- 投稿日:2019-12-02T23:47:42+09:00
ぼくのさいきょうのslack bot
この記事は東京理科大学 Advent Calendar 2019の12/2の記事です。
昨日は@piffettによるapt-getとaptの使い分けでした。こんにちは。にっし〜です。
ここではGoでslack botを作る話を書きます。はじめに
ここでは主にgoでの実装についてだけ書いて、slackへの導入だったり諸々は前提として話を進めます。
また、AWS Lambdaでの実装はここに追記するか別途記事にする予定です。経緯
バイト先で勉強会を運営しているのですが、参加登録だったり、終了後のアンケートを全てGoogle formを使って集計していました。
Google App Scriptを使って諸々自動化するなどの涙ぐましい努力()をしてきたのですが、流石に辛くなってきました。
AWSの社用アカウントをいただいたのをきっかけにGoで書き直して、slack内で全て完結する構成にしようと考えました。
ただ、これに割ける時間はそこまで多くはなく、先人の実装例があれば嬉しいなぁと思っていた矢先、shiimaxxさんのこちらを見つけました。
https://github.com/shiimaxx/slack-coffeebot
これをforkして機能を足していけば最速で欲しいものが完成させられるだろうということで、自分がforkして諸々実装したものがこちらです。
https://github.com/nisshii0313/slack-coffeebotやったこと
欲しかった機能は次の2つです。
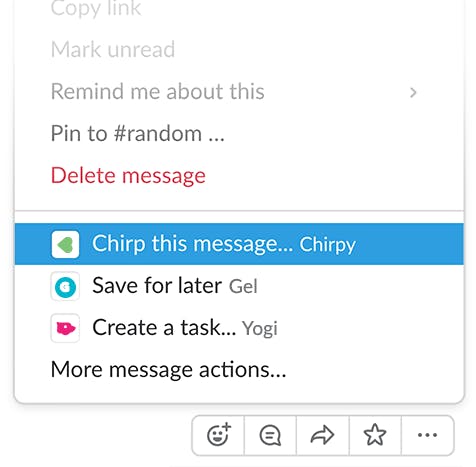
- message_actionへの対応
- Datepickerの実装1つずつ見ていきます
1, message_actionへの対応
自分がslack botを狂ったように作っていた1年前は主に2つの選択肢がありました。
slash commandかbotとの対話か、です。しかしながらworkspaceが大きい場合、slash commandもたくさんあるし、botもたくさん入ってるし、で自分で作ったものでも使い方・botの名前を忘れるということが発生していました。
そこで、今回はactionsを使用することにしました。
actionsであれば、勉強会の開催告知スレから直接開いてもらうこともできるし、この方法が最善だと考えました。
shiimaxxさんのものではbotとの対話に反応するように実装されていたので、次のようなコードを追記することでactionsに対応させました。main.goelse if message.Type == "message_action" { ... }簡単にactionsに対応させることができました。
2, Datepickerの実装
Datepickerの実装には新しい(2019/2~)UI フレームワークであるBlock Kitが必要です。
公式がドキュメントを用意してくれている他、使っているライブラリ(https://github.com/nlopes/slack) もv0.6.0からblock-kitに対応してくれています。優しい世界!!
ということでこれらに従って実装していきます。
まずはGopkg.toml[[constraint]] name = "github.com/nlopes/slack" version = "v0.6.0"と書いて
dep ensureします。
これでblock-kitに対応したライブラリが使えるようになりました。あとは
https://github.com/nlopes/slack/blob/445280bcb9c1b02b4a88b1ee9aa7afd735b2dc55/examples/blocks/blocks.go
あたりでも見ながらblockmessageを構築していきます。
blockを組み合わせる感じがコンポーネントを組み合わせてwebページを作る感じと似てるなって思いました。以下Datepickerのblockの作り方です。
NewDatePickerBlockElementしたものをNewSectionBlockのAccessoryに設定してあげます。main.gofunc datepicker(userID string) slack.MsgOption { dateText := slack.NewTextBlockObject("plain_text", "date_sample", false, false) datePick := slack.NewDatePickerBlockElement("sample") dateSection := slack.NewSectionBlock(dateText, nil, slack.NewAccessory(datePick)) return slack.MsgOptionBlocks( dateSection, ) }最後にblock-kitのslackへの投稿方法です。
上でMsgOptionで返したものを第二引数にして、PostMessageメソッド(nlopes/slack)を使って表示させることができます。main.gopicker := datepicker(message.User.ID) if _, _, err := s.slackClient.PostMessage(message.Channel.ID, picker); err != nil { log.Print("[ERROR] Failed to post message") }はいできた!!
以上です。ちょうど12月3日午前3時になりました。あらかたの投稿は2日のうちに済ませてたから許してね!

- 投稿日:2019-12-02T23:14:51+09:00
ARM64をターゲットとしたGoのクロスコンパイル
SENSYN ROBOTICS(センシンロボティクス)の中山です。
Webアプリやそのインフラ周り、Web側とドローンの接続を行うデバイスドライバ的なモジュールを担当しています。今回は、ドローン内部で動かすソフトウェアにGoを使った話です。上記の担当範囲から外れているように見えますが、そういうこともあります。
なんのために?
ドローンといっても色々あるのですが、今回はARM64のCPU(NVIDIA TX1)が載ったドローンです。CPUの上ではUbuntu 16.04が動いています。具体的にはSENSYN DRONE HUBというドローンです。
このドローンは、あらかじめ設定しておいた時刻になると自動的に基地から離陸し、事前に設定しておいたルートを飛行して動画・静止画を撮影し、基地に返ってきます。返ってきたら自動的に充電して次回の飛行に備えつつ、撮影したデータを自動的にクラウドにアップロードします。
つまり、ドローンの存在を意識せずにドローンによる設備点検や警備・監視ができるソリューションです。
今回、Goを使ったのはデータをクラウドにアップロードするモジュールで、ドローンの内部で動いています。
なぜGoなのか?
当初はGoを使うつもりはなく、Pythonで書く予定でした。ただ、Ubuntu上には既にドローンの制御機構が構築されており、そちらが一部にPythonを使っている都合上、既存の環境への干渉は絶対に避ける必要があります。ところが事前に入っているUbuntuにはpipすら入っておらず、環境分離ツールを入れること自体が難しい状況です。そのため、既存の環境を汚さずに新しいモジュールを入れるのは不可能ではないにしても、非常に面倒でした。
Pythonが使えないとなると…と悩んだ末、Goならシングルバイナリにできるので既存環境への干渉を避けたいときに理想的ではないか、と気づいて採用を決定しました。ARM64 Linux対応、というのも必須条件ですが、Goならこれも満たしています。
上記の理由だけならC++でも良かったのですが、Goの方がメンテできるひとが将来的に多くなりそう、というのもあります。
実際にやってみると?
環境を汚したくないので、コンパイル環境をドローンの中に作るわけにはいきません。そうなると、必然的にクロスコンパイルが必要になります。手元の開発環境で試行錯誤すると後が怖いので、Dockerを使いました。
docker run \ -v $(pwd):/go \ --rm \ -it \ dockercore/golang-cross:1.12.7 \ sh -c 'GOOS=linux GOARCH=arm64 CGO_ENABLED=1 go build src/main.go'(少し前の話なので、バージョンは古めです)
# runtime/cgo gcc_arm64.S: Assembler messages: gcc_arm64.S:27: Error: no such instruction: `stp x19,x20,[sp,' gcc_arm64.S:28: Error: no such instruction: `stp x21,x22,[sp,' gcc_arm64.S:29: Error: no such instruction: `stp x23,x24,[sp,' gcc_arm64.S:30: Error: no such instruction: `stp x25,x26,[sp,' gcc_arm64.S:31: Error: no such instruction: `stp x27,x28,[sp,' gcc_arm64.S:32: Error: no such instruction: `stp x29,x30,[sp,' gcc_arm64.S:33: Error: too many memory references for `mov' gcc_arm64.S:35: Error: too many memory references for `mov' gcc_arm64.S:36: Error: too many memory references for `mov' gcc_arm64.S:37: Error: too many memory references for `mov' gcc_arm64.S:39: Error: no such instruction: `blr x20' gcc_arm64.S:40: Error: no such instruction: `blr x19' gcc_arm64.S:42: Error: no such instruction: `ldp x29,x30,[sp],' gcc_arm64.S:43: Error: no such instruction: `ldp x27,x28,[sp],' gcc_arm64.S:44: Error: no such instruction: `ldp x25,x26,[sp],' gcc_arm64.S:45: Error: no such instruction: `ldp x23,x24,[sp],' gcc_arm64.S:46: Error: no such instruction: `ldp x21,x22,[sp],' gcc_arm64.S:47: Error: no such instruction: `ldp x19,x20,[sp],'エラーになりました…。
色々調べて、
FROM dockercore/golang-cross:1.12.7 RUN apt-get update \ && apt-get install -y gcc-aarch64-linux-gnuというDockerfileを作り、このイメージで
go buildしても、同じ結果…。更に調べ回って、上記のDockerイメージに加えて
CC=aarch64-linux-gnu-gccをコマンドラインに足したdocker run \ -v $(pwd):/go \ --rm \ -it \ my-golang-image \ sh -c 'GOOS=linux GOARCH=arm64 CGO_ENABLED=1 CC=aarch64-linux-gnu-gcc go build src/main.go'で最終的に通るようになりました。
結論
- 環境を汚さないためにGoを使うのは有効
- クロスコンパイルはできるようになれば簡単けど、そこまでがちょっと大変
- Dockerを使うとトライ&エラーを気楽にできて便利
- ARM64 Linuxをターゲットにクロスコンパイルするなら
gcc-aarch64-linux-gnuを入れて、CC=aarch64-linux-gnu-gccを環境変数に設定する
- 投稿日:2019-12-02T21:51:24+09:00
絵文字だけプログラミング!!を作ってみた&得られた知見
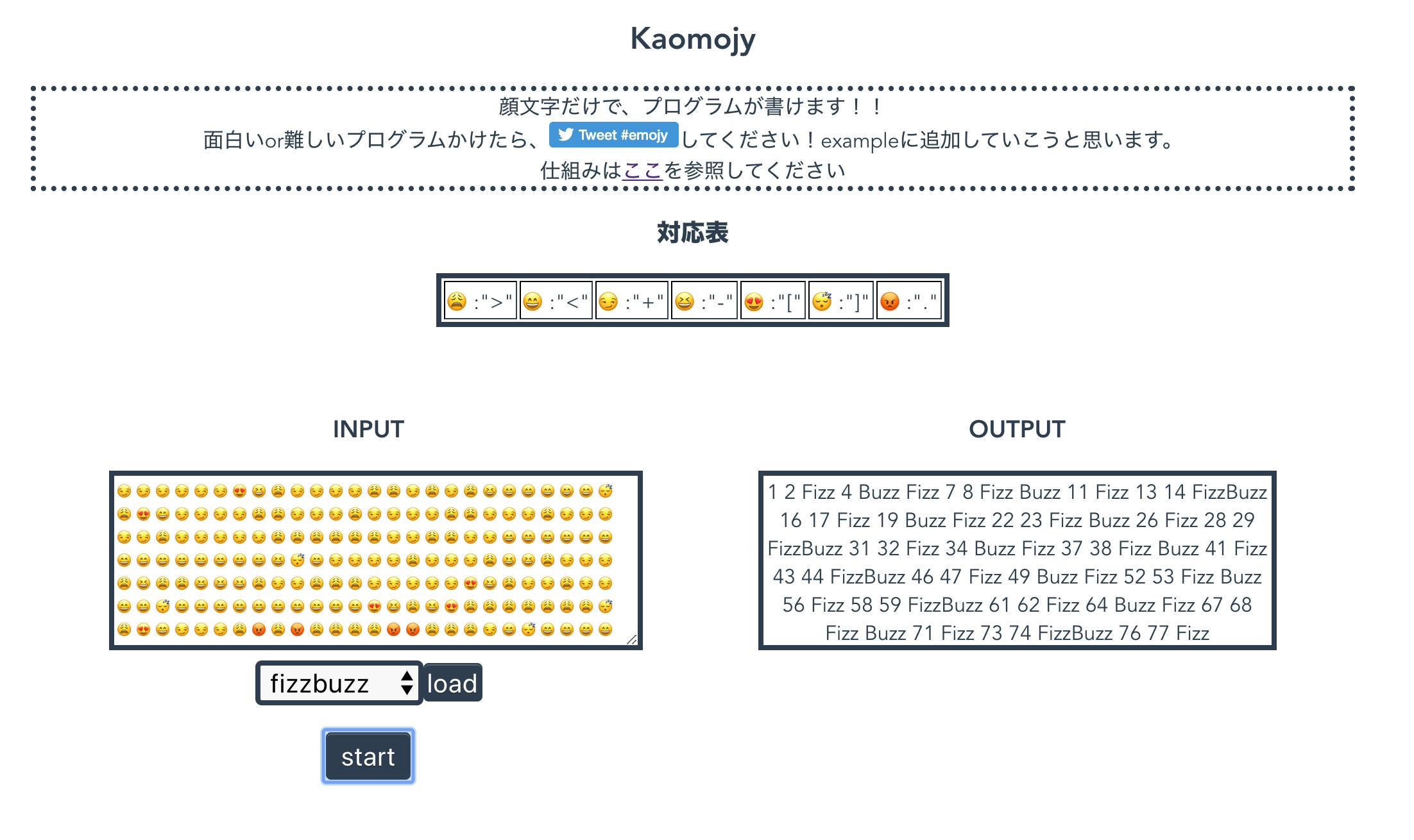
Kaomojy
上はfizzbuzzです内容
Kaomojyは
顔文字だけでプログラム書くことができます!!!
ただのそれだけ。。。モチベーション
Brainfxxkを出会った時に衝撃がすごすぎて、GoでBrainfxxk用のコマンド作ったりしていたのですが、今回はJavascript(vue)版を作ってみました!
絵文字だけで文字のやり取りできるの、暗号ぽくって面白い!!!
とか思って絵文字にしました得られた知見
絵文字のsplit
絵文字を分割して、配列として保持して置くという処理を実現するときに
当初const commands = inputStr.split("")このようなコードを書いていました。
しかし、このコードだと文字化けしてしまいます。調べてみると、jsは2バイトを一文字として受け取る仕組みですが、顔文字は例外的に4バイトで表されているそうです。(詳しくは→文字列を配列化する)
そのため、
const commands = Array.from(inputStr)とする必要があります!
memoryの初期化
Brainfxxkでは、処理の結果を擬似的なメモリとして配列で保持しています。
Goの場合int型のスライスを初期化する時、自動で0が挿入されますmemory := make([]int,100)//[0,0,0,...]一方javascriptでは、
let memory = new Array(100) //[undefined,undefined...]となってしまい、数値が入っていないため上手くメモリが動きませんでした。(書きながら考えていたのですが、上のコードだとそもそも型定義してないから、undefinedは納得ですw)
そのため、初期化時、0を挿入する処理を記述しました
let memory = Array.apply(null, Array(100)).map(function(){return 0;});まとめ
楽しくコードを書きながら、思わぬところで言語仕様の勉強ができました!
Goの実装については、以下にあるので、
https://github.com/ryomak/brainfuck-go
(悟空が使う言葉でプログラムを書く)Go空語があるので、是非お試しください!(こちらは正規表現を使って無駄なコードも受け入れる設定になっています)またKaomojyのコードはhttps://github.com/ryomak/brainfuck-web
にありますので、修正やexampleコードの追加待ってます!ts設定入れているのに、ゴリゴリjsで書いてますww
- 投稿日:2019-12-02T20:55:28+09:00
Goa v3 のテストをシュッとする
これは Go アドベントカレンダー 3日目の記事です。
はじめに
Goa というのは、Go で API を書くためのフレームワークで、APIデザインを Go のコードとして DSL を使って書けて、デザインからコードの生成、ビジネスロジックを実装というサイクルと上手に回していくことを目的にしています。
統一的なバリデーション、エラー処理、OpenAPIドキュメントの生成など API 開発で必要なあれこれが用意されています。
Goa v3 は今年の5月にリリースされました。v3 では、HTTP だけでなく、gRPC もサポートし、HTTP と gRPC の2つのトランスポートに対して共通のデザインを書くことが出来るようになっています。
Goa v3 では v1 で生成されていたようなテスト用ヘルパー関数を生成しなくなりました。また、v3 のサービスは、サービス毎にパッケージが切られてしまうので、interface での取り回しの自由も少なく、テスト用の環境を整えるのが少し面倒でした。Goa v3 用の(HTTP トランスポートの)テストヘルパーを用意したので、これを使ってテストする方法を紹介したいと思います。
gRPC を使っている場合でも、HTTP を用意しておけば特殊なものでなければサービスメソッドは共通なので、この方法でテストしてもいいのかも・・・。
サービスメソッドをテストする
サービスメソッドは REST API でいうところのエンドポイントです。サンプルとして、次のようなデザインを考えます。
var _ = Service("calc", func() { Description("The calc service performs operations on numbers.") Method("add", func() { Payload(func() { Field(1, "a", Int, "Left operand") Field(2, "b", Int, "Right operand") Required("a", "b") }) Result(Int) HTTP(func() { GET("/add/{a}/{b}") Response(StatusOK) }) }) })テストしたいエンドポイントは、
/add/{a}/{b}で、これは単純にaとbを足すものとします。たとえば/add/1/2とすると、レスポンスはステータスOK(200)が返ってきて、ボディは3が返ってくる事をテストしていきます。
goa genすると、gen/httpの下にサービス毎のフォルダが切られてパッケージ化されたコードが生成されます。やっかいなのは、サービス毎にパッケージ化されてしまうので、サービス毎の
Serverは共通して使えません(パッケージが違うから)。ぎりぎり共通で使えそうなのは、エンドポイント用のhttp.Handlerを生成するコンストラクターと、そのハンドラをサービスにマウントする関数だけです。テストヘルパー
テストを効率よく書けるようにするために、エンドポイント用の
http.Handlerを生成するコンストラクターと、そのハンドラをサービスにマウントする関数、エンドポイントを指定すると、テスト用のチェッカーを用意するヘルパーを作成しました。https://github.com/ikawaha/goahttpcheck
使い方は
- チェッカーを生成
- 必要ならオプションを設定してください。
- goa gen で生成されるメソッドのhttp.Handlerを生成するコンストラクター、ハンドラをサービスるにマウントする関数、エンドポイントをチェッカーに設定します。
- もし必要ならミドルウエアを
Use関数で追加します。Test関数を呼び出します。
Test関数はivpusic/httpcheckの http checker を返すので、あとはこれに従ってテストを調整します。上の足し算のエンドポイントの正常系テストする例は次です。
package calcapi import ( "encoding/json" "io/ioutil" "log" "net/http" "strings" "testing" "calc/gen/calc" "calc/gen/http/calc/server" "github.com/ikawaha/goahttpcheck" goa "goa.design/goa/v3/pkg" ) func TestCalcsrvc_Add(t *testing.T) { var logger log.Logger checker := goahttpcheck.New() // テストしたいエンドポイントをマウントします checker.Mount(server.NewAddHandler, server.MountAddHandler, calc.NewAddEndpoint(NewCalc(&logger))) // エンドポイントをテストします checker.Test(t, http.MethodGet, "/add/1/2"). Check(). HasStatus(http.StatusOK) // OK が返ってくるはず }レスポンスの値などもチェックしたければさらに細かくテストできます。
詳細は https://github.com/ivpusic/httpcheck を参照してください。
checker.Test(t, http.MethodGet, "/add/1/2"). Check(). HasStatus(http.StatusOK). Cb(func(r *http.Response) { b, err := ioutil.ReadAll(r.Body) if err != nil { t.Fatalf("unexpected error, %v", err) } r.Body.Close() if got, expected := strings.TrimSpace(string(b)), "3"; got != expected { t.Errorf("got %+v, expected %v", b, expected) } })異常系のテストも見てみましょう。足し算のエンドポイントを少し修正して、割り算のエンドポイントを用意します。割り算では0で割ろうとするとエラーを返すようになっているものとします。
Method("div", func() { Error("zero_division", ErrorResult) Payload(func() { Field(1, "a", Int, "Left operand") Field(2, "b", Int, "Right operand") Required("a", "b") }) Result(Int) HTTP(func() { GET("/div/{a}/{b}") Response(StatusOK) Response("zero_division", StatusBadRequest) }) })テストはこんな風に書けます。
func TestCalcsrvc_Div(t *testing.T) { var logger log.Logger checker := goahttpcheck.New() checker.Mount(server.NewDivHandler, server.MountDivHandler, calc.NewDivEndpoint(NewCalc(&logger))) // see. https://github.com/ivpusic/httpcheck checker.Test(t, "GET", "/div/1/0"). Check(). HasStatus(http.StatusBadRequest). Cb(func(r *http.Response) { b, err := ioutil.ReadAll(r.Body) if err != nil { t.Fatalf("unexpected error, %v", err) } r.Body.Close() var resp goa.ServiceError if err := json.Unmarshal(b, &resp); err != nil { t.Fatalf("unexpected error, %v", err) } if got, expected := resp.Message, "zero division error"; got != expected { t.Errorf("got %+v, expected %v", got, expected) } }) }見通しよく非常にスッキリ書けます。テストが書きやすいと安心ですね ╭( ・ㅂ・)و ̑̑
おわりに
HTTPとgRPCの2つのトランスポート統一的にデザインするという新たな挑戦が盛り込まれた Goa v3 が今年の5月にリリースされて、半年がたちました。HTTP による REST API を構築していた v1 ユーザーからすると、DSL の変更などもあり少し敷居が高いように感じます。v3 はまだこなれていない部分もありますが、みんなが使い始めて細かな問題点が報告され修正されるようになってきました。
僕はこの仕組みがかなり気に入っていて、事ある毎に推してるんですが、「コード生成はどうなの?」とか「標準で書いてなんぼじゃない?」みたいな意見もよく聞きます。なかなか「使ってる人は使ってるツール」から抜け出せない感はあります。v1 から v3 への移行などだいぶ知見も溜まってきたのですが、なかなか意見を交換できる人に出会えません。「ウチでも使ってるよー」という方がいらっしゃいましたら是非お教えいただきたいです。
Goa いいよ、Goa!
Happy hacking!
- 投稿日:2019-12-02T18:05:58+09:00
Goで簡単な関数を実装しながらgo testを理解する
この記事はtomowarkar ひとりAdvent Calendar 2019の3日目の記事です。
今日はgo testを理解していきます。
今回実装する関数
整数配列から最小値を求める関数をそれぞれ実装していきます。
pythonでいうmin関数ですね。$ python >>> min([1,2,3]) 1testingパッケージについて
- Goでのテストはtestingパッケージを使う。
- テストは
{filename}_test.goというファイルで作成。- テストのメソッドは命名則があるので注意(以下引用)。
func TestXxx(* testing.T)
ここで、Xxxは小文字で始まっていません。関数名は、テストルーチンを識別するのに役立ちます。
Package testingテストファイルを同時に作成する
テストを書く場合は同時に作成してしまうと楽そうです。
$ touch math{,_test}.go $ ls math.go math_test.goテストを書く
それでは上記で作成した
mathファイルにコードを書いていきます。TDD的にまずはテストから。
- テーブルを使ってテストを実装
min関数はminIntとして実装- サブテスト を使ってテストケース毎にテストを分類
math_test.gopackage math import ( "testing" ) func TestMinInt(t *testing.T) { tests := []struct { name string in []int want int }{ {"natural_number_slice", []int{1, 2, 3}, 1}, {"nega_posi", []int{-1, 0}, -1}, {"nega_nega", []int{-10, -11}, -11}, } for _, tt := range tests { t.Run(tt.name, func(t *testing.T) { got := minInt(tt.in) if got != tt.want { t.Fatalf("want %v but %v", tt.want, got) } }) } }math.gopackage math func minInt(slice []int) int { var min int return min }失敗することを確認
まだminIntを実装しておらずただ0を返すだけの関数なので、テストは当然落ちます。
$ go test --- FAIL: TestMinInt (0.00s) --- FAIL: TestMinInt/natural_number_slice (0.00s) math_test.go:21: want 1 but 0 --- FAIL: TestMinInt/nega_posi (0.00s) math_test.go:21: want -1 but 0 --- FAIL: TestMinInt/nega_nega (0.00s) math_test.go:21: want -11 but 0 FAIL exit status 1 FAIL math 0.006s一つ目のテスト結果をみてみます
--- FAIL: TestMinInt/natural_number_slice (0.00s) math_test.go:21: want 1 but 0データオブジェクトは
{"natural_number_slice", []int{1, 2, 3}, 1}で、テストログのwant 1 but 0より1が期待されたけれども、得られたのは0ですよといことがわかる。関数を実装する
テストが落ちることが確認できたので関数を実装します。簡単ですね。
math.gopackage math func minInt(slice []int) int { var min int = slice[0] for _, value := range slice { if min > value { min = value } } return min }成功することを確認する
関数を実装したので期待通りに動作することを確認します。
$ go test PASS ok math 0.005sテストの途中経過を確認する
PASSと出ているだけではどのテストを確認したのかわからないため、テストの途中経過を確認したくなりました。
そのような場合は-vオプションを追加します。TestMinIntの3つのサブテストを確認した結果PASSになっているのが分かります。
$ go test -v === RUN TestMinInt === RUN TestMinInt/natural_number_slice === RUN TestMinInt/nega_posi === RUN TestMinInt/nega_nega --- PASS: TestMinInt (0.00s) --- PASS: TestMinInt/natural_number_slice (0.00s) --- PASS: TestMinInt/nega_posi (0.00s) --- PASS: TestMinInt/nega_nega (0.00s) PASS ok math 0.006s各関数, サブテスト毎にテスト結果を確認する
今回はTestMinIntしかテスト対象がないため必要としませんが、
-run {your_test_method}オプションで各メソッド毎にテスト結果を確認することができます。$ go test -run TestMinIntまた同様にして
-run {your_test_method/sub_test}オプションを使ってサブテスト毎にテスト結果を確認することもできます。$ go test -v -run TestMinInt/natural_number_slic === RUN TestMinInt === RUN TestMinInt/natural_number_slice --- PASS: TestMinInt (0.00s) --- PASS: TestMinInt/natural_number_slice (0.00s) PASS ok math 0.005sテストカバレッジを確認する
最後に
-coverオプションを使ってテストカバレッジを確認します。$ go test -cover PASS coverage: 100.0% of statements ok math 0.005s参考記事
https://golang.org/pkg/testing/
https://budougumi0617.github.io/2018/08/19/go-testing2018/
まとめ
- go testの書き方がわかった
- go testの各オプションの理解ができた
- テストカバレッジ上げていこう
以上明日も頑張ります!!
tomowarkar ひとりAdvent Calendar Advent Calendar 2019
- 投稿日:2019-12-02T17:36:50+09:00
PHP案件に配属されたGopherはどうGo言語と向き合うべきか
今いるチームのメインリポジトリはPHPで書かれているのでそれに接する機会が多い。
インフラはガチガチのAWSだ。
普段の個人開発で使う言語はGo一択だしインフラは google app engine にのせてきた。
全然違うじゃん、と思われるかもしれないが雇用されて働く上で技術スタックを気にしてネガティブになる必要はあまりない。
新しい技術に対して前向きな意思決定ができるチームを作れるか、一緒に働きたいと思えるメンバーに恵まれているか、プロダクトは利益を上げているか、そういったことの方がボディに効きやすい。
まぁPHPでお仕事できますか?と聞かれたら当然YESだ。
PHPなんてものは特にその存在を意識しなくても読めるし書けるので勉強するに値しない言語だ。
それがLL言語の唯一の利点であるがどうにもお行儀が悪くて治安が乱れやすい。
PHPとGoどちらが優れていますかとGopherには尋ねない方が身のためだ、お前は朝食に和食と肥溜めどちらにするか聞くのか?という顔になってしまい声に出すのも億劫だとため息をつかれるだろう。若干言葉が荒れてしまっているがややワイルドな環境で育ったのと実は今アドベントカレンダー前日だということと風邪を引いて咳と鼻水の煩わしさと戦いながら書いているというバックグラウンドを知ってもらうことで共感性をキープしていただきたい。
そういうわけでGoを布教することにはメリットしかないので業務でGoを使う機会をどうやって作っていくかというのがターゲットになる。
まずやるべきは社内の開発プロセスにおけるお役立ちツールを作ることだ。
githubで管理されているプロジェクトが100あるとしてそれらを一気にcloneするツールや複数リポジトリに渡ってローカルでgit grepなどのシェルを一括実行するツールなどを実際に作って調査に役立てている。
便利なものができたなと思ったらそれをチームに配布しておすそわけするとGoって便利だね、というのがじわじわと伝わっていく。
それと時間がない中でもできるだけ綺麗にコードを書いておくと良い。
Goはバイナリで配布できるのだがそうしていてもエンジニアはすぐコードを見せてみろと言い始めるからだ。
オラついたコードを書いてしまっていると読みにくいのはGoのせいだとアンチが湧き始めてしまう。
ここはなるべく手を抜かず学習に適した教材となるように書いておくのがベストだ。そうして機を伺っていると、とある外部APIのバージョン対応で旧バージョンのインタフェースを新バージョンのインタフェースにプロキシしてくれ!言語は問わない!みたいな案件が降ってくることがある。
とにかく急ぎで手間をかけずにできれば安く、そしてパフォーマンスも出して欲しいみたいな要望に応えるには、サーバにバイナリをおいてデーモン起動させるだけでインフラマンたちの手を煩わせずに動かせてしまうことや、自前でWebサーバを書いてしまえること、ファイルサイズも小さく、メモリも食わないなどの特性を持つGoが狂おしいほど最適なわけだ。こうして晴れてプロダクション環境で恐らく社内史上初のGo環境を動作させることに成功したわけだが大規模Web開発での信頼度はまだまだこれからだ。
大規模Web開発での目下のライバルはSpring Boot Kotlinだ。
コトラー達に言わせるとGoはオールドスクールだと。
ラムダ使いたいとかDI自前で書きたくないとか設定ファイルを自動で読み込んで欲しいとか、まぁ分かる。
バイナリ生成はKotlin Nativeでも出来るとかimmutable思想じゃないとか色々。
Goの思想にシンプルさを保つことで得られる恩恵が色々あるよねというのが根底にある以上、今後は使いどころが分かれていくかもしれないしGo2で破壊的にWeb寄りの実装に変化していくのかもしれないがそこらへんの議論がコミュニティで活発に行われているのもGoの力強い魅力だ。
Sprint Bootフレームワークは重たいが強力だしKotlinはScalaほどやりすぎてなくて程よくモダンなバランスの良い言語なのでPHPの256億倍マシだと思っている。そもそもエンジニアは世界平和のために美しいプロダクトを世の中に発信したいだけなので技術スタックで争うなんて必要は全くなかったはずなのだ。
いつしか競争社会の都合で限られた時間、限られたリソース、慣習や歴史によって生まれた何かの中で生きるために望まぬ戦争をやらされているのだ。
ひたすらにスキルを研磨することも許されず銃と言論を渡され戦えと焚き付けられているのだ。
今はKotlin案件にもアサインされているので積極的にそれの利点を引き出すことを考えているが、時が来れば僕はコトラーの額に銃口を向けデヴィット・フィンチャー監督作セブンのラストシーンに出てくるブラピのような顔をしているかもしれない。小さい頃からそう育てられたのでいざという時には引き金をひけるタイプの人間ではあるが生まれる時代を間違えたのかもなぁと思ったところでこの記事は締めようかなと。
記事を書き始めた頃は何か同志にアドバイスを送るつもりだったのだがどうにも最後の言葉が浮かばない。
時計を見ると期日が迫っている。もっと早く書いとけばなぁ、と夏休みの宿題が終わらないあの頃と何も変わらないまま日々は過ぎて行く。
- 投稿日:2019-12-02T17:09:07+09:00
【Hyperledger Fabric】PrivateDataを使ってみよう
1.はじめに
12月になりましたね。寒いです。
AdventCalendarとは無縁の、どーも、のぶこふです。今回は、Hyperledger Fabric(HLF)のPrivate Data Collections(プライベート データ コレクション:PrivateData)の使用方法について書きます。
「PrivateData?」という方は、公式ドキュメントをご参照ください。
▼公式ドキュメント
https://hyperledger-fabric.readthedocs.io/en/release-1.4/private-data/private-data.htmlざっくり説明すると「許可したPeer間でTxを共有するので、許可されていないPeerはTxの内容を見ることができませんよ」というものです。
- 「チャネルでも同じようにTxの中身が見れないけど、違いはなんやねん?」
- 「どこに保存されんねん?」
- などなど、疑問が湧くかもしれませんが、公式ドキュメントや他の方が説明してくださっているので、私からは割愛させていただきます。 oO(ここで、少し興味を持ってくれたら嬉しい)
1.1.想定読者
- HLFのPrivateDataを使いたい人
1.2.ゴール
- HLFでPrivateDataが実装できるようになる
1.3.環境
- HLF v1.4.4
- CentOS7 On Oracle VM VirtualBox On Windows10
- Chaincode:Golang
という環境で、今回の記事をお送りいたします。
2.つくる
marbleだと、すでにサンプルがあるのですが、今回は1から作成するということで、fabcarを修正していきます。
2.1.サンプルダウンロード
おなじみのサンプルを使用します。
# cd /opt - /opt に移動します - 任意のディレクトリで構いません # curl -sSL http://bit.ly/2ysbOFE | bash -s 1.4.4 - ダウンロードが行われます - 失敗した場合は、proxyの設定などを見直してみてください # ls -l - 「fabric-samples」があることを確認してください # cd fabric-samples/chaincode/fabcar/go - fabric-samples/chaincode/fabcar/go のフォルダまで移動します2.2.collections_config.jsonの作成
collections_config.jsonを作成します。
collections_config.jsonは、その名の通り、PrivateDataの定義ファイルです。
PrivateDataの名前やポリシー、ブロックの存続時間などを設定できます。
詳細は「公式ドキュメント」をご参照ください。
▼公式ドキュメント
https://hyperledger-fabric.readthedocs.io/en/release-1.4/private-data-arch.html# vi collections_config.json - collections_config.jsonファイルを開きます(新規作成)collections_config.jsonの中身は、次のようにします。
おおまかな内容としては、下記の通りです。
- collectionCars という名前にする
- Org1MSP.memberのみ許可する
- ブロックの生存時間は、10ブロックにする
collections_config.json[ { "name": "collectionCars", "policy": "OR('Org1MSP.member')", "requiredPeerCount": 0, "maxPeerCount": 3, "blockToLive":10, "memberOnlyRead": true } ]2.3.Chaincode(CC)修正
PrivateDataに保存、取得ができるように、CCを修正します。
2.3.1.fabcar.go
# vi fabcar.go - fabcar.goファイルを開きますfabcar.go:新しく構造体を作成します// PrivateData用の構造体を定義します // 通常のCarとは異なり「Price」を追加しています type CarPrivate struct { Make string `json:"make"` Model string `json:"model"` Colour string `json:"colour"` Owner string `json:"owner"` Pirce string `json:"price"` }Invoke関数に、PrivateDataを保存、取得する関数を呼べるように修正しますfunc (s *SmartContract) Invoke(APIstub shim.ChaincodeStubInterface) sc.Response { // Retrieve the requested Smart Contract function and arguments function, args := APIstub.GetFunctionAndParameters() // Route to the appropriate handler function to interact with the ledger appropriately if function == "queryCar" { return s.queryCar(APIstub, args) } else if function == "initLedger" { return s.initLedger(APIstub) } else if function == "createCar" { return s.createCar(APIstub, args) } else if function == "queryAllCars" { return s.queryAllCars(APIstub) } else if function == "changeCarOwner" { return s.changeCarOwner(APIstub, args) + } else if function == "setPrivateData" { + return s.setPrivateData(APIstub, args) + } else if function == "getPrivateData" { + return s.getPrivateData(APIstub, args) + } return shim.Error("Invalid Smart Contract function name.") }fabcar.go:PrivateDataを保存する関数を作成しますfunc (s *SmartContract) setPrivateData(APIstub shim.ChaincodeStubInterface, args []string) sc.Response { if len(args) != 6 { return shim.Error("Incorrect number of arguments. Expecting 6") } var car = CarPrivate{Make: args[1], Model: args[2], Colour: args[3], Owner: args[4], Price:args[5]} carAsBytes, _ := json.Marshal(car) err := APIstub.PutPrivateData("collectionCars", args[0], carAsBytes) if err != nil { return shim.Error(err.Error()) } return shim.Success(nil) }fabcar.go:PrivateDataを取得する関数を作成しますfunc (s *SmartContract) getPrivateData(APIstub shim.ChaincodeStubInterface, args []string) sc.Response { var jsonResp string if len(args) != 1 { return shim.Error("Incorrect number of arguments. Expecting 1") } carAsBytes, err := APIstub.GetPrivateData("collectionCars", args[0]) if err != nil { jsonResp = "{\"Error\":\"Failed to get state for " + args[0] + "\"}" return shim.Error(jsonResp) } else if carAsBytes == nil { jsonResp = "{\"Error\":\"Car does not exist: " + args[0] + "\"}" return shim.Error(jsonResp) } return shim.Success(carAsBytes) }以上でCCの修正は終了です。
全量は下記を御覧ください。
全量(不要なコメントは削除しています)
fabcar.gopackage main import ( "bytes" "encoding/json" "fmt" "strconv" "github.com/hyperledger/fabric/core/chaincode/shim" sc "github.com/hyperledger/fabric/protos/peer" ) // Define the Smart Contract structure type SmartContract struct { } // Define the car structure, with 4 properties. Structure tags are used by encoding/json library type Car struct { Make string `json:"make"` Model string `json:"model"` Colour string `json:"colour"` Owner string `json:"owner"` } // <<<<<< ADD >>>>> type CarPrivate struct { Make string `json:"make"` Model string `json:"model"` Colour string `json:"colour"` Owner string `json:"owner"` Price string `json:"price"` } func (s *SmartContract) Init(APIstub shim.ChaincodeStubInterface) sc.Response { return shim.Success(nil) } // <<<<<< MOD >>>>> func (s *SmartContract) Invoke(APIstub shim.ChaincodeStubInterface) sc.Response { // Retrieve the requested Smart Contract function and arguments function, args := APIstub.GetFunctionAndParameters() // Route to the appropriate handler function to interact with the ledger appropriately if function == "queryCar" { return s.queryCar(APIstub, args) } else if function == "initLedger" { return s.initLedger(APIstub) } else if function == "createCar" { return s.createCar(APIstub, args) } else if function == "queryAllCars" { return s.queryAllCars(APIstub) } else if function == "changeCarOwner" { return s.changeCarOwner(APIstub, args) } else if function == "setPrivateData" { return s.setPrivateData(APIstub, args) } else if function == "getPrivateData" { return s.getPrivateData(APIstub, args) } return shim.Error("Invalid Smart Contract function name.") } func (s *SmartContract) queryCar(APIstub shim.ChaincodeStubInterface, args []string) sc.Response { if len(args) != 1 { return shim.Error("Incorrect number of arguments. Expecting 1") } carAsBytes, _ := APIstub.GetState(args[0]) return shim.Success(carAsBytes) } func (s *SmartContract) initLedger(APIstub shim.ChaincodeStubInterface) sc.Response { cars := []Car{ Car{Make: "Toyota", Model: "Prius", Colour: "blue", Owner: "Tomoko"}, Car{Make: "Ford", Model: "Mustang", Colour: "red", Owner: "Brad"}, Car{Make: "Hyundai", Model: "Tucson", Colour: "green", Owner: "Jin Soo"}, Car{Make: "Volkswagen", Model: "Passat", Colour: "yellow", Owner: "Max"}, Car{Make: "Tesla", Model: "S", Colour: "black", Owner: "Adriana"}, Car{Make: "Peugeot", Model: "205", Colour: "purple", Owner: "Michel"}, Car{Make: "Chery", Model: "S22L", Colour: "white", Owner: "Aarav"}, Car{Make: "Fiat", Model: "Punto", Colour: "violet", Owner: "Pari"}, Car{Make: "Tata", Model: "Nano", Colour: "indigo", Owner: "Valeria"}, Car{Make: "Holden", Model: "Barina", Colour: "brown", Owner: "Shotaro"}, } i := 0 for i < len(cars) { fmt.Println("i is ", i) carAsBytes, _ := json.Marshal(cars[i]) APIstub.PutState("CAR"+strconv.Itoa(i), carAsBytes) fmt.Println("Added", cars[i]) i = i + 1 } return shim.Success(nil) } func (s *SmartContract) createCar(APIstub shim.ChaincodeStubInterface, args []string) sc.Response { if len(args) != 5 { return shim.Error("Incorrect number of arguments. Expecting 5") } var car = Car{Make: args[1], Model: args[2], Colour: args[3], Owner: args[4]} carAsBytes, _ := json.Marshal(car) APIstub.PutState(args[0], carAsBytes) return shim.Success(nil) } func (s *SmartContract) queryAllCars(APIstub shim.ChaincodeStubInterface) sc.Response { startKey := "CAR0" endKey := "CAR999" resultsIterator, err := APIstub.GetStateByRange(startKey, endKey) if err != nil { return shim.Error(err.Error()) } defer resultsIterator.Close() // buffer is a JSON array containing QueryResults var buffer bytes.Buffer buffer.WriteString("[") bArrayMemberAlreadyWritten := false for resultsIterator.HasNext() { queryResponse, err := resultsIterator.Next() if err != nil { return shim.Error(err.Error()) } // Add a comma before array members, suppress it for the first array member if bArrayMemberAlreadyWritten == true { buffer.WriteString(",") } buffer.WriteString("{\"Key\":") buffer.WriteString("\"") buffer.WriteString(queryResponse.Key) buffer.WriteString("\"") buffer.WriteString(", \"Record\":") // Record is a JSON object, so we write as-is buffer.WriteString(string(queryResponse.Value)) buffer.WriteString("}") bArrayMemberAlreadyWritten = true } buffer.WriteString("]") fmt.Printf("- queryAllCars:\n%s\n", buffer.String()) return shim.Success(buffer.Bytes()) } func (s *SmartContract) changeCarOwner(APIstub shim.ChaincodeStubInterface, args []string) sc.Response { if len(args) != 2 { return shim.Error("Incorrect number of arguments. Expecting 2") } carAsBytes, _ := APIstub.GetState(args[0]) car := Car{} json.Unmarshal(carAsBytes, &car) car.Owner = args[1] carAsBytes, _ = json.Marshal(car) APIstub.PutState(args[0], carAsBytes) return shim.Success(nil) } // <<<<<< ADD >>>>> func (s *SmartContract) setPrivateData(APIstub shim.ChaincodeStubInterface, args []string) sc.Response { if len(args) != 6 { return shim.Error("Incorrect number of arguments. Expecting 6") } var car = CarPrivate{Make: args[1], Model: args[2], Colour: args[3], Owner: args[4], Price:args[5]} carAsBytes, _ := json.Marshal(car) err := APIstub.PutPrivateData("collectionCars", args[0], carAsBytes) if err != nil { return shim.Error(err.Error()) } return shim.Success(nil) } // <<<<<< ADD >>>>> func (s *SmartContract) getPrivateData(APIstub shim.ChaincodeStubInterface, args []string) sc.Response { var jsonResp string if len(args) != 1 { return shim.Error("Incorrect number of arguments. Expecting 1") } carAsBytes, err := APIstub.GetPrivateData("collectionCars", args[0]) if err != nil { jsonResp = "{\"Error\":\"Failed to get state for " + args[0] + "\"}" return shim.Error(jsonResp) } else if carAsBytes == nil { jsonResp = "{\"Error\":\"Car does not exist: " + args[0] + "\"}" return shim.Error(jsonResp) } return shim.Success(carAsBytes) } // The main function is only relevant in unit test mode. Only included here for completeness. func main() { // Create a new Smart Contract err := shim.Start(new(SmartContract)) if err != nil { fmt.Printf("Error creating new Smart Contract: %s", err) } }以上でCCの修正は完了です。
それでは実行・・・いえいえ、まだ大事な作業があります。2.4.インスタンス化時にcollections_config.jsonを読み込むようにする
PrivateDataを使用するには、先程作成したcollections_config.jsonを読み込むようにする必要があります。
読み込みのタイミングは、インスタンス化を行うタイミングです。# cd ../../../fabcar/ - /opt/fabric-samples/fabcar/ まで移動します # vi startFabric.sh - startFabric.sh を開きますインスタンス化を行っている箇所で、collections_config.jsonを読み込むように加筆します。
98行目の末尾に「\」を追記する事も忘れずに!82 echo "Instantiating smart contract on mychannel" 83 docker exec \ 84 -e CORE_PEER_LOCALMSPID=Org1MSP \ 85 -e CORE_PEER_MSPCONFIGPATH=${ORG1_MSPCONFIGPATH} \ 86 cli \ 87 peer chaincode instantiate \ 88 -o orderer.example.com:7050 \ 89 -C mychannel \ 90 -n fabcar \ 91 -l "$CC_RUNTIME_LANGUAGE" \ 92 -v 1.0 \ 93 -c '{"Args":[]}' \ 94 -P "AND('Org1MSP.member','Org2MSP.member')" \ 95 --tls \ 96 --cafile ${ORDERER_TLS_ROOTCERT_FILE} \ 97 --peerAddresses peer0.org1.example.com:7051 \ + 98 --tlsRootCertFiles ${ORG1_TLS_ROOTCERT_FILE} \ + 99 --collections-config /opt/gopath/src/github.com/chaincode/fabcar/go/collections_config.json2.5.CC呼び出し元アプリ作成
最後にCCを呼び出すアプリを作成します。
と言っても、すでにあるのを複製して作成します。
まずはPrivateDataを保存するCCを呼び出すアプリです。# cd javascript/ - javascriptフォルダに移動します # cp invoke.js setPrivateData.js - invoke.js をコピーします # vi setPrivateData.js - コピーしたファイルを開きます'use strict'; const { FileSystemWallet, Gateway } = require('fabric-network'); const path = require('path'); const ccpPath = path.resolve(__dirname, '..', '..', 'first-network', 'connection-org1.json'); async function main() { try { // Create a new file system based wallet for managing identities. const walletPath = path.join(process.cwd(), 'wallet'); const wallet = new FileSystemWallet(walletPath); console.log(`Wallet path: ${walletPath}`); // Check to see if we've already enrolled the user. const userExists = await wallet.exists('user1'); if (!userExists) { console.log('An identity for the user "user1" does not exist in the wallet'); console.log('Run the registerUser.js application before retrying'); return; } // Create a new gateway for connecting to our peer node. const gateway = new Gateway(); await gateway.connect(ccpPath, { wallet, identity: 'user1', discovery: { enabled: true, asLocalhost: true } }); // Get the network (channel) our contract is deployed to. const network = await gateway.getNetwork('mychannel'); // Get the contract from the network. const contract = network.getContract('fabcar'); // Submit the specified transaction. // createCar transaction - requires 5 argument, ex: ('createCar', 'CAR12', 'Honda', 'Accord', 'Black', 'Tom') // changeCarOwner transaction - requires 2 args , ex: ('changeCarOwner', 'CAR10', 'Dave') - await contract.submitTransaction('createCar', 'CAR12', 'Honda', 'Accord', 'Black', 'Tom'); + await contract.submitTransaction('setPrivateData', 'CAR12', 'Honda', 'Accord', 'Black', 'Tom', '1000' ); console.log('Transaction has been submitted'); // Disconnect from the gateway. await gateway.disconnect(); } catch (error) { console.error(`Failed to submit transaction: ${error}`); process.exit(1); } } main();続いて、PrivateDataを取得するアプリです。
# cp query.js getPrivateData.js - query.jsをコピーします # vi getPrivateData.js - コピーしたファイルを開きます'use strict'; const { FileSystemWallet, Gateway } = require('fabric-network'); const path = require('path'); const ccpPath = path.resolve(__dirname, '..', '..', 'first-network', 'connection-org1.json'); async function main() { try { // Create a new file system based wallet for managing identities. const walletPath = path.join(process.cwd(), 'wallet'); const wallet = new FileSystemWallet(walletPath); console.log(`Wallet path: ${walletPath}`); // Check to see if we've already enrolled the user. const userExists = await wallet.exists('user1'); if (!userExists) { console.log('An identity for the user "user1" does not exist in the wallet'); console.log('Run the registerUser.js application before retrying'); return; } // Create a new gateway for connecting to our peer node. const gateway = new Gateway(); await gateway.connect(ccpPath, { wallet, identity: 'user1', discovery: { enabled: true, asLocalhost: true } }); // Get the network (channel) our contract is deployed to. const network = await gateway.getNetwork('mychannel'); // Get the contract from the network. const contract = network.getContract('fabcar'); // Evaluate the specified transaction. // queryCar transaction - requires 1 argument, ex: ('queryCar', 'CAR4') // queryAllCars transaction - requires no arguments, ex: ('queryAllCars') - const result = await contract.evaluateTransaction('queryAllCars'); + const result = await contract.evaluateTransaction('getPrivateData', 'CAR12'); console.log(`Transaction has been evaluated, result is: ${result.toString()}`); } catch (error) { console.error(`Failed to evaluate transaction: ${error}`); process.exit(1); } } main();これで、ようやく準備が整いました。
それでは実行してみましょう。3.うごかす
3.1.startFabric.sh実行
# cd ../ - ディレクトリを移動します # ls -l - startFabric.sh があることを確認します # ./startFabric.sh - Errorが発生せずに終了すること3.2.admin&user1作成
# cd javascript/ - javascriptフォルダに移動します # npm install - 不足しているライブラリをインストールします - エラーが出た場合は、メッセージに則って対応します - 私の場合は「nycをインストールしてください」と出たので、下記コマンドでインストールしています # npm audit # npm install --save-dev nyc@14.1.1 # node enrollAdmin.js - エラーが発生しないこと # node registerUser.js - エラーが発生しないこと # ls -l wallet/ - adminとuser1のフォルダが作成されていること3.3.PrivateData保存、取得
# node setPrivateData.js - Transaction has been submitted # node getPrivateData.js - Transaction has been evaluated, result is: {"colour":"Black","make":"Honda","model":"Accord","owner":"Tom","price":"1000"}無事に保存、取得が行えたようですね。
3.4.StateDBの取得
続いて、普通のStateDBへ取得を行ってみましょう。
# node query.js - Transaction has been evaluated, result is: [{"Key":"CAR0", "Record":{"colour":"blue","make":"Toyota","model":"Prius","owner":"Tomoko"}},{"Key":"CAR1", "Record":{"colour":"red","make":"Ford","model":"Mustang","owner":"Brad"}},{"Key":"CAR2", "Record":{"colour":"green","make":"Hyundai","model":"Tucson","owner":"Jin Soo"}},{"Key":"CAR3", "Record":{"colour":"yellow","make":"Volkswagen","model":"Passat","owner":"Max"}},{"Key":"CAR4", "Record":{"colour":"black","make":"Tesla","model":"S","owner":"Adriana"}},{"Key":"CAR5", "Record":{"colour":"purple","make":"Peugeot","model":"205","owner":"Michel"}},{"Key":"CAR6", "Record":{"colour":"white","make":"Chery","model":"S22L","owner":"Aarav"}},{"Key":"CAR7", "Record":{"colour":"violet","make":"Fiat","model":"Punto","owner":"Pari"}},{"Key":"CAR8", "Record":{"colour":"indigo","make":"Tata","model":"Nano","owner":"Valeria"}},{"Key":"CAR9", "Record":{"colour":"brown","make":"Holden","model":"Barina","owner":"Shotaro"}}]PrivateDataに保存した「"Key":"CAR12"」がありませんね。
3.5.別ユーザで取得
デフォルトで作成すると、user1はOrg1の所属です。
Org2でも試してみます。# docker exec -it cli bash - cliコンテナに入ります - 以下、cliコンテナ内 CHANNEL_NAME=mychannel ORDERER_CA=/opt/gopath/src/github.com/hyperledger/fabric/peer/crypto/ordererOrganizations/example.com/orderers/orderer.example.com/msp/tlscacerts/tlsca.example.com-cert.pem PEER0_ORG1_CA=/opt/gopath/src/github.com/hyperledger/fabric/peer/crypto/peerOrganizations/org1.example.com/peers/peer0.org1.example.com/tls/ca.crt PEER0_ORG2_CA=/opt/gopath/src/github.com/hyperledger/fabric/peer/crypto/peerOrganizations/org2.example.com/peers/peer0.org2.example.com/tls/ca.crt CORE_PEER_LOCALMSPID="Org2MSP" CORE_PEER_TLS_ROOTCERT_FILE=$PEER0_ORG2_CA CORE_PEER_MSPCONFIGPATH=/opt/gopath/src/github.com/hyperledger/fabric/peer/crypto/peerOrganizations/org2.example.com/users/Admin@org2.example.com/msp CORE_PEER_ADDRESS=peer0.org2.example.com:9051 - 環境変数を設定 peer chaincode query -C $CHANNEL_NAME -n fabcar -c '{"Args":["getPrivateData","CAR12"]}' - Error: endorsement failure during query. response: status:500 message:"{\"Error\":\"Failed to get state for CAR12\"}"エラーが返ってきました。
念の為、Org1でも試してみましょう。CHANNEL_NAME=mychannel ORDERER_CA=/opt/gopath/src/github.com/hyperledger/fabric/peer/crypto/ordererOrganizations/example.com/orderers/orderer.example.com/msp/tlscacerts/tlsca.example.com-cert.pem PEER0_ORG1_CA=/opt/gopath/src/github.com/hyperledger/fabric/peer/crypto/peerOrganizations/org1.example.com/peers/peer0.org1.example.com/tls/ca.crt PEER0_ORG2_CA=/opt/gopath/src/github.com/hyperledger/fabric/peer/crypto/peerOrganizations/org2.example.com/peers/peer0.org2.example.com/tls/ca.crt CORE_PEER_LOCALMSPID="Org1MSP" CORE_PEER_TLS_ROOTCERT_FILE=$PEER0_ORG1_CA CORE_PEER_MSPCONFIGPATH=/opt/gopath/src/github.com/hyperledger/fabric/peer/crypto/peerOrganizations/org1.example.com/users/Admin@org1.example.com/msp CORE_PEER_ADDRESS=peer0.org1.example.com:7051 - 環境変数を設定 peer chaincode query -C $CHANNEL_NAME -n fabcar -c '{"Args":["getPrivateData","CAR12"]}' - {"colour":"Black","make":"Honda","model":"Accord","owner":"Tom","price":"1000"}想定通りの結果が返ってきました。
3.6.ブロックの生存時間を確認する
ブロックの生存時間は10と設定していました。
Txを大量に発行して、ブロックを進めてみます。peer channel fetch newest -o $ORDERER_CA -c mychannel last.block - ブロック番号を確認 peer chaincode invoke -o orderer.example.com:7050 --tls --cafile $ORDERER_CA -C $CHANNEL_NAME -n fabcar -c '{"Args":["changeCarOwner","CAR1", "Nobkov"]}' peer chaincode invoke -o orderer.example.com:7050 --tls --cafile $ORDERER_CA -C $CHANNEL_NAME -n fabcar -c '{"Args":["changeCarOwner","CAR1", "Nobkov"]}' peer chaincode invoke -o orderer.example.com:7050 --tls --cafile $ORDERER_CA -C $CHANNEL_NAME -n fabcar -c '{"Args":["changeCarOwner","CAR1", "Nobkov"]}' peer chaincode invoke -o orderer.example.com:7050 --tls --cafile $ORDERER_CA -C $CHANNEL_NAME -n fabcar -c '{"Args":["changeCarOwner","CAR1", "Nobkov"]}' peer chaincode invoke -o orderer.example.com:7050 --tls --cafile $ORDERER_CA -C $CHANNEL_NAME -n fabcar -c '{"Args":["changeCarOwner","CAR1", "Nobkov"]}' peer chaincode invoke -o orderer.example.com:7050 --tls --cafile $ORDERER_CA -C $CHANNEL_NAME -n fabcar -c '{"Args":["changeCarOwner","CAR1", "Nobkov"]}' peer chaincode invoke -o orderer.example.com:7050 --tls --cafile $ORDERER_CA -C $CHANNEL_NAME -n fabcar -c '{"Args":["changeCarOwner","CAR1", "Nobkov"]}' peer chaincode invoke -o orderer.example.com:7050 --tls --cafile $ORDERER_CA -C $CHANNEL_NAME -n fabcar -c '{"Args":["changeCarOwner","CAR1", "Nobkov"]}' peer chaincode invoke -o orderer.example.com:7050 --tls --cafile $ORDERER_CA -C $CHANNEL_NAME -n fabcar -c '{"Args":["changeCarOwner","CAR1", "Nobkov"]}' peer chaincode invoke -o orderer.example.com:7050 --tls --cafile $ORDERER_CA -C $CHANNEL_NAME -n fabcar -c '{"Args":["changeCarOwner","CAR1", "Nobkov"]}' peer chaincode invoke -o orderer.example.com:7050 --tls --cafile $ORDERER_CA -C $CHANNEL_NAME -n fabcar -c '{"Args":["changeCarOwner","CAR1", "Nobkov"]}' peer chaincode invoke -o orderer.example.com:7050 --tls --cafile $ORDERER_CA -C $CHANNEL_NAME -n fabcar -c '{"Args":["changeCarOwner","CAR1", "Nobkov"]}' peer chaincode invoke -o orderer.example.com:7050 --tls --cafile $ORDERER_CA -C $CHANNEL_NAME -n fabcar -c '{"Args":["changeCarOwner","CAR1", "Nobkov"]}' peer chaincode invoke -o orderer.example.com:7050 --tls --cafile $ORDERER_CA -C $CHANNEL_NAME -n fabcar -c '{"Args":["changeCarOwner","CAR1", "Nobkov"]}' peer chaincode invoke -o orderer.example.com:7050 --tls --cafile $ORDERER_CA -C $CHANNEL_NAME -n fabcar -c '{"Args":["changeCarOwner","CAR1", "Nobkov"]}' peer chaincode invoke -o orderer.example.com:7050 --tls --cafile $ORDERER_CA -C $CHANNEL_NAME -n fabcar -c '{"Args":["changeCarOwner","CAR1", "Nobkov"]}' peer chaincode invoke -o orderer.example.com:7050 --tls --cafile $ORDERER_CA -C $CHANNEL_NAME -n fabcar -c '{"Args":["changeCarOwner","CAR1", "Nobkov"]}' peer chaincode invoke -o orderer.example.com:7050 --tls --cafile $ORDERER_CA -C $CHANNEL_NAME -n fabcar -c '{"Args":["changeCarOwner","CAR1", "Nobkov"]}' peer chaincode invoke -o orderer.example.com:7050 --tls --cafile $ORDERER_CA -C $CHANNEL_NAME -n fabcar -c '{"Args":["changeCarOwner","CAR1", "Nobkov"]}' peer chaincode invoke -o orderer.example.com:7050 --tls --cafile $ORDERER_CA -C $CHANNEL_NAME -n fabcar -c '{"Args":["changeCarOwner","CAR1", "Nobkov"]}' - 大量にTx発行(ブロックを進める) peer channel fetch newest -o $ORDERER_CA -c mychannel last.block - ブロック番号を確認 peer chaincode query -C $CHANNEL_NAME -n fabcar -c '{"Args":["getPrivateData","CAR12"]}' - Error: endorsement failure during query. response: status:500 message:"{\"Error\":\"Car does not exist: CAR12\"}"削除されているので、参照ができなくなりました。
4.おわりに
さて、いかがでしたでしょうか。
CCの実装も特に大きく変えることなく、PrivateDataへ保存・取得する事ができました。
また、生存時間の確認も行えましたね。PrivateDataはチャネルと同様に重要な概念となるので、しっかりと抑えておきたいところです。
(肝に銘じる)今回はここまでです。
ありがとうございました。
- 投稿日:2019-12-02T14:36:25+09:00
golangでAzureDevOps
最近Goを勉強する機会があった為、まとめの意味も込めて書いてみます。
色々やり方はあると思いますが、この方法が作り易いと感じました。
まずはDevOpsプロジェクト作成まで。作り方
テンプレートからDevOpsのプロジェクトを作成
まずはテンプレートからDevOpsのプロジェクトを作成します。
Azure Portalへログインします。※最初にハマったんですが「Azure Portal」と「Azure DevOps」は別のサイトになってます。
これを理解するまで結構苦戦しました。
Azure DevOpsは元々Visual Studio Team Servicesという別のサービスだったようです。ポータル上部の検索ウィンドウに「devops」と入力すると候補が表示されます。
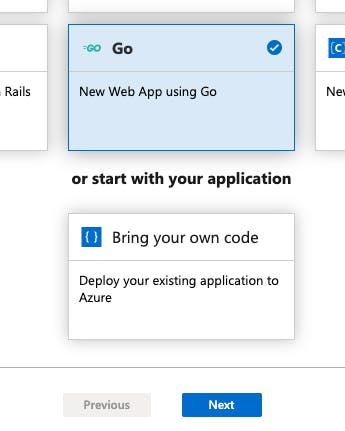
「DevOps Projects」を選択
プロジェクトを作成します。
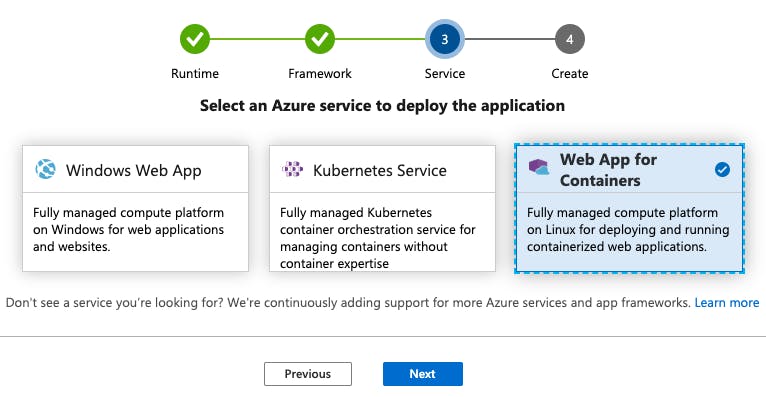
今回はGoを使うのでGoを選択します。
確認画面
コンテナを使いたいのでコンテナを選択します。
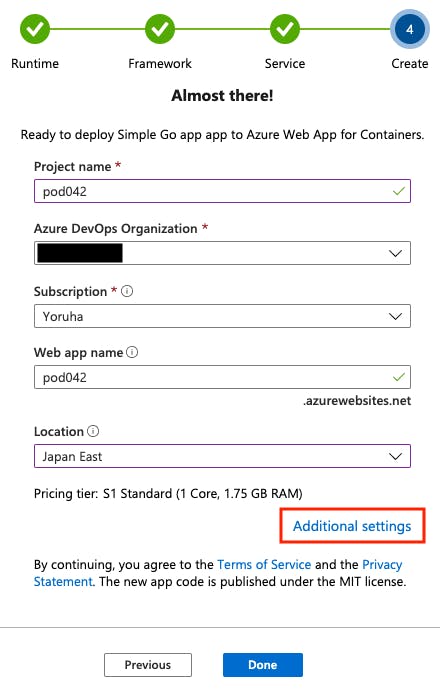
DevOpsのプロジェクト名とサーバー名を設定します。
Additional settingsでサーバー構成も設定しておきましょう。
WebAppとコンテナレジストリ名は勝手に入ってくれます。
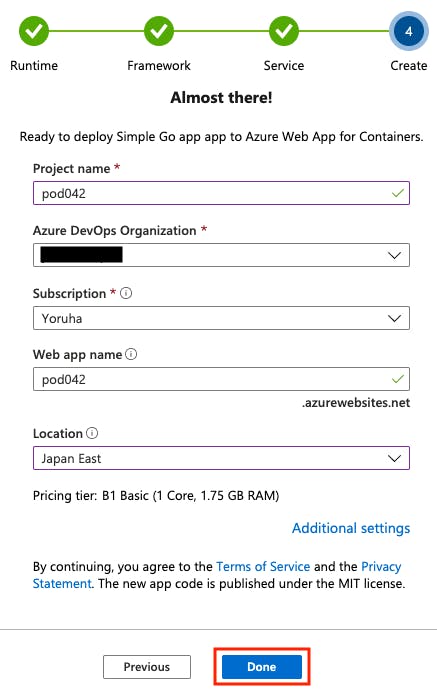
サーバー構成を設定します。
一番安いやつにしました。
これで設定は完了です。Doneを押します。
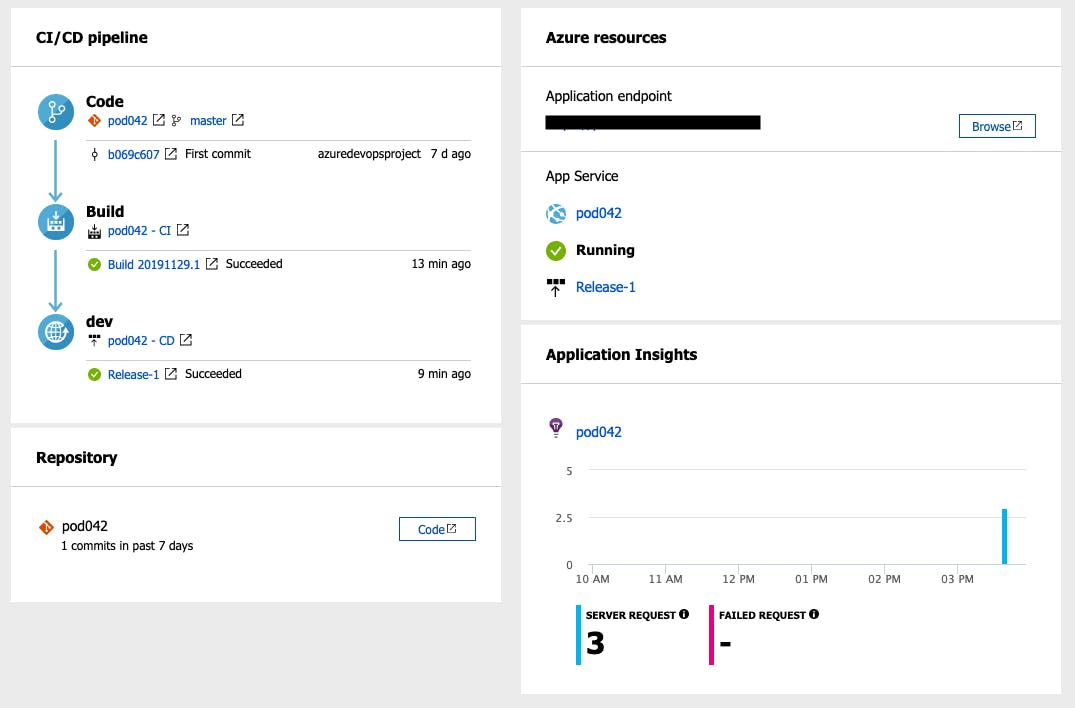
しばらく待つと完成します。
「リソース移動」から遷移すると下記のような画面が表示されます。
「Browse」からweb画面でサンプル表示を確認出来ます。
以上
お疲れ様でした。






- 投稿日:2019-12-02T13:46:24+09:00
Goを使って全探索で最長しりとりを解く
この記事はtomowarkar ひとりAdvent Calendar 2019の2日目の記事です。
Golangを書き始めて1ヶ月が過ぎた頃なのでアルゴリズム的な問題を解いてみようということで、最長しりとりを解くアルゴリズムを書いてみました。
今回全探索を使って最長しりとりを解くので、パフォーマンス最適ではありません。
計算量は最大で$O(n!)$になると思われます(自信ない)。実務でしりとりを解きたいという場合は(???)数理計画法などを使って解くことをお勧めします。
考え方
- 単語プールの中からしりとりの開始文字を決め、開始文字をしりとりプールに移す
- 残りの単語プールの中からしりとりが繋がる文字を探す。
- しりとりが繋がる場合、単語プールからしりとりプールに移動し、2に戻る。
- しりとりが繋がらない場合、そこでしりとりは終了する。
- 終了したしりとりプールの中で一番長いしりとりプールが求める最長しりとり。
コード全文
コード全文をのせると長くなるので、折りたたんで載せておきます。
コード全文
main.gopackage main import ( "fmt" "strings" "time" ) // Word は単語の頭と尻の文字を格納します. type Word struct { word string head string tail string } // Words は Wordの配列とその長さを格納します. type Words struct { length int words []Word } // Result は しりとりの結果を格納します. var Result Words // Append は Wordsに要素を追加します. func (ws *Words) Append(w string) { ww := Word{ word: w, head: string(w[0]), tail: string(w[len(w)-1]), } ws.words = append(ws.words, ww) ws.length++ } // shiritori は メインの探索アルゴリズムです. func shiritori(chain, words []Word) { tail := chain[len(chain)-1].tail flag := false for i, w := range words { if w.head == tail { flag = true tmp := append([]Word{}, words...) shiritori(append(chain, []Word{w}...), append(tmp[:i], tmp[i+1:]...)) } } if !flag { if len(chain) > Result.length { Result.words = chain Result.length = len(chain) } } } // solver はしりとり結果を返します. func solver(target []string) []string { var ans []string ws := Words{} for _, ta := range target { ws.Append(ta) } for i, w := range ws.words { tmp := append([]Word{}, ws.words...) shiritori([]Word{w}, append(tmp[:i], tmp[i+1:]...)) } for _, r := range Result.words { ans = append(ans, r.word) } return ans } func main() { target := "hc, radish, ginger, egg, apple, tuna, nut, onion, tomato, carrot" targetArr := strings.Split(target, ", ") start := time.Now() ans := solver(targetArr) fmt.Printf("%d個: %f秒\n", len(targetArr), (time.Now().Sub(start)).Seconds()) fmt.Println("in: ", strings.Join(targetArr, " ")) fmt.Println("out:", strings.Join(ans, " ")) }
考慮しなかったこと
コード解説に入る前に今回考慮しなかったことをあげておきます。
同じ単語の場合
同じ単語を使うことを許容しています。許容しない場合は
Appendにコードを追加すればできそうです。終了文字
日本語でしりとりをする場合は「ん」がついたらそこで終了しますが、ローマ字の場合はどうなるのでしょうかね?
コード解説
solver
単語スライス
targetを渡すと、最長のしりとりスライスを返します。
1. 単語スライスtargetを単語プールWordsに格納。
2. 各単語毎に後に続くしりとりを探索。
3. 最長のしりとりプールResult.wordsをstringのsliceに変換して返す。solver.go// solver はしりとり結果を返します. func solver(target []string) []string { var ans []string ws := Words{} for _, ta := range target { ws.Append(ta) } for i, w := range ws.words { tmp := append([]Word{}, ws.words...) shiritori([]Word{w}, append(tmp[:i], tmp[i+1:]...)) } for _, r := range Result.words { ans = append(ans, r.word) } return ans }shiritori
- しりとりプール
chainの一番最後の文字を取得。- 単語プール
wordsの中からしりとりができる単語を探す。- しりとりができる単語がある場合、その単語を単語プール
wordsからしりとりプールchainに移動し、再帰的にしりとりを探索する。- しりとりができる単語があった場合その長さを評価し、最長しりとり
Resultを取得する。shiritori.go// shiritori は メインの探索アルゴリズムです. func shiritori(chain, words []Word) { tail := chain[len(chain)-1].tail flag := false for i, w := range words { if w.head == tail { flag = true tmp := append([]Word{}, words...) shiritori(append(chain, []Word{w}...), append(tmp[:i], tmp[i+1:]...)) } } if !flag { if len(chain) > Result.length { Result.words = chain Result.length = len(chain) } } }動作確認
それでは動作確認をしてみます。
$ go run main.go 10個: 0.000114秒 in: hc radish ginger egg apple tuna nut onion tomato carrot out: hc carrot tomato onion nut tuna apple egg ginger radishパフォーマンス最適ではないと言いながら、なかなか早く結果が出てきました。
これはしりとりとして繋がりうる選択肢が限られているため、早めに枝切りされた結果ということが考察できます。試しに
"a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p, q, r, s, t, u, v, w, x, y, z"をぶち込んでみても26個: 0.000081秒 in: a b c d e f g h i j k l m n o p q r s t u v w x y z out: a早いですね。
次に逆のパターンをみてみます。
しりとりとして繋がりうる選択肢を最大化した場合なので、"a, a, a, a, a, a, a, a, a, a"で探索してみます。10個: 2.340494秒 in: a a a a a a a a a a out: a a a a a a a a a a一番最初の結果と比べてみても同じ単語数(10個)なのにも関わらず、探索時間が大きく変わることがわかりますね。
これは全ての単語の頭と尻が繋がりうるので、全て探索する必要があり時間がかかると考えられます。ざっくりまとめ
文字列 しりとり長さ 探索時間 "hc, radish, ginger, egg, apple, tuna, nut, onion, tomato, carrot" 10個 0.000114秒 "a, a, a, a, a, a, a, a, a, a" 10個 2.340494秒 "a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p, q, r, s, t, u, v, w, x, y, z" 26個 0.000081秒 計算量を考えてアルゴリズムを組む大切さがよくわかりますね。
まとめ
- 全探索で最長しりとりを解いた。
- 探索する単語によって探索時間が大きく変わる。
- 計算量を考えてアルゴリズムを組む重要性がわかった。
以上明日も頑張ります!!
tomowarkar ひとりAdvent Calendar Advent Calendar 2019
- 投稿日:2019-12-02T12:22:00+09:00
05. n-gram
05. n-gram
リストなど)からn-gramを作る関数を作成せよ.この関数を用い,"I am an NLPer"という文から単語bi-gram,文字bi-gramを得よ.
Go
package main import ( "fmt" "strings" ) // 文字単位の bi-gram func ch_bi_gram(src string) []string { var res []string // 文字数ループ(1文字少なく) for i:=0 ; i<(len(src)-1);i++ { // 添字の文字と次の文字を連結 res = append(res, string(src[i]) + string(src[i+1])) } return res } // 単語単位の bi-gram func wd_bi_gram(src string) []string { var res []string // 単語単位で文字列を分割 words := strings.Split(src, " ") // 単語数ループ(1配列少なく) for i:=0 ; i<(len(words)-1);i++ { // 空白で単語を区切ったため、空白を追加し単語を連結 res = append(res, words[i] + " " + words[i+1]) } return res } func main() { src := "I am an NLPer" // 文字単位の bi-gram res1 := ch_bi_gram(src) fmt.Printf("%q\n",res1) // 単語単位の bi-gram res2 := wd_bi_gram(src) fmt.Printf("%q\n",res2) }python
# -*- coding: utf-8 -*- # 文字単位の bi-gram def ch_bi_gram(src): res = list(range(0)) # 文字数ループ(1文字少なく) for i in range(len(src)-1): # 添字の文字と次の文字を連結 res.append(src[i] + src[i+1]) return res # 単語単位の bi-gram def wd_bi_gram(src): res = list(range(0)) # 単語単位で文字列を分割 words = src.split(" ") # 単語数ループ(1配列少なく) for i in range(len(words)-1): # 空白で単語を区切ったため、空白を追加し単語を連結 res.append(words[i] + " " + words[i+1]) return res src = "I am an NLPer" # 文字単位の bi-gram res = ch_bi_gram(src) print res # 単語単位の bi-gram res = wd_bi_gram(src) print resJavascript
// 文字単位の bi-gram function ch_bi_gram(src) { var res = []; // 文字数ループ(1文字少なく) for (var i = 0; i < (src.length-1); i++) { // 添字の文字と次の文字を連結 res.push(src[i] + src[i+1]); } return res; } // 単語単位の bi-gram function wd_bi_gram(src) { var res = []; // 単語単位で文字列を分割 var words = src.split(' '); // 単語数ループ(1配列少なく) for (var i=0;i<(words.length-1);i++) { // 空白で単語を区切ったため、空白を追加し単語を連結 res.push(words[i] + " " + words[i+1]); } return res; } var src = "I am an NLPer" // 文字単位の bi-gram var chr = ch_bi_gram(src); console.log(chr); // 単語単位の bi-gram var wd = wd_bi_gram(src); console.log(wd);まとめ
次の「05. n-gram」 は他の方の解説を読むが難しい。
[n番煎じ] 言語処理100本ノック 2015 第1章 with Python に結果が載ってた。文字列(入力): I am an NLPer 文字バイグラム: ['I ', ' a', 'am', 'm ', ' a', 'an', 'n ', ' N', 'NL', 'LP', 'Pe', 'er'] 単語バイグラム: ['I am', 'am an', 'an NLPer']解りやすい。文章解読能力が無いことを痛感。
気になってる点。文章を空白で分割したがその空白を後で結合している部分。
これでいいのかなぁ。なんかカッコよくない気がする。
- 投稿日:2019-12-02T09:53:30+09:00
goのenumは文字列でいいのではないかという話
goにおけるenumの一般的な定義
世の中で真っ当とされているgoにおけるenumの定義は、
type Zodiac int const ( Rat Zodiac = iota // 子 Ox // 丑 Tiger // 寅 : )ですね
とはいえ数値でJSON化されたり、ログ出されたり、DBに書き込まれたりされても、
理解が一歩遅れるので、文字列化は欲しくなるわけです。
enumを文字列化するために、String()設けたりします。func (z Zodiac) String() string { switch z { case Rat: return "Rat" case Ox: return "Ox" case Tiger: return "Tiger" : } return "" }何を書かされているんだ…
という悩みを解決するために Stringer とか Apache Thrift とかがよく使われます
ハナから文字列で良くない?
そもそも、別に数値である必要はないのでは。
type Zodiac string const ( Rat = Zodiac("Rat") Ox = Zodiac("Ox") Tiger = Zodiac("Tiger") Rabbit = Zodiac("Rabbit") Dragon = Zodiac("Dragon") Snake = Zodiac("Snake") Horse = Zodiac("Horse") Sheep = Zodiac("Sheep") Monkey = Zodiac("Monkey") Cock = Zodiac("Cock") Dog = Zodiac("Dog") Boar = Zodiac("Boar") )seealso: https://play.golang.org/p/kqHy0zm0vwn
String()もMarshalText()もMarshalYAML()もいらない。ライトに定義するならこれで大体良いのでは。
仕事でも3年ほど同じものを開発し続けていますが、そこでenumを定義するときもおおよそこれで困ってません。
必要なら諸々書けばいいし、必要ないなら書かなければいい。最初に書くのがダルいって声は聞こえそうですけど、このレベルならSnippetでどうにでもなります。
Goは割と手軽にGenerateしたら良いよという文化ですが、あんまりGenerate偏重ってのもどうなのかなと思っての提案でした。スペシャルサンクス
@po3rin さんの vim plugin のおかげで、この記事はとても快適に書けました。
https://qiita.com/po3rin/items/9b17a206fd8661235aa1
- 投稿日:2019-12-02T08:05:04+09:00
Goで正規表現を使うときに考えたいこと
はじめに
以前コードレビューをしたときに、日時形式のバリデーションに正規表現が利用されていたので、
time.Parse使おうとコメントしました。また、それについて記事にしてみようと伝え、記事も書いてもらいました。あらためてベンチマークを実行すると、time.Parseによるチェックが高速なことが分かります。
var validater = regexp.MustCompile(`\d{4}(/\d{2}){2} \d{2}(:\d{2}){2}`) func BenchmarkRegexpPack(b *testing.B) { b.ResetTimer() for i := 0; i < b.N; i++ { validater.MatchString("2012/12/10 12:30:45") } } func BenchmarkTimePack(b *testing.B) { layout := "2006/01/02 15:04:05" b.ResetTimer() for i := 0; i < b.N; i++ { time.Parse(layout, "2012/12/10 12:30:45") } } // BenchmarkRegexpPack-12 4026220 295 ns/op // BenchmarkTimePack-12 7007890 171 ns/opここでは、なぜ time.Parse は高速に処理ができるのかをチェックするとともに、Goでパターンマッチを高速に行いたい場合にどのように実装すればよいのかを見ていきます。
time.Parse の実装
ソースコードでいうと、主な処理は parse と nextStdChunk にまとめられています。
簡単に説明すると、以下のようなステップで実行されています。
- layoutを元に、日時に関係がある部分の文字を文字列として切り出す
- 切り出した文字列を数値に変換
- layoutを元に、1→2を繰り返す
- 文字列の長さが0になったら、数値への変換プロセスが終了
- これまでの値を元に数値を微調整
- 数値を元に
Date(year, Month(month), day, hour, min, sec, nsec, defaultLocation)としてtime.Timeを返却この処理のうち、4~5の処理はパターンマッチに関係ない部分です。また1,2の処理も、様々な時間フォーマットに対応するために余分な処理が多く含まれています。しかし、その条件を含めても冒頭のベンチマークでわかったとおりtime.Parseを利用したパターンマッチのほうが高速にできます。
func parse(layout, value string, defaultLocation, local *Location) (Time, error) { alayout, avalue := layout, value rangeErrString := "" // set if a value is out of range amSet := false // do we need to subtract 12 from the hour for midnight? pmSet := false // do we need to add 12 to the hour? // Each iteration processes one std value. for { var err error prefix, std, suffix := nextStdChunk(layout) stdstr := layout[len(prefix) : len(layout)-len(suffix)] value, err = skip(value, prefix) if err != nil { return Time{}, &ParseError{alayout, avalue, prefix, value, ""} } if std == 0 { if len(value) != 0 { return Time{}, &ParseError{alayout, avalue, "", value, ": extra text: " + value} } break } layout = suffix var p string switch std & stdMask { case stdYear: if len(value) < 2 { err = errBad break } hold := value p, value = value[0:2], value[2:] year, err = atoi(p) if err != nil { value = hold } else if year >= 69 { // Unix time starts Dec 31 1969 in some time zones year += 1900 } else { year += 2000 } // ... } if pmSet && hour < 12 { hour += 12 } else if amSet && hour == 12 { hour = 0 } // ... return Date(year, Month(month), day, hour, min, sec, nsec, defaultLocation), nil } func nextStdChunk(layout string) (prefix string, std int, suffix string) { for i := 0; i < len(layout); i++ { switch c := int(layout[i]); c { case 'J': // January, Jan if len(layout) >= i+3 && layout[i:i+3] == "Jan" { if len(layout) >= i+7 && layout[i:i+7] == "January" { return layout[0:i], stdLongMonth, layout[i+7:] } if !startsWithLowerCase(layout[i+3:]) { return layout[0:i], stdMonth, layout[i+3:] } } ...類似の事例
その他の標準ライブラリで見ると、
url.Parseもシンプルに実装されています。ソースコードはこちら。URLスキーマをチェックする部分では、パターンマッチではなく、
'a' <= c && c <= 'z' || 'A' <= c && c <= 'Z'のように文字列をbyte型として取り出し、byteの比較を用いて実装されています。func getscheme(rawurl string) (scheme, path string, err error) { for i := 0; i < len(rawurl); i++ { c := rawurl[i] switch { case 'a' <= c && c <= 'z' || 'A' <= c && c <= 'Z': // do nothing case '0' <= c && c <= '9' || c == '+' || c == '-' || c == '.': if i == 0 { return "", rawurl, nil } case c == ':': if i == 0 { return "", "", errors.New("missing protocol scheme") } return rawurl[:i], rawurl[i+1:], nil default: // we have encountered an invalid character, // so there is no valid scheme return "", rawurl, nil } } return "", rawurl, nil }Goで正規表現をあつかう場合
Goの正規表現が遅いのは、Perl, Ruby, PythonなどがCのライブラリを利用しているのに対し、Goの標準ライブラリはC言語を排除して実装されていることが一因です。
基本的には、言語を抽象化するほど速度は犠牲になるので速度の面ではC言語が有利です。例えばGoから高速に正規表現マッチを利用したい場合、Perl経由でC言語のライブラリを扱えるものを利用するのも手です。様々な言語で正規表現のベンチマークをとったページを参考にすると、go-pcreを利用した正規表現は113個中21番目に位置しており、それほど悪い成績ではないことが分かります。
(それにしてもRustの成績が優秀なので、このあたりは別記事で深堀りしたい)
https://benchmarksgame-team.pages.debian.net/benchmarksgame/performance/regexredux.html
ただし、Goの正規表現はNFA(Nondeterministic finite automaton)を利用して作られています。これは、Perl, Ruby, Pythonなどで利用されている再帰的にバックトラッキングしていく方法
O(2^n)に比べ、Goで採用されているのは最悪のパターンのときでも比較的速度を担保(O(n^2))できます。
利用する正規表現によっては、Goの方が早くなることもあるので見極めが必要です。
まとめ
Go言語は、C言語のライブラリを利用している正規表現エンジンに比べて低速になりやすいです。
単純なパターンマッチしているかのチェックであれば、標準ライブラリで利用されている方法のように、文字列チェックして処理すると高速になります。Goの正規表現を責める前に、まずはprofileの分析を行い、本当にパフォーマンスがクリティカルな部分で正規表現が問題になっているのかをチェック → 問題になっていれば、今回確認したような標準ライブラリを参考にして実装してみるとよいと思います。
- 投稿日:2019-12-02T07:51:38+09:00
Homebrew Taps 自動更新で比べる CircleCI Orbs と GitHub Actions
自分は Go で CLI ツールを作って配ることが多く、それの配布には GitHub Actions と Homebrew の Taps repository を利用している。このリリース作業は結構面倒になので、極力自動化したい。
リリースの流派は「どこでやるか」「どのようにやるか」などの観点で、いろいろな考え方がある。
- WHERE
- 手元でコマンド一発でぜんぶやる派
git push --tagsから CI でやる派- HOW
- 全部入りツールでエイッてやる(e.g. GoReleaser)
- 「一つのことをうまくやる」ツールを組み合わせる(e.g. goxz + ghr + maltmil)
自分は「CI でやる」「ツールの組み合わせでやる」派。そして、このリリースフローを実現・再利用するため、 CircleCI Orbs と GitHub Actions それぞれに公開している。本記事では、これらの利用・実装コードから CircleCI と GitHub Actions を比べてみたい。
利用者目線
CircleCI Orbs
izumin5210/github-releases および izumin5210/homebrew で実現している。
Go で CLI ツールを書いたときは timakin/go-module や izumin5210/go-crossbuild を組み合わせて良い感じにやってる。version: 2.1 orbs: github-release: izumin5210/github-release@0.1.1 homebrew: izumin5210/homebrew@0.1.3 aliases: filter-release: &filter-release filters: branches: ignore: /.*/ tags: only: /^v\d+\.\d+\.\d+$/ executors: default: docker: - image: circleci/golang:1.13 workflows: build: jobs: # build something to release... - github-release/create: <<: *filter-release executor: default context: tool-releasing requires: - build - homebrew/update: <<: *filter-release executor: default context: tool-releasing requires: - github-release/create
CircleCI の良いところでも悪いところでもある、かなりしっかりした記述
- YAML の Anchor と Alias を活用すればちょっと見やすくなる
CircleCI の Contexts による、credentials の中央管理
- Organization に Context(この例では
tool-releasing)を作り、必要な環境変数をセットしておく
- 同一 Organization であれば Context を使い回せるので、トークン取得の手間などが減る
- 要するに、2つ目以降のリポジトリであれば YAML のコピペだけで(だいたい)動く
GitHub Actions
izumin5210/homebrew-tap と softprops/action-gh-release で実現する。
Go で CLI ツールを書いたときは izumin5210/action-go-crossbuild を組み合わせて良い感じにやってる。name: Release on: push jobs: build: runs-on: ubuntu-latest steps: # build something to release... - name: Create GitHub Release uses: softprops/action-gh-release@v1 with: files: './dist/*' if: startsWith(github.ref, 'refs/tags/') env: GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }} - name: Update Homebrew Formula uses: izumin5210/action-homebrew-tap@releases/v0 with: tap: izumin5210/homebrew token: ${{ secrets.GITHUB_TOKEN }} tap-token: ${{ secrets.TAP_GITHUB_TOKEN }} if: startsWith(github.ref, 'refs/tags/')
- すなおに上から読み下すことができる
secrets.GITHUB_TOKENが生えてくる
- GitHub Releases へのアップロードだけなら YAML のコピペだけで OK
実装者目線
CircleCI Orbs
先程の2つは https://github.com/izumin5210/orbs-for-tools でコードを公開している。ShellScript がある程度書けないと基本しんどい(CI の宿命か?)。
- 複雑なものを書くと、どんどん長くなっていく(そしてインデントがよくわからなくなってくる)
- だが、ファイルをまたぐと Anchor & Alias が効かなくなってしまう…
GitHub Actions
実装は izumin5210/action-homebrew-tap にある。 Orb と同じく maltmil をうまく使う形。
- (ShellScript でもかけるが、Docker コンテナで動かすことになる。pull のオーバーヘッドが意外とでかい…)
- TypeScript には型があるので事前に色々チェックできる
- push して動かしてはじめて変数名の typo に気づく… なんてことが起きない!ステキ!
- 型の恩恵が大きすぎて、 ShellScript にくらべ多少記述が長くなるとか気にならない
- GitHub API を叩きたければ @actions/github が使える!など
- actions/toolkit に便利パッケージが置いてある
- もちろん普通に npm に置いてある諸々が利用できる
- maltmil の安定版を GitHub Releases から落としてきて、展開して、パス通して…
- ShellScript だと 2〜3行なのに… みたいな気持ちになること多し
所感
- 利用者目線では…
- 正直、大した差異は無い
- 結局、他に何やるかによって向いている CI が変わりそう
- e.g.
- 大きい Matrix を組みたい場合は GitHub Actions のほうが簡潔に書ける
- 複雑なワークフローを組む場合は CircleCI のほうが依存グラフを記述しやすい
- CircleCI の Contexts はかなり強力なので、組織とかでは有効かも?
- 実装者目線では…
- TypeScript はもたらされる複雑製よりも型・静的解析の恩恵がかなり強いという印象
- 一方で、ポータビリティを考えると結局ワンバイナリで動くツールをつくって CI 上で使うのが最善かも
- 「CI が落ちてもリリースできる」状態にしたい
- となると、CircleCI のほうが Orb 作るのはラクかも?
- なんなら Orb すらいらなくて、
curl ... | tar xf - && sudo cp ...をベタ書きすればいい結局、こういう Custom step みたいなものは自分のために作ることが多いので、自分が利用者として CI に何を求めているかによってどちらを選択するのかが変わってくるはず。
- 投稿日:2019-12-02T01:09:38+09:00
初心者でも簡単に理解して実装できるDIP(依存性逆転の原則)
SOLID原則というオブジェクト指向設計原則があります。
S : The Single Responsibility Principle(単一責任の原則)
O : The Open Closed Principle(オープン・クローズドの原則)
L : The Liskov Substitution Principle(リスコフの置換原則)
I : The Interface Segregation Principle(インターフェース分離の原則)
D : The Dependency Inversion Principle(依存性逆転の原則)本記事ではDの依存性逆転の原則について説明します。まだあまり知識・経験がないという方でもDIPを理解し、GoでDIPを適用した実装までできるようにかなり細かく解説しています。説明・実装に使用する言語はGo言語です。オープン・クローズドの原則についての説明記事はこちら。
良い設計とは?
DIPについて説明しても、良いソフトウェアの設計とはどのようなものかについての理解がないと、「・・・、で?」となってしまうかもしれません。良い設計を知るために、どのエンジニアも共感する悪い設計について確認しましょう。
Rigidity(硬直性):
It is hard to change because every change affects too many other parts of the system.
少し変更しようとするだけでシステムの多くの部分に影響が出てしまうため変更することが難しい。
Fragility(変更への脆弱性):
When you make a change, unexpected parts of the system break.
変更を加えると、システムの予想外の部分が動かなくなる。
Immobility(低い移植性):
It is hard to reuse in another application because it cannot be disentangled from the current application.
現在使われているアプリケーションと強く結びついているため、他のアプリケーションで使い回すことが難しい。誰もが納得する良い設計とはつまりはこの逆、変更に柔軟で変更してもシステムが壊れることなく、使い回しが効く設計です。その設計を実現するためにDIPが役立ちます。
この前提知識を確認した上で、DIPの説明に入ります。DIP(依存性逆転の原則)とは?
まずは言葉による説明を見てみましょう。Wikipediaでの説明を一部抜粋します。さらっと目を通していただければ構いません。
A. 上位レベルのモジュールは下位レベルのモジュールに依存すべきではない。両方とも抽象(abstractions)に依存すべきである。
B. 抽象は詳細に依存してはならない。詳細が抽象に依存すべきである。DIPは、モジュール(レイヤー)間を疎結合に保つことで変更に強い柔軟なシステムを作るに役立ちます。それでは、以下にDIP適用前と適用後の実装例を示します。
DIP適用前の悪い実装
よくDIPのメリットを説明する例として使われるのが、データアクセス層とそれに依存する上位層の問題です。
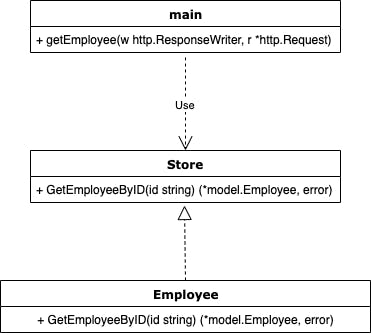
こちらの例では、DBに直接アクセスして社員情報を返すメソッドをハンドラが使用しています。main.goimport ( "encoding/json" "net/http" "github.com/masalennon/test/store" ) func main() { http.Handle("/employees/", http.StripPrefix("/employees/", http.HandlerFunc(getEmployee))) http.ListenAndServe(":8080", nil) } func getEmployee(w http.ResponseWriter, r *http.Request) { id := r.URL.Path employee, err := store.GetEmployeeByID(id) //詳細への依存がある if err != nil { panic(err) } json.NewEncoder(w).Encode(employee) }store/employee.gofunc GetEmployeeByID(id string) (*model.Employee, error) { var e model.Employee if err := db.GetDB().Where(&model.Employee{ID: id}).First(&e).Error; err != nil { return nil, nil } return &e, nil }DIP適用前の悪い実装図
この依存関係を示すと以下のようになるでしょう。
上位のモジュールが下位に依存するのは普通の依存関係です。しかし、ここで問題なのは、ハンドラ側のgetEmployeeメソッドはインフラストラクチャ層のGetEmployeeByIDを直接使用しているため、store/employee.goにあるGetEmployeeByIDに何らかの変更があった場合、もろに影響を受けてしまうということです。例えばgormの使用をやめるなどの変更があった場合、現状だとmain.goにある
getEmployeeにも変更を加えないといけません。main.gofunc getEmployee(w http.ResponseWriter, r *http.Request) { id := r.URL.Path employee, err := store.GetEmployeeByID(id) //依存があるこの部分にも変更の影響が及んでしまい改修が必要になる if err != nil { panic(err) } json.NewEncoder(w).Encode(employee) }これは先ほど紹介した悪い設計の一つであるRigidity(少し変更しようとするだけでシステムの多くの部分に影響が出てしまうため変更することが難しい。)に当てはまっていると言えるでしょう。
DIP適用後の実装
DIPはこのような問題を解決し、変更に柔軟で変更してもシステムが壊れることなく、使い回しが効く設計を可能にします。
DIP適用後の実装図
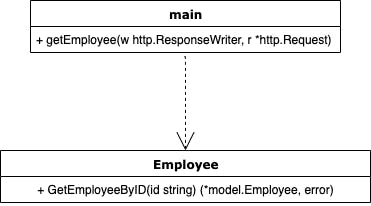
DIPを適用すると、先ほどのクラス図のようなものは次のようになります。
図ではデータアクセス層にあるEmployeeから矢印が伸びており、Employeeがインターフェースに逆に依存している格好となっています。DIP(依存性逆転の原則)というのはこれを指して命名されたようです。
この実装例ではハンドラ(
getEmployee)はGetEmployeeByIDを直接使う(依存する)のではなく、Storeというインターフェースに依存し、DBに直接アクセスするemployee.goはStoreインターフェースに依存させます。こうすることでgormを使っていようと使っていなかろうとDBがDynamoDBだろうとPostgresだろうとStoreインターフェースを満たしてやることで、簡単に交換可能になります。このように、インターフェースをはさむことでハンドラ側の
getEmployeeはデータアクセス層のGetEmployeeByIDの詳細がどうであろうと影響がなくなります。この状態をgetEmployeeはGetEmployeeByIDの詳細を知らないと表現することもあります。また、それだけでなく単体テストのためにモックを用意する時も、Storeインターフェースを満たすモックを用意すれば良いだけなので単体テストも簡単です。(ここら辺はクリーンアーキテクチャにも繋がってくる話ですが、この記事ではクリーンアーキテクチャまで話を広げず、DIPに留めておきたいと思います。)
DIP適用後の実装例 interface
上記の悪い例として説明した実装にDIPを適用するために、まずはinterfaceを用意します。
employee/employee.gopackage employee import ( "github.com/masalennon/DIP_sample/model" ) type Store interface { GetEmployeeByID(id string) (*model.Employee, error) }DIP適用後の実装例 データアクセス層
そうしたら、次はこのStoreインターフェースを満たすようにデータアクセス層を改修します。
store/employee_gorm.gotype EmployeeGormStore struct { db *gorm.DB } func NewEmployeeGormStore(db *gorm.DB) employee.Store { return &EmployeeStore{ db: db, } } func (es *EmployeeGormStore) GetEmployeeByID(id string) (*model.Employee, error) { var e model.Employee if err := es.db.Where(&model.Employee{ID: id}).First(&e).Error; err != nil { return nil, nil } return &e, nil }分かりにくいところ解説
少し長くなるので見やすくするために箇条書きで説明します。
1. EmployeeStore構造体を定義し、それにGetEmployeeByIDを定義してStoreインターフェースを満たします(Goはダックタイピングによってインターフェースを実装する)。
2.NewEmployeeGormStore(db *gorm.DB)はgormを使ってDBにアクセスすることを決定するために使います。(この例ではgormしか用意していないですが、例えばstore/employee_sql.goを用意して、gormを使わないNewEmployeeMysqlStore(Conn *sql.DB)にすることもできます。)
3.NewEmployeeGormStore(db *gorm.DB)ではemployee.StoreとしてStoreインターフェースを返すようにしています。GetEmployeeByIDを実装しているためEmployeeGormStoreがStoreインターフェースを満たしているので返り値にemployee.Storeを指定できます。そうすることで、このメソッドを呼び出す側でもStoreインターフェースという制約の中で使い回すことができるようになります。
4. なぜNewEmployeeGormStoreが必要になるかイメージが湧かないかもしれませんが、ひとまずその疑問は置いておいてください。
5.db *gorm.DBが構造体の中に入っていなくても動かせますが、入れておくことで同じdbインスタンスを使いまわせるので便利です。DIP適用後の実装例 ハンドラ側
ここまででこのクラス図の下半分の部分である、employeeがStoreの実現であるところを実装できました。ここからmain.goのハンドラ側で抽象に依存する部分を実装していきます。
DIPをハンドラ側に適用すると以下のようになるでしょう。main.gotype EmployeeHandler struct { es employee.Store } func NewEmployeeHandler(es employee.Store) *EmployeeHandler { return &EmployeeHandler{ es: es, } } func (h EmployeeHandler) getEmployee(w http.ResponseWriter, r *http.Request) { id := r.URL.Path employee, err := h.es.GetEmployeeByID(id) if err != nil { panic(err) } json.NewEncoder(w).Encode(employee) }分かりにくいところ解説
まず上記のコードを読んで分かりにくいところは、
getEmployeeの中でh.es.GetEmployeeByID(id)というようになっている部分- なぜ
EmployeeHandlerはes employee.Storeを持っているのか- そもそもなぜ
getEmployeeをEmployeeHandlerに定義しているのかというところだと思います。
まず、DIPを利用すると言っても結局データアクセス層のメソッドである
GetEmployeeByID(id)は当然ですが使用する必要があるのでgetEmployee内で使います。この時、上位層も抽象であるstore/employee.goにあるStoreインターフェースに依存するのだからemployee.Store.GetEmployeeByIDとなるのでは?と思うでしょうか。しかし、それでは一体
GetEmployeeByID(id)の実装はどれなのか、store/employee_gorm.goなのかstore/employee_mysql.goなのか見分けがつきません。そのため、内部にStoreインターフェース型の変数を持つ構造体(EmployeeHandler)を定義し、getEmployee(w http.ResponseWriter, r *http.Request)をその構造体に実装します。
こうすることで、その構造体を初期化する時に内部にStoreインターフェースを満たす実装クラス(構造体)の変数を持たせることが可能になります(この例ではNewEmployeeGormStore)。一見周りくどいかのように見えるかもしれないですが、柔軟にどのデータアクセス層の実装を使用するかを切り替えられます(その決定部分の説明は後述)。
今回はgormを使うので、NewEmployeeHandler(es employee.Store)の引数にEmployeeGormStore構造体を渡します。Storeインターフェースを引数として受け取るようにすることでStoreインターフェースを満たすものなら何でも引数に受けることができるという点で柔軟さを出すことができています。
ここにNewEmployeeGormStoreだったりNewEmployeeMySQLStoreを指定することでデータアクセスの方法が切り替えられます。ここまできたらもう後少しです。
main.gofunc main() { d := db.Init() es := store.NewEmployeeGormStore(d) h := NewEmployeeHandler(es) http.Handle("/employees/", http.StripPrefix("/employees/", http.HandlerFunc(h.getEmployee))) http.ListenAndServe(":8080", nil) }上記で説明したデータアクセスの方法を決定し、それをハンドラ側に共有し、ハンドラ側では内部的にそのデータアクセスの方法に基づいてデータにアクセスします。もしORMが嫌になりgormではなくsql文を使ってデータアクセスしたいとなっても、インターフェースからハンドラ側のコードには一切手を加える必要がありません。
インターフェースを満たすようにメソッドを定義したら、es := store.NewEmployeeGormStore(d)をes := store.NewEmployeeSQLStore(d)のように改修するだけで良いのです。「なぜ
NewEmployeeGormStoreが必要になるかイメージが湧かないかもしれませんが、ひとまずその疑問は置いておいてください。」と言いましたが、このように使います。DIP適用後では、冒頭で触れたRigidity(少し変更しようとするだけでシステムの多くの部分に影響が出てしまうため変更することが難しい。)という問題が解決されていることが分かると思います。
また、インターフェースを用意し抽象に依存することでFragility(変更への脆弱性):変更を加えると、システムの予想外の部分が動かなくなる。ということもなくなるでしょう。このように、インターフェースを用意し詳細ではなく抽象に依存することでより柔軟なシステムを構築することができます。それは良いことですが、コードの複雑性は増しますので、無条件でくまなくDIPを適用すれば良いというわけでもなく、そこは判断が必要になってくる部分です。しかし、アーキテクチャに関する知識はバックエンドエンジニアなら言語を問わず必要になってくると思うので、DIPを理解するためにここまで費やした時間は無駄ではなく、この知識を持っていて邪魔になることはないはずです。
サンプルコードはこちらに載せてあります。悪い例のコミットがありますので、そこからDIPを自力で適用してみるのも面白いでしょう。
この記事が何かのお役に立つことがあれば幸いです。最後までお読みいただきありがとうございました。
- 投稿日:2019-12-02T01:09:38+09:00
初心者でも理解して実装できるDIP(依存性逆転の原則)
SOLID原則というオブジェクト指向設計原則があります。
S : The Single Responsibility Principle(単一責任の原則)
O : The Open Closed Principle(オープン・クローズドの原則)
L : The Liskov Substitution Principle(リスコフの置換原則)
I : The Interface Segregation Principle(インターフェース分離の原則)
D : The Dependency Inversion Principle(依存性逆転の原則)本記事ではDの依存性逆転の原則について説明します。まだあまり知識・経験がないという方でもDIPを理解し、GoでDIPを適用した実装までできるようにかなり細かく解説しています。説明・実装に使用する言語はGo言語で、実装の説明が多いです。
オープン・クローズドの原則についての説明記事はこちら。良い設計とは?
DIPについて説明しても、良いソフトウェアの設計とはどのようなものかについての理解がないと、「・・・、で?」となってしまうかもしれません。良い設計を知るために、どのエンジニアも共感する悪い設計について確認しましょう。
Rigidity(硬直性):
It is hard to change because every change affects too many other parts of the system.
少し変更しようとするだけでシステムの多くの部分に影響が出てしまうため変更することが難しい。
Fragility(変更への脆弱性):
When you make a change, unexpected parts of the system break.
変更を加えると、システムの予想外の部分が動かなくなる。
Immobility(低い移植性):
It is hard to reuse in another application because it cannot be disentangled from the current application.
現在使われているアプリケーションと強く結びついているため、他のアプリケーションで使い回すことが難しい。誰もが納得する良い設計とはつまりはこの逆、変更に柔軟で変更してもシステムが壊れることなく、使い回しが効く設計です。その設計を実現するためにDIPが役立ちます。
この前提知識を確認した上で、DIPの説明に入ります。DIP(依存性逆転の原則)とは?
まずは言葉による説明を見てみましょう。Wikipediaでの説明を一部抜粋します。さらっと目を通していただければ構いません。
A. 上位レベルのモジュールは下位レベルのモジュールに依存すべきではない。両方とも抽象(abstractions)に依存すべきである。
B. 抽象は詳細に依存してはならない。詳細が抽象に依存すべきである。DIPは、モジュール(レイヤー)間を疎結合に保つことで変更に強い柔軟なシステムを作るに役立ちます。それでは、以下にDIP適用前と適用後の実装例を示します。
DIP適用前の悪い実装
よくDIPのメリットを説明する例として使われるのが、データアクセス層とそれに依存する上位層の問題です。
こちらの例では、DBに直接アクセスして社員情報を返すメソッドをハンドラが使用しています。*本記事での実装例ではORM(gorm)を使っているのでRDBMSをを変更してもデータアクセス層とインフラ層でのDBにアクセスするための定義は使い回しが効きますが、現実ではライブラリに依存したくない場合も往々にしてあります。
main.goimport ( "encoding/json" "net/http" "github.com/masalennon/test/store" ) func main() { http.Handle("/employees/", http.StripPrefix("/employees/", http.HandlerFunc(getEmployee))) http.ListenAndServe(":8080", nil) } func getEmployee(w http.ResponseWriter, r *http.Request) { id := r.URL.Path employee, err := store.GetEmployeeByID(id) //詳細への依存がある if err != nil { panic(err) } json.NewEncoder(w).Encode(employee) }store/employee.gofunc GetEmployeeByID(id string) (*model.Employee, error) { var e model.Employee if err := db.GetDB().Where(&model.Employee{ID: id}).First(&e).Error; err != nil { return nil, nil } return &e, nil }DIP適用前の悪い実装図
この依存関係を示すと以下のようになるでしょう。
上位のモジュールが下位に依存するのは普通の依存関係です。しかし、ここで問題なのは、ハンドラ側のgetEmployeeメソッドはインフラストラクチャ層のGetEmployeeByIDを直接使用しているため、store/employee.goにあるGetEmployeeByIDに何らかの変更があった場合、もろに影響を受けてしまうということです。例えばgormの使用をやめるなどの変更があった場合、現状だとmain.goにある
getEmployeeにも変更を加えないといけません。main.gofunc getEmployee(w http.ResponseWriter, r *http.Request) { id := r.URL.Path employee, err := store.GetEmployeeByID(id) //依存があるこの部分にも変更の影響が及んでしまい改修が必要になる if err != nil { panic(err) } json.NewEncoder(w).Encode(employee) }これは先ほど紹介した悪い設計の一つであるRigidity(少し変更しようとするだけでシステムの多くの部分に影響が出てしまうため変更することが難しい。)に当てはまっていると言えるでしょう。
DIP適用後の実装
DIPはこのような問題を解決し、変更に柔軟で変更してもシステムが壊れることなく、使い回しが効く設計を可能にします。
DIP適用後の実装図
DIPを適用すると、先ほどのクラス図のようなものは次のようになります。
図ではデータアクセス層にあるEmployeeから矢印が伸びており、Employeeがインターフェースに逆に依存している格好となっています。DIP(依存性逆転の原則)というのはこれを指して命名されたようです。
この実装例ではハンドラ(
getEmployee)はGetEmployeeByIDを直接使う(依存する)のではなく、Storeというインターフェースに依存し、DBに直接アクセスするemployee.goはStoreインターフェースに依存させます。こうすることでgormを使っていようと使っていなかろうとDBがDynamoDBだろうとPostgresだろうとStoreインターフェースを満たしてやることで、簡単に交換可能になります。このように、インターフェースをはさむことでハンドラ側の
getEmployeeはデータアクセス層のGetEmployeeByIDの詳細がどうであろうと影響がなくなります。この状態をgetEmployeeはGetEmployeeByIDの詳細を知らないと表現することもあります。また、それだけでなく単体テストのためにモックを用意する時も、Storeインターフェースを満たすモックを用意すれば良いだけなので単体テストも簡単です。(ここら辺はクリーンアーキテクチャにも繋がってくる話ですが、この記事ではクリーンアーキテクチャまで話を広げず、DIPに留めておきたいと思います。)
DIP適用後の実装例 interface
上記の悪い例として説明した実装にDIPを適用するために、まずはinterfaceを用意します。
employee/employee.gopackage employee import ( "github.com/masalennon/DIP_sample/model" ) type Store interface { GetEmployeeByID(id string) (*model.Employee, error) }DIP適用後の実装例 データアクセス層
そうしたら、次はこのStoreインターフェースを満たすようにデータアクセス層を改修します。
store/employee_gorm.gotype EmployeeGormStore struct { db *gorm.DB } func NewEmployeeGormStore(db *gorm.DB) employee.Store { return &EmployeeStore{ db: db, } } func (es *EmployeeGormStore) GetEmployeeByID(id string) (*model.Employee, error) { var e model.Employee if err := es.db.Where(&model.Employee{ID: id}).First(&e).Error; err != nil { return nil, nil } return &e, nil }分かりにくいところ解説
少し長くなるので見やすくするために箇条書きで説明します。
1. EmployeeStore構造体を定義し、それにGetEmployeeByIDを定義してStoreインターフェースを満たします(Goはダックタイピングによってインターフェースを実装する)。
2.NewEmployeeGormStore(db *gorm.DB)はgormを使ってDBにアクセスすることを決定するために使います。(この例ではgormしか用意していないですが、例えばstore/employee_sql.goを用意して、gormを使わないNewEmployeeMysqlStore(Conn *sql.DB)にすることもできます。)
3.NewEmployeeGormStore(db *gorm.DB)ではemployee.StoreとしてStoreインターフェースを返すようにしています。GetEmployeeByIDを実装しているためEmployeeGormStoreがStoreインターフェースを満たしているので返り値にemployee.Storeを指定できます。そうすることで、このメソッドを呼び出す側でもStoreインターフェースという制約の中で使い回すことができるようになります。
4. なぜNewEmployeeGormStoreが必要になるかイメージが湧かないかもしれませんが、ひとまずその疑問は置いておいてください。
5.db *gorm.DBが構造体の中に入っていなくても動かせますが、入れておくことで同じdbインスタンスを使いまわせるので便利です。DIP適用後の実装例 ハンドラ側
ここまででこのクラス図の下半分の部分である、employeeがStoreの実現であるところを実装できました。ここからmain.goのハンドラ側で抽象に依存する部分を実装していきます。
DIPをハンドラ側に適用すると以下のようになるでしょう。main.gotype EmployeeHandler struct { es employee.Store } func NewEmployeeHandler(es employee.Store) *EmployeeHandler { return &EmployeeHandler{ es: es, } } func (h EmployeeHandler) getEmployee(w http.ResponseWriter, r *http.Request) { id := r.URL.Path employee, err := h.es.GetEmployeeByID(id) if err != nil { panic(err) } json.NewEncoder(w).Encode(employee) }分かりにくいところ解説
まず上記のコードを読んで分かりにくいところは、
getEmployeeの中でh.es.GetEmployeeByID(id)というようになっている部分- なぜ
EmployeeHandlerはes employee.Storeを持っているのか- そもそもなぜ
getEmployeeをEmployeeHandlerに定義しているのかというところだと思います。
まず、DIPを利用すると言っても結局データアクセス層のメソッドである
GetEmployeeByID(id)は当然ですが使用する必要があるのでgetEmployee内で使います。この時、上位層も抽象であるstore/employee.goにあるStoreインターフェースに依存するのだからemployee.Store.GetEmployeeByIDとなるのでは?と思うでしょうか。しかし、それでは一体
GetEmployeeByID(id)の実装はどれなのか、store/employee_gorm.goなのかstore/employee_mysql.goなのか見分けがつきません。そのため、内部にStoreインターフェース型の変数を持つ構造体(EmployeeHandler)を定義し、getEmployee(w http.ResponseWriter, r *http.Request)をその構造体に実装します。
こうすることで、その構造体を初期化する時に内部にStoreインターフェースを満たす実装クラス(構造体)の変数を持たせることが可能になります(この例ではNewEmployeeGormStore)。一見周りくどいかのように見えるかもしれないですが、柔軟にどのデータアクセス層の実装を使用するかを切り替えられます(その決定部分の説明は後述)。
今回はgormを使うので、NewEmployeeHandler(es employee.Store)の引数にEmployeeGormStore構造体を渡します。Storeインターフェースを引数として受け取るようにすることでStoreインターフェースを満たすものなら何でも引数に受けることができるという点で柔軟さを出すことができています。
ここにNewEmployeeGormStoreだったりNewEmployeeMySQLStoreを指定することでデータアクセスの方法が切り替えられます。ここまできたらもう後少しです。
main.gofunc main() { d := db.Init() es := store.NewEmployeeGormStore(d) h := NewEmployeeHandler(es) http.Handle("/employees/", http.StripPrefix("/employees/", http.HandlerFunc(h.getEmployee))) http.ListenAndServe(":8080", nil) }上記で説明したデータアクセスの方法を決定し、それをハンドラ側に共有し、ハンドラ側では内部的にそのデータアクセスの方法に基づいてデータにアクセスします。もしORMが嫌になりgormではなくsql文を使ってデータアクセスしたいとなっても、インターフェースからハンドラ側のコードには一切手を加える必要がありません。
インターフェースを満たすようにメソッドを定義したら、es := store.NewEmployeeGormStore(d)をes := store.NewEmployeeSQLStore(d)のように改修するだけで良いのです。「なぜ
NewEmployeeGormStoreが必要になるかイメージが湧かないかもしれませんが、ひとまずその疑問は置いておいてください。」と言いましたが、このように使います。DIP適用後では、冒頭で触れたRigidity(少し変更しようとするだけでシステムの多くの部分に影響が出てしまうため変更することが難しい。)という問題が解決されていることが分かると思います。
また、インターフェースを用意し抽象に依存することでFragility(変更への脆弱性):変更を加えると、システムの予想外の部分が動かなくなる。ということもなくなるでしょう。このように、インターフェースを用意し詳細ではなく抽象に依存することでより柔軟なシステムを構築することができます。それは良いことですが、コードの複雑性は増しますので、無条件でくまなくDIPを適用すれば良いというわけでもなく、そこは判断が必要になってくる部分です。しかし、アーキテクチャに関する知識はバックエンドエンジニアなら言語を問わず必要になってくると思うので、DIPを理解するためにここまで費やした時間は無駄ではなく、この知識を持っていて邪魔になることはないはずです。
サンプルコードはこちらに載せてあります。悪い例のコミットがありますので、そこからDIPを自力で適用してみるのも面白いでしょう。
この記事が何かのお役に立つことがあれば幸いです。最後までお読みいただきありがとうございました。
- 投稿日:2019-12-02T00:56:42+09:00
Ubuntu18.04でLXD3.18をビルドからコンテナのデプロイまで
はじめに
このエントリーは,CyberAgent20新卒エンジニアAdvent Calendar 2019の2日目の記事です.
大学院の研究でLXDを取り扱っているので,LXDのビルドからコンテナのデプロイまでを紹介します.
興味があったら,ぜひやってみてください.目次
- CRIUのビルドとインストール
- LXCのビルドとインストール
- LXDのビルドとインストール
- LXD起動の準備とコンテナのデプロイ
1. CRIUのビルドとインストール
LXDのコンテナライブマイグレーションを行うためには,LinuxのプロセスマイグレーションツールであるCRIUが必要です.そのため,CRIUのビルドとインストールを行います.
CRIUのビルド準備(必要なパッケージのインストールとソースコードの取得)
ここはほとんど,公式ページの「Installing build dependencies」情報とおりです.
何行かに分かれていたり,私の環境では足りなかったりするパッケージがあったりと面倒なので,全部インストールするコマンドを記載します
sudo apt install make gcc libprotobuf-dev libprotobuf-c0-dev \ protobuf-c-compiler protobuf-compiler python-protobuf \ pkg-config python-ipaddress libbsd-dev iproute2 libcap-dev libnl-3-dev \ libnet-dev libaio-dev asciidoc続いて,ソースコードを取得します.GitHubからCloneするので,gitがない場合はインストールしてください.
ソースコードはこのリポジトリから取得できます.ビルドとインストール
ビルドとインストールも公式ページの「Building the tool」,「Installing」のとおりです.
ただ,criuリポジトリのデフォルトブランチでは動作が不安なので,リリースを確認して直近のタグにチェックアウトしてからビルドすることをおすすめします.ここでは3.13とします.make sudo make install正常にビルドされインストールも完了したことを確認するため,以下のコマンドを実行します.
CRIUのバージョンやgitのcommit id等の情報が表示されれば,ひとまず安心です.sudo criu --version2. LXCのビルドとインストール
LXDは内部でLXCをコンテナランタイムとして利用することで,コンテナの作成や削除を行っています.そのため,LXCのビルドとインストールを行います.
LXCのビルド準備(必要なパッケージのインストールとソースコードの取得)
LXCのビルドには,いくつかのビルドツールが必要なのでそれらをインストールします.それぞれのパッケージについては詳しく説明しません(私も理解していないため).
sudo apt install libtool automake docbook m4続いて,ソースコードの取得です.
このリポジトリからソースコードをクローンします.CRIUと同様にデフォルトのブランチでは動作が不安なため,直近のリリースタグにチェックアウトしておくと安心です.ここでは,3.1.0とします.ビルドとインストール
このリポジトリのREADMEにかかれているとおりです.以下のコマンドを実行しましょう.
./autogen.sh #configureの生成 ./configure #Makefileの生成 make #ビルド sudo make install #インストール3. LXDのビルドとインストール
ようやくLXDのビルドとインストールを行います.
LXDのビルド準備(必要なパッケージのインストールとソースコードの取得)
必要なパッケージはこのリポジトリのREADMEに記述されていますが,lxcのライブラリに関してはビルドしたライブラリを利用するため,インストールしません.ここでGo言語もインストールされています.
sudo apt install acl autoconf dnsmasq-base \ git golang libacl1-dev libcap-dev \ libtool libuv1-dev make pkg-config rsync squashfs-tools \ tar tcl xz-utils ebtables #liblxc1 liblxc-dev これらはインストールしないセキュリティに係るパッケージをインストールします.
sudo apt install libapparmor-dev libseccomp-dev libcap-devLXDのストレージ用パッケージをインストールします
sudo apt install lvm2 thin-provisioning-tools btrfs-toolsテスト用パッケージをインストールします.(LXDの開発者でなければ必要ないでしょう)
sudo apt install curl gettext jq sqlite3 uuid-runtime bzr socat続いて,ソースコードの取得を行います.LXDはGo言語で実装されているので,Goのお作法でソースコードを取得するのが良いです.
go get github.com/lxc/lxd依存ライブラリのビルド
まずは,依存するライブラリのビルドです.
その前に,やはりデフォルトのブランチでは動作が不安なため,直近のリリースタグにチェックアウトします.ここでは,3.18とします.
go getで取得したソースコードは${GOPATH}/src/github.com/lxc/lxdにあります.make depsエラーなくライブラリのビルドが終了すると,以下のような情報が表示されるはずです.
export CGO_CFLAGS="${CGO_CFLAGS} -I${GOPATH}/deps/sqlite/ -I${GOPATH}/deps/dqlite/include/ -I${GOPATH}/deps/raft/include/ -I${GOPATH}/deps/libco/" export CGO_LDFLAGS="${CGO_LDFLAGS} -L${GOPATH}/deps/sqlite/.libs/ -L${GOPATH}/deps/dqlite/.libs/ -L${GOPATH}/deps/raft/.libs -L${GOPATH}/deps/libco/" export LD_LIBRARY_PATH="${GOPATH}/deps/sqlite/.libs/:${GOPATH}/deps/dqlite/.libs/:${GOPATH}/deps/raft/.libs:${GOPATH}/deps/libco/:${LD_LIBRARY_PATH}"ビルドしたライブラリをOSに共有ライブラリとして登録する
CGO_CFLAGSとCGO_LDFLAGSはそのまま,
.bashrcなどに記述すればよいのですが,LD_LIBRARY_PATHに関しては少し工夫が必要です.後の話なのですが,ビルドしたLXDのバイナリはsudoで実行する必要があります.そのため,そのままLD_LIBRARY_PATHを
.bashrcに記述するとsudoで実行する場合,ビルドしたライブラリが見えません.この問題を解決するため,共有ライブラリとしてOSに登録する必要があります.
Ubuntu18.04の場合,
/ld.so.conf.d/配下にライブラリが配置されているパスが記述されている設定ファイルを配置することで,そのパスを見て共有ライブラリを登録してくれます.そのため,以下のファイルを作成します.
${GOPATH}の部分は,環境に合わせて変更された内容が依存ライブラリビルド時に表示されているはずなので,その内容と読み替えてください./ld/so.conf.d/lxd-lib.conf${GOPATH}/deps/sqlite/.libs/ ${GOPATH}/deps/dqlite/.libs/ ${GOPATH}/deps/raft/.libs ${GOPATH}/deps/libco/追加した設定ファイルの内容をOSに知らせるために,以下のコマンドを実行します.
sudo ldconfigLXDのビルドとインストール
続いて,LXD本体のビルドを行います.ビルドはとっても簡単です.
makeビルドが正常に終了した場合,${GOPATH}/bin配下に
lxdとlxcというバイナリが配置されているはずです.
そのため,特にインストール操作はありません.LXDビルドのトラブルシューティング(go-dqliteのエラー対処)
簡単なはずなのですが,私の環境ではLXDが利用するGo言語のパッケージである
go-dqliteでエラーが発生しました.そのエラーは以下です.use of internal package not allowedこれは,LXDが利用しているパッケージが
github.com/CanonicalLtd/go-dqliteであるにも関わらず,そのgithub.com/CanonicalLtd/go-dqliteはgithub.com/canonical/go-dqliteというパッケージの複製なので,ソースコード内のimport分が以下の様になってしまっていることが原因です.import ( github.com/canonical/go-dqlite/internal/bindings //本当は github.com/CanonicalLtd/go-dqlite/internal/bindings であるべき )なので,この様な状態になってしまっているファイルをすべて修正します.
具体的には,github.com/canonical/go-dqliteになっている部分をgithub.com/CanonicalLtd/go-dqliteに変更します.これで,上記のエラーは解消できました.
4. LXD起動の準備とコンテナのデプロイ
LXD起動の準備をします.
subuid/subgidの設定
ここに記述されている通り,LXDでコンテナのデプロイをするためには,以下の操作が必要です.
echo "root:1000000:65536" | sudo tee -a /etc/subuid /etc/subgidlxdグループの作成と,ユーザの追加
sudoなしでコマンドを実行できるようにします.
まず,以下のコマンドでlxdグループを作成します.sudo groupadd lxdその後,以下のコマンドでlxdを操作したいユーザをlxdに追加します.
sudo usermod -aG lxd $USERLXDの実行と初期化
まず以下のコマンドで,LXDを起動します.
--group オプションではsudoなしでlxcコマンドを実行できるようにするgroupを指定します.
logfileオプションは,ログを吐き出す場所を指定します.sudo $GOPATH/bin/lxd --group lxd --logfile=/var/log/lxd/lxd.log一度実行が確認できたら,systemdに自動起動してもらうようにします.
以下のserviceファイルを/lib/systemd/system配下に作成します./lib/systemd/system/lxd.service[Unit] Description=LXD - main daemon [Service] ExecStart=/home/yota/go/bin/lxd --debug --group lxd --logfile=/var/log/lxd/lxd.log [Install] WantedBy=multi-user.target続いて,以下のコマンドでLXDの設定を初期化します.
LXDをお好みに設定してください.
ただし,外部公開は必ずしてください.sudo $GOPATH/bin/lxd init参考までに,私はこの様な感じです
Would you like to use LXD clustering? (yes/no) [default=no]: Do you want to configure a new storage pool? (yes/no) [default=yes]: yes Name of the new storage pool [default=default]: Name of the storage backend to use (btrfs, dir, lvm) [default=btrfs]: Create a new BTRFS pool? (yes/no) [default=yes]: Would you like to use an existing block device? (yes/no) [default=no]: Size in GB of the new loop device (1GB minimum) [default=100GB]: Would you like to connect to a MAAS server? (yes/no) [default=no]: Would you like to create a new local network bridge? (yes/no) [default=yes]: What should the new bridge be called? [default=lxdbr0]: What IPv4 address should be used? (CIDR subnet notation, “auto” or “none”) [default=auto]: What IPv6 address should be used? (CIDR subnet notation, “auto” or “none”) [default=auto]: Would you like LXD to be available over the network? (yes/no) [default=no]: yes Address to bind LXD to (not including port) [default=all]: Port to bind LXD to [default=8443]: Trust password for new clients: Again: Would you like stale cached images to be updated automatically? (yes/no) [default=yes] Would you like a YAML "lxd init" preseed to be printed? (yes/no) [default=no]: yesコンテナのデプロイ
以下のコマンドで軽量なalpineイメージでコンテナをデプロイします.
sudo $GOPATH/bin/lxc launch images:alpine/3.9 hoge # hogeはコンテナの名前コマンドの実行
以下のコマンドで起動したコンテナのashに入って色々操作できます.
lxc exec hoge /bin/ashおわりに
いかがでしょうか?
Docker以外のコンテナランタイム使ってみたいなと思った方はぜひLXD使ってみてください.