- 投稿日:2019-12-02T23:41:04+09:00
Stress Test with Locust written in Python
この記事は Brainpad Advent Calender 2019 2日目の記事になります
こんにちは@nissy0409240です
BrainPadでエンジニアをしています
2019年もあと一ヶ月を切りましたが
皆様いかがお過ごしでしょうか今年はプライベートで東京ドームへ行くことが出来た
感動の一年でありました
東京ドームと言えば野球
野球と言えばピッチャーとバッターです
そんな前置きとは無関係に本エントリーでは
Pythonでシナリオを書ける負荷試験ツールLocustの基本的な機能を紹介させて頂きますLocustとは
LocustとはGUIのインターフェースもついているPython製の負荷試験ツールです
他の負荷試験ツールと比較して一番大きい特徴はPythonでシナリオを書けることです
言葉遊びなようでもありますがPythonでシナリオを書かないといけないとも言えます公式ドキュメント等の各種リンクはこちらになります
ちなみにLocustはバッタやイナゴという意味の英語です
イラストはトノサマバッタですインストール方法
早速インストールしていこうと思います
インストールは下記コマンドを実行するだけです
※Macのローカル(Python3系)で動かすことを前提に進めます$ brew install libev $ python3 -m pip install locustio実行後に
$ locust --helpコマンドを実行し、ヘルプが表示されればインストール成功です
イラストはイナゴですシナリオを作成
シナリオはPythonスクリプトに記述します。
記述するファイル名自体に制約は有りません。
ですが、起動時にファイル名の指定をしないとlocustfile.pyというファイル名のものが実行されるので
ファイル名の制約が無いのならlocustfile.pyというファイル名にすることをお薦めします。以下がサンプルです
from locust import HttpLocust, TaskSet, task, between class WebsiteTasks(TaskSet): @task def index(self): self.client.get('/') class WebsiteUser(HttpLocust): task_set = WebsiteTasks wait_time = between(5, 15)ちなみに受けるAPIサーバーはこんな感じです
from wsgiref.simple_server import make_server import json def api(environ, start_response): status = '200 OK' headers = [ ('Content-type', 'application/json; charset=utf-8'), ('Access-Control-Allow-Origin', '*'), ] start_response(status, headers) return [json.dumps({'message':'hoge'}).encode("utf-8")] with make_server('', 3000, api) as httpd: print("Serving on port 3000...") httpd.serve_forever()
イラストはショウリョウバッタです起動
下記コマンドにて起動します
$ locust [2019-12-01 00:56:13,884] locust.main: Starting web monitor at *:8089 [2019-12-01 00:56:13,885] locust.main: Starting Locust 0.9.0上の例では何もオプションを着けて実行しておりませんが
-fオプションで実行したいシナリオが書かれたファイルを
-Hオプションで叩きたいエンドポイントを指定できますデフォルトでLocustのプロセスは8089ポートで起動しますが
-Pオプションで起動時のポートを変更することが可能ですちゃんと指定すると
このように起動します$ locust -f locustfile.py -H http://localhost:3000 -P 8089 [2019-12-02 03:38:42,717] locust.main: Starting web monitor at *:8089 [2019-12-02 03:38:42,718] locust.main: Starting Locust 0.13.2
イラストはイナゴの佃煮ですテスト実行
起動後にブラウザから
http://localhost:8089にアクセスすると
以下のようなGUIにアクセス出来ます
先程何気なく指定した叩きたいエンドポイントがデフォルトで設定されています
※起動時にHostを指定しない場合、Hostは空欄になります空欄になっている設定項目があるので、以下の値を入力します
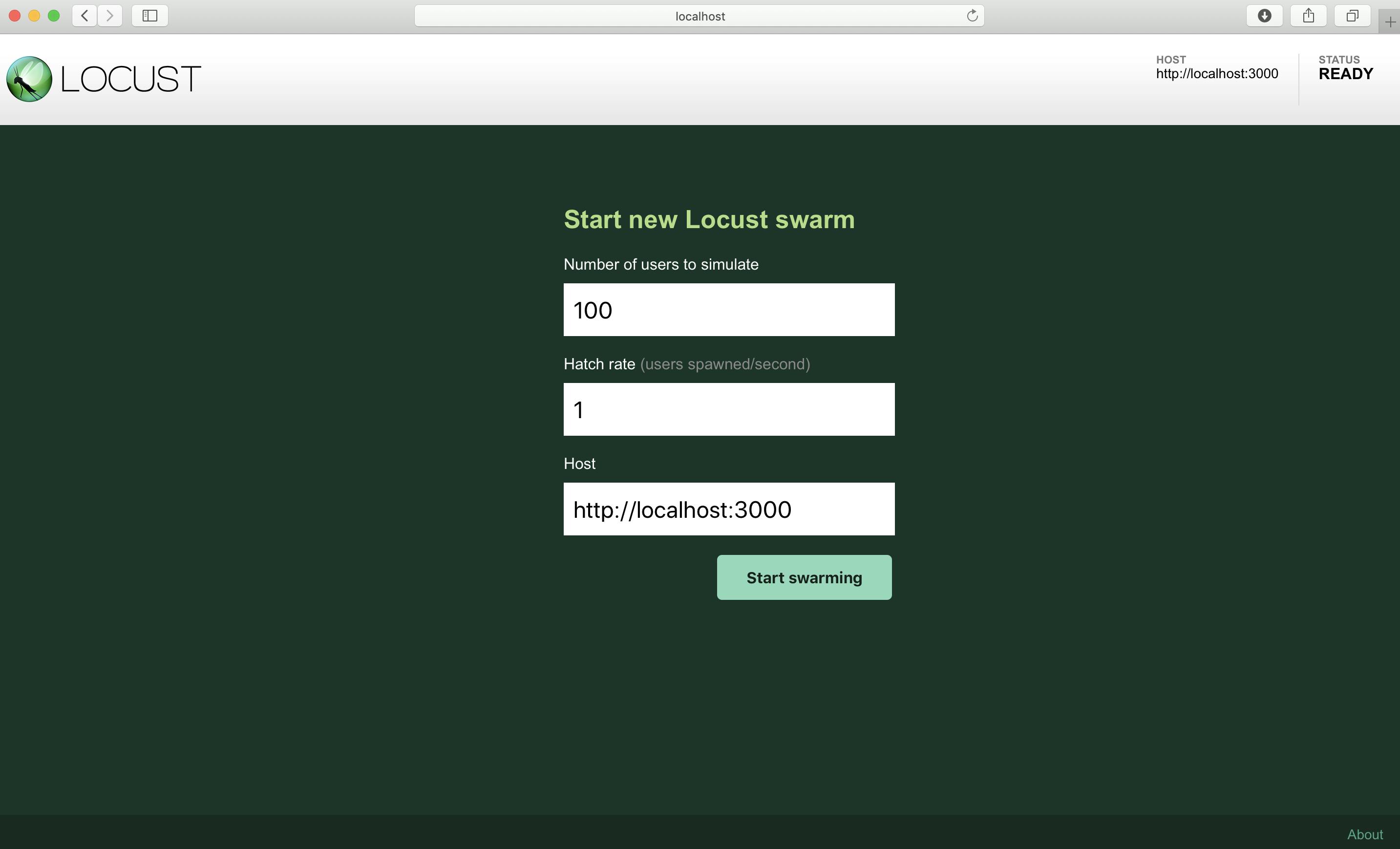
"Number of users to simulate" に100
"Hatch rate" に 1それぞれの意味は以下の通りです
Number of users to simulate:何クライアント作成するか(最大で秒間何リクエストを送るかと同義) Hatch rate:クライアントの作成スピード(毎秒ごと) Host:接続先エンドポイント今回は
http://localhost:3000に対して1秒ごとに1クライアントづつ増やしながらリクエストを送信する
この時、最大でもクライアント数は100まで増やすこととする
という条件で実行します
入力後「Start Swarming」ボタンを押すとリクエストが実行されます
実行を終了させたい場合はブラウザの右上のSTOPボタンを押しましょう
押した後はSTATUSがSTOPPEDになり、終了したことが確認出来ます
イラストはバッタやイナゴの大群ですメトリクス
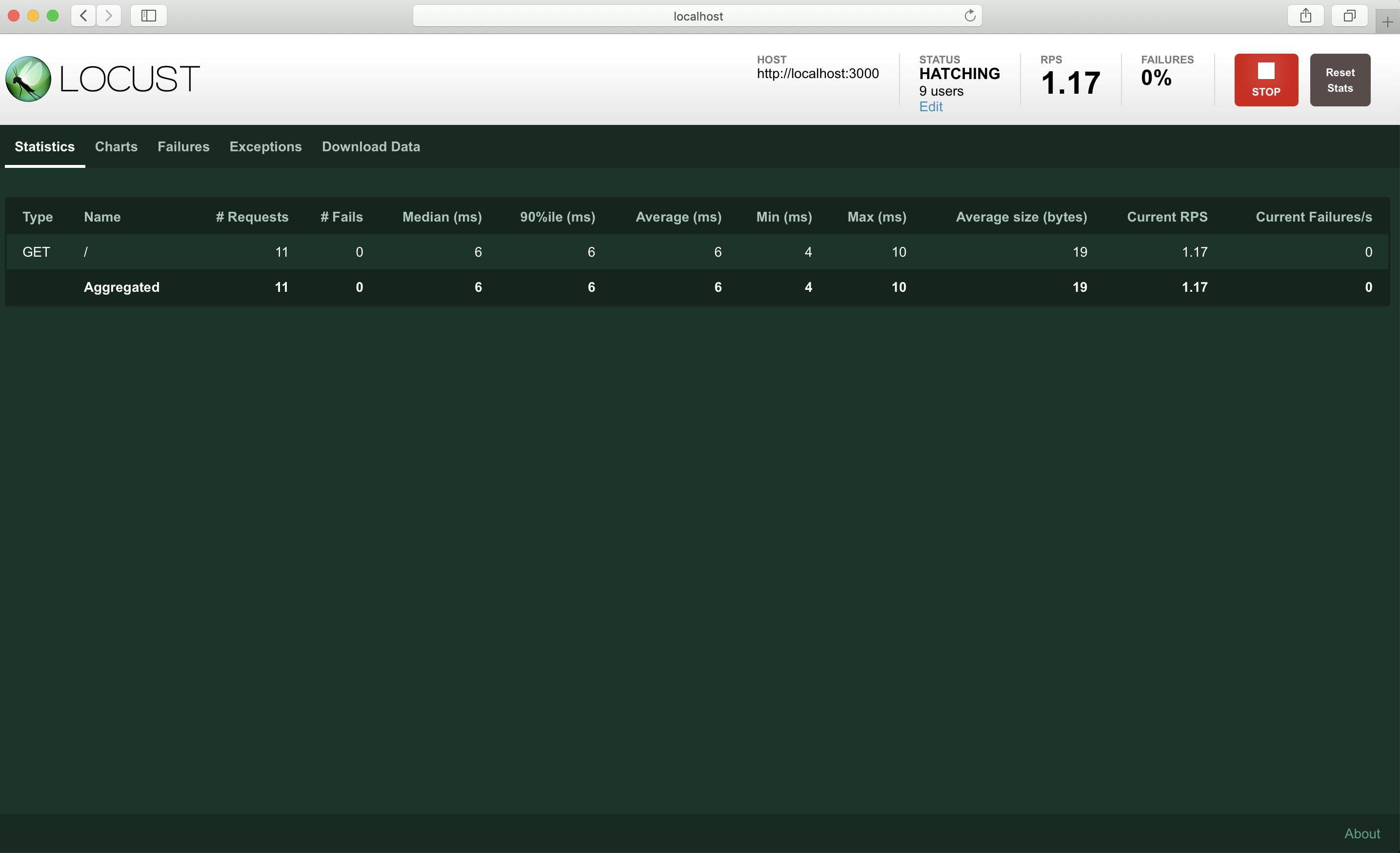
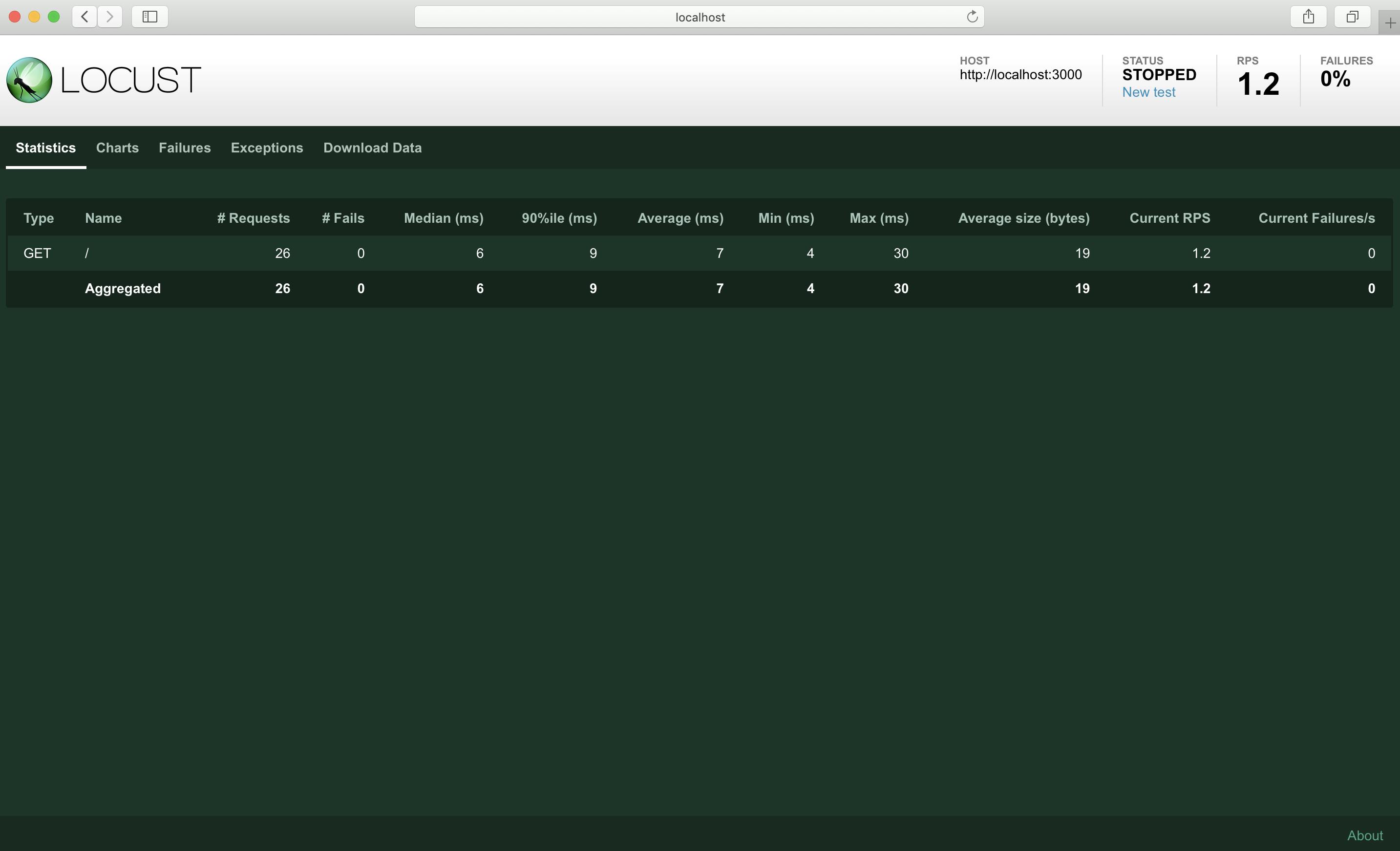
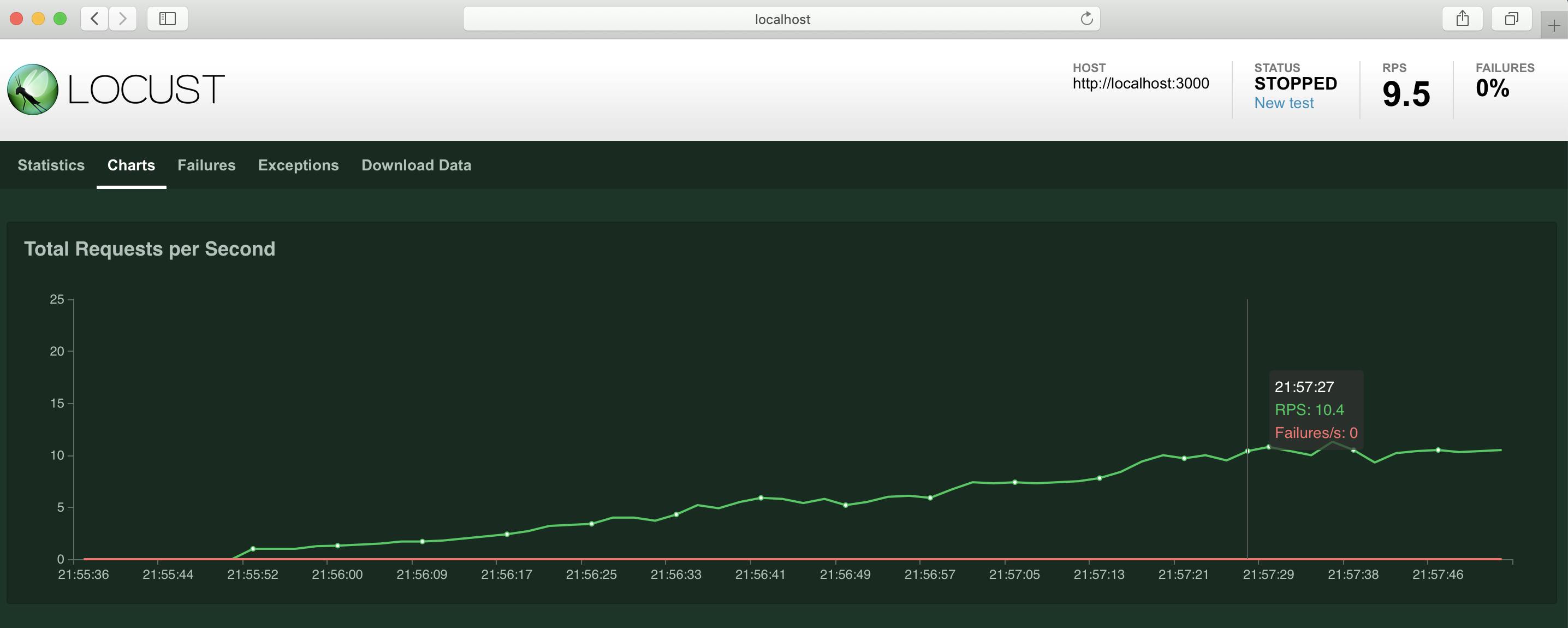
Chartsタブでメトリクスを見ることも出来ます
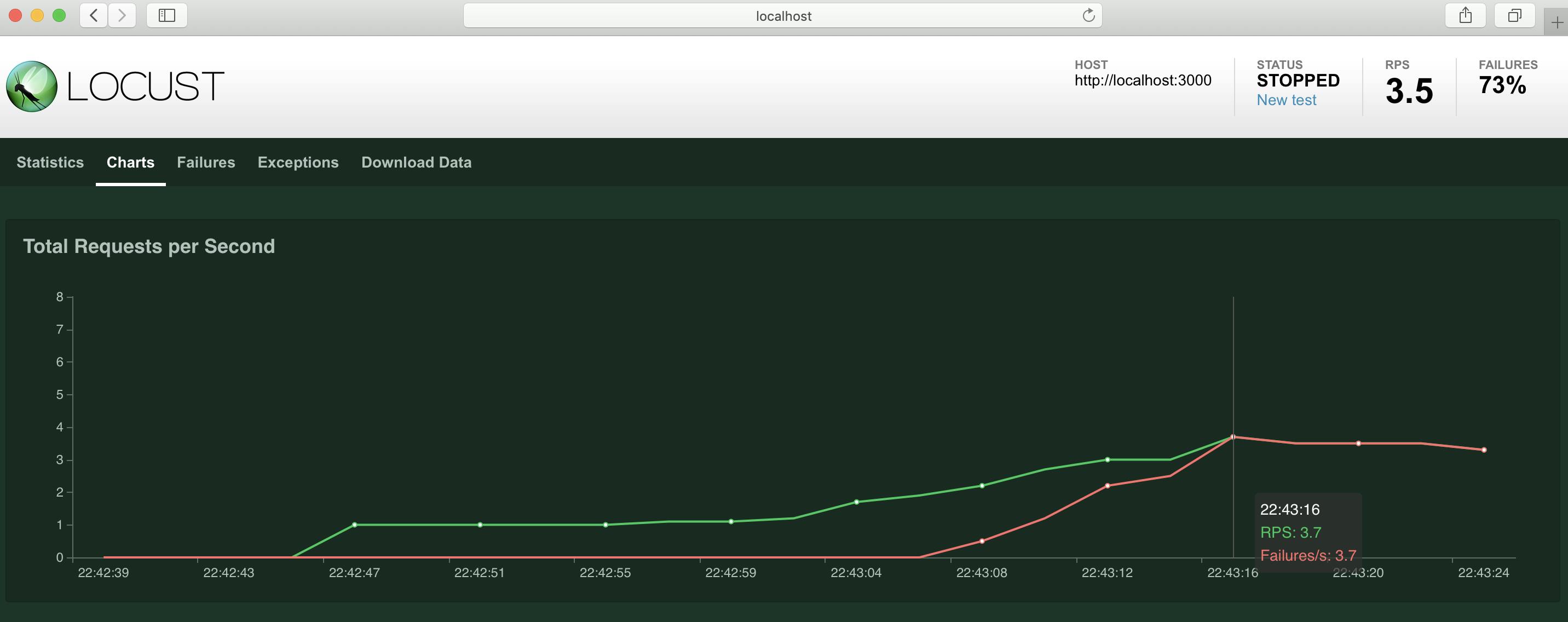
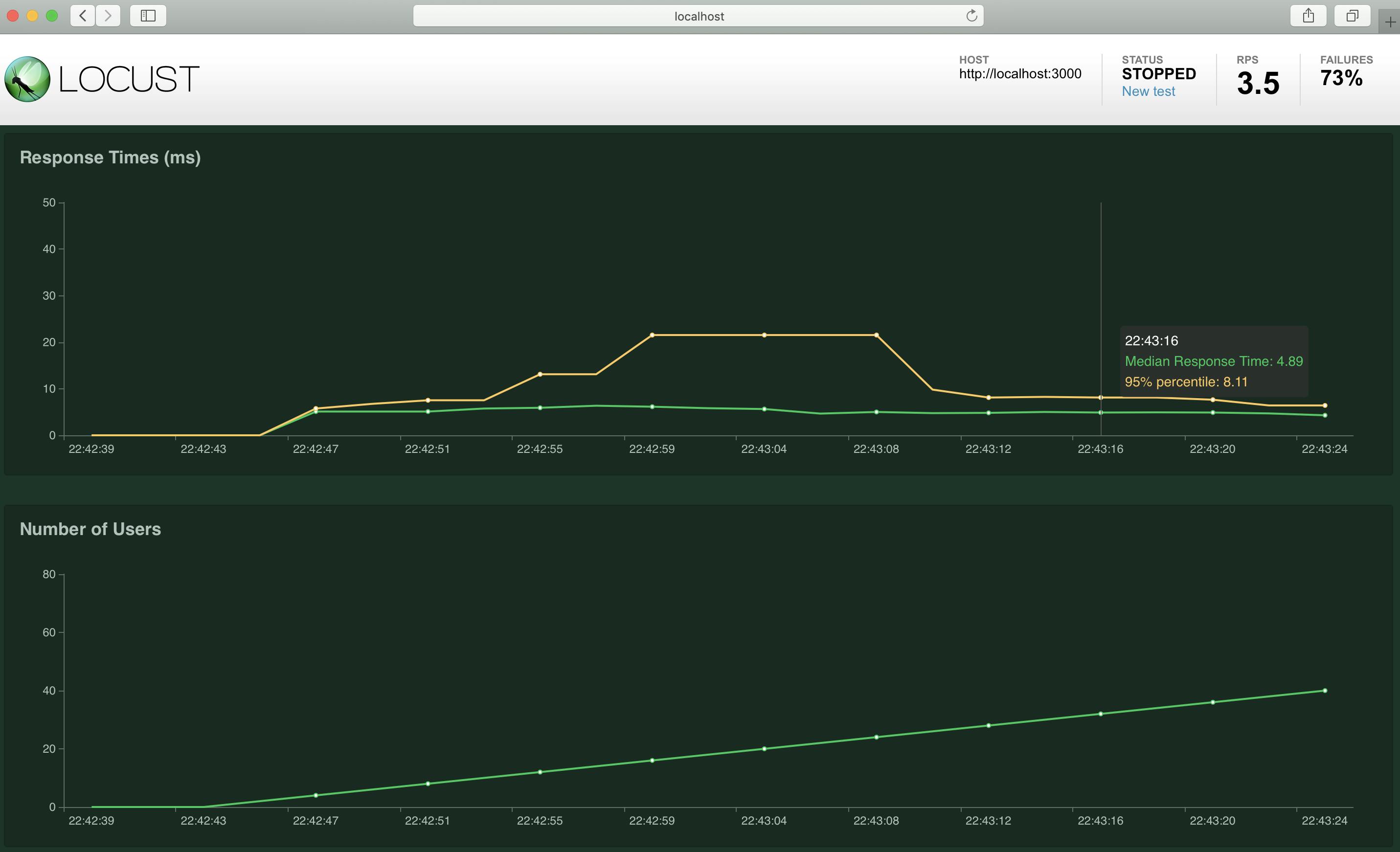
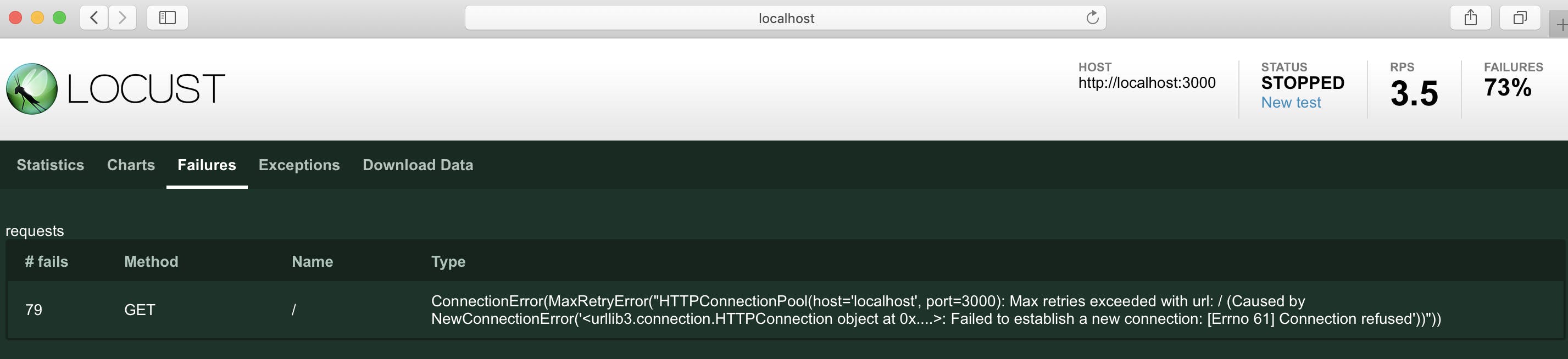
こちらは1秒ごとに1クライアントづつ増やし、最大100クライアントまで増えたらそのまま100クライアントでリクエストし続けた時のメトリクスです続いて、リクエストに失敗した時はどのようになるか見ていきましょう
今回はAPIサーバーのプロセスを途中で停止してみようと思います
各タブにてこのように確認出来ます
失敗したリクエストの増え方やリクエスト全体に対する失敗の割合
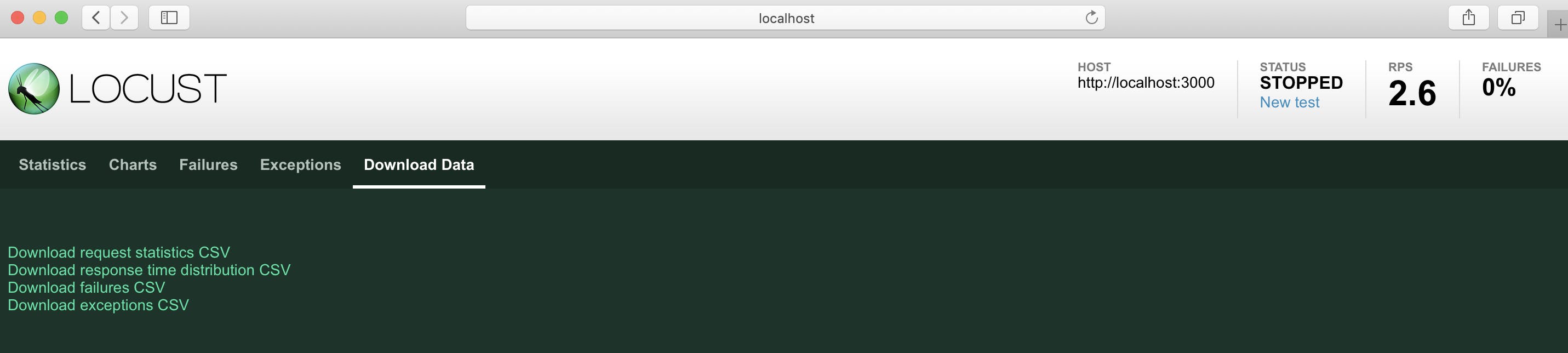
Failuresタブではどのような理由で失敗したかも確認出来ますまた、Downloads Dataタブからは結果をダウンロードすることも可能です
ダウンロードしたファイルの中身はこのようになっています
イラストはバッタのキャラクターです結び
以上、基本的な機能のみではございますがLocustの紹介をさせて頂きました
バッターのイラストとともにお別れです
最後までお付き合い頂きありがとうございました
参考
https://qiita.com/yamionp/items/17ffcc465272ad83c490
https://inside.pixiv.blog/east/5407
https://blog.htmlhifive.com/2015/08/14/web-server-load-testing-tools-2-locust/
https://docs.locust.io/en/stable/installation.html
https://docs.locust.io/en/stable/quickstart.html
https://co3k.org/blog/load-test-by-locust











- 投稿日:2019-12-02T23:29:45+09:00
Python joblibで並列処理を試みたけど、uWSGI環境だと動かなかった時の対処法!
はじめに
Pythonで、機械学習やディープランニングをやっていると処理が重たくなって、性能面で問題になることがありますよね。
最近、私も重い処理があり性能改善のために並列処理を入れることにしました。
ローカルでjoblibという並列処理用のライブラリを使い性能面で改善が見られれました。しかし、開発環境上で同じ処理を実行したエラーに。。。
どうやら、uWSGI環境だとjoblibは動かないようです。
そのあたりの対処についてまとめました。uWSGIとは
- uWSGIとはPythonでWebサービスを動かすためのアプリケーションサーバです。
環境情報
- python: 3.6.9
- nginx: 1.13.1
- uWSGI: 2.0.18
- joblib: 0.14.0
uWSGI上で失敗するjoblibのコード
- 並列化したい処理
length = 1000 def sum(i, j): return i + j
- 並列化
from joblib import Parallel, delayed sum_list = Parallel(n_jobs=-1)( [delayed(calc_sum)(i, j) for j in range(length) for i in range(length)])- しかし、uWSGI上で動かすとこんな感じのエラーに
exception calling callback for <Future at 0x7fbc520c7eb8 state=finished raised TerminatedWorkerError> Traceback (most recent call last): File "/usr/local/lib/python3.7/site-packages/joblib/externals/loky/_base.py", line 625, in _invoke_callbacks callback(self) File "/usr/local/lib/python3.7/site-packages/joblib/parallel.py", line 309, in __call__ self.parallel.dispatch_next() File "/usr/local/lib/python3.7/site-packages/joblib/parallel.py", line 731, in dispatch_next if not self.dispatch_one_batch(self._original_iterator): File "/usr/local/lib/python3.7/site-packages/joblib/parallel.py", line 759, in dispatch_one_batch self._dispatch(tasks) File "/usr/local/lib/python3.7/site-packages/joblib/parallel.py", line 716, in _dispatch job = self._backend.apply_async(batch, callback=cb) File "/usr/local/lib/python3.7/site-packages/joblib/_parallel_backends.py", line 510, in apply_async future = self._workers.submit(SafeFunction(func)) File "/usr/local/lib/python3.7/site-packages/joblib/externals/loky/reusable_executor.py", line 151, in submit fn, *args, **kwargs) File "/usr/local/lib/python3.7/site-packages/joblib/externals/loky/process_executor.py", line 1022, in submit raise self._flags.broken joblib.externals.loky.process_executor.TerminatedWorkerError: A worker process managed by the executor was unexpectedly terminated. This could be caused by a segmentation fault while calling the function or by an excessive memory usage causing the Operating System to kill the worker. The exit codes of the workers are {EXIT(1), EXIT(1), EXIT(1), EXIT(1)}対処法1: threadsなら動く
from joblib import Parallel, delayed sum_list = Parallel(n_jobs=-1, prefer='threads')( [delayed(calc_sum)(i, j) for j in range(length) for i in range(length)])
- もちろん、処理によってはthreadsにしてしまうと遅くなってしまうこともある。
対象法2: multiprocessingにする
import multiprocessing from multiprocessing import Process with multiprocessing.Pool() as pool: process = [pool.apply_async(calc_sum, (i, j)) for j in range(length) for i in range(length)] sum_list = [f.get() for f in process]対処法3: uWSGIではなく、guicornにする
私は、今回この方法をとりませんでした。
理由は、すでにuWSGIで稼働していたためAPサーバを変更するのはリスクがでかいためです。最後に
速度比較
通常 joblib(multiprocess) joblib(threads) multiprocessing 11 µs 40.1 µs 2.86 µs joblibの方が可読性はよく、書きやすいのですがmultiprocessingの方がPython本体に組み込まれている機能のため、性能が出ることも多いです。
また、今回みたいなエラーも踏むこともなさそうです。
- 投稿日:2019-12-02T23:29:45+09:00
Python joblibの並列処理はuWSGI環境だと動かない。uWSGI上で並列処理するには?
はじめに
Pythonで、機械学習やディープランニングをやっていると処理が重たくなって、性能面で問題になることがありますよね。
最近、私も重い処理があり性能改善のために並列処理を入れることにしました。
ローカルでjoblibという並列処理用のライブラリを使い性能面で改善が見られれました。しかし、開発環境上で同じ処理を実行したエラーに。。。
どうやら、uWSGI環境だとjoblibは動かないようです。
そのあたりの対処についてまとめました。uWSGIとは
- uWSGIとはPythonでWebサービスを動かすためのアプリケーションサーバです。
環境情報
- python: 3.6.9
- nginx: 1.13.1
- uWSGI: 2.0.18
- joblib: 0.14.0
uWSGI上で失敗するjoblibのコード
- 並列化したい処理
length = 1000 def sum(i, j): return i + j
- 並列化
from joblib import Parallel, delayed sum_list = Parallel(n_jobs=-1)( [delayed(calc_sum)(i, j) for j in range(length) for i in range(length)])- しかし、uWSGI上で動かすとこんな感じのエラーに
exception calling callback for <Future at 0x7fbc520c7eb8 state=finished raised TerminatedWorkerError> Traceback (most recent call last): File "/usr/local/lib/python3.7/site-packages/joblib/externals/loky/_base.py", line 625, in _invoke_callbacks callback(self) File "/usr/local/lib/python3.7/site-packages/joblib/parallel.py", line 309, in __call__ self.parallel.dispatch_next() File "/usr/local/lib/python3.7/site-packages/joblib/parallel.py", line 731, in dispatch_next if not self.dispatch_one_batch(self._original_iterator): File "/usr/local/lib/python3.7/site-packages/joblib/parallel.py", line 759, in dispatch_one_batch self._dispatch(tasks) File "/usr/local/lib/python3.7/site-packages/joblib/parallel.py", line 716, in _dispatch job = self._backend.apply_async(batch, callback=cb) File "/usr/local/lib/python3.7/site-packages/joblib/_parallel_backends.py", line 510, in apply_async future = self._workers.submit(SafeFunction(func)) File "/usr/local/lib/python3.7/site-packages/joblib/externals/loky/reusable_executor.py", line 151, in submit fn, *args, **kwargs) File "/usr/local/lib/python3.7/site-packages/joblib/externals/loky/process_executor.py", line 1022, in submit raise self._flags.broken joblib.externals.loky.process_executor.TerminatedWorkerError: A worker process managed by the executor was unexpectedly terminated. This could be caused by a segmentation fault while calling the function or by an excessive memory usage causing the Operating System to kill the worker. The exit codes of the workers are {EXIT(1), EXIT(1), EXIT(1), EXIT(1)}対処法1: threadsなら動く
from joblib import Parallel, delayed sum_list = Parallel(n_jobs=-1, prefer='threads')( [delayed(calc_sum)(i, j) for j in range(length) for i in range(length)])
- もちろん、処理によってはthreadsにしてしまうと遅くなってしまうこともある。
対象法2: multiprocessingにする
import multiprocessing from multiprocessing import Process with multiprocessing.Pool() as pool: process = [pool.apply_async(calc_sum, (i, j)) for j in range(length) for i in range(length)] sum_list = [f.get() for f in process]対処法3: uWSGIではなく、guicornにする
私は、今回この方法をとりませんでした。
理由は、すでにuWSGIで稼働していたためAPサーバを変更するのはリスクがでかいためです。最後に
速度比較
通常 joblib(multiprocess) joblib(threads) multiprocessing 32.9 µs 11 µs 40.1 µs 4.05 µs joblibの方が可読性はよく、書きやすいのですがmultiprocessingの方がPython本体に組み込まれている機能のため、性能が出ることも多いです。
また、今回みたいなエラーも踏むこともなさそうです。
- 投稿日:2019-12-02T23:23:21+09:00
Amazon SQSからAWS Lambdaを呼び出すTerraform
はじめに
SREエンジニアやってます。@hayaosatoです。
今回はサーバレスなアーキテクチャを組む上で超便利なAWS Lambda(以下、Lambda)をAmazon SQS(以下、SQS)から呼び出してみたいと思います。アーキテクチャ
Lambda
Lambdaのリソースは以下のように作ることができます。
アプリケーションはslack通知のスクリプトにしました。// IAM Role for Lambda Function resource "aws_iam_role" "default" { name = var.service_name description = "IAM Rolw for ${var.service_name}" assume_role_policy = file("${var.service_name}_role.json") } resource "aws_iam_policy" "default" { name = var.service_name description = "IAM Policy for ${var.service_name}" policy = file("${var.service_name}_policy.json") } resource "aws_iam_role_policy_attachment" "default" { role = aws_iam_role.default.name policy_arn = aws_iam_policy.default.arn } // Lambda Function Resources resource "aws_cloudwatch_log_group" "default" { name = "/aws/lambda/${var.service_name}" retention_in_days = 7 } data archive_file "default" { type = "zip" source_dir = "src" output_path = var.output_path } resource "aws_lambda_function" "default" { filename = var.output_path function_name = var.service_name role = aws_iam_role.default.arn handler = "lambda_function.lambda_handler" source_code_hash = data.archive_file.default.output_base64sha256 runtime = "python3.6" environment { variables = { SLACK_API_KEY = var.SLACK_API_KEY } } }Lambda関数をTerraformで作成する際は是非ともarchiveリソースの
archive_fileを利用していただきたいです。
これを利用することでzipを生成してそれをそのままLambda関数に適応できるので非常に楽です。
つまりはこの構成をそのままCIに組み込んでCIツールからterraform applyすればいい感じですね。SQS
SQSのリソースは以下のように作ることができます。
resource "aws_sqs_queue" "default" { name = "${var.service_name}.fifo" fifo_queue = true content_based_deduplication = true }SQSとLambdaの連携
TerraformにはLambdaのトリガ設定のためのリソースとしてlambda_event_source_mappingというものがあります。
今回はこれを使います。resource "aws_lambda_event_source_mapping" "default" { event_source_arn = aws_sqs_queue.default.arn function_name = aws_lambda_function.default.arn }また、このリソースは現在SQSとDynamoDB,Kinesisにしか対応していないため、SNSからの連携はできません(コードにSNSと連携させようと作ったリソースの残骸が。。。)
event_source_arnに指定できないリソースのARNを入れてしまうと、無限にcreating...になります。
ただ、S3からのイベントは普通に実行できます。結果
作ったリソースで実際にキューを発行して実行してみます。
できました
最後に
やっぱりサーバレスっていいですね
参考


- 投稿日:2019-12-02T22:48:40+09:00
Pythonでオリジナルのランダムドットステレオグラム(RDS)を作る
ランダムドットステレオグラム(RDS)
オリジナルのアップロード者はドイツ語版ウィキペディアのLosHawlosさん - de.wikipedia からコモンズに移動されました。, CC 表示-継承 3.0, https://commons.wikimedia.org/w/index.php?curid=1966500 によるあなたには見えるだろうか?
目の焦点を前後にずらすことで絵や文字が浮かび上がる(立体に見える)やつです。
スマホから見てる人はごめんなさい。パソコンから見てね。これを自作してみたい。
下記のサイトにPythonでの実装例があったので、参考にしてオリジナルのランダムドットステレオグラムを作ってみた。
使うもの
import numpy as np import matplotlib.pyplot as plt import cv2Notebook形式で実験していて、画像を表示させるために使い慣れている
matplotlibを使いましたが、画像が確認できれば何でも良いです。手順
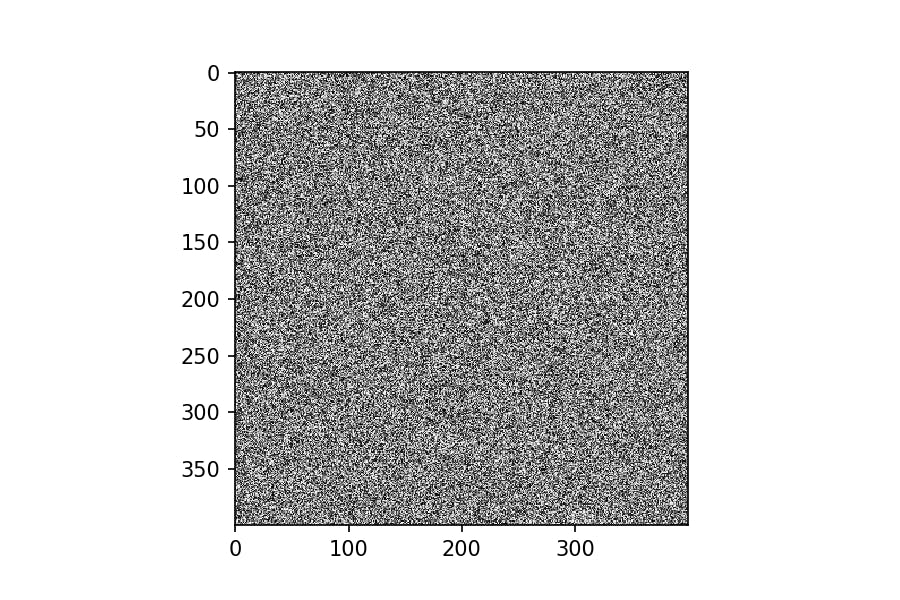
1.ランダムパターンを作成
def make_pattern(shape=(16, 16)): return np.random.uniform(0, 1, shape)実行してみる。
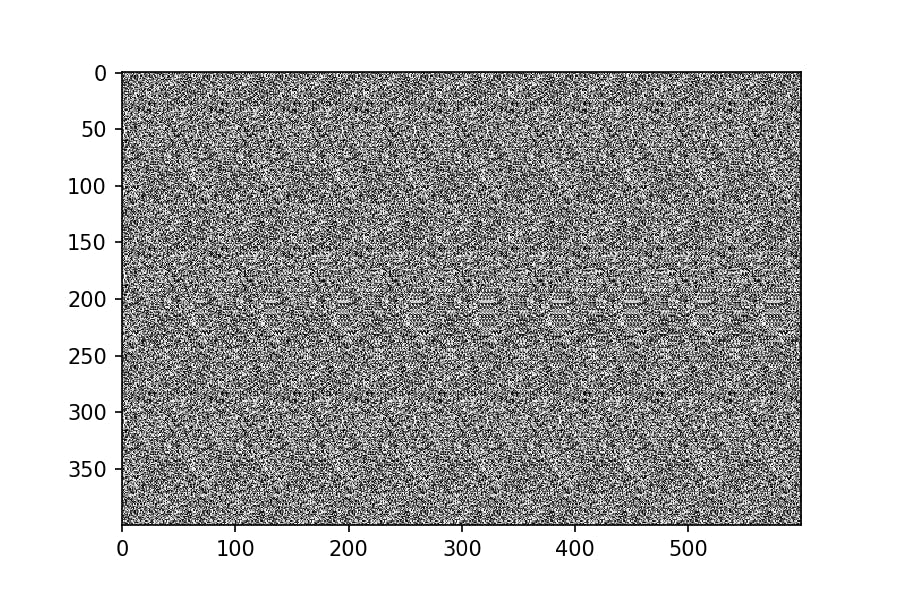
pattern = make_pattern((400,400)) plt.imshow(pattern, cmap='gray')
すでに何かが浮かび上がりそうである。
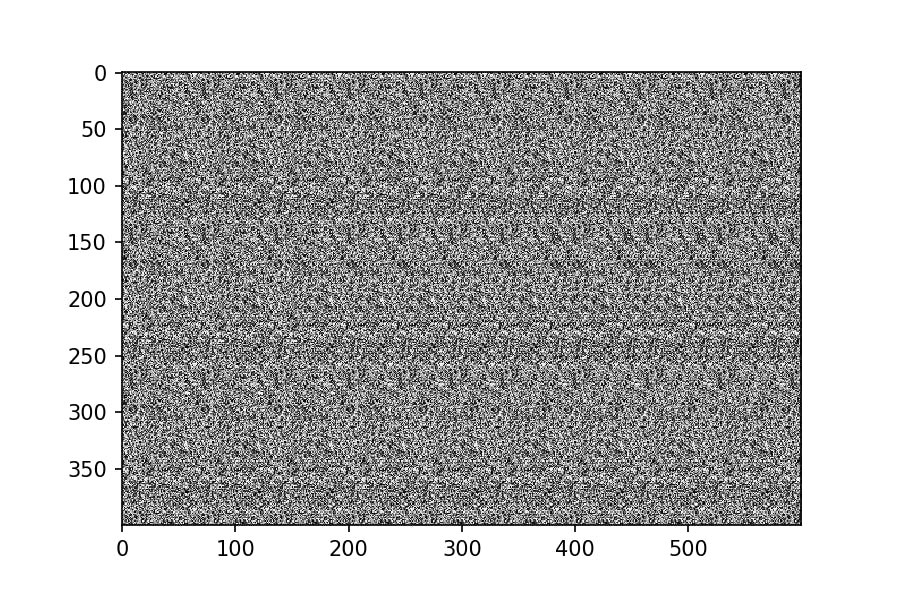
2.浮かび上がらせるパターンを作成
def make_depthmap(shape=(400, 600)): depthmap = np.zeros(shape, dtype=np.float) cv2.circle(depthmap, (int(shape[1]/2), int(shape[0]/2)), 100, (255 ,255, 255), -1) return depthmap実行してみる。
depthmap = make_depthmap() plt.imshow(depthmap, cmap='gray')
こいつが浮かび上がるはずである。3.やってみた
def make_autostereogram(depthmap, pattern, shift_amplitude=0.1, invert=False): "Creates an autostereogram from depthmap and pattern." depthmap = normalize(depthmap) if invert: depthmap = 1 - depthmap autostereogram = np.zeros_like(depthmap, dtype=pattern.dtype) for r in np.arange(autostereogram.shape[0]): for c in np.arange(autostereogram.shape[1]): if c < pattern.shape[1]: autostereogram[r, c] = pattern[r % pattern.shape[0], c] else: shift = int(depthmap[r, c] * shift_amplitude * pattern.shape[1]) autostereogram[r, c] = autostereogram[r, c - pattern.shape[1] + shift] return autostereogram def normalize(depthmap): return depthmap/255メインの処理は冒頭に挙げた参考サイトから引用させていただきました。
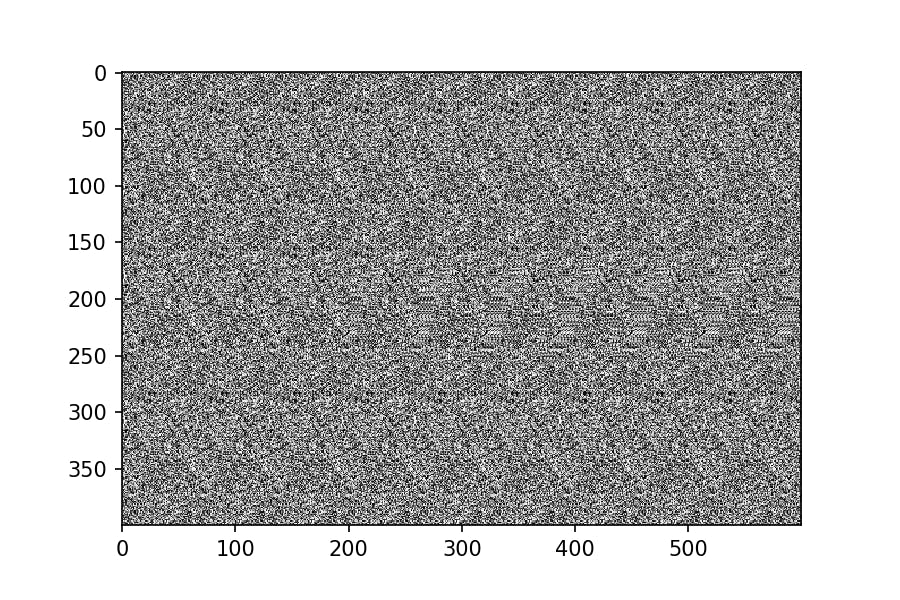
実行してみる。autostereogram = make_autostereogram(depthmap, pattern, 0.3) plt.imshow(autostereogram, cmap='gray')
はっきりと丸印が浮かび上がっている。
(交差法といって、目の焦点を近づける方法では丸印が凹んでみえます。)せっかくなので
テキストをランダムドットステレオグラムにしてみた。
def make_text_depthmap(shape=(400, 600), text='Q i i t a'): font = cv2.FONT_HERSHEY_SIMPLEX cv2.putText(depthmap, text, (50, 250), font, 4, (255,255,255), 12, cv2.LINE_AA) return depthmap浮かび上がらせるもの。
depthmap_text = make_text_depthmap() plt.imshow(depthmap, cmap='gray')
実行してみる。autostereogram = make_autostereogram(depthmap_text, pattern, 0.05) plt.imshow(autostereogram, cmap='gray')
さっきの丸印よりちょっとぼんやりしてるけど、見えるぞ。エンジニアのみなさんにクイズ
なんと書いてあるでしょう??テキストです。
答えはコメント欄でお待ちしています^^



- 投稿日:2019-12-02T22:05:18+09:00
DjangoのTemplatesでの条件分岐に苦戦した。
やりたいこと
Djangoで某サークルの機材予約をWebからできるようにしようとしていて、
過去の予約データを編集したり、削除できないようにするために
現在時刻より前の予定の編集ボタンや削除ボタンを非表示にしたい。そのための条件分岐をtemplatesに記述しようとして苦戦。
views.pycontext = { 'band_name' : band_name, 'schedules' : Schedule.objects.all(), 'target_date' : datetime.datetime.now() } return render(request, 'xxx.html', context)xxx.html{% schedule in schedules %} {% if schedule.target_date > target_date %} ボタン表示 {% endif %} {% endfor %}変数(今日の日付)とモデルをtemplatesに渡して
schedulesのループの中で日付で条件分岐をしてボタンを表示・非表示を制御したいしかし、うまく条件分岐できない。
単純に
{% if True %}
ではうまく条件分岐ができていたので、viewで予め判定して、モデルのidと判定結果(Bool)を辞書として
templatesに渡して制御しようとしたviews.pymy_dic = {} target_date = datetime.datetime.now() for schedule in schedules: if target_date < schedule.target_date: my_dic[schedule.id] = True else: my_dic[schedule.id] = False context = { 'schedules' : Schedule.objects.all(), 'my_dic' : my_dic, } return render(request, 'xxx.html', context)xxx.html{% schedule in schedules %} {% if my_dic[schedule.target_date] %} ボタン表示 {% endif %} {% endfor %}しかし、これもうまくいかない。
templates内で辞書の展開は
my_dic.id
でidにキーを指定すれば展開ができるが、この「.id」の部分にschedulesのループ内のschedule.idを渡したいが
これもうまくいかない。
withタグを使って変数を代入してもうまくいかない。
{% with target_id = schedule.id %}
{% if my_dic[schedule.target_id] %}これもうまくいかない。
{% if my_dic.schedule.id %}
{% if my_dic[schedule.id] %}
これらはもちろんダメだった。解決策
モデルに直接ニョキっとメソッドを生やした。
models.pyclass Schedule(models.Model): # カラムの定義 ・・・ target_date = models.DateField(default=timezone.now, verbose_name=‘予約日‘) def is_available(self): current_day = timezone.datetime.today() return current_day < self.active_datexxx.html{% schedule in schedules %} {% if schedule.is_available %} ボタン表示 {% endif %} {% endfor %}Done.
このメソッドを使えばURLでの直接アクセスに対してもredirectできそう。
やりたいことに書いたようなコーディングでうまくいかないものなのか、、、
もちろんtemplatesでロジックはなるべく書かない方がよいが、
辞書の参照などのちょっとした操作はうまく働いて欲しかった。他にもtemplates filterを自分で作ってしまうなどの解決策は見つけたが、
今のところはこのやり方が一番綺麗だと思う。以上です。
P.S.
ちゃんゆーさん(@chanyou0311)にご教授頂きました。感謝です。
- 投稿日:2019-12-02T21:33:36+09:00
matplotlibの日本語フォントについて(Macの場合)
結論
こうすれば良いはず。
もっと良いものや、考慮漏れがあれば追記します。# フォント設定 plt.rcParams['font.family'] = 'Hiragino Sans' # 太さ設定 plt.rcParams['font.weight'] = 'bold' """ fig,ax = plt.subplots() ax.plot()... などのプロット """ # legend使うとき #legend_properties = {'size':14,'weight':'bold'} #ax.legend(prop=legend_properties) # plt.draw()が無いとget_ticklabels()で帰ってくるtextが空文字になる plt.draw() # ticklabelのフォントはrc設定では変えられないっぽい ax.set_xticklabels(ax.get_xticklabels(),fontsize=14,fontweight='bold') ax.set_yticklabels(ax.get_yticklabels(),fontsize=14,fontweight='bold')導入
import matplotlib.font_manager [f.name for f in matplotlib.font_manager.fontManager.ttflist] # >['DejaVu Serif Display', # 'STIXGeneral', # ...]となりますが、よくよく見てみると、同じ文字列が複数存在していることがわかります。
例えばMacの場合l = [f.name for f in matplotlib.font_manager.fontManager.ttflist] l.count("Hiragino Sans") #> 10となります。何故10もあるのでしょうか。
それを知るために上のリスト内包表記でf.nameとしているころを、一旦fにして、fについて調べてみましょう。l = [f for f in matplotlib.font_manager.fontManager.ttflist] type(l[0]) # > matplotlib.font_manager.FontEntryとなるので、この各項目はmatplotlib.font_manager.FontEntryクラスのオブジェクトであることがわかります。
matplotlib.font_manager.FontEntryのクラス変数を見てましょう。l_hiragino= [f for f in matplotlib.font_manager.fontManager.ttflist if f.name == 'Hiragino Sans']として、Hiragino Sansのものだけを比較してみます。
matplotlib.font_manager.FontEntry.name
- 詳しく書くまでもないので、これはl_hiraginoの全ての項目で"Hiragino Sans"になります。
matplotlib.font_manager.FontEntry.fname
[f.fname for f in l_hiragino] """ >['/System/Library/Fonts/ヒラギノ角ゴシック W5.ttc', '/System/Library/Fonts/ヒラギノ角ゴシック W0.ttc', '/System/Library/Fonts/ヒラギノ角ゴシック W6.ttc', '/System/Library/Fonts/ヒラギノ角ゴシック W3.ttc', '/System/Library/Fonts/ヒラギノ角ゴシック W9.ttc', '/System/Library/Fonts/ヒラギノ角ゴシック W2.ttc', '/System/Library/Fonts/ヒラギノ角ゴシック W8.ttc', '/System/Library/Fonts/ヒラギノ角ゴシック W1.ttc', '/System/Library/Fonts/ヒラギノ角ゴシック W4.ttc', '/System/Library/Fonts/ヒラギノ角ゴシック W7.ttc'] """これを見ると、各要素は全てヒラギノ角ゴシックで、太さの違うもの1になっていることがわかります。
ヒラギノ丸ゴシックについても見てみるとl_hiragino_maru= [f for f in matplotlib.font_manager.fontManager.ttflist if f.name == 'Hiragino Maru Gothic Pro'] [f.fname for f in l_hiragino_maru] # > ['/System/Library/Fonts/ヒラギノ丸ゴ ProN W4.ttc']となり太さが一種類のものしか用意されていないことがわかります。
これでどのような影響が出るのかを見てみましょう。
matplotlib.font_manager.FontEntryの他のクラス変数はそこまで大きな発見などないので、後ろの方に載せておきます。ウェイト設定による違い
ウェイト設定出来るヒラギノ角ゴシック
まずヒラギノ角ゴシックで例を見てみましょう
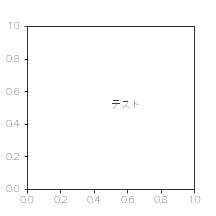
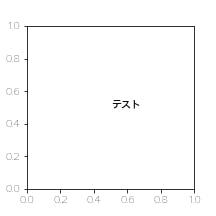
# フォントをヒラギノ角ゴシックで plt.rcParams['font.family'] = 'Hiragino Sans'fontsize=default, fontweight=default
fig,ax = plt.subplots(figsize=(3,3)) ax.annotate("テスト",xy=(0.5,0.5))
うっす!!
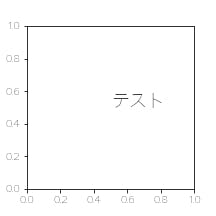
ということでフォントのサイズを変えてみましょうfontsize=18, fontweight=default
fig,ax = plt.subplots(figsize=(3,3)) ax.annotate("テスト",xy=(0.5,0.5),fontsize=18)
まあ読めるようにはなりましたが、解像度が高くないような印象を受けます。
そこで太さを変更してみましょう。fontsize=default, fontweight="bold"
fig,ax = plt.subplots(figsize=(3,3)) ax.annotate("テスト",xy=(0.5,0.5),weight="bold")
フォントサイズを大きくしなくても読みやすい印象を受けます。
fontweightについてはここ2を参照すると0-1000の数値で設定、もしくは' 'ultralight', 'light', 'normal', 'regular', 'book', 'medium', 'roman', 'semibold', 'demibold', 'demi', 'bold', 'heavy', 'extra bold', 'black'から選択
とあります。
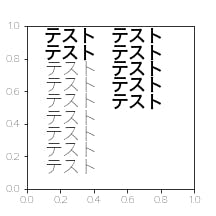
この差を見てみましょうfig,ax = plt.subplots(figsize=(3,3)) ax.annotate("テスト",xy=(0.1,0.1),weight="ultralight",fontsize=18) ax.annotate("テスト",xy=(0.1,0.2),weight="light",fontsize=18) ax.annotate("テスト",xy=(0.1,0.3),weight="normal",fontsize=18) ax.annotate("テスト",xy=(0.1,0.4),weight="regular",fontsize=18) ax.annotate("テスト",xy=(0.1,0.5),weight="book",fontsize=18) ax.annotate("テスト",xy=(0.1,0.6),weight="medium",fontsize=18) ax.annotate("テスト",xy=(0.1,0.7),weight="roman",fontsize=18) ax.annotate("テスト",xy=(0.1,0.8),weight="semibold",fontsize=18) ax.annotate("テスト",xy=(0.1,0.9),weight="demibold",fontsize=18) ax.annotate("テスト",xy=(0.5,0.9),weight="demi",fontsize=18) ax.annotate("テスト",xy=(0.5,0.8),weight="bold",fontsize=18) ax.annotate("テスト",xy=(0.5,0.7),weight="heavy",fontsize=18) ax.annotate("テスト",xy=(0.5,0.6),weight="extra bold",fontsize=18) ax.annotate("テスト",xy=(0.5,0.5),weight="black",fontsize=18)
2種類しか種類がないように見えます…
また、もう少し調べてみるとfontweightは細かく指定しても反映されない
引用元:http://ebcrpa.jamstec.go.jp/~yyousuke/matplotlib/options.htmlとの記述もあります。
それでは、これらを踏まえてデフォルトのrc設定を変更しましょう。3,4
# フォント設定 plt.rcParams['font.family'] = 'Hiragino Sans' # 太さ設定 plt.rcParams['font.weight'] = 'bold' """ fig,ax = plt.subplots() ax.plot()... などのプロット """ # legend使うとき #legend_properties = {'size':14,'weight':'bold'} #ax.legend(prop=legend_properties) # plt.draw()が無いとget_ticklabels()で帰ってくるtextが空文字になる plt.draw() # ticklabelのフォントはrc設定では変えられないっぽい ax.set_xticklabels(ax.get_xticklabels(),fontsize=14,fontweight='bold') ax.set_yticklabels(ax.get_yticklabels(),fontsize=14,fontweight='bold')以下蛇足
matplotlib.font_manager.FontEntry.size
[f.size for f in l_hiragino] """ > ['scalable', 'scalable', 'scalable', 'scalable', 'scalable', 'scalable', 'scalable', 'scalable', 'scalable', 'scalable'] """となり全て'scalable'となります。これについては公式doc5に
If size2 (the size specified in the font file) is 'scalable'
という記述があることから、'saclable'であるとは、サイズがフォントファイルによって指定されるものである、ということがわかります。
私の環境でヒラギノ以外のフォントも見てみましたが、全てscalableとなったのであまり良くわかりませんが、太さが指定されるということなのでしょうか…matplotlib.font_manager.FontEntry.stretch
[f.stretch for f in l_hiragino] """ > ['normal', 'normal', 'normal', 'normal', 'normal', 'normal', 'normal', 'normal', 'normal', 'normal'] """ヒラギノでは全てnormalでしたが、condensedになっているものも確認できました。
公式doc5に
The result is the absolute value of the difference between the CSS numeric values of stretch1 and stretch2
とあるので、CSSのfont-stretch6を参照するとフォントの幅を言っているのだと思います。
matplotlib.font_manager.FontEntry.style
[f.style for f in l_hiragino] """ > ['normal', 'normal', 'normal', 'normal', 'normal', 'normal', 'normal', 'normal', 'normal', 'normal'] """これもヒラギノでは全てnormalになりましたが、なかにはitalicになっているものも確認できました。
これは斜体などの書体の情報でしょう。
- 投稿日:2019-12-02T21:21:46+09:00
自然言語処理を始める準備
この記事では,自然言語処理をする時にはこういう作業をするんだよ,というアウトラインを紹介します.
形態素解析
形態素解析というのは,文章を単語に切り刻む作業です.品詞を調べたり,活用形を原形に戻します.例えば「身の丈に合った受験」というフレーズは,こう解析されます.
身の丈 名詞,一般,,,,,身の丈,ミノタケ,ミノタケ
に 助詞,格助詞,一般,,,,に,ニ,ニ
合っ 動詞,自立,,,五段・ワ行促音便,連用タ接続,合う,アッ,アッ
た 助動詞,,,,特殊・タ,基本形,た,タ,タ
受験 名詞,サ変接続,,,,,受験,ジュケン,ジュケン形態素解析にはMeCabを使っています.
https://taku910.github.io/mecab/
これは広く使われていますが,「管理栄養士試験」を「管理/栄養/士/試験」にしてしまうなど必要以上に単語を分割するため,新語や専門用語には弱い面もあります.新語についてはmecab-ipadic-NEologdという頻繁に更新されている辞書が公開されており,MeCabの弱点を補うことができます.
https://github.com/neologd/mecab-ipadic-neologd
わたしはこれ以外に,解析対象の新語辞書をローカルに作成して,いろいろ追加して使っています.精度の高さではJUMAN++も使ってみたいと思っています.
http://nlp.ist.i.kyoto-u.ac.jp/index.php?JUMAN++
「外国人参政権」をMeCabで処理すると,「外国/人参/政権」となりますが,JUMAN++だと「外国人/参政権」と解析します.機械学習で解析の腕を上げることができるのが特徴です.しかしJUMAN++をboostでbuildするところでエラーを解決できず今に至ります.このままMeCabを使うのかなあ.前処理
HTMLタグがついているようなテキストの場合は,タグを除去する必要があります.それ以外にも形態素解析に掛ける前に前処理をしておかないと,頻出キーワードに①やⅰが登場したり,同じ意味の単語が別々に集計されたりしてしまいます.
顔文字
何気に鬼門です.顔文字研究は実は,数十年の歴史がある奥深いものです.興味のある人は,人工知能学会誌 Vol. 32 No. 3 (2017/05)で特集が組まれているので読んでみてください.
https://www.ai-gakkai.or.jp/vol32_no3/
わたしは顔文字辞書を適当に拾って,自分の辞書に付け加えてお茶を濁していますが,カバー率は高くありません.解析対象テキストによっては,顔文字と真っ向から取り組む必要があるかもしれません.正規化
同じ意味の類似した単語が別々に集計されることを防ぐための処理です.
<例>
全角半角,大文字小文字(例: Qiita,QIITA,Qiita,QIITA)
記法を揃える(例: 高3,高3,高校三年生,高三,高三生)
略語を揃える(例: 広大,広島大,広島大学)数字
数字の扱いについては,文書の種類にもよるかもしれません.通常の文脈であれば数値はすべて削除でもいいかもしれません.一方,スポーツの記録など,数字がキーワードになるものは,数字は数字として扱えた場合が良いでしょう.この場合に面倒なのは,MeCabは小数点の入った数字を,整数部・ピリオド・小数部と,それぞれ別の単語に区切ってしまいます.この場合,いっぺん形態素解析を実施した後に,数値を復元するような処理が必要になります.
ストップワードの除去
ストップワードとは,「私」「です」のように,どこの文書にも顔を出すような単語のことです.わたしは,非自立語と,分析対象文書に登場頻度の高い単語を,ストップワードとして解析対象からはずしています.
その他
化学式,数学や物理の公式,URL,商品コードや型番などは,字句解析対象外とした方がよいでしょう.例えばフェノール(C6H5OH)の化学式を単純にMeCabに与えるとこうなってしまいます.
C 名詞,一般,*,*,*,*,*
6 名詞,数,*,*,*,*,*
H 名詞,一般,*,*,*,*,*
5 名詞,数,*,*,*,*,*
OH 名詞,固有名詞,組織,*,*,*,*
これでは全然フェノールと認識できません.また,英文やプログラムコードを日本語と同等の手法で解析しても,意味のないことも多いでしょう.文書のベクトル化
文書に含まれている単語を手掛かりに,文書をベクトル化します(Doc2Vec).
似たような文書であれば,似たようなベクトルになるはずです.
Doc2Vecはgensimというライブラリに含まれています.
https://radimrehurek.com/gensim/いったんベクトルにしてしまえば,似た文書をまとめることも可能です.
似た文書をまとめるには,後述するトピック分析という手法もあります.
トピック分析と,ベクトル化を併用する場合もあります.
このあたりもいろいろ試行錯誤したいところです.トピック分析
形態素解析済みの文書を自動的に分類し,指定したトピック数に分割するものです.
これまたgensimでできてしまいます.gensimおそるべし.
LDA(Latent Dirichlet Allocation):
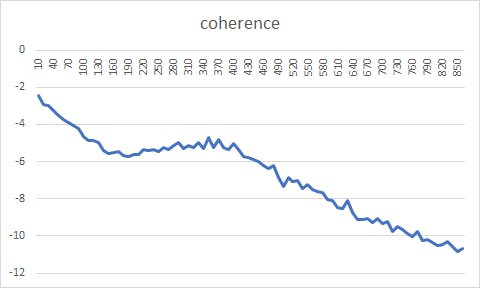
文書群を与えると,指定したトピック群に話題を分割してくれます.問題はいくつに分割したらいいかがわかりにくい.perplexityとかcoherenceとか指標はありますが,使ってみてそれっぽい形になりませんでした.
Rのtopicmodelsパッケージを使ってperplexityとcoherenceを出してみました.
https://cran.r-project.org/web/packages/topicmodels/index.html
文書の量が多すぎたのか,グラフ一本描くのに二週間連続実行しても足りませんでした.
DTM(Dynamic Topic Model):
LDAを拡張し,SNS上の一定期間の話題を解析する場合のように,新しいニュースが飛び込んできて話題が遷移する時に使うモデルです.HDP(Hierarchical Dirichlet Process):
LDAを拡張し,文書をいくつのトピックに分割すればいいかご託宣をくれるはず,なのですが,手持ちのデータセットを食わせたところ,トピックの半分以上が似たり寄ったりの内容で,妥当なトピック分けができていませんでした.BERT
Googleが昨年発表した自然言語処理モデルです。使ってみたいといいつつ,全然調べていません.これから勉強します.

- 投稿日:2019-12-02T20:30:26+09:00
ドローンを活用した避難勧告システム
はじめに
ドローンを使ったシステムの考案をします.実用的な運用を目指したシステムの開発を目指します.ただの提案だとつまらないので実際に動かすところがゴールです.
ドローンで救える命がある背景
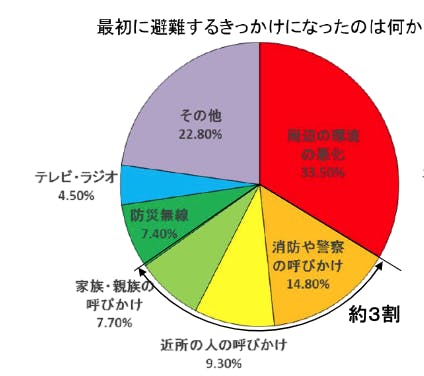
日本における自然災害は年々増加傾向にあり,人的被害や金銭的被害への対策が求められている.また,自宅を安全だと思い込み避難しない人は多く,よりパーソナルに危機感を煽る方法が模索されている.西日本豪雨の被災者310名に行ったNHKのアンケートでは対人的な呼びかけで避難をするきっかけになった人は全体の約3割存在している.
考案システム
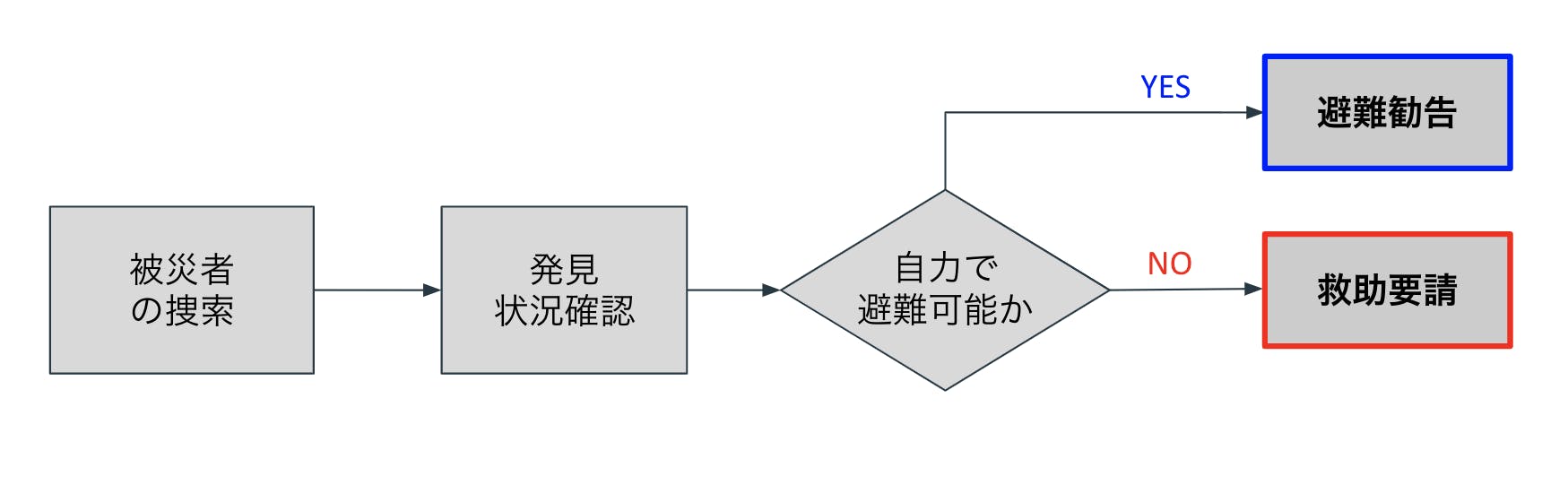
上記のようなドローン巡回システムを考案する. 災害発生後または災害中にドローンは被災者や被災予備軍を捜索する.人を見つけ次第,人と対話し,自力で避難可能かを判断する.対話方法としては音声解析,画像解析,姿勢解析を用いてフィードバックを行う.自力で避難可能な人には避難勧告を行い,身動きがとれない人や高齢者や身体的に不自由な人(避難困難者)には救助要請を行う.
開発環境
macOS Mojave
AWS
Python2系3系
telloドローン
Alexa(スピーカーデバイスがなくてもOK)要件定義
開発にはいくつかのフェーズに分けて行うこととする.(システム要件は今後増やす可能性はあり)
記事の続きとして各リンクを参照すること
0章はおまけ0 . 位置情報から周囲の避難場所を提示するシステムの構築
1 . ドローンの動作をクラウド環境から操作可能なシステムの構築
2 . 人の発声を自然言語処理,意図解釈し,ドローンをフィードバック制御するシステムの構築
3 . 画像解析された人の姿勢などの情報から状態を推定し,通知するシステムの構築
4 .
- 投稿日:2019-12-02T20:29:03+09:00
【写真でわかる】10分で、kaggle初心者が「初期ステータス(novice)」から「Contributor」にランクアップする方法。
kaggleの発言権はステータスに依存する
kaggleではユーザーにランクが付けられています。
Progressionと呼ばれるものです。
進捗レベルというか、称号のようなものです。このランクによって投稿したスクリプトに対する注目度や、発言の影響度合いが異なります。
登録時にはnoviceという称号が与えられ、所定条件を満たすとContributorになり、
そこからより上位ランクになりたい場合は他者からのイイネ評価を集める発言を行う、メダル獲得、等をしていかなければなりません。kaggleは競争型コンペティションであり、ただメダルを集めるだけであれば、ギリギリまで自分の回答を提出せず、他者の試行結果を読み込み、より精度を上げてから投稿するのがいいのですが、
それだけではkaggleが繁栄しません。
kaggleは技術交流の場でもあります。
繁栄ために自分自身の作った回答や、回答に関する解説を投稿するなど、kaggle繁栄に貢献しましょう。
有用な情報を投稿したことでイイネ評価が集まり、自分のランクを上げることができます。まず登録したら初心者noviceのままではつまらないので、Contributorを目指しましょう。
図解でなるべくわかりやすく、Contributorになる方法をまとめました。早速登録
右上に青い登録ボタンがあります。
私は楽なのでgoogleアカウントで結び付けてログインしています。Progression ランクを確認
ランクを確認するには上部タブの・・・上にマウスを置き、Progressionをクリックします。
下にスクロールしていくと、各ランクごとの達成条件が表示されます。
最初はNoviceにチェックマークがついていると思います。
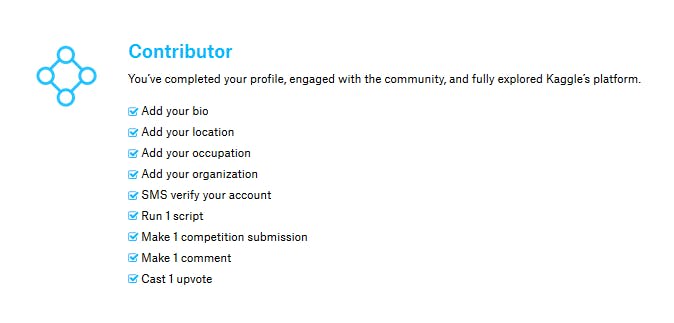
Noviceの達成条件は登録なので、登録した時点でチェックがついています。では今回めざす一つ上位のランクConstributorを見てみましょう。
達成するためのチェック項目は
・bioを更新する
・住んでいる場所を追加
・役職を追加
・組織を追加
・SMS認証を行う
・スクリプトを走らせる
・一つコンペに結果を提出する
・一つコメントを付ける
・いいね評価をひとつ付けるとなっています。
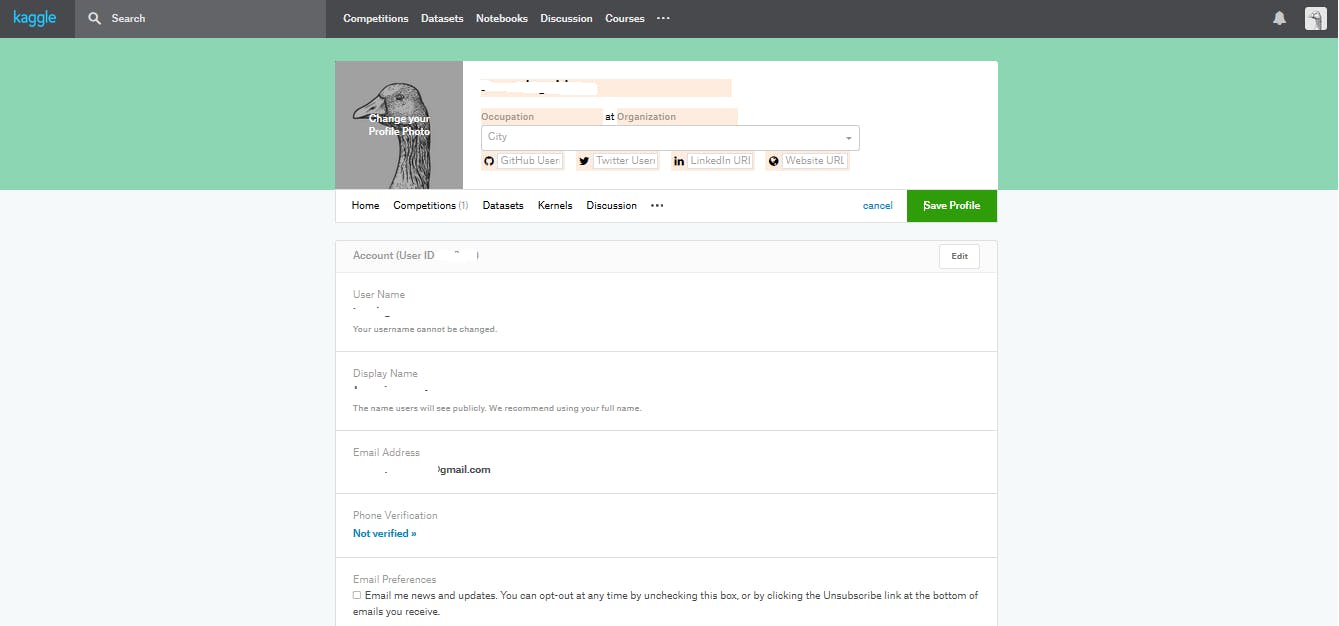
ひとつずつ確認しながらやっていきましょう。bioを更新
そもそもbioって?
biographyの略で、経歴を書く場所だったりしますが自己紹介や趣味など書いている人もいます。初期登録時は右上のログインボタンがあった部分に鳥さんの画像が表示されていると思います。
マウスを鳥さんの上に載せ、「my プロフィール」をクリックすると自分のプロフィール画面へ移動します。
メダルの下にbioが確認できます。
右側のeditをクリックして自己紹介を追加したらOKです。
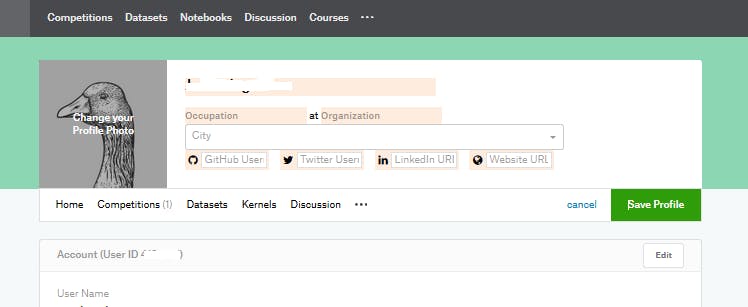
Progressionにチェックがついていると思います。住所・役職・組織を追加
さきほどbioを追加した図の右上に青色のedit profileボタンがあります。
ここを押すと
自分の情報を入力する場所が出てきます。
occupationに役職
organizationに所属組織
cityに住所
を入力しましょう。これでさらに三つチェックが付きました。
ついでにSMS認証もしておきましょう。
少し下にスクロールするとSMSの認証リンクがあります。
認証が済んでいなければNot verifiedになっていると思います。
実際にコンペに提出してみよう
・スクリプトを動かす
・結果を提出する
・コメントを付けるこれを達成していきます。
ここが一番壁に感じるのではないでしょうか?
なんかめんどくさそう?
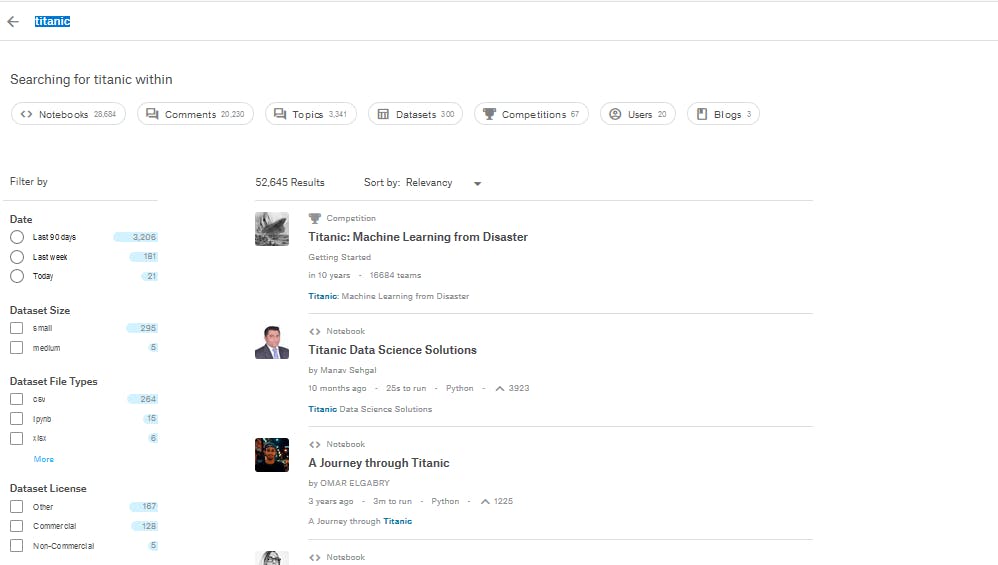
と感じる方のためにこの記事があります。まず上部タブのコンペティションの左に検索マークがあります。
ここでtitanicと入力して検索します。
一番上にトロフィーマークがついている「titanic: Machine Learning from Disaster」というコンペティションが見つかります。
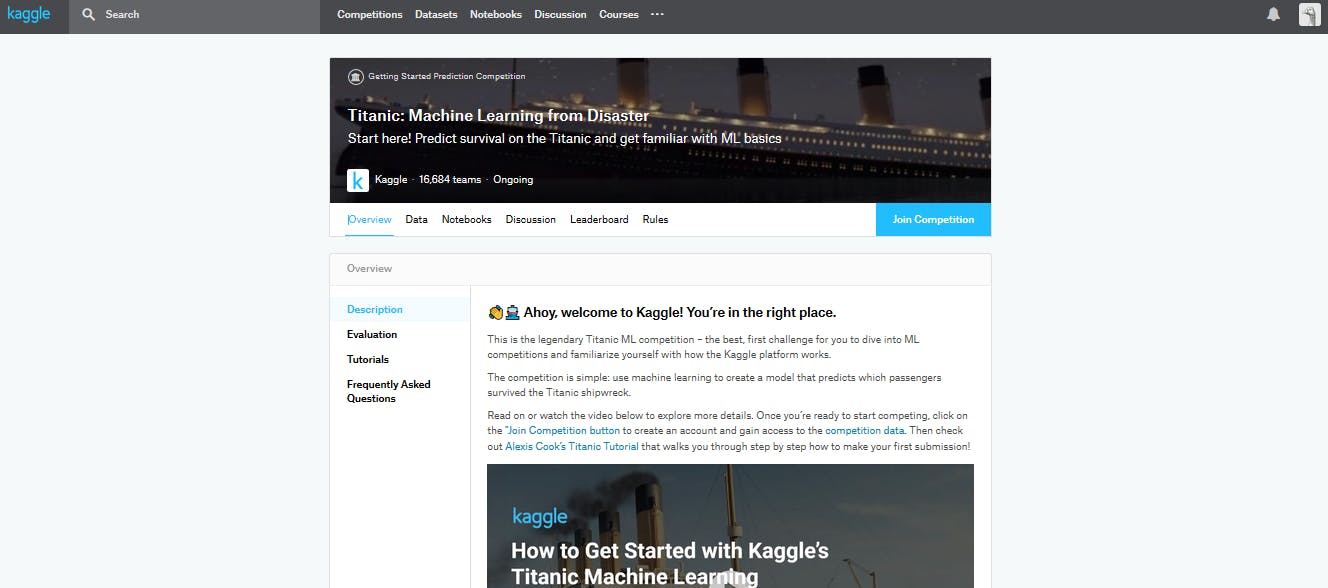
その下の「<>」マークは誰かが記述したスクリプトです。titanicコンペティションを選択してみましょう。
青いボタンでjoin competitionがあるのでjoinします。
規約を読んで同意します。
joinがsubmitというボタンに変化しました。
これでデータを使ってスクリプトを書き、提出することが出来ます。
ボタン押してみましょう。
他の人が書いたスクリプト(note book)が表示されます。
new notebookボタンから新しく自分のスクリプトを作っていきましょう。
どの言語で分析を行うか選択します。
提出形式はnotebookかscriptかを選びます。
説明文をつけ足したり、部分的に実行するならnotebook
言語は好きなものを選択。
今回はpythonでなくRのnotebookにしときましょう。
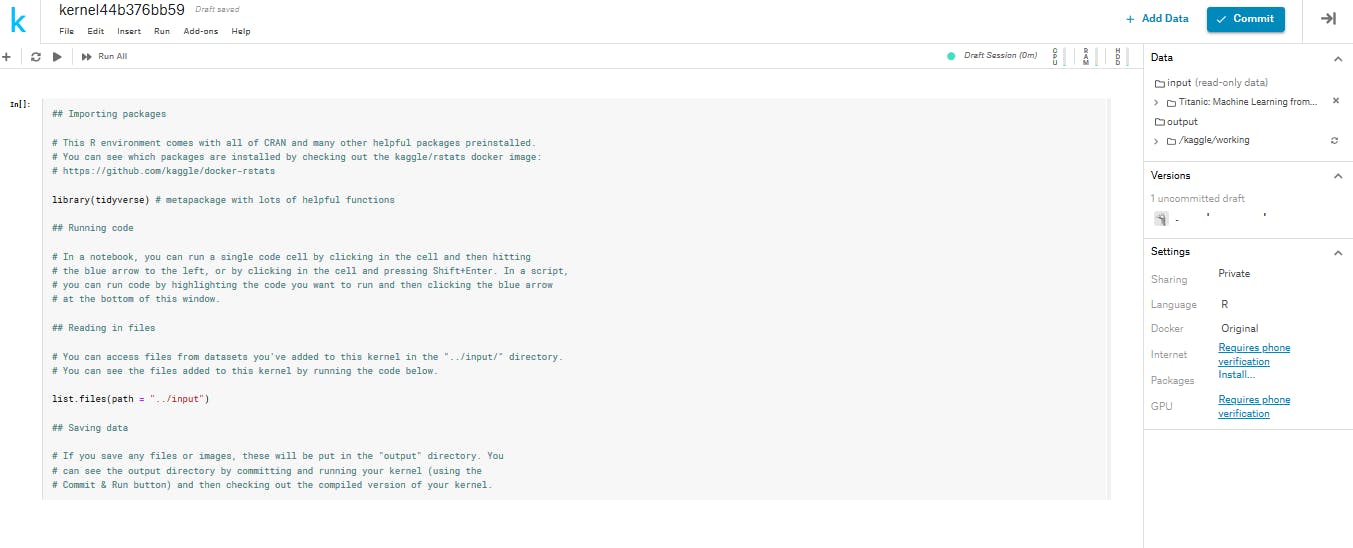
デモコードとしてライブラリの読み込みとかファイルの読み込みとか説明が書いてあります。
とりあえずここはすべて消して以下のように打ち込んでみましょう。
notebookのセルの実行はjupyterと同じくshift + enterです。
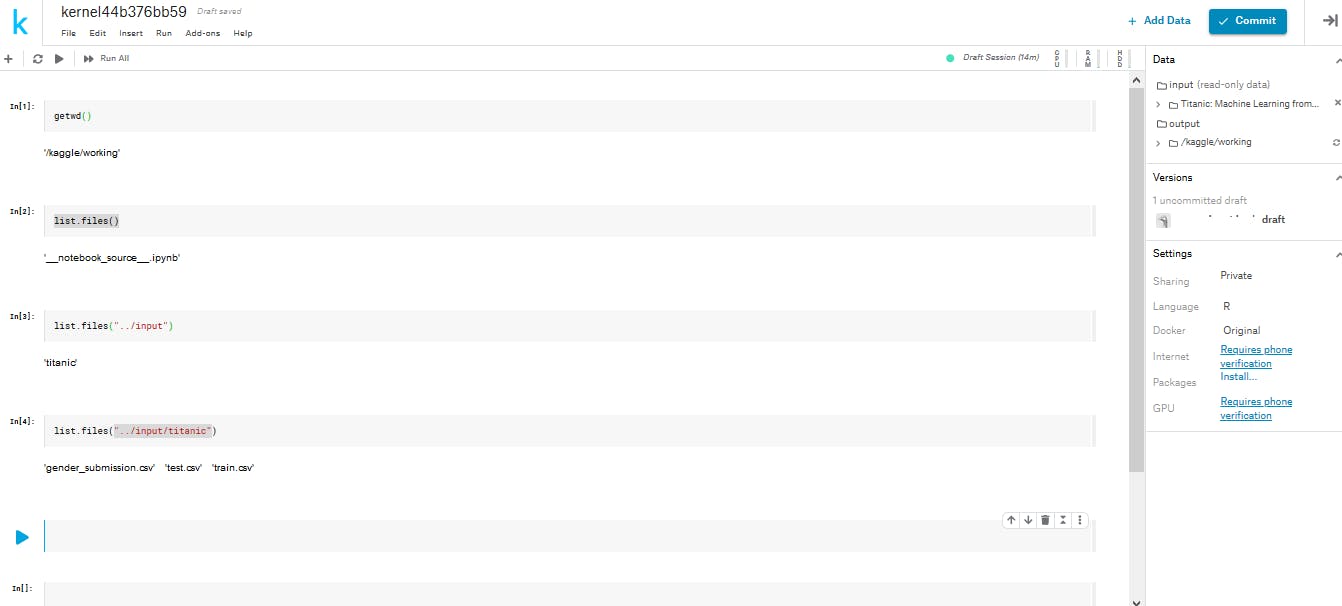
このnotebookの作業ディレクトリはkaggleにあります。
ファイルはコンペティションによって多少違いはありますが「..input」に入っています。
inputの中のファイルを確認してみると、「titanic」というフォルダがありました。
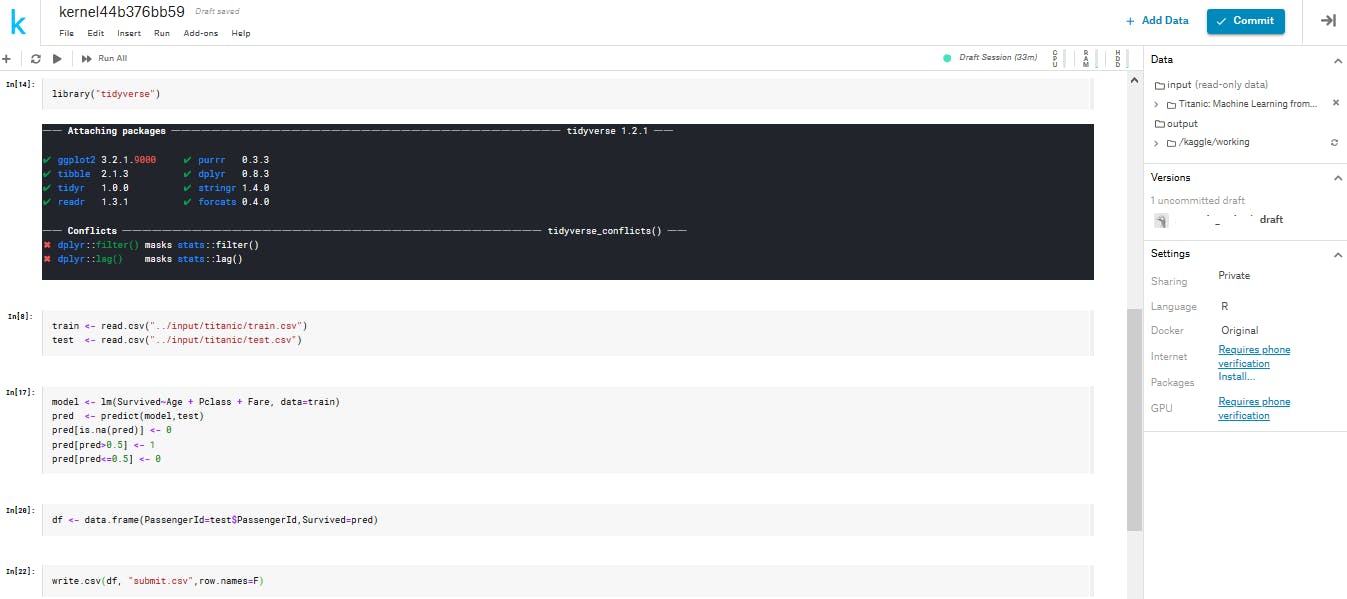
titanicの中をさらに確認してみると3つのファイルがあります。trainで訓練したモデルを使いtestを予測したらいいのです。
testには予想すべき変数"生存したかどうか"の列が抜けています。
これを予測する簡単なモデルを作りましょう。
write.csv関数で予測結果を提出します。予測データに必ず入力しなくてはいけない列名などがあります。
今回は乗客IDが該当します。
またwrite.csvは行名を書きだしてしまうのでエラーの原因になります。オフにしましょう。
作り終わったら右上のコミットボタンを押して提出しましょう。
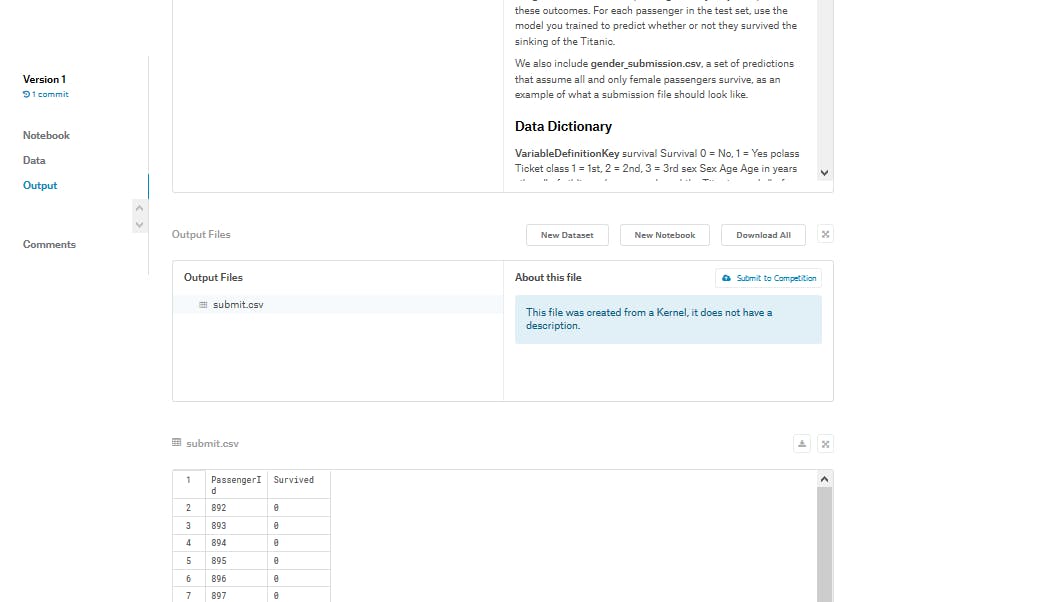
特にエラーが出なければスクリプトが登録できたという事です。
over viewボタンを押して提出しに行きましょう。orver viewで見える自分のスクリプトを下にスクロールしていくと、output filesの部分に自分の作った提出用csv
が確認できると思います。
いよいよ提出です。
completeになったら完了です。
スコアも確認できます。ついでに自分のスクリプトに対して説明文などをコメントしてみましょう。
これでチェックが付きました。
最後の一つ イイネを使う
たとえば上部タブのdiscussionを押すと他の人が自分の書いたスクリプトや技術についての議論をしています。
中をいくつか覗いてみて面白かった内容にイイネしてみましょう。
図中の右上に111という数字がついています。
イイなと思ったら△ボタンを押して支持しましょう。おめでとうございます
以上でランクアップです。
一通りおめでkaggleの使い方を経験したということでランクが上がります。
登録して人のスクリプトを読むだけでなく、自分でコンペティションに参加して、結果を提出することができるようになった証です。お疲れさまでした。
kaggleを楽しんでいきましょう。





- 投稿日:2019-12-02T20:17:24+09:00
Konduit-Servingでかんたんモデルデプロイ
こんにちは、 @kmotohas です。SB-AI Advent Calendar 2019 の2日目、よろしくお願いします。
本稿ではJavaベースの機械学習モデルデプロイツールである Konduit-Serving の紹介をします。
が、実は私、ソフトバンク株式会社公認のクラブ活動である SB AI部 の発起人でして、この団体の紹介や設立の背景から始めようと思います。
SB AI部とは
ソフトバンク株式会社には福利厚生の一環としてクラブ活動をサポートする制度があります。
社内には多数の部活がありますが、大きく分けてスポーツ系、文化系のジャンルがあります。
スポーツ系はイメージしやすいかと思いますが、バスケやフットサルなど、いわゆるクラブ活動感があるラインナップとなっています。
文化系にはテクノロジー企業らしく、ロボットやIoTを扱うPepper部やドローンレースに参加する団体などがあったりします。そこに昨年私が新たに設立したのが SB AI部 という団体です。
専用のSlackワークスペースには2019年12月2日現在568名(アクティブメンバーは160名くらい)のソフトバンク関連企業のメンバーが参加しています。
そちらでAI関連の話題の共有、イベント情報、質問、議論、企画、雑談、希望メンバー同士のシャッフルランチなどなどが行われています。SB AI部設立の背景
ソフトバンク株式会社のテクノロジーユニットではこれまた素敵な Technical Meister という社内認定制度があります。
Yahoo Japanの黒帯制度を参考に設立された制度で、社内に散らばっている技術に強い人にスポット当てるものです。
認定されると年間 ???万円(見せられないよ!)の個人予算が割り当てられ、国際会議やイベントへの参加費や渡航費に用いたり、イベント開催の費用に用いたり、ハイスペックなPCを買ったり、何かしらの発注を行ったりできるわけです。認定される「技術」には様々あり、ネットワーク、5G通信、インフラストラクチャ、ディープラーニング、画像処理、自然言語処理、ロボット制御などの分野でそれぞれ認定されている方がいます。
毎年審査があり、今後ももしかしたら量子コンピューターやブロックチェーンなど、先進的な分野においてTechnical Meister認定される方が出てくるかもしれません。認定されたTechnical Meisterの人々にはある程度社内外発信などの貢献が求められます。
そこで僭越ながらディープラーニング分野のTechnical Meisterとして認定された私はSB AI部を立ち上げたのです。設立以前から全社を上げて"AI"を推進していくというスローガンが掲げられていました。
エンジニアのみならず、経理・事務等バックオフィス系の方々や営業の方々もそれぞれ独自のAI施策を企画・実行していて非常に盛り上がっています。それぞれがそれぞれで頑張っていると多様性が出て色々独創的なアイデアが創出されます。
もちろんこれは素晴らしいことなのですが、どんな分野でも初学者は得てして同じようなところでつまずいたり、疑問を持ったりするものですよね。
そこで、部署横断的にAI関連の話題を扱えるコミュニティスペースを作ったわけです。なお現在部長の座は、学生時代全能アーキテクチャー若手の会副理事をやっていた松岡さんに譲っており、彼がまた精力的に部を盛り上げてくれています。
Twitterなどで有名なコミさんも春から社員となり、きっとまた部の熱量が上がっていくことでしょう。機械学習モデルのデプロイ
導入部分を書いていたら熱中してしまいつい長くなりました。本題に入ります。
近年のディープラーニングの発展には目を見張るものがあります。コンピュータービジョンや自然言語処理、レコメンデーション、自動運転、はたまたゲームの世界などの幅広い領域においてディープラーニングが応用され、華々しい研究成果が毎日のようにニュースとして流れてきています。TensorFlow、Keras、PyTorch、Chainerなど、研究開発向けの優れた Python ベースの開発フレームワークの存在もこの成功の一翼を担ってるかと思います。しかし、ディープラーニングのモデルを本番環境へデプロイする際の方法論にはまだ確固たるものはなく、実務者の方々がそれぞれ試行錯誤しているのが現状です。
と、いきなり引用しましたが、こちらはオライリージャパンの「詳説Deep Learning --- 実務者のためのアプローチ」の監訳者前書きの一説です。拙文です。(ステマ)
近年におけるディープラーニングなど機械学習分野の発達はそれはもう本当に凄まじいことになっており、個人で最新論文を追うのはもはや不可能なレベルになっています。
開発フレームワークとしてはGoogleが開発したTensorFlowが長らく圧倒的人気を誇っていたのですが、FaceBookが開発したPyTorchというフレームワークのユーザーが急増してきて、現在TensorFlowとPyTorchが二大ライブラリとなっています。
出典 https://www.oreilly.com/ideas/one-simple-graphic-researchers-love-pytorch-and-tensorflowただ注意したいのは、ディープラーニングとかいわゆるAIの文脈ではしばしば研究分野と産業分野がごっちゃに語られていることです。
PyTorchは学術研究分野やイノベーター・アーリーアダプター達に広く用いられていますが、産業分野ではまだまだTensorFlowに軍配が上がるようです1。The State of Machine Learning Frameworks in 2019 では、研究者は試行錯誤のしやすさを重視し、産業ではパフォーマンスが重視されると述べています。
また、モデルのデプロイにおける要件について以下のように述べています。
- No Python. Some companies will run servers for which the overhead of the Python runtime is too much to take.
- Mobile. You can’t embed a Python interpreter in your mobile binary.
- Serving. A catch-all for features like no-downtime updates of models, switching between models seamlessly, batching at prediction time, and etc.
企業のシステムをPythonで動かしている事例はまだ全体に比べると少なく、iOSやAndroidアプリのバイナリにPythonインタープリターを組み込むことはできないし、ダウンタイムなしにモデルを切り替えたり、バッチ推論したいという事情があります。
こういった要望に対してTensorFlowは静的なグラフ構築やTensorFlow Lite、TensorFlow Serving (TensorFlow Extended)といったサービスで対応しているのですね。
そもそも「デプロイ」とは
関係あるのかないのか微妙なところですが、学生の頃、捻くれていたので「ソリューション」って言葉が苦手でした。
就活時に企業研究としていろんな会社のホームページを見ていると「○○のソリューション」みたいな何だかよくわからない何も言っていない気がする言葉が並んでいて気色悪く感じたものです。今はもう慣れてむしろソリューションとしか表現できないなって気持ちになっているのですが、「デプロイ」も初めに聞いたとき何のこっちゃよくわかりませんでした。
要するに「システムを利用可能な状態にすること」ですね。Javaで開発したWebアプリケーションをパックしたJARファイルをサーバーに配置することをデプロイと呼んだりするって感じです。
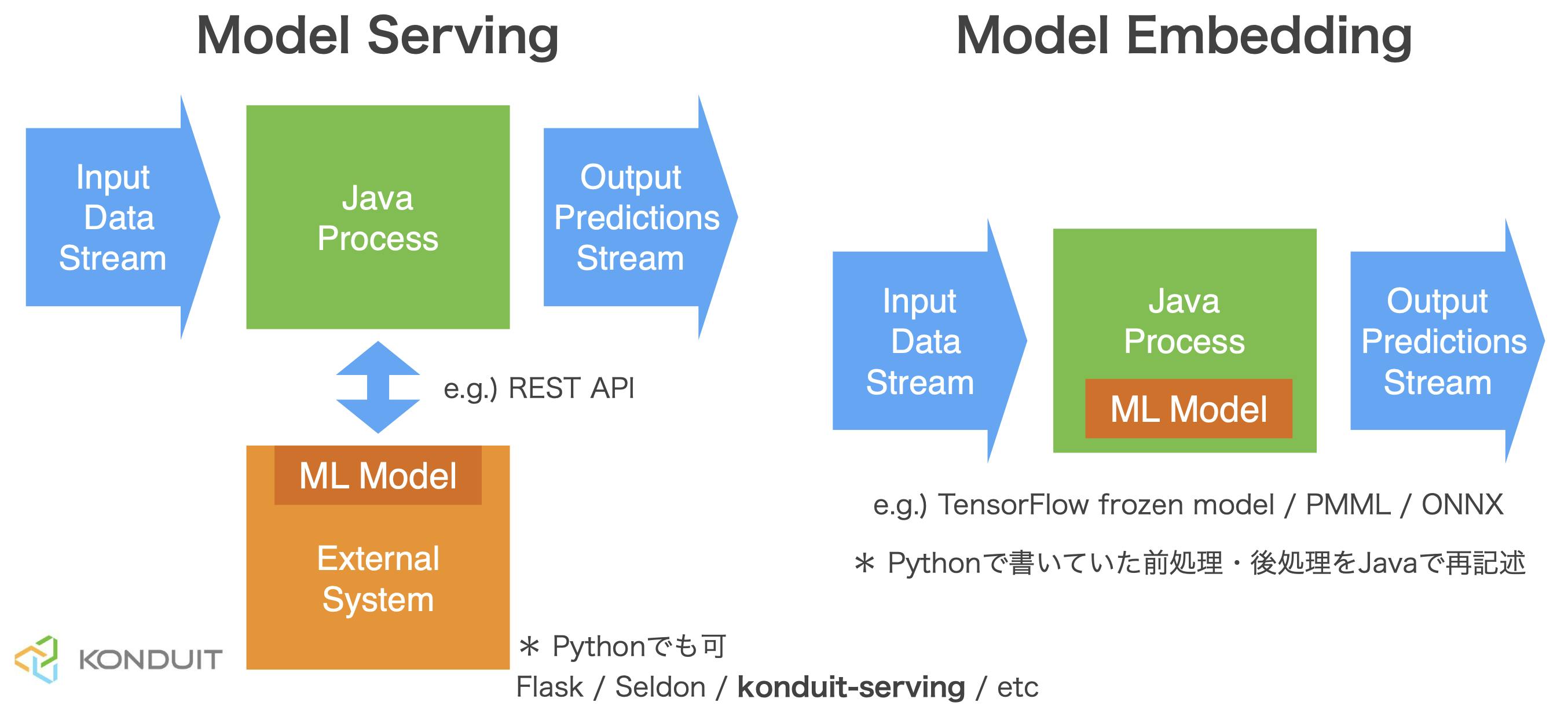
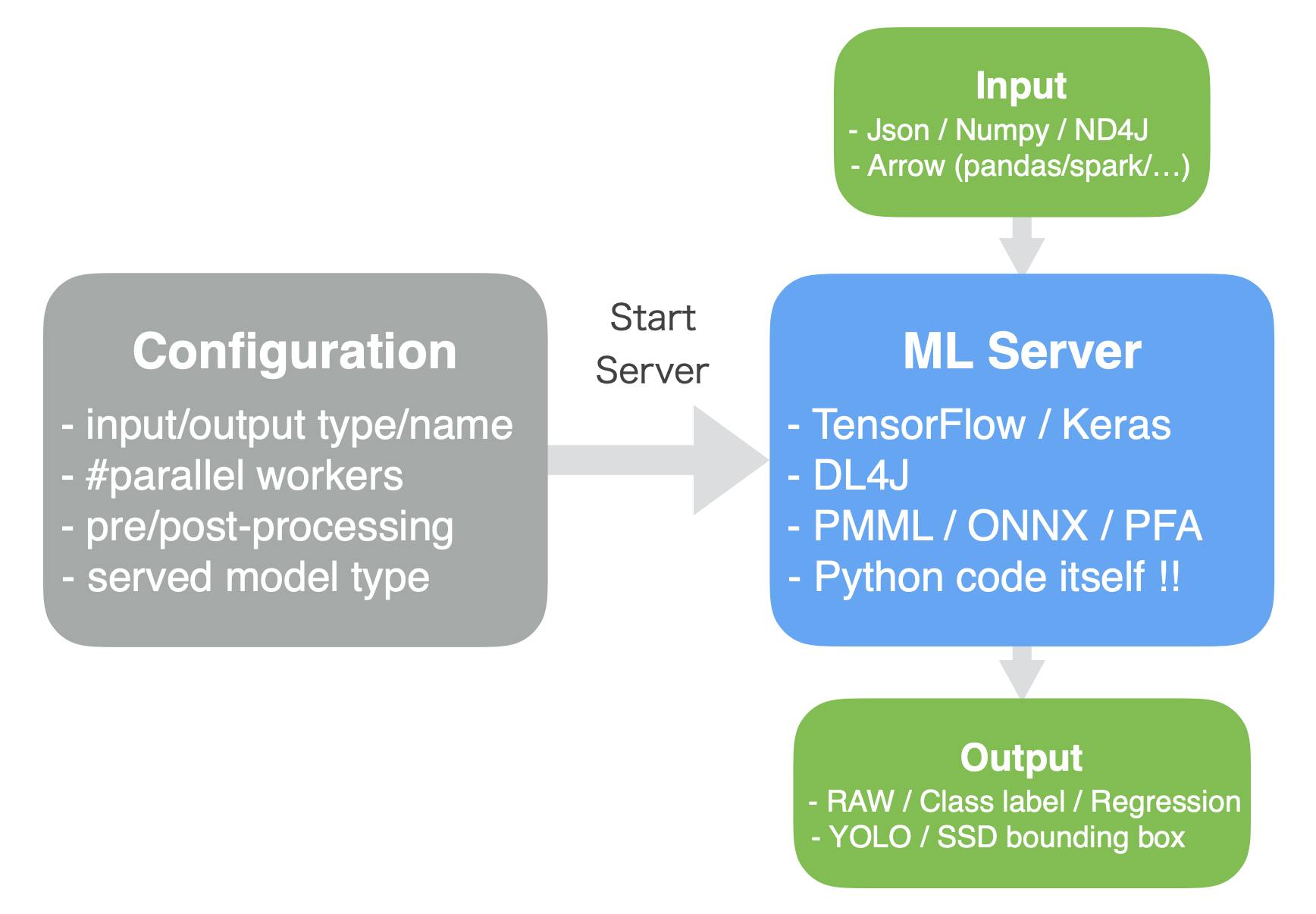
こと機械学習モデルにおいては以下の三つのアプローチがよく用いられています。(参考: Continuously Delivery for Machine Learning)
- モデルの組み込み: 一番単純なアプローチ。指定したモデルを読み込んで利用するコードを直接メインのアプリケーションの中に記述する。
- 外部サービスとしてモデルをデプロイ: メインのアプリケーションとは別のサービス(REST APIなど)としてモデルを配布する。モデルの更新を独立して個別にリリース、バージョニングできる。予測ごとにリモートの呼び出しが必要なので、レイテンシーが発生する可能性あり。
- データとしてモデルを配布: 2番目のアプローチと同様にモデルを独立に扱う。ただし、メインのアプリケーションの実行時にデータとしてモデルをsubscribeする。新しいバージョンのモデルがリリースされたらそのモデルをメモリに読み込んで利用する。
メインのシステムがJavaで記述されていて、そこに機械学習モデルをデプロイするケースを考えます。
1のアプローチが右図で、2のアプローチが左図にあたります。
1のアプローチでは例えばDeeplearning4jなどJavaで開発できるフレームワークで最初からモデル構築したりデータフローを作ったりします。
また、機械学習エンジニアの方々がTensorFlowなどPythonベースのフレームワークで作ったモデルを用いたい場合はTensorFlow for JavaやDeeplearning4j suiteのSameDiffを用いたりしてJavaのオブジェクトに変換します。ただし、モデルがやってくれることはテンソルに変換されたデータを受け取り、推論をし、結果のテンソルを出力することです。
その前後に必要な前処理や後処理は再度Javaで記述し直す必要があります。開発の分業のしやすさやモジュール化(マイクロサービス化)による柔軟性の利点から、感覚的には2のアプローチがよく用いられている気がします。
Javaプロセスの役割はREST APIなどを経由して生データを渡し、結果を受け取ることだけで、前処理や後処理は外部サービスに押し込めることができます。このREST API作成のサポートをしてくれる「ソリューション」のひとつがKonduit-Servingです。
Konduit-Servingとは
Konduit-Servingとは、Deeplearning4j 開発者 Adam Gibson を中心に開発されているJavaベースのオープンソースの機械学習モデルデプロイツールのことです。
TensorFlowやKeras、DL4Jといったフレームワークで作成されたモデルや、PMML、ONNX、PFAといった汎用的なフォーマットのモデルをREST APIとしてデプロイすることができます。
また、面白いのはPythonコードそのものをデプロイできる点です。これについては後述します。Konduit-Servingは主に以下の3つのライブラリをベースに開発されています。
- JavaCPP: C++で書かれたコード (CUDA/TensorFlow/NumPy/etc) のJavaラッパーを作成
- Eclipse Deeplearning4j: JVM用ディープラーニングフレームワーク
- Eclipse Vert.x: イベントドリブンアプリ開発フレームワーク
JavaCPPによりJavaでもCUDAによるGPUアクセラレーションの恩恵を受けることができ、TensorFlowやNumpyなどPython界隈で広く用いられているライブラリをJava上で用いることができます2。
また、Deeplearning4jのツール群を用いてND4JによるJava上での行列計算や、Keras model importの機能を利用しています。
そして、Vert.xベースにノンブロッキングで効率的なスケール性のあるAPIを構築できます。Javaの知識がないと利用できないかというとそういうこともなく、Python SDKが用意されているため、機械学習エンジニアにも安心です。
その他流行りのコンテナオーケストレーターKubernetes統合もサポートされており、PrometheusとGrafanaと連携してパフォーマンスや様々なメトリックのモニタリングも簡単に行うことができます。Java上の組み込みPythonインタープリターを利用してPythonコードそのままデプロイ
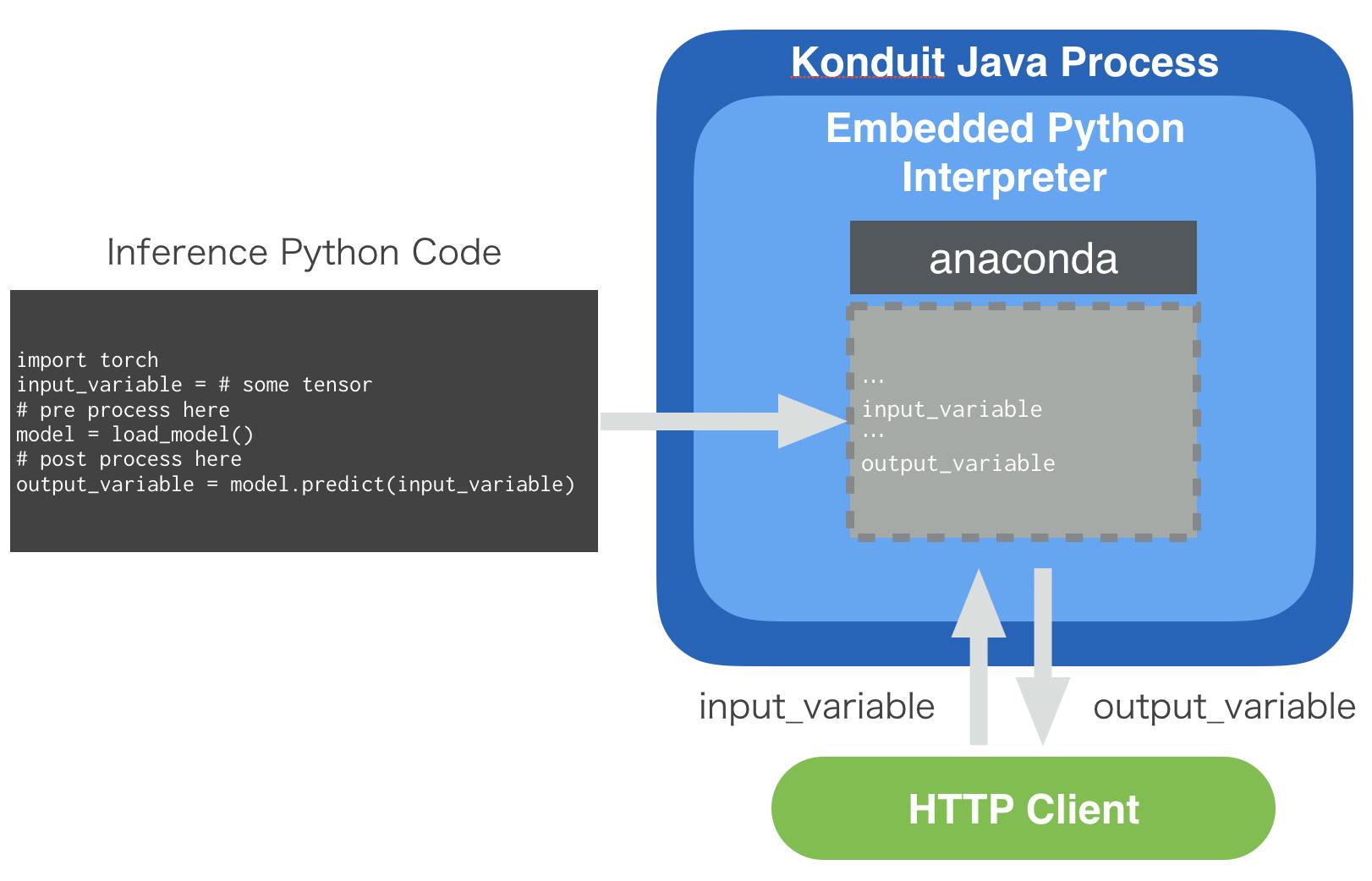
上記の「Pythonコードをそのままデプロイ」の意味を解説します。
Konduit-ServingにはPythonインタープリターが内包されています。
先ほど「Mobile. You can’t embed a Python interpreter in your mobile binary.」と書いたばかりですが、工夫すれば何とかなるのです。
Pythonコードに含まれているオブジェクトはメモリに展開され、そのポインターに直接アクセスすることでゼロコピーでJavaからPythonコードを扱えるようになります。まあ正直私も詳しいところは理解していないのですが、とにかくJava上でPythonを扱うことができるのです。
利用方法としてはKonduit-ServingでデプロイされたPythonコードに対して、HTTPのクライアントから入力データを送信します。
すると同名の変数のポインタが書き換えられ、組み込みのPythonが実行され、結果を格納した変数の中身をクライアントに返します。これの何が嬉しいかというと、機械学習エンジニアの方が実験に用いたコードをプロダクションに流用できるので、コード書き直しの工数を減らすことができるというのと、任意のPythonライブラリを利用できるメリットがあります。
(勘がいい方はお気づきかもしれませんが、Pythonを用いるとGILに囚われてしまい、せっかくのJavaのマルチスレッド性を失ってしまいます。トレードオフということですね。Konduit-Servingを用いてモデルをそのままデプロイする場合はマルチスレッドで高パフォーマンスを発揮できます。)
サンプル: 顔認識モデルのデプロイ
ここではPyTorchで開発された顔認識モデルを用いた推論コードをKonduit-Servingでデプロイするデモを紹介します。
Konduit-Servingのセットアップ
それではKonduit-Servingのセットアップから初めてみましょう。
なお、私は Ubuntu 18.04 (w/o GPU) で検証しました。git、Java Development Kit 8 (1.8)、Javaのビルド管理ツールのMavenが必要です。
まず、Anacondaなどを用いて環境を切ります。Pythonのバージョンは3.7(以上?)が推奨されています。
conda create -n konduit python=3.7 conda activate konduitGitHubからソースコードをクローンし、また、Python SDKをインストールします。
git clone https://github.com/KonduitAI/konduit-serving.git cd konduit-serving/python # conda install cython 必要かも python setup.py install cd ..プロジェクトをビルドし、uber jarファイルを作成します。
konduit init --os <your-platform> # windows-x86_64, linux-x86_64`, linux-x86_64-gpu, # macosx-x86_64, linux-armhf and windows-x86_64-gpu # e.g.) konduit init --os linux-x86_64現在のバージョンでは
~/.konduit/konduit-serving/konduit-serving-uberjar/target/konduit-serving-uberjar-1.2.1-bin.jarに生成されます。
1.2.1の部分はバージョンによります。
ドキュメントには~/.konduit/konduit-serving/konduit.jarにコピーが生成されると書いてありますが、私の環境ではできませんでした。
(すぐ修正されるでしょう。)
以下ではドキュメントに沿った解説をします。今のところはcp ~/.konduit/konduit-serving/konduit-serving-uberjar/target/konduit-serving-uberjar-1.2.1-bin.jar ~/.konduit/konduit-serving/konduit.jarなどしてあげてください。次に、uber jarのパスを環境変数
KONDUIT_JAR_PATHに設定します。echo export KONDUIT_JAR_PATH="~/.konduit/konduit-serving/konduit.jar" >> ~/.bashrc source ~/.bashrc # conda activate konduit し直す必要あるかもこれで準備完了です。
顔認識プロジェクトの準備とREST API化
サンプルが置いてあるディレクトリに移動します。
# konduit-servingのディレクトリにいると仮定 cd python/examples/face_detection_pytorchここで用いるモデルはPytorchで開発された非常に軽量な顔認識モデルです。
コードをクローンし、依存ライブラリをインストールします。git clone https://github.com/Linzaer/Ultra-Light-Fast-Generic-Face-Detector-1MB pip install -r ./Ultra-Light-Fast-Generic-Face-Detector-1MB/requirements.txtこちらのリポジトリで公開されている推論コードはこちらです。
https://github.com/Linzaer/Ultra-Light-Fast-Generic-Face-Detector-1MB/blob/master/detect_imgs.py
このコードではディレクトリを指定するとそこに含まれる画像をモデルに入力し、検出された顔のbounding boxを描画した画像を出力します。
今回のサンプルではもう少し単純なものになっています。
インプットはBase64エンコードされた画像データ、アウトプットは画像から検出された顔の数とします。
上記の推論コードをサンプル用に修正し、簡略化したものがこちらです。
https://github.com/KonduitAI/konduit-serving/blob/master/python/examples/face_detection_pytorch/detect_image.pydetect_image.pyimport os import sys work_dir = os.path.abspath('./Ultra-Light-Fast-Generic-Face-Detector-1MB') sys.path.append(work_dir) from vision.ssd.config.fd_config import define_img_size from vision.ssd.mb_tiny_RFB_fd import create_Mb_Tiny_RFB_fd, create_Mb_Tiny_RFB_fd_predictor from utils import base64_to_ndarray threshold = 0.7 candidate_size = 1500 define_img_size(640) test_device = 'cpu' label_path = os.path.join(work_dir, "models/voc-model-labels.txt") test_device = test_device class_names = [name.strip() for name in open(label_path).readlines()] model_path = os.path.join(work_dir, "models/pretrained/version-RFB-320.pth") net = create_Mb_Tiny_RFB_fd(len(class_names), is_test=True, device=test_device) predictor = create_Mb_Tiny_RFB_fd_predictor(net, candidate_size=candidate_size, device=test_device) net.load(model_path) # The variable "image" is sent from the konduit client in "konduit_server.py", i.e. in our example "encoded_image" image = base64_to_ndarray(image) boxes, _, _ = predictor.predict(image, candidate_size / 2, threshold) # "num_boxes" is then picked up again from here and returned to the client num_boxes = str(len(boxes))大事なのは下記の部分です。
detect_image.py# The variable "image" is sent from the konduit client in "konduit_server.py", i.e. in our example "encoded_image" image = base64_to_ndarray(image) boxes, _, _ = predictor.predict(image, candidate_size / 2, threshold) # "num_boxes" is then picked up again from here and returned to the client num_boxes = str(len(boxes))
imageがクライアントから送信される入力で、num_boxesが出力です。
こちらをKonduit-Servingでデプロイし、クライアントからリクエストを送ってみます。python run_server.pyうまく動作すれば、長々とログやデバッグメッセージが表示されたあと以下のように顔の数(この場合51)が返されます。
... 02:37:13.585 [vert.x-worker-thread-6] INFO a.k.s.executioner.PythonExecutioner - Exec done 02:37:13.586 [vert.x-worker-thread-6] INFO a.k.s.executioner.PythonExecutioner - CPython: PyEval_SaveThread() 02:37:13.586 [vert.x-worker-thread-6] INFO a.k.s.executioner.PythonExecutioner - CPython: PyEval_RestoreThread() 02:37:13.586 [vert.x-worker-thread-6] INFO a.k.s.executioner.PythonExecutioner - temp_27_main.json 02:37:13.586 [vert.x-worker-thread-6] INFO a.k.s.executioner.PythonExecutioner - Executioner output: 02:37:13.586 [vert.x-worker-thread-6] INFO a.k.s.executioner.PythonExecutioner - {"num_boxes": "51"} 02:37:13.586 [vert.x-worker-thread-6] INFO a.k.s.executioner.PythonExecutioner - CPython: PyEval_SaveThread() 02:37:13.586 [vert.x-worker-thread-6] INFO a.k.s.executioner.PythonExecutioner - CPython: PyEval_RestoreThread() 51
run_konduit.pyの中身は以下の通りです。run_konduit.pyfrom konduit import * from konduit.server import Server from konduit.client import Client from konduit.utils import default_python_path import os from utils import to_base_64 # Set the working directory to this folder and register the "detect_image.py" script as code to be executed by konduit. work_dir = os.path.abspath('.') python_config = PythonConfig( python_path=default_python_path(work_dir), python_code_path=os.path.join(work_dir, 'detect_image.py'), python_inputs={'image': 'STR'}, python_outputs={'num_boxes': 'STR'}, ) # Configure a Python pipeline step for your Python code. Internally, konduit will take Strings as input and output # for this example. python_pipeline_step = PythonStep().step(python_config) serving_config = ServingConfig(http_port=1337, input_data_format='JSON', output_data_format='JSON') # Start a konduit server and wait for it to start server = Server(serving_config=serving_config, steps=[python_pipeline_step]) server.start() # Initialize a konduit client that takes in and outputs JSON client = Client(input_data_format='JSON', output_data_format='RAW', return_output_data_format='JSON', host='http://localhost', port=1337) # encode the image from a file to base64 and get back a prediction from the konduit server encoded_image = to_base_64(os.path.abspath('./Ultra-Light-Fast-Generic-Face-Detector-1MB/imgs/1.jpg')) predicted = client.predict({'image': encoded_image}) # the actual output can be found under "num_boxes" print(predicted['num_boxes']) server.stop()今回はBase64エンコードされた画像(
image)をJSONで送って顔の数(num_boxes)をJSONに入れて返すというデモでした。そのため
PythonConfigで入出力の型を'STR'と指定しています。
ServingConfigではフォーマットを'JSON'にしています。参考:
+ PythonConfigで指定できるデータ型のリスト
+ ServingConfigで指定できるデータ型のリスト
server.start()でサーバーを走らせ、REST APIを準備します。
そして、predicted = client.predict({'image': encoded_image})の行でエンコードした画像を'image'という文字列をセットにしてサーバーにPOSTしています。
返ってきた結果のJsonがpredicted変数に格納されます。
print(predicted['num_boxes'])の出力が先ほどの51だったのです。おわりに
いかがでしたでしょうか。
Konduit-Servingはまだ公開されて間もないライブラリですので、変更が多かったりややドキュメントに不整合があったりしますが、デプロイ支援ツールとして可能性があると思っています。
今後また解説記事など公開していくつもりなので乞うご期待。SB-AI Advent Calendar 2019、次回は営業の期待のホープ、那俄牲さんです :)
https://adventar.org/calendars/4324
https://thegradient.pub/state-of-ml-frameworks-2019-pytorch-dominates-research-tensorflow-dominates-industry/ ↩
余談ですが、OpenCVのJavaラッパーであるJavaCVはJavaCPPを用いて移植されています。JavaCPPを用いて移植されたパッケージのプリセットたちはここで公開されています。 ↩


- 投稿日:2019-12-02T20:06:48+09:00
Python初心者がマイクロフレームワークFlaskを使って30秒でHello Worldしてみた
Flaskとは
- PythonのマイクロWebフレームワーク
- 標準で提供されている機能は最小限
- フルスタックフレームワークならDjangoとか
- 参考
about me
Python歴
3日
やった理由
楽しそう
やったこと
①Flaskインストール
pip install Flask②好きなフォルダに
hello.pyを作る
③以下を貼り付けるfrom flask import Flask app = Flask(__name__) @app.route('/') def hello_world(): return "Hello World!" if __name__ == '__main__': app.run()④実行
python hello.py⑤ http://127.0.0.1:5000/ にアクセス
参考
- 投稿日:2019-12-02T20:05:47+09:00
Chalice x Circle CI 環境における CI/CD について
序文
https://chalice.readthedocs.io/en/latest/
AWS Chalice は、AWS Lambda と API Gateway などを組み合わせて、Heroku のような手軽さで Serverless 環境を構築することができるフレームワークです。
現在のところ開発言語は Python しか対応していない(今後も対応する?かは不明)ですが、その制約を受け入れれば他の Serverless フレームワークよりも手軽で開発しやすい環境が提供されているように思います。
私の環境でも、簡易的な API の作成や、バッチ、cron 処理など、かなり広範囲の処理について Chalice を用いて開発をすることが多くなりました。当記事では Chalice でできることの説明は割愛します。
そして、テスト周りについてはすたじおさん (https://qiita.com/studio3104) が記事を書くようなので、私の方では Chalice で開発する際の CI/CD 環境をどのようにするか、自分の実例を基に記事を書きたいと思います。
なお、ここでは、使用する CI 環境はCircle CIとします。いくつかのテーマがありますが、ここでは以下のテーマについて記述します。
- monorepo 対応
- unit test / code coverage
- lint / code smells
- chalice 設定ファイルの validation
- 脆弱性診断
- auto deploy
monorepo 対応 (プロジェクトごとの差分チェック)
chalice は、作成したい機能ごとに
chalice new-project sadaのような形でプロジェクトの scaffold を作成し、開発をしていくスタイルになります。
プロジェクトごとに GitHub などのリポジトリを作成していくと細分化が激しくなります。なので monorepo 構成にしたいのですが、かといって単純にひとつのリポジトリに複数のプロジェクトを入れると、CI/CD の際に一部のプロジェクトの修正の際に全部のプロジェクトのテストや検証、デプロイが走ったりしがちで、CI/CDの速度が低下します。なので、基本的な戦略としては、
GitHub リポジトリの中で変更があったプロジェクトに対してのみ CI/CDを実施するという形を取りたいです。こちらの実現の際に、以下のブログの内容を参考にしました。GitHub の Head の内容と比較して、差分があるかどうかを判別するスクリプトです。
https://blog.hatappi.me/entry/2018/10/08/232625$ cat tools/is_changed #!/bin/bash if [ "${CIRCLE_BRANCH}" = "master" ]; then DIFF_TARGET="HEAD^ HEAD" else DIFF_TARGET="origin/master" fi DIFF_FILES=(`git diff ${DIFF_TARGET} --name-only --relative=${1}`) if [ ${#DIFF_FILES[@]} -eq 0 ]; then exit 1 else exit 0 fiこのような形でスクリプトを用意し、CI/CD の際にチェックしたい Chalice プロジェクトを当該スクリプトの引数にわたすことでプロジェクトごとに差分チェックが行え、差分が無いプロジェクトはスキップし差分があるものだけ後続の CI 処理を実施する、ということが実現できます。
$ cat tools/echo_changed for dir in ${PROJECTS}; do \ if ${WORKDIR}/is_changed "${dir}"; then echo "changed." else echo "nothing change." fi doneunit test / code coverage
テストの書き方などについては、すたじおさんが詳細に記載をされてると思うのでここでは詳細は割愛します。
私の環境では、
coverageとpytestを組み合わせて実施をしています。unittestの実施と、その結果としてどの程度 Test Coverage が達成されているかの測定を実施しています。$ coverage run -m pytest $ coverage reportName Stmts Miss Cover --------------------------------------- app.py 35 22 37% tests/__init__.py 0 0 100% tests/conftest.py 4 0 100% tests/test_app.py 5 0 100% --------------------------------------- TOTAL 44 22 50%unit テストがある環境で coverage を動作させると、上記のようなレポートを出力することができます。
レポートの内容については、HTML リポートを Circle CI の Artifacts として保存して CI 結果画面から確認することができます。- run: name: Run Tests command: | $HOME/.local/bin/coverage run -m pytest $HOME/.local/bin/coverage report $HOME/.local/bin/coverage html # open htmlcov/index.html in a browser - store_artifacts: path: htmlcov詳しい設定等については以下の公式ドキュメントを参照ください。
https://circleci.com/docs/2.0/code-coverage/#python
また、特定のカバレッジ率を下回った際にテストを止めたい場合は、
coverage report --fail-number [num]とすると、カバレッジが数値以下の場合にreturn code = 2が返却されます。
つまり、しきい値を満たさない時に CI を止めることができます。この辺の処理を shell として書くと以下のようになります。一通り monorepo 中のすべてのプロジェクトのうち、何かしら差分があるものついて unitetest / coverage 測定を実施し、テストが fail になるかひとつでも coverage がしきい値以下のものがあると、CI が止まります。
$ cat tools/coverage ret=0 for dir in ${PROJECTS}; do if ${WORKDIR}/is_changed "${dir}"; then cd ${WORKDIR}/../${dir}/ sudo pip install -r requirements.txt coverage run -m pytest coverage report --fail-under=${THRESHOLD} r=$? coverage html -d ../htmlcov/${dir} if [ $r != 0 ]; then ret=$r; fi else echo "nothing change." fi done exit $retlint / code smells
テストやカバレッジ測定だけでなく、Lint ツールや Code Smells ツールを使って、ヒューリスティックに 「あまり良くない書き方」 の箇所を特定することも CI/CD のフローではよく実施されています。
こちらについても詳細は割愛しますが、私の環境では
pep8 (pycodestyle)とpyflakesを組み合わせて実施します。
いずれのツールも、指摘事項がある際はreturn code = 1になるので、必要に応じて CI のハンドリングを行います。以下は pyflakes の結果サンプルですが、以下のケースでは
sadaという変数が宣言されているが使われていない、といったことが指摘されています。$ pyflakes app.py app.py:32: local variable 'sada' is assigned to but never usedただ、いずれも、初期設定のまま実施するとかなり細かく指摘事項を挙げてくるので、環境に応じて設定ファイルを記述して ignore する、もしくは環境に応じてルールを記述するのが現実的な運用だと思います。
この辺の処理を shell として書くと以下のようになります。
$ cat tools/lint ret=0 for dir in ${PROJECTS}; do if ${WORKDIR}/is_changed "${dir}"; then cd ${WORKDIR}/../${dir}/ sudo pip install -r requirements.txt pep8 ${WORKDIR}/../${dir}/*.py --config ${WORKDIR}/../.config/pep8 pyflakes ${WORKDIR}/../${dir}/*.py r=$? if [ $r != 0 ]; then ret=$r; fi else echo "nothing change." fi done exit $retchalice 設定ファイルの validation
上述の内容で、一般的な CI は実施できていると思いますが、chalice の場合それぞれの stage ごとに設定ファイル (config.json, deployed/) を用意する必要があり、その設定ファイルの妥当性も検証をしたいところです。
一番手軽な方法として、CI/CD の際に
chalice packageコマンドを実行し、ただしく chalice を Packaging できるかどうかを確認することで設定ファルの妥当性を簡易的に確認することができます。$ cat tools/package for dir in ${PROJECTS}; do if ${WORKDIR}/is_changed "${dir}"; then cd ${WORKDIR}/../${dir}/ sudo pip install -r requirements.txt chalice package /tmp/${CIRCLE_SHA1} else echo "nothing change." fi done脆弱性診断
昨今はアプリケーションのセキュリティについてセンシティブな事案も多いため、できる限り不安のあるコードをアプリケーションに紛れ込ませたくありません。
そのため使用しているライブラリなどに脆弱性が含まれているものがないか、CI のタイミングで都度確認したいところです。いくつかソリューションがあるとは思いますが、ここでは snyk (https://snyk.io/) というセキュリティベンチャー企業のサービスを使用します。
snyk はソースコードの vulunability chek (脆弱性診断) を行ってくれる機能を提供する SaaS です。様々な言語に対応していますが、もちろん Chalice で使用する Python も対応しています。
基本的にrequirements.txtの中身をみて使用ライブラリを把握し、脆弱性データベースに含まれるバージョンのライブラリが含まれていないかどうかをチェックします。GitHub との連携が用意な事もあり、 CI のフローに組み込みやすいのが特徴です。
public な OSS であれば無制限、Private リポジトリでも 200 テストまでは無料で使用することもできます。
https://snyk.io/plans/snyk は circle.yml に定義を書くというより、GitHub と連携設定を行う形になります。細かい設定方法などは公式ドキュメントに譲ります。
https://snyk.io/docs/github/auto deploy
最後に、CI/CD の CD の部分について。
chalice はchalice deployといったコマンドで簡単にデプロイ作業が行えるため、CI の結果問題がなかったソースを自動デプロイすることは容易です。以下は、差分があったプロジェクトのみ最新の状態に
chalice deployする処理を shell で書いたものです。$ cat tools/deploy for dir in ${PROJECTS}; do \ echo "${WORKDIR}/../${dir}/" if ${WORKDIR}/is_changed "${dir}"; then cd ${WORKDIR}/../${dir}/ sudo pip install -r requirements.txt AWS_ACCESS_KEY_ID=${AWS_ACCESS_KEY_ID} AWS_SECRET_ACCESS_KEY=${AWS_SECRET_ACCESS_KEY} chalice deploy --stage ${STAGE} else echo "nothing change." fi doneCI ツールで本番環境への自動デプロイを行うかは、議論が分かれるところかなとは思います。
(私の環境では本番環境への自動デプロイは実施せず、検証環境のみにすることが多いです)まとめにかえて
AWS Chalice は、Python 限定ではありますが Heroku のような形で手軽に Serverless な処理を書けるフレームワークで、普通のアプリケーションのように Lambda の処理を書けるのが利点だと思います。
そして、その利点があるため、Lambda のような Serverless 環境であっても上述のような CI/CD のフローに組み込む事も容易です。ということで、みなさんも Chalice を使いましょう。
Happy Chalice Life and Serverless Life!!
- 投稿日:2019-12-02T20:04:38+09:00
Optunaを使って関数最適化をしてみよう
はじめに
Optunaはハイパーパラメータの自動最適化フレームワークです。主に機械学習のハイパーパラメータチューニングのために使用されるようです。
公式ホームページ準備
まずはライブラリをインストールしましょう。
pip install optunaでインストールできます。実験
今回は
x^2+y^2+z^2の最小化問題を最適化しましょう。
目的関数の定義
はじめに目的関数を定義します。
# 目的関数を設定(今回はx^2+y^2+z^2) def objective(trial): # 最適化するパラメータを設定 param = { 'x': trial.suggest_int('x', -100, 100), 'y': trial.suggest_int('y', -100, 100), 'z': trial.suggest_int('z', -100, 100) } # 評価値を返す(デフォルトで最小化するようになっている) return param['x'] ** 2 + param['y'] ** 2 + param['z'] ** 2最適化実行
はじめにstudyオブジェクトを生成した後、最適化を実行していきます。
optimze()の引数であるn_trialsで探索回数を設定できます。# studyオブジェクト生成 study = optuna.create_study() # 最適化実行 study.optimize(objective, n_trials=500)実行すると、以下のような表示がされます。(一部抜粋)
[I 2019-12-01 23:01:21,564] Finished trial#381 resulted in value: 121.0. Current best value is 4.0 with parameters: {'x': 0, 'y': 0, 'z': 2}. [I 2019-12-01 23:01:21,705] Finished trial#382 resulted in value: 56.0. Current best value is 4.0 with parameters: {'x': 0, 'y': 0, 'z': 2}. [I 2019-12-01 23:01:21,866] Finished trial#383 resulted in value: 88.0. Current best value is 4.0 with parameters: {'x': 0, 'y': 0, 'z': 2}. [I 2019-12-01 23:01:22,012] Finished trial#384 resulted in value: 104.0. Current best value is 4.0 with parameters: {'x': 0, 'y': 0, 'z': 2}. [I 2019-12-01 23:01:22,170] Finished trial#385 resulted in value: 426.0. Current best value is 4.0 with parameters: {'x': 0, 'y': 0, 'z': 2}. [I 2019-12-01 23:01:22,361] Finished trial#386 resulted in value: 5249.0. Current best value is 4.0 with parameters: {'x': 0, 'y': 0, 'z': 2}. [I 2019-12-01 23:01:22,523] Finished trial#387 resulted in value: 165.0. Current best value is 4.0 with parameters: {'x': 0, 'y': 0, 'z': 2}. [I 2019-12-01 23:01:22,684] Finished trial#388 resulted in value: 84.0. Current best value is 4.0 with parameters: {'x': 0, 'y': 0, 'z': 2}.最適化されたパラメータを確認したい場合は以下を加えましょう。
print(study.best_params)最適化された目的関数値を確認したい場合は以下を加えましょう。
print(study.best_value)また各試行を確認したい場合は, study.trialsから情報を取り出します. 以下のコードで試行回数, パラメータ, 目的関数値を表示することができます.
for i in study.trials: print(i.number, i.params, i.value)コード
今回使用したコードを載せておきます.
# -*- coding: utf-8 -*- import optuna import matplotlib.pyplot as plt # 目的関数を設定(今回はx^2+y^2+z^2) def objective(trial): # 最適化するパラメータを設定 param = { 'x': trial.suggest_int('x', -100, 100), 'y': trial.suggest_int('y', -100, 100), 'z': trial.suggest_int('z', -100, 100) } # 評価値を返す(デフォルトで最小化するようになっている) return param['x'] ** 2 + param['y'] ** 2 + param['z'] ** 2 if __name__ == '__main__': # studyオブジェクト生成 study = optuna.create_study() # 最適化実行 study.optimize(objective, n_trials=500) epoches = [] # 試行回数格納用 values = [] # best_value格納用 best = 100000 # 適当に最大値を格納しておく # best更新を行う for i in study.trials: if best > i.value: best = i.value epoches.append(i.number+1) values.append(best) # グラフ設定等 plt.plot(epoches, values, color="red") plt.title("optuna") plt.xlabel("trial") plt.ylabel("value") plt.show()結果
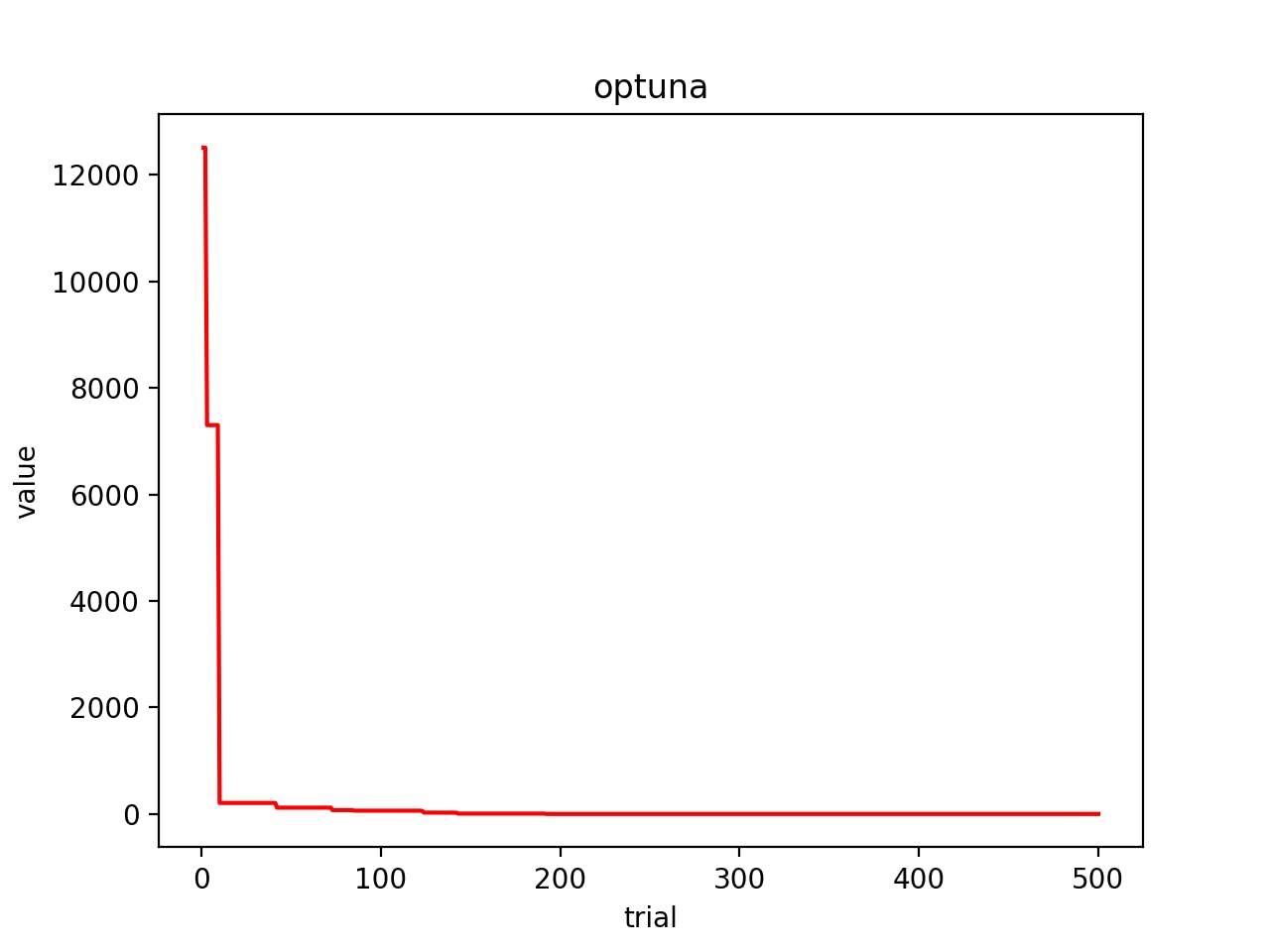
今回の実験結果の図は以下のようになりました.
best_valueの値は3.0でしたので真の最適解には達しませんでしたが, 早い段階で収束してきていることが確認できました。
- 投稿日:2019-12-02T20:04:38+09:00
Optunaを使って関数最適化をしてみる
はじめに
Optunaはハイパーパラメータの自動最適化フレームワークです。主に機械学習のハイパーパラメータチューニングのために使用されるようです。
公式ホームページ準備
まずはライブラリをインストールしましょう。
pip install optunaでインストールできます。実験
今回は
x^2+y^2+z^2の最小化問題を最適化しましょう。
目的関数の定義
はじめに目的関数を定義します。
# 目的関数を設定(今回はx^2+y^2+z^2) def objective(trial): # 最適化するパラメータを設定 param = { 'x': trial.suggest_int('x', -100, 100), 'y': trial.suggest_int('y', -100, 100), 'z': trial.suggest_int('z', -100, 100) } # 評価値を返す(デフォルトで最小化するようになっている) return param['x'] ** 2 + param['y'] ** 2 + param['z'] ** 2最適化実行
はじめにstudyオブジェクトを生成した後、最適化を実行していきます。
optimze()の引数であるn_trialsで探索回数を設定できます。# studyオブジェクト生成 study = optuna.create_study() # 最適化実行 study.optimize(objective, n_trials=500)実行すると、以下のような表示がされます。(一部抜粋)
[I 2019-12-01 23:01:21,564] Finished trial#381 resulted in value: 121.0. Current best value is 4.0 with parameters: {'x': 0, 'y': 0, 'z': 2}. [I 2019-12-01 23:01:21,705] Finished trial#382 resulted in value: 56.0. Current best value is 4.0 with parameters: {'x': 0, 'y': 0, 'z': 2}. [I 2019-12-01 23:01:21,866] Finished trial#383 resulted in value: 88.0. Current best value is 4.0 with parameters: {'x': 0, 'y': 0, 'z': 2}. [I 2019-12-01 23:01:22,012] Finished trial#384 resulted in value: 104.0. Current best value is 4.0 with parameters: {'x': 0, 'y': 0, 'z': 2}. [I 2019-12-01 23:01:22,170] Finished trial#385 resulted in value: 426.0. Current best value is 4.0 with parameters: {'x': 0, 'y': 0, 'z': 2}. [I 2019-12-01 23:01:22,361] Finished trial#386 resulted in value: 5249.0. Current best value is 4.0 with parameters: {'x': 0, 'y': 0, 'z': 2}. [I 2019-12-01 23:01:22,523] Finished trial#387 resulted in value: 165.0. Current best value is 4.0 with parameters: {'x': 0, 'y': 0, 'z': 2}. [I 2019-12-01 23:01:22,684] Finished trial#388 resulted in value: 84.0. Current best value is 4.0 with parameters: {'x': 0, 'y': 0, 'z': 2}.最適化されたパラメータを確認したい場合は以下を加えましょう。
print(study.best_params)最適化された目的関数値を確認したい場合は以下を加えましょう。
print(study.best_value)また各試行を確認したい場合は, study.trialsから情報を取り出します. 以下のコードで試行回数, パラメータ, 目的関数値を表示することができます.
for i in study.trials: print(i.number, i.params, i.value)コード
今回使用したコードを載せておきます.
# -*- coding: utf-8 -*- import optuna import matplotlib.pyplot as plt # 目的関数を設定(今回はx^2+y^2+z^2) def objective(trial): # 最適化するパラメータを設定 param = { 'x': trial.suggest_int('x', -100, 100), 'y': trial.suggest_int('y', -100, 100), 'z': trial.suggest_int('z', -100, 100) } # 評価値を返す(デフォルトで最小化するようになっている) return param['x'] ** 2 + param['y'] ** 2 + param['z'] ** 2 if __name__ == '__main__': # studyオブジェクト生成 study = optuna.create_study() # 最適化実行 study.optimize(objective, n_trials=500) epoches = [] # 試行回数格納用 values = [] # best_value格納用 best = 100000 # 適当に最大値を格納しておく # best更新を行う for i in study.trials: if best > i.value: best = i.value epoches.append(i.number+1) values.append(best) # グラフ設定等 plt.plot(epoches, values, color="red") plt.title("optuna") plt.xlabel("trial") plt.ylabel("value") plt.show()結果
今回の実験結果の図は以下のようになりました.
best_valueの値は3.0でしたので真の最適解には達しませんでしたが, 早い段階で収束してきていることが確認できました。
- 投稿日:2019-12-02T20:02:54+09:00
python でdbの標準ドライバを作る話。
概要
DB系のプロダクト開発でバックエンドがほぼほぼ完成した際に、
pythonやjavaで標準的に使われている形のドライバをラッパーとして用意し、ユーザの使いやすさを向上したいと考えました。javaはまだ書いたことないので勉強が必要ですが、まずはpythonでラッパーを書くことになり、標準のドライバーの仕様について勉強し、実装の流れについてまとめてみます。
参考文献
- python の Mysql用のドライバ
- python のdb APIの仕様
内容
今回ナイーブながら実装してみたものをまとめると、以下になります。
- Our_Api クラス
- Connection クラス
- Cursor クラス
- Error クラス
- Type クラス
コード的には、われわれのドライバをつかって
main.py#!/usr/bin/python import MySQLdb # Open database connection db = MySQLdb.connect("localhost","testuser","test123","TESTDB" ) # prepare a cursor object using cursor() method cursor = db.cursor() # execute SQL query using execute() method. cursor.execute("SELECT VERSION()") # Fetch a single row using fetchone() method. data = cursor.fetchone() print "Database version : %s " % data # disconnect from server db.close()みたいなことがしたいわけです。
ここでの
MySQLdbが自分たちの提供するドライバのライブラリになって、
MySQLdbがConnectionクラスのオブジェクトを必要な設定変数とともに作ります。
また、ConnectionクラスはCursorクラスのオブジェクトを生成します。
Cursorクラスのはcursor.execute()とか、cursor.fetchone()のようなメソッドを持ち、
渡されたSQLの結果が格納されますし、それらの結果にアクセスして見ることができます。また、Insert や Updateなどが行われるときは、
main.py#!/usr/bin/python import MySQLdb # Open database connection db = MySQLdb.connect("localhost","testuser","test123","TESTDB" ) # prepare a cursor object using cursor() method cursor = db.cursor() # Prepare SQL query to INSERT a record into the database. sql = """INSERT INTO EMPLOYEE(FIRST_NAME, LAST_NAME, AGE, SEX, INCOME) VALUES ('Mac', 'Mohan', 20, 'M', 2000)""" try: # Execute the SQL command cursor.execute(sql) # Commit your changes in the database db.commit() except: # Rollback in case there is any error db.rollback() # disconnect from server db.close()のようにして、
db.coimmit()すなわちconnectionクラスのcommit()メソッドを呼ぶことで変更したオペレーションを実際にDBに反映させ、もし戻したいと成った場合にはdb.rollback()などのメソッドで元に戻すことができます。また、
Errorクラスはエラーのハンドリングを指定された形で行うために実装されます。
さらに、Typeクラスは、仮にDB操作のバックエンドがPython以外で書かれていた場合など、戻ってくるデータ型を的確にpythonの対応するデータ型に変更する際に使われます。以上を踏まえて実装したものを簡単にまとめて紹介します。
実装
メインディレクトリでの
tree .の結果は
. ├── api_core │ ├── api_connection.py │ ├── api_cursor.py │ ├── api_error.py │ ├── api_type.py │ ├── __init__.py │ └── our_api.py ├── main.py └── requirements.txtのように成っています。
api_connection.pyfrom .api_cursor import Cursor class Connection: ''' Connection class class member: api_host: str api_port: int e.g) http://{api_host}:{api_port} class method: cursor: returns Cursor class object close: call destructor to delete the class object itself ''' def __init__(self, proxy_conf_dict = None, proxy_conf_file=None): if proxy_conf_dict: self.api_host = proxy_conf_dict['api_host'] self.api_port = proxy_conf_dict['api_port'] self.proxy_conf_dict = proxy_conf_dict def __del__(self): pass def cursor(self): return Cursor(self.proxy_conf_dict) def close(self): self.__del__()api_cursor.pyimport requests import json from .api_type import Type, Type_Enum class Cursor: def __init__(self, proxy_conf_dict=None): ''' Cursor class class member: result: list of retrieved records (list of dictionary) type_dict: dict of (telling which column is datetime, time or date) conf_dict: dict of (host and port) index which: integer telling where cursor points to query_execute_que: list of raw_query (query not related to select statement and they will be sent when connection.commit) class method: execute: params(raw_query:str) update self.result and self.type_dict commit: params() send post request for "not" select statement fetchone: params() return self.result(self.index) fetchall: params() return self.result next: params() increment self.index by one previous: params() increment self.index by minus one ''' # Cursor contains followings self.result = None self.type_dict = None self.proxy_conf_dict = None self.index = 0 self.query_execute_que = [] if conf_dict is not None: self.conf_dict = conf_dict def execute(self, raw_query:str): # execute function # sends query by post request to proxy, when sql is select statement # if not select statement, store the sql to self.query_execute_que if self.__parse_query_select_or_not(raw_query): url = f'http://{self.conf_dict["api_host"]}:{self.conf_dict["api_port"]}/query' result = requests.post(url, data=dict(sql=raw_query)) # post request to /query endpoint returns result (list of dictionary) and type_dict (dictionary) self.result = json.loads(result.text)['result'] self.type_dict = json.loads(result.text)['type_dict'] # if type_dict contains key, mean that result contains either datetime, time or date # therefore those records needs to be converted to the python class object instead of string. if self.type_dict.keys() is not None and len(self.type_dict.keys()) > 0: for i in range(len(self.result)): for key in self.type_dict.keys(): self.result[i][key] = Type.parse_string_to(self.result[i][key], self.type_dict[key]) else: self.query_execute_que.append(raw_query) def commit(self): # commit function # if there are stored raw_query in self.query_execute_que, send post request if len(self.query_execute_que) == 0: pass else: url = f'http://{self.conf_dict["api_host"]}:{self.conf_dict["api_port"]}/query' result = requests.post(url, data=dict(sql=self.query_execute_que, transaction=True)) self.query_execute_que = None def fetchone(self): # fetchone function # if there is record (dictionary) in self.result, # and if self.index is whithin the len(self.result) # return result[self.index] (one correspoinding record) assert self.result is not None, 'cursor does not have a result to fetch' if len(self.result) > 0: try: return self.result[self.index] except: raise Exception('cursor index is not appropriate for result') else: pass pass def fetchall(self): # fetch all function # if there is records (dictonary) in self.result, # return all teh result (as a list of dictionary) assert self.result is not None, 'cursor does not have a result to fetch' if len(self.result) > 0: return self.result else: pass pass def next(self): # next function # move index one forward self.index += 1 def previous(self): # previous function # move index one backward self.index -= 1 def __parse_query_select_or_not(self, raw_query:str): # parser for raw_query # raw_query: str # return True if raw_query is select statement, # False if raw_query is not select statement if raw_query.lower().startswith('select'): return True else: Falseapi_error.pyclass Error: ''' Error class TODO implementation ''' def __init__(self): passapi_type.pyfrom enum import Enum import datetime class Type_Enum(Enum): ''' Type_Enum class contains Data type which needs to be converted to python object from string in query result. class member: DATE = 'date' DATETIME = 'datetime' TIME = 'time' ''' DATE = 'date' DATETIME = 'datetime' TIME = 'time' class Type: ''' Type class class member: class method: @staticmethod parse_string_to: params(target_string:str, target_type:str) return either python datetime, date, time object which parsed string to. ''' def __init__(self): pass ## some data type such as date, datetime, time is returned as string, needs to be converted to corresponding python object. @staticmethod def parse_string_to(target_string:str, target_type:str): if target_type == Type_Enum.DATE.value: date_time_obj = datetime.datetime.strptime(target_string, '%Y-%m-%d') return date_time_obj.date() elif target_type == Type_Enum.TIME.value: date_time_obj = datetime.datetime.strptime(target_string, '%H:%M:%S.%f') return date_time_obj.time() elif target_type == Type_Enum.DATETIME.value: date_time_obj = datetime.datetime.strptime(target_string, '%Y-%m-%d %H:%M:%S.%f') return date_time_objour_api.pyfrom .api_connection import Connection class Our_API: ''' Our_API class class member: class method: connect: params(conf_dict, conf_file) return Connection class object ''' def __init__(self): pass def connect(conf_dict=None, conf_file=None): if conf_dict: return Connection(conf_dict) elif conf_file: return Connection(conf_file)おわりに
これがJavaで書くとどんな感じになるのか楽しみです。
おわり。
- 投稿日:2019-12-02T19:31:32+09:00
RaspberryPiがネットワーク接続したときに、接続環境を通知させたい
Raspberry Pi 4を買いました。で、SDカードにはArchLinuxを入れました。
今回LEDとかも別に買っているわけではなく、素の状態での運用となるのですが、困ることが一つあって、
どこに接続しているのかの確認が面倒くさい
基本的にはDHCP利用な上にモニターもない状態なので、有線接続だろうと無線接続だろうとIPアドレスを確認しに行くのも面倒です。
そこで今回は、タイトルの通り「ネットワーク接続が確立できた時点で接続情報を自分から伝えてもらう」ことにしました。まとめ
環境情報
- 筐体: Raspberry Pi 4
- OS: ArchLinux (ARM版)
- ネットワーク管理: NetworkManager
- Python 3.8.0
書いたコード
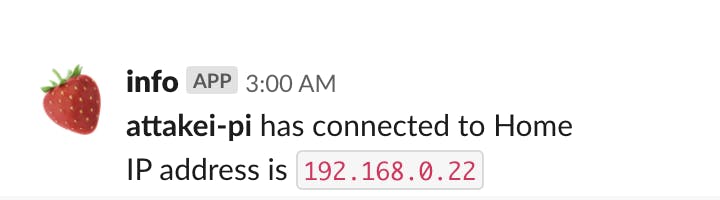
/etc/NetworkManager/dispatcher.d/notify-connection-information.py#!/usr/bin/env python import json import os import sys from urllib.request import urlopen WEBHOOK_URL = 'https://hooks.slack.com/services/THISIS/SLACK/WEBHOOK' def main(conn_id, ip_addr): payload = { 'username': 'info', 'icon_emoji': ':strawberry:', 'text': f'*attakei-pi* has connected to {conn_id}\n IP address is `{ip_addr}`', 'channel': '@attakei', } urlopen(WEBHOOK_URL, json.dumps(payload).encode()) if __name__ == '__main__': argv = sys.argv[1:] # if argv[0] != 'wlan0' or argv[1] != 'up': if argv[1] != 'up': sys.exit(0) ip_addr = os.environ['DHCP4_IP_ADDRESS'] conn_id = os.environ['CONNECTION_ID'] main(conn_id, ip_addr)出来上がった通知
NetworkManagerの話
NetworkManagerとは
ネットワーク接続に関するあれこれを管理するためのデーモン(+ツール)です。
SSIDの管理をしてくれたり、すでに登録済みのSSIDには自動接続を行ったりしてくれます。
systemd-networkdなどもありますが、とりあえず自分は現在これを利用しています。NetworkManagerのdispatch機能
さて、NetworkManagerには「ネットワークの切り割りをイベントとしてコマンド実行する」ことを可能にする、
dispatcher機能があります。
ArchLinuxのWikiに掲載されているサンプルなどでは、「有線接続をしたときは無線を無効化(+その逆)」「特定ネットワークに接続した場合は、続けてVPN接続する」みたいな例が書かれています。
今回はこれらのスクリプトを参考にして、上記のような「ネットワーク接続時に、指定されたSlackチャンネルに利用したSSIDとIPアドレスを申告する」スクリプトを作ってみました。dispatcherが受け取るもの
実際に使用してわかっている範囲だと、Disptcherはコマンド実行時に以下の情報を渡すようになってます。
- コマンドの引数として
- イベントのあったネットワークデバイス名
- どんなイベントが発生したか(例:
up=接続した)- 環境変数として
- 上記イベントに付随する情報各種
- 接続設定名
- IPアドレス
- などなど
情報を揃えてdispatchする
トリガーにしたい条件をもとに、どこから情報を取るかや振る舞いを整理します。
- 「ネットワーク接続時に」
- => コマンドの第2引数を参照する。
up以外は無視- 「指定されたSlackチャンネルに」
- => NetworkManager-dispacherの管理領域ではないので、とりあえずスクリプト直接記載
- 「
利用したSSID」
- => 環境変数の
CONNECTION_IDを参照- 「
IPアドレス」
- => とりあえずIPv4がほとんどなので、環境変数の
DHCP4_IP_ADDRESSを参照これで、必要な情報は揃ったので、コードが書けますね。コードは最初に記載したのでそちらを参照して下さい。
補足
スクリプトは直接呼び出されるので、shebangと実行権限付与を忘れずに。
※自分はこれで「あれっ」ってなり、頑張る系のIPアドレス探索をするはめになりかけました。URLs
- 投稿日:2019-12-02T19:05:43+09:00
GitHub + Travis-CI + pycodestyle で Pythonスクリプトを自動チェック
travis-ci + pycodestyle で自動チェック
本記事は,DSL アドベントカレンダー 3日目の記事です.
内容としては travis-ci の機能を使ってレポジトリにpushする度にそのPythonコードがPEP8に則っているか自動でチェックしてやろうみたいなお話です.
以前このようなことをやろうとして日本語の記事が全然なかった印象があるので,今回書くことにしました.
pycodestyleの自動チェックであり,pushやmergeを自動的に拒否するわけではないことは注意してください.travis-ciとは
さくらのナレッジ がわかりやすいです.
ざっくり抜粋すると,GitHubと連携した自動テスト実行サービスで以下のようなことが簡単に実行できます.
- 設定したGitHubリポジトリから自動でソースコードをチェックアウトしてあらかじめ指定しておいたビルドやテスト処理を実行する
- テスト結果をTravis CIのサイト上や各種API、メールなどで開発者に通知する
- テストが正常に完了して問題がなかった場合、あらかじめ指定しておいたホスティングサービスにソフトウェアをデプロイする
便利ですね.
pycodestyleとは
PEP8というPythonのコード規約があり,その規約にコードが則っているかどうかチェックしてくれるライブラリです.
詳しいPEP8やpycodestyleの出力結果についてのお話は他記事が参考になると思います.使ってみる
導入手順
手順はtravis-ciのチュートリアルページにも載っています.
1. Travis-ci.com にて GitHub連携でアカウント登録
2. Activateボタンを押して,機能を使いたいレポジトリを登録
3. レポジトリのrootに.travis.ymlを置く.
4. リモートレポジトリにpush
5. travis-ciで結果をチェック簡単にまとめるとこんなところです.
.travis.yml
.travis.ymlの中身にどんな処理を行うかを記述します.
今回は python パッケージの pycodestyle でコードチェックを行いたいので以下のような感じtavis.ymllanguage: python3 cache: pip sudo: false install: - pip install pycodestyle script: - pycodestyle .sample code
動作を確かめるために下記の簡単なコードでチェックしてみます.
helloworld.pyprint("hello",end="") # hello print("world") # worldちなみにこのコードでは,
1行目: 「,」の後にスペースが空いていない.
2行目: コメント文の「#」までにスペースが1つしか入っていない(正しくは2個).
がPEP8に則っていないのでここを自動で検出してほしい.動作確認
修正前
諸々の設定を済ませ,githubにpushしてみます.
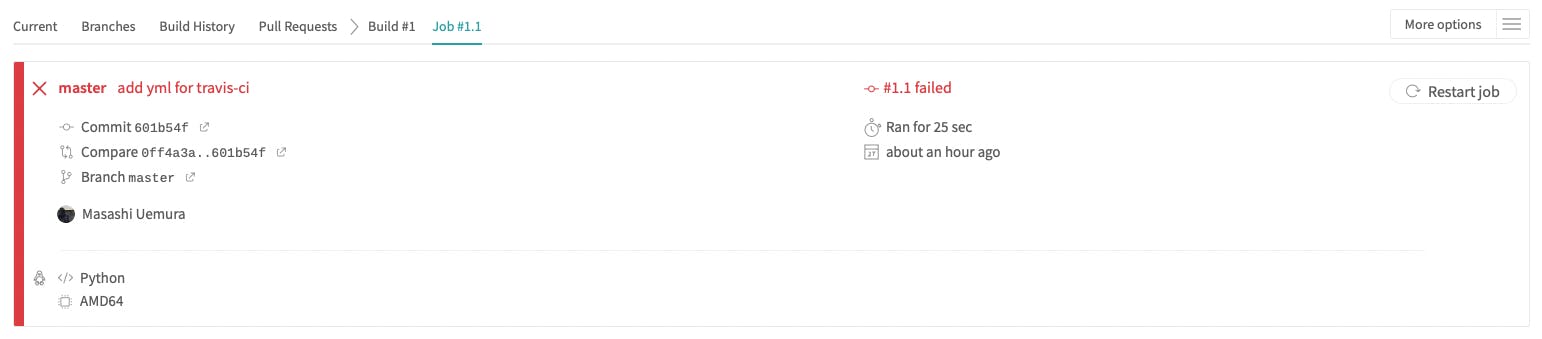
するとtravis-ciのlogで以下のようなログが出ていました.(一部抜粋)
log$ pycodestyle . ./helloworld.py:1:14: E231 missing whitespace after ',' ./helloworld.py:2:15: E261 at least two spaces before inline comment The command "pycodestyle ." exited with 1. store build cache Done. Your build exited with 1.pushした時点でpycodestyleのチェックが始まり,
引っかかると status code 1 で返してくれるので build faild となっているみたいです.
やはり2点がPEP8に則っていないと出ているようです.
修正します.修正後
引っかかったところを修正して再びpush
helloworld.pyprint("hello", end="") # hello print("world") # world
log$ pycodestyle . The command "pycodestyle ." exited with 0.はい!綺麗なコードになったみたいです.
まとめ
travis-ciとpycodestyleを用いてPythonのcodeが更新される度に自動チェックが入るようになりました.
自動で修正したい場合はautopep8などのモジュールを使うとコード整備がより楽になるかもしれません.
一人で開発する際はコードの綺麗さなどあまり気にしないかもしれませんが,現実ではそうも言っていられないので気にするようにしておくといいと思います(ブーメラン).参考

- 投稿日:2019-12-02T18:53:54+09:00
Python:ロジスティック回帰とは
ロジステック回帰とは
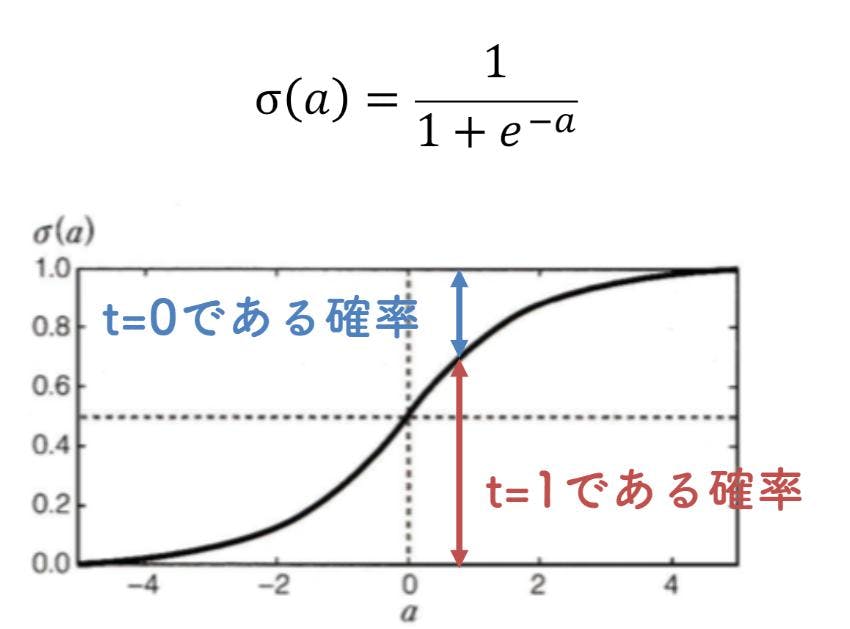
ここから本題です。一言で言うならば・・・
二つのデータを線で分けることです!
カタカナでロジスティックと書いてあるとかっこよいですが所詮線ってことです。
目的変数が2値(1か0や○か×みたいなこと)*誤差が正規分布に従わないため、実は線型モデルではないそうです・・
*ロジスティック方程式によってロジスティック曲線が扱えるそうですが今回はいったんロジスティック回帰と言ったら特選で二等分と覚えておきます。プログラムの基本
#sklearnからロジスティック回帰の入っているモジュールを取り出す from sklearn.linear_model import LogisticRegression # C=0.01, 0.1, 1, 10, 100を試した lr = LogisticRegression(C=0.01, random_state=0) scores = cross_val_score(lr, X, y, cv=10) print("正答率", np.mean(scores), "標準偏差 +/-", np.std(scores))プログラムの解説
LogisticRegressionの引数としてCが指定されています。
このCは正則化のためのパラメータです。正則化とは過学習を防ぐためにモデル式を調整すること。
過学習とは、モデルが複雑過ぎるために訓練データには当てはまるがテストデータでは当てはまらないこと。
パラメータCが減少するほど正則化の強さが増す。cross_val_scoreとはデータを分割して学習、判定を繰り返す検証方法です。 分割したトレーニングデータをさらに分割して、かつデータに偏りの無いように性能を検証できます。cv=10なので今回は10回パターンの分析をした平均値を出しています。
関連ワード
ロジスティック関数
シグモイド関数:ロジット関数の逆数
尤度関数:仮説が正しいものとしてトレーニングセットのデータが得られる確率
最尤推定法:尤度関数が最大になるようなパラメーターを決定する手法さいごに
PyQ(https://pyq.jp/)
でPythonを学習していますが、インプット過多になりがちなので学んだことのアウトプットとして投稿してきたいと思います。
- 投稿日:2019-12-02T18:53:17+09:00
pythonでバッチファイルを実行
pythonを使用してバッチファイルを実行したいと考えています。
多くのバッチファイルを一度に実行するにはどうしたらよろしいのでしょうか。
ご教授いただけましたら幸いです。
よろしくお願いいたします。
- 投稿日:2019-12-02T17:54:41+09:00
AirtestIDE でテスト自動化の環境をつくる(Tips)
はじめに
最近、AirtestIDE でスマホアプリ(ゲーム)のテスト自動化をはじめました。そこで実際に作成したスクリプトや環境をつくるために実施したことを綴ってみたいとおもいます
環境
macOS 10.13.6
Airtest IDE 1.2.2(Python)
Android 9スクリプト
共通で使うスクリプトを取り込む
from airtest.core.api import using using("common.air") from common import *どうやればいいのかなやんでいたら、公式ドキュメントに書いてあったという
https://airtest.readthedocs.io/en/latest/README_MORE.html#import-from-other-air処理を待つための処理
import sys def waitForExists(obj, timeout = 60): for t in range(timeout): if (exists(obj)): return 1 elif t == timeout - 1: print("timeout") sys.exit() sleep(1)objを見つけるまで処理を待ちます
まだ、timeoutの例外処理までつくりきれていない
raise WaitForObjectTimeoutError("処理がタイムアウトしました")
こんな感じにしたいdef waitAndTouch(obj, timeout = 60): for t in range(timeout): if (exists(obj)): sleep(1) touch(obj) return 1 elif t == timeout - 1: print("timeout") sys.exit() sleep(1)objをみつけるまで待って、みつけたらタップします
def swipeForExists(obj, obj2, vector, dulation = 8, maxCount = 10): for c in range(maxCount): if (exists(obj)): break elif c == maxCount - 1: print("maxCount") sys.exit() elif (exists(obj2)): swipe(obj2, vector, duration = dulation)objをみつけるまでobj2をスワイプします
def tapForExists(obj, obj2, timeout = 60): for t in range(timeout): if (exists(obj)): sleep(1) touch(obj) return 1 elif t == timeout - 1: print("timeout") sys.exit() elif (exists(obj2)): touch(obj2) sleep(1)objがみつかるまでobj2をタップし続けます(objがみつかったらタップします)
def tapForNotExists(obj, obj2, timeout = 60): for t in range(timeout): sleep(1) if (not exists(obj)): return 1 elif t == timeout - 1: print("timeout") sys.exit() elif (exists(obj2)): touch(obj2)objがみつからなくなるまでobj2をタップし続けます
def tapForNotExistsXY(obj, x, y, timeout = 60): for t in range(timeout): sleep(1) if (not exists(obj)): return 1 elif t == timeout -1: print("timeout") sys.exit() else: touch(v=(x,y))objがみつからなくなるまで特定の座標をタップし続けます
def tapIfExists(*args): n = 0 for i in args: n += 1 if (exists(args[0])): sleep(1) if (n == 1): touch(args[0]) elif (n == 2): touch(args[1])引数が1つの場合:対象のobjがあったらタップします
引数が2つの場合:対象のobjがあったら、obj2をタップしますこのぐらいつくると、大抵のやりたいことは事足りるようになってきました
ログを出力する
import datetime def log_ok(file, msg): now = datetime.datetime.now() #for airtestIDE file.write(now.strftime("%Y/%m/%d %H:%M:%S") + " [info] " + msg + " OK" + chr(10)) #for airtest #file.write(now.strftime("%Y/%m/%d %H:%M:%S") + " [info] " + msg.decode("utf-8") + " OK".decode("utf-8") + chr(10)) file.flush()AirtestIDEと、Airtest で文字コードの処理が異なる模様
import codecs file = codecs.open("<ログファイル名>", "w", "utf-8") log_ok(file, "自動テスト開始") ###for IDE install("../<アプリ>.apk") ###for CLI #install("<アプリ>.apk") log_ok(file, "Step1 - インストール") start_app("<アプリのid>") #(略) log_ok(file, "自動テスト終了") stop_app("<アプリのid>") file.close()使用例。なお、アプリのパスが、IDEから実行する場合と、CLIから実行する場合で若干異なる模様
IDE・・実行したairフォルダがホームになる
CLI・・実行した場所がホームになる結果をSlackに投稿する
import json import requests url = "https://slack.com/api/chat.postMessage" token = "<token>" channel = "<channel>" message = "ログ出力の" + chr(10) + "サンプルです" body = { 'token' : token, 'channel' : channel, 'text' : message, 'as_user' : 'true' } requests.post(url, data=body)出力したログファイルをとりこんで、Slackに投稿しようとおもっている
https://api.slack.com/methods/chat.postMessageコマンドライン
コマンドラインから実行する
adb shell input keyevent KEYCODE_WAKEUP cd $PROJECT_HOME /Applications/AirtestIDE.app/Contents/MacOS/AirtestIDE runner "<プロジェクト>.air" --device Android:/// --log logJenkinsとかからシェルを叩いてもらって起動するイメージ
レポートを取得する
/Applications/AirtestIDE.app/Contents/MacOS/AirtestIDE reporter "<プロジェクト>.air" --log_root log --export expairtestよりも、AirtestIDEの方がリッチなレポートが取得できる
レポートの出力先を apacheの DocumentRoot に設定して、イントラネットから参照できるようにするとよさそう複数台つないで実行する
$ airtest run argo.air --device Android://127.0.0.1:5037/<serialno>複数台のスマホ端末をUSBで接続している場合、
adb devicesコマンドでリストされる<serialno>を指定すれば、同時に複数台の実行ができそう(まだ AirtestIDEで試していない)おわりに
参考になった箇所などありましたでしょうか。実際にスクリプトを実装してみようとしたときに躓くポイントがいくつかありましたので、何かのお役に立てたなら幸いです
- 投稿日:2019-12-02T17:38:53+09:00
【非プログラマー向け】Kaggleの歩き方
この記事は、Kaggle Advent Calendar 2019のアドベントカレンダー3日目の記事です。
「Kaggle興味あるけど、ガチっぽくて怖い…」と思われている方向けの参考になればと思います!
※以下情報は2019/12現在のものです
Kaggleと出会うまで
Kaggleと出会う前の経歴は、ざっと以下です。
- マーケター ⇒ コンサルタント
- 文系出身(美術史専攻)
- プログラミング未経験(HTML少し触ったくらい)
- 黒い画面に畏敬の念しかない…
こんな状態でしたが、直近1年でPython&機械学習を勉強し、なんとかKaggleのことも分かってきました。なので、1年前の自分に向けて、これ知っとくと良いよ、という事を書いていきます。
対象読者
誰に?
- データ分析/機械学習スキルを伸ばしたい
- Kaggle楽しそうだけど、プログラミング未経験
- 主にマーケターや企画職
何を?
- Kaggleは試しておいて損はないぞ!
※Kaggleツヨツヨな方向けの内容ではありません
※個人的な主観がメインです(いわゆるポエム)「Kaggle」とは何か?
Kaggleとは
ひと言でいうと「機械学習」を用いたデータ分析の天下一武道会です
分析するデータ
- 企業がデータとテーマを提供し、コンペを開催
- テーマは、医療・マーケティング・金融など多岐にわたる
コンペ開催期間
- 1~3か月間ほど
- 比較的長い
順位
- 機械学習モデルを作成し、そのモデルの予測結果で順位づけ
賞金
- 上位者には賞金が出るコンペも
- 2019/12現在 開催中のDSBコンペは1位 $100,000(約1000万円!)
参加費
- 無料!
登録ユーザー
- 約12万人(2019/12現在) ※参照元
ランクについて
Kaggleには、強さによって5つのランクが存在します。
(厳密には、コンペでの強さ以外にもKernels,Discussion,DatasetsといったKaggleコミュニティへの貢献によっても、ランクがもらえます)
- Grandmaster ※最強…!
- Master
- Expert
- Contributor
- Novice ※まずはここから
Kaggleに取り組む人々(通称:Kaggler)は、このランクを上げるために日々大量の時間を投入してコンペを頑張っている、といっても過言ではありません(たぶん)
ランクごとの人数
2019/12時点での人数は以下
各ランクのイメージ
各ランクの概要とイメージ図です。(あくまで主観です)
ランクアップ条件
ランクアップ条件はこちら。(Competitionsにおいて)
Expertから、いきなりメダルを要求されます。。。初心者の方は、まずExpertを目標にしたいところです。
メダル獲得条件
メダルはGold、Silver、Bronzeの3種類。
メダル獲得条件はこちら。(Competitionsにおいて)
参加人数によって厳密な条件は異なりますが、以下が目安です。
- Gold:Top10
- Silver:Top 5%
- Bronze:Top 10%(※)
※いきなりTop10%なんて!と思われるかもしれませんが、一説によると、コンペ開催中の情報(Notebooks,Discussionなど)を丁寧に拾っていくだけでも、Bronze獲得は夢ではないらしい・・・(生存者バイアスの可能性あり)
例えばこんなコンペ
タイタニック号沈没事故の生存者予測
- Titanic: Machine Learning from Disaster
- Kaggleにおける「Hello World」的なコンペ
- 練習用コンペなので、特に期間の終わりは無い
- 乗船者の性別、年齢、乗り込んだ港、客室ランクなどのデータをもとに、その乗客が生存するか否かを予測

ペットショップでの犬・猫が引き取られる速さ予測
- PetFinder.my Adoption Prediction
- 2018/12~2019/3まで開催
- 1位賞金は10,000ドル
- 各ペットのプロフィール、説明文言、写真などのデータをもとに、そのペットが養子として引き取られる速さを予測
- テーブルデータ、画像、テキストといった複数ソースをもとに予測する実践的なコンペ
Kaggleをやるメリット
Kaggleをやるメリットを、3つ挙げてみました。
①自分のデータサイエンススキルがわかる(証明にもなる)
データサイエンススキルは、実践を通さないと実力が測りづらいものです。
ただ、Kaggleでメダルやランクを獲得していると、おおよそのデータサイエンススキルが証明できます。最近はKaggle採用をしている企業も徐々に増えており、ステップアップ時の証拠にもなります。
②世界のデータサイエンティストのノウハウが学べる(無料で!)
自分も実際にコンペに参加してわかったのですが、Kaggleではただ相手と競うだけでなく、ノウハウや情報をシェアし合うすばらしい文化があります。
特に、「Notebooks」では、データサイエンスのノウハウ&流行が、コードと一緒に分かりやすく説明されており、初心者にもおすすめです。
③機械学習が何をやっているのか、肌感レベルで理解できる
昨今、身の回りのアプリやマーケティングツールでは、どんどん機械学習が組み込まれています。
Kaggleをやっていれば、機械学習のモデリング過程をひととおりマスターできるので、機械学習で何ができて何ができないのか、肌感覚で理解できます。
Kaggleはここから始めるべし
いろいろと異論はありそうですが、個人的なポイントは以下3つ。
①機械学習/Python 知識ゼロなら、「松尾研」テキスト1択!
機械学習/AI関連で有名な東京大学の松尾研究室。
その松尾研究室が行っている「データサイエンティスト育成講座」のテキストを、無料でダウンロードできます。これはすごいことです、事件です!
文章とPythonコードで機械学習の初級者卒業レベルを丁寧に解説してくれていますので、Kaggleの内容が理解しにくい方は、こちらを完了させると良いかと思います。▼「松尾研」テキスト ダウンロード先はこちら
https://weblab.t.u-tokyo.ac.jp/gci_contents/
②「Notebooks」でvote数の高いものを写経し、コツをつかむ!
さきほどの述べましたが、各コンペ内の「Notebooks」は宝の宝庫です。
取り組みやすそうなコンペを選んだら、「Notebooks」のVotes数が高いNotebookを写経することがオススメです。Vote数が高いNotebookは、説明がていねいでわかりやすいものが厳選されているので、写経することでデータ取得~モデル結果提出までの流れを追体験でき、機械学習のコツが会得できます。
③1人だと情報もなく詰まるので、誰かとつながることがオススメ!
Kaggleは基本個人戦です。ただ、コンペ期間は1~3か月と長く、モチベーションが下がったり煮詰まったりすることもあります。
そんなときに、Kaggleをやっている仲間がいると、役立つ情報の共有(プライベートシェアリングはNG)や励まし合いができ、よりKaggleを楽しむことができます。
個人的には、以下3つがオススメです。
- Kaggle関連のセミナーに行ってみる(connpassなど)
- TwitterでKaggle勢をフォローする
- Kaggleコミュニティにゆるく参加してみる
このKaggleアドベントカレンダーも、専業Kagglerで有名な「カレーちゃんさん」のKaggleコミュニティから出てきたものです。PodcastやDiscardで活発に情報シェアや輪読会が行われており、楽しくKaggleを続けるうえで、おすすめのKaggleコミュニティです。
さいごに
Kaggleは、機械学習/データ分析の初心者~上級者まで楽しめる、とても優れたプラットフォームです。
Kaggleをやっていると、世界中のTOPデータサイエンティストとしのぎを削ったり、情報共有したり、教えてもらったり、といったことが当たり前のように出来てしまっています。ただ、よくよく考えると、これって凄いことだよなあと、この記事を書きながら、あらためて実感しました。
これから先も、Kaggleが良いプラットフォームであり続けるために、微力ながら貢献していきたいです!(まずは、メダルほしい…)





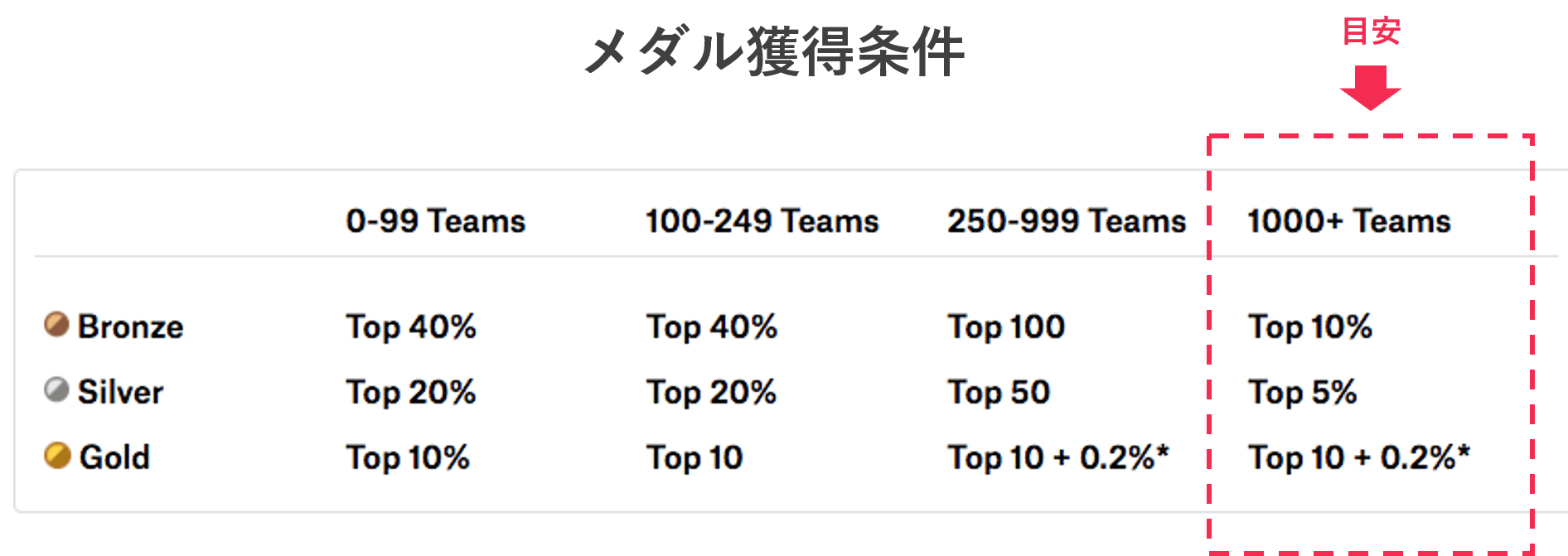
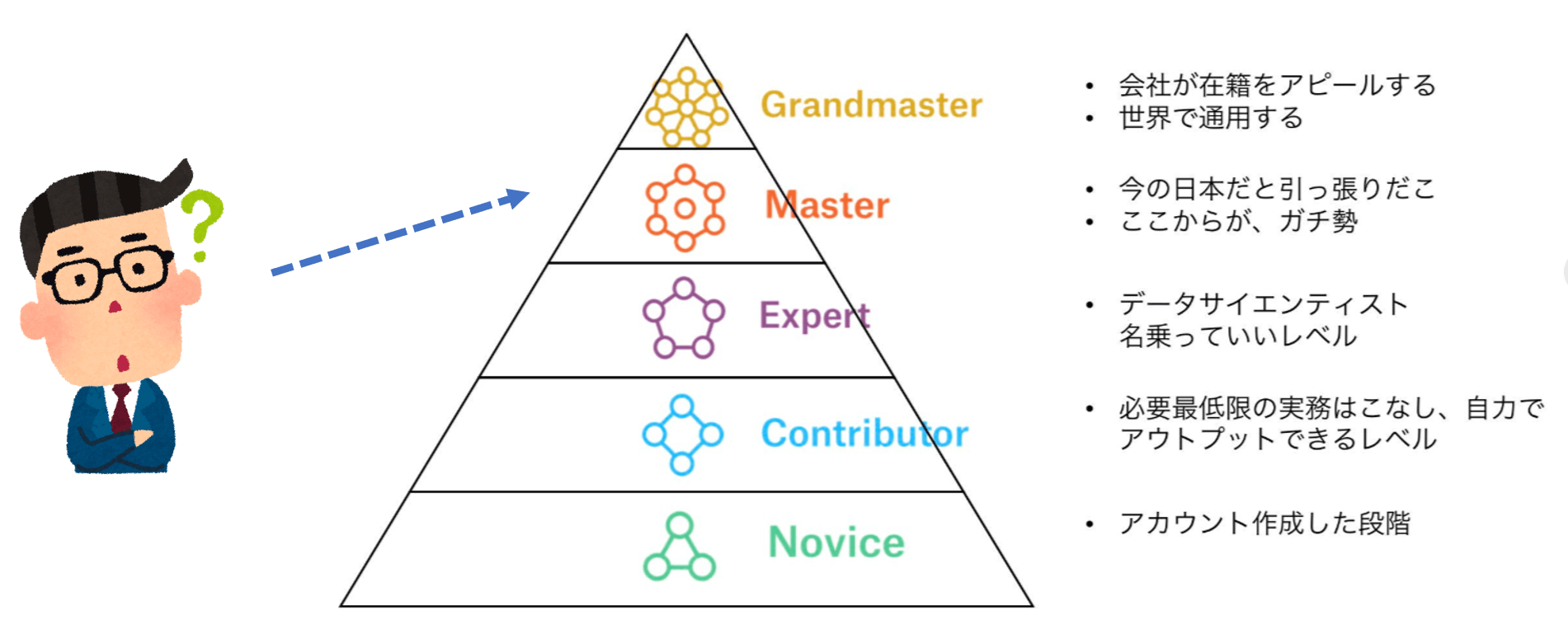



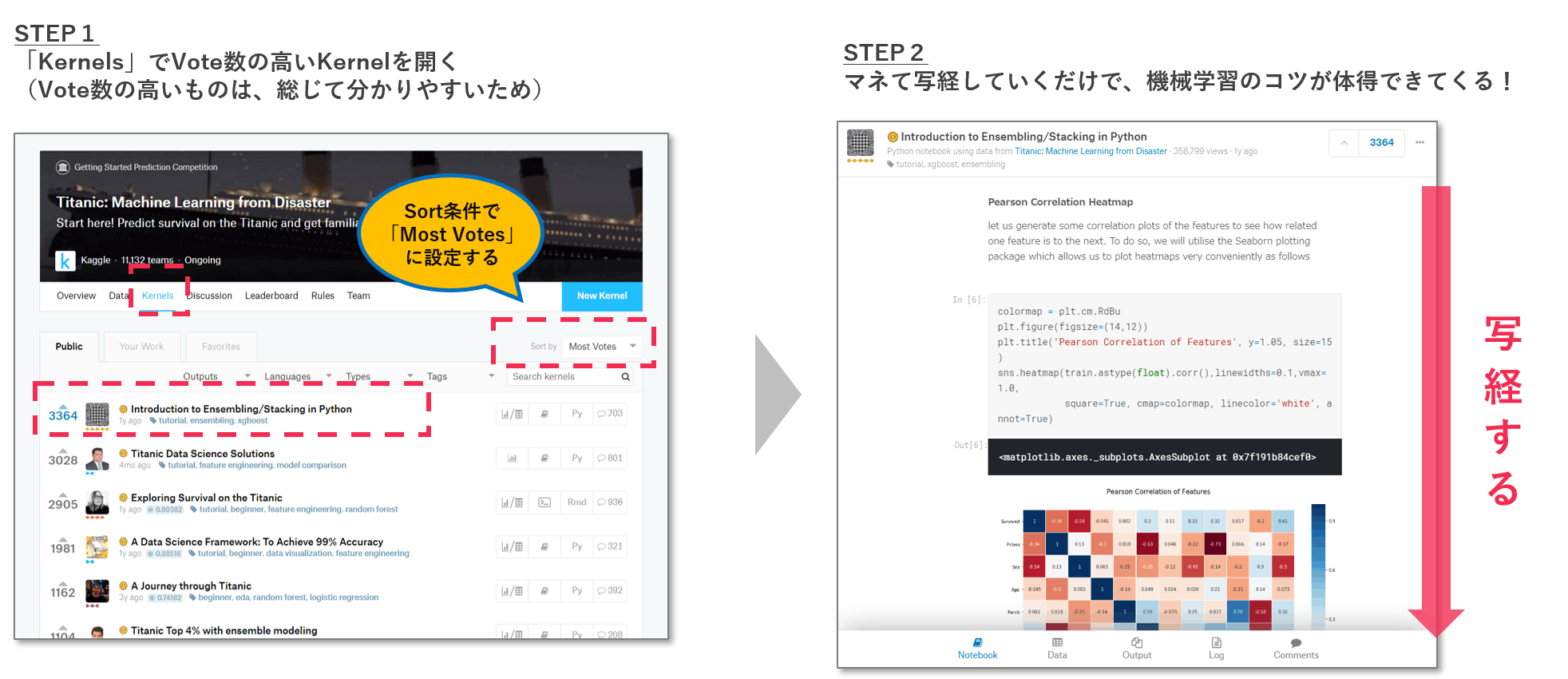
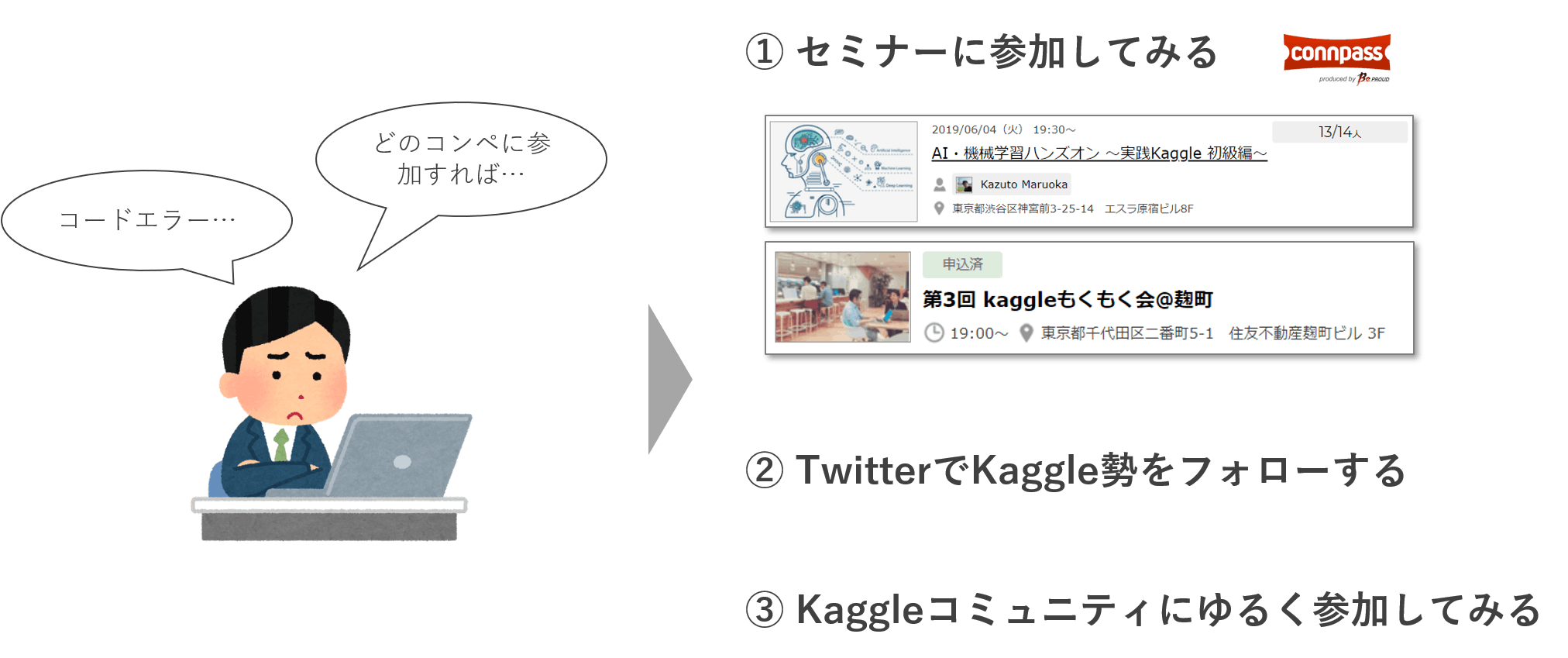

- 投稿日:2019-12-02T17:12:48+09:00
はじめての画像分類器
こんにちは。業務ではエンジニアリングから離れていて、やったことで書けるものあんまりないんですが、
ちょっと時間ができたので自分でちょっと勉強した内容をまとめておこうと思います。
アドベントカレンダー怖くないよ!チュートリアルやっただけの記事でも書いていいんだよ!ってことでひとつ...想定読者
機械学習のことを多々耳にするものの、あまり実装に触れたことがなかったので触れてみます。
なので想定読者は機械学習に触れたことがないけど興味があって、機械学習の実装を覗いてみようという方々です。
熟練の方々は温かい目で、ミスってる部分の指摘をいただけると助かります
テーマ
とっつきやすいテーマが無いと目指すべきゴールがわからず道に迷いますね。
ということで今回は画像を与えたときに、写っているものが何かを分類する、
画像分類器を作りましょう。なんでもいいですが、何の分類器にするかは最初に決めておきましょう。
私は最近カレーにハマり続けているので、スパイスの画像分類器を作ることを目的にしてみます。
弊ブログもよろしくお願いします
前提知識
画像分類器はキャッチーなテーマなので、チュートリアル記事なんかもたくさんあるわけですが、何の前提知識も無いまま読み始めるより、以下のような記事でサラッと全体を把握しておくことをおすすめします。
数学知識もいらないゼロからのニューラルネットワーク入門
ニューラルネットワークの「基礎の基礎」を理解する ~ディープラーニング入門|第1回あと、専門用語っぽい言葉には参考リンクを付けておきますのでそちらも参照ください。
チュートリアルをやる
tensorflow(てんそるふろー *1)転移学習(*2)のチュートリアルをやっていきます。
Transfer learning with TensorFlow Hubってやつですね。2019/12のバージョンの項目に合わせて書いていますが、変更があった場合はいい感じに読み替えてもらえると良いと思います。
それぞれのセクションのコードは転載していますが、一部を除いて結果は載せておりませんのでご自身で実行しながら読んでみてください。(*1)tensorflowとは機械学習のライブラリ群の一つです、googleが作ってます。wiki
(*2)転移学習とは別のタスクで学習したモデルを他のタスクに流用する手法です。
今回のケースだと本当はかなり大量のデータを用意しないと精度が上がらないのを、
かなり少ない枚数で解決出来るみたいな感じです。
プログラミング言語を1つ習熟すると、2つ目の習熟が早い〜みたいなノリですたぶん。参考Setup
前提としてこのチュートリアルはGoogleColaboratory(以下Colab *3)を使用しているので、上部の「Run in Google Colab」をクリックして実行できるようにしましょう。
Colabの画面が開いたら、上から順番に実行していってみましょう。コードの左上の[]のあたりにカーソルを合わせると実行ボタンが出てくるはず。from __future__ import absolute_import, division, print_function, unicode_literals import matplotlib.pylab as plt import tensorflow as tfこのあたりは諸々ライブラリのインポートをやっていますね。
__future__ ..の記述があるのはpython2-3の互換性を保つための記述。
import matplotlib.pylab as pltはあとで使用するプロットのためののライブラリ。!pip install -q -U tf-hub-nightly import tensorflow_hub as hub from tensorflow.keras import layers
!pip install -q -U tf-hub-nightlyの記述はpythonのライブラリのインストール。
tensorflow_hubとは事前学習済みのモデルを簡単に利用できるプラットフォーム(tensorflow hub)を利用するためのライブラリ。
tensorflow.kerasとは機械学習のライブラリで、googleのエンジニアが作ったようだがtensorflow以外からも使用できるもの。テキスト的にパチパチ書くだけで仮想マシン上でこんなに簡単に実行出来るってすごい。
(*3)Colaboratory は、完全にクラウドで実行される Jupyter ノートブック環境です。設定不要で、無料でご利用になれます。
Colaboratory を使用すると、コードの記述と実行、解析の保存や共有、強力なコンピューティング リソースへのアクセスなどをブラウザからすべて無料で行えます。
Colaboratoryへようこそより
ちなみに、こんなエラーが出たときは支持に従って[RESTART RUNTIME]のボタンを押して、もっかい再生ボタンを押すと良いです。
An ImageNet classifier
学習済みモデルを利用して、画像分類をやってみましょう、という項目です。
Download the classifier
classifier_url ="https://tfhub.dev/google/tf2-preview/mobilenet_v2/classification/2" #@param {type:"string"}学習済み分類器のURLです。チュートリアルに書いてる通り、ここに置いてあるやつだったらなんでもいいよーとのことです。
IMAGE_SHAPE = (224, 224) classifier = tf.keras.Sequential([ hub.KerasLayer(classifier_url, input_shape=IMAGE_SHAPE+(3,)) ])ニューラルネットワークの層として学習済みモデルを突っ込みます。
与えられる画像のフォーマットを教えておく必要があるようなので、(width, height, channel)で与えます。
channel(色数)の3は後で追加してますね。深い意味はあるんだろうか。Run it on a single image
準備ができたところで、適当な画像で判別させてみましょう。
import numpy as np import PIL.Image as Image grace_hopper = tf.keras.utils.get_file('image.jpg','https://storage.googleapis.com/download.tensorflow.org/example_images/grace_hopper.jpg') grace_hopper = Image.open(grace_hopper).resize(IMAGE_SHAPE) grace_hoppergrace_hopper氏の画像を取得しています。
grace_hopper = np.array(grace_hopper)/255.0 grace_hopper.shape型変換をしているようです。
result = classifier.predict(grace_hopper[np.newaxis, ...]) result.shape画像のデータに1次元追加して予測を走らせてみると、1001個の要素のベクトルの配列(正確にはndarrayかな)が帰ってきます。
predicted_class = np.argmax(result[0], axis=-1) predicted_classこの1001の要素はそれぞれのクラス(今回の場合は類推される要素)の確率を表しているので、最大の確率のものを取り出してみます。
653という値が帰ってきます。これが今回の分類器が類推したモノを表しています。Decodethe predictions
labels_path = tf.keras.utils.get_file('ImageNetLabels.txt','https://storage.googleapis.com/download.tensorflow.org/data/ImageNetLabels.txt') imagenet_labels = np.array(open(labels_path).read().splitlines())先程の結果が何を示しているのかを探るために、ラベルをダウンロードして配列に詰めておきます。
URLを直接アクセスするとすぐわかりますが、先程の1001の項目に対応しています。plt.imshow(grace_hopper) plt.axis('off') predicted_class_name = imagenet_labels[predicted_class] _ = plt.title("Prediction: " + predicted_class_name.title())
画像表示ライブラリを使って、さっきの653番目の画像が何だったのかを出力します。
無事、Military Uniformという結果が出ましたね。めでたし。
Simple transfer learning
ここからが本番です。今のは「こんな感じで学習済み分類器って使えるぞ〜」でしたが、
次は「自分が集めてきた画像で分類器作るぞ〜」です。Dataset
今回のチュートリアルでは花の画像を使います。最後にこのデータセットを適当に入れ替えて、別の分類器にしましょう。
data_root = tf.keras.utils.get_file( 'flower_photos','https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz', untar=True)データセットのダウンロード
image_generator = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1/255) image_data = image_generator.flow_from_directory(str(data_root), target_size=IMAGE_SHAPE)画像群を上手く処理するためにImageDataGenaratorに突っ込みます。
ちなみに画像の分類も先述のURLから画像群をダウンロードしてみるとわかりますが、
ディレクトリごとに特定の画像を集めている感じになってます。for image_batch, label_batch in image_data: print("Image batch shape: ", image_batch.shape) print("Label batch shape: ", label_batch.shape) breakimage_dataをイテレートしてimage_batchとlabel_batchの配列をつくります。
Run the classifier on a batch of images
学習後の状態と比較するために、学習していない状態で分類してみます。
result_batch = classifier.predict(image_batch) result_batch.shapeさっきと同じく予測してみましょう。
predicted_class_names = imagenet_labels[np.argmax(result_batch, axis=-1)] predicted_class_names32件の分類結果が出ました。画像と照らし合わせて確認します。
plt.figure(figsize=(10,9)) plt.subplots_adjust(hspace=0.5) for n in range(30): plt.subplot(6,5,n+1) plt.imshow(image_batch[n]) plt.title(predicted_class_names[n]) plt.axis('off') _ = plt.suptitle("ImageNet predictions")
結果を見るとかなりかけ離れてますね。
1001の対象物から選んでいるからと言うのもありそうですが、全然正解していません。Download the headless model
ということで分類器を自分で作ってみましょう。
feature_extractor_url = "https://tfhub.dev/google/tf2-preview/mobilenet_v2/feature_vector/2" #@param {type:"string"}例によってtensorflow hubから学習済みモデルをダウンロードしてきます。extractorは抽出機っぽいですね。
feature_extractor_layer = hub.KerasLayer(feature_extractor_url, input_shape=(224,224,3))モデルに突っ込むためのlayerを作成。
feature_batch = feature_extractor_layer(image_batch) print(feature_batch.shape)こいつは1280のベクトルをそれぞれの画像に対して返してくれるとのこと。
様々な要素から画像の分類を試みるんですね。feature_extractor_layer.trainable = False今回は抽出機の部分はチューニングしないので、学習されないように指定しておきます。
Attach a classification head
model = tf.keras.Sequential([ feature_extractor_layer, layers.Dense(image_data.num_classes, activation='softmax') ]) model.summary()さっき作った抽出機のインスタンスを分類器に突っ込んでいます。
作ったモデルのサマリーの表示もしていますね。predictions = model(image_batch)predictions.shapetensorのshape(形状)を確認しています。
Train the model
model.compile( optimizer=tf.keras.optimizers.Adam(), loss='categorical_crossentropy', metrics=['acc'])モデルをコンパイルします。
optimizer(最適化アルゴリズム):色々種類があるみたいです。 参考
loss(損失関数):損失が出来るだけ小さいように調整するために学習に使用される関数。これも色々あるみたいです。参考
metrics(評価関数):モデルの性能を評価するために使う値だが、損失関数のように学習には使われないもの。これも同じくいろいろある模様。 参考class CollectBatchStats(tf.keras.callbacks.Callback): def __init__(self): self.batch_losses = [] self.batch_acc = [] def on_train_batch_end(self, batch, logs=None): self.batch_losses.append(logs['loss']) self.batch_acc.append(logs['acc']) self.model.reset_metrics()損失関数、評価関数の値がどの様になっているかを観測するための関数定義です。
steps_per_epoch = np.ceil(image_data.samples/image_data.batch_size) batch_stats_callback = CollectBatchStats() history = model.fit_generator(image_data, epochs=2, steps_per_epoch=steps_per_epoch, callbacks = [batch_stats_callback])fit_generatorで学習を開始します。
学習回数などなどを指定してますね。参考
学習には多少時間がかかります。plt.figure() plt.ylabel("Loss") plt.xlabel("Training Steps") plt.ylim([0,2]) plt.plot(batch_stats_callback.batch_losses)
損失関数の推移です。徐々に下がっていっていてよさげですね。
plt.figure() plt.ylabel("Accuracy") plt.xlabel("Training Steps") plt.ylim([0,1]) plt.plot(batch_stats_callback.batch_acc)
評価関数の推移です。これは上がっていっているのでいい感じ。
Check the predictions
いよいよ分類してみましょう。
class_names = sorted(image_data.class_indices.items(), key=lambda pair:pair[1]) class_names = np.array([key.title() for key, value in class_names]) class_names実際に存在するクラスを取り上げます。存在するのは5種類だけですね。
predicted_batch = model.predict(image_batch) predicted_id = np.argmax(predicted_batch, axis=-1) predicted_label_batch = class_names[predicted_id]先程やったようにpredictして、最大値のものを取ってきてラベルにします。
label_id = np.argmax(label_batch, axis=-1)正解のラベルを確保しておきます
plt.figure(figsize=(10,9)) plt.subplots_adjust(hspace=0.5) for n in range(30): plt.subplot(6,5,n+1) plt.imshow(image_batch[n]) color = "green" if predicted_id[n] == label_id[n] else "red" plt.title(predicted_label_batch[n].title(), color=color) plt.axis('off') _ = plt.suptitle("Model predictions (green: correct, red: incorrect)")
正解のときは緑、失敗のときは赤で出力されるようになっています。
だいたい正解してるんじゃないでしょうか。よさげ。この後もチュートリアルはちょっとだけ続いて、学習したモデルのexportなどが書かれているんですが、今回使うのはここまでなので、これ以降は割愛しておきます。
自分だけの分類器造り
さて、チュートリアルで出てきたコードを利用して自分だけの分類器を作っていきましょう。今回はColab上で動くところまででゴールにしておきます。
画像収集
画像分類には画像の収集が欠かせません。
画像のダウンロード
google-images-downloadが便利です。(ダウンロードした画像のライセンスには注意しましょう)
pip経由でインストールできるので、macであれば以下のように使えると思います。
pip install google_images_download googleimagesdownload --keywords "探したい画像"画像の選別
ダウンロードしてきた画像をそのまま使おうとすると、ゴミが多くて使えません。
ので、画像を1枚ずつ見ながら変な画像を取り除いていきましょう。
この作業が一番大変でした..
最終的にはこんな感じでディレクトリごとにきれいになった特定の画像が集まっている状態を作りましょう。パッケージしてアップロード
とりあえずColabからdownload出来るようにtarで圧縮したファイルをどこかにuploadしておきましょう。私はGoogleDriveに上げときました。
GoogleDriveの場合はtar.gzをuploadした上で、共有可能なリンクを取得し、そのID部分を以下リンクと差し替えてみましょう。
https://drive.google.com/uc?export=download&id=XXXXXXXXXXXXXXXXXXXXXColabのコードに反映
こちらに分類機作る部分だけを抜き出したColabファイルを用意したので、xxxxのところを差し替えてみてください。
上手く動きましたでしょうか。
私の手元ではこんな感じ。
おわりに
なんとなーく機械学習の上辺を体験できましたが、分類器のイメージだと自分で撮った写真が分類されてほしい感じありますよね。
手元に環境構築したりして、もうちょっとカジュアルに触れる何か〜を作ってみたい気持ちがあります。がんばるぞ。







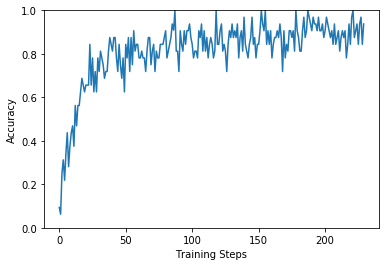




- 投稿日:2019-12-02T16:56:19+09:00
ハッシュリストをVTに突っ込んで検知結果をリストで受け取る
エモいやつのハッシュ値リストをまとめてVTでチェックするスクリプトです。
APIでまとめて取得します。クエリ量制限(4回/分)があるのでゆっくり待ちましょうimport requests import json import pandas as pd import time import csv hashlist= [ 'c9e17e63de9b882e820c829b415a4e13070453c8', 'dee5ff1d1910e27c2b6aed7ddffce3c3be6356d4'] url = 'https://www.virustotal.com/vtapi/v2/file/report' apikey ='USE_YOUR_API_KEY' f = open('vt_output.csv', 'w') writer = csv.writer(f, lineterminator='\n') for hash in hashlist: print(hash) params = {'apikey': apikey, 'resource': hash} response = requests.get(url, params=params) l = [hash] response_code =response.json()['response_code'] l.append(response_code) if response_code == 1: df=pd.read_json( json.dumps(response.json())) for x in range(df.index.size): l.append(df['scans'][x]['result']) writer.writerow(l) time.sleep(25) f.close()結果はリストで取得できます。
1 Trojan.Downloader.DOC.Gen Other:Malware-gen [Trj] W97m.Downloader.IQU Trojan.MSWord.Generic.4!c VBA/Downloader.S70 W97m.Downloader.IQU Other:Malware-gen [Trj] VBA/Dldr.Agent.zzlmg W97m.Downloader.IQU W97M.Emotet.36301 Doc.Dropper.Emotet-7399725-0 W97M/Downldr.HB.gen!Eldorado W97M.DownLoader.4186 VBA/TrojanDownloader.Agent.QMI malicious (high confidence) Malware.VBA/Dldr.Agent.zzlmg W97m.Downloader.IQU VBA/Agent.QLT!tr.dldr Macro.Trojan.Kryptik.NK@susp Trojan-Downloader.VBA.Emotet HEUR:Trojan.MSOffice.SAgent.gen malware (ai score=89) W97M/Downloader.xx BehavesLike.Downloader.cg W97m.Downloader.IQU TrojanDownloader:O97M/Emotet.GF!MTB Trojan.Script.Downloader.ghylsa O97M/Downloader virus.office.obfuscated.1 DFI - Malicious OLE Mal/DocDl-K Trojan.Gen.2 Suspicious/W97M.Obfus.Gen.8 Heur.Macro.Generic.Gen.f Trojan.W97M.EMOTET.JKBG Trojan.W97M.EMOTET.JKBG Trojan.AvsMofer.bSGLro HEUR:Trojan.MSOffice.SAgent.gen Probably W97Obfuscated
- 投稿日:2019-12-02T16:54:40+09:00
粒子群最適化(PSO)のパラメータについて
はじめに
これは「群知能と最適化2019 Advent Calender」5日目の記事です。
Qiitaに記事を投稿するのは初めてなのでつたない部分もあるかもですが、読んでいただけると嬉しいです。
また、この記事はPSOのパラメータに関する記事なので、そもそもPSOについて知らないという方は昨日のganariyさんの記事「粒子群最適化法(PSO)を救いたい」を先に読んでいただくとより理解できるかと思います。粒子群最適化(PSO)とパラメータについて
PSOの詳細については昨日の記事でganariyさんが述べてくださった通り、鳥や魚などの群れで行動する習性を基にしたメタヒューリスティックアルゴリズムの一つです。
1995年に基となる論文が発表されて以降、様々なモデルが提案されてきました。
PSOは各粒子が現在の位置$x$と速度$v$を持ち、それらを更新していくことで最適解を探索します。移動にかかる各粒子の速度と位置は以下の式で更新されます。
$$
v_{id}(t+1) = w_{id}(t) + c_p × r_p × (pBest_{id} - x_{id}(t)) + c_g × r_g × (gBest_{id} - x_{id}(t))
$$
$$
x_{id}(t+1) = x_{id}(t) + v_{id}(t+1)
$$
ここで、それぞれが見つけた最良の位置をパーソナルベスト(pBest)、群全体の最良の位置をグローバルベスト(gBest)と呼びます。
また、$v_{id}$はd次元のi番目の粒子の速度、$x_{id}$はd次元のi番目の粒子の位置、$w$は重み、$c_p$、$c_g$は加速係数と呼ばれる定数、$r_p$、$r_g$は0~1の乱数です。
この中で人が決めることのできるパラメータとして、重み$w$、加速係数$c_p$$c_g$がありますが、特に$w$は粒子の収束に大きな影響を与えるパラメータとして多くの研究が行われています。重みwに関して行われている研究
重みwに関するレビュー論文として、2011年に「A novel particle swarm optimization algorithm with adaptive inertia weight」という論文が報告されています。
この論文の中で、重みwは主に3つのタイプに分類されています。
重みが定数orランダム
定数を与える論文では、様々な定数での重みが試され、$w>1.2$では浅い探索となってしまう一方、$w<0.8$では局所解に収束する傾向があることを示しました。
また、ランダム値を与える論文では、最適な重みを動的な環境で決めるのは難しいため、以下の式のようなランダムな値を与えることを提案しています。
$$
w = 0.5 + rand()/2
$$時変する重み
PSOを用いた多くの手法では、重みの値を反復回数に基づいて決定する手法を用いています。
なかでも特に多くの論文で用いられている手法として、線形減少重みがあります[参考: 1, 2, 3]。これは、最大反復回数$iter_{max}$と反復回数$iter$、初期重み$w_{max}$と最終値$w_{min}$を用いて以下の式で表されます。
$$
w(iter) = ((iter_{max} - iter)/iter_{max})(w_{max} - w_{min}) + w_{min}
$$
時変する重みに関しては、これ以外にもカオスモデルを使用した手法や非線形減少重みなど様々な重みが提案されています。適応重み
これは適宜状況を監視し、フィードバックパラメータに基づいて重みを決定していくものです。非常に様々な手法が提案されているので、興味があればレビュー論文を読んでみてください。LDWPSOの実装
上記した中でも、最も有名で多く使われる線形減少重みPSO (LDWPSO) を実装してみたいと思います。
評価関数にはSphere functionを用います。
プログラムは以下のようになります。
実行すると4ループ目まで可視化して表示されるようにしています。import numpy as np import random import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D import time SWARM_SIZE = 100 # 粒子数 ITERATION = 30 # PSOループ回数 C1 = C2 = 2.0 # 加速係数 MIN_X, MIN_Y = -5.0, -5.0 # 探索開始時の範囲最小値 MAX_X, MAX_Y = 5.0, 5.0 # 探索開始時の範囲最大値 W_MAX, W_MIN = 0.9, 0.4 # 評価関数(z = x^2+y^2) def evaluation(x, y): return x**2 + y**2 # Sphere function # PSO def pso(position, velocity, personal_best_scores, personal_best_positions, best_position, search_space_x, search_space_y): # ループ回数分Particle移動 for i in range(ITERATION): for s in range(SWARM_SIZE): # 変更前の情報の代入 x, y = position[s]["x"], position[s]["y"] vx, vy = velocity[s]["x"], velocity[s]["y"] p = personal_best_positions[s] # 粒子の位置更新 new_x, new_y = update_position(x, y, vx, vy, search_space_x, search_space_y) position[s] = {"x": new_x, "y": new_y} # 粒子の速度更新 new_vx, new_vy = update_velocity(new_x, new_y, vx, vy, p, best_position, i) velocity[s] = {"x": new_vx, "y": new_vy} # 評価値を求める score = evaluation(new_x, new_y) # update personal best if score < personal_best_scores[s]: personal_best_scores[s] = score personal_best_positions[s] = {"x": new_x, "y": new_y} # update global best best_particle = np.argmin(personal_best_scores) best_position = personal_best_positions[best_particle] # PSO Visualization if i == 0 or i == 1 or i == 2 or i == 3: print("ITERATION = " + str(i+1)) visualization(personal_best_positions) # 粒子の位置更新関数 def update_position(x, y, vx, vy, search_space_x, search_space_y): new_x = x + vx new_y = y + vy # 探索範囲内か確認 if new_x < search_space_x["min"] or new_y < search_space_y["min"]: new_x, new_y = search_space_x["min"], search_space_y["min"] elif new_x > search_space_x["max"] or new_y > search_space_y["max"]: new_x, new_y = search_space_x["max"], search_space_y["max"] return new_x, new_y # 粒子の速度更新関数 def update_velocity(x, y, vx, vy, p, g, i): #random parameter (0~1) r1 = random.random() r2 = random.random() # 線形減少重み L = (ITERATION - i) / ITERATION D = W_MAX - W_MIN w = L * D + W_MIN print(w) # 速度更新 new_vx = w * vx + C1 * (g["x"] - x) * r1 + C2 * (p["x"] - x) * r2 new_vy = w * vy + C1 * (g["y"] - y) * r1 + C2 * (p["y"] - y) * r2 return new_vx, new_vy # 可視化関数 def visualization(positions): fig = plt.figure() ax = Axes3D(fig) # Mesh #mesh_x = np.arange(-0.5e-3, 0.5e-3, 0.1e-4) #mesh_y = np.arange(-0.5e-3, 0.5e-3, 0.1e-4) mesh_x = np.arange(-5.0, 5.0, 0.5) mesh_y = np.arange(-5.0, 5.0, 0.5) mesh_X, mesh_Y = np.meshgrid(mesh_x, mesh_y) mesh_Z = evaluation(mesh_X, mesh_Y) ax.plot_wireframe(mesh_X, mesh_Y, mesh_Z) # Particle for j in range(SWARM_SIZE): z = evaluation(positions[j]["x"], positions[j]["y"]) ax.scatter(positions[j]["x"], positions[j]["y"], z) ax.set_xlim([-5.0, 5.0]) ax.set_ylim([-5.0, 5.0]) ax.set_zlim([-1.0, 30.0]) ax.set_xlabel("x") ax.set_ylabel("y") ax.set_zlabel("f(x, y)") plt.show() def run(position, velocity, personal_best_scores, personal_best_positions, best_position, search_space_x, search_space_y): pso(position, velocity, personal_best_scores, personal_best_positions, best_position, search_space_x, search_space_y) return best_position, personal_best_scores def main(): # 時間計測開始 start = time.time() # 各粒子の初期位置, 速度, personal best, global best 及びsearch space設定 position = [] velocity = [] personal_best_scores = [] # 初期位置, 初期速度 for s in range(SWARM_SIZE): position.append({"x": random.uniform(MIN_X, MAX_X), "y": random.uniform(MIN_Y, MAX_Y)}) velocity.append({"x": random.uniform(0, 1), "y": random.uniform(0, 1)}) # personal best personal_best_positions = list(position) for p in position: personal_best_scores.append(evaluation(p["x"], p["y"])) # global best best_particle = np.argmin(personal_best_scores) best_position = personal_best_positions[best_particle] # search space search_space_x, search_space_y = {'min': MIN_X, "max": MAX_X}, {"min": MIN_Y, "max": MAX_Y} # run best_position, personal_best_scores = run(position, velocity, personal_best_scores, personal_best_positions, best_position, search_space_x, search_space_y) # 時間計測終了 process_time = time.time() - start # Optimal solution print("Best Position:", best_position) print("Score:", min(personal_best_scores)) print("time:", process_time) if __name__ == '__main__': main()本当はシンプルなPSOと比較するところまでできればいいのですが、気力が尽きたのでここまでで、、、$w_{min}$の値を0.9に変更するだけでシンプルなPSOになるので興味があれば試してみてください。
まとめ
かなりアカデミックな記事になってしまいましたが、まとめると、
・PSOの重み$w$は最適解への収束に大きな影響を与える
・重みは主に3つのタイプがある
・最もよく使われる重みとして、時変する重みの一つである線形減少重みがある
となります。
このように、パラメータ一つでも様々な研究が行われているということを知っていただければ嬉しいです。
- 投稿日:2019-12-02T16:39:30+09:00
意外と知らない?pipコマンド
よく使うコマンドから、込み入ったコマンドまでを使用ケース毎に紹介します (追記予定)。
Case 1. 依存関係のケア
パッケージの依存関係で問題が生じて、スクリプトが上手く動作しない...。
(1) 依存関係の問題をチェックしましょう。
$ pip check(2) パッケージの要求されているバージョンが確認できたら、利用可能なバージョンを確認します。
$ pip install <package>== # ERROR: Could not find a version that satisfies the requirement <package>== (... # とエラーが出力され、利用可能なパッケージのバージョンが確認出来ます。(3) バージョンを指定してインストール
$ pip install <package>==<version> # 最新状態にしたい時は $ pip install -U <package> # とあるバージョン未満で最新の状態にしたい時は $ pip install -U "<package> < <version>" # 不等号 < を使ってます。インストール済みパッケージの依存関係を確認
パッケージの詳細と共に依存関係を確認するには
showを使います。$ pip show <package>
pipdeptreeパッケージを使うと、バージョン情報込みの依存関係を表示できます。$ pip install pipdeptree # <package>が要求するパッケージとそのバージョンを表示。 $ pipdeptree -p <packgage> # <package>を要求するパッケージと、要求されるバージョンの表示。 $ pipdeptree -r -p <packgage>Case 2. オフライン環境でパッケージをインストール
sshで接続した先でpip install <package>したいけど、接続先がオフライン!(1) 先ずはオンラインで、必要なパッケージを
./src直下にダウンロードします(バージョンを指定したい時は<package>==<version>としましょう)。$ pip download -d ./src <package> # or $ pip download -d ./src -r requirements.txt(2)
scpで./srcを転送。$ scp -r -C ./src <user>@<host>:<path> # 容量が大きい場合は圧縮して送ろう。 $ tar czf src.tar.gz src $ scp -c ./src.tar.gz <user>@<host>:<path>(3)
sshで接続後、srcディレクトリの中に入ります。以下のコマンドでインストール完了です!$ pip install <package (file name)> # カレントディレクトリから1つずつインストール。 # or $ pip install ./* # まとめてインストール。 # srcを圧縮した場合は、事前に解凍しましょう。 $ tar xzf src.tar.gz
pip downloadのあれこれソースパッケージをダウンロード。
$ pip download -d ./src --no-binary :all: <package>バージョンやプラットフォームを指定してバイナリパッケージをダウンロード。
$ pip download -d ./src --only-binary :all: --platform <platform> --python-version <python_version> --implementation <implementation> --abi <abi> <package>以下、参考ページです。
- pip download — pip 19.3.1 documentation
- pip download --platform --python-version does not work for some packages · Issue #6121 · pypa/pip
Case 3.
pip installの保存先を変えるとあるパッケージを試しに使ってみたいけど、グローバル、ローカルのpipを汚したくない。仮想環境を使う程ではないしな...。
(1) ディレクトリを指定してパッケージをインストール。
$ pip install -t <dir> <package>(2) スクリプトに以下の行を加えることで、
<dir>以下のパッケージが使用可能になります。import sys sys.path.append(dirpath) # パスの指定方法その1 import os dirpath = sys.path.append(os.path.join(os.path.dirname(__file__), '<dir>の相対パス')) # パスの指定方法その2 from pathlib import Path dirpath = sys.path.append(str((Path(__file__).parent/'<dir>の相対パス').resolve())) # パスの指定方法その3 dirpath = '<dir>の絶対パス'
dirpathに相対パスを書いても実行出来ますが、書いたスクリプトを他のスクリプトから呼び出す場合、__file__を用いるか、絶対パスでdirpathを指定する必要があります。(3) パッケージが要らなくなったらディレクトリを消去。
$ rm -r <dir>同じパッケージで異なるバージョンのものを使いたい
パッケージをインストールしたディレクトリ内でスクリプトを実行すれば、そのディレクトリ内のパッケージが優先してインポートされます。
ディレクトリの外でスクリプトを実行し、かつディレクトリ内のパッケージを優先的に使いたい場合は、パス追加後、次の一行を加えましょう。
sys.path = sys.path[::-1]
- 投稿日:2019-12-02T16:12:33+09:00
Pythonでつくるアイテム付きNumer0n
Qiitaへの投稿は2度目になります。よろしくお願いします。
今回は、かつて一世を風靡したあのゲーム「Numer0n」を、Pythonで実装しました。
1 Numer0nとは?
それぞれのプレイヤーが、0-9までの数字が書かれた10枚のカードのうち3枚を使って、3桁の番号を作成する。カードに重複は無いので「550」「377」といった同じ数字を2つ以上使用した番号は作れない。
先攻のプレイヤーは相手の番号を推理してコールする。相手はコールされた番号と自分の番号を見比べ、コールされた番号がどの程度合っているかを発表する。数字と桁が合っていた場合は「EAT」(イート)、数字は合っているが桁は合っていない場合は「BITE」(バイト)となる。
例として相手の番号が「765」・コールされた番号が「746」であった場合は、3桁のうち「7」は桁の位置が合致しているためEAT、「6」は数字自体は合っているが桁の位置が違うためBITE。EATが1つ・BITEが1つなので、「1EAT-1BITE」となる。
これを先攻・後攻が繰り返して行い、先に相手の番号を完全に当てきった(3桁なら3EATを相手に発表させた)プレイヤーの勝利となる。今回は、(3桁では満足できない皆様のためにも)桁数を指定できるプログラムを実装しました。
2 基本プログラム
Numer0n_Basic.py#Numer0n_Basic import random #お題となる番号が決められます proper = 0 while proper == 0: print("Digit?") #桁数を決めます D = int(input()) N = [] #桁数は1桁から10桁まででないといけません if 1 <= D <= 10: while len(N) < D: n = random.randint(0,9) if n in N: pass else: N.append(n) proper += 1 else: print("Improper.") #数当てゲーム開始 count = 1 eat = 0 bite = 0 while eat < D: print("Call " + str(count) ) call = input() #正しいCallのとき、判定を行います if len(call) == D and len(set(call)) == len(call): eat = 0 bite = 0 for i in range(D): for j in range(D): if str(N[i]) == call[j]: if i == j: eat += 1 else: bite += 1 if eat == D: print(str(D) + " EAT") #ONE CALL達成時のみ特別な演出を加えます if count == 1: print("ONE CALL") else: print("Numer0n in " + str(count) + " Calls") else: print(str(eat) + " EAT " + str(bite) + " BITE") count += 1 #Miss Callの場合の対応です else: print("Again!")桁数
Dを変えることによって、本家で登場した3桁や4桁の他、5桁以上の数字を当てるゲームにも挑戦できます。
基本的に自分が攻めるだけのゲームであるため、「何回で当てられたか」というCallの回数を表示することにより、スコアアタック的要素を加えています。目指せONE CALL!このプログラムでは、元の数字
Nはint型に、入力した数字callは文字列型になっており、比較の部分ではNを文字列型に直して判定を行っています。なんでこんな面倒なことをしているのかの理由は、このあと実装する「アイテム」のためです。3 アイテム
Numer0nがHit and Blowと一線を画する点は、アイテムの存在にあります。
Numer0nでは、攻撃や防御の手助けとなる様々なアイテムが存在します。
今回はそれらのうち、攻撃系アイテムの3つを実装していきます。3.1 HIGH & LOW
相手の全ての桁の数字が、それぞれ「HIGH (5-9)」「LOW (0-4)」のどちらかを知ることができる。相手は左の桁から順に宣言をさせられる(例:「809」ならば「HIGH (8)・LOW (0)・HIGH (9)」)。序盤ではある程度の番号を絞り込むことができ、終盤では番号の確定にも役立たせることができる。(Wikipedia)
全ての桁の数字を絞り込める強力なアイテム。3桁の場合、最初にHIGH & LOWを使うことで、悪くとも候補を720個から100個まで、うまくいけば60個まで絞り込むことができます。
このアイテムをPythonで実装するとこうなります。
high_and_low.py#HIGH and LOW N = [int(input()) for _ in range(3)] HL = "" for i in range(len(N)): if N[i] <= 4: HL += 'L ' else: HL += 'H ' print(HL)桁ごとに数字を入力すると、数字のHIGH/LOWを返します。
入力
5
2
9出力
H L H4との大小比較をするだけなので簡単ですね。
3.2 SLASH
相手が使っているナンバーの最大数から最小数を引いた「スラッシュナンバー」を訊くことができる。例として「634」ならば、最大数「6」−最小数「3」=スラッシュナンバー「3」となる。
もしスラッシュナンバーが「9」だった場合、最大数「9」・最小数「0」での可能性しかないため、0と9の使用が確定する。また、「2」だった場合は必然的に「012」「123」のような連続した3種類の数字で構成されることがわかる。使い方次第では大勢がわかる他、使わず持っているだけで「9と0の使用」や「連続数字の使用」などへの抑止力として使える。
考えられる数字の使用パターンを「バッサリ斬り捨てる」ことができることから名付けられた。(Wikipedia)こちらも相手の数字を一気に絞り込めるアイテム。HIGH & LOWよりも使い方が難しいですが、ここぞの場面で使うと一気に使用している数字を確定できます。とくに、引用部分にもあるように「9と0の併用」など、特定の並びに対しては効果抜群。
このアイテムをPythonで実装するとこうなります。
slash.py#SLASH N = [int(input()) for _ in range(3)] SN = max(N) - min(N) print(SN)桁ごとに数字を入力すると、その数字のスラッシュナンバーをを返します。
入力
5
2
9出力
7これもそうたいしたことはしてないですね。max関数最高!
ちなみに、スラッシュナンバーが7になるのは、「7,0とその間の数字」「8,1とその間の数字」「9,2とその間の数字」というパターンに絞られます。それまでののCallの結果によってはここからより可能性を消していくこともできます。3.3 TARGET
10種類の番号のうち1つを指定して相手に訊くことができる。その番号が相手の組み合わせに含まれている場合は、どの桁に入っているかも判明する。
特に「含まれていることはわかるがどの桁かはわからないBITE状態の数字」を指定すれば、桁のありかを確実に知ることができる。逆に、訊いた数字が含まれていなければ、他の数字を使うことで絞り込みができる。(Wikipedia)ゲーム中盤から終盤で使われるアイテムです。残り少ない可能性からの絞り込みに有効です。
このアイテムをPythonで実装するとこうなります。
target.py#TARGET N = [int(input()) for _ in range(3)] TN = int(input()) judge = 0 for i in range(len(N)): if N[i] == TN: print("Place " + str(i+1)) judge = 1 if judge == 0: print("Nothing.")数字を入力、さらに10種類の数字から
TN(これはTARGET NUMBERの略)をひとつ入力すると、含まれている場合はその位置(左から何番目か)、含まれていない場合はNothing.を返します。入力
5
2
9ターゲットナンバー1
2出力1
Place 2ターゲットナンバー2
7出力2
Nothing.breakを使ってもいいのですが、高々ループを10回回せばいいだけなので別にいいですね。
4 アイテムつきNumer0n
上記3つのアイテムを組み込んだ、Numer0nのプログラムがこちらです。
ルールとして、
- アイテムはどれか一つのみが一回だけ使えます。
- アイテムの使用はCallの回数に入りません。例えば、はじめにSLASHを使用し、次のCallで数字を当てられた場合はONE CALLとなります。
Numer0n_Item.py#Numer0n_Item import random #お題となる番号を決めます proper = 0 while proper == 0: print("Digit?") #桁数が決められます D = int(input()) N = [] #桁数は1桁から10桁まででないといけません if 1 <= D <= 10: while len(N) < D: n = random.randint(0,9) if n in N: pass else: N.append(n) proper += 1 else: print("Improper.") #数当てゲーム開始 count = 1 eat = 0 bite = 0 #アイテムは合計1回までしか使えません item = 1 while eat < D: print("Call " + str(count) ) call = input() #正しいCallのとき、判定を行います if len(call) == D and len(set(call)) == len(call): eat = 0 bite = 0 for i in range(D): for j in range(D): if str(N[i]) == call[j]: if i == j: eat += 1 else: bite += 1 if eat == D: print(str(D) + " EAT") #ONE CALL達成時のみ特別な演出を加えます if count == 1: print("ONE CALL") else: print("Numer0n in " + str(count) + " Calls") else: print(str(eat) + " EAT " + str(bite) + " BITE") count += 1 #HIGH AND LOW elif call == "HIGH AND LOW": if item == 1: HL = "" for i in range(len(N)): if N[i] <= 4: HL += 'L ' else: HL += 'H ' print(HL) item = 0 else: print("Already used.") #SLASH elif call == "SLASH": if item == 1: SN = max(N) - min(N) print(SN) item = 0 else: print("Already used.") #TARGET elif call == "TARGET": if item == 1: print("TARGET Number?") TN = int(input()) judge = 0 for i in range(len(N)): if N[i] == TN: print("Place " + str(i+1)) judge = 1 if judge == 0: print("Nothing.") item = 0 else: print("Already used.") #Miss Callの場合の対応です else: print("Again!")
callを文字列型で受け取ったのは、アイテムの名前を宣言してアイテムを使えるようにしたかったのが主な理由でした。
TARGETとTarget,targetなどの表記ゆれには対応できませんがまあそれは許して。5 感想
Qiita記事にもPythonでNumer0nを実装していた方は多かったのですが、アイテムの実装がなかったので自分でやってみました。割とうまくいったのでよかったです。
人対人のゲームにしても面白そうですね。そうすると今回は実装しなかったDOUBLE, SHUFFLE, CHANGEの存在意義も生えそうです。単純にめんどくなりそうなのと、相手に出力を見られたら困るのでそこらへんの実装が苦しそうなのが課題。
CPUが攻めもやるゲームはさすがに僕の実力では厳しそうなのでだれか興味ある人がいたらやってください。
遊んでみた感想、改善点の指摘などのコメントお待ちしております。
それでは。
- 投稿日:2019-12-02T15:59:01+09:00
Pythonによる機械学習の基本的な流れのまとめ
最近,機械学習について勉強したので,Pythonで実装する際にどういった手順で行うかについてまとめておきました
データの前処理
機械学習ではまずデータを読み込んだり,どういった分布をしているのかといったことを知っておく必要があります.その手順について書いていきます
データの読み込み
データを実際に読み込むために,先程読み込んだpandasのread_csvというメソッドを使いcsvファイルを読み込みます
#ライブラリの読み込み import pandas as pd import numpy as np #直下にあるhoge.csvを読み込む df = pd.read_csv("./hoge.csv") #上から5行のみを取り出す df.head()読みこんだデータの確認
機械学習というと,データを突っ込めばなんとかしてくれるというイメージがありますが実際にはデータをしっかり見る必要があります
例えば,欠損値がないかやバラつきが大きすぎないか,相関があるかといったことです基本統計量
以下のコードを入力することで,データの数,平均値,標準偏差,最小値,最大値といったものが一気にわかります
#統計量の算出 df.describe()こんな感じで基本統計量が一覧でわかります
分布の確認
といっても標準偏差や平均値といった数字を見るだけではわかりづらいので,グラフにしたほうが人間にとってはわかりやすいです そのため分布を表します
%matplotlib inline #seabornというグラフを表示するライブラリの読み込み import seaborn as sns #分布の確認 sns.distplot(df["x1"]) #先にデータを確認する(ここでは列x1のデータを確認)これはデータが正規分布に従っていそうなのでいい感じのデータです
相関係数の確認
もし全く相関関係のないデータであれば,学習させたところで意味はないので相関係数を確認します.ちなみに相関係数は-1から+1の間で,高ければ高いほど相関があるということになります
#相関係数の算出 df.corr() #相関係数をグラフで確認 sns.pairplot(df)入力変数と出力変数の切り分け
実際には$ y = w0x0 + w1x1 + w2x2 +...+$というようなものを作るわけなので,データの中身を出力変数であるyと入力変数であるxに分ける必要があります
その際に使うのがpandasのilocというメソッドです#df.iloc[行,列]とすることでその行と列のデータを取り出せる 例 example = df.iloc[1,3] 結果 100 #最後の列-1まですべての行を取り出す(入力変数X) X = df.iloc[:,:-1] #こう書いてもいいが汎用性は低い X = df.iloc[:,:最後の列番号] #yを取り出す y = df.iloc[:,-1]前処理したデータを使って機械学習をする
上の作業をすることで機械学習を実際に行う下準備はできました.次から実際に学習を行っていきます.ここでは機械学習ライブラリのscikit-learnを使います.
訓練データと検証データに分ける
機械学習を行う目的はデータを学習させ,未知のデータを入れたときに予測するというものでした つまり,学習に用いたデータは使わないということです
当たり前ですが,学習に用いたデータを入れて予測を行えば,そのデータで学習したんだから,正確な答えが出るよね?ってことになりますそのため,学習をさせる前に訓練データ(train)と検証データ(test)に分ける必要があります
from sklearn.model_selection import train_test_split #訓練データと検証データの分割 X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.4,random_state=1)testsizeは訓練データと検証データの割合を指定しており,ここでは学習:訓練=6:4としています またrandom_stateは固定にすることで再現性を保っています
モデル構築・検証
scikit-learnを使えば以下のコードのみでモデルの構築から検証まで行えます
今回学習に使うモデルは重回帰分析です#ライブラリのインポート from sklearn.linear_model import LinearRegression #モデルの宣言(LinearRegressionは重回帰分析という意味) model = LinearRegression() #モデルの学習(パラメータの調整をする) model.fit(X,y) #パラメータの確認 model.coef_ #決定係数(予測の精度)0~1の間で高いほどいい model.score(X,y) #予測値の計算 x = X.iloc[0,:] #Xの一行目を取り出し y_pred = model.predict([x])モデルの保存・読み込み
モデルの保存は以下のコードで出来ます
#インポート from sklearn.externals import joblib #モデルの保存(hoge.pklという名前で保存 joblib.dump(model,"hoge.pkl")モデルの読み込みは以下のコードで行います
#hoge.pklの読み込み model_new = joblib.load("hoge.pkl") #読み込んだモデルの予測値を表示 model_new.predict([x])[0]以上が機械学習の基本的な流れになっています 今回はモデルを重回帰分析で行いましたが,例えばロジスティック回帰で行いたいとかSVMで行いたいといった時も基本的な流れは同じです
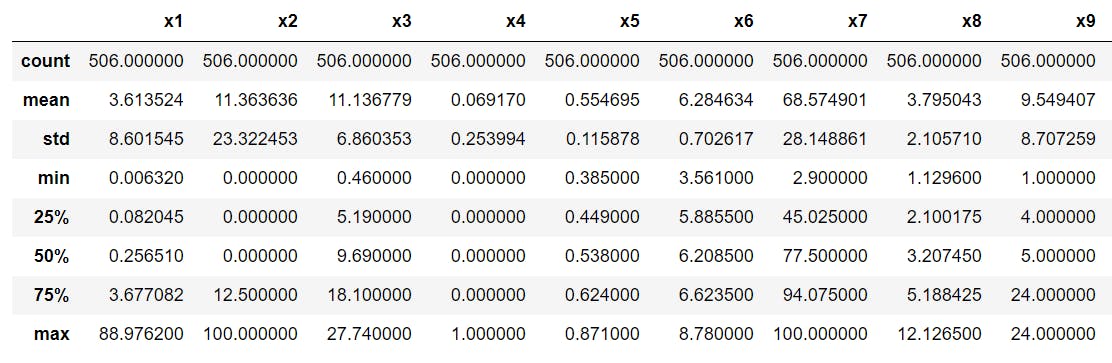
- 投稿日:2019-12-02T15:49:06+09:00
Dockerコンテナ内でKaggle APIをつかう
やること
- Kaggle公式イメージ(kaggle/python)をつかってコンテナ起動
kaggle ~コマンドでcsvファイルをダウンロードするkaggle ~コマンドで公開notebookをダウンロードするまずはまとめ
kaggle.jsonをDL (kaggle.com > My Account > Create New API Tokenボタン)$ docker run -it --rm --mount type=bind,src=pwd,dst=/root/dev kaggle/python$ pip install kaggle$ mkdir ~/.kaggle$ cp /root/dev/kaggle.json ~/.kaggle$ chmod 600 ~/.kaggle/kaggle.json$ kaggle competitions download -c titanic -p input/titanic$ unzip input/titanic/titanic.zip input/titanic$ kaggle kernels pull arthurtok/introduction-to-ensembling-stacking-in-python -p ./データセットはタイタニックコンペのものをダウンロードしてます
問題なく動いた方はここで閉じでもらって大丈夫です環境
macOS 10.14.6 (Mojave)
Docker 19.03.4なんでdockerつかうの?
- VSCodeでコード書きたい
- グローバル環境を汚しなくない
- pipとcondaの競合コワイ
- pipenv ✕ xgboostでつまった
- Kaggle公式イメージがあるので安心
Kaggle APIってなにさ?
Kaggleのサイト上でやってる操作をコマンドラインでできちゃうやつ
たとえば?
- データセットのダウンロード
- サブミット
- 参加可能コンペを一覧表示
- リーダーボードをダウンロード
などなど…
詳しくは公式リポジトリを
コマンド一覧kaggle competitions {list, files, download, submit, submissions, leaderboard} kaggle datasets {list, files, download, create, version, init} kaggle kernels {list, init, push, pull, output, status} kaggle config {view, set, unset}こんな構成をつくっておきます
kaggle_titanic ├── input │ └── titanic <- ここにcsvファイルをダウンロードできれば勝ち └── working <- ここにipynbファイルをダウンロードできれば優勝Kaggle API Tokenを取得
右上のMy Accountから
真ん中くらいにあるこれをポチ
kaggle.jsonがダウンロードされるのでkaggle_titanicディレクトリに保存しておく
中身はこんなかんじkaggle.json{"username":"anata_no_namae","key":"xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"}ちなみに
こっちでトークンを無効化できます
「まちがえてGitHubにkaggle.jsonもプッシュしちまった!」みたいな時が押し時
コンテナ起動
Kaggleの公式イメージ
kaggle/pythonをつかう
kaggle_titanicディレクトリで以下のコマンドdocker run -it --rm --mount type=bind,src=`pwd`,dst=/root/dev kaggle/pythonオプションの説明なんかはココに書いているのでもしよろしければ
-> 【画像で説明】DockerでAnaconda環境をつくり、コンテナの中でVSCodeを使うここからはコンテナ側のシェルで
マウントしたディレクトリに移動
cd /root/dev中身が同期されてればOK
ls input kaggle.json workingkaggleパッケージをインストール
pip install kaggleちゃんと動くかバージョン確認してみる
kaggle -v Traceback (most recent call last): File "/opt/conda/bin/kaggle", line 7, in <module> from kaggle.cli import main File "/opt/conda/lib/python3.6/site-packages/kaggle/__init__.py", line 23, in <module> api.authenticate() File "/opt/conda/lib/python3.6/site-packages/kaggle/api/kaggle_api_extended.py", line 149, in authenticate self.config_file, self.config_dir)) OSError: Could not find kaggle.json. Make sure it's located in /root/.kaggle. Or use the environment method.めっちゃ怒ってきよる
kaggle.jsonが見当たらんみたいなこと言ってますねkaggle.jsonを配置
~/.kaggle/ディレクトリをつくってその中にkaggle.jsonをコピーします
$ kaggle -vのタイミングで~/.kaggle/ディレクトリが作られている場合がありますmkdir ~/.kaggle # <- すでにディレクトリあるよーっていわれるかもしれないけど問題ありません cp /root/dev/kaggle.json ~/.kaggle今度こそ
kaggle -v Warning: Your Kaggle API key is readable by other users on this system! To fix this, you can run 'chmod 600 /root/.kaggle/kaggle.json' Kaggle API 1.5.6一応つかえるけど、まだ怒ってるな
他のユーザーにもAPI Keyが読めちゃうから権限変えなさいって権限変更
chmod 600 ~/.kaggle/kaggle.json次こそは
kaggle -v Kaggle API 1.5.6ふぅ
毎回やるのめんどい
ここの一連の処理はまとめてセルで実行してもいいかもです
ファイル化して使い回すって作戦もありますkaggle_settings.ipynb!pip install kaggle !mkdir ~/.kaggle !cp /root/dev/kaggle.json ~/.kaggle !chmod 600 ~/.kaggle/kaggle.jsonそれではデータのダウンロード
-cでコンペ名指定
-p保存先パス指定kaggle competitions download -c titanic -p input/titanic
titanic.zipがダウンロードされるls input/titanic titanic.zip
※ コンペ名はURL上の表記をつかう
例えばSeverstal: Steel Defect Detectionコンペであればコレ
解凍
ダウンロードした
titanic.zipを解凍unzip input/titanic/titanic.zip input/titanicls input/titanic gender_submission.csv test.csv titanic.zip train.csvこれでデータセットのダウンロードはOK
次はnotebookをpullしてみる
notebookの表記はここ
kaggle kernels pull arthurtok/introduction-to-ensembling-stacking-in-python -p ./workingls ./working introduction-to-ensembling-stacking-in-python.ipynbちゃんとpullされているので優勝
VSCodeをあわせてつかうと便利かも
インテリセンスや自分キーバインドなどでコード書けるのがいい
【画像で説明】DockerでAnaconda環境をつくり、コンテナの中でVSCodeを使う
おしまい
最後まで読んで頂いてありがとうございました




- 投稿日:2019-12-02T15:43:31+09:00
時間のない人のためのpyenv@Catalina
「Catalinaからzshがデフォルトになって、どうやったらいいかわかんねーよ。能書きはいいからインストールの仕方だけ教えろよ。」っていう、時間のない人の為に、5行でできるpyenv@Catalina(10.15.1)講座。
Homebrewインストール
$ /usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"pyenvインストール
$ brew install pyenv $ echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.zshenv $ echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.zshenv $ echo -e 'if command -v pyenv 1>/dev/null 2>&1; then\n eval "$(pyenv init -)"\nfi' >> ~/.zshenvまとめ
以上、Homebrewからpyenvのインストールまで5行でできます。.bash_profileが.zshenvに置き換わるだけです。
参考