- 投稿日:2019-12-02T23:11:03+09:00
headlessなChromeをPHPで操作する(2)
概要
(PHPで)headless ChromeをDevTools Protocolを使って操作してみようという前回の記事の続きです。
前回の記事作成からおよそ2年経過していますが、2019/12現在でもたまーにストックされたりしているので書きます。今回はフォーム操作についてです。具体的にはHTML上のtext inputに任意のテキストを入力してsubmitするという内容になります。
今回のお話を元にまとめたものがこちらにあります。
おさらい
細かな部分は前回の記事を参照ください。ざっくりとおさらいすると、
- headlessなChromeの操作はDevTools Protocolという名前で定義されている
- Chromeを起動すると開く特定のendpointに対してWebSocketを使い、JSON形式でやりとりすることによって操作ができる
- WebSocketで通信できれば良いので、実はこの記事の話はPHPに限らない話
- 前回同様、サンプルコードは
textalk/websocketを使ってますフォームにテキストを入力する
今回の流れとしては、以下の通りです。
- DOMのルートノードを取得(#document)
- document.querySelector('...')的に対象ノードである
<input>を取得- テキストを入力する
<form>をsubmitDOMのルートノードを取得
ドキュメントを読むと、そのものずばり
DOM.getDocumentというメソッドが用意されているのでまるっと使います。今回はrootNodeだけ取れれば十分なのでdepth=0を明示的に指定しました。idを指定してmethodを呼ぶと、レスポンスは呼び出し時のidを持って返ってくるので、どの呼び出しに対するレスポンスかはidを見て判断することになります。
$client = Client($endpoint); ...(中略)... // ここまででhttps://google.comに遷移しているものとする $client->send(json_encode(['id'=>10,'method'=>'DOM.getDocument','params' => ['depth' => 0])); $rootNode = null; while($data = json_decode($client->receive()){ if(isset($data->id) && $data->id === 10){ $rootNode = $data->result->root; break; } }対象ノードを取得
対象ノードの取得は、これまたずばり
DOM.querySelectorで大丈夫そうです。パラメータは親にあたるnodeIdとselectorの文字列になります。nodeIdには先程取得したrootNodeのnodeIdを指定してあげます。(jsでいうdocument.querySelector()のイメージですね)ちなみに、呼び出し時のidは前回の処理が確実に終わってるのであれば、重複しても問題ないです。
$client->send(json_encode([ 'id'=>10, 'method'=>'DOM.querySelector', [ 'nodeId' => $rootNode->nodeId, 'selector' => 'input[name=q]' ] )); while($data = json_decode($client->receive()){ if(isset($data->id) && $data->id === 10){ print_r($data->result->nodeId); // this is nodeId! yay! break; } }テキストを入力
テキストの入力は
DOM.setAttributeValueやDOM.setNodeValueでも出来そうな気配がありますが、せっかくブラウザということもあるので入力をエミュレーションしてみようと思います。とは言っても、1文字1文字キーボードの入力をエミュレーションすると面倒なので、テキスト単位で入力していきます。※UIテストなどで1文字1文字入力したい場合は、1文字1文この手順を1文字単位で繰り返せば良いはず。厳密性が必要であれば
Input.dispatchKeyEventを使用する先程のコードに
1) focus,2) insert textという手順を足します。$client->send(json_encode([ 'id'=>10, 'method'=>'DOM.querySelector', 'params' => [ 'nodeId' => $rootNode->nodeId, 'selector' => 'input[name=q]' ] )); while($data = json_decode($client->receive()){ if(isset($data->id) && $data->id === 10){ $client->send(json_encode([ 'id' => 11, 'method' => 'DOM.focus', 'params' => ['nodeId' => $data->result->nodeId ] ])); } elseif(isset($data->id) && $data->id === 11){ $client->send(json_encode([ 'id' => 12, 'method' => 'Input.insertText', 'params' => ['text' => 'Qiita'] ])); } elseif(isset($data->id) && $data->id === 12){ break; //break while loop } }こうして、id11でノードにフォーカスし、id12でテキストを流し込みました。この状態で、Chromeを落とさずhttp://localhost:9222にアクセスすると、まさにこの状態の様子を見れます。
submitする
submitにもいくつか方法があります。1つはevaluateで
form.submit()を実行してあげる。もう1つはボタンの画面上の座標を取得し、MouseイベントのClickを発火させるという方法です。ただ、画面上の座標を取得するのに結局evaluateでbutton.getBoundingClientRect()しなければならないので、ここではさくっと前者で実装します。
evaluateはRuntime.evaluateにexpressionを送ればよいので非常に簡単です。もとより、focusやinputも全部evaluateでやればいいんじゃないかという話もありますが、調べることに意義があるのです!$client->send(json_encode([ 'id'=>10, 'method'=>'Runtime.evaluate', 'params' => [ 'expression' => 'document.querySelector("form[name=f]").submit()' ] )); while($data = json_decode($client->receive()){ if(isset($data->id) && $data->id === 10){ //submit! } if(isset($data->method) && $data->method === Page.frameStoppedLoading){ // ..(中略).. キャプチャするなりタイトル取得するなり } }確認
繰り返しになりますが、あらかじめChromeをheadlessで起動しておき、
http://localhost:9222にアクセスすると状況が確認できますので、無事、検索結果が表示されているのを確認してください。さいごに
これでDevToolsProtocolを使って、UIテストも出来るようになりましたね!やったァ!
Seleniumやpuppetterがあるのになんでそんな遠回りするか? それは、私にもわかりません。
蛇足
今回のお話までをphpのライブラリにしました。気が向いたら、再び2年後あたりに他の機能も追加していくかもしれません。
https://github.com/nearprosmith/php-headless-chrome
Twitterのログインの例
$chrome = new Chrome('/Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome'); $page = $chrome->getPage(0); $page->moveTo('https://twitter.com/login'); $page->type('form.signin input[name="session[username_or_email]"]','username'->type('form.signin input[name="session[password]"]','password')->submit('form.signin'); $page->waitForLoading(); $page->captureTo('./capture3.png');
- 投稿日:2019-12-02T19:28:09+09:00
2019年phpカンファレンス②~弁護士ドットコムを作り続ける開発組織について~
2019年phpカンファレンスでの『弁護士ドットコムを作り続ける開発組織について』の講演について、思ったことをまとめてみました。
講義資料
https://speakerdeck.com/bengo4com/about-bengo4com-development-organization
話を聞いてみて
エンジニアにとって働きやすい環境を整えるのは大事だなぁと思いました。
プログラマが最大の力を発揮するために、十分に働ける環境を提供する。またプログラマはそれにこたえる。
この関係性をしっかりと作っていくことが大切だなぁと思いました。エンジニアの働きやすい環境の実現に向けて
技術選定の方針
エンジニアには新しい技術を知ったり使ってたりすることへの欲求は一定量あります。
それの解決として、新しい技術をどこで用いるか、最大限のリスク回避をしながらどのように進めていくか、というかじ取りは必要なんだと思いました。「コア機能の開発」で完全に新しい技術を入れようとしても、リスクが大きすぎる。コア機能では運用をメインとして、リスクが少ないことがわかってから新技術を入れていくべきだと思いました。
逆に新規案件では新しい技術を積極的に入れていく思想はとても大事になります。
ここで既存技術を使い、今まで通りの開発をやってしまうと、そのシステム自体にブレイクスルーが起こらず、無難な機能が出来上がる恐れがあります。新規の人はどれだけチャレンジできるか(影響は小さく、衝撃は大きい)、
コア機能の運用ではどれかけ堅実なものとなるか(影響は大きく、衝撃は小さい)。新たな技術を導入しようとしているシステムがどのような立場のシステムなのか、影響度を考えたうえで、リスクを取っていく必要があるなぁと感じました。
マネージドサービスの活用
リソースを自社だけでなく、外に求め、外部委託をどんどん行っていく。
これにより自分たちにしかできない自社サービスの開発に注力できるようにはなります。
一方で何か起こった時への対応が遅れてしまうのも事実。
この辺りのバランス感は難しいんだろうなぁと思いました。
Tech Focus Day
何これ、最高!
負債は常に返せるようにしておかないと!!エンジニアの働きやすい環境とは
エンジニアはわがままな生き物だ。
全部自由にできるようになったらなったで、不満が出るし、かといって、色々制約しても嫌だという。やりたいこととやるべきことをちゃんと見極めて、最大パフォーマンスを出せるように環境提供していくことが重要なのかなぁと思いました。
- 投稿日:2019-12-02T19:24:26+09:00
オープンソース CMS「eZ Platform」
eZ Platform とは
https://ezplatform.com/
eZ Platform は PHP で開発されている オープンソース のエンタープライズ向け CMS です。ノルウェー王国の eZ Systems 社によって1999年から eZ Publish として開発されてきました。
12月1日現在の最新安定版のバージョンは eZ Platform 2.5.6 (LTS) 、最新開発版のバージョンは 3.0.0-beta3 です。
eZ Platform の特徴
- 開発元企業 (eZ Systems 社) による 有償サポート
- フレームワークに Symfony をフルスタック採用
- コンテンツを視覚的な階層構造で管理できる ツリー表示
- ユーザーを階層的に整理できるユーザー管理
- ユーザー権限の詳細な設定が可能な権限管理
- ユーザーも含めて項目を自由に編集できるコンテンツタイプ機能
- 同一コンテンツを複製せずに複数配置できるロケーション機能
- 同一コンテンツに複数の翻訳言語を登録できる 多言語対応
- 同一コンテンツに複数のテンプレートを持たせられるサイトアクセス
eZ Platform に適したサイト
- 部署やユーザー数が多い組織で利用するサイト
- ユーザーやコンテンツの内容に応じて細かく権限を設定する必要のあるサイト
- 同一コンテンツを複数の出力(テンプレート)で配信するサイト
- 多言語展開が必要なサイト
- コンテンツの階層構造が複雑なサイト
- コンテンツの種類や決まった入力項目が多いサイト
システム要件
Requirements - eZ Platform Developer Documentation
システム 要件 OS Linux Web サーバー Apache 2.4
Nginx 1.12, 1.14DB サーバー MySQL 5.7, 8.0
MariaDB 10.0, 10.1, 10.2, 10.3
PostgreSQL 10 以上PHP 7.1
7.2
7.3Cluster Redis 3.2 以上
Solr 6
NFS or S3
Varnish 5.1 or 6.0LTS
Fastly

- 投稿日:2019-12-02T19:08:59+09:00
SpreadSheetを簡易データベースのように使う最も簡単な方法
この記事は StudioZ Tech Advent Calendar 2019 の6日目の記事です。
先日、ちょっとしたWebサイトの開発において不定期で企画側で表示上の数値を変更したいという要望がありました。
そんなとき、SpreadSheetなら誰でも扱えるし、スマートフォン上からでも操作できるし、DBマスタのように使う事ができればエンジニアの手を使わずに好きなタイミングで更新できるよね、ということで調べ、対応した内容を手順を追って記述します。新しいSpreadSheetを作る
特になにも考えず、新しいシートを作りましょう。
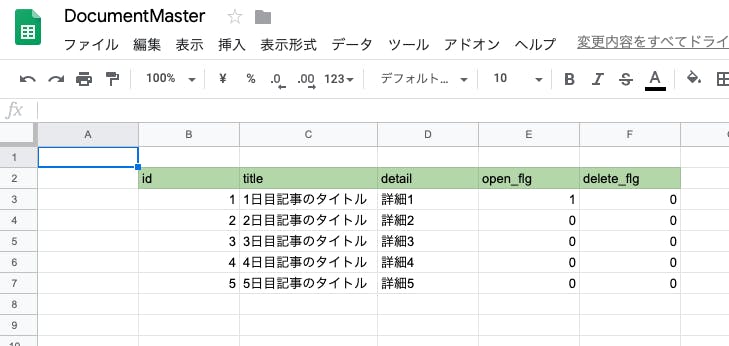
https://docs.google.com/spreadsheets/createDBのごとく必要な情報をまとめる
以下の画像は記事のマスタを扱うような感じで捉えてもらえればいいです。
id、title、detailはそのままキー名の通り、delete_flgは削除フラグとして。
開発環境と本番環境があるとして、open_flgが立っていたら本番で公開等、考えていただければいいでしょう。さて、早くも公開です
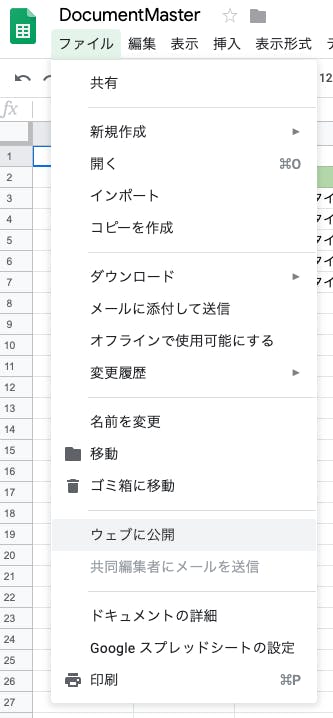
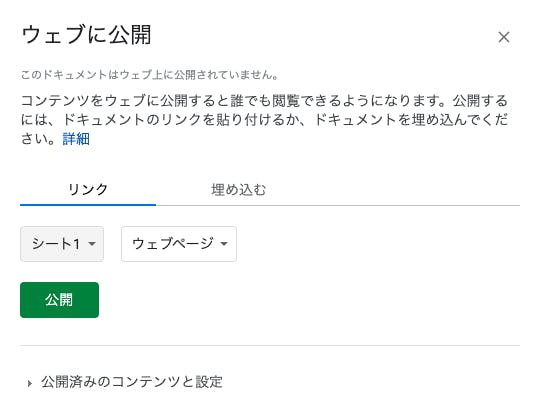
早くも作成したSpreadSheetを公開します。
画像のとおり、[ファイル]→[ウェブに公開]→[公開]で公開できます。
さて、ここで疑問に思った人も多いでしょう。
そんなことしたらこのファイルは誰でも閲覧できるようになってしまうのでは?
お察しの通り、この方法では編集はできないまでにしてもpre_flgが立っていてもdelete_flgが立っていても、この公開urlの存在を知ってしまった人は全員アクセスできてしまうのです。
このため、秘匿したい情報を含む場合はこの方法を使用することをおすすめしません。
(全体公開しない方法は「最も簡単な方法」ではなくなるのでまたの機会に・・・)公開したSpreadSheetをJson化する
サーバ側で扱うために取得はJsonで行います。
なんら難しいことはありません。例えば、SpreadSheetのurlが以下だとします。
https://docs.google.com/spreadsheets/d/1n6_Ix7VHcswzjcWN3tRE8h3qF-uCQ9ywojAtZXrl8g0/edit#gid=0コレに対して、jsonで取得する場合は、以下のようになります
https://spreadsheets.google.com/feeds/list/1n6_Ix7VHcswzjcWN3tRE8h3qF-uCQ9ywojAtZXrl8g0/od6/public/values?alt=json見ての通り、今回使用したSpreadSheetのシートIDは元のurlより
「1n6_Ix7VHcswzjcWN3tRE8h3qF-uCQ9ywojAtZXrl8g0」であることがわかります。jsonで取得する場合は、このIDを以下に当てはめてあげるだけです。
https://spreadsheets.google.com/feeds/list/{シートID}/od6/public/values?alt=json以下のような感じで取得できると思います。
これでSpreadSheet側の準備は整いました。
このJsonをサーバ側で取得し、整形して表示します。サーバ側でJsonを取得・整形する
今回はサンプルとしてphpで記述します。
必要な情報だけを引っこ抜きます。getSpreadSheetData/** * 対象のスプレッドシートデータを取得 * @return array */ public function getSpreadSheetData($sheetId){ $data = "https://spreadsheets.google.com/feeds/list/{$sheetId}/od6/public/values?alt=json"; $json = file_get_contents($data); $json_decode = json_decode($json, true); $list = $json_decode["feed"]["entry"]; foreach ($list as $key => $item) { foreach ($item as $id => $value) { if (!preg_match("/^gsx/", $id)) { unset($list[$key][$id]); continue; } $list[$key][str_replace('gsx$', '', $id)] = $value['$t']; unset($list[$key][$id]); } } return $list; }以上で終了です。
とても簡単ですよね!ただ、この方法は前述した「urlを知っている人は誰でも閲覧できてしまう」点以外にも、
アカウント(SpreadSheetの所持側)あたり100秒間に100リクエストの制限が存在するという弱点も存在します。
アクセスが多いサイトではそのまま使用しないほうがいいでしょう。
もちろん、キャッシュ等を使用してアクセス回数が100秒/100リクエストを超えないように操作すれば問題ないと思います!もし、他人から閲覧されたくない場合やもう少し込み入ったことをしたい場合は、SheetsAPIを使用しましょう。

- 投稿日:2019-12-02T18:50:41+09:00
laravel初歩的シンタックスエラー
laravel覚えようとlogin機能作成中につまづいた
syntax error, unexpected 'extends' (T_EXTENDS)シンタックスエラー起こしてたから調査
***.blade.phpファイルだから【<?php】いらないんだよね
ってだけ
削除したら正常に動作した。<?php @extends('layout')
- 投稿日:2019-12-02T18:30:29+09:00
Lumenを実用的に使うあれやこれや(シャーディング、Writeの遅延対策)
本記事は、サムザップ Advent Calendar 2019 #1 の12/10の記事です。
私のチームでは、サーバ側のフレームワークとして「Lumen」を使用しています。私は3年ぐらい前から「LumenかわいいよLumen」とずっと愛でてたのですが、いざ実用にしようとするといろいろハードルがありました。それらを紹介できればと思います。
■Lumenとは?
Lumenは、Laravelという現在人気のフレームワークからいろいろそぎ落として作られたマイクロフレームワークです。
PHPで出来ていて、Laravelより速度は速いぶん、Laravelの機能も一部はあとから足せたり、DBのORMとしてEloquantも使えるという、マイクロフレームワークにしてはなかなか便利なものに仕上がっています。
Laravel直系ということもあり、ドキュメントも豊富なLaravelのを読めば、ある程度理解できるのもよいとこかなと思っています。■Lumenにデフォルトであるものとないもの
弊社のゲームはなかなか高負荷になりがちで、負荷対策を施すのが必須になっています。また、チーム開発であり、コンテナでの開発も進めています。
その視点ではLumenは「持ってるもの」「持ってないもの」があります。・持っているもの
データベースのRead/Writeの参照先を分ける機能
マイグレーション
各種キャッシュ・持ってないもの
データベースの水平分割(シャーディング)
データベースのRead/Writeを分けることによる書き込み遅延対策
速いコレクション(Ver. 6.0以降の遅延評価がついて良くなりました)■Depotによる遅延書き込みとRead/Writeの書き込み遅延対応
Lumenはデフォルトで、Read/WriteのDBアクセスを分ける機能があります。ただ、書き込みにはやや時間がかかり、素のままでは、すぐ読み込みを走らせると、更新されたデータになりません。いくら高性能なAuroraでもこの現象はおきます。
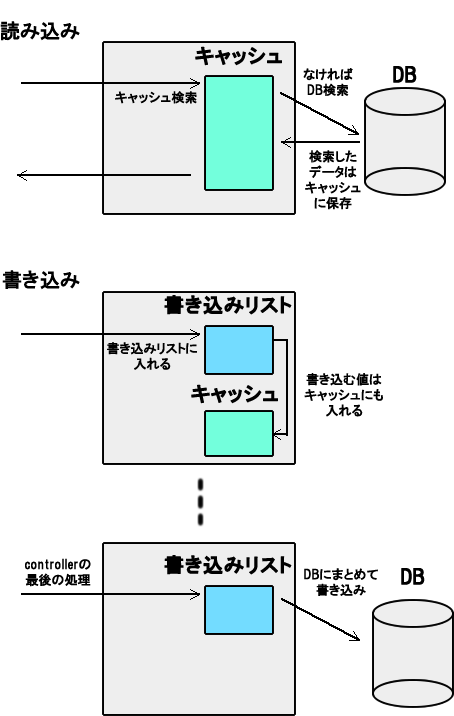
読み書きを同じDBにしてしまえば解消しますが、やはりパフォーマンスに問題があります。またクエリキャッシュと組み合わせるとさらに複雑になります。そこで以下のようにしてみました。
- 値の読み込みはキャッシュを対象とし、そこになければDBから読み込む
- 値の書き込みはキャッシュに行い、書き込みリストに入れておいて、この時点では書き込まない
- Controllerの最後でDB書き込みを実行する
図1
この仕組みを「Depot」と呼ぶことにしました。リクエストが来たら「Controller」「Library」「Depot」「Model」という順に呼ばれてデータをもらえます。このとき「Library」から「Model」を呼び出すのを原則禁止しています。
キャッシュについてはapcを使い、格納するリストには素直にLarabelのCollectionクラスを使いました。ただやはり重いので、whereとかは使わず、検索はforeachで済ませるようにしました。
いろいろやってこういう形に落ち着いたのですが、それでもアクセスが連続するAPIがあるときは、やはり古いものが読まれる現象がありました。そのときはトランザクションをかけて、読み書きを同一のDBにしたり、APIをまとめたりしました。
この状態で負荷試験をかけたところ、かなりよい成績が出せてよかったです。またコード的にはモデルにいろいろ書かずに済み、すっきりした感じはします。■Lumenでの水平分割
あまり資料がない部分で、フレームワークにないところです。みんなどうしているんでしょうね?
いくつかの実装が公開されているのですが、以下の点でどうしたものかなと思い、独自に実装しました。
・カードや武器は、強化などでユーザーが指定して使うため、ユニークなIDを持たせたい。とするとこのIDにシャード情報がないと、DBアクセスに困る
・ユーザーIDでシャーディングしたい。このユーザーIDはアプリでユニークにしたい
・ユーザーIDは通信に乗せない。シャーディングは内部で完結しているので、アプリからのアクセスで特定する何かしらが必要この処理もDepotで吸収しようかと思ってましたが、結局モデルでの分割となりました。
まずユーザーIDとは「ユニークID」+「シャーディング情報(テーブルやDBの番号)」の2つの組み合わせで実現しています。これはLumenのアクセサを使って、呼び出し側から見るとユニークなIDが割り当てられているように見せかけています。
クライアントからはUserKeyと呼ばれるワンタイムパスワード的なものが送られてくるので、それとユーザーIDを紐づいたものをRedisのキャッシュに乗せておきます。
ユーザーIDがわかったところで、ベースモデルクラスでは、地道に呼ばれるメソッド(saveやwhere)ごとに、このIDからシャーディング先を得て処理しています。
saveの場合はこんな感じです。public function save(array $options = []) { foreach ($this->sharding_type_list as $type) { $key_name = $type . '_shard_key'; if ($this->$key_name === null) { continue; } foreach ($this->$key_name as $column => $method) { $shard_key = $this->getAttributeFromArray($column) ?? null; if ($shard_key === null) { continue; } $this->setShardedParameter($type, $method, $shard_key); break; } } return parent::save($options); } protected function setShardedParameter(string $type, string $method, $key) { $shard_id = $this->$method($key); if ($shard_id === null) { throw new Exception('Error!! Invalid Query!!'); } switch ($type) { case 'dns': $this->setConnection(static::RAW_CONNECTION . '_' . $shard_id); break; case 'table': $this->setTable(static::RAW_TABLE . '_' . $shard_id); break; default: throw new Exception('Error!! Invalid Sharding Type!!'); } }指定されるcolumn(attribute)にuser_idが入っている想定になっており、setShardedParameter()で、それをもとにシャーディング先を決定しています。
configにもDBとテーブルぶんの設定を入れていて、これは各クラスのconstructorで取得し、そのあとの処理ですぐ使えるようにしています。
constructorでシャーディング先を決めているのではなく、各処理のメソッドでシャーディング先を決定しているのがミソかと思います。この場合、つなげて書けない(where()->where()->…みたいな)のですが、そこは一律ナシってルールにして割り切っています(もしかしたら解消される見込み)。■水平分割したときのマイグレーション
コンテナ化しているので、マイグレーションも水平分割に対応する必要があります。
Lumenにはマイグレーションの仕組みがあるので、それを利用しています。UserBase.php
use Illuminate\Database\Migrations\Migration; use Illuminate\Database\Schema\Blueprint; abstract class UsersBase extends Migration { protected $operation = 'create'; protected $table_name = null; protected $shard_count = 0; public function __construct() { $config = config('database.db_shard'); $this->shard_count = $config['table_shard_count']; } /** * Run the migrations. * * @return void */ public function up() { $count = 0; while ($count < $this->shard_count) { Schema::{$this->operation}( $this->table_name . '_' . $count, function (Blueprint $table) { $this->setSchema($table); } ); ++$count; } } abstract protected function setSchema(Blueprint $table); }2019_10_17_162227_create_user_profile_table.php
use Illuminate\Database\Schema\Blueprint; class CreateUserProfileTable extends UsersBase { protected $table_name = 'user_profile'; protected function setSchema(Blueprint $table) { $table->bigInteger('id', true); $table->bigInteger('user_id')->index('idx_user_id'); $table->string('profile', 256); $table->timestamps(); $table->softDeletes(); } }UsersBaseというベースクラスを用意してやり、そこでsetSchema()というテーブルを作るメソッドをテーブル分割数分呼び出している感じです。
デプロイのスクリプトでは、これを各DBに対して行うようにしています。■まとめ
いろいろ実用面で手を加えることになったLumenですが、今後は使用するプロダクトが増えていくかと思います。
本記事がその一助となり、これを機に「LumenかわいいよLumen」と皆さんも愛でてもらえたらうれしいです。明日は @kida_hironari さんの記事です。
- 投稿日:2019-12-02T18:01:58+09:00
【Laravel6】Vueがデフォルトでインストールされなくなっていた件【Vue.js】
前提
Laravelは5.3以降、yarn(npm)でインストールコマンドを実行すると
vueがデフォルトでインストールされるようになっていました。package.jsonから色々消えた
Laravel6ではいくつかのパッケージがデフォルトから除外されたようで、
package.jsonの中身がすっきりしています。Vue.js
masterのpackage.jsonからvueがいなくなっていました。
2019/6/28に消されたようで、
当然、この日付以降に取得したLaravelでは、
yarn installをしてもvueでプロジェクトが作れません。
なので、手動で追加する必要があります。例(追記参照:非正攻法のようです。)$yarn add --dev vue vue-router一方、Laravel5.8を確認してみるとvueは残っており、
更新履歴的に特に消える気配はなさそうなので、Laravel6からの方針と思われます。他の消えたパッケージ
上記コミットを見てわかる通り、下記パッケージも同様にデフォルトでインストールされなくなりました。
- bootstrap
- jquery
- popper.js
以上。
コミットメッセージを見ても特に消された経緯がわからなかったので、
本件について何か情報をお持ちの方がいらしたらコメントを頂けると幸いです。追記
既存記事に解決策がありました
Laravel6でBootstrap, jQueryを使う方法
composer require laravel/ui php artisan ui vueを使うのが正攻法のようです。
公式記事に解説がありました
- 投稿日:2019-12-02T17:43:51+09:00
PHP基礎 Part3
概要
PHPの独学で学んだことをアウトプットしていく
前回の内容
if文
「もし○○の場合、△△となる」といった条件に応じて、分岐が必要な場合に用いる文法
条件成立時は、{}の中の処理が実行されるsample.php<?php $num = 3; if ($num > 0){ // 条件式の展開 echo "変数numは0より大きい"; // 条件式を満たした為、"変数numは0より大きい"が出力される } ?>比較演算子
比較元の値と比較先の値を、比較する為に以下の比較演算子を用いて判定する
判定時の結果が真の場合は、「true」で偽の場合は「false」と表す
比較演算子 判定基準 < 右辺が大きい時にTrue <= 右辺が大きい時、もしくは等しい時にTrue > 左辺が大きい時にTrue >= 左辺が大きい時、もしくは等しい時にTrue == 右辺と左辺が等しい時にTrue != 右辺と左辺が等しくない時にTrue === データ型まで含め、右辺と左辺が等しい時にTrue !== データ型まで含め、右辺と左辺が等しくない時にTrue else
「もし○○の場合、△△となり、そうでない場合は□□となる」といった、
if文との組み合わせで条件分岐を作成する
elseを使うことで、if文で条件を満たせなかった場合の処理を実行させることが可能sample.php<?php $age = 19; if ($age >= 20){ // 条件式の展開 echo "あなたは成年です"; // $age = 19なので、条件に合致しない }else{ echo "あなたは未成年です"; // else文の処理実行 } ?>elseif
「もし○○の場合、△△となり、◇◇の場合は☓☓となり、そうでない場合は□□となる」といった、
条件の分岐が3つ以上になる時に使用可能
注意点として、複数条件に合致した場合は、先に条件が合致した分岐の処理を行うsample.php<?php $num = 23; if ($num > 30){ // 条件式の展開 echo "30より大きい数値"; // $num = 23なので、条件に合致しない }elseif ($num >= 20){ echo "20以上30以下の数値"; // 条件に合致するので、この分岐の処理が実行 }else{ echo "20以下の数値"; // elseifで合致する条件があった為、実行されない } ?>複数条件の組み合わせ
条件式を展開する際に、複数の条件を一纏めにしたい場合に論理演算子を使用する
andを表す論理演算子は「&&」、orを表す演算子は「||」となるsample.php<?php $age = 30; if ($age >= 25 && $age <= 30){ // 条件式の展開 echo "アラサーです"; // 条件に合致する為、この分岐の処理が実行 }else{ echo "それ以外の世代です"; } ?>switch文
if文では複雑になるような条件をswitch文を使い、読みやすいようにする
if文とは異なり、switchという条件式を展開し、条件式に当てはまるcaseの値が合致した時に、
該当するcaseの処理が実行される
もし、どのcaseにも当てはまらない場合は、defaultの処理が実行されるsample.php<?php $score = 4; switch ($score){ case 1: echo "E判定"; break; case 2: echo "D判定"; break; case 3: echo "C判定"; break; case 4: echo "B判定"; //$score = 4の為、このcaseの処理が実行される break; case 5: echo "A判定"; break; default: echo "判定外"; break; } ?>【補足】
各caseの末尾にbreakを記述しているが、
これがないと、caseに合致する条件のすぐ後ろのcaseも実行されてしまう為、
breakが入っているかを確認すること次回
- 配列
- 連想配列
- 投稿日:2019-12-02T17:36:50+09:00
PHP案件に配属されたGopherはどうGo言語と向き合うべきか
今いるチームのメインリポジトリはPHPで書かれているのでそれに接する機会が多い。
インフラはガチガチのAWSだ。
普段の個人開発で使う言語はGo一択だしインフラは google app engine にのせてきた。
全然違うじゃん、と思われるかもしれないが雇用されて働く上で技術スタックを気にしてネガティブになる必要はあまりない。
新しい技術に対して前向きな意思決定ができるチームを作れるか、一緒に働きたいと思えるメンバーに恵まれているか、プロダクトは利益を上げているか、そういったことの方がボディに効きやすい。
まぁPHPでお仕事できますか?と聞かれたら当然YESだ。
PHPなんてものは特にその存在を意識しなくても読めるし書けるので勉強するに値しない言語だ。
それがLL言語の唯一の利点であるがどうにもお行儀が悪くて治安が乱れやすい。
PHPとGoどちらが優れていますかとGopherには尋ねない方が身のためだ、お前は朝食に和食と肥溜めどちらにするか聞くのか?という顔になってしまい声に出すのも億劫だとため息をつかれるだろう。若干言葉が荒れてしまっているがややワイルドな環境で育ったのと実は今アドベントカレンダー前日だということと風邪を引いて咳と鼻水の煩わしさと戦いながら書いているというバックグラウンドを知ってもらうことで共感性をキープしていただきたい。
そういうわけでGoを布教することにはメリットしかないので業務でGoを使う機会をどうやって作っていくかというのがターゲットになる。
まずやるべきは社内の開発プロセスにおけるお役立ちツールを作ることだ。
githubで管理されているプロジェクトが100あるとしてそれらを一気にcloneするツールや複数リポジトリに渡ってローカルでgit grepなどのシェルを一括実行するツールなどを実際に作って調査に役立てている。
便利なものができたなと思ったらそれをチームに配布しておすそわけするとGoって便利だね、というのがじわじわと伝わっていく。
それと時間がない中でもできるだけ綺麗にコードを書いておくと良い。
Goはバイナリで配布できるのだがそうしていてもエンジニアはすぐコードを見せてみろと言い始めるからだ。
オラついたコードを書いてしまっていると読みにくいのはGoのせいだとアンチが湧き始めてしまう。
ここはなるべく手を抜かず学習に適した教材となるように書いておくのがベストだ。そうして機を伺っていると、とある外部APIのバージョン対応で旧バージョンのインタフェースを新バージョンのインタフェースにプロキシしてくれ!言語は問わない!みたいな案件が降ってくることがある。
とにかく急ぎで手間をかけずにできれば安く、そしてパフォーマンスも出して欲しいみたいな要望に応えるには、サーバにバイナリをおいてデーモン起動させるだけでインフラマンたちの手を煩わせずに動かせてしまうことや、自前でWebサーバを書いてしまえること、ファイルサイズも小さく、メモリも食わないなどの特性を持つGoが狂おしいほど最適なわけだ。こうして晴れてプロダクション環境で恐らく社内史上初のGo環境を動作させることに成功したわけだが大規模Web開発での信頼度はまだまだこれからだ。
大規模Web開発での目下のライバルはSpring Boot Kotlinだ。
コトラー達に言わせるとGoはオールドスクールだと。
ラムダ使いたいとかDI自前で書きたくないとか設定ファイルを自動で読み込んで欲しいとか、まぁ分かる。
バイナリ生成はKotlin Nativeでも出来るとかimmutable思想じゃないとか色々。
Goの思想にシンプルさを保つことで得られる恩恵が色々あるよねというのが根底にある以上、今後は使いどころが分かれていくかもしれないしGo2で破壊的にWeb寄りの実装に変化していくのかもしれないがそこらへんの議論がコミュニティで活発に行われているのもGoの力強い魅力だ。
Sprint Bootフレームワークは重たいが強力だしKotlinはScalaほどやりすぎてなくて程よくモダンなバランスの良い言語なのでPHPの256億倍マシだと思っている。そもそもエンジニアは世界平和のために美しいプロダクトを世の中に発信したいだけなので技術スタックで争うなんて必要は全くなかったはずなのだ。
いつしか競争社会の都合で限られた時間、限られたリソース、慣習や歴史によって生まれた何かの中で生きるために望まぬ戦争をやらされているのだ。
ひたすらにスキルを研磨することも許されず銃と言論を渡され戦えと焚き付けられているのだ。
今はKotlin案件にもアサインされているので積極的にそれの利点を引き出すことを考えているが、時が来れば僕はコトラーの額に銃口を向けデヴィット・フィンチャー監督作セブンのラストシーンに出てくるブラピのような顔をしているかもしれない。小さい頃からそう育てられたのでいざという時には引き金をひけるタイプの人間ではあるが生まれる時代を間違えたのかもなぁと思ったところでこの記事は締めようかなと。
記事を書き始めた頃は何か同志にアドバイスを送るつもりだったのだがどうにも最後の言葉が浮かばない。
時計を見ると期日が迫っている。もっと早く書いとけばなぁ、と夏休みの宿題が終わらないあの頃と何も変わらないまま日々は過ぎて行く。
- 投稿日:2019-12-02T16:08:06+09:00
Laravel SQLiteからMySQLに変更したら外部キー制約のマイグレーションが失敗してハマった
>php artisan -V Laravel Framework 6.1.0以下のusersに対して、user_idを外部キー制約として持つsubscribesテーブルを作りました。
Schema::create('users', function (Blueprint $table) { $table->bigIncrements('id'); $table->string('name'); $table->string('email')->unique(); $table->timestamp('email_verified_at')->nullable(); $table->string('password'); $table->rememberToken(); $table->timestamps(); });SQLiteで動作していたマイグレーションだったので、そのまま
php artisan migrateしたらエラーになりました。実行したマイグレーションSchema::create('subscribes', function (Blueprint $table) { $table->bigIncrements('id'); $table->integer('user_id')->unsigned(); $table->string('channel_id'); $table->string('channel_title'); $table->timestamps(); // userが削除されたとき、それに関連するも一気に削除する制約 $table->foreign('user_id') ->references('id') ->on('users') ->onDelete('cascade'); });Illuminate\Database\QueryException: SQLSTATE[HY000]: General error: 1215 Cannot add foreign key constraint (SQL: alter table `subscribes` add constraint `subscribes_user_id_foreign` foreign key (`user_id`) references `users` (`id`) on delete cascade)PHP - 【Laravel】外部キー制約があるテーブルのmigrateができません|teratail という記事をみて、
user_idカラムを作るときの記述が異なることに気づいてその部分を修正することで、解決しました!修正点- $table->integer('user_id')->unsigned(); + $table->unsignedBigInteger('user_id');正しいマイグレーションSchema::create('subscribes', function (Blueprint $table) { $table->bigIncrements('id'); $table->unsignedBigInteger('user_id'); $table->string('channel_id'); $table->string('channel_title'); $table->timestamps(); // userが削除されたとき、それに関連するも一気に削除する制約 $table->foreign('user_id') ->references('id') ->on('users') ->onDelete('cascade'); });型が違っているからエラーになったっぽいのですが、それじゃあSQLiteはなぜ通った?という疑問が…。
- 投稿日:2019-12-02T16:06:33+09:00
Laravel+Vue.js+MySQLで入力内容の途中保存機能を実装してみた
グレンジ Advent Calendar 2019 4日目担当の soyo と申します。
グレンジでクライアントエンジニアをしております。
とはいえ、今年の記事もクライアントとはまったく関係ありません。普段Googleフォームなどでアンケートを回答する際に、
「あれ、途中で保存することができないの?」って自分はたまに思います。ユーザーが一項目ずつ入力したらサーバーに送信してデータベースに記録するから、
ページに再度アクセスしたら記録されている情報を自動的に反映するまで、
PHPを使って簡単に実装してみました。目標
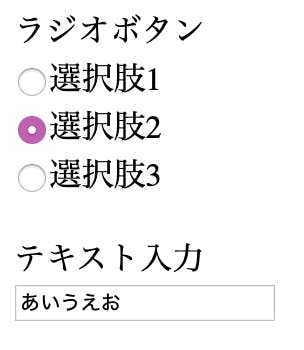
「ラジオボタンの選択内容」と「テキストの入力内容」を途中保存できるようにする
開発環境
- macOS 10.14.6
- PHP 7.3.8
- Laravel 6.6.0
- MySQL 8.0.18
フロントエンド
Vue.jsで入力内容の操作
今回の戦場はLaravelプロジェクトのwelcome画面にします。
まずはそこにVue.jsを導入して、ラジオボタン3つとテキストボックス1つを置きます。resources/views/welcome.blade.php... <script src="https://cdn.jsdelivr.net/npm/vue/dist/vue.js"></script> ... <div id="app"> ラジオボタン<br/> <input type="radio" value="1" v-model="radio">選択肢1<br/> <input type="radio" value="2" v-model="radio">選択肢2<br/> <input type="radio" value="3" v-model="radio">選択肢3<br/> <br/> テキスト入力<br/> <input type="text" v-model="text" placeholder="内容を入力"> <br/> </div> ...public/js/main.jsconst app = new Vue({ el: '#app', data: { radio: '2', text: 'あいうえお' }, });これで
radioとtextでラジオボタンとテキストボックスを操作することができます。
UUIDの作成と保存
javascriptで適当なUUIDを生成する方法がありまして、
生成したUUIDをJavaScript Cookieでローカルに保存するようにします。resources/views/welcome.blade.php... <script src="https://cdn.jsdelivr.net/npm/js-cookie@beta/dist/js.cookie.min.js"></script> ...public/js/main.jsconst app = new Vue({ el: '#app', data: { radio: '', text: '', uuid: '' }, methods: { initUUID: function() { if (Cookies.get('uuid') !== undefined) { this.uuid = Cookies.get('uuid'); return; } var d = new Date().getTime(); var d2 = (performance && performance.now && (performance.now() * 1000)) || 0; this.uuid = 'xxxxxxxx-xxxx-4xxx-yxxx-xxxxxxxxxxxx'.replace(/[xy]/g, function(c) { var r = Math.random() * 16; if (d > 0){ r = (d + r) % 16 | 0; d = Math.floor(d / 16); } else { r = (d2 + r) % 16 | 0; d2 = Math.floor(d2 / 16); } return (c === 'x' ? r : (r & 0x3 | 0x8)).toString(16); }); // とりあえず期限を10年にする Cookies.set('uuid', this.uuid, { expires: 3650 }); } } }); app.initUUID();これで画面を開く度にcookieからuuidを取得し、存在しない場合は生成できるようになりました。
サーバーとの通信
サーバーとの通信はaxiosで行います。
resources/views/welcome.blade.php... <script src="https://cdnjs.cloudflare.com/ajax/libs/axios/0.18.0/axios.min.js"></script> ...public/js/main.jsconst app = new Vue({ ... methods: { saveData: function(key, value) { let postData = { 'user_id': this.uuid, 'key': key, 'value': value }; axios.post("/saveData", postData).then(response => { // 成功 }).catch(error => { // 失敗 }); }, loadData: function () { let postData = { 'user_id': this.uuid }; axios.post("/loadData", postData).then(response => { // 成功 }).catch(error => { // 失敗 }); } } });送信する内容についてですが、
文字を入力する度に送信してしまうとサーバーに負荷をかける可能性がありますので、
今回は連続する入力を無視してくれるLodashのdebounceで制御します。resources/views/welcome.blade.php... <script src="https://cdnjs.cloudflare.com/ajax/libs/lodash.js/4.17.15/lodash.min.js"></script> ... <div id="app"> ラジオボタン<br/> <input type="radio" value="1" v-model="radio" @click="isRadioSelecting = true">選択肢1<br/> <input type="radio" value="2" v-model="radio" @click="isRadioSelecting = true">選択肢2<br/> <input type="radio" value="3" v-model="radio" @click="isRadioSelecting = true">選択肢3<br/> <br/> テキスト入力<br/> <input type="text" v-model="text" @input="isTextTyping = true" placeholder="内容を入力"> <br/> </div> ...public/js/main.jsconst app = new Vue({ el: '#app', data: { ... isTextTyping: false, isRadioSelecting: false, ... }, watch: { radio: _.debounce(function() { this.isRadioSelecting = false; }, 1000), text: _.debounce(function() { this.isTextTyping = false; }, 2000), isRadioSelecting: function(selecting) { if (selecting) { return; } this.saveData('radio', this.radio); }, isTextTyping: function(typing) { if (typing) { return; } this.saveData('text', this.text); }, }, ... });これでラジオボタンは選択停止後1秒、テキストボックスは入力停止後2秒からサーバーにデータを送るようになりました。
最後に、ステータスをわかるためにvue2-notifyを使ってプッシュ通知を表示させます。
resources/views/welcome.blade.php... <script src="https://cdnjs.cloudflare.com/ajax/libs/element-ui/2.4.0/index.js"></script> <link rel="stylesheet" href="https://unpkg.com/element-ui/lib/theme-chalk/index.css"> ...使い方の例
this.$notify.info({ title: '受信', message: '内容読み取り完了' });これで、フロントエンドの方は必要な機能を揃えました。
完成したコードはこの記事の最後にまとめております。サーバーサイド
データベース構造
テストのため、すごくシンプルなテーブルを作ります。
+------------+ | database() | +------------+ | vue_test | +------------+ +------------+ | TABLE_NAME | +------------+ | user_input | +------------+ +-------------+-----------+ | COLUMN_NAME | DATA_TYPE | +-------------+-----------+ | id | int | | user_id | varchar | | radio | int | | text | varchar | +-------------+-----------+リクエストデータ処理クラス
ユーザー入力内容をデータベースに書き込む・読み取り処理を行います。
app/Http/Controllers/UserInputController.php<?php namespace App\Http\Controllers; use Illuminate\Http\Request; use Illuminate\Support\Facades\DB; class UserInputController extends Controller { public function saveData(Request $request) { DB::table('user_input')->updateOrInsert( [ 'user_id' => $request->input('user_id') ], [ $request->input('key') => $request->input('value') ] ); } public function loadData(Request $request) { $user_id = $request->input('user_id'); $data = [ 'result' => DB::table('user_input')->where('user_id', $user_id)->first() ]; return $data; } }ルーティング
routes/web.php... Route::post('/saveData', 'UserInputController@saveData'); Route::post('/loadData', 'UserInputController@loadData'); ...コードまとめ
resources/views/welcome.blade.php<!DOCTYPE html> <html> <head> <script src="https://cdn.jsdelivr.net/npm/vue/dist/vue.js"></script> <script src="https://cdn.jsdelivr.net/npm/js-cookie@beta/dist/js.cookie.min.js"></script> <script src="https://cdnjs.cloudflare.com/ajax/libs/lodash.js/4.17.15/lodash.min.js"></script> <script src="https://cdnjs.cloudflare.com/ajax/libs/axios/0.18.0/axios.min.js"></script> <script src="https://cdnjs.cloudflare.com/ajax/libs/element-ui/2.4.0/index.js"></script> <link rel="stylesheet" href="https://unpkg.com/element-ui/lib/theme-chalk/index.css"> </head> <body> <div id="app"> ラジオボタン<br/> <input type="radio" value="1" v-model="radio" @click="isRadioSelecting = true">選択肢1<br/> <input type="radio" value="2" v-model="radio" @click="isRadioSelecting = true">選択肢2<br/> <input type="radio" value="3" v-model="radio" @click="isRadioSelecting = true">選択肢3<br/> <br/> テキスト入力<br/> <input type="text" v-model="text" @input="isTextTyping = true" placeholder="内容を入力"> <br/> </div> </body> <script src="{{ asset('/js/main.js') }}"></script> </html>public/js/main.jsconst app = new Vue({ el: '#app', data: { radio: '', text: '', isTextTyping: false, isRadioSelecting: false, uuid: '' }, watch: { radio: _.debounce(function() { this.isRadioSelecting = false; }, 1000), text: _.debounce(function() { this.isTextTyping = false; }, 2000), isRadioSelecting: function(selecting) { if (selecting) { return; } this.saveData('radio', this.radio, 'ラジオボタン'); }, isTextTyping: function(typing) { if (typing) { return; } this.saveData('text', this.text, 'テキスト入力'); }, }, methods: { initUUID: function() { if (Cookies.get('uuid') !== undefined) { this.uuid = Cookies.get('uuid'); return; } var d = new Date().getTime(); var d2 = (performance && performance.now && (performance.now() * 1000)) || 0; this.uuid = 'xxxxxxxx-xxxx-4xxx-yxxx-xxxxxxxxxxxx'.replace(/[xy]/g, function(c) { var r = Math.random() * 16; if (d > 0){ r = (d + r) % 16 | 0; d = Math.floor(d / 16); } else { r = (d2 + r) % 16 | 0; d2 = Math.floor(d2 / 16); } return (c === 'x' ? r : (r & 0x3 | 0x8)).toString(16); }); Cookies.set('uuid', this.uuid, { expires: 3650 }); }, saveData: function(key, value, description) { let postData = { 'user_id': this.uuid, 'key': key, 'value': value }; axios.post("/saveData", postData).then(response => { this.$notify.info({ title: '送信', message: '内容保存済み:' + description }); }).catch(error => { this.$notify.error({ title: '送信', message: '送信に失敗しました' }) }); }, loadData: function () { let postData = { 'user_id': this.uuid }; axios.post("/loadData", postData).then(response => { let data = response.data['result']; if (data == null) { this.$notify.info({ title: '受信', message: '新規ユーザー' }); return; } this.radio = data['radio']; this.text = data['text']; this.$notify.info({ title: '受信', message: '内容読み取り完了' }); }).catch(error => { this.$notify.error({ title: '受信', message: '受信に失敗しました' }) }); } } }); app.initUUID(); app.loadData();app/Http/Controllers/UserInputController.php<?php namespace App\Http\Controllers; use Illuminate\Http\Request; use Illuminate\Support\Facades\DB; class UserInputController extends Controller { public function saveData(Request $request) { DB::table('user_input')->updateOrInsert( [ 'user_id' => $request->input('user_id') ], [ $request->input('key') => $request->input('value') ] ); } public function loadData(Request $request) { $user_id = $request->input('user_id'); $data = [ 'result' => DB::table('user_input')->where('user_id', $user_id)->first() ]; return $data; } }routes/web.php<?php /* |-------------------------------------------------------------------------- | Web Routes |-------------------------------------------------------------------------- | | Here is where you can register web routes for your application. These | routes are loaded by the RouteServiceProvider within a group which | contains the "web" middleware group. Now create something great! | */ Route::get('/', function () { return view('welcome'); }); Route::post('/saveData', 'UserInputController@saveData'); Route::post('/loadData', 'UserInputController@loadData');最後に
Vue.jsが使いやすくて、サードパーティのライブラリもたくさんあって、
導入と実装がかなり楽でした(cocos2d-xとunityと比べるとねw)また、項目を増やす度にテーブルにカラムを追加するのはさすがに面倒ですね。
その場合はテーブルのスキーマをユーザーID、項目ID、内容にして、
select文でユーザーIDと項目IDで検索して、その結果を処理して反映すればいいと思います。ありがとうございました。

- 投稿日:2019-12-02T13:54:37+09:00
テストコードを書いて良かった3つの事
これはユアマイスター Advent Calendar 2019の2日目の記事です。
はじめに
少し時間は空いてしまいますが、先々月に技術的負債の撲滅の一環として、テストコードを書きました。
それまでしっかりとテストコードを書いたことのなかった自分としては、少しチャレンジングな内容でした。
テストコードをガッツリと書いた今だから思うことは、書いた方がいい。これに尽きます。
今回は、テストコードを書いて 良かった事 を個人の見解からいくつかお話ししたいと思います。
※悪かった事、は特に感じなかったため、良かった事にフォーカスしてます。前提
各種バージョン
- PHP
- 7.1.32
- CakePHP
- 3.6.14
- PHPUnit
- 6.5.13
用語
- Cake
- CakePHPを指す
1. アウトプットを意識する
1 <?php 2 class UsersTable extends Table 3 { 4 public function findUserById(Query $query, $options) 5 { 6 return $query->where(['id' => $options['id']]); 7 } 8 } 9 10 class UsersTableTest extends TestCase 11 { 12 public function testFindUserById() 13 { 14 $actual = $this->Users->findUserById($this->Users->find(), ['id' => 1]); 15 $this->assertInstanceOf('Cake\ORM\Query', $actual); 16 } 17 }例えば、上記のTableクラスのpublicメソッドと、そのテストコードがあったとします。
テストコードでは、期待値がQueryオブジェクトである事をアサートしてます。
テストコードを書くときは、実行値と期待値を考えなくてはなりません。
あるメソッドに対するテストをするとき、そのメソッドを実行する事で返す(得られる)値、これが 実行値。
逆に、そのメソッドを実行する事で〇〇という値を返すだろうと想定した値、これが 期待値 です。この考え方を身に付ける事で、あるロジックを組むときや、ソースコードレビューする時に非常に役に立ちます。
1 <?php 2 class UsersController extends AppController 3 { 4 public function index() 5 { 6 $this->loadModel('Users'); 7 8 $user = $this->Users->find('UserById', ['id' => 1])->all(); 9 if ($user->count() < 1) { 10 $this->Flash->error('データが存在しません。'); 11 return $this->redirect($this->referer()); 12 } 13 } 14 }上記は、特定のユーザー情報を取得する。もし、データが存在しなければ以前の画面へリダイレクトしてFlashメッセージを表示させるロジックです。
非常にシンプルで簡単なロジックですが、このロジックを組む時にもテストコードで培った考えが役に立ちます。
L:8で、UsersテーブルのfindUserByIdメソッドを呼び出してますが、テストコードが書かれている事・アウトプットに対する考え方、がある事で、以降の処理が直感的に書けるようになります。
findUserByIdメソッドが返す値がわかっているので、そのあとに->all()を利用してデータを取得し、L:9で、データの有無を確認する時に->count()を利用してます。
(※L:9の話は例えば、PHPのcountメソッドを利用する事も可能ですが、Cakeを利用してる以上、ORMのcountメソッドを利用することがお作法としてもコードの可読性の観点からも適切だ、と言えるでしょう)直感的にコードを書ける事はつまり、開発効率を上げる事に繋がります。
また、ソースコードレビューの時も、例えば、PHPのcountメソッドを利用して比較を行っていれば、ORMのcountメソッドを利用する事を指摘することができると思います。
アウトプットを意識する、だけでいろんな点で恩恵を受けられました。
実は、これが1番良かった点じゃないか、と思うくらい良かった点です。
2. フレームワークに関する知見が深まる
上記で登場したコードを一例にお話しすると、
10 class UsersTableTest extends TestCase 11 { 12 public function testFindUserById() 13 { 14 $actual = $this->Users->findUserById($this->Users->find(), ['id' => 1]); 15 $this->assertInstanceOf('Cake\ORM\Query', $actual); 16 } 17 }assertInstanceOfというメソッドは、Cakeで用意されてるアサーションメソッドです。
このメソッドに辿り着くまで、実は違うメソッドを利用したアサートを行ってました。
それは、PHPUnitが用意してるassertSameというメソッドと、PHPのget_classメソッドを利用したコードです。$this->assertSame('Cake\ORM\Query', get_class($actual));これでもやりたい事は満たしますが、ちょっと頑張りすぎというか適切ではありません。
ある一定期間このロジックで書き進めてたのですが、もっと簡単な方法ないのか?と疑問を持ち、調べていく中でassertInstanceOfメソッドを見つけました。
これをキッカケに Cakeが用意してるコードでやりたい事を満たすコードは存在するだろう が選択肢に増えました。
つまり、フレームワークに対する関心が高まったのです。それ以降、やりたい事を満たすために調べるときは、まずCakeのコードやCookbookを頻繁に読むようになりました。
この行動がフレームワークに対する知見を深めました。また、副産物的要素として、コードの読解力も上がりました。これも結果的に良かった事です。
身近なエンジニアの書いたコードを読んでいると、遭遇するコードのパターンは決まりきってくるので思考に偏りが出ます。
しかしCakeはオープンソースで、世界中のエンジニアがコミットしてます。
そういった様々な人が書いたコードを読むことで、思考の偏りは起こらず、あらゆるパターンをインプットできるので、結果、コードの読解力が上がる、といった恩恵を受けられた訳です。
読解力を上げるには、ただコードを読めば良い、という訳ではなく、様々なコードを読むことが重要、という気づきも得られました。3. プログラムにおける品質の担保
これは当たり前中の当たり前ですが、やはりテストコードで品質は担保できるようになりました。
もちろん100%中、数10%が現実的な担保としての役割だとは思いますが、それでも、最低限の担保としてその役割を担ってくれるのがテストコードだと感じます。上記で紹介したコードから一例を説明すると、
1 <?php 2 class UsersTable extends Table 3 { 4 public function findUserById(Query $query, $options) 5 { 6 return $query->where(['id' => $options['id']]); 7 } 8 } 9 10 class UsersTableTest extends TestCase 11 { 12 public function testFindUserById() 13 { 14 $actual = $this->Users->findUserById($this->Users->find(), ['id' => 1]); 15 $this->assertInstanceOf('Cake\ORM\Query', $actual); 16 } 17 }例えば、findUserByIdメソッドの中身を以下に変更したとします。
ASIS: return $query->where(['id' => $options['id']]); TOBE: return $query->where(['id' => $options['id']])->all();QueryオブジェクトからUsersエンティティーを返す処理に変えたとします。
当然テストは失敗します。
あまり現実的ではないサンプルコードで申し訳ないですが、ここで理解して欲しい事は、テストコードによってアウトプットの変更を検知する事ができる、という点です。
これがつまり、質の担保、を指してます。担保する量、の話は、テストコードの質、と比例すると自分は思っているので、ネクストチャレンジはテストコードの質を上げる事、だと個人的に思ってますが、それでもこの品質の担保、の側面を実感できた事は、テストコードを書いたからこそ気づけた事であり、良かった点だなと思います。
まとめ
冒頭でのコメントと重なりますが、テストコードは書いた方が良い、と自分は考えます。
経験上、自身の成長に寄与する事は間違いなく、そして、技術的負債を撲滅できたり、品質の担保に寄与する事ができます。ちょっとしたチャレンジングな出来事で、とても大きな恩恵を受ける事ができました。
結果論の話になってしまいがちですが、内容はともかく、チャレンジする事が重要ですね。
- 投稿日:2019-12-02T13:36:57+09:00
オニオンアーキテクチャのDomain層にバリデーション処理を実装した所感を書いてみる
この記事は うるる Advent Calendar 2019 2日目の記事です。
はじめに
この記事のターゲット
- オニオンアーキテクチャ/レイヤードアーキテクチャをやろうとしていてバリデーション実装で悩んでる
- Domain層でバリデーション実装したらどうなるのかイメージを持ちたい
この記事ではオニオンアーキテクチャを採用しているプログラムにて
Domain層 にバリデーションを実装してみて良かった点と課題に感じた点を書いたものになります。
(具体的なプログラムの全容などは本項では記述しておりません)あくまでも個人が感じた感想なので参考程度にとどめて頂ければと思います。
バリデーションとは
API開発などクライアントから情報を受け取って処理をするようなプログラムでは
クライアント側からどのようなリクエストが飛んでくるか分かりません。そのためサーバー側はクライアントから渡された値に対して精査を行い
基準にそぐわないリクエストの場合は処理を中断してクライアントにメッセージを返してあげる必要があります。
これがバリデーション実装です。オニオンアーキテクチャとは
プログラムをUI層/Service層/Domain層/InfraStructure層の4層に分ける
レイヤードアーキテクチャの考え方を元に、
Domain層とInfraStructure層の依存関係を逆転させたアーキテクチャです。下記の記事が綺麗にまとまっているのでそちらを参考にしてください。
ここでは詳細を記述することは省きます。
https://qiita.com/little_hand_s/items/2040fba15d90b93fc124バリデーション実装はどこでやるべきか
さて、ようやく本題です。
オニオンアーキテクチャを採用して開発している方々のバリデーション処理の実装箇所は人によって意見が異なっており
- 基本に忠実に! Domain層に書くべきだ!
- 全量やったらドメインモデル汚れるだろ! UI層に書くべきだ!
大体この2つで議論されている印象です。うん、どちらもわかる、わかるよ笑
ただこのままだと埒があかないので、それぞれのメリデメをざっくり書いてみましょう。
Domain 層で実装 UI 層で実装 メリット バリデーションがドメイン層にまとまるので プログラムを理解しやすい Domain 層でのチェックは ビジネスロジックに集中できる デメリット 低次元なチェックも含まれるため ドメイン層が肥大化しやすい UI層とDomain層の役割の分割で 混乱しやすい Domain層に書くのは比較的簡単ですが、低次元なチェックも詰め込まれやすいので肥大化リスクを抱える。
UI層に書くのは上手く書ければDomain層が綺麗になるものの、判断に迷うポイントがあるので初期設計が重要そうです。で、お前(たち)はどうしたんだと言うと…
上でも触れた通りうちのチームでは Domain層に書く ことで実装を進めました。
理由は下記の通りです。
- オニオンアーキテクチャでの実装が初の試みで、いきなり完璧なものを書くには敷居が高かった
- チームが立ち上げ期で経験も若いので、分かりやすさ重視で進めたかった
- 設計に迷う時間は短くしたかった
実装イメージを出してみましょう。
プラットフォームは PHP7, Laravel で公開日は必須/日付のフォーマットである/未来日ではないを表現したクラスの例です。class AnnouncementDate { /** * @var null */ protected $value = null; /** * AnnouncementDate constructor. * @param string|null $value */ public function __construct(?string $value) { $this->check($value); } /** * @param $value */ private function check($value) { if ($this->requiredSelect($value)) { // 必須チェック if ($this->dateFormat($value)) { // 日付フォーマット if ($this->futureThan($value)) { // 未来日 $this->value = $value; }; } } } /** * @return null|string */ public function string(): ?string { return (empty($this->value)) ? null : $this->carbon()->toDateString(); } }※各バリデーションチェックの具体的な処理はTraitで外出ししてます。
※今回の例ではExceptionは投げていませんが強制的に止めるならExceptionを投げても良いと思います。
(Exceptionを投げずにエラーを積み上げる方法についてもいずれ書けたらいいなあ)実装してみた感想
良かった点
Domain クラスを見るだけでどんなバリデーションチェックをしているのか一目瞭然
Domain層実装案のメリットにも記載した通り、
バリデーションが書かれているレイヤーが統一出来ているので直感的に分かりやすくなり、
実装もスピーディに進めることが出来ました!バリデーションチェックを簡単に追加/削除出来る
11月にまだプログラミング経験の若いメンバーがチームに参画したのですが、
その時に説明がしやすかったです。
「このチェックが足りてないよ」という指摘も実装もやりやすく
Domain層実装パターンは効果があったのかなと感じております。悪かった点・悩んだ点
低次元なチェックがDomain層に入り込む
日付フォーマットのチェックなども Domain 層に書いていったのですが、
ビジネスロジックというよりも入力規則な感じに近く違和感は正直ありました。今回、我々が実装したものについては数はそこまで多くないので割り切っておりますが、
ビジネスロジックが非常に複雑で入力規則チェックを混入させたく無い場合は
入力規則だけはUI層で弾く、と言う書き方も有効かと思います。
( Laravel で言うところの Request クラス)特定の入口からの特別な処理に対応しにくい
例えば
画面AからはXは必須項目だけど、B画面ではXは任意項目みたいな事があると
Domain クラスに対して Bool を引数に取らないと実装が難しくなります。今回、我々はチェックフラグのようなBoolを引数に追加することで解決(もとい逃げた)したのですが
UI層実装案を採用していたらUI層で必須か否かをハンドリング出来るので
もう少し綺麗に書けたんじゃないかなあ、と思った次第です。まとめ
シンプルに書きたいのであれば Domain 層実装パターン 、
Domain層はビジネスロジックだけ集中して書きたい場合は UI 層実装パターン で書けると良いのかなと思った次第です。しかしながらオニオンアーキテクチャって難しいですね。人によって持つ意見が違うので悩みの連続です。
チームで開発する場合は共通認識を持ちながら開発をする必要があるのでチームの理解度や力量も重要になります。Domain層での実装・UI層での実装、
どちらを取っても何かしらの悩みポイントは出ると思うので実装しようとしているサービスの複雑度や
チームの意見・力量などと加味して上手く判断していく事が重要なのかなと思います!あとがき
Advent Calendar 2日目でした。
明日3日目は Kazuna Doue さんによる記事を乞うご期待!
https://adventar.org/calendars/4548参考
- 投稿日:2019-12-02T12:47:19+09:00
Doctrineのドキュメント、Working with Objectsのページを意訳してみた【後編】
昨日の続きです。
各章の説明
The size of a Unit of Work
UnitOfWorkのサイズは主に特定の時点での管理下のエンティティの数を指します。
(あんまり多くのエンティティを更新するトランザクションをはるなよってことかな)The cost of flushing
flushのコストは主に以下の2つの要因に依存します。
- EntityManagerの現在のUnitOfWorkのサイズ
- 変更の追跡についての設定
UnitOfWorkのサイズは以下で取得できます。
<?php $uowSize = $em->getUnitOfWork()->size();UnitOfWorkのサイズはflushのパフォーマンスやメモリの消費量に影響を与えるため、開発中に見直してください。
Direct access to a Unit of Work
EntityManager#getUnitOfWork()を呼ぶことでUnitOfWorkに直接アクセスすることができます。
<?php $uow = $em->getUnitOfWork();※UnitOfWorkを直接操作することはお勧めしません。とのこと。
Entity State
エンティティの状態はこれまで言及してきたとおりNEW, MANAGED, REMOVED, DETACHEDの4つがあります。
エンティティの状態を知りたいときは以下のようなコードで知ることができます。<?php switch ($em->getUnitOfWork()->getEntityState($entity)) { case UnitOfWork::STATE_MANAGED: ... case UnitOfWork::STATE_REMOVED: ... case UnitOfWork::STATE_DETACHED: ... case UnitOfWork::STATE_NEW: ... }Querying
Doctrine 2は以下の紹介するようなクエリの実行方法を提供しています。
By Primary Key
EntityManager#find($entityName, $id)はPKによるエンティティの取得です。
指定されたエンティティまたはnullを返します。ショートカットとして以下のように書くこともできます。
<?php // $em instanceof EntityManager $user = $em->getRepository('MyProject\Domain\User')->find($id);By Simple Conditions
シンプルな条件ならfindByやfindOneByを使うことができます。
order byやlimitとoffsetをつけることも可能。
<?php $tenUsers = $em->getRepository('MyProject\Domain\User')->findBy(array('age' => 20), array('name' => 'ASC'), 10, 0);配列を指定すればin句に。
<?php $users = $em->getRepository('MyProject\Domain\User')->findBy(array('age' => array(20, 30, 40))); // translates roughly to: SELECT * FROM users WHERE age IN (20, 30, 40)マジックメソッドを使ったやり方もできる。
<?php // A single user by its nickname $user = $em->getRepository('MyProject\Domain\User')->findOneBy(array('nickname' => 'romanb')); // A single user by its nickname (__call magic) $user = $em->getRepository('MyProject\Domain\User')->findOneByNickname('romanb');countも取れる。
<?php // Check there is no user with nickname $availableNickname = 0 === $em->getRepository('MyProject\Domain\User')->count(['nickname' => 'nonexistent']);By Criteria
RepositoryはDoctrine\Common\Collections\Selectableインターフェースをimplements(実装)しています。それが何を意味するのかというと、Doctrine\Common\Collections\Criteriaオブジェクトを作成することができ、それをSelectableインターフェースのmatching($criteria)メソッドに渡すことができます。
By Eager Loading
エンティティ同士の関連をEAGERとしてマッピングすることもできます。
LAZYとは逆に、あるエンティティの取得時に同時にEAGERとして設定された関連のエンティティを取得し、アプリケーションですぐに利用できます。By Lazy Loading
LAZYとして設定された関連については、関連のエンティティへのアクセス時にDBから取得しますが、アプリケーション的にはEAGERと同様すでに取得済みのように振る舞います。
By DQL
永続化されたエンティティに対する最もパワフルでフレキシブルなクエリ発行のやり方はDoctrine Query Languageです。DQLを使用すると、オブジェクトの言語で永続化されたエンティティを取得できます。DQLは、クラス、フィールド、継承、および関連付けを理解します。DQLは、使い慣れたSQLと構文的に非常に似ていますが、SQLではありません。
DQLクエリはDoctrine\ORM\Queryクラスのインスタンスで表されます。 EntityManager#createQuery($dql)を使用してクエリを作成します。
以下に簡単な例を示します。<?php // $em instanceof EntityManager // All users with an age between 20 and 30 (inclusive). $q = $em->createQuery("select u from MyDomain\Model\User u where u.age >= 20 and u.age <= 30"); $users = $q->getResult();By Native Queries
DQLの代わりにネイティブなSQLを使用することもできます。
SQLの結果をResultSetMappingによりDoctrineのオブジェクトに変換できます。Custom Repositories
EntityManager#getRepository($entityClass)を呼び出すと、Doctrine\ORM\EntityRepositoryが返されます。あなたはこの振る舞いをアノテーションやXMLの設定やyamlの設定で上書きすることができます。
大規模なアプリケーションでは多くのDQLを使うので、カスタムリポジトリはそれらをグルーピングするためのおすすめの方法です。<?php namespace MyDomain\Model; use Doctrine\ORM\EntityRepository; use Doctrine\ORM\Mapping as ORM; /** * @ORM\Entity(repositoryClass="MyDomain\Model\UserRepository") */ class User { } class UserRepository extends EntityRepository { public function getAllAdminUsers() { return $this->em->createQuery('SELECT u FROM MyDomain\Model\User u WHERE u.status = "admin"') ->getResult(); } }という定義があったとるすと、以下のように呼び出すことができます。
<?php // $em instanceof EntityManager $admins = $em->getRepository('MyDomain\Model\User')->getAllAdminUsers();おわりに
最後のほうがちょっと雑ですが、個人的にはDoctrineについての理解を助けるドキュメントを全部読めて達成感があります。
他に読みたいなと思っているのはこのあたりですかね。
Working with Associations
https://www.doctrine-project.org/projects/doctrine-orm/en/latest/reference/working-with-associations.html関連まわりは上記の記事が詳しそうです。
関連まわりは結構ハマります。Transactions and Concurrency
https://www.doctrine-project.org/projects/doctrine-orm/en/latest/reference/transactions-and-concurrency.html#transactions-and-concurrencyflushがトランザクション的に扱われているけれども、SQLレベルのトランザクションもあり、そのあたりどう使い分けるべきか・・・よくわかっていないので。
Best Practices
https://www.doctrine-project.org/projects/doctrine-orm/en/latest/reference/best-practices.html#best-practicesベストプラクティスとは!?
- 投稿日:2019-12-02T12:45:14+09:00
Doctrineのドキュメント、Working with Objectsのページを意訳してみた【前編】
はじめに
Doctrineは自分の思ったように動かないことが多々ありますが、
それはDoctrineの根本を自分が理解していないのでは?ということを考えました。
以下のドキュメントを読んでみることが、理解に役に立つのではと思い、英語を自分なりに意訳してみました。Working with Objects
https://www.doctrine-project.org/projects/doctrine-orm/en/latest/reference/working-with-objects.html#working-with-objectsWorking with Objectsのドキュメントについて
ページの最初にもありますが、このドキュメントはEntityManagerとUnitOfWorkの理解を助けるためのページとのこと。
EntityManagerはDoctrineのORマッパーとしての中心的な役割を果たすクラスであり、
コネクションの取得からfindなどのオブジェクト取得、flushなどのクエリ発行を担っています。
UnitOfWorkとは、Doctrine固有の概念ではなく、Martin Fowler氏のPatterns of Enterprise Application Architectureというパターンについての書籍に記載されたパターンのようです。
ユニットオブワーク
https://bliki-ja.github.io/pofeaa/UnitofWork/
Doctrineのドキュメントでは、UnitOfWorkはオブジェクトレベルのトランザクションのようなもの、と記載されています。
このオブジェクトレベルのトランザクションはEntityManagerが作成されたまたはflushが呼ばれたあとから開始し、flushが呼ばれると終了します。各章の説明
Entities and the Identity Map
"Identity Map"パターンというパターンがあるようで、
一意マップ
https://bliki-ja.github.io/pofeaa/IdentityMap/ロードしたオブジェクトをマップに保存して、オブジェクトが一度だけロードされることを保証する。オブジェクトが参照されたときは、マップを使って探し出す。とパターンのページには解説がありますが、
Doctrineでもこの考え方を採用していて、find(id)で一度取得したものはマップに保存しておき、再度find(id)で取得しても同じインスタンスを返すということのようです。
なので、コード例にある<?php $article = $entityManager->find('CMS\Article', 1234); $article->setHeadline('Hello World dude!'); $article2 = $entityManager->find('CMS\Article', 1234); echo $article2->getHeadline();の最後のgetHeadline()は'Hello World dude!'を返し、
<?php if ($article === $article2) { echo "Yes we are the same!"; }はtrueとなるというわけです。
findをしたら毎度DBに値を取得しに行くものだと思っていたのでびっくりです。Entity Object Graph Traversal
Graph Traversalとはグラフというデータ構造の走査に関するアルゴリズムのようで、ここではエンティティの関連を走査する方法について書かれているようです。
エンティティの関連についてはいくらでも辿れるよ、と言っている感じです。
例としてArticleクラスにManyToOneでauthorが紐付いてたり、OneToManyでcommentsが紐付いていた場合に、find(id)で取ってくるときはarticleテーブルにselectを発行するだけだけど、Articleエンティティからはauthorやcommentsのデータを取得できるよ、とのこと。この関連を取ってくるやり方はlazy loading patternで行われるとのこと。
レイジーロード
https://bliki-ja.github.io/pofeaa/LazyLoad/レイジーロードとは、必要になったときにDBからデータを読み込むというやり方で、
上記ページには以下のように記載されています。Lazy Load (遅延ロード)ではロード処理をしばらく保留し、オブジェクト構造にしるしをつけておくことで、データが必要になった時に初めてロードするようにする。物事を後回しにしておくと、それをやらなくてよくなったときに得をする。なので、Articleエンティティからauthorやcommentsにアクセスするときに初めてデータベース読み込みが発生します。authorを使わない処理ではデータベースアクセスは発生しません。
authorの読み込みはDoctrineのプロキシインスタンスというクラスを介して行われます。
(authorがUserという型だったとして)Article->getAuthor()で得られるのはUserクラスではなくUserを取得するためのUserProxyクラスであり、以下のコードはイコールではありません。if ($article->getAuthor() instanceof User) { // a User Proxy is a generated "UserProxy" class }レイジーロードはSQLの発行回数を爆発的に増やす場合があります。
(Articleオブジェクトが1ページに1000個表示されて、それぞれのcommentやauthorを取得したら3000回のSQLが発行されますね。)
パフォーマンスの問題がある場合は、DQLで必要なデータをjoinして取得しましょう、とのこと。Persisting entities
EntityManager#persist($entity)について説明されています。
persistメソッドはエンティティをMANAGED(管理された)状態にします。
何に管理されているかというと、EntityManagerのよって管理された状態になります。
その結果、EntityManager#flush()が呼ばれたときに、管理されたエンティティはデータベースに同期されます。persistを呼んでも直ちにSQLのinsert文が発行されるわけではありません。
Doctrineはトランザクション後書きと呼ばれる戦略を取っています。
EntityManager#flush()が呼ばれるまで、SQLの実行は遅延され、flushが呼ばれて初めてデータベースにデータが同期されます。
このようにすることでデータの整合性を保つ簡易的なトランザクションとすることができます。
つまりDoctrineではSQLレベルでのトランザクションでなく、flushされるまでSQLの発行を遅延させることで、flushするまでの間を簡易的なトランザクションとして扱っているのです。
まさにこれがUnitOfWorkなんですね。
最初にこれを知るまでは、なんでコードにトランザクションがないのか、と思っていました・・・。Doctrineはflushが成功しないと、エンティティのPKを得ることができません。
persistしただけでは、新たなエンティティのPKは取得できません。persistの作用は以下の通りです。
- newされたエンティティをMANAGED状態にして、flush時にDBに登録する。
- すでにMANAGEDの状態のエンティティにpersistを発行しても無視される。しかし、このエンティティから他のエンティティへの関連がcascade=PERSISTまたはcascade=ALLの場合は他エンティティがまだpersistされていない場合はMANAGEDになる。例えば、ArticleがすでにMANAGEDでcommentsにまだMANAGEDになっていないものがあった場合、commentsの関連にcascaade=PERSISTが設定されていれば、persist(article)したときにcommentsも同時にpersistされる。
- removeされたエンティティをMANAGED状態にする
- detatchされたエンティティをpersistするとflush時に例外が発生する。
ときどき、newしてないエンティティにpersistしているコードを見かけますが、関連にcascade=PERSISTがない限りは意味がないということですね。
Removing entities
エンティティの削除について書かれています。
EntityManager#remove($entity)で削除を行うことができます。
removeするとエンティティはREMOVED(削除済み)の状態になります。
例によってflushが呼ばれるまでは実際にデータベースからデータが削除されず、
flushが呼ばれるとデータベースからデータが削除されます。removeの作用は以下の通りです。
- newされたエンティティに対してremoveを発行しても無視される。しかし、このエンティティから他のエンティティへの関連の設定がcascade=REMOVEまたはcascade=ALLだった場合には関連先のエンティティにはremoveが適用される。
- MANAGED状態のエンティティに対してremoveを発行するとREMOVED状態になる。このエンティティから他のエンティティへの関連の設定がcascade=REMOVEまたはcascade=ALLだった場合には関連先のエンティティにもremoveが適用される。
- detatchされたエンティティをremoveするとInvalidArgumentExceptionがスローされる。
- removeされたエンティティをremoveすると無視される。
- removeされたエンティティはflushするとデータベースから削除される。
エンティティ自体はremoveを呼び出してもID以外は普通に参照できます。
エンティティにManyToManyの関連がある場合、関連先のエンティティも自動的に削除されます。その動作は関連の定義のjoinColumnのonDelete属性によって決定されます。
- 関連がcascade=REMOVEだった場合はDoctrine2ではその関連先もすべてremoveします。もし関連がcollectionだった場合には、そのcollectionをloopしてさらにそのひとつひとつを再帰的にremoveするため、大きなオブジェクトだとかなりのコストがかかってしまいます。cascade=REMOVEはDoctrine側でdelete文を発行するための仕組みです。
- オブジェクトが大きいときはDQLでdelete文を書くことがパフォーマンス的には有効です。
- onDelete="CASCADE"はcascade=REMOVEとは異なりデータベースに用意されているFKによるcascadeです。アプリケーション側で削除を管理できないのでトリッキーではありますが、データベース側ですべて処理が行われるためパフォーマンスはとてもいいです。cascade=REMOVEをつけてしまうとonDelete="CASCADE"は無意味になります(・・・自信ないですが多分)
Detaching entities
detachとは切り離すという意味ですが、EntityManagerの管理下から外すという意味かと思います。
EntityManager#clear()メソッドが呼ばれた後は、エンティティに変更を加えてもそれがデータベースに同期されることはありません。clearの作用は以下の通りです。
- MANAGED状態のエンティティにたいしてclearを実行するとdetachされます。
- newしたエンティティにたいしてclearを実行しても無視されます。
- REMOVED状態のエンティティに対してclearを実行するとdetach状態のため削除されなくなります。
Synchronization with the Database
UnitOfWorkの考え方に基づいてEntityManagerでオブジェクトレベルのトランザクションを実現してるよ、flushしたときにデータベースに同期するよ、同期するときは関連も全部登録されるし、MANAGEDやREMOVEDなオブジェクトも全部見て同期するよ、という今までのまとめ的な話。
Effects of Database and UnitOfWork being Out-Of-Sync
とにかくflushを呼ばない限りはデータベースに同期されないよっていう話がまた書かれていて
- REMOVED状態のエンティティでもflushを呼ぶ前なら参照可能だし、データベースからもDQLなどで取得可能
- persistされたエンティティもflushを呼ぶ前だとクエリでは取得できない
- 変更されたエンティティはデータベースからの取得結果で上書きされない、これはIdentity Mapが何が最新の状態であるか把握しているため
で、flushは自動では呼ばれないこと、必ず手動で呼ぶことが書かれています。
Synchronizing New and Managed Entities
flushによってMANAGED状態のエンティティには以下の作用があります。
- 少なくとも管理されているフィールドの1つが変更されている場合に限りSQLのUPDATEが実行される
- 何も変更されていない場合は何も実行されない
flushによってnewされたエンティティには以下の作用があります。
- SQLのinsertが実行される。
関連については以下のとおり(ちょっと何言ってるかわからない状態)
- もしnewされたエンティティXが別のエンティティにcascade=PERSISTの設定がされている場合は、別のエンティティがpersistされたら、Xもpersistされる
- もしnewされたエンティティXが別のエンティティにcascade=PERSISの設定がされていない場合は、別のエンティティがpersistされた場合に、エラーが発生する
- もしremoveされたエンティティXが別のエンティティにcascade=PERSISの設定がされている場合は、別のエンティティがpersistされた場合に、エラーが発生する
- もしdetachされたエンティティXが別のエンティティにcascade=PERSISの設定がされている場合は、別のエンティティがpersistされた場合に、エラーが発生する
Synchronizing Removed Entities
removeもflush時にデータベースに同期されます。
flush時に関連するcascadeオプションはなく、CASCADE=REMOVEはEntityManager#remove($entity)実行時にもう実行されています。ちょっと長くなってきたので
明日に続く!
- 投稿日:2019-12-02T12:29:23+09:00
HttpPostでファイル受信(PHP)
はじめに
XAMPPのApacheを利用して、ファイル受信をしたかった。
コピペでPHPのファイル受信プログラムを作成したが、ファイルを受け取れず困ったのでメモ。エラーコードを見ると1が返されており、ファイルサイズが大きすぎたことが原因だとわかった。
php.ini の upload_max_filesizeを書き換えて再起動することによって解決した。送信側については書かない。
リファレンス
POST メソッドによるアップロード
エラーメッセージの説明アップロード用のphpファイル
upload.php<?php //情報取得 $name = $_FILES["file"]["name"]; // ファイル名 $mimetype = $_FILES["file"]["type"]; // Content-Type $filesize = $_FILES["file"]["size"]; // ファイルサイズ $tmpname = $_FILES["file"]["tmp_name"]; // 一時ファイル名 $error = $_FILES["file"]["error"]; // エラー //ログ $file = 'log.txt'; $current = file_get_contents($file); $current .= $name . "\n"; $current .= $mimetype . "\n"; $current .= $filesize . "\n"; $current .= $tmpname . "\n"; $current .= $error . "\n"; file_put_contents($file, $current); //なければフォルダを作成 $target_dir = "imgs"; if(!file_exists($target_dir)) { mkdir($target_dir, 0777, true); } //保存 $filename = $target_dir . "/" . $name; $result = @move_uploaded_file( $tmpname, $filename ); echo( $result ); ?>
- 投稿日:2019-12-02T09:49:57+09:00
cakephpでgroup byして最新レコード取得
testCREATE TABLE `test` ( `id` int(11) NOT NULL AUTO_INCREMENT, `page_id` varchar(50) NOT NULL, `update_date` datetime NOT NULL, `updater_name` varchar(50) NOT NULL, `reason` varchar(50) NOT NULL, PRIMARY KEY (`id`), UNIQUE KEY `test_UN` (`page_id`,`update_date`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4下記のようなテストデータを挿入
"id" "page_id" "update_date" "updater_name" "reason" 1 A-1 "2019-12-01 00:00:00.0" alice ページ新規追加 2 A-2 "2019-12-02 00:00:00.0" bob ページ新規追加 3 A-1 "2019-12-05 00:00:00.0" charlie 機能追加 4 A-3 "2019-12-05 00:00:00.0" alice 新規追加 5 A-1 "2019-12-06 00:00:00.0" delta 不要の為ページ削除 6 A-3 "2019-12-07 00:00:00.0" charlie デザイン修正
- 投稿日:2019-12-02T09:49:57+09:00
CakePHP2でgroup byして最新レコード取得
CakePHP2のfind()では特定IDでGROUP BYした上でそれぞれの最新レコード取得するのが難しかったので後の為にメモ
test_page_historyCREATE TABLE `test_page_history` ( `id` int(11) NOT NULL AUTO_INCREMENT, `page_id` varchar(50) NOT NULL, `update_date` datetime NOT NULL, `updater_name` varchar(50) NOT NULL, `reason` varchar(50) NOT NULL, PRIMARY KEY (`id`), UNIQUE KEY `test_UN` (`page_id`,`update_date`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4①のようなテストデータから②を取得したい
① 元データ
"id" "page_id" "update_date" "updater_name" "reason" 1 A-1 "2019-12-01 00:00:00.0" alice ページ新規追加 2 A-2 "2019-12-02 00:00:00.0" bob ページ新規追加 3 A-1 "2019-12-05 00:00:00.0" charlie 機能追加 4 A-3 "2019-12-05 00:00:00.0" alice 新規追加 5 A-1 "2019-12-06 00:00:00.0" delta 不要の為ページ削除 6 A-3 "2019-12-07 00:00:00.0" charlie デザイン修正 ② page_idでまとめた最新レコード
"id" "page_id" "update_date" "updater_name" "reason" 5 A-1 "2019-12-06 00:00:00.0" delta 不要の為ページ削除 2 A-2 "2019-12-02 00:00:00.0" bob ページ新規追加 6 A-3 "2019-12-07 00:00:00.0" charlie デザイン修正
- 投稿日:2019-12-02T09:49:57+09:00
CakePHP2にて任意カラムでGROUP BYした最新レコードの取得
内容
CakePHP2のfind()では特定のカラムでGROUP BYした上でそれぞれの最新レコード取得するのが難しかったので後の為にメモ
やりたいこと
下記のようなテーブルでpage_idをGROUP BYしてそのページごとの最新レコードが欲しい
test_page_history.sqlCREATE TABLE `test_page_history` ( `id` int(11) NOT NULL AUTO_INCREMENT, `page_id` varchar(50) NOT NULL, `update_date` datetime NOT NULL, `updater_name` varchar(50) NOT NULL, `reason` varchar(50) NOT NULL, PRIMARY KEY (`id`), UNIQUE KEY `test_UN` (`page_id`,`update_date`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4① 元データ
"id" "page_id" "update_date" "updater_name" "reason" 1 A-1 "2019-12-01 00:00:00.0" alice ページ新規追加 2 A-2 "2019-12-02 00:00:00.0" bob ページ新規追加 3 A-1 "2019-12-05 00:00:00.0" charlie 機能追加 4 A-3 "2019-12-05 00:00:00.0" alice 新規追加 5 A-1 "2019-12-06 00:00:00.0" delta 不要の為ページ削除 6 A-3 "2019-12-07 00:00:00.0" charlie デザイン修正 ② 取得したいテータ(page_idでまとめた最新レコード)
"id" "page_id" "update_date" "updater_name" "reason" 5 A-1 "2019-12-06 00:00:00.0" delta 不要の為ページ削除 2 A-2 "2019-12-02 00:00:00.0" bob ページ新規追加 6 A-3 "2019-12-07 00:00:00.0" charlie デザイン修正 やったこと
Modelにカスタムfinderを追加実装し
conditionsで力業を使ったTestPageHistory.php<?php App::uses('AppModel', 'Model'); class TestPageHistory extends AppModel { public $useTable = 'test_page_history'; public $primaryKey = 'id'; public $useDbConfig = 'admin'; // 自作するカスタムfinderを使用可能に設定 public $findMethods = [ 'newest' => true, ]; /** * newest実装 * * @param string $state * @param array $query * @param array $results */ protected function _findNewest($state, $query, $results = []) { if ($state === 'before') { $query['conditions']["{$this->alias}.update_date = (SELECT MAX(b.update_date) FROM test_page_history AS b WHERE TestPageHistory.page_id = b.page_id)"] = [true]; $query['order']["{$this->alias}.page_id"] = ['asc']; return $query; } return $results; } }Controllerはカスタムfinderを使うのみ
TestController.php<?php App::uses('AppController', 'Controller'); App::uses('TestPageHistory', 'Model'); class PointsListController extends AppController { public $uses = [ 'TestPageHistory', ]; /** * 一覧 * * @return void */ public function index(): void { // カスタムfinderである「'newest'」でデータ取得 $test = $this->TestPageHistory->find('newest'); var_dump($test); }↓
取得結果
page_idごとの最新レコードが取得できている?
array(3) { [0]=> array(1) { ["TestPageHistory"]=> array(5) { ["id"]=> string(1) "5" ["page_id"]=> string(3) "A-1" ["update_date"]=> string(19) "2019-12-06 00:00:00" ["updater_name"]=> string(5) "delta" ["reason"]=> string(27) "不要の為ページ削除" } } [1]=> array(1) { ["TestPageHistory"]=> array(5) { ["id"]=> string(1) "2" ["page_id"]=> string(3) "A-2" ["update_date"]=> string(19) "2019-12-02 00:00:00" ["updater_name"]=> string(3) "bob" ["reason"]=> string(21) "ページ新規追加" } } [2]=> array(1) { ["TestPageHistory"]=> array(5) { ["id"]=> string(1) "6" ["page_id"]=> string(3) "A-3" ["update_date"]=> string(19) "2019-12-07 00:00:00" ["updater_name"]=> string(7) "charlie" ["reason"]=> string(18) "デザイン修正" } } }
- 投稿日:2019-12-02T09:26:06+09:00
PHP基礎 Part2
概要
PHPの独学で学んだ内容をアウトプットしていく
前回の内容
データ型
Part1でも出てきた文字列や数字といった値には、それぞれデータ型というものが定義されている。
下の図1はデータ型の一覧である【図1】データ型と型名
データ型 型名 boolean 論理型 integer 整数型 float 浮動小数点型 string 文字列 array 配列 resource リソース NULL ヌル値 変数とは
初学者向けに説明されている内容は、「データを入れる箱」とされている
これでもざっくりとした理解にはつながるが、個人的には以下の記事の内容にしっくり来るものがあった。
なぜ日本人はオブジェクト指向をなかなか理解できないのか?変数の定義
PHPでは変数を定義するルールとして、頭に「$」を付ける
こうすることで変数の定義が可能となる
PHPでは「=」は右辺のデータを左辺のデータに代入することを示す
(上で紹介した記事の内容だと「代入する」より「割り当てる」がより適した意味ではないかと提唱している)sample.php<?php $number = 1; // 変数の定義を行う echo $number; // 定義した変数(1)を出力 ?>変数の役割
- データの命名
- 複数回使うデータをまとめられる
例えば直径の長さを求めるのに、変数を使う場合とそうでない場合とで想定する
変数を使う場合は以下の通りにコードが書かれるsample.php<?php $radius = 5; // 半径の長さを定義 $diameter = $radius * $radius * 3; // 直径の長さを算出し、変数$diameterへ割り当てる echo $diameter; // 変数$diameterを出力 ?>これを使わないと以下のようなコードとなる
sample.php<?php $diameter = 5 * 5 * 3; // 直径の長さを算出し、変数$diameterへ割り当てる echo $diameter; // 変数$diameterを出力 ?>両方とも出力される結果は同じであるが、
下の方は仮に半径の長さが変わった場合に2箇所修正する必要がある
一方で、上のコードは変数$radiusの値を修正するだけで解決する変数名の付け方
- 英単語を用いる(変数で年齢を定義したければ「age」を用いる等、何を定義したいかが明確に判別可能な単語を使う)
- 2語以上の場合は、大文字で区切る(例:$userName)
- 数字から始まる命名は不可
- ローマ字や日本語での命名は望ましくない
変数の更新
変数は割り当てられている値を更新することが可能
sample.php<?php $num = 5; echo $num; // 5が出力される $num = 10; echo $num; // 10が出力される ?>また、現在割り当てられている変数の値に別の数字を足すことも可能
sample.php<?php $num = 5; $num = $num + 5; // 変数$numに5を加える echo $num; // 10が出力される ?>これを他の四則演算も考慮した上で、省略した形が以下の形式となる
sample.php<?php $num = 10; $num += 5; // $num = $num + 5の省略系 $num -= 5; // $num = $num - 5の省略系 $num *= 5; // $num = $num * 5の省略系 $num /= 5; // $num = $num / 5の省略系 $num %= 5; // $num = $num % 5の省略系 ?>足す値、引く値が1のみである場合は、同じ記号を2度使うことで省略が可能
この形式をインクリメント、デクリメントと呼ぶsample.php<?php $num1 = 7; $num2 = 3; echo ++$num1; // 値は8 echo --$num2; // 値は2 ?>文字列や変数の連結
文字列や変数を「.」で繋げると、文字の連結が可能になる
index.php<?php $term = "あいう"; echo $term."えお"; // 出力結果は"あいうえお" ?>文字列の連結は「.=」を用いることで省略した形で記述できる
index.php<?php $term = "かきく"; $term .= "けこ"; // $term = $term . "けこ"の省略形 echo $term; // 出力結果は"かきくけこ" ?>変数展開
ダブルクォーテーションで囲われた文字列の中に、
変数を組み込むと変数に割り当てられた値が出力される
使い方は、変数を「{}」で囲うことindex.php<?php $today = "2019/12/02"; echo "本日は{$today}です"; // 出力結果は"本日は2019/12/02です" ?>次回
- if文
- switch文
- 投稿日:2019-12-02T02:00:46+09:00
Mac × MAMP × Laravelで接続した時に起こった事
事象
・なんかLaravelインストールしたらMAMPの「MY WEBSITE」に接続できなくなった
※正確に言うと、「The requested URL /~ was not found on this server.」の404エラーが出ました。原因
・Laravelインストールしたと思ったらできてなかった....
→composer導入した後に、インストールしたつもりになってた・Laravel側で複数設定が必要なファイルに対して追加できていなかった。
■database.php
→使用しているデータベースの情報を追加できていなかった・MAMP側の設定ファイルでLaravelの追加ができていなかった
■httpd-vhosts.conf
→設定されているPort番号がLaravelの行で設定している
Port番号と一致していなかった。
NameVitualHost *:oooo
※上記とここのファイルでLaravelの追加が必要
■httped.conf
→ここでVitural hostsの下の行でコメントアウトされている文章の#を外す
(ここは出来てきた)所感
・ターミナル時にコマンド実行して大量のメッセージが流れた時に、
読み取る前にやった気になってたかも
・MAMPを初めて導入した時より早く事象の解決が出来た気がした。//MAMP導入時→12,3時間くらい
//今回→6,7時間くらい参考元
PKunitoさんとCodedayの作者様、理解しやすい記事を作成いただいてありがとうございました。
・Laravel開発:1.環境構築をMAMPを使用して作成する
https://qiita.com/PKunito/items/6a3bb187ca3c67de4519・MAMPを使用してLaravelアプリをMySQLに接続する方法
https://codeday.me/jp/qa/20190324/474003.html
- 投稿日:2019-12-02T01:53:11+09:00
Laradockを用いてDocker/Apache/PHP7.2/MySQL/Laravelの開発環境を構築する
Laradockクローン
ルートディレクトリにて、下記を実行。
$ git clone https://github.com/LaraDock/laradock.git
.envをenv-exampleからコピーして作成。
$ cd laradock
$ cp env-example .env
プロジェクト作成まずは、ワークスペースを起動。
$ cd laradock
$ docker-compose up -d workspace
ワークスペースに入る。
$ docker-compose exec workspace bash
Laravelのプロジェクトを作成composer create-project laravel/laravel web
dockerを一旦終了
exit
$ docker-compose down
laradock/.envのpathを作成したプロジェクトに変更。Point to the path of your applications code on your host
APP_CODE_PATH_HOST=../new_project
apache2の設定変更
ハマったところ。
apache2を使用するので、laradock/apache2/sites/default.apache.confを変更。
ServerName localhost
DocumentRoot /var/www/public/
Options Indexes FollowSymLinks各バージョンを指定(.env)
PHP_VERSION=7.2
MYSQL_VERSION=latest
(mysql/Dockerfile)
ARG MYSQL_VERSION=5.7dockerにてコンテナを起動。
$ docker-compose up -d mysql apache2 workspace
localhostにアクセス。docker-compose stop
既存のLaravelプロジェクトを配置する場合
webに展開
docker-compose exec --user=laradock workspace bash # workspaceへ入る
composer install
laradock@hoge:/var/www$ exit # workspaceから抜ける
$ docker-compose restart # コンテナ再起動
http://localhost/ にアクセスLaravel のプロジェクトを Homestead 環境で 起動させました。
http://localhost:8000/ にアクセスするとエラーがでました。RuntimeException がでる
RuntimeException
No application encryption key has been specified.
encryption key がないとあります。key を生成する
php artisan key:generate
Application key [base64:Wdhku6YSePiOh0XjqauthSaeOhzwRKxasFjbuuHXz0w=] set successfully.
Application key が生成されました。再度アクセス
http://localhost:8000/ にアクセスすると Laravel の初期画面が表示されました
- 投稿日:2019-12-02T01:02:29+09:00
多次元連想配列の数値の合計値を出す
多次元連想配列の数値の合計値を出す
index.phparray(3) { [0]=> array(2) { ["name"]=> string(5) "apple" ["stock"]=> int(2) } [1]=> array(2) { ["name"]=> string(5) "lemon" ["stock"]=> int(4) } [2]=> array(2) { ["name"]=> string(5) "orange" ["stock"]=> int(8) } }こちらの連想配列の
"stock"の値を合計していきます。処理方法は
index.php$sum_stock = array_sum(array_column($fruits, 'stock'));です。
array_column()で配列の単一のカラムを抽出し、その値をarray_sum()で合計するという方法です。結果は
index.phpvar_dump($sum_stock); int(14)以上多次元連想配列の数値の合計値を出すでした。
ご閲覧ありがとうございました。
- 投稿日:2019-12-02T00:56:31+09:00
【PHP】インターフェイスとクラスの抽象化の使い分けついて
この記事はエイチーム引越し侍 / エイチームコネクト Advent Calendar 2019 2日目の記事です。
きっかけ
業界未経験からエンジニアなり、およそ半年が経ちました。最近ゼロからちょっとしたツールを作る機会をいただき、なんとか形にはなったのですが、拡張性や保守性を担保するには、コード側で制約するような設計が必要なのでは無いかと思い、これらについて調べてみました。
インターフェイスとクラスの抽象化は似ている
インターフェイス
複数のクラスに共通の機能を実装するために、その実体を定義することなく指定する仕組みで、インターフェイスを用いると、特定のオブジェクトが特定の機能(メソッド)を有することが保証されます。インターフェイスに定義されているメソッドを実装しないと致命的なエラーとなります。
クラスの抽象化
共通の機能を抽象的な親クラスで定義し、特有の機能は個々の子クラスでそれぞれ実装させたい場合に定義します。抽象化を使うには、抽象化したクラスを子クラスに継承し、すべてのabstractメソッドを実装する必要があります。
どう使うか
色々調べた結果、私が感じたイメージがこちらです。PHPは、クラスやインターフェイスの多重継承ができるが、クラスの場合は子が親のメソッドを呼ぶ際、どちらの親のメソッドを使用するかがわかりくくなるため、クラスの多重継承はあまり使用しないほうが良いと思いました。
クラスの抽象化については、通常の継承のように複数のクラスで共通する処理があるが、親のみで使用することがない或いはしたくない場合に使用するで良いと思いました(自分はこう思う、こう使っているなどあればコメントしていただけると幸いです
)。インターフェイスについては、指示書的な使い方をし、どういったメソッドを持ったクラスを作成するかを決めておき、他の開発メンバーが依存する部分を作業するときに使えるのでは無いかと思いました。(自分はこう(ry)。また、メソッドの型宣言も用いることで、クラスかインターフェイスかを切り分けることができるのもメリットかなと思いました。
使ってみた
インターフェイス
interface Player { public function play(); public function stop(); } class musicPlayer implements Player { public function play() { echo '音楽再生中' . PHP_EOL; } public function stop() { echo '音楽停止中' . PHP_EOL; } } class moviePlayer implements Player { public function play() { echo '動画再生中' . PHP_EOL; } public function stop() { echo '動画停止中' . PHP_EOL; } } $obj1 = new musicPlayer(); $obj2 = new moviePlayer(); $obj1->play(); // 音楽再生中 $obj1->stop(); // 音楽停止中 $obj2->play(); // 動画再生中 $obj2->stop(); // 動画停止中クラスの抽象化
abstract class Polygon { public function showHeight() { return $this->height; } public function showWidth() { return $this->width; } abstract public function clucArea(); } class Square extends Polygon { public $height = 1; public $width = 1; public function clucArea() { return $this->height * $this->width; } } class Triangle extends Polygon { public $height = 2; public $width = 2; public function clucArea() { return $this->height * $this->width / 2; } } $obj1 = new Square; $obj2 = new Triangle; echo $obj1->showHeight() . PHP_EOL; // 1 echo $obj2->showWidth() . PHP_EOL; // 2 echo $obj1->clucArea() . PHP_EOL; // 1 echo $obj2->clucArea() . PHP_EOL; // 2参考
- オブジェクト インターフェイス
- クラスの抽象化
- 型宣言
- [PHP]abstractとinterfaceの使い分けを整理してみる
- PHPのinterfaceとabstractを正しく理解して使い分けたいぞー
- PHPにおけるインターフェースと抽象クラス、多重継承、トレイトの使い方
- パーフェクトPHP
お知らせ
エイチームグループでは一緒に活躍してくれる優秀な人材を募集中です。
興味のある方はぜひともエイチームグループ採用ページよりご応募ください!Qiita Jobsのエイチーム引越し侍社内システム企画 / 開発チーム、社内システム開発エンジニアを募集!からチャットでご質問いただくことも可能です!
明日
明日は、@ikuma_hayashiさんの「php+mecab環境をdockerで構築する(仮)」です。
- 投稿日:2019-12-02T00:01:12+09:00
【PHP7.4】PHP7.4がリリースされたので新機能全部やる
2019/11/28にPHP7.4.0がリリースされました。
ということで、ここではドキュメント化されている新機能や変更点を片端から試してみます。これら以外にもドキュメント化するほどでもない軽微な変更が多々入っているはずですし、単なるバグ修正も山ほどあるのですが、今回はそのあたりには触れません。
把握しきれていませんしね。インストール
古いXAMPPが入っていたらディレクトリまるごと削除。
最新のXAMPPをインストール。
Windows版PHPからVC15 x64 Thread Safeをダウンロード。
解凍したディレクトリをpath\to\xampp\phpにまるごと上書きコピペ。
php.ini-developmentをphp.iniにコピー。
php.iniのextension_dirをエクステンションが入ってるディレクトリへのフルパスに変更し、mbstringやらgmpあたりの必要なエクステンションのコメントアウトを外す。
XAMPPコントロールパネルからApacheを起動してphpinfo()とかを表示してPHP7.4.0になっていたら成功。Linux? Mac? Docker?
あなたなら環境構築くらい自力でできるっしょ。新機能とか
プロパティ型指定
プロパティに型が指定できるようになりました。
class HOGE{ public int $i = 0; public string $s = ''; public object ?$obj; } $c = new HOGE(); $c->i = 1; $c->s = 'string'; $c->obj = new stdClass(); $c->i = 'string'; // Uncaught TypeError: Typed property HOGE::$i must be int, string usedPHP7.4最大の特徴といっていいでしょう。
アロー関数
アロー関数が使えるようになりました。
$square = fn($x) => $x ** 2; var_dump($square(2), $square(-5)); // 4, 25ちょっとした使い捨て関数を書くときなどに便利。
$a = 1; $hoge = fn() => ++$a; echo $hoge(); // 2 echo $a; // 1PHPではアロー関数の外にある変数は汚染されません。
また、アロー関数の実装に伴い
fnが予約語になります。
今後function fn(){}といった文は書けなくなります。FFI
PHP内に他言語を書けるようになりました。
$a = FFI::new("int[10]"); for ($i = 0; $i < 10; $i++) { $a[$i] = $i; } $p = FFI::cast("int*", $a); var_dump($p[0]); // 0 var_dump($p[2]); // 2脳が混乱する。
あと複雑な文を入れるとすぐエラーになるんだけどCのエラーなのかPHPのエラーなのかわからなくなる。プリローディング
php.iniを設定。
php.iniopcache.preload="path\to\preload.php"
opcache.preloadには"プリロードする対象ファイル"ではなく、"プリロードする対象ファイルを読み込むファイル"を指定します。preload.php// preload_cache.phpをプリロードする opcache_compile_file('path\to\preload_cache.php');プリロードさせたい中身は
opcache_compile_fileで呼ばれているファイルに書きます。preload_cache.phpfunction h(string $str):string{ return htmlspecialchars($str, ENT_QUOTES, 'UTF-8'); }Apacheを再起動すると、
h()がサーバ上のどこからでも使えるようになります。var_dump(h('a<b>c')); // a<b>c function h(){} // Fatal error: Cannot redeclare h()関数
h()がネイティブ関数……のようなものになりました。NULL合体代入演算子
NULL合体代入演算子
??=が導入されました。$id ??= 'hoge'; var_dump($id); // $idがfalsyであれば'hoge'、trulyであれば元の値そのまま $id = $id ?? 'hoge'; // これと同じもし
$idが未定義かfalseっぽい値であれば、NULL合体代入演算子の後ろの値になります。
trueっぽい値であればそのまま何もしません。
値のかわりに関数の返り値などを指定することもできます。上記みたいな
$idであれば先に定義しておけという話ですが、この機能が想定しているのは、リクエスト値やデータベースの値ような、入っているかどうかわからない値に対してだと思われます。HASHエクステンションの常時有効化
var_dump(hash_algos()); // ['md2', 'md4', 'md5', …]PHP7.3までは
--disable-hashオプションで無効にできました。
PHP7.4以降は無効にすることができません。Password Hashing Registry
エクステンションが独自のハッシュアルゴリズムを追加できるようになりました。
それに伴い、現在使用可能なハッシュアルゴリズムを確認するpassword_algos関数が追加されました。var_dump(password_algos()); // ['2y', 'argon2i', 'argon2id']今後追加アルゴリズムは出てくるでしょうか。
openssl_random_pseudo_bytesの改善
openssl_random_pseudo_bytes関数が異常時に例外を発生するようになりました。
openssl_random_pseudo_bytes(-1); // Fatal error: Uncaught Error: Length must be greater than 0PHP7.3までは例外が出ずにfalseが返ってきていました。
mb_str_split
mb_str_split関数が追加されました。
$x = mb_str_split('aAaA11!!あ?', 1); var_export($x);// ['a', 'A', 'a', 'A', '1', '1', '!', '!', 'あ', '?']半角全角入り交じりでも正常に分割してくれます。
これは素晴らしいですね。$x = mb_str_split('がが????', 1); var_export($x);// ['が', 'か', '゙', '?', '', '?', '', '?', '', '?' ]ZWJシーケンスもきれいに分割してくれる模様。
mbstring.regex_retry_limit
mbstring.regex_retry_limitディレクティブが追加されました。
デフォルト値は1000000です。$pattern = '(.*)*^'; $subject = '1234567890123456789012345678901234567890'; mb_ereg($pattern, $subject, $regs); // falseマルチバイト正規表現において、マッチ回数が一定値を超えたら検索を打ち切ります。
pcre.backtrack_limitと同じく、ReDoS攻撃を防ぐためのものです。ところでPCRE正規表現のエラーはpreg_last_errorで取れるんだけど、mb_ereg系のエラーはどうやって調べればいいんだろう。
ReflectionReference
ReflectionReferenceクラスが追加されました。
$ary = [0, 1, 2]; $ref1 =& $ary[1]; unset($ref1); $ref2 =& $ary[2]; var_dump(ReflectionReference::fromArrayElement($ary, 0)); // null var_dump(ReflectionReference::fromArrayElement($ary, 1)); // null var_dump(ReflectionReference::fromArrayElement($ary, 2)); // ReflectionReferenceリファレンスかどうかを調べることができます。
が、なんか思っていたのとちがって、何故か配列にしか使うことができないみたいです。数値セパレータ
数値リテラルを
_で区切れるようになりました。<?php echo 149_597_870_700; // 149597870700 echo 0x42_72_6F_77_6E; // 0x42726F776E echo 0b01010100_01101000_01100101_01101111; // 0b01010100011010000110010101101111 echo 1__2; // Parse error: syntax error人の目で見てわかりやすくするためのもので、値は
_が無い状態と全く同じです。
_の使用条件は"数値に挟まれてないといけない"であり、先頭や末尾、小数点や進数記号の前後などには付けられません。
また__と連続させることもできません。__toString()が例外を出せる
マジックメソッド__toString()が中から例外を出せるようになりました。
class HOGE{ public function __toString() { throw new Exception('hoge'); } } echo new HOGE(); // Fatal error: Uncaught Exception: hogePHP7.3までは
Method HOGE::__toString() must not throw an exceptionのFatal errorになっていました。共変戻り値・反変パラメータ
子クラスでパラメータの型を広げ、返り値の型を狭めることができるようになりました。
class BASE{} class EXTEND extends BASE{} class A{ public function make(EXTEND $param) : BASE{ return new BASE(); } } class B extends A{ /** @Override */ public function make(BASE $param) : EXTEND{ return new EXTEND(); } } (new A())->make(new EXTEND()); (new B())->make(new BASE());PHP7.3までは親クラスと子クラスの型は全く同じでないとならず、異なっていると
Declaration must be compatibleのFatal errorが出ていました。引数アンパック
$a = [1, 2]; $b = 3; $c = new ArrayObject([4, 5]); [$a, $b, $c]; // [[1, 2], 3, ArrayObject(4, 5)] [...$a, $b, ...$c]; // [1, 2, 3, 4, 5]可変長引数や関数呼び出しという特殊な場所でだけ使えていた引数アンパックを、普通に配列中で使えるようになります。
余計なマージとかを行わず単純に配列をくっつけたいときに便利です。数値キーは無視されて連番が振り直されます。
連想配列を渡すとCannot unpack array with string keysのFatal errorになります。弱い参照
WeakReferenceクラスが追加されました。
$dummy = new stdClass(); $wr = WeakReference::create($dummy); $wr->get(); // $dummy unset($dummy); $wr->get(); // null毎回インスタンス使い捨てのPHPでどういうときに使えばいいのか、正直わかりません。
WeakRefとの違いもわかりません。マジックメソッド
__serialize/__unserializeマジックメソッド
__serialize/__unserializeが追加されました。
__sleepおよびSerializableにかわる、新たなシリアライズのメカニズムです。unserializeに失敗するバグclass ObjectWithReferences { protected $var1; protected $var2; public function __construct() { $this->var1 = new StdClass(); $this->var2 = $this->var1; } } class WrapperObject implements Serializable { private $obj; public function __construct($obj) { $this->obj = $obj; } public function getObject() { return $this->obj; } public function serialize() { unserialize(serialize(new \StdClass)); // ??? return serialize($this->obj); } public function unserialize($serialized) { $this->obj = unserialize($serialized); } } $wrapper = new WrapperObject(new ObjectWithReferences()); var_dump($wrapper->getObject()); // ObjectWithReferences $wrapper = unserialize(serialize($wrapper)); // Notice: unserialize(): Error at offset 82 of 83 bytes var_dump($wrapper->getObject()); // falseこれはバグレポに上がっていた例です。
WrapperObject::serializeメソッドに何もしないserialize/unserializeがありますが、これが入っていると何故かunserializeに失敗します。
新たなシリアライズシステムではこのような問題が起こりません。__serializeclass WrapperObject { private $obj; public function __construct($obj) { $this->obj = $obj; } public function getObject() { return $this->obj; } public function __serialize(): array { return (array) $this->obj; } public function __unserialize(array $data) { return $this->obj = (object) $data; } } $wrapper = new WrapperObject(new ObjectWithReferences()); var_dump($wrapper->getObject()); ObjectWithReferences $wrapper = unserialize(serialize($wrapper)); var_dump($wrapper->getObject()); // stdClassこっちならとても簡単。
ただし受け渡しは配列で行わないといけないので、そのあたりは手動で実装が必要になります。
上記例は手抜きしているので元に戻りません。なお
Serializableと__serialize/__unserialize両方を入れた場合は__serialize/__unserializeだけが動きます。unserialize max_depth
unserialize関数にオプション
max_depthが追加されました。$array = [ 1=>[ 2=>[ 3=>[ 4=>[ 5 ] ] ] ] ]; $ser = serialize($array); unserialize($ser, []); // [ 1=>[ 2=>[ 3=>[ 4=>[ 5 ] ] ] ] ] unserialize($ser, ['max_depth'=>1]); // false unserialize(): Maximum depth of 1 exceeded名前からすると深い階層を無視するオプションのように見えますが、実際は
max_depthを超える階層が存在したらunserialize自体が失敗します。PEAR
PEARがデフォルトでインストールされなくなります。
require_once("Auth/Auth.php"); // failed to open stream: No such file or directory手動でインストールすれば当然ながら今後も使用可能です。
またコンパイルオプション--with-pearを指定することでもインストールできますが、このオプションは非推奨で、今後削除される可能性があります。Curl
PHPというより、同梱されるCurlのバージョンに依るものです。
$cfile = new CURLFile('https://www.google.com/images/srpr/logo1w.png','image/png','testpic');libcurlのバージョンが
7.56.0以降であれば、CURLFileにURLを指定できます。また定数CURLPIPE_HTTP1がE_DEPRECATEDになりました。
libcurlでdeprecateになったためです。
libcur7.62.0以降は使えなくなります。FILTER_VALIDATE_FLOAT
検証フィルタFILTER_VALIDATE_FLOATがオプション
min_range/max_rangeに対応し、FILTER_VALIDATE_INTと同じ挙動になりました。filter_var(10.1, FILTER_VALIDATE_FLOAT, [ 'options'=>[ 'min_range' => 1, 'max_range' => 10, ] ]); // falseむしろ何故今まで対応していなかったのだろう。
IMG_FILTER_SCATTER
GDに画像フィルタ定数IMG_FILTER_SCATTERが追加されました。
$img = imagecreatefrompng('image.png'); imagefilter($img, IMG_FILTER_SCATTER , 3, 5); header('Content-Type: image/png'); imagepng($img); imagedestroy($img);点描のようなかんじに画像をぼかします。
第三、第四引数でぼかし度合いを調整できます。imagefilter($img, IMG_FILTER_SCATTER, 3, 10); // 左 imagefilter($img, IMG_FILTER_SCATTER, 1, 100); // 右
正規表現フラグPREG_OFFSET_CAPTURE / PREG_UNMATCHED_AS_NULL
preg_replace_callbackおよびpreg_replace_callback_arrayが、正規表現フラグPREG_OFFSET_CAPTUREとPREG_UNMATCHED_AS_NULLを受け取るようになりました。
$subject = 'abcdedcba'; $pattern = '|.c.|'; $callback = function($matches){ // 第5引数が無い場合、 $matches = ['bcd'] / ['dcb'] // PREG_OFFSET_CAPTUREがある場合、 $matches = ['bcd', 1] / ['dcb', 5] return ''; }; preg_replace_callback($pattern, $callback, $subject, -1, $count, PREG_OFFSET_CAPTURE);PREG_OFFSET_CAPTUREがあると、マッチした位置も一緒にコールバック関数に渡ってきます。
引数の形が変わることに注意しましょう。PREG_UNMATCHED_AS_NULLはよくわからなかった。
PDO DSN
PDOのDSNにユーザ名userとパスワードpasswordを書けるようになりました。
$dsn = 'mysql:dbname=test;host=127.0.0.1;user=testuser;password=testpass'; $pdo = new PDO($dsn);元々Postgresだけ対応していたのが、MySQLなどその他のデータベースにも書けるようになったとのことです。
これは地味に便利では。DSNとコンストラクタが両方指定された場合はコンストラクタが優先されます。
PDO ?のエスケープ
SQLの構文中において、
?を??でエスケープできるようになりました。$sql = "SELECT * FROM my_table WHERE my_col ?? 'my_key'";SQL構文中で
?と書くとプレースホルダと解釈されてしまいますが、それを回避することができます。
これまでPostgresの?演算子を書くことができなかったため、その対策です。文字列値としては、これまでもこれからも普通に書けます。
strip_tags
strip_tags関数の第二引数を配列で渡せるようになりました。
$str = '<a><b><i><u>テキスト</u></i></b></a>'; strip_tags($str, ['b', 'u']); // <b><u>テキスト</u></b>むしろ今までできなかったのかよ。
なお、配列で渡す場合はタグの括弧は不要です。
array_merge
array_merge関数とarray_merge_recursive関数の第一引数を省略できるようになりました。
array_merge(); // []空の配列が返ります。
おそらくスプレッド構文に空の配列を渡してしまったとき用。$arr = []; array_merge(...$arr); // PHP7.3まではE_WARNINGproc_open
proc_open関数の第一引数を配列で渡せるようになりました。
proc_open(['php', '-r', 'echo "Hello World\n";'], $descriptors, $pipes);何がうれしいのかってOSコマンドインジェクションを考えなくて済むようになります。
また、第二引数がリダイレクタとnullに対応しました。
proc_open($cmd, [2 => ['redirect', 1]], $pipes); // 2>&1 proc_open($cmd, [2 => ['null']], $pipes); // 2>nullわりとexecってやっちゃうタイプなので、個人的にはあまり使わない関数です。
pcntl_unshare
pcntl_unshare関数が追加されました。
他プロセスと共有しているコンテキストを分離するとかなんとからしいのだけど、Windowsでは動かないのでよくわかりません。SplPriorityQueue
SplPriorityQueue::setExtractFlagsに0を渡すと即座に例外を出すようになりました。
$queue = new SplPriorityQueue(); $queue->setExtractFlags(0); // Fatal error: Uncaught RuntimeException: Must specify at least one extract flag $queue->insert('A', 1); $queue->top();PHP7.3までは、
setExtractFlagsした時点ではエラーは起こらず、その後topしたところでFatal errorが起きていました。MB_ONIGURUMA_VERSION
定数MB_ONIGURUMA_VERSIONが追加されました。
echo MB_ONIGURUMA_VERSION; // 6.9.3正規表現エンジン鬼車のバージョンがわかるようになります。
鬼車
鬼車がPHP本体にバンドルされなくなりました。
かわりにlibonigを導入しなければならないそうです。手元のXAMPPにはそんなファイルがなかったのですが、mb正規表現は普通に動いていました。
どうして動いているのかはわかりません。get_declared_classes
get_declared_classes関数が、まだインスタンス化されていない無名クラスを返さなくなりました。
$class1 = new class {}; var_dump(get_declared_classes()); // $class2は入ってない $class2 = new class {};PHP7.3までは一覧に
$class1も$class2も出てきていました。
PHP7.4以降は$class1しか出てきません。imagecreatefromtga
imagecreatefromtga関数が追加されました。
$img = imagecreatefromtga('image.tga'); header('Content-Type: image/png'); imagepng($img); imagedestroy($img);誰得にも程があるのではないか。
ファイル末尾の
<?php最後に改行がない <?phpファイル末尾に改行を入れずに
<?phpとだけ書くと、これまでは<?phpという文字列と解釈されていました。
すなわち<?phpという文字列がHTMLに出力されていました。
PHP7.4以降はPHP開始タグと解釈されるようになります。
その後が何もないので、実質的には何もしません。STREAM_OPTION_READ_BUFFER
includeやrequireをストリームで使用している場合、streamWrapper::stream_set_optionが
STREAM_OPTION_READ_BUFFERオプション付きで呼ばれるようになりました。
カスタムストリームラッパーを自作している場合、それに対する実装が必要です。定数PASSWORD_XXXの値変更
定数PASSWORD_XXXの定数値が変更になりました。
echo PASSWORD_ARGON2ID; // argon2id例としてPASSWORD_DEFAULTは1からnullに、PASSWORD_ARGON2IDは3から"argon2id"になります。
正しい実装をしているかぎりは影響ありません。fread / fwrite
fread / fwriteが失敗時にfalseを返すようになりました。
$fp = fopen('/path/to/dummy', 'a'); fread($fp, 100); // falsePHP7.3までは0や""が返ってきていました。
DateIntervalの曖昧な比較
DateIntervalの曖昧な比較ができなくなりました。
new DateInterval('P1D') == new DateInterval('P1D'); // Warning: Cannot compare DateInterval objectsE_WARININGが発生し、たとえ同じ値であろうとも常にfalseが返ってきます。
PHP7.3までは異なる値であろうが常にtrueとなっていました。厳密な比較は常にfalseで、警告も発生しません。
$dti = new DateInterval('P1D'); $dti2 = $dti; var_dump($dti == $dti2, $dti === $dti2); // true, true同じオブジェクトであれば当然trueであり、E_WARININGも発生しません。
リフレクションのシリアライズ
リフレクションをserializeするとFatal errorが発生するようになりました。
$ref = new ReflectionClass(new stdClass()); serialize($ref); // Serialization of 'ReflectionClass' is not allowedリフレクションのシリアライズはこれまでもサポートされておらず、壊れることがありました。
PHP7.4では明確に禁止されます。get_object_vars
get_object_varsにArrayObjectを突っ込んでも、値が取れなくなりました。
$arr = new ArrayObject([1, 2, 3]); get_object_vars($arr); // []PHP7.3までは
[1, 2, 3]が返ってきました。
これによってReflectionObject::getProperties、Iterator等が影響を受けます。
(array)$arrキャストは影響を受けず、値を取得することができます。get_mangled_object_vars
get_mangled_object_vars関数が追加されました。
class A { public $pub = 1; protected $prot = 2; private $priv = 3; } class B extends A { private $priv = 4; } $obj = new B; $obj->dyn = 5; $obj->{"6"} = 6; get_mangled_object_vars($obj); // [ ["Bpriv"]=> int(4), ["pub"]=> int(1), ["*prot"]=> int(2), ["Apriv"]=> int(3), ["dyn"]=> int(5), [6]=> int(6) ]get_object_vars($obj); // [ ["pub"]=> int(1), ["dyn"]=> int(5), [6]=> int(6) ]get_object_varsとだいたい同じですが、privateな値までナチュラルに取ってきます。
いいのかこれ?なお、ArrayObjectの値はこちらを使っても取得できません。
Countable SimpleXMLElement
SimpleXMLElementがCountableをimplementsしました。
$xmlstr = <<<XML <a> <bs> <b>1</b> <b>2</b> <b>3</b> </bs> </a> XML; $xml = new SimpleXMLElement($xmlstr); echo count($xml); // 1 echo count($xml->bs); // 1 echo count($xml->b); // 3実はずっと昔から
Countableでもないのにcountできていたので、単に現状を実態に合わせたというものです。sapi_windows_set_ctrl_handler
sapi_windows_set_ctrl_handler関数が追加されました。
sapi_windows_set_ctrl_handler( function (int $evt) { if ($evt === PHP_WINDOWS_EVENT_CTRL_C) { echo 'Ctrl+C pressed.'; exit(); } elseif ($evt === PHP_WINDOWS_EVENT_CTRL_BREAK) { echo 'Ctrl+Break pressed.'; exit(); }else{ echo 'What pressed???' , $evt; } } ); while (1) { usleep(100); }WindowsのCLIで
Ctrl+CとCtrl+Breakをハンドリングできます。WindowsのCLIでPHPを動かしてる人なんてどんだけ居るんだよ(鏡を見つつ)。
OpenSSL
openssl_x509_verify関数が追加されました。
$crt = <<<CRT -----BEGIN CERTIFICATE----- MIIDbDCCAtWgAwIBAgIJAK7FVsxyN1CiMA0GCSqGSIb3DQEBBQUAMIGBMQswCQYD VQQGEwJCUjEaMBgGA1UECBMRUmlvIEdyYW5kZSBkbyBTdWwxFTATBgNVBAcTDFBv cnRvIEFsZWdyZTEeMBwGA1UEAxMVSGVucmlxdWUgZG8gTi4gQW5nZWxvMR8wHQYJ KoZIhvcNAQkBFhBobmFuZ2Vsb0BwaHAubmV0MB4XDTA4MDYzMDEwMjg0M1oXDTA4 MDczMDEwMjg0M1owgYExCzAJBgNVBAYTAkJSMRowGAYDVQQIExFSaW8gR3JhbmRl IGRvIFN1bDEVMBMGA1UEBxMMUG9ydG8gQWxlZ3JlMR4wHAYDVQQDExVIZW5yaXF1 ZSBkbyBOLiBBbmdlbG8xHzAdBgkqhkiG9w0BCQEWEGhuYW5nZWxvQHBocC5uZXQw gZ8wDQYJKoZIhvcNAQEBBQADgY0AMIGJAoGBAMteno+QK1ulX4/WDAVBYfoTPRTz e4SZLwgael4jwWTytj+8c5nNllrFELD6WjJzfjaoIMhCF4w4I2bkWR6/PTqrvnv+ iiiItHfKvJgYqIobUhkiKmWa2wL3mgqvNRIqTrTC4jWZuCkxQ/ksqL9O/F6zk+aR S1d+KbPaqCR5Rw+lAgMBAAGjgekwgeYwHQYDVR0OBBYEFNt+QHK9XDWF7CkpgRLo Ymhqtz99MIG2BgNVHSMEga4wgauAFNt+QHK9XDWF7CkpgRLoYmhqtz99oYGHpIGE MIGBMQswCQYDVQQGEwJCUjEaMBgGA1UECBMRUmlvIEdyYW5kZSBkbyBTdWwxFTAT BgNVBAcTDFBvcnRvIEFsZWdyZTEeMBwGA1UEAxMVSGVucmlxdWUgZG8gTi4gQW5n ZWxvMR8wHQYJKoZIhvcNAQkBFhBobmFuZ2Vsb0BwaHAubmV0ggkArsVWzHI3UKIw DAYDVR0TBAUwAwEB/zANBgkqhkiG9w0BAQUFAAOBgQCP1GUnStC0TBqngr3Kx+zS UW8KutKO0ORc5R8aV/x9LlaJrzPyQJgiPpu5hXogLSKRIHxQS3X2+Y0VvIpW72LW PVKPhYlNtO3oKnfoJGKin0eEhXRZMjfEW/kznY+ZZmNifV2r8s+KhNAqI4PbClvn 4vh8xF/9+eVEj+hM+0OflA== -----END CERTIFICATE----- CRT; $rightKey = <<<KEY -----BEGIN PUBLIC KEY----- MIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQDLXp6PkCtbpV+P1gwFQWH6Ez0U 83uEmS8IGnpeI8Fk8rY/vHOZzZZaxRCw+loyc342qCDIQheMOCNm5Fkevz06q757 /oooiLR3yryYGKiKG1IZIiplmtsC95oKrzUSKk60wuI1mbgpMUP5LKi/Tvxes5Pm kUtXfimz2qgkeUcPpQIDAQAB -----END PUBLIC KEY----- KEY; $wrongKey = <<<KEY -----BEGIN PUBLIC KEY----- MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEArbUmVW1Y+rJzZRC3DYB0 kdIgvk7MAday78ybGPPDhVlbAb4CjWbaPs4nyUCTEt9KVG0H7pXHxDbWSsC2974z dvqlP0L2op1/M2SteTcGCBOdwGH2jORVAZL8/WbTOf9IpKAM77oN14scsyOlQBJq hh+xrLg8ksB2dOos54yDqo0Tq7R5tldV+alKZXWlJnqRCfFuxvqtfWI5nGTAedVZ hvjQfLQQgujfXHoFWoGbXn2buzfwKGJEeqWPbQOZF/FeOJPlgOBhhDb3BAFNVCtM 3k71Rblj54pNd3yvq152xsgFd0o3s15fuSwZgerUjeEuw/wTK9k7vyp+MrIQHQmP dQIDAQAB -----END PUBLIC KEY----- KEY; openssl_x509_verify($crt, $rightKey); // 1 openssl_x509_verify($crt, $wrongKey); // 0 openssl_x509_verify($crt, 'hoge'); // -1X.509証明書のチェックができます。
こんなことわざわざPHPでするなよって気もしますが。idn_to_utf8
idn_to_utf8およびidn_to_ascii関数の引数variantのデフォルト値がINTL_IDNA_VARIANT_UTS46になりました。
echo idn_to_utf8('xn--2-kq6aw43af1e4y9boczagup'); // 中島第2駐輪場そういえば日本語ドメイン最近見ませんね。
token_get_all
token_get_all関数が、不正な文字列にトークンシンボルT_BAD_CHARACTERを返すようになりました。
$tokens = token_get_all('<?php ' . chr(0)); echo token_name($tokens[1][0]); // T_BAD_CHARACTERこれまでは解釈できない文字は単に無視されていたのですが、そのような文字を含めて正確にパースできるようになりました。
正しくないソースを正しく解析しても仕方ない気がしますが。
pkg-config
設定を
pkg-configに寄せていくために、多くのコンパイルオプションがディレクトリ指定できなくなります。
例としてCurlは、コンパイルオプション--with-curl=path/to/dirとすることでディレクトリを指定することができました。
PHP7.4以降は--with-curlにはオプションを設定できず、ディレクトリ指定することができません。また
-with-png-dirのような、直接的にディレクトリを指定するオプションは削除されます。まあ、最近は自力でインストールとかあまりしませんけどね。
演算子+-.の優先順位変更
演算子
+-と.を並べて使うとE_DEPRECATEDが起こるようになりました。
PHP8において演算子.の優先順位を下げるための布石です。$a = 1; $b = 2; echo "sum: " . $a + $b; // Deprecated: The behavior of unparenthesized expressions containing both '.' and '+'/'-' will change in PHP 8PHP7.3までは前から順に
("sum: " . $a) + $bと解釈され、答えは2になっていました。
PHP7.4では、解釈は同じですが同時にE_DEPRECATEDが発生します。PHP8以降では
"sum: " . ($a + $b)と解釈されて、答えは"sum: 3"になります。三項演算子のネスト制限
解釈が一意に定まらない三項演算子のネストはPHP7.4でE_DEPRECATEDに、PHP8でエラーになります。
1 ? 2 : 3 ? 4 : 5; // Deprecated: Unparenthesized `a ? b : c ? d : e` is deprecated. (1 ? 2 : 3) ? 4 : 5; // ok 解釈が一意 1 ? 2 : (3 ? 4 : 5); // ok 解釈が一意 1 ? 2 ? 3 : 4 : 5; // ok 解釈が一意 1 ?: 2 ?: 3; // ok 解釈が一意その後の予定は未定ですが、おそらくPHP9あたりで他言語と同じ解釈に変更されると思われます。
波括弧による文字列アクセス
$string = 'ABCDEFG'; echo $string[1]; // B echo $string{2}; // Deprecated: Array and string offset access syntax with curly braces is deprecated文字列に波括弧でアクセスするとE_DEPRECATEDが発生します。
PHP7.3まではエラーが出ずにアクセス可能でした。PHP7.4リリース時点では、今後削除される予定はありません。
角括弧による文字列以外へのアクセス
$int = 1234567980; echo $int[1]; // Notice: Trying to access array offset on value of type int $null = null; echo $null[0]; // Notice: Trying to access array offset on value of type nullint、float、bool、null、resourceに角括弧でアクセスするとE_NOTICEが発生します。
これまではエラーは出ませんでしたが、値はnullでした。配列やstringへの
[]アクセスは当然ながら今後も可能です。htmlentities
htmlentities関数に、UTF-8以外のマルチバイト文字列を渡すとE_NOTICEが発生するようになります。
htmlentities('abc', ENT_COMPAT, 'Shift_JIS'); // htmlentities(): Only basic entities substitution is supported for multi-byte encodingsPHP7.1.25以降はE_STRICTが発生し、それ以前は何のエラーも起こりませんでした。
どういう意図なのかはよくわかりません。parent without parent
親クラスのないクラスで
parentを使うと、そのメソッドが呼ばれなくてもコンパイル時にE_DEPRECATEDが発生するようになります。class Dummy{ public function hoge(){ return parent::hoge(); } } // Deprecated: Cannot use "parent" when current class scope has no parentPHP7.3までは、メソッドを呼ばないかぎり何も起きませんでした。
メソッドを呼び出すと、PHP7.3でも7.4でも当然Fatal errorが発生します。
BCMath
BCMath関数に数値形式でない文字列を渡すとE_WARNINGが発生するようになりました。
echo bcadd("2", "3a"); // Warning: bcadd(): bcmath function argument is not well-formedPHP7.3までは何も出ませんでした。
値そのものは、昔から0として扱われていました。
上記例でいうと、出力はPHP5時代からずっと"2"のままです。
解釈が通常のPHP関数と異なるので少々わかりにくいですね。base_convert
base_convert関数に無効な文字が渡された場合、E_DEPRECATEDが発生するようになりました。
base_convert('012', 2, 10); // Deprecated: Invalid characters passed for attempted conversion, these have been ignoredPHP7.3までは何のエラーも出ませんでした。
いずれにせよ、途中に出てくる無効な値は単に無視されます。base_convertのほか、hexdec、octdec、bindecにも同じ変更が入ります。
単に全ての関数が同じ内部関数_php_math_basetozvalを使っているからという理由ですが。socket_addrinfo_lookup
socket_addrinfo_lookup関数において、引数AI_IDN_ALLOW_UNASSIGNEDとAI_IDN_USE_STD3_ASCII_RULESがE_DEPRECATEDになりました。
そもそもマニュアルが日本語化されてすらいないほど、この関数自体が使われていません。Deprecate LDAP
ldap_control_paged_result_responseとldap_control_paged_resultがE_DERECATEDになりました。
かわりにldap_searchを使えということだそうです。また、
nsldapとumich_ldapのサポートが削除されました。何のことだかさっぱりわかりません。
Deprecate is_real
is_real関数および
(real)キャストはPHP7.4でE_DEPRECATEDになり、PHP8で削除されます。is_real(1); // Deprecated: Function is_real() is deprecated is_float(1); // OKis_realではなくis_floatを使いましょう。
Deprecate Magic quotes
get_magic_quotes_gpcおよびget_magic_quotes_runtime関数はPHP7.4でE_DEPRECATEDになり、PHP8で削除されます。
get_magic_quotes_gpc(); // Deprecated: Function get_magic_quotes_gpc() is deprecated get_magic_quotes_runtime(); // Deprecated: Function get_magic_quotes_runtime() is deprecatedMagic quotesはPHP5.4で滅びました。
array_key_exists
array_key_exists関数がオブジェクトを受け付けなくなりました。
array_key_exists(1, new stdClass()); // Deprecated: array_key_exists(): Using array_key_exists() on objects is deprecated array_key_exists(1, []); // OKarray_key_existsの引数は
arrayですが、下位互換性のためにobjectも受け入れていました。
PHP7.4でE_DEPRECATEDになり、PHP8ではエラーになります。Deprecate FILTER_SANITIZE_MAGIC_QUOTES
定数FILTER_SANITIZE_MAGIC_QUOTESはPHP7.4でE_DEPRECATEDになり、PHP8で削除されます。
filter_var('s', \FILTER_SANITIZE_MAGIC_QUOTES); // Deprecated: filter_var(): FILTER_SANITIZE_MAGIC_QUOTES is deprecated filter_var('s', \FILTER_SANITIZE_ADD_SLASHES); // OKFILTER_SANITIZE_MAGIC_QUOTESとFILTER_SANITIZE_ADD_SLASHESは全く同じですが、magic_quotesという不穏当な表現を消去するために削除されます。
Deprecate ReflectionFunction::export
Reflector::exportはPHP7.4でE_DEPRECATEDになり、PHP8で削除されます。
ReflectionFunction::export('_'); // Deprecated: Function ReflectionFunction::export() is deprecated echo new ReflectionFunction('_'); // OK
Reflector::exportは引数がvoidなのに、継承した各クラスは引数を受け取ります。
これはおかしいのでどうにかしなければならなかったのですが、単純にexportが削除されることになりました。mb_strrpos
mb_strrpos関数の第三引数に文字エンコーディングを渡せなくなります。
mb_strrpos('haystack', 'needle', 'UTF-8'); // Deprecated: mb_strrpos(): Passing the encoding as third parameter is deprecated mb_strrpos('haystack', 'needle', 0, 'UTF-8'); // OKmb_strrposは、歴史的経緯により第三引数でも文字エンコーディングを受け取ることが可能でした。
この書き方はPHP7.4でE_DEPRECATEDになり、PHP8で削除されます。implode
implode関数の引数を逆にできなくなります。
implode([1, 2], ','); // Deprecated: implode(): Passing glue string after array is deprecated implode(',', [1, 2]); // OK implode([1, 2]); // OK ','区切りと同じimplodeは、歴史的経緯により第一引数と第二引数を逆に渡すことが可能でした。
この書き方はPHP7.4でE_DEPRECATEDになり、PHP8で削除されます。
引数がひとつでの場合は今後も受け付けますが、これも使用しない方が無難でしょう。クロージャ
クロージャから
$thisを削除できなくなります。(new class{ public function dummy(){ return function () {isset($this);}; } })->dummy()->bindTo(null); // Deprecated: Unbinding $this of closure is deprecatedクラスメソッドでクロージャを定義すると勝手に
$thisが入ってきます。
PHP7.3までは、これを無理矢理削除することができました。
PHP7.4でE_DEPRECATEDになり、PHP8でエラーになります。Deprecate hebrevc
hebrevc関数はPHP7.4でE_DEPRECATEDになり、PHP8で削除されます。
hebrevc('a'); // Deprecated: Function hebrevc() is deprecatedテキストに直接HTMLタグを書き込むという不適切な仕様が入っているためです。
かわりにnl2br(hebrev($str))を使いましょう。Deprecate convert_cyr_string
convert_cyr_string関数はPHP7.4でE_DEPRECATEDになり、PHP8で削除されます。
convert_cyr_string('str', 'k', 'i'); // Deprecated: Function convert_cyr_string() is deprecated非常に古い関数であるため、文字コードの指定方法が他の関数と一貫していません。
今後はiconvやmb_convert_encodingを使いましょう。Deprecate money_format
money_format関数はPHP7.4でE_DEPRECATEDになり、PHP8で削除されます。
money_format('%i', 123456789); // Fatal error: Uncaught Error: Call to undefined function money_format()money_format() は Windows では 定義されていません。
おふぅ。
money_formatは環境によって使用できなかったり、ロケールによって結果が変わったりします。
今後はNumberFormatter::formatCurrency等を使いましょう。Deprecate ezmlm_hash
ezmlm_hash関数はPHP7.4でE_DEPRECATEDになり、PHP8で削除されます。
ezmlm_hash('test@example.com'); // Deprecated: Function ezmlm_hash() is deprecatedそもそもこの関数を使っている人はいるのだろうか。
Deprecate restore_include_path
restore_include_path関数はPHP7.4でE_DEPRECATEDになり、PHP8で削除されます。
restore_include_path(); // Deprecated: Function restore_include_path() is deprecatedset_xxx関数をを多重に積んだ場合、restore_error_handlerやrestore_exception_handler等は変更をひとつ前の状態に戻すのに対し、restore_include_pathだけはいきなり初期値に戻します。
動作が異なっており混乱の元であるため削除されます。
今後はini_restore('include_path')を使いましょう。Deprecate allow_url_include
allow_url_includeディレクティブはPHP7.4でE_DEPRECATEDになり、PHP8で削除されます。
allow_url_include = OnApacheを起動すると、エラーログに
PHP Deprecated: Directive 'allow_url_include' is deprecated in Unknown on line 0が入ります。
allow_url_includeはrequire_once('http://example.com/')と書けるようになるという、ヤバみしかない機能なので絶対にオンにしてはいけません。感想
変更多過ぎぃ!
いやあPHP7.4やばいですね。
重量級だけでもプロパティ型指定・アロー関数・プリローディング・FFIなどがあって、これだけでも文法や書き方が大きく変化する勢いです。
さらに上記リストには、単なるバグ修正は含まれていません。
そこまで含めたら、とんでもない量の変更になってしまいますね。PHPは、特にPHP7以降はモダンな書き方をごりごり取り入れていて、きちんと使えば相当に堅牢で厳格な記述を行うことが可能です。
ただ同時に古い書き方も相変わらず可能で、しかも古い書式のほうが圧倒的に文献が多いせいでなかなか新しい文法が広まらないという現状は残念なところです。
新機能を使おうにも未だにPHP5系しか使えないようなサーバも存在したりしますし、そもそもCentOS7のデフォルトPHPが未だに5.4という地雷ですからね1。
もっと知識や環境を新陳代謝して使える仕組みが欲しいところです。
まあ、ほんのちょっとでも古い書き方をしようものなら全方位から銃弾が飛んでくるJavaScriptのような世界がいいかって言われたらそれも嫌ですけどね。さすがにいきなり仕事でプロパティ型指定を書き始めたりはしませんが、一年後には大抵の場所で使えるようになっている、くらいに程々に普及するくらいには進んでほしいところです。
2019年9月リリースのCentOS8でようやくPHP7.2になった。 ↩

- 投稿日:2019-12-02T00:00:42+09:00
Laravel のモデルクラスをどこに配置するか問題について考えてみる
この記事について
Laravel Advent Calender 2019 2日目の記事です。
Laravel では、モデルクラスの置き場所が決められておらず、デフォルトで作成される User クラスは app 直下に置かれています。とはいえ、app 直下にすべてのモデルクラスを置いてしまうと、ツリービューで見たときの視認性が悪くなってしまうので、できれば役割やコンテキストごとに分割して配置したい、という気持ちになります。
これまで10近く Laravel を使ったアプリケーションに携わってきて、様々な構成を見てきましたが、わりと最近はひとつの形に収斂されてきてる印象を受けるので、問題提起を兼ねて、様々なパターンについてメリット/デメリットを考察しつつ、どういう配置がいいのか探ってみようという試みです。
はじめに
環境
- Laravel 6.6.0
Model/モデルの定義
本記事では「Model」(アルファベット表記のもの)は Eloquent Model を指し、「モデル」(カタカナ表記のもの)は概念的なものを指します。本記事ではビューとコントローラー以外はすべてモデルとして扱います。
パターン一覧
- デフォルト
- Models
- Entities, ValueObjects, Services, etc
- アプリケーションと独立した Domain
初期構成
必要になったらディレクトリができるので、初期状態はすっきりしています。
$ tree -L 1 app app ├── Console ├── Exceptions ├── Http ├── Providers └── User.phpこれに、Events, Notifications, Policies といった標準で規定されたディレクトリが加わります(これらもカスタマイズは可能ですが、特別な理由がなければそのまま使うほうがいいでしょう。
パターン1: デフォルト
前述の通り、app 直下に配置するパターンです。
配置例
tree -L 1 app app ├── Console ├── Customer.php ├── Deliverer.php ├── Exceptions ├── Http ├── Order.php ├── Providers └── User.phpメリット
php artisan make:model Hogeと実行するとapp/Hoge.phpができます。最少のタイプ数で作成できるのがメリットです。デメリット
こちらも前述の通り、ツリービューで見たときにずらずらと Model のファイルが並んでしまうので、視認性が悪くなります。
所感
中には、ツリービューは見ないあるいは視認性の悪さは気にならない、という方もいるかもしれませんが、私は無理だったので、数個程度のファイルでアプリケーションが構成されているのでなければ、こちらのパターンは選択しないでしょう。
パターン2: Models
app/Models 以下に配置するパターンです。
Laravel4 の時代には models ディレクトリがあったんですが、5 になってなくなりました。4時代から触っていて、それに慣れていたので、なくなったときは、えーなんでなくしたの?と思いました。
配置例
$ tree -L 2 -d app app ├── Console ├── Exceptions ├── Http │ ├── Controllers │ └── Middleware ├── Models │ ├── Base │ ├── Delivery │ └── Order └── Providersメリット
パターン3 との対比になりますが、このパターンだと、役割ごとではなくコンテキストあるいは集約ルートごとの分割が容易になります。
注文と配送というコンテキストがあるとして、Models 以下のようにコンテキストごとに分割して配置することができます。さらにコンテキストごとに Entities, Services などをつくってもいいでしょう。
デメリット
こちらもパターン3 との対比になりますが、コンテキストがひとつないしはそれほど多くなく、コンテキストごとに振る舞いが変わらないようなドメインの場合は、階層が増えるだけであまり意味がなくなってしまうかもしれません。
所感
いまのところこれがいちばんしっくりきています。Policy や Observer のような Model に密接に関わるクラスをどこに配置するか(デフォルトか Models 以下か)というのは悩ましいところではあるんですが、いまのところはデフォルトがいいのかな、と感じています。
パターン3: Entities, ValueObjects, Services, etc
app/Entities, app/Services など、モデルの種類ごとにディレクトリを切って配置するパターンです。最近はわりとこのパターンに遭遇することが多いです(書籍やインターネット上のリソースで推奨しているものがあるんでしょうか)。
配置例
$ tree -L 2 -d app app ├── Console ├── Entities │ ├── Deliver │ └── Order ├── Exceptions ├── Http │ ├── Controllers │ └── Middleware ├── Providers ├── Services │ ├── Deliver │ └── Order └── ValueObjects ├── Deliver └── Orderメリット
パターン2 との対比になりますが、コンテキストごとに分けたいのであれば、種類ごとのディレクトリの下で分割する形になります。その結果、種類ごとのディレクトリの下にそれぞれディレクトリができることになるので、コンテキストがひとつあるいはごく少なければ、いちばん簡潔な構成かもしれません。
デメリット
普段これでやっててあまりデメリットは感じてないですが、強いて挙げるとすれば、クラスの種類に引きずられて、関連の強いクラスが分断されてしまう恐れがあるとか、実態は値オブジェクトでないのに ValueObjects の中にあって混乱する、とかでしょうか。
所感
パターン2を選ぶか3を選ぶか、というのは、極論で言えば好みの問題、ということになる気はします。個人的には、モデルの種類(Entity なのか Service なのか)というのはあまり気にならなくて、どちらかといえば、どのコンテキストのクラス(オブジェクト)なのか、のほうに意識があるので、パターン2 を推しますが、チームでよく話し合って決めればいいのかな、と思います。
パターン4: アプリケーションと独立した Domain
最近また盛り上がりを感じるドメイン駆動設計的な、クリーンアーキテクチャ的な、フレームワークへの依存性をゼロにする、あるいは極力小さくする、という戦略のもとにつくられる、ディレクトリ構成です。
私はこのような方針で Laravel を採用しているプロジェクトには関わったことがなく、細かいメリット・デメリットは想像の範囲内でしかわからないので、配置例のみ記載することにします。もし実際に採用されている方がいれば、コメントにてメリット・デメリットを教えていただけるとありがたいです。
実装の詳細はこちらの記事を参考にするといいかもしれません。
配置例
$ tree -L 2 -d ./app ./domain ./app ├── Console ├── Exceptions ├── Http │ ├── Controllers │ └── Middleware ├── Infrastructure │ └── Repositories └── Providers ./domain ├── Delivery │ ├── Entities │ └── Repositories └── Order ├── Entities └── Repositories上記例では、リポジトリパターンを導入し、domain/{Context}/Repositories 配下には interface を、app/Infrastructure/Repositories 配下には実装クラスをそれぞれ配置します。原則的に domain 以下は POPO (Plain Old PHP Object) なクラスになるので、フレームワークに対して疎結合にできるメリットがあります。
あと、「Policy や Observer のような Model に密接に関わるクラス」との関係をどうするか、という問題があって、これは、
- 使わないで自前で仕組みを用意する
- 使うが中身はドメインモデルに委譲できるようにする
といった解決策がありそうです。そこら辺も事前に決めておく必要があるでしょう。
おわりに
個人的にはパターン2 のように app/Models 以下にすべてを配置する形を推したいですが、パターン3 のようにクラスの種類ごとにディレクトリを切る形でもいまのところそれほど不満はありません。
上記以外のメリット・デメリットを感じている方、あるいは上記以外で、ウチではこんな構成でやってます、というのがあれば、メリット・デメリット合わせて教えていただけると助かります