- 投稿日:2020-10-06T23:59:53+09:00
【画像保管計画】Pillow Image to Blob in MySQL
背景
かつて誰もが為し得なかった神への道を目指し、僕はPythonで動画サイトのサムネ画像をスクレイピングで色々収集してまして、それをPillowモジュールで加工したものをMySQLで作ったテーブルのBlobカラムに保管しておきたいという必要に迫られました。画像の数は大量にあるので、ストレージの節約のため、いちいちファイルに書き出したりせずにオンメモリでBlobカラムに挿入する方法が欲しかった。その過程で調べて得られた手順をここに残しておきます。
BLOBフィールド、展開!
以下のようなBLOB型のカラムimgfileを含んだimg_materialテーブルをMySQLのDBで定義しておきます。
CREATE TABLE `img_material` ( `video_id` char(11) NOT NULL DEFAULT '' COMMENT '動画ID', `imgfile` blob DEFAULT NULL COMMENT '画像ファイル' ) ENGINE=InnoDB DEFAULT CHARSET=utf8;P.I.L.緊急排出!!
次のように指定したURLからrequestsで取得した画像があり、それをpillowのImageオブジェクトに格納し、トリミング加工をしています。
from PIL import Image import urllib.request as req import io thumbnail_url = "https://xxx.xxx.xxx/xxxxxx.jpg" # 取り込みたいサムネ画像のURL f = io.BytesIO(req.urlopen(thumbnail_url).read())#URLからサムネ画像を展開 thumbnail = Image.open(f).convert('RGB') #Imageオブジェクトに格納 thumbnail = thumbnail.crop((0, 11, 120, 79))#黒帯部分をトリミング一旦Imageオブジェクトに変換して加工しましたが、これを上記のテーブルのBlobカラムであるimgfileへ格納したい!なのでもう一度ByteIOによりバイナリデータに戻します。
imgdata = io.BytesIO() thumbnail.save(imgdata, "JPEG") imgdata.seek(0) #ファイルの先頭へ imgfile = imgdata.read() #バイナリデータを格納こうしてできたimgfileを先ほど定義したBlobカラムのあるテーブルへINSERTします。
挿入、カラム並べて
MySQLdbにより、DBへの接続を行います。db_configの中身は、ご自分の環境に合わせて適宜変えてください。
import MySQLdb # DB設定 db_config = { 'host': 'localhost', 'db': 'database_name', 'user': 'root', 'passwd': 'your_password', 'charset': 'utf8', } # 接続する conn = MySQLdb.connect( host=db_config['host'], db=db_config['db'], user=db_config['user'], passwd=db_config['passwd'], charset=db_config['charset'] )上記ののコネクションから得られたカーソルにより、先述のimgfileを挿入するINSERT文を実行します。
# SQLクエリ SQL_INSERT_IM = ''' insert into img_material values(%s,%s) ''' # DB操作用にカーソルを作成 cur = conn.cursor() try: # 挿入データをタプルに格納 insert_blob_tuple = ("VIDEO000001", imgfile) # INSERT文を実行 result = cur.execute(SQL_INSERT_IM , insert_blob_tuple) conn.commit() print("Image data inserted successfully as a BLOB into table", result) except MySQLdb.Error as error: print("Failed inserting BLOB data into MySQL table {}".format(error)) finally: if conn.open: cursor.close() conn.close() print("MySQL connection is closed")参考資料
Image Module — Pillow (PIL Fork) 7.2.0 documentation
https://pillow.readthedocs.io/en/stable/reference/Image.html
io --- ストリームを扱うコアツール — Python 3.8.6 ドキュメント
https://docs.python.org/ja/3/library/io.html
BLOB 型と TEXT 型
https://dev.mysql.com/doc/refman/5.6/ja/blob.html
裏死海文書
https://w.atwiki.jp/evacommu/pages/92.html
- 投稿日:2020-10-06T23:05:48+09:00
sort を使わずにバブルソート
こんばんは。
Python user なら sort 使えば良いのですが、
考え方を味わいたかったので
まとめてみました٩(ˊᗜˋ*)و取りあえず、以下の配列を小さい順に並べてみましょう。
x = [6,4,3,7,1,9,8]っと言っても、いきなりヤレと言われてもハードルが高いので
まずは、一番小さい 1 を左端に移動させてみましょう。
例えばですが、2 つの値を比較し、小さいほうを左に移動させるアクションを
右端からやったら如何でしょうか?
例として x[5],x[6] を考えてみましょう。test.py# x[5] が x[6] より大きければ、、 if x[6] < x[5]: # x[5] , x[6] の値を入れ替える x[6],x[5] = x[5],x[6]イメージはこんな感じです。
x[5], x[6] をブルーにハイライトしています。
次は x[4] VS x[5] で比較してみましょう。
x[4] < x[5] が成り立っています。
なので変更の必要はありません。このように順番に比較していくと、
全体像は以下のようなイメージになります。
よかった、1 を左端に移動させることが出来ました!(^^)!
最終目標は小さい順に並べる事なので、他も並び替えが必要です。ともあれ 1 が左端に寄せれたので、 1 は固定です!
誰が何と言おうと変えません(笑)!
取りあえず、固定の 1 は緑に変えました。
ここまでの流れを for 文で書いてみましょう。test.py#1.start は x[6],つまり n-1 です。 #2.end は x[1] vs x[0] なのでココでは、0 を入れておけば # 実質は 1 までの代入となるので x[1] vs x[0] が実現します。 #3.数字は-1 ずつ減っていきます #上記を並べると range(len(x)-1,0,-1) になります! for j in range(len(x)-1,0,-1): #例) x[6] < x[5] であれば入れ替えます! if x[j] < x[j-1]: x[j],x[j-1] = x[j-1],x[j]多分問題ないと思います。
何か分かりにくかったら言ってください。m(_ _)m
では次です。
以下の図にあるように 1が最小であることが分かったら、
その次に小さい値を 1 の隣に持ってきましょう。
もう x[0] までデータを移動させる必要はありません。
x[6] から x[1] までで良いです。
ちょっとコードにしてみます。test.py# ↓ここを 0 から 1 に変えました。 for j in range(len(x)-1,1,-1): #例) x[6] < x[5] であれば入れ替えます! if x[j] < x[j-1]: x[j],x[j-1] = x[j-1],x[j]上記により x[6] から x[1] までを前述と同じように
比較作業を繰り返していきます。
結果は以下のようになります。
次は x[6] から x[2] です。test.py# ↓ここを 1 から 2 に変えました。 for j in range(len(x)-1,2,-1): #例) x[6] < x[5] であれば入れ替えます! if x[j] < x[j-1]: x[j],x[j-1] = x[j-1],x[j]もう良いですよね?(笑)
そうなんです、for 文のネストをすると
やりたいことが表現できます。test.pyfor i in range (len(x)-1): for j in range(len(x)-1,i,-1): if x[j] < x[j-1]: x[j],x[j-1] = x[j-1],x[j]全体像は以下のようになりました。
bubble_test.pyx = [6,4,3,7,1,9,8] for i in range (len(x)-1): for j in range(len(x)-1,i,-1): if x[j] < x[j-1]: x[j],x[j-1] = x[j-1],x[j] print(x)実行結果.py[1, 3, 4, 6, 7, 8, 9]ソートは理解が楽しいんですけど、
説明に図が沢山いるので記事を書くのが疲れますね(笑)
本当は、もう変更の必要のない並びの場合は、
並び替えを切り上げたりする考え方もあるんでしょうけど、、ま、いっかな~
次はクイックソートかな。。





- 投稿日:2020-10-06T22:36:55+09:00
python googlemap api でレビューを取得
概要
最終目標はスクレイピングした店舗を口コミ等を参考にしてランキング付けするwebサイトを作ることです
前回(python googlemap api を利用したデータ取得)の続きです。
apiを利用して店舗情報の取得まではいけたのですが、'reviews'のパラメータが存在せず、口コミの取得に四苦八苦しました。参考サイト
Google Map APIからレビューを取得する
PythonでGoogle APIとぐるなび APIのデータを取得してみたやったこと
Google Map APIからレビューを取得するを見てみると、どうやら'place_id'と'api_key'で'review'の存在するデータにアクセスできるようだ
絶対に他の簡潔なやり方があるだろうけど、何とか以下のようにするとレビューを取り出すことが出来た。
astモジュールを用いているのは、bs4で取得したXML形式のデータを辞書型に変換して、レビューのみ取り出したかったからである。最大で5件までしか取得できないみたいなので、時間等の他の要素でソートして取り出す方法を模索していく
key = 'AIzaSyDdKdbQVGfN2SgQ2BNEkwAPhK1enpJzk_c' # 上記で作成したAPIキーを入れる placeId = 'ChIJJ4-os2znAGAReJ4AQRGTrcs' urlName = "https://maps.googleapis.com/maps/api/place/details/json?placeid={0}&key={1}".format(placeId,key) dataHTML = requests.get(urlName) soup = BeautifulSoup(dataHTML.content, "html.parser") soup = ast.literal_eval(str(soup)) pprint.pprint(soup['result']['reviews'])実行結果
{'author_name': 'Susie Mead', 'author_url': 'https://www.google.com/maps/contrib/109736572258034599657/reviews', 'language': 'en', 'profile_photo_url': 'https://lh5.googleusercontent.com/-yaP8l2DOlaE/AAAAAAAAAAI/AAAAAAAAAAA/AMZuucnHsZcunKg758to4D5rIfeVjwMqZg/s128-c0x00000000-cc-rp-mo/photo.jpg', 'rating': 2, 'relative_time_description': 'a year ago', 'text': 'The hotel is located in a really interesting area filled with shops ' 'and markets. The room was nice and updated. My downside is the ' 'building was hard to find and no English signs at all and the staff ' 'barley speak English making it very difficult to communicate.', 'time': 1562469388}, {'author_name': 'whenuaboynton', 'author_url': 'https://www.google.com/maps/contrib/118063609090864700050/reviews', 'language': 'en', 'profile_photo_url': 'https://lh3.googleusercontent.com/a-/AOh14GjXy-z98y7u9l702EwHvz5DN6AqQWihDh3Fsp-V=s128-c0x00000000-cc-rp-mo', 'rating': 5, 'relative_time_description': 'a year ago', 'text': 'Double room was amazing, biggest bed I’ve ever seen or slept on. ' 'Room far bigger than others experienced in Japan. Couldn’t get a ' 'better location in Osaka.', 'time': 1569917795}]
- 投稿日:2020-10-06T22:06:54+09:00
PythonでFizz Buzzをやってみよう
ルール
- 1-100までの数字を用意
- 3で割り切れたら「Fizz!」と表示する
- 5で割り切れたら「Buzz!」と表示する
- 3と5で割り切れたら「Fizz Buzz!」と表示する
上記以外の数字はそのまま表示するソースコード
# 1. 1-100までの数字を用意 # 2. 3で割り切れたら「Fizz!」と表示する # 3. 5で割り切れたら「Buzz!」と表示する # 4. 3と5で割り切れたら「Fizz Buzz!」と表示する # 上記以外の数字はそのまま表示する for num in range(1, 101): if num % 3 == 0: if num % 5 == 0: print('Fizz Buzz!') else: print('Fizz!') elif num % 5 == 0: print('Buzz!') else: print(num)実行結果
1 2 Fizz! 4 Buzz! Fizz! 7 8 Fizz! Buzz! 11 Fizz! 13 14 Fizz Buzz! 16 17 Fizz! 19 Buzz! Fizz! 22 23 Fizz! Buzz! 26 Fizz! 28 29 Fizz Buzz! 31 32 Fizz! 34 Buzz! Fizz! 37 38 Fizz! Buzz! 41 Fizz! 43 44 Fizz Buzz! 46 47 Fizz! 49 Buzz! Fizz! 52 53 Fizz! Buzz! 56 Fizz! 58 59 Fizz Buzz! 61 62 Fizz! 64 Buzz! Fizz! 67 68 Fizz! Buzz! 71 Fizz! 73 74 Fizz Buzz! 76 77 Fizz! 79 Buzz! Fizz! 82 Buzz! Fizz! 67 68 Fizz! Buzz! 71 Fizz! 73 74 Fizz Buzz! 76 77 Fizz! 79 Buzz! Fizz! 82 83 Fizz! Buzz! 86 Fizz! 88 89 Fizz Buzz! 91 92 Fizz! 94 Buzz! Fizz! 97 98 Fizz! Buzz!最後まで読んでいただきありがとうございました。
また次回お会いしましょう。
- 投稿日:2020-10-06T21:38:44+09:00
Bolt for PythonでSlack APIを作ろう - 下準備(ngrokのセットアップからvenv仮想環境の作り方、Windows版)
先日Bolt for PythonというPythonでAPIを作るためのフレームワークを発見して感動した報告&日本語ドキュメントはもちろん海外版ドキュメントもまだ少ないので自分が躓いた点を書いておこうというただの自己満足記事です。
Bolt for Pythonが何かというよりも「どう使うか」「どう設定するか」を書いているだけです。ngrokをダウンロードしよう
ngrokとはローカル環境をLAN上に公開するためのソフトで、今回はSlackからチャット内容を取得するために使います。
それではまずここへ行きます。
そうするとこのサイトが出ると思うので、中央やや下寄りにある青色の"Get started for free"をクリックしてください。
そうしたら以下のような画面が出ると思うので、メールアドレスで登録してもよし、googleやgithubで登録してもよし、とりあえずアカウント登録をしてください。
登録が完了したら再度このサイトへ行き、"Get started for free"をクリックしてください。
場合によってはログインが求められたり求められなかったりするので、画面の指示に沿ってください。
ちなみにSign Up画面が出る場合は一番下にこのようなボタンがあるかと思いますので、そこからログインしてください。
ログインが完了しましたらこのような画面が出ますので、Download for Windowsを押してダウンロードします。
ダウンロードはzipファイルです。解凍して適当な場所に中のexeファイルを置いて下さい。
ただ、後々都合が良いので"C:\Users<ユーザー名>"に保存することを推奨します。ngrokを動かす!!
あとは楽勝です。先ほどngrok.exeを解答した場所までパワーシェルで移動し、./ngrok http 3000と打てばngrokが起動します。
venv仮想環境を作る
これは正直どうしてやるのか良く分かってないのですが、公式ドキュメント(Bolt for Python)ではこの方法をとっていたのでそれに倣うことにします。
venvを動かす前にまずパワーシェルを管理者として実行し、
PowerShell Set-ExecutionPolicy RemoteSignedというコマンドを打ち込んでください。これを打たないとセキュリティーエラーが出ます。完了したら
py -3.8 -m venv <作りたい仮想環境の名前>というコマンドを打ち込みます。そうすると仮想環境が出来上がります。
私の場合はtestという環境を作りたいので、py -3.8 -m venv testとなります。
当然ですがpy -3.8 ~~の-3.8はpythonバージョンによって変わります。
例えば私の場合だとv3.8.3だったので3.8ですが、3.7なら3.7に変わります。これだけで完了ではありません。
venvに移動するには<作った仮想環境の名前>\Scripts\activateというコマンドを打ち込みます。
私の場合はtestという環境を作ったので、test\Scripts\activate
もちろん\はパワーシェルでは円マークになると思います。ということで今回は下準備編でした。次回からは実際にbolt for pythonを動かすためのモジュールのインストールやプログラムを組んでいきたいと思います。



- 投稿日:2020-10-06T21:00:10+09:00
numpy の min, max で TypeError になったときの対処方法
x_min, x_max = X[:, 0].min - 0.5, X[:, 0].max + 0.5
TypeError Traceback (most recent call last)
in ()
----> 1 x_min, x_max = X[:, 0].min - 0.5, X[:, 0].max + 0.5TypeError: unsupported operand type(s) for -: 'builtin_function_or_method' and 'float'
x_min, x_max = X[:, 0].min() - 0.5, X[:, 0].max() + 0.5エラーが消えました。
- 投稿日:2020-10-06T20:44:03+09:00
【Python】iTunesで聞いてる曲の情報を取得する
概要
MacのiTunesで今聞いている曲の情報を取得できないかなぁとふと思い調べたら
AppleScriptでそれが実現するらしいが,
今まで触ったことが一ミリもなく諦めようとしたところ
Pythonのappscriptというモジュールでそれが可能ということみたいなので試してた環境
Python 3.6.0
環境構築
まずはpythonを動かすための環境をvenvで構築をする(別にvenvを使わなくてもいい)
$ python3 -m venv venv$ source venv/bin/activate(venv)$ pip3 install appscriptこのモジュールの使い方自体の記事もなかったですがgithubのドキュメントをなんとか見つけたのでまずはベースは参考にしました。
アプリケーションごとのドキュメントが全くないのであとはここに書いてある通りAppleScriptをappscriptに落とし込めばいけそうな気がしたので,
だいたいのメソッド等は力技でこんな感じだろうで試して, Pythonの記法に落とし込みました。
※正直かなり疲れた実装
前提スクリプト
モジュールのimport等, 大前提として必要なものは切り出しておきます。
getiTunesInfo.pyfrom aeosa import appscript it = appscript.app('iTunes')まずはこれを冒頭に入れちゃって下さい。
以下からのpythonスクリプトはこれがある前提で書いていきます。プログラムからのちょっとした操作
1. iTunesが起動しているかどうかチェック
getiTunesInfo.pyit.isrunning()実行結果
これの戻り値としては以下になります。
- 起動していたら
- True
- 起動していなかったら
- False
2. iTunesを起動する
getiTunesInfo.pyit.run()実行結果
iTunesが起動します
※但し, 特に前面に出て来たり, アプリの画面に勝手に移動したりはしないiTunesを(起動して)最前面にする。
getiTunesInfo.pyit.activate()実行結果
iTunesが起動していなかったら起動して, 最前面になります(iTunesの画面にスライドする)
実行結果
これでiTunesが起動して尚且つ, 最前面にiTunesが開きます。
3. 曲を再生する
getiTunesInfo.pyit.play()実行結果
曲が再生されます(音量注意)
4. 曲を止める
4-1. 停止
getiTunesInfo.pyit.stop()実行結果
曲が止まります(再生しても途中からは流れない)
4-2. 一時停止
getiTunesInfo.pyit.pause()実行結果
曲が一時停止します(もう一度再生をすると止めたところから再生される)
4-3. 再生・一時停止メソッド
getiTunesInfo.pyit.playpause()実行結果
- 再生していたら一時停止する
- 一時停止していたら再生される(音量注意)
- 停止状態でも再生される(音量注意)
再生中の曲情報を取得する
テンプレート
曲詳細の取得に関しては以下がテンプレートでプロパティ名を適宜帰る形になる
曲詳細テンプレートit.current_track.{プロパティ名}.get()例: 以下の曲を例として, 画像の曲詳細の情報を取得する
取得したい情報 プロパティ名 備考 曲 name - アーティスト artist - アルバム album - アルバムアーティスト album_artist - 作曲者 composer - すべての表示に作曲者を表示 すみませんこれだけわからなかったです(泣)?? - グループ grouping - ジャンル genre - 年 year 多分発売された年?
もしかしたらアップルミュージックとかで配信になった年かも?ですが特に深掘りしてないですトラック track_number そのアルバムで何曲目か ディスク番号 disk_number 複数枚組のアルバムとかの場合ディスクによって変わってくるのだと思う コンピレーション compilation コンピレーションアルバムかどうか(True/False) 評価 rating 自身で入力したもの
☆=20❤️ loved または disliked 自身で入力したもの
lovedの場合、チェックなし=False, 好き=True, 好きじゃない=False
dislikedの場合,チェックなし=False, 好き=False, 好きじゃない=Truebpm bpm - 再生回数 played_count 自身が再生した回数 コメント comment 自身で入力したもの 実行結果
これらを標準出力する
getiTunesInfo.pyprint(it.current_track.name.get()) print(it.current_track.artist.get()) print(it.current_track.album.get()) print(it.current_track.album_artist.get()) print(it.current_track.composer.get()) print(it.current_track.grouping.get()) print(it.current_track.genre.get()) print(it.current_track.year.get()) print(it.current_track.track_number.get()) print(it.current_track.discc_number.get()) print(it.current_track.compilation.get()) print(it.current_track.rating.get()) print(it.current_track.loved.get()) print(it.current_track.disliked.get()) print(it.current_track.bpm.get()) print(it.current_track.played_count.get()) print(it.current_track.comment.get())実行結果
実行結果# 曲 Tokyo Invader # アーティスト 踊Foot Works # アルバム ODD FOOT WORKS # アルバムアーティスト 踊Foot Works # 作曲者 Odd Foot Works # グループ 踊Foot Works # ジャンル ヒップホップ/ラップ # 年 2017 # トラック 2 # ディスク番号 1 # コンピレーション False # 評価 60 # ❤️ ## loved False ## disliked False # bpm 1 # 再生回数 170 # コメント お気に入りアートワーク取得
参考にしたのはAppleScriptのiTunesのことが書かれた記事です
これが一番苦労した...先ほどの記事の対象の部分が↓こちら
Get_the_artwork_for_the_current_tracktell artwork 1 of current track -- get the bytes of the artwork set srcBytes to raw data -- set the file extension based on the type if format is <> then set ext to "png" else set ext to "jpg" end if end tell -- get the destination filename as cover.ext in a temporary folder set fileName to (path to temporary items folder from user domain as string) & "cover." & ext) -- start the output file set outFile to open for access file fileName with write permission -- truncate it set eof outFile to 0 -- write the bytes of the image to the file write srcBytes to outFile close access outFile端的に解説すると
- 画像のバイナリーデータを取得
- 落としてきてそれをファイルに出力する
っていうやり方
では早速pythonに直していきます。
バイナリー取得と拡張子判別
バイナリー取得と拡張子判別(AppleScript)tell artwork 1 of current track -- get the bytes of the artwork set srcBytes to raw data -- set the file extension based on the type if format is <> then set ext to "png" else set ext to "jpg" end if end tell↑がAppleScriptの記法
↓こちらがpythonの記法で尚且つappscriptを使用したものバイナリー取得と拡張子判別(python)# バイナリーデータ取得 artworkRaw = it.current_track.artworks[1].raw_data.get() # 拡張子判別 ## 一旦jpgかpngしか見られなかったのでキメでやっています。 if it.current_track.artworks[1].format.get().name == 'JPEG_picture': ext = 'jpg' else: ext = 'png'※とりあえず拡張子の判別は何曲か再生してjpgはpngしか見られなかったので深追いせずにキメでやっちゃってます。すんません?
ファイルに書き出し
ファイルに書き出し(AppleScript)-- get the destination filename as cover.ext in a temporary folder set fileName to (path to temporary items folder from user domain as string) & "cover." & ext) -- start the output file set outFile to open for access file fileName with write permission -- truncate it set eof outFile to 0 -- write the bytes of the image to the file write srcBytes to outFile close access outFile↑がAppleScriptの記法
↓こちらがpythonの記法で尚且つappscriptを使用したものファイルに書き出し(python)# ファイル名は '曲名+拡張子' にする ## ディレクトリは相対パスでわかりやすくデスクトップに出力されるようにしてます fileName = f'../../{it.current_track.name.get()}.{ext}' # バイナリ書き込みモードでファイルを開く with open(fileName, mode='wb') as f: # もし既にあった場合の為に一度中身をクリアする pass # バイナリーデータを書き込む f.write(artworkRaw)以上!
繋げるとこうなります。
getiTunesInfo.pyartworkRaw = it.current_track.artworks[1].raw_data.get() if it.current_track.artworks[1].format.get().name == 'JPEG_picture': ext = 'jpg' else: ext = 'png' fileName = f'../../{it.current_track.name.get()}.{ext}' with open(fileName, mode='wb') as f: pass f.write(artworkRaw)実行結果
↓こんな感じでデスクトップにちゃんと画像ファイルが出力されました?
実際のデータもこんな感じ↓?
最後に
今回はお遊び程度にやったのでとりあえず実行できる環境を作ってやりました。
何かに利用してみたい..!!!
これを使ってまたなんか記事書こうと思います!!!参考資料
とにかくappscriptとかAppleScriptの記事が少ないし,
日本語なんてほぼないし,
ましてやiTunesに特化した記事なんてほとんどなかったのでめちゃくちゃ大変でしたので参考にした記事には本当に感謝です?おわり



- 投稿日:2020-10-06T20:18:59+09:00
Pythonがうまくいかない理由
python 3.7.9
df.head()が上手くいかない??
print(df)が上手く表示されるのに。
- 投稿日:2020-10-06T20:11:13+09:00
[Python]YWTの日報をOutlookメールで自動作成してみた
概要
毎日YWTの日報メールを作るのがだるい...
メールのテンプレート作成をしても、件名に今日の日付を毎回打たなきゃいけない...
PythonでOutlookのメールを自動作成できないか試してみた記事になります。
初めての投稿のため、色々とおかしいところがありますがそこはスルーで...YWTについてはこちら
やりたいこと
- 日報メールのYWTテンプレートを自動作成したい
- 件名に今日の日付をいれたい
- 昨日の日報メールのTの<次にやること>を今日の日報メールのYの<やったこと>にする
3については昨日のTを今日のYに書くことが多いので、
必要にしている人は自分以外にいるのか微妙...コード
import win32com.client import datetime import re # 昨日の日報メールの本文を取得する today = datetime.datetime.now() object = win32com.client.Dispatch("Outlook.Application") ns = object.GetNamespace("MAPI") folder = ns.GetDefaultFolder(6) # 6はOutlookの受信トレイフォルダを表している days_cnt = 1 flag = False # 昨日の日報メールが見つかったらTrue、見つからなかったらFalse # 昨日の日報を探す while flag == False: yesterday = today - datetime.timedelta(days=days_cnt) yesterday_sub ="日報[{}月{}日]".format(yesterday.month,yesterday.day) for i in reversed(folder.Items): if yesterday_sub in i.Subject: text = i.Body # 昨日の日報メールの本文を入れる flag = True # 昨日の日報メールが見つかったのでTrue break days_cnt += 1 # 日付の日報メールが見つからなかったら、その日付の昨日にする # <次にやること>の内容を抜き出す result = re.findall('<次にやること>[^<]+',text) b = result[0].replace('<次にやること>', '') # 「・~~~」の内容を抜き出す result2 = re.findall('・.+\r\n',b) sentence = "" for i in result2: sentence += i # メール送信 object = win32com.client.Dispatch("Outlook.Application") mail = object.CreateItem(0) mail.BodyFormat = 1 # 宛先の設定 To,CC,Bcc mail.To = "yyy@vvv.com" # 自分のメールアドレス # mail.cc = "yyy@vvv.com" # mail.Bcc = "yyy@vvv.com" mail.Subject = "日報[{}月{}日]".format(today.month,today.day) # メールの件名 # メールの本文 mail.Body = """\ お疲れ様です。 日報を送ります。 <やったこと> """+sentence+"""\ <わかったこと> <次にやること> 以上です """ mail.Display(True) # 作成したメールの表示 # mail.Send() # メール送信結果
昨日の日報メールはこちら
今日の日報を自動作成
赤線は自分のメールアドレスです
まとめ
OutlookのメールをPythonで自動作成できた。
これで日報メールを作る手間が少し省ける!時間が合ったらリファクタリングをしたい!
TeamsやMattermostで日報をYWTで提出することがあるので、この2つでも自動作成してみたい。参考


- 投稿日:2020-10-06T19:00:21+09:00
Pythonによる正規表現操作
はじめに
Pythonで正規表現を扱いたいときの操作をよく忘れるので、よく検索するものをメモ。よく検索するものが増えたら追記していきます。
網羅された情報を見たいなら公式ドキュメントへ。
reのインポートを忘れずに。正規表現の文法についてはこちらでメモを残しているので参考までに。概要
紹介している関数のまとめ。
ここでは、patternは任意の正規表現オブジェクトを、matchは任意のマッチオブジェクトを表す。
関数 内容 re.compile(r"正規表現") 正規表現オブジェクトの生成 pattern.search(文字列) 文字列内でpatternに一致した最初のマッチオブジェクト pattern.finditer(文字列) 文字列内でpatternに一致した全てのマッチオブジェクトのイテレータ match.start( ) 検索結果の文字列内での開始インデックス match.end( ) 検索結果の文字列内での終了インデックス match[0] 検索結果の文字列 文字列の検索(1つ)
例えば、文字列
私はPython初心者Aですに「アルファベットの大文字」が入っているかどうかを知りたいとき。search_exam_1.pyimport re string = "私はPython初心者Aです" #文字列の定義 pattern = re.compile(r"[A-Z]") #正規表現パターンの定義 result = pattern.search(string) #検索 print(result) print(result.start()) print(result.end())<re.Match object; span=(2, 3), match='P'> 2 3正規表現を使うときは、それが正規表現であると認識してもらうための処理が必要。その処理が
re.compile()である。なお、re.search(r"[A-Z]",string)で3、4行目をまとめると、テキストが複数ある時に毎回正規表現オブジェクトを生成することになってしまう。
また、正規表現内に\(円記号)があった場合などにそれを正しく認識してもらうために、r" "で文字列を囲む必要がある。こうすると中の文字列がrawであるとPythonに認識される。詳しくは公式ドキュメント冒頭を参照。
resultに返ってきたオブジェクトはマッチオブジェクトといって、検索文字列の中で最初にヒットしたものの情報を持っている。start()とend()のメソッドでそれぞれ開始と終了のインデックスを取得できるのが便利。文字列の検索(複数)
文字列
私はPython初心者Aですに入っている「アルファベットの大文字」を全て取得したいとき。search_exam_2.pyimport re string = "私はPython初心者Aです" #文字列の定義 pattern = re.compile("[A-Z]") #正規表現パターンの定義 results = pattern.finditer(string) #文字列の検索 for result in results: #検索結果のイテレータ(results)をresultに入れる print(result[0]) #マッチオブジェクトのアイテム print(result.start(), result.end())P 2 3 A 11 12
finditerで文字列を検索すると、マッチオブジェクトのイテレータが返ってくるので、一つずつfor文で展開する。複数検索はこのようにして実現される。
result[0]は何かというと、マッチオブジェクト内のグループの0番目にアクセスするという操作。複数個の文字列を検索すれば、マッチオブジェクトの内のグループは複数個になる。まとめ
ここでは、patternは任意の正規表現オブジェクトを、matchは任意のマッチオブジェクトを表す。
関数 内容 re.compile(r"正規表現") 正規表現オブジェクトの生成 pattern.search(文字列) 文字列内でpatternに一致した最初のマッチオブジェクト pattern.finditer(文字列) 文字列内でpatternに一致した全てのマッチオブジェクトのイテレータ match.start( ) 検索結果の文字列内での開始インデックス match.end( ) 検索結果の文字列内での終了インデックス match[0] 検索結果の文字列 今のところは、
searchとfinditer関連を記載。今後また追記していきます。
- 投稿日:2020-10-06T18:39:39+09:00
AWS Chaliceの開発環境をdockerで構築し、超高速でサーバーレスアプリケーションをデプロイしてみた
AWS Chaliceの開発環境をdockerで構築し、超高速でサーバーレスアプリケーションをデプロイしてみた
ChaliceもLambdaも初めてですが、
初めてのサーバーレスアプリケーションに興奮したので書きますソースコード naokit-dev/python3_chalice_on_docker
Chalice (チャリス?)
AWSが提供するPythonフレームワーク
Lambdaを使ったサーバーレスアプリケーションを簡単にデプロイできる
Documentation — AWS Chalice環境
- macOS Catalina
- VS Code
- Docker Desktop
docker --version Docker version 19.03.13, build 4484c46d9d docker-compose --version docker-compose version 1.27.4, build 40524192その他、AWSのアクセスキーが必要になります
準備運動
Docker Hubで使用するイメージを確認します
python - Docker HubAWS ChaliceはLambdaでサポートされているすべてのpythonが使用できるが3系が推奨とのこと
AWS Chalice supports all versions of python supported by AWS Lambda, which includes python2.7, python3.6, python3.7, python3.8. We recommend you use a version of Python 3.
Quickstart — AWS Chaliceここでは、
3.8-alpineを使用してみますVS Codeで新規ワークスペースを作成
"python3_chalice_on_docker"としました(次の手順は必要ないのですが、pythonが動く最小構成として試してみました)
Docker HubのイメージをPullしてコンテナを起動します
- -it 標準入力にアタッチ
- --rm コンテナ終了時にコンテナを削除
- -v : host_pathをボリュームとしてマウント
docker run -it --rm -v $PWD:/python python:3.8-alpine /bin/sh(
-v .:/pythonのように相対パスでマウントしようとするとエラーとなるが、環境変数$PWDが使えるようで-v $PWD:/pythonなら問題ない | Volume相対パス指定でもdocker runがしたい! - Qiita)# python --version Python 3.8.6Dockerfileを作成
先程作成したワークスペースでの作業になります
Dockerfileを作成
pip install chaliceでchaliceをインストールしますtouch DockerfileFROM python:3.8-alpine WORKDIR /app RUN pip install chalice CMD [ "/bin/sh"]つぎに
docker-compose.ymlを作成
ポートマッピング、ボリューム作成のほか、.envに記述した環境変数をコンテナ内で扱えるようにしていますtouch docker-compose.ymlversion: "3.8" services: app: build: . ports: - "80:8000" volumes: - .:/app command: chalice local --host=0.0.0.0 --port=8000 tty: true stdin_open: true working_dir: "${APP_PATH}" environment: - AWS_ACCESS_KEY_ID=${AWS_ACCESS_KEY_ID} - AWS_SECRET_ACCESS_KEY=${AWS_SECRET_ACCESS_KEY} - AWS_DEFAULT_REGION=${AWS_DEFAULT_REGION}
.envを作成
ここに環境変数を定義します
APP_NAMEはいまはブランクのまま
ほかも今はそのままで構いませんが、AWSにデプロイするために必要なcredentialsを記述することになりますtouch .envAPP_NAME= APP_PATH=/app/${APP_NAME} AWS_ACCESS_KEY_ID=[YOUR_ACCESS_KEY_ID] AWS_SECRET_ACCESS_KEY=[YOUR_SECRET_ACCESS_KEY] AWS_DEFAULT_REGION=ap-northeast-1端末にAWSのcredentialsが保存されている場合
以下で確認できますcat ~/.aws/credentialschalice projectを作成
chalice new-project <project_name>で新規プロジェクトを作成しますdocker-compose run app chalice new-project test_chalice以下のような構成になります
. ├── .env ├── Dockerfile ├── docker-compose.yml └── test_chalice ├── .chalice │ └── config.json ├── .gitignore ├── app.py └── requirements.txt環境変数を定義
.envを編集します
APP_NAMEに先程のプロジェクト名を、AWS_ACCESS_KEY_IDおよびAWS_SECRET_ACCESS_KEYもここに記述します
Regionはap-northeast-1に設定してありますが適宜変更してくださいAPP_NAME=test_chalice APP_PATH=/app/${APP_NAME} AWS_ACCESS_KEY_ID=xxxxxxxxxxxxxxxxxx AWS_SECRET_ACCESS_KEY=xxxxxxxxxxxxxxxxxx AWS_DEFAULT_REGION=ap-northeast-1ローカルサーバーをたてる
ローカルサーバーを起動
docker-compose updocker-compose.ymlで
command: chalice local --host=0.0.0.0 --port=8000としてコマンドを上書きしてあるので、docker-compose up時にchalice localが実行されます
ports: - "80:8000"でホスト側のport 80をコンテナ内のport 8000にマッピングしてあるので、ホストからlocalhostにアクセスすると、chaliceのlocal serverにポートフォワーディングされますcurl localhost {"hello":"world"}%"hello world"が返ってきました
test_chalice/app.pyをみてみます
以下のコメントアウトされている部分を、コメントアウト解除します# @app.route('/hello/{name}') # def hello_name(name): # # '/hello/james' -> {"hello": "james"} # return {'hello': name}
/hello/chaliceにアクセスしてみるとcurl localhost/hello/chalice {"hello":"chalice"}%"hello chalice"が返ってきました
RESTfulな挙動が確認できますローカルサーバーを停止
docker-compose downデプロイしてみる
chalice deployでAWS Lambda関数としてデプロイされますdocker-compose run app chalice deploy Creating deployment package. Creating IAM role: test_chalice-dev Creating lambda function: test_chalice-dev Creating Rest API Resources deployed: - Lambda ARN: arn:aws:lambda:ap-northeast-1:xxxxxxxxxxxx:function:test_chalice-dev - Rest API URL: https://xxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/api/Rest API URLにアクセスしてみます
curl https://xxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/api/ {"hello":"world"}% curl https://xxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/api/hello/lambda {"hello":"lambda"}%chaliceがコードを解析し、
必要なIAM roleを付与してLambda関数としてデプロイしてくれるそうです次は少し実用的なアプリに挑戦してみたいと思います
Ref.
- 投稿日:2020-10-06T17:47:08+09:00
raspberryPiとJulius(音声認識)を使用する。⑤i2cキャラクタディスプレイ編
関連記事
ここまでの道のりが長くもはや何だか分からないが、自分のための参考サイトをまとめた資料として残したい。
raspberryPiとjulus(音声認識)を使用する。①マイク編
raspberryPiでjulius(音声認識)を使用する。②インストール編
raspberryPiとJulius(音声認識)を使用する。③辞書作成編
raspberryPiとJulius(音声認識)を使用する。④Lチカ編
raspberryPiとJulius(音声認識)を使用する。⑤i2cキャラクタディスプレイ編使用するもの
AQM0802(i2c接続小型ディスプレイ完成版を使用)
ジャンパワイヤ(オス‐メス)4-5本
raspberryPi 3B+
USBマイクAQM0802を接続する
ラズパイのi2c利用設定はやっておく。
ピン配置は上からUDD、RESET、SCL、SDA、GNDなので、下の画像を参考に配線する。
Raspberry Pi で LCD モジュールを使うより引用接続を確認する。
$ sudo i2cdetect -y 1
3eで接続されているのが確認できた。試しにファイルを作成してディスプレイ表示させる
$ sudo apt-get -y install i2c-tools $ nano I2C_LCD_TEST.shI2C_LCD_TEST.sh#!/bin/sh # AQM0802A Raspberry Pi I2C control # http://www.neko.ne.jp/~freewing/ # http://akizukidenshi.com/catalog/g/gP-06669/ # sudo nano I2C_LCD_TEST.sh # sudo chmod 755 I2C_LCD_TEST.sh # ./I2C_LCD_TEST.sh # AQM0802A LCD初期化 # 0x38 0x39 Function Set i2cset -y 1 0x3e 0x00 0x38 0x39 i # 0x10 Bias selection/Internal OSC frequency adjust # 0x70 Contrast set(low byte) # 0x56 Power/ICON control/Contrast set(high byte) # 0x6C Follower control i2cset -y 1 0x3e 0x00 0x10 0x70 0x56 0x6C i sleep 0.3 # 0x38 Function Set i2cset -y 1 0x3e 0x00 0x38 i # 0x02 Return Home i2cset -y 1 0x3e 0x00 0x02 i # 0x0C Display ON/OFF control # i2cset -y 1 0x3e 0x00 0x0C i # 0x0F Display ON/OFF control i2cset -y 1 0x3e 0x00 0x0F i # 0x01 Clear Display i2cset -y 1 0x3e 0x00 0x01 i sleep 0.5 # 0x40 CGRAM addres = 0x00 CHARACTER CODE = 0x00 i2cset -y 1 0x3e 0x00 0x40 b i2cset -y 1 0x3e 0x40 0x01 0x02 0x03 0x04 0x05 0x06 0x07 0x08 i # 0x40 CGRAM addres = 0x08 CHARACTER CODE = 0x01 i2cset -y 1 0x3e 0x00 0x48 b i2cset -y 1 0x3e 0x40 0x1F 0x1E 0x1D 0x1C 0x1B 0x1A 0x19 0x18 i # 1行目 DDRAM addres = 0x00 i2cset -y 1 0x3e 0x00 0x80 b # "=FREE ==" i2cset -y 1 0x3e 0x40 0x3D 0x46 0x52 0x45 0x45 0x20 0x3D 0x3D i sleep 0.5 # 2行目 DDRAM addres = 0x40 i2cset -y 1 0x3e 0x00 0xc0 b # "== WING=" i2cset -y 1 0x3e 0x40 0x3D 0x3D 0x20 0x57 0x49 0x4E 0x47 0x3D i$ chmod 755 I2C_LCD_TEST.sh $ sudo ./I2C_LCD_TEST.shRaspberry Pi 3の GPIOに I2C通信方式の液晶モジュール AQM0802Aを接続する方法をそのまま試している。
ディスプレイが動作することは確認できる。コマンドについてメモ
#画面初期化 $ i2cset -y 1 0x3e 0x00 0x38 0x39 0x14 0x70 0x56 0x6c i $ i2cset -y 1 0x3e 0x00 0x38 0x0c 0x01 i $ i2cset -y 1 0x3e 0x00 0x80 #全部消して1行目の最初にカーソル移動 sudo i2cset -y 1 0x3e 0 0x38 0x0d 0x01 i #指定したデータを連続して表示 sudo i2cset -y 1 0x3e 0x40 [data1] [data2] [data3] i #改行してカーソルを先頭に移動 sudo i2cset -y 1 0x3e 0x00 0xc0 i0x3eが書き込み対象(I2CBUS)。
i は「block data」、連続してデータを書き込む指定。
b はバイトでの通常書き込みのこと。
AQM0802の文字表示引用
Raspberry Pi zeroでLCDディスプレイに文字を表示する
RasberryPIのI2Cコマンド詳解言葉の表示はAQM0802のcharacter patternsを参照して作成する。
#アリガトウ sudo i2cset -y 1 0x3e 0x40 0xb1 0xd8 0xb6 0xde 0xc4 0xb3 i ア リ カ ゛ ト ウ #コンニチハ sudo i2cset -y 1 0x3e 0x40 0xba 0xdd 0xc6 0xc1 0xca i コ ン ニ チ ハJuliusとAQM0802を連携させて動かしてみる
話したことに対して、用意された文字を表示する。
モジュールモードでJuliusを起動して、下記ファイルを実行。
test_i2c001.py#!usr/bin/env python # -*- coding: utf-8 -*- import smbus import time import subprocess import socket import string i2c = smbus.SMBus(1) # 1 is bus number addr02=0x3e #lcd _command=0x00 _data=0x40 _clear=0x01 _home=0x02 display_On=0x0f LCD_2ndline=0x40+0x80 #LCD AQM0802/1602 def command( code ): i2c.write_byte_data(addr02, _command, code) time.sleep(0.1) def writeLCD( message ): mojilist=[] for moji in message: mojilist.append(ord(moji)) i2c.write_i2c_block_data(addr02, _data, mojilist) time.sleep(0.1) def init (): command(0x38) command(0x39) command(0x14) command(0x73) command(0x56) command(0x6c) command(0x38) command(_clear) command(display_On) def ari (): arigatoulist=[0xb1, 0xd8, 0xb6, 0xde, 0xc4, 0xb3] i2c.write_i2c_block_data(addr02, _data, arigatoulist) time.sleep(0.1) print(arigatoulist) def konnichiha(): konnichihalist=[0xba, 0xdd, 0xc6, 0xc1, 0xca] i2c.write_i2c_block_data(addr02, _data, konnichihalist) time.sleep(0.1) HOST = '127.0.0.1' # juliusサーバーのIPアドレス PORT = 10500 # juliusサーバーの待ち受けポート DATESIZE = 1024 # 受信データバイト数 class Julius: def __init__(self): self.sock = None def run(self): # socket通信でjuliusサーバーに接続 with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as self.sock: self.sock.connect((HOST, PORT)) strTemp = "" # 話した言葉を格納する変数 fin_flag = False # 話終わりフラグ while True: # juliusサーバからデータ受信 data = self.sock.recv(DATESIZE).decode('utf-8') for line in data.split('\n'): # 受信データから、<WORD>の後に書かれている言葉を抽出して変数に格納する。 # <WORD>の後に、話した言葉が記載されている。 index = line.find('WORD="') if index != -1: # strTempに話した言葉を格納 strTemp = strTemp + line[index+6:line.find('"',index+6)] # 受信データに</RECOGOUT>'があれば、話終わり ⇒ フラグをTrue if '</RECOGOUT>' in line: fin_flag = True # 話した言葉毎に、print文を実行 if fin_flag == True: if 'ありがとう' in strTemp: print("どういたしまして") init () command(_clear) ari() elif 'こんにちは' in strTemp: print("こんばんは") init () command(_clear) konichiwa() else: print("話した言葉:" + strTemp) fin_flag = False strTemp = "" if __name__ == "__main__": julius = Julius() julius.run()話したことを変換してオウム返し表示する。(julius独自辞書の言葉のみ)
AQM0802のcharacter patternsに則って日本語辞書ファイルを作成。
nihongo.pynihongo = {"あ":0xb1, "い":0xb2, "う":0xb3, "え":0xb4, "お":0xb5, "か":0xb6, "き":0xb7, "く":0xb8, "け":0xb9, "こ":0xba, "さ":0xbb, "し":0xbc, "す":0xbd, "せ":0xbe, "そ":0xbf, "た":0xc0, "ち":0xc1, "つ":0xc2, "て":0xc3, "と":0xc4, "な":0xc5, "に":0xc6, "ぬ":0xc7, "ね":0xc8, "の":0xc9, "は":0xca, "ひ":0xcb, "ふ":0xcc, "へ":0xcd, "ほ":0xce, "ま":0xcf, "み":0xd0, "む":0xd1, "め":0xd2, "も":0xd3, "や":0xd4, "ゆ":0xd5, "よ":0xd6, "ら":0xd7, "り":0xd8, "る":0xd9, "れ":0xda, "ろ":0xdb, "わ":0xdc, "ん":0xdd, "を":0xa6, "ぁ":0xa7, "ぃ":0xa8, "ぅ":0xa9, "ぇ":0xaa, "ぉ":0xab, "ゃ":0xac, "ゅ":0xad, "ょ":0xad, "っ":0xaf, "が":"182 222", "ぎ":"183 222", "ぐ":"184 222", "げ":"185 222", "ご":"186 222", "ざ":"187 222", "じ":"188 222", "ず":"189 222", "ぜ":"190 222", "ぞ":"191 222", "だ":"192 222", "ぢ":"193 222", "づ":"194 222", "で":"195 222", "ど":"196 222", "ば":"202 222", "び":"203 222", "ぶ":"204 222", "べ":"205 222", "ぼ":"206 222", "ぱ":"202 223", "ぴ":"203 223", "ぷ":"204 223", "ぺ":"205 223", "ぽ":"206 223" }test_i2c003.py#!usr/bin/env python # -*- coding: utf-8 -*- import smbus import time import subprocess import socket import string from nihongo import nihongo i2c = smbus.SMBus(1) # 1 is bus number addr02=0x3e #lcd _command=0x00 _data=0x40 _clear=0x01 _home=0x02 display_On=0x0f LCD_2ndline=0x40+0x80 #LCD AQM0802/1602 def command( code ): i2c.write_byte_data(addr02, _command, code) time.sleep(0.1) def word( message ): kotoba = [] for moji in message: kotoba.append(moji) wordlist = [] for idx in range(0, len(kotoba)): a = kotoba[idx] val = nihongo[a] if type(val) is int: wordlist.append(val) else: nums = val.split() for i in range(2): wordlist.append(int(nums[i])) print(wordlist) i2c.write_i2c_block_data(addr02, _data, wordlist) time.sleep(0.1) def init (): command(0x38) command(0x39) command(0x14) command(0x73) command(0x56) command(0x6c) command(0x38) command(_clear) command(display_On) HOST = '127.0.0.1' # juliusサーバーのIPアドレス PORT = 10500 # juliusサーバーの待ち受けポート DATESIZE = 1024 # 受信データバイト数 class Julius: def __init__(self): self.sock = None def run(self): # socket通信でjuliusサーバーに接続 with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as self.sock: self.sock.connect((HOST, PORT)) strTemp = "" # 話した言葉を格納する変数 fin_flag = False # 話終わりフラグ while True: # juliusサーバからデータ受信 data = self.sock.recv(DATESIZE).decode('utf-8') for line in data.split('\n'): # 受信データから、<WORD>の後に書かれている言葉を抽出して変数に格納する。 # <WORD>の後に、話した言葉が記載されている。 index = line.find('WORD="') if index != -1: # strTempに話した言葉を格納 strTemp = strTemp + line[index+6:line.find('"',index+6)] # 受信データに</RECOGOUT>'があれば、話終わり ⇒ フラグをTrue if '</RECOGOUT>' in line: fin_flag = True # 話した言葉毎に、print文を実行 if fin_flag == True: print(strTemp[4:-3]) init () command(_clear) word(strTemp[4:-3]) fin_flag = False strTemp = "" if __name__ == "__main__": julius = Julius() julius.run()認識した言葉をディスプレイ表示できた
何故「ありがとう」と「こんにちは」にしたのか。
辞書を作り直して他の言葉も表示できるか試したい。参考
ラズパイでAQM0802(i2c接続小型LCDモジュール)を使おう
Raspberry Pi で LCD モジュールを使う
I2C接続AQMシリーズのキャラクタ表示LCDをラズパイで使う (1) AQM0802


- 投稿日:2020-10-06T17:45:09+09:00
raspberryPiとJulius(音声認識)を使用する。④Lチカ編
関連記事
raspberryPiとjulus(音声認識)を使用する。①マイク編
raspberryPiでjulius(音声認識)を使用する。②インストール編
raspberryPiとJulius(音声認識)を使用する。③辞書作成編
raspberryPiとJulius(音声認識)を使用する。④Lチカ編
raspberryPiとJulius(音声認識)を使用する。⑤i2cキャラクタディスプレイ編使用するもの
raspberryPi 3B+
USBマイク
LED
抵抗220Ω
ジャンパワイヤ(オス‐メス)2本
モジュールモードでJuliusを動かしてみる
保存したい場所のディレクトリに移動して、pythonでソケット通信をするためのコードを準備する。
$ sudo vim testnet001.pytestnet001.pyimport socket import time HOST = '127.0.0.1' # juliusサーバーのIPアドレス PORT = 10500 # juliusサーバーの待ち受けポート DATESIZE = 1024 # 受信データバイト数 class Julius: def __init__(self): self.sock = None def run(self): # socket通信でjuliusサーバーに接続 with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as self.sock: self.sock.connect((HOST, PORT)) strTemp = "" # 話した言葉を格納する変数 fin_flag = False # 話終わりフラグ while True: # juliusサーバからデータ受信 data = self.sock.recv(DATESIZE).decode('utf-8') for line in data.split('\n'): # 受信データから、<WORD>の後に書かれている言葉を抽出して変数に格納する。 # <WORD>の後に、話した言葉が記載されている。 index = line.find('WORD="') if index != -1: # strTempに話した言葉を格納 strTemp = strTemp + line[index+6:line.find('"',index+6)] # 受信データに</RECOGOUT>'があれば、話終わり ⇒ フラグをTrue if '</RECOGOUT>' in line: fin_flag = True # 話した言葉毎に、print文を実行 if fin_flag == True: if 'ありがとう' in strTemp: print("どういたしまして") elif 'こんにちは' in strTemp: print("こんばんは") else: print("話した言葉:" + strTemp) fin_flag = False strTemp = "" if __name__ == "__main__": julius = Julius() julius.run()作成したらエディタを終了する。
独自辞書をモジュールモードで呼び出す。$ cd $ julius -C ~/julius/julius-4.6/julius-kit/dictation-kit-4.5/am-gmm.jconf -nostrip -gram ~/julius/dict/test -input mic -module
モジュールモードでJuliusが待機しているのでこのままにして、もう一つターミナルを立ち上げる。$ cd Pythonコード保存先のディレクトリ $ sudo python3 testnet001.py
話しかけて反応があれば、ソケット通信はできている。
18ピンに刺したLEDを光らせる
ラズパイのピン配置(画像はググって分かりやすいものを拝借)
LED配線は調べたら誰かの記事が出てくるので省略。ピンはGPIO18を使用。
testnet002.pyimport RPi.GPIO as GPIO import time import socket import string def main(): GPIO.setmode(GPIO.BCM) GPIO.setup(18, GPIO.OUT) for i in range(5): GPIO.output(18, True) time.sleep(0.1) GPIO.output(18, False) time.sleep(0.1) GPIO.output(18, GPIO.LOW) HOST = '127.0.0.1' # juliusサーバーのIPアドレス PORT = 10500 # juliusサーバーの待ち受けポート DATESIZE = 1024 # 受信データバイト数 class Julius: def __init__(self): self.sock = None def run(self): # socket通信でjuliusサーバーに接続 with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as self.sock: self.sock.connect((HOST, PORT)) strTemp = "" # 話した言葉を格納する変数 fin_flag = False # 話終わりフラグ while True: # juliusサーバからデータ受信 data = self.sock.recv(DATESIZE).decode('utf-8') for line in data.split('\n'): # 受信データから、<WORD>の後に書かれている言葉を抽出して変数に格納する。 # <WORD>の後に、話した言葉が記載されている。 index = line.find('WORD="') if index != -1: # strTempに話した言葉を格納 strTemp = strTemp + line[index+6:line.find('"',index+6)] # 受信データに</RECOGOUT>'があれば、話終わり ⇒ フラグをTrue if '</RECOGOUT>' in line: fin_flag = True # 話した言葉毎に、print文を実行 if fin_flag == True: if 'ありがとう' in strTemp: print("どういたしまして") main() elif 'こんにちは' in strTemp: print("こんばんは") else: print("話した言葉:" + strTemp) fin_flag = False strTemp = "" if __name__ == "__main__": julius = Julius() julius.run()モジュールモードで呼び出して、別ターミナルで上記コードを実行すると光る。
音声認識でLチカ完了
Juliusをモジュールモード動作させることができた。
次は言葉を認識してi2cディスプレイ表示編へ。
raspberryPiとJulius(音声認識)を使用する。⑤i2cキャラクタディスプレイ編参考
juliusをmoduleモードで起動して、pythonで話した言葉を取得する
Raspberry Pi×JuliusとPythonでスマートスピーカー風にカメラを操作
How to resolve that error“:TypeError: can only concatenate str (not ”bytes“) to str”
ラズパイで音声認識つかってLチカしてみる



- 投稿日:2020-10-06T17:44:13+09:00
raspberryPiとJulius(音声認識)を使用する。③辞書作成編
関連記事
raspberryPiとjulus(音声認識)を使用する。①マイク編
raspberryPiでjulius(音声認識)を使用する。②インストール編
raspberryPiとJulius(音声認識)を使用する。③辞書作成編
raspberryPiとJulius(音声認識)を使用する。④Lチカ編
raspberryPiとJulius(音声認識)を使用する。⑤i2cキャラクタディスプレイ編辞書ファイルの作成
これがまたすごく大変だった。
単語に読み仮名をつけたファイルの作成(.yomi)
まず辞書ファイルを作成するためのディレクトリを作る。
$ cd julius $ mkdr dict $ cd dict階層はこんな感じ。
~/julius |--dict |--julius-4.6 |--julius-kit |--dictation-kit-4.5 |--grammer-kit-4.3.1ファイルを作成して編集するためにvimコマンドを使う。
vimをインストールする。$ apt-get install vim $ vim --version
読み仮名ファイルを作成する$ sudo vim test.yomi右上のキーボードマークをクリックして日本語入力ができるようにする。
↓↓
単語→tab→読み仮名(ひらがな)
と下に下に書いていく。単語は漢字でも大丈夫。
余分な空白はエラーになるので入れないよう注意。
最後の単語を入力したら改行はしないこと。最後の一行が空にならないように注意する。
単語帳ができたら、ctrl+C→ZZでvimエディタを終了する。
vimの使い方はこの記事を参照。
よく使う Vim のコマンドまとめ読み仮名ファイルをローマ字ファイルにする(.phone)(.dic)
この次のコードにハマった。Julius4.5以降は変換の必要がないらしい。
$ sudo iconv -f utf8 -t eucjp うんたらかんたらなので次のコードで実行する。
$ perl ~/julius/julius-4.6/gramtools/yomi2voca/yomi2voca.pl test.yomi > ~/julius/dict/test.phoneターミナルに特に表示されないので、ファイルができていることを確認し表示する。
$ ls $ sudo vim test.phone
.yomiファイルがローマ字に変換されていればOKなので、特に弄らず閉じる。文法ファイルを作成する(.grammar)
$ sudo vim test.grammar開いたエディタに次のコードを書き込む。単語の数だけ書く。
.phoneファイルのローマ字と一致するように注意する。
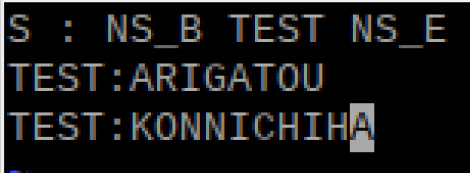
例)✕KONNNITIHA 〇KONNICHIWAS : NS_B TEST NS_E TEST:ARIGATOU TEST:KONNICHIWA構文ファイル1行目のSの部分は、構文定義を示し、NS_Bが文章の開始、NS_Eが文章の終了を表します。2行目以下のTESTの部分は認識させる文字列となっていて、先ほど生成された「音素」ファイル(hello.phone)の読みを大文字にして使います。一部改変し引用
書き込んだらエディタを終了する。
語彙ファイルを作成する(.voca)
.phoneファイルをコピーして語彙ファイルを作成する。
語彙ファイルを編集する。$ sudo cp test.phone test.voca $ sudo vim test.voca単語毎に形式をそろえて次のコードの形になるように書き加える。
単語とローマ字の間がtabで区切られていて、このまま動いたがスペースにした方がいいらしい。% ARIGATOU ありがとう a r i g a t o u % KONNICHIHA こんにちは k o N n i ch i w a % NS_B [s] silB % NS_E [/s] silE
辞書データに変換する
ディレクトリを移動する。
$ cd julius/julius-4.6/gramtools/mkdfa移動した先で次のコードを実行する。
$ mkdfa.pl ~/julius/dict/test成功すると、dictファイル内に「.dfa」「.term」「.dict」ファイルが生成される。
(何故か.dfatmpというファイルが出来上がってしまったので、名前の変更を行った。.tmpのファイルもやたらに作成されているが、良く分からないので放置。)
辞書を使って音声認識をする
$ cd次のコードを実行する。
$ julius -C ~/julius/julius-4.6/julius-kit/dictation-kit-4.5/am-gmm.jconf -nostrip -gram ~/julius/dict/test -input mic
何を言っても「ありがとう」と「こんにちは」だけをひたすら認識する。できた。
独自辞書の作成完了
次は言葉を認識してLチカ編へ。
raspberryPiとJulius(音声認識)を使用する。④Lチカ編参考
ラズパイ4日目①:Juliusで独自辞書を作成する
Raspberry PiとJuliusで特定の単語を認識させる
Raspberry Piでjuliusを使って音声認識をする
raspberry piにてjulius4.5を使い音声認識、文字化け
よく使う Vim のコマンドまとめ









- 投稿日:2020-10-06T17:43:51+09:00
raspberryPiでjulius(音声認識)を使用する。②インストール編
関連記事
raspberryPiとjulus(音声認識)を使用する。①マイク編
raspberryPiでjulius(音声認識)を使用する。②インストール編
raspberryPiとJulius(音声認識)を使用する。③辞書作成編
raspberryPiとJulius(音声認識)を使用する。④Lチカ編
raspberryPiとJulius(音声認識)を使用する。⑤i2cキャラクタディスプレイ編沢山の人がJuliusを使って記事にまとめているが、ハマりにハマって何本も読む羽目になったので統合する目的で備忘録として残していく。
皆さん順当にできていてすごい。使用するもの
raspberryPi 3B+
USBマイク(サンワサプライ USBマイクロホン 単一指向性 直挿し型 MM-MCU02BK)
Juliusをインストールする
juliusをインストールする$ wget https://github.com/julius-speech/julius/archive/v4.6.tar.gz解凍する
$ tar zxvf julius-4.6.tar.gzコンパイルとインストールをする(2行目大事、ハマった)
$ cd julius-4.6 $ ./configure --with-mictype=alsa $ make $ sudo make installjuliusを動かそうとした段階でハマった時のエラーはこれ
Stat: adin_oss: device name = /dev/dsp (application default) Error: adin_oss: failed to open /dev/dsp failed to begin input streamこれで解決するよーってのもエラーでダメ。それがこれ。
$sudo modprobe snd-pcm-oss modprobe: FATAL: Module snd-pcm-oss not found in directory /lib/modules/4.14.34-v7+./configureはjulius-4.6のディレクトリの中にあるのでそこに移動してから、実行すればハマらないはず。
ダウングレードする必要はなかった。
最初から上手くダウンロード解凍できたら最高。バージョンの確認
$ julius -version
こんな感じならOK。juliusパッケージのインストール
キット類はフォルダに入れている人が多いので適当に名前を付けてその中でダウンロード解凍するといいと思う。
$ cd julius-4.6 $ mk julius-kit $ cd julius-kit階層イメージはこう。階層作りすぎても面倒。
数字の前にvが付いていないので引っかからないように…。~/julius |--julius-4.6 |--julius-kit |--dictation-kit-4.5 |--grammer-kit-4.3.1dictationキットのインストール
$ wget https://osdn.net/dl/julius/dictation-kit-4.5.zip $ unzip dictation-kit-v4.4.zipgrammerキットのインストール
$ wget https://osdn.net/dl/julius/grammer-kit-4.3.1zip $ unzip grammer-kit-4.3.1.zip動かしてみる
自分のフォルダの階層はこうなっている。
~/julius |--julius-4.6 |--julius-kit |--dictation-kit-4.5 |--grammer-kit-4.3.1次の実行コードは自分のフォルダ階層に合わせて書き換えてください。
$ julius -C ~/julius/julius-4.6/julius-kit/dictation-kit-4.5/main.jconf -C ~/julius/julius-4.6/julius-kit/dictation-kit-4.5/am-gmm.jconf -nostrip
めちゃめちゃ長い文字の後にplease speakと出て、
精度はともかく何か反応があれば成功。
ctrl+Cで終了する。マイク編で書いたけれど、snd-pcm-ossは3B+には入っていなくて次のコードを打っても
$ sudo modprobe snd-pcm-ossエラーが出るので、ALSAモジュールをインストールしてALSAを使うように設定してください。
Juliusのインストール完了
次は独自辞書を作る。
raspberryPiとJulius(音声認識)を使用する。③辞書作成編参考
ラズパイ3日目②:Raspberry Pi+Juliusで音声を認識
Raspberry pi3B+でjuliusを動かせるようになるまでの覚書き(2019.3.10現在)
raspi最新カーネルでjuliusを動かす




- 投稿日:2020-10-06T17:40:01+09:00
白いマスクから怪人マスクへ、AWSでサーバレスLINE写真処理アプリの開発記
0.はじめに
初めまして、中国から参りましたポンです。
今は野村総合研究所で働いている新人エンジニアです。
日本語がまだ下手ですから、もし変な日本語が入りましたらご容赦ください。
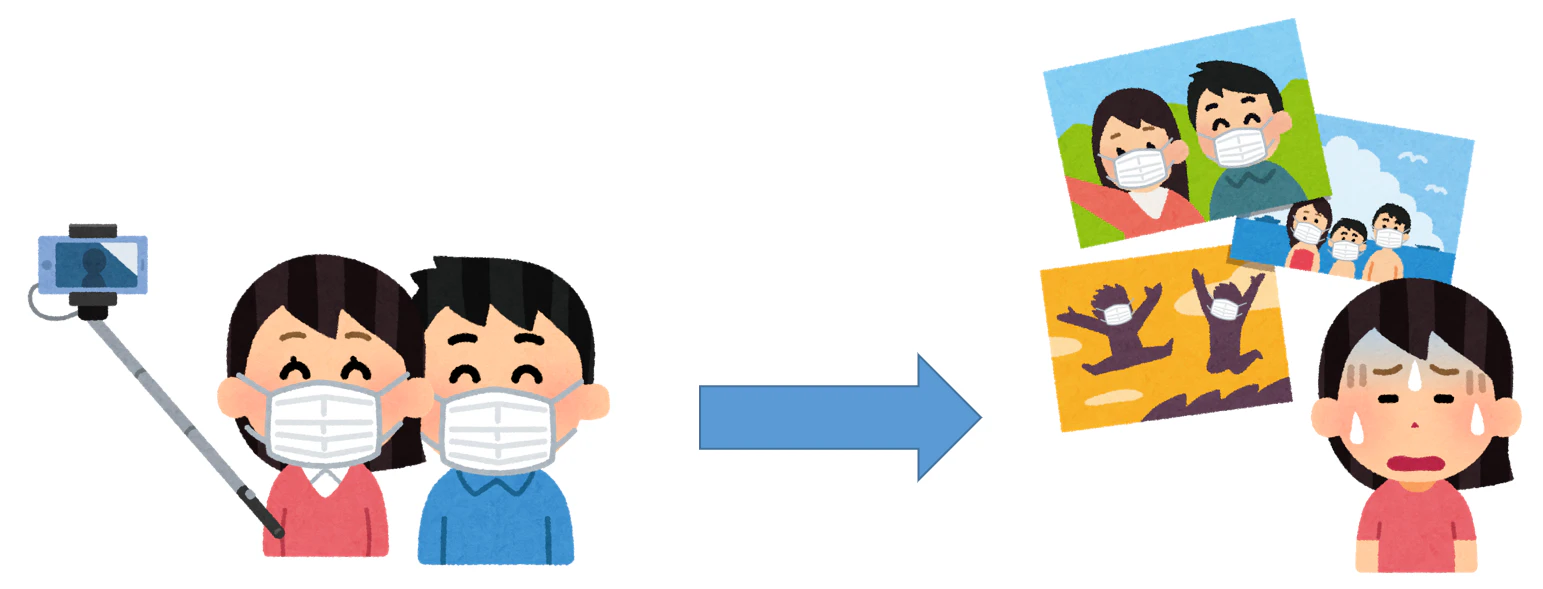
どうぞよろしくお願いいたします。コロナ時期の旅行写真には、白いマスクが多すぎで、
もう我慢できないですよね?
ちょうど今は新人開発研修があって、これを研修の課題にしました。
これを解決するため、写真中の白いマスクを怪人マスクに変換するアプリケーションを開発しました。
「できるだけ作業量を減らす」というコンセプトに基づいて、
AWSの色々なサービスを活用してサーバレスLINE写真処理アプリとして開発しました。
マスクだらけの写真にうんざりした方も、サーバレスに興味ある方も、
ぜひ、この開発記をお楽しみください。1.なぜこのアプリを開発?
筆者は夏休みの時に、彼女と千葉の銚子に旅行しました。
海で遊んだり、灯台を登ったり記念写真をいっぱい撮りました。
でも残念ですけど、写真の主役は人間または景色ではなく、白いマスクでした。
コロナ時代(時期)の写真は、白いマスクの出現率が一番高くて、どこでも登場しています。
こんな写真を見た彼女は、「もう白いマスクを見たくない」の文句が出てきた、じゃ写真中の白いマスクをほかのものに変換すればどうでしょう?ちょうど筆者も彼女も、スーパーヒーロー映画が好きで、その中の怪人マスク(e.g. バットマンの怪人Bane)が大好きです。
もし白いマスクが怪人マスクになればいいんじゃないですか?
※This work is a derivative of "Bane" by istolethetv, used under CC BY 2.0そういうことから、アイデアが生まれてきて、この写真処理アプリを開発することを決めました。
でも目の前に3つの問題が存在しています。
- どんなアプリケーション形態にする?
- どこでサーバーを立てる?
- どうやって画像認識システムを作る?
まず、アプリケーション形態について、色々な選択肢が存在しています。
WebページとしてのWebアプリ?スマホ専用のiosまたはandroidアプリ?
バックエンドの処理だけではなく、フロントエンドのインタフェースも設計しなければなりませんね。
色々考えて、やはりLINEアプリが一番適切だと思います。
理由が3つあります:
- 使いやすい:ほぼ誰でもLINE持っていて、LINEアプリ(bot)なら送信受信だけですごく簡単で、だれでも使えます。
- 作業量は少ない:Webアプリやiosアプリなら、インターフェースのデザインなども入って、正直言ってめんどくさいです。でもLINEアプリならそれらを考えなくてもいい、楽になります。
- シェアしやすい:SNSの特徴といえば共有しやすいですね。変換した写真だけではなく、このアプリもシェアされやすくなれます。
そこで、アプリケーション形態はLINEアプリと決めました!
そして次の課題は、どこでサーバーを立てるかです
Raspberry piなどの物理マシンで構築するか?AWS EC2などのクラウドサーバーを利用するか?
また、サーバーは構築だけではなく、後の保守管理も必要です。
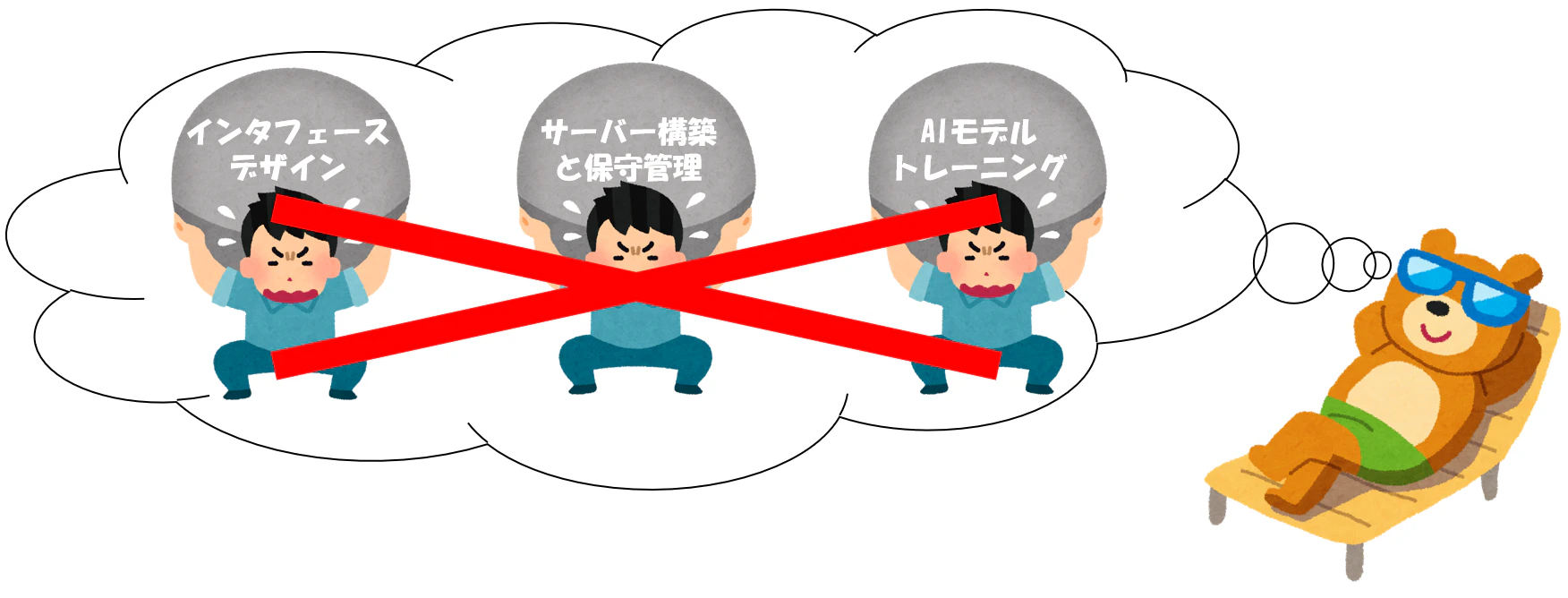
「できるだけ作業量を減らす」という理念を持っているlazyな私は、それをしたくないですね。。。
じゃ、サーバーを要らなく、サーバレスで開発すればいいじゃないですか?
調べると、AWS API GatewayとLambdaを使ったら、サーバレスを実現でき、サーバー構築と保守管理は一切なし!
よーし、君に決めた!!最後、今回は顔写真を処理するため、顔認識AIが必要です。
それで、「どんなAIモデル構造を使う?」、「訓練データどこから入手する?」や「データにどんなラベルを付ける?」などの問題がどんどん出てきました。
「すぐ使える顔認識AIがあればいいなぁ」と思ってAWSで調べてみて、結果は本当に出てきました!
Rekognition(recognitionではない)という画像または動画を分析するAWSサービスが存在します。
AIを作る必要がなく、Rekognitionをコールだけで、写真の顔の認識と分析ができます。
これで、「できるだけ作業量を減らす」が達成できます。
こういうことで、AWSでサーバレスLINE写真処理アプリを開発と決めました!
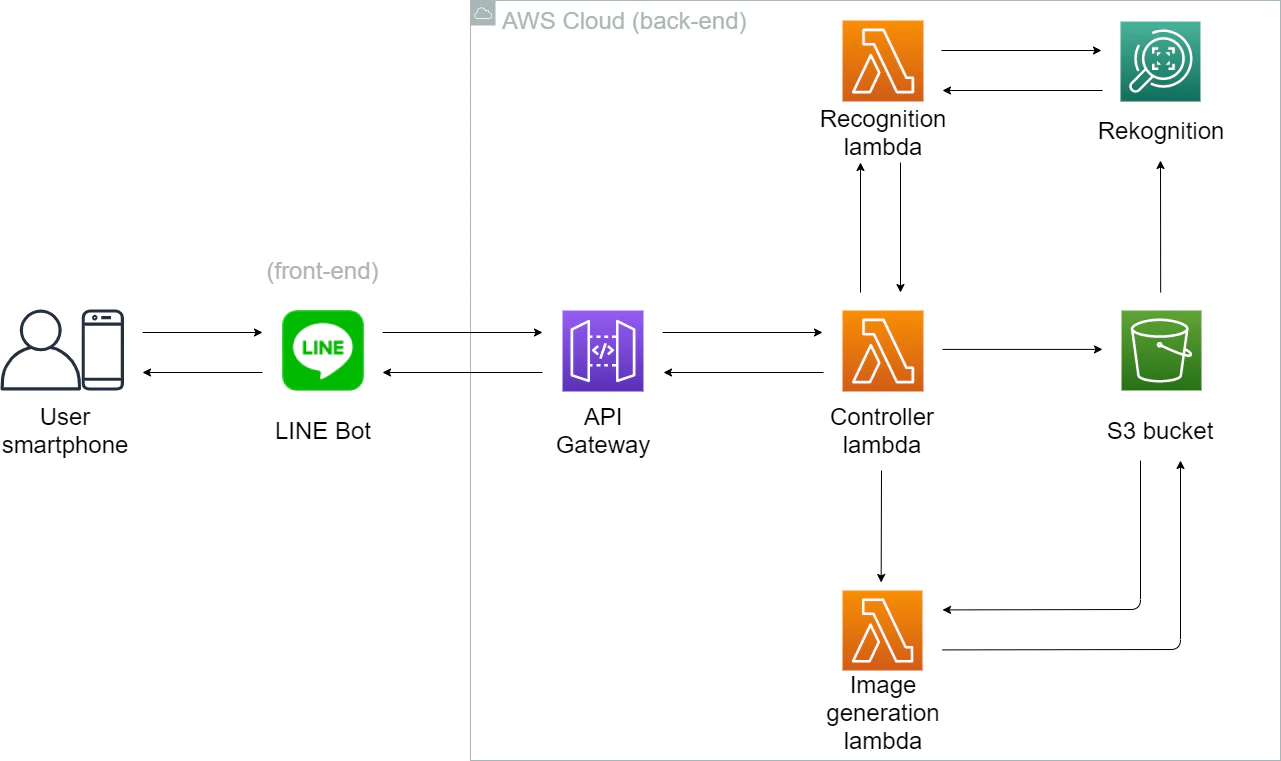
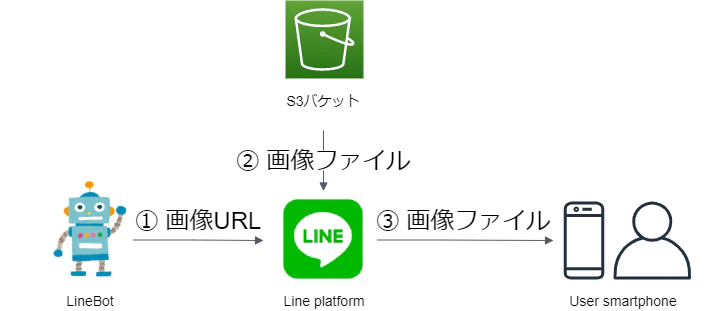
2.システム全体像
アプリケーション形態などはすでに決めましたので、これからシステムを構築しましょう!
今回作ったシステムの全体像は以下です:
ここでユーザとのやり取りはスマホと想定しています。(PC版LINEもできます)
フロントエンドはLINE Botです。
バックエンドは全部AWS Cloudで処理を行っています。
サーバレスを実現するため、処理は「コントローラー」、「顔認識」と「新画像生成」3つのLambda に実行されています。
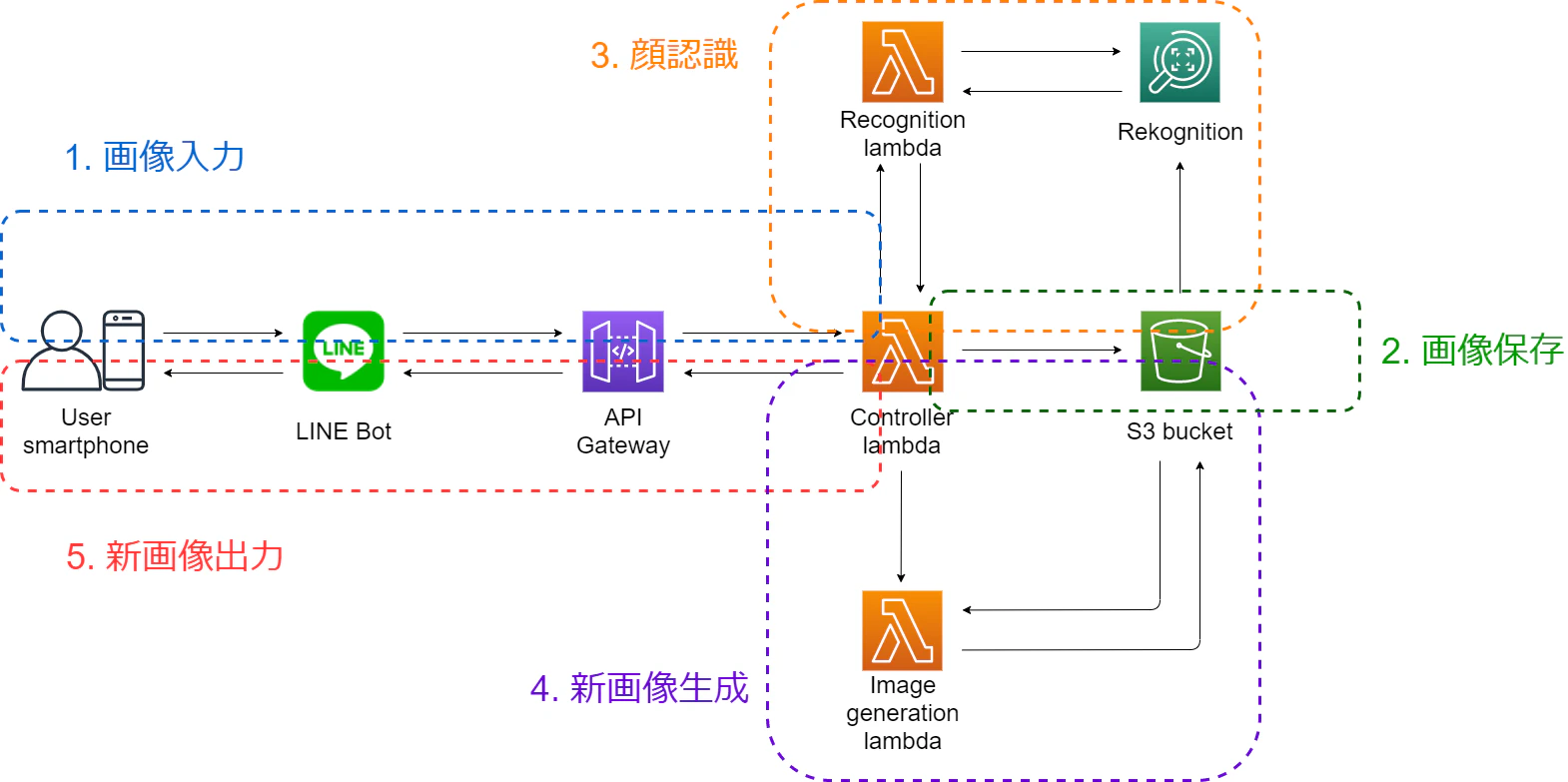
処理の流れから考えると、このシステムは以下の図のように5つ部分に分けられます:
それでは、処理の流れから、この5つ部分を説明いたします。
3.部分ごとの説明
3-1 画像入力部分
処理の流れ
第1部分は入力部分です。
機能は文字通りで、ユーザがLINE Bot に送信した画像を読み込むことです。
この部分に関するエンティティは「LINE Bot」、「API Gateway」および「コントローラーLambda 」です。
処理の流れは以下となっております:
まず、ユーザが写真画像をLINE Botに送信します。
そしてLINE Botが画像をline_eventにラッピングして、API Gatewayに送ります。
API Gatewayは何も変更せずに、eventをコントローラーLambdaに送ります。LINE Bot作成
この部分を作るために、まず玄関としてのLINE Bot(messagingApi)を作成。
作り方はこちらをご参照ください:
LINE公式ドキュメント:Messaging APIを始めよう
チャンネルを作成した後に、必要な設定はまだ2つあります。
1つ目はLambdaでの認証のため、「チャンネルアクセストークン」を発行することです。
2つ目はmessaging apiの応答機能をoff、webhook機能をonすることです。
webhook URLは今入力しなくて、API Gatewayの設定が終わった後に入力します。コントローラーLambdaを作成
次はLambdaなどのサービスを実行するIAMロールの作成です。
ダッシュボードからIAMサービスを入って、新しいロールを作ります。
新しいIAMロールはserverless-linebotなどをネーミングして、使うサービスはLambdaです。
ポリシーは「AmazonS3FullAccess」、「AmazonRekognitionFullAccess」、「CloudWatchLogsFullAccess」です。
またコントローラーLambdaがほかのLambdaを呼び出すのため、以下のポリシーも追加します:{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "lambda:InvokeFunction", "lambda:InvokeAsync" ], "Resource": [ "顔認識Lambdaのarn", "新画像生成Lambdaのarn" ] } ] }ここの「顔認識Lambdaのarn」と「新画像生成Lambdaのarn」はまだないですから、Lambda関数を作成した後に書き換えを忘れないでください。
今回の処理は全部このロールで実行します。コントローラーLambda関数を作成
API Gatewayは「繋がり」ですから、それを作る前に両端のLINE BotとコントローラーLambda関数を作らなければないので、次はコントローラーLambda関数を作成します。
関数作成に、今回はpythonを使うため、ランタイムをpython3.x(3.6~3.8)を選択します。
実行するIAMロールは先ほど作ったロールです。作成した後に、まずは「基本設定」で、メモリを512MBで、タイムアウトを1minのように設定します。
そして以下の環境変数を設定します:
キー 値 LINE_CHANNEL_ACCESS_TOKEN LINE Botのチャンネルアクセストークン LINE_CHANNEL_SECRET LINE Botのチャンネルシークレット Lambda関数の中身について、コントローラーLambdaはLINE Botとのやり取りが行いますので、「line-bot-sdk」パッケージが必要です。
Lambdaに導入するため、まずローカルで以下のコマンドを用いて、新フォルダにline-bot-sdkをインストールします:python -m pip install line-bot-sdk -t <new_folder>後同じフォルダにlambda_function.py(Lambdaはこの名前で「これがメインファンクション」と認識するので、必ずこの名前)ファイルを作って、以下のコードを記入ます:
lambda_function_for_controller.pyimport os import sys import logging import boto3 import json from linebot import LineBotApi, WebhookHandler from linebot.models import MessageEvent, TextMessage, TextSendMessage, ImageMessage, ImageSendMessage from linebot.exceptions import LineBotApiError, InvalidSignatureError logger = logging.getLogger() logger.setLevel(logging.ERROR) # 環境変数からline botのチャンネルアクセストークンとシークレットを読み込む channel_secret = os.getenv('LINE_CHANNEL_SECRET', None) channel_access_token = os.getenv('LINE_CHANNEL_ACCESS_TOKEN', None) if channel_secret is None: logger.error('Specify LINE_CHANNEL_SECRET as environment variable.') sys.exit(1) if channel_access_token is None: logger.error('Specify LINE_CHANNEL_ACCESS_TOKEN as environment variable.') sys.exit(1) # api&handlerを生成 line_bot_api = LineBotApi(channel_access_token) handler = WebhookHandler(channel_secret) # S3バケットとつながる s3 = boto3.client("s3") bucket = "<S3バケット名>" # Lambdaのメインファンクション def lambda_handler(event, context): # 認証用のX-Line-Signatureヘッダー signature = event["headers"]["X-Line-Signature"] body = event["body"] # リターン値の設定 ok_json = {"isBase64Encoded": False, "statusCode": 200, "headers": {}, "body": ""} error_json = {"isBase64Encoded": False, "statusCode": 403, "headers": {}, "body": "Error"} @handler.add(MessageEvent, message=ImageMessage) def message(line_event): # ユーザのプロフィール profile = line_bot_api.get_profile(line_event.source.user_id) # 送信したユーザのIDを抽出(push_messageなら使う, replyなら必要ない) # user_id = profile.user_id # メッセージIDを抽出 message_id = line_event.message.id # 画像ファイルを抽出 message_content = line_bot_api.get_message_content(message_id) content = bytes() for chunk in message_content.iter_content(): content += chunk # 画像ファイルを保存 key = "origin_photo/" + message_id new_key = message_id[-3:] s3.put_object(Bucket=bucket, Key=key, Body=content) # 顔認識lambdaを呼び出し lambdaRekognitionName = "<ここは顔認識lambdaのarn>" params = {"Bucket": bucket, "Key": key} # 画像ファイルのパス情報 payload = json.dumps(params) response = boto3.client("lambda").invoke( FunctionName=lambdaRekognitionName, InvocationType="RequestResponse", Payload=payload) response = json.load(response["Payload"]) # 新画像生成lambdaを呼び出し lambdaNewMaskName = "<ここは新画像生成lambdaのarn>" params = {"landmarks": str(response), "bucket": bucket, "photo_key": key, "new_photo_key": new_key} payload = json.dumps(params) boto3.client("lambda").invoke(FunctionName=lambdaNewMaskName, InvocationType="RequestResponse", Payload=payload) # 署名付きURL生成 presigned_url = s3.generate_presigned_url(ClientMethod="get_object", Params={ "Bucket": bucket, "Key": new_key}, ExpiresIn=600) # 新画像メッセージの返信 line_bot_api.reply_message(line_event.reply_token, ImageSendMessage( original_content_url=presigned_url, preview_image_url=presigned_url)) try: handler.handle(body, signature) except LineBotApiError as e: logger.error("Got exception from LINE Messaging API: %s\n" % e.message) for m in e.error.details: logger.error(" %s: %s" % (m.property, m.message)) return error_json except InvalidSignatureError: return error_json return ok_json上のはコントローラーLambda関数の全体で、すべての5つ部分と関連しています。
この第1部分に関するパートは以下です:
- LINE Botと繋がり
lambda_function_for_controller.py# 環境変数からline botのチャンネルアクセストークンとシークレットを読み込む channel_secret = os.getenv('LINE_CHANNEL_SECRET', None) channel_access_token = os.getenv('LINE_CHANNEL_ACCESS_TOKEN', None) if channel_secret is None: logger.error('Specify LINE_CHANNEL_SECRET as environment variable.') sys.exit(1) if channel_access_token is None: logger.error('Specify LINE_CHANNEL_ACCESS_TOKEN as environment variable.') sys.exit(1) # api&handlerを生成 line_bot_api = LineBotApi(channel_access_token) handler = WebhookHandler(channel_secret)
- イベントからlinebot署名とbody内容を受け取る
lambda_function_for_controller.py# 認証用のX-Line-Signatureヘッダー signature = event["headers"]["X-Line-Signature"] body = event["body"]これで、LINE Botの認証とイベント内容の受け取るができました。
後はそのフォルダの内容をzipに圧縮して、
Lambdaの「関数コード」→「アクション」→「.zipファイルをアップロード」でアップロードします。API Gatewayを作成
最後は繋がりとしてのAPI Gatewayの作成です。
ここ作成するAPI Gatewayの種類はREST APIです。
APIを作成した後に、リソースとメソッドを作成します。
メソッドはPOST方式で、統合タイプはLambda関数で、Lambdaプロキシ統合の使用も有効化にします。
Lambda関数はコントローラーLambda関数を選択します。あと、POSTメソッドリクエストの設定について、
まずリクエストの認証は「クエリ文字列パラメータおよびヘッダーの検証」を選択します。
そしてHTTPリクエストヘッダーには以下のヘッダーを追加します:
名前 必須 キャッシュ X-Line-Signature ☑ ☐ 設定できたらデプロイしましょう。
デプロイ完了したら、ステージでメソッドの呼び出しURLをコピーして、
LINE Botのwebhook URLに貼り付けます。
これで第1部分が完了します。3-2 画像保存部分
処理の流れ
第2部分は画像保存部分です。
この部分はすごく簡単で、ただコントローラーLambda読み込んだ画像をS3バケットに保存するだけです。
処理の流れは以下です:
S3バケットを作成
作業内容について、まずはS3バケットを作成します。
今回のプロジェクトにおいて、バケット名が長すぎると「署名付きURL長さ問題」が起きるため(詳細は3-5)、
バケット名はできれば短くします(私の場合は英4文字)。
また、自分の写真を他人に見られたくないですよね?
プライバシーを保護するため、
アクセス許可の設定に「パブリックアクセスをすべてブロック」をチェックして、バケットを作成します。
作成した後に、「origin_photo」というユーザがアップした写真を保存するフォルダと、
「masks」というマスク画像を保存するフォルダを作成します。
これで、S3側の作業が終わります。コントローラーLambda関数
コントローラーLambda関数は第1部分に記入したため、ここでの作業は特にありません。
ただこの部分に関するコード説明して、内容は以下です:
- バケットを指定
lambda_function_for_controller.py# S3バケットとつながる s3 = boto3.client("s3") bucket = "<S3バケット名>"
- イベントから画像ファイルを抽出して保存する
lambda_function_for_controller.py# メッセージIDを抽出 message_id = line_event.message.id # 画像ファイルを抽出 message_content = line_bot_api.get_message_content(message_id) content = bytes() for chunk in message_content.iter_content(): content += chunk # 画像ファイルを保存 key = "origin_photo/" + message_id new_key = message_id[-3:] s3.put_object(Bucket=bucket, Key=key, Body=content)ここはLINEメッセージIDで画像ファイルをリネームして、
複数ユーザが区別できるようになります。3-3 顔認識部分
第3部分は保存した写真の認識です。
具体的には顔の輪郭や目と鼻の位置を認識して、後のマスク画像と結合に使います。
「できるだけ作業量を減らす」というコンセプトを持って、
自分でゼロから顔認識AIを訓練したくないですから、
AWSの「Rekognition」というサービスを使って顔を認識します。Rekognitionとは
Rekognitionは「機械学習を使用して画像と動画の分析を自動化する」サービスであり、
簡単に言うと「訓練されたAIをそのまま使う」感じです。
Rekognitionについての紹介はこちらです:
Amazon RekognitionRekognitionはオブジェクトとシーンの検出や顔の比較などいろいろな機能があって、画像だけでなくビデオも処理できます。
今回は顔の位置を得るため、「顔の分析(face-detection)」機能を使います。
取得したい位置情報は「ランドマーク」と呼ばれます。
下の図はランドマークのイメージです:
※出典:https://docs.aws.amazon.com/ja_jp/rekognition/latest/dg/faces-detect-images.htmlこの図の分析結果:
Rekognition認識結果
{ "FaceDetails": [ { "AgeRange": { "High": 43, "Low": 26 }, "Beard": { "Confidence": 97.48941802978516, "Value": true }, "BoundingBox": { "Height": 0.6968063116073608, "Left": 0.26937249302864075, "Top": 0.11424895375967026, "Width": 0.42325547337532043 }, "Confidence": 99.99995422363281, "Emotions": [ { "Confidence": 0.042965151369571686, "Type": "DISGUSTED" }, { "Confidence": 0.002022328320890665, "Type": "HAPPY" }, { "Confidence": 0.4482877850532532, "Type": "SURPRISED" }, { "Confidence": 0.007082826923578978, "Type": "ANGRY" }, { "Confidence": 0, "Type": "CONFUSED" }, { "Confidence": 99.47616577148438, "Type": "CALM" }, { "Confidence": 0.017732391133904457, "Type": "SAD" } ], "Eyeglasses": { "Confidence": 99.42405700683594, "Value": false }, "EyesOpen": { "Confidence": 99.99604797363281, "Value": true }, "Gender": { "Confidence": 99.722412109375, "Value": "Male" }, "Landmarks": [ { "Type": "eyeLeft", "X": 0.38549351692199707, "Y": 0.3959200084209442 }, { "Type": "eyeRight", "X": 0.5773905515670776, "Y": 0.394561767578125 }, { "Type": "mouthLeft", "X": 0.40410104393959045, "Y": 0.6479480862617493 }, { "Type": "mouthRight", "X": 0.5623446702957153, "Y": 0.647117555141449 }, { "Type": "nose", "X": 0.47763553261756897, "Y": 0.5337067246437073 }, { "Type": "leftEyeBrowLeft", "X": 0.3114689588546753, "Y": 0.3376390337944031 }, { "Type": "leftEyeBrowRight", "X": 0.4224424660205841, "Y": 0.3232649564743042 }, { "Type": "leftEyeBrowUp", "X": 0.36654090881347656, "Y": 0.3104579746723175 }, { "Type": "rightEyeBrowLeft", "X": 0.5353175401687622, "Y": 0.3223199248313904 }, { "Type": "rightEyeBrowRight", "X": 0.6546239852905273, "Y": 0.3348073363304138 }, { "Type": "rightEyeBrowUp", "X": 0.5936762094497681, "Y": 0.3080498278141022 }, { "Type": "leftEyeLeft", "X": 0.3524211347103119, "Y": 0.3936865031719208 }, { "Type": "leftEyeRight", "X": 0.4229775369167328, "Y": 0.3973258435726166 }, { "Type": "leftEyeUp", "X": 0.38467878103256226, "Y": 0.3836822807788849 }, { "Type": "leftEyeDown", "X": 0.38629674911499023, "Y": 0.40618783235549927 }, { "Type": "rightEyeLeft", "X": 0.5374732613563538, "Y": 0.39637991786003113 }, { "Type": "rightEyeRight", "X": 0.609208345413208, "Y": 0.391626238822937 }, { "Type": "rightEyeUp", "X": 0.5750962495803833, "Y": 0.3821527063846588 }, { "Type": "rightEyeDown", "X": 0.5740782618522644, "Y": 0.40471214056015015 }, { "Type": "noseLeft", "X": 0.4441811740398407, "Y": 0.5608476400375366 }, { "Type": "noseRight", "X": 0.5155643820762634, "Y": 0.5569332242012024 }, { "Type": "mouthUp", "X": 0.47968366742134094, "Y": 0.6176465749740601 }, { "Type": "mouthDown", "X": 0.4807897210121155, "Y": 0.690782368183136 }, { "Type": "leftPupil", "X": 0.38549351692199707, "Y": 0.3959200084209442 }, { "Type": "rightPupil", "X": 0.5773905515670776, "Y": 0.394561767578125 }, { "Type": "upperJawlineLeft", "X": 0.27245330810546875, "Y": 0.3902156949043274 }, { "Type": "midJawlineLeft", "X": 0.31561678647994995, "Y": 0.6596118807792664 }, { "Type": "chinBottom", "X": 0.48385748267173767, "Y": 0.8160444498062134 }, { "Type": "midJawlineRight", "X": 0.6625112891197205, "Y": 0.656606137752533 }, { "Type": "upperJawlineRight", "X": 0.7042999863624573, "Y": 0.3863988518714905 } ], "MouthOpen": { "Confidence": 99.83820343017578, "Value": false }, "Mustache": { "Confidence": 72.20288848876953, "Value": false }, "Pose": { "Pitch": -4.970901966094971, "Roll": -1.4911699295043945, "Yaw": -10.983647346496582 }, "Quality": { "Brightness": 73.81391906738281, "Sharpness": 86.86019134521484 }, "Smile": { "Confidence": 99.93638610839844, "Value": false }, "Sunglasses": { "Confidence": 99.81478881835938, "Value": false } } ] }今回取得したいのはこの中の「landmarks」項目です。
「Type」は点の名前です(上のイメージ図を参照)。
ただし、xとyは具体的なピクセル点の座標ではなく、
画像の幅に対する比率を表しています。処理の流れ
第3部分の処理の流れは以下となっています:
Rekognitionは画像を読み込む仕組みが2つあります。
1つ目はS3バケット又はインターネット上の画像URLを用いて読み込みます。
2つ目はファイルを送って直接読み込みます。
今回は1つ目のURL方法を使います。
そのため、コントローラーLambdaから顔認識Lambdaに渡すのは画像ではなく、ファイルの保存位置情報です。
顔認識LambdaがRekognitionに渡すのも同じです。ここで顔認識Lambdaを実行するIAMロールは第1部分に作ったロールです。
S3とRekognitionを使う権限が持ってますので、
S3バケットが非公開でも、Rekognitionがその中の画像を読み込めて問題ないです。そして、Rekognitionからリターンされる結果は上の結果の例みたいです。
その中に「年齢」や「性別」など色々入ってますが、
今回使いたいのは「ランドマーク」だけです。
そのため、顔認識Lambdaがその結果からランドマークを抽出します。また、ランドマークもいっぱいありまして、
マスクのせいでうまく認識できない点(口など)もあるし、細かすぎてちょっと余計な点(瞳など)も存在します。
そのため、ここはただ以下の5つランドマークを抽出して、コントローラーLambdaにリターンします。
ランドマーク名 位置 eyeLeft 左目 eyeRight 右目 upperJawlineLeft 左こめかみ upperJawlineRight 右こめかみ chinBottom あご ※ランドマークの翻訳はちょっと変かもしれませんので、図を参考してください。
顔認識Lambda関数を作成
役割を分けるために、コントローラーLambda関数以外に別の顔認識Lambda関数を作ります。
作成する時に、コントローラーLambda関数と同じように、
python3.xを選んで、実行ロールも同じです。
また「基本設定」で同じように、1minのタイムアウトと512MBのメモリを設定します。作成した後に、ここで導入するパッケージがないですから、
zipをアップロードはいらなく、
以下のコードを自動生成されたLambda_function.pyに記入するだけで完了です。
※顔認識LambdaのarnリンクをIAMロールのinvokeポリシーに追加することを忘れないでください。lambda_function_for_rekognition.pyimport json import boto3 rekognition = boto3.client("rekognition") def lambda_handler(event, context): # イベントから画像ファイルのパスをゲット bucket = event["Bucket"] key = event["Key"] # Rekognitionをコールして顔認識を行う response = rekognition.detect_faces( Image={'S3Object': {'Bucket': bucket, 'Name': key}}, Attributes=['ALL']) # 写真に何人いる number_of_people = len(response["FaceDetails"]) # 全部の必要なランドマークのリストを作成 all_needed_landmarks = [] # 人数分で処理 for i in range(number_of_people): # これは辞書のリストである all_landmarks_of_one_person = response["FaceDetails"][i]["Landmarks"] # 今回は eyeLeft, eyeRight, upperJawlineLeft, upperJawlineRight, chinBottom だけを使って # needed_landmarks に抽出する needed_landmarks = [] for type in ["eyeLeft", "eyeRight", "upperJawlineLeft", "upperJawlineRight", "chinBottom"]: landmark = next( item for item in all_landmarks_of_one_person if item["Type"] == type) needed_landmarks.append(landmark) all_needed_landmarks.append(needed_landmarks) return all_needed_landmarksコントローラーLambda関数
コントローラーLambda関数はすでに記入したので、
ここは第3部分に関するコードの説明だけです。
- 顔認識Lambdaを呼び出し responseは取得した5つのランドマークです。
lambda_function_for_controller.pylambdaRekognitionName = "<ここは顔認識lambdaのarn>" params = {"Bucket": bucket, "Key": key} # 画像ファイルのパス情報 payload = json.dumps(params) response = boto3.client("lambda").invoke( FunctionName=lambdaRekognitionName, InvocationType="RequestResponse", Payload=payload) response = json.load(response["Payload"])3-4 新画像生成部分
処理の流れ
第4部分は新画像生成部分です。
つまり写真画像と以下の新マスク画像を結合する部分です:
名前 Bane Joker Immortan Joe マスク画像
※1
※2
※3出典 ダークナイト ライジング ダークナイト マッドマックス 怒りのデス・ロード ※1:This work is a derivative of "Bane" by istolethetv, used under CC BY 2.0.
※2:This work is a derivative of this photo, used under CC0 1.0.
※3:This work, "joe's mask" is a derivative of "File:Fan_Expo_2015_-Immortan_Joe(21147179383).jpg" by GabboT, used under CC BY-SA 2.0. "joe's mask" is licensed CC BY-SA 2.0 by y2-peng.AWSでの処理の流れは以下です:
まず、コントローラーLambdaは「写真画像の保存情報(S3バケット名とファイルパス)」、「5つのランドマーク情報」と「新画像ファイル名」を新画像生成Lambdaに渡します。
次、新画像生成Lambdaがファイル保存情報を用いて、S3バケットから写真画像とマスク画像を読み込みます。
なお、マスク画像を事前にS3バケットに保存して、ファイルパスを新画像生成Lambdaに保存する必要があります。
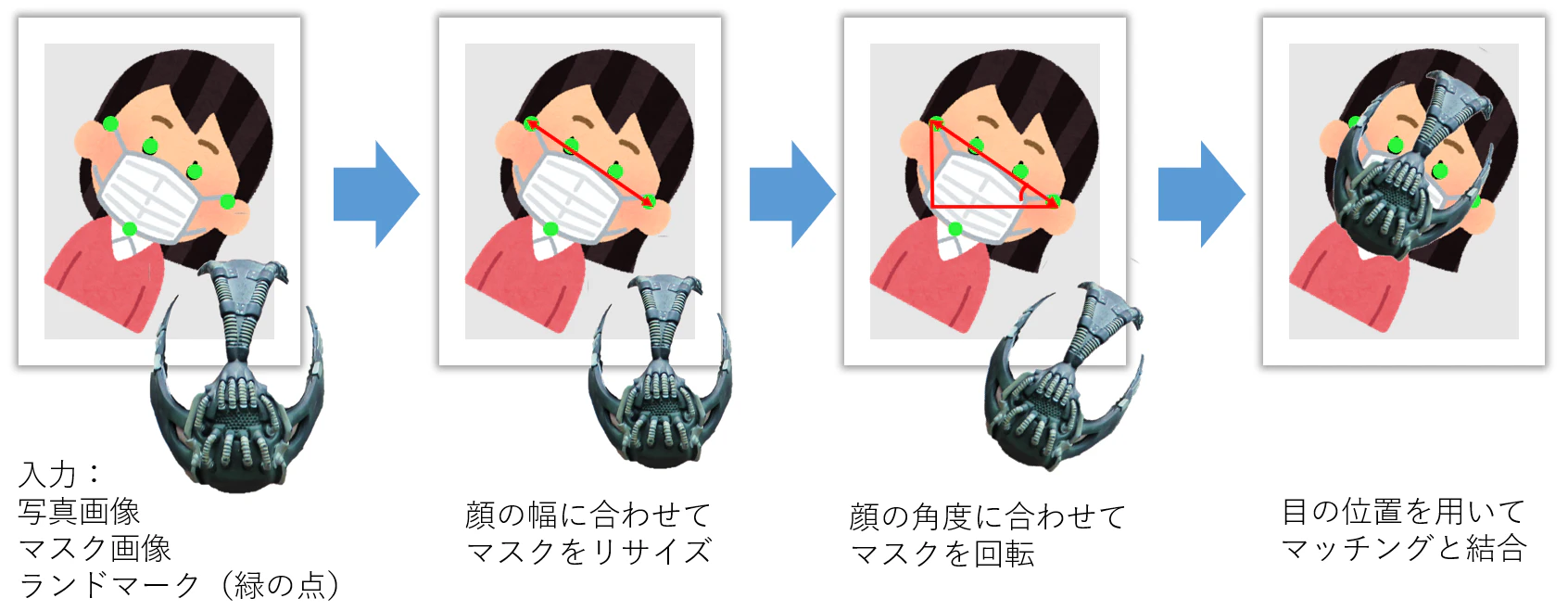
(ファイルパスなどの詳細設定はコードを参照してください)そして、人数分の回数で写真画像とマスク画像を結合します。
毎回ランダムに1つマスク画像を選択して使用します。
結合作業の順番は以下です:
※This work is a derivative of "Bane" by istolethetv, used under CC BY 2.0.
- 最後、新画像を「新画像ファイル名」でネーミングしてS3バケットに保存します。
処理は以上です。
新画像生成Lambdaを作成
まず、AWS Lambdaで新しいLambda関数を作成します。
ランタイムと実行ロールは先ほどと同じです。
あと、先ほどと同じように、「基本設定」からメモリとタイムアウトを設定します。今回は画像結合は、「pillow」と「numpy」2つのpythonパッケージが必要です。
そのため、まずは1つ新しいフォルダを生成して、以下のコマンドを用いてパッケージをインストールします。python -m pip install pillow numpy -t <new_folder>そして、そのフォルダに「lambda_function.py」を作って、以下のコードを記入します。
lambda_function_for_new_image_gengeration.pyimport json import boto3 import numpy as np from PIL import Image, ImageFile from operator import sub from io import BytesIO from random import choice s3 = boto3.client("s3") class NewPhotoMaker: def __init__(self, all_landmarks, bucket, photo_key, new_photo_key): self.all_landmarks = eval(all_landmarks) self.bucket = bucket self.photo_key = photo_key self.new_photo_key = new_photo_key # 写真画像を読み込む def load_photo_image(self): s3.download_file(self.bucket, self.photo_key, "/tmp/photo_file") self.photo_image = Image.open("/tmp/photo_file") # マスク画像を読み込み def load_mask_image(self): # bane(バットマン), joker(バットマン), immortan joe(マッドマックス)からランダム選択 mask_key = "masks/" + choice(["bane", "joker", "joe"]) + ".png" s3.download_file(self.bucket, mask_key, "/tmp/mask_file") self.mask_image = Image.open("/tmp/mask_file") # ランドマーク(比率)から具体的なポイントに変更する def landmarks_to_points(self): upperJawlineLeft_landmark = next( item for item in self.landmarks if item["Type"] == "upperJawlineLeft") upperJawlineRight_landmark = next( item for item in self.landmarks if item["Type"] == "upperJawlineRight") eyeLeft_landmark = next( item for item in self.landmarks if item["Type"] == "eyeLeft") eyeRight_landmark = next( item for item in self.landmarks if item["Type"] == "eyeRight") self.upperJawlineLeft_point = [int(self.photo_image.size[0] * upperJawlineLeft_landmark["X"]), int(self.photo_image.size[1] * upperJawlineLeft_landmark["Y"])] self.upperJawlineRight_point = [int(self.photo_image.size[0] * upperJawlineRight_landmark["X"]), int(self.photo_image.size[1] * upperJawlineRight_landmark["Y"])] self.eyeLeft_point = [int(self.photo_image.size[0] * eyeLeft_landmark["X"]), int(self.photo_image.size[1] * eyeLeft_landmark["Y"])] self.eyeRight_point = [int(self.photo_image.size[0] * eyeRight_landmark["X"]), int(self.photo_image.size[1] * eyeRight_landmark["Y"])] # 顔幅に合わせてマスク画像をリサイズする def resize_mask(self): face_width = int(np.linalg.norm(list(map(sub, self.upperJawlineLeft_point, self.upperJawlineRight_point)))) new_hight = int(self.mask_image.size[1]*face_width/self.mask_image.size[0]) self.mask_image = self.mask_image.resize((face_width, new_hight)) # 顔の角度(首回転による斜め顔ではない)に合わせてマスク画像を回転する def rotate_mask(self): angle = np.arctan2(self.upperJawlineRight_point[1] - self.upperJawlineLeft_point[1], self.upperJawlineRight_point[0] - self.upperJawlineLeft_point[0]) angle = -np.degrees(angle) # radian to dgree self.mask_image = self.mask_image.rotate(angle, expand=True) # 写真画像とマスク画像を結合 def match_mask_position(self): # 目の位置を用いてマッチング face_center = [int((self.eyeLeft_point[0] + self.eyeRight_point[0])/2), int((self.eyeLeft_point[1] + self.eyeRight_point[1])/2)] mask_center = [int(self.mask_image.size[0]/2), int(self.mask_image.size[1]/2)] x = face_center[0] - mask_center[0] y = face_center[1] - mask_center[1] self.photo_image.paste(self.mask_image, (x, y), self.mask_image) # 新画像ファイルをS3に保存 def save_new_photo(self): new_photo_byte_arr = BytesIO() self.photo_image.save(new_photo_byte_arr, format="JPEG") new_photo_byte_arr = new_photo_byte_arr.getvalue() s3.put_object(Bucket=self.bucket, Key=self.new_photo_key, Body=new_photo_byte_arr) # 実行 def run(self): self.load_photo_image() # 人数分の処理 for i in range(len(self.all_landmarks)): self.load_mask_image() # 毎回1つ新しいマスクをロード self.landmarks = self.all_landmarks[i] self.landmarks_to_points() self.resize_mask() self.rotate_mask() self.match_mask_position() self.save_new_photo() # lambdaメインファンクション def lambda_handler(event, context): landmarks = event["landmarks"] bucket = event["bucket"] photo_key = event["photo_key"] new_photo_key = event["new_photo_key"] photo_maker = NewPhotoMaker(landmarks, bucket, photo_key, new_photo_key) photo_maker.run()最後、フォルダのすべての内容をzipにして、Lambdaにアップロードします。
これで、新画像生成の作成が完了します。
※新画像生成LambdaのarnリンクをIAMロールのinvokeポリシーに追加することを忘れないでください。コントローラーLambda関数
この部分に関するコントローラーLambdaのコードは以下です:
lambda_function_for_controller.py# 新画像生成lambdaを呼び出し lambdaNewMaskName = "<ここは新画像生成lambdaのarn>" params = {"landmarks": str(response), "bucket": bucket, "photo_key": key, "new_photo_key": new_key} payload = json.dumps(params) boto3.client("lambda").invoke(FunctionName=lambdaNewMaskName, InvocationType="RequestResponse", Payload=payload)3-5 新画像出力部分
LINE Botにおける画像出力
最後の部分は新画像の出力部分です。
このアプリはLINE Botで画像を入出力で、入力するときは直接的に画像ファイルを渡しますが、
出力は画像ファイルを直接的に送信できません。LINE Bot MessageingApiにおけるImage message(画像メッセージ)のドキュメントにはユーザへの画像送信方式を規定しています。
それAPIが受けられるのは画像ファイルではなく、画像のURLです。
ドキュメントに見ると、ユーザとLINE Botの通信はLINE platformに経由しています。
つまりこの送信過程は
- 「LINE Botから画像URLをLINE platformに送る」
- 「LINE platformがS3バケットに保存されている画像を読み込む」
- 「LINE platformがユーザに画像を送信する」
となっています。
でもこの過程によって、S3バケットのアクセス権限が問題になります。
アクセス権限が「非公開」にすると、LINE platformが画像を読み込めなくて、ユーザがもらった画像がこうなります:
アクセス権限が「公開」にすると、画像のS3オブジェクトURLを分かればで誰でもアクセスできます。
つまり自分の写真が他の人に見られちゃう可能性があり、プライバシーの問題があります。一応DynamoDBなどを使って、LINEユーザ認証を行うことを考えましたが、
作業量が結構増やしまして、「できるだけ作業量を減らす」のコンセプトと衝突、
正直、やりたくないです。色々調べて、最後にいい方法を見つけました。
それは「署名付きURL」です。署名付きURL
プライバシーを保護するために、S3バケットへのアクセス権限は「非公開」にします。
画像のS3オブジェクトURL知ってもアクセスできません。
でもIAMロールの権限で発行した署名付きURLを使ったら、非公開的なS3バケットの特定オブジェクトへのアクセスは可能になります。
ちょっとzoomのパスワード付き会議URLみたいですね。また、この署名付きURLは有効期限も設定できます。
有効期限が切れるとURLを使えなくなり、安全性がもう一歩上げます:
でも1つ注意すべきことがあって、それは署名付きURLの長さ問題です。
IAMロールの権限で発行された署名付きURLには一時アクセスためのトークン情報が入ったため、URLが結構長くなります。
しかし、LINE BotのImage message APIの規定により、受け取れるURLの長さ上限が1000文字です。
そのため、S3バケット名、画像ファイルパスと画像ファイル名が長すぎると、URLが1000文字を超えて、送信できなくなります。
なので第2部分のS3バケットを作成する時に、「バケット名はできれば短く」ということがありました。
同じ理由で、新画像ファイル名はメッセージIDの最後3文字(ファイル名を短縮)することと、
新画像ファイルをS3バケットのロールフォルダに保存する(ファイルパスを短縮)こともしています。
これで署名付きURLの長さ問題が解決できました。補足:
署名付きURLの長さ問題について、実はもう1つ解決策が存在しています。
それはIAMロールではなく、IAMユーザの権限でURLを発行することです。
IAMユーザで発行したURLはトークンいらなく、URLを短くできますが、
IAMユーザの「アクセスキー ID」と「シークレットアクセスキー」を使う必要があります。
安全性から考えると、IAMユーザでURLを発行する方法をお勧めしません。処理の流れ
さあ、S3バケットの権限問題を解決できましたので、この部分を実装しましょう。
この部分の流れは以下です:
まず、コントローラーLambda関数が新画像の署名付きURLをLINE Botに渡します。
そして、LINE BotがS3バケットから画像ファイルを読み込んで(実際の読み込みはLINE platformで行う)、
最後ユーザに送信します。
これで、処理は終了です。コントローラーLambda関数
上の部分と同じように、この部分に関するコントローラーLambda関数コードを解説します。
- 署名付きURLを生成 有効期間は600秒と設定しています。
lambda_function_for_controller.py# 署名付きURL生成 presigned_url = s3.generate_presigned_url(ClientMethod="get_object", Params={ "Bucket": bucket, "Key": new_key}, ExpiresIn=600)
- 新画像を送信
lambda_function_for_controller.py# 新画像メッセージの返信 line_bot_api.reply_message(line_event.reply_token, ImageSendMessage( original_content_url=presigned_url, preview_image_url=presigned_url))4.実際の結果
早速ですが、作ったアプリを試してみましょう!
インターフェース
まずはLINEインターフェースでの受送信です。
LINE Botの「Messaging API設定」からBotのQRコードがあり、それを使って自分の友達に追加できます。
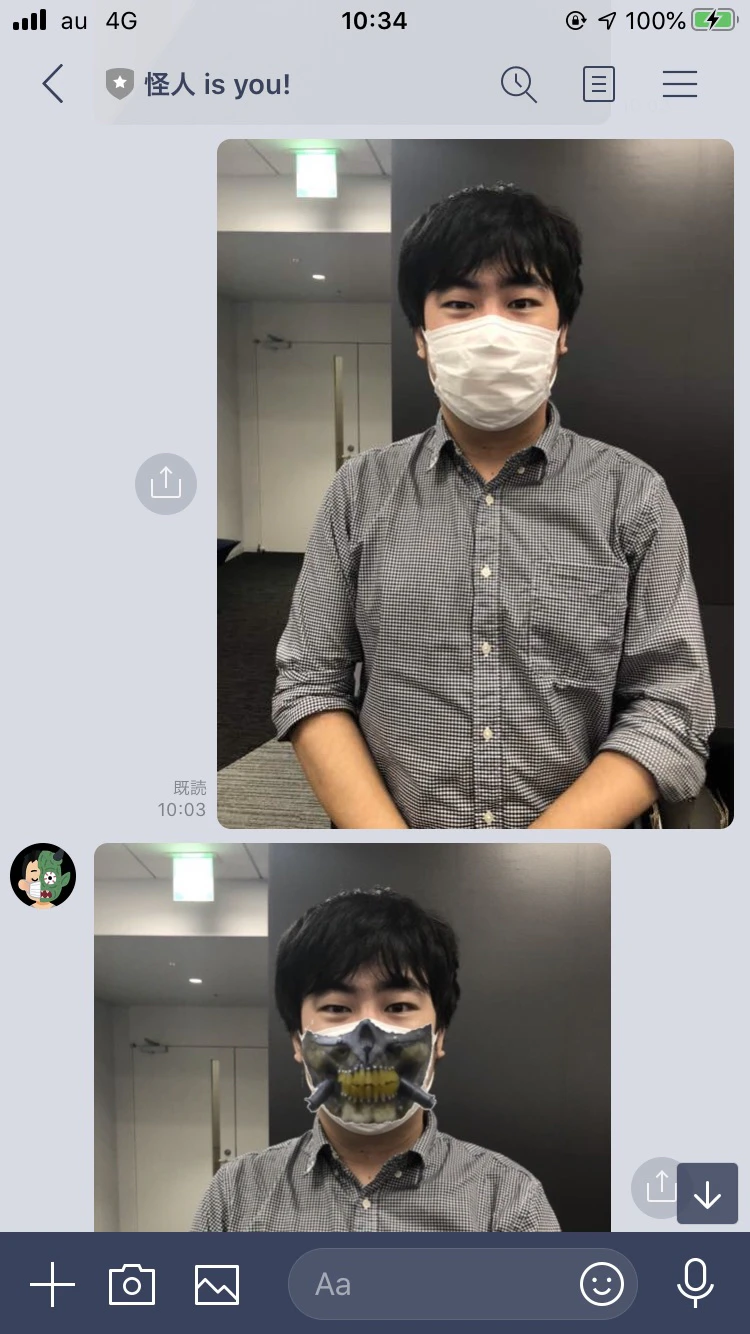
後に送信してみたら。。。
※This work, "wearing joe's mask" is a derivative of "File:Fan_Expo_2015_-Immortan_Joe(21147179383).jpg" by GabboT, used under CC BY-SA 2.0. "wearing joe's mask" is licensed CC BY-SA 2.0 by y2-peng.ちゃんとできましたね!
それでは、どんなパターンがちゃんと行けるか、どんなパターンがうまくいかないか調べましょう!うまくいったパターン
description before after 1人正面 
※1
1人正面(回転あり) 
※2
複数人正面 
※3
顔大きすぎでも 
※4
※1:This work is a derivative of this photo, used under CC0 1.0.
※2:This work, "result 2" is a derivative of "File:Fan_Expo_2015_-Immortan_Joe(21147179383).jpg" by GabboT, used under CC BY-SA 2.0. "result 2" is licensed CC BY-SA 2.0 by y2-peng.
※3:This work, "masked 4" is a derivative of "File:Fan_Expo_2015_-Immortan_Joe(21147179383).jpg" by GabboT, used under CC BY-SA 2.0, "Bane" by istolethetv, used under CC BY 2.0, and this photo, used under CC0 1.0. "masked 4" is licensed CC BY-SA 2.0 by y2-peng.
※4:This work is a derivative of "Bane" by istolethetv, used under CC BY 2.0.うまくいかないパターン
description before after 斜め顔 
※1
顔小さすぎ(一番後ろの人) 
※2
ぼかし(後ろの人) 
※3
※1:This work, "standing 2" is a derivative of "File:Fan_Expo_2015_-Immortan_Joe(21147179383).jpg" by GabboT, used under CC BY-SA 2.0 and "Bane" by istolethetv, used under CC BY 2.0. "standing 2" is licensed CC BY-SA 2.0 by y2-peng.
※2:This work, "standing 4" is a derivative of "File:Fan_Expo_2015_-Immortan_Joe(21147179383).jpg" by GabboT, used under CC BY-SA 2.0 and "Bane" by istolethetv, used under CC BY 2.0. "standing 4" is licensed CC BY-SA 2.0 by y2-peng.
※3:This work is a derivative of "Bane" by istolethetv, used under CC BY 2.0.分析
結果によって、正面及びクリアであれば、処理は大体できます。
ぼかしがある場合は、顔認識できなくて、処理が行いません。
斜め顔または顔が小さすぎる場合、処理は行いますが、正しい結果ではありません。5.まとめと所感
まとめ
今回は写真中の白いマスクを怪人マスクに変更するLINEアプリケーションを開発しました。
AWSのサービスを活用して、サーバレスで実現でき、「できるだけ作業量を減らす」というコンセプトを徹底できました。
正面でクリアな写真であれば、変換処理が大体大丈夫です。
ただ、斜め顔やぼかし顔の処理は今後の課題になります。今後の課題
- 斜め顔: 現在、斜め顔の処理は正しくないです。理由としてはマスクは正面だけで、斜め顔用のがありません。今後の解決策として、2Dマスクを3D座標系に回転してから結合を行い、または斜め顔専用マスク画像を用意することを考えています。
- 顔小さすぎまたはぼかし: 現在の顔認識はAWS Rekognitionを使って、そちらの性能がこのアプリの性能の上限を決めています。もし自分でもっと精度高い顔認識システムを開発できたら、この問題を解決できると思います。(でも「できるだけ作業量を減らす」と衝突ですね:()
- マスクの選択: 現在、怪人マスクは3つの中にランダムに使ってますが、今後はもっと増やしたいと思います。また、ランダム選択だけでなく、ユーザが選べるようにしたいです。マスクにタグをつけて、ユーザからの「○○のマスクをつけたい」や「かわいいマスクほしい」などの要求を全部満たせるようにします。
ほかの所感
- サーバレスの便利さ:今回最も感じたのはサーバレスの魅力です。サーバーがある場合は環境構築だけでなく、保守管理も必要で、かなり時間かかります。でもサーバレスでの開発はこれらをスキップでき、時間をセーブできました。アジャイル開発に使えますね。ただ、Lambdでのサーバレス処理が性能上の制限があり、複雑な処理があればやはりサーバーを立ちましょう。
- AWS一年間の無料最高!!:AWSの新規アカウントは1年間の「無料枠」があり、ある範囲内の使用はすべて無料です。今回の開発に使ったLambda、API Gateway、S3、RekognitionやCloudwatchは全部0円でできて、お得でした。残った数か月の無料期間には、いろいろ試したいと思います。皆様もし興味があればぜひ!無料ですよ!
6.全コード
lambda_function_for_controller.py
lambda_function_for_controller.pyimport os import sys import logging import boto3 import json from linebot import LineBotApi, WebhookHandler from linebot.models import MessageEvent, TextMessage, TextSendMessage, ImageMessage, ImageSendMessage from linebot.exceptions import LineBotApiError, InvalidSignatureError logger = logging.getLogger() logger.setLevel(logging.ERROR) # 環境変数からline botのチャンネルアクセストークンとシークレットを読み込む channel_secret = os.getenv('LINE_CHANNEL_SECRET', None) channel_access_token = os.getenv('LINE_CHANNEL_ACCESS_TOKEN', None) if channel_secret is None: logger.error('Specify LINE_CHANNEL_SECRET as environment variable.') sys.exit(1) if channel_access_token is None: logger.error('Specify LINE_CHANNEL_ACCESS_TOKEN as environment variable.') sys.exit(1) # api&handlerを生成 line_bot_api = LineBotApi(channel_access_token) handler = WebhookHandler(channel_secret) # S3バケットとつながる s3 = boto3.client("s3") bucket = "<S3バケット名>" # Lambdaのメインファンクション def lambda_handler(event, context): # 認証用のX-Line-Signatureヘッダー signature = event["headers"]["X-Line-Signature"] body = event["body"] # リターン値の設定 ok_json = {"isBase64Encoded": False, "statusCode": 200, "headers": {}, "body": ""} error_json = {"isBase64Encoded": False, "statusCode": 403, "headers": {}, "body": "Error"} @handler.add(MessageEvent, message=ImageMessage) def message(line_event): # ユーザのプロフィール profile = line_bot_api.get_profile(line_event.source.user_id) # 送信したユーザのIDを抽出(push_messageなら使う, replyなら必要ない) # user_id = profile.user_id # メッセージIDを抽出 message_id = line_event.message.id # 画像ファイルを抽出 message_content = line_bot_api.get_message_content(message_id) content = bytes() for chunk in message_content.iter_content(): content += chunk # 画像ファイルを保存 key = "origin_photo/" + message_id new_key = message_id[-3:] s3.put_object(Bucket=bucket, Key=key, Body=content) # 顔認識lambdaを呼び出し lambdaRekognitionName = "<ここは顔認識lambdaのarn>" params = {"Bucket": bucket, "Key": key} # 画像ファイルのパス情報 payload = json.dumps(params) response = boto3.client("lambda").invoke( FunctionName=lambdaRekognitionName, InvocationType="RequestResponse", Payload=payload) response = json.load(response["Payload"]) # 新画像生成lambdaを呼び出し lambdaNewMaskName = "<ここは新画像生成lambdaのarn>" params = {"landmarks": str(response), "bucket": bucket, "photo_key": key, "new_photo_key": new_key} payload = json.dumps(params) boto3.client("lambda").invoke(FunctionName=lambdaNewMaskName, InvocationType="RequestResponse", Payload=payload) # 署名付きURL生成 presigned_url = s3.generate_presigned_url(ClientMethod="get_object", Params={ "Bucket": bucket, "Key": new_key}, ExpiresIn=600) # 新画像メッセージの返信 line_bot_api.reply_message(line_event.reply_token, ImageSendMessage( original_content_url=presigned_url, preview_image_url=presigned_url)) try: handler.handle(body, signature) except LineBotApiError as e: logger.error("Got exception from LINE Messaging API: %s\n" % e.message) for m in e.error.details: logger.error(" %s: %s" % (m.property, m.message)) return error_json except InvalidSignatureError: return error_json return ok_json
lambda_function_for_rekognition.py
lambda_function_for_rekognition.pyimport json import boto3 rekognition = boto3.client("rekognition") def lambda_handler(event, context): # イベントから画像ファイルのパスをゲット bucket = event["Bucket"] key = event["Key"] # Rekognitionをコールして顔認識を行う response = rekognition.detect_faces( Image={'S3Object': {'Bucket': bucket, 'Name': key}}, Attributes=['ALL']) # 写真に何人いる number_of_people = len(response["FaceDetails"]) # 全部の必要なランドマークのリストを作成 all_needed_landmarks = [] # 人数分で処理 for i in range(number_of_people): # これは辞書のリストである all_landmarks_of_one_person = response["FaceDetails"][i]["Landmarks"] # 今回は eyeLeft, eyeRight, upperJawlineLeft, upperJawlineRight, chinBottom だけを使って # needed_landmarks に抽出する needed_landmarks = [] for type in ["eyeLeft", "eyeRight", "upperJawlineLeft", "upperJawlineRight", "chinBottom"]: landmark = next( item for item in all_landmarks_of_one_person if item["Type"] == type) needed_landmarks.append(landmark) all_needed_landmarks.append(needed_landmarks) return all_needed_landmarks
lambda_function_for_new_image_gengeration.py
lambda_function_for_new_image_gengeration.pyimport json import boto3 import numpy as np from PIL import Image, ImageFile from operator import sub from io import BytesIO from random import choice s3 = boto3.client("s3") class NewPhotoMaker: def __init__(self, all_landmarks, bucket, photo_key, new_photo_key): self.all_landmarks = eval(all_landmarks) self.bucket = bucket self.photo_key = photo_key self.new_photo_key = new_photo_key # 写真画像を読み込む def load_photo_image(self): s3.download_file(self.bucket, self.photo_key, "/tmp/photo_file") self.photo_image = Image.open("/tmp/photo_file") # マスク画像を読み込み def load_mask_image(self): # bane(バットマン), joker(バットマン), immortan joe(マッドマックス)からランダム選択 mask_key = "masks/" + choice(["bane", "joker", "joe"]) + ".png" s3.download_file(self.bucket, mask_key, "/tmp/mask_file") self.mask_image = Image.open("/tmp/mask_file") # ランドマーク(比率)から具体的なポイントに変更する def landmarks_to_points(self): upperJawlineLeft_landmark = next( item for item in self.landmarks if item["Type"] == "upperJawlineLeft") upperJawlineRight_landmark = next( item for item in self.landmarks if item["Type"] == "upperJawlineRight") eyeLeft_landmark = next( item for item in self.landmarks if item["Type"] == "eyeLeft") eyeRight_landmark = next( item for item in self.landmarks if item["Type"] == "eyeRight") self.upperJawlineLeft_point = [int(self.photo_image.size[0] * upperJawlineLeft_landmark["X"]), int(self.photo_image.size[1] * upperJawlineLeft_landmark["Y"])] self.upperJawlineRight_point = [int(self.photo_image.size[0] * upperJawlineRight_landmark["X"]), int(self.photo_image.size[1] * upperJawlineRight_landmark["Y"])] self.eyeLeft_point = [int(self.photo_image.size[0] * eyeLeft_landmark["X"]), int(self.photo_image.size[1] * eyeLeft_landmark["Y"])] self.eyeRight_point = [int(self.photo_image.size[0] * eyeRight_landmark["X"]), int(self.photo_image.size[1] * eyeRight_landmark["Y"])] # 顔幅に合わせてマスク画像をリサイズする def resize_mask(self): face_width = int(np.linalg.norm(list(map(sub, self.upperJawlineLeft_point, self.upperJawlineRight_point)))) new_hight = int(self.mask_image.size[1]*face_width/self.mask_image.size[0]) self.mask_image = self.mask_image.resize((face_width, new_hight)) # 顔の角度(首回転による斜め顔ではない)に合わせてマスク画像を回転する def rotate_mask(self): angle = np.arctan2(self.upperJawlineRight_point[1] - self.upperJawlineLeft_point[1], self.upperJawlineRight_point[0] - self.upperJawlineLeft_point[0]) angle = -np.degrees(angle) # radian to dgree self.mask_image = self.mask_image.rotate(angle, expand=True) # 写真画像とマスク画像を結合 def match_mask_position(self): # 目の位置を用いてマッチング face_center = [int((self.eyeLeft_point[0] + self.eyeRight_point[0])/2), int((self.eyeLeft_point[1] + self.eyeRight_point[1])/2)] mask_center = [int(self.mask_image.size[0]/2), int(self.mask_image.size[1]/2)] x = face_center[0] - mask_center[0] y = face_center[1] - mask_center[1] self.photo_image.paste(self.mask_image, (x, y), self.mask_image) # 新画像ファイルをS3に保存 def save_new_photo(self): new_photo_byte_arr = BytesIO() self.photo_image.save(new_photo_byte_arr, format="JPEG") new_photo_byte_arr = new_photo_byte_arr.getvalue() s3.put_object(Bucket=self.bucket, Key=self.new_photo_key, Body=new_photo_byte_arr) # 実行 def run(self): self.load_photo_image() # 人数分の処理 for i in range(len(self.all_landmarks)): self.load_mask_image() # 毎回1つ新しいマスクをロード self.landmarks = self.all_landmarks[i] self.landmarks_to_points() self.resize_mask() self.rotate_mask() self.match_mask_position() self.save_new_photo() # lambdaメインファンクション def lambda_handler(event, context): landmarks = event["landmarks"] bucket = event["bucket"] photo_key = event["photo_key"] new_photo_key = event["new_photo_key"] photo_maker = NewPhotoMaker(landmarks, bucket, photo_key, new_photo_key) photo_maker.run()












- 投稿日:2020-10-06T17:00:21+09:00
real-time-Personal-estimation(新たなモデル構築編)
はじめに
前々回は環境構築
前回は学習編と来ています.
次はちゃんと使えるモデル構築をしたいと思います.このプロジェクトのゴール
前回,このプロジェクトのゴールについて書いたのですが,ゴールはずばり「乃木坂ちゃん分類器を作る」ということでした.
まぁ達成はしていないものの作り方はわかったのでとりあえず,ゴールを半分くらい達成してしまいました.ってことで,どうしようかなぁと悩んでとりあえず決めました.
yoloで認識した人をもとにそれを観測できるツールも開発していこうということです.
これは昔,授業で似たようなコードを書いてあるのでそれを改良することも視野に入れています.詳しくは,gitを
ってことでそれがこのプロジェクトの今のところのゴールです.モデル構築
前回の記事でモデルの構築方法については述べているのでそれを参考に構築していきます.
あんまりこの記事で皆さんにお披露目するようなことは正直ありません.
もはや自分の為の記録になりますのでご了承ください.(1)与田ちゃんの画像を集める.
前回は適当に与田ちゃんの画像を10枚集めてそれを加工してモデルを作りました.
まぁこれじゃうまくいかないよなとか思いながらやってたんですけどまぁうまくいかないよな
ってことでモデルを作る為には素材が必要なので,素材集めの方法から考えていきます.from icrawler.builtin import BingImageCrawler crawler = BingImageCrawler(storage={"root_dir": "asuka"}) crawler.crawl(keyword="検索したい名前", max_num=100)モデルをもとにアノテーションを作っていくのですが,これは大変でした.
一応モデルのファイルみたいのを載せておきます.data.yamltrain: test1/train/images val: test1/valid/images nc: 2 names: ['asuka', 'yoda']結果を出力
約100枚2カテゴリ300epochで学習させました.時間がものすごくかかったので正直
現実的ではないです.
まぁできたので認識しているかをチェックする為に訓練データとは別の画像を使って推論させてみました.
結果はこちら
結果としてはうまくいっています.
これが動画とかでもできるのかな.
ちょっと後でやってみます.問題点
学習にかかる時間がローカルPC(CPU)だとえげつない時間が現在かかっています.
なんだったら今の感じだと130枚でも何時間もかかる予感しかしません.
そう考えると,クラウド上の実行(GPU)を使うやり方のが効率的かなぁって感じたりしています.(まぁ当たり前ですけどね)
追記
2カテゴリ,だと2カテゴリ内の推論はうまくいくけど,それ以外の人の画像を入れたときにどうしてもうまくいかない.
ここを対策する方法を模索中です.
検討事項
・計算スピードの向上
モデルを多く作って検討する為にまずはモデルをたくさん作る必要がある.
したがってモデルを早く作る方法を検討しなければいけない.
・ローカルマシン(GPU)を使ったモデル作成の検討次回
次はこれをどう使うかに特化して書いていこうと思います.
追記
追記したところをどうにかしたいので誰かアドバイスがあれば教えてください.


- 投稿日:2020-10-06T16:27:12+09:00
暗号化データをPythonとC#間でやりとりする
暗号化データをPythonとC#間でやりとりする
はじめに
公開鍵暗号、浪漫ですよね(個人の感想)。個人開発のソフトに組み込んだりとか、実用性は別にして愉快なことができそうです。
しかしながら、ざっくりググって見る限り、
自分みたいなスクリプトキディが嬉々としてコピペしたくなるシンプル側に極振りした実装がひとところに纏まっているというのが見当たらなかったため、練習のために作ってみました。5%位は実用性を考慮しても良いだろうと思ったので、PythonとC#の2つでシンプルに書いてみて、2者間で暗号データをやりとりしてみます。コレができれば、例えばクライアント側(C#)で暗号化したデータを、サーバ側(Python)で復号、とかができるので、ほんの少しですが実用に与することができます。
もっと実用に良い手段があるとか言わない。
想定する状況
- サーバ側(Python)でRSAのキーを作成
- クライアント側(C#)は作られた公開鍵を得ており、これでテキストファイルを暗号化する
- サーバ側に送られた(ことにする)暗号化ファイルを、秘密鍵で復号化する
環境
Python側
- Windows 10
- Anaconda3(4.8.2)
- Python 3.7.6
- pycrypto 2.6.1
Anacondaならだいたい全部入りで、暗号化モジュールも入ってるので楽です。
Python単体から始める場合、pycryptoをインストールします。1
cmd.exepip install -U pycryptoC#側
- Windows 10
- Visual Studio 2019 community
- .NET Core 3.1
- コンソールアプリケーション
一部の関数が.NET Standard 2.1の適用のため、.NET Core 3.0以上(.NET Frameworkは5.0 RC1)が必要です。
実装
公開鍵・秘密鍵の作成
CreateKey.pyfrom Crypto.PublicKey import RSA from Crypto.Cipher import PKCS1_v1_5 key_length = 1024 def createKey(): key = RSA.generate(key_length) private_key = key.exportKey().decode('utf-8') with open(file="private.pem", mode="w", encoding='utf-8') as file_out: file_out.write(private_key) public_key = key.publickey().exportKey().decode('utf-8') with open(file="public.pem", mode="w", encoding='utf-8') as file_out: file_out.write(public_key)これでキーが生成されます。変数key_lengthは1024以上を指定しますが、別の似たモジュールのマニュアルによれば、2048以上を推奨、1024,2048,3072のいずれかにすべき、とのお話。2 今回は長くする必要が無いので1024。
生成されたキーは、秘密鍵と公開鍵の2つに分けて保存します。3
暗号化(C#)
Pythonで作成した公開鍵ファイルを読み込み、短文を暗号化してみます。
サンプルはコンソールアプリ(.NET Core3.1)で作成しています。
main.csusing System; using System.IO; using System.Security.Cryptography; using System.Text; class Encrypt_sample { static void Main(string[] args) { const string message = @"This is test message!"; const string key_begin = "-----BEGIN PUBLIC KEY-----\r\n"; const string key_end = "\r\n-----END PUBLIC KEY-----"; string public_key = File.ReadAllText(@"public.pem"); public_key = public_key.Replace(key_begin, "").Replace(key_end, ""); var publicKeyBytes = Convert.FromBase64String(public_key); using (RSACryptoServiceProvider rsa = new RSACryptoServiceProvider()) { rsa.ImportSubjectPublicKeyInfo(publicKeyBytes, out _); byte[] encrypted = rsa.Encrypt(Encoding.UTF8.GetBytes(message), false); File.WriteAllText(@"encrypted.txt", Convert.ToBase64String(encrypted)); } } }変数messageはこれから暗号化する文字列です。
Python側で作成した公開鍵ファイルpublic.pemを読み込んだ後、ヘッダ、フッタを除いてからbyteに変換、RSACryptoServiceProvider型の変数rsaにImportSubjectPublicKeyInfo()で読み込んでいます。4
あとは、バイト列に変換したmessageをEncrypt()で暗号化して、base64変換したテキストを保存します。変換しているのは、テキストファイルとして読めるようにするためです。
Encrypt()の第2引数をfalseにすると、PKCS#1 v1.5のパディングを利用します。
暗号化(Python)
想定状況では暗号化はC#側で行いますが、Python上でも暗号化/復号化ができることを確認出来るよう、関数を作っておきます。
Encrypt.pyfrom Crypto.PublicKey import RSA from Crypto.Cipher import PKCS1_v1_5 message = R"This is test message!" def encrypt(): with open(file="public.pem", mode='rb') as file_read: public_pem = file_read.read() public_key = RSA.importKey(public_pem) public_cipher = PKCS1_v1_5.new(key=public_key) encrypted = public_cipher.encrypt(message=message.encode()) with open(file="encrypted.txt", mode='w', encoding='utf-8') as w: w.write(base64.b64encode(encrypted).decode('utf-8'))実作業としては、
- 公開鍵ファイルをインポートする(public_key)
- public_keyからPKCS1_v1_5のフォーマット(?)に変換(?)(public_cipher)
- public_cipherを使ってmessageを暗号化
です。
復号化(Python)
最後は復号化です。
Decrypt.pyfrom Crypto.PublicKey import RSA from Crypto.Cipher import PKCS1_v1_5 def decrypt(): with open(file="private.pem", mode='rb') as file_read: private_pem = file_read.read() private_key = RSA.importKey(private_pem) private_cipher = PKCS1_v1_5.new(key=private_key) with open(file="encrypted.txt", mode='r', encoding='utf-8') as r: encrypt_data = base64.b64decode(s=r.read()) decrypt_data = private_cipher.decrypt(ct=encrypt_data, sentinel="") print(decrypt_data.decode('utf-8'))
- 秘密鍵ファイルをインポート(private_key)
- private_keyからPKCS1_v1_5のフォーマット(?)に変換(?)(private_cipher)
- private_cipherを使って、暗号化ファイルの中身を復号化
最後のprint()で表示される文字列が、C#で作成したときのmessageと同一なら、復号化成功です。
感想
思った以上に短いコードでなんとかなるもんだ、と言うのが率直な感想です。エラー処理とか実際のセキュリティ面とか実用上の暗号強度とか、細かな設定をすっ飛ばせば、比較的簡単に言語を跨いで暗号化/復号化ができるのが分かってニッコリです。
なお、コードは本当に適当なので、実用にしないでください。
加えた方がよろしいもの
- エラー処理全般
- 署名に関するあれこれ
- より暗号強度の高い設定
- このやり方で実装して大丈夫だと信じれる強い心
Q&A
- Q: なんでC#側のキー作成と復号化が無いの?
→ 復号化はさておき(想定上のクライアント側に秘密鍵預けるの?)、キーの作成は共用できる形式への出力が微妙にめんどうくさい感じだったのでパス。良い手段があれば追記します。
同種の機能を持つモジュールが複数存在していて(かつ、関数名が微妙に異なったりして)検索時等に混乱の元になってるようです。ここではAnacondaに標準で入っているものを使います。 ↩
pycryptoのマニュアルが404になってるんですが、どこに正本があるんでしょう? ↩
実際には、秘密鍵ファイルの中には公開鍵のデータも入っているらしい(?) ↩
ImportRSAPublicKey()という、いかにもな名前の関数があるが、こっちが正解。 ↩
- 投稿日:2020-10-06T16:15:54+09:00
Remineの更新をslackに通知してみた
はじめに
今回、業務においてRemineのチケット更新をslackに通知させることにしたので、そのことをまとめます。
対応の経緯
私の会社ではとある業務の委託用にRedmineを使っているのですが、委託先からの差し戻しがあった場合にチケットへの回答が遅い!!(もう少し言葉は柔らかいですが・・)と度々言われていました。
その後何が原因かと探ってみたところ、、、そもそも差し戻しに気づいていないというのが一番の原因のようでした。
そりゃあねぇ、、Redmineでチケット更新をした際に通知をキャッチできるのはメールだけだからね。。その気持はわかる・・!
Backlogのようにお知らせ通知を設定できればまだ他業務をしていた際にでも気付けるのですが、そんな機能はもちろん無し。どうしようかなと思っていたところ、弊社でビジネスチャットツールとして大活躍しているslackに通知が行けば気づくのではないか?と思い今回の機能作成を行いました。
今回の要件
- Redmineで特定のステータスに更新されたチケットをslackに通知する
- 出来ればリアルタイム連携
- 通知内容はRedmineの題名、担当者 チケットへのリンク (差し戻し内容をslackに通知するとごちゃついてしまうと予想してこんだけ。まずは気づくことが大事)
まずは既存のインテグレーションで利用できそうなものが無いか探す
すぐに出てきたのがhttps://www.sejuku.net/blog/852461 こちらの記事
RSSアプリを利用
結果:✕
弊社で使用しているRedmineはイントラ内で作成しているものなので、そもそもslackからRSSを利用してRedmineに接続が行えないため断念。Redmineプラグインを利用
結果:✕
「Redmine Slack」というプラグインを利用しwebhookでslackに通知するというもの
こちら内容的には今回行いたいことと合ってはいたのですが、トリガーとなるのが新しくチケットを作成した場合のみ・・・。
おしい・・・。(せっかくこんな需要ありそうなプラグインなのでもう少し自由度を高めてほしかった・・)対応方針
最終的にRedmine APIを利用し、能動的に条件に合うデータ(チケット)を取得し、それをslackに通知する
という対応に落ち着きました。
自分で好きにAPIを叩くので、今後の汎用性も高そうだなと。改めて要件定義
- 30分に一回お知らせする(30分に1回バッチを動かす)
- 条件:チケットのステータスが「差し戻し」、更新時間が30分以内となっているチケットを取得
- slack通知する項目はチケット番号、URL、題名、担当者
実装内容
処理Pythonファイルの作成
sashimodoshi.py# -*- coding: utf-8 -*- import digdag import requests import sys import os from datetime import datetime, timedelta import json sys.path.append(os.path.dirname(os.path.abspath(__file__))) from .utils.util_slacker import UtilSlacker class Main(): def __init__(self, incoming_webhook_url, slack_token): self.incoming_webhook_url = incoming_webhook_url self.slack_token = slack_token self.slacker = UtilSlacker(self.incoming_webhook_url, self.slack_token) def main(self): redmine_api_key = "APIアクセスキー" # 個人設定>APIアクセスキーから取得 redmine_url = "http://redmineのURL" # 30分以内の更新日 now = datetime.utcnow() + timedelta(minutes=-30) now = now.strftime('%Y-%m-%dT%H:%M:%SZ') request_url_for_issues = redmine_url + "/issues.json" params = { "key": redmine_api_key, "project_id": "dd", "status_id": 4, "updated_on": ">=" + now } issues_res = requests.get(request_url_for_issues, params) issues_responses = json.loads(issues_res.text) print(issues_responses) fields = [] if len(issues_responses["issues"]) == 0: # 0件だったら処理抜ける return for issue in issues_responses["issues"]: issue_id = issue["id"] subject = issue["subject"] assigned_to_name = issue["assigned_to"]["name"] field = { "title": subject, "value": "担当者:" + assigned_to_name + "\r\nlink:<" + redmine_url + "/issues/{0}|{0}>".format(issue_id), } print(field) fields.append(field) msg = "`差し戻し`のチケットがあります。\r\n担当者はご確認ください。" channel = "#pj-〇〇" user = "redmine差し戻し通知" icon_emoji = ":redmine:" fallback = "redmine" title = "" attachment1 = self.slacker.attachment_creater( fallback=fallback, title=title, color="danger", fields=fields) attachments = [attachment1] self.slacker.slack_messenger( msg, channel, user, icon_emoji, is_link_name=1, attachments=attachments)この処理をバッチで呼ぶのですが、弊社では既にdigdagサーバーが用意されているため、そこ上で動かすようにしました。
sashimodoshi.digtimezone: Asia/Tokyo schedule: cron>: 00,30 10-18 * * 1-5 weekly>: Thu,10:30:00 _export: workflow_name: "sashimodoshi" +sashimodoshi: py>: bin.python_project.sashimodoshi.Main.main incoming_webhook_url: ${env.incoming_webhook_url} slack_token: ${env.slack_token}digファイルはこんな感じです。
scheduleの設定で月曜〜金曜の10時〜18時の間で30分感覚で実行するように設定してあります。
(ここらへんは見様見真似で書いているだけで、まだ理解は追いついてません・・)実際のslack通知
実装イメージはこの様になりました。
今回slack通知のAPIでattachmentを利用しているのですが、いい感じに見栄え良くできました!あとがき
今回作業効率化・自動化のために勢いでslack通知を実装しましたが、残課題としては
- Redmineの個人アカウントではなく、通知用の汎用アカウントでAPIキーを発行すべき
- そもそもPythonファイル内に設定情報を書くべきではない
あたりなので近々修正しておきます。
まともにPythonを触るのが今回初なのですが、APIの接続をサクッとできたり、場合によってはExcel操作も出来たりと作業効率化・自動化の面では今後も活躍してくれそうなのでまだまだ勉強していこうと思います!!

- 投稿日:2020-10-06T16:15:54+09:00
Redmineの更新をslackに通知してみた
はじめに
今回、業務においてRedmineのチケット更新をslackに通知させることにしたので、そのことをまとめます。
対応の経緯
私の会社ではとある業務の委託用にRedmineを使っているのですが、委託先からの差し戻しがあった場合にチケットへの回答が遅い!!(もう少し言葉は柔らかいですが・・)と度々言われていました。
その後何が原因かと探ってみたところ、、、そもそも差し戻しに気づいていないというのが一番の原因のようでした。
そりゃあねぇ、、Redmineでチケット更新をした際に通知をキャッチできるのはメールだけだからね。。その気持はわかる・・!
Backlogのようにお知らせ通知を設定できればまだ他業務をしていた際にでも気付けるのですが、そんな機能はもちろん無し。どうしようかなと思っていたところ、弊社でビジネスチャットツールとして大活躍しているslackに通知が行けば気づくのではないか?と思い今回の機能作成を行いました。
今回の要件
- Redmineで特定のステータスに更新されたチケットをslackに通知する
- 出来ればリアルタイム連携
- 通知内容はRedmineの題名、担当者 チケットへのリンク (差し戻し内容をslackに通知するとごちゃついてしまうと予想してこんだけ。まずは気づくことが大事)
まずは既存のインテグレーションで利用できそうなものが無いか探す
すぐに出てきたのがhttps://www.sejuku.net/blog/852461 こちらの記事
RSSアプリを利用
結果:✕
弊社で使用しているRedmineはイントラ内で作成しているものなので、そもそもslackからRSSを利用してRedmineに接続が行えないため断念。Redmineプラグインを利用
結果:✕
「Redmine Slack」というプラグインを利用しwebhookでslackに通知するというもの
こちら内容的には今回行いたいことと合ってはいたのですが、トリガーとなるのが新しくチケットを作成した場合のみ・・・。
おしい・・・。(せっかくこんな需要ありそうなプラグインなのでもう少し自由度を高めてほしかった・・)対応方針
最終的にRedmine APIを利用し、能動的に条件に合うデータ(チケット)を取得し、それをslackに通知する
という対応に落ち着きました。
自分で好きにAPIを叩くので、今後の汎用性も高そうだなと。改めて要件定義
- 30分に一回お知らせする(30分に1回バッチを動かす)
- 条件:チケットのステータスが「差し戻し」、更新時間が30分以内となっているチケットを取得
- slack通知する項目はチケット番号、URL、題名、担当者
実装内容
処理Pythonファイルの作成
sashimodoshi.py# -*- coding: utf-8 -*- import digdag import requests import sys import os from datetime import datetime, timedelta import json sys.path.append(os.path.dirname(os.path.abspath(__file__))) from .utils.util_slacker import UtilSlacker class Main(): def __init__(self, incoming_webhook_url, slack_token): self.incoming_webhook_url = incoming_webhook_url self.slack_token = slack_token self.slacker = UtilSlacker(self.incoming_webhook_url, self.slack_token) def main(self): redmine_api_key = "APIアクセスキー" # 個人設定>APIアクセスキーから取得 redmine_url = "http://redmineのURL" # 30分以内の更新日 now = datetime.utcnow() + timedelta(minutes=-30) now = now.strftime('%Y-%m-%dT%H:%M:%SZ') request_url_for_issues = redmine_url + "/issues.json" params = { "key": redmine_api_key, "project_id": "dd", "status_id": 4, "updated_on": ">=" + now } issues_res = requests.get(request_url_for_issues, params) issues_responses = json.loads(issues_res.text) print(issues_responses) fields = [] if len(issues_responses["issues"]) == 0: # 0件だったら処理抜ける return for issue in issues_responses["issues"]: issue_id = issue["id"] subject = issue["subject"] assigned_to_name = issue["assigned_to"]["name"] field = { "title": subject, "value": "担当者:" + assigned_to_name + "\r\nlink:<" + redmine_url + "/issues/{0}|{0}>".format(issue_id), } print(field) fields.append(field) msg = "`差し戻し`のチケットがあります。\r\n担当者はご確認ください。" channel = "#pj-〇〇" user = "redmine差し戻し通知" icon_emoji = ":redmine:" fallback = "redmine" title = "" attachment1 = self.slacker.attachment_creater( fallback=fallback, title=title, color="danger", fields=fields) attachments = [attachment1] self.slacker.slack_messenger( msg, channel, user, icon_emoji, is_link_name=1, attachments=attachments)この処理をバッチで呼ぶのですが、弊社では既にdigdagサーバーが用意されているため、そこ上で動かすようにしました。
sashimodoshi.digtimezone: Asia/Tokyo schedule: cron>: 00,30 10-18 * * 1-5 weekly>: Thu,10:30:00 _export: workflow_name: "sashimodoshi" +sashimodoshi: py>: bin.python_project.sashimodoshi.Main.main incoming_webhook_url: ${env.incoming_webhook_url} slack_token: ${env.slack_token}digファイルはこんな感じです。
scheduleの設定で月曜〜金曜の10時〜18時の間で30分感覚で実行するように設定してあります。
(ここらへんは見様見真似で書いているだけで、まだ理解は追いついてません・・)実際のslack通知
実装イメージはこの様になりました。
今回slack通知のAPIでattachmentを利用しているのですが、いい感じに見栄え良くできました!あとがき
今回作業効率化・自動化のために勢いでslack通知を実装しましたが、残課題としては
- Redmineの個人アカウントではなく、通知用の汎用アカウントでAPIキーを発行すべき
- そもそもPythonファイル内に設定情報を書くべきではない
あたりなので近々修正しておきます。
まともにPythonを触るのが今回初なのですが、APIの接続をサクッとできたり、場合によってはExcel操作も出来たりと作業効率化・自動化の面では今後も活躍してくれそうなのでまだまだ勉強していこうと思います!!
- 投稿日:2020-10-06T15:33:06+09:00
【pandas高速化】mergeが遅いと思ったらmapを使え
mergeが遅い!
と感じませんか?
特にコンペで行数が多いときとかマジで遅い。特徴量作成にどんだけ時間使うねん!
そういう時はmapを使うと速くなります。例
それなりに行数がないと差が出ないので今回はkaggleのタイタニックを使います。
その中にAgeというカラムがあるので、それのカウントエンコーディングをしたい。merge_map.pyimport pandas as pd import time df = pd.read_csv("train.csv") df["Age"] = df["Age"].dtype("str") t1 = time.time() #pettern 1 df = pd.merge(df,df.Age.value_counts().reset_index().rename(columns = {"Age":"Age_count1"}), left_on = "Age", right_on = "index", how = "left") t2 = time.time() #pettern 2 df["Age_count2"] = df["Age"].map(df.Age.value_counts()) t3 =time.time() print(t2-t1) print(t3-t2)#output 0.004603147506713867 0.0012080669403076172この場合、mapの方が4倍高速です。
target encodingなんかもmapでできます。df = pd.merge(df, df.groupby("Age").Survived.mean().reset_index().rename(columns = {"Survived":"Age_target1"}), on = "Age", how = "left") t4 = time.time() df["Age_target2"] = df["Age"].map(df.groupby(["Age"]).Survived.mean()) print(t4-t3) print(t5-t4)#output 0.005101919174194336 0.001428842544555664これも4倍くらいはやいです。このスケールならまだしも、10秒か40秒か。1分か4分かっってなってくるとだいぶ違います。
キーが2つある場合
mapはキーが1つじゃないといけません。
その場合は無理やりキーを作ります。df = pd.merge(df, df.assign(sex_age_count = 0).groupby( ["Sex", "Age"])["sex_age_count"].count().reset_index(),on = ["Sex", "Age"] ,how = "left") t6 = time.time() #キーを無理やり作る df["Sex_Age"] = df["Sex"] + df["Age"] t7 = time.time() df["Sex_Age_count"] = df["Sex_Age"].map(df["Sex_Age"].value_counts()) t8 = time.time() print(t6-t5) print(t8-t7)これも4倍くらいはやいです。
#output 0.006415843963623047 0.0015180110931396484
- 投稿日:2020-10-06T15:15:37+09:00
PythonからFilemakerを操作する
Pythonを使ってFilemakerを操作してみようってことでやってみました。
環境
サーバー
windows server 2012 R2
Filemaker server 17クライアント
windows 10 pro
office 2016Python 3.8.1
Pycharm Community Edition 2020.2やりたいこと
Filemaker serverにアップロードした適当なデータベースに対して検索、更新を行います。想定している業務はマスターメンテナンスです。FilemakerはCRM的な使い方をされることが多いと思うのですが、会計システムなどからマスターを流し込めたら便利ではないかと思います。まあ手でやればいいのかもしれない。
準備
Filemaker Serverに適当なデータベースがあるものとします。当データベースはWebAPIが公開されてWebAPIでアクセスできるユーザーが既にいるものとします。SSL通信のための証明書は導入していないものとします。
requestsを使います。importしてください。
アクセストークン取得
headers = {'Authorization': 'Basic XXXXXXXXXXXXXXXX', 'Content-Type': 'application/json'} r_post = requests.post(https://[hostname]/fmi/data/v1/databases/[databasename]/sessions', headers=headers, verify=False)Excelでゴリゴリ書いていたものがたったの2行で実現できる!素晴らしいぞPython。Basicの後ろはidpwをbase64でエンコードした文字列をコピペしてください。この辺りもっとうまいやり方があるのかもしれないですね。[hostname]と[databasename]はお使いの環境にあわせてください。
検索する
headers = {'Authorization': 'Bearer ' + token, 'Content-Type': 'application/json'} query = {'query': [{"検索対象フィールド名": keyword}]} r_post = requests.post( https://[hostname]/fmi/data/v1/databases/[databasename]/layouts/[layoutname]/_find, json=query, headers=headers, verify=False)非常に簡単ですね。requests.postにはjsonとdataの二つの指定の方法があるみたいですがFilemakerが相手の場合はjsonが楽です。検索のkeywordに対してはFilemakerの検索モードの指定の仕方が使えるようです。
更新する
headers = {'Authorization': 'Bearer ' + token, 'Content-Type': 'application/json'} fieldData = {'fieldData': {'更新対象フィールド名' : value1, '更新ン対象フィールド名' : value2}} r_post = requests.patch(https://[hostname]/fmi/data/v1/databases/[databasename]/layouts/[layoutname]/records/[recordId], json=fieldData, headers=headers,verify=False)
メソッドがpatchなんだとわかるまで2時間かかりました・・・。精進が足りない。おわりに
これで手元のCSVファイルを1行づつ読み取ってFilemaker上にあるマスター系データーベースを部分的に更新することができるようになりました。一括で全データを置換するのであればこんなめんどくさいことはしなくてもよさそうです。
- 投稿日:2020-10-06T13:50:03+09:00
山梨県の新型コロナウイルス感染症に関する統計情報をスクレイピング・データラングリング
山梨県の新型コロナウイルス感染症に関する統計情報をスクレイピング・データラングリング
はじめに
- 新型コロナウイルス感染症に関する統計情報(発生状況、検査状況、相談件数)からスクレイピング
- 一週間ごとにまとまっていて日別は日・件でまとまっている
手順
- 期間を開始と終了に分割、内訳を日ごとに分割、結合
- 開始と終了を日付に変換
- 日付ごとに整然化
- 日と件数に分割
- 開始・終了と日・件数を結合
- 日から日付に変換
- 日付と小計
スクレイピング
dfs = pd.read_html( "https://www.pref.yamanashi.jp/koucho/coronavirus/info_coronavirus_data.html" ) df0 = df.iloc[1:].set_axis(["期間", "件数", "内訳"], axis=1)
期間 件数 内訳 1 10月4日(日曜日) ~10月10日(土曜日) 25 4日25件 2 9月27日(日曜日) ~10月3日(土曜日) 245 27日18件、28日21件、29日56件、30日46件、10月1日44件、2日27件、3日33件 3 9月20日(日曜日) ~9月26日(土曜日) 230 20日23件、21日23件、22日17件、23日38件、24日44件、25日32件、26日53件 4 9月13日(日曜日) ~9月19日(土曜日) 296 13日35件、14日63件、15日51件、16日29件、17日48件、18日31件、19日39件 5 9月6日(日曜日) ~9月12日(土曜日) 285 6日33件、7日36件、8日39件、9日37件、10日50件、11日20件、12日40件 6 8月30日(日曜日) ~9月5日(土曜日) 280 30日34件、31日23件、9月1日57件、2日35件、3日42件、4日49件、5日40件 7 8月23日(日曜日) ~8月29日(土曜日) 371 23日26件、24日90件、25日54件、26日58件、27日56件、28日49件、29日38件 8 8月16日(日曜日) ~8月22日(土曜日) 537 16日83件、17日54件、18日94件、19日108件、20日95件、21日69件、22日34件 9 8月9日(日曜日) ~8月15日(土曜日) 500 9日68件、10日75件、11日57件、12日73件、13日77件、14日63件、15日87件 10 8月2日(日曜日) ~8月8日(土曜日) 711 2日52件、3日43件、4日90件、5日84件、6日126件、7日141件、8日175件 データラングリング
期間を開始と終了に分割、内訳を日ごとに分割、結合
df1 = pd.concat( [ df0["期間"].str.split("~", expand=True).rename(columns={0: "開始", 1: "終了"}), df0["内訳"].str.split("、", expand=True), ], axis=1, )
開始 終了 0 1 2 3 4 5 6 1 10月4日(日曜日) 10月10日(土曜日) 4日25件 2 9月27日(日曜日) 10月3日(土曜日) 27日18件 28日21件 29日56件 30日46件 10月1日44件 2日27件 3日33件 3 9月20日(日曜日) 9月26日(土曜日) 20日23件 21日23件 22日17件 23日38件 24日44件 25日32件 26日53件 4 9月13日(日曜日) 9月19日(土曜日) 13日35件 14日63件 15日51件 16日29件 17日48件 18日31件 19日39件 5 9月6日(日曜日) 9月12日(土曜日) 6日33件 7日36件 8日39件 9日37件 10日50件 11日20件 12日40件 6 8月30日(日曜日) 9月5日(土曜日) 30日34件 31日23件 9月1日57件 2日35件 3日42件 4日49件 5日40件 7 8月23日(日曜日) 8月29日(土曜日) 23日26件 24日90件 25日54件 26日58件 27日56件 28日49件 29日38件 8 8月16日(日曜日) 8月22日(土曜日) 16日83件 17日54件 18日94件 19日108件 20日95件 21日69件 22日34件 9 8月9日(日曜日) 8月15日(土曜日) 9日68件 10日75件 11日57件 12日73件 13日77件 14日63件 15日87件 10 8月2日(日曜日) 8月8日(土曜日) 2日52件 3日43件 4日90件 5日84件 6日126件 7日141件 8日175件 開始と終了を日付に変換
df1["開始"] = df1["開始"].str.normalize("NFKC").apply(my_parser) df1["終了"] = df1["終了"].str.normalize("NFKC").apply(my_parser)
開始 終了 0 1 2 3 4 5 6 1 2020-10-04 00:00:00 2020-10-10 00:00:00 4日25件 2 2020-09-27 00:00:00 2020-10-03 00:00:00 27日18件 28日21件 29日56件 30日46件 10月1日44件 2日27件 3日33件 3 2020-09-20 00:00:00 2020-09-26 00:00:00 20日23件 21日23件 22日17件 23日38件 24日44件 25日32件 26日53件 4 2020-09-13 00:00:00 2020-09-19 00:00:00 13日35件 14日63件 15日51件 16日29件 17日48件 18日31件 19日39件 5 2020-09-06 00:00:00 2020-09-12 00:00:00 6日33件 7日36件 8日39件 9日37件 10日50件 11日20件 12日40件 6 2020-08-30 00:00:00 2020-09-05 00:00:00 30日34件 31日23件 9月1日57件 2日35件 3日42件 4日49件 5日40件 7 2020-08-23 00:00:00 2020-08-29 00:00:00 23日26件 24日90件 25日54件 26日58件 27日56件 28日49件 29日38件 8 2020-08-16 00:00:00 2020-08-22 00:00:00 16日83件 17日54件 18日94件 19日108件 20日95件 21日69件 22日34件 9 2020-08-09 00:00:00 2020-08-15 00:00:00 9日68件 10日75件 11日57件 12日73件 13日77件 14日63件 15日87件 10 2020-08-02 00:00:00 2020-08-08 00:00:00 2日52件 3日43件 4日90件 5日84件 6日126件 7日141件 8日175件 日付ごとに整然化
df2 = df1.melt(id_vars=["開始", "終了"]).dropna()
開始 終了 variable value 0 2020-10-04 00:00:00 2020-10-10 00:00:00 0 4日25件 1 2020-09-27 00:00:00 2020-10-03 00:00:00 0 27日18件 2 2020-09-20 00:00:00 2020-09-26 00:00:00 0 20日23件 3 2020-09-13 00:00:00 2020-09-19 00:00:00 0 13日35件 4 2020-09-06 00:00:00 2020-09-12 00:00:00 0 6日33件 5 2020-08-30 00:00:00 2020-09-05 00:00:00 0 30日34件 6 2020-08-23 00:00:00 2020-08-29 00:00:00 0 23日26件 7 2020-08-16 00:00:00 2020-08-22 00:00:00 0 16日83件 8 2020-08-09 00:00:00 2020-08-15 00:00:00 0 9日68件 9 2020-08-02 00:00:00 2020-08-08 00:00:00 0 2日52件 日と件数に分割
df3 = ( df2["value"] .str.extract("([0-9,]+)[日件]([0-9,]+)件", expand=True) .rename(columns={0: "日", 1: "小計"}) .astype(int) )
日 小計 0 4 25 1 27 18 2 20 23 3 13 35 4 6 33 5 30 34 6 23 26 7 16 83 8 9 68 9 2 52 開始・終了と日・件数を結合
df4 = pd.concat([df2, df3], axis=1)
開始 終了 variable value 日 小計 0 2020-10-04 00:00:00 2020-10-10 00:00:00 0 4日25件 4 25 1 2020-09-27 00:00:00 2020-10-03 00:00:00 0 27日18件 27 18 2 2020-09-20 00:00:00 2020-09-26 00:00:00 0 20日23件 20 23 3 2020-09-13 00:00:00 2020-09-19 00:00:00 0 13日35件 13 35 4 2020-09-06 00:00:00 2020-09-12 00:00:00 0 6日33件 6 33 5 2020-08-30 00:00:00 2020-09-05 00:00:00 0 30日34件 30 34 6 2020-08-23 00:00:00 2020-08-29 00:00:00 0 23日26件 23 26 7 2020-08-16 00:00:00 2020-08-22 00:00:00 0 16日83件 16 83 8 2020-08-09 00:00:00 2020-08-15 00:00:00 0 9日68件 9 68 9 2020-08-02 00:00:00 2020-08-08 00:00:00 0 2日52件 2 52 日から日付に変換
- 終了の日と日を比較し、大きければ開始日の日を置換、小さければ終了の日を置換し日付を作成
df4["日付"] = df4.apply( lambda x: x["開始"].replace(day=x["日"]) if x["終了"].day < x["日"] else x["終了"].replace(day=x["日"]), axis=1, )
開始 終了 variable value 日 小計 日付 0 2020-10-04 00:00:00 2020-10-10 00:00:00 0 4日25件 4 25 2020-10-04 00:00:00 1 2020-09-27 00:00:00 2020-10-03 00:00:00 0 27日18件 27 18 2020-09-27 00:00:00 2 2020-09-20 00:00:00 2020-09-26 00:00:00 0 20日23件 20 23 2020-09-20 00:00:00 3 2020-09-13 00:00:00 2020-09-19 00:00:00 0 13日35件 13 35 2020-09-13 00:00:00 4 2020-09-06 00:00:00 2020-09-12 00:00:00 0 6日33件 6 33 2020-09-06 00:00:00 5 2020-08-30 00:00:00 2020-09-05 00:00:00 0 30日34件 30 34 2020-08-30 00:00:00 6 2020-08-23 00:00:00 2020-08-29 00:00:00 0 23日26件 23 26 2020-08-23 00:00:00 7 2020-08-16 00:00:00 2020-08-22 00:00:00 0 16日83件 16 83 2020-08-16 00:00:00 8 2020-08-09 00:00:00 2020-08-15 00:00:00 0 9日68件 9 68 2020-08-09 00:00:00 9 2020-08-02 00:00:00 2020-08-08 00:00:00 0 2日52件 2 52 2020-08-02 00:00:00 日付と小計
df = pd.DataFrame( {"小計": df4.set_index("日付")["小計"].sort_index().asfreq("D", fill_value=0)} )
日付 小計 2020-02-02 00:00:00 1 2020-02-03 00:00:00 2 2020-02-04 00:00:00 1 2020-02-05 00:00:00 1 2020-02-06 00:00:00 0 2020-02-07 00:00:00 0 2020-02-08 00:00:00 0 2020-02-09 00:00:00 0 2020-02-10 00:00:00 0 2020-02-11 00:00:00 1 import datetime import re import pandas as pd def my_parser(s): y = dt_now.year m, d = map(int, re.findall("(\d{1,2})", s)) return pd.Timestamp(year=y, month=m, day=d) def df_conv(df): df0 = df.iloc[1:].set_axis(["期間", "件数", "内訳"], axis=1) # 期間を開始日と終了日に分割、内訳を日ごとに分割、結合 df1 = pd.concat( [ df0["期間"].str.split("~", expand=True).rename(columns={0: "開始", 1: "終了"}), df0["内訳"].str.split("、", expand=True), ], axis=1, ) # 日付に変換 df1["開始"] = df1["開始"].str.normalize("NFKC").apply(my_parser) df1["終了"] = df1["終了"].str.normalize("NFKC").apply(my_parser) # 日付ごとに整然化 df2 = df1.melt(id_vars=["開始", "終了"]).dropna() # 日と件数に分割 df3 = ( df2["value"] .str.extract("([0-9,]+)[日件]([0-9,]+)件", expand=True) .rename(columns={0: "日", 1: "小計"}) .astype(int) ) # 開始・終了と日・件数を結合 df4 = pd.concat([df2, df3], axis=1) # 日から日付に変換 df4["日付"] = df4.apply( lambda x: x["開始"].replace(day=x["日"]) if x["終了"].day < x["日"] else x["終了"].replace(day=x["日"]), axis=1, ) # 日付と小計 df = pd.DataFrame( {"小計": df4.set_index("日付")["小計"].sort_index().asfreq("D", fill_value=0)} ) return df JST = datetime.timezone(datetime.timedelta(hours=+9)) dt_now = datetime.datetime.now(JST) dfs = pd.read_html( "https://www.pref.yamanashi.jp/koucho/coronavirus/info_coronavirus_data.html" ) len(dfs) # 県衛生環境研究所における疑似症例の検査状況 df1 = df_conv(dfs[1]) df1.to_csv("pcr.csv", encoding="utf_8_sig") # 帰国者・接触者相談センター df2 = df_conv(dfs[2]) df2.to_csv("soudan.csv", encoding="utf_8_sig") # 新型コロナウイルス感染症専用相談ダイヤル df3 = df_conv(dfs[3]) df3.to_csv("dial.csv", encoding="utf_8_sig")

- 投稿日:2020-10-06T13:49:48+09:00
pydubがインストールできないとき
正常状態
多分このように表示されていれば成功。
エラー
私場合は「C++ のビルドツールがない!」と怒られました。
スクショ取っておけばよかったかな、見づらいくらい真っ赤でした。。。対策
Visual Studio 2019 ダウンロードページに行ってもらって、
無料ダウンロードを押す
実行すると書き画面のようになるので、(ならなかったらおそらく変更ボタンを押す)
「C++によるデスクトップ開発」にチェックしインストール!
再起動後
pip install pydubで成功!
お役に立てたらうれしいです



- 投稿日:2020-10-06T13:22:06+09:00
Codeforces Round #610 (Div. 2) バチャ復習(10/5)
今回の成績
今回の感想
今回は実装をバグらせたり誤読をしたりミスのオンパレードでした。もう少し落ち着いて解けるようになりたいのですが、なかなか安定してこないのでかなり悩んでいます。
今週は常に実装のバグと誤読を減らすように意識してバチャをやってみようと思います。
A問題
A問題ですが、場合分けを上手く行えなかったので時間を無駄にかけてしまいました。
$c-r$と$c+r$の位置で場合分けをします。また、$a→b$と$b→a$で答えは変わらないので、常に$a \leqq b$になるように$a$と$b$をswapします。
$c-r$と$c+r$の位置が知りたいので、言葉より図で説明した方が早いです。つまり、下図を場合分けで実装すればよいです。
A.pyfor _ in range(int(input())): a,b,c,r=map(int,input().split()) if a>b: a,b=b,a ans=0 if c+r<a: print(b-a) elif c+r<=b: if c-r<=a: print(b-(c+r)) else: print(b-(c+r)+(c-r)-a) else: if c-r<=a: print(0) elif c-r<=b: print((c-r)-a) #print(c-r,b) else: print(b-a)B1問題,B2問題
見た感じでそこまで難しくないと思ったので合わせて解きました。沼りかけたので危なかったです。実装で予想外のところで無駄な計算をしたので反省します。提出前に必ず見直すようにします。
まず、小さい方から買えばよいのは自明です。この元で(ちょうど)$k$個買う場合と1個の場合のうち制約の大きい$k$個の方から買うことを考えましたが、冷静に実験すれば先に1個の方から買えばよいことはわかります。よって、$x$個を買うとすれば、$x \ \% \ k$個を初めに買って$x-x \ \% \ k$個は$k$個ずつ買うのが最適です。しかし、$x$を全て試そうとすると$O(n^2)$間に合いません。また、単調性があって二分探索ができるのではないかと考えたのですが、例えば$k=99$であったとすると、$x=98$の場合は前から98個全てを買うことになり$x=99$の場合は前から99番目の1個のみを買えば良いので、単調性が成り立たないことが示せます(コンテスト中は二分探索の実装をするまで気づきませんでした…)。
また、この単調性が成り立たないことを示すときにそれぞれの余りに注目すれば良いことに気づきました。つまり、余りが$a$になる$x$については$p$を超えないように$k$個ずつできるだけとった時に最大となります。よって、それぞれの余りについての最大値は求められるので、全体の最大値を出力すれば良いです。
B.cc//デバッグ用オプション:-fsanitize=undefined,address //コンパイラ最適化 #pragma GCC optimize("Ofast") //インクルードなど #include<bits/stdc++.h> using namespace std; typedef long long ll; //マクロ //forループ //引数は、(ループ内変数,動く範囲)か(ループ内変数,始めの数,終わりの数)、のどちらか //Dがついてないものはループ変数は1ずつインクリメントされ、Dがついてるものはループ変数は1ずつデクリメントされる //FORAは範囲for文(使いにくかったら消す) #define REP(i,n) for(ll i=0;i<ll(n);i++) #define REPD(i,n) for(ll i=n-1;i>=0;i--) #define FOR(i,a,b) for(ll i=a;i<=ll(b);i++) #define FORD(i,a,b) for(ll i=a;i>=ll(b);i--) #define FORA(i,I) for(const auto& i:I) //xにはvectorなどのコンテナ #define ALL(x) x.begin(),x.end() #define SIZE(x) ll(x.size()) //定数 #define INF 1000000000000 //10^12:∞ #define MOD 1000000007 //10^9+7:合同式の法 #define MAXR 100000 //10^5:配列の最大のrange //略記 #define PB push_back //挿入 #define MP make_pair //pairのコンストラクタ #define F first //pairの一つ目の要素 #define S second //pairの二つ目の要素 signed main(){ //入力の高速化用のコード //ios::sync_with_stdio(false); //cin.tie(nullptr); ll t;cin>>t; REP(i,t){ ll n,p,k;cin>>n>>p>>k; vector<ll> a(n);REP(i,n)cin>>a[i]; sort(ALL(a)); vector<ll> cand(k,0); vector<ll> acc(n,0); acc[0]=a[0]; REP(i,n-1){ acc[i+1]=a[i+1]+acc[i]; } REP(i,k){ ll q=p; if(i!=0){ q-=acc[i-1]; } ll ret=0; if(q<0)continue; ret+=i; REP(j,(n-i)/k){ if(a[i-1+(j+1)*k]<=q){ ret+=k; q-=a[i-1+(j+1)*k]; }else{ break; } } cand[i]=ret; } cout<<*max_element(ALL(cand))<<endl; } }C問題
誤読して沼りました…。
この問題では、ある時間$s$で抜ける時に$t_i \leqq s$を満たす任意の問題(必須問題)が解き終わってる元で解ける最大の問題数(✳︎)を求めます。ここで、自分は(✳︎)の部分を誤読して最大の必須問題の数だと思っていて、サンプルすら合わないという状態に陥りました。流石に方針は完璧だったので誤読を疑うべきでした。
ともかく、とりあえず任意の問題を$t_i$の順番でソートします。ここで、$i$番目までの問題を解くとすると($t_i <t_{i+1}$のとき)$t_{i+1}$より前に解き終わる必要があります。この時、できるだけ長い時間をかければ良く、$t_{i+1}-1$までを使って解けば良いです。したがって、1~$i$番目の問題を解くのに必要な時間を$s$として保存しておけば、$s \leqq t_{i+1}-1$を満たす時に必須の問題は全て解き終わることになります。また、それぞれの時間で複数の問題が必須問題になる可能性があるので、keyが必須となる時間でvalueがその時間の問題の情報(簡単か難しいか)として辞書を保存して昇順に調べていけば良いです。そして、必須の問題を解き終わった後に$t_{i+1}-1-s$だけの時間が余っているので、残りの必須でない問題を解く時間**があります。この時間では残りの問題のうち簡単な問題→難しい問題の順で余っている時間でできるだけ解けばよいです(残りの簡単な問題と難しい問題の数は$easy,hard$という変数に保存しておきます。)。以上より、必須の問題と必須でない問題の合計の問題数が$i$番目までの必須の問題を解く際に解ける最大の問題数に等しいです。これを任意の$i$について求めてあげれば答えとなります。
C.cc//デバッグ用オプション:-fsanitize=undefined,address //コンパイラ最適化 #pragma GCC optimize("Ofast") //インクルードなど #include<bits/stdc++.h> using namespace std; typedef long long ll; //マクロ //forループ //引数は、(ループ内変数,動く範囲)か(ループ内変数,始めの数,終わりの数)、のどちらか //Dがついてないものはループ変数は1ずつインクリメントされ、Dがついてるものはループ変数は1ずつデクリメントされる //FORAは範囲for文(使いにくかったら消す) #define REP(i,n) for(ll i=0;i<ll(n);i++) #define REPD(i,n) for(ll i=n-1;i>=0;i--) #define FOR(i,a,b) for(ll i=a;i<=ll(b);i++) #define FORD(i,a,b) for(ll i=a;i>=ll(b);i--) #define FORA(i,I) for(const auto& i:I) //xにはvectorなどのコンテナ #define ALL(x) x.begin(),x.end() #define SIZE(x) ll(x.size()) //定数 #define INF 1000000000000 //10^12:∞ #define MOD 1000000007 //10^9+7:合同式の法 #define MAXR 100000 //10^5:配列の最大のrange //略記 #define PB push_back //挿入 #define MP make_pair //pairのコンストラクタ #define F first //pairの一つ目の要素 #define S second //pairの二つ目の要素 signed main(){ //入力の高速化用のコード //ios::sync_with_stdio(false); //cin.tie(nullptr); ll m;cin>>m; REP(_,m){ ll n,t,a,b;cin>>n>>t>>a>>b; vector<ll> level(n);REP(i,n)cin>>level[i]; vector<ll> tim(n);REP(i,n)cin>>tim[i]; //追加で解いても良い問題(簡単なやつ,難しいやつ) ll easy=0;ll hard=0; //時刻に対してのlevel map<ll,vector<ll>> problem; REP(i,n){ if(level[i]==0)easy++; else hard++; problem[tim[i]].PB(level[i]); } //最大のポイント ll ans=0; //今の合計のproblem数 ll now=0; //ここまでの必要な時間 ll s=0; FORA(i,problem){ if(s<=i.F-1){ if(s+easy*a>i.F-1){ ans=max(ans,ll(now+(i.F-1-s)/a)); }else{ ans=max(ans,min(ll(now+easy+(i.F-1-s-easy*a)/b),now+easy+hard)); } } FORA(j,i.S){ if(j==0){ s+=a; easy--; }else{ s+=b; hard--; } now++; } } if(s<=t){ ans=max(ans,now); } cout<<ans<<endl; } }D問題以降
今回は飛ばします。


- 投稿日:2020-10-06T12:50:24+09:00
Pythonで不等流計算:水路幅・水路床標高が変化する水路(沈砂池)の水面形計算
不等流計算により沈砂池の水面形を追跡する。
断面形状は矩形であるが、水路幅・水路床標高が変化する場合の水面形計算となる。
常流計算であるため、下流から上流に向かって水位を追跡する。解くべき 不等流の基本方程式は以下の通り。
\begin{equation*} \left(\cfrac{Q^2}{2 g A_2{}^2}+h_2+z_2\right) - \left(\cfrac{Q^2}{2 g A_1{}^2}+h_1+z_1\right) = \cfrac{1}{2}\left(\cfrac{n_2{}^2 Q^2}{R_1{}^{4/3} A_1{}^2} + \cfrac{n_1{}^2 Q^2}{R_2{}^{4/3} A_2{}^2}\right)\cdot(x_2-x_1) \end{equation*}
$Q$ 流量(一定値) $x_2, z_2, A_2, R_2, n_2, h_2$ 上流側断面特性(距離程、水路床標高、流水断面積、動水半径、マニングの粗度係数、水深) $x_1, z_1, A_1, R_1, n_1, h_1$ 下流側断面特性(距離程、水路床標高、流水断面積、動水半径、マニングの粗度係数、水深) 添字1 は下流側を意味し、添字2 は上流側を意味する。
このケースは常流であるため、下流側条件(添字1)はすべて既知であり、上流側の水深 $h_2$ を逐次求めていく。
断面特性は、関数def sec(x,h)の中で距離程xの関数として定めている。
断面変化箇所が多いので、断面特性の定義箇所(def sec(x,h))が長いが、計算の核の部分(二分法)は非常に単純である。
def sec(x,h)は、距離程(x)と水深(h)を入力し、断面諸元(z, A, R, n)を出力する関数なので、ここを変えれば任意断面の計算にも応用することができる。この事例では断面形は単純な矩形であるが、通水断面積 $A$ および動水半径 $R$ は以下に示すとおり、水深 $h$ の関数であるため、二分法により上流側水深を求めている。
\begin{equation*} A=b\cdot h \qquad R=\cfrac{b\cdot h}{b+2\cdot h} \end{equation*}ここに $b$ は水路幅、$h$ は水深。
二分法における2つの初期値は、関数def bisection(h1,x1,x2,q)の中で、ha=3.0およびhb=7.0として指定している。これらの値は、解くべき問題に応じて、適切に書き換える必要がある。プログラム全文を以下に示す。
# Non-Uniform Flow Analysis (Subcritical flow) import numpy as np def sec(x, h): # definition of section property # x : distance # h : water depth # zz : invert level # aa : secion area # rr : hydraulic radius # nn : Manning's roughness coefficient n0=0.014 # roughness coefficient (normal value) zz,aa,rr,nn=0,0,0,0 if 0.0 <= x < 11.0: ds=11 nn=n0 z1=562.2; b1=4.0 z2=560.5; b2=26.0 zz=z1-(z1-z2)/ds*x bb=b1+(b2-b1)/ds*x aa=bb*h rr=bb*h/(bb+2*h) if 11.0 <= x < 19.0: ds=8.0 nn=n0 z1=560.5; b1=12 z2=560.5; b2=12 zz=z1-(z1-z2)/ds*(x-11) bb=b1+(b2-b1)/ds*(x-11) ah=bb*h rh=bb*h/(bb+2*h) aa=ah*2 rr=rh*2 if 19.0 <= x < 47.0: ds=29.0 nn=n0 z1=560.5 ; b1=12.0 z2=z1+ds*0.02; b2=12.0 zz=z1-(z1-z2)/ds*(x-19) bb=b1+(b2-b1)/ds*(x-19) ah=bb*h rh=bb*h/(bb+2*h) aa=ah*2 rr=rh*2 if 47.0 <= x < 62.0: ds=15.0 nn=n0 z1=561.06 ; b1=12.0 z2=z1+ds*0.02; b2=6.0 zz=z1-(z1-z2)/ds*(x-47) bb=b1+(b2-b1)/ds*(x-47) ah=bb*h rh=bb*h/(bb+2*h) aa=ah*2 rr=rh*2 if 62.0 <= x < 69.0: ds=7.0 nn=n0 z1=561.36 ; b1=6.0 z2=z1+ds*0.02; b2=6.0 zz=z1-(z1-z2)/ds*(x-62) bb=b1+(b2-b1)/ds*(x-62) ah=bb*h rh=bb*h/(bb+2*h) aa=ah*2 rr=rh*2 if 69.0 <= x < 69.5: ds=0.5 nn=n0 z1=561.5; b1=6.0 z2=562.0; b2=6.0 zz=z1-(z1-z2)/ds*(x-69) bb=b1+(b2-b1)/ds*(x-69) ah=bb*h rh=bb*h/(bb+2*h) aa=ah*2 rr=rh*2 if 69.5 <= x < 73.5: ds=4.0 nn=n0 z1=562.0; b1=6.0 z2=562.0; b2=6.0 zz=z1-(z1-z2)/ds*(x-69.5) bb=b1+(b2-b1)/ds*(x-69.5) ah=bb*h rh=bb*h/(bb+2*h) aa=ah*2 rr=rh*2 if 73.5 <= x < 74.0: ds=0.5 nn=n0 z1=562.0; b1=6.0 z2=561.5; b2=6.5 zz=z1-(z1-z2)/ds*(x-73.5) bb=b1+(b2-b1)/ds*(x-73.5) ah=bb*h rh=bb*h/(bb+2*h) aa=ah*2 rr=rh*2 if 74.0 <= x < 77.0: ds=3.0 nn=n0 z1=561.5; b1=6.5 z2=561.5; b2=6.5 zz=z1-(z1-z2)/ds*(x-74.0) bb=b1+(b2-b1)/ds*(x-74.0) ah=bb*h rh=bb*h/(bb+2*h) aa=ah*2 rr=rh*2 if 77.0 <= x < 96.625: ds=19.625 nn=n0 z1=561.5; b1=6.5 z2=563.0; b2=6.5 zz=z1-(z1-z2)/ds*(x-77.0) bb=b1+(b2-b1)/ds*(x-77.0) ah=bb*h rh=bb*h/(bb+2*h) aa=ah*2 rr=rh*2 if 96.625 <= x <= 102.125: ds=5.5 nn=n0 z1=563.0; b1=6.5 z2=563.0; b2=6.5 zz=z1-(z1-z2)/ds*(x-96.625) bb=b1+(b2-b1)/ds*(x-96.625) ah=bb*h rh=bb*h/(bb+2*h) aa=ah*2 rr=rh*2 return zz,aa,rr,nn def func(h2,h1,x1,x2,q): g=9.8 z1,a1,r1,n1=sec(x1,h1) z2,a2,r2,n2=sec(x2,h2) e2=q**2/2/g/a2**2+h2+z2 e1=q**2/2/g/a1**2+h1+z1 e3=0.5*(n1**2*q**2/r1**(4/3)/a1**2 + n2**2*q**2/r2**(4/3)/a2**2)*(x2-x1) return e2-e1-e3 def bisection(h1,x1,x2,q): ha=3.0 # lower initial value for bisection method hb=7.0 # upper initial value for bisection method for k in range(100): hi=0.5*(ha+hb) fa=func(ha,h1,x1,x2,q) fb=func(hb,h1,x1,x2,q) fi=func(hi,h1,x1,x2,q) if fa*fi<0: hb=hi if fb*fi<0: ha=hi #print(fa,fi,fb) if np.abs(hb-ha)<1e-10: break return hi def main(): g=9.8 # gravity acceleration q=42.0 # discharge # starting point (sub-critical flow) h1=3.9 # water depth at starting point x1=0.0 # origin of distance coordinate z1,a1,r1,n1=sec(x1,h1) # section property v1=q/a1 # flow velocity print('{0:>8s}{1:>8s}{2:>8s}{3:>8s}{4:>10s}{5:>8s}'.format('x','z','h','z+h','Energy','v')) print('{0:8.3f}{1:8.3f}{2:8.3f}{3:8.3f}{4:10.5f}{5:8.3f}'.format(x1,z1,h1,z1+h1,z1+h1+v1**2/2/g,v1)) # calculation point #xp=np.arange(1,103,1) xp=np.array([11,19,47,62,69,69.5,73.5,74,77,96.625,102.125]) # water level calculation to upstream direction for x2 in xp: h2=bisection(h1,x1,x2,q) z2,a2,r2,n2=sec(x2,h2) v2=q/a2 print('{0:8.3f}{1:8.3f}{2:8.3f}{3:8.3f}{4:10.5f}{5:8.3f}'.format(x2,z2,h2,z2+h2,z2+h2+v2**2/2/g,v2)) x1=x2 # distance h1=h2 # water depth #============== # Execution #============== if __name__ == '__main__': main()計算結果は以下の通り。
意外に水面低下が大きいのにびっくり!
計算する価値がある。x z h z+h Energy v 0.000 562.200 3.900 566.100 566.46982 2.692 11.000 560.500 5.971 566.471 566.47522 0.293 19.000 560.500 5.971 566.471 566.47523 0.293 47.000 561.060 5.410 566.470 566.47528 0.323 62.000 561.360 5.091 566.451 566.47541 0.687 69.000 561.500 4.950 566.450 566.47553 0.707 69.500 562.000 4.444 566.444 566.47554 0.788 73.500 562.000 4.444 566.444 566.47562 0.788 74.000 561.500 4.954 566.454 566.47563 0.652 77.000 561.500 4.954 566.454 566.47567 0.652 96.625 563.000 3.431 566.431 566.47615 0.942 102.125 563.000 3.431 566.431 566.47634 0.942以 上
- 投稿日:2020-10-06T12:20:12+09:00
python googlemap api を利用したデータ取得
概要
pythonでgoogle api を利用したデータ取得の備忘録です。
取得したデータの構造がわかりにくかったのでメモ。apiキー取得からスクレイピングは参考サイトの通りに行いました。
参考サイト
PythonでGoogle Places API使ってデータ取得してみた
PythonでGoogle Places APIを使って取得したデータを表示させる方法
Google Places APIで会社付近の「お食事処」を取得してみる
google api reference取得したファイルの構成
データを出力すると以下のようになります。
{'html_attributions': [], 'next_page_token': 'CqQCEwEAAND0XppPuvvrCXmUQzMNptKvNU7uZqS-Rq2gRv0w9yD2ZsQDh-G1qr-hn81mrh-SWe_DG6jU2tyhjw-45yKrcPzXuOgs64avoooWYhoV68bXFGB75bH7StQLeqGzIuX30zQL5WY3MPX2Jke5aDrH45Tp28hL8LpK-vohhX3fobc9mgRJSY8HC_9_qiFOLqeYRDEdPu_dlHkqusMuALzXLYrn00-Y_hh8HdXRuAZGOyfgfn9ebP-DNdHvUZSykKfFFAfuUfuJHMv52Ilyhc4DJ4HHVLn7Kdn_5AXjyOl7JLSwHhiwXXR4FIlMziEo4IuE--fezO0oDiWJQKTHFnpuw5fAf6sEZTad1A3Hi7gRzuSHsCCeCRdwDU7Afd4bsnv7tRIQUjmDjaLVulM6S7C0y2hu_xoULb-LLjjS2Hk356DGIg_pMyFMotY', 'results': [{'geometry': {'location': {'lat': 35.6803997, 'lng': 139.7690174}, 'viewport': {'northeast': {'lat': 35.8174453, 'lng': 139.9188743}, 'southwest': {'lat': 35.519042, 'lng': 139.5628611}}}, 'icon': 'https://maps.gstatic.com/mapfiles/place_api/icons/v1/png_71/geocode-71.png', 'name': 'Tokyo', 'photos': [{'height': 3394, 'html_attributions': ['<a ' 'href="https://maps.google.com/maps/contrib/117659812595877252927">Yujin ' 'Flin</a>'], 'photo_reference': 'CmRaAAAAqhq5iHusvG2XuIy2ytbybDLzf1Ral74YI8qLoCBU2Gr4JE1p2pSRhHs6KEF1qtZ8m2RLNW_2SqLXB6pN8anGfIcKnSNARD0Vb4xY4oOcHD2bMfTv2vtrBxO61oA3LJ9NEhDe0VxlVJns646OdP0_nxW1GhRFjIHJ4aEwUUnbrWMYpbAZcfPMpQ', 'width': 5000}], 'place_id': 'ChIJXSModoWLGGARILWiCfeu2M0', 'reference': 'ChIJXSModoWLGGARILWiCfeu2M0', 'scope': 'GOOGLE', 'types': ['colloquial_area', 'locality', 'political'], 'vicinity': 'Tokyo'}, {'business_status': 'OPERATIONAL', 'geometry': {'location': {'lat': 35.65861110000001, 'lng': 139.6997222}, 'viewport': {'northeast': {'lat': 35.65996008029151, 'lng': 139.7010711802915}, 'southwest': {'lat': 35.65726211970851, 'lng': 139.6983732197085}}}, 'icon': 'https://maps.gstatic.com/mapfiles/place_api/icons/v1/png_71/lodging-71.png', 'name': 'Shibuya Excel Hotel Tokyu', 'opening_hours': {'open_now': True}, 'photos': [{'height': 1701, 'html_attributions': ['<a ' 'href="https://maps.google.com/maps/contrib/101297695086602663090">渋谷エクセルホテル東急</a>'], 'photo_reference': 'CmRaAAAAzCl7D_cLECSouuCGIWrTZxi9PiZAY2SOD7VkIJaehZagYQG8IvQjCHIhhIPFXm8C1NBRSwVOj2isqVY1Y8D0J-QEXxtPg8hAUTOMIDQ2rw2H-TJQj1sYNSzAStGOzmuBEhATXspuQcWTZYdPCG3YPb39GhRMadylKeVy4oSpN4RnxPgPi-9lrQ', 'width': 2268}], 'place_id': 'ChIJTzNfw1eLGGARagCmVhCOmP4', 'plus_code': {'compound_code': 'MM5X+CV Shibuya City, Tokyo, ' 'Japan', 'global_code': '8Q7XMM5X+CV'}, 'price_level': 2, 'rating': 4.1, 'reference': 'ChIJTzNfw1eLGGARagCmVhCOmP4', 'scope': 'GOOGLE', 'types': ['lodging', 'restaurant', 'food', 'point_of_interest', 'establishment'], 'user_ratings_total': 1853, 'vicinity': '1 Chome-12-2 Dogenzaka, Shibuya City'}, {'business_status': 'OPERATIONAL', 'geometry': {'location': {'lat': 35.656286, 'lng': 139.7015866}, 'viewport': {'northeast': {'lat': 35.6576349802915, 'lng': 139.7029355802915}, 'southwest': {'lat': 35.65493701970851, 'lng': 139.7002376197085}}}, 'icon': 'https://maps.gstatic.com/mapfiles/place_api/icons/v1/png_71/lodging-71.png', 'name': 'Shibuya Granbell Hotel', 'opening_hours': {'open_now': True}, 'photos': [{'height': 3745, 'html_attributions': ['<a ' 'href="https://maps.google.com/maps/contrib/102750292639177188533">Sakurai ' 'Daisuke</a>'], 'photo_reference': 'CmRaAAAAqgA3yyukqjzUrJynEUc0MiSicVaas7mSYJtDxIYbFxjnPPSDxjEdOEcLRxGMY_zTeKH7RF_cQbsLXE1fWg6zwpG8wPkuRcyu5u6GeZyP1irGJ7hfydeLGOoQJEkah1hzEhBTXJyTR0gVkYuGwOMGr6BuGhTSiw-guLPEDDzOJWd9hXrbR9Jc3Q', 'width': 3000}], 'place_id': 'ChIJkwh-41mLGGARZASpROEIZrk', 'plus_code': {'compound_code': 'MP42+GJ Shibuya City, Tokyo, ' 'Japan', 'global_code': '8Q7XMP42+GJ'}, 'rating': 4, 'reference': 'ChIJkwh-41mLGGARZASpROEIZrk', 'scope': 'GOOGLE', 'types': ['lodging', 'point_of_interest', 'establishment'], 'user_ratings_total': 533, 'vicinity': '15-17 Sakuragaokacho, Shibuya City'},ネスト構造の辞書になっていて、最上位階層のキーは以下の4つで構成されています。
html_attributions
next_page_token
results
status
このうち、主なデータは'results'に入っています。
results以下もキーによってはネスト構造になっています。評価は'rate'で表示されてますね。
レビューコメント一覧はどうやって取得するのだろうか・・・
- 投稿日:2020-10-06T11:14:28+09:00
サポートベクタマシン(初学者向け)~コード編~
今回はサポートベクタマシン(分類)の実装をまとめていきます。
※以降、SVMと省略することがあります。
■ サポートベクタマシンの手順
次の7つのSTEPで進めます。
- モジュールの用意
- データの準備
- データの可視化
- モデルの作成
- モデルのプロット
- 分類を予測
- モデルの評価
1. モジュールの用意
最初に、必要なモジュールをインポートしておきます。
import numpy as np import pandas as pd import matplotlib.pyplot as plt # データセットを読み込むモジュール from sklearn.datasets import load_iris # 標準化(分散正規化)を行うモジュール from sklearn.preprocessing import StandardScaler # 訓練データとテストデータを分割するモジュール from sklearn.model_selection import train_test_split # サポートベクトルマシンを実行するモジュール from sklearn.svm import SVC # 分類の評価を行うモジュール from sklearn.metrics import classification_report
2. データの準備
今回はirisデータセットを使って、二値分類をしていきます。
最初にデータの取得をし、標準化を行ってから分割します。
# irisデータセットの読み込み iris = load_iris() # 目的変数と説明変数に分ける X, y = iris.data[:100, [0, 2]], iris.target[:100] # 標準化(分散正規化) std = StandardScaler() X = std.fit_transform(X) # 訓練データとテストデータに分割する X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)二値分類を行うために、データセットを100行目まで(Setosa・Versicolor のみ)と指定しています。
またプロットしやすくするために、説明変数も2つに絞っています。(Sepal Length・Petal Lengh のみ)標準化は、例えば2桁と4桁の特徴量(説明変数)があった際に、後者の影響が大きくなってしまうため
全ての特徴量に対して平均を0・分散を1にして、スケールを揃えています。
3. データの可視化
SVMで分類をする前のデータをプロットして見ておきます。
# 描画オブジェクトとサブプロットの作成 fig, ax = plt.subplots() # Setosa のプロット ax.scatter(X_train[y_train == 0, 0], X_train[y_train == 0, 1], marker = 'o', label = 'Setosa') # Versicolor のプロット ax.scatter(X_train[y_train == 1, 0], X_train[y_train == 1, 1], marker = 'x', label = 'Versicolor') # 軸ラベルの設定 ax.set_xlabel('Sepal Length') ax.set_ylabel('Petal Length') # 凡例の設定 ax.legend(loc = 'best') plt.show()Setosa (y_train ==0) に対応する特徴量(0:Sepal Lengh を横軸, 1: Petal Length を縦軸)でプロット
Versicolor (y_train ==1) に対応する特徴量(0:Sepal Lengh を横軸, 1: Petal Length を縦軸)でプロット<出力結果>
4. モデルの作成
最初にSVMの実行関数(インスタンス)を作成し、訓練データに当てはめます。
# インスタンスを作成 svc = SVC(kernel = 'linear', C = 1e6) # 訓練データからモデルを作成 svc.fit(X_train, y_train)今回はすでに線形分離(1本の直線で分ける)が可能なので、引数を kernel = 'linear' に設定しています。
また C はハイパーパラメータで、出力数値やプロットを見ながら自身で調整していくものです。
5. モデルのプロット
訓練データからサポートベクタマシンのモデルが作成できたので
どのように分類ができているのか、プロットして確認します。前半は、先ほどの散布図のコードと全く同じです。
# 描画オブジェクトとサブプロットの作成 fig, ax = plt.subplots() # Setosa のプロット ax.scatter(X_train[y_train == 0, 0], X_train[y_train == 0, 1], marker = 'o', label = 'Setosa') # Versicolor のプロット ax.scatter(X_train[y_train == 1, 0], X_train[y_train == 1, 1], marker = 'x', label = 'Versicolor') ax.set_xlabel('Sepal Length') ax.set_ylabel('Petal Length') ax.legend(loc = 'upper left') # ここから下は、他データの場合でもそのままペーストして毎回流用できます。(数値の微調整は必要) # 決定境界(直線)のプロット範囲を指定 xmin = -2.0 xmax = 2.5 ymin = -1.5 ymax = 1.8 # 決定境界とマージンをプロット xx, yy = np.meshgrid(np.linspace(xmin, xmax, 100), np.linspace(ymin, ymax, 100)) xy = np.vstack([xx.ravel(), yy.ravel()]).T p = svc.decision_function(xy).reshape(100, 100) ax.contour(xx, yy, p, colors = 'k', levels = [-1, 0, 1], alpha = 1, linestyles = ['--', '-', '--']) # サポートベクタをプロット ax.scatter(svc.support_vectors_[:, 0], svc.support_vectors_[:, 1], s = 250, facecolors = 'none', edgecolors = 'black') plt.show()alpha:直線の濃さ
s:サポートベクタ(○)の大きさ<出力結果>
6. 分類を予測
モデルが完成したので、分類の予測をしていきます。
# 分類結果を予測する y_pred = svc.predict(X_test) # 予測値と正解値を出力 print(y_pred) print(y_test)<出力結果>
# 予測値と正解値を比較してみる y_pred: [0 1 1 1 0 0 1 0 1 0 0 1 0 0 0 0 0 0 1 1 1 0 0 1 0 0 1 1 1 1] y_test: [0 1 1 1 0 0 1 0 1 0 0 1 0 0 0 0 0 0 1 1 1 0 0 1 0 0 1 1 1 1]0:Setosa 1:Versicolor
今回の場合は全て一致(正解)していることが分かります。
7. モデルの評価
今回は分類(二値分類)となるので、混同行列を用いた適合率・再現率・F値で評価を行います。
# 適合率、再現率、F値を出力 print(classification_report(y_test, y_pred))<出力結果>
以上より、Setosa と Versicolor における分類の評価を行うことができました。
■ 最後に
SVMでは上記1~7の手順をもとに、モデルの作成・評価を行っていきます。
今回は初学者の方向けに、実装(コード)のみまとめさせていただきましたが
今後タイミングを見て、理論(数式)についても記事を作成していければと思います。ご精読いただき、ありがとうございました。
参考文献:Pythonによるあたらしいデータ分析の教科書
(Python 3 エンジニア認定データ分析試験 主教材)



- 投稿日:2020-10-06T10:46:49+09:00
【PyQt × pySerial】PCに接続されたCOMポート一覧をコンボボックスに表示
始めに
このような感じで、PCに接続されたCOMポートを選択できるようなコンボボックスをPyQtで作成します。
PyQt, Qt Designerを使ったGUIアプリの作成方法はこちらを参照。環境
- Windows 10
- Python 3.8.5
- PyQt 5.15.1
- pyserial 3.4
インストール
$ pip install pyqt5 $ pip install pyserial①UIファイルの作成
Qt Designerを起動し、Combo Boxを配置したてきとうなWidgetを作成。
Combo Boxの名前は"portComboBox"としています。
port_combo_box_sample.ui<?xml version="1.0" encoding="UTF-8"?> <ui version="4.0"> <class>Form</class> <widget class="QWidget" name="Form"> <property name="geometry"> <rect> <x>0</x> <y>0</y> <width>219</width> <height>70</height> </rect> </property> <property name="windowTitle"> <string>Form</string> </property> <widget class="QComboBox" name="portComboBox"> <property name="geometry"> <rect> <x>30</x> <y>20</y> <width>171</width> <height>22</height> </rect> </property> </widget> </widget> <resources/> <connections/> </ui>②UIファイルをPythonファイルに変換
$ pyuic5 port_combo_box_sample.ui > port_combo_box_sample_ui.pyport_combo_box_sample_ui.py# -*- coding: utf-8 -*- # Form implementation generated from reading ui file 'port_combo_box_sample.ui' # # Created by: PyQt5 UI code generator 5.15.1 # # WARNING: Any manual changes made to this file will be lost when pyuic5 is # run again. Do not edit this file unless you know what you are doing. from PyQt5 import QtCore, QtGui, QtWidgets class Ui_Form(object): def setupUi(self, Form): Form.setObjectName("Form") Form.resize(219, 70) self.portComboBox = QtWidgets.QComboBox(Form) self.portComboBox.setGeometry(QtCore.QRect(30, 20, 171, 22)) self.portComboBox.setObjectName("portComboBox") self.retranslateUi(Form) QtCore.QMetaObject.connectSlotsByName(Form) def retranslateUi(self, Form): _translate = QtCore.QCoreApplication.translate Form.setWindowTitle(_translate("Form", "Form"))③メインのGUIファイルを作成
port_combo_box_sample_gui.pyimport sys from PyQt5.QtWidgets import QMainWindow, QApplication from serial.tools import list_ports from port_combo_box_sample_ui import Ui_Form class PortComboBoxSampleGui(QMainWindow, Ui_Form): def __init__(self, parent=None): super(PortComboBoxSampleGui, self).__init__(parent) self.setupUi(self) self._init_port_combo_box() def _init_port_combo_box(self): comports = list_ports.comports() if not comports: print("ポートが見つかりません") return for index, comport in enumerate(comports): self.portComboBox.addItem(comport.device) if __name__ == "__main__": argvs = sys.argv app = QApplication(argvs) main_gui = PortComboBoxSampleGui() main_gui.show() sys.exit(app.exec_())


- 投稿日:2020-10-06T10:22:31+09:00
Django×Postgresql on DockerをHerokuへデプロイしたメモ
はじめに
DjangoGirlsなどのチュートリアルで作成したDjangoアプリをDocker化した。そしてアプリをHerokuへデプロイしたい。チュートリアルでもHerokuのデプロイ方法は載っているので基本的にそれを参考にすればデプロイできる。分からなくなったら1,2度はローカルで環境構築、開発、デプロイをしてみると良いかもしれない
前提
herokuについての知識がある
手順
- Pythonライブラリのリストにherokuへ必要なパッケージを追加編集し、保存
requirements.txtDjango==2.2.16 psycopg2 # この下が新たに追加するライブラリ dj-database-url gunicorn whitenoise==3.0.02.ルートディレクトリにProcfileを作成し、編集、保存
Procfileweb: gunicorn 管理インターフェース名.wsgi --log-file -3.どのバージョンのPythonを使いたいのかをHerokuに知らせるため。
runtime.txtpython-3.6.44.開発環境ファイルを作成し、編集保存する
今回は開発環境でもpostgresqlなので、DATABASEの欄は自身のsettings.pyのデータベース設定をコピーする。
以下はサンプル。管理インターフェース/local_settings.pyimport os BASE_DIR = os.path.dirname(os.path.dirname(__file__)) DATABASES = { 'default': { 'ENGINE': 'django.db.backends.postgresql', 'NAME': 'postgres', 'USER': 'postgres', 'PASSWORD': 'postgres', 'HOST': 'db', 'PORT': 5432, } } DEBUG = True5.本番環境のため設定ファイルを編集する
こちらもデータベースの設定は各自の環境を設定管理インターフェース/settings.pyimport dj_database_url ... DEBUG = False ALLOWED_HOSTS = ['127.0.0.1', '.herokuapp.com'] ... DATABASES = { 'default': { 'ENGINE': 'django.db.backends.postgresql_psycopg2', 'NAME': 'postgres', 'USER': 'postgres', 'PASSWORD': 'postgres', 'HOST': 'db', 'PORT': '5432', } } ... db_from_env = dj_database_url.config(conn_max_age=500) DATABASES['default'].update(db_from_env)6.wsgi.pyを編集する
管理インターフェース/wsgi.py... # Heroku from whitenoise.django import DjangoWhiteNoise application = DjangoWhiteNoise(application)7.herokuへデプロイする
herokuへのデプロイは大きくわけてコマンドラインから直接pushするか、Githubのコードを自動デプロイできます。どちらかの方法でherokuへコードをupします。8.本番環境(heroku)のデータベースを設定する
herokuのサーバ上でマイグレーションを実行し、管理者ユーザーを作成します
こちらもコマンドラインとherokuのサイトから操作することも可能です9.デプロイ成功
URLからきちんとデプロイできているか確認する参考文献
https://tutorial-extensions.djangogirls.org/ja/heroku/
https://devcenter.heroku.com/articles/getting-started-with-python