_region) response = { 'status': '451', 'statusDescription': 'Unavailable For Legal Reasons', } return responseいくつか注意点があります
- https://ipinfodb.com/ に新規登録してAPIキーを発行します。
- block_regionが"Tokyo"なんだけど?
- 動作確認のためです。あとで"Kagawa"に変更します。
lambda@Edgeは環境変数に対応していません。APIキーとかもベタ書きにならざるを得ません。物騒ですね。
リターンコード 451 ってなんだ?
- 筆者も調べて初めて知ったんですが、Unavailable For Legal Reasons i つまり「法的理由により取得不能」とのこと。今回の要件にぴったりですね。
- 有名な小説『華氏451度』にちなんでつけられたそうです。
IAM roleを作成する
lambda実行用のIAM Roleを作成します。terraform で書くとこのようになります。
resource "aws_iam_role" "lambda_edge" { name = "lambda" assume_role_policy = data.aws_iam_policy_document.lambda_assume_role.json } data "aws_iam_policy_document" "lambda_assume_role" { statement { actions = ["sts:AssumeRole"] principals { type = "Service" identifiers = [ "lambda.amazonaws.com", "edgelambda.amazonaws.com" ] } } } resource "aws_iam_role_policy_attachment" "lambda_basic_role" { role = aws_iam_role.lambda_edge.name policy_arn = "arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole" }
- IAMの信頼関係で"edgelambda.amazonaws.com"を追加して、アクセス権限にCloudWatch Logsにログを流すためにAWSLambdaBasicExecutionRoleのポリシーを付与しています
lambdaをデプロイする
準備ができたら、us-east-1(バージニア北部)リージョンにデプロイします。
terraformでデプロイしてもいいのですが、ここではlambrollというlambdaへのデプロイツールを用いました。
- lambroll: https://github.com/fujiwara/lambroll
デプロイ用の設定は以下のとおりです。
$ lambroll init $ cat function.json { "FunctionName": "block", "Handler": "block.lambda_handler", "MemorySize": 128, # さきほど作成したIAM Role "Role": "arn:aws:iam::XXXXXXXXXXXX:role/lambda", "Runtime": "python3.7", "Timeout": 3 }デプロイを実行します
$ lambroll deploy --region us-east-1 2020/02/07 01:41:02 [info] lambroll v0.3.3 2020/02/07 01:41:02 [info] starting deploy function block 2020/02/07 01:41:03 [info] creating zip archive from . 2020/02/07 01:41:03 [info] zip archive wrote 973 bytes 2020/02/07 01:41:03 [info] creating function 2020/02/07 01:41:03 [info] deployed function version 1 2020/02/07 01:41:03 [info] creating alias set current to version 1 2020/02/07 01:41:04 [info] alias created 2020/02/07 01:41:04 [info] completedこれでlambdaの準備は完了です。
S3を用意する
このあたりはちゃっとやっちゃいましょう。S3を作成します。名前はなんか適当に付けます。
resource "aws_s3_bucket" "web-hosting" { bucket = "sakutomo-webhosting-test" acl = "private" }できたバケットには適当な画像でもいれておきましょう。
香川なんでうどんでもおいておきましょう。
$ aws s3 ./bukkake_udon.png s3://sakutomo-webhosting-test/つづいて、CloudFrontもつくります。
resource "aws_cloudfront_origin_access_identity" "web-hosting" { comment = "sakutomo-webhosting-origin-access-identity" } resource "aws_cloudfront_distribution" "web-hosting" { enabled = true price_class = "PriceClass_All" comment = "Web Hosting Sakutomo Test" origin { domain_name = aws_s3_bucket.web-hosting.bucket_domain_name origin_id = "S3-sakutomo-webhosting-test.s3.amazonaws.com" s3_origin_config { origin_access_identity = aws_cloudfront_origin_access_identity.web-hosting.cloudfront_access_identity_path } } default_cache_behavior { allowed_methods = ["GET", "HEAD"] cached_methods = ["GET", "HEAD"] target_origin_id = "S3-sakutomo-webhosting-test.s3.amazonaws.com" forwarded_values { query_string = false cookies { forward = "none" } } viewer_protocol_policy = "redirect-to-https" min_ttl = 0 default_ttl = 3600 max_ttl = 86400 } restrictions { geo_restriction { restriction_type = "none" } } viewer_certificate { cloudfront_default_certificate = true minimum_protocol_version = "TLSv1.1_2016" ssl_support_method = "sni-only" } wait_for_deployment = false }オリジンには先程のS3バケットを指定しています。
最後に、CloudFrontからS3においた画像が見られるように、バケットポリシーを作成します。data "aws_iam_policy_document" "web-hosting" { statement { actions = ["s3:GetObject", "s3:ListBucket"] resources = [ aws_s3_bucket.web-hosting.arn, format("%s/*", aws_s3_bucket.web-hosting.arn), ] principals { type = "AWS" identifiers = [aws_cloudfront_origin_access_identity.web-hosting.iam_arn] } } } resource "aws_s3_bucket_policy" "web-hosting" { bucket = aws_s3_bucket.web-hosting.id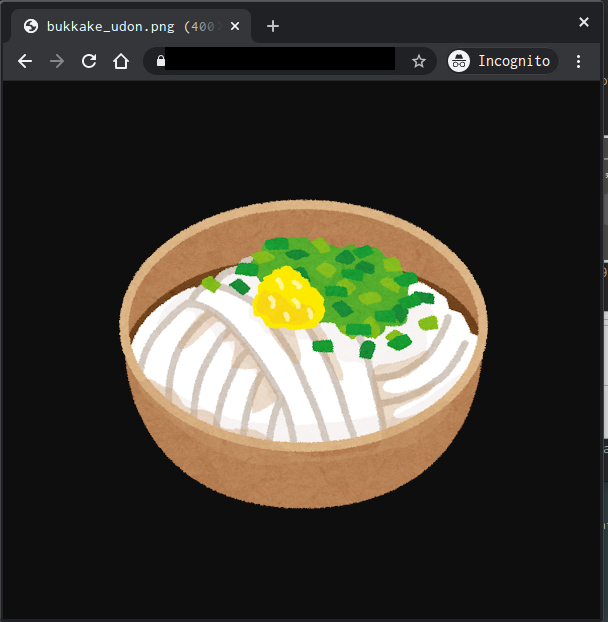 policy = data.aws_iam_policy_document.web-hosting.json }ここまでできたらCloudFrontのアドレスから先程のうどんが見えるかどうかを確認しましょう。
CLIでもリターンコードを確認します。
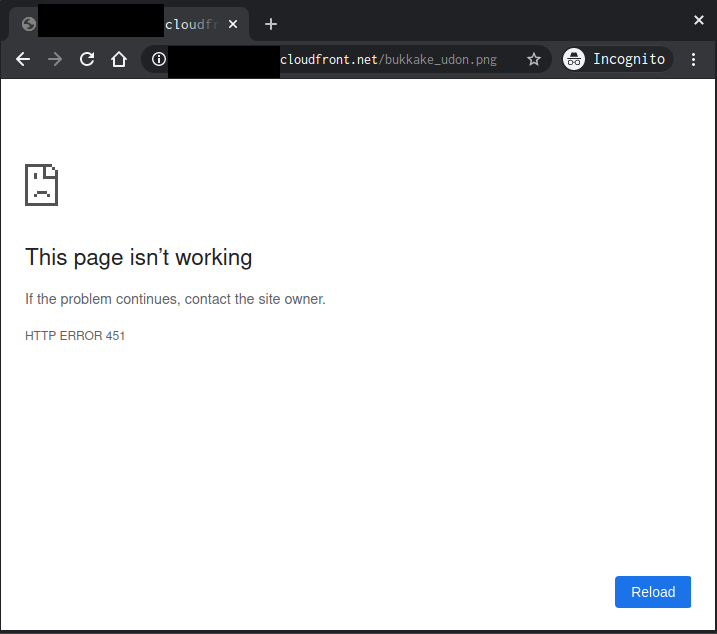
$ curl https://XXXXXXXXXXXXXx.cloudfront.net/bukkake_udon.png -I HTTP/2 200 content-type: image/png .... server: AmazonS3 x-cache: Hit from cloudfront ...ちゃんとうどんが見えますね。
Lambd@Edgeを適用する
このうどんを香川県から見えなくします。
先程のterraformに以下のオプションを追加します
resource "aws_cloudfront_distribution" "web-hosting" { ... default_cache_behavior { + lambda_function_association { + event_type = "viewer-request" + lambda_arn = "arn:aws:lambda:us-east-1:XXXXXXXX:function:block:1" + }これでCloudFrontへのViewerRequest時にLambda@Edgeが実行されるようになりました!!
確認する
本当にうどんが見えなくなったのか確認しましょう。
反映するまでに少々時間がかかります。CloudFrontのDestributionのStatusがグルグルまわる In Progress からDeployedになるまで気長に待ちます。
ぐるぐるが終わったら先程のようにブラウザでアクセスしてみましょう。
$ curl https://XXXXXXXXXXX.cloudfront.net/bukkake_udon.png -I 02:06:26 HTTP/2 451 content-length: 0 server: CloudFront date: Thu, 06 Feb 2020 17:13:29 GMTしっかり、リターンコードが451となって返ってきていますね。
うどんは見えなくなってしまいました。
香川県からのアクセスをブロックする
block_region = "Tokyo"となっているところを"Kagawa"に書き換えます。
block.pydef lambda_handler(event, context): ... - block_region = "Tokyo" + block_region = "Kagawa"再度Lambdaをデプロイします。
$ lambroll deploy --region us-east-1 2020/02/07 02:07:05 [info] lambroll v0.3.3 2020/02/07 02:07:05 [info] starting deploy function block 2020/02/07 02:07:06 [info] creating zip archive from . 2020/02/07 02:07:06 [info] zip archive wrote 974 bytes 2020/02/07 02:07:06 [info] updating function configuration 2020/02/07 02:07:06 [info] updating function code 2020/02/07 02:07:07 [info] deployed version 2 2020/02/07 02:07:07 [info] updating alias set current to version 2 2020/02/07 02:07:07 [info] alias updated 2020/02/07 02:07:07 [info] completedCloudFrontの設定も変更します。versionを 1 -> 2へ。
resource "aws_cloudfront_distribution" "web-hosting" { ... default_cache_behavior { lambda_function_association { event_type = "viewer-request" - lambda_arn = "arn:aws:lambda:us-east-1:XXXXXXXX:function:block:1" + lambda_arn = "arn:aws:lambda:us-east-1:XXXXXXXX:function:block:2" }おめでとうございます!!!これでKagawaからのアクセスをブロックすることができた(はず)です!!!!(香川県民の人、確認をおねがいします。)
その他補足事項とかツッコミとか
Lambda@Edgeのログはどこにでるの?
- リクエストを受け取ったCloudFrontのエッジサーバのあるリージョンです。
- 日本からのアクセスだと東京リージョンのCloudWatch Logsに出力されます。
本当にIPから特定できる場所があっているの?
- IP DBINFOのデータが古ければ誤ってブロックしてしまうこともあります。常に正しいわけではないです。
リクエスト毎にIP DBINFOへのリクエストが走るよね?本番運用では現実的ではないのでは?
- そのとおりです。ただ、同じ手法でLambda内にIPデータベースをもたせるなどすれば外部への通信なしに制御することも可能かもしれないです。
条例での対象はインターネットではなく、コンピューターゲームだけど?
- 今回は試してないけど、CloudFrontのオリジンをALBにすればゲームなどのapiサーバーでも応用ができそうですその他、気になることがあればコメントかTwitterまで!!


- 投稿日:2020-02-07T02:16:08+09:00
Apache2.4でテスト環境を構築する話
はじめに
こんにちは、はるちゃです。
開発環境にAWSを使用しています。
テスト環境に移行した際に社外の人に見られたくない。。。
と思ったので、メモとして置いときます。前提
- AWSのアカウントを所持していること
- インスタンスを生成していること
- apacheをインストールしていること
私はAWS初心者なので Amazon Linux 2 AMI (HVM), SSD Volume Typeを使用しています。
目次
1.ip制限をかける
2.Basic認証の導入
3.ip制限、Basic認証の併用ip制限をかける
httpd.conf<Directory "/var/www/html"> ... # Require all granted #ここのコメントをオンにすると全体から閲覧できるようになります。 Require ip XXX.XXX.XX.X #IPアドレスを挿入します。 ... </Directory>この方法が一番簡単です。
自社の人なら誰でも見ていいよーって時はこの方法でいいと思います。Basic認証の導入
はじめにhtpasswdが存在するか確認。。。
[ec2-user@プライベートip]$htpasswd Usage: htpasswd [-cimBdpsDv] [-C cost] passwordfile username htpasswd -b[cmBdpsDv] [-C cost] passwordfile username password htpasswd -n[imBdps] [-C cost] username htpasswd -nb[mBdps] [-C cost] username password -c Create a new file. -n Don't update file; display results on stdout. -b Use the password from the command line rather than prompting for it. -i Read password from stdin without verification (for script usage). -m Force MD5 encryption of the password (default). -B Force bcrypt encryption of the password (very secure). -C Set the computing time used for the bcrypt algorithm (higher is more secure but slower, default: 5, valid: 4 to 17). -d Force CRYPT encryption of the password (8 chars max, insecure). -s Force SHA encryption of the password (insecure). -p Do not encrypt the password (plaintext, insecure). -D Delete the specified user. -v Verify password for the specified user. On other systems than Windows and NetWare the '-p' flag will probably not work. The SHA algorithm does not use a salt and is less secure than the MD5 algorithm.存在しない場合は↓のリンクを参照してinstallしてください。
http://tanihiro.hatenablog.com/entry/2014/02/05/172938次に
$ cd /etc/httpd/conf #このコマンドでconf階層まで必ず移動してください $sudo htpasswd -c <filepass名> <username> New password: パスワード入力 Re-type new password: パスワード再入力 Adding password for user <username>あとは下記の通りにDirectoryにBasic認証条件を記入します。
httpd.conf<Directory "/var/www/html"> ... AuthType Basic AuthName "Basic Auth" AuthUserFile /etc/httpd/conf/.htpasswd Require valid-user ... </Directory>ここまでの設定が終わったら、apacheを再起動してください。
こんな画面が出てきたら成功です!
ip制限、Basic認証の併用
httpd.conf<Directory "/var/www/html"> ... <RequireAll> Require ip 自分のIPアドレス <RequireAny> AuthType Basic AuthName "適当なコメント" AuthUserFile /etc/httpd/conf/<ファイル名> Require valid-user </RequireAny> </RequireAll> ・・・ </Directory>上記のように設定すれば、IPアドレスが違うユーザーはサイトに入ることができません。
仮にIPアドレスが一致していた場合もBasic認証が作動します。
うっかり開発者以外の人が入ってデータを消してしまう心配が少し減ります。終わりに
今回はここまでです。
テスト環境を構築するのに困っている人の役に立てば幸いです。記載にミスがあったり書き方が違うなど、あればコメントよろしくお願いします!