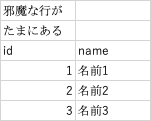
Selenium::WebDriver::Error::UnknownError:
unknown error: session deleted because of page crash
from unknown error: cannot determine loading status
from tab crashed
constMyCounter=require('./my_counter');counter=newMyCounter(0);counter.print();counter.name='John Doe';constcurrentName=counter.name;console.log('Current Name='+currentName);constcurrentValue=counter.addCount(10);console.log('Current Value='+currentValue);counter.print();MyCounter.createGlobalCounter('JavaScript was born from Netscape Navigator 2.0',256);MyCounter.global_counter.print();
実行結果
$ node my_main.js
No Name: 0
Current Name=John Doe
Current Value=10
John Doe: 10
JavaScript was born from Netscape Navigator 2.0: 256
frommy_counterimportMyCountercounter=MyCounter(0)counter.print()counter.name="John Doe"current_name=counter.nameprint("Current Name={}".format(current_name))current_value=counter.add_count(10)print("Current Value={}".format(current_value))counter.print()MyCounter.create_global_counter("Batteries included. Beautiful is better than ugly.",256)MyCounter.global_counter.print()
実行結果
$ python my_main.py
No Name: 0
Current Name=John Doe
Current Value=10
John Doe: 10
Batteries included. Beautiful is better than ugly.: 256
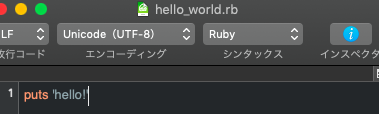
require'./my_counter'counter=MyCounter.new(0)counter.printcounter.name='John Doe'current_name=counter.nameputs"Current Name=#{current_name}"current_value=counter.add_count(10)puts"Current Value=#{current_value}"counter.printMyCounter.create_global_counter('Everything is an object in Ruby',256)MyCounter.global_counter.print
$ ruby my_main.rb
No Name: 0
Current Name=John Doe
Current Value=10
John Doe: 10
Everything is an object in Ruby: 256
「Windows Subsystem for Linux上のUbuntu上のRuby」のメモです。やったのは下記。
Windows 10でWSL(Windows Subsystem for Linux)を有効化してUbuntuインストール
Ubuntu上でrbenvインストール
rbenvを使ってRubyインストール
bundlerを使ってgem(ライブラリ)インストール
ローカルにRuby環境を整えておこうと思ったのだけど、これまでよく使っていたPerlではWindows固有の問題で手間取ることがあったので、「Windows版Ruby」「Windows Subsystem for Linux上のUbuntu上のRuby」の両方を用意することにしました。これは後者の作業メモということになります。
[コントロールパネル]-[アプリ]-[プログラムと機能]-[Windowsの機能]ダイアログを開き、[Windowsの機能の有効化または無効化]をクリックしてダイアログを開き、そこで「Windows Subsystem for Linux」にチェックを入れる。再起動が要求されるので、再起動を実行すること。
PG::DatatypeMismatch: ERROR: argument of WHERE must be type boolean, not type integer
LINE 1: SELECT "users".* FROM "users" WHERE (1) LIMIT $1
: SELECT "users".* FROM "users" WHERE (1) LIMIT $1):
app/controllers/posts_controller.rb:89:in `follows'
# Factory block take a container as argumentcontainer[:new_user]do|c|# You can get the service object by calling Container#[](service_name)NewUserService.new(c[:user_repository])end
ブロックなしでよびだす、いい感じに動く。
app.rb
new_user=container[:new_user].call("hanachin")# => #<struct User name="hanachin">
# Using container as refinements for shorthand for container.newusingcontainer.to_refinementsnew_user=NewUserService.new.call("hanachin")# => #<struct User name="hanachin">
moduleHabumoduleAnnotationCollectorHelperrefine(RubyVM::AbstractSyntaxTree::Node)dodefdeconstruct[type,*children]enddefeach_constructor_annotations(&block)klass_name=nilinject_annotation_found=falsetraversedo|ast|caseastin:CLASS,[:COLON2,nil,klass_name],*_# TODO: Support namespacein:IVAR,:@Injectinject_annotation_found=truein:DEFN,:initialize,*_ifinject_annotation_found==trueblock.call(klass_name)inject_annotation_found=falseelseinject_annotation_found=falseendendendendendend