- 投稿日:2019-04-15T22:13:00+09:00
DeepRacerの報酬関数トレースログをLogsInsightsでパース
DeepRacerのSageMakerサンプルノートブックを動かすと、CWLogsに報酬関数のトレースログが吐かれます。これをLogsInsightsでパースしてみました。
サンプルノートブック 自体は下記の記事を参考に動かしています。
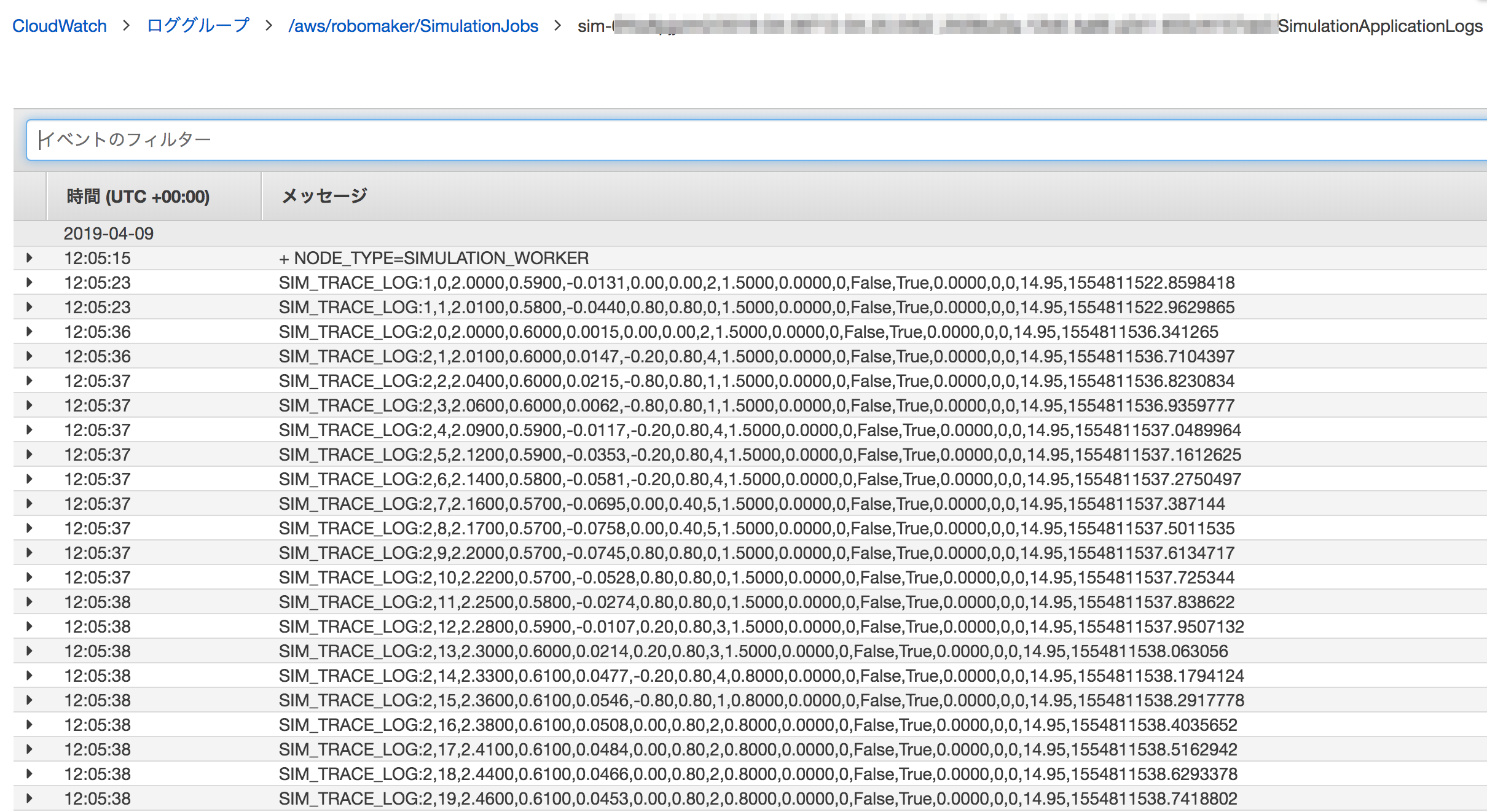
吐かれるログ
ログはデフォルトで以下のCloudWatchlogsに吐かれる。
ロググループ名
/aws/robomaker/SimulationJobs
対象ログイベント
- SIM_TRACE_LOGで始まるログ
- deepracer_env.py の def infer_reward_state の中で「入力パラメータ」と「結果の報酬」を出力している
ソースコードを見ると報酬関数に渡しているものとは若干違うパラメータもログ出力していますが、今回はそのままパースしてみます。
デフォルトの出力
どれがどのパラメータかパッと見ではわからない...
Logs Insights でパース
実装コードから、どの出力がどのパラメータなのか確認し、insightsのparseコマンドに反映。
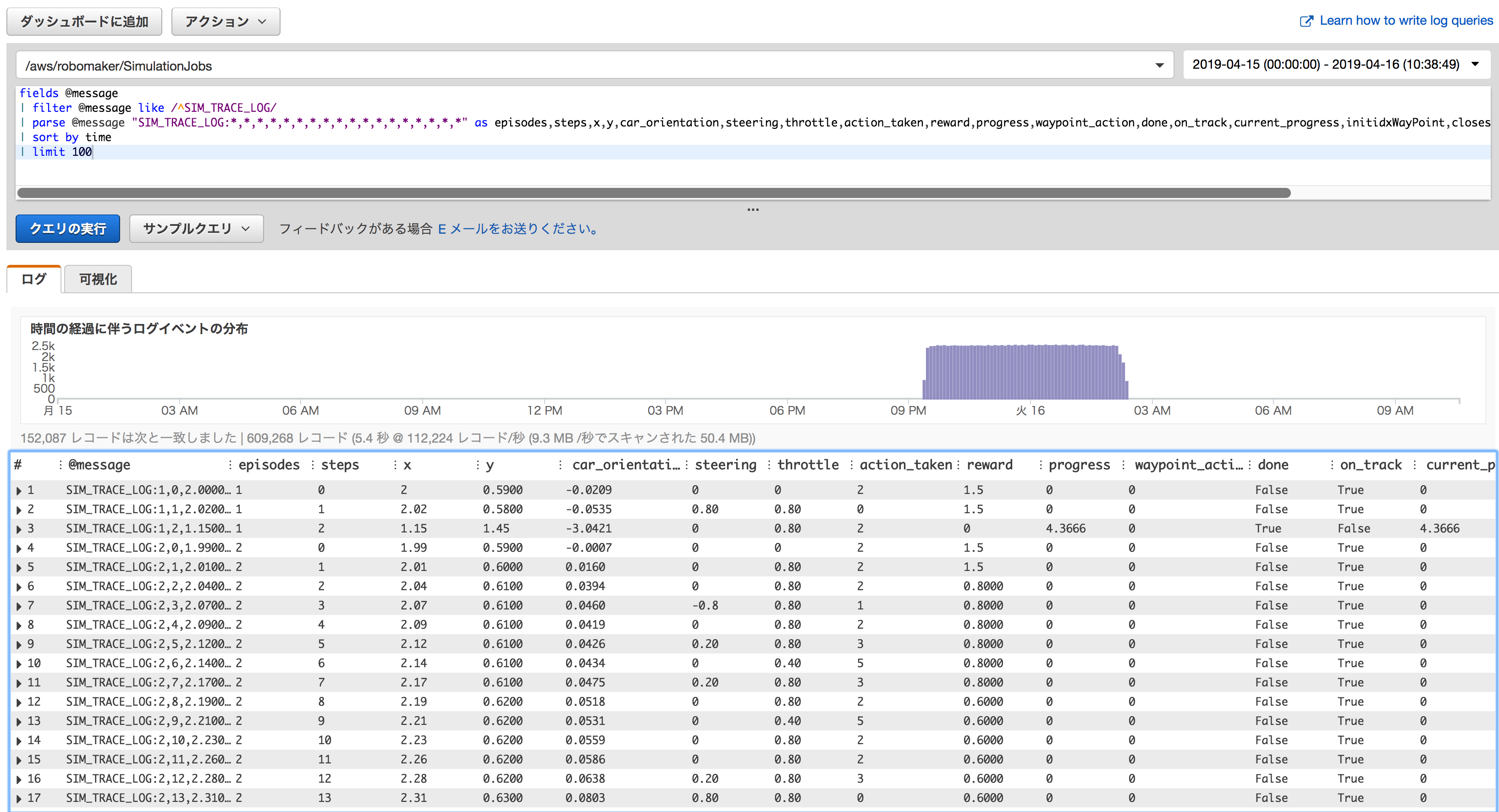
トレースログをパースして100行表示
クエリ
fields @message | filter @message like /^SIM_TRACE_LOG/ | parse @message "SIM_TRACE_LOG:*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*" as episodes,steps,x,y,car_orientation,steering,throttle,action_taken,reward,progress,waypoint_action,done,on_track,current_progress,initidxWayPoint,closest_waypoint_index,track_length,time | sort by time | limit 100出力結果
これでまともに見れそうな気がしてきました。
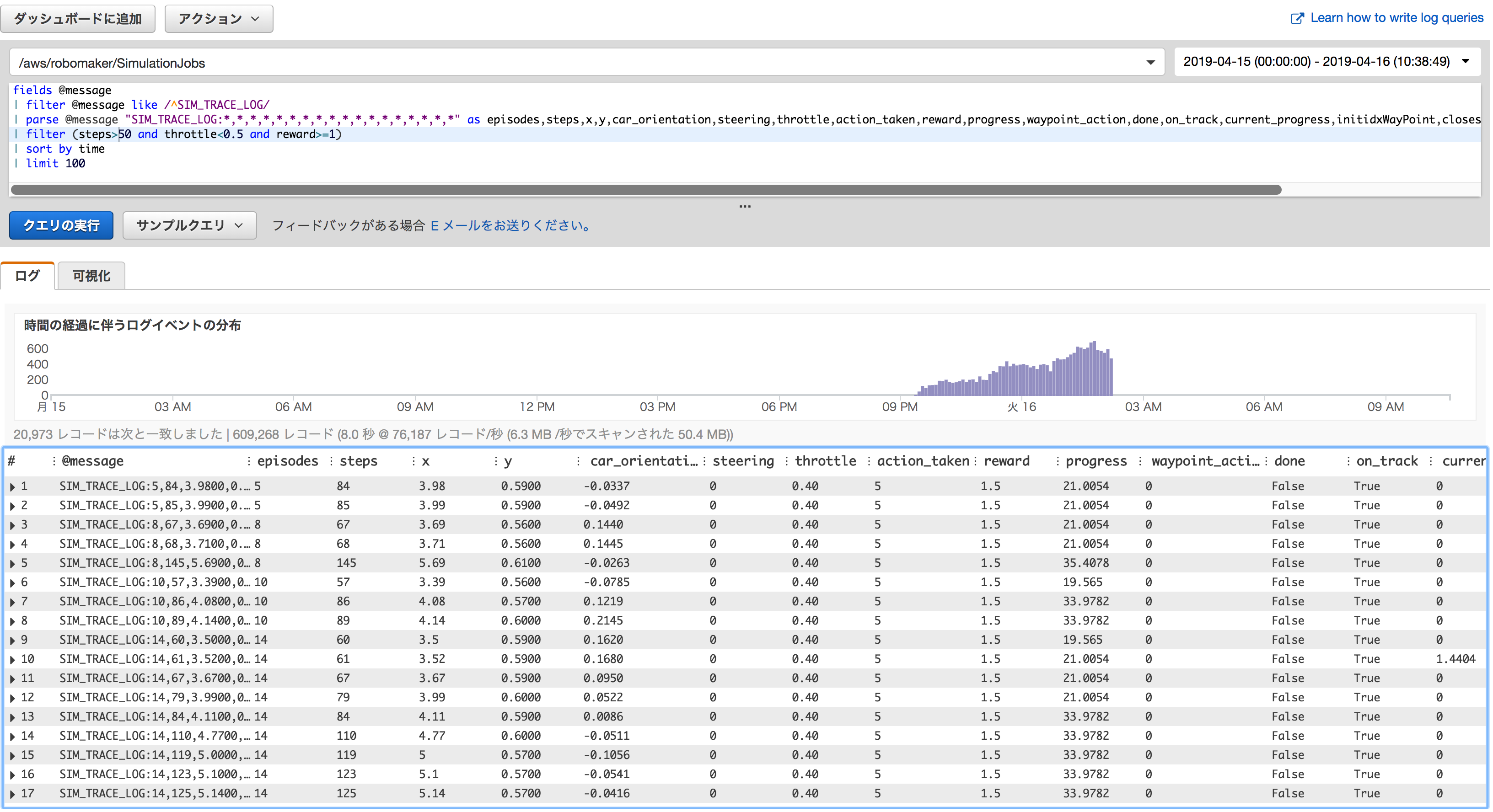
条件に合うログのみ表示してみる
50steps以降で、スロットル0.5未満で1以上の報酬を与えたログを100行表示してみます。
クエリ
fields @message | filter @message like /^SIM_TRACE_LOG/ | parse @message "SIM_TRACE_LOG:*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*,*" as episodes,steps,x,y,car_orientation,steering,throttle,action_taken,reward,progress,waypoint_action,done,on_track,current_progress,initidxWayPoint,closest_waypoint_index,track_length,time | filter (steps>50 and throttle<0.5 and reward>=1) | sort by time | limit 100出力結果
補足
progress(コード上はtotal_progressという変数)はドキュメント上、0.0〜1.0が入るように読めたが
progress float [0,1] Percentage of track completed. 実際は0〜100のレンジっぽい値が出力された。コードを確認すると積算用の進捗をcurrent_progress *= 100.0 していたり気になりましたがパラメータの詳細についてはこの記事で触れません。
参考
- 分析(Logs Insightsのクエリ)スキャンされたデータ 1GBあたり0.005USD@バージニア(2019/04/16)
- 投稿日:2019-04-15T21:50:50+09:00
AWSでデータ分析環境を構築する
自分用の備忘メモになります。
AWSのサービスの中には、機械学習向けにSagemakerがありますが、EC2インスタンスを用いて地道に分析環境構築してみようとチャレンジしてみました。
Sagemakerを利用するより、価格がお手軽になるのではないかと期待しています。1.EC2インスタンスのGPUの制限解除申請
GPUを利用する際には、利用申請が必要になります。利用申請は、日本語で大丈夫です。日本のAWSで申請受付されてから、US本国のAWSでチェックされます。
私が実際に2019年3月末に行った際は、申請から承認まで3日間(営業日)でした。日本側は即USへ申請した旨の返事あり。そこからUSの承認まで数日かかりました。
なお、GCPでは使用申請はないものの、無料枠を消化しないとGPUの使用制限解除にならないことがわかりました。2.ubuntu 1604 のリモートデスクトップ接続環境の構築
GPUを用いて分析を行うには、CUDA、Anaconda、Chainer等々のPythonライブラリ等のインストールと設定が必要になります。AWSの場合、AMIといってあらかじめ必要なツールを用意してくれるセットがあります。
(利用目的によって、OSをwindowsにしたり、SQLが用意されていたり等々)
2019年4月時点、Ubuntuで、データ分析、深層学習を行うAMIは、Ubuntuバージョンは、16.04になります。Ubuntu 16.04のインスタンスに対して、自分のPCからWINDOWS10を用いて、リモートデスクトップ接続実行したい場合は、下記対応が必要になります。
https://aws.amazon.com/jp/premiumsupport/knowledge-center/connect-to-ubuntu-1604-windows/3.ブラウザツールのインストール
anaconda navigatorを用い、JupyterNotebookを起動する場合は、ブラウザツールのインストールが必要になります。今回は、Firefoxをインストールしました。
Firefoxのインストール方法は下記URLになります。
https://qiita.com/rokusyou/items/8089b7495119b7c8e29b4.日本語化対応
英語でUbuntu環境が作成されていますので、下記URLで日本語対応いたしました。
https://qiita.com/hachisukansw/items/154b5349f99a7152fd465.困ったこと
(1)リモートデスクトップ接続した際に、“真っ黒画面”が表示される。
リモートデスクトップの設定を試したのですが何も改善されませんでした。AMIのツール類、GUI等でインスタンスのボリュームの使用率が100%になっていたのが原因と推測されます。ストレージのサイズはデフォルト75GiBでは足りませんでした。
(結果的に、ストレージを300GiBで再作成して解消しました。)
ストレージを追加して、下記URLでパーテーションの容量を大きくしようと試みたのですがうまくいかず(これは、私のLinuxの知識不足が大きな原因です。)、インスタンスを再作成しました。
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/recognize-expanded-volume-linux.html(2)キーボード配列の設定
Anaconda Navigatorでは、日本語用のキーボードの配列で入力できませんでした。先にインストールしたFirefoxでは、日本語キーボード配列で正しく入力できたのですが・・・。
以下URLに対応方法がありますが、未実施です。
https://geek-memo.com/ubukey/
https://tech-mmmm.blogspot.com/2017/08/xubuntu-1604xrdprdp.html※ご参考1
ここまで環境を作成するのに、p2xlargeのインスタンスサイズで100円程度と思います。
(再作成したり、他に色々動かしたので推測です。今のところ7.4$です。)※ご参考2
Sagemakerでml.p2.xlargeの3つのGPUインスタンスを30時間使ったら260$でした。GCPでも同様にインスタンス構築からチャレンジしてみようと思います。
- 投稿日:2019-04-15T21:37:00+09:00
Amazon Web Services 基礎からのネットワーク&サーバ構築のまとめ Chapter1
Amazon Web Services 基礎からのネットワーク&サーバ構築の個人的な学習記録として、この記事を書いています。問題があるようでしたら消します。
1-1 ネットワークとサーバーの知識を付けておくメリット
- 障害が起きた時に、どこで起きてるのか分かる
- 一人で色々できるようになる
1-2, 1-3 ネットワークとサーバーについて
サーバー
サーバーには用途別で色々種類がある。「Webサーバー」、「メールサーバー」、「データベースサーバー」などなど。その用途に合わせて、OSからソフトウェアをインストールする必要がある。
- WEBサーバー
- Apache
- nginx
- データベースサーバー
- MySQL
- PostgreSQL
- メールサーバー
- Sendmail
- Postfix
ネットワーク
用語
- TCP/IP:インターネットと接続する為のプロトコル。
- IPアドレス:サーバーに振り当てるピリオドで区切られた4つの数字で住所と同じ役割。重複することはない。
- DNSサーバー:ドメイン名とIPアドレスを関連付けてくれるサーバー。
公開されたネットワークと隠されたネットワーク
「パプリックサブネット」と呼ばれる公開されたネットワークと「プライベートネットワーク」と呼ばれるインターネットに直接接続しないネットワークがある。前者には見てもらう為のWebサーバー、後者には見られたくないDBサーバーを置く。
NAT
隠しておきたいけど、DBサーバーとやり取りする為にはインターネットと接続する必要がある。そんな時にNATを使うと、片方だけの接続ができるようになり、外から見られないで済む。
1-4 AWS
こいつのおかげで、物理的にサーバーとかルーターを用意しなくてもネットワーク、サーバーが構築できる。
ネットワークとVPC
VPC = ネットワークの領域
EC2 = サーバー
サーバー1つをインスタンスと呼ぶ。感想
1章を読んでみた感じ、ネットワークとサーバー、AWSを全く知らない人向けって感じでしたね。個人的には良い復習になった章でした。
- 投稿日:2019-04-15T21:27:32+09:00
AWS CLI の全てのコマンドをMFA認証必須にする
AWS CLIでMFA認証を必須にする
AWS CLIはアクセスキーを使用して認証するのでアクセスキーが流出してしまうと
そのユーザの権限でなんでもできてしまう。権限を絞ることで被害を抑えることもできるが
AWS CLIでもMFAの認証を行うこともできる。明示的な拒否のポリシーの方が強いのでMFA認証されるまでは全てのアクションが拒否されるが
認証後は全てのアクションが許可される。
AWS CLIでMFA認証するためのaws sts get-session-tokenを実行するのに必要な権限はないpolicy{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "*", "Resource": "*" }, { "Effect": "Deny", "Action": "*", "Resource": "*", "Condition": { "BoolIfExists": { "aws:MultiFactorAuthPresent": false } } } ] }認証方法
MFA認証するにはget-session-tokenでセッショントークンを取得して環境変数に入れる必要がある。
consoleaws sts get-session-token --serial-number arn:aws:iam::アカウントID:mfa/ユーザ名 --token-code ワンタイムパスワード { "Credentials": { "AccessKeyId": "xxxxxxxxxxxxxxxxxx", "SecretAccessKey": "xxxxxxxxxxxxxxxxxxxxxxxxxxxxx", "SessionToken": "xxxxxxxxxxxxxxxxxxxxxxxx", "Expiration": "yyyy-mm-ddThh:MM:ssZ" } }
- 投稿日:2019-04-15T20:40:46+09:00
AWS CLI ローカルからS3へディレクトリ構造を保ちながらコピーする
bucketバケットに folder1/file1と folder2/file2をコピーする
$ tree . ├── folder1 │ └── file1 └── folder2 └── file2$ find folder* -type f | xargs -I{} aws s3 cp {} s3://bucket/{}/ --recursive
- 投稿日:2019-04-15T19:12:08+09:00
(メモ) CloudFormation StackSetsでIAM Policyを展開するときに、Policy記述内に展開先のアカウントIDを記載する方法
背景
CloudFormation StackSetsでIAM Policyを展開するとき、Policy記述内に展開先のアカウントIDを記載しないといけない場合にどうしようと一瞬考えたのでメモ。例えばResourceエレメントを使う場合はARNにリージョンやアカウントIDが入るため、展開先のアカウントごとに値が異なる。
解決策
単純にCloudFormationの擬似パラメータ(AWS::AccountIdとかAWS::Regionとか)を使えば良いだけだった。
これで展開先アカウント/リージョンの値に変換される。サンプルAWSTemplateFormatVersion: "2010-09-09" Resources: TestPolicy: Type: AWS::IAM::ManagedPolicy Properties: ManagedPolicyName: TestPolicy Description: test policy Path: / PolicyDocument: Version: '2012-10-17' Statement: - Sid: DenyAdminRoleChange Effect: Deny Action: iam:* Resource: !Sub arn:aws:iam::${AWS::AccountId}:role/AdminRole蛇足
IAM Boundaryの設定展開がきっかけでこれを考えていたが、最初に以下のようにWildcardを試してみたがうまくいかず。
特定のPermissions Boundaryを付与していないとRoleのCreateやらPolicyの付与ができないようにするステートメントのCondition句でアカウントIDをワイルドカードにした場合、適切なBoundaryを付与してもRole作成が拒否されてしまった。
これがなぜかは今の所不明。。。この書き方自体は問題ないはずだが。。。ステートメント例<...snip...> { "Sid": "DenyCreateOrChangeRoleWithoutBoundary", "Effect": "Deny", "Action": [ "iam:CreateRole", "iam:PutRolePolicy", "iam:DeleteRolePolicy", "iam:AttachRolePolicy", "iam:DetachRolePolicy", "iam:PutRolePermissionsBoundary" ], "Resource": "*", "Condition": { "StringNotEquals": { "iam:PermissionsBoundary": "arn:aws:iam::*:policy/ExampleBoundaryPolicy" } } }, <...snip...>
- 投稿日:2019-04-15T19:05:25+09:00
GoでAmazon S3をKVSとして使う
これはなに
永続化が必要なバイナリKVSとしてAmazon S3を使いたい場合があります。
セッションの取り回しや、aws.WriteAtBufferやエラーがトリッキーなのでスニペットです。package s3kvs import ( "bytes" "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/awserr" "github.com/aws/aws-sdk-go/aws/session" "github.com/aws/aws-sdk-go/service/s3" "github.com/aws/aws-sdk-go/service/s3/s3manager" ) var PersistentS3Store = &S3Store{} type S3Store struct { Bucket string Uploader *s3manager.Uploader Downloader *s3manager.Downloader } func (s *S3Store) Init(bucket, region string) (err error) { s.Bucket = bucket sess, err := session.NewSession(&aws.Config{ Region: aws.String(region), }) if err != nil { return } s.Uploader = s3manager.NewUploader(sess) s.Downloader = s3manager.NewDownloader(sess) return } func (s *S3Store) Set(key string, body []byte) (err error) { params := &s3manager.UploadInput{ Bucket: aws.String(s.Bucket), Key: aws.String(key), Body: bytes.NewReader(body), } _, err = s.Uploader.Upload(params) return } func (s *S3Store) Get(key string) ([]byte, error) { buffer := aws.NewWriteAtBuffer([]byte{}) _, err := s.Downloader.Download(buffer, &s3.GetObjectInput{ Bucket: aws.String(s.Bucket), Key: aws.String(key), }) if err != nil { if aerr, ok := err.(awserr.Error); ok && aerr.Code() == "NoSuchKey" { return nil, nil } return nil, err } return buffer.Bytes(), nil }
- 投稿日:2019-04-15T14:31:11+09:00
Cloudwatch Logs Insights の parse 関数の使い方
最近プロダクション環境でFARGATE on ECSを導入しました。この場合ログはCloudwatch Logsに送られることになります。
ログから簡単なデータ集計をしたい場合に昨年発表されたCloudwatch Logs Insightsが使えるのではないかと思い試してみたところ、非常に便利だった、かつちょっとparse関数に手間取ったので備忘録がてら残しておきます。Cloudwatch Logs Insightsとは
(詳細は公式ドキュメントに任せて、便利なところを)
Cloudwatch LogsのデータをWebコンソール上から確認する場合、これまではLog Group内のLog Streamを指定しなければフィルタがかけられませんでした。
FARGATEで複数コンテナが動く場合、コンテナ1つ1つに対してLog Streamが作られるため、APIコンテナが4つ稼働していた場合、4つのログに対して同時にログのフィルタをかけることが(Webコンソール単体では)できませんでした。Insightsを使うことで、
Log Streamをまたいでクエリを発行できるようになり、前述の問題点が解消されます。
さらに、構造化(=JSON)ログを出力している場合はSQLライクな集計も簡単にできます。また、構造化されていないログを出している場合でも、今回説明するparse関数を使うことである程度集計を行うことができます。やりたいこと
Go製のメッセージ配信APIサーバがあり、あるIDに対して何個のメッセージを配信したかをログに出しています。(通知に相当するものであり、量が多くなるためにデータベースには記録していません)
[GIN] 2019/04/14 - 18:35:55 | 200 | 387.381544ms | 10.0.0.167 | POST /api/v1/message/ 2019/04/14 18:35:55.044306: [I] message(s) sent to 2 address(es) for id 01234567 2019/04/14 18:59:56.772482: [I] message(s) sent to 1 address(es) for id 98765432 [GIN] 2019/04/14 - 18:59:56 | 200 | 49.884µs | 10.0.1.163 | GET /(フレームワークのログとアプリケーションのログの形式が違うのはいつか直したいところです)
2行目と3行目のログを抽出し、特定期間のidと送信したメッセージの数を集計したいです。
できたこと
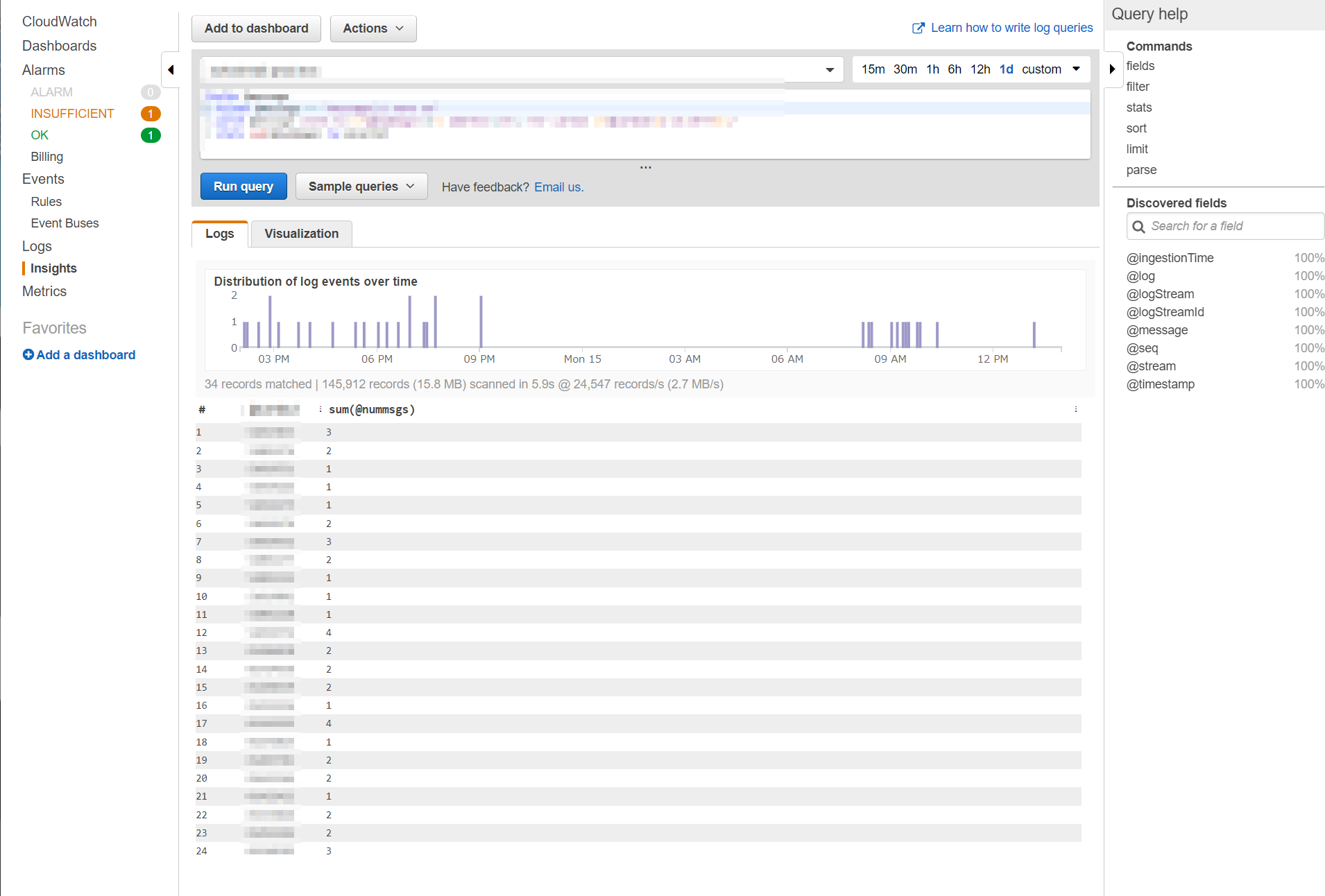
まず始めに完成したクエリと、実行した画面サンプルを表示します。
fields @message | filter @message =~ "message(s) sent to" | parse @message /sent to (?<@nummsgs>\d+) address\(es\) for id (?<@cid>[a-zA-Z0-9]+)/ | stats sum(@nummsgs) by @cid画面サンプルはちょっとだけ正規表現が違ったりするのでぼかしています。上のものがそのまま入ってるとお考え下さい。
ご覧のように、SQLライクな感じで集計ができています。メインでないので省きますが期間はクエリを書くボックスの右上から指定できています(もちろんクエリ内で指定する方法もある、はず)
やってること
1行目
fileds @messagefields関数を使い、Logsからもってくる
フィールドを指定します。 サポートされるログと検出されるフィールド - Amazon CloudWatch Logs にある表では「その他のログタイプ」に相当します。今回欲しいのはログのテキストだけなので@messageを指定します2行目
filter @message =~ "message(s) sent to"filter関数を使い、 欲しいデータのみにそぎ落としています。
=~はlikeでも大丈夫ですし、正規表現で指定することも可能です3行目
parse @message /sent to (?<@nummsgs>\d+) address\(es\) for id (?<@cid>[a-zA-Z0-9]+)/使い方や注意点は後述しますが、parse関数を用いてログからデータを作っています。
4行目
stats sum(@nummsgs) by @cidSQL(どちらかというとElasticsearchに近いですかね?)のようにグルーピングと集計を行っています。
少し補足ですが、実行イメージ画像の棒グラフの下に「34 records matched」となっており、結果は24recordsなので、ちゃんとグルーピングされていることもわかります。parse関数の使い方、注意点
本題です。
CloudWatch Logs Insights クエリ構文 - Amazon CloudWatch Logs にparse関数の使い方は書いてあるのですが、非常に簡単なサンプルがかいてあるだけで、*が使えることしかわかりません。ですが、英語版のドキュメントやStack Overflowを覗くと以下のようにもかけることがわかりました。
- 正規表現の名前付きグループ
(?<名前>正規表現)を使って次のクエリに渡せるクエリを読めばわかるのでこれ以上の説明はないのですが、他にもはまったことがあるので記載します
- 新たに作成するfieldに
@idは使えない何かとバッティングしているのでしょう。
@cidの部分を初めは@idにしていたのですが、クエリが失敗するエラーが出ました。終わりに
月1の報告のためにこの集計がしたかったのですが、「ログ全部S3にもってって手元にDLしてから集計するか~」とか思っていたのですが、これで十分でした。
料金については以下のような感じなので、データ量が多い場合は注意が必要ではありますが、コンソール右上で期間が予め指定されており、普通にクエリを打つだけでは全走査は走らないので安心です。
料金はクエリごとに走査したログデータの量に対してかかります。US East (N. Virginia)の場合、$0.005/GB で、他のリージョンも同様の料金です。
新機能 – Amazon CloudWatch Logs Insights – 高速でインタラクティブなログ分析 | Amazon Web Services ブログ
Cloudwatch LogsからElasticsearchに流し込む方法も用意されていますが、簡単なものだとこれで十分ですね!スバラシイ!
- 投稿日:2019-04-15T12:35:41+09:00
AWS-CLI & CloudWatch Insightでログを集計する
概要
とある案件でCloudWatch Logsの集計をAWS-CLI & CloudWatch Insightを用いて行うことになったので、その方法を共有します。
定期的に集計をレポーティングすることを想定しているため、最終的な出力はcsvを想定しています。CloudWatch Ingihtとは?
新しいサービス CloudWatch Logs Insights がお役に立ちます。これはクラウドスケールで動作するよう設計され、セットアップやメンテナンスが不要なフルマネージドのサービスです。これは大量のログを数秒で走査し、インタラクティブなクエリの実行と可視化を提供します。あらゆるログフォーマットや、JSON ログから自動検出したフィールドを扱えます。使ってみると分かるように、これは大変フレキシブルであり、ログを調査するためのお気に入りのツールの一つになるでしょう。
公式ドキュメントより抜粋。
ログの検索自体はすでに実装されているfilter_log_eventsで近しいことはできます。
しかしこれにはクエリ言語が設定されておらず、ちょっと工夫した検索をしたい場合はとても使いづらいものになります。CloudWatch Insightは独自の検索クエリ言語を持っており、多様なログフォーマットの検索を柔軟に実行できます。
非常に強力なツールです。しかし、後述の問題点があります。背景
この強力なツールは当然各種AWS-SDKに含まれていると思うでしょう?
実は本記事執筆時点でCloudWatch InsightはSDKに含まれていないのです。
だから定期的に集計バッチ処理を行おうとすると、シェルスクリプトとAWS-CLIで頑張るしかないのです。
ということで、この解説記事を書きました。必要なパッケージ
- AWS-CLI ver.1.16以上(このバージョンじゃないとInsightが使えない)
- jq(レスポンスを処理するために使う)
インストール方法は割愛します。
なお、実行環境はMacかec2上とします。ソース
実際に動作するソースを見ながら解説していきます。
サンプルプログラムでは、あるロググループに対して昨日中の集計を行うことを目的としています。#!/bin/sh alias date='gdate' YESTERDAY=`date -d '1 days ago' '+%Y/%m/%d'` START_TIME=`date -d $YESTERDAY' 00:00:00 9 hours ago' '+%s'` END_TIME=`date -d $YESTERDAY' 23:59:59 9 hours ago' '+%s'` #必要な設定 CLOUDWATCH_LOG_GROUP_NAME="ここにロググループ名" REGION="ap-northeast-1" QUERY="fields @timestamp, @message | limit 10" echo 'Start aggregation.' QUERYID=` aws logs start-query \ --log-group-name $CLOUDWATCH_LOG_GROUP_NAME \ --start-time $START_TIME \ --end-time $END_TIME \ --query-string "$QUERY" \ --region $REGION \ --output text ` #終了を待つ printf 'Wait for complete' while : do STATUS=`aws logs get-query-results --query-id $QUERYID --output text --region $REGION | sed -n '1p'` if [ "$STATUS" = "Complete" ]; then break fi printf "." sleep 1s; done #終了したら結果をjsonで出力 aws logs get-query-results --query-id $QUERYID --output table --region $REGION RESULT_JSON=`aws logs get-query-results --query-id $QUERYID --output json --region $REGION` #マッチ件数が1件以上ならjsonをcsvに変換し、results以下に保存する MATCHED=`echo $RESULT_JSON | jq '.statistics.recordsMatched'` if [ $MATCHED -gt 0 ] ; then # #header書き込み echo $RESULT_JSON \ | jq '.results[0]' \ | jq -r -c '([ .[].field | values ]) | @csv' \ > ./result.csv #内容書き込み echo $RESULT_JSON \ | jq '.results[]' \ | jq -r -c '([ .[].value | values ]) | @csv' \ >> ./result.csv fi echo 'Aggregation has completed.'解説
前準備
#!/bin/sh alias date='gdate' YESTERDAY=`date -d '1 days ago' '+%Y/%m/%d'` START_TIME=`date -d $YESTERDAY' 00:00:00 9 hours ago' '+%s'` END_TIME=`date -d $YESTERDAY' 23:59:59 9 hours ago' '+%s'` #必要な設定 CLOUDWATCH_LOG_GROUP_NAME="ここにロググループ名" REGION="ap-northeast-1" QUERY="fields @timestamp, @message | limit 10"ここではクエリ実行に必要な変数を定義しています。
注意したいのは期間指定であり、ここはUTC標準時のタイムスタンプを設定する必要があります。
なぜならAWS-CLIにおけるCloudWatch Insightの期間指定は、タイムスタンプで指定する必要があるからです。
これは他のlogs関連クエリでも同様です。今回の例では前日の丸一日を走査の対象としています。
Insightは走査したログのデータ量によって料金が変わってきますので、不要に長い期間を設定するのは時間と金の無駄遣いと心得ましょう。なお、冒頭のgdateのエイリアスはMacでは必要ですが、ec2で動かすなら不要です。
クエリの実行
QUERYID=` aws logs start-query \ --log-group-name $CLOUDWATCH_LOG_GROUP_NAME \ --start-time $START_TIME \ --end-time $END_TIME \ --query-string "$QUERY" \ --region $REGION \ --output text `ここからが本題です。AWS-CLIでCloudWatch Insightを実行するためのコマンドは
aws logs start-queryとなっています。
詳しくは公式ドキュメントを見る必要がありますが、ここでは使用しているパラメータについて解説します。
log-group-nameはそのままロググループ名です。必須です。start-timeは集計開始のタイムスタンプです。必須です。end-timeは集計終了のタイムスタンプです。必須です。query-stringはクエリ本文です。必須です。regionはリージョンです。configでデフォルト値を設定している場合は不要です。outputは出力形式です。このコマンドの出力結果は実行結果を得るためのクエリIDなので、単にテキストを取得できればいいので指定しています。このパラメータで注意したいのは、期間指定のタイムスタンプは秒ということです。
というのも他のCloudWatch logsの取得コマンドではマイクロ秒を指定する場合があるためです。
例えばfilter-log-eventsでは期間指定がマイクロ秒となっているので注意してください。ややこしいな!クエリ実行完了の待機
while : do STATUS=`aws logs get-query-results --query-id $QUERYID --output text --region $REGION | sed -n '1p'` if [ "$STATUS" = "Complete" ]; then break fi printf "." sleep 1s; done #終了したら結果をjsonで出力 aws logs get-query-results --query-id $QUERYID --output table --region $REGION RESULT_JSON=`aws logs get-query-results --query-id $QUERYID --output json --region $REGION`
start-queryを実行するとAWSのほうで集計タスクが走りますが、これはすぐに完了するものではありません。
完了するまでクエリIDを用い、レスポンスを確認する処理が必要です。スクリプト側は
get-query-resultコマンドをクエリIDを指定して実行することで、集計ステータスおよび集計結果を得ることができます。
出力形式をテキストにしている場合、レスポンスの1行目は単なるテキストRunningとなり、完了するとcompleteとなります。よってレスポンスがRunningの間はループを実行しています。ステータスが
completeになった後、出力形式をテーブルにした上で結果を表示しています。
最終的には出力形式をjsonにした上で変数に格納します。集計結果がjsonで得られれば十分であればここで完了となります。
次のパートから実用的と思われるcsvに変換します。結果の処理
#マッチ件数が1件以上ならjsonをcsvに変換し、results以下に保存する MATCHED=`echo $RESULT_JSON | jq '.statistics.recordsMatched'` if [ $MATCHED -gt 0 ] ; then # #header書き込み echo $RESULT_JSON \ | jq '.results[0]' \ | jq -r -c '([ .[].field | values ]) | @csv' \ > ./result.csv #内容書き込み echo $RESULT_JSON \ | jq '.results[]' \ | jq -r -c '([ .[].value | values ]) | @csv' \ >> ./result.csv fi echo 'Aggregation has completed.'ここは本題から外れるので詳しくは解説はしません。
awscliの出力は
text, json, tableと選択できます。
簡単なメッセージのみ取得したいのであればtextで十分ですし、データを視覚的に認識したい場合はtableで出力します。
今回はcsvとして最終的な結果を得るために、処理をしやすいjson形式で出力しています。この部分は
statistics.recordsMatchedが0以上の場合、jsonからcsvに変換しています。
statistics.recordsMatchedは条件に一致した件数をさします。最後に
そのうちSDKでもCloudWatch Insightが利用できるようになると思います。
おそらく、このような定期実行によるレポーティングをするベストプラクティスは下記のような構成でしょう。
- 実行環境はLambda、Pythonならboto3ライブラリでクエリを実行する
- CloudWatch EventsでLambdaを定期実行する
- 検索クエリはs3に配置して、集計結果もs3にアップロード
私が作った集計バッチプログラムも、実行環境がec2上という以外は上にならっています。
直近で必要な方はここのソースを参考にしてみてください。
- 投稿日:2019-04-15T11:45:19+09:00
AWSを使ってLAMP環境を構築する手順
自己学習のメモとして。
AWS上にLAMP環境を作成する手順を書いておきます。Linux仮想マシン(EC2)を起動
1、AWSのマネジメントコンソールからEC2を選択。
※この段階でリージョンを日本にしておく2、インスタンスの作成を選択
・AMAZON Lunux AMIを選択
・無料利用枠のt2.microを選択
→インスタンスを作成キーペアが生成できるのでダウンロードしておく。
パブリックIPアドレスを設定
パブリックIPアドレスが毎回変化してしまうので固定する。
・左のメニューからElastic IPを選択
・新しいアドレスの割り当てをクリック
・出来上がったアドレスを選択し、アクション→アドレスの関連付け
・インスタンスをクリックし、先ほど設定したLinuxのIDが出るので選択して紐づけ
・インスタンスからセキュリティグループをクリッ
アクション→インバウンドルールの編集を選択
・ルールの追加→http→保存リモートアクセス
・ターミナル(コマンドプロンプト)を起動
・.sshフォルダがあるか確認する。(無ければmkdirでユーザーディレクトリの中に作っておく)
・.sshの中に先ほどのKey.pemファイルを移動しておく
・以下のsshコマンドでAWSにアクセスssh -i ~/.ssh/xxx.pem ec2-user@xx.xxx.xxx.xxx※デフォルトで名前はec2-userになっている
初回はyesを選択して接続今後接続するときは毎回このコマンドを打つので覚えておきたい
exitで接続を終了できる
Apacheを導入
・Linuxをアプデしておく
sudo yum -y update※-yをつけると確認画面なしにできる
・Apacheをインストールする
sudo yum -y install httpd・Apacheを起動する
sudo service httpd start・今後自動で立ち上がるように設定する
sudo chkconfig httpd on※ブラウザに切り替えてIPアドレスからapacheが見られるか確認するとよい
おまけ1
htmlファイルを作って試しに見てみる方法
htmlを作成
sudo vi /var/www/html/index.html1、編集画面になったら「i」を打って適当にhtmlファイルを作成する
2、「esc」を押してから「:wq」で上書き保存しenter※:q!で保存せず終了できる
ファイルの確認方法
ls /var/www/htmlブラウザにIPアドレスを打ち込んで確認できる
おまけ2
scpコマンドで、ローカルで作成したhtmlファイルを転送する
※scpはPC間で安全に転送するコマンドおまけ1でAWSに作ったhtmlファイルをローカルにダウンロードする(デスクトップの場合)
scp -i ~/.ssh/xxx.pem ec2-user@xx.xxx.xxx.xxx:/var/www/html/index.html ~/Desktop適当にhtmlファイルを編集し、AWSに転送する
scp -i ~/.ssh/xxx.pem ~/Desktop/index.html ec2-user@xx.xxx.xxx.xxx:成功したかどうかsshコマンドで接続して確認
(pwd、lsで見られる。)現状htmlファイルはec2-userの中にあるので正しい保存先に移動させる
sudo mv ~/index.html /var/www/htmlこれでブラウザで見ることができるようになる
この流れは面倒なのでもう少し簡略化できるよう設定する
EC2にリモートアクセスしている状態でwwwというグループを作成する
sudo groupadd wwwこのグループに自分のユーザー名を追加する
sudo usermod -a -G www ec2-userいったんexitでログアウトし、もう一度ログイン→グループの権限が有効になっているはず
groupsで確認すると
ec2-user wheel wwwとなっているはず
htmlを保存するディレクトリのグループ所有権を変更する
sudo chown -R root:www /var/www/var/www以下のディレクトリに書き込み許可を設定する
sudo chmod 2775 /var/www将来のサブディレクトリにグループIDを設定
find /var/www -type d -exec sudo chmod 2775 {} \;/var/www及びサブディレクトリのファイル許可を繰り返し、グループの書き込み許可を与える
find /var/www -type f -exec sudo chmod 0664 {} \;今後は転送先に直接/var/www/htmlを指定できる
scp -i ~/.ssh/xxx.pem ~/Desktop/index.html ec2-user@xx.xxx.xxx.xxx:/var/www/htmlPHPをインストール
※お決まりのコマンドでリモートログインしておく
管理者権限に切り替えておく
sudo suユーザー名の部分に#がつけばOK。
切り替えておけばsudoコマンドを打つ必要が無くなる。時間の設定
dateロンドンの時間になっていたりすると、掲示板などのサービスを作った際におかしくなるので日本時間に修正
ln -sf /usr/share/zoneinfo/Japan /etc/localtimedateコマンドで確認して問題なければOK
・PHPをインストールする
yum install -y php動作確認
・PHPの設定をしておく
※バックアップを取っておくと良いcp /etc/php.ini /etc/php.bakもしバックアップの必要が出た場合は
cp /etc/php.bak /etc/php.iniviでphp.iniの設定をいじる
vi /etc/php.ini行番号を表示させると見やすくなるのでescキーを押して
:set number520行目あたりを編集したいので
:520iモードにして
error_reporting = E_ALL &E_DEPRECATEDに追記をすれば、phpの余分なエラーメッセージを表示させずに済む
error_reporting = E_ALL &E_DEPRECATED & ~E_NOTICE次に537行目を編集。
ディスプレイエラーをOnにしておく
これでphpのエラーがブラウザに表示されるようになるdisplay_errors = Onターミナルに戻り、apacheを再起動
service httpd restartviでindex.phpを作って動作確認をすると良い
ブラウザでxx.xxx.xxx.xxx/index.php、(または番号のみで閲覧できる?)で確認できる。MySQLのインストール
※sshでリモートアクセスし、sudo suで管理者にしておく。
yumでmysqlをインストールする
yum install -y mysql-serverphpからmysqlをコントロールするため追加プログラムを入れる
yum install -y php-mysqlndmysqlを起動してみる
service mysqld start・mysqlの設定
mysql_secure_installationパスワードを聞かれるが無いのでそのままenter
すると新しくパスワードを設定するかを聞かれるのでyを押し、パスワードを設定する
※パスワードは忘れないように
確認のためにもう一度打ち込む
そしてRemove anonyemous users?(ゲストユーザーを消しますか?)と尋ねられるのでyを押す。
そのあとはすべてyでOK。・mysqlの文字コードをviで設定
vi /etc/my.cnf11行目あたりにある[mysqld_safe]の前に
character-set-server = utf8を追加。:wqで保存
再起動して確認service mysqld restartOKと表示されているればOK。
phpMyAdminを導入
phpMyAdminをインストールするためにyumコマンドの設定を変更する
yum-config-manager --enable epelこれで準備ができたので、phpmyadminをインストールする
yum install -y phpmyadmin・自分のローカルPCのみでphpmyadminにログインできるよう設定する
自分のPCのグローバルIPアドレスを確認する
→確認くん確認できたらviで設定をいじる
vi /etc/httpd/conf.d/phpMyAdmin.conf※大文字に注意
127.0.0.1の部分をグローバルIPアドレスに書き換えればOK
せっかくなので置換機能を使ってみる
:%s/127.0.0.1/xxx.xx.xx.xx/g全4か所が修正されていればOK
設定を反映させるために再起動するservice httpd restart確認のためxx.xx.xx.xx/phpmyadminをブラウザで確認する
ユーザー名はroot、パスワードはmysqlで設定したものを入力。これにてLAMP環境が完成!
今後はLaravel環境を作る方法を書けるようになれればと思っています!
ありがとうございました。
- 投稿日:2019-04-15T10:49:01+09:00
S3のファイルの中身をダウンロードせずに簡単に確認する方法
AWS S3のバケットにaaaというファイルがあったとしましょう。
$ aws s3 ls s3://(バケット名)/ 2019-04-15 01:42:01 65 aaa 2019-04-15 01:42:08 65 aaa.gz $このaaaの中身ってみるのっていちいちダウンロードしたし、コンソール開いたり、
結構めんどくさかったりしませんか?
今回はこのファイルの中をちょろちょろって確認する方法を紹介します。Linuxのコマンドだけでできるんで簡単ですよ。
はいいきなりですが、コマンドは下記です。
ポイントはcp の結果を - にすると標準出力になるんです。
それをcat連結するとみれますよ。$ aws s3 cp s3://(バケット名)/aaa - | cat testhogehoge1 testhogehoge1 吾輩は猫である testhogehoge1 testhogehoge1 $応用その1.
$ aws s3 cp s3://(バケット名)/aaa.gz - | zcat testhogehoge1 testhogehoge1 吾輩は猫である testhogehoge1 testhogehoge1 $応用その2.
$ aws s3 cp s3://(バケット名)/aaa.gz - | zcat | grep 猫 吾輩は猫である $そしてこれ、ローカルにファイルのこりません。(当然か..)
ちょっとろしたログの調査のときとかにすごく便利ですよ!よい Linux AWS ライフを!!
- 投稿日:2019-04-15T10:49:01+09:00
AWS S3上ファイルの中身をLinuxコマンドだけで超絶簡単に確認する方法
AWS s3のファイルの中を見るときにいちいちダウンロード→解凍→中身を確認 とか
コンソールとかで頑張ってファイルを参照とかしていませんか?あれ、結構めんどくさかったりしませんか?
今回はこのファイルの中をちょろちょろって確認する方法を紹介します。AWS S3のバケットにaaaというファイルがあったとしましょう。
$ aws s3 ls s3://(バケット名)/ 2019-04-15 01:42:01 65 aaa 2019-04-15 01:42:08 65 aaa.gz $このaaaの中身ってみるの超絶簡単に確認する方法の紹介します。
Linuxのコマンドだけでできるんですよ。はいいきなりですが、コマンドは下記です。
ポイントはcp の結果を - にすると標準出力になるんです。
それをcat連結するとみれますよ。$ aws s3 cp s3://(バケット名)/aaa - | cat testhogehoge1 testhogehoge1 吾輩は猫である testhogehoge1 testhogehoge1 $応用その1.
$ aws s3 cp s3://(バケット名)/aaa.gz - | zcat testhogehoge1 testhogehoge1 吾輩は猫である testhogehoge1 testhogehoge1 $応用その2.
$ aws s3 cp s3://(バケット名)/aaa.gz - | zcat | grep 猫 吾輩は猫である $そしてこれ、ローカルにファイルのこりません。(当然か..)
ちょっとろしたログの調査のときとかにすごく便利ですよ!よい Linux AWS ライフを!!
- 投稿日:2019-04-15T02:46:13+09:00
【AWS】ポイントをおさえてAWS IoT Jobsを概説する #1/2【IoT】
はじめに
AWS IoT Jobsについての記事が少ないこと、あってもAWS IoTのREST APIを利用した検証でMQTTを利用した内容でなかったりと、情報が少ないので書きました。
本稿の方針
- AWS IoT Jobsがカバーする領域を理解し、その特徴・制約を理解することを第一の目的とする。
- そのため、シーケンス図と、授受されるデータを中心に説明する。
- デバイス側はMQTTによる操作を行い、クラウド側はAWS Management Consoleで操作を行うことを想定する。
- MQTT通信するコード・個別具体的なAPI仕様の記載は極力避け、最低限必要なものだけを記載する。
- MQTTの基本的な概念(以下の項目)は理解していることを前提とする。
- MQTT Broker
- Connect
- Subscribe
- Publish
- QoS0/1/2
TL;DR
- AWS IoT Jobsの本質は、デバイス側とクラウド側で一定のルールに従ってJSONドキュメントを共有・更新すること、といえる。
- MQTTでのJobs操作は少し面倒くさいが、通信の途絶・デバイスの長時間の停止を考慮した、よく考えられた仕組みであると言える。
- QoS0(0回以上メッセージが送信される=メッセージがロストする可能性がある)だけで通信しても問題がない仕組みであると言える。
用語の定義
用語 説明 備考 AWS IoT Jobs AWS IoTの機能の一つとして提供されるもの。遠隔地で稼働しているIoTデバイスに対してなんらか実行させたい処理を配信し、その実行状況を管理することができる。本稿では、「IoT Jobs」と表現することもある。 Jobs - AWS IoT デバイス MQTTでAWS IoT MQTT Brokerと通信し、AWS IoT Jobsに関するデータをやり取りする。いわゆるIoTデバイスを想定。 クラウド AWS側全般を指す。 JobDocument デバイスに実行させたい内容を記述したJSONドキュメント。記載内容をもとにどのような処理を行うかについては、完全にユーザ側に任されている。 環境・事前準備
AWSアカウントは既に取得済みであるものとします。
本稿では以下のAWSリソースを使います。S3 Bucket/IAM Roleは作成済みであるものとします。
- S3 Bucket
- investigate-iot-jobs
- IAM Role
- Name: role-investigate-iot-jobs
- Trust Relationship: 「iot.amazonaws.com」からAssumeRole出来るよう設定
- Permissions: S3 BucketのファイルをGetObject出来る権限を付与
検証作業の中で、以下のThing/Jobを作成します。
- IoTデバイス名(Thing Name)
- device01
- ジョブ名:
- iot-job01
- iot-job02
S3 Bucketを作成する
手順は省略します。AWS Management ConsoleやAWS CLIなどでS3 Bucketを作成しておきます。
Bucket Policyなどは特に設定しません。IAM Roleを作成する
詳細は後述しますが、AWS IoTサービスがAssumeRoleする必要がありますので、この用途で用いるIAM Roleをあらかじめ作成しておきます。
デバイスで何らかファイルを取得する必要がある場合、配信対象となるファイルは通常S3 Bucketに格納しておきます。このIAM Roleの権限を利用して、各デバイスはS3上のファイルの取得します。Permissionとしては、最低限、当該S3 Bucket上のファイルに対するGetObjectが必要となります。
Trust Relationshipsは「iot.amazonaws.com」を指定します。
具体的な設定は以下のようになります。Permissions
最低限、下記のPolicyを設定します。今回はinline policyとして付与しました。
inlinepolicy{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "s3:GetObject", "Resource": "arn:aws:s3:::investigate-iot-jobs/*" } ] }Trust Relationship
「iot.amazonaws.com」からAssumeRole出来るように、Trust Relationshipを設定します。
Trust Relationship{ "Version": "2012-10-17", "Statement": [ { "Sid": "", "Effect": "Allow", "Principal": { "Service": "iot.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }Thingの作成
Thingをdevice01という名前で作成する
AWS CLIでThingを作成するには以下のように実行します。
### Thingを作成する $ aws iot create-thing --thing-name device01 { "thingArn": "arn:aws:iot:ap-northeast-1:4**********8:thing/device01", "thingName": "device01", "thingId": "f2******-****-****-****-**********43" } ### Thingの存在を確認する $ aws iot list-things { "things": [ { "thingArn": "arn:aws:iot:ap-northeast-1:4**********8:thing/device01", "version": 1, "thingName": "device01", "attributes": {} } ] }解説
概要
AWS IoT Jobsとは、遠隔地の無数のデバイスに対して何らかのオペレーションを送信し、実行させることを目的とした機能です。
ただし、AWS IoT Jobsはリモートデバイスで実行させる処理の内容そのものは定義しません。この機能は、既定のルールに従ってクラウド側とデバイス側でJSONドキュメントをやり取りすること、MQTTメッセージがロストしても最終的には必要な情報を確実に相互に更新・参照できる仕組みであること、が本質といえます。デバイス上で具体的に何を実行するかについては、予め利用者が設計する必要があります。
授受されるJSONドキュメント(≒Job Document)の内容に従い、デバイス上での処理内容を制御する、という形になります。重要な用語の定義は下記公式ドキュメントにまとめられています。
Jobs - AWS IoT
https://docs.aws.amazon.com/iot/latest/developerguide/iot-jobs.html配信するファイルの準備
AWS IoT Jobsで必要となるファイルをあらかじめ作成し、S3 Bucketに格納しておきます。
詳細は後述します。iot-job01/iot-job02用のJobDocumentを作成し、S3 Bucketに格納する
JobDocumentを「JobDocument-iot-job01.txt」及び「JobDocument-iot-job02.txt」というファイル名で作成します。中身は単純なJSONドキュメントです。このJSONドキュメントの構造・内容は、AWS利用者が自由に設定できます。
ここでは、「jobType」と「fileUrl」というオブジェクトを持つJSONドキュメントとします。「fileUrl」項目で配信ファイルのURLを指定することとなります。
それぞれ下記のようになります。JobDocument-iot-job01.txt{ "jobType": "fetchFile", "fileUrl": "${aws:iot:s3-presigned-url:https://s3.amazonaws.com/investigate-iot-jobs/iot-job01-files/distfile.bin}" }JobDocument-iot-job02.txt{ "jobType": "fetchFile", "fileUrl": "${aws:iot:s3-presigned-url:https://s3.amazonaws.com/investigate-iot-jobs/iot-job02-files/distfile.bin}" }「${}」でくくられた文字列は特殊な値です。この値は、デバイスに渡される際にS3 Presigned URLが生成されて置き換えられます。Presigned URLとは一定時間のみ有効なURLのことで、生成からxx分間を超えてアクセスするとエラーとなります。
具体的な説明は下記ドキュメントを参照ください。Managing Jobs - AWS IoT
https://docs.aws.amazon.com/iot/latest/developerguide/create-manage-jobs.htmlYour job document can contain a presigned Amazon S3 URL that points to your code file (or other file). Presigned Amazon S3 URLs are valid for a limited amount of time and so are not generated until a device requests a job document. Because the presigned URL has not been created when you are creating the job document, you put a placeholder URL in your job document instead. A placeholder URL looks like the following: ${aws:iot:s3-presigned-url:https://s3.region.amazonaws.com/\/<code file>} where bucket is the Amazon S3 bucket that contains the code file and code file is the Amazon S3 key of the code file.
また、S3 Presinged URLについての仕様・詳細な仕組みについて下記記事にまとめましたので併せて参考にしてください。
【AWS IoT Jobs】有効期限付きのURLでファイルを配信する【S3 Presigned URL】
【AWS S3】S3 Presigned URLの仕組みを調べてみた作成した「JobDocument-iot-job01.txt」及び「JobDocument-iot-job02.txt」ファイルをS3 Bucketにアップロードします。
配布用ファイルをアップロードする
配信用ファイルとして適当なバイナリファイルを作り、これをS3 Bucketに格納しておきます。JobDocumentの「fileUrl」に一致するファイル名でアップロードする必要があります。
本稿では10MBのファイルを作成してS3 Bucketに格納しています。S3 Bucketに格納されたファイルの確認
最終的には、JobDocument・配信ファイルは下記のように格納されます。
iot-job02用のファイル$ aws s3 ls --recursive s3://investigate-iot-jobs/ 2019-04-14 17:13:30 150 JobDocument-iot-job01.txt 2019-04-14 17:13:30 150 JobDocument-iot-job02.txt 2019-04-14 16:20:21 10485760 iot-job01-files/distfile.bin 2019-04-14 16:20:44 10485760 iot-job02-files/distfile.bin基本的なフロー
Jobの配信から完了までの時間軸を考えた場合、一連の処理はまず大きく「Jobの取得」と「Jobの実行」という2つに分けられます。
「Jobの取得」処理はさらに、「能動的な取得」と「受動的な取得」に分けることができます。
整理すると、以下の3つのフローになります。
- 1. Jobの取得:クラウド側で作成されたJobを、デバイスが認知する
- 1-1. 受動的なJob取得:クラウド側でJobを作成したことをトリガーとし、その内容がデバイス側に通知される。
- 1-2. 能動的なJob取得:デバイス側から、自分宛に割り当てられたJobを取得しにいく。
- 2. Jobの実行:デバイス側で、認知したJobを実行し、完了させる。
1. Jobの取得
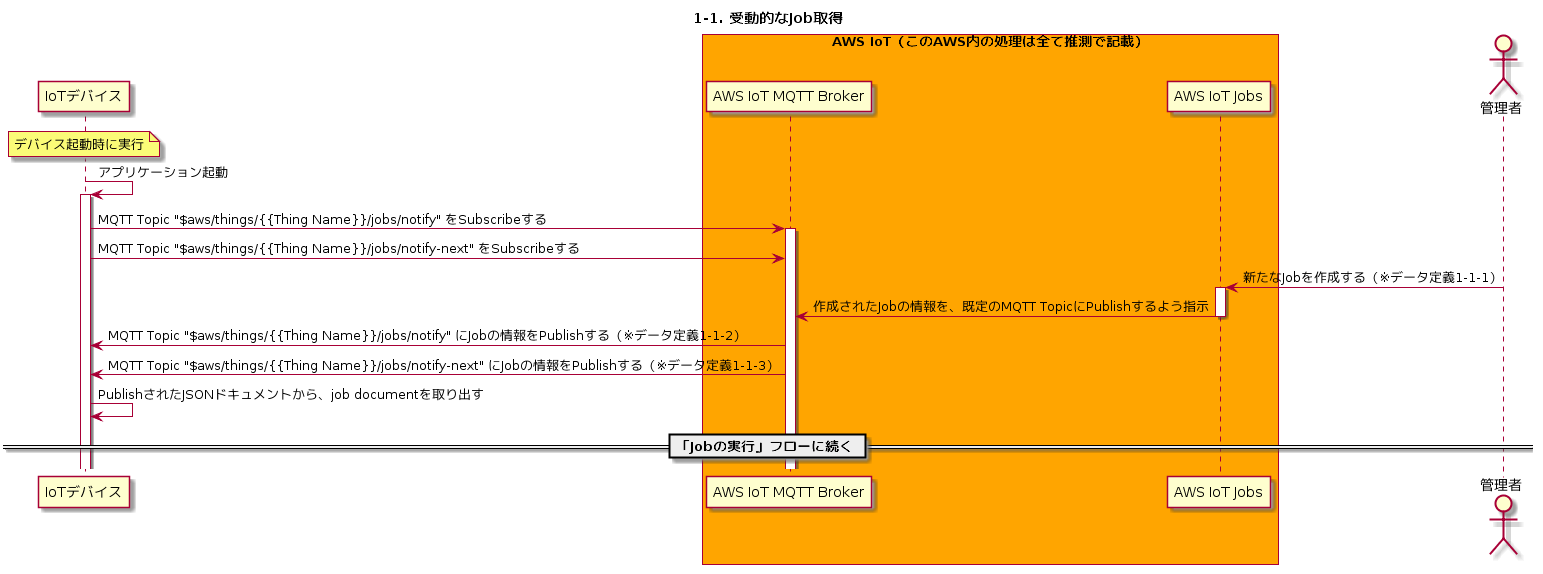
1-1. 受動的なJob取得
まずは、受動的にJobを取得するフローを見ていきます。
通常、デバイスの電源投入後、必要なプログラムが初期化・実行されていきますが、一般的には常駐してなんらか処理を行うプログラムが実行されます。
このプログラムの初期化処理の中で、MQTT Connectionの確立・TopicのSubscribeが行われることで、いつでもMQTTメッセージを受け取れる状態になります。
また必要に応じて、MQTTメッセージを任意のTopicにPublishする、ということも行います。まず最初に、以下の2つのTopicをSubscribeします。「{{Thing Name}}」は、各デバイスのThing Nameが入りますので、実際に動作検証する際には適宜読み替えてください。
- $aws/things/{{Thing Name}}/jobs/notify
- $aws/things/{{Thing Name}}/jobs/notify-next
Management ConsoleなりAWS CLIなりでJobを追加すると、その情報が上記TopicにPublishされます。Topicの詳細については下記も併せてごらんください。
Devices and Jobs - AWS IoT -> Jobs Notifications
https://docs.aws.amazon.com/iot/latest/developerguide/jobs-devices.htmlJobを作成する際に必要な情報は以下の項目があります。
- JobId: 当該Jobを識別するためのUniqueな名前。
- DocumentSource: JobDocumentが格納されているS3パス。
- JobDocument: デバイスに実行させたい処理内容を記載したJSONドキュメント。
詳細は下記ドキュメントを合わせて参照ください。
Creating and Managing Jobs (CLI) - AWS IoT -> Create Jobs
https://docs.aws.amazon.com/iot/latest/developerguide/manage-job-cli.html#create-jobMQTT Topic「\$aws/things/{{Thing Name}}/jobs/notify」および「\$aws/things/{{Thing Name}}/jobs/notify-next」をSubscribeした状態で、AWS Management Console等からJobを作成(「iot-job01」という名称で作成)すると、下記のようなメッセージが当該TopicにPublishされます。
「\$aws/things/{{Thing Name}}/jobs/notify」にはjobIdなどの情報しかPublishされませんが、「\$aws/things/{{Thing Name}}/jobs/notify-next」には次に実行するべきJobの詳細情報がPublishされます。
デバイスは基本的に「\$aws/things/{{Thing Name}}/jobs/notify-next」にPublishされた内容をもとに、必要な処理を実行していきます。\$aws/things/device01/jobs/notify(※データ定義1-1-2){ "timestamp": 1555262670, "jobs": { "QUEUED": [ { "jobId": "iot-job01", "queuedAt": 1555262670, "lastUpdatedAt": 1555262670, "executionNumber": 1, "versionNumber": 1 } ] } }下記JSONドキュメントで重要な情報は「execution.jobDocument」です。これは先ほど作成してS3に格納したJobDocumentoファイルと同等の内容になります。ただし、S3 Presinged URLを利用する場合は、下記のように実際のURLに置き換わります。
\$aws/things/device01/jobs/notify-next(※データ定義1-1-3){ "timestamp": 1555262670, "execution": { "jobId": "iot-job01", "status": "QUEUED", "queuedAt": 1555262670, "lastUpdatedAt": 1555262670, "versionNumber": 1, "executionNumber": 1, "jobDocument": { "jobType": "fetchFile", "fileUrl": "https://investigate-iot-jobs.s3.ap-northeast-1.amazonaws.com/iot-job01-files/distfile.bin?X-Amz-Security-Token=AgoGb3JpZ2luEGUaDmFwLW5vcnRoZWFzdC0xIoACFZBtrnE5T6QTP7%2FElU9iW06MYGK%2FmRVNuOZWGSV8WjY63nnm37IYbREWtVNkqSZ7gMf%2BSIf7o9fFW4r6IIWA7YDdfpYUCSBJWSt8zcr2hQTlXwtMc4FJlZztw2D%2F%2F5XBK32%2FJH22LuH0Tleac6a1f6hdGqxPPh8S5pysWz8XOzG4Qsa9qtaet4rM8iPMVH3fXfttMvYPYSHn7hNUsJyWnAyIBXiF920wspUDA%2BxFdV%2B%2FoQNkzusn%2F36mOgsToee9pgko3YgrDVm%2B3pica2E5vArQN1aW5SLFSAyE%2BPjNOF6PKBVjfPVa8UehzUrQ7CiVmEwPYe5M2YAVFRgpp6MWoiqPAgjb%2F%2F%2F%2F%2F%2F%2F%2F%2F%2F8BEAAaDDQ5NzMzOTA2MzAwOCIM28PN%2F0N3kY5OS2XdKuMBKnMV7KWUxHpw5CuLGWCgi9rce6A6%2Fyq3Y%2Fmiz6AfqWECjivGPzYiaN77u7u7z3kOKdQJJ7Jd8OQU%2B%2Fm9vF09JuVJe6II5IDvSorw%2FXUDafZj78bayCIApioHbjVDt8jrMgEeBiW%2Bxj8OcwDA1rYVhElA8qIdT6snzQRnKXAjhBt3nqNTQKU2N6PqLLiLRuZT51ENF1kfiY0FOLb6Hqyimmt1za2Pk9vrNo9poQeVCIAIZnKuhqzQzdp%2B1KRrYhTzhGEA3r%2FSvMiTDwcY%2FexRYWxIVOZGo418jLakBuUi6z%2B6PkMwztnN5QU%3D&X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Date=20190414T172430Z&X-Amz-SignedHeaders=host&X-Amz-Expires=300&X-Amz-Credential=ASIAXHS5X3LQDCAJRFN4%2F20190414%2Fap-northeast-1%2Fs3%2Faws4_request&X-Amz-Signature=636cc1afc7156948b49d6c8eff86af4f4d055117d9a0a7dda9fc4e394a4b8218" } } }今はJobが一つだけ存在する状態ですが、さらに新たなJobを作成するとどうなるでしょうか。「iot-job02」を作成してみます。
「\$aws/things/device01/jobs/notify」には下記のようなJSONドキュメントがPublishされます。
\$aws/things/device01/jobs/notify(※データ定義1-1-2){ "timestamp": 1555263139, "jobs": { "QUEUED": [ { "jobId": "iot-job01", "queuedAt": 1555262670, "lastUpdatedAt": 1555262670, "executionNumber": 1, "versionNumber": 1 }, { "jobId": "iot-job02", "queuedAt": 1555263139, "lastUpdatedAt": 1555263139, "executionNumber": 1, "versionNumber": 1 } ] } }上記Topicには、最大10個までのpending jobの情報がPublishされます。先ほどの公式ドキュメントの「Jobs Notifications」に記載の内容を引用します。
- A ListNotification contains a list of no more than 10 pending job executions. The job executions in this list have status values of either IN_PROGRESS or QUEUED. They are sorted by status (IN_PROGRESS job executions before QUEUED job executions) and then by the times when they were queued.
「\$aws/things/device01/jobs/notify-next」には何もPublishされません。このTopicにメッセージがPublishされるタイミングは下記のとおりです。先ほどの公式ドキュメントの「Jobs Notifications」に記載の内容を引用します。
- A NextNotification contains summary information about the one job execution that is next in the queue.
A NextNotification is published whenever the first job execution in the list changes.
- A new job execution is added to the list as QUEUED, and it is the first one in the list.
- The status of an existing job execution that was not the first one in the list changes from QUEUED to IN_PROGRESS and becomes the first one in the list. (This happens when there are no other IN_PROGRESS job executions in the list or when the job execution whose status changes from QUEUED to IN_PROGRESS was queued earlier than any other IN_PROGRESS job execution in the list.)
- The status of the job execution that is first in the list changes to a terminal status and is removed from the list.
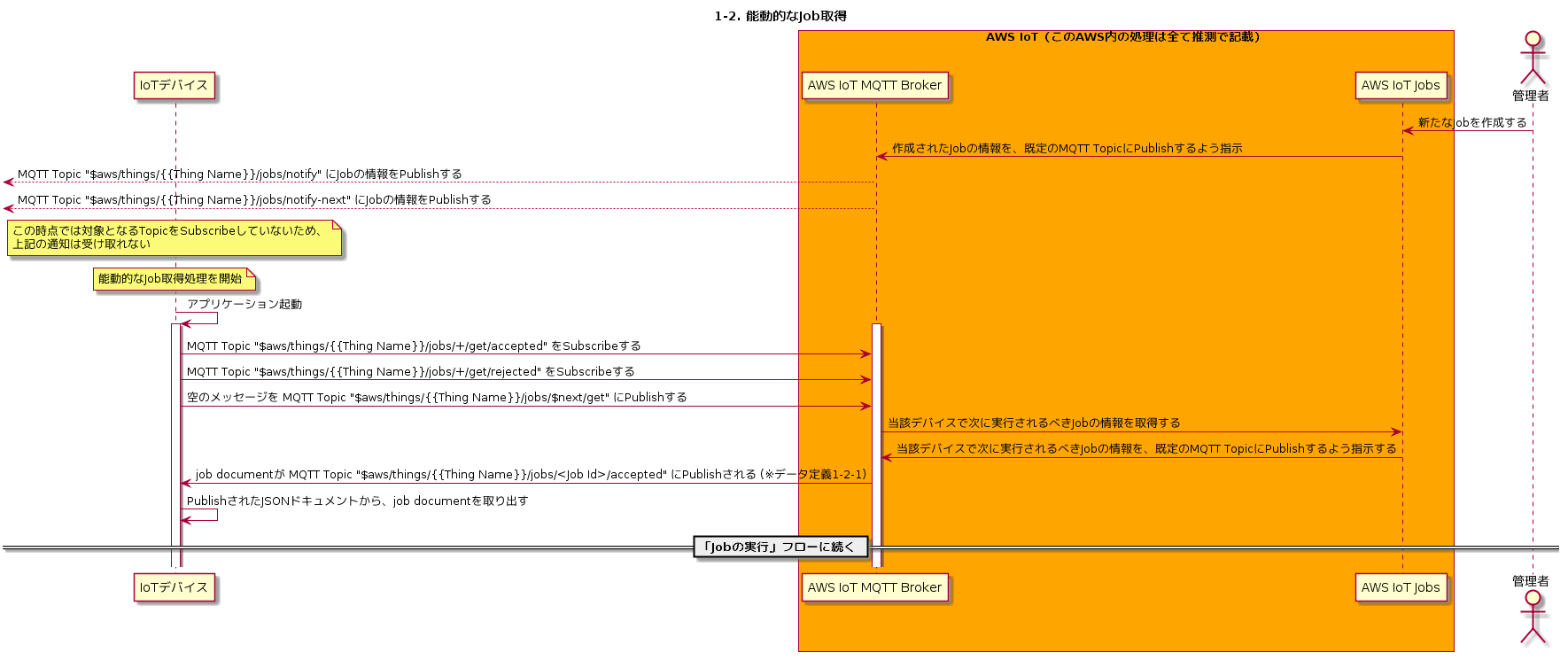
1-2. 能動的なJob取得
次に、デバイス側から能動的にJobを取得するフローを見ていきます。
通常、長時間のネットワーク切断・電源停止などの最中にJobが作成された場合、デバイスはこのタイミングではJobの情報を取得できません。そこでデバイスの起動時に、自分宛に登録されたJobがあるかどうか確認し、あればこれを実行するという処理が必要になります。
AWS IoT Jobsにはこの目的のために「DescribeJobExecution」というAPIが用意されています。Using the AWS IoT Jobs APIs - AWS IoT -> DescribeJobExecution
https://docs.aws.amazon.com/iot/latest/developerguide/jobs-api.html#mqtt-describejobexecutionまず、下記2つのMQTT TopicをSubscribeします。「+」はワイルドカードを意味し、任意の文字列にマッチします。
- $aws/things/{{Thing Name}}/jobs/+/get/accepted
- $aws/things/{{Thing Name}}/jobs/+/get/rejected
次に、下記MQTT Topicに空のメッセージをPublishします。実際には任意の文字列を指定することができますが、内容は無視されます。
「jobId」の箇所には「$next」という特殊な文字列を指定することが可能です。これは、当該デバイスが次に実行するべきJob(statusがIN_PROGRESSかQUEUEDのもの)を意味します。
- $aws/things/{{Thing Name}}/jobs/{{jobId}}/get
上記MQTT TopicにメッセージをPublishすると、「$aws/things/{{Thing Name}}/jobs/+/get/accepted」にJobの内容がPublishされます。
$aws/things/device01/jobs/+/get/accepted(※データ定義1-2-1){ "timestamp": 1555263695, "execution": { "jobId": "iot-job01", "status": "QUEUED", "queuedAt": 1555262670, "lastUpdatedAt": 1555262670, "versionNumber": 1, "executionNumber": 1, "jobDocument": { "jobType": "fetchFile", "fileUrl": "https://investigate-iot-jobs.s3.ap-northeast-1.amazonaws.com/iot-job01-files/distfile.bin?X-Amz-Security-Token=AgoGb3JpZ2luEGUaDmFwLW5vcnRoZWFzdC0xIoACQqsC5krx0S6azrc4h%2BGxErc2Bn56FRw3Wv1HWRY3REaruyiGNHA7iW3zyc9eBmY1%2FyGNNzPJSxaSsnOrWtgS0hfRChjB9Kp7rPgi9pRAxd7ZeSspaXH1s5mTJnBSzzbChCUbpsX1x5WdMp97Gi5LcbYff8rM8JirZr6kXxhOuVLtXSSvPgtGnzjdpvP1ERcRtFCj2e%2FchTmOtUCSakYlT04Qeek%2BKuRdkstdQh9w25p6NtOgFWsUqbMlGHVKuW7xalXecx0XZ1bOZ1NRChv1vj6qHt%2FNPX4XEvhprK47I0t1PyjsAA%2Fl8UR31uhBffAjVFsmvrhVwtE24QD2zfZgViqPAgjb%2F%2F%2F%2F%2F%2F%2F%2F%2F%2F8BEAAaDDQ5NzMzOTA2MzAwOCIMDgPv2Nu%2FenWUH1EOKuMBbpGvp77yjc7XjEwgybl9SSgDVzKhJIp9vuGsRp95ly9yMUJbpYSNI6DTpseq1W1LIeDs%2FACxlvLl%2B5COdHGurn0IHP42w4b6RL0UxtB1goo36225Jk9jLSdMfYGXVPvM%2F5DtT4BRlC81PNuzlwvBQmfdZavjZD1%2Fp6fkQnIbjD8PlB9MC17UPi%2FlZGUB2LhYl0o3XDSp8NmQ2qJyHwJXsV3BaCLWztmqj8JALGQlqqVVtvc%2FbCWlNZ1vM5czj%2Fb7Llbsr9N3lqTuuThTEnfgCKF67DoumQ7sQ4dmK2efktoVvVswz%2BHN5QU%3D&X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Date=20190414T174135Z&X-Amz-SignedHeaders=host&X-Amz-Expires=300&X-Amz-Credential=ASIAXHS5X3LQCRWMEZ7L%2F20190414%2Fap-northeast-1%2Fs3%2Faws4_request&X-Amz-Signature=71f4b9575a89fba54315441b306f915c6231cdb5bf20f7f8c43752f5f9900edb" } } }2. Jobの実行
上記までのフローにより、デバイス側でJobの内容を取得することができました。デバイスはJobDocumentに記載の内容をもとに必要な処理を実行していきます。
分量が多くなったので、Job実行時のフローは別記事にまとめます。※続きます。
- 投稿日:2019-04-15T02:46:13+09:00
【AWS】ポイントをおさえてAWS IoT Jobsを理解する #1/2【IoT】
はじめに
AWS IoT Jobsについての記事が少ないこと、あってもAWS IoTのREST APIを利用した検証でMQTTを利用した内容でなかったりと、情報が少ないので書きました。
本稿の方針
- AWS IoT Jobsがカバーする領域を理解し、その特徴・制約を理解することを第一の目的とする。
- そのため、シーケンス図と、授受されるデータを中心に説明する。
- デバイス側はMQTTによる操作を行い、クラウド側はAWS Management Consoleで操作を行うことを想定する。
- MQTT通信するコード・個別具体的なAPI仕様の記載は極力避け、最低限必要なものだけを記載する。
- MQTTの基本的な概念(以下の項目)は理解していることを前提とする。
- MQTT Broker
- Connect
- Subscribe
- Publish
- QoS0/1/2
TL;DR
- AWS IoT Jobsの本質は、デバイス側とクラウド側で一定のルールに従ってJSONドキュメントを共有・更新すること、といえる。
- MQTTでのJobs操作は少し面倒くさいが、通信の途絶・デバイスの長時間の停止を考慮した、よく考えられた仕組みであると言える。
- QoS0(0回以上メッセージが送信される=メッセージがロストする可能性がある)だけで通信しても問題がない仕組みであると言える。
用語の定義
用語 説明 備考 AWS IoT Jobs AWS IoTの機能の一つとして提供されるもの。遠隔地で稼働しているIoTデバイスに対してなんらか実行させたい処理を配信し、その実行状況を管理することができる。本稿では、「IoT Jobs」と表現することもある。 Jobs - AWS IoT デバイス MQTTでAWS IoT MQTT Brokerと通信し、AWS IoT Jobsに関するデータをやり取りする。いわゆるIoTデバイスを想定。 クラウド AWS側全般を指す。 JobDocument デバイスに実行させたい内容を記述したJSONドキュメント。記載内容をもとにどのような処理を行うかについては、完全にユーザ側に任されている。 環境・事前準備
AWSアカウントは既に取得済みであるものとします。
本稿では以下のAWSリソースを使います。S3 Bucket/IAM Roleは作成済みであるものとします。
- S3 Bucket
- investigate-iot-jobs
- IAM Role
- Name: role-investigate-iot-jobs
- Trust Relationship: 「iot.amazonaws.com」からAssumeRole出来るよう設定
- Permissions: S3 BucketのファイルをGetObject出来る権限を付与
検証作業の中で、以下のThing/Jobを作成します。
- IoTデバイス名(Thing Name)
- device01
- ジョブ名:
- iot-job01
- iot-job02
S3 Bucketを作成する
手順は省略します。AWS Management ConsoleやAWS CLIなどでS3 Bucketを作成しておきます。
Bucket Policyなどは特に設定しません。IAM Roleを作成する
詳細は後述しますが、AWS IoTサービスがAssumeRoleする必要がありますので、この用途で用いるIAM Roleをあらかじめ作成しておきます。
デバイスで何らかファイルを取得する必要がある場合、配信対象となるファイルは通常S3 Bucketに格納しておきます。このIAM Roleの権限を利用して、各デバイスはS3上のファイルの取得します。Permissionとしては、最低限、当該S3 Bucket上のファイルに対するGetObjectが必要となります。
Trust Relationshipsは「iot.amazonaws.com」を指定します。
具体的な設定は以下のようになります。Permissions
最低限、下記のPolicyを設定します。今回はinline policyとして付与しました。
inlinepolicy{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "s3:GetObject", "Resource": "arn:aws:s3:::investigate-iot-jobs/*" } ] }Trust Relationship
「iot.amazonaws.com」からAssumeRole出来るように、Trust Relationshipを設定します。
Trust Relationship{ "Version": "2012-10-17", "Statement": [ { "Sid": "", "Effect": "Allow", "Principal": { "Service": "iot.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }Thingの作成
Thingをdevice01という名前で作成する
AWS CLIでThingを作成するには以下のように実行します。
### Thingを作成する $ aws iot create-thing --thing-name device01 { "thingArn": "arn:aws:iot:ap-northeast-1:4**********8:thing/device01", "thingName": "device01", "thingId": "f2******-****-****-****-**********43" } ### Thingの存在を確認する $ aws iot list-things { "things": [ { "thingArn": "arn:aws:iot:ap-northeast-1:4**********8:thing/device01", "version": 1, "thingName": "device01", "attributes": {} } ] }AWS IoT Jobsとは
AWS IoT Jobsとは、遠隔地の無数のデバイスに対して何らかのオペレーションを送信し、実行させることを目的とした機能です。
ただし、AWS IoT Jobsはリモートデバイスで実行させる処理の内容そのものは定義しません。この機能は、既定のルールに従ってクラウド側とデバイス側でJSONドキュメントをやり取りすること、MQTTメッセージがロストしても最終的には必要な情報を確実に相互に更新・参照できる仕組みであること、が本質といえます。デバイス上で具体的に何を実行するかについては、予め利用者が設計する必要があります。
授受されるJSONドキュメント(≒Job Document)の内容に従い、デバイス上での処理内容を制御する、という形になります。重要な用語の定義は下記公式ドキュメントにまとめられています。
Jobs - AWS IoT
https://docs.aws.amazon.com/iot/latest/developerguide/iot-jobs.html配信するファイルの準備
AWS IoT Jobsで必要となるファイルをあらかじめ作成し、S3 Bucketに格納しておきます。
詳細は後述します。iot-job01/iot-job02用のJobDocumentを作成し、S3 Bucketに格納する
JobDocumentを「JobDocument-iot-job01.txt」及び「JobDocument-iot-job02.txt」というファイル名で作成します。中身は単純なJSONドキュメントです。このJSONドキュメントの構造・内容は、AWS利用者が自由に設定できます。
ここでは、「jobType」と「fileUrl」というオブジェクトを持つJSONドキュメントとします。「fileUrl」項目で配信ファイルのURLを指定することとなります。
それぞれ下記のようになります。JobDocument-iot-job01.txt{ "jobType": "fetchFile", "fileUrl": "${aws:iot:s3-presigned-url:https://s3.amazonaws.com/investigate-iot-jobs/iot-job01-files/distfile.bin}" }JobDocument-iot-job02.txt{ "jobType": "fetchFile", "fileUrl": "${aws:iot:s3-presigned-url:https://s3.amazonaws.com/investigate-iot-jobs/iot-job02-files/distfile.bin}" }「${}」でくくられた文字列は特殊な値です。この値は、デバイスに渡される際にS3 Presigned URLが生成されて置き換えられます。Presigned URLとは一定時間のみ有効なURLのことで、生成からxx分間を超えてアクセスするとエラーとなります。
具体的な説明は下記ドキュメントを参照ください。Managing Jobs - AWS IoT
https://docs.aws.amazon.com/iot/latest/developerguide/create-manage-jobs.htmlYour job document can contain a presigned Amazon S3 URL that points to your code file (or other file). Presigned Amazon S3 URLs are valid for a limited amount of time and so are not generated until a device requests a job document. Because the presigned URL has not been created when you are creating the job document, you put a placeholder URL in your job document instead. A placeholder URL looks like the following: ${aws:iot:s3-presigned-url:https://s3.region.amazonaws.com/\/<code file>} where bucket is the Amazon S3 bucket that contains the code file and code file is the Amazon S3 key of the code file.
また、S3 Presinged URLについての仕様・詳細な仕組みについて下記記事にまとめましたので併せて参考にしてください。
【AWS IoT Jobs】有効期限付きのURLでファイルを配信する【S3 Presigned URL】
【AWS S3】S3 Presigned URLの仕組みを調べてみた作成した「JobDocument-iot-job01.txt」及び「JobDocument-iot-job02.txt」ファイルをS3 Bucketにアップロードします。
配布用ファイルをアップロードする
配信用ファイルとして適当なバイナリファイルを作り、これをS3 Bucketに格納しておきます。JobDocumentの「fileUrl」に一致するファイル名でアップロードする必要があります。
本稿では10MBのファイルを作成してS3 Bucketに格納しています。S3 Bucketに格納されたファイルの確認
最終的には、JobDocument・配信ファイルは下記のように格納されます。
iot-job02用のファイル$ aws s3 ls --recursive s3://investigate-iot-jobs/ 2019-04-14 17:13:30 150 JobDocument-iot-job01.txt 2019-04-14 17:13:30 150 JobDocument-iot-job02.txt 2019-04-14 16:20:21 10485760 iot-job01-files/distfile.bin 2019-04-14 16:20:44 10485760 iot-job02-files/distfile.binAWS IoT Jobsのフロー
Jobの配信から完了までの時間軸を考えた場合、一連の処理はまず大きく「Jobの取得」と「Jobの実行」という2つに分けられます。
「Jobの取得」処理はさらに、「能動的な取得」と「受動的な取得」に分けることができます。
整理すると、以下の3つのフローになります。
- 1. Jobの取得:クラウド側で作成されたJobを、デバイスが認知する
- 1-1. 受動的なJob取得:クラウド側でJobを作成したことをトリガーとし、その内容がデバイス側に通知される。
- 1-2. 能動的なJob取得:デバイス側から、自分宛に割り当てられたJobを取得しにいく。
- 2. Jobの実行:デバイス側で、認知したJobを実行し、完了させる。
1. Jobの取得
1-1. 受動的なJob取得
まずは、受動的にJobを取得するフローを見ていきます。
通常、デバイスの電源投入後、必要なプログラムが初期化・実行されていきますが、一般的には常駐してなんらか処理を行うプログラムが実行されます。
このプログラムの初期化処理の中で、MQTT Connectionの確立・TopicのSubscribeが行われることで、いつでもMQTTメッセージを受け取れる状態になります。
また必要に応じて、MQTTメッセージを任意のTopicにPublishする、ということも行います。まず最初に、以下の2つのTopicをSubscribeします。「{{Thing Name}}」は、各デバイスのThing Nameが入りますので、実際に動作検証する際には適宜読み替えてください。
- $aws/things/{{Thing Name}}/jobs/notify
- $aws/things/{{Thing Name}}/jobs/notify-next
Management ConsoleなりAWS CLIなりでJobを追加すると、その情報が上記TopicにPublishされます。Topicの詳細については下記も併せてごらんください。
Devices and Jobs - AWS IoT -> Jobs Notifications
https://docs.aws.amazon.com/iot/latest/developerguide/jobs-devices.htmlJobを作成する際に必要な情報は以下の項目があります。(※データ定義1-1-1)
- JobId: 当該Jobを識別するためのUniqueな名前。
- Targets: Job実行対象のThingを指定する。Thing名/Thing Group名で指定が可能。
- DocumentSource: JobDocumentが格納されているS3パス。
- JobDocument: デバイスに実行させたい処理内容を記載したJSONドキュメント。JSONドキュメントでさえあれば、データ構造・内容は自由に設定できます。
詳細は下記ドキュメントを合わせて参照ください。
Creating and Managing Jobs (CLI) - AWS IoT -> Create Jobs
https://docs.aws.amazon.com/iot/latest/developerguide/manage-job-cli.html#create-jobMQTT Topic「\$aws/things/{{Thing Name}}/jobs/notify」および「\$aws/things/{{Thing Name}}/jobs/notify-next」をSubscribeした状態で、AWS Management Console等からJobを作成(「iot-job01」という名称で作成)すると、下記のようなメッセージが当該TopicにPublishされます。
「\$aws/things/{{Thing Name}}/jobs/notify」にはjobIdなどの情報しかPublishされませんが、「\$aws/things/{{Thing Name}}/jobs/notify-next」には次に実行するべきJobの詳細情報がPublishされます。
デバイスは基本的に「\$aws/things/{{Thing Name}}/jobs/notify-next」にPublishされた内容をもとに、必要な処理を実行していきます。「\$aws/things/{{Thing Name}}/jobs/notify」には、対象デバイスで実行するべきJob一覧が、最大10個まで表示されます。StatusがIN_PROGRESS/QUEUEDのものが対象となり、Status・timestampの順にソートされています。
\$aws/things/device01/jobs/notify(※データ定義1-1-2){ "timestamp": 1555262670, "jobs": { "QUEUED": [ { "jobId": "iot-job01", "queuedAt": 1555262670, "lastUpdatedAt": 1555262670, "executionNumber": 1, "versionNumber": 1 } ] } }下記JSONドキュメントで重要な情報は「execution.jobDocument」です。これは先ほど作成してS3に格納したJobDocumentoファイルと同等の内容になります。ただし、S3 Presinged URLを利用する場合は、下記のように実際のURLに置き換わります。
\$aws/things/device01/jobs/notify-next(※データ定義1-1-3){ "timestamp": 1555262670, "execution": { "jobId": "iot-job01", "status": "QUEUED", "queuedAt": 1555262670, "lastUpdatedAt": 1555262670, "versionNumber": 1, "executionNumber": 1, "jobDocument": { "jobType": "fetchFile", "fileUrl": "https://investigate-iot-jobs.s3.ap-northeast-1.amazonaws.com/iot-job01-files/distfile.bin?X-Amz-Security-Token=AgoGb3JpZ2luEGUaDmFwLW5vcnRoZWFzdC0xIoACFZBtrnE5T6QTP7%2FElU9iW06MYGK%2FmRVNuOZWGSV8WjY63nnm37IYbREWtVNkqSZ7gMf%2BSIf7o9fFW4r6IIWA7YDdfpYUCSBJWSt8zcr2hQTlXwtMc4FJlZztw2D%2F%2F5XBK32%2FJH22LuH0Tleac6a1f6hdGqxPPh8S5pysWz8XOzG4Qsa9qtaet4rM8iPMVH3fXfttMvYPYSHn7hNUsJyWnAyIBXiF920wspUDA%2BxFdV%2B%2FoQNkzusn%2F36mOgsToee9pgko3YgrDVm%2B3pica2E5vArQN1aW5SLFSAyE%2BPjNOF6PKBVjfPVa8UehzUrQ7CiVmEwPYe5M2YAVFRgpp6MWoiqPAgjb%2F%2F%2F%2F%2F%2F%2F%2F%2F%2F8BEAAaDDQ5NzMzOTA2MzAwOCIM28PN%2F0N3kY5OS2XdKuMBKnMV7KWUxHpw5CuLGWCgi9rce6A6%2Fyq3Y%2Fmiz6AfqWECjivGPzYiaN77u7u7z3kOKdQJJ7Jd8OQU%2B%2Fm9vF09JuVJe6II5IDvSorw%2FXUDafZj78bayCIApioHbjVDt8jrMgEeBiW%2Bxj8OcwDA1rYVhElA8qIdT6snzQRnKXAjhBt3nqNTQKU2N6PqLLiLRuZT51ENF1kfiY0FOLb6Hqyimmt1za2Pk9vrNo9poQeVCIAIZnKuhqzQzdp%2B1KRrYhTzhGEA3r%2FSvMiTDwcY%2FexRYWxIVOZGo418jLakBuUi6z%2B6PkMwztnN5QU%3D&X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Date=20190414T172430Z&X-Amz-SignedHeaders=host&X-Amz-Expires=300&X-Amz-Credential=ASIAXHS5X3LQDCAJRFN4%2F20190414%2Fap-northeast-1%2Fs3%2Faws4_request&X-Amz-Signature=636cc1afc7156948b49d6c8eff86af4f4d055117d9a0a7dda9fc4e394a4b8218" } } }今はJobが一つだけ存在する状態ですが、さらに新たなJobを作成するとどうなるでしょうか。「iot-job02」を作成してみます。
「\$aws/things/device01/jobs/notify」には下記のようなJSONドキュメントがPublishされます。
\$aws/things/device01/jobs/notify(※データ定義1-1-2){ "timestamp": 1555263139, "jobs": { "QUEUED": [ { "jobId": "iot-job01", "queuedAt": 1555262670, "lastUpdatedAt": 1555262670, "executionNumber": 1, "versionNumber": 1 }, { "jobId": "iot-job02", "queuedAt": 1555263139, "lastUpdatedAt": 1555263139, "executionNumber": 1, "versionNumber": 1 } ] } }上記Topicには、最大10個までのpending jobの情報がPublishされます。先ほどの公式ドキュメントの「Jobs Notifications」に記載の内容を引用します。
- A ListNotification contains a list of no more than 10 pending job executions. The job executions in this list have status values of either IN_PROGRESS or QUEUED. They are sorted by status (IN_PROGRESS job executions before QUEUED job executions) and then by the times when they were queued.
「\$aws/things/device01/jobs/notify-next」には何もPublishされません。このTopicにメッセージがPublishされるタイミングは下記のとおりです。先ほどの公式ドキュメントの「Jobs Notifications」に記載の内容を引用します。
- A NextNotification contains summary information about the one job execution that is next in the queue.
A NextNotification is published whenever the first job execution in the list changes.
- A new job execution is added to the list as QUEUED, and it is the first one in the list.
- The status of an existing job execution that was not the first one in the list changes from QUEUED to IN_PROGRESS and becomes the first one in the list. (This happens when there are no other IN_PROGRESS job executions in the list or when the job execution whose status changes from QUEUED to IN_PROGRESS was queued earlier than any other IN_PROGRESS job execution in the list.)
- The status of the job execution that is first in the list changes to a terminal status and is removed from the list.
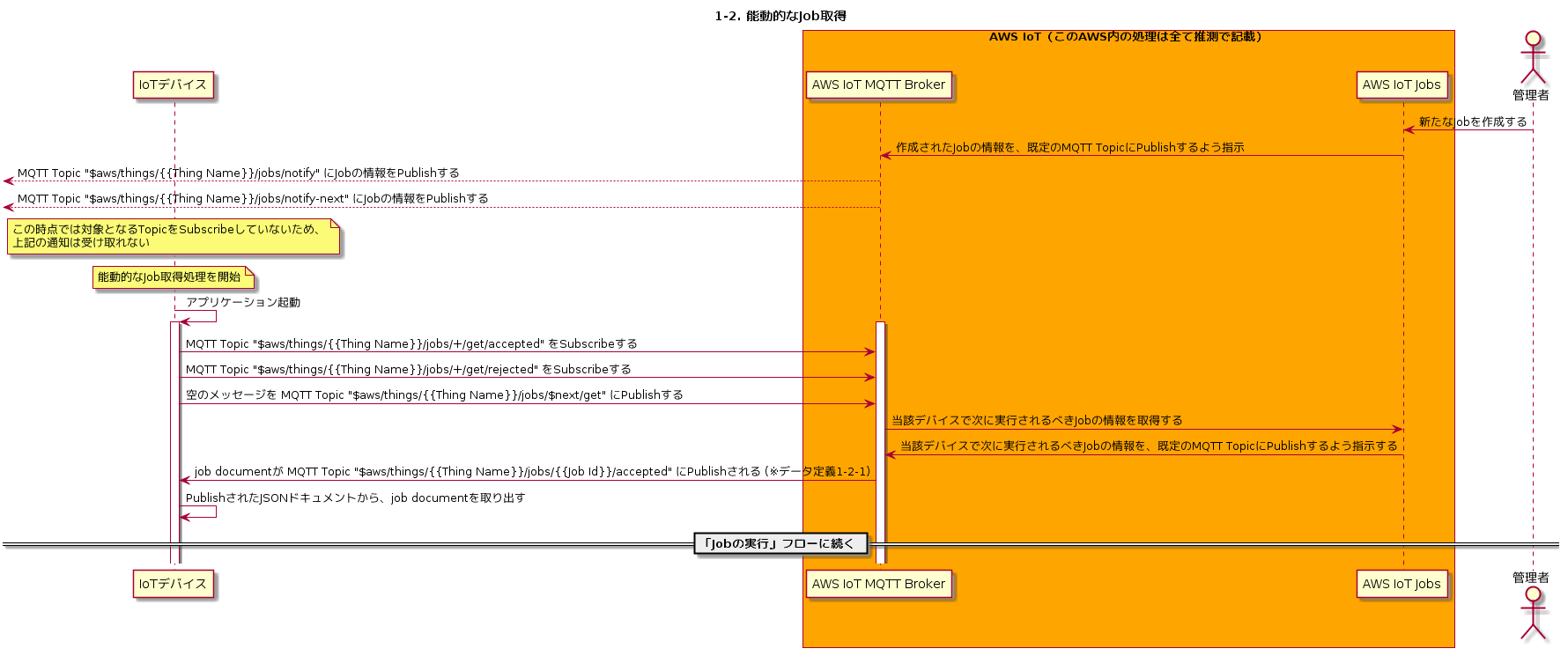
1-2. 能動的なJob取得
次に、デバイス側から能動的にJobを取得するフローを見ていきます。
通常、長時間のネットワーク切断・電源停止などの最中にJobが作成された場合、デバイスはこのタイミングではJobの情報を取得できません。そこでデバイスの起動時に、自分宛に登録されたJobがあるかどうか確認し、あればこれを実行するという処理が必要になります。
AWS IoT Jobsにはこの目的のために「DescribeJobExecution」というAPIが用意されています。Using the AWS IoT Jobs APIs - AWS IoT -> DescribeJobExecution
https://docs.aws.amazon.com/iot/latest/developerguide/jobs-api.html#mqtt-describejobexecutionまず、下記2つのMQTT TopicをSubscribeします。「+」はワイルドカードを意味し、任意の文字列にマッチします。
- $aws/things/{{Thing Name}}/jobs/+/get/accepted
- $aws/things/{{Thing Name}}/jobs/+/get/rejected
次に、下記MQTT Topicに空のメッセージをPublishします。実際には任意の文字列を指定することができますが、内容は無視されます。
「jobId」の箇所には「$next」という特殊な文字列を指定することが可能です。これは、当該デバイスが次に実行するべきJob(statusがIN_PROGRESSかQUEUEDのもの)を意味します。
- $aws/things/{{Thing Name}}/jobs/{{jobId}}/get
上記MQTT TopicにメッセージをPublishすると、「$aws/things/{{Thing Name}}/jobs/+/get/accepted」にJobの内容がPublishされます。
$aws/things/device01/jobs/+/get/accepted(※データ定義1-2-1){ "timestamp": 1555263695, "execution": { "jobId": "iot-job01", "status": "QUEUED", "queuedAt": 1555262670, "lastUpdatedAt": 1555262670, "versionNumber": 1, "executionNumber": 1, "jobDocument": { "jobType": "fetchFile", "fileUrl": "https://investigate-iot-jobs.s3.ap-northeast-1.amazonaws.com/iot-job01-files/distfile.bin?X-Amz-Security-Token=AgoGb3JpZ2luEGUaDmFwLW5vcnRoZWFzdC0xIoACQqsC5krx0S6azrc4h%2BGxErc2Bn56FRw3Wv1HWRY3REaruyiGNHA7iW3zyc9eBmY1%2FyGNNzPJSxaSsnOrWtgS0hfRChjB9Kp7rPgi9pRAxd7ZeSspaXH1s5mTJnBSzzbChCUbpsX1x5WdMp97Gi5LcbYff8rM8JirZr6kXxhOuVLtXSSvPgtGnzjdpvP1ERcRtFCj2e%2FchTmOtUCSakYlT04Qeek%2BKuRdkstdQh9w25p6NtOgFWsUqbMlGHVKuW7xalXecx0XZ1bOZ1NRChv1vj6qHt%2FNPX4XEvhprK47I0t1PyjsAA%2Fl8UR31uhBffAjVFsmvrhVwtE24QD2zfZgViqPAgjb%2F%2F%2F%2F%2F%2F%2F%2F%2F%2F8BEAAaDDQ5NzMzOTA2MzAwOCIMDgPv2Nu%2FenWUH1EOKuMBbpGvp77yjc7XjEwgybl9SSgDVzKhJIp9vuGsRp95ly9yMUJbpYSNI6DTpseq1W1LIeDs%2FACxlvLl%2B5COdHGurn0IHP42w4b6RL0UxtB1goo36225Jk9jLSdMfYGXVPvM%2F5DtT4BRlC81PNuzlwvBQmfdZavjZD1%2Fp6fkQnIbjD8PlB9MC17UPi%2FlZGUB2LhYl0o3XDSp8NmQ2qJyHwJXsV3BaCLWztmqj8JALGQlqqVVtvc%2FbCWlNZ1vM5czj%2Fb7Llbsr9N3lqTuuThTEnfgCKF67DoumQ7sQ4dmK2efktoVvVswz%2BHN5QU%3D&X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Date=20190414T174135Z&X-Amz-SignedHeaders=host&X-Amz-Expires=300&X-Amz-Credential=ASIAXHS5X3LQCRWMEZ7L%2F20190414%2Fap-northeast-1%2Fs3%2Faws4_request&X-Amz-Signature=71f4b9575a89fba54315441b306f915c6231cdb5bf20f7f8c43752f5f9900edb" } } }2. Jobの実行
上記までのフローにより、デバイス側でJobの内容を取得することができました。デバイスはJobDocumentに記載の内容をもとに必要な処理を実行していきます。
分量が多くなったので、Job実行時のフローは下記記事にまとめます。
- 投稿日:2019-04-15T01:57:05+09:00
気付いたこと備忘録
- 投稿日:2019-04-15T01:45:32+09:00
TerraformでEC2インスタンスを構築(実践編)
はじめに
AWSを使ってて、毎回コンソールから環境を構築するのは面倒です。
Terraformというツールを使えば、環境をドカッと作れて、ゴソッと消せるらしいので触ってみました。まずは、お試し感覚でAWSのEC2を構築します。
この実践編ではインストールが終わったあとの構築方法を説明しています。
インストールや初期設定についてはインストール編で説明しています。目標
Terraformを用いたインフラの構築は以下のような流れで行うことを目標にします。
① .tfファイルにインフラのコードを書く
② terraform planコマンドで現状との差分を比較する
③ terraform applyコマンドでインフラを構成を適用する
④ terraform showコマンドで状態を確認する今回は環境を構築したあとに、削除します。
削除は以下の流れで行います。⑤ terraform destroyコマンドで削除
⑥ terraform showコマンドで削除されたことを確認実践
環境構築
① .tfファイル作成
Terraformはインフラの構成情報をHCL(HaashCorp Configuration Language)というDSLで.tfファイルに記述します。
今回は、VPCとサブネットとインスタンスをresourceとして定義します。
パラメータは公式ドキュメントを見ながらやればOK。
Provider: AWS - Terraform by HashiCorpaws_ec2_config.tfresource "aws_instance" "linux" { ami = "ami-00a5245b4816c38e6" instance_type = "t2.micro" subnet_id = "${aws_subnet.public_subnet.id}" } resource "aws_vpc" "vpc" { cidr_block = "10.0.0.0/16" instance_tenancy = "default" } resource "aws_subnet" "public_subnet" { vpc_id = "${aws_vpc.vpc.id}" cidr_block = "10.0.10.0/24" availability_zone = "ap-northeast-1a" }② terraform plan
terraform planコマンドで現在の環境と.tfファイルの差分を確認します。
今回は、VPCとサブネットとインスタンスが新規作成されるので「+」で表示されます。$ ./terraform plan Terraform will perform the following actions: + aws_instance.linux id: <computed> ami: "ami-00a5245b4816c38e6" arn: <computed> ・ ・ ・ + aws_subnet.public_subnet id: <computed> arn: <computed> assign_ipv6_address_on_creation: "false" ・ ・ ・ + aws_vpc.vpc id: <computed> arn: <computed> ・ ・ ・ Plan: 3 to add, 0 to change, 0 to destroy.③ terraform apply
構成情報の確認ができたら、terraform applyコマンドで構成情報を適用します。
途中でアクションを続行するか聞かれるので「yes」を入力します。$ ./terraform apply ・ ・ ・ Do you want to perform these actions? Terraform will perform the actions described above. Only 'yes' will be accepted to approve. Enter a value: yes以下のように表示されれば、処理が完了です。
Apply complete! Resources: 3 added, 0 changed, 0 destroyed.④ terraform show
terraform showコマンドで構成情報を確認できます。
また、AWSコンソールなどからも確認することができます。$ ./terraform show aws_instance.linux: id = i-***************** ami = ami-00a5245b4816c38e6 arn = arn:aws:ec2:ap-northeast-1:************:instance/i-***************** ・ ・ ・ aws_subnet.public_subnet: id = subnet-***************** arn = arn:aws:ec2:ap-northeast-1:************:subnet/subnet-***************** ・ ・ ・ aws_vpc.vpc: id = vpc-***************** arn = arn:aws:ec2:ap-northeast-1:************:vpc/vpc-***************** ・ ・ ・環境の削除
⑤ terraform destroy
terraform destroyコマンドで定義したリソースを削除することができます。
削除のときも、途中でアクションを続行するか聞かれるので「yes」を入力します。$ ./terraform destroy ・ ・ ・ Do you really want to destroy all resources? Terraform will destroy all your managed infrastructure, as shown above. There is no undo. Only 'yes' will be accepted to confirm. Enter a value: yes以下のように表示されれば、処理が完了です。
Apply complete! Resources: 3 added, 0 changed, 0 destroyed.⑥ terraform show
最後にもう一度、terraform showコマンドで現在の構成を確認します。
正常に削除できている場合は、以下のように何も表示されません。$ ./terraform showおわり
今回までで、TerraformのインストールとEC2インスタンスの構築までが一旦終わりました。
応用すれば、もっと複雑なインフラも構築できるはず!また、時間があればTerraformのstateやBackendという概念についても深掘っていきたいと思います。
- 投稿日:2019-04-15T01:05:50+09:00
【AWS IoT Jobs】有効期限付きのURLでファイルを配信する【S3 Presigned URL】
はじめに
AWS IoT Jobsを使ってデバイスにファイルを配信する際には、デバイスからHTTPSでダウンロード可能なURLを指定することが多いかと思います。
公式ドキュメント上はS3 Presigned URLを使うことが想定されていますが、これはいったいどういうものか、なぜ使うのか、といった観点での説明が足りないように思えるので、これらを補足する意味で記事にまとめます。なぜS3 Presigned URLを使うのか
通信方向・プロトコル
まずはS3 Presigned URLのことを考える前に、なぜHTTPSを利用するのか、何故デバイスからGetする形でファイルを取得するのか、という点を考えます。
原理上は、デバイス側で何らかMQTT TopicをSubscribeしておいて、MQTT Brokerから当該TopicにファイルをPublishすることで、ファイルの送達は可能です。
しかしながらこれは、全てがうまく動いているとき/うまく動くと保証されているときのみ有効な手段です。まず、当該ファイルがPublishされる前に、デバイス側は確実にMQTT TopicをSubscribeした状態になっている必要があります。また、ファイルの送信中に通信が切断された場合は、リトライする必要があります。またMQTT Brokerからデバイスに対してQoS1でメッセージを送信することで、メッセージのロストはなくなりますが、
AWSのMQTT Brokerでは、QoS1のメッセージを保持できる件数には限りがあります。いずれにせよ、IoTシステムにおいて、デバイス側とクラウド側の通信処理を考える際には、「すべてがうまく動かない」ということを前提に考える必要があります。
この観点から出発すると、デバイス側からの操作を起点に考えた場合、以下の条件を満たす構成が一番都合がよいことに気づきます。
- ファイル配信に関する情報(JobDocument)はいつでも・何度でも取得可能
- 配信ファイル自体を取得する操作は、デバイスから何度でもリトライできる
AWS IoT Jobsの仕様においては、すでに前者の要件は考慮されています。
後者の要件を満たすためには、HTTPSでファイルをダウンロードできるようにしておいて、デバイス側からGetする、という方式がベストであるように見えます。セキュリティ
上記までの構成そのままでは、だれでも情報を取得できるという状態になります。
つぎに、予め許可されたデバイスに対してのみ、情報・ファイルの取得が可能なようにする方法を考えます。ファイル配信に関する情報(JobDocument)の取得
- ファイル配信に関する情報(JobDocument)はいつでも・何度でも取得可能
まずこの操作は、デバイス側からMQTT over TLSで行われるを前提とします(AWS APIで取得することも可能ですが、ここでは考慮しません)。AWS IoTのMQTT BrokerとMQTT通信する際には、有効なクライアント証明書・秘密鍵を持っていないと行えませんので、ここでセキュリティを担保できることになります。
どのデバイスがどのMQTT Topicを操作できるかは、AWS IoTのPolicyで設定することが可能です配信ファイルの取得
- 配信ファイル自体を取得する操作は、デバイスから何度でもリトライできる
次に、上記の操作に関して、許可したデバイスのみファイルをダウンロードできるようにする方法を考えます。
まず、S3 Bucket上のファイルをダウンロードさせる場合、2つの方法があります。
- AWS S3 API経由で取得する(≒AWS CLIやAWS SDKを利用する)
- HTTPSを利用して取得する
前者の方法を利用する場合、デバイス側はAWS Credentials(AccessKey/SecretAccessKey、Temporary Credentialsの場合はさらにSessionToken)を持っている必要があります。
デバイスからのリクエストに応じてTemporary Credentialsを返却する、デバイスはこれを使ってAWS S3 API経由でファイルを取得する、という方法で原理上は実現可能です。
ただしこの方法は、デバイスからのリクエストに応じてTemporary Credentialsを返却する仕組みを作りこむ必要があり、少し大仰です。つぎに、HTTPSでファイルを取得する方式を考えます。
クライアントに権限があるかどうかをチェックするために、MQTT over TLS用のクライアント証明書を利用できればベストですが、現状ではS3はそこまで対応していません(おそらく今後も対応されないと思います)。
では、クライアントからのリクエストに応じ、一時的に有効なダウンロードURL(HTTPSベース)を発行することはどうでしょうか。S3 Presigned URLを利用することで、これを実現できます。
ダウンロードURLはJobDocument内に記載されてデバイスに渡されます。JobDocumentを渡す操作において権限チェックが行われるため、セキュリティ上も問題ありません。
なお、S3 Presigned URLについての説明が長くなったので、下記記事に個別にまとめました。
【AWS S3】S3 Presigned URLの仕組みを調べてみた - Qiita試してみる
環境を準備する
試した環境は以下のようになります。
- AWSアカウント
- アカウントID: 4**********8
- S3
- Bucket名: investigate-iot-jobs
- 配信ファイル: s3://investigate-iot-jobs/example-distfile.bin
- JobDocumentファイル: s3://investigate-iot-jobs/example-job-document.json
- IAM Role(配信ファイルのPresigned URLを生成するためのRole)
- role-investigate-iot-jobs
- Permissions: 後述するinline policyを付与
- AWS IoT Thing(配信対象のデバイス)
- Thing Name: example-device01
role-investigate-iot-jobsのinline policy{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "s3:GetObject", "Resource": "arn:aws:s3:::investigate-iot-jobs/*" } ] }S3 Bucketには、配信ファイルとJobDocumentファイルが必要です。
まず、JobDocumentファイル「example-job-document.json」として下記JSONファイルを作成します。
example-job-document.json{ "distFileUrl": "${aws:iot:s3-presigned-url:https://s3.amazonaws.com/investigate-iot-jobs/example-distfile.bin}" }example-distfile.binは、1MBのバイナリファイルを生成したものとなります。このファイルは何でもよいです。
$ dd if=/dev/zero of=example-distfile.bin bs=1024 count=1024 1024+0 records in 1024+0 records out 1048576 bytes (1.0 MB) copied, 0.00191433 s, 548 MB/s $ ls -la example-distfile.bin -rw-rw-r-- 1 vagrant vagrant 1048576 Apr 14 09:51 example-distfile.bin上記2つのファイルとS3 Bucket格納します。最終的に下記のように2つのファイルが格納されます。
$ aws s3 ls --recursive s3://investigate-iot-jobs/ 2019-04-14 09:52:20 1048576 example-distfile.bin 2019-04-14 09:54:59 120 example-job-document.jsonAWS IoT Jobsでのファイル配信対象となるデバイスが必要ですので併せて作成します。
example-device01という名称で作成しました。aws iot create-thing$ aws iot create-thing --thing-name example-device01 { "thingArn": "arn:aws:iot:ap-northeast-1:4**********8:thing/example-device01", "thingName": "example-device01", "thingId": "81******-****-****-****-**********f6" }IoT Jobを作成する
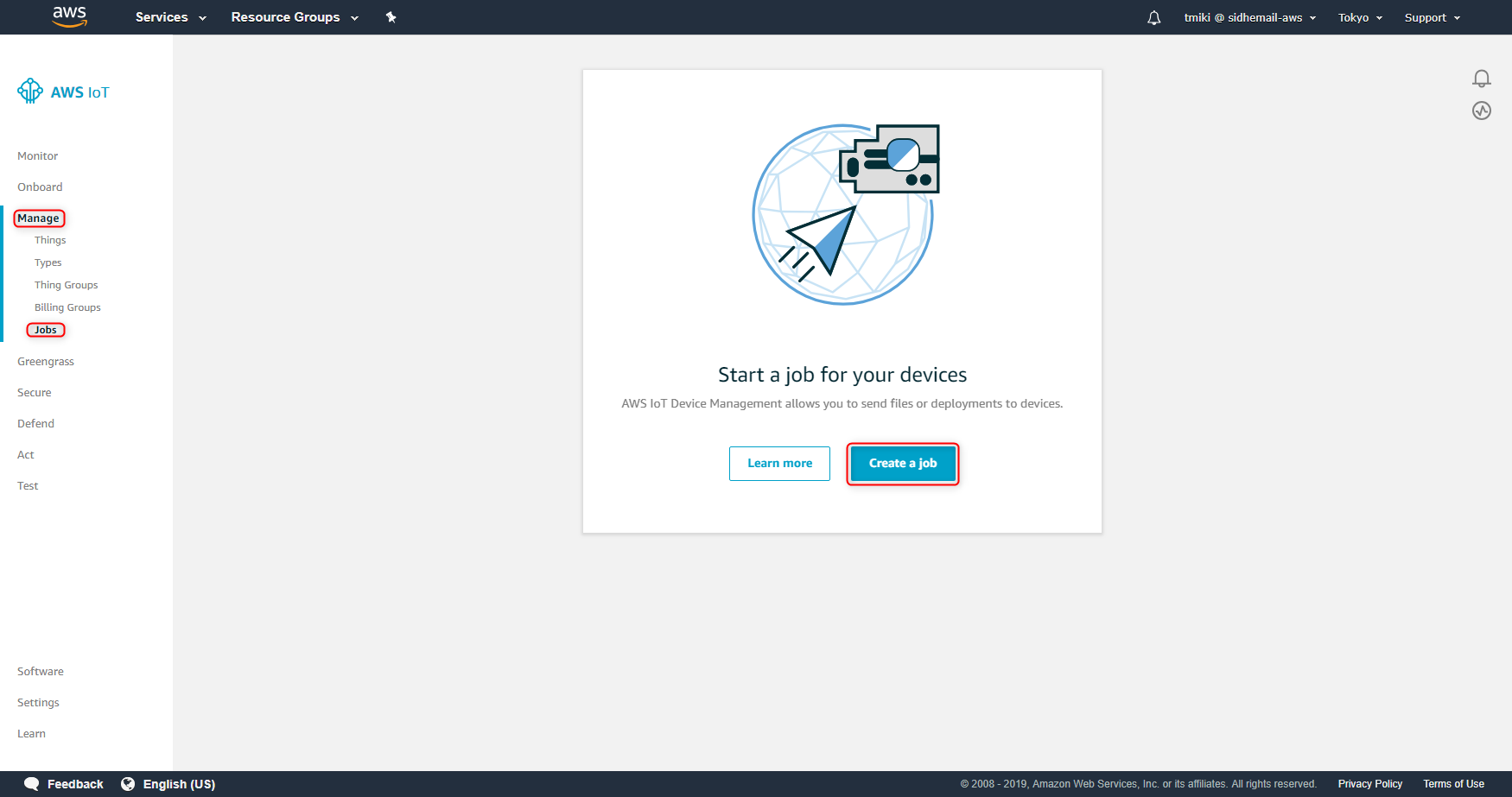
この作業はAWS Management Consoleから行ってみます。
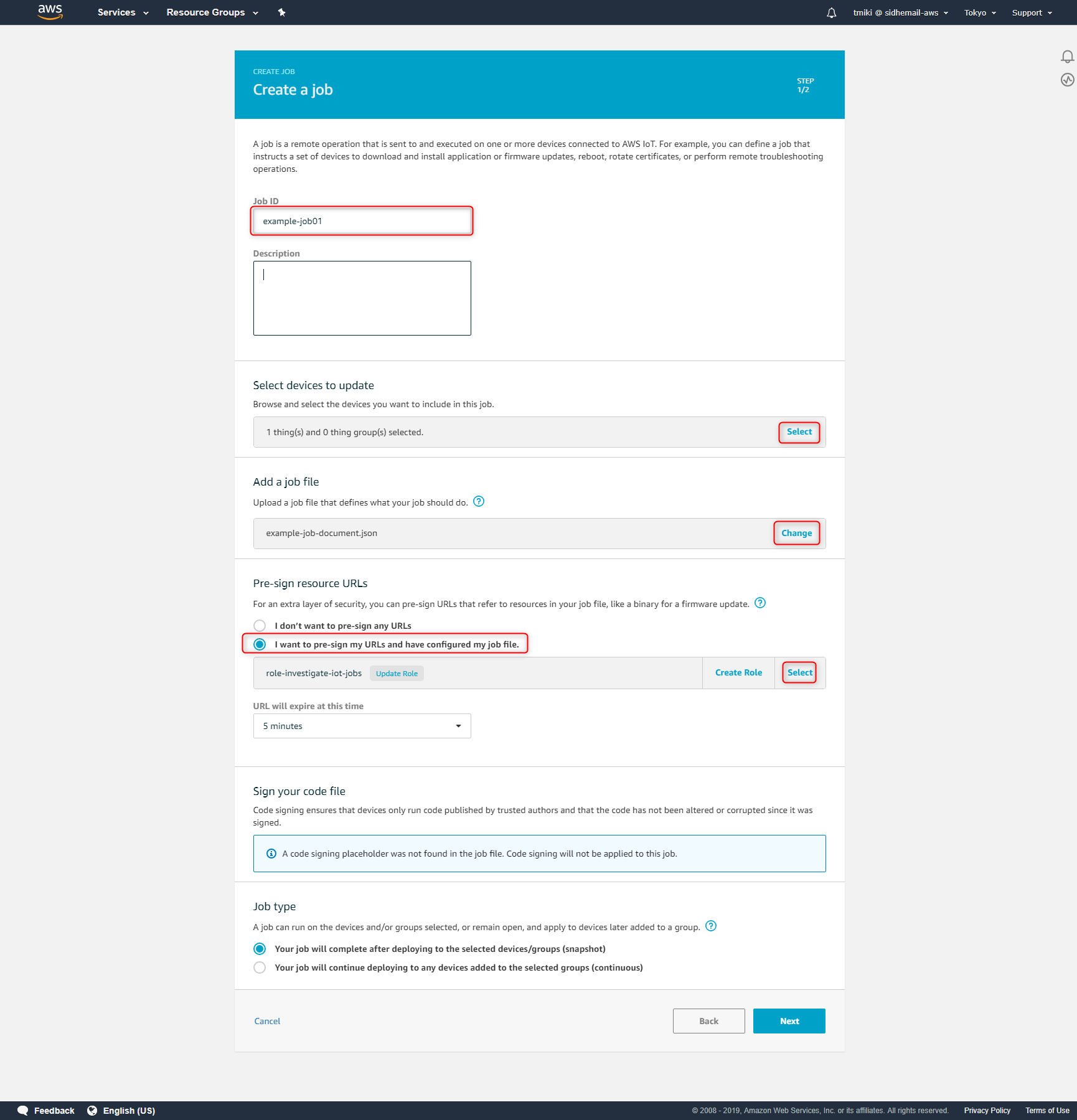
以下の内容でJobを作ります。
- JobID: example-job01
- Select devices to update: example-device01
- Add a job file: s3://investigate-iot-jobs/example-job-document.json
- Pre-sign resource URLs
- I want to pre-sign my URLs and have configured my job file.
- Role: role-investigate-iot-jobs
まず、下記のURL等からAWS IoT CoreのDashboardを開きます。
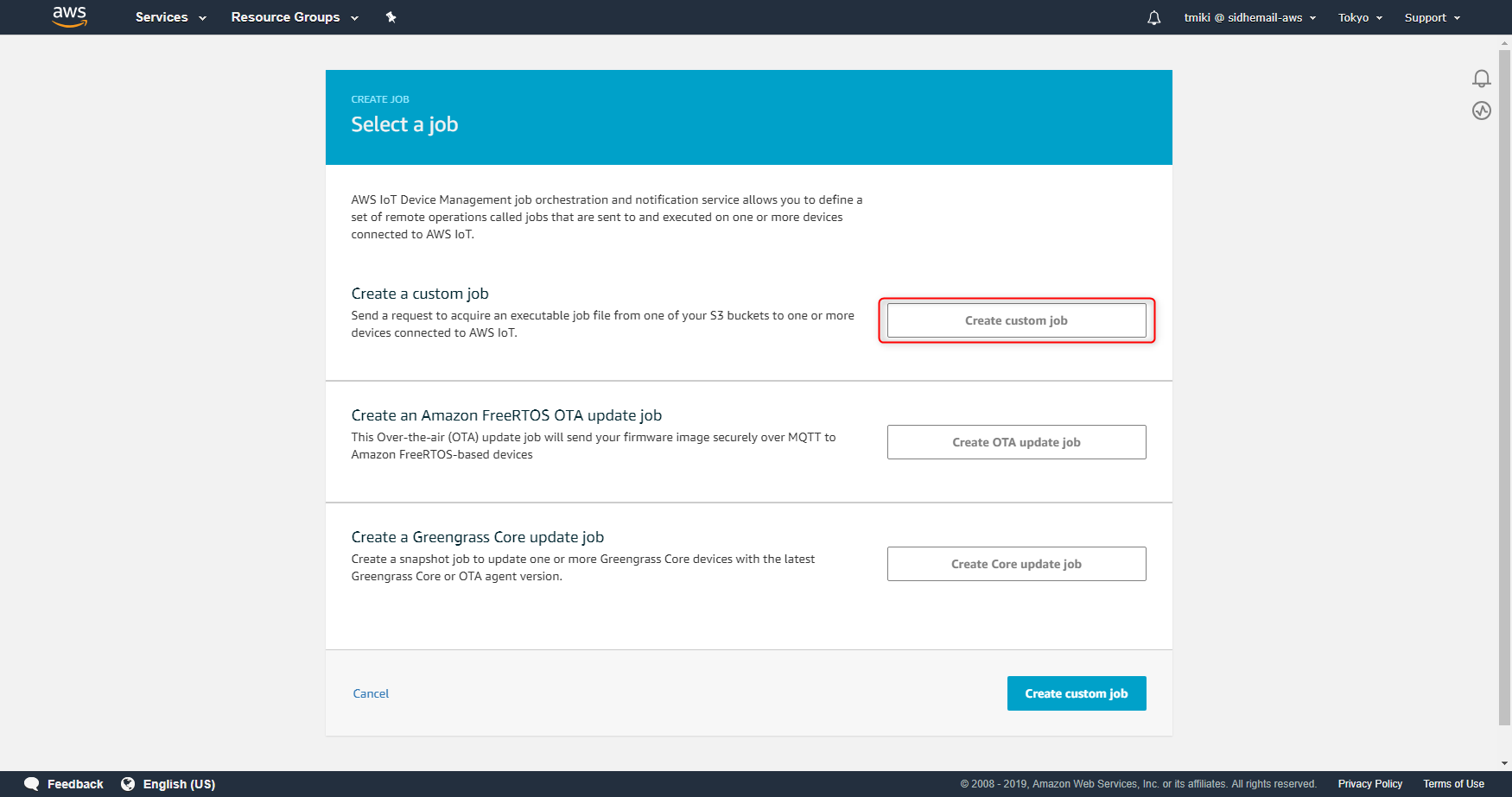
https://ap-northeast-1.console.aws.amazon.com/iot/home?region=ap-northeast-1#/dashboard次に、「Manage」->「Jobs」を選択します。遷移した画面で「Create a job」ボタンを押します。
どのようなジョブを作成するかを選択する画面になりますので「Create custom job」ボタンを押します。
具体的な値を設定する画面に遷移しますので、上述した内容でJobを作っていきます。入力したら「Next」ボタンを押します。
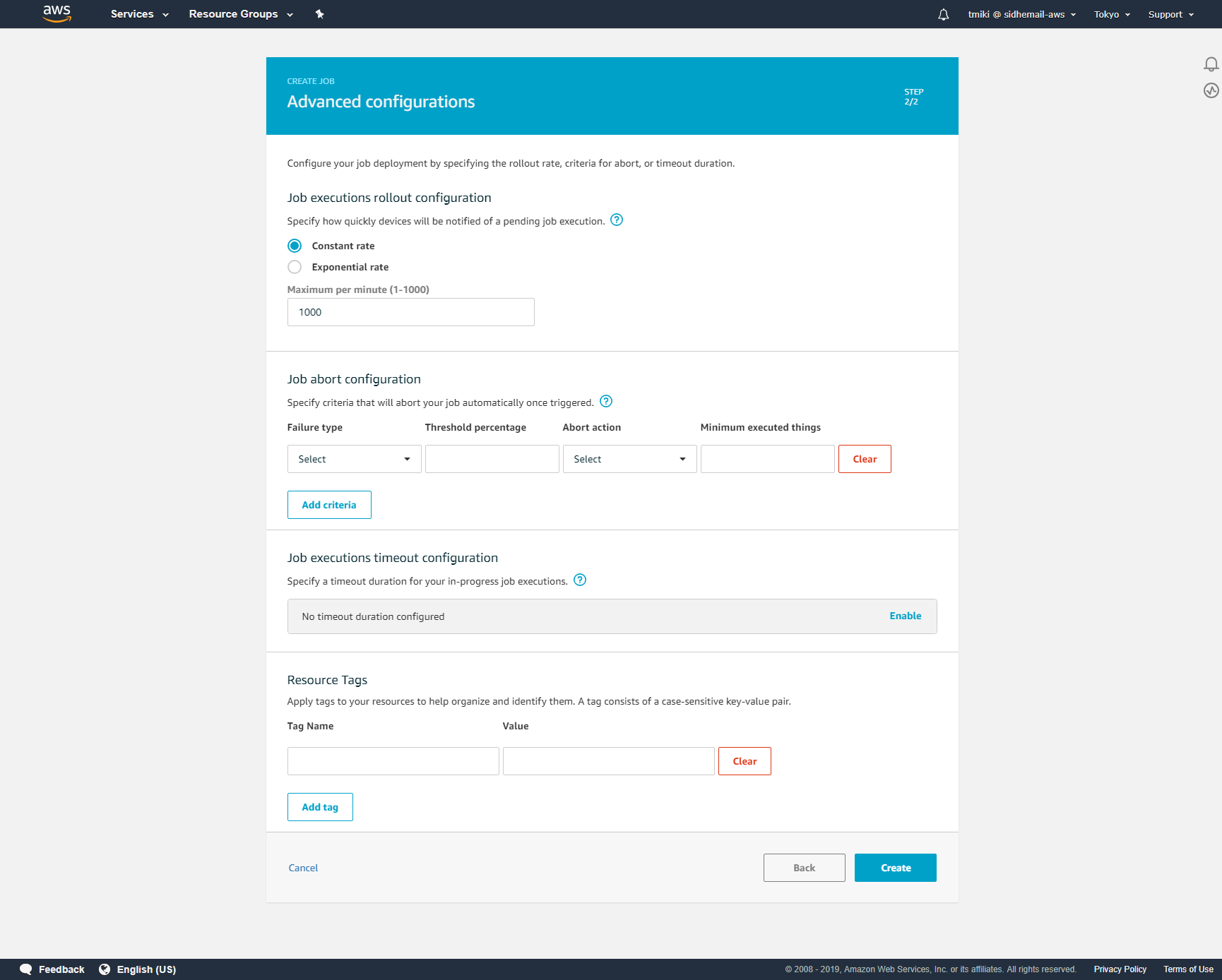
次のページは、特に変更する点はありません。そのまま「Create」ボタンを押します。
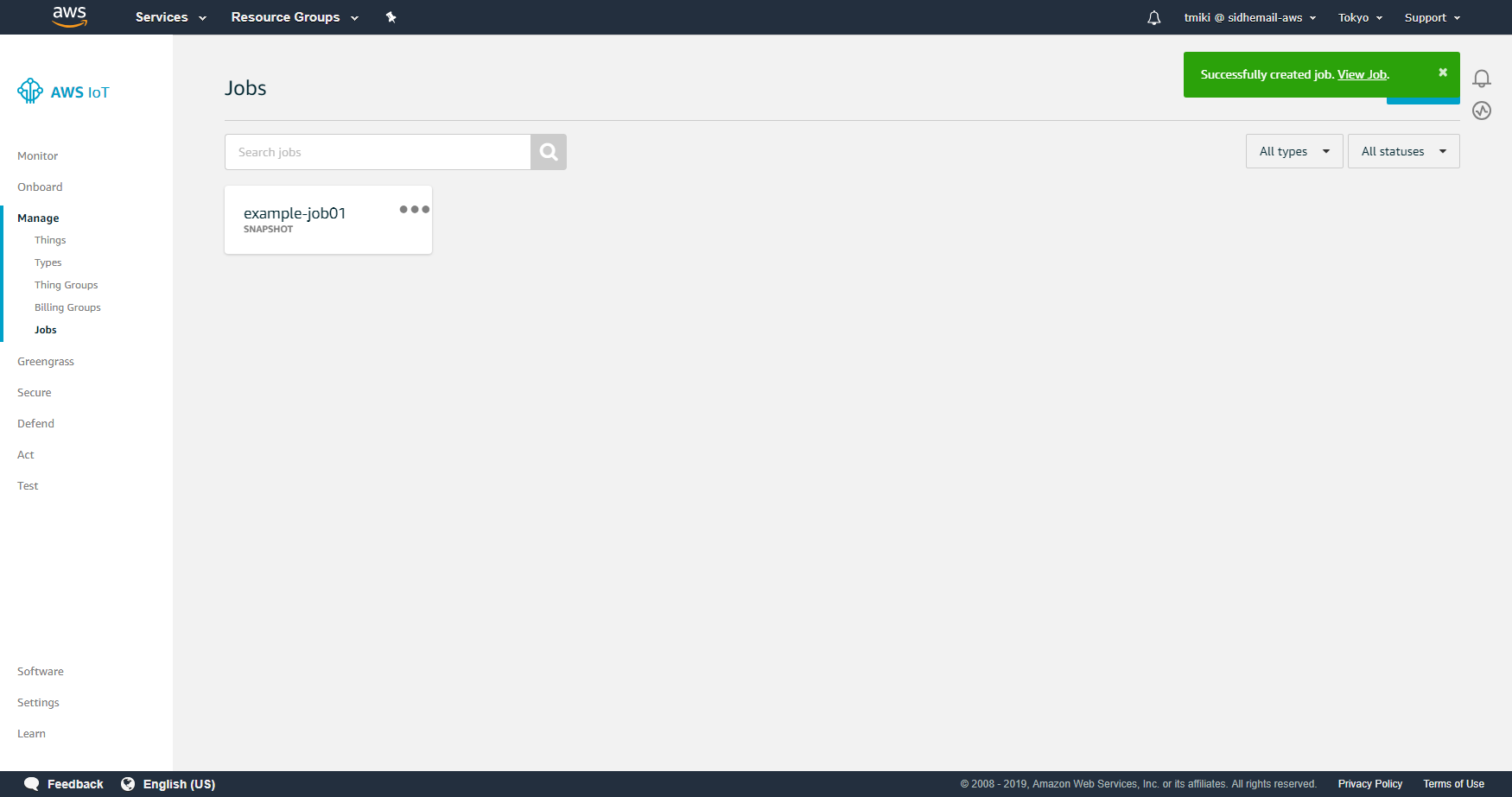
作成が完了すると、以下のように作成されたJobが表示されます。
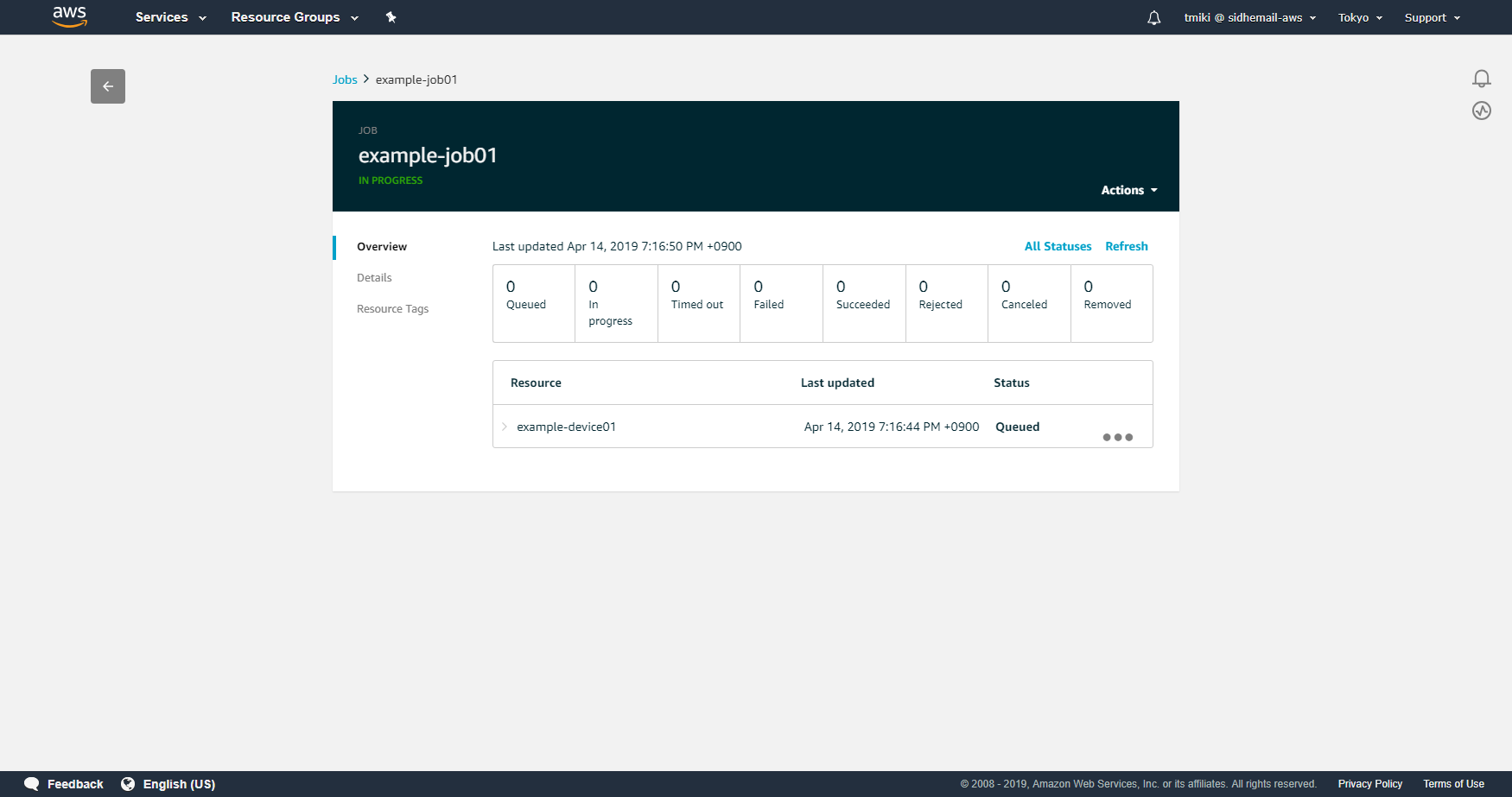
Jobをクリックすると、詳細を参照することが可能です。
作成したIoT JobをAWS CLIから参照する
AWS CLIからは、iot list-jobsおよびiot describe-jobで参照することができます。
aws iot list-jobs$ aws iot list-jobs { "jobs": [ { "status": "IN_PROGRESS", "jobArn": "arn:aws:iot:ap-northeast-1:4**********8:job/example-job01", "jobId": "example-job01", "lastUpdatedAt": 1555237008.749, "targetSelection": "SNAPSHOT", "createdAt": 1555237002.922 } ] }aws iot describe-job$ aws iot describe-job --job-id example-job01 { "documentSource": "https://investigate-iot-jobs.s3.ap-northeast-1.amazonaws.com/example-job-document.json", "job": { "status": "IN_PROGRESS", "jobArn": "arn:aws:iot:ap-northeast-1:4**********8:job/example-job01", "jobProcessDetails": { "numberOfQueuedThings": 1, "numberOfInProgressThings": 0, "numberOfSucceededThings": 0, "numberOfTimedOutThings": 0, "numberOfCanceledThings": 0, "numberOfFailedThings": 0, "numberOfRemovedThings": 0, "numberOfRejectedThings": 0 }, "presignedUrlConfig": { "expiresInSec": 300, "roleArn": "arn:aws:iam::4**********8:role/role-investigate-iot-jobs" }, "jobId": "example-job01", "lastUpdatedAt": 1555237008.749, "targetSelection": "SNAPSHOT", "timeoutConfig": {}, "jobExecutionsRolloutConfig": { "maximumPerMinute": 1000 }, "targets": [ "arn:aws:iot:ap-northeast-1:4**********8:thing/example-device01" ], "createdAt": 1555237002.922 } }デバイスからJobの情報を取得する
ではいよいよ、デバイスからMQTT経由で作成したJobの情報を取得します。
ただし、実際に組み込み系デバイスでMQTT経由でJobを取得するためには、それ相応のプログラムを実装する必要があり、冗長です。
本稿では、AWS Management ConsoleのMQTTクライアント機能を利用し、デバイスから行う操作を疑似的に再現することとします。デバイスからJobを取得するフローは、下記ドキュメントの「DescribeJobExecution」に従います。
Using the AWS IoT Jobs APIs - AWS IoT -> DescribeJobExecution
https://docs.aws.amazon.com/iot/latest/developerguide/jobs-api.html#mqtt-describejobexecutionこれはjobIdで指定したJobの内容を取得することができます。
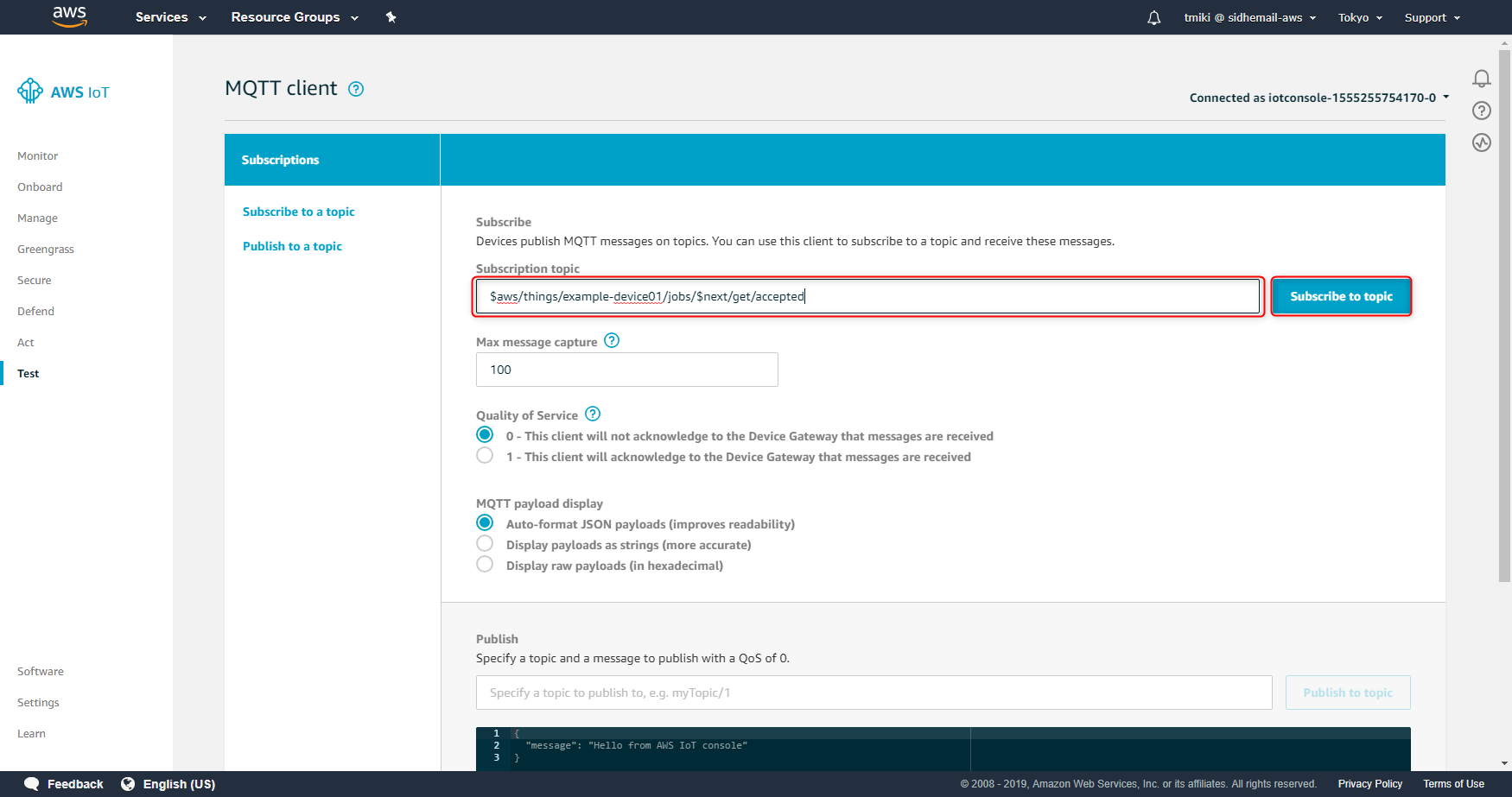
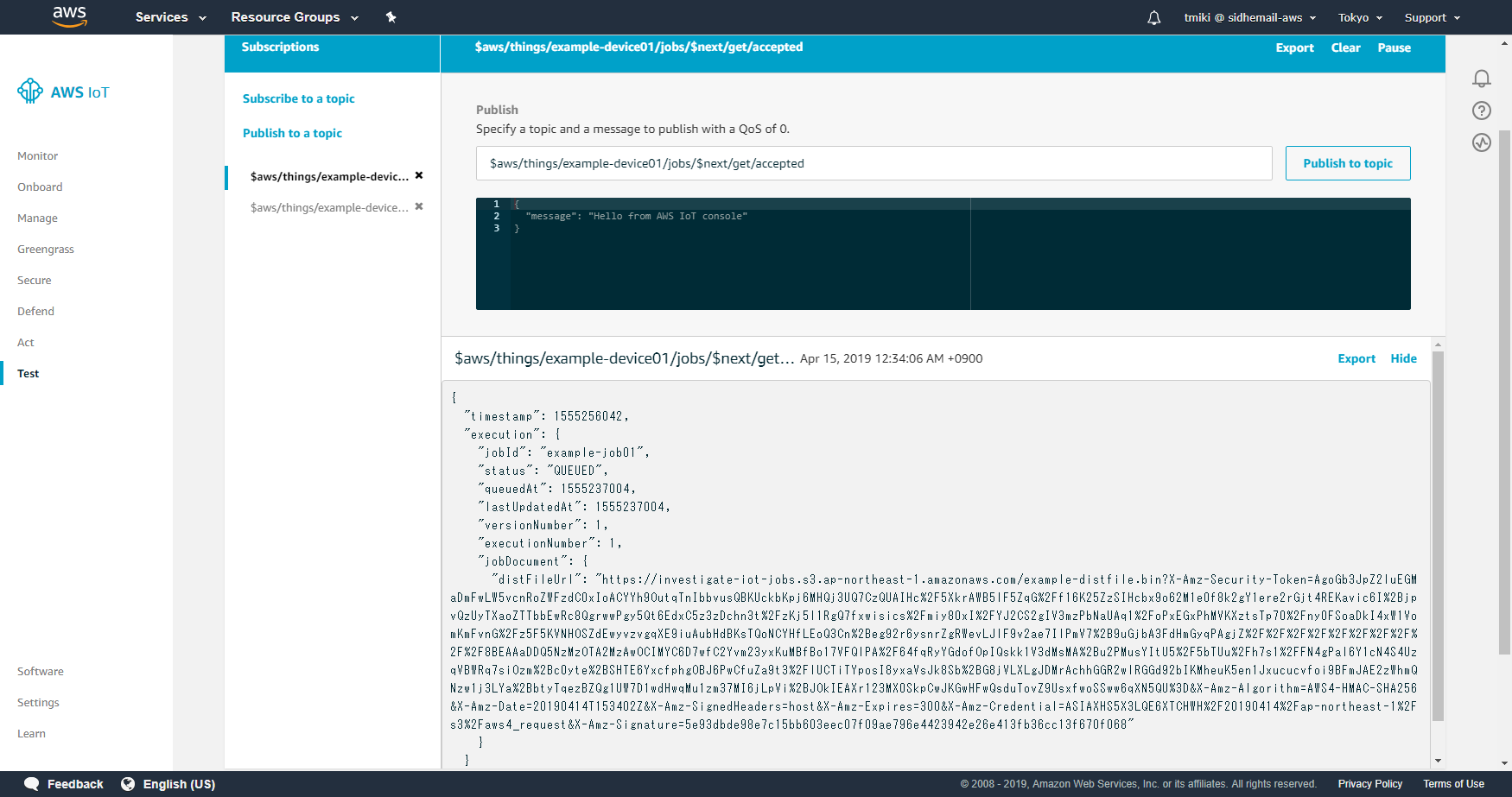
MQTTのTopic名にjobIdを指定しますが、「$next」という特殊な文字列を設定することで、当該Thingに割り当てられたJobのうち実行待ちのもの(statusがIN_PROGRESSかQUEUEDのもの)のを対象とすることができます。まず、AWS IoT CoreのDashboardから「Test」をクリックし、MQTTクライアントを実行します。
以下のMQTT TopicをSubscribeします。「Subscription topic」にSubscribeしたいTopicを入力し「Subscribe to topic」ボタンを押します。
- \$aws/things/example-device01/jobs/$next/get/accepted
- \$aws/things/example-device01/jobs/$next/get/rejected
次に、「Publish to a topic」リンクをクリックします。
「Specify a topic and a message to publish with a QoS of 0.」の欄に下記のTopic名を入力します。
メッセージ本文は何でもよいです。ここでは空オブジェクト「{}」を指定します。
入力後、「Publish to topic」ボタンをクリックします。
- \$aws/things/example-device01/jobs/$next/get
すると、「\$aws/things/example-device01/jobs/$next/get/accepted」TopicにメッセージがPublishされます。
「\$aws/things/example-device01/jobs/$next/get/accepted」Topicを見てみると、下記のようなJSONドキュメントがPublishされていることが分かります。
\$aws/things/example-device01/jobs/$next/get/accepted{ "timestamp": 1555256042, "execution": { "jobId": "example-job01", "status": "QUEUED", "queuedAt": 1555237004, "lastUpdatedAt": 1555237004, "versionNumber": 1, "executionNumber": 1, "jobDocument": { "distFileUrl": "https://investigate-iot-jobs.s3.ap-northeast-1.amazonaws.com/example-distfile.bin?X-Amz-Security-Token=AgoGb3JpZ2luEGMaDmFwLW5vcnRoZWFzdC0xIoACYYh9OutqTnIbbvusQBKUckbKpj6MHQj3UQ7CzQUAIHc%2F5XkrAWB5lF5ZqG%2Ff16K25ZzSIHcbx9o62M1e0f8k2gY1ere2rGjt4REKavic6I%2BjpvQzUyTXaoZTTbbEwRc8QgrwwPgy5Qt6EdxC5z3zDchn3t%2FzKj5l1RgQ7fxwisics%2Fmiy80xI%2FYJ2CS2gIV3mzPbNaUAq1%2FoPxEGxPhMVKXztsTp70%2Fny0FSoaDkI4xW1VomKmFvnG%2Fz5F5KVNHOSZdEwyvzvgqXE9iuAubHdBKsTQoNCYHfLEoQ3Cn%2Beg92r6ysnrZgRWevLJlF9v2ae7IlPmV7%2B9uGjbA3FdHmGyqPAgjZ%2F%2F%2F%2F%2F%2F%2F%2F%2F%2F8BEAAaDDQ5NzMzOTA2MzAwOCIMYC6D7wfC2Yvm23yxKuMBfBo17VFQlPA%2F64fqRyYGdofOpIQskk1V3dMsMA%2Bu2PMusYItU5%2F5bTUu%2Fh7s1%2FFN4gPal6Y1cN4S4UzqVBWRq7siOzm%2Bc0yte%2BSHTE6YxcfphgOBJ6PwCfuZa9t3%2FlUCTiTYposI8yxaVsJk8Sb%2BG8jVLXLgJDMrAchhGGR2wlRGGd92bIKMheuK5en1Jxucucvfoi9BFmJAE2zWhmQNzw1j3LYa%2BbtyTqezBZQg1UW7D1wdHwqMu1zm37MI6jLpVi%2BJOkIEAXr123MX0SkpCwJKGwHFwQsduTovZ9UsxfwoSSww6qXN5QU%3D&X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Date=20190414T153402Z&X-Amz-SignedHeaders=host&X-Amz-Expires=300&X-Amz-Credential=ASIAXHS5X3LQE6XTCHWH%2F20190414%2Fap-northeast-1%2Fs3%2Faws4_request&X-Amz-Signature=5e93dbde98e7c15bb603eec07f09ae796e4423942e26e413fb36cc13f670f068" } } }ここで重要な項目は「execution.jobDocument」になります。これは先ほど作ってS3上に格納したもJobDocumentファイルの内容が入ります。
ただし、1点大きく違う点があります。「distFileUrl」の値が書き換わり、実際のPresigned URLになっていることです。
ちなみに、Job作成時に有効期限を「5 minutes」に設定しているので、上記のPresigned URLの有効期限は5分になります。もともとのファイルは下記の内容でした。「\${aws:iot:s3-presigned-url:.......}」の項目が、実際のPresigned URLに置き換わっています。
example-job-document.json{ "distFileUrl": "${aws:iot:s3-presigned-url:https://s3.amazonaws.com/investigate-iot-jobs/example-distfile.bin}" }JobDocumentに記載のPresigned URLの仕様
まずPresigned URLは、MQTT経由で取得した場合のみ置き換えられます。
Using the AWS IoT Jobs APIs - AWS IoT -> GetJobDocument
https://docs.aws.amazon.com/iot/latest/developerguide/jobs-api.htmlGetJobDocumentというAPIがありますが、ここのNoteにその旨、記載があります。
GetJobDocument
Gets the job document for a job.Note
Placeholder URLs are not replaced with presigned Amazon S3 URLs in the document returned. Presigned URLs are generated only when the AWS IoT Jobs service receives a request over MQTT.
Presigned URLは、デバイスから取得のリクエストが行われた場合に生成されます。
したがって、Presigned URLの有効期限が切れた場合は、デバイス側から再度JobDocumentを取得することで、新たなPresigned URLを得ることができます。Managing Jobs - AWS IoT
https://docs.aws.amazon.com/iot/latest/developerguide/create-manage-jobs.htmlManaging Jobs
When a device requests the job document, AWS IoT generates the presigned URL and replaces the placeholder URL with the presigned URL. Your job document is then sent to the device.
おわりに
現実的にAWS IoTを利用してリモートデバイスをコントロールする場合、MQTTが主な通信手段となるでしょう。この構成でファイル配信する場合、JobDocumentにPresigned URLを記載し、デバイスからダウンロードさせる方式が現時点ではベストな方式になると思います。
- 投稿日:2019-04-15T00:10:36+09:00
エンジニア初心者がRailsでランキング機能実装の際につまづいたところ
CDの発売日を管理できるサービスを作っていて、発売日が過ぎたときにランキングから除外しなきゃ!と思ったものの微妙に詰まったのでここに備忘録として書き残しておきます。?
環境:cloud9(IDE)EC2(仮想サーバー)rails(rubyFW)mysql(DB)
まず大前提の知識としてModelはDBの情報を引っ張ってくるということです!(今更)
MVCのそれぞれの役割をしっかり理解しておくことは本当に重要で、理解してプログラミングをしていると今自分が何をやっているのか頭の中で整理できます。今回は実際に色々試した過程を書きます。
大まかな流れとして、
1.DB設計を考える 2.mysql(DB)でコマンドを色々試す→3.処理が成功したらmodelに実装
という形で行いました。1.DB設計を考える
ランキングは中間テーブル(relationships)で集計しているので、中間テーブルに発売日カラムを登録することで発売日でフィルターをかけることができるのでは?
2.mysqlでコマンドを色々試す
▼カラム追加(mysql)
alter table relationships add sales_date date;
楽天apiから発売日情報を文字列型で引っ張って来ているのでエラーになってしまった。
alter table relationships add sales_date varchar(255);
文字列型で登録〜うん良さそう▼発売日を過ぎたものは非表示にするコマンドをチェック
私が実際にやったときはmodelの記述を先に行ってしまったのですごい時間を食ってしまった…先にこっちで確認すべきだった…良い学び
select * from relationships where sales_date > date_format(current_date(),'%Y年%m月%d日');
処理内容としては、現在日時をdate_formatを用いて年月日に変更し、sales_dateと比較演算子を用いて比較しています。これをそのままmodelに実装します。3.処理が成功したらmodelに実装
▼記述方法
relationship.rbdef Relationship.ranking Relationship.where().group().order().limit().count() end前述の通り、modelはdbから情報を引っ張ってくるので書き方としてはかなりdbに近いです。
まずwhereで絞り込み、groupで重複した値をまとめ、orderで並べ替え、limitで表示制限をして最後のcountでCDの登録された数を数えるといった流れです。実際のコードを書いていきます。relationship.rbdef self.ranking self.where("sales_date > date_format(current_date(),'%Y年%m月%d日')").group(:item_id).order('count_item_id DESC').limit(12).count(:item_id) endwhere以外はそこまで特別なことはしていないので省きます。
結論から書くとwhereにdbで成功した文をダブルクォーテーションで囲むだけでOKです!笑
これでできたときは拍子抜けしました…それと同時にMVCの理解度が低かったとかなり痛感しました。
modelはdbの情報を引っ張ってくるわけだからdbで実際に成功した文をそのまま書けば確かに間違いはないですねwまとめ
MVCの役割を理解することの重要性を書きたかったのですがシッチャカメッチャカになっちゃった感。。。
まあそれなりに自分の考えは整理できた気がするので良しとします笑
反省点としては何を書くのか考えていなかったこと、考えをまとめていなかったことの二点ですかね?精進します!
- 投稿日:2019-04-15T00:09:05+09:00
TerraformでEC2インスタンスを構築(インストール編)
はじめに
AWSを使ってて、毎回コンソールから環境を構築するのは面倒です。
Terraformというツールを使えば、環境をドカッと作れて、ゴソッと消せるらしいので触ってみました。まずは、お試し感覚でAWSのEC2を構築します。
このインストール編ではインストールから初期設定までを説明しています。
実際の構築については実践編で説明しています。Terraformとは
Terraformとは、HashiCorp社製のAWSやGCPなどのクラウド上のリソース管理をする構成管理ツールです。
HashiCorp社のツールはTerraformの他にもVargrantなどがあり、これらはOSSとして公開されています。
Terraformの使い方
- インフラの構成情報を.tfという拡張子のファイルに記述します。
- terraformの各コマンドを実行することで、記述したインフラの構成を管理することができます。
- .tfファイルは複数に分かれていても、同じディレクトリに存在すればまとめて適用することが可能。
Terraformの開発フロー
Terraformを用いたインフラの開発は以下のような流れで行います。
- .tfファイルにインフラのコードを書く
- terraform planコマンドで現状との差分を比較する
- terraform applyコマンドでインフラを構成を適用する
- terraform showコマンドで状態を確認する
Terraformのインストール
ダウンロード先
Terraform は、下記のリンクからダウンロードできる。
MacOS 版(AMD64)、Linux 版 (i386, AMD64)、Windows 版(i386) に対応https://www.terraform.io/downloads.html
インストール
①インストール先のディレクトリを作成する。
$ mkdir terraform $ cd terraform②URLからダウンロード & 解凍
$ wget -O terraform_0.11.13_linux_amd64.zip https://releases.hashicorp.com/terraform/0.11.13/terraform_0.11.13_linux_amd64.zip $ unzip terraform_0.11.13_linux_amd64.zip③ディレクトリを見てみる
$ tree . . ├── 0.1.0_linux_amd64.zip ├── terraform └── terraform_0.11.13_linux_amd64.zip④バージョン確認のコマンドを実行してみる
$ ./terraform --version Terraform v0.11.13インストールは以上で完了。必要であればパスを通してある/usr/bin/などにコピーしてもいいかも。
初期設定
事前準備 for AWS
Trraformを使ってAWS環境を構築する前に、以下2つをやっておく。
① IAMユーザの作成
TerraforでAWS環境を管理するにはアクセスキーIDとシークレットキーが必要なのでIAMユーザを作成しておく
② AWS CLIのインストール
事前にAWSCLIのインストールをインストールしておく。
pip install awscliでインストールできる。Terraform初期設定
① IAMなどを登録
TerraformでAWSを管理する場合、アクセスキーの登録が必要になります。
Terraformをインストールしたディレクトリに.tfファイルを作成し、アクセスキーを記述します。
ファイル名は適当でOK。
リージョンも指定しておきます。aws_setting.tfprovider "aws" { access_key = "YOUR_ACCESS_KEY" secret_key = "YOUR_SECRET_KEY" region = "ap-northeast-1" }② Terraform初期化
IAMのアクセスキーをterraform init コマンドを実行する。
Terraformの作業ディレクトリを初期化し、AWSを操作するためのプラグインをインストールします。
このコマンドを実行すると、terraform planやterraform applyコマンドが実行可能になります。$ ./terraform init Initializing provider plugins... - Checking for available provider plugins on https://releases.hashicorp.com... - Downloading plugin for provider "aws" (2.6.0)... The following providers do not have any version constraints in configuration, so the latest version was installed. To prevent automatic upgrades to new major versions that may contain breaking changes, it is recommended to add version = "..." constraints to the corresponding provider blocks in configuration, with the constraint strings suggested below. * provider.aws: version = "~> 2.6" Terraform has been successfully initialized! You may now begin working with Terraform. Try running "terraform plan" to see any changes that are required for your infrastructure. All Terraform commands should now work. If you ever set or change modules or backend configuration for Terraform, rerun this command to reinitialize your working directory. If you forget, other commands will detect it and remind you to do so if necessary.③ terraform planで現在の状態を見てみる
terraform planコマンドを実行して、現在の状態を確認してみます。
変更なし、最新の状態であるというメッセージが表示される。
まだ、Terraformの設定ファイルにはAWSの構成情報は記述していないのでOK。$ ./terraform plan Refreshing Terraform state in-memory prior to plan... The refreshed state will be used to calculate this plan, but will not be persisted to local or remote state storage. ------------------------------------------------------------------------ No changes. Infrastructure is up-to-date. This means that Terraform did not detect any differences between your configuration and real physical resources that exist. As a result, no actions need to be performed.おわり
今回はインストール編なのでここまでです。
次回は実際にTerraformを使って、EC2インスタンスを作成してみようと思います。
- 投稿日:2019-04-15T00:01:50+09:00
AWS認定ソリューションアーキテクトアソシエイトへの道 その7 VPC関連のハンズオン
tl;dr
現在Webエンジニアをやっているが下記の理由のためにAWSソリューションアーキテクトアソシエイト取得を目指す。
- スキルアップ
- 業務の幅を広げる
- 知的好奇心
現在のAWSスキル
- テスト用にEC2を作成したことはある(LAMP環境を構築)
- ネットワーク用語はある程度わかる(マスタリングTCP/IP 入門編は名著だと思う)
学習方法
- 対策本を読むことを考えたが、手を動かしながら学んだほうが身につくと考え、Udemyの動画教材を購入
- AWS INNOVATE(Amazonが主催するAWSを学ぶためのONLINE CONFERENCE) → 開催中だったために登録
- 参考書も購入
購入した教材はこちら
AWS認定ソリューションアーキテクト – アソシエイト試験突破講座
購入した本はこちら
合格対策 AWS認定ソリューションアーキテクト - アソシエイト
本日の課題
- VPC/サブネットにサーバーを設定する(ハンズオン)
- ネットワークACL(ハンズオン)
- VPCエンドポイント(ハンズオン)
- VPC Flow logs
- VPCのまとめ
- 小テスト VPCテスト
課題メモ
- ネットワークACLのinbound rule,outbound ruleは番号が小さい方が優先される
参考URL