- 投稿日:2019-12-02T23:41:48+09:00
driver failed programming external connectivity on endpointとなった時の対処法(redwood-broker 編)
概要
docker-composeでなんらかの理由により強制終了し、再度起動してもdriver failed programming external connectivity on endpointと言われる時の対処法原因
他のプロセスが使用しようとしているポート番号とかぶっています。
多くの場合
まずはこちらをご覧ください。
それでも解決しない時
- 何がプロセスを利用しているのか調べる 1-1. ネットワークユーティリティを起動(mac OS High Sierraでは、
/System/Library/CoreServices/Applications/にあります) 1-2. Portscanタブをクリック 1-3. 確認したいポートを指定して、scanを実行redwood-brokerが出て来たら、Dockerを再起動、Macを再起動してもredwood-brokerは消えませんでしたが、Dockerを再起動すると消えます。- その他の場合は、Googleさんに聞いてください。
- 投稿日:2019-12-02T23:18:36+09:00
Windowsコンテナについて調べてみた
このエントリは 赤帽エンジニア Advent Calendar 2019 - Qiitaの2日目の投稿です。
Windowsのコンテナを中心とした技術の現在の状況について調べてみました。
技術自体は日々変わるので、2019年12月現在のスナップショットとして読み進めください。
用語
- Windowsコンテナ: Windowsでコンテナを動かすことの概念、総称のようなもの。バズワード的な印象。
- Windows Serverコンテナ: プロセス分離を用いてWindowsのベースイメージを実行すること。
- Hyper-vコンテナ: 正しくはHyper-V分離。Hyper-Vの機能を使ってLinuxコンテナを実行。
- プロセス分離(Process Isolation): Linuxのコンテナ実行方法とほぼ同じ。カーネルをホストと共有する。
- Hyper-V分離(Hyper-V Isolation): 各コンテナーは仮想マシンの内部で実行され、独自のカーネルを利用する。
- WCOW:Windows containers on Windows.
- LCOW:Linux containers on Windows.
Windows版Dockerの導入
Windows 10Pro/Enterprise Edition
- Docker Desktop Community(Docker CE)を利用
- インストーラーをダウンロードしてインストール
- Hyper-V分離を使い、Linuxコンテナを実行可能
- Windows 10 ver.1809 + Docker Desktop 2.0.0.2(Docker Engine 18.09.1)以降では、プロセス分離でWindows Serverコンテナを実行可能
Windows Server
- PowerShellでDocker Enterprise(Docker EE)インストール
- Hyper-V分離を使い、Linuxコンテナを実行可能
- プロセス分離でWindows Serverコンテナを実行可能
コンテナベースイメージ
4種類ある
- Windows Server Core:Supports traditional .NET framework applications.
- Nano Server:Built for .NET Core applications.
- Windows:Provides the full Windows API set.
- Windows IoT Core:Purpose-built for IoT applications.
課題
- ベースイメージのサイズが大きい
- Windows Serverのリリースサイクル
- 半期チャネル(SAC)のサービス期間が18ヶ月
- ベースイメージの前方互換サポート無し
Kubernetes on Windows
- LinuxベースのK8sクラスターWindows Server(version 1809以降)をワーカーノードとして追加
- K8s 1.14で正式サポート。
- OVN-Kubernetes
コンテナランタイム(調査中)
- CRIランタイム
- docker EEのみ
- OCIランタイム
- runhcs:runcのフォーク。Host Compute Serviceと通信。
まとめ
Windowsコンテナと一言で言っても用語が統一されていなかったり、利用者の背景(Linuxコンテナなのか、Windows Serverなのか、K8sに関することなのか)によっても情報の意味することがバラバラだということが分かりました。
技術が枯れてくるまでは、相手が今何のことを指して言っているのか確認するのが良いと思います。Red HatではOpenShift 4.xの今後のロードマップでWindowsワーカーノードのサポートが予定されています。リリースされるまでにもう少し情報を整理していきたいと思います。
参考リンク
Containers on Windows Documentation | Microsoft Docs
マイクロソフト公式のドキュメント。ここに一番情報が集まってる。About Windows containers | Microsoft Docs
Windowsコンテナの概要Isolation Modes | Microsoft Docs
分離モードの解説Windows container platform | Microsoft Docs
アーキテクチャー解説Windows Server, version 1909が正式リリース――「プロセス分離モード」の制限が緩和:Microsoft Azure最新機能フォローアップ(94) - @IT
日本語の最近のニュース記事Kubernetes on Windows | Microsoft Docs
マイクロソフト公式のK8sに関するドキュメントIntro to Windows support in Kubernetes - Kubernetes
K8s公式のWindowsサポートに関するドキュメントEssentials of container
MS真壁さんのスライド。分かりやすくまとまっている。
- 投稿日:2019-12-02T22:56:27+09:00
Nginx で WEB サーバを構築してみる
はじめに
Advent Calender の枠が埋まらないから、無理矢理投稿してみます。
初めてやるけど、これって普通毎日枠埋まる(埋める)ものよね...??1 日目: [初心者向け]色んなサーバ達の役割を知る
さて、そんなことはどうでもよくて、みなさん、1 日目の記事は読みましたか??
(特に最近飲みに行っていない後輩のお前。忘年会しよ。)ここに出てきた、WEB サーバをサクッと構築してみます。
ただ、個人的に Virtual Box で仮想マシン作って〜、Nginx インストールして〜
ってのはめんどくさいので Docker でやってしまいます。(ごめんね)
Docker も大きな括りで言えば仮想マシンなので気にしないでください。()WEB サーバ
[実行環境]
OS: macOS Mojave ver.10.14.6まず、2 つのファイルを用意します。
DockerfileFROM nginx:latest COPY index.html /usr/share/nginx/html/index.html<html> <head> <title> web1 </title> </head> <body> <h1> web1 server </h2> </body> </html>これらを、web1 という名前のディレクトリに突っ込んで、以下のコマンドを実行してください。
docker build -t web:01 . docker run --rm -d -p 8080:80 web:01さて、これで仮想マシンが起動するはずです。
ブラウザから、http://localhost:8080にアクセスしてみてください。
おそらく、web1 server とでっかく表示されるはずです。
これは、先ほど作ったindex.htmlが WEB サーバを介して表示されています。WEB サーバの構築はこれで以上です。
...簡単ですね ??リバプロ
これだけでは物足りないので、発展系として "リバプロ" こと リバースプロキシを構築してみます。
プロキシ
まず、プロキシ(proxy) とは、英語で "代理人" という意味で、クライアントからサーバへのリクエストを
そのクライアントの代わりに行ってくれるサーバのことです。 (リクエストを"する側"の代理人)何がいいかというと、セキュリティの観点から社内の PC の情報を外に出さないようにであったり、
こいつのおかげで業務中に YouTube をこっそり見たりができないよに監視したりできます。リバプロ
さて肝心の リバースプロキシ(reverse proxy) は、先ほどとは逆で、リクエストを受ける立場である WEB サーバにアクセスする前にこいつを経由するように置かれます。
(リクエストを"受ける側"の代理人)何がいいかというと、複数台の WEB サーバを運用している時に満遍なくリクエストをバラつかせたり、
様々な役割をもつサーバ軍の拡張がしやすかったりします。今回は、シンプルにこんな構成を作ります。
proxy の 8081 ポートヘのアクセスを web1 サーバに、
proxy の 8082 ポートヘのアクセスを web2 サーバに流します。
構築
$ tree . ├── docker-compose.yml ├── proxy │ ├── Dockerfile │ └── default.conf ├── web1 │ ├── Dockerfile │ └── index.html └── web2 ├── Dockerfile └── index.html新しく用意するのは、
docker-compose.ymlとdafault.confです。
docker-compose は、複数の仮想マシンを一括で管理できてしまう便利なやつです。docker-compose.ymlversion: '3' services: proxy: build: ./proxy ports: - 8081:8081 - 8082:8082 web1: build: ./web1 web2: build: ./web2default.confserver { listen 8081; server_name localhost; location / { proxy_pass http://web1; } } server { listen 8082; server_name localhost; location / { proxy_pass http://web2; } }web2/index.html は、わかりやすいように、
web2 serverとか表示されるようにしてください。
準備ができたら、以下のコマンドを実行します。docker-compose up -dブラウザから、http://localhost:8081 、 http://localhost:8082 にアクセスしてください。
この場合、アクセス自体は、proxy に対して行っていますがコンテンツを返すのはそれぞれの WEB サーバです。Docker に慣れてしまったら、Virtual Box には戻れないね
おわり
明日は誰か(先輩)、頼んだで
以上

- 投稿日:2019-12-02T22:37:47+09:00
【Docker】crond専用のコンテナからHTTPリクエストを送ったり他コンテナのコマンドを実行してみたりする【cron】
こんにちは!
鍋が美味しくてごきげんな季節になってまいりました。おさむです。Dockerコンテナでcronによる定期処理を実行したいなあと思いたち、
いろいろ試してみた結果をまとめてみます。この記事のゴール
粛々と時を刻み続けるDockerコンテナを手に入れる
前提
- Dockerがインストールされており、hello-worldが動作する状態になっていること
試したこと
①あるURLに対して定期的にリクエストを送ってみる
AlpineLinuxはapkというパッケージマネージャにより、コマンドを追加することが出来ます。
この項ではcurlコマンドを追加でインストールし、
それを用いてGoogleのトップページにリクエストを送ってみます。Dockerfile# 公式版でもたぶんOK FROM gliderlabs/alpine:latest # 必要パッケージの取得とタイムゾーンの変更処理(Asia/Tokyo) RUN \ apk add --no-cache curl tzdata && \ cp /usr/share/zoneinfo/Asia/Tokyo /etc/localtime && \ apk del tzdata # あらかじめ用意しておいたcrontabs用ファイルをコンテナへコピーする RUN mkdir -p /var/spool/cron/crontabs COPY ./resource/cron/crontabs/root /var/spool/cron/crontabs/root CMD busybox crond -l 2 -L /dev/stderr -froot# GoogleへGETリクエストを送信し、帰ってきたレスポンスのヘッダをひたすら追記していく * * * * * curl https://www.google.co.jp/ -I >> /root/header.txt # POSTも出来る。JSONを特定のAPIに流し込んだり。 # * * * * * curl -X POST -H "Content-Type: application/json" -d '{"id":"114514", "num":"810"}' localhost:8080/api②定期的に別コンテナのコマンドを実行してみる
コンテナの中にdockerのバイナリを配置し、ホストマシンにある/var/run/docker.sockをマウントすると、
Dockerコンテナの中からでも別コンテナの操作が可能になります。
これを利用して他のコンテナのコマンドを実行してみました。ただし、ちょっとトリッキーな方法であるため、こちらで言及されている通りWebAPI化し、
①の方法でリクエストを発行したほうが良いかもしれません。お好みで。今度は複数のコンテナで連携するため、docker-composeも使用していきます。
docker-compose.ymlversion: '2' services: app: build: ./app cron: build: ./cron volumes: - /var/run/docker.sock:/var/run/docker.sock volumes: db-data:Dockerfile# 公式版でもたぶんOK FROM gliderlabs/alpine:latest # 必要パッケージの取得とタイムゾーンの変更処理(Asia/Tokyo) RUN \ apk add --no-cache tzdata && \ cp /usr/share/zoneinfo/Asia/Tokyo /etc/localtime && \ apk del tzdata # dockerのバイナリを取得し、クライアントのみを/usr/local/binへコピー RUN apk add --no-cache ssl_client && \ mkdir -p /usr/local/bin && \ wget https://get.docker.com/builds/Linux/x86_64/docker-latest.tgz -O - | tar -xzC /usr/local/bin --strip=1 docker/docker # あらかじめ用意しておいたcrontabs用ファイルをコンテナへコピーする RUN mkdir -p /var/spool/cron/crontabs COPY ./resource/cron/crontabs/root /var/spool/cron/crontabs/root CMD busybox crond -l 2 -L /dev/stderr -froot# appコンテナにあるコマンドを実行する * * * * * docker exec example_app_1 /root/example.sh # ちなみに、Laravelのスケジュール実行も同じ要領で起動できる # * * * * * docker exec example_app_1 php artisan schedule:run余談
なんでこんな事してるかと言うと、↑の「Laravelのスケジュール実行」を実現したかったから。
php-fpmをFROMに書いたDockerfileの中で無理やりbusyboxを起動するというのもアリなんですが、
それをするとphp-fpmのプロセスが上がってこないという現象が発生したりで色々と難があったため。参考
Dockerコンテナ上でCronを動かしたい
curlコマンドを実行するだけのDockerfile
Alpine Linux でタイムゾーンを変更する
Alpine LinuxでDockerコンテナ開発を加速する
Docker コンテナから別のコンテナへコマンドを実行し、返り値を得る
- 投稿日:2019-12-02T22:06:51+09:00
docker toolboxでマウントできずに苦しんだ話
Railsの開発環境をDockerで作成しようとしようとした際に、うまくホストのディレクトリがマウントできずに苦しんだ話。
最終的にはDocker ToolboxとVM VisualBoxを再インストールし直したらマウントできました。メモとして残しておきます。
導入環境
- Windows10 Home 64bit
1.何をやろうとしたか
Railsの開発環境をローカルで構築しようと、Dockerをインストールするところからスタート。
私のPCはWindows10 Homeだったため、Docker ToolBoxを使用。Windows環境にDocker Toolboxをインストールする
丁寧すぎるDocker-composeによるrails5 + MySQL on Dockerの環境構築(Docker for Mac)こちらの記事を参考に必要なファイルを用意し、rails newを実行しました。
(分かりやすくDocker初心者でも構築できるナイスな記事たちです。)
2.実行結果
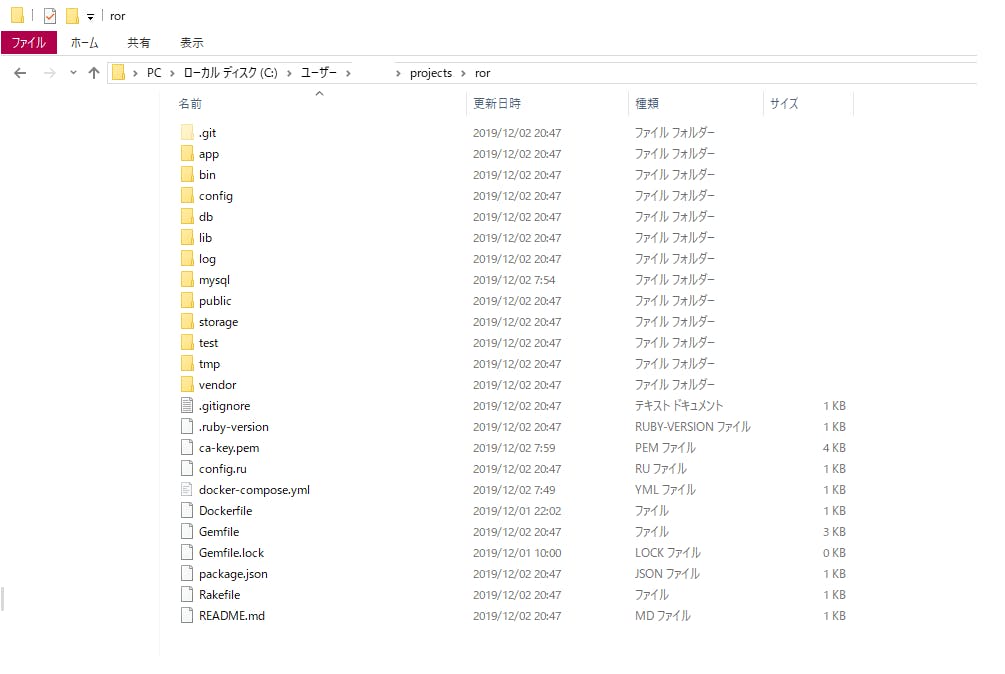
エラーは発生しませんでしたが、指定したディレクトリにうまくマウントできておらず、想定とは違う結果に。
本来の想定ではrails newを実行したフォルダ直下にファイルがずらっと並ぶはずでした。3.やったこと
いくつかの方法を試して見ました。
(1)docker-compose.ymlのvolumesを変更
マウントが失敗している原因として真っ先に浮かんだのが、volumesの指定だったためパスの指定を絶対パスに変えてみました。
結果は駄目でした。いくつかのパターンを試してみましたが、どれもマウントできませんでした。docker-compose.ymlweb: build: . command: rails s -p 3000 -b '0.0.0.0' volumes: - #.:/app_name 修正前 - C:\Users\ユーザー名\projects\ror:/app_name #修正後(2)boot2docker.isoを入れ直し、
docker-machine create実行調査中こちらの記事を見たため、実施。
docker toolboxでホストのディレクトリがマウントできない場合の対処方法結果は変わらずにマウントできませんでした。
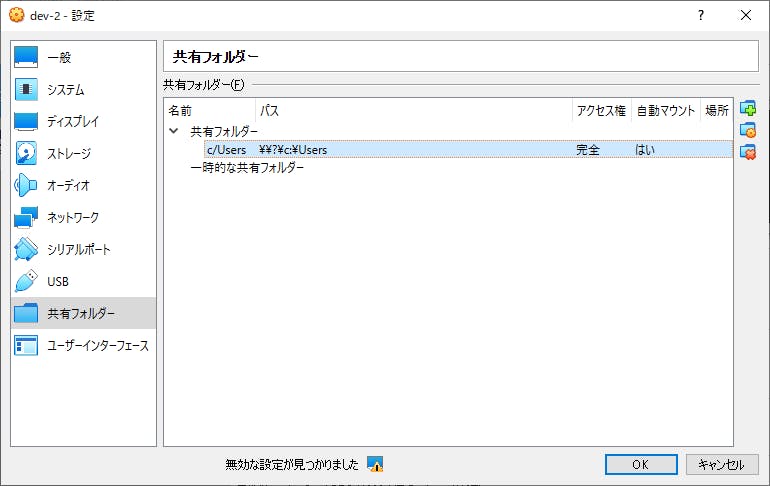
(3)Oracle VM VirtualBoxの共有フォルダ変更
Docker Toolboxはホストのディレクトリをマウントするとき、CドライブのUsers内のみ共有できるとの記載を見たので、確認してみました。
確かに設定上はUsersフォルダになっています。
今回マウントしようとしていたフォルダもUsers下にありますが、念の為プロジェクトのパスを指定してみました。これもマウントできない。。。
4.初心に立ち返る
ここまでで私の心は疲れ果ててしまったので、全部まっさらにしてやり直すことにしました。
Docker ToolboxとVM VisualBoxを殺意を持ってアンインストールして、最初から再インストール。
使用するファイル(docker-compose.yml等)もすべて最初から作成し直し、半ば諦めながらrails newを実行。
・・・
理由は全くわかりませんが、なぜかマウントできました。
5.学んだこと
最後はあっけなく、また理由もわからないというしょうもない解決でしたが、学んだことも多かったです。
特に今回始めてDockerを使用したため、構築に必要なファイルの記述方法やコンテナの概念に詳しくなりました。
恐らく手順通りに実施できていれば、ここまで調査することもなかったと思うのでその点は収穫だと思います。まとめ
わけがわからなくなったときは、最初からやり直す。急がば回れ。
- 投稿日:2019-12-02T21:11:10+09:00
Docker Rails Sampleアプリ構築
適当なRailsアプリを作成するのに脳死で作成する
前提
- Ruby 2.6.5
- Railsバージョン6.0.1
- MySQL 5.7
- Node.js 8系
- webpacker用のコンテナは用意していない
$ mkdir rails-sample $ rbenv local [使用するrubyバージョン] $ git init $ bundle init gem 'rails'のコメントアウトを外す $ bundle install --path vendor/bundle $ bundle exec rails new . -B -d mysql --skip-test -B bundle install をスキップする(お好み) -d 利用するDBを指定(デフォルトはSQLite) --skip-test railsのデフォルトのminitestというテストを利用しない場合は指定(お好み) Gemfileの上書きしていいかどうかは Y でEnter $ bundle exec rails webpacker:install .gitignore に vendor/bundleを追記(お好み)docker-compose.ymlとDockerfile作成
Dockerfile
FROM ruby:2.6.5 ENV LANG C.UTF-8 RUN apt-get update -qq && apt-get install -y build-essential libpq-dev nodejs # nodejsとyarnはwebpackをインストールする際に必要 # Node.js RUN curl -sL https://deb.nodesource.com/setup_8.x | bash - && \ apt-get install nodejs # yarnパッケージ管理ツール RUN apt-get update && apt-get install -y curl apt-transport-https wget && \ curl -sS https://dl.yarnpkg.com/debian/pubkey.gpg | apt-key add - && \ echo "deb https://dl.yarnpkg.com/debian/ stable main" | tee /etc/apt/sources.list.d/yarn.list && \ apt-get update && apt-get install -y yarn WORKDIR /tmp COPY Gemfile Gemfile COPY Gemfile.lock Gemfile.lock RUN bundle install ENV APP_HOME /rails-sample RUN mkdir -p $APP_HOME WORKDIR $APP_HOME COPY . /rails-sampledocker-compose.ymlversion: '3' services: db: image: mysql:5.7 environment: MYSQL_USER: root MYSQL_ROOT_PASSWORD: password volumes: - ./tmp/docker/mysql:/var/lib/mysql:delegated web: build: . command: bundle exec rails s -p 3000 -b '0.0.0.0' volumes: - .:/chiko ports: - "3000:3000" depends_on: - dbdatabase.ymlを編集(お好み)
database.ymldefault: &default adapter: mysql2 timeout: 5000 encoding: utf8mb4 charset: utf8mb4 collation: utf8mb4_general_ci pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %> username: root password: password host: db port: 3306 development: <<: *default database: rails-sample_development test: <<: *default database: rails-sample_test production: <<: *default database: <%= ENV["DATABASE_NAME"] %> username: <%= ENV["DATABASE_USERNAME"] %> password: <%= ENV["DATABASE_PASSWORD"] %> host: <%= ENV["DATABASE_HOST"] %> port: <%= ENV["DATABASE_PORT"] %>defaultに
- charset: utf8mb4
- collation: utf8mb4_general_ci
- port: 3306を追記
productionは
- database: <%= ENV["DATABASE_NAME"] %>
- username: <%= ENV["DATABASE_USERNAME"] %>
- password: <%= ENV["DATABASE_PASSWORD"] %>
- host: <%= ENV["DATABASE_HOST"] %>
- port: <%= ENV["DATABASE_PORT"] %>を全部環境変数に変更
$ docker-compose build $ docker-compose run --rm web rails db:createScaffoldでUserモデル作成
$ docker-compose run --rm web rails g scaffold user name:string age:integerトップページを用意
$ bundle exec rails g home indexroutes.rbRails.application.routes.draw do root 'home#index' # これを追記 resources :users endUserページへのリンクを付与
index.html.erb<h1>Home#index</h1> <p>Find me in app/views/home/index.html.erb</p> <%= link_to "user", users_path %> <%# これを追記マイグレーションして、コンテナを立ち上げる
$ docker-compose run --rm web rails db:migrate $ docker-compose up -d=> http://localhost:3000 にアクセスして確認
- 投稿日:2019-12-02T21:05:33+09:00
僕はまだDockerの辛さを知らなかった
はじめに
Leverages Advent Calendar 2日目担当のいっちーです。
弊社の開発環境の移行を行いましたので、その振り返りです。
TL;DR
- 開発環境はもともとオンプレのサーバで稼働していた
- 簡単にスペックアップできず、辛かった
- スノーフレーク化している
- 開発環境をDocker化した
- ローカル開発環境を持てた
- 結局スペック問題は発生した
- レビュータイミングの調整は変わらず辛いらしい
- docker-sync何もしてないから壊れた
- なにかしたら治った!
- docker-sync何かしたら壊れた
本題
そもそも弊社の移行前の開発環境(一部の媒体)については次の通りです。
- リモートに開発環境が存在
- オンプレミス
- リモート環境では各個人のディレクトリ配下にアプリのファイルを配置
- Virtual HostによりRootPathを切り分け
という状態でした。
オンプレミス!という言葉を聞いて、むむっ!となる人もいると思います。(僕自身がその一人)
実際にむむっ!となることがありましたのでそられも含めて書いていきます。インターネットにつながっていないと(全く)開発できない
当然のことながら、リモート開発環境なので、インターネットにつながっていないと、開発ができません。
コードを書くことはローカルのエディタで可能ですが、実際に書いたコードが反映されることは無いのです。もちろんデザインレビューを他の人から確認してもらうことも叶いません。簡単にスペックアップできない
これが一番困りましたね(僕は困ってないです)。
何が起こったかというと、
- プロジェクトのデータ保存用のストレージが枯渇
- yarnを実行している間コンピュータリソース的に他の人の作業に影響がでる
- インストールされているものが何かわからないw
という現象です。
スペックアップに関しては、サーバーの管理先に依頼して、対応して頂く必要があります。
(社外の人に依頼することになるため、コミュニケーションコストが発生します)また、インストールされているミドルウェアやソフトウェアの確認は自分たちでできますが、時間かかりそうなのでやりたくはないですねw
開発環境なのに開発に必要なソフトウェアなどを簡単にインストールできない
開発環境といえば、色々試行錯誤すると思います。
しかし、色んな人が色んなものを入れてしまうと、他の開発者にも影響が出てしまいます。
そのため、sudoの権限がなかったりして、「実験的に使いたいのに…sudo yumが実行できない…」というような状態に陥ってしまうこともあります。辛いのでDocker化してみた
そこで、Dockerを使って開発環境構築してしまおう、と考えました。
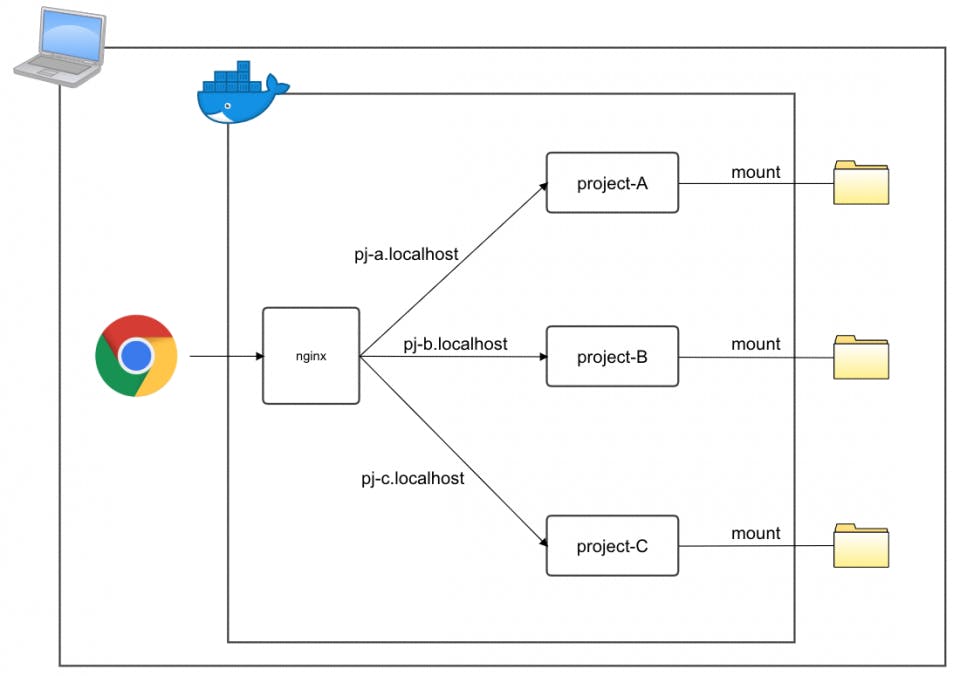
複数プロジェクトの開発を行っている人もいるので、そういった要望にも答えられるように次のような構成を考えました。
コンテナは次の4つです
- nginx
- project-A
- project-B
- project-C
コンテナの構成はとても簡単なものにしており、コンテナ間ネットワーク周りは
docker-composeに任せております。
そのため、各アプリケーションへのアクセスは、nginxのserver_nameと同じホスト名を、Mac内にある/etc/hostsファイルに設定を加えるのみです。こうすることで、
project-Aの開発を行っている人の場合は、project-Aのコンテナを立ち上げて、ブラウザからhttp://pj-a.localhostへアクセスするのみとなります。同じように、
project-Bとproject-Cを開発している人の場合は、
プロジェクトに応じて、コンテナを立ち上げ、http://pj-b.localhostやhttp://pj-c.localhostにアクセスするかたちになります。発生した問題
とはいえ、数々の問題がありました…。
Docker for MacのVolume Sync遅いマン
Dockerには
volumesというデータ永続化用の機能を持っています。
永続化する理由としては、言わずもがなですが、コンテナ上でデータの更新などを行ったとしても、コンテナを破壊すると内部のデータごと消えてしまうからです。
使い方としては、次のように-vをつけてPATHを指定します。$ docker run -d --rm -v $(pwd):/tmp imageName:tag
docker-composeの場合は、docker-compose.yml# ... services: pja: # ... volumes: - ./project-data/project-A:/www/project-A:cachedというように
volumesを指定します。ここで問題になってくるのが、Volume同期の遅さです。
公式ドキュメントを見るとcachedをつけると早くなる、などの記載があり試してみました。Runの場合
- $ docker run -d --rm -v $(pwd):/tmp imageName:tag + $ docker run -d --rm -v $(pwd):/tmp:cached imageName:tagdocker-composeの場合
docker-compose.yml# ... services: pja: # ... volumes: - - ./project-data/project-A:/www/project-A + - ./project-data/project-A:/www/project-A:cachedしかし、
cachedを試してみても… 1s程の改善にしかならなかったです。
(このときのレスポンスタイムは、 13s)ここらへんで、「Docker辛い…」と思い始め、
公式ドキュメントを参考にした速度改善は力尽きました。。。救いの手であるdocker-syncがぶっ壊れた
docker for macを使うメリットよりも、VirtualBoxなどに移行したほうがいいのでは?と思い始めたころにdocker-syncと出会いました。
docker-syncについては、 docker-syncでホスト-コンテナ間を爆速で同期するという記事を見ていただきたいです。
こちらにdocker-syncが出しているパフォーマンス表があります。
docker for macが明らかに遅いですが、docker-sync版を見たときにこれだ!と思いました。
早速、docker-syncを利用して環境を作って、アクセスしてみると、レスポンスタイムが3sまで縮んでおり、初期に比べて爆速になりました。ここで終わればよかったんですが、
その数ヶ月後くらいに、ヤツが来ました。Docker for macのバージョンアップ!!!!
Docker for macのバージョンを上げてしまったところ、
docker-syncが動かなくなりました。
正確には動かなくなったのではなく、ファイルの更新をしてくれなくなりました。
docker-compose upを実行した際には、その時の最新版になっているのですが、実際に変更を加えてもそれがコンテナ内のファイルに変更が加わらなくなりました。
全く原因も分からず、issueも立っていなかったので、力尽きました。一日寝かせて、ふっと、 同期方法がだめになったのでは?と思い、同期方法を
native_osxにしたところ、これが見事に当たり、再びできるようになりました。
これが、2019年5月くらいの出来事ですね。そして、2019年10月下旬…再び問題が発生しました。
Docker-sync with unision strategy broken for newer MacOS / homebrew installationgemのアップデートも、docker for macのアップデートも行ったのですが、解決していないです。
docker-syncの0.5.13を利用していることも確認しましたが、だめでした…
(native_osxを使っても、ファイルの更新がされない…)この問題は力尽きてしまい、まだ解決に至っていないです。(知見ほしい)
PCのスペック問題
デザイナーさんはAbstractというツールを利用しているのですが、
AbstractとDockerを併用するとメモリが枯渇し、PCが動かなくなってしまうことが多々ありました。
デザイナーさんはコーディングを行ったりしながら、Abstractを確認することもあるので、同時に起動できないとなると、きっと作業効率も落ちてしまったのでは?と思っています。最終的には、マンモスPCだとしても、メモリが足りなくなるんだなぁと思いました。
良かったこと
下げて最後に上げるので、ここからは良かったことを述べます。
構成がコードで管理されているためスノーフレーク状態にならない
Dockerなので、
Infrastructure as code、Immutable Infraを体現しています。
そのため、コンテナを起動する際に、コンテナ内に何がインストールされているのかを事前に知ることができますし、コンテナを破壊して再構築すれば試行錯誤前の状態になります。開発する上で、コンテナ内に入って試行錯誤するので環境が壊れてもいいというのは非常にありがたいですね。
更に、開発者は、インストールしたいものをインストールして、Dockerfileに記述し、PRを作成するというフローができます。これが、リモートの開発環境だったら、試行錯誤を簡単にできない、かつスノーフレーク状態になるので辛いところです。
(例えばsudoの実行権限がない…など)社内ネットワーク(サブネット)間で確認ができるようになった
開発途中のものを一度ネット上に上げる必要がなくなり、
確認してほしい人とのタイミングが合いさえすれば、すぐに確認してもらうことができるようになりました。デザイン周りとかは特にPR上げる前にレビューしていただきたいところなので、良くなりました。
Dockerに詳しくなった
DockerのVolumeや、ネットワーク周りはちょっと詳しくなった気がします。
人並みには使っていましたが、ちゃんとドキュメントを読んで改善するみたいなことは全然していなかったのでいい機会になりました。
--volumes-fromと-vって同じでしょ?と思っていた頃の自分が懐かしいです。
(ちゃんと読まなくても違うの分かるはず)ネットワーク周りでいうと、
depends_onやlinks周りですね。(linksはdepends_onがあれば必要ない)
depends_onはコンテナの起動順番の制御するために使いますが、それ以外にも名前解決の設定もしてくれるという驚きの機能がありました。
起動順番に関しては、あくまで起動タイミングであり、起動完了を待つわけではない、ということは知らなかったので、知見を得ました。おわりに
そして今…
開発環境で利用するファイルのリポジトリができました。
サブネット間通信では、レビューする時間を開発者と合わせなければならず、コミュニケーションコストになるという問題が発生しました。
開発では使ってもらっていますが、上記の問題により、リモートの環境はどちらにせよ必要になったので、ECSを利用してリモートの確認環境を作っています。
Docker環境で開発を行っているので、ECSを利用するという選択肢は良かったです。今後の取組
まだまだ改善すべきことが、山盛りなので、実際に使っている人にヒアリングして改善していきます。
とは言いつつも、個人的な感想ですが、
MacでDockerを使うのはまだ早かったなぁwと思いました。
Linuxなら早いので、そろそろMac OSXからLinuxに移行する日も近そう!
- 投稿日:2019-12-02T20:05:31+09:00
【Ruby | Rails】Dockerfileの中で"ADD Gemfile ~ RUN bundle install"をするのはやめませんかという話
今回の検証環境
- Ruby
2.6.5- Docker
19.03.5- Docker-Compose
1.24.1はじめに
- Railsの設定を例にすると結構複雑になっちゃうので、今回は単純にRubyをDocker上で使用する例で解説します。
Railsを使用する場合も要点は同じなので適宜読み替えてください。- 今回は
hogehogeディレクトリ配下で作業します。サンプルコード中のhogehogeの部分は自由に変更して構いません。やめませんか
RailsやRubyのDocker環境構築の解説をしている記事で、
Dockerfile内で以下のようにADD Gemfile~RUN bundle installしている記事を本当にたくさんよく見かけます。DockerfileFROM ruby:2.6.5 WORKDIR /hogehoge RUN gem install bundler # ↓こういうの↓ ADD Gemfile Gemfile ADD Gemfile.lock Gemfile.lock RUN bundle installこれ、やめませんか?
なんでやねん
Dockerfileの中でADD Gemfile~RUN bundle installをすることには以下のようなデメリットがあります。
- Gemfileを編集するたびに毎回
docker buildやdocker-compose buildをしないといけなくなる。
- Gemを1つ追加するだけでも全Gemをインストールし直す羽目になる。
nokogiriとかインストール遅いよね!毎回待たされるの嫌だよね!何よりRubyistの皆さんとしては、
Gemfileを編集したら本能的にbundle installしたいですよね?したくないですか?したいですよね?じゃあどうすんねん
docker-composeを上手く使えばもっと効率よく楽しく開発できます。Dockerfile
containersディレクトリ配下にDockerfileを作成します。containers/DockerfileFROM ruby:2.6.5 WORKDIR /hogehoge RUN gem install bundlerこんだけ。
docker-compose.yml
次に、アプリケーションのルートディレクトリに
docker-compose.ymlを作成します。docker-compose.ymlversion: '3' services: app: build: context: . dockerfile: containers/Dockerfile environment: # これがないとGemを`vendor/bundle`以下から読み込んでくれないので注意 # (正確には、`.bundle/config`の設定を読み込んでくれない) BUNDLE_APP_CONFIG: /hogehoge/.bundle volumes: - .:/hogehogeこんだけ。
単純にカレントディレクトリ全体をマウントしてるだけですね。ビルドしよう
さぁ
docker-compose buildしていきましょう。$ docker-compose build Building app Step 1/4 : FROM ruby:2.6.5 ---> d98e4013532b Step 2/4 : ENV APP_ROOT /hogehoge ---> Using cache ---> 97b5a8bca2d0 Step 3/4 : WORKDIR $APP_ROOT ---> Using cache ---> 54066d2ae384 Step 4/4 : RUN gem install bundler ---> Using cache ---> 290d99a58c5b Successfully built 290d99a58c5b Successfully tagged hogehoge_app:latestすぐ終わりますね。
(初回だけruby:2.6.5のDocker imageのpullに時間がかかります。)Gemをインストールしてみよう
とりあえず
Gemfileを作成します。$ docker-compose run --rm app bundle init Writing new Gemfile to /hogehoge/Gemfile適当に
bcryptでも入れてみますかね。Gemfile# frozen_string_literal: true source "https://rubygems.org" git_source(:github) {|repo_name| "https://github.com/#{repo_name}" } # gem "rails" # ↓追加↓ gem 'bcrypt'それでは念願の
bundle installです。
docker-compose経由で実行するのと、--pathオプションを指定するのを忘れずに。補足: 一度
--pathオプションを付けてbundle installを実行すると、.bundle/configが作成されて設定が追加されるため、次回以降bundle installの際に--pathオプションを付ける必要はありません。$ docker-compose run --rm app bundle install --path vendor/bundle Creating network "hogehoge_default" with the default driver Fetching gem metadata from https://rubygems.org/. Resolving dependencies... Fetching bcrypt 3.1.13 Installing bcrypt 3.1.13 with native extensions Using bundler 2.0.2 Bundle complete! 1 Gemfile dependency, 2 gems now installed. Bundled gems are installed into `./vendor/bundle`ちゃんとインストールできているか確認してみましょう。
$ docker-compose run --rm app bundle exec gem list *** LOCAL GEMS *** bcrypt (3.1.13) bundler (2.0.2)できていますね。
次回以降もGemfileを編集した際にはdocker-compose run --rm app bundle installするだけで大丈夫です。
docker-compose buildし直す必要はありません。試しにRubyスクリプトを実行してみよう
test.rbを作って適当にbcryptを使ってみます。test.rb# vendor/bundle配下から読み込むようにしてくれる require 'bundler/setup' # Gemfileの中のGemを一発でrequireしてくれる Bundler.require # NOTE: ↑上の2つはRailsの場合は勝手にやってくれるため必要ないです↑ puts BCrypt::Password.create('password')$ docker-compose run --rm app ruby test.rb $2a$12$xWXitLplfvcIuxUdTg.1I.bb/Jo0btGGnqWE02ZiMFsne.hDQXaDW実行できましたね。
1つ問題点が!!
現状だとインストールしたGemはローカルの
vendor/bundleディレクトリ配下に配置されます。
docker-compose run ...を実行するたびにこのvendor/bundleディレクトリ配下が毎回マウントされるため、
Gemが増えてくるとdocker-compose run ...を実行するたびにマウントに時間がかかり、コマンド実行が遅くなってしまいます。(この問題はDocker for Macを使用している場合のみ発生するらしいです)「毎回
docker-compose buildし直すのが面倒だからこうしたのに、本末転倒じゃねぇか!!」落ち着いてください。こんな時のためにDockerには
volumeという機能があるじゃないですか。
vendor/bundleをボリュームに切り出す
docker-compose.ymlを以下のように修正するだけで解決します。docker-compose.ymlversion: '3' services: app: build: context: . dockerfile: containers/Dockerfile environment: BUNDLE_APP_CONFIG: /hogehoge/.bundle # これがないとGemを`vendor/bundle`以下から読み込んでくれないので注意 volumes: - .:/hogehoge # ↓追加↓ - bundle:/hogehoge/vendor/bundle # ↓追加↓ volumes: bundle: driver: localローカルの方の
vendor/bundle配下のファイルはもう必要ないため削除しちゃいましょう。$ rm -rf vendor/bundle/*ボリュームとして切り出したら改めて
bundle installし直しましょう。$ docker-compose run --rm app bundle install Creating volume "hogehoge_bundle" with local driver Fetching gem metadata from https://rubygems.org/. Fetching bcrypt 3.1.13 Installing bcrypt 3.1.13 with native extensions Using bundler 2.0.2 Bundle complete! 1 Gemfile dependency, 2 gems now installed. Bundled gems are installed into `./vendor/bundle`これで
vendor/bundleディレクトリ配下はbundleボリュームとして切り出されて毎回ローカルからマウントされることがなくなるため、docker-compose runで余計な時間がかかることはなくなります。注意しておくこと
Gemのコマンドを使う際には
bundle execを付け足すのを忘れないようにしてください。
こんな感じで↓$ docker-compose run --rm app bundle exec rpsecえ?
docker-compose run --rm appだけでも長いのにbundle execまで毎回付けるのは面倒くさいって?
alias設定するなりMakefile使うなりやりようはいくらでもあるじゃないですか。おわりに
僕自身エンジニア歴1年ちょっと、Dockerを使い始めて2ヶ月程度なので知識不足が否めません。
見当違いの事を言っている可能性も十分にあります。
誤った表現や設定等ありましたらコメントにてご指摘をお願いします。Docker便利ですね!
- 投稿日:2019-12-02T18:11:38+09:00
【Docker】とにかく触ってみる(07:Docker Machine作成/リトライ版)
最初に
Domaker ImageとDocker Machineの区別が今ひとついておらず、Docker Imageはなんとか使えるようになった気がしているけれど、Docker Machineが作れず行き詰まっていました。。。
前回失敗したけれど、気を取り直して新規EC2で再実行してみます。
Virtual Machineのインストール
teratermsudo yum install -y wget wget http://download.virtualbox.org/virtualbox/5.1.28/VirtualBox-5.1-5.1.28_117968_el7-1.x86_64.rpm実行結果--2019-11-26 13:52:03-- http://download.virtualbox.org/virtualbox/5.1.28/VirtualBox-5.1-5.1.28_117968_el7-1.x86_64.rpm Resolving download.virtualbox.org (download.virtualbox.org)... 23.50.236.23 Connecting to download.virtualbox.org (download.virtualbox.org)|23.50.236.23|:80... connected. HTTP request sent, awaiting response... 200 OK Length: 79284648 (76M) [application/x-redhat-package-manager] Saving to: ‘VirtualBox-5.1-5.1.28_117968_el7-1.x86_64.rpm’ 100%[======================================>] 79,284,648 44.6MB/s in 1.7s 2019-11-26 13:52:05 (44.6 MB/s) - ‘VirtualBox-5.1-5.1.28_117968_el7-1.x86_64.rpm’ saved [79284648/79284648]teratermsudo yum install VirtualBox-5.1-5.1.28_117968_el7-1.x86_64.rpm実行結果(前略) Transaction Summary ================================================================================ Install 1 Package (+29 Dependent packages) Total size: 176 M Total download size: 4.9 M Installed size: 187 MteratermIs this ok [y/d/N]: y実行結果(前略) libglvnd-glx.x86_64 1:1.0.1-0.8.git5baa1e5.el7 libpciaccess.x86_64 0:0.14-1.el7 libvpx.x86_64 0:1.3.0-5.el7_0 libxcb.x86_64 0:1.13-1.el7 libxshmfence.x86_64 0:1.2-1.el7 mesa-libGL.x86_64 0:18.3.4-5.el7 mesa-libglapi.x86_64 0:18.3.4-5.el7 CompleteDocker-Machineのインストール(失敗)
teratermcurl -L https://github.com/docker/machine/releases/download/v0.16.2/docker-machine-`uname -s`-`uname -m` >/tmp/docker-machine && chmod +x /tmp/docker-machine && sudo cp /tmp/docker-machine /usr/local/bin/docker-machine実行結果% Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 617 0 617 0 0 1445 0 --:--:-- --:--:-- --:--:-- 1448 100 32.6M 100 32.6M 0 0 6238k 0 0:00:05 0:00:05 --:--:-- 7014kteratermdocker-machine ls実行結果NAME ACTIVE DRIVER STATE URL SWARM DOCKER ERRORSteratermdocker-machine create --driver virtualbox default実行結果Creating CA: /home/centos/.docker/machine/certs/ca.pem Creating client certificate: /home/centos/.docker/machine/certs/cert.pem Running pre-create checks... Error with pre-create check: "We support Virtualbox starting with version 5. Your VirtualBox install is \"WARNING: The vboxdrv kernel module is not loaded. Either there is no module\\n available for the current kernel (3.10.0-957.1.3.el7.x86_64) or it failed to\\n load. Please recompile the kernel module and install it by\\n\\n sudo /sbin/vboxconfig\\n\\n You will not be able to start VMs until this problem is fixed.\\n5.1.28r117968\". Please upgrade at https://www.virtualbox.org"Virtual Boxのバージョンが古かった?
Virtual Machineのインストール(再)
teratermwget http://download.virtualbox.org/virtualbox/6.0.14/VirtualBox-6.0-6.0.14_133895_el8-1.x86_64.rpm実行結果--2019-11-26 14:03:06-- http://download.virtualbox.org/virtualbox/6.0.14/VirtualBox-6.0-6.0.14_133895_el8-1.x86_64.rpm Resolving download.virtualbox.org (download.virtualbox.org)... 23.50.236.23 Connecting to download.virtualbox.org (download.virtualbox.org)|23.50.236.23|:80... connected. HTTP request sent, awaiting response... 200 OK Length: 108385412 (103M) [application/x-redhat-package-manager] Saving to: ‘VirtualBox-6.0-6.0.14_133895_el8-1.x86_64.rpm’ 100%[===================================================================================================>] 108,385,412 3.73MB/s in 18s 2019-11-26 14:03:25 (5.66 MB/s) - ‘VirtualBox-6.0-6.0.14_133895_el8-1.x86_64.rpm’ saved [108385412/108385412]teratermsudo yum install VirtualBox-6.0-6.0.14_133895_el8-1.x86_64.rpm実行結果(前略) Error: Package: VirtualBox-6.0-6.0.14_133895_el8-1.x86_64 (/VirtualBox-6.0-6.0.14_133895_el8-1.x86_64) Requires: libQt5Core.so.5(Qt_5.11)(64bit) Error: Package: VirtualBox-6.0-6.0.14_133895_el8-1.x86_64 (/VirtualBox-6.0-6.0.14_133895_el8-1.x86_64) Requires: libssl.so.1.1(OPENSSL_1_1_0)(64bit) Error: Package: VirtualBox-6.0-6.0.14_133895_el8-1.x86_64 (/VirtualBox-6.0-6.0.14_133895_el8-1.x86_64) Requires: libssl.so.1.1()(64bit) You could try using --skip-broken to work around the problem You could try running: rpm -Va --nofiles --nodigestこれも失敗・・・
前にインストールしたVirtual Box 5と競合しているのか?
CentOSについてまだ詳しくないので、再度新しいEC2で構築し直してみます。teratermsudo yum install -y wget wget http://download.virtualbox.org/virtualbox/6.0.14/VirtualBox-6.0-6.0.14_133895_el8-1.x86_64.rpm実行結果(前略) Error: Package: VirtualBox-6.0-6.0.14_133895_el8-1.x86_64 (/VirtualBox-6.0-6.0.14_133895_el8-1.x86_64) Requires: libQt5Core.so.5(Qt_5.11)(64bit) Error: Package: VirtualBox-6.0-6.0.14_133895_el8-1.x86_64 (/VirtualBox-6.0-6.0.14_133895_el8-1.x86_64) Requires: libssl.so.1.1(OPENSSL_1_1_0)(64bit) Error: Package: VirtualBox-6.0-6.0.14_133895_el8-1.x86_64 (/VirtualBox-6.0-6.0.14_133895_el8-1.x86_64) Requires: libssl.so.1.1()(64bit) You could try using --skip-broken to work around the problem You could try running: rpm -Va --nofiles --nodigestこれも失敗。。。
ここで気づいたのは、VirtualBox-6.0-6.0.14_133895_el8-1.x86_64.rpmの「el8」ってCentOS8のことを指しているのではないか?
ということで、VirtualBox-6.0-6.0.14_133895_el7-1.x86_64.rpmをダウンロードして再実行teratermwget http://download.virtualbox.org/virtualbox/6.0.14/VirtualBox-6.0-6.0.14_133895_el7-1.x86_64.rpm sudo yum install VirtualBox-6.0-6.0.14_133895_el7-1.x86_64.rpm実行結果(前略) libdrm.x86_64 0:2.4.97-2.el7 libglvnd.x86_64 1:1.0.1-0.8.git5baa1e5.el7 libglvnd-glx.x86_64 1:1.0.1-0.8.git5baa1e5.el7 libpciaccess.x86_64 0:0.14-1.el7 libvpx.x86_64 0:1.3.0-5.el7_0 libxcb.x86_64 0:1.13-1.el7 libxshmfence.x86_64 0:1.2-1.el7 mesa-libGL.x86_64 0:18.3.4-5.el7 mesa-libglapi.x86_64 0:18.3.4-5.el7 opus.x86_64 0:1.0.2-6.el7 Complete!成功しました。
これは、普通にCentOSの知識が足りていないだけですね・・・
Dockerを覚えようとしても、インフラ知識は必須ですと。teratermcurl -L https://github.com/docker/machine/releases/download/v0.16.2/docker-machine-`uname -s`-`uname -m` >/tmp/docker-machine && chmod +x /tmp/docker-machine && sudo cp /tmp/docker-machine /usr/local/bin/docker-machine実行結果% Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 617 0 617 0 0 1534 0 --:--:-- --:--:-- --:--:-- 1534 100 32.6M 100 32.6M 0 0 6452k 0 0:00:05 0:00:05 --:--:-- 8692kteratermdocker-machine create --driver virtualbox default実行結果Creating CA: /home/centos/.docker/machine/certs/ca.pem Creating client certificate: /home/centos/.docker/machine/certs/cert.pem Running pre-create checks... Error with pre-create check: "We support Virtualbox starting with version 5. Your VirtualBox install is \"WARNING: The vboxdrv kernel module is not loaded. Either there is no module\\n available for the current kernel (3.10.0-957.1.3.el7.x86_64) or it failed to\\n load. Please recompile the kernel module and install it by\\n\\n sudo /sbin/vboxconfig\\n\\n You will not be able to start VMs until this problem is fixed.\\n6.0.14r133895\". Please upgrade at https://www.virtualbox.org"うーーーーーーーーーーーーーーーーーーむ。
普通にエラーメッセージから解決策を探したほうが早そうな気がしてきた。
というか、やっぱりEC2上にVirtual Boxをインストールするのが無理なのでしょうか??
まぁ、仮想マシン上に仮想マシンをインストールしている時点で無理かなぁ。。。とは思っていたのですが。EC2でDocker Machineを使いたいだけなのだけど、、、
参考書ではなく、ネット情報でもう一度リトライしてみます。
EC2でDocker Machineを使うケースは、それほどレアではないと思っていますし。。。
愚直に参考書の通りやるには、実機のLinux環境が必要なんだよなぁ。ただ、手順としてはWindowsでVirtual Boxを使う手順が記載されていたので、それに従おうと思う。
Docker-Machineのインストール(Virtual Box)
teratermdocker-machine create --driver amazonec2 \ --amazonec2-access-key xxxxxxxxxxxxxxxxxxxx \ --amazonec2-secret-key xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx \ --amazonec2-vpc-id vpc-xxxxxxxxxxxxxxxxx \ --amazonec2-subnet-id subnet-xxxxxxxxxxxxxxxxx \ --amazonec2-region ap-northeast-1 \ --amazonec2-ami ami-0c1c738e580f3e01f \ aws-waka-taka1202実行結果Running pre-create checks... Creating machine... (aws-waka-taka1202) Launching instance... Waiting for machine to be running, this may take a few minutes... Detecting operating system of created instance... Waiting for SSH to be available... Error creating machine: Error detecting OS: Too many retries waiting for SSH to be available. Last error: Maximum number of retries (60) exceededキーペアとかはアクセスキーとシークレットキーを使っているので問題ないはずだし。。。
これは完全に別の要因があるような気がしてきた。ただ、Stopは正常に行えた。。。
teratermdocker-machine stop aws-waka-taka1202実行結果Stopping "aws-waka-taka1202"... Machine "aws-waka-taka1202" was stopped.Startさせると、あいも変わらずエラー発生。。。
teratermdocker-machine start aws-waka-taka1202実行結果Starting "aws-waka-taka1202"... Machine "aws-waka-taka1202" was started. Waiting for SSH to be available... Too many retries waiting for SSH to be available. Last error: Maximum number of retries (60) exceededamiを指定しなかったら、うまくいきおった。。。
teratermdocker-machine create --driver amazonec2 \ --amazonec2-access-key xxxxxxxxxxxxxxxxxxxx \ --amazonec2-secret-key xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx \ --amazonec2-vpc-id vpc-xxxxxxxxxxxxxxxxx \ --amazonec2-subnet-id subnet-xxxxxxxxxxxxxxxxx \ --amazonec2-region ap-northeast-1 \ aws-waka-taka1202今まで、CentOSのamiを指定していたから失敗していたということ???
原因?も分かったので、気を取り直して最初からやり直してみます。
Docker-Machineのインストール(再々トライ)
Docker-Machineのインストール
teratermcurl -L https://github.com/docker/machine/releases/download/v0.16.2/docker-machine-`uname -s`-`uname -m` >/tmp/docker-machine && chmod +x /tmp/docker-machine && sudo cp /tmp/docker-machine /usr/local/bin/docker-machine実行結果% Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 617 0 617 0 0 695 0 --:--:-- --:--:-- --:--:-- 695 100 32.6M 100 32.6M 0 0 5682k 0 0:00:05 0:00:05 --:--:-- 7968kteratermdocker-machine lsteratermdocker-machine create --driver amazonec2 \ --amazonec2-access-key xxxxxxxxxxxxxxxxxxxx \ --amazonec2-secret-key xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx \ --amazonec2-vpc-id vpc-xxxxxxxxxxxxxxxxx \ --amazonec2-subnet-id subnet-xxxxxxxxxxxxxxxxx \ --amazonec2-region ap-northeast-1 \ awstaka4実行結果Running pre-create checks... Creating machine... (awstaka4) Launching instance... Waiting for machine to be running, this may take a few minutes... Detecting operating system of created instance... Waiting for SSH to be available... Detecting the provisioner... Provisioning with ubuntu(systemd)... Installing Docker... Copying certs to the local machine directory... Copying certs to the remote machine... Setting Docker configuration on the remote daemon... Checking connection to Docker... Docker is up and running! To see how to connect your Docker Client to the Docker Engine running on this virtual machine, run: docker-machine env awstaka4※やっと成功!
なんでOSがCentOSだったら失敗したのかは、Linuxの知識が足りないので保留します。。。teratermeval $(docker-machine env awstaka4) docker-machine ls実行結果NAME ACTIVE DRIVER STATE URL SWARM DOCKER ERRORS awstaka4 * amazonec2 Running tcp://52.68.69.235:2376 v19.03.5Dockerのインストール
teratermsudo yum install -y yum-utils device-mapper-persistent-data lvm2 sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo sudo yum install -y docker-ce docker-ce-cli containerd.io sudo systemctl start docker sudo systemctl enable docker docker --version実行結果Docker version 19.03.5, build 633a0eateratermsudo docker run -d -p 8080:80 --name webserver kitematic/hello-world-nginx実行結果Unable to find image 'kitematic/hello-world-nginx:latest' locally latest: Pulling from kitematic/hello-world-nginx Image docker.io/kitematic/hello-world-nginx:latest uses outdated schema1 manifest format. Please upgrade to a schema2 image for better future compatibility. More information at https://docs.docker.com/registry/spec/deprecated-schema-v1/ 77c6c00e8b61: Pull complete 9b55a9cb10b3: Pull complete e6cdd97ba74d: Pull complete 7fecf1e9de6b: Pull complete 6b75f22d7bea: Pull complete e8e00fb8479f: Pull complete 69fad424364c: Pull complete b3ba6e76b671: Pull complete a956773dd508: Pull complete 26d2b0603932: Pull complete 3cdbb221209e: Pull complete a3ed95caeb02: Pull complete Digest: sha256:ec0ca6dcb034916784c988b4f2432716e2e92b995ac606e080c7a54b52b87066 Status: Downloaded newer image for kitematic/hello-world-nginx:latest db61372a439fc0e5c0887196ba1e91b31fcc86c2e12ac15fca68c78586abe1e1teratermdocker-machine ip awstaka4実行結果52.68.69.235sudo docker runを実行してみたかったので、Docker Imageをインストールしたけど、このやり方だったら、自身のホストにDocker Imageが起動するだけで、Docker Machineの学習にならないか。。。
最後に
たかだかDocker Machineを使うだけで1週間近くのロス。。。
正直、最近のIT関連の知識についていけないです。次稿からDocker Machineを具体的に使って理解していこうと思います。
- 投稿日:2019-12-02T17:39:08+09:00
buildkitを使ってKubernetesクラスタでDockerのコンテナイメージをビルドする方法
はじめに
こんにちは、(株)日立製作所 研究開発グループ サービスコンピューティング研究部の露木です。
最近のKubernetesの隆盛により,Dockerコンテナの実行環境はとても充実しています。一方で,コンテナイメージのビルド環境はどうでしょうか。開発者が,手元のノートPCの限られた計算リソースをやりくりしながら docker build しているのはよくある話です。Kubernetesクラスタには潤沢な計算リソースがあるのですから,これを利用してビルド環境も効率化してしまいましょう。
目指す構成
このような背景から,本記事では
- moby/buildkit を既存のKubernetesクラスタにデプロイ
- 手元のノートPCで開発したDockerfileをKubernetes上でビルド
- 社内にあるDockerレジストリへ自動的にpushする
までの手順を公開します。この構成では KubernetesからDockerレジストリへコンテナイメージを送信するため,手元のノートPCの計算リソースは一切消費しません。
なお,buildkitと同様にKubernetesでDockerfileをビルドするシステムにはKanikoがあります。 buildkitはDockerに組み込まれている ため,今回はこちらを利用することにしました。
前提環境
さっそくですが,buildkitを使う手順を解説していきます。本記事では,以下の環境はすでにあるものとします。
buildkitのクライアント側 (手元のノートPC)
- Ubuntu 18.04
- Docker 19.03
- kubectlの利用設定済み
buildkitのサーバ側 (KubernetesのPod)
- Buildkit version 0.5.1
プライベートなDockerレジストリのサーバがある
準備
buildkitを使えるように環境を整えていきます。ます,buildkitのクライアント側 (手元のノートPC) に操作用のコマンド
buildctlをインストールします。wget https://github.com/moby/buildkit/releases/download/v0.5.1/buildkit-v0.5.1.linux-amd64.tar.gz tar xzf buildkit-v0.5.1.linux-amd64.tar.gz rm -f buildkit-v0.5.1.linux-amd64.tar.gz sudo mv ./bin/* /usr/local/bin/ buildctl --version次に,buildkitのサーバ側のDockerイメージを作成します。ここ実行する処理はSSL証明書
myoriginal.crtを組み込むのみです (社内のオンプレ環境にあるDockerレジストリを利用したいから)。特別な証明書が必要ない場合は,この手順は不要です。buildkitのコンテナイメージについて,技術的な詳細は 公式ドキュメント を参考にしてください。
FROM moby/buildkit:latest # 証明書を追加 RUN apk update \ && apk add ca-certificates \ && rm -rf /var/cache/apk/* ADD myoriginal.crt /usr/share/ca-certificates/ RUN echo myoriginal.crt >> /etc/ca-certificates.conf RUN update-ca-certificates上記のDockerfileをビルドし,DockerレジストリへPushしておきます。
<DockerレジストリのURL>と<プロジェクト名>の部分はご自身の環境に合わせて書き換えてください。docker login <DockerレジストリのURL> docker build -t <DockerレジストリのURL>/<プロジェクト名>/buildkit . docker pushbuildkitのサーバをKubernetesへデプロイするための
deployment.yamlを作成します。
なお,公式ドキュメントにあるyamlとの差分は,image名のみです。apiVersion: apps/v1 kind: Deployment metadata: labels: app: buildkitd name: buildkitd spec: selector: matchLabels: app: buildkitd template: metadata: labels: app: buildkitd spec: containers: - image: <DockerレジストリのURL>/<プロジェクト名>/buildkit args: - --addr - tcp://0.0.0.0:1234 name: buildkitd ports: - containerPort: 1234 securityContext: privileged: truebuildkitのサーバをKubernetesへデプロイします。
kubectl apply -f deployment.yaml以上で準備は終了です。
使い方
デプロイしたbuildkitのpod名を調べます。
kubectl get podsbuildkitのpodに接続できるように,
kubectl port-forwardでportを転送します。もし,tcp (httpではない) でKubernetesに直接接続できるネットワーク環境であれば,この手順は不要です。kubectl port-forward pod/<buildkitのpod名> 1234:1234環境変数でbuildctlコマンドがport転送先を参照するように指定します。
export BUILDKIT_HOST=tcp://127.0.0.1:1234buildctlコマンドでコンテナイメージのbuildを実行します。
コマンドオプションがとても長いのでスクリプト化して利用しましょう。buildctl build --output type=image,name=<Dockerレジストリ名>/<プロジェクト名>/<イメージ名>:<タグ>,push=true --frontend=dockerfile.v0 --local context=. --local dockerfile=<ビルドしたいDockerfileのパス>なお,Dockerfile名まで指定したい場合は,こちらのようなコマンドになります: specify name of dockerfile · Issue #684 · moby/buildkit · GitHub 。また,ビルドしたコンテナイメージのpushに失敗することがあるので,buildの最後に
ERROR exporting to imageというエラーが出たら再度実行してみてください。まとめ
以上の手順が正しく動作していれば,Dockerレジストリに新しいコンテナイメージが登録されているはずです。本記事で解説したようにbuildkitを使えばコンテナイメージのビルドもKubernetesで実行し,潤沢な計算リソースを利用できる利点があります。
補足
今回は利用しませんでしたが,
dockerコマンドからbuildKitを利用可能にするdocker/buildxプラグインがあります。将来的にはこちらを利用すれば ,buildctlは不要になると思います。buildkitの動作確認をしていた時期 (2019年7月) には,このプラグインではレジストリへの自動pushする機能 (--pushオプション) を実行できず,ローカルマシンのストレージ容量を消費するため利用しませんでした。また,調べきれていませんが,環境変数BUILDKIT_HOSTに対応する設定が見当たらず,リモートのbuildkitdを指定する方法も2019年7月当時には不明でした。もし,buildxプラグインを使ってみたい場合は,下記手順を参考にしてください。
まず,docker/buildxプラグインをインストールします。
export DOCKER_BUILDKIT=1 docker build --platform=local -o . https://github.com/docker/buildx.git mkdir -p ~/.docker/cli-plugins/ mv buildx ~/.docker/cli-plugins/docker-buildx動作確認します。
~ $ docker buildx --help Usage: docker buildx COMMAND Build with BuildKit Management Commands: imagetools Commands to work on images in registry Commands: bake Build from a file build Start a build create Create a new builder instance inspect Inspect current builder instance ls List builder instances rm Remove a builder instance stop Stop builder instance use Set the current builder instance version Show buildx version information Run 'docker buildx COMMAND --help' for more information on a command.
docker buildをdocker buildx buildに差し替えます。docker buildx install
docker buildでdocker buildx buildが実行されることを確認します。$ docker build "docker buildx build" requires exactly 1 argument.なお,元に戻すときは
docker buildx uninstallを実行すればOKです。
- 投稿日:2019-12-02T17:32:45+09:00
ジョブスケジューラPBSProでGPU計算クラスタを組みAIを効率的に学習させる方法 (後編)
はじめに
こんにちは、(株)日立製作所 研究開発グループ サービスコンピューティング研究部の露木です。
前編の記事ではPBSProのパッケージをインストール・設定して,CPUを利用するジョブを実行可能にするまでを実施しました。後編となる今回の記事では,GPUを利用したnvidia-dockerによるAI学習用のジョブを実行可能にする手順をご紹介します。
前編で説明した内容は実施済みであることを前提としますので,未実施の場合はまず前編をご覧ください。
GPUを計算リソースとして管理する設定
早速ですが,GPUを計算リソースとして管理するために設定を追加していきます。
まず,管理ノードで以下のコマンドを実行します。
sudo /opt/pbs/bin/qmgr -c "create resource ngpus type=long, flag=nh"管理ノードの設定ファイル
/var/spool/pbs/sched_priv/sched_configを編集し,resources:の行にngpusを追加します。追加後のresources:の行は下記のようになります。resources: "ncpus, mem, arch, host, vnode, netwins, aoe, ngpus"PBSProを再起動し,設定を反映させます。
sudo /etc/init.d/pbs restart計算ノードごとにGPUの本数を登録します。例えば計算ノード
sioにGPUが3本,別の計算ノードmisoにGPUが2本ある場合は下記のコマンドを実行します。sudo /opt/pbs/bin/qmgr -c "set node sio resources_available.ngpus=3" sudo /opt/pbs/bin/qmgr -c "set node miso resources_available.ngpus=2"ここで,GPUの登録を動作確認します。
pbsnodesコマンドで計算ノード一覧を見ると,追加した設定に対応してngpusの項目が増えていることがわかります。$ pbsnodes -a miso Mom = miso ntype = PBS state = free pcpus = 8 resources_available.arch = linux resources_available.host = miso resources_available.mem = 32803912kb resources_available.ncpus = 8 resources_available.ngpus = 2 resources_available.vnode = miso resources_assigned.accelerator_memory = 0kb resources_assigned.hbmem = 0kb resources_assigned.mem = 0kb resources_assigned.naccelerators = 0 resources_assigned.ncpus = 0 resources_assigned.vmem = 0kb resv_enable = True sharing = default_shared last_state_change_time = Tue Aug 6 20:33:19 2019 last_used_time = Tue Aug 6 19:16:10 2019 sio Mom = sio ntype = PBS state = free pcpus = 48 resources_available.arch = linux resources_available.host = sio resources_available.mem = 198036808kb resources_available.ncpus = 48 resources_available.ngpus = 3 resources_available.vnode = sio resources_assigned.accelerator_memory = 0kb resources_assigned.hbmem = 0kb resources_assigned.mem = 0kb resources_assigned.naccelerators = 0 resources_assigned.ncpus = 0 resources_assigned.vmem = 0kb resv_enable = True sharing = default_shared last_state_change_time = Tue Aug 6 20:33:19 2019動作確認のために,GPUの本数を指定してジョブを投入します。
具体的には nvidia-docker を使って nvida-smi コマンドを実行するジョブです。
上手く行けばGPUの情報がジョブ実行結果として保存されるはずです。echo 'sleep 30; docker run --gpus 3 --rm nvidia/cuda nvidia-smi' | qsub -l select=host=miso:ngpus=1 echo 'sleep 30; docker run --gpus 3 --rm nvidia/cuda nvidia-smi' | qsub -l select=host=sio:ngpus=1ジョブ投入結果を確認します。misoとsioに1つずつ,GPUを1本専有したジョブが流れている事がわかります。
$ qstat -s miso: Req'd Req'd Elap Job ID Username Queue Jobname SessID NDS TSK Memory Time S Time --------------- -------- -------- ---------- ------ --- --- ------ ----- - ----- 715.miso tsuyuki batch STDIN 27818 1 1 -- 100:0 R 00:00 Job run at Tue Aug 06 at 15:52 on (miso:ngpus=1:ncpus=1) 716.miso tsuyuki batch STDIN 31988 1 1 -- 100:0 R 00:00 Job run at Tue Aug 06 at 15:52 on (sio:ngpus=1:ncpus=1)しばらくするとジョブが終了し,
qstatコマンドで何も表示されなくなります。$ qstatジョブが正しく終了していれば,カレントディレクトリに実行結果のファイルが保存されているはずです。
$ ls STDIN.e715 STDIN.e716 STDIN.o715 STDIN.o716拡張子が
.eのファイルには標準エラー出力が保存されています。今回はdockerコマンドをジョブとして実行したため,コンテナイメージを取得したログが保存されています。$ cat STDIN.e716 Unable to find image 'nvidia/cuda:latest' locally latest: Pulling from nvidia/cuda 7413c47ba209: Already exists 0fe7e7cbb2e8: Already exists 1d425c982345: Already exists 344da5c95cec: Already exists 43bcc41986db: Pulling fs layer 76661327d908: Pulling fs layer abdc887b90e5: Pulling fs layer eb38470de0e2: Pulling fs layer 0adb8d7f107f: Pulling fs layer eb38470de0e2: Waiting 0adb8d7f107f: Waiting abdc887b90e5: Verifying Checksum abdc887b90e5: Download complete 43bcc41986db: Verifying Checksum 43bcc41986db: Download complete 76661327d908: Verifying Checksum 76661327d908: Download complete 43bcc41986db: Pull complete 76661327d908: Pull complete abdc887b90e5: Pull complete eb38470de0e2: Verifying Checksum eb38470de0e2: Download complete eb38470de0e2: Pull complete 0adb8d7f107f: Verifying Checksum 0adb8d7f107f: Download complete 0adb8d7f107f: Pull complete Digest: sha256:b89fbc1c8c238f6e838d4394cc4a9fdbb4ea9a3c2f7058cc9700fab3e8c6651b Status: Downloaded newer image for nvidia/cuda:latest拡張子が
.oのファイルには標準出力が保存されています。今回はdockerコンテナ内部で実行したnvidia-smiコマンドの出力結果が保存されることになります。下記の
nvidia-smiの実行結果をみればわかるように,GPUは3本認識されてしまっています。ジョブ投入時のqsubコマンドではngpus=1としてGPU1本だけ専有するように指定したのですが,ここまでの設定だけではジョブ実行時にリソースが正しく制限されていないことがわかります。PBSProで指定するGPUの本数とジョブが実際に利用するGPUの本数を一致させないと事故の元なので要注意です。$ cat STDIN.o716 Tue Aug 6 15:51:11 2019 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 430.40 Driver Version: 430.40 CUDA Version: 10.1 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===============================+======================+======================| | 0 GeForce GTX 108... Off | 00000000:01:00.0 Off | N/A | | 29% 29C P8 7W / 250W | 10MiB / 11178MiB | 0% Default | +-------------------------------+----------------------+----------------------+ | 1 GeForce GTX 108... Off | 00000000:02:00.0 Off | N/A | | 29% 29C P8 8W / 250W | 10MiB / 11178MiB | 0% Default | +-------------------------------+----------------------+----------------------+ | 2 GeForce GTX 108... Off | 00000000:03:00.0 Off | N/A | | 29% 27C P8 7W / 250W | 10MiB / 11178MiB | 0% Default | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: GPU Memory | | GPU PID Type Process name Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+cgroupsによるGPUリソースの分離
ここまでの設定ではジョブの利用可能なリソースを制限する機能がありません。先の例で示したように,qsubコマンドでジョブ投入する際にはGPUを1本しか使わないと言いつつ,実際には3本を利用するような使い方ができてしまうわけです。それではGPUのメモリを使い果たして他人のジョブが異常終了するなど,障害が発生してしまいます。
そこで,Linuxのcgroupsを利用してリソース制限する設定を追加します。本節の設定を追加すれば,例えば
ngpus=2を指定したジョブに対しては 環境変数CUDA_VISIBLE_DEVICES=0,1が自動的に設定され,GPUを2本までしか使えないようになります。 (細かい話をすると環境変数は本質ではなく,cgroupsによる制限で実際に2本までしかGPUが見えなくなるのですが詳細は割愛します)。具体的には,以下の2つの設定を加えていきます。
- PBSProの側に仮想的な計算ノードvnodeを設定する
- Linuxカーネルのcgroupsを自動設定してGPUの分離を実現するhookを有効化
vnodeの設定
まず,下記コマンドを実行して gpu_id` をリソースとして追加定義します。
sudo /opt/pbs/sbin/qmgr -c "create resource gpu_id type=string, flag=h"
/var/spool/pbs/sched_priv/sched_configのresources:の行にgpu_idを追加します。resources: "ncpus, mem, arch, host, vnode, aoe, eoe, ngpus, gpu_id"PBSProを再起動して設定変更を反映します。
sudo /etc/init.d/pbs restart次に,GPUごとに仮想的な計算ノード
vnodeの設定ファイルを作成します。例えば,計算ノードmisoの設定ファイルとしてmiso_vnodesというファイルを下記の内容で作成します。ここではmisoがGPUを2本積んでいる計算ノードなので,miso[0]とmiso[1]という2つのvnodeを設定して管理することになります。また,misoは32GBのメモリと4コアのCPUを持つので,2つのvnodeに均等に配分しています。$configversion 2 miso: resources_available.ncpus = 0 miso: resources_available.mem = 0 miso[0]: resources_available.ncpus = 4 miso[0]: resources_available.mem = 16gb miso[0]: resources_available.ngpus = 1 miso[0]: resources_available.gpu_id = gpu0 miso[0]: sharing = default_excl miso[1]: resources_available.ncpus = 4 miso[1]: resources_available.mem = 16gb miso[1]: resources_available.ngpus = 1 miso[1]: resources_available.gpu_id = gpu1 miso[1]: sharing = default_excl以下のコマンドを実行し,作成したvnodeの設定ファイル
miso_vnodesをPBSProの設定ファイル群があるディレクトリへコピーします。/opt/pbs/sbin/pbs_mom -s insert miso_vnodes miso_vnodesこのようなvnodeの設定ファイルの作成とコピーをすべての計算ノードで実行します。
vnodeの設定が終わったら,設定ファイルのpbsのデーモンを再起動して設定変更を反映します。sudo /etc/init.d/pbs restart設定の反映を確認します。これでvnodeの設定は終了です。
$ pbsnodes -v 'miso[0]' 'miso[1]' miso[0] Mom = miso ntype = PBS state = free resources_available.arch = linux resources_available.gpu_id = gpu0 resources_available.host = miso resources_available.hpmem = 0b resources_available.mem = 33522974720b resources_available.ncpus = 4 resources_available.ngpus = 3 resources_available.vmem = 35602300928b resources_available.vnode = miso[0] resources_assigned.accelerator_memory = 0kb resources_assigned.hbmem = 0kb resources_assigned.mem = 0kb resources_assigned.naccelerators = 0 resources_assigned.ncpus = 0 resources_assigned.ngpus = 0 resources_assigned.vmem = 0kb resv_enable = True sharing = default_excl last_state_change_time = Wed Aug 7 23:27:42 2019 last_used_time = Wed Aug 7 23:27:42 2019 miso[1] Mom = miso ntype = PBS state = free pcpus = 4 resources_available.arch = linux resources_available.gpu_id = gpu1 resources_available.host = miso resources_available.mem = 16gb resources_available.ncpus = 4 resources_available.ngpus = 1 resources_available.vnode = miso[1] resources_assigned.accelerator_memory = 0kb resources_assigned.hbmem = 0kb resources_assigned.mem = 0kb resources_assigned.naccelerators = 0 resources_assigned.ncpus = 0 resources_assigned.vmem = 0kb resv_enable = True sharing = default_excl last_state_change_time = Wed Aug 7 23:16:34 2019cgroups用hookの設定
PBSProにおいてcgroupsの設定は,ジョブ実行時のhookでpythonスクリプトを実行して実現しています。そのPythonスクリプトの設定ファイルを編集するために,まずは現在の設定を
pbs_cgroups.jsonというファイルにエクスポートします。sudo /opt/pbs/bin/qmgr -c "export hook pbs_cgroups application/x-config default" > pbs_cgroups.jsonこの
pbs_cgroups.jsonの中身を下記のように変更します。
- vnode_per_numa_nodeをtrueに変更 (vnodeで利用するCPUが同じ物理CPUに収まるように指定)
- devicesの enabled をtrueに変更 (cgroupによるデバイスのアクセス制限を有効化)
- devicesの allow にnvidia-uvm等のデバイスを追加 (nvidia-docker関連のデバイスは常にアクセスを許可する)
一部,環境に依存しますが変更後の
pbs_cgroups.jsonの中身は以下のようになります。{ "cgroup_prefix" : "pbspro", "exclude_hosts" : [] , "exclude_vntypes" : ["no_cgroups"], "run_only_on_hosts" : [], "periodic_resc_update" : true, "vnode_per_numa_node" : true, "online_offlined_nodes" : true, "use_hyperthreads" : false, "ncpus_are_cores" : false, "cgroup" : { "cpuacct" : { "enabled" : true, "exclude_hosts" : [], "exclude_vntypes" : [] }, "cpuset" : { "enabled" : true, "exclude_cpus" : [], "exclude_hosts" : [], "exclude_vntypes" : [], "mem_fences" : true, "mem_hardwall" : false, "memory_spread_page" : false }, "devices" : { "enabled" : true, "exclude_hosts" : [], "exclude_vntypes" : [], "allow" : [ "b *:* m", "c *:* m", "c 195:* m", "c 136:* rwm", ["fuse","rwm"], ["net/tun","rwm"], ["tty","rwm"], ["ptmx","rwm"], ["console","rwm"], ["null","rwm"], ["zero","rwm"], ["full","rwm"], ["random","rwm"], ["urandom","rwm"], ["cpu/0/cpuid","rwm","*"], ["nvidia-modeset", "rwm"], ["nvidia-uvm", "rwm"], ["nvidia-uvm-tools", "rwm"], ["nvidiactl", "rwm"] ] }, "hugetlb" : { "enabled" : false, "exclude_hosts" : [], "exclude_vntypes" : [], "default" : "0MB", "reserve_percent" : 0, "reserve_amount" : "0MB" }, "memory" : { "enabled" : true, "exclude_hosts" : [], "exclude_vntypes" : [], "soft_limit" : false, "default" : "256MB", "reserve_percent" : 0, "reserve_amount" : "64MB" }, "memsw" : { "enabled" : true, "exclude_hosts" : [], "exclude_vntypes" : [], "default" : "256MB", "reserve_percent" : 0, "reserve_amount" : "64MB" } } }作成した設定ファイル
pbs_cgroups.jsonをPBSProにインポートします。sudo /opt/pbs/bin/qmgr -c "import hook pbs_cgroups application/x-config default pbs_cgroups.json"cgroupのためのhookを有効化します。
sudo /opt/pbs/bin/qmgr -c "set hook pbs_cgroups enabled = true"PBSを再起動し,設定を反映させます。
sudo /etc/init.d/pbs restart動作確認
動作確認のために
ngpu=1を指定したジョブを実行します。$ echo 'hostname; echo CUDA_VISIBLE_DEVICES=$CUDA_VISIBLE_DEVICES; nvidia-smi ' | qsub -l select=host=miso:ngpus=1 -N test; 1576.miso実行結果を確認します。cgroupsを利用しない場合と比較して,環境変数
CUDA_VISIBLE_DEVICES=0が自動的に設定されており,nvidia-smiでも1本しかGPUが見えていないことがわかります。このようにcgroupsによってリソースの利用を制限し,リソース枯渇による障害発生を防止できます。$ cat test.o1576 miso CUDA_VISIBLE_DEVICES=0 Wed Aug 7 17:12:29 2019 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 430.40 Driver Version: 430.40 CUDA Version: 10.1 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===============================+======================+======================| | 0 GeForce GTX 108... Off | 00000000:01:00.0 Off | N/A | | 29% 29C P8 7W / 250W | 10MiB / 11178MiB | 0% Default | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: GPU Memory | | GPU PID Type Process name Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+まとめ
ここまで設定すれば,nvidia-dockerを使ってAIを学習させるジョブを安全に実行可能になります。
従来は,例えばハイパーパラメータの異なる1000個の学習ジョブを一度に実行すると計算リソース不足で異常終了しますし,学習ジョブの終了を人手で確認して次のジョブを実行するのでは大変な手間がかかってしまっていました。そこで,本記事ではジョブスケジューラを整備し,qsubコマンドを使ってジョブを登録するようにしました。これにより,計算リソースの空きを待ってから次のジョブが実行されるようになりますので,効率よく大量のAIを学習できます。
[補足] Dockerコンテナでジョブを実行する設定
PBSProには,明示的に
docker runコマンドを指定しなくてもコンテナ内部でジョブを実行する設定もありますが,今回は設定しませんでした。その理由はジョブのスクリプト内部でdocker runするほうが環境変数等を柔軟に設定できるからです。また,PBSProのコンテナ統合機能だと,GPU利用時にnvidia-dockerコマンドを内部的に実行するため,最近のnvidia-docker2に対応しているのか不明な問題もありました。もし,コンテナ向けの設定を追加したい場合は PBS Professional with Docker Integration を参考に実施してみてください。
参考URL
- PBS Works Documentation
- Scheduling Jobs onto NVIDIA Tesla GPU Computing Processors using PBS Professional
- PBS Professional with Docker Integration
- GitHub - PBSPro/pbspro: An HPC workload manager and job scheduler for desktops, clusters, and clouds.
- Building and Packaging PBS on Debian/Ubuntu - PBS Pro - PBS Pro Confluence
- Building PBS Pro Using rpmbuild - PBS Pro - PBS Pro Confluence
- pbspro/INSTALL at master · PBSPro/pbspro · GitHub
- pbspro - Chaperone
- 投稿日:2019-12-02T17:24:22+09:00
ジョブスケジューラPBSProでGPU計算クラスタを組みAIを効率的に学習させる方法 (前編)
はじめに
こんにちは、(株)日立製作所 研究開発グループ サービスコンピューティング研究部の露木です。
多人数で効率的に機械学習・AIの学習処理や,HPCライクな数値実験をしたければジョブスケジューラは必須といえます。表題の通り,本記事ではジョブスケジューラの一種であるPBSProをインストールして,GPUを利用した計算ジョブをnvidia-dockerで実行可能にする手順を前後編に分けて示します。
前編である今回は,CPUを利用したジョブを実行可能にするまでの手順を解説します。後編では,GPU利用に関する部分を解説します。
本記事で目指す構成
本記事では図のようにPBSProの管理ノードと計算ノードのシンプルな2台構成を目指します。
+------------+ +------------+ | 管理ノード | --- | 計算ノード | +------------+ +------------+それぞれのノードの詳細は下記の通りです。
管理ノードの構成
- ホスト名: miso
- IPアドレス: 192.168.1.2
- GPU: 2本
- 計算ノードとしての役割も兼用させる
計算ノードの構成
- ホスト名: sio
- IPアドレス: 192.168.1.3
- GPU: 3本
前提環境
管理ノードと計算ノードには下記の環境が整っていることを前提とします。その上で,PBSProをインストールする手順を次節以後に説明していきます。
- OS (Ubuntu 18.04) はインストール済み
- Docker と nvidia-docker 2.0をインストール済み
- 管理ノードと計算ノードの
/homeディレクトリはNFSで共有済みPBSProパッケージのコンパイル
まず,PBSProのインストール用パッケージ (rpm, debファイル) をコンパイルします。コンパイル環境として,以下の内容でDockerfileを作成します。
FROM ubuntu:bionic MAINTAINER tsuyuki ARG DEBIAN_FRONTEND="noninteractive" RUN apt update && apt upgrade -y \ && apt install -y git make python tar wget WORKDIR /root RUN wget https://github.com/PBSPro/pbspro/releases/download/v19.1.2/pbspro-19.1.2.tar.gz RUN tar xzf pbspro-19.1.2.tar.gz WORKDIR /root/pbspro-19.1.2/ RUN apt install debhelper build-essential autotools-dev gcc automake autoconf comerr-dev libhwloc-dev libx11-dev x11proto-core-dev libxt-dev libedit-dev libical-dev libncurses-dev perl libpq-dev libpython2.7-minimal:amd64 libpython2.7-dev tcl-dev tk-dev swig dpkg-dev libexpat-dev libssl-dev zlib1g-dev:amd64 libxt-dev:amd64 libxext-dev libxft-dev dh-make debhelper devscripts fakeroot xutils lintian -y RUN bash ./autogen.sh RUN bash ./configure RUN make dist # build rpm RUN apt install -y rpm alien RUN mkdir -p /root/rpmbuild WORKDIR /root/rpmbuild RUN mkdir BUILD BUILDROOT RPMS SOURCES SPECS SRPMS RUN cp /root/pbspro-19.1.2/pbspro*tar.gz /root/rpmbuild/SOURCES RUN cp /root/pbspro-19.1.2/pbspro.spec /root/rpmbuild/SPECS WORKDIR /root/rpmbuild/SPECS RUN rpmbuild -ba --nodeps pbspro.spec WORKDIR /root/rpmbuild/RPMS/x86_64 # convert rpm to deb RUN alien --to-deb --scripts *.rpm下記コマンドを実行し,Dockerコンテナの中でPBSProをコンパイルします。
docker build -t pbsbuild:19.1.2 .UbuntuやDebianにインストールする場合
debファイルをカレントディレクトリにコピーするため,下記コマンドを実行します。
docker run --rm -it -v `pwd`:/host pbsbuild:19.1.2 bash -c "cp pbs*.deb /host"正しくコピーできていれば,debファイルがコンテナホスト側に保存されています。
$ ls *.deb pbspro-client_19.1.2-0_amd64.deb pbspro-devel_19.1.2-0_amd64.deb pbspro-execution_19.1.2-0_amd64.deb pbspro-server_19.1.2-0_amd64.deb pbspro_19.1.2-0_amd64.deb[オプション] CentOSやRHLにインストールする場合
Ubuntuにインストールする場合は不要ですが,下記コマンドでrpmファイルを取得することもできます。もし,CentOSやRedHat Enterprise Linux などに PBSPro をインストールしたい場合は,このrpmファイルを利用したうえで以後のコマンドを適宜読み替えながら進めてください。
docker run --rm -it -v `pwd`:/host pbsbuild:19.1.2 bash -c "cp pbs*.rpm /host"PBSProのインストールと設定
コンパイルしたパッケージを利用してPBSProをインストールし,設定していきます。なお, 開発元の PBS Works Documentation にはすべての情報がまとまっています。本稿でわからないことがあったら,開発元のドキュメントを参照するとスムーズに問題解決できるはずです。
管理ノードのインストールと設定
まず,管理ノードに必要な依存パッケージ (PostgreSQL) をインストールします。
sudo apt install postgresql libpq-dev次に,コンパイルしておいたPBSProを下記コマンドでインストールします。なお,
<pbsproのバージョン>は適宜読み替えてください。もし,ここで依存関係のエラーがでた場合はsudo apt install -fコマンドの実行で解決できます。sudo dpkg -i pbspro-server_<pbsproのバージョン>_amd64.debジョブ実行時の環境変数にタイムゾーンを追加します。
sudo bash -c 'echo TZ=\"Asia/Tokyo\" >> /var/spool/pbs/pbs_environment'
/etc/pbs.confを編集し,下記の2点を変更します。
PBS_SERVER=misoに変更 (管理ノードのホスト名を記入する)PBS_START_MOM=1に変更 (管理ノードへのジョブ投入を許可する設定)変更後の
/etc/pbs.confは以下のようになります。PBS_EXEC=/opt/pbs PBS_SERVER=miso PBS_START_SERVER=1 PBS_START_SCHED=1 PBS_START_COMM=1 PBS_START_MOM=1 PBS_HOME=/var/spool/pbs PBS_CORE_LIMIT=unlimited PBS_SCP=/usr/bin/scp
/var/spool/pbs/mom_priv/configに$usecp *:/home/ /home/の記載を追加します。今回は/homeディレクトリ以下をNFSで共有するため,scpではなくcpコマンドでジョブ実行結果をコピーするように$usecpオプションを指定しています。設定変更後の/var/spool/pbs/mom_priv/configの中身は以下のようになります。$clienthost miso $restrict_user_maxsysid 999 $usecp *:/home/ /home/なお,計算ノードと管理ノードの
/homeディレクトリをNFSで共有していない場合は,$usecpの設定は不要ですい。この場合,scpコマンドでジョブ実行結果をコピーすることになるので,計算ノードと管理ノードの間はパスワードなしでsshログインできるように設定しておく必要があります (具体的にはパスフレーズなしの証明書を設定するなど)。次に,
/etc/hostsを変更し,管理ノードmisoと計算ノードsioの名前解決を可能にします。ここでは,自ホストもNICに割り当てられたIPアドレス192.168.1.2に解決できるように指定する必要がります。デフォルトの127.0.0.1ではpbs_momは起動しません。192.168.1.2 miso 192.168.1.3 sio 127.0.0.1 localhost # 127.0.1.1 misoここまで設定ができたら,PBSProの各種daemonを起動します。
sudo /etc/init.d/pbs startdaemonの起動は,以下のコマンドで確認できます。
$ sudo /etc/init.d/pbs status pbs_server is pid 18909 pbs_mom is pid 18721 pbs_sched is pid 18733 pbs_comm is 18689もし,ここで4つのdaemonが起動していなければ障害対応が必要です。下記のディレクトリにある,PBSの動作ログを見ると,起動しない原因がわかると思います。
- /var/spool/pbs/server_logs/
- /var/spool/pbs/mom_logs/
- /var/spool/pbs/sched_logs/
- /var/spool/pbs/comm_logs/
正しく4つのdaemonが起動していたら,次は管理ノード自体を計算ノードとして登録します。
sudo /opt/pbs/bin/qmgr -c "create node miso"ジョブを流すキューを作成するため,下記のコマンドを実行します。細かい設定は PBS Works Documentation を見ながらお好みに合わせて設定してください。
sudo /opt/pbs/bin/qmgr -c "create queue batch queue_type=execution" sudo /opt/pbs/bin/qmgr -c "set queue batch enabled=True" sudo /opt/pbs/bin/qmgr -c "set queue batch resources_default.nodes=1" sudo /opt/pbs/bin/qmgr -c "set queue batch resources_default.walltime=360000" sudo /opt/pbs/bin/qmgr -c "set queue batch started=True" sudo /opt/pbs/bin/qmgr -c "set server acl_hosts = "`hostname` sudo /opt/pbs/bin/qmgr -c "set server default_queue = batch" sudo /opt/pbs/bin/qmgr -c "set server scheduling = True" sudo /opt/pbs/bin/qmgr -c 'set server node_pack = True' # 他ユーザのジョブもqstatで見えるようにする sudo /opt/pbs/bin/qmgr -c "set server query_other_jobs = True" # 管理ノード以外からもジョブ投入を許可する sudo /opt/pbs/bin/qmgr -c "set server flatuid = True"下記コマンドで登録済みの計算ノード一覧を確認します。ここまでの設定では管理ノード
misoが計算ノードとしても認識されていることがわかるはずです。$ pbsnodes -a miso Mom = miso ntype = PBS state = free pcpus = 8 resources_available.arch = linux resources_available.host = miso resources_available.mem = 32803912kb resources_available.ncpus = 8 resources_available.vnode = miso resources_assigned.accelerator_memory = 0kb resources_assigned.hbmem = 0kb resources_assigned.mem = 0kb resources_assigned.naccelerators = 0 resources_assigned.ncpus = 0 resources_assigned.vmem = 0kb resv_enable = True sharing = default_shared last_state_change_time = Tue Aug 6 18:57:38 2019今後,管理ノードからジョブ投入や計算ノードの死活管理をします。PBSProのコマンド群をパスに追加しておくと便利です。
export PAHT=$PATH:/opt/pbs/bin/動作確認のためにジョブを投入してみます。
echo "sleep 60; echo done" | qsubqstatコマンドでジョブの状態を確認すると,正しくジョブが登録されていることがわかります。
$ qstat Job id Name User Time Use S Queue ---------------- ---------------- ---------------- -------- - ----- 1.miso STDIN tsuyuki 00:00:00 R batch今回は
sleep 60を実行するジョブなので1分立つとジョブが終わります。
ジョブの実行結果としてカレントディレクトリにstdoutとstderrが保存されます。$ qstat $ ls STDIN.e1 STDIN.o1 $ cat STDIN.o1 done計算ノードのインストールと設定
次に,計算ノード
sioを追加します。計算ノードにSSHでログインしてから下記コマンドを実行し,計算ノード用のパッケージをインストールします。ただし,<pbsproのバージョン>は適宜読み替えてください。sudo dpkg -i pbspro-execution_<pbsproのバージョン>_amd64.debこのとき,依存関係のエラーが出たら場合は下記コマンドの実行で解決できます。
sudo apt install -f計算ノードの
/etc/pbs.confを変更します。具体的な変更点は下記の1点のみです。
PBS_SERVER=misoに変更 (管理ノードのホスト名を記入)変更後の
/etc/pbs.confは以下のようになります。PBS_EXEC=/opt/pbs PBS_SERVER=miso PBS_START_SERVER=0 PBS_START_SCHED=0 PBS_START_COMM=0 PBS_START_MOM=1 PBS_HOME=/var/spool/pbs PBS_CORE_LIMIT=unlimited PBS_SCP=/usr/bin/scp計算ノードの
/var/spool/pbs/mom_priv/configに下記の2点の変更を加えます。
$clienthost misoの記載に変更 (管理ノードのホスト名を記入)$usecp *:/home/ /home/の記載を追加
- 今回は
/homeディレクトリ以下をNFSで共有するため,scpではなくcpコマンドで実行結果をコピーする設定設定変更後の
/var/spool/pbs/mom_priv/configの中身は以下のようになります。$clienthost miso $restrict_user_maxsysid 999 $usecp *:/home/ /home/なお,計算ノードと管理ノードの
/homeディレクトリをNFSで共有しない場合は,$usecpの設定は不要です。この場合,scpでジョブ実行結果をコピーすることになるので,計算ノードと管理ノードの間はパスワードなしでsshログインできるように設定しておく必要があります (具体的にはパスフレーズなしの証明書を設定するなど)。次に,計算ノードでも管理ノードのホスト名
misoと計算ノードのホスト名sioを名前解決できるように/etc/hostsに書き込みます。192.168.1.2 miso 192.168.1.3 sioタイムゾーンをジョブ実行時の環境変数に追加します。
sudo bash -c 'echo TZ=\"Asia/Tokyo\" >> /var/spool/pbs/pbs_environment'PBSProのdaemonを起動します。
sudo /etc/init.d/pbs startPBSProのdaemon起動を確認します。計算ノードではpbs_momのみが動作していればOKです。
$ sudo /etc/init.d/pbs status pbs_mom is pid 29095計算ノード
sioを追加登録させるため,管理ノードにSSHでログインして下記コマンドを実行します。sudo /opt/pbs/bin/qmgr -c "create node sio"ここまで設定すると,下記のように計算ノードが増えていることがわかります。
$ pbsnodes -a miso Mom = miso ntype = PBS state = free pcpus = 8 resources_available.arch = linux resources_available.host = miso resources_available.mem = 32803912kb resources_available.ncpus = 8 resources_available.vnode = miso resources_assigned.accelerator_memory = 0kb resources_assigned.hbmem = 0kb resources_assigned.mem = 0kb resources_assigned.naccelerators = 0 resources_assigned.ncpus = 0 resources_assigned.vmem = 0kb resv_enable = True sharing = default_shared last_state_change_time = Tue Aug 6 20:33:19 2019 last_used_time = Tue Aug 6 19:16:10 2019 sio Mom = sio ntype = PBS state = free pcpus = 48 resources_available.arch = linux resources_available.host = sio resources_available.mem = 198036808kb resources_available.ncpus = 48 resources_available.vnode = sio resources_assigned.accelerator_memory = 0kb resources_assigned.hbmem = 0kb resources_assigned.mem = 0kb resources_assigned.naccelerators = 0 resources_assigned.ncpus = 0 resources_assigned.vmem = 0kb resv_enable = True sharing = default_shared last_state_change_time = Tue Aug 6 20:33:19 2019新しい計算ノードにジョブが流れるか,動作確認のためにノード名を指定してジョブを投入します。
echo "sleep 60; hostname; echo done" | qsub -l select=host=miso echo "sleep 60; hostname; echo done" | qsub -l select=host=sioジョブ投入結果を確認します。misoとsioに1つずつのジョブが流れている事がわかります。
$ qstat -s miso: Req'd Req'd Elap Job ID Username Queue Jobname SessID NDS TSK Memory Time S Time --------------- -------- -------- ---------- ------ --- --- ------ ----- - ----- 714.miso tsuyuki batch STDIN 27878 1 1 -- 100:0 R 00:00 Job run at Tue Aug 06 at 15:47 on (miso:ncpus=1) 715.miso tsuyuki batch STDIN 30988 1 1 -- 100:0 R 00:00 Job run at Tue Aug 06 at 15:47 on (sio:ncpus=1)ここまでの設定で,CPUを利用した計算ジョブは問題なく実行できるようになりました。次回は,GPUを計算リソースとしてジョブスケジューリングするための設定をし,動作確認を行います。
- 投稿日:2019-12-02T16:40:10+09:00
既存のRailsアプリをDocker上で起動させる
はじめに
railsを勉強しているのですが、勉強のために、サンプルコードなどを自分の環境上で動かしたかったのですが、
githubなどに上がっているサンプルコードをdocker上で立ち上げるのに苦労したのでメモします。新規のプロジェクトを立ち上げる際のDockerFileの書き方は情報がたくさんあったのですが、
既存のものを立ち上げる際の情報はほとんど無くて、あってもRuby2.4のものだったりしたので、
いろいろなサイトを参考にして、Ruby2.5環境で既存のプロジェクトを立ち上げるためのコンテナ構築をしました。Ruby2.5でのDocker環境構築
ディレクトリ構造(完成形)
workディレクトリでrailsアプリ(DockerFileのないもの)をクローンします。sampleapp/ ├ work │ └ app/ │ └ config/ │ └ ... │ ├ Dockerfile └ docker-compose.yml作業用ディレクトリを作成し、GithubからRailsプロジェクト(DockerFileのないもの)をクローンします。
クローンしたら、dockerコマンドを入力するためにsampleappディレクトリに戻ります。$ cd $ mkdir sampleapp $ cd sampleapp $ mkdir work $ cd work $ git clone ....(URLを入れる) $ cd ..Dockerfile
FROM ruby:2.5 #日本語対応 ENV LANG C.UTF-8 #作業用ディレクトリを作成 ENV ROOT_PATH /work RUN mkdir -p $ROOT_PATH WORKDIR $ROOT_PATH #Railsアプリに必要なパッケージをインストールする RUN curl -sL https://deb.nodesource.com/setup_10.x | bash - \ && apt-get install -y nodejs build-essential libpq-dev\ && rm -rf /var/lib/apt/lists/* #Rspec用chromedriver RUN apt-get update && apt-get install -y unzip && \ CHROME_DRIVER_VERSION=`curl -sS chromedriver.storage.googleapis.com/LATEST_RELEASE` && \ wget -N http://chromedriver.storage.googleapis.com/$CHROME_DRIVER_VERSION/chromedriver_linux64.zip -P ~/ && \ unzip ~/chromedriver_linux64.zip -d ~/ && \ rm ~/chromedriver_linux64.zip && \ chown root:root ~/chromedriver && \ chmod 755 ~/chromedriver && \ mv ~/chromedriver /usr/bin/chromedriver && \ sh -c 'wget -q -O - https://dl-ssl.google.com/linux/linux_signing_key.pub | apt-key add -' && \ sh -c 'echo "deb [arch=amd64] http://dl.google.com/linux/chrome/deb/ stable main" >> /etc/apt/sources.list.d/google-chrome.list' && \ apt-get update && apt-get install -y google-chrome-stable ADD ./work/Gemfile $ROOT_PATH/Gemfile ADD ./work/Gemfile.lock $ROOT_PATH/Gemfile.lock RUN gem install bundler RUN bundle install ADD ./work $ROOT_PATHdocker-compose.yml
version: '3' services: db: image: mysql:5.7 environment: MYSQL_USER: root MYSQL_ALLOW_EMPTY_PASSWORD: 1 ports: - "3306:3306" web: build: . command: bundle exec rails s -b 0.0.0.0 environment: volumes: - ./work:/work:cached ports: - "3000:3000" links: - dbrailsアプリのconfig/database.ymlでデータベースとの接続情報を編集します。
以下、work/config/database.ymldefault: &default adapter: mysql2 encoding: utf8 pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %> username: root password: host: db # development環境だけ書き換えてます。 development: <<: *default username: root password: database: docker_development test: <<: *default database: docker_test production: <<: *default database: docker_production username: root password: <%= ENV['DATABASE_PASSWORD'] %>設定が終わったらビルドします。
$ docker-compose build $ docker-compose exec web rails db:create db:migraterailsアプリに必要なパッケージやgemがインストールできるので、
終わったらdocker-compose upで起動させます。localhost:3000でアプリのトップページにアクセスできます。
3306や、3000の部分はポートがかぶらないように、お好みの番号に設定できます。
※指定できないポートもあるので、エラーが出る際は下記のサイトなどを参考にするといいと思います。開発中、ChromeでERR_UNSAFE_PORTエラーが出たときにチェックすべきこと(312エラー):http://nanoappli.com/blog/archives/7772
あとは新規からアプリを作成する時と同じように開発できます。
参考にしたサイト
既存railsプロジェクトのdocker運用開始時の作業録:https://www.dendoron.com/boards/50
Docker+既存Rails(+Puppeteer) やっぱりdockerで環境作るのを諦められなかった話:https://note.com/mick_sato/n/nfb521d6b2a4c
開発中、ChromeでERR_UNSAFE_PORTエラーが出たときにチェックすべきこと(312エラー):http://nanoappli.com/blog/archives/7772
- 投稿日:2019-12-02T16:25:12+09:00
Docker: CentOS 8のイメージでの日本locale対応
自分の中ではCentOS7と微妙にやり方が異なったので備忘
FROM centos:8 RUN dnf -y install langpacks-ja \ && cp /usr/share/zoneinfo/Asia/Tokyo /etc/localtime ENV LANG="ja_JP.UTF-8" \ LANGUAGE="ja_JP:ja" \ LC_ALL="ja_JP.UTF-8"
- 投稿日:2019-12-02T15:49:06+09:00
Dockerコンテナ内でKaggle APIをつかう
やること
- Kaggle公式イメージ(kaggle/python)をつかってコンテナ起動
kaggle ~コマンドでcsvファイルをダウンロードするkaggle ~コマンドで公開notebookをダウンロードするまずはまとめ
kaggle.jsonをDL (kaggle.com > My Account > Create New API Tokenボタン)$ docker run -it --rm --mount type=bind,src=pwd,dst=/root/dev kaggle/python$ pip install kaggle$ mkdir ~/.kaggle$ cp /root/dev/kaggle.json ~/.kaggle$ chmod 600 ~/.kaggle/kaggle.json$ kaggle competitions download -c titanic -p input/titanic$ unzip input/titanic/titanic.zip input/titanic$ kaggle kernels pull arthurtok/introduction-to-ensembling-stacking-in-python -p ./データセットはタイタニックコンペのものをダウンロードしてます
問題なく動いた方はここで閉じでもらって大丈夫です環境
macOS 10.14.6 (Mojave)
Docker 19.03.4なんでDockerつかうの?
- VSCodeでコード書きたい
- グローバル環境を汚しなくない
- pipとcondaの競合コワイ
- pipenv ✕ xgboostでつまった
- Kaggle公式イメージがあるので安心
Kaggle APIってなにさ?
Kaggleのサイト上でやってる操作をコマンドラインでできちゃうやつ
たとえば?
- データセットのダウンロード
- サブミット
- 参加可能コンペを一覧表示
- リーダーボードをダウンロード
などなど…
詳しくは公式リポジトリを
コマンド一覧kaggle competitions {list, files, download, submit, submissions, leaderboard} kaggle datasets {list, files, download, create, version, init} kaggle kernels {list, init, push, pull, output, status} kaggle config {view, set, unset}こんな構成をつくっておきます
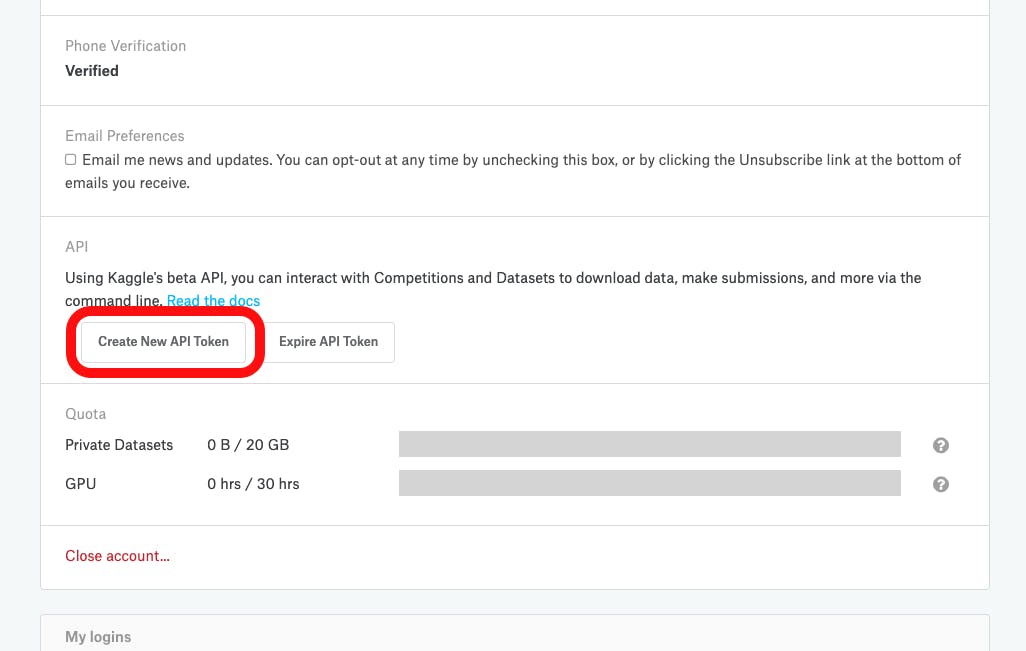
kaggle_titanic ├── input │ └── titanic <- ここにcsvファイルをダウンロードできれば勝ち └── working <- ここにipynbファイルをダウンロードできれば優勝Kaggle API Tokenを取得
右上のMy Accountから
真ん中くらいにあるこれをポチ
kaggle.jsonがダウンロードされるのでkaggle_titanicディレクトリに保存しておく
中身はこんなかんじkaggle.json{"username":"anata_no_namae","key":"xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"}ちなみに
こっちでトークンを無効化できます
「まちがえてGitHubにkaggle.jsonもプッシュしちまった!」みたいな時が押し時
コンテナ起動
Kaggleの公式イメージ
kaggle/pythonをつかう
kaggle_titanicディレクトリで以下のコマンドdocker run -it --rm --mount type=bind,src=`pwd`,dst=/root/dev kaggle/pythonオプションの説明なんかはココに書いているのでもしよろしければ
-> 【画像で説明】DockerでAnaconda環境をつくり、コンテナの中でVSCodeを使うここからはコンテナ側のシェルで
マウントしたディレクトリに移動
cd /root/dev中身が同期されてればOK
ls input kaggle.json workingkaggleパッケージをインストール
pip install kaggleちゃんと動くかバージョン確認してみる
kaggle -v Traceback (most recent call last): File "/opt/conda/bin/kaggle", line 7, in <module> from kaggle.cli import main File "/opt/conda/lib/python3.6/site-packages/kaggle/__init__.py", line 23, in <module> api.authenticate() File "/opt/conda/lib/python3.6/site-packages/kaggle/api/kaggle_api_extended.py", line 149, in authenticate self.config_file, self.config_dir)) OSError: Could not find kaggle.json. Make sure it's located in /root/.kaggle. Or use the environment method.めっちゃ怒ってきよる
kaggle.jsonが見当たらんみたいなこと言ってますねkaggle.jsonを配置
~/.kaggle/ディレクトリをつくってその中にkaggle.jsonをコピーします
$ kaggle -vのタイミングで~/.kaggle/ディレクトリが作られている場合がありますmkdir ~/.kaggle # <- すでにディレクトリあるよーっていわれるかもしれないけど問題ありません cp /root/dev/kaggle.json ~/.kaggle今度こそ
kaggle -v Warning: Your Kaggle API key is readable by other users on this system! To fix this, you can run 'chmod 600 /root/.kaggle/kaggle.json' Kaggle API 1.5.6一応つかえるけど、まだ怒ってるな
他のユーザーにもAPI Keyが読めちゃうから権限変えなさいって権限変更
chmod 600 ~/.kaggle/kaggle.json次こそは
kaggle -v Kaggle API 1.5.6ふぅ
毎回やるのめんどい
ここの一連の処理はまとめてセルで実行してもいいかもです
ファイル化して使い回すって作戦もありますkaggle_settings.ipynb!pip install kaggle !mkdir ~/.kaggle !cp /root/dev/kaggle.json ~/.kaggle !chmod 600 ~/.kaggle/kaggle.jsonそれではデータのダウンロード
-cでコンペ名指定
-p保存先パス指定kaggle competitions download -c titanic -p input/titanic
titanic.zipがダウンロードされるls input/titanic titanic.zip
※ コンペ名はURL上の表記をつかう
例えばSeverstal: Steel Defect Detectionコンペであればコレ
解凍
ダウンロードした
titanic.zipを解凍unzip input/titanic/titanic.zip -d input/titanicls input/titanic gender_submission.csv test.csv titanic.zip train.csvこれでデータセットのダウンロードはOK
次はnotebookをpullしてみる
notebookの表記はここ
kaggle kernels pull arthurtok/introduction-to-ensembling-stacking-in-python -p ./workingls ./working introduction-to-ensembling-stacking-in-python.ipynbちゃんとpullされているので優勝
VSCodeをあわせてつかうと便利かも
インテリセンスや自分キーバインドなどでコード書けるのがいい
【画像で説明】DockerでAnaconda環境をつくり、コンテナの中でVSCodeを使う
おしまい
最後まで読んで頂いてありがとうございました




- 投稿日:2019-12-02T15:19:51+09:00
Docker環境でAngular、AngularJSのライブリロード化
Angular はバージョンで呼び方が違ってる件
下記のようになっております
AngularJS(1.x 系)
Angular(2.0 系 ~ latest)やりたいこと
docker と Angular を使用して、
ローカルのファイルが変更された時 コンテナ上でもライブリロードが効いて開発がしやすくするなんと今回は AngularJS 付き!(誰得)
これなんて呼ぶか教えてください orz
下記の現象って正式な名称ついているかわからないけど
ローカルのファイルが変更された時、ライブリロードが効いて開発がしやすくする
「コンテナのライブリロード化」って以下からは呼称しますTL;DR
docker で Angular(8.3.0) を動かす
付録:AngularJS(1.7.9) 付き前提
- Angular → angular cli で生成した新規プロジェクト
- AngularJS → webpack で構築された既存プロジェクト
環境
Angular: 8.3.0 Angular CLI: 8.3.20 Docker desktop: 2.1.0.5 AngularJS: 1.7.9 Webpack: 4.41.2ポイント
host に 0.0.0.0 を渡す
どちらも webpack で動いているのがみそですかね
docker-compose.ymlでvolumesを設定
.dockerignoreもvolumesでもnode_modulesも除外しましょうAngular の コンテナのライブリロード化 の流れ
- angular-cli のインストール
- プロジェクト新規作成
- dockerfile, .dockerignore を追加
- docker-compose.yml を追加
- お疲れさまでした
1. angular-cli をインストール
公式が提供している angular-cli でプロジェクトを新規作成しましょう
brew でインストールするのがおすすめですangular-cli が入っている人は飛ばしてください
brew install angular-cliangular cli が入ったか確認です
ng v _ _ ____ _ ___ / \ _ __ __ _ _ _| | __ _ _ __ / ___| | |_ _| / △ \ | '_ \ / _` | | | | |/ _` | '__| | | | | | | / ___ \| | | | (_| | |_| | | (_| | | | |___| |___ | | /_/ \_\_| |_|\__, |\__,_|_|\__,_|_| \____|_____|___| |___/ Angular CLI: 8.3.20 〜〜以下省略〜〜2. 新規 angular のプロジェクトを作成
version 8.1 だったか、
--enableIvy=trueを渡せば高速でレンダリングされる Ivy 使用できるので試しに引数でわたしてみまそうng new angular-sample --enableIvy=true3. dockerfile, .dockerignore を追加
dockerfileと、.dockerignoreを追加しましょう
ビルドの高速化のために.dockerignoreも忘れずに追加しましょうdockerfile
# 現バージョンでは、10.9.0以降を推奨しているので、nodeのstableの12系の最新を使用 # https://angular.jp/guide/setup-local#nodejs FROM node:12.13.1 # ローカルフォルダのファイルを置いていくフォルダ作成 RUN mkdir /usr/src/app # package.json と package.lockをコピー COPY ./package*.json /usr/src/app/ # yarnの人はこちらもコピー COPY ./yarn.lock /usr/src/app/ # yarn install する箇所を WORKDIR /usr/src/app/ # yarn使用している人は yarn.lock を元にインストールする yarn install --frozen-lockfile でもいいと思います RUN npm ci # ローカルのファイルすべてコピー COPY . /usr/src/app/ # docker上でコピーした angular-cli で ビルド実行 RUN npx ng build --aot.dockerignore
node_modulesdockerfile はあくまでビルドまで!
無事ビルドできるか試してみてくだせぇ
docker build --rm .最後に
Successfully built 4f89bd9818ae(hash値っぽいやつ)と出ていれば OK だと思いますdocker-compose.yml でサーバーを立ち上げます
4. docker-compose.yml を追加
大事なポイント
- volumes の
- $PWD/:/usr/src/appでローカルのファイルを上書きしている- だけど、node_modules はビルド遅くなるので除外している
- command で
--host=0.0.0.0を渡してる(恐らく webpack に渡している)docker-compose.ymlversion: '3.7' services: anguar-app: image: anguar-app build: context: $PWD/ ports: - '4201:4200' volumes: - $PWD/:/usr/src/app - /usr/src/app/node_modules # node_modulesは除外 command: npx ng serve --aot --host=0.0.0.05. お疲れさまでした
設定はお終いです、お疲れさまでした
ローカルの変更が反映されるか確かめてみましょう
docker-compose up -d;\ sleep 3;\ open http://localhost:4201;docker-compose をバックグラウンドで立ち上げ
↓
3 秒待つ
↓
ブラウザで localhost を立ち上げる変更がない状態で立ち上げると、デフォルトの Angular の画面のままです
なにかローカルの変更をしてみましょう
今回は echo コマンドで、ローカルのファイルを上書きしてみましょう
echo "<h1>反映やっほー</h1>" > ./src/app/app.component.html
ファイル更新しただけで、画面が反映されたので完了です
付録
AngularJS(webpack 前提) の コンテナのライブリロード化 の流れ
- うちは webpack-dev-server がこれで動いています
- dockerfile, dockerignore を追加
- docker-compose.yml を追加
- お疲れさまでした
0. うちは webpack-dev-server がこれで動いています
devServer のとこだけ参照していただければいいかと思います
コンテナのライブリロード化をするには、host: '0.0.0.0'を渡すとうまくいきます
webpack.config.jsconst path = require('path'); const webpack = require('webpack'); const NODE_ENV = process.env.NODE_ENV; console.log(`${NODE_ENV} modeで実行`); module.exports = { mode: NODE_ENV, entry: path.join(__dirname, 'src/app/entry.ts'), output: { filename: 'bundle[hash].js', path: path.resolve(__dirname, 'dist'), chunkFilename: '[name][hash].js', publicPath: '', }, module: (省略), resolve: (省略), devtool: (省略), optimization: (省略), devServer: { historyApiFallback: true, contentBase: path.join(__dirname, 'dist'), publicPath: 'http://localhost:8080/', host: '0.0.0.0', port: 8080, stats: 'minimal', hot: true, inline: true, proxy: (省略) }, plugins:(省略), }1. dockerfile, dockerignore を追加
既存のプロジェクトで webpack-dev-server で動いているが前提なのですが、必然というべきか奇跡というべきか
dockerfile、.dockerignoreは一緒でただ、ビルドコマンドが違うだけです
node のバージョンが 12.13.0 でも、typescript が 3.7.2 でも問題なく動きます# dockerfile 〜Angularと一緒のため省略〜 # docker上でコピーした angular-cli で ビルド実行 RUN NODE_ENV=production npm run webpack2. docker-compose.yml を追加
docker-compose.ymlservices: spa-dev: build: context: $PWD/ image: spa-dev ports: - '8080:8080' volumes: - $PWD/:/usr/src/app - /usr/src/app/node_modules # node_modulesは除外 command: NODE_ENV=development npm run webpack-dev-server3. お疲れさまでした
検証は各自の既存プロジェクトで試してみてください
ちなみに、上記の docker の設定で
AngularJS(1.7.9)
typescript(3.7.2)
webpack(4.41.2)
webpack-dev-server(3.9.0)で問題なく動いておりますあとがき
既存の AngularJS を Angular にかえる話は出ましたが、コードが多く、リプレイスしていく工数と事業インパクトがあるのかで Go の判断が降りず
最新の Angular のプロジェクトではないのですが
それでも、最新の フロントエンド は触っていたいので、AngularJS で新規でつくる機能は
componentの書き方で記述しプロジェクトを維持してますdocker 化を行ったあとは、AWS 上で ECR・ECS 化も済ませ、CircleCI の Orbs を使用し CI も回しています
なので、フレームワークのバージョン以外は技術トレンドにやっとのっけられたかなと思います
Angular Element で機能単位かドメインごとで AngularJS→Angular への置き換えも考えましたが
やはり既存のコードが多く、事業インパクトと見合うかに辿り着き、でもAngular は個人的に触っているからいいですかね同じような境遇にあっている人は少ないとは思いますが、自分はdocker化すると、ローカル環境でのライブリロードが効かなくなってしまうと勘違いし
開発の便利さが失われてしまうのであれば、docker化はあとだ!と思ってましたが
上記のhostを設定するだけで、簡単にライブリロードはできるようになりました!webpackまわりなど、ライブリロードと関係ない箇所は省略した部分など質問がありましたら!

- 投稿日:2019-12-02T14:15:56+09:00
【CI/CD】 Github Actionsを使ってDocker ImageをGitHub Package Registry にpushする
Githubにもワークフローの実行ツールのGithub Actionsとパッケージの管理機能のGitHub Package Registryが追加されました。これらを使うことで、CIプロセスにおけるDockerのbuildやpushをGithubの機能で完結できます。ここでは、Docker imageをGithub Actions、GitHub Package Registry によって公開するまでの手順を解説します。
前準備
手順を進めて最終的に出来上がるリポジトリはこちらです。
準備として、以下のような構成のリポジトリをGithubに作成します。
./ ┣ README.md ┗ app/ ┗ DockerfileDockerfileは3秒ごとに
echo helloを実行するだけの単純なものです。# ./app/Dockerfile FROM alpine:3.10.3 CMD while :; do echo hello; sleep 3; done上記のリポジトリをpushしたら準備は完了です。
Workflowを追加
GithubのUI上でベースとなるファイルを生成します。
上部のActionsからSet up a workflow yourselfをクリックします。
編集画面が出ますが一旦このまま右上の緑のボタンからcommitしてください。
この操作で
.github/workflows/main.ymlが生成されました。ローカルで編集するためgit pullして中身を確認すると以下のymlファイルが作成されています。name: CI on: [push] jobs: build: runs-on: ubuntu-latest steps: - uses: actions/checkout@v1 - name: Run a one-line script run: echo Hello, world! - name: Run a multi-line script run: | echo Add other actions to build, echo test, and deploy your project.リポジトリ全体はこのようになりました。
./ ┣ README.md ┣ .github/ ┃ ┗ workflows/ ┃ ┗ main.yml ┗ app/ ┗ DockerfileWorkflowが実行されていることを確認
この時点でmain.ymlがpushされているのでWorkflowが動くことを確認できます。
ActionsのCIをクリックすると実行結果画面になり
main.ymlでechoされたものが確認できます。
secretsの設定
認証情報等の秘密情報はmain.ymlに埋め込むわけには行かないので、リポジトリのsecretsに設定する必要があります。今回は埋め込んでしまっても問題ないのですが、secretsにユーザー名を設定してみます。
Settings > Secrets > Add a new secret と進むと下のような画面になり、ここにsecretを追加しておきます。
一つは
GITHUB_DOCKER_USERNAMEでここはリポジトリのオーナー(自分のユーザ名)を指定します。今回は特にこれ以外の登録すべきものはありませんが、他にもパスワード等の情報が必要な場合はここに登録することでGithub Actionsの中で使用できます。※ Gitlab CIだと
$CI_REGISTRY_USERでregistryにloginできるのでGithub Actionsでもこれに相当するものがありそうな気がするが調べきれませんでした。そのうち見つかれば直します。Dockerfileをbuildしてpushするようにする。
.github/workflows/main.ymlを編集してDockerのbuildとpushが行われるようにします。以下のように編集してください。test_containerというimageがブランチ名をタグとしてpushされるようになります。name: CI on: [push] jobs: build: runs-on: ubuntu-latest steps: - uses: actions/checkout@v1 - name: build Dockerfile and push image # userで外部ファイル or 定義済みの処理を実行できる。ここではリポジトリのcheckout run: | IMAGE_NAME=test_container:${GITHUB_REF#refs/heads/} # docer imageの名前とそのタグ、${GITHUB_REF#refs/heads/}でブランチ名を取得している docker build ./app --tag docker.pkg.github.com/${GITHUB_REPOSITORY}/${IMAGE_NAME} docker login docker.pkg.github.com --username ${DOCKER_USERNAME} --password ${DOCKER_PASSWORD} docker push docker.pkg.github.com/k8shiro/github_docker_push_example/${IMAGE_NAME} env: DOCKER_USERNAME: ${{ secrets.GITHUB_DOCKER_USERNAME }} # リポジトリのsecretsとして定義した値を環境変数に渡す DOCKER_PASSWORD: ${{ secrets.GITHUB_TOKEN }}ファイルの内容の説明です。詳細や今回使用していないものは
https://help.github.com/ja/actions/automating-your-workflow-with-github-actions/workflow-syntax-for-github-actions
に記載されています。name: CI # ワークフローの名前on: [push] # ワークフローをトリガーするGitHubイベントの名前、ここではリポジトリへのpushでワークフローが実行されるトリガーはwikiの変更やissueに関するイベント等様々なものがあります。
参照: https://help.github.com/ja/actions/automating-your-workflow-with-github-actions/events-that-trigger-workflowsruns-on: ubuntu-latest # ワークフローの実行環境の指定runs-onでワークフローの実行環境となるrunnerを指定します。Windows Server等も用意されているようです→GitHub-hosted runners。
また自分でrunnerを用意することもできます。
- Self-hosted runners について:
uses: actions/checkout@v1 # 既定のアクションを実行、ここではリポジトリのcheckoutのアクションを実行している
usesではGithub既定のアクションの呼び出し、または自分で定義した別ファイルのアクションを呼び出せます。- name: build Dockerfile and push image run: | IMAGE_NAME=test_container:${GITHUB_REF#refs/heads/} # docer imageの名前とそのタグ、${GITHUB_REF#refs/heads/}でブランチ名を取得している docker build ./app --tag docker.pkg.github.com/${GITHUB_REPOSITORY}/${IMAGE_NAME} # Dockerfileのbuild docker login docker.pkg.github.com --username ${DOCKER_USERNAME} --password ${DOCKER_PASSWORD} # GitHub Package Registryへのlogin docker push docker.pkg.github.com/k8shiro/github_docker_push_example/${IMAGE_NAME} # imageのpush env: DOCKER_USERNAME: ${{ secrets.GITHUB_DOCKER_USERNAME }} # リポジトリのsecretsとして定義した値を環境変数に渡す DOCKER_PASSWORD: ${{ secrets.GITHUB_TOKEN }} # Github Actionsで規定で定義されるGITHUB_TOKENを使用Dockerのbuild・pushを行う処理です。まず、一番下の
envですが、ここで環境変数を設定しています。先ほど設定したsecretsがsecrets.*****で読み込まれ、これがDOCKER_USERNAMEとして設定されています。また、secrets.GITHUB_TOKENはデフォルトで定義されるTokenでPermissions等はここに記載されています。GITHUB_REF、GITHUB_REPOSITORYはデフォルトで定義されている環境変数です。その他の環境変数はこちらです。ここまで編集が終了したら
.github/workflows/main.ymlをcommitとpushしてください。動作確認
先ほどWorkflowの実行を確認した時と同様に動作確認してください。
また、packageにimageがpushされているかも確認しておきます。packageをクリックすると以下のようにレジストリが作成されていることが確認できます。
これでdocker pullできます。pullする時には先ほどのToken(or 同等の権限を持つもの)でdocker loginする必要があります。pullコマンドは以下のように表示されています。
ImageをPullする
自分の開発環境に作成されたdocker imageを落としてくるには、上記画像の通り
docker pullコマンドを実行すればよいのですが、pullの前にdocker loginコマンドを実行する必要があります。docker login docker.pkg.github.com -u <username> -p <personal access token> docker pull docker.pkg.github.com/k8shiro/github_docker_push_example/test_container:masterここでは自分のユーザー名でよいのですが、はGithubのパスワードではだめで、Personal Access Tokenを取得する必要があります。
personal access token
GitHub Package Registryへのloginには、personal access tokenを使用する必要があります。
自分のアカウントのSettingsから
Developer settingsに移動し
Generate new tokenから新しいTokenを作成します。
まずNoteの部分にこのTokenの説明(他のTokenと区別がつくように、今回はリポジトリ名を記載)を設定し、その下のScopeを設定していきます。必要なScopeは
- repo
- write:packages
- read:packages
あたりになります。
これでページ下部のGenerate TokenをクリックするとTokenが表示されます。
Tokenは11aaaa1aba999951abca2406b92a66665d3cb22のような文字列でこのタイミング以外では二度と表示されないのでからなず確認し、また流出等扱いには気をつけてください。まとめ
Github Actionsを使ってDocker ImageをGitHub Package Registry にpushする一連の操作を説明しました。CI/CDツールとしての利用は多くの場合、Github ActionsとGitHub Package Registryを利用することで完結できるのではないかと思います。また、課金プランによって使用制限があるようですが無料アカウントでも個人レベルでの使用では問題なさそうです。ただし、使用制限下部に記載がある通り、仮想通貨の採掘やサーバーレスコンピューティングを目的とする場合等、コード開発プロセスの自動化以外の目的に使うことは制限されているようなので注意しましょう。
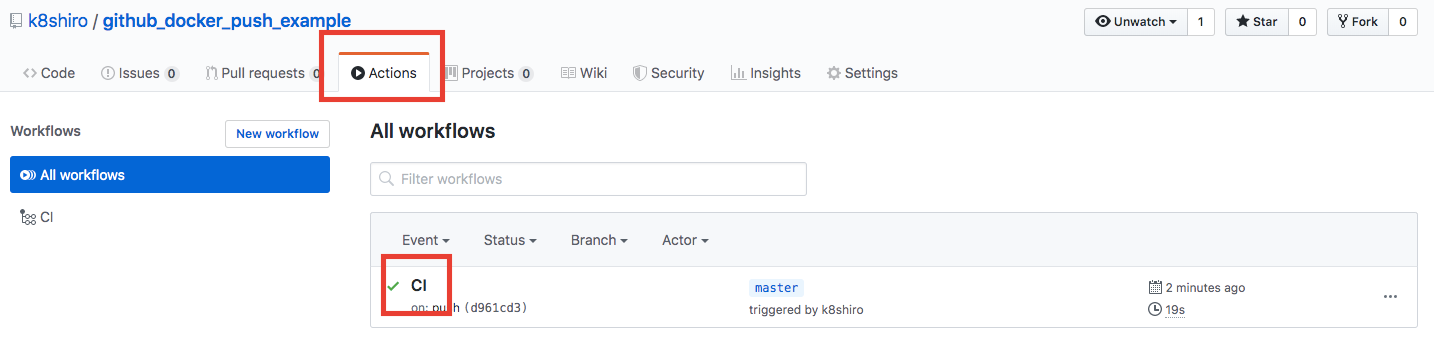
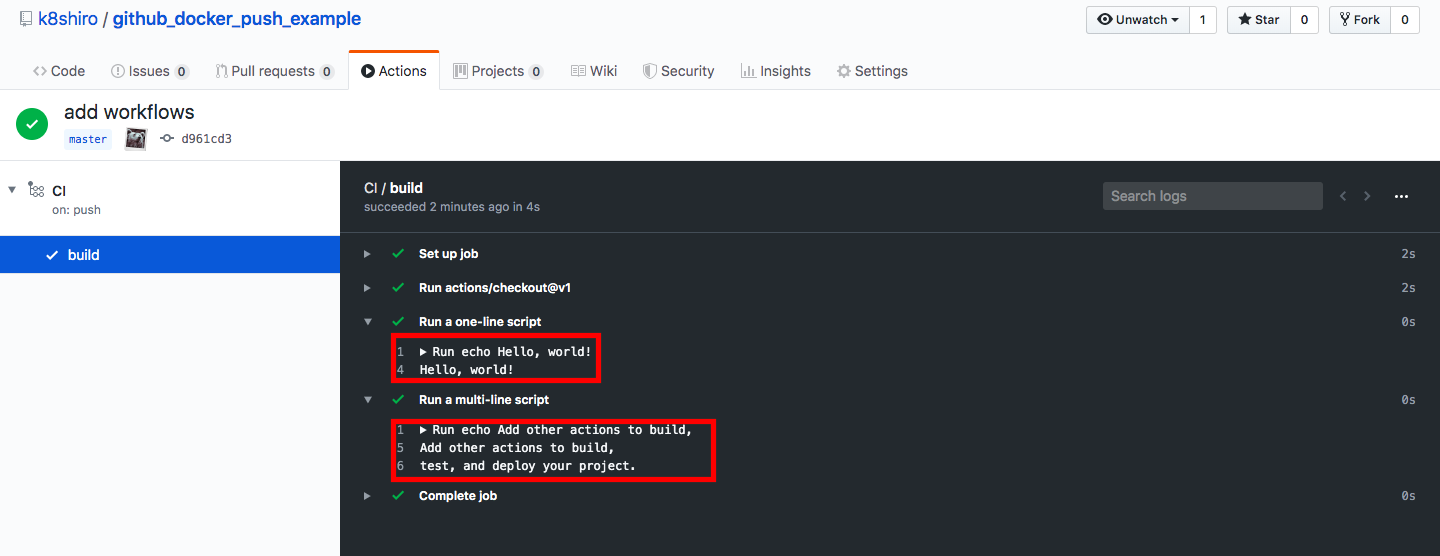

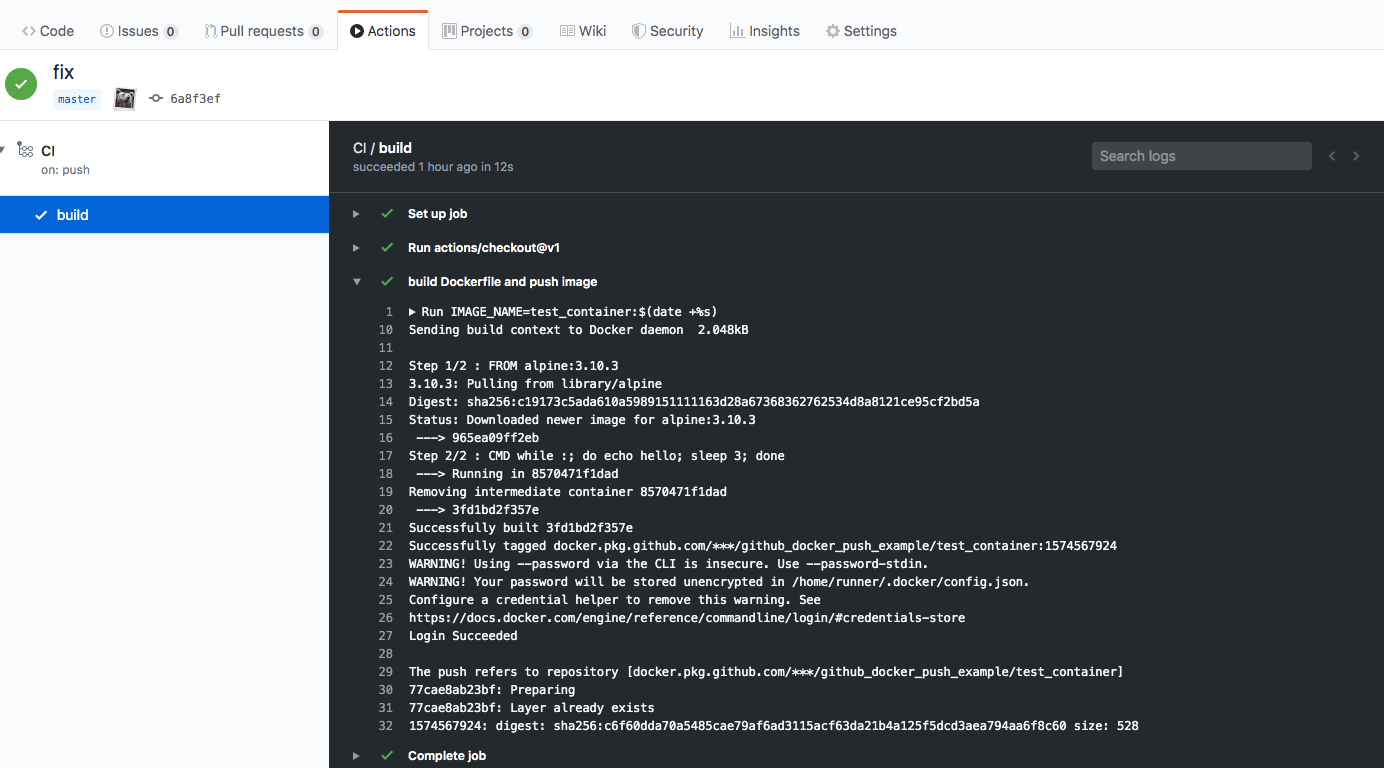
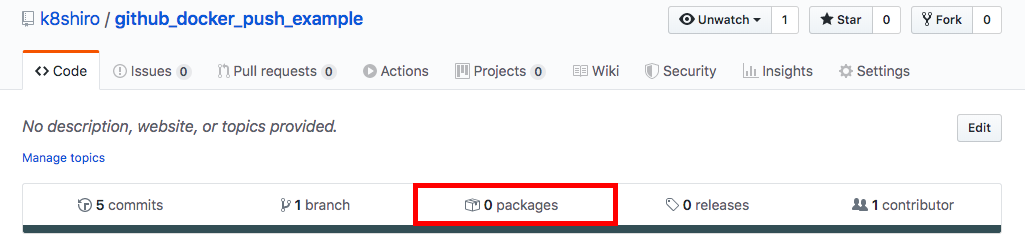
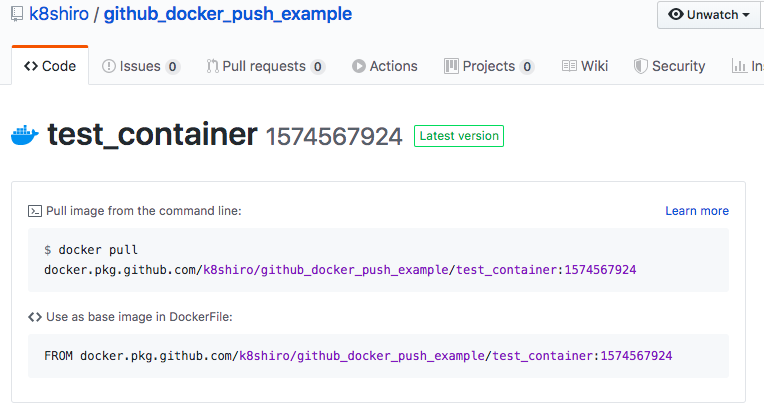



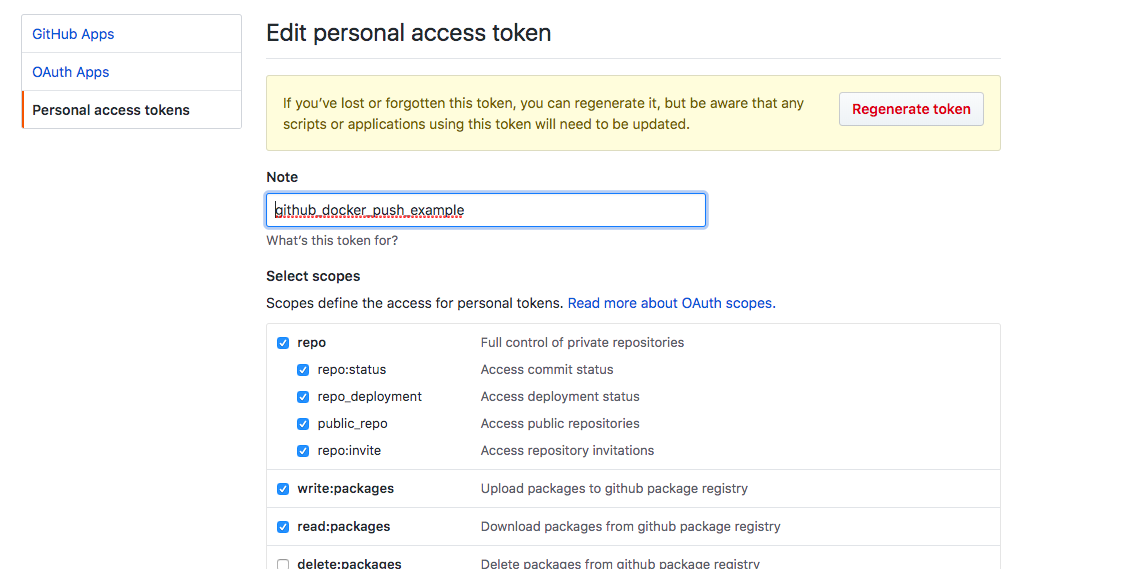
- 投稿日:2019-12-02T14:07:11+09:00
PycharmでローカルのLambdaをDocker Toolboxで動かす時にデバッグ実行できない事象の回避
PycharmでLambdaのデバッグ実行を行う際に、ローカル環境のDockerが「Docker Desktop for Windows」でなく「Docker ToolBox」の場合、デバッグが行えない現象が発生することがあります。
原因はDocker ToolBoxのフォルダのマウント設定です。
Docker ToolBoxでは初期設定で「C:\Users」フォルダ以外がマウントされません。
しかしデバッグでは "C:\Program Files\JetBrains\PyCharm Community Edition 2019.2.3\helpers\pydev\pydevconsole.py(※フォルダはバージョンによってことなります)"というマウントされてないフォルダのモジュールを使用するので、モジュールの読み込みが行えずデバッグが行えないのです。回避策としては、モジュールの格納されているフォルダをマウント設定する必要があります。
今回はCドライブの直下をまとめてマウント設定してしまいました。# ▼VirtualBoxのDockerイメージを停止する、NAMEは「default」。 # ▼VboxManageで VMの default に C:\ を c として共有フォルダ追加を行う。 $ "C:\Program Files\Oracle\VirtualBox\VBoxManage.exe" sharedfolder add default --name c --hostpath "C:/" --automount # ▼VirtualBoxのDockerイメージを起動する、NAMEは「default」。 # ※「Docker Quickstart Terminal」からの起動でもよい # ▼dockerホスト上に共有フォルダ c を /c にマウントする $ docker-machine ssh default "sudo mkdir -p /c" $ docker-machine ssh default "sudo mount -t vboxsf -o uid=0,gid=0 c /c"
- 投稿日:2019-12-02T13:18:04+09:00
open-wc 開発 with Docker
open-wcというプロジェクトがある。
open-wc自体は、(デフォルトは)lit-elementを使って、webcomponentを開発するベストプラクティスを開発者に提供しようという感じのプロジェクト。でも、今回はそこは主眼ではない。
このプロジェクト、フロントエンド開発環境としてやばいぐらいリッチなので最近使い始めている。
- test
- karma
- snapshot testing
- coverage
- storybook
- demo server
これら設定済で完備である。
このプロジェクトのscafoldがコマンド一発でできるのだから素晴らしい。んで、開発用ツールのWebサーバーをdocker-composeでポンと一発で起動したら素敵だと思ったので書いてみました。
(open-wcのusage)
open-wcの導入(公式見たほうが早い)$ npm init @open-wc > ✔ What would you like to do today? › Scaffold a new project > ✔ What would you like to scaffold? › Web Component > ✔ What would you like to add? › Linting, Testing, Demoing > ✔ Would you like to scaffold examples files for? › Testing, Demoing > ✔ What is the tag name of your application/web component? … hoge-piyo > npm init @open-wc --destinationPath /hoge-piyo --type scaffold --scaffoldType wc --features linting testing demoing --scaffol dFilesFor testing demoing --tagName hoge-piyo --writeToDisk true --installDependencies falseDockerのための設定
ここから以下を調整する
es-dev-server.config.jsmodule.exports = { hostname: "0.0.0.0", port: Number(process.env.PORT) };DockerfileFROM node:lts RUN \ # for karma test wget -q -O - https://dl-ssl.google.com/linux/linux_signing_key.pub | apt-key add - \ && echo "deb [arch=amd64] http://dl.google.com/linux/chrome/deb/ stable main" >> /etc/apt/sources.list.d/google.list \ && apt-get update -y && apt-get install -y google-chrome-stable \ && apt-get clean \ && rm -rf /var/lib/apt/lists/* WORKDIR /app COPY package.json yarn.lock ./ RUN yarn install COPY . ./ CMD [ "npm", "start" ]docker-compose.ymlversion: '3.7' volumes: node_modules: {} services: app: &app build: . volumes: - .:/app - /app/node_modules command: - bash tty: true demo: &demo <<: *app environment: PORT: 8000 ports: - 8000:8000 entrypoint: - npm - run command: - start test: <<: *app command: - npm - run - test:watch - -- - --coverage coverage: <<: *demo depends_on: - test environment: PORT: 8001 ports: - 8001:8001 entrypoint: - npx - es-dev-server - --root-dir - coverage - --watch storybook: <<: *demo environment: PORT: 8002 ports: - 8002:8002 command: storybookこのプロジェクトの使い方
サービス起動用ターミナル窓$ docker-compose up -d $ open http://localhost:8000/demo/ # demo $ open http://localhost:8001 # coverage $ open http://localhost:8002 # storybook $ docker-compose log -f test # test watching # $ docker-compose down -v # 終わるときブラウザが3窓でリアルタイムに色々出してくれる。
- 投稿日:2019-12-02T12:08:18+09:00
Docker+Laravel+MeCabで言語解析のWebアプリ環境を構築する
この記事はエイチーム引越し侍 / エイチームコネクト Advent Calendar 20193日目の記事です。
本日はエイチームコネクト入社4ヶ月目に突入した@ikuma_hayashiが担当します。
SIerから転職して4ヶ月目、まだまだ日は浅く勉強中ですが、Qiita初投稿です!気になる点ありましたらぜひコメントくださいエイチームコネクトって何やってるの?
当社グループのサイトをご利用いただいたユーザー様へ、生活に紐づく必要なサービスのご案内をお電話にて行っております。主に引越しされたお客様に対し、居住場所の変化に伴って生活が豊かになるインターネット回線や電力サービスをご紹介しています。
生活が豊かになるお客様・各種サービスを運営されている会社様・エイチームグループの三方よしを実現するべく、日々追求しております。なんでやるの?
お客様とオペレーターでされた会話を自然言語処理で解析し、より良いユーザービリティを追求するために、Dockerで言語解析+Webアプリの超基本的な基盤を構築します。
対象の読者
- Laravelで言語解析したい(文字列から単語を抜き取って重要度を計算したい)
- Laravel, Dockerは使ったことある
MeCabってなに?
MeCabは 京都大学情報学研究科−日本電信電話株式会社コミュニケーション科学基礎研究所 共同研究ユニットプロジェクトを通じて開発されたオープンソース 形態素解析エンジンです。
中略
ちなみに和布蕪(めかぶ)は, 作者の好物です。引用元:MeCab: Yet Another Part-of-Speech and Morphological Analyzer
形態素解析とは、文章を形態素という最小単位に分解する技術です。
コマンドラインベースで下記のように形態素解析してくれます。$ mecab $ みんなで幸せになれる会社にすること みんな 名詞,代名詞,一般,*,*,*,みんな,ミンナ,ミンナ で 助詞,格助詞,一般,*,*,*,で,デ,デ 幸せ 名詞,形容動詞語幹,*,*,*,*,幸せ,シアワセ,シアワセ に 助詞,副詞化,*,*,*,*,に,ニ,ニ なれる 動詞,自立,*,*,一段,基本形,なれる,ナレル,ナレル 会社 名詞,一般,*,*,*,*,会社,カイシャ,カイシャ に 助詞,格助詞,一般,*,*,*,に,ニ,ニ する 動詞,自立,*,*,サ変・スル,基本形,する,スル,スル こと 名詞,非自立,一般,*,*,*,こと,コト,コトMeCabのみではPHPから直接利用できないため、php-mecabも併せて導入し、Laravelから利用できるようにしています。
今回は、これらを用いてLaravel環境で形態素解析を行えるようにします。
環境
- ホストOS
- Windows10 Pro
- Docker for Windows
- Dockerコンテナ
- Laravel 6.0
- php-fpm7.3
- MySQL 8.0
- nginx 1.17
ディレクトリ・ファイル構造(一部省略)
laramecab │ ├─docker-compose.yml │ └─README.md ├─docker │ ├─mysql │ │ └─my.cnf │ ├─nginx │ │ └─default.conf │ └─php │ ├─Dockerfile │ └─php.ini ├─logs : 各種ログ・ファイル └─projects └─myapp : Laravelのプロジェクト(laradockにちなんでlaramecabとかいう大それた名前をつけてみた
)
環境構築
コンテナを起動
# 適当なフォルダにてgit clone PS C:\> git clone https://github.com/IkumaHayashi/laramecab.git Cloning into 'laramecab'... remote: Enumerating objects: 18, done. remote: Counting objects: 100% (18/18), done. remote: Compressing objects: 100% (13/13), done. remote: Total 18 (delta 1), reused 14 (delta 0), pack-reused 0 Unpacking objects: 100% (18/18), done. # 出来たフォルダにてdockerイメージの構築と起動(5分くらいかかります) PS C:\> cd .\laramecab\ PS C:\laramecab> docker-compose up -d Creating laramecab_app_1 ... done Creating laramecab_db_1 ... done Creating laramecab_web_1 ... done # 正常に起動しているか確認 PS C:\laramecab> docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES ad8e3d23fbc5 mysql:8.0 "docker-entrypoint.s…" 7 seconds ago Up 4 seconds 33060/tcp, 0.0.0.0:13306->3306/tcp laramecab_db_1 c6bce5731a4e nginx:1.17-alpine "nginx -g 'daemon of…" About a minute ago Up 4 seconds 0.0.0.0:8000->80/tcp laramecab_web_1 b58a85b0aa2f laramecab_app "docker-php-entrypoi…" About a minute ago Up 5 seconds 9000/tcp, 0.0.0.0:18000->8000/tcp laramecab_app_1MeCabがappコンテナで使えるかどうか確認
# appコンテナのshを起動 PS C:\laramecab> docker-compose exec app sh # MeCabを起動 $ mecab 今から100年続く会社にすること 今 名詞,副詞可能,*,*,*,*,今,イマ,イマ から 助詞,格助詞,一般,*,*,*,から,カラ,カラ 100 名詞,数,*,*,*,*,* 年 名詞,接尾,助数詞,*,*,*,年,ネン,ネン 続く 動詞,自立,*,*,五段・カ行イ音便,基本形,続く,ツヅク,ツズク 会社 名詞,一般,*,*,*,*,会社,カイシャ,カイシャ に 助詞,格助詞,一般,*,*,*,に,ニ,ニ する 動詞,自立,*,*,サ変・スル,基本形,する,スル,スル こと 名詞,非自立,一般,*,*,*,こと,コト,コト EOS # 終了するときはCtrl + Cで抜けられます ^CLaravelのプロジェクトを作成
# Laravelプロジェクトの作成 PS C:\laramecab> docker-compose exec app composer create-project --prefer-dist laravel/laravel myapp # いったんdockerコンテナを終了する PS C:\laramecab> docker-compose stop Stopping laramecab_db_1 ... done Stopping laramecab_web_1 ... done Stopping laramecab_app_1 ... donenginxの公開フォルダを変更する必要があります。
laramecab\docker\nginx\default.confを開き、下記の通り書き換えてください。laramecab\docker\nginx\default.confserver { listen 80; #root /work/public; root /work/myapp/public; index index.php; charset utf-8; location / { #root /work/public; root /work/myapp/public; try_files $uri $uri/ /index.php$is_args$args; } #省略ふたたびdockerコンテナを起動していきます。
PS C:\laramecab> docker-compose up -d Starting laramecab_app_1 ... done Starting laramecab_db_1 ... done Starting laramecab_web_1 ... doneあとは下記URLを起動すれば、例のLaravelの画面が見えてきます!
http://localhost:8000/
php-mecabが使えるか確認
laravelにはtinkerというコマンドラインでコードを実行できる機能がありますので、tinkerで確認していきましょう。
# ホストOSからappコンテナでmyappに移動してtinkerを起動する PS C:\laramecab> docker-compose exec app sh -c "cd myapp/ && php artisan tinker" Psy Shell v0.9.11 (PHP 7.3.11 — cli) by Justin Hileman # MeCabのインスタンスを生成 >>> $mecab = new \Mecab\Tagger(); => MeCab\Tagger {#3006} # 文字列を渡し解析 >>> $nodes = $mecab->parseToNode('今から100年続く会社にすること'); # 解析結果を表示 >>> foreach ($nodes as $n) { print_r($n->getFeature().PHP_EOL); } BOS/EOS,*,*,*,*,*,*,*,* 名詞,副詞可能,*,*,*,*,今,イマ,イマ 助詞,格助詞,一般,*,*,*,から,カラ,カラ 名詞,数,*,*,*,*,* 名詞,接尾,助数詞,*,*,*,年,ネン,ネン 動詞,自立,*,*,五段・カ行イ音便,基本形,続く,ツヅク,ツズク 名詞,一般,*,*,*,*,会社,カイシャ,カイシャ 助詞,格助詞,一般,*,*,*,に,ニ,ニ 動詞,自立,*,*,サ変・スル,基本形,する,スル,スル 名詞,非自立,一般,*,*,*,こと,コト,コト BOS/EOS,*,*,*,*,*,*,*,*以上で、appコンテナ内でlaravel上でMeCabによる解析ができたことを確認できました!
どうでもいい話ですが、powershellはcdやlsなど、linuxライクなコマンドの利用が可能なので結構おすすめですせっかくなんでコード書く
ここまでで終わろうと思ってましたがせっかくなんでコードも書いていきます
下記の流れでアプリを作成していきます。
- 解析対象の文字列(Text)、抽出された重要後と重要度(ImportanceTerm)のテーブル、モデル作成
- 文字列を渡すとの結果と出現回数をDBに格納するcommandを作成
- 重要度を計算し、レコードをupdateするcommandを作成
今回は重要度の計算にtfidf法というものを使っていきます。
tfidf法については、こちらにて概要が解説されていますのでご参照ください。めちゃくちゃ乱暴に言ってしまうと、
- その文書内で重要な単語って何回も出るくね?(出現回数tf:Term Frequency)
- でも一般的な言葉って重要度低いから、レア度が高いほうが重要度高くね?(レア度、固く言うと逆文書頻度idf:Inverse Document Frequency)
- この2つをかけたら重要度じゃね?(出現回数×レア度=重要度)
というものです
1. 解析対象の文字列(Text)、抽出された重要後と重要度(ImportanceTerm)のテーブル、モデル作成
今回はTextsテーブル、ImportanceTermsの2つのテーブルを作成していきます。ER図にすると下記のようにTextsとImportanceTermsは1対多の関係になります。
マイグレーションファイルの作成
appコンテナ$ php artisan make:migration create_texts_table --create=texts Created Migration: 2019_12_02_140747_create_texts_table $ php artisan make:migration create_importance_terms_table --create=importance_terms Created Migration: 2019_12_02_140908_create_importance_terms_tableマイグレーションファイルの編集
必要なカラムの追加とリレーションを張っていきます。
myapp\database\migrations\2019_12_02_140747_create_texts_table.php<?php use Illuminate\Database\Migrations\Migration; use Illuminate\Database\Schema\Blueprint; use Illuminate\Support\Facades\Schema; class CreateTextsTable extends Migration { /** * Run the migrations. * * @return void */ public function up() { Schema::create('texts', function (Blueprint $table) { $table->bigIncrements('id'); $table->longText('text'); $table->timestamps(); }); } /** * Reverse the migrations. * * @return void */ public function down() { Schema::dropIfExists('texts'); } }myapp\database\migrations\2019_12_02_140908_create_importance_terms_table.php<?php use Illuminate\Database\Migrations\Migration; use Illuminate\Database\Schema\Blueprint; use Illuminate\Support\Facades\Schema; class CreateImportanceTermsTable extends Migration { /** * Run the migrations. * * @return void */ public function up() { Schema::create('importance_terms', function (Blueprint $table) { $table->bigIncrements('id'); $table->bigInteger('text_id')->unsigned(); $table->foreign('text_id')->references('id')->on('texts'); $table->string('term', 50); $table->integer('frequency')->default(0); $table->double('tf', 8, 4)->default(0.0); $table->double('idf', 8, 4)->default(0.0); $table->double('tfidf', 8, 4)->virtualAs('tf * ( idf + 1 )'); $table->timestamps(); }); } /** * Reverse the migrations. * * @return void */ public function down() { Schema::dropIfExists('importance_terms'); } }migrateの実行
appコンテナ$ artisan migrate Migration table created successfully. Migrating: 2019_12_02_140747_create_texts_table Migrated: 2019_12_02_140747_create_texts_table (0.19 seconds) Migrating: 2019_12_02_140908_create_importance_terms_table Migrated: 2019_12_02_140908_create_importance_terms_table (0.48 seconds)DBコンテナでテーブルの存在を確認していきます。
dbコンテナ$ # mysql -u root -p Enter password: mysql> use default; Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A mysql> show tables; +-------------------+ | Tables_in_default | +-------------------+ | migrations | | importance_terms | | texts | +-------------------+ 3 rows in set (0.00 sec)モデルの作成
下記の通りコマンドを実行します。
appコンテナ$ php artisan make:model Text Model created successfully. $ php artisan make:model ImportanceTerm Model created successfully.モデルファイルが下記の通り作成されますので、Modelsというディレクトリを作成して移動させ、それぞれ編集していきます。
- myapp\app\Text.php → myapp\app\Models\Text.php
- myapp\app\ImportanceTerm.php → myapp\app\Models\ImportanceTerm.php
ImportanceTermモデルの編集
先にImportanceTermのほうから。ImportanceTermから見ると、Textは1つしかないので、belogsToを使ってリレーションを張ります。
myapp\app\Models\ImportanceTerm.php<?php namespace App\Models; use Illuminate\Database\Eloquent\Model; class ImportanceTerm extends Model { public function text(){ return $this->belongsTo('App\Models\Text'); } }Textモデルの編集
今度はTextモデルです。Textから見るとImportanceTermsは多なので、hasManyを使ってリレーションを張ります。
ついでに、重要度の降順で並び替えて取得するようにします。
また、textフィールドに設定された文字列からmecabによる解析および単語の出現回数(tf)の計算を行い、一緒に保存するようにします。myapp\app\Models\Text.php<?php namespace App\Models; use Illuminate\Database\Eloquent\Model; class Text extends Model { public function importanceTerms() { return $this->hasMany('App\Models\ImportanceTerm')->orderByDesc('tfidf'); } public function setImportanceTerms() { //名詞の抽出と重要度の算出 $frequencyAndTfs = $this->generateFrequencyAndTfs(); //DBに保存 foreach ($frequencyAndTfs as $key => $frequencyAndTf) { $importanceTerm = new \App\Models\ImportanceTerm(); $importanceTerm->term = $key; $importanceTerm->tf = $frequencyAndTf['tf']; $importanceTerm->frequency = $frequencyAndTf['frequency']; $this->importanceTerms()->save($importanceTerm); } } private function generateFrequencyAndTfs() : array { //文字列を解析 $mecab = new \Mecab\Tagger(); $nodes = $mecab->parseToNode($this->text); //形態素ごとに名詞かどうか、重要度はいくつかを算出 $allTerms = array(); $terms = array(); $compoundNoun = ''; foreach ($nodes as $n) { $result = explode(',', $n->getFeature()); //空白は無視 if($n->getSurface() == '') continue; //全単語の頻出回数を記録 $this->incrementFrequency($allTerms, $n->getSurface()); //名詞ではない かつ 前も名詞ではない場合はスキップ if($compoundNoun == '' && $result[0] != '名詞'){ continue; //名詞ではない かつ 複合名詞が空でない場合は、複合名詞としてカウント }else if($compoundNoun != '' && $result[0] != '名詞'){ //ひらがな1文字は除外する if(preg_match('/^[ぁ-ん]$/u', $compoundNoun)){ $compoundNoun = ''; continue; } //複合名詞がまだ単名詞の場合は除外する if($compoundNoun == $n->getSurface()){ $compoundNoun = ''; continue; } //複合名詞を格納 $this->incrementFrequency($terms, $compoundNoun); $compoundNoun = ''; //名詞 かつ 前の形態素も名詞の場合 }else if($compoundNoun != '' && $result[0] == '名詞'){ //前の名詞と複合名詞が一致する場合、前の名詞を単名詞としてカウント if($compoundNoun == $n->getPrev()->getSurface()){ $this->incrementFrequency($terms, $n->getPrev()->getSurface()); } $this->incrementFrequency($terms, $n->getSurface()); $compoundNoun .= $n->getSurface(); //名詞 かつ 最初の出現の場合 }else{ $compoundNoun .= $n->getSurface(); } } $frequencyAndTfs = array(); $sumFrequency = array_sum($allTerms); foreach ($terms as $term => $value) { $frequencyAndTfs[$term] = ['frequency'=> $value , 'tf' => $value / $sumFrequency]; } return $frequencyAndTfs; } private function incrementFrequency(&$terms, $term) { isset($terms[$term]) ? $terms[$term]++ : $terms[$term] = 1; } }2. 文字列を渡すとの結果と出現回数をDBに格納するcommandを作成
appコンテナでコマンドを作成していきます。詳しい解説は下記を参照してください。
Laravelでコマンドラインアプリケーションを作成する今回は下記のようにコマンドを打つことで、MeCabによる解析結果をDBに登録し、重要度の計算・更新を行っていきます。
#解析対象の文字列を登録 php artisan TermImportance:store みんなで幸せになれる会社にすること php artisan TermImportance:store 今から100年続く会社にすること #idfの計算および重要度の算出 php artisan TermImportance:calcコマンドの作成
実際にコマンドを作成していきます。
appコンテナ$ php artisan make:command StoreTextCommand $ php artisan make:command CalcCommandそうすると下記の2ファイルができるのでコードを編集していきます。
myapp\app\Console\Commands\StoreTextCommand.phpmyapp\app\Console\Commands\CalcCommand.phpコマンドの編集
StoreTextCommandの編集
myapp\app\Console\Commands\StoreTextCommand.php(一部省略)<?php namespace App\Console\Commands; use Illuminate\Console\Command; class StoreTextCommand extends Command { protected $signature = 'TermImportance:store {text}'; protected $description = '計算対象の文字列と各単語の重要度をDBに保管します。'; public function __construct() { parent::__construct(); } public function handle() { $text = new \App\Models\Text(); $text->text = $this->argument("text"); $text->save(); $text->setImportanceTerms(); } }StoreTextCommandの動作確認
appコンテナ$ php artisan TermImportance:store みんなで幸せになれる会社にすることdbコンテナ$ mysql -u root -p $ mysql> select * from texts; +----+-----------------------------------------------------+---------------------+---------------------+ | id | text | created_at | updated_at | +----+-----------------------------------------------------+---------------------+---------------------+ | 1 | みんなで幸せになれる会社にすること | 2019-12-02 15:29:16 | 2019-12-02 15:29:16 | +----+-----------------------------------------------------+---------------------+---------------------+ 1 row in set (0.00 sec) mysql> select * from importance_terms; +----+---------+-----------+-----------+--------+--------+--------+---------------------+---------------------+ | id | text_id | term | frequency | tf | idf | tfidf | created_at | updated_at | +----+---------+-----------+-----------+--------+--------+--------+---------------------+---------------------+ | 1 | 1 | みんな | 1 | 0.1111 | 0.0000 | 0.1111 | 2019-12-02 15:29:16 | 2019-12-02 15:29:16 | | 2 | 1 | 幸せ | 1 | 0.1111 | 0.0000 | 0.1111 | 2019-12-02 15:29:16 | 2019-12-02 15:29:16 | | 3 | 1 | 会社 | 1 | 0.1111 | 0.0000 | 0.1111 | 2019-12-02 15:29:16 | 2019-12-02 15:29:16 | +----+---------+-----------+-----------+--------+--------+--------+---------------------+---------------------+ 3 rows in set (0.01 sec)よき!当然ですがまだ文章が短くtfは1回だし、idfは計算を実装していないので、デフォルト値0.0になります。
CalcCommandの編集
最後に、idfを計算するロジックを書いていきます。
idfは、全文書のうち該当の単語が存在する文書数を元に計算されます。
(厳密には idf = log10(該当の単語がある文書数/全文書数) )videoモデルに、重要語有無をチェックするメソッドを実装
myapp\app\Console\Commands\CalcCommand.php<?php namespace App\Console\Commands; use Illuminate\Console\Command; use Illuminate\Support\Facades\DB; class CalcCommand extends Command { /** * The name and signature of the console command. * * @var string */ protected $signature = 'TermImportance:calc'; /** * The console command description. * * @var string */ protected $description = '各単語のidfを計算します。'; /** * Create a new command instance. * * @return void */ public function __construct() { parent::__construct(); } /** * Execute the console command. * * @return mixed */ public function handle() { $texts = \App\Models\Text::all(); foreach ($texts as $text) { $importanceTerms = $text->importanceTerms()->get(); foreach ($importanceTerms as $importanceTerm) { $hasTermCount = \App\Models\ImportanceTerm::where('term', $importanceTerm->term) ->distinct() ->count(); $idf = $hasTermCount > 0 ? log10(count($texts) / $hasTermCount) : log10(0); $importanceTerm->idf = $idf; $importanceTerm->save(); } } } }CalcCommandの動作確認
さきほど、「みんなで幸せになれる会社にすること」という言葉を登録しましたが、テストのために下記のように追加でTextの登録と計算を行います。
appコンテナ$ php artisan TermImportance:store みんなが幸せになれる会社にすることという経営理念では、主体性が生まれないので、みんな”で”に変わった $ php artisan TermImportance:store 今から100年続く会社にすること $ php artisan TermImportance:calc続いて結果の確認を行っていきます。
dbコンテナ$ mysql -u root -p mysql> select it.term, it.frequency, it.tf, it.idf, it.tfidf -> from importance_terms it -> order by it.tfidf desc; +--------------+-----------+--------+--------+--------+ | term | frequency | tf | idf | tfidf | +--------------+-----------+--------+--------+--------+ | 今 | 1 | 0.1111 | 0.4771 | 0.1641 | | 100 | 1 | 0.1111 | 0.4771 | 0.1641 | | 年 | 1 | 0.1111 | 0.4771 | 0.1641 | | 100年 | 1 | 0.1111 | 0.4771 | 0.1641 | | みんな | 1 | 0.1111 | 0.1761 | 0.1307 | | 幸せ | 1 | 0.1111 | 0.1761 | 0.1307 | | 会社 | 1 | 0.1111 | 0.0000 | 0.1111 | | 会社 | 1 | 0.1111 | 0.0000 | 0.1111 | | みんな | 2 | 0.0714 | 0.1761 | 0.0840 | | こと | 1 | 0.0357 | 0.4771 | 0.0527 | | 経営 | 1 | 0.0357 | 0.4771 | 0.0527 | | 理念 | 1 | 0.0357 | 0.4771 | 0.0527 | | 経営理念 | 1 | 0.0357 | 0.4771 | 0.0527 | | 主体性 | 1 | 0.0357 | 0.4771 | 0.0527 | | 幸せ | 1 | 0.0357 | 0.1761 | 0.0420 | | 会社 | 1 | 0.0357 | 0.0000 | 0.0357 | +--------------+-----------+--------+--------+--------+母数が少ないのでわかりにくいのですが、
- 「今」や「100年」という言葉は全体で1回しか出ていない→レア度が高い
- 「会社」という言葉はすべての文書で出ているためレア度が低い
という結果となりました。まとめ
- Dockerfileでphp-fpmのコンテナにMeCab、ipadic(辞書)、php-mecabをインストールしました
- DBと連携してtfidf法を用いてテキストから抽出した単語の重要度を計算しました
留意点
- 本記事ではLaravelとしてどこに処理を記述するか、について主眼を置いてません。
- 実際はMeCabを使うのであればpythonなどライブラリが充実している言語がおすすめです。PHPと連携したいときは参考になるかと思います。
- Amazon Lexといった音声から解析できるサービスも出てきており、自然言語処理を実装する必要性がなくなっています。
ソースコード
ソースコードは下記にて公開しております。(個人のGithubアカウントのため会社の活動とは全く関係ありませんのでご了承ください。)
参考記事
お知らせ
エイチームグループでは一緒に活躍してくれる優秀な人材を募集中です。
興味のある方はぜひともエイチームグループ採用ページよりご応募ください!Qiita Jobsのエイチーム引越し侍社内システム企画 / 開発チーム、社内システム開発エンジニアを募集!からチャットでご質問いただくことも可能です!
明日
明日はいつも助けてくれる @ex_SOULさんの記事です!
魂のこもった記事をお楽しみに!

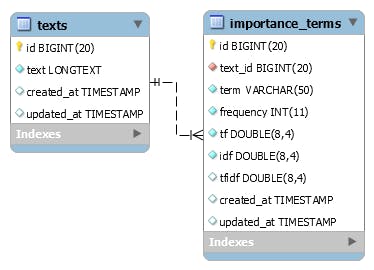
- 投稿日:2019-12-02T11:15:02+09:00
docker-composeでMySQLを起動してみた
docker-composeでMySQLを起動してみた
開発環境
- Windows10
- IntelliJIDE
- Docker for Windows
- MySQL8.0
作業内容
- docker-composeを利用して、MySQLイメージをコンテナで起動
docker-composeでMySQL構築
- docker-composeのバ‐ジョン確認
>docker-compose --version docker-compose version 1.24.1, build 4667896b
- ディレクトリの作成
prototype-docker/ ├ docker/ | └ mysql/ | ├ conf.d/ | | └ my.cnf | ├ initdb.d/ | | ├ schema.sql | | └ testdata.sql | └ Dockerfile └ docker-compose.yml
- Dockerfileの作成
Dockerfileにイメージのビルド内容を記述します。
FROM mysql:8.0 # 指定の場所にログを記録するディレクトリを作る RUN mkdir /var/log/mysql # 指定の場所にログを記録するファイルを作る RUN touch /var/log/mysql/mysqld.log
- docker-compose.ymlの作成
docker-compose.ymlにMYSQLの設定を記述します。
version: '3.3' services: db: build: ./docker/mysql image: mysql:8.0 restart: always environment: MYSQL_DATABASE: prototype MYSQL_USER: user MYSQL_PASSWORD: password MYSQL_ROOT_PASSWORD: password TZ: 'Asia/Tokyo' ports: - "3306:3306" volumes: - ./docker/mysql/initdb.d:/docker-entrypoint-initdb.d - ./docker/mysql/conf.d:/etc/mysql/conf.d
- my.confの作成
my.confに、独自のMySQLの設定を記述します。
[mysqld] # mysqlサーバー側が使用する文字コード character-set-server=utf8mb4 # テーブルにTimeStamp型のカラムをもつ場合、推奨 explicit-defaults-for-timestamp=1 # 実行したクエリの全ての履歴が記録される(defaultではOFF) general-log=1 # ログの出力先 general-log-file=/var/log/mysql/mysqld.log [client] # mysqlのクライアント側が使用する文字コード default-character-set=utf8mb4
- schema.sqlの作成
初期化するテーブル定義のDDLを記述します。
create TABLE IF NOT EXISTS `prototype`.`users` ( `id` INT NOT NULL AUTO_INCREMENT COMMENT 'ユーザーID' , `mail` VARCHAR (256) NOT NULL COMMENT 'メールアドレス' , `gender` SMALLINT (1) NOT NULL COMMENT '性別' , `password` VARCHAR (256) NOT NULL COMMENT 'パスワード' , `birthdate` DATE NOT NULL COMMENT '生年月日' , `create_user_id` INT NULL COMMENT '作成者ID' , `create_timestamp` TIMESTAMP NULL COMMENT '作成日時' , PRIMARY KEY (`id`) , UNIQUE INDEX `mail_UNIQUE` (`mail`) ) ENGINE = Innodb , DEFAULT character set utf8 , COMMENT = 'ユーザー' ;
- testdata.sqlの作成
初期化したテーブルに投入するデータのDMLを記述します。
INSERT INTO users(mail, gender, password, birthdate, create_user_id, create_timestamp) VALUES ('test@gmail.com', 1, '暗号化したパスワード', '1991/01/01', 0, current_timestamp);
- docker-composeコマンドの実行
ディレクトリ構成と各種ファイルの作成が完了したら、docker-composeコマンドを実行します。
> docker-compose up -d #コンテナの起動 Creating prototype-docker_db_1 ... done >docker-compose ps #存在するコンテナの一覧とその状態を表示 Name Command State Ports ----------------------------------------------------------------------------------------------- prototype-docker_db_1 docker-entrypoint.sh mysqld Up 0.0.0.0:3306->3306/tcp, 33060/tcp
- 初期化クエリ実行確認
schema.sqlとtestdata.sqlの実行結果を確認します。
>docker exec -it prototype-docker_db_1 bash root@aabd0f319f85:/# mysql -u user -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 24 Server version: 8.0.18 MySQL Community Server - GPL Copyright (c) 2000, 2019, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> show tables from prototype; +---------------------+ | Tables_in_prototype | +---------------------+ | users | | users_history | +---------------------+ 2 rows in set (0.00 sec)ソースコード
- 投稿日:2019-12-02T08:48:40+09:00
コンテナ型仮想化技術 Study09 / Helm
はじめに
今回はHelmです。
関連記事
コンテナ型仮想化技術 Study01 / Docker基礎
コンテナ型仮想化技術 Study02 / Docker レジストリ
コンテナ型仮想化技術 Study03 / Docker Compose
コンテナ型仮想化技術 Study04 / Minikube & kubectl簡易操作
コンテナ型仮想化技術 Study05 / Pod操作
コンテナ型仮想化技術 Study06 / ReplicaSet, Deployment, Service
コンテナ型仮想化技術 Study06' / Kubernetesネットワーク問題判別
コンテナ型仮想化技術 Study07 / ストレージ
コンテナ型仮想化技術 Study08 / Statefulset, Ingress
コンテナ型仮想化技術 Study09 / Helm参考情報
Helmの概要とChart(チャート)の作り方
Helm Documentation(V3)
Helm Documentation(V2)
Helm 3.0 のお試しレポート
Get Started with Kubernetes using Minikube
chartを作りながらhelmの概要を理解するHelm Templateについて色々説明してみる
[Helm入門] Templateで使える関数の実行例 ~ 文字列操作編 ~※Helmの全体像を理解するには、上の一番目の記事が秀逸で分かりやすい。
HelmはGo言語で実装されているらしく、Helm ChartのテンプレートもGo言語の作法に準拠している所があるようです。Go言語にはあまり馴染みがないせいか、出来合いのHelm Chart見ても、結構直感的に分かりにくい! Helm Chartを読んで理解するためには、公式ドキュメントの以下の章を一通り目を通すべし。
The Chart Template Developer’s Guide用語の整理
- Chart(Helm Chart): Kubernetesクラスター上に作成する一連のリソース定義のテンプレートをパッケージングしたもの
- Repository: Helm Chartを管理する場所/サービス (Dockerイメージを管理するDockerレジストリとは全く別物)
- Release: Kubernetesクラスター上にデプロイされたHelm Charのインスタンス
※Helmのリポジトリは必ずしも必要では無いようです。Helm Chartは最終的にはテンプレート等のファイル群を.tgzとしてまとめたアーカイブファイルとして作成されることになりますが、そのファイルを直接指定してkubernetesクラスターに適用させることも可能ですし、アーカイブ前のディレクトリを指定することも可能です。限定的な利用とかテスト中はこれで充分な場合もありそうです。
Helmセットアップ
参考: Installing Helm
直近でHelmV3がリリースされたようですが、結構変更が入っていそうなのと情報が少ないので、一旦Helm V2.16.1を使うことにします。
Kubernetesクラスターとしては、Windows VirtualBox上のUbuntu上にあるminikubeを使います。
kubectlが実行できる環境にHelm本体(クライアント)をインストールし、Kubernetesクラスター側にはhelmからの指示を受けて各種操作を行うサーバー側のモジュール(Tiller)をセットアップすることになります。(ちなみにHelm V3ではTillerのセットアップは不要らしい)
ここではminikubeが乗っているUbuntu上にインストールします。Helm本体のインストール
以下からV2.16.1のLinux amd64版のバイナリを入手します。
https://github.com/helm/helm/releasesvagrant@minikube:~/helm$ wget https://get.helm.sh/helm-v2.16.1-linux-amd64.tar.gz --2019-11-30 23:45:56-- https://get.helm.sh/helm-v2.16.1-linux-amd64.tar.gz Resolving get.helm.sh (get.helm.sh)... 152.199.39.108, 2606:2800:247:1cb7:261b:1f9c:2074:3c Connecting to get.helm.sh (get.helm.sh)|152.199.39.108|:443... connected. HTTP request sent, awaiting response... 200 OK Length: 25262108 (24M) [application/x-tar] Saving to: ‘helm-v2.16.1-linux-amd64.tar.gz’ helm-v2.16.1-linux-amd64.tar.gz 100%[============================================================================>] 24.09M 4.65MB/s in 5.3s 2019-11-30 23:46:01 (4.55 MB/s) - ‘helm-v2.16.1-linux-amd64.tar.gz’ saved [25262108/25262108]解凍してhelmのモジュールをPATHが通っているディレクトリ(/usr/local/bin/)に配置
vagrant@minikube:~/helm$ tar -zxvf helm-v2.16.1-linux-amd64.tar.gz linux-amd64/ linux-amd64/helm linux-amd64/LICENSE linux-amd64/tiller linux-amd64/README.md vagrant@minikube:~/helm$ ls -l linux-amd64/ total 79692 -rwxr-xr-x 1 vagrant vagrant 40460288 Nov 12 18:35 helm -rw-r--r-- 1 vagrant vagrant 11343 Nov 12 18:37 LICENSE -rw-r--r-- 1 vagrant vagrant 3444 Nov 12 18:37 README.md -rwxr-xr-x 1 vagrant vagrant 41127936 Nov 12 18:37 tiller vagrant@minikube:~/helm$ sudo mv linux-amd64/helm /usr/local/bin/これでhelmコマンドが使えるようになりました。
vagrant@minikube:~$ helm version Client: &version.Version{SemVer:"v2.16.1", GitCommit:"bbdfe5e7803a12bbdf97e94cd847859890cf4050", GitTreeState:"clean"} Error: could not find tillerTillerセットアップ
※Helm V3だとこのステップが不要になっている!
次に、Kubernetesクラスター側にTillerというサーバーサイドのモジュールをセットアップしますが、これはHelmをインストールしたノード(=kubectlが入っているノード)からhelm initコマンドで実施します。vagrant@minikube:~$ helm init Creating /home/vagrant/.helm Creating /home/vagrant/.helm/repository Creating /home/vagrant/.helm/repository/cache Creating /home/vagrant/.helm/repository/local Creating /home/vagrant/.helm/plugins Creating /home/vagrant/.helm/starters Creating /home/vagrant/.helm/cache/archive Creating /home/vagrant/.helm/repository/repositories.yaml Adding stable repo with URL: https://kubernetes-charts.storage.googleapis.com Adding local repo with URL: http://127.0.0.1:8879/charts $HELM_HOME has been configured at /home/vagrant/.helm. Tiller (the Helm server-side component) has been installed into your Kubernetes Cluster. Please note: by default, Tiller is deployed with an insecure 'allow unauthenticated users' policy. To prevent this, run `helm init` with the --tiller-tls-verify flag. For more information on securing your installation see: https://docs.helm.sh/using_helm/#securing-your-helm-installation
helm initでは、デフォルトで、その環境のkubectlのデフォルトの接続先kubenetesに対してkube-systemネームスペースに必要なリソースを定義してくれるようです。確認
むむ??
helm versionコマンドがエラーになる。vagrant@minikube:~$ helm version Client: &version.Version{SemVer:"v2.16.1", GitCommit:"bbdfe5e7803a12bbdf97e94cd847859890cf4050", GitTreeState:"clean"} E1201 00:06:00.424955 7038 portforward.go:400] an error occurred forwarding 32784 -> 44134: error forwarding port 44134 to pod 335e7345d4361233ebb592cff534be3c9adb2317e436260cbe1917f76a2478a9, uid : unable to do port forwarding: socat not found E1201 00:06:01.428787 7038 portforward.go:400] an error occurred forwarding 32784 -> 44134: error forwarding port 44134 to pod 335e7345d4361233ebb592cff534be3c9adb2317e436260cbe1917f76a2478a9, uid : unable to do port forwarding: socat not found E1201 00:06:03.291790 7038 portforward.go:400] an error occurred forwarding 32784 -> 44134: error forwarding port 44134 to pod 335e7345d4361233ebb592cff534be3c9adb2317e436260cbe1917f76a2478a9, uid : unable to do port forwarding: socat not found E1201 00:06:36.327123 7038 portforward.go:340] error creating error stream for port 32784 -> 44134: Timeout occured E1201 00:07:00.058581 7038 portforward.go:362] error creating forwarding stream for port 32784 -> 44134: Timeout occured E1201 00:07:27.722853 7038 portforward.go:362] error creating forwarding stream for port 32784 -> 44134: Timeout occured E1201 00:07:58.293685 7038 portforward.go:340] error creating error stream for port 32784 -> 44134: Timeout occured E1201 00:08:37.563451 7038 portforward.go:362] error creating forwarding stream for port 32784 -> 44134: Timeout occured E1201 00:09:27.977955 7038 portforward.go:362] error creating forwarding stream for port 32784 -> 44134: Timeout occured E1201 00:10:40.394108 7038 portforward.go:340] error creating error stream for port 32784 -> 44134: Timeout occured Error: cannot connect to Tillerちょっと古いが以下のようなIssueがあったので、これを参考に
sudo apt install socatで socatパッケージをインストールしたら上のエラーは解消しました。
参考: https://github.com/helm/helm/issues/1371vagrant@minikube:~$ helm version Client: &version.Version{SemVer:"v2.16.1", GitCommit:"bbdfe5e7803a12bbdf97e94cd847859890cf4050", GitTreeState:"clean"} Server: &version.Version{SemVer:"v2.16.1", GitCommit:"bbdfe5e7803a12bbdf97e94cd847859890cf4050", GitTreeState:"clean"}Helm操作例
Helmチャートを使ったインストール例 / redis
参考: Get Started with Kubernetes using Minikube - Step 5: Install an application using a Helm Chart
リポジトリ確認
helm chartを管理するリポジトリ情報を事前に設定しておく必要があります。デフォルトでは以下のリポジトリが設定されています。今回は、この公式のリポジトリ使うので、このままでOK。
vagrant@minikube:~$ helm repo list NAME URL stable https://kubernetes-charts.storage.googleapis.com local http://127.0.0.1:8879/chartsインストール
使用するHelm Chartはこちら。
Kubeapps Hub - Redisvagrant@minikube:~$ helm install stable/redis NAME: truculent-buffalo LAST DEPLOYED: Sun Dec 1 01:21:06 2019 NAMESPACE: default STATUS: DEPLOYED RESOURCES: ==> v1/ConfigMap NAME AGE truculent-buffalo-redis 1s truculent-buffalo-redis-health 1s ==> v1/Pod(related) NAME AGE truculent-buffalo-redis-master-0 0s truculent-buffalo-redis-slave-0 0s ==> v1/Secret NAME AGE truculent-buffalo-redis 1s ==> v1/Service NAME AGE truculent-buffalo-redis-headless 1s truculent-buffalo-redis-master 0s truculent-buffalo-redis-slave 0s ==> v1/StatefulSet NAME AGE truculent-buffalo-redis-master 0s truculent-buffalo-redis-slave 0s NOTES: ** Please be patient while the chart is being deployed ** Redis can be accessed via port 6379 on the following DNS names from within your cluster: truculent-buffalo-redis-master.default.svc.cluster.local for read/write operations truculent-buffalo-redis-slave.default.svc.cluster.local for read-only operations To get your password run: export REDIS_PASSWORD=$(kubectl get secret --namespace default truculent-buffalo-redis -o jsonpath="{.data.redis-password}" | base64 --decode) To connect to your Redis server: 1. Run a Redis pod that you can use as a client: kubectl run --namespace default truculent-buffalo-redis-client --rm --tty -i --restart='Never' \ --env REDIS_PASSWORD=$REDIS_PASSWORD \ --image docker.io/bitnami/redis:5.0.7-debian-9-r0 -- bash 2. Connect using the Redis CLI: redis-cli -h truculent-buffalo-redis-master -a $REDIS_PASSWORD redis-cli -h truculent-buffalo-redis-slave -a $REDIS_PASSWORD To connect to your database from outside the cluster execute the following commands: kubectl port-forward --namespace default svc/truculent-buffalo-redis-master 6379:6379 & redis-cli -h 127.0.0.1 -p 6379 -a $REDIS_PASSWORDredis関連のpod, service, statefulsetが作成されました!
確認
kubectlで作成されたリソースを確認
vagrant@minikube:~$ kubectl get all -o wide | grep redis pod/truculent-buffalo-redis-master-0 1/1 Running 0 20m 172.17.0.11 minikube <none> <none> pod/truculent-buffalo-redis-slave-0 1/1 Running 0 20m 172.17.0.10 minikube <none> <none> pod/truculent-buffalo-redis-slave-1 1/1 Running 0 19m 172.17.0.12 minikube <none> <none> service/truculent-buffalo-redis-headless ClusterIP None <none> 6379/TCP 20m app=redis,release=truculent-buffalo service/truculent-buffalo-redis-master ClusterIP 10.97.52.153 <none> 6379/TCP 20m app=redis,release=truculent-buffalo,role=master service/truculent-buffalo-redis-slave ClusterIP 10.102.26.9 <none> 6379/TCP 20m app=redis,release=truculent-buffalo,role=slave statefulset.apps/truculent-buffalo-redis-master 1/1 20m truculent-buffalo-redis docker.io/bitnami/redis:5.0.7-debian-9-r0 statefulset.apps/truculent-buffalo-redis-slave 2/2 20m truculent-buffalo-redis docker.io/bitnami/redis:5.0.7-debian-9-r0helmコマンドでの状態確認
vagrant@minikube:~$ helm ls NAME REVISION UPDATED STATUS CHART APP VERSION NAMESPACE truculent-buffalo 1 Sun Dec 1 01:21:06 2019 DEPLOYED redis-10.1.0 5.0.7 default削除
vagrant@minikube:~$ helm delete truculent-buffalo release "truculent-buffalo" deletedリソース一式削除されます。
vagrant@minikube:~$ helm ls vagrant@minikube:~$ kubectl get all -o wide | grep redisHelm Chartを作成してみる
参考: The Chart Template Developer’s Guide
雛形作成
helm createコマンドで、helmチャートとして必要なディレクトリ構造の雛形が出来上がります。vagrant@minikube:~/helmchart$ helm create mychar01 Creating mychar01 vagrant@minikube:~/helmchart$ tree . . `-- mychar01 |-- Chart.yaml |-- charts |-- templates | |-- NOTES.txt | |-- _helpers.tpl | |-- deployment.yaml | |-- ingress.yaml | |-- service.yaml | |-- serviceaccount.yaml | `-- tests | `-- test-connection.yaml `-- values.yaml 4 directories, 9 filesSimple Chart / Deployment
templatesディレクトリ下に、雛形となるサンプルファイルが各種できあがっていますが、これらは使わないので一旦削除します。
vagrant@minikube:~/helmchart/mychar01$ rm -rf templates/*templatesディレクトリ下に、kubernetesクラスタに定義したいマニフェストファイルを配置します。※本当は"テンプレート"なのでマニフェストの中身に変数とか埋め込めますが、まずは単純なケースを試すため、出来合いのマニフェストを配置して試します。
Deploymentのテストで使用した、以下のマニフェストファイルを、上のtemplatesディレクトリ下にそのまま配置します。
https://github.com/takara9/codes_for_lessons/blob/master/step08/deployment1.ymlvagrant@minikube:~/helmchart/mychar01$ tree . . |-- Chart.yaml |-- charts |-- templates | `-- deployment1.yml `-- values.yaml 2 directories, 3 files
helm lintコマンドで、Chartの文法チェックを行うことができるようです。vagrant@minikube:~/helmchart$ helm lint mychar01/ ==> Linting mychar01/ [INFO] Chart.yaml: icon is recommended 1 chart(s) linted, no failuresOKっぽいので、このChartを適用してみます。リポジトリに登録する場合は、
helm packageでパッケージングすることになると思いますが、このままでも適用はできるのでそのままやってみます。
helm installでインストールしますが、この時、--debug --dry-runで、デプロイ前に確認できます。まぁ今回は変数とか使ってないのであまり関係無いですが。vagrant@minikube:~/helmchart$ helm install --debug --dry-run --namespace test ./mychar01 [debug] Created tunnel using local port: '44871' [debug] SERVER: "127.0.0.1:44871" [debug] Original chart version: "" [debug] CHART PATH: /home/vagrant/helmchart/mychar01 NAME: foppish-uakari REVISION: 1 RELEASED: Tue Dec 3 05:19:10 2019 CHART: mychar01-0.1.0 USER-SUPPLIED VALUES: {} COMPUTED VALUES: affinity: {} fullnameOverride: "" image: pullPolicy: IfNotPresent repository: nginx tag: stable imagePullSecrets: [] ingress: annotations: {} enabled: false hosts: - host: chart-example.local paths: [] tls: [] nameOverride: "" nodeSelector: {} podSecurityContext: {} replicaCount: 1 resources: {} securityContext: {} service: port: 80 type: ClusterIP serviceAccount: create: true name: null tolerations: [] HOOKS: MANIFEST: --- # Source: mychar01/templates/deployment1.yml apiVersion: apps/v1 kind: Deployment metadata: name: web-deploy spec: replicas: 3 selector: matchLabels: app: web template: metadata: labels: app: web spec: containers: - name: nginx image: nginx:1.16では適用してみます。
vagrant@minikube:~/helmchart$ helm install --namespace test ./mychar01 NAME: queenly-pig LAST DEPLOYED: Tue Dec 3 05:21:49 2019 NAMESPACE: test STATUS: DEPLOYED RESOURCES: ==> v1/Deployment NAME AGE web-deploy 0s ==> v1/Pod(related) NAME AGE web-deploy-866f97c649-55vnj 0s web-deploy-866f97c649-7tv9n 0s web-deploy-866f97c649-kmjhz 0sステータスを確認してみます。
vagrant@minikube:~/helmchart$ helm list NAME REVISION UPDATED STATUS CHART APP VERSION NAMESPACE queenly-pig 1 Tue Dec 3 05:21:49 2019 DEPLOYED mychar01-0.1.0 1.0 test vagrant@minikube:~/helmchart$ kubectl -n test get all -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES pod/web-deploy-866f97c649-55vnj 1/1 Running 0 62s 172.17.0.10 minikube <none> <none> pod/web-deploy-866f97c649-7tv9n 1/1 Running 0 62s 172.17.0.12 minikube <none> <none> pod/web-deploy-866f97c649-kmjhz 1/1 Running 0 62s 172.17.0.11 minikube <none> <none> NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR deployment.apps/web-deploy 3/3 3 3 62s nginx nginx:1.16 app=web NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR replicaset.apps/web-deploy-866f97c649 3 3 3 62s nginx nginx:1.16 app=web,pod-template-hash=866f97c649namespace "test"に、Deployment関連リソース(deployment, replicaset, pod)が意図した通りに作成されました!
削除するには、作成されたhelmリリース名を指定してhelm deleteコマンドを実行します。
vagrant@minikube:~/helmchart$ helm delete queenly-pig release "queenly-pig" deletedこれで、作成されたリソース一式が削除されます。
memo
https://v2.helm.sh/docs/chart_template_guide/#accessing-files-inside-templates
It is okay to add extra files to your Helm chart. These files will be bundled and sent to Tiller. Be careful, though. Charts must be smaller than 1M because of the storage limitations of Kubernetes objects.
- 投稿日:2019-12-02T02:37:01+09:00
FastAPIの負荷実験環境を作ってみる
自己紹介
こんにちは,ZOZOテクノロジーズの内定者さっとです.
APIフレームワークの中ではFastAPIは結構好きで、個人で使うならほぼほぼこれを使っています。
FastAPIについては、以前に何個か記事を書います!
興味ある方は最後にリンクを貼っているので、そちらも見ていただければ思います!※本記事はZOZOテクノロジーズ#4の22日目です.
概要(3行)
- Dockerを使ってFastAPIとMySQLの環境を構築
- 負荷実験ツールとしてLocustをローカルにインストール
- Locustを使ってコンテナへ向けて負荷実験
FastAPIとは?
Python3.6以上で動作する高速なAPIフレームワークです。
https://fastapi.tiangolo.com/
2019年初頭頃、少し話題になったと思います。特徴としては、Node.jsやGoと同等のパフォーマンス性能でかつFlaskライクな書き方で簡単にAPIを生やすことができます。ハッカソンなど時間が限られた開発で有効なフレームワークだと思います。
また、Swaggerが自動で生成されるため、動作チェックやドキュメント作成の時間が大幅に短縮されます。
Locustとは?
Pythonで書かれた、負荷テストツールです。
https://locust.io/負荷実験のシナリオはPythonで記述し、簡単に実装することができます。また、実行結果はWebで確認することができ、攻撃対象へアクセスするユーザ数の設定や実験の停止などテストツールを制御することができます。
事前準備
- Docker及びDocker Composeがインストール済み
- Python3.6以上がインストール済み
- 以下のファイル構成を用意(GitHubに完成版があります)
. ├── api │ ├── db.py │ ├── main.py │ └── model.py ├── docker │ ├── mysql │ │ ├── Dockerfile │ │ ├── conf.d │ │ │ └── my.cnf │ │ └── initdb.d │ │ └── schema.sql │ └── uvicorn │ ├── Dockerfile │ └── requirements.txt ├── docker-compose.yml └── locustfile.pyAPIサーバとMySQLの用意
docker-composeを使って必要なAPIサーバとDBを構築します。
version: '3' services: # MySQL db: container_name: "db" # path配下のDockerfile読み込み build: ./docker/mysql # コンテナが落ちたら再起動する restart: always tty: true environment: MYSQL_DATABASE: sample_db MYSQL_USER: user MYSQL_PASSWORD: password # ユーザのパスワード MYSQL_ROOT_PASSWORD: password # ルートパスワード ports: - "3306:3306" volumes: - ./docker/mysql/initdb.d:/docker-entrypoint-initdb.d # 定義通りテーブルを作成 - ./docker/mysql/conf.d:/etc/mysql/conf.d # MySQLの基本設定(文字化け対策) networks: - local-net # FastAPI api: # db起動後に立ち上げる links: - db container_name: "api" build: ./docker/uvicorn restart: always tty: true ports: - 8000:8000 volumes: - ./api:/usr/src/api networks: - local-net # コンテナ間で通信を行うためのネットワークブリッジ networks: local-net: driver: bridge詳しい内容については、以下の記事で書いているので参考にしてください。
FastAPIをMySQLと接続してDockerで管理してみるLocustのインストール
以下のコマンドで、ローカルにLocustをインストールします。
$ python -m pip install locustio負荷を受けるAPIサーバのメインコード
- ユーザの情報を取得や登録する簡単なAPIを用意しました。
- ORMであるSQLAlchemyでMySQLを操作しています。
- 各エンドポイントの定義(def)の前にasyncとつけて非同期化しています。
./api/main.py# -*- coding: utf-8 -*- from fastapi import FastAPI from db import session # DBと接続するためのセッション from model import UserTable # Userテーブルのモデル # fastapiでエンドポイントを定義するために必要 app = FastAPI() # ユーザ情報を返す GET @app.get("/users/{user_id}") async def read_user(user_id: int): # DBからuser_idを元にユーザを検索 user = session.query(UserTable).\ filter(UserTable.id == user_id).first() # ユーザが見つからなかった場合 if (user is None): return {"code": 404, "message": "User Not Found"} return user # ユーザ情報を登録 POST @app.post("/users") # クエリでnameとageを受け取る async def create_user(name: str, age: int): user = UserTable() user.name = name user.age = age session.add(user) session.commit()負荷実験シナリオ
- UserTaskSetクラスに実験シナリオを定義していきます。
- on_startメソッドに初期設定を定義します。
- taskに書かれた数字は重みで、
@task(2)は@task(1)の2倍実行されることを表しています。./locustfile.pyfrom locust import HttpLocust, TaskSet, task, between import random import string class UserTaskSet(TaskSet): def on_start(self): self.client.headers = {'Content-Type': 'application/json;'} @task(1) def fetch_user(self): self.client.get("/users/{}".format(random.randint(0, 100))) @task(2) def create_user(self): # ランダムに適当に名前を生成 name = ''.join(random.choices(string.ascii_letters, k=10)) age = random.randint(0, 80) self.client.post("/users?name={}&age={}".format(name, age)) class UserLocust(HttpLocust): task_set = UserTaskSet wait_time = between(0.100, 1.500)実行
- コンテナを立ち上げます。
$ docker-compose up -d --build
- Locustを起動します。
APIサーバはlocalhost:8000で待ち受けているので、これに向けて負荷をかけるように指定してあげます。
$ locust -f locustfile.py --host=http://localhost:8000LocustをWebで監視
- Locustを起動すると以下のログが通知されます。
[2019-12-02 02:13:58,632] hoge/INFO/locust.main: Starting web monitor at *:8089 [2019-12-02 02:13:58,633] hoge/INFO/locust.main: Starting Locust 0.13.2
- ログでは、*:8089でリッスンしているみたいなので、http://localhost:8089 へアクセスします。
初回起動時では、Number of users to simulateでどのぐらいのユーザ数でアクセスするかと
Hatch rateで毎秒何人ユーザを増やすかを設定できます。
- テストが実行されると、Statisticsページではログが流れます。
ログでは、リクエスト数やレスポンスタイム、失敗した数などが見れます。
- Chartsページでは、一行ごとのリクエスト数やレスポンスタイム、現在のユーザ数がチャートで表示されます。
- 最後に、上部のSTOPで簡単に負荷を停止することができます。
おわりに
今回は、Locustを使った負荷実験環境の構築を行いました。
今後は、FastAPIって本当に早いの?を検証するために、この環境を使い様々なAPIフレームワークと比較したいと思います。今回使ったコードは、GitHubにあげているので、興味ある方はぜひ触ってみてくださいね!
https://github.com/sattosan/stress_fastapiその他FastAPIの記事
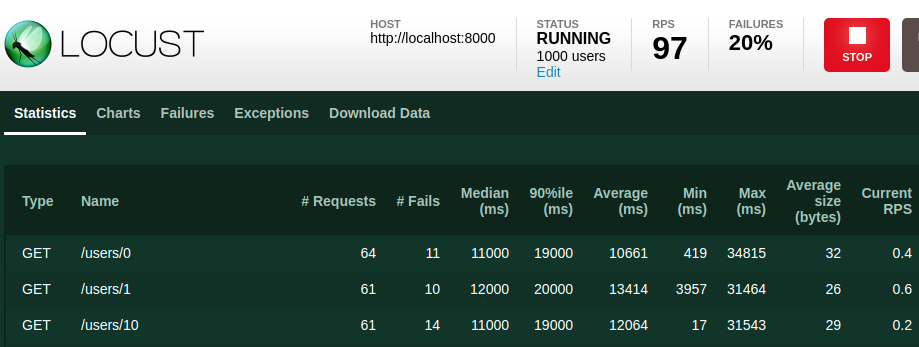
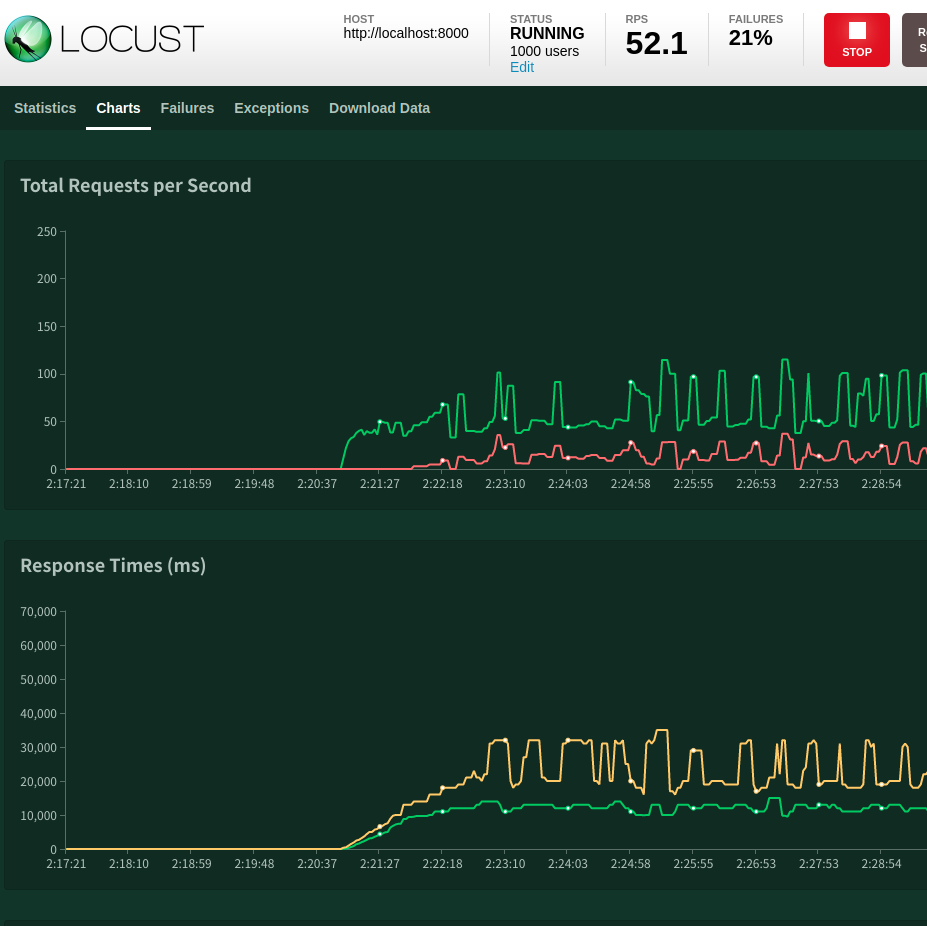
- 投稿日:2019-12-02T01:53:11+09:00
Laradockを用いてDocker/Apache/PHP7.2/MySQL/Laravelの開発環境を構築する
Laradockクローン
ルートディレクトリにて、下記を実行。
$ git clone https://github.com/LaraDock/laradock.git
.envをenv-exampleからコピーして作成。
$ cd laradock
$ cp env-example .env
プロジェクト作成まずは、ワークスペースを起動。
$ cd laradock
$ docker-compose up -d workspace
ワークスペースに入る。
$ docker-compose exec workspace bash
Laravelのプロジェクトを作成composer create-project laravel/laravel web
dockerを一旦終了
exit
$ docker-compose down
laradock/.envのpathを作成したプロジェクトに変更。Point to the path of your applications code on your host
APP_CODE_PATH_HOST=../new_project
apache2の設定変更
ハマったところ。
apache2を使用するので、laradock/apache2/sites/default.apache.confを変更。
ServerName localhost
DocumentRoot /var/www/public/
Options Indexes FollowSymLinks各バージョンを指定(.env)
PHP_VERSION=7.2
MYSQL_VERSION=latest
(mysql/Dockerfile)
ARG MYSQL_VERSION=5.7dockerにてコンテナを起動。
$ docker-compose up -d mysql apache2 workspace
localhostにアクセス。docker-compose stop
既存のLaravelプロジェクトを配置する場合
webに展開
docker-compose exec --user=laradock workspace bash # workspaceへ入る
composer install
laradock@hoge:/var/www$ exit # workspaceから抜ける
$ docker-compose restart # コンテナ再起動
http://localhost/ にアクセスLaravel のプロジェクトを Homestead 環境で 起動させました。
http://localhost:8000/ にアクセスするとエラーがでました。RuntimeException がでる
RuntimeException
No application encryption key has been specified.
encryption key がないとあります。key を生成する
php artisan key:generate
Application key [base64:Wdhku6YSePiOh0XjqauthSaeOhzwRKxasFjbuuHXz0w=] set successfully.
Application key が生成されました。再度アクセス
http://localhost:8000/ にアクセスすると Laravel の初期画面が表示されました
- 投稿日:2019-12-02T00:59:42+09:00
code-server (2) Dockerで独自のCode-Server 環境を作って見る
これは、2019年 code-server に Advent Calender の 第2日目の記事です。
一日目 の続きです。
今回も、code-server って何だろう?と言う事を解説していきます。(1) code-server って何?
(2) Dockerで独自のcode-server 環境を作って見るあらすじ
前回は、Hello World!! を動かしてみました。ブラウザー上で動作するVSCodeを確認できたと思います。
実際に触ってみた方は、"/home/coder/project" と dockerを起動したディレトリーブ作成したコードが格納されたと思います
Docker で独自の環境を作ってみる。
今回は、皆さんがよく使う Linux環境上でCode-Serverを動かしてみましょう。私はUbuntuをよく使うので、Ubuntu上に構築してみたいと思います!!
まずは、ubuntuを動かしてみましょう
Dockerfile を作成します。
FROM ubuntu:20.04ビルドして、Docker上でBashを起動してみましょう
# cs02 という名前でイメージを作成 $ docker build -t cs02 . # cs02 上で bash を 起動してみる $ docker run -it cs02 bash root@9e2f79078fcd:/#はい、ubuntu を Docker 上で動かせました!!
code-server を インストールしてみましょう
https://github.com/cdr/code-server に 記載されている、https://github.com/cdr/code-server/releases のページから最新のものを拾ってきます。
今回は、code-server2.1692-vsc1.39.2-linux-x86_64.tar.gz を利用することにします。
FROM ubuntu:20.04 RUN apt-get update # code-server を取得するのに wget を install しておく RUN apt-get install -y wget # 作業ディレクトリを /works にする。どこでも良いです WORKDIR /works # code-server のバイナリーを取得 RUN wget https://github.com/cdr/code-server/releases/download/2.1692-vsc1.39.2/code-server2.1692-vsc1.39.2-linux-x86_64.tar.gz # code-server を /works 配下に解凍する RUN tar -xzf code-server2.1692-vsc1.39.2-linux-x86_64.tar.gz -C ./ --strip-components 1 WORKDIR /works/app # デフォルトは、/works/app で起動するようにする。 CMD [ "/works/code-server", "--allow-http", "--auth", "none", "--port", "8443", "/works/app"]※ dockerの中の ubuntu 上の bash で動作確認しながら、Dockerfileを作成していますが省略しています。
docker build -t cs02 .作成したイメージを起動してみましょう
# bash などは指定しない # カレントディレクトリ(絶対パス) と /works/app を mount する # PCの8443 Portへの接続を Dockerの8443 Port への接続とする docker run -v "$PWD:/works/app" -p "8443:8443" -it cs02とした後で、ブラウザーで、http://127.0.0.1:8443/ にアクセスすると、
VSCode が 立ち上がりました!!
次回
作成したImageを配布してみましょう。 一度、作成したImageは、ほぼほぼ、同じ状態で動かす事ができます。