- 投稿日:2019-12-02T23:54:53+09:00
誤り検出方法 checksumについて
ブロックチェーン関連の実装を行なっていた際に、チェックサムで引っかかり「アドレスがinvalidです」と表示されることがあった。その際に、「チェックサムって誤り検出のやつだよな?仕組み知らないわ」となったので、少し調べて簡易的に実装してみた。
チャックサムとは?
チャックサムとは、データの信頼性を検査するための算出した値のことを言う。この値を元に、データが適切なものであるかを調べることができる
非常に単純な誤り検出方法の1つで、誤り検出の精度は低いが原理が簡単で容易に実装でき、計算コストも低いため、簡単な誤り検出方法として広く普及している
データの誤り検出の方法としてハッシュ関数を利用する方法もあるが、誤り検出のために送信する必要のあるデータのサイズが大きく、処理負荷が大きい。しかし、誤り検出の信頼性はチャックサムを利用する場合よりも高い。
チェックサムの求め方
チャックサムの求め方については、様々な手法があるが簡単な方法としては、データ列を整数値の列としてみなし和を求め、これをある定数で割った余りを検査用データとするものがある。
チャックサムの計算の例
[0xc0 0xA8 0xFF 0x58]から1バイトのチェックサムを算出するのは、
0xc0+0xA8 +0xFF+0x58 = 0x2BFを求め、0x100で割った余りの0xBFがチャックサムになるデータのサイズが大きい場合は、一定の大きさごとに区切ってチャックサムを算出付加する方法が利用される
チャックサムを利用した誤り検知の実装
文字列に関してチェックサムを利用したデータの作成の関数と、誤り検出を行う関数を簡易的に実装した。
チャックサムを付加したデータを作る関数
文字列を整数値に変換して、その和を100で割ったものをチャックサムにし、データに付加して送信用のデータを作成する関数
def make_data(raw_data) checksum = 0 raw_data.unpack("C*").each do |byte| checksum += byte end return raw_data.unpack("C*").push(checksum / 100) end付加されたチェックサムを確認する関数
受信したデータのチャックサムを確認し、適正なデータであれば表示し、データが破損していれば、その旨を表示する関数
def check_data(data) sent_checksum = data.pop checksum = 0 data.each do |byte| checksum += byte end return sent_checksum == checksum / 100 end def show_data(hex_data) data = "" if(check_data(hex_data)) then hex_data.each do |byte| data += byte.chr end p data + ":データは破損していません" else p "データが破損しています" end end利用例
raw_data = "Hello" send_data = make_data(raw_data) show_data(send_data) // => "Hello:データは破損していません" raw_data = "Hello" send_data = make_data(raw_data) send_data[1] = 0 //通信経路で意図的にデータを書き換える show_data(send_data) // =>"データが破損しています"今回の例では、利用できるchecksumは0から99の100通りである。そのため、通信経路で改ざんや破損があった際に、必ず検出することができるとは限らない。和を割る数を100から大きいものにすれば、誤りを検出できる確率は高くなるが、検出に必要なデータサイズが大きくなってしまう。そうなってしまうと、データのハッシュ値を利用する方がより信頼性の高い誤り検出ができる。あくまで簡易的な誤り検出であることがわかった。
また、アルゴリズム的にもチャックサムを用いる方法では矛盾が生じないような改ざんも行うことができる。これに対して、ハッシュ関数では基本的にこのようなことを行うことができない。まとめ
個人的に気になったことを簡単にまとめた。誤り検出に関しての知識がほとんどないので、これを機に理解を深めたい。
- 投稿日:2019-12-02T23:54:53+09:00
誤り検出方法 Checksumについて
ブロックチェーン関連の実装を行なっていた際に、チェックサムで引っかかり「アドレスがinvalidです」と表示されることがあった。その際に、「チェックサムって誤り検出のやつだよな?仕組み知らないわ」となったので、少し調べて簡易的に実装してみた。
チャックサムとは?
チャックサムとは、データの信頼性を検査するための算出した値のことを言う。この値を元に、データが適切なものであるかを調べることができる
非常に単純な誤り検出方法の1つで、誤り検出の精度は低いが原理が簡単で容易に実装でき、計算コストも低いため、簡単な誤り検出方法として広く普及している
データの誤り検出の方法としてハッシュ関数を利用する方法もあるが、誤り検出のために送信する必要のあるデータのサイズが大きく、処理負荷が大きい。しかし、誤り検出の信頼性はチャックサムを利用する場合よりも高い。
チェックサムの求め方
チャックサムの求め方については、様々な手法があるが簡単な方法としては、データ列を整数値の列としてみなし和を求め、これをある定数で割った余りを検査用データとするものがある。
チャックサムの計算の例
[0xc0 0xA8 0xFF 0x58]から1バイトのチェックサムを算出するのは、
0xc0+0xA8 +0xFF+0x58 = 0x2BFを求め、0x100で割った余りの0xBFがチャックサムになるデータのサイズが大きい場合は、一定の大きさごとに区切ってチャックサムを算出付加する方法が利用される
チャックサムを利用した誤り検知の実装
文字列に関してチェックサムを利用したデータの作成の関数と、誤り検出を行う関数を簡易的に実装した。
チャックサムを付加したデータを作る関数
文字列を整数値に変換して、その和を100で割ったものをチャックサムにし、データに付加して送信用のデータを作成する関数
def make_data(raw_data) checksum = 0 raw_data.unpack("C*").each do |byte| checksum += byte end return raw_data.unpack("C*").push(checksum / 100) end付加されたチェックサムを確認する関数
受信したデータのチャックサムを確認し、適正なデータであれば表示し、データが破損していれば、その旨を表示する関数
def check_data(data) sent_checksum = data.pop checksum = 0 data.each do |byte| checksum += byte end return sent_checksum == checksum / 100 end def show_data(hex_data) data = "" if(check_data(hex_data)) then hex_data.each do |byte| data += byte.chr end p data + ":データは破損していません" else p "データが破損しています" end end利用例
raw_data = "Hello" send_data = make_data(raw_data) show_data(send_data) // => "Hello:データは破損していません" raw_data = "Hello" send_data = make_data(raw_data) send_data[1] = 0 //通信経路で意図的にデータを書き換える show_data(send_data) // =>"データが破損しています"今回の例では、利用できるchecksumは0から99の100通りである。そのため、通信経路で改ざんや破損があった際に、必ず検出することができるとは限らない。和を割る数を100から大きいものにすれば、誤りを検出できる確率は高くなるが、検出に必要なデータサイズが大きくなってしまう。そうなってしまうと、データのハッシュ値を利用する方がより信頼性の高い誤り検出ができる。あくまで簡易的な誤り検出であることがわかった。
また、アルゴリズム的にもチャックサムを用いる方法では矛盾が生じないような改ざんも行うことができる。これに対して、ハッシュ関数では基本的にこのようなことを行うことができない。まとめ
個人的に気になったことを簡単にまとめた。誤り検出に関しての知識がほとんどないので、これを機に理解を深めたい。
- 投稿日:2019-12-02T23:35:46+09:00
Capybaraで壊れにくいテストを書くために気を付けていること
この記事はSmartHR Advent Calendar 2019 2日目の記事です。
SmartHRではRuby on Railsを広く採用しています。アプリケーションを長期的にメンテナンスしていくためにテストは欠かせません。特にReact.jsなどを用いた複雑なUIにおいては、単なるAPIのテストやモデルのテストだけではなく「実際にブラウザを操作して、ユーザーが期待する結果を得られるかどうか」をテストすることが重要です。
Rubyではこのようなブラウザを操作するテストを書くために、Capybaraという便利なフレームワークがあり、比較的簡単にテストを書き始めることができます。ただ、この手のテストは保守が大変であったり、手間の大きさからテストが追加されなくなったり、ということがよくあります。本記事では、私がこれまでの経験から学んだ、壊れにくいテストを書くためのTipsを紹介します。
なお、特に説明のない限り、ここではCapybara + RSpec + Selenium + Chrome (Headless)の環境を想定しています。
sleepしない出オチっぽいですが、非常に重要です。非同期なリクエストの結果を待っているときや、時間差でレンダリングされる画面など「いい感じに少し待って」と言いたくなる状況は確かにあります。
そういった場合に、単に
sleep 5などとしてしまうと
- テストを実行する環境によって適切な待ち時間が異なるため、落ちたり落ちなかったりするテストが生まれやすい
- テストが落ちたときに、適当に待ち時間を伸ばされることが多く、テストの実行時間が伸びがち
などの問題があります。このような場合では、何を待っているかを短いスパンで定期的にタイムアウトまで待つようなヘルパーメソッドを定義して、それを利用するようにしましょう。
it "何かのアクションの結果、Successメッセージが帰ってくる" do click_button "何かのアクション" finally do expect(page).to have_content "Success!" end end def finally(timeout: Capybara.default_max_wait_time) start = Time.now begin yield return rescue RSpec::Expectations::ExpectationNotMetError, Capybara::ElementNotFound raise if Time.now > start + timeout sleep 0.1 retry end endXPathやclassに依存しない
Capybaraでは
have_buttonやfill_inなど基本的なHTMLの要素に対するヘルパーが定義されているため、素直な画面に対しては比較的読みやすいテストを書くことができます。しかし、現実には画面が複雑な構造になっていることが多く、これらのヘルパーだけでは力不足であることはよくあります。そういったときに、XPathやclassに依存したテストを書いてしまうこともきっとよくあるでしょう。
find('form active-form button').click expect(page).to have_xpath '//*[@id="form"]/div[2]'しかし、これでは後からテストだけ見たときに、何をテストしているのかわからなくなってしまいます。例えば、あなたが画面を大幅に弄った後に、「よーし、テスト直すかー」とこのテストを見たら... きっとこのテストごと消えてしまうことになるでしょう。
このような悲劇を産まないためにも、テストは後から読めるように、XPathやclassに依存しないことをおすすめしています。とはいえ、素直にヘルパーが利用できない画面というのは当然ありますから、話はそんな簡単ではありません。こういった場合にはデータ属性を利用し、さらにそれを指定するヘルパーメソッドを生やすと良い感じになります。
click_form_button expect_to_have_error_messagedef click_form_button find(spec_selector('active-form-button')).click end def expect_to_have_error_message expect(page).to have spec_selector('active-form-error-message') end def spec_selector(name) "[data-spec='#{name}']" endデータ属性は他の用途に利用されることがなく、自由に目印をつけられるので、テストを見たときに何を指しているかわかりやすく、HTML側の編集時にも目を引く良い方法です。適切な単位でデータ属性を割り当てていれば「なぜかわからないけどdivをひとつズラしたらテストが通らなくなった」といった問題も起きにくくなるでしょう。
withinを活用するこの記事をテストすると仮定して、「本文の書き出しに"Capybara"というリンクが含まれていること」をテストするとします。
expect(page).to have_link "Capybara", href: "https://github.com/teamcapybara/capybara"これでもテストは通りますが、これでは「本文の書き出しの中に」という重要な条件が抜けてしまっています。例えば、末尾の参考文献に"Capybara"を含むリンクを追加した途端、本当にテストしたかった書き出しのリンクが消えても、テストが通る状態になってしまいます。
他にも「保存」ボタンをクリックしたい状況があるとして、同じ画面中にいくつも「保存」ボタンがあると、単に
click_button "保存"では、Ambiguous matchを引き起こしてしまいます。match: :firstやallしてアクセスする方法もありますが、あまり良い方法ではありませんよね。click_button "保存", match: :first # firstって何? all('button', text: "保存")[1].click # うーん...こういった場合では、
withinによるスコープの絞り込みが役に立ちます。it "書き出しにリンクが含まれる" do within_introduction do expect(page).to have_link "Capybara", href: "https://github.com/teamcapybara/capybara" end end it "ヘッダーの保存ボタンをクリック" do within_header do click_button "保存" end end def within_introduction within(spec_selector("introduction")) { yield } end def within_header within(spec_selector("header")) { yield } endデータ属性を使ったヘルパーメソッドの定義と合わせると、随分と読みやすく感じるはずです。
ユーザーの目に見えないもの(気にしないもの)をテストしない
これは書き方というか、心構えの問題だと思うのですが、基本的にデータベースの中身だったり、DOMの構造など「ユーザーが意識しないもの」はテストするべきではない、と考えています。例えば、こんなテストです。
visit edit_user_path(user) fill_in "名前", with: "新しい名前" click_button "保存" expect(user).to have_attribute(name: "新しい名前")もちろん、こういったテストを書かざるを得ない状況というのもあると思うのですが、可能な限りユーザーの体験をテストしたいので、ユーザーが知ることができないデータベースの値をテストするのは望ましくないでしょう。実際にユーザーが更新済みの値を見ることができる画面でテストするべきです。
visit edit_user_path(user) fill_in "名前", with: "新しい名前" click_button "保存" expect(page).to have_current_path user_path(user) expect(page).to have_content "新しい名前"ボタンクリックなどの操作も同様です。ユーザーは「divタグの3番目の中のボタンをクリックするぞ!」とクリックすることはありませんよね。
withinなどと組み合わせて「新着メニューの中にあるボタンをクリックする」というように表現すると、後から見た時に読みやすくなります。# Bad all('button', text: "詳細")[2].click # Good within_new_menu do click_button "詳細" endブラウザのサイズを大きくする
当たり前のことだからしれませんが、あまり言及されている印象がないので書いておきます。ブラウザのサイズは大きければ大きいほどいいです。
Capybara.register_driver(:chrome_headless) do |app| options = Selenium::WebDriver::Chrome::Options.new(args: [ "window-size=3000,3000", "headless", "disable-gpu", ]) Capybara::Selenium::Driver.new(app, browser: chrome, options: options) endブラウザのサイズが小さい場合、別の要素が被ってくることによって、テストが落ちるなどの問題が起きることがあります。もちろん、ブラウザサイズが小さい画面でテストをしたい状況もあるので、必ずしもこの手が使えるわけではないのですが、特に理由がないならば、ある程度大きく設定しておくことをおすすめします。
簡単にブラウザを起動できる環境を用意する
CIでテストを回すことを考えると、ヘッドレスモードでChromeを動かすことになると思いますが、開発中やテストを書いている段階では、実際にブラウザが立ち上がって操作しているところを見れる方がテンションもあがりますし、問題を特定しやすくなります。
個人的には、環境変数でdriverを簡単に切り替えられるようにしておくと、さっとブラウザを起動してテストが落ちた原因を探ることができるので便利です。
Capybara.configure do config.default_driver = ENV['FOREGROUND'] ? :chrome : :chrome_headless endおわりに
ブラウザを操作するテストはコストが高く、メンテが難しい、という意見をよく聞きますが、個人的にはコツを抑えて書けば、もっとうまくできるのではないかと思っています。
SmartHRもまだ十分と言える状況ではありませんが、QAチームとも協力しながら、うまくテストを増やしていきたいところです。
- 投稿日:2019-12-02T23:35:16+09:00
【ruby】エイリアスメソッドの生成/メソッドの削除 /クラスのネスト
エイリアスメソッドの定義
独自に作成したクラスもエイリアスメソッドを定義することができる。
alias 新しいメソッド名 既存メソッド名とすればokclass User def hello 'hello' end alias greeting hello end user = User.new p user.hello p user.greetingメソッドの削除
undef 削除したいメソッド名とする
objectクラスに定義されたfreezeメソッドを削除するclass User undef freeze end user = User.new p user.freeze #=> Traceback (most recent call last): test2.rb:7:in `<main>': undefined method `freeze' for #<User:0x00007fcb77059f70> (NoMethodError)ネストしたクラスの定義
クラスの内部に定義したクラスは次のようにして参照できる
外側のクラス::内側のクラスclass User class BloodType attr_reader :type def initialize(type) @type=type end end end blood_type = User::BloodType.new('B') p blood_type.type #=>B演算子の挙動を独自に再定義する
rubyでは=で終わるメソッドを定義できる
=で終わるメソッドは変数に代入するような形式ででそのメソッドを呼ぶことができるclass User #=で終わるメソッドを定義する def name=(value) @name=value end end user=User.new #変数を代入するような形でname=メソッドを呼び出せる p user.name="Alice" #=> "Alice"==を再定義する
次のようなコードがあったとする
rb:
a=Product.new('A-0001','A GREAT MOVIE')
b=Product.new('B-0001','A AWSOME MOVIE')
c=Product.new('A-0001','A GREAT MOVIE')
同じ商品コードであれば同じ商品であると判別したい
こうなってほしいa == b #=> false a == c #=> trueしかしどちらも結果はfalseになります。
なぜならスーパークラスのobjectクラスでは==はobject_idが一致したときにtrueを返す。
なにもしないとこうなるa==b #=> false a==c #=> false本当は次のようになってほしい
rb:
a==b #=> false
a==c #=> true
Productクラスでオーバーライドする
class Product attr_reader :code, :name def initialize(code, name) @code=code @name=name end def ==(other) if other.is_a?(Product) #商品コードが一致したら同じProductと見直す code == other.code else #otherがProductでなければ常にfalse false end end end a=Product.new('A0001','Agreatmovie') b=Product.new('B0001','Anawesomefilm') c=Product.new('A0001','Agreatmovie') p a == b p a == c
- 投稿日:2019-12-02T23:29:43+09:00
C++で作るRuby拡張
はじめに
この記事はRuby Advent Calendar 2019の8日目の記事です。
C++でのRuby拡張実装について、つらつらと書いている記事になります。
内容としてはTataraというRubyで型を使えるライブラリを作ってみたで紹介した自作Ruby拡張を作るにあたって得たC++でのRuby拡張実装知見の記事になります。
Ruby拡張って?
皆さんが普段使っているRuby(ここではCRubyのことです)はCによって実装されています。ですので、Cを使ってRubyの拡張機能を作成することもできます。
つまり、Cで既に作成されているライブラリなどをRuby拡張として作成することができるというメリットがあります。CでRuby拡張を実装した場合、Rubyで実装するよりも高速に処理できるケースもあるようです。
実際にCで拡張機能が実装されているgemとしてはsqlite3やmysql2などがあります。
またRustやC++でRubyの拡張機能を作成するケースもあります。
例えば最近面白いなぁと思ったのはRustでのRuby拡張を実装できるHelixですね。Rustを使うことでCやC++よりも安全にRuby拡張を書くことができます。
また実装コード自体もかなり読みやすく以下のようなコードでクラスとメソッドを実装できます(※ HelixのREADMEより引用)。
ruby! { class Console { def log(string: String) { println!("LOG: {}", string); } } }ただHelix公式のチュートリアルではRails向けに拡張機能を実装する内容になっています。そのためRuby向けの拡張を作成する際のドキュメントがあまりなく、少し辛いところがあります。
実際にHelixでRuby拡張を作成しているものとしては以下の記事などがあります。
ref: RubyからRustを呼び出すいくつかの方法のまとめ - Qiita
ref: Rustでgemを書く際のハマりどころ in 2017
ref: Writing Ruby gems with Rust and Helix
またC++ではRiceやExt++などのRuby拡張を実装できるライブラリも存在しています。
RubyKaigi 2017ではImprove extension API: C++ as better language for extensionにてC++でのRuby拡張実装について紹介されています。
興味のある方はそちらも確認してみると良いでしょう。
今回はC++でのRuby拡張の実装方法について解説します。具体的にはRiceやExt++、C++のみでの実装方法などを解説していきます。
つくるもの
今回は、
Helloというクラスを作成し、Hello Ruby Extension!と画面に表示するsayというメソッドを実装します。具体的には以下のようなコードが実行できるRuby拡張を実装していきます。
require 'hello' Hello.new.say # => "Hello Ruby Extension!"今回はRice、Ext++、C++でそれぞれ実装していきます。
今回の記事作成にあたって各ライブラリでの実装サンプルをGitHubに上げておきました。興味のある方はこちらも見ると良いかも。
S-H-GAMELINKS/RubyAdventCalendarExtensionSample
実装
Riceでの実装
Riceとは?
Riceとは、C++を使ってRuby拡張を簡単に作成できるライブラリになります。
RiceはgemとしてRubyGemsからインストールすることができます。
gem install riceこれでRiceが使えるようになります!
ちなみに、実際にRiceを使ったサンプルコードは以下のようになります。
#include <iostream> #include <rice/Data_Type.hpp> #include <rice/Constructor.hpp> using namespace Rice; class Hello { public: Hello() {}; void say() { std::cout << "Hello Ruby Extension!" << std::endl; }; }; extern "C" { void Init_hello() { Data_Type<Hello> rb_cHello = define_class<Hello>("Hello") .define_constructor(Constructor<Hello>()) .define_method("say", &Hello::say); } }このようにRiceを使う場合、非常に簡単にRuby拡張を作ることができます。
またC++のテンプレートなどを使って以下のようなコードを書くこともできます。
template <class T> class CppArray { public: CppArray<T>() {}; }; Data_Type<CppArray<int>> rb_cIntArray = define_class<CppArray<int>>("IntArray") .define_constructor(Constructor<CppArray<int>>());Riceを使うメリットととしては、非常に簡単にC++でのRuby拡張を作ることができる点ですね。C++のライブラリなどをRubyで使えるようにするラッパーなどは、Riceを使って実装するといいかもしれません。
デメリットとしては、日本語のドキュメントもあまりないことと、開発自体があまり活発でない印象があることですね。
日本語で書かれた記事はあまり(Rice以外での実装とかはあったりする)なく、IBMのRice を使用して Ruby の拡張機能を C++ で作成するが日本語で唯一詳しく書かれたRiceのチュートリアルになりそうです、
英語が読める方であれば、こちらのドキュメントを読み解けばよいかと思います。
GitHubのリポジトリでのコミットログなどを見るた印象ではあまり開発が活発な印象はないです。最近、いくつかPull Requestが取り込まれてはいるようですが……。
そのため、Rice側の開発が打ち切られると辛いことになりそうな気配がありますね……。とはいえ、大きな変更が入る可能性は少ないのでとりあえずC++でのRuby拡張を作る分には良いライブラリだと思います。
実装
それでは、Riceを使ってRuby拡張を実装してみましょう。
なにはともあれ、Riceをインストールしましょう。
gem install riceインストールが無事終了した後は、
extconf.rbというファイルを作成します。これはC++のコードをビルドするMakefileを自動生成するためのファイルになります。CでRuby拡張を作る場合も同様にextconf.rbを作成します。extconf.rbrequire 'mkmf-rice' create_makefile('hello')
mkmf-riceはRiceを使ってかかれたC++のソースをもとにMakefileを作成するためのライブラリになります。ちなみに、Cで拡張機能を実装する場合はmkmfというライブラリを読み込んでMakefileを自動生成していますね。また
create_makefileに渡している文字列がビルドされた拡張ライブラリの名前になります。次に、
hello.cppをextconf.rbと同じ階層に作成します。#include <iostream> #include <rice/Data_Type.hpp> #include <rice/Constructor.hpp> using namespace Rice; class Hello { public: Hello() {}; void say() { std::cout << "Hello Ruby Extension!" << std::endl; }; }; extern "C" { void Init_hello() { Data_Type<Hello> rb_cHello = define_class<Hello>("Hello") .define_constructor(Constructor<Hello>()) .define_method("say", &Hello::say); } }軽くコードの解説をすると、以下の二行でRiceのヘッダーを読み込んでいます。
#include <rice/Data_Type.hpp> #include <rice/Constructor.hpp>Riceでは
Data_Typeを使い、既存のクラスをもとにRuby向けにコンバートしています。Data_Type<Hello> rb_cHello = define_class<Hello>("Hello")上記のコードではC++で定義した
HelloクラスをRubyで呼び出すHelloというクラスに変換しています。.define_constructor(Constructor<Hello>())
.define_constructor(Constructor<Hello>())ではC++で定義したHelloクラスのコンストラクタ(Rubyでいうところのinitializeのようなもの)を使って、RubyでHelloクラスのインスタンスを作成できるようにしています。
つまり、Rubyのinitializeを実装しています。最後に
.define_method("say", &Hello::say);でsayというメソッドをHelloクラスに追加しています。.define_method("say", &Hello::say);これでC++側での実装は完了です。
次に、
extconf.rbを実行してMakefileを生成します。ruby extconf.rb # => Makefileを自動生成あとは、
makeコマンドでビルドすればhello.oとhello.soが生成されていると思います。make # => hello.o と hello.so が生成される最後に、作成したRuby拡張を実際に動かしてみましょう。
hello.rbを以下のように作成して実行してみましょう。hello.rbrequire './hello.so' Hello.new.sayruby hello.rb # => Hello Ruby Extension!
Hello Ruby Extension!と表示されていればOKです!Ext++での実装
Ext++とは?
Ext++はRice同様にC++を使って、Ruby拡張を作成できるライブラリです。
Ext++もRubyGemsで配布されているのでgemとしてインストールできます。
gem install extppExt++での実装は以下のようになります。
#include <iostream> #include <ruby.hpp> RB_BEGIN_DECLS void Init_hello() { rb::Class klass("Hello"); klass.define_method("initialize", [](VALUE rb_self, int argc, VALUE *argv) { return Qnil; }); klass.define_method("say", [](VALUE rb_self) { std::cout << "Hello Ruby Extension!" << std::endl; return Qnil; }); } RB_END_DECLSExt++ではC++のラムダ式を引数に渡して実装することができる点が特徴的です。そのためラムダ式をうまく使うことでRubyのメソッドとC++の実装を一度に書くことができます。
また、Ext++では
ruby.hppをインクルードするだけで良いところも便利です。Riceの場合、必要なヘッダーを個別に読み込まなければならずRiceではラムダ式を使ってメソッドの定義などはできないため、ラムダ式でメソッドを定義したい人はExt++を使うと良いかもしれません
Ext++を使うメリットとしては、実装が一か所で済む点かなと思います。また開発者が日本の方(というか @kou さん)ですので開発者本人にあって話が聴けるという点もメリットかもしれません。
デメリットとしては、サンプルのコードが一つしかなく、人によってはどのように実装を進めていけばいいのかが分かりにくい時がある点でしょうか?その点に関しては今後Pull Requestなどでサンプルコードを投げれたらと思っていますね。
また開発バージョンであり、今後のバージョンアップでは大きな変更も入る可能性もありそうです。しかしながら、開発者本人に直接話を聞くことができそう(日本人からすると)なので採用するメリットはかなり大きいと思います。
またRiceと違い、Rubyの実装自体に近い実装コードを書くのでCRubyの実装を学んでみたいという人にもオススメかもしれませんね。
実装
それでは、Ext++を使ってRuby拡張を実装していきましょう。
まずはExt++をインストールします。
gem install extppインストール完了後、Riceでの実装の時と同じように
extconf.rbを作成します。extconf.rbrequire 'extpp' create_makefile('hello')Riceの時とおおよそ同じコードですね。違う点としては
mkmf-riceではなく、extppを読み込んでいます。次に、
hello.cppをextconf.rbと同じ階層に作成します。hello.cpp#include <iostream> #include <ruby.hpp> RB_BEGIN_DECLS void Init_hello() { rb::Class klass("Hello"); klass.define_method("initialize", [](VALUE rb_self, int argc, VALUE *argv) { return Qnil; }); klass.define_method("say", [](VALUE rb_self) { std::cout << "Hello Ruby Extension!" << std::endl; return Qnil; }); } RB_END_DECLSExt++では
rb::Classで新しいクラスを作成します。また、作成したklassとdefine_methodを使うことで必要なメソッドを新しく定義しています。
QnilはRubyでのnilを返しています。CRubyのメソッドなどでnilが返ってきているメソッドでは、子のようにreturn Qnil;と書かれています。興味のある方はRuby Hack Challenge Holidayに参加したり、GitHubのruby/rubyのコードを読んでみると良いかもしれません。あとは。
extconf.rbを実行し、Makefileを生成します。ruby extconf.rb # => Makefileが生成されるその後、
makeで作成したRuby拡張をビルドします。make # => hello.o と hello.soが生成される最後に
hello.rbを以下のように作成し、実行してみましょう。hello.rbrequire './hello.so' Hello.new.sayruby hello.rb # => Hello Ruby Extension!
Hello Ruby Extension!と表示されていればOKです!C++での実装
実装
最後にC++でのみで作成するRuby拡張について紹介します。
まずは
extconf.rbを作成します。extconf.rbrequire "mkmf" create_makefile("hello")
mkmfはCRubyに添付されているRuby拡張のためのMakefile作成ライブラリですね。次に、
hello.cppを以下のように作成します。#include <ruby.h> #include <iostream> class Hello { public: Hello() {}; ~Hello() {}; void say() { std::cout << "Hello Ruby Extension!" << std::endl; }; }; static Hello* get_hello(VALUE self) { Hello *ptr; Data_Get_Struct(self, Hello, ptr); return ptr; } static void wrap_hello_free(Hello *ptr) { ptr->~Hello(); ruby_xfree(ptr); } static VALUE wrap_hello_alloc(VALUE klass) { void *ptr = ruby_xmalloc(sizeof(Hello)); ptr = std::move(new(Hello)); return Data_Wrap_Struct(klass, NULL, wrap_hello_free, ptr); } static VALUE wrap_hello_init(VALUE self) { return Qnil; } static VALUE wrap_hello_say(VALUE self) { get_hello(self)->say(); return Qnil; } extern "C" { void Init_hello() { VALUE rb_cHello = rb_define_class("Hello", rb_cObject); rb_define_alloc_func(rb_cHello, wrap_hello_alloc); rb_define_private_method(rb_cHello, "initialize", RUBY_METHOD_FUNC(wrap_hello_init), 0); rb_define_method(rb_cHello, "say", RUBY_METHOD_FUNC(wrap_hello_say), 0); } }ポイントとしては
#include <ruby.h>でRuby拡張の実装で使用するマクロや関数などを呼び出している点ですね。これがないとRuby拡張を実装することができません。また
get_hello関数はRubyのインスタンスを引数に受け取って、C++のインスタンスのポインタを返しています。この関数を使うことでC++のクラスのメソッドをラップ関数から呼び出して使うことができるようになります。
wrap_hello_free関数はRubyのGCが呼び出された際にメモリから解放する際の処理がかかれた関数になります。
wrap_hello_allocはインスタンスを作成する際のアロケータになります。wrap_hello_initはRubyでのinitializeになりますね。あとは、
extconf.rbを実行し、makeを実行してビルドしてみましょうruby extconf.rb # => Makfileが生成される make # => hello.o と hello.so が生成される最後に、
hello.rbを以下のように作成して実行しましょう。hello.rbrequire './hello.so' Hello.new.sayruby hello.rb # => Hello Ruby Extension!
Hello Ruby Extension!と表示されていればOKです!おわりに
C++でのRuby拡張についてRice、Ext++、C++それぞれでのでの実装を紹介しました。意外と簡単そうと思っていただければ幸いです。
あと今回の記事ではC++をベースに紹介しましたが、もちろんCでの実装を行う方法もあります。むしろ、そちらのほうが参考になる記事が多いので、Ruby拡張を作る際にはCで作ると良いかもしれません。
あと、この記事でRubyの実装に興味を持たれた方はRuby Hack Challenge Holidayなどに参加してみると良いかもしれません。
意外と簡単にC++でもRubyの拡張機能を作ることができるので、今後もC++の良さげなライブラリなどをRuby向けに実装していきたいと思います。
参考記事
ref: Rice
ref: Ext++
ref: Improve extension API: C++ as better language for extension
ref: Rice を使用して Ruby の拡張機能を C++ で作成する
ref: Rice - Ruby Interface for C++ Extensions
ref: ko1/rubyhackchallenge
ref: ruby/ruby
ref: C++言語で簡単なRuby拡張ライブラリを書いてみた
ref: Rubyの拡張ライブラリの作り方
ref: Rubyソースコード完全解説
ref: TataraというRubyで型を使えるライブラリを作ってみた
- 投稿日:2019-12-02T23:05:50+09:00
rails独学でポートフォリオを作成中
こんにちは!現在転職活動中のバスケンです。
初めての投稿です!railsの独学を初めて3か月が経ちました。
この3か月間の私の学習経過は下記になります。1、progateでhtml,css,ruby,ruby on rails,githubを1周
2、ruby on rails チュートリアル2週
3、railsでオリジナルのポートフォリオを作成途中今日は3にて私が作成したポートフォリオの概要を説明します。
ポートフォリオ「KuiShare」の概要
私は人の後悔を聞いたとき似たような後悔が自分に起きないように気をつけるよにします。
このことから、みんなとたくさんの後悔が共有できればおのずと注意深くなり先々で自分に起きうる後悔を減らすことができるのではないかと考えました。
みんなと気軽に後悔を共有することができるのが今回作成した「KuiShare」です。
「KuiShare」のURL「https://kuishare.herokuapp.com/」
「KuiShare」でできること
・後悔したことを投稿/編集/削除
・後悔を共有したいユーザーをフォローする機能
★人の後悔にコメントをする機能
★人の後悔に『ドンマイ』(instagramでいういいね!)をつける機能
・プロフィールの編集機能利用している技術
・rails
・heroku
・S3(画像置き場)★印をつけている機能はこれから追加しようとしている機能です。
今回は初投稿でしたのでただ自分の学習経過を記しただけになってしまい申し訳ございません!!
明日からはちゃんとした技術ブログを投稿していきたいと思います!
- 投稿日:2019-12-02T22:25:45+09:00
RubyでDBMSを実装 字句解析(2日目)
この記事は RubyでDBMS Advent Calendar 2019 の2日目の記事です。
本日の概要
初日は特に中身のないechoサーバとクライアントで終わってしまいましたが、
本日から実際にサーバに渡ってきた文字列をSQLとして解析していきます。
本日はその中でも前半のフェーズである字句解析を実装します。実装はこちらのGitHubリポジトリに置いてあります。
字句解析とは
字句解析とは、ただの文字列をそれ以上分割できない意味のある最小単位(トークン)に分割する処理です。
例として、以下のSQLを想定した文字列をトークンに分割してみます。SELECT id,email FROM users WHERE id=5;
文字列 種別 値 SELECT select keyword - id string literal id , comma - string literal FROM from keyword - users string literal users WHERE where keyword - id string literal id = equal - 5 numeric literal 5 ; semicolon (種別の部分は筆者の勝手な命名となります)
一部トークン(リテラル)には値も含まれます。
とりあえず、classとして切り出しておきます。rbdb/query/token.rb# frozen_string_literal: true module Rbdb module Query class Token attr_reader :kind, :value def initialize(kind, value = nil) @kind = kind @value = value end end end endクエリ設計
では、早速分割処理を実装していきたいところですが、
今後の初期開発でサポートする最低限のクエリを決めておきます。CREATE文
- 型はint, varcharのみ。
- 制約などは含まず。
INSERT文
- CREATE文でデフォルト値を指定できないので、全カラムを指定するもののみ。
INSERT INTO table_name VALUES (value1, value2);SELECT文
- * による全カラム指定と一部カラムのみ指定どちらも可能。
- WHERE句あり。
- 条件部分は単純な
operand (=|<>|<=|>=|<|>) operandのようなもののみ。解析処理
では、Lexer(字句解析器という意味)というクラスを作って実装していきます。
rbdb/query/lexer.rb# frozen_string_literal: true require 'rbdb/query/token' module Rbdb module Query class Lexer def initialize(query) @query = query @sio = StringIO.new(@query) @tokens = [] end def scan while ch = @sio.read(1) do if ch == "'" then @tokens << Token.new(:quote) elsif ch == '(' then @tokens << Token.new(:left_paren) elsif ch == ')' then @tokens << Token.new(:right_paren) elsif ch == '*' then @tokens << Token.new(:asterisk) elsif ch == ',' then @tokens << Token.new(:comma) elsif ch == ';' then @tokens << Token.new(:semicolon) elsif ch == '=' then @tokens << Token.new(:equal) elsif ch == '<' then _next = @sio.read(1) if _next == '>' then @tokens << Token.new(:not_equal) elsif _next == '=' then @tokens << Token.new(:less_than_equal) else back @tokens << Token.new(:less_than) end elsif ch == '>' then _next = @sio.read(1) if _next == '=' then @tokens << Token.new(:greater_than_equal) else back @tokens << Token.new(:greater_than) end elsif ch =~ /[A-Za-z]/ then buf = ch while _next = @sio.read(1) do if _next =~ /[A-Za-z0-9_]/ then buf += _next else back break end end _keyword = keyword(buf) if _keyword then @tokens << Token.new(_keyword) else @tokens << Token.new(:string_literal, buf) end elsif ch =~ /[0-9]/ then buf = ch has_period = false while _next = @sio.read(1) do if _next =~ /[0-9\.]/ then raise 'tokenize error' if has_period && _next == '.' has_period = true if _next == '.' buf += _next else back break end end if has_period then @tokens << Token.new(:numeric_literal, buf.to_f) else @tokens << Token.new(:numeric_literal, buf.to_i) end end end @tokens end def back @sio.seek(-1, IO::SEEK_CUR) end def keyword(str) case str.upcase when "SELECT" :select_keyword when "FROM" :from_keyword when "WHERE" :where_keyword when "INSERT" :insert_keyword when "INTO" :into_keyword when "VALUES" :values_keyword when "CREATE" :create_keyword when "TABLE" :table_keyword when "INT" :int_keyword when "VARCHAR" :varchar_keyword end end end end end大分長いメソッドや、ネストが激しくなってしまいましたが………
StringIOクラスを用いて、先頭から一文字ずつ走査していきます。
'や(など一文字目でそのトークン種別を決定できるものもある一方で、
<は、<>や<=,<など複数の可能性があるため、
さらに文字の読み込みを進めることで判定します。
また、backというメソッドを用意して、不要な読み込みをしてしまった場合一文字前に戻るようにしています。
アルファベットから始まる文字列は、予約語に当てはまるかをチェックした上で、それ以外を文字列リテラルと解釈します。動作確認
1日目でそのままechoしていたクエリの代わりに、
分割したTokenクラスをinspectしてそのままレスポンスで返してみます。rbdb/server.rbtokens = Rbdb::Query::Lexer.new(query).scan # TODO: tokens.each do |token| res.body += token.inspect res.body += "\n" endクライアントからクエリを叩いてみます。
>> SELECT id,email FROM users WHERE id=5; #<Rbdb::Query::Token:0x00007f7feb0c5360 @kind=:select_keyword, @value=nil> #<Rbdb::Query::Token:0x00007f7feb0c51a8 @kind=:string_literal, @value="id"> #<Rbdb::Query::Token:0x00007f7feb0c5130 @kind=:comma, @value=nil> #<Rbdb::Query::Token:0x00007f7feb0c4bb8 @kind=:string_literal, @value="email"> #<Rbdb::Query::Token:0x00007f7feb0c4578 @kind=:from_keyword, @value=nil> #<Rbdb::Query::Token:0x00007f7ffb05faa0 @kind=:string_literal, @value="users"> #<Rbdb::Query::Token:0x00007f7ffb05f690 @kind=:where_keyword, @value=nil> #<Rbdb::Query::Token:0x00007f7ffb05f4d8 @kind=:string_literal, @value="id"> #<Rbdb::Query::Token:0x00007f7ffb05f460 @kind=:equal, @value=nil> #<Rbdb::Query::Token:0x00007f7ffb05f398 @kind=:numeric_literal, @value=5> #<Rbdb::Query::Token:0x00007f7ffb05f348 @kind=:semicolon, @value=nil>大丈夫そうですね!
まとめ
筆者は自作コンパイラなどに手を出したこともないので、
今回初めて字句解析を実装したのですが、なかなか思ってたよりも愚直な処理になりますね。明日は分割したもののただの配列でしかないTokenたちをSQLの構文として解析していく予定です。
- 投稿日:2019-12-02T21:55:18+09:00
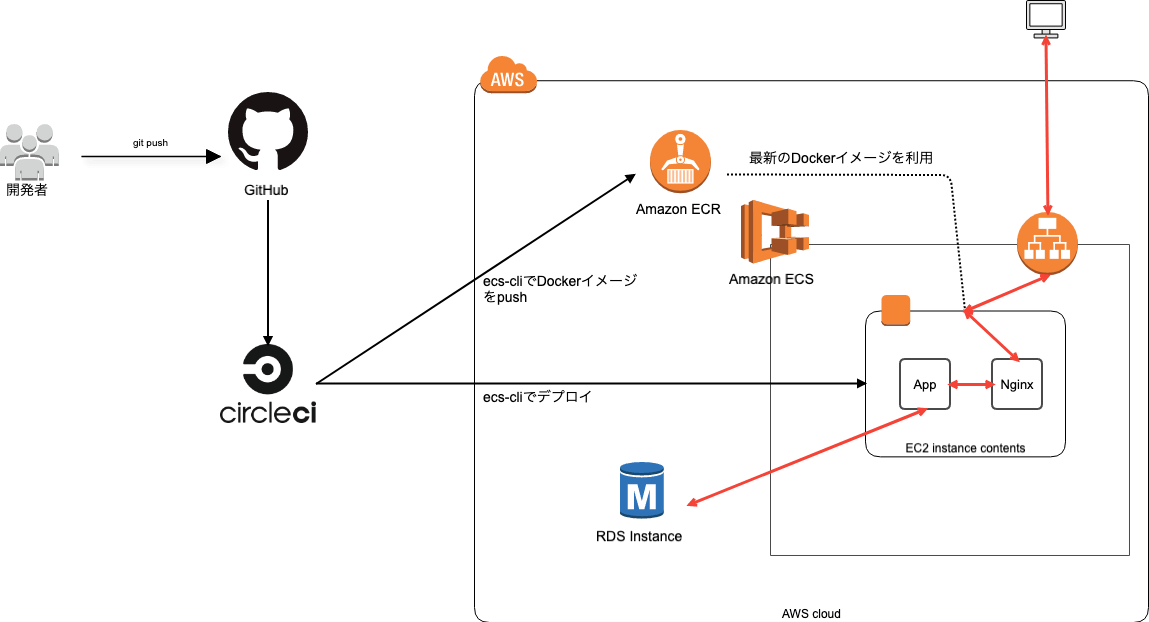
Rails × CircleCI × ECSのインフラ構築
簡単なDocker RailsアプリをECSを利用して本番環境に上げるまでのまとめ
* あくまで参考に(実務でそのまま利用できるほどしっかり構築しておりません)
前提知識
ECSとは?クラスターとは?サービスとは?タスクとは?って人は
ECSの概念を理解しよう
などを読んでください。Railsアプリ作成
まずはローカルでRailsアプリを作成しましょう。
機能は簡単なものでいいので、scaffoldなどを利用してサクッと作成してしまいましょう。
脳死で作成したい人は下記をご覧下さい。
Docker Rails Sampleアプリ構築 - QiitaAWS上で利用するリソースの作成
コンソール上(or Terraformなど)からあらかじめ作成しておくべきものになります。
IAMロール・ポリシーの作成
ECSで運用するための必要なIAMロール・ポリシーを作成していきます。
ちなみにポリシーとは、ロールに付与される権限情報です。なのでポリシーのないロールは何も権限がない状態なのでまずはポリシーを作成してロールを作成していきましょう。ポリシーの作成
作成手順
- IAMページに行って、サイドバーの「ポリシー」選択
- 「ポリシーの作成」ボタン押下
- JSONタブを開いて下記に記載したJSON内容をコピペして、「ポリシーの確認」押下
- それぞれのポリシー名を入力する
下記の4つのポリシーを作成する。
- AmazonSSMReadAccess
- AmazonECSTaskExecutionRolePolicy
- AmazonEC2ContainerServiceforEC2Role
- AmazonECSServiceRolePolicy
AmazonSSMReadAccess
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "ssm:GetParameters", "secretsmanager:GetSecretValue", "kms:Decrypt" ], "Resource": "*" } ] }AmazonECSTaskExecutionRolePolicy
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "ecr:GetAuthorizationToken", "ecr:BatchCheckLayerAvailability", "ecr:GetDownloadUrlForLayer", "ecr:BatchGetImage", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "*" } ] }AmazonEC2ContainerServiceforEC2Role
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "ec2:DescribeTags", "ecs:CreateCluster", "ecs:DeregisterContainerInstance", "ecs:DiscoverPollEndpoint", "ecs:Poll", "ecs:RegisterContainerInstance", "ecs:StartTelemetrySession", "ecs:UpdateContainerInstancesState", "ecs:Submit*", "ecr:GetAuthorizationToken", "ecr:BatchCheckLayerAvailability", "ecr:GetDownloadUrlForLayer", "ecr:BatchGetImage", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "*" } ] }AmazonECSServiceRolePolicy
{ "Version": "2012-10-17", "Statement": [ { "Sid": "ECSTaskManagement", "Effect": "Allow", "Action": [ "ec2:AttachNetworkInterface", "ec2:CreateNetworkInterface", "ec2:CreateNetworkInterfacePermission", "ec2:DeleteNetworkInterface", "ec2:DeleteNetworkInterfacePermission", "ec2:Describe*", "ec2:DetachNetworkInterface", "elasticloadbalancing:DeregisterInstancesFromLoadBalancer", "elasticloadbalancing:DeregisterTargets", "elasticloadbalancing:Describe*", "elasticloadbalancing:RegisterInstancesWithLoadBalancer", "elasticloadbalancing:RegisterTargets", "route53:ChangeResourceRecordSets", "route53:CreateHealthCheck", "route53:DeleteHealthCheck", "route53:Get*", "route53:List*", "route53:UpdateHealthCheck", "servicediscovery:DeregisterInstance", "servicediscovery:Get*", "servicediscovery:List*", "servicediscovery:RegisterInstance", "servicediscovery:UpdateInstanceCustomHealthStatus" ], "Resource": "*" }, { "Sid": "ECSTagging", "Effect": "Allow", "Action": [ "ec2:CreateTags" ], "Resource": "arn:aws:ec2:*:*:network-interface/*" }, { "Sid": "CWLogGroupManagement", "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:DescribeLogGroups", "logs:PutRetentionPolicy" ], "Resource": "arn:aws:logs:*:*:log-group:/aws/ecs/*" }, { "Sid": "CWLogStreamManagement", "Effect": "Allow", "Action": [ "logs:CreateLogStream", "logs:DescribeLogStreams", "logs:PutLogEvents" ], "Resource": "arn:aws:logs:*:*:log-group:/aws/ecs/*:log-stream:*" } ] }ロールの作成
IAMページに行って、サイドバーの「ロール」→「ロールの作成」より下記のロールを作成する。
作成後、各ロールのページにて「ポリシーをアタッチする」を押下して上記で作成したポリシーを紐づける。
- ecsInstanceRole(→AmazonEC2ContainerServiceforEC2Roleに紐づける)
- AWSServiceRoleForECS(→AmazonECSServiceRolePolicyに紐づける)
- ecsTaskExecutionRole(→AmazonECSTaskExecutionRolePolicy,AmazonSSMReadAccessを紐づける)
ALBの作成
ECSのサービス作成時にALBを登録しておけば、コンテナに動的にポートマッピングをしてくれるようになるので楽になります。
- Application Load Balancerを選択
- 名前を入力。サブネットを二つ選択。(ない場合は、適宜作成)
- セキュリティグループを選択。(ない場合は、適宜作成)
- ターゲットグループを選択or作成
- ターゲットグループにインスタンスを登録
クラスターの作成
ECSのサイドバーにある「クラスター」から「クラスターの作成」ボタンを押下
「クラスターテンプレートの選択」は「EC2 Linux + ネットワーキング」を選択
1. クラスター名記載
2. EC2インスタンスタイプの選択(お好み)
3. キーペア(お好み。ただし、デバッグ時にSSHできた方がいいので設定しておくことをおすすめ)
4. コンテナインスタンスの IAM ロールに「ecsInstanceRole」を選択RDSの作成
aws-cliでのRDS作成。
コンソール上からでもOKです。aws rds create-db-instance \ --db-instance-identifier rails-sample-db-production \ --db-instance-class db.t2.micro \ --db-subnet-group-name rails-sample-db-subnet-group \ --engine mysql \ --engine-version 5.7.26 \ --allocated-storage 20 \ --master-username [username] \ --master-user-password [password] \ --backup-retention-period 3 \参考
AWS CLI を使って RDS を作成する (自分用メモ) - Qiita
AWS-CLI Amazon Aurora インスタンス作成 - QiitaAWS Systems Managerの設定
AWS Systems Managerは、タスク実行時にコンテナに注入する秘匿情報(環境変数)の管理に使えるAWSサービスです。
初めての人は設定の仕方を含め、
ECSでごっつ簡単に機密情報を環境変数に展開できるようになりました!
を見れば大体分かると思います。AWS Systems Managerの左側メニューから「パラメータストア」→「パラメータの作成」をクリック。パラメータの詳細画面が表示されるので、パラメータのキー名と値を入力します。タイプには「安全な文字列」を選択します。
パラメータのキー名と値一覧
キー名 値 /production/database_username [RDSに設定したusername] /production/database_password [RDSに設定したpassword] /production/database_host [RDSインスタンスのエンドポイント] RDSインスタンスのエンドポイント(RDS→データベース→[インスタンス名])
CircleCIの設定
circleci/config.ymlversion: 2.1 orbs: aws-cli: circleci/aws-cli@0.1.13 executors: builder: docker: - image: circleci/buildpack-deps commands: init: steps: - checkout - aws-cli/install - install_ecs-cli - setup_remote_docker install_ecs-cli: steps: - run: name: Install ECS-CLI command: | sudo curl -o /usr/local/bin/ecs-cli https://amazon-ecs-cli.s3.amazonaws.com/ecs-cli-linux-amd64-latest sudo chmod +x /usr/local/bin/ecs-cli jobs: build: executor: builder steps: - init - run: name: Build application Docker image command: | docker build -f build.Dockerfile --rm=false -t rails-sample-app-build:latest . - run: name: Save image command: | mkdir -p /tmp/docker docker save rails-sample-app-build:latest -o /tmp/docker/image - persist_to_workspace: root: /tmp/docker paths: - image deploy: executor: builder steps: - init - attach_workspace: at: /tmp/docker - run: docker load -i /tmp/docker/image - run: name: Assets precompile and Push Docker image command: | docker build -f assets.Dockerfile --build-arg RAILS_MASTER_KEY=${RAILS_MASTER_KEY} --rm=false -t rails-sample-app-build:latest . - run: name: Push Docker image command: | ecs-cli push rails-sample-app-build:latest - run: name: ECS Config command: | ecs-cli configure \ --cluster rails-sample-${CIRCLE_BRANCH} \ --region ${AWS_DEFAULT_REGION} \ --config-name rails-sample-${CIRCLE_BRANCH} - run: name: migrate deploy command: | ecs-cli compose \ --file ecs/${CIRCLE_BRANCH}/migrate/docker-compose.yml \ --ecs-params ecs/${CIRCLE_BRANCH}/migrate/ecs-params.yml \ --project-name rails-sample-${CIRCLE_BRANCH}-migrate \ up \ --launch-type EC2 \ --create-log-groups \ --cluster-config rails-sample-${CIRCLE_BRANCH} - run: name: Unicorn + Nginx deploy command: | ecs-cli compose \ --file ecs/${CIRCLE_BRANCH}/app/docker-compose.yml \ --ecs-params ecs/${CIRCLE_BRANCH}/app/ecs-params.yml \ --project-name rails-sample-${CIRCLE_BRANCH}-app \ service up \ --container-name nginx \ --container-port 80 \ --target-group-arn ${TARGET_GROUP_ARN} \ --timeout 0 \ --launch-type EC2 \ --create-log-groups \ --cluster-config rails-sample-${CIRCLE_BRANCH} workflows: version: 2 build-deploy: jobs: - build - deploy: requires: - build filters: branches: only: - masterCircleCIに設定する環境変数
CircleCIのプロジェクトの設定ページ(Settings→[アカウント名or組織名]→[プロジェクト名])に行き、下記の画像の箇所から設定する
https://circleci.com/gh/[アカウント名or組織名]/[プロジェクト名]/edit#env-vars
環境変数名 値 AWS_ACCESS_KEY_ID [AWSのアクセスキーID] AWS_ACCOUNT_ID [AWSのアカウントID] AWS_DEFAULT_REGION [AWSのデフォルトリージョン] AWS_ECR_REPOSITORY_URL [AWSのECRリポジトリURL] AWS_SECRET_ACCESS_KEY [AWSのシークレットアクセスキー] RAILS_MASTER_KEY [config/master.keyの値] TARGET_GROUP_ARN [ターゲットグループのarn] Task definitionの作成
docker-compose.yml
rails-sample/ecs/production/app/docker-compose.ymlversion: "3" services: app: image: [ECRのリポジトリURI] entrypoint: bundle exec unicorn -c config/unicorn.rb env_file: - ../env working_dir: /projects/rails-sample logging: driver: "awslogs" options: awslogs-region: "ap-northeast-1" awslogs-group: "rails-sample-production/app" awslogs-stream-prefix: "rails-sample-app" nginx: image: [ECRのリポジトリURI] ports: - 0:80 links: - "app:app" env_file: - ../env working_dir: /projects/rails-sample logging: driver: "awslogs" options: awslogs-region: "ap-northeast-1" awslogs-group: "rails-sample-production/nginx" awslogs-stream-prefix: "rails-sample-nginx"* Nginxの設定ファイルは適宜用意してください。上記のnginxの欄にnginx設定ファイル群の設置・起動用のスクリプト
entrypoint: /bin/bash /etc/nginx/start.shを用意するなど。ecs-params.yml
タスク実行時に実行ロールの指定やコンテナに注入する環境変数をAWS Systems Managerから取得するして設定するためのファイル
rails-sample/ecs/production/app/ecs-params.ymlversion: 1 task_definition: # タスク実行時のロールを指定 task_execution_role: ecsTaskExecutionRole services: # 起動するコンテナを記載(app, nginx) app: # 何らかの理由で失敗・停止した際に、タスクに含まれる他のすべてのコンテナを停止するかどうか(デフォルトはtrue) essential: true # AWS Systems Managerから秘匿情報を取得してコンテナに環境変数を注入 secrets: - value_from: /production/database_username name: DATABASE_USERNAME - value_from: /production/database_password name: DATABASE_PASSWORD - value_from: /production/database_host name: DATABASE_HOST nginx: essential: true run_params: network_configuration: awsvpc_configuration: assign_public_ip: ENABLEDコンテナ全体に注入する環境変数の設定
各環境(production, stagingなど)ごとのディレクトリ以下に
envファイルを用意してそこに記載する# ここのファイルに追加した環境変数は全てのコンテナに展開されます # Rails APP_HOST=54.238.241.230 RAILS_ENV=production RAILS_LOG_TO_STDOUT=1 RAILS_SERVE_STATIC_FILES=1 # RDS DATABASE_NAME=rails-sample_production DATABASE_PORT=3306 DATABASE_POOL=10 # Unicorn UNICORN_PORT=23380 UNICORN_TIMEOUT=180 UNICORN_WORKER_PROSESSES=2 # Nginx専用 NGINX_APP_SERVER_NAME=app NGINX_APP_SERVER_PORT=23380 NGINX_DOCUMENT_ROOT=/projects/rails-sample/public NGINX_FRONT_SERVER_NAME=54.238.241.230構築の際に詰まる可能性のあるポイント
ECSコンテナインスタンスの作成
- インスタンスへのIAMロールを付与すること
- ecs-agentのインストール ( Amazon ECS コンテナエージェントのインストール - Amazon Elastic Container Service )
- EC2インスタンスの
/etc/ecs/ecs.configにCLUSTER_NAME=クラスター名の登録- 所属するクラスターを変更する場合、
/var/lib/ecs/data/ecs_agent_data.jsonを削除してからecs-agentを再起動するDefaultクラスター作成しているし、IAMロールにecs:CreateClusterの権限付与されているから自動で作成なんかもしてくれるのかと思ったら作成してくれなかった。
なので、クラスター作成→インスタンス作成の方が良い(ちな、クラスター作成時にインスタンスも作成するようにはできるっぽい)
→カスタマイズされてるAMI利用時のみ初期スクリプトによってDefaultクラスターを作成しているのかもしれない
参考
Amazon ECS コンテナインスタンスの起動 - Amazon Elastic Container Service
Amazon ECS-optimized AMI - Amazon Elastic Container Serviceインスタンスタイプについて
ある程度余裕持たないとタスク実行するための容量を持たなくて死ぬ
(ほんとは、ローカルや本番環境で動かした時の使用量見てタスク実行に必要なメモリを設定した方が良い)ecs-cliでのタスク実行
ecs-params.ymlファイル内でtask_execution_roleを指定することtask_execution_roleで指定した適切なポリシーを適用したIAM Roleを用意すること(エラーが出なくて、単純に実行されないので気づきにくい)まとめ
ECSについてググればたくさん記事出てくるのですが、実際に活用しようとしてみるとたくさん落とし穴があります。もし利用しようか考えている人は一度デモアプリで利用してみることをお勧めします。
最後に
UUUMではインフラに詳しいエンジニアを欲しています。
詳しくはこちら →→→→→→ UUUM攻殻機動隊の紹介


- 投稿日:2019-12-02T21:11:10+09:00
Docker Rails Sampleアプリ構築
適当なRailsアプリを作成するのに脳死で作成する
前提
- Ruby 2.6.5
- Railsバージョン6.0.1
- MySQL 5.7
- Node.js 8系
- webpacker用のコンテナは用意していない
$ mkdir rails-sample $ rbenv local [使用するrubyバージョン] $ git init $ bundle init gem 'rails'のコメントアウトを外す $ bundle install --path vendor/bundle $ bundle exec rails new . -B -d mysql --skip-test -B bundle install をスキップする(お好み) -d 利用するDBを指定(デフォルトはSQLite) --skip-test railsのデフォルトのminitestというテストを利用しない場合は指定(お好み) Gemfileの上書きしていいかどうかは Y でEnter $ bundle exec rails webpacker:install .gitignore に vendor/bundleを追記(お好み)docker-compose.ymlとDockerfile作成
Dockerfile
FROM ruby:2.6.5 ENV LANG C.UTF-8 RUN apt-get update -qq && apt-get install -y build-essential libpq-dev nodejs # nodejsとyarnはwebpackをインストールする際に必要 # Node.js RUN curl -sL https://deb.nodesource.com/setup_8.x | bash - && \ apt-get install nodejs # yarnパッケージ管理ツール RUN apt-get update && apt-get install -y curl apt-transport-https wget && \ curl -sS https://dl.yarnpkg.com/debian/pubkey.gpg | apt-key add - && \ echo "deb https://dl.yarnpkg.com/debian/ stable main" | tee /etc/apt/sources.list.d/yarn.list && \ apt-get update && apt-get install -y yarn WORKDIR /tmp COPY Gemfile Gemfile COPY Gemfile.lock Gemfile.lock RUN bundle install ENV APP_HOME /rails-sample RUN mkdir -p $APP_HOME WORKDIR $APP_HOME COPY . /rails-sampledocker-compose.ymlversion: '3' services: db: image: mysql:5.7 environment: MYSQL_USER: root MYSQL_ROOT_PASSWORD: password volumes: - ./tmp/docker/mysql:/var/lib/mysql:delegated web: build: . command: bundle exec rails s -p 3000 -b '0.0.0.0' volumes: - .:/chiko ports: - "3000:3000" depends_on: - dbdatabase.ymlを編集(お好み)
database.ymldefault: &default adapter: mysql2 timeout: 5000 encoding: utf8mb4 charset: utf8mb4 collation: utf8mb4_general_ci pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %> username: root password: password host: db port: 3306 development: <<: *default database: rails-sample_development test: <<: *default database: rails-sample_test production: <<: *default database: <%= ENV["DATABASE_NAME"] %> username: <%= ENV["DATABASE_USERNAME"] %> password: <%= ENV["DATABASE_PASSWORD"] %> host: <%= ENV["DATABASE_HOST"] %> port: <%= ENV["DATABASE_PORT"] %>defaultに
- charset: utf8mb4
- collation: utf8mb4_general_ci
- port: 3306を追記
productionは
- database: <%= ENV["DATABASE_NAME"] %>
- username: <%= ENV["DATABASE_USERNAME"] %>
- password: <%= ENV["DATABASE_PASSWORD"] %>
- host: <%= ENV["DATABASE_HOST"] %>
- port: <%= ENV["DATABASE_PORT"] %>を全部環境変数に変更
$ docker-compose build $ docker-compose run --rm web rails db:createScaffoldでUserモデル作成
$ docker-compose run --rm web rails g scaffold user name:string age:integerトップページを用意
$ bundle exec rails g home indexroutes.rbRails.application.routes.draw do root 'home#index' # これを追記 resources :users endUserページへのリンクを付与
index.html.erb<h1>Home#index</h1> <p>Find me in app/views/home/index.html.erb</p> <%= link_to "user", users_path %> <%# これを追記マイグレーションして、コンテナを立ち上げる
$ docker-compose run --rm web rails db:migrate $ docker-compose up -d=> http://localhost:3000 にアクセスして確認
- 投稿日:2019-12-02T21:06:40+09:00
つくってまなぶ★DES☆
この記事は信州大学kstmアドベントカレンダー2019の三日目の記事です。
去年と同様に人不足のためわたくし @arsley の1/2回目の記事となります。よろしくお願いします。
導入
本記事では私がゼミにて勉強した DES (Data Encryption Standard) とかいう「暗号化方式の1手法として聞いたことはあるけど、どういうものか知らない」という技術について、
得た知識をすぐに他者に伝えマウントをとってしまう若き頃のような気持ちで実装例を挙げながら説明します。
これを機に暗号分野にホーーーーンの少しでも興味を持っていただければ幸いです
TL;DWR
too long don't wanna read
完成品はこちら(3分間クッキング)(Ruby実装)(雑README)「手っ取り早くどういう挙動をするものなのか知りたい」という方はご参照ください。
DES (Data Encryption Standard)
DES (Data Encryption Standard) は共通鍵暗号方式のブロック暗号の一つです。
64ビットをブロック長、鍵も同じく64ビットで与え一連の暗号化処理により暗号文を得ます。
ただし、鍵については64ビットのうち8ビットは誤り訂正ビット(パリティビット)として扱うため、実際の鍵長は56ビットとなります。
また、暗号化に用いた 共通の 鍵を用いて暗号文の復号を行うことが可能です。共通鍵暗号は字面でわかると思うので、ブロック暗号について少しだけ補足します。
ブロック暗号
ブロック暗号とは、その名の通りデータを固定長の ブロック という単位に区切り、ブロックごとに暗号化を行う方式のことを指します。
共通鍵暗号におけるもう一つの暗号化方式はストリーム暗号と呼ばれるもので、1ビットもしくは1バイト単位で逐次暗号化していく方式のことを指します。一般的にブロック暗号は、ラウンド関数と呼ばれる処理を繰り返し適用し暗号文を得る構造となっており、これをFeistel構造と言います。
DESの開発者であるHorst Feistelに由来するそうです1。
また、暗号には平文→暗号文といった暗号化のほかに、暗号文→平文といった復号が可能である必要がある(復号可能性)のですが、このFeistel構造は逆変換が自身と同じ形になることから復号可能性を保証できるそうです。不思議ですね
もちろんDESもこのFeistel構造により実装されています。ちょっとわかりにくいので「逆変換が自身と同じ形になる」ということを線形代数の一次変換でお話をすると、たとえば点 $(x,y)$ から $(x^\prime, y^\prime)$ への一次変換を
A = \left( \begin{matrix} 1 & 0 \\ 0 & 1 \end{matrix} \right)\left( \begin{matrix} x^\prime \\ y^\prime \end{matrix} \right) = A \left( \begin{matrix} x \\ y \end{matrix} \right)で与えると、これの逆変換すなわち$A^{-1}$も同じであり、これが「逆変換が自身と同じ形になる」ということの意です(多分)。
DESのDEA (Data Encryption Algorithm)
以降、転置表などのデータはこちらのサイトのものを利用させていただいています。
DESにおいて暗号文を得るまでのプロセスをDEA(Data Encryption Algorithm)と呼ぶこともあるそうです
初耳でした。上述したように、DESはラウンド関数を繰り返し適用するFeistel構造により構成されます。
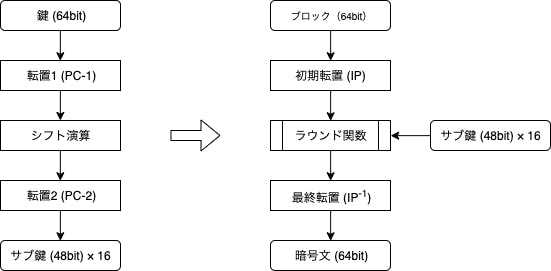
64ビット長のデータをブロックとして扱い、同じく64ビットを鍵として扱います(実際に使う鍵長は56ビット)。DESは大きく分けて次の手順で暗号化を行います。
- 元々の鍵64ビットから転置・シフト演算を用いて16個のサブ鍵を取得
- ブロックの初期データに対し初期転置を適用
- (2)にて得られたデータに対しサブ鍵と共にラウンド関数へ適用
- これを16回繰り返す
- (3)にて得られたデータに対して最終転置を適用、これを暗号文とする
図にするとこんな感じです。
中身を明らかにする前に、転置という操作について説明します。
例えば8文字の文字列abcdefghに対して次のような数列8 7 6 5 4 3 2 1が与えられた時、これは元の文字列を
hgfedcbaに変換することを意味します。
具体的にいうと、「元の文字列における8番目を1文字目に、元の文字列における7番目を2文字目に、元の文字列における6番目を3文字目に...置き直す(転置する)」という操作を行わせることを意味します。
まずサブ鍵生成について説明します。
今回鍵としては文字列kkkeeyyyの2進表記 $0110101101101011011010110110010101100101011110010111100101111001$ を利用します。以下は文字列→二進表記変換の例です2。
key_bin = key.bytes.map { |k| k.to_s(2).rjust(8, '0') }.join転置1 PC-1
まずはじめに最初の転置 PC-1 を行います。
この転置PC-1は次の数列により表されます3。PC-157 49 41 33 25 17 9 1 58 50 42 34 26 18 10 2 59 51 43 35 27 19 11 3 60 52 44 36 63 55 47 39 31 23 15 7 62 54 46 38 30 22 14 6 61 53 45 37 29 21 13 5 28 20 12 4転置を行い得られたビット列は $00000000111111111111111111100000011100011000111001110000$ となります(めっちゃ整っててびっくり)。
この転置から使われているのは8,16,24,32,40,48,56,64を除く56ビットであり、鍵長が与えたデータよりも短いことがわかるかと思います。転置処理には
mapを用いるのが楽かなと思います4。PC1.map { |index| key_bin.chars[index] }シフト演算
シフト演算はその名の通り、与えられたビット列を左方向へシフトさせるものです。
ここで用いるシフト演算は循環シフトで、上位方向へ溢れた桁は一番下位の桁へと戻るものとなります。シフト演算の適用に際して、先ほどの転置で得られたビット列を28ビットで半分に分割し、これを
C_0 = 0000000011111111111111111110 \\ D_0 = 0000011100011000111001110000とおくこととします。
そしてこのシフト演算を 16回 適用するのですが、「何回目のシフト演算か」によりシフト量が異なります。
シフト量は以下の表の通りです。
何回目? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 シフト量 1 1 2 2 2 2 2 2 1 2 2 2 2 2 2 1 1度目のシフト演算により
C_1 = 0000000111111111111111111100\\ D_1 = 0000111000110001110011100000が得られ、この操作を$C_{16}, D_{16}$が求まるまで繰り返します。
コード例については次の説明で示します。
転置2 PC-2
前述したシフト演算により得られる$C_{1\dots 16}, D_{1\dots 16}$それぞれについて、各々を結合した $C_nD_n$に対して以下の転置を適用することで 16個 のサブ鍵 $K_{1\dots 16}$ を得ます。
PC-214 17 11 24 1 5 3 28 15 6 21 10 23 19 12 4 26 8 16 7 27 20 13 2 41 52 31 37 47 55 30 40 51 45 33 48 44 49 39 56 34 53 46 42 50 36 29 32例として一つ目のサブ鍵 $K_1$ は $C_1D_1 = 00000001111111111111111111000000111000110001110011100000$ より $K_1 = 111100001011111011100110000000011110111010101000$ となります。
各シフトにより得られる$C_n,D_n$を利用するので、シフト演算の繰り返し操作と同時に行うといいと思います5。
SHIFT.each do |s| c << (c.last[s..-1] + c.last[0...s]) d << (d.last[s..-1] + d.last[0...s]) @keys << permutate_with_pc2(c.last + d.last) end
サブ鍵を生成したらいよいよ暗号化のプロセスに入ります。
今回は暗号化したい文字列としてddaattaaおよびその二進表記 $0110010001100100011000010110000101110100011101000110000101100001$ を用います。初期転置 IP
入力として与えられたブロックに対し以下の転置を適用します。
IP58 50 42 34 26 18 10 2 60 52 44 36 28 20 12 4 62 54 46 38 30 22 14 6 64 56 48 40 32 24 16 8 57 49 41 33 25 17 09 1 59 51 43 35 27 19 11 3 61 53 45 37 29 21 13 5 63 55 47 39 31 23 15 7
ddaattaaの二進表記に対して適用すると $1111111100110000001100111100110000000000111111110000000000000000$ となります。
得られた転置後のデータを半分(32ビット)で分割しL_0 = 11111111001100000011001111001100\\ R_0 =00000000111111110000000000000000とおきます。
コード例はこんな感じです6。
def permutate_with_ip IP.map { |index| message_bin.chars[index] } end
ラウンド関数
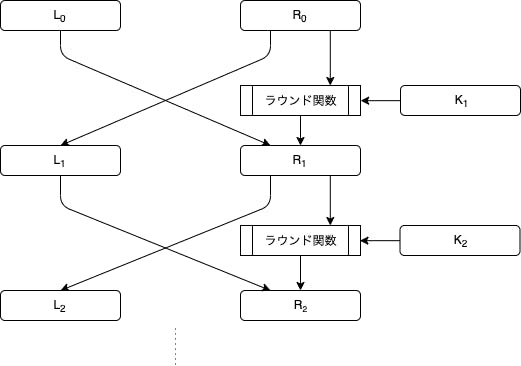
それではDESの要となるラウンド関数について説明していきます。
ラウンド関数を $F$ としたとき、DESにおける処理プロセスは以下の式で表されます($n = 0\dots 15$、$\oplus$ はXORの意)。\begin{aligned} L_{n+1} &= R_n \\ R_{n+1} &= L_n \oplus F(R_n, K_{n+1}) \end{aligned}$n$ の範囲からわかるようにラウンド関数は 16回 適用します。おそろしい。
図で表すとこのような形です。
このラウンド関数には次の処理が含まれています。
- 拡大転置Eを$R_n$に対して適用 (32ビット→48ビット)
- 対応するサブ鍵 $K_{n+1}$ と(1)の結果とのXORをとる (48ビット→48ビット)
- (2)の結果に対してSボックスを適用 (48ビット→32ビット)
- (3)の結果を結合したものに対して転置Pを適用 (32ビット→32ビット)
(3)のSボックスの説明は後に譲ることとして、拡大転置E・転置Pおよびサブ鍵とのXORの説明を簡単にしておきます。
拡大転置Eと転置P
拡大転置Eと転置Pは以下のように表されます。
E,P# E 32 1 2 3 4 5 4 5 6 7 8 9 8 9 10 11 12 13 12 13 14 15 16 17 16 17 18 19 20 21 20 21 22 23 24 25 24 25 26 27 28 29 28 29 30 31 32 1 # P 16 7 20 21 29 12 28 17 1 15 23 26 5 18 31 10 2 8 24 14 32 27 3 9 19 13 30 6 22 11 4 25# E def permutate_with_e(r) E.map { |index| r[index] } end # P def permutate_with_p(transposed_r) P.map { |index| transposed_r[index] } endまたサブ鍵とのXORについてですが、RubyにおけるXORは他言語と同じく (?)
^で表現できるため以下のように書きました9。def xor_with_key(permutated_r, key_index) r_xor_key = [] permutated_r .zip(keys[key_index]) .each { |right, key| r_xor_key << (right.to_i ^ key.to_i).to_s } r_xor_key endあんまりいい書き方ではなさそうですね...
Sボックス
Sボックスも今までに示した転置と同様に「与えられた入力を一定の法則に基づいて並べ換える」操作であることには変わりありません。
ただし単純な転置と異なり、表の中から対応する数値を一つ選択しそれの2進数表記を返すというものとなっています。この操作の前に、
ddaattaaに対し拡大転置Eを適用しサブ鍵 $K_1 = 111100001011111011100110000000011110111010101000$ とのXORをとった結果を $I = 111100001010100100011000100000011110111010101000$ とおきます(用意しておきます)。
この $I$ (48ビット)をまず6ビットごと8つに分割します。I = 111100\quad 001010\quad 100100\quad 011000\quad 100000\quad 011110\quad 111010\quad 101000簡単のためそれぞれのビットの塊を $i_n$ としてまとめ
I = i_1 i_2 i_3 i_4 i_5 i_6 i_7 i_8と表すこととします。
この各々の $i_1 \dots i_8$ 対して $S_1 \dots S_8$ というSボックスをそれぞれ適用します。
具体的にはS_1(i_1)S_2(i_2)S_3(i_3)S_4(i_4)S_5(i_5)S_6(i_6)S_7(i_7)S_8(i_8)ということです。
お気づきかもしれませんが、このSボックスは 8つ あります。
解説のために $S1$ のみ示します。
$S1$ row\col 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 0 14 4 13 1 2 15 11 8 3 10 6 12 5 9 0 7 1 0 15 7 4 14 2 13 1 10 6 12 11 9 5 3 8 2 4 1 14 8 13 6 2 11 15 12 9 7 3 10 5 0 3 15 12 8 2 4 9 1 7 5 11 3 14 10 0 6 13 Sボックスは入力ビット列における 最初と最後 を合わせたビット列を 行番号とし、残った 中間の4ビット列 を 列番号 とし、対応する数値の 4ビット二進表記 を返す関数のような働きをします。
入力ビット列を $b_1 b_2 b_3 b_4 b_5 b_6$ と表すならば、$(b_1 b_6)_2$ 行 $(b_2 b_3 b_4 b_5)_2$ 列に相当する数値 $y$ の2進表記を返します。$S1$ へ適用する $i_1 = 111100$ を例にとって説明すると、$10_2$ 行 $1110_2$ 列目すなわち2行14列目に相当する $5_{10}$ の2進表記 $0101_2$ を返します。
この操作を全ての $i_n$ に適用すると結果としてS_1(i_1)S_2(i_2)S_3(i_3)S_4(i_4)S_5(i_5)S_6(i_6)S_7(i_7)S_8(i_8) = 01011011010010110100101101011001が得られます。
8つあるSボックスはここを参考にしてもらうとして、コード例はこんな感じです9。
def transpose_with_s_table(xored_r) transposed_r = [] xored_r.each_slice(6).with_index do |bits, i| x = bits[1..4].join.to_i(2) y = (bits[0] + bits[-1]).to_i(2) transposed_r += DES::S[i][y][x].to_s(2).rjust(4, '0').split('') end transposed_r end最終転置 IPinverse
暗号文
暗号文を得る最後のプロセスとなる最終転置について説明します。
ラウンド関数 $F$ を複数回適用して $L_{16}$ および $R_{16}$ を得ることができました(唐突)。
L_{16} = 10000000100010100101010011100110 \\ R_{16} = 01010101111011001100101000000010この2つを 左右を逆にして結合 します。
すなわちR_{16} L_{16} =0101010111101100110010100000001010000000100010100101010011100110となります。
これに対して下記の最終転置 $IP^{-1}$ を適用します。ipinverse40 8 48 16 56 24 64 32 39 7 47 15 55 23 63 31 38 6 46 14 54 22 62 30 37 5 45 13 53 21 61 29 36 4 44 12 52 20 60 28 35 3 43 11 51 19 59 27 34 2 42 10 50 18 58 26 33 1 41 9 49 17 57 25はい。これにて
ddaattaaをkkkeeyyyにて暗号化した暗号文Encrypted = 0100000000100111010110100011010001001000000100100101111010110110が得られました
無理やり文字化すると@'Z4H\x12^\xB6だそうです。読めませんね。
復号?
最後に復号について話します。
ブロック暗号の説明でFeistel構造のはなしをしました。
Feistel構造は 逆変換が自身と同じになる という性質がありました。
そのため、 暗号化のプロセスを全て逆に行うことで平文が得られる ということになります。結論をいうと、暗号文に対してサブ鍵を $K_1, K_2 \dots K_{15}, K_{16}$ のような昇順ではなく、 $K_{16}, K_{15} \dots K_2, K_1$ のように降順にして適用することで平文が得られます。
不思議ですね...
おしまい
あんまり「つくってまなぶ」要素がなくなってしまいましたね、残念。
まあでも数多あるプログラミング言語はどれも「目的を達成するためのツール」でしかないと思っているので、実装したいものを理解し、実装方針を立てれば自ずと作れるはずですよね...?
今回お話しした「DESをつくる」というものは車輪の再発明になってしまうものの典型ですが、これを機に「他の暗号方式はどんな実装になっているんだろう...?」というような興味をもつ一歩になってくれれば嬉しいですね
RSA暗号とか楕円曲線暗号とかになると多少の数学要素が混じってくるので厳しいものもあるとは思いますが...あ、Gistを見てくださった方はわかると思うのですが、参考にさせていただいたサイトの数値を使ってテストも書いてあります、TDDで作ってました。
欲しい答えとか欲しい結果が明確な場合にはTDDはさいっこうにキマりますねえ、皆さんもTDDキメていきませんか?
- 投稿日:2019-12-02T20:05:31+09:00
【Ruby | Rails】Dockerfileの中で"ADD Gemfile ~ RUN bundle install"をするのはやめませんかという話
今回の検証環境
- Ruby
2.6.5- Docker
19.03.5- Docker-Compose
1.24.1はじめに
- Railsの設定を例にすると結構複雑になっちゃうので、今回は単純にRubyをDocker上で使用する例で解説します。
Railsを使用する場合も要点は同じなので適宜読み替えてください。- 今回は
hogehogeディレクトリ配下で作業します。サンプルコード中のhogehogeの部分は自由に変更して構いません。やめませんか
RailsやRubyのDocker環境構築の解説をしている記事で、
Dockerfile内で以下のようにADD Gemfile~RUN bundle installしている記事を本当にたくさんよく見かけます。DockerfileFROM ruby:2.6.5 WORKDIR /hogehoge RUN gem install bundler # ↓こういうの↓ ADD Gemfile Gemfile ADD Gemfile.lock Gemfile.lock RUN bundle installこれ、やめませんか?
なんでやねん
Dockerfileの中でADD Gemfile~RUN bundle installをすることには以下のようなデメリットがあります。
- Gemfileを編集するたびに毎回
docker buildやdocker-compose buildをしないといけなくなる。
- Gemを1つ追加するだけでも全Gemをインストールし直す羽目になる。
nokogiriとかインストール遅いよね!毎回待たされるの嫌だよね!何よりRubyistの皆さんとしては、
Gemfileを編集したら本能的にbundle installしたいですよね?したくないですか?したいですよね?じゃあどうすんねん
docker-composeを上手く使えばもっと効率よく楽しく開発できます。Dockerfile
containersディレクトリ配下にDockerfileを作成します。containers/DockerfileFROM ruby:2.6.5 WORKDIR /hogehoge RUN gem install bundlerこんだけ。
docker-compose.yml
次に、アプリケーションのルートディレクトリに
docker-compose.ymlを作成します。docker-compose.ymlversion: '3' services: app: build: context: . dockerfile: containers/Dockerfile environment: # これがないとGemを`vendor/bundle`以下から読み込んでくれないので注意 # (正確には、`.bundle/config`の設定を読み込んでくれない) BUNDLE_APP_CONFIG: /hogehoge/.bundle volumes: - .:/hogehogeこんだけ。
単純にカレントディレクトリ全体をマウントしてるだけですね。ビルドしよう
さぁ
docker-compose buildしていきましょう。$ docker-compose build Building app Step 1/4 : FROM ruby:2.6.5 ---> d98e4013532b Step 2/4 : ENV APP_ROOT /hogehoge ---> Using cache ---> 97b5a8bca2d0 Step 3/4 : WORKDIR $APP_ROOT ---> Using cache ---> 54066d2ae384 Step 4/4 : RUN gem install bundler ---> Using cache ---> 290d99a58c5b Successfully built 290d99a58c5b Successfully tagged hogehoge_app:latestすぐ終わりますね。
(初回だけruby:2.6.5のDocker imageのpullに時間がかかります。)Gemをインストールしてみよう
とりあえず
Gemfileを作成します。$ docker-compose run --rm app bundle init Writing new Gemfile to /hogehoge/Gemfile適当に
bcryptでも入れてみますかね。Gemfile# frozen_string_literal: true source "https://rubygems.org" git_source(:github) {|repo_name| "https://github.com/#{repo_name}" } # gem "rails" # ↓追加↓ gem 'bcrypt'それでは念願の
bundle installです。
docker-compose経由で実行するのと、--pathオプションを指定するのを忘れずに。補足: 一度
--pathオプションを付けてbundle installを実行すると、.bundle/configが作成されて設定が追加されるため、次回以降bundle installの際に--pathオプションを付ける必要はありません。$ docker-compose run --rm app bundle install --path vendor/bundle Creating network "hogehoge_default" with the default driver Fetching gem metadata from https://rubygems.org/. Resolving dependencies... Fetching bcrypt 3.1.13 Installing bcrypt 3.1.13 with native extensions Using bundler 2.0.2 Bundle complete! 1 Gemfile dependency, 2 gems now installed. Bundled gems are installed into `./vendor/bundle`ちゃんとインストールできているか確認してみましょう。
$ docker-compose run --rm app bundle exec gem list *** LOCAL GEMS *** bcrypt (3.1.13) bundler (2.0.2)できていますね。
次回以降もGemfileを編集した際にはdocker-compose run --rm app bundle installするだけで大丈夫です。
docker-compose buildし直す必要はありません。試しにRubyスクリプトを実行してみよう
test.rbを作って適当にbcryptを使ってみます。test.rb# vendor/bundle配下から読み込むようにしてくれる require 'bundler/setup' # Gemfileの中のGemを一発でrequireしてくれる Bundler.require # NOTE: ↑上の2つはRailsの場合は勝手にやってくれるため必要ないです↑ puts BCrypt::Password.create('password')$ docker-compose run --rm app ruby test.rb $2a$12$xWXitLplfvcIuxUdTg.1I.bb/Jo0btGGnqWE02ZiMFsne.hDQXaDW実行できましたね。
1つ問題点が!!
現状だとインストールしたGemはローカルの
vendor/bundleディレクトリ配下に配置されます。
docker-compose run ...を実行するたびにこのvendor/bundleディレクトリ配下が毎回マウントされるため、
Gemが増えてくるとdocker-compose run ...を実行するたびにマウントに時間がかかり、コマンド実行が遅くなってしまいます。(この問題はDocker for Macを使用している場合のみ発生するらしいです)「毎回
docker-compose buildし直すのが面倒だからこうしたのに、本末転倒じゃねぇか!!」落ち着いてください。こんな時のためにDockerには
volumeという機能があるじゃないですか。
vendor/bundleをボリュームに切り出す
docker-compose.ymlを以下のように修正するだけで解決します。docker-compose.ymlversion: '3' services: app: build: context: . dockerfile: containers/Dockerfile environment: BUNDLE_APP_CONFIG: /hogehoge/.bundle # これがないとGemを`vendor/bundle`以下から読み込んでくれないので注意 volumes: - .:/hogehoge # ↓追加↓ - bundle:/hogehoge/vendor/bundle # ↓追加↓ volumes: bundle: driver: localローカルの方の
vendor/bundle配下のファイルはもう必要ないため削除しちゃいましょう。$ rm -rf vendor/bundle/*ボリュームとして切り出したら改めて
bundle installし直しましょう。$ docker-compose run --rm app bundle install Creating volume "hogehoge_bundle" with local driver Fetching gem metadata from https://rubygems.org/. Fetching bcrypt 3.1.13 Installing bcrypt 3.1.13 with native extensions Using bundler 2.0.2 Bundle complete! 1 Gemfile dependency, 2 gems now installed. Bundled gems are installed into `./vendor/bundle`これで
vendor/bundleディレクトリ配下はbundleボリュームとして切り出されて毎回ローカルからマウントされることがなくなるため、docker-compose runで余計な時間がかかることはなくなります。注意しておくこと
Gemのコマンドを使う際には
bundle execを付け足すのを忘れないようにしてください。
こんな感じで↓$ docker-compose run --rm app bundle exec rpsecえ?
docker-compose run --rm appだけでも長いのにbundle execまで毎回付けるのは面倒くさいって?
alias設定するなりMakefile使うなりやりようはいくらでもあるじゃないですか。おわりに
僕自身エンジニア歴1年ちょっと、Dockerを使い始めて2ヶ月程度なので知識不足が否めません。
見当違いの事を言っている可能性も十分にあります。
誤った表現や設定等ありましたらコメントにてご指摘をお願いします。Docker便利ですね!
- 投稿日:2019-12-02T17:50:41+09:00
Railsチュートリアル学習メモ3
- 投稿日:2019-12-02T17:25:14+09:00
Railsでmodelに動的なカウンターをつける
要約
railsで一覧画面に何かしらの集計値とかフラグを表示したいときがあると思います。
いいね数とかそういうの。
それをcounter_cacheとかでデータとして持たずに、動的に集計してきれいに組み込む方法です。やり方
class Post < ApplicationRecord has_many :likes, as: :likable end class Like < ApplicationRecord belongs_to :likable, polymorphic: true end @posts = Post.all.select("posts.*, (select count(*) from likes l where l.likable_type='Post' and l.likable_id=posts.id) as likes_count") @posts.first.likes_count # as xxxがattributeになる => 3サブクエリ
(select count(*) from likes l where l.likable_type='Post' and l.likable_id=posts.id)の中は好きなように書けるので、かなり汎用性高くフラグなりなんなりつけられるので、これだけ覚えておけば集計付き一覧はだいたいできると思います。個人的にrailsのjoin+preload/eager_load/includesなどを使ってrailsのオブジェクトとしてしっかりつくる、という方法にこだわってきたのですが、これだとassociationの書かれ方に影響されて毎回違う書き方になってしまいます。フラグがひとつふたつ付けばいい場合にはやりすぎになってしまいがちです。
一方で、この書き方は多少生のsql書いてしまいますが、使い回しが効くのではないかと思います。
- 投稿日:2019-12-02T16:44:26+09:00
RailsのGeneratorGeneratorが便利すぎたので早く帰れる
どうも、株式会社Fusicでプリンシパルエンジニアやってる南部です。この記事はFusic その2 Advent Calendar 2019の2日目の記事です。
経緯
エンジニアは怠惰であれ、という言葉は誰が言ったのか、知るよしもありませんが、私もその例にもれず、怠惰な人間です。
ルーチンで作るものは5秒でつくってしまって、本当に頭を使うべきものに時間を割きたいと思うのは私だけではないでしょう。RailsにはGeneratorをGenerateするGeneratorGeneratorというものがあります。もう何を言ってるのかわかりませんが、とにかくそういうものがあるのです。
これを導入すると、ルーチンワークを5秒で終わらせる夢が叶います。
みなさんも是非お試しください。GeneratorGeneratorでGeneratorのテンプレートを作ろう
$ bundle exec rails generate generator nantoka create lib/generators/nantoka create lib/generators/nantoka/nantoka_generator.rb create lib/generators/nantoka/USAGE create lib/generators/nantoka/templatesこのように
lib/generators/nantokaの中にファイルやディレクトリが作られます。
本体になるのはnantoka_generatorです。lib/generators/nantoka/nantoka_generator.rbclass NantokaGenerator < Rails::Generators::NamedBase source_root File.expand_path('templates', __dir__) endまず、試しにこんなコードを書いてみます。
lib/generators/nantoka/nantoka_generator.rbclass NantokaGenerator < Rails::Generators::NamedBase source_root File.expand_path('templates', __dir__) def step1 puts "step1: #{self.name}" end def step2 puts "step2: #{self.name}" end end$ bundle exec rails g nantoka hoge step1: hoge step2: hogeおわかりの通りに、このGeneratorに実装されたメソッドが順番に実行されるようです。
ファイルを作る
ファイルを作るには
create_fileを使って実装します。lib/generators/nantoka/nantoka_generator.rbclass NantokaGenerator < Rails::Generators::NamedBase source_root File.expand_path('templates', __dir__) def create_generator_test_file create_file "generator_test.txt", "これはgeneratorのテストです: #{self.name}" end endcreate_fileは第一引数がRailsのrootパスからの相対パスを指定し、第二引数はそのファイルに書かれる内容です。
$ bundle exec rails g nantoka hoge create generator_test.txt $ cat generator_test.txt これはgeneratorのテストです: hogeちゃんとファイルができてますね。
テンプレートからファイルを作る
create_fileはちょっとした内容をファイルに出力するには便利ですが、コードを出力するには結構難ありです。
やっぱりテンプレートエンジンほしくないですか?ほしいですよね?
ほら、我らがERBがあるじゃないですか。lib/generators/nantoka/nantoka_generator.rbclass NantokaGenerator < Rails::Generators::NamedBase source_root File.expand_path('templates', __dir__) def create_generator_test_file template "generator_test.txt.erb", "generator_test.txt" end endlib/generators/nantoka/templates/generator_test.txt.erbthis is test <%= name %>これを実行してみましょう。
$ bundle exec rails g nantoka hoge create generator_test.txt $ cat generator_test.txt this is test hoge引数がほしい
引数がほしい?じゃあ、作ればいいじゃない。
lib/generators/nantoka/nantoka_generator.rbclass NantokaGenerator < Rails::Generators::NamedBase source_root File.expand_path('templates', __dir__) # 引数を追加 argument :words, type: :array, default: [] def create_graphql_schema template "generator_test.txt.erb", "generator_test.txt" end endlib/generators/nantoka/templates/generator_test.txt.erbthis is test <%= name %> <% words.each do |word| -%> <%= word %> <% end -%>$ bundle exec rails g nantoka hoge arg-foo arg-bar create generator_test.txt $ cat generator_test.txt this is test hoge arg-foo arg-bar実際何に使うか?
例えば、
graphql-rubyを使ってスキーマ定義したりするとき、似たようなRubyのコードがいっぱい出てくると思います。
そういうときに、一つGeneratorをつくっておけば、あら簡単。
どこかでバグが見つかっても、作り直すことも簡単です。時間を無駄に浪費して残業してしまうなんてことがなくなりますように。
まとめ
エンジニアとは自らの幸せを自ら掴み取る人間である
- 投稿日:2019-12-02T16:40:10+09:00
既存のRailsアプリをDocker上で起動させる
はじめに
railsを勉強しているのですが、勉強のために、サンプルコードなどを自分の環境上で動かしたかったのですが、
githubなどに上がっているサンプルコードをdocker上で立ち上げるのに苦労したのでメモします。新規のプロジェクトを立ち上げる際のDockerFileの書き方は情報がたくさんあったのですが、
既存のものを立ち上げる際の情報はほとんど無くて、あってもRuby2.4のものだったりしたので、
いろいろなサイトを参考にして、Ruby2.5環境で既存のプロジェクトを立ち上げるためのコンテナ構築をしました。Ruby2.5でのDocker環境構築
ディレクトリ構造(完成形)
workディレクトリでrailsアプリ(DockerFileのないもの)をクローンします。sampleapp/ ├ work │ └ app/ │ └ config/ │ └ ... │ ├ Dockerfile └ docker-compose.yml作業用ディレクトリを作成し、GithubからRailsプロジェクト(DockerFileのないもの)をクローンします。
クローンしたら、dockerコマンドを入力するためにsampleappディレクトリに戻ります。$ cd $ mkdir sampleapp $ cd sampleapp $ mkdir work $ cd work $ git clone ....(URLを入れる) $ cd ..Dockerfile
FROM ruby:2.5 #日本語対応 ENV LANG C.UTF-8 #作業用ディレクトリを作成 ENV ROOT_PATH /work RUN mkdir -p $ROOT_PATH WORKDIR $ROOT_PATH #Railsアプリに必要なパッケージをインストールする RUN curl -sL https://deb.nodesource.com/setup_10.x | bash - \ && apt-get install -y nodejs build-essential libpq-dev\ && rm -rf /var/lib/apt/lists/* #Rspec用chromedriver RUN apt-get update && apt-get install -y unzip && \ CHROME_DRIVER_VERSION=`curl -sS chromedriver.storage.googleapis.com/LATEST_RELEASE` && \ wget -N http://chromedriver.storage.googleapis.com/$CHROME_DRIVER_VERSION/chromedriver_linux64.zip -P ~/ && \ unzip ~/chromedriver_linux64.zip -d ~/ && \ rm ~/chromedriver_linux64.zip && \ chown root:root ~/chromedriver && \ chmod 755 ~/chromedriver && \ mv ~/chromedriver /usr/bin/chromedriver && \ sh -c 'wget -q -O - https://dl-ssl.google.com/linux/linux_signing_key.pub | apt-key add -' && \ sh -c 'echo "deb [arch=amd64] http://dl.google.com/linux/chrome/deb/ stable main" >> /etc/apt/sources.list.d/google-chrome.list' && \ apt-get update && apt-get install -y google-chrome-stable ADD ./work/Gemfile $ROOT_PATH/Gemfile ADD ./work/Gemfile.lock $ROOT_PATH/Gemfile.lock RUN gem install bundler RUN bundle install ADD ./work $ROOT_PATHdocker-compose.yml
version: '3' services: db: image: mysql:5.7 environment: MYSQL_USER: root MYSQL_ALLOW_EMPTY_PASSWORD: 1 ports: - "3306:3306" web: build: . command: bundle exec rails s -b 0.0.0.0 environment: volumes: - ./work:/work:cached ports: - "3000:3000" links: - dbrailsアプリのconfig/database.ymlでデータベースとの接続情報を編集します。
以下、work/config/database.ymldefault: &default adapter: mysql2 encoding: utf8 pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %> username: root password: host: db # development環境だけ書き換えてます。 development: <<: *default username: root password: database: docker_development test: <<: *default database: docker_test production: <<: *default database: docker_production username: root password: <%= ENV['DATABASE_PASSWORD'] %>設定が終わったらビルドします。
$ docker-compose build $ docker-compose exec web rails db:create db:migraterailsアプリに必要なパッケージやgemがインストールできるので、
終わったらdocker-compose upで起動させます。localhost:3000でアプリのトップページにアクセスできます。
3306や、3000の部分はポートがかぶらないように、お好みの番号に設定できます。
※指定できないポートもあるので、エラーが出る際は下記のサイトなどを参考にするといいと思います。開発中、ChromeでERR_UNSAFE_PORTエラーが出たときにチェックすべきこと(312エラー):http://nanoappli.com/blog/archives/7772
あとは新規からアプリを作成する時と同じように開発できます。
参考にしたサイト
既存railsプロジェクトのdocker運用開始時の作業録:https://www.dendoron.com/boards/50
Docker+既存Rails(+Puppeteer) やっぱりdockerで環境作るのを諦められなかった話:https://note.com/mick_sato/n/nfb521d6b2a4c
開発中、ChromeでERR_UNSAFE_PORTエラーが出たときにチェックすべきこと(312エラー):http://nanoappli.com/blog/archives/7772
- 投稿日:2019-12-02T15:56:05+09:00
Rubyのmap.flatten(1)よりもflat_mapの方が高速な理由をふわっと調べてみる
概要
タイトルの通りですが、具体的にソースを見るまで納得できなかったので調べてみました。
Rubyのソースコードを見てみる
本当はバージョンとかも考慮したほうがいいですが、下記リポジトリの最新版で見てみます。
https://github.com/ruby/rubyまずはflat_mapを見てみる
どうやらEnumeratorのソースは
enum.cにありそうでしたので、flat_mapに関連する箇所を確認してみました。
単純に配列を生成して、yieldした結果を格納しているというシンプルな内容でした。enum.cenum_flat_map(VALUE obj) { VALUE ary; RETURN_SIZED_ENUMERATOR(obj, 0, 0, enum_size); ary = rb_ary_new(); rb_block_call(obj, id_each, 0, 0, flat_map_i, ary); return ary; } flat_map_i(RB_BLOCK_CALL_FUNC_ARGLIST(i, ary)) { VALUE tmp; i = rb_yield_values2(argc, argv); tmp = rb_check_array_type(i); if (NIL_P(tmp)) { rb_ary_push(ary, i); } else { rb_ary_concat(ary, tmp); } return Qnil; }map.flatten(1)を見てみる
こちらは挙動そのままなので言わずもがなでした。
enum.c# map static VALUE enum_collect(VALUE obj) { VALUE ary; int min_argc, max_argc; RETURN_SIZED_ENUMERATOR(obj, 0, 0, enum_size); ary = rb_ary_new(); min_argc = rb_block_min_max_arity(&max_argc); rb_lambda_call(obj, id_each, 0, 0, collect_i, min_argc, max_argc, ary); return ary; }hash.c# flatten static VALUE rb_hash_flatten(int argc, VALUE *argv, VALUE hash) { VALUE ary; rb_check_arity(argc, 0, 1); if (argc) { int level = NUM2INT(argv[0]); if (level == 0) return rb_hash_to_a(hash); ary = rb_ary_new_capa(RHASH_SIZE(hash) * 2); # flatten(1)なのでここが1回だけ実行される rb_hash_foreach(hash, flatten_i, ary); level--; if (level > 0) { VALUE ary_flatten_level = INT2FIX(level); rb_funcallv(ary, id_flatten_bang, 1, &ary_flatten_level); } else if (level < 0) { /* flatten recursively */ rb_funcallv(ary, id_flatten_bang, 0, 0); } } else { ary = rb_ary_new_capa(RHASH_SIZE(hash) * 2); rb_hash_foreach(hash, flatten_i, ary); } return ary; } static int flatten_i(VALUE key, VALUE val, VALUE ary) { VALUE pair[2]; pair[0] = key; pair[1] = val; rb_ary_cat(ary, pair, 2); return ST_CONTINUE; }結論
確かに
map.flatten(1)の方が配列の生成、ループ処理が1回づつ多かったので、早くなるのは納得でした。
- 投稿日:2019-12-02T15:07:37+09:00
JScript 覚書(実践編その壱)
この記事は、富士通ソーシアルサイエンスラボラトリ Advent Calendar 2019の 3 日目の記事です。
はじめに
@GORO_Nekoです。ご存知の方ご無沙汰してます。初めての方お初にお目にかかります。
えーっと、先にお断りをば一言。
以下は、自分が所属する会社の意向を反映したものでもスタンスを示すものでもなく、単なる一個人の趣味の活動から産まれた記述です。
JScriptって知ってます?
知らない方、まずこちらの記事をご覧ください。
てぇわけでこの記事、じつは単品記事じゃなくて上で紹介した記事「JScript 覚書」の続編デス。
前の記事で「JScript とは何か」および「JScript で Windows の標準入力・標準出力・標準エラー出力を利用する方法」を紹介してみたつもりでいたのですが、読み返してみるとなんか座りが悪い。
使い方の説明として、若干コードも載っけてみたけど、どうも中途半端に感じちゃったんですよね。
てなわけで、もう少し意味のあるコードを記載して、「JScript で Windows の標準入力・標準出力・標準エラー出力を利用する方法」をコードを通して再解説しようと思います。
数あてゲームを作ってみる
正式名称かどうか実はよくわかっていませんが「数あてゲーム」ってありますよね?
コンピュータが考えた数値がいくつか、言い当てるゲーム。
人間が「コンピュータが考えた数は、xxx だろ?」とキーボードを通して通知すると、コンピュータが「もっと大きな数」「もっと小さな数」「あたり!」を答えるアレです。
以下、JScript で実装した数あてゲームのソースコードを掲載します(注意: 入力内容のチェック等エラーチェック処理ちゃんとやってません(:p )。
コード中のコメント等を読んで「JScript で Windows の標準入力・標準出力・標準エラー出力を利用する方法」を体感してみてください(体感してもらえるといいなぁ)。
// 0 ~ 999 の数字を一つ生成 var random_no = Math.floor(Math.random() * 1000); // 人間が撃ち込んだ数値を読み取る変数を用意する var input_number = 0; // 人間が行った発言回数を記録するカウンタを用意する var cnt = 0; // 発言数の上限を定義する var MAX_CNT = 20; // あたり判定フラグを用意する var hit_flg = false; // コンピュータが返すメッセージ文字列を定義する var OOKII = "大きいです。"; var TIISAI = "小さいです。"; var ATARI = "あたりです。"; // コンピュータが返すメッセージの格納変数を用意する var pcAns = ""; // 開始メッセージを出力する WScript.StdOut.WriteLine("0~999の数字を入力してください。"); WScript.StdOut.WriteLine("私の考えた数より大きい数だった場合「大きいです。」"); WScript.StdOut.WriteLine("私の考えた数より小さい数だった場合「小さいです。」"); WScript.StdOut.WriteLine("私の考えた通りの数だった場合「あたりです。」とお答えします。"); while(cnt < MAX_CNT){ // ユーザに入力を促す WScript.StdOut.WriteLine("数を入力して[Enter]キーを押してください。"); // 標準入力に入力された情報を読み取る input_number = WScript.StdIn.ReadLine(); //当たりはずれを判定する if(random_no < input_number){ pcAns = OOKII; }else if(random_no > input_number){ pcAns = TIISAI; }else{ pcAns = ATARI; hit_flg = true; } // 結果表示 WScript.StdOut.WriteLine(pcAns); // 状態確認処理 if(true == hit_flg){ // ループを脱出する break; }else{ // 入力数カウンタをカウントアップしてループ処理を続ける cnt++; } } // 終了処理 if(true == hit_flg){ WScript.StdOut.WriteLine("おめでとうございます。" + (cnt + 1) + "回で正解です。"); }else{ WScript.StdOut.WriteLine("残念。" + MAX_CNT + "回以内で正解できませんでした。"); }先の記事で解説していますが、一応上記のコードの実行方法を書きます。
上記コードを "kaduate.js" ファイルに書き込んだとします。
その場合、実行方法は以下のようになります。
x:\> cscript kaduate.jscscript にマイクロソフトのロゴを出させたくない場合は以下の通り。
x:\> cscript /nologo kaduate.jsうまく動きましたでしょうか?
なお、いつものごとく Ruby で書くとこんな感じ…かな?
require 'readline' # # 注意: # windows OS 上で実行する場合は、管理者モードで起動し、以下のコマンドを実行したCMD上で実行すること # > chcp 650001 # このコード自体はエンコード UTF-8 でファイル化して実行のこと # # 0 ~ 999 の数字を一つ生成 random_no = Random.new.rand(0..999) # 人間が撃ち込んだ数値を読み取る変数を用意する input_number = 0; # 人間が行った発言回数を記録するカウンタを用意する cnt = 0; # 発言数の上限を定義する MAX_CNT = 20; # あたり判定フラグを用意する hit_flg = false; # コンピュータが返すメッセージ文字列を定義する OOKII = '大きいです。' TIISAI = '小さいです。' ATARI = 'あたりです。' # コンピュータが返すメッセージの格納変数を用意する pcAns = ""; # 開始メッセージを出力する p '0~999の数字を入力してください。' p '私の考えた数より大きい数だった場合「大きいです。」' p '私の考えた数より小さい数だった場合「小さいです。」' p '私の考えた通りの数だった場合「あたりです。」とお答えします。' while cnt < MAX_CNT do # ユーザに入力を促す p '数を入力して[Enter]キーを押してください。' # 標準入力に入力された情報を読み取る input_number = Readline.readline.to_i # 当たりはずれを判定する if random_no < input_number then pcAns = OOKII elsif random_no > input_number then pcAns = TIISAI else pcAns = ATARI hit_flg = true end # 結果表示 p pcAns # 状態確認処理 if true == hit_flg then # ループを脱出する break else # 入力数カウンタをカウントアップしてループ処理を続ける cnt = cnt + 1 end end # 終了処理 if true == hit_flg then p 'おめでとうございます。' + (cnt + 1).to_s + '回で正解です。' else p '残念。' + MAX_CNT.to_s + '回以内で正解できませんでした。' endでは、また。
- 投稿日:2019-12-02T14:48:32+09:00
#Stripe #API でカスタマー = 顧客を作成・取得する ( 公式ドキュメントのまま ) ( #Ruby )
Command
Ruby
require 'stripe' Stripe.api_key = 'sk_test_xxxxx' Stripe::Customer.create({ description: 'Customer for jenny.rosen@example.com', })curl
curl https://api.stripe.com/v1/customers -u sk_test_xxxxx: -d description="Customer for jenny.rosen@example.com"API Doc
https://stripe.com/docs/api/customers/create?lang=curl
example
$ curl -s curl https://api.stripe.com/v1/customers -u sk_test_4eC39HqLyjWDarjtT1zdp7dc: -d description="Customer for jenny.rosen@example.com" { "id": "cus_GHaC8VxZWYuwcl", "object": "customer", "account_balance": 0, "address": null, "balance": 0, "created": 1575239418, "currency": null, "default_source": null, "delinquent": false, "description": "Customer for jenny.rosen@example.com", "discount": null, "email": null, "invoice_prefix": "B92698A0", "invoice_settings": { "custom_fields": null, "default_payment_method": null, "footer": null }, "livemode": false, "metadata": { }, "name": null, "phone": null, "preferred_locales": [ ], "shipping": null, "sources": { "object": "list", "data": [ ], "has_more": false, "total_count": 0, "url": "/v1/customers/cus_GHa5lNIgPs4wF3/sources" }, "subscriptions": { "object": "list", "data": [ ], "has_more": false, "total_count": 0, "url": "/v1/customers/cus_GHa5lNIgPs4wF3/subscriptions" }, "tax_exempt": "none", "tax_ids": { "object": "list", "data": [ ], "has_more": false, "total_count": 0, "url": "/v1/customers/cus_GHa5lNIgPs4wF3/tax_ids" }, "tax_info": null, "tax_info_verification": null }ダッシュボードで確認
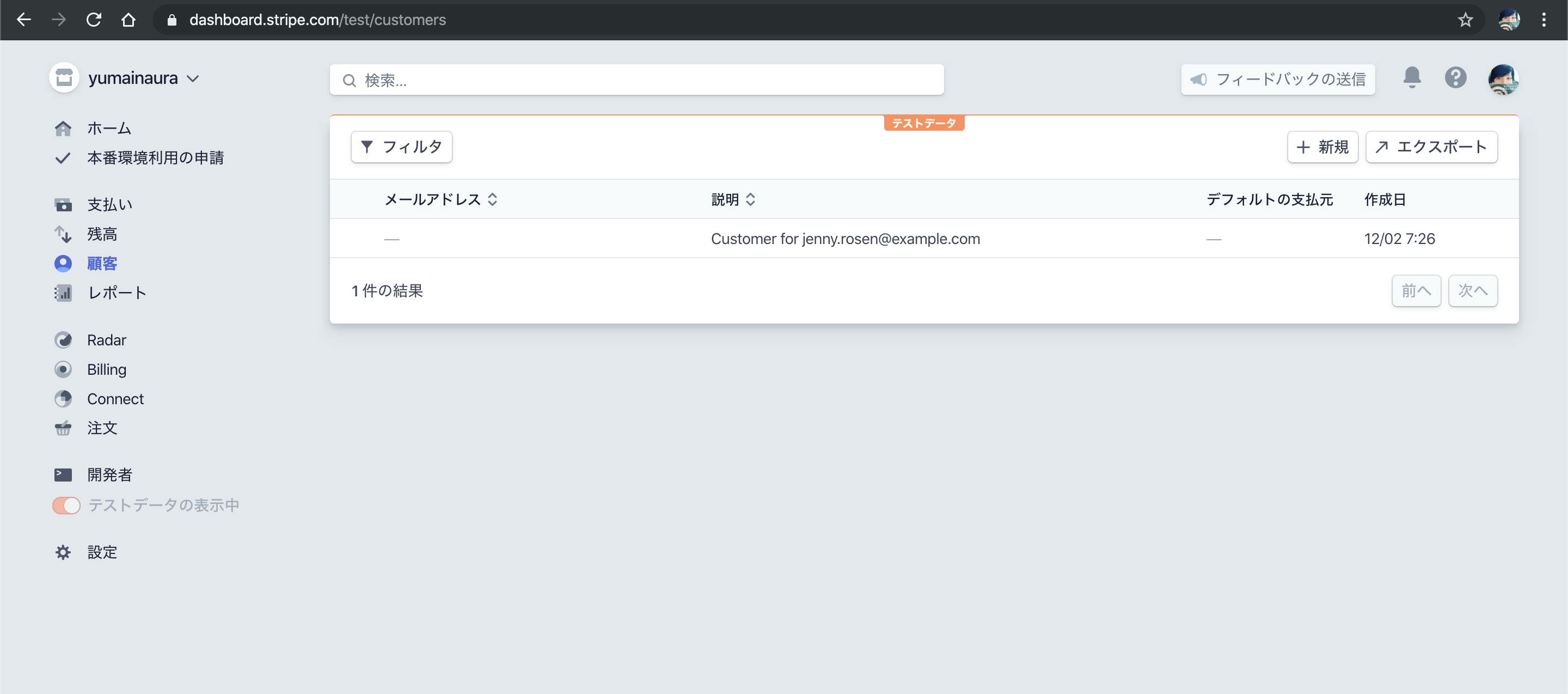
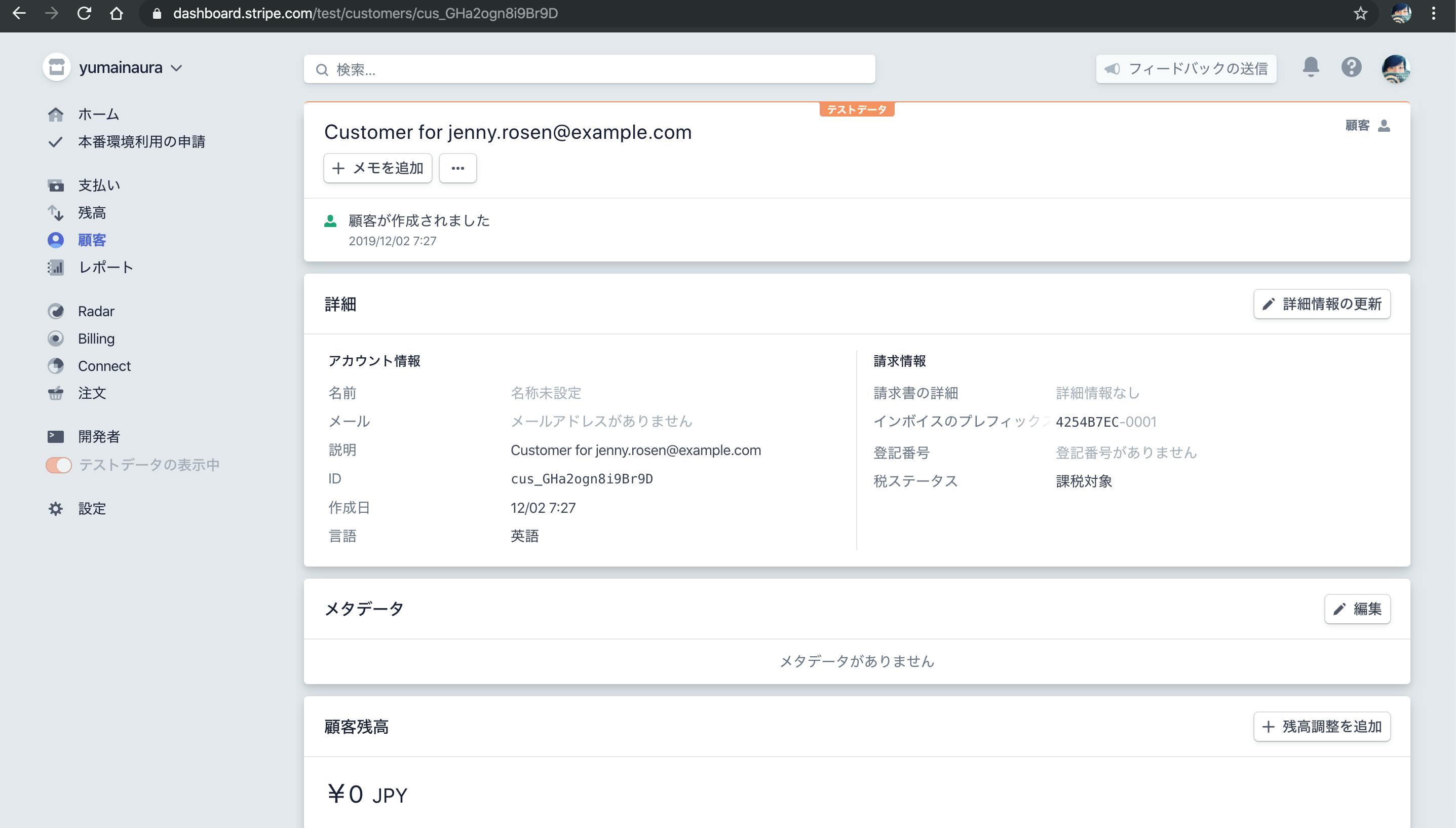
https://dashboard.stripe.com/test/customers
発行された customer_id がURLにも反映されるみたいだ
https://dashboard.stripe.com/test/customers/cus_GHaC8VxZWYuwcl
Original by Github issue
- 投稿日:2019-12-02T13:56:38+09:00
Rails+DeviseへのOmniauthの導入(ざっくり仕組み、CSRF対策、単体テスト含む)
内容
RailsアプリにOmniauth認証(google_oauth2, facebook)を導入する方法とその過程で学んだことを紹介する記事です。全体の流れやコードの意図を説明した記事はあまり見つからなかったと思ったので、その辺りを中心に解説したいと思います。
対象
rails初心者でOmniauth認証の導入に挑む人。
もし某スクールの後輩で見てくれた人がいた場合、
非常に面白い機能なので、まずは自力で挑戦することをお勧めします。
(そもそも違う環境でちゃんと動くとも、正解とも限りません。。。)
少しでもご参考になれば、と思って書きます。前提条件
-ruby 2.5.1p57
-Rails 5.2.3
-gem 'devise' 4.7.1
(ローカル環境のみの対応です)
1.そもそも
omniauthでは、あるアプリにおけるログイン認証の代わりや、外部機能の使用許可をすることができます。
本実装においては、前者の機能を使用しています。
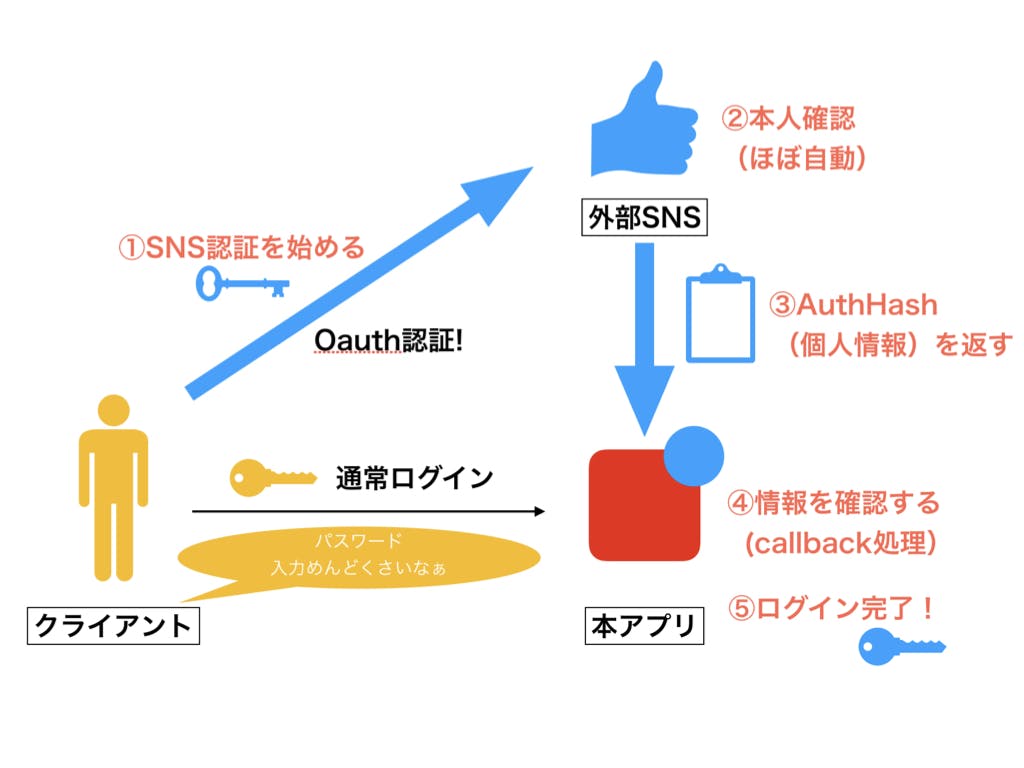
流れとしては、本アプリのパスワード入力を、SNSへのログイン(≒Cookieによりほぼ自動ログイン)で代用するイメージです。以下に全体図のイメージを示します。
青矢印のフローを実装していきます!2.実装
2-1.gemの導入
まず、gemfileに以下を追記後、bundle installを実施します。
Gemfilegem 'omniauth-facebook' gem 'omniauth-google-oauth2'2-2.設定
各SNSサイト(Google developers console, facebook for developers)にて、
URLの登録および、ID, SECRET KEYを取得します。
(ご参考サイト様:https://qiita.com/hidepino/items/a1eb9d2f32ce33389f20)環境変数を設定します。
config/initializers/devise.rbconfig.omniauth :facebook, ENV['FACEBOOK_ID'], ENV['FACEBOOK_KEY'] config.omniauth :google_oauth2, ENV['GOOGLE_ID'], ENV['GOOGLE_KEY']ターミナルにて、"vim ~/.bash_profile"を実行し、取得したIDとキーを記入します。
bash_profileexport FACEBOOK_ID="取得したID" export FACEBOOK_KEY="取得したキー" export GOOGLE_ID="取得したID" export GOOGLE_KEY="取得したキー""source ~/.bash_profile"を実行し、環境変数を有効化しましょう。
2-3.routingの設定
SNS側からcallbackが来た際に使用するコントローラーを定義してあげます。
routes.rbdevise_for :users, controllers: { omniauth_callbacks: 'users/omniauth_callbacks' }2-4.callbackコントローラーの作成、記述 (イメージ図の手順④⑤に当たります)
"rails g devise:controllers users"を実行し、users/omniauth_callbacks_controllerを作成し、以下を記述します。ここでは、callbackが来た際に行うアクションを設定しています。SNS側から来た情報であるauth_hashは、request.env["omniauth.auth"]として使用していきます。
クラスメソッド"from_omniauth"は次のステップでUser.rbに定義します。controllers/users/omniauth_callbacks_controller.rbdef facebook @user = User.from_omniauth(request.env["omniauth.auth"]) if @user.persisted? #もし@userがDBに既にいたら、ログイン状態にします sign_in_and_redirect @user, event: :authentication set_flash_message(:notice, :success, kind: 'Facebook') if is_navigational_format? else #もし@userがDBにいない場合、新規登録ページにリダイレクトします session["devise.facebook_data"] = request.env["omniauth.auth"] #データをsessionに入れることによって、新規登録ページの入力欄に、予め情報を入れておくなどが可能になります。 redirect_to 新規登録ページ end end def google_oauth2 @user = User.from_omniauth(request.env["omniauth.auth"]) if @user.persisted? sign_in_and_redirect @user, event: :authentication set_flash_message(:notice, :success, kind: 'google') if is_navigational_format? else session["devise.google_data"] = request.env["omniauth.auth"][:info] #google認証の場合は、なぜかauth_hashの容量が大きく、一瞬で容量オーバーとなるため、新規登録時に必要な情報のみをsessionに渡すこととしました。(おそらく画像データのせい?) redirect_to 新規登録ページ end end2-5.メソッドの定義 (イメージ図の手順④⑤に当たります)
ユーザー登録の流れを設定します。 ここは設計により異なります!
既存ユーザーであるかの識別は,uidやemailアドレスにて、実施されている記事を多く見受けましたが、
本実装では、usersテーブルとsns_credentialsテーブルを別で用意したため、
(1人のuserが複数のsns_credentialsを持つことを想定しています。)
ユーザーの識別はemailで行うことにしました。さらに、既存ユーザーがいなかった場合に関して、
ここでuser, sns_credentialをDBへ登録することもできますが、
本アプリにて必要な情報が、auth_hash上で欠けている場合を想定し、
インスタンスの作成に留めました。models/user.rbdef self.from_omniauth(auth) user = User.where(email: auth.info.email).first sns_credential_record = SnsCredential.where(provider: auth.provider, uid: auth.uid) if user.present? unless sns_credential_record.present? SnsCredential.create( user_id: user.id, provider: auth.provider, uid: auth.uid ) end elsif user = User.new( id: User.all.last.id + 1, email: auth.info.email, password: Devise.friendly_token[0, 20], nickname: auth.info.name, last_name: auth.info.last_name, first_name: auth.info.first_name, ) SnsCredential.new( provider: auth.provider, uid: auth.uid, user_id: user.id ) end user end2-6.リンクの導入
最後にViewにリンク先を記入して終了です!!
view.html.erb<%= link_to "Sign in with Facebook", user_facebook_omniauth_authorize_path %> <%= link_to "Sign in with Google", user_google_oauth2_omniauth_authorize_path %>2-7.CSRF対策
と言いたいところですが、Omniauth認証はCSRF脆弱性が指摘されているので、
以下の対策用のgemを導入し、リンクの書き方を変更して、本当の終了です。Gemfilegem "omniauth-rails_csrf_protection"rspec/view.html.erb<%= link_to "Sign in with Facebook", user_facebook_omniauth_authorize_path, method: :post %> <%= link_to "Sign in with Google", user_google_oauth2_omniauth_authorize_path, method: :post %>3.テストコード(一例)
対象:sns_credential.rbのuidのunique制約が作動するか
ダミーのauth_hashを作成したり、omniauthをtestモードにするなど、少し設定が必要です。
↓設定rails_helper.rbmodule OmniauthMocks def facebook_mock OmniAuth.config.mock_auth[:facebook] = OmniAuth::AuthHash.new( { provider: 'facebook', uid: '12345', info: { name: 'mockuser', email: 'sample@test.com' }, credentials: { token: 'hogefuga' } } ) end end RSpec.configure do |config| OmniAuth.config.test_mode = true config.include OmniauthMocks end↓テストコード
spec/models/sns_credentials_spec.rbRSpec.describe SnsCredential, type: :model do describe '#facebook validation' do before do Rails.application.env_config['omniauth.auth'] = facebook_mock end context '認可サーバーから返ってきたメールアドレスを、すでに登録済みのuserが持っていた場合' do before do user = create(:user, email: 'sample@test.com') end context '認可サーバーから帰ってきた情報とprovider名が異なるが、同じuidを持つSnsCredentialレコードがあった場合' do before do SnsCredential.create(provider: 'google_oauth2', uid: '12345', user_id: '1') end example 'uidのvalidation(unique制約)が機能するか' do expect(SnsCredential.create(provider: 'facebook', uid: '12345', user_id: '1').errors[:uid]).to include('はすでに存在します') end end end end end4.考察
・設計が良くなかったと思いますが、結局、"本アプリに登録したemailアドレス"と"SNS側からトークンで帰って来るemailアドレス"の照合をしているだけと言えます。結果、SNSに登録したemailとパスワードがあれば、本アプリの認証をパスされてしまう事になるので、セキュリティ的な甘さを感じました。。。
(SNS側は別デバイスでのログインを見張る、SMS認証等、強固なようなので、そこは安心と思います)
対策としては、認証時にもう1ハードルが必要かもしれません。・また、アドレスや住所等の個人情報がサーバーサイド側に飛ぶので、ユーザー目線としては、信頼できないサイトでは使うべきではない、と思いました。。。
5.参考にさせて頂いた記事様
https://github.com/plataformatec/devise/wiki/OmniAuth%3A-Overview
https://github.com/mkdynamic/omniauth-facebook/blob/master/README.md
https://github.com/zquestz/omniauth-google-oauth2/blob/master/README.md
https://github.com/cookpad/omniauth-rails_csrf_protection
https://qiita.com/hidepino/items/a1eb9d2f32ce33389f20長文にも関わらず、最後までお読みいただきありがとうございました。

初投稿記事なので、ご意見、修正点などいただけましたら、幸いです!

- 投稿日:2019-12-02T12:32:53+09:00
Rails6 のちょい足しな新機能を試す109(while_preventing_writes 編)
はじめに
Rails 6 に追加された新機能を試す第109段。 今回は、while_preventing_writes 編です。
Rails 6 では、while_preventing_writesが追加されました。multi-db 関連のメソッドで、 while_preventing_writes のブロック内では、 DBへの書き込みができません。
同じDBに対してDBのConnection を別に作成しても書き込みはできないようになっています。Ruby 2.6.5, Rails 6.0.0 で確認しました。
$ rails --version Rails 6.0.0今回は、簡単なスクリプトを作って確認します。
Rails プロジェクトを作成する
$ rails new rails_sandbox $ cd rails_sandboxUser モデルを作成する
Userモデルを作成します。$ bin/rails g model User nameUser モデルを編集する
User モデルのDBの Connection を
ActiveRecord::Base.connectionとは別になるように変更します。app/models/user.rbclass User < ApplicationRecord connects_to database: { writing: :primary, reading: :primary } end動作確認のスクリプトを作成する
ActiveRecord::Base.connectionとUser.connectionが違うことを確認し、while_preventing_writesのブロック内では、DBへの書き込みができないことを確認します。scripts/while_preventing_writes.rbputs User.count if ActiveRecord::Base.connection.object_id != User.connection.object_id puts 'ActiveRecord::Base.connection != User.connection' end # ActiveRecord::Base.connection.while_preventing_writes do # Rails 6.0.0.rc1 ActiveRecord::Base.connection_handler.while_preventing_writes do # Rails 6.0.0 User.create!(name: 'Taro') end puts User.countマイグレーションを実行する
$ bin/rails db:create db:migrateスクリプトを実行する
スクリプトを実行します。
Write query attempted while in readonly mode:のメッセージが出力され、書き込みが失敗することがわかります。$ bin/rails runner scripts/while_preventing_writes.rb Running via Spring preloader in process 81 0 ActiveRecord::Base.connection != User.connection Traceback (most recent call last): ... /usr/local/bundle/gems/activerecord-6.0.0/lib/active_record/connection_adapters/postgresql_adapter.rb:643:in `execute_and_clear': Write query attempted while in readonly mode: INSERT INTO "users" ("name", "created_at", "updated_at") VALUES ($1, $2, $3) RETURNING "id" (ActiveRecord::ReadOnlyError)ちなみに
Rails 6.0.0rc1 では、エラーにならず、保存できてしまいます。(6.0.0rc1 では、メソッドの定義場所が異なるため、
ActiveRecord::Base.connection.while_preventing_writesとする必要があります。)試したソース
試したソースは以下にあります。
https://github.com/suketa/rails_sandbox/tree/try109_while_preventing_writes参考情報
- 投稿日:2019-12-02T11:43:05+09:00
Reformで親子関係のあるフォームオブジェクトを作ってみる
Ateam cyma Adevent Calendar 2019、4日目です!
本日は株式会社エイチームでcymaのエンジニアの @bayasist が務めさせていただきます。Ruby on Railsで書かれたプログラムでは、フォームオブジェクトを利用することで、分かりやすく書くことができる場合があります。RailsでFormObjectを簡単に作れるtrailblazerというgemのReformというものがあり、使いこなせばなかなか便利です。
フォームオブジェクトが楽に作れるようにいくつか機能はありますが、ドキュメント(特に日本語)が少ないので、今回は特に親子関係をもつデータのReformを用いたフォームオブジェクトの作り方を解説できたらと思います。フォームオブジェクトを利用する利点
フォームオブジェクトはmodelをそのままformにするのではなく、バリデートなどformに関係する処理を行うオブジェクトです。これらのオブジェクトを作成することで、以下のようなメリットがあります。
- 複数モデルをまたがったFormの処理をコントローラに書かなくても済む
- ActiveRecordのモデル以外のデータの更新などでも同じようなお作法でView,Controllerが書ける
Reformのメリット
Reformは下記のような特徴があります
フォームオブジェクトを簡易的に作成できるtrailblazerというgemのReformというものがあります。それを用いると下記のようなメリットを受けることができます。
- ActiveModelと同じような記法でValidateや要素などが記載できる
- ActiveModel以外のデータの読み書きでも同様の記法で扱える
- 親子関係など多少データ構造が多少複雑になってもプログラムが複雑になることはない
まずはReformでフォームオブジェクトの基本形を作る
まずは、一つのmodelのみでReformを使ったフォームオブジェクトを作っていきます。nameカラムを持ったparentというモデルを更新するだけのものを作ります。(あとでchildというモデルをparentの子供にします)
app/models/parent.rbclass Parent < ApplicationRecord endapp/forms/parent_form.rbclass ParentForm < Reform::Form property :name validates :name, length: { maximum: 5} endapp/controllers/parent_controller.rbclass ParentController < ActionController::Base def edit @form = form end def update @form = form if @form.validate(update_param) @form.save end end private def form ParentForm.new(Parent.find(params[:id])) end def update_param params.require(:parent).permit(:name) end endapp/views/parent/edit.html.rb<%= form_with model: @form do |form| %> <%= form.text_field :name %> <%= form.submit %> <% end %>formオブジェクトができました。
Controllerを見ていただきたいのですが、ほとんどActiveRecordのお作法で書くことができます。
一点大きく違うところはvalidateの部分。Reformでは、validateメソッドでパラメータのバリデートをし、フォームオブジェクトの各要素ににパラメータを渡していきます。
またsaveメソッドでは、フォームオブジェクトの値をもとのモデルに渡してから、モデルのsaveメソッドが呼び出されています。モデルのsaveメソッドを呼び出さず、元のモデルへのデータの移動のみをやりたい場合はsyncメソッドを用います。parentモデルにchildという子要素を作る
parentモデルの子要素としてchildモデルを作ります。
app/models/parent.rbclass Parent < ApplicationRecord has_many :children endapp/models/child.rbclass Child < ApplicationRecord belongs_to :parent endapp/forms/parent_form.rbclass ParentForm < Reform::Form property :name validates :name, length: { maximum: 5} collection :children, populate_if_empty: Child do property :name validates :name, length: { maximum: 5} end endapp/controllers/parent_controller.rbclass ParentController < ActionController::Base def edit @form = form end def update @form = form if @form.validate(update_param) @form.save end end private def form ParentForm.new(Parent.includes(:children).find(params[:id])) end def update_param params.require(:parent).permit(:name, children_attributes: [:name]) end endapp/views/parent/edit.html.rb<%= form_with model: @form do |form| %> <%= form.text_field :name %><br /> <%= form.fields_for :children do |child_form| %> <%= child_form.text_field :name %><br /> <% end %> <%= form.submit %> <% end %>Formオブジェクトでcollectionを使うこと以外はActiveRecordを使用したときとほとんど変わらずに実装できます。
複数モデルのバリデーションや保存処理はフォームオブジェクトが引き受けるため、モデルが複数になってもControllerが散らかったりすることなく記述できます。また、Reformではそれらの処理をほとんど書くことなく行えます。上記プログラムの重要な問題点
上記プログラムではChildのアップデートの際に、Textboxの値を上からDBで検索された順にあてはめていきます。/editの表示からアップデートまでにほかのブラウザなどでChildの一部要素がdeleteやinsert等されると予期せぬ動作につながります。
そこで、/editの表示の際にHiddenFieldにchildのidを入れておき、保存の際にChildのidとPOSTで送られてきたidを突合しながら保存していく必要があります。
そのために下記のプログラムを変更する必要があります。app/controllers/parent_controller.rbclass ParentController < ActionController::Base # (中略) def update_param params.require(:parent).permit(:name, children_attributes: [:id, :name]) end endapp/views/parent/edit.html.rb<%= form_with model: @form do |form| %> <%= form.text_field :name %><br /> <%= form.fields_for :children do |child_form| %> <%= child_form.text_field :name %><br /> <%= child_form.hidden_field :id %> <% end %> <%= form.submit %> <% end %>app/forms/parent_form.rbclass ParentForm < Reform::Form property :name validates :name, length: { maximum: 5} collection :children, populate_if_empty: Child, populator: ->(fragment:, **) { children.find_by(id: fragment["id"].to_i) } do property :name validates :name, length: { maximum: 5} end endこれを行うことでHiddenFieldのidとDBのIDが同一のものを更新するようになります。ほかのブラウザで該当レコードが削除されていた際はvalidateを行う際にエラーとなり、ほかの関係ないデータを更新しに行くということはありません。
ここではfragmentはvalidateの際に送られてきたデータ(今回でいうとformで入力したデータ)、childrenはDBから持ってきたデータとなります。
この機能を用いれば、複合キーなどID以外で突合することもできます。例)
app/forms/parent_form.rbclass ParentForm < Reform::Form property :name validates :name, length: { maximum: 5} collection :children, populate_if_empty: Child, populator: ->(fragment:, **) { children.find(***_id: fragment["***_id"].to_i, ~~~_code: fragment["~~~_code"].to_i) } do property :name validates :name, length: { maximum: 5} end endChildのFormを外だしする
Childが複雑になってきたら、Childのフォームを別のファイルに移したくなるかもしれません。そのようにFormObjectの子要素を外に出すことも可能です。
app/forms/parent_form.rbclass ParentForm < Reform::Form property :name validates :name, length: { maximum: 5} collection :children, populate_if_empty: Child, populator: ->(fragment:, **) { children.find_by(id: fragment["id"].to_i) }, form: ChildForm endapp/forms/child_form.rbclass ChildForm < Reform::Form property :name validates :name, length: { maximum: 5} end他にもいろいろなことができます
Reformを使うことで、子要素の追加や削除、デフォルト値の設定等がModel,Controllerを大きく汚すことなく比較的簡単に行えます。また、ActiveRecord以外のインスタンスにも利用できるため、FormからDBと関係ないインスタンスにデータを移すときに重宝します。
もっと調べてみたい人は公式ドキュメントを見てみてくださいね。最後に
Ateam cyma Adevent Calendar 2019 の 4日目、いかがでしたか。
5日目は cymaのインフラつよつよエンジニアの @ihsiek がSQLのチューニング入門の記事を書くそうですよ!SQL苦手な人、早く動くSQLを書きたい人は必見ですよ!株式会社エイチームでは、一緒に働けるチャレンジ精神旺盛な仲間を募集しています。
エンジニアとしての働き方に興味を持たれた方はcymaの Qiita Jobs をご覧ください。
そのほかの職種は、エイチームグループ採用サイトをご覧ください。
- 投稿日:2019-12-02T11:16:09+09:00
rails-tutorial第7章
Restfulってなんだ?
RESTfulなアーキテクチャの場合、URLは同一のものを使うかわりに、HTTPリクエストメソッドにそれぞれ、GET、POST、PATCH、DELETEを使って異なるアクションに結びつけるようです。
こうすることでURLを名詞とし、HTTPリクエストメソッドを動詞とすることができ
シンプルにURLをいろいろなアクションに結びつけることができるようになります。ところで、現在のブラウザにはPATCHやDELETEといったメソッドはないようです。
Railsは存在しないHTTPメソッドを存在するかのように見せかけ
RESTfulなアーキテクチャの実装を実現しているようです。なんでRestfulなアーキテクチャがいいのか?
Progateのrailsアプリを作った時もそうだったけど、
現在使われているHTTPリクエストメソッドは、GETとPOSTのため
普通は、showアクションは/users_show/1、updateアクションは/users_update/1、
destroyアクションは/users_destroy/1とかのURLを考えますよね。昔Django(pythonのwebフレームワーク)でアプリを作った時は実際にそうしてました。
でもそうするとurlを管理するファイルの中がアクションの数によっては大変なことになったのを
記憶しています。これをresources :users
とすることで、ファイルを見やすくすることができる。ユーザー登録機能を実装する
まずは開発環境でのみデバッグ情報を表示するようにしてみよう
app/views/layouts/application.html.erb<!DOCTYPE html> <html> . . . <body> <%= render 'layouts/header' %> <div class="container"> <%= yield %> <%= render 'layouts/footer' %> <%= debug(params) if Rails.env.development? %> </div> </body> </html><%= debug(params) if Rails.env.development? %>
ここではデバッグメソッドが使われている。paramsでデバッグ情報を受け取り、開発環境でのみそれを表示させる。putsメソッドと似ている。ついでに、後置if文を使うときは1行で済む時に使われることが多い。2行以上の時は前置if文を使おう。ルーティングを設定しよう
config/routes.rbRails.application.routes.draw do root 'static_pages#home' get '/help', to: 'static_pages#help' get '/about', to: 'static_pages#about' get '/contact', to: 'static_pages#contact' get '/signup', to: 'users#new' resources :users endここで、どのurlがどのアクションに対応するのか知りたい。
そんな時は、$ rails routes
このコマンドを打つと、
ec2-user:~/environment/sample_app (sign-up) $ rails routes Prefix Verb URI Pattern Controller#Action root GET / static_pages#home help GET /help(.:format) static_pages#help about GET /about(.:format) static_pages#about contact GET /contact(.:format) static_pages#contact signup GET /signup(.:format) users#new users GET /users(.:format) users#index POST /users(.:format) users#create new_user GET /users/new(.:format) users#new edit_user GET /users/:id/edit(.:format) users#edit user GET /users/:id(.:format) users#show PATCH /users/:id(.:format) users#update PUT /users/:id(.:format) users#update DELETE /users/:id(.:format) users#destroyというように、urlと対応するアクションを調べることができる。
PUTリクエストとPATCHリクエストの違いって?
どちらもupdateアクションを指定しているが、PUTリクエストは基本的に全ての情報を更新する時に使う。PATCHリクエストは全部、または一部の情報を更新する時に使う。そのため情報の更新にはPATCHリクエストの方が適切であると言える。
ローカル変数とインスタンス変数
user ローカル変数
ローカル変数のスコープはメソッド内。@userはインスタンス変数
インスタンス変数は、method外、例えばviewで使うことができる。Userリソースのshowアクションを実装
app/controllers/users_controller.rbclass UsersController < ApplicationController def show @user = User.find(params[:id]) end def new end endshowアクションが実行される条件は、GET /users/:id
そのため、showアクションが実行される時は必ずidがurlに含まれている。
paramsにはハッシュで情報が保存されるので、params[:id]という書き方で情報を取得する。params[:id]超わかりやすく解説
・User.new ~ @user.saveでインスタンスが保存される。
・@userは {id: 1}というハッシュの情報を持っている。
・で、例えば/users/1というurlにアクセスしたとする。
・このurlは/users/:idという型に当てはまるので{id: 1}という前提でshowアクションが呼び出される。
・重要なのは、urlにアクセスすると、{id: 1}という情報が送られ、それをparamsで取得することができるということ。debuggerメソッド
app/controllers/users_controller.rbdef show @user = User.find(params[:id]) debugger end def new end enddebuggerメソッドはブレイクポイントみたいなもの。
そこで処理を止めて何が起きてるかrails sをしたターミナルに表示される。ユーザー登録機能を作ろう
form_forを使ったUser登録フォーム
app/views/users/new.html.erb<% provide(:title, 'Sign up') %> <h1>Sign up</h1> <div class="row"> <div class="col-md-6 col-md-offset-3"> <%= form_for(@user) do |f| %> <%= f.label :name %> <%= f.text_field :name %> <%= f.label :email %> <%= f.email_field :email %> <%= f.label :password %> <%= f.password_field :password %> <%= f.label :password_confirmation, "Confirmation" %> <%= f.password_field :password_confirmation %> <%= f.submit "Create my account", class: "btn btn-primary" %> <% end %> </div> </div>例えば、
<%= f.label :email %>
<%= f.email_field :email %>
は、ユーザーがemail欄に書いたvalueを:emailというキーに対応させますよーって意味。<%= f.label :password_confirmation, "Confirmation" %>
はpassword_confirmationという文字列だと長いので、"Confirmation"に上書きするよーって意味。
表示される文字がConfirmationになる。<%= f.submit "Create my account", class: "btn btn-primary" %>
このボタンを押すと、フォームの中身がparamsに代入される。createアクションを見てみよう
app/controllers/users_controller.rbdef create @user = User.new(params[:user]) # 実装は終わっていないことに注意! if @user.save # 保存の成功をここで扱う。 else render 'new' end end本来User登録は、
User.new(name: ~~, email: ~~....)という感じ。で、paramsには
{user: {name:, email:}}というハッシュが代入されている。
なので、params[:user]とすれば、:userをキーとするハッシュが代入されてインスタンスを作れるが、、、、、このままだとクラッキングされてしまう。
{ admin: true }などのメッセージを入れられると、管理者権限を付与することになってしまう。そこで、、
Strong Parametersを使おう
app/controllers/users_controller.rbclass UsersController < ApplicationController . . . def create @user = User.new(user_params) if @user.save # 保存の成功をここで扱う。 else render 'new' end end private def user_params params.require(:user).permit(:name, :email, :password, :password_confirmation) end endこうすることで、permitで指定したキー以外は扱わないよー、変なキーと値が入ってたら弾くよーってしている。
エラーメッセージを出そう。
validationに引っかかって登録に失敗した時、errors.full_messagesオブジェクトは、エラーメッセージの配列を持っています。
なので、
>> user.errors.full_messages => ["Email is invalid", "Password is too short (minimum is 6 characters)"]このように、失敗した理由を出すことができる。エラー要因が複数あれば複数渡してくれる。
登録フォームのviewにエラーメッセージを表示させよう。
app/views/users/new.html.erb<% provide(:title, 'Sign up') %> <h1>Sign up</h1> <div class="row"> <div class="col-md-6 col-md-offset-3"> <%= form_for(@user) do |f| %> <%= render 'shared/error_messages' %> <%= f.label :name %> <%= f.text_field :name, class: 'form-control' %> <%= f.label :email %> <%= f.email_field :email, class: 'form-control' %> <%= f.label :password %> <%= f.password_field :password, class: 'form-control' %> <%= f.label :password_confirmation, "Confirmation" %> <%= f.password_field :password_confirmation, class: 'form-control' %> <%= f.submit "Create my account", class: "btn btn-primary" %> <% end %> </div> </div>render 'shared/error_messages'これはエラーメッセージを表示するviewをパーシャル化しますよーってこと。
ディレクトリの作成
$ mkdir app/views/shared
$ touch app/views/shared/_error_messages.html.erbapp/views/shared/_error_messages.html.erb<% if @user.errors.any? %> <div id="error_explanation"> <div class="alert alert-danger"> The form contains <%= pluralize(@user.errors.count, "error") %>. </div> <ul> <% @user.errors.full_messages.each do |msg| %> <li><%= msg %></li> <% end %> </ul> </div> <% end %>signup(失敗時)の統合テストを書いていこう。
$ rails generate integration_test users_signup
インテグレーションテストの名前の付け方は、この場合、signupという一連の動作を確認するものだから、users_signupとしている。
test/integration/users_signup_test.rbrequire 'test_helper' class UsersSignupTest < ActionDispatch::IntegrationTest test "invalid signup information" do get signup_path assert_no_difference 'User.count' do post users_path, params: { user: { name: "", email: "user@invalid", password: "foo", password_confirmation: "bar" } } end assert_template 'users/new' end endpost users_pathは/usersにpostリクエストを送っていますよー。
その際に、params: { user: ~~~}を送ってますよーって意味。上記のテストはユーザー登録が失敗することを期待している。
じゃあ、どうやってそれを判断するのか?
test/integration/users_signup_test.rbassert_no_difference 'User.count' do post users_path, params: { user: { name: "", email: "user@invalid", password: "foo", password_confirmation: "bar" } } endassert_no_difference は引数(この場合、User.count)がdo end を実行する前と後では変更ないよね?っていうアサーション。
この場合、validationを設定しているのでuserインスタンスは登録されず、テストは通る。
ユーザー登録成功
まずはcreateアクションの中身を埋めよう
app/controllers/users_controller.rbclass UsersController < ApplicationController . . . def create @user = User.new(user_params) if @user.save redirect_to @user else render 'new' end end private def user_params params.require(:user).permit(:name, :email, :password, :password_confirmation) end endredirect_to @userこれ気になる。
rails routesを見てみよう
user GET /users/:id(.:format) users#show PATCH /users/:id(.:format) users#update PUT /users/:id(.:format) users#update DELETE /users/:id(.:format) users#destroy/users/:id は名前付きルートでuser_pathで表すことができる。
本来は user_path(@user.id)で実現できる。
しかし、user_pathはデフォルトで:idに値を入れて渡すそのため、user_path(@user)というように引数を渡すことでuserインスタンスの情報を渡すことができる。
これをさらに省略すると、
redirect_to @user というようにredirect_toメソッドの引数に直接Userオブジェクトを渡すことで、showアクションへリクエストできる。補足すると、redirect_toは基本的に指定したurlにgetリクエストを送るという考えでいいと思う。
flash 成功時に一時的なメッセージを出そう!
flashは特殊な変数で、使いたい時はflashという特殊な変数が最初から用意されていると考えるとわかりやすい。実際はメソッド。
usersコントローラに実装してみよう
app/controllers/users_controller.rbclass UsersController < ApplicationController . . . def create @user = User.new(user_params) if @user.save flash[:success] = "Welcome to the Sample App!" redirect_to @user else render 'new' end end private def user_params params.require(:user).permit(:name, :email, :password, :password_confirmation) end endflashはキーと値を設定すると、それが次のリクエストまで残り、次の次のリクエストが来た時に消えてくれるという特徴をもつ。
flashメッセージを画面に表示するには?
flashはいろいろなところで使われるので、共通のapplicationテンプレートに表示するためのコードをかくと便利。
具体的には、
app/views/layouts/application.html.erb<!DOCTYPE html> <html> . . . <body> <%= render 'layouts/header' %> <div class="container"> <% flash.each do |message_type, message| %> <div class="alert alert-<%= message_type %>"><%= message %></div> <% end %> <%= yield %> <%= render 'layouts/footer' %> <%= debug(params) if Rails.env.development? %> </div> . . . </body> </html><% flash.each do |message_type, message| %>には先ほどコントローラで設定したキーと値が入っている。
この場合、キーがmessage_type 値が、messageに代入されてeachメソッドが実行される。
先ほどは キーに :successを入れた。
実はbootstrapで alert-successというclassが元から用意されているため、キーをsuccessにした。これはcssによって、緑色の文字と縁を作る。
そのため、実際に表示されるのはmessageに代入された値だけとなる。成功時のテスト
test/integration/users_signup_test.rbclass UsersSignupTest < ActionDispatch::IntegrationTest . . . test "valid signup information" do get signup_path assert_difference 'User.count', 1 do post users_path, params: { user: { name: "Example User", email: "user@example.com", password: "password", password_confirmation: "password" } } end follow_redirect! assert_template 'users/show' end endfollow_redirect!は「POSTリクエストを送信した結果を見て、指定されたリダイレクト先に移動するメソッド」だそうです。ちなみに、このアプリケーションではユーザー登録がうまくいった場合そのユーザーのページ(users/show.html.erb)にリダイレクトするようにしています。assert_template 'users/show'はそれをチェックしているわけですね。
つまり、 redirect_toする前のテストの結果を精査してから、redirect_to後のテストに進みたい時に使うってこと?ch7には以下のように書いてある。
ここで、users_pathにPOSTリクエストを送信した後に、follow_redirect!というメソッドを使っていることに注目してください。このメソッドは、POSTリクエストを送信した結果を見て、指定されたリダイレクト先に移動するメソッドです。したがって、この行の直後では'users/show'テンプレートが表示されているはずです。
これが わかりやすい!!!!!!!
つまり、follow_redirect!は、assert_difference内で、users_pathへのPOSTリクエスト(URL:/users、アクション:create)を送信した結果(レスポンス)を見て、controllerで指定しているリダイレクト先のuser_url @user(ユーザ登録完了後のユーザ画面)へ移動している。
これにより、assert_template 'users/show'がテストされるのはpostリクエストがうまくいった時のみとなる。重要なのはredirect_toの前と後どちらもテストが存在するということ。
SSLを使ったデプロイ
SSLを使うと、http から httpsになる。
httpsは流れる情報が暗号化されるらしい。herokuのサブドメインの場合は問題ないが、自分で独自ドメインを設定する際はSSL証明書を発行する必要がある。
Railsではありがたいことに、本番環境用の設定ファイルであるproduction.rbのコードをたった1行変更するだけでSSLを強制し、httpsによる安全な通信を確立できます。具体的には次のリスト 7.36に示すように、config.force_sslをtrueに設定するだけで完了です。
config/environments/production.rbRails.application.configure do . . . # Force all access to the app over SSL, use Strict-Transport-Security, # and use secure cookies. config.force_ssl = true . . . endコメントアウトされてるので外してあげればOK
pumaの設定は7章見ながら設定すればOK
- 投稿日:2019-12-02T11:11:47+09:00
Classiの新卒エンジニア向け研修、「万葉研修」について
皆様こんにちは!この記事はClassi Advent Calendar 4日目の記事です。
新卒の小野優子(@yukoono)と申します。ポートフォリオチームで、高校生がやったことを記録し、振り返るための「ポートフォリオ」の開発を行っております。
5月にClassiにjoinして以来、合同会社Fjordさんの「Fjord boot camp」で2ヶ月の研修→社内で2ヶ月半の研修→チームに配属され業務へ、というフローで動いておりました。
今回は社内で受けた新卒研修、通称「万葉研修」について書いていきます。万葉研修とは
株式会社万葉さんがgithub上に公開している、Ruby on Railsのプログラマーになるための教育プログラムです。リンクはこちら。25ステップ+αあり、エンジニアとしてClassiにjoinした新卒メンバーは、この研修プログラムに2ヶ月程かけて取り組みます。メンターとして、「ゼロからわかるRuby超入門」の著者であるigaigaさん、12/21のTokyoGirls.rbで登壇されるただあきさんをはじめとした社内のエンジニアの皆様にお世話になりました。
大まかな流れ
プログラムのステップ3を終えた後、ステップ4で自分が作りたいアプリの仕組みやDB構造を考えます。私の場合は、「暇な時間を使って、普段先延ばしにしていることをやるアプリ」をコンセプトに置きました。利用の流れとしては、
1. アプリに筋トレや英語の勉強など、「やりたいけれど緊急ではない」ことを登録する
2. 暇な時間ができたら、何分程度暇なのかを登録する
3. 所要時間に合わせて、やることをアプリが提案する
4. 終わった後、記録をアプリに入力し、保存するという感じです。このアプリのペーパープロトタイピングやDB構造案を見せながら、メンターとどう実装するかを相談します。私の場合は最初にやりたいことをかなり盛りだくさんで考えていたため、「まずはやりたいことを登録するだけの、最小の機能で実装してみよう。研修が進むのに合わせて、コンセプトの要素を取り入れていこう」という話になりました。
このようにしてアプリの方向性を決定した後は、研修のステップに沿って実装していきます。方向性がそれぞれ違うため、同じ研修を受けていても出来上がるアプリは人によってかなり違ったものになります。例として、同期の@ruru8は社内で利用できる書籍サービスを作っていました。詳細は22日の投稿をお楽しみに。研修期間中の過ごし方
- プログラムに沿って、アプリに機能を実装する
- 取り組んでいたステップの実装が終わる、または途中でもキリのいい単位で実装が行えたら、Githubの自分のリポジトリにローカルの内容をpushする
- 見て欲しいところにコメントを書いてプルリクエストを出し、メンターにレビューをお願いする
- LGTM(Looks Good To Me…レビューがOKであるという意味)がもらえれば次の実装に取り掛かる。修正が必要な場合は、ローカルで修正を行い、pushして再レビューをお願いする
という感じです。
わからないことがあったときは、会社で買っていただいている参考書籍を読むか、メンターや社内の先輩に質問します。参考書籍についてはこちらにまとめられています。
また、Classiはコミュニケーションツールとしてslackを使っておりまして、個人が分報チャンネルを持ち、困りごとや思ったことなどをつぶやく文化が活発です。分報についてはこちら。私も自分の分報である「times_ono」というチャンネルに研修の進捗を書くようにしておりまして、ここで質問するとチャンネルを見ていただいている先輩からよくアドバイスを頂けます。
これはtimes_onoの一幕でして、私がわからない!と言ったことに対して、同期の@hxrxchang君が席に助けに来てくれて、参考になるリンクも貼ってくれたところです。こんな感じで、気軽にSOSが出せて、助けてくれる人が社内にたくさんいる、すごく温かい環境です。
成果物
出来上がったアプリがこんな感じです。
私はレビューで時間をかけたため、ステップ4で考えていたコンセプトの実現は十分には行えず、シンプルに万葉研修のステップを進めたアプリ、という感じの成果物になりました。ただ、私の場合はレビューで得た知識が評価され、チームで研修内容の共有会を開かせていただきました。
研修のゴールは人それぞれです。私はステップ23まで+研修内容の共有会の開催がゴールになりましたが、今研修中のベトナム人の新卒二人は1ヶ月で早くもステップ25を完了し、オプション要件に取り組んでいます。また、フロントエンドのスキルがあるメンバーはRailsのプログラミングと並行してAngular jsで画面の作成を行い、操作性に優れた格好いいアプリを作っています。Classiの先輩方に協力してもらい、ユーザビリティテストを行なったメンバーもいます。
研修を終えて
研修を通して、「プログラマーの仕事の大部分は、人への気遣いである」という感想を持ちました。なぜなら、メンターからの指摘事項のほとんどは、「他のエンジニアがアプリをメンテナンスする時に分かりやすい/後で困らないコーディング」についてのアドバイスだったためです。
- こうした方が、他のプログラマーが分かりやすい!
- この方がRailsや他のgemのアップデートに関わらず使える!
- このコメントをつけた方が、レビュアーや他のエンジニアに親切!
などのコメントをたくさん頂くうちに、プログラマーの仕事像が「黙々と実装だけ行えれば良い、他の人とは関わらない」から、「他の人へ気遣い、情報を伝達し、理解して貰えるコードを書く」に変わっていきました。この意識は、現在チームで仕事をする上でも、チームメンバーへの気遣いや、伝わりやすいプルリクエストという形で活きています。
終わりに
この研修について社内の先輩エンジニアに話したところ、「羨ましい」という声を多く頂きました。2ヶ月以上かけてコードの書き方を教えてもらえる機会はとても貴重で、多くのプログラマーは仕事の中でコードの書き方やプルリクエストの仕方を覚えていくそうです。手厚い研修プログラムを組んでいただいたigaigaさん、ただあきさん、わからないところを教えて頂いた先輩エンジニアの皆さん、また充実した研修を受けさせて貰える会社の懐の広さに感謝しつつ、この投稿を締めます。
明日の投稿は@onigraさんです。お楽しみに。


- 投稿日:2019-12-02T11:11:47+09:00
Classiの新卒エンジニア向け研修について
皆様こんにちは!この記事はClassi Advent Calendar 4日目の記事です。
新卒の小野優子(@yukoono)と申します。ポートフォリオチームで、高校生がやったことを記録し、振り返るための「ポートフォリオ」の開発を行っております。
5月にClassiにjoinして以来、合同会社Fjordさんの「Fjord boot camp」で2ヶ月の研修→社内で2ヶ月半の研修→チームに配属され業務へ、というフローで動いておりました。
今回は社内で受けた新卒研修について書いていきます。研修内容
株式会社万葉さんがgithub上に公開している、Ruby on Railsのプログラマーになるための教育プログラムを使っています。リンクはこちら。
25ステップ+αあり、エンジニアとしてClassiにjoinした新卒メンバーは、この研修プログラムに2ヶ月程かけて取り組みます。メンターとして、「ゼロからわかるRuby超入門」の著者であるigaigaさん、12/21のTokyoGirls.rbで登壇されるただあきさんをはじめとした社内のエンジニアの皆様にお世話になりました。大まかな流れ
プログラムのステップ3を終えた後、ステップ4で自分が作りたいアプリの仕組みやDB構造を考えます。私の場合は、「暇な時間を使って、普段先延ばしにしていることをやるアプリ」をコンセプトに置きました。利用の流れとしては、
1. アプリに筋トレや英語の勉強など、「やりたいけれど緊急ではない」ことを登録する
2. 暇な時間ができたら、何分程度暇なのかを登録する
3. 所要時間に合わせて、やることをアプリが提案する
4. 終わった後、記録をアプリに入力し、保存するという感じです。このアプリのペーパープロトタイピングやDB構造案を見せながら、メンターとどう実装するかを相談します。私の場合は最初にやりたいことをかなり盛りだくさんで考えていたため、「まずはやりたいことを登録するだけの、最小の機能で実装してみよう。研修が進むのに合わせて、コンセプトの要素を取り入れていこう」という話になりました。
このようにしてアプリの方向性を決定した後は、研修のステップに沿って実装していきます。方向性がそれぞれ違うため、同じ研修を受けていても出来上がるアプリは人によってかなり違ったものになります。例として、同期の@ruru8は社内で利用できる書籍サービスを作っていました。詳細は22日の投稿をお楽しみに。研修期間中の過ごし方
- プログラムに沿って、アプリに機能を実装する
- 取り組んでいたステップの実装が終わる、または途中でもキリのいい単位で実装が行えたら、Githubの自分のリポジトリにローカルの内容をpushする
- 見て欲しいところにコメントを書いてプルリクエストを出し、メンターにレビューをお願いする
- LGTM(Looks Good To Me…レビューがOKであるという意味)がもらえれば次の実装に取り掛かる。修正が必要な場合は、ローカルで修正を行い、pushして再レビューをお願いする
という感じです。
わからないことがあったときは、会社で買っていただいている参考書籍を読むか、メンターや社内の先輩に質問します。参考書籍についてはこちらにまとめられています。
また、Classiはコミュニケーションツールとしてslackを使っておりまして、個人が分報チャンネルを持ち、困りごとや思ったことなどをつぶやく文化が活発です。分報についてはこちら。私も自分の分報である「times_ono」というチャンネルに研修の進捗を書くようにしておりまして、ここで質問するとチャンネルを見ていただいている先輩からよくアドバイスを頂けます。
これはtimes_onoの一幕でして、私がわからない!と言ったことに対して、同期の@hxrxchang君が席に助けに来てくれて、参考になるリンクも貼ってくれたところです。こんな感じで、気軽にSOSが出せて、助けてくれる人が社内にたくさんいる、すごく温かい環境です。
成果物
出来上がったアプリがこんな感じです。
私はレビューで時間をかけたため、ステップ4で考えていたコンセプトの実現は十分には行えず、シンプルに研修プログラムのステップを進めたアプリ、という感じの成果物になりました。ただ、私の場合はレビューで得た知識が評価され、チームで研修内容の共有会を開かせていただきました。
研修のゴールは人それぞれです。私はステップ23まで+研修内容の共有会の開催がゴールになりましたが、今研修中のベトナム人の新卒二人は1ヶ月で早くもステップ25を完了し、オプション要件に取り組んでいます。また、フロントエンドのスキルがあるメンバーはRailsのプログラミングと並行してAngularで画面の作成を行い、操作性に優れた格好いいアプリを作っています。Classiの先輩方に協力してもらい、ユーザビリティテストを行なったメンバーもいます。
研修を終えて
研修を通して、「プログラマーの仕事の大部分は、人への気遣いである」という感想を持ちました。なぜなら、メンターからの指摘事項のほとんどは、「他のエンジニアがアプリをメンテナンスする時に分かりやすい/後で困らないコーディング」についてのアドバイスだったためです。
- こうした方が、他のプログラマーが分かりやすい!
- この方がRailsや他のgemのアップデートに関わらず使える!
- このコメントをつけた方が、レビュアーや他のエンジニアに親切!
などのコメントをたくさん頂くうちに、プログラマーの仕事像が「黙々と実装だけ行えれば良い、他の人とは関わらない」から、「他の人へ気遣い、情報を伝達し、理解して貰えるコードを書く」に変わっていきました。この意識は、現在チームで仕事をする上でも、チームメンバーへの気遣いや、伝わりやすいプルリクエストという形で活きています。
終わりに
この研修について社内の先輩エンジニアに話したところ、「羨ましい」という声を多く頂きました。2ヶ月以上かけてコードの書き方を教えてもらえる機会はとても貴重で、多くのプログラマーは仕事の中でコードの書き方やプルリクエストの仕方を覚えていくそうです。手厚い研修プログラムを組んでいただいたigaigaさん、ただあきさん、わからないところを教えて頂いた先輩エンジニアの皆さん、また充実した研修を受けさせて貰える会社の懐の広さに感謝しつつ、この投稿を締めます。
明日の投稿は@onigraさんです。お楽しみに。
- 投稿日:2019-12-02T09:07:42+09:00
CarrierWaveでpng画像を処理したときに色空間がGRAYになってしまってた
バージョン
- ruby 2.6.1
- Ruby on Rails 5.2.3
- MacOS Catalina 10.15.1
- ImageMagick 7.0.9-5
- gem mini_magick 4.9.5
- gem carrierwave 1.3.1
問題
CarrierWaveでMiniMagickを使って画像を処理する時。例えば、resize_to_fit とかresize_and_pad とか resize_to_fill とかを使うと、png画像の色空間が元々RGBだったのにGRAYになってしまう現象があった。
調査
どうやら、色空間をカラーで持っていても、グレイスケールっぽい画像だとImageMagickがカラースペースをグレイスケールに変換してしまうようだった。
なぜ・・、やめてくれ・・!解決方法
上記した resize_to_fit とかのメソッドには、 combine_options という名前付き引数が渡せる。これはImageMagickのオプションと対応しているので、とにかく大量のものが指定できて、その中で、png画像での色の設定は、
-defineオプションでpng:color-type=?を指定できる。
今回はRGBAで色情報を持ってほしかったので、png:color-type=6となる。つまり、
combine_options: {define: 'png:color-type=6'}を指定することで解決した。
Carrierwaveがどうとかいう問題ではなく、ImageMagick側の話だったようだ。注意
これで解決したんだけど、このオプションは要注意なことが書いてあるので、png:color-typeの説明は見ておいた方が良さそう。
最初は色空間が変わるという現象だったから、combine_optionsに
-colorspace sRGBを指定してたんだけど、これでは問題は解決できなかったのでちょっとハマった・・。
- 投稿日:2019-12-02T07:59:08+09:00
最近勉強して、知った言葉まとめてみた
はじめに
私が最近、知った言葉を、自分なりにまとめてみました。参考にしてもらえると、嬉しいです
ハッシュ化
パスワードを、保管する際に用いられる手法。
平文のパスワードからハッシュ値と呼ばれる値を求め、そのハッシュ値という値でパスワードを保管する手法。暗号化とは違い、不可逆変換であり、元の平文のパスワードに戻すことが不可能である。データベースのNOTNULL制約
データベースに、nullを入れることを許容しない制約。制約をつけることにより、nullが入るとエラーが起きることにより、nullを入れることが出来なくなる。データベースの必須項目などに付けるといいと思います。
キーワード引数(Ruby)
関数を作った際の引数の末尾に
:をつけることで、関数を呼び出す際にどの引数に、どの数や文字、変数を渡すのか指定することが出来る。引数が多くなった場合などに便利。CSSセレクタ
CSSを指定することにより、要素を取得できる。多くのセレクタの種類があり、それらを組み合わせることにより、細かいとこまで指定して、要素を取得できる。おすすめチートシート
最後に
説明が曖昧ですが、もっと上手く説明できるように精進致します。
- 投稿日:2019-12-02T04:24:39+09:00
【Rails】パンクズリストの作り方
まえがき
みなさんパンくずリストは知っていますでしょうか。どこかで耳にした方もいるかもしれません。ちょっと変わった名前ですがbreadcrumbsと書くとかっこいいですね。このパンくずリストですが名前によらずとても便利な物なのでぜひ作り方を覚えましょう。
パンクズリストとは
ホーム>おすすめ一覧>家電製品
のような現在いる位置を視覚的に見ることができる物です。大抵画面上部に用いられることが多いです。
これはよくSEO対策的に使われることが多く、SEOに詳しい人にとってはおなじみなのではないでしょうか。パンクズリストを作るメリットは以下の通りですです。
設置するメリット
ユーザビリティーの向上
パンくずリストを用いることで視覚的に現在いる位置を構造的に見ることができるので、そのwebアプリを使うユーザーがサイト内で迷子になることがなくなり、ストレスなくサイト内巡回をすることができます。また、様々なユーザーはみなトップページからサイトに訪れるわけではなくそれぞれ必要なページに直接飛んでくるので、本当に目的のページを開けているか確認をするという使い方もされます。
検索ページに表示される時がある
googleなどで検索をかけた時にページの説明欄にパンクズリストが表示されているのを見たことがある人もいるかもしれません。パンくずが表示されていると検索ページにいるだけでサイト内の構造を見ることができ、飛びたいページの上層カテゴリも表示されるのでクリック率対策になります。
内部SEO対策
googleはページ内を評価する際に一つ一つのページに飛びリンクの文字などを認識しそのページが有用なのかどうかを判断しています。その際にパンクズリストがあるとその作業がスムーズになるために高く評価されSEO対策に効くとされています。
設置方法
では本題です。今回はRailsでの設置になります。
RailsではGretelというgemを用意してくれています。GitHub
https://github.com/lassebunk/gretelgem "gretel"このようにgemfileの一番下に追加します。
$ bundle installそしてコマンドを打ち、設定ファイルを作っていきます。
$ rails generate gretel:installすると以下のようなファイルが生成されます。
config/breadcrumbs.rbcrumb :root do link "Home", root_path end # crumb :projects do # link "Projects", projects_path # end # crumb :project do |project| # link project.name, project_path(project) # parent :projects # end # crumb :project_issues do |project| # link "Issues", project_issues_path(project) # parent :project, project # end # crumb :issue do |issue| # link issue.title, issue_path(issue) # parent :project_issues, issue.project # end # If you want to split your breadcrumbs configuration over multiple files, you # can create a folder named `config/breadcrumbs` and put your configuration # files there. All *.rb files (e.g. `frontend.rb` or `products.rb`) in that # folder are loaded and reloaded automatically when you change them, just like # this file (`config/breadcrumbs.rb`).今回はマイページを作っていきたいのでrootを設定した後にマイページを表記していきます。
config/breadcrumbs.rb# ルート crumb :root do link "ホーム", root_path end # マイページ crumb :mypage do link "マイページ", mypage_users_path end
crumbs :mypage doはなんという名前でhtml上に表記し呼び出すかを書きます、後々使います。
linkはパンクズリストに表示される文字とそのページがどこのパスに属しているかを表記します。
パンクズリストはリンクになっている場合が多いのでそのリンクはここで設定します。ではビューファイルに表記していきます
mypage.html.haml- breadcrumb :mypage = breadcrumbs pretext: "You are here:",separator: " › "
- breadcrumb :mypageはconfig/breadcrumbs.rbに定義したmypageを呼び出すことができ、
= breadcrumbs pretext: "You are here:",separator: " › "
で表示したい位置を指定することができます。
›という表記はHTML特殊文字と言われる物で>の部分を表記しています。また親子の関係を示すために以下のような表記方法もあります
profile.haml.haml# プロフィール crumb :profile do link "プロフィール", edit_user_path parent :mypage end
parentと表記しdoとendで挟むことによりcrumb :profile doの親を書くことができます。
この表記だと次のような表示になります。
ホーム > マイページ > プロフィール
といった感じでしょうか。まとめ
いかがだったでしょうか、今回書いて行ったパンクズリストは企業としても重宝する技術ですし、習得していて損はないのではないでしょうか。ぜひポートフォリオなどにも実装してみてください!
- 投稿日:2019-12-02T01:22:35+09:00
Rubyで「大石泉スキ」を標準出力する & idol++
この記事は 「大石泉すき」アドベントカレンダー 2日目の記事となります。
2日目は、1日目のPythonに対抗してRubyで標準出力してみます。概要
以下のような方を対象にした内容になります。
- 大石泉P
- 大石泉に興味がある人
- Rubyでプログラミングを始めたいと思っている人
なお、すそ野を広げるという観点にたって記事内のコードは以下の環境で実行しています。
OS: Windows 10 Rubyバージョン: ruby 2.6.3p62 (2019-04-16 revision 67580) [x64-mingw32]とりあえず、Rubyで出力してみよう
初歩的な標準出力
Rubyがインストールされている状態でコマンドプロンプトを立ち上げて以下のコマンドを入力して実行します。
ruby -e "文字列"は"文字列"のコードをRubyが解釈して実行します。
いわゆるevalですね。ruby -e "puts '大石泉スキ'"
複数回出力する
ruby -e "5.times { puts '大石泉スキ' }"
n.times { (処理) }はnで指定した回数分だけ{}内の処理を実行するループ構文です。
この場合はn = 5を指定しているので5回文字列の出力が実行されます。ランダム要素を加えてみよう
文字列を出力するだけでは面白味もないし、 idol++ ではないのでランダム要素を加えてみましょう。
ruby -e "puts ['大石泉スキ', 'idol++', 'ネイビーウェーブ', 'ビット・パフォーマー', 'ニューウェーブ・ネイビー', 'ニューウェーブ・バースデー'].sample"
実行する毎に以下の要素のなかからランダムに出力されます。
Aray#sample を利用しています。
- 大石泉スキ
- idol++
- ネイビーウェーブ
- ビット・パフォーマー
- ニューウェーブ・ネイビー
- ニューウェーブ・バースデー
Rubyのclassファイルを作成してみよう
コマンドラインからの入力だけでは ビット・パフォーマー にはなれないのでRubyでclassを定義してコードを書いてみましょう。
初歩的なclass定義とコマンドラインからの実行
テキストエディタで以下のコードを入力して
izumi.rbという名前で保存します。class Izumi def perform puts '大石泉スキ' end end # コマンドラインから呼び出された時に実行される処理 izumi = Izumi.new izumi.performコマンドプロンプトで以下のコマンドを入力して
izumi.rbを実行します。ruby izumi.rb
irbからの実行
コマンドラインからの実行では1回限りの操作しか行えないので複数回の操作を繰り返して変化が起こるようにしてみましょう。
まずは、Rubyの対話型の実行環境であるirbを立ち上げましょう。
--noreadlineオプションをつけないと日本語入力が行えないので気を付けてください。irb --noreadline以下のようにRubyのコードを実行することができます。
izumi.rbを以下のように書き換えます。class Izumi def initialize @idol = 0 end # Rubyはインクリメント演算子がないので全角文字を利用したメソッド名にしています def idol++ @idol += 1 end def perform puts '大石泉スキ' idol++ if @idol % 3 == 0 idol_rank = @idol / 3 puts '' puts "大石泉のアイドルランクが上がった! => アイドルランク #{idol_rank}" end @idol end end
izumi.rbファイルのあるディレクトリに移動してirbを起動し、以下のコマンドを入力してizumi.rbの内容をirbに読み込みます。require './izumi'class定義から
izumiインスタンスを作成してperformメソッドを呼び出します。izumi = Izumi.new izumi.perform
performメソッドを呼び出す毎にidol++されて3回毎にアイドルランクがアップしていきます。




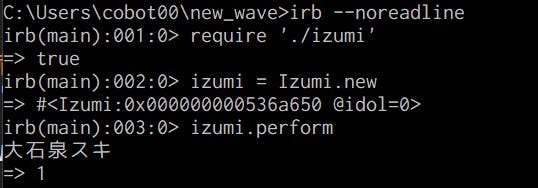
- 投稿日:2019-12-02T01:20:34+09:00
Active Storageを用いた複数ファイルアップロード機能の実装〜過程〜
今日のアウトプット
Railsから、
「Argument is too long」
というお叱りを受け、Active Storageでのファイルアップロード機能実装からの、Pythonプログラムにコントローラーでアップロードしたファイルを渡す部分を修正。開発環境
Rails 5.2
Ruby 2.4
MySQL 14.14ファイルアップロードの流れと実現したいこと
1,3つのファイルをViewからアップロードさせる。
new.html.erb<div id="input-search"> <%= form_with model: @context, local: true do |form| %> <%= form.file_field :files, multiple: true %> <%= form.submit "プログラムを実行する" %> <% end %> </div>2,inputされたファイルをDBに登録し、登録したファイルのフルパスを取得する。
contexts_controller.rbclass ContextsController < ApplicationController def new @context = Context.new end def create @context = Context.create context_params redirect_to context_path(@context.id, path_info) #→このように、paramsにそれぞれのファイルのフルパス が入ったarrayを渡して、showアクションに飛ばしたい。 end def show @context = Context.find(params[:id]) @file_result = ` python3 /~~/test.py "#{フルパス}" "#{フルパス}" "#{フルパス}" ` end private def context_params params.require(:context).permit(files: []) end def params_info params[:context].permit! end end現状、どのような情報がViewからコントローラーへ渡っているのか?
View(new.html.erb)からControllerのcreateアクションに渡る際のparams内容↓
Parameters: {"utf8"=>"✓", "authenticity_token"=>"L3qyctBHnYGUObv4Hgs/9+TuGhy+/Xpp2sCMQbTdI8l3uEM/sH+didAiDvATkr8exoH7ZE/aHNfm6OmUC2AHqw==", "context"=>{"files"=>[#<ActionDispatch::Http::UploadedFile:0x007fd74d3eb620 @tempfile=#<Tempfile:/var/folders/9j/zkxb427x5zd1xjty84shsmk80000gn/T/RackMultipart20191201-676-1k0ld8p.txt>, @original_filename="testtest_1.txt", @content_type="text/plain", @headers="Content-Disposition: form-data; name=\"context[files][]\"; filename=\"testtest_1.txt\"\r\nContent-Type: text/plain\r\n">, #<ActionDispatch::Http::UploadedFile:0x007fd74d3eb5d0 @tempfile=#<Tempfile:/var/folders/9j/zkxb427x5zd1xjty84shsmk80000gn/T/RackMultipart20191201-676-1jnpfkq.txt>, @original_filename="testtest_2.txt", @content_type="text/plain", @headers="Content-Disposition: form-data; name=\"context[files][]\"; filename=\"testtest_2.txt\"\r\nContent-Type: text/plain\r\n">, #<ActionDispatch::Http::UploadedFile:0x007fd74d3eb558 @tempfile=#<Tempfile:/var/folders/9j/zkxb427x5zd1xjty84shsmk80000gn/T/RackMultipart20191201-676-1komhhu.txt>, @original_filename="testtest.txt", @content_type="text/plain", @headers="Content-Disposition: form-data; name=\"context[files][]\"; filename=\"testtest.txt\"\r\nContent-Type: text/plain\r\n">]}, "commit"=>"プログラムを実行する"}ファイルを3つアップロードさせたので、paramsには、「ActionDispatch::Http::UploadedFile」クラスのオブジェクトが3つ生成されていることが確認できる。それぞれを分けて別々に記載すると、、
<ActionDispatch::Http::UploadedFile:0x007fd74d3eb620 @tempfile=#<Tempfile:/var/folders/9j/zkxb427x5zd1xjty84shsmk80000gn/T/RackMultipart20191201-676-1k0ld8p.txt>, @original_filename="testtest_1.txt", @content_type="text/plain", @headers="Content-Disposition: form-data; name=\"context[files][]\"; filename=\"testtest_1.txt\"\r\nContent-Type: text/plain\r\n">#<ActionDispatch::Http::UploadedFile:0x007fd74d3eb5d0 @tempfile=#<Tempfile:/var/folders/9j/zkxb427x5zd1xjty84shsmk80000gn/T/RackMultipart20191201-676-1jnpfkq.txt>, @original_filename="testtest_2.txt", @content_type="text/plain", @headers="Content-Disposition: form-data; name=\"context[files][]\"; filename=\"testtest_2.txt\"\r\nContent-Type: text/plain\r\n">#<ActionDispatch::Http::UploadedFile:0x007fd74d3eb558 @tempfile=#<Tempfile:/var/folders/9j/zkxb427x5zd1xjty84shsmk80000gn/T/RackMultipart20191201-676-1komhhu.txt>, @original_filename="testtest.txt", @content_type="text/plain", @headers="Content-Disposition: form-data; name=\"context[files][]\"; filename=\"testtest.txt\"\r\nContent-Type: text/plain\r\n">]}上記のようになっている。
3つのファイルのフルパス取得実現のために試したこと(コメントアウトして書いてあります)
その1
→上記で確認したparamsの内容から、@tempfileについての情報を抜き出せば良いと考えた。
ContectsControllerclass ContextsController < ApplicationController def new @context = Context.new end def create @context = Context.create context_params #その1 paramsからtempfileについての情報を抜き出して、配列化し、それをparamsに渡して利用する。 path_info = [] path_info.push(params[:context][:files][0].tempfile) path_info.push(params[:context][:files][1].tempfile) path_info.push(params[:context][:files][2].tempfile) redirect_to context_path(@context.id, path_info) end def show @context = Context.find(params[:id]) @file_result = ` python3 /Users/~省略~/test.py "#{フルパス}" "#{フルパス}" "#{フルパス}" ` end private def context_params params.require(:context).permit(files: []) end def params_info params[:context].permit! end end・createアクションで一度動作を止めて、path_infoに意図した情報が入っているか確認。
>> path_info => [#<Tempfile:/var/folders/9j/zkxb427x5zd1xjty84shsmk80000gn/T/RackMultipart20191201-676-1gr9kjh.txt>, #<Tempfile:/var/folders/9j/zkxb427x5zd1xjty84shsmk80000gn/T/RackMultipart20191201-676-1dw6zqz.txt>, #<Tempfile:/var/folders/9j/zkxb427x5zd1xjty84shsmk80000gn/T/RackMultipart20191201-676-1j304y7.txt>]それぞれのファイルのフルパスがしっかりと代入されているのがわかる。
・showアクションで一度動作を止めて、paramsにpath_infoに渡したフルパスが入っているかを確認。
<ActionController::Parameters {"controller"=>"contexts", "action"=>"show", "id"=>"92", "format"=>"#<File:0x007fd74e106558>/#<File:0x007fd74e948130>/#<File:0x007fd74e928f60>"} permitted: false>formatとして、意図していない情報が入っている。フルパス を渡したはずなのに・・・
この時点で詰まりそうな予感がしている。その2
params file read について
Ruby on Rails master@23b7382→上記サイトからの情報を参考にし、「ActionDispatch::Http::UploadedFileのインスタンスに対して、readメソッドを使用することができる」とのことだったので、それぞれアップロードしたファイルの要素に対してreadメソッドを適用してみた。同様に、pathメソッドについても試して見た。
ソースコード(.readメソッド)
ContextsControllerclass ContextsController < ApplicationController def new @context = Context.new end def create @context = Context.create context_params path_info = [] #その2 @temfileを用意し、paramsからそれぞれ情報を取り出して.readメソッドをかける。これについてはソースサイトがあったのだが、、 @tempfile_1 = params[:context][:files][0].read @tempfile_2 = params[:context][:files][1].read @tempfile_3 = params[:context][:files][2].read path_info.push(@tempfile_1) path_info.push(@tempfile_2) path_info.push(@tempfile_3) #結果=> path_infoには何も代入されない。["","",""]となる redirect_to context_path(@context.id, path_info) end def show @context = Context.find(params[:id]) @file_result = ` python3 /Users/~省略~/test.py "#{フルパス}" "#{フルパス}" "#{フルパス}" ` end private def context_params params.require(:context).permit(files: []) end def params_info params[:context].permit! end end・createアクションで一度動作を止めて、path_infoに意図した情報が入っているか確認。
>> path_info => ["", "", ""]そもそもパスが取れていないので、これ以上は何もしない。
ソースコード(.pathメソッド)
ContextsControllerclass ContextsController < ApplicationController def new @context = Context.new end def create @context = Context.create context_params path_info = [] @tempfile_1 = params[:context][:files][0].path @tempfile_2 = params[:context][:files][1].path @tempfile_3 = params[:context][:files][2].path path_info.push(@tempfile_1) path_info.push(@tempfile_2) path_info.push(@tempfile_3) redirect_to context_path(@context.id, context_params) end def show @context = Context.find(params[:id]) @file_result = ` python3 /Users/~省略~/test.py "#{フルパス}" "#{フルパス}" "#{フルパス}" ` end private def context_params params.require(:context).permit(files: []) end def params_info params[:context].permit! end end・createアクションで一度動作を止めて、path_infoに意図した情報が入っているか確認。
>> path_info => ["/var/folders/9j/zkxb427x5zd1xjty84shsmk80000gn/T/RackMultipart20191202-676-1y9ie46.txt", "/var/folders/9j/zkxb427x5zd1xjty84shsmk80000gn/T/RackMultipart20191202-676-ppvmbd.txt", "/var/folders/9j/zkxb427x5zd1xjty84shsmk80000gn/T/RackMultipart20191202-676-15y9jdz.txt"]pathメソッドがそれぞれのpathを取得してくれた。
これをparamsに絡めて、showアクションへと送れば良い!!しかし、実際にやってみると、そんなURLはないぞ!とルーティングエラーが出てしまったので、そもそもparamsに絡める方法はダメなことがわかった。(今までなんとかparamsに絡めようとしていたのが馬鹿だったんだ)
しかし、pathメソッドを用いることで、それぞれのファイルのpathを得ることはできた。
ということはだ。paramsに絡めずに、createアクションで取得した取得した内容を、showアクションへ渡せばいい。
しかし、どうすれば良い??
考えついたのは以下の2パターン、これ等でいいのか?を吟味しよう。
・アクションの遷移に伴って、paramsには情報を含めずに、別の形でクラスインスタンスメソッド間でのやりとりをする方法を探す。
・クラスインスタンスメソッド(createアクション)が呼ばれた場合、欲しい値を取得するためのメソッドを新たに定義し、クラスインスタンスメソッド(showアクション)でこのメソッドを呼び出して、欲しい情報を取得する。
これ等について調べていこう。
- 投稿日:2019-12-02T00:19:26+09:00
プログラミング未経験者向けにRubyワークショップをやった話
【島根県内学生限定】初心者向けプログラミング講座を実施する機会をもらったので、
そこで、やったこと、わかったこと、次にやることをまとめて残しておく(YWT)。用意した題材
やったこと(Y)
- プログラミングとはなにかを伝える
- チームで取り組む楽しさを伝える
- 参加者に次のステップを伝える
今回は題材として、Railsを使わない素の状態のRubyを使用。
島根県が推しているということもあるけど、県内にしっかりしたコミュニティがあること、学生の間は授業やイベントで触れる機会が多いことが大きな選定理由。もし、職業としてのソフトウェアエンジニアに進むなら、遅かれ早かれ複数言語に触れることになるだろうし、県外に出ると「じゃあ、Rubyできるんでしょ?」と聞かれることもそれなりにあるので、触れたことがあるのは無駄にはならない(と思う)。
プログラミングの初期に学んでもらいたいこと様々あるけど、今回はプログラミングが目的達成のための道具という観点から、手ごろな課題に対して手持ちの武器(知識)をひねくり回して解決することを第一に。
ずっと以前に、勉強会で体験したDevnomiを下敷きにして「ポーカーの役判定プログラムをつくる」「みんなでひとつの画面をみながらキーを叩く人間を交代しながら」「用意されたテストコードをクリアする」というかたちで企画した。コードを書くこと自体は、孤独にやらざるをえない場合も多いけど、同じようなレベルの人間が集まってわいわいやる楽しさを通して、学ぶことでレベルアップしていき、できることが増えるという正のフィードバックがあるということを体験してもらいたかった。
ちょっと前とはまた状況が変わったようで、情報関係の学生であっても自分のパソコンを持っていないことも多いので、無料のクラウドIDEPaiza CloudとGitHubを組み合わせることで、ワークショップ後も持ち帰って再現したり、続きに取り組めるようにすることで、エコシステムの一端に触れつつ、今後プログラミングに触れる際の足掛かりとしてもらうことを期待。
わかったこと(W)
- 講座資料にScrapBoxがとても便利
- モブプロはチーム学習として有効
- 未経験者には構造化の話がもっと必要
講座の資料作成は、ScrapBoxがとっても便利だった。全体の構成を粗くきめておきつつ、細部を思いつく都度作り込んでいくというやり方で資料作成をするのにぴったり。後からの推敲もとてもやりやすい。簡単なプレゼンテーション機能もついているので、資料=プレゼンテーションにもなり、最初にURLを共有すれば完全にペーパーレスで実施することができる。
加えてワークショップなので手を動かしてもらうシーンも多いのだけど、説明にスクリーンショットを追加したかったらGyazoと連携した画像の貼り付けで一発だし、シンタックスハイライトは完璧とはいわないけど、サンプルコードも組み込みやすく、臨機応変に資料を改変&共有するのには、ものすごく便利だった。今回は初心者向けとターゲットを設定していたけど、次のイベントにつなげるという目的があるため、割と難しめのハードルをぶつけて、そこをチームで会話、協力しながら超えてほしいという期待を参加者にぶつけてみた。
これがうまくいった部分、いかなかった部分はあったけど、チームの中で議論しながらつくることを強制するやり方は、ある程度機能しており、事後アンケートでもチームだからついていけたという感想も得られた。学習については、とっかかりができればある程度ひとりでも進めることができるが、推進力=楽しさや好奇心というモチベーションは、体験や仲間がいることで得やすくなってくれると考えた。とはいえ、サポートで各チームをまわっていると、比較的初歩の部分のとっかかりでつまづいたり、苦労していたので、導入部分のステップをもっと小刻みにしたり、例題を増やして理解度をサポートする小さな階段、をもっとつくるべきだったと痛感した。
参加者アンケートでは配列、ハッシュあたりから理解に苦労したという話もあったが、加えてチームで議論を進めるためには、メソッドの分割とか構造化のあたりの設計よりをもうちょっと丁寧にやらないといけなかったと感じた。次にやること(T)
主に課題、資料のブラッシュアップの観点で、3つ。まだまだ改善の余地はいろいろある。
- 構造化の観点の追加
- シンプルなアルゴリズムの実装例題
- よりよく書く観点の追加
「この部分をプライベートメソッドとして切り出して」とか、モノシリックなメソッドではなく、ある程度構造化するという考え方について、今回思い切り抜けてしまっていたので、ここは本当に簡単な例題を用意するなり対策が必要だった。
また、初歩のアルゴリズムの例題もなにかあったほうがスムーズだった。カードの並び替えにしても、たしかにEnumerableのsort使えば確かに一発なんだけど、いったんべったべたな実装でバブルソートを実装してみて、それを少しずつ改善して読みやすくして、最終的にはこの便利メソッド使って、と漸進的に進化させることを体感してもらったほうがよかった。
外のワークショップでもほとんどの場合、やりたいことから逆算して、必要なものを調べながら学ぶという方法をとっているのだけど、未経験者向けにやるということから、もっと足がかりとなるとなる材料が必要だった。これは、当日その場で出したような直接的なサンプルより、もっと抽象度をあげたアルゴリズムの形で例題を事前にこなすよう、1日目のインプット時間の使い方を変えた方がよかった。参考サイト、当日持ち込んだ書籍等
イラスト素材