- 投稿日:2019-04-15T16:13:27+09:00
10行で画像の判別やってみる【TensorFrow】
windowsです。anacondaです。
すべてDOS画面で完結します
pythonは開きません
ブラックホールとポンデリングを見分ける人がいて、これならできそうと感じたので、
やってみたかった画像認識に踏み出してみる仮想環境の作成
まず現状の環境を確認
windowsのコマンドプロンプトからconda info -eデフォルトだとbaseがあるだけ
どうもkerasやtensolを入れようとするとエラーが起こる。
baseに悪影響を及ぼしたこともあるので仮想環境を作っておくほうがいい。
pythonを起動するたびにエラーが出る事もあった・・・conda create -n IR python=3.7IRという名前で仮想環境を作成
activate tensorflowプロンプト画面でbaseからIRに切り替わるのが確認できる
IRという仮想環境に切り替わったことを確認してpip installを行う
(baseに戻るときはdeactivat)
(間違えて作って消したいときはconda remove -n IR --all)
(名前を確認したいときはconda info -e)pip install tensorflow pip install tensorflow_hub pip install tensorboardcd でディレクトリを移動する
認識したい画像が入っているフォルダまで移動
仮にフォルダ名「train」とするC:\user\desktop> cd train C:\user\desktop\train>trainというフォルダーの中にはimagesというフォルダとtestというフォルダ、retrain.pyとlabel_image.pyのスクリプトを置く。
testには学習に使わない画像であり、判別したい画像を入れておく。仮に画像名をcat_test_01.pngというものを入れてあるとする。
スクリプトはここから。(ありがたい)https://raw.githubusercontent.com/tensorflow/hub/master/examples/image_retraining/retrain.py https://github.com/tensorflow/tensorflow/raw/master/tensorflow/examples/label_image/label_image.pyさらにimagesというフォルダの中に判別したい画像をフォルダわけして入れておく。
()
train
-images
-cat
|-cat01.png
-dog
|-dog02.png
プロンプトの画面から
python retrain.py --image_dir images --how_many_training_steps 1000を実行
学習のステップ数が1000回
imagesはフォルダを指定学習が終わってから
tensorboard --logdir /tmp/retrain_logs
を入力すると学習のステップが確認できる
交差誤差はプロンプトの画面でもどんどん減っていくのが見える
ステップを何回に増やすとうまくいくのか、
データが少ないときの回数など試してみたい学習が終了した後、Cドライブ直下のtmpに
output_graph.pb
output_labels.txt
が出来ていた。
続いて以下のコマンドを打ち込む。
最後のpngでテストフォルダの中の画像を指定する。python label_image.py --graph /tmp/output_graph.pb --labels /tmp/output_labels.txt --input_layer Placeholder --output_layer final_result --image "C:\Users\Desktop\train\tes\cat_test_01.png"結果は
cat 0.90095603 dog 0.09904399ネコである確率が90%です。という判断が出てくる。
今回はアニメキャラの顔画像が都合よくフォルダわけされているこちら
http://www.nurs.or.jp/~nagadomi/animeface-character-dataset/のデータセットを使用させていただいたが、正確に判断できていた。
実際に判断出来ると感動する。
というか拾いものだけでこんなに簡単にできてしまう便利さに感動。データセットは顔部分を切り取って、サイズを統一して、とやっているのできれいにできたが、写真を撮る(集める)・学習用に振り分ける、といった前処理が大変そう。
画像をデータセットでなく自分でやるときは便利そうな手法を知っていると楽になりそう。あとは原理も理解していきたい。
- 投稿日:2019-04-15T03:33:56+09:00
TensorFlow から bfloat16 のデータをつくって FPGA で使う
TensorFlow からごくごく簡単な MNIST のモデルを作り bfloat16 に変換して、最終的には FPGA(Zybo) で動くようにしてみた。
MNIST のデータ
散々書かれているので省略。
https://github.com/ryos36/polyphony-with-tf-mnist
にソース等を置いた。とにかく浮動小数点のデータを作ればよいbfloat16 に変換
Session で eval とすれば NumPy 形式に落としてくれる。tf.cast でキャストすればよい。
bfloat16.pyimport numpy as np import tensorflow as tf w_np = np.loadtxt('w_value.txt', delimiter=',') b_np = np.loadtxt('b_value.txt', delimiter=',') print(type(w_np), type(w_np[0][0])) w_b = tf.cast(w_np, tf.bfloat16) b_b = tf.cast(b_np, tf.bfloat16) print(type(w_b), type(w_b[0][0])) with tf.Session() as sess: w_b_np = w_b.eval() b_b_np = b_b.eval() print(type(w_b_np[0][0]))NumPy でセーブしたものをちょちょいと加工
ヘッダ付きのバイナリ形式でセーブされる。pickle?
python:save.py
np.save('w_b_value.npy', w_b_np)
np.save('b_b_value.npy', b_b_np)
dd で 128バイトスキップする。Python で予測ようプログラムを作る
mnist7def do_mnist7_mem(a:List[bit16], _mem:List[bit16], lst_len = LEN): rom_w = W_PARAM rom_b = B_PARAM mem = [0] * 10 xi = 0 for i in range(lst_len): x = a[i] for j in range(10): mem[j] = bfloat.mul_add(x, rom_w[xi + j], mem[j]) xi += 10 for j in range(10): _mem[j] = bfloat.add(mem[j], rom_b[j])コンパイルし Zybo にもっていく
持っていくときに少し細工。これで Vivado の BRAM の I/F とリセット極性が設定される。あと BRAM 用にクロックも追加。
インタフェースinput wire clk, (* X_INTERFACE_INFO = "xilinx.com:signal:reset:1.0 rst RST" *) (* X_INTERFACE_PARAMETER = "POLARITY ACTIVE_HIGH" *) input wire rst, input wire do_mnist7_mem_ready, input wire do_mnist7_mem_accept, output reg do_mnist7_mem_valid, (* X_INTERFACE_INFO = "xilinx.com:interface:bram:1.0 bram_in CLK" *) output wire do_mnist7_in_a_clk, (* X_INTERFACE_INFO = "xilinx.com:interface:bram:1.0 bram_in DOUT" *) input wire signed [15:0] do_mnist7_mem_in_a_q, input wire [10:0] do_mnist7_mem_in_a_len, (* X_INTERFACE_INFO = "xilinx.com:interface:bram:1.0 bram_in ADDR" *) output wire signed [10:0] do_mnist7_mem_in_a_addr, (* X_INTERFACE_INFO = "xilinx.com:interface:bram:1.0 bram_in DIN" *) output wire signed [15:0] do_mnist7_mem_in_a_d, (* X_INTERFACE_INFO = "xilinx.com:interface:bram:1.0 bram_in WE" *) output wire do_mnist7_mem_in_a_we, (* X_INTERFACE_INFO = "xilinx.com:interface:bram:1.0 bram_in EN" *) output wire do_mnist7_mem_in_a_req, <中略> assign do_mnist7_in_a_clk = clk;おそるべし Polyphony の最適化
かなり最適化が効いてほとんど assign になる。ただ DSP をつかってくれない。
そこで、ちょっとこれも Verilog を細工して DSP を使うようにしてみる。assign new_n_inl1_inl13 = (t622_inl1_inl1 * t623_inl1_inl1);の部分を reg にしてステートを一つ入れてみた。たしかに DSP を使うようにはなった。ただ、結局 fmax のボトルネックはメモリアクセスなのでこの改造は意味がなかった。
unroll してみる
これは失敗に終わる。よーく考えたらメモリアクセスを同時にできないと意味がない。ここは将来的な検討項目。
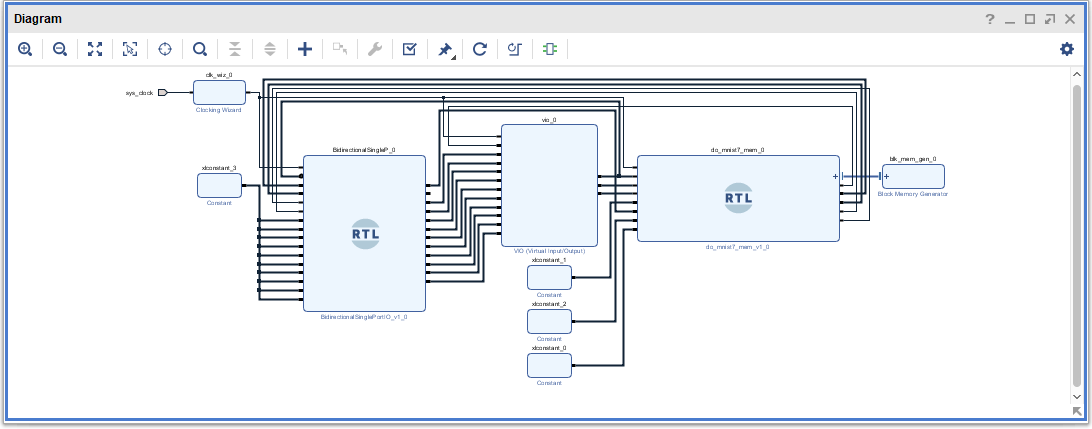
システム全体はこんな感じ
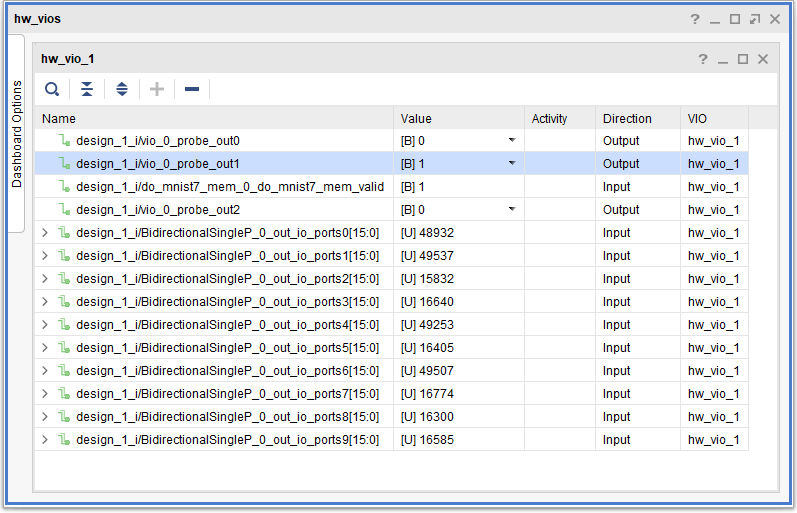
VIO で確認
10進だからわかりづらい。
今後の展開
Retro FORTH と連携する。AXI Stream と連携する。unroll 対応をする。といったところか。
現時点でも使えているので、パラメタのリアルタイムの可視化とかできそうな気がしている。
- 投稿日:2019-04-15T00:15:01+09:00
どうびじゅの連載が終了し心に深い傷を負うも素晴らしい最終回に胸をうたれ明日への希望を見出すきららMAX読者のための機械学習を使ったキャラクター分類入門
はじめに
【おしらせ】本日3月19日発売のまんがタイムきららMAXに『どうして私が美術科に!?』最終話となる39話目載せてもらっています。それぞれの「どうして」と向き合ってきた一年間、それは桃音たちの世界にどんな彩りをもたらしたのでしょうか。今月もよろしくお願いします。 pic.twitter.com/KT928QWd58
— 相崎うたう?どうびじゅ3巻4/25発売 (@py_py_ai) 2019年3月19日あっ...(落涙)
前回から1ヶ月の間、僕は胃痛と不眠と吐き気に悩まされ続けていました。
雑念を振り払うように言語処理100本ノックに打ち込み胃痛と戦う日々を過ごし、あっという間に1ヶ月が過ぎ去り5月号の発売日が来てしまいました。
内容は言うまでもなく、この1ヶ月の僕の苦しみを救済するような本当に素晴らしい最終回でした。お陰で僕は廃人同然の生活から脱却し、今では機械学習のデータ集めと称して毎日どうびじゅの画像を眺めることを心の拠り所にする毎日を送っています。今回はTensorflowのretrain.pyを使って画像認識の転移学習を使って、主要キャラ5人の判定器を作りたいと思います。環境
# python3 --version Python 3.7.2+ # pip3 show tensorflow Name: tensorflow Version: 1.13.1 # pip3 show tensorflow-hub Name: tensorflow-hub Version: 0.3.0 ------------------------------------------------------ # pip3 show pillow Name: Pillow Version: 5.4.1 # pip3 python -m tkinter This is Tcl/Tk version 8.6 # pip3 show matplotlib Name: matplotlib Version: 2.2.2前提
はじめに書いた通り、Tensorflowのretrain.pyを使って画像認識の転移学習を使って、どうして私が美術科に!?の主要キャラ5人を判別します。
主要キャラは桃音、黄奈子、蒼、紫苑、翠玉の5人です。
『どうして私が美術科に!?』第6話まで無料公開中です。初めて読むという方にも分かりやすい?メイン5人の簡単な紹介を描いてみました。美術科に通う女の子たちのお話です。https://t.co/QK8CMmUTJk pic.twitter.com/lN6X21Ts1H
— 相崎うたう?どうびじゅ3巻4/25発売 (@py_py_ai) 2018年6月29日
retrain.pyを使い学習を行い、生成された分類器に判定したい画像をlabel_imageに引数で与えると各ラベルとの類似度を返すのでその値でどのキャラクターなのかを判定を行います。
説明を楽にするため、登場するディレクトリを以下のように仮定します。
作業ディレクトリ:~/doubiju_train/
分類前の画像:~/Picture/data_src/
分類後の画像:~/doubiju_train/data/また、retrain.pyを今回使いますが、何か問題が起きたら、公式サイトをみて下さい。僕もいろいろなサイトを参考にして、手詰まりになりましたが公式サイトの通りにやったら一発でした。
https://www.tensorflow.org/hub/tutorials/image_retraining学習に必要なデータを集める
まずは、学習に必要なデータを集めるのですが、その前に一つ疑問になることがあります。
著作権
著作権です。今回必要なデータとなるイラストや漫画の画像には、当然著作権が存在します。もし、法律で複製が認められていないならそれを守るべきです。好きな作品なら尚更です。
早速ボツネタだなこれ...と思いながら調べてみるとこんな記事が。この条文を簡単に言うと、「情報解析目的なら、データなどの著作物を記録媒体にコピーできる」ということ。2009年に改正された条文で、当時はWeb解析や言語解析、自動翻訳の技術開発などを想定していたという。現在は(学習の手法にもよるが)、機械学習や深層学習も「情報解析」に含まれるとの考え方が主流だと、柿沼弁護士は話す。
「日本は機械学習パラダイス」 その理由は著作権法にあり - ITmedia NEWSどうやら著作権法47条の7が肝らしい。
さらに調べて見ると、
情報解析のための複製(著作権法第47条の7)
コンピュータを使った情報解析のために、必要と認められる限度において、著作物を複製することができる。
著作物が自由に使える場合は? | 著作権って何? | 著作権Q&A | 公益社団法人著作権情報センター CRIC本当だ。サンキュー著作権法。
ただし、複製はあくまでも機械学習などの情報解析の場合に認められており、複製した情報をそのまま公開するなどの行為は著作権法に違反します。
データを使わせていただく側なのでこれらのことには十分気をつけましょう。画像を集める
今度こそ本筋です。今回はキャラクターの分類・判定を行うので顔が写っている画像をかたっぱしから集めます。とにかく沢山です。多すぎということはありません。
僕は、単行本と所持している雑誌から顔が写っている部分を無音カメラで撮影し、PCに取り込みました。このとき写真はスクエアで撮影すると後で楽です。
また、作者の過去のツイートなどから画像を収集し、同様に保存しました。画像を加工する
顔でキャラクターを判定するので、画像に余計なものが写りこんでいると検知率が落ちてしまいます。なので、画像に顔だけが写るように画像を切り抜かなくてはいけません。
方法はいろいろありますが、後述する効率化のプログラムを使わないならアニメキャラの顔を検知するカスケード分類器があるのでそれを利用するのが簡単だと思います。
僕は、画像の少なさを正確さで補いたかったので手作業で加工しました。(後述)画像を分類する
いわゆるラベルづけの作業です。画像がどのキャラクターの画像かを教えていきます。
今回の場合は学習用のデータを格納するディレクトリを作成し、# mkdir ~/doubiju_train/data/その中に分類したい種類ごとにディレクトリを作成していきます。
# mkdir ~/doubiju_train/data/momone/ # mkdir ~/doubiju_train/data/kinako/ # mkdir ~/doubiju_train/data/aoi/ # mkdir ~/doubiju_train/data/shion/ # mkdir ~/doubiju_train/data/suigyoku/これらのディレクトリの中に入ったファイルには自動的にそのディレクトリの名前がラベルとして与えられます。
なので、得られた画像のなかから桃音ちゃんだと思う画像は、data/momone/に格納すれば良いのです。効率化
ぶっちゃけ苦行です。
どうびじゅだから死ぬほど楽しいだけであって、これが無機質な文字だったり、だんごむしとわらじむしとかだったら発狂しかねません。しかも結構非効率です。
画像を開いて目視で確認して移動先を指定して移動を繰り替えしていたら苦行以外の何でもありません。さらに僕には画像の切り取りの作業もあります。
そこで、画像を開いて切り抜き・分類・保存をするツールを作成しました。
ディレクトリ単位で画像を読み込み、切り抜き・分類・保存をするツール - Qiita
リンク先にもプログラムはありますが一応。
動作環境はリンク先を参照して下さい。import cv2 import sys import os import tkinter as tk from tkinter import * from PIL import Image,ImageTk image_dir=os.path.expanduser('~/Pictures/data_src/') save_dir=os.path.expanduser('~/doubiju_train/data/') characters=["momone","kinako","aoi","shion","suigyoku"] name_list=os.listdir(image_dir) name_list.sort() class Window(tk.Frame): def __init__(self, master=None): super().__init__(master) self.master = master self.index=0 self.local_num=0 self.max_width=1400 self.max_height=800 self.count=1 self.start_x=0 self.start_y=0 self.end_x=0 self.end_y=0 self.canvas = Canvas(master, width=1400, height=800) self.canvas.grid(row=0, column=0, columnspan=2, rowspan=4) self.load_img() self.create_widgets() self.grid() self.canvas.bind("<Button-1>", self.clicked) self.canvas.bind("<ButtonRelease-1>", self.release) self.canvas.bind("<B1-Motion>", self.move) def scale_to_height(self,img): img_width,img_height=img.size if img_width>self.max_width and img_height>self.max_height: if img_width>img_height and img_height/img_width<self.max_height/self.max_width: rate=img_height/img_width img=img.resize((self.max_width,int(self.max_width*rate))) else: rate=img_width/img_height img=img.resize((int(self.max_height*rate),self.max_height)) else: scale = self.max_height / img_height img=img.resize((int(img_width*scale),int(img_height*scale))) return img def load_img(self): path=image_dir+name_list[self.index] img=Image.open(path) self.resize_image = self.scale_to_height(img) self.img=ImageTk.PhotoImage(self.resize_image) self.image_on_canvas = self.canvas.create_image(0, 0, anchor=NW, image=self.img) def create_widgets(self): self.button_back_skip=Button(self) self.button_back_skip["text"]="<<" self.button_back_skip["command"]=self.back_skip self.button_back_skip.grid(row=1, column=0) self.button_back=Button(self) self.button_back["text"]="back" self.button_back["command"]=self.back_image self.button_back.grid(row=1, column=1) self.button_next=Button(self) self.button_next["text"]="next" self.button_next["command"]=self.next_image self.button_next.grid(row=1, column=2) self.button_next_skip=Button(self) self.button_next_skip["text"]=">>" self.button_next_skip["command"]=self.next_skip self.button_next_skip.grid(row=1, column=3) self.button_save=Button(self) self.button_save["text"]="rotate" self.button_save["command"]=self.rotate_image self.button_save.grid(row=2, column=0) for col,character in enumerate(characters): self.button_save=Button(self) self.button_save["text"]=character self.button_save["command"]= lambda: self.save_image(character) self.button_save.grid(row=2, column=col+1) self.button_save=Button(self) self.button_save["text"]="save" self.button_save["command"]=self.save_image_default self.button_save.grid(row=2, column=len(characters)+1) self.quit = tk.Button(self, text="QUIT", fg="red", command=self.master.destroy) self.quit.grid(row=2, column=len(characters)+2) #------- button press -------------------------------------------------------------- def next_image(self): self.canvas.delete("tmp") self.canvas.delete("rect") self.index+=1 if self.index==len(name_list): self.index=0 self.load_img() def back_image(self): self.canvas.delete("tmp") self.canvas.delete("rect") self.index-=1 if self.index==-1: self.index=len(name_list)-1 self.load_img() def next_skip(self): self.canvas.delete("tmp") self.canvas.delete("rect") self.index=(self.index+10)%len(name_list) self.load_img() def back_skip(self): self.canvas.delete("tmp") self.canvas.delete("rect") self.index=(len(name_list)+self.index-10)%len(name_list) self.load_img() def save_image(self,chara): cropped_img=self.resize_image.crop((self.start_x,self.start_y,self.end_x,self.end_y)) cropped_img.save(save_dir+chara+"/"+name_list[self.index],quality=95) def save_image_default(self): cropped_img=self.resize_image.crop((self.start_x,self.start_y,self.end_x,self.end_y)) cropped_img.save(save_dir+str(self.local_num)+name_list[self.index],quality=95) self.local_num+=1 def rotate_image(self): rotated_image=self.resize_image.rotate(90*self.count,expand=True) self.img=ImageTk.PhotoImage(rotated_image) self.image_on_canvas = self.canvas.create_image(0, 0, anchor=NW, image=self.img) self.count+=1 #------- key press -------------------------------------------------------------- def clicked(self,event): self.canvas.delete("rect") self.start_x=event.x self.start_y=event.y def move(self,event): self.canvas.delete("tmp") self.canvas.create_rectangle(self.start_x,self.start_y,event.x,event.y,outline="blue",width=2,tag="tmp") def release(self,event): self.canvas.create_rectangle(self.start_x,self.start_y,event.x,event.y,outline="blue",width=2,tag="rect") self.end_x=event.x self.end_y=event.y root = tk.Tk() root.title("cropper") win=Window(master=root) win.mainloop()試しにここで配布されているアイコンを動かしてみるとこんな感じ。
これで楽にデータを用意することができました。
データの水増し
おそらくすべてのイラストの画像を入手してもデータは足りません。
そこで、画像を反転したりノイズを追加したりしてデータを水増しします。
データ量が増えるので学習結果の向上が期待できますが、逆に訓練データになれすぎて未知のデータに対応できなくなる過学習を引き起こす場合もあります。
ここを参考にデータを水増ししていきたいと思います。import cv2 import numpy as np import sys import os import re def addGaussianNoise(src): row,col,ch= src.shape mean = 0 var = 0.1 sigma = 15 gauss = np.random.normal(mean,sigma,(row,col,ch)) gauss = gauss.reshape(row,col,ch) noisy = src + gauss return noisy def addSaltPepperNoise(src): row,col,ch = src.shape s_vs_p = 0.5 amount = 0.004 out = src.copy() num_salt = np.ceil(amount * src.size * s_vs_p) coords = [np.random.randint(0, i-1 , int(num_salt)) for i in src.shape] out[coords[:-1]] = (255,255,255) num_pepper = np.ceil(amount* src.size * (1. - s_vs_p)) coords = [np.random.randint(0, i-1 , int(num_pepper)) for i in src.shape] out[coords[:-1]] = (0,0,0) return out if __name__ == '__main__': min_table = 50 max_table = 205 diff_table = max_table - min_table gamma1 = 0.75 gamma2 = 1.5 average_square = (10,10) character=["momone/","kinako/","aoi/","shion/","suigyoku/"] for chara in character: path=os.path.expanduser('~/doubiju_data/data/'+chara) output=os.path.expanduser('~/doubiju_data/data/'+chara) name_list=os.listdir(path) for name in name_list: img_src = cv2.imread(path+name) trans_img = [] trans_img.append(cv2.blur(img_src, average_square)) trans_img.append(addGaussianNoise(img_src)) trans_img.append(addSaltPepperNoise(img_src)) flip_img = [] for img in trans_img: flip_img.append(cv2.flip(img, 1)) flip_img.append(cv2.flip(img, 0)) flip_img.append(cv2.flip(img, -1)) trans_img.extend(flip_img) img_src.astype(np.float64) name=re.sub(r'\.jpg',r'',name) for i, img in enumerate(trans_img): cv2.imwrite(output + name + "_" + str(i+1) + ".jpg" ,img)これで1枚の画像から16枚の画像が生成され、データ数が16倍になります。
ここら辺の兼ね合いはいろいろ試してみるといいと思います。
僕はこの処理の後にグレースケール化してみたり、ガウシアンノイズやコントラスト処理を加えてみたりしました。実際に動かしてみる
さぁ、ようやっと実行です。
プログラムを準備します。# cd ~/doubiju_train/ # curl -LO https://github.com/tensorflow/hub/raw/master/examples/image_retraining/retrain.py # curl -LO https://github.com/tensorflow/tensorflow/raw/master/tensorflow/examples/label_image/label_image.py--image_dirには訓練データの入ったディレクトリのpathを指定しましょう。
# python ~/doubiju_train/retrain.py --image_dir ~/doubiju_train/dataデータ量にもよりますが結構時間がかかります。
学習が終わったら、出力されたデータを元に画像と各ラベルの類似度を出力させます。
--imageには、判別させたい画像のpathを指定します。# python ~/doubiju_train/label_image.py \ --graph=/tmp/output_graph.pb --labels=/tmp/output_labels.txt \ --input_layer=Placeholder \ --output_layer=final_result \ --image=~/Pictures/data_src/momone.jpg/tmp/output_graph.pbと/tmp/output_labels.txtは今後label_image.pyで判別するときに必要になるのでバックアップをとっておきましょう。
# cp /tmp/output_graph.pb ~/doubiju_train/output_graph.pb # cp /tmp/output_labels.txt ~/doubiju_train/output_labels.txtいちいちコマンドをうつのは面倒なので、シェルスクリプトにしちゃいましょう。
jadge.sh#!/bin/sh image="$HOME/Pictures/data_src/20190403_234740119.jpg" python3 ~/doubiju_train/label_image.py\ --graph=output_graph.pb\ --labels=output_labels.txt\ --input_layer=Placeholder\ --output_layer=final_result\ --image=$image# ./jadge.sh 2019-04-08 22:53:17.506321: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA 2019-04-08 22:53:17.530495: I tensorflow/core/platform/profile_utils/cpu_utils.cc:94] CPU Frequency: 2395585000 Hz 2019-04-08 22:53:17.530958: I tensorflow/compiler/xla/service/service.cc:150] XLA service 0x2147380 executing computations on platform Host. Devices: 2019-04-08 22:53:17.531005: I tensorflow/compiler/xla/service/service.cc:158] StreamExecutor device (0): <undefined>, <undefined> shion 0.95736223 momone 0.016319819 suigyoku 0.010770504 aoi 0.01067509 kinako 0.004872421動きました。成功です。
与えた画像に対してどのラベルが近いかを数値で表しています。結果を見やすくする
一応成功しましたが、問題も残ります。
まず、与えた画像が何なのか確認するのが非常に面倒です。いちいちファイル名で検索して中身を確認するしかありません。
それから、値を文字で出されても一目でピンときません。グラフで表したら見やすそうです。
せっかくディレクトリ毎に画像を表示するプログラムができているので、表示するツールも作ってみました。
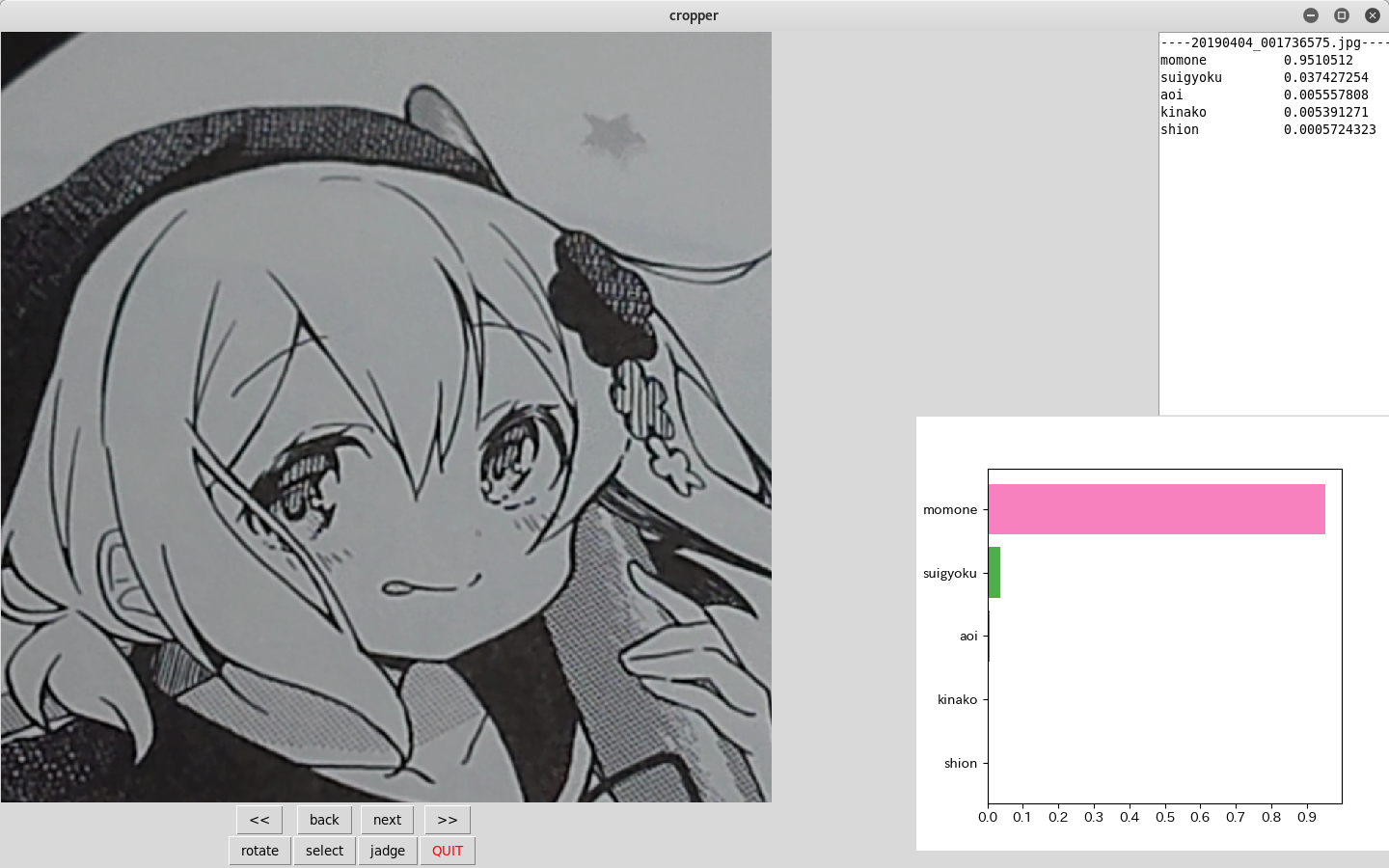
こんな感じです。import os import cv2 import sys import tkinter as tk import subprocess as sp import matplotlib.pyplot as plt from tkinter import * from PIL import Image,ImageTk from matplotlib.figure import Figure from matplotlib.backends.backend_tkagg import FigureCanvasTkAgg, NavigationToolbar2TkAgg image_dir=os.path.expanduser('~/Pictures/data_src/') image_dir=os.path.expanduser('~/python/Machine_learning/crop_output/') name_list=[f for f in os.listdir(image_dir) if os.path.isfile(image_dir+f)] name_list.sort() chara_colors={"momone":"#f781bf","kinako":"#ffff33","aoi":"#377eb8","shion":"#984ea3","suigyoku":"#4daf4a"} class Window(tk.Frame): def __init__(self, master=None): super().__init__(master) self.master = master self.index=0 self.max_width=1400 self.max_height=800 self.count=1 self.canvas = Canvas(master, width=1200, height=800) self.canvas.grid(row=0, column=0, columnspan=2, rowspan=4) self.load_image() self.create_widgets() self.grid() self.canvas.bind("<Button-1>", self.clicked) self.canvas.bind("<ButtonRelease-1>", self.release) self.canvas.bind("<B1-Motion>", self.move) text_widget = Text(master) text_widget.place(x=1200,y=0,width=300,height=400) text_widget.place() self.text_widget=text_widget self.f = Figure(figsize=(5,4), dpi=100) self.plt = self.f.add_subplot(111) self.f.subplots_adjust(left=0.15) self.dataPlot = FigureCanvasTkAgg(self.f, master=master) self.dataPlot.draw() self.dataPlot.get_tk_widget().place(x=950,y=400,width=490,height=450) def resize_image(self,img): img_width,img_height=img.size if img_width>self.max_width and img_height>self.max_height: if img_width>img_height and img_height/img_width<self.max_height/self.max_width: rate=img_height/img_width img=img.resize((self.max_width,int(self.max_width*rate))) else: rate=img_width/img_height img=img.resize((int(self.max_height*rate),self.max_height)) else: scale = self.max_height / img_height img=img.resize((int(img_width*scale),int(img_height*scale))) return img def load_image(self): path=image_dir+name_list[self.index] img=Image.open(path) self.resized_img = self.resize_image(img) self.img=ImageTk.PhotoImage(self.resized_img) self.image_on_canvas = self.canvas.create_image(0, 0, anchor=NW, image=self.img) def create_widgets(self): self.button_back_skip=Button(self) self.button_back_skip["text"]="<<" self.button_back_skip["command"]=self.back_skip self.button_back_skip.grid(row=1, column=0) self.button_back=Button(self) self.button_back["text"]="back" self.button_back["command"]=self.back_image self.button_back.grid(row=1, column=1) self.button_next=Button(self) self.button_next["text"]="next" self.button_next["command"]=self.next_image self.button_next.grid(row=1, column=2) self.button_next_skip=Button(self) self.button_next_skip["text"]=">>" self.button_next_skip["command"]=self.next_skip self.button_next_skip.grid(row=1, column=3) self.button_save=Button(self) self.button_save["text"]="rotate" self.button_save["command"]=self.rotate_image self.button_save.grid(row=2, column=0) self.button_save=Button(self) self.button_save["text"]="select" self.button_save["command"]=self.jadge_image self.button_save.grid(row=2, column=1) self.button_save=Button(self) self.button_save["text"]="jadge" self.button_save["command"]=self.jadge_image self.button_save.grid(row=2, column=2) self.quit = tk.Button(self, text="QUIT", fg="red", command=self.master.destroy) self.quit.grid(row=2, column=3) #------- button press -------------------------------------------------------------- def next_image(self): self.canvas.delete("tmp") self.canvas.delete("rect") self.index+=1 if self.index==len(name_list): self.index=0 self.load_image() def back_image(self): self.canvas.delete("tmp") self.canvas.delete("rect") self.index-=1 if self.index==-1: self.index=len(name_list)-1 self.load_image() def next_skip(self): self.canvas.delete("tmp") self.canvas.delete("rect") self.index=(self.index+10)%len(name_list) self.load_image() def back_skip(self): self.canvas.delete("tmp") self.canvas.delete("rect") self.index=(len(name_list)+self.index-10)%len(name_list) self.load_image() def save_image(self,chara): cropped_img=self.resized_img.crop((self.start_x,self.start_y,self.end_x,self.end_y)) cropped_img.save(save_dir+chara+name_list[self.index],quality=95) def rotate_image(self): rotated_image=self.resized_img.rotate(90*self.count,expand=True) rotated_image=self.resize_image(rotated_image) self.img=ImageTk.PhotoImage(rotated_image) self.image_on_canvas = self.canvas.create_image(0, 0, anchor=NW, image=self.img) self.count+=1 def jadge_image(self): cmd="python3 $HOME/doubiju_train/label_image.py "\ "--graph=$HOME/doubiju_train/output_graph.pb "\ "--labels=$HOME/doubiju_train/output_labels.txt "\ "--input_layer=Placeholder "\ "--output_layer=final_result "\ "--image=$HOME/Picture/data_src/"+name_list[self.index] chara_list=[] value_list=[] color_list=[] proc=sp.Popen(cmd, shell=True, stdout=sp.PIPE, stderr=sp.PIPE) std_out, std_err = proc.communicate() result_list = std_out.decode('utf-8').rstrip().split('\n') self.text_widget.delete('1.0','end') self.text_widget.insert('end',"----"+name_list[self.index]+"----\n") for result in result_list: name,value=result.split(" ") chara_list.append(name) value_list.append(float(value)) color_list.append(chara_colors[name]) self.text_widget.insert('end',name+"\t\t"+value+"\n") value_list.reverse() chara_list.reverse() color_list.reverse() self.plt.clear() self.plt.set_xticks([i/10 for i in range(0,11)]) self.plt.set_xticklabels([i/10 for i in range(0,11)]) self.plt.barh(list(range(5)),value_list,tick_label=chara_list,color=color_list) self.dataPlot.draw() #------- key press -------------------------------------------------------------- def clicked(self,event): self.canvas.delete("rect") self.start_x=event.x self.start_y=event.y def move(self,event): self.canvas.delete("tmp") self.canvas.create_rectangle(self.start_x,self.start_y,event.x,event.y,outline="blue",width=2,tag="tmp") def release(self,event): self.canvas.create_rectangle(self.start_x,self.start_y,event.x,event.y,outline="blue",width=2,tag="rect") self.end_x=event.x self.end_y=event.y root = tk.Tk() root.title("cropper") win=Window(master=root) win.mainloop()実行するとこんな感じです。
か゛わ゛い゛い゛な゛ぁ゛桃゛音゛ち゛ゃ゛ん゛
コマンドを実行し、返された値を取得して数値とグラフを表示しています。いずれも90%を越えていていい感じです。
それぞれのグラフの色は各キャラクターの名前に含まれている色をそのまま表示しています。
name color 桃音 #f781bf 黄奈子 #ffff33 蒼 #377eb8 紫苑 #984ea3 翠玉 #4daf4a グラフをウィジェットとして埋め込むのが大変だった。(満身創痍)
最後に
サンプルでもデータ側を工夫すれば、結構良い結果が得られるんだなと思いました。
機械学習を学ぶという建前でどうびじゅの画像をprprして心の隙間を埋めようとするだけの計画でしたが、なかなか有意義な学習だった気がします。また、困ったときに有効なツールを作って対処できたのは自分のなかで大きな成長だと思います。
これからは、機械学習の基本を学ぶとともに自分でコードを書いて更なる精度向上をしていきたいと思います。また、画像認識はなにも機械学習を使わなくても沢山方法はあるので、機械学習に縛られずに特徴量分析など別の方法でのアプローチもしていきたいと思います。
どうして私が美術科に!?3巻は4月25日発売なので興味のある方やきららMAX読者諸君は買われてみてはいかかがでしょうか。買え。
『どうして私が美術科に!?』完結の第3巻は4月25日発売です!
— まんがタイムきらら編集部 (@mangatimekirara) 2019年3月18日
本日カバーと帯を初公開いたします!
やっぱり美術科って最高! pic.twitter.com/Zs4VDcQHPu
参考
TensorFlowで画像認識「〇〇判別機」を作る - Qiita
How to Retrain an Image Classifier for New Categories | TensorFlow Hub | TensorFlow
Python + Tkinterで連番画像ファイルを素早く切り抜くGUI画像トリミングツール - Qiita
Python + Tkinter で作る、GUIな画像トリミングツール - Qiita
相崎うたう(2017)『どうして私が美術科に!?』 芳文社


- 投稿日:2019-04-15T00:15:01+09:00
どうびじゅの連載が終了し心に深い傷を負うも素晴らしい最終回に胸をうたれ未来への希望を明日に見出すきららMAX読者のための機械学習を使ったキャラクター分類入門
はじめに
【おしらせ】本日3月19日発売のまんがタイムきららMAXに『どうして私が美術科に!?』最終話となる39話目載せてもらっています。それぞれの「どうして」と向き合ってきた一年間、それは桃音たちの世界にどんな彩りをもたらしたのでしょうか。今月もよろしくお願いします。 pic.twitter.com/KT928QWd58
— 相崎うたう?どうびじゅ3巻4/25発売 (@py_py_ai) 2019年3月19日あっ...(落涙)
前回から1ヶ月の間、僕は胃痛と不眠と吐き気に悩まされ続けていました。
雑念を振り払うように言語処理100本ノックに打ち込み胃痛と戦う日々を過ごし、あっという間に1ヶ月が過ぎ去り5月号の発売日が来てしまいました。
内容は言うまでもなく、この1ヶ月の僕の苦しみを救済するような本当に素晴らしい最終回でした。お陰で僕は廃人同然の生活から脱却し、今では機械学習のデータ集めと称して毎日どうびじゅの画像を眺めることを心の拠り所にする毎日を送っています。今回はTensorflowのretrain.pyを使って画像認識の転移学習を使って、主要キャラ5人の判定器を作りたいと思います。環境
# python3 --version Python 3.7.2+ # pip3 show tensorflow Name: tensorflow Version: 1.13.1 # pip3 show tensorflow-hub Name: tensorflow-hub Version: 0.3.0 ------------------------------------------------------ # pip3 show pillow Name: Pillow Version: 5.4.1 # pip3 python -m tkinter This is Tcl/Tk version 8.6 # pip3 show matplotlib Name: matplotlib Version: 2.2.2前提
はじめに書いた通り、Tensorflowのretrain.pyを使って画像認識の転移学習を使って、どうして私が美術科に!?の主要キャラ5人を判別します。
主要キャラは桃音、黄奈子、蒼、紫苑、翠玉の5人です。
『どうして私が美術科に!?』第6話まで無料公開中です。初めて読むという方にも分かりやすい?メイン5人の簡単な紹介を描いてみました。美術科に通う女の子たちのお話です。https://t.co/QK8CMmUTJk pic.twitter.com/lN6X21Ts1H
— 相崎うたう?どうびじゅ3巻4/25発売 (@py_py_ai) 2018年6月29日
retrain.pyを使い学習を行い、生成された分類器に判定したい画像をlabel_imageに引数で与えると各ラベルとの類似度を返すのでその値でどのキャラクターなのかを判定を行います。
説明を楽にするため、登場するディレクトリを以下のように仮定します。
作業ディレクトリ:~/doubiju_train/
分類前の画像:~/Picture/data_src/
分類後の画像:~/doubiju_train/data/また、retrain.pyを今回使いますが、何か問題が起きたら、公式サイトをみて下さい。僕もいろいろなサイトを参考にして、手詰まりになりましたが公式サイトの通りにやったら一発でした。
https://www.tensorflow.org/hub/tutorials/image_retraining学習に必要なデータを集める
まずは、学習に必要なデータを集めるのですが、その前に一つ疑問になることがあります。
著作権
著作権です。今回必要なデータとなるイラストや漫画の画像には、当然著作権が存在します。もし、法律で複製が認められていないならそれを守るべきです。好きな作品なら尚更です。
早速ボツネタだなこれ...と思いながら調べてみるとこんな記事が。この条文を簡単に言うと、「情報解析目的なら、データなどの著作物を記録媒体にコピーできる」ということ。2009年に改正された条文で、当時はWeb解析や言語解析、自動翻訳の技術開発などを想定していたという。現在は(学習の手法にもよるが)、機械学習や深層学習も「情報解析」に含まれるとの考え方が主流だと、柿沼弁護士は話す。
「日本は機械学習パラダイス」 その理由は著作権法にあり - ITmedia NEWSどうやら著作権法47条の7が肝らしい。
さらに調べて見ると、
情報解析のための複製(著作権法第47条の7)
コンピュータを使った情報解析のために、必要と認められる限度において、著作物を複製することができる。
著作物が自由に使える場合は? | 著作権って何? | 著作権Q&A | 公益社団法人著作権情報センター CRIC本当だ。サンキュー著作権法。
ただし、複製はあくまでも機械学習などの情報解析の場合に認められており、複製した情報をそのまま公開するなどの行為は著作権法に違反します。
データを使わせていただく側なのでこれらのことには十分気をつけましょう。画像を集める
今度こそ本筋です。今回はキャラクターの分類・判定を行うので顔が写っている画像をかたっぱしから集めます。とにかく沢山です。多すぎということはありません。
僕は、単行本と所持している雑誌から顔が写っている部分を無音カメラで撮影し、PCに取り込みました。このとき写真はスクエアで撮影すると後で楽です。
また、作者の過去のツイートなどから画像を収集し、同様に保存しました。画像を加工する
顔でキャラクターを判定するので、画像に余計なものが写りこんでいると検知率が落ちてしまいます。なので、画像に顔だけが写るように画像を切り抜かなくてはいけません。
方法はいろいろありますが、後述する効率化のプログラムを使わないならアニメキャラの顔を検知するカスケード分類器があるのでそれを利用するのが簡単だと思います。
僕は、画像の少なさを正確さで補いたかったので手作業で加工しました。(後述)画像を分類する
いわゆるラベルづけの作業です。画像がどのキャラクターの画像かを教えていきます。
今回の場合は学習用のデータを格納するディレクトリを作成し、# mkdir ~/doubiju_train/data/その中に分類したい種類ごとにディレクトリを作成していきます。
# mkdir ~/doubiju_train/data/momone/ # mkdir ~/doubiju_train/data/kinako/ # mkdir ~/doubiju_train/data/aoi/ # mkdir ~/doubiju_train/data/shion/ # mkdir ~/doubiju_train/data/suigyoku/これらのディレクトリの中に入ったファイルには自動的にそのディレクトリの名前がラベルとして与えられます。
なので、得られた画像のなかから桃音ちゃんだと思う画像は、data/momone/に格納すれば良いのです。効率化
ぶっちゃけ苦行です。
どうびじゅだから死ぬほど楽しいだけであって、これが無機質な文字だったり、だんごむしとわらじむしとかだったら発狂しかねません。しかも結構非効率です。
画像を開いて目視で確認して移動先を指定して移動を繰り替えしていたら苦行以外の何でもありません。さらに僕には画像の切り取りの作業もあります。
そこで、画像を開いて切り抜き・分類・保存をするツールを作成しました。
ディレクトリ単位で画像を読み込み、切り抜き・分類・保存をするツール - Qiita
リンク先にもプログラムはありますが一応。
動作環境はリンク先を参照して下さい。import cv2 import sys import os import tkinter as tk from tkinter import * from PIL import Image,ImageTk image_dir=os.path.expanduser('~/Pictures/data_src/') save_dir=os.path.expanduser('~/doubiju_train/data/') characters=["momone","kinako","aoi","shion","suigyoku"] name_list=os.listdir(image_dir) name_list.sort() class Window(tk.Frame): def __init__(self, master=None): super().__init__(master) self.master = master self.index=0 self.local_num=0 self.max_width=1400 self.max_height=800 self.count=1 self.start_x=0 self.start_y=0 self.end_x=0 self.end_y=0 self.canvas = Canvas(master, width=1400, height=800) self.canvas.grid(row=0, column=0, columnspan=2, rowspan=4) self.load_img() self.create_widgets() self.grid() self.canvas.bind("<Button-1>", self.clicked) self.canvas.bind("<ButtonRelease-1>", self.release) self.canvas.bind("<B1-Motion>", self.move) def scale_to_height(self,img): img_width,img_height=img.size if img_width>self.max_width and img_height>self.max_height: if img_width>img_height and img_height/img_width<self.max_height/self.max_width: rate=img_height/img_width img=img.resize((self.max_width,int(self.max_width*rate))) else: rate=img_width/img_height img=img.resize((int(self.max_height*rate),self.max_height)) else: scale = self.max_height / img_height img=img.resize((int(img_width*scale),int(img_height*scale))) return img def load_img(self): path=image_dir+name_list[self.index] img=Image.open(path) self.resize_image = self.scale_to_height(img) self.img=ImageTk.PhotoImage(self.resize_image) self.image_on_canvas = self.canvas.create_image(0, 0, anchor=NW, image=self.img) def create_widgets(self): self.button_back_skip=Button(self) self.button_back_skip["text"]="<<" self.button_back_skip["command"]=self.back_skip self.button_back_skip.grid(row=1, column=0) self.button_back=Button(self) self.button_back["text"]="back" self.button_back["command"]=self.back_image self.button_back.grid(row=1, column=1) self.button_next=Button(self) self.button_next["text"]="next" self.button_next["command"]=self.next_image self.button_next.grid(row=1, column=2) self.button_next_skip=Button(self) self.button_next_skip["text"]=">>" self.button_next_skip["command"]=self.next_skip self.button_next_skip.grid(row=1, column=3) self.button_save=Button(self) self.button_save["text"]="rotate" self.button_save["command"]=self.rotate_image self.button_save.grid(row=2, column=0) for col,character in enumerate(characters): self.button_save=Button(self) self.button_save["text"]=character self.button_save["command"]= lambda: self.save_image(character) self.button_save.grid(row=2, column=col+1) self.button_save=Button(self) self.button_save["text"]="save" self.button_save["command"]=self.save_image_default self.button_save.grid(row=2, column=len(characters)+1) self.quit = tk.Button(self, text="QUIT", fg="red", command=self.master.destroy) self.quit.grid(row=2, column=len(characters)+2) #------- button press -------------------------------------------------------------- def next_image(self): self.canvas.delete("tmp") self.canvas.delete("rect") self.index+=1 if self.index==len(name_list): self.index=0 self.load_img() def back_image(self): self.canvas.delete("tmp") self.canvas.delete("rect") self.index-=1 if self.index==-1: self.index=len(name_list)-1 self.load_img() def next_skip(self): self.canvas.delete("tmp") self.canvas.delete("rect") self.index=(self.index+10)%len(name_list) self.load_img() def back_skip(self): self.canvas.delete("tmp") self.canvas.delete("rect") self.index=(len(name_list)+self.index-10)%len(name_list) self.load_img() def save_image(self,chara): cropped_img=self.resize_image.crop((self.start_x,self.start_y,self.end_x,self.end_y)) cropped_img.save(save_dir+chara+"/"+name_list[self.index],quality=95) def save_image_default(self): cropped_img=self.resize_image.crop((self.start_x,self.start_y,self.end_x,self.end_y)) cropped_img.save(save_dir+str(self.local_num)+name_list[self.index],quality=95) self.local_num+=1 def rotate_image(self): rotated_image=self.resize_image.rotate(90*self.count,expand=True) self.img=ImageTk.PhotoImage(rotated_image) self.image_on_canvas = self.canvas.create_image(0, 0, anchor=NW, image=self.img) self.count+=1 #------- key press -------------------------------------------------------------- def clicked(self,event): self.canvas.delete("rect") self.start_x=event.x self.start_y=event.y def move(self,event): self.canvas.delete("tmp") self.canvas.create_rectangle(self.start_x,self.start_y,event.x,event.y,outline="blue",width=2,tag="tmp") def release(self,event): self.canvas.create_rectangle(self.start_x,self.start_y,event.x,event.y,outline="blue",width=2,tag="rect") self.end_x=event.x self.end_y=event.y root = tk.Tk() root.title("cropper") win=Window(master=root) win.mainloop()試しにここで配布されているアイコンを動かしてみるとこんな感じ。
これで楽にデータを用意することができました。
データの水増し
おそらくすべてのイラストの画像を入手してもデータは足りません。
そこで、画像を反転したりノイズを追加したりしてデータを水増しします。
データ量が増えるので学習結果の向上が期待できますが、逆に訓練データになれすぎて未知のデータに対応できなくなる過学習を引き起こす場合もあります。
ここを参考にデータを水増ししていきたいと思います。import cv2 import numpy as np import sys import os import re def addGaussianNoise(src): row,col,ch= src.shape mean = 0 var = 0.1 sigma = 15 gauss = np.random.normal(mean,sigma,(row,col,ch)) gauss = gauss.reshape(row,col,ch) noisy = src + gauss return noisy def addSaltPepperNoise(src): row,col,ch = src.shape s_vs_p = 0.5 amount = 0.004 out = src.copy() num_salt = np.ceil(amount * src.size * s_vs_p) coords = [np.random.randint(0, i-1 , int(num_salt)) for i in src.shape] out[coords[:-1]] = (255,255,255) num_pepper = np.ceil(amount* src.size * (1. - s_vs_p)) coords = [np.random.randint(0, i-1 , int(num_pepper)) for i in src.shape] out[coords[:-1]] = (0,0,0) return out if __name__ == '__main__': min_table = 50 max_table = 205 diff_table = max_table - min_table gamma1 = 0.75 gamma2 = 1.5 average_square = (10,10) character=["momone/","kinako/","aoi/","shion/","suigyoku/"] for chara in character: path=os.path.expanduser('~/doubiju_data/data/'+chara) output=os.path.expanduser('~/doubiju_data/data/'+chara) name_list=os.listdir(path) for name in name_list: img_src = cv2.imread(path+name) trans_img = [] trans_img.append(cv2.blur(img_src, average_square)) trans_img.append(addGaussianNoise(img_src)) trans_img.append(addSaltPepperNoise(img_src)) flip_img = [] for img in trans_img: flip_img.append(cv2.flip(img, 1)) flip_img.append(cv2.flip(img, 0)) flip_img.append(cv2.flip(img, -1)) trans_img.extend(flip_img) img_src.astype(np.float64) name=re.sub(r'\.jpg',r'',name) for i, img in enumerate(trans_img): cv2.imwrite(output + name + "_" + str(i+1) + ".jpg" ,img)これで1枚の画像から16枚の画像が生成され、データ数が16倍になります。
ここら辺の兼ね合いはいろいろ試してみるといいと思います。
僕はこの処理の後にグレースケール化してみたり、ガウシアンノイズやコントラスト処理を加えてみたりしました。実際に動かしてみる
さぁ、ようやっと実行です。
プログラムを準備します。# cd ~/doubiju_train/ # curl -LO https://github.com/tensorflow/hub/raw/master/examples/image_retraining/retrain.py # curl -LO https://github.com/tensorflow/tensorflow/raw/master/tensorflow/examples/label_image/label_image.py--image_dirには訓練データの入ったディレクトリのpathを指定しましょう。
# python ~/doubiju_train/retrain.py --image_dir ~/doubiju_train/dataデータ量にもよりますが結構時間がかかります。
学習が終わったら、出力されたデータを元に画像と各ラベルの類似度を出力させます。
--imageには、判別させたい画像のpathを指定します。# python ~/doubiju_train/label_image.py \ --graph=/tmp/output_graph.pb --labels=/tmp/output_labels.txt \ --input_layer=Placeholder \ --output_layer=final_result \ --image=~/Pictures/data_src/momone.jpg/tmp/output_graph.pbと/tmp/output_labels.txtは今後label_image.pyで判別するときに必要になるのでバックアップをとっておきましょう。
# cp /tmp/output_graph.pb ~/doubiju_train/output_graph.pb # cp /tmp/output_labels.txt ~/doubiju_train/output_labels.txtいちいちコマンドをうつのは面倒なので、シェルスクリプトにしちゃいましょう。
jadge.sh#!/bin/sh image="$HOME/Pictures/data_src/20190403_234740119.jpg" python3 ~/doubiju_train/label_image.py\ --graph=output_graph.pb\ --labels=output_labels.txt\ --input_layer=Placeholder\ --output_layer=final_result\ --image=$image# ./jadge.sh 2019-04-08 22:53:17.506321: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA 2019-04-08 22:53:17.530495: I tensorflow/core/platform/profile_utils/cpu_utils.cc:94] CPU Frequency: 2395585000 Hz 2019-04-08 22:53:17.530958: I tensorflow/compiler/xla/service/service.cc:150] XLA service 0x2147380 executing computations on platform Host. Devices: 2019-04-08 22:53:17.531005: I tensorflow/compiler/xla/service/service.cc:158] StreamExecutor device (0): <undefined>, <undefined> shion 0.95736223 momone 0.016319819 suigyoku 0.010770504 aoi 0.01067509 kinako 0.004872421動きました。成功です。
与えた画像に対してどのラベルが近いかを数値で表しています。結果を見やすくする
一応成功しましたが、問題も残ります。
まず、与えた画像が何なのか確認するのが非常に面倒です。いちいちファイル名で検索して中身を確認するしかありません。
それから、値を文字で出されても一目でピンときません。グラフで表したら見やすそうです。
せっかくディレクトリ毎に画像を表示するプログラムができているので、表示するツールも作ってみました。
こんな感じです。import os import cv2 import sys import tkinter as tk import subprocess as sp import matplotlib.pyplot as plt from tkinter import * from PIL import Image,ImageTk from matplotlib.figure import Figure from matplotlib.backends.backend_tkagg import FigureCanvasTkAgg, NavigationToolbar2TkAgg image_dir=os.path.expanduser('~/Pictures/data_src/') image_dir=os.path.expanduser('~/python/Machine_learning/crop_output/') name_list=[f for f in os.listdir(image_dir) if os.path.isfile(image_dir+f)] name_list.sort() chara_colors={"momone":"#f781bf","kinako":"#ffff33","aoi":"#377eb8","shion":"#984ea3","suigyoku":"#4daf4a"} class Window(tk.Frame): def __init__(self, master=None): super().__init__(master) self.master = master self.index=0 self.max_width=1400 self.max_height=800 self.count=1 self.canvas = Canvas(master, width=1200, height=800) self.canvas.grid(row=0, column=0, columnspan=2, rowspan=4) self.load_image() self.create_widgets() self.grid() self.canvas.bind("<Button-1>", self.clicked) self.canvas.bind("<ButtonRelease-1>", self.release) self.canvas.bind("<B1-Motion>", self.move) text_widget = Text(master) text_widget.place(x=1200,y=0,width=300,height=400) text_widget.place() self.text_widget=text_widget self.f = Figure(figsize=(5,4), dpi=100) self.plt = self.f.add_subplot(111) self.f.subplots_adjust(left=0.15) self.dataPlot = FigureCanvasTkAgg(self.f, master=master) self.dataPlot.draw() self.dataPlot.get_tk_widget().place(x=950,y=400,width=490,height=450) def resize_image(self,img): img_width,img_height=img.size if img_width>self.max_width and img_height>self.max_height: if img_width>img_height and img_height/img_width<self.max_height/self.max_width: rate=img_height/img_width img=img.resize((self.max_width,int(self.max_width*rate))) else: rate=img_width/img_height img=img.resize((int(self.max_height*rate),self.max_height)) else: scale = self.max_height / img_height img=img.resize((int(img_width*scale),int(img_height*scale))) return img def load_image(self): path=image_dir+name_list[self.index] img=Image.open(path) self.resized_img = self.resize_image(img) self.img=ImageTk.PhotoImage(self.resized_img) self.image_on_canvas = self.canvas.create_image(0, 0, anchor=NW, image=self.img) def create_widgets(self): self.button_back_skip=Button(self) self.button_back_skip["text"]="<<" self.button_back_skip["command"]=self.back_skip self.button_back_skip.grid(row=1, column=0) self.button_back=Button(self) self.button_back["text"]="back" self.button_back["command"]=self.back_image self.button_back.grid(row=1, column=1) self.button_next=Button(self) self.button_next["text"]="next" self.button_next["command"]=self.next_image self.button_next.grid(row=1, column=2) self.button_next_skip=Button(self) self.button_next_skip["text"]=">>" self.button_next_skip["command"]=self.next_skip self.button_next_skip.grid(row=1, column=3) self.button_save=Button(self) self.button_save["text"]="rotate" self.button_save["command"]=self.rotate_image self.button_save.grid(row=2, column=0) self.button_save=Button(self) self.button_save["text"]="select" self.button_save["command"]=self.jadge_image self.button_save.grid(row=2, column=1) self.button_save=Button(self) self.button_save["text"]="jadge" self.button_save["command"]=self.jadge_image self.button_save.grid(row=2, column=2) self.quit = tk.Button(self, text="QUIT", fg="red", command=self.master.destroy) self.quit.grid(row=2, column=3) #------- button press -------------------------------------------------------------- def next_image(self): self.canvas.delete("tmp") self.canvas.delete("rect") self.index+=1 if self.index==len(name_list): self.index=0 self.load_image() def back_image(self): self.canvas.delete("tmp") self.canvas.delete("rect") self.index-=1 if self.index==-1: self.index=len(name_list)-1 self.load_image() def next_skip(self): self.canvas.delete("tmp") self.canvas.delete("rect") self.index=(self.index+10)%len(name_list) self.load_image() def back_skip(self): self.canvas.delete("tmp") self.canvas.delete("rect") self.index=(len(name_list)+self.index-10)%len(name_list) self.load_image() def save_image(self,chara): cropped_img=self.resized_img.crop((self.start_x,self.start_y,self.end_x,self.end_y)) cropped_img.save(save_dir+chara+name_list[self.index],quality=95) def rotate_image(self): rotated_image=self.resized_img.rotate(90*self.count,expand=True) rotated_image=self.resize_image(rotated_image) self.img=ImageTk.PhotoImage(rotated_image) self.image_on_canvas = self.canvas.create_image(0, 0, anchor=NW, image=self.img) self.count+=1 def jadge_image(self): cmd="python3 $HOME/doubiju_train/label_image.py "\ "--graph=$HOME/doubiju_train/output_graph.pb "\ "--labels=$HOME/doubiju_train/output_labels.txt "\ "--input_layer=Placeholder "\ "--output_layer=final_result "\ "--image=$HOME/Picture/data_src/"+name_list[self.index] chara_list=[] value_list=[] color_list=[] proc=sp.Popen(cmd, shell=True, stdout=sp.PIPE, stderr=sp.PIPE) std_out, std_err = proc.communicate() result_list = std_out.decode('utf-8').rstrip().split('\n') self.text_widget.delete('1.0','end') self.text_widget.insert('end',"----"+name_list[self.index]+"----\n") for result in result_list: name,value=result.split(" ") chara_list.append(name) value_list.append(float(value)) color_list.append(chara_colors[name]) self.text_widget.insert('end',name+"\t\t"+value+"\n") value_list.reverse() chara_list.reverse() color_list.reverse() self.plt.clear() self.plt.set_xticks([i/10 for i in range(0,11)]) self.plt.set_xticklabels([i/10 for i in range(0,11)]) self.plt.barh(list(range(5)),value_list,tick_label=chara_list,color=color_list) self.dataPlot.draw() #------- key press -------------------------------------------------------------- def clicked(self,event): self.canvas.delete("rect") self.start_x=event.x self.start_y=event.y def move(self,event): self.canvas.delete("tmp") self.canvas.create_rectangle(self.start_x,self.start_y,event.x,event.y,outline="blue",width=2,tag="tmp") def release(self,event): self.canvas.create_rectangle(self.start_x,self.start_y,event.x,event.y,outline="blue",width=2,tag="rect") self.end_x=event.x self.end_y=event.y root = tk.Tk() root.title("cropper") win=Window(master=root) win.mainloop()実行するとこんな感じです。
か゛わ゛い゛い゛な゛ぁ゛桃゛音゛ち゛ゃ゛ん゛
コマンドを実行し、返された値を取得して数値とグラフを表示しています。いずれも90%を越えていていい感じです。
それぞれのグラフの色は各キャラクターの名前に含まれている色をそのまま表示しています。
name color 桃音 #f781bf 黄奈子 #ffff33 蒼 #377eb8 紫苑 #984ea3 翠玉 #4daf4a グラフをウィジェットとして埋め込むのが大変だった。(満身創痍)
最後に
サンプルでもデータ側を工夫すれば、結構良い結果が得られるんだなと思いました。
機械学習を学ぶという建前でどうびじゅの画像をprprして心の隙間を埋めようとするだけの計画でしたが、なかなか有意義な学習だった気がします。また、困ったときに有効なツールを作って対処できたのは自分のなかで大きな成長だと思います。
これからは、機械学習の基本を学ぶとともに自分でコードを書いて更なる精度向上をしていきたいと思います。また、画像認識はなにも機械学習を使わなくても沢山方法はあるので、機械学習に縛られずに特徴量分析など別の方法でのアプローチもしていきたいと思います。
どうして私が美術科に!?3巻は4月25日発売なので興味のある方やきららMAX読者諸君は買われてみてはいかかがでしょうか。買え。
『どうして私が美術科に!?』完結の第3巻は4月25日発売です!
— まんがタイムきらら編集部 (@mangatimekirara) 2019年3月18日
本日カバーと帯を初公開いたします!
やっぱり美術科って最高! pic.twitter.com/Zs4VDcQHPu
参考
TensorFlowで画像認識「〇〇判別機」を作る - Qiita
How to Retrain an Image Classifier for New Categories | TensorFlow Hub | TensorFlow
Python + Tkinterで連番画像ファイルを素早く切り抜くGUI画像トリミングツール - Qiita
Python + Tkinter で作る、GUIな画像トリミングツール - Qiita
相崎うたう(2017)『どうして私が美術科に!?』 芳文社