- 投稿日:2019-12-02T22:24:08+09:00
�Tensorflow v2とTensorflowHub KerasLayerを使った最小の労力で自然言語処理
Tensorflow v2から利用できるTensorflowHub KerasLayerがすごい便利なので紹介。データが少なくても簡単に自然言語系のタスクを実装できるようになり、Keras利用者にとって
KerasLayerのおかげでTensorflowHubがもっと組み込みやすくなってます。そもそもTensorflowHubとは
- 学習済みモデルを利用/公開できるサービス
- https://tfhub.dev/で利用したいモデルを探す
pip install tensorflow-hubとサンプルコードですぐ試せる- 画像関連はもちろん、自然言語で日本語に対応したモデルもある
- 転移学習に利用できる
環境
私はpyenvを使っているので
pyenvで3.7.1をインストール。
tensorflowとtensorflow-hubもインストールします。
tensorflowに組み込まれたkerasを利用します。$ pyenv install 3.7.1 $ pip install tensorflow==2.0.0 tensorflow-hub==0.7.0簡単なnnlmを使ってみる
TensorflowHubからモデルをロードして文章をベクトル化できます。(これは以前と同じ)このベクトルを自作のモデルなどに転移学習する事もできます。
import tensorflow_hub as hub embed = hub.load('https://tfhub.dev/google/nnlm-ja-dim128-with-normalization/2') embed(['ネコ'])<tf.Tensor: id=182, shape=(1, 128), dtype=float32, numpy= array([[-0.10296704, 0.01587082, 0.0573468 , 0.059175 , -0.03958198, -0.08217786, -0.14779228, -0.24691384, -0.07068112, -0.11670566, -0.08285586, -0.01857655, -0.04645912, -0.05692579, 0.0815312 , -0.07908769, -0.05466406, -0.02179208, 0.10979927, -0.05734158, -0.06557054, 0.07709339, 0.12023042, 0.00258559, -0.07060173, 0.10960913, -0.08923677, 0.06238426, 0.08451481, 0.14662118, -0.03688983, 0.10679894, 0.01809704, -0.08754648, 0.0429281 , 0.11621989, 0.11202757, 0.05788481, 0.00816733, 0.009843 , 0.05847297, -0.0869061 , -0.12621959, 0.04002178, 0.12822641, 0.07994641, -0.00221055, -0.19458152, -0.02742083, 0.14718114, 0.0555301 , 0.11112078, 0.10370145, 0.08804794, 0.09565531, 0.16998029, 0.05571814, -0.03676133, 0.08836656, -0.02724845, 0.07221054, -0.04380354, -0.09449258, 0.01015431, -0.0904016 , 0.10437841, 0.0442632 , -0.06275094, -0.00733054, -0.0532412 , 0.05747321, 0.08354431, 0.14614691, -0.03355311, -0.04487225, 0.018634 , -0.16693713, 0.01418052, -0.1447136 , -0.02863057, 0.11374816, -0.02529281, -0.15476134, 0.00983464, 0.11917529, 0.08267409, 0.01913127, 0.07049622, -0.08751827, 0.00729084, -0.03081291, 0.03002417, -0.03669447, -0.10596528, 0.045755 , -0.07780168, 0.03002104, 0.12458465, 0.01451691, 0.01804689, 0.03775274, -0.05732382, 0.06064591, 0.07148866, -0.16499299, 0.21076469, 0.0302352 , 0.08122093, -0.15884502, 0.06737471, 0.0686043 , 0.02858042, -0.067475 , -0.08131913, 0.03652628, 0.0554016 , -0.13050069, -0.01471644, 0.13639897, -0.1885046 , -0.16372472, -0.03479837, 0.02419067, 0.02371116, 0.02106602, 0.10979195, 0.01713384, -0.01521267]], dtype=float32)>KerasLayerを使ってkerasに組み込んでみる
KerasLayerに対応したモデルだとhub.KerasLayerでkerasに組み込めるレイヤとしてロードできます。オリジナルのKerasレイヤーを作成するを見て実装する必要がなくなりました。
import tensorflow as tf from tensorflow import keras hub_layer = hub.KerasLayer( 'https://tfhub.dev/google/nnlm-ja-dim128-with-normalization/2', output_shape=[128], input_shape=[], dtype=tf.string, ) model = keras.Sequential() model.add(hub_layer) model.add(keras.layers.Dense(64, activation='relu')) model.add(keras.layers.Dense(16, activation='relu')) model.add(keras.layers.Dense(1, activation='sigmoid')) model.summary()Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= keras_layer (KerasLayer) (None, 128) 117568128 _________________________________________________________________ dense (Dense) (None, 64) 8256 _________________________________________________________________ dense_1 (Dense) (None, 16) 1040 _________________________________________________________________ dense_2 (Dense) (None, 1) 17 ================================================================= Total params: 117,577,441 Trainable params: 9,313 Non-trainable params: 117,568,128 _________________________________________________________________雑に2値分類で学習してみる
10個とかなり少ないデータセットを用意しました。食べ物と動物を2値分類するタスクです。
雑に50エポック回してみます。
model.compile( optimizer=keras.optimizers.RMSprop(), loss='binary_crossentropy', metrics=['acc'], ) model.fit( [ 'ピザ', '寿司', 'ステーキ', 'パスタ', 'コーラ', 'イヌ', 'ネコ', 'トラ', 'ゾウ', 'キリン', ], [ 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, ], epochs=50, )試してみる
import numpy as np model.predict(np.array(['ラザニア', 'チキン', '牛', 'ワニ', 'サル']))array([[0.06712804], [0.10662787], [0.6637654 ], [0.8527697 ], [0.9033404 ]], dtype=float32)ラザニアは94%、チキンは90%で食べ物と判定し、
ワニは85%、サルは90%で動物だと判定しています。
動物であり、割と食べ物な牛は66%で動物と、的を得ています。
TensorflowHubから転移学習しなければこんな少ないデータセットで学習する事など無理ですが、簡単かつ強力なモデルを作る事ができました。
さいごに
簡単に自然言語系のタスクを実装できる
TensorflowHub KerasLayerを紹介しました。universal-sentence-encoder-xling-manyを転移学習させて質疑応答できるシステムを作ってますが、それ専用にカスタムモデル作ったり、tensorflow/servingに載せる際にハマった事などいろいろあるのでまた今度紹介しようと思います。
- 投稿日:2019-12-02T22:11:25+09:00
Windows10にTensorFlowとKerasをインストールする方法(適宜更新)
ディープラーニングの環境構築
目次
- Anaconda(Miniconda)のインストール
- CUDAのインストール
- cuDNNのインストール
- TensorFlowのインストール
- Kerasのインストール
初めに
この記事はTensorFlowを公式のインストール方法に従ってインストールしていきます。
公式記事はこちら(2019年12月2日現在)Anaconda(Miniconda)のインストール
minicondaをインストール
そのあと、Anaconda Pronptでconda create -n [name] python=3.7を実行
[name]には自分が作成する仮想環境の名前を入力conda activate [name]で仮想環境を起動
CUDAのインストール
ここからCuda10.0のダウンロード
※今回はTensorFlowの公式インストールガイドに合わせてCuda10.0にしています。cuDNNのインストール
ここからcuDNNのダウンロード
zipを展開し、得られたファイルをCUDAのインストール先のフォルダに対応させて入れる。
※基本的にCUDAのインストールフォルダはC:\Program Files\NVIDIA GPU Computing Toolkit\CUDAあたりにあります。TensorFlowのインストール
Anaconda Pronptで
pip install tensorflow-gpuバージョンを変更したいときは
pip install tensorflow-gpu==1.14Kerasのインストール
Anaconda Pronptで
pip install keras以上
最後に
この記事は適宜更新していくと思います。
- 投稿日:2019-12-02T17:12:48+09:00
はじめての画像分類器
こんにちは。業務ではエンジニアリングから離れていて、やったことで書けるものあんまりないんですが、
ちょっと時間ができたので自分でちょっと勉強した内容をまとめておこうと思います。
アドベントカレンダー怖くないよ!チュートリアルやっただけの記事でも書いていいんだよ!ってことでひとつ...想定読者
機械学習のことを多々耳にするものの、あまり実装に触れたことがなかったので触れてみます。
なので想定読者は機械学習に触れたことがないけど興味があって、機械学習の実装を覗いてみようという方々です。
熟練の方々は温かい目で、ミスってる部分の指摘をいただけると助かります
テーマ
とっつきやすいテーマが無いと目指すべきゴールがわからず道に迷いますね。
ということで今回は画像を与えたときに、写っているものが何かを分類する、
画像分類器を作りましょう。なんでもいいですが、何の分類器にするかは最初に決めておきましょう。
私は最近カレーにハマり続けているので、スパイスの画像分類器を作ることを目的にしてみます。
弊ブログもよろしくお願いします
前提知識
画像分類器はキャッチーなテーマなので、チュートリアル記事なんかもたくさんあるわけですが、何の前提知識も無いまま読み始めるより、以下のような記事でサラッと全体を把握しておくことをおすすめします。
数学知識もいらないゼロからのニューラルネットワーク入門
ニューラルネットワークの「基礎の基礎」を理解する ~ディープラーニング入門|第1回あと、専門用語っぽい言葉には参考リンクを付けておきますのでそちらも参照ください。
チュートリアルをやる
tensorflow(てんそるふろー *1)転移学習(*2)のチュートリアルをやっていきます。
Transfer learning with TensorFlow Hubってやつですね。2019/12のバージョンの項目に合わせて書いていますが、変更があった場合はいい感じに読み替えてもらえると良いと思います。
それぞれのセクションのコードは転載していますが、一部を除いて結果は載せておりませんのでご自身で実行しながら読んでみてください。(*1)tensorflowとは機械学習のライブラリ群の一つです、googleが作ってます。wiki
(*2)転移学習とは別のタスクで学習したモデルを他のタスクに流用する手法です。
今回のケースだと本当はかなり大量のデータを用意しないと精度が上がらないのを、
かなり少ない枚数で解決出来るみたいな感じです。
プログラミング言語を1つ習熟すると、2つ目の習熟が早い〜みたいなノリですたぶん。参考Setup
前提としてこのチュートリアルはGoogleColaboratory(以下Colab *3)を使用しているので、上部の「Run in Google Colab」をクリックして実行できるようにしましょう。
Colabの画面が開いたら、上から順番に実行していってみましょう。コードの左上の[]のあたりにカーソルを合わせると実行ボタンが出てくるはず。from __future__ import absolute_import, division, print_function, unicode_literals import matplotlib.pylab as plt import tensorflow as tfこのあたりは諸々ライブラリのインポートをやっていますね。
__future__ ..の記述があるのはpython2-3の互換性を保つための記述。
import matplotlib.pylab as pltはあとで使用するプロットのためののライブラリ。!pip install -q -U tf-hub-nightly import tensorflow_hub as hub from tensorflow.keras import layers
!pip install -q -U tf-hub-nightlyの記述はpythonのライブラリのインストール。
tensorflow_hubとは事前学習済みのモデルを簡単に利用できるプラットフォーム(tensorflow hub)を利用するためのライブラリ。
tensorflow.kerasとは機械学習のライブラリで、googleのエンジニアが作ったようだがtensorflow以外からも使用できるもの。テキスト的にパチパチ書くだけで仮想マシン上でこんなに簡単に実行出来るってすごい。
(*3)Colaboratory は、完全にクラウドで実行される Jupyter ノートブック環境です。設定不要で、無料でご利用になれます。
Colaboratory を使用すると、コードの記述と実行、解析の保存や共有、強力なコンピューティング リソースへのアクセスなどをブラウザからすべて無料で行えます。
Colaboratoryへようこそより
ちなみに、こんなエラーが出たときは支持に従って[RESTART RUNTIME]のボタンを押して、もっかい再生ボタンを押すと良いです。
An ImageNet classifier
学習済みモデルを利用して、画像分類をやってみましょう、という項目です。
Download the classifier
classifier_url ="https://tfhub.dev/google/tf2-preview/mobilenet_v2/classification/2" #@param {type:"string"}学習済み分類器のURLです。チュートリアルに書いてる通り、ここに置いてあるやつだったらなんでもいいよーとのことです。
IMAGE_SHAPE = (224, 224) classifier = tf.keras.Sequential([ hub.KerasLayer(classifier_url, input_shape=IMAGE_SHAPE+(3,)) ])ニューラルネットワークの層として学習済みモデルを突っ込みます。
与えられる画像のフォーマットを教えておく必要があるようなので、(width, height, channel)で与えます。
channel(色数)の3は後で追加してますね。深い意味はあるんだろうか。Run it on a single image
準備ができたところで、適当な画像で判別させてみましょう。
import numpy as np import PIL.Image as Image grace_hopper = tf.keras.utils.get_file('image.jpg','https://storage.googleapis.com/download.tensorflow.org/example_images/grace_hopper.jpg') grace_hopper = Image.open(grace_hopper).resize(IMAGE_SHAPE) grace_hoppergrace_hopper氏の画像を取得しています。
grace_hopper = np.array(grace_hopper)/255.0 grace_hopper.shape型変換をしているようです。
result = classifier.predict(grace_hopper[np.newaxis, ...]) result.shape画像のデータに1次元追加して予測を走らせてみると、1001個の要素のベクトルの配列(正確にはndarrayかな)が帰ってきます。
predicted_class = np.argmax(result[0], axis=-1) predicted_classこの1001の要素はそれぞれのクラス(今回の場合は類推される要素)の確率を表しているので、最大の確率のものを取り出してみます。
653という値が帰ってきます。これが今回の分類器が類推したモノを表しています。Decodethe predictions
labels_path = tf.keras.utils.get_file('ImageNetLabels.txt','https://storage.googleapis.com/download.tensorflow.org/data/ImageNetLabels.txt') imagenet_labels = np.array(open(labels_path).read().splitlines())先程の結果が何を示しているのかを探るために、ラベルをダウンロードして配列に詰めておきます。
URLを直接アクセスするとすぐわかりますが、先程の1001の項目に対応しています。plt.imshow(grace_hopper) plt.axis('off') predicted_class_name = imagenet_labels[predicted_class] _ = plt.title("Prediction: " + predicted_class_name.title())
画像表示ライブラリを使って、さっきの653番目の画像が何だったのかを出力します。
無事、Military Uniformという結果が出ましたね。めでたし。
Simple transfer learning
ここからが本番です。今のは「こんな感じで学習済み分類器って使えるぞ〜」でしたが、
次は「自分が集めてきた画像で分類器作るぞ〜」です。Dataset
今回のチュートリアルでは花の画像を使います。最後にこのデータセットを適当に入れ替えて、別の分類器にしましょう。
data_root = tf.keras.utils.get_file( 'flower_photos','https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz', untar=True)データセットのダウンロード
image_generator = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1/255) image_data = image_generator.flow_from_directory(str(data_root), target_size=IMAGE_SHAPE)画像群を上手く処理するためにImageDataGenaratorに突っ込みます。
ちなみに画像の分類も先述のURLから画像群をダウンロードしてみるとわかりますが、
ディレクトリごとに特定の画像を集めている感じになってます。for image_batch, label_batch in image_data: print("Image batch shape: ", image_batch.shape) print("Label batch shape: ", label_batch.shape) breakimage_dataをイテレートしてimage_batchとlabel_batchの配列をつくります。
Run the classifier on a batch of images
学習後の状態と比較するために、学習していない状態で分類してみます。
result_batch = classifier.predict(image_batch) result_batch.shapeさっきと同じく予測してみましょう。
predicted_class_names = imagenet_labels[np.argmax(result_batch, axis=-1)] predicted_class_names32件の分類結果が出ました。画像と照らし合わせて確認します。
plt.figure(figsize=(10,9)) plt.subplots_adjust(hspace=0.5) for n in range(30): plt.subplot(6,5,n+1) plt.imshow(image_batch[n]) plt.title(predicted_class_names[n]) plt.axis('off') _ = plt.suptitle("ImageNet predictions")
結果を見るとかなりかけ離れてますね。
1001の対象物から選んでいるからと言うのもありそうですが、全然正解していません。Download the headless model
ということで分類器を自分で作ってみましょう。
feature_extractor_url = "https://tfhub.dev/google/tf2-preview/mobilenet_v2/feature_vector/2" #@param {type:"string"}例によってtensorflow hubから学習済みモデルをダウンロードしてきます。extractorは抽出機っぽいですね。
feature_extractor_layer = hub.KerasLayer(feature_extractor_url, input_shape=(224,224,3))モデルに突っ込むためのlayerを作成。
feature_batch = feature_extractor_layer(image_batch) print(feature_batch.shape)こいつは1280のベクトルをそれぞれの画像に対して返してくれるとのこと。
様々な要素から画像の分類を試みるんですね。feature_extractor_layer.trainable = False今回は抽出機の部分はチューニングしないので、学習されないように指定しておきます。
Attach a classification head
model = tf.keras.Sequential([ feature_extractor_layer, layers.Dense(image_data.num_classes, activation='softmax') ]) model.summary()さっき作った抽出機のインスタンスを分類器に突っ込んでいます。
作ったモデルのサマリーの表示もしていますね。predictions = model(image_batch)predictions.shapetensorのshape(形状)を確認しています。
Train the model
model.compile( optimizer=tf.keras.optimizers.Adam(), loss='categorical_crossentropy', metrics=['acc'])モデルをコンパイルします。
optimizer(最適化アルゴリズム):色々種類があるみたいです。 参考
loss(損失関数):損失が出来るだけ小さいように調整するために学習に使用される関数。これも色々あるみたいです。参考
metrics(評価関数):モデルの性能を評価するために使う値だが、損失関数のように学習には使われないもの。これも同じくいろいろある模様。 参考class CollectBatchStats(tf.keras.callbacks.Callback): def __init__(self): self.batch_losses = [] self.batch_acc = [] def on_train_batch_end(self, batch, logs=None): self.batch_losses.append(logs['loss']) self.batch_acc.append(logs['acc']) self.model.reset_metrics()損失関数、評価関数の値がどの様になっているかを観測するための関数定義です。
steps_per_epoch = np.ceil(image_data.samples/image_data.batch_size) batch_stats_callback = CollectBatchStats() history = model.fit_generator(image_data, epochs=2, steps_per_epoch=steps_per_epoch, callbacks = [batch_stats_callback])fit_generatorで学習を開始します。
学習回数などなどを指定してますね。参考
学習には多少時間がかかります。plt.figure() plt.ylabel("Loss") plt.xlabel("Training Steps") plt.ylim([0,2]) plt.plot(batch_stats_callback.batch_losses)
損失関数の推移です。徐々に下がっていっていてよさげですね。
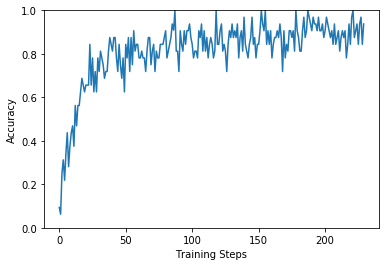
plt.figure() plt.ylabel("Accuracy") plt.xlabel("Training Steps") plt.ylim([0,1]) plt.plot(batch_stats_callback.batch_acc)
評価関数の推移です。これは上がっていっているのでいい感じ。
Check the predictions
いよいよ分類してみましょう。
class_names = sorted(image_data.class_indices.items(), key=lambda pair:pair[1]) class_names = np.array([key.title() for key, value in class_names]) class_names実際に存在するクラスを取り上げます。存在するのは5種類だけですね。
predicted_batch = model.predict(image_batch) predicted_id = np.argmax(predicted_batch, axis=-1) predicted_label_batch = class_names[predicted_id]先程やったようにpredictして、最大値のものを取ってきてラベルにします。
label_id = np.argmax(label_batch, axis=-1)正解のラベルを確保しておきます
plt.figure(figsize=(10,9)) plt.subplots_adjust(hspace=0.5) for n in range(30): plt.subplot(6,5,n+1) plt.imshow(image_batch[n]) color = "green" if predicted_id[n] == label_id[n] else "red" plt.title(predicted_label_batch[n].title(), color=color) plt.axis('off') _ = plt.suptitle("Model predictions (green: correct, red: incorrect)")
正解のときは緑、失敗のときは赤で出力されるようになっています。
だいたい正解してるんじゃないでしょうか。よさげ。この後もチュートリアルはちょっとだけ続いて、学習したモデルのexportなどが書かれているんですが、今回使うのはここまでなので、これ以降は割愛しておきます。
自分だけの分類器造り
さて、チュートリアルで出てきたコードを利用して自分だけの分類器を作っていきましょう。今回はColab上で動くところまででゴールにしておきます。
画像収集
画像分類には画像の収集が欠かせません。
画像のダウンロード
google-images-downloadが便利です。(ダウンロードした画像のライセンスには注意しましょう)
pip経由でインストールできるので、macであれば以下のように使えると思います。
pip install google_images_download googleimagesdownload --keywords "探したい画像"画像の選別
ダウンロードしてきた画像をそのまま使おうとすると、ゴミが多くて使えません。
ので、画像を1枚ずつ見ながら変な画像を取り除いていきましょう。
この作業が一番大変でした..
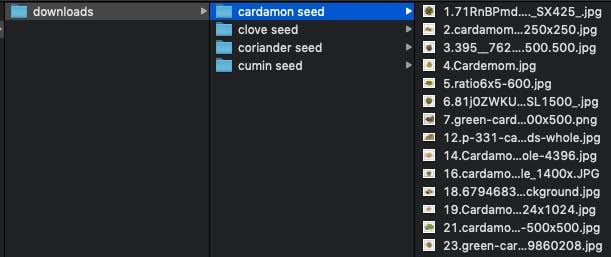
最終的にはこんな感じでディレクトリごとにきれいになった特定の画像が集まっている状態を作りましょう。パッケージしてアップロード
とりあえずColabからdownload出来るようにtarで圧縮したファイルをどこかにuploadしておきましょう。私はGoogleDriveに上げときました。
GoogleDriveの場合はtar.gzをuploadした上で、共有可能なリンクを取得し、そのID部分を以下リンクと差し替えてみましょう。
https://drive.google.com/uc?export=download&id=XXXXXXXXXXXXXXXXXXXXXColabのコードに反映
こちらに分類機作る部分だけを抜き出したColabファイルを用意したので、xxxxのところを差し替えてみてください。
上手く動きましたでしょうか。
私の手元ではこんな感じ。
おわりに
なんとなーく機械学習の上辺を体験できましたが、分類器のイメージだと自分で撮った写真が分類されてほしい感じありますよね。
手元に環境構築したりして、もうちょっとカジュアルに触れる何か〜を作ってみたい気持ちがあります。がんばるぞ。











- 投稿日:2019-12-02T02:26:54+09:00
pbファイルのグラフをTensorBoardで可視化
環境
OS
Ubuntu 18.04
Docker
REPOSITORY: tensorflow/tensorflow
TAG: latest-gpu-py3-jupyter
IMAGE ID: 88178d65d12c※上記Dockerは、Tensorflow2.0、TensorBoard 2.0.0
今回はeager executionモデル*を
tf.saved_model.saveで保存したpbファイルで試した。
*: 例えばtutorialのモデル。時間がない人は、pb2tensorboardのまとめへ。
試したこと
tensorflow githubのissue #8854 に記載されていた内容
https://github.com/tensorflow/tensorflow/issues/8854
jubjamie commented on 31 Mar 2017
https://github.com/tensorflow/tensorflow/issues/8854#issuecomment-290672527
import tensorflow as tf from tensorflow.python.platform import gfile with tf.Session() as sess: model_filename ='PATH_TO_PB.pb' with gfile.FastGFile(model_filename, 'rb') as f: graph_def = tf.GraphDef() graph_def.ParseFromString(f.read()) g_in = tf.import_graph_def(graph_def) LOGDIR='YOUR_LOG_LOCATION' train_writer = tf.summary.FileWriter(LOGDIR) train_writer.add_graph(sess.graph)上記のコードは、v1用のコードのため、v2では動かない。
(tf.Session()など対応していないものがあるため。)
そこで、tf_upgrade_v2コマンドを使って、v1のコードをv2のコードに変換して実行。
【参考】https://www.tensorflow.org/guide/upgrade
結果、graph_def.ParseFromString(f.read())で下記のエラーメッセージが出る。
google.protobuf.message.DecodeError: Error parsing messagebrandondutra commented on 1 Apr 2017
https://github.com/tensorflow/tensorflow/issues/8854#issuecomment-290799958
上記、デコードエラーに対して、解決案のコメントがあった。
import tensorflow as tf import sys from tensorflow.python.platform import gfile from tensorflow.core.protobuf import saved_model_pb2 from tensorflow.python.util import compat with tf.Session() as sess: model_filename ='saved_model.pb' with gfile.FastGFile(model_filename, 'rb') as f: data = compat.as_bytes(f.read()) sm = saved_model_pb2.SavedModel() sm.ParseFromString(data) #print(sm) if 1 != len(sm.meta_graphs): print('More than one graph found. Not sure which to write') sys.exit(1) #graph_def = tf.GraphDef() #graph_def.ParseFromString(sm.meta_graphs[0]) g_in = tf.import_graph_def(sm.meta_graphs[0].graph_def) LOGDIR='YOUR_LOG_LOCATION' train_writer = tf.summary.FileWriter(LOGDIR) train_writer.add_graph(sess.graph)上記のコードは、v1用のコードのため、v2では動かないので、同様に、
tf_upgrade_v2を使って変換。
変換後のコードがこちら。import tensorflow as tf import sys from tensorflow.python.platform import gfile from tensorflow.core.protobuf import saved_model_pb2 from tensorflow.python.util import compat with tf.compat.v1.Session() as sess: model_filename ='saved_model.pb' with gfile.FastGFile(model_filename, 'rb') as f: data = compat.as_bytes(f.read()) sm = saved_model_pb2.SavedModel() sm.ParseFromString(data) #print(sm) if 1 != len(sm.meta_graphs): print('More than one graph found. Not sure which to write') sys.exit(1) #graph_def = tf.GraphDef() #graph_def.ParseFromString(sm.meta_graphs[0]) g_in = tf.import_graph_def(sm.meta_graphs[0].graph_def) LOGDIR='YOUR_LOG_LOCATION' train_writer = tf.compat.v1.summary.FileWriter(LOGDIR) train_writer.add_graph(sess.graph)デコードエラーは解消されたが、下記エラーメッセージによると、
tf.summary.FileWriter(tf.compat.v1.summary.FileWriter)はeager executionに対応してない。File "/usr/local/lib/python3.6/dist-packages/tensorflow_core/python/summary/writer/writer.py", line 360, in __init__ "tf.summary.FileWriter is not compatible with eager execution. " RuntimeError: tf.summary.FileWriter is not compatible with eager execution. Use tf.contrib.summary instead.代わりに、
tf.contrib.summaryを使うようにあるが、下記のようにエラーメッセージが出る。# import tensorflow as tfのとき AttributeError: module 'tensorflow' has no attribute 'contrib' # import tensorflow.compat.v1 as tfのとき AttributeError: module 'tensorflow_core.compat.v1' has no attribute 'contrib'ちなみにv2の
tf.summaryはFileWriterを持っていないので、tf.compat.v1.summary.FileWriterを使うことになる。
tf.disable_v2_behavior()を入れる。tf.summary.FileWriterのエラーメッセージが出なくなる。
(上記エラーメッセージからすると正しい対処の方法ではなさそう。)この段階で、TensorBoardに読み込ませるlogファイルが生成できる。
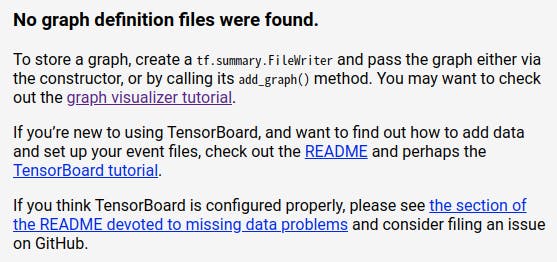
しかし、下図のように表示され、グラフが表示されない。
add_graphが、反映されていない。
FileWriterの引数にsess.graphを渡す。
train_writer.add_graph(sess.graph)でグラフを追加するのではなく、
train_writer = tf.compat.v1.summary.FileWriter(LOGDIR, sess.graph)
として、一括で行う。あるいは、下記のようにwithを使っても解決できる。
with tf.summary.FileWriter(LOGDIR) as writer: writer.add_graph(sess.graph)pb2tensorboardのまとめ
以上の試行をまとめて、サンプルコード(pb2tensorboard.py)を作成した。
【使い方】
※logの出力先ディレクトリは実行前に作成してはいけない。実行時に作成される。$ python pb2tensorboard.py --in_pb <pbファイルのパス> --out_log_dir <TensorBoardにインポートするlogの出力先>【コード】
import os import sys import argparse import tensorflow.compat.v1 as tf from tensorflow.python.platform import gfile from tensorflow.core.protobuf import saved_model_pb2 from tensorflow.python.util import compat def main(): parser = argparse.ArgumentParser() parser.add_argument("--in_pb", help="input pb file path.", type=str, default=None) parser.add_argument( "--out_log_dir", help='output log directory.', type=str, default=os.path.join('.', 'log')) args = parser.parse_args() tf.disable_v2_behavior() with tf.Session() as sess: with gfile.GFile(args.in_pb, 'rb') as f: data = compat.as_bytes(f.read()) sm = saved_model_pb2.SavedModel() sm.ParseFromString(data) if 1 != len(sm.meta_graphs): print('More than one graph found. Not sure which to write') sys.exit(1) g_in = tf.import_graph_def(sm.meta_graphs[0].graph_def) train_writer = tf.summary.FileWriter(args.out_log_dir, sess.graph) if __name__ == '__main__': main()つぶやき
- 実は、Tensorflow公式githubには
import_pb_to_tensorboard.pyが用意されているが、うまく動かない(19.12.2)。- もっとスマートな方法があれば、教えてください。
- 投稿日:2019-12-02T01:56:01+09:00
Ubuntu18.04をインストールしたRazerBlade15でTensorflow-gpuを使う
http://demura.net/misc/14779.html
https://openrazer.github.io/
sudo add-apt-repository ppa:openrazer/stable
sudo apt update
sudo apt install openrazer-metasudo apt purge nvidia-*
sudo add-apt-repository ppa:graphics-drivers/ppa
sudo apt update
sudo apt install nvidia-390NVIDIA Driverのチェック
$ nvidia-smi省電力 (バッテリ持ちが格段によくなる)
sudo add-apt-repository ppa:nilarimogard/webupd8 sudo apt -y install tlp tlp-rdw powertop sudo tlp start sudo systemctl start tlp sudo systemctl enable tlpsudo dpkg -i '/home/taka/ダウンロード/cuda-repo-ubuntu1704-9-0-local_9.0.176-1_amd64.deb'
sudo apt-key add /var/cuda-repo-9-0-local/7fa2af80.pub
sudo apt-get update
sudo apt-get install cuda-toolkit-9-0sudo nano ~/.bashrc
sudo reboot
nvcc -Vcudnnがインストールされているかを確認する
dpkg -l | grep "cudnn"sudo dpkg -i libcudnn7_7.3.1.20-1+cuda9.0_amd64.deb
sudo dpkg -i libcudnn7-dev_7.3.1.20-1+cuda9.0_amd64.deb
sudo dpkg -i libcudnn7-doc_7.3.1.20-1+cuda9.0_amd64.deb\\
nvidia-smi
Command 'nvidia-smi' not found, but can be installed with:
sudo apt install nvidia-340
sudo apt install nvidia-utils-390https://knowledge.autodesk.com/ja/support/maya/troubleshooting/caas/sfdcarticles/sfdcarticles/kA230000000u016.html
最近のLinuxディストリビューションでは、インストール時からnouveauグラフィックスドライバを有効にするものがあります。
X-Windowが起動しないランレベル3で起動しているにもかかわらず、高解像度で、起動中に画像が表示されたり、プロンプトが小さかったり、いわゆるVGA画面でない場合は、このnouveauグラフィックスドライバが有効になっている可能性があります。とても有用なドライバーですが、これが有効になっているとNVIDIAドライバーのインストールが失敗してしまいますhttps://www.tensorflow.org/install/source#common_installation_problems
tensorflow-gpuとCUDAのバージョン