- 投稿日:2019-12-02T23:49:26+09:00
AWS CDKを使って ほぼ一撃で静的サイトを構築する
AWS CDKとは?
AWS において Infrastructure as Code (以下 IaC) を実現するためのツールです。
CDK 登場以前も CloudFormation を利用して JSON や YAML での IaC は実現可能でしたが、
- 複数のスタックに共通する構成を定義しづらい
- ほぼ同一構成なリソースを複数作成するのが面倒
という課題がありました。
CDK は プログラミング言語を使って定義できるので、
IF文によるパラメータ切り替えや、ループ処理による複数リソース定義が可能です!利用できるプログラミング言語は、
- TypeScript
- Python
- .Net
- Java
です。
今回は、サンプルコードが充実している TypeScript を使用して、CloudFront + S3 の静的サイトを構築してみます。
前提
AWS CLIが利用できる状態。
※AWS CDKは内部的に AWS-CLI と CloudFormation を利用して、リソースを操作しています。構築手順
CDKのインストール
$ yarn global add aws-cdk ## バージョン確認 $ cdk --version 1.18.0 (build bc924bc)CDKを書いていく
CDKプロジェクトを作成していきましょう。
$ cdk init --app cdk-static-site --language=typescript必要なライブラリをインストールします。
$ yarn add @aws-cdk/aws-iam @aws-cdk/aws-s3 @aws-cdk/aws-cloudfrontCloudFront と S3 を定義します。
lib/cdk-static-site.tsimport cdk = require('@aws-cdk/core'); import s3 = require("@aws-cdk/aws-s3"); import cloudfront = require("@aws-cdk/aws-cloudfront"); import iam = require("@aws-cdk/aws-iam"); type Stage = 'prod' | 'stg' | 'test'; export class CdkStaticSiteStack extends cdk.Stack { readonly AppDomain: string = 'example.com'; readonly AppName: string = 'example'; readonly Stage: Stage = 'prod'; constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) { super(scope, id, props); // 独自ドメインを設定する場合に使用する(証明書ARNチェック) // const acmArn: string = this.node.tryGetContext('acmArn'); // if (!acmArn) { // throw new Error('CloudFrontに設定する証明書のARNをContextに設定してください。'); // } // CloudFront オリジン用のS3バケットを作成する const originBucket = new s3.Bucket(this, this.prefix() + '-bucket', { // バケット名 bucketName: this.prefix() + '-' + this.account, // バージョニング(無効) versioned: false, // CDKスタック削除時の挙動(スタック削除時にバケットも削除する) removalPolicy: cdk.RemovalPolicy.DESTROY, }); // CloudFront で設定する オリジンアクセスアイデンティティ を作成する const oai = new cloudfront.CfnCloudFrontOriginAccessIdentity(this, this.prefix() + '-oai', { cloudFrontOriginAccessIdentityConfig: { comment: 's3 access.', } }); // S3バケットポリシーで、CloudFrontのオリジンアクセスアイデンティティを許可する const policy = new iam.PolicyStatement({ effect: iam.Effect.ALLOW, actions: ['s3:GetObject'], principals: [new iam.CanonicalUserPrincipal(oai.attrS3CanonicalUserId)], resources: [ originBucket.bucketArn + '/*' ] }); originBucket.addToResourcePolicy(policy); // CloudFrontディストリビューションを作成する const distribution = new cloudfront.CloudFrontWebDistribution(this, this.prefix() + '-cloudfront', { defaultRootObject: '/index.html', viewerProtocolPolicy: cloudfront.ViewerProtocolPolicy.REDIRECT_TO_HTTPS, httpVersion: cloudfront.HttpVersion.HTTP2, priceClass: cloudfront.PriceClass.PRICE_CLASS_200, originConfigs: [ { s3OriginSource: { s3BucketSource: originBucket, originAccessIdentityId: oai.ref }, behaviors: [ { isDefaultBehavior: true, compress: true, minTtl: cdk.Duration.seconds(0), maxTtl: cdk.Duration.days(365), defaultTtl: cdk.Duration.days(1), } ] } ], // 独自ドメインを設定する場合に使用する // viewerCertificate: { // aliases: [this.AppDomain], // props: { // acmCertificateArn: acmArn, // minimumProtocolVersion: "TLSv1.2_2018", // sslSupportMethod: "sni-only", // } // }, errorConfigurations: [ { errorCode: 403, errorCachingMinTtl: 300, responseCode: 200, responsePagePath: '/index.html' } ] }); cdk.Tag.add(this, 'App', this.AppName); cdk.Tag.add(this, 'Stage', this.Stage); } private prefix(): string { return this.AppName.toLowerCase() + '-' + this.Stage.toLowerCase(); } }デプロイしてみます。
# TypeScriptをコンパイルする $ yarn build # CloudFomationテンプレートを生成する $ cdk synth # デプロイする # しばらく待ちます。CloudFrontディストリビューションの作成に10分程度かかります。 $ cdk deploy
$ cdk deployが終わり次第、S3にindex.htmlをアップロードし、
CloudFrontエンドポイントにアクセスするとindex.htmlの内容が表示されるはずです!まとめ
このように、100行未満のコードを書くだけで、静的サイトが構築できます。
プログラミング言語を利用するので、柔軟に書けて、パラメータ切り替えや構成の再利用が行いやすいです。
今回は単純な構成例ですが、実務での冗長化構成や監視定義など、大規模になればなるほど、
プログラミング言語で定義できるというのが活きてくるかと思います。まだまだ発展途上で、AWSJのSAの方にも「まだ手を出すのは早い」と言われたこともありますが、
どんどんCDKで構築していきたいと思います!補足: 独自ドメインを設定する場合
上記コードの
// 独自ドメインを設定する場合に使用するとコメントしている処理を利用してください。
CDKを実行する前に、ACMで証明書を発行しておき、その証明書のARNをcdk.context.jsonに追記してください。/cdk.context.json{ "@aws-cdk/core:enableStackNameDuplicates": "true", "acmArn": "" }
- 投稿日:2019-12-02T23:44:19+09:00
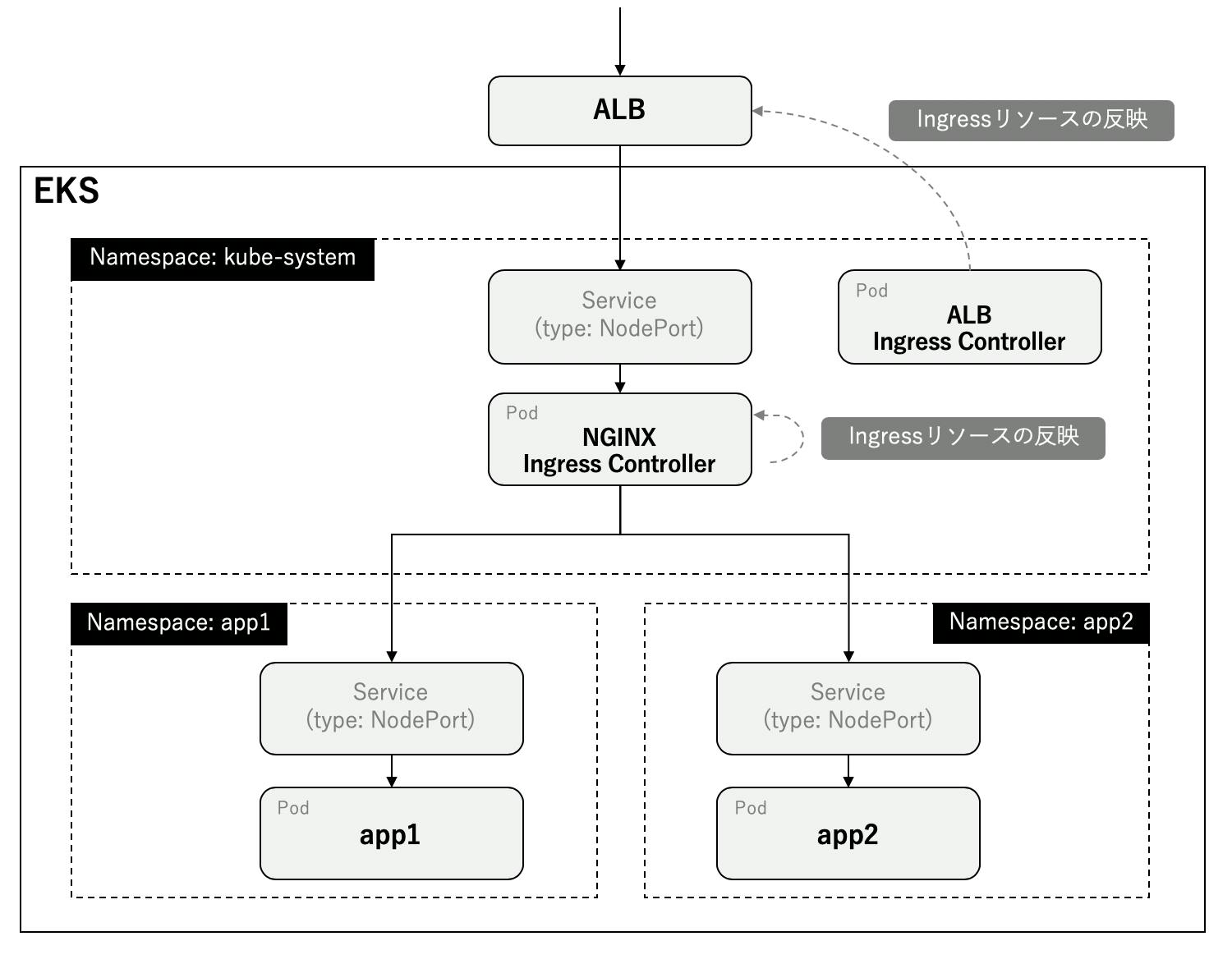
Namespaceの異なるIngressリソースを1つのALBで対応する
はじめに
EKSでIngressを使用するときはALB Ingress ControllerやNGINX Ingress Controllerが必要となります。LBを作成するよう設定するとそれぞれALB、CLBを作成します。CLBはALBより値段が高いのでALBに寄せた方が良いです。ただ、ALB Ingress ControllerはNamespaceの異なるIngressリソースに対応しておらず、デプロイした分ALBが作成されてしまいます。
本記事ではALB Ingress ControllerとNGINX Ingress Controllerを組み合わせて1つのALBで済む方法を紹介します。概観は次のようになります。
環境情報
macOS Mojave 10.14.1
terraform: v0.12.16
helm: v2.14.3
helmfile: v0.87.0
kubectl: v1.13.11-eks-5876d6ディレクトリ構成は次のようになります。
. ├── terraform │ ├── providers.tf │ ├── vpc.tf │ ├── eks.tf │ └── iam.tf └── kubernetes ├── helmfile.yaml ├── alb-ingress.yaml └── app.yamlAWSリソース
AWSリソースはTerraformでデプロイします。
providers.tfではリージョンを定義します。providers.tfprovider "aws" { version = ">= 1.24.0" region = "ap-northeast-1" }
vpc.tfではVPCを定義します。ALB Ingress Controllerのauto discoveryを使用するためにsubnetのタグに
kubernetes.io/role/elbを付けておきます。これはpublic subnetの場合なのでprivate subenetを使う場合は異なるので注意してください。vpc.tfdata "aws_availability_zones" "available" {} module "vpc" { source = "terraform-aws-modules/vpc/aws" version = "2.15.0" name = "test-vpc" cidr = "10.0.0.0/16" azs = "${data.aws_availability_zones.available.names}" public_subnets = ["10.0.1.0/24", "10.0.2.0/24", "10.0.3.0/24"] enable_nat_gateway = true single_nat_gateway = false one_nat_gateway_per_az = false tags = "${merge(local.tags, map("kubernetes.io/cluster/${local.cluster_name}", "shared"))}" public_subnet_tags = { "kubernetes.io/role/elb" = "" } }
eks.tfではEKSを定義します。EKS moduleを使用するのでインプットの情報が少なくて済みます。eks.tflocals { cluster_name = "test-cluster" worker_groups = [ { name = "test-worker" instance_type = "t3.medium" subnets = "${module.vpc.public_subnets}" autoscaling_enabled = true asg_desired_capacity = "2" asg_max_size = "3" asg_min_size = "2" root_volume_size = "10" key_name = "ec2-key" } ] tags = { Environment = "test" } } module "eks" { source = "terraform-aws-modules/eks/aws" version = "6.0.2" cluster_name = "${local.cluster_name}" cluster_version = "1.13" subnets = "${module.vpc.public_subnets}" tags = "${local.tags}" vpc_id = "${module.vpc.vpc_id}" worker_groups = "${local.worker_groups}" cluster_create_timeout = "30m" cluster_delete_timeout = "30m" }
iam.tfではIAMを定義します。ALB Ingress ControllerにはIngressリソースを元にALBを作成するためのIAM Roleを付与する必要があります。今回はkube2iamを使用せず、IAM Role for Service Accountを使用します。kube2iamはDaemonsetをデプロイしなければならないのでできるだけ避けましょう。Service Accountは
system:serviceaccount:kube-system:alb-ingress-controller-aws-alb-ingress-controllerと定義しています。この名前はALB Ingress Controller Helm ChartでデプロイするService Accountと同一の名前になるようにしています。IAM Policyは公式 IAM Policy jsonをそのまま用いています。
iam.tfresource "aws_iam_openid_connect_provider" "oidc_provider" { url = "${module.eks.cluster_oidc_issuer_url}" thumbprint_list = ["9e99a48a9960b14926bb7f3b02e22da2b0ab7280"] client_id_list = [ "sts.amazonaws.com" ] } data "aws_iam_policy_document" "alb_ingress_controller" { statement { effect = "Allow" actions = [ "sts:AssumeRoleWithWebIdentity" ] principals { type = "Federated" identifiers = ["${aws_iam_openid_connect_provider.oidc_provider.arn}"] } condition { test = "StringEquals" variable = "${replace(aws_iam_openid_connect_provider.oidc_provider.url, "https://", "")}:sub" values = [ "system:serviceaccount:kube-system:alb-ingress-controller-aws-alb-ingress-controller" ] } } } resource "aws_iam_role" "alb_ingress_controller" { name = "alb-ingress-controller" assume_role_policy = "${data.aws_iam_policy_document.alb_ingress_controller.json}" } resource "aws_iam_role_policy_attachment" "alb_ingress_controller" { role = "${aws_iam_role.alb_ingress_controller.id}" policy_arn = "${aws_iam_policy.alb_ingress_controller.arn}" } resource "aws_iam_policy" "alb_ingress_controller" { name = "alb-ingress-controller" policy = <<EOF { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "acm:DescribeCertificate", "acm:ListCertificates", "acm:GetCertificate" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "ec2:AuthorizeSecurityGroupIngress", "ec2:CreateSecurityGroup", "ec2:CreateTags", "ec2:DeleteTags", "ec2:DeleteSecurityGroup", "ec2:DescribeAccountAttributes", "ec2:DescribeAddresses", "ec2:DescribeInstances", "ec2:DescribeInstanceStatus", "ec2:DescribeInternetGateways", "ec2:DescribeNetworkInterfaces", "ec2:DescribeSecurityGroups", "ec2:DescribeSubnets", "ec2:DescribeTags", "ec2:DescribeVpcs", "ec2:ModifyInstanceAttribute", "ec2:ModifyNetworkInterfaceAttribute", "ec2:RevokeSecurityGroupIngress" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "elasticloadbalancing:AddListenerCertificates", "elasticloadbalancing:AddTags", "elasticloadbalancing:CreateListener", "elasticloadbalancing:CreateLoadBalancer", "elasticloadbalancing:CreateRule", "elasticloadbalancing:CreateTargetGroup", "elasticloadbalancing:DeleteListener", "elasticloadbalancing:DeleteLoadBalancer", "elasticloadbalancing:DeleteRule", "elasticloadbalancing:DeleteTargetGroup", "elasticloadbalancing:DeregisterTargets", "elasticloadbalancing:DescribeListenerCertificates", "elasticloadbalancing:DescribeListeners", "elasticloadbalancing:DescribeLoadBalancers", "elasticloadbalancing:DescribeLoadBalancerAttributes", "elasticloadbalancing:DescribeRules", "elasticloadbalancing:DescribeSSLPolicies", "elasticloadbalancing:DescribeTags", "elasticloadbalancing:DescribeTargetGroups", "elasticloadbalancing:DescribeTargetGroupAttributes", "elasticloadbalancing:DescribeTargetHealth", "elasticloadbalancing:ModifyListener", "elasticloadbalancing:ModifyLoadBalancerAttributes", "elasticloadbalancing:ModifyRule", "elasticloadbalancing:ModifyTargetGroup", "elasticloadbalancing:ModifyTargetGroupAttributes", "elasticloadbalancing:RegisterTargets", "elasticloadbalancing:RemoveListenerCertificates", "elasticloadbalancing:RemoveTags", "elasticloadbalancing:SetIpAddressType", "elasticloadbalancing:SetSecurityGroups", "elasticloadbalancing:SetSubnets", "elasticloadbalancing:SetWebACL" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "iam:CreateServiceLinkedRole", "iam:GetServerCertificate", "iam:ListServerCertificates" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "cognito-idp:DescribeUserPoolClient" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "waf-regional:GetWebACLForResource", "waf-regional:GetWebACL", "waf-regional:AssociateWebACL", "waf-regional:DisassociateWebACL" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "tag:GetResources", "tag:TagResources" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "waf:GetWebACL" ], "Resource": "*" } ] } EOF }用意したtfファイルと同じディレクトリで下記コマンドを実行すればAWSリソースが作成されます。
$ terraform init $ terraform applyKubernetesリソース
helmfileでALB Ingress ControllerとNGINX Ingress Controllerをデプロイします。
ALB Ingress ControllerのvaluesのserviceAccountAnnotationsの値のXXXXXXXXXXXXには自身のAWSアカウント名を指定してください。helmfile.yamlrepositories: - name: incubator url: https://kubernetes-charts-incubator.storage.googleapis.com - name: stable url: https://kubernetes-charts.storage.googleapis.com releases: # https://github.com/helm/charts/tree/master/incubator/aws-alb-ingress-controller - name: alb-ingress-controller namespace: kube-system chart: incubator/aws-alb-ingress-controller version: 0.1.11 wait: true values: - clusterName: test-cluster autoDiscoverAwsRegion: true autoDiscoverAwsVpcID: true rbac: serviceAccountAnnotations: eks.amazonaws.com/role-arn: arn:aws:iam::XXXXXXXXXXXX:role/alb-ingress-controller # https://github.com/helm/charts/tree/master/stable/nginx-ingress - name: nginx-ingress namespace: kube-system chart: stable/nginx-ingress version: 1.24.3 wait: true values: - controller: service: type: NodePortあとは下記コマンドを実行してデプロイするだけです。
$ helmfile apply
alb-ingress.yamlはALB Ingress Controllerに読み込ませてALBを作成させるためのものです。任意のリクエストをNGINX Ingress ControllerのServiceにルーティングさせます。alb-ingress.yamlapiVersion: extensions/v1beta1 kind: Ingress metadata: name: alb-ingress namespace: kube-system annotations: kubernetes.io/ingress.class: alb alb.ingress.kubernetes.io/scheme: internet-facing alb.ingress.kubernetes.io/listen-ports: '[{"HTTP": 80}]' spec: rules: - http: paths: - backend: serviceName: nginx-ingress-controller servicePort: 80下記コマンドを実行すればALBが自動で作成されます。
$ kubectl apply -f alb-ingress.yaml
テスト用のnginxを2つのNamespace分作成します。IngressのhostにはALBのDNS名を指定し、rewrite-targetで
/app1のパスが/に変換されるようにしています。app.yaml--- kind: Namespace apiVersion: v1 metadata: name: app1 --- apiVersion: extensions/v1beta1 kind: Ingress metadata: name: app1-ing namespace: app1 annotations: kubernetes.io/ingress.class: nginx nginx.ingress.kubernetes.io/rewrite-target: /$2 spec: rules: - host: d7f12bb1-kubesystem-albing-65d9-811539212.ap-northeast-1.elb.amazonaws.com http: paths: - path: /app1(/|$)(.*) backend: serviceName: app1-svc servicePort: 80 --- apiVersion: v1 kind: Service metadata: name: app1-svc namespace: app1 spec: type: NodePort ports: - name: http-port protocol: TCP port: 80 targetPort: 80 selector: app: app1 --- apiVersion: apps/v1 kind: Deployment metadata: name: app1-deploy namespace: app1 spec: replicas: 1 selector: matchLabels: app: app1 template: metadata: labels: app: app1 spec: containers: - name: nginx-container image: nginx:1.13 ports: - containerPort: 80 --- kind: Namespace apiVersion: v1 metadata: name: app2 --- apiVersion: extensions/v1beta1 kind: Ingress metadata: name: app2-ing namespace: app2 annotations: kubernetes.io/ingress.class: nginx nginx.ingress.kubernetes.io/rewrite-target: /$2 spec: rules: - host: d7f12bb1-kubesystem-albing-65d9-811539212.ap-northeast-1.elb.amazonaws.com http: paths: - path: /app2(/|$)(.*) backend: serviceName: app2-svc servicePort: 80 --- apiVersion: v1 kind: Service metadata: name: app2-svc namespace: app2 spec: type: NodePort ports: - name: http-port protocol: TCP port: 80 targetPort: 80 selector: app: app2 --- apiVersion: apps/v1 kind: Deployment metadata: name: app2-deploy namespace: app2 spec: replicas: 1 selector: matchLabels: app: app2 template: metadata: labels: app: app2 spec: containers: - name: nginx-container image: nginx:1.13 ports: - containerPort: 80あとはデプロイするだけでNGINX Ingress Controllerにルーティング設定が反映されます。
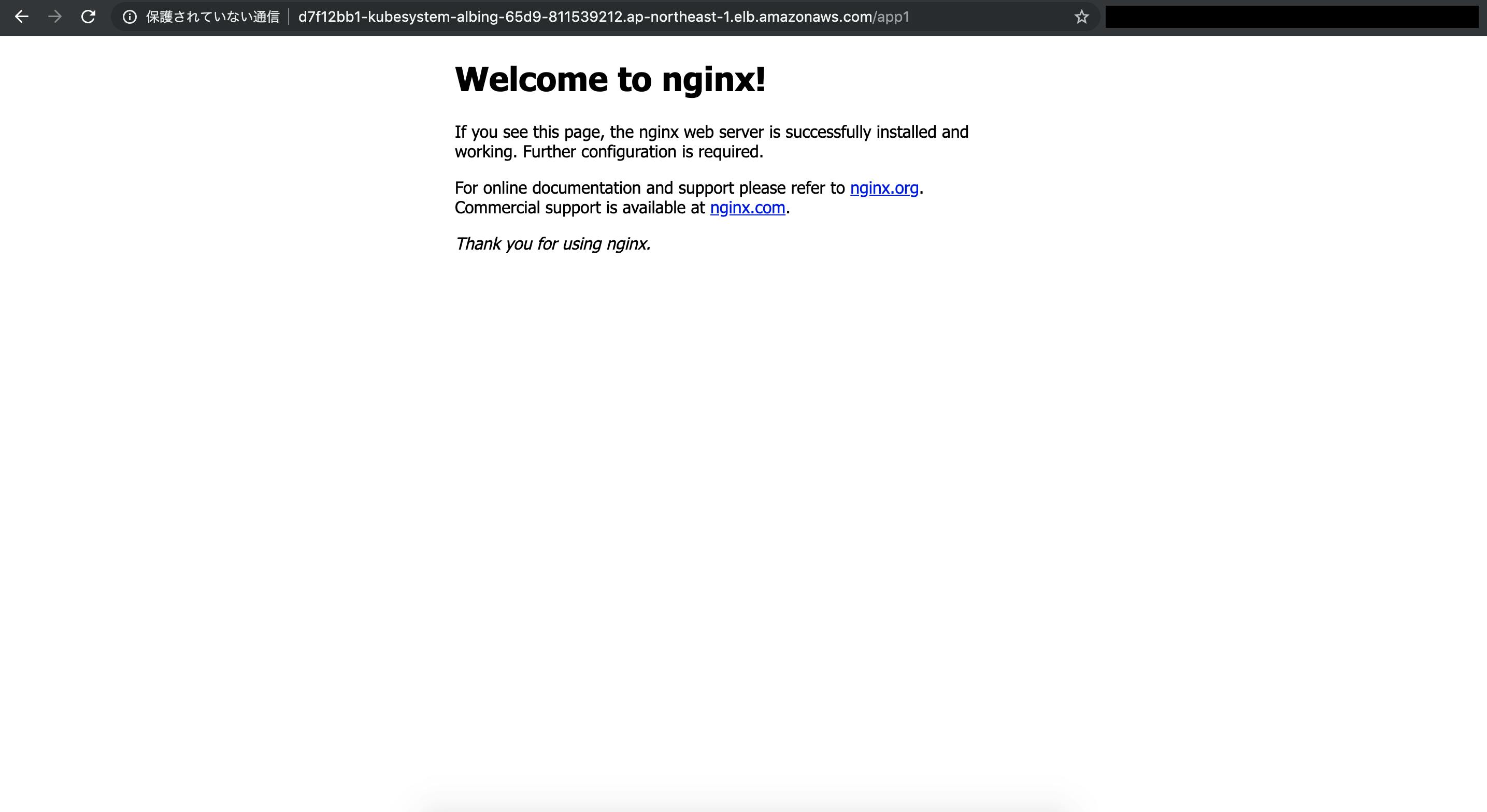
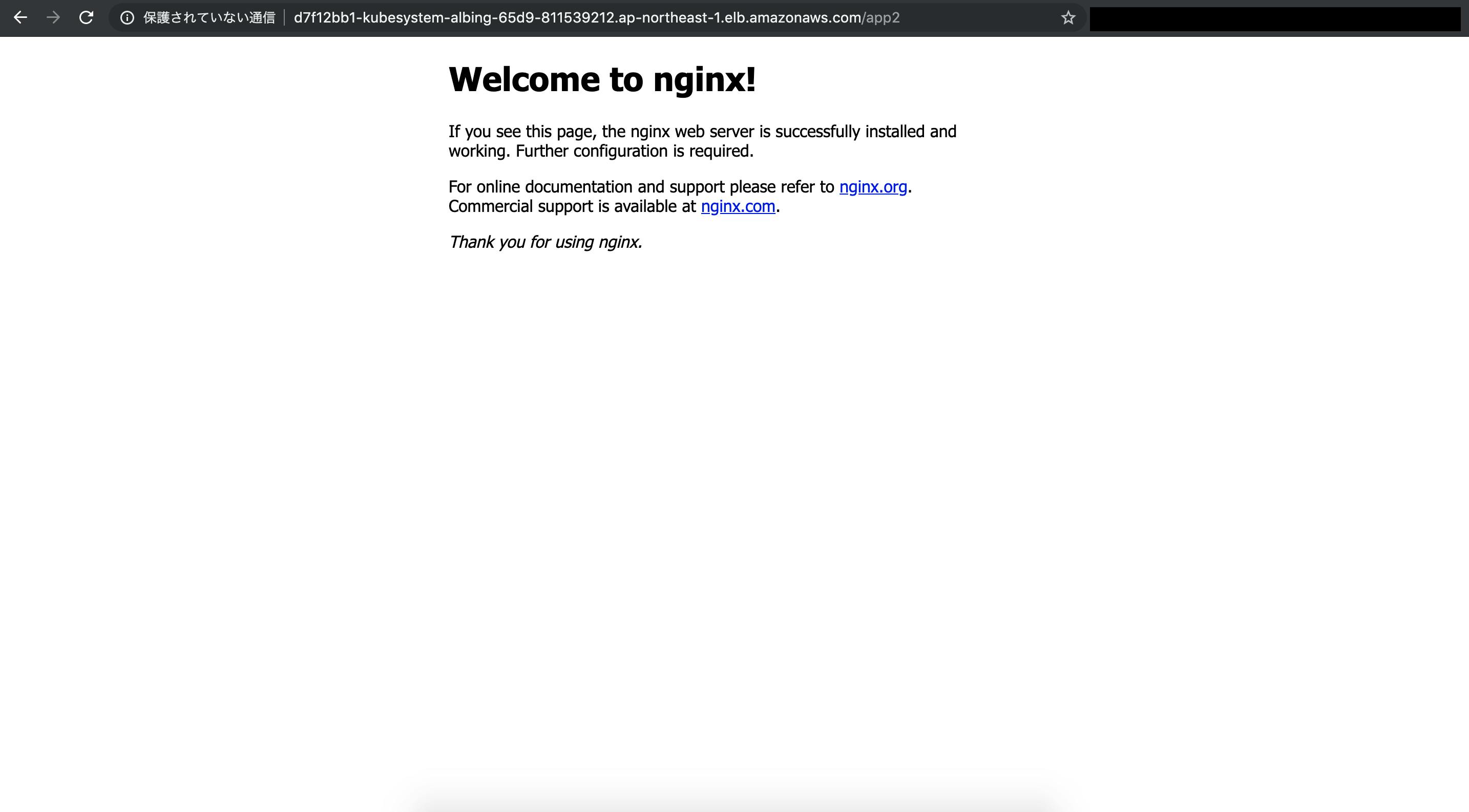
$ kubectl apply -f app.yaml結果
/app1と/app2にアクセスします。正しくルーティングされることがわかります。
終わりに
Namespaceの異なるIngressリソースを1つのALBで対応できることを確認しました。
できればNGINX Ingress Controllerをデプロイしたくありませんが現状技術的に無理なので、今回の構成が最もコストが低いものだと思います。
- 投稿日:2019-12-02T23:23:21+09:00
Amazon SQSからAWS Lambdaを起動する構成のTerraform
はじめに
SREエンジニアやってます。@hayaosatoです。
今回はサーバレスなアーキテクチャを組む上で超便利なAWS Lambda(以下、Lambda)をAmazon SQS(以下、SQS)から呼び出してみたいと思います。
コードはこちらアーキテクチャ
Lambda
Lambdaのリソースは以下のように作ることができます。
アプリケーションはslack通知のスクリプトにしました。// IAM Role for Lambda Function resource "aws_iam_role" "default" { name = var.service_name description = "IAM Rolw for ${var.service_name}" assume_role_policy = file("${var.service_name}_role.json") } resource "aws_iam_policy" "default" { name = var.service_name description = "IAM Policy for ${var.service_name}" policy = file("${var.service_name}_policy.json") } resource "aws_iam_role_policy_attachment" "default" { role = aws_iam_role.default.name policy_arn = aws_iam_policy.default.arn } // Lambda Function Resources resource "aws_cloudwatch_log_group" "default" { name = "/aws/lambda/${var.service_name}" retention_in_days = 7 } data archive_file "default" { type = "zip" source_dir = "src" output_path = var.output_path } resource "aws_lambda_function" "default" { filename = var.output_path function_name = var.service_name role = aws_iam_role.default.arn handler = "lambda_function.lambda_handler" source_code_hash = data.archive_file.default.output_base64sha256 runtime = "python3.6" environment { variables = { SLACK_API_KEY = var.SLACK_API_KEY } } }Lambda関数をTerraformで作成する際は是非ともarchiveリソースの
archive_fileを利用していただきたいです。
これを利用することでzipを生成してそれをそのままLambda関数に適応できるので非常に楽です。
つまりはこの構成をそのままCIに組み込んでCIツールからterraform applyすればいい感じですね。SQS
SQSのリソースは以下のように作ることができます。
resource "aws_sqs_queue" "default" { name = "${var.service_name}.fifo" fifo_queue = true content_based_deduplication = true }SQSとLambdaの連携
TerraformにはLambdaのトリガ設定のためのリソースとしてlambda_event_source_mappingというものがあります。
今回はこれを使います。resource "aws_lambda_event_source_mapping" "default" { event_source_arn = aws_sqs_queue.default.arn function_name = aws_lambda_function.default.arn }また、このリソースは現在SQSとDynamoDB,Kinesisにしか対応していないため、SNSからの連携はできません(コードにSNSと連携させようと作ったリソースの残骸が。。。)
event_source_arnに指定できないリソースのARNを入れてしまうと、無限にcreating...になります。
ただ、S3からのイベントは普通に実行できます。結果
作ったリソースで実際にキューを発行して実行してみます。
できました
最後に
やっぱりサーバレスっていいですね
参考


- 投稿日:2019-12-02T23:23:21+09:00
Amazon SQSからAWS Lambdaを呼び出すTerraform
はじめに
SREエンジニアやってます。@hayaosatoです。
今回はサーバレスなアーキテクチャを組む上で超便利なAWS Lambda(以下、Lambda)をAmazon SQS(以下、SQS)から呼び出してみたいと思います。アーキテクチャ
Lambda
Lambdaのリソースは以下のように作ることができます。
アプリケーションはslack通知のスクリプトにしました。// IAM Role for Lambda Function resource "aws_iam_role" "default" { name = var.service_name description = "IAM Rolw for ${var.service_name}" assume_role_policy = file("${var.service_name}_role.json") } resource "aws_iam_policy" "default" { name = var.service_name description = "IAM Policy for ${var.service_name}" policy = file("${var.service_name}_policy.json") } resource "aws_iam_role_policy_attachment" "default" { role = aws_iam_role.default.name policy_arn = aws_iam_policy.default.arn } // Lambda Function Resources resource "aws_cloudwatch_log_group" "default" { name = "/aws/lambda/${var.service_name}" retention_in_days = 7 } data archive_file "default" { type = "zip" source_dir = "src" output_path = var.output_path } resource "aws_lambda_function" "default" { filename = var.output_path function_name = var.service_name role = aws_iam_role.default.arn handler = "lambda_function.lambda_handler" source_code_hash = data.archive_file.default.output_base64sha256 runtime = "python3.6" environment { variables = { SLACK_API_KEY = var.SLACK_API_KEY } } }Lambda関数をTerraformで作成する際は是非ともarchiveリソースの
archive_fileを利用していただきたいです。
これを利用することでzipを生成してそれをそのままLambda関数に適応できるので非常に楽です。
つまりはこの構成をそのままCIに組み込んでCIツールからterraform applyすればいい感じですね。SQS
SQSのリソースは以下のように作ることができます。
resource "aws_sqs_queue" "default" { name = "${var.service_name}.fifo" fifo_queue = true content_based_deduplication = true }SQSとLambdaの連携
TerraformにはLambdaのトリガ設定のためのリソースとしてlambda_event_source_mappingというものがあります。
今回はこれを使います。resource "aws_lambda_event_source_mapping" "default" { event_source_arn = aws_sqs_queue.default.arn function_name = aws_lambda_function.default.arn }また、このリソースは現在SQSとDynamoDB,Kinesisにしか対応していないため、SNSからの連携はできません(コードにSNSと連携させようと作ったリソースの残骸が。。。)
event_source_arnに指定できないリソースのARNを入れてしまうと、無限にcreating...になります。
ただ、S3からのイベントは普通に実行できます。結果
作ったリソースで実際にキューを発行して実行してみます。
できました
最後に
やっぱりサーバレスっていいですね
参考
- 投稿日:2019-12-02T22:19:33+09:00
AWS Cloud9環境でdocker-composeをできるようにする
はじめに
とある事情でAWS Cloud9でローカル開発環境をdockerで構築しようとした時の備忘録。
今回は全てデフォルト設定でAmazonLinuxのインスタンスを立ち上げました。
OSバージョンはこれ(Amazon Linux2じゃないんだね...)$ cat /etc/system-release Amazon Linux AMI release 2018.03ちなみにDockerはデフォルトでセットアップされてました。
$ docker -v Docker version 18.09.9-ce, build 039a7dfDocker-composeは存在しない模様
$ docker-compose -v bash: docker-compose: command not found導入手順
公式ドキュメントを参考に導入してみる
Docker Composeの現在の安定リリースバージョンをダウンロード
$ sudo curl -L "https://github.com/docker/compose/releases/download/1.25.0/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose実行権限を付与する
$ sudo chmod +x /usr/local/bin/docker-compose動作確認
$ docker-compose -v docker-compose version 1.25.0, build 0a186604以上です。
- 投稿日:2019-12-02T20:30:26+09:00
ドローンを活用した避難勧告システム
はじめに
ドローンを使ったシステムの考案をします.実用的な運用を目指したシステムの開発を目指します.ただの提案だとつまらないので実際に動かすところがゴールです.
ドローンで救える命がある背景
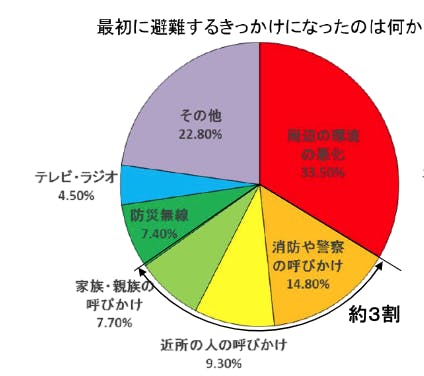
日本における自然災害は年々増加傾向にあり,人的被害や金銭的被害への対策が求められている.また,自宅を安全だと思い込み避難しない人は多く,よりパーソナルに危機感を煽る方法が模索されている.西日本豪雨の被災者310名に行ったNHKのアンケートでは対人的な呼びかけで避難をするきっかけになった人は全体の約3割存在している.
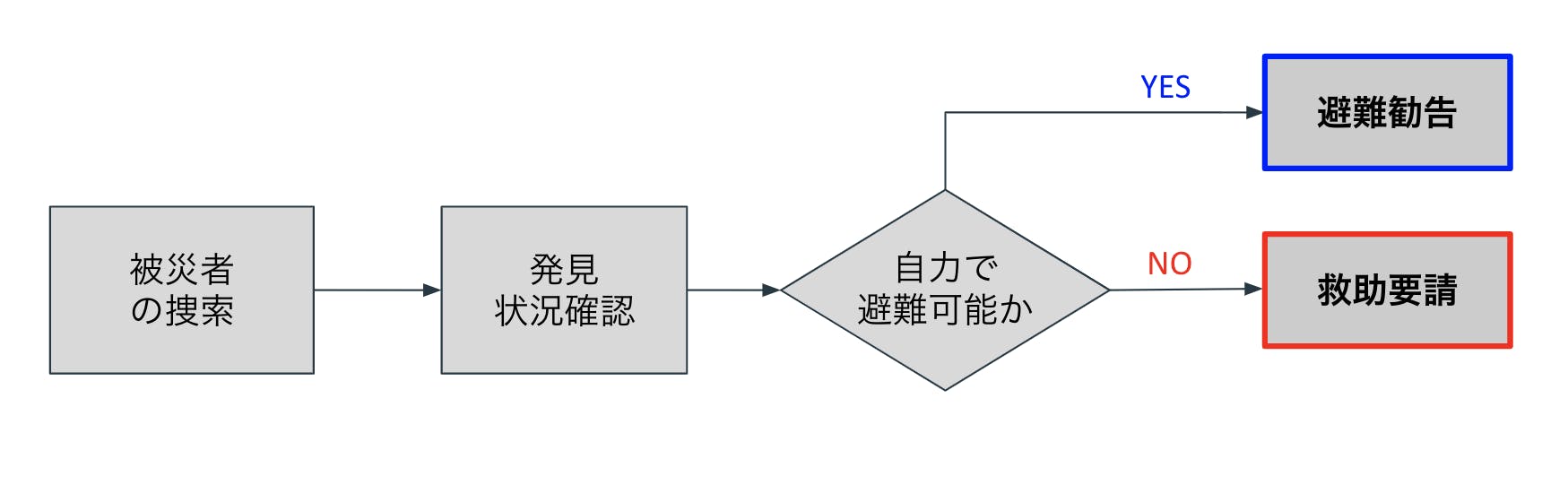
考案システム
上記のようなドローン巡回システムを考案する. 災害発生後または災害中にドローンは被災者や被災予備軍を捜索する.人を見つけ次第,人と対話し,自力で避難可能かを判断する.対話方法としては音声解析,画像解析,姿勢解析を用いてフィードバックを行う.自力で避難可能な人には避難勧告を行い,身動きがとれない人や高齢者や身体的に不自由な人(避難困難者)には救助要請を行う.
開発環境
macOS Mojave
AWS
Python2系3系
telloドローン
Alexa(スピーカーデバイスがなくてもOK)要件定義
開発にはいくつかのフェーズに分けて行うこととする.(システム要件は今後増やす可能性はあり)
記事の続きとして各リンクを参照すること
0章はおまけ0 . 位置情報から周囲の避難場所を提示するシステムの構築
1 . ドローンの動作をクラウド環境から操作可能なシステムの構築
2 . 人の発声を自然言語処理,意図解釈し,ドローンをフィードバック制御するシステムの構築
3 . 画像解析された人の姿勢などの情報から状態を推定し,通知するシステムの構築
4 .
- 投稿日:2019-12-02T20:25:21+09:00
はじめてのECS(Fargete)
はじめに
ECSの動きがドキュメントで読んだだけではわかりにくかったので、動かしながら試して行こうと思います。
ECSってなんだかコンテナだし難しそう!って思ってたのですが、サンプルは「次へ」押していくだけで完成します。
動かしたほうが理解しやすいので、まだ触ったことない方はお薦めいたします。
htpdコンテナが実際に動いてブラウザで画面が見えるところまで確認していきます。
所要時間:15~20分です。手順
- まずは、「今すぐ始める」を選びました。
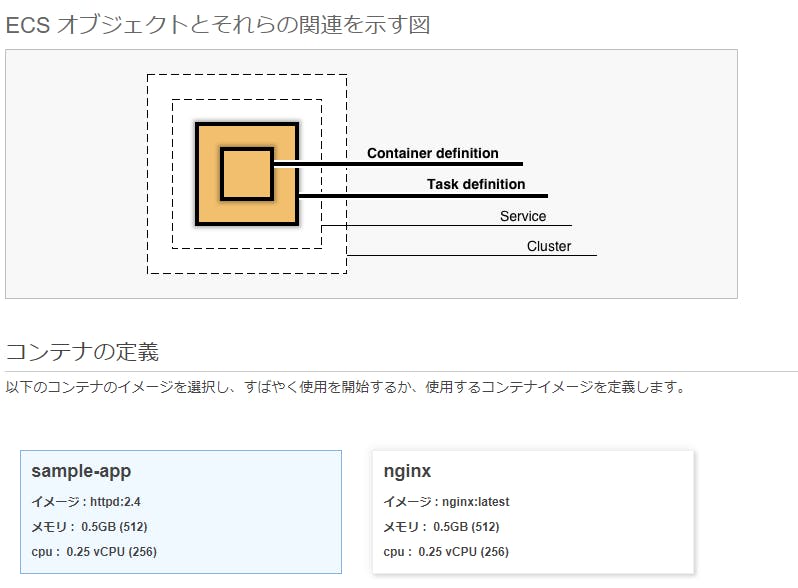
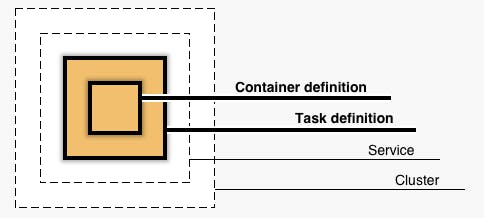
コンテナとタスク
コンテナの定義
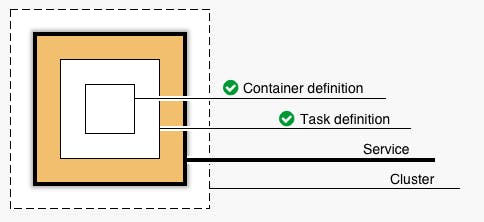
- まずは「コンテナの定義」です。図の一番内側です。
- 使用する
docker imageを決めます。- ようく見ると、
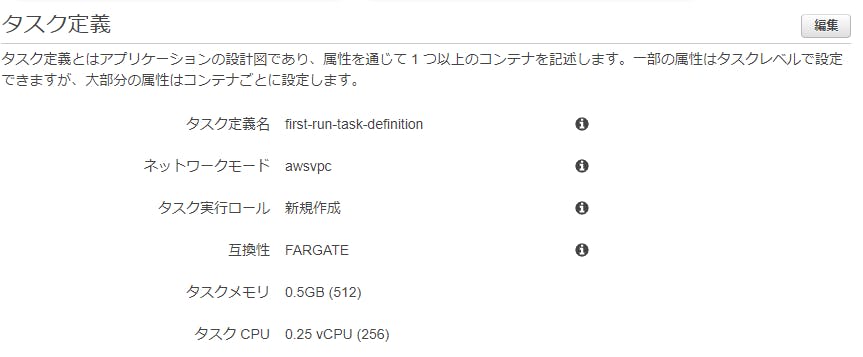
httpd:2.4のイメージを利用し、0.5GBのメモリ予約、0.25のvCPU(1/4コア)予約されていることがわかります。- そのまま「sample-app」を使うことにします。
タスク定義
- 次は「タスク定義」です。図ではコンテナの1つ外を囲っています。
first-run-task-definitionという定義名はVPC内で動作し、ECSの実行ロールが付与され、fargateの実行タイプのが選択されています。- タスクサイズは1つのタスクレベルの設定値で割り当てられているタスクメモリとCPUが請求対象になってきます。
- Lambdaと違い、メモリとCPUのパワーは別に設定できるようになっています。
- 今回はそのまま設定値を利用することにします。
サービス
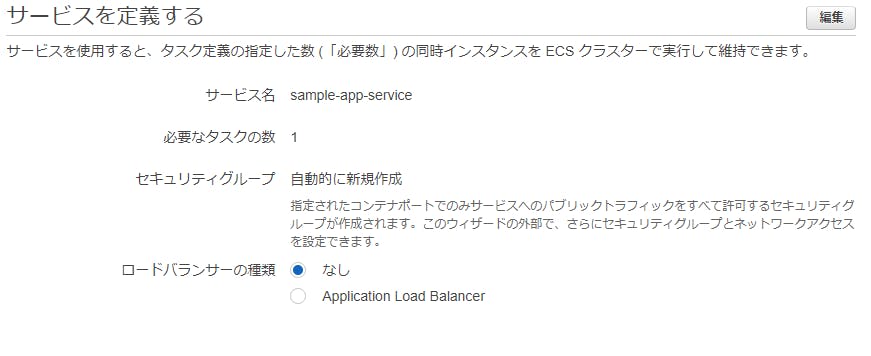
サービスを定義する
- タスク定義されたものにサービスを関連づけましょう
- 同時実行する必要数のインスタンスを維持できます。
- ALBとの連動ができます。APIのコンテナなんかはALBと連動させるのでしょうか?
クラスター
クラスターを定義する
- いよいよ最後に近づいてきました。
- クラスターを設定します。
- 今回は、クラスター名を設定するだけです。
作成
- 10分ほど待てば完成します。実際にはそんなに待ちません。
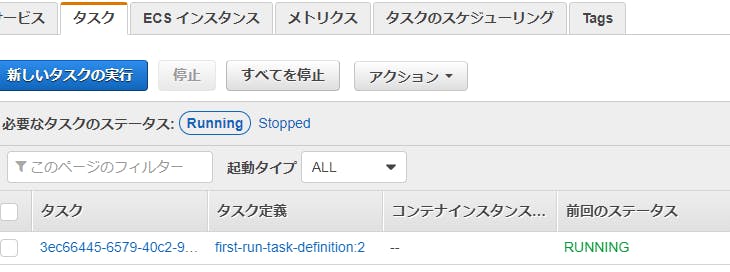
動かしてみる
- クラスター
defaultができていると思います。
- タスクから実行中であることが確認できたでしょうか?
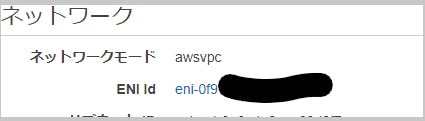
- ENIが設定されていることが確認できました。
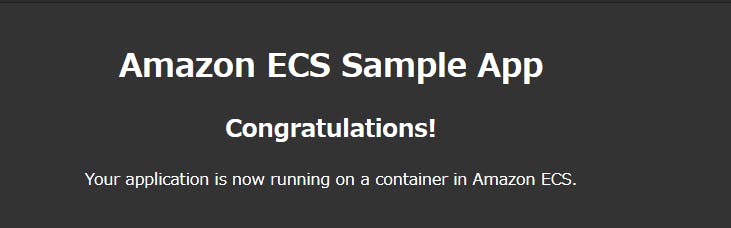
- 割り当てられているIPアドレスを確認し、アクセスしてみましょう。
httpdイメージのコンテナにアクセスすることができました。Congratulations!
さいごに
- サンプルだったため、本来考えなければならない箇所を大幅に省略しています。
- ここから、実際に作るとしたら何が足りないのか1つずつ埋めていけば理解が深まっていくと思います。




- 投稿日:2019-12-02T20:16:11+09:00
ネットワーク回線初心者がオンプレとAWS接続のために調べたこと
はじめに
オンプレとAWSの接続でVPNやDirect Connectも会社によってプランや言い方が違う印象を感じた。
今後のオンプレ-AWS間の接続方法の判断や運用時の理解のために「VPN」「DirectConnect」とはどういうものかをまとめる。他社情報
- 基本的にVPNでレイヤー3の領域に関しては冗長化している会社は少ない(Colt情報)
- Direct Connectを本気で利用する会社は副回線もダイレクトコネクトにする場合が多い(クラスメソッド情報)
- 1Gbps利用するならDXか閉域VPNの利用が多い(クラスメソッド情報)
- IPsec-VPN使う方もいるが利用シーンとしては帯域食わない使い方(クラスメソッド情報)
AWSとの接続においてのVPNやDirect Connectの言い方
(色んな情報を調べたり、回線業者と話したりして)
- AWSとのVPN接続と言えばIPsec VPNでの接続のことを言うケースが多い
- VPN接続の中でも閉域網と言う言葉が出れば最終的にはDirect Connectのことを指しているイメージ
- Direct Connectと言ってもAPNパートナーによっては専有型と共有型の二つがある。
社内とAWSの接続方法
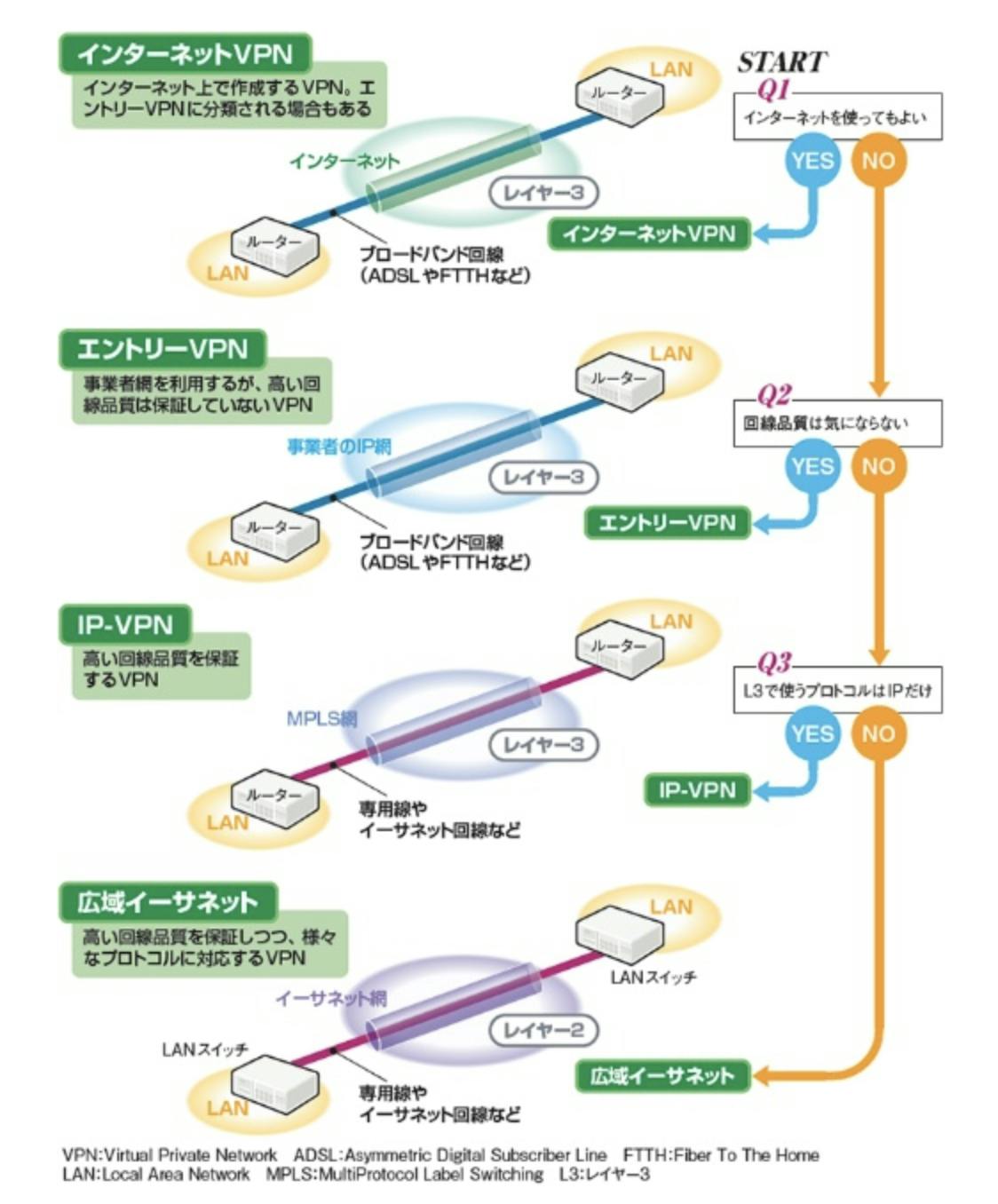
インターネット接続 (回線業者接続) 専用線接続 1.接続方式 HTTPS/SSH VPN接続 VPN接続 2.VPNの種類 インターネットVPN エントリーVPN IP-VPN 広域イーサネット 3.インターネットVPNの種類 IPsec-VPN SSL-VPN 4.相互データセンターへの接続方式 物理専用線 AWS Direct Connectパートナーサービス(APNパートナーサービス) 5.パートナーサービスのDirect Connectの契約プラン 共有型(共有port)
IP-VPN or 広域イーサネット専有型(専有port)
IP-VPN or 広域イーサネット一般的な考え方・言い方 インターネット接続 閉域網接続 レイヤ レイヤ3(IPのみ) レイヤ2(IP以外も可) 通信ネットワークの形態 ベストエフォート ギャランティ型(帯域保証・確保型) 1. 接続方式
HTTPS/SSH
- インターネット回線
- ブラウザでアクセスするときにHTTPSを使ったり、SSHクライアントツールを使ってアクセス
VPN接続
- 仮想専用回線
- インターネット接続と閉域網接続(通信事業業者が用意している回線を利用する)の大きく二つにまず分類出来る。
- その中でも細かく分けられる( 2. VPNの種類 を参照すると分かりやすいかも)
参考URL:
https://www.gate02.ne.jp/column/26/AWS Direct Connect
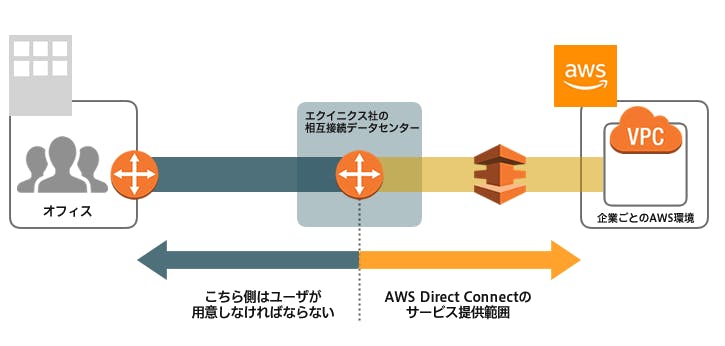
- AWSが提供する専用線接続サービス
- ユーザーのオフィスやオンプレミスのデータセンターからAWS環境までの専用ネットワークを確立出来る
- AWSはセキュリティ上の理由からデータセンターの場所を公表していない
- AWSから提供されている帯域は1Gbps or 10Gbpsの2種類
- DirectConnectパートナーの持っているプランによって帯域は細分される
- インターネット回線を経由しないため、高いセキュリティがある
- AWSからインターネットへの送信量よりもDirect Connect通信料金の方が安い
参考URL:
https://www.bit-drive.ne.jp/managed-cloud/column/column_19.html
https://www.business-on-it.com/2003-aws-direct-connect/2. VPNの種類
インターネット接続
インターネットVPN
- 社内オフィスにVPNルーターを設置する
- AWS環境(VPC)にIPsec VPNで接続
- インターネット回線をベースとするため、速度は契約しているインターネット回線の帯域に影響する
閉域網接続
エントリーVPN
- 事業者網を利用するが、高い回線品質は保証していないVPN
IP-VPN
- 高い回線品質を保証するVPN
- 例:Colt https://www.colt.net/wp-content/uploads/2019/03/asia-services-ipvpn-jp.pdf
- 広域イーサネットとの比較はIPのみの接続になる
広域イーサネット
- 高い回線品質を保証しつつ、様々なプロトコルに対応するVPN
- 例:Colt https://www.colt.net/wp-content/uploads/2019/03/asia-ethernet-services-jp.pdf
参考URL:
https://tech.nikkeibp.co.jp/it/atcl/column/17/011900625/011900003/3. インターネットVPNの種類
IPsec-VPN
- ネットワーク層
- 決まった拠点間の通信が多い場合に利用されることが多い
- 組織間を繋ぐプライベートネットワークとして開発された
- Webブラウザなどのアプリケーションとは無関係に、全ての通信を自動暗号化している
- 通信の出口となるIP層で暗号化・認証を行う
- IP層で暗号化するため、アプリケーションごとにウェブ化したり、暗号化したりする必要がない。
SSL-VPN
- セッション層
- VPNを通じて社内情報にアクセスさせたい端末が多い場合に利用されることが多い
- WebブラウザからサーバにSSL通信出来るように開発された
- リバースプロキシ,ポートフォワーディング,L2フォワーディングの3方式ある
※メリット・デメリットとしてまとめようとしましたが、必要条件によってどちらを使うか変わると思うので箇条書きにしました。
参考URL:
https://it-trend.jp/vpn/article/48-0063
https://jp.globalsign.com/blog/articles/vpn_structure.html
https://www.yamanjo.net/knowledge/internet/internet_36.html
https://it-trend.jp/remote_access/article/147-00174. 相互データセンターへの接続方式
物理専用線
- ユーザー自身がエクイニクスの相互接続ポイントにラックスペースを確保して専用線を直接引き込む
AWS Direct Connectパートナーサービス
- 通信事業者などのAWS Direct Connectパートナーが提供するサービスを利用する
- AWS接続提供プラン-EQUINIX
- AWS接続提供プラン-TOKAIコミュニケーションズ
- AWS接続提供プラン-Coltテクノロジーサービス
- AWS接続提供プラン-ARTELIA
※パートナー毎のプラン等もまとめてあるが公開していいのか迷ったため、今回は非公開
5. パートナーサービスのDirect Connectの契約プラン
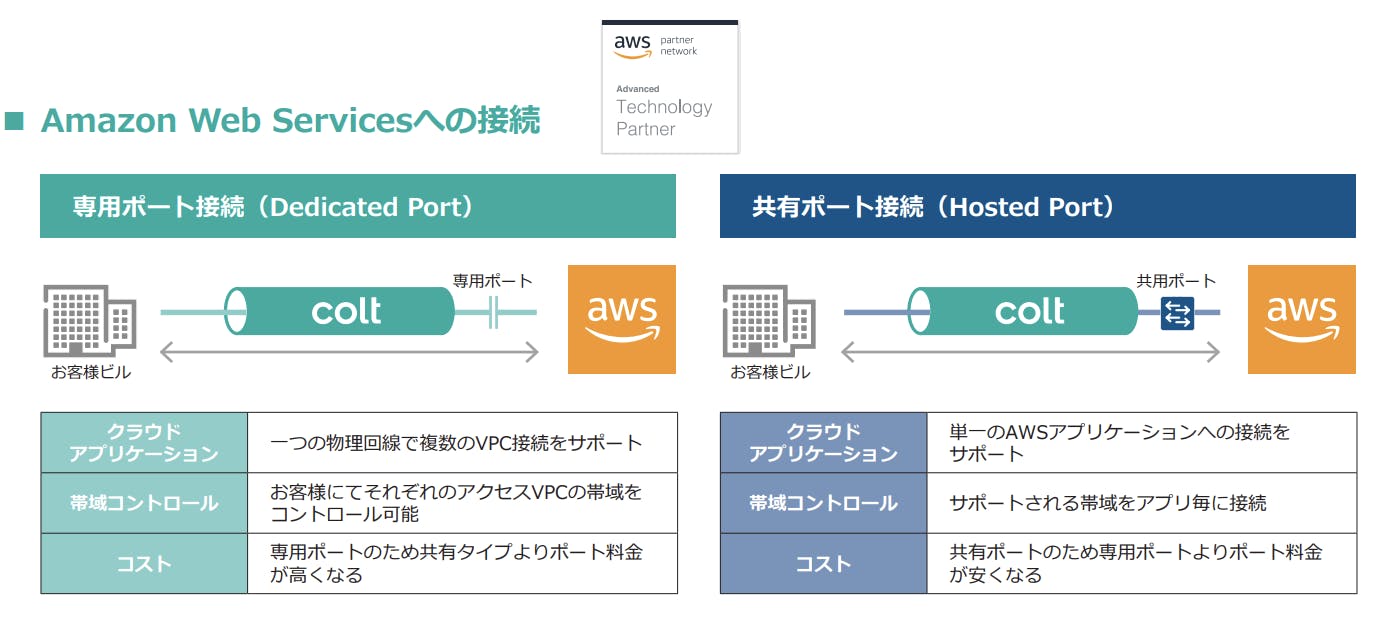
専有型/専有タイプ(専用ポート)
- 1Gbps以上の回線を契約する場合にオススメされることが多い
- AWS が指定するデータセンターにて、ルータに直接接続します。
共有型/共有タイプ(共有ポート)
- 1Gbps未満の回線を契約する場合にオススメされることが多い
- 複数の利用者を束ねて、Direct Connect を共有するイメージ
- 共有とはいえ、専有できる帯域が保証されている場合が殆ど
参考URL:
https://xn--o9j8h1c9hb5756dt0ua226amc1a.com/?p=2669
https://www.business-on-it.com/2003-aws-direct-connect/
https://alexander.achanblog.mydns.jp/?p=181
https://businessnetwork.jp/tabid/65/artid/3836/page/2/Default.aspx
https://alexander.achanblog.mydns.jp/?p=181
- 投稿日:2019-12-02T20:05:47+09:00
Chalice x Circle CI 環境における CI/CD について
序文
https://chalice.readthedocs.io/en/latest/
AWS Chalice は、AWS Lambda と API Gateway などを組み合わせて、Heroku のような手軽さで Serverless 環境を構築することができるフレームワークです。
現在のところ開発言語は Python しか対応していない(今後も対応する?かは不明)ですが、その制約を受け入れれば他の Serverless フレームワークよりも手軽で開発しやすい環境が提供されているように思います。
私の環境でも、簡易的な API の作成や、バッチ、cron 処理など、かなり広範囲の処理について Chalice を用いて開発をすることが多くなりました。当記事では Chalice でできることの説明は割愛します。
そして、テスト周りについてはすたじおさん (https://qiita.com/studio3104) が記事を書くようなので、私の方では Chalice で開発する際の CI/CD 環境をどのようにするか、自分の実例を基に記事を書きたいと思います。
なお、ここでは、使用する CI 環境はCircle CIとします。いくつかのテーマがありますが、ここでは以下のテーマについて記述します。
- monorepo 対応
- unit test / code coverage
- lint / code smells
- chalice 設定ファイルの validation
- 脆弱性診断
- auto deploy
monorepo 対応 (プロジェクトごとの差分チェック)
chalice は、作成したい機能ごとに
chalice new-project sadaのような形でプロジェクトの scaffold を作成し、開発をしていくスタイルになります。
プロジェクトごとに GitHub などのリポジトリを作成していくと細分化が激しくなります。なので monorepo 構成にしたいのですが、かといって単純にひとつのリポジトリに複数のプロジェクトを入れると、CI/CD の際に一部のプロジェクトの修正の際に全部のプロジェクトのテストや検証、デプロイが走ったりしがちで、CI/CDの速度が低下します。なので、基本的な戦略としては、
GitHub リポジトリの中で変更があったプロジェクトに対してのみ CI/CDを実施するという形を取りたいです。こちらの実現の際に、以下のブログの内容を参考にしました。GitHub の Head の内容と比較して、差分があるかどうかを判別するスクリプトです。
https://blog.hatappi.me/entry/2018/10/08/232625$ cat tools/is_changed #!/bin/bash if [ "${CIRCLE_BRANCH}" = "master" ]; then DIFF_TARGET="HEAD^ HEAD" else DIFF_TARGET="origin/master" fi DIFF_FILES=(`git diff ${DIFF_TARGET} --name-only --relative=${1}`) if [ ${#DIFF_FILES[@]} -eq 0 ]; then exit 1 else exit 0 fiこのような形でスクリプトを用意し、CI/CD の際にチェックしたい Chalice プロジェクトを当該スクリプトの引数にわたすことでプロジェクトごとに差分チェックが行え、差分が無いプロジェクトはスキップし差分があるものだけ後続の CI 処理を実施する、ということが実現できます。
$ cat tools/echo_changed for dir in ${PROJECTS}; do \ if ${WORKDIR}/is_changed "${dir}"; then echo "changed." else echo "nothing change." fi doneunit test / code coverage
テストの書き方などについては、すたじおさんが詳細に記載をされてると思うのでここでは詳細は割愛します。
私の環境では、
coverageとpytestを組み合わせて実施をしています。unittestの実施と、その結果としてどの程度 Test Coverage が達成されているかの測定を実施しています。$ coverage run -m pytest $ coverage reportName Stmts Miss Cover --------------------------------------- app.py 35 22 37% tests/__init__.py 0 0 100% tests/conftest.py 4 0 100% tests/test_app.py 5 0 100% --------------------------------------- TOTAL 44 22 50%unit テストがある環境で coverage を動作させると、上記のようなレポートを出力することができます。
レポートの内容については、HTML リポートを Circle CI の Artifacts として保存して CI 結果画面から確認することができます。- run: name: Run Tests command: | $HOME/.local/bin/coverage run -m pytest $HOME/.local/bin/coverage report $HOME/.local/bin/coverage html # open htmlcov/index.html in a browser - store_artifacts: path: htmlcov詳しい設定等については以下の公式ドキュメントを参照ください。
https://circleci.com/docs/2.0/code-coverage/#python
また、特定のカバレッジ率を下回った際にテストを止めたい場合は、
coverage report --fail-number [num]とすると、カバレッジが数値以下の場合にreturn code = 2が返却されます。
つまり、しきい値を満たさない時に CI を止めることができます。この辺の処理を shell として書くと以下のようになります。一通り monorepo 中のすべてのプロジェクトのうち、何かしら差分があるものついて unitetest / coverage 測定を実施し、テストが fail になるかひとつでも coverage がしきい値以下のものがあると、CI が止まります。
$ cat tools/coverage ret=0 for dir in ${PROJECTS}; do if ${WORKDIR}/is_changed "${dir}"; then cd ${WORKDIR}/../${dir}/ sudo pip install -r requirements.txt coverage run -m pytest coverage report --fail-under=${THRESHOLD} r=$? coverage html -d ../htmlcov/${dir} if [ $r != 0 ]; then ret=$r; fi else echo "nothing change." fi done exit $retlint / code smells
テストやカバレッジ測定だけでなく、Lint ツールや Code Smells ツールを使って、ヒューリスティックに 「あまり良くない書き方」 の箇所を特定することも CI/CD のフローではよく実施されています。
こちらについても詳細は割愛しますが、私の環境では
pep8 (pycodestyle)とpyflakesを組み合わせて実施します。
いずれのツールも、指摘事項がある際はreturn code = 1になるので、必要に応じて CI のハンドリングを行います。以下は pyflakes の結果サンプルですが、以下のケースでは
sadaという変数が宣言されているが使われていない、といったことが指摘されています。$ pyflakes app.py app.py:32: local variable 'sada' is assigned to but never usedただ、いずれも、初期設定のまま実施するとかなり細かく指摘事項を挙げてくるので、環境に応じて設定ファイルを記述して ignore する、もしくは環境に応じてルールを記述するのが現実的な運用だと思います。
この辺の処理を shell として書くと以下のようになります。
$ cat tools/lint ret=0 for dir in ${PROJECTS}; do if ${WORKDIR}/is_changed "${dir}"; then cd ${WORKDIR}/../${dir}/ sudo pip install -r requirements.txt pep8 ${WORKDIR}/../${dir}/*.py --config ${WORKDIR}/../.config/pep8 pyflakes ${WORKDIR}/../${dir}/*.py r=$? if [ $r != 0 ]; then ret=$r; fi else echo "nothing change." fi done exit $retchalice 設定ファイルの validation
上述の内容で、一般的な CI は実施できていると思いますが、chalice の場合それぞれの stage ごとに設定ファイル (config.json, deployed/) を用意する必要があり、その設定ファイルの妥当性も検証をしたいところです。
一番手軽な方法として、CI/CD の際に
chalice packageコマンドを実行し、ただしく chalice を Packaging できるかどうかを確認することで設定ファルの妥当性を簡易的に確認することができます。$ cat tools/package for dir in ${PROJECTS}; do if ${WORKDIR}/is_changed "${dir}"; then cd ${WORKDIR}/../${dir}/ sudo pip install -r requirements.txt chalice package /tmp/${CIRCLE_SHA1} else echo "nothing change." fi done脆弱性診断
昨今はアプリケーションのセキュリティについてセンシティブな事案も多いため、できる限り不安のあるコードをアプリケーションに紛れ込ませたくありません。
そのため使用しているライブラリなどに脆弱性が含まれているものがないか、CI のタイミングで都度確認したいところです。いくつかソリューションがあるとは思いますが、ここでは snyk (https://snyk.io/) というセキュリティベンチャー企業のサービスを使用します。
snyk はソースコードの vulunability chek (脆弱性診断) を行ってくれる機能を提供する SaaS です。様々な言語に対応していますが、もちろん Chalice で使用する Python も対応しています。
基本的にrequirements.txtの中身をみて使用ライブラリを把握し、脆弱性データベースに含まれるバージョンのライブラリが含まれていないかどうかをチェックします。GitHub との連携が用意な事もあり、 CI のフローに組み込みやすいのが特徴です。
public な OSS であれば無制限、Private リポジトリでも 200 テストまでは無料で使用することもできます。
https://snyk.io/plans/snyk は circle.yml に定義を書くというより、GitHub と連携設定を行う形になります。細かい設定方法などは公式ドキュメントに譲ります。
https://snyk.io/docs/github/auto deploy
最後に、CI/CD の CD の部分について。
chalice はchalice deployといったコマンドで簡単にデプロイ作業が行えるため、CI の結果問題がなかったソースを自動デプロイすることは容易です。以下は、差分があったプロジェクトのみ最新の状態に
chalice deployする処理を shell で書いたものです。$ cat tools/deploy for dir in ${PROJECTS}; do \ echo "${WORKDIR}/../${dir}/" if ${WORKDIR}/is_changed "${dir}"; then cd ${WORKDIR}/../${dir}/ sudo pip install -r requirements.txt AWS_ACCESS_KEY_ID=${AWS_ACCESS_KEY_ID} AWS_SECRET_ACCESS_KEY=${AWS_SECRET_ACCESS_KEY} chalice deploy --stage ${STAGE} else echo "nothing change." fi doneCI ツールで本番環境への自動デプロイを行うかは、議論が分かれるところかなとは思います。
(私の環境では本番環境への自動デプロイは実施せず、検証環境のみにすることが多いです)まとめにかえて
AWS Chalice は、Python 限定ではありますが Heroku のような形で手軽に Serverless な処理を書けるフレームワークで、普通のアプリケーションのように Lambda の処理を書けるのが利点だと思います。
そして、その利点があるため、Lambda のような Serverless 環境であっても上述のような CI/CD のフローに組み込む事も容易です。ということで、みなさんも Chalice を使いましょう。
Happy Chalice Life and Serverless Life!!
- 投稿日:2019-12-02T19:39:41+09:00
DynamoDB移行小話〜移行の恩恵及び注意点〜
はじめに:
弊社で開発しているプロダクトのデータベースについて、オンプレのRDBからAWSのNoSQLDBであるDynamoDBに移行しましたので、移行を経験した上で得た恩恵と移行の注意点についてお話しさせて頂きます。
DynamoDB移行による恩恵
今回移行対象となった記録データはユーザとともに増加傾向であり、大量のデータ保管が可能なAWSとの相性は良好でした。
本項では移行を行なったことで得られた恩恵について紹介いたします。
スケールアップが容易に
DBへの負荷への対処がオンプレに比べて容易なのが最大の恩恵となりました。
テーブルサイズにも実用的な制限がないのも魅力です。オンプレDBと比べてカラム追加が簡易的
基本的に「入れれば入る」ようになっており、カラムについても数値や文字列などの基本的なものからJsonや配列まで使用可能です。
ただしカラム単位での削除ができないので、施策を入れる時に
- 事前の設計
- 今後の追加開発での考慮
がないと参照しないで無駄にサイズを圧迫するデータを生むだけなので気軽に追加ができるとはいえ注意が必要です。
各種AWSサービスとの連携
データをs3に保存し、Lambdaによる定期集計を実施するなどが可能になります。
移行によって実施できた施策も多々有ります。
AWS初心者で時間こそかかりましたが移行によるメリットは十分あったと思います。
DynamoDB移行における注意点
DynamoDBに移行するにあたり、考慮が必要な点について解説いたします。
検索機能が独特
実施可能な検索方法が
キー 実施可能な検索条件 パーティションキー 完全一致 ソートキー =、<、<=、>、>=
Between、BeginWith(前方一致)と独特な検索条件となっており、これを踏まえた設計が必要になります。
例:
- 「2019年4月のデータのリストが欲しい」場合は日付を20190401のような数値に設定してBetween等で範囲検索して絞る
- 文字列での部分一致検索は出来ないのでリストを取ってきた後で別途絞る処理を入れる
一括での更新や削除ができない
NoSQLのため、まとめて更新や削除ができず、1件ずつ処理する必要があります。
更新対象リストを取得し、そのリストに対して1つずつ処理を適用していく形になると思います。予約語
DynamoDBには予約語があり、これらの単語を使ってscanするとエラーになってしまいます。
予約語一覧:
https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/ReservedWords.htmlDynamoDBにて設定可能なTTL(Time To Live)も予約語なので、使用する場合は名称に気をつけるか、下記のようにwithNameMapを経由してあげる必要があります。
javaでの一例UpdateItemSpec updateItemSpec = new UpdateItemSpec() .withPrimaryKey( "id", Id, "targetDate", targetDate) .withUpdateExpression("set #t = :ttl") ←#tがttlだとエラーになる .withValueMap(new ValueMap().withLong(":ttl", ttl)) .withNameMap(new NameMap().with("#t", "ttl")) ←これを追加 .withReturnValues(ReturnValue.UPDATED_NEW);最大サイズの存在
移行において一番キモである「既存データのコンバート」において立ちふさがるのが最大項目サイズの存在です。
DynamoDBの最大項目サイズは400KBと制限されており、
- 移行後から登録されるデータ
- 移行元のデータ
の2点においてこの制限に引っかからないデータ設計が必要となります(特に移行元のデータ量が多い場合の想定が必須)
仮に入れるデータ量が多く、400KBをオーバーする場合は
バイナリ型を使用する
- DynamoDBで完結するが結局最大サイズという問題がのしかかる
s3に別途データを設置してパスをDynamoDBで持つようにする
- 管理箇所が増えるが、シンプルでわかりやすい
といった工夫によって最大項目サイズの削減を行うことができます。
最大項目サイズを考慮して最初に十分な時間をかけて移行のための設計を行わないと制限に引っかかり、急遽データ構成を変更、なんてことも起こり得ます。
この最大項目サイズは移行が済んだ後でも当然意識する必要があるので、施策等で新しいカラムを追加する際にも注意が必要です。
最後に
DynamoDB移行はメリットがある分独特な特性を持ち、移行前後のデータ保証と共に今後のデータの利用方法もある程度予測しての設計が求められるので、移行の際は入念な設計とレビューが大事と感じました。
この記事が今後AWSへのデータ移行を行う方の参考になれば幸いです。
- 投稿日:2019-12-02T19:31:55+09:00
IAM本を読んでみた
ちょっと時が過ぎましたが書評を書いてみようかと。
ちなみに自分は物理本派です。
IAM(Identity and Access Management)の話です。
作者の佐々木さん(@dkfj)はAWS関係で、色々な書籍を出されており、先日も執筆されたAWS試験対策本のおかげ(他2つ含む)で、
AWS Certified Solutions Architectに見事合格することができました。
その話は以下にて、
AWS Certified Solutions Architect 受験記その佐々木さんが技術書典で本、しかもIAMに関する本を出されるとのこのことで、
IAMってAWSでは結構重要な機能ではあるものの、特化した本ってなかったなと思って、技術書典自体も初参戦でしたが、参戦して、ゲットしてみました。
基本的なルール、
rootは使うな、MFAは設定すべし、キー情報は公開する
などは、守っているものの、ちゃんと理解してない点があったなと読んでいて思いました。
デザインパターン(名前は佐々木さん命名?って言っていた気がする)については、
- ホワイトリストパターン
- ブラックリストパターン
- ハイブリッドパターン
について、それぞれ、メリット、デメリット書かれておりますが、
実際、関わっていた案件で、
ホワイトリストパターンで運用してるロールがあって、
ロールに設定していなかったサービスを見ようと思ったら、参照すらできず、
悲しみに打ちひしがれていた(大袈裟)のですが、
なるほど、これがホワイトリストのデメリットかと
そして、ハイブリッドパターンがいいだなと実感しました。CloudFormationでIAMを管理するというのは、結構目から鱗でした。
そして、CloudFormationちゃんと使ったことがなかったので(Serverless Framework等で裏で動いているのは知ってる)、
勉強がてら、使ってみたいですね。テンプレート集は、実務にも使えそうで、よかったです。
個人アカウントはお一人様アカウントですが、
普通にAdministrator権限ついたユーザーで作業してますが、
はい。すみませんって感じでした。
この辺は今後見直します。
IAM本を読んだという同僚に聞いたところ、
- すごい読みやすい本でした。
- やっぱそうだよね〜〜って内容が多かったので、安心感が得られてよかったです
とのことでした。
次の技術書典でも本を出されるということでなので、
また買いに行きたいですね。なお、今回のIAM本は、電子版は以下で購入できますよ。
https://booth.pm/ja/items/1574937
他にも読んでない本がまだまだあるので読みます。。。(ダメな人)
- 投稿日:2019-12-02T19:16:00+09:00
手順メモ:lambdaでzipファイルをアップロードするまでに必要なこと
やりたいこと
- lambdaでapiを叩きたい。
- python3でやるためには必要なライブラリをlambdaにzipでアップロードする
前提
- lambdaのランタイムはpython 3.7
- awsのlambdaの画面で関数の基本情報(関数名、ランタイム、アクセス権限)を作成しておく
やり方
- アップロードするzipファイルを作成する
python3なので、仮想環境を作成する実行コマンド$ python3 -m venv dev $ . dev/bin/activate $ mkdir upload $ cd upload/ $ pip install --upgrade pip $ pip install requests -t ./ $ ls -la total 8 drwxr-xr-x 14 ~ 省略 ~ . drwxr-xr-x 6 ~ 省略 ~ .. drwxr-xr-x 3 ~ 省略 ~ bin drwxr-xr-x 7 ~ 省略 ~ certifi drwxr-xr-x 10 ~ 省略 ~ certifi-2019.6.16.dist-info drwxr-xr-x 43 ~ 省略 ~ chardet drwxr-xr-x 10 ~ 省略 ~ chardet-3.0.4.dist-info drwxr-xr-x 11 ~ 省略 ~ idna drwxr-xr-x 8 ~ 省略 ~ idna-2.8.dist-info drwxr-xr-x 21 ~ 省略 ~ requests drwxr-xr-x 8 ~ 省略 ~ requests-2.22.0.dist-info drwxr-xr-x 16 ~ 省略 ~ urllib3 drwxr-xr-x 8 ~ 省略 ~ urllib3-1.25.3.dist-info *.dist-infoファイルは不要(というか、あると適切に読み込んでくれない)なので、全て削除する $ rm -rf *.dist-info lambda_function.pyを追加する $ vim lambda_function.py lambda上でapiを叩く処理を書き、ファイルを保存する。 zipにまとめる。zipファイル名は作成するlambda_function名と同じにする。 しないと、zipファイルを読み込みときに階層がずれてしまう。 $ zip -r hoge.zip ./*
- awsコンソール画面からzipファイルをアップロードする
- 問題なく読み込まれていたら、テストで確認する
注意点
zipファイルは3MB以内に抑える必要がある
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/lambda-python-how-to-create-deployment-package.htmlzipにまとめるファイルのパーミッションは変更していないが、できるだけ755に合わせたほうが良さそう。
- 投稿日:2019-12-02T19:16:00+09:00
手順メモ:AWS Lambdaでzipファイルをアップロードするまでに必要なこと
やりたいこと
- lambdaでapiを叩きたい。
- python3でやるためには必要なライブラリをlambdaにzipでアップロードする
前提
- lambdaのランタイムはpython 3.7
- awsのlambdaの画面で関数の基本情報(関数名、ランタイム、アクセス権限)を作成しておく
やり方
- アップロードするzipファイルを作成する
python3なので、仮想環境を作成する実行コマンド$ python3 -m venv dev $ . dev/bin/activate $ mkdir upload $ cd upload/ $ pip install --upgrade pip $ pip install requests -t ./ $ ls -la total 8 drwxr-xr-x 14 ~ 省略 ~ . drwxr-xr-x 6 ~ 省略 ~ .. drwxr-xr-x 3 ~ 省略 ~ bin drwxr-xr-x 7 ~ 省略 ~ certifi drwxr-xr-x 10 ~ 省略 ~ certifi-2019.6.16.dist-info drwxr-xr-x 43 ~ 省略 ~ chardet drwxr-xr-x 10 ~ 省略 ~ chardet-3.0.4.dist-info drwxr-xr-x 11 ~ 省略 ~ idna drwxr-xr-x 8 ~ 省略 ~ idna-2.8.dist-info drwxr-xr-x 21 ~ 省略 ~ requests drwxr-xr-x 8 ~ 省略 ~ requests-2.22.0.dist-info drwxr-xr-x 16 ~ 省略 ~ urllib3 drwxr-xr-x 8 ~ 省略 ~ urllib3-1.25.3.dist-info *.dist-infoファイルは不要(というか、あると適切に読み込んでくれない)なので、全て削除する $ rm -rf *.dist-info lambda_function.pyを追加する $ vim lambda_function.py lambda上でapiを叩く処理を書き、ファイルを保存する。 zipにまとめる。zipファイル名は作成するlambda_function名と同じにする。 しないと、zipファイルを読み込みときに階層がずれてしまう。 $ zip -r hoge.zip ./*
- awsコンソール画面からzipファイルをアップロードする
- 問題なく読み込まれていたら、テストで確認する
注意点
zipファイルは3MB以内に抑える必要がある
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/lambda-python-how-to-create-deployment-package.htmlzipにまとめるファイルのパーミッションは変更していないが、できるだけ755に合わせたほうが良さそう。
- 投稿日:2019-12-02T19:15:47+09:00
S3 Select
◾️S3 Select とは
オブジェクトから必要なデータのみを抽出するよう設計された、新しい Amazon S3 機能で、パフォーマンスを大幅に改善し、S3 のデータへのアクセスに必要なアプリケーションのコストを削減することができます。
ほとんどのアプリケーションでは、オブジェクト全体を取得した後、詳細な分析に必要なデータのみをフィルタで除外する必要があります。
S3 Select を使用すると、アプリケーションは、Amazon S3 サービスへのオブジェクト内にあるデータのフィルタリングやデータへのアクセスといった手間のかかる作業から解放されます。
アプリケーションでロードおよび処理しなければならないデータ量を減らすことで、S3 Select は S3 のデータに頻繁にアクセスするほとんどのアプリケーションのパフォーマンスを最大で 400% 改善することができます。
ただし、S3 Select の料金は、入力、出力、および転送されたデータのサイズに基づいています。
クエリごとに、スキャンした GB あたり 0.00225 USD と、返された GB あたり 0.0008 USD の料金がかかるため、特定のデータだけを抽出したいときなどに便利かと思われる。◾️やってみた
適当なCSVファイルを準備し、S3へアップロードする。
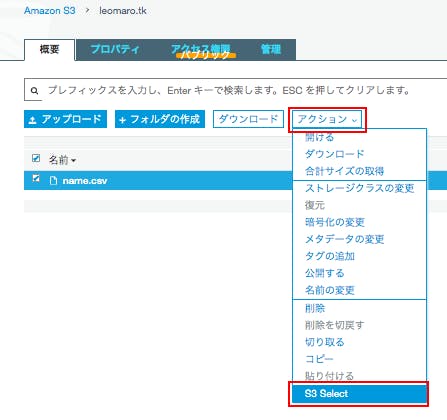
namae.csvnamae,type,age,city sato,man,20,sapporo tanaka,man,30,kanagawa kimura,woman,20,okayama hogawa,woman,10,miyagi sato,woman,20,yamanashi amuro,man,10,kanagawa「アクション」から「S3 select」をクリック。
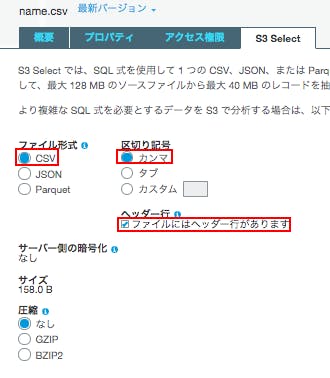
ファイル形式:「CSV」
区切り記号:「カンマ」
「ファイルにはヘッダー行があります」にチェック。
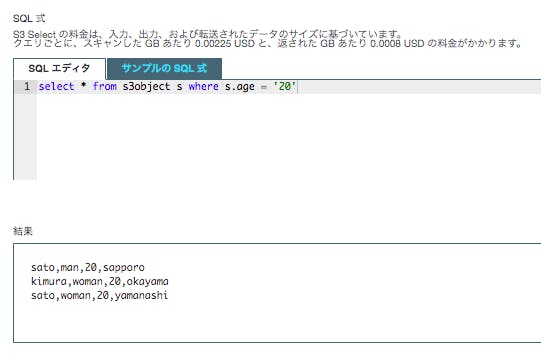
デフォルトのSQLを実行してみます。
select * from s3object s limit 5最大で 5 つのデータが取得(limit 5)されたことがわかる。
他のサンプルも確認してみましょう。age=20のものだけ抽出します。
select * from s3object s where s.age = '20'age = 20 のものだけが抽出された。

- 投稿日:2019-12-02T19:11:19+09:00
GhostscriptがCLIから実行できない
問題点
ec2イスタンス上で使用できるフォント一覧を確認する際に
ghostscriptで確認しようとしたらこんなエラーが出てgsの起動に失敗した$ gs GPL Ghostscript 8.70 (2009-07-31) Copyright (C) 2009 Artifex Software, Inc. All rights reserved. This software comes with NO WARRANTY: see the file PUBLIC for details. GPL Ghostscript 8.70: Cannot open X display `(null)'. **** Unable to open the initial device, quitting.対処
-sDEVICE=png256のオプション追記で実行できた$ gs -sDEVICE=png256 GPL Ghostscript 8.70 (2009-07-31) Copyright (C) 2009 Artifex Software, Inc. All rights reserved. This software comes with NO WARRANTY: see the file PUBLIC for details. GS> (*) { == } 256 string /Font resourceforall (Adobe-Japan1-UniJISPro-UTF8-V) (Utopia-Regular) ...参考
- 投稿日:2019-12-02T19:01:00+09:00
サーバーレスCrystalのための自作Custom Runtimeを改良した話
みなさんCustom Runtimeしてますか?
確かLambdaの新機能としてCustom Runtimeが発表されてから大体一年くらい経ちましたね。
私は去年のアドベントカレンダーで壮大に渾身のネタを潰されたのでよく覚えています。
今qiitaなどで検索をかけてみると直近ではphp勢が目立つ感じですかね?
まあRubyが対応してしまった今となっては人口の多くてLambdaを使いたいような言語のうち対応してないのはphpくらいでしょうしね。あれから発表当時作ったCrystal用のCustom Runtimeでいくらか開発をしてきて私のLambdaやCrystalへの理解に合わせて更新していってもはや見る影もなく変わってしまったので更新版について適当に書いていこうと思います。
あ、基本的にServerless Frameworkを使うのを前提としますのであしからず。
最終的な成果物はこちらに置いてあります。本文
serverless.yml
とりあえず前回と同じ様にserverless.ymlから。
serverless.ymlservice: serverless-crystal-sls custom: defaultStage: dev api_version: v0 provider: name: aws runtime: provided timeout: 300 region: ap-northeast-1 stage: ${opt:stage, self:custom.defaultStage} environment: ${file(./env.yml)} functions: hello: handler: hello events: - http: path: test method: post integration: lambdaここはとくに代わり映えしないですね。
helloというハンドラーが/testにpostすると動きますよというだけです。ディレクトリ構成
次にディレクトリ構成。
. ├ src/ │ ├ runtime/ │ │ ├ error.cr │ │ └ handler.cr │ └ main.cr ├ deploy.sh ├ env.yml └ serverless.yml今度は結構様変わりしてます。
bootstrapとかhandlerごとのディレクトリとか色々なくなってますね。ハンドラー
次はCrystalの動作の起点となる
main.crです。src/main.crrequire "./runtime/handler" require "./runtime/error" Lambda.handler "hello" do |event| begin event["body"] rescue err LambdaError.alert err raise err end endもう完全に前回とは別物ですね。
今回はSinatra系のWAFっぽい感じを目指しました。
引数がハンドラーとして設定せれている文字列と一致すれば、ブロック内の処理を実行します。
ちなみにこのサンプルではbeginでエラーを一度握りつぶしていますがこれは単にslackへアラートを飛ばすという完全に自分用の処理を入れるためのものです。src/runtime/error.crrequire "json" module LambdaError extend self def alert(error) post = { fallback: ENV["FAILD_FALLBACK"], pretext: "<@#{ENV["SLACK_ID"]}> #{ENV["FAILD_FALLBACK"]}", title: error.message, text: error.backtrace.join("\n"), color: "#EB4646", footer: "function-name", } body = { attachments: [post], } HTTP::Client.post("#{ENV["FAILD_WEBHOOK_URL"]}", body: body.to_json ) end endイベントループ
さて次に本丸のイベントループの実装です。
src/runtime/handler.crrequire "json" require "http/client" module Lambda extend self def handler(name : String) return if name != ENV["_HANDLER"] ENV["SSL_CERT_FILE"] = "/etc/pki/tls/cert.pem" while true response = HTTP::Client.get "http://#{ENV["AWS_LAMBDA_RUNTIME_API"]}/2018-06-01/runtime/invocation/next" event = JSON.parse(response.body) request_id = response.headers["Lambda-Runtime-Aws-Request-Id"] begin body = yield event header = nil url = "http://#{ENV["AWS_LAMBDA_RUNTIME_API"]}/2018-06-01/runtime/invocation/#{request_id}/response" rescue err body = { msg: "Internal Lambda Error", err: err.message, } header = HTTP::Headers{"Lambda-Runtime-Function-Error-Type" => "Unhandled"} url = "http://#{ENV["AWS_LAMBDA_RUNTIME_API"]}/2018-06-01/runtime/invocation/#{request_id}/error" end HTTP::Client.post url, headers: header, body: body.to_json end end endCustom Runtimeのイベントループが一体何者なのか、という話はすでに何回もされているものなので詳しくは解説しませんが、ざっと説明するとCustom Runtimeはループの中で用意されたhttpのエンドポイントから実際のリクエストを受け取り、成功時用と失敗時用のエンドポイントへそれぞれ結果を引き渡すという処理を繰り返しています。
前回からの変更点はいくつかあります。
まず引数としてハンドラーを指定する形になったので合わせて一致しない場合は早期returnするようにしてます。次に環境変数
SSL_CERT_FILEにパスを入れています。
これは外部とHTTPSでやり取りをするのにCrystalでは自力でSSL証明書を見つけられないのでこうやって指定してやる必要があるからです。それからまたbeginが入っています。
これはエラー時にはエラーが起きたときのためのエンドポイントへ結果を流すようにするためです。そしてこれが一番大きいですが、マクロを使うのをやめてyieldとブロックを利用するようにした点ですね。
最初にこのCustom Runtimeを作成したときはそもそもCrystal(とその元ネタとなったRuby)に関する知識が足りてなかったのでマクロを使わないとこういったcallback的な処理は解決できないものだと思いこんでいたのですが、見ての通りyieldとブロックを利用した処理のほうがむしろ綺麗ですね。
そしてそれ以上の利点として、マクロでバイナリごとにハンドラーを指定するのをやめたので、ビルドするバイナリを1つにできるという点があります。デプロイスクリプト
では最後にデプロイ用のスクリプトを見ていきましょう。
deploy.sh#!/bin/bash stg=$1 [ "$stg" = "" ] && stg="dev" [ -e bootstrap ] && sudo rm bootstrap sudo docker run --rm -v $(pwd):/src -w /src \ crystallang/crystal crystal build \ --link-flags -static -o bootstrap src/main.cr && \ sudo chmod +x bootstrap || exit 1 sls deploy -s $stg前回の記事を読んでいない方のための説明として、Custom Runtimeではbootstrapというファイルが実行の起点になっています。
前回との大きな違いはビルドが1回になっていることですね。
bootstrapではわざわざハンドラーごとにどのバイナリを動かすか、という制御が不要になったのでビルドの時点で直接bootstrapを作るようにしています。
Crystalはビルドにとくに時間のかかる言語なのでなおさらですが、ほぼ同じソースに対して何回もビルドを行うのは非効率ですし容量も比較的かさまなくなったのではないでしょうか。あとがき
ということで自作Custom Runtimeを改良した話をしました。
Media Do Advent Calendar 2019、実は明日も担当は私なのでもう1日お付き合いいただければと思います。
- 投稿日:2019-12-02T18:01:43+09:00
AWS re:Inventで発表された新サービスまとめ (2019/12/2更新)
現地組です。とりあえず自身の備忘録を兼ねてまとめています。
12/1(日)
AWS DeepComposer
自動学習、自動作曲
https://aws.amazon.com/about-aws/whats-new/2019/12/introducing-aws-deepcomposer/Amazon Transcribe Medical
AWS License Manager BYOL対応
BYOLに対応し、ライセンスルール違反の検知が可能に。
https://aws.amazon.com/about-aws/whats-new/2019/12/aws-license-manager-adds-dedicated-host-management-capabilities/
https://aws.amazon.com/about-aws/whats-new/2019/12/aws-license-manager-allows-administrators-to-automate-discovery-of-existing-software-licenses/Amazon EventBridge Schema Registry (Preview)
AWS DeepRacer 拡張機能
https://aws.amazon.com/about-aws/whats-new/2019/12/aws-deepracer-expands-participate-learn-win/
EC2 Image Builder
https://aws.amazon.com/about-aws/whats-new/2019/12/introducing-ec2-image-builder/
AWS IoT SiteWise 5つの機能追加
EMP for Windows Server
サポート切れするWindows Server上アプリの移行促進ツール
https://aws.amazon.com/about-aws/whats-new/2019/12/aws-launches-program-drive-migration-windows-server/12/2(月)
12/3(火)
12/4(水)
12/5(木)
- 投稿日:2019-12-02T18:01:43+09:00
AWS re:Inventで発表された新サービス/アップデートまとめ (2019/12/2更新)
現地組です。とりあえず自身の備忘録を兼ねてまとめています。
12/1(日)
AWS DeepComposer
- AWS DeepComposerキーボードを使用し、数秒で完全なオリジナルの曲となるメロディを作成可能。
- AWS DeepComposerにはチュートリアル、サンプルコード、トレーニングデータが含まれており、これらを使用して、1行たりともコードを記述することなく、モデルの構築を開始可能。
- AWS DeepComposerキーボードは、2020年第1四半期に99ドルで購入可能となる予定。

https://aws.amazon.com/about-aws/whats-new/2019/12/introducing-aws-deepcomposer/
Amazon Transcribe Medical
AWS License Manager BYOL対応
BYOLに対応し、ライセンスルール違反の検知が可能に。
https://aws.amazon.com/about-aws/whats-new/2019/12/aws-license-manager-adds-dedicated-host-management-capabilities/
https://aws.amazon.com/about-aws/whats-new/2019/12/aws-license-manager-allows-administrators-to-automate-discovery-of-existing-software-licenses/Amazon EventBridge Schema Registry (Preview)
AWS DeepRacer 拡張機能
https://aws.amazon.com/about-aws/whats-new/2019/12/aws-deepracer-expands-participate-learn-win/
EC2 Image Builder
https://aws.amazon.com/about-aws/whats-new/2019/12/introducing-ec2-image-builder/
AWS IoT SiteWise 5つの機能追加
EMP for Windows Server
サポート切れするWindows Server上アプリの移行促進ツール
https://aws.amazon.com/about-aws/whats-new/2019/12/aws-launches-program-drive-migration-windows-server/12/2(月)
12/3(火)
12/4(水)
12/5(木)
- 投稿日:2019-12-02T18:01:43+09:00
AWS re:Invent 2019で発表された新サービス/アップデートまとめ (2019/12/2更新)
現地組です。とりあえず自身の備忘録を兼ねてまとめています。
できるだけ簡単に振り返られるようまとめていきます。12/1(日)
AWS DeepComposer
- AWS DeepComposerキーボードを使用し、数秒で完全なオリジナルの曲となるメロディを作成可能
- AWS DeepComposerにはチュートリアル、サンプルコード、トレーニングデータが含まれており、これらを使用して、1行たりともコードを記述することなく、モデルの構築を開始可能
- 音源に対し、ポップ、ロック、ジャズなど編曲が可能
- AWS DeepComposerキーボードは、2020年第1四半期に99ドルで購入可能となる予定
https://aws.amazon.com/about-aws/whats-new/2019/12/introducing-aws-deepcomposer/
Amazon Transcribe Medical
- Amazon Transcribeの新しい音声認識機能であるAmazon Transcribe Medical
- Amazon Transcribe Medicalを使用すると、開発者は、医師による医療文書の効率的な作成を支援するアプリケーションに医療転写サービスを簡単に統合可能
- 医師の口述と患者との会話を自動的に正確にテキストに書き込み
- さらに、このサービスは自動句読点と大文字化を可能にし、医師が音声メモを書き写すときに自然な会話を再現
- 医療分野でのディクテーションおよび会話音声の正確な医療記録を作成可能
AWS License Manager Dedicated HostsのBYOL対応
- WindowsやSQL Serverなど、専用の物理サーバーを必要とするソフトウェアライセンスに対して新しいBYOLエクスペリエンスを提供
- License ManagerはEC2 Image Builder (新サービス) と統合して、インストールメディアのメンテナンスを自動化
- BYOL使用の検出を自動化
- 指定されたソフトウェアがインストールされているインスタンスを自動的に追跡し、ライセンスルール違反を管理者に通知
https://aws.amazon.com/about-aws/whats-new/2019/12/aws-license-manager-adds-dedicated-host-management-capabilities/
https://aws.amazon.com/about-aws/whats-new/2019/12/aws-license-manager-allows-administrators-to-automate-discovery-of-existing-software-licenses/Amazon EventBridge Schema Registry (Preview)
- イベントとその構造、またはスキーマを自動的に検索し、中央集権的に管理
- スキーマはイベントの構造を表し、通常、各データのタイトルやタイプなどの情報を含むもの
- スキーマレジストリには、スキーマのコレクションを格納
- スキーマを見つけてレジストリに追加するプロセスを自動化
- JetBrains IntelliJとPyCharm、Microsoft Visual Studio Codeなどの一般的な統合開発環境(IDE)との統合
- 詳しい手順の説明
AWS DeepRacer 拡張機能と新リーグ
- AWS DeepRacerコンソールの新しいGarageセクションで、仮想カメラにステレオカメラとLIDARセンサーを追加可能
- ステレオカメラは、車が道路内のオブジェクトを検出し、その環境により敏感に反応できるように、奥行き知覚を追加
- LIDARセンサーは連続スキャンレーザーを使用して、強化学習モデルに、車が後ろから高速で接近しているかどうかに関するデータを提供
- これらのレース形式の追加により、AWS DeepRacer Leagueに新しいレースが登場
- re:Invent 2020 招待を競う次年度のリーグ開幕
https://aws.amazon.com/about-aws/whats-new/2019/12/aws-deepracer-expands-participate-learn-win/
EC2 Image Builder
- EC2 Image Builderは、安全なイメージの構築と維持をより簡単かつ迅速にするサービス
- Image Builderは、LinuxまたはWindows Serverイメージの作成、パッチ適用、テスト、配布、および共有を簡素化
- OSのデフォルトイメージをベースに作成
https://aws.amazon.com/about-aws/whats-new/2019/12/introducing-ec2-image-builder/
AWS IoT SiteWise 5つの機能追加
* MQTTまたはREST APIを使用してAWS IoT SiteWiseでデータを収集し、時系列データストアに保存
* 単一のセンサー、ライン、サプライチェーンを表すモデルの作成
* 組み込みライブラリを使用して、機器のデータを変換し、メトリックを計算
* AWS IoT SiteWise内から、機器にリンクされた測定値と計算されたメトリックスを含むライブデータストリームを公開
* 新しいSiteWise Monitor機能を使用して、AWS IoT SiteWiseに保存されている機器データをユーザーに可視化するためのフルマネージド型Webアプリケーションを作成EMP for Windows Server
- Windows Server用EMPは、サポート切れするWindows Server上アプリの移行促進ツール
- EMPテクノロジーは、基盤となるOSからアプリケーションを分離し、アプリケーションをAWS上のサポートされている新しいバージョンのWindows Serverに移行
12/2(月)
Amazon Braket (Preview)
- 科学者や開発者が量子コンピューティングを簡単に探索して実験できるようにするフルマネージドサービス
- 独自の量子アルゴリズムをゼロから設計したり、事前に構築された一連のアルゴリズムから選択が可能
- プレビューを以下より申し込み可能
https://aws.amazon.com/about-aws/whats-new/2019/12/introducing-amazon-braket/
12/3(火)
12/4(水)
12/5(木)
- 投稿日:2019-12-02T17:49:45+09:00
AmazonLinux2 EC2インスタンス作成後、mysql: コマンドが見つかりません の状態からRDS接続するまで
環境
- AmazonLinux2(AWS EC2)
目的
AmazonLinux2 EC2インスタンス作成後、既存のRDSにmysqlコマンドを使ってデータベース接続したい。
つまづいたところ
EC2インスタンス作成後に「mysql: コマンドが見つかりません」というトラブルに遭遇。mysqlがインストールされていないようなのでインストールする。
しかし、mysqlのインストールを試みるものの、mysqlではなく下のようにmariadbをインストールしようとしてくる。$ sudo yum install mysql : : ======================================================================================================================== Package アーキテクチャー バージョン リポジトリー 容量 ======================================================================================================================== インストール中: mariadb x86_64 1:5.5.64-1.amzn2 amzn2-core 9.0 M解決方法
- mysql-communityリポジトリを使ってmysqlをyumインストールする。
以下、mysqlのインストール手順
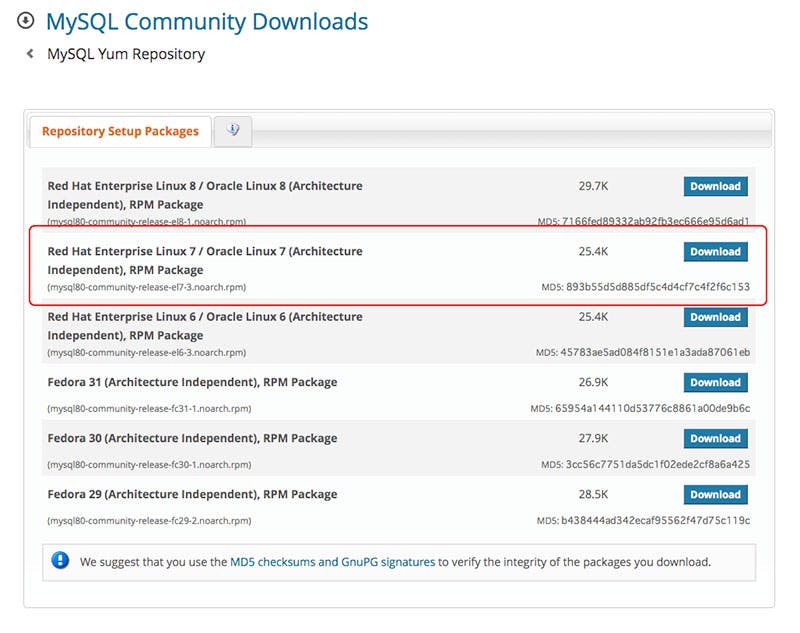
MySQL Community Downloadsページよりダウンロードしたいmysql-communityリポジトリのパッケージを選択する。ここでは、「Red Hat Enterprise Linux 7 / Oracle Linux 7 (Architecture Independent), RPM Package」を指定。
↓
上記ページから移動した先のページに記載してあるダウンロードリンクをコピペしてmysql-communityリポジトリのインストールを実行。$ sudo yum install https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm↓
mysqlをインストールする。$ sudo yum install mysql : : ======================================================================================================================== Package アーキテクチャー バージョン リポジトリー 容量 ======================================================================================================================== インストール中: mysql-community-client x86_64 8.0.18-1.el7 mysql80-community 38 M mysql-community-libs x86_64 8.0.18-1.el7 mysql80-community 3.7 M mariadb-libs.x86_64 1:5.5.64-1.amzn2 を入れ替えます mysql-community-libs-compat x86_64 8.0.18-1.el7 mysql80-community 1.3 M mariadb-libs.x86_64 1:5.5.64-1.amzn2 を入れ替えます 依存性関連でのインストールをします: mysql-community-common x86_64 8.0.18-1.el7 mysql80-community 597 k↓
インストールしたmysqlのバージョンを確認。$ mysql --version mysql Ver 8.0.18 for Linux on x86_64 (MySQL Community Server - GPL)↓
本件目的のRDS接続を試みる。接続できるようになった。$ mysql -h 'エンドポイント' -P 'ポート番号' -u 'ユーザー名' -p Enter password: 'パスワード' : : : mysql>参考
- 投稿日:2019-12-02T17:22:09+09:00
Serverless Frameworkのオプションを使ってLambdaのデプロイ先を切り替える
はじめに
個人開発アプリケーションで、Serverless Frameworkを利用してLambdaをデプロイしています。デプロイ先を開発環境と本番環境で切り替えるには
slsコマンドにオプションを渡すことで実現できるので紹介します。呼び出し方法
先に呼び出し方法を記載します。
# 開発環境にデプロイする $ sls deploy --stage dev # 本番環境にデプロイする $ sls deploy --stage prod
--stageオプションに環境名を渡します。serverless.yml
次に
serverless.ymlを見てみます。serverless.ymlservice: usn-batch frameworkVersion: ">=1.28.0 <2.0.0" provider: name: aws runtime: go1.x timeout: 60 logRetentionInDays: 14 # `--stage`オプションの値を受け取る、デフォルト値としてdevを利用する stage: ${opt:stage, "dev"} region: ap-northeast-1 iamRoleStatements: - Effect: "Allow" Action: - "logs:CreateLogGroup" - "logs:CreateLogStream" - "logs:PutLogEvents" Resource: Fn::Join: - ':' - - 'arn:aws:logs' - Ref: 'AWS::Region' - Ref: 'AWS::AccountId' - 'log-group:/aws/lambda/*:*:*' - Effect: "Allow" Action: - "dynamodb:PutItem" - "dynamodb:UpdateItem" # 各環境のDynamoDBテーブルのみ権限を付与する Resource: Fn::Join: - ':' - - 'arn:aws:dynamodb' - Ref: 'AWS::Region' - Ref: 'AWS::AccountId' - 'table/${self:custom.table.${self:provider.stage}}' # 接続先のDynanoDBテーブルを切り替える environment: table: ${self:custom.table.${self:provider.stage}} custom: table: dev: "usn-dev" prod: "usn" package: exclude: - ./** include: - ./bin/** functions: hourly: handler: bin/usn-batch events: - schedule: cron(30 * * * ? *)コメント記載の通り
provider.stageにコマンドのオプションで指定した値をセットします。それを利用してIAMやDynamoDBテーブル接続先の環境変数を切り替えています。おわりに
共通の
serverless.ymlでデプロイする環境を切り替えることができました。
- 投稿日:2019-12-02T17:08:38+09:00
AWS認定試験の話し
最近はアプリやフロントエンドにハマって、久しぶりにインフラやサーバ周りを触ってたら以前より面白い感じがありました。
数年前インフラやネットワーク関連の仕事をして忘れた知識は多い。。
去年知り合いと一緒にACP (Alibaba Cloud Professional)を取得しました。
今年はAWS Solution Architecture Associate(SAA)認定試験。どうやって勉強したのか
- 以前関連の仕事経験があり、概念など理解している
- AWSのドキュメントを読む
- 社外の勉強会にて経験や勉強した知識などの共有によりアウトプットする
どのぐらい勉強したのか
- 試験向け準備するには試験前3日
- ドキュメント読む:まとめて24時間ぐらい
- ほか:アウトプットや実験など時間がまとめられない
何を参考したのか
- AWS Well-Architectedを理解する
- AWSホワイトペーパー
- Amazon EC2 || Amazon S3 || Amazon VPC || Amazon Route 53 || Amazon RDS || Amazon DynamoDB || Amazon SQS 。。などの よくある質問を参考
- 各カテゴリのAWS ドキュメント
- AWSオンラインセミナー
- 初心者向けAWS Tutorial Videos For Beginners | Simplilearn
- 参考になったWeb:
次は
Solution Architecture Professional(SAP) or
AWS Certified Developer Associateということで
生きる・学ぶ
- 投稿日:2019-12-02T15:01:08+09:00
AmazonConnect のオペレータ状態変化などをリアルタイムに取得する方法
はじめに
この記事は、NTTコミュニケーションズ Advent Calendar 2019 6日目の記事です。
概要
AmazonConnectのエージェントイベントストリームを利用してオペレータの状態情報等をAWS側にて取得してみました。
オペレータ側にて取得するのではなくサーバ側で一括取得できることから、CC全体のリアルタイム情報を取得するのに役立ちます。AmazonConnectのAPIなど他の取得方法との違い
・APIでは各ユーザのステータスを取得することができない。
・CCPから情報を取得する場合、オペレータ側での情報取得となるので、集約することができない。
・イベントストリームでは、サーバ側にてオペレータ情報を集約取得できる。今後の発展性
・座席管理システムなどオペレータの現在の状態をリアルタイムに外部で利用する場合での活用が考えられます。
・オペレータのステータス変化から終話や保留の時間を検知できるので、その時間情報をもとにアラートを出すなどの活用も考えられます。環境
lambdaの環境はpython3.8です。
AmazonConnectの新機能であるchat機能については考慮していません。構成
構成は下の図の通りになっています。AmazonConnectからイベントデータをKinesisに流し、lambdaをKinesisトリガで起動しています。
事前設定方法
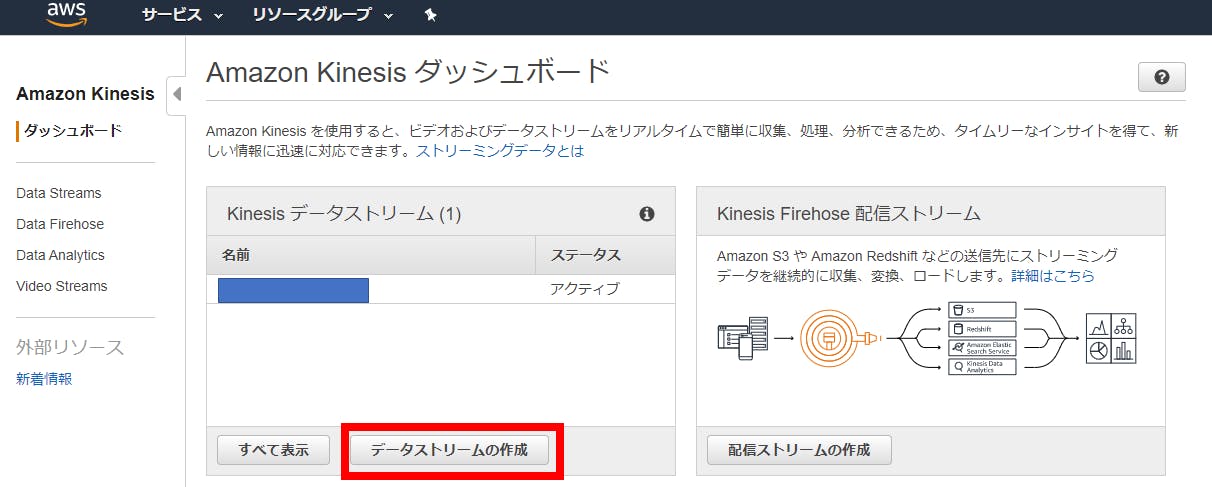
・kinesis data streamの作成
①AWSコンソールからkinesisを検索
②下記のようにデータストリームの作成をクリック
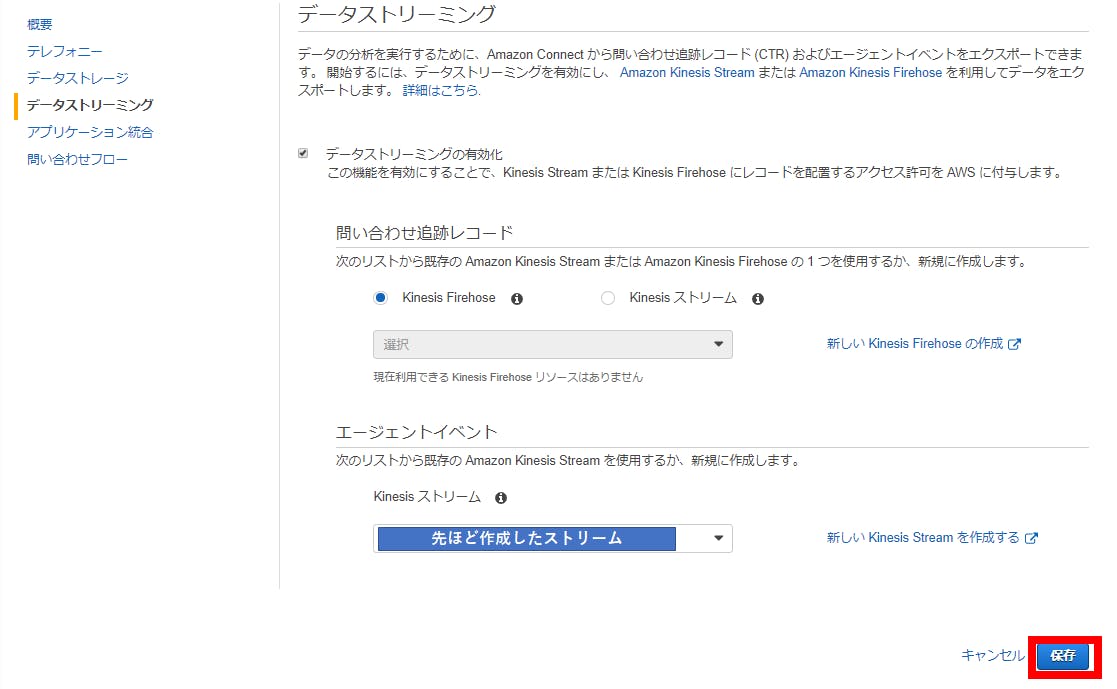
③Kinesis ストリームの名前、シャード数を設定して作成。(シャード数はとりあえず1で大丈夫です。)・AmazonConnectのインスタンスにてデータストリーミングの設定を実施
①AWSコンソールからAmazonConnect選択、資料するインスタンスにてデータストリーミングを選択。
②下記のようにデータストリーミングの有効化+エージェントイベントに作成したストリームを設定。
・lambda にてトリガーにkinesis data streamを設定
作成する際に必要な権限としては、
AmazonKinesisReadOnlyAccess
AWSLambdaKinesisExecutionRole
の2つです。トリガの追加からkinesisを設定。
バッチウィンドウ等は必要に応じて変えてください。取得方法
データは下のコードの様に、jsonのデータを取得し、それを利用して確認できる。
詳細はこちらの公式ドキュメントの122ページ参照取得できるものの例
・オペレータ名
・Offlineにした時間
・Availableにした時間
・ACW開始時刻(通話終了時刻)
・ACW終了時刻
・エージェントとの通話開始時刻
・通話保留開始
・通話保留終了現状ではcloud watchに投げているだけですが、そのタイミングでDBにデータ保管などを行うことも可能です。
注意点等
・特殊なパターンはテストしてません。(転送・三者通話など)
コード
lamdaimport base64 import json def lambda_handler(event, context): for record in event['Records']: b64_data = record['kinesis']['data'] data = base64.b64decode(b64_data).decode('utf-8') kinesis_json_datas = json.loads(data) # ステータス変更のイベントのみを確認する if kinesis_json_datas["EventType"] == "STATE_CHANGE": # offlineに変更したタイミング if kinesis_json_datas["CurrentAgentSnapshot"] and kinesis_json_datas["PreviousAgentSnapshot"] and kinesis_json_datas["CurrentAgentSnapshot"]["AgentStatus"]["Name"] == "Offline" and kinesis_json_datas["PreviousAgentSnapshot"]["AgentStatus"]["Name"] != "Offline": print("エージェント名:" + kinesis_json_datas["CurrentAgentSnapshot"]["Configuration"]["Username"]) print("Offlineになりました:" + kinesis_json_datas["CurrentAgentSnapshot"]["AgentStatus"]["StartTimestamp"]) # Availableに変更したタイミング elif kinesis_json_datas["CurrentAgentSnapshot"] and kinesis_json_datas["PreviousAgentSnapshot"] and kinesis_json_datas["CurrentAgentSnapshot"]["AgentStatus"]["Name"] == "Available" and kinesis_json_datas["PreviousAgentSnapshot"]["AgentStatus"]["Name"] != "Available": print("エージェント名:" + kinesis_json_datas["CurrentAgentSnapshot"]["Configuration"]["Username"]) print("Availableになりました:" + kinesis_json_datas["CurrentAgentSnapshot"]["AgentStatus"]["StartTimestamp"]) # ACW開始タイミング。(通話終了タイミング) elif kinesis_json_datas["CurrentAgentSnapshot"]["Contacts"] and kinesis_json_datas["CurrentAgentSnapshot"]["Contacts"][0]["State"] == "ENDED": print("エージェント名:" + kinesis_json_datas["CurrentAgentSnapshot"]["Configuration"]["Username"]) print("通話終了タイミングです:" + kinesis_json_datas["CurrentAgentSnapshot"]["Contacts"][0]["StateStartTimestamp"]) # ACW→通話可能への変更タイミング elif kinesis_json_datas["PreviousAgentSnapshot"] and kinesis_json_datas["PreviousAgentSnapshot"]["Contacts"] and (not kinesis_json_datas["CurrentAgentSnapshot"]["Contacts"]) and kinesis_json_datas["PreviousAgentSnapshot"]["Contacts"][0]["State"] == "ENDED": print("エージェント名:" + kinesis_json_datas["CurrentAgentSnapshot"]["Configuration"]["Username"]) print("ACW終了タイミング:" + kinesis_json_datas["EventTimestamp"]) # 通話中のステータス変更について elif kinesis_json_datas["PreviousAgentSnapshot"] and kinesis_json_datas["PreviousAgentSnapshot"]["Contacts"] and kinesis_json_datas["CurrentAgentSnapshot"] and kinesis_json_datas["CurrentAgentSnapshot"]["Contacts"]: # エージェントと繋がったタイミング if (not kinesis_json_datas["PreviousAgentSnapshot"]["Contacts"][0]["ConnectedToAgentTimestamp"]) and kinesis_json_datas["CurrentAgentSnapshot"]["Contacts"][0]["ConnectedToAgentTimestamp"]: print("エージェント名:" + kinesis_json_datas["CurrentAgentSnapshot"]["Configuration"]["Username"]) print("エージェント接続タイミング:" + kinesis_json_datas["EventTimestamp"]) # 通話保留タイミング elif kinesis_json_datas["PreviousAgentSnapshot"]["Contacts"][0]["State"] == "CONNECTED" and kinesis_json_datas["CurrentAgentSnapshot"]["Contacts"][0]["State"] == "CONNECTED_ONHOLD": print("エージェント名:" + kinesis_json_datas["CurrentAgentSnapshot"]["Configuration"]["Username"]) print("通話保留開始:" + kinesis_json_datas["EventTimestamp"]) # 通話解除タイミング elif kinesis_json_datas["PreviousAgentSnapshot"]["Contacts"][0]["State"] == "CONNECTED_ONHOLD" and kinesis_json_datas["CurrentAgentSnapshot"]["Contacts"][0]["State"] == "CONNECTED": print("エージェント名:" + kinesis_json_datas["CurrentAgentSnapshot"]["Configuration"]["Username"]) print("通話保留終了:" + kinesis_json_datas["EventTimestamp"]) return {'statusCode': 200, 'body': 'FINISH'}終わりに
今回はCloudWatchに投げましたが、様々なシステムに投げることができるので色々連携する際に試してみてください。
明日は@y-iさんの記事です。


- 投稿日:2019-12-02T14:53:14+09:00
AWS CloudFront + ALB + httpd の組み合わせで一部のブラウザでページが表示できなかった問題の原因と対処
はじめに
https 通信で CloudFront を経由し、ALB -> EC2 という非常に標準的な構成を採っていたのだが、一部のツール・ブラウザで表示が行われなかったため調査を実施した。
概要は以下の通り。
- iPhone の Safari ではページが全く表示されない
- curl を打つと
curl: (92) HTTP/2 stream 1 was not closed cleanly: PROTOCOL_ERROR (err 1)- Windows の Safari (古いけど...) では
キュリティ保護された接続を確立できませんという表示結果として、2つの問題があった。
問題1. Upgrade: h2,h2c
これは全く同じ問題が公開されていたので引用。
https://dev.classmethod.jp/cloud/aws/resolve-safari-and-alb-https-connection-errors/
ALB は HTTP2 を受け付けるが、ALB-EC2間は HTTP 1.1 で通信される。
Apache の mod_http2 を有効にしていると、HTTP 2 通信が可能なので Upgrade をレスポンスヘッダに含めてしまう。
すると、ユーザーとALBの間は HTTP2 でやり取りされているので、HTTP2 通信にも関わらず、レスポンスヘッダにUpgradeタグが注入されてしまう。
しかし、HTTP 2のRFCでは8.1.2.2. Connection-Specific Header Fields
HTTP/2 does not use the Connection header field to indicate
connection-specific header fields; in this protocol, connection-
specific metadata is conveyed by other means. An endpoint MUST NOT
generate an HTTP/2 message containing connection-specific header
fields; any message containing connection-specific header fields MUST
be treated as malformed (Section 8.1.2.6).
引用元: https://tools.ietf.org/html/rfc7540#section-8.1.2.2となっており、HTTP2 通信の中に HTTP2 をupgradeさせる情報を含めてはいけない(MUST NOT)。
この仕様を厳格に守った場合はそのような通信を受け入れてはならないので、Safari や curl では通信を行うことができない。対処方法は EC2 側の httpd で HTTP2 を無効化して HTTP 1.1 のみを有効とすればよい。 一般的には mod_http2 を Load しなければよい。 やり方は上記URL参照。
問題2. TLS のデフォルトバージョン
問題1. を対処した結果、iPhone と curl は正常に通信できるようになったが、Windows の Safari のみ通信ができない状態だった。また、CloudFrontへ向けた場合は失敗、ALBへ向けた場合は成功、と地味にふるまいが一貫していない。
あれやこれやと試してみた結果、WindowsのSafariリリースが2012年で止まっているということで思い当たったのがサーバーサイドで受け入れ可能なTLSバージョンだったので確認。
リソースの生成時には CloudFront も ALB もセキュリティポリシーには、Management Console から選択可能なデフォルト/recommended を選択した。
しかし、実はこの2つで受け入れ可能なTLSのバージョンが異なっている(※記事執筆の19/12/02時点)
コンテンツ デフォルト(recommend)ポリシー サポートするTLSの最低バージョン ALB ELBSecurityPolicy-2016-08 TLSv1.0 CloudFront TLSv1.1_2016 (recommended) TLSv1.1 今回は、下位側に合わせる意味で CloudFront 側のセキュリティポリシーを
TLSv1_2016に修正してDeployを実施。 ステータスが Deployed になった後に再度 Windows Safari で接続すると接続できた。
- 投稿日:2019-12-02T11:42:21+09:00
AWS上に、Re:dashを導入する。
未経験エンジニアがRe:dashをAWS上に構築してみた
株式会社パーソンリンクにエンジニア未経験で入社して3週目の高島です。
高校では、情報技術科に所属していました。授業でC言語やJavaの基本文法を学びました。高卒で東京に上京してきて、印刷系の仕事を約5年半やっていました。
しかしながら、今日のIT業界は、キャッシュレス決済、SNSなど、めまぐるしいスピードで進化していることを実感しました。上京する前の自分に言っても信じてもらえないようなことが、実際に起こっている現状を見て、いわゆる「ゆとり世代」として、そのスピードについていかなければいけないと危機感を持ったと同時に、その開発に携わってみたいと思い、転職を決意しました。
自分と同じように、未経験からエンジニアを目指している方々の刺激に少しでもなれたらと思いますので、よろしくお願いいたします。
今担当しているプロジェクトにて、運用・保守業務を今後していくのですが、それにあたってAWS上でRedashを導入することになったので、その過程をメモしました。初心者なので、至らない点たくさんあると思います。間違いなどありましたら、ご指摘いただけると幸いです。今回は、MySQL (Amazon RDS)を利用できるようにするところまで進めました。Re:dashとは
オープンソースのダッシュボードツールです。自分なりに解釈した結果、データベースなどのデータを、表や、グラフにすることができるツール(?)です。SQLを実行することもできます。
定期的にグラフを更新する機能があるので、リアルタイムでグラフ化した情報を見ることができそうです。参考にさせていただいた記事
やり方
Redashの公式ホームページから、AMIを選択
https://redash.io/help/open-source/setup#
awsap-northeast-1(東京)を選択。選択すると、ステップ2の、インスタンス選択画面に遷移します。インスタンスタイプの設定
無料利用枠から外れてしまいますが、t2.small以上を選択してください。公式の説明書には、t2.small以上推奨と書いています。
セキュリティーグループの設定
3〜5をそのままで、セキュリティーグループの設定です。画像の通り、SSHに加え、HTTP,HTTPSも追加します。
ソースと書いてある部分に、自分のIPアドレスを入れます。
自分のIPアドレスは、ブラウザ上でIPアドレスと検索すれば、出てきます。
https://www.cman.jp/network/RDSの設定
- AWSのコンソールから、RDSを選択。
- 左カラムににある、データベースを選択。
- 自分のデータベースを選択し、接続とセキュリティのタブ
- 画面中央右側にある、VPCセキュリティグループをクリック
- 画面遷移するので、下部にある、インバウンドタブを選択、編集ボタンをクリック
- 先ほどのセキュリティーグループの設定にて作成した、セキュリティーグループを追加。
Re:dashにログイン
Redashにログインしていくのですが、ここでつまづきました。
本来ならこのページに行きたいのですが、Redashのホームページからログインしようとすると、
本来入力したいメールアドレスとパスワードとは違う情報を入力する画面に行ってしまいました。以下の手順で操作すると解決することができました。
1. AWSコンソールから、EC2を選択し、先ほど作成した、自分のインスタンスを選択
2. 画面右下に、パブリック DNS (IPv4)があるので、そのURLのページに行くと、直接Redashのサインアップページに遷移する
3. 自分の情報を入力し、サインアップを完了させるデータベースに接続
- 右上のはてなマークの右のボタン
- Data Sourcesのタブ
- + New Data Source
- MySQL (Amazon RDS)を選択。
情報を入力していきます。ここでつまづきました。
hostの欄に、何を入力すればいいかわからなかったです。
以下の方法で解決しました。
- host の部分は、AWSコンソールから、RDSに飛んで、自分のデータベースを選択。
接続とセキュリティタブの、エンドポイントが、hostにあたります。これですべての設定は終わりです。さて無事に動作できるでしょうか?
入社3週間の未経験エンジニアでもなんとか環境を構築することができました。
いざ、右も左もわからない状態で環境構築をしてみると、まずはAWS周りの単語の理解が難しかったです。記事通りにやっているのに、目的の画面に遷移しないのは何故なのか、全然見当もつきませんでした(^_^;)
記事を見落としていたり、公式ドキュメントに書いてあるところを飛ばして読んでいたりと、少し焦っていたので、落ち着いてやっていきたいと思います。目的のリソースに対しての情報が少ない場合は、公式ドキュメントを翻訳していくというのは、避けて通れないので苦手意識を少しでもなくしていきたいです。明日も、高島が担当させていただきます。
最後まで読んで頂き、ありがとうございました。




- 投稿日:2019-12-02T11:32:00+09:00
Amazon Athenaのユーザー定義関数(UDF)のPreview版を試してみた
Amazon Athenaが遂にユーザー定義関数(UDF)をサポートするようです。
Amazon Athena Adds support for User Defined Functions (UDF)
独自に関数を作成する事で、ビルトイン関数では不可能な処理を実現できるようになります。
Preview版が公開されたので使い勝手を確かめてみました。まとめ
- UDFはJava言語のAthena Query Federation SDKで開発し、AWS Lambdaに登録する
- Athenaから利用する際の構文は以下
USING FUNCTION <function name>(col1 <type>) RETURNS <type> TYPE LAMBDA_INVOKE WITH (lambda_name = '<lambda name>') AS SELECT ...
- 1回のLambda関数で複数のレコードがまとめて処理される為、リクエスト料金面の問題は現時点ではなさそう
Amazon Athenaとは
Amazon S3内のデータを標準SQLを用いて分析できるサービスです。
試してみた
2019/11/27現在、Preview版のUDFはus-east-1リージョンでのみ利用可能です。
UDFの作成はJava言語のAthena Query Federation SDKを用いて行います。
既存ソースコードに以下の関数を追加して、jarファイルをビルドします。
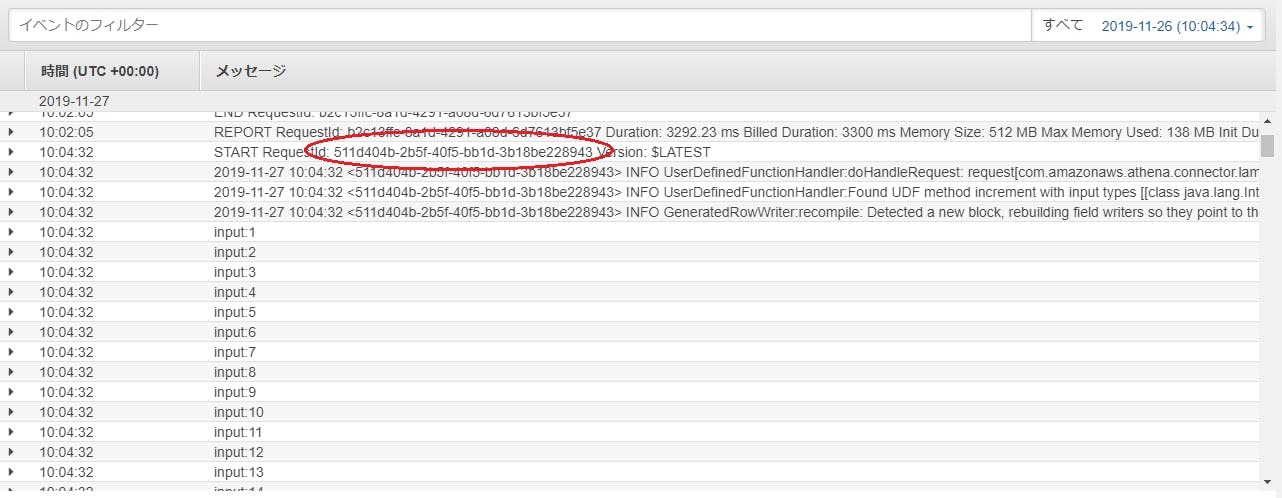
aws-athena-query-federation/athena-udfs/src/main/java/com/.../udfs/AthenaUDFHandler.javapublic Long increment(Long input) { System.out.println("input:" + input); return input + 1; }作成したUDF(athena-udfs-1.0.jar)をus-east-1リージョンのAWS Lambdaに登録します。
AthenaでPreview版のUDFを利用する為に、"AmazonAthenaPreviewFunctionality"という名称のワークグループを作成し、作成したワークグループに切り替えます。
以下のクエリを実行します。
USING FUNCTION increment(col1 BIGINT) RETURNS BIGINT TYPE LAMBDA_INVOKE WITH (lambda_name = 'athena_udfs_test') SELECT v,increment(v) AS v_ FROM UNNEST(SEQUENCE(1,10000)) AS t(v)結果
LambdaのCloudWatchログを見る限り、1回のLambda関数で多数の行がまとめて処理されている様子でした。1レコード毎にLambda関数が実行されるとリクエスト料金が跳ね上がる事を懸念していたのですが、その懸念は(あまり)なさそうです。
所感
待ちに待った機能が遂に出た、という印象です。これでビルトイン関数だけでは手が届かなかった事を実現できるようになります。
現時点での不満は、都度UDFを宣言するのに手間がかかる事でしょうか。この点は事前登録する機能が今後リリースされる事に期待します。



- 投稿日:2019-12-02T11:00:16+09:00
CloudFormationでEC2の初期構築の工数削減
構築目的と背景
お断り:目新しい情報はないかと思います。
業務でCloudFormationを活用するようになりました。
その中で単にEC2を作成した場合、作成後の手作業が多く自動化のありがたみが薄いと感じました。
そこでcfn-init ヘルパースクリプトを活用したいと思います。
※AmazonLinux2では上記のヘルパースクリプトが標準でインストールされている為、前準備は不要です。できること
- コマンドの実行
- ファイル作成
- ユーザー/グループの作成
- パッケージのインストール
- サービスの起動設定
- ソース(アーカイブファイルをダウンロード)
活用内容
私が活用したのはパッケージのインストールとコマンドの実行です。
パッケージ
- yumでインストールが可能なものはパッケージ名を記載
- バージョンに関しては[]であればOSがインストールできる最新版がインストールされます。
- 指定のバージョンがあればリストの書式で記載してください。
- 更に新しいバージョンを指定したい場合はrpmにURLを記載することでインストールが可能となります。
EC2: Type: AWS::EC2::Instance Metadata: AWS::CloudFormation::Init: config: packages: rpm: mysql80-community-release: https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm yum: python3: [] mysql-community-client: [] git: - "2.20.1"コマンド
Amazon Linux2であればamazon-linux-extrasを使ってインストールすることもありますし、
Pythonであればpip installもあります。他にもyum以外の手段はあるかと思います。
それらは上記パッケージのインストールでは対応できない(と思ってます)のでコマンドにて対応します。また、名前のアルファベット順にコマンドが実行される為、順番に考慮が必要な場合は
コマンド名に数字を付けておくと良いです。EC2: Type: AWS::EC2::Instance Metadata: AWS::CloudFormation::Init: config: commands: 01php73: command: "amazon-linux-extras install php7.3" 02pytest: command: "pip3 install pytest" 03mount: command: "mkdir -p /home/storage" 04mount: command: "echo \"xxx.xxx.xxx.xxx:/storage /home/storage nfs nolock,hard 0 0\" >> /etc/fstab" 05mount: command: "mount -a"適用方法
上記をCloudFormationのテンプレートに記載しただけでは適用されません。
UserDataへcfn-init ヘルパースクリプトを実行する手順の記載が必要です。UserData: Fn::Base64: !Sub | #!/bin/bash yum -y update /opt/aws/bin/cfn-init --stack ${AWS::StackName} --resource EC2 --region ${AWS::Region}まとめ
上記を駆使すると工数が削減でき、手作業よりも結果にブレがなく良いのではないでしょうか。
余談
ユーザー作成ですがuidが選ぶことが可能ですが、強制で/sbin/nologinとして作成する為、用途が限定されてしまいます。
コマンドにて対応するとCloudFormationのテンプレートにパスワードが記載されてしまうので、ユーザー作成は別途検討が必要だと感じました。参考
- 投稿日:2019-12-02T10:57:32+09:00
Athena+embulk で ETL
目的
日毎のバッチで、S3にある ParquetファイルをQueryし、その結果をRedshift(DWH)へ入れたかった。
背景
- QueryしたいParquetファイルは Data Lake 上にすべて存在していた。
- 必要なParquetファイルはすべて AWS Glue Datacatalog でテーブル構造が定義されていた。
- Queryした結果をRedshift上にテーブル化し、他のアプリケーションで使いたかった。
- Embulkは本番環境はすでにバリバリ使っていた。
ということで
これだけ揃ってんなら、AthenaでQueryして、結果をEmbulkでRedshiftに入れればいいんでない。
作る
AthenaでQueryして、結果のCSVファイルを確認する
- AWS CLI でAthenaにQueryを投げる。
- Queryを投げるコマンドはQuery要求を出すだけですぐ終了するので終了を待つ。
- jqコマンドを予め yum か何かでインストールしておく
#!/bin/bash export RESULT_BACKET="result-bucket" export RESULT_PATH="result-files" # 結果待ち wait_query(){ max_retry=100 check_interval=10 echo -n "sleep ${check_interval} seconds" for((i = 0; i <= ${max_retry}; i++)); do sleep ${check_interval} resultJson=$(aws --profile athena_query athena get-query-execution --query-execution-id $1) runningStatus=$(echo ${resultJson} | jq -r '.QueryExecution.Status.State') echo -n "." if [ "${runningStatus}" == "SUCCEEDED" ]; then break fi if [ "${runningStatus}" == "FAILED" -o "${runningStatus}" == "CANCELLED" ]; then echo "query error !!" echo "${resultJson}" exit -1 fi done } ### 結果の確認 check_result(){ json=$(aws --profile athena_query athena get-query-execution --query-execution-id $1 ) status=$(echo ${json} | jq -r '.QueryExecution.Status.State') if [ "$status" == "SUCCEEDED" ]; then outputLocation=$(echo ${json} | jq -r '.QueryExecution.ResultConfiguration.OutputLocation') echo "query finished!! to ${outputLocation}" else echo "query result is not found !!" echo "${json}" exit -1 fi } ########## START ### Queryを実行する QueryId を取得する export QUERY_ID=$(aws --profile athena_query athena start-query-execution \ --query-string \ " SELECT * FROM test_schema.table_a FULL JOIN test_schema.table_b on test_schema.table_a.id = test_schema.table_b = id " \ --result-configuration OutputLocation="s3://${RESULT_BACKET}/${RESULT_PATH}" \ | jq -r '.QueryExecutionId') ### Query 実行待ち wait_until_end ${QUERY_ID} ### resulr file を取得 check_result ${QUERY_ID}ResultのCSVファイルをEmbulkでRedshiftへInsertする
- source となるCSVファイルのファイル名は ${QUERY_ID}.csv
- embulk の定義ファイルはこちら
insert.ymlin: type: s3 access_key: {{env.ACCESS_KEY}} secret_key: {{env.SECRET_KEY}} default_timezone: Asia/Tokyo bucket: {{env.RESULT_BACKET}} path_prefix: {{env.RESULT_PATH}}/{{env.QUERY_ID}} parser: type: csv delimiter: "," skip_header_lines: 1 columns: - {name: id, type: long } - {name: point, type: long } - {name: count, type: long } - {name: regist_date, type: timestamp, format: '%Y-%m-%d %H:%M:%S.%N' } out: type: redshift host: {{ env.REDSHIFT_HOST }} port: 5439 user: {{ env.REDSHIFT_USER }} password: {{ env.REDSHIFT_PASSWORD }} database: {{ env.REDSHIFT_DATABASE }} table: redshift_test_table mode: truncate_insert aws_auth_method: profile aws_profile_name: embulk iam_user_name: IAM-Embulk-S3-Accsess s3_bucket: embulk-s3-to-redshift s3_key_prefix: embulk delete_s3_temp_file: false default_timezone: "Japan" column_options: id: {type: 'bigint'} point: {type: 'int'} count: {type: 'int'} regist_date: {type: 'timestamp'}
- embulk 実行コマンドライン
- AthenaからQueryしたshに追加する
/home/embulk/.embulk/bin/embulk run ./insert.yml注意点
- AWSの都合でAthenaへのQueryの実行が待たされる場合があるので、日毎のバッチ時実行したいときは実行時間に注意
その他
- jqコマンド超便利。AWS Cli のresult値取得に超便利。
- 投稿日:2019-12-02T10:18:03+09:00
AWSサーバレスでWebSocketを使ったWEBチャットを作ってみます!
この記事は NTTテクノクロス Advent Calendar 2019の2日目の記事です。
こんにちは。安田と申します。
NTTテクノクロスでAI関連の新製品開発を担当しています。早速本題からズレますけれども、マンガを描くのが最近の息抜きで、次のようなマンガを描いています。マンガでわかるデータ連携
マンガでわかるAI時代のエンタープライズ・アーキテクチャ
マンガでわかるITストラテジー
・・・さて、本記事ではAWSサーバレスで「WebSocket」やる方法を見て行きたいと思います。2018年12月からAWS API GatewayがWebSocket通信を張れるようになっているようで、いつか試してみたいなと思っていまして、試してみました。調べてみると、AWS Lambdaにnode.jsを使うサンプルプログラムはたくさん見つかるのですが、なかなかPythonサンプルが見つからず・・・私はPythonの方が得意なのでPythonコードを書いていきたいと思います。
作るもの
WEBチャットを作ります。そのWebページに接続して、メッセージを書き込むと、そのときそのページに接続している(WebSocketのセッションを張っている)全ての端末にリアルタイムでメッセージが配信されます。
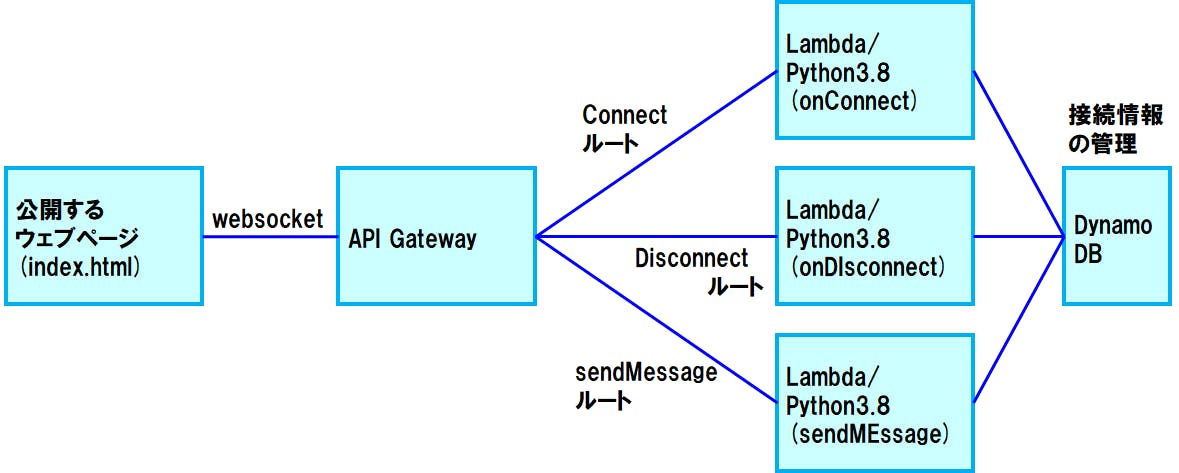
システム構成
AWSのサーバレスの代表的な要素であるAPI Gateway、Lambda、DynamoDBを組み合わせて作ります。 公開するWebページはPCローカル上にHTMLファイルを置くだけでも動きますし、S3の静的ホスティングに置いて簡単に公開しても動きます。
コーディング
1. まずは、API Gatewayを用意するぞ!
1-1. 「WebSocket」のAPI Gatewayを新規作成
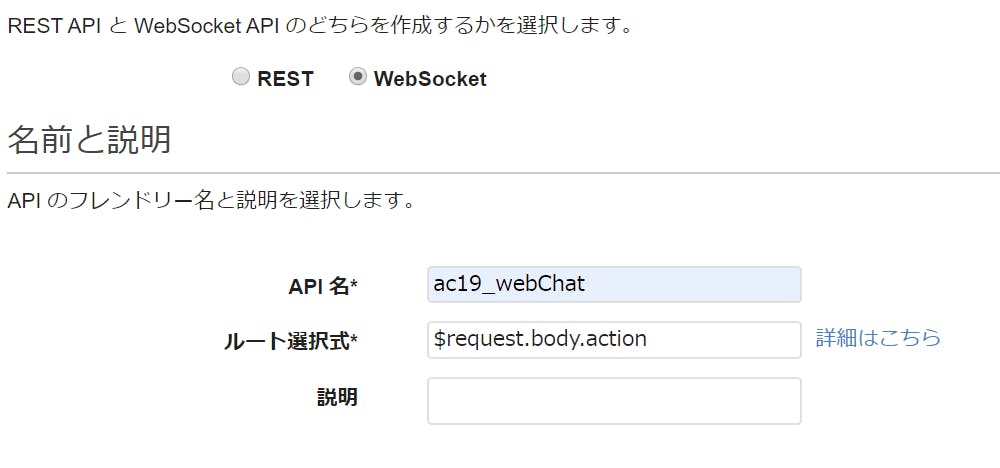
「WebSocket」を選択して、新しいAPI Gatewayを作成します。
ルート選択式は、ここでは「$request.body.action」としておきました。これは後から変更できます。
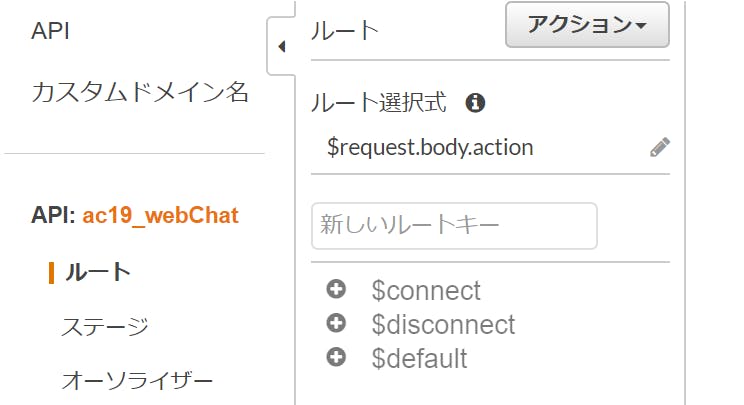
1-2. ここから一つひとつルートを作っています
接続したときのルート(connect)、接続が外れたときのルート(disconnnect)、メッセージを送った時のルート(sendMessage)を一つひとつ作っていきます。
・・・ですが、その前にDynamoDBとIAMロールを作らなくては、です。
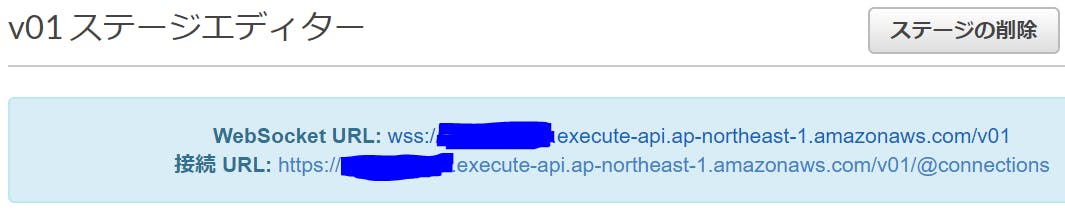
1-3. デプロイしてステージを作る
まだ何もルートを作っていない段階ですが、デプロイしてステージを作っておきます。
青く消したところは、固有の文字列が入ります。この固有の文字列は、次のIAMロール作成のときに使います。
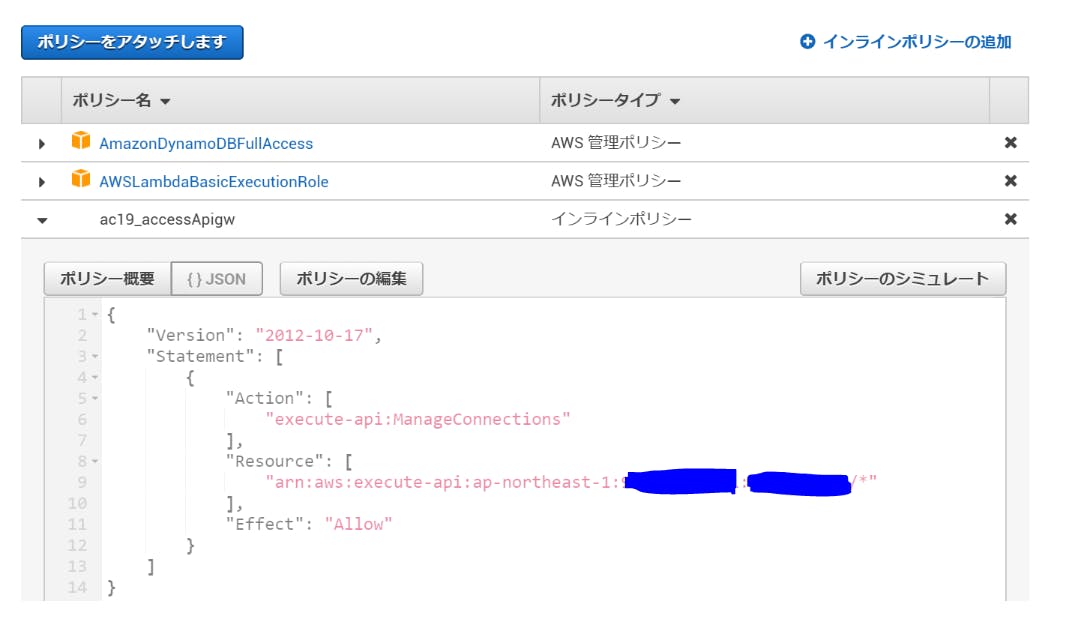
2. LambdaのためのIAMロールを作る
まず、Lambdaを動かすための"AWSLambdaBasicExecutionRole"と、DynamoDBを動かすための"AmazonDynamoDBFullAccess"を追加します。 ※FullAccessである必要はないが、簡単なため。
そのあと、次のようなインラインポリシーを設定しておきます。これで、LambdaからAPI Gattewayにアクセスできます。
インラインポリシー{ "Version": "2012-10-17", "Statement": [ { "Action": [ "execute-api:ManageConnections" ], "Resource": [ "arn:aws:execute-api:ap-northeast-1:<ここにテナントID>:<ここに、さっき設定したAPI Gatewayの固有文字列を書く>/*" ], "Effect": "Allow" } ] }上記のロールの画像で青く消しているところは、先にAPI Gatewayをデプロイしたときに出てきた固有の文字列を設定してみてください。
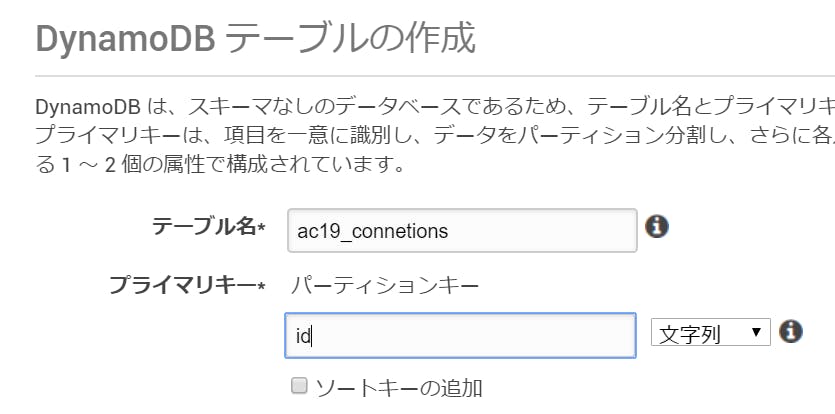
3. 接続情報を管理するテーブル(DynamoDB)を作る
プライマリキーは、文字列"id"としておきましょうか。
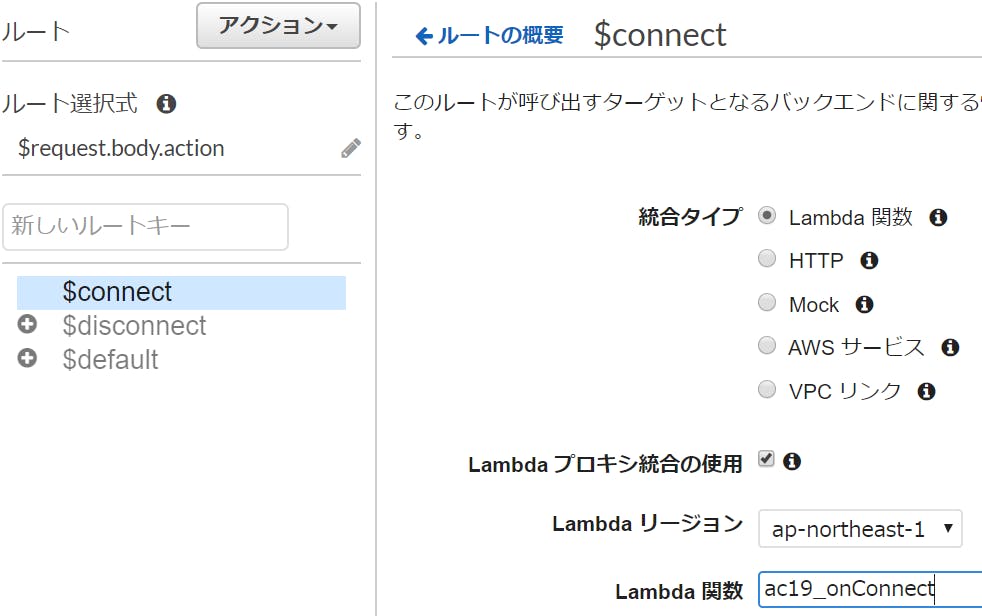
4. 接続したときのルート(connect)を作る
4-1. Lambdaを作る
新しいLambda/Python3.8を作ります。先ほど使ったIAMロールを設定します。
プログラムは、異常系を鑑みなければ、実質2行のみなので簡単です。(実際には、異常系を考慮した作りにすべきです。)
接続されたconnection_idを取得して、それをDynamoDBに登録するだけです。ac19_onConnect/lambda_function.pyimport json import os import boto3 dynamodb = boto3.resource('dynamodb') connections = dynamodb.Table(os.environ['CONNECTION_TABLE']) def lambda_handler(event, context): connection_id = event.get('requestContext',{}).get('connectionId') result = connections.put_item(Item={ 'id': connection_id }) return { 'statusCode': 200,'body': 'ok' }Lambdaの環境変数"CONNECTION_TABLE"には、先ほど作成したDynamoDBの名前を設定しておきます。タイムアウト時間は3秒でも大丈夫でしょうけど、1分くらいに設定しておきました。
4-2. API GatewayとLambdaを統合する
先ほど作ったAPI Gatewayのconnectルートと、上記のLambda"ac19_onConnect"を統合します。
以降で説明するdisconnectとsendMessageのルートをLambdaと統合する際も、同様の手順となります。統合したら、ステージのデプロイも忘れずに。
5. 接続解除したときのルート(disconnect)を作る
connectルートと同様の手順で、まずLambdaのプログラムを作って、API Gatewayのdisconnectルートと統合します。異常系を考えなければプログラムは簡単で、接続解除されたconnection_idを取得して、それをDynamoDBから削除するだけです。Lambdaの他の設定(ロール、タイムアウト、環境変数)は、先のonConnectのプログラムと同じ。
ac19_onDisconnect/lambda_function.pyimport json import os import logging import boto3 dynamodb = boto3.resource('dynamodb') connections = dynamodb.Table(os.environ['CONNECTION_TABLE']) def lambda_handler(event, context): connection_id = event.get('requestContext',{}).get('connectionId') result = connections.delete_item(Key={ 'id': connection_id }) return { 'statusCode': 200, 'body': 'ok' }6. sendMessageを受信したときのルート(sendMessage)を作る
sendMessageだけ少し行数がありますが、やっていることは簡単です。
sendMessageを受信したら、DynamoDBに登録されている各接続に対して、それぞれメッセージを配信しているだけです。これまでと同様の手順で、まずLambdaのプログラムを作って、API GatewayにsendMessageルートを作成して、そのルートと統合します。その後、忘れずにAPI Getewayをステージにデプロイしておいてください。Lambdaの他の設定(ロール、タイムアウト、環境変数)は、先の2つのLambdaと同じ。ac19_sendMessage/lambda_function.pyimport json import os import sys import logging import boto3 import botocore dynamodb = boto3.resource('dynamodb') connections = dynamodb.Table(os.environ['CONNECTION_TABLE']) def lambda_handler(event, context): post_data = json.loads(event.get('body', '{}')).get('data') print(post_data) domain_name = event.get('requestContext',{}).get('domainName') stage = event.get('requestContext',{}).get('stage') items = connections.scan(ProjectionExpression='id').get('Items') if items is None: return { 'statusCode': 500,'body': 'something went wrong' } apigw_management = boto3.client('apigatewaymanagementapi', endpoint_url=F"https://{domain_name}/{stage}") for item in items: try: print(item) _ = apigw_management.post_to_connection(ConnectionId=item['id'], Data=post_data) except: pass return { 'statusCode': 200,'body': 'ok' }7. HTMLのWebページを作る
プログラム内の"wss://"のところには、さっき設定したAPI Gatewayの固有文字列を書いておいてください。このHTMLはPCローカルに置いても動きますし、AWS S3の静的ホスティングなどで公開しても動かせます。
index.html<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>「WebSocket」お試しチャット!</title> </head> <body> <H3>「WebSocket」お試しチャット!</H3> <input id="input" type="text" /> <button onclick="send()">送信</button> <pre id="output"></pre> <script> var input = document.getElementById('input'); var output = document.getElementById('output'); var socket = new WebSocket("wss://<ここに、さっき設定したAPI Gatewayの固有文字列を書く>.execute-api.ap-northeast-1.amazonaws.com/v01"); socket.onopen = function() { output.innerHTML += "接続できました!\n"; }; socket.onmessage = function(e) { output.innerHTML += "受信:" + e.data + "\n"; }; function send() { socket.send(JSON.stringify( { "action":"sendMessage", "data": input.value } )); input.value = ""; }; </script> </body> </html>よし!これで完成です!試してみましょう!
参考
主に、AWSのページを見ながら作りました。
https://aws.amazon.com/jp/blogs/news/announcing-websocket-apis-in-amazon-api-gateway/


- 投稿日:2019-12-02T10:18:03+09:00
AWSサーバレス(Python)でWebSocketを使ったWEBチャットを作ってみます!
この記事は NTTテクノクロス Advent Calendar 2019の2日目の記事です。
こんにちは。安田と申します。
NTTテクノクロスでAI関連の新製品開発を担当しています。早速本題からズレますけれども、マンガを描くのが最近の息抜きで、次のようなマンガを描いています。マンガでわかるデータ連携
マンガでわかるAI時代のエンタープライズ・アーキテクチャ
マンガでわかるITストラテジー
・・・さて、本記事ではAWSサーバレスで「WebSocket」やる方法を見て行きたいと思います。2018年12月からAWS API GatewayがWebSocket通信を張れるようになっているようで、いつか試してみたいなと思っていまして、試してみました。調べてみると、AWS Lambdaにnode.jsを使うサンプルプログラムはたくさん見つかるのですが、なかなかPythonサンプルが見つからず・・・私はPythonの方が得意なのでPythonコードを書いていきたいと思います。
作るもの
WEBチャットを作ります。そのWebページに接続して、メッセージを書き込むと、そのときそのページに接続している(WebSocketのセッションを張っている)全ての端末にリアルタイムでメッセージが配信されます。
システム構成
AWSのサーバレスの代表的な要素であるAPI Gateway、Lambda、DynamoDBを組み合わせて作ります。 公開するWebページはPCローカル上にHTMLファイルを置くだけでも動きますし、S3の静的ホスティングに置いて簡単に公開しても動きます。
コーディング
1. まずは、API Gatewayを用意するぞ!
1-1. 「WebSocket」のAPI Gatewayを新規作成
「WebSocket」を選択して、新しいAPI Gatewayを作成します。
ルート選択式は、ここでは「$request.body.action」としておきました。これは後から変更できます。
1-2. ここから一つひとつルートを作っています
接続したときのルート(connect)、接続が外れたときのルート(disconnnect)、メッセージを送った時のルート(sendMessage)を一つひとつ作っていきます。
・・・ですが、その前にDynamoDBとIAMロールを作らなくては、です。
1-3. デプロイしてステージを作る
まだ何もルートを作っていない段階ですが、デプロイしてステージを作っておきます。
青く消したところは、固有の文字列が入ります。この固有の文字列は、次のIAMロール作成のときに使います。
2. LambdaのためのIAMロールを作る
まず、Lambdaを動かすための"AWSLambdaBasicExecutionRole"と、DynamoDBを動かすための"AmazonDynamoDBFullAccess"を追加します。 ※FullAccessである必要はないが、簡単なため。
そのあと、次のようなインラインポリシーを設定しておきます。これで、LambdaからAPI Gattewayにアクセスできます。
インラインポリシー{ "Version": "2012-10-17", "Statement": [ { "Action": [ "execute-api:ManageConnections" ], "Resource": [ "arn:aws:execute-api:ap-northeast-1:<ここにテナントID>:<ここに、さっき設定したAPI Gatewayの固有文字列を書く>/*" ], "Effect": "Allow" } ] }上記のロールの画像で青く消しているところは、先にAPI Gatewayをデプロイしたときに出てきた固有の文字列を設定してみてください。
3. 接続情報を管理するテーブル(DynamoDB)を作る
プライマリキーは、文字列"id"としておきましょうか。
4. 接続したときのルート(connect)を作る
4-1. Lambdaを作る
新しいLambda/Python3.8を作ります。先ほど使ったIAMロールを設定します。
プログラムは、異常系を鑑みなければ、実質2行のみなので簡単です。(実際には、異常系を考慮した作りにすべきです。)
接続されたconnection_idを取得して、それをDynamoDBに登録するだけです。ac19_onConnect/lambda_function.pyimport json import os import boto3 dynamodb = boto3.resource('dynamodb') connections = dynamodb.Table(os.environ['CONNECTION_TABLE']) def lambda_handler(event, context): connection_id = event.get('requestContext',{}).get('connectionId') result = connections.put_item(Item={ 'id': connection_id }) return { 'statusCode': 200,'body': 'ok' }Lambdaの環境変数"CONNECTION_TABLE"には、先ほど作成したDynamoDBの名前を設定しておきます。タイムアウト時間は3秒でも大丈夫でしょうけど、1分くらいに設定しておきました。
4-2. API GatewayとLambdaを統合する
先ほど作ったAPI Gatewayのconnectルートと、上記のLambda"ac19_onConnect"を統合します。
以降で説明するdisconnectとsendMessageのルートをLambdaと統合する際も、同様の手順となります。統合したら、ステージのデプロイも忘れずに。
5. 接続解除したときのルート(disconnect)を作る
connectルートと同様の手順で、まずLambdaのプログラムを作って、API Gatewayのdisconnectルートと統合します。異常系を考えなければプログラムは簡単で、接続解除されたconnection_idを取得して、それをDynamoDBから削除するだけです。Lambdaの他の設定(ロール、タイムアウト、環境変数)は、先のonConnectのプログラムと同じ。
ac19_onDisconnect/lambda_function.pyimport json import os import logging import boto3 dynamodb = boto3.resource('dynamodb') connections = dynamodb.Table(os.environ['CONNECTION_TABLE']) def lambda_handler(event, context): connection_id = event.get('requestContext',{}).get('connectionId') result = connections.delete_item(Key={ 'id': connection_id }) return { 'statusCode': 200, 'body': 'ok' }6. sendMessageを受信したときのルート(sendMessage)を作る
sendMessageだけ少し行数がありますが、やっていることは簡単です。
sendMessageを受信したら、DynamoDBに登録されている各接続に対して、それぞれメッセージを配信しているだけです。これまでと同様の手順で、まずLambdaのプログラムを作って、API GatewayにsendMessageルートを作成して、そのルートと統合します。その後、忘れずにAPI Getewayをステージにデプロイしておいてください。Lambdaの他の設定(ロール、タイムアウト、環境変数)は、先の2つのLambdaと同じ。ac19_sendMessage/lambda_function.pyimport json import os import sys import logging import boto3 import botocore dynamodb = boto3.resource('dynamodb') connections = dynamodb.Table(os.environ['CONNECTION_TABLE']) def lambda_handler(event, context): post_data = json.loads(event.get('body', '{}')).get('data') print(post_data) domain_name = event.get('requestContext',{}).get('domainName') stage = event.get('requestContext',{}).get('stage') items = connections.scan(ProjectionExpression='id').get('Items') if items is None: return { 'statusCode': 500,'body': 'something went wrong' } apigw_management = boto3.client('apigatewaymanagementapi', endpoint_url=F"https://{domain_name}/{stage}") for item in items: try: print(item) _ = apigw_management.post_to_connection(ConnectionId=item['id'], Data=post_data) except: pass return { 'statusCode': 200,'body': 'ok' }7. HTMLのWebページを作る
プログラム内の"wss://"のところには、さっき設定したAPI Gatewayの固有文字列を書いておいてください。このHTMLはPCローカルに置いても動きますし、AWS S3の静的ホスティングなどで公開しても動かせます。
index.html<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>「WebSocket」お試しチャット!</title> </head> <body> <H3>「WebSocket」お試しチャット!</H3> <input id="input" type="text" /> <button onclick="send()">送信</button> <pre id="output"></pre> <script> var input = document.getElementById('input'); var output = document.getElementById('output'); var socket = new WebSocket("wss://<ここに、さっき設定したAPI Gatewayの固有文字列を書く>.execute-api.ap-northeast-1.amazonaws.com/v01"); socket.onopen = function() { output.innerHTML += "接続できました!\n"; }; socket.onmessage = function(e) { output.innerHTML += "受信:" + e.data + "\n"; }; function send() { socket.send(JSON.stringify( { "action":"sendMessage", "data": input.value } )); input.value = ""; }; </script> </body> </html>よし!これで完成です!試してみましょう!
参考
主に、AWSのページを見ながら作りました。
https://aws.amazon.com/jp/blogs/news/announcing-websocket-apis-in-amazon-api-gateway/