- 投稿日:2020-10-06T23:25:43+09:00
AWS 自分なりに主要サービスをまとめてみた。
【AWS 自分なりに主要サービスをまとめてみた。】
AWSクラウドプラクティショナーの学習をしています。
自分の独断と偏見で重要そうだなと判断したものをまとめました。
個人メモのような感じです。・コンピューティングサービス
Amazon EC2 (Elastic Compute Cloud)
AWS上の仮想的なプライベートサーバー。起動されたものをEC2インスタンス。
AWS Elastic Beanstalk
マネージドな仮想マシンでソフトウェアを実行できるサービス。
Amazon Lightsail
Amazonの提供するホスティングサービス。様々なアプリがある。とても簡単にデプロイ可能。
AWS Lambda
サーバーなし、かつイベント駆動でコードを実行できるサービス。
Amazon Machine Image (AMI)
EC2インスタンス起動に必要なEBSの全体のイメージ(スナップショット)などを指す。
・コンテナサービス
Amazon ECS (Elastic Container Service)
EC2やFargate上でコンテナを起動できるサービス。コンテナ化したアプリの管理が容易。
Amazon EKS (Elastic Kubernetes Service)
Amazonの提供するKubernetesのフルマネージドサービス。
AWS Fargate
ECS/EKSで稼働するコンテナ用サーバーレスコンピューティングエンジンであり、プロヒジョニング不要。
・ストレージサービス
Amazon EBS (Elastic Block Store)
ブロックストレージ。 EC2から直接マウントして利用。
Amazon S3 (Simple Storage Service)
ファイルストレージ。直接マウントはNG。 HTTP経由で大容量なファイルを置くことが可能。
Amazon S3 Transfer Acceleration
S3に高速でデータをアップロードできるサービス。
・データベースサービス
Amazon RDS (Relational Database Service)
マネージドなMySQL、PostgreSQLデータベース。
Amazon Aurora
クラスタ構成の高性能なマネージドリレーショナルデータベース。
Amazon DynamoDB
大規模&スケーラブルなマネージド非リレーショナルデータベース。
Amazon Redshift
データウェアハウス。ストリーム処理ができるデータを大量に保存可能。
・移行、転送サービス
Amazon Migration Hub
データセンタからAWSへマイグレーションの進行状況の確認ができるサービス。
Amazon Database Migration Service
データセンタをRDSへ安全にマイグレーションできるサービス。
AWS DataSync
AWSとデータセンタ間でデータを同期できるサービス。
・ネットワークサービス
Amazon VPC (Virtual Private Cloud)
プライベートな仮想ネットワーク。VPC内で自システムのAWSリソースの起動が可能。
Amazon VPN (Virtual Private Network)
オンプレミス、リモートオフィス、デバイス、AWS間で安全に接続できるソリューション。
Amazon Route 53
AWS提供のDNS。ドメインネームとレコードを管理。
Amazon CloudFront
AWS提供のグローバルコンテンツッ配信ネットワーク。
・開発者用ツール
AWS CodeCommit
AmazonによるプライベートGitリポジトリによるコード保管ツール。
・マネジメント、ガバナンスサービス
AWS Organizations
AWSアカウント間での請求一元化や、アクセス、コンプライアンス、リソースなど共有できるサービス。
Amazon CloudWatch
リソースとアプリケーションからログを取得してモニタリングできるサービス。
AWS Auto Scaling
設定したルールに基づき、リソースのスケーリングを実現するサービス。
AWS CloudFormation
テンプレートを使ってAWSのリソースを作成、管理できるサービス。
AWS Config
AWSリソースのインベントリーと変更履歴を監査するサービス。
・セキュリティ、アイデンティティ、コンプライアンスサービス
AWS IAM (Identity & Access Management)
ユーザーなどを認証してリソースへのアクセスを認可できる権限システム。
Amazon Cognito
ユーザーとパスワードの管理システム。アプリケーションのユーザー管理に便利。
Amazon GuardDuty
CloudTrailやVPCフローログなどのイベントを元にセキュリティ脅威を検出するサービス。
Amazon Inspector
AWSにデプロイしたアプリケーションの脆弱性、 ベストプラクティスからの逸脱等を評価するサービス。
AWS Certificate Manager
SSL/TSL証明書のプロビジョニング、管理、(無料の) デプロイができるサービス。
AWS WAF (Web Application Firewall)
脆弱性やセキュリティ侵害からウェブアプリやAPIを保護するファイアウォール。
AWS Shield
分散サービス妨害(DD0S)に対するフルマネージドの保護サービス。可用性を向上させる。
AWS Artifact
AWSのコンプライアンスレポートにオンデマンドでアクセスできるサービス。
・アプリケーション統合サービス
Amazon SQS (Simple Queue Service)
メッセージキューサービス。
・コスト管理サービス
AWS CUR (Cost and Usage Report)
AWSサービスの包括的なコストと使用状況のレポートを提供するサービス。
AWS Budgets
AWSサービスの予算を作成し、超過の場合にアラートサービス。
TCO Calculator
AWSのTCO計算ツール。
さいごに。
問題集を一通り解いてみて、自分的に重要度が高いのではと判断したものをまとめました。
これらをまずは確実に覚えようと思います。AWSのこれ重要だよといったものがありましたら、是非教えていただけると嬉しいです。
- 投稿日:2020-10-06T23:25:43+09:00
自分なりにAWSの主要サービスをまとめてみた。
【自分なりにAWSの主要サービスをまとめてみた。】
AWSクラウドプラクティショナーの学習をしています。
自分の独断と偏見で重要そうだなと判断したものをまとめました。
個人メモのような感じです。・コンピューティングサービス
Amazon EC2 (Elastic Compute Cloud)
AWS上の仮想的なプライベートサーバー。起動されたものをEC2インスタンス。
AWS Elastic Beanstalk
マネージドな仮想マシンでソフトウェアを実行できるサービス。
Amazon Lightsail
Amazonの提供するホスティングサービス。様々なアプリがある。とても簡単にデプロイ可能。
AWS Lambda
サーバーなし、かつイベント駆動でコードを実行できるサービス。
Amazon Machine Image (AMI)
EC2インスタンス起動に必要なEBSの全体のイメージ(スナップショット)などを指す。
・コンテナサービス
Amazon ECS (Elastic Container Service)
EC2やFargate上でコンテナを起動できるサービス。コンテナ化したアプリの管理が容易。
Amazon EKS (Elastic Kubernetes Service)
Amazonの提供するKubernetesのフルマネージドサービス。
AWS Fargate
ECS/EKSで稼働するコンテナ用サーバーレスコンピューティングエンジンであり、プロヒジョニング不要。
・ストレージサービス
Amazon EBS (Elastic Block Store)
ブロックストレージ。 EC2から直接マウントして利用。
Amazon S3 (Simple Storage Service)
ファイルストレージ。直接マウントはNG。 HTTP経由で大容量なファイルを置くことが可能。
Amazon S3 Transfer Acceleration
S3に高速でデータをアップロードできるサービス。
・データベースサービス
Amazon RDS (Relational Database Service)
マネージドなMySQL、PostgreSQLデータベース。
Amazon Aurora
クラスタ構成の高性能なマネージドリレーショナルデータベース。
Amazon DynamoDB
大規模&スケーラブルなマネージド非リレーショナルデータベース。
Amazon Redshift
データウェアハウス。ストリーム処理ができるデータを大量に保存可能。
・移行、転送サービス
Amazon Migration Hub
データセンタからAWSへマイグレーションの進行状況の確認ができるサービス。
Amazon Database Migration Service
データセンタをRDSへ安全にマイグレーションできるサービス。
AWS DataSync
AWSとデータセンタ間でデータを同期できるサービス。
・ネットワークサービス
Amazon VPC (Virtual Private Cloud)
プライベートな仮想ネットワーク。VPC内で自システムのAWSリソースの起動が可能。
Amazon VPN (Virtual Private Network)
オンプレミス、リモートオフィス、デバイス、AWS間で安全に接続できるソリューション。
Amazon Route 53
AWS提供のDNS。ドメインネームとレコードを管理。
Amazon CloudFront
AWS提供のグローバルコンテンツッ配信ネットワーク。
・開発者用ツール
AWS CodeCommit
AmazonによるプライベートGitリポジトリによるコード保管ツール。
・マネジメント、ガバナンスサービス
AWS Organizations
AWSアカウント間での請求一元化や、アクセス、コンプライアンス、リソースなど共有できるサービス。
Amazon CloudWatch
リソースとアプリケーションからログを取得してモニタリングできるサービス。
AWS Auto Scaling
設定したルールに基づき、リソースのスケーリングを実現するサービス。
AWS CloudFormation
テンプレートを使ってAWSのリソースを作成、管理できるサービス。
AWS Config
AWSリソースのインベントリーと変更履歴を監査するサービス。
・セキュリティ、アイデンティティ、コンプライアンスサービス
AWS IAM (Identity & Access Management)
ユーザーなどを認証してリソースへのアクセスを認可できる権限システム。
Amazon Cognito
ユーザーとパスワードの管理システム。アプリケーションのユーザー管理に便利。
Amazon GuardDuty
CloudTrailやVPCフローログなどのイベントを元にセキュリティ脅威を検出するサービス。
Amazon Inspector
AWSにデプロイしたアプリケーションの脆弱性、 ベストプラクティスからの逸脱等を評価するサービス。
AWS Certificate Manager
SSL/TSL証明書のプロビジョニング、管理、(無料の) デプロイができるサービス。
AWS WAF (Web Application Firewall)
脆弱性やセキュリティ侵害からウェブアプリやAPIを保護するファイアウォール。
AWS Shield
分散サービス妨害(DD0S)に対するフルマネージドの保護サービス。可用性を向上させる。
AWS Artifact
AWSのコンプライアンスレポートにオンデマンドでアクセスできるサービス。
・アプリケーション統合サービス
Amazon SQS (Simple Queue Service)
メッセージキューサービス。
・コスト管理サービス
AWS CUR (Cost and Usage Report)
AWSサービスの包括的なコストと使用状況のレポートを提供するサービス。
AWS Budgets
AWSサービスの予算を作成し、超過の場合にアラートサービス。
TCO Calculator
AWSのTCO計算ツール。
さいごに。
問題集を一通り解いてみて、自分的に重要度が高いのではと判断したものをまとめました。
これらをまずは確実に覚えようと思います。AWSのこれ重要だよといったものがありましたら、是非教えていただけると嬉しいです。
- 投稿日:2020-10-06T22:50:24+09:00
Apex UpでNode.js × expressをAWS Lambda, API Gatewayに速攻デプロイしてみる
はじめに
Node.js × expressのAPIのデプロイ先としてLambdaを使おうと思ったのですが
手取り早くデプロイして試したかったので、Apex Upを使ってみた。今回はその時の備忘録Upとは
APIや静的ウェブサイトをLambda × API Gatewayに
upコマンドでデプロイしてくれるツールです。使ってみる
Upのインストール
curl -sf https://up.apex.sh/install | shプロジェクト作成
mkdir node-up cd node-up npm init entry point: (index.js) app.js # 自分はapp.jsに変更expressのインストール
npm install express touch app.js touch up.json # Upの設定ファイルapp.js
const express = require('express') const app = express() const { PORT = 3000 } = process.env app.get('/', (req, res) => { res.send('Hello World!') }) app.listen(PORT);Upの設定は以下の内容に設定
{ "name": "node-up" }これで設定は完了です。
最後にgit commitします。
git commitしとかないとupしたときにエラーが出てしまいます。git init git add . git commit -m "First commit"最後にデプロイします。
upしばらくすると以下のような内容が出てくるのでURLをチェックして表示されればおkです。
stack: complete (19.175s) endpoint: https://.../staging/実際の表示
削除
up stack deleteさいごに
Apex Upを使えば気軽にデプロイできるのでとりあえずデプロイしたいときは重宝しそうです。
参考資料

- 投稿日:2020-10-06T22:46:07+09:00
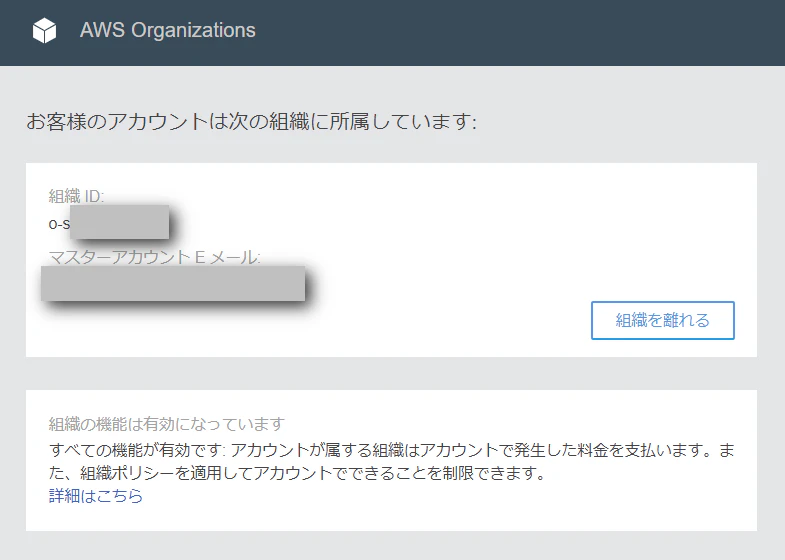
Muiti-AWS Accountのアクセス制限(AWS Organizations)
AWS Organizations を利用したアカウント制限
想定対象読者
- 複数のAWS Accountの制限について困っている方
- アカウントの解約を勝手にされると困る
- 組織から勝手に離脱をされると困る
- サポートケースを勝手に起票されると困る ... etc
本稿で取り扱っている内容
AWS Organizationsにおける SCP で制限
AWSのアカウント権限について
IAM でのセキュリティのベストプラクティスでも記載されていますが、
AWSにおける rootアカウント とは特権ユーザであり通常サービス制限はありません。
(AWSアカウント開設時登録したEメールアドレスでログインする場合)ただし、AWS Organizationsでは rootアカウント に対して制限を掛けることが可能です。
一般的に、AWS Organizationsは一括請求の利用するケースでイメージをされる方が多いかと思います。検証の前に
SCP定義
【禁止】組織から離脱とアカウント解約
- denyModifyRoot.json
- rootアカウント でAWS Organizationsから離脱
- rootアカウント でアカウント解約
{ "Version": "2012-10-17", "Statement": [ { "Sid": "DenyLeaveOrg4Root", "Effect": "Deny", "Action": [ "organizations:LeaveOrganization" ], "Resource": [ "*" ], "Condition": { "StringLike": { "aws:PrincipalArn": [ "arn:aws:iam::*:root" ] } } }, { "Sid": "DenyModAct4Root", "Effect": "Deny", "Action": [ "aws-portal:ModifyAccount" ], "Resource": [ "*" ], "Condition": { "StringLike": { "aws:PrincipalArn": [ "arn:aws:iam::*:root" ] } } } ] }【禁止】サポートへアクセス
- denyRootAccessSupport.json
- rootアカウントでサポートへアクセス
{ "Version": "2012-10-17", "Statement": [ { "Sid": "DenyActionsRoot", "Effect": "Deny", "Action": [ "support:*" ], "Resource": [ "*" ], "Condition": { "StringLike": { "aws:PrincipalArn": [ "arn:aws:iam::*:root" ] } } } ] }検証
AWS Organizationsの設定
- サービスコントロールポリシーを有効
- サービスコントロールポリシーを定義
AWS Organizationsの階層に適用
ポリシーを「アタッチ」「デタッチ」をするだけであり、
画面上「デタッチ」と表示されている箇所は適用されている箇所です。
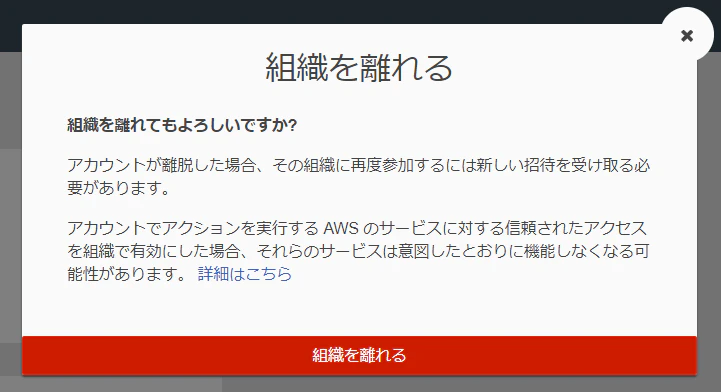
- 【例】組織の離脱とアカウント解約を禁止する組織(OU)
【禁止】組織から離脱とアカウント解約
- Organizationsサービスメニューに移動
- 組織を離脱
※ 本検証以外で上記のオペレーションを行っている方は自己責任でお願いいたします
- 権限不足が表示され組織の離脱を禁止
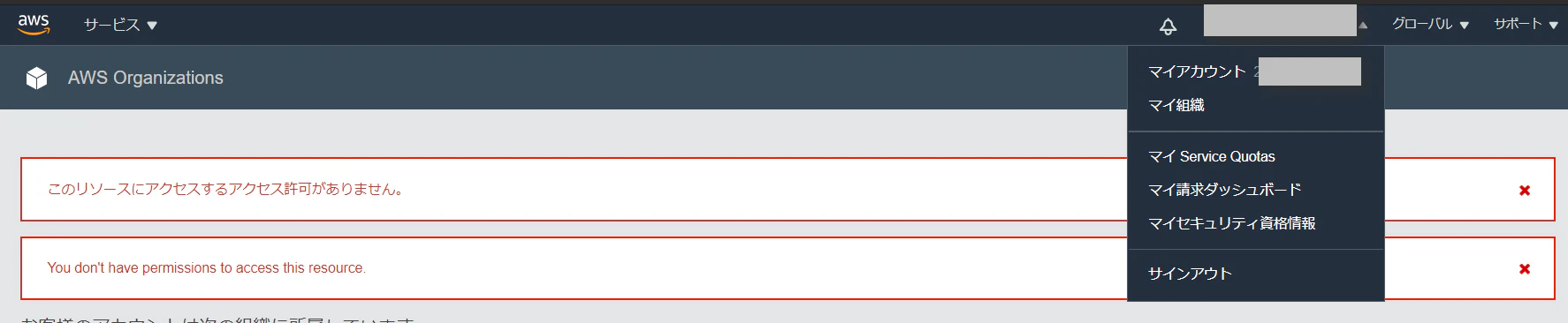
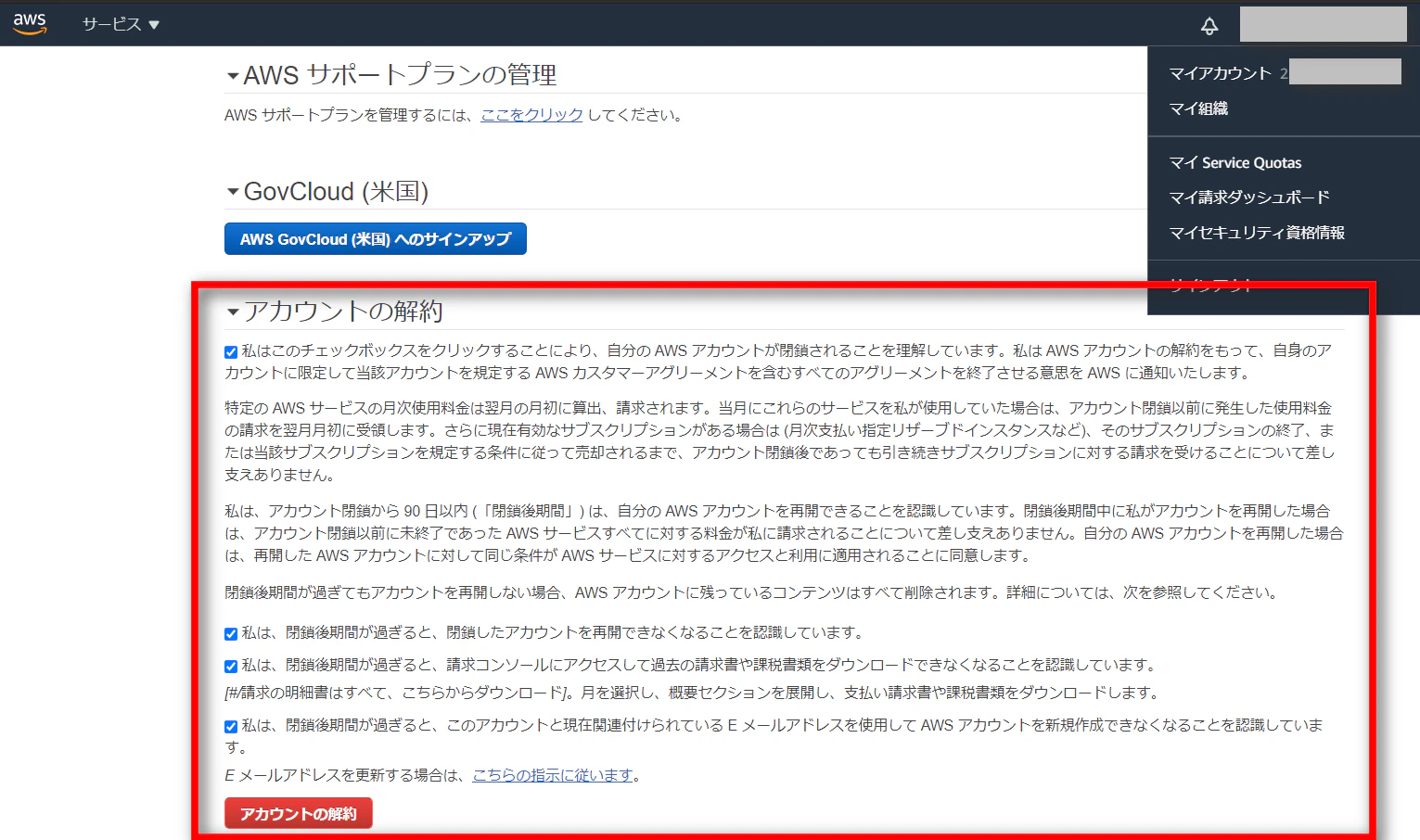
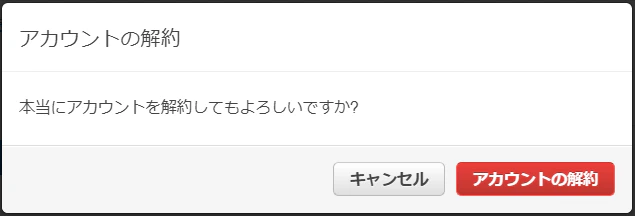
- アカウント解約のチェックボックス
- ポップアップの表示
※ 本検証以外で上記のオペレーションを行っている方は自己責任でお願いいたします
- 画面上部に権限不足のエラーが表示され解約できない
【禁止】サポートへアクセス
- サポートページの上部にエラーが表示
まとめ
AWS Organizationsを利用すると、例えrootアカウントでも操作をできないよう制限できることが確認できました。
また、今回のようにrootアカウントで行うことが一般的なアカウント解約や組織の離脱といった、
オペレーションについても制限することが可能です。今回はあくまでも一例であり、なかなかニッチな利用方法だとは思いますが、
複数のアカウント運用でお困りの方で参考になれば幸いです。




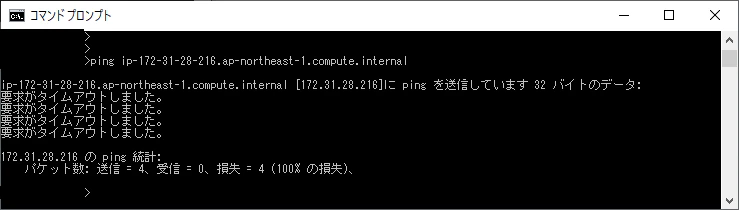
- 投稿日:2020-10-06T20:45:46+09:00
AWS 認定 セキュリティ – 専門知識(SCS)に合格しました。
AWS認定 ソリューションアーキテクト プロフェッショナル(SAP-C01)
に合格したので、
AWS 認定 セキュリティ – 専門知識(SCS)を受験し合格しました。合格時のAWS歴
業務歴1年程度
点数
816点(思ったより点数がとれませんでした。。)
難易度
AWS SAPと比べると問題文も短く、答えも内容がわかっていれば明確に選べる問題も多かった気がします。
SAAよりは難しいかもしれませんがSAPよりは確実に簡単です。試験時間も見直し含め1時間程度で私は解けました。
※試験ガイドに記載のサービス内容について実際に業務で触れていたのは大きいかもしれません。勉強方法
今回は書籍の要点整理から攻略する『AWS認定 セキュリティ-専門知識』のみで試験勉強を実施しました。
※上記でまとまっているサービスのblackbeltと理解が怪しい分野のよくある質問を熟読しました。まとめ
当たり前ですが、実務で触れている範囲を勉強する場合学習効率が良いです。(その割には点数取れませんでしたので復習したいと思います。。)
実務で触れられない場合でも、アソシエイト以上の資格を受験する場合はAWSのチュートリアル程度は自分の環境で触ってみることをお勧めします。
- 投稿日:2020-10-06T19:14:25+09:00
EC2インスタンス起動後に必要なセキュリティ設定
EC2 に SSH でログインした後、最低限必要な設定をまとめます。
ユーザ設定
ユーザ追加、パスワード設定
# ユーザ追加とパスワード設定 sudo useradd hogehoge sudo passwd hogehogewheel グループに追加
作成したユーザのディレクトリを確認
# wheelグループに追加 sudo usermod -aG wheel hogehoge # wheelに所属しているユーザーの確認 less /etc/group | grep wheel公開鍵設定
# 公開鍵のコピーとパーミッション設定 sudo cp -R ~/.ssh/ /home/hogehoge/.ssh sudo chown -R hogehoge:hogehoge /home/hogehoge/.ssh sudo chmod -R go-rwx /home/hogehoge/.sshSSH 設定
ec2-user へ直接 ssh を禁止
sudo echo "DenyUsers ec2-user" >> /etc/ssh/sshd_config sudo systemctl restart sshdSSH ポート変更
sudo vi /etc/ssh/sshd_config # デフォルトListen Portを修正 # Port 22 Port 12345sshd を再起動しておきます
sudo systemctl restart sshd※指定したポートは AWS の Security Group で開けておいてください
セキュリティパッチの自動実行設定
賛否両論ありますが yum update を定期的に実行してくれる設定をします。
sudo yum install yum-cron # 設定ファイルのバックアップ sudo cp /etc/yum/yum-cron.conf /etc/yum/yum-cron.conf.backup # sed コマンドで書き換え sudo sed -i "s/^update_cmd.*$/update_cmd = security/g" /etc/yum/yum-cron.conf sudo sed -i "s/^apply_updates.*$/apply_updates = yes/g" /etc/yum/yum-cron.conf # yum-cronの起動と自動起動の設定 # 起動 sudo systemctl start yum-cron # 自動起動の設定 sudo systemctl enable yum-cron # ステータスの確認 systemctl status yum-cronタイムゾーンの変更
timedatectl status sudo timedatectl set-timezone Asia/Tokyo
- 投稿日:2020-10-06T18:39:39+09:00
AWS Chaliceの開発環境をdockerで構築し、超高速でサーバーレスアプリケーションをデプロイしてみた
AWS Chaliceの開発環境をdockerで構築し、超高速でサーバーレスアプリケーションをデプロイしてみた
ChaliceもLambdaも初めてですが、
初めてのサーバーレスアプリケーションに興奮したので書きますソースコード naokit-dev/python3_chalice_on_docker
Chalice (チャリス?)
AWSが提供するPythonフレームワーク
Lambdaを使ったサーバーレスアプリケーションを簡単にデプロイできる
Documentation — AWS Chalice環境
- macOS Catalina
- VS Code
- Docker Desktop
docker --version Docker version 19.03.13, build 4484c46d9d docker-compose --version docker-compose version 1.27.4, build 40524192その他、AWSのアクセスキーが必要になります
準備運動
Docker Hubで使用するイメージを確認します
python - Docker HubAWS ChaliceはLambdaでサポートされているすべてのpythonが使用できるが3系が推奨とのこと
AWS Chalice supports all versions of python supported by AWS Lambda, which includes python2.7, python3.6, python3.7, python3.8. We recommend you use a version of Python 3.
Quickstart — AWS Chaliceここでは、
3.8-alpineを使用してみますVS Codeで新規ワークスペースを作成
"python3_chalice_on_docker"としました(次の手順は必要ないのですが、pythonが動く最小構成として試してみました)
Docker HubのイメージをPullしてコンテナを起動します
- -it 標準入力にアタッチ
- --rm コンテナ終了時にコンテナを削除
- -v : host_pathをボリュームとしてマウント
docker run -it --rm -v $PWD:/python python:3.8-alpine /bin/sh(
-v .:/pythonのように相対パスでマウントしようとするとエラーとなるが、環境変数$PWDが使えるようで-v $PWD:/pythonなら問題ない | Volume相対パス指定でもdocker runがしたい! - Qiita)# python --version Python 3.8.6Dockerfileを作成
先程作成したワークスペースでの作業になります
Dockerfileを作成
pip install chaliceでchaliceをインストールしますtouch DockerfileFROM python:3.8-alpine WORKDIR /app RUN pip install chalice CMD [ "/bin/sh"]つぎに
docker-compose.ymlを作成
ポートマッピング、ボリューム作成のほか、.envに記述した環境変数をコンテナ内で扱えるようにしていますtouch docker-compose.ymlversion: "3.8" services: app: build: . ports: - "80:8000" volumes: - .:/app command: chalice local --host=0.0.0.0 --port=8000 tty: true stdin_open: true working_dir: "${APP_PATH}" environment: - AWS_ACCESS_KEY_ID=${AWS_ACCESS_KEY_ID} - AWS_SECRET_ACCESS_KEY=${AWS_SECRET_ACCESS_KEY} - AWS_DEFAULT_REGION=${AWS_DEFAULT_REGION}
.envを作成
ここに環境変数を定義します
APP_NAMEはいまはブランクのまま
ほかも今はそのままで構いませんが、AWSにデプロイするために必要なcredentialsを記述することになりますtouch .envAPP_NAME= APP_PATH=/app/${APP_NAME} AWS_ACCESS_KEY_ID=[YOUR_ACCESS_KEY_ID] AWS_SECRET_ACCESS_KEY=[YOUR_SECRET_ACCESS_KEY] AWS_DEFAULT_REGION=ap-northeast-1端末にAWSのcredentialsが保存されている場合
以下で確認できますcat ~/.aws/credentialschalice projectを作成
chalice new-project <project_name>で新規プロジェクトを作成しますdocker-compose run app chalice new-project test_chalice以下のような構成になります
. ├── .env ├── Dockerfile ├── docker-compose.yml └── test_chalice ├── .chalice │ └── config.json ├── .gitignore ├── app.py └── requirements.txt環境変数を定義
.envを編集します
APP_NAMEに先程のプロジェクト名を、AWS_ACCESS_KEY_IDおよびAWS_SECRET_ACCESS_KEYもここに記述します
Regionはap-northeast-1に設定してありますが適宜変更してくださいAPP_NAME=test_chalice APP_PATH=/app/${APP_NAME} AWS_ACCESS_KEY_ID=xxxxxxxxxxxxxxxxxx AWS_SECRET_ACCESS_KEY=xxxxxxxxxxxxxxxxxx AWS_DEFAULT_REGION=ap-northeast-1ローカルサーバーをたてる
ローカルサーバーを起動
docker-compose updocker-compose.ymlで
command: chalice local --host=0.0.0.0 --port=8000としてコマンドを上書きしてあるので、docker-compose up時にchalice localが実行されます
ports: - "80:8000"でホスト側のport 80をコンテナ内のport 8000にマッピングしてあるので、ホストからlocalhostにアクセスすると、chaliceのlocal serverにポートフォワーディングされますcurl localhost {"hello":"world"}%"hello world"が返ってきました
test_chalice/app.pyをみてみます
以下のコメントアウトされている部分を、コメントアウト解除します# @app.route('/hello/{name}') # def hello_name(name): # # '/hello/james' -> {"hello": "james"} # return {'hello': name}
/hello/chaliceにアクセスしてみるとcurl localhost/hello/chalice {"hello":"chalice"}%"hello chalice"が返ってきました
RESTfulな挙動が確認できますローカルサーバーを停止
docker-compose downデプロイしてみる
chalice deployでAWS Lambda関数としてデプロイされますdocker-compose run app chalice deploy Creating deployment package. Creating IAM role: test_chalice-dev Creating lambda function: test_chalice-dev Creating Rest API Resources deployed: - Lambda ARN: arn:aws:lambda:ap-northeast-1:xxxxxxxxxxxx:function:test_chalice-dev - Rest API URL: https://xxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/api/Rest API URLにアクセスしてみます
curl https://xxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/api/ {"hello":"world"}% curl https://xxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/api/hello/lambda {"hello":"lambda"}%chaliceがコードを解析し、
必要なIAM roleを付与してLambda関数としてデプロイしてくれるそうです次は少し実用的なアプリに挑戦してみたいと思います
Ref.
- 投稿日:2020-10-06T18:39:15+09:00
DynamoDBをローカルで構築する
実施環境はWindowsのPC内にVagrantで立てたCentOSの仮想マシンです。
Javaがなかったので入れる
[root@localhost ~]# yum install java-1.8.0-openjdk [root@localhost ~]# java -version openjdk version "1.8.0_181" OpenJDK Runtime Environment (build 1.8.0_181-b13) OpenJDK 64-Bit Server VM (build 25.181-b13, mixed mode)dynamodb-localをダウンロード
[vagrant@localhost ~]$ sudo su - [root@localhost ~]# wget http://dynamodb-local.s3-website-us-west-2.amazonaws.com/dynamodb_local_latest.tar.gz 100%[========================================================================================================================================>] 16,884,788 3.26MB/s in 4.9s 2018-09-12 06:52:31 (3.26 MB/s) - ‘dynamodb_local_latest.tar.gz’ saved [16884788/16884788]展開
[root@localhost ~]# tar zxvf dynamodb_local_latest.tar.gz起動
[root@localhost ~]# java -Djava.library.path=./DynamoDBLocal_lib -jar DynamoDBLocal.jar -sharedDb Initializing DynamoDB Local with the following configuration: Port: 8000 InMemory: false DbPath: null SharedDb: true shouldDelayTransientStatuses: false CorsParams: *停止するときはCtrt + cで
AWSCLIを入れる
公式ページを参考に
https://docs.aws.amazon.com/ja_jp/cli/latest/userguide/awscli-install-linux.htmlまずpython-pipを使えるようにする
[root@localhost~]# yum install python-setuptools -y [root@localhost~]# easy_install pipAWS CLIをインストール
[root@localhost ~]# pip install awscli [root@localhost ~]# aws --version aws-cli/1.16.12 Python/2.7.5 Linux/3.10.0-514.26.2.el7.x86_64 botocore/1.12.2AWS CLIを使ってDynamoDBをいじる
aws configureを設定
[root@localhost ~]# aws configure AWS Access Key ID [None]: <アクセスキーID> AWS Secret Access Key [None]: <シークレットアクセスキー> Default region name [None]: ap-northeast-1 // なんとなく東京に Default output format [None]: jsonアクセスキーIDとシークレットアクセスキーは一度AWSのコンソールから発行してもらったものを設定したけど
ローカルで動かす場合はダミーでよかった。
むしろ本当のアクセスキーを設定したので「--endpoint-url http://192.168.33.11:8000」を付けなかった場合、
ローカルのDynamoDBではなくAWS上のDynamoDBにアクセスしてしまった( ´△`)テーブル一覧
[root@localhost ~]# aws dynamodb list-tables --endpoint-url http://192.168.33.11:8000 { "TableNames": [] }endpoint-urlは接続先ホスト名。
今回はVagrantで立てた仮想マシン内で実行するためVagrantfileに書いてあるIPアドレス(192.168.33.10)を指定した。
- 投稿日:2020-10-06T18:39:15+09:00
DynamoDBをローカルで構築し、AWS CLIコマンドを使っていじるまで
実施環境はWindowsのPC内にVagrantで立てたCentOSの仮想マシンです。
Javaがなかったので入れる
[root@localhost ~]# yum install java-1.8.0-openjdk [root@localhost ~]# java -version openjdk version "1.8.0_181" OpenJDK Runtime Environment (build 1.8.0_181-b13) OpenJDK 64-Bit Server VM (build 25.181-b13, mixed mode)dynamodb-localをダウンロード
[vagrant@localhost ~]$ sudo su - [root@localhost ~]# wget http://dynamodb-local.s3-website-us-west-2.amazonaws.com/dynamodb_local_latest.tar.gz 100%[========================================================================================================================================>] 16,884,788 3.26MB/s in 4.9s 2018-09-12 06:52:31 (3.26 MB/s) - ‘dynamodb_local_latest.tar.gz’ saved [16884788/16884788]展開
[root@localhost ~]# tar zxvf dynamodb_local_latest.tar.gz起動
[root@localhost ~]# java -Djava.library.path=./DynamoDBLocal_lib -jar DynamoDBLocal.jar -sharedDb Initializing DynamoDB Local with the following configuration: Port: 8000 InMemory: false DbPath: null SharedDb: true shouldDelayTransientStatuses: false CorsParams: *停止するときはCtrt + cで
AWSCLIを入れる
公式ページを参考に
https://docs.aws.amazon.com/ja_jp/cli/latest/userguide/awscli-install-linux.htmlまずpython-pipを使えるようにする
[root@localhost~]# yum install python-setuptools -y [root@localhost~]# easy_install pipAWS CLIをインストール
[root@localhost ~]# pip install awscli [root@localhost ~]# aws --version aws-cli/1.16.12 Python/2.7.5 Linux/3.10.0-514.26.2.el7.x86_64 botocore/1.12.2AWS CLIを使ってDynamoDBをいじる
aws configureを設定
[root@localhost ~]# aws configure AWS Access Key ID [None]: <アクセスキーID> AWS Secret Access Key [None]: <シークレットアクセスキー> Default region name [None]: ap-northeast-1 // なんとなく東京に Default output format [None]: jsonアクセスキーIDとシークレットアクセスキーは一度AWSのコンソールから発行してもらったものを設定したけど
ローカルで動かす場合はダミーでよかった。
むしろ本当のアクセスキーを設定したので「--endpoint-url http://192.168.33.11:8000」を付けなかった場合、
ローカルのDynamoDBではなくAWS上のDynamoDBにアクセスしてしまった( ´△`)テーブル一覧
[root@localhost ~]# aws dynamodb list-tables --endpoint-url http://192.168.33.11:8000 { "TableNames": [] }endpoint-urlは接続先ホスト名。
今回はVagrantで立てた仮想マシン内で実行するためVagrantfileに書いてあるIPアドレス(192.168.33.10)を指定した。
- 投稿日:2020-10-06T18:07:52+09:00
(DynamoDBで)苦しかったときの話をしようか
はじめに
本記事はAWSのDynamoDBを使った開発で苦しんだ経験をまとめたものです。ちなみにタイトルの元ネタはこれです。
DynamoDBとは
- AWSが提供するNoSQLのデータベース
- フルマネージドで分散データベースの運用とスケーリングに伴う管理作業をまかせることができる
- 高い可用性と耐久性が特徴
RDSとの違い
- 単純なデータの読み書きに強い
- 複雑なデータの更新に弱い
- Lambdaとの相性が良い
苦しんだこと
- 大規模データの書き込み
- バックアップデータのリストア
大規模データの書き込み
はじめに
こういうよくあるサーバーレスな構成を作りました。
ここまではテンプレ(?)
ある日のこと
これに数千件のデータが書き込きこまれることになりました。
これには数個のテーブルへの書き込みや更新が生じます。
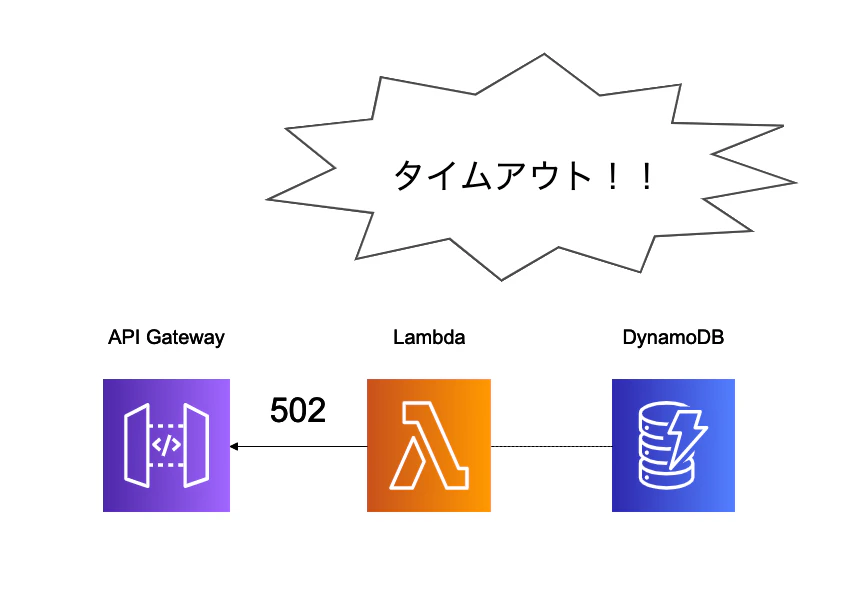
結果
残念!DynamoDBへのデータ書き込み途中でタイムアウトが起こりました。Lambdaは予め設定した実行時間を超えるとタイムアウトを起こして502エラーを返します。
とりあえず対策してみる(1)
タイムアウトが起こったということでLambdaの実行時間やメモリを増設してみました。処理時間は1分くらいでした。
しかしここで知ったのですが、API Gatewayはタイムアウト時間が最大30秒に決まっていて、これ以上の拡張ができません。
とりあえず対策してみる(2)
DynamoDBへの書き込み方法について見直してみました。DynamoDBへのデータの書き込みにPutItemを使用していましたが、BatchWriteItemを使うようにしました。
ここまでは良かったのですが、問題はUpdateItemのためのBatchWrite的なAPIがなかったということです。結局30秒以内に処理を終えることができませんでした。
最終的に行った対策
最終的にこんな感じの構成になりました。
間にS3が入ることになりました。
ざっくりとした説明
- Lambda1がアップロードされたデータをS3に書き込み
- LambdaトリガーをセットしたS3が、データ書き込み後にLambda2を呼び出す
- Lambda2がDynamoDBへデータを書き込む
これでAPI Gatewayのタイムアウト時間以内にステータスコードを返すことができました。
しかしこの変更でいくつかの問題も生じたのです。まあ苦肉の策という感じでしたね。。。。
バックアップデータのリストア
DynamoDBの自動バックアップ
DynamoDBにはポイントインタイムリカバリ(PIP)を有効化することができます。これを有効化すると、ある特定の日時のDynamoDBのデータの状態を復元することができるのです。
ポイントインタイムリカバリをやってみる
PIPを行うとバックアップテーブルが別のテーブル名で作成されます。
ここまでは良かったのです。
テーブルの移し替えをどうするか
ここでテーブルデータの移し替えを実際に行うのですが、最初に想定していたのは
- バックアップテーブルを作成する
- 元テーブルの名前を変更する
- バップアップテーブルの名前を元テーブルの名前に変更する
なのですが、DynamoDBにはテーブル名を変更するという機能がありませんでした。
結局どうするのか
この問題の解決はできていないのですが、考えた方法は
- 一度削除元テーブルを削除して、バックアップテーブルから元テーブル名のテーブルを作成する
- 元テーブルを削除してバックアップテーブルからのデータを移植するスクリプトを書く(AWS CLIを使う)
どちらもダウンタイムが避けられないのでやりたくはありませんでした。。。
さいごに
今回の失敗で学んだことは、
- DynamoDBで複数テーブルを作ったり、大量のデータ更新をさせるような設計はよろしくない
- PIPの機能は元テーブルへのリストアを公式でサポートはしていない(これについては単純な私の知見不足であればご指摘いただきたいです)
ですね。とりあえず今後の反省ということで。。。



- 投稿日:2020-10-06T17:48:31+09:00
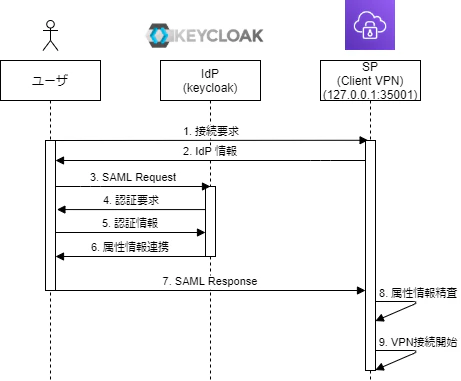
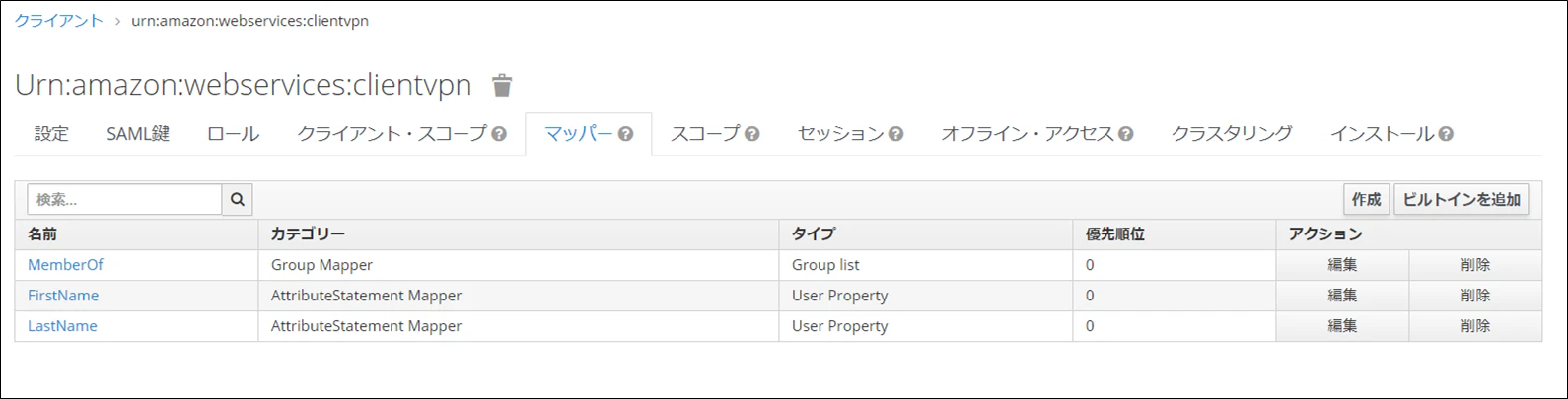
AWS Client VPNの承認ルールに複数のADグループを設定する場合の注意点
AWSにはAWS Client VPNというマネージドのVPNサービスがあり、OpenVPN ベースのVPN クライアントを使用すれば、VPN接続を簡単に実施することができます。
その中で、Active Directory認証と相互認証(証明書)を使用して認証することができるのですが、
Active Directory認証を使用した際に通常のネットワークの使用とは異なる部分がありました。Active Directory認証をする際の注意点
※動作としては以下のトラブルシュート
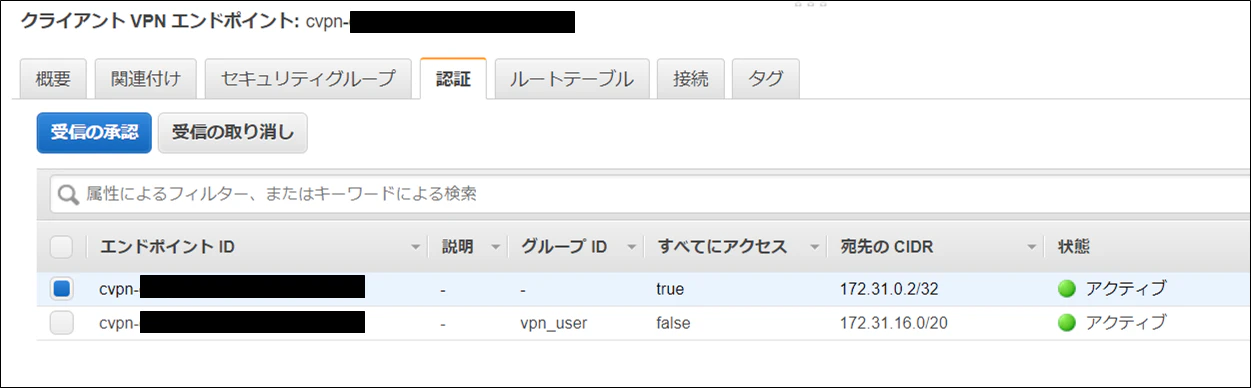
https://docs.aws.amazon.com/ja_jp/vpn/latest/clientvpn-admin/troubleshooting.html#ad-group-auth-rules例えば、ひとつのClientVPNにおなじディレクトリに所属する2つのADグループと承認ルールを設定していたとします。
ADグループ名 承認ルール test1 10.0.0.0/16 test2 10.0.0.0/16 上記のADグループ”test1”に"10.0.1.0/24"を追加したとします。
ADグループ名 承認ルール test1 10.0.0.0/16 test1 10.0.1.0/24 test2 10.0.0.0/16 その場合、"test2"のADグループに含まれるユーザは10.0.0.0/16に含まれるはずの10.0.1.0/24にはアクセスできなくなります。
※test1のADグループに紐づいている10.0.1.0/24への承認ルールが先に評価されてしまって、test2のユーザがアクセスしようとする際は10.0.1.0/24への通信が拒否されてしまう仕様のようです。なので、test2のADグループに所属するユーザが10.0.1.0/24にアクセスさせたい場合は以下のように設定する必要があります。
ADグループ名 承認ルール test1 10.0.0.0/16 test1 10.0.1.0/24 test2 10.0.0.0/16 test2 10.0.1.0/24 結論
ClientVPNに複数のADグループを設定する場合は、同じClientVPNに設定されているADグループに承認ルールの追加が通信に影響を及ぼさないかの確認が必要そうです。
細かく通信を制御させたい場合は、ClientVPNエンドポイントをユーザごとに分けることも検討したほうがよさそうです。
- 投稿日:2020-10-06T17:40:01+09:00
白いマスクから怪人マスクへ、AWSでサーバレスLINE写真処理アプリの開発記
0.はじめに
初めまして、中国から参りましたポンです。
今は野村総合研究所で働いている新人エンジニアです。
日本語がまだ下手ですから、もし変な日本語が入りましたらご容赦ください。
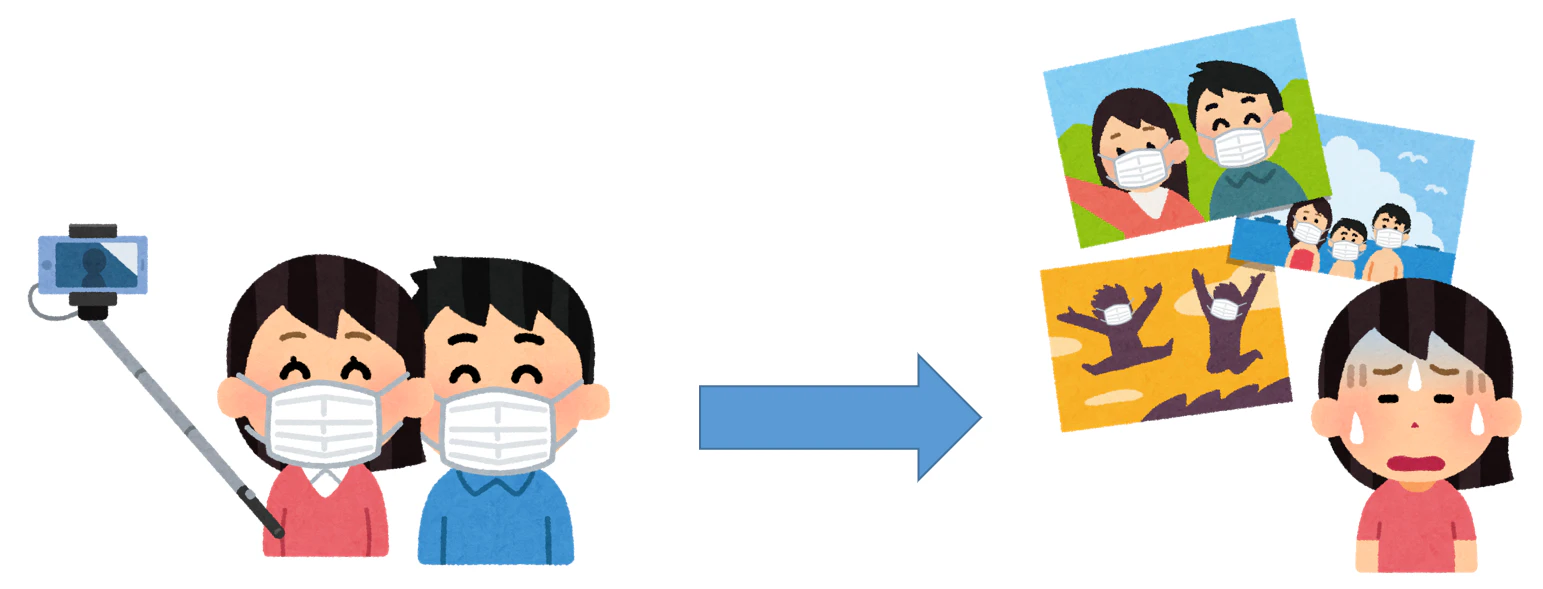
どうぞよろしくお願いいたします。コロナ時期の旅行写真には、白いマスクが多すぎで、
もう我慢できないですよね?
ちょうど今は新人開発研修があって、これを研修の課題にしました。
これを解決するため、写真中の白いマスクを怪人マスクに変換するアプリケーションを開発しました。
「できるだけ作業量を減らす」というコンセプトに基づいて、
AWSの色々なサービスを活用してサーバレスLINE写真処理アプリとして開発しました。
マスクだらけの写真にうんざりした方も、サーバレスに興味ある方も、
ぜひ、この開発記をお楽しみください。1.なぜこのアプリを開発?
筆者は夏休みの時に、彼女と千葉の銚子に旅行しました。
海で遊んだり、灯台を登ったり記念写真をいっぱい撮りました。
でも残念ですけど、写真の主役は人間または景色ではなく、白いマスクでした。
コロナ時代(時期)の写真は、白いマスクの出現率が一番高くて、どこでも登場しています。
こんな写真を見た彼女は、「もう白いマスクを見たくない」の文句が出てきた、じゃ写真中の白いマスクをほかのものに変換すればどうでしょう?ちょうど筆者も彼女も、スーパーヒーロー映画が好きで、その中の怪人マスク(e.g. バットマンの怪人Bane)が大好きです。
もし白いマスクが怪人マスクになればいいんじゃないですか?
※This work is a derivative of "Bane" by istolethetv, used under CC BY 2.0そういうことから、アイデアが生まれてきて、この写真処理アプリを開発することを決めました。
でも目の前に3つの問題が存在しています。
- どんなアプリケーション形態にする?
- どこでサーバーを立てる?
- どうやって画像認識システムを作る?
まず、アプリケーション形態について、色々な選択肢が存在しています。
WebページとしてのWebアプリ?スマホ専用のiosまたはandroidアプリ?
バックエンドの処理だけではなく、フロントエンドのインタフェースも設計しなければなりませんね。
色々考えて、やはりLINEアプリが一番適切だと思います。
理由が3つあります:
- 使いやすい:ほぼ誰でもLINE持っていて、LINEアプリ(bot)なら送信受信だけですごく簡単で、だれでも使えます。
- 作業量は少ない:Webアプリやiosアプリなら、インターフェースのデザインなども入って、正直言ってめんどくさいです。でもLINEアプリならそれらを考えなくてもいい、楽になります。
- シェアしやすい:SNSの特徴といえば共有しやすいですね。変換した写真だけではなく、このアプリもシェアされやすくなれます。
そこで、アプリケーション形態はLINEアプリと決めました!
そして次の課題は、どこでサーバーを立てるかです
Raspberry piなどの物理マシンで構築するか?AWS EC2などのクラウドサーバーを利用するか?
また、サーバーは構築だけではなく、後の保守管理も必要です。
「できるだけ作業量を減らす」という理念を持っているlazyな私は、それをしたくないですね。。。
じゃ、サーバーを要らなく、サーバレスで開発すればいいじゃないですか?
調べると、AWS API GatewayとLambdaを使ったら、サーバレスを実現でき、サーバー構築と保守管理は一切なし!
よーし、君に決めた!!最後、今回は顔写真を処理するため、顔認識AIが必要です。
それで、「どんなAIモデル構造を使う?」、「訓練データどこから入手する?」や「データにどんなラベルを付ける?」などの問題がどんどん出てきました。
「すぐ使える顔認識AIがあればいいなぁ」と思ってAWSで調べてみて、結果は本当に出てきました!
Rekognition(recognitionではない)という画像または動画を分析するAWSサービスが存在します。
AIを作る必要がなく、Rekognitionをコールだけで、写真の顔の認識と分析ができます。
これで、「できるだけ作業量を減らす」が達成できます。
こういうことで、AWSでサーバレスLINE写真処理アプリを開発と決めました!
2.システム全体像
アプリケーション形態などはすでに決めましたので、これからシステムを構築しましょう!
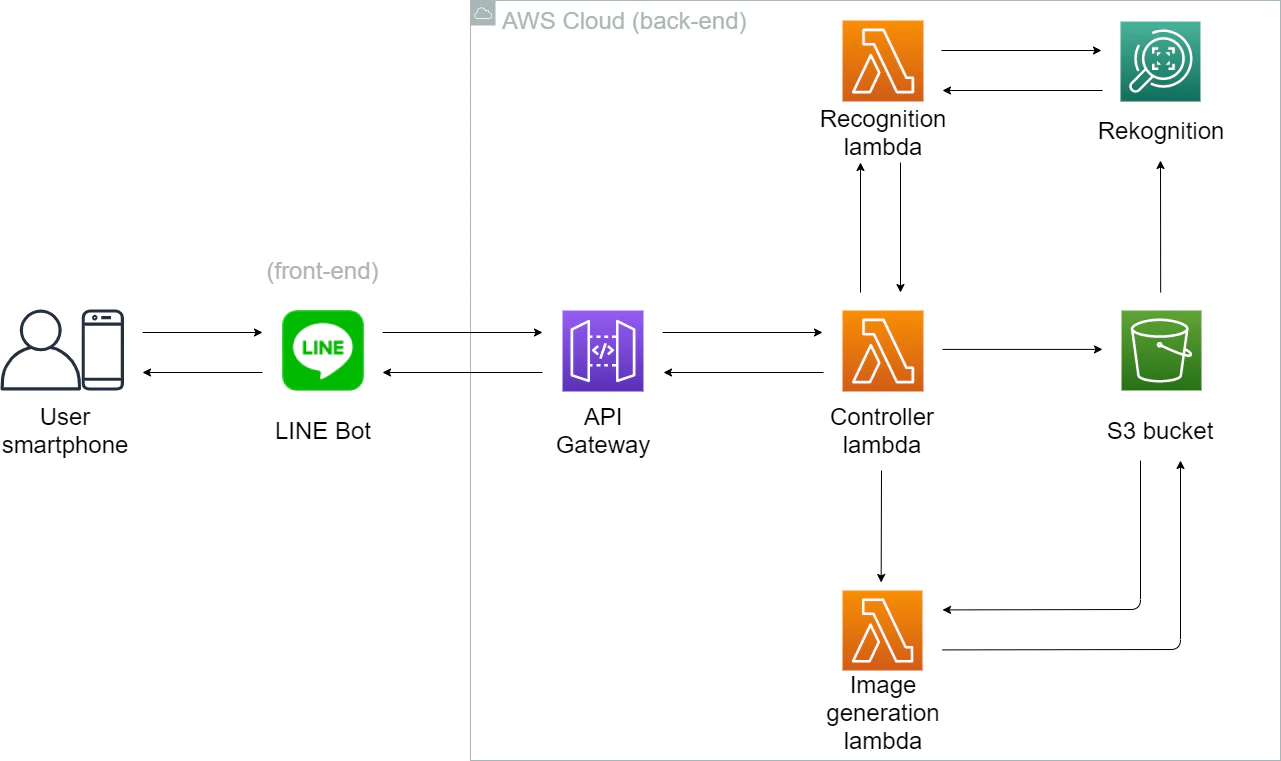
今回作ったシステムの全体像は以下です:
ここでユーザとのやり取りはスマホと想定しています。(PC版LINEもできます)
フロントエンドはLINE Botです。
バックエンドは全部AWS Cloudで処理を行っています。
サーバレスを実現するため、処理は「コントローラー」、「顔認識」と「新画像生成」3つのLambda に実行されています。
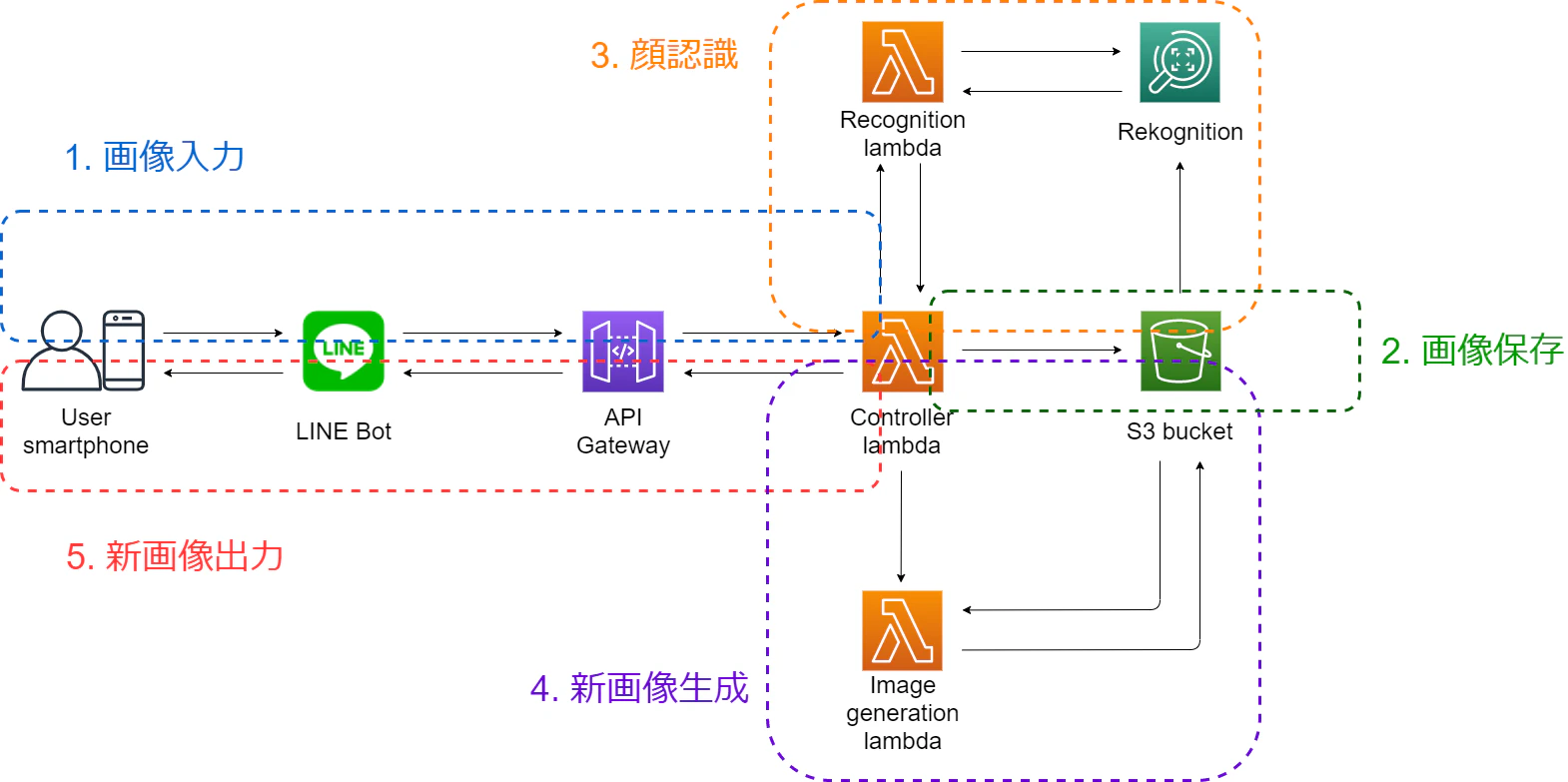
処理の流れから考えると、このシステムは以下の図のように5つ部分に分けられます:
それでは、処理の流れから、この5つ部分を説明いたします。
3.部分ごとの説明
3-1 画像入力部分
処理の流れ
第1部分は入力部分です。
機能は文字通りで、ユーザがLINE Bot に送信した画像を読み込むことです。
この部分に関するエンティティは「LINE Bot」、「API Gateway」および「コントローラーLambda 」です。
処理の流れは以下となっております:
まず、ユーザが写真画像をLINE Botに送信します。
そしてLINE Botが画像をline_eventにラッピングして、API Gatewayに送ります。
API Gatewayは何も変更せずに、eventをコントローラーLambdaに送ります。LINE Bot作成
この部分を作るために、まず玄関としてのLINE Bot(messagingApi)を作成。
作り方はこちらをご参照ください:
LINE公式ドキュメント:Messaging APIを始めよう
チャンネルを作成した後に、必要な設定はまだ2つあります。
1つ目はLambdaでの認証のため、「チャンネルアクセストークン」を発行することです。
2つ目はmessaging apiの応答機能をoff、webhook機能をonすることです。
webhook URLは今入力しなくて、API Gatewayの設定が終わった後に入力します。コントローラーLambdaを作成
次はLambdaなどのサービスを実行するIAMロールの作成です。
ダッシュボードからIAMサービスを入って、新しいロールを作ります。
新しいIAMロールはserverless-linebotなどをネーミングして、使うサービスはLambdaです。
ポリシーは「AmazonS3FullAccess」、「AmazonRekognitionFullAccess」、「CloudWatchLogsFullAccess」です。
またコントローラーLambdaがほかのLambdaを呼び出すのため、以下のポリシーも追加します:{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "lambda:InvokeFunction", "lambda:InvokeAsync" ], "Resource": [ "顔認識Lambdaのarn", "新画像生成Lambdaのarn" ] } ] }ここの「顔認識Lambdaのarn」と「新画像生成Lambdaのarn」はまだないですから、Lambda関数を作成した後に書き換えを忘れないでください。
今回の処理は全部このロールで実行します。コントローラーLambda関数を作成
API Gatewayは「繋がり」ですから、それを作る前に両端のLINE BotとコントローラーLambda関数を作らなければないので、次はコントローラーLambda関数を作成します。
関数作成に、今回はpythonを使うため、ランタイムをpython3.x(3.6~3.8)を選択します。
実行するIAMロールは先ほど作ったロールです。作成した後に、まずは「基本設定」で、メモリを512MBで、タイムアウトを1minのように設定します。
そして以下の環境変数を設定します:
キー 値 LINE_CHANNEL_ACCESS_TOKEN LINE Botのチャンネルアクセストークン LINE_CHANNEL_SECRET LINE Botのチャンネルシークレット Lambda関数の中身について、コントローラーLambdaはLINE Botとのやり取りが行いますので、「line-bot-sdk」パッケージが必要です。
Lambdaに導入するため、まずローカルで以下のコマンドを用いて、新フォルダにline-bot-sdkをインストールします:python -m pip install line-bot-sdk -t <new_folder>後同じフォルダにlambda_function.py(Lambdaはこの名前で「これがメインファンクション」と認識するので、必ずこの名前)ファイルを作って、以下のコードを記入ます:
lambda_function_for_controller.pyimport os import sys import logging import boto3 import json from linebot import LineBotApi, WebhookHandler from linebot.models import MessageEvent, TextMessage, TextSendMessage, ImageMessage, ImageSendMessage from linebot.exceptions import LineBotApiError, InvalidSignatureError logger = logging.getLogger() logger.setLevel(logging.ERROR) # 環境変数からline botのチャンネルアクセストークンとシークレットを読み込む channel_secret = os.getenv('LINE_CHANNEL_SECRET', None) channel_access_token = os.getenv('LINE_CHANNEL_ACCESS_TOKEN', None) if channel_secret is None: logger.error('Specify LINE_CHANNEL_SECRET as environment variable.') sys.exit(1) if channel_access_token is None: logger.error('Specify LINE_CHANNEL_ACCESS_TOKEN as environment variable.') sys.exit(1) # api&handlerを生成 line_bot_api = LineBotApi(channel_access_token) handler = WebhookHandler(channel_secret) # S3バケットとつながる s3 = boto3.client("s3") bucket = "<S3バケット名>" # Lambdaのメインファンクション def lambda_handler(event, context): # 認証用のX-Line-Signatureヘッダー signature = event["headers"]["X-Line-Signature"] body = event["body"] # リターン値の設定 ok_json = {"isBase64Encoded": False, "statusCode": 200, "headers": {}, "body": ""} error_json = {"isBase64Encoded": False, "statusCode": 403, "headers": {}, "body": "Error"} @handler.add(MessageEvent, message=ImageMessage) def message(line_event): # ユーザのプロフィール profile = line_bot_api.get_profile(line_event.source.user_id) # 送信したユーザのIDを抽出(push_messageなら使う, replyなら必要ない) # user_id = profile.user_id # メッセージIDを抽出 message_id = line_event.message.id # 画像ファイルを抽出 message_content = line_bot_api.get_message_content(message_id) content = bytes() for chunk in message_content.iter_content(): content += chunk # 画像ファイルを保存 key = "origin_photo/" + message_id new_key = message_id[-3:] s3.put_object(Bucket=bucket, Key=key, Body=content) # 顔認識lambdaを呼び出し lambdaRekognitionName = "<ここは顔認識lambdaのarn>" params = {"Bucket": bucket, "Key": key} # 画像ファイルのパス情報 payload = json.dumps(params) response = boto3.client("lambda").invoke( FunctionName=lambdaRekognitionName, InvocationType="RequestResponse", Payload=payload) response = json.load(response["Payload"]) # 新画像生成lambdaを呼び出し lambdaNewMaskName = "<ここは新画像生成lambdaのarn>" params = {"landmarks": str(response), "bucket": bucket, "photo_key": key, "new_photo_key": new_key} payload = json.dumps(params) boto3.client("lambda").invoke(FunctionName=lambdaNewMaskName, InvocationType="RequestResponse", Payload=payload) # 署名付きURL生成 presigned_url = s3.generate_presigned_url(ClientMethod="get_object", Params={ "Bucket": bucket, "Key": new_key}, ExpiresIn=600) # 新画像メッセージの返信 line_bot_api.reply_message(line_event.reply_token, ImageSendMessage( original_content_url=presigned_url, preview_image_url=presigned_url)) try: handler.handle(body, signature) except LineBotApiError as e: logger.error("Got exception from LINE Messaging API: %s\n" % e.message) for m in e.error.details: logger.error(" %s: %s" % (m.property, m.message)) return error_json except InvalidSignatureError: return error_json return ok_json上のはコントローラーLambda関数の全体で、すべての5つ部分と関連しています。
この第1部分に関するパートは以下です:
- LINE Botと繋がり
lambda_function_for_controller.py# 環境変数からline botのチャンネルアクセストークンとシークレットを読み込む channel_secret = os.getenv('LINE_CHANNEL_SECRET', None) channel_access_token = os.getenv('LINE_CHANNEL_ACCESS_TOKEN', None) if channel_secret is None: logger.error('Specify LINE_CHANNEL_SECRET as environment variable.') sys.exit(1) if channel_access_token is None: logger.error('Specify LINE_CHANNEL_ACCESS_TOKEN as environment variable.') sys.exit(1) # api&handlerを生成 line_bot_api = LineBotApi(channel_access_token) handler = WebhookHandler(channel_secret)
- イベントからlinebot署名とbody内容を受け取る
lambda_function_for_controller.py# 認証用のX-Line-Signatureヘッダー signature = event["headers"]["X-Line-Signature"] body = event["body"]これで、LINE Botの認証とイベント内容の受け取るができました。
後はそのフォルダの内容をzipに圧縮して、
Lambdaの「関数コード」→「アクション」→「.zipファイルをアップロード」でアップロードします。API Gatewayを作成
最後は繋がりとしてのAPI Gatewayの作成です。
ここ作成するAPI Gatewayの種類はREST APIです。
APIを作成した後に、リソースとメソッドを作成します。
メソッドはPOST方式で、統合タイプはLambda関数で、Lambdaプロキシ統合の使用も有効化にします。
Lambda関数はコントローラーLambda関数を選択します。あと、POSTメソッドリクエストの設定について、
まずリクエストの認証は「クエリ文字列パラメータおよびヘッダーの検証」を選択します。
そしてHTTPリクエストヘッダーには以下のヘッダーを追加します:
名前 必須 キャッシュ X-Line-Signature ☑ ☐ 設定できたらデプロイしましょう。
デプロイ完了したら、ステージでメソッドの呼び出しURLをコピーして、
LINE Botのwebhook URLに貼り付けます。
これで第1部分が完了します。3-2 画像保存部分
処理の流れ
第2部分は画像保存部分です。
この部分はすごく簡単で、ただコントローラーLambda読み込んだ画像をS3バケットに保存するだけです。
処理の流れは以下です:
S3バケットを作成
作業内容について、まずはS3バケットを作成します。
今回のプロジェクトにおいて、バケット名が長すぎると「署名付きURL長さ問題」が起きるため(詳細は3-5)、
バケット名はできれば短くします(私の場合は英4文字)。
また、自分の写真を他人に見られたくないですよね?
プライバシーを保護するため、
アクセス許可の設定に「パブリックアクセスをすべてブロック」をチェックして、バケットを作成します。
作成した後に、「origin_photo」というユーザがアップした写真を保存するフォルダと、
「masks」というマスク画像を保存するフォルダを作成します。
これで、S3側の作業が終わります。コントローラーLambda関数
コントローラーLambda関数は第1部分に記入したため、ここでの作業は特にありません。
ただこの部分に関するコード説明して、内容は以下です:
- バケットを指定
lambda_function_for_controller.py# S3バケットとつながる s3 = boto3.client("s3") bucket = "<S3バケット名>"
- イベントから画像ファイルを抽出して保存する
lambda_function_for_controller.py# メッセージIDを抽出 message_id = line_event.message.id # 画像ファイルを抽出 message_content = line_bot_api.get_message_content(message_id) content = bytes() for chunk in message_content.iter_content(): content += chunk # 画像ファイルを保存 key = "origin_photo/" + message_id new_key = message_id[-3:] s3.put_object(Bucket=bucket, Key=key, Body=content)ここはLINEメッセージIDで画像ファイルをリネームして、
複数ユーザが区別できるようになります。3-3 顔認識部分
第3部分は保存した写真の認識です。
具体的には顔の輪郭や目と鼻の位置を認識して、後のマスク画像と結合に使います。
「できるだけ作業量を減らす」というコンセプトを持って、
自分でゼロから顔認識AIを訓練したくないですから、
AWSの「Rekognition」というサービスを使って顔を認識します。Rekognitionとは
Rekognitionは「機械学習を使用して画像と動画の分析を自動化する」サービスであり、
簡単に言うと「訓練されたAIをそのまま使う」感じです。
Rekognitionについての紹介はこちらです:
Amazon RekognitionRekognitionはオブジェクトとシーンの検出や顔の比較などいろいろな機能があって、画像だけでなくビデオも処理できます。
今回は顔の位置を得るため、「顔の分析(face-detection)」機能を使います。
取得したい位置情報は「ランドマーク」と呼ばれます。
下の図はランドマークのイメージです:
※出典:https://docs.aws.amazon.com/ja_jp/rekognition/latest/dg/faces-detect-images.htmlこの図の分析結果:
Rekognition認識結果
{ "FaceDetails": [ { "AgeRange": { "High": 43, "Low": 26 }, "Beard": { "Confidence": 97.48941802978516, "Value": true }, "BoundingBox": { "Height": 0.6968063116073608, "Left": 0.26937249302864075, "Top": 0.11424895375967026, "Width": 0.42325547337532043 }, "Confidence": 99.99995422363281, "Emotions": [ { "Confidence": 0.042965151369571686, "Type": "DISGUSTED" }, { "Confidence": 0.002022328320890665, "Type": "HAPPY" }, { "Confidence": 0.4482877850532532, "Type": "SURPRISED" }, { "Confidence": 0.007082826923578978, "Type": "ANGRY" }, { "Confidence": 0, "Type": "CONFUSED" }, { "Confidence": 99.47616577148438, "Type": "CALM" }, { "Confidence": 0.017732391133904457, "Type": "SAD" } ], "Eyeglasses": { "Confidence": 99.42405700683594, "Value": false }, "EyesOpen": { "Confidence": 99.99604797363281, "Value": true }, "Gender": { "Confidence": 99.722412109375, "Value": "Male" }, "Landmarks": [ { "Type": "eyeLeft", "X": 0.38549351692199707, "Y": 0.3959200084209442 }, { "Type": "eyeRight", "X": 0.5773905515670776, "Y": 0.394561767578125 }, { "Type": "mouthLeft", "X": 0.40410104393959045, "Y": 0.6479480862617493 }, { "Type": "mouthRight", "X": 0.5623446702957153, "Y": 0.647117555141449 }, { "Type": "nose", "X": 0.47763553261756897, "Y": 0.5337067246437073 }, { "Type": "leftEyeBrowLeft", "X": 0.3114689588546753, "Y": 0.3376390337944031 }, { "Type": "leftEyeBrowRight", "X": 0.4224424660205841, "Y": 0.3232649564743042 }, { "Type": "leftEyeBrowUp", "X": 0.36654090881347656, "Y": 0.3104579746723175 }, { "Type": "rightEyeBrowLeft", "X": 0.5353175401687622, "Y": 0.3223199248313904 }, { "Type": "rightEyeBrowRight", "X": 0.6546239852905273, "Y": 0.3348073363304138 }, { "Type": "rightEyeBrowUp", "X": 0.5936762094497681, "Y": 0.3080498278141022 }, { "Type": "leftEyeLeft", "X": 0.3524211347103119, "Y": 0.3936865031719208 }, { "Type": "leftEyeRight", "X": 0.4229775369167328, "Y": 0.3973258435726166 }, { "Type": "leftEyeUp", "X": 0.38467878103256226, "Y": 0.3836822807788849 }, { "Type": "leftEyeDown", "X": 0.38629674911499023, "Y": 0.40618783235549927 }, { "Type": "rightEyeLeft", "X": 0.5374732613563538, "Y": 0.39637991786003113 }, { "Type": "rightEyeRight", "X": 0.609208345413208, "Y": 0.391626238822937 }, { "Type": "rightEyeUp", "X": 0.5750962495803833, "Y": 0.3821527063846588 }, { "Type": "rightEyeDown", "X": 0.5740782618522644, "Y": 0.40471214056015015 }, { "Type": "noseLeft", "X": 0.4441811740398407, "Y": 0.5608476400375366 }, { "Type": "noseRight", "X": 0.5155643820762634, "Y": 0.5569332242012024 }, { "Type": "mouthUp", "X": 0.47968366742134094, "Y": 0.6176465749740601 }, { "Type": "mouthDown", "X": 0.4807897210121155, "Y": 0.690782368183136 }, { "Type": "leftPupil", "X": 0.38549351692199707, "Y": 0.3959200084209442 }, { "Type": "rightPupil", "X": 0.5773905515670776, "Y": 0.394561767578125 }, { "Type": "upperJawlineLeft", "X": 0.27245330810546875, "Y": 0.3902156949043274 }, { "Type": "midJawlineLeft", "X": 0.31561678647994995, "Y": 0.6596118807792664 }, { "Type": "chinBottom", "X": 0.48385748267173767, "Y": 0.8160444498062134 }, { "Type": "midJawlineRight", "X": 0.6625112891197205, "Y": 0.656606137752533 }, { "Type": "upperJawlineRight", "X": 0.7042999863624573, "Y": 0.3863988518714905 } ], "MouthOpen": { "Confidence": 99.83820343017578, "Value": false }, "Mustache": { "Confidence": 72.20288848876953, "Value": false }, "Pose": { "Pitch": -4.970901966094971, "Roll": -1.4911699295043945, "Yaw": -10.983647346496582 }, "Quality": { "Brightness": 73.81391906738281, "Sharpness": 86.86019134521484 }, "Smile": { "Confidence": 99.93638610839844, "Value": false }, "Sunglasses": { "Confidence": 99.81478881835938, "Value": false } } ] }今回取得したいのはこの中の「landmarks」項目です。
「Type」は点の名前です(上のイメージ図を参照)。
ただし、xとyは具体的なピクセル点の座標ではなく、
画像の幅に対する比率を表しています。処理の流れ
第3部分の処理の流れは以下となっています:
Rekognitionは画像を読み込む仕組みが2つあります。
1つ目はS3バケット又はインターネット上の画像URLを用いて読み込みます。
2つ目はファイルを送って直接読み込みます。
今回は1つ目のURL方法を使います。
そのため、コントローラーLambdaから顔認識Lambdaに渡すのは画像ではなく、ファイルの保存位置情報です。
顔認識LambdaがRekognitionに渡すのも同じです。ここで顔認識Lambdaを実行するIAMロールは第1部分に作ったロールです。
S3とRekognitionを使う権限が持ってますので、
S3バケットが非公開でも、Rekognitionがその中の画像を読み込めて問題ないです。そして、Rekognitionからリターンされる結果は上の結果の例みたいです。
その中に「年齢」や「性別」など色々入ってますが、
今回使いたいのは「ランドマーク」だけです。
そのため、顔認識Lambdaがその結果からランドマークを抽出します。また、ランドマークもいっぱいありまして、
マスクのせいでうまく認識できない点(口など)もあるし、細かすぎてちょっと余計な点(瞳など)も存在します。
そのため、ここはただ以下の5つランドマークを抽出して、コントローラーLambdaにリターンします。
ランドマーク名 位置 eyeLeft 左目 eyeRight 右目 upperJawlineLeft 左こめかみ upperJawlineRight 右こめかみ chinBottom あご ※ランドマークの翻訳はちょっと変かもしれませんので、図を参考してください。
顔認識Lambda関数を作成
役割を分けるために、コントローラーLambda関数以外に別の顔認識Lambda関数を作ります。
作成する時に、コントローラーLambda関数と同じように、
python3.xを選んで、実行ロールも同じです。
また「基本設定」で同じように、1minのタイムアウトと512MBのメモリを設定します。作成した後に、ここで導入するパッケージがないですから、
zipをアップロードはいらなく、
以下のコードを自動生成されたLambda_function.pyに記入するだけで完了です。
※顔認識LambdaのarnリンクをIAMロールのinvokeポリシーに追加することを忘れないでください。lambda_function_for_rekognition.pyimport json import boto3 rekognition = boto3.client("rekognition") def lambda_handler(event, context): # イベントから画像ファイルのパスをゲット bucket = event["Bucket"] key = event["Key"] # Rekognitionをコールして顔認識を行う response = rekognition.detect_faces( Image={'S3Object': {'Bucket': bucket, 'Name': key}}, Attributes=['ALL']) # 写真に何人いる number_of_people = len(response["FaceDetails"]) # 全部の必要なランドマークのリストを作成 all_needed_landmarks = [] # 人数分で処理 for i in range(number_of_people): # これは辞書のリストである all_landmarks_of_one_person = response["FaceDetails"][i]["Landmarks"] # 今回は eyeLeft, eyeRight, upperJawlineLeft, upperJawlineRight, chinBottom だけを使って # needed_landmarks に抽出する needed_landmarks = [] for type in ["eyeLeft", "eyeRight", "upperJawlineLeft", "upperJawlineRight", "chinBottom"]: landmark = next( item for item in all_landmarks_of_one_person if item["Type"] == type) needed_landmarks.append(landmark) all_needed_landmarks.append(needed_landmarks) return all_needed_landmarksコントローラーLambda関数
コントローラーLambda関数はすでに記入したので、
ここは第3部分に関するコードの説明だけです。
- 顔認識Lambdaを呼び出し responseは取得した5つのランドマークです。
lambda_function_for_controller.pylambdaRekognitionName = "<ここは顔認識lambdaのarn>" params = {"Bucket": bucket, "Key": key} # 画像ファイルのパス情報 payload = json.dumps(params) response = boto3.client("lambda").invoke( FunctionName=lambdaRekognitionName, InvocationType="RequestResponse", Payload=payload) response = json.load(response["Payload"])3-4 新画像生成部分
処理の流れ
第4部分は新画像生成部分です。
つまり写真画像と以下の新マスク画像を結合する部分です:
名前 Bane Joker Immortan Joe マスク画像
※1
※2
※3出典 ダークナイト ライジング ダークナイト マッドマックス 怒りのデス・ロード ※1:This work is a derivative of "Bane" by istolethetv, used under CC BY 2.0.
※2:This work is a derivative of this photo, used under CC0 1.0.
※3:This work, "joe's mask" is a derivative of "File:Fan_Expo_2015_-Immortan_Joe(21147179383).jpg" by GabboT, used under CC BY-SA 2.0. "joe's mask" is licensed CC BY-SA 2.0 by y2-peng.AWSでの処理の流れは以下です:
まず、コントローラーLambdaは「写真画像の保存情報(S3バケット名とファイルパス)」、「5つのランドマーク情報」と「新画像ファイル名」を新画像生成Lambdaに渡します。
次、新画像生成Lambdaがファイル保存情報を用いて、S3バケットから写真画像とマスク画像を読み込みます。
なお、マスク画像を事前にS3バケットに保存して、ファイルパスを新画像生成Lambdaに保存する必要があります。
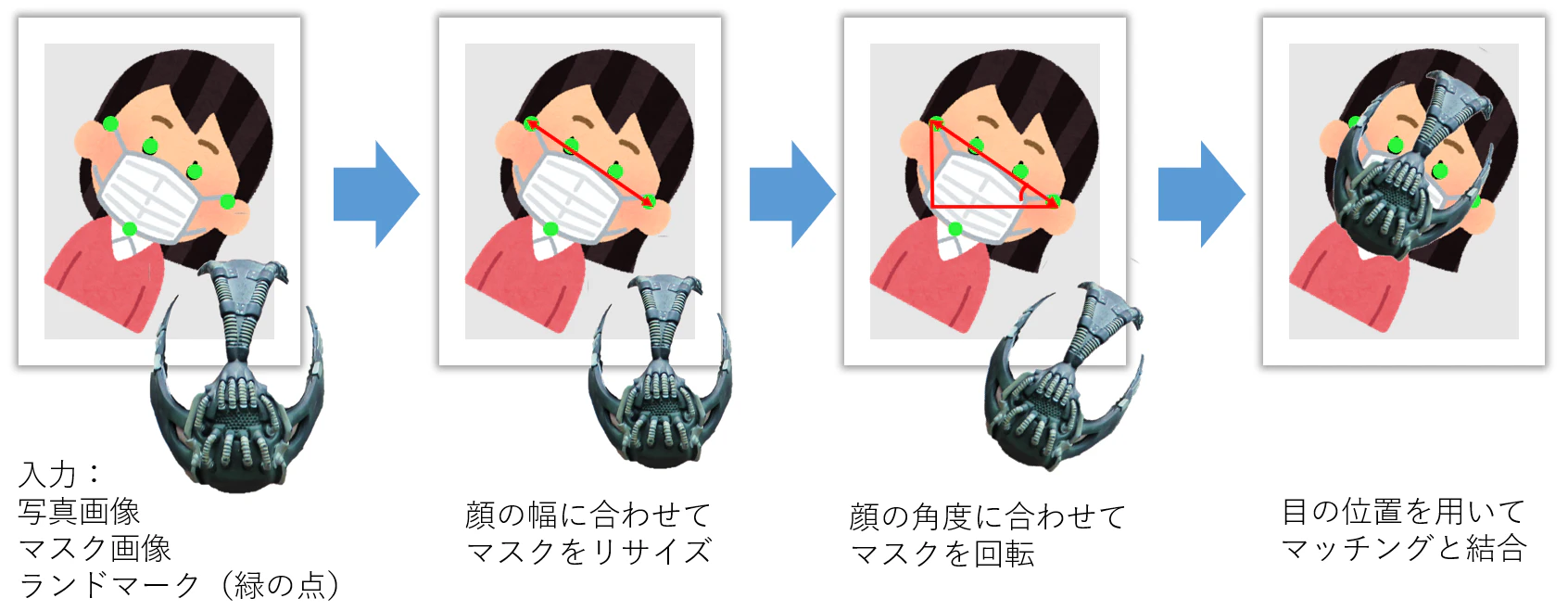
(ファイルパスなどの詳細設定はコードを参照してください)そして、人数分の回数で写真画像とマスク画像を結合します。
毎回ランダムに1つマスク画像を選択して使用します。
結合作業の順番は以下です:
※This work is a derivative of "Bane" by istolethetv, used under CC BY 2.0.
- 最後、新画像を「新画像ファイル名」でネーミングしてS3バケットに保存します。
処理は以上です。
新画像生成Lambdaを作成
まず、AWS Lambdaで新しいLambda関数を作成します。
ランタイムと実行ロールは先ほどと同じです。
あと、先ほどと同じように、「基本設定」からメモリとタイムアウトを設定します。今回は画像結合は、「pillow」と「numpy」2つのpythonパッケージが必要です。
そのため、まずは1つ新しいフォルダを生成して、以下のコマンドを用いてパッケージをインストールします。python -m pip install pillow numpy -t <new_folder>そして、そのフォルダに「lambda_function.py」を作って、以下のコードを記入します。
lambda_function_for_new_image_gengeration.pyimport json import boto3 import numpy as np from PIL import Image, ImageFile from operator import sub from io import BytesIO from random import choice s3 = boto3.client("s3") class NewPhotoMaker: def __init__(self, all_landmarks, bucket, photo_key, new_photo_key): self.all_landmarks = eval(all_landmarks) self.bucket = bucket self.photo_key = photo_key self.new_photo_key = new_photo_key # 写真画像を読み込む def load_photo_image(self): s3.download_file(self.bucket, self.photo_key, "/tmp/photo_file") self.photo_image = Image.open("/tmp/photo_file") # マスク画像を読み込み def load_mask_image(self): # bane(バットマン), joker(バットマン), immortan joe(マッドマックス)からランダム選択 mask_key = "masks/" + choice(["bane", "joker", "joe"]) + ".png" s3.download_file(self.bucket, mask_key, "/tmp/mask_file") self.mask_image = Image.open("/tmp/mask_file") # ランドマーク(比率)から具体的なポイントに変更する def landmarks_to_points(self): upperJawlineLeft_landmark = next( item for item in self.landmarks if item["Type"] == "upperJawlineLeft") upperJawlineRight_landmark = next( item for item in self.landmarks if item["Type"] == "upperJawlineRight") eyeLeft_landmark = next( item for item in self.landmarks if item["Type"] == "eyeLeft") eyeRight_landmark = next( item for item in self.landmarks if item["Type"] == "eyeRight") self.upperJawlineLeft_point = [int(self.photo_image.size[0] * upperJawlineLeft_landmark["X"]), int(self.photo_image.size[1] * upperJawlineLeft_landmark["Y"])] self.upperJawlineRight_point = [int(self.photo_image.size[0] * upperJawlineRight_landmark["X"]), int(self.photo_image.size[1] * upperJawlineRight_landmark["Y"])] self.eyeLeft_point = [int(self.photo_image.size[0] * eyeLeft_landmark["X"]), int(self.photo_image.size[1] * eyeLeft_landmark["Y"])] self.eyeRight_point = [int(self.photo_image.size[0] * eyeRight_landmark["X"]), int(self.photo_image.size[1] * eyeRight_landmark["Y"])] # 顔幅に合わせてマスク画像をリサイズする def resize_mask(self): face_width = int(np.linalg.norm(list(map(sub, self.upperJawlineLeft_point, self.upperJawlineRight_point)))) new_hight = int(self.mask_image.size[1]*face_width/self.mask_image.size[0]) self.mask_image = self.mask_image.resize((face_width, new_hight)) # 顔の角度(首回転による斜め顔ではない)に合わせてマスク画像を回転する def rotate_mask(self): angle = np.arctan2(self.upperJawlineRight_point[1] - self.upperJawlineLeft_point[1], self.upperJawlineRight_point[0] - self.upperJawlineLeft_point[0]) angle = -np.degrees(angle) # radian to dgree self.mask_image = self.mask_image.rotate(angle, expand=True) # 写真画像とマスク画像を結合 def match_mask_position(self): # 目の位置を用いてマッチング face_center = [int((self.eyeLeft_point[0] + self.eyeRight_point[0])/2), int((self.eyeLeft_point[1] + self.eyeRight_point[1])/2)] mask_center = [int(self.mask_image.size[0]/2), int(self.mask_image.size[1]/2)] x = face_center[0] - mask_center[0] y = face_center[1] - mask_center[1] self.photo_image.paste(self.mask_image, (x, y), self.mask_image) # 新画像ファイルをS3に保存 def save_new_photo(self): new_photo_byte_arr = BytesIO() self.photo_image.save(new_photo_byte_arr, format="JPEG") new_photo_byte_arr = new_photo_byte_arr.getvalue() s3.put_object(Bucket=self.bucket, Key=self.new_photo_key, Body=new_photo_byte_arr) # 実行 def run(self): self.load_photo_image() # 人数分の処理 for i in range(len(self.all_landmarks)): self.load_mask_image() # 毎回1つ新しいマスクをロード self.landmarks = self.all_landmarks[i] self.landmarks_to_points() self.resize_mask() self.rotate_mask() self.match_mask_position() self.save_new_photo() # lambdaメインファンクション def lambda_handler(event, context): landmarks = event["landmarks"] bucket = event["bucket"] photo_key = event["photo_key"] new_photo_key = event["new_photo_key"] photo_maker = NewPhotoMaker(landmarks, bucket, photo_key, new_photo_key) photo_maker.run()最後、フォルダのすべての内容をzipにして、Lambdaにアップロードします。
これで、新画像生成の作成が完了します。
※新画像生成LambdaのarnリンクをIAMロールのinvokeポリシーに追加することを忘れないでください。コントローラーLambda関数
この部分に関するコントローラーLambdaのコードは以下です:
lambda_function_for_controller.py# 新画像生成lambdaを呼び出し lambdaNewMaskName = "<ここは新画像生成lambdaのarn>" params = {"landmarks": str(response), "bucket": bucket, "photo_key": key, "new_photo_key": new_key} payload = json.dumps(params) boto3.client("lambda").invoke(FunctionName=lambdaNewMaskName, InvocationType="RequestResponse", Payload=payload)3-5 新画像出力部分
LINE Botにおける画像出力
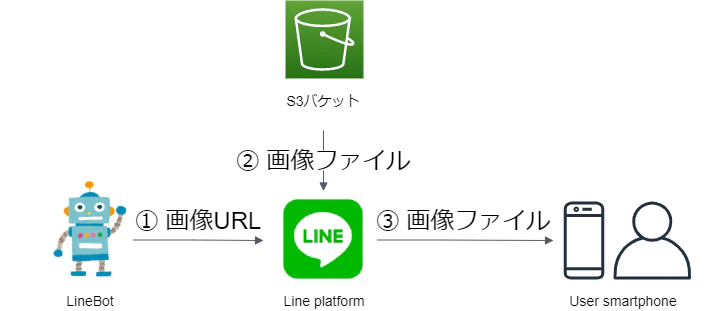
最後の部分は新画像の出力部分です。
このアプリはLINE Botで画像を入出力で、入力するときは直接的に画像ファイルを渡しますが、
出力は画像ファイルを直接的に送信できません。LINE Bot MessageingApiにおけるImage message(画像メッセージ)のドキュメントにはユーザへの画像送信方式を規定しています。
それAPIが受けられるのは画像ファイルではなく、画像のURLです。
ドキュメントに見ると、ユーザとLINE Botの通信はLINE platformに経由しています。
つまりこの送信過程は
- 「LINE Botから画像URLをLINE platformに送る」
- 「LINE platformがS3バケットに保存されている画像を読み込む」
- 「LINE platformがユーザに画像を送信する」
となっています。
でもこの過程によって、S3バケットのアクセス権限が問題になります。
アクセス権限が「非公開」にすると、LINE platformが画像を読み込めなくて、ユーザがもらった画像がこうなります:
アクセス権限が「公開」にすると、画像のS3オブジェクトURLを分かればで誰でもアクセスできます。
つまり自分の写真が他の人に見られちゃう可能性があり、プライバシーの問題があります。一応DynamoDBなどを使って、LINEユーザ認証を行うことを考えましたが、
作業量が結構増やしまして、「できるだけ作業量を減らす」のコンセプトと衝突、
正直、やりたくないです。色々調べて、最後にいい方法を見つけました。
それは「署名付きURL」です。署名付きURL
プライバシーを保護するために、S3バケットへのアクセス権限は「非公開」にします。
画像のS3オブジェクトURL知ってもアクセスできません。
でもIAMロールの権限で発行した署名付きURLを使ったら、非公開的なS3バケットの特定オブジェクトへのアクセスは可能になります。
ちょっとzoomのパスワード付き会議URLみたいですね。また、この署名付きURLは有効期限も設定できます。
有効期限が切れるとURLを使えなくなり、安全性がもう一歩上げます:
でも1つ注意すべきことがあって、それは署名付きURLの長さ問題です。
IAMロールの権限で発行された署名付きURLには一時アクセスためのトークン情報が入ったため、URLが結構長くなります。
しかし、LINE BotのImage message APIの規定により、受け取れるURLの長さ上限が1000文字です。
そのため、S3バケット名、画像ファイルパスと画像ファイル名が長すぎると、URLが1000文字を超えて、送信できなくなります。
なので第2部分のS3バケットを作成する時に、「バケット名はできれば短く」ということがありました。
同じ理由で、新画像ファイル名はメッセージIDの最後3文字(ファイル名を短縮)することと、
新画像ファイルをS3バケットのロールフォルダに保存する(ファイルパスを短縮)こともしています。
これで署名付きURLの長さ問題が解決できました。補足:
署名付きURLの長さ問題について、実はもう1つ解決策が存在しています。
それはIAMロールではなく、IAMユーザの権限でURLを発行することです。
IAMユーザで発行したURLはトークンいらなく、URLを短くできますが、
IAMユーザの「アクセスキー ID」と「シークレットアクセスキー」を使う必要があります。
安全性から考えると、IAMユーザでURLを発行する方法をお勧めしません。処理の流れ
さあ、S3バケットの権限問題を解決できましたので、この部分を実装しましょう。
この部分の流れは以下です:
まず、コントローラーLambda関数が新画像の署名付きURLをLINE Botに渡します。
そして、LINE BotがS3バケットから画像ファイルを読み込んで(実際の読み込みはLINE platformで行う)、
最後ユーザに送信します。
これで、処理は終了です。コントローラーLambda関数
上の部分と同じように、この部分に関するコントローラーLambda関数コードを解説します。
- 署名付きURLを生成 有効期間は600秒と設定しています。
lambda_function_for_controller.py# 署名付きURL生成 presigned_url = s3.generate_presigned_url(ClientMethod="get_object", Params={ "Bucket": bucket, "Key": new_key}, ExpiresIn=600)
- 新画像を送信
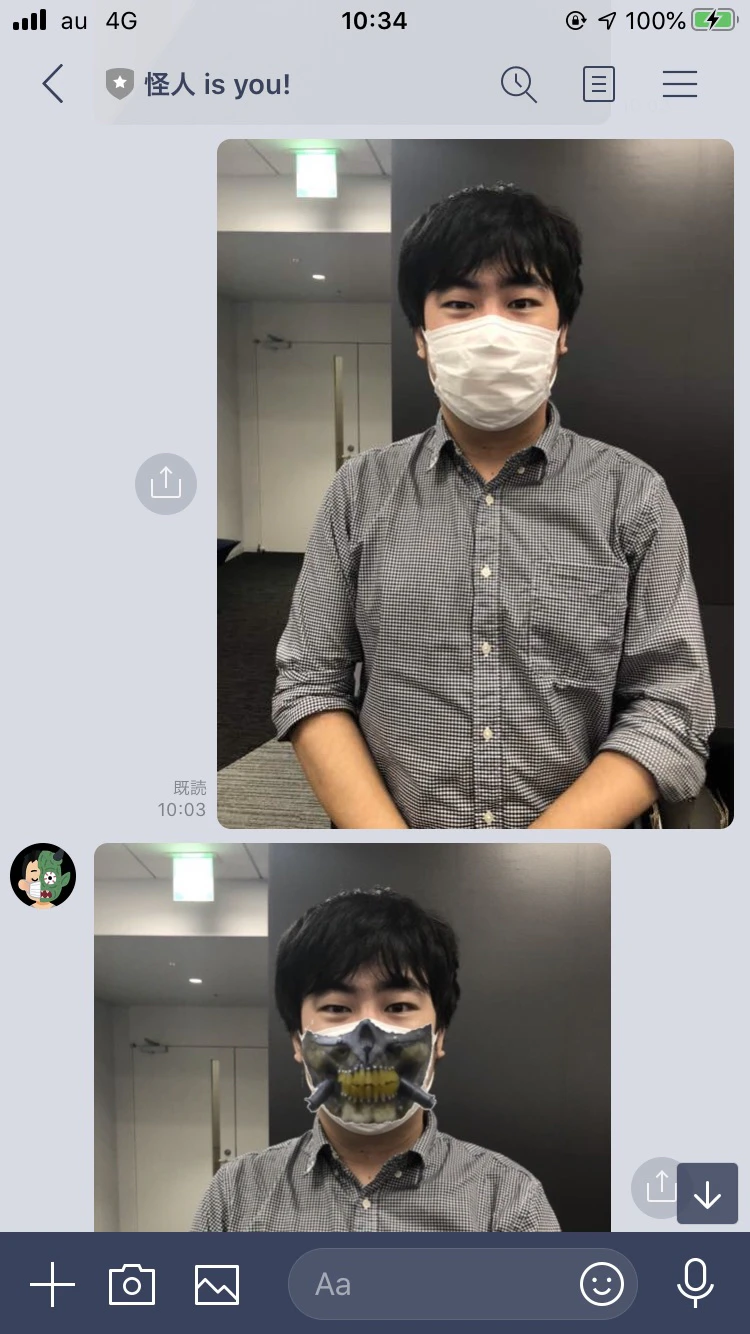
lambda_function_for_controller.py# 新画像メッセージの返信 line_bot_api.reply_message(line_event.reply_token, ImageSendMessage( original_content_url=presigned_url, preview_image_url=presigned_url))4.実際の結果
早速ですが、作ったアプリを試してみましょう!
インターフェース
まずはLINEインターフェースでの受送信です。
LINE Botの「Messaging API設定」からBotのQRコードがあり、それを使って自分の友達に追加できます。
後に送信してみたら。。。
※This work, "wearing joe's mask" is a derivative of "File:Fan_Expo_2015_-Immortan_Joe(21147179383).jpg" by GabboT, used under CC BY-SA 2.0. "wearing joe's mask" is licensed CC BY-SA 2.0 by y2-peng.ちゃんとできましたね!
それでは、どんなパターンがちゃんと行けるか、どんなパターンがうまくいかないか調べましょう!うまくいったパターン
description before after 1人正面 
※1
1人正面(回転あり) 
※2
複数人正面 
※3
顔大きすぎでも 
※4
※1:This work is a derivative of this photo, used under CC0 1.0.
※2:This work, "result 2" is a derivative of "File:Fan_Expo_2015_-Immortan_Joe(21147179383).jpg" by GabboT, used under CC BY-SA 2.0. "result 2" is licensed CC BY-SA 2.0 by y2-peng.
※3:This work, "masked 4" is a derivative of "File:Fan_Expo_2015_-Immortan_Joe(21147179383).jpg" by GabboT, used under CC BY-SA 2.0, "Bane" by istolethetv, used under CC BY 2.0, and this photo, used under CC0 1.0. "masked 4" is licensed CC BY-SA 2.0 by y2-peng.
※4:This work is a derivative of "Bane" by istolethetv, used under CC BY 2.0.うまくいかないパターン
description before after 斜め顔 
※1
顔小さすぎ(一番後ろの人) 
※2
ぼかし(後ろの人) 
※3
※1:This work, "standing 2" is a derivative of "File:Fan_Expo_2015_-Immortan_Joe(21147179383).jpg" by GabboT, used under CC BY-SA 2.0 and "Bane" by istolethetv, used under CC BY 2.0. "standing 2" is licensed CC BY-SA 2.0 by y2-peng.
※2:This work, "standing 4" is a derivative of "File:Fan_Expo_2015_-Immortan_Joe(21147179383).jpg" by GabboT, used under CC BY-SA 2.0 and "Bane" by istolethetv, used under CC BY 2.0. "standing 4" is licensed CC BY-SA 2.0 by y2-peng.
※3:This work is a derivative of "Bane" by istolethetv, used under CC BY 2.0.分析
結果によって、正面及びクリアであれば、処理は大体できます。
ぼかしがある場合は、顔認識できなくて、処理が行いません。
斜め顔または顔が小さすぎる場合、処理は行いますが、正しい結果ではありません。5.まとめと所感
まとめ
今回は写真中の白いマスクを怪人マスクに変更するLINEアプリケーションを開発しました。
AWSのサービスを活用して、サーバレスで実現でき、「できるだけ作業量を減らす」というコンセプトを徹底できました。
正面でクリアな写真であれば、変換処理が大体大丈夫です。
ただ、斜め顔やぼかし顔の処理は今後の課題になります。今後の課題
- 斜め顔: 現在、斜め顔の処理は正しくないです。理由としてはマスクは正面だけで、斜め顔用のがありません。今後の解決策として、2Dマスクを3D座標系に回転してから結合を行い、または斜め顔専用マスク画像を用意することを考えています。
- 顔小さすぎまたはぼかし: 現在の顔認識はAWS Rekognitionを使って、そちらの性能がこのアプリの性能の上限を決めています。もし自分でもっと精度高い顔認識システムを開発できたら、この問題を解決できると思います。(でも「できるだけ作業量を減らす」と衝突ですね:()
- マスクの選択: 現在、怪人マスクは3つの中にランダムに使ってますが、今後はもっと増やしたいと思います。また、ランダム選択だけでなく、ユーザが選べるようにしたいです。マスクにタグをつけて、ユーザからの「○○のマスクをつけたい」や「かわいいマスクほしい」などの要求を全部満たせるようにします。
ほかの所感
- サーバレスの便利さ:今回最も感じたのはサーバレスの魅力です。サーバーがある場合は環境構築だけでなく、保守管理も必要で、かなり時間かかります。でもサーバレスでの開発はこれらをスキップでき、時間をセーブできました。アジャイル開発に使えますね。ただ、Lambdでのサーバレス処理が性能上の制限があり、複雑な処理があればやはりサーバーを立ちましょう。
- AWS一年間の無料最高!!:AWSの新規アカウントは1年間の「無料枠」があり、ある範囲内の使用はすべて無料です。今回の開発に使ったLambda、API Gateway、S3、RekognitionやCloudwatchは全部0円でできて、お得でした。残った数か月の無料期間には、いろいろ試したいと思います。皆様もし興味があればぜひ!無料ですよ!
6.全コード
lambda_function_for_controller.py
lambda_function_for_controller.pyimport os import sys import logging import boto3 import json from linebot import LineBotApi, WebhookHandler from linebot.models import MessageEvent, TextMessage, TextSendMessage, ImageMessage, ImageSendMessage from linebot.exceptions import LineBotApiError, InvalidSignatureError logger = logging.getLogger() logger.setLevel(logging.ERROR) # 環境変数からline botのチャンネルアクセストークンとシークレットを読み込む channel_secret = os.getenv('LINE_CHANNEL_SECRET', None) channel_access_token = os.getenv('LINE_CHANNEL_ACCESS_TOKEN', None) if channel_secret is None: logger.error('Specify LINE_CHANNEL_SECRET as environment variable.') sys.exit(1) if channel_access_token is None: logger.error('Specify LINE_CHANNEL_ACCESS_TOKEN as environment variable.') sys.exit(1) # api&handlerを生成 line_bot_api = LineBotApi(channel_access_token) handler = WebhookHandler(channel_secret) # S3バケットとつながる s3 = boto3.client("s3") bucket = "<S3バケット名>" # Lambdaのメインファンクション def lambda_handler(event, context): # 認証用のX-Line-Signatureヘッダー signature = event["headers"]["X-Line-Signature"] body = event["body"] # リターン値の設定 ok_json = {"isBase64Encoded": False, "statusCode": 200, "headers": {}, "body": ""} error_json = {"isBase64Encoded": False, "statusCode": 403, "headers": {}, "body": "Error"} @handler.add(MessageEvent, message=ImageMessage) def message(line_event): # ユーザのプロフィール profile = line_bot_api.get_profile(line_event.source.user_id) # 送信したユーザのIDを抽出(push_messageなら使う, replyなら必要ない) # user_id = profile.user_id # メッセージIDを抽出 message_id = line_event.message.id # 画像ファイルを抽出 message_content = line_bot_api.get_message_content(message_id) content = bytes() for chunk in message_content.iter_content(): content += chunk # 画像ファイルを保存 key = "origin_photo/" + message_id new_key = message_id[-3:] s3.put_object(Bucket=bucket, Key=key, Body=content) # 顔認識lambdaを呼び出し lambdaRekognitionName = "<ここは顔認識lambdaのarn>" params = {"Bucket": bucket, "Key": key} # 画像ファイルのパス情報 payload = json.dumps(params) response = boto3.client("lambda").invoke( FunctionName=lambdaRekognitionName, InvocationType="RequestResponse", Payload=payload) response = json.load(response["Payload"]) # 新画像生成lambdaを呼び出し lambdaNewMaskName = "<ここは新画像生成lambdaのarn>" params = {"landmarks": str(response), "bucket": bucket, "photo_key": key, "new_photo_key": new_key} payload = json.dumps(params) boto3.client("lambda").invoke(FunctionName=lambdaNewMaskName, InvocationType="RequestResponse", Payload=payload) # 署名付きURL生成 presigned_url = s3.generate_presigned_url(ClientMethod="get_object", Params={ "Bucket": bucket, "Key": new_key}, ExpiresIn=600) # 新画像メッセージの返信 line_bot_api.reply_message(line_event.reply_token, ImageSendMessage( original_content_url=presigned_url, preview_image_url=presigned_url)) try: handler.handle(body, signature) except LineBotApiError as e: logger.error("Got exception from LINE Messaging API: %s\n" % e.message) for m in e.error.details: logger.error(" %s: %s" % (m.property, m.message)) return error_json except InvalidSignatureError: return error_json return ok_json
lambda_function_for_rekognition.py
lambda_function_for_rekognition.pyimport json import boto3 rekognition = boto3.client("rekognition") def lambda_handler(event, context): # イベントから画像ファイルのパスをゲット bucket = event["Bucket"] key = event["Key"] # Rekognitionをコールして顔認識を行う response = rekognition.detect_faces( Image={'S3Object': {'Bucket': bucket, 'Name': key}}, Attributes=['ALL']) # 写真に何人いる number_of_people = len(response["FaceDetails"]) # 全部の必要なランドマークのリストを作成 all_needed_landmarks = [] # 人数分で処理 for i in range(number_of_people): # これは辞書のリストである all_landmarks_of_one_person = response["FaceDetails"][i]["Landmarks"] # 今回は eyeLeft, eyeRight, upperJawlineLeft, upperJawlineRight, chinBottom だけを使って # needed_landmarks に抽出する needed_landmarks = [] for type in ["eyeLeft", "eyeRight", "upperJawlineLeft", "upperJawlineRight", "chinBottom"]: landmark = next( item for item in all_landmarks_of_one_person if item["Type"] == type) needed_landmarks.append(landmark) all_needed_landmarks.append(needed_landmarks) return all_needed_landmarks
lambda_function_for_new_image_gengeration.py
lambda_function_for_new_image_gengeration.pyimport json import boto3 import numpy as np from PIL import Image, ImageFile from operator import sub from io import BytesIO from random import choice s3 = boto3.client("s3") class NewPhotoMaker: def __init__(self, all_landmarks, bucket, photo_key, new_photo_key): self.all_landmarks = eval(all_landmarks) self.bucket = bucket self.photo_key = photo_key self.new_photo_key = new_photo_key # 写真画像を読み込む def load_photo_image(self): s3.download_file(self.bucket, self.photo_key, "/tmp/photo_file") self.photo_image = Image.open("/tmp/photo_file") # マスク画像を読み込み def load_mask_image(self): # bane(バットマン), joker(バットマン), immortan joe(マッドマックス)からランダム選択 mask_key = "masks/" + choice(["bane", "joker", "joe"]) + ".png" s3.download_file(self.bucket, mask_key, "/tmp/mask_file") self.mask_image = Image.open("/tmp/mask_file") # ランドマーク(比率)から具体的なポイントに変更する def landmarks_to_points(self): upperJawlineLeft_landmark = next( item for item in self.landmarks if item["Type"] == "upperJawlineLeft") upperJawlineRight_landmark = next( item for item in self.landmarks if item["Type"] == "upperJawlineRight") eyeLeft_landmark = next( item for item in self.landmarks if item["Type"] == "eyeLeft") eyeRight_landmark = next( item for item in self.landmarks if item["Type"] == "eyeRight") self.upperJawlineLeft_point = [int(self.photo_image.size[0] * upperJawlineLeft_landmark["X"]), int(self.photo_image.size[1] * upperJawlineLeft_landmark["Y"])] self.upperJawlineRight_point = [int(self.photo_image.size[0] * upperJawlineRight_landmark["X"]), int(self.photo_image.size[1] * upperJawlineRight_landmark["Y"])] self.eyeLeft_point = [int(self.photo_image.size[0] * eyeLeft_landmark["X"]), int(self.photo_image.size[1] * eyeLeft_landmark["Y"])] self.eyeRight_point = [int(self.photo_image.size[0] * eyeRight_landmark["X"]), int(self.photo_image.size[1] * eyeRight_landmark["Y"])] # 顔幅に合わせてマスク画像をリサイズする def resize_mask(self): face_width = int(np.linalg.norm(list(map(sub, self.upperJawlineLeft_point, self.upperJawlineRight_point)))) new_hight = int(self.mask_image.size[1]*face_width/self.mask_image.size[0]) self.mask_image = self.mask_image.resize((face_width, new_hight)) # 顔の角度(首回転による斜め顔ではない)に合わせてマスク画像を回転する def rotate_mask(self): angle = np.arctan2(self.upperJawlineRight_point[1] - self.upperJawlineLeft_point[1], self.upperJawlineRight_point[0] - self.upperJawlineLeft_point[0]) angle = -np.degrees(angle) # radian to dgree self.mask_image = self.mask_image.rotate(angle, expand=True) # 写真画像とマスク画像を結合 def match_mask_position(self): # 目の位置を用いてマッチング face_center = [int((self.eyeLeft_point[0] + self.eyeRight_point[0])/2), int((self.eyeLeft_point[1] + self.eyeRight_point[1])/2)] mask_center = [int(self.mask_image.size[0]/2), int(self.mask_image.size[1]/2)] x = face_center[0] - mask_center[0] y = face_center[1] - mask_center[1] self.photo_image.paste(self.mask_image, (x, y), self.mask_image) # 新画像ファイルをS3に保存 def save_new_photo(self): new_photo_byte_arr = BytesIO() self.photo_image.save(new_photo_byte_arr, format="JPEG") new_photo_byte_arr = new_photo_byte_arr.getvalue() s3.put_object(Bucket=self.bucket, Key=self.new_photo_key, Body=new_photo_byte_arr) # 実行 def run(self): self.load_photo_image() # 人数分の処理 for i in range(len(self.all_landmarks)): self.load_mask_image() # 毎回1つ新しいマスクをロード self.landmarks = self.all_landmarks[i] self.landmarks_to_points() self.resize_mask() self.rotate_mask() self.match_mask_position() self.save_new_photo() # lambdaメインファンクション def lambda_handler(event, context): landmarks = event["landmarks"] bucket = event["bucket"] photo_key = event["photo_key"] new_photo_key = event["new_photo_key"] photo_maker = NewPhotoMaker(landmarks, bucket, photo_key, new_photo_key) photo_maker.run()












- 投稿日:2020-10-06T16:56:50+09:00
AWS SDK for Ruby profile変更 & assume role
AWS SDK for Rubyにてcredentialsのprofile指定とassume role方法についてわかりづらかったので記載
↓profileはaws-cliで下記のように作成した際のもの
$ aws configure --profile hogeprofile指定
Clientの引数に渡すだけ
例:EC2ec2 = Aws::EC2::Client.new( profile: "hoge", # ... )assume role
require 'aws-sdk-core' require 'aws-sdk-ec2' role_credentials = Aws::AssumeRoleCredentials.new( client: Aws::STS::Client.new(opts), role_arn: "arn:aws:iam::xxxxxxxxxxxx:role/hoge_role", role_session_name: hoge ) ec2 = Aws::EC2::Client.new( credentials: role_credentials, # ... )
- 投稿日:2020-10-06T14:51:59+09:00
Amazon Linux2にECS Agent登録&デバッグ
ECSでEC2を使う場合のデバッグ
- Amazon Linux2に公式マニュアルを元にecs-agentを入れてクラスターにつないでみた
- マニュアルのとおりにやっても正常に起動しない場合があり、そういう時にどうやってデバグするのか情報がまとまっていなかったので、自分のメモがてら記事にしてみる
- 今回のケースではAmazon Linux2に手動でagentをインストールした場合を扱います。他のケースだと細かいパスとかは違っているかもしれません
デバッグに有用なファイルのパス
# 設定情報 ## 設定情報。どのクラスタに所属させるか、などを設定 /etc/ecs/ecs.config ## エージェント状態ファイル。インスタンスがクラスターに作成された後に作られる。曲者なやつ。 /var/lib/ecs/data/ecs_agent_data.json # ログファイル ## 初期化ログ。起動、失敗、再起動、終了がイベントベースでざっくり載っている。 ## なんで止まったとかは書いてないけど、何回リトライしたかとかはここを見ると追える /var/log/ecs/ecs-init.log ## エージェントログ。実際のデバッグに有用な情報は大体ここ /var/log/ecs/ecs-agent.log ## ボリュームログ。ecsエージェントがmountするdockerのvolumeのログ?まだあまり使ったことはない /var/log/ecs/ecs-volume-plugin.logデバッグのステップ
systemdの確認
まずはsystemdでちゃんとecsのデーモンが動いているか確認。Activeがactive(running)になっていなければ、ECSエージェントが正しくインストールされていないかも。
$ sudo systemctl status ecs ● ecs.service - Amazon Elastic Container Service - container agent Loaded: loaded (/usr/lib/systemd/system/ecs.service; enabled; vendor preset: disabled) Active: active (running) since 月 2020-08-24 20:42:32 UTC; 3 days ago Docs: https://aws.amazon.com/documentation/ecs/ Process: 5195 ExecStopPost=/usr/libexec/amazon-ecs-init post-stop (code=exited, status=0/SUCCESS) Process: 5179 ExecStop=/usr/libexec/amazon-ecs-init stop (code=exited, status=0/SUCCESS) Process: 5213 ExecStartPre=/usr/libexec/amazon-ecs-init pre-start (code=exited, status=0/SUCCESS) Main PID: 5279 (amazon-ecs-init) Tasks: 7 Memory: 3.4M CGroup: /system.slice/ecs.service └─5279 /usr/libexec/amazon-ecs-init startmetadataの取得
jsonが表示されればOK。うまく動いていない場合は何も表示されない
$ curl -s http://localhost:51678/v1/metadata | python -mjson.tool { "Cluster": "my-cluster", "ContainerInstanceArn": "arn:aws:ecs:ap-northeast-1:xxxxxxx:container-instance/1111-22222-33333-44444", "Version": "Amazon ECS Agent - v1.39.0 (61d418ea)" }上記2コマンドで異常が検知された場合のやること
- 公式マニュアルに従ってちゃんとecs agent入れるコマンド打っているか確認
- /etc/ecs/ecs.configにちゃんとECS_CLUSTERが正しく指定されているか確認
ECS_CLUSTER=my-cluster
- /var/log/ecs/ecs-agent.logのログ内容を確認
- エラーの内容を確認。明確なエラー原因がつかめなかったら、とりあえず次のステップを行う
- /var/lib/ecs/data/ecs_agent_data.jsonの中身を消す
- 何回か発生した不具合のほとんどは、ここのデータが更新されていないために発生していた。ecs.configの内容の書き換えや、EC2インスタンスのタイプを変更しての再起動など、何か環境が変わった場合、基本はここをリセットしないとうまく立ち上がってくれない
- 投稿日:2020-10-06T14:48:05+09:00
ALBでHostBasedRouting
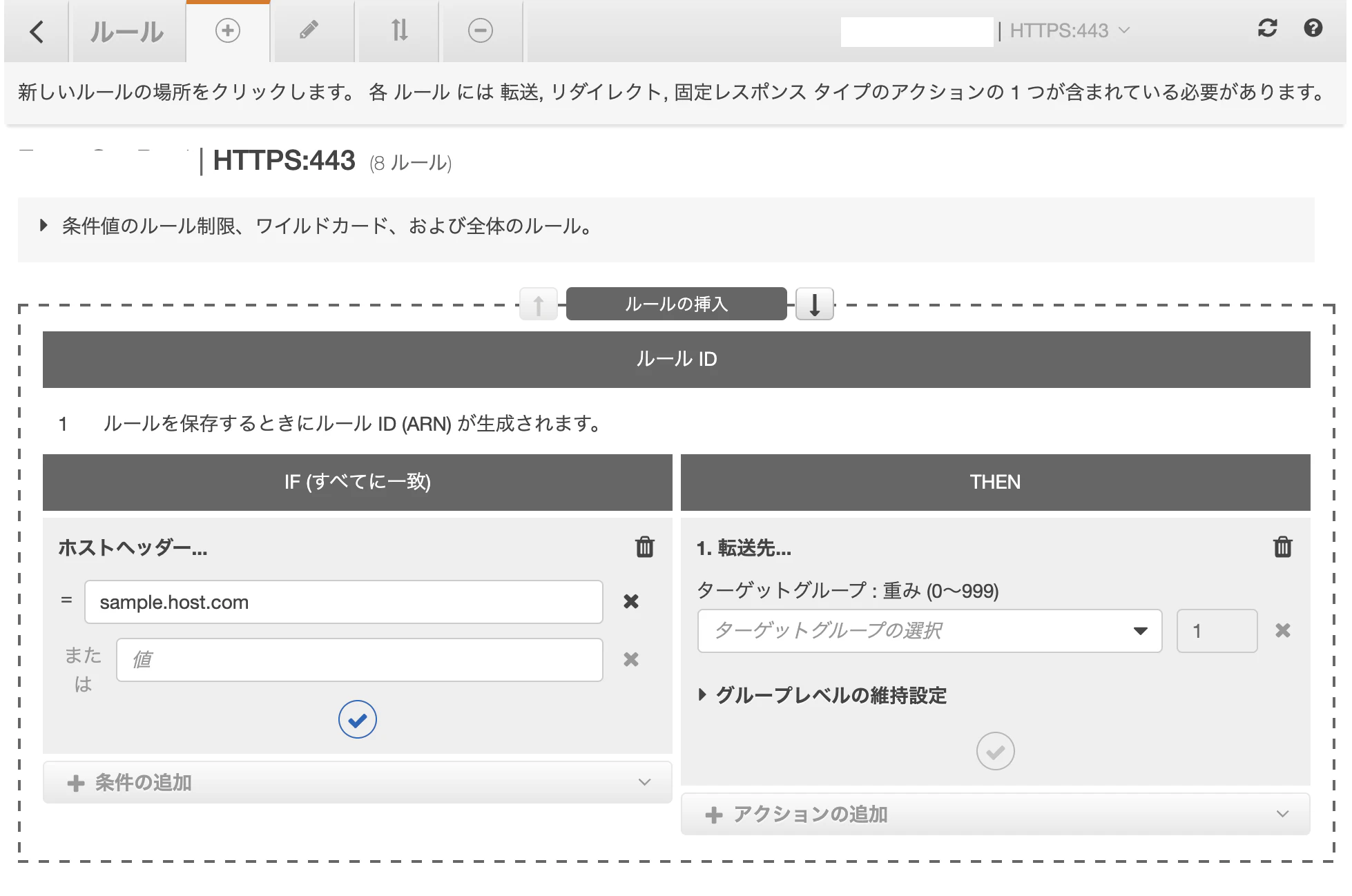
概要
アプリケーションを複数のサービスの集合体として運用している場合に、それぞれのドメインごとにALBを立てて管理する方法と、ALBのリスナールールで管理する方法がある。後者の方が管理コストが低いので試してみた。
ALBの設定
設定はすごく簡単、EC2からロードバランサーを選択、対象のロードバランサーをチェック
編集したいリスナーを選び、ルールの編集をクリックし、ルールの追加をクリック。
条件式をホストヘッダーにし、ドメインを記入、このドメインの時に転送する転送先(ターゲットグループ)を選択。以上
おまけ
更新するときなど、メンテナンスモード用の固定レンスポンスを設定しておくとメンテナンス時にルールの順序を変更するだけなので至極簡単


- 投稿日:2020-10-06T13:32:14+09:00
PrivateSubnetからNatGatewayを経由してSESメール配信
NATGatewayの作成
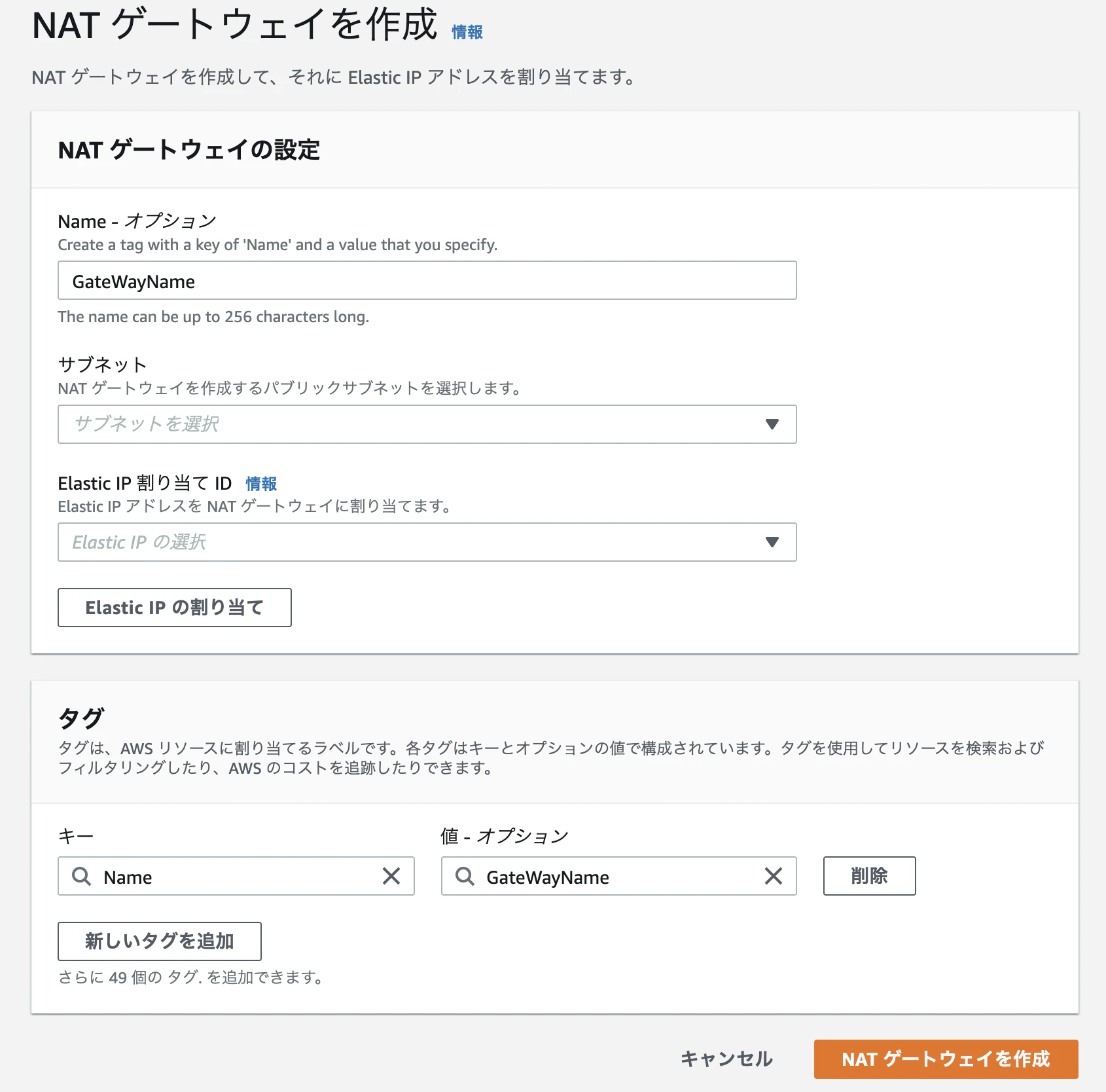
VPCからNATゲートウェイ選択、作成クリック
適当に名前をつけ、NATゲートウェイをおくパブリックサブネットを指定。ElasticIPの割り当ては自動でよければElasticIpの割り当てボタンをクリックすると勝手に振ってくれる。
EC2から外部ネットワークへNATGatewayを経由して接続
VPCのルートテーブルから、対象のEC2インスタンスが存在するPrivateSubnetが明示的に関連づけられたルートテーブルを選択
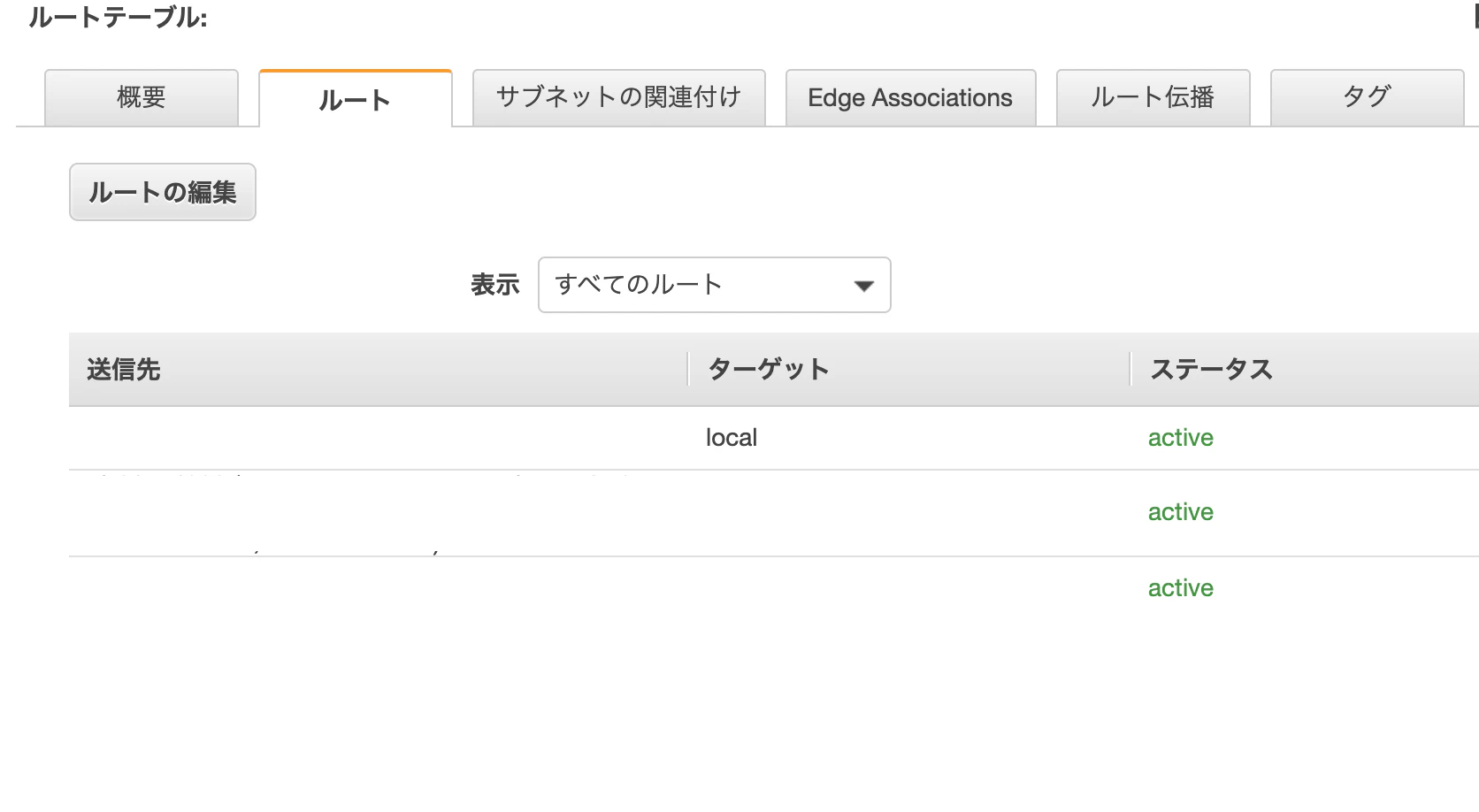
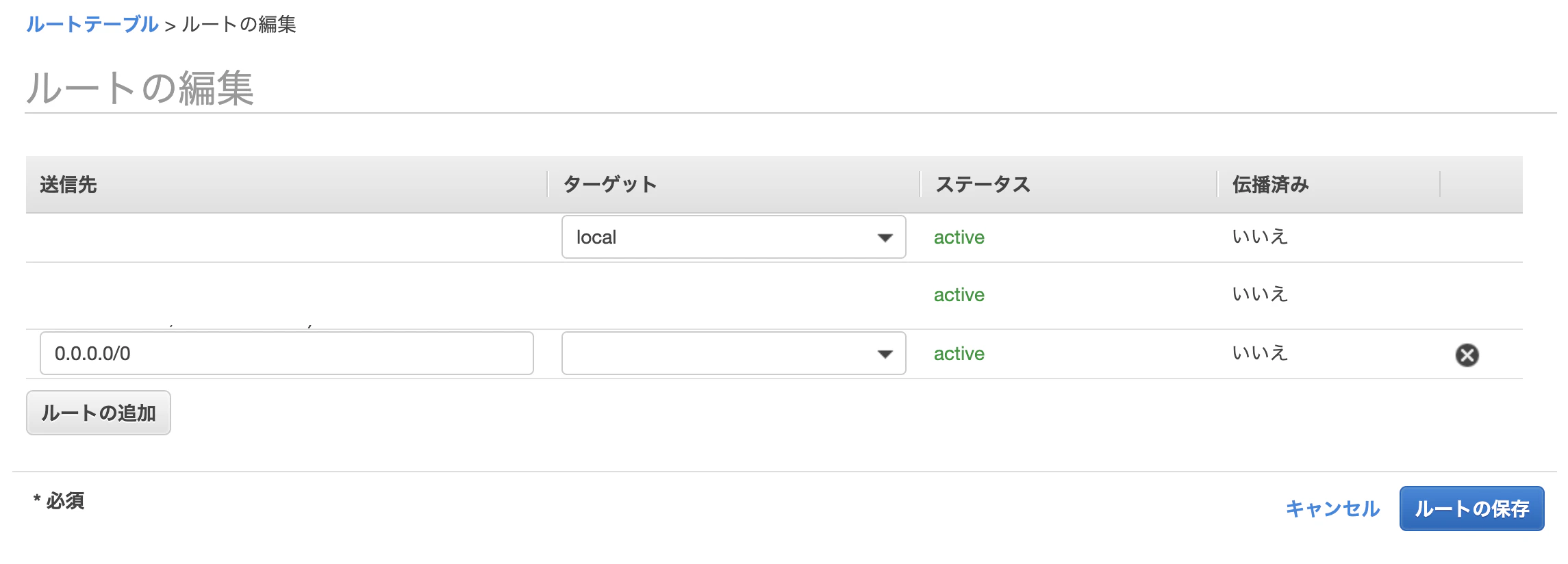
ルートの編集をクリック
送信先を指定、ターゲットに先ほどPublicSubnetに配置したNATを指定。このNATGatewayをSESだけに使用したい場合には、SESのサポートからElasticIPをメールサバーに紐づけるようリクエストして、送信先をそのIPにする。(今回はIP絞らないお手軽版)
ルートの保存をクリック
アクセステスト
コマンドラインを使用して Amazon SES SMTP インターフェイスへの接続をテストする
送信元になる予定のインスタンス内部で接続テストを実施openssl s_client -crlf -quiet -starttls smtp -connect email-smtp.us-west-2.amazonaws.com:587上記で接続確認ができれば、あとはアプリケーションから認証情報を持たせて普通に配信できる。
備考
S3の場合いはVPCエンドポイントを使用してセキュアにアクセスすることができた、SESの場合にもエンドポイントの使用が可能になったがまだ東京リージョンでは利用できないため今回の対応は暫定的。
- 投稿日:2020-10-06T12:41:05+09:00
AWS CLIでオートスケーリンググループの更新・デプロイ
TL;DL
bash deploy.sh v1.1.1deploy.sh#!/bin/bash echo "" echo "### Start Deploy $1 ###" echo "" echo "" echo "### SSH Server ###" echo "" ssh -A YourSSHTarget bash deploy.sh echo "" echo "### Creating New AMI ###" echo "" created_ami_id=$(aws ec2 create-image --instance-id YourInstanceId --name "InstanceName-$1" | jq -r .ImageId) echo "AMI_ID: $created_ami_id created" echo "" echo "### Update Launch Template ###" echo "" # update launch template prev_template_ver=$( aws ec2 describe-launch-templates \ --launch-template-ids YourTemplateId | \ jq -r '.LaunchTemplates[].DefaultVersionNumber') new_template_json=$(aws ec2 create-launch-template-version \ --launch-template-id YourTemplateId \ --version-description $1 \ --source-version $prev_template_ver \ --launch-template-data "ImageId=$created_ami_id") echo $new_template_json| jq . echo "" echo "### Restart Autoscaling Group ###" echo "" # restart servers aws autoscaling start-instance-refresh --auto-scaling-group-name YourAutoscalingGroupName概要
パイプラインとかコードデプロイとかを使うのがモダンだが、まずはシェルでも良いかということで、書いてみた。
sshで対象のインスタンスに接続、今回はprivate subnetにあるインスタンスだったので、ssh configのプロキシ使用し、踏み台経由でアクセス。リモートサーバーで実行したい処理を実行(ソースコードもってくるなど) githubの認証情報をssh-agentに持たせたため、-Aオプション使用。
echo "" echo "### SSH Server ###" echo "" ssh -A your-ssh-target bash deploy.sh対象のインスタンス、でアップデート等が済み新しいバージョンが動き始めるようになったら、対象インスタンスからAMI作成。
echo "" echo "### Creating New AMI ###" echo "" created_ami_id=$(aws ec2 create-image --instance-id YourInstanceId --name "InstanceName-$1" | jq -r .ImageId) echo "AMI_ID: $created_ami_id created"更新したAMIを元に起動テンプレートの新しいバージョン作成
--source-versionを指定したかったので、対象起動テンプレートのデフォを取得した。echo "" echo "### Update Launch Template ###" echo "" # update launch template prev_template_ver=$( aws ec2 describe-launch-templates \ --launch-template-ids YourTemplateId | \ jq -r '.LaunchTemplates[].DefaultVersionNumber') new_template_json=$(aws ec2 create-launch-template-version \ --launch-template-id YourTemplateId \ --version-description $1 \ --source-version $prev_template_ver \ --launch-template-data "ImageId=$created_ami_id") echo $new_template_json| jq .今回はオートスケーリング グループの設定として常に起動テンプレートの最新バージョンを参照するように設定しているため、あとはインスタンス更新をトリガーする。
echo "" echo "### Restart Autoscaling Group ###" echo "" # restart servers aws autoscaling start-instance-refresh --auto-scaling-group-name YourAutoscalingGroupName注意
AWS CLI v2.0.54
バージョンが違うと一部コマンドが実行できない。またpipだと最新版まで上げられなかったため公式ドキュメントの方法で最新版をインストールした。試しに動かす際は、--dray-runをつけた方がいい。実際に変更は加えられないがエラーが起きるかどうか確認できる
ちゃんと使うなら、各種IDは別ファイルを参照させたりする、インスタンスが起動状態を確認する、例外処理を加えるなどの追記が必要。現状とりあえずお手軽版
- 投稿日:2020-10-06T12:30:06+09:00
AWS Organizationsと無料枠
AWSの無料枠ってOrganizationsのメンバーアカウントだとどうなるんだっけ、というのを再確認したのでメモ。
AWSの無料枠
AWSアカウントごとに、無料で使えるリソース量が提供される。特にアカウント作成直後は「12 か月無料」「無期限無料」のものが両方利用できるので、使えるサービスの幅が広い。
AWS 無料利用枠では、さまざまな AWS のサービスをそれぞれの上限まで無料でお試しいただけます。無料利用枠には、12 か月無料、無期限無料、短期トライアルの 3 タイプがあります。12 か月無料タイプを使用したサービスでは、アカウント作成日からの 1 年間、所定の上限まで製品を無料でご使用いただけます。無期限無料タイプを使用したサービスでは、AWS アカウントをお持ちのあいだは常に、所定の上限まで製品を無料でご使用いただけます。短期トライアルタイプを使用したサービスでは、選択されたサービスに応じて、所定の期間か、または 1 回に限り、製品を無料でご使用いただけます。
(無料利用枠に関するよくある質問)具体的な利用可能サービスは、「AWS クラウド無料利用枠 | AWS」参照。「750 時間/月のLinux、RHEL、またはSLES t2.microインスタンスの使用」「750時間/月のWindows t2.microインスタンスの使用」などが含まれる。
AWS Organizationsと無料枠
Organizationsで複数アカウントを統合管理している場合、そのうち1つのアカウントでしか利用できない。利用できない前提で、たまたま無料枠で費用が賄われたらラッキーぐらいに思っておいた方がよさそう。
お客様がある組織にリンクされている (AWS Organizations において) 場合、当該組織で無料利用枠を利用できるアカウントは 1 つだけです。どのタイプの無料利用枠でも、当該組織の AWS のサービスの使用量は、組織の全アカウントの使用量を集計した数字になります。
(無料利用枠に関するよくある質問)Organizations利用組織ではサンドボックス的なアカウントをどうするか
Organizationsを利用している組織は多いと思うのだけど、そうした組織でも従業員がAWSさわってみたいという時のサンドボックス的なAWS環境をどうするかという方針は必要だろう。AWSアカウントを独立させれば、いろいろな面で業務利用中の他AWSリソースに影響を及ぼさないことを担保できるけど、AWSアカウント作成には次のものが必要になる。
- rootメールアドレス
- (Organizationsのメンバーアカウントでない場合)支払い手段
- (Organizationsのメンバーアカウントでない場合)連絡先情報
Organizations内のメンバーアカウントを使うと、個別に支払い手段(多くの場合クレジットカード)を登録する必要がなく、また統合請求の形で支払い処理が簡素化され、各アカウント(≒利用者)毎の利用料も管理しやすい。一方でAWSの無料枠の恩恵はほとんどなくなる。そのメリット、デメリットを踏まえて…
- Organizations内でメンバーアカウントを払い出す
- 各自で(おそらく自分のクレジットカードと連絡先情報で)AWSアカウントを取得する
- 各自で(〃)AWSアカウントを取得し、サンドボックスを卒業する必要が出てきたら、Organizationsにそのアカウントを招待する
…といったことが考えられそうに思う。3番目がいちばんオイシイのだけど、後から組織の運用ルールとかOrganizationsでの設定とかからくる制約を課すことになる。これをやりたければ、あらかじめルールを整えておいた方がよさそうに思われた。
- 投稿日:2020-10-06T11:43:03+09:00
AmazonLinux2 の EC2 からサクッと MSK の kafka topic を作ったりする方法
kafkacat とか kafka-topic.sh などの kafka-tools をインストールするのめんどいので、Docker でやるアプローチ
MSK で kafka cluster の describe を得る
aws kafka describe-cluster --cluster-arn {{arn:aws:kafka:X:X:cluster/analytical-msk/X}}kafka-topic.sh で topic を create する
sudo docker run wurstmeister/kafka:2.12-2.4.1 /opt/kafka/bin/kafka-topics.sh --create --zookeeper "{{z1,z2,z3}}" --topic test --partitions 1 --replication-factor 1MSK で bootstrap-brokers を get する
aws kafka get-bootstrap-brokers --cluster-arn {{arn:aws:kafka:X:X:cluster/analytical-msk/X}}kafkacat で topic の list をする
sudo docker run -it --network=host edenhill/kafkacat:1.5.0 -b {{BROKER_HOST}} -L
- 投稿日:2020-10-06T11:15:14+09:00
『2000年創業エムスリーが挑む 大規模クラウド移行の舞台裏』 視聴メモ
はえーすっごい。
下記 connpass の視聴メモをざっくりまとめたものです。
https://m3-engineer.connpass.com/event/187265/タイトルの通り オンプレ=>クラウド移行に関するお話でした。
移行自体の知見というより、クラウドリソースの運用ルールなど、仕組みを整えるうえで
大変だったことや工夫した点について聴ければいいなというモチベーションでした。
特に権限管理周り。※ 個人的にまとめたものなので、内容に不備がある場合はコメントして頂けると幸いですm
0. エムスリーについて
- 「インターネットというメディアを活用し、医療の世界を変革します。」
- 2000 年創業
- 1996 Yahoo Japan
- 1997 楽天
- 1998 サイバーエージェント
- 1999 DeNA
- と振り返ると改めて歴史を感じる。
- 20年間増収・増益
- コロナ下の社会に対しても強いスタンスを持って臨んでいる
- アクセス数の増加
- 医師/製薬マーケから、インターネット経由の情報収集ニーズの高まり
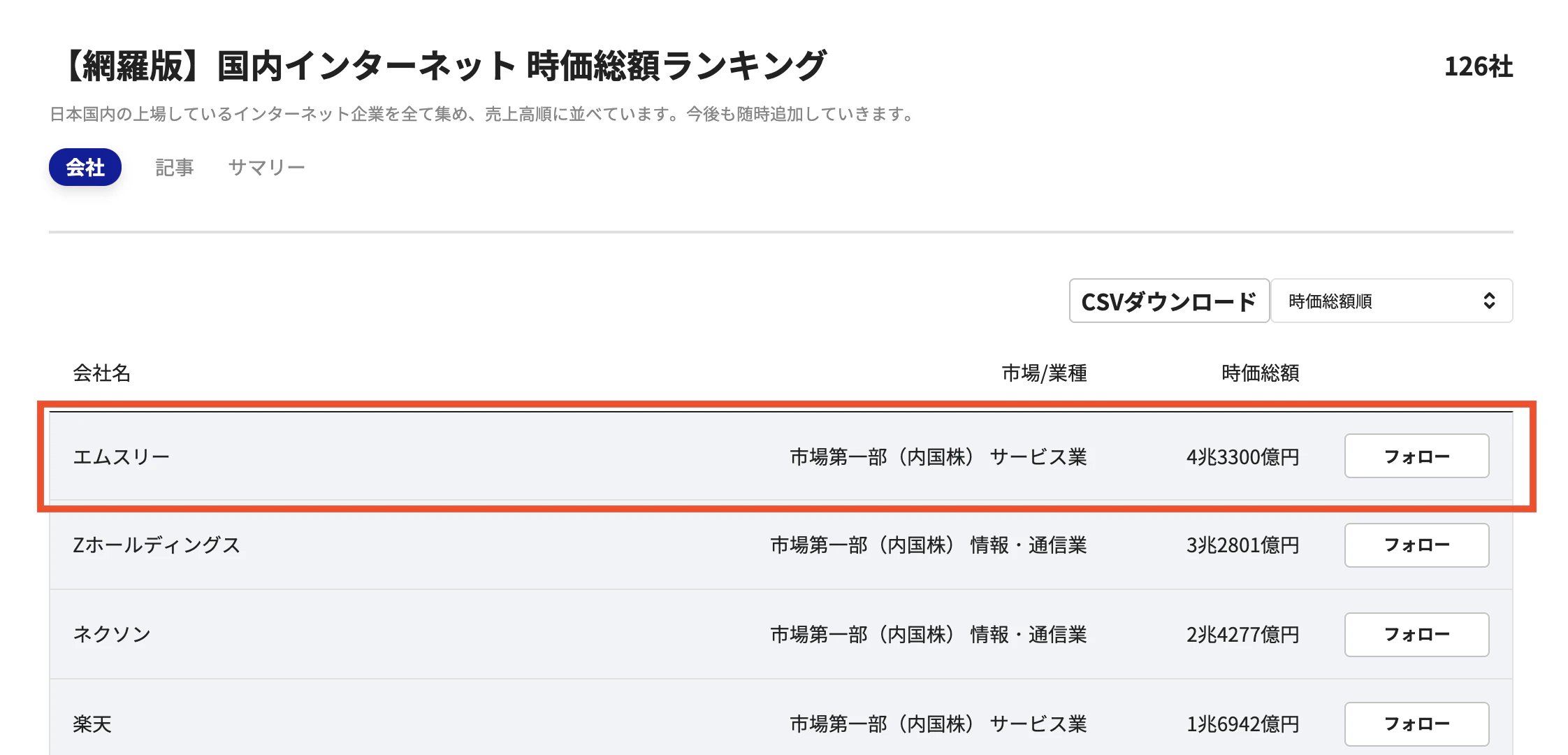
- インターネット企業時価総額 No.1 (4.33兆円)
- エンジニアの組織構成
- エンジニア 90 人, プロダクトごとのチーム 16 チームほど
- めちゃくちゃ個人の裁量ありそう
- 「技術選定は原則チームの自由」
1. 大規模クラウド移行の背景
移行に踏み切った要因
- ポジティブな要因
- さらなる事業拡大のため。
- ネガティブな要因
- 諸事情が重なり、どうしようもなくなったから。
起こってしまった諸事情 (2019. 8)
- SRE チームメンバー 5 名のうち 2 名の退職申し出
- インフラ作業全般を SRE に任せていたのでヤバイとなった。
- オンプレSREがなかなか採用できない。
- 慢性的なハードウェアの負債
- 積み読ならぬ積みサーバの増加
- セットアップなどの運用も SRE の仕事
- オンプレ機器の故障が結構あった。
移行に関わるターニングポイント
- Algolia Solultion Engineer の方
- 『事業のコア技術としてオンプレが必要なら必要、そうでなければ不要』
- オンプレに拘らず、その分野が得意な人( AWS とか )に任せてしまうフルクラウドへの機運が高まる。
- sansan CTO 藤倉さん
- 『フルクラウドに移行する際、経営陣の説明が必要になる。その際、事業拡大を支える開発スピードこそ強み。』
- マネジメントチームによる逆転の発想
- 「クラウド化をネタにSREを大量採用できるのでは?」
=> やっていき
移行に関わる希望
2009 から SOA を導入していて、多くのサービスがマイクロサービス化されていた。
- Release It を愛読していた前CTO の功績の一つだとか。
いくつかのチームが、独自にクラウド技術の知見が溜まっている状態だった。
- 研究開発的なことをやっていたらしい。
チームごとに必要な技術を採用できる文化的な基盤が揃っていた
- いざとなればキャッチアップがサクッとできる(というか好きな)文化、ということっぽい。
そして、諸事情の発覚から2ヶ月後の 2019. 10 にクラウド移行宣言!!
2. 移行後のネットワーク設計について
全体のサービス環境
- 300 microservices
- 30 VPCs
- オンプレ + AWS + GCP
移行時に起こり得るカオス
- 属人化による管理不能化
- 構成要素の依存関係が不透明になる
- VPC間のセキュリティリスク
- スケールしない ( => 後からの入れ替えが簡単ではない) 技術設計に起因する事業成長への足かせ
- IPレンジとか
カオスを防ぐ技術的アプローチ
- マネージドなルーター技術の採用 ( to 3 )
- AWS Transit Gateway
- terraform によるリソースのコード管理 ( to 1, 2 )
- 1つのパラメータの値から関連リソースのパラメータを計算するなどして、同じ情報や相関性のある値を2回書かないようにしている。
- ただし「技術選定は原則チームの自由」のため強制ではない。
- VPC, subnet, ACL設計の標準化 ( to 3, 4 )
- 「技術選定は原則チームの自由」とはいえ、VPC, subnet, ACL レベルで構成を変えたいニーズは実際無い。
- 仕組みを設けることで、全チームに自由に選ばせるための理解をしてもらうコストを減らした形。
- private IP レンジ割り当ての設計・体系の構築 ( to 4 )
- 二分木的に CIDR レンジを切っている。
- 構成図の整備・書籍化 ( to 1, 2, 3, 4)
- 以上のアプローチを「どうやったか」はコードから読み取れるが、「なぜそうしたのか」までは汲み取れない。
- そこをプラスしたものをテックブックに載せている。
- インフラは寿命の長いリソースのため、書籍化にも向いている。
3. "止められないサービス" のクラウド移行
止められないサービスの例
- サイトの認証基盤
- 100 ほどの認証 API
認証基盤のサービス構成
( 他サービス -> ) LB -> web サーバ -> AP サーバ -> DB サーバ
移行の流れ
- 予定
- 難易度の低い順に、AP サーバ -> DB サーバ -> web サーバ / LB をそれぞれ移行させていく。
- 実際
- オンプレの LB の性能限界?により、AP サーバ / web サーバ / LB -> DB サーバ と順番を変更。
発生したトラブル
- SSL 証明書が切り替わり、キャッシュ関係でエラー。
- 個別に名前解決するクライアントや AP サーバに直接アクセスするアカウントなど個別の対応が必要なパターンが生じた。
- DB のフェイルオーバーによるマスタ昇格とコネクションプールの機能がかち合って、コネクションの切り替えがうまくいかなかった。
freee でも最近起こった DNS 障害と同じような現象が起こっていたっぽい。
4. 質疑応答
- AWS について、アカウント分割についての戦略はありますか?
- チームに対応した vpc の割り当てを行っているまでで、チームごとのアカウント分割はしていない。
- セキュリティ基盤などは別アカウントで運用。
- BIT VALLEY 2020では山口さんからterraformからaws cdkへの移行の話が出ていましたが、terraformとの使い分けなどされているのでしょうか?
- 技術選定はチームで自由なので、全チーム terraform をつかえ!と言うポリシーはない
- 移行時のテスト体制やテスト中のチェックシート、テストにかかった時間など可能な範囲で教えていただけますか?
- 明確に計測はしていないが、半分以上チェックにかかった印象。
- 移行の周知や他チームとの連携、QAに機能の担保 / エンジニア バックエンドの担保など実作業以外の工数が目立っていたよう。
awsリソースの権限管理(IAM, AWS account など)の仕組みについて、特に気をつけた点があれば聞きたいです。
- 権限管理というかインフラリソースをどう運用するかもチームで自由っぽい。
- 1 チーム 1 SRE (一人) 体勢
- admin 権限を付与して、チームのインフラ構成をお任せ
- 9割以上のチームが実施
- 一部チーム(認証基盤とか)は階層的な感じ
チーム(プロダクト)横断での開発が必要なった場合、チーム間での terraform 利用の有無の差は問題になりますでしょうか?
- IaC (Infrastructure as Code) 使ってないチームがほぼない。
- 一定のキャッチアップは必要だが、プロダクト自体のキャッチアップの方が割合が多め
- AI チームとか共同開発多めなやつだと、キャッチアップ用の Doc が充実している
- OSS 的にチーム横断な開発体制が整っているので、問題になっている感じはなさそう。
感想
SRE チームメンバー 5 名のうち 2 名の退職申し出
何があったんだ... (質問すればヨカタ)
(インフラ)構成図の整備・書籍化
アプローチを「どうやったか」はコードから読み取れるが、「なぜそうしたのか」までは汲み取れない。
これは面白そうだと思った!
実際に書くとなるとキャッチアップやばそうだけど、歴史的背景とかも含めて書籍に残すのは
後々の振り返りに使えそう。「技術選定は原則チームの自由」
1 チーム 1 SRE (一人) 体勢
チームの自由度の高さにとても驚いたし、ただ回しているだけじゃなくてめちゃくちゃデカい成果を出してるから、
エンジニア一人ひとりの裁量の大きさがちゃんと活かされているんだなぁと思った。
少数精鋭の集まりって印象が強かった...
メモを書き起こしてみて、「あ、ここ質問すればよかった...」てポイントがたくさんあって反省。
なんとな〜く聴いちゃってるのもったいない...
話聴くこと自体も大事だけど、自分が興味のある部分に特にフォーカスできるようになりたいなぁ
- 投稿日:2020-10-06T11:09:37+09:00
AWS データ分析環境の構築
AWS データ分析環境の構築
EC2環境構築
CloudFormationを使用し、VPCを作成。作成されたVPCにログを出力するEC2を構築していきます。
CloudFormationの画面に移動し、スタックの作成を行います。
今回使用するyamlファイルは参考資料のGitのほうにあるのでそれを利用します。
実行が終わるとEC2が出来上がり、/root/esdemo/testapp.logにログ出力が始まります。
実行がうまくいけば下のようにEC2のコンソール画面にインスタンスが一つ立っているのでSSH接続します。SSH接続を行い以下のようにコマンドを打つとログが出力されます。
$ sudo su - # tail -f /root/es-demo/testapp.log
このようにして可視化を行うことが出来ます。
IAMロールの作成とEC2へのアタッチ
IAMのコンソール画面に移動しロールを選択し作成を行います。
AWSサービスを選択し「EC2」を選択。アクセス権限ポリシー、タグの追加画面は何もせず次に行き、ロール名を入力し作成を行います。作成したIAMロールをEC2へアタッチするためにEC2のコンソール画面に移動し、先ほど作成したインスタンスを選択します。選択した後、アクションボタンから「インスタンスの設定」→「IAMロールを変換」をクリックします。そして先ほど作成したIAMロールをアタッチします。
Fluentdのインストール
Fluentdはログデータを収集しJSONに変換して出力する機能を提供するオープンソースソフトウェアです。これを使用する事でログの収集を効率よく行うことが出来ます。
EC2にSSHでログインし以下のコマンドを実行します。
$ sudo su - #yum -y install redhat-lsb-core gcc # rpm -ivh http://packages.treasuredata.com.s3.amazonaws.com/3/redhat/6/x86_64/td-agent-3.1.1-0.el6.x86_64.rpm # vi /etc/init.d/td-agent (好きなエディタで大丈夫です) TD_AGENT_USER=td-agent → TD_AGENT_USER=root # chkconfig td-agent onElasticsearch Service の設定
マネジメントコンソール画面からElasticsearch Serviceを選択します。
新しいドメインの作成を行い、デプロイタイプを「開発およびテスト」を選択します。
ドメインの設定ではドメイン名を入力しインスタンスタイプは「t2.small.elasticsearch」を選択しました。
アクセスとセキュリティの設定においてネットワーク構成をパブリックアクセスにします。
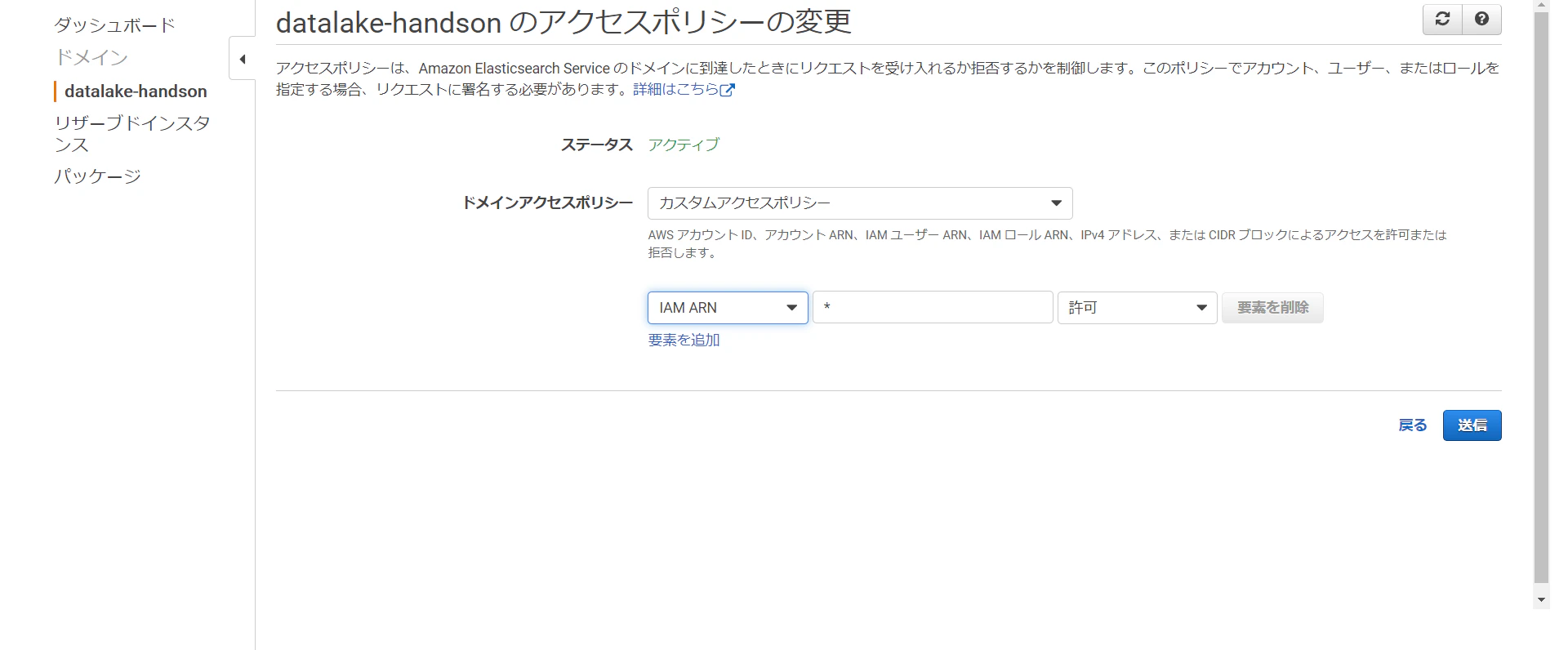
ドメインアクセスポリシーにおいて「カスタムアクセスポリシー」を選択し、タイプに「IPv4アドレス」プリンシパルに「*」を入力、アクションに「許可」を選択して構築を行います。
構築するのに少し時間が掛かります。IAMロールの設定
先程作成したIAMロールに以下のようにポリシーを設定します。
IAMの画面からロールをクリックします。そして先ほど作成したロールを選択します。
そのロールのアクセス権限タブにある「ポリシーをアタッチします」をクリックします。
[AmazonESFullAccess]を検索しアタッチします。Fluentdの設定
FluentdからElasticsearch Serviceにログデータを送信するための設定を行います。
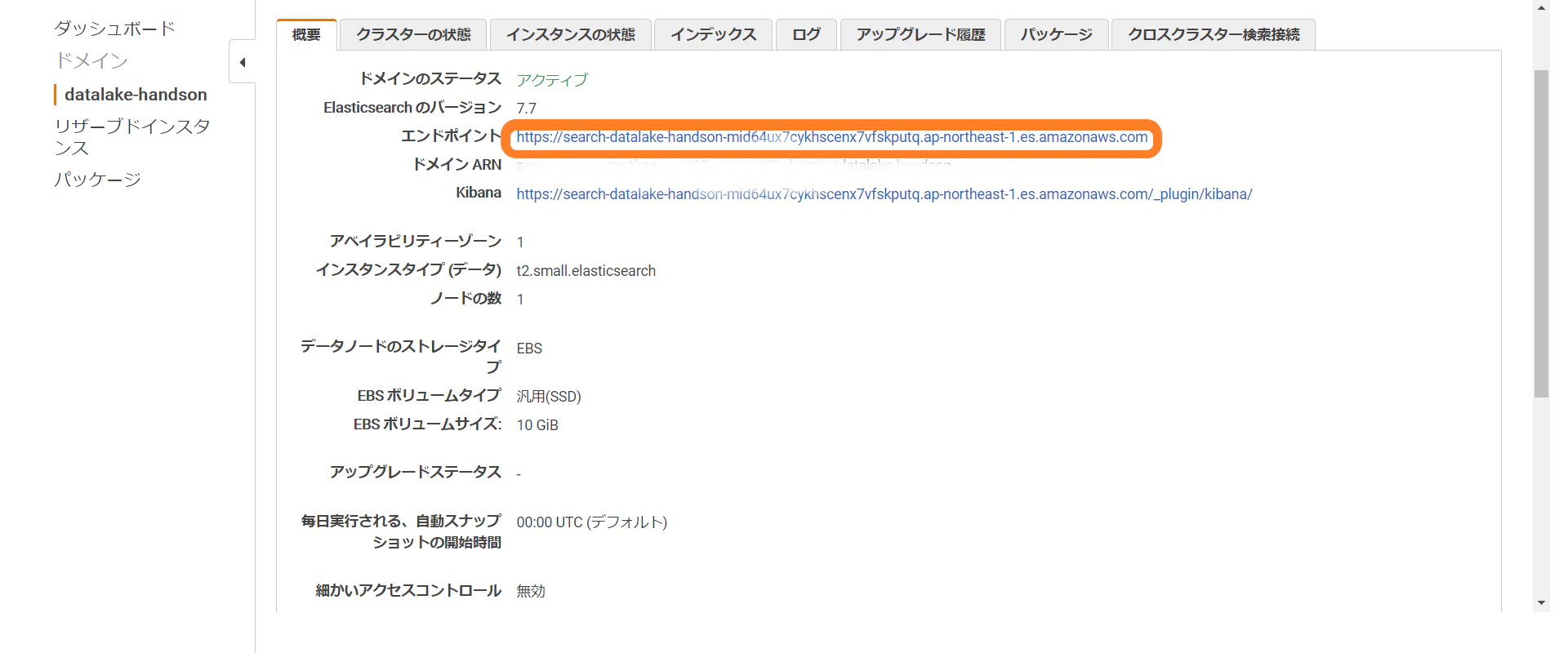
まずElasticsearch Serviceを選択しダッシュボードから先ほど作成したドメイン名をクリック。
エンドポイントにあるURLの文字列を控えておきます。続いてそのままElasticsearch Serviceのところから「アクション」を選択し「アクセスポリシーの変更」を選択します。
ドメインアクセスポリシーにおいてカスタムアクセスポリシーを選択し、以下の内容を設定し画面一番下の送信をクリックします。
タイプに「IAM ARN」を選択、プリンシパルに「*」を入力、アクションに「許可を選択」
送信が終わったらEC2にログインしElasticsearchのプラグインをインストールします。
$ sudo su - #Elasticsearch のプラグインをインストール # td-agent-gem install -v 2.6.0 fluent-plugin-elasticsearch #プラグインのインストールの確認 # td-agent-gem list | grep plugin-elasticsearch #td-agent.confを書き直します。 # vi /etc/td-agent/td-agent.conftd-agent.confを書き直す内容は以下になります。
<source> @type tail path /root/es-demo/testapp.log pos_file /var/log/td-agent/testapp.log.pos format /^\[(?<timestamp>[^ ]* [^ ]*)\] (?<alarmlevel>[^ ]*) *? (?<host>[^ ]*) * (?<user>[^ ]*) * (?<number>.*) \[(?<text>.*)\]$/ time_format %d/%b/%Y:%H:%M:%S %z types size:integer, status:integer, reqtime:float, runtime:float, time:time tag testappec2.log </source> <match testappec2.log> type_name testappec2log @type elasticsearch include_tag_key true tag_key @log_name host ここに先程控えたURLを記入します。https:// は含めないです。 port 443 scheme https logstash_format true logstash_prefix testappec2log flush_interval 10s retry_limit 5 buffer_type file buffer_path /var/log/td-agent/buffer/testapp.log.buffer reload_connections false </match>編集が終わったら以下のコマンドを入力し動作を確認します。
#td-agent のプロセスを起動します。 # /etc/init.d/td-agent start #Fluentd のログを確認 # tail -f /var/log/td-agent/td-agent.logElasticsearch Serviceの設定
マネジメントコンソール画面からElasticsearch Serviceを選択します。
まず作成したドメインの「ドメインのステータス」が「アクティブ」で「検索可能なドキュメント」の件数が1件以上になっていることを確認し選択します。
Kibanaの右のURLをクリックします。
[Welcome to Elastic Kibana] 画面が表示されるため、 [Explore on my own] を選択し、 Kibana の画面を開きます。
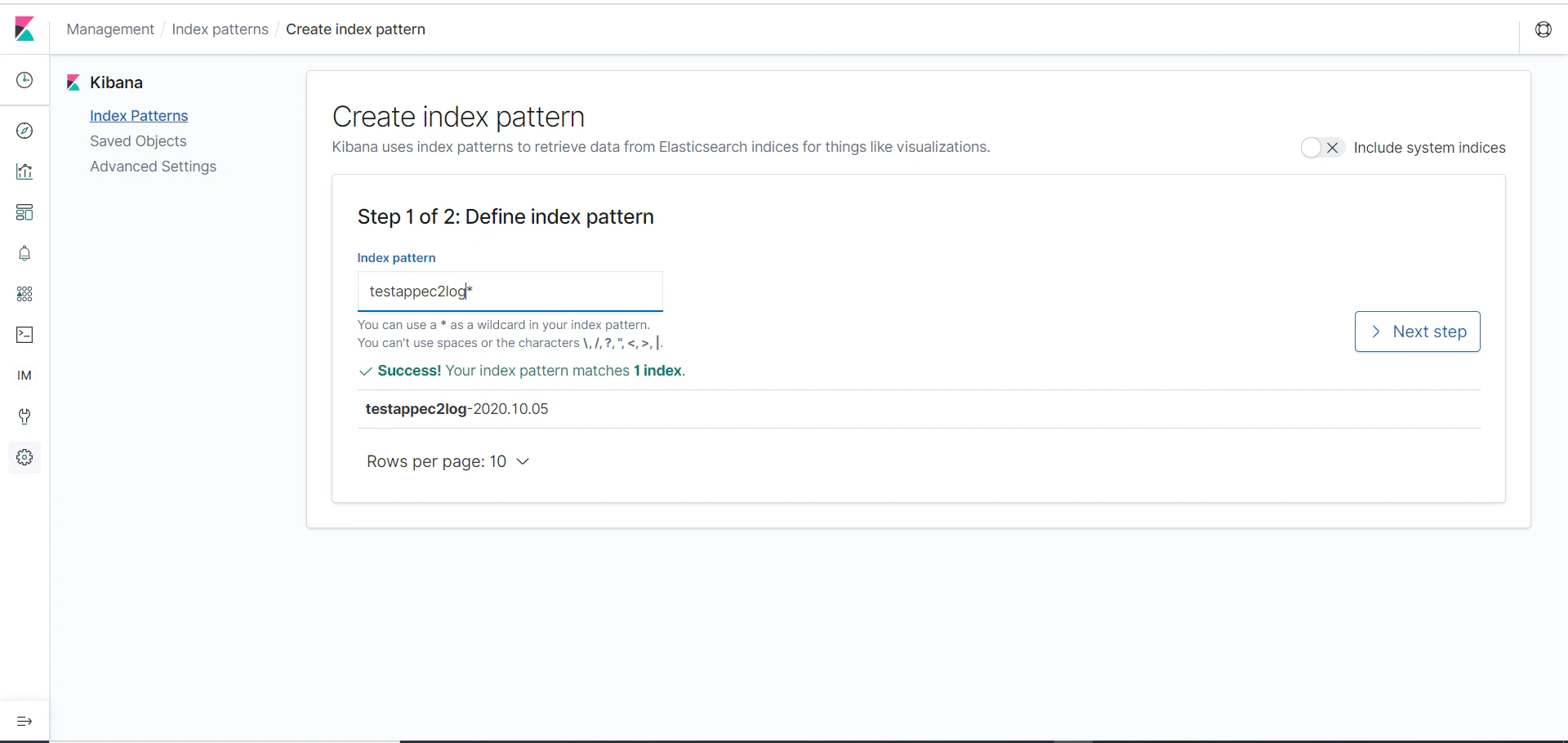
[Create index pattern] をクリックし、 [Create index pattern] 画面において、 [Index pattern] に「 testappec2log-* 」を入力し、右側の [Next step] をクリックします。[Time Filter field name] において、 [@timestamp] を選択し、画面右下の [Create index pattern] をクリックします。
Kibana の画面の左ペインからkibana_managementアイコンをクリックし、 [Saved Objects] をクリックします。画面右上の [Import] をクリックします。[Saved Objects] 画面において、[Import] アイコンをクリックし「 2-visualization.json 」を選択し、 [Import] をクリックします。続いての画面において、 [New index patten] に対して、「 testappec2log-* 」を選択し、 [Confirm all changes] をクリックし、インポートを完了します。問題なくインポートが完了したら、 [Done] をクリックすると、元の画面に戻ります。(この2-visualization.jsonファイルは参考資料のGitにあるのでそれを参照してください。 )
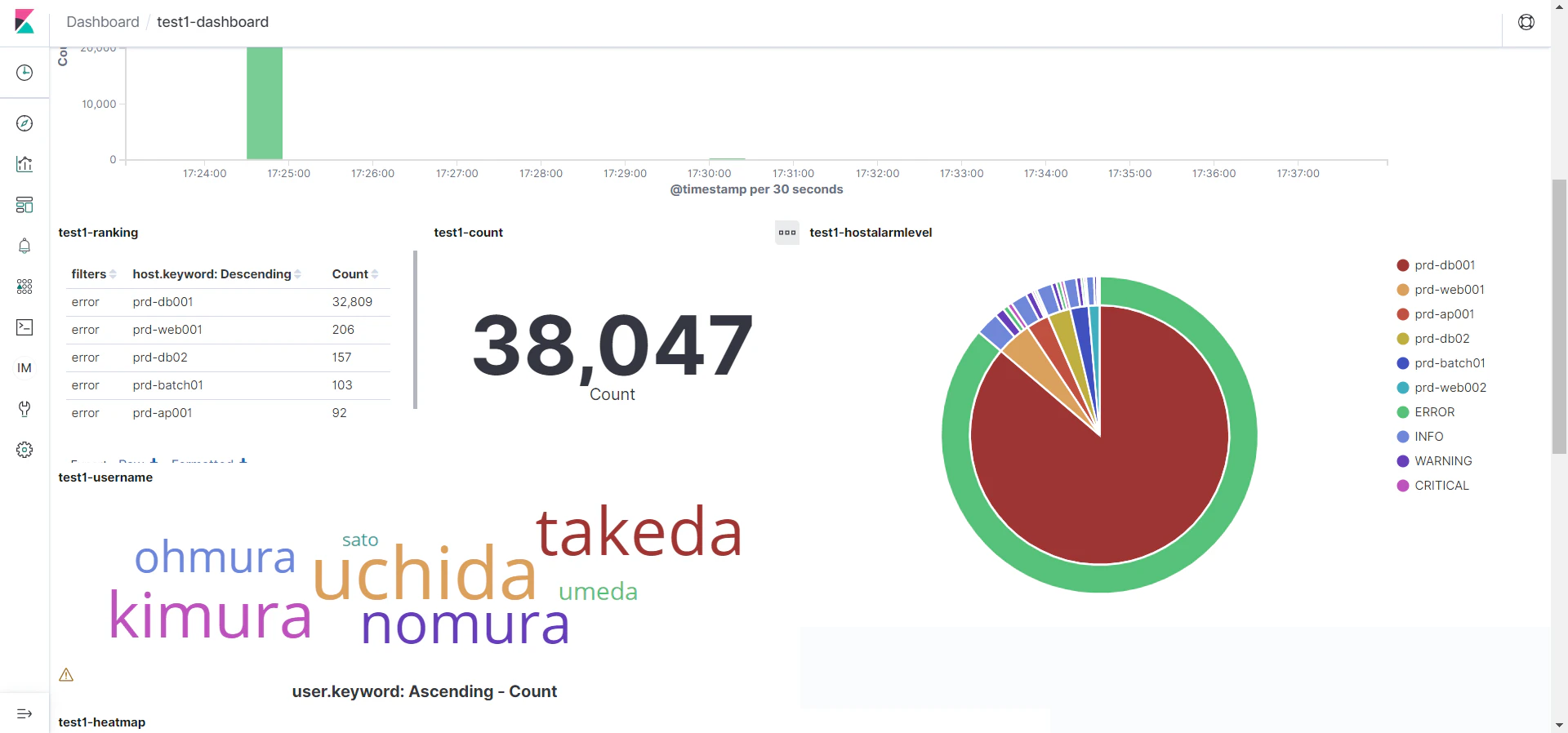
続いて、再度 [Saved Objects] 画面において、[Import] アイコンをクリックし、 Asset 資料の「 2-dashboard.json 」を選択し、 [Import] をクリックし、インポートします。問題なくインポートが完了したら、 [Done] をクリックすると、元の画面に戻ります。(この2-dashboard.jsonファイルも参考資料のGitにあるのでそれを参照してください。 )以上のような設定を行うことが出来るとKibana の画面で以下のような値が表示されます。
<参考資料>
https://github.com/aws-samples/amazon-s3-datalake-handson/tree/master/JP
Fluentdに関して
AWSのIAMロールとポリシーの違い

- 投稿日:2020-10-06T10:52:10+09:00
EC2のインスタンスの違い(オンデマンド・リザーブド・スポット)
オンデマンドインスタンス
概要
- 時間課金制の料金体系
- 初期費用なし
- 普通にインスタンスを立てると、こちらの費用が発生する
購入方法
- EC2 > インスタンス > インスタンスの作成 から作成可能 (普通のサーバ作成方法)
リザーブドインスタンス
概要
- 予約金の支払いをすることで、時間単価の割引が行われる
- 前払い有りにすると初期費用が発生する
- 1年や3年単位での購入になる
購入方法
- EC2 > リザーブドインスタンス > リザーブドインスタンスの購入 から購入できる
スポットインスタンス
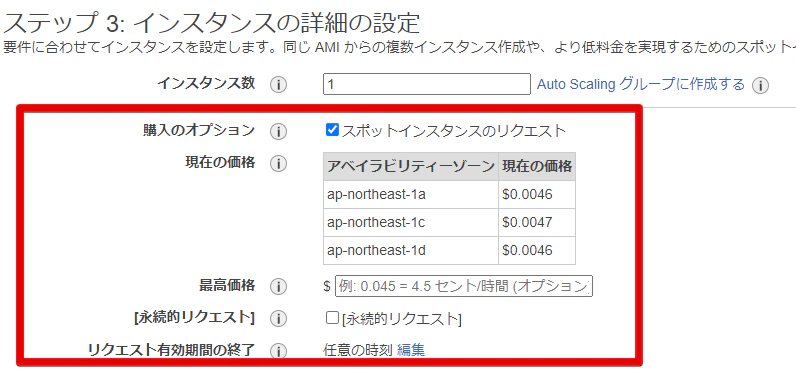
概要
- 初期費用なし
- 余剰のインスタンスを入札制で使用することで安い価格で利用できる。
- 需要と供給によりオンデマンドより高い場合がある
- サーバ使用中に、入札価格よりサーバ価格が高くなればサーバが落ちる
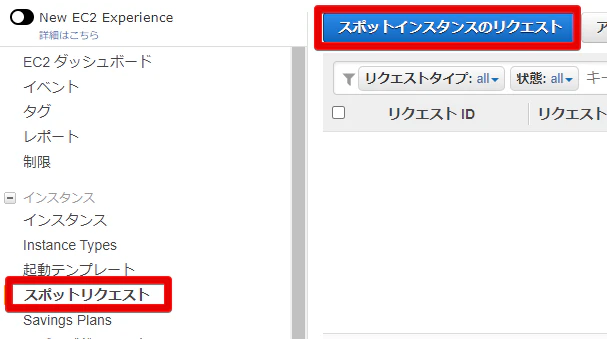
購入方法
- EC2 > スポットリクエスト > スポットインスタンスのリクエスト から購入できる
- ※EC2の作成の画面からでも、
スポットインスタンスのリクエストから購入できる
参考


- 投稿日:2020-10-06T10:37:45+09:00
AWS CodePipeline メモ 複数ブランチの追跡
更新日:2019/10/06
目的
現状
CodePipelineの設定画面で、Githubを選択した場合、ブランチ選択が必須になっている
ゴール
Master以外のいずれのブランチにPushされてもCodePipelineが発火し、デプロイされてほしい
なぜやりたいか?
- 他のCIツールでは複数ブランチからの発火ができている。
- 同じことやりたい
AWS CodePipelineの仕様
複数ブランチの選択
スタックオーバーフロー
AWS CodePipelineで複数ブランチのTrackingしたい
以下のスタックオーバーフローで質問あり
Can AWS CodePipeline track multiple feature branches and run tests on each? - Stack Overflow提案された解決法は以下
- 1. AWS Lambdaを使用して動的にパイプラインを作成(複製)する。
- 2. 外部CIを使ってCodePipelineに反映
※2019年現在もAWSには複数ブランチ対応はされていない
1. 動的にパイプラインを作成
残念ながら、CodePipelineの複数のブランチからビルドをトリガーすることはできません。
私が使用した他のすべてのCIツールがすぐにこの機能を提供するため(GitLabCI、TravisCI、CircleCI、Bitbucket Pipelines、TeamCity)少し驚きです。以下を参考にPushのたびに動的にパイプラインを作成する方法
2. 外部CIを使う
仕様について
Serverless CI/CD for the enterprise on AWS
aws-quickstart/quickstart-trek10-serverless-enterprise-cicd: AWS Quick Start Team
情報
GitHub/CodeBuild/CodePipelineを利用してCloudFormationのCI/CDパイプラインを構築する | DevelopersIO
CodePipelineの場合、GitHubをアクションに指定すると1ブランチ1パイプラインで設定するようです
cloud formation
AWS CodePipelineをCloudFormationで構築してみた | DevelopersIO
設定にBranchは必須のようである
Branch: Type: String Description: GitHub Branchmatch
AWS::CodePipeline::Webhook WebhookFilterRule - AWS CloudFormation
ここで指定した値が「refs/heads/{Branch}」であり、ターゲットアクションのアクション設定プロパティが「Branch」という名前で値が「master」である場合、MatchEquals 値は「refs/heads/master」として評価されます。
AWS 仕様
CodePipeline パイプライン構造のリファレンス - CodePipeline
GitHub > Branch > 必須

- 投稿日:2020-10-06T08:55:31+09:00
AWSSAAに落ちた時の悔しさを書く
はじめに
自分のスキル感
- 実務4ヶ月程度(メインはバックエンド)
- AWSたまに触るぐらい(超主要なサービスは理解していた)
よーするにAWSあんまり知らない駆け出しエンジニアということになります。
資格を取りたいと思った理由は以下の2つ
- 昨今AWSがインフラに使われるのは主流になってきていて自分も体系的な知識をつけたいと思っていたから。
- 資格を持っているとAWSに関してこれぐらいの知識ありますよ〜という明確な基準ができるから。
一口に「AWS触ったことがある」と言ってもどのサービスなのか、どれぐらいの知識があるのかなど、線引きがしづらいと思っていた。
そこで資格の勉強をしてみようと思いました。勉強したこと
勉強期間は1ヶ月ちょっとです。
基本的に勉強したのは下記の2つのみですこの1冊で合格!AWS認定ソリューションアーキテクトアソシエイト テキスト&問題集
上記の本を軽く読み通してSAAに試験に出そうなサービスの概要を知りました。
各サービスの内容もある程度書かれているため、ざっくり学ぶにはちょーどよかったです。
少し出たのが古いのですが、サービスを体系的に学ぶ分にはそう悪くはないかなという印象です。
最後に一応軽い模擬試験もあります。
あとで見返したりして何回も使いました。【SAA-C02版】AWS 認定ソリューションアーキテクト アソシエイト模擬試験問題集(6回分390問)
ネットで合格体験記を読んでいるとよく出てきていたので、こちらもやりました。
セール時は安くなっているので、その時に購入するといいです。
模擬試験が6回分ありますが、3周ぐらいはやったかなという印象です模擬試験1 1回目:49% 2回目:86% 3回目:83%
模擬試験2 1回目:38% 2回目:56% 3回目:73%
模擬試験3 1回目:47% 2回目:56% 3回目:69%
模擬試験4 1回目:43% 2回目:86% 3回目:74%
模擬試験5 1回目:41% 2回目:49% 3回目:69%
模擬試験6 1回目:43% 2回目:63% 3回目:78%わからないサービスの内容についてはqiitaの記事を見たり、本を見たり、blackbeltもたまに参考にしていました。
自分の中では、これぐらいでギリギリ受かるか受からないかどちらかぐらいだろうと思っていました。試験当日
試験の内容は言えないのですが、問題を1周といてフラグ立てていた問題だけ見直して終了しました。
他の方も言っていますが、2択までは絞り込めるのですが、そこからは直感で選んでいました。
なかなか難しかったです。問題を解き終わってアンケートを答えると、目の前に
不合格
の文字があり、自分は崩れ落ちました。
目の前が真っ暗になりました。試験結果
自分の中で大体何点かも予想できませんでした。
ギリギリ落ちたとかそのレベルであって欲しかったのですが、結果は642点と話にならないレベルでした。。。
高パフォーマンス、セキュリティ、コスト最適化 この辺は再学習の必要があるとのことです。ふむふむ
最後に
めちゃめちゃ悔しい
次こそはAWSSAAを必ず取りたいと思いました。しかしながら、勉強するのがなかなか難しい。。。
どのサービスの知識が抜けているのか、実際の問題はいろんなサービスが関連して出てきて、いろんな場面を想定(コスト最適化するのか、パフォーマンスを重視するのかなど)しなければならないため、何を勉強すれば良いのかというのがあまり明確ではないと思いました。自分の努力不足を認め、また1から勉強していきたいと思います。
何かAWSSAAに関してアドバイスをいただけると幸いです。
最後まで見ていただきありがとうございました。次こそは必ずAWSSAAに1000倍返しダァ!!!!!!!!!!!!!!!!!!!!!!!

- 投稿日:2020-10-06T08:51:53+09:00
データ管理・活用でAWS/Azule/その他で使えそうなサービス探し
AWS/Azure問わず、データ管理・活用形のサービスを調べることになったので、自分用メモ
AWSから
https://aws.amazon.com/jp/big-data/datalakes-and-analytics/
上記のページを参考に構成してみるデータ管理・活用サービス構成例
カテゴリ ユースケース AWS のサービス 分析 インタラクティブ分析 Amazon Athena ビッグデータ処理 Amazon EMR データウェアハウジング Amazon Redshift リアルタイム分析 Amazon Kinesis 運用上の分析 Amazon Elasticsearch Service ダッシュボードと可視化 Amazon QuickSight 予測分析と機械学習 フレームワークとインターフェイス AWS 深層学習 AMI プラットフォームサービス Amazon SageMaker データの移動 リアルタイムのデータ移動 Amazon Managed Streaming for Apache Kafka (MSK) Amazon Kinesis Data Streams Amazon Kinesis Data Firehose Amazon Kinesis Data Analytics Amazon Kinesis Video Streams AWS Glue データ統合・データ処理 データ統合・品質管理 AWS Glue データ統合・データ処理 データ統合・品質管理 AWS Lambda データレイク オブジェクトストレージ Amazon S3 /AWS Lake Formation バックアップとアーカイブ Amazon S3 Glacier/AWS Backup データカタログ AWS Glue AWS Lake Formation サードパーティーのデータ AWS Data Exchange S3に対してクエリ等でデータを呼び出せるサービス
Amazon Athena
概要:S3に保存・蓄積したログに対してSQLクエリを投げて分析を行えるサービスです。
特徴:サーバーレスでS3上のデータに対して直接クエリを投げられます。
というかほぼほぼPrestoという理解でよさそう。
ただ、説明を見ていると結構Hiveに近いもののイメージ
Amazon Document DB/Amazon Dynamo DB/Amazon HBase/Amazon Athena Elasticsearchに対してもクエリを投げられる機能あり
なお、限定的だがAmazon Athena Lambda JDBCを利用すると一般のDBにクエリを投げる機能もある模様(MySQL、PostgresSQL、Amazon Redshift)
https://docs.aws.amazon.com/ja_jp/athena/latest/ug/athena-prebuilt-data-connectors.html
S3上のファイルに対してクエリを投げられるエンジンということで、一般的なDBへのアクセスはできないことに注意
非構造化データに対してが扱えるのが強みだと思われる(一般的なログ、CSVなど、画像データなんかはSparkで加工したものだったら入れられそう)
https://aws.amazon.com/jp/athena/faqs/
データベース・テーブル作成はHiveのものをそのまま使っているようなので、シリアライザ・デシリアライザも共通で使えるっぽい
機械学習機能が搭載された(https://aws.amazon.com/jp/athena/features/?nc=sn&loc=2)
制約として、原則S3上のファイルに対してのみクエリを飛ばせることから、データはS3に投入する必要がある
また、データベースとS3間でのクエリの実行は不可
データ加工ツールとしては非推奨で、データ分析ツールとして使うことを推奨しているもよう
EMRやRedShiftとの違い:EMRやRedShiftはインスタンス管理の手間がかかるが、こちらはクエリエンジンなので手間かからず
使い道考察:
S3に投入できる非構造化データ・半構造化データ・構造化データを取り扱えるということで、ログ解析などには使用できそう。
ただし、一般的なDBとの接続が困難であるため、データ分析に使用するには機能不足(一般的なDB上のデータが扱えないので)
また、クエリによる加工しかできないので、加工ツールとしての機能もいまいちかなという印象
DB上のデータと非構造データを取り扱えるほかのツールを探す必要がありそう(そういう意味でtrifactaとかDataRefineryは高性能だと思う)
使用できるファイル形式:
S3上のファイルに対してクエリを実行するということで、以下のファイル形式をサポート
CSV、JSON、ORC、Avro、Parquet
料金体系:
Amazon Athena では、実行したクエリに対してのみ料金が発生します。
各クエリでスキャンされるデータ量に基づいて課金されます。
データの圧縮、分割、列形式への変換を行うと、大幅なコスト削減とパフォーマンス向上を実現できます。
このようなオペレーションにより、Athena でクエリを実行するためにスキャンする必要のあるデータ量が減少するためです。
→パーティションの設計とかちゃんとしておこうねっていうことだと思うが、大容量データを使用した場合の課金量が増大する懸念がある
Amazon EMR
概要:Hadoopクラスタです。
使用できるHadoopのサービスは以下
https://aws.amazon.com/jp/emr/features/?nc=sn&loc=5
使い道考察:
Hadoopクラスタの一般的なサービス+ sqoop,spark,各種ノートブック,Tensorflowなどが入っているのでビックデータ向け解析基盤として利用できそう
ただ、これも一般的なDB上のデータを統合する際に工夫が必要となりそう
データ格納先としてはS3またはHDFSを使用しているもよう
Amazon Athenaとの差別化はS3上のデータに対しての分析処理をどの程度複雑にやりたいか+扱うデータ量になるか
クエリを実行するデータ量が多いほど、EMRを使用したほうがよさそう(ビッグデータ向け)
AthenaとEMRは費用曲線作ってもよさそう
料金体系:
Amazon EMR の料金は、Amazon EC2 の料金 (基本的なサーバーの料金) と (Amazon EBS ボリュームをアタッチしていれば) Amazon EBS の料金に別途追加されます。こちらも 1 秒ごとに課金、最小課金時間は 1 分となっています。Amazon EC2 にはさまざまな料金オプションが用意されています。例えば、オンデマンド (下記参照)、1 年間および 3 年間のリザーブドインスタンス、スポットインスタンスなどです。スポットインスタンスは予備の Amazon EC2 キャパシティーで、オンデマンド料金と比べて最大 90% の割引価格でご利用いただけます。オンデマンドと比較したスポットインスタンスの費用節約については、スポットインスタンスアドバイザーのページで「EMR でサポートされるインスタンスタイプ」でフィルタリングしてご確認ください。Amazon RedShift
概要:中身postgresqlっぽい列指向DB
特徴:S3をデータ格納元としてデータ管理するための列指向データベース
使い道考察:AWSサービス上にDWHを作成する場合は、RedShiftを使用するのが定番のようす
S3をデータ格納先とするクラスタを作成、DBとしてRedShiftを使用しているイメージ
ただ、使い方を見ているとS3上にソースデータを配置する際はS3側で作業していて、S3上のデータをロードするところからRedShiftの機能のようにみえるので、S3にデータを入れた後、それが見られるならAthenaでもよい?サービスごとの使い分けについて:
https://aws.amazon.com/jp/athena/faqs/
Q: Amazon Athena、Amazon EMR、Amazon Redshift の違いは何ですか?
Amazon Athena などのクエリサービス、Amazon Redshift などのデータウェアハウス、Amazon EMR などの洗練されたデータ処理フレームワークはすべて、異なるニーズおよびユースケースに対応します。その作業に適したツールを選択する必要があります。Amazon Redshift では、特に複数の結合やサブクエリを伴うきわめて複雑な SQL を使用する場合に、エンタープライズレポートやビジネスインテリジェンスワークロードで高速なクエリパフォーマンスが利用できます。Amazon EMR を使用すると、オンプレミスのデプロイと比較して、Hadoop、Spark、Presto などの高度に分散された処理フレームワークをシンプルでコスト効率の高い方法で実行できます。Amazon EMR は柔軟性を備えています。カスタムアプリケーションやコードを実行し、詳細なコンピューティング、メモリ、ストレージ、およびアプリケーションパラメータを定義して、分析要件を最適化できます。Amazon Athena を使用すると、サーバーのセットアップや管理をしなくても、S3 内のデータに対してアドホッククエリを簡単に実行できます。Q: Amazon Redshift のようなフル機能のエンタープライズデータウェアハウスと、Amazon Athena のようなクエリサービスはどのように使い分ければよいですか?
Amazon Redshift のようなデータウェアハウスは、在庫システム、金融システム、および小売販売システムなどのさまざまなソースからデータを一般的な形式で取得し、長期間保存して、履歴データから洗練されたビジネスレポートを構築する必要がある場合に適しています。こうした場合には、Amazon Redshift のようなデータウェアハウスは最適です。データウェアハウスは、企業全体からデータを収集し、「信頼できる唯一の情報源」としてレポート生成および分析に使用できます。データウェアハウスでは、多くのソースからデータが取得され、形式化および整理され、保存されます。また、ビジネスレポートの生成を行う複雑で高速なクエリに対応しています。Amazon Redshift のクエリエンジンは、非常に大規模なデータベーステーブルを多数結合する複雑なクエリを実行する必要がある場合のユースケースで、パフォーマンスを特に発揮するように最適化されています。TPC-DS は、このユースケースをレプリケートするために設計された標準のベンチマークで、Redshift では、これらのクエリを非構造化データ用に最適化されているクエリサービスと比べて最大 20 倍高速で実行します。非常に大規模な多数のテーブル間で多数の結合がある、高度に構造化されたデータに対してクエリを実行する必要がある場合は、Amazon Redshift をお勧めします。
これに対して、Amazon Athena のようなクエリサービスを使用すると、データの形式化やインフラストラクチャの管理について心配することなく、Amazon S3 のデータに対して直接インタラクティブにクエリを実行できます。例えば、Athena は、一部のウェブログですばやくクエリを実行し、サイトのパフォーマンス問題のトラブルシューティングのみが必要とされる場合に適しています。クエリサービスを使用すると、迅速に開始できます。データのテーブルを定義し、標準 SQL を使用してクエリを開始するのみです。
また、両方のサービスを併用することもできます。Amazon Redshift にロードする前に、Amazon S3 でデータをステージングすると、そのデータも Amazon Athena で登録され、クエリを実行できます。
Q: Amazon EMR とAmazon Athena はどのように使い分ければよいですか?
Amazon EMR の機能は、単なる SQL クエリの実行をはるかに超えるものです。EMR を使用すれば、機械学習、グラフ分析、データ変換、ストリーミングデータ、および実質的にコード可能なすべてのアプリケーション向けに、スケールアウトする幅広いデータ処理タスクを実行できます。Spark、Hadoop、Presto、Hbase などの最新のビッグデータ処理フレームワークを使って、きわめて大規模なデータセットを処理および分析するためにカスタムコードを使用する場合は、Amazon EMR を使用できます。Amazon EMR では、クラスターの構成や、インストールされているソフトウェアを完全に制御できます。Amazon S3 のデータに対して、インフラストラクチャやクラスターを管理せずにインタラクティブなアドホック SQL クエリを実行する場合は、Amazon Athena を使用できます。
リアルタイムデータ処理
リアルタイムデータ処理については後回し
Amazon Kinesis
特徴:リアルタイムデータストリーミング
kafkaのようなものAmazon Elasticsearch Service
特徴:全文検索エンジン
OSのログやアプリケーションのログを収集して、一画面上でログの閲覧
使い道:
いちいちOSに入ってログを探さなくても、Elasticsearchで収集して検索することで高い効率でログ解析できる。
サーバー台数が多い、openshiftなどでリソースが変化(サーバー台数が動的に変わる)して監視が難しい環境などには効果が高いと思われる
比較されるものとしてelastic + kibana とsplunkがある
https://blog.yoslab.com/entry/2014/11/22/002107
非構造データの取り扱いは一番強そうに感じる
代表的なお試し例はTwitter→Spark→Elasticsearch→kibanaの可視化例
ほかにはS3 → lambda → elasticsearchなどの流れただ、データ分析するにあたって、クエリエンジンではなく独特な使用感なのがネックになりそう
trifactaとかに入れて加工できたら便利かな
なお、データ格納先としてelasticsearch→hiveでデータ検索(クエリを使える)も実装できるもよう
ただし、並列化の数はelasticsearchのシャード数で固定されるようなので、速度的な問題がありそうAmazon Lambda
特徴:プログラム実行環境の提供
以下の言語の開発環境を提供する
Java
Go
PowerShell
Node.js
C#
Python
Ruby
さらに、拡張機能(Lambdaレイヤー)を利用することで、以下の言語にも対応
C++
Rust
Erlang
Elixir
COBOL
PHP
使い道:
上記の言語に対応していることであれば大体何でもできそう
ログ収集・データ加工・分析・機械学習など
使用者のスキルレベル依存になると思うので、プログラムが使用できる人向けになりそう
IT企業としては導入しやすいと思うが、他企業だとIT部門以外には導入が厳しいように感じる。
Excelくらい簡単にとか、GUIでやりたいとか言われそう
データ統合に使う場合、Glueと比較してどちらがやりやすいか
ただ、できること自体はLambdaのほうが万能(プログラム作るので・・・)
- 投稿日:2020-10-06T00:33:12+09:00
AWS Client VPN と OSS の IdP(Keycloak) を SAML 連携する (後編)
はじめに
_s__o_ です。
前回 の記事の続きとなります。
前回、Keycloak の構築まで完了したので、今回は具体的な SAML 連携から始めていきたいと思います。
Keycloak との SAML 連携
では、ここから実際の SAML 連携の設定に入っていきます。
認証の流れ
最初に軽く認証の流れを説明しておきます。環境構成後は、下記の流れで SSO を実現します。
※私の想定を記載しています。認識違いなどあれば、ご指摘いただければ幸いです。
- ユーザは、SP(Client VPN クライアント)に接続要求を出す
- SP は、ユーザに IdP(Keycloak)情報を伝える
- ユーザは、IdP に対して SAML Request を投げる(GET 処理)
- IdP は、ユーザに認証画面を返す
- ユーザは、認証情報を入力する
- (認証 OK の場合9 IdP は、SP に渡すべき属性情報(名前や email など)をユーザに渡す
- ユーザ、受け取った情報を SAML Response として SP に渡す(POST 処理)
- SP は、情報を受け取り、問題がなければ VPN 接続を開始する
- VPN 接続が確立する
Keycloak 作業
はじめに、Client VPN のマニュアル を参照し、IdP に設定すべき情報を確認しておきます。左記ドキュメントには下記パラメータが記載されています。後々使うので、頭の片隅においておきましょう。
VPN サービスプロバイダ情報
項目 値 備考 Assertion Consumer Service (ACS) URL http://127.0.0.1:35001 IdP の認証成功後に属性情報を Post する SP の URL? Audience URI urn:amazon:webservices:clientvpn SP を一意に識別する文字列? IdP はこの文字列をもとに、どの SP からの SAML Request かを判別する? 属性情報
項目 説明 備考 NameID ユーザの E メールアドレス "メールアドレス" なので注意 FirtstName ユーザの名 LastName ユーザの性 memberOf ユーザが属するグループ 「NameID」=「ユーザの Email」は必須属性となりますので、IdP で定義したユーザの Email 値が空の場合は、SAML Response のタイミングで接続失敗となってしまいます。
それでは、次から具体的な Keycloak の設定作業に入っていきましょう。
クライアントの作成
Keycloak の管理コンソールにログインし、「設定 > クライアント」を選択します。クライアント一覧が表示されるので、「作成」ボタンを押下します。
「クライアントの追加」画面が表示されますので、下記の通り入力し、「保存」ボタンを押下してください。
項目 値 備考 クライアント ID urn:amazon:webservices:clientvpn 前述の「Audience URI」の値です クライアントプロトコル saml クライアント SAML エンドポイント (空) 空値で問題ありません
「設定」タブ
クライアントの作成に成功すると、自動的に「設定」タブに遷移します。続けて、下記のとおり設定していきます (記入必須項目のみ記載しています)。
項目 値 備考 Name ID フォーマット 前述の「NameID 」です。E メール形式のため、「email」とします ルート URL ${authBaseUrl} Keycloak のベース URL を自動補完させるため、環境変数で指定します IDP Initiated SSOのURL名 cvpn 認証エンドポイントを Keycloak 上に作成するための設定です。任意の文字列でよいですが、ここでは「cvpn」としています。最終的に「ルート URL」 + 「/realms/master/protocol/saml/clients/」 + 「IDP Initiated SSOのURL名」の文字列が、このクライアントを示す URL となります ベースURL /realms/master/protocol/saml/clients/cvpn 認証エンドポイント (上記) の URL を指定します アサーション・コンシューマー・サービスのPOSTバインディングURL http://127.0.0.1:35001 認証成功後に属性情報を Post する URL を指定します。前述の「ACS URL」の値を指定します 設定値の入力例を下図に示します。
入力に問題がなければ、下部の「保存」ボタンを押下して設定を一旦保存します。
「クライアント・スコープ」タブ
続いて、「クライアント・スコープ」タブを選択します。クライアント・スコープは Keycloak 独自の概念で、属性の集合体を指します。Keycloak ではデフォルト「role_list」というクライアント・スコープにより、認証対象ユーザに紐付いた (IdP 上で定義された) ロールの一覧を SP に渡すように設定されています。
ただ、他の SP はどうか分かりませんが、AWS Client VPN の場合、余計な属性を受け取ると接続時にエラーとなってしまうため、「role_list」の紐付けを解除しておく必要があります。
「割り当てられたデフォルトのクライアント・スコープ」で「role_list」を選択し、「選択されたものを削除」ボタンを押下してください。結果、下記のような画面になっていれば OK です。
「マッパー」タブ
最後に、IdP から SP に渡す属性を定義するために、「マッパー」タブを開きます。Clinet VPN のマニュアルに従えば、渡すべき属性は「NameID」、「FirstName」、「LastName」、「memberOf」の 4 つです。このうち、「NameID」については「設定」タブ内で定義済みのため、ここでは特に定義不要です。残った 3 つの属性を下記のとおり設定します (例によって、設定が必要な項目のみに絞っています)。
名前 マッパータイプ プロパティー SAML (Group) Attribute Name SAML Attribute NameFormat Single Group Attribute FirstName User Property firstName FirstName Basic - LastName User Property lastName LastName Basic - MemberOf Group list - memberOf Basic オン
- 「プロパティー」は IdP 上の属性名を示しています。
- 「SAML (Group) Attribute Name」は SP 上の属性名を示しています。
- memberOf に関して「Single Group Attribute」をオンにしています。これをオンにしていないと、ユーザが複数グループに所属する場合、SP に属性を渡したタイミングでエラーとなります (SP = VPN Client は、「memberOf」の定義を一つしか許容していないようです。複数グループにユーザが所属する場合は、memberOf の " 値" を列挙する構文を要求している……はずです)
すべての属性設定が終わった後は下記のような画面になっているはずです。
グループ & ユーザ作成
SSO で使用するグループとユーザを作成します。作成したグループ名は「memberOf」属性として ClientVPN に渡され、ClientVPN はその内容をもとにどの環境へアクセスさせるかを決定します。
(例) 「user」グループの場合は「192.168.100.0/24」のレンジを、「admin」グループの場合は「192.168.0.0/16」のレンジを許可する。グループ作成
「管理 > グループ」を選択します。グループ一覧が表示されるので、「新規作成」ボタンを押下します。
ここでは「vpn_user」という名前のグループを作成します。
名前以外の項目は作成不要です。
ユーザ作成
「管理 > ユーザ」を選択します。ユーザ一覧が表示されるので、「ユーザーの追加」ボタンを押下します。ユーザ登録画面が表示されるので、下記の通り設定します。
項目 値 備考 ユーザー名 john-doe Eメール <到達可能な Email> 自身のメールアドレスなど 名 John 性 Doe Eメールが確認済み オン ロケール ja
ユーザの詳細設定画面に遷移するので、「クレデンシャル」タブを選択します。下記のとおり入力し、「パスワードを設定」ボタンを押下します。
項目 値 備考 パスワード <任意のパスワード> 新しいパスワード (確認) <上記と同じパスワード> 一時的 オフ ログイン時のパスワード変更を無効化します 設定後、下記のような画面が表示されていれば OK です。
次に、ユーザのグループを設定します。「グループ」タブを選択し、使用可能なグループから「vpn_user」を選択し、「参加」ボタンを押下してください。最終的に下記のような画面になっていれば OK です。
IdP メタデータの取得 & 編集
最後に、AWS に登録するため、KeyClient の IdP メタデータ (XML) を取得します。また、取得した XML は、AWS の登録にあたって修正が必要になるため、それも行います。
メタデータの取得
IdP 情報は「レルム」から取得します。
※旧い Keycloak では「クライアント > インストール」から取得できたみたい (参考) ですが、「11.0.2」では不可となっていました (正確には、インストールの Format Option で「SAML Metadata IDPSSODescriptor」が選択できないようになっているみたいです)。下図のように、「レルム設定」の「一般」タブを選択し、「SAML 2.0 アイデンティティー・プロバイダー・メタデータ」をクリックし、遷移先の文字列をコピーして、テキストファイルなどに貼付け、ローカルに保存します。
※リンクを右クリックして「リンク先を名前を付けて保存」でもよいかもしれませんが、私の環境では、左記のやり方の場合、メタデータを IAM に登録したタイミングで「parse error」となって、登録に失敗しました。そのため、上記のようなやり方を記載しています。メタデータの編集
取得したメタデータですが、レルムから取得したので、認証エンドポイント (クライアントを示す URL) まで記載されていません。ですので、これを追記する必要があります。下記が修正例です。
(前) https://<Keycloak のホスト名(FQDN)>/auth/realms/master/protocol/saml
(後) https://<Keycloak のホスト名(FQDN)>/auth/realms/master/protocol/saml/clients/cvpnまた、AWS IAM の IdP の仕様で、「IDPSSODescriptor」の「WantAuthnRequestsSigned」属性が「true」になっていると、メタデータのインポート時にエラーとなります。そのため、これを「false」にする必要があります。
修正前後のメタデータの diff 結果を下記に示しますので、下記を参照しながらメタデータを修正してください。
$ diff descriptor_前.xml descriptor_後.xml # WantAuthnRequestsSigned の値を true から false に変更 3c3 < <md:IDPSSODescriptor WantAuthnRequestsSigned="true" protocolSupportEnumeration="urn:oasis:names:tc:SAML:2.0:protocol"> --- > <md:IDPSSODescriptor WantAuthnRequestsSigned="false" protocolSupportEnumeration="urn:oasis:names:tc:SAML:2.0:protocol"> # URL を「https://(前略)/saml」から「https://(前略)/saml/clients/cvpn」に修正 12,13c12,13 < <md:SingleLogoutService Binding="urn:oasis:names:tc:SAML:2.0:bindings:HTTP-POST" Location="https://<Keycloak のホスト名(FQDN)>/auth/realms/master/protocol/saml"/> < <md:SingleLogoutService Binding="urn:oasis:names:tc:SAML:2.0:bindings:HTTP-Redirect" Location="https://<Keycloak のホスト名(FQDN)>/auth/realms/master/protocol/saml"/> --- > <md:SingleLogoutService Binding="urn:oasis:names:tc:SAML:2.0:bindings:HTTP-POST" Location="https://<Keycloak のホスト名(FQDN)>/auth/realms/master/protocol/saml/clients/cvpn"/> > <md:SingleLogoutService Binding="urn:oasis:names:tc:SAML:2.0:bindings:HTTP-Redirect" Location="https://<Keycloak のホスト名(FQDN)>/auth/realms/master/protocol/saml/clients/cvpn"/> # URL を「https://(前略)/saml」から「https://(前略)/saml/clients/cvpn」に修正 18,20c18,20 < <md:SingleSignOnService Binding="urn:oasis:names:tc:SAML:2.0:bindings:HTTP-POST" Location="https://<Keycloak のホスト名(FQDN)>/auth/realms/master/protocol/saml"/> < <md:SingleSignOnService Binding="urn:oasis:names:tc:SAML:2.0:bindings:HTTP-Redirect" Location="https://<Keycloak のホスト名(FQDN)>/auth/realms/master/protocol/saml"/> < <md:SingleSignOnService Binding="urn:oasis:names:tc:SAML:2.0:bindings:SOAP" Location="https://<Keycloak のホスト名(FQDN)>/auth/realms/master/protocol/saml"/> --- > <md:SingleSignOnService Binding="urn:oasis:names:tc:SAML:2.0:bindings:HTTP-POST" Location="https://<Keycloak のホスト名(FQDN)>/auth/realms/master/protocol/saml/clients/cvpn"/> > <md:SingleSignOnService Binding="urn:oasis:names:tc:SAML:2.0:bindings:HTTP-Redirect" Location="https://<Keycloak のホスト名(FQDN)>/auth/realms/master/protocol/saml/clients/cvpn"/> > <md:SingleSignOnService Binding="urn:oasis:names:tc:SAML:2.0:bindings:SOAP" Location="https://<Keycloak のホスト名(FQDN)>/auth/realms/master/protocol/saml/clients/cvpn"/> $以上で Keycloak 側の作業は完了です。Keycloak からはしっかりとログインしておきましょう。admin のセッションが残った状態のため、この状態で ClientVPN を起動すると、admin が SSO に使用されてしまいます (初期状態であれば admin の Email 欄は空なので、認証後の接続は失敗するはずです)。
AWS 作業
Keycloak からログアウトしたら、次に AWS 作業に移ります。
IdP の作成
IdP を作成するため、先ほど作成したメタデータ (XML) を登録します。
まず、IAM を開き、「ID プロバイダー」を選択してください。IdP 一覧が表示されるので、「プロバイダの作成」ボタンを押下してください。
プロバイダの詳細設定画面に移行します。下記のとおり入力し、「次のステップ」ボタンを押下します。
項目 値 備考 プロバイダーのタイプ SAML プロバイダ名 <任意の名称。keycloak_cvpn など> メタデータドキュメント <前述の「メタデータの編集」で編集した XML ファイル>
IdP 一覧画面に戻りますので、上部に「SAML プロバイダーの作成が完了しました。」というメッセージが表示されているのを確認してください。
ちなみにですが、ここで登録したメタデータが「IdP 情報」として Client VPN に組み込まれます。ユーザが Client VPN への接続を開始すると、ClientVPN から「IdP 情報」としてこのメタデータの内容がユーザに連携されます。ユーザはその情報を見て、IdP にアクセスする……というわけです。先ほどの手順 (メタデータの編集) でメタデータの URL を認証エンドポイントの URL に更新したのは、ClientVPN の接続開始時にユーザをその URL に誘導するためとなります。
また、メタデータは ClientVPN 作成時に、ハードコードで Client VPN に組み込まれます。そのため、Client VPN 作成後にメタデータの修正を行った場合 (修正後のメタデータを再び IdP にアップロードした場合)、その修正を反映させるために、Client VPN の再作成が必要となります。
Client VPN の作成
それでは、仕上げとして Client VPN を作成していきましょう。なお、Client VPN の作成には Client VPN 用のセキュリティグループと、Client VPN 用のサーバ証明書 (on ACM) が必要となります。左記 2 点は、あらかじめ準備をお願いします (セキュリティグループは、中身は空でも大丈夫です)。証明書の作成方法については、こちら の記事が詳しいです。
※ちなみに、私は自信の Windows10 端末上に WSL を構築し、そこに EasyRSA を設置して、オレオレ証明書を発行しました。VPC > クライアント VPN エンドポイントに移動し、「クライアント VPN エンドポイントの作成」ボタンを押下してください。
Clinet VPN の設定画面に遷移しますので、下記のとおり設定して (例によって、必要な項目のみ記載しています)、「クライアント VPN エンドポイントの作成」ボタンを押下してください。
項目 値 備考 名前タグ <任意> Client VPN の名前を任意に指定してください。cvpn など クライアント IPv4 CIDR <任意の CIDR> 任意の CIDR を指定してください。なお、最小レンジは「/22」ですので注意してください サーバ証明書 ARN <ACM に登録済みのサーバ証明書> 認証オプション ユーザーベースの認証を使用 : 統合認証 SAML 連携のため統合認証を指定します SAML プロバイダー ARN <先ほど作成した IdP の ARN> クライアント接続の詳細を記録しますか いいえ 検証用途なので「いいえ」を指定してください DNS サーバ1 IP アドレス <Amazon DNS の IP> AWS のホスト名を解決できるよう、Amazon DNS の IP を指定してください。Amazon DNs の IP は、VPC の 2 つ目の ホスト IP となります。(例) VPC の CIDR が 172.31.0.0/16 の場合、Amazon DNS の IP は 172.31.0.2 となる トランスポートプロトコル <任意> TCP/UDP のいずれかを選択してください。UDP の場合、たしか何か制約があった筈なので、下図の例では TCP を指定しています スプリットトンネルを有効にする <任意> ON/OFF のいずれかを選択してください。VPN 通信中もインターネットアクセスが必要な場合は ON にしてください VPC ID <Client VPN を作成したい VPC> セキュリティグループ <Client VPN 用のセキュリティグループ>
Client VPN の作成が完了したら、「関連付け」タブを選択します。Client VPN を接続させたいサブネットを選択し、「関連付け」ボタンを押下します。なお、「関連付け」はしばらく時間がかかりますので、ご留意ください (だいたい 10 分前後?)
次に、「認証」タブで通信先を許可します。Keycloak のユーザが所属するグループ名に従って、接続先を指定することができますので、ここでは例として、下記のような構成にしてみたいと思います。
- Amazon DNS にはすべてのユーザがアクセス可能
- プライベートサブネットには「vpn_user」グループに所属するユーザのみがアクセス可能
上記を踏まえた設定内容は下記の通りです。
アクセスを有効にする送信先ネット アクセスを付与する対象 アクセスグループ ID 備考 172.31.0.2/32 すべてのユーザーにアクセスを許可する - Amazon DNS はすべてのユーザがアクセス可とする 172.31.16.0/20 特定のアクセスグループのユーザーへのアクセスを許可する vpn_user サーバサブネットには「vpn_user」グループのユーザのみアクセスを可とする 上記設定後は、下記のような状態となるはずです。
最後に、「クライアント設定のダウンロード」を押下して、当該 Client VPN 用の ovpn ファイルをローカルに保管します。
お疲れ様でした。以上で、接続に必要な設定はすべて完了となります。
接続試行
それでは、早速 VPN に接続してみましょう。こちら から Client VPN ソフトウェアをダウンロード & インストールしてください。
インストールが完了したらソフトウェアを起動し、先ほどダウンロードしたクライアント設定 (ovpn ファイル) をインポートしてください。
インポートが完了すれば、「接続」ボタンが押せるようになるので、「接続」ボタンを押して接続を開始します。
ClientVPN が起動したら、IdP メタデータの定義従って、Keycloak のログイン画面にリダイレクトされます。Keycloak のログイン画面が表示されたら、ID/Password を入力して、「ログイン」ボタンを押下してください。
認証成功後は下記のページが表示されるはずです。ページに記載があるとおり、このページは閉じて問題ありません。
しばらく後、Clinet VPN ソフトウェアで「接続済み」と表示されれば、接続成功です。
AWS 環境につながっているか確認していきましょう。まずは IP アドレスの確認です。
Clinet VPN で設定した IP アドレスが振られていますね。次に名前解決をできるか試してみましょう。
AWS 環境のホスト名が IP に解決できていますね。最後にサーバへの Ping 疎通を確認しましょう。
Ping も通っています。成功です。(参考)「vpn_user」に所属していないユーザの場合
「vpn_user」に所属していないユーザの場合も確認しておきましょう。
まず、適当なユーザを作成し(クレデンシャルの設定を忘れずに)、「vpn_user」以外の適当なグループに所属させます (もしくはどこにも所属させない)。
Keycloak からログアウトし、再び Clinet VPN ソフトウェアで「接続」ボタンを押下します。
Keycloak のログイン画面にリダイレクトされるので、上記で作成したユーザでログインします。
認証が成功したら VPN 接続が確立しますので、先ほどと同様に通信テストを行っていきましょう。
まずは、名前解決です。
成功します。Clinet VPN の認証設定において、Amazon DNS への通信は、すべてのユーザに対して許可されているためです。次に、サーバへの ping 疎通を確認します。
失敗します。Client VPN の認証設定において、サーバ NW への通信が許可されているのは、「vpn_user」に所属するユーザだけだからです。トラブルシューティング
ここからは、私が環境を構成する際に体験した、発生しやすい問題と、その解決方法を記載していきたいと思います。
その 1 : Client VPN 接続時にエラーになる
Client VPN ソフトウェアで接続を行ったタイミングで、下記のようなエラーが出ます。
原因
IdP メタデータ内の URL のホスト名が、FQDN (完全ドメイン名) になっていない (ホスト名のみ、などになっている)。
解決方法
メタデータ内の URL のホスト名を FQDN に修正する。下記は修正例。
(前) keycloak
(後) keycloak.localdomain※値は FQDN である必要があります。IP アドレスの直指定も許可されなかった……はずです。
コメント
自 PC 上の検証環境などで実施した際、起こりやすい問題です。教訓としては「たとえ検証目的であったとしても、URL のホスト名はきちんと FQDN で記載する」といったところです。なお、メタデータの修正が発生するため、Client VPN は再作成が必要となります (現行の Client VPN は、修正前のメタデータがハードコードされたままになっています)。
本件の問題、ログにそれっぽいことも出ていなかったので、原因を掴むまではかなり時間を要しました。。。
その 2 : 認証画面に遷移した際にエラーになる
Client VPN ソフトウェアで接続を行ったタイミングで、下記のようなエラーが出ます。
原因
IdP メタデータ内の URL が到達できない値になっている。
解決方法
URL を到達可能な URL に修正する。下記は修正例。
(前) https://<Keycloak のホスト名(FQDN)>/auth/realms/master/protocol/saml/
(後) https://<Keycloak のホスト名(FQDN)>/auth/realms/master/protocol/saml/clients/cvpnコメント
IdP のメタデータの URL を失敗した際に起こりやすいエラーです。メタデータの修正は、忘れず実施しましょう。なお、メタデータの修正が発生するため、Client VPN は再作成が必要となります (現行の Client VPN は、修正前のメタデータがハードコードされたままになっています)。
その 3 : 認証成功した後にエラーになる (1)
認証画面に遷移し、認証情報を入力した後、下記のようなエラーメッセージが表示されます。
原因
「アサーション・コンシューマー・サービスのPOSTバインディングURL」が空値になっている。
解決方法
「アサーション・コンシューマー・サービスのPOSTバインディングURL」に正しい値 (http://127.0.0.1:35001) に修正する。
コメント
「アサーション・コンシューマー・サービスのPOSTバインディングURL」は初期状態では隠れているため、結構見落としがちです。注意しましょう。
その 4 : 認証成功した後にエラーになる (2)
認証画面に遷移し、認証情報を入力した後、下記のようなエラーメッセージが表示されます。
※「その 1」と同じエラー文章です。原因
SAML Request (ユーザが SP に POST する情報) 内容に誤りがある。POST 内容は IdP が生成するため、IdP の設定 (or 仕様) に根本原因があるはず。
解決方法
IdP の設定を見直す。必須属性の定義漏れが無いか、余計な属性 (NameID、FirstName、LastName、memberOf 以外の属性) が無いかを確認する。あれば、是正する。
コメント
Client VPN は、属性が多くても少なくても、上記のようなエラーを出してきます。実際に SAML がどのようなやり取りを行っているかは、SAML キャプチャー(「SAML-tracer」など) を使って調べてください。
「SAML-tracer」は AWS 公式ブログの Client VPN x SAML のページ でも紹介されています。SAML の色々な問題に使えるツールですので、とりあえず入れておいて損はないと思っています。
まとめ
以上、AWS Client VPN とOSS の IdP (Keycloak) を SAML 連携する、でした。
手探りばかりでしたが、何とか実現にこぎつけました。なかなか骨が折れましたが、その分学びも大きかったです。
Keycloak は他にもいろいろな機能 (MFA や認可サーバとしての機能など) があるみたいですので、機会があればそれらにも触れてみたいと考えています。