- 投稿日:2020-08-24T21:00:00+09:00
データサイエンス100本ノック解説(P041~060)
1. はじめに
前回に引き続き、データサイエンス100本ノックの解説を行う。
データサイエンス100本ノック解説(P001~020)
データサイエンス100本ノック解説(P021~040)導入についてはこちらの記事を参考に進めてください(※ MacでDockerを扱います)
基本的には解答の解説ですが別解についても記述しています。
※徐々に難易度が上がってきています。2. 解説編
P-041: レシート明細データフレーム(df_receipt)の売上金額(amount)を日付(sales_ymd)ごとに集計し、前日からの売上金額増減を計算せよ。なお、計算結果は10件表示すればよい。
P-041# 売上金額(amount)を日付(sales_ymd)ごとに集計(groupbyメソッド) # reset_index()でインデックスを振り直す。 df_sales_amount_by_date = df_receipt[['sales_ymd', 'amount']].groupby('sales_ymd').sum().reset_index() # 比較用に売上金額(amount)を日付(sales_ymd)のコピーを下に1行移動したものを結合する。 # concat([df1, df2], axis=1)で横方向に結合。shift()で1行下に移動 df_sales_amount_by_date = pd.concat([df_sales_amount_by_date, df_sales_amount_by_date.shift()], axis=1) # カラム名を変更する df_sales_amount_by_date.columns = ['sales_ymd','amount','lag_ymd','lag_amount'] # 売上金額増減(diff_amount)を追加する df_sales_amount_by_date['diff_amount'] = df_sales_amount_by_date['amount'] - df_sales_amount_by_date['lag_amount'] df_sales_amount_by_date.head(10)
参考: pandas.DataFrame, Seriesを連結するconcat
参考: pandasでデータを行・列(縦・横)方向にずらすshiftP-042: レシート明細データフレーム(df_receipt)の売上金額(amount)を日付(sales_ymd)ごとに集計し、各日付のデータに対し、1日前、2日前、3日前のデータを結合せよ。結果は10件表示すればよい。
P-042# (縦持ちのケース) # 売上金額(amount)を日付(sales_ymd)ごとに集計(groupby) df_sales_amount_by_date = df_receipt[['sales_ymd', 'amount']].groupby('sales_ymd').sum().reset_index() # for文で繰り返す。range(1, 4)>>>1, 2, 3がiに入る。 for i in range(1, 4): # i==1のときは横方向に結合。shiftで1行下に移動(1日前) if i == 1: df_lag = pd.concat([df_sales_amount_by_date, df_sales_amount_by_date.shift()], axis=1) # iが1以外の場合、データフレームに追加する。 else: df_lag = df_lag.append(pd.concat([df_sales_amount_by_date, df_sales_amount_by_date.shift(i)], axis=1)) # カラム名を変更する df_lag.columns = ['sales_ymd', 'amount', 'lag_sales_ymd', 'lag_amount'] # 欠損値NaNを除外(dropna())し、ソートする(sort_values)。 df_lag.dropna().sort_values('sales_ymd').head(10)P-042# 横持ちのケース # 売上金額(amount)を日付(sales_ymd)ごとに集計(groupby) df_sales_amount_by_date = df_receipt[['sales_ymd', 'amount']].groupby('sales_ymd').sum().reset_index() # for文で繰り返す。range(1, 4)>>>1, 2, 3がiに入る。 for i in range(1, 4): # iが1の時、横方向に連結したdf_lagを作成する。 if i == 1: df_lag = pd.concat([df_sales_amount_by_date, df_sales_amount_by_date.shift(1)], axis=1) # iが1以外の場合、すでにdf_lagが作成されているのでdf_lagと連結させる。 else: df_lag = pd.concat([df_lag, df_sales_amount_by_date.shift(i)], axis=1) # カラム名を変更する df_lag.columns = ['sales_ymd', 'amount', 'lag1_sales_ymd', 'lag1_amount', 'lag2_sales_ymd', 'lag2_amount', 'lag3_sales_ymd', 'lag3_amount'] # 欠損値NaNを除外(dropna())し、ソートする(sort_values)。 df_lag.dropna().sort_values('sales_ymd').head(10)参考: pandasで欠損値NaNを除外(削除)・置換(穴埋め)・抽出
P-043: レシート明細データフレーム(df_receipt)と顧客データフレーム(df_customer)を結合し、性別(gender)と年代(ageから計算)ごとに売上金額(amount)を合計した売上サマリデータフレーム(df_sales_summary)を作成せよ。性別は0が男性、1が女性、9が不明を表すものとする。
ただし、項目構成は年代、女性の売上金額、男性の売上金額、性別不明の売上金額の4項目とすること(縦に年代、横に性別のクロス集計)。また、年代は10歳ごとの階級とすること。
P-043# レシート明細データフレーム(df_receipt)と顧客データフレーム(df_customer)を結合 # merge(df1, df2, on='キー名', how='inner') df_tmp = pd.merge(df_receipt, df_customer, on='customer_id', how='inner') # 年代を10歳ごとの階級にする。 # math.floor: 小数点以下を切り捨て。ex) 22の場合 22/10 * 10 = 2(2.2の切り捨て) *10 = 20 df_tmp['era'] = df_tmp['age'].apply(lambda x: math.floor(x/10)*10) # ピボットテーブルを作成(pivot_table()関数)詳細は下記 df_sales_summary = pd.pivot_table(df_tmp, index='era', columns='gender_cd', values='amount', aggfunc='sum').reset_index() # カラム名を変更する df_sales_summary.columns = ['era', 'male', 'female', 'unknown'] df_sales_summarypivot_table()関数
・data(第一引数): 参照するデータフレーム
・index: 行名を指定
・columns: 列名を指定
・values: 参照しているデータフレームの列名を指定すると、その列に対する結果のみが算出
・aggfunc: 結果の値の算出方法を指定
参考: pandasのピボットテーブルでカテゴリ毎の統計量などを算出P-044: 前設問で作成した売上サマリデータフレーム(df_sales_summary)は性別の売上を横持ちさせたものであった。このデータフレームから性別を縦持ちさせ、年代、性別コード、売上金額の3項目に変換せよ。ただし、性別コードは男性を'00'、女性を'01'、不明を'99'とする。
P-044# set_indexで既存の列をインデックスindex(行名、行ラベル)に割り当てる # stack()で列から行へピボット。 # replace()で文字列を置換する # rename()メソッドで任意の行名・列名を変更する df_sales_summary.set_index('era').stack().reset_index().replace( {'female': '01', 'male': '00', 'unknown': '99'}).rename( columns={'level_1': 'gender_cd', 0: 'amount'})参考: pandas.DataFrameの列をインデックス(行名)に割り当てるset_index
参考: pandasでstack, unstack, pivotを使ってデータを整形
参考: Pythonで文字列を置換(replace, translate, re.sub, re.subn)
参考: pandas.DataFrameの行名・列名の変更P-045: 顧客データフレーム(df_customer)の生年月日(birth_day)は日付型(Date)でデータを保有している。これをYYYYMMDD形式の文字列に変換し、顧客ID(customer_id)とともに抽出せよ。データは10件を抽出すれば良い。
P-045# 顧客ID(customer_id)とYYYYMMDD形式の文字列に変換した生年月日(birth_day)を結合する。 # concat([df1, df2], axis=1)で横方向に結合する。 # pd.to_datetimeで文字列をdatetime64[ns]型に変換する。 # dt.strftime()で列を一括で任意のフォーマットの文字列に変換する。 pd.concat([df_customer['customer_id'], pd.to_datetime(df_customer['birth_day']) \ .dt.strftime('%Y/%m/%d')], axis=1).head(10)参考: pandasで日付・時間の列を処理(文字列変換、年月日抽出など)
P-046: 顧客データフレーム(df_customer)の申し込み日(application_date)はYYYYMMDD形式の文字列型でデータを保有している。これを日付型(dateやdatetime)に変換し、顧客ID(customer_id)とともに抽出せよ。データは10件を抽出すれば良い。
P-046# 顧客ID(customer_id)と日付型(dateやdatetime)に変換した申し込み日(application_date)を結合する # P-045を参考 pd.concat([df_customer['customer_id'], pd.to_datetime(df_customer['application_date'])], axis=1).head(10)参考: pandasで日付・時間の列を処理(文字列変換、年月日抽出など)
P-047: レシート明細データフレーム(df_receipt)の売上日(sales_ymd)はYYYYMMDD形式の数値型でデータを保有している。これを日付型(dateやdatetime)に変換し、レシート番号(receipt_no)、レシートサブ番号(receipt_sub_no)とともに抽出せよ。データは10件を抽出すれば良い。
P-047# 売上日(sales_ymd)をto_datetime()で日付型に変換する # pandas.concat()で横方向に結合する # astype()メソッドで文字列str型に変換すると、標準的な書式で文字列に変換する pd.concat([df_receipt[['receipt_no', 'receipt_sub_no']], pd.to_datetime(df_receipt['sales_ymd'].astype('str'))],axis=1).head(10) # (別解) pd.concat([df_receipt[['receipt_no', 'receipt_sub_no'], pd.to_datetime(df_receipt['sales_ymd']).dt.strftime('%Y-%m-%d')]], axis=1).head(10)参考: pandasで日付・時間の列を処理(文字列変換、年月日抽出など)
P-048: レシート明細データフレーム(df_receipt)の売上エポック秒(sales_epoch)は数値型のUNIX秒でデータを保有している。これを日付型(dateやdatetime)に変換し、レシート番号(receipt_no)、レシートサブ番号(receipt_sub_no)とともに抽出せよ。データは10件を抽出すれば良い。
P-048# pd.concat()を用いての売上エポック秒(sales_epoch)のデータフレームとレシート番号(receipt_no)、レシートサブ番号(receipt_sub_noを結合 # 売上エポック秒(sales_epoch)を日付型に変換する(to_datetime(df, unit='s')で変換) pd.concat([df_receipt[['receipt_no', 'receipt_sub_no']], pd.to_datetime(df_receipt['sales_epoch'].astype(int), unit='s')], axis=1).head(10)参考: Pandasで時間や日付データに変換するto_datetime関数の使い方
P-049: レシート明細データフレーム(df_receipt)の売上エポック秒(sales_epoch)を日付型(timestamp型)に変換し、"年"だけ取り出してレシート番号(receipt_no)、レシートサブ番号(receipt_sub_no)とともに抽出せよ。データは10件を抽出すれば良い。
P-049# 売上エポック秒(sales_epoch)を日付型(timestamp型)に変換 # "年"だけ取り出す(dt.year) pd.concat([df_receipt[['receipt_no', 'receipt_sub_no']], pd.to_datetime(df_receipt['sales_epoch'], unit='s').dt.year], axis=1).head(10)参考: Pandasで時間や日付データに変換するto_datetime関数の使い方
P-050: レシート明細データフレーム(df_receipt)の売上エポック秒(sales_epoch)を日付型(timestamp型)に変換し、"月"だけ取り出してレシート番号(receipt_no)、レシートサブ番号(receipt_sub_no)とともに抽出せよ。なお、"月"は0埋め2桁で取り出すこと。データは10件を抽出すれば良い。
P-050# 売上エポック秒(sales_epoch)を日付型に変換(to_datetime(, unit='s')) # "月"だけ取り出す(0埋め2桁で取り出すためstrftime('%m')) # pd.concatでデータフレームを結合する pd.concat([df_receipt[['receipt_no', 'receipt_sub_no']], pd.to_datetime(df_receipt['sales_epoch'], unit='s') \ .dt.strftime('%m')], axis=1).head(10)P-051: レシート明細データフレーム(df_receipt)の売上エポック秒(sales_epoch)を日付型(timestamp型)に変換し、"日"だけ取り出してレシート番号(receipt_no)、レシートサブ番号(receipt_sub_no)とともに抽出せよ。なお、"日"は0埋め2桁で取り出すこと。データは10件を抽出すれば良い。
P-051# 売上エポック秒(sales_epoch)を日付型に変換(to_datetime(, unit='s')) # 日だけを抜き出す(dt.strftime('%d')) # pd.concat()で結合 pd.concat([df_receipt[['receipt_no', 'receipt_sub_no']], pd.to_datetime(df_receipt['sales_epoch'], unit='s') \ .dt.strftime('%d')], axis=1).head(10)P-052: レシート明細データフレーム(df_receipt)の売上金額(amount)を顧客ID(customer_id)ごとに合計の上、売上金額合計に対して2000円以下を0、2000円超を1に2値化し、顧客ID、売上金額合計とともに10件表示せよ。ただし、顧客IDが"Z"から始まるのものは非会員を表すため、除外して計算すること。
P-052# lambdaを使った場合 # 顧客IDが"Z"から始まるのものを除外する(queryで探し、notで以外、str.startswith('Z')) df_sales_amount = df_receipt.query('not customer_id.str.startswith("Z")', engine='python') # 顧客ID(customer_id)ごとにグループ分けする。売上金額(amount)を合計(sum) df_sales_amount = df_sales_amount[['customer_id', 'amount']].groupby('customer_id').sum().reset_index() # 2000円以下を0、2000円超を1に2値化(apply(lambda)で指定の列に1行ずつ条件を適用する) df_sales_amount['sales_flg'] = df_sales_amount['amount'].apply(lambda x: 1 if x>2000 else 0) df_sales_amount.head(10) # (別解: np.where) df_sales_amount = df_receipt.query('not customer_id.str.startswith("Z")', engine='python') df_sales_amount = df_sales_amount[['customer_id', 'amount']].groupby('customer_id').sum().reset_index() # np.where(条件式, x(真の場合), y(偽の場合)) df_sales_amount['sales_flg'] = np.where(df_sales_amount['amount']>2000, 1, 0) df_sales_amount.head(10) # (別解) df_sales_amount = df_receipt[~df_receipt['customer_id'].str.startswith('Z')].groupby('customer_id').amount.sum().reset_index() df_sales_amount.loc[df_sales_amount['amount']<=2000, 'threshold'] = 0 df_sales_amount.loc[df_sales_amount['amount']>2000, 'threshold'] = 1 df_sales_amount.head(10)参考:pandasで指定の列に1行ずつ関数を適用するapply+lambdaの使い方
P-053: 顧客データフレーム(df_customer)の郵便番号(postal_cd)に対し、東京(先頭3桁が100〜209のもの)を1、それ以外のものを0に2値化せよ。さらにレシート明細データフレーム(df_receipt)と結合し、全期間において買い物実績のある顧客数を、作成した2値ごとにカウントせよ。
P-053# 郵便番号(postal_cd)を2値化する(東京:1, その他:0) df_tmp = df_customer[['customer_id', 'postal_cd']].copy() df_tmp['postal_flg'] = df_tmp['postal_cd'].apply(lambda x: 1 if 100 <= int(x[0:3]) <=209 else 0) # レシート明細データフレーム(df_receipt)と結合(pd.merge(df1, df2, on='キー', how='inner')) # ユニークな要素の個数(重複のない個数)をcustomer_idごとに算出(pandas.DataFrame.nunique()) pd.merge(df_tmp, df_receipt, on='customer_id', how='inner') \ .groupby('postal_flg').agg({'customer_id': 'nunique'}) # (別解) np.whereの使い方はP-052を参考 df_tmp = df_customer[['customer_id', 'postal_cd']].copy() df_tmp['postal_flg'] = np.where(df_tmp['postal_cd'].str[0:3].astype(int) .between(100, 209), 1, 0) pd.merge(df_tmp, df_receipt, how='inner', on='customer_id'). \ groupby('postal_flg').agg({'customer_id':'nunique'})P-054: 顧客データデータフレーム(df_customer)の住所(address)は、埼玉県、千葉県、東京都、神奈川県のいずれかとなっている。都道府県毎にコード値を作成し、顧客ID、住所とともに抽出せよ。値は埼玉県を11、千葉県を12、東京都を13、神奈川県を14とすること。結果は10件表示させれば良い。
P-054# 住所(address)の都道府県部分を抽出し、それぞれ値をつける # map()の引数に辞書dict({key: value})を指定すると、keyと一致する要素がvalueに置き換えられる。 pd.concat([df_customer[['customer_id', 'address']], df_customer['address'].str[0:3] \ .map({'埼玉県': '11', '千葉県': '12', '東京都': '13', '神奈川': '14'})], axis=1).head(10)参考: pandas.Seriesのmapメソッドで列の要素を置換
P-055: レシート明細データフレーム(df_receipt)の売上金額(amount)を顧客ID(customer_id)ごとに合計し、その合計金額の四分位点を求めよ。その上で、顧客ごとの売上金額合計に対して以下の基準でカテゴリ値を作成し、顧客ID、売上金額と合計ともに表示せよ。カテゴリ値は上から順に1〜4とする。結果は10件表示させれば良い。
P-055# 顧客ID(customer_id)ごとにグループ分け(groupby)し、売上金額(amount)を合計する(sum) df_sales_amount = df_receipt[['customer_id', 'amount']].groupby('customer_id').sum().reset_index() # 売上金額(amount)ごとに四分位点を求める。(25パーセンタイル: 25pct, 50パーセンタイル: 50pct, 75パーセンタイル: 75pct) pct25 = np.quantile(df_sales_amount['amount'], 0.25) pct50 = np.quantile(df_sales_amount['amount'], 0.5) pct75 = np.quantile(df_sales_amount['amount'], 0.75) # カテゴリ値の関数を作成し、適用する def pct_group(x): if x < pct25: return 1 elif pct25 <= x < pct50: return 2 elif pct50 <= x < pct75: return 3 elif pct75 <= x: return 4 # applyを用いてpct_groupを各行に適用する df_sales_amount['pct_group'] = df_sales_amount['amount'].apply(lambda x: pct_group(x)) df_sales_amount参考: pandasのcut, qcut関数でビニング処理(ビン分割)
P-056: 顧客データフレーム(df_customer)の年齢(age)をもとに10歳刻みで年代を算出し、顧客ID(customer_id)、生年月日(birth_day)とともに抽出せよ。ただし、60歳以上は全て60歳代とすること。年代を表すカテゴリ名は任意とする。先頭10件を表示させればよい。
P-056# 年齢(age)を10歳刻みで年代を算出 # math.floorで切り捨て。min(, 60)で60以上が出力されない。 df_customer_era = pd.concat([df_customer[['customer_id', 'birth_day']], df_customer['age'].apply(lambda x: math.floor(x / 10) * 10, 60)], axis=1) df_customer_era.head(10) # (別解) # 年齢(age)を(10代未満、10代、20代、30代、40代、50代、60代以上)で分ける。(flg_age) def age_group(x): if x < 10: return '10代未満' elif 10 <= x <20: return '10代' elif 20 <= x < 30: return '20代' elif 30 <= x < 40: return '30代' elif 40 <= x < 50: return '40代' elif 50 <= x < 60: return '50代' elif 60 <= x: return '60代以上' df_customer['flg_age'] = df_customer['age'].apply(lambda x: age_group(int(x))) # 顧客ID(customer_id)、生年月日(birth_day)とともに抽出 df_customer[['customer_id', 'birth_day', 'flg_age']].head(10)P-057: 前問題の抽出結果と性別(gender)を組み合わせ、新たに性別×年代の組み合わせを表すカテゴリデータを作成せよ。組み合わせを表すカテゴリの値は任意とする。先頭10件を表示させればよい。
P-057# カテゴリーデータ(性別x年代)'gender_era'を作成する # ageはint型なのでastype(str)で変換する df_customer_era['gender_era'] = df_customer['gender_cd'] + df_customer_era['age'].astype(str) df_customer_era.head(10)P-058: 顧客データフレーム(df_customer)の性別コード(gender_cd)をダミー変数化し、顧客ID(customer_id)とともに抽出せよ。結果は10件表示させれば良い。
P-058# 性別コード(gender_cd)をダミー変数化する(get_dummies) # 引数columnsにダミー化したい列の列名をリストで指定 pd.get_dummies(df_customer[['customer_id', 'gender_cd']], columns=['gender_cd'])参考: pandasでカテゴリ変数をダミー変数に変換(get_dummies)
P-059: レシート明細データフレーム(df_receipt)の売上金額(amount)を顧客ID(customer_id)ごとに合計し、合計した売上金額を平均0、標準偏差1に標準化して顧客ID、売上金額合計とともに表示せよ。標準化に使用する標準偏差は、不偏標準偏差と標本標準偏差のどちらでも良いものとする。ただし、顧客IDが"Z"から始まるのものは非会員を表すため、除外して計算すること。結果は10件表示させれば良い。
P-059# 顧客IDが"Z"から始まるのものを除外し、顧客ID(customer_id)ごとに売上金額(amount)を合計する df_sales_amount = df_receipt.query("not customer_id.str.startswith('Z')", engine='python') \ .groupby('customer_id').agg({'amount': 'sum'}).reset_index() # 売り上げ金額を標準化する df_sales_amount['amount_ss'] = preprocessing.scale(df_sales_amount['amount']) df_sales_amount.head(10) # (別解) # コード例2(fitを行うことで、別のデータでも同じの平均・標準偏差で標準化を行える) df_sales_amount = df_receipt.query('not customer_id.str.startswith("Z")', engine='python'). \ groupby('customer_id').agg({'amount':'sum'}).reset_index() scaler = preprocessing.StandardScaler() scaler.fit(df_sales_amount[['amount']]) df_sales_amount['amount_ss'] = scaler.transform(df_sales_amount[['amount']]) df_sales_amount.head(10)参考: Pythonで正規化・標準化(リスト、NumPy配列、pandas.DataFrame)
P-060: レシート明細データフレーム(df_receipt)の売上金額(amount)を顧客ID(customer_id)ごとに合計し、合計した売上金額を最小値0、最大値1に正規化して顧客ID、売上金額合計とともに表示せよ。ただし、顧客IDが"Z"から始まるのものは非会員を表すため、除外して計算すること。結果は10件表示させれば良い。
P-060# 売上金額(amount)を顧客ID(customer_id)ごとに合計 df_sales_amount = df_receipt.query("not customer_id.str.startswith('Z')", engine='python') \ .groupby('customer_id').agg({'amount': 'sum'}).reset_index() df_sales_amount # 売上金額を最小値0、最大値1に正規化(preprocessing.minmax_scale) df_sales_amount['amount_mm'] = preprocessing.minmax_scale(df_sales_amount['amount']) df_sales_amount.head(10) # (別解) # コード例2(fitを行うことで、別のデータでも同じの平均・標準偏差で標準化を行える) df_sales_amount = df_receipt.query('not customer_id.str.startswith("Z")', engine='python'). \ groupby('customer_id').agg({'amount':'sum'}).reset_index() scaler = preprocessing.MinMaxScaler() scaler.fit(df_sales_amount[['amount']]) df_sales_amount['amount_mm'] = scaler.transform(df_sales_amount[['amount']]) df_sales_amount.head(10)参考: Pythonで正規化・標準化(リスト、NumPy配列、pandas.DataFrame)
3. 参考文献
データサイエンス100本ノック
Macでデータサイエンス100本ノックを動かす方法4. 所感
40以降難易度が上がった。写経でもいいので何が書かれているか言語化する。

- 投稿日:2020-08-24T14:50:05+09:00
dockerで「An HTTP request took too long to complete.」のエラー
問題
❯ docker-compose run --rm ほげ ERROR: An HTTP request took too long to complete. Retry with --verbose to obtain debug information. If you encounter this issue regularly because of slow network conditions, consider setting COMPOSE_HTTP_TIMEOUT to a higher value (current value: 60).解決方法
dockerを再起動する事で解決しました
- 投稿日:2020-08-24T13:28:21+09:00
Apache Flink SQLプログラミングの実践
この記事は、Apache Flink 基本チュートリアルシリーズの一部で、5 つの例を使って Flink SQL プログラミングの実践に焦点を当てています。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
ジャーク・ウーより
この記事では、Ververicaのオープンソースのsql-trainingプロジェクト、およびFlink 1.7.2をベースにしたチュートリアルの練習を説明します。FlinkのSQLプログラミング実習全体を通して5つの例を使用しており、主に以下の点をカバーしています。
- SQL CLIクライアントの使い方。
- ストリーム上でSQLクエリを実行する方法。
- ウィンドウアグリゲートと非ウィンドウアグリゲートを実行して、それらの違いを理解する。
- SQLを使用してKafkaデータを消費する方法。
- SQLを使用してKafkaとElasticSearchに結果を書き込む方法。
- この記事では、すでに基本的なSQLの知識があることを前提としています。
環境を整える
このチュートリアルはDockerをベースにしているので、他のプログラムや追加のプログラムをインストールする必要はありません。この演習はJava環境、Scala、IDEに依存しません。
注意: デフォルトでDockerに設定されているリソースが十分でない可能性があり、そのためにFlinkジョブの実行中にクラッシュする可能性があります。そのため、Docker内のリソースを3~4GB、CPUを3~4台に設定することをお勧めします。
今回のチュートリアルでは、様々なサービスのコンテナを収容するDocker Composeを使って環境をインストールしました。
- Flink SQL Client:クエリを送信し、結果を可視化します。
- Flink JobManagerとTaskManager:Flink SQLタスクを実行します。
- Apache Kafka:入力ストリームの生成と結果ストリームの書き込み。
- Apache ZooKeeper: Kafkaの依存関係。
- ElasticSearch: 結果を書き込む。
Docker Composeの設定ファイルが用意されています。docker-compose.ymlファイルは直接ダウンロードできます。
次に、コマンドラインウィンドウを開き、docker-compose.ymlファイルが保存されているディレクトリを入力し、以下のコマンドを実行します。
- Linux & MacOSの場合
docker-compose up -d
- Windows
set COMPOSE_CONVERT_WINDOWS_PATHS=1 docker-compose up -ddocker-composeコマンドは、必要なコンテナごとに起動します。Dockerは初回起動時にDocker Hubから自動的にイメージ(2.3GB近く)をダウンロードしますが、これには時間がかかるかもしれません。その後はあっという間に起動します。操作が成功すると、コマンドラインに以下のような出力が表示されます。
http://localhost:8081の Flink Web UI にもアクセスできます。
Flink SQL CLI クライアントの実行
以下のコマンドを実行して、Flink SQL CLIに入ります。
docker-compose exec sql-client ./sql-client.shこのコマンドを実行すると、コンテナ内のFlink SQL CLIクライアントが起動します。すると、以下のような「welcome」インターフェースが表示されます。
データ紹介
一部のテーブルやデータはDocker Composeにあらかじめ登録されているので、show tablesを実行することで見ることができます。記事中のRidesテーブルのデータを利用することで、タクシーの走行記録データのストリームを、時間や場所などを含めて確認することができます。DESCRIBE Rides;コマンドを実行することでテーブル構造を見ることができます。
Flink SQL> DESCRIBE Rides; root |-- rideId: Long // Ride ID (including two records, an input and an output) |-- taxiId: Long // Taxi ID |-- isStart: Boolean // Start or end |-- lon: Float // Longitude |-- lat: Float // Latitude |-- rideTime: TimeIndicatorTypeInfo(rowtime) // Time |-- psgCnt: Integer // Number of passengersRides テーブルの詳細については、training-config.yaml を参照してください。
例 1. フィルタ
今、ニューヨークの運転記録を調べたいとしましょう。
注意:Docker環境では、ニューヨークに緯度経度があるかどうかを調べるisInNYC(lon, lat)や、特定の地域に変換するtoAreaId(lon, lat)など、いくつかのビルトイン関数があらかじめ定義されています。
そのため、isInNYCを使用して、ニューヨークの運転記録を素早くフィルタリングすることができます。SQL CLIで以下のクエリを実行します。
SELECT * FROM Rides WHERE isInNYC(lon, lat)SQL CLIはSQLタスクをDockerクラスタにサブミットします; それは継続的にデータソース(RidesのストリームはKafkaにあります)からデータをプルし、isInNYCを介して必要なデータをフィルタリングします。また、SQL CLIは可視化モードに入り、フィルタリングされた結果を常にリフレッシュしてリアルタイムで表示します。
また、
http://localhost:8081にアクセスして、Flink ジョブの実行状況を確認することもできます。例 2: グループ集計
もう一つの要件は、異なる数の乗客を乗せた運転イベントの数を計算することです。例えば、1人の乗客を運ぶドライビングイベントの数、2人の乗客を運ぶドライビングイベントの数などです。
乗客数をpsgCntでグループ化し、COUNT(*)を使用して各グループのイベント数を計算します。グループ化する前に、ニューヨークで発生した運転記録データ(isInNYC)をフィルタリングする必要があることに注意してください。SQL CLIで以下のクエリを実行します。
SELECT psgCnt, COUNT(*) AS cnt FROM Rides WHERE isInNYC(lon, lat) GROUP BY psgCnt;SQL CLIで可視化された結果は以下のようになっています;結果は1秒ごとに変化していますが、乗客の最大数は6人を超えることはできません。
例 3: Windowの集計
ニューヨークの交通の流れを継続的に監視するには、5分ごとに各エリアに入る車の数を計算する必要があります。少なくとも5台の車が入ってくるエリアにのみ、そして主に焦点を当てたいとします。
この処理にはウィンドウの集約(5分ごと)が必要なので、Tumbling Window構文が必要です。
各エリアについては、進入した車の数に基づいてAreaIdでグループ化する必要があります。グループ化する前に、isStartフィールドを使用して入力された車両の走行記録をフィルタリングし、COUNT(*)を使用して車両数をカウントする必要があります。
車両数が5台以上のエリア これは、SQL HAVING句を使用して統計値に基づいてフィルタ条件を設定したものです。
最終的なクエリは以下のようになります。
SELECT toAreaId(lon, lat) AS area, TUMBLE_END(rideTime, INTERVAL '5' MINUTE) AS window_end, COUNT(*) AS cnt FROM Rides WHERE isInNYC(lon, lat) and isStart GROUP BY toAreaId(lon, lat), TUMBLE(rideTime, INTERVAL '5' MINUTE) HAVING COUNT(*) >= 5;SQL CLIでクエリを実行すると、可視化された結果は以下のようになります。エリアごと、window_endごとの結果は出力後も変化はありませんが、5分ごとに新しいウィンドウのバッチが生成された結果が出力されます。
Docker環境でソースを読み込むことで10倍速を実行しているため、デモ中は30秒ごとに新しいウィンドウのバッチが生成されています(本来の速度との相対的な比較)。
Window AggregateとGroup Aggregatの違い
例2と例3の結果から、Window AggregateとGroup Aggregateが明らかな違いを表示していることがわかります。主な違いは、Window Aggregateの出力結果はウィンドウが終了したときにのみ表示され、出力結果は最終的な値であり、変更されていないことです。出力ストリームはAppendストリームです。
しかし、Group Aggregateは、データの一部が処理されるたびに最新の結果を出力します。結果は、データベース内のデータと同様に更新されたステータスを持ち、その出力ストリームは更新ストリームです。
もう一つの違いは、ウィンドウに透かしがあることです。この機能を使えば、安定した状態サイズを確保するために、期限切れ状態をクリアするためにどのウィンドウが期限切れになったかを正確に知ることができます。
しかし、Group Aggregateの場合、どのデータが期限切れになったかを知ることができないため、ステートサイズが無限に大きくなってしまい、本番運用では安定した状態ではありません。そのため、グループアグリゲートのジョブでは、ステートTTLを設定してください。
例えば、各店舗のリアルタイムPVを毎日カウントするには、1日前の状態は一般的には使われないので、TTLを24時間以上に設定する必要があります。
SELECT DATE_FORMAT(ts, 'yyyy-MM-dd'), shop_id, COUNT(*) as pv FROM T GROUP BY DATE_FORMAT(ts, 'yyyy-MM-dd'), shop_idTTL値が小さすぎると、有用な状態やデータのクリアが行われ、データの精度の問題が発生します。これもユーザーが考慮する必要があるパラメータです。
例 4: Kafka へのアペンドストリームの書き込み
前項では、Window AggregateとGroup Aggregateの違い、AppendストリームとUpdateストリームの違いについて説明しました。Flinkでは、MySQL、HBase、ElasticSearchなどのアップデートをサポートする外部ストレージシステムにのみアップデートストリームを書き込むことができます。
While Appendストリームを任意のストレージシステムやKafkaなどのログシステムに書き込むことは可能です。
例えば、「10分ごとの乗客数」というストリームをKafkaに書きたいとします。
Kafka の結果テーブル Sink_TenMinPsgCnts があらかじめ定義されています (テーブルの完全な定義については training-config.yaml を参照してください)。
クエリを実行する前に、以下のコマンドを実行して、TenMinPsgCntsトピックに書き込まれたデータを監視します。
docker-compose exec sql-client /opt/kafka-client/bin/kafka-console-consumer.sh --bootstrap-server kafka:9092 --topic TenMinPsgCnts --from-beginningタンブリングウィンドウには、10分ごとの乗客数を記述することができます。クエリ結果を結果テーブルに直接書き込むには、
INSERT INTO Sink_TenMinPsgCntsコマンドを使用することができます。INSERT INTO Sink_TenMinPsgCnts SELECT TUMBLE_START(rideTime, INTERVAL '10' MINUTE) AS cntStart, TUMBLE_END(rideTime, INTERVAL '10' MINUTE) AS cntEnd, CAST(SUM(psgCnt) AS BIGINT) AS cnt FROM Rides GROUP BY TUMBLE(rideTime, INTERVAL '10' MINUTE);上で見たように、TenMinPsgCntsのデータトピックをJSON形式でKafkaに書き込みます。
例5: ElasticSearchに更新ストリームを書き込む
最後に、継続的に更新される更新ストリームをElasticSearch(ES)に書きます。ESには「"各エリア発車数"」のストリームを書きたいと思います。
ElasticSearchの結果テーブルSink_AreaCntsが定義されています(テーブルの完全な定義については、training-config.yamlを参照してください)。このテーブルには、areaId と cnt の 2 つのフィールドのみが含まれています。
同様に、INSERT INTOを使用して、クエリ結果を
Sink_AreaCnts tableに直接書き込むこともできます。INSERT INTO Sink_AreaCnts SELECT toAreaId(lon, lat) AS areaId, COUNT(*) AS cnt FROM Rides WHERE isStart GROUP BY toAreaId(lon, lat);SQL CLIで先行するクエリを実行すると、Elasticsearchは自動的にarea-cntsインデックスを作成します。ElasticsearchはREST APIを提供しています。以下のURLにアクセスできます。
- area-cnts インデックスを表示するには:
http://localhost:9200/area-cnts- area-cntsインデックスの統計情報を表示するには:
http://localhost:9200/area-cnts/_stats- area-cntsインデックスの内容を返すには:
http://localhost:9200/area-cnts/_search- エリア 49791 の車両数を表示するには:
http://localhost:9200/area-cnts/_search?q=areaId:49791クエリを実行し続けると、いくつかの統計値
(_all.primaries.docs.count and _all.primaries.docs.deleted)が常に増加していることがわかります:http://localhost:9200/area-cnts/_stats概要
この記事では、Docker Composeを使ってFlinkのSQLプログラミングをすぐに始めるためのガイドをしました。また、Window AggregateとGroup Aggregateの違いを比較し、この2種類のジョブを外部システムに書き込む方法も紹介しています。
興味があれば、独自のUDF、UDTF、UDAFを実行したり、他の組み込みのソーステーブルをクエリするなど、Docker環境をベースにしたより深い実践を行うことができます。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ









- 投稿日:2020-08-24T12:23:46+09:00
Docker内でcomposer require したらkilledになったときの対応
Mac上で Docker (docker-compose) で開発環境を作り、開発中の Laravel のアプリケーションに
composer requireをしたら、中断されてしまいましたcomposer require ****/***** (中略) killedcomposer が途中で終わってしまうといえば、メモリ不足が定石かなと思います。
会社の先輩からこのリンクを送ってもらい、疑惑が確信に変わりました。[PHP] composer install が killed で失敗するときの原因と対処
https://webbibouroku.com/Blog/Article/composer-killedPHP memory_limit の引き上げ
メモリ不足とわかったところで、まずDocker内で使っている
php.iniの memory_limit を増やしました。
どのくらい必要なのかわからなかったけど、とりあえず2GB(2048MB)にしました。memory_limit = 2048M設定変更後、 docker build して再起動
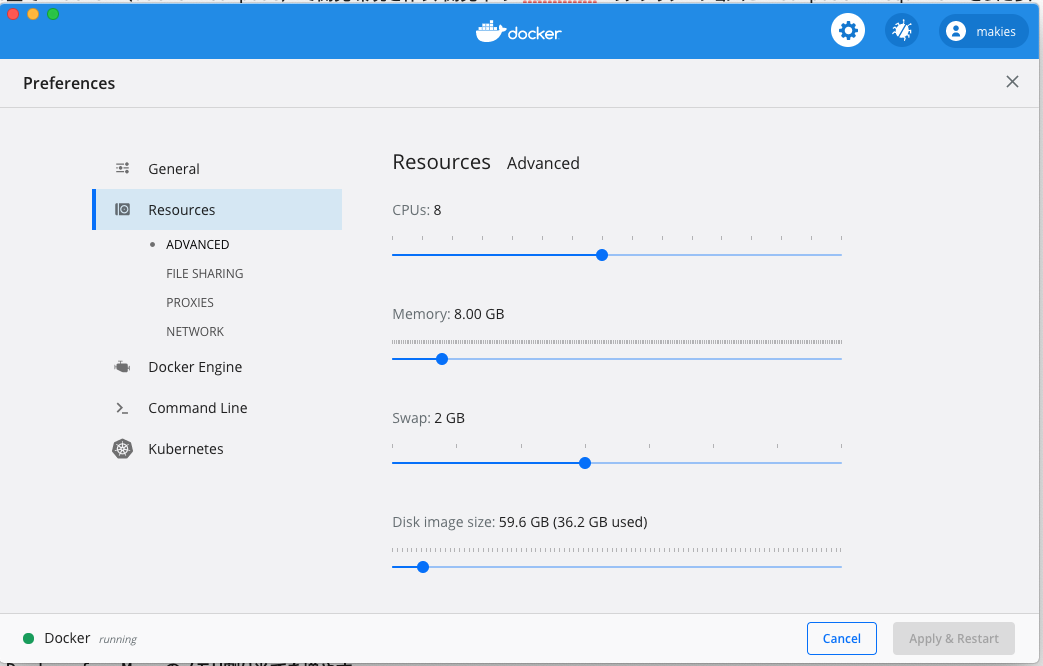
Docker for Mac のメモリ割り当てを増やす
Docker for Mac で指定しているDockerが利用できるリソースが、当初 2GBとなっていました。使っている MacBook Pro には 64GBものメモリを積んでいるので、ドドーンと 8GB まで増やしました。ここはマシンスペックとの相談かなと思います。
変更後、Dockerホストの再起動がかかりました。
解決!!
上記2点でメモリの設定を変更して、
composer requireが無事実行できました。
composer updateでも同様に大量のメモリが必要なので、同じような対応が必要になるかもしれません。
- 投稿日:2020-08-24T12:14:15+09:00
nginx-unitのdocker版でflaskやるとちょっと大変だった
パッケージのnginx-unitは前回の通り問題なく使えたが、dockerの方ではなかなかうまく動かず手こずった。
公式にもあまり書いてないことが多かったので、書いておく。dockerイメージ
公式doc↓
https://unit.nginx.org/howto/docker/#running-apps-in-containerized-unit
最初にapt叩くので、apt叩いたあとのイメージ作っててもいいかも。
(エラー出まくったときaptで待ちまくるのが面倒だったので…)FROM nginx/unit:1.19.0-python3.7 RUN apt-get update && apt-get install -y python3-pip \ && rm -rf /var/lib/apt/lists/*だけにしといて、build with name(適当な名前にしておく)
docker build -t nginx-unit-python .flaskを動かそうとした
flask自体はVisual Studioでつくってくれるサンプルを使う。
githubはこちら
https://github.com/microsoft/python-sample-vs-learning-flask(実際はapp.pyから動くように少々変更している)
nginx-unit用のconfig.json
これはdocker版でも必要なので、作成
config.json{ "listeners":{ "*:8000":{ "pass":"applications/webapp" } }, "applications":{ "webapp":{ "type":"python 3", "path":"/www/", "module":"app" } } }で、アプリイメージ用のdockerfile
FROM nginx-unit-python:latest COPY requirements.txt /config/requirements.txt RUN pip3 install --no-cache-dir -r /config/requirements.txt \ && rm -rf /var/lib/apt/lists/* COPY ./config /docker-entrypoint.d/ # config.json を入れる COPY --chown=nobody:nogroup webapp/ /www/ # chown重要 EXPOSE 8000イメージは上で作成したローカルのイメージを使っている。
もちろん一回イメージを作らなくて、そのままaptコマンド入れても大丈夫。一応公式のコマンドに寄せて、copyしていく。(公式はbindオプションで入れてるけど)
requirements.txtを/configに入れて、pip
config.jsonは/docker-entrypoint.d/に入れる重要だったこと
webapp/にflaskが入っていて、これを/wwwに入れるのだが、そのままだと
テンプレート読み出しなどのときにpremission deniedと出てきて、動かない。2020/08/21 13:45:42 [alert] 19#19 Python failed to import module "views" Traceback (most recent call last): File "<frozen importlib._bootstrap>", line 983, in _find_and_load File "<frozen importlib._bootstrap>", line 967, in _find_and_load_unlocked File "<frozen importlib._bootstrap>", line 677, in _load_unlocked File "<frozen importlib._bootstrap_external>", line 724, in exec_module File "<frozen importlib._bootstrap_external>", line 859, in get_code File "<frozen importlib._bootstrap_external>", line 916, in get_data PermissionError: [Errno 13] Permission denied: '/www/views.py'こんな感じ。(テンプレートでも同じpermission deniedと言われる)
dockerコンテナ内は基本rootで動いてるものとばっかり思ってたので、ここでかなりハマった。
いろいろアプリの場所変えたりしてもだめ。
仕方なく思い、コンテナ内に入って、/www以下を777に変えたらちゃんと動いた。コンテナ内ユーザー調査
これはいったい?と思ったので、どんなプロセスがコンテナ内で動いているのか調査する。
(なお、コンテナ内でのps auxコマンドは使えません)
docker container top [container id]
で見るとUID PID PPID C STIME TTY TIME CMD root 27891 27874 0 13:50 ? 00:00:00 unit: main v1.19.0 [unitd --no-daemon --control unix:/var/run/control.unit.sock] nobody 27947 27891 0 13:50 ? 00:00:00 unit: controller nobody 27948 27891 0 13:50 ? 00:00:00 unit: router nobody 27949 27891 0 13:50 ? 00:00:00 unit: "webapp" application↑こんな感じだった。
で、よく見るとunitの本体はnobodyで動いているようだ。
あとnobodyのグループも確認。コンテナ内に入って、
# groups nobody→nogroupと返ってくる。なので、copyのときに--chownオプションをつける。
(最初はdockerfileにchmodなり、chownを入れないとだめなのかな、と思ったけどオプションができたらしい)
https://ken5scal.hatenablog.com/entry/2017/10/13/DockerfileのADD/COPYに--chownオプションができた
↑参考にしました。ありがとうございます。これでやっと問題なく動くようになった。大変
思ったこと
情報が少ないものは使うのがつらい。特にlatestバージョンについての情報が少ないものは…
急がば回れ、ということでスタンダードなuWSGIなどを使え、ということなのか…
- 投稿日:2020-08-24T11:23:26+09:00
アリババクラウドECSインスタンスを使ってDockerコンテナにDHIS2をインストールする方法
この記事では、 Alibaba Cloud ECSインスタンスを使ってDockerコンテナにDHIS2を簡単な手順でインストールする方法を説明します。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
アリババクラウドコミュニティブログ執筆者 グレース・アモンディより
DHISをインストールする方法は現在2つあります。
1、Dockerコンテナ上で。
2、Tomcatユーザーの場合。代わりにこれを読むには https://alibabacloud.com/blog/deploy-dhis2-on-alibaba-cloud-ecs-instance_594616 にアクセスしてください。
この記事では、Alibaba CloudのElastic Compute Service (ECS)を使ってDockerコンテナにDHIS2を簡単な手順でインストールする方法を説明します。DHIS2の詳細については、公式ガイドを参照してください:DHIS 2ユーザーガイドステップ1:Dockerのインストール
すでにdockerとdocker-composeがインストールされている場合は、ステップ1と2をスキップしてください。このチュートリアルでは、UbuntuバージョンのXenial 16.04 (LTS)で作業します。異なるバージョンやOSで作業している場合は、以下のリンクを参照してください。
リポジトリを使ってインストール
新しいホストマシンに初めてDocker Engine - Communityをインストールする前に、Dockerリポジトリを設定する必要があります。その後、リポジトリからDockerをインストールして更新します。
apt パッケージインデックスを更新します。
$ sudo apt-get updateaptがHTTPSでリポジトリを利用できるようにするためのパッケージをインストールします。
$ sudo apt-get install \ apt-transport-https \ ca-certificates \ curl \ gnupg-agent \ software-properties-commonDockerの公式GPGキーを追加します。
$ curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -以下のコマンドを使用して、安定したリポジトリを設定します。
$ sudo add-apt-repository \ "deb [arch=amd64] https://download.docker.com/linux/ubuntu \ $(lsb_release -cs) \ stable"Dockerエンジンのインストール-コミュニティ
aptパッケージのインデックスを更新します。
$ sudo apt-get updateDocker Engine - Communityとcontainerdの最新バージョンをインストールするか、次のステップで特定のバージョンをインストールします。
$ sudo apt-get install docker-ce docker-ce-cli containerd.iohello-worldイメージを実行して、Docker Engine - Communityが正しくインストールされていることを確認します。
$ sudo docker run hello-worldステップ2:Docker Composeをインストールする
このコマンドを実行して、Docker Composeの現在の安定版リリースをダウンロードします。
$ sudo curl -L "https://github.com/docker/compose/releases/download/1.24.1/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose別のバージョンのComposeをインストールするには、1.24.1を使用したいComposeのバージョンに置き換えてください。
curl でのインストールに問題がある場合は、上記の「代替インストールオプション」タブを参照してください。
バイナリに実行可能な権限を適用します。
$ sudo chmod +x /usr/local/bin/docker-compose注意: インストール後に docker-compose コマンドが失敗した場合は、パスを確認してください。また、/usr/bin やパス内の任意のディレクトリへのシンボリックリンクを作成することもできます。
例えば、以下のようにします。
$ sudo ln -s /usr/local/bin/docker-compose /usr/bin/docker-composeオプションで、bashとzshシェルのコマンド補完をインストールします。
インストールをテストします。
$ docker-compose —versionステップ3:DHIS2のソースコードをクローンする
以下のコマンドを実行します。
$ git clone https://github.com/pgracio/dhis2-docker.gitディレクトリをプロジェクトに変更します。
$ cd dhis2-dockerステップ4:DHIS2の実行
デフォルトの設定、シエラレオネのデータセットでdocker-composeを実行するか、docker-compose-empty-db.ymlを使用してください。
クリーンな状態から始めたい場合は
$ docker-compose up -d或いは
$ docker-compose -f docker-compose-empty-db.yml up -dコンテナが立ち上がったら、url http://:8085 を開き、dhis2 のドキュメントで説明されているように、ユーザー名 admin とパスワード district を使って接続してください。
Mac OS XやWindowsで実行する場合、localhostを指して実行すると失敗します。失敗するのは、Docker Hostのアドレスがlocalhostではなく、docker host VMのアドレスになっているからです。
$docker-machine ip defaultを実行してDocker Hostのアドレスを取得します。アプリケーションログ
アプリケーションのログにアクセスするには、
docker-compose logs -fを実行してください。アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ
- 投稿日:2020-08-24T09:05:43+09:00
MySQL 認証プラグイン caching_sha2_password
はじめに
MySQLに接続できないエラーでハマったので対処法を備忘録としてまとめました。
エラー内容
認証プラグインがcaching_sha2_passwordとなっていることが原因だそうです。
そこで、まずはMySQLに接続して認証プラグインを確認します。ターミナル$ mysql -u root //mysqlにrootで接続。rootにパスワードを設定している場合はオプションでパスワードを指定する mysql> SELECT User, Host, Plugin FROM mysql.user; //User, Host, Pluginを確認 +------------------+-----------+-----------------------+ | User | Host | Plugin | +------------------+-----------+-----------------------+ | mysql.infoschema | localhost | caching_sha2_password | | mysql.session | localhost | caching_sha2_password | | mysql.sys | localhost | caching_sha2_password | | root | localhost | caching_sha2_password | +------------------+-----------+-----------------------+rootの認証プラグインがcaching_sha2_passwordになっています。
対策(caching_sha2_passwordをmysql_native_passwordに変更)
認証プラグインをcaching_sha2_passwordからmysql_native_passwordに変更します。
下記が変更するためのコマンドです。ターミナルmysql> ALTER USER <User>@<Host> IDENTIFIED WITH mysql_native_password BY '<password>';User, Host, passwordの部分は置き換えてください。
私の場合はrootを変更したいので下記のようにしました。
ターミナルmysql> ALTER USER root@localhost IDENTIFIED WITH mysql_native_password BY 'password';変更できているか確認する
ターミナルmysql> SELECT User, Host, Plugin FROM mysql.user; //User, Host, Pluginを確認 +------------------+-----------+-----------------------+ | User | Host | Plugin | +------------------+-----------+-----------------------+ | mysql.infoschema | localhost | caching_sha2_password | | mysql.session | localhost | caching_sha2_password | | mysql.sys | localhost | caching_sha2_password | | root | localhost | mysql_native_password | <= 変更されている! +------------------+-----------+-----------------------+Dockerの場合
Dockerのコンテナ内で認証プラグインを変更する場合にはまずコンテナに入る必要があります。
ターミナル$ docker ps //DockerのCONTAINER IDを確認 $ docker exec -it <CONTAINER ID> bash //確認したMySQLのCONTAINER IDを指定してコンテナに接続 # mysql -u root -p Enter password: <database.ymlで設定したpassword> mysql> SELECT User, Host, Plugin FROM mysql.user; //User, Host, Pluginを確認 +------------------+-----------+-----------------------+ | User | Host | Plugin | +------------------+-----------+-----------------------+ | root | % | caching_sha2_password | | mysql.infoschema | localhost | caching_sha2_password | | mysql.session | localhost | caching_sha2_password | | mysql.sys | localhost | caching_sha2_password | | root | localhost | caching_sha2_password | +------------------+-----------+-----------------------+ mysql> ALTER USER <User>@<Host> IDENTIFIED WITH mysql_native_password BY '<password>' //rootの認証プラグインを変更変更されているか確認↓
ターミナルmysql> SELECT User, Host, Plugin FROM mysql.user; //User, Host, Pluginを確認 +------------------+-----------+-----------------------+ | User | Host | Plugin | +------------------+-----------+-----------------------+ | root | % | caching_sha2_password | | mysql.infoschema | localhost | caching_sha2_password | | mysql.session | localhost | caching_sha2_password | | mysql.sys | localhost | caching_sha2_password | | root | localhost | mysql_native_password | <= 変更されている! +------------------+-----------+-----------------------+コンテナを削除して、再度Buildすれば完了です。
ターミナル$ docker-compose down $ docker-compose build終わりに
RailsとMySQLを使用しているとたまーにハマって抜け出せなくなるので、私みたいに時間を無駄にしてほしくないという思いも込めてまとめてみました。
みなさんの一助となれば幸いです。
- 投稿日:2020-08-24T09:05:43+09:00
MySQLの認証プラグインを変更する方法(caching_sha2_password)
はじめに
MySQLに接続できないエラーでハマったので対処法を備忘録としてまとめました。
エラー内容
Plugin caching_sha2_password could not be loaded: /usr//usr/lib/x86_64-linux-gnu/mariadb19/plugin/caching_sha2_password.so: cannot open shared object file: No such file or directory認証プラグインがcaching_sha2_passwordとなっていることが原因だそうです。
そこで、まずはMySQLに接続して認証プラグインを確認します。ターミナル$ mysql -u root //mysqlにrootで接続。rootにパスワードを設定している場合はオプションでパスワードを指定する mysql> SELECT User, Host, Plugin FROM mysql.user; //User, Host, Pluginを確認 +------------------+-----------+-----------------------+ | User | Host | Plugin | +------------------+-----------+-----------------------+ | mysql.infoschema | localhost | caching_sha2_password | | mysql.session | localhost | caching_sha2_password | | mysql.sys | localhost | caching_sha2_password | | root | localhost | caching_sha2_password | +------------------+-----------+-----------------------+rootの認証プラグインがcaching_sha2_passwordになっています。
対策(caching_sha2_passwordをmysql_native_passwordに変更)
認証プラグインをcaching_sha2_passwordからmysql_native_passwordに変更します。
下記が変更するためのコマンドです。ターミナルmysql> ALTER USER <User>@<Host> IDENTIFIED WITH mysql_native_password BY '<password>';User, Host, passwordの部分は置き換えてください。
私の場合はrootを変更したいので下記のようにしました。
ターミナルmysql> ALTER USER root@localhost IDENTIFIED WITH mysql_native_password BY 'password';変更できているか確認する
ターミナルmysql> SELECT User, Host, Plugin FROM mysql.user; //User, Host, Pluginを確認 +------------------+-----------+-----------------------+ | User | Host | Plugin | +------------------+-----------+-----------------------+ | mysql.infoschema | localhost | caching_sha2_password | | mysql.session | localhost | caching_sha2_password | | mysql.sys | localhost | caching_sha2_password | | root | localhost | mysql_native_password | <= 変更されている! +------------------+-----------+-----------------------+Dockerの場合
Dockerのコンテナ内で認証プラグインを変更する場合にはまずコンテナに入る必要があります。
ターミナル$ docker ps //DockerのCONTAINER IDを確認 $ docker exec -it <CONTAINER ID> bash //確認したMySQLのCONTAINER IDを指定してコンテナに接続 # mysql -u root -p Enter password: <database.ymlで設定したpassword> mysql> SELECT User, Host, Plugin FROM mysql.user; //User, Host, Pluginを確認 +------------------+-----------+-----------------------+ | User | Host | Plugin | +------------------+-----------+-----------------------+ | root | % | caching_sha2_password | | mysql.infoschema | localhost | caching_sha2_password | | mysql.session | localhost | caching_sha2_password | | mysql.sys | localhost | caching_sha2_password | | root | localhost | caching_sha2_password | +------------------+-----------+-----------------------+ mysql> ALTER USER <User>@<Host> IDENTIFIED WITH mysql_native_password BY '<password>' //rootの認証プラグインを変更変更されているか確認↓
ターミナルmysql> SELECT User, Host, Plugin FROM mysql.user; //User, Host, Pluginを確認 +------------------+-----------+-----------------------+ | User | Host | Plugin | +------------------+-----------+-----------------------+ | root | % | caching_sha2_password | | mysql.infoschema | localhost | caching_sha2_password | | mysql.session | localhost | caching_sha2_password | | mysql.sys | localhost | caching_sha2_password | | root | localhost | mysql_native_password | <= 変更されている! +------------------+-----------+-----------------------+コンテナを削除して、再度Buildすれば完了です。
ターミナル$ docker-compose down $ docker-compose build終わりに
RailsとMySQLを使用しているとたまーにハマって抜け出せなくなるので、私みたいに時間を無駄にしてほしくないという思いも込めてまとめてみました。
みなさんの一助となれば幸いです。
- 投稿日:2020-08-24T07:33:52+09:00
Dockerでよく使うコマンドはaliasに登録しておくと便利だよ
aliasって何?
新しいコマンドも作れる!aliasコマンド詳細まとめ【Linuxコマンド集】
aliasコマンドはコマンドを別名で登録または、登録されている内容を確認するLinuxコマンドだ
最近のコマンドは色々と長くていちいち打つのが面倒くさいですよね。。
$ docker-compose up -daliasを登録すれば、以下のコマンドでこれと同じ処理をさせることができます。
$ dcualiasの登録方法
~/.bashrcに以下のように記載すればOK。
もしない場合は新規作成すれば良いです。~/.bashrcalias dcu='docker-compose up -d'危険なコマンドと打ち間違えそうなaliasは登録しない方がいいです!
自分の.bashrc
こんな感じです。よく使うコマンドだけ登録しました。
~/.bashrcalias dcu='docker-compose up -d' alias dcd='docker-compose down' alias dcr='docker-compose restart' alias dp='docker ps' alias dx='docker exec -it'最後に
Twitterの方でも、モダンな技術習得やサービス開発の様子を発信したりしているので良かったらチェックしてみてください!
Docker起動時に、毎回毎回「docker-compose up -d」と入力するのに嫌気がさしたので、alias使って「dcu」と入力するだけで済むようにしました
— やぎぬ?行動力エンジニア (@yagi_eng) August 23, 2020
そしたらめちゃ捗る…aliasの存在は知ってたからもっと早くやれば良かった?
他のコマンドも省略形にできるからaliasおすすめですhttps://t.co/64BXijZyhi
- 投稿日:2020-08-24T03:24:11+09:00
起動しているコンテナを全て止める
Dockerで起動している複数のコンテナを一気に停止させたい時があります。
docker psを実行し、コンテナIDをチェックしてstopしていくのは面倒です。docker stop コンテナIDpsコマンドの
-qオプションを使うとプロセスIDだけが出力されるので、パイプを使ってstopさせます。docker ps -q | xargs docker stopこれで起動しているコンテナを全て停止させることが出来ます。