- 投稿日:2019-04-15T23:32:49+09:00
Pythonでプログレスバーを出す

- 投稿日:2019-04-15T23:00:45+09:00
Pythonでキーが押されているか判定する
- 投稿日:2019-04-15T22:50:16+09:00
Python3で実行途中にインタラクティブな操作へ移る
はじめに
デバッグのために実行を任意の時点で一度停止して,コンソールで対話的な操作をしたいときの方法.良い方法があったので自分用に書き残しておく.
使い方
当たり前だが下のコードでは2と3が順に出力される.
test1.pyx=2 print("x:", x) x=3 print("x:", x)これを途中で一時停止して対話的な操作をしてみる.
test2.pyimport code x=2 print("x:", x) x=3 code.InteractiveConsole(globals()).interact() #ここに達した時点で一時停止してインタラクティブな操作に移る print("x:", x)これを実行すると,"x = 2"が出力された後,いつものインタラクティブモードに切り替わる.
C:\Python>python test2.py x: 2 Python 3.7.1 (default, Dec 10 2018, 22:54:23) [MSC v.1915 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. (InteractiveConsole) >>>このモードの間は,普段使うコンソールと同じように使える.対話モードを終了するには
Ctrl+Zを押してEnter.プログラムそのものを終了するなら通常通りexit()関数を実行する.>>> x 3 >>> x=4 >>> ^Z now exiting InteractiveConsole... x: 4この例では,最後にxを出力するので書き換えた値の4が出力される.
- 投稿日:2019-04-15T22:21:14+09:00
Pythonを導入しよう インストールまで
未来電子テクノロジーでインターンをしているポッセです。
HackerRankに挑戦しようと思いましたが、使用できるコードの中で使ったことがあるのがJavaScriptとPHPしかありませんでした。
そのため、この際だからPythonを覚えてHackerRankで使おうと思い立ったので、その際に行ったPythonをインストールするまでの流れを記載します。なお、今回はWindowsでPython3の構築をする際のインストール方法を紹介するので、Python2を構築したい方や(これからPythonをしようと考えている方はPython2だと2020年以降サポートがされなくなるのでPython3から始めた方がいいかもしれません)Macの場合は異なりますので注意してください。
Pythonをダウンロードする
まずは、Pythonの公式サイトに行きます。Pythonの公式サイトはこちら。
その後、「Downloads」ボタンを押したら下に「Looking for a specific release?」の下にある「Release version」から使いたいバージョンを選んでください。
特別な事情がない限りは一番新しいバージョンでいいでしょう。(ちなみに、2019/04/15の段階では3.7.3が一番新しいバージョンです)その後、「Files」の下にある「Version」から、64bit型のWindowsの場合は「Windows x86-64 executable installer」32bit型のWindowsの場合は「Windows x86 executable installer」を選択してください。
自分のPCのbitが分からない方で、Windows10の方はこちら、vistaや7の方はこちらで調べてください。パッケージをインストールしたら
ここまで行えば後は簡単です。
Add Python 3.x to PATH(xの部分は入れたバージョンによって違います)は、追加しておいた方が後々便利なのでチェックしましょう。
その後、カスタマイズしたい場合はCustomize installationを、特にいじらないならInstall nowをクリックしてインストールを開始させてインストールは完了です。最後に
ここまでできれば後はPythonのチュートリアルを見てコマンドラインで動かしたり、Progateさんを利用したりしてPythonを動かせるようになってPythonライフを過ごしましょう!
私はまだ2日しかPythonしてないけど
- 投稿日:2019-04-15T21:58:12+09:00
ROS講座31 python基礎
環境
この記事は以下の環境で動いています。
項目 値 CPU Core i5-8250U Ubuntu 16.04 ROS Kinetic python 2.7.12 インストールについてはROS講座02 インストールを参照してください。
またこの記事のプログラムはgithubにアップロードされています。ROS講座11 gitリポジトリを参照してください。概要
ここまでROSノードをC++で作成していましたがpythonでも作成をすることができます。C++との違いを解説していきます。
ソースコード
talker
String型のROSメッセージをpublishするノードの記述です。
/home/erio/catkin_ws/src/ros_lecture/py_lecture/scripts/python_talker.py#!/usr/bin/env python import rospy import rosparam from std_msgs.msg import String def talker(): rospy.init_node('talker') word = rospy.get_param("~content", "default") pub = rospy.Publisher('chatter', String, queue_size=10) r = rospy.Rate(1) # 10hz while not rospy.is_shutdown(): str = "send: %s" % word rospy.loginfo(str) pub.publish(str) r.sleep() if __name__ == '__main__': try: talker() except rospy.ROSInterruptException: pass
- msgファイルのインクルード
from std_msgs.msg import Stringと記述します。(パッケージ名).msgの中を読み込みます。- privateパラメーターの読み込みは
word = rospy.get_param("~content", "default")と記述します。~(パラメーター)という名前でアクセスします。- publisherの宣言
pub = rospy.Publisher('chatter', String, queue_size=10)と記述します。- loggerの実行
rospy.loginfo(str)でROS_INFO()と同等のloggerを出力します。- C++と違いspinOnce()を実行する必要はありません。
listener
py_lecture/scripts/python_listener.py#!/usr/bin/env python import rospy from std_msgs.msg import String def callback(data): rospy.loginfo("recieved %s", data.data) now = rospy.Time.now() rospy.loginfo("now: %f", now.to_sec()) def listener(): rospy.init_node('listener') rospy.Subscriber("chatter", String, callback) rospy.spin() if __name__ == '__main__': listener()
- subscriverの宣言
rospy.Subscriber("chatter", String, callback)で宣言します。- ros time
rospy.Time.now()でC++のros::Time::now()と同等の値を取得します。- spin
rospy.spin()と記述します。timerのサンプル
py_lecture/scripts/python_timer.py#!/usr/bin/env python import rospy def timerCallback(event): rospy.loginfo("timer callback") def timer(): rospy.init_node('timer') rospy.sleep(2.0) rospy.loginfo("sleep 2s") rospy.Timer(rospy.Duration(2), timerCallback) rospy.spin() if __name__ == '__main__': try: timer() except rospy.ROSInterruptException: pass
- sleep
rospy.sleep(2.0)で2秒間のスリープをします。- tiemrの設定
rospy.Timer(rospy.Duration(2), timerCallback)で2秒ごとにtimerCallbackが起動します。実行権限の付与
pythonはスクリプト言語なのでこれ自体はビルドは必要ありません。ただpythonファイルを実行するためには実行権限を付ける必要があります。
実行権限の付与roscd py_lecture/scripts/ chmod +x python_talker.py chmod +x python_listener.py実行
1つ目のターミナルroscore2つ目のターミナルrosrun py_lecture python_talker.py _content:=data3つ目のターミナルrosrun py_lecture python_listener.pypythonのパス
pythonのモジュール等を探索するパスは環境変数の
PYTHONPATHに入っています。echo $PYTHONPATHとすると標準では/home/{user名}/catkin_ws/devel/lib/python2.7/dist-packages:/opt/ros/kinetic/lib/python2.7/dist-packagesとなっています。これらのパスにあるpythonモジュールをpythonのノード内で使用することができます。コメント
python自体はmakeは必要ありませんがカスタムmsgの生成等でmakeが必要なことはあります。
参考
目次ページへのリンク
- 投稿日:2019-04-15T21:50:50+09:00
AWSでデータ分析環境を構築する
自分用の備忘メモになります。
AWSのサービスの中には、機械学習向けにSagemakerがありますが、EC2インスタンスを用いて地道に分析環境構築してみようとチャレンジしてみました。
Sagemakerを利用するより、価格がお手軽になるのではないかと期待しています。1.EC2インスタンスのGPUの制限解除申請
GPUを利用する際には、利用申請が必要になります。利用申請は、日本語で大丈夫です。日本のAWSで申請受付されてから、US本国のAWSでチェックされます。
私が実際に2019年3月末に行った際は、申請から承認まで3日間(営業日)でした。日本側は即USへ申請した旨の返事あり。そこからUSの承認まで数日かかりました。
なお、GCPでは使用申請はないものの、無料枠を消化しないとGPUの使用制限解除にならないことがわかりました。2.ubuntu 1604 のリモートデスクトップ接続環境の構築
GPUを用いて分析を行うには、CUDA、Anaconda、Chainer等々のPythonライブラリ等のインストールと設定が必要になります。AWSの場合、AMIといってあらかじめ必要なツールを用意してくれるセットがあります。
(利用目的によって、OSをwindowsにしたり、SQLが用意されていたり等々)
2019年4月時点、Ubuntuで、データ分析、深層学習を行うAMIは、Ubuntuバージョンは、16.04になります。Ubuntu 16.04のインスタンスに対して、自分のPCからWINDOWS10を用いて、リモートデスクトップ接続実行したい場合は、下記対応が必要になります。
https://aws.amazon.com/jp/premiumsupport/knowledge-center/connect-to-ubuntu-1604-windows/3.ブラウザツールのインストール
anaconda navigatorを用い、JupyterNotebookを起動する場合は、ブラウザツールのインストールが必要になります。今回は、Firefoxをインストールしました。
Firefoxのインストール方法は下記URLになります。
https://qiita.com/rokusyou/items/8089b7495119b7c8e29b4.日本語化対応
英語でUbuntu環境が作成されていますので、下記URLで日本語対応いたしました。
https://qiita.com/hachisukansw/items/154b5349f99a7152fd465.困ったこと
(1)リモートデスクトップ接続した際に、“真っ黒画面”が表示される。
リモートデスクトップの設定を試したのですが何も改善されませんでした。AMIのツール類、GUI等でインスタンスのボリュームの使用率が100%になっていたのが原因と推測されます。ストレージのサイズはデフォルト75GiBでは足りませんでした。
(結果的に、ストレージを300GiBで再作成して解消しました。)
ストレージを追加して、下記URLでパーテーションの容量を大きくしようと試みたのですがうまくいかず(これは、私のLinuxの知識不足が大きな原因です。)、インスタンスを再作成しました。
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/recognize-expanded-volume-linux.html(2)キーボード配列の設定
Anaconda Navigatorでは、日本語用のキーボードの配列で入力できませんでした。先にインストールしたFirefoxでは、日本語キーボード配列で正しく入力できたのですが・・・。
以下URLに対応方法がありますが、未実施です。
https://geek-memo.com/ubukey/
https://tech-mmmm.blogspot.com/2017/08/xubuntu-1604xrdprdp.html※ご参考1
ここまで環境を作成するのに、p2xlargeのインスタンスサイズで100円程度と思います。
(再作成したり、他に色々動かしたので推測です。今のところ7.4$です。)※ご参考2
Sagemakerでml.p2.xlargeの3つのGPUインスタンスを30時間使ったら260$でした。GCPでも同様にインスタンス構築からチャレンジしてみようと思います。
- 投稿日:2019-04-15T21:23:09+09:00
Pythonでエクセルから条件付きCSV出力
経緯
最近参画していた案件でタイトル通りの機能が必要であったため。
作成した内容を抜粋。Github
https://github.com/biz-nakashima001/python_xlsx2csv
機能
- エンコード、改行コードを指定できる。
- スキップする行を指定できる。
- 文字列か数値か判断して、出力形式を分ける。
- 小数(パーセント)は桁数指定
- 結合セルもよしなに処理。
ライブラリについて
当初は、エクセル上00.0%書式のところ、ロジック上で書式を読み取り判断する仕様だった為、
書式データも読み取り可能なpandas、openpyxlを検討した。採用
- 速かったから。2000行で4秒程度。20000行で40秒ぐらい
- 結合セルも補間して処理してくれるから。
- 書式読み取り不要になった為。
不採用
- エクセル良い取って、csv出力するだけにしたら、dataflameは機能過多で複雑に感じたから。
- 重たかったから。2000行で15秒。xlrdの約三倍。 書式データを保持しているからか、初期読み込みに時間がかかる模様。
- 結合セルをよしなに処理してくれなかったから。
ロジック詳細
import
import xlrdエクセル読み取り
xls = xlrd.open_workbook(INPUT_XLSX) sheet = xls.sheet_by_index(0) rows = sheet.nrows # 行数 cols = sheet.ncols # 列数 for r in range(0, rows): for c in range(0, cols): cell = sheet.cell(r,c)cell.value # 値を取得 cell.ctype # 値のタイプを取得CSV出力
エンコード、改行コード
file = open(OUTPUT_CSV, 'w', encoding = ENCODE, newline = NEWLINE)ENCODE => 'utf_8_sig' # UTF8 BOM付き 'utf_8' # UTF8NEWLINE => '\r\n' # CRLF '\n' # LF出力用関数
# 文字列出力 (""で囲む) def writeStr(value): return '\"' + str(value) + '\"' # 数値出力 def writeNum(value): return str(value)文字列か否か
# 文字列の場合 if(cell.ctype == xlrd.XL_CELL_TEXT): writeStr(cell.value)数値か否か
if(cell.ctype == xlrd.XL_CELL_NUMBER): if(cell.value.is_integer()): writeNum(int(cell.value)) # 少数の時 第3位まで else: writeNum(round(cell.value, ROUND))# 許有少数桁 ROUND = 3整数か否か
value.is_integer()実施方法
python3 tocsv.py
- 投稿日:2019-04-15T20:50:53+09:00
Pythonスクレイピング 備忘録② 画像のURLの取得してみる
初めに
前回同様スクレイピングの練習です
今回は、https://gigazine.net
から記事の画像のURLを取得してみたいと思います前回 備忘録① URLを相対パスを絶対パスに変換
https://qiita.com/Rainkee/items/53a150829f68e39bce0fサイトのコード
サイトに記事画像のURLがどのように埋め込まれているのか見てみます
大まかに見ると
まず記事のデータは
"content"というクラス内にあって
その下の <section>~</section>内に夫々まとめられています。
その中に<img src = "https://~">で画像のURLがありますねですが、不思議なことに3つ目以降の記事では
<img data-src = "https://~">となってますimg src と img data-scr の違いって何なんでしょうか?(HTML知らないので教えてください)
書いてみたコード
img_linkfrom urllib import request from bs4 import BeautifulSoup from urllib.parse import urljoin base_url = "https://gigazine.net/" html = request.urlopen(base_url) soup = BeautifulSoup(html,"html.parser") imgs = soup.find(class_="content") for i in imgs.find_all("img"): print(i.get("src")) for i in imgs.find_all("img"): print(i.get("data-src"))img-src と img-data-scrの違いが判らないので両方指定して取得しています
結果
img_link_kekkahttps://i.gzn.jp/img/2019/04/15/short-breaks-consolidate-skill-learning/00_m.jpg https://gigazine.asia/a/www/delivery/avw.php?zoneid=633&cb={random}&n=adc3afbe https://i.gzn.jp/img/2019/04/15/game-developers-help-nasa/00_m.png None None None #~略~ None https://i.gzn.jp/img/2019/04/15/headline/00_m.jpg https://i.gzn.jp/img/2019/04/15/amazon-music-service-complimentary/00_m.jpg https://i.gzn.jp/img/2019/04/15/stratolaunch-takes-flight-first-time/00_m.jpg https://i.gzn.jp/img/2019/04/15/acecook-spices-creamy-curry-ramen/00_m.jpg https://i.gzn.jp/img/2019/04/15/openai-defeat-world-champion/00.jpg https://i.gzn.jp/img/2019/04/15/apple-arcade-budget/00_m.jpg https://i.gzn.jp/img/2019/04/15/internet-explorer-zero-day-vulnerability/00_m.jpg https://i.gzn.jp/img/2019/04/15/bodybuilding-forums-trolls-history/00_m.jpg https://i.gzn.jp/img/2019/04/14/what-school-good/00_m.jpg https://i.gzn.jp/img/2019/04/15/gunmachan/00_m.jpg https://i.gzn.jp/img/2019/04/15/cambridge-bicycle-plan/00_m.jpg https://i.gzn.jp/img/2019/04/14/tiger-steam-less-thermos/00_m.jpg https://i.gzn.jp/img/2019/04/14/two-ladies-kitchen/00_m.jpg https://i.gzn.jp/img/2019/04/14/partner-intimidated-having-sex/00_m.jpg https://i.gzn.jp/img/2019/04/14/twitch-sings/00_m.jpg https://i.gzn.jp/img/2019/04/14/how-to-save-our-planet/00_m.png https://i.gzn.jp/img/2019/04/14/carnivore-animals-vegan/00.jpg https://i.gzn.jp/img/2019/04/13/hackers-personal-data-police/00_m.jpg https://i.gzn.jp/img/2019/04/13/ripcord-discord-slack/00.png https://i.gzn.jp/img/2019/04/13/startup-stock-option-gone-bad/00_m.jpg https://i.gzn.jp/img/2019/04/13/exercise-for-busy/00.jpg https://i.gzn.jp/img/2019/04/13/israel-lunar-lander-picture/00.jpg https://i.gzn.jp/img/2019/04/13/bury-pet-backyard/00.jpg https://i.gzn.jp/img/2019/04/13/problem-with-5-whys/00_m.jpg https://i.gzn.jp/img/2019/04/13/star-wars-the-rise-of-skywalker-special-clip/00.jpg https://i.gzn.jp/img/2019/04/12/the-game-obake-suuji-akuma/00_m.jpg https://i.gzn.jp/img/2019/04/12/starbucks-ginger-ale-cloud/00_m.jpg https://i.gzn.jp/img/2019/04/12/waai-illust/00_m.png https://i.gzn.jp/img/2019/04/12/nasa-twins-study/00_m.jpg https://i.gzn.jp/img/2019/04/12/access/00_m.jpg https://i.gzn.jp/img/2019/04/12/headline/00_m.jpg https://i.gzn.jp/img/2019/04/12/poorer-childrens-holiday-experiences-worse/00_m.jpg https://i.gzn.jp/img/2019/04/12/playstation-network-id-changed-temp/00_m.jpg https://i.gzn.jp/img/2019/04/12/disney-plus-streaming-launch/00_m.png https://i.gzn.jp/img/2019/04/12/arrest-assange-wikileaks/00_m.png https://i.gzn.jp/img/2019/04/12/yellowcake-uranium/00_m.jpg https://i.gzn.jp/img/2019/04/12/court-forced-wikipedia-history-remove/00_m.jpg終わり
別の条件でうまく取得できたかもしれませんが
とりあえずここで終わります
勉強します!
備忘録③予定

- 投稿日:2019-04-15T20:15:53+09:00
Python3でのコマンド実行
はじめに
いままでPython3だと思って実行してきたのは、実はPython2系であることが判明した。
現在の環境ではpython3とするとPython3系が動作するようである。
あらためてコマンド実行をさせてみたら、2系で動いていたものが動かなかった。
本記事では3系で動作するコードを掲載する。実装
import subprocess res = subprocess.check_output('ls', stderr=subprocess.STDOUT) resStr = res.decode('utf8') #2系にはなかったbyte列->文字列変換処理 print( resStr )結果
3系で動作することが確認できた。
参考(実行確認バージョン)
Python 3.7.3 (v3.7.3:ef4ec6ed12, Mar 25 2019, 16:52:21)
[Clang 6.0 (clang-600.0.57)]
- 投稿日:2019-04-15T20:10:20+09:00
#Qiita #API で任意のユーザーの記事一覧を得る簡単な #python スクリプトの例 (改善版) ( + #jq #JSON )
公開情報なので TOKEN やログインなどは不要
script
#!/usr/bin/env python3 # -*- coding: utf-8 -*- # https://qiita.com/api/v2/docs#item import requests, json, os, sys USER_ID = os.environ.get('QIITA_ITEMS_USER_NAME') ROUND = int(os.environ.get('QIITA_ITEMS_ROUND')) if os.environ.get('QIITA_ITEMS_ROUND') else 1 PER_PAGE = os.environ.get('QIITA_ITEMS_PER_PAGE') if os.environ.get('QIITA_ITEMS_PER_PAGE') else 100 api_url = 'https://qiita.com/api/v2/users/' + USER_ID + '/items' results = [] for num in range(ROUND): page = str(num+1) params = { "page": page, "per_page" : str(PER_PAGE) } response = requests.get(api_url, params=params) results += response.json() print(json.dumps(results))exe
QIITA_ITEMS_USER_NAME=YumaInaura QIITA_ITEMS_ROUND=3 ./list.py | jq . > log/list.jsonuse case of jq
jq コマンドでタイトルだけ抜き出す例
cat log/list.json| jq '.[].title' | p"#python で値を持った既存の辞書に、デフォルト値つきの辞書をマージする例 ( もう if 'key' in dict なんて書きたくないんですよ‥ )" "#python の defaultdict を利用して KeyError を防ぎたい" "Example of using defaultdict to prevent KeyError in # python's nested dictionary (#ruby comparison)" "# Service ideas for \"My English Learning\" on Twitter. Google translates Japanese into English and pursues!" "I want to do something like a beauty watch by switching profile images every minute on #Twitter (Try it)" "#python の ネストされた辞書で KeyError を起こさないように defaultdict を利用する例 ( #ruby 比較 )" "#Twitter で「俺の英語学習」のサービスアイディア。日本語を英語にGoogle翻訳して追撃!" "#Twitter でプロフィール画像を1分毎に切り替えて美女時計みたいなことがやりたい (お試し)" "Why did #python open up dictionary access to match objects? (`TypeError: '_sre.SRE_Match' object is not subscriptable`)" "とあるRailsエンジニアが再就職活動を共有したがっているようだ 2019-04-14 on Twitter" "なぜ #python は match オブジェクトへの辞書アクセスなんかを開放したりしたのだい? ( `TypeError: '_sre.SRE_Match' object is not subscriptable` )" "An example of writing multiple standard output of echo and cat together in one file with #shell" "Example of randomly generating tomorrow's hour and minute with datetime of #python" "A simple example of creating a datetime object with a specific date / hour / minute / second specification in #python and parsing it into a string" "An example of a simple script that combines multiple #JSON arrays flat with #python" "A simple Dockerfile example that creates an image or container with various gems in #ruby with #docker" "I want to switch profile images in night mode on Twitter at night. (#Python script example of updating profile image with #Twitter # API)" "Twitterで夜はナイトモード的にプロフィール画像を切り替えたい。 ( #Twitter #API でプロフィール画像を更新する #python スクリプトの例 )" "とあるRailsエンジニアが再就職活動を共有したがっているようだ 2019-04-13 on Twitter" "#python の datetime で明日の 時・分をランダムに生成する例" "#python で 特定の年月日・時分秒・マイクロ秒指定で datetime オブジェクトを作成し、それを文字列にパースする簡単な例" "#docker で #ruby に色々と gem を入れたイメージやコンテナを作成するごく簡単な Dockerfile の例" "#python で 複数の #JSON 配列をフラットに結合する簡単なスクリプトの例 " "#shell で複数の echo や cat の標準出力をまとめて一個のファイルに書き込む例" "とあるRailsエンジニアが再就職活動を共有したがっているようだ 2019-04-12 on Twitter" "A Rails engineer Toma Inaura Summary of recent learning and re-employment activities (early April 2018)" "とあるRailsエンジニア 稲浦悠馬 最近の学習や再就職活動のまとめ (2018年4月前半) #Github や Google 翻訳 #API や #python や #JSON #jq などを触っていた" "Example of deleting specific value from array of # python (I want to subtract array like # ruby)" "#Github # Update API using API or delete only a specific label # python script example" "#Github #API を利用して Issue を更新したり 特定のラベルだけ削除したりする #python スクリプトの例" "#python の配列から特定の値を削除する例 ( #ruby みたいに配列の引き算がしたい )" "Do some plucky things like #Ruby on #Rails against the #python dictionary" "#python の 辞書 に対して #Ruby on #Rails の pluck 的なことをやる" "#Mac OS A shortcut to delete a line of text at the current cursor position regardless of application (Control + A-> K)" "( やばい -> dangerous ) #Google 翻訳 #API を利用して、標準入力に #JSON を与えると 翻訳結果を同じく JSON で標準出力する #python スクリプトの例" "#JSON を標準入力として受け取り #Github #API を叩いて 複数の Issue を作成する #python スクリプトの例" "#python でサブプロセスを起動し #shell に引数・環境変数・標準入力を与え標準出力する例" "#Mac で アプリケーションを問わずに現在のカーソル位置にある1行のテキストを削除するショートカット ( Control + A -> K )" "#jq コマンドで #JSON の ネストされた配列の中のオブジェクトの中の配列からちょっと複雑な検索をする ( select filter )" "とあるRailsエンジニアが再就職活動を共有したがっているようだ 2019-04-11 on Twitter" "#jq コマンドで配列を解除してまた囲む例" "#python で #ruby の Hash#merge 的なことをやる ( 複数のディクショナリをマージする )" "#GCP ( Google Cloud Platform ) の Google翻訳API で #MarkDown を翻訳するとスタイルが崩れてしまうので #ruby gem で一旦 #HTML 変換してから Markdown に逆変換する #shell コマンドの例" "#ruby や #python で #markdown を #HTML に #shell のコマンドで変換できるモジュール四種類の簡単な結果比較" "とあるRailsエンジニアが再就職活動を共有したがっているようだ 2019-04-10 on Twitter" "#shell で #cd コマンドを引数なしで実行したら ホームディレクトリに一発で移動できて驚愕した件 ( #linux #mac )" "プログラマに必要なのは危機感?好奇心?" "#Twitter で ツイートIDを指定して URL を得る方法 ( リダイレクトを利用 )" "#jq コマンドで #JSON 配列の個数を調べる例" "#jq コマンドで #JSON 配列の shift & push 的なことをやる ( 配列の最初の要素を最後に入れ替える例 )" "#python の正規表現で名前付きキャプチャグループを使う例 ( ?P<name> )" "とあるRailsエンジニアは再就職活動にWantedlyを活用し始めているようだ 2019-04-09 on Twitter" "#jq コマンドと #shell の組み合わせで、 JSON 配列が空かどうかを条件判定する例" "#python スクリプトで #Twitter #API を叩いて複数のツイートを作成する例。標準入力に #JSON を与える場合。" "#Twitter Timeline #API で得られる created_at の時刻を元に unixtimestamp 基準で絞り込む #python スクリプトの例" "#python で 英語月表記・タイムゾーン尽きの日付文字列を parse して datetime オブジェクトに変換し、さらに unixtimestamp に変換する例 ( UTC VS JST )" "#GCP の Google 翻訳 #API を叩く #python スクリプト例。 #JSON を標準入力に与えると 翻訳結果のテキストを付与させて同じく JSON を標準出力する。" "#jq コマンドむずい。オブジェクトの配列から、任意のキーを指定してフィルタし、新しいオブジェクトの配列を組み立て直そうとして失敗した例。" "#python の __main__ 関数とは何なのか (いや関数じゃないよ) (初心者向け)" "#jq コマンドを利用して エンコード済みのUTF-16 の文字列をデコードする例 (日本語)" "#jq コマンドで文字列中のダブルクォートのエスケープを解除する例" "とあるRailsエンジニアは就職活動体験をシェアしたがっている 2019-04-08 on Twitter" "#perl で標準入力でテキストを受け取り指定の文字数で切り取るコマンド例 (正規表現利用)" "#jq コマンドで出力されるダブルクォートを #perl で削除する例" "#python で datetime を microsecond までの timestamp に変換する例" "とあるRailsエンジニアの転職活動の共有 2019-04-07 on Twitter" "Wantedly探訪 株式会社ポテパン ( Twitter @potepan0901 ) #エンジニア #就職 #転職" "#python で #ruby の instance#methods みたいな感じで全てのメソッドを表示するらしき例" "#python からどんな #Twitter #API でも叩けるようにしておきたい、ごく簡単な汎用インターフェイス的スクリプトの例" "とあるRailsエンジニアをお求めの方はこちらまで 2019-04-06 on Twitter" "#python の 正規表現で何故か match が起こらない ? 複数行どころか先頭文字列にしかマッチしないから気をつけて!" "#python の IPython で #ruby の binding.pry 的なデバッグがしたいけど 標準入力が奪われてうまく動かなかった件の共有" "#Twitter #API の使う Bearer のアクセストークンを curl で得る例 (公式ドキュメントのまま)" "#Centos 6 .10 + #docker で yum install がエラーで落ち curl さえ clould not resolve host とかわけの分からないことを言い出したが service docker restart で直った件" "とあるRailsエンジニアをお求めの方はこちらまで 2019-04-05 on Twitter" "Wantedly は超モダンな就活サービスの未来かもしれないぜ。とあるエンジニアの仕事探し 2019-04-04" "#docker + #MySQL 5.7 で、コンテナを終了・再起動してもデータが消えないように volume mount しながら port 指定でDBサーバーを作る docker-compose の例" "#python でカンマ区切りの文字列を split して tuple を作る例" "#python で複数の候補から startswidh endwitds を判定をする例" "#python スクリプトにコマンドオプションを引数で渡す例" "#python では標準ライブラリと同名のファイルは作ってはいけない ( わけではないかもしれないが、謎の import エラーが出る場合の対処 )" "#GCP ( Google Cloud Platform ) を Centos に build する #docker image ( Dockerfile ) の例 " "#docker で コンテナIDを指定して毎回 docker kill するのが面倒なので peco を使ってインタラクティブに削除できるようにする" "#docker ps で コンテナIDだけ表示する #shell のコマンド例" "#shell の標準出力から最初の1行だけ削除する例" "#docker コンテナをバックグラウンド ( detach ) モードで起動させて、すぐに終了しない方法。 (初心者向け)" "#Zapier | #Twitter でハッシュタグ付きの自分のツイートを #Slack チャンネルに投稿する例" "とあるエンジニアの問題意識 2019-04-03" "#vue.js の component が分かりにくいので手で動かして理解する ( 公式チュートリアルより ) ( Codepen )" "未知の言語のコードリーディングのコツは、記号を読まずに自然言語に読むことかもしれない。" "v-bind を使って、カーソルをテキストに合わせると、現在時刻を表示する例 #Vue.js のチュートリアルを Codepen でやる (初心者向け)" "#vue.js のチュートリアルを Codepen でやる ( Hello World ) ( 初心者向け )" "#vue.js で if else の条件分岐をする基本" "#python で日付を JST=日本時刻=現地時刻で与えると日の始まりの unixtimstamp を出力する例" "とあるエンジニアの再就職日記 2019-04-01 by 稲浦悠馬 いなうらゆうま" "#shell で上位ディレクトリに cd で移動するのが面倒過ぎるのでエイリアスを作っておくだけの人生だった" "#jq コマンドでリストを逆順に反転させる ( reverse )" "#Twitter #API で1個のツイートIDを指定すると、ツリーの最上段までたどって全ツイートを取得する #python スクリプトの例 ( + #jq )" "転職ドラフト第17回の最高年収提示額は「1100万円」だったようだ。 #就職 #転職 #エンジニア" "(改善版) ( timeline API を利用) #Twitter #API で1個のツイートIDを指定すると、ツリーの最上段までたどって全ツイートを取得する #python スクリプトの例" "#python でJST=日本時間=現地時刻を現在時刻を文字列で得る例" "#python で unixtimestamp を日付形式の文字列に変換する例" "#python で JST(日本時間)などの現地時刻で今日の始まりの unixtimstamp を得る例" "#Slack #API を叩いて #jq コマンドで チャンネル名からチャンネルIDを取得する例" "#Twitter が気になってプログラミングに集中できない人のための #GoogleChrome 拡張" "東京リモートワークの夢を見る大阪求職者 by 業務経験約4年 Ruby on Rails エンジニア #転職 #ノベル 2019-03-30" "エンジニア勉強会への参加が死ぬほど苦手な人のためのエンジニア勉強会の参加方法とは。 #エンジニア #学習 #勉強会" "個人開発の #git で毎回コミットメッセージを考えるのが面倒臭すぎるので対策する" "#python で ハッシュの配列から、特定の値を持ったものだけを絞り込む例" "#Mac の MissionControl って Command + Tab でアプリケーションを切り替えても 何も起こらないことがあって使いにくいよね?" "#vim を開いて一瞬で終了する何の意味もない例の提示" "#Twitter #API を叩いて 10秒で消えるツイートを作成する例 ( #python #shell #jq )" "#python で標準入力を全行読む例" "#python で #Github #API を叩いて1個の Issue 情報を取得するスクリプト例" "#shell script で標準入力を全て読む" "Qiitaで就職もできる。" "プログラミングの原始衝動を思い出す旅の途中で by 業務経験約4年 Ruby on Rails エンジニア #転職 #ノベル 2019-03-29" "スクラム開発 の勉強会で教わった「マルチタスクゲーム」とは? by スクラム道関西 #スクラム" "#python スクリプトに shebang を書いてファイル直接指定で実行できるようにする" "#jq コマンドで結果が空配列の場合に何も出力しない例" "#jq コマンドでオブジェクトの配列から key の value で検索絞り込みする例" "#jq コマンドは #JSON 的には不正な、フラットなオブジェクトの連続も解釈してくれるっぽい" "#jq コマンドで要素全体を配列で囲う、もしくは逆に解除する例" "なぜエラーメッセージでGoogle検索しないプログラマがいるのの私見であり、メモの断片である。" "#jq コマンドで特定のキーを持つオブジェクトだけを絞り込み検索する例" "#python で標準入力を #json で受け取る例" "#python や #ruby コマンドの標準入力がコード評価で直接実行されることに気付いて驚いた件" "僕が思うポートフォリオ作成のコツは、自分自身に最大素直になることだ。 #エンジニア #就職 #ノベル" "エンジニア就職面接の想定問答集を自分で作って答えてみよう。 #就職 #転職 #ポエム" "最終出社日を迎え、1ヶ月の有給消化期間に、プログラミングの原始衝動を思い出したいエンジニア。" "題名のない退職エントリ by 大阪Ruby開発エンジニア #ノベル #ポエム 2019-03-25" "僕がQiitaで転職ポエムを書き綴っていると、TwitterのDM経由で" "人類に希望を与えない35歳エンジニアの再就職活動ポエムとは 2019-03-24" "#jq コマンドで特定の文字列を含むオブジェクトを検索する例" "#API を叩くには #python と #shell と #jq コマンドを組み合わせて、標準入出力でパイプするのが良さげじゃない?" "#python で #Twitter API を叩いてツイートを削除するスクリプト例 (複数ツイート対応)" "大阪Web開発 Rubyエンジニア 35歳 転職活動ポエムはまだ続く 2019-03-23" "コンビニバイトとエンジニアの時給差はどこまで開くべきなのか。#超ポエム" "大阪地下街のドトールで考える、プログラミングスクール講師としての転職の話。 #ポエム #ノベル #エンジニア #就職 #転職" "大阪Web開発 Rubyエンジニア 35歳 転職活動はじまる 2019-03-22" "エンジニアの就職面接で、あなたが自分の夢を語れないとしても。" "とあるエンジニアの再就職活動 2019-03-21" "眠りすぎる症候群、ナルコレプシー・エンジニアに俺はならない。" "とあるエンジニアの再就職 〜退職が決まった〜" "とあるエンジニアの問題意識 2019-03-20" "とあるエンジニアの問題意識 2019-03-19" "駆け出しのエンジニアの頃、僕は人より10倍も速いスピードで、プログラミングしようと思っていた" "とあるエンジニアの問題意識 2019-03-18" "とあるエンジニアの問題意識 2019-03-16" "とあるエンジニアの問題意識 2019-03-15" "#Slack で画像をアップロードすると #Twitter にもアップロードする例 by #Zapier + #python" "とあるエンジニアの問題意識 2019-03-14" "#Slack に添付ファイル・画像がアップロードされると自動的に public の共有リンクを作成する #python + #Zapier の活用例" "とあるエンジニアの問題意識 2019-03-13" "スクラム歴は長いけど #スクラム 初心者" "#Zapier 活用事例 - #Slack のチャンネルに bot ではなく自分のユーザーとして投稿できる" "とあるエンジニアの問題意識 2019-03-12" "アプリケーションのORDERが重要な理由をスターバックスで考える #UI #UX #設計" "#Twitter で いいねの履歴が検索しづらいので #IFTTT 連携させて #Slack に送る活用例" "とあるエンジニアの問題意識 2019-03-10" "#Mac のMissionControlを使わずに人生損していた" "#python で #Github #API を叩いて Issue を 新規作成するスクリプトの例" "Mac でウィンドウをDockにしまう / 元に戻すショートカット" "君はベロシティという刀を見たことがあるか" "「仕事した感」を殺し「生産性」の刀を挿せ ― とあるアジャイルエンジニアより" "コードレビューは眠らせよ 〜難しい #レビュー のコツ〜" "迷う時間はもったいなくない" "#Divvy アプリで #Mac のウィンドウサイズをショートカットで最大化する" "なぜおでんとチーム開発は難しいのか in スクラムフェス大阪2019 #スクラム" "#Slack でいつの間にか、エンターキーで送信せず、改行だけする設定が追加されていた" "集中力が低いプログラマへ" "2019年の #スクラム フェス大阪で「ピンポン玉」のブレイクスルーゲームを体験してきた" "#Mac の作業で #集中力 を上げるための禅モード" "世界の設定に100倍の優しさを" "君はMacのデスクトップ背景を見たことがあるか? とあるアジャイルエンジニアより愛を込めて" "とあるエンジニアの問題意識 2019-03-01" "とあるエンジニアの問題意識 2019-02-28" "とあるエンジニアの問題意識 2019-02-27" "とあるエンジニアの問題意識 2019-02-26" "とあるエンジニアの問題意識 2019-02-25" "とあるエンジニアの問題意識 2019-02-24" "とあるエンジニアの問題意識 2019-02-23" "#Slack で未読チャンネルに移動したときの位置を設定で変更する" "とあるエンジニアの問題意識 2019-02-21" "とあるエンジニアの問題意識 2019-02-20" "とあるエンジニアの問題意識 2019-02-19" "とあるエンジニアの問題意識 2019-02-18" " sublimetext で 文字の折返しをオンオフするショートカット #Sublime" "とあるエンジニアの問題意識 2019-02-17" "#Twitter #API で得た #JSON を #jq と #shell でパースして URLの一覧を得る例" "#Github #API で特定レポジトリの Issues の一覧を得る。Webブラウザからもアクセス可能で認証必要なし。" "とあるエンジニアの問題意識 2019-02-16" "#Twitter #API でページめくりをして200件超のツイートを取得する #python スクリプトの例" "#Twitter #API でタイムラインから最新5件を取得して、はてなブックマークを一斉追加する #python スクリプトの例。 #sh " "はてなブックマークを #API で追加する #python スクリプトの例" "とあるエンジニアの問題意識 2019-02-15" "とあるエンジニアの問題意識 2019-02-14" "とあるエンジニアの問題意識 2019-02-13" "摩擦コストの自己認識。 #超ポエム" "とあるエンジニアの問題意識 2019-02-12" "#python で #Twitter #API を叩き、日本時間基準で、昨日のまとめを #Markdown で作る例" "#python 初心者が Twitter API で得られる created_at の String を日本時間で年月日出力しようとした記録コード" "#Twitter の #API で、タイムラインから、省略なしのテキスト全文 + Media画像付きツイートの一覧を取得して #Github に使える #Markdown を取得する #python スクリプトの例" "#Twitter #API でタイムラインから、メディアの画像URLつきの #Json を得る #python スクリプトの例" "とあるエンジニアの問題意識 2019-02-09" "#Github issue を作成すると #Medium #API で新規ポストする自動連携の例。Zapierを利用。" "IFTTT と Zapier を使い、Twitterへのツイートをためて、1日ごとに Github issue を作成・更新し、エンジニアの振り返り日記のまとめを作るサンプル。" "エンジニアの行動も心理要因に依存する。心理療法的な日記メソッドで、自己分析をして問題解決したい。 #ポエム" "とあるエンジニアの問題意識。 意外にコスト感の高い #Markdown の論理マークアップ。会社の理想は基礎的勉強に理解のあること。優秀なエンジニアの口癖も「あれ、今何しようとしてたっけ」。 #ポエム" "とあるエンジニアの問題意識。" "はじめてプログラミングを覚える時のように python を触る。エンジニアのビギナーズマインドに、再会するには別言語。 #ポエム" "#python スクリプトからMedium #API を叩いて新規ポストする例。公式APIリファレンスより。 @yumainaura" "#python から Medium #API を叩いて自分のユーザー情報を取得する例" "プログラミング中に話しかけられると、集中力の回復に時間がかかるのは何故? 短い時間のチャットやメールが集中力を奪う。「注意残余」とは。 #Slack #生産性 #ディープワーク" "Medium #API で使えるトークンを設定する。サポートに問い合わせして有効化してもらった例。" "#ssh コマンドで直接パスワードを記憶・指定する方法。公開鍵を使わないパターン。" "#エンジニア の仕事術。口頭で話しかけるか #Slack などのチャットツールを使うか。どっちにするか? ここでもコストとオーバーヘッドの関係性を考えたい。TCP と UDP のプロトコルの違いみたいな。 " "IFTTTを使って、Twitterにハッシュタグつきでツイートしたら、はてなブログに自動投稿する例。画像表示もインライン対応。" "python で テキストから複数個のハッシュタグを正規表現で抽出して、結果を配列で得る" "Zappier で Github Issue 作成をトリガーにして、pythonスクリプトからGoogle翻訳APIを叩き、翻訳済みの新しいGithub Issue を作成する例。日本語から英語へバージョン。" "Google翻訳APIをpythonスクリプトで叩いて英語を日本語に翻訳する。" "Google翻訳APIをシェルスクリプトで叩いて英語を日本語に翻訳する。ほとんど公式チュートリアルのまま。" "Google Cloud の認証トークンを gcloud コマンドで取得する。環境変数でサービスアカウントファイルを指定する例。" "「ソフトウェア開発者の人生マニュアル」にキャリア、就職、転職の裏技を学びたい、3行スナップショットまとめ。" "Zapierを使って、Github Issue作成をトリガーに、PythonスクリプトからQiita APIを叩いて新規投稿する例" "PythonでQiita APIを叩いて新規投稿するスクリプトの例 (最小構成的な)" "Qiita API を使って Ruby スクリプトで新規投稿する例。json の gem とか使わず、ヒアドキュメントで強引に json 投げつけるバージョン。" "Qiita API で自分のユーザー情報を取得するRubyのスクリプト例" "Qiita API で公開情報の記事一覧を取得する、アクセストークンなどの認証必要なしのスクリプト例 " "Zapier で python script を走らせて Qiita API で自分の記事投稿一覧を取得する。" "世界で一番簡単に幸せになる方法。それは太陽の光を浴びること。本当の幸福を感じてる?重要なのは、お金か、社会的成功か、自己啓発か、アウトプット学習か、自己投資家、株式投資か。自然を忘れた人間が生きるための、必要なもののすべてより。愛を込めて。" "人間の幸福のために科学や技術が役立てられる時代。iPhoneの音声入力で、僕は自然な人間生活のための、デバイスの未来を感じる。スターバックスやマクドナルドにいながら、ディスプレイを見ずに、スマホゾンビにならず、街行く人々を見ながらTwitterもできる。妻と観光旅行だってできる。素晴らしさ。" "エンジニアの仕事論。もし就職、転職するならどんな会社?給与や待遇以外にも10項目ぐらい書き出してみない?セルフチェック。就職の心理的ジャーナリングみたいな?" "ヨドバシカメラでMacBookAirの充電に使える、充電ケーブルを探す。物理的世界の互換性の問題があって、なかなか0.5メートルが見つからない。膨大なラインナップするがある。だけどデジタルのサービスやソフトウェアも、結局は現実世界の、限界の中に存在する。エンジニアも生物的な人間だし。" "Zapier 最高すぎるよね! Github Issue への Post を Twitter に画像つきでツイートする例。" "これはやばい。ZapierでGithub Issueを作成すると、はてなブログに投稿する連携のサンプル。" "ZapierでGit hub Issue を自動翻訳して Github Gist に投稿して Twitterに共有する例 (1000文字数制限あり) (有料ププラン)" "新MacBook Pro (2018)のキーボード改良は静音化だけ?嘘でしょ?明らかに打ちやすくなったような気がしたのだけれど‥。" "2つの絵文字を組み合わせてオリジナルを作るジェネレーター的な「絵文字ビルダー」が全然日本語でGoogle 検索できなかったので標識を残す" "? root権限無しで利用できるらしいRed Hat Enterprise Linuxの新コンテナエンジン Podman が気になるだけの人生だった" "名刺を持たないエンジニア。Twitter/Qiita/Githubアカウント交換には、自分の本名をひらがなでGoogle検索できるようにしておけば良い。" "2019-01-21 大阪IT勉強会のLTで、機械学習使える Tensorflow.js や、新しい美術メディア「ARTLOGE」の話を聞いてきた!僕はQiitaプチ炎上案件や、最近のiPhone音声入力の素晴らしさについて声ガラガラで語った。" "ネット炎上。匿名アカウントの批判はノーカウント。匿名のいいねも。1人の人間が複数アカウントで荒らしてる説。証明不可能なので攻め手有利。ずるっ。暴力やハラスメントのロジックを理解して、心のレジリエンスな対策しよう。ここでもセルフトークは役立つから心理セラピーとしてオススメ。" "たとえばRubyのgitignoreを一瞬で作るだけで強くなれること" "OSXのSublimeText3でGoogle日本語入力のタブキーが効かない問題を解消する。コマンド例付き。" "エンジニアとして長く続けていくにはどうすれば良い?プログラミングを好きになって、嫌いにならないためには?周囲のエンジニアとの難易度調整、精神のバッファはとても重要かもしれない。" "「文系でプログラマーになったけど色々失敗して3年半で会社を辞めた話」を一瞬でまとめたい" "システム設計と腐敗度の関係。人を苦しめるコーディング。時限爆弾のコントロール。" "Qiitaプチ炎上の著者が語る、ネットでの炎上対策はどうする?自然災害時のレジリエンスの持ち方、メンタル対策と根本的に同じかもしれない。悪いイメージの咀嚼を止める。人間の心理構造について理解する。マインドフルネスと瞑想の習慣はとても役立つ。いつ起こるかわからない自然災害、ネット炎上対策のリテラシ。" "SQLアンチパターンは勉強するのに、炎上アンチパターンは勉強しないの? エンジニアの国語力について、人知れず記事を書いたつもりが、プチ炎上の要素がたくさん詰まっていた件。iPhone音声入力で日本語がおかしい。複数のツッコミどころ。感情的になりやすいトピック。炎上に必要な燃料が勢ぞろい。" "エンジニアは無理数とか、そんな数式を知らなくてもできる職業。数学の世界も面白そうだけどね。" "スーパーエンジニアの話は、相槌を打ってヒアリングするだけでも生産性が上がるかも。" "2019/01/20 まとめ 私の最強アウトプット生活。 Twitterでリプライのチェーン。着想、試行錯誤、140文字の圧縮まとめ。IFTTTでSlack連携してQiita / はてなブログにコピペで投稿。Github Issues / Google Docsでアウトプット財産をキープ。" "最強のアウトプット生活を目指して。iPhone音声入力 iPHone Notes Twitter Github Medium IFTTT Zapier などの連携方法を改めて考え直したい" "Twitterのリプライと引用リツイートは、人間活動であるサインの送受信に使われている。小さな違いかもしれないが、大きな違い。そのサインを見て、僕らは自分自身の反応を決める。僕らはTwitterのインターフェイスを使いながら、人間同士のサインを読みあっている。" "エンジニアには国語的能力が重要だ。実は言語的能力が80%を占める文系の仕事だとさえ思える。理系的な要素だけでプログラミングが成り立つと思ったら間違いだ。ロマンロランのジャンクリストフを読もう。良い小説だから。日本語や言語的なものを大いに愛そうじゃないか。僕らプログラマは。" "最強のアウトプットの発信体勢を作りたい。本当に惜しいEvernoteの共有。" "EvernoteのNoteをTwitterで共有してみるテスト 。イメージ画像反映されず。微妙かな‥。" "認可期間をユーザーが指定できるタイプ Evernote with IFTTT" "世界はデバイスが作る。人間はデバイスが生む。手が不器用なエンジニアのフリック入力は、10文字ぐらいしか打ち込めず、超要約まとめ感想ツイートで、Twitterのリプライ遊びをしていた。iPhone音声入力で人間性が変わったように見える。" "大学生が Unity で作った有料スマホゲーム、iPhone の pertica で3分遊んでみた感想" "ゲーム制作にはインゲーム・アウトゲームという制作の分類があるらしい。「大学生が有料スマホゲームを作った全てを公開するよ」を三分でまとめる!" "65歳からのプログラミング入門を5分で読む!" " デポジットでお金を預けて、判定者を設定して、目標達成できなかったら全額没収! ( @nodenodenode1 on Twitter ) mobet.gq が気になったので調べてみた。" "Paypalにはサンドボックス用のアカウントがあって1億円送金できるらしい。Qiita3分まとめクッキング。" "Bigquery TIMESTAMP を unixtime INTEGER にキャストする" "bq query コマンドで Standard SQL を使うオプションは --nouse_legacy_sql" "Googleイメージ検索をGoogleChromeで、クリックせずに1ステップで使えるようにする" "3分読書。戦略なきエンジニアは孫氏に学びたい。 Thanks @hiroshimatsuno on Twitter 傾聴のメンタルモデルは風林火山の「林」。名経営者のおすすめ本。 " "低レーヤーの技術って勉強すべきなの?フレームワークだけじゃだめなの?Binary Hacks ―ハッカー秘伝のテクニック100選を一瞬だけ読む!" "Twitter の全てのツイートのダウンロード機能を使ってみる。月単位でJsonファイルが吐き出され、HTMLとjsで読み込む、わりとモダンな作りだった。そのままHTMLとしての利用はしづらそう?" "ときにはコミットメッセージは変更ファイル名のコメントを外すだけでは良いのでは?gitのメッセージ書くのが面倒くさい、どうにか省略化したい人へ。" "Github PR / Issue の編集でテキストエリアが縦に狭い!短い!編集しづらい!広げたい! まさかの Edit ボタンを押した位置で高さが変わるみたいだ。" "「入門 監視 ――モダンなモニタリングのためのデザインパターン」の目次だけ、ほんの少し読む!" "社員のやる気を出すためには、やる気を出させようとしてはいけない。プラスをプラスするのではなく、マイナスをマイナスするのが良い。株式会社アクシアの記事、抜粋まとめ + エンジニアひとりごと。" "Qiitaに記事を全部で1000個書いた。GoogleAnalyticsのアクセス解析を入れたら1日3000ユーザーのアクセスがあることがわかった。Qiitaすごいな。" "スターバックスカードの登録には膨大なコストがかかる。アプリで番号入力を間違うとバックスペースできずに最初からやり直し。人間に優しいデバイスやインターフェイスの世界が来てほしい。" "ときめきメモリアルが「ワクワクメモリアル」だったらどうする?エンジニアならわかる、言葉や名前の魔法。プログラミングは名前が9割。" "Github PR Issue でのコメントでは Tabキー移動ではなく Control / Command + Enter のショートカットを使うべき" "Twitterの初期プロトタイプと2019年版年版を見比べて感慨に浸ってみるテスト" "エンジニアは集中力が必要な仕事。集中力を計測するメガネで、最も効果が上がったのは「周囲から遮断した空間で仕事をする」だったらしい。やばい情報だ。ディープワークだ。" "エンジニアの勉強はスターバックスで。問題意識のスタート地点は別でも、ゴール地点は同じかも?戦士や魔法使いや鋼の剣など、たくさんの道具や仲間を用意して、自分のもやもや、問題意識をクリアしたい。" "MacBookAir2018のバタフライキーボードは使いやすいけど、手が凍っている冬に使うのは辛いかもしれない。バリアフリーなデバイスとは、おじいちゃんおばあちゃんの手でも使える端末だ。僕らの肉体も日々変化しているから、最低状態でも使える端末。" "特にエンジニアとという人間には、理解したいと言う根本的な欲求がある。だけど全てを理解することなど到底できないと言うジレンマも抱えている。これが非常に辛い。神様にならなければ無理だ。神様だって無理だ。" "Twitterでは面白いツイートが流れてくるということが大事だ。根本的なことに改めて気づいたぞ。だけどタイムラインはとても荒れやすいし壊れやすい。やはり機械による情報集約が求められる時代じゃないだろうか。" "エンジニアとしてアラサーで初就職してナルコレプシー的な病気から命が救われたかもしれない話。" "Mac Book 2018 OS Mojave Touch ID の指の登録上限は三個だけ?人間の指は10本あるのになぜだよ。" "いまさらだけど Qiita と Google Analytics の連携は一瞬で簡単すぎた" "release の単位に対して git tag を切る" "仕事に集中できない?注意散漫?MacBookのタッチパッドとか、ミニホワイトボードに世界にひとつだけのタスクを書いて、眼の前のやることに集中するハック。" "プログラミングのトリビア。「ネットワーク漢字フィルターの頭文字」をとって nkf らしい。" "今更 Desktop MAc Github 使ってみたけど、何ができるかよく分からなかった報告。" "視覚過敏?聴覚過敏?どっちもかも? エンジニアの仕事術。集中力と生産性を上げる「集中スコープ」みたいなのがほしかったけど、ニット帽がそのかわりになるかも?コンビニで1000円で買える2Wayのやつ。" "コードにコメントを書かなくても、モックしているだけで事情は伝わるのでは?とスーパーエンジニアと話した思い出" "エンジニアがドラクエなら?どの作戦が好き?ぼくは完全に「いのちだいじに」だけど。" "iPhoneの音声入力の日本版のローカライズがひどい。サービス品質を支えるのは国民ユーザの利用度や熱望かもしれない。" "まだアウトプット学習のローカライズしてないの? タイトルを変えてQiitaにも、はてなブログにも投稿する実験。Googleは dont be evil とは言わないよね?" "Twitterは日本語でも140文字の制限を撤廃してブログみたいになるべきなのか?でも完全な自由はTwitter独自の生態系を壊してしまうかもしれないな。" "ドリカムの「未来予想図Ⅱ」に学びたい。エンジニアのアウトプット学習のチャンスを逃すともう二度と戻ってこないかもしれない。描かれなかったQiitaも永遠に戻ってこないかもしれない。夜の中で星をつかむように、いつでも名言を残せる手段を用意しておきたい。" "Googleの画像アップロード検索はなぜ使われないんだろう。街角のおじちゃんにジャンパーのビジュアルからテキスト情報を教えてもらって考えた。"use case
最初の1個の JSON を見てみる
```
$ cat log/list.json| jq '.[0]'```json { "rendered_body": "<p>collections の defaultdict と ChainMap を合わせて使う</p>\n\n<h1>\n<span id=\"wanna-do\" class=\"fragment\"></span><a href=\"#wanna-do\"><i class=\"fa fa-link\"></i></a>wanna do</h1>\n\n<ul>\n<li>こういう辞書を <code>d = {\"a\":1, \"b\",2}</code> </li>\n<li>こう呼び出した時 <code>d[\"c\"]</code>\n</li>\n<li> KeyError ではなくデフォルト値が入っていてほしい</li>\n</ul>\n\n<h1>\n<span id=\"example\" class=\"fragment\"></span><a href=\"#example\"><i class=\"fa fa-link\"></i></a>example</h1>\n\n<div class=\"code-frame\" data-lang=\"py\"><div class=\"highlight\"><pre><span class=\"kn\">from</span> <span class=\"nn\">collections</span> <span class=\"kn\">import</span> <span class=\"n\">defaultdict</span>\n<span class=\"kn\">import</span> <span class=\"nn\">collections</span>\n\n<span class=\"n\">existing_dict</span> <span class=\"o\">=</span> <span class=\"p\">{</span><span class=\"s\">\"a\"</span><span class=\"p\">:</span><span class=\"mi\">1</span><span class=\"p\">,</span> <span class=\"s\">\"b\"</span><span class=\"p\">:</span><span class=\"mi\">2</span><span class=\"p\">}</span>\n\n<span class=\"n\">default_dict</span> <span class=\"o\">=</span> <span class=\"n\">defaultdict</span><span class=\"p\">(</span><span class=\"nb\">int</span><span class=\"p\">)</span>\n\n<span class=\"n\">merged_dict</span> <span class=\"o\">=</span> <span class=\"n\">collections</span><span class=\"o\">.</span><span class=\"n\">ChainMap</span><span class=\"p\">(</span><span class=\"n\">existing_dict</span><span class=\"p\">,</span> <span class=\"n\">default_dict</span><span class=\"p\">)</span>\n</pre></div></div>\n\n<h1>\n<span id=\"exe\" class=\"fragment\"></span><a href=\"#exe\"><i class=\"fa fa-link\"></i></a>exe</h1>\n\n<div class=\"code-frame\" data-lang=\"py\"><div class=\"highlight\"><pre><span class=\"n\">Python</span> <span class=\"mf\">3.7</span><span class=\"o\">.</span><span class=\"mi\">2</span> <span class=\"p\">(</span><span class=\"n\">default</span><span class=\"p\">,</span> <span class=\"n\">Jan</span> <span class=\"mi\">13</span> <span class=\"mi\">2019</span><span class=\"p\">,</span> <span class=\"mi\">12</span><span class=\"p\">:</span><span class=\"mi\">50</span><span class=\"p\">:</span><span class=\"mo\">01</span><span class=\"p\">)</span>\n<span class=\"p\">[</span><span class=\"n\">Clang</span> <span class=\"mf\">10.0</span><span class=\"o\">.</span><span class=\"mi\">0</span> <span class=\"p\">(</span><span class=\"n\">clang</span><span class=\"o\">-</span><span class=\"mf\">1000.11</span><span class=\"o\">.</span><span class=\"mf\">45.5</span><span class=\"p\">)]</span> <span class=\"n\">on</span> <span class=\"n\">darwin</span>\n<span class=\"n\">Type</span> <span class=\"s\">\"help\"</span><span class=\"p\">,</span> <span class=\"s\">\"copyright\"</span><span class=\"p\">,</span> <span class=\"s\">\"credits\"</span> <span class=\"ow\">or</span> <span class=\"s\">\"license\"</span> <span class=\"k\">for</span> <span class=\"n\">more</span> <span class=\"n\">information</span><span class=\"o\">.</span>\n<span class=\"o\">>>></span> <span class=\"kn\">from</span> <span class=\"nn\">collections</span> <span class=\"kn\">import</span> <span class=\"n\">defaultdict</span>\n<span class=\"o\">>>></span> <span class=\"kn\">import</span> <span class=\"nn\">collections</span>\n<span class=\"o\">>>></span> <span class=\"n\">existing_dict</span> <span class=\"o\">=</span> <span class=\"p\">{</span><span class=\"s\">\"a\"</span><span class=\"p\">:</span><span class=\"mi\">1</span><span class=\"p\">,</span> <span class=\"s\">\"b\"</span><span class=\"p\">:</span><span class=\"mi\">2</span><span class=\"p\">}</span>\n<span class=\"o\">>>></span> <span class=\"n\">default_dict</span> <span class=\"o\">=</span> <span class=\"n\">defaultdict</span><span class=\"p\">(</span><span class=\"nb\">int</span><span class=\"p\">)</span>\n<span class=\"o\">>>></span> <span class=\"n\">merged_dict</span> <span class=\"o\">=</span> <span class=\"n\">collections</span><span class=\"o\">.</span><span class=\"n\">ChainMap</span><span class=\"p\">(</span><span class=\"n\">existing_dict</span><span class=\"p\">,</span> <span class=\"n\">default_dict</span><span class=\"p\">)</span>\n<span class=\"o\">>>></span> <span class=\"n\">merged_dict</span><span class=\"p\">[</span><span class=\"s\">\"a\"</span><span class=\"p\">]</span>\n<span class=\"mi\">1</span>\n<span class=\"o\">>>></span> <span class=\"n\">merged_dict</span><span class=\"p\">[</span><span class=\"s\">\"b\"</span><span class=\"p\">]</span>\n<span class=\"mi\">2</span>\n<span class=\"o\">>>></span> <span class=\"n\">merged_dict</span><span class=\"p\">[</span><span class=\"s\">\"c\"</span><span class=\"p\">]</span>\n<span class=\"mi\">0</span>\n<span class=\"o\">>>></span> <span class=\"n\">merged_dict</span><span class=\"p\">[</span><span class=\"s\">\"d\"</span><span class=\"p\">]</span>\n<span class=\"mi\">0</span>\n</pre></div></div>\n\n<h1>\n<span id=\"ps\" class=\"fragment\"></span><a href=\"#ps\"><i class=\"fa fa-link\"></i></a>p.s</h1>\n\n<ul>\n<li>もしかしたらものすごく迂遠なことをやっていないだろうか</li>\n<li>何か変だったら白ヤギさんからお手紙ください</li>\n</ul>\n\n<h1>\n<span id=\"original-by-github-issue\" class=\"fragment\"></span><a href=\"#original-by-github-issue\"><i class=\"fa fa-link\"></i></a>Original by Github issue</h1>\n\n<p><a href=\"https://github.com/YumaInaura/YumaInaura/issues/1289\" class=\"autolink\" rel=\"nofollow noopener\" target=\"_blank\">https://github.com/YumaInaura/YumaInaura/issues/1289</a></p>\n", "body": "collections の defaultdict と ChainMap を合わせて使う\n\n# wanna do\n\n- こういう辞書を `d = {\"a\":1, \"b\",2}` \n- こう呼び出した時 `d[\"c\"]`\n- KeyError ではなくデフォルト値が入っていてほしい\n\n# example\n\n```py\nfrom collections import defaultdict\nimport collections\n\nexisting_dict = {\"a\":1, \"b\":2}\n\ndefault_dict = defaultdict(int)\n\nmerged_dict = collections.ChainMap(existing_dict, default_dict)\n```\n\n# exe\n\n```py\nPython 3.7.2 (default, Jan 13 2019, 12:50:01)\n[Clang 10.0.0 (clang-1000.11.45.5)] on darwin\nType \"help\", \"copyright\", \"credits\" or \"license\" for more information.\n>>> from collections import defaultdict\n>>> import collections\n>>> existing_dict = {\"a\":1, \"b\":2}\n>>> default_dict = defaultdict(int)\n>>> merged_dict = collections.ChainMap(existing_dict, default_dict)\n>>> merged_dict[\"a\"]\n1\n>>> merged_dict[\"b\"]\n2\n>>> merged_dict[\"c\"]\n0\n>>> merged_dict[\"d\"]\n0\n```\n\n# p.s\n\n- もしかしたらものすごく迂遠なことをやっていないだろうか\n- 何か変だったら白ヤギさんからお手紙ください\n\n# Original by Github issue\n\nhttps://github.com/YumaInaura/YumaInaura/issues/1289\n", "coediting": false, "comments_count": 7, "created_at": "2019-04-15T13:10:04+09:00", "group": null, "id": "52e110976b069106f0c2", "likes_count": 3, "private": false, "reactions_count": 0, "tags": [ { "name": "Python", "versions": [ "0.0.1" ] } ], "title": "#python で値を持った既存の辞書に、デフォルト値つきの辞書をマージする例 ( もう if 'key' in dict なんて書きたくないんですよ‥ )", "updated_at": "2019-04-15T13:10:04+09:00", "url": "https://qiita.com/YumaInaura/items/52e110976b069106f0c2", "user": { "description": "https://www.wantedly.com/users/93140896 / Ruby on Rails 業務経験 約4年 / Perl PHP Python Golang Linux Apache MySQL BigQuery Jenkins ansible など / いなうらゆうま / YumaInaura / 稲浦悠馬", "facebook_id": "yumainaura", "followees_count": 184, "followers_count": 164, "github_login_name": "YumaInaura", "id": "YumaInaura", "items_count": 1237, "linkedin_id": "", "location": "Osaka", "name": "Inaura いなうら 稲浦 Yuma ゆうま 悠馬", "organization": "", "permanent_id": 89618, "profile_image_url": "https://qiita-image-store.s3.amazonaws.com/0/89618/profile-images/1546214964", "team_only": false, "twitter_screen_name": "YumaInaura", "website_url": "http://twitter.com/yumainaura" }, "page_views_count": null }Original by Github issue
- 投稿日:2019-04-15T18:40:21+09:00
Example of merging a dictionary with default values into an existing dictionary with values in #python (I don't want to write if 'key' in dict anymore ..)
another answers here comments
#python で値を持った既存の辞書に、デフォルト値つきの辞書をマージする例 ( もう if 'key' in dict なんて書きたくないんですよ‥ ) - Qiita
Using collections defaultdict and ChainMap together
wanna do
- This dictionary
d = {"a":1, "b",2}- When calling this way
d["c"]- I want the default value to be entered instead of KeyError
example
from collections import defaultdict import collections existing_dict = {"a":1, "b":2} default_dict = defaultdict(int) merged_dict = collections.ChainMap(existing_dict, default_dict)EXE
Python 3.7.2 (default, Jan 13 2019, 12:50:01) [Clang 10.0.0 (clang-1000.11.45.5)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>> from collections import defaultdict >>> import collections >>> existing_dict = {"a":1, "b":2} >>> default_dict = defaultdict(int) >>> merged_dict = collections.ChainMap(existing_dict, default_dict) >>> merged_dict["a"] 1 >>> merged_dict["b"] 2 >>> merged_dict["c"] 0 >>> merged_dict["d"] 0ps
- Maybe we aren't doing something really careless
- Please write from the white goat if something is wrong
Original by Github issue
- 投稿日:2019-04-15T18:25:49+09:00
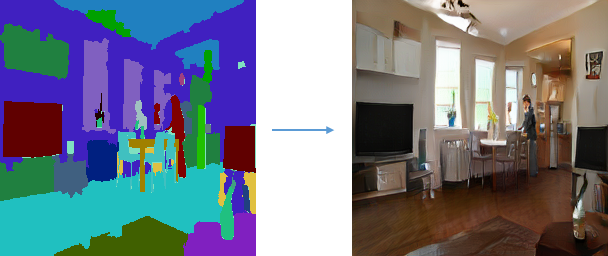
NVIDIAさんのSPADEを使ってみた。

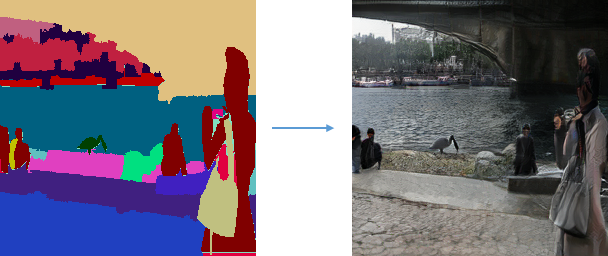





- 投稿日:2019-04-15T17:09:47+09:00
Djangoでmatplotlibの図をPNG画像で表示
環境
OS : macOS Mojave
Anaconda : python3.6.7
Django==2.1.5matplotlibの図を表示する
Djangoでの計算アプリを作成するときにはmatplotlibの図をhtml上に埋め込むことが不可欠。
いろいろ調べるとsvg形式で埋め込む方法がよく出てくるが、svg形式だとアプリ上から保存したときにsvg形式で保存されてしまいその後の活用が厳しい。
PNG画像で出力できるように試行錯誤してみた。
結果としてはsvgの場合とほぼ同じだった。views.py
自分の現在作成中のものから一部を取り出す形で書くので少し見にくいかもしれないがご了承ください
views.pyfrom django.http import HttpResponse from django.shortcuts import render import io import matplotlib.pyplot as plt #png画像形式に変換数関数 def plt2png(): buf = io.BytesIO() plt.savefig(buf, format='png', dpi=200) s = buf.getvalue() buf.close() return s # html表示view def analysis_screen(request): return render(request, 'analysis.html') #画像埋め込み用view def img_plot(request): # matplotを使って作図する (ex) x = [1, 5, 9] y = [4, 6, 8] ax = plt.subplot() ax.scatter(x, y) png = plt2png() plt.cla() response = HttpResponse(png, content_type='image/png') return responseurls.py
urls.pyfrom django.urls import path from . import views app_name = 'analysis_app' urlpatterns = [ path('analysis', views.analysis_screen, name='analysis_screen'), path('analysis/plot', views.img_plot, name="img_plot"), ]analysis.html
analysis.html<img src="{% url 'analysis_app:img_plot' %}" alt="">終わりに
これでおそらくできるはずです(僕はできました。)
言葉少なめコードのみで申し訳ありません
- 投稿日:2019-04-15T16:46:06+09:00
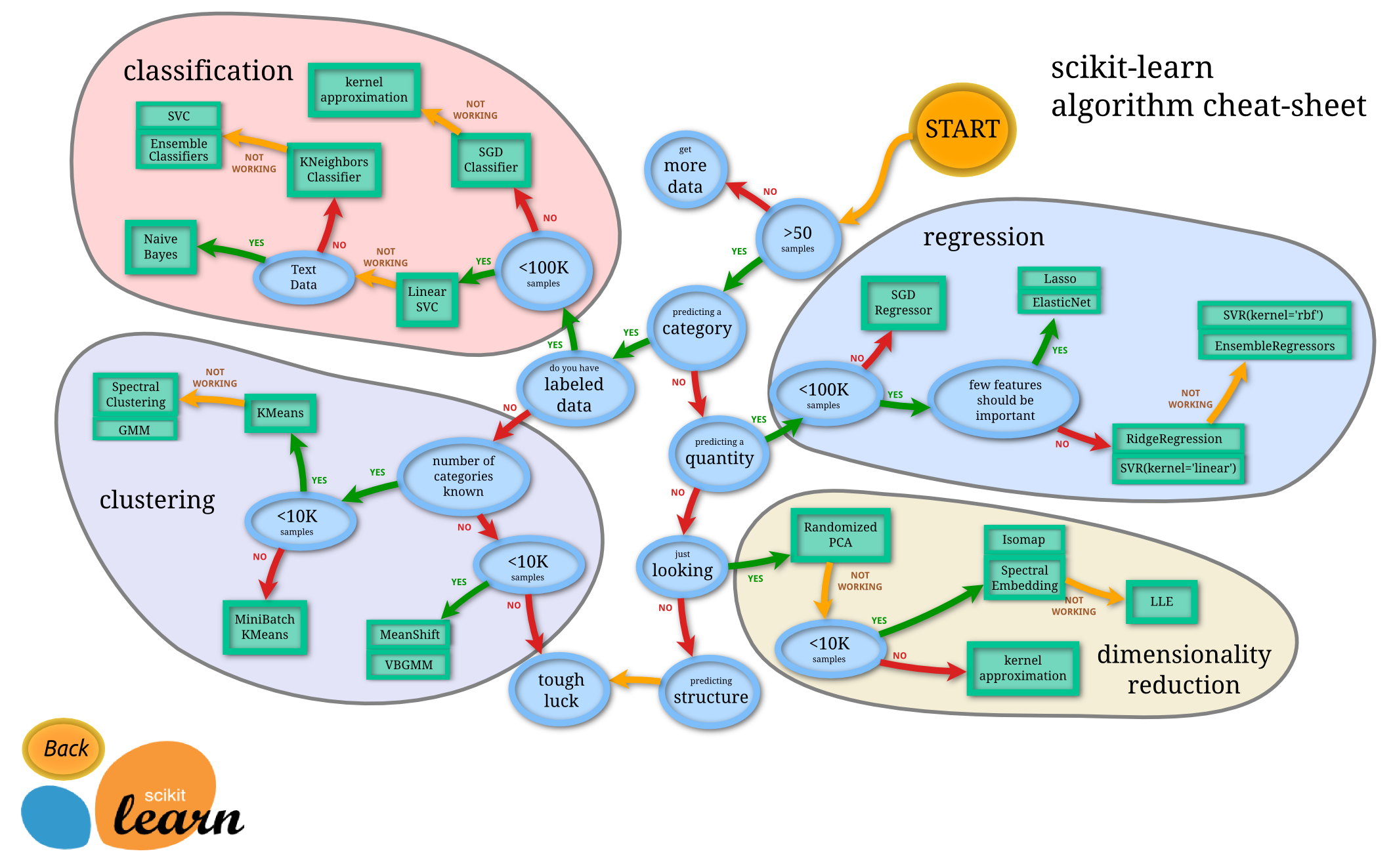
Pythonで機械学習(sckit-learn)
概要
sckit-learnのまとめみたいなもの書きたいなーと。
インストール方法
pip install scikit-learn手法の選択
公式サイトにも記載されています。
- classification(分類) - ラベルとデータを学習し、データに対してのラベルを予測する。
- regression(回帰) - 実数値をデータで学習して、実数値を予測する。
- clustering(クラスタリング) - データの似ているもの同士をまとめて、データの構造を発見する。
- dimensionality reduction(次元削減) - データの次元を削減して、要因を発見 (主成分分析など) したり、他の手法の入力に使う (次元の呪い回避)。
ここから画像の手法名と公式でリンクされているクラスを記載します。
手法:classification
手法:regression
記載名 クラス SGD Regressor sklearn.linear_model.SGDRegressor Lasso sklearn.linear_model.Lasso Lasso sklearn.linear_model.MultiTaskLasso Elastic Net sklearn.linear_model.ElasticNet Elastic Net sklearn.linear_model.MultiTaskElasticNet Ridge Regression sklearn.linear_model.Ridge SVR(kernel='linear') sklearn.svm.SVR SVR(kernel='rbf') sklearn.svm.SVR Ensemble Regressors sklearn.ensemble.BaggingRegressor Ensemble Regressors sklearn.ensemble.RandomForestRegressor Ensemble Regressors sklearn.ensemble.ExtraTreesRegressor Ensemble Regressors sklearn.ensemble.AdaBoostRegressor Ensemble Regressors sklearn.ensemble.GradientBoostingRegressor 手法:clustering
記載名 クラス Mean Shift sklearn.cluster.MeanShift VBGMM sklearn.mixture.BayesianGaussianMixture MiniBatch KMeans sklearn.cluster.MiniBatchKMeans Kmeans sklearn.cluster.Kmeans Spectral Clustering sklearn.cluster.SpectralClustering GMM sklearn.mixture.GaussianMixture 手法:dimensionality reduction
記載名 クラス Randomized PCA sklearn.decomposition.PCA Randomized PCA sklearn.decomposition.IncrementalPCA Randomized PCA sklearn.decomposition.KernelPCA Randomized PCA sklearn.decomposition.SparsePCA Randomized PCA sklearn.decomposition.MiniBatchSparsePCA Isomap sklearn.manifold.Isomap Spectral Embedding sklearn.manifold.SpectralEmbedding LLE sklearn.manifold.LocallyLinearEmbedding 参考
https://qiita.com/ynakayama/items/9c5867b6947aa41e9229
終わりに
- 公式サイトの画像でのリンク先で記載されているものをまとめたものです。
- 各手法の詳細は自身で調査してください
- 誤字・脱字、記載漏れはご了承ください
- 投稿日:2019-04-15T16:18:53+09:00
pykwalifyを使ったYaml検証
yamlファイルのバリデーションをおこなうpykwalifyというPythonのツールを使う機会があったので
使い方をまとめる環境情報
検証に使用した環境のバージョン情報
python3 --version
- Python 3.6.5
pip3.6 --version
- pip 9.0.1 from /usr/lib/python3.6/site-packages (python 3.6)
インストール
- pip install pykwalify
バリデーションの種類
type チェック対象 str 文字列 int 整数 float 浮動小数点数 number intとfloat text numberとstr bool 真理値 seq シーケンス map マップ scalar スカラー date 日付 timestamp 日付と時刻 any なんでも 使い方
- 値の形式チェック
チェックするYamlファイル
hoge: hoge1: 1 hoge2: hogeスキーマファイル
type: map mapping: hoge: type: map mapping: hoge1: type: int hoge2: type: str
- 値の必須チェック
スキーマファイル
type: map mapping: hoge: type: map mapping: hoge1: type: int required: true hoge2: type: str required: truerequired: true を指定する
- 正規表現を使用した文字列形式チェック
スキーマファイル
type: map mapping: hoge: type: map mapping: hoge1: type: int required: true hoge2: type: str pattern: '[a-zA-z]' required: truepattern にチェックする正規表現を定義する
- リスト
チェックするYamlファイル
hoge: seq - hoge1 hoge2スキーマファイル
type: map mapping: seq: type: seq sequence: - type: str required: true
- Mapのリスト
チェックするYamlファイル
hoge: seq - hoge1: 1 hoge2: hogeスキーマファイル
type: map mapping: seq: type: seq sequence: - type: map mapping: hoge1: type: int required: true hoge2: type: str required: true実行例
- OK
# pykwalify -d hoge.yml -s hoge-schema.yml INFO - validation.valid
- NG
- type: int 項目に文字列を指定
# pykwalify -d hoge.yml -s hoge-schema.yml ERROR - validation.invalid ERROR - --- All found errors --- ERROR - ["Value 'fuga' is not of type 'int'. Path: '/hoge/hoge1'"] Traceback (most recent call last): File "/usr/bin/pykwalify", line 11, in <module> sys.exit(cli_entrypoint()) File "/usr/lib/python3.6/site-packages/pykwalify/cli.py", line 95, in cli_entrypoint run(parse_cli()) File "/usr/lib/python3.6/site-packages/pykwalify/cli.py", line 82, in run c.validate() File "/usr/lib/python3.6/site-packages/pykwalify/core.py", line 167, in validate error_msg=u'.\n - '.join(self.validation_errors))) pykwalify.errors.SchemaError: <SchemaError: error code 2: Schema validation failed: - Value 'fuga' is not of type 'int'. Path: '/hoge/hoge1'.: Path: '/'>
- 投稿日:2019-04-15T16:13:27+09:00
10行で画像の判別やってみる【TensorFrow】
windowsです
すべてDOS画面で完結します
pythonは開きません
ブラックホールとポンデリングを見分ける人がいて、これならできそうと感じたので、
やってみたかった画像認識に踏み出してみる仮想環境の作成
まず現状の環境を確認
windowsのコマンドプロンプトからconda info -eデフォルトだとbaseがあるだけ
どうもkerasやtensolを入れようとするとエラーが起こる。
baseに悪影響を及ぼしたこともあるので仮想環境を作っておくほうがいい。
pythonを起動するたびにエラーが出る事もあった・・・conda create -n IR python=3.7IRという名前で仮想環境を作成
activate tensorflowプロンプト画面でbaseからIRに切り替わるのが確認できる
IRという仮想環境に切り替わったことを確認してpip installを行うpip install tensorflow pip install tensorflow_hub pip install tensorboardcd でディレクトリを移動する
認識したい画像が入っているフォルダまで移動
仮にフォルダ名「train」とするC:\user\desktop> cd train C:\user\desktop\train>trainというフォルダーの中にはimagesというフォルダとtestというフォルダ、retrain.pyとlabel_image.pyのスクリプトを置く。
testには学習に使わない画像であり、判別したい画像を入れておく。仮に画像名をcat_test_01.pngというものを入れてあるとする。
スクリプトはここから。(ありがたい)https://raw.githubusercontent.com/tensorflow/hub/master/examples/image_retraining/retrain.py https://github.com/tensorflow/tensorflow/raw/master/tensorflow/examples/label_image/label_image.pyさらにimagesというフォルダの中に判別したい画像をフォルダわけして入れておく。
()
train
-images
-cat
|-cat01.png
-dog
|-dog02.png
プロンプトの画面から
python retrain.py --image_dir images --how_many_training_steps 1000を実行
学習のステップ数が1000回
imagesはフォルダを指定学習が終わってから
tensorboard --logdir /tmp/retrain_logs
を入力すると学習のステップが確認できる
交差誤差はプロンプトの画面でもどんどん減っていくのが見える
ステップを何回に増やすとうまくいくのか、
データが少ないときの回数など試してみたい学習が終了した後、Cドライブ直下のtmpに
output_graph.pb
output_labels.txt
が出来ていた。
続いて以下のコマンドを打ち込む。
最後のpngでテストフォルダの中の画像を指定する。python label_image.py --graph /tmp/output_graph.pb --labels /tmp/output_labels.txt --input_layer Placeholder --output_layer final_result --image "C:\Users\Desktop\train\tes\cat_test_01.png"結果は
cat 0.90095603 dog 0.09904399ネコである確率が90%です。という判断が出てくる。
今回はアニメキャラの顔画像が都合よくフォルダわけされているこちら
http://www.nurs.or.jp/~nagadomi/animeface-character-dataset/のデータセットを使用させていただいた。
実際に判断出来ると感動する。
というか拾いものだけでこんなに簡単にできてしまう便利さに感動。データセットは顔部分を切り取って、サイズを統一して、とやっているのできれいにできたが、写真を撮る(集める)・学習用に振り分ける、といった前処理が大変そう。
画像をデータセットでなく自分でやるときは便利そうな手法を知っていると楽になりそう。あとは原理も理解していきたい。
- 投稿日:2019-04-15T15:10:48+09:00
WikipediaページをDBPedia Instance Typesで分類
DBPedia Instance Typesは、DBPediaのオントロジー情報によって各記事を分類したものです。今回は、Wikipediaの記事をこのDBPedia Instance Typesで分類してみます。
特徴量
- Wikipedia記事の定義文の単語の平均ベクトル。
- Wikipedia記事のカテゴリー。
実行の流れ
- DBPediaのType情報を持っているWikipedia記事を取得し、タイプと記事名を対応付けて保存。
- 記事名に対する定義文を抽出。
- 記事名に対するカテゴリーを抽出。
- 事前訓練済みword2vecを使って定義文の平均ベクトルを生成。
- 記事のもつ全カテゴリー名をスペース結合してからBoWする。
- 平均ベクトルとBoWを水平結合。
- 水平結合したスパース行列をSparseRandomProjectionで次元削減。
- タイプ情報をOneHot化してラベルとして使う。
- 次元削減された特徴量とラベルを使ってKerasモデルを訓練。
- 精度を出す。
- 最終的に、このモデルを使って未知のWikipedia記事を、定義文とカテゴリーからInstance Typesで分類できる。
訓練部分のコード
import pickle import numpy as np from keras import optimizers from keras.callbacks import ModelCheckpoint from keras.layers import Dense, Input, Dropout from keras.models import Model from scipy.sparse import coo_matrix, hstack from sklearn.feature_extraction.text import CountVectorizer from sklearn.metrics import classification_report from sklearn.model_selection import train_test_split from sklearn.random_projection import SparseRandomProjection from tqdm import tqdm def build_model(num_labels, inputlen): inp = Input(shape=(inputlen, )) tmp = Dense(1024, activation="relu", kernel_initializer="he_normal")(inp) tmp = Dropout(0.5)(tmp) tmp = Dense(1042, activation="relu", kernel_initializer="he_normal")(tmp) tmp = Dropout(0.5)(tmp) out = Dense(units=num_labels, activation='softmax')(tmp) model = Model(inp, out) opt = optimizers.Adam(lr=0.001, clipvalue=0.5) model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['acc']) return model def gen_data(data, page2cat, kv, labels): X = [] X_cat = [] y = [] for d in tqdm(data): tmp = [] tmp_cat = "" for cat in page2cat[d["entity"]]: tmp_cat += cat.lower() + " " tmp_cat = tmp_cat.replace("_", " ") for word in d["definition"].replace(".", " ").replace(",", " ").split(): try: x = kv.wv[word] except Exception: continue tmp.append(x) if tmp: X.append(np.mean(tmp, axis=0)) X_cat.append(tmp_cat) y.append(int(labels[d["type"]])) vect = CountVectorizer().fit(X_cat) X_cat = vect.transform(X_cat) X = coo_matrix(X) X = hstack([X, X_cat]) return X, y, vect def y_fix(y, ylen): out = [] for target in y: tmp = np.zeros(ylen) tmp[int(target)] = 1.0 out.append(tmp) return out def generate_data(X, y, batch_size=1000): y = np.array(y) print(X.shape) print(y.shape) while True: for i in range(int(X.shape[0]/1000)): yield X[i*batch_size:(i+1)*batch_size], y[i*batch_size:(i+1)*batch_size] if __name__ == "__main__": #print("data loading...") #with open("./wiki_definition.json") as f: #data = json.load(f) #with open("../scripts/labels.json") as f: # tmp = json.load(f) # labels = tmp[1] #data = shuffle(data) #kv = KeyedVectors.load("./enwiki_model/word2vec.model", mmap="r") #with open("./categories.pkl", "rb") as f: # page2cat = pickle.load(f) #print("done loading") #print("generating data...") #X, y, vect = gen_data(data, page2cat, kv, labels) #print("done generating") #print("saveing data...") #with open("data.pkl", "wb") as f: # pickle.dump((X, y, vect), f, protocol=4) #print("done saving") print("loading") with open("data.pkl", "rb") as f: X, y, _ = pickle.load(f) print("done loading") y_len = np.unique(y).shape[0] + 1 print(y_len) y = y_fix(y, y_len) print("projection") projection = SparseRandomProjection(n_components=1024).fit(X) X = projection.transform(X) with open("proj.pkl", "wb") as f: pickle.dump(projection, f) print(X.shape) X = X.toarray() print("done projection") print("training...") X_train, X_test, y_train, y_test = train_test_split(X, y) X_test, X_val, y_test, y_val = train_test_split(X_test, y_test) model = build_model(y_len, X_train.shape[1]) print("done model building") callbacks = [ ModelCheckpoint("model.h5", save_best_only=False, monitor="val_loss", mode="min"), ModelCheckpoint("model_best.h5", save_best_only=True, monitor="val_loss", mode="min") ] model.fit_generator(generate_data(X_train, y_train), validation_data=generate_data(X_val, y_val), steps_per_epoch=1000, validation_steps=5, epochs=10, callbacks=callbacks) print("done training") print("evaluating...") y_pred = [np.argmax(x) for x in model.predict(X_test)] y_test = [np.argmax(x) for x in y_test] with open("eval.txt", "w") as f: f.write(classification_report(y_test, y_pred)) print("done eval")精度
precision recall f1-score support AcademicConference 0.67 0.86 0.75 14 AcademicJournal 0.98 0.97 0.97 1252 Actor 0.49 0.49 0.49 810 AdministrativeRegion 0.89 0.90 0.90 3979 AdultActor 0.86 0.67 0.75 161 Aircraft 0.99 0.99 0.99 1932 Airline 0.99 0.99 0.99 696 Airport 0.98 0.96 0.97 2509 Album 0.99 1.00 1.00 22773 AmateurBoxer 0.36 0.72 0.48 72 Ambassador 0.46 0.35 0.40 130 AmericanFootballLeague 0.64 0.41 0.50 17 AmericanFootballPlayer 0.80 0.98 0.88 3584 AmericanFootballTeam 0.50 1.00 0.67 5 Amphibian 0.94 0.93 0.94 636 AmusementParkAttraction 0.74 0.91 0.82 90 AnatomicalStructure 0.60 0.88 0.71 309 Animal 0.79 0.77 0.78 1240 AnimangaCharacter 0.89 0.91 0.90 34 Anime 0.63 0.81 0.71 193 Arachnid 0.81 0.93 0.87 745 Archaea 0.80 0.86 0.83 42 Architect 0.52 0.73 0.61 520 ArchitecturalStructure 0.47 0.56 0.51 52 Artery 0.93 0.94 0.93 53 ArtificialSatellite 0.94 0.99 0.96 438 Artist 0.53 0.52 0.53 2765 ArtistDiscography 0.98 0.98 0.98 721 Artwork 0.92 0.94 0.93 911 Asteroid 1.00 0.14 0.25 7 Astronaut 0.82 0.92 0.87 115 Athlete 0.91 0.88 0.90 6782 AustralianFootballTeam 0.59 0.93 0.72 70 AustralianRulesFootballPlayer 0.99 1.00 0.99 2280 AutoRacingLeague 0.00 0.00 0.00 2 Automobile 0.95 0.97 0.96 999 AutomobileEngine 0.90 0.96 0.93 68 Award 0.89 0.96 0.92 946 Bacteria 0.74 0.15 0.25 187 BadmintonPlayer 0.95 0.99 0.97 267 Band 0.86 0.97 0.91 6034 Bank 0.65 0.74 0.69 516 Baronet 0.63 0.88 0.73 130 BaseballLeague 0.90 0.86 0.88 51 BaseballPlayer 0.98 0.99 0.99 4023 BaseballSeason 0.91 0.70 0.79 43 BaseballTeam 0.38 1.00 0.55 3 BasketballLeague 0.74 0.89 0.81 98 BasketballPlayer 0.95 0.97 0.96 2193 BasketballTeam 0.86 0.95 0.90 278 Bay 0.00 0.00 0.00 1 BeachVolleyballPlayer 0.83 0.13 0.22 39 BeautyQueen 0.78 0.97 0.87 392 Beverage 0.79 0.83 0.81 179 BiologicalDatabase 0.90 0.97 0.94 67 Bird 0.97 0.99 0.98 2455 BodyOfWater 0.66 0.54 0.60 228 Bodybuilder 0.82 0.75 0.78 53 Bone 0.87 0.55 0.67 62 Book 0.96 0.97 0.97 6533 Boxer 0.90 0.91 0.90 733 Brain 0.95 0.70 0.80 99 Brewery 0.25 0.09 0.13 45 Bridge 0.91 0.94 0.92 751 BroadcastNetwork 0.65 0.24 0.35 218 Building 0.76 0.80 0.78 8573 BusCompany 0.75 0.90 0.82 256 BusinessPerson 0.38 0.05 0.08 130 CanadianFootballTeam 0.65 0.70 0.68 37 Canal 0.80 0.94 0.87 79 Canoeist 0.86 0.93 0.89 72 Cardinal 0.47 0.78 0.59 137 Castle 0.61 0.79 0.69 265 Cave 0.66 0.89 0.76 91 Chancellor 0.00 0.00 0.00 19 Cheese 0.95 0.72 0.82 57 Chef 0.71 0.74 0.72 118 ChemicalCompound 0.84 0.86 0.85 1869 ChessPlayer 0.81 0.96 0.88 277 ChristianBishop 0.77 0.87 0.82 1655 City 0.79 0.83 0.81 3829 ClassicalMusicArtist 0.31 0.21 0.25 52 ClassicalMusicComposition 0.52 0.74 0.61 122 Cleric 0.76 0.51 0.61 470 ClubMoss 0.00 0.00 0.00 15 College 0.86 0.92 0.89 13 CollegeCoach 0.91 0.91 0.91 1286 Colour 0.92 0.87 0.89 38 Comedian 0.52 0.34 0.41 246 ComedyGroup 0.44 0.33 0.38 12 Comic 0.81 0.94 0.87 374 ComicStrip 0.85 0.81 0.83 62 ComicsCharacter 0.93 0.95 0.94 710 ComicsCreator 0.65 0.83 0.73 531 Company 0.89 0.88 0.89 9169 ConcentrationCamp 0.55 0.73 0.63 15 Congressman 0.47 0.63 0.54 597 Conifer 0.84 0.61 0.71 128 Constellation 1.00 0.93 0.97 15 Continent 0.00 0.00 0.00 4 Convention 0.68 0.70 0.69 387 Country 0.78 0.73 0.75 608 Crater 0.82 0.98 0.89 121 CricketGround 0.82 0.97 0.89 38 CricketTeam 0.76 0.98 0.86 109 Cricketer 0.98 0.99 0.99 3426 Criminal 0.64 0.67 0.65 424 Crustacean 0.92 0.80 0.86 485 CultivatedVariety 0.99 0.93 0.96 307 Curler 0.90 0.99 0.94 150 CurlingLeague 0.00 0.00 0.00 2 Currency 0.90 0.91 0.91 69 Cycad 1.00 0.20 0.34 44 CyclingRace 0.87 0.99 0.93 147 CyclingTeam 0.97 0.98 0.98 62 Cyclist 0.96 0.99 0.97 2097 Dam 0.94 0.91 0.93 602 DartsPlayer 0.98 0.93 0.96 105 Device 0.91 0.98 0.94 218 Diocese 0.95 1.00 0.97 601 Disease 0.86 0.95 0.90 1111 Drug 0.82 0.89 0.85 1143 Earthquake 0.97 0.99 0.98 137 Economist 0.49 0.70 0.57 240 EducationalInstitution 0.74 0.65 0.70 84 Election 0.68 0.68 0.68 25 Embryology 0.70 0.17 0.28 40 Engineer 0.44 0.53 0.48 137 Entomologist 0.49 0.63 0.55 76 Enzyme 0.97 0.97 0.97 939 EthnicGroup 0.81 0.95 0.88 885 Eukaryote 0.46 0.60 0.52 218 EurovisionSongContestEntry 0.83 0.96 0.89 193 Event 0.89 0.55 0.68 820 Fashion 0.54 0.45 0.49 71 FashionDesigner 0.50 0.72 0.59 125 Fern 0.85 0.83 0.84 179 FictionalCharacter 0.84 0.88 0.86 772 FieldHockeyLeague 0.50 0.67 0.57 3 FigureSkater 0.96 0.99 0.97 549 Film 0.96 0.98 0.97 19838 FilmFestival 0.86 0.97 0.91 169 Fish 0.94 0.97 0.95 3295 FloweringPlant 0.00 0.00 0.00 23 Food 0.87 0.96 0.92 850 FootballLeagueSeason 0.91 0.98 0.94 1674 FootballMatch 0.93 0.91 0.92 620 FormulaOneRacer 0.91 0.79 0.85 146 FormulaOneTeam 0.94 0.94 0.94 32 Fungus 0.96 0.98 0.97 2043 GaelicGamesPlayer 0.98 0.99 0.99 670 Galaxy 0.96 1.00 0.98 155 Game 0.93 0.88 0.90 254 Garden 0.76 0.92 0.83 61 Ginkgo 0.00 0.00 0.00 1 GivenName 0.93 0.96 0.95 665 Glacier 0.95 0.92 0.94 129 Gnetophytes 0.00 0.00 0.00 5 GolfCourse 0.89 0.98 0.93 63 GolfLeague 0.50 0.33 0.40 3 GolfPlayer 0.97 1.00 0.98 609 GolfTournament 0.99 0.99 0.99 336 GovernmentAgency 0.73 0.87 0.79 979 Governor 0.67 0.42 0.52 518 GrandPrix 0.99 0.99 0.99 289 Grape 0.94 1.00 0.97 58 GreenAlga 0.57 0.70 0.63 70 GridironFootballPlayer 0.91 0.36 0.52 1166 Guitarist 0.00 0.00 0.00 25 Gymnast 0.94 0.90 0.92 410 HandballLeague 1.00 0.25 0.40 4 HandballPlayer 0.93 0.97 0.95 400 HandballTeam 0.79 0.97 0.87 72 Historian 0.35 0.21 0.26 115 HistoricBuilding 0.80 0.92 0.86 1667 HistoricPlace 0.71 0.64 0.67 4491 HockeyTeam 0.94 0.99 0.96 454 Holiday 0.88 0.82 0.85 188 HollywoodCartoon 0.91 0.96 0.93 293 HorseRace 0.98 0.99 0.99 447 HorseRider 0.76 0.90 0.82 113 HorseTrainer 0.64 0.62 0.63 37 Hospital 0.92 0.94 0.93 534 Hotel 0.64 0.80 0.71 234 IceHockeyLeague 0.83 0.85 0.84 53 IceHockeyPlayer 0.98 1.00 0.99 2787 InformationAppliance 0.89 0.72 0.80 218 InlineHockeyLeague 0.00 0.00 0.00 1 Insect 0.99 0.99 0.99 24521 Island 0.82 0.92 0.86 1136 Jockey 0.77 0.86 0.81 102 Journalist 0.46 0.28 0.35 280 Judge 0.53 0.53 0.53 548 LacrosseLeague 1.00 0.78 0.88 9 LacrossePlayer 0.94 0.97 0.95 62 Lake 0.91 0.95 0.93 1779 Language 0.96 0.97 0.97 1487 LaunchPad 0.76 0.90 0.83 21 LawFirm 0.91 0.79 0.85 66 Legislature 0.82 0.92 0.87 332 Library 0.82 0.76 0.79 197 Ligament 0.82 0.72 0.77 32 Lighthouse 0.96 0.98 0.97 341 Locomotive 0.99 0.98 0.99 577 Lymph 0.93 0.87 0.90 15 Magazine 0.86 0.93 0.90 871 Mammal 0.93 0.95 0.94 1499 Manga 0.96 0.87 0.92 570 MartialArtist 0.92 0.92 0.92 604 Mayor 0.46 0.47 0.47 307 Medician 0.40 0.07 0.12 88 MemberOfParliament 0.68 0.79 0.73 1385 MilitaryConflict 0.95 0.97 0.96 2443 MilitaryPerson 0.80 0.90 0.85 5016 MilitaryStructure 0.67 0.73 0.70 803 MilitaryUnit 0.95 0.96 0.96 3174 Mineral 0.98 0.92 0.95 266 MixedMartialArtsEvent 0.95 0.99 0.97 136 Model 0.74 0.60 0.66 309 Mollusca 0.99 0.99 0.99 4859 Monarch 0.51 0.62 0.56 409 Monument 0.44 0.54 0.49 107 Moss 0.89 0.18 0.30 89 Motorcycle 0.98 0.98 0.98 212 MotorcycleRacingLeague 0.00 0.00 0.00 5 MotorcycleRider 0.92 0.98 0.95 211 MotorsportSeason 0.96 0.99 0.97 534 Mountain 0.91 0.93 0.92 3025 MountainPass 0.93 0.95 0.94 189 MountainRange 0.82 0.87 0.84 461 Murderer 0.00 0.00 0.00 16 Muscle 1.00 0.98 0.99 47 Museum 0.79 0.87 0.83 989 MusicFestival 0.48 0.80 0.60 69 MusicGenre 0.67 0.91 0.77 221 Musical 0.91 0.97 0.94 246 MusicalArtist 0.70 0.88 0.78 9249 MusicalWork 0.47 0.69 0.56 52 MythologicalFigure 0.67 0.94 0.78 151 NCAATeamSeason 0.99 1.00 1.00 3100 NascarDriver 0.82 0.95 0.88 166 NationalCollegiateAthleticAssociationAthlete 0.50 0.03 0.05 36 NationalFootballLeagueEvent 0.33 0.50 0.40 2 NationalFootballLeagueSeason 0.97 0.99 0.98 635 Nerve 0.93 0.74 0.83 58 NetballPlayer 0.95 0.92 0.94 39 Newspaper 0.94 0.92 0.93 1189 Noble 0.59 0.57 0.58 870 Non-ProfitOrganisation 0.46 0.02 0.04 328 Novel 0.00 0.00 0.00 6 OfficeHolder 0.65 0.76 0.70 12280 OlympicEvent 0.96 1.00 0.98 809 OlympicResult 0.85 0.99 0.92 149 Olympics 0.88 0.78 0.82 9 Organisation 0.65 0.78 0.71 3162 Painter 0.58 0.59 0.58 469 Park 0.76 0.67 0.71 699 Person 0.68 0.68 0.68 33152 Philosopher 0.33 0.63 0.43 361 Photographer 0.36 0.29 0.32 92 Place 0.90 0.65 0.75 1348 Planet 0.98 0.99 0.99 663 Plant 0.96 0.98 0.97 9790 Play 0.83 0.93 0.88 373 PlayboyPlaymate 0.88 0.79 0.84 48 Poem 0.59 0.60 0.59 62 Poet 0.32 0.37 0.34 49 PokerPlayer 0.98 0.96 0.97 130 PoliticalParty 0.93 0.96 0.95 1343 Politician 0.64 0.49 0.56 3440 PoloLeague 0.75 0.43 0.55 7 Pope 0.86 0.97 0.91 63 PowerStation 0.89 0.95 0.92 386 Presenter 0.00 0.00 0.00 21 President 0.61 0.20 0.30 417 PrimeMinister 0.41 0.29 0.34 249 Prison 0.96 0.98 0.97 260 ProgrammingLanguage 0.86 0.53 0.66 180 ProtectedArea 0.90 0.87 0.88 1738 Protein 0.81 0.84 0.83 416 PublicTransitSystem 0.63 0.54 0.58 337 Publisher 0.81 0.67 0.73 263 RaceHorse 1.00 0.99 1.00 742 Racecourse 0.78 0.84 0.81 45 RacingDriver 0.82 0.89 0.86 455 RadioHost 0.26 0.14 0.18 74 RadioProgram 0.86 0.91 0.89 234 RadioStation 0.98 0.99 0.99 3641 RailwayLine 0.80 0.91 0.85 645 RailwayStation 0.84 0.82 0.83 315 RailwayTunnel 0.88 0.68 0.77 41 RecordLabel 0.90 0.96 0.93 576 Religious 0.73 0.56 0.64 199 ReligiousBuilding 0.80 0.67 0.73 794 Reptile 0.95 0.91 0.93 878 ResearchProject 0.00 0.00 0.00 1 Restaurant 0.84 0.84 0.84 216 River 0.98 0.99 0.99 5047 Road 0.97 0.99 0.98 3725 RoadJunction 0.95 0.61 0.75 31 RoadTunnel 0.67 0.96 0.79 52 Rocket 0.74 0.81 0.78 43 RollerCoaster 0.99 0.98 0.99 122 Rower 0.94 0.89 0.91 53 Royalty 0.70 0.84 0.76 1833 RugbyClub 0.92 0.95 0.94 418 RugbyLeague 0.87 0.87 0.87 98 RugbyPlayer 0.98 0.99 0.99 3033 Saint 0.81 0.93 0.86 710 School 0.95 0.97 0.96 5821 Scientist 0.58 0.60 0.59 4383 ScreenWriter 0.55 0.26 0.35 138 Sea 0.43 0.38 0.40 8 Senator 0.33 0.45 0.38 141 Settlement 0.92 0.95 0.93 43480 Ship 0.99 0.99 0.99 5209 ShoppingMall 0.97 0.96 0.96 428 Single 0.96 0.98 0.97 8900 SiteOfSpecialScientificInterest 0.85 0.97 0.91 191 Skater 0.76 0.93 0.84 99 SkiArea 0.90 0.87 0.89 107 Skier 0.82 0.89 0.85 449 SnookerChamp 0.00 0.00 0.00 5 SnookerPlayer 0.74 0.96 0.84 76 SoapCharacter 0.96 0.91 0.93 441 SoccerClub 0.97 0.99 0.98 3770 SoccerClubSeason 0.97 0.99 0.98 1737 SoccerLeague 0.79 0.90 0.84 318 SoccerManager 0.93 0.79 0.86 3417 SoccerPlayer 0.96 0.99 0.98 20789 SoccerTournament 0.78 0.94 0.85 1232 SoftballLeague 0.67 0.40 0.50 5 Software 0.86 0.90 0.88 1926 SolarEclipse 0.97 1.00 0.98 62 Song 0.77 0.62 0.69 1124 SpaceShuttle 0.00 0.00 0.00 6 SpaceStation 0.75 0.60 0.67 5 Spacecraft 0.00 0.00 0.00 3 Species 0.79 0.83 0.81 1108 SpeedwayLeague 0.75 0.75 0.75 4 SpeedwayRider 0.98 0.98 0.98 135 SpeedwayTeam 0.81 0.91 0.86 23 Sport 0.85 0.52 0.65 42 SportsEvent 0.80 0.84 0.82 215 SportsLeague 0.54 0.48 0.51 77 SportsTeam 0.79 0.70 0.74 455 SportsTeamMember 0.97 0.61 0.75 135 SquashPlayer 0.95 0.93 0.94 81 Stadium 0.63 0.58 0.60 1058 Star 0.99 0.98 0.99 561 Station 0.98 0.98 0.98 5128 Stream 0.00 0.00 0.00 9 SumoWrestler 0.96 0.96 0.96 80 SupremeCourtOfTheUnitedStatesCase 0.98 1.00 0.99 500 Surname 0.49 0.69 0.57 80 Swimmer 0.86 0.98 0.92 1096 TableTennisPlayer 0.83 0.93 0.88 88 TelevisionEpisode 0.98 0.98 0.98 1546 TelevisionHost 0.00 0.00 0.00 13 TelevisionSeason 0.88 0.94 0.91 640 TelevisionShow 0.90 0.95 0.93 6608 TelevisionStation 0.90 0.98 0.94 1334 TennisLeague 0.00 0.00 0.00 3 TennisPlayer 0.97 0.99 0.98 951 TennisTournament 0.95 0.99 0.97 213 Theatre 0.46 0.28 0.35 127 Town 0.88 0.78 0.83 7785 TradeUnion 0.91 0.86 0.89 298 Train 0.90 0.94 0.92 272 Tunnel 0.00 0.00 0.00 24 University 0.92 0.90 0.91 3383 Valley 0.76 0.57 0.65 23 Vein 0.97 0.88 0.93 43 Venue 0.51 0.56 0.53 1085 VideoGame 0.99 0.99 0.99 3492 VideogamesLeague 0.00 0.00 0.00 1 Village 0.96 0.97 0.97 30851 VoiceActor 0.36 0.41 0.38 22 Volcano 0.64 0.88 0.74 131 VolleyballCoach 0.60 0.21 0.32 14 VolleyballLeague 1.00 0.69 0.82 13 VolleyballPlayer 0.88 0.99 0.93 676 WaterRide 0.83 0.29 0.43 17 WaterwayTunnel 0.57 1.00 0.73 4 Weapon 0.92 0.95 0.93 893 Website 0.63 0.60 0.61 609 WineRegion 0.89 0.85 0.87 67 Winery 0.86 0.90 0.88 63 WomensTennisAssociationTournament 0.92 0.98 0.95 94 WorldHeritageSite 0.45 0.54 0.49 122 Wrestler 0.93 0.89 0.91 618 WrestlingEvent 0.96 1.00 0.98 226 Writer 0.49 0.55 0.52 5418 WrittenWork 0.84 0.93 0.89 272 Year 0.96 0.97 0.97 281 YearInSpaceflight 1.00 0.92 0.96 12 owl#Thing 0.68 0.51 0.58 49682 micro avg 0.86 0.86 0.86 586369 macro avg 0.75 0.75 0.74 586369 weighted avg 0.86 0.86 0.86 586369
- 投稿日:2019-04-15T13:10:04+09:00
#python で値を持った既存の辞書に、デフォルト値つきの辞書をマージする例 ( もう if 'key' in dict なんて書きたくないんですよ‥ )
collections の defaultdict と ChainMap を合わせて使う
wanna do
- こういう辞書を
d = {"a":1, "b",2}- こう呼び出した時
d["c"]- KeyError ではなくデフォルト値が入っていてほしい
example
from collections import defaultdict import collections existing_dict = {"a":1, "b":2} default_dict = defaultdict(int) merged_dict = collections.ChainMap(existing_dict, default_dict)exe
Python 3.7.2 (default, Jan 13 2019, 12:50:01) [Clang 10.0.0 (clang-1000.11.45.5)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>> from collections import defaultdict >>> import collections >>> existing_dict = {"a":1, "b":2} >>> default_dict = defaultdict(int) >>> merged_dict = collections.ChainMap(existing_dict, default_dict) >>> merged_dict["a"] 1 >>> merged_dict["b"] 2 >>> merged_dict["c"] 0 >>> merged_dict["d"] 0p.s
- もしかしたらものすごく迂遠なことをやっていないだろうか
- 何か変だったら白ヤギさんからお手紙ください
Original by Github issue
- 投稿日:2019-04-15T12:40:55+09:00
#python の defaultdict を利用して KeyError を防ぎたい
import
>>> from collections import defaultdictint
どんなキーでもデフォルト値が0のディクショナリを作る
>>> a = defaultdict(int) >>> a defaultdict(<class 'int'>, {}) >>> a["1"] 0 >>> a[1] 0 >>> a["a"] 0 >>> a["b"] 0 >>> a["c"] 0 >>> a[0] 0 >>> a[1] 0 >>> a[2] 0 >>> a[1] 0str
どんなキーでもデフォルトが空白文字列の辞書を作る
>>> a = defaultdict(str) >>> a[0] '' >>> a[1] '' >>> a['some'] '' >>> a['what'] ''dict
デフォルト値がディクショナリのディクショナリ
>>> a = defaultdict(dict) >>> a[0] {} >>> a['some'] {}nested
デフォルト値が defaultdict の defaultdict
>>> a = defaultdict(lambda: defaultdict(int)) >>> a[0] defaultdict(<class 'int'>, {}) >>> a[0][0] 0 >>> a["a"]["b"] 0Original by Github issue
- 投稿日:2019-04-15T12:40:08+09:00
Python matplotlib 時系列グラフ(時間軸の設定)
はじめに
年末より忙しくて、久しぶりに記事を書いています。
何年か前にやった仕事のフォローのため2周間の出張でマレーシアに来ています。お客さんに提出する報告書で久しぶりに時系列グラフを作成する必要があったので、その時調べたものをアップしたいと思います。(実はお客さん提出用グラフの時間軸はデフォルトで出してしまったのですが、提出後今後のために調べたものをアップしているのが本当です)当方の環境は以下の通り。
- MacBook Pro (Retina, 13-inch, Mid 2014)
- macOS MOjave
- Python 3.7.2
時間軸設定には以下のサイトを参考にしました。
- https://stackoverflow.com/questions/17452179/not-write-out-all-dates-on-an-axis-matplotlib
- https://bunseki-train.com/setting_ticks_by_matplotlib_dates/
- https://matplotlib.org/api/dates_api.html
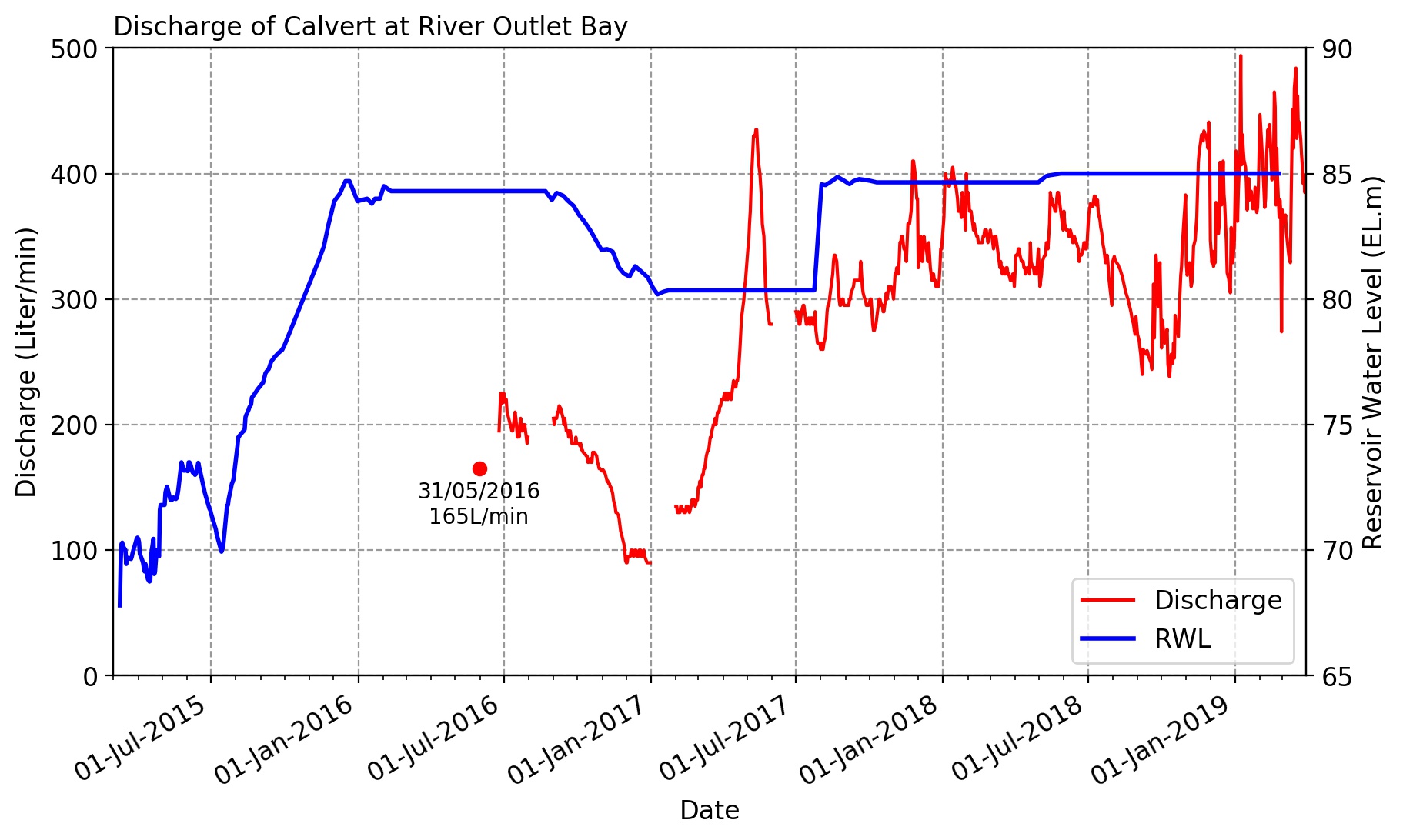
作例は以下の通り。ただの時系列グラフですが、よくサイトで目にするものよりはスパンが長く、月単位に目盛りを入れているところがミソです。
モジュールのインポート
下記のモジュールをインポート。この他、エクセルからデータを読み込むので、xlrd を pip でインストールしておく必要があります。
import numpy as np import pandas as pd import matplotlib.pyplot as plt import datetime import matplotlib.dates as mdatesデータ読み込み
データは2つのエクセルファイルから読み込みます。
ファイル calvert.xlsx
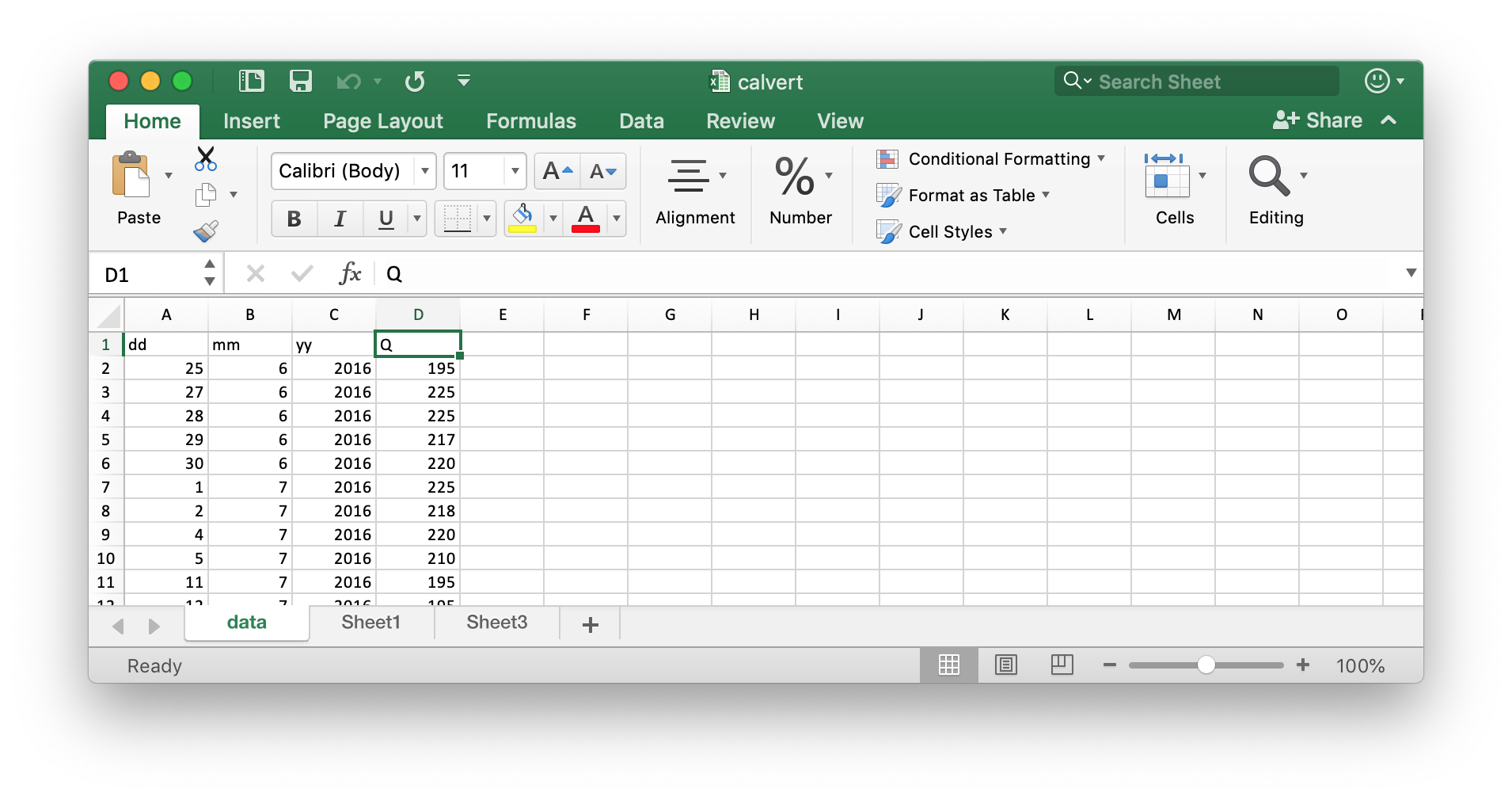
1つめのデータは下に示すもので、作例グラフの緑線を描くためのもの。
エクセルで以下のような形で収納されています。これは自分でデータを打ち込んだので、打ち込みやすいよう、日付(dd)、月(mm)、年(yy)、値(Q) という並びにしています。
欠測期間が長く、グラフの線を連続させたくない場合は、欠測期間中に nan をいれるとグラフの線を結ばないで描画してくれます。
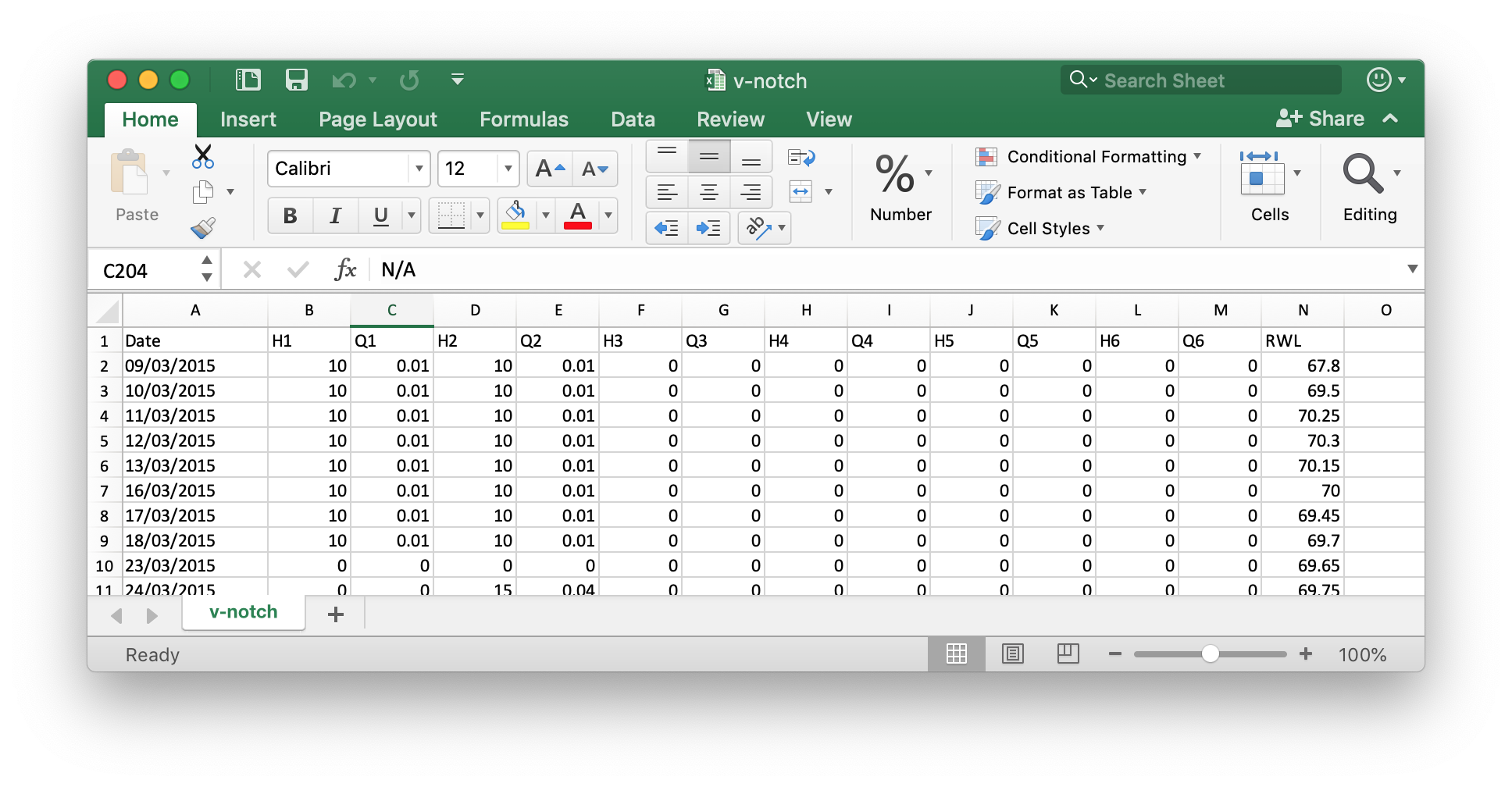
ファイル v-notch.xlsx
2つめのデータは下に示すもので、作例グラフの濃い青線を描くためのもの。
これは既存のエクセルファイルがあったのでそれを用いていますが、ここで使用するのは、カラムDateとカラムRWLだけです。
エクセルファイルからのデータ読み込み
エクセルからのデータ読み込みはpandasで行っています。
calvert.xlsxの読み込みでは日付・月・年の各カラムを連結した文字列を作り、これを以下のように、日付データとしてデータフレームのインデックスとします。
df.index=pd.to_datetime(ss, format='%d/%m/%Y')v-notch.xlsxの読み込みでは、下に示すように、必要なカラム(0と13)のみを読み込み、カラム0をデータフォレームのインデックスとします。またインデックスを日付データにします。
dfr = pd.read_excel(fnameR,usecols=[0,13],index_col=0) dfr.index = pd.to_datetime(dfr.index, format='%d/%m/%Y')データ読み込み部のコードは以下の通り。
calvert.xlsxからのデータをデータフレームdf,v-notch.xlsxからのデータをデータフレームdfrに格納しています。
# discharge data input fnameR='calvert.xlsx' df = pd.read_excel(fnameR,sheet_name='data') ss=[] for sd,sm,sy in zip(df['dd'],df['mm'],df['yy']): s1='{0:0>2d}'.format(sd) s2='{0:0>2d}'.format(sm) s3='{0:0>4d}'.format(sy) ss=ss+[s1+'/'+s2+'/'+s3] df.index=pd.to_datetime(ss, format='%d/%m/%Y') # reservoir water level input fnameR='v-notch.xlsx' dfr = pd.read_excel(fnameR,usecols=[0,13],index_col=0) dfr.index = pd.to_datetime(dfr.index, format='%d/%m/%Y')横軸最小値と最大値の指定
横軸最小値を2015年3月1日、横軸最大値を2019年3月31日に指定します。このとき下のように日付を示す文字列を作成し、日付型に変換し、これを用いてx軸範囲を指定しています。
日付の指定は、%Y-%m-%dという形にしています。Pythonは日付はデフォルトでこの形で扱っているようですので。sxmin='2015-03-01' sxmax='2019-03-31' xmin = datetime.datetime.strptime(sxmin, '%Y-%m-%d') xmax = datetime.datetime.strptime(sxmax, '%Y-%m-%d') plt.xlim([xmin,xmax])横軸の書式設定
横軸の書式設定は、以下のように
xaxis.set_major_formatterとxaxis.set_minor_locatorを用います。
マレーシアでは通常は、日・月・年の順で表示するのでDateFormatterで%d-%b-%Yを指定します。月の%bは短縮形英語表現です。月と日付の順番が紛らわしいので、これではっきりします。主目盛の位置は
xaxis.set_major_locatorのMonthLocator(interval=6)で、6ヶ月単位に指定します。また補助目盛の位置はxaxis.set_minor_locatorのMonthLocator(interval=1)で1ヶ月単位に指定します。autofmt_xdate()は長い表記を適当に斜めに表示してくれます。グリッドは主目盛・補助目盛双方に指定するとうっとおしいので主目盛のみ(major)としました。
plt.gca().xaxis.set_major_formatter(mdates.DateFormatter('%d-%b-%Y')) plt.gca().xaxis.set_major_locator(mdates.MonthLocator(interval=6)) plt.gca().xaxis.set_minor_locator(mdates.MonthLocator(interval=1)) plt.gcf().autofmt_xdate()この事例では、
twinx()を用いた2軸利用のグラフとしていますが、上記記載は最後にしておく必要があります。twinx()の前に書いてもこの記載は有効にならずデフォルトの軸が表示されてしまいます。プログラム全文
import numpy as np import pandas as pd import matplotlib.pyplot as plt import datetime import matplotlib.dates as mdates def main(): # discharge data input fnameR='calvert.xlsx' df = pd.read_excel(fnameR,sheet_name='data') ss=[] for sd,sm,sy in zip(df['dd'],df['mm'],df['yy']): s1='{0:0>2d}'.format(sd) s2='{0:0>2d}'.format(sm) s3='{0:0>4d}'.format(sy) ss=ss+[s1+'/'+s2+'/'+s3] df.index=pd.to_datetime(ss, format='%d/%m/%Y') # reservoir water level input fnameR='v-notch.xlsx' dfr = pd.read_excel(fnameR,usecols=[0,13],index_col=0) dfr.index = pd.to_datetime(dfr.index, format='%d/%m/%Y') fsz=12 plt.figure(figsize=(10,6), dpi=200,facecolor='w') plt.rcParams['font.size']=fsz sxmin='2015-03-01' sxmax='2019-03-31' xmin = datetime.datetime.strptime(sxmin, '%Y-%m-%d') xmax = datetime.datetime.strptime(sxmax, '%Y-%m-%d') plt.xlim([xmin,xmax]) plt.ylim([0,500]) plt.xlabel('Date') plt.ylabel('Discharge (Liter/min)') plt.grid(which='major',axis='both',color='#999999',linestyle='--') plt.plot(df.index,df['Q'],'-',color='#ff0000',label='Discharge') qs=165.0; spot='2016-05-31' dsp = datetime.datetime.strptime(spot, '%Y-%m-%d') plt.plot([dsp],[qs],'o',color='#ff0000') ss='31/05/2016\n{0:.0f}L/min'.format(qs) plt.text(dsp,qs-10,ss,va='top',ha='center',fontsize=fsz-2) plt.plot([0],[0],'-',lw=2,color='#0000ff',label='RWL') plt.title('Discharge of Calvert at River Outlet Bay',loc='left',fontsize=fsz) plt.legend(loc='lower right',fontsize=fsz) plt.twinx() plt.ylim([65,90]) plt.ylabel('Reservoir Water Level (EL.m)') plt.plot(dfr.index,dfr['RWL'],'-',lw=2,color='#0000ff') plt.gca().xaxis.set_major_formatter(mdates.DateFormatter('%d-%b-%Y')) plt.gca().xaxis.set_major_locator(mdates.MonthLocator(interval=6)) plt.gca().xaxis.set_minor_locator(mdates.MonthLocator(interval=1)) plt.gcf().autofmt_xdate() fnameF='fig_qiita.jpg' plt.savefig(fnameF, dpi=200, bbox_inches="tight", pad_inches=0.1) plt.show() #============== # Execution #============== if __name__ == '__main__': main()雑感
普段からエクセルは好んでは使わないのですが、データ入力などには向いている。テキストエディタでブランクをいれながら入力するよりは、エクセルのような表計算形式の入力のほうが楽です。またエクセル入力したファイルもpandasで楽々読み込みできるので、とても便利。
軸の単位を示すのに、
xaxis.set_major_locatorにはMonthLocatorの他、WeekdayLocator, DayLocator, HourLocator, MinuteLocator, SecondLocatorがあり、色々な単位に対応できるようです。これで色々な時系列グラフの自分としてのベースができた気がします。
この投稿が、何かしら皆様のお役にもたてば幸いです。
以 上
- 投稿日:2019-04-15T12:10:39+09:00
atom使いのためのdockerとHydrogenによるお手軽python環境構築
atomを使いたい
dockerを使うとお手軽にjupyterを使えるpython環境が手に入ります。ただjupyterをそのまま使いたくないという謎のこだわりがある。
pythonを書くときの環境はjupyter notebookが便利。最近だとjupyterLabなんかも拡張機能とかもあって楽しいらしい。(参考:https://qiita.com/canonrock16/items/d166c93087a4aafd2db4)しかし、私はatomを使いたい。特別理由はないがatomを使いたい。
pythonに関してはatomにHydrogenというパッケージを導入すればjupyterライクに出力を得られる。ただ、SSHでリモートマシンに接続したり、dockerコンテナ上のカーネルに接続する場合多少の設定が必要になる。
今回は、いろいろあって環境がぐちゃぐちゃになったので、docker上にpython環境を用意しatom上でHydrogenを使う環境を整えたのでその流れをメモに残します。dockerコンテナの起動
docker imageを自分で用意する時間がなかったため、jupyter環境が最初から構築してあるimageを使わせてもらった。docker hubにいろいろあるが、自分はjupyter/scipy-notebookを使わせてもらった。
詳細は省かせていただきます。
1.docker imageをpulldocker pull jupyter/scipy-notebook2.docker imageをrun
docker run -p 8888:8888 -v ~/hoge:/home/jovyan/work jupyter-notebook start-notobook.sh —NotebookApp.token="yourpass"オプションとして、
- -p: コンテナのポートをホスト側に公開。
- -v: ボリュームをマウント。フォルダの同期のため。
- jupyter-notebook start-notobook.sh: jupyterのコマンドを使用するために必要なオプション.
- NotebookApp.token="yourtoken": jupyter側のコマンドで、tokenを指定
tokenは指定しないと毎回変わるので指定することをオススメ。
ここで、Executing the command: jupyter notebook --NotebookApp.token=yourtoken [I 14:19:25.923 NotebookApp] Writing notebook server cookie secret to /home/jovyan/.local/share/jupyter/runtime/notebook_cookie_secret [I 14:19:27.362 NotebookApp] JupyterLab extension loaded from /opt/conda/lib/python3.7/site-packages/jupyterlab [I 14:19:27.362 NotebookApp] JupyterLab application directory is /opt/conda/share/jupyter/lab [I 14:19:27.365 NotebookApp] Serving notebooks from local directory: /home/jovyan [I 14:19:27.366 NotebookApp] The Jupyter Notebook is running at: [I 14:19:27.367 NotebookApp] http://(***):8888/?token=… [I 14:19:27.367 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).とでてきてdockerコンテナ上にjupyter kernelが起動できた。
ここまでできたら、Hydrogenへの設定へ。
Hydrogenの準備
調べればたくさん丁寧に説明してくれてる記事があるので、Hydrogenのインストール等は省略する。(こことか)
atomのpacageからHydrogenの設定画面へ行き、Kernel Gatewayというところに、こんな感じで記入。
nameは自分の好きなものを、baseUrlはdockerを起動したときにでてきたurlをコピペ、tokenは自分で設定したtokenを記入。
詳細はここ参照。Hydrogenからリモートカーネルへ接続
- atomの画面からコマンドパレットを開き,Hydrogen:Connect To Remote Kernelを選択。
2.remote kernelが見つかれば次のように出てくるので、使いたいカーネルを選択。
3.セッションを選択。
ここまできたら、あとは通常のHydrogenと同じように使えるはず。
まとめ
Hydrogenを使えば、atomのエディタ機能を使いながらjupyterのインタラクティブな機能をふんだんに使える。jupyter用のショートカットを覚える必要もない。docker使えば環境設定の必要もほぼいらない。python使う人はatomとHydrogen使いましょ。
(jupyter labとかは進化が目まぐるしいので、ちょっとさわってもいいかな・・・)ssh接続でリモートマシン上のカーネルを使いたいときも同じようにできると思います。
参考
Jupyterをブラウザで使うのをやめてAtomのHydrogenに移行した話
JupyterのDockerイメージまとめ
Hydrogen
jupyter docker stacks

- 投稿日:2019-04-15T10:56:54+09:00
GoogleのAIとNTTのAIを融合したら最強の業務カイゼンツールが爆誕した
作ったもの
紙の書類などスキャンして管理してると
↓こんな感じでファイル名がカオスになりがち…
そこで、今回のツールを一発たたくとこうなります。
何となく中身が推測できるようになりました。このツールは何?
請求書・名刺・Webページなどのpdf・画像ファイルの中身を読み取り、重要(っぽい)ワードで自動リネームするツールです。
内部では以下を行ってます。
- ファイルをGoogle Driveにアップロード (G Suiteが理想)
- OCRされたテキストを抽出
- 重要部分をNTTコミュニケーションズの固有表現抽出APIで抽出 (企業名とかの専門用語辞書使うと精度上がるっぽいけど無料版だと使えない…)
- 日付、会社名、人名を結合したファイル名を作りリネーム
動作確認環境
Mac 10.14.3
Python 3.7.2動かし方手順
1.ファイルをGoogle Drive APIでアップロードできるようにする
Google Drive APIを使えるようにするために、
Python Quickstartを行います。
STEP1、STEP2をこなせばOKです。
STEP1でダウンロードしたcredentials.jsonは以降も使います。2.ファイルをアップロードしてOCR結果を取得してみる
以下のコードをcredentials.jsonと同じフォルダにおいて実行します。
コードはこちら(クリックで展開する)
ocr_img.pyfrom __future__ import print_function import httplib2 import os import io import sys from apiclient import discovery from oauth2client import client from oauth2client import tools from oauth2client.file import Storage from apiclient.http import MediaFileUpload, MediaIoBaseDownload SCOPES = 'https://www.googleapis.com/auth/drive' CLIENT_SECRET_FILE = 'credentials.json' APPLICATION_NAME = 'Drive API Python Quickstart' def get_credentials(): """Gets valid user credentials from storage. If nothing has been stored, or if the stored credentials are invalid, the OAuth2 flow is completed to obtain the new credentials. Returns: Credentials, the obtained credential. """ credential_path = os.path.join("./", 'drive-python-quickstart.json') store = Storage(credential_path) credentials = store.get() if not credentials or credentials.invalid: flow = client.flow_from_clientsecrets(CLIENT_SECRET_FILE, SCOPES) flow.user_agent = APPLICATION_NAME if flags: credentials = tools.run_flow(flow, store, flags) else: # Needed only for compatibility with Python 2.6 credentials = tools.run(flow, store) print('Storing credentials to ' + credential_path) return credentials if __name__ == '__main__': credentials = get_credentials() http = credentials.authorize(httplib2.Http()) service = discovery.build('drive', 'v3', http=http) imgfile = 'sample.pdf' # Image with texts (png, jpg, bmp, gif, pdf) txtfile = 'output.txt' # Text file outputted by OCR args = sys.argv if len(args) >= 2: imgfile = str(args[1]) mime = 'application/vnd.google-apps.document' res = service.files().create( body={ 'name': imgfile, 'mimeType': mime, }, media_body=MediaFileUpload(imgfile, mimetype=mime, resumable=True), ocrLanguage='ja', ).execute() downloader = MediaIoBaseDownload( io.FileIO(txtfile, 'wb'), service.files().export_media(fileId=res['id'], mimeType="text/plain") ) done = False while done is False: status, done = downloader.next_chunk() service.files().delete(fileId=res['id']).execute() print("----- OCR Done. -----") f = open(txtfile, 'r') line = f.readline() while line: print(line.strip()) line = f.readline() f.close()OCR結果
PDFeerさんの請求書サンプルをOCRしてみます。
output.txtというファイルにOCR結果を保存して、それを表示しています。$ python3 ocr_img.py sample.pdf ----- OCR Done. ----- 御請求書 山田サンプル株式会社 御中 発行日 : 2013年12月31日 請求書番号 : 12345678 サンプルテスト株式会社 平素は格別のご高配を賜り、厚く御礼申し上げます。 下記の通りご請求申し上げます。 鈴木一郎 〒123-4567 東京都品川区1-1-1 御請求金額 ¥ 210,000 アパートメント1F TEL 090-123-4567 FAX 090-123-4568 項 目 数 量 単 価 金 額 デザイン費用 5 10,000 50,000 コーディング費用 10 5,000 50,000 プロデュース費用 1 100,000 100,000 小計 200,000 消費税 10,000 合計金額 210,000 備考振込先 : サンプル銀行 サンプル支店 普通 123456789 振込先 : サンプル銀行 サンプル支店 普通 123456780 振込先 : サンプル銀行 サンプル支店 普通 123456781 いつもお世話になっております。 鈴木無事OCRできました。
2.OCR結果を固有表現抽出APIに投げてみる
日付や会社名など重要そうなところをファイル名にしたいので、まずはOCR結果を一行ずつ固有表現抽出APIに投げて、固有名詞として認識されたものをカテゴリとともに表示します。
コードはこちら(クリックで展開する)
(COTOHA APIに登録して、CLIENT IDとシークレットを書き換える必要があります。)
ocr_img_cotoha.pyfrom __future__ import print_function import httplib2 import os import io import requests import json import sys from apiclient import discovery from oauth2client import client from oauth2client import tools from oauth2client.file import Storage from apiclient.http import MediaFileUpload, MediaIoBaseDownload # If modifying these scopes, delete your previously saved credentials # at ~/.credentials/drive-python-quickstart.json SCOPES = 'https://www.googleapis.com/auth/drive' CLIENT_SECRET_FILE = 'credentials.json' APPLICATION_NAME = 'Drive API Python Quickstart' BASE_URL = "https://api.ce-cotoha.com/api/dev/nlp/" CLIENT_ID = "COTOHA APIクライアントID" CLIENT_SECRET = "COTOHA APIクライアントSecret" def auth(client_id, client_secret): token_url = "https://api.ce-cotoha.com/v1/oauth/accesstokens" headers = { "Content-Type": "application/json", "charset": "UTF-8" } data = { "grantType": "client_credentials", "clientId": client_id, "clientSecret": client_secret } r = requests.post(token_url, headers=headers, data=json.dumps(data)) return r.json()["access_token"] def ne(sentence, access_token): base_url = BASE_URL headers = { "Content-Type": "application/json", "charset": "UTF-8", "Authorization": "Bearer {}".format(access_token) } data = { "sentence": sentence, } r = requests.post(base_url + "v1/ne", headers=headers, data=json.dumps(data)) return r.json() def get_credentials(): """Gets valid user credentials from storage. If nothing has been stored, or if the stored credentials are invalid, the OAuth2 flow is completed to obtain the new credentials. Returns: Credentials, the obtained credential. """ credential_path = os.path.join("./", 'drive-python-quickstart.json') store = Storage(credential_path) credentials = store.get() if not credentials or credentials.invalid: flow = client.flow_from_clientsecrets(CLIENT_SECRET_FILE, SCOPES) flow.user_agent = APPLICATION_NAME if flags: credentials = tools.run_flow(flow, store, flags) else: # Needed only for compatibility with Python 2.6 credentials = tools.run(flow, store) print('Storing credentials to ' + credential_path) return credentials if __name__ == '__main__': credentials = get_credentials() http = credentials.authorize(httplib2.Http()) service = discovery.build('drive', 'v3', http=http) imgfile = 'sample.pdf' # Image with texts (png, jpg, bmp, gif, pdf) txtfile = 'output.txt' # Text file outputted by OCR args = sys.argv if len(args) >= 2: imgfile = str(args[1]) mime = 'application/vnd.google-apps.document' res = service.files().create( body={ 'name': imgfile, 'mimeType': mime }, media_body=MediaFileUpload(imgfile, mimetype=mime, resumable=True), ocrLanguage='ja', ).execute() downloader = MediaIoBaseDownload( io.FileIO(txtfile, 'wb'), service.files().export_media(fileId=res['id'], mimeType="text/plain") ) done = False while done is False: status, done = downloader.next_chunk() service.files().delete(fileId=res['id']).execute() print("----- OCR Done. -----") access_token = auth(CLIENT_ID, CLIENT_SECRET) f = open(txtfile, 'r') line = f.readline() while line: ne_document = ne(line.strip(),access_token) for chunks in ne_document['result']: if chunks['form'] is not None: print(chunks['class'] + ':' + chunks['form']) line = f.readline() f.close()固有名詞抽出結果
$ python3 ocr_img_cotoha.py sample.pdf ----- OCR Done. ----- ORG:山田サンプル株式会社 御中 DAT:2013年12月31日 ART:発行日 PSN:鈴木一郎 LOC:〒123-4567 東京都 LOC:品川区1-1-1 MNY:¥ 210,000 LOC:アパートメント1f ART:tel LOC:090-123-4567 NUM: NUM:fax 090-123-4568 NUM: NUM: 50,000 NUM: NUM: 50,000 NUM: NUM: 100,000 NUM: 200,000 ART:消費税 ART:普通 123456789 ART:普通 123456780 ART:普通 PSN:鈴木日付はDAT、会社名はORG、人名はPSNで認識されているようなので、
その辺りを使いたいと思います。3.ファイル名を生成してみる
上記のコードを少し変えて、
日付、会社名、人名として出てきたものを結合してファイル名を生成します。
それを標準出力に吐くようにします。
コードはこちら(クリックで展開する)
(COTOHA APIに登録して、CLIENT IDとシークレットを書き換える必要があります。)
ocr_img_cotoha_filename.pyfrom __future__ import print_function import httplib2 import os import io import requests import json import sys import re from apiclient import discovery from oauth2client import client from oauth2client import tools from oauth2client.file import Storage from apiclient.http import MediaFileUpload, MediaIoBaseDownload from collections import defaultdict # If modifying these scopes, delete your previously saved credentials # at ~/.credentials/drive-python-quickstart.json SCOPES = 'https://www.googleapis.com/auth/drive' CLIENT_SECRET_FILE = 'credentials.json' APPLICATION_NAME = 'Drive API Python Quickstart' BASE_URL = "https://api.ce-cotoha.com/api/dev/nlp/" CLIENT_ID = "COTOHA APIクライアントID" CLIENT_SECRET = "COTOHA APIシークレット" def auth(client_id, client_secret): token_url = "https://api.ce-cotoha.com/v1/oauth/accesstokens" headers = { "Content-Type": "application/json", "charset": "UTF-8" } data = { "grantType": "client_credentials", "clientId": client_id, "clientSecret": client_secret } r = requests.post(token_url, headers=headers, data=json.dumps(data)) return r.json()["access_token"] def ne(sentence, access_token): base_url = BASE_URL headers = { "Content-Type": "application/json", "charset": "UTF-8", "Authorization": "Bearer {}".format(access_token) } data = { "sentence": sentence, } r = requests.post(base_url + "v1/ne", headers=headers, data=json.dumps(data)) return r.json() def get_credentials(): """Gets valid user credentials from storage. If nothing has been stored, or if the stored credentials are invalid, the OAuth2 flow is completed to obtain the new credentials. Returns: Credentials, the obtained credential. """ credential_path = os.path.join("./", 'drive-python-quickstart.json') store = Storage(credential_path) credentials = store.get() if not credentials or credentials.invalid: flow = client.flow_from_clientsecrets(CLIENT_SECRET_FILE, SCOPES) flow.user_agent = APPLICATION_NAME if flags: credentials = tools.run_flow(flow, store, flags) else: # Needed only for compatibility with Python 2.6 credentials = tools.run(flow, store) print('Storing credentials to ' + credential_path) return credentials if __name__ == '__main__': credentials = get_credentials() http = credentials.authorize(httplib2.Http()) service = discovery.build('drive', 'v3', http=http) imgfile = 'sample.pdf' # Image with texts (png, jpg, bmp, gif, pdf) txtfile = 'output.txt' # Text file outputted by OCR args = sys.argv if len(args) >= 2: imgfile = str(args[1]) mime = 'application/vnd.google-apps.document' res = service.files().create( body={ 'name': imgfile, 'mimeType': mime }, media_body=MediaFileUpload(imgfile, mimetype=mime, resumable=True), ocrLanguage='ja', ).execute() downloader = MediaIoBaseDownload( io.FileIO(txtfile, 'wb'), service.files().export_media(fileId=res['id'], mimeType="text/plain") ) done = False while done is False: status, done = downloader.next_chunk() service.files().delete(fileId=res['id']).execute() access_token = auth(CLIENT_ID, CLIENT_SECRET) f = open(txtfile, 'r') line = f.readline() result_d = defaultdict(list) while line: ne_document = ne(line.strip(),access_token) for chunks in ne_document['result']: if chunks['form'] is not None: if chunks['class'] == 'ORG' or chunks['class'] == 'DAT' \ or chunks['class'] == 'PSN': result_d[chunks['class']].append(chunks['form']) line = f.readline() f.close() dirname = os.path.dirname(imgfile) fn,ext = os.path.splitext(imgfile) filename_tmp = '_'.join(result_d['DAT']) + '_' + '_'.join(result_d['ORG']) + '_' + '_'.join(result_d['PSN']) filenewname = re.sub(r'[\\|/|:|?|.|"|<|>|\|]', '-', filename_tmp) + ext print(filenewname)ファイル名生成結果
$ python3 ocr_img_cotoha_filename.py sample.pdf 2013年12月31日_山田サンプル株式会社 御中_鈴木一郎_鈴木.pdfいい感じにファイル名が生成できました。
4.上記スクリプトを利用してリネームする
一個ずつファイルリネームしてもいいんですが、面倒なのでディレクトリを指定しファイル名を読み取って上記のコードを実行するようなbashを書きます。
$ find [ディレクトリ名] -type f | while read -r f; do cp "$f" "$(dirname $f)/$(python3 ocr_img_cotoha_filename.py $f)" ;done(一応cpコマンドで元ファイルも残してます。)
これで冒頭の画像のようにファイルを一括リネームすることができます。
まとめ
Google DriveのAPIでOCR、その結果をCOTOHA APIで言語処理してファイルをリネームするという、単純だけど面倒な作業を自動で行うツールを作りました。
毎日のように紙をスキャンしている部署などであれば、使い所はそこそこ有るような気もします。
「AIってやつでなんとかできないのか」とか言われたときにうってつけ一方で、いくつか課題はあります。
- そもそも実業務で使えるレベルなのか検証できてない
- フォーマットのバリエーションを試せてない
- 手書き文字とか多言語とか入ってきた時にちゃんと認識できるかどうか未検証
- Google Driveにアップロードするのは実務だとセキュリティ的に難しそう。なにか別のOCRプロダクト使うか、G suite使えるならこのままでもいけるかも?
- Cloud Vision API使う手はあるけど、GCP登録必要でpdfをGCSにあげたりする必要もあり万人向けでは無さそう。今回は割愛
- OCR失敗する時のハンドリングしてない
- Google DriveのOCRはたまに超文字化けする(言語の認識ミス?)。そこを検知する仕組みは入れたい
- ファイル名が長すぎる場合のハンドリングしてない
- もう少しチューニングしてファイル名に入れるべき文言を選択すれば解決できそう
こんな感じで色々と未検証なので実際に利用される方がもしいましたらご注意ください。
特にセキュリティ周りなどは一切責任を負えませんので……。とはいえ、社内システムと連携したり、スキャナに組み込んだり、サービス化したりと、うまくやればOCR×言語処理でまだまだ面白いことができる可能性はありそうだと感じました。
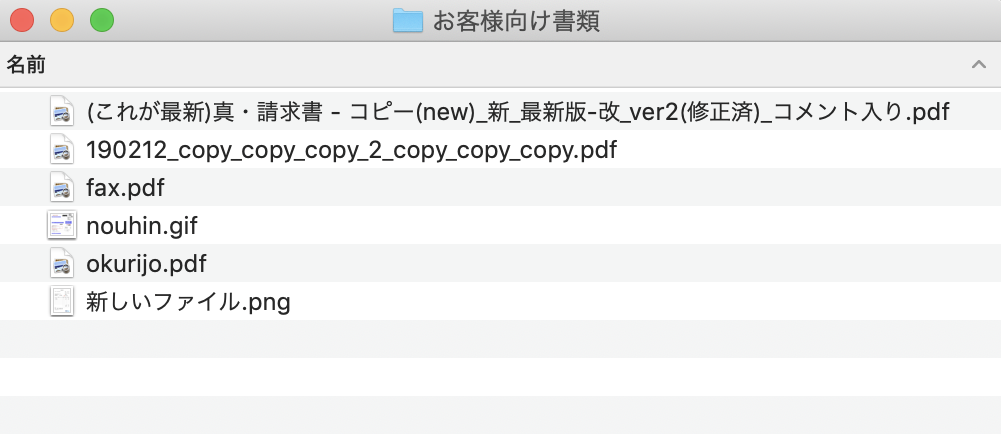
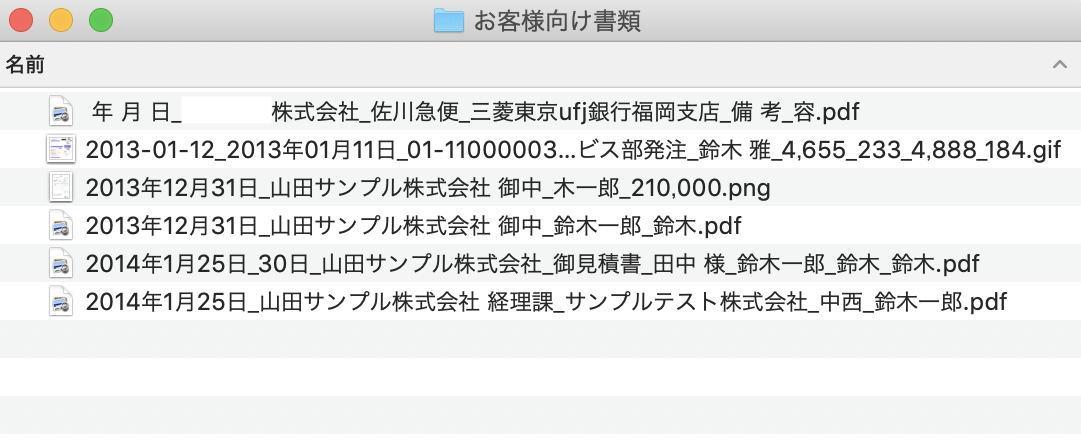
- 投稿日:2019-04-15T10:09:04+09:00
#python の ネストされた辞書で KeyError を起こさないように defaultdict を利用する例 ( #ruby 比較 )
example
- defaultdict を何層にもネストして使ってみる
d["x"]["y"]["z"]のように存在しないキーを書いても怒られない- もしかしたら良い子は真似しちゃダメかもしれない
>>> from collections import defaultdict >>> d = defaultdict(lambda: defaultdict(lambda: defaultdict(lambda: 0))) >>> d["a"]["b"]["c"] = 1 >>> d["a"]["b"]["c"] 1 >>> d["x"]["y"]["z"] 0ruby で書くなら
こんな感じだったかな。こちらも良い子はマネし‥。
[27] pry(main)> h = Hash.new(Hash.new(Hash.new(0))) => {} [28] pry(main)> h["a"]["b"]["c"] = 1 => 1 [29] pry(main)> h["a"]["b"]["c"] => 1 [30] pry(main)> h["x"]["y"]["z"] => 0ref
Python defaultdict の使い方 - Qiita
Original by Github issue
- 投稿日:2019-04-15T10:00:48+09:00
matplotlibで使える色の名前一覧
Introduction
matplotlibであるグラフを描画したところ、「色がビビッドすぎで見づらい」とのご意見をいただきました。そこでふと思ったのです、matplotlibが標準でサポートしている色名って何だろう、と。
何はともあれスクリプト
以下に色の名前とそのカラーコードを一覧表示するスクリプトを示します。
matplotlib_color.py#!/usr/bin/env python # -*- coding: utf-8 -*- import matplotlib print(matplotlib.colors.cnames)実行結果
結果は以下のように辞書型で一覧がバーっと出てきます。
{'aliceblue': '#F0F8FF', 'antiquewhite': '#FAEBD7', 'aqua': '#00FFFF', 'aquamarine': '#7FFFD4', 'azure': '#F0FFFF', 'beige': '#F5F5DC', 'bisque': '#FFE4C4', 'black': '#000000', 'blanchedalmond': '#FFEBCD', 'blue': '#0000FF', 'blueviolet': '#8A2BE2', 'brown': '#A52A2A', 'burlywood': '#DEB887', 'cadetblue': '#5F9EA0', 'chartreuse': '#7FFF00', 'chocolate': '#D2691E', 'coral': '#FF7F50', 'cornflowerblue': '#6495ED', 'cornsilk': '#FFF8DC', 'crimson': '#DC143C', 'cyan': '#00FFFF', 'darkblue': '#00008B', 'darkcyan': '#008B8B', 'darkgoldenrod': '#B8860B', 'darkgray': '#A9A9A9', 'darkgreen': '#006400', 'darkgrey': '#A9A9A9', 'darkkhaki': '#BDB76B', 'darkmagenta': '#8B008B', 'darkolivegreen': '#556B2F', 'darkorange': '#FF8C00', 'darkorchid': '#9932CC', 'darkred': '#8B0000', 'darksalmon': '#E9967A', 'darkseagreen': '#8FBC8F', 'darkslateblue': '#483D8B', 'darkslategray': '#2F4F4F', 'darkslategrey': '#2F4F4F', 'darkturquoise': '#00CED1', 'darkviolet': '#9400D3', 'deeppink': '#FF1493', 'deepskyblue': '#00BFFF', 'dimgray': '#696969', 'dimgrey': '#696969', 'dodgerblue': '#1E90FF', 'firebrick': '#B22222', 'floralwhite': '#FFFAF0', 'forestgreen': '#228B22', 'fuchsia': '#FF00FF', 'gainsboro': '#DCDCDC', 'ghostwhite': '#F8F8FF', 'gold': '#FFD700', 'goldenrod': '#DAA520', 'gray': '#808080', 'green': '#008000', 'greenyellow': '#ADFF2F', 'grey': '#808080', 'honeydew': '#F0FFF0', 'hotpink': '#FF69B4', 'indianred': '#CD5C5C', 'indigo': '#4B0082', 'ivory': '#FFFFF0', 'khaki': '#F0E68C', 'lavender': '#E6E6FA', 'lavenderblush': '#FFF0F5', 'lawngreen': '#7CFC00', 'lemonchiffon': '#FFFACD', 'lightblue': '#ADD8E6', 'lightcoral': '#F08080', 'lightcyan': '#E0FFFF', 'lightgoldenrodyellow': '#FAFAD2', 'lightgray': '#D3D3D3', 'lightgreen': '#90EE90', 'lightgrey': '#D3D3D3', 'lightpink': '#FFB6C1', 'lightsalmon': '#FFA07A', 'lightseagreen': '#20B2AA', 'lightskyblue': '#87CEFA', 'lightslategray': '#778899', 'lightslategrey': '#778899', 'lightsteelblue': '#B0C4DE', 'lightyellow': '#FFFFE0', 'lime': '#00FF00', 'limegreen': '#32CD32', 'linen': '#FAF0E6', 'magenta': '#FF00FF', 'maroon': '#800000', 'mediumaquamarine': '#66CDAA', 'mediumblue': '#0000CD', 'mediumorchid': '#BA55D3', 'mediumpurple': '#9370DB', 'mediumseagreen': '#3CB371', 'mediumslateblue': '#7B68EE', 'mediumspringgreen': '#00FA9A', 'mediumturquoise': '#48D1CC', 'mediumvioletred': '#C71585', 'midnightblue': '#191970', 'mintcream': '#F5FFFA', 'mistyrose': '#FFE4E1', 'moccasin': '#FFE4B5', 'navajowhite': '#FFDEAD', 'navy': '#000080', 'oldlace': '#FDF5E6', 'olive': '#808000', 'olivedrab': '#6B8E23', 'orange': '#FFA500', 'orangered': '#FF4500', 'orchid': '#DA70D6', 'palegoldenrod': '#EEE8AA', 'palegreen': '#98FB98', 'paleturquoise': '#AFEEEE', 'palevioletred': '#DB7093', 'papayawhip': '#FFEFD5', 'peachpuff': '#FFDAB9', 'peru': '#CD853F', 'pink': '#FFC0CB', 'plum': '#DDA0DD', 'powderblue': '#B0E0E6', 'purple': '#800080', 'rebeccapurple': '#663399', 'red': '#FF0000', 'rosybrown': '#BC8F8F', 'royalblue': '#4169E1', 'saddlebrown': '#8B4513', 'salmon': '#FA8072', 'sandybrown': '#F4A460', 'seagreen': '#2E8B57', 'seashell': '#FFF5EE', 'sienna': '#A0522D', 'silver': '#C0C0C0', 'skyblue': '#87CEEB', 'slateblue': '#6A5ACD', 'slategray': '#708090', 'slategrey': '#708090', 'snow': '#FFFAFA', 'springgreen': '#00FF7F', 'steelblue': '#4682B4', 'tan': '#D2B48C', 'teal': '#008080', 'thistle': '#D8BFD8', 'tomato': '#FF6347', 'turquoise': '#40E0D0', 'violet': '#EE82EE', 'wheat': '#F5DEB3', 'white': '#FFFFFF', 'whitesmoke': '#F5F5F5', 'yellow': '#FFFF00', 'yellowgreen': '#9ACD32'}実際に使える色見本
このままでは記事としてあまりにもお粗末...なのでmatplotlibの公式を見ると、使える色名とその色の見本があったので、その図を添付します。
例
これまで描画には単純な'blue', 'red'を使って以下のようなバープロット出力をしていました。
そこで色合いを調整、バープロットのカラーを'blue'->'deepskyblue'、'red'->'lightcoral'に変更しました。するとなんということでしょう。
色合いが見事、目に優しくなりました。
結論
これでビビッドな'blue'や'red'だけでなく、様々な色が使えることがわかりました。皆さんも自分の好きな色でバーや線を彩ってみてください。
参考サイト:
https://matplotlib.org/examples/color/named_colors.html
matplotlib で指定可能な色の名前と一覧



- 投稿日:2019-04-15T09:20:07+09:00
初心者Pythonistの日記 Day3
お疲れ様です。
さて3日目です。昨日(4月12日)はかなり重要な経営会議が長時間ありなかなか疲れました。
(土日の間にアップロードを忘れていたので、いまします。)今日は入力フォームも含めたWebアプリを作ってみたいと思います。
参考文献:https://qiita.com/tom_S/items/2ea407eda4bec3e720efこちらの参考文献が非常にわかりやすかったです。
背番号を入力すると、選手の名前がでるものです。server.py
すいません、、、わたしは最近の野球はイチローさんの名前くらいしか知らないので、まったく未知の名前ですが、面白かったです。
参考文献のserver.pyをそのまま動かしてみました。if int(request.form["num"]) <= 5: return """ {}は{}です! <form action="/" method="POST"> <input name="num"></input> </form>""".format(str(request.form["num"]), list[int(request.form["num"])])その中で、初心者的に進んでいくと、ここが面白い感覚に包まれます。特に、
{}は{}です!ここですね。ずっと、cの世界にいたら、これに来るものは、前を見てしまうところですが、.と後なんですね。
次は、
DB(MySQL)を利用する
をしてみたいと思います。
こちらも、参考文献が非常にわかりやすかったです。ありがとうございます。
参考文献:https://qiita.com/zaburo/items/5091041a5afb2a7dffc8cursor()は、なかなか奥深く
参考文献:https://qiita.com/knoguchi/items/3d5631505b3f08fa37cc
こちらにかなり詳しく書かれています。cursor()などについて。ちょっとSQLの復習が必要ですね。。。いくつか疑問点が出てきたので、
次回は、もう少し、SQL x Pythonまわりを深掘ってみたいと思います。
- 投稿日:2019-04-15T08:09:19+09:00
ボーナスでたら、ゼロからLinuxのGPU機械学習環境を作る ~Ubuntu18.04のインストールからPyTorch実行まで全手順~
概要
- 特に難しいことを考えることなくGPUを使った機械学習(主にディープラーニング向け)環境をPCに構築します
- Linux OSのインストール、各種ドライバ・ソフトウェア類のインストール手順を1つずつハンズオンで確認します
- セットアップしたLinuxに、人気急上昇中の機械学習ライブラリPyTorchを導入します
対象
- そろそろ機械学習はじめようと思ってるけど、とっかかりがつかめない人
- ボーナス出たら「GPU買うぞ~」と思っている人
- Linux,Python,Anaconda,PyTorch,機械学習のいずれかまたは全ての初心者
環境
- OSは Ubuntu 18.04 LTS を導入します
- Pythonは version 3.7 を導入します
- 機械学習フレームワークは PyTorch 1.0 を導入します
- GPUは NVIDIA GEFORCE RTX 2080 Ti を使いますが、CUDAコア搭載の他のNVIDIA GPUでも同等です
ゴール
- OSインストールから、PyTorchでCUDAをつかったテンソル演算を確認するところまでやります。
本編
Linuxをインストールするマシンを用意する
手元で機械学習(主にディープラーニング用途)を実行するために以下のようなスペックのPC(自作)を準備した。
CPU Core i7-9700K マザボ Z390チップセット メモリ 16GB HDD 1TB GPU NVIDIA Geforce RTX 2080 Ti 11GB 搭載 電源 ATX 800W Linuxインストール用のUSBメモリ(Live USB)を作成する
まず、Linuxをインストールするために、インストール用のUSBメモリ(Live USB)を作成するところから開始する。
USBメモリへの書き込みにはWindows PCを利用した例で説明するが、書き込みアプリはWindow版、Mac版、Linux版があり、どれも同じ手順でインストール用USBメモリを作成可能。Ubuntu 18.04のディスクイメージは 2GB程度なので、USBメモリは8GBもあれば十分。
Ubuntu 18.04のディスクイメージのダウンロード
Linuxのディストリビューションには、Ubuntu 18.04 LTSを使用する。
https://www.ubuntu.com にアクセスして、Downloadタブを開いて、Ubuntu Desktop > 18.04 LTS をクリックすると、Ubuntuのディスクイメージ(ISO)がダウンロードされる。
ここでは、ubuntu-18.04.2-desktop-amd64.isoがダウンロードされたので、これのディスクイメージをUSBメモリに書き込む。
USBメモリにLinuxのディスクイメージを焼く
(1)USBメモリ書き込み用のアプリ UNetbootin を以下からダウンロードし、インストールする。
(2)UNetbootinを起動
UNetbootinを起動する
ディスクイメージを選択して、さきほどダウンロードしたISOディスクイメージ ubuntu-18.04.2-desktop-amd64.iso を指定する。
タイプは USBドライブで、ドライブ名は USBメモリが挿入されたドライブを指定する。
OKを押すと、USBメモリの作成が開始する。
あとは、しばらく待っていれば Ubuntu 18.04 LTS をインストールすることができるUSBメモリが完成する
USBメモリからUbuntu 18.04 をインストールしていく
さて、今つくったUSBメモリをPCに挿入して、電源オン
USBメモリから起動したいので、PC起動時にBIOS設定画面を出す。
BIOS設定画面の起動方法は、たいていの場合 PC起動時に F2またはDELを押せばOK。
BIOS設定画面のブートメニュー(Boot Menu)にて、USBメモリでブートを選択すればUSBメモリからブートする。USBメモリからブートできると、以下のようにUNetbootin のブート画面がでるのでInstall Ubuntuを選択する
インストールが開始される
言語設定画面では、日本語を選択
キーボードレイアウトも日本語を選択
画面に従いすすめていく
今回はまっさらにした状態のPCにLinuxをインストールする
(既存のWindows PCにインストールする場合は削除するか、残すかオプションが出る)
ロケールは Tokyo で。(日本語選んでおくとデフォルトでそうなる)
次にユーザー名とコンピューター名を入れ 続ける を押す
あとはインストールが自動で進むので待つ
しばらくするとインストール終了ダイアログがでるので、今すぐ再起動する
再起動すると、このとおり、Ubuntu 18.04 LTSを無事インストール終了!
ただしまだ最適なグラフィックドライバをインストールしていないので、画面描画で残像が出たり、画面解像度などは最適化されていない。
Ubuntu 18.04 をセットアップする
OSは無事インストールできたので、これから基本的な設定や、必要になるソフトウェア群をインストールしていく。
Ubuntuで日本語入力を使えるようにする
Ubuntu 18.04のインストール直後だと、半角/全角ボタンを押しても、日本語IMEが使えず日本語入力ができない場合があるので、画面の右上の▼をクリックして、開いたメニューで 日本語(Mozc)入力を有効にする。
downloadsディレクトリ(フォルダ)を作る
これからら、いくつかのドライバーやパッケージをネットからダウンロードするので、ダウンロードしたファイルの保存先ディレクトリを作成する
左のアプリメニューからファイル
クリックしてファイルマネージャを起動して、開いたユーザーディレクトリ以下にダウンロード用ディレクトリ(フォルダ)を作成する。右クリックでフォルダ作成を選択し、フォルダ名を downloads として作成する。
実は日本語環境でインストールすると、デフォルトでダウンロードというディレクトリ(フォルダ)ができるが、端末(ターミナル)から扱うとき日本語のディレクトリ名(フォルダ名)だとコマンドラインと相性がわるいため、ここでdownloadディレクトリ(フォルダ)を作っておいた。
Chrome(ブラウザ)をインストールする
さきほどのインストール方法でインストールしたUbuntu 18.04 LTSデスクトップディストリビューションでは、Firefoxがデフォルトで入っているが、ブラウザにはChromeを使いたいので、そちらを導入する
以下からGoogle Chrome(Linux版)をダウンロードする
https://www.google.com/intl/ja_ALL/chrome/
64ビット .debパッケージを選択する
こんな画面がでるのでOKする
インストールをクリック
ChromeのインストールはGUIから行ったが、これでインストール完了。
左下のメニューボタンを押してアプリ一覧を表示すれば、ちゃんとGoogle Chromeがインストールされている。
ここで、左側のアプリメニューにあるアプリアイコン上で右クリックして、常時表示が不要なものをお気に入りから削除して、スッキリさせた。
さて、ここで
をクリックして、Chromeを起動。
規定のブラウザにするにチェック。
■Chromeの規定のダウンロードフォルダの変更
Chromeが起動したら、右上の
ボタンでメニューを開き、設定を選択する
検索窓
に 保存先 と入力すると、ダウンロードしたファイルの保存先の設定画面がでるので、変更を押すと
フォルダ選択画面がでるので、さきほど作成した downloads を選択してフォルダを選択するをクリックする。
NVIDIA グラフィックドライバーのインストール
さて、いままではインストールした素の状態で作業してきたが、解像度が最大になっていなかったり場合によっては描画に残像がでるなどの動作が適正ではなかった。
ここでは、GPUにあったグラフィックドライバーをインストールする。
本稿のPCにはGeForce RTX 2080 Tiを導入しているので、以下サイトからドライバーをダウンロードする。
https://www.nvidia.com/download/driverResults.aspx/138279/en-us
上のリンクをChromeで開いて、GeForce RTX 2080 Tiに対応したドライバをダウンロードする。
■ 端末(ターミナル)をつかってドライバーをインストールする
左下の
を押して 端末(ターミナル)を起動する
ここからはコマンドラインでインストールしていく。
1.グラフィックドライバのダウンロードディレクトリに行く
$ cd downloads/2.dirでディレクトリの中身を確認
$ dir NVIDIA-Linux-x86_64-410.57.run3.chmodでパーミッションを変更して、ダウンロードしたドライバインストーラーを実行できるようにする
$ chmod +x NVIDIA-Linux-x86_64-410.57.run4.sudoをつかってルート権限でドライバのインストールを実行する
$ sudo ./NVIDIA-Linux-x86_64-410.57.run --no-x-check
■ NVIDIAグラフィックドライバーのインストール・ステップをみていく。
The distribution-provided pre-install script failed! Are you sure you want to continue?と出るが気にせず Continue installation を選択してエンター。
次の画面ではこのように出る。
ERROR: Unable to find the development tool`cc` in your path; please make sure that you have the package 'gcc' installed. If gcc is installed on your system, then please check that `cc` is in your PATH.
「ccにパスが通って無いみたいだけど、gccはインストールしておいてね!」というエラー。
OKを押すとインストーラーが終了する。
gccがインストールされていないようなので、gccをインストールすることにする。
■ gcc をインストールする
端末(ターミナル)から以下のコマンドで gcc を含むビルドツール(makeなども)をインストールする
sudo apt install build-essential
インストール準備がはじまり、続行しますか? [Y\n] 確認があるので Yでインストールが実行される。
■ 再度、NVIDIAグラフィックドライバのインストールを試みる
さきほどはgccが無くて止まってしまったので、gccをインストールした。
ここで、再度、NVIDIAグラフィックドライバのインストールを試みる。
$ sudo ./NVIDIA-Linux-x86_64-410.57.run --no-x-checkふたたび、この画面
The distribution-provided pre-install script failed! Are you sure you want to continue?と出るが気にせず Continue installation を選択してエンター。
次は、この画面、
今度はちゃんとビルドできている模様。
次は、この画面、
WARNING:
Unable to find a suitable destination to install 32-bit
compatibility libraries. Your system may not be set up for 32-bit
compatibility. 32-bit compatibility files will not be installed; if
you wish to install them, re-run the installation and set a valid
directory with the --compat32-libdir option.こんな警告メッセージがでて、「32-bit互換ライブラリをインストールしたいなら再実行してね」と言っている。今回の用途では32-bit互換ライブラリは不要なので、気にせずOKを選択。
次は、この画面
An incomplete installation of libglvnd was found. All of the essential
libglvnd libraries are present, but one or more optional components are
missing. Do you want to install a full copy of libglvnd? This will overwrite
any existing libglvnd libraries.libglvndの上書き確認があるので Install and overw を選択で上書きでOK。
次は、この画面
Would you like to run the nvidia-xconfig utility to automatically update
your X configuration file so that the NVIDIA X driver will be used when you
restart X? Any pre-existing X configuration file will be backed up.「Xの設定を更新するか?」聞いている、今はNoでOK。
nvidia-xconfigコマンドを使えばいつでも実行可能。次は、この画面
Installation of the NVIDIA Accelerated Graphics Driver for Linux-x86_64
(version: 410.57) is now complete. Please update your XF86Config or
/usr/share/doc/NVIDIA_GLX-1.0/README.txt for details.これで、NVIDIAグラフィックドライバのインストールは無事成功。OKを押して終了
設定を反映するために、再起動する
rebootコマンドで再起動する
rebootすると、
画面がFullHDになった。NVIDIAグラフィックドライバが有効になって、ちゃんと適正な解像度がセットされた。
Anacondaを導入する
ここでは、Pythonの実行環境をサクっと構築してくれるAnacondaを導入する
■ Anaconda をダウンロードする
Chromeを開いて、以下を開く
https://www.anaconda.com/distribution/#download-section
上部のタブでLinuxを選び、Python 3.7 versionを選んで、64-Bit(x86) Installer をダウンロードする。
すると、Anaconda3-2019.03-Linux-x86_64.sh というファイルがダウンロードされた
■ Anaconda3をインストールする
ダウンロードしたAnaconda3を
端末(ターミナル)を開いて、以下コマンドを入力して、Anacondaをインストールするcd downloads/ bash Anaconda3-2019.03-Linux-x86_64.sh
ライセンスの確認画面はエンターでページおくりできる
同意したら yes をタイプする
次にAnacondaの保存先を聞かれる
Anaconda3 will now be installed into this location: /home/ml/anaconda3 - Press ENTER to confirm the locationとなっているので、エンターを押して保存先を確定する
インストールが終わると、
Do you with the installer to initialize Anaconda3 by running conda init? [yes|no]「conda initをしてAnaconda3を初期化するかい?」と聞いてくるので
yesと入力する。
これで、Anaconda3のインストールが完了!
また、Pythonのインストールも同時に完了!■ Pythonが動作するかを確認する
Anacondaのインストールが終わったら、いったん、端末(ターミナル)を閉じて、再度 端末(ターミナル)を開く。
端末(ターミナル)を開き直したら以下のコマンドで、インストールされたPythonを確認してみる
- Pythonのバージョン
$ python --version Python 3.7.3
- Pythonのインストール先
$ which python /home/ml/anaconda3/bin/python
■ condaコマンドとは
ところで、プロンプトの先頭に以下のように(base)がつくようになった
(base) ml@ml:~$ python --version Python 3.7.3 (base) ml@ml:~$ which python /home/ml/anaconda3/bin/python (base) ml@ml:~$これはcondaが環境名を表示している。
そもそもcondaとは、パッケージ管理や環境の管理してくれるための便利なツールで、Anacondaのインストールと同時にcondaもインストールされている。
さきほどの(base)はcondaのインストール時にデフォルトで付与されたものだが、ジャマなら非表示にすることもできる。
以下のコマンドを実行する
(base)表記を消すconda config --set changeps1 Falseここまでで、Anaconda3のインストールは終了。
この段階で、Python 3.7やcondaコマンドもインストールされており、Pythonの基本的な開発ができるようになっている。PyTorchの導入
さて、ようやくお膳立てができたので、いよいよ機械学習ライブラリ PyTorch を導入する
■ PyTorchのインストール
以下にあるPyTorchのインストールガイドを開く
https://pytorch.org/get-started/locally/
このサイトでは、自分の環境に応じたPyTorchのインストール方法を教えてくれる
ここでは、いままでセットアップしてきた環境にあわせて以下を選択した
PyTorch Build Stable(1.0) Your OS Linux Package Conda Language Python 3.7 CUDA 10.0 すると、Run this Command:の欄に親切にconda install pytorch torchvision cudatoolkit=10.0 -c pytorch と表示される。
これを端末(ターミナル)にそのまま入力すれば PyTorchがインストールできる。とっても簡単。
conda install pytorch torchvision cudatoolkit=10.0 -c pytorch
The following NEW packages will be INSTALLED:と聞かれるので y を入力して、パッケージのダウンロード開始
これにて、NVIDIA GPU対応のPyTorchのインストールが完了!
【補足】
他のライブラリだと CUDA Toolkit 10.0 や cudnn 7.4 といった、GPU処理を行うためのソフトウェアを別途インストールする必要があるのが一般的だが、PyTorchの場合は、上記 condaコマンドで CUDA Toolkit 10.0 もあわせてインストールしておいてくれるし、cudnnはPyTorchに組み込まれた状態のものを、さきほどのcondaコマンドでインストールしているため、別途インストールする必要は無い。以下が具体的なインストール先となる
■ PyTorch(v.1.0.1 CUDA対応版)のインストール先ディレクトリ
~/anaconda3/pkgs/pytorch-1.0.1-py3.7_cuda10.0.130_cudnn7.4.2_2■ PyTorchが使うCUDA Toolkit(v.10.0)のインストール先ディレクトリ
~/anaconda3/pkgs/cudatoolkit-10.0.130-0Pythonのプログラムを書くため、Jupyter Notebookを起動する
では、本稿の最後に、ちゃんとGPUが有効な状態でPyTorchが使えるか試す。
端末(ターミナル)を開いて、PyTorchプロジェクト用のディレクトリを作る
mkdir pytorch_pj cd pytorch_pjディレクトリに移動したら
jupyter notebookでJupyter Notebook(ジュピターノートブック)を起動する。
Jupyter Notebook はPythonのコード作成と実行、実行結果表示、自由コメント(Markdown)編集の3つの機能をそなえたツールで、気軽に利用できるので、Jupyter Notebook上で試す。
jupyter notebookというコマンドを入力するだけでブラウザが立ち上がり、すぐに使える状態になる。
こんな風に、起動する。
これから、Python用のノートブックを作成する。
右上あたりにある New を押して、ポップアップしたメニューからPython3を選択
すると、もう1枚タブが開いて、以下のようなノートブック画面が表示される
PyTorchをGPUで動作させる
さて、ノートブックが起動したところで、早速コードを書く
PyTorchでCUDAが有効か確認するコードfrom __future__ import print_function import torch if torch.cuda.is_available(): # CUDAが有効なら TRUE device = torch.device("cuda") # CUDA(クーダ)デバイスを取得 x = torch.empty(5, 3) # CPU上にテンソルを作る y = torch.ones_like(x, device=device) # GPU上に直接テンソルを作る print(y) x = x.to(device) # CPU上に作ったテンソルをCUDAデバイスに転送 print(x) print("CUDA version:"+torch.version.cuda) #PyTorchが使っているCUDA toolkitバージョンを表示する↓のようにコードをノートブックに記述する
コードを書いたら、
を押す
すると、コードが実行され結果が得られる
このとおり、実行結果が表示された
tensor([[1., 1., 1.], [1., 1., 1.], [1., 1., 1.], [1., 1., 1.], [1., 1., 1.]], device='cuda:0') tensor([[0.0000e+00, 0.0000e+00, 0.0000e+00], [0.0000e+00, 0.0000e+00, 0.0000e+00], [0.0000e+00, 0.0000e+00, 1.4013e-45], [0.0000e+00, 1.4013e-45, 0.0000e+00], [1.4013e-45, 0.0000e+00, 0.0000e+00]], device='cuda:0') cudatoolkit-10.0.130device='cuda:0'となっている部分で、実際にこのテンソルがCUDAデバイス(GPU)に作られたことが確認できた!
GPUで機械学習できる環境が完成
これにて、Ubuntu 18.04 LTS上に、GPUを活用した機械学習を行う最低限の環境が完成した!
あとは、PyTorchを使って、ディープラーニングをさせるのもよし、他のライブラリを追加するのもよし。
まとめ
- ゼロからLinuxのGPU機械学習環境を構築しました
- PyTorchを動かすのに必要となる各種ソフトウェアを導入し、最終的にGPUをつかって演算をするところまで試すことができました
- 環境はできたので、GPUの性能確認の為にこのあたりから試してみるのも面白いかも知れません。
おまけ(拡張のヒント)
- nvidia-settingsコマンドでGPUの設定画面を表示することができます
nvidia-settings
- nvidia-smiコマンドでGPUの使用率等を取得することができるので、負荷などを測定可能です
nvidia-smi -l
- 今回は環境を固定して愚直にインストールしましたが、ポータビリティをあげるためにDockerを使いたい、という場合は、しっかりとNVIDIA GPU対応を考慮したNVIDIA Docker2が活用できそうです。

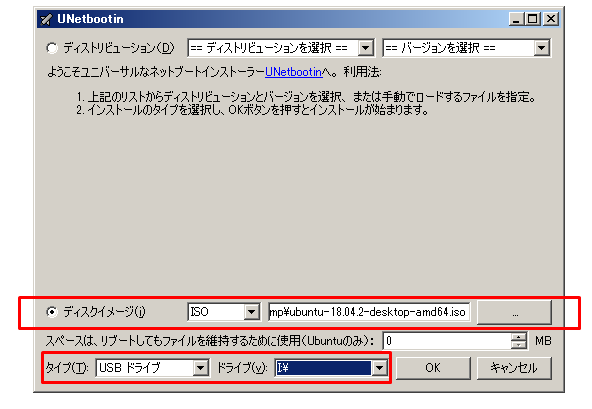
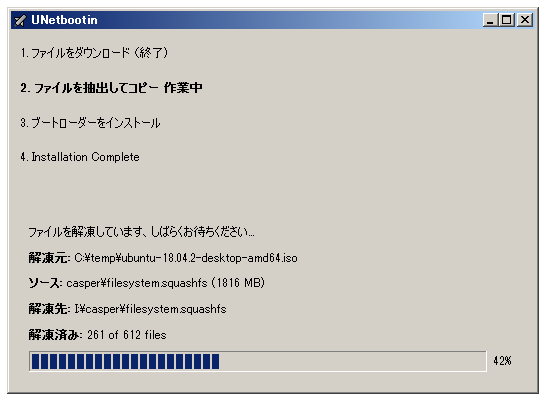
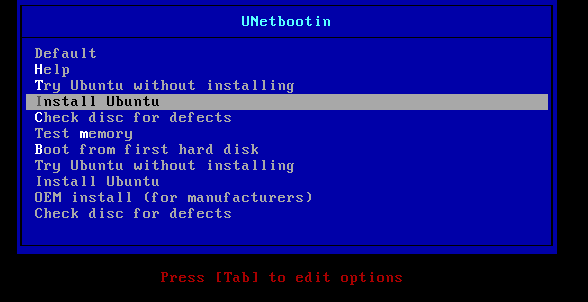

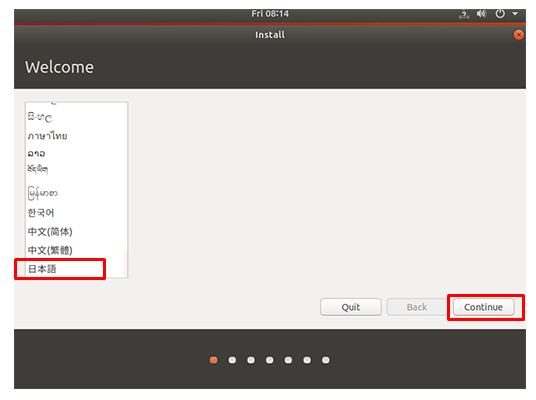
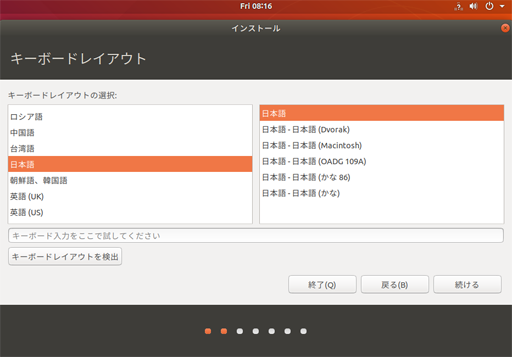
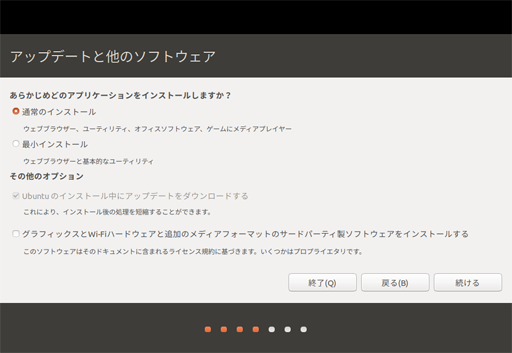
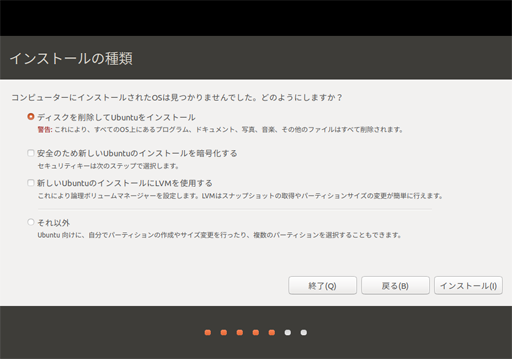
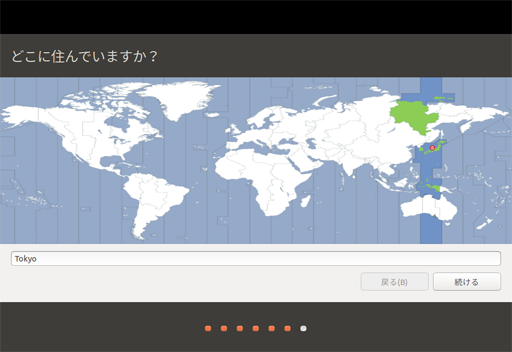
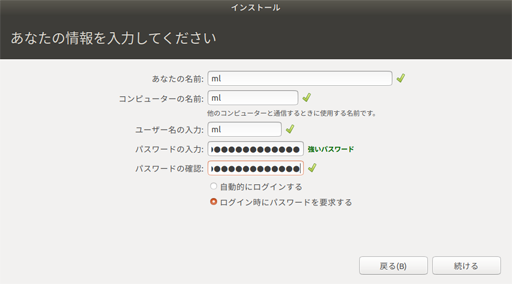
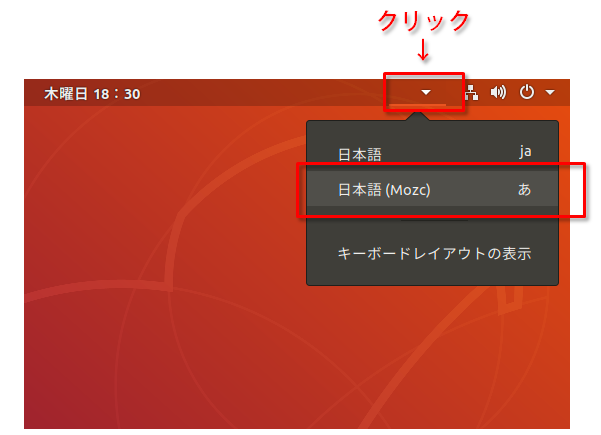

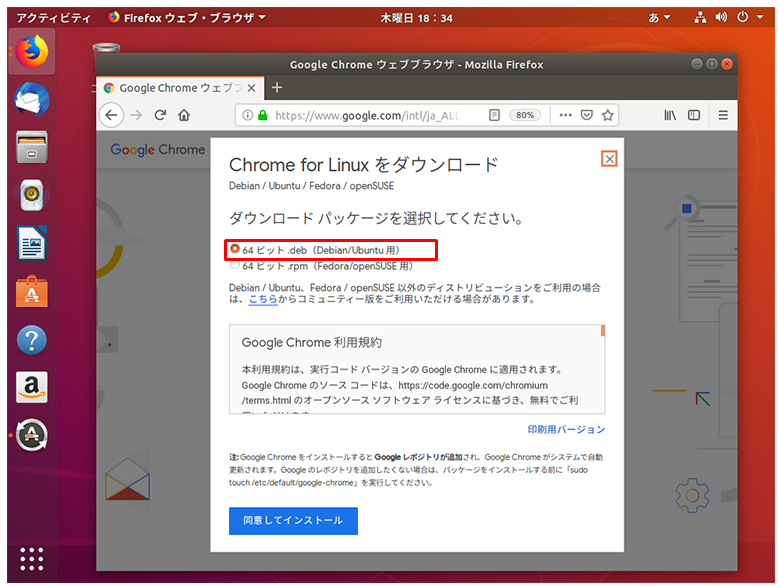
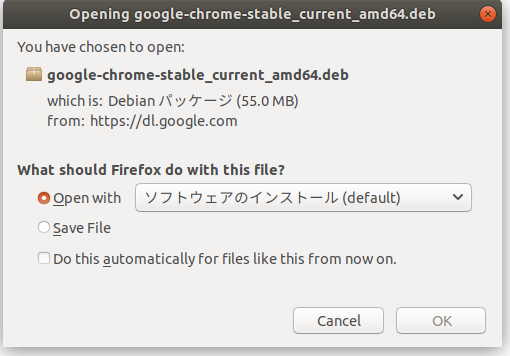
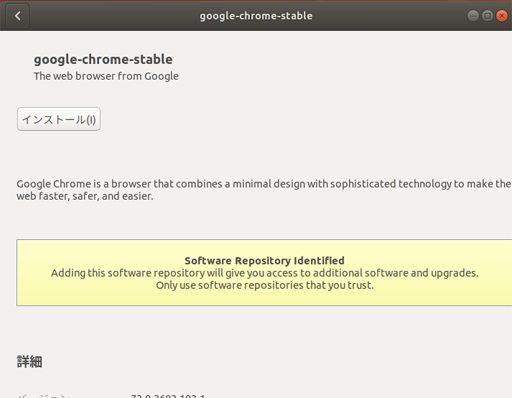

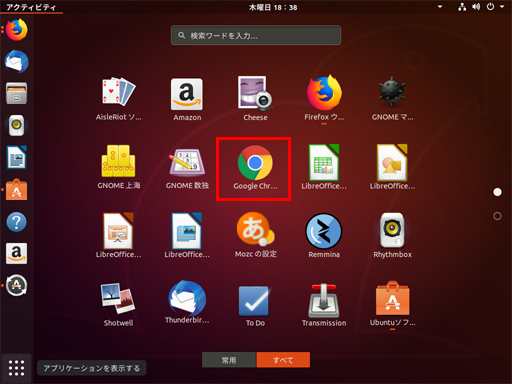





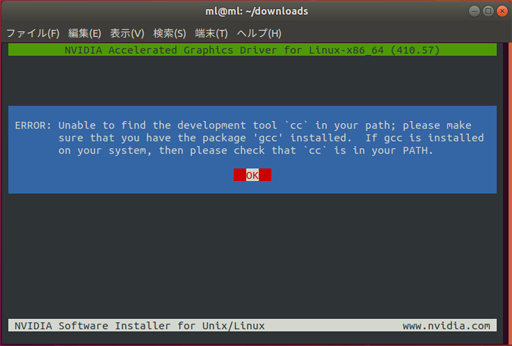
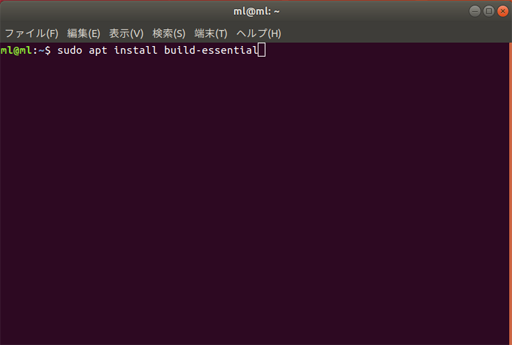
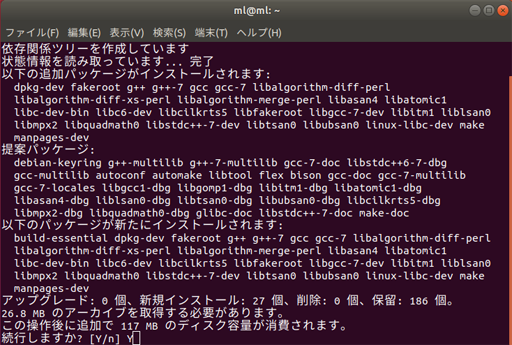
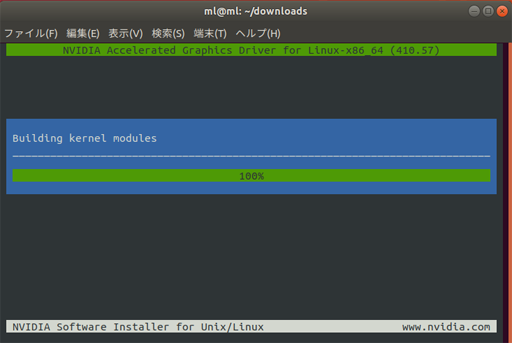
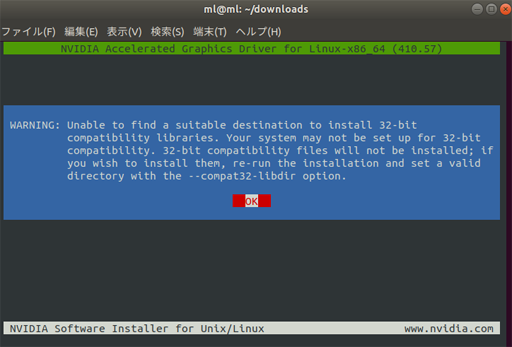
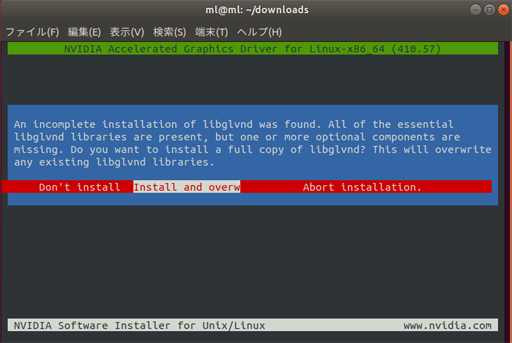
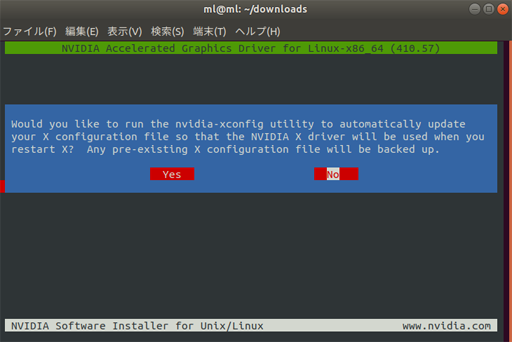
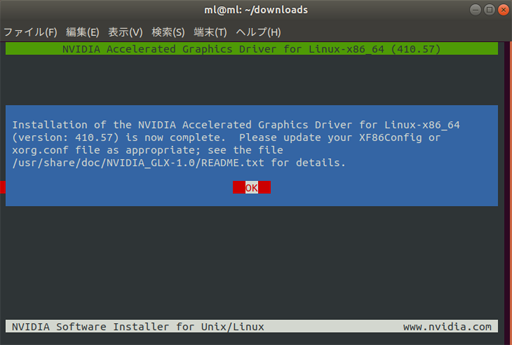
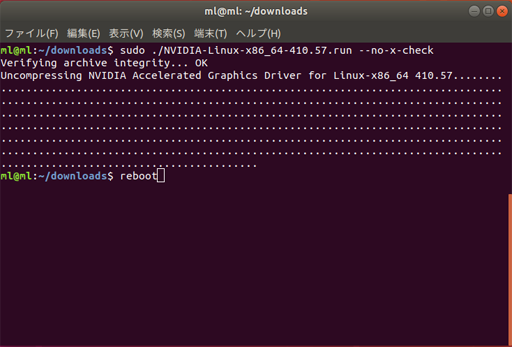
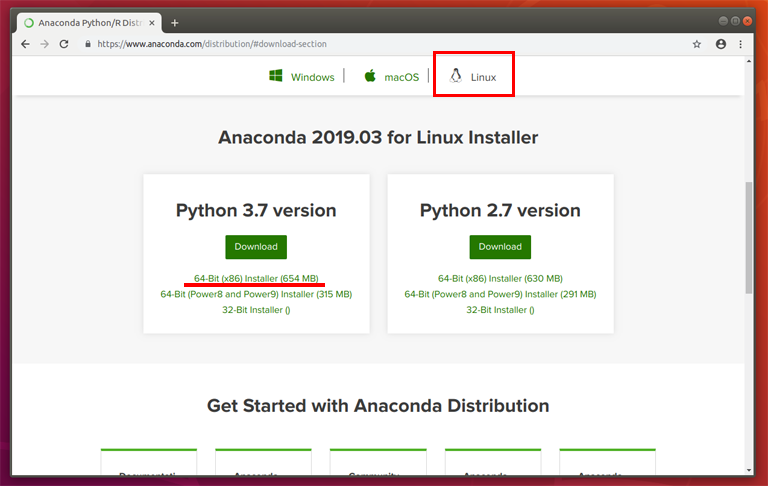
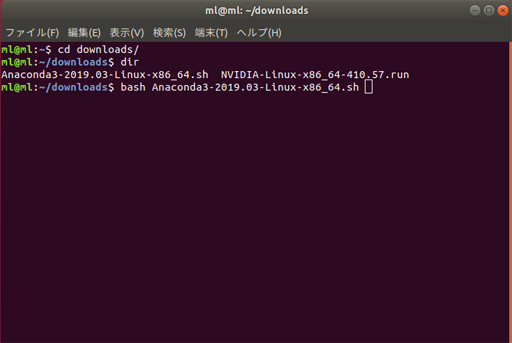
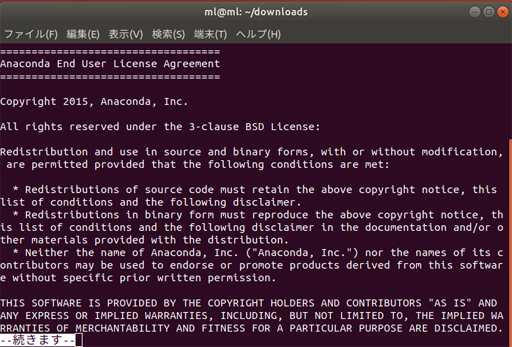
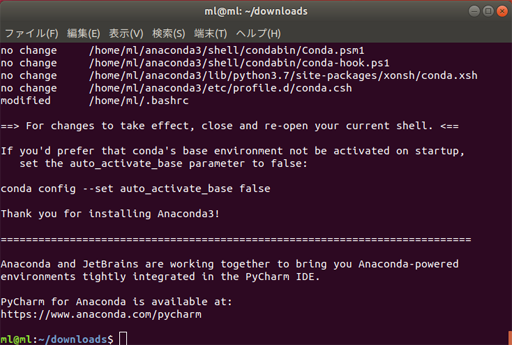
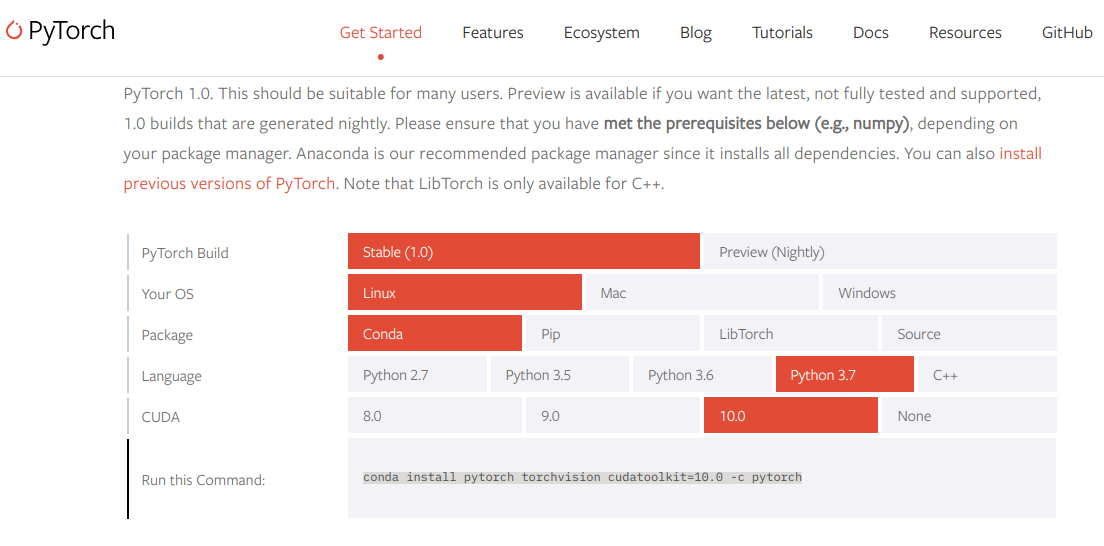
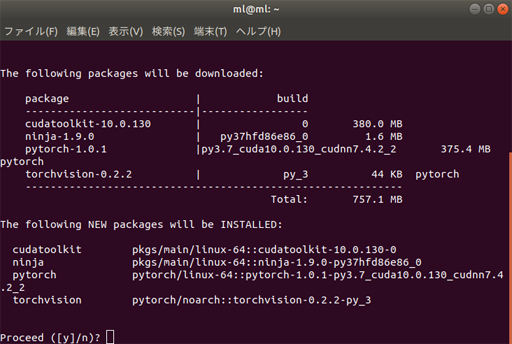
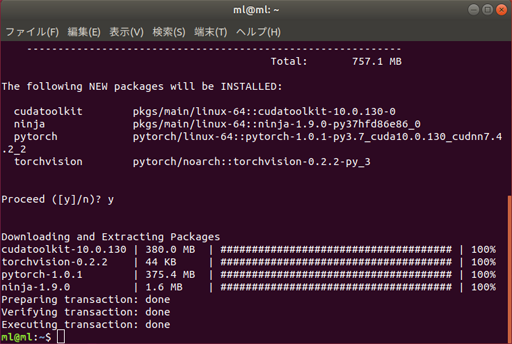
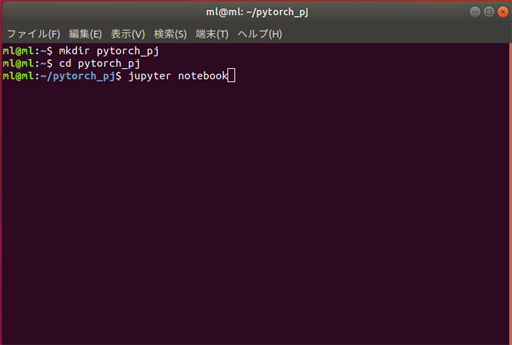
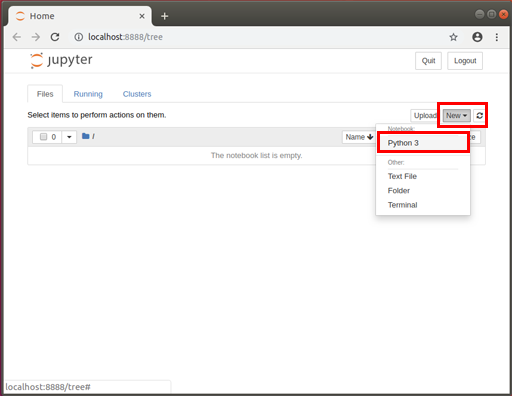
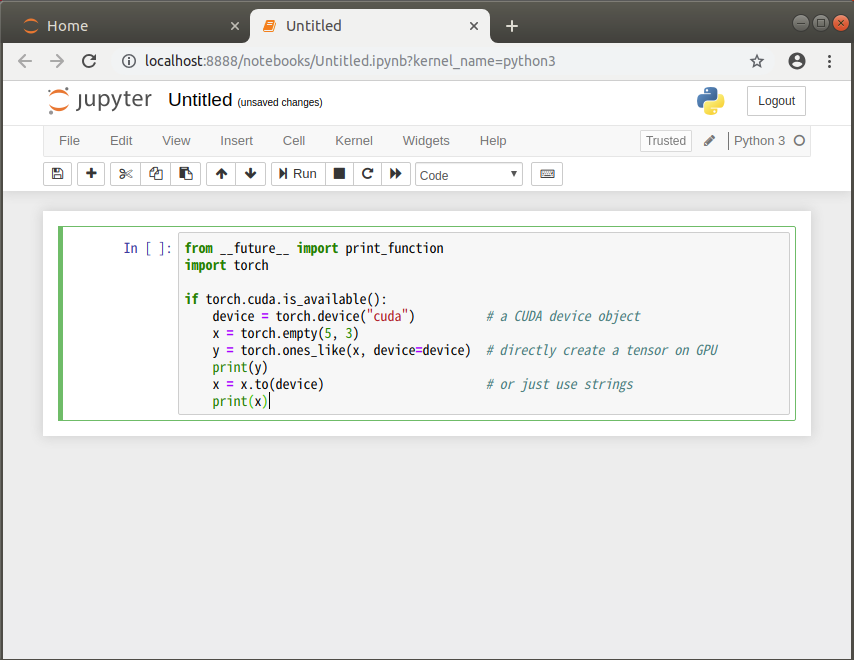

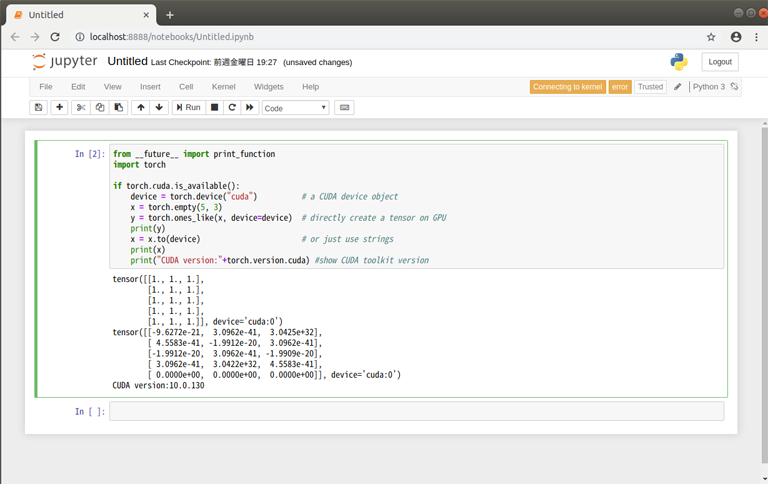
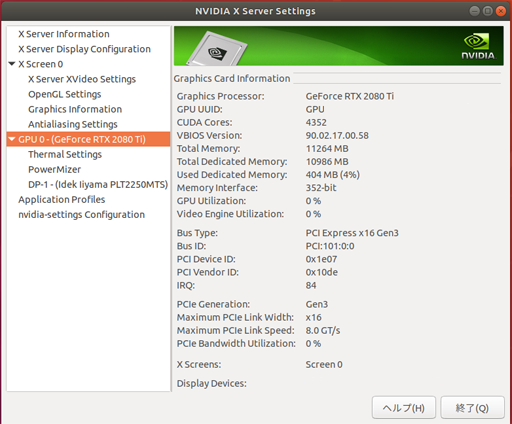
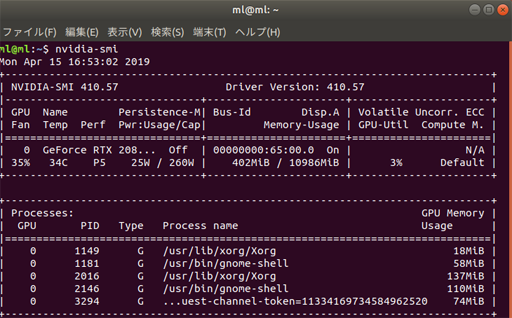
- 投稿日:2019-04-15T08:01:55+09:00
Why did #python open up dictionary access to match objects? (`TypeError: '_sre.SRE_Match' object is not subscriptable`)
3.4.8
Python 3.4.8 (default, Apr 9 2018, 11:43:18) [GCC 4.4.7 20120313 (Red Hat 4.4.7-18)] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import re >>> re.search(r'b', 'abc').group(0) 'b' >>> re.search(r'b', 'abc')[0] Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: '_sre.SRE_Match' object is not subscriptable3.7.2
Python 3.7.2 (default, Jan 13 2019, 12:50:01) [Clang 10.0.0 (clang-1000.11.45.5)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>> import re >>> re.search(r'b', 'abc').group(0) 'b' >>> re.search(r'b', 'abc')[0] 'b'ref
re — Regular expression operations — Python 3.7.3 documentation
Easy access to group! It seems like. Thanks python
By the way ruby example
[5] pry(main)> 'abc'.match(/b/)[0] => "b"It may be easier to understand the dictionary
Original by Github issue

- 投稿日:2019-04-15T07:46:46+09:00
Pythonスクレイピング 備忘録① URLを相対パスを絶対パスに変換
初めに
pythonスクレイピング慣れたいので今日から備忘録を書きながら学習していこうと思います。
基本的にわからないところを調べて検証してできたらここに備忘録としてまとめます。細かな説明はしません相対パスで表示される
https://gigazine.net/
にあるaタグの要素からURLを取得しますsoutaifrom urllib import request from bs4 import BeautifulSoup url = "https://gigazine.net/" html = request.urlopen(url) soup = BeautifulSoup(html,"html.parser") for i in soup.find_all("a"): print(i.get("href"))soutai_kekkahttps://gigazine.net/ https://twitter.com/gigazine https://www.facebook.com/GIGAZINE https://www.youtube.com/user/gigazine # # None https://gigazine.net/gsc/ https://gigazine.net/club/ https://gigazine.net/news/20190415-cambridge-bicycle-plan/ https://gigazine.net/news/20190415-cambridge-bicycle-plan/ https://gigazine.net/news/20190415-cambridge-bicycle-plan/ #~省略~ https://gigazine.net/news/C34/ https://gigazine.net/news/C16/ https://gigazine.net/news/C36/ https://gigazine.net/news/C21/ #相対パスになってる /news/contact2/ /news/contact3/ /news/contact4/ /news/about/ http://gigazine.co.jp/絶対パスに変換
こちらの記事で解決しました
https://teratail.com/questions/27753urllib.parseモジュール概要
https://docs.python.org/ja/3/library/urllib.parse.html
このモジュールでは URL (Uniform Resource Locator) 文字列をその構成要素 (アドレススキーム、ネットワーク上の位置、パスその他) に分解したり、構成要素を URL に組みなおしたり、 "相対 URL (relative URL)" を指定した "基底 URL (base URL)" に基づいて絶対 URL に変換するための標準的なインタフェースを定義しています。urljoin 関数概要
“基底 URL”(base)と別のURL(url)を組み合わせて、完全な URL (“絶対 URL”) を構成します。おーいろいろとお世話になりそう(適当)
zettaifrom urllib import request from bs4 import BeautifulSoup from urllib.parse import urljoin url = "https://gigazine.net/" html = request.urlopen(url) soup = BeautifulSoup(html,"html.parser") for i in soup.find_all("a"): print(urljoin(url, i.get("href")))zettai_kekkahttps://gigazine.net/ https://twitter.com/gigazine https://www.facebook.com/GIGAZINE https://www.youtube.com/user/gigazine https://gigazine.net/ https://gigazine.net/ https://gigazine.net/ https://gigazine.net/gsc/ https://gigazine.net/club/ https://gigazine.net/news/20190415-cambridge-bicycle-plan/ https://gigazine.net/news/20190415-cambridge-bicycle-plan/ https://gigazine.net/news/20190415-cambridge-bicycle-plan/ #〜省略~ https://gigazine.net/news/C34/ https://gigazine.net/news/C16/ https://gigazine.net/news/C36/ https://gigazine.net/news/C21/ #絶対パスで表示されるようになった https://gigazine.net/news/contact2/ https://gigazine.net/news/contact3/ https://gigazine.net/news/contact4/ https://gigazine.net/news/about/ http://gigazine.co.jp/終わり
備忘録②予定
- 投稿日:2019-04-15T07:14:41+09:00
Lesson9: Clustering まとめ Intro to Machine learning@Udacity
概要
Unsupervised learning:教師なし学習は重要。ここでやるのはクラスタリング。実際に機械学習で使われるデータは、値はあるが、正解ラベルがついていないことが多い。それらを分類して、ラベルを付けるのが、教師なし学習のクラスタリング。
そのほかの教師なし学習としては、次元削減がある。例えば下の図のように複雑なs字線上にある点があるとすると、このs字上の関数上にプロットすることで、X, Yの2次元を、その関数で表現できれば、1次元で表現できる。
内容
クラスタリングの具体例。映画の分類。katieの好きな映画がわかれば、その映画を見るように提案して、買ってもらえる。
図1
クラスタリングのメジャーな方法の一つはK-means法。
これからどのようなアルゴリズムなのか解説する。K-means法
例えば上記のように、7点赤✖のデータがあってそれを2つのクラスに分けるタスクを考える。緑の✖はその中心。
①中心位置の設置→距離計算:Assign
最初は下記のようにランダムに2つのクラスの中心をおいてみる。(クラスが2つなのは人が指示する。これが自動でできたらねー)その後、各7点のデータと各2点の中心位置の距離を測定して、各データに対して一番近い中心位置をAssignする。下図では線で結んでいる。
②最適化:Optimize
直感的には、上記のように結んだ線をゴムだとおもって、どの位置で各中心位置が釣り合うかを考える。その釣り合う位置に中心を移動する。具体的にはつながっている各線のトータルの長さが最も短くなる一に中心を移動する。移動後が下記。
その後、①②を繰り返すと、図1のようになる。
直感的にわかるのは下記のサイトと紹介してくれている。
Visualizing K-Means Clustering
真ん中らへんの
How to pick the initial centroids?
のところ。
最初に、中心位置をどのように設定するか聞かれる。その後、データを選んで、Goをクリックすると中心位置が各ステップごとにどのように動くか見ることができる。
ここでわかるのは中心位置の初期値がいかに重要かということ。それによって結果が全く違ってくる。Sklearn
sklearn : 2.3. ClusteringにK-means法も含めた、様々なアルゴリズムの種類とそのユースケース等が記載されているので、これを参考にすること。
K-means法では、一般的に調整すべきパラメーターが3つ
<調整すべきパラメーター>
n_clusters ・・・分けたいクラスタリングの数。デフォルトは8
max_iter・・・上記①assign、②optimizeをくりかえす最大回数。デフォルトは300
n_init・・・クラスタリングは最初に設定する中心位置で結果が変わってしまうので、中心初期位置を何度実施するか。デフォルトは10。Mini-project
Enronデータのデータを使って行う。
sklearnのK-meansクラスタリングページ
sklearn.cluster.KMeansを参照して課題を行った。Quiz20
コード全部はこちら
GitHub:ud120-projects/k_means/k_means_cluster.py
クラスタリングに使った特徴量は書き2つ
feature_1 = "salary"
feature_2 = "exercised_stock_options"追加したところは下記
k_means_cluster.py### cluster here; create predictions of the cluster labels ### for the data and store them to a list called pred from sklearn.cluster import KMeans kmeans = KMeans(n_clusters=2).fit(finance_features) pred = kmeans.labels_<出力>
Quiz21
変えたところだけ抜粋。
第3の特徴量total_paymentsを加えた。### the input features we want to use ### can be any key in the person-level dictionary (salary, director_fees, etc.) feature_1 = "salary" feature_2 = "exercised_stock_options" feature_3 = "total_payments"#今回追加 poi = "poi" features_list = [poi, feature_1, feature_2, feature_3]#feature_3追加 data = featureFormat(data_dict, features_list ) poi, finance_features = targetFeatureSplit( data ) ### in the "clustering with 3 features" part of the mini-project, ### you'll want to change this line to ### for f1, f2, _ in finance_features: ### (as it's currently written, the line below assumes 2 features) for f1, f2, f3 in finance_features:#f3追加 plt.scatter( f1, f2 ) plt.show()<出力>
薄い青色のデータが5個から1個に減った。ちなみにpredの中身は0か1の値が入っている。2枚目の散布図に出てくるように、1つのデータだけ1だった。total_paymentsの特徴量を加えることで、この変化が起こった。
次のレッスン:Feature scalingの準備
Quiz22, 23
feature scalingとは、クラスタリングや回帰で、それぞれの特徴量のレンジを0~1に合わせること。
そのために、まずはexercised_stock_options, salaryの特徴量の最小値:min, と最大値:maxを計算する。特徴量を0~1に調整することで、分類結果も変わってくる。##Quiz 22: Stock Option Range name_list = data_dict.keys() serch_feature = "exercised_stock_options" list_ex_st_op = [] for v in name_list: if data_dict[v][serch_feature] != "NaN": list_ex_st_op.append(data_dict[v][serch_feature]) print(list_ex_st_op) print("Max_stock:"+str(max(list_ex_st_op))) print("Min_stock:"+str(min(list_ex_st_op))) ##Quiz22 ends ##Quiz 23: Salary Range serch_feature = "salary" list_sal = [] for v in name_list: if data_dict[v][serch_feature] != "NaN": list_sal.append(data_dict[v][serch_feature]) print(list_sal) print("Max_sal:"+str(max(list_sal))) print("Min_sal:"+str(min(list_sal)))<出力>
Max_stock:34348384
Min_stock:3285Max_sal:1111258
Min_sal:477ちなみに、2つの特徴量で、feature scalingありでやると下図のような出力になるみたい。
Quiz20のクラスタリング結果の図は使っている特徴量は同じ。だけどfeature scalingがない。今回はある。チェックが入っている部分がfeature scalingの結果、POIとして分類されたデータ。feature scaling有り無しで結果が変わってくることがわかる。
詳しくは次のlesson10で!感想
大まかにどのようにコードを書けばクラスタリングができるのか分かった。feature scaling大事だね。何となくアルゴリズムの原理も理解できた気がする。
調べた英単語
deduce・・・v, 演繹(えんえき)する、推論する、推測する、
quadratic・・・adj, 二次の
blob・・・n, (インクなどの)しみ、(半固体の)小塊、ぼんやりした(形の)もの
ex)a blob of jelly.ゼリーの塊。
this blob of data.データの塊。pedagogical・・・adj, 教育学の、教授法の
deceptive・・・adj, 人を欺(あざむ)くような、当てにならない
deceive・・・v, だます、欺(あざむ)く、思い違いをさせる
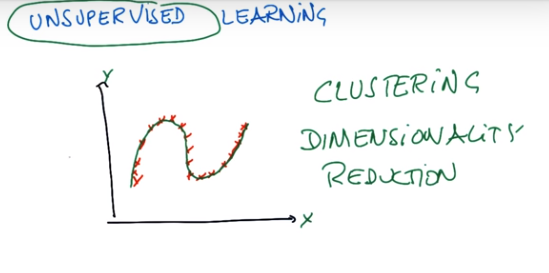
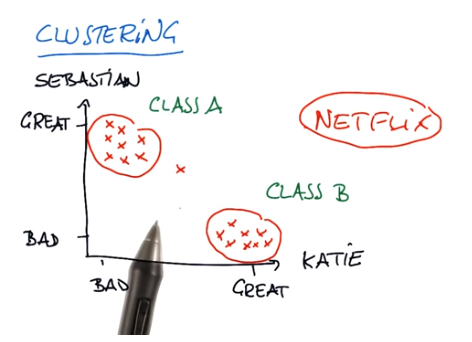
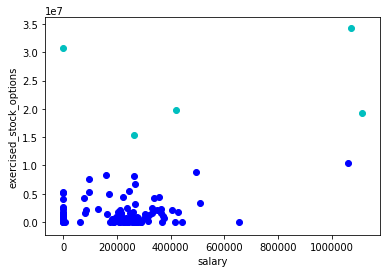
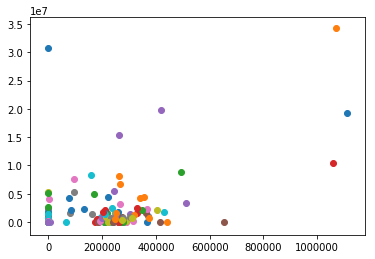
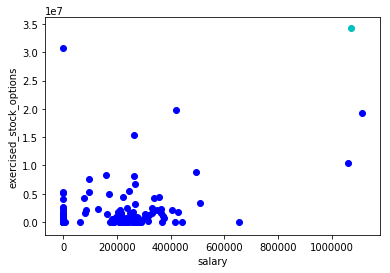
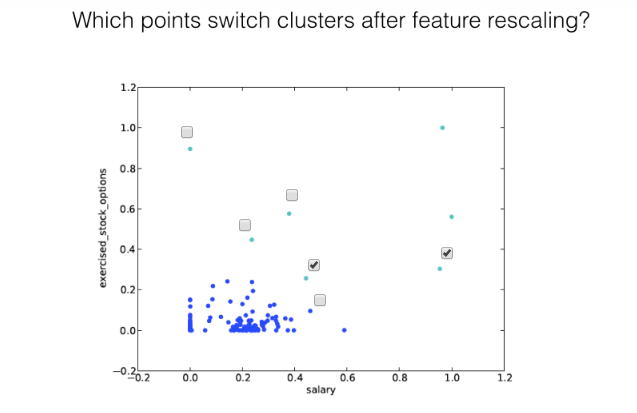
- 投稿日:2019-04-15T07:06:53+09:00
プログラミング初心者がKaggleチュートリアルに挑戦してみた
はじめに
はじめまして。初めてQiitaに投稿します。
一週間前から、機械学習に興味を持ち、pythonをかじり始めました。
Qittaの存在を知ったのもその頃なので、技術系ブログ作法というかマナーというか、そういうものが抜けていたら、こっそり教えていただけると幸いです。投稿者の紹介
機械学習はおろか、プログラミングもほぼ初心者。
数年前に、ドットインストールを視聴して、HTMLやCSS、PHP、MY SQL等のコードを真似て、遊んでいた程度。
(当時は全コース無償提供されていました。)
統計学どころか基本的な数学の知識にも乏しい。英語も儘ならず。環境
Windows OS
jupyter notebookpythonとの出会い
『機械学習エンジニアになりたい人のための本』を読み、機械学習にはpythonが適していることを知りました。
現在、ProgateやUdemyで学びながら、Kaggleのタイタニック号の課題にサブミットする日々です。Titanic:Machine Learning from Disaster との闘い
まだまだ自分でコードを書くこともできないのに、チュートリアルならできるだろうとたかをくくり、学習を初めて5日あまりでKaggleのアカウントを作成しました。
甘かった・・・Qiitaで関連記事をとりあえず読み漁ります。何が関連しているのかすら分からないまま読みます。
Kaggle入門者へ タイタニックチュートリアルを比較してみた
この記事を参考に、様々な手法が用いられるのを確認しました。まず最初に
【Kaggle初心者入門編】タイタニック号で生き残るのは誰?
上記のコードを一つずつ理解しながら打ち込んでいき、無事にcsvファイルを提出。
参考記事と同じ、0.71770のスコアを確認できました。
これをサンプルと呼ぶことにします。次は自分でコードを変えていきます。
細かなことはリンク先を参照していただくとして割愛しますが、最初の提出分では’Age’の欠損値には中央値を入れています。
’Name’に含まれるMr.などの敬称の情報で年齢を推定できるとあったので、これに挑戦してみることにしました。
ここで、初心者あるあるにぶつかります。
コードが全部載っていないと真似できない・・・・・・A Data Science Framework: To Achieve 99% Accuracy
kaggle/titanic 欠損値の補完と特徴量エンジニアリング
この2つの記事を参考にして進めました。そもそも見たことのないコードの書き方だと、どういう風にサンプルを変更していけば良いか分からないので、理解でき、納得して書けるコードを探しました。まず、’Name’から’Title’を抽出し、新たに列名として追加します。
train['Title'] = train['Name'].str.split(", ", expand=True)[1].str.split(" ", expand=True)[0]次に、主要な'Title'毎に格納し、'Age'の平均値を出します。
train_mr = train[train['Title'] == 'Mr.'] train_mr['Age'].dropna().mean()'Mr.'の平均値は32.368.9.452261306
となりました。
この32という数値で、欠損したセルを埋めていきます。train_mr['Age'] = train_mr['Age'].fillna(32)さらに、元の学習データを補完していきます。
train['Age'][train['Title'] == 'Mr.' ] = train_mr['Age']後は、サンプルと同様、決定木を用いて分析しています。
提出結果はというと、0.73205でした。
1.5%ほど良くなりました。まとめ
・初心者はコードを真似て、Kaggleチュートリアルにサブミットすることができる。
・基本的なコードの書き方を知らないため、なかなか応用がきかない。
・ひたすら試行錯誤すればなんとかなる。
・とりあえず、現在の分析方法は、決定木しか分からない。・'Age'は、平均値や中央値で埋めるより、'Title'から推定した方が結果が良くなる。
まだまだタイタニック号の課題への挑戦は続きます・・・・・・。