- 投稿日:2019-05-29T23:50:33+09:00
Enhancing the Spatial Resolution of Stereo Images using a Parallax Prior(再現実装)
論文
【タイトル】 Enhancing the Spatial Resolution of Stereo Images using a Parallax Prior (CVPR2018)
【概要】
- Stereo Imageを用いた超解像手法の提案
- 白黒画像の生成→カラー画像の生成のtwo stage学習
- 視差を表現したシフト画像の利用
開発環境
- Windows10
- Pytorch
データセット
Flickr1024: A Dataset for Stereo Image Super-resolution (https://yingqianwang.github.io/Flickr1024/)
ソースコード
- 投稿日:2019-05-29T23:50:33+09:00
ステレオ画像における深層学習超解像:Enhancing the Spatial Resolution of Stereo Images using a Parallax Prior(再現実装)
論文
【タイトル】 Enhancing the Spatial Resolution of Stereo Images using a Parallax Prior (CVPR2018)
【概要】
- Stereo Imageを用いた超解像手法の提案
- 白黒画像の生成→カラー画像の生成のtwo stage学習
- 視差を表現したシフト画像の利用
開発環境
- Windows10
- Pytorch
データセット
Flickr1024: A Dataset for Stereo Image Super-resolution (https://yingqianwang.github.io/Flickr1024/)
ソースコード
- 投稿日:2019-05-29T18:25:50+09:00
MFCC(メル周波数ケプストラム係数)入門
MFCCとは
MFCCは聴覚フィルタに基づく音響分析手法で、主に音声認識の分野で使われることが多いです。
最近だとニューラルネットワークに学習させる音声特徴量としてよく使われていますね。
2019.5.29訂正
Deep Learning for Audio Signal ProcessingによるとDeep Learningにおいては必要な情報が失われるためMFCCは使わずに、最後の計算ステップである離散コサイン変換を省いたメルスペクトラム(log-mel spectrum)が使われるそうです。MFCCは従来手法である隠れマルコフモデル、混合ガウスモデル、サポートベクターマシンで使われることが多いです。今回はMFCC「メル周波数」や「ケプストラム」についても説明し、具体的なMFCCの実装方法も見ていきたいと思います。
メル尺度
心理学者のStanley Smith Stevensらによって提案された、人間の音高知覚が考慮された尺度です。
1000Hzの純音の高さの感覚を1000メルと決めた上で、1000メルの半分の高さに感じた音を500メル、1000メルの2倍の高さに感じた音を2000メルという容量で定めたものです。
実験により、可聴域の下限に近い音は高め、上限に近い音は低めに聞こえることがわかっています。
メル尺度は基底膜上の座標とほとんど一致します。1000メルは基底膜の1cmに相当し、臨海帯域幅は約137メルに相当します。
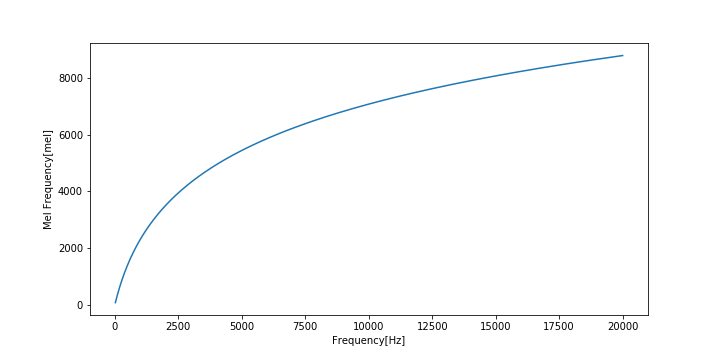
周波数$f$をメル尺度$m$に変換する式は
m = m_0\log(\frac{f}{f_0} + 1)逆変換は
f = f_0(\exp\frac{m}{m_0} - 1)で与えられます。
$f_0$は自由パラメータの周波数パラメータであり、$m_0$は「1000Hzは1000メル」という成約から導かれる
m_0 = \frac{1000}{\log(\frac{1000\mathrm{Hz}}{f_0} + 1)}であらわされる縦続パラメータです。
よく用いられるパラメータとして
f_0 = 700, m_0 = 2595があります。
周波数[Hz]とメル周波数[mel]の関係をグラフに表すとこのようになります。
ケプストラム
音声信号のフーリエ変換の絶対値に対数をかけ、さらに逆フーリエ変換(フーリエ変換とする場合もある)したもの。
信号$x(n)$のフーリエ変換を$X(e^{j\omega}$とすると、ケプストラム$c(m)$は
c(m) = \frac{1}{2\pi}\int_{\pi}^{\pi}\log|X(e^{j\omega})|e^{j\omega n}d\omega高ケフレンシ領域は微細振動(音声でいうと声帯の振動)、低ケフレンシ領域はスペクトル包絡(音声でいうと声道フィルタの特性)を表します。
リフタリングという処理を施すことによってこれらを分離することができます。
変換手順
この記事を参考にしながら実際に変換してみます。
コードはほぼそのままですが、Python3対応させたり、変数名やパラメータをちょこちょこ変えたりしてます。
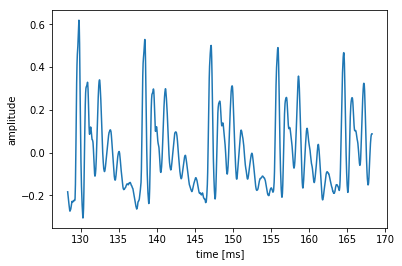
今回は「あ」の音声波形の定常部分のMFCCを求めてみましょう。(音声ファイルは各自用意してください。)
まずは必要なモジュールのインポートから
import numpy as np import matplotlib.pyplot as plt import soundfile as sf1. 波形を適当な長さに分割し、窓関数をかけてFFTを行う
# 音声の読み込み master, fs = sf.read('wavfiles/a_1.wav') t = np.arange(0, len(master) / fs, 1/fs) # 音声波形の中心部分(定常部)を切り出す center = len(master)//2 # 中心のサンプル番号 cuttime = 0.04 # 秒 x = master[int(center - cuttime / 2 * fs):int(center + cuttime / 2 * fs)] time = t[int(center - cuttime/2*fs): int(center + cuttime/2*fs)] plt.plot(time * 1000, x) plt.xlabel("time [ms]") plt.ylabel("amplitude") plt.show()上のコードを実行するとこのようなグラフが描けます。
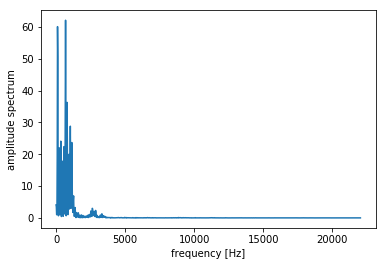
次に窓処理を行って振幅スペクトルを求めます。
# ハミング窓をかける hamming = np.hamming(len(x)) x = x * hamming # 振幅スペクトルを求める N = 2048 # FFTのサンプル数 spec = np.abs(np.fft.fft(x, N))[:N//2] fscale = np.fft.fftfreq(N, d = 1.0 / fs)[:N//2] plt.plot(fscale, spec) plt.xlabel("frequency [Hz]") plt.ylabel("amplitude spectrum") plt.show()
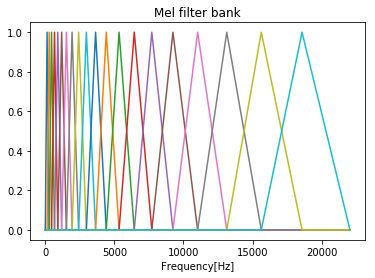
2.メルフィルタバンクをかける
フィルタバンクは複数のバンドパスフィルタを並べたものです。
MFCCでは三角形のバンドパスフィルタをオーバラップさせながら並べ、フィルタバンクとしたメルフィルタバンクを用います。
メルフィルタバンクは周波数領域での三角窓がメル尺度上で等間隔になるように並べたものであり、低周波ほど幅が狭く、高周波ほど幅が広くなります。
並べられたバンドパスフィルタの数をチャンネル数といいます。
まずは周波数とメル尺度を変換する関数を実装します。
def hz2mel(f): """Hzをmelに変換""" return 2595 * np.log(f / 700.0 + 1.0) def mel2hz(m): """melをhzに変換""" return 700 * (np.exp(m / 2595) - 1.0)次にメルフィルタバンクを作る関数を実装します。
def melFilterBank(fs, N, numChannels): """メルフィルタバンクを作成""" # ナイキスト周波数(Hz) fmax = fs / 2 # ナイキスト周波数(mel) melmax = hz2mel(fmax) # 周波数インデックスの最大数 nmax = N // 2 # 周波数解像度(周波数インデックス1あたりのHz幅) df = fs / N # メル尺度における各フィルタの中心周波数を求める dmel = melmax / (numChannels + 1) melcenters = np.arange(1, numChannels + 1) * dmel # 各フィルタの中心周波数をHzに変換 fcenters = mel2hz(melcenters) # 各フィルタの中心周波数を周波数インデックスに変換 indexcenter = np.round(fcenters / df) # 各フィルタの開始位置のインデックス indexstart = np.hstack(([0], indexcenter[0:numChannels - 1])) # 各フィルタの終了位置のインデックス indexstop = np.hstack((indexcenter[1:numChannels], [nmax])) filterbank = np.zeros((numChannels, nmax)) print(indexstop) for c in range(0, numChannels): # 三角フィルタの左の直線の傾きから点を求める increment= 1.0 / (indexcenter[c] - indexstart[c]) for i in range(int(indexstart[c]), int(indexcenter[c])): filterbank[c, i] = (i - indexstart[c]) * increment # 三角フィルタの右の直線の傾きから点を求める decrement = 1.0 / (indexstop[c] - indexcenter[c]) for i in range(int(indexcenter[c]), int(indexstop[c])): filterbank[c, i] = 1.0 - ((i - indexcenter[c]) * decrement) return filterbank, fcenters # メルフィルタバンクを作成 numChannels = 20 # メルフィルタバンクのチャネル数 df = fs / N # 周波数解像度(周波数インデックス1あたりのHz幅) filterbank, fcenters = melFilterBank(fs, N, numChannels) # メルフィルタバンクのプロット for c in np.arange(0, numChannels): plt.plot(np.arange(0, N / 2) * df, filterbank[c]) plt.title('Mel filter bank') plt.xlabel('Frequency[Hz]') plt.show()
次に振幅スペクトルにメルフィルタバンクをかけます。
振幅スペクトルに対して作成した各フィルタバンクをかけ、フィルタリングされた振幅を足し合わせて対数を取ります。
forループを使って書いてもいいですが、内積の形でも書け、こっちの方がエレガントです。
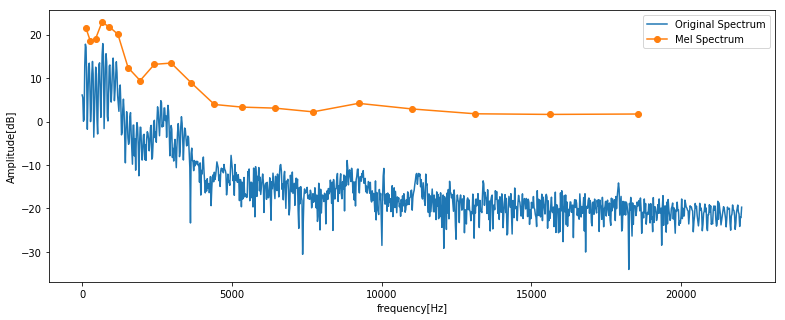
# 振幅スペクトルにメルフィルタバンクを適用 mspec = np.dot(spec, filterbank.T)元の振幅スペクトルとフィルタバンクをかけた後のスペクトルを比べてみましょう。
# 元の振幅スペクトルとフィルタバンクをかけて圧縮したスペクトルを表示 plt.figure(figsize=(13, 5)) plt.plot(fscale, 10* np.log10(spec), label='Original Spectrum') plt.plot(fcenters, 10 * np.log10(mspec), "o-", label='Mel Spectrum') plt.xlabel("frequency[Hz]") plt.ylabel('Amplitude[dB]') plt.legend() plt.show()
3.離散コサイン変換を行う
メルフィルタバンクをかけた後のスペクトルをケフレンシ空間に戻すために離散コサイン変換を行います。
離散コサイン変換を行う理由として、係数間の相関が減り、特徴量としての性能が向上するなどがあります。
離散コサイン変換の結果から低次の係数を取り出すと、MFCCが得られます。大体12次まで取ることが多いです。
from scipy.fftpack.realtransforms import dct ceps = dct(mspec, type=2, norm="ortho", axis=-1) nceps = 12 mfcc = ceps[:nceps] print(mfcc) [185.60782114 200.56668729 92.15345128 1.16538975 -47.4746488 -60.60365351 -43.46459693 3.15481979 50.37136343 64.6038092 48.42430931 27.41620554]LibrosaでMFCCを求める
上では音声データ全体の中の1フレームのみを用いてMFCCを求めましたが、Librosaを使うと簡単に各フレームごとのMFCCを求めることができます。
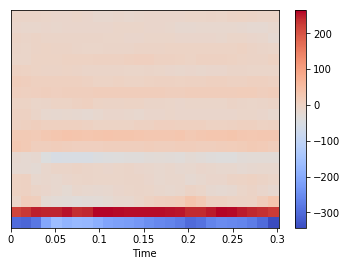
import librosa x, fs = sf.read('wavfiles/a_1.wav') mfccs = librosa.feature.mfcc(x, sr=fs) print(mfccs.shape) print(mfccs[0]) (20, 26) [-299.48698558 -306.19008252 -281.77019349 -205.61561205 -165.07338147 -182.40750356 -172.10454081 -175.49027956 -191.51493931 -210.77326972 -217.29547751 -223.91082068 -232.23909119 -247.65589292 -256.91669445 -263.66001621 -275.46132992 -299.72892089 -288.90436044 -262.39782466 -252.39945491 -256.61596037 -260.47453287 -274.17839766 -299.54783037 -342.87809203]カラーマップで可視化することも出来ます。
import librosa.display librosa.display.specshow(mfccs, sr=fs, x_axis='time') plt.colorbar()
おわりに
今回はMFCCに入門してみました。
GitHubにJupyter Notebookを置いていますので、よかったらこちらもどうぞ。https://github.com/tmtakashi/signal_processing/blob/master/mfcc.ipynb
参考
音楽と機械学習 前処理編 MFCC ~ メル周波数ケプストラム係数
- 投稿日:2019-05-29T12:14:31+09:00
【爆速】OpenCVで複数の物体検出 -ラズパイ-
「背景差分で物体検出をしてみた」の記事が面白くて、「複数の物体」でも
検出できるのか検証してみました。ディープラーニングを使わずに、ラズパイで複数の「物体検出」を
— shinmura0 (@shinmura0) 2019年5月24日
実装しました。OpenCVを使っております。 pic.twitter.com/5DQjPO1sfHはじめに
きっかけは、ラズパイで2つのディープラーニングモデルを動かしていたときのこと。
予想通り、速度は激遅で使いものになりませんでした。そのため、OpenCVで物体検出できないか?と考え実装してみました。
本稿では、ディープラーニングを使わないOpenCVによる複数の物体検出を行ってみます。
OpenCVによる物体検出
まずは、背景写真を用意します。
そして、フィルターによる前処理を行います。
import cv2 img1 = cv2.imread("background.jpg") img1 = cv2.GaussianBlur(img1, (5, 5), 0)次に、物体検出させたい写真を用意します。
同じく前処理をしておきます。
img1 = cv2.imread("test.jpg") img2 = cv2.GaussianBlur(img2, (5, 5), 0)そして、OpenCVの機能で物体検出をさせます。
fgbg = cv2.bgsegm.createBackgroundSubtractorMOG() fgmask = fgbg.apply(np.uint8(img1)) fgmask = fgbg.apply(np.uint8(img2))cv2.imshow(fgmask)
恐ろしく簡単に検出することができました。
しかも、爆速です。k-means法によるクラスタリング
次に得られたモノクロマップで物体を分割します。
今回は、k-means法によるクラスタリングを行います。
本当は混合ガウス分布の方が良いのですが、処理を少しでも軽くするために
k-means法(正確にはk-means++)を使います。得られたマップに対し、k-means法を適用します。
from sklearn.cluster import KMeans Y, X = np.where(fgmask > 200) y = KMeans(n_clusters=2, random_state=0).fit_predict(np.array([X,Y]).T)これも爆速で実行することができます。
一応可視化します。
import matplotlib.pyplot as plt plt.scatter(X, -Y+288, c=y) plt.xlim(0,288) plt.ylim(0,288) plt.show()
あとは、クラスタに合わせてバウンディングボックスを作ります。
def get_x_y_limit(Y, X, result, cluster): NO = np.where(result==cluster) x_max = np.max(X[NO]) x_min = np.min(X[NO]) y_max = np.max(Y[NO]) y_min = np.min(Y[NO]) x_max = int(x_max) x_min = int(x_min) y_max = int(y_max) y_min = int(y_min) return x_min, y_min, x_max, y_max def bounding_box(img, x_min, y_min, x_max, y_max): img = cv2.rectangle(img, (x_min, y_min), (x_max, y_max), (0, 255, 0), 5) return imgx_min, y_min, x_max, y_max = get_x_y_limit(Y, X, y, 0) img2 = bounding_box(img2, x_min, y_min, x_max, y_max) x_min, y_min, x_max, y_max = get_x_y_limit(Y, X, y, 1) img2 = bounding_box(img2, x_min, y_min, x_max, y_max)cv2_imshow(img2)
注目すべきは「矢印」の部分。
影が映り込んでいるのにも関わらず、検出されない点が素晴らしいです。単に背景写真と差分をとると、どうしても影が検出されてしまうのですが、
ここは天下のOpenCV、さすがです!制約
ただし、本手法は制約があります。
それは、「物体が一つでも必ず複数に分割されてしまう」ということです。具体例を挙げます。
今回は手を二つ認識させたいため、クラスタリングの数を「2」に設定します。
手が二つある写真は、先ほど見ていただいたとおり、手が別々に検出されます。
ところが、手が一つの写真を入れても二つの物体が検出されてしまいます。
ここはk-means法を使っている以上、しょうがないところです。
また、k-means法は特性上、距離が近いものを同じ物体と認識します。
従って、よく言われる半月が重なったような形状ではうまく検出することが
できません。「物体数が決まっていない」、もしくは「複雑な形状を検出したい」場合は、
DBSCANを使うと良いかもしれません。ラズパイで実行
ラズパイでリアルタイムに動かすコードはこちらに置きました。
main_opencv.pyを実行し、「p」キーを押せば、以下のようにリアルタイムで
検出することができます。ディープラーニングを使わずに、ラズパイで複数の「物体検出」を
— shinmura0 (@shinmura0) 2019年5月24日
実装しました。OpenCVを使っております。 pic.twitter.com/5DQjPO1sfH本気を出せば、13FPSくらいになります。
終了したい場合は、「q」キーを押してください。ただし、単にopencvをインストールしただけだと動かず、以下のようにラズパイで
cotribをインストールする必要がありました。sudo -H pip3 install opencv-contrib-python==3.4.3.18バージョンはお好みで指定してください。
まとめ
- ラズパイでも、OpenCVを使えば爆速で複数の物体検出ができる。
- ただし、固定カメラ限定で、かつ事前に検出したい物体数を決めておく必要がある。
- 本技術を応用すれば、物体検出で必要なアノテーションデータも手軽に作成することができる。







- 投稿日:2019-05-29T11:36:14+09:00
GPT-2で作るJoke BotからSlack Botまで
イントロダクション
こんにちわ!このシリーズではOpenAIが出したGPT-2でJokeを生成して最終的にSlackでジョークを出せるようにしたいと思います。これは前回のシリーズGPT-2で日本語生成とは違い、学習終了のところまではできていますので先にこれから始める予定です。
GPT-2とは
OpenAIのGPT-2は文章を出力する機械学習のアルゴリズムであり、フェイクニュースや人物のなりすましなどが恐れられているほどの文章が生成できるアルゴリズムです。サンプルコードはもう公開されています。
段階
1. データ収集
ジョークのデーターセットをここからダウンロードしてGPT-2の学習をこれでできるようにしました。
2. コードを編集
ColaboratoryでGPT-2を学習させてみたいので少しコードを変えてGoogle Driveに学習し終わったモデルをどんどん載せていくようにしました。
3. 学習
ここでは単純に学習した結果を報告します。
4. Slackに実装
最後にここではSlack Botとして実装したいと思います。
全部でき次第リンクをつけておきます。
- 投稿日:2019-05-29T00:45:29+09:00
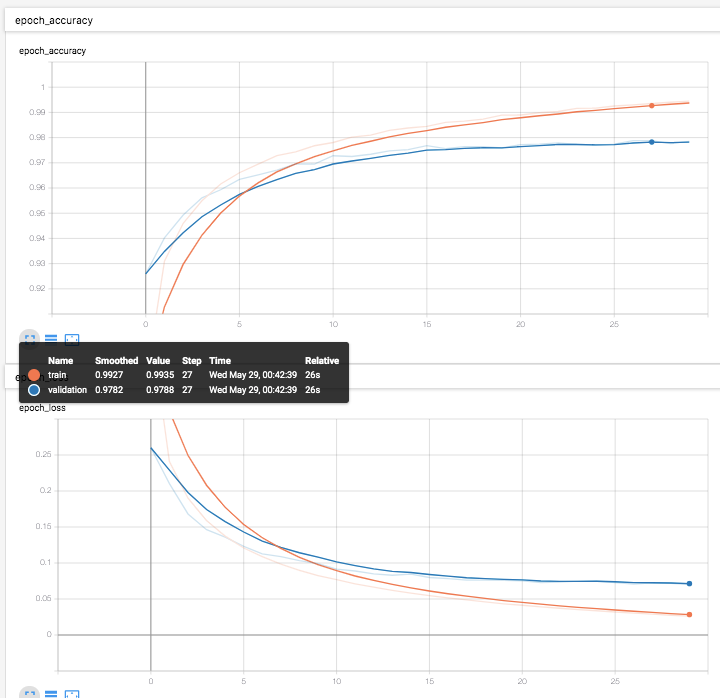
多層パーセプトロン [TensorFlow2.0でDeep Learning 3]
(目次はこちら)
はじめに
多層パーセプトロン [TensorFlowでDeep Learning 3]をtensorflow2.0で実現するためにはどうしたらいいのかを書く(
tf.keras)。コード
Python: 3.6.8, Tensorflow: 2.0.0a0で動作確認済み
多層パーセプトロン [TensorFlowでDeep Learning 3] (mnist_softmax_fc.py)を書き換えると、
v2/mnist_softmax_fc.pyfrom helper import * IMAGE_SIZE = 28 * 28 CATEGORY_NUM = 10 LEARNING_RATE = 0.1 FEATURE_DIM = 100 EPOCHS = 30 BATCH_SIZE = 100 LOG_DIR = 'log_softmax_fc' EPS = 1e-10 def loss_fn(y_true, y): y = tf.clip_by_value(y, EPS, 1.0) return -tf.reduce_sum(y_true * tf.math.log(y), axis=1) class Dense(tf.keras.layers.Layer): def __init__(self, units, activation, *args, **kwargs): super().__init__(*args, **kwargs) self.units = units self.activation = tf.keras.activations.get(activation) def build(self, input_shape): input_dim = int(input_shape[-1]) self.W = self.add_weight( name='weight', shape=(input_dim, self.units), initializer=tf.keras.initializers.GlorotUniform() ) self.b = self.add_weight( name='bias', shape=(self.units,), initializer=tf.keras.initializers.Zeros() ) self.built = True def call(self, x): if self.activation is None: raise Exception('Activation function is None') return self.activation(tf.matmul(x, self.W) + self.b) if __name__ == '__main__': (X_train, y_train), (X_test, y_test) = mnist_samples(flatten_image=True) model = tf.keras.models.Sequential() model.add(Dense(FEATURE_DIM, input_shape=(IMAGE_SIZE,), activation='relu')) model.add(Dense(CATEGORY_NUM, input_shape=(FEATURE_DIM,), activation='softmax')) model.compile(loss=loss_fn, optimizer=tf.keras.optimizers.SGD(LEARNING_RATE), metrics=['accuracy']) cb = [tf.keras.callbacks.TensorBoard(log_dir=LOG_DIR)] model.fit(X_train, y_train, batch_size=BATCH_SIZE, epochs=EPOCHS, callbacks=cb, validation_data=(X_test, y_test)) print(model.evaluate(X_test, y_test))と書ける。結局2つの層は活性化関数が異なるだけなのでそれを引数として渡せるように変更。
で、この、Denseクラスは、tf.keras.layers.Dense(tensorflow/python/keras/layers/core.py)とほぼ同じものなので、
わざわざ定義する必要は全くなく、シンプルに書ける。v2/mnist_softmax_fc_simple.pyfrom helper import * IMAGE_SIZE = 28 * 28 CATEGORY_NUM = 10 LEARNING_RATE = 0.1 FEATURE_DIM = 100 EPOCHS = 30 BATCH_SIZE = 100 LOG_DIR = 'log_softmax_fc' EPS = 1e-10 if __name__ == '__main__': (X_train, y_train), (X_test, y_test) = mnist_samples(flatten_image=True) model = tf.keras.models.Sequential() model.add(tf.keras.layers.Dense(FEATURE_DIM, input_shape=(IMAGE_SIZE,), activation='relu')) model.add(tf.keras.layers.Dense(CATEGORY_NUM, input_shape=(FEATURE_DIM,), activation='softmax')) model.compile( loss='categorical_crossentropy', optimizer=tf.keras.optimizers.SGD(LEARNING_RATE), metrics=['accuracy']) cb = [tf.keras.callbacks.TensorBoard(log_dir=LOG_DIR)] model.fit(X_train, y_train, batch_size=BATCH_SIZE, epochs=EPOCHS, callbacks=cb, validation_data=(X_test, y_test)) print(model.evaluate(X_test, y_test))めでたしめでたし