- 投稿日:2019-05-29T23:50:33+09:00
Enhancing the Spatial Resolution of Stereo Images using a Parallax Prior(再現実装)
論文
【タイトル】 Enhancing the Spatial Resolution of Stereo Images using a Parallax Prior (CVPR2018)
【概要】
- Stereo Imageを用いた超解像手法の提案
- 白黒画像の生成→カラー画像の生成のtwo stage学習
- 視差を表現したシフト画像の利用
開発環境
- Windows10
- Pytorch
データセット
Flickr1024: A Dataset for Stereo Image Super-resolution (https://yingqianwang.github.io/Flickr1024/)
ソースコード
- 投稿日:2019-05-29T23:50:33+09:00
ステレオ画像における深層学習超解像:Enhancing the Spatial Resolution of Stereo Images using a Parallax Prior(再現実装)
論文
【タイトル】 Enhancing the Spatial Resolution of Stereo Images using a Parallax Prior (CVPR2018)
【概要】
- Stereo Imageを用いた超解像手法の提案
- 白黒画像の生成→カラー画像の生成のtwo stage学習
- 視差を表現したシフト画像の利用
開発環境
- Windows10
- Pytorch
データセット
Flickr1024: A Dataset for Stereo Image Super-resolution (https://yingqianwang.github.io/Flickr1024/)
ソースコード
- 投稿日:2019-05-29T23:42:14+09:00
Leafletでマンデルブロ集合の表示してみる (1)
はじめに
突然ですが、なんの脈絡もなく、マンデルブロ集合を描きたくなりました。
マンデルブロ集合 (Wikipedia)↓こんなやつ↓
ただ描くだけだと面白くないので、Google Mapみたいにスクロールしたり拡大したり…というのをやってみよう…と思いちょっと手を動かしてみました。
先に完成品…
先に完成品をリンクしておきます。目標としては、このリンク先のようなことをやりたい、ということになります。
技術選定
Google Mapみたいな地図のアプリを作る、となると、いくつか選択肢はありますが、今回はタイル画像を用意してLeafletを使ってブラウザ上に描画する、という方法をとってみることにしました。
タイル画像
地図アプリで一般的なのが、縮尺、緯度、経度ごとに地図の画像を用意して、それをつなぎ合わせて表示する、という方法。国土地理院のサイトでわかりやすく説明されていますので詳細はそちらを参照ください。
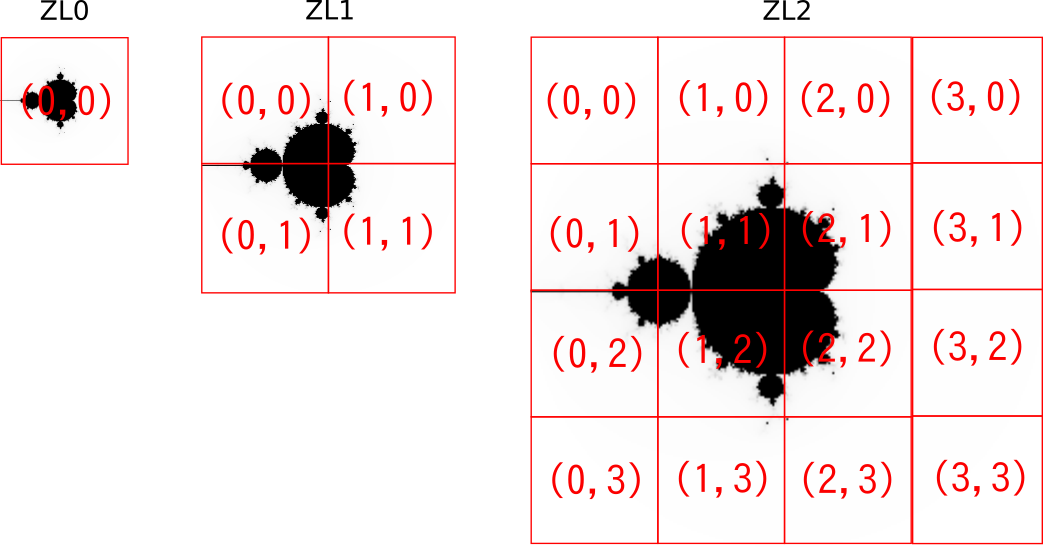
地理院地図 | 地理院タイル仕様上記リンク先で図示されているような形でズームレベルごとのタイル分割してみると、こんな感じになります。
一般的にタイル1枚の画像のサイズは256x256ピクセルにします。(Retina用だと512x512ピクセルとかを使うこともあるようです)
この画像を{z}/{x}/{y}.pngというパスに配置します。(zはズームレベル、x,yはそのズームレベルでの画像の位置)
Leaflet
詳細はLeafletのサイトを参照のこと。
日本語での説明は、Wikipediaによると
Leaflet は広く使われているWeb地図のためのJavaScriptライブラリである。 2011年に最初にリリースされた。 モバイルとデスクトップのプラットフォームのほとんどに対応し、HTML5とCSS3に対応している。 OpenLayersやGoogle Maps API(英語版)とともに最も人気のあるJavaScript地図ライブラリの一つであり、FourSquare、Pinterest、Flickrなどの有名なサイトで使われている。
ということになります。
上記のようなタイル画像を使ってWeb上で地図表示をするのによく使われています。(地理院タイルを使って地図表示とかも簡単)地図表示用に使われるLeafletを今回のように地図でない画像表示に使う方法に関しては、この記事の続きで記載したいと思います。
マンデルブロ集合のタイル画像の作成
で、マンデルブロ集合のタイル画像の作成に関してです。
-2-2i〜2+2iの範囲をズームレベル0で描画するとすると、-2〜2の4の範囲を256分割で計算するわけなので、1ピクセルあたり4/256=1/64単位で計算することになります。
ズームレベル1だとタイル1枚あたり、2の範囲を256分割になりますので、1ピクセルあたり2/256=1/128、ズームレベル2だと1/256…という形で計算単位を細かくしていきます。実際にPythonで計算してPNGに保存するソースはこちら。githubにもおいてあります。
mandelbrot.py"""マンデルブロ集合を描画する.""" from argparse import ArgumentParser from itertools import product from os import makedirs, path import numpy from PIL import Image from tqdm import tqdm def main(): """メイン関数.""" parser = ArgumentParser() parser.add_argument('outdir') parser.add_argument('level', type=int) args = parser.parse_args() outpath = path.join(args.outdir, str(args.level)) tile_num = 2 ** args.level tile_wid = 4.0 / tile_num lefttop = -2.0+2.0j delta = tile_wid / 256 xylist = list(product(range(tile_num), range(tile_num))) for x, y in tqdm(xylist): img = get_image(lefttop + x * tile_wid - (y * tile_wid) * 1j, delta) outpath = path.join(args.outdir, str(args.level), str(x)) makedirs(outpath, exist_ok=True) imgname = path.join(outpath, f'{y}.png') img.save(imgname) def get_image(lefttop, delta): """マンデルブロ集合のpillowイメージを取得する Arguments: lefttop {complex} -- 左上 delta {float} -- 1pxの差 Returns: Image -- 作成したイメージ """ imgarray = numpy.zeros((256, 256), dtype=numpy.uint8) for rstep, istep in product(range(256), range(256)): c = lefttop + rstep * delta - (istep * delta) * 1j z = 0 for i in range(256): z = z ** 2 + c if abs(z) > 2: imgarray[istep][rstep] = 255 - i break img = Image.fromarray(imgarray) return img if __name__ == "__main__": main()1ピクセルごと愚直に計算する処理にしてます。
python mandelbrot.py docs/tiles/grayscale 2とすることで、ズームレベル2のタイルをdocs/tiles/grayscaleディレクトリの下に出力する…という動作になります。
最後に
まずはタイル画像の生成までをこの記事に書きました。
そのタイル画像をLeafletを使って実際に表示するところに関しては続きの記事に記載したいと思います。
↓
続きを書きました。

- 投稿日:2019-05-29T23:22:19+09:00
様々なプログラミング言語でクラス (あるいはクラスもどき) を書く
概要
- 様々なプログラミング言語でクラス (あるいはクラスもどき) を書く
Java
MyCounter.java
public class MyCounter { public static MyCounter globalCounter = null; private String name = "No Name"; private int count; public MyCounter(int initValue) { count = initValue; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int addCount(int number) { count += number; return count; } public void print() { System.out.println(format()); } private String format() { return name + ": " + count; } public static void createGlobalCounter(String name, int initValue) { globalCounter = new MyCounter(initValue); globalCounter.setName(name); } }MyMain.java
public class MyMain { public static void main(String[] args) { MyCounter counter = new MyCounter(0); counter.print(); counter.setName("John Doe"); String currentName = counter.getName(); System.out.println("Current Name=" + currentName); int currentValue = counter.addCount(10); System.out.println("Current Value=" + currentValue); counter.print(); MyCounter.createGlobalCounter("CafeBabe! Write once, run anywhere", 256); MyCounter.globalCounter.print(); } }実行結果
No Name: 0 Current Name=John Doe Current Value=10 John Doe: 10 CafeBabe! Write once, run anywhere: 256JavaScript
my_counter.js
class MyCounter { constructor(initValue) { this._name = 'No Name'; this.count = initValue; } get name() { return this._name; } set name(name) { this._name = name; } addCount(number) { this.count += number; return this.count; } print() { console.log(this._format()); } _format() { return this._name + ': ' + this.count; } static createGlobalCounter(name, init_value) { MyCounter.global_counter = new MyCounter(init_value); MyCounter.global_counter.name = name; } } module.exports = MyCounter;my_main.js
const MyCounter = require('./my_counter'); counter = new MyCounter(0); counter.print(); counter.name = 'John Doe'; const currentName = counter.name; console.log('Current Name=' + currentName); const currentValue = counter.addCount(10); console.log('Current Value=' + currentValue); counter.print(); MyCounter.createGlobalCounter('JavaScript was born from Netscape Navigator 2.0', 256); MyCounter.global_counter.print();実行結果
$ node my_main.js No Name: 0 Current Name=John Doe Current Value=10 John Doe: 10 JavaScript was born from Netscape Navigator 2.0: 256Python
my_counter.py
class MyCounter: global_counter = None def __init__(self, init_value): self.__name = "No Name" self.__count = init_value @property def name(self): return self.__name @name.setter def name(self, name): self.__name = name def add_count(self, number): self.__count += number return self.__count def print(self): print(self.__format()) def __format(self): return "{0}: {1}".format(self.__name, self.__count) @classmethod def create_global_counter(cls, name, init_value): cls.global_counter = MyCounter(init_value) cls.global_counter.name = namemy_main.py
from my_counter import MyCounter counter = MyCounter(0) counter.print() counter.name = "John Doe" current_name = counter.name print("Current Name={}".format(current_name)) current_value = counter.add_count(10) print("Current Value={}".format(current_value)) counter.print() MyCounter.create_global_counter("Batteries included. Beautiful is better than ugly.", 256) MyCounter.global_counter.print()実行結果
$ python my_main.py No Name: 0 Current Name=John Doe Current Value=10 John Doe: 10 Batteries included. Beautiful is better than ugly.: 256Ruby
my_counter.rb
class MyCounter attr_accessor :name @@global_counter = nil def initialize(init_value) @name = 'No Name' @count = init_value end def add_count(number) @count += number end def print puts format end private def format "#{@name}: #{@count}" end def self.create_global_counter(name, init_value) @@global_counter = self.new(init_value) @@global_counter.name = name end def self.global_counter @@global_counter end endmy_main.rb
require './my_counter' counter = MyCounter.new(0) counter.print counter.name = 'John Doe' current_name = counter.name puts "Current Name=#{current_name}" current_value = counter.add_count(10) puts "Current Value=#{current_value}" counter.print MyCounter.create_global_counter('Everything is an object in Ruby', 256) MyCounter.global_counter.print$ ruby my_main.rb No Name: 0 Current Name=John Doe Current Value=10 John Doe: 10 Everything is an object in Ruby: 256
- 投稿日:2019-05-29T23:17:39+09:00
リスト内包表記 #2 (条件)
- 投稿日:2019-05-29T23:15:54+09:00
Scrapyを使ってクローラーを作る
クローラーとは
まず
クローリングとは、スクレイピングとセットで扱われ、自動的にインターネットを巡回し、
様々なWebサイトからコンテンツを収集・保存していく処理
それを行うソフトウェアをクローラーと呼ぶ
スクレイピング
webページから取得したコンテンツから必要な情報を抜き出したり、整形したりすることを指す
クローリング
ソフトウェアが自動的にWebコンテンツを収集・保存していくことを指す
コンテンツ内のハイパーリンクを次々辿っていったりもできるScrapy
役割的には
Requests、BeautifulSoupと同じ
コンテンツのダウンロード、解析、保存をより簡単にできる、かつ多機能なのがScrapy(先に言ってよ...w)
scrapyのプロジェクトを作る必要があるみたい$ pip install scrapyいつも通りインストール なんかちょっと長かった
- Create new Scrapy Project
$ scrapy startproject sample
なるほど〜Spider
- spiderというクラスを定義してscrapyコマンドを実行するだけでクローリングしてくれる(ずいぶん簡単に言いますな)
sample/spiders/sample_spider.pyimport scrapy class SampleSpider(scrapy.Spider): name = 'sample' # このクローラーの名前 allowed_domains = ['google.com'] # クローリングを許可するドメイン start_urls = ['https://www.google.com/?hl=ja'] # 起点となるURL(もちろん許可されたドメインでないとNG) def parse(self, response): print(response.text)上記のようにいくつか設定値があるみたい
starts_urls・・・ 順不同で実行される
parseメソッド ・・・ コンテンツ取得後のコールバックとして実行される、つまりHTML取ってきたあとはここが動くHTMLを取得してみる
あとは実行するだけでHTMLを取得して表示してくれるとのこと、、、ほんまかいな、、前より簡単すぎぃ
(どうでもいいけど allow を アロウ って発音されると気になって一瞬思考停止する)$ scrapy crawl sample ... 2019-05-29 14:40:16 [scrapy.core.engine] INFO: Spider opened 2019-05-29 14:40:16 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min) 2019-05-29 14:40:16 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023 2019-05-29 14:40:16 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.google.com/robots.txt> (referer: None) 2019-05-29 14:40:16 [scrapy.downloadermiddlewares.robotstxt] DEBUG: Forbidden by robots.txt: <GET https://www.google.com/?hl=ja> 2019-05-29 14:40:16 [scrapy.core.engine] INFO: Closing spider (finished) ...おー?なんかSpiderがopenしてcloseしてるし、crawledでURLが表示されてる!!
でも Forbidden が出てる... うまくはいってないっぽい
robots.txtに設定が足りてないってこと?robots.txtないけど。。。httpsも許可する設定とかがあるのかしら。
今は置いておいてsample/spiders/sample_spider.py# (略) allowed_domains = ['quotes.toscrape.com'] start_urls = ['http://quotes.toscrape.com/page/1/'] # Scrapy公式チュートリアルで使われてたサンプルURL # (略)こう変えたらゴチャゴチャ返ってくる中にHTMLが!!
... 2019-05-29 20:26:02 [scrapy.core.engine] INFO: Spider opened 2019-05-29 20:26:02 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min) 2019-05-29 20:26:02 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023 2019-05-29 20:26:03 [scrapy.core.engine] DEBUG: Crawled (404) <GET http://quotes.toscrape.com/robots.txt> (referer: None) 2019-05-29 20:26:03 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://quotes.toscrape.com/page/1/> (referer: None) <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Quotes to Scrape</title> ... </footer> </body> </html> 2019-05-29 20:26:03 [scrapy.core.engine] INFO: Closing spider (finished) 2019-05-29 20:26:03 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 453, 'downloader/request_count': 2, 'downloader/request_method_count/GET': 2, 'downloader/response_bytes': 2701, 'downloader/response_count': 2, 'downloader/response_status_count/200': 1, 'downloader/response_status_count/404': 1, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2019, 5, 29, 11, 26, 3, 683008), 'log_count/DEBUG': 2, 'log_count/INFO': 9, 'memusage/max': 49848320, 'memusage/startup': 49848320, 'response_received_count': 2, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/404': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2019, 5, 29, 11, 26, 2, 333924)} 2019-05-29 20:26:03 [scrapy.core.engine] INFO: Spider closed (finished)いい感じ!! 成功したから長めに結果を載せちゃう
取得したHTMLを解析、保存してみる
より実戦で使えそうな感じにするため、上記の方法で取得したHTMLから必要な情報だけ抜き出して、CSVに出してみる
さっきのチュートリアルのサイトは、名言?とその主がダーっと載っているので、名言&主CSVを出す
さっきsample/spiders/sample_spider.pyimport scrapy class SampleSpider(scrapy.Spider): name = 'sample' allowed_domains = ['quotes.toscrape.com'] start_urls = ['http://quotes.toscrape.com/page/1/'] def parse(self, response): result_list = [] div_quotes = response.css('div.quote') for div_quote in div_quotes: span_text = div_quote.css('span.text::text').extract_first() # css同様class指定だと複数取れるため1件目 quote = span_text.strip() author = div_quote.css('small.author::text').extract_first().strip() # 属性で抜きたい場合は ::attr(href) とかできるので覚えといたほうがよさそう result_list.append({ 'quote': quote, 'author': author }) print(result_list)
- ポイント1:必要なデータのlistを作ることを目指す 各要素は辞書にしておく
- ポイント2:
response.css('~~~')のようにするとCSSセレクターを利用して欲しい情報まで辿れる
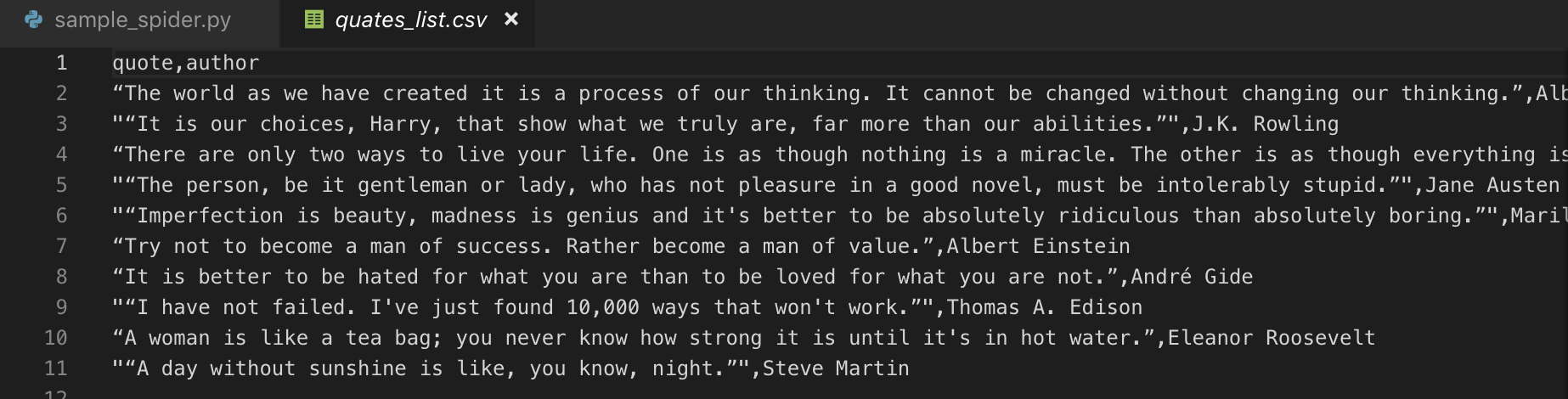
printの結果(1行なので見やすく整形しました).txt[ { 'quote': '“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”', 'author': 'Albert Einstein' }, { 'quote': '“It is our choices, Harry, that show what we truly are, far more than our abilities.”', 'author': 'J.K. Rowling' }, ... ]1発でうまくいってちょっと感動!
さてここまでくればもう簡単、printではなくcsvに出すぞ
printの箇所をreturnに変えるsample/spiders/sample_spider.py# (略) return result_listそして実行するコマンドを以下のようにする
$ scrapy crawl sample -o quates_list.csv
おおおおおおででで出てきた!!
完璧すぎる
そう、
辞書のlistにしておくだけで、ファイル種類(今回はcsv)に合わせて良しなに出してくれる
という涙級の優しさなのでコマンドを変えるだけでjsonにもなる(泣)
もっと深掘り:リンクを辿ってクローリング
さっきのサイトの
Aboutリンクの先のお誕生日まで抜いてきちゃおう
はじめにポイント
- 別のページを取得するにはscrapy.Request()を使う
- その別のページ取得後に実行したいcallbackを引数で渡すsample/spiders/sample_spider.pydef parse(self, response): result_list = [] div_quotes = response.css('div.quote') for div_quote in div_quotes: span_text = div_quote.css('span.text::text').extract_first() quote = span_text.strip() author = div_quote.css('small.author::text').extract_first().strip() about_link = div_quote.css('a::attr(href)').extract_first().strip() # 初めはこう書いてたけど・・・ # yield scrapy.Request(f'http://quotes.toscrape.com{about_link}', callback=self.parse_about_page) # 公式に倣えばもっとスマートに書けた urljoin() でURL調整 # yield scrapy.Request(response.urljoin(about_link), callback=self.parse_about_page) # もっともっとスマートに follow() を使えばurljoinすら要らない yield response.follow(about_link, callback=self.parse_about_page) result_list.append({ 'quote': quote, 'author': author, }) return result_list def parse_about_page(self, response): birthday = response.css('span.author-born-date::text').extract_first().strip() return { 'birthday':birthday }一応詳細ページのクローリングには成功したけど、一覧と詳細を組み合わせることはできなかった・・・
(quote, author, birthday のCSVが出したかった)
yield、returnを書いた時点でそこで結果が出力されてしまう
イメージ的にはこういうことがしたかったのにな〜 やりたいことは伝わるはずwimage.py# ここでクローリングして解析してきた結果を変数に保持して birthday = yield response.follow(about_link, callback=self.parse_about_page) # 一緒に出す result_list.append({ 'quote': quote, 'author': author, 'birthday': birthday }) return result_list def parse_about_page(self, response): birthday = response.css('span.author-born-date::text').extract_first().strip() return { 'birthday':birthday }一旦別々に出力しておいて、あとでうまいことすれば結果的には同じことできなくはないけど、
もっとスマートにできそう。。。一旦断念感想
色々やり方、機能があるみたいだけど、基本的なことするだけなら超お手軽
一覧で取得したデータと詳細のデータを組み合わせてってのができそうでできなかったけど、これらを活かして自分用のクローラーとか作ってみたいな〜
うまくいかなかったのはもう少し調べてみる
わかったら更新します


- 投稿日:2019-05-29T23:15:54+09:00
Python - Scrapyを使ってクローラーを作る
クローラーとは
まず
クローリングとは、スクレイピングとセットで扱われ、自動的にインターネットを巡回し、
様々なWebサイトからコンテンツを収集・保存していく処理
それを行うソフトウェアをクローラーと呼ぶ
スクレイピング
webページから取得したコンテンツから必要な情報を抜き出したり、整形したりすることを指す
クローリング
ソフトウェアが自動的にWebコンテンツを収集・保存していくことを指す
コンテンツ内のハイパーリンクを次々辿っていったりもできるScrapy
役割的には
Requests、BeautifulSoupと同じ
コンテンツのダウンロード、解析、保存をより簡単にできる、かつ多機能なのがScrapy(先に言ってよ...w)
scrapyのプロジェクトを作る必要があるみたい$ pip install scrapyいつも通りインストール なんかちょっと長かった
- Create new Scrapy Project
$ scrapy startproject sample
なるほど〜Spider
- spiderというクラスを定義してscrapyコマンドを実行するだけでクローリングしてくれる(ずいぶん簡単に言いますな)
sample/spiders/sample_spider.pyimport scrapy class SampleSpider(scrapy.Spider): name = 'sample' # このクローラーの名前 allowed_domains = ['google.com'] # クローリングを許可するドメイン start_urls = ['https://www.google.com/?hl=ja'] # 起点となるURL(もちろん許可されたドメインでないとNG) def parse(self, response): print(response.text)上記のようにいくつか設定値があるみたい
starts_urls・・・ 順不同で実行される
parseメソッド ・・・ コンテンツ取得後のコールバックとして実行される、つまりHTML取ってきたあとはここが動くHTMLを取得してみる
あとは実行するだけでHTMLを取得して表示してくれるとのこと、、、ほんまかいな、、前より簡単すぎぃ
(どうでもいいけど allow を アロウ って発音されると気になって一瞬思考停止する)$ scrapy crawl sample ... 2019-05-29 14:40:16 [scrapy.core.engine] INFO: Spider opened 2019-05-29 14:40:16 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min) 2019-05-29 14:40:16 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023 2019-05-29 14:40:16 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.google.com/robots.txt> (referer: None) 2019-05-29 14:40:16 [scrapy.downloadermiddlewares.robotstxt] DEBUG: Forbidden by robots.txt: <GET https://www.google.com/?hl=ja> 2019-05-29 14:40:16 [scrapy.core.engine] INFO: Closing spider (finished) ...おー?なんかSpiderがopenしてcloseしてるし、crawledでURLが表示されてる!!
でも Forbidden が出てる... うまくはいってないっぽい
robots.txtに設定が足りてないってこと?robots.txtないけど。。。httpsも許可する設定とかがあるのかしら。
今は置いておいてsample/spiders/sample_spider.py# (略) allowed_domains = ['quotes.toscrape.com'] start_urls = ['http://quotes.toscrape.com/page/1/'] # Scrapy公式チュートリアルで使われてたサンプルURL # (略)こう変えたらゴチャゴチャ返ってくる中にHTMLが!!
... 2019-05-29 20:26:02 [scrapy.core.engine] INFO: Spider opened 2019-05-29 20:26:02 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min) 2019-05-29 20:26:02 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023 2019-05-29 20:26:03 [scrapy.core.engine] DEBUG: Crawled (404) <GET http://quotes.toscrape.com/robots.txt> (referer: None) 2019-05-29 20:26:03 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://quotes.toscrape.com/page/1/> (referer: None) <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Quotes to Scrape</title> ... </footer> </body> </html> 2019-05-29 20:26:03 [scrapy.core.engine] INFO: Closing spider (finished) 2019-05-29 20:26:03 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 453, 'downloader/request_count': 2, 'downloader/request_method_count/GET': 2, 'downloader/response_bytes': 2701, 'downloader/response_count': 2, 'downloader/response_status_count/200': 1, 'downloader/response_status_count/404': 1, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2019, 5, 29, 11, 26, 3, 683008), 'log_count/DEBUG': 2, 'log_count/INFO': 9, 'memusage/max': 49848320, 'memusage/startup': 49848320, 'response_received_count': 2, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/404': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2019, 5, 29, 11, 26, 2, 333924)} 2019-05-29 20:26:03 [scrapy.core.engine] INFO: Spider closed (finished)いい感じ!! 成功したから長めに結果を載せちゃう
取得したHTMLを解析、保存してみる
より実戦で使えそうな感じにするため、上記の方法で取得したHTMLから必要な情報だけ抜き出して、CSVに出してみる
さっきのチュートリアルのサイトは、名言?とその主がダーっと載っているので、名言&主CSVを出す
さっきsample/spiders/sample_spider.pyimport scrapy class SampleSpider(scrapy.Spider): name = 'sample' allowed_domains = ['quotes.toscrape.com'] start_urls = ['http://quotes.toscrape.com/page/1/'] def parse(self, response): result_list = [] div_quotes = response.css('div.quote') for div_quote in div_quotes: span_text = div_quote.css('span.text::text').extract_first() # css同様class指定だと複数取れるため1件目 quote = span_text.strip() author = div_quote.css('small.author::text').extract_first().strip() # 属性で抜きたい場合は ::attr(href) とかできるので覚えといたほうがよさそう result_list.append({ 'quote': quote, 'author': author }) print(result_list)
- ポイント1:必要なデータのlistを作ることを目指す 各要素は辞書にしておく
- ポイント2:
response.css('~~~')のようにするとCSSセレクターを利用して欲しい情報まで辿れる
printの結果(1行なので見やすく整形しました).txt[ { 'quote': '“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”', 'author': 'Albert Einstein' }, { 'quote': '“It is our choices, Harry, that show what we truly are, far more than our abilities.”', 'author': 'J.K. Rowling' }, ... ]1発でうまくいってちょっと感動!
さてここまでくればもう簡単、printではなくcsvに出すぞ
printの箇所をreturnに変えるsample/spiders/sample_spider.py# (略) return result_listそして実行するコマンドを以下のようにする
$ scrapy crawl sample -o quates_list.csv
おおおおおおででで出てきた!!
完璧すぎる
そう、
辞書のlistにしておくだけで、ファイル種類(今回はcsv)に合わせて良しなに出してくれる
という涙級の優しさなのでコマンドを変えるだけでjsonにもなる(泣)
もっと深掘り:リンクを辿ってクローリング
さっきのサイトの
Aboutリンクの先のお誕生日まで抜いてきちゃおう
はじめにポイント
- 別のページを取得するにはscrapy.Request()を使う
- その別のページ取得後に実行したいcallbackを引数で渡すsample/spiders/sample_spider.pydef parse(self, response): result_list = [] div_quotes = response.css('div.quote') for div_quote in div_quotes: span_text = div_quote.css('span.text::text').extract_first() quote = span_text.strip() author = div_quote.css('small.author::text').extract_first().strip() about_link = div_quote.css('a::attr(href)').extract_first().strip() # 初めはこう書いてたけど・・・ # yield scrapy.Request(f'http://quotes.toscrape.com{about_link}', callback=self.parse_about_page) # 公式に倣えばもっとスマートに書けた urljoin() でURL調整 # yield scrapy.Request(response.urljoin(about_link), callback=self.parse_about_page) # もっともっとスマートに follow() を使えばurljoinすら要らない yield response.follow(about_link, callback=self.parse_about_page) result_list.append({ 'quote': quote, 'author': author, }) return result_list def parse_about_page(self, response): birthday = response.css('span.author-born-date::text').extract_first().strip() return { 'birthday':birthday }一応詳細ページのクローリングには成功したけど、一覧と詳細を組み合わせることはできなかった・・・
(quote, author, birthday のCSVが出したかった)
yield、returnを書いた時点でそこで結果が出力されてしまう
イメージ的にはこういうことがしたかったのにな〜 やりたいことは伝わるはずwimage.py# ここでクローリングして解析してきた結果を変数に保持して birthday = yield response.follow(about_link, callback=self.parse_about_page) # 一緒に出す result_list.append({ 'quote': quote, 'author': author, 'birthday': birthday }) return result_list def parse_about_page(self, response): birthday = response.css('span.author-born-date::text').extract_first().strip() return { 'birthday':birthday }一旦別々に出力しておいて、あとでうまいことすれば結果的には同じことできなくはないけど、
もっとスマートにできそう。。。一旦断念感想
色々やり方、機能があるみたいだけど、基本的なことするだけなら超お手軽
一覧で取得したデータと詳細のデータを組み合わせてってのができそうでできなかったけど、これらを活かして自分用のクローラーとか作ってみたいな〜
うまくいかなかったのはもう少し調べてみる
わかったら更新します
- 投稿日:2019-05-29T23:09:54+09:00
Boto2 使用の古いシステムを AWS S3 の署名バージョン4に対応させる
TL;DR
$ . your-venv/bin/activate $ pip install -U boto $ sudo cat > /etc/boto.cfg <<'^Z' [s3] use-sigv4 = True host = s3.ap-northeast-1.amazonaws.com ^Zはじめに
間もなく 2019/6/24 に AWS S3 の署名バージョン2が廃止になり、現在署名バージョン2を使って S3 アクセスを行っているシステムに影響が出ます。
私が前任者から受け継がされたシステムも古い Boto2 ライブラリ (Python 2.7) を利用し、アップデートもせずに放置されているので、当然署名バージョン2を利用しています。
このシステムは再デプロイのやり方も不明(というかデプロイされた後にサーバー上でいじられた形跡がある)なため、なんとか動作したままライブで署名バージョン4に対応したいところです。
なぜか Boto2 を署名バージョン4に対応させる情報がググってもあまり出てこず、ややはまったのでここに書き記しておきます。
Boto2 と Boto3
この記事で説明する方法は Boto2 が対象です。Boto3 には当てはまらないので注意してください。
署名バージョン2を使っていることを確認する
実際にこのシステムが署名バージョン2を使っていることを確かめるために「【Amazon S3を利用しているすべての人が安心して2019/06/24を迎えるために】CloudTrailとAthenaを用いたS3の署名バージョンの確認方法 | DevelopersIO」を参考に署名バージョン2を利用した S3 アクセスを検出しました。
上の記事の最後の Athena に対するクエリを実行すると CSV がダウンロードできるようになります。この CSV(巨大です)を data.csv として、以下のようにすると簡単にインスタンスが特定できます。
$ tail -n +2 data.csv | sort -t, -k1r,1 | sort -sut, -k6,6 -k5,5 > data.uniq.csv $ tail -n +2 data.csv | sort -t, -k1r,1 | sort -st, -k6,6 -k5,5 > data.sorted.csvdata.uniq.csv は (S3 バケット名, インスタンスの IP アドレス)が同一のもののうち、最も最近にあったアクセスだけが抽出されます。data.sorted.csv は同一のものを時間順にソートしただけのものです。data.uniq.csv は小さいので見やすいです。詳細(バケット名に加えてキーを見たい場合など)を見たい場合は data.sorted.csv を参照します。
この方法で、修正対象のシステムのインスタンスの IP から確かに署名バージョン2でアクセスがされており、そのユーザーエージェントが
[Boto/2.25.0 Python/2.7.4 Linux/3.4.73-64.112.amzn1.x86_64]であることが確認できました。Boto2 の 2.25.0 が使われているのが観察できますね。修正方法を調べる
AWS SDK の種類ごとの修正方法が「署名バージョン 2 から署名バージョン 4 への移行」に掲載されています。これによると:
SDK Upgrade コード変更が必要 Boto2 Boto2 v2.49.0 にアップグレード はい う~む「コード変更が必要」は困る...
さらに「リクエスト認証での署名バージョンの指定」を見ると:
boto デフォルト設定ファイルに以下を指定します。
[s3] use-sigv4 = Trueとあります。コード変更といっても設定ファイルの変更だけで済みそうですが、この boto デフォルト設定ファイルってどこにあるの?しかも何この変なフォーマットは
[s3] use-sigv4 = Trueじゃないの?
Boto2 の設定ファイル
Boto2 の設定ファイルは「Boto Config — boto v2.49.0」に書いてあります。 /etc/boto.cfg とか ~/.boto に書けばいいみたい。
あと、やはりフォーマットは ini フォーマットで、
[s3]の後に改行が必要みたいです。修正作業
材料が揃ったので修正しましょう。今回修正対象のシステムは cron で動作しているので、まずそれを止めます。virtualenv を利用して動いている(よかった...)ので virtualenv 内の boto をアップグレードします。
$ cp -a your-venv your-venv-backup # ← 非常時ロールバック用 $ . your-venv/bin/activate $ pip install -U boto $ pip show boto --- Name: boto Version: 2.49.0 Location: /home/user/your-venv/lib/python2.7/site-packages Requires:Boto2 は依存先が無く他のパッケージを巻き添えにせずにアップグレードできてレガシーシステムにやさしいです。
次に Boto2 設定ファイルを変更します。今回は既存の設定ファイルは無さそうだったので新規で作成します。
$ sudo cat > /etc/boto.cfg <<'^Z' [s3] use-sigv4 = True ^Zさてテスト実行してみると... S3 に全くアクセスできず!!!... 困った。
さらなる修正
原因をググってもなかなか探し当てられませんでしたが、それらしきものを発見: python - Using boto for AWS S3 Buckets for Signature V4 - Stack Overflow
この記事には API エンドポイントに
s3.amazonaws.comではなくs3.eu-central-1.amazonaws.comというリージョン毎のエンドポイントを指定しなくてはならない、と書いてあります。う~ん、これ boto.cfg に書けるのか?まず東京リージョンの S3 API エンドポイントを調べます: AWS のリージョンとエンドポイント - アマゾン ウェブ サービス によると
s3.ap-northeast-1.amazonaws.comでした。ということで...$ sudo cat > /etc/boto.cfg <<'^Z' [s3] use-sigv4 = True host = s3.ap-northeast-1.amazonaws.com ^Zテスト実行は... うまくいきました。cron を元通りにして終了。
この
[s3]セクションの設定の公式ドキュメントは一体どこにあるのだろうか?見つからない。
- 投稿日:2019-05-29T22:22:36+09:00
遺伝的アルゴリズムでOneMax問題を解いてみる
OneMax問題
OneMax問題とは, [0, 1, 1, 1, 0, 1, 0, 1, 1, 0]のように0/1からなる数列の和を最大化する問題です. 和が最大となるには, すべての要素が1となることを目指します.
今回は遺伝的アルゴリズムを用いて, OneMax問題を解いてみます.遺伝的アルゴリズム
遺伝的アルゴリズムは, 生物の進化の過程を真似て作られたアルゴリズムで確率的探索手法の1つです. 交叉や突然変異という操作を繰り返しながら, 個体を進化させていきます.
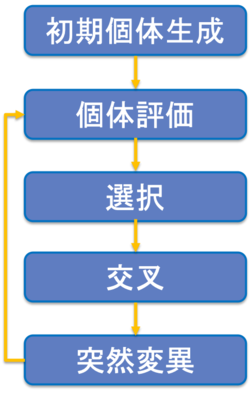
基本的な流れは以下のようになります.
選択
次世代個体群を生成するために, 親個体を選択します.
親個体の選択方法には以下のようなものがあります.
-ルーレット方式
-ランキング方式
-エリート方式交叉
選択した親個体を交叉させて, 子個体を生成します.
交叉方法には以下のようなものがあります.
-一様交叉
-一点交叉
-多点交叉突然変異
生成した個体に突然変異を加えます.
実践
それでは実際にGAでOneMax問題を解いてみます.
実験の設定は
遺伝子長:100
世代数:100
選択:トーナメント選択(トーナメントサイズ:2)
交叉:一様交叉
突然変異確率:1/遺伝子長
親個体数:100
子個体数:50
個体更新:親個体の優良個体50+子個体# -*- coding: utf-8 -*- import random import copy # 各種パラメータ length = 100 # 遺伝子長 population = 100 # 親個体数 offspring_n = 50 # 子個体数 generation = 100 # 世代数 mutation_rate = 1.0/100.0 # 突然変異確率(1/遺伝子長) # 初期個体群生成 def initialize(): gene = [[random.randint(0,1) for i in range(length)] for j in range(population)] return gene # 個体評価 def evaluate(gene): fitness = [] for i in range(population): fitness.append(sum(gene[i])/length) return fitness # minを見つける def find_min(fitness): min = 10 for i in range(population): if fitness[i] < min: min = fitness[i] return min # maxを見つける def find_max(fitness): max = 0 for i in range(population): if fitness[i] > max: max = fitness[i] return max # 親選択 def choice_parents(gene, fitness): father_index = random.randint(0,population-1) mother_index = random.randint(0,population-1) if fitness[father_index] > fitness[mother_index]: parents = gene[father_index] else: parents = gene[mother_index] return parents # 交叉 def crossover(father, mother): offspring = [] for i in range(length): p = random.random() if p < 0.5: offspring.append(father[i]) else: offspring.append(mother[i]) return offspring # 突然変異 def mutation(offspring): for i in range(length): p = random.random() if p < mutation_rate: if offspring[i] == 0: offspring[i] = 1 else: offspring[i] = 0 return offspring # 個体更新(親個体エリート50 + 子個体50 = 計100) def elite(gene, fitness, next_gene): sort_fitness = sorted(fitness, reverse=True) gen_tmp = [] for i in range(int(population/2)): index = fitness.index(sort_fitness[i]) gen_tmp.append(gene[index]) gen_tmp.extend(next_gene) return gen_tmp def main(): generation_count = 1 next_gene = [] # 初期個体群生成 gene = initialize() while generation_count <= generation: next_gene.clear() #print(gene) # 個体評価 fitness = evaluate(gene) min = find_min(fitness) max = find_max(fitness) print("generation:", generation_count) print("min", min) print("max", max) if min == 100: break # 次世代個体群生成 for i in range(offspring_n): # 個体選択 father = choice_parents(gene, fitness) mother = choice_parents(gene, fitness) # 交叉 offspring = crossover(father, mother) # 突然変異 offspring = mutation(offspring) next_gene.append(offspring) # 個体更新 gene = elite(gene, fitness, next_gene) generation_count += 1 print("--------------------------------") if __name__ == "__main__": main()結果は以下のようになりました.
最初の世代ではmin, maxともに低い値となっています.
それが最終世代ではmaxは最大値に達し, minも大きな値を獲得できています.
遺伝的アルゴリズムもより, 個体が進化していることを確認できました.generation: 1 min 0.37 max 0.62 -------------------------------- generation: 2 min 0.39 max 0.63 -------------------------------- . . . generation: 99 min 0.96 max 1.0 -------------------------------- generation: 100 min 0.95 max 1.0 --------------------------------
- 投稿日:2019-05-29T21:09:55+09:00
【Python】Tkinterによる70行で作るGUIアプリ「追いかけっこゲーム」
はじめに
こんにちは。
今回は「追いかけっこゲーム」を作っていきたいと思います。
完成するとこんな感じに動きます!
赤い円が自分(player)で青い円が敵(enemy)です。
マウスカーソルを操作して、赤い円を動かすことができます。青い円に触れたら止まります。つまりゲームオーバーといった感じです!環境
- Windows 10 home
- Python 3.7.1
numpyを使うので以下のコマンドでインストールしておきましょう。
pip install numpy「追いかけっこゲーム」の制作
インポート
使うライブラリは以下の2つです。
import tkinter as tk import numpy as npウィンドウの作成
import tkinter as tk import numpy as np class Application(tk.Frame): def __init__(self,master): super().__init__(master) self.pack() self.width=self.height=500 master.geometry(str(self.width)+"x"+str(self.height)) master.title("追いかけっこゲーム") def main(): win = tk.Tk() app = Application(master = win) app.mainloop() if __name__ == "__main__": main()このプログラムでウィンドウを作っていきます。
サイズは500×500です。タイトル名は追いかけっこゲームです。
詳しくはPythonによるTkinterを使った雛形(クラス化手法)の記事をご参照ください。敵の動きのベクトル取得に関して
敵の動きのベクトルは以下のenemyVec関数で取得しています。少しややこしい部分なので、解説を入れようと思います。
def enemyVec(self,player,enemy,speed):#敵の動き(x,y)のベクトルを返す rad=np.arctan((player.y-enemy.y)/(player.x-enemy.x))#向き(角度の計算) if player.x-enemy.x >= 0: vx=np.cos(rad)*speed vy=np.sin(rad)*speed else: vx=np.cos(rad)*(-1*speed) vy=np.sin(rad)*(-1*speed) return [vx,vy]引数として、playerオブジェクトとenemyオブジェクトを渡しています。それぞれの中心座標を計算で使うためです。ここで、この2つのオブジェクトの向きの計算が少しややこしくなると思います。つまり、2点間の角度の計算です。
2点の座標が分かっているので、ベクトルのx成分とy成分を求めることができます。(例) A(x1,y1),B(x2,y2)の場合
\vec{AB} = \begin{matrix} x2 - x1 \\ y2 - y1 \end{matrix}そして、x軸とベクトルがなす角度θを以下のtanの逆関数を使って表すことができます。
θ = \tan^-1(\frac{y}{x})tanθの範囲が-π/2~π/2なので、playerとenemyのx座標の差の正負で場合分けをし、speedに-1をかけて、方向を変えています。
完成したプログラム
こちらが完成したプログラムになります。
追いかけっこゲーム.pyimport tkinter as tk import numpy as np class Circle(): def __init__(self,canvas,x,y,r,color,tag=None): self.canvas = canvas self.x = x #円の中心のx座標 self.y = y #円の中心のy座標 self.r = r #円の半径 self.color = color self.tag = tag def createCircle(self): self.canvas.create_oval(self.x-self.r,self.y-self.r,self.x+self.r,self.y+self.r,fill=self.color,tag=self.tag) class Application(tk.Frame): def __init__(self,master): super().__init__(master) self.pack() self.width=self.height=500 master.geometry(str(self.width)+"x"+str(self.height)) master.title("追いかけっこゲーム") self.canvas = tk.Canvas(master,width=self.width,height=self.height,bg="black") self.canvas.pack() self.player = Circle(self.canvas,250,250,30,"red","player") #インスタンスplayerの生成 self.enemy = Circle(self.canvas,0,0,30,"blue","enemy") #インスタンスenemyの生成 self.canvas.bind("<Motion>",self.mouseEvent) self.master.after(50,self.update) def update(self): if self.judgeflag(self.player,self.enemy): eV = self.enemyVec(self.player,self.enemy,10) self.enemy.x += eV[0] self.enemy.y += eV[1] self.canvas.delete("player") self.canvas.delete("enemy") self.player.createCircle() self.enemy.createCircle() self.master.after(50,self.update) def enemyVec(self,player,enemy,speed): #敵の動き(x,y)のベクトルを返す rad=np.arctan((player.y-enemy.y)/(player.x-enemy.x)) #向き(角度の計算) if player.x-enemy.x >= 0: vx=np.cos(rad)*speed vy=np.sin(rad)*speed else: vx=np.cos(rad)*(-1*speed) vy=np.sin(rad)*(-1*speed) return [vx,vy] def judgeflag(self,player,enemy): #当たり判定 if np.sqrt((player.x-enemy.x)**2+(player.y-enemy.y)**2) > player.r+enemy.r: return True else: return False def mouseEvent(self,event): self.player.x = event.x self.player.y = event.y def main(): win = tk.Tk() app = Application(master=win) app.mainloop() if __name__ == "__main__": main()以上で追いかけっこゲームは完成になります。
ここまで読んでいただき、ありがとうございました。

- 投稿日:2019-05-29T21:07:44+09:00
FriedmanのGradient Boostingを説明する
はじめに
今ではお馴染みとなったGradient Boostingですが、きちんと説明を読んだことがなかったので調べてみました。
Boostingというと色々ありますが、今回まとめたのはFriedmanのGradient Boostingです。
参考
手順
定義
説明変数を$\mathbf{x}_i(i=1,...,N)$とし、目的変数を$t_i (i=1,...,N)$とします。説明変数の次元は$d$とします。
予測器を$f$と書き、予測値を$y$で表します。我々が求めたいものは、損失関数$\Psi$を最小にする$\hat f$です。
\begin{align} y_i &= \hat f(\mathbf{x_i}) \\ \hat f &= \arg \min_{f \in \mathcal{F}} \sum_{i=1}^N \Psi(t_i, f(\mathbf{x_i})) \end{align}ここで$\mathcal{F}$は関数$f$の空間です。
関数推定の問題を扱いやすくするために、関数$f$を関数空間がパラメータ$\theta$で張られる族$f(\mathbf{x}, \theta)$に制限します。すると上の式は次のように書き直せます。
\begin{align} y_i &= \hat f(\mathbf{x_i}) \\ \hat f(\mathbf{x}) &= f(\mathbf{x}, \hat\theta) \\ \hat \theta &= \arg \min_{\theta \in D} \sum_{i=1}^N \Psi(t_i, f(\mathbf{x_i}, \theta)) \end{align}勾配降下法
$\theta$を導入したことで全データの損失関数を次のように表せます。
J(\theta) = \sum_{i=1}^N \Psi(t_i, f(\mathbf{x_i}, \theta))$J$が最小になる$\theta$が$\hat \theta$です。解析的には$J$のgradを計算し、大域的に極小となる点を求めればよいです。しかし、損失関数の形によっては解析的に解を求めるのが難しいこともあります。そこで、$J$の微分を計算し、$J$が小さくなる方向に$\theta$を変化させる、ということを逐次的に行います。
\theta_{\mathrm{new}} =\theta - \eta \nabla_\theta J(\theta)上記の式では更新ごとにすべての訓練用データが含まれていますが、データ一つごとに$\theta$を更新すればオンライン学習に、少量ごとに更新すればミニバッチ法になります。ちなみに、訓練データをすべて使い切るのに必要な回数をイテレーション数と呼びます。
\mathrm{イテレーション数} = \mathrm{データ数} / \mathrm{バッチサイズ}Gradient Boosting
前章での$\theta$の更新ですが、勾配法との比較のために次のように書き直してみましょう。
イテレーションを$M$回行うとし、各イテレーションを$m=1,...,M$でラベルします。更新の式を次のように書き換えます。
\begin{align} \theta^{(m)} &= \theta^{(m-1)} + \delta\theta^{(m)}\\ \delta \theta^{(m)} &= - \eta \nabla_\theta J(\theta^{(m-1)}) \end{align}ここで$\theta^{(0)}$は初期値で、適当に与えます。すると$M$回のイテレーションで$\theta$が次のように更新されることが分かります。
\theta^{(M)} = \theta^{(0)} + \sum_{m=1}^{M}\delta\theta^{(m)}式からわかるように、初期パラメータ$\theta^{(0)}$に修正$\delta\theta^{(m)}$を加えていくことで最適な$\hat\theta$を求める仕組みになっています。
そこで、この発想を関数空間に適用することを考えます。すなわちパラメータを修正するのではなく、初期予測器に対して修正予測器を加えていく仕組みを考えます。
f^{(M)} = f^{(0)} + \sum_{m=1}^{M}\delta f^{(m)}勾配法とのアナロジーで更新は次のようにすれば良いとわかります。
\begin{align} f^{(m)}(\mathbf{x}) &= f^{(m-1)}(\mathbf{x}) + \delta f^{(m)}(\mathbf{x})\\ \delta f^{(m)} &= -\rho \nabla_f J(f^{(m-1)}) \end{align}上の式は素朴なアナロジーでしたが、関数空間の場合はこの更新をブラッシュアップできます。
どういうことかというと、$\theta$の空間の場合、どれくらい$\theta$をシフトさせれば良いかわかりませんでしたので、学習率$\eta$を手動でチューニングする必要がありました。ところが、関数空間の場合は手元に予測器があるので、予測がより良くなるように、すなわち損失関数が小さくなるように関数のシフトを決めることができます。
\begin{align} f^{(m)}(\mathbf{x}) &= f^{(m-1)}(\mathbf{x}) - \rho^{(m)}\nabla_f J\left(f^{(m-1)}(\mathbf{x})\right) \\ \rho^{(m)} &= \arg \min_{\rho} \sum_{i=1}^N \Psi\left(t_i, f^{(m-1)}(\mathbf{x_i}) - \rho \nabla_f J\left(f^{(m-1)}(\mathbf{x_i})\right)\right) \end{align}この発想で考えれば、もはやシフトに使用する関数も自由に選べます。したがってより一般には次のように書けます。
\begin{align} f^{(m)}(\mathbf{x}) &= f^{(m-1)}(\mathbf{x}) +g^{(m)}(\mathbf{x}) \\ g^{(m)} &= \arg \min_{g\in \mathcal{G}} \sum_{i=1}^N \Psi\left(t_i, f^{(m-1)}(\mathbf{x_i}) + g(\mathbf{x_i})\right) \end{align}このようにしてGradient Boostingでは、ひとつ前のイテレーションの予測器に新たな予測器を加えていくことで、経験損失を小さくしていきます。
Friedmanの論文の説明について補足
Friedmanの論文は実装のことも考えて書かれており、説明が少し異なるので、これについて補足を残します。
前章の最後で、関数のシフトに任意の$g$を使用しました。Friedmanの論文では、この$g$(と$f^{(0)}$)にパラメータ$\theta$を持つ弱学習器$h(\mathbf{x}, \theta)$を考えます。すなわち、前章の最後の式は次のようになります。
\begin{align} f^{(m)}(\mathbf{x}) &= f^{(m-1)}(\mathbf{x}) + \beta^{(m)} h(\mathbf{x}, \theta^{(m)}) \\ \left(\beta^{(m)}, \theta^{(m)}\right) &= \arg \min_{\beta, \theta} \sum_{i=1}^N \Psi\left(t_i, f^{(m-1)}(\mathbf{x_i}) + \beta h(\mathbf{x}_i, \theta)\right) \end{align}$g$をこのように置くのは、任意の損失関数に対応するためです。損失関数が複雑な場合、$\beta^{(m)}, \theta^{(m)}$を求めるのは大変です。そこで、gradient boosting近似を行います。
まず、損失関数の勾配に予測器をフィットさせます。
\begin{align} \theta^{(m)} &= \arg \min_{\rho, \theta}\left[ \sum_{i=1}^N\left(\tilde y_{i}^{(m)} - \rho h(\mathbf{x}_i, \theta) \right)^2\right] \\ \tilde y_{i}^{(m)} &= -\left[\frac{\partial\Psi(t_i, f)}{\partial f}\right]_{f=f^{(m-1)}, \mathbf{x}=\mathbf{x}_i} \end{align}次に、この弱学習機の係数を最適化します。
\beta^{(m)} = \arg \min_{\beta} \sum_{i=1}^N \Psi\left(t_i, f^{(m-1)}(\mathbf{x_i}) + \beta h(\mathbf{x}_i, \theta^{(m)})\right)この手順によって、最適化問題を最二乗問題と損失関数$\Psi$の1変数最適化問題に分解しました。
予測器の具体例として、弱学習器である決定木を考えます。この決定木は葉を$L$個持つとします。また、この決定木は回帰木です。イテレーション$m$の決定木により、説明変数$\mathbf{x}$の空間が$L$個に分割されます。この分割された領域を$R_m^l (m=1,...,M;l=1,...,L)$でラベルします。gradient boosting近似によって、決定木は次の予測値を出力するように学習します。
\begin{align} h(\mathbf{x}, \{R_m^l\}_{l=1}^L) &= \sum_{l=1}^L \bar y_l^{(m)} 1(\mathbf{x} \in R_m^l)\\ \bar y_l^{(m)} &= \frac{1}{\#(\mathbf{x}_i \in R_m^l)}\sum_{\mathbf{x}_i \in R_m^l}\tilde y_{i}^{(m)} \end{align}あとは$\beta$を決めるのですが、領域ごとに$\beta$を最適化できます。予測器が出力する値は$R_m^l$の各領域内で定数なので、$\beta$との積にしてしまって、これを$\gamma$とすると次のように書けます。
\gamma_{l}^{(m)} = \arg \min_{\gamma} \sum_{\mathbf{x}_i\in R_m^l} \Psi\left(t_i, f^{(m-1)}(\mathbf{x_i}) + \gamma\right)これによって学習器が更新されます。
f^{(m)}(\mathbf{x}) = f^{(m-1)}(\mathbf{x}) + \gamma_{l}^{(m)}1(\mathbf{x} \in R_m^l)オーバーフィッティングを避けるために、学習率$\nu(0<\nu<1)$を導入して次のようにする場合もあります。
f^{(m)}(\mathbf{x}) = f^{(m-1)}(\mathbf{x}) + \nu \gamma_{l}^{(m)}1(\mathbf{x} \in R_m^l)これをShrinkageと呼びます。Friedmanによると$\nu<0.1$とすると汎化性能が上がるそうです。
おわりに
Boostingアルゴリズムは残差を予測する予測器を加えていくというアルゴリズムですが、他にもいくつか手法があり、それぞれアルゴリズムが結構違うので調べてみると面白いです。
- XGBoost -> XGBoostの概要
- AdaBoost -> AdaBoostについて調べたのでまとめる
- 投稿日:2019-05-29T20:46:14+09:00
【書評】現場で使える Django REST Framework の薄い本
買ったきっかけ
Django REST Framework(DRF)を使った開発を行うことになり、
ネット等で情報収集やサンプルプログラムの作成をしていたのですが、
なかなか欲しい情報がなく、まとまった知識を得る為に購入しました。
(ちなみにDjangoはいくつか本があるのですが、DRFはこの本以外にたぶんない)
現場で使える Django REST Framework の薄い本【紙の本】(技術書典6バージョン) - - BOOTH
で買いました。内容と感想
第1章: Django REST Framework(DRF)の概要
REST APIの基本から、DRFの全体構成などの説明など
図があってわかりやすい。第2章: モデル・シリアライザ・ビュー・URLconf の基本的な使い方
使い方や処理の流れが記載されてます。
他サイトのチュートリアルは、ModelViewSetを使ったものばかりで、
少し複雑なAPIを作ろうとする時にどうすればいいかわからなかったのですが、
ここでは、APIViewにも言及されていて、こちらの方が汎用的であることがわかりました。
開発ではAPIViewを使うことが多くなりそうです。第3章: DRF とセキュリティ
基本的なセキュリティーに関する知識で、DRF特有の情報が少ないです。
第4章: DRF と認証
Basic認証、Cokkie認証、トークン認証、リモートユーザー認証、JWT認証の各方式に関しての紹介とどれを使うべきが記載されています。
今回使う予定だった認証方式についても詳しく紹介されていて参考になりました。第5章: チュートリアル その1、第6章チュートリアル その2
よくある本では、前半はチュートリアルで、後半に詳細な機能やリファレンスが記載されていることが多いのですが、この本は逆でした。
書籍にもソースコードが記載されていますが、全部ではないので、サンプルコードをダウンロードした上で読み進めるとわかりやすいです。
チュートリアル その1は比較的簡単にできますが、チュートリアル その2はVueの知識が少し必要です。
(dockerを使ったローカルの動作環境が特殊でその2はうまく動かなかった・・・。)
今回、APIのみ実装予定だったので、その1を作り、JWT認証に変えたものを試しました。
JWT認証は第6章よりも、第4章の方が参考になります。第7章: 現場で使える Tips 集
今後、実際に開発する中で適宜読む予定。
全体を通して
DRFは、Djangoの知識が前提になるので、Djangoをうろ覚えだったらまずDjangoを覚えた方がいいです。
ネットのチュートリアルの方が環境の作り方からわかりやすく載ってたりするので、この書籍が難しければそちらを試してから読む方がいいです。
全体通してとてもわかりやすく詳しく書かれていて、最初からこれを読んだらよかったと思いました。今後は
書籍にも書かれていましたが、
[Django REST Framework] Serializer の 使い方 をまとめてみた
[Django REST Framework] View の使い方をまとめてみた
を見ていく予定です。
- 投稿日:2019-05-29T19:26:19+09:00
sklearn.feature_extraction.text.CountVectrizerのanalyzerを試してみた
概要
前回の記事で取り上げた、scikit-learnのCountVectorizerの
analyzerキーワード引数について、変えると具体的にどう結果が変化するんだろう?
と思ったので一式コードを書いて確認。環境
- Windows10 Pro
- Python 3.7.3
- scikit-learn 0.21.2
コード
一通りの
analyzerキーワード引数を使ったインスタンスを作成するfrom sklearn.feature_extraction.text import CountVectorizer # 単語でN-gram cv_word = CountVectorizer(analyzer = 'word') # 文字でN-gram cv_char = CountVectorizer(analyzer = 'char') # 'char_wb'でN-gram cv_wb = CountVectorizer(analyzer = 'char_wb') # 呼び出し可能オブジェクト cv_callable = CountVectorizer(analyzer = lambda x: [x])対象にする単語と文章の配列を作成する
即興で書いたので、英文の不味さには目をつぶってください……
words = ['Tokyo', 'Osaka', 'Sendai', 'Fukuoka', 'Sapporo', 'Kouchi'] texts = ['Tokyo is the biggest city in japan.', 'Osaka is the secondary biggest city in japan.', 'Fukuoka is most nearly city from Koria, China in japan.', 'Sendai called we ''Mori no Miyako''.', 'Sapporo is most nearly city from Russia in japan.', 'Kouchi is a japanese city, in japanese region in ''Shikoku''.']単語の配列で、
fit_transformでの特徴抽出と特徴を出力print("CountVectorizer: target is words") X = cv_word.fit_transform(words) print("CountVectorizer: analyzer is word") print("results array:") print(str(X.toarray())) print("feature_names:") print(str(cv_word.get_feature_names())) X = cv_char.fit_transform(words) print("CountVectorizer: analyzer is char") print("results array:") print(str(X.toarray())) print("feature_names:") print(str(cv_char.get_feature_names())) X = cv_wb.fit_transform(words) print("CountVectorizer: analyzer is char_wb") print("results array:") print(str(X.toarray())) print("feature_names:") print(str(cv_wb.get_feature_names())) X = cv_callable.fit_transform(words) print("CountVectorizer: analyzer is callable object") print("results array:") print(str(X.toarray())) print("feature_names:") print(str(cv_callable.get_feature_names()))単語で試した出力結果
CountVectorizer: target is words CountVectorizer: analyzer is word results array: [[0 0 0 0 0 1] [0 0 1 0 0 0] [0 0 0 0 1 0] [1 0 0 0 0 0] [0 0 0 1 0 0] [0 1 0 0 0 0]] feature_names: ['fukuoka', 'kouchi', 'osaka', 'sapporo', 'sendai', 'tokyo'] CountVectorizer: analyzer is char results array: [[0 0 0 0 0 0 0 1 0 2 0 0 0 1 0 1] [2 0 0 0 0 0 0 1 0 1 0 0 1 0 0 0] [1 0 1 1 0 0 1 0 1 0 0 0 1 0 0 0] [1 0 0 0 1 0 0 2 0 1 0 0 0 0 2 0] [1 0 0 0 0 0 0 0 0 2 2 1 1 0 0 0] [0 1 0 0 0 1 1 1 0 1 0 0 0 0 1 0]] feature_names: ['a', 'c', 'd', 'e', 'f', 'h', 'i', 'k', 'n', 'o', 'p', 'r', 's', 't', 'u', 'y'] CountVectorizer: analyzer is char_wb results array: [[2 0 0 0 0 0 0 0 1 0 2 0 0 0 1 0 1] [2 2 0 0 0 0 0 0 1 0 1 0 0 1 0 0 0] [2 1 0 1 1 0 0 1 0 1 0 0 0 1 0 0 0] [2 1 0 0 0 1 0 0 2 0 1 0 0 0 0 2 0] [2 1 0 0 0 0 0 0 0 0 2 2 1 1 0 0 0] [2 0 1 0 0 0 1 1 1 0 1 0 0 0 0 1 0]] feature_names: [' ', 'a', 'c', 'd', 'e', 'f', 'h', 'i', 'k', 'n', 'o', 'p', 'r', 's', 't', 'u', 'y'] CountVectorizer: analyzer is callable object results array: [[0 0 0 0 0 1] [0 0 1 0 0 0] [0 0 0 0 1 0] [1 0 0 0 0 0] [0 0 0 1 0 0] [0 1 0 0 0 0]] feature_names: ['Fukuoka', 'Kouchi', 'Osaka', 'Sapporo', 'Sendai', 'Tokyo']結果から見えるもの
fit_transformした結果の配列をDataFrameの値部分と考えると、Indexを元の配列、Columnを特徴(feature_name)とすることが出来る。
例として、一番最初の結果を表とすると以下のようになる。
Index fukuoka kouchi osaka sapporo sendai tokyo Tokyo 0 0 0 0 0 1 Osaka 0 0 1 0 0 0 Sendai 0 0 0 0 1 0 Fukuoka 1 0 0 0 0 0 Sapporo 0 0 0 1 0 0 Kouchi 0 1 0 0 0 0
- 文字列で指定した場合は特徴(feature_name)は基本的にlower case
- 公式を見ると、キーワード引数として
lowercaseが存在し、デフォルト値がTrueとなっているので、ここの設定を変えることで変わるかも- 特徴(feature_name)は文字の昇順で格納される
analyzerにchar_wbを指定した場合は、特徴(feature_name)に' 'が含まれる
- おそらくは単語境界を
' 'としている、2回カウントされるのは、前後を1回ずつ単語境界とカウントしているから?- カテゴリ変数のエンコーディングに使う場合、lower caseな単語のみが格納されていて、単純にOne-hotエンコードの結果を取得するだけだけなら、
analyzer = 'word'でいけるのでは?文章の配列で、
fit_transformでの特徴抽出と特徴を出力print("CountVectorizer: target is texts") X = cv_word.fit_transform(texts) print("CountVectorizer: analyzer is word") print("results array:") print(str(X.toarray())) print("feature_names:") print(str(cv_word.get_feature_names())) X = cv_char.fit_transform(texts) print("CountVectorizer: analyzer is char") print("results array:") print(str(X.toarray())) print("feature_names:") print(str(cv_char.get_feature_names())) X = cv_wb.fit_transform(texts) print("CountVectorizer: analyzer is char_wb") print("results array:") print(str(X.toarray())) print("feature_names:") print(str(cv_wb.get_feature_names())) X = cv_callable.fit_transform(texts) print("CountVectorizer: analyzer is callable object") print("results array:") print(str(X.toarray())) print("feature_names:") print(str(cv_callable.get_feature_names()))文章で試した出力結果
CountVectorizer: target is texts CountVectorizer: analyzer is word results array: [[1 0 0 1 0 0 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 0] [1 0 0 1 0 0 1 1 1 0 0 0 0 0 0 0 0 1 0 0 0 1 0 0 1 0 0] [0 0 1 1 1 1 1 1 1 0 1 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0] [0 1 0 0 0 0 0 0 0 0 0 0 1 1 0 0 1 0 0 0 0 0 1 0 0 0 1] [0 0 0 1 1 0 1 1 1 0 0 0 0 0 1 1 0 0 0 1 1 0 0 0 0 0 0] [0 0 0 1 0 0 2 1 0 2 0 1 0 0 0 0 0 0 1 0 0 0 0 1 0 0 0]] feature_names: ['biggest', 'called', 'china', 'city', 'from', 'fukuoka', 'in', 'is', 'japan', 'japanese', 'koria', 'kouchi', 'miyako', 'mori', 'most', 'nearly', 'no', 'osaka', 'region', 'russia', 'sapporo', 'secondary', 'sendai', 'shikoku', 'the', 'tokyo', 'we'] CountVectorizer: analyzer is char results array: [[6 0 1 2 1 1 0 2 0 2 1 4 1 1 0 0 2 2 1 0 2 4 0 0 2] [7 0 1 5 1 2 1 3 0 2 1 4 1 1 0 0 3 2 1 1 4 3 0 0 2] [9 1 1 6 0 2 0 1 2 0 1 5 1 3 1 2 4 4 1 3 2 2 2 0 2] [5 0 1 3 0 1 2 3 0 0 0 3 0 1 2 2 2 3 0 1 1 0 0 1 1] [8 0 1 5 0 1 0 1 1 0 0 4 1 0 1 2 3 4 3 4 5 2 1 0 2] [9 1 1 5 0 2 0 5 0 1 2 7 2 3 0 0 5 3 2 1 4 1 2 0 1]] feature_names: [' ', ',', '.', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'r', 's', 't', 'u', 'w', 'y'] CountVectorizer: analyzer is char_wb results array: [[14 0 1 2 1 1 0 2 0 2 1 4 1 1 0 0 2 2 1 0 2 4 0 0 2] [16 0 1 5 1 2 1 3 0 2 1 4 1 1 0 0 3 2 1 1 4 3 0 0 2] [20 1 1 6 0 2 0 1 2 0 1 5 1 3 1 2 4 4 1 3 2 2 2 0 2] [12 0 1 3 0 1 2 3 0 0 0 3 0 1 2 2 2 3 0 1 1 0 0 1 1] [18 0 1 5 0 1 0 1 1 0 0 4 1 0 1 2 3 4 3 4 5 2 1 0 2] [20 1 1 5 0 2 0 5 0 1 2 7 2 3 0 0 5 3 2 1 4 1 2 0 1]] feature_names: [' ', ',', '.', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'r', 's', 't', 'u', 'w', 'y'] CountVectorizer: analyzer is callable object results array: [[0 0 0 0 0 1] [0 0 1 0 0 0] [1 0 0 0 0 0] [0 0 0 0 1 0] [0 0 0 1 0 0] [0 1 0 0 0 0]] feature_names: ['Fukuoka is most nearly city from Koria, China in japan.', 'Kouchi is a japanese city, in japanese region in Shikoku.', 'Osaka is the secondary biggest city in japan.', 'Sapporo is most nearly city from Russia in japan.', 'Sendai called we Mori no Miyako.', 'Tokyo is the biggest city in japan.']結果から見えるもの
analyzerにcharとchar_wbを指定した場合の結果を比較すると、analyzer = 'char'の場合の' 'の抽出回数をxとしたとき、analyzer = 'char_wb'の場合の' 'の抽出回数は2x+2回になる
analyzer = 'char'の場合は単純に文章中に含まれる' 'の数、analyzer = 'char_wb'の場合は加えて単語の前後が' 'ではない場合も境界として' 'に計上しているanalyzer = lambda x: [x]としたインスタンスで実行した場合、入力した文章が特徴(feature_name)としてそのまま戻ってくる。
- 投稿日:2019-05-29T18:46:22+09:00
機械学習のモデル評価と説明可能性のための指標 その3。Brier Score(ブライアスコア)
予測された延滞率が実際どれだけ当たっているか。予測と結果の合致性の評価
はじめに
- 今回は、説明可能性についての3回目、モデルを評価するための指標の1つであるブライアスコアについてまとめています。
- MLで作成されたモデルをどう評価するか、どう説明するかについてさまざまな指標・方法を用いて行うことを目的としており、主にPoCなどで利用していくことを想定しています。
- 説明可能性についてのまとめはこちら。
Brier Score(ブライアスコア)
- Brier Scoreとは
日本語ではWIKIもないブライアスコアですが、天気予報のWIKIの中にこんな記述があります。
予報確率Fi、実際値Ai(発生した場合1、発生しなかった場合0などとする)としたときの確率誤差の総和を予報回数Nで割ったもの。値が0に近いほど精度が高い。
$$\frac{1}{N} \sum_{i=1}^N(F_i - A_i)^2$$
英語版のWikiにある例を引用すると
- 延滞予測が100%($F_i$=1)で結果も延滞($A_i$=1)の場合は、Brier scoreは0となり、最高値となります。
- 延滞予測が100%($F_i$=1)で結果は延滞しない($A_i$=0)の場合は、Brier scoreは1となり、最低値となります。
- 延滞予測が70%($F_i$=0.7)で結果も延滞($A_i$=1)の場合は、Brier scoreは$(0.70-1)^2$=0.09となります。
- 延滞予測が30%($F_i$=0.3)で結果も延滞($A_i$=1)の場合は、Brier scoreは$(0.30-1)^2$=0.49となります。
予測値と結果に乖離があるほどスコアが下がる(Bier scoreの値が高くなる)ことになります。
上記のように、確率は0から1の値となり、結果も0と1の2項分類となるときには機能しますが、それ以外の場合には別な方法を使用することとなります。別な方法についてはWikiのOriginal definition by Brierを参照してください。
検索して出てくる文献のほとんどは天気予報関連でした。たぶんそちらの業界ではかなり一般的な指標と思われますが、あまり金融系では使われていないようです。
こちらでも書いた通りに、Forecastに拘りたい私としては、予測した確率の精度は重要な指標の1つとなります。
クレジットスコアで置き換えて考えると、機械学習で得られた延滞確率が実際にはどれだけの確率で発生しているのか、その確率の誤差を評価できます。
- 利用方法
- 上記のように計算も割と単純ですが、Sklernにも準備されているので容易に使うことができます。
サンプルは下記のようになります。
import numpy as np from sklearn.metrics import brier_score_loss # Probabilityの値 y_prob = np.array([0.1, 0.9, 0.8, 0.3]) # 2項分類の場合 # 結果の値。 y_true = np.array([0, 1, 1, 0]) brier_score_loss(y_true, y_prob) 0.037...ちなみに、多項分類なども準備されています。
# 多項分類の場合 # 結果の値。 y_true_categorical = np.array(["spam", "ham", "ham", "spam"]) brier_score_loss(y_true_categorical, y_prob, pos_label="ham") 0.037...まとめ
- 0と1の予測結果の精度を評価するのがAUCやジニ係数などになります。今回のブライアスコアは何%の確率と予測して、その結果がどうだったのかを評価します。
- クレジットスコアでは、延滞する・しないの予測のほかに、何%で延滞するのかを適切に予測する必要があります。その確率が正しければ、延滞確率に見合う融資金額や利率、全体のポートフォリオでの許容アセットなどを適切にすることで、しっかりとリスクをコントロールしていくことができます。
- 学習する分類器によっては、予測値の値をそのまま使用すると正確ではない数値を利用することになります。それを防ぐため適切な予測値に変換するprobability calibrationを行ってから利用しましょう。たとえばランダムフォレストの場合は予測値が >0.1 <0.7の値になっていますので、他の分類器と比較する際は注意が必要です。
関連・参考記事
- 投稿日:2019-05-29T18:25:50+09:00
MFCC(メル周波数ケプストラム係数)入門
MFCCとは
MFCCは聴覚フィルタに基づく音響分析手法で、主に音声認識の分野で使われることが多いです。
最近だとニューラルネットワークに学習させる音声特徴量としてよく使われていますね。
2019.5.29訂正
Deep Learning for Audio Signal ProcessingによるとDeep Learningにおいては必要な情報が失われるためMFCCは使わずに、最後の計算ステップである離散コサイン変換を省いたメルスペクトラム(log-mel spectrum)が使われるそうです。MFCCは従来手法である隠れマルコフモデル、混合ガウスモデル、サポートベクターマシンで使われることが多いです。今回はMFCC「メル周波数」や「ケプストラム」についても説明し、具体的なMFCCの実装方法も見ていきたいと思います。
メル尺度
心理学者のStanley Smith Stevensらによって提案された、人間の音高知覚が考慮された尺度です。
1000Hzの純音の高さの感覚を1000メルと決めた上で、1000メルの半分の高さに感じた音を500メル、1000メルの2倍の高さに感じた音を2000メルという容量で定めたものです。
実験により、可聴域の下限に近い音は高め、上限に近い音は低めに聞こえることがわかっています。
メル尺度は基底膜上の座標とほとんど一致します。1000メルは基底膜の1cmに相当し、臨海帯域幅は約137メルに相当します。
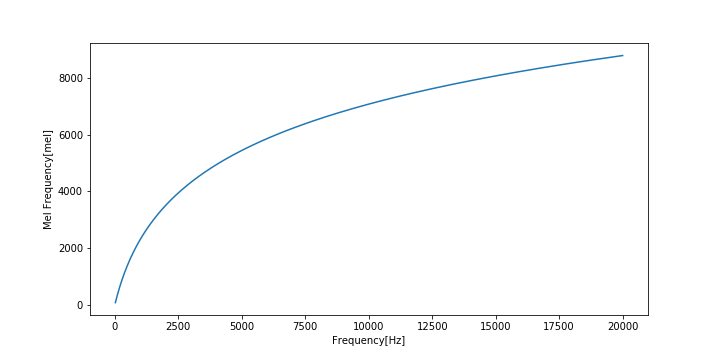
周波数$f$をメル尺度$m$に変換する式は
m = m_0\log(\frac{f}{f_0} + 1)逆変換は
f = f_0(\exp\frac{m}{m_0} - 1)で与えられます。
$f_0$は自由パラメータの周波数パラメータであり、$m_0$は「1000Hzは1000メル」という成約から導かれる
m_0 = \frac{1000}{\log(\frac{1000\mathrm{Hz}}{f_0} + 1)}であらわされる縦続パラメータです。
よく用いられるパラメータとして
f_0 = 700, m_0 = 2595があります。
周波数[Hz]とメル周波数[mel]の関係をグラフに表すとこのようになります。
ケプストラム
音声信号のフーリエ変換の絶対値に対数をかけ、さらに逆フーリエ変換(フーリエ変換とする場合もある)したもの。
信号$x(n)$のフーリエ変換を$X(e^{j\omega}$とすると、ケプストラム$c(m)$は
c(m) = \frac{1}{2\pi}\int_{\pi}^{\pi}\log|X(e^{j\omega})|e^{j\omega n}d\omega高ケフレンシ領域は微細振動(音声でいうと声帯の振動)、低ケフレンシ領域はスペクトル包絡(音声でいうと声道フィルタの特性)を表します。
リフタリングという処理を施すことによってこれらを分離することができます。
変換手順
この記事を参考にしながら実際に変換してみます。
コードはほぼそのままですが、Python3対応させたり、変数名やパラメータをちょこちょこ変えたりしてます。
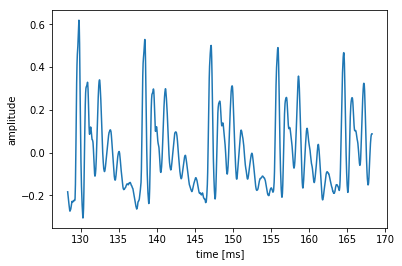
今回は「あ」の音声波形の定常部分のMFCCを求めてみましょう。(音声ファイルは各自用意してください。)
まずは必要なモジュールのインポートから
import numpy as np import matplotlib.pyplot as plt import soundfile as sf1. 波形を適当な長さに分割し、窓関数をかけてFFTを行う
# 音声の読み込み master, fs = sf.read('wavfiles/a_1.wav') t = np.arange(0, len(master) / fs, 1/fs) # 音声波形の中心部分(定常部)を切り出す center = len(master)//2 # 中心のサンプル番号 cuttime = 0.04 # 秒 x = master[int(center - cuttime / 2 * fs):int(center + cuttime / 2 * fs)] time = t[int(center - cuttime/2*fs): int(center + cuttime/2*fs)] plt.plot(time * 1000, x) plt.xlabel("time [ms]") plt.ylabel("amplitude") plt.show()上のコードを実行するとこのようなグラフが描けます。
次に窓処理を行って振幅スペクトルを求めます。
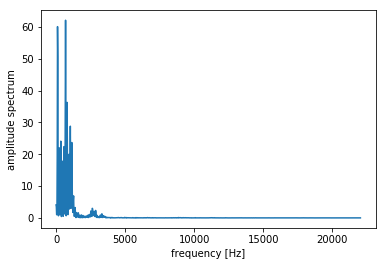
# ハミング窓をかける hamming = np.hamming(len(x)) x = x * hamming # 振幅スペクトルを求める N = 2048 # FFTのサンプル数 spec = np.abs(np.fft.fft(x, N))[:N//2] fscale = np.fft.fftfreq(N, d = 1.0 / fs)[:N//2] plt.plot(fscale, spec) plt.xlabel("frequency [Hz]") plt.ylabel("amplitude spectrum") plt.show()
2.メルフィルタバンクをかける
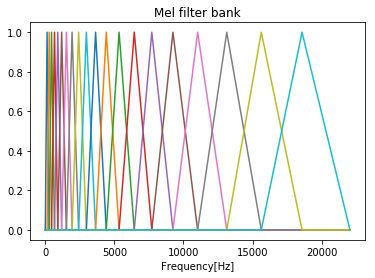
フィルタバンクは複数のバンドパスフィルタを並べたものです。
MFCCでは三角形のバンドパスフィルタをオーバラップさせながら並べ、フィルタバンクとしたメルフィルタバンクを用います。
メルフィルタバンクは周波数領域での三角窓がメル尺度上で等間隔になるように並べたものであり、低周波ほど幅が狭く、高周波ほど幅が広くなります。
並べられたバンドパスフィルタの数をチャンネル数といいます。
まずは周波数とメル尺度を変換する関数を実装します。
def hz2mel(f): """Hzをmelに変換""" return 2595 * np.log(f / 700.0 + 1.0) def mel2hz(m): """melをhzに変換""" return 700 * (np.exp(m / 2595) - 1.0)次にメルフィルタバンクを作る関数を実装します。
def melFilterBank(fs, N, numChannels): """メルフィルタバンクを作成""" # ナイキスト周波数(Hz) fmax = fs / 2 # ナイキスト周波数(mel) melmax = hz2mel(fmax) # 周波数インデックスの最大数 nmax = N // 2 # 周波数解像度(周波数インデックス1あたりのHz幅) df = fs / N # メル尺度における各フィルタの中心周波数を求める dmel = melmax / (numChannels + 1) melcenters = np.arange(1, numChannels + 1) * dmel # 各フィルタの中心周波数をHzに変換 fcenters = mel2hz(melcenters) # 各フィルタの中心周波数を周波数インデックスに変換 indexcenter = np.round(fcenters / df) # 各フィルタの開始位置のインデックス indexstart = np.hstack(([0], indexcenter[0:numChannels - 1])) # 各フィルタの終了位置のインデックス indexstop = np.hstack((indexcenter[1:numChannels], [nmax])) filterbank = np.zeros((numChannels, nmax)) print(indexstop) for c in range(0, numChannels): # 三角フィルタの左の直線の傾きから点を求める increment= 1.0 / (indexcenter[c] - indexstart[c]) for i in range(int(indexstart[c]), int(indexcenter[c])): filterbank[c, i] = (i - indexstart[c]) * increment # 三角フィルタの右の直線の傾きから点を求める decrement = 1.0 / (indexstop[c] - indexcenter[c]) for i in range(int(indexcenter[c]), int(indexstop[c])): filterbank[c, i] = 1.0 - ((i - indexcenter[c]) * decrement) return filterbank, fcenters # メルフィルタバンクを作成 numChannels = 20 # メルフィルタバンクのチャネル数 df = fs / N # 周波数解像度(周波数インデックス1あたりのHz幅) filterbank, fcenters = melFilterBank(fs, N, numChannels) # メルフィルタバンクのプロット for c in np.arange(0, numChannels): plt.plot(np.arange(0, N / 2) * df, filterbank[c]) plt.title('Mel filter bank') plt.xlabel('Frequency[Hz]') plt.show()
次に振幅スペクトルにメルフィルタバンクをかけます。
振幅スペクトルに対して作成した各フィルタバンクをかけ、フィルタリングされた振幅を足し合わせて対数を取ります。
forループを使って書いてもいいですが、内積の形でも書け、こっちの方がエレガントです。
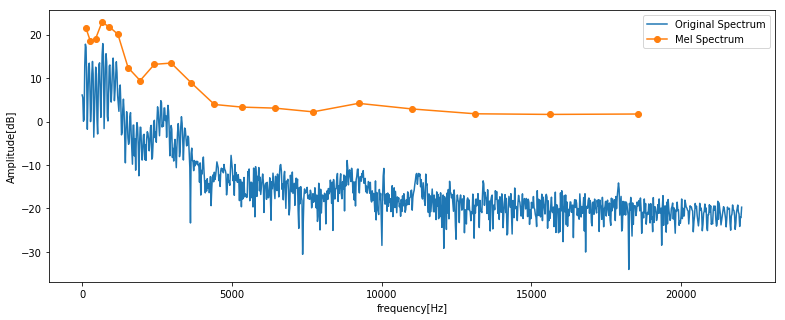
# 振幅スペクトルにメルフィルタバンクを適用 mspec = np.dot(spec, filterbank.T)元の振幅スペクトルとフィルタバンクをかけた後のスペクトルを比べてみましょう。
# 元の振幅スペクトルとフィルタバンクをかけて圧縮したスペクトルを表示 plt.figure(figsize=(13, 5)) plt.plot(fscale, 10* np.log10(spec), label='Original Spectrum') plt.plot(fcenters, 10 * np.log10(mspec), "o-", label='Mel Spectrum') plt.xlabel("frequency[Hz]") plt.ylabel('Amplitude[dB]') plt.legend() plt.show()
3.離散コサイン変換を行う
メルフィルタバンクをかけた後のスペクトルをケフレンシ空間に戻すために離散コサイン変換を行います。
離散コサイン変換を行う理由として、係数間の相関が減り、特徴量としての性能が向上するなどがあります。
離散コサイン変換の結果から低次の係数を取り出すと、MFCCが得られます。大体12次まで取ることが多いです。
from scipy.fftpack.realtransforms import dct ceps = dct(mspec, type=2, norm="ortho", axis=-1) nceps = 12 mfcc = ceps[:nceps] print(mfcc) [185.60782114 200.56668729 92.15345128 1.16538975 -47.4746488 -60.60365351 -43.46459693 3.15481979 50.37136343 64.6038092 48.42430931 27.41620554]LibrosaでMFCCを求める
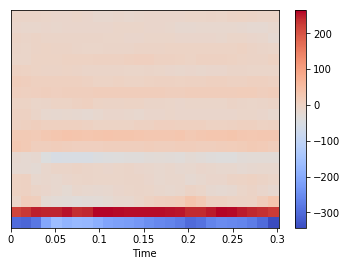
上では音声データ全体の中の1フレームのみを用いてMFCCを求めましたが、Librosaを使うと簡単に各フレームごとのMFCCを求めることができます。
import librosa x, fs = sf.read('wavfiles/a_1.wav') mfccs = librosa.feature.mfcc(x, sr=fs) print(mfccs.shape) print(mfccs[0]) (20, 26) [-299.48698558 -306.19008252 -281.77019349 -205.61561205 -165.07338147 -182.40750356 -172.10454081 -175.49027956 -191.51493931 -210.77326972 -217.29547751 -223.91082068 -232.23909119 -247.65589292 -256.91669445 -263.66001621 -275.46132992 -299.72892089 -288.90436044 -262.39782466 -252.39945491 -256.61596037 -260.47453287 -274.17839766 -299.54783037 -342.87809203]カラーマップで可視化することも出来ます。
import librosa.display librosa.display.specshow(mfccs, sr=fs, x_axis='time') plt.colorbar()
おわりに
今回はMFCCに入門してみました。
GitHubにJupyter Notebookを置いていますので、よかったらこちらもどうぞ。https://github.com/tmtakashi/signal_processing/blob/master/mfcc.ipynb
参考
音楽と機械学習 前処理編 MFCC ~ メル周波数ケプストラム係数
- 投稿日:2019-05-29T18:22:51+09:00
#Slack API を叩いて全メンバーを一個のチャンネルに招待する #python スクリプトの例 (雑バージョン)
ATTENTION
- チャンネルIDの取得方法は適当にググる (チャンネル名ではない)
- Slack App を登録して Tokenを得て、適切な Permission を設定しておく
- メンバー数が多い場合には対応していない、ページングに対応していない
- 重複招待でエラーが返ってくる問題にも対応していない
- API制限に引っかかったら適当に sleep 入れるなりして対処してください
- 例では無意味に jq コマンドかましてます
all-member-list.py
#!/usr/bin/env python3 # https://api.slack.com/methods/users.list import requests, os, json url = "https://slack.com/api/users.list" params = { "token" : os.environ.get('SLACK_TOKEN'), } headers = { 'Content-type': 'application/json' } res = requests.get(url, headers=headers, params=params) print(json.dumps(res.json()))invite-to-channel.py
#!/usr/bin/env python3 # https://api.slack.com/methods/channels.invite # https://slack.com/api/channels.invite import requests, os, json, sys url = "https://slack.com/api/channels.invite" members = json.loads(sys.stdin.read()) for member in members: params = { "token" : os.environ.get('SLACK_TOKEN'), "channel" : os.environ.get('CHANNEL'), "user" : member.get('id'), } headers = { 'Content-type': 'application/json' } res = requests.post(url, headers=headers, params=params) print(json.dumps(res.json()))exe
export SLACK_TOKEN=xxxxxxxxxxxxxxxx && ./all-member-list.py | jq -r '.members' | CHANNEL=xxxxxxx ./invite-to-channel.pyワークスペースのデフォルトチャンネルを設定
一度全員招待しても、WorkSpaceのメンバーが増えたらやり直しなので、admin設定でデフォルトチャンネルも設定しておくと良いかも
https://example.slack.com/admin/settings
有料プランなら
- 全メンバーをSlackグループに入れておく
- グループに対して invite する
っていう手順で、API叩かなくてもできるかもしれません。
Original by Github issue

- 投稿日:2019-05-29T17:59:11+09:00
simplekmlのシンプルな使い方
初カキコ…ども…
表題の通りですが、簡単に使い方を説明していこうと思います
simplekmlとは
簡単に言えばKMLをシンプルに作成できるpythonのパッケージですね。
あんまりsimplekmlに関する記事がないようでしたので、自分のコードとかを備忘録的に記事にしておこうと思いました。記事作成時点でのバージョンは1.3.1になります。
https://simplekml.readthedocs.io/en/latest/index.htmlめちゃ簡単なsample
simplekml.pykml = simplekml.Kml() kml.newpoint(name="Kirstenbosch", coords=[(18.432314,-33.988862)]) # lon, lat, optional height kml.save("botanicalgarden.kml")ざっくりこれだけでkmlが作れます。
sampleでは点だけを作ってますが、これ以外にもpolygonやlineが描画できます。
またフォルダを作成して、その中にpointやlineを作ることももちろん可能です。ポリゴンのスタイル
polygonやline,pointにはそれぞれスタイルが設定できます。
設定できるものはオブジェクトによって違います。詳細は公式Documentを参照してくださいpolygonStyle.pypol = kml.newpolygon(name = testName) pol.outerboundaryis = [a, b, c, d, a] pol.style.linestyle.color = "bf00ffff" pol.style.polystyle.color = "3f00ff00" pol.style.linestyle.width = 3上のサンプルではまずポリゴンの外形境界線(outerBoundary)を設定し
境界線の色、ポリゴンの色、境界線の太さを設定しています。
また、このほかに内側の境界線(innerBoundary)を設定することもできます。ポイントのスタイル
pointStyle.pypoint = kml.newpoint(name = testName) point.coords = [(a,b)] point.style.iconstyle.icon.href = None point.style.labelstyle.scale = 0.8pointのスタイルになります。
割と使いそうなのはiconstyleだと思います。
こう記述するとiconなしで表示することができます。注意点
最後に注意したい点なんですが、kmlの座標の表記は度分秒ではなく十進数表記になります。
若干めんどうなんですけど、そこだけ注意してください。おわり
いかがでしたか!?
初めての記事なのでちょっと締めの言葉がわかりません。
転職やめ太郎師父の記事がめちゃおもしろいので皆さんも読んでください
https://qiita.com/Yametaro以上です。
- 投稿日:2019-05-29T17:42:29+09:00
NumPy で行列の差分計算
極めてニッチで一体誰の参考になるのかという小ネタだけど、自分用のメモとして。
前提
npで NumPy を使えるものとする。import numpy as npやりたいこと
以下のような要素のリスト (例: 1から6までの整数) があったとする。
arr = np.arange(1, 7) # array([1, 2, 3, 4, 5, 6])このリストから2つの要素を選ぶ全ての組み合わせについて、何らかの計算 (例: 2要素の積) をした行列を求めたとする。
X, Y = np.meshgrid(arr, arr) matrix = X * Y # array([[ 1, 2, 3, 4, 5, 6], # [ 2, 4, 6, 8, 10, 12], # [ 3, 6, 9, 12, 15, 18], # [ 4, 8, 12, 16, 20, 24], # [ 5, 10, 15, 20, 25, 30], # [ 6, 12, 18, 24, 30, 36]])(補足) 上記のコードは、下記のコードでも同じ結果が得られる。
prod = lambda X, Y: X * Y matrix = prod(*np.meshgrid(arr, arr)) # 上記と同じ行列が得られるここで、リストに対して要素が追加されることになった、とする。
arr_new = np.arange(7, 10) # array([7, 8, 9])もともとの要素 arr と追加要素 arr_new を結合した新しいリストについて、先ほど計算したような行列を再び求めたい。
愚直に書くとこうなる。
arr_all = np.concatenate([arr, arr_new]) matrix_new = prod(*np.meshgrid(arr_all, arr_all)) # array([[ 1, 2, 3, 4, 5, 6, 7, 8, 9], # [ 2, 4, 6, 8, 10, 12, 14, 16, 18], # [ 3, 6, 9, 12, 15, 18, 21, 24, 27], # [ 4, 8, 12, 16, 20, 24, 28, 32, 36], # [ 5, 10, 15, 20, 25, 30, 35, 40, 45], # [ 6, 12, 18, 24, 30, 36, 42, 48, 54], # [ 7, 14, 21, 28, 35, 42, 49, 56, 63], # [ 8, 16, 24, 32, 40, 48, 56, 64, 72], # [ 9, 18, 27, 36, 45, 54, 63, 72, 81]])しかし、もともとの要素 arr に関する計算済みの行列 matrix があるので、この行列を利用して新しい要素に関する拡張部分だけを計算することにして、計算量を抑えたい。
この差分計算を NumPy で書きたい。
解法
このような関数を作ると実現できる。
def extend_matrix(matrix_base, arr_base, arr_new, func): part0 = func(*np.meshgrid(arr, arr_new)) part1 = func(*np.meshgrid(arr_new, arr_new)) return np.concatenate([ np.concatenate([matrix_base, part0], axis=0), np.concatenate([part0.T, part1], axis=0), ], axis=1)行列の新しく増える部分だけを計算して、既存の行列と結合している。
使うときは、こう。
matrix_new = extend_matrix(matrix, arr, arr_new, prod) # array([[ 1, 2, 3, 4, 5, 6, 7, 8, 9], # [ 2, 4, 6, 8, 10, 12, 14, 16, 18], # [ 3, 6, 9, 12, 15, 18, 21, 24, 27], # [ 4, 8, 12, 16, 20, 24, 28, 32, 36], # [ 5, 10, 15, 20, 25, 30, 35, 40, 45], # [ 6, 12, 18, 24, 30, 36, 42, 48, 54], # [ 7, 14, 21, 28, 35, 42, 49, 56, 63], # [ 8, 16, 24, 32, 40, 48, 56, 64, 72], # [ 9, 18, 27, 36, 45, 54, 63, 72, 81]])追加要素についての差分計算だけで全体の行列を求めることができた。
- 投稿日:2019-05-29T17:36:27+09:00
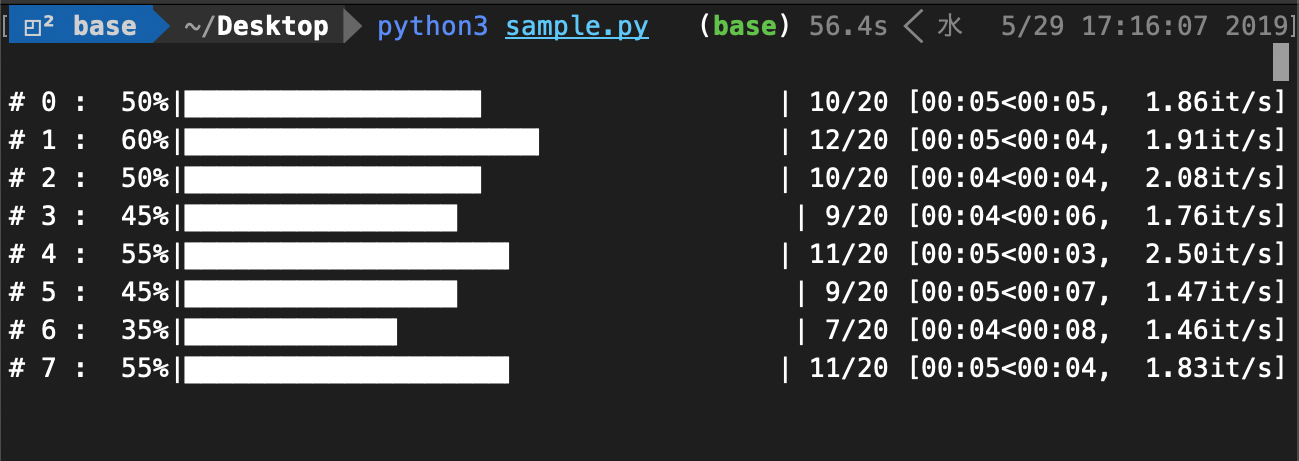
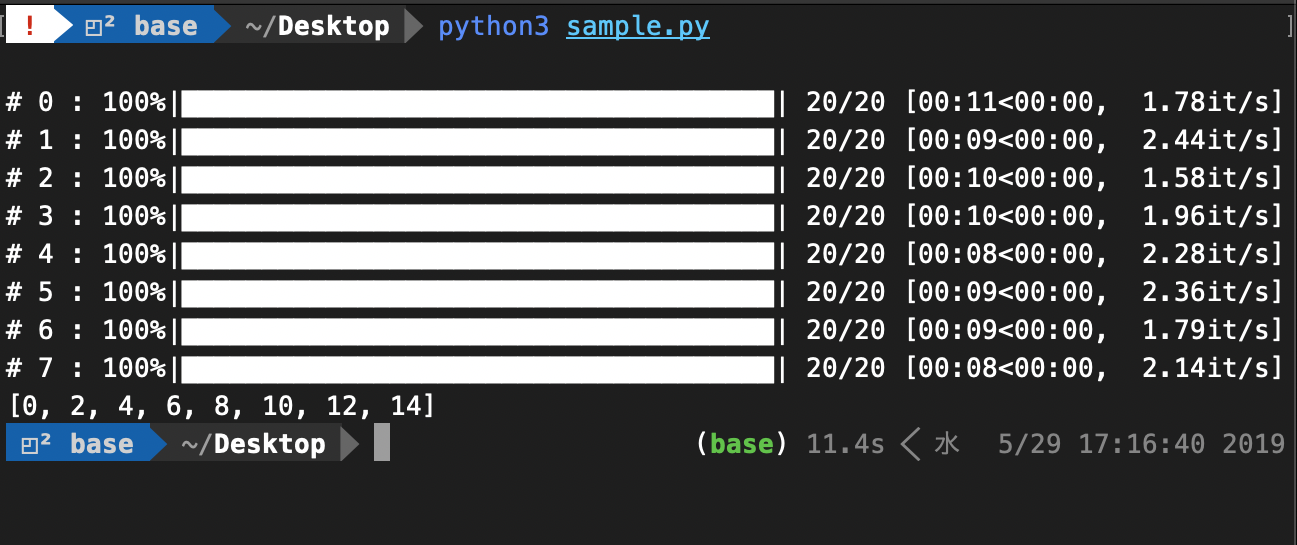
Pythonでmultiprocessingを用いて並列実行するときに、プロセスそれぞれの進捗バーをtqdmで表示する
概要
Pythonでmultiprocessingを使って並列処理を実行するときに、それぞれのプロセス毎に進捗を表示したい時があるかと思います。
そこで、tqdm を用いてプロセス毎にバーを表示してみました。参考 : tqdm
目標
プロセス毎に独立してプログレスバーを表示!
Code
from time import sleep import random from tqdm import tqdm from multiprocessing import Pool, freeze_support, RLock L = 8 def long_time_process(p): info = f'#{p:>2} ' # 進捗バーの左側に表示される文字列 for _ in tqdm(range(20), desc=info, position=p+1): sleep(random.random()) return p * 2 if __name__ == '__main__': freeze_support() # Windows のみ必要 with Pool(L, # Windows のみ必要 initializer=tqdm.set_lock, initargs=(RLock(),)) as p: result = p.map(long_time_process, range(L)) print("\n" * L) # tqdm終了後のカーソル位置を最下部に持ってくる print(result)解説
long_time_process: 並列実行したい関数
freeze_support, initializer, initargs: Windowsでのみ必要になるそうです。Macではこれを省いても特に問題ありませんでした。
position=p+1: 本来はpositionは0から始まるため、画像を見るとわかるように、プログラムを実行したときに上に1行分のスペースができています。position=0から表示させると、一番上のプログレスバーが終了したタイミングで全体の表示がずれてしまうため、ここでは1から始めています。結果
レイアウトが崩れることなく、プログレスバーの表示、及びその後のprint出力もできています。
- 投稿日:2019-05-29T17:36:22+09:00
QuantXで作成したアルゴリズムをQuantopianのアルゴリズムコンテスト基準に当てはめてみる
TurnoverをQuantX上で算出
- positive returns:収益が正である
- Low exposure to sector risk and style risk:Quantopian独自の Risk model の条件を満たしている
- Beta-to-spy:
- Leverage:レバレッジ0.8-1.1倍(QuantXには関係ない?)想定資本に対して80%〜110%の範囲で投資
- turnover : 中程度のturnoverを維持。
- アルゴリズムに用いる株はある程度の流動性を持っていないといけない
- position concentration :アルゴリズムは1つの銘柄に対して全資産の5%以上投資してはいけない
- Long and short positions :買いポジションと売りポジションの差額がトータル資金に対して10%以上になってはいけない。
以下補足
- Risk model は大きく分けて2つ。セクター要因とスタイル要因
- セクター要因とは株式会社を11のセクターに業界で分別して(ex,技術、金融、不動産...)、各セクターに20%以上の資金を投資していはいけない
- スタイル要因とは???momentum size volatility とかで計算していく
- turnover =(1日の投資資金の絶対値)/(全ポートフォリオの価値)
- コンテストに使用できる株が流動性のある株に限定するために、Quantopianは独自で流動性があるとみなした株式銘柄群(株の集合)を作成し、コンテストに使用する株はその銘柄群の中から選ぶ必要がある。
この中で投資比率制約、turnover制約、を実際に実装してみてこれらを満たしているかを確認する。
turnover制約の実装
turnoverの具体的な計算方法としては(1日の投資資金の絶対値)/(全ポートフォリオの価値)を毎日計算して、それの63日営業日移動平均をとる。この値が5〜65%の間に入っていることが条件。
X日目のturnover = \sum_{銘柄} \frac{X日目の、ある銘柄の投資量}{全資産} = \sum_{銘柄} {|(X日目の、ある銘柄の全資産に対する保有割合)-(X-1日目の、ある銘柄の全資産に対する保有割合)|}で算出できる。
以下でQuantX上でturnoverを表示する
X日目の、ある銘柄の全資産に対する保有割合 current_portfolio_ratio は、symで銘柄を指定して
current_portfolio_ratio = ctx.portfolio.positions[sym]["portfolio_ratio"]で取得できる。
さらにあらかじめctx.localStorageを利用して保存しておいた、X-1日目のある銘柄の全資産に対する保有割合 previous_portfolio_ratio も用いてX日目のturnoverは
X日目のturnover = \sum_{銘柄} |current_portfolio_ratio - previous_portfolio_ratio|で求まる。ここでQuantopian上での制約はturnoverの63日移動平均を計算してそれが5~63%に入ることが条件である。
ゆえに、上で算出したX日目のturnoverを毎日localStorageに保管して、実際にはlocalStorageに保管されている過去63日分のturnoverの平均を数値評価するのである。以上を実際にQuantX上で実装してみる。
とりあえず、取り扱う通過などを設定するimport pandas as pd import talib as ta import numpy as np def initialize(ctx): ctx.flag_profit = False #利益確定売りを用いるかTrueなら用いるFalseなら用いない ctx.flag_loss = False #損切りを用いるかTrueなら用いるFalseなら用いない ctx.loss_cut = -0.03 #損切りのボーダーマイナス% ctx.profit_taking = 0.05 #利益確定売りのボーダープラス% ctx.codes = [ 4502, 4506, ] ctx.symbol_list = ["jp.stock.{}".format(code) for code in ctx.codes] ctx.configure( channels={ # 利用チャンネル "jp.stock": { "symbols":ctx.symbol_list, "columns": [ "close_price", # 終値 "close_price_adj", # 終値(株式分割調整後) ]}})次にmy_signal内でbuy_sigとsell_sigを設定する
しかし今回はわかりやすいようにするためにbuysigの値を全てTrueに、sell_sigの値を全てFalseに設定する。def _my_signal(data): # この部分に作成するアルゴの指標を書き込んで下さい。 #シグナル定義 #各銘柄の終値(株式分割調整後)を取得、欠損データの補完 cp = data["close_price_adj"].fillna(method="ffill") #単純移動平均線(SMA)の設定 #データの入れ物を用意 s_sma = pd.DataFrame(data=0,columns=[], index=cp.index) m_sma = pd.DataFrame(data=0,columns=[], index=cp.index) l_sma = pd.DataFrame(data=0,columns=[], index=cp.index) #TA-Libによる計算 for (sym,val) in cp.items(): s_sma[sym] = ta.SMA(cp[sym].values.astype(np.double), timeperiod=5) m_sma[sym] = ta.SMA(cp[sym].values.astype(np.double), timeperiod=25) l_sma[sym] = ta.SMA(cp[sym].values.astype(np.double), timeperiod=75) #SMAの売買シグナルの定義 s_sma_ratio = s_sma/m_sma l_sma_ratio = m_sma/l_sma buy_sig = (s_sma_ratio > 1.00) & (s_sma_ratio < 1.10) & (l_sma_ratio > 1.00) & (l_sma_ratio < 1.10) sell_sig = (s_sma_ratio < 0.99) & (l_sma_ratio < 0.99) #実験的にbuy_sigの値を全てtrueに、sell_sigの値を全てFalseに設定。 buy_sig.iloc[:,:] = True sell_sig.iloc[:,:] = False return { "sma5":s_sma, "sma25":m_sma, "sma75":l_sma, "buy:sig": buy_sig, "sell:sig": sell_sig, } # シグナル登録 ctx.regist_signal("my_signal", _my_signal)さらにhandle_signal内で売買を行い、その売買結果を利用してturnoverの値を算出する。
なお設定としてbuy_sigにヒットすると、一回の取引で全資産の5%分の株を買うように設定している。
実際には全資産の5%ちょうど売買することは不可能で、5%未満でキリのいいunit数売買することになる。
また、quantopianではturnoverの63日の移動平均をとって数値評価しているが、今回の試験的なQuantX上でのturnoverの実装なので、簡単にturnoverの5日移動平均をとって数値評価する。def handle_signals(ctx, date, current): ''' current: pd.DataFrame ''' df = current.copy() done_syms = set([]) #X日目の各銘柄の全資産に対する保有割合の変化を足し合わせるためにsum_rate_changeを作成 sum_rate_change = 0 for (sym,val) in ctx.portfolio.positions.items(): current_portfolio_rate = ctx.portfolio.positions[sym]["portfolio_ratio"] ''' localStorageにsymbolのkeyがあれば先に進み、なければsymbolをkey、 valueは空の辞書とする、辞書を作る ''' if sym in ctx.localStorage: pass else: ctx.localStorage[sym] = {} ''' localStorage[sym]に"portfolio_ratio"のkeyがあれば、 前日と当日のportfolio_ratioの差の絶対値を計算しsum_rate_changeにたす なければ、新しくlocalStorage[sym]にからの辞書を作る ''' if "portfolio_ratio" in ctx.localStorage[sym]: previous_portfolio_rate = ctx.localStorage[sym]["portfolio_ratio"] abs_rate_change = abs(current_portfolio_rate - previous_portfolio_rate) sum_rate_change += abs_rate_change ctx.localStorage[sym]["portfolio_ratio"] = current_portfolio_rate else: ctx.localStorage[sym]["portfolio_ratio"] = current_portfolio_rate returns = val["returns"] if (ctx.flag_loss) & (returns < ctx.loss_cut): sec = ctx.getSecurity(sym) sec.order(-val["amount"], comment="損切り(%f)" % returns) done_syms.add(sym) elif (ctx.flag_profit) & (returns > ctx.profit_taking): sec = ctx.getSecurity(sym) sec.order(-val["amount"], comment="利益確定売(%f)" % returns) done_syms.add(sym) if "turnover" in ctx.localStorage.keys(): ctx.localStorage["turnover"] = np.append(ctx.localStorage["turnover"], float(sum_rate_change)) sma_turnover = ta.SMA(ctx.localStorage["turnover"], timeperiod=5) ctx.logger.debug(sma_turnover[-1]) elif "turnover" not in ctx.localStorage.keys(): ctx.localStorage["turnover"] = np.zeros(1) ctx.logger.debug(ctx.localStorage['turnover']) # 買いシグナル df_long = df[df["buy:sig"]] # ctx.logger.debug(df_long) if not df_long.empty: for (sym, val) in df_long.iterrows(): if sym in done_syms: continue sec = ctx.getSecurity(sym) sec.order_percent(0.05, comment="SIGNAL BUY") # 売りシグナル df_sell = df[df["sell:sig"]] if not df_sell.empty: for (sym, val) in df_sell.iterrows(): if sym in done_syms: continue sec = ctx.getSecurity(sym) sec.order_percent(0, comment= "SIGNAL SELL")これを実行するとdebug画面に
array型のturnoverと、そのarrayの5日移動平均をとった実際に数値評価するsma_turnoverが得られる。ところで今回、二銘柄に対してsignalが発火するごとに5%づつ取引するように設定しているので、1日の取引量の全資産に対する割合はおおよそ8〜10%であると予想される。
実際の結果は以下である。(以下はn日目のturnoverのarrayと)
# turnoverのarray [0. 0. 0. 0.08652656 0.08774072 0.08964686 0.08793647 0.08958893 0.08674776 0.08879918 0.09168621 0.08819629] turnoverのarrayの最新5日分の平均をとった値。 0.0888118524395898となり予想して結果と一致している。
以上よりturnoverのQuantX上での計算が完了
- 投稿日:2019-05-29T16:44:16+09:00
Openpyxlでのマージされたセルについて
はじめに
Openpyxlを使って、エクセルを読み込み、マージされたセルをどのように扱うのかについてメモを残しておきます。
このようなデータを使用。
Excelデータを読み込む
import openpyxl # エクセエルファイルを指定し、読み込みたいシート名を指定 excel_file = 'sample.xlsx' wb = openpyxl.load_workbook(filename = excel_file) sheet = wb['Sheet4']セル範囲を指定してセルを取得する
# 先ほど読み込んだシートの中で読み込みたい範囲を指定する for 行変数 in シート変数[開始セル:終了セル]: for セル変数 in 行変数: print(セル変数.value )例えば、A1~D7に書かれたデータを読み込みたい場合は以下のように範囲を指定する
# 1回目のfor文では、行単位で、2回目のfor文で行のなかにあるcell単位で出力することができる for row in sheet['A1:D7']: for cell in row: print(cell, cell.value)出力結果
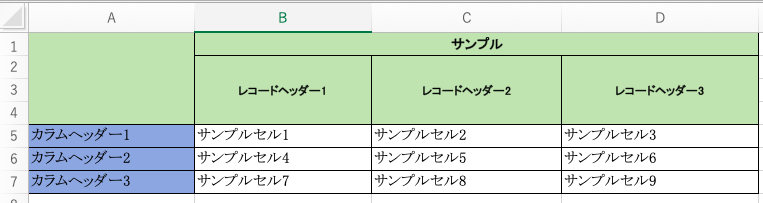
<Cell 'Sheet4'.A1> None <Cell 'Sheet4'.B1> サンプル <MergedCell 'Sheet4'.C1> None <MergedCell 'Sheet4'.D1> None <MergedCell 'Sheet4'.A2> None <Cell 'Sheet4'.B2> レコードヘッダー1 <Cell 'Sheet4'.C2> レコードヘッダー2 <Cell 'Sheet4'.D2> レコードヘッダー3 <MergedCell 'Sheet4'.A3> None <MergedCell 'Sheet4'.B3> None <MergedCell 'Sheet4'.C3> None <MergedCell 'Sheet4'.D3> None <MergedCell 'Sheet4'.A4> None <MergedCell 'Sheet4'.B4> None <MergedCell 'Sheet4'.C4> None <MergedCell 'Sheet4'.D4> None <Cell 'Sheet4'.A5> カラムヘッダー1 <Cell 'Sheet4'.B5> サンプルセル1 <Cell 'Sheet4'.C5> サンプルセル2 <Cell 'Sheet4'.D5> サンプルセル3 <Cell 'Sheet4'.A6> カラムヘッダー2 <Cell 'Sheet4'.B6> サンプルセル4 <Cell 'Sheet4'.C6> サンプルセル5 <Cell 'Sheet4'.D6> サンプルセル6 <Cell 'Sheet4'.A7> カラムヘッダー3 <Cell 'Sheet4'.B7> サンプルセル7 <Cell 'Sheet4'.C7> サンプルセル8 <Cell 'Sheet4'.D7> サンプルセル9cellオブジェクトから得られる情報は
マージされたセルか(Cell or MergedCell)
セルの属するシート名 (シート名)
セルの座標 (アルファベット+数字)cell.valueから得られる情報は
セルの中に書かれたテキスト
(* mergeされたcellの場合はNoneになる)mergeされたセルの値
セルが縦方向または横方向にマージされている場合、そのセルの一番左上が代表のセルとなり、
(縦方向でのマージでは一番上にあるセル、横方向のマージでは一番左にあるセル)
それ以外のセルはMergedCellとなる。具体的には、
今回のデータでは、サンプルと書かれたセルが、B1~D1にかけてマージされている。
この時、先ほどの実行結果を見てみると、
<Cell 'Sheet4'.B1> サンプル <MergedCell 'Sheet4'.C1> None <MergedCell 'Sheet4'.D1> None <MergedCell 'Sheet4'.A2> None <Cell 'Sheet4'.B2> レコードヘッダー1 <Cell 'Sheet4'.C2> レコードヘッダー2 <Cell 'Sheet4'.D2> レコードヘッダー3左上のB1のセルは'Cell'として、"サンプル"というテキストをもち、
それ以外のC1, D1は'MergedCell'となり、valueがNoneとなる。同様に、レコードヘッダー1, レコードヘッダー2, レコードヘッダー3と書かれた
縦にマージされたセルについて、一番上のB2, C2, D2のみテキストが入り、
それ以外のセルは'MergedCell'とされる。<Cell 'Sheet4'.B2> レコードヘッダー1 <Cell 'Sheet4'.C2> レコードヘッダー2 <Cell 'Sheet4'.D2> レコードヘッダー3 <MergedCell 'Sheet4'.A3> None <MergedCell 'Sheet4'.B3> None <MergedCell 'Sheet4'.C3> None <MergedCell 'Sheet4'.D3> None <MergedCell 'Sheet4'.A4> None <MergedCell 'Sheet4'.B4> None <MergedCell 'Sheet4'.C4> None <MergedCell 'Sheet4'.D4> Nonemergeされたセルの範囲を取得
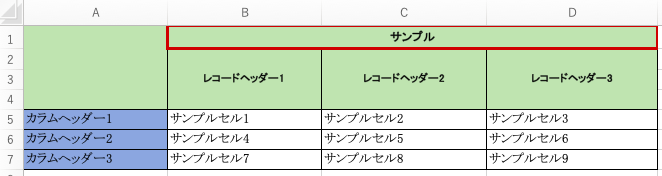
sheetの中のマージされたセルの範囲を取得する関数が用意されていたのでメモ。
sheet.merged_cells.ranges
- merged_cell_rangesが廃止されて、バージョンいくつからmerged_cells.rangesを使用することになったそう。 https://openpyxl.readthedocs.io/en/stable/api/openpyxl.worksheet.worksheet.html#openpyxl.worksheet.worksheet.Worksheet.merged_cell_ranges
出力結果
[<CellRange B1:D1>,
<CellRange B2:B4>,
<CellRange C2:C4>,
<CellRange A1:A4>,
<CellRange D2:D4>]
これを使えば、どのセルがどこからどこまでマージされているのかリストで取得できるため、
先ほどの実行結果と組み合わせれば、色々使えそう!
- 投稿日:2019-05-29T16:35:50+09:00
通り魔を自動で感知し110番通報するAI
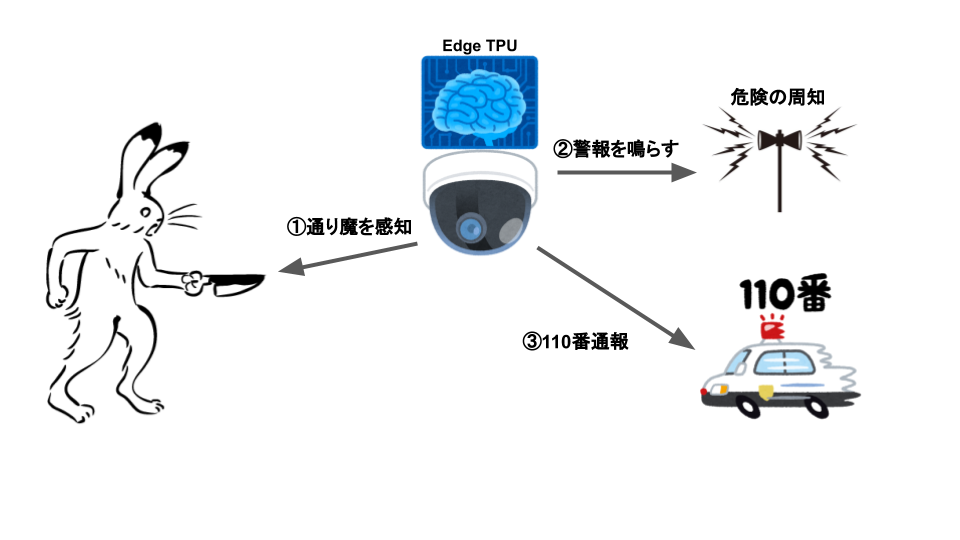
昨日、川崎で通り魔殺傷事件が発生しました。人工知能で何かできないかと思い考えてみました。
①通り魔を感知
刃物を持っているかどうかで通り魔か判断します。
データセットは、AGH科学技術大学のKnives Images Databaseからダウンロードしました。
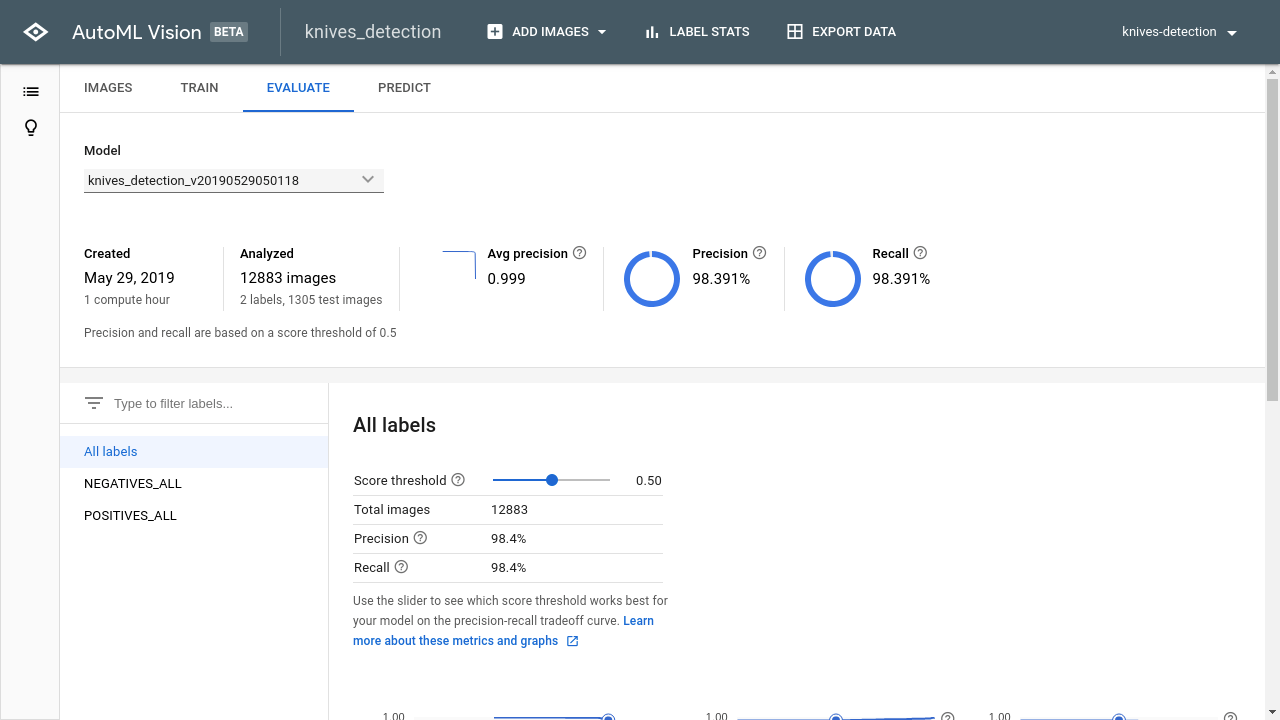
刃物を持っているかどうかで2クラス分類を行います。
精度は、99%と通り魔をほぼ完全に認識できました。EdgeTPUで認識すると200fps(レイテンシ5ms)で認識可能です。
最近はTecoGANやSENetなど超解像技術の進歩がめざましいのでコンビニのような荒くてノイズが入るカメラでも高精度で認識することが可能です。
②警報を鳴らす
コンビニなどの警報機と連携がんばる
警報ブザーを鳴らすことで周囲に危険を伝え逃げる時間を与えたり、犯人を動揺させることができるかも知れません。③110番通報
AmazonConnectで110番通報(未検証)
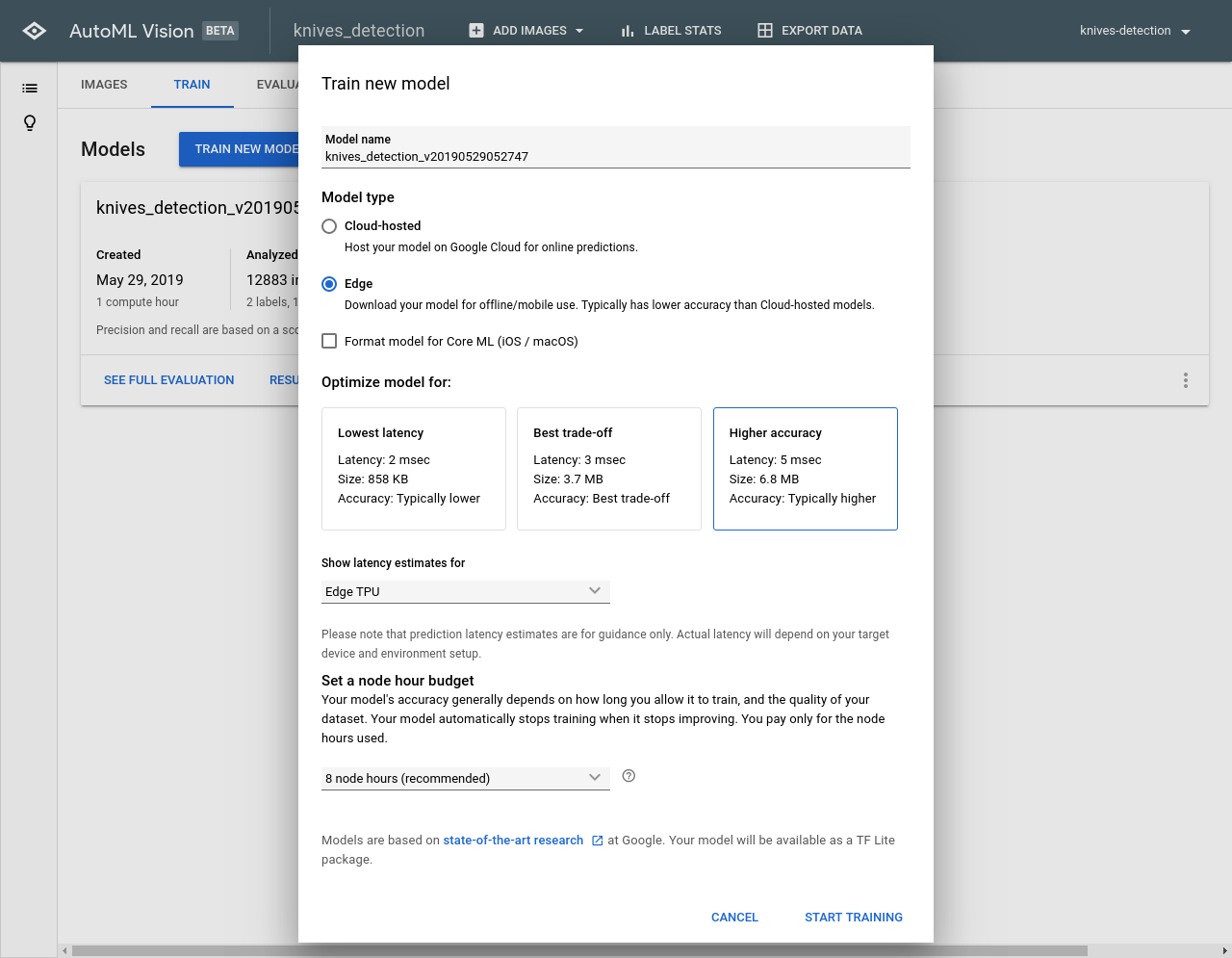
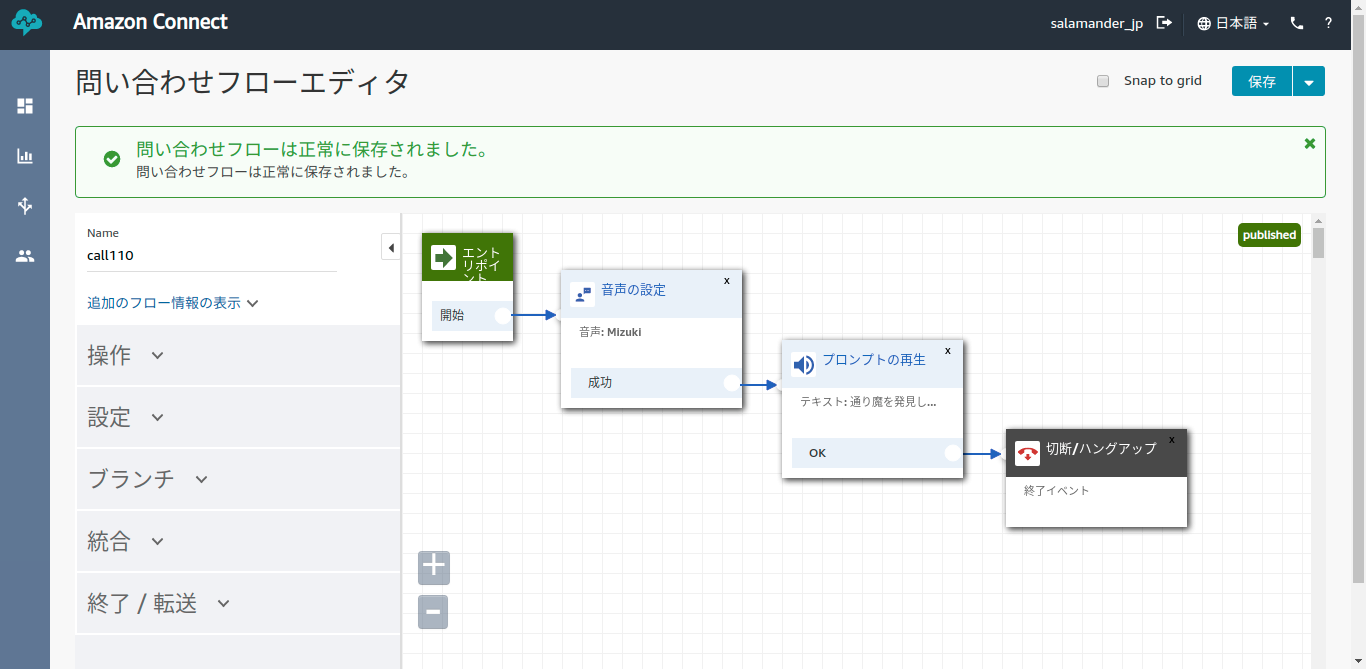
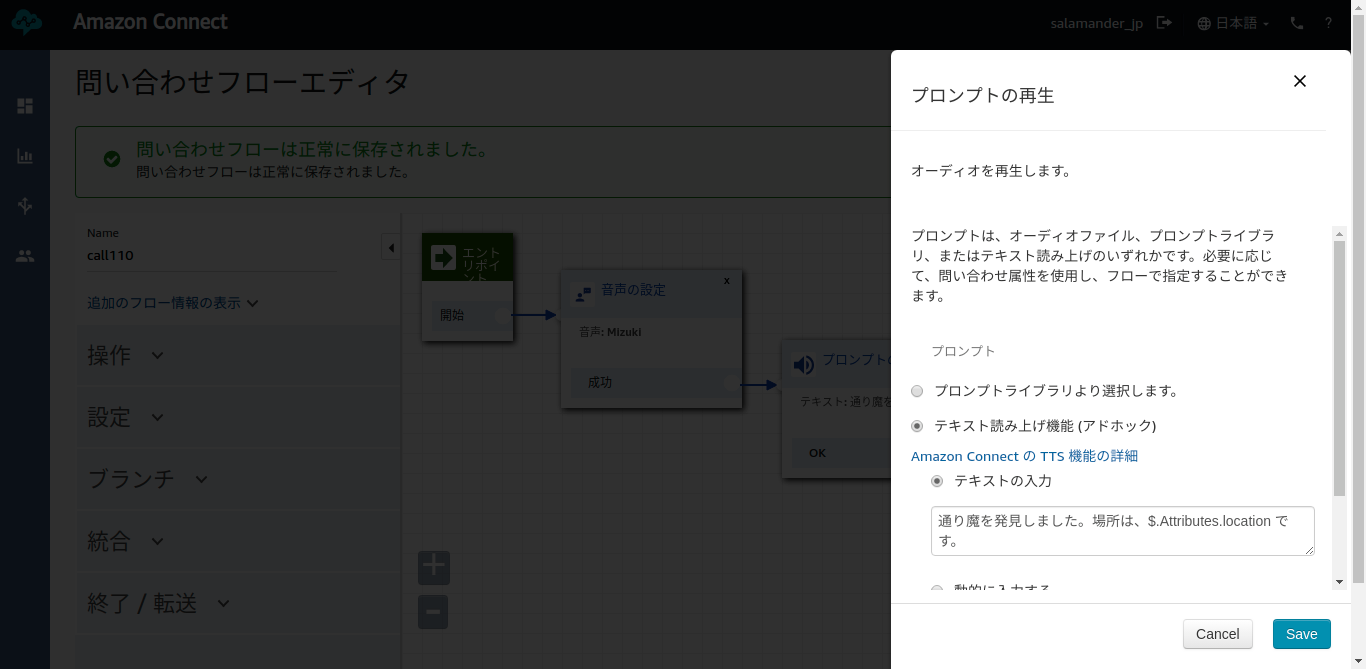
問い合わせフローを作成
場所は、柔軟に変更できるようにしました。
startOutboundVoiceContact APIで110番に通報(未検証)
// import entire SDK var AWS = require('aws-sdk'); // load config file AWS.config.loadFromPath('./config.json'); // create amazon connect object connect = new AWS.Connect({apiVersion: '2017-08-08'}); // create API request parameter var params = { Attributes: { location: 'ファミリーマート登戸新町店' }, ContactFlowId: "875a14b4-3685-47ee-9fcd-8a233d0470c6", // 電話番号をE.164形式で設定するため、例えば「050-0000-0000」の場合は、 //国番号(日本:81)を付けて以下のようになります。 DestinationPhoneNumber: "+81110", // amazon connectのコールセンターのインスタンスID InstanceId: "c966ced7-ca79-43f3-af67-dbe8da954848", // 電話番号の設定方法は、DestinationPhoneNumberと同様 SourcePhoneNumber: "+810000000000" }; // call API with parameter connect.startOutboundVoiceContact(params, function(err, data) { if (err) { console.log(err); } else if (data) { console.log(JSON.stringify(data)); } });まとめ
防犯カメラをコンビニだけでなく、バス停やバスにも取り付けて、このシステムを実用化すれば、致命傷を回避できるかもしれません。
そもそもいくら対策を講じても通り魔を0にすることが難しいと思います。(対策を否定するわけではない)
危険を1秒でも早く察知することで、もっと救える命があるかもしれません。

- 投稿日:2019-05-29T15:59:51+09:00
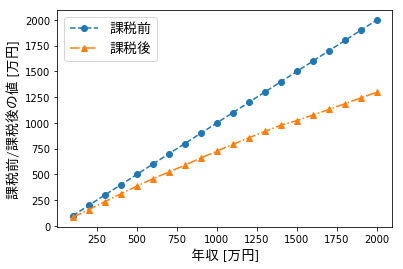
年収に対する手取り金額を図示
このサイトに書かれている値を基に計算しました。
以下のコードにより表示されます。(Jupyterなどで実行してください。)
デフォルトでは、Matplotlibは日本語が文字化けするため、こちらの様にしてFONT_PROPに日本語用のフォントを設定しています。import numpy as np import matplotlib.pyplot as plt from matplotlib.font_manager import FontProperties FONT_PROP = FontProperties(fname='TakaoPGothic.ttf', size=14) # 年収 x = (np.arange(20)+1)*100 # 手取り金額の割合(https://www.sakai-zeimu.jp/blog/archives/7051 よりコピー) y = np.array([ 83, 160, 236, 312, 387, 458, 524, 590, 660, 727, 792, 856, 917, 978, 1023, 1077, 1131, 1187, 1243, 1299, ]) / x plt.plot(x, x, label="課税前", ls='--', marker='o') plt.plot(x, x*y, label="課税後", ls='-.', marker='^') plt.xlabel("年収 [万円]", fontproperties=FONT_PROP) plt.ylabel("課税前/課税後の値 [万円]", fontproperties=FONT_PROP) plt.legend(prop=FONT_PROP) plt.show() plt.plot(x, y*100, ls='--', marker='o') plt.xlabel("年収 [万円]", fontproperties=FONT_PROP) plt.ylabel("手取り金額の割合 [%]", fontproperties=FONT_PROP) plt.title('年収に対する手取り金額の割合', fontproperties=FONT_PROP) plt.show()
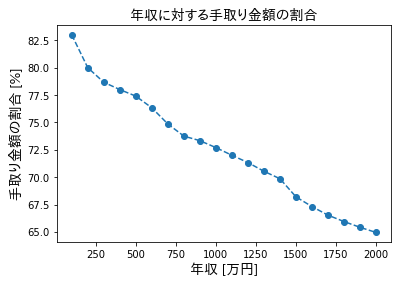
- 投稿日:2019-05-29T15:57:36+09:00
[Python3] Fleiss' Kappa値を求める
はじめに
複数人の評価の一致率を調べてみたかったのですが,評価者が2人か3人以上で求めるカッパ値が違う(2人のときはCohen's Kappaで3人以上のときはFleiss' Kappa)とのことでした.
調べてみるとCohen's Kappaについては沢山情報やプログラム,数式等があったのですが,Fleiss' Kappaについては「3人以上のときにはこっち使えよ」程度の文献しか引っかからず,英語じゃないと見つからなかった(ggり力不足かも?)ので日本語の情報として残したいというモチベーションで記事を書いています.※とりあえず動かしたい人は下にプログラムがあります.
Fleiss' Kappa値の求め方
英語のwikipediaのページが例題つきでわかりやすかたので,英語アレルギーじゃない方はこちらを参照してください.
以下の式で計算できます.
\kappa=\frac{\bar{P}-\bar{P_e}}{1-\bar{P_e}}ただし,
p_j = \frac{1}{Nn} \sum_{i=1}^{N} n_{ij} \\ \sum_{j=1}^{k} p_j = 1 \\ \bar{P} = \frac{1}{Nn(n-1)} \biggl(\sum_{i=1}^{N} \sum_{j=1}^{k} n_{ij}^2 - Nn \biggr) \\ \bar{P_e}= \frac{1}{N} \sum_{j=1}^{k} p_j^2で,$n$は評価者の数,$N$は評価対象の数,$k$は評価対象への評価カテゴリーの数,$n_{ij}$はある$i$番目の評価対象にカテゴリー$j$を付与した人の数です.
(ここらへんの式はCohen's Kappaの話を見たほうがイメージがつかみやすいかもしれません)
kappa値の解釈
これも英語のwikipediaのページからそのまま持ってきました.
$\kappa$ 解釈 <0 一致していない 0.01 - 0.20 わずかに一致 0.21 - 0.40 だいたい一致 0.41 - 0.60 適度に一致 0.61 - 0.80 かなり一致 0.81 - 1.00 ほとんど一致 プログラム
入力値の例外処理とかはやっていないので,使う方は関数に投げる前に処理お願いします.
fleiss_kappa.py# config:utf-8 ''' fleiss kappa値を計算するプログラム ''' def compute_fleiss_kappa(rate_list: list, n: int) -> float: ''' 与えられた集計結果に対してのfleiss kappa値を返す関数 Parameters ---------- rate_list: list [size N * k: N = 評価対象の総数, k = 評価のカテゴリー数] n: int 評価者の数 Return ---------- kappa: float fleiss kappa値 ''' N = len(rate_list) k = len(rate_list[0]) # 入力された情報の確認 print('評価者の数 = {}'.format(n)) print('評価対象の数 = {}'.format(N)) print('評価カテゴリー数 = {}'.format(k)) # Piの値を求めて,P_barを求める P_bar = sum([(sum([el**2 for el in row]) - n) / (n * (n - 1)) for row in rate_list]) / N print('P_bar = {}'.format(P_bar)) # pjの値を求めて,Pe_barを求める Pe_bar = sum([(sum([row[j] for row in rate_list]) / (N * n)) ** 2 for j in range(k)]) print('Pe_bar = {}'.format(Pe_bar)) # fleiss kappa値の計算 kappa = float(0) try: kappa = (P_bar - Pe_bar) / (1 - Pe_bar) except ZeroDivisionError: kappa = float(1) return kappa def main(): n = 14 test_list = [ [0, 0, 0, 0, 14], [0, 2, 6, 4, 2], [0, 0, 3, 5, 6], [0, 3, 9, 2, 0], [2, 2, 8, 1, 1], [7, 7, 0, 0, 0], [3, 2, 6, 3, 0], [2, 5, 3, 2, 2], [6, 5, 2, 1, 0], [0, 2, 2, 3, 7] ] print('kappa = {}'.format(compute_fleiss_kappa(test_list, n))) if __name__ == '__main__': main()実行結果例
英語のwikipediaのページのworked exampleを実行した結果です.
評価者が14人いて,評価対象1(表の1行目)に対して5と評価した人が14人中14人といった見方になるかと思います.
2つめの評価対象には1を付けた人が0人,2が2人,3が6人,4が4人,5が2人です.$ python3 fleiss_kappa.py 評価者の数 = 14 評価対象の数 = 10 評価カテゴリー数 = 5 P_bar = 0.378021978021978 Pe_bar = 0.21275510204081632 kappa = 0.20993070442195522おわりに
もし何か間違いがあったり,わかりやすい文献をご存じの方はコメントお願い致しますm(_ _)m
(統計難しい...)その他参考文献
- 投稿日:2019-05-29T15:57:09+09:00
写経中に遭遇したscikit-learnのワーニングに対応してみた
概要
あたらしいPythonによるデータ分析の教科書を写経中に遭遇したワーニングへ対応したことに関する忘備録。
環境
- Windows 10 Pro
- Python 3.7.3
ことの始まり
- 案件が無いので会社を休業になる
- 何か勉強しようとPythonと機械学習に挑戦(2019/1~)
- とりあえず目についた入門書を購入
- 以下のコマンドで写経に必要なライブラリをインストールしてJupyter Notebook上で進める
pip install numpy pip install pandas pip install matplotlib pip install scikit-learn pip install jupyterワーニングの出た根本的原因
本書に記載されたサンプルデータ一式をダウンロードし、
requirements.txtを見てみると、以下の記載がある。scikit-learn==0.19.1そして現在(2019/05)インストールしたバージョンをチェックすると、以下の通りとなる。
scikit-learn==0.21.2遭遇したワーニングとその対応
4.4 scikit-learn
欠損値の補完
from sklearn.preprocessing import Imputer # 平均値で欠損値を補完するためのインスタンスを作成する imp = Imputer(strategy = 'mean', axis = 0) # 欠損値を補完 imp.fit(df) imp.transform(df)参考書通りに写経して実行すると
DeprecationWarning: Class Imputer is deprecated; Imputer was deprecated in version 0.20 and will be removed in 0.22. Import impute.SimpleImputer from sklearn instead. warnings.warn(msg, category=DeprecationWarning)のワーニングが表示される。
意味としては、「Imputerクラスは0.20で廃止予定となっていて、0.22で削除されます。SimpleInputerクラスを使用してください」ということ。ワーニングにしたがって、
SimpleImputerクラスを使うと、ワーニングは表示されないfrom sklearn.impute import SimpleImputer # 平均値で欠損値を補完するためのインスタンスを作成する imp = SimpleImputer(strategy = 'mean') # 欠損値を補完 imp.fit(df) imp.transform(df)sklearn.preprocessing.Inputerクラス
~0.19までで欠損値補完に使用するクラス。
strategyキーワード引数:文字列をとり、欠損値の補完方法を指定する。デフォルトは"mean"。
- "mean" :平均値
- "median":中央値
- "most_frequent":最頻値
axisキーワード引数:数値をとり、補完の方向を指定する。デフォルトは0。
- 0:列方向
- 1:行方向
sklearn.impute.SimpleImputerクラス
0.20以降で欠損値補完に使用するクラス。
strategyキーワード引数:文字列をとり、欠損値の補完方法を指定する。デフォルトは"mean"。
- "mean":平均値
- "median":中央値
- "most_frequent":最頻値
- "constant":
fill_valueキーワード引数で指定した値(fill_valueキーワード引数を指定しない場合はデフォルトのNone)※
axisキーワード引数は存在せず、列方向の補完のみを行うOne-hotエンコーディング
from sklearn.preprocessing import LabelEncoder, OneHotEncoder # DataFrameをコピー df_ohe = df.copy() # ラベルエンコーダのインスタンス化 le = LabelEncoder() # 英語のa,b,cを1,2,3に変換 df_ohe['B'] = le.fit_transform(df_ohe['B']) # One-hotエンコーダのインスタンス化 ohe = OneHotEncoder(categorical_features = [1]) # One-hotエンコーディング ohe.fit_transform(df_ohe).toarray()参考書通りに写経して実行すると
FutureWarning: The handling of integer data will change in version 0.22. Currently, the categories are determined based on the range [0, max(values)], while in the future they will be determined based on the unique values. If you want the future behaviour and silence this warning, you can specify "categories='auto'". In case you used a LabelEncoder before this OneHotEncoder to convert the categories to integers, then you can now use the OneHotEncoder directly. warnings.warn(msg, FutureWarning) DeprecationWarning: The 'categorical_features' keyword is deprecated in version 0.20 and will be removed in 0.22. You can use the ColumnTransformer instead. "use the ColumnTransformer instead.", DeprecationWarning)のワーニングが表示される。
全体の意味としては「categorical_featuresキーワードは0.20で廃止予定となっていて、0.22で削除されます。ColumnTransformerを使用してください」ということらしい。ワーニングに従って、
ColumnTransformerを使用すると、ワーニングは表示されない。
scikit-learn公式:ColumnTransformerのUsers Guidefrom sklearn.compose import ColumnTransformer from sklearn.feature_extraction.text import CountVectorizer # DataFrameをコピー df_ohe = df.copy() print(df_ohe) # ColumnTransformerのインスタンス化 ct = ColumnTransformer([('B_x', CountVectorizer(analyzer=lambda x: [x]), 'B')], remainder = 'passthrough') ct.fit_transform(df_ohe)sklearn.preprocessing.OneHotEncoderクラス
~0.19までで、One-Hotエンコードを行うためのクラス。
categorical_featuresキーワード引数:どの列をOne-Hotエンコードの対象とするかを指定する
0.20で廃止予定、0.22で削除予定sklearn.compose.ColumnTransformerクラス
DataFrameの列の変更を行うためのクラス。
- 第1引数:リストで[
変換後の列名パターン名称,列の変換方法,対象となる列]を指定する。remainderキーワード引数:文字列をとり、変更しない列の戻り値での取り扱いを指定する。デフォルトはdrop。
drop:変更しない列を取り除いた配列を戻り値とするpassthrough:変更しない列を含めた配列を戻り値とするsklearn.feature_extraction.text.CountVectorizerクラス
文章から単語または文字の出現の有無をマトリックス化するためのクラス。
analyzerキーワード引数:文字列または呼び出し可能オブジェクトをとり、N-gramを文字によって行うか、単語によって行うか、あるいはその他の方法で行うかを指定する。
word:単語を用いたN-gramを使用する。char:文字を用いたN-gramを使用する。char_wb:文章内の文字のみを用いたN-gramを使用する。- 呼び出し可能オブジェクト:文章を受け取り、抽出結果を返す。
- 投稿日:2019-05-29T15:54:27+09:00
CODE VS Rebornのjnlp上でPythonを動かす方法
1. はじめに
これはチームラボ株式会社・株式会社リクルートが主催するプログラミング大会であるCODE VSの参戦記事です。
2. 競技内容
2人対戦型の落ち物パズルゲームのAIを作成し、参加者同士でオンライン対戦を行います。
以下はゲームのルール詳細(PDF)からの引用です。
ゲームの目的
このゲームは、フィールドの一定の高さまでブロックを積み上げないようにしながら、相手のフィールドをブロックでいっぱいにするゲームです。ブロックは条件を満たすと消えます。消えたときの条件次第では相手に消えないブロックが送られ、妨害できます。うまくブロックを積み上げ消すことで、相手より長く生存することを目指しましょう。
ゲームの画面
対戦動画
NormalAIに100-0したし、オンライン参戦しよう pic.twitter.com/6DI9TdomCq
— ブロコロン (@burokoron_) 2019年4月21日
3. PythonでCODE VSに参戦する
CODE VSのJavaアプリ上でPythonで上手く実行できなかったので、
その解決方法をここに記述します。動作環境
- Windows 10
- Python3.6 (Anaconda)
最近であれば、おそらくたいていの人はAnacondaを使用してPythonをインストールしていると思います。その場合、PythonはAnacondaの仮想環境上にしか入っていないため、普通にjnlpを起動すると、pythonコマンドが使えずにエラーになります。
Anacondaの仮想環境上でjnlpを起動すれば問題なくpythonコマンドを使用できます。
4. AIを作る
ソースコードはGithubにアップロードしています。
4.1. 戦略方針
このゲームに勝つには相手に大量のプロックを送り付けなければいけないわけですが、主な戦略方針として、
- 大連鎖をする
- スキルを使用する
2種類が考えられます。
大連鎖をするには高度な探索技術が必要なので、今回はスキルを使用してブロックを大量生成を狙う通称ボマーを選択しました。
4.2. 探索
探索はビームサーチを使用しました。
ビームサーチは基本的には幅優先探索ですが、各階層のノードのうち評価値が上位N個のみ探索を継続し、残りは枝刈りする探索手法です。深くまで探索したいが、探索空間が広いときにしばしば用いられます。ただし、評価関数の精度がとても重要になります。探索は自分のフィールドだけ探索して、相手のフィールドは完全に無視しました。今回は幅10、深さ4でビームサーチしました。(ビームサーチの意味がない気はしなくはないが、深さ2の全探索よりは強かった。)
さすがに探索できてなさすぎるので、今日から使えないビット演算(CODE VS Reborn編)などを参考に高速化とか頑張りたいですね。(そもそもpythonを使うべきじゃなかったということには目をそらしつつ……)
4.3. 評価関数
全探索できないゲーム&探索量がかなり少ないので評価関数の精度はとても重要です。
評価は以下の要素を考慮しました。上に書かれている要素ほど重要視しました。
プラス評価
- 数字ブロックを消した(スキルを上昇させるため)
- 5ブロック(ボム)がある(これがないと何もできない)
- 数字ブロックがある(スキルを効率良く使用するため)
マイナス評価
- ブロックの高さが一定値を超えた(ゲームオーバーなので……)
- 最もブロック積みあがった列と最もブロックが積まれてない列に差がある(事故死を防ぐため)
- フィールドの任意の3×3の領域において5ブロック(ボム)の数が2個以上ある(スキル使用の効率が落ちるため)
- 5ブロック(ボム)の周りに数字ブロックがない(スキル使用の効率が落ちるため)
- 座標(x, y)と座標(x+1, y+2)のような位置関係にある数字ブロックの合計が10(連鎖が起きにくくするため)
4.4. スキルの使用
5ブロック(ボム)を爆発させるタイミングは相手がブロックを相殺しなかったら、負けになるブロック量を送り込めるときとしました。ちなみに評価関数の評価値でだいたい送り込めるブロック量がわかったので正確な爆発スコアを計算せずに、評価値でブロック量を推定しました。
(爆発スコアを計算するのがめんどくさかっただけ)5. 結果
最終的な予選結果は48位でした。ゴールデンウイーク前の時点では25~30位くらいをうろうろしてたのですが、ゴールデンウイークでずるずると順位が落ちていき、諸事情によりAIも改良できず……といった感じでした。
CODE VS 5.0では38位だったので、このときより順位を上げたかったのですが、叶いませんでした。もし次回大会があればもっと実力を上げて挑みたいを思います。
- 投稿日:2019-05-29T14:57:44+09:00
主成分分析(PCA)によるプロ野球選手の打者の分類
概要
野球選手の打者にはいろいろなタイプがいるといわれていて、
- ボールを遠くに飛ばせてホームランを多く打つけど安打が少ない
- ボールを遠くに飛ばせないけど良くヒットを打っていて安打が多い
- ホームランもヒットもそこそこだけど足が速くて二塁打や盗塁が多い
- ホームランもヒットも盗塁も多い万能型
などなど。このようにバッティング(走力も含めて)にはいろいろなタイプがいるといわれています。そこで2018年のプロ野球のデータから主成分分析を用いて打者をタイプ別に分類したいと思います!!!!
環境
- Windows10
- google Colaboratory
- google ドライブ
データはgoogle ドライブに保存しています
主成分分析とは
主成分分析は多次元の量的なデータから、情報をできるだけ残すようにして、より少ない指標や合成変数(複数の変数が合体したもの)に要約する手法です。
例えば、ホームランと打点から「パワー系」という指標を導くなどです。データ
日本プロ野球の2018年の規定打席に達したセリーグとパリーグの60選手
分析には以下のようなデータセットを用いました
選手名 安打 二塁打 三塁打 本塁打 打点 三振 四球 盗塁 盗塁死 ビシエド 178 26 1 26 99 61 51 3 4 坂本 勇人 152 27 2 18 67 83 61 9 5 平田 良介 162 26 5 9 55 69 67 8 7 青木 宣親 162 37 3 10 67 48 51 3 4 アルモンテ 160 37 0 15 77 95 44 1 1 分析
必要なライブラリをインポート
import os import pandas as pd import numpy as np import scipy.stats as stats from sklearn.decomposition import PCA from sklearn.preprocessing import StandardScaler import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline %config InlineBackend.figure_formats = {'png', 'retina'} sns.set(font = "IPAGothic") from IPython.display import display, Image pd.options.display.max_columns = 500データの取り込み
googleドライブへマウント
from google.colab import drive drive.mount('/content/drive')ディレクトリの移動
cd drive/My\ Drive/********* #データが保存されているディレクトリまで移動しますcsvの読み込み
b_data = pd.read_csv('batting_data.csv') # 選手名を抜く b_data_select = b_data.iloc[:, 1:10] b_data_select標準化
主成分分析を行う際は標準化するのが一般的なようです。標準化のメリットは「スケールの異なる変量を扱う時に比較しやすくする」というものがあります。
sc = StandardScaler() b_data_std = pd.DataFrame(sc.fit_transform(b_data_select)) b_data_std.head()
0 1 2 3 4 5 6 7 8 0 1.757838 0.269390 -0.633609 0.724544 1.287217 -1.141774 -0.188878 -0.581232 0.079771 1 0.644017 0.415006 -0.288004 0.035869 -0.088872 -0.230013 0.257290 -0.037742 0.345675 2 1.072410 0.269390 0.748810 -0.738892 -0.604906 -0.810225 0.524991 -0.128324 0.877482 3 1.072410 1.871166 0.057601 -0.652807 -0.088872 -1.680542 -0.188878 -0.581232 0.079771 4 0.986731 1.871166 -0.979213 -0.222385 0.341156 0.267312 -0.501196 -0.762396 -0.717940 次元を決定及び、次元の圧縮
主成分分析は多次元の量的な情報を、情報をできるだけ残すようにして、より少ない指標や合成変数(複数の変数が合体したもの)に圧縮する手法なので、いくつの合成変数にするかを決める必要があります。
今回は3次元に圧縮したいと思います。野球では「パワーヒッター」と「アベレージヒッター」といわれるタイプがあり、今回はそれにプラスしてどちらでもないタイプ(例えば、ホームランも安打数も平均的だけど、足は速いみたいなタイプ)の選手もいると思い、3次元に圧縮したいと思います。# 3次元に圧縮するPCAインスタンスを作成 pca = PCA(n_components = 3, random_state = 0) # n_components()の部分で合成変数の数を決めます # b_data_stdデータをPCAで次元圧縮 X_pca = pca.fit_transform(b_data_std)固有ベクトルを算出
固有ベクトルとは主成分に対して元の変数がどの程度影響を与えているかの値です。
pd.DataFrame(pca.components_)
0 1 2 3 4 5 6 7 8 0 0.236712 0.313554 -0.292690 0.481108 0.510233 0.229937 0.287450 -0.251096 -0.263881 1 0.411177 0.182261 0.392873 0.028260 0.055126 0.260939 0.354493 0.473114 0.471101 2 0.445215 0.563800 0.037510 -0.281719 -0.098115 -0.600219 -0.038400 -0.147453 -0.100175 データフレームにして見ましたが、これだと判断するのが難しいので、各成分ごとに可視化して解釈して見たいと思います。
各成分の可視化と解釈
成分0
colorlist= ['grey', 'grey', 'grey', 'darkblue', 'darkblue', 'grey', 'grey', 'grey', 'grey'] plt.figure(1) ax = plt.subplot(111) ax.bar(b_data_select.columns, pca.components_[0], color=colorlist) ax.set_xticks(b_data_select.columns) ax.set_xticklabels(b_data_select.columns, rotation = 270) ax.set_title('成分0の固有ベクトル') ax.set_ylabel('固有ベクトルの値') plt.ylim([-0.7, 0.7]) plt.xticks(rotation = '0') for xtick, color in zip(ax.get_xticklabels(), colorlist): xtick.set_color(color)
成分0のグラフを確認すると、特に本塁打と打点の固有ベクトルの値が大きくなっていますね。つまり、成分0では、これらの影響が大きいといえます。
本塁打と打点の特徴のある選手となれば、やはり「パワーヒッター」ではないでしょうか。成分0は「パワーヒッター」とします。成分1
colorlist = ('darkblue', 'grey', 'darkblue', 'grey', 'grey', 'grey', 'grey', 'darkblue', 'darkblue') plt.figure(1) ax = plt.subplot(111) ax.bar(b_data_select.columns, pca.components_[1], color = colorlist) ax.set_xticks(b_data_select.columns) ax.set_xticklabels(b_data_select.columns, rotation = 270) ax.set_title('成分1の固有ベクトル') ax.set_ylabel('固有ベクトルの値') plt.ylim([-0.7, 0.7]) plt.xticks(rotation = '0') for xtick, color in zip(ax.get_xticklabels(), colorlist): xtick.set_color(color)
成分1のグラフを確認すると、特に安打、三塁打、盗塁、盗塁死の固有ベクトルの値が大きくなっています。
分類するのにここは少し迷いますが、「良く打つ上に足が速い」ということで成分1を「リードオフマン」とします!成分2
colorlist= ('darkblue', 'darkblue', 'grey', 'grey', 'grey', 'darkblue', 'grey', 'grey', 'grey') plt.figure(1) ax = plt.subplot(111) ax.bar(b_data_select.columns, pca.components_[2], color = colorlist) ax.set_xticks(b_data_select.columns) ax.set_xticklabels(b_data_select.columns, rotation = 270) ax.set_title('成分2の固有ベクトル') ax.set_ylabel('固有ベクトルの値') plt.ylim([-0.7, 0.7]) plt.xticks(rotation = '0') for xtick, color in zip(ax.get_xticklabels(), colorlist): xtick.set_color(color)
成分1のグラフを確認すると、安打と二塁打の成分が大きく、三振はマイナスに大きくなっています。
良く打ち、三振が少ないとなるとこれぞ「アベレージヒッター」といえますね。成分2はアベレージヒッターとします。寄与率
主成分分析は多次元の量的な情報を、情報をできるだけ残すようにして、より少ない指標や合成変数(複数の変数が合体したもの)に要約する手法です。そうです。どれだけの情報が残ったのかを確認する必要があります。その判断をするのが、寄与率です。各成分ごとに寄与率があり、すべての成分(今回は全部で3)を足したものが累積寄与率といわれるものです。この累積寄与率が0.7から0.8くらいあれば良しとされているようです。逆に累積寄与率が少なすぎると情報を多く失っていることになり、分析をするには堪えないものになってしまいます。
ということで、今回の累積寄与率を確認してみます。print('各主成分の寄与率:', pca.explained_variance_ratio_) print('寄与率の累積:', sum(pca.explained_variance_ratio_))各主成分の寄与率: [0.35970777 0.26324623 0.14976546]
寄与率の累積: 0.7727194534681444見事、0.77ということで、情報を残したまま主成分分析ができました!
主成分得点の算出
それでは、各選手の主成分得点を算出して、各選手をタイプ別に割り振っていたいと思います!
result = pd.DataFrame(X_pca) result.columns = ['成分0', '成分1','成分2'] result['選手タイプ'] = result.idxmax(axis = 1) result['name'] = b_data['選手名'] type_mapping = {'成分0': '成分0_パワーヒッター', '成分1': '成分1_リードオフマン', '成分2': '成分2_アベレージヒッター'} result['選手タイプ'] = result['選手タイプ'].map(type_mapping) result = pd.concat([result, b_data_select], axis = 1 ) result.head()
成分0 成分1 成分2 選手タイプ name 安打 二塁打 三塁打 本塁打 打点 三振 四球 盗塁 盗塁刺 1.499452 0.012090 1.350596 成分0_パワーヒッター ビシエド 178 26 1 26 99 61 51 3 4 0.278110 0.399589 0.607633 成分2_アベレージヒッター 坂本 勇人 152 27 2 18 67 83 61 9 5 -0.779698 1.057367 1.322105 成分2_アベレージヒッター 平田 良介 162 26 5 9 55 69 67 8 7 0.148472 0.038389 2.820863 成分2_アベレージヒッター 青木 宣親 162 37 3 10 67 48 51 3 4 1.472248 -0.432263 1.529855 成分2_アベレージヒッター アルモンテ 160 37 0 15 77 95 44 1 1 主成分得点の一番高いものを各選手のタイプとして割り振っていきます。例えばビシエド選手でいえば、成分0、成分1、成分2がそれぞれ「1.499452」、「0.012090」、「1.350596」となっており、この中で最も値の高いのは成分0となり、成分0はパワーヒッターの特徴があるため、ビシエド選手は「パワーヒッター」に分類されます。
これで各選手にタイプ別の分類が終わりました!!
今回の主成分分析による分類が主観とあっているか見てみたいと思います!パワーヒッター
result.query('選手タイプ == "成分0_パワーヒッター"').sort_values(by = '成分0', ascending = False).head(10)
成分0 成分1 成分2 選手タイプ name 安打 二塁打 三塁打 本塁打 打点 三振 四球 盗塁 盗塁刺 4.119948 0.399654 -1.756427 成分0_パワーヒッター 山川 穂高 152 24 1 47 124 138 88 0 0 3.475278 -0.104278 -1.623849 成分0_パワーヒッター バレンティン 138 22 0 38 131 121 85 1 1 3.233612 0.468008 0.015143 成分0_パワーヒッター 浅村 栄斗 175 27 0 32 127 105 68 4 2 2.931323 -0.033810 0.018800 成分0_パワーヒッター 筒香 嘉智 146 33 1 38 89 107 80 0 0 2.865723 0.253480 -0.456502 成分0_パワーヒッター 岡本 和真 167 26 0 33 100 120 72 2 1 2.536532 2.034039 -2.279998 成分0_パワーヒッター 丸 佳浩 132 22 0 39 97 130 130 10 10 2.268064 0.770411 -0.484774 成分0_パワーヒッター 鈴木 誠也 135 32 2 30 94 116 88 4 4 2.048710 0.229483 1.799239 成分0_パワーヒッター 吉田 正尚 165 37 2 26 86 74 69 3 1 1.998534 -0.981408 0.793577 成分0_パワーヒッター 中田 翔 143 32 0 25 106 81 43 0 1 1.828866 -0.454304 -0.338458 成分0_パワーヒッター 井上 晴哉 139 26 2 24 99 106 63 1 0 山川選手、浅村選手、中田選手などいかにもな選手が綺麗にパワーヒッターに分類されました!皆さんの感覚ではいかがでしょうか?僕としてはかなり良い感じに分類できたと思います!!
リードオフマン
result.query('選手タイプ == "成分1_リードオフマン"').sort_values(by = '成分1', ascending = False).head(10)
成分0 成分1 成分2 選手タイプ name 安打 二塁打 三塁打 本塁打 打点 三振 四球 盗塁 盗塁刺 -1.972976 3.789957 -1.174956 成分1_リードオフマン 田中 広輔 150 19 10 10 60 118 75 32 13 1.074528 3.617441 1.717807 成分1_リードオフマン 秋山 翔吾 195 39 8 24 82 96 77 15 10 -1.560951 3.296507 0.307986 成分1_リードオフマン 中村 奨吾 157 30 3 8 57 94 60 39 15 1.934455 3.075147 -0.619577 成分1_リードオフマン 山田 哲人 165 30 4 34 89 119 106 33 4 -1.871698 2.957498 0.488734 成分1_リードオフマン 源田 壮亮 165 27 9 4 57 101 48 34 8 -1.033007 2.756313 -0.297568 成分1_リードオフマン 西川 遥輝 147 25 6 10 48 103 96 44 3 1.540711 2.269514 -0.249914 成分1_リードオフマン 柳田 悠岐 167 29 5 36 102 105 62 21 7 -1.050262 1.870962 -0.271466 成分1_リードオフマン 上林 誠知 149 26 14 22 62 117 30 13 4 -1.892742 1.762230 0.410165 成分1_リードオフマン 大島 洋平 161 20 7 7 57 80 47 21 9 -0.826188 1.239028 -0.814193 成分1_リードオフマン 外崎 修汰 130 24 3 18 67 102 47 25 9 さて、続いてリードオフマンに分類される選手たちです。田中選手、秋山選手、西川選手、大島選手などリードオフマンらしい選手たちが分類されたのではないでしょうか。なかには、山田選手、柳田選手のように万能型の選手も混ざっていますね。両選手はホームランも打つためパワーヒッターの主成分得点も高い値を示しています。
アベレージヒッター
result.query('選手タイプ == "成分2_アベレージヒッター"').sort_values(by = '成分2', ascending = False).head(10)
成分0 成分1 成分2 選手タイプ name 安打 二塁打 三塁打 本塁打 打点 三振 四球 盗塁 盗塁刺 0.148472 0.038389 2.820863 成分2_アベレージヒッター 青木 宣親 162 37 3 10 67 48 51 3 4 1.433628 -1.033999 2.573731 成分2_アベレージヒッター 宮﨑 敏郎 175 34 0 28 71 45 38 0 0 -0.875345 0.640445 1.617678 成分2_アベレージヒッター 糸原 健斗 152 29 4 1 35 73 86 6 4 1.472248 -0.432263 1.529855 成分2_アベレージヒッター アルモンテ 160 37 0 15 77 95 44 1 1 -1.520669 0.812603 1.379947 成分2_アベレージヒッター 坂口 智隆 161 22 4 3 37 60 75 9 7 0.306141 -0.835488 1.327918 成分2_アベレージヒッター 中村 晃 148 28 1 14 57 68 60 1 1 -0.779698 1.057367 1.322105 成分2_アベレージヒッター 平田 良介 162 26 5 9 55 69 67 8 7 -1.581069 -0.304457 1.266761 成分2_アベレージヒッター 鈴木 大地 127 27 6 8 49 55 44 8 4 -0.318830 -1.842122 1.128704 成分2_アベレージヒッター 松山 竜平 120 25 2 12 74 46 42 2 0 -1.692304 -1.282355 0.964900 成分2_アベレージヒッター 銀次 136 16 5 5 48 47 48 1 1 最後にアベレージヒッターに分類される選手たちです。青木選手や糸原選手、銀二選手など良く打つうえに三振が少ない選手が並びました。三振の数はみんな2桁です(この表に載っていないアベレージヒッターに分類される選手全員が三振の数が2桁でした)!まさにアベレージヒッターが綺麗に分類されたのではないでしょうか!
まとめ
今回は主成分分析を用いて、昨年のプロ野球のデータから打者のタイプを3つに分類しました。その結果、ホームランが多く打点が多い「パワーヒッター」、良く打ち盗塁も多い「リードオフマン」、良く打ち三振の少ない「アベレージヒッター」の3つに分類されました。個人的には良い感じに分類できたのではないかと思います。
- 投稿日:2019-05-29T13:42:16+09:00
pybindで no module named hogehoge と怒られたときの対処法
- 投稿日:2019-05-29T13:00:53+09:00
【GetOldTweets-python】無料でTwitterの過去7日より前のツイートを取得してみる
はじめに
研究のデータ収集のために大量のツイートを取得したかったのですが、Twitterの無料のSearch APIには
・180リクエスト/15分 かつ 100ツイート/1リクエストという取得件数の制限
・過去7日間分のみという取得対象期間の制限
があり、非常に不便でした。特に取得対象期間が過去7日間分のみなのがツラい...有料のAPIを用いれば
・900リクエスト/15分 かつ 500ツイート/1リクエスト
・過去30日間分
まで機能を拡張できるのですが、その前にGetOldTweets-pythonと呼ばれるツイート収集用のパッケージ(無料)を見つけたので、まずこれを使ってみることに。参考文献が少ないようなので記事にしました。
パッケージはこちら
https://github.com/Jefferson-Henrique/GetOldTweets-python環境
Ubuntu 18.04.2
Anaconda3 5.3.1
Python3.7準備
インストール
Githubからパッケージをクローンした後、
GetOldTweets-pythonフォルダ内にあるgot3フォルダを丸ごと、〇〇/anaconda3/lib/python3.7/site-packages/の中に置きます。Anacondaを特別なディレクトリ下にインストールしていなければ、~/anaconda3/lib/python3.7/site-packages/になるかと思います。
Python2系を使用している場合は、got3ではなくgotを用いるそうです。git clone https://github.com/Jefferson-Henrique/GetOldTweets-python cd GetOldTweets-python mv got3 ~/anaconda3/lib/python3.7/site-packagesまた、pyqueryというライブラリも必要になるようなので、
pip install pyqueryを実行。
これでAnacondaのPythonから、ツイートの取得に必要なモジュールを呼び出すことができます。
バグの修正(2019/5/29現在)
2019/5/29現在では、デフォルトのコードだと重大なバグが多い...(あまり使われない原因かも)。思うような結果が取得できず、修正に苦戦しました。
今回は僕が不便に感じた&直せる箇所のみ修正しましたが、人によっては他にも直したい箇所が見つかるかもしれません。1箇所目
ドキュメントでは取得できることになっている、ツイート投稿者のユーザー名(アカウントの文字列)を取得できませんでした。
got3/manager/TweetManager.pyにおける59行目のtweet.username = usernameTweetを
tweet.username = re.split('/', permalink)[1]に変更すれば直ります。
2箇所目
これまたドキュメントでは取得できることになっている、
ハッシュタグ(#)やメンション(@)の内容が取得できませんでした。
原因としては、ツイートのテキストを整形した際に、#や@の後に半角スペースが挿入されてしまうためであると思われます。
とりあえずこのバグを直したところ、@に関して、@の後にスペースor改行が出るまで全ての文字をメンションの対象として取得してしまうという新たなバグが発生。
got3/manager/TweetManager.pyにおける66~67行目のtweet.mentions = " ".join(re.compile('(@\\w*)').findall(tweet.text)) tweet.hashtags = " ".join(re.compile('(#\\w*)').findall(tweet.text))というコードを
tweet.mentions = " ".join(re.compile(r'(@\s[a-zA-Z0-9]*)').findall(tweet.text)) tweet.hashtags = " ".join(re.compile(r'(#\s\w*)').findall(tweet.text))というコードに修正することで、まとめて解決できました。
補足
修正できていないのですが、他に不便に感じた箇所を記入しておきます。
- 取得したツイートが、あるツイートに対する返信ツイートだった場合、メンションの内容を取得できない(返信先を取得できない)
- キーワード指定で検索した際に、キーワードがユーザーの名前(アカウントの@付き文字列ではない方の名前)に含まれる場合、内容にかかわらずそのユーザーのツイートを取得してしまう
実行
実際に試したコードを示します。
# -*- coding: utf-8 -*- import got3 as got def print_tweets(tweets): for tweet in tweets: print("取得件数:", len(tweets)) print("---------------------------------") print("ツイートID:", tweet.id) print("ツイートURL:", tweet.permalink) print("アカウントの文字列:", tweet.username) print(tweet.text) print("投稿日:", tweet.date) print("リツイート数:", tweet.retweets) print("いいねの数:", tweet.favorites) if tweet.mentions: print("メンションの内容:", tweet.mentions) if tweet.hashtags: print("ハッシュタグの内容", tweet.hashtags) # アカウントの文字列で取得 tweetCriteria = got.manager.TweetCriteria().setUsername("sugoiyamanaka").setMaxTweets(5) tweets = got.manager.TweetManager.getTweets(tweetCriteria) print("---------------------------------") print("①アカウントの文字列で取得") print_tweets(tweets) # キーワードで取得 tweetCriteria = got.manager.TweetCriteria().setQuerySearch("ポケモン").setMaxTweets(5) tweets = got.manager.TweetManager.getTweets(tweetCriteria) print("---------------------------------") print("②キーワードで取得") print_tweets(tweets) # 複雑なクエリで取得 tweetCriteria = got.manager.TweetCriteria().setQuerySearch("ライオンズ AND (ソフトバンク OR 楽天) -失点 #野球").setMaxTweets(5) tweets = got.manager.TweetManager.getTweets(tweetCriteria) print("---------------------------------") print("③複雑なクエリで取得") print_tweets(tweets) # 期間を指定して取得 tweetCriteria = got.manager.TweetCriteria().setUsername("sugoiyamanaka").setSince("2018-11-10").setUntil("2018-11-30") tweets = got.manager.TweetManager.getTweets(tweetCriteria) print("---------------------------------") print("④期間を指定して取得") print_tweets(tweets)各ツイートに関して取得できるデータは以下のとおりです。
- id (str)
- permalink (str)
- username (str)
- text (str)
- date (date)
- retweets (int)
- favorites (int)
- mentions (str)
- hashtags (str)
- geo (str)
TwitterCriteria()において指定できるパラメータは以下の通りです。
- setUsername (str): アカウントの文字列(@を除いて指定する)
- setSince (str. "yyyy-mm-dd"):検索対象の下限日時(〜日から)
- setUntil (str. "yyyy-mm-dd"):検索対象の上限日時(〜日まで)
- setQuerySearch (str): 検索クエリ
- setTopTweets (bool): Trueの場合はトップツイートのみを取得する
- setNear(str): ツイートが投稿されたエリア
- setWithin (str): "setNear"の位置からの距離半径(例:15mi)
- setMaxTweets (int): 取得するツイートの最大数(未設定の場合は全てのツイートを取得)
上記コード内の
③複雑なクエリではANDOR-#といった演算子を使用しましたが、Twitter公式APIで使用できる他の演算子も使えそうです。
参考:http://westplain.sakuraweb.com/translate/twitter/Documentation/REST-APIs/Public-API/The-Search-API.cgi実際に実行してみると、過去7日より前のツイートがきちんと取得できることを確認できると思います。また、setMaxTweetsを30,000に設定しても、ちゃんと取得してくれました(時間はかかる)。
便利ですね。長所
・APIキーが必要ない(=Twitter Developerアカウントの作成および審査が不要)
・無料で制限なしにツイートを取得できる短所
- Twitter公式のAPIに比べると、取得できるデータの種類が乏しい
- (パッケージが更新されない限り)バグが多いため、必要に応じて自分で直さなければならない
- 取得数が多いと取得にかなり時間がかかる
感想
導入時に自分でコードを修正するのは面倒かもしれませんが、Twitter Developerの審査が不要ですし、各ツイートの簡単なデータであれば無制限に取得できるので、ツイートを遊びや簡単なアプリの制作に使用する場合は、公式APIよりもGetOldTweets-pythonの方が便利かもしれません。
取得できるデータの種類は少ないので、高度な事がしたいようであれば、素直に有料のAPIを導入したほうが良さそうですね。以上
- 投稿日:2019-05-29T12:45:10+09:00
ラズパイで廉価だけどちょっと立派な温度センサDHT21(AM2302)をDHT11の気軽さで使いたい
猛暑到来
5月では観測事情まれにみる猛暑。我が家もあっついです。家では猫が留守番しているのですが、高齢というのもあってちと心配。部屋が高温になったらお知らせするボットを作れないかなあと、とりあえずセンサの巻。
調達する
Amazonか秋月のような電子部品屋に売ってます。Amazonすごいな。
DHT11が定番だけど
とりあえずラズパイで温度といえばDHT11。安いしGPIOで繋げられるし、ネットにライブラリが転がってる。ですけど、、、測定誤差±2℃っていくらなんでも大きすぎじゃないですか?そんなに精度はいらないけど、もう一息ほしいところです。
ということでDHT22を購入
DHT22を購入。DHT11に比べると高いけど、まあ安い(800円位)。
買うときはセンサ単体と基盤に実装済のものがあります。
板に実装する予定がないときは実装済みのほうが楽だと思います。ジャンパピンまでついてるし。
基盤実装品で買う場合
同じ外見をしていても制作業者によって質が様々のようです。レビューを見て慎重に買ってください。
僕はHiletgo制を買いました。
あとピンのアサインが業者やロットによって様々なので、配線は基盤の表記を見て行ってください。僕は何も考えずにネットのとおりに配線したらDHT11が焼け落ちました。センサ単体で買う場合
こんな感じに抵抗を入れる必要があるそうです。詳しくはデータシートを。
とりあえず使ってみる。
とりあえずDHT11のライブラリそのままで使えないかな、ということでやってみます。
配線
僕の買ったものはDAT/VCC/GNDの3つがあったので以下のように配線
DAT -> 7(GPIO4) | VCC -> 1 | GND -> 9VCCはデータシートを見ると6.0Vまで動くようなので、3.3Vのピンが余ってなければ5Vピンでも行けると思います。
DHT11用ライブラリの導入
gitに転がっているDHT11ライブラリをcloneします。
gitをインストールしていない人はインストールsudo apt-get install gitそんで
git clone https://github.com/szazo/DHT11_Python.gitそうするとカレントディレクトリに必要なファイルがダウンロードされます。
tree ├── DHT11_Python ├── dht11_example.py ├── dht11.py ├── __init__.py ├── LICENSE.md └── README.md参考:Raspberry PiとDHT11で温度・湿度を測る
https://qiita.com/mininobu/items/1ba0223af84be153b850使ってみる
ピン番号だけ書き換え。
[変更点]dht11_example.pyinstance = dht11.DHT11(pin=4)そんで実行
python dht11_example.py Last valid input: 2019-05-29 03:23:42.870835 Temperature: 1 C Humidity: 2 % Last valid input: 2019-05-29 03:23:46.116768 Temperature: 1 C Humidity: 2 %だめです!
我が家はそんなに寒くない。dht11.pyを改造する
DHT22ってなんか情報が少ないんですよね、調べ不足かもしれませんが。dht11のライブラリ書き換えてなんとかなんないかなあ。
のぞいてみる
センサーからの読み出しの核になってるのはdht11.py、これをのぞいてみるとCRCまでチェックしてくれててエラー出てない。読み出しのフォーマットとかバイト数はDHT11と一緒みたい。
ソースのぞくとDHT11/22が送ってくるシリアルデータは5バイト。DHT11のビット配置は下のようになっています。DHT11は測定範囲が狭いから1バイトで十分なんですね。
順当に考えると、湿度/温度2バイトづつなんですけど、2バイトの少数扱う変数ってありましたっけ?ローデータを出してみる。
root@raspberrypi:/home/pi# python dht22_dump.py [1, 241, 1, 10, 253]これを単純に16バイト整数として見ると
湿度:497 | 温度:266小数点型を使ってるわけではなくて、16バイト整数型で読んで、10で割るといいみたいです。
dht22.pyを作る
dht11.pyからの変更点はこちら。
もっとスマートな方法があるのかな、[変更点]dht22.py#追加 temp = (float(the_bytes[2]) * 256 + the_bytes[3]) / 10 hum = (float(the_bytes[0]) * 256 + the_bytes[1]) / 10 #変更 return DHT22Result(DHT22Result.ERR_NO_ERROR, temp, hum)あとclass名をDHT22にした。
dht22.py# -*- coding: utf-8 -*- import time import RPi class DHT22Result: 'DHT22 sensor result returned by DHT22.read() method' ERR_NO_ERROR = 0 ERR_MISSING_DATA = 1 ERR_CRC = 2 error_code = ERR_NO_ERROR temperature = -1 humidity = -1 def __init__(self, error_code, temperature, humidity): self.error_code = error_code self.temperature = temperature self.humidity = humidity def is_valid(self): return self.error_code == DHT22Result.ERR_NO_ERROR class DHT22: 'DHT22 sensor reader class for Raspberry' __pin = 0 def __init__(self, pin): self.__pin = pin def read(self): RPi.GPIO.setup(self.__pin, RPi.GPIO.OUT) # send initial high self.__send_and_sleep(RPi.GPIO.HIGH, 0.05) # pull down to low self.__send_and_sleep(RPi.GPIO.LOW, 0.02) # change to input using pull up RPi.GPIO.setup(self.__pin, RPi.GPIO.IN, RPi.GPIO.PUD_UP) # collect data into an array data = self.__collect_input() # parse lengths of all data pull up periods pull_up_lengths = self.__parse_data_pull_up_lengths(data) # if bit count mismatch, return error (4 byte data + 1 byte checksum) if len(pull_up_lengths) != 40: return DHT22Result(DHT22Result.ERR_MISSING_DATA, 0, 0) # calculate bits from lengths of the pull up periods bits = self.__calculate_bits(pull_up_lengths) # we have the bits, calculate bytes the_bytes = self.__bits_to_bytes(bits) # calculate checksum and check checksum = self.__calculate_checksum(the_bytes) if the_bytes[4] != checksum: return DHT22Result(DHT22Result.ERR_CRC, 0, 0) #dump時に使用 #print(str(the_bytes) ) #追加 temp = (float(the_bytes[2]) * 256 + the_bytes[3]) / 10 hum = (float(the_bytes[0]) * 256 + the_bytes[1]) / 10 #変更 return DHT22Result(DHT22Result.ERR_NO_ERROR, temp, hum) def __send_and_sleep(self, output, sleep): RPi.GPIO.output(self.__pin, output) time.sleep(sleep) def __collect_input(self): # collect the data while unchanged found unchanged_count = 0 # this is used to determine where is the end of the data max_unchanged_count = 100 last = -1 data = [] while True: current = RPi.GPIO.input(self.__pin) data.append(current) if last != current: unchanged_count = 0 last = current else: unchanged_count += 1 if unchanged_count > max_unchanged_count: break return data def __parse_data_pull_up_lengths(self, data): STATE_INIT_PULL_DOWN = 1 STATE_INIT_PULL_UP = 2 STATE_DATA_FIRST_PULL_DOWN = 3 STATE_DATA_PULL_UP = 4 STATE_DATA_PULL_DOWN = 5 state = STATE_INIT_PULL_DOWN lengths = [] # will contain the lengths of data pull up periods current_length = 0 # will contain the length of the previous period for i in range(len(data)): current = data[i] current_length += 1 if state == STATE_INIT_PULL_DOWN: if current == RPi.GPIO.LOW: # ok, we got the initial pull down state = STATE_INIT_PULL_UP continue else: continue if state == STATE_INIT_PULL_UP: if current == RPi.GPIO.HIGH: # ok, we got the initial pull up state = STATE_DATA_FIRST_PULL_DOWN continue else: continue if state == STATE_DATA_FIRST_PULL_DOWN: if current == RPi.GPIO.LOW: # we have the initial pull down, the next will be the data pull up state = STATE_DATA_PULL_UP continue else: continue if state == STATE_DATA_PULL_UP: if current == RPi.GPIO.HIGH: # data pulled up, the length of this pull up will determine whether it is 0 or 1 current_length = 0 state = STATE_DATA_PULL_DOWN continue else: continue if state == STATE_DATA_PULL_DOWN: if current == RPi.GPIO.LOW: # pulled down, we store the length of the previous pull up period lengths.append(current_length) state = STATE_DATA_PULL_UP continue else: continue return lengths def __calculate_bits(self, pull_up_lengths): # find shortest and longest period shortest_pull_up = 1000 longest_pull_up = 0 for i in range(0, len(pull_up_lengths)): length = pull_up_lengths[i] if length < shortest_pull_up: shortest_pull_up = length if length > longest_pull_up: longest_pull_up = length # use the halfway to determine whether the period it is long or short halfway = shortest_pull_up + (longest_pull_up - shortest_pull_up) / 2 bits = [] for i in range(0, len(pull_up_lengths)): bit = False if pull_up_lengths[i] > halfway: bit = True bits.append(bit) return bits def __bits_to_bytes(self, bits): the_bytes = [] byte = 0 for i in range(0, len(bits)): byte = byte << 1 if (bits[i]): byte = byte | 1 else: byte = byte | 0 if ((i + 1) % 8 == 0): the_bytes.append(byte) byte = 0 return the_bytes def __calculate_checksum(self, the_bytes): return the_bytes[0] + the_bytes[1] + the_bytes[2] + the_bytes[3] & 255クラス名をDHT22に変更したのでサンプルも少し変更。
あとGPIOは結構入れ替えるので、ピン番号を最初に出しました。dht22_example.pyimport RPi.GPIO as GPIO import dht22 import time import datetime GPIO_PIN = 4 # initialize GPIO GPIO.setwarnings(False) GPIO.setmode(GPIO.BCM) GPIO.cleanup() # read data using pin GPIO_PIN instance = dht22.DHT22(pin=GPIO_PIN) while True: result = instance.read() if result.is_valid(): print("Last valid input: " + str(datetime.datetime.now())) print("Temperature: %s C" % result.temperature) print("Humidity: %s %%" % result.humidity) time.sleep(1)動かしてみるよ
python dht22_example.py Last valid input: 2019-05-29 04:27:36.415902 Temperature: 28.5 C Humidity: 53.7 %温度は結構正確だけど、湿度は手元の温度湿度計と比べると4%くらい高め。
他のひとの結果を見てもそんな感じだからここは補正が必要かな。これから
とりあえず自宅の温度は確認できるようになりました。ただこののままじゃ不便なので、敷居の温度を超えたらSlackに通知して、冷房のONを促す仕組みを作ろうと思います。
夏がくる前に!


