- 投稿日:2019-04-15T15:07:18+09:00
サーバー屋以外でも使えるSQL コマンド閲覧編
SQLとは
- RDBMSにおけるデータ操作や定義を行うための問い合わせ言語
- DBを使用するアプリケーションは全て、裏でこれを打っている
- コマンドラインでこれを操作できると運用管理が爆速になる
- 直接DBを触らないクライアントエンジニアでも、閲覧コマンドを覚えればいちいち担当者に問い合わせをしなくて済む
使い方
用意
今回はWordpressサイトを立ち上げてDBを覗いてみましょう。
docker-composeはこちら。
基本的に公式が公開しているものにMySQLへのポートを開けただけです。
これ書いてる時別の開発で3306番を使ってたんでポートは3307で。$ docker-compose run
接続
$ mysql -u {USER_NAME} -p -h {接続先ホスト} -P {接続先ポート番号(3306)}よく使うオプションは大体これだけ。
-p{PASSWORD}みたいに-pオプションとの間に スペースを入れずにパスワードを入れれば 、後からパスワードを聞かれませんが、セキュリティの観点から基本的に非推奨。$ mysql -u wordpress -pwordpress -h 127.0.0.1 -P 3307$ mysql -u wordpress -p -h 127.0.0.1 -P 3307 Enter password: Welcome to the MariaDB monitor. Commands end with ; or \g. Your MySQL connection id is 7 Server version: 5.7.25 MySQL Community Server (GPL) Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. MySQL [(none)]>
存在しているデータベース一覧を確認する
正確に言えば、接続ユーザーに許可されているデータベースの一覧ですが、rootユーザーなら全てが見れます。
MySQL [(none)]> SHOW DATABASES; +--------------------+ | Database | +--------------------+ | information_schema | | wordpress | +--------------------+ 2 rows in set (0.001 sec)
データベースを選択
使用するデータベースを選択する。
MySQL [(none)]> use wordpress Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Database changed MySQL [wordpress]>
検索
テーブル一覧の確認
選択したデータベースにどんなテーブルが存在しているかの確認。
これも正確にいえば権限が与えられているもの。MySQL [wordpress]> SHOW TABLES; +-----------------------+ | Tables_in_wordpress | +-----------------------+ | wp_commentmeta | | wp_comments | | wp_links | | wp_options | | wp_postmeta | | wp_posts | | wp_term_relationships | | wp_term_taxonomy | | wp_termmeta | | wp_terms | | wp_usermeta | | wp_users | +-----------------------+ 12 rows in set (0.001 sec)
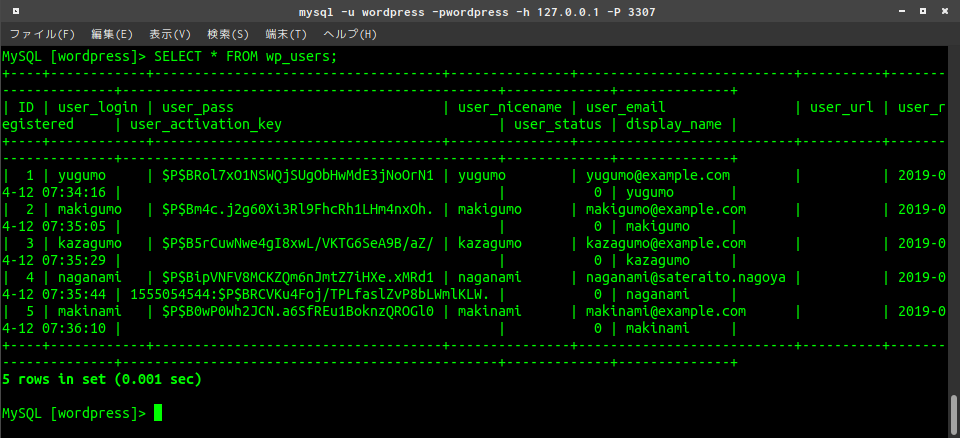
テーブル構造の確認
SHOW CREATE TABLE {テーブル名}MySQL [wordpress]> SHOW CREATE TABLE wp_users; +----------+------------------------------------------------------------------------- | wp_users | CREATE TABLE `wp_users` ( `ID` bigint(20) unsigned NOT NULL AUTO_INCREMENT, `user_login` varchar(60) COLLATE utf8mb4_unicode_520_ci NOT NULL DEFAULT '', `user_pass` varchar(255) COLLATE utf8mb4_unicode_520_ci NOT NULL DEFAULT '', `user_nicename` varchar(50) COLLATE utf8mb4_unicode_520_ci NOT NULL DEFAULT '', `user_email` varchar(100) COLLATE utf8mb4_unicode_520_ci NOT NULL DEFAULT '', `user_url` varchar(100) COLLATE utf8mb4_unicode_520_ci NOT NULL DEFAULT '', `user_registered` datetime NOT NULL DEFAULT '0000-00-00 00:00:00', `user_activation_key` varchar(255) COLLATE utf8mb4_unicode_520_ci NOT NULL DEFAULT '', `user_status` int(11) NOT NULL DEFAULT '0', `display_name` varchar(250) COLLATE utf8mb4_unicode_520_ci NOT NULL DEFAULT '', PRIMARY KEY (`ID`), KEY `user_login_key` (`user_login`), KEY `user_nicename` (`user_nicename`), KEY `user_email` (`user_email`) ) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_520_ci | +----------+----------------------------------------------------------------------------- 1 row in set (0.001 sec)
データ検索
テーブル全てを取得する
一番簡単なやつ。レコード数が少ないテーブルとかに使用する。SELECT * FROM {テーブル名} LIMIT 100;MySQL [wordpress]> SELECT * FROM wp_terms LIMIT 100; +---------+-----------------------+-----------------------------------------------------------------+------------+ | term_id | name | slug | term_group | +---------+-----------------------+-----------------------------------------------------------------+------------+ | 1 | Uncategorised | uncategorised | 0 | | 2 | #お礼 | uncategorised | 0 | | 3 | ホスピタリティ | %e3%83%9b%e3%82%b9%e3%83%94%e3%82%bf%e3%83%aa%e3%83%86%e3%82%a3 | 0 | | 4 | #Integrity | integrity | 0 | | 5 | #Delivery | delivery | 0 | | 6 | #神アプデ | %e7%a5%9e%e3%82%a2%e3%83%97%e3%83%87 | 0 | +---------+-----------------------+-----------------------------------------------------------------+------------+ 6 rows in set (0.001 sec)
条件つき検索
おそらく一番使うタイプ。
SELECT * FROM {テーブル名} WHERE {ターゲットにしたいカラム名} = {ターゲットの値};MySQL [wordpress]> SELECT * FROM wp_terms WHERE term_id = 3; +---------+-----------------------+-----------------------------------------------------------------+------------+ | term_id | name | slug | term_group | +---------+-----------------------+-----------------------------------------------------------------+------------+ | 3 | ホスピタリティ | %e3%83%9b%e3%82%b9%e3%83%94%e3%82%bf%e3%83%aa%e3%83%86%e3%82%a3 | 0 | +---------+-----------------------+-----------------------------------------------------------------+------------+ 1 row in set (0.000 sec)MySQL [wordpress]> SELECT * FROM wp_terms WHERE name = 'ホスピタリティ'; +---------+-----------------------+-----------------------------------------------------------------+------------+ | term_id | name | slug | term_group | +---------+-----------------------+-----------------------------------------------------------------+------------+ | 3 | ホスピタリティ | %e3%83%9b%e3%82%b9%e3%83%94%e3%82%bf%e3%83%aa%e3%83%86%e3%82%a3 | 0 | +---------+-----------------------+-----------------------------------------------------------------+------------+ 1 row in set (0.001 sec)
いろいろな条件
WHEREで使える条件式は何種類かあります。
これらは全て同義のもの。
SELECT * FROM wp_posts WHERE id > 1 AND id <= 5; SELECT * FROM wp_posts WHERE id IN (2,3,4,5); SELECT * FROM wp_posts WHERE id BETWEEN 2 AND 5; SELECT * FROM wp_posts WHERE id=2 OR id=3 OR id=4 OR id=5;
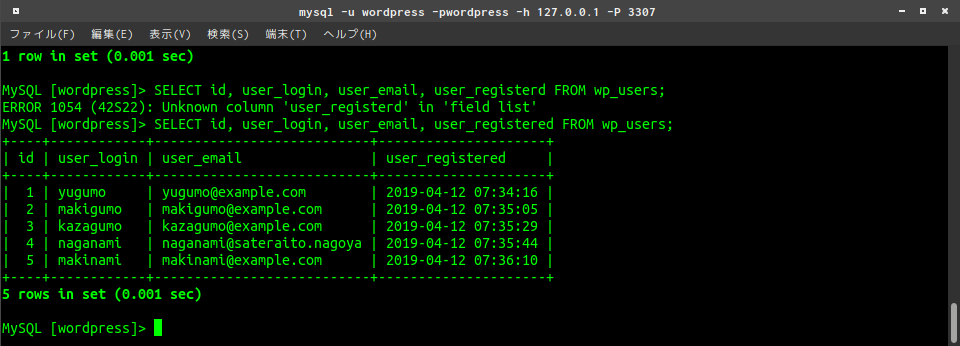
検索カラムの制限
見づらい・・・
そんなときは、
SELECT {表示カラム} FROM {テーブル名} WHERE ~~~~;で見たいカラムだけを選択する。
気をつけるべきこと
ここまでが基本的なSELECTの方法。
実務でデータ処理する場合は注意すべき点がいくつかあります。
- SELECTは常に最低限の範囲にする
- 時間がかかるクエリは打たない
- 用が済んだらすぐに切断する
1. SELECTは常に最低限の範囲にする
実際の運用では一つのテーブルに数億レコードが収められているという場合が往々にして存在します。
そこまで巨大なテーブルとなるとデータ量だけで数ギガバイトの容量。
これを出力するだけでDBにそこそこの負荷をかけたり、帯域を消費してしまいます。
何よりそんな大量のデータを人が見てどうこうできるわけがない。例えば…
SELECT * FROM wp_posts WHERE id = 5; #必要なレコードだけ出力 SELECT * FROM wp_posts LIMIT 10; #表示するレコード数を10までに制限する特に
LIMITはなるべくつける癖をつけたほうがいいです。
間違えて打ってしまった場合、一応クエリの途中でCtrl + cで中止することもできる。
2. 時間がかかるクエリは打たない
前のとかぶっている部分もありますが、処理に時間がかかるクエリは極力避ける。
同時に捌けるクエリ数には上限があります。
うっかり時間がかかるクエリを打ってしまうと、DBを専有してしまうことになる。例えば…
- 巨大なテーブルに対する複雑なWHERE条件
- 巨大なテーブルに対するインデックスが効かないクエリ
- 巨大なテーブルに対するあれこれ
相手が巨大な時ほど注意
3. 用が済んだらすぐに切断する
意図しないクエリを防ぐのと、コネクション数を節約するため。
DBにはmax_connectionsという設定項目があり、同時接続数に上限があります。
これを浪費しないようにしましょう。終了は
Ctrl + cや、exitコマンドを使います。MySQL [wordpress]> exit Bye $
結論
判断の基準となるのは、極力DBに負荷をかけないということです。
ローカルに立てている自分だけしか使用しないDBなら好きにしてもらえばいいですが、
開発テスト環境でも複数人での使用が考えられますし、本番環境ならいわずもがな。SQLを打つときは、常に自分に問いかけてください。 このクエリはDBにやさしいか?と。
まあ、慣れないうちはGUIツール使ったほうがいいですよ
- 投稿日:2019-04-15T15:03:38+09:00
Google Data Studioでオープンデータを可視化してみた
Google Data Studioとは
Googleが無償で提供するBIツールです。
BigQuery等と連携して、膨大なデータの分析と報告が可能です。今回使用するオープンデータ
今回は新宿区が公開している新宿区民の意識調査を利用します。
新宿区民から2500名を無作為抽出して調査表を送付し、返送があったものを有効回答としています。
データ自体はエクセルのためcsv形式に変換するために若干の操作が必要ですが、
ローデータが手に入るため分析の練習には有用かと思います。
新宿区民意識調査オープンデータをBigQueryに入れる
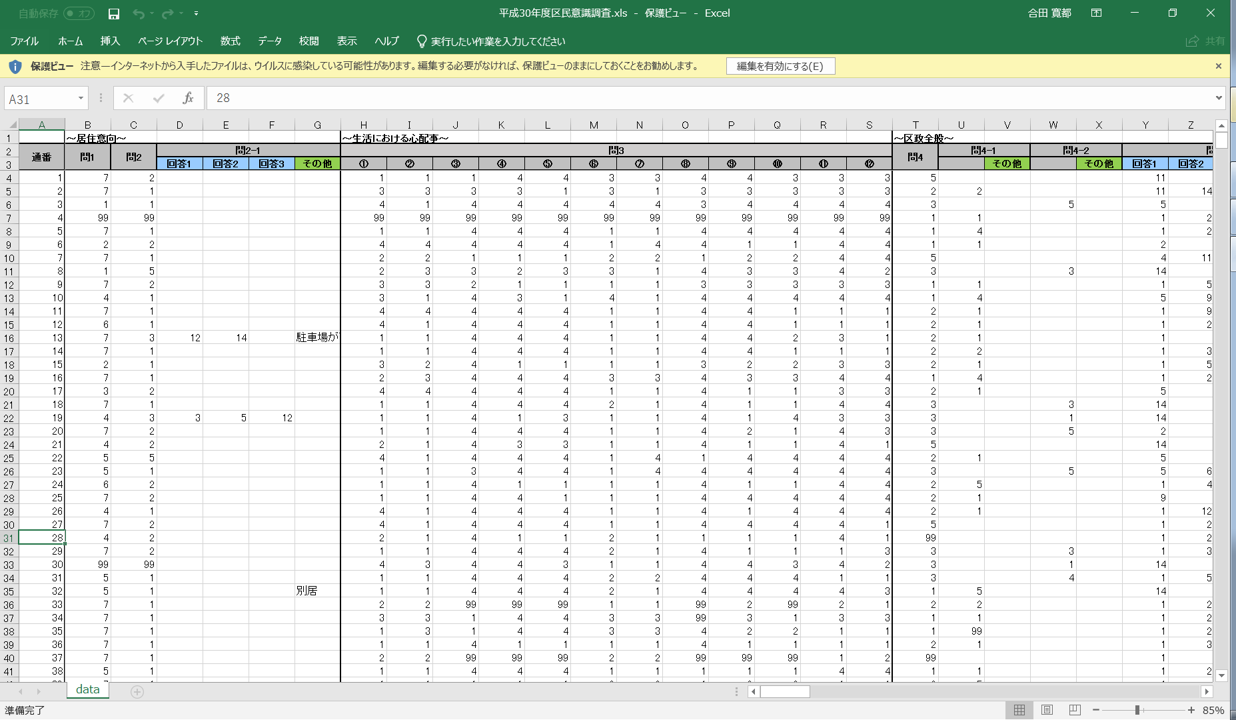
ダウンロードしたデータは、エクセル形式で下記のようになっています。
下記をBigQueryに読み込めるように手を加えます。
調査項目が大量にあるため、今回分析対象にしたい項目だけ残し他は削除します。
また、調査表を参照して質問内容を確認しながら、各項目のヘッド部分に名前を記載します。
それをCSV化したのがこちら。
これをBigQueryに読み込みます。BigQueryにデータを入れて抽出・集計する。
BigQueryにデータをいれる
BigQueryにデータをいれていきます。
データの入れ方は下記記事と殆ど同じです。
オープンデータをBigQueryに入れてみるデータを抽出する
今回は、新宿区民の年収と生活への満足度の関係をさぐっていきたいと思います。
抽出する列名と各回答の意味はこんな感じです。
列名 項目の意味 annual_income 世帯年収 satisfaction 生活への満足度
annual_incomeの回答 回答の詳細 1 200万円未満 2 200万円~300万円未満 3 300万円~500万円未満 4 500万円~700万円未満 5 700万円~1000万円未満 6 1000万円~1500万円未満 7 1500万円以上 8 わからない
satisfactionの回答 回答の詳細 1 たいへん満足している 2 満足している 3 やや不満である 4 たいへん不満である 5 どちらともいえない クエリを実行する
今回は、世帯年収毎にグループ化しそれぞれの生活への満足度の回答を集計します。
また、それぞれの回答に対して「as~」で名前を付け、わかりやすくしていきます。
そして「is not null」 で年収質問への無回答者を省く対応も行います。
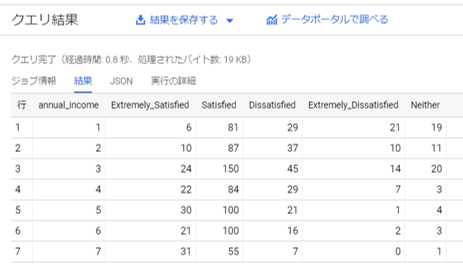
コードはこちらです。SELECT annual_income, count(satisfaction = 1 or null) as Extremely_Satisfied, count(satisfaction = 2 or null) as Satisfied, count(satisfaction = 3 or null) as Dissatisfied, count(satisfaction = 4 or null) as Extremely_Dissatisfied, count(satisfaction = 5 or null) as Neither From `population-237107.Survey.survey_shinzyuku` Where annual_income is not null Group by annual_income order by annual_income ascデータを確認する
このようにデータが書き出されています。
こちらを可視化していきます。
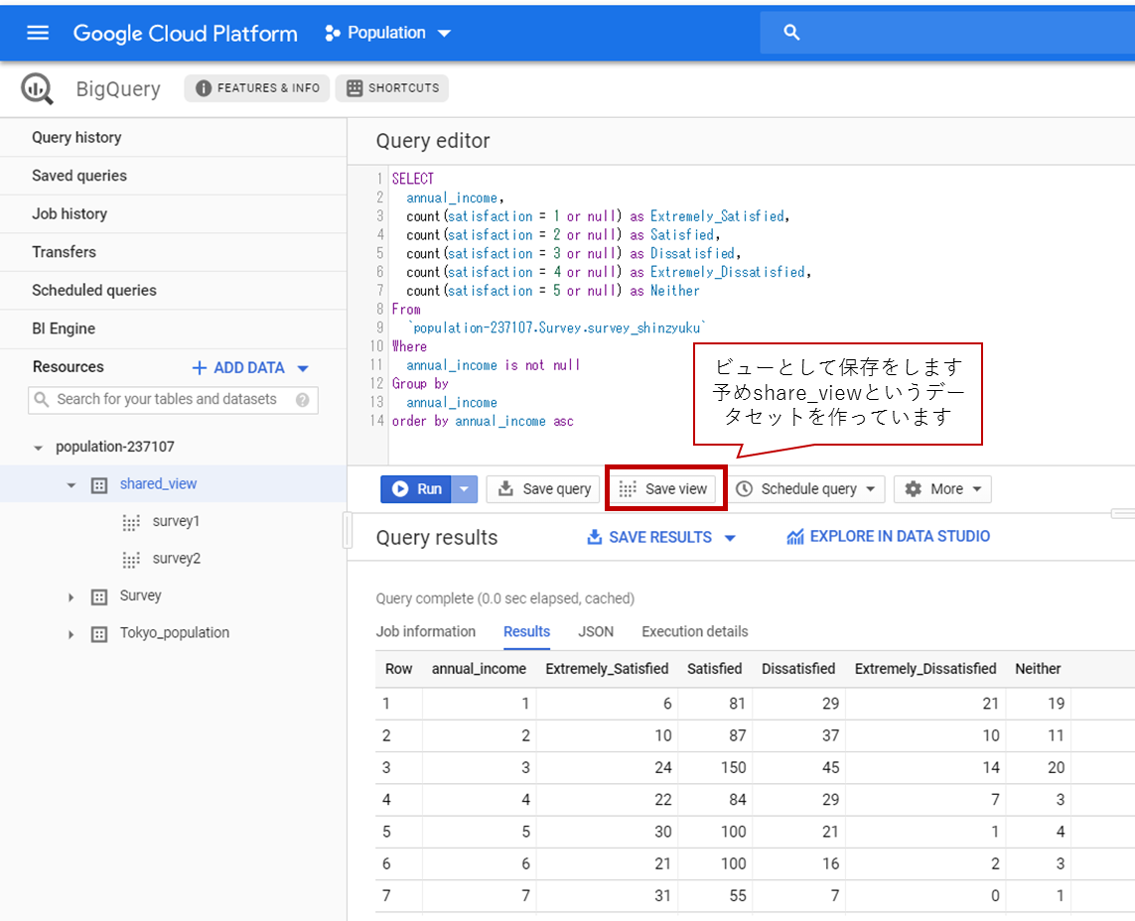
ビューとして保存
上記の結果を、GoogleDataStudioに接続して使用するため、ビューとして保存をします。
今回はSurvey1という名称とします。
こちらで準備は完了です。
GoogleDataStudioにて可視化をしていきます。GoogleDataStudioで可視化する
BigQueryと接続する
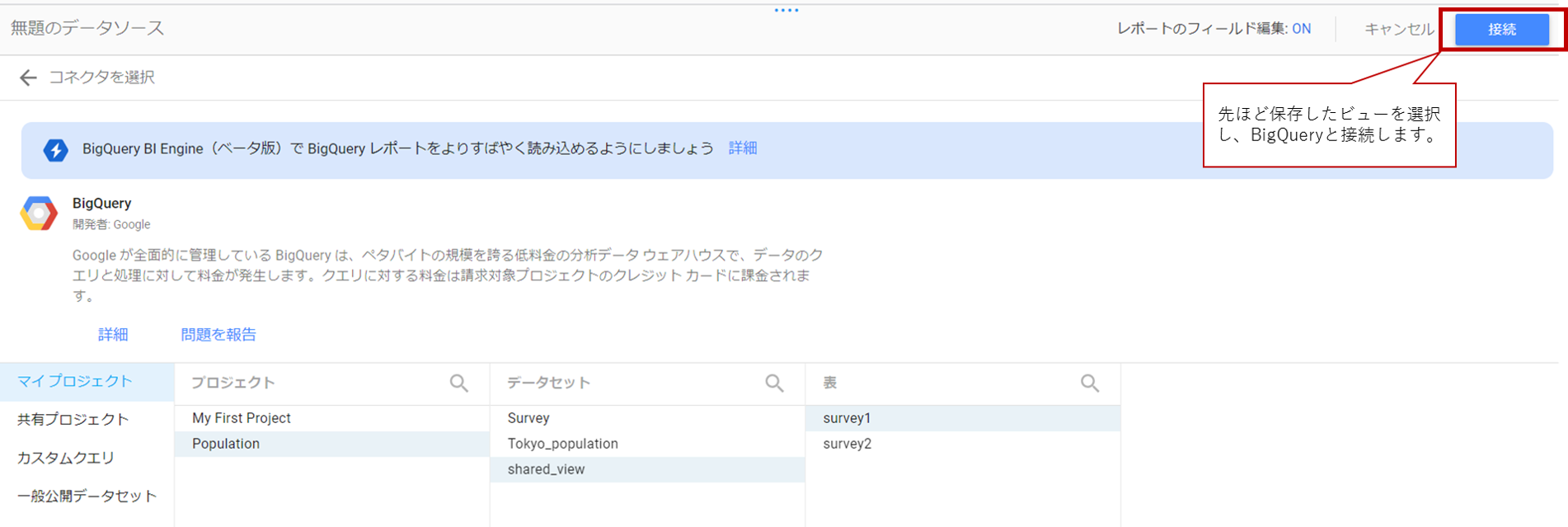
まず、下記GoogleDataStudioのページにアクセスし、新しいレポートの開始を選択します。
GoogleDataStudio
画面右下の「新しいデータソースを作成」ボタンを押下し、
先ほど作成したデータを読み込んでいきます。
先ほど保存したビューを選択肢、BigqQueryと接続します。
こちらで準備完了です。
データを可視化する
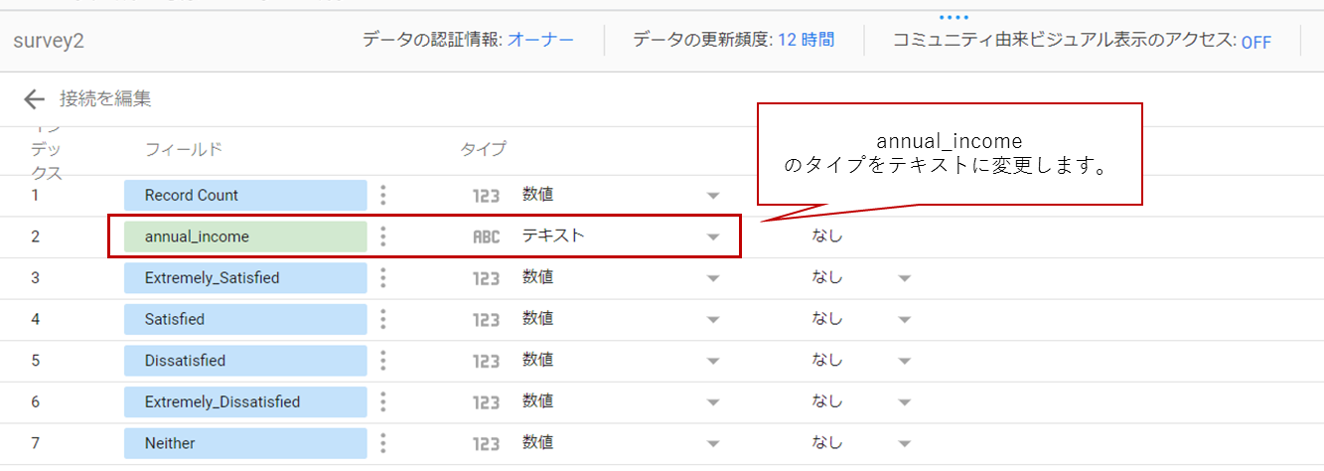
BigQueryと接続を行うと、下記画面が出てきます。
今回は世帯年収毎の生活への満足度の割合を可視化していきたいと思うので、
annual_incomeのフィードはテキストタイプとして読み込みます。
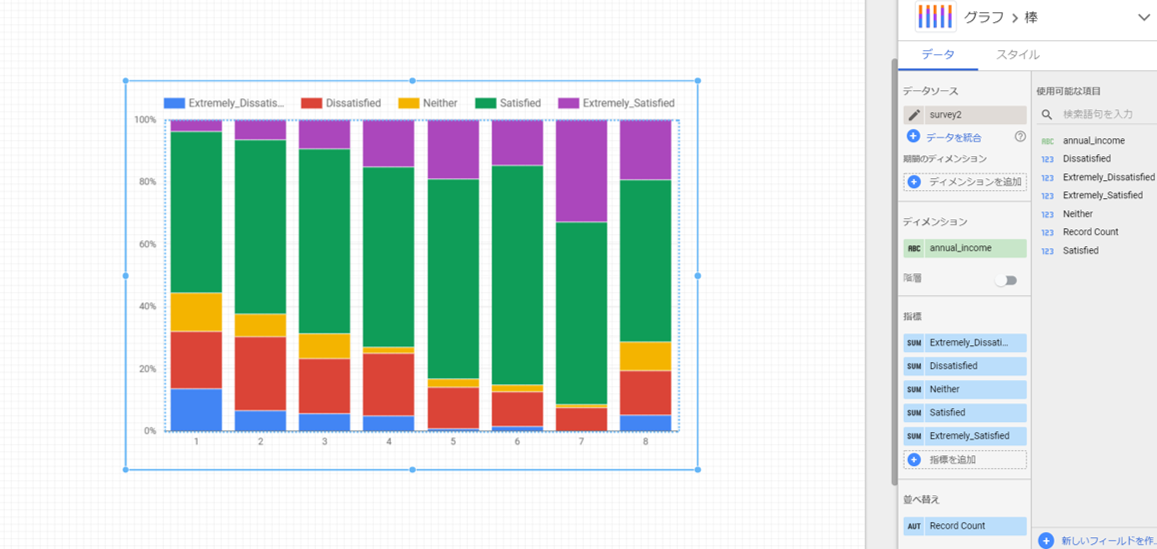
今回は、100%積み上げの縦棒グラフを用いて、世帯年収毎の各満足度の割合をひと目で見えるようにします。ディメンションにannual_income、指標に各満足度(satisfied,dissatisfied等)を入れ、グラフを作成します。
結果がこちらです。
annual_incomeの回答 回答の詳細 1 200万円未満 2 200万円~300万円未満 3 300万円~500万円未満 4 500万円~700万円未満 5 700万円~1000万円未満 6 1000万円~1500万円未満 7 1500万円以上 8 わからない 上手く可視化ができました。
世帯年収700万円を超えると、生活に対して「大変不満」と答える人は殆どいなくなりますね。
逆に、世帯年収300万円未満でも生活に対して「満足」と答える人は半数以上いるようです。
一概に世帯年収が低いといっても、学生であれば「満足」と答え、家族が多いと「不満」が多くなるみたいな現象はありそうですね。新宿区民の意識調査の中にそのような項目も含まれているので、また見てみたいと思います。
またこのような調査に、「大変不満」と答えるほど生活に困っている人は調査表が送られてきても返送しない、みたな標本自体の偏りもありそうです。Next
次はより複雑なデータの可視化や統計的な分析、
Pythonとの連携にも挑戦してみようと思います。

- 投稿日:2019-04-15T11:30:27+09:00
D-Oceanとその利用方法
D-Oceanとその利用方法
1.D-Oceanとは
そもそもD-oceanとは、ユーザー同士がビッグデータを含む様々なデータを共有することができるSNSのことである。会員登録はgoogleやtwitterアカウントを使用することができ、誰でも簡単に利用することができるようになっている。
データの公開範囲も自由に設定することができ、完全に誰でも利用できるものと、申請・承認制となっているものがある。2.利用方法
利用方法は比較的簡単である。ファイル形式は主に.csvとなっているのでおおよそのプログラミング言語で対応・処理できる。
また、D-Oceanの特徴としてサイト内でSQL文を使用して無料でデータをソート・絞り込みすることが可能になっている。(SQL文の使い方参考:データベース入門(SQL文)https://cfm-art.sakura.ne.jp/sys/archives/703)
まだ比較的新しいサービスということもありUIには若干の使いづらさを感じるものの、非常に便利で有用なものとなっている。