- 投稿日:2019-04-15T23:01:26+09:00
OpenSiv3DをArchLinuxでビルドする
現在いくつかLinux版OpenSiv3Dをビルドし利用する記事がありますが,
どれも指示通りにはうまく行かなかったので試行錯誤と成功の過程を残しておくことにします.ライブラリのビルド
いくつかある記事を試した中で最も後の段階まで成功したこちらを参考にライブラリをビルドしました.
/optなど場所を決めて次を実行してください.
# GitレポジトリをClone git clone https://github.com/Siv3D/OpenSiv3D.git cd OpenSiv3D # Linuxブランチを使用します git checkout Linux cd Linux mkdir build cd build # 現在パッケージ名はopencv4となりエラーが発生するので sed -i -e 's/opencv//' ../CMakeLists.txt cmake -DCMAKE_BUILD_TYPE=Release .. make -j4成功していれば
[100%] Linking CXX static library libSiv3D.a
[100%] Built target Siv3Dと表示されています.
念のためlibSiv3D.aが存在することを確かめます.サンプルプログラムのビルド
./make_release.shが存在せず簡単にはビルドさせてくれませんでした.公式のサンプルソースを適当なディレクトリに保存します.
app.cpp#include <Siv3D.hpp> void Main() { Graphics::SetBackground(ColorF(0.8, 0.9, 1.0)); const Font font(50); const Texture textureCat(Emoji(U"?"), TextureDesc::Mipped); while (System::Update()) { font(U"Hello, Siv3D!?").drawAt(Window::Center(), Palette::Black); font(Cursor::Pos()).draw(20, 400, ColorF(0.6)); textureCat.resized(80).draw(540, 380); Circle(Cursor::Pos(), 60).draw(ColorF(1, 0, 0, 0.5)); } }そして,ビルドするためのコマンドはとても長いのでMakefileを置きます.
Makefile,長いので折りたたみ
MakefileTARGET := main$(EXEEXT) HDRS := $(wildcard $(SRCDIR)/*.hpp) LIBS := /opt/OpenSiv3D/Linux/libSiv3D.a CC = clang++ CFLAGS = \ -std=c++1z \ -Wall \ -Wextra \ -Wpedantic \ -O2 \ -I/opt/OpenSiv3D/Siv3D/include \ -I/opt/OpenSiv3D/Siv3D/include/ThirdParty/ \ -lboost_filesystem \ -lboost_system \ -lpthread \ -lGL \ -lGLEW \ -lglib-2.0 \ -lgobject-2.0 \ -lgio-2.0 \ -lpng \ -lturbojpeg \ -lX11 \ -lXi \ -lXrandr \ -lXinerama \ -lXcursor \ -ldl \ -lgif \ -lfreetype \ -lharfbuzz \ -lopenal \ -ludev \ -lopencv_core \ -lopencv_imgproc \ -lopencv_core \ -lopencv_highgui \ -lopencv_imgcodecs \ -lopencv_imgproc \ -lBox2D \ -lfontconfig .PHONY: all all: $(TARGET) $(TARGET): $(OBJS) $(LIBS) $(CC) $(CFLAGS) -o $@ $^ clean: rm -rf $(OUTDIR)試しにmakeするとUndefined referenceで落ちます.
これは
- OpenCVのバージョンに3が期待されている
- AngelScriptが欠けている
が原因なので,次で直していきます.
OpenCV3のインストール
OpenCVは3と4では仕様に多くの差があるため,諦めて古いバージョンを使用します.
yay -S opencv3-optでインストールできます が
ビルドに必要なディスク容量がめっちゃでかい(5GB)ので
ディスクに余裕がない場合はAURのURLからポータブルHDDなどにCloneしてmakepkg -si
をします.そして,Makefileにライブラリディレクトリを追加します.
Makefile-I/opt/OpenSiv3D/Siv3D/include \ -I/opt/OpenSiv3D/Siv3D/include/ThirdParty/ \ + -L/opt/opencv3/lib/ \ -lboost_filesystem \ -lboost_system \これでmakeをするとエラーがある程度減ります.
AngelScriptのインストール
AngelScriptはOpenSiv3Dのスクリプト機能を支えているようです.
ここにソースが公開されており,
これをダウンロードしてビルドします.
例によって/optにDLをします.cd /opt mkdir angelscript cd angelscript wget https://www.angelcode.com/angelscript/sdk/files/angelscript_2.32.0.zip unzip -d 2.32.0 angelscript_2.32.0.zip cd sdk/angelscript注意
最新バージョンは2019/04/15現在2.33.0ですが,AngelScriptはinit時に同一バージョン以外を認めません.
そのため,OpenSiv3Dで使用されているバージョンを必ず使用してください.現状のAngelScriptバージョンはこちらで確認が可能です.
次のようにバージョンが定義されているはずです.#define ANGELSCRIPT_VERSION_STRING "2.32.0"ビルドはめんどくさいのでMakefileを書きました.
MakefileTARGET := lib/libangelscript.a SRCDIR := source OUTDIR := bin INCDIR := include TARGET := $(TARGET) HDRS := $(wildcard $(INCDIR)/*.h) OBJS := $(addprefix $(OUTDIR)/,$(patsubst %.cpp,%.o,$(wildcard $(SRCDIR)/*.cpp))) DEPS := $(OBJS:%.o=%.d) #$(warning $(OBJS)) CC = g++ CFLAGS = \ -std=c++1z \ -Wall \ -Wextra \ -Wpedantic \ -O2 \ -fPIC \ -I $(INCDIR) \ -I $(SRCDIR) .PHONY: all clean all: $(TARGET) #-include $(DEPS) $(TARGET): $(OBJS) ar -rcs $@ $^ $(OUTDIR)/%.o:%.cpp $(HDRS) @if [ ! -e `dirname $@` ]; then mkdir -p `dirname $@`; fi rm -f $@ $(CC) $(CFLAGS) -o $@ -c $< clean: rm -rf $(OUTDIR) rm -rf $(TARGET)これでmakeをするとlib/libangelscript.soが生成されます.
また,サンプルプログラム側のMakefileも次のように編集します.
Makefile- LIBS := /opt/OpenSiv3D/Linux/libSiv3D.a + LIBS := /opt/OpenSiv3D/Linux/libSiv3D.a /opt/angelscript/2.32.0/sdk/angelscript/lib/libangelscript.aこれでサンプルプログラムをmakeするとビルドが通りました.
bin/mainを実行すると正常動作を確認できると思います.
あとがき,諸注意
筆者の環境での2019/04/15現在の方法です.
モチベが続いていれば情報が更新されるかもしれませんがそうではないと思ってください.
最新のものに対応させたソースと公式のインストール方法の公開をしてくれることを願っています.1
OSSの精神からすれば私が作るという選択をするべきなのかもしれませんがそこまで奥深く複雑なプロジェクトは私には力不足なのです… ↩
- 投稿日:2019-04-15T22:09:58+09:00
Nginx Unit のインストール
やってみたのでメモ
手順
リポジトリ情報を登録する
# vi /etc/yum.repos.d/unit.repounit.repo[unit] name=unit repo baseurl=https://packages.nginx.org/unit/centos/$releasever/$basearch/ gpgcheck=0 enabled=1ベースのソフトウェアをインストールする
# yum install unit追加のソフトウェアをインストールする
# yum install unit-devel unit-go unit-jsc8 unit-php unit-perl unit-python参考
- 投稿日:2019-04-15T19:21:11+09:00
Ubuntuローカル環境で教師データを作りたいからスワップ領域を50GB拡張した
最近終えたとある機械学習 (CNN, LSTM) のプロジェクトで30GBくらいの画像データをもとに教師データを作成、加工したのですが
私の社用PCはメモリ15GBだったのですぐ死んでしまっていました。
学習を回す以外にもかなりメモリ食うんですね。。
(このプロジェクトではクラウドサービスは使わず全てローカルでやってました。。)
そこで行ったことを自分の勉強用にまとめます。実行環境
Linux (Ubuntu 14.06 LTS)
メモリ約15GB, もともと割り当てられていたスワップ領域 約2GB
CPU Core i7 x 8コア
ディスク容量は忘れましたが、少なくとも220GB以上はありました。手順
50GBの”swapfile”という名のダミーファイルを作成
ディスク容量をよくご確認のうえコマンド叩いてくださいね。
$ fallocate -l 50G swapfileswapfileの権限をrootのみに変更
$ sudo chmod 600 /swapfile(失敗: swap有効化を試みる)
いきなりswapfileがswapとして認識されるわけではない
$ sudo swapon /swapfile swapon: /swapfile: read swap header failedスワップ領域を割り当てる
$ sudo mkswap -f /swapfile Setting up swapspace version 1, size = 50 GiB (53687087104 bytes) no label, UUID=(略)swapを有効化
エラーが出なかったから上手くいったぽい
$ sudo swapon /swapfile実際のスワップ領域の容量を確認
$ free total used free shared ...とりあえず耐えられる程度にはなりました。
参考リンク
https://kazmax.zpp.jp/linux_beginner/mkswap.html
http://itengine.seesaa.net/article/441296089.html
https://yukiosugiyama.com/blog/post-2369/
https://gist.github.com/koudaiii/0ed6a8558aa297af463e
- 投稿日:2019-04-15T11:37:20+09:00
SSHの初期設定(公開鍵認証設定とパスワードログインの無効化)
- パーミッションの設定とかどうすればいいかいつも忘れるのでまとめてみました
- rootで実行する必要があります。
- python2で書かれています。python3では動きません。OSでデフォルトで入っているのは2ばかりなので問題ないと思います。
- 保証等は一切ありません。
- CentOSじゃないと動きません(たぶん)。
sshsettings.py# -*- coding: utf8 -*- import os import time username = raw_input("input new user name\n>>") os.system("useradd %s" % unicode(username)) os.system("passwd %s" % unicode(username)) os.system("chmod 701 /home/%s" % unicode(username)) os.system("mkdir /home/%s/.ssh" % unicode(username)) os.system("chmod 700 /home/%s/.ssh" % (unicode(username),)) os.system("chown %s:%s /home/%s/.ssh" % (unicode(username), unicode(username), unicode(username))) os.system("vi /home/%s/.ssh/authorized_keys" % (unicode(username),)) os.system("chmod 600 /home/%s/.ssh/authorized_keys" % (unicode(username),)) os.system("chown %s:%s /home/%s/.ssh/authorized_keys" % (unicode(username), unicode(username), unicode(username))) print "please change setting password authentication -> no" time.sleep(2) os.system("vi /etc/ssh/sshd_config") os.system('usermod -aG wheel ' + username) print "ssh setting finished."
- 投稿日:2019-04-15T10:56:54+09:00
[X.org] 接続されているディスプレイ(モニター)の配置と解像度を一覧表示する
前提知識
Xでモニターを特定するために以下の概念があります。
display... Xサーバーを特定するための数字のようなもの?/tmp/.X11-unixの中身を見ればわかる。普通は1つのscreenで構成される。screen...displayに属する。複数のmonitorで構成される。各ウィンドウはscreenの中を自由に移動できる。(2つのmonitorにまたがってもよい)monitor... 実際のディスプレイ等の機器と1対1に対応する。なお、デフォルトのディスプレイは
DISPLAY環境変数で指定します。# display, screenを指定する例 export DISPLAY=localhost:0.0 # 最小の例 export DISPLAY=:0
xrandrコマンドを実行することで、monitorの情報などを表示できます。今回はlibXrandrを用いてC言語からこれらの情報を扱ってみます。コード
#include <X11/extensions/Xrandr.h> #include <stdio.h> #include <dirent.h> #include <string.h> #include <X11/Xlib.h> int main(void) { Display *disp = XOpenDisplay(NULL); int screen = DefaultScreen(disp); Window root = RootWindow(disp, screen); XRRScreenResources *res = XRRGetScreenResources(disp, root); printf("Screen %d (%dx%d):\n", screen, DisplayWidth(disp, screen), DisplayHeight(disp, screen)); info->connection == 0int i, j; for (i = 0; i < res->noutput; i++) { XRROutputInfo *info = XRRGetOutputInfo(disp, res, res->outputs[i]); printf(" %s state:%d\n", info->name, info->connection); if (info->crtc) { XRRCrtcInfo *cinfo = XRRGetCrtcInfo(disp, res, info->crtc); printf(" %d %d %d %d\n", cinfo->width, cinfo->height, cinfo->x, cinfo->y); } } return 0; }コンパイル
gcc main.c -lXrandr -lX11出力の例
Screen 0 (1920x2160): eDP1 state:0 1920 1080 0 1080 DP1 state:1 DP2 state:1 HDMI1 state:1 HDMI2 state:1 1920 1080 0 0 VIRTUAL1 state:1
- 投稿日:2019-04-15T10:49:01+09:00
S3のファイルの中身をダウンロードせずに簡単に確認する方法
AWS S3のバケットにaaaというファイルがあったとしましょう。
$ aws s3 ls s3://(バケット名)/ 2019-04-15 01:42:01 65 aaa 2019-04-15 01:42:08 65 aaa.gz $このaaaの中身ってみるのっていちいちダウンロードしたし、コンソール開いたり、
結構めんどくさかったりしませんか?
今回はこのファイルの中をちょろちょろって確認する方法を紹介します。Linuxのコマンドだけでできるんで簡単ですよ。
はいいきなりですが、コマンドは下記です。
ポイントはcp の結果を - にすると標準出力になるんです。
それをcat連結するとみれますよ。$ aws s3 cp s3://(バケット名)/aaa - | cat testhogehoge1 testhogehoge1 吾輩は猫である testhogehoge1 testhogehoge1 $応用その1.
$ aws s3 cp s3://(バケット名)/aaa.gz - | zcat testhogehoge1 testhogehoge1 吾輩は猫である testhogehoge1 testhogehoge1 $応用その2.
$ aws s3 cp s3://(バケット名)/aaa.gz - | zcat | grep 猫 吾輩は猫である $そしてこれ、ローカルにファイルのこりません。(当然か..)
ちょっとろしたログの調査のときとかにすごく便利ですよ!よい Linux AWS ライフを!!
- 投稿日:2019-04-15T10:49:01+09:00
AWS S3上ファイルの中身をLinuxコマンドだけで超絶簡単に確認する方法
AWS s3のファイルの中を見るときにいちいちダウンロード→解凍→中身を確認 とか
コンソールとかで頑張ってファイルを参照とかしていませんか?あれ、結構めんどくさかったりしませんか?
今回はこのファイルの中をちょろちょろって確認する方法を紹介します。AWS S3のバケットにaaaというファイルがあったとしましょう。
$ aws s3 ls s3://(バケット名)/ 2019-04-15 01:42:01 65 aaa 2019-04-15 01:42:08 65 aaa.gz $このaaaの中身ってみるの超絶簡単に確認する方法の紹介します。
Linuxのコマンドだけでできるんですよ。はいいきなりですが、コマンドは下記です。
ポイントはcp の結果を - にすると標準出力になるんです。
それをcat連結するとみれますよ。$ aws s3 cp s3://(バケット名)/aaa - | cat testhogehoge1 testhogehoge1 吾輩は猫である testhogehoge1 testhogehoge1 $応用その1.
$ aws s3 cp s3://(バケット名)/aaa.gz - | zcat testhogehoge1 testhogehoge1 吾輩は猫である testhogehoge1 testhogehoge1 $応用その2.
$ aws s3 cp s3://(バケット名)/aaa.gz - | zcat | grep 猫 吾輩は猫である $そしてこれ、ローカルにファイルのこりません。(当然か..)
ちょっとろしたログの調査のときとかにすごく便利ですよ!よい Linux AWS ライフを!!
- 投稿日:2019-04-15T08:09:19+09:00
ボーナスでたら、ゼロからLinuxのGPU機械学習環境を作る ~Ubuntu18.04のインストールからPyTorch実行まで全手順~
概要
- 特に難しいことを考えることなくGPUを使った機械学習(主にディープラーニング向け)環境をPCに構築します
- Linux OSのインストール、各種ドライバ・ソフトウェア類のインストールなど全ての手順をスキップ無しで1つずつハンズオンで確認します
- セットアップしたLinuxに、人気急上昇中の機械学習ライブラリPyTorchを導入します
対象
- そろそろ機械学習はじめようと思ってるけど、とっかかりがつかめない人
- ボーナス出たら「GPU買うぞ~」と思っている人
- Linux,Python,Anaconda,PyTorch,機械学習のいずれかまたは全ての初心者
環境
- OSは Ubuntu 18.04 LTS を導入します
- Pythonは version 3.7 を導入します
- 機械学習フレームワークは PyTorch 1.0 を導入します
- GPUは NVIDIA GEFORCE RTX 2080 Ti を使いますが、CUDAコア搭載の他のNVIDIA GPUでも同等です
ゴール
- OSインストールから、PyTorchでCUDAをつかったテンソル演算を確認するところまでやります。
本編
Linuxをインストールするマシンを用意する
手元で機械学習(主にディープラーニング用途)を実行するために以下のようなスペックのPC(自作)を準備した。
CPU Core i7-9700K マザボ Z390チップセット メモリ 16GB HDD 1TB GPU NVIDIA Geforce RTX 2080 Ti 11GB 搭載 電源 ATX 800W Linuxインストール用のUSBメモリ(Live USB)を作成する
まず、Linuxをインストールするために、インストール用のUSBメモリ(Live USB)を作成するところから開始する。
USBメモリへの書き込みにはWindows PCを利用した例で説明するが、書き込みアプリはWindow版、Mac版、Linux版があり、どれも同じ手順でインストール用USBメモリを作成可能。Ubuntu 18.04のディスクイメージは 2GB程度なので、USBメモリは8GBもあれば十分。
Ubuntu 18.04のディスクイメージのダウンロード
Linuxのディストリビューションには、Ubuntu 18.04 LTSを使用する。
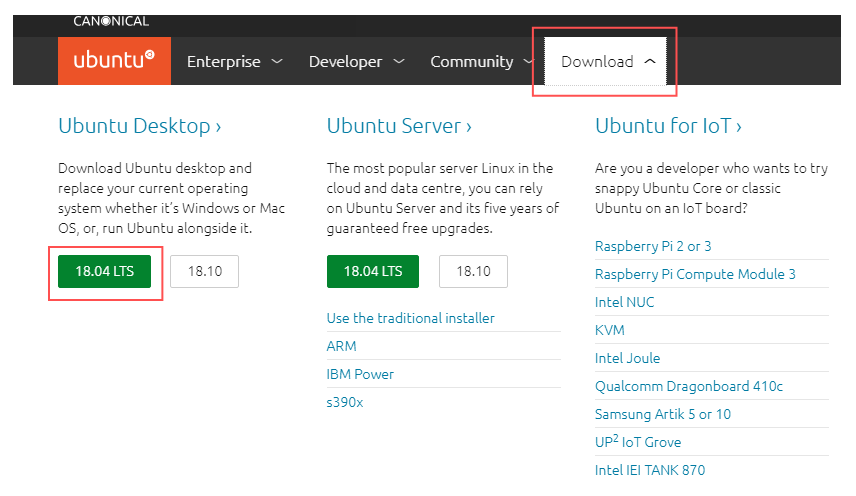
https://www.ubuntu.com にアクセスして、Downloadタブを開いて、Ubuntu Desktop > 18.04 LTS をクリックすると、Ubuntuのディスクイメージ(ISO)がダウンロードされる。
ここでは、ubuntu-18.04.2-desktop-amd64.isoがダウンロードされたので、これのディスクイメージをUSBメモリに書き込む。
USBメモリにLinuxのディスクイメージを焼く
(1)USBメモリ書き込み用のアプリ UNetbootin を以下からダウンロードし、インストールする。
(2)UNetbootinを起動
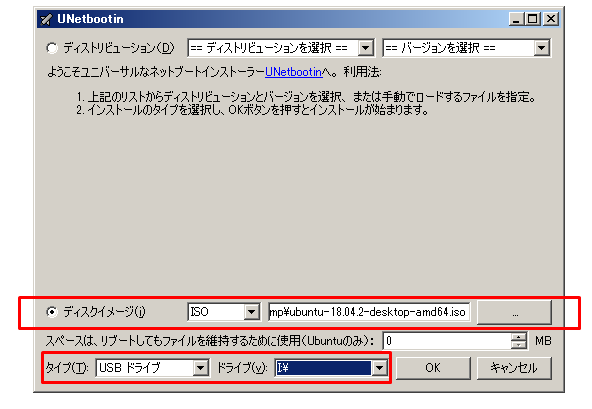
UNetbootinを起動する
ディスクイメージを選択して、さきほどダウンロードしたISOディスクイメージ ubuntu-18.04.2-desktop-amd64.iso を指定する。
タイプは USBドライブで、ドライブ名は USBメモリが挿入されたドライブを指定する。
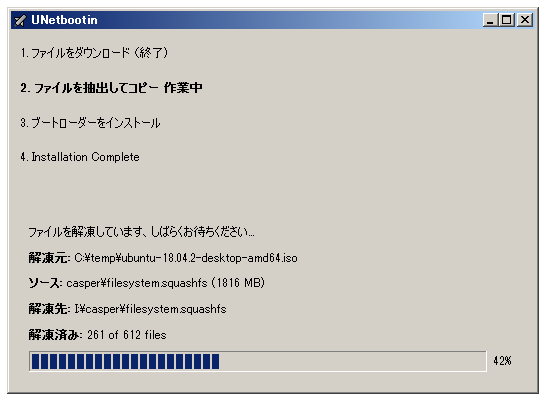
OKを押すと、USBメモリの作成が開始する。
あとは、しばらく待っていれば Ubuntu 18.04 LTS をインストールすることができるUSBメモリが完成する
USBメモリからUbuntu 18.04 をインストールしていく
さて、今つくったUSBメモリをPCに挿入して、電源オン
USBメモリから起動したいので、PC起動時にBIOS設定画面を出す。
BIOS設定画面の起動方法は、たいていの場合 PC起動時に F2またはDELを押せばOK。
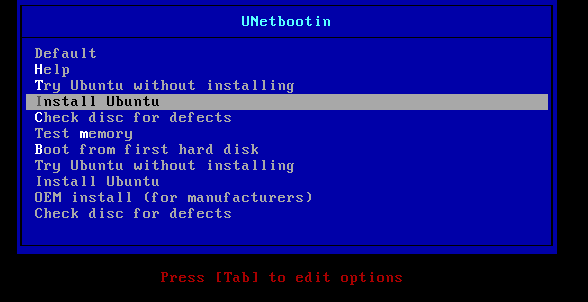
BIOS設定画面のブートメニュー(Boot Menu)にて、USBメモリでブートを選択すればUSBメモリからブートする。USBメモリからブートできると、以下のようにUNetbootin のブート画面がでるのでInstall Ubuntuを選択する
インストールが開始される
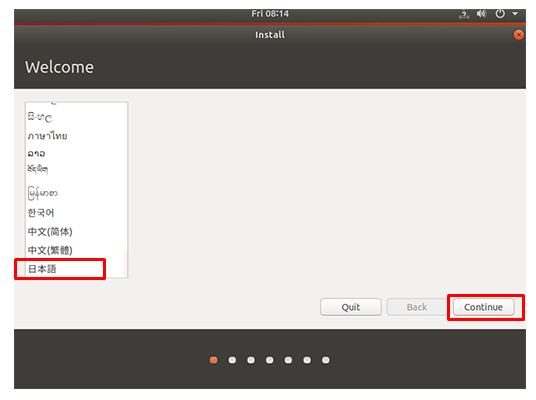
言語設定画面では、日本語を選択
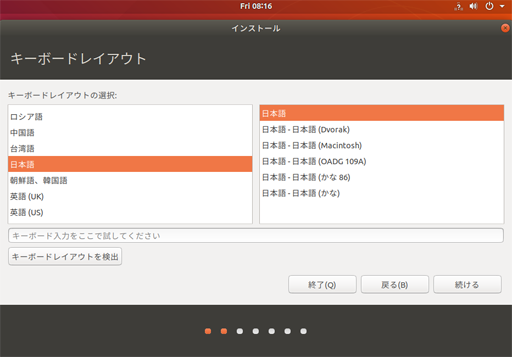
キーボードレイアウトも日本語を選択
画面に従いすすめていく
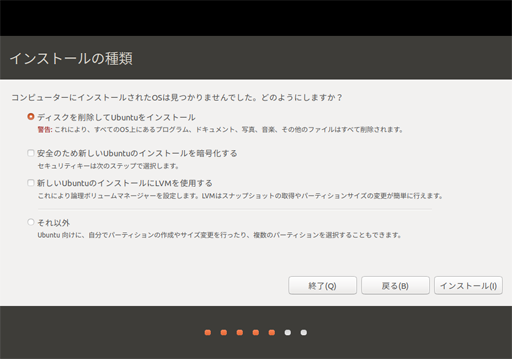
今回はまっさらにした状態のPCにLinuxをインストールする
(既存のWindows PCにインストールする場合は削除するか、残すかオプションが出る)
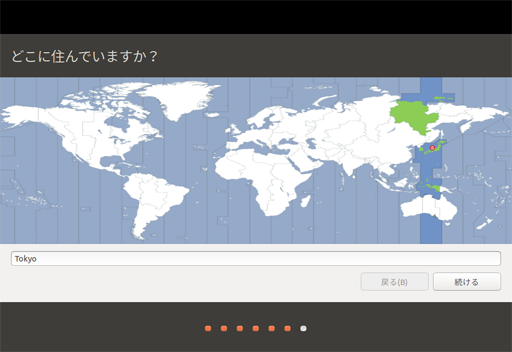
ロケールは Tokyo で。(日本語選んでおくとデフォルトでそうなる)
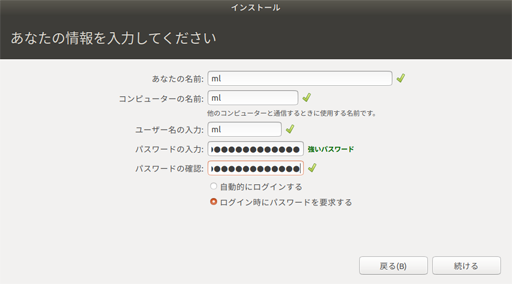
次にユーザー名とコンピューター名を入れ 続ける を押す
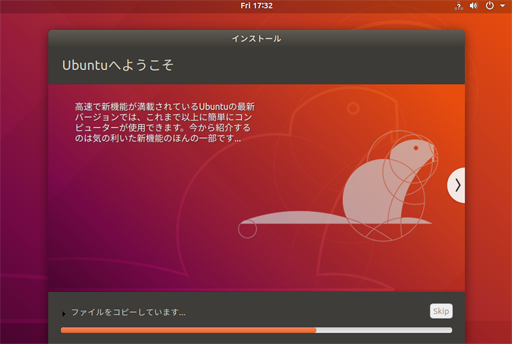
あとはインストールが自動で進むので待つ
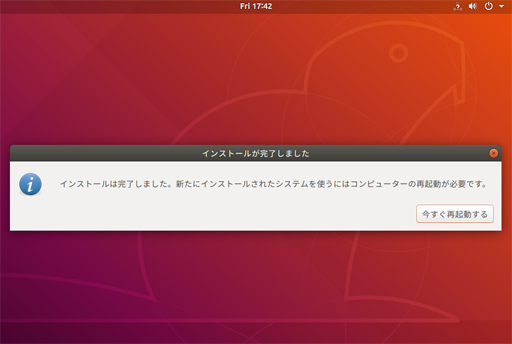
しばらくするとインストール終了ダイアログがでるので、今すぐ再起動する
再起動すると、このとおり、Ubuntu 18.04 LTSを無事インストール終了!
ただしまだ最適なグラフィックドライバをインストールしていないので、画面描画で残像が出たり、画面解像度などは最適化されていない。
Ubuntu 18.04 をセットアップする
OSは無事インストールできたので、これから基本的な設定や、必要になるソフトウェア群をインストールしていく。
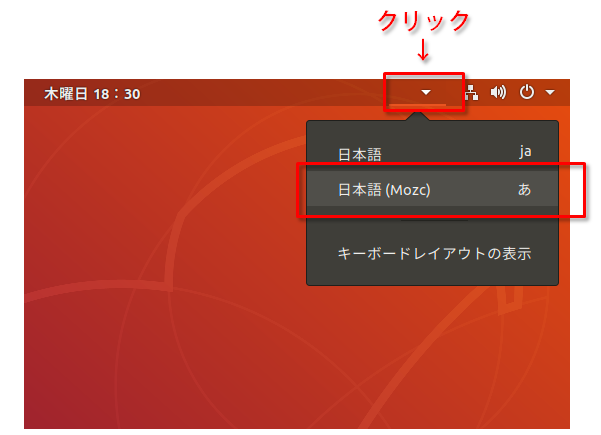
Ubuntuで日本語入力を使えるようにする
Ubuntu 18.04のインストール直後だと、半角/全角ボタンを押しても、日本語IMEが使えず日本語入力ができない場合があるので、画面の右上の▼をクリックして、開いたメニューで 日本語(Mozc)入力を有効にする。
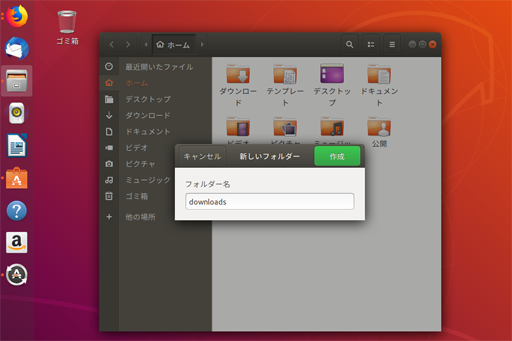
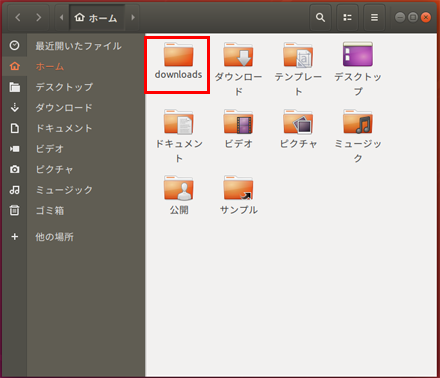
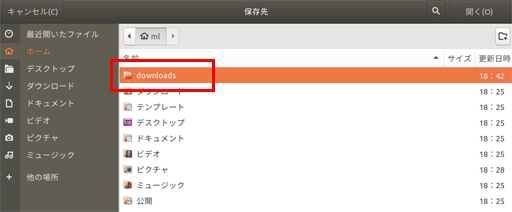
downloadsディレクトリ(フォルダ)を作る
これからら、いくつかのドライバーやパッケージをネットからダウンロードするので、ダウンロードしたファイルの保存先ディレクトリを作成する
左のアプリメニューからファイル
クリックしてファイルマネージャを起動して、開いたユーザーディレクトリ以下にダウンロード用ディレクトリ(フォルダ)を作成する。右クリックでフォルダ作成を選択し、フォルダ名を downloads として作成する。
実は日本語環境でインストールすると、デフォルトでダウンロードというディレクトリ(フォルダ)ができるが、端末(ターミナル)から扱うとき日本語のディレクトリ名(フォルダ名)だとコマンドラインと相性がわるいため、ここでdownloadディレクトリ(フォルダ)を作っておいた。
Chrome(ブラウザ)をインストールする
さきほどのインストール方法でインストールしたUbuntu 18.04 LTSデスクトップディストリビューションでは、Firefoxがデフォルトで入っているが、ブラウザにはChromeを使いたいので、そちらを導入する
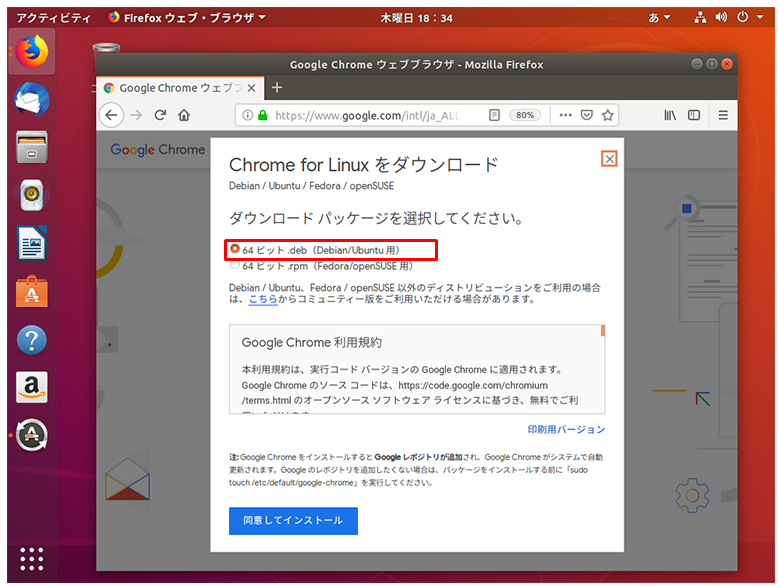
以下からGoogle Chrome(Linux版)をダウンロードする
https://www.google.com/intl/ja_ALL/chrome/
64ビット .debパッケージを選択する
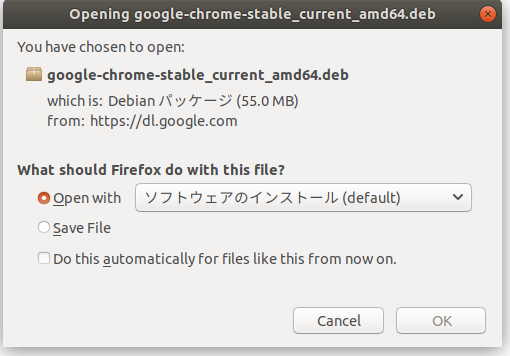
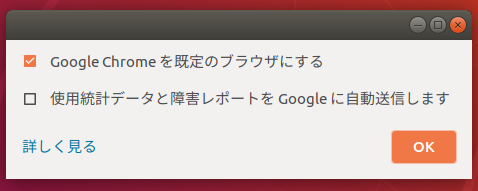
こんな画面がでるのでOKする
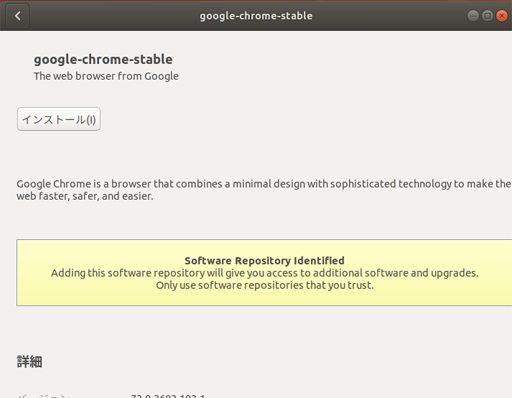
インストールをクリック
ChromeのインストールはGUIから行ったが、これでインストール完了。
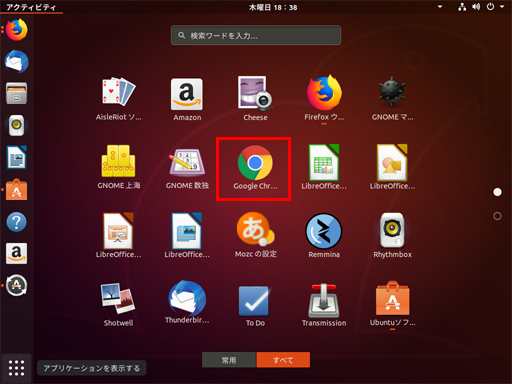
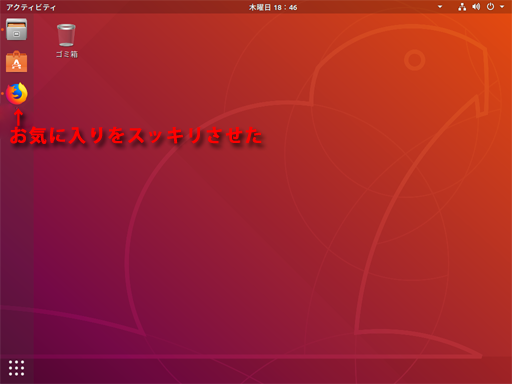
左下のメニューボタンを押してアプリ一覧を表示すれば、ちゃんとGoogle Chromeがインストールされている。
ここで、左側のアプリメニューにあるアプリアイコン上で右クリックして、常時表示が不要なものをお気に入りから削除して、スッキリさせた。
さて、ここで
をクリックして、Chromeを起動。
規定のブラウザにするにチェック。
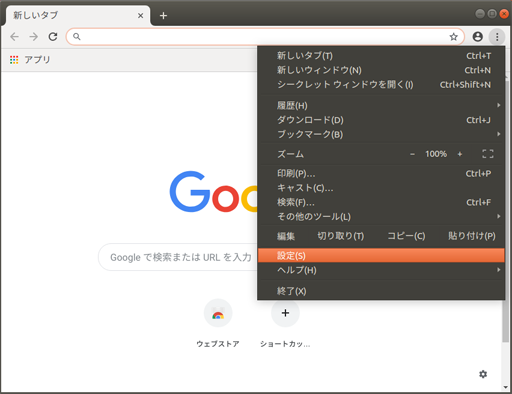
■Chromeの規定のダウンロードフォルダの変更
Chromeが起動したら、右上の
ボタンでメニューを開き、設定を選択する
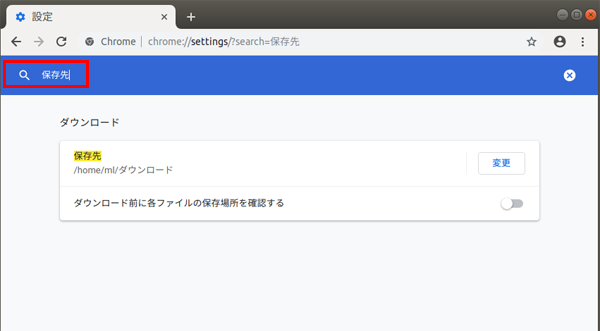
検索窓
に 保存先 と入力すると、ダウンロードしたファイルの保存先の設定画面がでるので、変更を押すと
フォルダ選択画面がでるので、さきほど作成した downloads を選択してフォルダを選択するをクリックする。
NVIDIA グラフィックドライバーのインストール
さて、いままではインストールした素の状態で作業してきたが、解像度が最大になっていなかったり場合によっては描画に残像がでるなどの動作が適正ではなかった。
ここでは、GPUにあったグラフィックドライバーをインストールする。
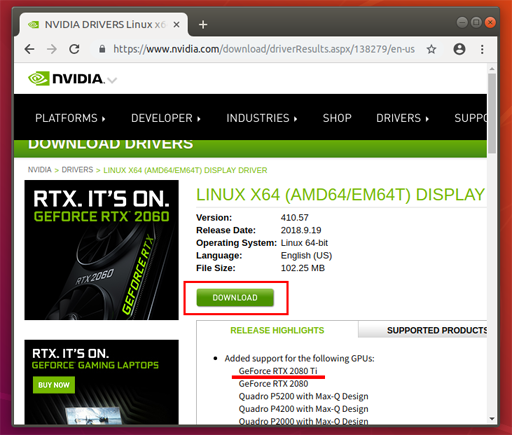
本稿のPCにはGeForce RTX 2080 Tiを導入しているので、以下サイトからドライバーをダウンロードする。
https://www.nvidia.com/download/driverResults.aspx/138279/en-us
上のリンクをChromeで開いて、GeForce RTX 2080 Tiに対応したドライバをダウンロードする。
■ 端末(ターミナル)をつかってドライバーをインストールする
左下の
を押して 端末(ターミナル)を起動する
ここからはコマンドラインでインストールしていく。
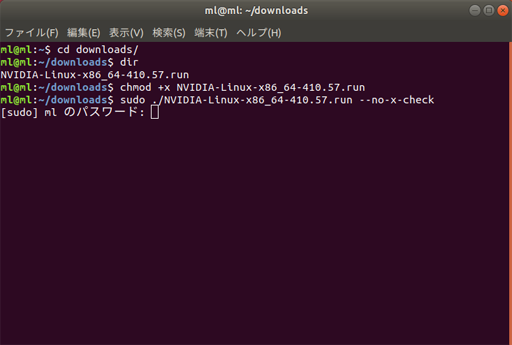
1.グラフィックドライバのダウンロードディレクトリに行く
$ cd downloads/2.dirでディレクトリの中身を確認
$ dir NVIDIA-Linux-x86_64-410.57.run3.chmodでパーミッションを変更して、ダウンロードしたドライバインストーラーを実行できるようにする
$ chmod +x NVIDIA-Linux-x86_64-410.57.run4.sudoをつかってルート権限でドライバのインストールを実行する
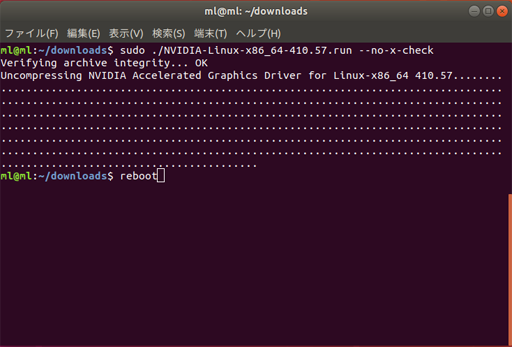
$ sudo ./NVIDIA-Linux-x86_64-410.57.run --no-x-check
■ NVIDIAグラフィックドライバーのインストール・ステップをみていく。
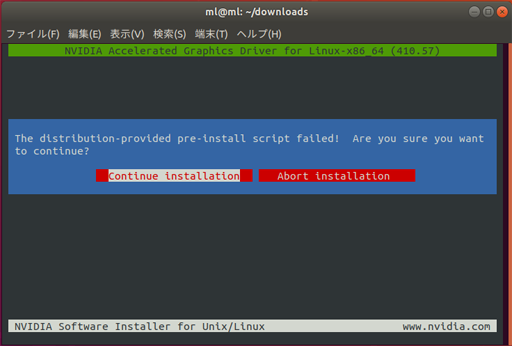
The distribution-provided pre-install script failed! Are you sure you want to continue?と出るが気にせず Continue installation を選択してエンター。
次の画面ではこのように出る。
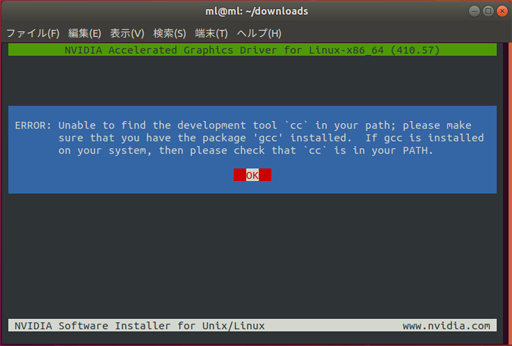
ERROR: Unable to find the development tool`cc` in your path; please make sure that you have the package 'gcc' installed. If gcc is installed on your system, then please check that `cc` is in your PATH.
「ccにパスが通って無いみたいだけど、gccはインストールしておいてね!」というエラー。
OKを押すとインストーラーが終了する。
gccがインストールされていないようなので、gccをインストールすることにする。
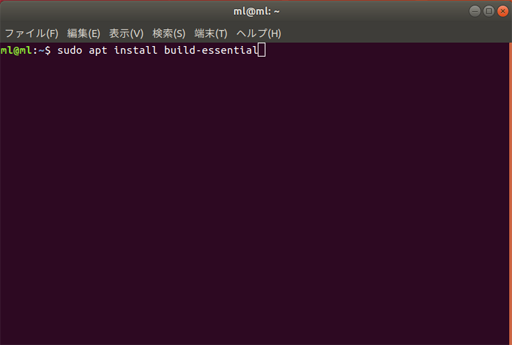
■ gcc をインストールする
端末(ターミナル)から以下のコマンドで gcc を含むビルドツール(makeなども)をインストールする
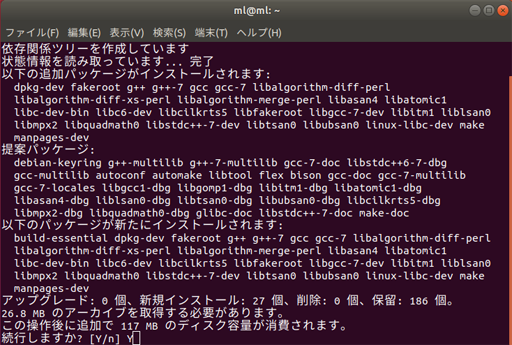
sudo apt install build-essential
インストール準備がはじまり、続行しますか? [Y\n] 確認があるので Yでインストールが実行される。
■ 再度、NVIDIAグラフィックドライバのインストールを試みる
さきほどはgccが無くて止まってしまったので、gccをインストールした。
ここで、再度、NVIDIAグラフィックドライバのインストールを試みる。
$ sudo ./NVIDIA-Linux-x86_64-410.57.run --no-x-checkふたたび、この画面
The distribution-provided pre-install script failed! Are you sure you want to continue?と出るが気にせず Continue installation を選択してエンター。
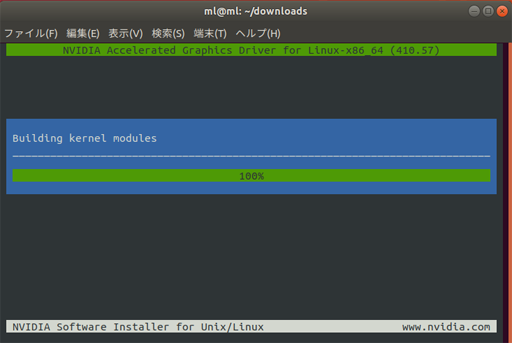
次は、この画面、
今度はちゃんとビルドできている模様。
次は、この画面、
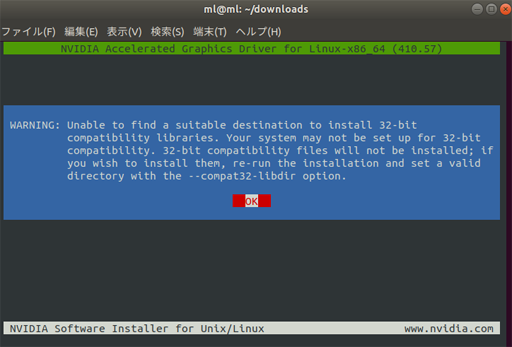
WARNING:
Unable to find a suitable destination to install 32-bit
compatibility libraries. Your system may not be set up for 32-bit
compatibility. 32-bit compatibility files will not be installed; if
you wish to install them, re-run the installation and set a valid
directory with the --compat32-libdir option.こんな警告メッセージがでて、「32-bit互換ライブラリをインストールしたいなら再実行してね」と言っている。今回の用途では32-bit互換ライブラリは不要なので、気にせずOKを選択。
次は、この画面
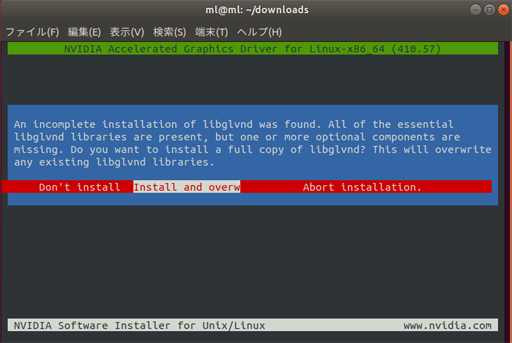
An incomplete installation of libglvnd was found. All of the essential
libglvnd libraries are present, but one or more optional components are
missing. Do you want to install a full copy of libglvnd? This will overwrite
any existing libglvnd libraries.libglvndの上書き確認があるので Install and overw を選択で上書きでOK。
次は、この画面
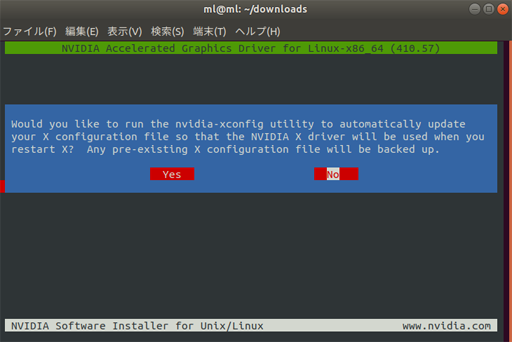
Would you like to run the nvidia-xconfig utility to automatically update
your X configuration file so that the NVIDIA X driver will be used when you
restart X? Any pre-existing X configuration file will be backed up.「Xの設定を更新するか?」聞いている、今はNoでOK。
nvidia-xconfigコマンドを使えばいつでも実行可能。次は、この画面
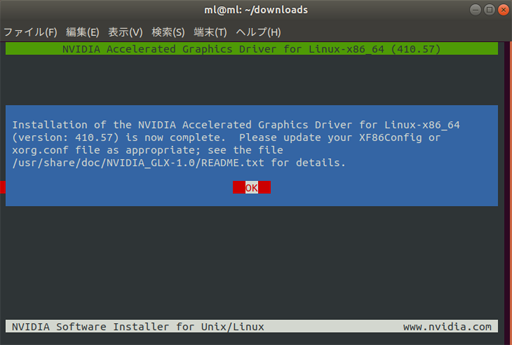
Installation of the NVIDIA Accelerated Graphics Driver for Linux-x86_64
(version: 410.57) is now complete. Please update your XF86Config or
/usr/share/doc/NVIDIA_GLX-1.0/README.txt for details.これで、NVIDIAグラフィックドライバのインストールは無事成功。OKを押して終了
設定を反映するために、再起動する
rebootコマンドで再起動する
rebootすると、
画面がFullHDになった。NVIDIAグラフィックドライバが有効になって、ちゃんと適正な解像度がセットされた。
■ GPUの設定画面を開く
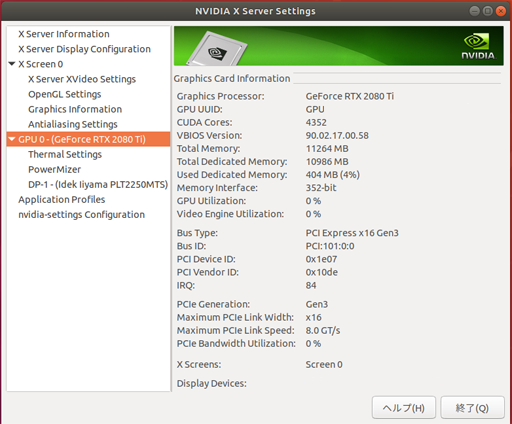
nvidia-settingsコマンドでGPUの設定画面を表示することができますnvidia-settings
これにて、GPUは正しくインストールされた
Anacondaを導入する
ここでは、Pythonの実行環境をサクっと構築してくれるAnacondaを導入する
■ Anaconda をダウンロードする
Chromeを開いて、以下を開く
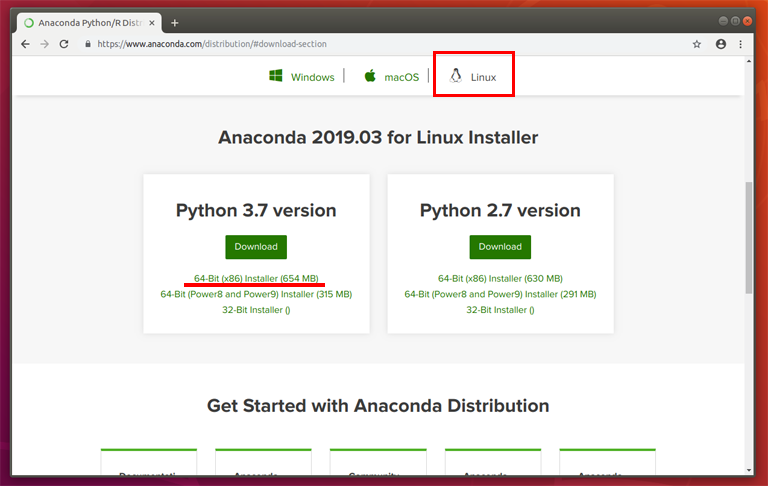
https://www.anaconda.com/distribution/#download-section
上部のタブでLinuxを選び、Python 3.7 versionを選んで、64-Bit(x86) Installer をダウンロードする。
すると、Anaconda3-2019.03-Linux-x86_64.sh というファイルがダウンロードされた
■ Anaconda3をインストールする
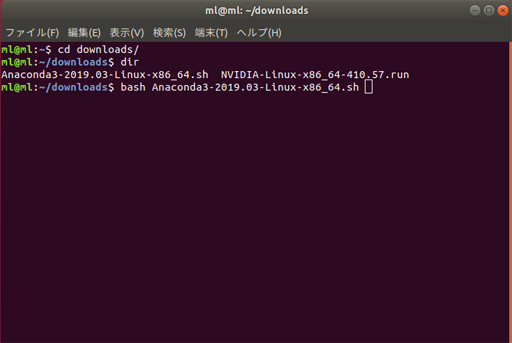
ダウンロードしたAnaconda3を
端末(ターミナル)を開いて、以下コマンドを入力して、Anacondaをインストールするcd downloads/ bash Anaconda3-2019.03-Linux-x86_64.sh
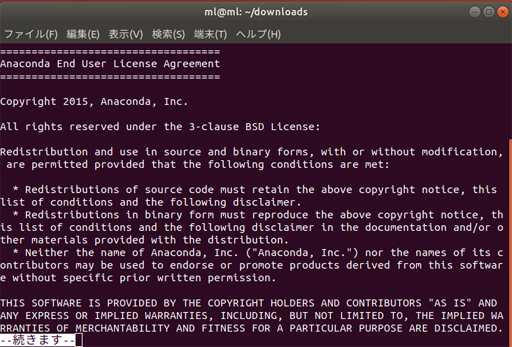
ライセンスの確認画面はエンターでページおくりできる
同意したら yes をタイプする
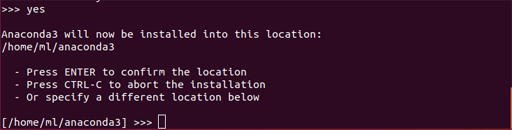
次にAnacondaの保存先を聞かれる
Anaconda3 will now be installed into this location: /home/ml/anaconda3 - Press ENTER to confirm the locationとなっているので、エンターを押して保存先を確定する
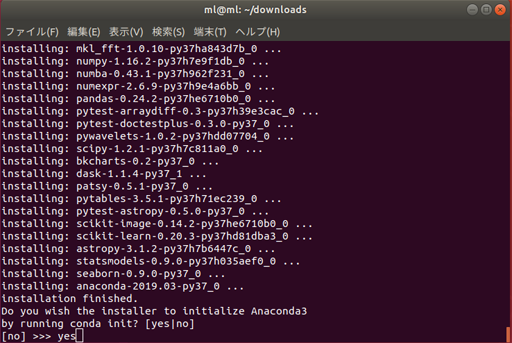
インストールが終わると、
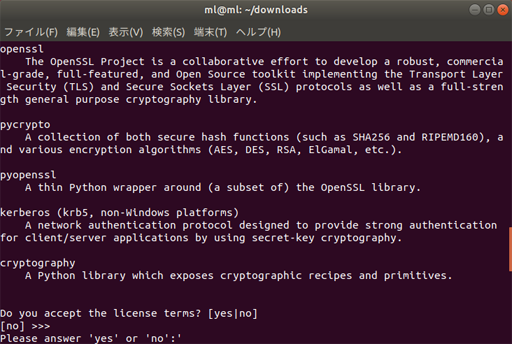
Do you with the installer to initialize Anaconda3 by running conda init? [yes|no]「conda initをしてAnaconda3を初期化するかい?」と聞いてくるので
yesと入力する。
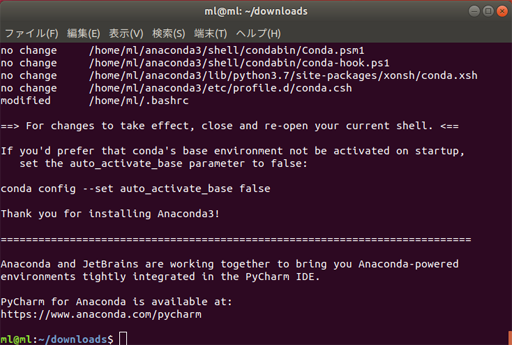
これで、Anaconda3のインストールが完了!
また、Pythonのインストールも同時に完了!■ Pythonが動作するかを確認する
Anacondaのインストールが終わったら、いったん、端末(ターミナル)を閉じて、再度 端末(ターミナル)を開く。
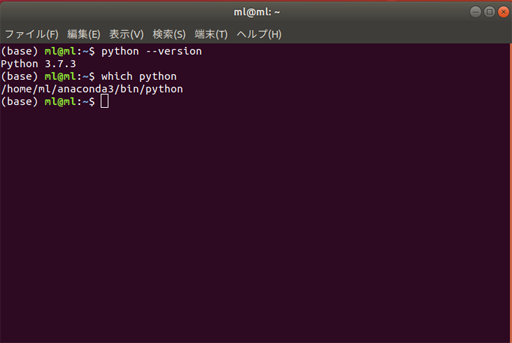
端末(ターミナル)を開き直したら以下のコマンドで、インストールされたPythonを確認してみる
- Pythonのバージョン
$ python --version Python 3.7.3
- Pythonのインストール先
$ which python /home/ml/anaconda3/bin/python
■ condaコマンドとは
ところで、プロンプトの先頭に以下のように(base)がつくようになった
(base) ml@ml:~$ python --version Python 3.7.3 (base) ml@ml:~$ which python /home/ml/anaconda3/bin/python (base) ml@ml:~$これはcondaが環境名を表示している。
そもそもcondaとは、パッケージ管理や環境の管理してくれるための便利なツールで、Anacondaのインストールと同時にcondaもインストールされている。
さきほどの(base)はcondaのインストール時にデフォルトで付与されたものだが、ジャマなら非表示にすることもできる。
以下のコマンドを実行する
(base)表記を消すconda config --set changeps1 Falseここまでで、Anaconda3のインストールは終了。
この段階で、Python 3.7やcondaコマンドもインストールされており、Pythonの基本的な開発ができるようになっている。PyTorchの導入
さて、ようやくお膳立てができたので、いよいよ機械学習ライブラリ PyTorch を導入する
■ PyTorchのインストール
以下にあるPyTorchのインストールガイドを開く
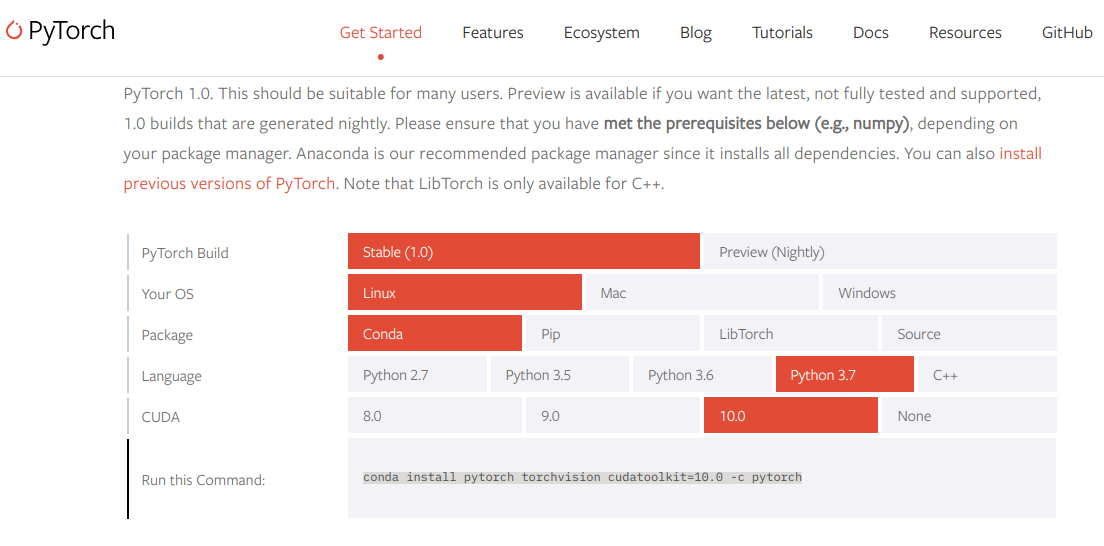
https://pytorch.org/get-started/locally/
このサイトでは、自分の環境に応じたPyTorchのインストール方法を教えてくれる
ここでは、いままでセットアップしてきた環境にあわせて以下を選択した
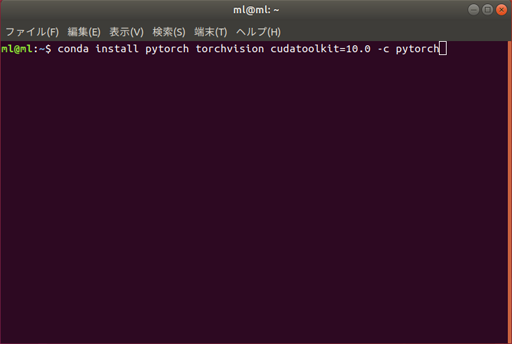
PyTorch Build Stable(1.0) Your OS Linux Package Conda Language Python 3.7 CUDA 10.0 すると、Run this Command:の欄に親切にconda install pytorch torchvision cudatoolkit=10.0 -c pytorch と表示される。
これを端末(ターミナル)にそのまま入力すれば PyTorchがインストールできる。とっても簡単。
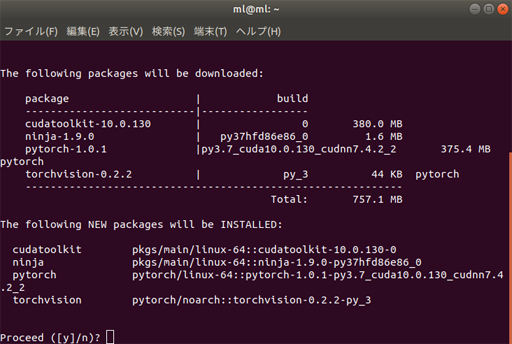
conda install pytorch torchvision cudatoolkit=10.0 -c pytorch
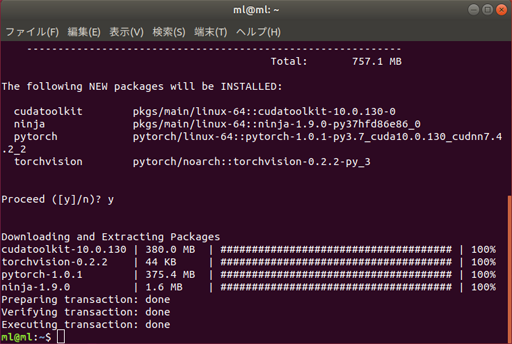
The following NEW packages will be INSTALLED:と聞かれるので y を入力して、パッケージのダウンロード開始
これにて、NVIDIA GPU対応のPyTorchのインストールが完了!
【補足】
他のライブラリだと CUDA Toolkit 10.0 や cudnn 7.4 といった、GPU処理を行うためのソフトウェアを別途インストールする必要があるのが一般的だが、PyTorchの場合は、上記 condaコマンドで CUDA Toolkit 10.0 もあわせてインストールしておいてくれるし、cudnnはPyTorchに組み込まれた状態のものを、さきほどのcondaコマンドでインストールしているため、別途インストールする必要は無い。以下が具体的なインストール先となる
■ PyTorch(v.1.0.1 CUDA対応版)のインストール先ディレクトリ
~/anaconda3/pkgs/pytorch-1.0.1-py3.7_cuda10.0.130_cudnn7.4.2_2■ PyTorchが使うCUDA Toolkit(v.10.0)のインストール先ディレクトリ
~/anaconda3/pkgs/cudatoolkit-10.0.130-0Pythonのプログラムを書くため、Jupyter Notebookを起動する
では、本稿の最後に、ちゃんとGPUが有効な状態でPyTorchが使えるか試す。
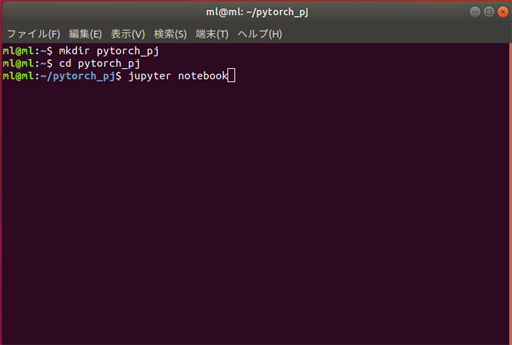
端末(ターミナル)を開いて、PyTorchプロジェクト用のディレクトリを作る
mkdir pytorch_pj cd pytorch_pjディレクトリに移動したら
jupyter notebookでJupyter Notebook(ジュピターノートブック)を起動する。
Jupyter Notebook はPythonのコード作成と実行、実行結果表示、自由コメント(Markdown)編集の3つの機能をそなえたツールで、気軽に利用できるので、Jupyter Notebook上で試す。
jupyter notebookというコマンドを入力するだけでブラウザが立ち上がり、すぐに使える状態になる。
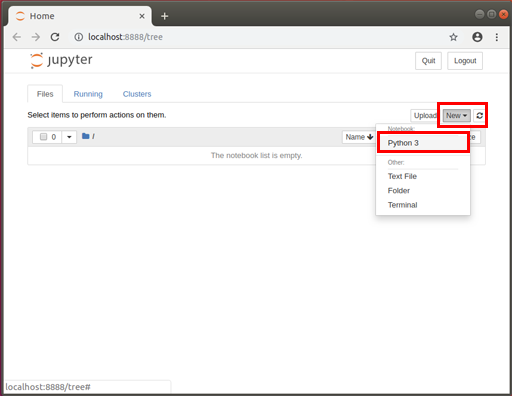
こんな風に、起動する。
これから、Python用のノートブックを作成する。
右上あたりにある New を押して、ポップアップしたメニューからPython3を選択
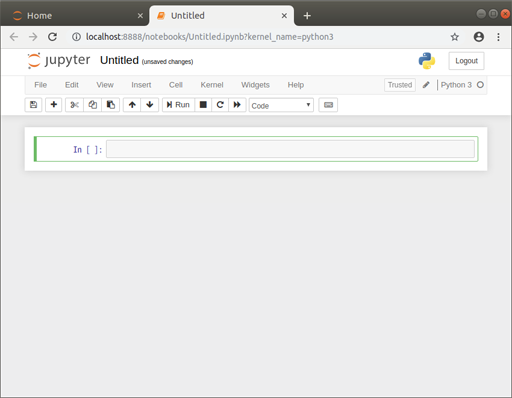
すると、もう1枚タブが開いて、以下のようなノートブック画面が表示される
PyTorchをGPUで動作させる
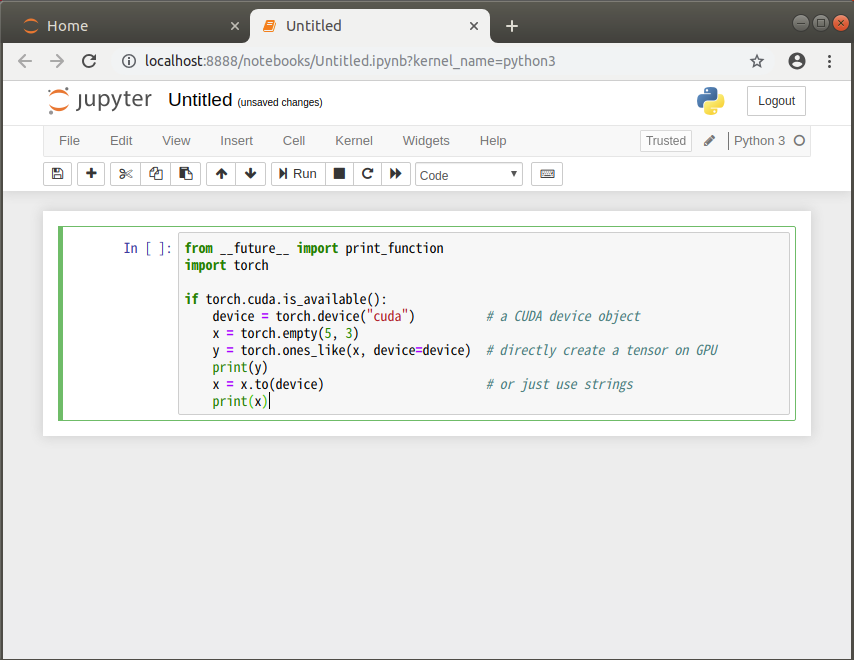
さて、ノートブックが起動したところで、早速コードを書く
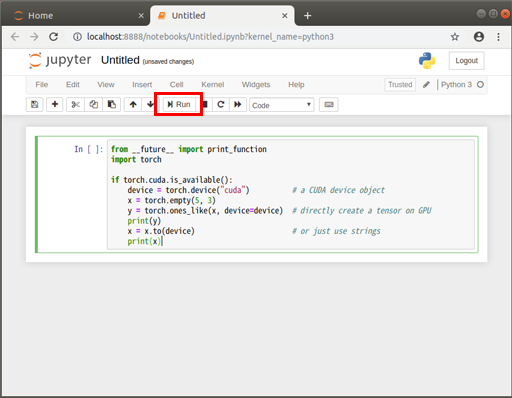
PyTorchでCUDAが有効か確認するコードfrom __future__ import print_function import torch if torch.cuda.is_available(): # CUDAが有効なら TRUE device = torch.device("cuda") # CUDA(クーダ)デバイスを取得 x = torch.empty(5, 3) # CPU上にテンソルを作る y = torch.ones_like(x, device=device) # GPU上に直接テンソルを作る print(y) x = x.to(device) # CPU上に作ったテンソルをCUDAデバイスに転送 print(x) print("CUDA version:"+torch.version.cuda) #PyTorchが使っているCUDA toolkitバージョンを表示する↓のようにコードをノートブックに記述する
コードを書いたら、
を押す
すると、コードが実行され結果が得られる
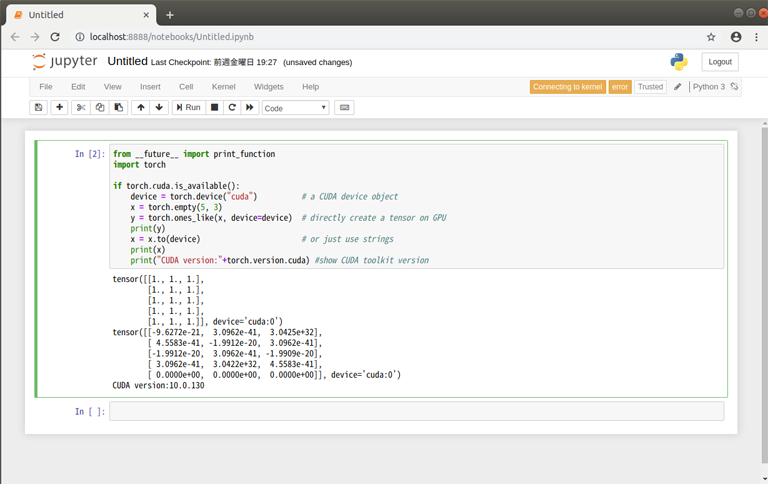
このとおり、実行結果が表示された
tensor([[1., 1., 1.], [1., 1., 1.], [1., 1., 1.], [1., 1., 1.], [1., 1., 1.]], device='cuda:0') tensor([[0.0000e+00, 0.0000e+00, 0.0000e+00], [0.0000e+00, 0.0000e+00, 0.0000e+00], [0.0000e+00, 0.0000e+00, 1.4013e-45], [0.0000e+00, 1.4013e-45, 0.0000e+00], [1.4013e-45, 0.0000e+00, 0.0000e+00]], device='cuda:0') cudatoolkit-10.0.130device='cuda:0'となっている部分で、実際にこのテンソルがCUDAデバイス(GPU)に作られたことが確認できた!
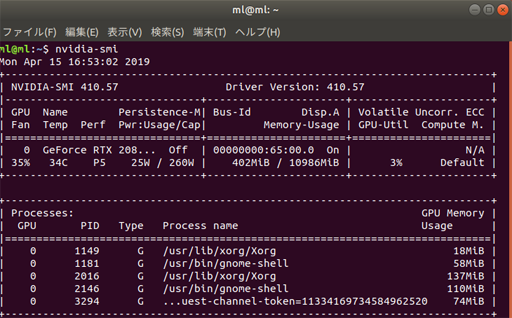
■ GPUの負荷を計測する
nvidia-smiコマンドでGPUの使用率等を取得することができるので、本格的な学習時には以下コマンドでモニタすると良い。
nvidia-smi -l
GPUで機械学習できる環境が完成
これにて、Ubuntu 18.04 LTS上に、GPUを活用した機械学習を行う最低限の環境が完成した!
あとは、PyTorchを使って、ディープラーニングをさせるのもよし、他のライブラリを追加するのもよし。
まとめ
- ゼロからLinuxのGPU機械学習環境を構築しました
- PyTorchを動かすのに必要となる各種ソフトウェアを導入し、最終的にGPUをつかって演算をするところまで試すことができました
- 環境はできたので、GPUの性能確認の為にこのあたりから試してみるのも面白いかも知れません。
おまけ(拡張のヒント)
- 今回は環境を固定して愚直にインストールしましたが、ポータビリティをあげるためにDockerを使いたい、という場合は、しっかりとNVIDIA GPU対応を考慮したNVIDIA Docker2が活用できそうです。